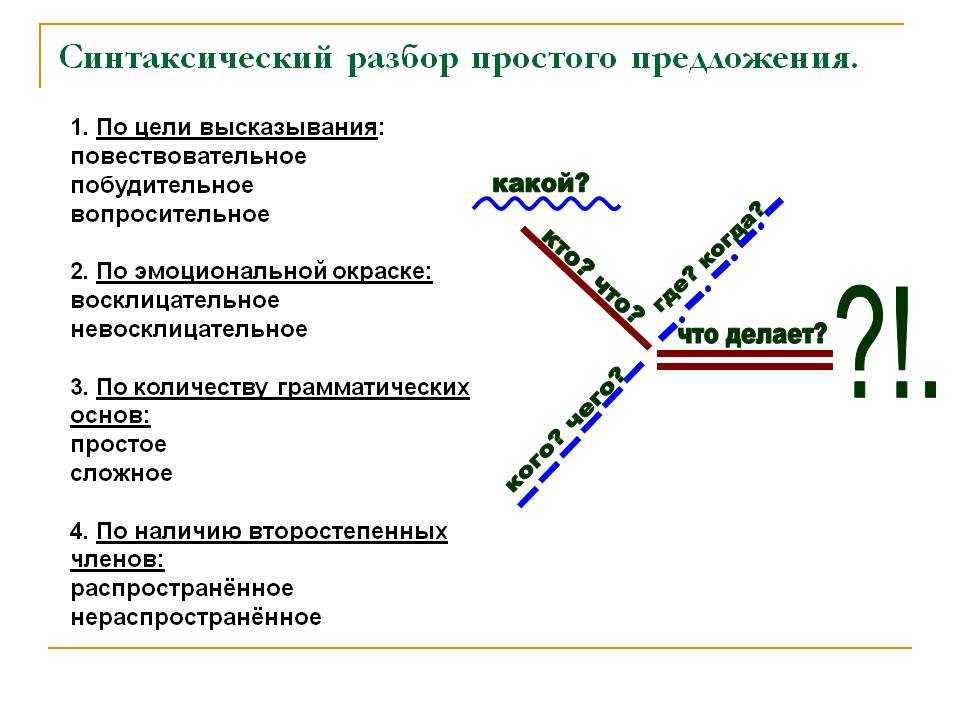
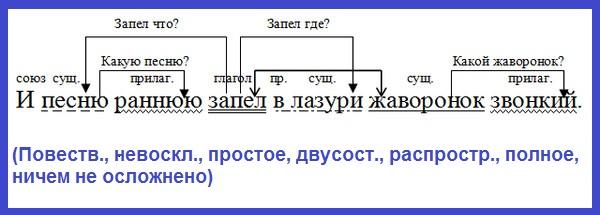
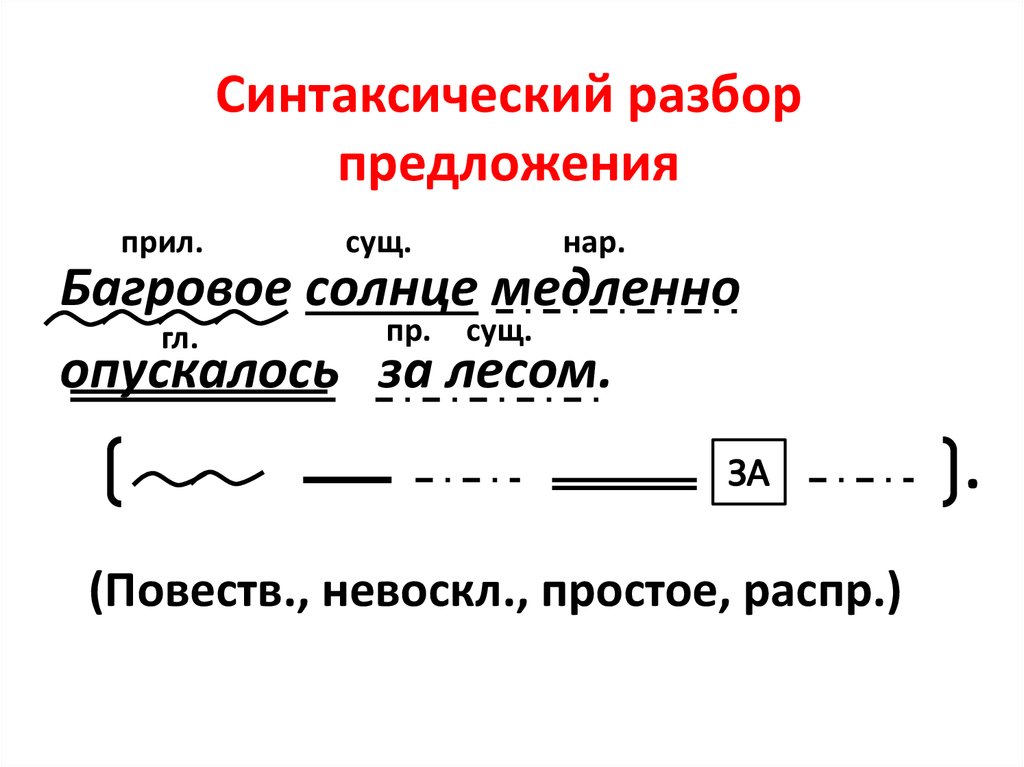
Сделайте синтаксический разбор выделенного предложения.
Определите тип текста, объясните свой выбор.
Вставьте пропущенные буквы и расставьте знаки препинания.
Разберите по составу подчёркнутые слова.
Объясните значение слова горизонт.
Текст 8
Лет двести тому (на)зад ветер-сеятель пр..нёс два семечка в Блудово болото: семя сосны и семя ели. Оба семечка л..гли в одну ямку возле больш..го плоского камня. С тех пор уже лет двести эти ель и сосна вместе р..стут. Дерев..я разных пород ужасно боролись между собой корнями за питание, суч..ями — за воздух и свет. Поднимаясь всё выше они вп..вались сухими суч..ями в ж..вые ств..лы и местами насквозь прокололи друг друга. Злой ветер устроив дерев..ям таую (не)счастную жизнь прил..тел сюда иногда пок..чать их. И тогда дерев..я ст..нали и выли на всё Блудово болото, как живые существа.
(М. М. Пришвин.
Сказка-быль «Кладовая солнца»)
М. Пришвин.
Сказка-быль «Кладовая солнца»)
Выполните следующие задания:
Определите стиль текста, объясните свой выбор.
Вставьте пропущенные буквы, раскройте скобки и расставьте недостающие знаки препинания.
Разберите по составу слово поднимаясь.
Укажите количество букв и звуков в слове: сучьями.
Произведите морфологический разбор слова устроив.
Текст № 9
Золотая осень.
Вот и наступил первый месяц осени. Ра(с,сс)ыпал золото и багрянец по рощам и дубравам.
Осень то порадует
погожими и ясными днями, то засв..стит
ветер и пойдёт скучный и долгий дождь. Осень од..рила все деревья разными
нарядами. Например, дуб стоит как грозный
богатырь, одетый в ж..лтую одежду, а
берёзка, в белом платьице, как девушка.
Только ёлочка (не)меняет свой наряд, она
вечно зелёная. В солнечную погоду листья
кажутся з.
Выполните следующие задания:
1. Выразительно прочитайте текст.
2. Определите стиль текста, объясните свой выбор.
3. Вставьте пропущенные буквы и раскройте скобки.
4. Разберите по составу слово (по)разному.
Текст № 10
Осе(н,нн)яя роза.
Осыпал лес свои в..ршины,
Са.. обнажил своё чело,
Дохнул сентябрь, и георгины
Дыханьем ночи обожгло.
Но в дуновении м..роза
Между п..гибшими одна
Лишь ты одна, царица – роза,
Бл..гоуханна и пышна.
Назло ж..стоким испытаньям
И злобе гаснущего дня
Ты очертаньем и дыханьем
В..сною ве..шь на меня.
(А.Фет.)
Выполните следующие задания:
Выразительно прочитайте текст.

Определите его тему, основную мысль.
Объясните смысл выделенных слов.
Вставьте пропущенные буквы, объясните графически вставленные орфограммы.
Выпишите все служебные части речи (предлоги, союзы, частицы).
Текст № 11
Пятый день несло (не)проглядной в..югой. В белом от снега и холодном хуторском доме стоял бледный сумрак. Было больше горе: был т..жело болен ребёнок. И в жару в бреду он часто плакал и просил дать ему какие(то) красные лапти. И мать не отходившая от постели то(же) плакала горькими слезами.
Нефёд пр..нёс соломы на топку свалил её на пол отдуваясь дыша холодом приотворил дверь заглянул:
— Ну что барыня как? Не полегчало?
— Куда там Нефёдушка! Верно, и не выживет! Всё какие (то) красные лапти просит…
_ Лапти? Что за лапти такие?
— А Господь его
знает.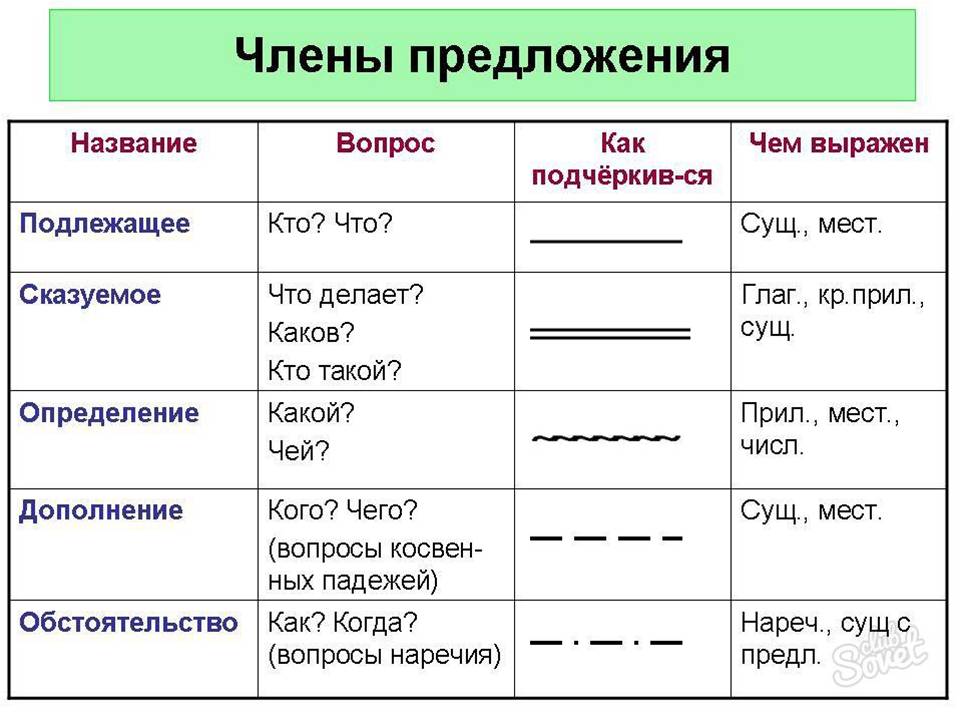 Бредит, весь огнём горит…
Бредит, весь огнём горит…
Мотнул шапкой задумался. И вдруг твёрдо:
— Значит, надо добывать. Значит, душа желает.
(И.А. Бунин. «Лапти»)
Выполните следующие задания
Помогите записать, расставляя знаки препинания. Русский язык. 11 класс. Пар.№82. Упр.№448. Учебник Греков В.Ф. ГДЗ. – Рамблер/класс
Помогите записать, расставляя знаки препинания. Русский язык. 11 класс. Пар.№82. Упр.№448. Учебник Греков В.Ф. ГДЗ. – Рамблер/классИнтересные вопросы
Подскажите, как бороться с грубым отношением одноклассников к моему ребенку?
Новости
Поделитесь, сколько вы потратили на подготовку ребенка к учебному году?
Школа
Объясните, это правда, что родители теперь будут информироваться о снижении успеваемости в школе?
Школа
Когда в 2018 году намечено проведение основного периода ЕГЭ?
Новости
Будет ли как-то улучшаться система проверки и организации итоговых сочинений?
Вузы
Подскажите, почему закрыли прием в Московский институт телевидения и радиовещания «Останкино»?
Здравствуйте! Помогите записать, расставляя знаки препинания. Сделать морфологический и синтаксический разбор выделенного предложения.
Сделать морфологический и синтаксический разбор выделенного предложения.
Дорогой Михаил Осипович что за болезнь у Толстого по-
нять (н..)могу. Черинов мне (н..)ответил а из того что я чи-
тал в газетах и что Вы пиш..те вывести (н..)чего нельзя…
Болезнь его напугала меня и держала в напряжени.. .
(Во)первых я (н..)одного человека (н..)любил так как его…
(Во)вторых когда в литературе есть Толстой то легко и
пр..ятно быть литератором; даже созн..вать что (н..)чего
(н..)сделал и (н..)сделаешь (н..)так страшно так как Тол-
стой делает за всех. Его деятельность служит опр..вданием
тех упований и чаяний какие на литературу возл..гаются.
(В)третьих Толстой стоит крепко авторитет у него гр..мад-
ный и пока он жив дурные вкусы в литературе всякое по-
шлячество наглое и слезливое всякие шершавые озлоб-
ле..ые самолюбия будут далеко и глубоко в тени.
(Из письма А. Чехова М. Меньшикову, журналисту, 28 января 1892 г.)
ответы
ваш ответ
Можно ввести 4000 cимволов
отправить
дежурный
Нажимая кнопку «отправить», вы принимаете условия пользовательского соглашения
похожие темы
Иностранные языки
Юмор
Олимпиады
ЕГЭ
похожие вопросы 5
Почему то как пишется?
Почему то? Почему-то? или Почемуто?
И чур не стебаться. я просто забыла
я просто забыла
Русский язык
ГДЗ Тема 21 Физика 7-9 класс А.В.Перышкин Задание №476 Изобразите силы, действующие на тело.
Привет всем! Нужен ваш совет, как отвечать…
Изобразите силы, действующие на тело, когда оно плавает на поверхности жидкости. (Подробнее…)
ГДЗФизикаПерышкин А.В.Школа7 класс
ГДЗ §15 Русский язык 10-11 класс Греков В. Ф. Вопрос 99 От данных глаголов образуйте краткие страдательные причастия.
Привет, помогите , пожалуйста, ответить на вопрос…заранее спасибо))))
От данных глаголов образуйте краткие страдательные (Подробнее…)
10 классГДЗРусский языкГреков В.Ф.Школа
Подскажите, почему закрыли прием в Московский институт телевидения и радиовещания «Останкино»?
С чем связано окончание приема учащихся в Московский институт телевидения и радиовещания «Останкино»? (Подробнее…)
ВузыПоступление11 классНовости
Какой был проходной балл в вузы в 2017 году?
Какой был средний балл ЕГЭ поступивших в российские вузы на бюджет в этом году? (Подробнее. ..)
..)
Поступление11 классЕГЭНовости
python — При запуске программа добавляет большой раздел выделенного текста в конце?
спросил
Изменено 3 года, 9 месяцев назад
Просмотрено 37 раз
Смысл сценария состоит в том, чтобы разбить блок текста на предложения, а затем сгенерировать случайное число, чтобы увидеть, будет ли предложение выделено или нет. Когда приведенный ниже код запускается, он вырезает все отдельные предложения и вставляет их в конец документа. Я ищу предложения, которые нужно заменить, а не добавлять в конце.
из документа импорта docx
импортировать повторно
из nltk импортировать токенизацию
функция импорта
импортировать случайный
из docx.enum.text импортировать WD_COLOR_INDEX
doc = Документ('raw. docx')
необработанные данные = (Funtion.gettext('raw.docx'))
sen = tokenize.sent_tokenize (необработанные данные)
сенлен = лен (сен)
p = doc.add_paragraph()
для индсен в сен:
рандом = случайный.randint(1,11)
если кольцо == 8:
p.add_run(indsen).font.highlight_color = WD_COLOR_INDEX.YELLOW
doc.save('TTTCH.docx')
 docx')
необработанные данные = (Funtion.gettext('raw.docx'))
sen = tokenize.sent_tokenize (необработанные данные)
сенлен = лен (сен)
p = doc.add_paragraph()
для индсен в сен:
рандом = случайный.randint(1,11)
если кольцо == 8:
p.add_run(indsen).font.highlight_color = WD_COLOR_INDEX.YELLOW
doc.save('TTTCH.docx')
docx')
необработанные данные = (Funtion.gettext('raw.docx'))
sen = tokenize.sent_tokenize (необработанные данные)
сенлен = лен (сен)
p = doc.add_paragraph()
для индсен в сен:
рандом = случайный.randint(1,11)
если кольцо == 8:
p.add_run(indsen).font.highlight_color = WD_COLOR_INDEX.YELLOW
doc.save('TTTCH.docx')
- питон
- документ
1
Предложения добавляются в конце, потому что вы вызываете
p = doc.add_paragraph()
Что добавляет абзац к концу документа, а затем вы вызываете
p.add_run()
Что добавляет прогон к концу ранее созданного абзаца.
Вместо этого вам нужно будет получить доступ к параграфам , уже созданным в документе, вместо того, чтобы создавать свои собственные. Как и в https://python-docx.readthedocs.io/en/latest/api/document.html#docx.document.Document.
для абзаца в док.абзацах:
# обрабатываем абзац на месте
Я полагаю, вы хотели бы использовать информацию на https://python-docx.readthedocs.io/en/latest/api/text.html#paragraph-objects
В частности:
для абзаца в doc.paragraphs:
text_being_read = абзац.текст
# обработать текст
абзац.очистить()
para.text = "Новинки"
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Как создавать выделенные фрагменты результатов поиска — документация Whoosh 2.
 7.4
7.4Обзор
Система выделения работает как конвейер с четырьмя типами компонентов.
- Фрагментаторы разбивают исходный текст на __фрагменты__ на основе расположение совпадающих терминов в тексте.
- Оценщики присваивают оценку каждому фрагменту, позволяя системе ранжировать фрагмент. лучшие фрагменты по любому критерию.
- Функции заказа контролировать, в каком порядке располагаются самые результативные фрагменты представлены пользователю. Например, вы можете показать фрагменты в порядке они появляются в документе (ПЕРВЫЕ) или сначала показывают фрагменты с более высокой оценкой (ОЦЕНКА)
- Средства форматирования превращают объекты-фрагменты в удобочитаемый вывод, например HTML-строка.
Требования
Выделение требует наличия текста проиндексированного документа.
Вы можете сохранить текст в сохраненном поле или, если исходный текст доступен
в файле, столбце базы данных и т. д., просто перезагрузите его на лету. Обратите внимание, что вы можете
необходимо обработать текст, чтобы удалить, например. HTML-теги, вики-разметка и т. д.
д., просто перезагрузите его на лету. Обратите внимание, что вы можете
необходимо обработать текст, чтобы удалить, например. HTML-теги, вики-разметка и т. д.
Как
Получить результаты поиска:
results = mysearcher.search(myquery)
за попадание в результаты:
распечатать (нажать ["название"])
Вы можете использовать метод highlights() на whoosh.searching.Нажмите объект , чтобы получить выделенные фрагменты из
документ, содержащий условия поиска.
Первый аргумент — это имя поля для выделения. Если поле хранится, это единственный аргумент, который вам нужно указать:
results = mysearcher.search(myquery)
за попадание в результаты:
распечатать (нажать ["название"])
# Предположим, что поле "content" сохранено
печать (hit.highlights («контент»))
Если поле не сохранено, вам нужно получить текст поля через некоторое время.
другой путь. Например, чтение из исходного файла или базы данных. затем
вы можете предоставить текст для выделения с аргументом
затем
вы можете предоставить текст для выделения с аргументом text :
results = mysearcher.search(myquery)
за попадание в результаты:
распечатать (нажать ["название"])
# Предположим, что сохраненное поле "путь" содержит путь к исходному файлу
с open(hit["path"]) как fileobj:
содержимое файла = файлobj.read()
печать (hit.highlights («контент», текст = содержимое файла))
Лимит символов
По умолчанию Whoosh извлекает фрагменты только из первых 32К символов текст. Это предотвращает увязание очень длинных текстов в процессе выделения. слишком много, и обычно это оправдано, поскольку важная/обобщающая информация обычно в начале документа. Однако, если вы обнаружите, что основные моменты отсутствующая информация (например, очень длинные энциклопедические статьи, в которых термины появятся в следующем разделе), вы можете увеличить характер фрагментатора предел.
Вы можете изменить ограничение количества символов в объекте результатов следующим образом:
results = mysearcher.
 search(myquery)
results.fragmenter.charlimit = 100000
search(myquery)
results.fragmenter.charlimit = 100000
Чтобы отключить ограничение символов:
results.fragmenter.charlimit = None
Если вы создаете пользовательский фрагментатор, вы можете установить для него ограничение на количество символов напрямую:
sf = highlight.SentenceFragmenter(charlimit=100000) результаты.фрагментер = sf
См. ниже информацию о настройке подсветки.
Если вы увеличите или отключите лимит символов для выделения длинных документов, вы возможно, потребуется воспользоваться советами из раздела «Ускорение выделения» ниже, чтобы сделать выделение быстрее.
Настройка выделения
Количество фрагментов
Вы можете использовать аргумент ключевого слова top для управления количеством фрагментов
возвращено в каждом фрагменте:
# Показать максимум 5 фрагментов из документа
распечатать hit.highlights("content", top=5)
Размер фрагмента
Фрагментатор по умолчанию имеет атрибут maxchars (по умолчанию 200), управляющий
максимальная длина фрагмента и атрибут объемного звучания (по умолчанию 20)
управление максимальным количеством символов контекста, добавляемых в начале
и конец фрагмента:
# Разрешить фрагменты большего размера результаты.
 фрагментер.maxchars = 300
# Показать больше контекста до и после
results.fragmenter.surround = 50
фрагментер.maxchars = 300
# Показать больше контекста до и после
results.fragmenter.surround = 50
Фрагментатор
Фрагментатор контролирует, как извлекать отрывки из исходного текста.
Модуль highlight имеет следующие готовые фрагментаторы:
-
whoosh.highlight.ContextFragmenter(по умолчанию) - Это «умный» фрагментатор, который находит совпадающие термины, а затем извлекает в объемном тексте для формирования фрагментов. Этот фрагментатор дает только фрагменты, содержащие совпадающие термины.
-
whoosh.highlight.SentenceFragmenter - Пытается разбить текст на фрагменты на основе знаков препинания в предложениях. («.», «!», и «?»). Этот объект работает, глядя в оригинал текст предложения заканчивается следующим символом после каждой лексемы «конечный символ». Можно обмануть, например. исходный код, десятичные знаки и т. д.
-
свист.хайлайт.WholeFragmenter - Возвращает весь текст как один «фрагмент». Это может быть полезно, если вы
выделяют короткий фрагмент текста, и его не нужно фрагментировать.
 Это может быть полезно, если вы
выделяют короткий фрагмент текста, и его не нужно фрагментировать.
Это может быть полезно, если вы
выделяют короткий фрагмент текста, и его не нужно фрагментировать. Различные фрагментаторы имеют разные параметры. Например, по умолчанию ContextFragmenter позволяет установить максимальное
размер фрагмента и размер контекста для добавления с обеих сторон:
my_cf = highlight.ContextFragmenter(maxchars=100, Surround=30)
Для получения дополнительной информации см. документацию whoosh.highlight .
Чтобы использовать другой фрагментатор:
results.fragmenter = my_cf
Scorer
Scorer — это вызываемый объект, который принимает объект whoosh.highlight.Fragment и
возвращает сортируемое значение (где более высокие значения представляют лучшие фрагменты).
Оценщик по умолчанию суммирует количество совпадающих терминов во фрагменте и
добавляет «бонус» за количество __различных__ совпадающих терминов. Подсветка
система использует эту оценку, чтобы выбрать лучшие фрагменты для показа пользователю.
В качестве примера пользовательского счетчика для ранжирования фрагментов по самому низкому стандарту отклонение позиций совпадающих терминов во фрагменте:
def StandardDeviationScorer(fragment):
"""Присваивает более высокие баллы фрагментам, где совпадающие термины близки
все вместе.
"""
# Так как в этом случае меньшие значения лучше, нам нужно инвертировать
# стоимость
вернуть 0 - stddev([t.pos для t во фрагменте.сопоставлено])
Чтобы использовать другой счетчик:
results.scorer = StandardDeviationScorer
Порядок
Порядок — это функция, которая принимает фрагмент и возвращает используемое сортируемое значение. для сортировки фрагментов с наивысшей оценкой перед представлением их пользователю (где фрагменты с более низкими значениями появляются перед фрагментами с более высокими значениями).
Модуль highlight имеет следующие функции заказа.
-
ПЕРВЫЙ(по умолчанию) - Показать фрагменты в порядке их появления в документе.
-
ОЦЕНКА - Сначала показывать фрагменты с наибольшим количеством очков.

Модуль highlight также включает LONGER (сначала более длинные фрагменты) и КОРОЧЕ (сначала более короткие фрагменты), но они, вероятно, не так
полезный.
Чтобы использовать другой порядок:
results.order = highlight.SCORE
Средство форматирования
Средство форматирования контролирует, как фрагменты с наивысшим рейтингом превращаются в форматированный бит текста для отображения пользователю. Он может вернуть что угодно (например, обычный текст, HTML, поток событий Genshi, генератор событий SAX, или что-нибудь еще полезное для вызывающей системы).
Модуль highlight содержит следующие готовые средства форматирования.
-
whoosh.highlight.HtmlFormatter - Выводит строку, содержащую теги HTML (с атрибутом класса)
вокруг совпадающих терминов.
-
whoosh.highlight.UppercaseFormatter - Преобразует совпадающие термины в ПРОПИСНЫЕ.
-
whoosh.highlight.GenshiFormatter - Выводит поток событий Genshi с совпавшими терминами, заключенными в настраиваемый элемент.
Самый простой способ создать собственный модуль форматирования — создать подкласс highlight.Formatter и переопределить метод format_token :
class BracketFormatter(highlight.Formatter):
"""Квадратные скобки окружают совпадающие термины.
"""
def format_token (я, текст, токен, replace = False):
# Используйте функцию get_text для получения текста, соответствующего
# токен
tokentext = highlight.get_text (текст, токен, замена)
# Вернуть текст, как вы хотите, чтобы он отображался в выделенном
# нить
вернуть "[%s]" % tokentext
Чтобы использовать другой модуль форматирования:
brf = BracketFormatter() результаты.
 formatter = brf
formatter = brf
Если вам нужно больше контроля над форматированием (или вы хотите вывести что-то другое чем строки), вам нужно будет переопределить другие методы. См. документацию для класса whoosh.highlight.Formatter .
Объект выделения
Вместо установки атрибутов объекта результатов можно создать
многоразовый объект whoosh.highlight.Highlighter . Аргументы ключевого слова let
ты меняешь фрагментатор , счетчик , порядок и/или форматировщик :
hi = highlight.Highlighter(fragmenter=my_cf, scorer=sds)
Затем вы можете использовать метод whoosh.highlight.Highlighter.highlight_hit() чтобы получить блики для объекта Hit :
для попадания в результаты:
распечатать (нажать ["название"])
печать (привет.highlight_hit (попадание))
(При назначении объекту Results фрагментатора , бомбардир , порядок ,
или атрибутов formatter , вы фактически изменяете значения в
объект результатов по умолчанию Highlighter объект. )
)
Ускорение выделения
Запись того, какие термины совпали в каких документах во время поиска может сделать выделяя быстрее, так как он будет пропускать документы, которые, как он знает, не содержат никаких совпадающие термины в данном поле:
# Запись совпадений терминов для каждого документа результаты = searcher.search(myquery, terms=True)
PinpointFragmenter
Обычно система выделения использует анализатор поля для повторной маркировки текст документа, чтобы найти соответствующие термины в контексте. Если вы давно документы и увеличили/отключили лимит символов, и/или если поле имеет очень сложный анализатор, повторная токенизация может быть медленной.
Вместо ретокенизации Whoosh может искать позиции символов в совпадающие термины в указателе. Поиск позиций символов не мгновенно, но обычно быстрее, чем анализ больших объемов текста.
Чтобы использовать whoosh.highlight.PinpointFragmenter и избежать повторной маркировки
текст документа, необходимо выполнить все следующие действия:
Проиндексировать поле с символьной информацией (для этого потребуется переиндексировать существующий индекс):
# Индексировать начальный и конечный символы каждого термина схема = поля.
 Схема (содержание = поля. ТЕКСТ (хранится = Истина, символы = Истина))
Схема (содержание = поля. ТЕКСТ (хранится = Истина, символы = Истина))
Запись совпадений терминов для каждого документа в результатах:
# Запись совпадений терминов для каждого документа результаты = searcher.search(myquery, terms=True)
Установите whoosh.highlight.PinpointFragmenter в качестве фрагментатора:
results.fragmenter = highlight.PinpointFragmenter()
Ограничения PinpointFragmenter
Когда система выделения не выполняет повторную маркировку текста, она не знает где в тексте есть любые другие слова, кроме совпадающих терминов, в которых он искался индекс. Поэтому, когда фрагментатор добавляет окружающий контекст, он просто добавляет или определенное количество символов вслепую, и поэтому не различает содержание и пробелы или разбить границы слов, например:
>>> hit.highlights("контент")
когда фрагментатор\n объявление'
(Это может смущать, когда фрагменты слов образуют грязные слова!)
Один из способов избежать этого — не показывать окружающий контекст, но затем фрагменты, содержащие один совпадающий термин, будут содержать ТОЛЬКО этот совпадающий термин:
>>> hit.
 highlights("content")
'фрагментатор'
highlights("content")
'фрагментатор'
Кроме того, вы можете нормализовать пробелы в тексте, прежде чем передавать его в система подсветки:
>>> текст = searcher.stored_
>>> re.sub("[\t\r\n ]+", " ", текст)
>>> hit.highlights("content", text=text)
…и используйте опцию autotrim в PinpointFragmenter для автоматического
убирать текст до первого пробела и после последнего пробела во фрагментах:
>>> results.fragmenter = highlight.PinpointFragmenter(autotrim=True)
>>> hit.highlights("контент")
'когда фрагментатор'
Использование низкоуровневого API
Использование
Следующая функция позволяет повторно маркировать и выделять фрагмент текста с помощью анализатор:
из whoosh.highlight импортировать подсветку
выдержки = выделение(текст, термины, анализатор, фрагментатор, форматтер, верх=3,
scorer=BasicFragmentScorer, minscore=1, order=FIRST)
-
текст - Исходный текст документа.
