Предложение с обращением / Предложение / Синтаксис и синтаксический разбор / Справочник по русскому языку для начальной школы
- Главная
- Справочники
- Справочник по русскому языку для начальной школы
- Синтаксис и синтаксический разбор
- Предложение
- Предложение с обращением
В предложениях, особенно побудительных, очень часто используются обращения.
Обращение — это слово или сочетание слов, называющее того, к кому обращаются с речью.
Обращение обычно является именем существительным в именительном падеже (Здравствуй, солнце!), или сочетанием существительного с прилагательным (Здравствуй, солнце ясное!).
Запомни, что обращение не является членом предложения!
В устной речи обращения особо выделяются голосом.
На письме обращения всегда выделяются запятыми:
- Если обращение стоит в начале предложения, то оно отделяется запятой.


Например:
- Если обращение стоит в середине предложения, то оно выделяется запятыми с обеих сторон.
Например: На этот раз, Толя, я тебя обязательно обгоню!
- Если обращение стоит в конце предложения, то запятая ставится перед обращением.
Например: До новых встреч, дорогие ребята!
Обращение может отделяться восклицательным знаком, если произносится с сильным чувством. В этом случае после восклицательного знака следующее слово пишется с заглавной буквы.
Например: Мама! Я так соскучилась по тебе!
Советуем посмотреть:
Виды предложения по цели высказывания
Предложения и их эмоциональная окраска (интонация)
Главные члены предложения – подлежащее и сказуемое
Второстепенные члены предложения
Предложения распространенные и нераспространенные
Однородные члены предложения
Простое и сложное предложения
Предложения с прямой речью
Словосочетание
Предложение
Синтаксис и синтаксический разбор
Правило встречается в следующих упражнениях:
1 класс
Страница 7, Климанова, Рабочая тетрадь
2 класс
Упражнение 229, Полякова, Учебник, часть 2
3 класс
Упражнение 25, Канакина, Рабочая тетрадь, часть 1
Упражнение 26, Канакина, Рабочая тетрадь, часть 1
Упражнение 88, Канакина, Рабочая тетрадь, часть 1
Упражнение 167, Канакина, Горецкий, Учебник, часть 2
Упражнение 168, Канакина, Горецкий, Учебник, часть 2
Упражнение 19, Климанова, Бабушкина, Учебник, часть 1
4 класс
Упражнение 19, Канакина, Горецкий, Учебник, часть 1
Упражнение 25, Канакина, Рабочая тетрадь, часть 1
Упражнение 26, Канакина, Рабочая тетрадь, часть 1
Упражнение 161, Канакина, Рабочая тетрадь, часть 2
Упражнение 19, Климанова, Бабушкина, Учебник, часть 1
Упражнение 21, Климанова, Бабушкина, Учебник, часть 1
Упражнение 22, Климанова, Бабушкина, Учебник, часть 1
Упражнение 23, Климанова, Бабушкина, Учебник, часть 1
Упражнение 2, Климанова, Бабушкина, Учебник, часть 1
Упражнение 17, Климанова, Бабушкина, Рабочая тетрадь, часть 1
5 класс
Упражнение 215, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 221, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 356, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 486, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 594, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 226, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 777, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 500, Разумовская, Львова, Капинос, Учебник
Упражнение 502, Разумовская, Львова, Капинос, Учебник
Упражнение Задачка стр. 140,
Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 2
140,
Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 2
6 класс
Упражнение 48, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 550, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 553, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 152, Разумовская, Львова, Капинос, Учебник
Упражнение 153, Разумовская, Львова, Капинос, Учебник
Упражнение 154, Разумовская, Львова, Капинос, Учебник
Упражнение 598, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 2
Упражнение 603, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 2
7 класс
Упражнение 17, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник
Упражнение 19, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник
Упражнение 22, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник
Упражнение 11, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 59, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 460, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 463, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 512, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 205, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник, часть 1
Упражнение 424, Разумовская, Львова, Капинос, Учебник
8 класс
Упражнение 344, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 346, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 347, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 393, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 395, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 398, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 229, Разумовская, Львова, Капинос, Учебник
Упражнение 279, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник
Упражнение Повторение стр. 198 — 199,
Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник
198 — 199,
Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник
Упражнение 424, Бархударов, Крючков, Максимов, Учебник
Порядок синтаксического разбора сложносочинённого предложения
План разбора:
Вид предложения по цели высказывания (повествовательное, вопросительное или побудительное).
Вид предложения по эмоциональной окраске (восклицательное или невосклицательное).
Сложное.
Союзное.
Сложносочинённое.
Количество частей в составе сложного, их границы (выделить грамматические основы в простых предложениях).
Средства связи между частями (указать союзы и определить значение сложного предложения).
Схема предложения.

Образец разбора:
Была зима, но все последние дни стояла оттепель. (И.Бунин).
(Повествовательное, невосклицательное, сложное, союзное, сложносочинённое, состоит из двух частей, между первой и второй частями выражено противопоставление, части соединены противительным союзом но.)
Схема предложения:
[ ]1, но [ ]2.
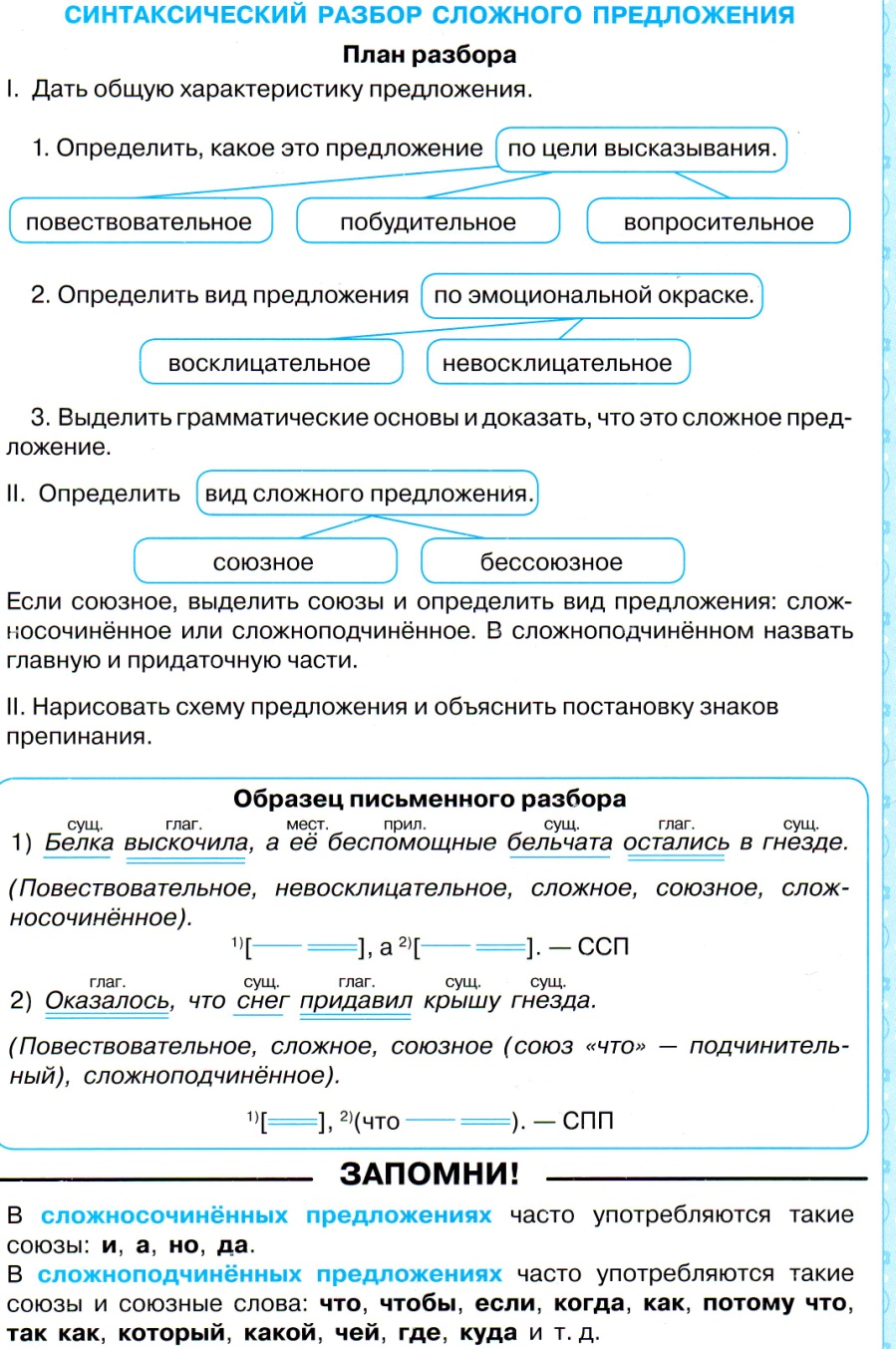
Порядок синтаксического разбора сложноподчинённого предложения
План разбора:
Союзное.
Сложноподчинённое.
Количество частей (выделить грамматические основы в простых предложениях).
Главная и придаточная части.
Что распространяет придаточная часть.
Чем присоединяется придаточная часть.
Расположение придаточной части.
Тип придаточной части.
Схема сложноподчинённого предложения.

Образец разбора:
Когда она играла внизу на рояле1, я вставал и слушал2. (А.П. Чехов)
(Повествовательное, невосклицательное, сложное, союзное, сложноподчинённое, состоит из двух частей. 2-я часть главная, 1-я – придаточная, придаточная часть распространяет главную часть и присоединяется к ней союзом когда, придаточная часть располагается перед главной, тип придаточной части – придаточное времени).
Схема предложения:
Когда?
(союз когда…)1, [ … ]2.
придаточное
времени
Сущ.. глаг. союз мест. Глаг.
пр. прил. сущ.
союз мест. Глаг.
пр. прил. сущ.
Путники увидели, что они находятся на маленькой поляне. (Повеств., невоскл., сложное, СПП с прид. изъяснительным, 1) нераспр., двусост., полное. 2) распр., двусост., полдное).
[ ____ ], (что…).
Порядок синтаксического разбора бессоюзного сложного предложения
План разбора:
Вид предложения по цели высказывания (повествовательное, вопросительное или побудительное).
Вид предложения по эмоциональной окраске (восклицательное или невосклицательное).
Сложное.
Бессоюзное.
Количество частей (выделить грамматические основы в простых предложениях).
Схема предложения.
Образец разбора:
Песенка кончилась1 – раздались обычные рукоплескания2. (И.С. Тургенев)
(И.С. Тургенев)
(Повествовательное, невосклицательное, сложное, бессоюзное, состоит из двух частей, первая часть указывает на время действия того, о чём говорится во второй части, между частями ставится тире.)
Схема предложения:
[]1 — []2 .
17
Что такое синтаксис? || Справочник штата Орегон по грамматике | | Колледж свободных искусств
Что такое синтаксис? — Стенограмма
Написано и исполнено доктором Теклой Бьюд, доцентом кафедры английской литературы Университета штата Орегон
Я собираюсь прочитать вам два предложения, и я хотел бы, чтобы вы сказали мне, какое из них имеет смысл: «бесцветные зеленые идеи яростно спят» или «яростно спят идеи зеленые бесцветные»? Если бы вы сказали «ни то, ни другое», вы были бы правы. Ни одно из этих предложений не имеет семантического смысла. То есть, если вы думаете об идеях, которые представлены в этих предложениях, оба совершенно нелепы. Идеи не могут быть зелеными. А даже если бы и могли, то они по определению не могли бы быть «бесцветными» (если только мы не используем какое-то поэтическое определение «зеленого», например «новые или неопытные»).
Идеи не могут быть зелеными. А даже если бы и могли, то они по определению не могли бы быть «бесцветными» (если только мы не используем какое-то поэтическое определение «зеленого», например «новые или неопытные»).
Идеи определенно не спят, и даже вещи, которые спят, не спят яростно, если только у них нет какой-нибудь ужасной проблемы с желудком. Но что, если я попрошу вас сказать мне, какое из этих двух предложений построено разумно — имеет грамматический смысл?
Этот знаменитый пример исходит от Ноама Хомского, и вы, вероятно, видели его раньше. Это прекрасный пример идеи синтаксиса : то, как мы объединяем слова в предложение, чтобы придать этому предложению смысл . Важно отметить, что когда мы говорим о синтаксисе, мы говорим, по крайней мере не сразу, об идеях внутри предложения, а вместо этого о том, как мы организуем различные классы слов (например, существительных , глаголов , наречий и прилагательных). ) и размещаем их рядом друг с другом, как кусочки головоломки, чтобы мы оправдали ожидания наших читателей и слушателей: то есть, чтобы мы имели максимально возможный смысл.
Большинство простых современных английских предложений следуют теме 9.0006 -синтаксис объекта-глагола. То есть: «Ребенок ударил по мячу» (подлежащее-глагол-дополнение)[BJT2] . Но не каждый язык использует такое расположение подлежащего, глагола и дополнения для простейших предложений. В некоторых языках, таких как современный стандартный арабский, используется глагол-подлежащее-дополнение, а во многих языках, включая хинди и японский, предпочтительнее ставить глагол в конце, субъект-дополнение-глагол. Хотя такой синтаксис является нормальным для арабского, хинди и японского языков, его нет в английском языке. Таким образом, «ударил ребенка по мячу» (глагол-подлежащее-дополнение) и «ребенок ударил по мячу» (подлежащее-дополнение-глагол) немного неуклюжи. Мы все еще можем их понять, но они не совсем правильно работают на английском языке.
Все становится еще более шатким, если мы попробуем некоторые другие синтаксические схемы, такие как объект-глагол-подлежащее.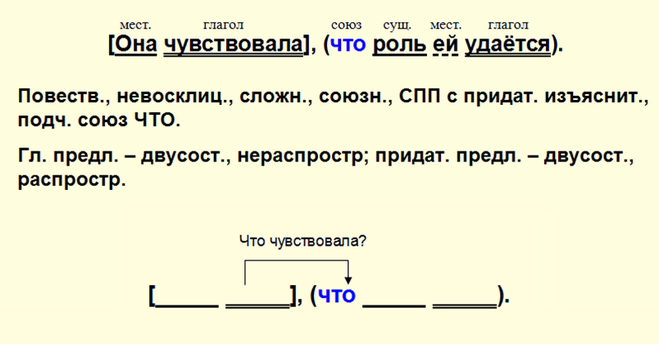 В повседневном контексте фраза «мячик ударил ребенка» не просто звучит неловко, она буквально меняет смысл предложения, потому что наши ожидания относительно расположения грамматических элементов в английском языке, то есть наши ожидания в отношении синтаксиса, настолько сильны. . Синтаксис помогает нам быстро и легко анализировать значение языка. Поскольку носители данного языка разделяют ожидания относительно того, какие типы слов входят в какую часть предложения, мы обычно можем выяснить семантическое значение предложения, используя наш опыт его грамматики.
В повседневном контексте фраза «мячик ударил ребенка» не просто звучит неловко, она буквально меняет смысл предложения, потому что наши ожидания относительно расположения грамматических элементов в английском языке, то есть наши ожидания в отношении синтаксиса, настолько сильны. . Синтаксис помогает нам быстро и легко анализировать значение языка. Поскольку носители данного языка разделяют ожидания относительно того, какие типы слов входят в какую часть предложения, мы обычно можем выяснить семантическое значение предложения, используя наш опыт его грамматики.
Но это не всегда так! Иногда мы меняем ожидаемый порядок слов, чтобы подчеркнуть определенную мысль, выделить определенные слова, подобрать ритмическую или схему рифм в стихах или просто ради творчества. Возьмем эту строчку, которую Ричард, герцог Йоркский, произносит в начале шекспировского «Ричарда III»: «Заговоры я строил, опасные наведения, пьяными пророчествами, клеветами и мечтами, чтобы вызвать смертельную ненависть к моему брату Кларенсу и королю, одно против другого».
«Plots have I lay» инвертирует нормальный порядок слов субъект-глагол-объект в английском языке на объект-глагол-субъект, а «опасные индукции» нарушает правило нормативного английского порядка слов, которое требует, чтобы прилагательные стояли перед существительным, которое они изменяют, а не после. Это не простое предложение, такое как «ребенок пнул мяч», и в некоторых из них не используется нормативный синтаксис, но мы все же можем его разобрать, потому что то, как оно изгибает и изгибает наши ожидания в отношении языка, соответствует диапазону нормальных это зависит от контекста. Когда мы читаем и слушаем поэзию, мы ожидаем, что наши ожидания оправдаются.
Это всего лишь пара примеров того, как работает синтаксис в английском языке. Какие еще синтаксические нормы вы замечаете в своем письменном и разговорном английском? Какие еще особенности порядка слов помогают вам, вашим слушателям и читателям понять значение вашего языка?
ПОСМОТРЕТЬ ПОЛНУЮ СЕРИЮ:Справочник штата Орегон по грамматике
2 примера
2 примера Далее: 3 Грамматика Вверх: Яппы 2. 0 Руководство Предыдущий: 1 Введение Подразделы
0 Руководство Предыдущий: 1 Введение Подразделы В этом разделе несколько примеров, которые показывают использование яппов. Во-первых, введение показывает, как создавать грамматики и писать их. в яппской форме. Этот пример может пропустить тот, кто знаком с грамматика и парсинг. Далее идет грамматика выражений Лиспа, которая производит дерево синтаксического анализа в качестве вывода. Этот пример демонстрирует использование токенов и правила, а также возврат значений из правил. Третий пример это грамматика оценки выражения, которая оценивает во время синтаксического анализа (вместо создания дерева синтаксического анализа).
Грамматика естественного языка определяет, как слова могут быть помещены
вместе, чтобы сформировать большие структуры, такие как фразы и предложения. А
грамматика для компьютерного языка аналогична в том, что она определяет, как
небольшие компоненты (называемые жетонами) могут быть объединены в
более крупные структуры. В этом разделе мы напишем грамматику для крошечного
подмножество англ.
В этом разделе мы напишем грамматику для крошечного
подмножество англ.
Простые английские предложения можно описать как словосочетание с существительным. за которым следует глагол, за которым следует именное словосочетание. Например, в предложение «Джек потопил синий корабль», слово «Джек» является первым словосочетание, «потонул» — это глагол, а «голубой корабль» — второе словосочетание. Кроме того, мы должны сказать, что такое именное словосочетание; для В этом примере мы скажем, что именное словосочетание является необязательным артиклем. (a, an, the), за которыми следует любое количество прилагательных, за которыми следует существительное. Токенами в нашем языке являются артикли, существительные, глаголы и прилагательные. Правила нашего языка подскажут нам, как объединяйте токены вместе, чтобы сформировать списки прилагательных, словосочетаний с существительными, и предложения:
- предложение: фраза_существительного глагол фраза_существительного
- существительное_фраза: [статья] прилагательное* существительное
Обратите внимание, что некоторые вещи, которые мы легко произносим по-английски, например,
«необязательный артикль» выражаются с использованием специального синтаксиса, такого как
кронштейны. Когда мы говорили «любое количество прилагательных», мы писали
прилагательное*, где * означает «ноль или более
предыдущий шаблон».
Когда мы говорили «любое количество прилагательных», мы писали
прилагательное*, где * означает «ноль или более
предыдущий шаблон».
Приведенная выше грамматика близка к грамматике Яппса. Мы также должны укажите, что представляют собой токены и что делать при совпадении шаблона. В этом примере мы ничего не будем делать при сопоставлении шаблонов; в следующий пример объяснит, как выполнять действия сопоставления.
парсер TinyEnglish: игнорировать: "\\W+" символическое существительное: "(Джек|спам|корабль)" символический глагол: «(затонул | бросил)» символический артикль: "(a|an|the)" токен прилагательное: "(синий | красный | зеленый)" правило предложение: фраза_существительного глагол фраза_существительного правило фраза_существительного: [статья] прилагательное* существительное
Токены указаны как регулярные выражения Python. С
Yapps создает код Python, вы можете написать любое регулярное выражение, которое
будет принят Python. (Примечание: это Python 1. 5
регулярные выражения из модуля re, а не Python 1.4
регулярные выражения из модуля regex.) В дополнение к
токены, которые вы хотите видеть (имеющие имена), вы также можете
укажите токены для игнорирования, отмеченные ключевым словом ignore. В
в этом синтаксическом анализаторе мы хотим игнорировать все, что не является символом слова, поэтому
мы используем \W+ в качестве шаблона игнорирования. Чтобы вставить регулярное выражение с обратной косой чертой (\) в строку Python, мы должны экранировать обратную косую черту, поэтому в грамматике она отображается как «\W+». Во многих грамматиках вы
хотите игнорировать пробелы, поэтому вы должны использовать \s+, записанный как «\s+» в Python.
5
регулярные выражения из модуля re, а не Python 1.4
регулярные выражения из модуля regex.) В дополнение к
токены, которые вы хотите видеть (имеющие имена), вы также можете
укажите токены для игнорирования, отмеченные ключевым словом ignore. В
в этом синтаксическом анализаторе мы хотим игнорировать все, что не является символом слова, поэтому
мы используем \W+ в качестве шаблона игнорирования. Чтобы вставить регулярное выражение с обратной косой чертой (\) в строку Python, мы должны экранировать обратную косую черту, поэтому в грамматике она отображается как «\W+». Во многих грамматиках вы
хотите игнорировать пробелы, поэтому вы должны использовать \s+, записанный как «\s+» в Python.
Грамматика TinyEnglish показывает, как вы определяете токены и правила, но это не указывает, что должно произойти после того, как мы сопоставили правила. В в следующем примере мы возьмем грамматику и произведем синтаксический анализ дерево из него.
Синтаксис Лиспа, хотя и не нравится некоторым, имеет искупительное качество: он
просто разобрать. В этом разделе мы построим грамматику Яппса для
анализировать выражения Lisp и создавать дерево разбора в качестве вывода.
В этом разделе мы построим грамматику Яппса для
анализировать выражения Lisp и создавать дерево разбора в качестве вывода.
Определение грамматики
Синтаксис Лиспа прост. Он имеет выражения, которые
идентификаторы, строки, числа и списки. Список слева
скобки, за которыми следует некоторое количество выражений (разделенных
пробелы), за которыми следует правая скобка. Например, 5 , "ni" и (print "1+2 = " (+ 1 2)) являются выражениями Лиспа.
Написано как грамматика,
выражение: ID | СТР | ЧИСЛО | список
список: (выражение*)
В дополнение к грамматике нам нужно указать, что делать каждый раз. раз что-то совпадает. Для токенов, которые являются строками, мы просто хотите получить «значение» токена, прикрепите его тип (идентификатор, строка или число) каким-либо образом и вернуть его. Для списков мы хотим для создания и возврата списка Python.
Как только какой-либо шаблон соответствует, мы заключаем оператор возврата, заключенный
в {{. . Фигурные скобки позволяют нам вставить любую одну строку
заявление в парсер. В рамках этого утверждения мы можем обратиться к
значения, возвращаемые путем сопоставления каждой части правила. После сопоставления
токен, такой как ID, «ID» будет привязан к тексту
совпадающий токен. Давайте посмотрим на правило: ..}}
..}}
выражение правила: ID {{ return ('id', ID) }}
...
В правиле токены возвращают совпадающий текст. Для идентификаторов,
мы просто возвращаем идентификатор вместе с «тегом», сообщающим нам, что
это идентификатор, а не строка или какое-либо другое значение. Иногда
нам может понадобиться преобразовать этот текст в другую форму. Например, если
строка соответствует, мы хотим удалить кавычки и обрабатывать специальные формы
нравится \n . Если число совпадает, мы хотим преобразовать его в
число. Давайте посмотрим на возвращаемые значения для других токенов:
...
| STR {{ return ('str', eval(STR)) }}
| ЧИСЛО {{ вернуть ('число', atoi(ЧИСЛО)) }}
. ..
 ..
..
Если мы получаем строку, мы хотим удалить кавычки и обработать любой специальные коды обратной косой черты, поэтому мы запускаем eval для строки в кавычках. Если мы получаем число, мы преобразуем его в целое с помощью atoi и затем верните число вместе с его тегом типа.
Для сопоставления со списком нам нужно сделать кое-что еще сложный. Если мы сопоставляем список выражений Лиспа, мы хотим создайте список Python с этими значениями.
список правил: "\\(" # Соответствует открывающей скобке
{{ result = [] }} # Создаем список Python
(
expr # Когда мы сопоставляем выражение,
{{ result.append(expr) }} # добавляем в список
)* # * означает повторить это, если необходимо
"\\)" # Совпадение с закрывающей скобкой
{{ return result }} # Возвращаем список Python
9\\"]+|\\\\.)*"'
выражение правила: ID {{ return ('id', ID) }}
| STR {{ return ('str', eval(STR)) }}
| ЧИСЛО {{ вернуть ('число', atoi(ЧИСЛО)) }}
| список {{ вернуть список}}
список правил: "\\(" {{ результат = [] }}
( выражение {{ результат. приложение (выражение) }}
)*
"\\)" {{ возвращаемый результат }}
 приложение (выражение) }}
)*
"\\)" {{ возвращаемый результат }}
приложение (выражение) }}
)*
"\\)" {{ возвращаемый результат }}
Одна вещь, которую вы, возможно, заметили, это то, что "\\(" и "\\)" появляются в списке правил. Это встроенные токены:
они появляются в правилах без имени с
ключевое слово токена. Встроенные токены более удобны в использовании, но
поскольку у них нет имени, совпадающий текст не может быть использован
в возвращаемом значении. Их лучше всего использовать для коротких простых узоров.
(обычно знаки препинания или ключевые слова).
Еще одна вещь, на которую следует обратить внимание, это то, что токены номера и идентификатора
перекрывать. Например, «487» соответствует как NUM, так и ID. У яппов,
сканер пытается сопоставить только те токены, которые приемлемы для синтаксического анализатора.
Это правило здесь не поможет, так как в поле может стоять как NUM, так и ID.
одно и то же место в грамматике. Есть два правила, используемые для выбора жетонов, если
более одного совпадения. Во-первых, самый длинный матч
предпочтительно. Например, «487x» будет соответствовать идентификатору (487x), а не
чем в виде ЧИСЛА (487), за которым следует идентификатор (x). Второе правило состоит в том, что если
две спички имеют одинаковую длину, первая из них указана в
грамматика предпочтительнее. Например, «487» будет соответствовать NUM.
а не ID, потому что NUM указан первым в грамматике. В соответствии
токены имеют преимущество перед любыми перечисленными вами токенами.
Во-первых, самый длинный матч
предпочтительно. Например, «487x» будет соответствовать идентификатору (487x), а не
чем в виде ЧИСЛА (487), за которым следует идентификатор (x). Второе правило состоит в том, что если
две спички имеют одинаковую длину, первая из них указана в
грамматика предпочтительнее. Например, «487» будет соответствовать NUM.
а не ID, потому что NUM указан первым в грамматике. В соответствии
токены имеют преимущество перед любыми перечисленными вами токенами.
Теперь, когда наша грамматика определена, мы можем запустить Yapps для создания синтаксического анализатора, а затем запустите синтаксический анализатор, чтобы создать дерево синтаксического анализа.
Бегущие яппы
В модуле Yapps есть функция generate, которая принимает введите имя файла и записывает парсер в другой файл. Мы можем использовать это функция для генерации синтаксического анализатора Лиспа, который, как предполагается, находится в сюсюкать
% питон Python 1.5.
 1 (№ 1, 3 сентября 1998 г., 22:51:17) [GCC 2.7.2.3] на linux-i386
Copyright 1991-1995 Stichting Mathematicsch Centrum, Амстердам
>>> импортировать яппы
>>> yapps.generate('lisp.g')
1 (№ 1, 3 сентября 1998 г., 22:51:17) [GCC 2.7.2.3] на linux-i386
Copyright 1991-1995 Stichting Mathematicsch Centrum, Амстердам
>>> импортировать яппы
>>> yapps.generate('lisp.g')
На данный момент Yapps написал файл lisp.py, который содержит парсер. В этом файле два класса (один сканер и один парсер) и функция (называемая синтаксическим анализом), которая объединяет данные для ты.
Кроме того, мы можем запустить Yapps из командной строки, чтобы сгенерировать файл парсера:
% Python yapps.py lisp.g
После запуска Yapps либо из Python, либо из команды строку, мы можем использовать синтаксический анализатор Лиспа, вызвав синтаксический анализ функция. Первым параметром должно быть правило, которому мы хотим соответствовать, а вторым параметром должна быть строка для анализа.
>>> импортировать лисп
>>> lisp.parse('выражение', '(+ 3 4)')
[('id', '+'), ('num', 3), ('num', 4)]
>>> lisp.parse('expr', '(print "3 = " (+ 1 2))')
[('id', 'print'), ('str', '3 = '), [('id', '+'), ('num', 1), ('num', 2)]]
Функция синтаксического анализа — не единственный способ использования синтаксического анализатора;
раздел описывает, как получить доступ к объектам парсера
напрямую.
Теперь мы прошли этапы создания грамматики, написания файл грамматики для яппов, создание синтаксического анализатора и использование синтаксического анализатора. В В следующем примере мы увидим, как правила могут принимать параметры, а также как для выполнения вычислений вместо того, чтобы просто возвращать дерево синтаксического анализа.
Обычный пример синтаксического анализатора, приведенный во многих учебниках, — это простой выражения с числами, сложение, вычитание, умножение, деление и заключение в скобки подвыражений. Мы напишем это Например, в Yapps, оценивая выражение при разборе.
В отличие от yacc, в Yapps нет способа указать правила приоритета, поэтому мы должны сделать это сами. Мы говорим, что выражение есть сумма терминов, а термин есть произведение факторы, и что фактор представляет собой число или выражение в скобках:
выражение: фактор ( ("+"|"-") фактор )*
фактор: термин ( ("*"|"/") термин )*
срок: ЧИСЛО | "("выражение")"
Чтобы вычислить выражение по мере продвижения, мы должны
аккумулятор при оценке списков терминов или факторов. Как только
мы сохранили переменную «результат» для построения дерева синтаксического анализа для Лиспа
выражения, мы будем использовать переменную для оценки числового
выражения. Полная грамматика приведена ниже:
Как только
мы сохранили переменную «результат» для построения дерева синтаксического анализа для Лиспа
выражения, мы будем использовать переменную для оценки числового
выражения. Полная грамматика приведена ниже:
парсер калькулятор:
token END: "$" # $ означает конец строки
токен ЧИСЛО: "[0-9]+"
цель правила: expr END {{ return expr }}
# Выражение представляет собой сумму и разность множителей
выражение правила: фактор {{ v = фактор }}
( "[+]" фактор {{ v = v+фактор }}
| "-" фактор {{ v = v-фактор }}
)* {{возврат v}}
# Фактор - это произведение и деление терминов
фактор правила: термин {{ v = термин }}
( "[*]" термин {{ v = v * термин }}
| "/" термин {{v = v/термин}}
)* {{возврат v}}
# Термин представляет собой либо число, либо выражение, заключенное в круглые скобки.
термин правила: NUM {{ return atoi(NUM) }}
| "\\(" выражение "\\)" {{ вернуть выражение }}
Правило верхнего уровня — это цель, которое говорит, что мы ищем
выражение, за которым следует конец строки. Конец
токен нужен, потому что без него непонятно, когда остановиться
разбор. Например, строка «1+3» может быть проанализирована как
выражение «1», за которым следует строка «+3», или это может быть
анализируется как выражение «1+3». Требуя, чтобы выражения заканчивались
с END синтаксический анализатор вынужден принимать «1+3».
Конец
токен нужен, потому что без него непонятно, когда остановиться
разбор. Например, строка «1+3» может быть проанализирована как
выражение «1», за которым следует строка «+3», или это может быть
анализируется как выражение «1+3». Требуя, чтобы выражения заканчивались
с END синтаксический анализатор вынужден принимать «1+3».
В двух правилах с повторением аккумулятор называется v. Прочитав одно выражение, мы инициализируем аккумулятор. Каждый время в цикле, мы модифицируем аккумулятор, добавляя, вычитание, умножение или деление предыдущего аккумулятора на выражение, которое было проанализировано. В конце правила мы вернуть аккумулятор.
Пример калькулятора показывает, как обрабатывать списки элементов, используя циклы, а также как обрабатывать приоритеты операторов.
Примечание. Часто бывает важно ввести токен END, поэтому
вставьте его, если только вы не уверены, что в вашей грамматике есть какой-то другой
недвусмысленный токен, обозначающий конец программы.
В предыдущем примере мы узнали, как написать калькулятор, который оценивает простые числовые выражения. В этом разделе мы будем расширить пример для поддержки как локальных, так и глобальных переменных.
Для поддержки глобальных переменных мы добавим операторы присваивания в Правило «цели».
цель правила: expr END {{ return expr }}
| 'установить' ID expr END {{ global_vars[ID] = expr }}
{{ вернуть выражение}}
Чтобы использовать эти переменные, нам нужен новый тип терминала:
термин правила: ... | ID {{ return global_vars[ID] }}
Пока эти изменения очевидны. У нас просто глобальная словарь global_vars, в котором хранятся переменные и значения, мы изменяем его, когда есть оператор присваивания, и мы ищем переменных в нем, когда мы видим имя переменной.
Для поддержки локальных переменных мы добавим объявления переменных в
набор разрешенных выражений.
термин правила: ... | 'let' VAR '=' expr 'in' expr ...
Вот где становится сложно. Локальные переменные должны храниться в локальный словарь, а не глобальный. Один трюк должен был бы сохранить копию глобального словаря, изменить его, а затем восстановить позже. В этом примере вместо этого мы будем использовать атрибуты для создавать локальную информацию и передавать ее субправилам.
Правило может дополнительно принимать параметры. Когда мы вызываем правило, мы должны передаваться в аргументах. Для локальных переменных давайте использовать один параметр, локальные_вары:
выражение правила<>: ...
фактор правила<>: ...
правило term<>: ...
Каждый раз, когда мы хотим сопоставить expr, factor или term мы передадим локальные переменные в текущем правиле в субправило. Один интересный случай, когда мы передаем в качестве аргумента что-то кроме local_vars:
правило term<>: . > {{ local_vars = [(VAR, expr)] + local_vars }} 'in' expr< > {{ вернуть выражение}}
 ..
| 'let' VAR '=' expr<
..
| 'let' VAR '=' expr<Обратите внимание, что присваивание списку локальных переменных не изменяет исходный список. Это важно, чтобы локальные переменные не быть замеченным за пределами «пусть».
Другой интересный случай, когда мы находим переменную:
глобальные_вары = {}
поиск по определению (карта, имя):
для x,v на карте: если x==name: вернуть v
вернуть global_vars[имя]
%%
...
правило term<: ...
| VAR {{ вернуть поиск (local_vars, VAR) }}
Функция поиска будет искать в списке локальных переменных и если он не может найти имя там, он будет искать его в глобальном словарь переменных.
Полная грамматика для этого примера, включая цикл чтения-оценки-печати.
для взаимодействия с калькулятором, можно найти в примерах
подкаталог, входящий в состав Yapps.