СДЕЛАТЬ МОРФЕМНЫЙ РАЗБОР (ПО СОСТАВУ) СЛОВА «ПРЕДОБРЕЙШИЙ».
Помогите написать изложение!!!»Выстрел» А.С. Пушкин»Пять лет тому назад я женился. — Первый месяц, the honeymoon, провел я здесь, в этой деревне. Этом
… у дому обязан я лучшими минутами жизни и одним из самых тяжелых воспоминаний. Однажды вечером ездили мы вместе верьхом; лошадь у жены что-то заупрямилась, она испугалась, отдала мне поводья и пошла пешком домой, я поехал вперед. На дворе увидел я дорожную телегу, мне сказали, что у меня в кабинете сидит человек, не хотевший объявить своего имени, но сказавший просто, что ему до меня есть дело. Я вошел в эту комнату, и увидел в темноте человека, запыленного и обросшего бородой, он стоял здесь у камина Я подошел к нему, стараясь припомнить его черты. «Ты не узнал меня, граф?» сказал он дрожащим голосом, — Сильвио! закричал я, и признаюсь, я почувствовал, как волоса стали вдруг на мне дыбом. — «Так точно, продолжал он, выстрел за мною; я приехал разрядить мой пистолет; готов ли ты? Пистолет у него торчал из бокового кармана. Я отмерил двенадцать шагов, и стал там в углу, прося его выстрелить скорее, пока жена не воротилась. Он медлил — он спросил огня. Подали свечи. — Я запер двери, не велел никому входить, и снова просил его выстрелить. Он вынул пистолет и прицелился… Я считал секунды… я думал о ней… Ужасная прошла минута! Сильвио опустил руку — «Жалею, сказал он, что пистолет заряжен не черешневыми косточками… пуля тяжела. Мне все кажется, что у нас не дуэль, а убийство: я не привык целить в безоружного. Начнем сызнова, кинем жеребий, кому стрелять первому». Голова моя шла кругом… Кажется, я не соглашался… Наконец мы зарядили еще пистолет, свернули два билета, он положил их в фуражку, некогда мною простреленную; я вынул опять первый нумер -«Ты, граф, дьявольски счастлив», сказал он с усмешкою, которой никогда не забуду. Не понимаю, что со мною было, и каким образом могон меня к тому принудить… но я выстрелил, и попал вот в эту картину. (Граф указывал пальцем на простреленную картину, лицо его горело как огонь, графиня была бледнее своего платка: я не мог воздержаться от восклицания.
1- Что стоишь, качаясь, тонкая рябина? 2- Рябина в красных бусинках так грустно гроздья свесила 3- Я б тогда не стала гнуться и качаться надо разобрат … ь И указать что это СГС СИС ПГС РУССКИЙ 9 класс
По. Мо. Ги. Те. Пппжжжж
230. Спиши, вставляя пропущенные буквы. Некоторые словаможешь записывать не отдельно каждое, а объединяя ИХв пары. При этом можно немного изменять сло
… ва, например:обы..ный, сосул..киобы..ные сосул..КИ.Оч..нь, сосул..ки, со..нце, хор..шо, л..нейка, Ч..ловек,кора..лик, огл..нулась, коне.. но, ме..ведь, пт..цы,н..льзя, три..цать, пом..гаешь, любопы..ство, обы..ный.Значение каких слов из данных ты можешь объяснить?
Некоторые словаможешь записывать не отдельно каждое, а объединяя ИХв пары. При этом можно немного изменять сло
… ва, например:обы..ный, сосул..киобы..ные сосул..КИ.Оч..нь, сосул..ки, со..нце, хор..шо, л..нейка, Ч..ловек,кора..лик, огл..нулась, коне.. но, ме..ведь, пт..цы,н..льзя, три..цать, пом..гаешь, любопы..ство, обы..ный.Значение каких слов из данных ты можешь объяснить?
230. Спиши, вставляя пропущенные буквы. Некоторые сможешь записывать не отдельно каждое, а объединяв пары. При этом можно немного изменять слова, напр … иобы..ный, сосул..ки обы..ные сосул..ки.Оч..нь, сосул..ки, со..нце, хор..шо, л..нейка, Ч..лс
13. Соедини подходящие по смыслу слова. Запиши получившиеся словосочета-ния. Обозначь главное слово, поставь от него вопрос к зависимому слову.Водаред … киесосновыеозеролесагорнаяЖивотныеудивительныйпрозрачноеуголокЧистаярека
Помогите пж Это срочно!!!!!
Задание 264• Спишите предложения, расставьте знаки препинания. Охарактеризуйте предложе-ния, разберите их по членам предложения.1. Ни магазинов ни фот … ографий ни театров ни винных лавок ничеготут не было. (А. Солженицын) 2. Не спеша давая себя обгонять и тол-кать лег шел по солнечной сторон около площади щурился и улыбалсясолнцу. Однако этот легко-веселый взгляд промелькнувший у ЛьваЛеонидовича эта очень неогражденная манера держаться открывалиКостоглотову возможность задать и третий приготовленный вопростоже не совсем пустячный. (А. Солженицын)
Помогите пожалуйста!!!!
старое колесо скрипнуло и медленно повернулосьсинтакстсеский разбор срочн
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL.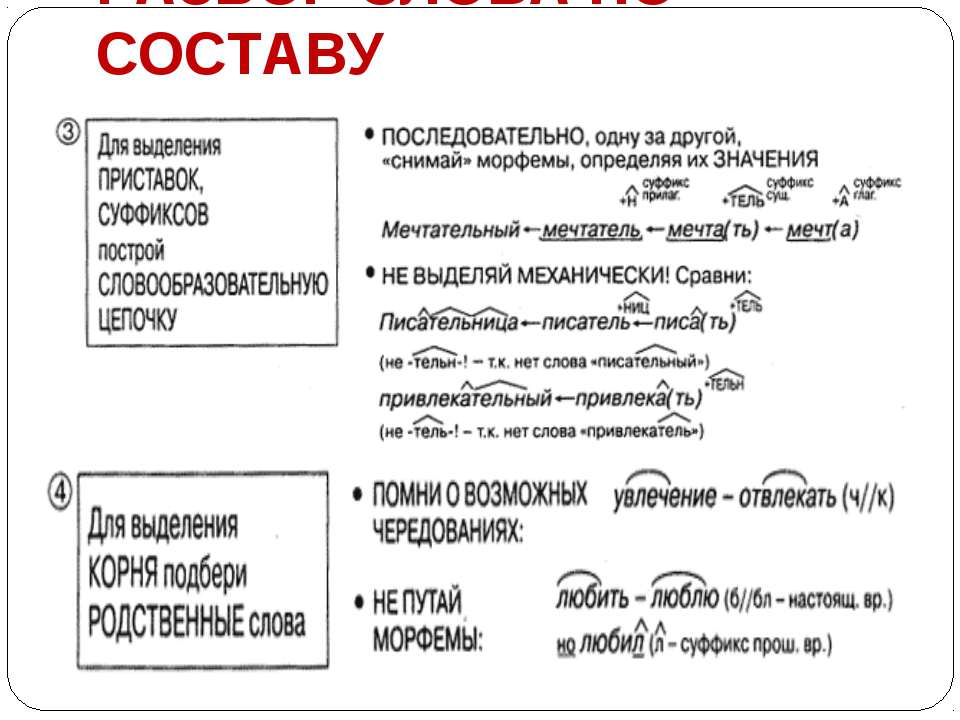 Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Как Сделать Морфологический Разбор Слова? ТОП-5 сервисов
СохранитьSavedRemoved 0
Морфология – раздел языкознания, изучающий все части речи, их морфологический состав. Для установления последнего, необходим морфологический разбор слова. Производится он по – разному для:
Самостоятельных:
- Имён существительных
- Имён прилагательных
- Имён числительных
- Наречий
- Местоимений
- Глаголов
- Причастий
- Деепричастий
И служебных
- Союза
- Частицы
- Междометия
- Предлога
Проанализировать слова онлайн можно на сайтах:
Или по плану.
Имя существительное
Существительное — часть речи, отвечающая на вопросы «кто», «что» (и другие падежные формы) и указывающая на предмет.
План разбора:
Часть речи (в данном случае существительное) и общее значение:
- Всё, что связанно с человеком (мама, школьник),
- Объекты и субъекты (стол, кнопка, стакан),
- Живые существа (амёба, мышь, кот),
- Продукты, вещи, предметы (соль, яд, молоко),
- События и явления природы (снегопад, встреча),
- Деятельность (прочтение, употребление),
- Качества, атрибуты (честность, прямодушие)
Поставить слово в начальную форму (падеж – именительный, число — единственное).
Перечесть постоянные морфологические признаки:
1Нарицательность
- Собственные — имена, названия имён, топонимов, названий чего-либо и т. п., начинаются с заглавной буквы (Атлантический, Австралия).
- Нарицательные — категория группы, предметов, понятий, начинаются со строчной (уравнение, счастье, картина).
2Одушевлённость
- Одушевлённое — названия живых существ (комар, парень, личинка),
- Неодушевлённое – наоборот (потолок, двигатель).
3Род
- Мужской (оборот),
- Средний (тесто),
- Женский (фабрика).
4Склонение
- Первое включает существительные мужского, женского и среднего рода, имеющие в начальной форме окончание -а, -я (романтика, страница).
- Второе – мужского и среднего с нулевым окончанием или на -о, -е, например, «волос», «заболевание».
- Третье содержит существительные только женского рода, имеющие в начальной нулевое окончание, например, «честность», «окись» или «роль».
Указать непостоянные морфологические признаки:
1Падеж
- Именительный, отвечает на вопрос кто? Что? (Отвёртка (1 склонение), устройство (2), соль (3)).
- Родительный (Кого? Чего?). (Отвёртки, устройства, соли).
- Дательный (Кому? Чему?). (Отвёртке, устройству, соли).

- Винительный (Кого? Что?). (Отвёртку, устройство, соль).
- Творительный (Кем? Чем?). (Отвёрткой, устройством, солью).
- Предложный (О ком? О чём?). (Об отвёртке, об устройстве, о соли).

Порядок падежей можно запомнить с помощью фразы «Иван Родил Девчонку, Велел Тащить Пелёнку».
2Число
- Единственное (обозначает один предмет), к примеру, «один флакон или одна цель».
- Множественное (обозначает группу предметов или объектов) — «несколько флаконов или большое количество целей».
Указать синтаксическую роль в предложении. Существительное чаще всего является подлежащим или сказуемым («кто? что?»), дополнением (отвечает только на вопросы косвенных падежей) или обстоятельством (наречные вопросы)).
Морфологический разбор слова изучает такой предмет, как русский язык
вернуться к меню ↑Имя прилагательное
Прилагательное — часть речи, отвечающая на вопросы «чей», «который», «каков» и обозначающая признак предмета.
План:
Установить часть речи и общее значение, которое отдельно классифицируется для
Качественных:
Относительных:
И притяжательных прилагательных. Они обозначают принадлежность к чему-либо (Софьин, змеиный).
Представить слово в начальной форме (род – мужской, падеж – именительный, число — единственное).
Перечислить постоянные признаки:
- Разряд прилагательного: качественное (признак предмета, проявляет признак в большей или меньшей степени, например, (несносный – более несносный), относительное (предмет, не проявляющийся в разной степени, например, водорослевый. Внимание! Нельзя сказать «более водорослевый») или относительное (принадлежность предмета, например, учительский).
 Внимание! Нельзя сказать «более водорослевый») или относительное (принадлежность предмета, например, учительский).
Внимание! Нельзя сказать «более водорослевый») или относительное (принадлежность предмета, например, учительский).Перечислить непостоянные признаки:
- Полная или краткая форма (лучистый (полная), лучист (краткая))
- Степень сравнения (Например, внимательный – более внимательный)
Различная форма и степень сравнения может быть только у качественных прилагательных.
- Падеж (Прилагательное имеет тот же, что и существительное, с которым оно координирует). Падеж может быть предложным, творительным, винительным, дательным, родительным или именительным.
- Число (множественное или единственное).
- Род (средний, женский или мужской). Виден только в единственном числе. К примеру, нелицеприятный (м), нелицеприятная (ж) и нелицеприятное (ср).
Определить роль в предложении. Прилагательное чаще всего является определением или сказуемым (чаще всего в краткой форме).
вернуться к меню ↑Имя числительное
Числительное – самостоятельная часть речи, обозначающая количество объектов или предметов.
Часть речи. Общее значение.
Указать начальную форму (именительный падеж, единственное число, мужской род у порядковых, именительный падеж у количественных).
Постоянные морфологические признаки:
1Количественное или порядковое
- Количественное (девяносто, пять тысяч, шестьдесят два)
- Порядковое (шестой, девятнадцатый и так далее)
2Простое или составное.
- Простое. Состоит из одного слова (одиннадцать, сто).
- Составное. Состоит из нескольких слов (тридцать четыре, одна тысяча триста пятьдесят семь)
3Разряд (есть только у количественных)
Непостоянные морфологические признаки:
1Падеж
- Именительный (восемьдесят два, четыре),
- Родительный (восьмидесяти двух, четырёх),
- Дательный (восьмидесяти двум, четырём),
- Винительный (восемьдесят два, четыре)
- Творительный (восьмьюдесятью двумя, четырьмя),
- Предложный (о восьмидесяти двух, о четырёх)
2Число (есть не всегда)
3Род (есть не всегда)
Синтаксическая роль.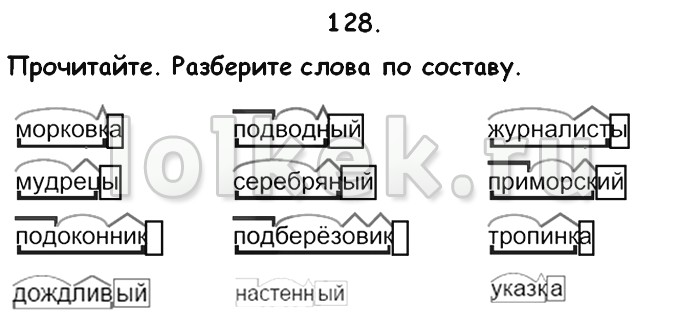
Важно делать разбор слова грамотно
вернуться к меню ↑Наречие
Наречие – самостоятельная часть речи, обозначающие признак признака или признак предмета.
Часть речи. Общее значение.
Постоянные морфологические признаки
1Группа по значению
- Времени (Когда?)
- Образа действия (Каким образом? Как?)
- Меры и степени (В какой степени? Насколько?)
- Причины (По какой причине? Почему?)
- Цели (С какой целью?)
- Места (Откуда? Где?)
2Наличие сравнительной степени (бывает не всегда)
3Неизменяемость
Непостоянных признаков у наречий нет, так как это неизменяемая часть речи.
Роль в предложении. Наречия чаще всего являются обстоятельствами или сказуемыми.
вернуться к меню ↑Глагол
Глагол – самостоятельная часть речи, имеющая значение действия.
Часть речи. Общее значение.
Постоянные признаки:
1Вид
- Совершенный (Что сделать?)
- Несовершенный (Что делать?)
2Переходность
- Переходный. Сочетается с существительным в винительном падеже. (рассчитываю на (Кого? Что?) честную конкуренцию)
- Непереходный. Требуют дополнения при сочетании с существительными в винительном падеже. (помогаю (Кому? Чему?) дальнему родственнику)
Переходность глагола можно проверить, подставив к нему слово «кошку», при этом словосочетание может не иметь логического смысла. К примеру, «понял (Кого? Что?) кошку» содержит переходный глагол, а «помогать (Кому? Чему?) Кошке».
3Спряжение
- Первое (глаголы, заканчивающиеся на -оть, -еть, -ыть, -ать, -ять, например, «фабриковать»)
Запомните слова – исключения: смотреть, вертеть, гнать, дышать, держать, слышать, терпеть, видеть, обидеть, зависеть, ненавидеть.
- Второе (глаголы, заканчивающиеся на -ить, например, «изучить»).
Запомните слова – исключения: стелить, брить.
Непостоянные признаки
1Наклонение
- Изъявительное (конспектирую)
- Сослагательное или условное (конспектировал бы)
- Побудительное (конспектируй)
2Время (глаголы изменяются по временам только в изъявительном наклонении)
- Прошедшее (воодушевлял)
- Настоящее (воодушевляю)
- Будущее (буду воодушевлять или воодушевлю)
3Число (единственное или множественное)
4Лицо (Глаголы изменяются по лица в изъявительном (в настоящем будущем времени) и повелительном наклонении)
- Первое (согласуются с местоимениями «мы, я»)
- Втрое («вы, ты»)
- Третье («они, она, оно, он»)
5Род (Только у глаголов прошедшего времени)
Синтаксическая роль. В предложении глагола являются сказуемыми.
В предложении глагола являются сказуемыми.
Местоимение
Местоимение – самостоятельная часть речи, указывающая, но не называющая предметы.
Часть речи. Общее значение.
Поставить число в начальную форму (падеж – именительный, число – единственное)
Постоянные признаки:
1Разряд
- Личные: они, он, она, он, вы, ты, мы, я
- Возвратное: себя
- Вопросительно – относительные: сколько, чей, что, кто, который, какой
- Притяжательные: их свой, наш, их, её, его, твой, мой, ваш
- Указательные: столько таков, тот, такой, этот
- Отрицательные: никакой, ничей никто, некого, нечего
- Неопределённые: некто, нечто, некоторый, некий, несколько, а также местоимения с суффиксами -либо, -то или приставкой кое-
2Лицо (Только у личных местоимений)
- Первое (мы, я)
- Втрое (вы, ты)
- Третье (они, оно, он, она)
Непостоянные признаки:
- Падеж
- Число (при наличии)
- Род (если есть)
Синтаксическая роль. Местоимения чаще всего являются подлежащими или определениями.
вернуться к меню ↑Причастие
Причастие – особая глагольная форма, поэтому многие его признаки нужно искать у глагола, от которого слово и образовано.
Часть речи. Общее значение.
Поставить слово в начальную форму (мужской род, падеж – именительный, число – единственное)
Постоянные признаки:
1Вид
2Залог
- Действительный (действие совершается предметом, например, «подвергающий опасности»)
- Страдательный (действие совершается над предметом, например, «подвергаемый опасности»)
3Время
Непостоянные признаки:
1Форма
- Полная. Отвечает на вопрос «какой?» (очищенный)
- Краткая. Отвечает на вопрос «каков?» (очищен)
2Число
3Род (виден только у причастий в единственном числе)
4Падеж (присутствует только у причастий в полной форме)
Синтаксическая роль. Отдельные причастия являются определениями. Причастные обороты выделяются запятыми с обеих сторон только, если находятся после определяемого слова.
Отдельные причастия являются определениями. Причастные обороты выделяются запятыми с обеих сторон только, если находятся после определяемого слова.
Деепричастие
Деепричастие — особая форма глагола, поэтому его признаки совпадают с признаками глагола, от которого оно образовано.
Часть речи. Общее значение.
Данная часть речи является неизменяемой, поэтому у неё отсутствуют непостоянные признаки.
Морфологические признаки:
- Начальная форма (глагол, от которого образовано)
- Вид
- Переходность
- Неизменяемость
Вид, переходность и неизменяемость находятся так же, как и у глагола, от которого оно образовано.
Роль в предложении. Деепричастные обороты на письме выделяются запятыми с обеих сторон.
вернуться к меню ↑Союз
Союз – служебная часть речи, связывающая простые предложения в составе сложного или однородные члены предложения.
Часть речи. Общее значение.
Морфологические признаки:
1Простой или составной
- Простой. Состоит из одного слова (но, а)
- Составной. Состоит из нескольких слов (так же, как и; не только, но и)
2Производный или непроизводный.
- Производный. Образован от других частей речи (зато, чтобы)
3Неизменяемость
вернуться к меню ↑Частица
Частица – служебная часть речи, вносящая эмоциональное значение в предложение.
Часть речи. Общее значение.
Признаки:
1Разряд
- Уточняющие (как раз, точно)
- Указательные (это, тот, то)
- Вопросительно – относительные (почти, просто)
- Усилительные (даже, всё же)
- Отрицательны (отнюдь не, вовсе не)
- Положительная (ни)
- Модальные (будто, ли, ну – ка)
- Формообразующие (давайте)
2Группа по значению (есть только у модальных)
- Побудительные (ну – ка, ну)
- Сравнительные (словно, как будто)
- Вопросительные (ли, неужели)
3Неизменяемость
вернуться к меню ↑Междометие
Междометие – слова, выражающие эмоции.
Часть речи. Общее значение.
Морфологические признаки:
1Разряд по значению
- Эмоциональные (ух ты, ой – ой)
- Императивные (караул, кыш)
- Этикетные (пока, здравствуйте)
2Производное или непроизводное
3Неизменяемость
вернуться к меню ↑Предлог
Предлог – служебная часть речи, выражающая отношения между самостоятельными частями речи, согласующая их.
Общее значение. Часть речи.
Признаки:
1Разряд по строению
- Простые
- Сложные
- Составные
2Группа (по смыслу)
3Изменяемый или неизменяемый
4Производный (впоследствии, в течение) или непроизводный (на, около)
Если входит в состав падежного вопроса, то является производным предлогом, а если можно задать вопрос, то существительным с предлогом. К примеру, «писал (в течение чего?) в течение нескольких лет» — производный предлог, «заметил (где?) в течении реки» — существительное с предлогом.
9 Общий Балл
Чтобы сделать морфологический разбор слова, вам достаточно прочитать эту статью. Она будет полезна всем нашим посетителям сайта. Если вы не согласны с оценками статьи, просто поставьте свои собственные. Мы вас благодарим!
Достоверность информации
9.5
Универсальность
9.5
Раскрытие темы
0
Плюсы
- Тщательный и правильный разбор
Минусы
- Материал может быть сложным для понимания
Операция по спасению» – WARHEAD.SU
Великая сила кино
Вы когда-нибудь задумывались, с чего вы вдруг вообще заинтересовались оружием? Служба в армии? Поездки на охоту с отцом? Водяные пистолеты, которые мама вам купила в шесть лет?
Я долго думал над этим вопросом, рассматривал старые фото, пытался вспомнить — что же именно послужило причиной покупки первого оружейного журнала, первой оружейной энциклопедии или первого похода в тир.
Ответ нашёлся быстро — фильмы. В начале 90-х и по телевизору, и на видеокассетах мы видели «героев нашего времени», и они непременно были с оружием — будь то Терминатор, Рэмбо, Данила Багров или майор Дукалис. Я удивлён, почему после такого детства всё поколение 80-х и 90-х не проводит свободное время в тире или в обсуждении, какое ружьё стоит купить следующим.
В начале 90-х и по телевизору, и на видеокассетах мы видели «героев нашего времени», и они непременно были с оружием — будь то Терминатор, Рэмбо, Данила Багров или майор Дукалис. Я удивлён, почему после такого детства всё поколение 80-х и 90-х не проводит свободное время в тире или в обсуждении, какое ружьё стоит купить следующим.
Но пересматривая боевики того времени сейчас, невозможно серьёзно воспринимать происходящее на экране. Бесконечные магазины, сверхточная стрельба от пояса, люди, улетающие за горизонт при попадании пистолетной пули, и дурацкие ляпы вроде рассказа про фарфоровый «Глок» из второй части «Крепкого орешка».
Поэтому каждый раз, когда в современном кино демонстрируют более-менее реалистичное обращение с оружием, я никак не могу пройти мимо, даже если диалоги в фильме приходится проматывать из-за их тупости, как в случае с фильмом Extraction — в переводе на русский «Эвакуация», или, согласно мнению дипломированных переводчиков, «Тайлер Рейк: Операция по спасению».
Каскадёры и постановщики
Сюжет можно пересказать одним предложением: мрачный бывший спецназовец из Австралии едет в город Дакка, столицу Бангладеш, чтобы спасти маленького мальчика, и всё идёт наперекосяк. Впрочем, создатели фильма не заморачиваются и в самом начале показывают нам концовку, как будто шепча зрителю на ухо: «Давай, братан, перематывай всю болтовню, слава богу, мы не в кинотеатре».
Если вы не выключили фильм и досмотрели до первых драк и перестрелок, происходящее начинает затягивать — снято очень интересно, персонажи умело перезаряжают оружие, устраняют задержки, переносят оружия с одного плеча на другое, приспосабливаясь к укрытию, — словом, ведут себя так, будто всё свободное время проводят на стрельбище.
Почему так получилось?
Режиссёр «Эвакуации» Сэм Харгрейв раньше фильмы не снимал — зато много лет проработал сначала каскадёром, а потом постановщиком трюков.
Кстати, ровно по тому же пути прошёл Чад Стахелски, режиссёр фильмов про знаменитого белорусского цыгана «Джона Уика».
Манера съёмки у Харгрейва весьма нестандартная: режиссёр привязывал себя на «капот» специальной багги, чтобы лично снять сцены погони по городу, прыгал с актёрами с крыши на крышу и со второго этажа на улицу, чтобы сцены получились непрерывными и максимально затягивающими, с эффектом присутствия.
Но никакие ухищрения с камерой не помогут, если актёры не обучены обращению с оружием.
Особенно это важно во время съёмки длинных планов без монтажа, когда одна неудачная перезарядка, выроненный магазин или спутанный порядок действий заставят режиссёра переснимать всю сцену.
Создатели «Эвакуации» подошли к обучению исполнителей главных ролей довольно легкомысленно, но благодаря удачному актёрскому составу итоговый результат получился весьма неплохой. Военным консультантом фильма стал инструктор Крейг Чили Палмер.
До этого он работал всего над одной картиной, How It Ends, но зато 25 лет прослужил в Армии США на различных должностях, 13 раз был в Афганистане и Ираке, а теперь занимается беспилотниками и иногда преподаёт в «академии „Зиг-Зауэр“», где известный производитель оружия обучает гражданских и военных.
Чили ПалмерКак и многие его бывшие сослуживцы, по старой и очаровательной американской традиции, он старается напрямую не говорить, что служил в знаменитом американском спецназе «Дельта», но зато — как и его коллеги — активно на это намекает при любом удобном и неудобном случае.
В отличие от «морских котиков», где написанию мемуаров скоро начнут учить на курсе молодого бойца, в «Дельте» (1st SFOD-D, CAG) некоторые отставники ещё пытаются соблюдать приличия и о месте службы рассказывают очень толстыми намёками, помня, что когда-то их называли «тихими профессионалами».
Я связался c Чили Палмером, чтобы расспросить его о работе над фильмом, и узнал много интересного. Он готовил к съёмкам Криса Хемсворта и Рандипа Худа, которые в первой половине картины являются главными антагонистами, а также «иностранных каскадёров и их коллег, которые изображали группу наёмников в конце фильма».
Он готовил к съёмкам Криса Хемсворта и Рандипа Худа, которые в первой половине картины являются главными антагонистами, а также «иностранных каскадёров и их коллег, которые изображали группу наёмников в конце фильма».
Основных проблем было две. Первая — больше половины фильма (а именно — все сцены, снятые в Индии) закончили без привлечения военного консультанта. В итоги Чили Палмер оказался крайне недоволен одеждой и бронёй главных героев, которые выбрали без него, — результат был далёк от идеала.
Меня этот вопрос беспокоил при просмотре — всю первую половину фильма главный герой бегает с огромным подсумком на спине, в который почти невозможно залезть рукой и который к тому же мешает сидеть в машине. Кому-то это покажется мелочью, но когда-то я ощутил это на своей шкуре и с сожалением снял со спины все красиво закреплённые подсумки.
Вторая проблема оказалась серьёзнее — времени для тренировок с актёрами специально не выделяли, и Чили Палмер занимался с ними прямо в гостинице, перед съёмками, а потом ходил по площадке и вмешивался в процесс, чтобы всё выглядело более-менее реалистично.
В итоге сам инструктор тоже сыграл небольшую роль — пулемётчика в вертолёте полицейского спецназа.
По его словам, кастинг на роль он проходил недолго, в следующем ключе: «Кто тут у нас более-менее умный да с опытом — давай-ка за пулемёт».
Однако, несмотря на очень краткое обучение, все актёры с оружием смотрятся хорошо и глупостей не делают.
Особенно интересно на эту тему высказалась Гольшифте́ Фарахани́ — иранская актриса, сыгравшая Ник Кхан, идейного руководителя группы наёмников: «Как ни странно, оружие для меня — это инструмент. Могу с ним управляться, и ощущается оно, как продолжение меня самой. Может, это древняя какая-то вещь, а может, в душе что-то такое».
Правильный реквизит
Но мало обучить актёров — нужно ещё дать им в руки правильный реквизит, а не как в «Ходячих мертвецах», где фонарик, приклеенный на ствол, изображал глушитель, а прицельные приспособления на оружии забывали ставить везде, где только можно.
При съёмках «Эвакуации» проблемы с оружием оказались гораздо серьёзнее, чем режиссёр мог предположить. Часть фильма снималась в Индии, где оружейное законодательство и коррупция приводят в замешательство даже самого прожжённого американского юриста, и в итоге реквизиторам не удалось заполучить никакого настоящего оружия.
Пришлось обходиться резиновыми макетами и парой страйкбольных пистолетов, что объясняет, почему весь фильм в кадре у бангладешского спецназа автоматы Калашникова поставлены на предохранитель.
Магия кино на многое способна, но переключить предохранитель на резиновой болванке ей не под силу.
Однако съёмочная группа достойно вышла из положения. Режиссёр в сценах драк со стрельбой за кадром кричал: «Бах, бах, бах!» в моменты, когда должны были происходить выстрелы; актёры реагировали, а вспышки и звук выстрелов добавили уже в постпродакшене.
Было сделано всё возможное, чтобы ненастоящее оружие в кадре выглядело реалистично, стоит только посмотреть этот короткий отрывок:
У главного героя хватают пистолет, блокируют движение затвора, при выстреле происходит задержка, он устраняет её одной рукой, зацепив пистолет целиком о бронежилет, выбрасывает гильзу и продолжает стрелять. Почти что учебное пособие по быстрому устранению задержек и, без сомнения, люди, рисовавшие графику, очень постарались.
Но когда компьютерные эффекты выглядят настолько реалистично, возникает вопрос: а надо ли вообще стрелять на съёмках — может, проще всё нарисовать?
Оружие и экипировка
С этим вопросом я обратился к оружейнику Рону Ликари, который работал непосредственно на съёмках этого фильма, и он любезно ответил:
«Да, мы использовали большое количество холостых патронов на съёмках, когда это было безопасно и возможно сделать. Для сцен рукопашного боя часто использовали страйкбольное оружие. Да, в фильме много графики, но и холостых патронов мы отстреляли немало. И не надо забывать, что графикой часто „дорабатывают“ стрельбу из реального оружия».
Все большие перестрелки в фильме снимали в Тайланде, и здесь уже использовалось нормальное оружие, стрелявшее холостыми патронами, которое предоставила американская компания ISS.
Конечно, тут американские оружейники разгулялись. Главный герой в фильме использует пистолет «Глок 17», 40-мм гранатомёт М79 и две разные винтовки AR-15.
Опознавать и отличать различные варианты коммерческих AR-15 сложнее, чем различить цвета маджента и фуксия, когда покупаешь жене в подарок лак для ногтей, поэтому я решил не позориться и обратился непосредственно к оружейникам ISS, которые готовили эти винтовки к съёмкам.
Оружие подбирал оружейник Джордж Кавалло, а за весь проект отвечал Ларри Зэнофф — очень уважаемый профессионал своего дела, который уже не первый год является соведущим программы «Голливудское оружие».
Общими усилиями они выдали следующий ответ: в начале фильма Крис Хемсворт использует винтовку BCM AR-15 с цевьём KMR-A10 и передней рукояткой BCM GUNFIGHTER Vertical Grip, голографическим прицелом Eo Tech с увеличителем, глушителем AAC M4-2000 и инфракрасным целеуказателем.
В конце фильма у него в руках оказывается не менее модная винтовка фирмы Daniel Defense M4 V1, с прицелом Leupold Mark 4 High Accuracy Multi-Range Riflescope (HAMR) с дополнительным коллиматором Delta-Pro сверху, глушителем Gemtech Halosuppressor и тактическим фонарём.
Вопрос, где в Бангладеш наёмник может достать себе такие винтовки, я решил оставить при себе.
Зато выбор оружия и экипировки главного антагониста — Саджи, бывшего индийского спецназовца — привёл меня в полный восторг. Несколько лет назад в Индии у меня появилась возможность поработать вместе с антитеррористическим подразделением «Чёрные коты», и персонаж фильма был экипирован точь-в-точь, как настоящие индийские спецназовцы.
Чёрная одежда, устаревший разгрузочный жилет и неизменный пистолет-пулемёт МП5 с израильским коллиматорным прицелом попадали в образ на сто процентов.
Ларри Зэнофф в беседе подтвердил, что образ взяли не с потолка — они ориентировались именно на индийских «Чёрных котов». Отличная работа!
Выбор оружия у второстепенных героев тоже интересный. В руках у Ник Кхан в заключительной сцене — бельгийский SCAR-H, отличное решение для изящной и целеустремлённой барышни.
Коррумпированный полковник бангладешской полиции использует довольно редкую винтовку SL-8, модификацию немецкой G-36, что достаточно реалистично — в таких странах в загашнике у местного спецназа почти всегда лежат очень интересные образцы.
С этой же винтовкой связан самый очевидный оружейный ляп в фильме. Во время сцены на мосту мы слышим выстрел и попадание пули, хотя снайпер находится на дистанции нескольких сотен метров. В такой ситуации сначала прилетает пуля и только потом раздаётся звук самого выстрела, ведь пуля патрона 5,56×45 летит в три раза быстрее звука.
В остальном фильм неплохо демонстрирует ситуацию, когда в мирном городе внезапно начинают применять стрелковое и гранатомётное вооружение — хаос, огонь и пули 7,62×54, которые насквозь прошивают всё, что обычно в фильмах считается укрытием.
Не знаю, будем ли мы помнить «Эвакуацию» через 20 лет, как сейчас помним боевики 80-х годов. Этот фильм страдает от всех болезней, которые охватили современное кино — как в Голливуде, так и в нашей стране: чудовищный, смехотворный сценарий, бездушные диалоги и местами утомительная актёрская игра заставляют усомниться, что он станет классикой. Тем не менее, вторая часть уже анонсирована, и на американском рынке это кино стало самым популярным полнометражным творением «Нетфликса».
Одно ясно точно: этот фильм, вместе с «Джоном Уиком», определённо задаёт новую планку, когда речь заходит об оружии в кино. Похоже, что добавление красивых и хоть немного реалистичных перестрелок позволяет превратить фильм из проходного боевика в серьёзный кассовый успех, так что, возможно, другие режиссёры намотают это на ус и тоже порадуют нас красивыми перестрелками в своих новых произведениях.
А я буду надеяться, что какой-нибудь мальчишка, посмотрев это кино, тоже, как я когда-то, пойдёт в тир и через много лет скажет: «Я заинтересовался оружием, посмотрев фильм „Эвакуация“».
Мнение редакции не всегда совпадает с мнением автора.
Вернуться на Землю — Блоги — Эхо Москвы, 12.04.2021
2021-04-12T18:27:00+03:00
2021-04-12T18:30:32+03:00
https://echo.msk.ru/blog/julia_galyamina/2820710-echo/
https://cdn.echo.msk.ru/files/3435970.png
Радиостанция «Эхо Москвы»
https://echo.msk.ru//i/logo.png
Юлия Галямина
https://echo.msk.ru/files/2462854.jpg
Сегодня каждый, кто вспомнит про День космонавтики, вспомнит и про ту радостную энергию, которая объединила людей по всему миру, а особенно тут, в России.
Объединила всех: и молодых и пожилых, и страстных сторонников коммунистического строя, и его противников. Потому что в них было ощущение осмысленности жизни, прорыва в будущее, веры в человека.
Сегодня, 60 лет спустя, нам так не хватает этих чувств и этой энергии! Чтобы открыть новости или выйти на улицу и подняться на невидимых крыльях: вперед, вперед, к звездам, к мечте.
Именно об этом чувстве тоскуют многие, тоскуя сейчас по Советскому Союзу. Именно это ощущение не позволяет многим радоваться жизни сегодня. Потому что в российском обществе нет больше этой общей мечты и ощущения общего будущего.
Но где же искать эту мечту? Опять в Космосе? Но кажется, космос стал таким обыденным делом, что не может сам по себе вдохновлять. У меня есть совершенно другой ответ: тут на Земле. Вернее — на земле. В том месте, где ты живешь. Увидеть в своем городе, поселке, селе — мечту. Сделать место, где ты родился — местом для жизни. Вернее: для Жизни!
Конечно, мне многие возразят, что это невозможно, потому что у нас олигархи, и Росгвардия, и местное самоуправление загублено, и люди у нас не те… Но так же могли отвечать пессимисты Королеву и Гагарину, пока они воплощали свою мечту, нашу общую мечту.
Я знаю множество людей по всей России, которые смогли это сделать: увидеть мечту под своими ногами. И которые начали ее реализовывать, вопреки всем сложностям: очищать берега озер и спасать реки, создавать музеи и небольшие фермерские хозяйства, развивать свое небольшое дело, спасать дома, выбираться местными депутатами и помогать людям вокруг себя.
Открывать свою землю, а не только космос! Чем не объединяющая и дарящая радостную энергию идея?
002459 Плакат «Русский язык Ч.2» (А2, текст), (МирОткр)
002459 Плакат «Русский язык Ч.2» (А2, текст), (МирОткр) | Открытки. Товары к 9 маяВы выключили JavaScript. Для правильной работы сайта необходимо включить его в настройках браузера.
0.0231500414 c
Смотрите также
43,87 р.
Габариты: 59 x 41,5 x 0,1 см; Мин. кол-во для заказа: 3; Вес: 50 г; Страна: Россия; В боксе: 100 шт…
кол-во для заказа: 3; Вес: 50 г; Страна: Россия; В боксе: 100 шт…
70 р.
Габариты: 60 x 45 x 0,1 см; Мин. кол-во для заказа: 10; Вес: 53 г; Страна: Россия; В боксе: 300 шт;…
Габариты: 60 x 45 x 0,1 см; Мин. кол-во для заказа: 10; Вес: 53 г; Страна: Россия; В боксе: 200 шт;…
67 р.
Габариты: 69 x 50 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 67 г; Страна: Россия; В боксе: 50 шт; С…
67 р.
Габариты: 69 x 50 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 67 г; Страна: Россия; В боксе: 100 шт;…
67 р.
Габариты: 69 x 50 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 67 г; Страна: Россия; В боксе: 100 шт;…
67 р.
Габариты: 69 x 50 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 67 г; Страна: Россия; В боксе: 100 шт;…
67 р.
Габариты: 69 x 50 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 67 г; Страна: Россия; В боксе: 50 шт; С…
67 р.
Габариты: 69 x 50 x 0,1 см; Мин. кол-во для заказа: 10; Вес: 67 г; Страна: Россия; В боксе: 50 шт;…
359 р.
Габариты: 34 x 49 x 0,4 см; Мин. кол-во для заказа: 1; Вес: 262 г; Страна: Россия; В боксе: 20 набо…
223 р.
Габариты: 29 x 29 x 0,2 см; Мин. кол-во для заказа: 1; Вес: 168 г; Страна: Россия; В боксе: 100 шт;…
67 р.
Габариты: 69,5 x 50 x 0,1 см; Мин. кол-во для заказа: 10; Вес: 89 г; Страна: Россия; В боксе: 50 шт…
45,52 р.
Габариты: 34 x 49 x 0,1 см; Мин. кол-во для заказа: 10; Вес: 32 г; Страна: Россия; В боксе: 150 шт;…
70 р.
Габариты: 69 x 49 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 30 г; Страна: Россия; В боксе: 120 шт;…
45,52 р.
Габариты: 49 x 34 x 0,1 см; Мин. кол-во для заказа: 10; Вес: 40 г; Страна: Россия; В боксе: 200 шт;…
74 р.
Габариты: 69 x 50 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 68 г; Страна: Россия; В боксе: 230 шт;…
43,87 р.
Габариты: 59 x 41,5 x 0,1 см; Мин. кол-во для заказа: 3; Вес: 60 г; Страна: Россия; В боксе: 160 шт…
74 р.
Габариты: 4 x 0 x 0 см; Мин. кол-во для заказа: 1; Вес: 65 г; Страна: Россия; В боксе: 50 шт; Соста…
444 р.
1 заказ
В состав набора входит 8 ярких плакатов размером 34×50 см, упакованных в красивый тубус. Плакаты п…
от 7 лет.
558 р.
Габариты: 40 x 2 x 60 см; Мин. кол-во для заказа: 1; Вес: 333 г; Страна: Китай; В боксе: 36 шт; Сос…
9,63 р.
Габариты: 29 x 21 x 0,1 см; Мин. кол-во для заказа: 20; Вес: 10 г; Страна: Россия; В боксе: 500 шт;…
19,53 р.
Габариты: 0,1 x 21 x 29,5 см; Мин. кол-во для заказа: 10; Вес: 15 г; Страна: Россия; В боксе: 800 ш…
33,42 р.
Габариты: 41,5 x 29 x 0,1 см; Мин. кол-во для заказа: 3; Вес: 50 г; Страна: Россия; В боксе: 160 шт…
45,52 р.
Габариты: 34 x 49 x 0,1 см; Мин. кол-во для заказа: 10; Вес: 32 г; Страна: Россия; В боксе: 500 шт;…
54 р.
Габариты: 60 x 45 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 53 г; Страна: Россия; В боксе: 150 шт;…
43,87 р.
Габариты: 59 x 41,5 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 60 г; Страна: Россия; В боксе: 500 шт…
43,87 р.
Габариты: 59 x 41,5 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 50 г; Страна: Россия; В боксе: 500 шт…
43,87 р.
Габариты: 59 x 41,5 x 0,1 см; Мин. кол-во для заказа: 3; Вес: 55 г; Страна: Россия; В боксе: 200 шт…
43,87 р.
Габариты: 59 x 41,5 x 0,1 см; Мин. кол-во для заказа: 2; Вес: 60 г; Страна: Россия; В боксе: 60 шт;…
46,34 р.
Габариты: 34 x 49 x 0,1 см; Мин. кол-во для заказа: 2; Вес: 61 г; Страна: Россия; В боксе: 200 шт;…
46,34 р.
Габариты: 49 x 34 x 0,1 см; Мин. кол-во для заказа: 2; Вес: 34 г; Страна: Россия; В боксе: 60 шт; С…
46,34 р.
Габариты: 49 x 34 x 0,1 см; Мин. кол-во для заказа: 2; Вес: 35 г; Страна: Россия; В боксе: 60 шт; С…
45,52 р.
Габариты: 49 x 34 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 33 г; Страна: Россия; В боксе: 150 шт;…
45,52 р.
Габариты: 49 x 34 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 33 г; Страна: Россия; В боксе: 150 шт;…
45,52 р.
Габариты: 49 x 34 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 33 г; Страна: Россия; В боксе: 150 шт;…
45,52 р.
Габариты: 49 x 34 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 33 г; Страна: Россия; В боксе: 150 шт;…
45,52 р.
Габариты: 49 x 34 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 32 г; Страна: Россия; В боксе: 150 шт;…
46,34 р.
Габариты: 49 x 34 x 0,1 см; Мин. кол-во для заказа: 2; Вес: 33 г; Страна: Россия; В боксе: 150 шт;…
45,52 р.
Габариты: 34 x 49 x 0,1 см; Мин. кол-во для заказа: 10; Вес: 32 г; Страна: Россия; В боксе: 60 шт;…
45,52 р.
Габариты: 49 x 34 x 0,1 см; Мин. кол-во для заказа: 1; Вес: 34 г; Страна: Россия; В боксе: 150 шт;…
Мы используем метаданные (cookie, данные об IP-адресе и местоположении) для функционирования сайта. Продолжая пользоваться нашим сайтом, вы соглашаетесь с использованием метаданных Закрытьstring — Как создать дерево синтаксического анализа в Python для грамматики
Я пытаюсь создать синтаксический анализатор грамматики для общей структуры предложения, которую изучаю. У меня много логики, так как грамматическая структура большинства предложений похожа. то есть я жестко запрограммировал операторы if, которые проверяют индексы определенных ключевых слов и соответствующим образом токенизируют их, что в определенной степени работает. Однако я хотел бы найти способ воспринимать это как гораздо более объектно-ориентированный подход с древовидной структурой.
примеров предложений: боб один три врага фланг на юг
Пример токенизации:
bob — это токен «имени», - один — дополнительная информация об имени, поскольку она идет сразу после первого слова в предложении.
врагов — это жетон «объявления врага», а три — дополнительная информация о противнике, поскольку она идет прямо перед словом «враги».
фланг — жетон действия, а юг — направление «действия», так как оно идет на одно слово после действия.
Эти правила одинаковы для всех предложений на языке, который я разбираю.
Итак, в идеале я хочу создать архитектуру древовидной модели, которая анализирует все предложение, по одному слову за раз, и маркирует специальные ключевые слова, такие как «враги» или «фланг», но мне также нужен способ сбора дополнительной информации который прикреплен к каждому ключевому слову в непосредственной близости (предшествующему или последующему), как указано в примерах выше. Скорее всего, здесь пригодится моя логика оператора if.
Как я могу настроить ООП-подход для добавления дополнительной информации в эти классы. Мои первые мысли заключались в том, чтобы создать ClassTokens для ключевых слов, но как бы я справился с добавлением описательных слов? Должен ли я делать классы и для каждого из этих слов, или это излишне?
Кроме того, я полагаю, что мне нужен отдельный класс, такой как «Parser», который анализирует все предложение и поддерживает состояние предложения, а также некоторые функции предварительного просмотра или просмотра предыдущих функций? Просто пытаюсь провести мозговой штурм и подумать о том, как объединить все это.Спасибо.
Например,
название класса:
def __init __ (self, name_keyword: str):
self.name = name_word
self.additional = []
def add_additional (self, add_word: str):
# если что - то добавить в self.additional
класс Parser:
def __init __ (self, full_sentence: str):
self.sentence = full_sentence.split () # инициализируем полное предложение слов
self.index = 0 # начальный индекс
def lookahead (self, n: int):
вернуть себя.предложение [self.index + n]
def lookprior (self, n: int):
вернуть self.sentence [self.index - n]
Диаграммы предложений
Когда вы составляете схемы предложений, вы определяете различные части речи предложения и то, как они работают вместе. Даже в самых простых предложениях должны быть подлежащее и глагол, а грамматические правила диктуют, как взаимодействуют подлежащее и глагол. Продолжайте читать, чтобы узнать, как составить схему предложения и почему построение предложений может помочь вам глубже понять английский язык.
Компоненты предложений
Предложения содержат ряд различных компонентов или частей, которые должны работать вместе. Составление диаграмм предложений позволяет вам разделять и идентифицировать эти различные компоненты предложений, располагая их наглядно.
Хотя существует несколько методов построения диаграммы предложения, каждый из них включает разделение подлежащего, сказуемого (глагола) и других компонентов предложения.
Эти компоненты могут включать:
- тему — о ком или о чем идет речь в предложении; существительное, выполняющее действие
- предикат — глагол или действие, выполняемое
- прямой объект — что-то / кто-то действие выполнено с
- косвенный объект — человек / вещь, с которой или для или для которого выполняется действие
- предлоги — слова отношения, которые предоставляют информацию о том, как другие части предложения сочетаются друг с другом
- модификаторы — слова, которые предоставляют дополнительную информацию о предмете, действии или объекте в предложении
- статьи — слова, которые изменяют существительные
- зависимые (придаточные) придаточные предложения — предложения, которые не могут быть изолированы друг от друга
- союзы — слова, соединяющие другие слова вместе
Диаграмма предложений помогает вам определить, как части предложения работают вместе.Он обеспечивает более глубокое понимание функции, которую слова играют в предложениях. Это поможет сделать ваш собственный текст более четким и свободным от грамматических ошибок.
Как построить диаграмму предложения
Теперь, когда вы знаете части предложения, вы готовы приступить к построению диаграммы! Есть четыре типа линий, которые вам понадобятся для построения диаграмм предложений:
- горизонтальных линий (⎯⎯⎯) для написания субъектов, глаголов и объектов
- вертикальных линий (|) для разделения субъектов, глаголов и объектов
- диагональных линий (/) для написания модификаторов, предлогов и артиклей
- пунктирные вертикальные или диагональные линии (⦙) для союзов
Спланируйте свое предложение на диаграмме, найдя наиболее важные слова — подлежащее и глагол — и продолжая оттуда.Следуйте этим простым шагам, чтобы правильно построить схему любого предложения.
Базовая линия
Базовая линия — это верхняя линия вашей диаграммы. Он выделяет основные части предложения: субъект , глагол и объект .
- Нарисуйте базовую линию (верхнюю линию диаграммы), разделенную короткой вертикальной линией.
- Напишите подлежащее слева и глагол справа.
- Если есть объект, добавьте его после глагола диагональной линией.
Ниже базовой линии
Каждый из других компонентов предложения находится ниже базовой линии предложения в соответствии с определенными правилами построения диаграмм предложений. Эти части включают модификаторы , предлоги , косвенные объекты , придаточные предложения , статьи , междометия и так далее.
- Напишите модификаторы и предлоги на диагональных линиях, отходящих от слова, которое они изменяют, под базовой линией.
- Предлог стоит на горизонтальной линии под предлогом.
- Если есть косвенный объект, напишите его на горизонтальной линии под глаголом и соедините диагональной линией.
- Добавляйте статьи по диагонали под изменяемыми существительными.
Добавление сложного предложения
Если в вашем сложном предложении есть придаточное предложение, а также независимое предложение, вам также нужно будет изобразить его на диаграмме. Придаточные предложения рассматриваются как модификаторы, соединенные конъюнкциями в диаграммах предложений.
- Напишите подчиненный союз на диагональной пунктирной линии под словом, которое оно изменяет.
- Проведите горизонтальную линию под пунктирной линией.
- Добавьте существительное, глагол и объект на горизонтальной линии, разделив их вертикальными линиями.
- Нарисуйте сплошные диагональные линии под любыми словами, у которых есть модификаторы, и добавьте модификаторы к их словам.
Сложные предложения
Сложные предложения состоят из двух или более независимых предложений.Каждое независимое предложение получает свою собственную отдельную диаграмму со своей отдельной базовой линией для его подлежащего и глагола.
- Создайте новую базовую линию под первым предложением на диаграмме.
- Начать с начала: добавить подлежащее, глагол, объект и другие части второго предложения.
- Когда вы изобразили все предложения, соедините их пунктирными линиями.
- Напишите координирующее соединение на горизонтальной линии рядом с пунктирной линией.
Цель построения диаграмм предложений
Существует ряд различных причин, по которым диаграмма предложений может быть полезной, и все они связаны с развитием более глубокого понимания английской грамматики.Составление схем предложений может помочь вам:
- изучить и идентифицировать части речи
- понять, как части речи функционируют вместе, чтобы создать составные предложения
- изучить методы соединения предметов, глаголов и объектов
- понять используемые сложные грамматические инструменты составлять составные предложения, включая предложные фразы, глагольные существительные, модификаторы и составные предметы
Если вы пишете предложение и что-то звучит не совсем правильно, попробуйте нарисовать его в виде диаграммы.Вы можете обнаружить, что ваши модификаторы слишком далеки от измененных слов, что вам не хватает статьи или ваше предложение является фрагментом. Составление схем предложений — отличный способ устранить распространенные грамматические ошибки в вашем письме.
Примеры составления диаграмм предложений
Составление диаграмм предложений — это простой способ изучить вашу собственную грамматику, но освоить ее может быть немного сложно. Самый простой способ понять составление диаграмм предложений — это изучить предложения, которые были составлены в виде диаграмм, и попрактиковаться в составлении диаграмм самостоятельно.Чтобы узнать больше о практике построения диаграмм предложений, ознакомьтесь с этими увлекательными рабочими листами.
10 советов по YAML для людей, которые ненавидят YAML
Существует множество форматов файлов конфигурации: список значений, пары ключей и значений, файлы INI, YAML, JSON, XML и многие другие. Из них YAML иногда называют особенно сложным для обработки по нескольким различным причинам. Хотя его способность отражать иерархические ценности значительна, а его минимализм может быть освежающим для некоторых, его Python-подобная зависимость от синтаксических пробелов может расстраивать.
Однако мир с открытым исходным кодом достаточно разнообразен и гибок, чтобы никому не приходилось страдать от абразивных технологий, поэтому, если вы ненавидите YAML, вот 10 вещей, которые вы можете (и должны!) Сделать, чтобы сделать его терпимым. Начиная с нуля, как и положено любому разумному индексу.
0. Заставьте ваш редактор делать всю работу
Какой бы текстовый редактор вы ни использовали, вероятно, есть плагины, упрощающие работу с синтаксисом. Если вы не используете плагин YAML для своего редактора, найдите его и установите. Усилия, которые вы потратите на поиск плагина и его настройку по мере необходимости, окупятся в десять раз при следующем редактировании YAML.
Например, редактор Atom по умолчанию поставляется с режимом YAML, и хотя GNU Emacs поставляется с минимальной поддержкой, вы можете добавить дополнительные пакеты, такие как yaml-mode, чтобы помочь.
Emacs в режиме YAML и пробелов.
Если в вашем любимом текстовом редакторе отсутствует режим YAML, вы можете решить некоторые из своих проблем с помощью небольших изменений конфигурации. Например, текстовый редактор по умолчанию для рабочего стола GNOME, Gedit, не имеет доступного режима YAML, но по умолчанию обеспечивает подсветку синтаксиса YAML и имеет настраиваемую ширину вкладки:
Настройка ширины вкладки и типа в Gedit.
С помощью пакета подключаемого модуля drawspaces Gedit вы можете сделать пустое пространство видимым в виде ведущих точек, снимая любые вопросы об уровнях отступа.
Найдите время, чтобы изучить свой любимый текстовый редактор. Узнайте, что делает редактор или его сообщество, чтобы упростить YAML, и используйте эти функции в своей работе. Вы не пожалеете.
1. Используйте линтер
В идеале языки программирования и языки разметки используют предсказуемый синтаксис.Компьютеры, как правило, преуспевают в предсказуемости, поэтому концепция линтера была изобретена в 1978 году. Если вы не используете линтер для YAML, то пора принять эту 40-летнюю традицию и использовать yamllint .
Вы можете установить yamllint в Linux с помощью диспетчера пакетов вашего дистрибутива. Например, в Red Hat Enterprise Linux 8 или Fedora:
$ sudo dnf установить yamllint
Вызвать yamllint так же просто, как сказать ему проверить файл.Вот пример ответа yamllint на файл YAML, содержащий ошибку:
$ yamllint errorprone.yaml
errorprone.yaml
Ошибка синтаксиса 23:10: здесь недопустимы значения сопоставления
23:11 ошибка конечных пробелов (конечные пробелы)
Это не отметка времени слева. Это номер строки и столбца ошибки. Вы можете понять, а можете и не понять, о какой ошибке идет речь, но теперь вы знаете, где находится ошибка. Если еще раз взглянуть на место, то природа ошибки часто становится очевидной.Успех пугающе тих, поэтому, если вам нужна обратная связь, основанная на успехе линта, вы можете добавить условную вторую команду с двойным амперсандом ( && ). В оболочке POSIX && завершается ошибкой, если команда возвращает что-нибудь , кроме 0, поэтому в случае успеха ваша команда echo проясняет это. Эта тактика несколько поверхностна, но некоторые пользователи предпочитают уверенность в правильности выполнения команды, а не молчаливую ошибку. Вот пример:
$ yamllint perfect.yaml && echo "ОК"
ОК
Причина, по которой yamllint так тихо при успешном завершении, заключается в том, что он возвращает 0 ошибок, когда ошибок нет.
2. Пишите на Python, а не на YAML
Если вы действительно ненавидите YAML, перестаньте писать на YAML, по крайней мере, в буквальном смысле. Возможно, вы застряли в YAML, потому что это единственный формат, который принимает приложение, но если единственное требование — закончить в YAML, тогда работайте в другом, а затем конвертируйте. Python вместе с отличной библиотекой pyyaml упрощает эту задачу, и у вас есть два метода на выбор: самопреобразование или сценарий.
Самоконвертация
В методе самопреобразования ваши файлы данных также являются сценариями Python, которые создают YAML. Это лучше всего подходит для небольших наборов данных. Просто запишите данные JSON в переменную Python, добавьте к ней оператор import и завершите файл простым трехстрочным оператором вывода.
#! / Usr / bin / python3
импортировать ямл
d = {
"глоссарий": {
"title": "пример глоссария",
"GlossDiv": {
"title": "S",
"GlossList": {
"GlossEntry": {
«ID»: «SGML»,
«SortAs»: «SGML»,
"GlossTerm": "Стандартный обобщенный язык разметки",
«Акроним»: «SGML»,
«Аббревиатура»: «ISO 8879: 1986»,
"GlossDef": {
«para»: «Язык мета-разметки, используемый для создания языков разметки, таких как DocBook.",
"GlossSeeAlso": ["GML", "XML"]
},
"GlossSee": "разметка"
}
}
}
}
}
f = open ('output.yaml', 'ш')
f.write (yaml.dump (d))
f.close
Запустите файл с помощью Python, чтобы создать файл с именем output.yaml file.
$ python3 ./example.json
$ cat output.yaml
глоссарий:
GlossDiv:
GlossList:
GlossEntry:
Сокращение: ISO 8879: 1986.
Акроним: SGML
GlossDef:
GlossSeeAlso: [GML, XML]
para: язык мета-разметки, используемый для создания языков разметки, таких как DocBook.GlossSee: разметка
GlossTerm: стандартный обобщенный язык разметки
ID: SGML
Сорта: SGML
название: S
название: пример глоссария
Этот вывод является совершенно правильным YAML, хотя yamllint действительно выдает предупреждение о том, что файл не имеет префикса --- , который вы можете настроить либо в скрипте Python, либо вручную.
Преобразование по сценарию
В этом методе вы пишете в JSON, а затем запускаете скрипт преобразования Python для создания YAML.Это масштабируется лучше, чем самопреобразование, потому что оно отделяет преобразователь от данных.
Создайте файл JSON и сохраните его как example.json . Вот пример с json.org:
{
"глоссарий": {
"title": "пример глоссария",
"GlossDiv": {
"title": "S",
"GlossList": {
"GlossEntry": {
«ID»: «SGML»,
«SortAs»: «SGML»,
"GlossTerm": "Стандартный обобщенный язык разметки",
«Акроним»: «SGML»,
«Аббревиатура»: «ISO 8879: 1986»,
"GlossDef": {
«para»: «Язык мета-разметки, используемый для создания языков разметки, таких как DocBook.",
"GlossSeeAlso": ["GML", "XML"]
},
"GlossSee": "разметка"
}
}
}
}
}
Создайте простой конвертер и сохраните его как json2yaml.py . Этот скрипт импортирует модули Python YAML и JSON, загружает файл JSON, определенный пользователем, выполняет преобразование и затем записывает данные в output.yaml .
#! / Usr / bin / python3
импортировать ямл
import sys
импортировать json
OUT = open ('output.yaml', 'ш')
IN = открытый (sys.argv [1], 'r')
JSON = json.нагрузка (IN)
IN.close ()
yaml.dump (JSON, ВЫХОД)
OUT.close ()
Сохраните этот сценарий в системном пути и выполните при необходимости:
$ ~ / bin / json2yaml.py example.json 3. Анализировать рано, анализировать часто
Иногда помогает взглянуть на проблему под другим углом. Если ваша проблема — YAML, и вам трудно визуализировать отношения данных, вы можете найти полезным временно реструктурировать эти данные во что-то, с чем вы более знакомы.
Если вам удобнее работать со списками в стиле словаря или, например, JSON, вы можете преобразовать YAML в JSON двумя командами, используя интерактивную оболочку Python. Предположим, ваш файл YAML называется mydata.yaml .
$ python3
>>> f = open ('mydata.yaml', 'r')
>>> yaml.load (f)
{'document': 34843, 'date': datetime.date (2019, 5, 23), 'bill-to': {'given': 'Seth', 'family': 'Kenlon', 'address': { 'street': '51b Mornington Road \ n', 'city': 'Brooklyn', 'state': 'Wellington', 'postal': 6021, 'country': 'NZ'}}, 'words': 938, 'comments': 'Хорошая статья.Могло быть лучше.'}
Есть много других примеров, и существует множество онлайн-конвертеров и локальных парсеров, поэтому не бойтесь переформатировать данные, когда они начинают больше походить на список для стирки, чем на разметку.
4. Прочтите спецификацию
После того, как я какое-то время отлучился от YAML и обнаружил, что снова использую его, я сразу же возвращаюсь на yaml.org, чтобы перечитать спецификацию. Если вы никогда не читали спецификацию YAML и находите YAML сбивающим с толку, взгляд на спецификацию может дать разъяснение, о котором вы даже не подозревали.Спецификацию на удивление легко читать, а требования к действительному YAML прописаны с множеством примеров в главе 6.
5. Псевдоконфигурация
Перед тем, как я начал писать свою книгу «Разработка игр на Raspberry Pi», Apress, 2019, издатель попросил меня дать набросок. Казалось бы, набросок будет легким. По определению, это просто названия глав и разделов без реального содержания. И все же из 300 опубликованных страниц сложнее всего было написать первоначальный план.
YAML может быть таким же. Вы можете иметь представление о данных, которые необходимо записать, но это не значит, что вы полностью понимаете, как все это связано. Поэтому, прежде чем вы сядете писать YAML, попробуйте вместо этого выполнить псевдоконфигурацию.
Псевдоконфигурация похожа на псевдокод. Вам не нужно беспокоиться о структуре или отступах, родительско-дочерних отношениях, наследовании или вложенности. Вы просто создаете итерации данных в том виде, в котором вы их понимаете в своей голове.
Псевдоконфиг.
После того, как вы напишите свою псевдоконфигурацию, изучите ее и преобразуйте свои результаты в действительный YAML.
6. Разрешите споры о пробелах и табуляциях
Хорошо, возможно, вы не решите окончательно споры о пробелах и табуляциях, но вы должны хотя бы разрешить споры внутри вашего проекта или организации. Независимо от того, решаете ли вы этот вопрос с помощью сценария постобработки sed , конфигурации текстового редактора или клятвы крови уважать результаты вашего линтера, любой в вашей команде, который касается проекта YAML, должен согласиться использовать пробелы (в соответствии с YAML спец).
Любой хороший текстовый редактор позволяет вам определять количество пробелов вместо символа табуляции, поэтому выбор не должен отрицательно сказаться на клавишах Tab .
Табуляторы и пробелы, как вы, наверное, слишком хорошо знаете, по сути невидимы. А когда что-то скрывается из виду, это редко приходит в голову до самого конца, когда вы протестировали и устранили все «очевидные» проблемы. Час, потраченный на ошибочную вкладку или группу пробелов, — это ваш сигнал для создания политики для использования того или другого, а затем для разработки отказоустойчивой проверки на соответствие (например, ловушки Git для принудительного линтинга).
7. Меньше значит больше (или больше меньше)
Некоторым нравится писать YAML, чтобы подчеркнуть его структуру. Они энергично отступают, чтобы помочь себе визуализировать фрагменты данных. Это своего рода чит для имитации языков разметки с явными разделителями.
Вот хороший пример из документации Ansible:
# Записи сотрудников
- Мартин:
имя: Мартин Д'Влопер
работа: Разработчик
навыки и умения:
- питон
- перл
- паскаль
- табита:
имя: Табита Битум
работа: Разработчик
навыки и умения:
- шепелявить
- фортран
- эрланг
Для некоторых пользователей этот подход является полезным способом разметки YAML-документа, в то время как другие пользователи упускают из виду структуру из-за отсутствия, казалось бы, ненужного пустого пространства.
Если вы владеете и поддерживаете документ YAML, то вы, , можете определить, что означает «отступ». Если блоки горизонтального белого пространства отвлекают вас, используйте минимальное количество белого пространства, требуемое спецификацией YAML. Например, тот же YAML из документации Ansible может быть представлен с меньшим количеством отступов без потери своей достоверности или значения:
---
- Мартин:
имя: Мартин Д'Влопер
работа: Разработчик
навыки и умения:
- питон
- перл
- паскаль
- табита:
имя: Табита Битум
работа: Разработчик
навыки и умения:
- шепелявить
- фортран
- эрланг
8.Сделать рецепт
Я большой поклонник повторного разведения знакомых, но иногда повторение просто порождает повторяющиеся глупые ошибки. К счастью, умная крестьянка испытала это явление еще в 396 году нашей эры (не проверяйте меня) и изобрела концепцию рецепта .
Если вы обнаружите, что снова и снова ошибаетесь в документе YAML, вы можете встроить рецепт или шаблон в файл YAML в виде закомментированного раздела. Когда вы добавляете раздел, скопируйте прокомментированный рецепт и перезапишите фиктивные данные своими новыми реальными данными.Например:
---
# - <обычное имя>:
# name: Данная фамилия
# работа: РАБОТА
# навыки и умения:
# - ЯЗЫК
- Мартин:
имя: Мартин Д'Влопер
работа: Разработчик
навыки и умения:
- питон
- перл
- паскаль
- табита:
имя: Табита Битум
работа: Разработчик
навыки и умения:
- шепелявить
- фортран
- эрланг
9. Используйте что-нибудь другое
В общем, я поклонник YAML, но иногда YAML — не ответ. Если вы не привязаны к YAML используемым приложением, вам может быть лучше подойдет какой-нибудь другой формат конфигурации.Иногда файлы конфигурации перерастают сами себя, и их лучше преобразовать в простые сценарии Lua или Python.
YAML — отличный инструмент, популярный среди пользователей за свой минимализм и простоту, но это не единственный инструмент в вашем наборе. Иногда лучше расстаться. Одним из преимуществ YAML является то, что библиотеки синтаксического анализа являются обычным явлением, поэтому, пока вы предоставляете варианты миграции, ваши пользователи должны иметь возможность безболезненно адаптироваться.
Если YAML является обязательным требованием, помните об этих советах и победите свою ненависть к YAML раз и навсегда!
5 Принципов визуального дизайна в UX
Глядя на визуальный элемент, мы обычно сразу можем сказать, нравится он или нет.(Потому что они часто проявляются на интуитивном уровне в модели эмоционального дизайна Дона Нормана.) Однако немногие могут словесно объяснить, почему макет визуально привлекателен. Графика, основанная на принципах хорошего визуального дизайна, может стимулировать взаимодействие и повысить удобство использования.
Принципы визуального дизайна сообщают нам, как элементы дизайна, такие как линия, форма, цвет, сетка или пространство, сочетаются друг с другом для создания хорошо округленных и продуманных визуальных эффектов.
В этой статье определены 5 принципов визуального дизайна, которые влияют на UX:
- Масштаб
- Визуальная иерархия
- Весы
- Контрастность
- Гештальт
Следование этим 5 принципам визуального дизайна может повысить вовлеченность и удобство использования.
1. Масштаб
Этот принцип широко используется: почти каждый хороший визуальный дизайн использует его преимущества.
Определение: Принцип шкалы относится к использованию относительного размера для обозначения важности и ранга в композиции.
Другими словами, при правильном использовании этого принципа наиболее важные элементы в дизайне больше, чем менее важные. Причина этого принципа проста: когда что-то крупное, это с большей вероятностью будет замечено.
Для визуально приятного дизайна обычно используется не более 3-х различных размеров. Наличие ряда элементов разного размера не только создаст разнообразие в вашем макете, но также установит визуальную иерархию (см. Следующий принцип) на странице. Обязательно подчеркните самые важные аспекты своего дизайна, сделав их самыми большими.
При правильном использовании принципа масштабирования и выделении правильных элементов пользователи легко проанализируют визуальное оформление и узнают, как его использовать.
Medium для iPhone: популярные статьи визуально больше других статей. Шкала направляет пользователей к потенциально более интересным статьям. В этой автостоянке в Кракове самая важная часть информации (зона H — где вы в данный момент находитесь) — самая большая по размеру. (Источник изображения: www.behance.com)2. Визуальная иерархия
Макет с хорошей визуальной иерархией будет легко понят для ваших пользователей.
Определение : Принцип визуальной иерархии относится к направлению взгляда на страницу таким образом, чтобы он обращал внимание на различные элементы дизайна в порядке их важности.
Визуальная иерархия может быть реализована посредством изменения масштаба, значения, цвета, интервала, размещения и множества других сигналов.
Визуальная иерархия контролирует доставку опыта. Если вам сложно понять, где искать страницу, скорее всего, в ее макете отсутствует четкая визуальная иерархия.
Чтобы создать четкую визуальную иерархию, используйте 2–3 размера шрифта, чтобы указать пользователям, какие фрагменты контента являются наиболее важными или находятся на самом высоком уровне в мини-информационной архитектуре страницы.Или рассмотрите возможность использования ярких цветов для важных предметов и приглушенных цветов для менее важных.
Scale также может помочь определить визуальную иерархию, поэтому включите различные масштабы для различных элементов дизайна. Общее практическое правило — включать в проект мелкие, средние и большие компоненты.
Среднее мобильное приложение: имеется четкая визуальная иерархия заголовка, подзаголовка и основного текста. Каждый компонент статьи имеет размер шрифта, равный его важности. Мобильное приложение Uber: в мобильном приложении Uber визуальная иерархия ясна.Экран разделен пополам между картой и формой ввода (нижняя половина экрана), что наводит на мысль, что эти компоненты одинаково важны для пользователя. Взгляд сразу же привлекает внимание к вопросу «Куда?» поле из-за его серого фона, затем к недавним местоположениям под ним, которые немного меньше по размеру шрифта. Мобильное приложение Dropbox: в мобильном приложении Dropbox визуальная иерархия менее четкая. Несмотря на то, что пояснительный текст меньше по размеру, чем имя файла, трудно различить разные файлы.Миниатюры обеспечивают дополнительный уровень иерархии, но их наличие зависит от доступных типов файлов. В конечном итоге пользователям приходится много разбираться и читать, чтобы найти папку или файл, которые они ищут.3. Баланс
Балансировка похожа на качели: вместо веса вы балансируете элементы дизайна.
Определение : Принцип баланса относится к удовлетворительному расположению или соотношению элементов дизайна. Баланс возникает, когда имеется равномерно распределенное (но не обязательно симметричное) количество визуального сигнала по обе стороны от воображаемой оси, проходящей через середину экрана.Эта ось часто бывает вертикальной, но может быть и горизонтальной.
Как и при балансировке веса, если бы у вас был один маленький элемент дизайна и один большой элемент дизайна с двух сторон от оси, дизайн был бы немного несбалансированным. При создании баланса имеет значение не только количество элементов, но и площадь, занимаемая элементом дизайна.
Воображаемая ось, которую вы устанавливаете на своем визуале, будет точкой отсчета для того, как организовать макет, и поможет вам понять текущее состояние баланса вашего визуала.В сбалансированном дизайне ни одна область не привлекает внимание настолько, чтобы вы не могли видеть другие области (даже если некоторые элементы могут иметь больший визуальный вес и быть фокусными точками). Остаток может быть:
Тип баланса, который вы используете в своем визуале, зависит от того, что вы хотите передать. Асимметрия динамична и увлекательна. Это создает ощущение энергии и движения. Симметрия тихая и статичная. Радиальный баланс всегда уводит взгляд в центр композиции.
The Hub Style Exploration: композиция кажется стабильной, что особенно уместно, когда вы ищете работу, которая вам нравится.Баланс здесь симметричный. Если бы вы нарисовали воображаемую вертикальную ось по центру веб-сайта, элементы распределялись бы равномерно по обе стороны от оси. (Источник изображения: dribbble.com) Nike: эта страница асимметрично сбалансирована, что дает ощущение энергии и движения, соответствующее бренду Nike. Если бы вы нарисовали вертикальную ось по центру этого визуала, количество элементов по обе стороны от оси будет примерно одинаковым. Однако разница в том, что они не идентичны и находятся в одних и тех же точных местах.Несмотря на то, что технически на левой стороне обуви немного больше текста, он уравновешен более крупным текстом справа, который занимает больше места и визуального веса, что делает их очень похожими. Наручные часы Brathwait: Классические часы с радиальной балансировкой. Взгляд сразу же притягивается к центру циферблата, и весь визуальный вес распределяется равномерно, независимо от того, где нарисована воображаемая ось. Этот редакторский разворот не сбалансирован.Если вы проведете вертикальную ось вниз по странице, элементы не будут равномерно распределены по обеим сторонам оси. (Источник изображения: www.behance.net)4. Контрастность
Это еще один часто используемый принцип, который выделяет определенные части вашего дизайна среди пользователей.
Определение : Принцип контрастности относится к сопоставлению визуально непохожих элементов, чтобы передать тот факт, что эти элементы различны (например, принадлежат к разным категориям, имеют разные функции, ведут себя по-разному).
Другими словами, контраст дает глазу заметную разницу (например, по размеру или цвету) между двумя объектами (или между двумя наборами объектов), чтобы подчеркнуть их различие.
Принцип контраста часто применяется через цвет. Например, красный цвет часто используется в дизайне пользовательского интерфейса, особенно в iOS, для обозначения удаления. Яркий цвет сигнализирует о том, что красный элемент отличается от остальных.
Приложение «Напоминания» для iOS: красный цвет, который сильно контрастирует с окружающим контекстом, зарезервирован для удаления.Часто в UX слово «контраст» напоминает о контрасте между текстом и его фоном. Иногда дизайнеры намеренно уменьшают контраст текста, чтобы не акцентировать внимание на менее важном тексте. Но этот подход опасен — уменьшение контрастности текста также снижает разборчивость и может сделать ваш контент недоступным. Используйте средство проверки цветового контраста, чтобы убедиться, что ваш контент все еще может быть прочитан всеми вашими целевыми пользователями.
Greenhouse Juice Co: Читаемость текста на бутылке зависит от цвета сока.Хотя контраст прекрасно работает для некоторых соков, этикетки бутылок со светлыми соками практически невозможно прочитать. (Источник изображения: www.instagram.com)5. Принципы гештальта
Это набор принципов, установленных в начале двадцатого века гештальт-психологами. Они фиксируют, как люди понимают смысл изображений.
Определение : Принципы гештальта объясняют, как люди упрощают и организуют сложные изображения, состоящие из многих элементов, подсознательно объединяя части в организованную систему, которая создает единое целое, а не интерпретирует их как серию разрозненных элементов.Другими словами, принципы гештальт отражают нашу склонность воспринимать целое в отличие от отдельных элементов.
Существует несколько гештальт-принципов, включая сходство, продолжение, завершение, близость, общую область, фигуру / фон, а также симметрию и порядок. Близость особенно важна для UX — это относится к тому факту, что элементы, которые визуально ближе друг к другу, воспринимаются как часть одной группы.
Это принцип гештальт-замыкания, который позволяет нам видеть две целующиеся фигуры вместо случайных фигур на картине Пикассо.Наш мозг заполняет недостающие части, чтобы создать две фигуры. Мы также часто видим приложения теории гештальта в логотипах. В логотипе NBC нет павлина в белом пространстве, но наш мозг понимает, что он есть. В форме регистрации Uber используется принцип гештальт-близости: метки полей расположены рядом с соответствующими текстовыми полями, что позволяет легко понять, какую информацию вводить в какие поля. Если бы между полем и последующей меткой (для следующего поля) оставалось меньше места, пользователям было бы сложно понять, что и чему принадлежит. Налоговая форма США за 2017 год: из-за недостатка места между полями ее заполнение затруднительно. Вы можете легко пропустить то, к чему относится второе поле «Фамилия». Использование принципа гештальт-близости для различения полей, относящихся к себе и супругу, принесло бы пользу UX.Почему важны принципы визуального дизайна
Почему мы должны заботиться о принципах визуального дизайна и понимать их? Помимо того, чтобы что-то «выглядело красиво», понимание и использование их в интересах:
- Повышение удобства использования. Следование этим принципам визуального дизайна часто приводит к созданию простых в использовании макетов. Например, золотое сечение, которое часто используется для создания красивых произведений искусства, также использовалось при наборе текста, чтобы создать визуально приятную связь между размером шрифта, высотой строки и шириной строки. Результат обычно приводил к сокращению длины строк, что создавало баланс (через пробелы) на веб-странице и облегчало чтение текста. В сочетании с сильным интерактивным дизайном визуальный дизайн увеличит показатели успешности задач и вовлеченности пользователей.
- Вызвать эмоции и восторг. Красивые вещи вызывают положительные эмоции. (Фактически, эффект эстетики и удобства использования говорит о том, что, когда люди находят дизайн визуально привлекательным, они могут быть более снисходительными к незначительным неудачам с удобством использования.) Следуя принципам хорошего визуального дизайна, дизайнеры могут создавать интерфейсы, которые хорошо выглядят и, таким образом, привлекают пользователей хорошо себя чувствовать.
- Укрепление восприятия бренда. Сильная визуальная система вызывает у пользователей доверие и интерес к продукту, а также надлежащим образом представляет и укрепляет бренд.
Список литературы
Луптон, Э. (2008). Графический дизайн: новые основы. Нью-Йорк: Princeton Architectural Press.
Poulin, R. (2018). Язык графического дизайна. Беверли: Quarto Publishing Group USA, Inc.
14 струн | R для науки о данных
Введение
Эта глава знакомит вас с манипуляциями со строками в R. Вы узнаете основы того, как работают строки и как создавать их вручную, но основное внимание в этой главе будет уделено регулярным выражениям или, для краткости, регулярным выражениям.Регулярные выражения полезны, потому что строки обычно содержат неструктурированные или частично структурированные данные, а регулярные выражения — это краткий язык для описания шаблонов в строках. Когда вы впервые посмотрите на регулярное выражение, вы подумаете, что кошка прошла по клавиатуре, но по мере того, как ваше понимание улучшится, они скоро начнут обретать смысл.
Предпосылки
В этой главе основное внимание будет уделено пакету stringr для манипуляций со строками, который является частью основного тидиверса.
Основы работы со струнами
Вы можете создавать строки как в одинарных, так и в двойных кавычках.В отличие от других языков, нет никакой разницы в поведении. Я рекомендую всегда использовать ", если вы не хотите создать строку, содержащую несколько " .
строка1 <- "Это строка"
string2 <- 'Если я хочу включить «кавычку» внутри строки, я использую одинарные кавычки » Если вы забудете закрыть цитату, вы увидите + , символ продолжения:
> "Это строка без закрывающей кавычки.
+
+
+ ПОМОГИТЕ Я застрял Если это случилось с вами, нажмите Escape и попробуйте еще раз!
Чтобы включить буквальную одинарную или двойную кавычку в строку, вы можете использовать \ , чтобы «экранировать» ее:
double_quote <- "\" "# или '"'
single_quote <- '\' '# или "'" Это означает, что если вы хотите включить буквальную обратную косую черту, вам нужно будет удвоить ее: "\\" .
Помните, что напечатанное представление строки не совпадает с самой строкой, потому что напечатанное представление показывает escape-последовательности. Чтобы увидеть необработанное содержимое строки, используйте writeLines () :
x <- c ("\" "," \\ ")
Икс
#> [1] "\" "" \\ "
writeLines (x)
#> "
#> \ Есть несколько других специальных символов. Наиболее распространенными являются "\ n" , новая строка и "\ t" , вкладка, но вы можете увидеть полный список, запросив помощь по телефону ": ? '"' или ? "' «.Иногда встречаются строки вроде "\ u00b5" , это способ написания неанглийских символов, который работает на всех платформах:
x <- "\ u00b5"
Икс
#> [1] «µ» Несколько строк часто хранятся в векторе символов, который можно создать с помощью c () :
c («один», «два», «три»)
#> [1] "один" "два" "три" Длина струны
Base R содержит множество функций для работы со строками, но мы будем избегать их, потому что они могут быть несовместимыми, что затрудняет их запоминание.Вместо этого мы будем использовать функции из stringr. У них более понятные названия, и все они начинаются с str_ . Например, str_length () сообщает вам количество символов в строке:
str_length (c ("a", "R для науки о данных", NA))
#> [1] 1 18 NA Общий префикс str_ особенно полезен, если вы используете RStudio, потому что ввод str_ вызовет автозаполнение, что позволит вам увидеть все функции Stringr:
Объединение струн
Для объединения двух или более строк используйте str_c () :
str_c ("x", "y")
#> [1] "ху"
str_c ("x", "y", "z")
#> [1] "xyz" Используйте аргумент sep , чтобы контролировать, как они разделяются:
str_c ("x", "y", sep = ",")
#> [1] "x, y" Как и в большинстве других функций в R, пропущенные значения заразительны.Если вы хотите, чтобы они печатались как «NA» , используйте str_replace_na () :
x <- c ("abc", нет данных)
str_c ("| -", x, "- |")
#> [1] "| -abc- |" NA
str_c ("| -", str_replace_na (x), "- |")
#> [1] "| -abc- |" "| -NA- |" Как показано выше, str_c () векторизован и автоматически перерабатывает более короткие векторы до той же длины, что и самый длинный:
str_c ("префикс-", c ("a", "b", "c"), "-suffix")
#> [1] «префикс-а-суффикс» «префикс-b-суффикс» «префикс-с-суффикс» Объекты длины 0 отбрасываются без уведомления.Это особенно полезно в сочетании с , если :
имя <- "Хэдли"
time_of_day <- "утро"
день рождения <- ЛОЖЬ
str_c (
"Хорошо", время_дня, "", имя,
if (день рождения) "и С ДНЕМ РОЖДЕНИЯ",
"."
)
#> [1] "Доброе утро, Хэдли". Чтобы свернуть вектор строк в одну строку, используйте collapse :
str_c (c ("x", "y", "z"), collapse = ",")
#> [1] "x, y, z" Подмножество строк
Вы можете извлечь части строки с помощью str_sub () .Помимо строки, str_sub () принимает аргументы start и end , которые задают (включительно) позицию подстроки:
x <- c («Яблоко», «Банан», «Груша»)
str_sub (х, 1, 3)
#> [1] "App" "Ban" "Pea"
# отрицательные числа считают в обратном порядке от конца
str_sub (х, -3, -1)
#> [1] "ple" "ana" "ear" Обратите внимание, что str_sub () не завершится ошибкой, если строка слишком короткая: она просто вернет столько, сколько возможно:
str_sub ("а", 1, 5)
#> [1] "a" Вы также можете использовать форму назначения str_sub () для изменения строк:
str_sub (x, 1, 1) <- str_to_lower (str_sub (x, 1, 1))
Икс
#> [1] «яблоко» «банан» «груша» Регионы
Выше я использовал str_to_lower () , чтобы изменить текст на нижний регистр.Вы также можете использовать str_to_upper () или str_to_title () . Однако изменить регистр сложнее, чем может показаться на первый взгляд, потому что разные языки имеют разные правила изменения регистра. Вы можете выбрать, какой набор правил использовать, указав локаль:
# Турецкий имеет два i: с точкой и без точки, и это
# имеет другое правило использования заглавных букв:
str_to_upper (c ("я", "ı"))
#> [1] «Я» «Я»
str_to_upper (c ("i", "ı"), locale = "tr")
#> [1] "İ" "I" Локаль указывается в виде кода языка ISO 639, который представляет собой двух- или трехбуквенное сокращение.Если вы еще не знаете код своего языка, в Википедии есть хороший список. Если вы оставите языковой стандарт пустым, он будет использовать текущий языковой стандарт, предоставленный вашей операционной системой.
Еще одна важная операция, на которую влияет локаль, - это сортировка. Базовые функции order () и sort () в R сортируют строки, используя текущую локаль. Если вы хотите надежного поведения на разных компьютерах, вы можете использовать str_sort () и str_order () , которые принимают дополнительный аргумент locale :
x <- c («яблоко», «баклажан», «банан»)
str_sort (x, locale = "en") # английский
#> [1] "яблоко" "банан" "баклажан"
str_sort (x, locale = "haw") # гавайский
#> [1] "яблоко" "баклажан" "банан" Упражнения
В коде, который не использует строку, вы часто встретите
paste ()иpaste0 ().В чем разница между двумя функциями? Какие функции Stringr они эквивалентны? Чем отличаются функции по обработкеNA?Опишите своими словами разницу между
sepиcollapseаргументы дляstr_c ().Используйте
str_length ()иstr_sub ()для извлечения среднего символа из строка. Что вы будете делать, если в строке будет четное количество символов?Что делает
str_wrap ()? Когда вы можете захотеть его использовать?Что делает
str_trim ()? Что противоположноstr_trim ()?Напишите функцию, которая поворачивает (например,g.) вектор
c ("a", "b", "c")в строкаa, b и c. Тщательно подумайте, что ему делать, если для вектора длины 0, 1 или 2.
Сопоставление шаблонов с регулярными выражениями
Регулярные выражения - очень сжатый язык, который позволяет описывать шаблоны в строках. На их понимание уходит время, но как только вы их поймете, вы найдете их чрезвычайно полезными.
Для изучения регулярных выражений мы будем использовать str_view () и str_view_all () .Эти функции принимают вектор символов и регулярное выражение и показывают, как они совпадают. Мы начнем с очень простых регулярных выражений, а затем постепенно будем усложнять их. Освоив сопоставление с образцом, вы научитесь применять эти идеи с различными строковыми функциями.
Основные матчи
Самые простые шаблоны соответствуют точным строкам:
x <- c («яблоко», «банан», «груша»)
str_view (x, "an") Следующая ступень сложности - ., что соответствует любому символу (кроме новой строки):
Но если «. »соответствует любому символу, как сопоставить символ« . ”? Вам нужно использовать «escape», чтобы указать регулярному выражению, которое вы хотите точно ему сопоставить, а не использовать его особое поведение. Подобно строкам, регулярные выражения используют обратную косую черту, \ , чтобы избежать особого поведения. Таким образом, чтобы соответствовать . , вам нужно регулярное выражение \. . К сожалению, это создает проблему. и - .
Вы можете использовать чередование , чтобы выбрать один или несколько альтернативных шаблонов. Например, abc | d..f будет соответствовать либо «abc», либо «глухой» . Обратите внимание, что приоритет для | является низким, поэтому abc | xyz соответствует abc или xyz , а не abcyz или abxyz . Как и в случае с математическими выражениями, если приоритеты когда-либо сбивают с толку, используйте круглые скобки, чтобы прояснить, что вы хотите:
str_view (c ("серый", "серый"), "gr (e | a) y") Упражнения
Создайте регулярные выражения, чтобы найти все слова, которые:
Начните с гласной.
Это только согласные. (Подсказка: подумайте о сопоставлении «Не» - гласные.)
Заканчивается на
ed, но не наeed.Заканчивается на
ingилиise.
Эмпирически проверьте правило «i до e, кроме c».
Всегда ли за «q» следует «u»?
Напишите регулярное выражение, которое соответствует слову, если оно, вероятно, написано на британском, а не на американском английском.
Создайте регулярное выражение, которое будет соответствовать телефонным номерам, как обычно написано в вашей стране.
Повторение
Следующий шаг в развитии - это контроль количества совпадений шаблона:
-
?: 0 или 1 -
+: 1 или более -
*: 0 или больше
x <- "1888 год - самый длинный год в римских цифрах: MDCCCLXXXVIII"
str_view (x, "CC?") Обратите внимание, что приоритет этих операторов высок, поэтому вы можете написать: colou? R для соответствия американскому или британскому написанию.Это означает, что в большинстве случаев требуются круглые скобки, например bana (na) + .
Также можно точно указать количество совпадений:
-
{n}: ровно n -
{n,}: n или более -
{, m}: не более м -
{n, m}: между n и m
По умолчанию эти совпадения являются «жадными»: они будут соответствовать самой длинной возможной строке. Вы можете сделать их «ленивыми», сопоставив кратчайшую возможную строку, поставив ? после них.* $
"\\ {. + \\}" \ d {4} - \ d {2} - \ d {2} "\\\\ {4}" Создайте регулярные выражения, чтобы найти все слова, которые:
- Начните с трех согласных.
- Имеет три или более гласных подряд.
- Имеются две или более пары гласный-согласный подряд.
Решите кроссворды с регулярными выражениями для начинающих на https://regexcrossword.com/challenges/beginner.
Группировка и обратные ссылки
Ранее вы узнали о скобках как о способе устранения неоднозначности сложных выражений. Круглые скобки также создают группу захвата с номером (номер 1, 2 и т. Д.) С номером . Группа захвата хранит часть строки , совпадающую с частью регулярного выражения в круглых скобках. Вы можете ссылаться на тот же текст, который ранее соответствовал группе захвата с обратными ссылками , например \ 1 , \ 2 и т. Д.Например, следующее регулярное выражение находит все фрукты с повторяющейся парой букв.
str_view (fruit, "(..) \\ 1", match = TRUE) (Вскоре вы также увидите, насколько они полезны в сочетании с str_match () .)
Упражнения
Опишите словами, чему будут соответствовать эти выражения:
-
(.) \ 1 \ 1 -
"(.) (.) \\ 2 \\ 1" -
(..) \ 1 -
"(.). \\ 1. \\ 1" -
"(.) (.) (.). * \\ 3 \\ 2 \\ 1"
-
Создавать регулярные выражения для поиска слов, которые:
Начало и конец одного и того же символа.
Содержит повторяющуюся пару букв (например, «церковь» содержит дважды повторяемую букву «ч».)
Содержит одну букву, повторяющуюся как минимум в трех местах (например, «одиннадцать» содержит три буквы «е».)
Инструменты
Теперь, когда вы изучили основы регулярных выражений, пора научиться применять их к реальным задачам.В этом разделе вы познакомитесь с широким спектром строковых функций, которые позволят вам:
- Определите, какие строки соответствуют шаблону.
- Найдите позиции совпадений.
- Извлечь содержимое совпадений.
- Заменить совпадения новыми значениями.
- Разделить строку на основе совпадения.
Перед тем, как продолжить, сделаем небольшое предостережение: поскольку регулярные выражения настолько эффективны, легко попытаться решить любую проблему с помощью одного регулярного выражения.\ [\] \ r \\] | \\.) * \] (?: (?: \ r \ n)? [\ t]) *)) * \> (? 🙁 ?: \ r \ n)? [\ t]) *)) *)?; \ s *)
Это несколько патологический пример (потому что адреса электронной почты на самом деле удивительно сложны), но он используется в реальном коде. Подробнее см. Обсуждение stackoverflow на http://stackoverflow.com/a/201378.
Не забывайте, что вы изучаете язык программирования и в вашем распоряжении есть другие инструменты. Вместо создания одного сложного регулярного выражения часто проще написать серию более простых регулярных выражений.Если вы застряли, пытаясь создать одно регулярное выражение, которое решает вашу проблему, сделайте шаг назад и подумайте, можете ли вы разбить проблему на более мелкие части, решая каждую задачу, прежде чем переходить к следующей. aeiou] + $") идентичные (no_vowels_1, no_vowels_2) #> [1] ИСТИНА
Результаты идентичны, но я думаю, что первый подход значительно легче понять.Если ваше регулярное выражение становится слишком сложным, попробуйте разбить его на более мелкие части, дать каждой части имя, а затем объединить части с помощью логических операций.
Обычно str_detect () используется для выбора элементов, соответствующих шаблону. Вы можете сделать это с помощью логического подмножества или удобной оболочки str_subset () :
слов [str_detect (words, "x $")]
#> [1] "коробка" "секс" "шестерка" "налог"
str_subset (слова, "x $")
#> [1] «коробка» «пол» «шестерка» «налог» Однако, как правило, ваши строки представляют собой один столбец фрейма данных, и вместо этого вы хотите использовать фильтр:
df <- tibble (
слово = слова,
я = seq_along (слово)
)
df%>%
фильтр (str_detect (слово, "x $"))
#> # Стол: 4 x 2
#> слово i
#>
#> 1 коробка 108
#> 2 пол 747
#> 3 шесть 772
#> 4 налог 841 Вариант str_detect () - str_count () : вместо простого да или нет он сообщает вам, сколько совпадений в строке:
x <- c («яблоко», «банан», «груша»)
str_count (x, «а»)
#> [1] 1 3 1
# Сколько в среднем гласных в слове?
означает (str_count (слова, "[aeiou]"))
#> [1] 1.aeiou] ")
)
#> # Стол: 980 x 4
#> слово i гласные согласные
#>
#> 1 а 1 1 0
#> 2 в состоянии 2 2 2
#> 3 примерно 3 3 2
#> 4 абсолютное 4 4 4
#> 5 принять 5 2 4
#> 6 счет 6 3 4
#> #… С еще 974 строками Обратите внимание, что совпадения никогда не перекрываются. Например, в «abababa» , сколько раз будет совпадать шаблон «aba» ? Регулярные выражения говорят два, а не три:
str_count ("abababa", "aba")
#> [1] 2
str_view_all ("abababa", "aba") Обратите внимание на использование str_view_all () .Как вы вскоре узнаете, многие строковые функции работают парами: одна функция работает с одним совпадением, а другая - со всеми совпадениями. Вторая функция будет иметь суффикс _all .
Упражнения
Для каждой из следующих задач попробуйте решить ее, используя как одну регулярное выражение и комбинация нескольких вызовов
str_detect ().Найдите все слова, которые начинаются или заканчиваются на
x.Найдите все слова, которые начинаются с гласной и заканчиваются согласной.
Существуют ли слова, содержащие хотя бы одно из разных гласный звук?
В каком слове больше всего гласных? Какое слово имеет высшее доля гласных? (Подсказка: какой знаменатель?)
Групповые матчи
Ранее в этой главе мы говорили об использовании круглых скобок для уточнения приоритета и для обратных ссылок при сопоставлении.] +) " has_noun <- предложения%>% str_subset (имя существительное)%>% голова (10) has_noun%>% str_extract (имя существительное) #> [1] "гладкая" "простыня" "глубина" "курица" "припаркованная" #> [6] "солнышко" "огромный" "мяч" "женщина" "помогает"
str_extract () дает нам полное совпадение; str_match () дает каждый отдельный компонент. Вместо вектора символов он возвращает матрицу с одним столбцом для полного соответствия, за которым следует один столбец для каждой группы:
has_noun%>%
str_match (имя существительное)
#> [, 1] [, 2] [, 3]
#> [1,] "гладкий" "" гладкий "
#> [2,] "лист" "" "лист"
#> [3,] "глубина" "" "глубина"
#> [4,] "курица" "a" "курица"
#> [5,] "припаркованный" "" "припаркованный"
#> [6,] "солнце" "" "солнце"
#> [7,] "огромный" "" огромный "
#> [8,] "мяч" "" "мяч"
#> [9,] "женщина" "" женщина "
#> [10,] «а помогает» «а» «помогает» (Неудивительно, что наша эвристика для определения существительных оставляет желать лучшего, и мы также подбираем такие прилагательные, как гладкий и припаркованный.] +) ",
remove = FALSE
)
#> # Таблица: 720 x 3
#> предложение статья существительное
#> Как и Найдите все слова, которые идут после «числа», например «один», «два», «три» и т. Д.
Вытяните и число, и слово. Найдите все схватки.Разделите части до и после
апостроф. С помощью Вместо замены на фиксированную строку вы можете использовать обратные ссылки для вставки компонентов соответствия.] +) «,» \\ 1 \\ 3 \\ 2 «)%>%
голова (5)
#> [1] «Каноэ-береза скользила по гладким доскам».
#> [2] «Приклейте лист к темно-синему фону».
#> [3] «Глубину колодца легко определить».
#> [4] «В наши дни куриная ножка — редкое блюдо».
#> [5] «Рис часто подают в круглых мисках». Заменить все косые черты в строке обратными. Реализуйте простую версию Переключение первых и последних букв в Используйте Поскольку каждый компонент может содержать разное количество частей, возвращается список. Если вы работаете с вектором длины 1, проще всего извлечь первый элемент списка: В противном случае, как и другие строковые функции, возвращающие список, вы можете использовать Вы также можете запросить максимальное количество штук: Вместо разделения строк по шаблонам вы также можете разделить их по символам, строкам, предложениям и словам. Разделите строку Почему лучше Что делает разделение с пустой строкой ( Персональный помощник «Онлайн» обучение: Персональные помощники несколько статичны в том смысле, что они моделируются и обучаются с использованием больших объемов данных, но, похоже, со временем они не очень улучшаются в том, как они взаимодействуют со своими пользователями.Цель этого исследовательского проекта - помочь личному помощнику (на основе Kennington and Schlangen, 2016) начать с очень минимального количества данных и дать ему возможность улучшать взаимодействие. Предыстория: полезно хорошее программирование на Java и Python, полезно также знание машинного обучения. Раскрытие медицинской информации и заполнение форм: Целью этого проекта является отображение естественного человеческого языка (в данном случае речи) для заполнения обычных форм, которые врачи в настоящее время должны заполнять вручную.Научившись извлекать релевантную информацию из разговора между врачом и пациентом, целью этого исследовательского проекта будет инструмент, который будет автоматически заполнять цифровые формы. Чтобы добраться туда, нам нужно иметь возможность извлекать соответствующую информацию из речевого сигнала. Сверление по произношению: Компьютеры использовались для помощи в изучении языка по-разному. Один из способов, который еще не полностью реализован, но потенциально может быть очень полезным, - это тренировка произношения.Например, человек, чей родной язык - английский, но желающий выучить японский, может с трудом произносить определенные слова. Инструмент, с которым пользователь мог бы поговорить, который мог бы дать обратную связь о том, насколько хорошо было произнесено слово, и информацию о частях слова, которые были произнесены неправильно, действительно был бы очень полезным. Для этого можно использовать распознаватель речи, такой как CMU Sphinx4. Этот проект потребует создания интуитивно понятного графического интерфейса для пользователей. Работа с роботами: В общей области исследований, посвященной освоению обоснованного языка и диалога, мы заинтересованы в отображении намерений человека в роботах (или транспортных средствах и т. Д.).) используя не просто речевые команды, а естественную интерактивную речь. Мы работаем с роботами Anki Cozmo и планируем расширить их до других видов (в потенциальном сотрудничестве с доктором Ходой Мехрпуян из штата Бойсе). Мультимодальное выравнивание с использованием InproTK: В системе, которая пытается использовать несколько источников информации (например, речь, жест, взгляд, социальные сигналы и т. Д.). Их необходимо интегрировать на семантическом уровне, чтобы понимать и делать использование всех источников информации.Однако, прежде чем это может произойти, необходимо рассмотреть синхронизацию: например, различные датчики и службы, считывающие информацию датчиков, частоту дискретизации и т. Д., Делают невозможным определение того, был ли жест, который произошел 30 мс в прошлом совпадает с речью, которая происходила 1000 мс в прошлом. Предпосылки: Требуется отличное программирование на Java. Полезен опыт работы с данными временных рядов. Системы диалога в автомобиле: Было доказано, что разговаривать по телефону (даже без помощи рук!) Во время вождения автомобиля требует умственных способностей.В буквальном смысле единственное, что водитель может безопасно делать во время разговора по телефону, - это двигаться по прямой с постоянной скоростью. Это не тот случай, когда водитель разговаривает с другим взрослым пассажиром, потому что этот пассажир может прекратить говорить в любой момент, позволяя водителю сосредоточить все когнитивные способности на основной задаче вождения. Хуже, чем разговаривать с людьми, разговаривать с помощью диалоговых систем, но возможность выполнять задачи во время вождения с помощью голосового помощника - это потенциальный способ сэкономить время и деньги для многих.Цель этого проекта - изучить стратегии, позволяющие системам быть «ситуативно осведомленными», чтобы они могли реагировать и помогать водителю, а не мешать ему. Объединение нескольких источников ASR: С 2011 года в автоматическом распознавании речи (ASR) произошли впечатляющие улучшения, некоторые из которых являются либо открытыми, либо находятся в свободном доступе. Google, Nuance, IBM и MS имеют свои собственные API-интерфейсы ASR / Speech, которые дают впечатляющие результаты и охватывают большие словари на нескольких языках.Механизмы ASR с открытым исходным кодом, такие как Sphinx (от CMU) и Kaldi, также внесли впечатляющие улучшения и имеют готовые модели. У разных компаний и движков с открытым исходным кодом разные сильные и слабые стороны. Например, Google ASR дает хорошие результаты (на представленных языках, таких как английский и немецкий) за счет задержки: даже при быстром подключении к Интернету результаты могут задерживаться до 1500 мс. Кроме того, важно знать время начала и окончания каждого распознаваемого слова, но Google ASR этого не предоставляет.С другой стороны, Sphinx ASR имеет довольно высокую частоту ошибок, но может давать очень быстрые результаты и обеспечивать время начала и окончания для слов. Цель этого проекта - объединить сильные стороны различных источников ASR для получения точных, быстрых и временных данных. Это требует интеграции нескольких источников ASR (потенциально, чем больше, тем лучше) в виде модуля (или интеграции модулей) в структуру InproTK (написанную на Java). Распознавание и отслеживание наведения рук (с использованием MS Kinect или HD Camera): Я хотел бы разработать систему, которая может обнаруживать и отслеживать дейктические жесты и, что более важно, определять, на какой объект направлен.Это можно сделать, следуя Matuszek et al. (2014), с помощью стандартной веб-камеры, или это можно сделать с помощью MS Kinect (с новейшим серверным программным обеспечением), который может определять общие направления наведения (рассматривая руку как своего рода коготь). Его разработка станет первым шагом в использовании дейктических жестов для закрепления изучения языка на реальных объектах в интерактивных настройках. Предпосылки: полезен опыт работы с Java и Python. Модель эталонного разрешения WAC (Kennington & Schlangen, 2015; Schlangen et al., 2016) показала себя многообещающим за свою пока короткую жизнь. В основе модели учится «соответствие» слов и визуальных аспектов предметов. Сопоставление выполняется с использованием классификатора логистической регрессии для каждого слова, а примеры слова и упомянутого объекта передаются классификатору этого слова для изучения сопоставления. Он использовался в задачах эталонного разрешения, начиная от простых геометрических фигур и заканчивая объектами на реальных фотографиях. Выученные классификаторы также применялись к задачам генерации языков (Zarieß & Schlangen, 2016).Он также был применен в демонстрации с использованием простого робота, который может манипулировать объектами (Hough & Schlangen, 2016). Классификаторы логистической регрессии учатся «подбирать» слова и предметы. Например, учитывая достаточное количество примеров красных объектов, классификатор для красного учится возвращать высокие вероятности при воздействии на свойства красных объектов и более низкие вероятности для объектов, которые не являются красными. Чем более прототипным является красный цвет (согласно обучающим данным), тем выше вероятность. Состав семантического значения с использованием модели WAC: См. Описание здесь. Изучение значений глаголов с помощью модели WAC: Я предполагаю, что изучение значений глаголов происходит таким же образом, как и невербальные слова, такие как существительные, и может быть смоделировано так же, как и другие слова в модели WAC, что нужно добавить (или изменено) - это особенности. Глаголы обозначают движение, поэтому могут оказаться полезными функции, представляющие движение предметов, изменение состояния или движение придатка, выполняющего глагол.Для этого нам нужно будет либо найти существующие данные (например, корпус REX), либо создать новые данные самостоятельно, записывая взаимодействия между людьми или людьми и машинами (например, используя объекты Пентомино в простой задаче построения объектов головоломки). . Эти данные (вероятно) должны быть аннотированы, и мы можем использовать эти данные для обучения классификаторов глаголов WAC. Обоснованная семантика с моделью WAC и семантическим формализмом: В настоящий момент классификаторы рассматривают слова как независимые сущности и комбинируются лишь в некоторой степени произвольно путем усреднения результатов работы классификаторов, когда они применяются к визуально представленным объектам.Другой возможный способ объединения этих классификаторов - использовать их в качестве лексического семантического представления и применить реализацию известного семантического формализма (например, PLTAG, RMRS, Dependency Parsing или TTR и DS). Формализмы могут направлять процесс композиции и интерпретации, делая модель WAC более полезной в реальных приложениях. Количественное определение с использованием модели WAC: Модель WAC производит распределение по возможным референтам. Простой определитель (например,g., «the») обозначает верхний элемент, тогда как другие квантификаторы (например, «a», «некоторые» или «все») обозначают больше, чем просто верхний элемент. Определение того, как слова-кванторы соотносятся с распределением, является основной частью этого исследовательского проекта. Быстрое отображение с помощью WAC: Когда дети впервые учат слова, им требуется множество примеров, когда воспитатели указывают на предметы или иным образом обозначают их, произнося соответствующие отсылочные выражения. Позже дети могут быстро подбирать новые слова с помощью только одного употребления.Например, ребенок, который знает несколько слов, но впервые видит сосновую шишку, может спросить, что это такое, и только один раз услышав отсылку «сосновая шишка», ребенок может ее вспомнить. Это явление известно как быстрое отображение. Вопрос для этого исследовательского проекта: можно ли использовать модель WAC для быстрого картирования? Некоторые предварительные работы показывают, что это очень возможно. Как подающий надежды толкователь «Я - Морж», я никогда не продвигался дальше, чем замечал аллюзии на Льюиса Кэрролла, детские стишки и другие песни «Битлз» песни.В более поздних куплетах я чувствовал, как песня отталкивает меня или любого, кто осмелился бы ее разобрать. «Эксперту-специалисту» сообщают, что «шутник» просто смеется над ним. И тут голоса на заднем плане смеются от насмешек. Ну что сказать? Я проигнорировал смех и все равно вырос экспертом по тексту. * * * Magical Mystery Tour - один из моих любимых альбомов, потому что он был таким странным. «I Am The Walrus» - также один из моих любимых треков - потому что я его, конечно, записал, но еще и потому, что это один из тех, в котором достаточно мелочей, которые сохранят интерес даже через сто лет . Когда я стал старше и поглощал книгу за книгой о Битлз, некоторые истории о «Я - Морж» говорили мне больше, чем другие. Меня не очень волновало, что «Эггман» якобы произошел от прозвища Эрика Бурдона из The Animals, благодаря его склонности разбивать яйца во время своих сексуальных завоеваний (или, как позже пояснил Бердон, разбивать яйца на ). ему ). Я предпочел думать о Шалтай-Болтае как о подлинном Эггмане. Мне действительно понравилось воспоминание Пита Шоттона, школьного приятеля Леннона и товарища по карьере, который объяснил происхождение «заварного крема из желтого вещества», который отвратительно капает из глаза мертвой собаки. Это было основано на британской игровой стишке, которая гласила: Заварной крем из желтой материи, зеленый помойный пирог, смешанный вместе с глазом мертвой собаки . На моей американской игровой площадке у нас тоже была такая отвратительная песня, но она началась с больших зеленых комков жирных, грязных кишок суслика . Шоттон далее объяснил, что воспоминания о «заварном креме из желтого вещества» были вызваны письмом Леннону от ученика Quarry Bank, их старой средней школы в Ливерпуле. Студент сказал, что его класс литературы анализировал тексты песен Beatles, которые Леннон находил совершенно смешными. Образ «литературного мастера Quarry Bank, рассуждающего о символике Леннона-Маккартни» вдохновил его на создание «заварного крема из желтой материи» и столь же дерзких линий. Как рассказывает Шоттон, после того, как Леннон написал строчку о «манной сардинии», необъяснимо взлетевшей на Эйфелеву башню, он улыбнулся и сказал: «Пусть эти лохи разберутся с этим, Пит!» Ну ладно.Может быть, песня - это просто шутка или своего рода вызов. str_extract () , если вам нужны все совпадения для каждой строки, вам понадобится str_match_all () . Упражнения
Замена спичек
str_replace () и str_replace_all () позволяют заменять совпадения новыми строками. Самый простой способ — заменить шаблон фиксированной строкой:
x <- c («яблоко», «груша», «банан»)
str_replace (x, «[aeiou]», «-»)
#> [1] "-pple" "p-ar" "b-nana"
str_replace_all (x, «[aeiou]», «-»)
#> [1] "-ppl-" "p - r" "b-n-n-" str_replace_all () вы можете выполнить несколько замен, указав именованный вектор:
x <- c («1 дом», «2 машины», «3 человека»)
str_replace_all (x, c ("1" = "один", "2" = "два", "3" = "три"))
#> [1] "один дом" "две машины" "три человека" Упражнения
str_to_lower () , используя replace_all () . слов . Какая из этих струн
еще слова? Колка
str_split () , чтобы разбить строку на части. Например, мы можем разбить предложения на слова:
предложений%>%
голова (5)%>%
str_split ("")
#> [[1]]
#> [1] "" березовая "каноэ" скользнула "" по "" "гладью"
#> [8] "доски".
#>
#> [[2]]
#> [1] "Приклейте" "" лист "" к "" "
#> [6] "темный" "синий" "фон."
#>
#> [[3]]
#> [1] «Легко» «сказать» «о« глубине »» «колодца».
#>
#> [[4]]
#> [1] "В эти" "дни" "" "курица" "нога" "" "" а "
#> [8] «редкое» «блюдо».
#>
#> [[5]]
#> [1] "Рис" "часто" подается "в" круглых "мисках."
"a | b | c | d"%>%
str_split ("\\ |")%>%
.[[1]]
#> [1] "a" "b" "c" "d" simpleify = TRUE для возврата матрицы:
предложений%>%
голова (5)%>%
str_split ("", simpleify = ИСТИНА)
#> [, 1] [, 2] [, 3] [, 4] [, 5] [, 6] [, 7] [, 8]
#> [1,] "" березовое "каноэ" скользило "" по "" гладким "доскам".
#> [2,] "Приклейте" "" лист "" к "" "" темному "" синему "" фону."
#> [3,] "" легко "" "сказать" "" глубину "" "" а "
#> [4,] "В эти" "дни" "" "курица" "нога" "" "а" "редко"
#> [5,] "Рис" "часто" подается "в" круглых "мисках." ""
#> [, 9]
#> [1,] ""
#> [2,] ""
#> [3,] "хорошо".
#> [4,] "блюдо".
#> [5,] ""
полей <- c ("Имя: Хэдли", "Страна: Новая Зеландия", "Возраст: 35")
поля%>% str_split (":", n = 2, simpleify = TRUE)
#> [, 1] [, 2]
#> [1,] "Имя" "Хэдли"
#> [2,] "Country" "NZ"
#> [3,] "Возраст" "35" border () s:
x <- "Это приговор.Это еще одно предложение ».
str_view_all (x, граница ("слово"))
str_split (x, "") [[1]]
#> [1] «Это» «есть» «предложение». "" "Этот"
#> [7] "это" другое "предложение".
str_split (x, граница ("слово")) [[1]]
#> [1] "This" "is" "" предложение "" This "" is "" другое "
#> [8] "предложение" Упражнения
"яблоки, груши и бананы" на отдельные
составные части. разделить на границу ("слово") , чем на "" ? "" )? Экспериментируйте и
затем прочтите документацию. Найти совпадения
str_locate () и str_locate_all () дают вам начальную и конечную позиции каждого совпадения. Они особенно полезны, когда ни одна из других функций не делает именно то, что вы хотите.Вы можете использовать str_locate (), , чтобы найти соответствующий шаблон, str_sub () , чтобы извлечь и / или изменить их. тем и идей проектов - речь, язык и интерактивные машины (SLIM)
Общие идеи исследовательских проектов
Исследование с использованием недавней модели слов как классификаторов (WAC)
Серьезная глупость The Beatles «Я - Морж», 50 лет спустя
—Джон Леннон Деннису Эльзасу на WNEW-FM, 28 сентября 1974 г.