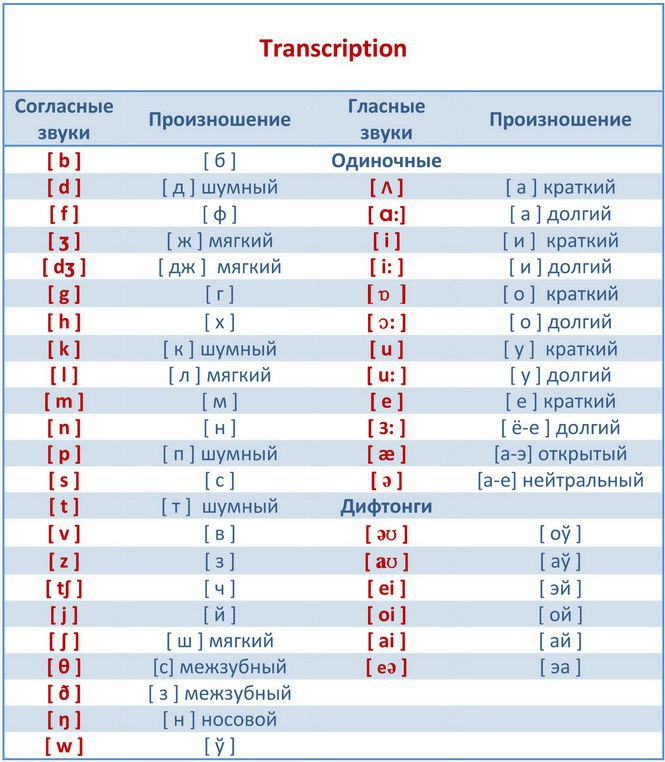
Пасхальное Евангелие на разных языках с русской транскрипцией
Оглавление- Английский (из Библии короля Якова)
- Белорусский
- Болгарский
- Гагаузский
- Греческий
- Иврит
- Испанский
- Итальянский
- Китайский
- Латинский
- Немецкий
- Украинский
- Французский
- Зачало с вензелем
См. также Чтение евангелия в первый день Пасхи на разных языках и обряды, сопровождающие это чтение проф. А.А. Дмитриевский
Евангелие от Иоанна, глава 1 стихи 1–17
Порядок чтения пасхального Евангелия на нескольких языках следующий. После того, как старший диакон испросит благословение “Благослови, владыко, благовестителя” и предстоятель даст это благословение словами “Бог молитвами”, предстоятель возглашает “Премудрость, прости, услышим святаго Евангелия”. Эти же слова вслед за предстоятелем повторяют все иереи и диаконы, кончая старшим диаконом, — каждый, по возможности, на том языке, на котором он будет читать Евангелие. Потом предстоятель произносит “Мир всем”. Этот возглас никто из священнослужителей не повторяет. Певцы отвечают “И духови твоему”.
Потом предстоятель произносит “Мир всем”. Этот возглас никто из священнослужителей не повторяет. Певцы отвечают “И духови твоему”.
Предстоятель возглашает “От Иоанна святаго Евангелия чтение”. За ним повторяют эти слова все иереи и диаконы, также, по возможности, на том языке, на котором будет прочтено Евангелие. После того, как все священнослужители, кончая старшим диаконом, скажут эти слова, певцы поют “Слава Тебе, Господи, слава Тебе”. Предстоятель — “Вонмем”. То же все священнослужители, кончая старшим диаконом, каждый также на языке, на котором будет читать Евангелие. Предстоятель начинает 1‑ю статию, за ним повторяют ее иереи и диаконы и последним — старший диакон. В таком же порядке читаются 2‑я и 3‑я статии.
Во время чтения Евангелия на колокольне производится так называемый “перебор”, т. е. ударяют по одному разу во все колокола, начиная от маленьких. По окончании Евангелия краткий трезвон.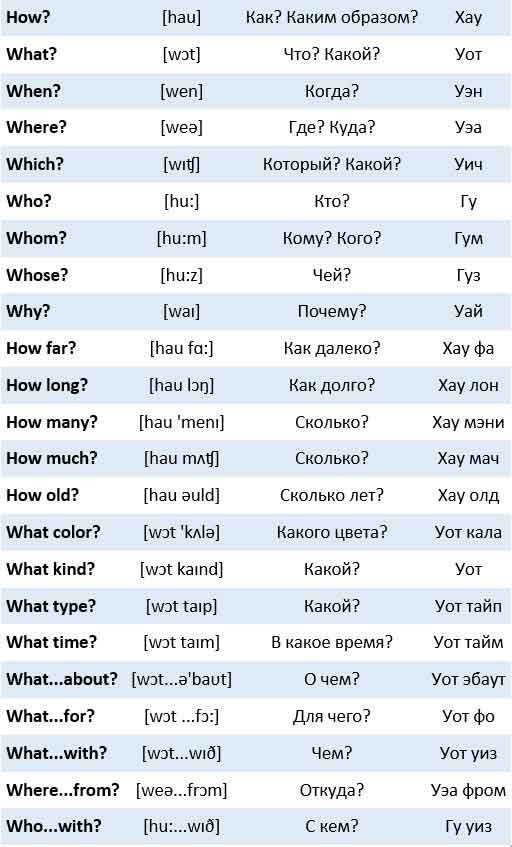 Когда старший диакон закончит 3‑ю статию, певцы поют “Слава Тебе, Господи, слава Тебе”.
Когда старший диакон закончит 3‑ю статию, певцы поют “Слава Тебе, Господи, слава Тебе”.
Старший диакон отдает Евангелие предстоятелю. Прочие диаконы за ним входят в алтарь с Евангелиями и относят их на свои места.
***
Английский (из Библии короля Якова)
Прослушать:
1. In the beginning was the Word, and the Word was with God, and the Word was God.
2. The same was in the beginning with God.
3. All things were made by him; and without him was not any thing made that was made.
4. In him was life; and the life was the light of men.
5. And the light shineth in darkness; and the darkness comprehended it not.
6. There was a man sent from God, whose name was John.
7. The same came for a witness, to bear witness of the Light, that all men through him might believe.
8. He was not that Light, but was sent to bear witness of that Light.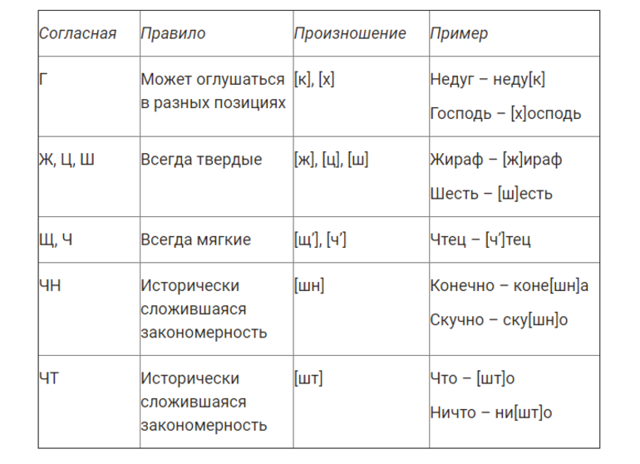
9. That was the true Light, which lighteth every man that cometh into the world.
10. He was in the world, and the world was made by him, and the world knew him not.
11. He came unto his own, and his own received him not.
12. But as many as received him, to them gave he power to become the sons of God, even to them that believe on his name:
13. Which were born, not of blood, nor of the will of the flesh, nor of the will of man, but of God.
14. And the Word was made flesh, and dwelt among us, (and we beheld his glory, the glory as of the only begotten of the Father,) full of grace and truth.
15. John bare witness of him, and cried, saying, This was he of whom I spake, He that cometh after me is preferred before me: for he was before me.
16. And of his fulness have all we received, and grace for grace.
17. For the law was given by Moses, but grace and truth came by Jesus Christ.
***
Белорусский
1. На пачатку было Слова, і Слова было ў Бога, і Слова было Богам.
2. Яно было на пачатку ў Бога:
3. усё празь Яго пачалося, і безь Яго нішто не пачалося з таго, што пачало быць.
4. У Ім было жыцьцё, і жыцьцё было сьвятлом людзей.
5. І сьвятло ў цемры сьвеціць, і цемра не агарнула яго.
6. Быў чалавек, пасланы ад Бога; імя яму Ян;
7. Ён прыйшоў дзеля сьведчаньня, каб сьведчыць пра Сьвятло, каб усе ўверавалі празь Яго;
8. ён ня быў сьвятло, а быў пасланы, каб сьведчыць пра Сьвятло.
9. Было Сьвятло сапраўднае, Якое прасьвятляе кожнага чалавека, што прыходзіць у сьвет.
10. У сьвеце было, і сьвет празь Яго пачаў быць, і сьвет Яго не пазнаў;
11. прыйшоў да сваіх, і свае Яго не прынялі;
12. а тым, якія прынялі Яго, веруючым у імя Ягонае, даў уладу быць дзецьмі Божымі,
13. якія не ад крыві, ні ад хаценьня плоці, ні ад хаценьня мужа, а ад Бога нарадзіліся.
14. І Слова стала плоцьцю, і ўсялілася ў нас, поўнае мілаты і праўды; і мы бачылі славу Ягоную, славу, як Адзінароднага ад Айца.
15. Ян сьведчыць пра Яго і ўсклікаючы кажа: Гэта быў Той, пра Якога я сказаў, што Той, Хто ідзе за мною, апярэдзіў мяне, бо быў раней за мяне.
16. І ад паўнаты Яго ўсе мы прынялі і мілату да мілаты;
17. бо закон дадзены праз Майсея, а мілата і праўда сталіся празь Ісуса Хрыста.
***
Болгарский
От Иоа́на Свето́ Ева́нгелие. Глава 1
1. В нача́ло бе́ше Сло́вото, и Сло́вото бе́ше у Бо́га, и Бо́г бе́ше Сло́вото.
2. То́ бе́ше в нача́ло у Бо́га.
3. Вси́чко чрез Не́го ста́на, и без Не́го не ста́на ни́што е́дно от о́нова, кое́то е ста́нало.
4. В Не́го и́маше живо́т, и живо́тат бе́ше светлина́та на чове́ците.
5. И светлина́та в мра́ка све́ти, и мра́кът я не обзе́.
6. И́маше еди́н чове́к, пра́тен от Бо́га, име́то му Иоа́н;
7. то́й дойде́ за свиде́телство, да свиде́телствува за светлина́та, та вси́чки да повя́рват чре́з не́го.
8. То́й не бе́ше светлина́та, а бе пра́тен да свиде́телствува за светлина́та.
9. Съще́ствуваше и́стинската светлина́, коя́то просветя́ва все́ки чове́к, и́дващ на света́.
10. В света́ бе́ше, и све́тът чре́з Не́го ста́на, но све́тът Го не позна́.
11. Дойде́ у Сво́ите Си, и Сво́ите Го не прие́ха.
12. А на вси́чки ония, кои́то Го прие́ха, – на вя́рващите в Не́говото и́ме, – да́де възмо́жност да ста́нат че́да Бо́жии;
13. те не́ от кръв, ни от по́хот пло́тска, нито от по́хот мъ́жка, а от Бо́га се роди́ха.
14. И Слов́ото ста́на пло́т, и живя́ ме́жду на́с, пъ́лно с благода́т и и́стина; и ние видя́хме сла́вата Му, сла́ва като на Единоро́ден от Отца́.
15. Иоа́н свиде́телствуваше за Не́го и ви́каше, ду́майки: То́я бе́ше, за Ко́гото гово́рих: Иде́щият сле́д ме́не ме изпрева́ри, защо́то съще́ствуваше по-напре́д от ме́не.
16. И от Не́говата пъ́лнота вси́чки ние́ прие́хме и благода́т въз благода́т;
17. защо́то Зако́нът бе да́ден чре́з Моисе́я, а благодатта́ и и́стината произле́зе чре́з Иису́с Христо́с.
***
Гагаузский
ИИ́ ХАБЕ́Р ИОАНДА́Н
Сӧз ада́м олду́
1 Ба́штан Сӧз ва́рды, Сӧз Аллахта́йды, Сӧз Алла́хты.
2 Ба́штан О Аллахта́йды.
3 Хе́пси Ону́ннан курулду́, Онсу́з би́шей куру́лмады.
4 Онда́ йашама́к ва́рды. Йашама́к инса́н ичи́н айдынны́кты.
5 Айдынны́к каранныкта́ шафк еде́р, каранны́к ону́ енсейä́меди.
6 Аллахта́н бир ада́м гелди́, ону́н ады́ Иоа́н.
7 Гелди́ Айдынны́к ичи́н шаатлы́к етси́н, хе́пси инса́н ону́н ашыры́ инансы́н.
8 О Кенди́ дии́лди Айдынны́к, ама́ гелди́ Айдынны́к ичи́н сӧлеси́н.
9 О́дур хакына́ Айдынны́к, Ангысы́ хе́рбир адамы́, бу дӱннейä́ гелä́н, айдыннадэ́р.
10 О Кенди́ бу дӱннейӓ́ гелди́. Дӱннӓ́ Ону́н ашыры́ йарадылды́, ама́ дӱннä́ Ону́ таны́мады.
11 Кендикилеринä́ гелди́, кендикилери́ Ону́ кабле́тмеди.
12 Ама́ хе́пси онна́р, ким Ону́ каблетти́, ким Ону́н адына́ инанды́, О изи́н верди́ онна́р олсу́н Аллахы́н ушаклары́,
13 ангылары́ дии́л канда́н, дии́л еттä́н хем дии́л ада́м истедииндä́н, ама́ Аллахта́н дууду́.
14 Сöз ада́м олду́, бизи́м арамызда́ йашады́, ииверги́йлäн хем аслылы́клан долу́. Ону́н метинниини́ гöрдÿ́к, ни́ӂä Бобада́н би́риӂик Оолу́н метинниини́.
Ону́н метинниини́ гöрдÿ́к, ни́ӂä Бобада́н би́риӂик Оолу́н метинниини́.
15 Иоа́н Ону́н ичи́н шаатлы́к етти́ да бÿÿ́к се́слäн бöлä́ деди́: “Бу́дур О, Кими́н ичи́н хаберледи́м: “О, Ким бендä́н со́ра геле́р, таа́ ÿстÿ́н бендä́н, зе́рä Бендäн таа́ илери́йди”.
16 Ону́н долушунда́н хе́псимиз ииверги́ ÿстÿнä́ ииверги́ едендик”.
17 Зерä́ Зако́н Моисе́й ашыры́ верилди́, ама́ хайы́р хем аслылы́к Иису́с Христо́с ашыры́ гелди́.
***
Греческий
| Греческий язык | Транскрипция |
|---|---|
1. ἐν ἀρχῇ ἦν ὁ λόγος καὶ ὁ λόγος ἦν πρὸς τὸν θεόν καὶ θεὸς ἦν ὁ λόγος 2. οὗτος ἦν ἐν ἀρχῇ πρὸς τὸν θεόν 3. πάντα δι᾿ αὐτοῦ ἐγένετο καὶ χωρὶς αὐτοῦ ἐγένετο οὐδὲ ἕν ὃ γέγονεν 4. ἐν αὐτῷ ζωὴ ἦν καὶ ἡ ζωὴ ἦν τὸ φῶς τῶν ἀνθρώπων 5. 6. ἐγένετο ἄνθρωπος ἀπεσταλμένος παρὰ θεοῦ ὄνομα αὐτῷ Ἰωάννης 7. οὗτος ἦλθεν εἰς μαρτυρίαν ἵνα μαρτυρήσῃ περὶ τοῦ φωτός ἵνα πάντες πιστεύσωσιν δι᾿ αὐτοῦ 8. οὐκ ἦν ἐκεῖνος τὸ φῶς ἀλλ᾿ ἵνα μαρτυρήσῃ περὶ τοῦ φωτός 9. ἦν τὸ φῶς τὸ ἀληθινόν ὃ φωτίζει πάντα ἄνθρωπον ἐρχόμενον εἰς τὸν κόσμον 10. ἐν τῷ κόσμῳ ἦν καὶ ὁ κόσμος δι᾿ αὐτοῦ ἐγένετο καὶ ὁ κόσμος αὐτὸν οὐκ ἔγνω 11. εἰς τὰ ἴδια ἦλθεν καὶ οἱ ἴδιοι αὐτὸν οὐ παρέλαβον 12. ὅσοι δὲ ἔλαβον αὐτόν ἔδωκεν αὐτοῖς ἐξουσίαν τέκνα θεοῦ γενέσθαι τοῖς πιστεύουσιν εἰς τὸ ὄνομα αὐτοῦ 13. οἳ οὐκ ἐξ αἱμάτων οὐδὲ ἐκ θελήματος σαρκὸς οὐδὲ ἐκ θελήματος ἀνδρὸς ἀλλ᾿ ἐκ θεοῦ ἐγεννήθησαν 14. καὶ ὁ λόγος σὰρξ ἐγένετο καὶ ἐσκήνωσεν ἐν ἡμῖν καὶ ἐθεασάμεθα τὴν δόξαν αὐτοῦ δόξαν ὡς μονογενοῦς παρὰ πατρός πλήρης χάριτος καὶ ἀληθείας 15. Ἰωάννης μαρτυρεῖ περὶ αὐτοῦ καὶ κέκραγεν λέγων οὗτος ἦν ὃν εἶπον ὁ ὀπίσω μου ἐρχόμενος ἔμπροσθέν μου γέγονεν ὅτι πρῶτός μου ἦν 16. 17. ὅτι ὁ νόμος διὰ Μωϋσέως ἐδόθη ἡ χάρις καὶ ἡ ἀλήθεια διὰ Ἰησοῦ Χριστοῦ ἐγένετο | Софи́а, орфи́, аку́сомэн ту аги́у Эвангели́у. (Премудрость, прости…) Ири́ни па́си. (Мир всем) *** 1. Эн архи́ ин о Ло́гос, ке о Ло́гос ин про́с то́н Фэо́н, ке Фэо́с, ин о Ло́гос. 2. У́тос и́н эн архи́ про́с то́н Фэо́н. 3. Па́нта ди авту́ эге́нэто, кэ хори́с авту́ эге́нэто у́дэ ен, о е́гонон. 4. Эн авто́ зои́ ин, ке и зои́ ин то фо́с антро́пон. 5. Кэ то фо́с, эн ти скоти́а фэ́ни, кэ и скоти́а авто́ у кате́лавэн. 6. Эге́нето а́нтропос, апесталме́нос пара́ Фэу́, о́нома авто́ Иоа́ннис. 7. Уто́с и́лфен ис мартири́ан и́на мартири́си пэ́ри ту фото́с, и́на па́ндис пистэ́рсусин ди авту́. 8. Ук ин экино́с то фо́с, алл и́на мартири́си пэ́ри ту фото́с. 9. Ин то фо́с то алифино́н, о фоти́си па́нда а́нфропон, эрхо́менон ис тон го́змон. 11. Ис та и́дьа и́лфен, ки ои и́дии авто́н ун паре́лабон. 12. О́си ди э́лабон а́втон, э́докен, авти́с эксуси́ан тэ́кна Фэ́у генэ́стэ тис пистэ́нусин ис то о́нома афту́, 13. И́и ук эс има́тон уде́ эк Фэли́матос сарко́с уде́ эк Фэли́матос андро́с алл эк Фэу́ егенни́тисан. 14. Ке о Ло́гос са́ркс эге́нето ке эски́носэн эн ими́н, кэ эаса́мефа тин до́ксан авту́, до́ксан оз моноену́с пара́ патро́с, пли́рис ха́ритус ке алифи́ас. 15. Иоа́ннис мартири́ пэри́, авту́ ке, ке́креген ле́гон, У́тос ин он и́пон, О опи́со му эрхо́менос э́мпросфен му е́гонэн, о́ти про́доз му ин. 16. О́ти эк ту плиро́матос авту́ ими́с па́ндэс, эла́бомэн, ке ха́рин а́нти ха́ритос. 17. О́ти о но́мос, дьа́ Моисе́ос эдо́фи, и ха́рис ке и эли́фиа дьа́ Иису́ Христу́ эге́нэто. |
 καὶ τὸ φῶς ἐν τῇ σκοτίᾳ φαίνει καὶ ἡ σκοτία αὐτὸ οὐ κατέλαβεν
καὶ τὸ φῶς ἐν τῇ σκοτίᾳ φαίνει καὶ ἡ σκοτία αὐτὸ οὐ κατέλαβεν ὅτι ἐκ τοῦ πληρώματος αὐτοῦ ἡμεῖς πάντες ἐλάβομεν καὶ χάριν ἀντὶ χάριτος
ὅτι ἐκ τοῦ πληρώματος αὐτοῦ ἡμεῖς πάντες ἐλάβομεν καὶ χάριν ἀντὶ χάριτος
***
Иврит
1. бəрэши́т hайа́ hадава́р, вəhадава́р hайа́ эт hаəлоhи́м, вэлоhи́м hайа́ hадава́р
2. hу hайа́ бəрэши́т э́цэль hаəлоhи́м.
hу hайа́ бəрэши́т э́цэль hаəлоhи́м.
3. hако́ль ниhйа́ ‘аль-йадо́ умибаль‘ада́в ло ниhйа́ каль-ашэ́р ниhйа́.
4. бо hайу́ хаййи́м, вəhахаййи́м hайу́ ор бəнэ́ hа-ада́м.
5. вəhао́р бахо́шэх зара́х вəhахо́шэх ло hишиго́.
6. вайəhи́ иш шалу́ах мээ́т hаəлоhи́м, ушмо́ йохана́н
7. hу ба лə‘эду́т лəhа‘и́д ‘аль-hао́р лəма́‘ан йа-ами́ну хула́м ‘аль-йадо́.
8. hу ло hайа́ hао́р ки им-лəhа‘и́д ‘аль-hао́р.
9. hао́р hа-ами́тти hамэи́р лəха́ль-ада́м hайа́ ва эль-hа‘ола́м.
10. ба‘ола́м hайа́ вə‘аль-йадо́ ниhйа́ hа‘ола́м, вəhа‘ола́м ло hикиро́.
11. hу ва эль-ашэ́р ло, ва-ашэ́р hэ́мма ло, ло qибəлуhу́.
12. вəhамqабли́м ото́ ната́н ‘оз ламо́ лиhйо́т бани́м лэлоhи́м hама-амини́м бишмо́.
13. ашэ́р ло мида́м, вəло-мэхэ́фэц hабаша́р, аф ло-мэхэ́фэц гавэ́р, ки им-мэəлоhи́м ноладу́.
14. вəhадава́р ниhйа́ ваша́р, вайишко́н бəтохэ́ну ванэхэзэ́ тиф-арто́, кэти
[‘] – гортанный согласный, образуется глубоко в горле, очень сдавленный.
[ə] – редуцированный, очень краткий звук, почти исчезает.
[x] – гортанный, как русский [х], но образуется гораздо глубже, как при отхаркивании
[h] – звук на выдохе
[а] – всегда безударный, скорее призвук, чем звук.
[q] – гортанный, как русский [к], но образуется гораздо глубже
***
Испанский
LECTURA DEL SANTO EVANGELIO SEGÚN SAN JUAN
1 En el principio existía el Verbo, y el Verbo estaba con Dios, y el Verbo era Dios.
2 Él estaba en el principio con Dios.
3 Por Él fueron hechas todas las cosas, y sin Él no se ha hecho cosa alguna de cuantas han sido hechas.
4 En Él estaba la vida, y la vida era la luz de los hombres.
5 Y la luz resplandece en medio de las tinieblas, y las tinieblas no pudieron retenerla.
6 Hubo un hombre enviado por Dios que se llamaba Juan.
7 Éste vino como testigo para dar testimonio de la luz, a fin de que por medio de él todos creyeran.
8 No era él la luz, sino quien daría testimonio de la luz.
9 El Verbo era la luz verdadera que alumbra a todo hombre que viene al mundo.
10 En el mundo estaba, y el mundo fue por Él hecho, pero el mundo no lo conoció.
11 Vino a su propia casa, y los suyos no lo recibieron.
12 Pero a todos los que lo recibieron, que son los que creen en su Nombre, les dio poder de llegar a ser hijos de Dios.
13 Los cuales no nacieron de sangre, ni de deseo de carne, ni de voluntad de hombre, sino que de Dios nacieron.
14 Y el Verbo se hizo carne y habitó entre nosotros; y nosotros hemos visto su gloria, gloria que tiene del Padre como el Unigénito, lleno de gracia y de verdad.
15 De Él da testimonio Juan, y clama diciendo: He aquí Aquél de quien yo les decía: el que viene detrás de mí, se ha puesto delante de mí, por cuanto era antes que yo.
16 Así pues de la plenitud de Él hemos participado todos nosotros y recibido gracia sobre gracia.
17 Porque la Ley fue dada por Moisés; mas la Gracia y la Verdad fueron traídas por Jesucristo.
Транскрипция
1 эн эль принси́пио э́ра эль бэ́рбо, и эль бэ́рбо э́ра кон дьос, и эль бэ́рбо э́ра дьос
2 э́стэ э́ра эн эль принси́пио кон дьос
3 то́дас лас ко́сас пор эль фуэ́рон э́час, и син эль на́да дэ ло кэ а си́до э́чо фуэ́ э́чо
4 эн эль эста́ба ла би́да, и ла би́да э́ра ла лус дэ лос о́мбрэс
5 ла лус эн лас тинье́блас рэспландэ́сэ, и лас тинье́блас но пребалэсье́рон ко́нтра э́йа
6 у́бо ун о́мбре энбьа́до дэ дьос, эль куа́ль сэ йама́ба Хуа́н
7 э́стэ би́но пор тэстимо́ньо, па́ра кэ дье́сэ тэстимо́ньо дэ ла лус, а фин дэ кэ то́дос крэйэ́сэн пор эль.
8 но э́ра ла лус, си́но па́ра кэ дье́сэ тэстимо́ньо дэ ла лус
9 акэ́йа лус бэрдадэ́ра, кэ алу́мбра а то́до о́мбрэ, бэни́а а э́стэ му́ндо
10 эн эль му́ндо эста́ба, и эль му́ндо пор эль фуэ́ э́чо, пэ́ро эль му́ндо но лэ коносьо́.
11 а ло су́йо би́но, и лос су́йос но лэ ресибье́рон
12 мас а то́дос лос кэ лэ ресибье́рон, а лос кэ крэ́эн эн су но́мбрэ, лэс дьо потеста́д дэ сэр э́чос и́хос дэ дьос
13 лос куа́лэс но сон энхендра́дос дэ са́нгрэ, ни дэ болунта́д дэ ка́рнэ, ни дэ болунта́д дэ баро́н, си́но дэ дьос
14 и акэ́ль бэ́рбо фуэ́ э́чо ка́рнэ, и абито́ э́нтрэ носо́трос, и би́мос су гло́рья ко́мо дэль унихэ́нито дэль па́дрэ, йэ́но дэ гра́сьа и дэ бэрда́д
15 Хуа́н дьо́ тэстимо́ньо дэ эль, и кламо́ дисье́ндо, э́стэ эс дэ кьен йо дэси́а, эль кэ бье́нэ дэспуэ́с дэ ми, эс а́нтэс дэ ми, по́ркэ э́ра примэ́ро кэ йо
16 по́ркэ дэ су плэниту́д тома́мос то́дос, и гра́сьа со́брэ гра́сьа
17 пуэ́с ла лэй пор мэ́дьо дэ мойсэ́с фуэ́ да́да, пэ́ро ла гра́сьа и ла берда́д бинье́рон пор мэ́дьо дэ Хэсукри́сто
с = [θ]
б = [β] (звук средний между [b] и [v] )
у = [w] (очень краткий неслоговой [u] )
д = [đ] (очень слабый [d] , от которого остался один только призвук)
***
Итальянский
LETTURA DAL SANTO VANGELO SECONDO GIOVANNI
1 In principio era il Verbo, il Verbo era presso Dio e il Verbo era Dio.
2 Egli era in principio presso Dio:
3 Tutto è stato fatto per mezzo di lui, e senza di lui niente è stato fatto di tutto ciò che esiste.
4 In lui era la vita e la vita era la luce degli uomini;
5 La luce splende nelle tenebre, ma le tenebre non l’hanno accolta.
6 Venne un uomo mandato da Dio e il suo nome era Giovanni.
7 Egli venne come testimone per rendere testimonianza alla luce, perché tutti credessero per mezzo di lui.
8 Egli non era la luce, ma doveva render testimonianza alla luce.
9 Veniva nel mondo la luce vera, quella che illumina ogni uomo.
10 Egli era nel mondo, e il mondo fu fatto per mezzo di lui, eppure il mondo non lo riconobbe.
11 Venne fra la sua gente, ma i suoi non l’hanno accolto.
12 A quanti però l’hanno accolto, ha dato potere di diventare figli di Dio: a quelli che credono nel suo nome,
13 I quali non da sangue, né da volere di carne, né da volere di uomo, ma da Dio sono stati generati.
14 E il Verbo si fece carne e venne ad abitare in mezzo a noi; e noi vedemmo la sua gloria, gloria come di unigenito dal Padre, pieno di grazia e di verità.
15 Giovanni gli rende testimonianza e grida: Ecco l’uomo di cui io dissi: Colui che viene dopo di me mi è passato avanti, perché era prima di me.
16 Dalla sua pienezza noi tutti abbiamo ricevuto e grazia su grazia.
17 Perché la legge fu data per mezzo di Mosè, la grazia e la verità vennero per mezzo di Gesù Cristo.
***
Китайский
| Китайский язык | Транскрипция |
|---|---|
1 太 初 有 道 , 道 與 神 同 在 , 道 就 是 神 。 2 這 道 太 初 與 神 同 在 。 3 萬 物 是 藉 著 他 造 的 ; 凡 被 造 的 , 沒 有 一 樣 不 是 藉 著 他 造 的 。 4 生 命 在 他 裡 頭 , 這 生 命 就 是 人 的 光 。 5 光 照 在 黑 暗 裡 , 黑 暗 卻 不 接 受 光 。 6 有 一 個 人 , 是 從 神 那 裡 差 來 的 , 名 叫 約 翰 。 7 這 人 來 , 為 要 作 見 證 , 就 是 為 光 作 見 證 , 叫 眾 人 因 他 可 以 信 。 8 他 不 是 那 光 , 乃 是 要 為 光 作 見 證 。 9 那 光 是 真 光 , 照 亮 一 切 生 在 世 上 的 人 。 10 他 在 世 界 , 世 界 也 是 藉 著 他 造 的 , 世 界 卻 不 認 識 他 。 11 他 到 自 己 的 地 方 來 , 自 己 的 人 倒 不 接 待 他 。 12 凡 接 待 他 的 , 就 是 信 他 名 的 人 , 他 就 賜 他 們 權 柄 , 作 神 的 兒 女 。 13 這 等 人 不 是 從 血 氣 生 的 , 不 是 從 情 慾 生 的 , 也 不 是 從 人 意 生 的 , 乃 是 從 神 生 的 。 14 道 成 了 肉 身 , 住 在 我 們 中 間 , 充 充 滿 滿 的 有 恩 典 有 真 理 。 我 們 也 見 過 他 的 榮 光 , 正 是 父 獨 生 子 的 榮 光 。 15 約 翰 為 他 作 見 證 , 喊 著 說 : 「 這 就 是 我 曾 說 : 『 那 在 我 以 後 來 的 , 反 成 了 在 我 以 前 的 , 因 他 本 來 在 我 以 前 。 』 」 16 從 他 豐 滿 的 恩 典 裡 , 我 們 都 領 受 了 , 而 且 恩 上 加 恩 。 17 律 法 本 是 藉 著 摩 西 傳 的 ; 恩 典 和 真 理 都 是 由 耶 穌 基 督 來 的 。 | 1 Tàichū yǒu dào, dào yǔ shén tóng zài, dào jiùshì shén. 2 Zhè dào tàichū yǔ shén tóng zài. 3 Wànwù shì jízhe tā zào de; fán bèi zào de, méiyǒu yīyàng bùshì jízhe tā zào de. 4 Shēngmìng zài tā lǐ tóu, zhè shēngmìng jiùshì rén de guāng. 5 Guāngzhào zài hēi’àn lǐ, hēi’àn què bù jiēshòu guāng. 6 Yǒuyī gèrén, shì cóng shén nàlǐ chà lái de, míng jiào yuēhàn. 7 Zhè rén lái, wèi yào zuò jiànzhèng, jiùshì wèi guāng zuò jiànzhèng, jiào zhòngrén yīn tā kěyǐ xìn. 8 Tā bùshì nà guāng, nǎi shì yào wèi guāng zuò jiànzhèng. 9 Nà guāng shì zhēnguāng, zhào liàng yīqiè shēng zài shìshàng de rén. 10 Tā zài shìjiè, shìjiè yěshì jízhe tā zào de, shìjiè què bù rènshí tā. 11 Tā dào zìjǐ de dìfāng lái, zìjǐ de rén dào bù jiēdài tā. 12 Fán jiēdài tā de, jiùshì xìn tā míng de rén, tā jiù cì tāmen quánbǐng, zuò shén de érnǚ. 13 Zhè děng rén bùshì cóng xuèqì shēng de, bùshì cóng qíngyù shēng de, yě bùshì cóng rényì shēng de, nǎi shì cóng shén shēng de. 14 Dàochéngle ròushēn, zhù zài wǒmen zhōngjiān, chōng chōngmǎn mǎn de yǒu ēndiǎn yǒu zhēnlǐ. 15 Yuēhàn wèi tā zuò jiànzhèng, hǎnzhe shuō: ‘Zhè jiùshì wǒ céng shuō: “Nà zài wǒ yǐ hòulái de, fǎn chéngle zài wǒ yǐqián de, yīn tā běnlái zài wǒ yǐqián. 16 Cóng tā fēngmǎn de ēndiǎn lǐ, wǒmen dōu lǐngshòule, érqiě ēn shàng jiā ēn. 17 Lǜ fǎ běn shì jízhe móxī chuán de; ēndiǎn hé zhēnlǐ dōu shì yóu yé sū jīdū lái de. |
 Wǒmen yě jiànguò tā de róngguāng, zhèng shì fù dú shēng zi de róngguāng.
Wǒmen yě jiànguò tā de róngguāng, zhèng shì fù dú shēng zi de róngguāng.***
Латинский
| Латинский язык | Транскрипция |
|---|---|
1. In principio erat Verbum, et Verbum erat apud Deum, et Deus erat Verbum. 2. Hoc erat in principio apud Deum. 3. Omnia per ipsum facta sunt, et sine ipso factum est nihil, quod factum est; 4. in ipso vita erat, et vita erat lux hominum, 5. 6. Fuit homo missus a Deo, cui nomen erat Ioannes; 7. hic venit in testimonium, ut testimonium perhiberet de lumine, ut omnes crederent per illum. 8. Non erat ille lux, sed ut testimonium perhiberet de lumine. 9. Erat lux vera, quae illuminat omnem hominem, veniens in mundum. 10. In mundo erat, et mundus per ipsum factus est, et mundus eum non cognovit. 11. In propria venit, et sui eum non receperunt. 12. Quotquot autem acceperunt eum, dedit eis potestatem filios Dei fieri, his, qui credunt in nomine eius, 13. qui non ex sanguinibus neque ex voluntate carnis neque ex voluntate viri, sed ex Deo nati sunt. 14. Et Verbum caro factum est et habitavit in nobis; et vidimus gloriam eius, gloriam quasi Unigeniti a Patre, plenum gratiae et veritatis. 15. Ioannes testimonium perhibet de ipso et clamat dicens: «Hic erat, quem dixi: Qui post me venturus est, ante me factus est, quia prior me erat». 16. Et de plenitudine eius nos omnes accepimus, et gratiam pro gratia; 17. quia lex per Moysen data est, gratia et veritas per Iesum Christum facta est. | 1. ин принци́пио э́рат вэ́рбум, эт вэ́рбум э́рат а́пуд дэ́ум, эт дэ́ус э́рат вэ́рбум |
 et lux in tenebris lucet, et tenebrae eam non comprehenderunt.
et lux in tenebris lucet, et tenebrae eam non comprehenderunt.
2. хок э́рат ин принци́пио а́пуд дэ́ум
3. о́мниа пэр и́псум фа́кта сунт, эт си́нэ и́псо фа́ктум эст ни́хиль квод фа́ктум эст
4. ин и́псо ви́та э́рат, эт ви́та э́рат люкс хо́минум
5. эт люкс ин тэнэ́брис лю́цет, эт тэнэ́брэ э́ам нон конпрэхэ́ндэрунт
6. фу́ит хо́мо ми́ссус а Дэ́о ку́и но́мэн э́рат Иоха́ннэс
7. хик вэ́нит ин тэстимо́ниум, ут тэстимониум пэрхи́бэрэт дэ лю́минэ, ут о́мнэс крэ́дэрэнт пэр и́ллум
8. нон э́рат и́ллэ люкс, сэд ут тэстимо́ниум пэрхи́бэрэт дэ лю́минэ
9. э́рат люкс квэ инлю́минат о́мнэ хо́минэм вэниэ́нтэм ин му́ндум
10. ин му́ндо э́рат, эт му́ндус пэр и́псум фа́ктус эст, эт му́ндус э́ум нон когно́вит
11. ин про́приа вэ́нит, эт су́и э́ум нон рэце́пэрунт
12.
13. кви нон экс сангви́нибус, нэ́квэ экс волю́нтатэ ка́рнис, нэ́квэ экс волю́нтатэ ви́ри, сэд экс Дэ́о на́ти сунт
14. эт Вэ́рбум ка́ро фа́ктум эст, эт хабита́вит ин но́бис, эт види́мус гло́риам э́йус, гло́риам ква́зи униге́нити а Па́трэ пле́нум гра́циэ эт вэрита́тис
15. Иоха́ннэс тэстимо́ниум пэрхи́бэт дэ и́псо эт кля́мат дице́нс, хик э́рат квэм ди́кси во́бис кви пост мэ вэ́нтурус эст, а́нтэ мэ фа́ктус эст, кви́а при́ор мэ э́рат
16. эт дэ плениту́динэ э́йус нос о́мнэс акце́пимус эт гра́циам про гра́циа
17. кви́а лекс пэр Мо́зэн да́та эст, эт вэ́ритас пэр Йэ́зум Хри́стум фа́кта эст
***
Немецкий
LESUNG AUS DEM HEILIGEN EVANGELIUM NACH JOHANNES
1 Im Amfang war das Wort, und das Wort war bei Gott, und Gott war das Wort.
2 Dasselbe war im Anfang bei Gott.
3 Alle Dinge sind durch dasselbe gemacht, und ohne dasselbe ist nichts gemacht, was gemacht ist.
4 In ihm war das Leben, und das Leben war das Licht der Menschen.
5 Und das Licht scheint in der Finsternis, und die Finsternis hat’s nicht begriffen.
6 Es ward ein Mensch, von Gott gesandt, der hieß Johannes.
7 Dieser kam zum Zeugnis, daß er von dem Licht zeugete, auf daß sie alle durch ihn glaubten.
8 Er war nicht das Licht, sondern daß er zeugete von dem Licht.
9 Das war das wahrhaftige Licht, welches alle Menschen erleuchtet, die in diese Welt kommen.
10 Es war in der Welt, und die Welt ist durch dasselbe gemacht; und die Welt kannte es nicht.
11 Er kam in sein Eigentum; und die Seinen nahmen ihn nicht auf.
12 Wie viele ihn aber aufnahmen, denen gab er Macht, Gottes Kinder zu warden, die an seinen Namen glauben;
13 Welche nicht von dem Geblüt noch von dem Willen des Fleisches noch von dem Willen eines Mannes, sondern von Gott geboren sind.
14 Und das Wort ward Fleisch und wohnte unter uns, und wir sahen seine Herrlichkeit, eine Herrlichkeit als des eingebornen Sohnes vom Vater, voller Gnade und Wahrheit.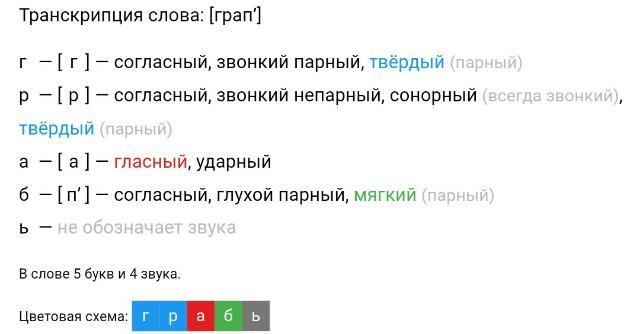
15 Johannes zeugt von ihm, ruft und spricht: Dieser war es, von dem ich gesagt habe: Nach mir wird kommen, der vor mir gewesen ist; den er war eher den ich.
16 Und von seiner Fülle haben wir alle genommen Gnade um Gnade.
17 Denn das Gesetz ist durch Mose gegeben; die Gnade und Wahrheit ist durch Jesum Christum geworden.
Транскрипция
1 им а́нфаŋ ваа дас воат, унт дас воат ваа бай гот, унт гот ваа дас ворт.
2 дасзэ́льбə ваа им а́нфаŋ бай гот.
3 а́лə ди́ŋə зинт дуаç дасзэ́льбə гəма́хт, унт о:нə дасзэ́льбə ист ниçтс гəма́хт, вас гəма́хт ист.
4 ин и:м ваа дас ле́:бəн, унт дас ле́:бəн ваа дас лиçт дэа мэ́ншəн.
5 унт дас лиçт шайнт ин дəа фи́нстэанис, унт ди фи́нстэанис hатс ниçт бəгри́фəн
6 эс ваат айн мэнш фон гот гəза́нт, дəа hи:с йоhа́нəс
7 ди́зəа кам цум цо́йкнис, дас э́а фон дэм лиçт цо́йктə, ауф дас зи: а́лə дуаç и:н гла́уптəн
8 э́а ваа ниçт дас лиçт, зо́ндəан дас э́а цо́йктə фон дəм лиçт
9 дас ваа дас ва́:аhафтигə лиçт, вэ́льçəс а́лə мэ́ншəн эало́йçтəт, ди ин ди́:зə вэльт ко́мəн
10 эс ваа ин дəа вэльт, унт ди вэльт ист дурç дасзэ́льбə гəма́хт, унт ди вэльт ка́нтə эс ниçт.
11 э́а ка:м ин зайн а́йгəнтум, унт ди за́йнəн на́:мəн и:н ниçт ауф
12 ви фи́:лə и:н а́бəа а́уфна:мəн, дэ́нəн га:п э́а махт ки́ндəа го́тəс цу вэ́адəн, ди ан за́йнəн на́:мəн гла́убəн,
13 вэ́льçə ниçт фон дəм гəблю́:т нох фон дəм ви́́лəн дəс фла́йшəс нох фон дəм ви́лəн а́йнəс ма́нəс, зо́ндəан фон гот гəбо́:ан зинт.
14 унт дас воат ваат флайш унт во́:нтə у́нəа унс, унт ви́а за́:əн за́йнə hэ́алиçкайт, а́йнə hэ́алиçкайт альс дəс а́йнгəборəнəн зо́:нəс фом фа́тəа, фо́лəа гна́:дə унт ва́:аhайт.
15 йоhа́нəс цойкт фон и:м, руфт унт шприхт, ди́:зəа ваа эс, фон дəм иç гəза́кт hа:бə, нах миа виат ко́мəн, дəа фоа миа гəве́:зəн ист, дэн э́а ваа э́:а альс иç
16 унт фон за́йнəа фю́лə hа́:бəн виа а́лə гəно́мəн гна́:дə ум гна́:дə
17 дэн дас гəзэ́ц ист дуаç мо́:зəс гəге́:бəн, ди гна́:дə унт ва́:аhайт ист дуаç йэ́зум кри́стум гəвоадəн
[ə] — редуцированный, очень краткий звук, почти исчезает.
[ç] — глухая параллель к звуку [j] , похож на очень мягкий русский [х]
[h] — звук на выдохе
[а] — вокализованый [r] (то же в английском), как очень неясный, исчезающий [а]
— долгий гласный
[ŋ] — носовой [n]
***
Украинский
1 Споконвіку було Слово, а Слово в Бога було, і Бог було Слово.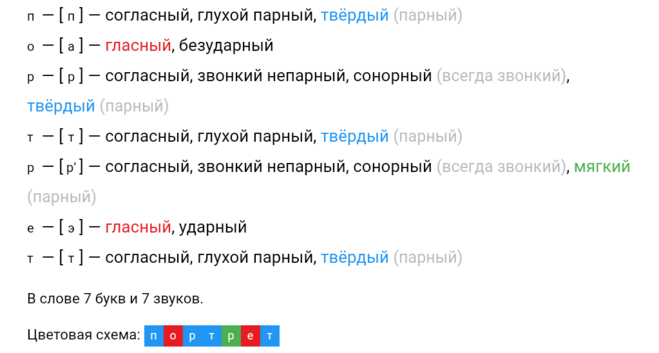
2 Воно в Бога було споконвіку.
3 Усе через Нього повстало, і ніщо, що повстало, не повстало без Нього.
4 І життя було в Нім, а життя було Світлом людей.
5 А Світло у темряві світить, і темрява не обгорнула його.
6 Був один чоловік, що від Бога був посланий, йому ймення Іван.
7 Він прийшов на свідоцтво, щоб засвідчити про Світло, щоб повірили всі через нього.
8 Він тим Світлом не був, але свідчити мав він про Світло.
9 Світлом правдивим був Той, Хто просвічує кожну людину, що приходить на світ.
10 Воно в світі було, і світ через Нього повстав, але світ не пізнав Його.
11 До свого Воно прибуло, та свої відцурались Його.
12 А всім, що Його прийняли, їм владу дало дітьми Божими стати, тим, що вірять у Ймення Його,
13 що не з крови, ані з пожадливости тіла, ані з пожадливости мужа, але народились від Бога.
14 І Слово сталося тілом, і перебувало між нами, повне благодаті та правди, і ми бачили славу Його, славу як Однородженого від Отця.
15 Іван свідчить про Нього, і кликав, говорячи: Це був Той, що про Нього казав я: Той, Хто прийде за мною, існував передо мною, бо був перше, ніж я.
16 А з Його повноти ми одержали всі, а то благодать на благодать.
17 Закон бо через Мойсея був даний, а благодать та правда з’явилися через Ісуса Христа.
***
Французский
LECTURE DU SAINT EVANGILE SELON SAINT JEAN
1 Au commencement était le Verbe, et le Verbe était avec Dieu, et le Verbe était Dieu.
2 Il était au commencement avec Dieu.
3 Toutes choses ont été faites par lui, et rien de ce qui a été fait nˋa été fait sans lui.
4 En lui était la vie, et la vie était la lumière des hommes.
5 Et la lumière luit dans les ténèbres, et les ténèbres ne lˋont point comprise.
6 Il y eut un homme, appelé Jean, qui fut envoyé de Dieu.
7 Il vint pour servir de témoin, et pour rendre témoignage à la lumière, afin que tous crussent par lui.
8 Il n’était pas la lumière, mais avait à rendre témoignage à la lumière.
9 Le Verbe était la vraie lumière, qui éclaire tout homme venant en ce monde.
10 Il était dans le monde, et le monde a été fait par lui, et le monde ne lˋa point connu.
11 Il est venu chez lui; et les siens ne lˋont point reçu.
12 Mais à tous ceux qui l’ont reçu, il a donné le pouvoir de devenir les enfants de Dieu, à ceux qui croient en son nom,
13 Lui qui n’est pas né du sang, ni de la volonté de la chair, ni de la volonté de lˋhomme, mais de Dieu.
14 Et le Verbe a été fait chair, et il a habité parmi nous, plein de grâce et de vérité; et nous avons vu sa gloire, gloire qu’il tient de son Père comme Fils Unique.
15 Jean rend témoignage de lui, et il crie, disant: C’est de lui que j’ai dit: Celui qui vient après moi, le voilà passé devant moi, parce quˋil était avant moi.
16 Et nous avons tous reçu de sa plénitude, et grâce pour grâce.
17 Car la loi a été donnée par Moïse; mais la grâce et la vérité sont venues par Jésus-Christ.
***
Зачало с вензелем
Фонетика.
 Звуки речи. Алфавит 5 класс онлайн-подготовка на Ростелеком Лицей
Звуки речи. Алфавит 5 класс онлайн-подготовка на Ростелеком ЛицейВведение
Изо дня в день мы произносим хорошо знакомые нам слова. Но очень редко задумываемся над тем, как это у нас получается. Например, как у нас получается произносить такое знакомое слово «здравствуйте»? Мы произносим определенное сочетание звуков, которое складывается в нашем сознании в соответствующее понятие. В слове «здравствуйте» мы произнесли 11 звуков. Три из них гласные звуки, 8 согласные. Все эти звуки произносятся нами в определенном порядке. Произносим мы не просто звуки, ведь звуками мы считаем и шум автомобиля, и скрип открывающейся двери, и лошадиный топот. Животные тоже производят самые различные звуки. Мы же произносим звуки, из которых состоят слова. Это звуки речи.
Фонетика. Звуки и буквы. Графика
Фонетика – раздел науки о языке, в котором изучаются звуки речи.
Звуки мы произносим и слышим. Но ведь мы умеем читать и писать. Видим и пишем мы буквы.
Видим и пишем мы буквы.
Графика – раздел науки о языке, изучающий обозначение буквами звуков речи на письме.
Алфавит
Алфавит – буквы, расположенные в определенном порядке.
В русском алфавите 33 буквы. 10 букв обозначают гласные звуки и 21 – согласные. Две буквы – ъ и ь – не обозначают звуков.
Рис. 1. Русский алфавит (Источник)
Знание алфавитного порядка поможет нам, например, сориентироваться в орфографическом или каком-либо другом словаре, в алфавитном порядке располагаются различные списки, например, фамилии учащихся в классном журнале.
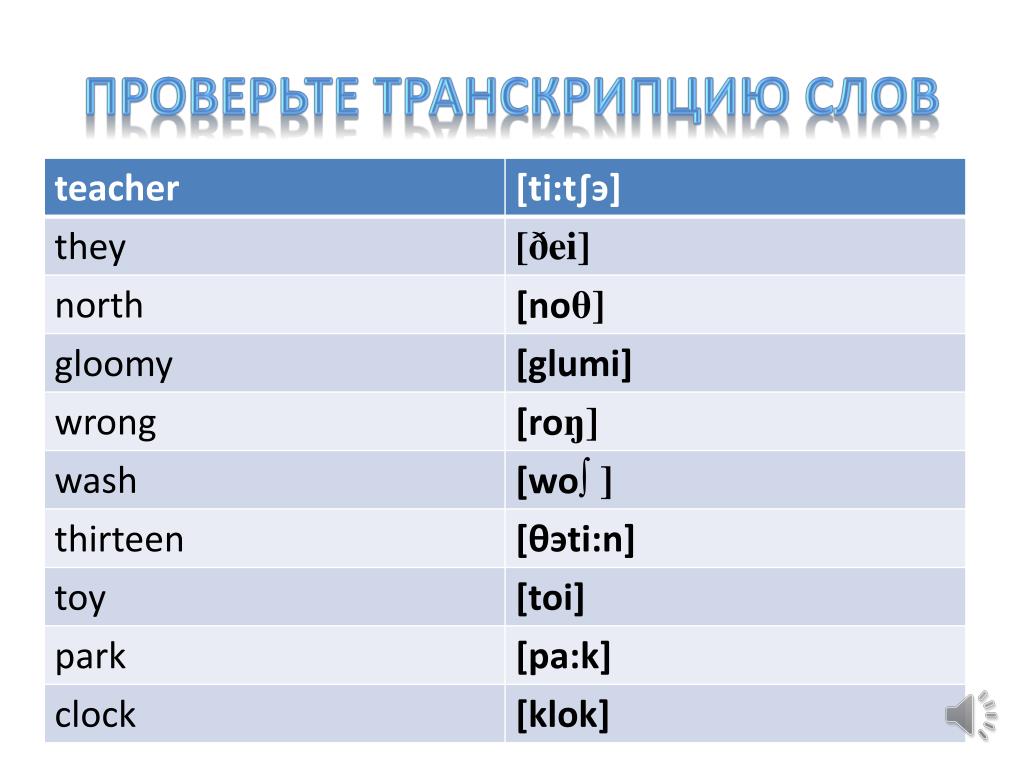
Транскрипция слова
Нам часто приходится запоминать правописание безударных гласных и удвоенных согласных. Почему нам приходится запоминать написание таких слов? Почему нам приходится искать проверочные слова и изучать большое количество правил орфографии? Всё потому, что произношение слова далеко не всегда совпадает с его написанием. И не всегда количество звуков и букв в слове одинаковое. И мы можем записать не только слово по правилам орфографии, но и с помощью букв и дополнительных знаков записать звучание слова. Такая «звуковая» запись называется транскрипцией.
И мы можем записать не только слово по правилам орфографии, но и с помощью букв и дополнительных знаков записать звучание слова. Такая «звуковая» запись называется транскрипцией.
Практическое наблюдение
Транскрипция слова записывается в квадратных скобках.
Транскрипция слова «молоко» – [ малако́ ]. Обратите внимание, что в безударном положении мы не произносим звук [о], а произносим звук [а]. В этом слове 6 букв и 6 звуков. Транскрипция слова «перила» – [ п’ир’и́ла ]. В безударном положении всегда произносится звук [и]. Кроме этого, вы видите специальные знаки в виде «запятой» вверху буквы. Это апостроф, он обозначает мягкость согласного.
Транскрипция слова «тень» –[т’эн’]. Обратите внимание на то, что буква е в этом слове передает звук [э]. Мягкий знак не обозначает букву. Таким образом, в этом слове 4 буквы, 3 звука.
Транскрипция слова «солнце» – [со́нцэ]. Здесь обращаем внимание на непроизносимый согласный. Звук [л] в этом слове мы не произносим, следовательно, и в транскрипции он не отображается. Таким образом, в слове 6 букв, 5 звуков.
Звук [л] в этом слове мы не произносим, следовательно, и в транскрипции он не отображается. Таким образом, в слове 6 букв, 5 звуков.
Транскрипция слова «ягода» – [j’а́гада]. В этом слове буква я обозначает два звука, поэтому в нем 5 букв, 6 звуков.
Звукопись
Возможно, вы заметили, что определенные звуки или их сочетания вызывают у нас ассоциации о том или ином явлении. Например, сочетание звуков [г] и [р] напоминает нам раскаты грома. В своем стихотворении Федор Тютчев специально повторяет сочетание этих звуков, чтобы создать образ грозы:
Люблю грозу в начале мая,
Когда весенний первый гром,
Как бы резвяся и играя,
Грохочет в небе голубом.
Гремят раскаты молодые…
Или отрывок из стихотворения Михаила Лермонтова. Поэт с помощью звука [л] передает образ текущей воды, плавные движения плывущей русалки:
Русалка плыла по реке голубой,
Озаряема полной луной;
И старалась она доплеснуть до луны
Серебристую пену волны.
Такое свойство выразительной речи называется звукописью.
Высокая музыкальность поэзии предполагает тонкое проникновение в особенности звучащей речи, в ее способность производить впечатление не только смыслом слов, но и их звучанием, их музыкой.
На досуге можете попробовать рассказать о каком-то явлении, используя звукопись. Или предложите в классе творческое соревнование на самое оригинальное использование звукописи.
Следует заметить, что возможность звукописи была давно замечена народом и нашла свое отражение в шуточных песенках, частушках и, конечно же, в скороговорках. Скороговорки придуманы не только для забавы, они помогают отработать хорошую дикцию. Сначала скороговорку произносят медленно, обращая особое внимание на сложные для произношения сочетания звуков. А затем скороговорку нужно произносить как можно быстрее, повторяя ее несколько раз.
От топота копыт пыль по полю летит.
Вёз корабль карамель, наскочил корабль на мель. И матросы две недели карамель на мели ели.
В поле полет Поля просо, а сорняки выносит Фрося.
Все бобры для своих бобрят добры.
Два щенка щека к щеке щиплют щетку в уголке.
Список литературы
- Русский язык. Теория. 5–9 кл.: В. В. Бабайцева, Л. Д. Чеснокова – М.: Дрофа, 2008.
- Русский язык. 5 кл.: под ред. М. М. Разумовской, П. А. Леканта – М.: Дрофа, 2010.
- Русский язык. Практика. 5 кл.: под ред. А. Ю. Купаловой. – М.: Дрофа, 2012.
Дополнительные рекомендованные ссылки на ресурсы Интернет
- Научно-образовательный портал «originweb.info». О происхождении русского алфавита (Источник)
- Энциклопедия Брокгауза Ф. А. и Ефрона И. А. Фонетика (Источник)
Домашнее задание
Задание № 1
Запишите транскрипцию данных слов и определите количество букв и звуков.
Якорь, молва, грустный, река.
Задание № 2
Запишите данные слова в алфавитном порядке.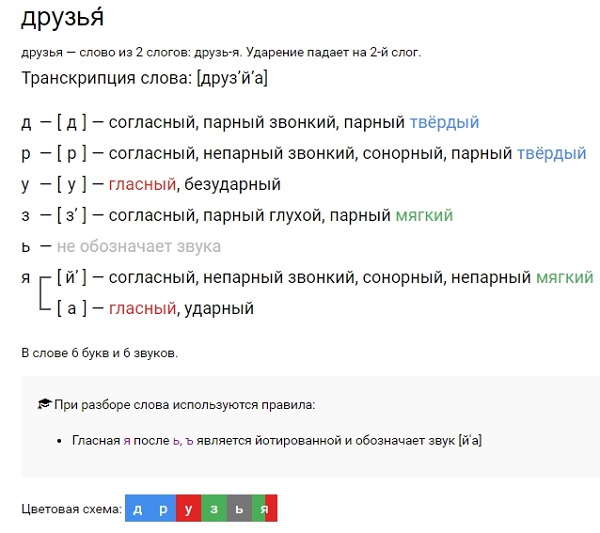 Если первая буква в разных словах одинаковая, следует смотреть на вторую букву, если и вторая одинаковая, то на третью. Запомните написание выделенных букв.
Если первая буква в разных словах одинаковая, следует смотреть на вторую букву, если и вторая одинаковая, то на третью. Запомните написание выделенных букв.
Винегрет, аккуратный, алфавит, путешествие, горизонт, хозяйство, директор, количество, пассажир, шоссе, чернила, коллекция, карикатура, авиация, одиннадцать, фиалка, акробат, долина.
Уникальные слова в разных языках
В каждом языке есть особенные слова, для перевода которых требуется либо описательная конструкция, либо сноска с толкованием. Но чаще переводчик подбирает самый близкий аналог из целевого языка, в определенной степени жертвуя семантическим богатством оригинала, зато выигрывая в скорости и доходчивости.
Плекайте мову пильно й ненастанно…
Украинские слова любов и кохання переводятся как любовь, love, amour, amore,… Даже искусный в любовной лексике французский язык не делает различий между любов’ю и коханням. А чего стоит слово наснага! Мало сказать, что оно означает вдохновение, на это в украинском языке есть натхнення. Это нечто большее, этимологически происходящее от древнего слова снага. Оно означает душевный подъем, творческий запал, обилие физической и духовной энергии одновременно. Мне чудится здесь древний санскритский корень -наг-, но утверждать не берусь. Так далеко мой скромный обзор не заходит! В украинском языке есть целый пласт слов, которые своею емкостью могут поставить переводчика в тупик: шануватися (шануймося, браття!), небокрай, митець, вирій, шубовснути, викохувати, плекати,…
А чего стоит слово наснага! Мало сказать, что оно означает вдохновение, на это в украинском языке есть натхнення. Это нечто большее, этимологически происходящее от древнего слова снага. Оно означает душевный подъем, творческий запал, обилие физической и духовной энергии одновременно. Мне чудится здесь древний санскритский корень -наг-, но утверждать не берусь. Так далеко мой скромный обзор не заходит! В украинском языке есть целый пласт слов, которые своею емкостью могут поставить переводчика в тупик: шануватися (шануймося, браття!), небокрай, митець, вирій, шубовснути, викохувати, плекати,…
Вы когда-нибудь испытывали такие чувства, как onsra, oodal, gigil? Сто процентов испытывали, но вряд ли могли вместить их описание в одно слово. В 2015 году преподаватель психологии из East London University Тим Ломас начал проект The Positive Lexicography, нацеленный на сбор уникальных слов и выражений, которые отражают яркие эмоции, оттенки любви и привязанности, тонкости мироощущения, удовольствие и радость в разных языках. Его список насчитывает более 400 слов из шестидесяти двух языков. По мнению Ломаса, мы не испытываем некоторые эмоции только потому, что не придумали им названия. Суметь назвать – значит, осознать, ощутить. Нейробиолог Лиза Фельдман Баррет из Northeastern University, на работы которой ссылается автор проекта, утверждает, что чем точнее человек определяет («детализирует») свои чувства, тем проще он справляется со стрессовой ситуацией, ими вызванной. Исследователь Марк Бракет (Yale University) предположил, что освоение новой «лексики эмоций» улучшит социализацию и школьные результаты детей. Он провел эксперимент с группой детей в возрасте 10-11 лет: те, кто заучивал новые слова из словаря эмоций показали рост успеваемости и снижение конфликтности. Как видим, проект преследует более масштабные цели, чем чисто лингвистический интерес к уникальным словам.
Его список насчитывает более 400 слов из шестидесяти двух языков. По мнению Ломаса, мы не испытываем некоторые эмоции только потому, что не придумали им названия. Суметь назвать – значит, осознать, ощутить. Нейробиолог Лиза Фельдман Баррет из Northeastern University, на работы которой ссылается автор проекта, утверждает, что чем точнее человек определяет («детализирует») свои чувства, тем проще он справляется со стрессовой ситуацией, ими вызванной. Исследователь Марк Бракет (Yale University) предположил, что освоение новой «лексики эмоций» улучшит социализацию и школьные результаты детей. Он провел эксперимент с группой детей в возрасте 10-11 лет: те, кто заучивал новые слова из словаря эмоций показали рост успеваемости и снижение конфликтности. Как видим, проект преследует более масштабные цели, чем чисто лингвистический интерес к уникальным словам.
Идея начать исследование пришла к Тиму Ломасу на IV Международном конгрессе по позитивной психологии с подачи финской исследовательницы, рассказавшей о слове sisu [сису]. Оно означает сложное сочетание выдержки, упорства с переходом в упрямство, выносливости, стойкости, настойчивости, мужества, смелости и прямолинейности. Слово-символ Финляндии. Согласно Википедии, его можно описать приблизительно так: Что должно быть сделано – то будет сделано, несмотря ни на что. Тим Ломас был настолько заинтригован непереводимостью этого термина, вернее, отсутствием прямых соответствий в английском языке, что решил посвятить этой теме отдельное исследование.
Оно означает сложное сочетание выдержки, упорства с переходом в упрямство, выносливости, стойкости, настойчивости, мужества, смелости и прямолинейности. Слово-символ Финляндии. Согласно Википедии, его можно описать приблизительно так: Что должно быть сделано – то будет сделано, несмотря ни на что. Тим Ломас был настолько заинтригован непереводимостью этого термина, вернее, отсутствием прямых соответствий в английском языке, что решил посвятить этой теме отдельное исследование.
Пожалуй, самая интересная часть подобного исследования – примеры! Наша подборка создана на основе словаря Тима Ломаса и других открытых источников. Например, франкоязычные и италоязычные ресурсы предлагают массу собственных вариантов. Пытливому уму интересно всё, поэтому предлагаем вам, дорогие читатели, насладиться семантическим богатством других языков, прочувствовать глубину и чуткость мировосприятия в других культурах. Приятного путешествия в мир уникальных слов! P.S. Скандинавская лексика вынесена в отдельный раздел – она того заслуживает))))
Oodal
Притворный гнев влюбленных. Конфликт называется oodal только, если он улетучивается быстро, как обида ребенка (тамильский язык, Индия)
Конфликт называется oodal только, если он улетучивается быстро, как обида ребенка (тамильский язык, Индия)
Onsra
Горько-сладкое ощущение, что любовь будет недолгой (язык боро, Индия, Непал)
Gigil
Непреодолимое желание ущипнуть или потискать того, кого любишь (тагальский язык, Филиппины)
Cafuné
Нежное касание руками волос любимого человека (бразильский португальский)
Mbuki—mvuki
Сбрасывание одежды перед танцем (язык банту, Африка)
Tarab
Состояние экстаза от музыки (арабский язык)
Duende
Таинственная сила, которая может заставить человека выйти за пределы собственного «я» в любом виде творчества. Это не муза, а нечто внутреннее, прорывающееся из недр человеческого естества (знаковое слово для Ф.Г.Лорки, испанский язык)
Iktsuarpok
То чувство, когда ты кого-то ждешь и постоянно смотришь в окно (эскимосский язык)
Mamihlapinatapei
Взгляд, которым смотрят друг на друга симпатизирующие люди, но каждый хочет, чтобы инициатором первого шага стал другой. Слово занесено в Книгу рекордов Гиннеса, как «самое емкое слово» (яганский язык, Огненная Земля)
Слово занесено в Книгу рекордов Гиннеса, как «самое емкое слово» (яганский язык, Огненная Земля)
Tsundoku
Привычка покупать и накапливать книги, не читая их (японский язык)
Datzuzoku
Трансцендентная свобода от рутины, законов и ограничений. Готовность к чистому творчеству (японский язык)
Guru
Братская дружба с оттенком восхищения (бенгальский язык, не путать с санскритом, где это слово означает «духовный наставник»)
Abbiocco
Дремотное состояние после еды, отбирающее всю жизненную энергию. Больше, чем просто сонливость (диалектизм, распространенный в современном итальянском языке)
Apericena
Аперитив перед ужином (итальянский язык)
Dadirri
Духовное действо, заключающееся в уважительном и вдумчивом выслушивании (язык одного из племен Австралии)
Aware
Печальное очарование, вызванное трансцендентной красотой (японский язык)
Desenrascanço
Искусство красиво выходить из сложной ситуации (португальский язык)
Thróisma
Звук ветра, шелестящего в деревьях (греческий язык)
Shinrin-yoku
буквально “купание в лесу”, расслабленность от общения с природой (японский язык)
Yuan bei
ощущение, что вы выполнили задание полностью и совершенно (китайский язык)
Wabi-sabi
Красота несовершенства, быстротечности бытия (японский язык)
Gumusservi
Мерцание лунного света на водной глади (турецкий язык)
Jayus
Шутка, которая настолько не смешна (или так бездарно рассказана), что не остается ничего другого, как посмеяться (индонезийский язык)
Schnapsidee
Идея, навеянная шнапсом (немецкий язык)
Sobremesa
Момент, когда совместная трапеза уже закончена, но все еще сидят, оживленно разговаривая, перед пустыми тарелками (испанский язык)
Uitwaaien
Чувство свежести после прогулки в ветреную погоду (голландский язык)
Kilig
Лёгкое дрожание в коленях при разговоре с тем, кто вам нравится (тагальский язык)
Retrouvailles
Счастье от встречи после долгой разлуки (французский язык)
Manabamáte
Отсутствие аппетита в связи с влюбленностью (язык Острова Пасхи)
Viraha
Осознание любви благодаря разлуке (хинди)
Bricolage
Искусство создавать нечто полезное буквально из ничего (французский язык)
Frisson
Сочетание возбуждения, ожидания и страха (французский язык)
Bon vivant
Любитель жизни, кутила (французский язык)
Надеюсь, этот перечень не вогнал читателя в состояние abbiocco и не вызвал Iktsuarpok в ожидании его завершения. Все примеры настолько «вкусные», что выбрать какой-то список фаворитов просто невозможно. Поверьте, за бортом осталось еще множество интереснейших слов со всех уголков земного шара. А нас ждет продолжение в духе скандинавского «хюгге».
Все примеры настолько «вкусные», что выбрать какой-то список фаворитов просто невозможно. Поверьте, за бортом осталось еще множество интереснейших слов со всех уголков земного шара. А нас ждет продолжение в духе скандинавского «хюгге».
Начнем с самого утра, а вернее, с кукушечьего утра)))
Gökotta [yeuh—kottah]
Каюсь, попытки прослушать произношение этого слова, причем, в двух вариантах (вероятно, в двух диалектах) не приблизили меня к пониманию его фонетики. Это так красиво, что захотелось выучить шведский))) Но еще более интригующим оказалось его значение: проснуться на рассвете, чтобы пойти послушать пение птиц. На одном франкоязычном ресурсе мне попалось очень поэтическое толкование, настоящий образец произведений Серебряного века: утренняя прогулка по лесу с целью устроить пикник на поляне, при этом гуляющие надеются услышать вернувшихся из теплых стран кукушек (в праздник Вознесения), которые предскажут им удачу или неудачу. И это все gökotta!
И это все gökotta!
Lagom
Философия счастья у шведов, означает баланс и умеренность во всем. Если не придерживаться lagom, то может произойти
Morkkis
Смущенье, стыд, «психологическое похмелье» из-за поведения накануне (финский язык)
Utepils [утэпильс]
Пить пиво в хорошую погоду на улице и всецело наслаждаться процессом (норвежский язык). Чтобы понять этот феномен, обратите внимание на ключевые условия наслаждения: в хорошую погоду и на улице))))
Arbejdsglaede [арбайсглед]
Радость от работы (датский язык). В данном случае, речь следует вести не о непереводимости слова (на самом деле, непереводимых слов нет), а о наличии самого понятия «радость от работы» в другой культуре и, соответственно, языке. Не формального присутствия, а ментального)))
Serieotrohet [сериэутрухет]
Шведский неологизм: вы посмотрели новую серию любимого сериала без своего партнера, хотя ранее делали это вместе.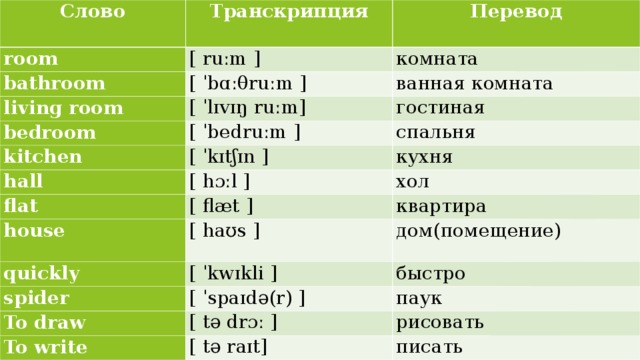 И вам от этого неловко)))
И вам от этого неловко)))
Fika [фика]
Кофе-пауза, когда шведы пьют любимый напиток в кругу коллег, друзей, семьи. Зачастую со сладостями. Выпить кофе на ходу – никакая не фика)))) Это явление стало неотъемлемой частью шведской культуры. В 2007 г. жители города Кальмар установили рекорд, организовав фику с участием 2620 человек. Правда, спустя два года жители города Эстерсунд этот рекорд побили, собрав на фику почти 4000 человек!
Hygge [хюгге]
Чувство уюта и психологического комфорта. Словарь Collins English Dictionary: «понятие, возникшее в Дании, которое заключается в создании уютной и дружеской атмосферы, способствующей благополучию». Основатель датского Института исследования счастья (!) написал книгу Hygge. Секрет датского счастья, где он сформулировал 8 советов достижения хюгге. Любопытно, что это слово имеет одинаковое значение в датском и норвежском языках, но символом национальной культуры оно стало только в Дании, приобретя особое имплицитное значение.
В заключении хочется процитировать Тима Ломаса, ведь он надеется, что задуманный им словарь эмоций сделает людей богаче в плане жизненного опыта, поможет понять самих себя, позволит увидеть мир другими глазами: “Из всех терминов, которые я нашёл, чаще всего я размышляю о японском понятии wabi-sabi. Оно импонирует мне идеей поиска красоты в несовершенстве и скоротечности мира. Если бы мы видели жизнь в таком свете, возможно, проживали бы её совершенно иначе”.
Поддержите нас в соцсетях:
17 синонимов и антонимов слова ТРАНСКРИПЦИЯ
существительное
Сохранить словоКак и в Copy , Transcript
- Копия,
- Транскрипт
- Цитата,
- Цитата
- Пафраза,
- Rephrasing,
- Restatement,
- .
 0012
0012 - restating,
- rewording,
- translating,
- translation
- rehash
- abstract,
- recap,
- recapitulation,
- reiteration,
- summary
See the Dictionary Definition
Поделиться транскрипция
Разместите больше слов для транскрипции на Facebook Поделитесь другими словами для транскрипции в Твиттере
Путешественник во времени для транскрипции
Первое известное использование транскрипции
было в 1598Другие слова из того же года
Тезаурус Записи рядом с
транскрипциястенограмма
транскрипция
транскрипционист
Просмотреть другие записи рядомПроцитировать эту запись
«Транскрипция». Merriam-Webster.com Тезаурус , Merriam-Webster, https://www.merriam-webster.com/thesaurus/transcription. По состоянию на 8 октября 2022 г.
Merriam-Webster.com Тезаурус , Merriam-Webster, https://www.merriam-webster.com/thesaurus/transcription. По состоянию на 8 октября 2022 г.
Стиль: MLA
Merriam-Webster.com Thesaurus, Merriam-Webster, https://www.merriam-webster.com/thesaurus/transcription. По состоянию на 8 октября 2022 г.»> MLA Merriam-Webster.com Тезаурус, с.в. «транскрипция», по состоянию на 8 октября 2022 г., https://www.merriam-webster.com/thesaurus/transcription.»>Chicago Тезаурус Merriam-Webster.com. Получено 8 октября 2022 г. с https://www.merriam-webster.com/thesaurus/transcription»>APA. Merriam-Webster.com Thesaurus, https://www.merriam-webster.com/thesaurus/transcription. По состоянию на 08.10.2022.»> Merriam-Webster
Подробнее от Merriam-Webster о транскрипции
Нглиш: перевод транскрипции для говорящих на испанском языке
СЛОВО ДНЯ
шпиль
См. Определения и примеры »
Определения и примеры »
Получайте ежедневно по электронной почте Слово дня!
Проверьте свой словарный запас
Слова, названные в честь людей
- Тезка купальника , какая профессия была у Жюля Леотара?
- Акробат Хирург
- Судья Пожарный
Проверьте свой визуальный словарный запас, ответив на 10 вопросов!
ПРОЙДИТЕ ТЕСТ
Ежедневное задание для любителей кроссвордов.
ПРОЙДИТЕ ТЕСТ
Подпишитесь на крупнейший словарь Америки и получите тысячи дополнительных определений и расширенный поиск без рекламы!
Merriam-Webster без сокращений
Слова в игре
«Дундерхед» и другие «приятные» способы сказать «глупый»
На примере некоторых очень умных щенков
10 слов из географических названий
Бикини, бурбон и бадминтон заняли первые места
«Гордость»: слово, которое превратилось из порока в силу
Вы гордитесь Прайдом?
Когда впервые были использованы слова?
Найдите любой год, чтобы узнать
Спросите у редакторов
Буквально
Как использовать слово, которое (буквально) приводит некоторых людей в.
..«Все интенсивные цели» или «Все намерения и цели»?
Мы намерены разобраться
Лэй против лжи
Редактор Эмили Брюстер разъясняет разницу.
горячий беспорядок
«Публика в беспорядке»
 ..
..Игра слов
Мегавикторина «Назови эту вещь»: Vol. 2
Проверьте свой визуальный словарный запас!
Пройди тест
Любимые новые слова в словаре
Повысьте свой словарный запас с помощью этих новых слов.
..Пройдите тест
Назовите эту вещь
Проверьте свой визуальный словарный запас, ответив на 10 вопросов…
Пройдите тест
Орфографическая викторина
Сможете ли вы превзойти прошлых победителей национального конкурса Spelli…
Примите участие в викторине
Голосовые команды и транскрипции в Microsoft Word
Используйте силу своего голоса
Сейчас, больше, чем когда-либо, мы все очень заняты — жонглируем семьей, работой, друзьями и всем остальным, что бросает нам жизнь. Новые улучшения в Office используют платформу искусственного интеллекта Azure Cognitive Services, поэтому вы можете использовать силу своего голоса, чтобы тратить меньше времени и энергии на создание лучшей работы и сосредоточиться на самом важном.
Экономьте время и создавайте отличный контент с помощью Transcribe в Word для Интернета
Являетесь ли вы репортером, проводящим интервью, исследователем, записывающим сеансы фокус-группы, или онлайн-предпринимателем, записывающим неформальные обсуждения, вы хотите иметь возможность сосредоточиться на людей, с которыми вы разговариваете, не беспокоясь о том, чтобы делать заметки и не тратя часы на расшифровку ваших разговоров постфактум. Если это похоже на вас, вам поможет Transcribe в Word.
Теперь вы можете записывать свои разговоры прямо в Word для Интернета и автоматически расшифровывать их. Transcribe обнаруживает разных говорящих, поэтому после завершения записи вы можете легко следить за ходом стенограммы. После разговора вы можете вернуться к частям записи, воспроизведя аудио с отметкой времени, и даже отредактировать расшифровку, если заметите, что что-то не так.
Ваша расшифровка будет отображаться рядом с документом Word вместе с записью, что позволит вам использовать расшифровку для создания отличного контента удобным для вас способом.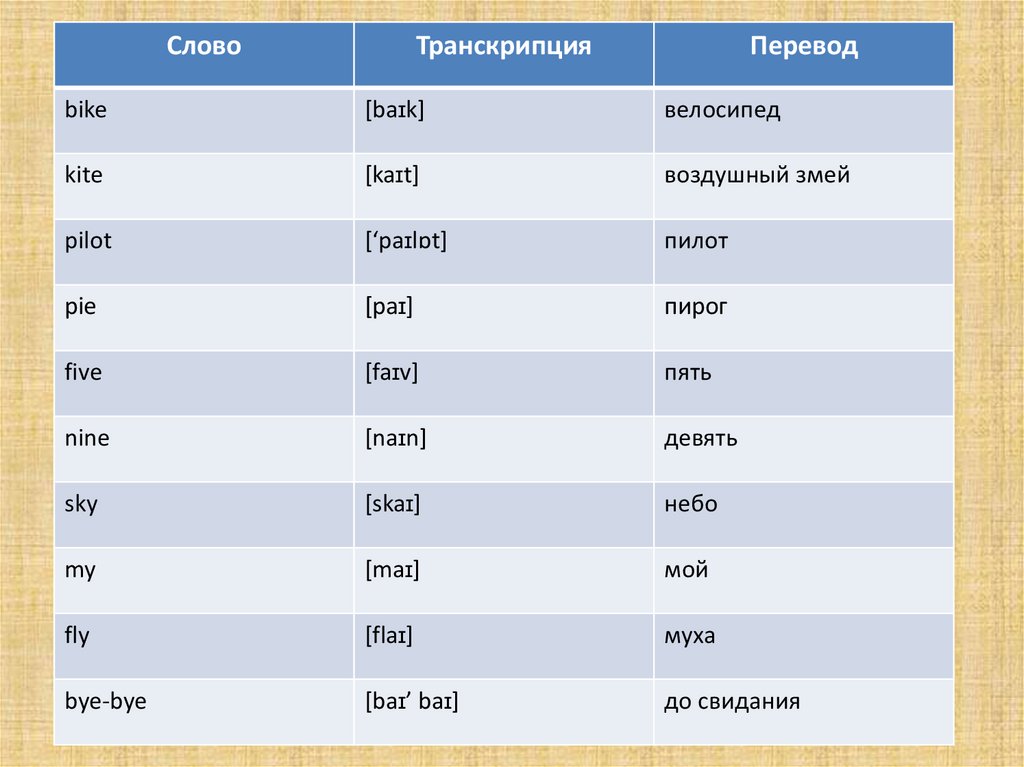 Допустим, вы хотите взять идеальную цитату из интервью, чтобы поддержать основную мысль вашей истории. Просто нажмите значок плюса в любой строке стенограммы, и вуаля, точная цитата будет вставлена. Хотите отправить всю расшифровку своему коллеге? Просто нажмите «добавить все в документ», и ваша полная стенограмма будет размещена в Word.
Допустим, вы хотите взять идеальную цитату из интервью, чтобы поддержать основную мысль вашей истории. Просто нажмите значок плюса в любой строке стенограммы, и вуаля, точная цитата будет вставлена. Хотите отправить всю расшифровку своему коллеге? Просто нажмите «добавить все в документ», и ваша полная стенограмма будет размещена в Word.
Как и многие люди, вы можете использовать различные инструменты для выполнения работы, поэтому Transcribe позволяет загружать аудио или видео, записанные вне Word. Независимо от того, записываете ли вы на свой телефон или через одно из множества приложений для звонков и видеоконференций, вы можете просто выбрать файл для загрузки и расшифровки. Transcribe поддерживает файлы .mp3, .wav, .m4a или .mp4.
Расшифровка в Word сегодня доступна в Word для Интернета для всех подписчиков Microsoft 365 и поддерживается в новых браузерах Microsoft Edge или Chrome. С Transcribe вы совершенно не ограничены в том, сколько вы можете записывать и транскрибировать в Word для Интернета. В настоящее время существует ограничение на пять часов в месяц для загружаемых записей, а размер каждой загружаемой записи ограничен 200 МБ. Transcribe в Office Mobile появится к концу года! В настоящее время транскрипция аудио на английский (EN-US) является единственным поддерживаемым языком, но мы работаем над поддержкой других языков.
В настоящее время существует ограничение на пять часов в месяц для загружаемых записей, а размер каждой загружаемой записи ограничен 200 МБ. Transcribe в Office Mobile появится к концу года! В настоящее время транскрипция аудио на английский (EN-US) является единственным поддерживаемым языком, но мы работаем над поддержкой других языков.
Расшифровка в Word позволяет вам сосредоточиться на разговоре в данный момент, экономит ваше драгоценное время и энергию, расшифровывая его для вас, и интегрирована в Word, чтобы вы могли сосредоточиться на сообщении своего документа, а не суетиться с различными окна или приложения.
Откажитесь от клавиатуры, используя диктовку с помощью голосовых команд.
С тех пор, как на сцену вышел Диктат, миллионы людей использовали силу своего голоса, чтобы покорить пустую страницу. Если вы застряли в машине, чтобы забрать еду на вынос, на короткой прогулке, чтобы размять ноги, у вас есть временная или постоянная инвалидность, из-за которой сложно печатать, или вы просто лучше думаете в пути, вам нужна гибкость, чтобы переходить в любое время. ваш день, пока все успеваете. Мы добавили в Диктовку голосовые команды, чтобы вы могли оторваться от клавиатуры. Будь то настольный компьютер или мобильный телефон (или переходя между устройствами), вы можете оставаться в потоке и сосредоточиться на своем сообщении, используя диктовку с голосовыми командами для добавления, форматирования, редактирования и организации текста.
ваш день, пока все успеваете. Мы добавили в Диктовку голосовые команды, чтобы вы могли оторваться от клавиатуры. Будь то настольный компьютер или мобильный телефон (или переходя между устройствами), вы можете оставаться в потоке и сосредоточиться на своем сообщении, используя диктовку с голосовыми командами для добавления, форматирования, редактирования и организации текста.
Произнесите такие слова, как «стартовый список» или «выделение жирным шрифтом в последнем предложении», чтобы дать волю своим идеям, не останавливаясь для корректировки текста. Голосовые команды понимают различные символы, поэтому вы можете добавлять такие слова, как «амперсанд» и «знак процента», и вам не нужно говорить как робот! Мы создали команды на основе того, как люди обычно говорят, чтобы вы могли легко фиксировать свои идеи. Так что такие вещи, как «точка-точка-точка», когда вы не можете вспомнить «многоточие», работают так же хорошо.
Поскольку вы постоянно совмещаете работу и жизнь, вы можете получить тот телефонный звонок, которого ждали, работая над своей статьей. Не нужно в панике бросаться к клавиатуре. Просто скажите «приостановить диктовку» и примите вызов. Работаете с другими в документе? Вы также можете сотрудничать, используя свой голос — скажите «добавить комментарий [с вашим контентом здесь]» и запишите свое сообщение одним кадром, не упустив ни единого шага.
Не нужно в панике бросаться к клавиатуре. Просто скажите «приостановить диктовку» и примите вызов. Работаете с другими в документе? Вы также можете сотрудничать, используя свой голос — скажите «добавить комментарий [с вашим контентом здесь]» и запишите свое сообщение одним кадром, не упустив ни единого шага.
Диктовка также может помочь в неформальной переписке — иногда сообщение нуждается в индивидуальности! Теперь вы можете сказать такие слова, как «смайлик» или «эмодзи в виде сердца», чтобы придать своему сообщению дополнительный штрих. В этой статье есть список всех голосовых команд.
Диктовка с помощью голосовых команд в Word доступна в Word для Интернета и Office для мобильных устройств бесплатно при входе в учетную запись Microsoft. Голосовые команды появятся в Word для настольных ПК и в приложениях Word для Mac ближе к концу года для подписчиков Microsoft 365.
Мы надеемся, что эти новые голосовые возможности сэкономят ваше время и обеспечат гибкость, необходимую вам в течение рабочего дня!
Транскрипция
Транскрипция- Виды транскрипции: узкая и широкая
- Предложения/рекомендации по улучшению транскрипции
- Распространенные ошибки
- Гласные в безударных слогах
Виды транскрипций
Нет такого понятия, как транскрипция слова. Строго
говоря, можно только расшифровать, как, например, Кевин Рассел произносил
это слово cat в 12:58:03 15 января 1997 года. Вы можете
записать это высказывание как можно точнее, в пределах
ваше слушание и соглашения, установленные IPA.
Строго
говоря, можно только расшифровать, как, например, Кевин Рассел произносил
это слово cat в 12:58:03 15 января 1997 года. Вы можете
записать это высказывание как можно точнее, в пределах
ваше слушание и соглашения, установленные IPA.Если вы хотите пойти дальше этого, попробуйте описать, как Кевин Рассел произносит это слово в целом, или еще больше того, как англоговорящие произносите его вообще, тогда вы должны начать делать абстракции — вы должны решить, какие детали включить, а какие игнорировать.
Обычно различают два вида транскрипции на основе сколько деталей транскрибаторы решают игнорировать:
- Узкая транскрипция: охватывает как можно больше аспектов определенного произношение настолько, насколько это возможно, и игнорирует как можно меньше деталей. С использованием диакритические знаки, представленные в IPA, можно сделать очень тонкими различия между звуками.
- Широкая транскрипция (или фонематическая транскрипция): игнорирует как можно больше
как можно больше деталей, фиксируя только те аспекты произношения, которые необходимы для
показать, чем это слово отличается от других слов в языке.

- Для английского языка узкая транскрипция заметит разницу между [i] и [], и возможно, и более тонкие детали. Широкая транскрипция также нужно отметить разницу, потому что два слова означают разные вещи.
- Для канадского французского языка в узкой транскрипции будет указано разница. И [i], и [] встречаются в языке, но никогда не противопоставляются .0 , что то есть они вызывают разницу в значении, поэтому широкая транскрипция может игнорируйте разницу и пишите оба как [liv]. [Сноска]
С имеющимися у нас символами мы можем делать широкие транскрипции. канадского английского.
Сноска: Ну а если нет разница в значении между ними, то почему бы не написать [lv]?
На самом деле это было бы совершенно законно. Но один из невысказанных Принципы широкой транскрипции заключаются в том, что когда вам предоставляется выбор между двумя символами и при прочих равных условиях (иногда даже если это не так), вы выберете тот, который легче напечатать.

Предложения/рекомендации по улучшению транскрипции
Вот несколько предложений, которые некоторые люди оказались полезными для получения более точной широкой транскрипции английского.- Представьте, что вы не умеете писать по буквам (например, рекламный
должностное лицо). Как бы вы написали это слово с ошибкой, если бы захотели
намеренно ошиблись? Например, вы можете ошибиться в написании рыцарь как ночь или ночь — что дает вам
некоторые подсказки о том, какие звуки действительно существуют, а какие нет.
- Сравните это слово с другими словами, транскрипцию которых вы
более уверен в. Если два слова являются омонимами, их транскрипция
должны быть идентичными. Если два слова рифмуются, их транскрипция
должно закончиться так же.
- Определите, сколько звуков в слове и какие звуки
звук, как прежде, чем вы будете беспокоиться о том, какие символы использовать для звуков.
- Мы читаем слева направо — нет закона, который нужно писать
туда. Не думайте, что вам нужно получить символ для одного звука
идеально, прежде чем перейти к следующему. Если вы знаете первый
согласная и последняя согласная, но не уверены в гласной в
середину, запиши согласные на бумаге и позаботься о
гласная позже.
- Если вы не уверены в отдельном звуке, рассмотрите другие
слова, в которых встречается этот звук. Например, если вы не уверены
какой символ использовать для гласной, какое слово вы получите, если вы
поставить эту гласную между h_d или b_t ?
- Прочтите свою транскрипцию вслух. Убедитесь, что он говорит
что вы думаете, что это говорит.
- Когда вы читаете свою транскрипцию вслух, притворитесь,
ты очень глупый компьютер, который не может ничего больше, чем
воспроизводить небольшие звуковые клипы один за другим. Если единственное
что звучит странно в вашем чтении, так это паузы ([d —
—
г]), то
Ваша транскрипция, вероятно, правильная. Если это звучит как
компьютер пытается сказать другое слово или бессмысленное слово ([d
— о — г]), попробуйте еще раз.
- Обратите внимание на то, что вы делаете со своим телом. Часто
фонетики, которые пытаются транскрибировать незнакомый звук
будут максимально точно имитировать звук, а затем выбирать
символ больше на основе того, что они делают со своим вокалом
тракт во время имитации, чем на то, как это звучит. Если это
Разве не ощущается как как [n], если тело вашего языка
касаться мягкого неба, а не касаться кончика языка
сразу за зубами, то это не [н].
- Упражняться. Упражняться. Упражняться.
- Выполните упражнения из учебника.
- Получите больше учебников. Делайте их упражнения тоже.
- Выполняйте упражнения на веб-странице.
- Записывайте слова в уме, пока ждете автобус.
- Пишите списки покупок в IPA.
- Напишите свой дневник в IPA.
- Читать истории в IPA всякий раз, когда у вас бессонница.
- …
 Не думайте, что вам нужно получить символ для одного звука
идеально, прежде чем перейти к следующему. Если вы знаете первый
согласная и последняя согласная, но не уверены в гласной в
середину, запиши согласные на бумаге и позаботься о
гласная позже.
Не думайте, что вам нужно получить символ для одного звука
идеально, прежде чем перейти к следующему. Если вы знаете первый
согласная и последняя согласная, но не уверены в гласной в
середину, запиши согласные на бумаге и позаботься о
гласная позже. 
Некоторые распространенные ошибки
Квадратные скобки
Всегда используйте квадратные скобки вокруг ваших транскрипций в чтобы отличить их от обычного текста.
немые письма
Нет такой вещи, как непроизносимый символ в фонетическая транскрипция.[с]
Символ IPA [c] представляет звук, который вы издаете с помощью тело языка касается твердого неба. Английский не использует это звук. Если у вас возникнет соблазн использовать [c] при расшифровке речь нормального носителя английского языка, вы почти наверняка неправильный.нг, нк
Звук, обычно записываемый как ng , имеет символ []. Ты не следует добавлять [g], если на самом деле не произносится [g] — это больше похоже на певца или на палец ? Кластеры пишутся нк (и часто нк ) также обычно есть этот звук: [к].и
Помните: и — это [j], а j — это [d].Отличники
Будьте осторожны, не перепутайте «машинописный» [а] и «сценарный» []. Эти звуки произносятся по-разному. В некоторых языках переключение одно за другим может изменить значение слова.Заглавные буквы
Не используйте заглавные буквы там, где английские правила правописания делать.