База данных результатов разбора | Робот Ф-2
Все разборы предложений хранятся в базе данных Emotional.
fact_valencies (факты и семантические валентности)
Это центральная таблица базы, в ней хранятся семантические разборы предложений. Одна строка таблицы – один сегмент структуры: слово-вершина этого сегмента (поле lemma), семантическая валентность (valency_alias), которую этот сегмент занимает в этом факте (fact).
Поля таблицы fact_valencies:
- id, int
- fact, int, id факта (поле id из таблицы facts)
- referent, int, референт (поле id из таблицы referents)
- valency_id, int, id семантической валентности
- valency_alias, varchar, название семантической валентности
- lemma_id, int, id леммы
- lemma, varchar, лемма
- wordform_id, int, id словоформы
- wordform, varchar, словоформа
Запрос, который выводит все предикаты, которые есть в базе, с указанием id факта:
select lemma, fact
from fact_valencies
where valency_alias = 'p'Результат:
| lemma | fact |
|---|---|
| превращаться | 3602304 |
| перевезти | 3602363 |
| смочь | 3602378 |
| мочь | 3602381 |
| подумать | 3602386 |
Объединив таблицу саму с собой, можно делать более сложные запросы. Например, вывести всё, что пьют, для этого нужно найти все факты, в которых место предиката занимает лемма пить, после чего вывести значения лемм, занимающих в этих фактах место пациенса (в конструкции пить Икс Икс занимает валентность пациенса при предикате пить).
Например, вывести всё, что пьют, для этого нужно найти все факты, в которых место предиката занимает лемма пить, после чего вывести значения лемм, занимающих в этих фактах место пациенса (в конструкции пить Икс Икс занимает валентность пациенса при предикате пить).
select FV2.fact, FV2.lemma
from fact_valencies FV1
join fact_valencies FV2 on FV1.fact = FV2.fact
where FV1.valency_alias = 'p'
and FV1.lemma = 'пить'
and FV2.valency_alias = 'pat' Результат:
| lemma | fact |
|---|---|
| вода | 3604495 |
| чай | 3604512 |
| вода | 3604547 |
| пиво | 3626456 |
facts (все факты)
В этой таблице хранится список фактов. Факт – это семантическая структура предложения: предикат (и его семантические признаки) и его актанты (и их семантические признаки). Из одного предложения может быть извлечено несколько фактов – по числу предикатов в этом предложении. Из предложений без предиката извлекается один факт, однако его семантические валентности (см fact_valencies) остаются незаполненными.
Из одного предложения может быть извлечено несколько фактов – по числу предикатов в этом предложении. Из предложений без предиката извлекается один факт, однако его семантические валентности (см fact_valencies) остаются незаполненными.
Поля таблицы facts:
- id, int
- meta, jsonb, метаинформация о факте: версии всех компонентов анализа
- hash, varchar, hash конкретного запуска
Запрос, который выводит все предложения, из которых были извлечены факты:
select id, meta->'metadata'->'splitter'->>'text' sentence
from factsРезультат:
| id | sentence |
|---|---|
| 870645 | себе испортил, людям испортил. |
| 870639 | цокал языком, стыдил, укорял- я его почти не слушала. |
| 870640 | цокал языком, стыдил, укорял- я его почти не слушала. |
| 870642 | — крутил башкой турок,- зачем все испортил? |
| 870644 | себе испортил, людям испортил. |
Видно, что из предложения цокал языком, стыдил, укорял- я его почти не слушала. извлечено по крайней мере два факта: 870639, 870640, всего в этом предложении четыре факта: 1) цокал языком, 2) стыдил, 3) укорял, 4) я его почти не слушала.
Можно это проверить. Запрос, который выводит id фактов, которые были извлечены из конкретного предложения:
select id, meta->'metadata'->'splitter'->>'text' sentence
from facts
where meta->'metadata'->'splitter'->>'text' = 'цокал языком, стыдил, укорял- я его почти не слушала.'Результат подтверждает: фактов действительно четыре:
| id | sentence |
|---|---|
| 870638 | цокал языком, стыдил, укорял- я его почти не слушала. |
| 870641 | цокал языком, стыдил, укорял- я его почти не слушала. |
| 870639 | цокал языком, стыдил, укорял- я его почти не слушала. |
| 870640 | цокал языком, стыдил, укорял- я его почти не слушала. |
Теперь объединим таблицы facts и fact_valencies, чтобы увидеть, какие леммы занимают какие валентности в этих четырех фактах:
select F.id fact_id, FV.lemma, FV.valency_alias
from facts F
join fact_valencies FV on FV.fact = F.id
where F.id in (870638, 870641, 870639, 870640)Результат:
| fact_id | lemma | valency_alias |
|---|---|---|
| 870638 | цокать | p |
| 870638 | язык | instr |
| 870639 | стыдить | p |
| 870640 | укорять | p |
| 870641 | я | ag |
| 870641 | он | pat |
| 870641 | слушать | p |
fact_markers (семантические признаки сегментов факта)
В этой таблице хранится информация о том, какие семантические признаки (маркеры) есть у сегмента, занимающего некоторую валентность в некотором факте.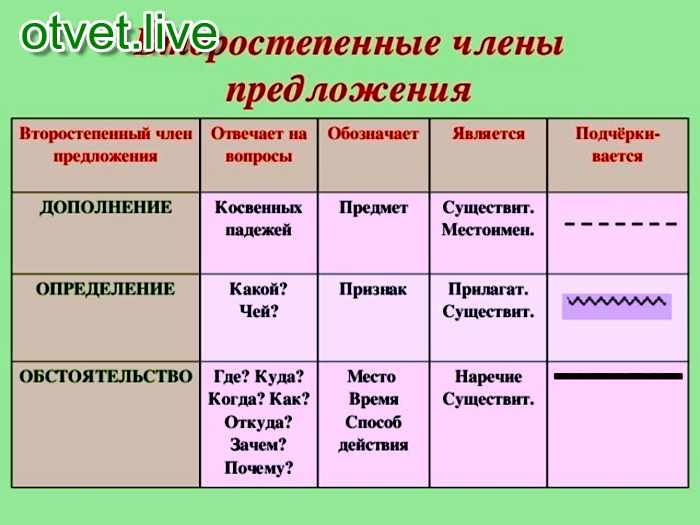 Для каждого объекта из таблицы fact_valencies в таблице fact_markers может быть как множество строк (по одной на каждый семантический признак каждой леммы, входящей в сегмент), так и ни одной строки (в случае, если у всех лемм, входящих в этот сегмент, не размечено ни одного семантического маркера).
Для каждого объекта из таблицы fact_valencies в таблице fact_markers может быть как множество строк (по одной на каждый семантический признак каждой леммы, входящей в сегмент), так и ни одной строки (в случае, если у всех лемм, входящих в этот сегмент, не размечено ни одного семантического маркера).
Поля таблицы fact_markers:
- id, int
- valency, int, ссылка на объект из таблицы fact_valencies
- marker_id, int, id семантического признака (поле sql_id таблицы markers)
- marker, к удалению
- attr, int, семантическая зона
Выведем семантические признаки для всех сегментов конкретного факта, например, для факта я его почти не слушала (id 870641). Для этого нужно объединить таблицы fact_valencies и fact_markers:
select FV.fact fact_id, FV.lemma, FV.valency_alias, FM.marker_id
from fact_valencies FV
join fact_markers FM on FM. valency = FV.id
where FV.fact = 870641
valency = FV.id
where FV.fact = 870641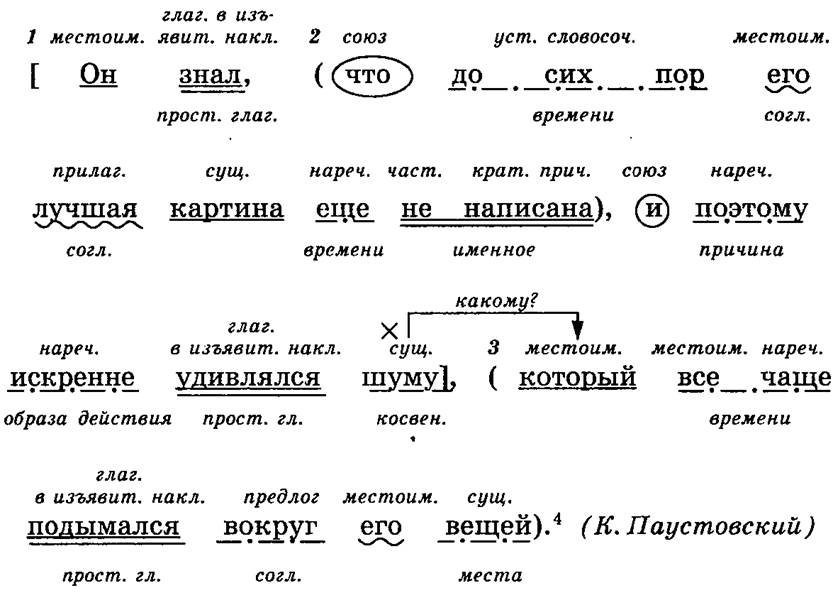 valency = FV.id
where FV.fact = 870641
valency = FV.id
where FV.fact = 870641Результат:
| fact_id | lemma | valency_alias | marker_id |
|---|---|---|---|
| 870641 | я | ag | 1 |
| 870641 | я | ag | 11 |
| 870641 | я | ag | 14 |
| 870641 | я | ag | 62 |
| 870641 | он | pat | 14 |
| 870641 | слушать | p | 31 |
| 870641 | слушать | p | 36 |
| 870641 | слушать | p | 187 |
| 870641 | слушать | p | 389 |
Видно, что у сегмента с вершиной он только один семантический признак, в то время как у сегмента с вершиной слушать их четыре.
h4. markers (все семантические признаки)
В этой таблице перечислены все семантические признаки. Важно, что с таблицей fact_markers таблица markers связана полем sql_id.
Поля таблицы markers:
- id, int
- sql_id, int, реальный идентификатор семантического маркера
- name, varchar, название семантического маркера
Усовершенствуем запрос, выводящий семантические признаки для всех сегментов конкретного факта, из главы про таблицу fact_markers. Теперь запрос будет выводить не просто идентификаторы семантических признаков сегментов факта я его почти не слушала (id 870641), но и названия этих признаков:
select FV.fact fact_id, FV.lemma, FV.valency_alias, FM.marker_id, M."name" marker_name
from fact_valencies FV
join fact_markers FM on FM.valency = FV. id
join markers M on M.sql_id = FM.marker_id
where FV.fact = 870641 id
join markers M on M.sql_id = FM.marker_id
where FV.fact = 870641
id
join markers M on M.sql_id = FM.marker_id
where FV.fact = 870641Результат:
| fact_id | lemma | valency_alias | marker_id | marker_name |
|---|---|---|---|---|
| 870641 | я | ag | 1 | ч-некто |
| 870641 | я | ag | 11 | ч-другой |
| 870641 | я | ag | 14 | о-об |
| 870641 | я | ag | 62 | ч-ПРИНЦИПАЛ |
| 870641 | он | pat | 14 | о-об |
| 870641 | слушать | p | 31 | пм-думать |
| 870641 | слушать | p | 36 | пм-слышать |
| 870641 | слушать | p | 187 | пм-внимание |
| 870641 | слушать | p | 389 | л-не |
Рассмотрим запрос, который обращен не к конкретному факту, а ко всей базе. Он выводит все предикаты, имеющие конкретный семантический признак, на примере семантического признака пф-ингест, обозначающего прием пищи.
Он выводит все предикаты, имеющие конкретный семантический признак, на примере семантического признака пф-ингест, обозначающего прием пищи.
select FV.fact fact_id, FV.valency_alias, FV.lemma, M."name" marker_name
from fact_valencies FV
join fact_markers FM on FV.id = FM.valency
join markers M on M.sql_id = FM.marker_id
where FV.valency_alias = 'p'
and M.name = 'пф-ингест' Результат:
| fact_id | lemma | valency_alias | marker_name |
|---|---|---|---|
| 799889 | p | есть | пф-ингест |
| 799893 | p | есть | пф-ингест |
| 800138 | p | хлебнуть | пф-ингест |
| 800142 | p | выпить | пф-ингест |
| 800116 | p | хлебнуть | пф-ингест |
| 800117 | p | закусить | пф-ингест |
sentences (все предложения со всеми словами)
В эту таблицу сохраняются все прошедшие анализ предложения.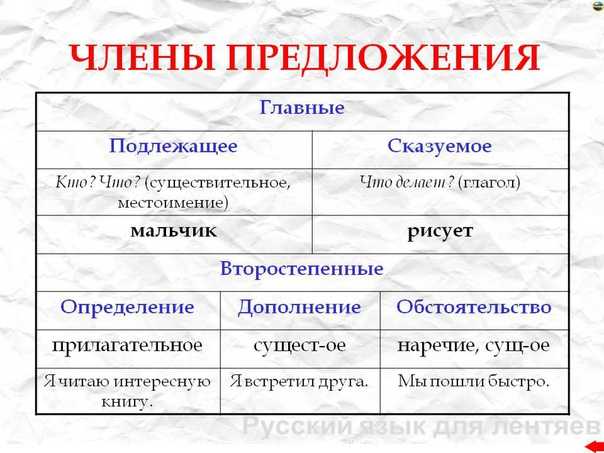 Если в таблице fact_valencies перечислены только леммы-вершины сегмента, то в таблице sentences в поле sentence в формате json перечислены все слова предложения со всеми возможными омонимами.
Если в таблице fact_valencies перечислены только леммы-вершины сегмента, то в таблице sentences в поле sentence в формате json перечислены все слова предложения со всеми возможными омонимами.
Поля таблицы sentences:
- id, int
- meta, jsonb, метаинформация о предложении: версии всех компонентов анализа
- sentence, jsonb, все сегменты предложения
- hash, varchar, hash конкретного запуска
Запрос, который выводит все предложения, в которых есть конкретное слово, например слово смеяться:
select meta->'metadata'->'splitter'->>'text' sentence
from sentences
where sentence @@ '*.token_lemma = "смеяться"'Результат:
| sentence |
|---|
| но ольга умеет смеяться над собой тайский трансвестит развлёк российских туристов, спародировав песню ольги бузовой” под звуки поцелуев”. |
( and today our royal navy is about as powerful as a f@rt in a teacup- от переводчика, долго смеялся и не стал заменять английскую идиому на русскую, решил сохранить британский колорит))). |
| и обязательно продолжайте шутить и смеяться— это удлиняет жизнь,— закончил своё поздравление министр. |
| глава мид рф сергей лавров поздравил россиян с новым годом и посоветовал как можно больше смеяться и шутить. |
| ( смеётся. |
| несмотря на полную адекватность и ориентированность, он то смеялся над обращённой к нему фразой, то пытался вспоминать молодость, которая, по его мнению, тоже была полна веселья и радости. |
| пятиминутка ещё не закончена,— заведующий, уже устав смеяться, взывал к порядку. |
| — она так здорово играет, так здорово смеется, так здорово читает и катается на роликах, что я не верю тем докторам, о которых ты говорил. |
| она смеётся, радуется отличной погоде и отправляется на прогулку. |
| во время выступления бирна она много смеялась и одновременно ела m&m. |
syntax (синтаксические разборы)
В этой таблице хранятся синтаксические разборы предложений.
Поля таблицы syntax:
- id, int
- meta, jsonb, метаинформация о дереве: версии всех компонентов анализа
- tree, jsonb, синтаксическое дерево
- hash, varchar, hash конкретного запуска
referents (референты)
Русский язык. «Синтаксис и пунктуация.» Обобщающие таблицы для 5-11 классов Таблицы по русскому языку. Учебно наглядные пособия
Количество таблиц в комплекте: 19 таблиц
Размер: 70х50см
Материал: картон не менее 250гр./кв.м.
Покрытие: таблицы покрыты защитной пластиковой пленкой 13 мкн.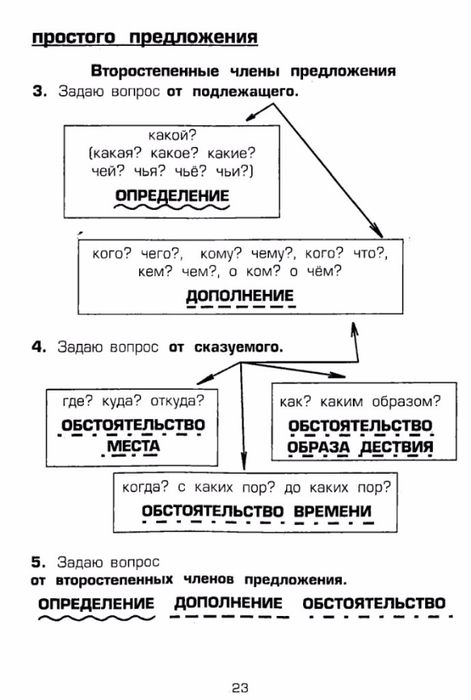 (ламинация)
(ламинация)
Автор: Л.П. Абросимова.
В формировании пунктуационных навыков учащихся необходимо создать условия, чтобы анализ предложений носил обучающий, развивающий характер.
В решении этой задачи поможет комплект таблиц «Изучение синтаксиса и пунктуации на уроках русского языка», который отражает порядок разбора, графические схемы пунктуационных правил, алгоритмы распознавания пунктуационных ситуаций.
Обобщающий характер таблиц — одно из звеньев комплексного анализа текста.
Знание порядка разбора словосочетания, предложения организует мысль учащегося, дает план ответа, предполагает развитие монологической речи.
В таблицах-памятках даны образцы ответов. Эти таблицы помогут учителю в работе над одним из сложнейших разделов курса русского языка, а их цветное оформление – более глубокому и прочному усвоению учащимися материала по синтаксису и пунктуации.
Материал в таблицах составлен с учетом последних требований к методике преподавания русского языка.
Комплект таблиц предназначен для учащихся
Перечень таблиц входящих в комплект:
1. Вводные слова и словосочетания;
2. Вводные предложения и вставные конструкции;
3.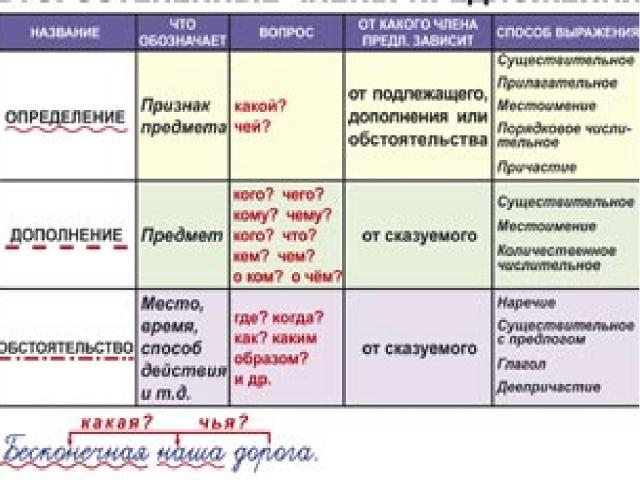 Диалог;
Диалог;
4. Точка с запятой при однородных членах предложения;
5. Тире СТАВИТСЯ между подлежащим и сказуемым;
6. Тире НЕ СТАВИТСЯ между подлежащим и сказуемым;
7. Предложение со сравнительными оборотами;
8. Слова-предложения ДА, НЕТ;
9. Тире в неполном предложении;
10. Обособление определений;
11. Обособление приложений;
12. Обособление обстоятельств;
Обособление обстоятельств;
13. Обособление дополнений;
14. Типы сложных предложений;
15. Синтаксический разбор словосочетания;
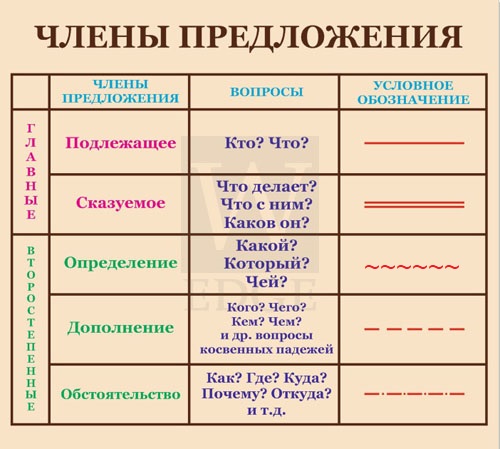
16. Главные члены предложения;
17. Второстепенные члены предложения;
18. Синтаксический разбор предложения;
19. Пунктуация в сложных предложениях с разными видами связи.
Как парсить таблицы со сложной раскладкой?
Docparser предлагает различные инструменты для извлечения табличных данных из PDF и отсканированных документов.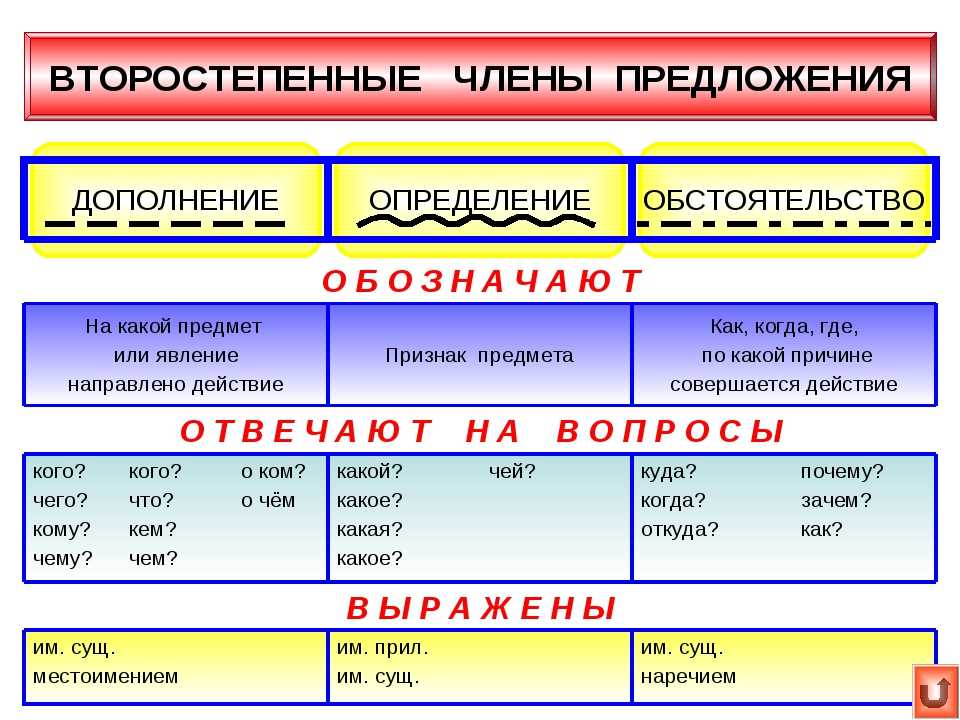 Самый простой способ извлечь таблицы — использовать предустановку правила синтаксического анализа «Данные таблицы» или, если вы обрабатываете счета, нашу предустановку «Статьи затрат». Оба пресета позволяют определить границы столбцов таблицы с помощью простого интерфейса «укажи и щелкни». Этот метод прекрасно работает, если вы имеете дело с простыми таблицами, в которых одна запись таблицы представлена одной строкой.
Самый простой способ извлечь таблицы — использовать предустановку правила синтаксического анализа «Данные таблицы» или, если вы обрабатываете счета, нашу предустановку «Статьи затрат». Оба пресета позволяют определить границы столбцов таблицы с помощью простого интерфейса «укажи и щелкни». Этот метод прекрасно работает, если вы имеете дело с простыми таблицами, в которых одна запись таблицы представлена одной строкой.
Но что, если ваши таблицы вложены друг в друга или имеют сложную компоновку?
Если вы имеете дело с вложенными таблицами, в которых одна запись распределена по нескольким строкам, как показано на снимке экрана ниже, вам необходимо применить обходной путь, чтобы получить четкое представление данных вашей таблицы. Ниже мы проведем вас через процесс настройки нескольких правил синтаксического анализа, каждое из которых будет извлекать определенные части вашей таблицы.
1/ Извлеките «Основные строки» с помощью инструмента извлечения таблицы
Сначала мы создаем правило разбора, которое извлекает все «основные строки» таблицы. Мы делаем это, выбирая предустановку «Данные таблицы», а затем определяя соответствующие границы столбцов.
Мы делаем это, выбирая предустановку «Данные таблицы», а затем определяя соответствующие границы столбцов.
После подтверждения границ столбцов мы получаем весь текст документа, разделенный на столбцы на основе только что определенных нами границ столбцов. Теперь нам нужно отфильтровать все строки, которые не являются «основными строками». Мы делаем это, добавляя фильтры «Сохранить строки, где…».
Результатом является чистое представление всех «основных строк» таблицы. Сохраним это правило разбора и продолжим.
2/ Создайте дополнительные правила синтаксического анализа для получения вторичных строк
Цель этого шага — извлечь все поля данных, которые не включены в основные строки таблицы. В нашем примере это номер продукта (например, № ABC12345678) и удельный вес. Оба они расположены во второстепенном ряду.
В зависимости от ваших данных у вас есть разные варианты получения оставшихся данных. Например, вы можете создать правило синтаксического анализа для поиска строк, соответствующих определенным шаблонам, правило синтаксического анализа с использованием ключевых слов привязки для поиска повторяющихся текстовых значений или просто создать другое правило извлечения таблицы.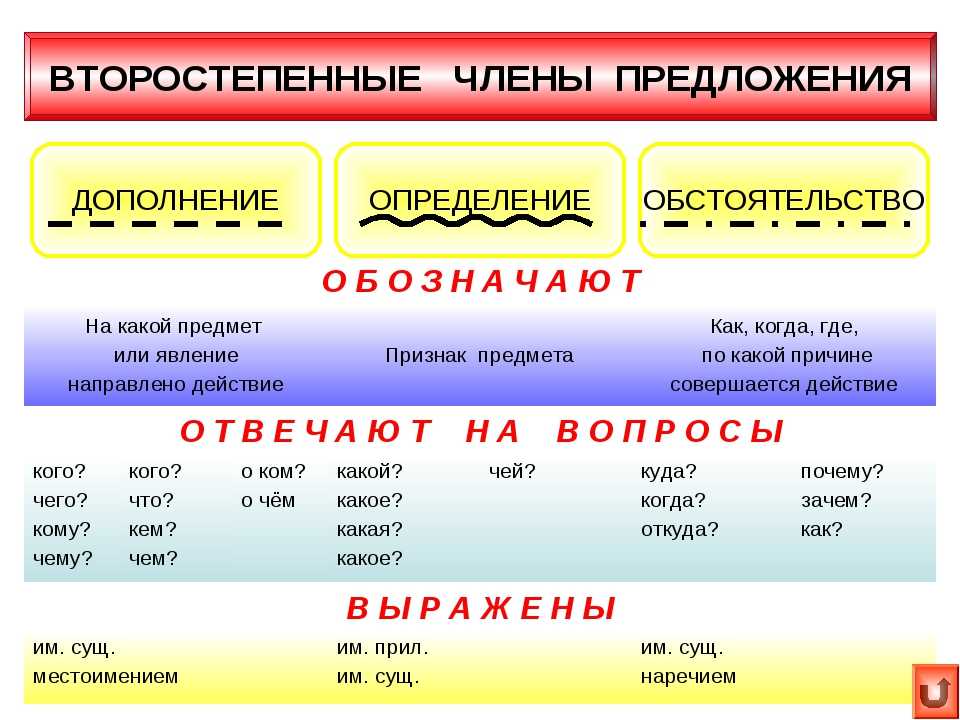 В нашем примере проще всего создать еще одно правило извлечения таблицы.
В нашем примере проще всего создать еще одно правило извлечения таблицы.
Повторяем ту же процедуру, что и на первом шаге, и добавляем дополнительный фильтр «Сохранить строки, где…» для очистки возвращаемых данных на втором шаге редактора правил синтаксического анализа.
3/ Создать дополнительное правило синтаксического анализа «Поля слияния» (необязательно)
Теперь мы создали два правила анализа таблиц, каждое из которых извлекает определенные части вложенной таблицы. В качестве необязательного заключительного шага мы можем создать дополнительное правило синтаксического анализа для объединения двух проанализированных таблиц. Создание правила синтаксического анализа «Объединение полей» полезно, например, если вы хотите использовать интеграцию с веб-перехватчиком и перебирать все данные таблицы за один раз.
Выберите предустановку правила синтаксического анализа «Объединить поля» и установите для первого фильтра значение «Добавлять данные таблицы по горизонтали».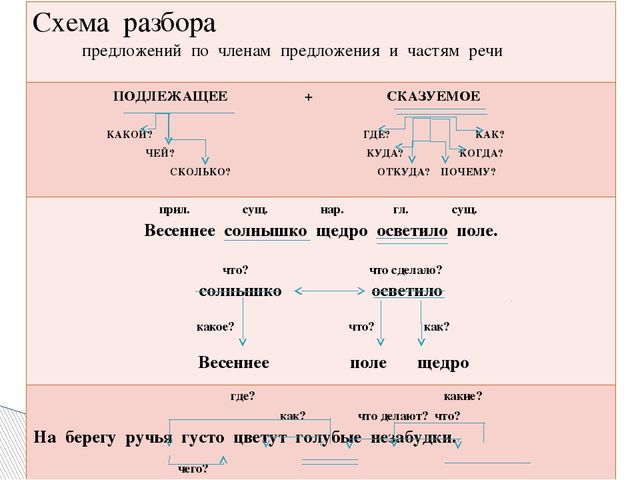 Это приведет к созданию одной таблицы, содержащей все данные вашей таблицы. Кроме того, вы можете добавить еще один фильтр, чтобы назвать заголовки столбцов. Сохраните это правило синтаксического анализа, и все готово!
Это приведет к созданию одной таблицы, содержащей все данные вашей таблицы. Кроме того, вы можете добавить еще один фильтр, чтобы назвать заголовки столбцов. Сохраните это правило синтаксического анализа, и все готово!
Обратите внимание: Метод создания нескольких правил синтаксического анализа и объединения возвращаемых данных прекрасно работает, когда все строки таблицы содержат одинаковую структуру данных. Однако объединение данных не будет работать, если строки вашей таблицы имеют переменное количество подстрок (например, строка заголовка с N подэлементами).
Если у вас есть дополнительные вопросы, пожалуйста, не стесняйтесь обращаться к нашей службе поддержки!
Вы получили ответ на свой вопрос?
Спасибо за ответ
Не удалось отправить отзыв. Пожалуйста, повторите попытку позже.
разбор — Нужна ли запись в столбце $ в таблице разбора LL(1)?
спросил
Изменено 7 лет, 5 месяцев назад
Просмотрено 443 раза
Необходимо ли получить хотя бы одну запись в столбце для $ в таблице синтаксического анализа для грамматики LL(1) для языка программирования.
Если да, то какие возможные ошибки мы можем найти в нашей грамматике.
- синтаксический анализ
- компилятор-конструкция
- грамматика
- контекстно-свободная грамматика
2
Столбец $ (конец ввода) может быть пустым. Один класс грамматик, где это происходит, — это когда все продукции для S не пусты и заканчиваются терминалом.
Возьмем пример S -> ( S* ) или более явно:
-
S -> ( T ) -
Т -> С Т -
Т -> ε
Мы можем построить следующую таблицу разбора LL(1) для этой грамматики:
| ( | ) | $ | ---+---------+-----+-----+ С | ( Т ) | | | Т | С Т | ε | |
Имейте в виду, что стек анализатора LL содержит терминалы и нетерминалы. Если вход и стек начинаются с одних и тех же терминалов, они оба удаляются. То же самое касается конца ввода (который часто представляется в виде специального терминала): синтаксический анализ завершился успешно тогда и только тогда, когда мы достигли конца ввода и наш стек анализатора пуст.
Единственная разумная запись для столбца $ , которую я могу придумать , будет ε . В конце концов, было бы невозможно разобрать пустую строку, если у вас есть (непустые) терминалы в вашем стеке. Когда столбец $ содержит ε для некоторого терминала, это означает, что вы можете удалить его из стека, когда дойдете до конца ввода.