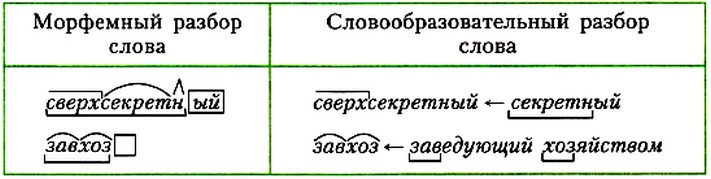
морфемный и словообразовательный разбор слова; стояла
Пожалуйста замените выделенные слова личными местоимениями. Образец: Капитан с вернулся с ружьём. — Капитан с вернулся с ним.1. Я должен встретиться с … КАРЕНОМ после уроков. 2.Индейцы лечили ПРИПАРКАМИ все болезни. 3. Завтра я с ПАПОЙ пойду в кино. 4. Озлобленные матросы стояли перед КОЛУМБОМ. 5. Обезьяна со ШЛЯПОЙ полезла на мачту.6. Матросы смеялись над МАЛЬЧИКОМ.
Мы знаем как выглядит наша планетa стороны.
Но в недра земные человек проник всего на десятки километров. Ниже невед… мый мир, и время от времени он
… напоминает о себе. И тогда гр…мят взрывы, камни как бомбы летят вокруг, пары и газы окутывают вершины вулканов, а по их склонам ползёт всё сжигающий поток. сотр… …сают крошится землю, eë лихорадит и Тогда голчки лихорадит, трескается, возникают она исчезают острова. Тогда в море вздымаются волны, несутся со скоростью реактивного самолёта и обруш…ваются сокрушая на пути. на берег, всё
1.
В каком примере НЕ с глаголом пишется слитно? А) В воскресенье мне (не) здоровилось. В) Соловей (не) поёт, и дергач (не) кричит. С) В оконной раме (не … ) хватает одного стекла.
Упражнение 40. Вставьте пропущенные буквы. Расставьтенедостающие знаки препинания.1Был утре..ий час. В огромном лесу стоял тонкийпар наполненный стра.
… .ыми в..дениями.
Упражнение 39. Расставьте, где нужно, пропущенныезапятые.Даю 22 балла
Выпиши из предложений обособленные члены с главным (определяемым) словом. Определи их синтаксическую функцию, задав вопрос.
Пример:
«Щурясь от ветра,
… я гляжу в эту тёмную даль» (И. Бунин).
Гляжу (Как?) щурясь от ветра — обособленное обстоятельство.
Тимирязев, замечательный ботаник, открыл законы жизни растений —
( ?) — обособленное —
.
ПОМОГИТЕ СРОЧНО ДАМ 15 БАЛЛОВ!!!
ПОМОГИТЕ ОЧЕНЬ СРОЧНО 15 БАЛЛОВ!!
Текст 1.У знакомых старая нянька. Из Москвы вывезена. Плавна, самая настоящая – толстая, сердитая, новых порядков не любит, старые блюдёт, умеет ватру
… шку печь и весь дом в страхе держит. Вечером, когда дети улягутся и уснут, идет нянька на кухню. Там француженка кухарка готовит поздний французский обед. – Asseyez-vous! {Садитесь (фр.).} – подставляет она табуретку. Нянька не садится. – Не к чему, ноги еще, слава Богу, держат. Стоит у двери, смотрит строго. – А вот скажи ты мне, отчего у вас благовесту не слышно? Церкви есть, а благовесту не слышно. Небось молчишь! Молчать всякий может, молчать очень даже легко. А за свою веру, милая моя, каждый обязан вину нести и ответ держать. Вот что! – Я в суп кладу селлери и зеленый горошек! – любезно отвечает кухарка. – Вот то-то и оно… Как же ты к заутрене попадешь без благовесту? То-то, я смотрю, у вас и не ходят.

Значение слова вынесла в предложении «*И ещё один драгоценный подарок вынесла я из своего детства — бюстик Пушкина, подаренный отцом.*» А)принять реше … ние, объявить В)извлечь, знакомясь с чем-нибудь С)переместить куда-нибудь Д)вытерпеть, выдержать Е)доставить наружу НАПИШИТЕ ОБЪЯСНЕНИЕ!
Browse Eckher Glossary and expand your business and technology vocabulary.
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики.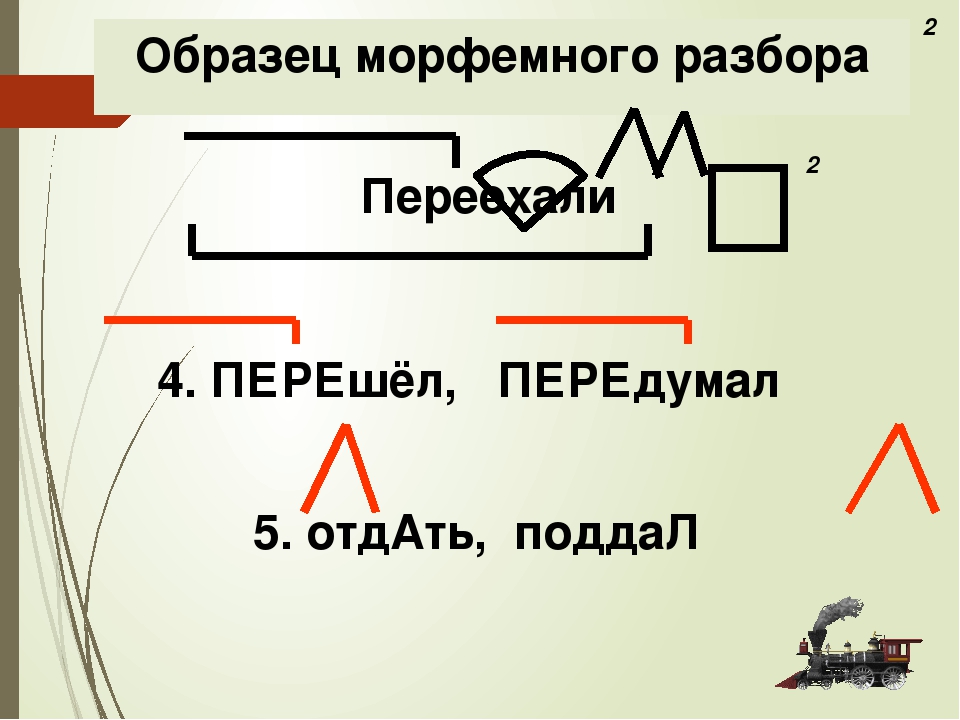 Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
How to pronounce «featurize» in English?
How to pronounce «Onehunga» in English?
How to pronounce «Takapuna» in English?
How to pronounce «İzmir» in English?
How to pronounce «Coronaviridae» in English?
How to pronounce «Whanganui» in English?
How to pronounce «Chlöe Swarbrick» in English?
How to pronounce «Kohimarama» in English?
How to pronounce «Tua Tagovailoa» in English?
How to pronounce «Craig Federighi» in English?
How to pronounce «Stefanos Tsitsipas» in English?
How to pronounce «Jacob deGrom» in English?
How to pronounce «myocarditis» in English?
How to pronounce «SZA» in English?
How to pronounce «Cassie Kozyrkov» in English?
Как разобрать по составу слово «избушка»
Выполним морфемный разбор слова «избушка». В морфемном составе слова «избушка» вычленим корень, суффикс и окончание.
В морфемном составе слова «избушка» вычленим корень, суффикс и окончание.
Прежде чем разбирать исследуемое слово по составу, выясним часть речи, к которой оно принадлежит. Имеем в виду, что в составе слов разных частей речи имеется свой набор характерных морфем.
В гуще леса стоит избушка охотника Матвея.
Это слово обозначает предмет и отвечает на вопрос что?
По этим грамматическим признакам можно понять, что, это неодушевлённое имя существительное. Его морфемный разбор начнем с выделения окончания. В русском языке окончание имеют только изменяемые части речи. Узнаем, изменяется ли анализируемое слово. Это существительное женского рода первого склонения может менять свою грамматическую форму.
Понаблюдаем:
- стоять около избушки
- вижу избушку
- подойду к избушке.
Сравнив падежные формы существительного, в конце слова выделим словоизменительную морфему — окончание -а. Окончание не включается в основу.
Окончание не включается в основу.
Основой слова является часть избушк-.
Далее в морфемном составе рассматриваемого слова укажем уменьшительно-ласкательный суффикс -ушк-, наличие которого прослеживается также в словах:
- чернушка
- молодушка
- говорушка.
Оставшаяся часть изб- является корнем рассматриваемого слова. В этом убедимся, подобрав близкие по смыслу родственные лексемы:
изба, избёнка, избушечный, избяной, избач.
Во всех родственных словах имеется общая значимая часть изб-, в которой заключено их лексическое значение.
Морфемный состав слова «избушка» запишем в виде итоговой схемы:
избушка — корень/суффикс/окончание.
Скачать статью: PDFМорфологический разбор глагола «стоять» онлайн. План разбора.
Для слова «стоять» найден 1 вариант морфологического разбора
- Часть речи.
 Общее значение
Общее значение
Часть речи слова «стоять» — глагол - Морфологические признаки.
- стоять (инфинитив)
- Постоянные признаки:
- 1-е спряжение
- непереходный
- несовершенный вид
- изъявительное наклонение.
- Может относится к разным членам предложения.
 Общее значение
Общее значение Поделитесь страницей с друзьями — это лучшая благодарность
Морфологический разбор другого слова
План разбора глагола
- Часть речи. Общее значение
- Морфологические признаки.
- Начальная форма (инфинитив)
- Постоянные признаки:
- Вид (совершенный (что сделать?) или несовершенный (что делать?)
- переходный (употребляется с сущeствительным в винительном падеже без предлога)/ непереходный (не употребляется с существительным в винительном падеже без предлога).
- Спряжение
- Наклонение в зависимости от вопроса:
- Изъявительное — что делал? что делает? что сделает?
- Повелительное — что делай?
- условное — что делал бы? что сделал бы?
- Число
- Время (если есть)
- Лицо (если есть)
- Род (если есть)
- Синтаксическая роль (подчеркнуть как член предложения, является главным или второстепенным членом предложения)

Поделитесь страницей с друзьями — это лучшая благодарность
Оцени материал
8 голосов, оценка 4.500 из 5
План разбора составлен на основе общих правил, в зависимости от класса и предпочтений учителя ответ может отличаться. Если ваш план разбора отличается от представленного, просто сопоставьте его с данными нашего ответа.
Если морфологический разбор глагола «стоять» имеет несколько вариантов, то выберите наиболее подходящий вариант разбора исходя из контекста предложения.
Разборы производились исходя из заложенного программного алгоритма, результаты в редких случаях могут быть недостоверны, если вы нашли несоответствие пожалуйста сообщите нам. Представленный результат используется вами на свой страх и риск.
Морфологический разбор слова стоять онлайн
Слово ‘стоять’
Слово стоять является Глаголом (это самостоятельная часть речи, которая отвечает на вопросы «что делать?», «что сделать?»). У глагола стоять есть постоянные признаки:
- Возвратный/Невозвратный — слово ‘стоять’ является невозвратный;
- Переходный/Непереходный — слово ‘стоять’ это непереходный глагол. ; Глагол ‘стоять’ относится к несовершенному виду.
- Первое лицо: Я — стою/ Мы — стоим;
- Второе лицо: Ты — стоишь/ Вы — стоите;
- Третье лицо: Он/Она/Оно — стоит/ Они — стоят.

- Пример изъявительного наклонения: Солдат стоял на посту.;
- Пример cослагательного наклонения: Не стояли бы вы здесь больше.;
- Пример повелительного наклонения: Стой здесь и жди меня.;
- Род слова определить не возможно потому, что глагол является Инфинитивом.
- Лицо — не определяется в инфинитиве;
- У данного слово время не определяется потому, что слово стоять является Инфинитивом;
Слово «стоять» значит:
- Находится в вертикальном положении, не передвигаясь.
- Стоять в очереди.
- Иметься в наличии, нуждаясь в решении.
- Быть, находиться, занимая какое-нибудь положение, выполняя какую-нибудь работу, обяз анности.
- Быть, находиться, иметь место.
- Быть поставленным, расположенным где-нибудь, находиться где-нибудь шкафу.
- Иметь местопребывание.
- Не двигаться, бездействовать.
- Сохраняться, не портиться.
- Действовать в чьих-нибудь интересах, в каком-нибудь направлении, защищать, ограждать кого-нибудь.
- Призыв подождать, не торопиться.

«СТОЯТЬ» — это Глагол. Обозначающая действие предмета и отвечает на вопросы «Что делать?» или «Что сделать?». В предложении обычно выполняет роль сказуемого.
стоЯть
Ударение падает на слог с буквой Я.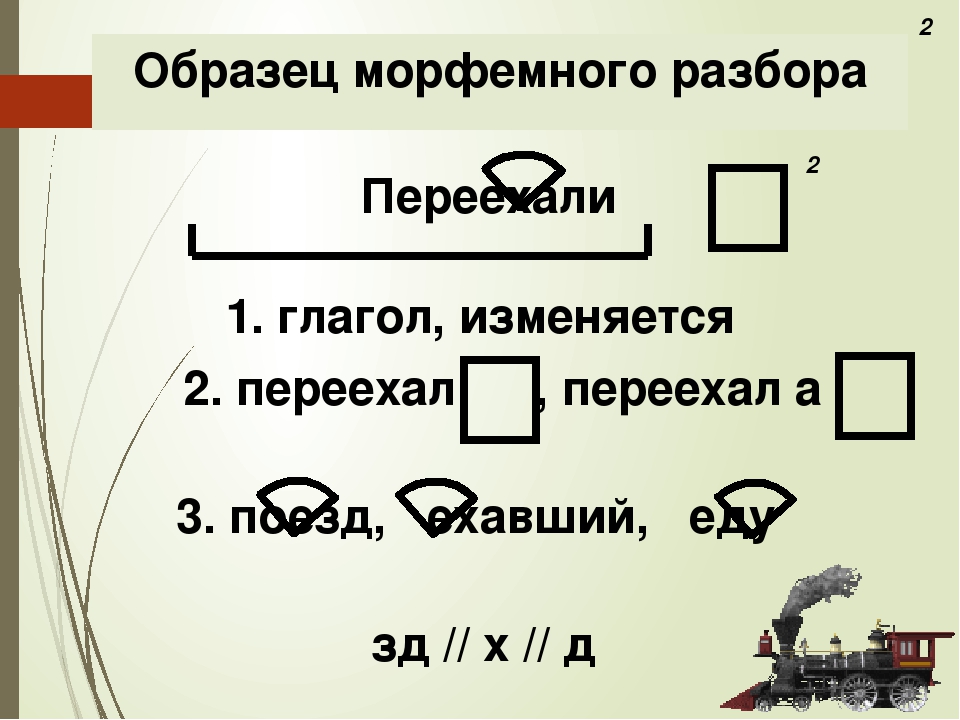 На четвертую букву в слове.
На четвертую букву в слове.
Слово «стоять» — род не определяется в инфинитиве
Глагол ‘стоять’ является несовершенным видом.
Переходность глагола «стоять» — непереходный
Лицо у глагола «стоять» — не определяется в инфинитиве
«СТОЯТЬ» — это невозвратный глагол
Пример использования наклоненийИзъявительное
Солдат стоял на посту.
Сослагательное (условное)
Не стояли бы вы здесь больше.
Стой здесь и жди меня.
Время глагола «стоять» — не определяется в инфинитиве
Слово «стоять» — относится к Второму спряжению
будешь стоять
будете стоять
Глагол в прошедшем времени
Она (ед. число)
число)
Оно (ед. число)
Они (мн. число)
- инструментовать
- ходить
- колобродить
- окоротить
- редеть
- рационализировать
- аннексировать
- модничать
- сбивать
- осторожничать
Морфемный разбор » Страница 2
Задания » Морфемный разбор
 Сделать словообразовательный разбор:покорность, царствует, набирается, доверчиво-тихого, бережно, уверенность, чем-то, свечение, поднебесный, вечность.
Сделать словообразовательный разбор:покорность, царствует, набирается, доверчиво-тихого, бережно, уверенность, чем-то, свечение, поднебесный, вечность.
Принесённое
Открытое
Сообщаемые
Невидимые
Принесший
Вошедшие
Сверкающая

паросшие, заночевали, усилиться, бездомная
“Нашей” морфологический разбор | Грамота
Сделаем морфологический разбор слова “нашей”. Грамматически, рассматриваемая словесная форма, может быть отнесена к нескольким вариантам (необходимо смотреть по контексту).
Грамматически, рассматриваемая словесная форма, может быть отнесена к нескольким вариантам (необходимо смотреть по контексту).
Для грамотного морфологического разбора, необходимо следовать схеме, которая состоит из обязательных пунктов. Давайте остановимся на ней более детально в двух случаях разбора.
Часть речи (глагол)
Часть речи, к которой принадлежит указанное слово – глагол.
Морфологические признаки
Неопределенная (начальная) форма – “нашить”.
- Неизменяемые признаки: относится ко 2-му спряжению (на “ить”), переходный (действие направлено на изменение или создание предмета), совершенного вида (что сделать?).
- Изменяемые признаки: повелительное наклонение (что делай?), единственное число, настоящее время, действительный залог.
Синтаксическая роль
В предложении выполняет роль сказуемого.
- Мама, нашей мне аппликацию на рубашку.

Часть речи (местоимение)
Как часть речи слово “нашей” может быть местоименным прилагательным. Это особый класс местоимений по синтаксическим признакам объединённый с прилагательным.
Морфологические признаки
Начальная форма – “наш”.
- Неизменяемые признаки: нет.
- Изменяемые признаки: полное, женского рода, единственного числа. Может стоять в родительном, дательном, творительном или предложном падежах.
Проверь себя: “Наконец” морфологический разбор слова
Синтаксическая роль
Является зависимым от подлежащего или находится в составе именной части сказуемого. Пример:
- Нашей дружбе пришёл конец.
Крапля чи капля як правильно?
Правильно Крапля, капля – обидва слова є правильними і абсолютно рівноправними у використанні. Слово «капля» частіше використовується в розмовній мові. Дівчатка були схожі одна на одну як дві краплі води. І капля камінь точить. Захищати до останньої краплі крові. Смажити не було на чому – в пляшці залишилась лише капля олії.… Читать дальше »
Слово «капля» частіше використовується в розмовній мові. Дівчатка були схожі одна на одну як дві краплі води. І капля камінь точить. Захищати до останньої краплі крові. Смажити не було на чому – в пляшці залишилась лише капля олії.… Читать дальше »
3.2 Морфологический анализ
Цель морфологического анализа — выяснить, из каких морфем построено данное слово. Например, морфологический синтаксический анализатор должен уметь сказать нам, что слово cats является формой множественного числа от основы существительного cat , и что слово mice является формой множественного числа от основы существительного mouse . Таким образом, при вводе строки cats морфологический синтаксический анализатор должен выдать результат, похожий на cat N PL .Вот еще несколько примеров:
мышь | мышь N SG |
мыши | мышь N PL |
fox N PL |
Морфологический анализ дает информацию, которая полезна во многих приложениях НЛП. Например, при синтаксическом анализе это помогает узнать особенности согласования слов.Точно так же специалистам по проверке грамматики необходимо знать информацию о соглашении, чтобы обнаруживать такие ошибки. Но морфологическая информация также помогает специалистам по проверке орфографии решить, является ли что-то возможным словом или нет, и при поиске информации она используется для поиска не только cats , если это вводит пользователь, но и cat .
Например, при синтаксическом анализе это помогает узнать особенности согласования слов.Точно так же специалистам по проверке грамматики необходимо знать информацию о соглашении, чтобы обнаруживать такие ошибки. Но морфологическая информация также помогает специалистам по проверке орфографии решить, является ли что-то возможным словом или нет, и при поиске информации она используется для поиска не только cats , если это вводит пользователь, но и cat .
Чтобы перейти от поверхностной формы слова к его морфологическому анализу, мы сделаем два шага. Во-первых, мы собираемся разделить слова на возможные составляющие.Итак, мы сделаем cat + s из cats , используя + для обозначения границ морфем. На этом этапе мы также учтем правила орфографии, поэтому есть два возможных способа разделить foxes , а именно foxe + s и fox + s . Первый предполагает, что foxe — это ствол, а s — суффикс, а второй предполагает, что стержнем является fox и что e было введено из-за правила правописания, которое мы видели выше.
На втором этапе мы будем использовать словарь основ и аффиксов, чтобы найти категории основ и значения аффиксов. Таким образом, cat + s будет сопоставлено с cat NP PL , а fox + s — с fox N PL . Теперь мы также узнаем, что foxe не является юридической основой. Это говорит нам о том, что разделение foxe + s на foxe + s на самом деле было неправильным способом разделения foxe + s , от которого следует отказаться.Но обратите внимание, что для слова домов правильным является разделение его на домов + s .
Вот изображение, иллюстрирующее два шага нашего морфологического синтаксического анализатора с некоторыми примерами.
Теперь мы построим два преобразователя: один для преобразования формы поверхности в промежуточную форму, а другой — для преобразования промежуточной формы в нижележащую форму.
3.2.1 От поверхности к промежуточной форме
Для выполнения морфологического анализа этот преобразователь должен преобразовать поверхностную форму в промежуточную форму. А пока мы просто хотим рассмотреть случаи английских существительных единственного и множественного числа, которые мы видели выше. Это означает, что преобразователь может или не может вставлять границу морфемы, если слово заканчивается на s . Могут быть слова в единственном числе, оканчивающиеся на s (например, kiss ). Вот почему мы не хотим делать вставку границы морфемы обязательной. Если слово заканчивается на ses , xes или zes , оно может, кроме того, удалить e при введении границы морфемы.Вот преобразователь, который это делает. « Другая » дуга в этом преобразователе обозначает переход, который отображает все символы, кроме s, z, x , на себя.
А пока мы просто хотим рассмотреть случаи английских существительных единственного и множественного числа, которые мы видели выше. Это означает, что преобразователь может или не может вставлять границу морфемы, если слово заканчивается на s . Могут быть слова в единственном числе, оканчивающиеся на s (например, kiss ). Вот почему мы не хотим делать вставку границы морфемы обязательной. Если слово заканчивается на ses , xes или zes , оно может, кроме того, удалить e при введении границы морфемы.Вот преобразователь, который это делает. « Другая » дуга в этом преобразователе обозначает переход, который отображает все символы, кроме s, z, x , на себя.
Давайте посмотрим, как этот преобразователь работает с некоторыми из наших примеров. На следующих графиках показаны возможные последовательности состояний, через которые может пройти датчик, учитывая, что на входе формируется поверхность кошек и лис .
3.2.2 От промежуточной формы к морфологической структуре
Теперь мы хотим взять промежуточную форму, которую мы создали в предыдущем разделе, и сопоставить ее с базовой формой.Ввод, который должен принимать этот преобразователь, может иметь одну из следующих форм:
корень обычного существительного, например cat
корень существительного + s, например cat + s
корень неправильного существительного единственного числа, например мышь
неправильная основа существительного множественного числа, например мышей
В первом случае преобразователь должен сопоставить все символы ствола с собой, а затем вывести N и SG .Во втором случае он отображает все символы основы на себя, но затем выводит N и заменяет PL на s . В третьем случае он делает то же, что и в первом случае. Наконец, в четвертом случае преобразователь должен сопоставить неправильную основу существительного множественного числа с соответствующей основой единственного числа (например, мышей — мыши ), а затем он должен добавить N и PL . Итак, общая структура этого преобразователя выглядит следующим образом:
Итак, общая структура этого преобразователя выглядит следующим образом:
Что еще нужно указать, так это то, как именно выглядят части между состоянием 1 и состояниями 2, 3 и 4 соответственно.Здесь нам нужно распознать основы существительных и решить, правильные они или нет. Мы делаем это, кодируя лексикон следующим образом. Часть преобразователя, которая распознает cat , например, выглядит следующим образом:
И часть преобразователя, отображающая мышей — мыши , может быть указана следующим образом:
Подключив эти (частичные) преобразователи к преобразователю, указанному выше, мы получите преобразователь, который проверяет правильность формы ввода и добавляет информацию о категориях и числовых значениях.
3.2.3 Объединение двух преобразователей
Если теперь мы позволим двум преобразователям для отображения от поверхности к промежуточной форме и для сопоставления от промежуточной формы к нижележащей форме работать каскадом (т. Е. Мы позволим второму датчику работать на вывод первого), мы можем провести морфологический анализ (некоторых) английских словосочетаний с существительными. Однако мы также можем использовать этот преобразователь для создания формы поверхности из формы, лежащей ниже. Помните, что мы можем изменить направление трансляции при использовании преобразователя в режиме трансляции.
Е. Мы позволим второму датчику работать на вывод первого), мы можем провести морфологический анализ (некоторых) английских словосочетаний с существительными. Однако мы также можем использовать этот преобразователь для создания формы поверхности из формы, лежащей ниже. Помните, что мы можем изменить направление трансляции при использовании преобразователя в режиме трансляции.
Теперь рассмотрим ввод ягод . Что из этого сделают наши каскадные преобразователи? Первый вернет два возможных разделения, ягод и ягод , но тот, который нам нужен, ягод , не входит в их число. Причина в том, что здесь действует другое правило правописания, которое мы совсем не приняли во внимание. Это правило гласит, что « y меняется на , т.е. до s ».Итак, на первом этапе может быть несколько правил правописания, которые все должны быть применены.
Есть два основных способа справиться с этим. Во-первых, мы можем сформулировать преобразователи для каждого из правил таким образом, чтобы их можно было запускать каскадом. Другая возможность — указать преобразователи таким образом, чтобы их можно было применять параллельно.
Другая возможность — указать преобразователи таким образом, чтобы их можно было применять параллельно.
Существуют алгоритмы для объединения нескольких каскадных преобразователей или нескольких преобразователей, которые предполагается использовать параллельно, в один преобразователь.Однако эти алгоритмы работают только в том случае, если отдельные преобразователи подчиняются некоторым ограничениям, поэтому мы должны проявлять осторожность при их указании.
3.2.4 Помещение его в Пролог
Если вы хотите реализовать небольшой морфологический синтаксический анализатор, который мы видели в предыдущем разделе, все, что вам действительно нужно сделать, это перевести спецификации преобразователя в формат Пролога, который мы использовали в последняя лекция. Затем вы можете использовать программу преобразователя из последней лекции, чтобы позволить им работать.
Мы не будем подробно показывать, как преобразователи выглядят в Prolog, но мы хотим быстро взглянуть на вставной преобразователь e , потому что он имеет одну интересную особенность; а именно, другой переход . ‘): -!.
‘): -!.
arc (6,1, X: X): -!.
Граммарпедия — Морфология
Морфология касается внутренней структуры слов. Слова состоят из единиц значения, называемых морфемами . Каждая морфема представляет собой отдельную смысловую единицу. Например, слово банан — это одна морфема, в то время как слово без событий содержит четыре морфемы: un-event -ful и -ness. Значение может быть лексическим (например, банан) или грамматическим (например, морфемы множественного числа в таких существительных, как бананы).
Морфемы отличаются от слогов. Слово бананы содержит две морфемы banana-s и три слога ba-na-nas. (Вы можете определить слоги, хлопая в ритме слова.)
Морфология также учитывает способ объединения морфем в слова. Таким образом, он различает формы, которые могут стоять отдельно (основы, например, глагол run), и формы, которые могут быть добавлены к основам (например, суффикс -ing, который отмечает причастия настоящего времени).
Слова и лексемы
Одно предварительное различие, которое необходимо провести, — это слова и лексемы.Термин «слово» — это нетехнический термин. Мы все согласимся с количеством слов в следующем предложении:
Мел позвонил международному оператору, чтобы попросить помощи в звонке представителю профсоюза операторов вилочных погрузчиков, который выполнял волонтерскую работу в Зимбабве.
В этом предложении мы хотели бы сказать еще кое-что о словах оператор, операторы и телефон, телефон. Мы бы хотели сказать, что это версии одного и того же. Эти пары включают разные варианты одной и той же лексемы.Лексема — это простая форма слова.
Оператор лексемы имеет оператор формы единственного числа и операторы формы множественного числа.
Лексема телефон имеет два смысла. Существительное phone имеет форму единственного числа phone и множественное число phone; глагол phone имеет простую форму phone, форма настоящего времени в единственном числе от третьего лица — телефонная форма причастия прошедшего времени — телефонная и форма причастия настоящего времени — телефонная связь.

Связанные и свободные морфемы
Свободные морфемы могут стоять отдельно как самостоятельные слова (например, custom).Многие, но не все основания являются свободными морфемами.
Связанные морфемы не могут существовать отдельно; они должны быть присоединены к другой морфеме (например, суффикс -er в слове «покупатель»).
Лексико-грамматические морфемы
Значение, которое кодирует каждая морфема, может быть лексическим или грамматическим. Например, слово «яблоки» содержит две морфемы: лексическое основание «яблоко» и грамматический суффикс, маркер множественного числа -s.
Флективные морфемы — это аффиксы, которые несут грамматическое значение (например, суффикс множественного числа -s у кошек или прогрессивный -ing в парусном спорте).
Основания и приспособления
Морфемы могут быть базисами (например, событие) или аффиксами (например, un-, -ful или -ness). Аффиксы, стоящие перед основанием, называются префиксами; суффиксы следуют за основанием.
Деривационные и флективные аффиксы являются примерами связанных морфем.
Базовая модификация
Базовая модификация — это когда основания разных флективных форм лексемы различаются, например, sing-sang-sung и mouse-mice. Это также известно как добавка.Эти разные формы исторически были более продуктивными, но теперь они появляются только как неправильные наборы глагольных склонений и склонений существительных.
Базовая модификация также может использоваться для сопоставления разных частей речи. Многие базовые модифицированные наборы различаются произношением, но пишутся одинаково, например глагол perMIT с ударением на втором слоге и существительное PERmit с ударением на первом.
SEM1A5 — Часть 2 — Морфологический анализ
SEM1A5 — Часть 2 — Морфологический анализМорфологический анализ
Этот раздел состоит из трех частей.В первой части вводятся некоторые основные термины в морфологии, в частности, морфема , аффикс, префикс , суффикс , связанный и свободный формы. Во втором рассматриваются традиционные способы группировки языков, такие как изолирующий , агглютинативный и склоняющийся . В последнем разделе рассматриваются некоторые морфологические процессы, концентрируясь только на тех, которые имеют большее отношение к инженерии естественного языка.
Во втором рассматриваются традиционные способы группировки языков, такие как изолирующий , агглютинативный и склоняющийся . В последнем разделе рассматриваются некоторые морфологические процессы, концентрируясь только на тех, которые имеют большее отношение к инженерии естественного языка.
Некоторая терминология
Лингвистика стремится описывать язык.Любое описание требует некоторой терминологии для его описания. Мы можем рассматривать это как технический словарь дисциплины. В естественных языках есть свои термины для описания самих себя. Например, мы в разговорной речи говорим о «словах», «фразах», «предложениях» и «абзацах». Знаем ли мы, что означают эти слова?
Мы рассмотрим только определение этого слова. В таком тексте мы можем легко обнаружить «слова», потому что они отделены друг от друга пробелами или знаками препинания.Однако, если вы запишете обычную разговорную речь, вы обнаружите, что между словами нет разрывов. Несмотря на это, мы могли снова и снова выделять единицы, которые мы используем в речи, но в разных комбинациях. Это говорит о том, что существует небольшая единица чего-то вроде слова. Но как определить «слово»? Мы все согласимся, что черный и птица — это слова. blackbird одно слово или два слова? blackbird s — это то же слово, что и blackbird , или отдельное слово?
Несмотря на это, мы могли снова и снова выделять единицы, которые мы используем в речи, но в разных комбинациях. Это говорит о том, что существует небольшая единица чего-то вроде слова. Но как определить «слово»? Мы все согласимся, что черный и птица — это слова. blackbird одно слово или два слова? blackbird s — это то же слово, что и blackbird , или отдельное слово?
На эти вопросы нет простых ответов.Ситуация более сложная, потому что
- лингвистическая теория также должна учитывать, как звуки ( фонология ) связаны со «словами»
- , потому что английский на данный момент является относительно простым языком: в других языках есть гораздо более сложные способы изменения форм слов, чем в английском.
Морфология — это изучение структуры и образования слов. Его наиболее важной единицей является морфема , которая определяется как «минимальная единица значения».(Учебники лингвистики обычно определяют его немного иначе как «минимальную единицу грамматического анализа». ) Рассмотрим такое слово, как «несчастье». Он состоит из трех частей:
) Рассмотрим такое слово, как «несчастье». Он состоит из трех частей:
Есть три морфемы, каждая из которых несет определенное значение. un означает «нет», а ness означает «находиться в состоянии или состоянии». Happy — это свободная морфема , потому что она может появляться сама по себе (как «слово» само по себе). Связанные морфемы должны быть присоединены к свободной морфеме, и поэтому не могут быть словами сами по себе.Таким образом, у вас не может быть предложений на английском языке, таких как «Джейсон чувствует себя сегодня очень беспомощным».
Вооружившись этими определениями, мы можем рассмотреть способы, используемые для классификации языков в соответствии с их морфологической структурой.
Классификация морфологических структурных типов
Выше было высказано предположение, что английский с морфологической точки зрения является довольно простым языком. Подразумевается, что другие языки ведут себя по-другому, и это является основой данной схемы классификации. Лингвисты предыдущих поколений были весьма заинтересованы в создании генеалогических деревьев языков, чтобы показать, какие современные языки произошли от каких более ранних, и, возможно, даже иметь возможность восстановить утраченные языки. Морфологическая структура — это всего лишь один из способов группировки языков.
Лингвисты предыдущих поколений были весьма заинтересованы в создании генеалогических деревьев языков, чтобы показать, какие современные языки произошли от каких более ранних, и, возможно, даже иметь возможность восстановить утраченные языки. Морфологическая структура — это всего лишь один из способов группировки языков.
В этой классификации обычно три класса.
- Изолирующие языки
- Слова изолирующего языка неизменны. Другими словами, он состоит из свободных морфем, поэтому здесь нет морфем для обозначения такой информации, как грамматическое число (например, множественное число) или время (прошлое, настоящее, будущее).Китайский часто цитируется как пример такого языка (хотя некоторые утверждают, что вьетнамский является лучшим примером). Транслитерированное предложение:
gou bú ài chi qingcài
дословно можно перевести как:собака не любит есть овощи
В зависимости от контекста это может означать любое из четырех следующих предложений:собака не любит есть овощи
собаки не любят есть овощи
собаки не любят есть овощи
собаки не любят есть овощи - Агглютинативные языки
- Мой словарь дает определение агглютината как «соединить как с клеем; (языка) объединять простые слова без изменения формы для выражения сложных идей». Примеры из учебников обычно основаны на турецком или суахили, из которых мы будем использовать первый. В нашем примере мы будем использовать следующие морфемы:
- ler = множественное число
- i = притяжательный (например, его, ее, его )
- den = аблатив (например, грамматическое окончание «падежа», показывающее источник, например, от дом).
Чтобы завершить наш пример, нам понадобится турецкое существительное, в данном случае ev , что означает «дом».Из этого существительного можно составить следующие слова:
- ev: дом
- evler: домов
- evi: его / ее дом
- evleri: его дома, их дома
- evden: из дома
- evlerden: от домов
- evinden: из его / ее дома
- evlerinden: из его / ее домов, из их домов
(Обратите внимание, что за притяжательной морфемой i обычно следует n перед den.
)В этом примере важно заметить, как все морфемы представляют «единицу значения» и как они остаются абсолютно идентифицируемыми в структуре слов. Это контрастирует с тем, что происходит в последнем классе: склоняющиеся языки.
- Изменение языков
- Слова в флективных языках имеют разные формы, и можно разбить слова на более мелкие единицы и пометить их так же, как турецкий пример был представлен выше.Однако результат — очень запутанный и противоречивый отчет. Обычные примеры основаны на латыни и основаны на знании латинского грамматического примера, которого нет у большинства английских студентов. В качестве простого примера, латинское слово «я люблю» — это амо. Это означает, что окончание o используется для выражения значений, от первого лица, («я» или «мы»), в единственном числе, , в настоящем времени, , а также других значений.
 Примеры из учебников обычно основаны на турецком или суахили, из которых мы будем использовать первый. В нашем примере мы будем использовать следующие морфемы:
Примеры из учебников обычно основаны на турецком или суахили, из которых мы будем использовать первый. В нашем примере мы будем использовать следующие морфемы: )
) В этой классификации всего три класса.Действительно ли возможно объединить все языки мира в три класса? С одной стороны, невозможно поместить какой-либо из языков в какой-либо из классов, потому что каждый язык нечист. То есть, если вы посмотрите достаточно внимательно, вы обнаружите флексию в основном в агглютинативных языках, флексию в изолирующих языках, агглютинацию в флективных языках и так далее.
То есть, если вы посмотрите достаточно внимательно, вы обнаружите флексию в основном в агглютинативных языках, флексию в изолирующих языках, агглютинацию в флективных языках и так далее.
Какие уроки мы можем извлечь из этого? Я думаю, что есть два момента, на которые стоит обратить внимание. Во-первых, языки сильно различаются, и обобщения, основанные на опыте владения только одним языком (например, английским), могут быть легко противопоставлены другим языкам.Во-вторых, язык — это естественное явление, и «инструменты», которые мы используем для его изучения (например, классификации и технические термины), — всего лишь инструменты, которые могут быть несовершенными попытками описать что-то слишком сложное для нашей современной науки.
Морфологические процессы
В приведенном выше примере несчастья, мы видели два вида аффиксов: префикс и суффикс. Чтобы показать, что языки действительно сильно различаются, есть также инфиксы.Например, язык Bontoc с Филиппин использует инфикс um для преобразования прилагательных и существительных в глаголы. Таким образом, слово fikas, , что означает «сильный», преобразовано в глагол «быть сильным» путем добавления инфикса: f-um-ikas.
Таким образом, слово fikas, , что означает «сильный», преобразовано в глагол «быть сильным» путем добавления инфикса: f-um-ikas.
Существует ряд морфологических процессов, некоторые из которых более важны для НЛП, чем другие. Представленный здесь отчет является выборочным и необычным, поскольку он указывает на практические аспекты выбранных процессов.
- Перегиб
- Флексия — это процесс изменения формы слова таким образом, чтобы оно выражало такую информацию, как число, личность, падеж, пол, время, настроение и аспект, но синтаксическая категория слова остается неизменной. Например, форма множественного числа существительного в английском языке обычно образуется из формы единственного числа путем добавления s.
- легковых / легковых
- стол / столы
- собака / собаки
Не нужно много времени, чтобы найти примеры, где приведенное выше простое правило не подходит.
Итак, есть меньшие группы существительных, образующих множественное число по-разному:- волк / волки
- нож / ножи
- переключатель / переключатели.
Еще немного подумайте, и мы сможем подумать о совершенно неправильных формах множественного числа, таких как:
- фут / фут
- ребенок / дет.
Английские глаголы относительно просты (особенно по сравнению с такими языками, как финский, в котором более 12 000 глагольных преобразований).
- косилка — штанга
- mow s — третье лицо единственного числа, настоящее время
- mow ed — прошедшее время и причастие прошедшего времени
- mow ing — настоящее непрерывное время
Аспекты НЛП
Такие языки, как французский или немецкий, имеют гораздо больше интонаций, чем английский, поэтому принято включать морфологические анализаторы в системы, которые обрабатывают эти языки. Системы НЛП для английского языка часто не включают каких-либо морфологических процессов, особенно если это небольшие системы. В тех случаях, когда системы на основе английского языка действительно включают анализ флексии, обычные формы слов анализируются с использованием одного из стандартных методов (например, конечных автоматов), а исключения (неправильные слова) перечисляются индивидуально. Это означает, что обычные формы нужно вводить в словарь только один раз, что может сэкономить много места и сэкономить ввод данных, если словарь содержит много синтаксической и семантической информации. - Вывод
- Как было показано выше, словоизменение не меняет синтаксическую категорию слова.Деривация не меняет категорию . Лингвисты классифицируют словообразование в английском языке в зависимости от того, вызывает ли оно изменение произношения. Например, добавление суффикса ity изменяет произношение корня active , поэтому ударение находится на втором слоге: activity. Добавление суффикса al к Approve не меняет произношения корня: Approve.
Аспекты НЛП
Очевидное использование деривационной морфологии в системах НЛП состоит в том, чтобы уменьшить количество сохраняемых форм слов.Итак, если уже существует запись для базовой формы глагола sing, , тогда должна быть возможность добавить правила для сопоставления существительных Singers и singers в одной и той же записи. Проблема ее в том, что обнаружение производных певца от певца должно позволить морфологическому анализатору также вносить информацию, которая является особенной для певца . Это кажется немного непонятным, но пример прояснит это. Добавление к слову или указывает на то, что действие совершает человек.Эта семантическая информация должна быть добавлена к сохраненной информации из словарной статьи для корневой формы и , чтобы можно было найти правильное значение предложения. Это кажется прекрасным, но предположим, что следующие два слова: рекордер, и драгстер . Использование морфемы er не обязательно означает кого-то, кто предпринимает действие, представленное корневой формой.Любая лингвистическая обработка может привести к обнаружению потенциальной двусмысленности, особенно там, где люди этого не ожидают.Деривационные морфологические анализаторы могут сделать это довольно легко, потому что они всегда пытаются сократить слова до более мелких единиц. Таким образом, слово на самом деле может быть проанализировано как на самом деле (т.е. само слово) и как относительно + союзник. Эта введенная двусмысленность может быть устранена с помощью более поздней синтаксической обработки, но, тем не менее, это означает, что требуется больше обработки (и, следовательно, более медленная система).
Деривационная морфология особенно полезна для машинного перевода.Успешный МП должен обрабатывать большие объемы текста, который может содержать много ранее невидимых слов. Некоторые слова являются неологизмами (то есть новыми словами).
Если анализатор сможет преобразовать эти слова в их базовую форму, он сможет перевести это и, по сути, создать новое слово на целевом языке, просто следуя правилам. Приведу пару примеров: неологизмы часто имеют в качестве корня собственное имя. Знание того, как Thatcherite и Majorism образовались из имен собственных, могло позволить системе машинного перевода перевести их в идиоматический эквивалент на целевом языке. - Полуаффиксы и комбинированные формы
- Полуаффиксы — это связанные морфемы, сохраняющие словесность. Примеры: анти-, контр-, -подобный и -заслуживающий внимания. Итак, мы можем иметь:
- против часовой стрелки или против часовой стрелки
- контрпример или контрпример
- птице или птице
- достойный внимания или заслуживающий внимания
Комбинированные формы даже более похожи на слова, чем полуаффиксы, и часто встречаются в технической литературе, например, индоевропейский или гастроэнтерит.
Некоторые слова могут состоять полностью из связанных форм, но без свободной морфемы, например, franco-phile. Аспекты НЛП
Как и в случае деривационной морфологии, полуаффиксы и комбинирующие формы могут быть проанализированы в их морфемы и, как и в случае деривационной морфологии, могут быть использованы для анализа ранее невидимых слов. Расстановка переносов представляет собой особую проблему для таких языков, как английский и немецкий, и понимание полуаффиксов и комбинирования форм может способствовать выявлению необязательных и вероятных точек переноса при обработке текста. - Клитицизация
- Клитика — это элемент, который ведет себя как аффикс и слово. Однако они довольно сложны, поскольку также являются частью словообразования. В отличие от других морфологических явлений, клитики встречаются в синтаксической структуре, и их привязка к словам не является частью правил словообразования, как остальная часть морфологии.
Мы подробно остановимся на этом.
- «Клитика — это элемент, который ведет себя как аффикс и слово.»
- Английский язык имеет очевидную клитику, « ‘s », используемую для обозначения притяжательного падежа (иногда известного как родительный падеж). Лингвисты называют его энклитикой , что означает, что это клитика, которая прикрепляется справа от слова, как и суффикс.
- «Однако они довольно сложны в том, что они также являются частью словообразования».
- « ‘s » присоединяется («приклеивается») к слову или фразе, к которым относится притяжательное.
- «В отличие от других морфологических явлений, клитики возникают в синтаксической структуре, и их привязка к словам не является частью правил словообразования, как остальная часть морфологии».
- « ‘s » присоединяется к определенному составному элементу независимо от того, где он встречается в предложении. В следующих двух примерах « ‘s » сначала присоединяется к существительному, а затем к предлогу:
- девочка пингвин
- машина, в которую я врезалась фарами
Английский также показывает другой источник клитификации. Некоторые слова можно сократить до более короткой формы. Например, Я в Бирмингеме можно уменьшить до Я м в Бирмингеме и Это весенний цыпленок можно уменьшить до Я весенний цыпленок. Обратите внимание, что сокращаемое слово имеет свою собственную синтаксическую категорию и будет фигурировать само по себе при любом синтаксическом анализе предложения.
Аспекты НЛП
Клитицизация — интересная проблема для НЛП.Обычные системы НЛП являются модульными и поэтому имеют различные модули морфологической, синтаксической и семантической обработки. Однако такие клитики, как «‘s », не могут быть удовлетворительно проанализированы только на одном уровне. Морфологический анализатор должен уметь отделить клитику от присоединенной к ней морфемы, но он не может сделать это правильно, если не знает синтаксической структуры высказывания. В традиционной архитектуре системы НЛП синтаксическая структура недоступна морфологическому анализатору.Существуют различные методы, которые можно использовать для решения этой проблемы, например, передача как можно большего количества альтернатив от морфологического анализатора синтаксическому анализатору и надежда, что последний сможет разрешить неоднозначности. Другой метод может заключаться в попытке провести морфологический и синтаксический анализ параллельно — или, возможно, морфология и синтаксис — несовершенные способы описания языка, и мы должны найти лучшую описательную модель.
 Итак, есть меньшие группы существительных, образующих множественное число по-разному:
Итак, есть меньшие группы существительных, образующих множественное число по-разному: В тех случаях, когда системы на основе английского языка действительно включают анализ флексии, обычные формы слов анализируются с использованием одного из стандартных методов (например, конечных автоматов), а исключения (неправильные слова) перечисляются индивидуально. Это означает, что обычные формы нужно вводить в словарь только один раз, что может сэкономить много места и сэкономить ввод данных, если словарь содержит много синтаксической и семантической информации.
В тех случаях, когда системы на основе английского языка действительно включают анализ флексии, обычные формы слов анализируются с использованием одного из стандартных методов (например, конечных автоматов), а исключения (неправильные слова) перечисляются индивидуально. Это означает, что обычные формы нужно вводить в словарь только один раз, что может сэкономить много места и сэкономить ввод данных, если словарь содержит много синтаксической и семантической информации.
 Использование морфемы er не обязательно означает кого-то, кто предпринимает действие, представленное корневой формой.
Использование морфемы er не обязательно означает кого-то, кто предпринимает действие, представленное корневой формой. Если анализатор сможет преобразовать эти слова в их базовую форму, он сможет перевести это и, по сути, создать новое слово на целевом языке, просто следуя правилам. Приведу пару примеров: неологизмы часто имеют в качестве корня собственное имя. Знание того, как Thatcherite и Majorism образовались из имен собственных, могло позволить системе машинного перевода перевести их в идиоматический эквивалент на целевом языке.
Если анализатор сможет преобразовать эти слова в их базовую форму, он сможет перевести это и, по сути, создать новое слово на целевом языке, просто следуя правилам. Приведу пару примеров: неологизмы часто имеют в качестве корня собственное имя. Знание того, как Thatcherite и Majorism образовались из имен собственных, могло позволить системе машинного перевода перевести их в идиоматический эквивалент на целевом языке. Некоторые слова могут состоять полностью из связанных форм, но без свободной морфемы, например, franco-phile.
Некоторые слова могут состоять полностью из связанных форм, но без свободной морфемы, например, franco-phile. 


Критика морфологии Морфология была частью основной лингвистики на протяжении шестидесяти или более лет.Как, по-видимому, происходит со всеми лингвистическими теориями, время служит только для выявления все новых и новых недостатков в теории и дальнейших разработок, направленных на укрепление исходной теории — даже до той стадии, когда она настолько обременена, что рушится полностью.
Морфология, безусловно, расширилась и представляет собой отдельную область с обширным техническим словарем, таким как morph и allomorph (упомянем только два наиболее распространенных). Более подробное описание см. В Lyons (1968; стр. 180–194), а описание некоторых трудностей с морфемами см. Палмер (1971, стр. 187–199), который писал:
Более подробное описание см. В Lyons (1968; стр. 180–194), а описание некоторых трудностей с морфемами см. Палмер (1971, стр. 187–199), который писал:
«Однако сегодня ясно, что концепция морфемы имеет лишь ограниченную ценность.Он, безусловно, может отображать минимальные единицы грамматического анализа в огромном количестве языковых данных. В конце концов, неправильного английского языка не так уж и много. И когда дело доходит до анализа агглютинативных языков, концепция морфемы неоценима, поскольку эти языки как бы специально созданы для нее. Но когда мы рассматриваем трудности морфемной идентификации в целом … становится ясно, что это понятие не такое всеобъемлющее, как это иногда представляется ».
© П[email protected]
aps1100019a
% PDF-1.3 % 1 0 объект > эндобдж 5 0 obj > эндобдж 2 0 obj > эндобдж 3 0 obj > поток Acrobat Distiller 6.0.1 (Windows) 2011-06-07T07: 46: 33 + 05: 302011-06-07T08: 48: 00 + 05: 30aps1100019aAdobe Illustrator CS4Adobe Illustrator CS42011-06-07T07: 46: 33 + 05: 302011- 06-07T08: 48: 00 + 05: 302011-06-07T08: 48: 00 + 05: 30
 сделал: 74117FF320071168A7BAF477210F36D0xmp.iid: 74117FF320071168A7BAF477210F36D0adobe: DocId: фотошоп: 0ab54ac2-6857-11e0-8a8e-9c18c2bd8d67uuid: 0ab54ac4-6857-11e0-8a8e-9c18c2bd8d67adobe: DocId: фотошоп: 0ab54ac2-6857-11e0-8a8e-9c18c2bd8d67adobe: DocId: фотошоп: 0ab54ac2-6857-11e0-8a8e-9c18c2bd8d67
сделал: 74117FF320071168A7BAF477210F36D0xmp.iid: 74117FF320071168A7BAF477210F36D0adobe: DocId: фотошоп: 0ab54ac2-6857-11e0-8a8e-9c18c2bd8d67uuid: 0ab54ac4-6857-11e0-8a8e-9c18c2bd8d67adobe: DocId: фотошоп: 0ab54ac2-6857-11e0-8a8e-9c18c2bd8d67adobe: DocId: фотошоп: 0ab54ac2-6857-11e0-8a8e-9c18c2bd8d67 adobe.illustrator
adobe.illustrator PWÇRPvIA;, aJE) — h 旦% SOĺ`UX + PȜT (| V82] ֆ We! Bq1H} iHZKӀԀ ӾD q
PWÇRPvIA;, aJE) — h 旦% SOĺ`UX + PȜT (| V82] ֆ We! Bq1H} iHZKӀԀ ӾD qДоказательства морфологического состава сложных слов с использованием MEG
Abstract
Психолингвистические и конвергентные электрофизиологические исследования лексики свидетельство основанного на морфемах лексического доступа к морфологически сложным словам, который включает раннюю декомпозицию на составляющие их морфемы с последующей некоторой комбинаторной операцией, учитывая, что как семантически прозрачные (например, парусник), так и семантически непрозрачные (например.g., bootleg) соединения подвергаются морфологическому разложению на ранних стадиях лексической обработки, последующие комбинаторные операции должны учитывать разницу во вкладе составляющих морфем в значение этих разных типов слов. В этом исследовании мы используем магнитоэнцефалографию (МЭГ), чтобы определить нейронные основы этой комбинаторной стадии распознавания составных слов английского языка. Данные МЭГ были получены, когда участники выполняли задание по именованию слов, в котором три типа слов, прозрачные соединения (например,g. , обочина дороги), непрозрачные соединения (например, бабочка) и морфологически простые слова (например, бордель) были противопоставлены в парадигме частичного повторения прайминга, где интересующее слово было начато одной из составляющих его морфем. Анализ начальной задержки выявил более короткие задержки для наименования составных слов, чем симплексные слова при включении, что дополнительно поддерживает стадию морфологической декомпозиции в лексическом доступе. Анализ ассоциированной активности МЭГ выявил интересующую область, вовлеченную в морфологический состав, левую переднюю височную долю (LATL).Только прозрачные соединения показали повышенную активность в этой области с 250 до 470 мс. Предыдущие исследования с использованием предложений и фраз подчеркнули роль LATL в выполнении вычислений для основных комбинаторных операций. Результаты согласуются с моделями декомпозиции для доступности морфем на ранних этапах обработки и предполагают, что семантика играет роль в объединении значений морфем, когда их состав прозрачен для общего значения слова.
, обочина дороги), непрозрачные соединения (например, бабочка) и морфологически простые слова (например, бордель) были противопоставлены в парадигме частичного повторения прайминга, где интересующее слово было начато одной из составляющих его морфем. Анализ начальной задержки выявил более короткие задержки для наименования составных слов, чем симплексные слова при включении, что дополнительно поддерживает стадию морфологической декомпозиции в лексическом доступе. Анализ ассоциированной активности МЭГ выявил интересующую область, вовлеченную в морфологический состав, левую переднюю височную долю (LATL).Только прозрачные соединения показали повышенную активность в этой области с 250 до 470 мс. Предыдущие исследования с использованием предложений и фраз подчеркнули роль LATL в выполнении вычислений для основных комбинаторных операций. Результаты согласуются с моделями декомпозиции для доступности морфем на ранних этапах обработки и предполагают, что семантика играет роль в объединении значений морфем, когда их состав прозрачен для общего значения слова.
Ключевые слова: соединений, МЭГ, левая передняя височная доля (LATL), именование слов, морфология, семантическая прозрачность, морфологическая декомпозиция, морфологический состав
1.Введение
Некоторые слова простые, а некоторые нет. Поначалу это звучит как очень банальная тавтология, но споры о том, хранятся ли мультиморфемные слова просто в виде целой словоформы (Butterworth, 1983; Giraudo and Grainger, 2001) или всегда строятся из их морфемных частей (Taft, 2004). ) был развлекательным, провокационным и спорным в области лексической обработки в течение последних 40 лет. Комплексная модель того, как слова сохраняются и извлекаются, требует понимания того, как связаны форма и значение и как эта связь разворачивается во времени в естественной речи.
Потенциальный контраст между хранением целого слова и хранением морфем впервые обсуждался в классической модели удаления аффиксов (Taft and Forster, 1975), которая предполагала, что лексический доступ включает доступ к основе морфологически сложных слов. Это исследование показало, что псевдосложные слова с реальными основами (например, de- juvenate ) требовали больше времени для отклонения в задаче лексического решения (и часто выбирались неверно как слова), чем псевдосложные слова с реальными префиксами и несуществующие. стебли (e.г., de- pertoire ). Это было воспринято как доказательство того, что морфемы были доступны до лексического доступа, и они способствуют поиску лексического элемента в памяти. При использовании различных парадигм прайминга накопились доказательства в пользу доступности морфем во время лексического доступа (Marslen-Wilson et al., 1994; Rastle and Davis, 2003; Taft, 2004). Это привело к появлению моделей обработки, в которых морфологическая декомпозиция является автоматическим и необходимым этапом обработки сложных слов (Rastle et al., 2004). В недавних исследованиях (Fiorentino et al., 2014; Semenza and Luzzatti, 2014) изучались этапы разложения, чтобы увидеть, как значение морфемы интегрируется в значение сложного слова.
Это исследование показало, что псевдосложные слова с реальными основами (например, de- juvenate ) требовали больше времени для отклонения в задаче лексического решения (и часто выбирались неверно как слова), чем псевдосложные слова с реальными префиксами и несуществующие. стебли (e.г., de- pertoire ). Это было воспринято как доказательство того, что морфемы были доступны до лексического доступа, и они способствуют поиску лексического элемента в памяти. При использовании различных парадигм прайминга накопились доказательства в пользу доступности морфем во время лексического доступа (Marslen-Wilson et al., 1994; Rastle and Davis, 2003; Taft, 2004). Это привело к появлению моделей обработки, в которых морфологическая декомпозиция является автоматическим и необходимым этапом обработки сложных слов (Rastle et al., 2004). В недавних исследованиях (Fiorentino et al., 2014; Semenza and Luzzatti, 2014) изучались этапы разложения, чтобы увидеть, как значение морфемы интегрируется в значение сложного слова. Результаты электрофизиологии (Fiorentino et al., 2014) выявили большую негативность для лексикализованных соединений (например, чашка) и новых соединений (например, надгробная сноска) по сравнению с мономорфемными словами во временном окне 275-400 мс, устанавливая стадию где значения морфем объединены в английских соединениях.Эти психологические модели дают четкие прогнозы относительно стадий и динамики лексического доступа, но в настоящее время отсутствуют доказательства привязки этих стадий к определенным областям мозга. Это исследование направлено на выявление области, ответственной за состав значений морфем. Исследования из литературы по именованию картинок (Dohmes et al., 2004) показывают, что на этом этапе должна быть большая активация для семантически прозрачных сложных слов, поскольку они демонстрируют большую концептуальную активацию и конкуренцию лемм в дополнение к эффекту морфологического перекрывать.Следовательно, эта область должна быть чувствительной только к составу сложных слов, значение морфемы которых имеет семантически прозрачное отношение к общему значению по сравнению со сложными словами, морфемы которых не имеют семантических отношений, opaque .
Результаты электрофизиологии (Fiorentino et al., 2014) выявили большую негативность для лексикализованных соединений (например, чашка) и новых соединений (например, надгробная сноска) по сравнению с мономорфемными словами во временном окне 275-400 мс, устанавливая стадию где значения морфем объединены в английских соединениях.Эти психологические модели дают четкие прогнозы относительно стадий и динамики лексического доступа, но в настоящее время отсутствуют доказательства привязки этих стадий к определенным областям мозга. Это исследование направлено на выявление области, ответственной за состав значений морфем. Исследования из литературы по именованию картинок (Dohmes et al., 2004) показывают, что на этом этапе должна быть большая активация для семантически прозрачных сложных слов, поскольку они демонстрируют большую концептуальную активацию и конкуренцию лемм в дополнение к эффекту морфологического перекрывать.Следовательно, эта область должна быть чувствительной только к составу сложных слов, значение морфемы которых имеет семантически прозрачное отношение к общему значению по сравнению со сложными словами, морфемы которых не имеют семантических отношений, opaque .
Один из способов взглянуть на лексическую обработку сложных слов — посмотреть, может ли активация морфологической структуры модулировать доступность сложного слова. Некоторые исследования кросс-модального прайминга (Marslen-Wilson et al., 1994) показали, что прайминг в лексическом решении между словами, имеющими общий корень, происходил только тогда, когда простое число и цель имели связанные значения (например, отправление началось от , но отдел не имело), в то время как другие исследования (Zwitserlood, 1994) ) с использованием прайминга с частичным повторением обнаружил, что прайминг не зависит от семантических отношений между простым и целевым. Однако исследования с использованием замаскированного прайминга, парадигмы сублиминального прайминга, в котором простому слову предшествует прямая маска и за ним следует целевое слово (Forster and Davis, 1984), обнаружили, что при манипулировании семантической прозрачностью эффекты облегчения возникали для сложных слов независимо от имеют ли прайм и мишень один и тот же морфологический корень (Longtin et al.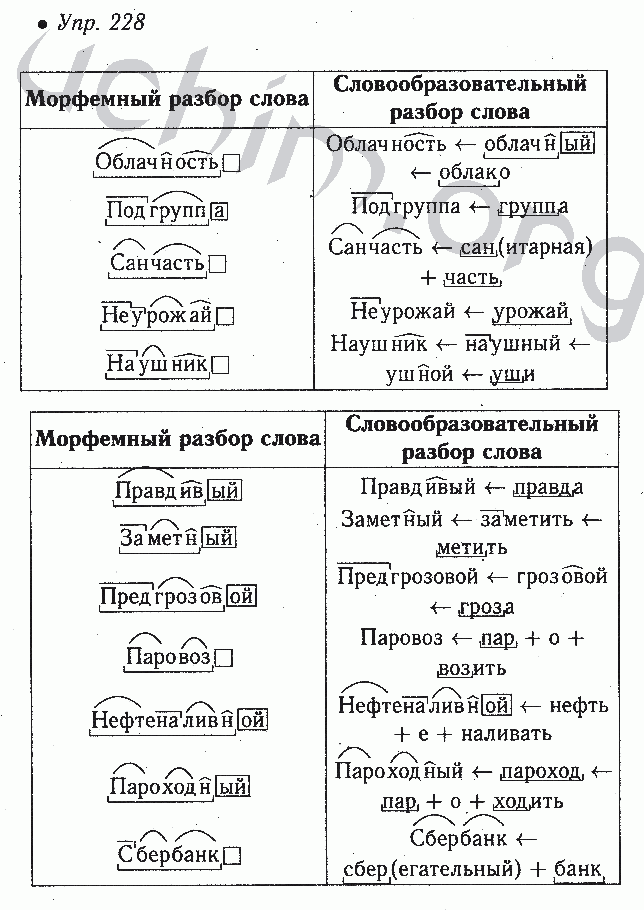 , 2003; Растл и др., 2004; Фиорентино и Поппель, 2007; McCormick et al., 2008). Эти эффекты не проявлялись для морфологически простых слов (например, бордель ). Было обнаружено более быстрое лексическое время принятия решений для сложных слов, которые можно сегментировать на существующие морфемы, что означает, что замаскированные простые / немаскированные целевые пары без семантических отношений, такие как corner-corn и bootleg-boot , показали ускоренное распознавание целевых слов с помощью величины, неотличимые от пар с семантическими отношениями, такими как очиститель-очиститель и чашка-чай .
, 2003; Растл и др., 2004; Фиорентино и Поппель, 2007; McCormick et al., 2008). Эти эффекты не проявлялись для морфологически простых слов (например, бордель ). Было обнаружено более быстрое лексическое время принятия решений для сложных слов, которые можно сегментировать на существующие морфемы, что означает, что замаскированные простые / немаскированные целевые пары без семантических отношений, такие как corner-corn и bootleg-boot , показали ускоренное распознавание целевых слов с помощью величины, неотличимые от пар с семантическими отношениями, такими как очиститель-очиститель и чашка-чай .
Поскольку общепринято, что морфологическая декомпозиция выполняется для каждого сложного слова, которое может быть исчерпывающим образом разобрано на существующие морфемы, исследования визуального распознавания слов должны сместить акцент с декомпозиции на последующие механизмы, задействованные для активации фактического значения сложной цели. слово. Meunier и Longtin (2007) предположили, что активация слова вступает в игру поэтапно, которые включают по крайней мере одну раннюю стадию морфологической декомпозиции и более позднюю стадию семантической интеграции морфологических частей.Fiorentino et al. (2014) представили доказательства основанного на морфемах пути активации слова, который включает разложение на морфологические составляющие и комбинаторные процессы, действующие на эти представления. Поскольку предыдущие исследования показали, что ранняя декомпозиция, вызванная морфологической структурой, происходит автоматически для прозрачных и непрозрачных слов, разница между этими двумя типами слов может проявиться на более позднем этапе комбинаторных операций.
слово. Meunier и Longtin (2007) предположили, что активация слова вступает в игру поэтапно, которые включают по крайней мере одну раннюю стадию морфологической декомпозиции и более позднюю стадию семантической интеграции морфологических частей.Fiorentino et al. (2014) представили доказательства основанного на морфемах пути активации слова, который включает разложение на морфологические составляющие и комбинаторные процессы, действующие на эти представления. Поскольку предыдущие исследования показали, что ранняя декомпозиция, вызванная морфологической структурой, происходит автоматически для прозрачных и непрозрачных слов, разница между этими двумя типами слов может проявиться на более позднем этапе комбинаторных операций.
Другой способ взглянуть на лексическую обработку сложных слов — это посмотреть, как форма отображается на значение.Это очень важно при обработке морфологически сложных слов, чтобы отделить то, как мозг воспринимает прозрачные слова от того, как он воспринимает непрозрачные. Это можно исследовать, посмотрев, как значения морфем складываются в мозгу. Существуют модели общего механизма связывания в построении предложений (Friederici et al., 2000) и в базовой композиции именных фраз (Bemis and Pylkkänen, 2011), которые вовлекают левую переднюю височную долю (LATL) в состав слов во фразы. .В парадигме минимальной композиции Bemis и Pylkkänen (2011) обнаружили, что два составных элемента во фразе прилагательное-существительное (например, красная лодка ) вызвали большую активацию в левой передней височной доле, LATL, примерно на 225 мс, чем два. несоставные элементы (например, xkq boat , случайная последовательность букв и слова). Это было воспринято как доказательство того, что базовая комбинаторная обработка данных поддерживается LATL. Внутри сложных слов есть специальный подкласс слов, которые имеют структуру, параллельную именным фразам, известным как составные слова.Сложные слова обладают уникальным свойством состоять только из свободных морфем (отдельных слов).
Это можно исследовать, посмотрев, как значения морфем складываются в мозгу. Существуют модели общего механизма связывания в построении предложений (Friederici et al., 2000) и в базовой композиции именных фраз (Bemis and Pylkkänen, 2011), которые вовлекают левую переднюю височную долю (LATL) в состав слов во фразы. .В парадигме минимальной композиции Bemis и Pylkkänen (2011) обнаружили, что два составных элемента во фразе прилагательное-существительное (например, красная лодка ) вызвали большую активацию в левой передней височной доле, LATL, примерно на 225 мс, чем два. несоставные элементы (например, xkq boat , случайная последовательность букв и слова). Это было воспринято как доказательство того, что базовая комбинаторная обработка данных поддерживается LATL. Внутри сложных слов есть специальный подкласс слов, которые имеют структуру, параллельную именным фразам, известным как составные слова.Сложные слова обладают уникальным свойством состоять только из свободных морфем (отдельных слов). Составные слова также различаются по измерению семантической прозрачности , степени, в которой комбинация значений морфем соответствует общему значению слова. Это означает, что мы можем варьировать вклад морфем в композицию значения. Эти свойства делают составные слова отличным кандидатом для исследования морфологического состава сложных слов, поскольку они могут обеспечивать аналогичную структуру для работы, выполняемой на уровне фразы.Эти параллели приводят к тому, что LATL является кандидатом на композицию внутри слова, и это обеспечивает интересную основу для изучения эффектов внутрилексической семантической композиции как аналога композиции на уровне фразы.
Составные слова также различаются по измерению семантической прозрачности , степени, в которой комбинация значений морфем соответствует общему значению слова. Это означает, что мы можем варьировать вклад морфем в композицию значения. Эти свойства делают составные слова отличным кандидатом для исследования морфологического состава сложных слов, поскольку они могут обеспечивать аналогичную структуру для работы, выполняемой на уровне фразы.Эти параллели приводят к тому, что LATL является кандидатом на композицию внутри слова, и это обеспечивает интересную основу для изучения эффектов внутрилексической семантической композиции как аналога композиции на уровне фразы.
Таким образом, семантически прозрачные составные слова (например, почтовый ящик) должны вызывать большую активность в этой области, чем простые слова, поскольку их значения происходят из состава их морфемных частей, тогда как семантически непрозрачные составные слова (например, бутлег) не должны вызывать большей активности поскольку нет никакой связи между их частями и значениями. Таким образом, модель сложного распознавания слов потребует, по крайней мере, этих двух этапов обработки: разбора на базовые единицы (декомпозиция) и композиции этих словоформ в сложное значение. Чтобы распаковать эти этапы, мы предлагаем использовать два типа парадигм грунтования: грунтовку с частичным повторением (например, ДОРОГА-обочина), аналогичные парадигмам, используемым в исследованиях замаскированного грунтования, которые будут использоваться для исследования эффектов разложения в соединениях, и прайм с полным повторением (например, ROADSIDE-Roadside), который будет использоваться для исследования композиционных эффектов их морфем.Штрихи условия повторения прайминга использовали для оценки эффекта композиции в отсутствие поведенческой реакции. В этом отношении метод анализа аналогичен принятому Zweig и Pylkkänen (2009), в котором авторы напрямую сравнивают сложные (производные) слова, таким образом стремясь найти эффекты разложения, которые не зависят от прайминга. В этом исследовании используется задача создания именования слов для изучения этих этапов, связанных с лексической обработкой, поскольку она обеспечивает сопоставимые эффекты с задачами лексического принятия решений (Neely, 1991) и не требует пробного заполнения.Эта задача была выполнена, пока активность мозга регистрировалась с помощью МЭГ, чтобы исследовать, есть ли в левой височной доле область, отвечающая за морфологический состав. Это исследование вносит свой вклад в работу по характеристике нейронных основ лексической обработки сложных слов, предоставляя доказательства композиции в составных словах и связывая их с их нейронными коррелятами. Учитывая предшествующую литературу, мы ожидаем найти доказательства разложения для сложных слов, но не для симплексных слов.Это открытие согласуется с литературой по визуальному распознаванию слов, особенно с литературой по замаскированному праймингу, где есть облегчающие эффекты при прайминге морфологически сложных слов, но не морфологически простых слов. Однако мы не ожидаем увидеть это общее преимущество морфологической сложности в составе. Поскольку состав смысла регулируется семантически, мы ожидаем обнаружить влияние композиции на активность мозга только для прозрачных соединений.
Таким образом, модель сложного распознавания слов потребует, по крайней мере, этих двух этапов обработки: разбора на базовые единицы (декомпозиция) и композиции этих словоформ в сложное значение. Чтобы распаковать эти этапы, мы предлагаем использовать два типа парадигм грунтования: грунтовку с частичным повторением (например, ДОРОГА-обочина), аналогичные парадигмам, используемым в исследованиях замаскированного грунтования, которые будут использоваться для исследования эффектов разложения в соединениях, и прайм с полным повторением (например, ROADSIDE-Roadside), который будет использоваться для исследования композиционных эффектов их морфем.Штрихи условия повторения прайминга использовали для оценки эффекта композиции в отсутствие поведенческой реакции. В этом отношении метод анализа аналогичен принятому Zweig и Pylkkänen (2009), в котором авторы напрямую сравнивают сложные (производные) слова, таким образом стремясь найти эффекты разложения, которые не зависят от прайминга. В этом исследовании используется задача создания именования слов для изучения этих этапов, связанных с лексической обработкой, поскольку она обеспечивает сопоставимые эффекты с задачами лексического принятия решений (Neely, 1991) и не требует пробного заполнения.Эта задача была выполнена, пока активность мозга регистрировалась с помощью МЭГ, чтобы исследовать, есть ли в левой височной доле область, отвечающая за морфологический состав. Это исследование вносит свой вклад в работу по характеристике нейронных основ лексической обработки сложных слов, предоставляя доказательства композиции в составных словах и связывая их с их нейронными коррелятами. Учитывая предшествующую литературу, мы ожидаем найти доказательства разложения для сложных слов, но не для симплексных слов.Это открытие согласуется с литературой по визуальному распознаванию слов, особенно с литературой по замаскированному праймингу, где есть облегчающие эффекты при прайминге морфологически сложных слов, но не морфологически простых слов. Однако мы не ожидаем увидеть это общее преимущество морфологической сложности в составе. Поскольку состав смысла регулируется семантически, мы ожидаем обнаружить влияние композиции на активность мозга только для прозрачных соединений.
2.Материалы и методы
2.1 Участники
Восемнадцать правшей, носителей английского языка в возрасте от 18 до 30 лет, с нормальным или исправленным зрением, все дали информированное согласие и участвовали в этом эксперименте. Исследование было одобрено Университетским комитетом по деятельности с участием людей (UCAIHS) Нью-Йоркского университета. Данные MEG от трех участников были исключены из-за большого количества отказов от испытаний, вызванных шумовыми помехами (> 25%). Подробности отказа описаны в процедуре.
2.2. Материал
Все стимулы состояли из английских би-морфемных соединений (например, чашка) и морфологически простых существительных (например, шпинат), сопоставленных по длине и частоте встречаемости. Мы манипулировали семантической прозрачностью, включая полностью семантически прозрачные (например, чайная чашка) слова, в которых обе составляющие морфемы имеют семантическое отношение к значению всего соединения, и полностью семантически непрозрачные слова (например, фигня), в которых ни один из составляющих морфемы имеют семантическое отношение к составному значению.
311 английских словосочетаний были собраны из предыдущих исследований (Juhasz et al., 2003; Fiorentino and Poeppel, 2007; Fiorentino and Fund-Reznicek, 2009; Drieghe et al., 2010) и классифицированы с точки зрения семантической прозрачности с помощью Задача семантического родства, выполняемая с помощью инструмента Amazon Mechanical Turk. В этом задании 20 участникам было предложено оценить по шкале от 1 до 7, насколько каждый компонент соединения относится к целому слову. По шкале 1 соответствует несвязанному, а 7 — очень близкому.Каждому участнику случайным образом представили один из компонентов каждого соединения. Соединения классифицировались как семантически непрозрачные (далее непрозрачные ), если сумма баллов их составляющих находилась в интервале 2–6, и как семантически прозрачные (далее прозрачные ), если сумма была в интервале 10–14. Например, непрозрачный состав крайний срок получил суммарный рейтинг 3,76 с мертвых , что дает рейтинг прозрачности 1.44 и строка дает рейтинг 2.32. Точно так же составной кукольный домик получил суммарную оценку 11,79, где кукла внесла свой вклад в рейтинг прозрачности 6,47, а дом дал оценку 5,32. Для каждого типа слова было выбрано шестьдесят соединений. Этот метод нормирования семантической прозрачности соответствовал методам, использованным в упомянутых предыдущих исследованиях. Морфологически простые слова (далее simplex : например, шпинат) были объединены из Rastle et al.(2004) и English Lexicon Project отбирали слова, закодированные на наличие только одной морфемы (Balota et al., 2007). Симплексные слова (например, бордел ) были выбраны так, чтобы они имели неморфологическую связь формы с их простыми числами (например, бульон ). Кроме того, эти слова были ограничены и выбраны таким образом, чтобы простое слово нельзя было разбить на более мелкие части без создания недопустимых морфем.
2.3. Дизайн
Три разных типа слов были сопоставлены в двух условиях прайминга: полное повторение и частичное (составляющее) повторение (см. Таблицу).Для условия повторного прайминга в качестве прайма и мишени использовали одно и то же соединение (например, чашка TEACUP). Для прайминга с частичным повторением мы использовали первый компонент соединения в качестве праймера (например, чайную чашку TEA). Для симплексного условия неморфологическая родственная форма использовалась в качестве составляющей в условии частичного повторения прайминга (например, SPIN-шпинат). Эти два условия прайминга были объединены для управления условиями, в которых прайм не имел семантического отношения к цели (например,г., DOORBELL-чашка; ДВЕРЬ-чашка).
Таблица 1
| Прозрачный | Непрозрачный | Симплекс | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Основной | 902 902 902 902 902 902 902 902 902 902 Prime | Target | ||||||||||
| Control | Дверной звонок | Чашка | Семейная реликвия | Hogwash | Бордель | Hogwash | Repetacup 9097Spinac | RepetacupШпинат | Шпинат | |||
| Control | Дверь | Чашка | Наследник | Hogwash | Бульон | Шпинат | ||||||
| Частичное повторение | Чай | Чай | Hog ясеньОтжим | Шпинат | ||||||||
2.4. Процедура
Все участники прочитали все задания во всех условиях (всего 720), которые были разделены на три списка по 240 слов и рандомизированы в каждом списке. Порядок представления списков был сбалансирован между испытуемыми. Экспериментальной задачей было наименование слов: испытуемым предлагались пары слов, и их просили прочитать вслух второе слово каждой пары. Стимулы были представлены белым шрифтом Courier размером 30 пунктов на сером фоне с помощью PsychToolbox (Brainard, 1997).Каждое испытание начиналось с предъявления фиксирующего креста, затем штриховки, затем мишени. Каждая из этих визуальных презентаций была представлена в течение 300 мс с последующим пропуском 300 мс (см. Рисунок). Мы записали начальную латентность речи и высказывания каждого испытуемого для поведенческого анализа.
Структура эксперимента .
Перед экспериментом форма головы каждого участника была оцифрована с использованием системы Polhemus Fastscan вместе с пятью точками индикатора положения головы, которые используются для совместной регистрации положения головы по отношению к датчикам MEG во время сбора данных.Электромагниты, прикрепленные к этим точкам, локализуются после того, как участники лежат внутри массива датчиков МЭГ, что обеспечивает совместную регистрацию систем координат головы и датчика. Форма головы используется во время анализа для совместной регистрации головы на МРТ участников. Половине участников МРТ не проводились; поэтому мы масштабировали общий эталонный мозг, который предоставляется в FreeSurfer, чтобы он соответствовал размеру голов этих участников.
Во время эксперимента участники оставались лежать в комнате с магнитной защитой, а реакцию их мозга контролировали градиентометры MEG.Экспериментальные элементы проецировались на экран, чтобы участник мог прочитать и выполнить задание. Данные МЭГ были собраны с использованием аксиальной системы градиентометра для всей головки с 157 каналами и тремя опорными каналами (Канадзавский технологический институт, Ноноичи, Япония). Запись проводилась в режиме постоянного тока, то есть без фильтра верхних частот, с фильтром нижних частот 300 Гц и режекторным фильтром 60 Гц.
2,5. Анализ
Мы исследовали латентность начала, время реакции на наименование слова, чтобы оценить эффекты морфологического разложения на основе Fiorentino and Poeppel (2007).Поскольку время реакции чувствительно к лексическим свойствам слов (Fiorentino and Poeppel, 2007), составные слова должны обрабатываться быстрее при праймировании, чем симплексные слова из-за остаточной активации ранее активированных морфем. Недекомпозиционный счет не предсказывает никаких различий из-за структуры слова, если слова правильно сопоставлены для соответствующих свойств всего слова. Таким образом, начальная задержка может использоваться, чтобы понять, есть ли эффект разложения. Поведенческие данные были проанализированы с использованием традиционного дисперсионного анализа для типа слова с помощью модели взаимодействия с частичным повторением.Прайминг с частичным повторением в задачах лексического решения использовался, чтобы продемонстрировать доступность морфем в сложных словах (Rastle et al., 2004). Подобные поведенческие эффекты были также обнаружены при использовании именования слов (см. Neely, 1991 для сравнительного обзора лексического решения и именования слов). Таким образом, свидетельство эффектов разложения можно наблюдать во времени реакции, чтобы говорить, , задержка начала . Предыдущие исследования привели к предсказанию, что должен быть стимулирующий эффект более короткой задержки начала из-за прайминга для соединений по сравнению с их эквивалентами из симплексных слов, поскольку сегментация на морфемы приводит к более быстрому доступу к сложному слову.
После сбора данных мозга мы применили метод непрерывно скорректированных наименьших квадратов (Adachi et al., 2001), процедуру снижения шума в программном обеспечении MEG160 (Yokogawa Electric Corporation и Eagle Technology Corporation, Токио, Япония), которая вычитает шум из градиентометры МЭГ основаны на измерениях шума в опорных каналах, удаленных от головы. Данные подвергались полосовой фильтрации в диапазоне 1–40 Гц с использованием БИХ-фильтра. Запись всего эксперимента была сегментирована на интересующие эпохи, от -200 мс до до 600 мс после визуального отображения основного слова.Мы отклонили испытания, в которых максимальная амплитуда размаха превышала предел 4000fT, и уравняли испытания, чтобы иметь равное количество испытаний для каждого условия и для каждого типа слова для правильного сравнения. Средний процент отклоненных испытаний среди субъектов составлял 1,9%, а для каждого типа слова: 1,3% для непрозрачных, 2,2% для симплексных, 1,8% для прозрачных. Каналы датчиков были отмечены как плохие и отбрасывались для каждого испытуемого, если полное отклонение канала превышало 10%.
Матрица ковариации шума была вычислена для каждого участника с использованием процедуры автоматического выбора модели (Engemann and Gramfort, 2015) на случайном выборе базовых эпох (120 эпох) от -200 мс до начала представления креста фиксации. .Для участников с МРТ кортикальные реконструкции были сгенерированы с использованием FreeSurfer, в результате чего пространство источника составляло 5124 вершины (CorTechs Labs Inc., Ла-Хойя, Калифорния и MGH / HMS / MIT Центр биомедицинской визуализации Athinoula A. Martinos, Чарльстон, Массачусетс). Метод модели граничных элементов (БЭМ) использовался для моделирования активности в каждой вершине для расчета прямого решения. Обратное решение было сгенерировано с использованием этой прямой модели и матрицы ковариации шума и вычислено с ограничением фиксированной ориентации, требующим, чтобы дипольные источники были перпендикулярны кортикальной поверхности.Затем данные датчиков для каждого испытуемого проецировались в их индивидуальное исходное пространство с использованием оценки минимальной нормы с корковыми ограничениями (все анализы проводились с использованием MNE-Python: Gramfort et al., 2013, 2014), в результате чего получались нормализованные по шуму карты динамических статистических параметров. (dSPM: Dale et al., 2000).
Для этого анализа наш план (таблица) сводится к простому сравнению между составными (например, TEACUP) и симплексными словами (например, SPINACH) одинакового размера, которые служили простыми числами в условии повторения (например,g., TEACUP-teacup), описанный выше в разделе «Дизайн». Поскольку для этого анализа мы используем нейрофизиологические данные, относящиеся к молчаливому чтению слов, которые служили простыми числами, поведенческих данных для этих слов нет. Таким образом, мы также избегаем артефактов, связанных с произвольными движениями, которые могут поставить под угрозу анализ эффектов, представляющих интерес для исследования (Hansen et al., 2010).
Таблица 2
| Типы слов | Примеры | |
|---|---|---|
| Непрозрачный | Hogwash | |
| Прозрачный | Элемент управления для чашки | 99932
Мы исследовали нервную активность, локализованную во всей левой височной доле.Этот регион был выбран на основе композиционных эффектов, обнаруженных в предложениях (Friederici et al., 2000) или фразах прилагательное-существительное (Bemis and Pylkkänen, 2011). Чтобы проверить, была ли повышена активность соединений в этой области, был проведен тест t на остаточную активацию типа составного слова (непрозрачный, прозрачный) после удаления активации из симплексного контрольного слова от 100 до 600. мс после появления стимула. Карта мозга с p была создана для временных рядов, а пространственно-временные кластеры были идентифицированы для смежных пространственно-временных кластеров, у которых значение p было меньше 0.05 и длительностью не менее 10 мс. Значения t были суммированы для тех точек в кластере, которые соответствовали этим критериям. Затем сначала был выполнен тест непараметрической перестановки путем перетасовки меток типов слов, а затем вычисления кластеров, образованных новыми метками. Распределение, сгенерированное из 10 000 перестановок, было вычислено путем вычисления значимых уровней наблюдаемого кластера. Скорректированное значение p было определено из процента кластеров, которые были больше, чем исходный вычисленный кластер (Maris and Oostenveld, 2007).Эти тесты были рассчитаны с использованием пакета статистического анализа данных MEG, Eelbrain (https://pythonhosted.org/eelbrain/).
4. Обсуждение
Анализ различных типов слов по отдельности выявил очень последовательные доказательства того, что существует разница в том, как простые и сложные слова обрабатываются в мозгу. Поведенческие результаты подтвердили, что существует стадия лексического доступа, которая чувствительна к морфологическим формам в сложных словах, и продемонстрировали, что эти эффекты также могут наблюдаться в других модальностях тестирования, а именно, в именовании слов.Эффект начального латентного взаимодействия, когда составные слова создавались быстрее, чем морфологически простые слова, когда они начинались с их составной морфемы, в значительной степени согласуется с результатами в литературе по замаскированному праймингу по распознаванию слов и дает дополнительные доказательства того, что в лексическом доступе есть стадия декомпозиции. где сложные слова разбираются на их морфемы (Rastle et al., 2004; Taft, 2004; Morris et al., 2007; McCormick et al., 2008; Fiorentino and Fund-Reznicek, 2009).Операция синтаксического анализа происходит независимо от семантических отношений между составляющими морфемами и их сложным словом. Поскольку ранняя активация составляющих посредством морфологического разложения происходит независимо от семантической прозрачности, то, что отличает прозрачное и непрозрачное соединение, должно происходить, таким образом, на более поздней стадии морфемного состава. Повышенная активность прозрачных соединений в передней височной доле с 250 до 470 мс свидетельствует о стадии лексического доступа, на которой значения морфемы играют роль в доступе к общему значению слова.Bemis и Pylkkänen (2011) показывают комбинаторные эффекты в LATL для прилагательных слов примерно через 225 мс после предъявления критического слова. Разницу во времени можно объяснить разными моментами времени, когда мы фиксируем начало действия стимула. В Bemis and Pylkkänen (2011) начало совпадает с началом существительного boat во фразе red boat , тогда как в нашем исследовании критическим стимулом является весь состав sailboat .
Повышенная активация в задней височной доле прозрачных соединений с 430 до 600 мс, которая следует за активностью в LATL, согласуется с тем фактом, что эта область участвует в лексическом поиске (Hickok and Poeppel, 2007; Lau et al., 2008). Lau et al. (2008) предположили, что задняя область височной доли является лучшим кандидатом для лексического хранения слов. Поскольку LATL отвечает за составление значения составляющих морфем, задняя височная доля будет отвечать за извлечение информации из сохраненного лексико-семантического представления. Эта область также участвует в преобразовании звука в значение (Binder et al., 2000), которое включает поиск фонологической информации. Это исследование согласуется с моделями декомпозиции из литературы по визуальному распознаванию слов и обеспечивает нейронную основу для этапа лексического доступа, участвующего в композиции значения в составных словах, тем самым помогая распутать когнитивные процессы, которые нечеткие, когда время реакции является единственной мерой. .Объединяя результаты психолингвистических исследований с записями МЭГ активности мозга, полученные результаты предполагают, что распознавание соединений включает в себя различные стадии: стадию декомпозиции, которая не зависит от семантики, и стадию композиции, которая регулируется семантикой. Мы показали, что ход активации различается по сложности слова и семантической прозрачности.
| A | B |
|---|---|
| производные морфемы | Имеет два или более дополнения, может быть суффиксом или префиксом, может изменять 3 вещи: значение, произношение или часть речи |
| флективная морфема | 8 и только суффиксы: pl, притяжательное, -ed прошедшее время или иррег.как было, было, пение в 3-м лице, причастие настоящего, причастие прошедшего времени, сравнительное, в превосходной степени, |
| открытая морфема | может быть добавлена с производной или флективной морфемой или грамматической морфемой |
| закрыто морфема | не может быть добавлена, такие слова, как предлоги, артикли, местоимения |
| изолированных языков | китайский например, морфемы (кекс) являются индив. слова |
| агглютинированные языки | (нарезанный хлеб), такие как турецкий и венгерский, морфемы имеют четкую границу и соответствуют грамматической категории, когда-то прошедшее время, всегда прошедшее время |
| фузионные языки | (торт) как английский , морфемы иногда не имеют четких границ, например was, I, me, содержит больше слов-портфелей |
| portmanteau | морфема, которая содержит более одной значимой единицы (было, было, пошло, хорошо), но не может быть разбита на отдельные элементы |
| морфема | слов или частей слов, которые не могут быть разбиты на более мелкие части |
| дополнение | возникновение неправильных слов, таких как хорошее к здоровью, я для меня, в неправильной форме. |
| полностью дополняющий | неправильных слов, которые не имеют ничего общего с исходной формой, например, хорошо и хорошо |
| частично дополняющий | неправильных слов, которые показывают некоторую часть корневого слова, например, покупают, учат, поют -sang, ring-rang |
| морфология | Изучение структуры слов или словообразования |
| Лингвистика | Научное изучение языка, не имеет особого интереса к предписывающей грамматике |
| Универсальный или ментальный Грамматика | Неявная лингвистическая компетенция |
| Лингвистическая способность | Как человек использует язык, на него могут влиять внешние факторы, наркотики, алкоголь |
| Лингвистическая компетенция | Неявное знание грамматики, но реальная или явная (преподаваемая) грамматика , а не универсальная грамматика.Уровень владения языком, не подверженный влиянию внешних факторов |
| Диалекты | Собственная манера речи человека, множество диалектов на каждом языке |
| Дескриптивная лингвистика | Непрямое обучение, нет истинных указаний относительно того, как преподавать язык |
| Прескриптивная лингвистика | Управляемое структурное обучение, правила грамматики, |
| Сложные морфемы | 2 или более морфемы вместе, анализируемые или способные к разделению на несколько морфем |
| простые морфемы | , даже если длинные, как , не может делиться на более мелкие морфемы |
| Аффиксы | три подгруппы исправлений..pre, in и суффикс |
| Paradigm | набор связанных слов из одного корня … jump, jump, jump или нерегулярный, быть, был, есть, был |
| орфография | система письма, нет единого правила, например, алфавита |
| глянец | Лингвистическая аббревиатура под анализируемыми морфемами .. человек, глагол, множитель, время и т.д. Зависит от качества звука перед ним, независимо от того, является ли он s или z, например, |
| zero allomorph | как абсолютное «i» в Толкапайе.иногда «s» нет в третьем лице поют на других языках, это нулевой алломорф или рыба, олень для нулевого пл алломорфа |
| иерархическая структура | способов прикрепления аффиксов к словам |
| номинализатор | как ness , может присоединяться к глаголу или adj и превращаться в существительное |
| доминирующий узел | вершина дерева, указывает, какое последнее слово стало |
| сестринскими узлами или конечными узлами, | позиционными терминалами в дереве |
| сложные структуры | с древовидными диаграммами, более одного аффикса к диаграмме |
| округ | все элементы преобладают в одном узле дерева: несчастье преобладает над несчастьем |
| составных слов | 1) два или более слов, соединенных вместе, чтобы образовать одно слово 2) имели голову справа для обозначения части речи 3) ударение слева для обозначения произношение |
| ablaut | изменение одного звука, чтобы выразить изменение значения, обычно в гласных, ругань-ругань, качели |
| Согласные исключения ablaut | слов, которые не соответствуют обычным правилам и являются исключениями : дом дом, жизнь вживую, зубы зубы, ванна для ванны |
| составные головы | часть составного слова, придающая значение: церковный двор, где ставится ударение |
| клитицизация | фонологическое присоединение морфемы как «the» к другому слову…. яблоко как бы становится одним звуком из-за гласной в яблоке., также s, a, an и сокращений |
| повторный анализ | изменение восприятия говорящим местоположения границы слова или морфемы, часто с неопределенными артиклями. Это ell или это nell. |
| относительное придаточное слово | используется как подлежащее или как глагол. Цветы девушки, которую я видел … люди все время делают это в речи, а не в письменной форме. |
| лексикон | ограниченное количество слов в языке, но обычно в одном языке около 60 000. |
| немаркированные формы | неспецифическая форма в языке, например «тот, кто что-то делает» или «кто» или «человек» |
| нулевая морфема | третье лицо единственного числа, без определенного окончания на морфема для обозначения человека в некоторых языках. |
| типология | изучение основного порядка слов |
| полисинтетический язык | одно слово выражает множество значений, обычно используемых в других языках, но не в английском |
| Грамматические категории | пол , голос, настроение, время, число |
| Лингвистические знания | Грамматика, состоящая из: лексики, морфологии, синтаксиса, семантики, фонетики, фонологии |
| Синтаксиса | Структура или порядок слов в хорошей фразе или предложения, мы знаем плохо сформированные и хорошо сформированные |
| Семантика | Что означают эти слова, особеннов предложении или фразе |
| Фонетика | Изучение звуков человеческого языка |
| Фонемы | Один из основных звуков языка |
| Двуязычный | Более чем бегло, как носитель языка |
| Неявная грамматика | Грамматика, которую мы знаем без необходимости обучения |
| Явная грамматика | преподаваемая грамматика |
| Сложная морфема | две или более морфемы, соединенные вместе |
| Синхронная лингвистика язык в определенное время, просто старый английский или просто современный и т.д. отрицание, а обращение) не может быть присоединено к наречиям, только прилагательным.«re» применяется только к глаголам. | |
| Суффиксные правила | , такие как «способный», не могут присоединяться к интуитивным словам, требуется слово, которое может принимать объект. Не может быть «go -able», но может иметь Thinkable |
| Allophone | фонетическая вариация отдельного звука d или t |
| backformations | мы изобретаем слово, подходящее к нашему добавлению суффикса, например, editor и мошенник |
| супрасегментные | сегменты — это согласные и гласные фонемы, а верхние означают громкость или тон, который вы растягиваете, продолжительность, энергию также |
| Отличительные тона | В частности, в азиатских языках, где тон может изменять звук значение слова, написанного таким же образом |
| озвученных | тонов, которые вибрируют в наших голосовых связках |
| глухих | тонов, которые не вибрируют в наших голосовых связках |
| голосовых связок | пространство между нашими голосовые связки |
| язычок | свисающий предмет в задней части рта |
| велум | мягкое небо до конца нёба |
| твердое нёбо | средняя часть нёба |
| альвеолярный гребень | сразу за верхними зубами |
| язычок | середина язык |
| корень языка | спинка языка |
| остановка (взрывная) | остановка прохождения воздуха через звуковую систему |
| носовая остановка | воздушная остановка через нос |
| лексический морфема | морфема, которая является существительным, глаголом, прилагательным или наречием, может быть описана картинками |
| грамматическая морфема | аффиксов, определителей, предлогов.сигнализирует слово и контекстное отношение, в котором оно находится. |
| связанная морфема | морфема, которая должна присоединяться к другой морфеме, чтобы иметь смысл, иметь смысл и т. д. |
| свободная морфема | морфема, которая может стоять отдельно или быть добавлен к |
| производительность | производство и понимание речи могут быть затронуты внешними факторами, такими как наркотики или алкоголь |
| компетентность | ваша ментальная грамматика, явные знания могут добавить к этому, но они всегда есть, а не влияют по внешним факторам |
| Три вопроса Хомского | 1) что составляет знание языка? 2) как приобретаются знания? 3) Как использовать знания? |
| овладение языком | как выучить язык, чтобы заполнить пробелы в универсальной грамматике |
| ментальная грамматика | неявная общая совокупность знаний, которая позволяет людям общаться |
| универсальная грамматика | врожденная, генетическая грамматика, которой мы обладаем при рождении |
| описательная грамматика | обобщения и идеализированные формы мысленной грамматики всех людей в языковом сообществе |
| предписывающая грамматика | преподавала грамматику, «никогда не заканчивайте предложение предлогом» Используется только в письменной грамматике |
| педагогическая грамматика | преподавала грамматику другого языка или его разновидности (диалекта) |
| Именительная форма | подлежащая в предложении |
| винительная форма | объект в предложении |
| дублирование | 911 30 на самом деле не существует в английском языке, но в других языках может предписывать многие вещи, от ударения в слове до множественного числа — нет-нет было бы английским.
Что такое морфемы? | SEA
Определение
«Морфема» — это короткий языковой сегмент, отвечающий трем основным критериям:
1. Это слово или часть слова, имеющее значение.
2. Его нельзя разделить на более мелкие значимые сегменты, не изменив его значения или не оставив бессмысленного остатка.
3. Оно имеет относительно одинаковое устойчивое значение в разных вербальных средах.
Свободные и связанные морфемы
Есть два типа морфем без морфем и связанных морфем.«Свободные морфемы» могут иметь особое значение, например, есть , дата , слабый . «Связанные морфемы» не могут оставаться в одиночестве со значением. Морфемы состоят из двух отдельных классов, называемых (а) базовыми (или корнями) и (б) аффиксами.
«Основа» или «корень» — это морфема в слове, придающая этому слову его основное значение. Пример морфемы со «свободным основанием» — женщина в слове женщина . Пример морфемы «связанное основание» — -sent в слове dissent .
Аффиксы
«Аффикс» — это связанная морфема, которая встречается с до или после основания. Аффикс, стоящий перед основанием, называется «префиксом». Некоторые примеры префиксов: ante- , pre- , un- и dis- , как в следующих словах:
анте дата
до исторический
un здоровый
dis относительно
Аффикс, идущий после основания, называется суффиксом.»Некоторые примеры суффиксов: -ly , -er , -ism и -ness , как в следующих словах:
хэппи ily
сад эр
капитал изм
вид несс
Производные аффиксы
Аффикс может быть словообразовательным или словоизменительным. «Производные аффиксы» служат для изменения значения слова, опираясь на основу. В приведенных выше примерах слов с префиксами и суффиксами добавление префикса un- к здоровый изменяет значение здорового .Получившееся слово означает «не здоровый». Добавление суффикса -er к сад изменяет значение слова сад , где растут растения, цветы и т. Д., На слово, которое относится к «человеку, который ухаживает за садом». Следует отметить, что все префиксы в английском языке являются производными. Однако суффиксы могут быть как словообразовательными, так и словоизменительными.
Флективные аффиксы
В английском языке существует большое количество производных аффиксов.Напротив, в английском языке всего восемь «флективных аффиксов», и все это суффикса . В английском языке есть следующие флективные суффиксы, которые при добавлении к определенным типам слов выполняют множество грамматических функций.