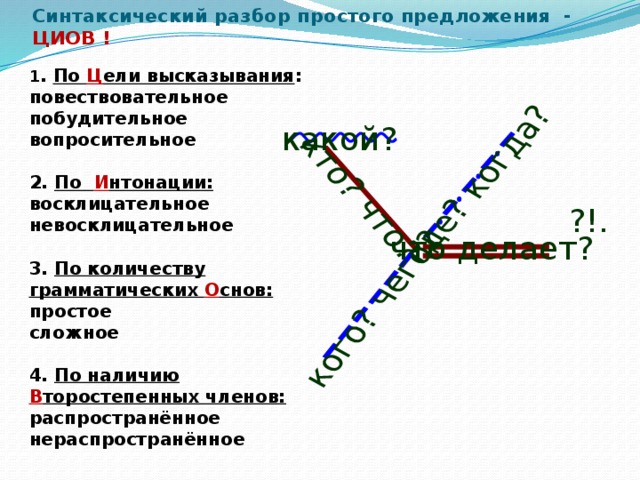
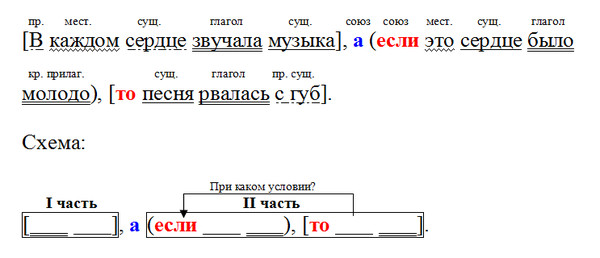
100 ballov.kz образовательный портал для подготовки к ЕНТ и КТА
Приготовьтесь к захватывающему приключению всей жизни с игрой Spribe Aviator! В этой игре казино вы должны сделать ставку до того, как самолет взлетит. Вы должны действовать стратегически, поскольку ставки варьируются от 0,1 до 1000 единиц и определяют, сколько денег вы можете выиграть, когда начнется раунд; с течением времени увеличивается и ваш потенциальный множитель приза. Парить в воздухе в середине полета — это захватывающее зрелище, которое каждый раз будет вызывать у вас желание большего — но не забудьте обналичить деньги, пока не стало слишком поздно, иначе всех на борту ждет аварийная посадка!
Авиатор от Spribe — это простая в освоении игра с захватывающим поворотом. Когда самолет падает без предупреждения, быстро нажмите на кнопку cash out, чтобы удвоить множитель вашей ставки! Не верите? Попробуйте бесплатно сыграть в Авиатор и убедитесь на собственном опыте, насколько захватывающей может быть эта игра.
Что такое Aviator и как он работает?
Эта игра вписывается в ряд других краш-игр, поскольку она невероятно непредсказуема, подобно волатильности цен, с которой знакомы криптовалютные инвесторы. Ее паттерн демонстрирует высокую степень непредсказуемости и нестабильности, следуя закономерностям, которые хорошо знакомы многим криптоинвесторам.
В этой игре летающий объект поднимается вверх и, благодаря алгоритму RNG, продолжает подниматься, пока не решит покинуть экран. Когда это происходит, игра заканчивается и ее необходимо перезапустить.
Конечная цель игры — обналичить деньги, пока не стало слишком поздно, и это можно сделать, пока ваш самолет поднимается вверх. По мере того как вы поднимаетесь все выше, приз на кону становится все больше с каждым появляющимся множителем. Но если вы дождетесь, пока ваш самолет достигнет пиковой высоты, и вовремя не обналичите деньги, то все ставки будут сделаны!
Советы и рекомендации
- Две интуитивно понятные функции Aviator — автоматическая ставка и автоматическая наличность — могут дать вашей игре преимущество.
 Чтобы раскрыть ее потенциал, вам следует как можно скорее ознакомиться с этими инструментами.
Чтобы раскрыть ее потенциал, вам следует как можно скорее ознакомиться с этими инструментами. - Воспользуйтесь возможностью разделения ставок — Вместо того чтобы делать одну ставку в €10, вы можете разделить ее на две отдельные ставки по €5 каждая. Таким образом, у вас остается шанс выиграть в два раза больше!
- Начните раунд с помощью функции Auto Bet — эта функция автоматически делает ставку перед началом игры, позволяя вам без промедления приступить к игре.
- Auto cash — это идеальное решение для тех, кто хочет иметь больше контроля над своими инвестициями. Вы можете заранее установить множитель, который подходит именно вам, и если ваш самолет не разобьется до того, как достигнет своей отметки, то Auto cash автоматически снимет ваши средства. Это простой способ максимизировать прибыль, обеспечивая при этом безопасность возврата инвестиций!
 Чтобы раскрыть ее потенциал, вам следует как можно скорее ознакомиться с этими инструментами.
Чтобы раскрыть ее потенциал, вам следует как можно скорее ознакомиться с этими инструментами.Авиатор — это новый вид азартных игр, и пока еще не разработаны окончательные стратегии. Поскольку результаты каждого раунда определяются случайным образом, маловероятно, что в будущем будет найден безошибочный подход. Как и при игре в слоты или рулетку, есть вероятность, что любая Авиатор игра стратегия может не сработать вообще!
Как и при игре в слоты или рулетку, есть вероятность, что любая Авиатор игра стратегия может не сработать вообще!
Подведем итог
Авиатор — это стремительная, захватывающая игра, которая обязательно станет развлечением и потенциальной прибылью для любого геймера. Непредсказуемость игры делает игровой процесс захватывающим, а функции Auto Bet и Cash обеспечивают контроль над ставками. Благодаря таким уникальным функциям Aviator стал мгновенной классикой в мире азартных игр!
[PDF] Метод вероятностного анализа для устранения неоднозначности предложений
- title={Вероятностный метод синтаксического анализа для устранения неоднозначности предложения},
автор = {Тетсуносукэ Фуджисаки, Фредерик Елинек, Джон Кок, Эзра Блэк и Тетсуро Нишино},
booktitle={Международный семинар/конференция по технологиям синтаксического анализа},
год = {1989}
}
Создание грамматики, способной анализировать предложения, выбранные из корпуса естественного языка, — сложная задача.
Одной из самых серьезных проблем является неуправляемо большое количество неоднозначностей. Чистый синтаксический анализ, основанный только на синтаксическом знании, иногда приводит к сотням неоднозначных анализов.View on ACL
aclanthology.orgGrammar induction and PP attachment disambiguation
- J. Jonker
Linguistics, Computer Science
- 2007
An survey on the literature on both parsing and grammar construction, wher PP -вложение значений касается, дается.
Надежный стохастический анализ с использованием алгоритма «внутри-вне»
- Тед Бриско, Н. Вэгнер
Информатика
ArXiv
- 1994
Синтаксический анализатор последовательностей (английских) меток частей речи, который использует вероятностную грамматику, обученную с использованием внутреннего-внешнего алгоритма, что дает синтаксический анализатор с широким охватом, способный ранжировать альтернативные анализы.
Обобщенный вероятностный LR-разбор естественного языка (корпус) с помощью грамматик на основе унификации
- Тед Бриско, Джон А. Кэрролл
Информатика
Вычисл. Лингвистика
- 1993
Построение системы вероятностного анализа естественного языка (ЕЯ) с очень широким охватом, основанной на методах анализа НЯ, предназначенной для ранжирования большого количества синтаксических анализов, производимых грамматиками ЕЯ, в соответствии с частотой появления отдельные правила, развернутые в каждом анализе.
Разбор N лучших деревьев из решетки слов
- Х. Вебер, Дж. Спилкер, Гюнтер Гёрц
Информатика
KI
- 1997
Описан вероятностный метод аппроксимации контекстно-свободной грамматики для унифицирующих грамматик и эффективная N-лучшая схема упаковки и распаковки для разбора диаграмм.
Анализ на основе корпуса и изучение подъязыков
- С. Секин
Информатика, лингвистика
- 1998
Были разработаны два метода повышения точности анализатора на основе корпуса и подъязыка. для включения лексической информации, и были обнаружены несколько многообещающих случаев, когда синтаксический анализатор мог исправлять ошибки распознавания.
Вероятностная грамматика без контекста для неоднозначности при морфологическом анализе
- Хосе С. Хемскерк
Компьютерная наука
EACL
- 1993
. система преобразования текста в речь, которая сочетает в себе «традиционную» контекстно-свободную морфологическую грамматику для фильтрации неграмматических сегментаций с функцией оценки на основе вероятности, которая определяет вероятность каждого успешного анализа.
Показатели и модели для распознавания фраз
- Стивен П. Эбни
Информатика
HLT
- 1993
Для оценки и калибровки моделей представлены серии энтропии для оценки и калибровки моделей.
«мера путем определения того, какие баллы могут быть получены с использованием наиболее очевидных видов информации.Статистический и символьный синтаксический анализ для поиска информации с субтитрами
- Н. Роу
Информатика
ArXiv
- 1994
Утверждается, что смешанный подход MARIE-2 должен быть лучше для этого корпуса, потому что его алгоритмы (не данные) проще.
Помимо грамматики: основанная на опыте теория языка
- Р. Бод
Информатика
- 1998
неконтекстно-свободные представления для композиционных семантических представлений.
Что такое грамматика Treebank
- D. Prescher, R. Scha, K. Sima’an, A. Zollman
Computer Science
- 2006
приводит обоснование методов сглаживания в рамках теории оценивания.
ПОКАЗАНЫ 1-10 ИЗ 21 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантности Наиболее влиятельные документыНедавность
Синтаксическая структура и двусмысленность английского языка
- С. Куно, А. Эттингер
Лингвистика
AFIPS ’63 (Осень)
- 1963
Предложена интуитивная модификация новой грамматики, с которой предлагается дополнительная модификация формы текущей грамматики , упрощенную версию настоящей программы анализа и описания структуры предложений в формах обобщенной нотации без скобок, легко интерпретируемой как дерево.
ПРЕДВАРИТЕЛЬНЫЙ АНАЛИЗ АЛГОРИТМА В ПЕРВУЮ ШИРИНУ: ТЕОРЕТИЧЕСКИЕ И ЭКСПЕРИМЕНТАЛЬНЫЕ РЕЗУЛЬТАТЫ
- W. Martin, Kenneth Ward Church, R. Patil
Computer Science
- 1987
s и его варианты) для разбора сложного и обширного корпуса предложений.
Понимание естественного языка
- Виноград Т.
Информатика
- 1972
Компьютерная система для понимания английского языка, которая содержит синтаксический анализатор, грамматику распознавания английского языка, программы семантического анализа и общую систему решения проблем, основанную на убеждении, что при моделировании понимания языка она должна действовать комплексно со всеми аспектами языка — синтаксисом, семантикой и выводом.
Прогнозирование и энтропия печатного английского языка
- К. Шеннон
Информатика
- 1951
Описан новый метод оценки энтропии и избыточности языка. Этот метод использует знание языковой статистики, которым обладают те, кто говорит на этом языке, и зависит от…
 Одной из самых серьезных проблем является неуправляемо большое количество неоднозначностей. Чистый синтаксический анализ, основанный только на синтаксическом знании, иногда приводит к сотням неоднозначных анализов.
Одной из самых серьезных проблем является неуправляемо большое количество неоднозначностей. Чистый синтаксический анализ, основанный только на синтаксическом знании, иногда приводит к сотням неоднозначных анализов.
 Секин
Секин «мера путем определения того, какие баллы могут быть получены с использованием наиболее очевидных видов информации.
«мера путем определения того, какие баллы могут быть получены с использованием наиболее очевидных видов информации.

Есть надежда, что алгоритмы и концепции, представленные в этой книге, переживут следующее поколение компьютеров и языков программирования и что по крайней мере некоторые из них будут применимы не только к написанию компиляторов, но и в других областях.
Расширенный предсказательный анализатор для контекстно-свободных языков — его относительная эффективность
- С. Куно
Информатика
CACM
- 1966
сравнивается с двумя другими алгоритмами синтаксического анализа: селективным алгоритмом «сверху вниз», подобным «алгоритму синтаксического анализа с исправлением ошибок» Айронса, и алгоритмом, первоначально разработанным Эбботтом, который преобразует заданную контекстно-свободную грамматику в грамматику стандартной формы каждый раз. правила которого находятся в стандартной форме.
Распознавание непрерывной речи статистическими методами
Представлены экспериментальные результаты, указывающие на мощность методов и касающиеся моделирования говорящего и акустического процессора, извлечения статистических параметров моделей и процедур поиска гипотез, а также вычислений правдоподобия лингвистического декодирования .
Синтаксические методы распознавания образов
- К. Фу, М. Айзерман
Информатика
IEEE Transactions on Systems, Man, and Cybernetics
- 1976
Эта книга представляет собой сборник статей, опубликованных профессором Мичи для широкой аудитории за последнее десятилетие или около того. Он содержит следующее: Введение Метод проб и ошибок (Наука…
Язык как познавательный процесс 1: Синтаксис
- Т. Виноград
Информатика
- 1982
Интернет должен быть максимально расширен, так как одно из преимуществ состоит в том, чтобы получить онлайновый язык как книгу по синтаксису когнитивного процесса, как окно в мир, как предлагают многие люди.0011
Язык как когнитивный процесс
- Виноград Т.
Образование
CL
- 1983
также могут быть рассмотрены книги по тесно связанным дисциплинам. Цель рецензии на книгу — проинформировать читателей о…
Цель рецензии на книгу — проинформировать читателей о…
Разбор и разбор
Разбор и разборГлава: Разбор и разбор
Всякий раз, когда интерпретатор интерпретирует данную часть ввода, две вещи должно произойти. Во-первых, вход должен быть проанализировано или разделены на составные части таким образом, что части можно легко работать. Затем переводчик может приступить к своей работе. интерпретации. Разбор имеет дело с синтаксическими соображениями, а интерпретация имеет дело с семантическими соображениями.
- Q. 3
- Почему нам нужно разделить эти два шага? Разве мы не можем просто объединить их вместе?
Фактический синтаксис языка, подобного Scheme, известен как конкретный синтаксис . Синтаксис, сгенерированный синтаксическим анализатором и используемый
интерпретатор известен как абстрактный синтаксис . Прежде чем мы сгенерируем
синтаксический анализатор, то нам нужно принять решение об абстрактном синтаксисе и о том, как его
будут представлены. Мы будем работать с тем, чей конкретный синтаксис определяется приведенной ниже грамматикой.
Мы будем работать с тем, чей конкретный синтаксис определяется приведенной ниже грамматикой.
::= <число> | | (лямбда ( ) <тело>) | (<выражение> <выражение>)
Эта грамматика может работать с числами, ссылками на переменные, лямбда-выражениями. выражения одной переменной и применения одного выражения к другой.
Чтобы сделать абстрактный синтаксис для этой грамматики, нам нужно принять решение о имя для каждой продукции в грамматике и имена для каждого нетерминала в производстве. Один из возможных вариантов
::= <число> lit-exp (датум) | var-exp (id) | (лямбда ( ) <тело>) lambda-exp (тело идентификатора) | (<выражение> <выражение>) app-exp (ранд ранда)
(В этом примере rator означает оператор , а rand означает операнд .)
Проще всего рассуждать об абстрактном синтаксическом представлении как о абстрактное синтаксическое дерево . Например, реферат
синтаксическое дерево для выражения ((лямбда (x) (f x)) 3), следующее
спецификация выше, выглядит так.
Например, реферат
синтаксическое дерево для выражения ((лямбда (x) (f x)) 3), следующее
спецификация выше, выглядит так.
Мы будем использовать механизм определения типа данных, описанный в EOPL, и предоставлено доктором Схемом. Чтобы использовать определение типа данных, вы должны иметь (require (lib «eopl.ss» «eopl»)) в верхней части ваш файл.
С помощью define-datatype мы определяем каждую продукцию как вариант выражения типа данных . В каждом варианте есть поля соответствующие именам нетерминалов. Вот определение, которое мы будем использовать. Он практически идентичен коду в разделе 2.2 ЭОП.
(выражение выражения определения типа данных? (лит-эксп (номер базы?)) (var-exp (идентификационный символ?)) (лямбда-эксп (идентификационный символ?) (выражение тела?)) (приложение-exp (раторское выражение?) (ранд выражение?)))
Учитывая это определение, синтаксический анализатор может быть определен очень легко.
(определить выражение-разбора
(лямбда (датум)
(состояние
((число? данные) (данные lit-exp))
((символ? данные) (данные var-exp))
((пара? данные)
(if (eqv? (автомобильное значение) 'лямбда)
(лямбда-выражение (данные caadr)
(выражение-анализа (данные caddr)))
(приложение-exp
(выражение-анализа (автомобильных данных))
(выражение-анализа (данные кадра)))))
(иначе (ошибка 'parse-expression
"Недопустимый конкретный синтаксис ~s" данные)))))
К сожалению, когда вы используете define-datatype для построения своих данных структуры, детали структуры базового компонента не раскрытый.(определить unparse-expression (лямбда (эксп) (случаи выражения exp (лит-эксп (данные) данные) (var-exp (id) идентификатор) (лямбда-эксп (тело идентификатора) (список лямбда (идентификатор списка) (тело unparse-expression))) (app-exp (ратор ранд) (список (ратор выражения unparse) (ранд-выражения-разбора))))))
 Вы можете просмотреть структуру этого компонента, используя следующую
Функция, которая преобразует структуру, созданную с помощью define-datatype, в вектор, отображающий все ее компоненты.
Вы можете просмотреть структуру этого компонента, используя следующую
Функция, которая преобразует структуру, созданную с помощью define-datatype, в вектор, отображающий все ее компоненты.
(определить структуру
(лямбда (эксп)
(состояние [(пара? exp) (структура карты exp)]
[(не (структура? выражение)) выражение]
[еще
(список->вектор (структура карты-из (вектор->список (структура->вектор exp))))])))
[Примечание. Обозначение, такое как #3(a b c), указывает на вектор длины 3, содержащий элементы a, b и c. В некоторых примеры ниже векторов опускают длину после хэша символ и вывести как #(x y z … )].> (определить exp1 (выражение-анализа '(лямбда (x) x))) > exp1 #<структура:лямбда-выражение> > (структура-из exp1) # 3 (структура: lambda-exp x # 2 (структура: var-exp x))
Скопируйте этот код в свои файлы решения, чтобы вы могли проверить
валидность ваших парсеров.
Поэкспериментируйте с разбором и разбором. Вам не нужно сдавать что-нибудь для этого упражнения. Тем не менее, вы должны достаточно поиграться с parse и unparse, чтобы хорошо их понять. Не могли бы вы предсказать, что произойдет, если вы попытаетесь разобрать приложение функция 2? Попробуйте придумать другие примеры предсказания/тестирования твой собственный. Идея здесь в том, чтобы вы не торопились и действительно понять этот процесс разбора. Спросите своего друга или инструктора, если вы не уверены в каких-либо деталях здесь.
> (определить g (выражение-анализа '(лямбда (x) (f x)))) > (распарсить-выражение g) (лямбда (х) (ф х)) > (структура-г) #3(struct:lambda-exp x #3(struct:app-exp #2(struct:var-exp f) #2(struct:var-exp x))) > (unparse-expression (parse-expression '(лямбда (x) (лямбда (t) (t ((лямбда (x) p) z)))))) (лямбда (x) (лямбда (t) (t ((лямбда (x) p) z))))
Вот расширение грамматики, используемой в этом разделе:
::= <число> lit-exp (датум) | var-exp (id) | (if ) if-exp (test-exp then-exp else-exp) | (лямбда ({ }*) ) lambda-exp (тело id) | ( { }*) app-exp (раторские ранды)
Расширение вносит следующие изменения в более раннюю грамматику.
- Вводит новый тип выражения, if-exp
- Лямбда-выражения могут принимать несколько аргументов; в частности id поле в первом грамматике, которое может быть только одиночным идентификатором, становится ids , представляя список идентификаторов.
- Соответственно, приложения также могут принимать несколько аргументов; рандов 9Поле 0369 становится рандов , представляя список операндов.
- Измените спецификацию типа данных (т. е. код в (define-datatype…)) для реализации этого расширения.
- Напишите parse-2, синтаксический анализатор для этой грамматики.
> (структура-из (разбор-2 '(лямбда (х) (+ х 2)))) #(структура:лямбда-выражение (Икс) #(struct:app-exp #(struct:var-exp +) (#(struct:var-exp x) #(struct:lit-exp 2)))) >
- Запись unparse-2.
