Почему итоговое сочинение в школе не так страшно, как про него говорят? — FONAR.TV
На каждом занятии я слышу удивительные вводные от учеников: «нельзя брать зарубежную литературу», «поэзию не берите», «ошибётесь в имени героя — получите незачёт», «надо два произведения, Карл! Два!». В этой колонке мы разберём основные заблуждения об итоговом сочинении. Для удобства мы их выделили тёмно-синим цветом.
1. Учителя воспитывают из всех литературоведов
«Зачем моему ребёнку писать сочинение по литературе, если он поступает в технический вуз?» — задаются вопросом родители будущих инженеров и программистов. Почитаем аннотацию к сочинению на сайте Федерального института педагогических измерений (ФИПИ) — разработчика всех контрольно-измерительных материалов:
«Итоговое сочинение, с одной стороны, носит надпредметный характер, то есть нацелено на проверку общих речевых компетенций обучающегося, выявление уровня его речевой культуры, оценку умения выпускника рассуждать по избранной теме, аргументировать свою позицию.С другой стороны, оно является литературоцентричным, так как содержит требование построения аргументации с обязательной опорой на литературный материал».
А теперь разберёмся и объясним просто, зачем же нужно сочинение: выпускники пишут сочинение, чтобы показать, что они способны мыслить и рассуждать, защищать свою точку зрения аргументами, а не топаньем ножки со словами «Я так хочу!». Этот навык очень пригодится во взрослой жизни. Например, чтобы аргументировать в вузе своё желание быть на паре, а не разбирать кирпичную стену. Или чтобы объяснить любимой девушке, что брать графитовую норковую шубку в кредит — не лучшая затея. Или чтобы вести интересный диалог с друзьями, а не обмениваться мемасиками.
Уметь мыслить логически — полезно. Но зачем же обязательно опираться на литературу? Давайте зададим этот вопрос иначе: зачем вообще читать книги?
Ответа в
документах ФИПИ мы не найдём, поэтому
поделюсь своими мыслями.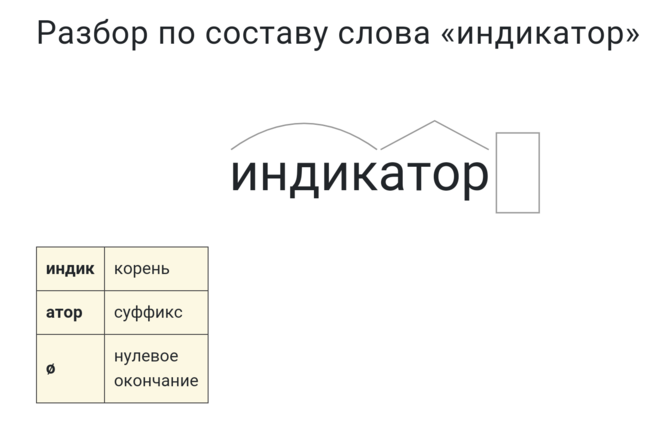 Литература
показывает нам опыт поколений, даёт
возможность понять, что мы не первые
испытываем те или иные чувства. Не мы
первые влюблены безответно; не мы первые
расходимся во взглядах с родителями;
не мы первые чувствуем отчаяние; не мы
первые испытываем детский восторг от
первого снега. То есть литература
становится для нас незримым другом,
неосязаемым кладезем ответов на вопросы,
которые нас мучают. Перечитаем «Маленького
принца» Экзюпери и вспомним, что в жизни
важны не цифры (деньги, статистика
лайков), а дружба и любовь. Познакомимся
с романом «Зулейха открывает глаза»
Яхиной и поймём, что человек способен
устоять перед натиском любых невзгод.
Поэтому читать литературу, а не только
постики и новости, невероятно важно для
стабильности нашего состояния. Уметь
сопоставлять эпизод из книги со своей
жизнью — значит развивать своё
аналитическое мышление. А оно нам
пригождается всякий раз, когда мы стоим
перед выбором.
Литература
показывает нам опыт поколений, даёт
возможность понять, что мы не первые
испытываем те или иные чувства. Не мы
первые влюблены безответно; не мы первые
расходимся во взглядах с родителями;
не мы первые чувствуем отчаяние; не мы
первые испытываем детский восторг от
первого снега. То есть литература
становится для нас незримым другом,
неосязаемым кладезем ответов на вопросы,
которые нас мучают. Перечитаем «Маленького
принца» Экзюпери и вспомним, что в жизни
важны не цифры (деньги, статистика
лайков), а дружба и любовь. Познакомимся
с романом «Зулейха открывает глаза»
Яхиной и поймём, что человек способен
устоять перед натиском любых невзгод.
Поэтому читать литературу, а не только
постики и новости, невероятно важно для
стабильности нашего состояния. Уметь
сопоставлять эпизод из книги со своей
жизнью — значит развивать своё
аналитическое мышление. А оно нам
пригождается всякий раз, когда мы стоим
перед выбором.
Выпускнику не нужно уметь делать литературоведческий анализ — ему нужно уметь мыслить, выражать свою точку зрения и аргументировать её.
Как оценивают-то?
Теперь вчитаемся в критерии оценивания сочинения. Сначала эксперты принимают решение, нужно ли вообще оценивать это сочинение. Для этого они, во-первых, считают количество слов: не меньше 250, лучше около 350. Во-вторых, смотрят, самостоятельно ли написано сочинение. Если оба требования выполнены, то дальше сочинение скрупулёзно исследуют по пяти критериям.
2. Не согласишься с высказыванием — получишь «незачёт»
Первый
критерий — соответствие теме.
Если
ученик заявил тему надежды и отчаяния,
а говорит о гордости и небесных пряниках,
увы, сочинение не зачтут. Но если он не
согласился с предложенным мнением и
аргументировал свою точку зрения, то
всё в порядке.
Например, в 2018 году в одном из комплектов тем была такая: «Согласны ли Вы с утверждением Джека Лондона: „Как легко быть добрым!“?»
Можно не согласиться с такой формулировкой? Я думаю, что быть добрым в современном мире не очень-то легко. Если ты добряк, каждый норовит ноги вытереть о тебя. С другой стороны, доброта открывает любые двери. Не может быть однозначного ответа на этот вопрос! И тем более, нет
3. Ученик должен опираться только на русскую литературу
Второй критерий — аргументация. Привлечение литературного материала.
Закройте глаза, сделайте вдох, досчитайте до десяти, когда вновь услышите, что нужно брать для аргументации два произведения из русской классики. Это самый распространённый миф.
Читаем методические рекомендации ФИПИ:
«При проверке итогового сочинения по критерию № 2 „Аргументация.Привлечение литературного материала“ нужно учитывать следующее. В соответствии с данным критерием участник сочинения, приводя примеры из литературного материала, имеет право привлекать не только художественные произведения, но и дневники, мемуары, публицистику, произведения устного народного творчества (за исключением малых жанров), другие источники отечественной или мировой литературы (достаточно опоры на один текст)».
 Привлечение литературного
материала“ нужно учитывать следующее.
В соответствии с данным критерием
участник сочинения, приводя примеры из
литературного материала,
имеет право
привлекать не только художественные
произведения, но и дневники, мемуары,
публицистику, произведения устного
народного творчества (за исключением
малых жанров), другие источники
отечественной или мировой литературы
(достаточно опоры на один текст)».
Привлечение литературного
материала“ нужно учитывать следующее.
В соответствии с данным критерием
участник сочинения, приводя примеры из
литературного материала,
имеет право
привлекать не только художественные
произведения, но и дневники, мемуары,
публицистику, произведения устного
народного творчества (за исключением
малых жанров), другие источники
отечественной или мировой литературы
(достаточно опоры на один текст)».
Взять для примера «Чайку по имени Джонатан Ливингстон» Баха? Пожалуйста. Рассмотреть «Сказку о мёртвой царевне» Пушкина? На здоровье. Вспомнить песню «Когда мы были на войне» на стихи Самойлова? Не проблема.
Сочинение — не проверка на знание кратких содержаний произведений школьной программы, а возможность поделиться мыслями, которые возникли во время чтения произведения .
Достаточно
одного литературного произведения.
В этом
абзаце идёт речь о том, что
некоторые
вузы за итоговое сочинение дают
дополнительные баллы
. Так, Высшая
школа экономики может прибавить до десяти
баллов. Весомый вклад, верно? В приёмной
комиссии желанного вуза можно выяснить,
какие требования здесь предъявляют к
сочинению, и получить отличную прибавку
к портфолио.
Если же сочинение не отвечает хотя бы одному из этих критериев, оно не будет зачтено: «Для получения оценки „зачёт“ необходимо иметь положительный результат по трём критериям (по критериям № 1 и № 2 — в обязательном порядке), а также „зачёт“ по одному из других критериев».
Посмотрим на «другие критерии». Третий критерий — композиция и логика рассуждения .
Логические связи между тезисом — основной мыслью высказывания — и аргументами делают нашу речь понятной и удобной для восприятия. Если логика нарушена, то такая речь тяжело воспринимается.
Классический
пример нарушения логики нам подарил
известный политик ещё в 2013 году:

Кроме того, важен композиционный баланс. Вступление и заключение по объёму должны быть меньше основной части. Если праздные рассуждения о космических кораблях, бороздящих просторы Вселенной, занимают большую часть сочинения, а собственная точка зрения и её доказательство — меньшую, то это похоже на пустословие.
Через сочинение мы стремимся научить подростка быть ответственным за свои слова.
Четвёртый критерий — качество письменной речи.
Мы предполагаем, что к середине одиннадцатого класса ученик может говорить приличным литературным языком. Он использует простые и сложные предложения, избегает просторечия. Если же сочинение насыщено штампами, канцеляризмами и бедно по своему составу, то по этому критерию будет «незачёт».4. Ошибёшься в имени — получишь «незачёт»
Пятый критерий — грамотность. Если в тексте сочинения есть орфографические (неправильно написано слово: «карова») и пунктуационные (неверно расставлены знаки препинания: мальчик ждущий автобус) ошибки, то их считают. На каждые 20 слов допустима одна ошибка. Представим, что ученик написал сочинение объёмом 400 слов. Делим 400 на 20 — получаем 20. Значит, если в тексте обнаружат 20 ошибок, то по этому критерию он получит «зачёт». Если ученик допустил 21 ошибку — незачёт.
На каждые 20 слов допустима одна ошибка. Представим, что ученик написал сочинение объёмом 400 слов. Делим 400 на 20 — получаем 20. Значит, если в тексте обнаружат 20 ошибок, то по этому критерию он получит «зачёт». Если ученик допустил 21 ошибку — незачёт.
Я неоднократно слышала от своих учеников такую фразу: «Нам сказали, что если мы забудем имя второстепенного героя и назовём его просто „герой“ или напишем другое имя — Роман Раскольников, например, — то всё, „незачёт“».
Как видите, ни в одном из критериев оценивания нет такой информации. Мы имеем право на ошибку. Намного важнее понимать суть произведения, поэтому лучше перечитать несколько любимейших шедевров, чем неустанно зубрить имена персонажей русской классики.
5. Не выбирай простые произведения!
Иногда школьников упорно просят не выбирать «простые произведения»: рассказы, повести, сказки. Вы же взрослые! Берите аргументы из «Мастера и Маргариты», «Тихого Дона», «Обломова»!
Положа руку на сердце: я сама прониклась любовью к «Обломову» уже после аспирантуры. Ни в школе, ни в университете я не испытывала нежных чувств к этому произведению. И я знаю, почему так. У меня-подростка не было созвучного жизненного опыта. Я не понимала, как человек может сутками лежать на диване, как можно вообще допустить себе такое состояние. Когда же я познала времена личностного кризиса, неудач, провалов, тогда и понимание Обломова пришло.
Ни в школе, ни в университете я не испытывала нежных чувств к этому произведению. И я знаю, почему так. У меня-подростка не было созвучного жизненного опыта. Я не понимала, как человек может сутками лежать на диване, как можно вообще допустить себе такое состояние. Когда же я познала времена личностного кризиса, неудач, провалов, тогда и понимание Обломова пришло.
Поэтому я обращаюсь ко всем, кто пишет сочинение в этом году. Мой друг! Пиши о том, что отзывается в твоём сердце. Лучше ты хорошо проанализируешь басню «Стрекоза и муравей», чем плохо и поверхностно расскажешь о «Войне и мире». Опирайся на народную мудрость: «Лучше меньше, да лучше».
И прошу всех верить только документам. Не допускайте проникновения мифов в ваши светлые головы.
С удовольствием отвечу на вопросы, касающиеся подготовки к итоговой аттестации по русскому языку и литературе, здесь в комментариях или в личной переписке: Instagram.com/leshkreba.
#ЕГЭ #школьники #экзамены
Даны слова ряд родители подруга поделки народ закладка падать редкий записать в два столбика один столбик со
Русский язык
Yulion ·
30. 08.2019 03:40
08.2019 03:40
Ответов: 3 Показать ответы
7 Обсудить
Ответы
Ответ разместил: diman20783407893
10.03.2019 18:48
холодный кофе
хладнокровный человек.
твердый грунт
суровый климат
жесткий матрац
тяжелый камень
тяжелый, сложный урок
сильный мороз
черствый хлеб
старый журнал
грязный ношеный воротничок
Ответ разместил: DariannGrey
10.03.2019 18:48
1). когда моя мама училась в школе, школы были еще восьмилетними. отапливались печками. парты были соединены со скамьей в единое целое. образование было качественным. моя мама поступила в институт.
2). когда моя мама училась в школе, то она делала сидя на печке с зажженной свечой, писала карандашом, не было денег покупать ручки и чернила. в старших классах ходила в школу за 7 км и пешком.
Ответ разместил: alleksees
10. 03.2019 18:48
03.2019 18:48
с наступлнием весны появляются почечки на дереьях, которые со времеем набухают и превращаются в свеже-зеленые листики.
когда светит солнце вся зелень становится такой яркой, что становится тепло и весело, а когда льют нескончаемые дожди, то лисья выглядят вяло, на улице ставится пасмурно и все хорошее уходит неизвестно куда!
запах весенних листьев напоминает о новой жизни, о тепле, счастье, и в первую очередь, они пахнут свежестью и зарядом бодрости!
самым красивыми на мой взгляд являются листья клена, ведь так не привычно видеть их зеленыи после осенней желтой окраски!
Ответ разместил: 89539123898
30.08.2019 03:40
Вот тут я все сделала
Другие вопросы по Русскому языку
.(Прочитайте предложения. к обобщающим словам подберите подходящие по смыслу однородные члены. 1.и снова в небе вьются птицы: .. 2.сразу стали слышны все предутренние лесные звуки:…
Русский язык
26.02.2019 15:30
4 ответ(ов)
Открыть
ирммри
Что относится к типичным языковым средствам?. ..
..
Русский язык
28.02.2019 12:00
3 ответ(ов)
Открыть
putinal
Подберите однокаренные слова к словам (величайшее, достижение, человечество)…
Русский язык
28.02.2019 15:30
4 ответ(ов)
Открыть
DEKTG
Составить текст-рассуждение «живительная сила солнечных лучей»(5-7 пр.)заранее !…
Русский язык
28.02.2019 21:30
4 ответ(ов)
Открыть
ника2092
Вкакой из фраз () слово походил употребленно неправильно? (а)щенок походил на медвежонка, и его назвали умкой. (б)коля походил по комнате и успокоился. (в)гроссмейстер походил пеш…
Русский язык
01.03.2019 04:30
2 ответ(ов)
Открыть
vakfor
Разбор по членам предложения .вкомнате отдыха дети и взрослые читают журналы и играют в настольные игры….
Русский язык
01.03.2019 14:00
4 ответ(ов)
Открыть
Онил180
Хотя 5-7 предложений скажите) ) эссе на тему статья лихачева «в чем самая большая цель жизни». ..
..
Русский язык
01.03.2019 18:10
2 ответ(ов)
Открыть
willzymustdie
На какие вопросы отвечают- дополнение, обсоятельство и определение?…
Русский язык
02.03.2019 01:50
2 ответ(ов)
Открыть
lorunshik
Уменя зазвонил телефон. — кто говорит? — слон. — откуда? — от верблюда. — что вам надо? — шоколада. — для кого? — для сына моего. — а много ли прислать? — да пудов этак пять и…
Русский язык
02.03.2019 02:20
4 ответ(ов)
Открыть
витльд
Определи склонения данных существительных и запиши их в три столбика аромат, калитка, лень, мужчина, вася, одежда, иней, дочь, перрон, правило, исповедь, природа, горечь, предмед,…
Русский язык
02.03.2019 09:00
2 ответ(ов)
Открыть
кисюня011088
Придумайте и запишите по 1 предложению с наречиями наглухо засветло набело изредка досуха справа влево. ..
..
Русский язык
02.03.2019 17:30
4 ответ(ов)
Открыть
akur12
Составить два предложения со словосочитаниями: лесную тропинку, большую поляну. ( словосочитания уже поставленны в винительный падеж) !…
Русский язык
02.03.2019 22:00
2 ответ(ов)
Открыть
Anna678901
Больше вопросов по предмету: Русский язык Еще вопросы
Самые популярные сегодня
«родители» — морфемный разбор по составу
Разбор по составу (морфемный) слова «родители»: Родители – корень [род], суффикс [и], суффикс [тел], окончание [и]; …
Содержание
Уважаемые учителя, ученики и родители школы № 10!
Поздравляю с окончанием самой трудной и длинной третьей четверти и началом весенних каникул!!! Желаю всем приятного, активного отдыха! Занимайтесь физкультурой и спортом, катайтесь на лыжах, коньках, играйте в снежки, гуляйте на свежем воздухе! Отвлекитесь от компьютеров и игровых приставок!!! В дни, когда вся страна с гордостью вспоминает о грандиозных успехах наших олимпийцев и паралимпийцев, занятия спортом будут самыми естественными и необходимыми!
Каникулы продлятся с 24 по 30 марта.
 31 марта снова ждем вас всех в школу!
31 марта снова ждем вас всех в школу! Поздравляю вас всех с еще одним важным событием в стране: Крым и Севастополь стали субъектами Российской Федерации!!! Нас соединяют прочные исторические, культурные, социальные связи! Возможно, 18 марта станет новой памятной датой — Днем воссоединения России и Крыма!
Мы, россияне приветствуем вхождение Крыма в состав России!
Просмотров: 3847
Благодарственные письма родителям от учителя: примеры, образцы и рекомендации по составлению текста благодарности
Тексты благодарственных писем, адресованные родителям, составляются администрацией, учителем или заинтересованной группой лиц и являются официальным документом. Вручаются письма в торжественной обстановке, поскольку являются выражением признательности и уважения к адресату, с одной стороны, и предметом гордости и воодушевления — с другой. Поэтому публичность процедуры вручения письма приветствуется. Читать далее >>>
Читать далее >>>
Пример уведомления родителям ученика
Муниципальное бюджетное образовательное учреждение
Средняя общеобразовательная школа № 87 города Батайска
Ростовской области
МБОУ СОШ № 87 г. Батайска
346880, Россия, Ростовская область, г. Батайск, ул. Победы, 23
тел. 44953468746(приемная)
Исх. № 198
от 30.09.2017 г.
Уведомление родителям ученика
Уважаемые Анна Борисовна и Константин Сергеевич!
Администрация школы, в которой проходит обучение Ваш сын, Степанов Богдан Константинович, настоящим уведомляет Вас о необходимости назначить психолого-медико-педагогическую комиссию для обследования Вашего ребенка. Законному представителю ребенка необходимо явиться 10 октября 2017 года к 10 час. 00 мин., приемная директора (каб. № 103), для получения рекомендаций и составления программы обследования.
В соответствии с п. 8 ч. 3, п. 2 ч. 4 ст. 44 Федерального закона от 29.12.2012 г. № 273-ФЗ «Об образовании в Российской Федерации» законные представители ребенка обязаны соблюдать правила внутреннего распорядка образовательной организации, вправе присутствовать при обследовании детей психолого-медико-педагогической комиссией, обсуждении результатов обследования и рекомендаций, полученных по результатам обследования, высказывать свое мнение относительно предлагаемых условий для организации обучения и воспитания детей.
У Вашего ребенка вследствие систематического пропуска занятий без уважительных причин возникли проблемы с усвоением общеобразовательной программы, что привело к низкой успеваемости.
В случае неявки законных представителей комиссия состоится без Вашего участия, с рекомендациями и программой обследования можно ознакомиться при личном обращении.
Директор Веретенникова Е.Д.
Красивые слова благодарности родителям на выпускном в детском саду – от воспитателей, в стихах и прозе
Выпускной утренник в детском саду – важный и ответственный шаг для малышей-дошкольников, их первая ступенька во взрослую жизнь. Оглядываясь назад, многие родители выпускников с теплотой вспоминают «как все начиналось», а воспитатели с трудом сдерживают волнение и грусть. Ведь совсем скоро предстоит прощание с любимыми воспитанниками – заметно повзрослевшими девочками и мальчиками. По сценарию выпускного, родители выражают искреннюю благодарность всему коллективу дошкольного учреждения, ставшего ребятам настоящим «вторым домом». В свою очередь, красивые слова благодарности родителям на выпускном в детском саду произносит воспитатель группы или заведующая – за помощь в благоустройстве группы, активное участие во всех мероприятиях. Предлагаем вашему вниманию подборку красивых благодарственных слов для родителей от воспитателей детского сада в стихах и прозе, которые точно запомнятся всем присутствующим на празднике.
В свою очередь, красивые слова благодарности родителям на выпускном в детском саду произносит воспитатель группы или заведующая – за помощь в благоустройстве группы, активное участие во всех мероприятиях. Предлагаем вашему вниманию подборку красивых благодарственных слов для родителей от воспитателей детского сада в стихах и прозе, которые точно запомнятся всем присутствующим на празднике.
Стихи и проза со словами благодарности для родителей в честь выпускного в детском саду
Вот и выросли ребятки,
В жизни первый выпускной.
Группа, детские кроватки —
Детский сад наш дорогой!
И глаза у мамы с папой
Уж слезинками блестят.
Расставаться очень грустно,
Но мы рады за ребят.
Вам, родители, — терпенья,
А детишкам лишь похвал.
Чтобы ваш ребёнок в школе
Лишь пятёрки получал.
Спасибо за то вам большое,
Что можно на вас положиться,
В спокойное время, лихое
За помощью к вам обратиться!
Живите спокойно, богато,
В красивой любви гармоничной,
Вы – лучшие мама и папа,
Желаем вам жизни отличной!
Дорогие и уважаемые родители! Всем нам сейчас немножко грустно от того, что мы выпускаем ваших детей с нашего детского сада. Вместе мы прожили столько лет, столько дней были вместе, бок о бок, рука об руку. Но время не стоит на месте, оно идет вперед, идет вместе с детьми. Дети растут, развиваются, им уже мало детского сада, и для дальнейшего роста им необходимо идти в школу. И нам грустно от расставания с ними. Но нам радостно и гордимся тем, что смогли воспитать ваших детей до уровня школьника. Мы подготовили их к школе, и теперь они могут показать свою грамотность и воспитанность.
Вместе мы прожили столько лет, столько дней были вместе, бок о бок, рука об руку. Но время не стоит на месте, оно идет вперед, идет вместе с детьми. Дети растут, развиваются, им уже мало детского сада, и для дальнейшего роста им необходимо идти в школу. И нам грустно от расставания с ними. Но нам радостно и гордимся тем, что смогли воспитать ваших детей до уровня школьника. Мы подготовили их к школе, и теперь они могут показать свою грамотность и воспитанность.
Мы благодарим всех родителей за ту поддержку, которую каждый из них оказывал нам, своим детям на протяжении длительного времени пребывания их детей в детском саду. Мы рады тему, что вы доверили нам своих детей, и мы сумели оправдать ваше доверие. Спасибо вам за ваших детей, за вашу помощь. Мы очень надеемся, что еще не раз увидимся с вами и вашими детьми, когда они уже станут совершенно взрослыми людьми.
Дорогие мамы и папы! Сегодня у ваших детей и у вас настоящий праздник. Сегодня вы вместе со своими детьми сделали шаг вперед, вы стали взрослее. Мы от лица всего рабочего коллектива детского сада хотим поблагодарить вас за то, что вы доверили нам воспитание своих детей. Сказать вам спасибо за то, что вы все эти годы помогали нам и нашему детскому саду. Спасибо за то, что всегда приходили на помощь, откликались на наши просьбы. Мы искренне надеемся, что вы сможете и дальше быть примерными родителями для своих детей. А они вырастут в примерных детей для своих родителей.
Мы от лица всего рабочего коллектива детского сада хотим поблагодарить вас за то, что вы доверили нам воспитание своих детей. Сказать вам спасибо за то, что вы все эти годы помогали нам и нашему детскому саду. Спасибо за то, что всегда приходили на помощь, откликались на наши просьбы. Мы искренне надеемся, что вы сможете и дальше быть примерными родителями для своих детей. А они вырастут в примерных детей для своих родителей.
Дорогие мамы и папы,
Мы хотим вам спасибо сказать
За здоровых, счастливых детишек,
Что вам удалось воспитать!
Сегодня они стали старше,
Мы их проведем в первый класс,
Но оставим их в душах наших –
Они стали родными для нас!
Разобрать слово по составу, что это значит?
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор.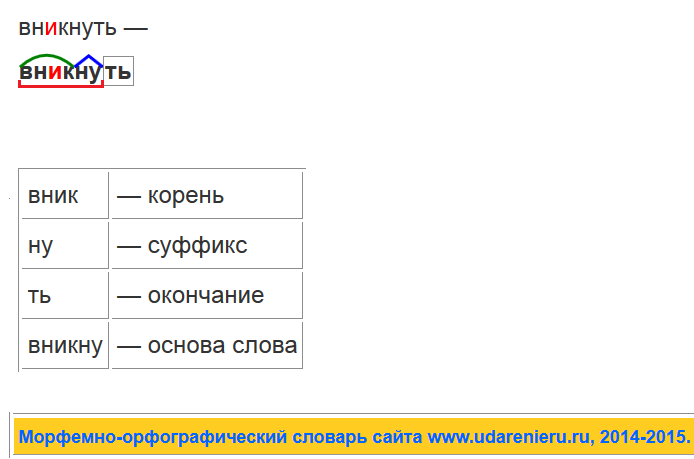 Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
Номера букв в слове
Номера букв в слове «родители» в прямом и обратном порядке:
- 8
р1
- 7
о2
- 6
д3
- 5
и4
- 4
т5
- 3
е6
- 2
л7
- 1
и8
Вариант №5
Администрация муниципального
образовательного учреждения
«Средняя общеобразовательная школа №2»
г. Краснослободска
выражает благодарность
Сидоровым
Ирине Петровне
и Геннадию Ивановичу
за воспитание замечательной дочери, постоянную заботу и интерес к её учебе, активное участие в решении дел класса и школы.
Директор МОУ СОШ №8
В. З. Алькафрахова
Кл. руководитель
И. Ф. Талитханова
2021 г.
Значение слова родители
Словарь Ушакова:
родители, родителей, ед. нет.
нет.
1. Отец и мать (по отношению к детям). Его родители еще живы. Социальное положение родителей.
2. Предки, деды (прост.). Не хотим жить, как родители наши жили.
Все значения
Примерные тексты благодарственных писем
Образец №1
Уважаемые Иван Иванович и Юлия Игоревна!
Администрация школы выражает Вам огромную благодарность за хорошее воспитание Вашего сына, Иванова Юрия Ивановича, который показал себя как способный и ответственный ученик, стремящийся к достижению лучших результатов в учебной и творческой деятельности.
Желаем Вам крепкого здоровья, успехов и семейного благополучия.
Выражаем уверенность, что и впредь Вы будете надежными друзьями и помощниками школы в деле воспитания и образования подрастающего поколения.
С уважением,
Директор школы Кузнецов П.П. Кузнецов
Образец №2
Уважаемые Иван Иванович и Юлия Игоревна!
Искренне благодарю Вас и выражаю свою глубочайшую признательность за прекрасное воспитание Вашей дочери, Ивановой Анастасии, и за активное участие в жизни нашего класса и школы.
Ваш ежедневный незримый труд, терпение и ответственное отношение к воспитанию приводят к неизменным и уверенным победам Ваших детей. Анастасия показала себя как человек способный глубоко мыслить, преодолевать трудности, отстаивать свое мнение. Успехи Вашего ребенка – это наши общие успехи и общая радость!
Благодаря Вашей активной жизненной позиции, пониманию и поддержке мы сможем и впредь растить достойную смену, устремленную к знаниям и творчеству.
От всей души желаю Вам огромного счастья, оптимизма и семейного тепла!
Буду искренне рада дальнейшему нашему плодотворному сотрудничеству на благо нашей школы.
С огромным уважением,
Классный руководитель Серова Н.Н.Серова
Семья – это крохотная страна.
И радости наши произрастают,
Когда в подготовленный грунт бросают
Лишь самые добрые семена!
(Э. Асадов)
Цитаты со словом родители
Цитата дня
“Стремись не к тому, чтобы добиться успеха, а к тому, чтобы твоя жизнь имела смысл. ”
”
Альберт Эйнштейн
Рейтинг
( 1 оценка, среднее 5 из 5 )
android — Ошибка Lottie java.lang.IllegalStateException: невозможно проанализировать композицию
Попытка интегрировать файл анимации Lottie в мой проект Android Studio. Я выполнил и перепроверил все этапы интеграции.
в build.gradle я добавил последнюю версию:
реализация "com.airbnb.android:lottie:4.1.0"
перенес экспортированный файл JSON (с сайта lottiefiles.com) в папку res/raw. (Я также попробовал папку /asset, но она все равно не работает)
в одном из моих файлов макета я ссылаюсь на него:
Как ни странно, интерфейс дизайна показывает ошибку:
Неожиданный тип ресурса: необработанный.
Ожидается: строка.

Эта ошибка не отображается в коде интерфейса XML, а только в интерфейсе дизайна.
Изображение, показывающее ошибку макета при использовании файла Lottie:
Следовательно, при запуске проекта приложение падает, и я получаю эту ошибку:
--------- начало сбоя
`2021-09-11 01:17:13.538 13479-13479/com.intelligentemo.dialogoengkor E/AndroidRuntime: НЕИСПРАВНОЕ ИСКЛЮЧЕНИЕ: main
Процесс: com.intelligentemo.dialogoengkor, PID: 13479**java.lang.IllegalStateException: невозможно проанализировать состав**
на com.airbnb.lottie.LottieAnimationView$1.onResult(LottieAnimationView.java:79)
на com.airbnb.lottie.LottieAnimationView$1.onResult(LottieAnimationView.java:72)
на com.airbnb.lottie.LottieAnimationView$3.onResult(LottieAnimationView.java:96)
на com.airbnb.lottie.LottieAnimationView$3.onResult(LottieAnimationView.java:89)
на com.airbnb.lottie.LottieTask.notifyFailureListeners(LottieTask. java:162)
на com.airbnb.lottie.LottieTask.access$200(LottieTask.java:28)
на com.airbnb.lottie.LottieTask$1.run(LottieTask.java:137)
в android.os.Handler.handleCallback(Handler.java:888)
в android.os.Handler.dispatchMessage(Handler.java:100)
на android.os.Looper.loop(Looper.java:213)
в android.app.ActivityThread.main(ActivityThread.java:8178)
в java.lang.reflect.Method.invoke (собственный метод)
в com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:513)
на com.android.internal.os.ZygoteInit.main(ZygoteInit.java:1101)
**Вызвано: java.lang.StringIndexOutOfBoundsException: length=0; индекс=0**
в java.lang.String.charAt (собственный метод)
в android.graphics.Color.parseColor(Color.java:1384)
на com.airbnb.lottie.parser.LayerParser.parse(LayerParser.java:136)
на com.airbnb.lottie.parser.LottieCompositionMoshiParser.parseLayers(LottieCompositionMoshiParser.java:120)
на com. airbnb.lottie.parser.LottieCompositionMoshiParser.parse(LottieCompositionMoshiParser.java:86)
на com.airbnb.lottie.LottieCompositionFactory.fromJsonReaderSyncInternal(LottieCompositionFactory.java:390)
на com.airbnb.lottie.LottieCompositionFactory.fromJsonReaderSync(LottieCompositionFactory.java:383)
на com.airbnb.lottie.LottieCompositionFactory.fromJsonInputStreamSync(LottieCompositionFactory.java:313)
на com.airbnb.lottie.LottieCompositionFactory.fromJsonInputStreamSync(LottieCompositionFactory.java:306)
на com.airbnb.lottie.LottieCompositionFactory.fromRawResSync(LottieCompositionFactory.java:269)
на com.airbnb.lottie.LottieCompositionFactory$3.call(LottieCompositionFactory.java:234)
на com.airbnb.lottie.LottieCompositionFactory$3.call(LottieCompositionFactory.java:229)
в java.util.concurrent.FutureTask.run(FutureTask.java:266)
в java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1167)
в java. util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:641)
на java.lang.Thread.run(Thread.java:929)
 java:162)
на com.airbnb.lottie.LottieTask.access$200(LottieTask.java:28)
на com.airbnb.lottie.LottieTask$1.run(LottieTask.java:137)
в android.os.Handler.handleCallback(Handler.java:888)
в android.os.Handler.dispatchMessage(Handler.java:100)
на android.os.Looper.loop(Looper.java:213)
в android.app.ActivityThread.main(ActivityThread.java:8178)
в java.lang.reflect.Method.invoke (собственный метод)
в com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:513)
на com.android.internal.os.ZygoteInit.main(ZygoteInit.java:1101)
**Вызвано: java.lang.StringIndexOutOfBoundsException: length=0; индекс=0**
в java.lang.String.charAt (собственный метод)
в android.graphics.Color.parseColor(Color.java:1384)
на com.airbnb.lottie.parser.LayerParser.parse(LayerParser.java:136)
на com.airbnb.lottie.parser.LottieCompositionMoshiParser.parseLayers(LottieCompositionMoshiParser.java:120)
на com.
java:162)
на com.airbnb.lottie.LottieTask.access$200(LottieTask.java:28)
на com.airbnb.lottie.LottieTask$1.run(LottieTask.java:137)
в android.os.Handler.handleCallback(Handler.java:888)
в android.os.Handler.dispatchMessage(Handler.java:100)
на android.os.Looper.loop(Looper.java:213)
в android.app.ActivityThread.main(ActivityThread.java:8178)
в java.lang.reflect.Method.invoke (собственный метод)
в com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:513)
на com.android.internal.os.ZygoteInit.main(ZygoteInit.java:1101)
**Вызвано: java.lang.StringIndexOutOfBoundsException: length=0; индекс=0**
в java.lang.String.charAt (собственный метод)
в android.graphics.Color.parseColor(Color.java:1384)
на com.airbnb.lottie.parser.LayerParser.parse(LayerParser.java:136)
на com.airbnb.lottie.parser.LottieCompositionMoshiParser.parseLayers(LottieCompositionMoshiParser.java:120)
на com. airbnb.lottie.parser.LottieCompositionMoshiParser.parse(LottieCompositionMoshiParser.java:86)
на com.airbnb.lottie.LottieCompositionFactory.fromJsonReaderSyncInternal(LottieCompositionFactory.java:390)
на com.airbnb.lottie.LottieCompositionFactory.fromJsonReaderSync(LottieCompositionFactory.java:383)
на com.airbnb.lottie.LottieCompositionFactory.fromJsonInputStreamSync(LottieCompositionFactory.java:313)
на com.airbnb.lottie.LottieCompositionFactory.fromJsonInputStreamSync(LottieCompositionFactory.java:306)
на com.airbnb.lottie.LottieCompositionFactory.fromRawResSync(LottieCompositionFactory.java:269)
на com.airbnb.lottie.LottieCompositionFactory$3.call(LottieCompositionFactory.java:234)
на com.airbnb.lottie.LottieCompositionFactory$3.call(LottieCompositionFactory.java:229)
в java.util.concurrent.FutureTask.run(FutureTask.java:266)
в java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1167)
в java.
airbnb.lottie.parser.LottieCompositionMoshiParser.parse(LottieCompositionMoshiParser.java:86)
на com.airbnb.lottie.LottieCompositionFactory.fromJsonReaderSyncInternal(LottieCompositionFactory.java:390)
на com.airbnb.lottie.LottieCompositionFactory.fromJsonReaderSync(LottieCompositionFactory.java:383)
на com.airbnb.lottie.LottieCompositionFactory.fromJsonInputStreamSync(LottieCompositionFactory.java:313)
на com.airbnb.lottie.LottieCompositionFactory.fromJsonInputStreamSync(LottieCompositionFactory.java:306)
на com.airbnb.lottie.LottieCompositionFactory.fromRawResSync(LottieCompositionFactory.java:269)
на com.airbnb.lottie.LottieCompositionFactory$3.call(LottieCompositionFactory.java:234)
на com.airbnb.lottie.LottieCompositionFactory$3.call(LottieCompositionFactory.java:229)
в java.util.concurrent.FutureTask.run(FutureTask.java:266)
в java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1167)
в java. util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:641)
на java.lang.Thread.run(Thread.java:929)
util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:641)
на java.lang.Thread.run(Thread.java:929)
Проверил так много ресурсов и руководств, но, похоже, ни у кого еще не было этой проблемы… 1
Твой ответ
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Интерпретируемый визуальный ответ на вопрос с помощью рассуждений о деревьях зависимостей — arXiv Vanity
Цинсин Цао, Байлинь Ли, Сяодань Лян и Лян Линь
Эта работа была частично поддержана Национальной ключевой программой исследований и разработок Китая в рамках гранта № 2016YFB1001004, частично Национальным фондом естественных наук Китая (NSFC) в рамках гранта № 619. 76233, 61836012, 61622214 и частично Фондом естественных наук провинции Гуандун в рамках гранта № 2017A030312006.
К. Цао и С. Лян из Школы интеллектуальных систем проектирования Университета Сунь Ятсена, Китай. Б. Ли из DMAI Great China. Л. Лин из Школы данных и компьютеров.
Наука, Университет Сунь Ятсена, Китай
Соответствующий автор:
Сяодань Лян (Электронная почта:)
76233, 61836012, 61622214 и частично Фондом естественных наук провинции Гуандун в рамках гранта № 2017A030312006.
К. Цао и С. Лян из Школы интеллектуальных систем проектирования Университета Сунь Ятсена, Китай. Б. Ли из DMAI Great China. Л. Лин из Школы данных и компьютеров.
Наука, Университет Сунь Ятсена, Китай
Соответствующий автор:
Сяодань Лян (Электронная почта:)
Abstract
Совместное рассуждение для понимания пар изображение-вопрос является очень важной, но недостаточно изученной темой в интерпретируемых визуальных системах ответов на вопросы. Хотя в самых недавних исследованиях были предприняты попытки использовать явные композиционные процессы для сборки нескольких подзадач, встроенных в вопросы, их модели в значительной степени полагаются на аннотации или созданные вручную правила для получения действительных процессов рассуждений, что приводит либо к большим нагрузкам, либо к плохой производительности композиционного мышления. В этой статье, чтобы лучше согласовать домены изображения и языка в различных и неограниченных случаях, мы предлагаем новую модель нейронной сети, которая выполняет глобальные рассуждения на дереве зависимостей, проанализированном из вопроса; таким образом, наша модель называется сетью рассуждений, управляемой деревом синтаксического анализа (PTGRN). Эта сеть состоит из трех совместных модулей: i) модуль внимания, который использует локальные визуальные доказательства каждого слова, проанализированного в вопросе, ii) закрытый модуль остаточного состава, который составляет ранее добытые данные, и iii) модуль, управляемый деревом синтаксического анализа. модуль распространения, который передает добытые доказательства по дереву синтаксического анализа. Таким образом, PTGRN способна построить интерпретируемую систему визуального ответа на вопрос (VQA), которая постепенно выводит подсказки изображения, следуя рассуждениям дерева синтаксического анализа, основанного на вопросах. Эксперименты с реляционными наборами данных демонстрируют превосходство PTGRN над современными современными методами VQA, а результаты визуализации подчеркивают объяснимую способность нашей системы рассуждений.
Эта сеть состоит из трех совместных модулей: i) модуль внимания, который использует локальные визуальные доказательства каждого слова, проанализированного в вопросе, ii) закрытый модуль остаточного состава, который составляет ранее добытые данные, и iii) модуль, управляемый деревом синтаксического анализа. модуль распространения, который передает добытые доказательства по дереву синтаксического анализа. Таким образом, PTGRN способна построить интерпретируемую систему визуального ответа на вопрос (VQA), которая постепенно выводит подсказки изображения, следуя рассуждениям дерева синтаксического анализа, основанного на вопросах. Эксперименты с реляционными наборами данных демонстрируют превосходство PTGRN над современными современными методами VQA, а результаты визуализации подчеркивают объяснимую способность нашей системы рассуждений.
Визуальные ответы на вопросы, анализ изображений и языка, глубокое рассуждение, модель внимания
1. Введение
Задача визуального ответа на вопрос (VQA) состоит в том, чтобы предсказать правильный ответ, учитывая изображение и текстовый вопрос. Ключом к этой задаче является способность применять совместное рассуждение к областям изображения и языка.
Однако большинство предыдущих методов [1, 2, 3] работают по принципу «черного ящика», т. е. просто отображают визуальное содержимое на текстовые слова путем создания нейронных сетей. Основным недостатком этих методов является отсутствие интерпретируемости результатов, т. е. почему выдаются эти ответы?
Более того, было показано, что точность этих результатов может быть повышена за счет переобучения смещения данных в тесте VQA 9.0086 [4] и что неиспользование явным образом структур текста и изображений приводит к неудовлетворительной эффективности реляционных рассуждений [5] .
Совсем недавно в нескольких новаторских работах [6, 7, 8] использовалась внутренняя структура текста и изображений; эти работы анализируют входное изображение вопроса в макет дерева или графика и собирают локальные особенности узлов для прогнозирования ответа.
Ключом к этой задаче является способность применять совместное рассуждение к областям изображения и языка.
Однако большинство предыдущих методов [1, 2, 3] работают по принципу «черного ящика», т. е. просто отображают визуальное содержимое на текстовые слова путем создания нейронных сетей. Основным недостатком этих методов является отсутствие интерпретируемости результатов, т. е. почему выдаются эти ответы?
Более того, было показано, что точность этих результатов может быть повышена за счет переобучения смещения данных в тесте VQA 9.0086 [4] и что неиспользование явным образом структур текста и изображений приводит к неудовлетворительной эффективности реляционных рассуждений [5] .
Совсем недавно в нескольких новаторских работах [6, 7, 8] использовалась внутренняя структура текста и изображений; эти работы анализируют входное изображение вопроса в макет дерева или графика и собирают локальные особенности узлов для прогнозирования ответа. Например, расклад « больше ( найти ( шар ), найти ( желтый ))» означает, что модуль должен сначала найти на изображении шар и желтый объект, а затем объединить два результата, чтобы определить, больше ли шаров, чем желтых объектов.
Однако эти методы полагаются либо на созданные вручную правила для понимания вопросов, либо на синтаксический анализатор макета, который обучается с нуля; первый подход требует, чтобы специалисты-люди разрабатывали соответствующие правила в определенной области или требовали тяжелой работы для аннотирования определенного набора данных [9] , а второй приводит к значительному снижению производительности [7] . Мы утверждаем, что эти ограничения серьезно ограничивают потенциал применения этих подходов для понимания общих пар изображение-вопрос, которые могут содержать разнообразные и открытые стили вопросов.
Например, расклад « больше ( найти ( шар ), найти ( желтый ))» означает, что модуль должен сначала найти на изображении шар и желтый объект, а затем объединить два результата, чтобы определить, больше ли шаров, чем желтых объектов.
Однако эти методы полагаются либо на созданные вручную правила для понимания вопросов, либо на синтаксический анализатор макета, который обучается с нуля; первый подход требует, чтобы специалисты-люди разрабатывали соответствующие правила в определенной области или требовали тяжелой работы для аннотирования определенного набора данных [9] , а второй приводит к значительному снижению производительности [7] . Мы утверждаем, что эти ограничения серьезно ограничивают потенциал применения этих подходов для понимания общих пар изображение-вопрос, которые могут содержать разнообразные и открытые стили вопросов.
 В зависимости от предшествующих узлов слов PTGRN поочередно извлекает визуальные свидетельства для узлов с помощью модуля внимания и интегрирует функции дочерних узлов с помощью закрытого остаточного модуля композиции.
В зависимости от предшествующих узлов слов PTGRN поочередно извлекает визуальные свидетельства для узлов с помощью модуля внимания и интегрирует функции дочерних узлов с помощью закрытого остаточного модуля композиции. Чтобы создать общую и мощную систему рассуждений, которая может позволить рассуждать над любым деревом синтаксического анализа вопросов без знания предметной области, мы предлагаем новую сеть рассуждений, управляемую деревом синтаксического анализа (PTGRN), которая содержит три совместных модуля для выполнения адаптированных операций рассуждения. для решения двух наиболее распространенных словесных отношений в вопросах. Как показано на рисунке 1, при наличии определенного дерева зависимостей вопроса, проанализированного готовым синтаксическим анализатором, мы строим маршрут рассуждений, который следует структуре дерева синтаксического анализа, которое представляет собой древовидную структуру, состоящую из нескольких типов узлов или ребер. Затем предлагаемая нами сеть поочередно применяет три совместных модуля к каждому словному узлу для глобальных рассуждений, чтобы 1) использовать локальные визуальные свидетельства каждого слова, руководствуясь эксплуатируемыми областями его дочерних узлов, 2) интегрировать сообщения дочерних узлов через закрытую остаточную композицию, и 3) распространять скрытую и используемую карту к ее родителю в соответствии с типом ребер. Примечательно, что в отличие от предыдущих методов, PTGRN представляет собой общую и интерпретируемую структуру рассуждений VQA, которая не требует каких-либо сложных правил ручной работы или аннотаций достоверности для получения определенного макета.
Примечательно, что в отличие от предыдущих методов, PTGRN представляет собой общую и интерпретируемую структуру рассуждений VQA, которая не требует каких-либо сложных правил ручной работы или аннотаций достоверности для получения определенного макета.
В частности, мы наблюдаем, что часто используемые типы отношений зависимости можно разделить на две группы в зависимости от того, является ли голова предикатом, описывающим отношение своих дочерних элементов (например, цвет ← равно , равно → нос ) или слово, описанное его дочерним элементом (например, самый дальний → объект ). Мы называем первый набор отношением клаузального предиката, которое описывает, как родительский узел составляет своих дочерних элементов, а второй набор — отношением модификатора, которое поможет более конкретно указать объект с учетом пар родитель-потомок.
Таким образом, мы разрабатываем модуль внимания для унификации информации, распространяемой из отношений модификаторов, модуль закрытой остаточной композиции для составления сообщений от дочерних узлов и, наконец, модуль распространения, управляемый деревом синтаксического анализа, для передачи внутренних представлений узла его родителю. обусловлены мелкозернистыми типами отношений.
обусловлены мелкозернистыми типами отношений.
Во-первых, модуль внимания извлекает визуальные доказательства из карты признаков изображения с заданным словом и закодированными картами внимания из дочерних узлов. Мы суммируем закодированные карты внимания из дочерних узлов и объединяем результат с функцией изображения и кодировкой слова. Затем мы выполняем операцию внимания на объединенной скрытой карте, чтобы извлечь новые локальные визуальные свидетельства для текущего узла.
Во-вторых, два закрытых модуля остаточной композиции отдельно интегрируют как добытые локальные визуальные свидетельства, так и карту внимания с дочерними узлами. Чтобы сохранить информацию от произвольного числа дочерних узлов, модуль суммирует дочерние узлы и изучает вентиль и невязку, которые забудут и обновят скрытые представления. Наконец, модуль распространения, управляемый деревом синтаксического анализа, преобразует составленное визуальное скрытое представление и скрытое представление внимания на основе типа отношения, зависящего от головы, и распространяет выходное сообщение на родительские узлы. Этот зависящий от края модуль способен научиться кодировать, какая часть скрытого вектора должна быть сохранена с учетом определенного типа, зависящего от головы. Таким образом, закрытый модуль остаточного состава родительских узлов может при необходимости забыть предыдущее сообщение. Скрытое выходное сообщение корневого узла будет проходить через многоуровневый персептрон, чтобы предсказать окончательный ответ.
Этот зависящий от края модуль способен научиться кодировать, какая часть скрытого вектора должна быть сохранена с учетом определенного типа, зависящего от головы. Таким образом, закрытый модуль остаточного состава родительских узлов может при необходимости забыть предыдущее сообщение. Скрытое выходное сообщение корневого узла будет проходить через многоуровневый персептрон, чтобы предсказать окончательный ответ.
Предварительная версия этой работы опубликована в CVPR2018. В этой работе мы унаследовали идею рассуждений по дереву синтаксического анализа зависимостей, но мы переработали оба модуля таким образом, чтобы они зависели от конкретных типов отношений, а не от общего отношения модификатора и клаузального предикатного отношения. Кроме того, чтобы повысить эффективность ответов на вопросы типа «счет» и «сравнить число», мы составляем и распространяем карту внимания, аналогичную скрытым представлениям. Эти изменения включают в себя меньше структур, разработанных вручную, и, таким образом, приводят к повышению производительности и универсальности. Мы проводим дополнительные эксперименты, чтобы показать влияние переработанных компонентов, и оцениваем обобщаемость для различных задач.
Мы проводим дополнительные эксперименты, чтобы показать влияние переработанных компонентов, и оцениваем обобщаемость для различных задач.
Обширные эксперименты показывают, что наша модель может обеспечить самую современную производительность VQA для реляционных наборов данных CLEVR и FigureQA. Более того, качественные результаты дополнительно демонстрируют интерпретируемость PTGRN при совместном рассуждении в области изображения и языка.
Наш вклад резюмируется следующим образом. 1) Мы представляем общую и интерпретируемую систему рассуждений VQA, которая следует общей схеме зависимостей, состоящей из отношений модификаторов и отношений предикатов клаузальных. 2) Предлагается модуль внимания для обеспечения эффективного извлечения визуальных свидетельств, модуль составного остатка с вентиляцией предлагается для интеграции знаний о дочерних узлах, а модуль распространения, управляемый деревом синтаксического анализа, предлагается для распространения знаний по дереву синтаксического анализа зависимостей.

2 Связанные работы
Визуальный ответ на вопрос. Задание VQA требует совместного анализа как изображения, так и текста, чтобы сделать правильный ответ.
Базовый метод, предложенный в наборе данных VQA [10] для решения этой задачи, использует архитектуру на основе сверточной нейронной сети (CNN) с долговременной кратковременной памятью (LSTM), которая состоит из CNN для извлечения признаков изображения и LSTM. кодировать функции вопроса. Метод объединяет эти две функции для прогнозирования окончательного ответа. В последние годы большое количество работ последовало за этим конвейером и добилось значительных улучшений по сравнению с базовой моделью. Среди этих работ механизм внимания [11, 12, 13, 14, 15, 2] и совместное вложение изображения и представления вопроса [16, 3, 17] широко изучались. Механизм внимания учится сосредотачиваться на наиболее различимой части изображения, а не на всем изображении, обеспечивая определенную степень обоснованности ответа. Различные методы внимания, такие как групповое внимание [15] и наложение между вопросом и изображением на разных уровнях [2] последовательно улучшают выполнение задачи VQA. Для мультимодальной заделки швов Fukui и др. [16] , Ким и др. [3] и Hedi et al. [18] использовал компактный билинейный метод, чтобы объединить встраивание изображения и вопроса и включить механизм внимания для дальнейшего повышения производительности.
Различные методы внимания, такие как групповое внимание [15] и наложение между вопросом и изображением на разных уровнях [2] последовательно улучшают выполнение задачи VQA. Для мультимодальной заделки швов Fukui и др. [16] , Ким и др. [3] и Hedi et al. [18] использовал компактный билинейный метод, чтобы объединить встраивание изображения и вопроса и включить механизм внимания для дальнейшего повышения производительности.
Однако некоторые недавно предложенные работы [4, 19] показали, что многообещающая производительность этих глубоких моделей может быть достигнута за счет использования смещения набора данных. Одинаково хорошо можно работать, запоминая пары вопрос-ответ (QA) или кодируя вопрос с помощью метода мешка слов. Чтобы решить эту проблему, недавно были выпущены новые наборы данных. Набор данных VQAv2 [4] был предложен для устранения смещения данных путем балансировки пар QA. Набор данных CLEVR [5] состоит из синтетических изображений и предлагает более сложные вопросы, включающие несколько объектов. Этот набор данных также сбалансировал распределение ответов, чтобы подавить смещение данных.
Набор данных CLEVR [5] состоит из синтетических изображений и предлагает более сложные вопросы, включающие несколько объектов. Этот набор данных также сбалансировал распределение ответов, чтобы подавить смещение данных.
Модель рассуждения. В некоторых предыдущих работах предпринимались попытки явного включения знаний в структуру сети. [20, 21] кодировал как изображения, так и вопросы в дискретные векторы, такие как атрибуты изображения или запросы к базе данных. Эти векторы позволяют модели запрашивать внешние источники данных для получения общих знаний и базовых фактических знаний для ответа на вопросы. [22] активно собирал предопределенные типы доказательств для получения внешней информации и предсказания ответов. В других недавних работах предлагались сети для обработки композиционных рассуждений. [23] расширил дифференцируемую память и закодировал долгосрочные знания для получения ответов. Сеть нейронных рассуждений недавно была предложена для решения композиционных визуальных рассуждений. Вместо того, чтобы использовать фиксированную структуру для предсказания ответа на каждый вопрос, это направление работы собирает макет структуры для различных вопросов в предопределенные подзадачи.
Затем создается набор нейромодулей для решения той или иной подзадачи.
Некоторые репрезентативные работы [6, 7] использовал рекуррентную нейронную сеть последовательностей (RNN) для прогнозирования обратного порядка макета и совместно обучал RNN и нейронный модуль на наборе данных CLEVR, используя обучение с подкреплением или максимизацию ожидания. Однако для обучения RNN требуются наземные макеты для наблюдения. Производительность CLEVR быстро падает, если не используются наземные макеты.
В наборе данных VQA [24, 25, 6] сгенерировали макеты на основе разбора зависимостей. Эти три работы сначала фильтруют набор зависимостей до тех, которые связаны с wh-словом на определенном расстоянии. Затем они применили предопределенные модули к оставшимся словам, чтобы создать схему вывода.
Вместо того, чтобы использовать фиксированную структуру для предсказания ответа на каждый вопрос, это направление работы собирает макет структуры для различных вопросов в предопределенные подзадачи.
Затем создается набор нейромодулей для решения той или иной подзадачи.
Некоторые репрезентативные работы [6, 7] использовал рекуррентную нейронную сеть последовательностей (RNN) для прогнозирования обратного порядка макета и совместно обучал RNN и нейронный модуль на наборе данных CLEVR, используя обучение с подкреплением или максимизацию ожидания. Однако для обучения RNN требуются наземные макеты для наблюдения. Производительность CLEVR быстро падает, если не используются наземные макеты.
В наборе данных VQA [24, 25, 6] сгенерировали макеты на основе разбора зависимостей. Эти три работы сначала фильтруют набор зависимостей до тех, которые связаны с wh-словом на определенном расстоянии. Затем они применили предопределенные модули к оставшимся словам, чтобы создать схему вывода. [6] далее использовал сгенерированные макеты в качестве контроля для обучения синтаксического анализатора макетов RNN. Фильтр дерева синтаксического анализа и назначение модулей включают слишком много правил, разработанных вручную, и поэтому их трудно обобщать для разных задач. Наша работа направлена на решение этой проблемы путем применения модульной сети к необработанному дереву синтаксического анализа.
Совсем недавно [26] предложил явно интерпретируемую модульную сеть, ограничив модули прохождением только масок внимания. [9] преобразовывал и вопрос, и изображения в символические представления и выполнял символическую программу для рассуждений. Эти работы основаны на наземных макетах в CLEVR, но обеспечивают высокую точность и интерпретируемые результаты.
Помимо древовидной структуры, [27, 28] выполнял последовательные рассуждения с расширенной памятью. На каждом этапе зависящий от времени модуль считывает память на основе как вопроса, так и изображения и записывает в память вновь сгенерированную кодировку для предсказания ответа.
[6] далее использовал сгенерированные макеты в качестве контроля для обучения синтаксического анализатора макетов RNN. Фильтр дерева синтаксического анализа и назначение модулей включают слишком много правил, разработанных вручную, и поэтому их трудно обобщать для разных задач. Наша работа направлена на решение этой проблемы путем применения модульной сети к необработанному дереву синтаксического анализа.
Совсем недавно [26] предложил явно интерпретируемую модульную сеть, ограничив модули прохождением только масок внимания. [9] преобразовывал и вопрос, и изображения в символические представления и выполнял символическую программу для рассуждений. Эти работы основаны на наземных макетах в CLEVR, но обеспечивают высокую точность и интерпретируемые результаты.
Помимо древовидной структуры, [27, 28] выполнял последовательные рассуждения с расширенной памятью. На каждом этапе зависящий от времени модуль считывает память на основе как вопроса, так и изображения и записывает в память вновь сгенерированную кодировку для предсказания ответа. В отличие от этих работ, наша модель предназначена для достижения аналогичных интерпретируемых композиционных рассуждений на древовидных структурах [6, 7, 24, 25] без макетов с достоверностью или вручную разработанных правил [27, 28] .
В отличие от этих работ, наша модель предназначена для достижения аналогичных интерпретируемых композиционных рассуждений на древовидных структурах [6, 7, 24, 25] без макетов с достоверностью или вручную разработанных правил [27, 28] .
Рассуждения с помощью счетных вопросов. Подсчет объектов на изображении изучался годами. Лемпицки и Зиссерман [29] научились составлять карту плотности для подсчета. [30, 31] использовал сверточную сеть для оценки плотности и подсчета целевых объектов. Чжан и др. [32] изучал проблему субитизации значимых объектов, которая распознает количество значимых объектов, когда присутствует только несколько объектов. Chattopadhyay и др. [33] расширил этот подход, применив стратегию «разделяй и властвуй»; они разделили изображение на подрегионы, подсчитали внутри регионов по отдельности и объединили результаты.
Однако проблема подсчета редко решается в VQA. Андерсон и др. [34] улучшили точность вопроса о «подсчете» в VQAv2 [4] , сначала обучив детектор объектов на наборе данных Visual Genome [35] . Предварительно обученный детектор использовался для извлечения объектов из набора данных VQAv2, а операция внимания выполнялась на объектах-кандидатах, а не только на карте объектов сетки.
Тротт и др. [36] следовал этому конвейеру, представляя каждое изображение как набор обнаруженных объектов. Затем они рассмотрели проблему подсчета как последовательный процесс принятия решения, определяя, какой объект-кандидат следует подсчитывать на каждом шаге. Наконец, они использовали обучение с подкреплением для обучения модели. Однако этот конвейер ограничен вопросами на подсчет и не может быть легко применен к другим типам вопросов.
Чжан и др. [37] сообщил, что именно механизм мягкого внимания ограничивает возможности подсчета моделей VQA. Если нужно ответить, сколько кошек на изображении, то кошки, подсчитанные с помощью нормализованной карты внимания, будут иметь веса, которые в сумме равны 1.
Андерсон и др. [34] улучшили точность вопроса о «подсчете» в VQAv2 [4] , сначала обучив детектор объектов на наборе данных Visual Genome [35] . Предварительно обученный детектор использовался для извлечения объектов из набора данных VQAv2, а операция внимания выполнялась на объектах-кандидатах, а не только на карте объектов сетки.
Тротт и др. [36] следовал этому конвейеру, представляя каждое изображение как набор обнаруженных объектов. Затем они рассмотрели проблему подсчета как последовательный процесс принятия решения, определяя, какой объект-кандидат следует подсчитывать на каждом шаге. Наконец, они использовали обучение с подкреплением для обучения модели. Однако этот конвейер ограничен вопросами на подсчет и не может быть легко применен к другим типам вопросов.
Чжан и др. [37] сообщил, что именно механизм мягкого внимания ограничивает возможности подсчета моделей VQA. Если нужно ответить, сколько кошек на изображении, то кошки, подсчитанные с помощью нормализованной карты внимания, будут иметь веса, которые в сумме равны 1. Объединение взвешенной суммы этих кошек приводит к вектору признаков, подобному одной кошке. Чтобы решить эту проблему, Чжан и др. [37] сначала сгенерировал вес внимания для каждого обнаруженного объекта; затем выполняли «мягкое» немаксимальное подавление весов для подсчета посещаемых объектов.
Объединение взвешенной суммы этих кошек приводит к вектору признаков, подобному одной кошке. Чтобы решить эту проблему, Чжан и др. [37] сначала сгенерировал вес внимания для каждого обнаруженного объекта; затем выполняли «мягкое» немаксимальное подавление весов для подсчета посещаемых объектов.
Вдохновленные этими наблюдениями, мы отдельно кодируем и распространяем добытые визуальные доказательства и карту внимания. Карта внимания в каждом узле будет составлена из выходных данных его дочерних элементов через сверточный GRU и будет передана его родительскому элементу. Мы сохраняем функцию посещенного региона и используем ее для предсказания счетных вопросов.
3 Сеть рассуждений о композиции с древовидной структурой
3.1 Обзор
При наличии вопросов Q и изображений I в произвольной форме предлагаемая нами модель PTGRN учится предсказывать ответы y и соответствующие им объяснимые карты внимания. Сначала мы создаем макет с древовидной структурой, анализируя входной вопрос Q в дерево синтаксического анализа с помощью стандартного универсального синтаксического анализатора Stanford [38] . Мы обрезаем листовые узлы, которые не являются существительными, чтобы уменьшить вычислительную сложность.
Мы обрезаем листовые узлы, которые не являются существительными, чтобы уменьшить вычислительную сложность.
Мы обозначаем макет с древовидной структурой как тройку G=(u,X,E), а u=(v,q) представляет собой глобальные атрибуты, которые содержат элемент изображения v и кодировку вопроса q. X={wi}i=1:N представляет узлы в проанализированном дереве, а N — количество узлов. Каждый узел связан с кодировкой слова wi в исходном вопросе Q. E={ei,j}i,j=1:N представляет набор ребер в проанализированном дереве, а ei,j обозначает тип ребра между головным узлом j и его зависимый узел i в дереве синтаксического анализа зависимостей.
Затем мы выполняем визуальное рассуждение вопроса снизу вверх по дереву синтаксического анализа. В частности, функция изображения v извлекается из каждого изображения с помощью любой CNN, предварительно обученной в ImageNet (например, функции conv5 из ResNet-152 [39] или функции conv4 из ResNet-101 [39] ). Кодировка слова w получается с помощью Bi-GRU [40] . Каждое слово в вопросе сначала встраивается в виде 200-мерного вектора, а затем слова передаются в двунаправленный GRU. Последнее слово, кодирующее w, является скрытым вектором Bi-GRU в соответствующей позиции, а скрытый вектор в конце вопроса извлекается как кодирование вопроса q.
Каждое слово в вопросе сначала встраивается в виде 200-мерного вектора, а затем слова передаются в двунаправленный GRU. Последнее слово, кодирующее w, является скрытым вектором Bi-GRU в соответствующей позиции, а скрытый вектор в конце вопроса извлекается как кодирование вопроса q.
Узел j имеет несколько входных данных: функция изображения v, кодировка вопроса q, кодировка слова wj и сообщения {mij} от его входного ребра {eij}. Сообщение mij=[maij,mhij] включает сообщение maij для карты внимания и mhij для скрытого представления. Он генерирует карту внимания attj с модулем внимания fa, а также скрытое представление hj и карту внимания, кодирующую hattj, с закрытым модулем остаточного состава fh.
Входными данными ребра jk являются скрытое представление hj и карта внимания, кодирующая hattj, сгенерированная узлом j. Имея входные данные и тип ребра ejk, ребро jk генерирует сообщение [majk,mhjk] с модулем распространения на основе дерева синтаксического анализа fe и передает эти сообщения узлу k.
Мы обновляем каждый узел снизу вверх, обходя дерево в обратном порядке. Наконец, в корневом узле N [mhN,maN] передаются многоуровневому классификатору персептрона для прогнозирования ответа, как показано на рисунке 2.
Рис. 3: Подробная архитектура модуля внимания. Функция изображения, ранее посещаемые регионы и кодировка слов проецируются на функции 2048-d. Затем они объединяются путем поэлементного умножения. Наконец, объединенная функция проецируется на одномерную карту внимания и нормализуется с помощью softmax. Рис. 4. Модуль закрытой остаточной композиции использует архитектуру закрытой рекуррентной единицы для интеграции функций своих дочерних элементов с локальными визуальными свидетельствами или картой внимания. Сумма входных данных детей считается памятью, а локальные визуальные свидетельства или карта внимания являются входными данными на текущем шаге. 5: модуль распространения на основе дерева синтаксического анализа выполняет билинейное слияние между скрытой картой/картой внимания и кодировкой вопроса. Разные типы ребер имеют одинаковую архитектуру, но разные наборы весов.
Разные типы ребер имеют одинаковую архитектуру, но разные наборы весов.3.2 Модуль внимания
В узле j модуль внимания fa используется для обнаружения области изображения, которая соответствует словам, кодирующим wj, и входному сообщению внимания {maij}eij∈E. В частности, как показано на рисунке 3, входная характеристика внимания ~attj каждого узла j сначала получается путем суммирования {maij}eij∈E как ~attj. Затем мы проецируем функцию изображения v, функцию внимания ввода ~attj и кодировку слов wj в функции 2048-d и выполняем поэлементное умножение этих трех функций 2048-d. Наконец, объединенная функция 2048-d передается в другой слой свертки, в результате чего создается новая карта внимания attj. Далее мы применяем softmax, чтобы упорядочить полученную карту внимания в диапазоне [0,1]. Локальный признак изображения vj узла j затем генерируется взвешенной суммой каждой сетки в признаке изображения v с учетом весов в карте внимания attj.
3.3 Модуль закрытого остаточного состава
Узел j содержит два закрытых остаточных модуля композиции с похожей архитектурой, но разными весами, как показано на рисунке 4. Этот модуль используется для составления вновь сгенерированной карты внимания attj и локального элемента изображения vj с входными сообщениями {maij} и {mhij}. соответственно.
В предварительной работе узлы разделяют только вес на одном уровне, который содержит много параметров и не подходит для глобальных рассуждений с разными деревьями синтаксического анализа.
Однако многократное применение одного модуля узла по сути действует как рекуррентная сеть и будет страдать от проблем взрыва/исчезновения градиента.
Между тем, в наборе данных CLEVR имеется большое количество объектов, на которые ссылаются их отношения с другими объектами, такие как «слева от большой сферы» или «слева от коричневого металла». Чтобы ответить на вопрос, визуальное представление «большой сферы» не обязательно и может повлиять на окончательный прогноз. Ранее мы отказались от скрытой функции этих узлов, когда их отношение, зависящее от головы, является отношением модификатора. Мы хотим позволить модулю изучить этот процесс сброса, а не использовать созданные вручную правила.
Этот модуль используется для составления вновь сгенерированной карты внимания attj и локального элемента изображения vj с входными сообщениями {maij} и {mhij}. соответственно.
В предварительной работе узлы разделяют только вес на одном уровне, который содержит много параметров и не подходит для глобальных рассуждений с разными деревьями синтаксического анализа.
Однако многократное применение одного модуля узла по сути действует как рекуррентная сеть и будет страдать от проблем взрыва/исчезновения градиента.
Между тем, в наборе данных CLEVR имеется большое количество объектов, на которые ссылаются их отношения с другими объектами, такие как «слева от большой сферы» или «слева от коричневого металла». Чтобы ответить на вопрос, визуальное представление «большой сферы» не обязательно и может повлиять на окончательный прогноз. Ранее мы отказались от скрытой функции этих узлов, когда их отношение, зависящее от головы, является отношением модификатора. Мы хотим позволить модулю изучить этот процесс сброса, а не использовать созданные вручную правила. Здесь мы используем широко используемый вентильный рекуррентный блок, чтобы модуль мог изучить процесс сброса.
Здесь мы используем широко используемый вентильный рекуррентный блок, чтобы модуль мог изучить процесс сброса.
Как показано на рис. 4, стробируемый остаточный модуль композиции fh сначала суммирует сообщения скрытого представления {mhij} своих дочерних элементов в ~hj, а затем объединяет ~hj с извлеченным локальным элементом изображения vj. Подобно вентилируемому рекуррентному блоку, модуль генерирует вентиль сброса rj и вентиль обновления zj на основе сцепленных [~hj,vj]. Затем модуль создает вектор обновления cj, обновляет и выводит скрытое представление hj:
| ~хдж | =∑(i,j)∈Emhij | (1) | ||
| зж | =σ(Wz⋅[~hj,vj]) | |||
| рж | =σ(Wr⋅[~hj,vj]) | |||
| cj | =танх(Вт⋅[r*~hj,vj]) | |||
| хдж | =(1−zj)∗~hj+zj∗cj |
Для кодирования карты внимания attj выполняем аналогичные операции. Сначала мы суммируем {maij}, чтобы получить ~attj. Поскольку карта внимания представляет собой двумерную сетку, мы используем рекуррентную единицу свертки, чтобы обновить кодировку карты внимания hattj.
По сравнению с нашей предварительной работой, в которой cj=tanh(W⋅[~hj,vj]) и hj=~hj+cj, в нашей текущей работе мы добавляем ворота обновления и ворота сброса к остаточной композиции. Эти два вентиля могут уменьшить влияние проблем взрыва/исчезновения градиента при многократном применении одного узла, что позволяет нам повторно использовать модуль узла на нескольких высотах дерева синтаксического анализа.
Процесс обновления также аналогичен процессу в Child-Sum Tree-LSTM 9.0086 [41] . В [41] ячейка LSTM вычисляет ворота забывания для каждого из воспоминаний своего дочернего элемента; мы упрощаем этот процесс, сначала суммируя скрытое представление дочерних элементов и выводя один вентиль сброса и забывания для обновления скрытого представления hj.
3.4 Модуль распространения на основе дерева синтаксического анализа
При наличии ребра jk модуль распространения, управляемый деревом синтаксического анализа, используется для передачи скрытого представления hj и кодировки карты внимания hattj узла j в сообщения mhjk и majk на основе типа ребра ejk, как показано на рисунке 5. Этот модуль для передачи скрытого представления его родительскому узлу основан на детальном отношении зависимости, а не на прямой блокировке скрытого представления или карты внимания, основанной на двух общих категориях, а именно, отношениях модификатора и отношениях предиката предложения. Для разных типов ребер применяется один и тот же модуль скрытого представления hj, но с разными наборами весов. Модуль выполняет мультимодальный билинейный пул [3] о скрытом представлении hj и вопросе кодировки q. Затем он генерирует сообщение для своего родительского mhjk.
В частности, полносвязные слои применяются для проецирования как скрытого представления hj, так и вопроса, кодирующего q, в два вектора признаков, имеющих тот же размер, что и hj. Затем мы выполняем поэлементное умножение этих двух функций и применяем к результату нелинейность ReLU. Наконец, мы добавляем результат к hj, в результате чего получается скрытый вектор mhjk, который будет пропущен через ребро.
| mhjk=hj+ReLU((Whejk⋅hj+bhejk)∗(Wqejk⋅q+bqejk)) | (2) |
Здесь ejk указывает тип отношения зависимости между узлом j и его родительским узлом k.
При распространении карты внимания, кодирующей attj, мы используем свертку для проецирования attj, как показано на рис. 5. Всего существует 22 типа отношений, которые находятся в дереве синтаксического анализа зависимостей для вопросов в наборе данных CLEVR; таким образом, имеем ejk∈[1,22].
3.5 Предлагаемая модель PTGRN
Учитывая древовидную структуру дерева зависимостей, наш модуль PTGRN последовательно используется на каждом словном узле для извлечения визуальных свидетельств и интеграции функций его дочерних узлов снизу вверх, а затем он предсказывает окончательный ответ в корне дерева. дерево. Формально каждый модуль PTGRN можно записать как
| . | по адресу | =fa({maij}eij∈E,v,w), | (3) | |
| вж | = attj∗v, | |||
| хдж | =fh({mhij}eij∈E,vj), | |||
| хаттдж | =fatth({maij}eij∈E,attj), | |||
| мхжк | =fhejk(hj,q), | |||
| майк | =faejk(hattj,q) |
Мы обрабатываем каждый узел обходом дерева зависимостей в обратном порядке. Тип ребра указывает, служит ли узел модификатором, который может модифицировать свой родительский узел, ссылаясь на более конкретный объект, или как субъект/объект своего родительского узла предиката. Таким образом, мы передаем как карту внимания, так и скрытое представление узла его родителю на основе ребра, чтобы родительский узел мог генерировать более точную карту внимания как attj или интегрировать функции дочерних узлов для улучшения представления с учетом предикатного слова. .
После прохождения через все узлы слов выходное сообщение корневого узла [mhroot,maroot] используется для предсказания ответа. Мы выполняем глобальное максимальное объединение закодированной карты внимания maroot и объединяем ее с mhroot. Этот объединенный признак проходит через многослойный персептрон с тремя слоями для предсказания окончательного ответа y.
Наша модель состоит из списка узловых модулей с древовидной структурой. Веса распределяются между всеми модулями узла. Всю модель можно обучить сквозным образом, используя только контрольный сигнал y.
4 Эксперимент
Рис. 6: Два примера деревьев зависимостей вопросов и соответствующих областей, которые посещает наша модель на каждом этапе набора данных CLEVR. Вопросы показаны внизу. Входные изображения и деревья анализа зависимостей показаны в левой и нижней частях. Стрелки в дереве зависимостей проведены от заглавных слов к зависимым словам. Изогнутые стрелки указывают на слова с обрезанными листьями, которые не являются существительными. Таким образом, слово «являются» является корневым узлом для обоих примеров.Мы проверяем эффективность и возможность интерпретации наших моделей на обоих синтетических наборах данных (т.
4.1 Наборы данных
CLEVR [5] — это синтезированный набор данных, содержащий 100 000 изображений и 853 554 вопроса. Изображения представляют собой фотореалистичные визуализированные изображения с объектами случайных форм, цветов, материалов и размеров. Вопросы генерируются с помощью наборов функциональных программ, состоящих из функций, которые могут фильтровать определенные цвета и формы или сравнивать два объекта. Таким образом, пути рассуждений, необходимые для ответа на каждый вопрос, могут быть точно определены лежащей в основе функциональной программой. В отличие от наборов данных естественных изображений, для этого набора данных требуется модель, способная рассуждать об отношениях, чтобы ответить на вопросы.
FigureQA [42] также является синтезированным набором данных. Этот набор данных содержит 100 000 изображений и 1 327 368 вопросов для обучения. В отличие от CLEVR, изображения представляют собой цифры в научном стиле. Набор данных включает пять классов: линейные графики, точечные графики, вертикальные и горизонтальные гистограммы и круговые диаграммы. Вопросы также касаются различных взаимосвязей между элементами на рисунках, таких как максимум, площадь под кривой, пересечения и т. д. Таким образом, этот набор данных также требует, чтобы модель VQA выполняла реляционные рассуждения на элементах графика.
VQAv2 [4] — это широко используемый эталонный тест VQA для естественных изображений. Он содержит 204 721 естественное изображение из COCO [43] и 1 105 904 вопроса в произвольной форме. По сравнению с первой версией [10] , этот набор данных фокусируется на уменьшении смещения набора данных за счет сбалансированных пар: для каждого вопроса есть пара изображений с разными ответами.
4.2 Детали реализации
Для набора данных CLEVR мы используем те же настройки, что и в [44, 5] , для извлечения признаков изображения и кодировки слов. Сначала мы изменяем размер всех изображений до 224×224, а затем извлекаем функцию conv4 из ResNet-101, предварительно обученной в ImageNet. Полученные карты объектов 1024×14×14 объединяются с 2-канальной картой координат, которая затем подается в один сверточный слой 3×3. Полученные карты объектов размером 128×14×14 также объединяются с двухканальной картой координат, а затем проходят через наш модуль PTGRN. Мы кодируем вопросы, используя двунаправленный GRU с 512 скрытыми состояниями для обоих направлений. Скрытый вектор Bi-GRU в соответствующей позиции слова извлекается как кодировка этого слова w. Скрытые представления закрытых остаточных модулей композиции имеют 128-й размер как для hj, так и для hattj.
Сообщения, генерируемые модулями модуля распространения, управляемого деревом синтаксического анализа, также являются 128-d как для карты внимания, так и для скрытого представления. Трехслойный MLP имеет выходные размеры 512, 1024 и 29., где 29 — количество возможных ответов.
Мы изменяем размер изображений на рисунке QA до 256×256. Затем мы используем пятислойную CNN для извлечения признаков изображения. Каждый слой имеет ядро 3 × 3 и шаг 2. Размеры карты признаков в первых четырех слоях равны 64, а последний слой имеет 128-канальные выходные данные. Полученная карта признаков объединяется с двумерной картой координации. Таким образом, карта признаков изображения имеет размер 130×8×8. Скрытые выходные представления вентилируемых остаточных модулей композиции и модулей распространения имеют длину 128 d. Слова в вопросе сначала встраиваются в виде 200-мерного вектора, а затем весь вопрос кодируется двунаправленным GRU, который имеет 1024-значные скрытые единицы в обоих направлениях. Вектор кодирования слова представлен скрытым вектором GRU в соответствующей позиции.
Для набора данных VQAv2 мы используем функции изображения, предоставляемые восходящей сетью внимания [34] . Восходящая сеть внимания [34] обнаруживает 36 объектов для каждого изображения и извлекает 2048 региональных признаков для каждого объекта. Векторы слов извлекаются из 512-дневного двунаправленного LSTM в соответствующих позициях. Кодирование скрытого представления и карты внимания — 1024-d и 128-d соответственно.
Поскольку внимание выполняется на 36 объектах вместо карты объектов, для кодирования результатов внимания мы используем полносвязный слой, а не сверточный слой. В частности, мы объединяем 36-мерные веса внимания с соответствующими 4-мерными координатами ограничивающей рамки, затем сглаживаем их до 36*5-мерного вектора и, наконец, загружаем 180-мерный вектор в полносвязный слой для получения 128-мерного вектора. d кодирование карты внимания.
Для набора данных CLEVR и FigureQA модель обучается с помощью оптимизатора Adam [47] . Базовая скорость обучения составляет 0,0003 для CLEVR и 0,0001 для FigureQA. Размер партии составляет 64 шт. Распад веса, β1 и β2, составляет 0,00001, 0,9 и 0,999 соответственно. Мы обучаем нашу модель на тренировочном сплите, а затем оцениваем проверочный или тестовый сплит.
Для набора данных VQAv2 мы обучаем модель на VQAv2 на разделении обучения и проверки с помощью Adamax [47] со скоростью обучения 0,001 и размером пакета 128,9. 0003
ТАБЛИЦА II: Сравнение точности ответов на вопросы при проверке FigureQA и тестовых наборах с альтернативными цветовыми схемами.
4.3 Сравнение с современными моделями
4.3.1 Набор данных CLEVR
В таблице I показаны характеристики различных работ на тестовом наборе CLEVR. Предыдущая сквозная модульная сеть [6] и механизм выполнения программы [7] называются N2NMN и PE соответственно. Оба подхода используют функциональные программы в качестве основного макета, и они обучают свой анализатор вопросов последовательно от последовательности под строгим контролем. У них также есть варианты, которые обучаются с использованием сигналов с полуконтролем или без контроля. «Скретч N2NMN» указывает на сквозную модульную сеть без контроля компоновки, а «Эксперт по клонированию N2NMN» показывает результаты моделей, обученных с полным контролем. «Поиск политики N2NMN» обеспечивает наилучшие результаты этой модели, если он дополнительно обучает синтаксический анализатор из «эксперта по клонированию N2NMN» с RL. Как показано, наша модель значительно превосходит предыдущие модели без использования макета, специфичного для набора данных, что демонстрирует хорошую обобщаемость PTGRN. PTGRN также превосходит механизм выполнения программ [7] Вариант , обученный с полуприсмотром (как «ПЭ-полу-9К»).
Кроме того, PE-Strong [7] , NS-VQA [9] и TbD+reg+hres [26] использовали дополнительные макеты программ в качестве дополнительных сигналов контроля. RN [45] и FiLM [46] представляют собой модели черного ящика, не поддающиеся интерпретации. PTGRN не только обеспечивает сравнимую точность, но также предоставляет более четкие результаты рассуждений без контроля компоновки конкретного набора данных.
«ACMN» показывает результаты нашей предварительной работы. Он выполняет структурированные рассуждения по дереву зависимостей, но имеет три отличия. 1) Вместо того, чтобы изучать ворота забывания, он отбрасывает карту внимания или скрытое представление в зависимости от того, является ли ребро отношением клаузального предиката или отношением модификатора. 2) Он выполняет слияние между скрытой кодировкой и кодировкой вопроса независимо от типа ребра, но каждый узел разделяет веса только с другими узлами на той же высоте. 3) Он распространяет карту внимания без дополнительного кодирования, а модуль внимания маскирует объект изображения противника на основе карт внимания детей. Как показано, предлагаемые нами модули значительно улучшают производительность на 6,2%.
На рис. 6 показаны многообещающие промежуточные результаты рассуждений, полученные с помощью PTGRN. Изображения и деревья разбора зависимостей показаны слева и внизу. Карта внимания, полученная нашей моделью в каждом узле дерева, отображается справа и сверху. Первый пример показывает, что наша модель может сначала найти «большой металлический объект», в то время как фраза «такая же форма» относится к той же области. Позже наша модель посещает все объекты, кроме металлического объекта, с учетом фразы «любые другие вещи», а фраза «есть ли там» извлекает характеристики посещаемых объектов и предсказывает ответ «нет». Второй пример сначала определяет местонахождение предмета «желтая резина» и не обращает внимания на фразу «маленькие красные шарики», потому что такого предмета на изображении нет. Затем он последовательно посещает «левые» и «блестящие вещи» на основе желтого резинового предмета и предсказывает ответ «да».
4.3.2 Набор данных FigureQA
В таблице II представлены сравнения нашей модели с предыдущими работами над набором данных FigureQA. Базовые методы «Только текст», «CNN+LSTM», «CNN+LSTM на функциях VGG-16» и «RN [45] » были первоначально описаны в [42] . Как показано, PTGRN значительно превосходит все базовые методы, включая реляционную сеть, которая показала высокую производительность на наборе данных CLEVR. Этот результат демонстрирует обобщаемость нашей модели для разных наборов данных.
На рис. 7 показан маршрут рассуждений в наборе данных FigureQA. Первый вопрос касается того, больше ли график фиолетового, чем графика полуночного синего. Наша модель успешно находит темно-синий цвет на первых двух этапах, а затем находит пунктирную фиолетовую линию и предсказывает ответ. Второй пример сначала находит несколько столбцов, которые являются «медианными», а затем посещает столбец «темно-пурпурный», чтобы предсказать, что это нижний медианный столбец.
4.3.3 Набор данных VQAv2
Мы сравниваем нашу модель с современными методами на наборе данных VQAv2. Результаты показаны в таблице III, а промежуточные результаты рассуждений показаны на рисунке 8.
По сравнению с восходящим [48] базовым уровнем, наша модель улучшает общую точность и значительно улучшает ответы на вопросы «Число».
Наша модель не превосходит другие современные модели по следующим двум причинам. Во-первых, в современных современных моделях для достижения высокой точности используется множество методов, таких как множественный взгляд, комплексное внимание и увеличение данных. Эти методы могут применяться в целом и, таким образом, не могут определять вклад конкретной модели.
Во-вторых, наша модель выполняет рассуждения на деревьях синтаксического анализа зависимостей и обрабатывает композиционные рассуждения слов в вопросах, но не получает преимуществ при рассуждениях с одним словом.
Однако, как показано на рис. 8, большинство вопросов в VQAv2 структурно просты. Они не требуют композиционных рассуждений об элементах изображения, но требуют сложных рассуждений на основе здравого смысла, находящихся за пределами изображения. Одним из самых распространенных примеров является слово «почему». Чтобы дать интерпретируемый процесс рассуждений, может потребоваться выполнить многоэтапный вывод на графе знаний здравого смысла, который не включен в набор данных VQAv2.
4.4 Обобщающий тест состава CLEVR
ТАБЛИЦА IV: Сравнение точности ответов на вопросы в проверочном наборе CLEVR-CoGenT. Каждый метод обучается только для условия A и оценивается как для условия A, так и для условия B.Тест обобщения состава CLEVR (CLEVR-CoGenT) [5] был предложен для исследования обобщаемости состава модели VQA. Этот набор данных содержит синтезированные изображения и вопросы, аналогичные CLEVR, но имеет два условия: в условии A все кубы серые, синие, коричневые или желтые, а все цилиндры красные, зеленые, фиолетовые или голубые; в состоянии B кубы и цилиндры меняют цветовые палитры. Таким образом, одна модель не может обеспечить хорошую производительность в условиях B, просто запоминая и подгоняя выборки в условиях A.
Мы сообщаем о точности нашей модели в Таблице IV. «Наша» представляет собой модель, которую мы обучили на наборе данных CLEVR с теми же настройками и гиперпараметрами. Мы обучаем ее на тренировочном наборе, который соответствует условию А, и оцениваем его на проверочном наборе, который соответствует условию А и условию Б. Наша модель достигает точности 97,35 % при условии А и достигает точности 83,50 % при условии В без тонкой настройки. на альтернативном наборе цветовых схем B. Наш метод обеспечивает более высокую точность при условии B, а точность при условии A аналогична PE [7] и FiLM [46] . Этот результат демонстрирует, что наша модель имеет лучшую обобщаемость композиции.
На рис. 9 показаны маршруты рассуждений нашей модели в наборе проверки условия B CLEVR-CoGenT. Мы отображаем изображение и дерево синтаксического анализа слева, а карта внимания на каждом шаге показана справа. Первые вопросы касаются количества фиолетовых блоков и голубых металлических кубиков. Когда «голубых металлических кубиков» нет, первый шаг ничего не меняет, а второй успешно обслуживает три фиолетовых блока. Обратите внимание, что в тренировочном наборе нет фиолетового блока, и наша модель правильно отличает фиолетовые блоки от красного блока. Второй пример следует за разобранным деревом и последовательно посещает «зеленый объект», его «левый» и «серый объект». Серых цилиндров в тренировочном наборе нет, но наша модель может найти «серый» цвет и затем предсказать ответ. Эти примеры показывают, что наша модель может определять местонахождение цвета и объекта по отдельности и что она в определенной степени обладает композиционной обобщаемостью.
4.5 Исследования абляции
| Сравните целое число | Запрос | Сравнить | ||||||||||||
| Метод | Существует | Граф | Равно | Меньше | Еще | Размер | Цвет | Материал | Форма | Размер | Цвет | Материал | Форма | Комбинезон |
| АКМН | 94.20 | 80,46 | 74. 21 | 88,98 | 83,62 | 93.10 | 86,42 | 92.16 | 89,72 | 97,17 | 96,54 | 95,94 | 96,64 | 89.01 |
| базовый уровень | 91.38 | 75,62 | 76,24 | 89.00 | 85,26 | 92,71 | 86.20 | 92,33 | 89.18 | 98,29 | 96.06 | 97,43 | 97.05 | 87,62 |
| + Край | 93,98 | 80.18 | 72,18 | 87,55 | 84,86 | 93,37 | 86,61 | 92,35 | 90,36 | 98,92 | 98.01 | 98.20 | 97,72 | 89,28 |
| + Край + ГРУ | 95,23 | 82,62 | 83,93 | 92.04 | 91,89 | 92,61 | 85,92 | 92,23 | 89,44 | 98,56 | 98,37 | 97,88 | 97,69 | 90,44 |
| +Эдж+КонкатАтт | 96,38 | 85,51 | 86,28 | 95,37 | 93,81 | 95,99 | 95,22 | 95,37 | 94,48 | 98,74 | 97,59 | 98. 12 | 97,66 | 93,36 |
| + Край + ГРУ + ConcatAtt | 95,81 | 86,31 | 85,44 | 94,90 | 93.13 | 96.03 | 96.12 | 95,58 | 94.06 | 98,72 | 98,32 | 98.23 | 97,88 | 93,53 |
| +Эдж+ГРУ+ГРУат | 96,80 | 87,50 | 89.00 | 96.04 | 95,33 | 96,76 | 96.18 | 96,31 | 95.11 | 99,39 | 98,76 | 98,27 | 98.03 | 94,42 |
| + Край + ГРУ + ConvGRUAtt | 97,83 | 91,78 | 92.08 | 96.00 | 96.46 | 95,90 | 94.00 | 95,46 | 96,15 | 99.30 | 98,32 | 98,52 | 98,19 | 95,42 |
Мы постепенно заменяем компоненты базовой модели переработанными модулями и сообщаем их результаты по каждой строке.
ТАБЛИЦА VI: Точность проверки CLEVR для PTGRN с другой кодировкой слов и предоставленным макетом.Сначала мы сравним производительность с переработанными компонентами и без них в нашей модели. Мы постепенно добавляем модули в базовую модель и показываем точность на проверочном наборе CLEVR в таблице V.
ACMN Модульная сеть состязательной композиции (ACMN), представленная в предварительной работе, выполняет структурированные рассуждения по общему дереву синтаксического анализа зависимостей. В каждом узле он сначала извлекает локальные визуальные доказательства с помощью модуля внимания противника: функция изображения маскируется ReLU(1-~att), где ~att — сумма карт внимания детей; затем функция замаскированного изображения объединяется с встраиванием слов и свертывается в одномерную карту внимания att. Затем посещаемый локальный признак изображения v составляется из суммы скрытого представления дочерних элементов ~h: он генерирует остаток, применяя полносвязный слой к конкатенированному [v,~h]; затем остаток добавляется к ~h и объединяется с кодировкой вопроса, и в результате получается текущий скрытый h. Наконец, карта внимания att распространяется на своего родителя, если тип ребра принадлежит модификаторному отношению, или hidden h распространяется, если ребро является клаузальным предикативным отношением. Каждый узел будет разделять веса с другими узлами на той же высоте.
Базовая модель. По сравнению с ACMN, в базовую модель внесены следующие изменения: 1) каждый узел теперь разделяет свои веса с другими узлами на разных высотах в проанализированном дереве и 2) модуль внимания со стороны противника заменен на предложенный, описанный в разделе 3.2. . Чтобы выполнить исследования абляции на PTGRN, мы заменяем каждый модуль в базовой модели предлагаемыми нами компонентами и оцениваем их постепенно.
Распространение в зависимости от края “+Edge” выполняет дополнительные преобразования функций в зависимости от края между дочерними и родительскими элементами. Эти изменения повышают производительность на 0,27% по сравнению с ACMN и упрощают применение модели к различным наборам данных без корректировки максимальной высоты дерева. Более того, повторное использование одного и того же модуля для выполнения одних и тех же задач более целесообразно, а точность повышается на 1,66% по сравнению с базовой моделью.
Невязка со стробированием Мы исследуем влияние модуля невязки со стробированием, сравнивая точность с точностью модели «+Edge».
Модель «+Edge» строит добытое визуальное свидетельство vj и сообщение ~h его дочерних узлов, объединяя их и выполняя линейное преобразование с полностью связанным слоем, в то время как модель «+Edge+GRU» заменяет его на GRU, где vj соответствует текущему вводу, а сообщение является памятью. Добавление ГРУ повышает точность на 1,16%. Этот результат говорит о том, что модуль GRU стабилизировал повторяющийся процесс и улучшил производительность.
Если карта внимания закодирована в виде скрытого представления, то то, закрыто ли входящее сообщение, мало повлияет на производительность. С забытыми воротами точность увеличивается с 9от 3,36% до 93,53%, как показано в «+Edge+ConcatAtt» и «+Edge+GRU+ConcatAtt».
Кодирование карты внимания Существует несколько методов кодирования карты внимания как скрытого представления. Мы оцениваем несколько методов и сообщаем о точности их ответов в таблице V.
Первый метод заключается в выравнивании карты внимания, применении линейного слоя и объединении полученного вектора со скрытым и распространении его на родительский элемент. В случае с набором данных CLEVR карта внимания 14∗14 attj сглаживается до 196-мерный вектор и спроецированный на 128-мерный объект hattj с двумя полносвязными слоями. Затем он объединяется с добытыми визуальными доказательствами vj. Точность сообщается как «+Edge+ConcatAtt» и «+Edge+GRU+ConcatAtt», где первый составляет текущие скрытые [vj,hattj] и вводит скрытые ~h, объединяя их, как в предварительной работе. В «+Edge+GRU+ConcatAtt» мы составляем [vj,hattj] и ~h с модулем GRU, как описано в разделе 3.3. Оба метода передают исходную карту внимания attj ее родителю. «+Edge+ConcatAtt» достигает 9Общая точность 3,36%. «+Edge+GRU+ConcatAtt» достигает 93,53 %, что немного выше 93,36 %, полученных моделью без GRU. Судя по точности для каждого типа вопроса, мы видим, что «+Edge+ConcatAtt» работает немного лучше в вопросах «сравнить целочисленные». Эти результаты показывают, что совместное обновление закодированной карты внимания и скрытого представления повредит счетной способности нашей модели.
Второй метод исследует влияние отдельных модулей на карту внимания. Мы проводим эксперимент, обозначенный как «+Edge+GRU+GRUAtt». Этот метод также сначала сглаживает карту внимания до 196-мерный вектор. Затем этот вектор используется для обновления входного признака внимания ~attj с помощью другого GRU, а не для объединения его с добытыми визуальными свидетельствами vj. Выходное скрытое представление ГРУ hattj будет распространено на его родительский узел k на основе ребра ejk. Наконец, закодированная карта внимания к корневому узлу maroot будет объединена со скрытым mhroot и передана в классификатор для предсказания ответа. Он достигает общей точности 94,42% на проверочном наборе, что повышает точность базового уровня «+Edge+GRU+ConcatAtt» на 0,89.%, иллюстрируя необходимость обработки карты внимания и скрытого представления с разными весами. Этот результат также согласуется с нашей предварительной моделью, которая по-разному обрабатывает карту внимания и скрытое представление в зависимости от того, является ли ребро отношением-модификатором или отношением клаузального предиката.
Последний подход — это наша полная модель, о которой сообщается как «+Edge+GRU+ConvGRUAtt». По сравнению со вторым, этот подход использует сверточный GRU для сохранения пространственной информации и распространения карт признаков по дереву. Мы выполняем глобальное максимальное объединение на карте функций maroot и объединяем ее со скрытым представлением, чтобы предсказать окончательный ответ. Он выигрывает 1% по сравнению со вторым подходом в наборе проверки. Показано, что сохранение пространственной информации приведет к повышению производительности.
Двунаправленное кодирование сокращенных слов В нашей реализации мы удалили конечные узлы, которые не являются существительными, чтобы уменьшить вычислительную нагрузку. Таким образом, мы можем игнорировать определяющие слова и предлоги, такие как «the» и «of». Однако этот метод также сокращает некоторые слова-модификаторы, такие как «большой» и «металлический» на рисунке 6. Поскольку модификаторы находятся рядом со словами объекта, мы используем двунаправленный LSTM для извлечения скрытых представлений, которые кодируют как модификаторы, так и слова объекта. Мы обучаем два варианта, которые используют таблицу поиска и LSTM для извлечения кодировок слов. Результаты представлены в Таблице VI и обозначены как «PTGRN (поиск)» и «PTGRN (LSTM)» соответственно. Кодирование таблицы поиска, в котором не учитывались контексты, привело к значительному падению точности с 95,42% до 87,75%. LSTM может кодировать слова-модификаторы, предшествующие объекту, поэтому его производительность немного снижается на 3,6%.
Наземная схема программы Мы также исследуем эффективность наших нейронных модулей, предоставляя наземные схемы программы. Макеты программы используются для генерации вопросов в CLEVR и строятся путем объединения набора основных функций в древовидную/цепочечную структуру. Каждая функция выполняет один тип операции на основе входных данных объекта и входных значений. Например, функции с типом «filter_color» и значением «синий» выводят подмножество синих входных объектов.
Учитывая макеты программы, мы выполняем структурированные рассуждения, рассматривая каждую функцию как узел и применяя наш нейронный модуль. Учитывая функцию i, мы кодируем входное значение с помощью таблицы поиска и используем результат как кодировку слова wi; мы используем тип функции как eij, где j — последующая функция. Результаты обозначены как «PTGRN (компоновка GT)» в Таблице VI. Показано, что наша модель может достигать хороших результатов по сравнению с другими методами, в которых использовалась эта аннотация макета.
Сравнение качества. Далее мы сравниваем результаты рассуждений, полученные ACMN и PTGRN, на рисунке 10. В верхней части показана тепловая карта, предоставленная ACMN, а в нижней части — результаты PTGRN. Первый вопрос запрашивает количество конкретных объектов. ACMN правильно посещает «красные резиновые» предметы, но находит только один из синих предметов; PTGRN также нашла «красную резину» и определила местонахождение всех объектов с помощью фраз «вещей» и «какое количество». Наконец, PTGRN посещает два синих объекта, далеких от «красной резины» на последнем шаге. Второй пример иллюстрирует процесс нахождения «большого предмета» и «металлического шара». Хотя обе модели добывали соответствующие объекты на каждом этапе, PTGRN может точно определить местоположение этих объектов.
| Метод | MAC [27] | ПТГРН | TbD+reg+hres [26] | ПТГРН (компоновка ГТ) |
| Точность | 32,72 | 64,71 | 77. 11 | 91,85 |
4.6 Оценка интерпретируемости
Мы оцениваем и сравниваем интерпретируемость нашей модели с интерпретируемостью предыдущего метода, вычисляя, насколько хорошо сгенерированная карта внимания соответствует ограничивающим прямоугольникам.
В частности, набор данных CLEVR предоставляет функциональные макеты программ для каждого вопроса. Макеты программы состоят из функций, и некоторые функции выводят наборы объектов. Учитывая набор выходных объектов функции и карту внимания, мы суммируем нормализованный вес внимания внутри ограничивающих рамок объектов как точность внимания для этой функции. Мы оцениваем интерпретируемость модели, усредняя точность внимания по всем функциям в макетах программы.
Для MAC [27] и наши методы, процессы рассуждения отличаются от макетов программы. Таким образом, для каждой функции мы используем карту внимания, которая обеспечивает максимальную точность внимания в качестве точности для этой функции. Результаты представлены в Таблице VII. Учитывая наземные макеты, наша модель достигает лучших результатов, чем TbD [26] ; Наша модель также превосходит MAC [27] на 31,99 %, если не заданы наземные схемы, что демонстрирует интерпретируемость нашей модели.
4.7 Возмущенная древовидная структура
Поскольку наша модель опирается на результаты анализа синтаксического анализатора, мы проводим эксперименты для изучения влияния неправильно проанализированных деревьев. Мы случайным образом искажаем сгенерированные деревья зависимостей, чтобы наблюдать, как это повлияет на окончательный прогноз. В частности, мы случайным образом возмущаем каждое отношение зависимости с определенной вероятностью, заменяя его родительский узел и ребро отношения словом, случайно выбранным из предложения и возможных отношений соответственно. Результаты перечислены в Таблице VIII. Как показано, производительность резко снижается по мере увеличения количества возмущенных отношений. Этот результат указывает на то, что результаты синтаксического анализа имеют решающее значение для производительности.
5. Вывод
В этой статье мы предлагаем новую сеть рассуждений, управляемую деревом синтаксического анализа (PTGRN), оснащенную модулем внимания, вентилируемым модулем остаточной композиции и модулем распространения, управляемым деревом синтаксического анализа. В отличие от предыдущих работ, которые полагаются на аннотации или созданные вручную правила для выполнения явных композиционных рассуждений, наша модель PTGRN может автоматически выполнять интерпретируемый процесс рассуждений по общему дереву синтаксического анализа зависимостей на основе вопроса, что может значительно расширить области ее применения. Модуль внимания побуждает модель посещать локальные визуальные свидетельства, модуль закрытой остаточной композиции может научиться составлять и обновлять знания из своих дочерних узлов, а модуль распространения, управляемый деревом синтаксического анализа, генерирует и распространяет информацию, зависящую от края, от дочерних узлов. своим родителям.
Эксперименты показывают, что PTGRN может достичь современной производительности VQA и хорошей интерпретируемости без использования каких-либо конкретных макетов или сложных правил, созданных вручную.
Каталожные номера
- [1] М. Малиновский, М. Рорбах и М. Фриц, «Спросите свои нейроны: подход к ответам на вопросы об изображениях», в ICCV , 2015, стр. 1–9.
- [2] Дж. Лу, Дж. Ян, Д. Батра, Д. Парих, “Иерархический вопрос-образ совместное внимание для визуальных ответов на вопросы», в NIPS , 2016, стр. 289–297.
- [3] Ж.-Х. Ким, К. В. Он, Дж. Ким, Дж. Ха и Б.-Т. Чжан, «Продукт Адамара для билинейное объединение низкого ранга», CoRR , том. абс/1610.04325, 2016.
- [4] Ю. Гоял, Т. Хот, Д. Саммерс-Стэй, Д. Батра, Д. Парих, «Создание V в вопросе VQA: Повышение роли понимания изображения в визуальном Ответ на вопрос», в CVPR , 2017.
- [5] Дж. Джонсон, Б. Харихаран, Л. ван дер Маатен, Л. Фей-Фей, К. Л. Зитник и
Р. Гиршик, «CLEVR: диагностический набор данных для композиционного языка и
элементарное визуальное мышление», в CVPR , 2017.
- [6] Р. Ху, Дж. Андреас, М. Рорбах, Т. Даррелл, К. Саенко, «Учимся причина: Сквозные модульные сети для визуальных ответов на вопросы», в МСКВ , 2017.
- [7] Дж. Джонсон, Б. Харихаран, Л. ван дер Маатен, Дж. Хоффман, Ф. Ли, К. Л. Зитник, и Р. Б. Гиршик, «Вывод и выполнение программ для визуальных рассуждения», в ICCV , 2017.
- [8] Д. Тени, Л. Лю, А. ван ден Хенгель, “Представления структурированных графов для визуальные ответы на вопросы», в CVPR , июль 2017 г.
- [9]
К. Йи, Дж. Ву, К. Ган, А. Торральба, П. Кохли и Дж. Тененбаум,
«Нейро-символическая vqa: отделение рассуждений от видения и языка.
понимания», в NIPS , С. Бенжио, Х. Уоллах, Х. Ларошель,
К. Грауман, Н. Чеза-Бьянки и Р. Гарнетт, ред. Curran Associates, Inc., 2018 г., стр. 1031–1042.
- [10] С. Антол, А. Агравал, Дж. Лу, М. Митчелл, Д. Батра, К. Л. Зитник и Д. Парих, «VQA: визуальные ответы на вопросы», в ICCV , 2015 г.
- [11] И. Илиевски, С. Ян, Дж. Фэн, “Модель сфокусированного динамического внимания для визуальные ответы на вопросы», CoRR , vol. абс/1604.01485, 2016.
- [12] Х. Сюй и К. Саенко, Спрашивайте, посещайте и отвечайте: изучение с помощью вопросов Пространственное внимание для визуальных ответов на вопросы . Чам: Springer International Publishing, 2016, стр. 451–466.
- [13] К. Дж. Ши, С. Сингх и Д. Хойем, «Где искать: области фокусировки для визуального ответ на вопрос», в CVPR , 2016.
- [14] Ю. Чжу, О. Грот, М. С. Бернстайн и Л. Фей-Фей, «Visual7w: обоснованный ответы на вопросы в изображениях», в CVPR , 2016, стр. 49.95–5004.
- [15] З. Ян, С. Хе, Дж. Гао, Л. Дэн и А. Смола, «Сети с накоплением внимания для
ответ на вопрос изображения», в CVPR , июнь 2016 г. , стр. 21–29.
- [16] А. Фукуи, Д. Х. Парк, Д. Ян, А. Рорбах, Т. Даррелл и М. Рорбах, «Мультимодальное компактное билинейное объединение для визуальных ответов на вопросы и визуальное заземление», в EMNLP , 2016, стр. 457–468.
- [17] З. Ю, Дж. Ю, Дж. Фан, Д. Тао, «Мультимодальное факторизованное билинейное объединение с обучением совместному вниманию для визуальных ответов на вопросы» ICCV , стр. 1839–1848 гг., 2017 г.
- [18] Х. Бен-юнес, Р. Каден, М. Корд и Н. Томе, «Мутан: мультимодальный сборщик fusion для визуальных ответов на вопросы», в ICCV , октябрь 2017 г.
- [19] А. Джабри, А. Джоулин и Л. ван дер Маатен, «Пересматривая визуальный вопрос ответы на исходные данные», в ECCV , сер. Конспекты лекций на компьютере Наука, том. 9912. Спрингер, 2016 г., стр. 727–739.
- [20]
А. Кумар, О. Ирсой, П. Ондруска, М. Ийер, Дж. Брэдбери, И. Гулраджани, В. Чжун,
Р. Паулюс и Р. Сохер, «Спросите меня о чем угодно: сети динамической памяти для
обработка естественного языка», в ICML , 2016, стр. 1378–1387.
- [21] П. Ван, К. Ву, К. Шен, А. ван ден Хенгель и А. Р. Дик, «FVQA: визуальные ответы на вопросы, основанные на фактах», CoRR , vol. абс/1606.05433, 2016.
- [22] Ю. Чжу, Дж. Дж. Лим и Л. Фей-Фей, «Приобретение знаний для визуальных вопросов». Ответ через итеративный запрос», в CVPR , 2017.
- [23] К. Сюн, С. Мерити и Р. Сочер, «Сети динамической памяти для визуального и текстовый ответ на вопрос», в ICML , 2016 г., стр. 2397–2406.
- [24] Дж. Андреас, М. Рорбах, Т. Даррелл и Д. Кляйн, «Нейронные модульные сети». в CVPR . IEEE-компьютер Общество, 2016. С. 39–48.
- [25] ——, «Учимся составлять нейронные сети для ответов на вопросы», в HLT-NAACL . Ассоциация для компьютерной лингвистики, 2016 г., стр. 1545–1554.
- [26]
Д. Масчарка, П. Тран, Р. Сокласки и А. Маджумдар, «Прозрачность по замыслу:
Сокращение разрыва между производительностью и интерпретируемостью в визуальном
рассуждения», в CVPR , июнь 2018 г.
- [27] Д. А. Хадсон и К. Д. Мэннинг, «Сети композиционного внимания для машинных рассуждения», в ICLR , 2018.
- [28] Р. Ху, Дж. Андреас, Т. Даррелл и К. Саенко, «Объяснимые нейронные вычисления через сети нейронных модулей стека», в ECCV , сентябрь 2018 г.
- [29] Лемпицкий В. С., Зиссерман А. Учимся считать предметы на изображениях. НИПС . Курран Ассошиэйтс, Inc., 2010, стр. 1324–1332.
- [30] К. Чжан, Х. Ли, С. Ван и С. Ян, «Подсчет толпы через сцену с помощью глубокого сверточные нейронные сети», в CVPR . Компьютерное общество IEEE, 2015 г., стр. 833–841.
- [31] Д. Оноро-Рубио и Р. Х. Лопес-Састре, «На пути к бесперспективный подсчет объектов с глубоким обучением», в ECCV (7) , сер. Конспект лекций по информатике, том. 9911. Springer, 2016, стр. 615–629.
- [32] Дж. Чжан, С. Ма, М. Самеки, С. Скларофф, М. Бетке, З. Линь, С. Шен, Б. Л.
Прайс и Р. Мех, «Выделение существенных объектов», стр. 9.0094 Международный
Журнал компьютерного зрения , том. 124, нет. 2, стр. 169–186, 2017.
- [33] П. Чаттопадхьяй, Р. Ведантам, Р. Р. Селвараджу, Д. Батра и Д. Парих, «Подсчет повседневных предметов в повседневных сценах», в CVPR . Компьютерное общество IEEE, 2017 г., стр. 4428–4437.
- [34] П. Андерсон, X. Хе, К. Бюлер, Д. Тени, М. Джонсон, С. Гулд и Л. Чжан, «Внимание снизу вверх и сверху вниз для подписи к изображению и визуального вопроса отвечаю», препринт arXiv arXiv:1707.07998 , 2017.
- [35] Р. Кришна, Ю. Чжу, О. Грот, Дж. Джонсон, К. Хата, Дж. Кравиц, С. Чен, Ю. Калантидис, Л.-Дж. Ли, Д. А. Шамма, М. С. Бернштейн, Л. Фей-Фей, «Визуальный геном: соединение языка и зрения с помощью плотных краудсорсинговых аннотации изображений», International Journal of Computer Vision , vol. 123, нет. 1, стр. 32–73, май 2017 г. [Онлайн]. Доступный: https://doi.org/10.1007/s11263-016-0981-7
- [36] А. Тротт, К. Сюн и Р. Сочер, «Интерпретируемый счет для визуальных вопросов
отвечаю», CoRR , том. абс/1712.08697, 2017.
- [37] Ю. Чжан, Дж. Хэйр и А. Прюгель-Беннетт, «Учимся считать предметы в естественные изображения для визуальных ответов на вопросы», в ICLR , 2018.
- [38] Д. Чен и К. Д. Мэннинг, «Быстрый и точный синтаксический анализатор зависимостей с использованием нейронных сетях», в EMNLP , 2014.
- [39] К. Хе, С. Чжан, С. Рен и Дж. Сун, «Глубокое остаточное обучение для изображений признание», в CVPR . Компьютерное общество IEEE, 2016 г., стр. 770–778.
- [40] Дж. Чанг, Ч. Гюльчере, К. Чо и Ю. Бенжио, «Эмпирический оценка закрытых рекуррентных нейронных сетей при моделировании последовательностей», CoRR , том. абс/1412.3555, 2014.
- [41] К. С. Тай, Р. Сочер, К. Д. Мэннинг, «Улучшенные семантические представления
из древовидных сетей долговременной кратковременной памяти», в ACL
(1) . Ассоциация компьютеров
Лингвистика, 2015. С. 1556–1566.
- [42] С. Э. Кахоу, А. Аткинсон, В. Михальски, А. Кадар, А. Тришлер и Ю. Бенжио, «Фигураqa: набор данных с аннотациями для визуальное мышление» CoRR , том. абс/1710.07300, 2017.
- [43] Т.-Ю. Лин, М. Мэр, С. Белонги, Дж. Хейс, П. Перона, Д. Раманан, П. Доллар и К. Л. Зитник, Microsoft COCO: общие объекты в Контекст . Чам: Springer International Издательство, 2014 г., стр. 740–755.
- [44] К. Чжу, Ю. Чжао, С. Хуанг, К. Ту и Ю. Ма, «Структурированное внимание для визуальных ответ на вопрос», в ICCV , октябрь 2017 г.
- [45] А. Санторо, Д. Рапозо, Д. Г. Т. Барретт, М. Малиновски, Р. Паскану, П. Батталья и Т. П. Лилликрап, «Простой модуль нейронной сети для реляционное рассуждение» CoRR , том. абс/1706.01427, 2017.
- [46]
Э. Перес, Ф. Струб, Х. де Фрис, В. Дюмулен и А. К. Курвиль, «Фильм:
Визуальные рассуждения с общим кондиционирующим слоем», в AAAI . АААИ Пресс, 2018.
- [47] Д. П. Кингма, Дж. Ба, «Адам: метод стохастической оптимизации», сб. ICLR , 2015.
- [48] Д. Тени, П. Андерсон, Х. Хе и А. ван ден Хенгель, «Советы и рекомендации по визуальные ответы на вопросы: уроки 2017 года», СоRR , об. абс/1708.02711, 2017.
- [49] Ж.-Х. Ким, Дж. Джун и Б.-Т. Чжан, «Билинейные сети внимания», в NIPS , 2018 г., стр. 1571–1581.
Цинсин Цао Цинсин Цао в настоящее время является постдокторантом в Школе разработки интеллектуальных систем Университета Сунь Ятсена, где работает с профессором Сяодань Ляном. Он получил докторскую степень. степень Университета Сунь Ятсена в 2019 году, по рекомендации профессора Лян Линя. Его текущие исследовательские интересы включают компьютерное зрение и визуальные ответы на вопросы. |
Байлин Ли
Байлин Ли получил степень B. |
Сяодань Лян
Сяодань Лян в настоящее время является адъюнкт-профессором Университета Сунь Ятсена. С 2016 по 2018 год она работала постдокторантом в отделе машинного обучения в Университете Карнеги-Меллон, работая с профессором Эриком Сином. Она получила степень доктора философии в Университете Сунь Ятсена в 2016 году по рекомендации Лян Линь. Она опубликовала несколько передовых проектов по анализу, связанному с человеком, включая синтаксический анализ человека, обнаружение пешеходов и сегментацию экземпляров, оценку позы человека в 2D / 3D и распознавание активности. |
Лян Линь
Лян Линь — генеральный директор DMAI Great China и профессор компьютерных наук Университета Сунь Ятсена. Он занимал должность исполнительного директора SenseTime Group с 2016 по 2018 год, руководя группами исследований и разработок по разработке передовых и эффективных решений в области компьютерного зрения, анализа и добычи данных, а также интеллектуальных роботизированных систем. Он является автором или соавтором более 200 статей в ведущих научных журналах и на конференциях (например, TPAMI/IJCV, CVPR/ICCV/NIPS/ICML/AAAI). Он является помощником редактора IEEE Trans, Human-Machine Systems и IET Computer Vision, а также председательствовал на многочисленных конференциях, таких как CVPR, ICME, ICCV, ICMR. Он был лауреатом ежегодной премии за лучшую статью от Pattern Recognition (Elsevier) в 2018 году, премии Даймонда за лучшую статью в IEEE ICME в 2017 году, награды ACM NPAR за лучшую статью, занявшей второе место в 2010 году, премии Google факультета в 2012 году, награда за лучший студенческая работа в IEEE ICME в 2014 году и премия ученых Гонконга в 2014 году. |
Патент США на системы и методы повышения эффективности синтаксического и семантического анализа в автоматизированных процессах понимания естественного языка с использованием общей композиции. Патент (Патент № 9,594,745, выдан 14 марта 2017 г.)
Настоящая заявка испрашивает преимущества предварительной заявки на патент США № 61/771,105, поданной 1 марта 2013 г. и озаглавленной «СИСТЕМЫ И МЕТОДЫ ДЛЯ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ СИНТАКСИЧЕСКОГО И СЕМАНТИЧЕСКОГО АНАЛИЗА В АВТОМАТИЗИРОВАННЫХ ПРОЦЕССАХ ДЛЯ ПОНИМАНИЯ ЕСТЕСТВЕННОГО ЯЗЫКА», содержание которой настоящим включено сюда посредством ссылки во всей своей полноте. Эта заявка связана с заявкой на патент США Ser. № 14/1, поданной одновременно с настоящим документом и озаглавленной «СИСТЕМЫ И МЕТОДЫ ДЛЯ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ СИНТАКСИЧЕСКОГО И СЕМАНТИЧЕСКОГО АНАЛИЗА В АВТОМАТИЗИРОВАННЫХ ПРОЦЕССАХ ПОНИМАНИЯ ЕСТЕСТВЕННОГО ЯЗЫКА», содержание которой настоящим полностью включено в настоящий документ посредством ссылки. В этой заявке заявлено преимущество заявки на патент США Ser. № 14/195,500, поданный одновременно с настоящим документом и озаглавленный «СИСТЕМЫ И МЕТОДЫ ДЛЯ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ СИНТАКСИЧЕСКОГО И СЕМАНТИЧЕСКОГО АНАЛИЗА В АВТОМАТИЗИРОВАННЫХ ПРОЦЕССАХ ДЛЯ ПОНИМАНИЯ ЕСТЕСТВЕННОГО ЯЗЫКА С ИСПОЛЬЗОВАНИЕМ АРГУМЕНТИРОВАНИЯ ПОРЯДКА АРГУМЕНТОВ», содержание которого настоящим включено в настоящее описание посредством ссылки во всей своей полноте. В этой заявке заявлено преимущество заявки на патент США Ser. № 14/195,529, поданной одновременно с настоящим и озаглавленной «СИСТЕМЫ И МЕТОДЫ ДЛЯ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ СИНТАКСИЧЕСКОГО И СЕМАНТИЧЕСКОГО АНАЛИЗА В АВТОМАТИЗИРОВАННЫХ ПРОЦЕССАХ ПОНИМАНИЯ ЕСТЕСТВЕННОГО ЯЗЫКА С ИСПОЛЬЗОВАНИЕМ ПЕРЕМЕЩАЮЩИХСЯ ФУНКЦИЙ», содержание которой настоящим включено в настоящее описание посредством ссылки во всей своей полноте.
ОБЛАСТЬ ТЕХНИКИ
Настоящее раскрытие относится к пониманию естественного языка. Более конкретно, настоящее раскрытие относится к повышению эффективности синтаксического и семантического анализа в автоматизированных процессах для понимания естественного языка.
ПРЕДПОСЫЛКИ
Понимание естественного языка (NLU) имеет целью программирование компьютеров для имитации понимания компьютерами естественных языков, чтобы они могли выполнять действия, связанные с языком, включая ответы на вопросы, нахождение определенных видов фактов в обычном «неструктурированном» текст и вести диалог с людьми на естественном языке. Вообще говоря, есть два подхода к NLU, символический и статистический, хотя их комбинации часто оказываются лучшими. Символический подход обычно включает методы, основанные на правилах, и язык представления знаний (KRL), такой как лямбда-исчисление или исчисление предикатов. Символьные системы NLU анализируют значение английских выражений в процессе построения выражений в своих KRL. Эти выражения KRL представляют значение введенного английского языка таким образом, который обычно менее двусмыслен, чем введенный английский язык, и таким образом, который впоследствии может использоваться компьютерами для вывода и анализа. Естественные языки, такие как английский, по своей природе неоднозначны во многих отношениях. Большая часть проблем при разработке систем NLU связана с поиском способов надлежащим образом и эффективно уменьшить или устранить такую неоднозначность при построении структур данных KRL.
Конечной целью NLU является предоставление компьютерным программам возможности понимать и общаться с помощью устной и письменной речи, по крайней мере, так же, как взрослые носители естественного языка общаются друг с другом. Современное состояние техники далеко от достижения этой цели, хотя современные технологии хорошо справляются с ограниченными или специализированными приложениями, такими как ответы на вопросы по заранее определенному набору тем, поиск документов или предложений, связанных с данной фразой или фразой. ключевые слова или ограниченное взаимодействие с пользователем-человеком для бронирования авиабилетов. Даже ранние системы могли понимать язык далеко за пределами своих реальных возможностей, потому что пользователи склонны видеть человеческий интеллект там, где его нет. Например, ранняя программа NL имитировала работу психолога и задавала такие вопросы, как «Как вы себя чувствуете при этом?». Эта система просто сопоставляла части входных утверждений от пользователя с готовым списком ответов и использовала несколько стандартных фраз, таких как «Расскажите мне об этом подробнее», чтобы вернуться, когда совпадений не было найдено.
Когда компьютерные программы могут: (1) вести постоянный диалог, (2) отслеживать текущую тему и изменения в этой теме, (3) инициировать и реагировать на цели коммуникации надлежащим образом, (4) делать соответствующие выводы во время диалог, (5) справляться со многими небуквальными употреблениями языка, такими как метафора, (5) понимать, что другие участники диалога, вероятно, понимают или должны знать, и (6) должным образом догадываться о том, каковы коммуникативные цели другой стороны. участники диалога могут быть по ходу диалога, это может быть признаком того, что мы приближаемся к достижению конечной цели NLU. Все эти аспекты общения на естественном языке исследуются в академическом сообществе. Утверждалось, что NLU является «искусственным интеллектом завершенным», что означает, что для достижения этой общей цели NLU необходимо будет решить большинство целей более широкой области искусственного интеллекта.
Многие из этих критериев производительности в настоящее время могут быть достигнуты для специализированных приложений, где цели диалога и самого языка ограничены. Ключевым показателем того, что системы NLU достигли чего-то, сравнимого с компетенцией человеческого уровня, может быть их способность выполнять перечисленные действия с неограниченным разнообразием предметов, как это могут делать люди. Конечно, прогресс в любой области может привести к появлению новых коммерческих приложений. Кроме того, прогресс в расширении универсальности систем NLU означает, что для решения новых задач необходимо разрабатывать (или разрабатывать с нуля) меньше новых отдельных коммерческих продуктов. Ценность успешной разработки более широких систем NLU легко оправдывает затраты на сбор дополнительных знаний, необходимых для поддержки их работы. Ключевым моментом является демонстрация того, что менее специализированная система может поддерживать новые приложения, когда ее словарный запас и знания достаточно велики. Подобные аргументы приводились и в отношении еще более амбициозной цели создания общего искусственного интеллекта.
Примерно за последние два десятилетия во многих исследованиях NLU особое внимание уделялось статистическому анализу, прежде всего, чтобы свести к минимуму или избежать применения больших наборов ручных правил о структуре и использовании языка, сбор которых является трудоемким. В отличие от символических подходов или подходов, основанных на правилах, эти статистические подходы стремятся избежать зависимости от больших коллекций общих знаний здравого смысла, знаний, специфичных для предметной области, и подробных спецификаций грамматики, полученных вручную или полуавтоматически. Ограничения символических подходов, на которые часто ссылаются сторонники статистических подходов, включают изменяющийся и расширяющийся характер правильной грамматики и словарного запаса, а также трудоемкий характер спецификации только что описанного вида сложных декларативных знаний.
Статистические подходы имеют свои ограничения. Некоторые статистические методы пытаются обучить систему естественного языка на основе «тренировочного набора» аннотированных вручную наборов примеров задач и решений. Эти аннотации могут варьироваться от синтаксических категорий слов и фраз до различных «тегов», указывающих семантическую информацию. В отличие от этого, «неконтролируемые» методы обучения требуют, чтобы система достигла желаемой производительности, обучаясь на примерах пар «задача-решение» без предоставления каких-либо аннотаций. Область, связанная со способами обучения компьютерных программ таким образом, называется «машинное обучение».
Некоторые приложения ЕЯ, такие как перевод с одного естественного языка на другой, могут достигать довольно высокой производительности (по крайней мере, при первом проходе перед проверкой опытными переводчиками) без построения каких-либо выражений на языке представления знаний. Следовательно, статистические методы подходят для многих задач перевода. Другие приложения, такие как ответы на вопросы, значительно выигрывают от использования KRL. KRL может отражать детали NL, такие как количественная оценка утверждений и их отрицание. Такие лингвистические особенности являются ключевыми для ответа на вопрос. Машинная склонность с трудом справляется с такими особенностями при отсутствии КРЛ. Недавно по крайней мере одна исследовательская группа начала сочетать машинное обучение с построением KRL, используя пары «задача-решение», которые включают небольшое количество созданных вручную шаблонов выражений в KRL, которые имеют связанные параметры. При определении значений параметров их шаблонов результирующие выражения напоминают исчисление предикатов. Для их системы задача машинного обучения состоит в том, чтобы сопоставить выражения на естественном языке с этими шаблонами с подставленными правильными значениями параметров, в результате чего в их KRL будет полностью заданное выражение. Одной из их главных задач было разработать шаблоны так, чтобы существующие алгоритмы машинного обучения были эффективными.
Ввиду вышеизложенного желательно предоставить системы и способы для повышения эффективности синтаксического и семантического анализа в автоматизированных процессах для NLU.
РЕЗЮМЕ
Это резюме представлено для ознакомления с набором концепций в упрощенной форме, которые дополнительно описаны ниже в подробном описании. Это краткое изложение не предназначено для определения ключевых признаков или существенных признаков заявленного предмета, а также не предназначено для использования для ограничения объема заявленного предмета.
В настоящем документе раскрыты системы и способы для повышения эффективности синтаксического и семантического анализа в автоматизированных процессах понимания естественного языка, для обеспечения возможности использования более простой грамматики естественного языка и для обеспечения возможности использования стандартизированных логических представлений значения частично для получить некоторые преимущества семантических грамматик (часто связанных с ограниченными областями применения) для систем NLU, которые не ограничены какими-либо конкретными областями применения. В связи с этим в одном варианте осуществления способ включает использование процессора и памяти для получения фразы на естественном языке, содержащей по меньшей мере один токен. Способ дополнительно включает получение множества последовательностей тематических ролей, где каждая из множества последовательностей тематических ролей соответствует последовательности аргументов-предикатов. Способ дополнительно включает применение множества последовательностей тематических ролей к предикативному выражению на естественном языке. Способ дополнительно включает перевод фразы на естественном языке в предикативное выражение на искусственном языке на основе применения множества последовательностей тематических ролей к предикативному выражению на естественном языке.
В связи с этим в другом варианте осуществления способ включает процессор и память для получения спецификации по меньшей мере одного элемента первого правила грамматики в качестве источника перемещаемого элемента. Способ дополнительно содержит получение процесса вычисления значения движущегося признака, связанного по меньшей мере с одним первым элементом правила грамматики. Способ дополнительно включает связывание части выражения естественного языка с одним из по меньшей мере одного элемента первого правила грамматики. Способ дополнительно содержит применение процесса вычисления значения перемещающегося признака к одному из по меньшей мере одного элемента первого грамматического правила и к части выражения естественного языка для идентификации любых первых значений перемещающегося признака. Способ дополнительно содержит построение первого узла на основе применения процесса вычисления значения движущегося признака.
В связи с этим в другом варианте осуществления способ включает использование по меньшей мере процессора и памяти для приема первой фразы на естественном языке. Способ дополнительно включает идентификацию по меньшей мере одной фразы-модификатора на естественном языке, содержащейся в первой фразе на естественном языке.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ Приведенное выше краткое описание, а также последующее подробное описание различных вариантов осуществления будут лучше поняты при чтении вместе с приложенными чертежами. В иллюстративных целях на чертежах показаны примерные варианты осуществления; однако раскрытый в настоящее время объект изобретения не ограничивается раскрытыми конкретными способами и инструментальными средствами. На рисунках:
РИС. 1 представляет собой блок-схему системы повышения эффективности синтаксического и семантического анализа в автоматизированных процессах понимания естественного языка в соответствии с вариантами осуществления настоящего изобретения;
РИС. 2 представляет собой блок-схему, показывающую процесс упорядочения аргументов предикативных выражений естественного языка с последовательностями тематических ролей согласно вариантам осуществления настоящего изобретения;
РИС. 3 представляет собой блок-схему, показывающую получение предикатного выражения на естественном языке, применение множества последовательностей тематических ролей и перевод предикатного выражения на естественном языке в предикативное выражение на искусственном языке в соответствии с вариантами осуществления настоящего изобретения;
РИС. 4 представляет собой блок-схему, показывающую применение множества последовательностей тематических ролей в соответствии с вариантами осуществления настоящего изобретения;
РИС. 5 представляет собой блок-схему, показывающую разбор предикатного выражения на естественном языке на множество частей и определение порядка предикатного выражения на искусственном языке в соответствии с вариантами осуществления настоящего изобретения;
РИС. 6А представляет собой концептуальную схему, показывающую взаимосвязь грамматических правил и значений перемещающихся признаков согласно вариантам осуществления настоящего изобретения;
РИС. 6B представляет собой концептуальную схему, показывающую взаимосвязь, соединяющую два частичных дерева синтаксического анализа для формирования третьего частичного дерева синтаксического анализа в соответствии с вариантами осуществления настоящего изобретения;
РИС. 7 представляет собой блок-схему, показывающую получение идентификации по меньшей мере одного грамматического правила и получение процесса вычисления бегущей характеристики, затем применение процесса вычисления значения бегущей характеристики к правилу грамматики в соответствии с вариантами осуществления настоящего изобретения;
РИС. 8 представляет собой блок-схему, показывающую получение выражения на естественном языке и присвоение значения на основе семантических критериев согласно вариантам осуществления настоящего изобретения;
РИС. 9 представляет собой блок-схему, показывающую шаги рекурсивной процедуры, которая находит приемлемые комбинации пар модификатор-модификатор, так что для каждой пары [X, Y], соответствующие смыслы для X и Y, Xs и Ys, и представление, которое отражает, как X со смыслом X могут модифицировать Y со смыслом Y указаны в соответствии с вариантами осуществления настоящего изобретения;
РИС. 10 представляет собой блок-схему, показывающую процесс, который при каждом вызове вычисляет комбинацию значения для данного модификатора X, модификатора Y, который связан с X, соответствующих значений для X и Y, Xs и Ys и представления, которое отражает как X со значением Xs может изменить Y со значением Ys в соответствии с вариантами осуществления настоящего изобретения;
РИС. 11 представляет собой блок-схему, показывающую процесс создания значений перемещаемых атрибутов на основе обозначений в правилах грамматики и объединения значений перемещаемых атрибутов «родительского» узла, расширяемого во время построения диаграммы, с соответствующими значениями перемещаемых атрибутов дочернего узла, который используется для расширения родительского узла согласно вариантам осуществления настоящего изобретения;
РИС. 12 представляет собой блок-схему, показывающую процесс стандартизации порядка, в котором аргументы появляются в каждом атомарном логическом предикате, используемом как часть представления знаний, независимо от порядка, в котором эти аргументы выражены в выражении на естественном языке, к которому применяется предикат, в соответствии с вариантами осуществления. настоящего изобретения; и
РИС. 13 представляет собой концептуальную диаграмму, показывающую примерные пять (5) деревьев синтаксического анализа, которые без использования перемещающихся атрибутов должны были бы быть построены, возможно, многократно для заданного входного выражения на естественном языке, где бы подвыражение, соответствующее им, не имело соответствующего подвыражения. -tree в дереве синтаксического анализа, конструируемом для всего входного выражения в соответствии с вариантами осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
Предмет, раскрытый в настоящее время, описан со спецификой для удовлетворения требований законодательства. Однако само описание не предназначено для ограничения объема этого патента. Скорее, изобретатели предполагали, что заявленный предмет изобретения может быть также реализован другими способами, чтобы включать другие этапы или элементы, подобные тем, которые описаны в этом документе, в сочетании с другими настоящими или будущими технологиями. Более того, хотя термин «стадия» может использоваться здесь для обозначения различных аспектов применяемых методов, этот термин не следует интерпретировать как подразумевающий какой-либо конкретный порядок между различными стадиями, раскрытыми в настоящем документе, за исключением случаев, когда порядок отдельных стадий явно описан. .
Естественный язык — это такой язык, как, например, английский или французский.
Как упоминается здесь, фраза на естественном языке представляет собой последовательность одного или нескольких слов.
Как упоминается в данном документе, токен представляет собой вхождение символа, которому можно присвоить значение и который не имеет значимого вхождения какого-либо символа в качестве компонента. Например, токены включают вхождения слов, вхождения знаков препинания.
Как упоминается в настоящем документе, выражение на естественном языке представляет собой любую последовательность одной или нескольких лексем естественного языка, которые рассматриваются как синтаксическая или значимая единица этого естественного языка. В качестве неограничивающего примера выражение на естественном языке может называться выражением. Предикативное выражение на естественном языке — это выражение на естественном языке, которое можно интерпретировать как выражающее отношения между сущностями или выражающее одно или несколько свойств или характеристик сущности или сущностей. Неограничивающие примеры включают предложения, фразы с прилагательными и фразы с предлогами. В качестве неограничивающего примера, предикативное выражение на естественном языке может называться выражением на естественном языке. В качестве другого неограничивающего примера, предикативное выражение на естественном языке может называться предикативным выражением.
Как указано в настоящем документе, часть выражения, предикативная на естественном языке, содержит одно или несколько выражений на естественном языке. В качестве неограничивающего примера, часть предикативного выражения на естественном языке может называться выражением на естественном языке. В качестве еще одного неограничивающего примера, часть выражения, предикативная на естественном языке, может упоминаться как английское выражение.
Как упоминается в данном документе, тематическая роль является элементом последовательности тематических ролей. В качестве неограничивающего примера первая тематическая ролевая последовательность может упоминаться как тематическая ролевая последовательность. В качестве другого неограничивающего примера первая тематическая ролевая последовательность может называться выраженной ролевой последовательностью. В качестве еще одного неограничивающего примера первая тематическая ролевая последовательность может называться тематической ролевой последовательностью, которая отражает фактически выраженные тематические роли. В качестве неограничивающего примера вторая тематическая ролевая последовательность может упоминаться как основная ролевая последовательность. В качестве другого неограничивающего примера вторая тематическая ролевая последовательность может упоминаться как тематическая ролевая последовательность.
Как упоминается в данном документе, место аргумента предикативного выражения искусственного языка представляет собой соответствие между аргументом выражения предикатора искусственного языка и некоторым аспектом выражения предикатора искусственного языка. В качестве неограничивающего примера, место аргумента предикативного выражения искусственного языка может относиться к местоположению в предикативном выражении искусственного языка. В качестве неограничивающего примера место аргумента выражения, определяющее место искусственного языка, может упоминаться как место аргумента. В качестве неограничивающего примера, предикативное выражение искусственного языка может называться логическим предикатом. В качестве другого неограничивающего примера, предикативное выражение искусственного языка может называться предикатом. В качестве еще одного неограничивающего примера, предикативное выражение искусственного языка может называться представлением знаний. В качестве другого неограничивающего примера, предикативное выражение искусственного языка может упоминаться как предикатное представление. В качестве неограничивающего примера, аргумент выражения, предицирующий искусственный язык, может называться структурой данных. В качестве еще одного неограничивающего примера, аргумент выражения с предикатом искусственного языка может упоминаться как аргумент.
Как указано в настоящем документе, структура данных содержит по меньшей мере один символ, при этом структура данных может содержать расположение по меньшей мере одного символа. В качестве неограничивающего примера частичное значение может называться смыслом.
Как упоминается в настоящем документе, грамматическое правило представляет собой спецификацию одного или нескольких приемлемых выражений естественного языка.
Как упоминается в данном документе, элемент правила грамматики является частью правила грамматики, которая соответствует второму выражению на естественном языке, где второе выражение на естественном языке состоит из выражения на естественном языке, указанного как приемлемое правилом грамматики.
Как указано в данном документе, признак — это объект, связанный с правилом грамматики, который может быть связан с элементом правила грамматики, в котором признак может иметь связанные значения. В качестве неограничивающего примера характеристика может относиться к атрибуту.
Как указано в данном документе, процесс вычисления значения движущегося элемента соответствует любому средству, посредством которого идентифицируется одно или несколько значений для движущегося элемента.
Как упоминается в данном документе, узел является компонентом дерева синтаксического анализа, при этом дерево синтаксического анализа может быть частичным деревом синтаксического анализа и при этом узел может соответствовать элементу правила грамматики в соответствии с правилом грамматики.
Как указано в данном документе, компонент может быть записан в диаграмму анализатора диаграмм и может записывать информацию о выражениях на естественном языке и информацию о токенах. В качестве неограничивающего примера компонент может называться краем. В качестве другого неограничивающего примера компонент может называться узлом.
В данном документе модификатор представляет собой выражение на естественном языке, которое модифицирует второе выражение на естественном языке. В качестве неограничивающего примера модификатор может называться модифицирующим выражением.
Как упоминается в настоящем документе, модификация представляет собой выражение на естественном языке, которое модифицируется вторым выражением на естественном языке. В качестве неограничивающего примера модифицируемый объект может называться целью.
Как упоминается в данном документе, совместимый смысл может называться дополнительным смыслом.
Как упоминается в данном документе, узел является компонентом диаграммы синтаксического анализатора диаграмм.
Система и изобретения, описанные здесь, относятся к технической области компьютерной лингвистики. Компьютерная лингвистика (CL) занимается технологией, которая позволяет компьютерам работать с естественными языками, такими как английский (в отличие от искусственных языков программирования, используемых для программирования компьютеров, таких как C и Java). На него влияют и сообщают смежные области лингвистики (общее изучение естественных языков), компьютерных наук и философии языка. CL включает в себя задачу «понимание естественного языка» (NLU).
Хотя некоторые из раскрытых механизмов и методов не ограничиваются использованием синтаксических анализаторов диаграмм для NLU, большая часть описания использования этих элементов предоставляется в контексте применения синтаксического анализатора диаграмм. Следовательно, обзор некоторых аспектов работы синтаксических анализаторов диаграмм может предоставить соответствующую справочную информацию. Некоторые синтаксические анализаторы используются для определения того, какие слова и фазы являются синтаксическими компонентами других слов и фраз. Типичным конечным продуктом (выходом) такого синтаксического анализатора является дерево синтаксического анализа. Дерево синтаксического анализа — это граф в виде дерева, в котором каждый дочерний узел имеет только одного родителя, а самый верхний узел не имеет родителя. Например, предложение может состоять из имени собственного, выступающего в качестве подлежащего, глагола и другого имени собственного, выступающего в качестве прямого объекта предложения, например, «Мэри видела Иоанна». В этом случае единственное дерево синтаксического анализа имеет три уровня со словами «Мария», «пила» и «Иоанн» на нижнем уровне, их соответствующие категории (имя собственное, глагол, имя собственное) на среднем уровне и узел категория, такая как S (для предложения) в качестве корня на верхнем уровне. Каждый узел в дереве синтаксического анализа часто помечается своей синтаксической категорией, но любая полезная информация может быть связана с узлами деревьев синтаксического анализа.
Синтаксические анализаторы, включая анализаторы диаграмм, используют грамматику для анализируемого естественного языка, которая указывает, какие последовательности слов и фраз являются приемлемыми как часть этого языка. Любая английская грамматика может использоваться для определения того, какие выражения являются правильными, а какие нет, и нет единого мнения о том, что составляет все синтаксически правильные английские выражения. Например, в текущей реализации нашей системы английская грамматика представляет собой «грамматику структуры фраз, управляемую заголовком» (HPSG), предназначенную для облегчения построения KRL. HPSG указывает, какие слова и фразы являются компонентами каких других слов и фраз. Существуют и другие виды грамматик, например, «грамматика зависимостей» определяется тем, какие слова «зависят» от каких других слов. В грамматике зависимостей считается, что модификатор зависит от слова, которое он изменяет, а дополнение считается зависящим от глагола, которому оно принадлежит. Изобретения, раскрытые в данном документе, описаны в контексте их использования с грамматикой фазовой структуры и, как уже было описано, применительно к синтаксическому анализатору диаграмм сверху вниз. Между прочим, упор на пары модификатор-модификатор в подходе, описанном ниже, обеспечивает некоторые преимущества, обычно связанные с грамматикой зависимостей, по отношению к описанной здесь системе.
Анализатор диаграмм записывает набор синтаксических «компонентов» (слов и фраз), поскольку в соответствии с грамматикой обнаруживается, что они могут встречаться в определенных местах во входном выражении. Компоненты иногда называют ребрами или узлами. Далее в этом документе они называются «узлами». Например, грамматика может допускать, чтобы именная фраза «четыре собаки под стулом» встречалась с позиции 5 до позиции 10 во входном выражении. Один из методов отслеживания позиций слов в синтаксическом анализаторе диаграмм состоит в том, чтобы пометить позицию перед первым словом «0», пометить другие позиции между словами последовательными целыми числами и пометить позицию после последнего слова конечным целым числом. Информация, которую необходимо отслеживать для каждого компонента, — это его синтаксическая категория, такая как существительное, прилагательное, артикль и т. д., и его положение во входном выражении, которое можно рассматривать как последовательность слов. В процессе работы анализатора диаграмм узлы, соответствующие полным выражениям своей синтаксической категории, строятся постепенно. Например, именная фраза «четыре собаки» может быть санкционирована грамматическим правилом np [искусство, целое число, существительное]. Анализаторы диаграмм могут работать либо сверху вниз, либо снизу вверх. Подход «сверху вниз» будет использовать это правило грамматики, начиная с цели построения np и просматривая ввод справа от его текущей позиции, чтобы определить, позволяют ли последующие слова построить np. Вводится узел [k, k, np, {}, N], где k — целое число, указывающее текущую позицию, а пустой список {} указывает на то, что этому узлу еще не назначены дочерние элементы. K появляется дважды, потому что, не имея дочерних элементов, узел начинается и заканчивается в одной и той же позиции во входных данных. N является целым числом, идентифицирующим узел, если этот узел не соответствует слову. Поскольку каждое входное слово сканируется слева направо, новая дуга строится путем добавления еще одного дочернего узла к первоначально пустому списку дочерних узлов. Когда добавляется последний дочерний узел соответствующей синтаксической категории в соответствии с правилом грамматики, узел считается «завершенным». До этого узел считается «незавершенным». Например, последовательность построения узлов для фразы «четыре собаки» может быть следующей.
1. [0, 0, np, { }, 1], Чтобы начать с категории верхнего уровня.
2. [0, 0, art, { }, 2], потому что правило грамматики указывает, что «np» может начинаться с «art».
3. [0, 1, «the» ], слово «the» сканируется и для него создается дуга (без возможных потомков).
- Также узлы для слов не нуждаются в идентификаторе, потому что слово и его расположение однозначно идентифицируют такие узлы.
4. [0, 1, art, {[0, 1, «the»]}, 3] — здесь узел 2 «расширяется» на [0, 1, «the»] для построения узла 3.
5. [0, 1, np, {[0, 1, art, 3]}, 4] — дочерний узел 3 расширяет узел 1 для построения узла 4.
6. [1, 1, целое число, { }, 5 ] — потому что правило грамматики указывает, что за артиклем может следовать целое число.
7. [1, 2, «четыре»] — слово «четыре» сканируется и для него создается дуга.
8. [1, 2, целое число, {[1, 2, «четыре»] }, 6] — узел [1, 2, «четыре»] расширяет узел 5 для построения узла 6.
9. [0, 2 , np, {[0, 1, ст, 4], [1, 2, целое число, 6] }, 7]
10. [2, 2, существительное, { }, 8]
11. [2, 3″ собаки], слово «собаки» сканируется и создается его дуга.
12. [2, 3, сущ., {[2, 3, «собаки»]}, 9]
13. [0, 3, нп, [{[0, 1, ст, 5], [1, 2 , существительное, 6], [2, 3, существительное]} 10]
- Также узлы для слов не нуждаются в идентификаторе, потому что слово и его расположение однозначно идентифицируют такие узлы.
В этот момент именная фраза «четыре собаки» была распознана, как указано в узле 10. Если спецификация детей детей сохраняется по мере расширения узлов, представление поддерева под каждым узлом может быть связано с этим узлом. Если эти данные сохраняются, то при обнаружении узла, такого как узел 10 в примере, который простирается от начала до конца входного выражения, тогда поддерево под этим узлом представляет собой целое дерево синтаксического анализа для ввода.
Узлы, соответствующие отдельным словам, добавляются в диаграмму по мере сканирования входных данных путем добавления одного узла для каждой разрешенной синтаксической категории слова. Все применимые правила грамматики рассматриваются, поскольку входные данные сканируются слева направо, чтобы сформировать все узлы, которые допускает грамматика в целом. Все узлы как неполные, так и полные сохраняются. В рамках этого процесса можно вести отдельный список полных узлов, называемый повесткой дня. Повестку дня можно использовать, чтобы гарантировать, что все полные узлы, начинающиеся в текущей позиции, считаются возможными дочерними элементами всех незавершенных узлов в диаграмме, для продолжения построения которых требуется дочерний элемент в этой позиции. Можно думать об узлах как о расширении при добавлении дочернего элемента, но может быть полезно думать об узле как о связанном с отдельным узлом, который идентичен, но имеет на один дочерний элемент больше, чем первый. Это связано с тем, что неполные узлы сохраняются на диаграмме на случай, если будут найдены новые способы их «расширения», а новые полные узлы будут завершены и могут рассматриваться как потенциальные дочерние узлы. Незавершенный узел может не иметь дочерних узлов, пока не будет полностью просканировано все входное выражение. Затем каскад завершений узла снизу вверх может привести к расширению этого узла, которое инициируется добавлением последнего просканированного слова. Деревья синтаксического анализа состоят только из полных узлов. Хорошее описание синтаксических анализаторов диаграмм можно найти в книге James Allan Natural Language Understanding, The Benjamin/Cummings Publishing Company, Inc., 19.95.
Список:
1. Просканируйте входное выражение (обычно одно предложение) и постройте диаграмму.
2. Определите альтернативные упорядоченные дочерние наборы для каждого узла на диаграмме и другие связанные данные.
3. Выполнить восходящую семантическую композицию «правило за правилом», как если бы все пары модификатор-модификатор содержали братьев и сестер в потенциальных деревьях синтаксического анализа, отложив любое определение того, какие модификаторы изменяют какие модификаторы, где задействована любая серия модифицирующих выражений.
4. Если какой-либо модификатор имеет более одного модификатора-кандидата, отдельно определить когерентные пары модификаторов с модификаторами.
5. Преобразование структур данных, представляющих значение входного выражения, в набор относительно простых фактов в стандартизированной форме. (Разнообразие этих «простых» фактов может быть расширено вместе со словарем и знаниями системы.)
6. Вернитесь к шагам с 4 по 6, чтобы получить дополнительные интерпретации входного выражения.
Завершение построения диаграммы не обязательно завершает процесс синтаксического анализа. Хотя одно или несколько деревьев синтаксического анализа неявно содержатся в диаграмме, их все же может потребоваться идентифицировать. Если соответствующие поддеревья для узлов не были построены при создании каждого узла в диаграмме, то деревья синтаксического анализа все же могут быть построены. Каждое дерево синтаксического анализа может быть построено путем выбора узлов из диаграммы и дочерних элементов для каждого узла до тех пор, пока не будет построено дерево узлов, где корень дерева имеет желаемую синтаксическую категорию всего входного выражения в целом, а дочерние элементы каждого узла являются набор дочерних элементов, которые были найдены, поскольку узлы были завершены при построении диаграммы. В некоторых системах деревья синтаксического анализа строятся на одном этапе, а затем передаются на следующий этап обработки, который выполняет семантический анализ каждого дерева синтаксического анализа, чтобы определить, можно ли найти какие-либо интерпретации (значения) для каждого дерева синтаксического анализа. Говорят, что такие системы имеют «конвейерную» системную архитектуру. Системы, которые не имеют чисто конвейерной архитектуры, могут использовать альтернативные методы для ограничения построения дерева синтаксического анализа, комбинируя семантический анализ с построением дерева синтаксического анализа. Системы могут следовать принципу наличия одного правила семантической композиции для каждого правила грамматики. Правило семантической композиции определяет, как определить значение родительского узла по значению дочерних узлов этого узла. Формализм, называемый лямбда-исчислением, часто используется для составления смысловых представлений одновременно с составлением соответствующих частей деревьев синтаксического анализа; однако выражения лямбда-исчисления могут стать чрезвычайно сложными, и может быть непрактично поддерживать вывод и анализ на основе результирующих представлений значения.
Чтобы ограничить количество требуемых грамматических правил, можно использовать «функции», каждая из которых определяет конкретное свойство узла. Функции также могут использовать переменные, чтобы указать, что значения указанных функций дочерних узлов должны быть одинаковыми, должны «согласовываться». Например, для обработки слов в единственном и множественном числе без использования признаков можно использовать два правила грамматики:
S→[число_местоимения_множественное число, число_глагола_множественное число, прил.] и
S→[число_местоимения_единственного числа, число_местоимения_единственного числа, прил.].
По мере увеличения количества свойств узлов и количества значений этих свойств количество правил грамматики при отсутствии признаков будет увеличиваться. Напротив, можно использовать функции, как в следующем правиле грамматики.
S→[местоимение_номер=X, глагол_номер=X, прил].
Использование признака «число» и требование, чтобы значение X было одинаковым для обоих вхождений переменной, выполняет работу обоих правил грамматики, которые не используют признаки. Как правило, согласование функций обеспечивается с помощью процесса, называемого «унификация». При унификации используются списки альтернативных значений каждого признака. Узел может иметь один список значений для функции, а потенциальный дочерний элемент этого узла может иметь другой список значений для той же функции. Потенциальный дочерний элемент может быть добавлен в качестве фактического дочернего элемента к родительскому узлу, если эти два списка значений «согласуются». Два списка согласуются, если их пересечение не пусто, и список для родительского узла, расширяемый дочерним узлом, содержит это непустое пересечение значений. Если какой-либо узел имеет список значений для функции, а другой узел не имеет списка для этой функции, то списки согласуются, и новый создаваемый узел получает список от любого узла, имеющего его для этой функции.
Изобретения, раскрытые здесь, включают введение различных функций, использование которых соответствует традиционному поведению функций и использованию унификации. Также представлен новый тип функций, называемых «путешествующими функциями», которые имеют другое поведение. Функции перемещения используются для обозначения путей через потенциальные деревья разбора по мере построения диаграммы. В отличие от традиционных функций, здесь нет вопроса о соглашении. Вместо этого значения перемещающихся признаков накапливаются во всех узлах, которых они достигают. Поскольку перемещающиеся признаки распространяются на узлы по всей диаграмме во время построения диаграммы, их комбинации можно использовать для обнаружения и записи синтаксических отношений в деревьях синтаксического анализа до того, как эти деревья синтаксического анализа будут построены. Основное текущее использование функций путешествия в текущей системе состоит в том, чтобы идентифицировать английские слова и фразы, которые являются потенциальными модификаторами других слов и фраз строго в силу синтаксических соображений.
Если
1. Лямбда-исчисление дало поддающиеся обработке выражения для вывода и анализа и
2. Можно было следовать подходу использования одного правила семантической композиции для каждого правила грамматики без умножения (по крайней мере, в пределах определенных поддеревьев) количества деревья синтаксического анализа для каждой комбинации модификатор-модификатор и
3. Связанная с этим «проблема прикрепления» может быть решена каким-либо семантическим анализом, и
4. Грамматика и словарь, обеспечивающие широкий охват естественного языка (грамматики никогда не были полными и совершенными) задействованы были использованы, и
5. Все вышеперечисленное можно было бы сделать эффективно, тогда системы NLU, по-видимому, могли бы всесторонне и довольно хорошо обрабатывать буквальное значение выражений естественного языка (вплоть до уровня предложения).
Дополнительные проблемы по-прежнему будут связаны с обработкой небуквального и неправильно сформированного языка, с интеграцией значения нескольких предложений, с отслеживанием дискурса, как указано выше, и т. д. частично воображаемый список) другими практическими и реализуемыми средствами позволит системам NLU достичь описанного уровня компетентности. Эти усовершенствования позволят применять NLU по-новому и улучшат производительность и возможности существующих коммерческих приложений.
Изобретения, раскрытые здесь, решают проблемы, соответствующие пунктам 2, 3 и 5 выше. Вариант исчисления предикатов используется вместо альтернативного представления, такого как лямбда-исчисление, чтобы результирующие представления знаний можно было использовать более непосредственно для вывода и анализа.
Вместо лямбда-исчисления используется версия исчисления предикатов, которая более наглядна, чем лямбда-исчисление и традиционные версии исчисления предикатов, и имеет выразительную силу, сравнимую с естественным языком с расширениями, которые используют фреймы или простые структуры данных для записи аспектов значения для которых исчисление предикатов менее подходит, например, для нечетких терминов, пропозициональных отношений и времени.
Описанный здесь подход уменьшает количество деревьев синтаксического анализа за счет предоставления механизмов, позволяющих сглаживать грамматику. Например, вместо использования правил грамматики, таких как
np→[искусство, существительное, pp]
np→[существительное]
pp→[prep, np], где np означает «именная группа», pp означает «предложная фраза», а искусство означает «статья», используются грамматические правила, такие как
series_postNomMods→[postNomMod, postNomMod, postNomMod].
Когда первый набор грамматических правил применяется к предложению, такому как классический пример «Она видела мужчину на холме с телескопом», получается несколько деревьев синтаксического анализа в зависимости от того, какие модификаторы (предложные фразы) интерпретируются как модифицирующие ‘ человек» или «холм», а также в зависимости от того, использовала ли она телескоп, чтобы что-то увидеть, или она видела телескоп. Дело здесь в том, что даже когда доступна информация для устранения неоднозначности различных интерпретаций, необходимо иметь дело со всеми деревьями синтаксического анализа, чтобы либо поддержать соответствующую интерпретацию, либо отвергнуть ее.
Использование подхода, включающего категорию postNomMods, по-прежнему будет давать два дерева синтаксического анализа, потому что изменение в грамматике не устраняет альтернативу того, использовала ли она телескоп или нет. Зависимые предложения, такие как «который побежал на улицу», также обрабатываются как постименные модификаторы (категория postNomMod) и могут разделять правило грамматики с предложными фразами.
Количество деревьев синтаксического анализа, которые должны быть построены, дополнительно сокращается за счет систематического удаления узлов и «альтернативных дочерних наборов», определенных ниже, узлов из диаграммы до построения дерева синтаксического анализа на основе узлов, которые не имеют интерпретации. Любой узел, для которого не найдена интерпретация (значение), удаляется с диаграммы. Запись о происхождении узла (запись о том, какие создания и расширения узлов приводят к каждому узлу на диаграмме) используется для перечисления всех возможных упорядоченных наборов дочерних элементов для каждого узла. Это называется списком альтернативных дочерних наборов для каждого узла.
Когда узел X удаляется из диаграммы, его список альтернативных дочерних наборов также удаляется. Для каждого узла Y, отличного от X, на диаграмме и для каждого альтернативного дочернего набора A узла Y, содержащего X, A удаляется из списка альтернативных дочерних наборов Y. Если список альтернативных дочерних наборов узел становится пустым, этот узел удаляется, и весь этот процесс повторяется до тех пор, пока из диаграммы нельзя будет удалить альтернативные дочерние наборы или узлы. Этот процесс может быть инициирован на этапе восходящей семантической композиции, описанном ниже, всякий раз, когда определено, что узел не имеет интерпретации.
Для каждого правила грамматики существует правило семантической композиции, которое используется для вычисления всех альтернативных представлений значений (интерпретаций) каждого узла в диаграмме. Всякий раз, когда обнаруживается, что какой-либо узел не имеет интерпретаций, используется подход для систематического удаления узлов из диаграммы, начиная с узла, изначально обнаруженного без интерпретаций. Сначала находится максимальная глубина любого возможного дерева разбора. У каждого узла на диаграмме есть функция, определяющая его уровень. Это уровень этого узла в любом дереве синтаксического анализа, в котором он может появиться. Узлы просто проверяются, чтобы определить самый глубокий уровень любого узла на диаграмме. Далее вычисляются все возможные интерпретации каждого узла на максимальной глубине, которые обязательно являются листьями в любом дереве разбора, в котором они появляются. Уровень 0 — это уровень корней всех возможных деревьев разбора, которые в принципе могут быть построены из узлов диаграммы. Затем предпринимаются следующие действия.
Для каждого уровня L узлов до уровня 0:
- Для каждого узла N уровня L:
- Для каждого альтернативного дочернего набора A из N:
- Для каждой комбинации интерпретаций of A:
- Используйте правило семантической композиции правила грамматики, используемого для создания N, чтобы вычислить одну новую интерпретацию для узла N, если это возможно.
- Для каждой комбинации интерпретаций of A:
- Для каждого альтернативного дочернего набора A из N:
- Для каждого узла N уровня L:
Восходящий процесс семантической композиции дает список альтернативных интерпретаций для каждого узла на диаграмме, который имеет одну или несколько интерпретаций. Для каждого узла его интерпретации вычисляются из интерпретаций его дочерних элементов в каждом дочернем наборе. Один альтернативный дочерний набор может иметь несколько интерпретаций, основанных на различных комбинациях интерпретаций узлов в этом наборе.
Если бы во всех случаях было известно, какой элемент правой части грамматического правила изменяет какой другой элемент этой правой части, то любая семантическая композиция, аналогичная построению дерева синтаксического анализа, могла бы надежно представлять значение всего входное выражение. Это может быть сделано за счет наличия грамматики, которая во многих случаях приводит к неприятному увеличению числа деревьев синтаксического анализа. Кроме того, возможно применение других раскрытых здесь изобретений для ограничения построения дерева синтаксического анализа другими способами, так что это увеличение количества деревьев синтаксического анализа не представляет большой проблемы. Тем не менее, подход, который был разработан достаточно подробно для завершения первой реализации, использует этап семантической композиции, описанный в этом разделе.
Перед окончательным этапом семантической композиции пары-кандидаты модификатор-модификатор собираются во время построения диаграммы с использованием перемещающихся признаков. Также перед этим этапом выполняется восходящая семантическая композиция, которая обеспечивает альтернативные интерпретации, описанные в предыдущем абзаце, для каждого оставшегося узла в диаграмме, удаляя при этом узлы, которые не могут внести вклад, как описано выше.
На заключительном этапе семантической композиции находит один модификатор для каждого модификатора в случаях, когда существует более одного модификатора-кандидата для любого модификатора, так что все отношения между сущностями, на которые ссылаются в задействованных выражениях, согласуются со смыслом задействованных предикативных терминов и согласуется с дополнительными предикатами, которые вводятся из общей базы знаний в качестве «объяснений» того, как каждый модификатор изменяет каждый модификатор. Этот анализ проводится для каждой серии модификаторов отдельно. Узел на диаграмме, который соответствует серии модификаторов, все еще может быть связан с успешным семантическим анализом этой серии модификаторов. Если такой узел соответствует ряду модификаторов без приемлемой интерпретации, то сам этот узел не имеет интерпретации и может быть удален с диаграммы. В принципе, каждой интерпретации ряда таких модификаторов соответствует дерево разбора; однако эти деревья синтаксического анализа никогда не нужно строить. Вместо этого каждая интерпретация ряда в целом (по одному) приписывается узлу на диаграмме, который соответствует этому ряду (просто корень деревьев синтаксического анализа, которые никогда не строились). Одно условие должно быть выполнено, чтобы приписать любую интерпретацию этому узлу на диаграмме. Должна быть модификация для серии модификаторов в целом, которая соответствует узлу, фактически присутствующему на диаграмме. Использование движущихся признаков может обеспечить идентичность кандидатов-модификаций для ряда модификаторов, как это обычно делается для модификаторов, или можно использовать другие средства для идентификации соответствующего модификатора.
Правило грамматики для «атомарного» предложения показано ниже. Атомарное предложение — это предложение, которое не включает числовой количественный анализ, вложенный или повторный количественный анализ. Пример атомарного предложения: «Время оценивалось по солнечным часам». Атомарное предложение может иметь любое разнообразие дополнений к своему основному глаголу. Дополнения здесь; «Время» и «солнечные часы». Поскольку это пассивное предложение, тематическая роль «тема» соответствует подлежащему в предложении. На это указывает признак [роль, [1], [тема]]. Здесь «роль» — это имя функции. Средний элемент выражения равен [1].
Как правило, средний элемент такой спецификации функции представляет собой список целых чисел, которые представляют собой индексы с отсчетом от 1 к синтаксическим элементам правой части правила грамматики, а целое число 0 относится к левой части правила грамматики. . Для признаков с традиционной интерпретацией этот список целых чисел может указывать, какие элементы грамматического правила должны согласовываться относительно значений названного признака согласно стандартным критериям унификации. Для перемещающихся признаков этот список целых чисел может обеспечивать «область» значений признака. Например, если значение x подвижного объекта A достигает правой части правила грамматики, потому что это значение передается от дочернего узла к родительскому узлу, соответствующему этому правилу грамматики, а значение y подвижного объекта B достигает той же правой стороны стороне родительского узла, то эти значения x и y «встречаются» в любых элементах правой части родительского узла, которые у них есть общие. Следствием того, что пути через потенциальные деревья анализа на диаграмме пересекаются, является полезная информация, которую предоставляет эта встреча перемещающихся значений признаков. Когда перемещающиеся объекты используются для поиска кандидатов-модификаторов для модификаторов, знание того, что значение из модификатора соответствует значению из кандидата-модификатора, подразумевает, что этот модификатор является кандидатом на изменение этим модификатором. В правиле грамматики, показанном ниже, нет функций перемещения.
Как описано здесь, тематические роли используются для согласования аргументов с местами аргументов в стандартном предикате в определенном смысле этого предиката, где эти аргументы являются референтами дополнений предикативных терминов, таких как глаголы. В примере грамматического правила [role, [4], [inst]] означает, что четвертый элемент правой части грамматического правила имеет тематическую роль «инструмент». [passive, [2], [yes]] указывает, что для второго элемента правой части, verbGroup, значение признака «пассивный» должно быть «да», иначе это правило грамматики неприменимо. [tense, [0,2], all] указывает, что время всего выражения должно совпадать с временем группы глаголов. [ref, [1], [entity]] указывает, что любое выражение, соответствующее первому элементу правой части, arg, должно ссылаться на одну или несколько сущностей типа entity. Поскольку объект является наиболее общей записью в онтологии, это фактически не является ограничением, что отражает общий характер этого правила грамматики. Каждое правило грамматики имеет уникальное целое число, как показано [rId, [0], [676]]. Чтобы упростить обработку различных операторов с вложенной квантизацией, атомарные выражения, над которыми нет квантификации в любом дереве синтаксического анализа, в котором они могут появиться, могут обрабатываться иначе, чем те, над которыми есть квантификация. [topLev, [0], [yes]] указывает, что любой узел в диаграмме, к которому применяется это правило грамматики, не имеет над собой количественного определения ни в одном из этих потенциальных деревьев синтаксического анализа.
Каждая тематическая роль может быть концептом в онтологии или просто индикатором лингвистической структуры. Тема и инструмент являются индикаторами лингвистической структуры, потому что любое понятие/сущность может предположительно служить темой предложения, а орудием (что-то, что используется для чего-то) может быть любая сущность при определенных обстоятельствах. Напротив, от агента может потребоваться, чтобы он был сущностью, способной принимать решения или предпринимать преднамеренные действия. Люди и роботы считаются агентами. Тематическая роль genAgent (обобщенный агент) является индикатором лингвистического использования в том, что предложения могут быть построены для выражения утверждения таким же образом, как и в случаях, когда агент задействован, но когда не предпринимается никаких действий, например, в предложении ‘ Шина ударилась о камень», лингвистическая структура аналогична предложению «Человек ударился о камень», где неоднозначно, предпринял ли человек действие или нет. Возможно, он просто упал на скалу. Дополнительные соглашения могут быть указаны, когда и агент, и genAgent в противном случае применялись бы для выбора между ними. В этом случае можно указать, что если агент/genAgent является одушевленным объектом, то используемая тематическая роль будет агентом. Это позволяет избежать более сложных соображений, таких как наличие у одушевленного объекта достаточного интеллекта или возможности для выполнения определенного действия преднамеренным или случайным образом, или может ли конкретное действие быть случайным.
Конкретные спецификации тематических ролей являются предварительными и подлежат пересмотру. Суть в том, что они выбираются всякий раз, когда это возможно, для наложения реальных онтологических ограничений, а когда это невозможно, то они должны быть указаны (как, по-видимому, в целом происходит среди исследователей, у которых нет единого мнения относительно тематических ролей), чтобы зафиксировать обобщения в использовании лингвистов и структура. Некоторые ученые утверждают, что от тематических ролей следует вообще отказаться. Как упоминалось выше, описанное здесь использование в основном используется в качестве инструмента для стандартизации представления знаний, но другая цель состоит в том, чтобы связать, когда это возможно, сущности, на которые ссылаются дополнения глаголов, с понятиями в онтологии.
Дополнительные ограничения типа исходят из смысла предикативных терминов, включая глаголы, в сочетании с любыми ограничениями типа для этого аргумента для каждого конкретного смысла предикативного термина. Эти ограничения типов не обязательно являются спецификациями отдельных типов в онтологии. Они могут быть любой булевой комбинацией типов и могут быть представлены в дизъюнктивной нормальной форме для единообразия.
Для каждого значения глагола указана стандартная «основная» последовательность тематических ролей. Эта последовательность содержит все тематические роли, которые когда-либо мыслимо могли быть выражены для этого значения глагола. Независимо от того, какие тематические роли соответствуют фактически выраженным дополнениям входного выражения, соответствующие предикатные аргументы выраженных дополнений помещаются в место аргумента, соответствующее местоположению их тематической роли в мастер-последовательности. Места аргументов в сказуемом, для которых не выражено дополнение, заполняются символом «ne», что означает «не выражено».
Каждое правило грамматики естественного языка имеет атрибут, указывающий, какая мастер-последовательность применяется. У него также есть атрибут, указывающий, какая тематическая ролевая последовательность (во многих случаях отличная от основной последовательности) используется в выражении предложения. Эта вторая тематическая ролевая последовательность содержит только те тематические роли, которые выражены в предложении, исходя из которых дополнения присутствуют в самом грамматическом правиле. В грамматическом правиле, показанном выше, единственными тематическими ролями, для которых грамматическое правило определяет дополнения, являются инструмент и тема. Следовательно, тематическая ролевая последовательность 11 , который используется в этом правиле грамматики, содержит только те тематические роли. Если бы отдельные тематические роли были указаны как функции для всех правил грамматики, как в показанном правиле грамматики, можно было бы опустить использование функции для указания использования последовательности тематических ролей 11 и «извлечь» последовательность из самого правила грамматики. ; однако это будет отражать один (возможно, менее эффективный вариант) из многих вариантов метода использования последовательностей тематических ролей для стандартизации порядка аргументов в KRL. Другие системы используют «рамки глаголов» для характеристики глаголов со сходным поведением. Раскрытый здесь подход предназначен для поддержки более детального анализа, достаточного для того, чтобы нулевая или почти нулевая терпимость могла применяться к обобщениям должным образом ограниченных правил грамматики. Ожидается, что для коммерческих приложений будет больше правил грамматики из-за этого мелкозернистого анализа, многие из которых похожи друг на друга, но их будет легче систематически собирать с помощью машинного обучения или других средств.
Восходящая семантическая композиция, процесс идентификации модификатора-цели и другие процедуры в системе используют последовательности тематических ролей для изменения порядка аргументов-предикатов по мере необходимости для построения стандартного представления значения выражений-предикатов.
Практические цели использования тематических ролей заключаются в том, чтобы стандартизировать порядок аргументов предикатов в KRL, оппортунистически отразить лингвистические обобщения и связать аргументы предикатов с онтологией, таким образом ограничивая конкретизацию этих предикатов надлежащим образом в соответствии со смыслом предиката. термин, с которым связана каждая тематическая ролевая последовательность.
В настоящем документе раскрыты способ анализа значения каждого последовательного ряда модификаторов, новый тип признаков, называемых «перемещающимися признаками», для использования с грамматическими правилами, который используется для поддержки этого метода анализа последовательных рядов модификаторов, и способ для стандартизации последовательности аргументов в логических предикатах, чтобы различные выражения на естественном языке, которые интерпретируются системой NLU как имеющие одинаковое значение и значение каждого из которых представлено атомарной логической формулой, в конечном итоге имели идентичные представления своих значений. Также раскрыты способы обеспечения интерпретации выражений естественного языка, соответствующих атомарным логическим формулам, которые учитывают смысл слов (как тех, которые являются предикативными словами, такими как глаголы, так и слов, которые относятся к сущностям, а не вводят предикацию), и которые учитывает типы понятий, к которым могут относиться слова и выражения, а также типы сущностей, которые могут соответствовать аргументам в предикатах. Методы, учитывающие эти последние несколько пунктов, являются неотъемлемой частью метода стандартизации порядка аргументов в атомарных логических формулах.
Теперь раскрытое изобретение описано более подробно. Например, фиг. 1 показана блок-схема системы , 100, согласно вариантам осуществления настоящего изобретения. Система 100 может быть реализована полностью или частично в любой подходящей вычислительной среде. Вычислительное устройство 102 может быть коммуникативно подключено через сеть связи 104 , которая может быть любой подходящей локальной сетью (LAN), либо беспроводной (например, технология связи BLUETOOTH®), либо проводной. Вычислительное устройство 102 , планшетное устройство 106 , связанное с вычислительным устройством 102 , и другие компоненты, не показанные, могут быть сконфигурированы для сбора данных в розничной среде, для обработки данных и для передачи данных в централизованный сервер 108 . Например, вычислительное устройство 102 и планшетное устройство 106 могут работать вместе для реализации функции розничной торговли и передачи данных, связанных с этим, на сервер 108 9.1181 . Сервер 108 может находиться в розничном магазине или удаленно.
Компоненты системы 100 могут включать аппаратное обеспечение, программное обеспечение, микропрограмму или их комбинации. Например, программное обеспечение, находящееся в памяти соответствующего компонента, может включать в себя инструкции, реализованные процессором для выполнения раскрытых здесь функций. Например, вычислительное устройство , 102, может включать в себя пользовательский интерфейс , 110, , включающий дисплей (например, сенсорный дисплей), сканер штрих-кода и/или другое оборудование для взаимодействия с медицинским персоналом и для проведения диагностического анализа. Вычислительное устройство 102 может также включать память 112 . Вычислительное устройство , 102, может также включать в себя подходящий сетевой интерфейс , 114, для связи с сетью , 104, . Планшетное устройство , 106, может включать в себя аппаратные средства (например, устройства захвата изображения, сканеры и т.п.) для захвата различных данных в вычислительной среде. Система 100 может также включать смартфон 116 , сконфигурированный аналогично планшетному устройству 9.1180 106 . Система 100 может также содержать базу данных 118 для хранения грамматических правил, определений и значений слов и фраз, например. Кроме того, сервер 108 может быть подключен к вычислительным устройствам 102 через сеть 104 или через беспроводную сеть 120 .
Продолжая ссылаться на фиг. 1, система 100 , содержащая по меньшей мере процессор и память вычислительного устройства и анализатор естественного языка 122 предоставляется. Как будет более подробно описано на фиг. 2-4 синтаксический анализатор 122 естественного языка сконфигурирован для анализа предикативных выражений естественного языка в предикативные выражения искусственного языка. Кроме того, синтаксический анализатор , 122, естественного языка сконфигурирован для сохранения проанализированного предикатного выражения естественного языка и предикатного выражения искусственного языка в базе данных 118 . База данных , 118, может также использоваться для хранения правил и/или инструкций, связанных с анализом предикативного выражения на естественном языке. Следует отметить, что база данных 118 может быть расположен как внутри, так и снаружи серверов 108 .
РИС. 2 представляет собой блок-схему, показывающую примерное сопоставление между множеством частей , 200, выражений, предикативных на естественном языке, первых элементов последовательности тематических ролей из множества последовательностей первых тематических ролей , 202 , элементов последовательности вторых тематических ролей из одной второй последовательности тематических ролей. 204 , а искусственный язык предикативного выражения аргумент места 206 , который может использоваться для перевода каждого из трех предикативных выражений естественного языка 208 в одно и то же предикативное выражение искусственного языка 210 . В этом неограничивающем примере множество первых тематических ролевых последовательностей , 202, включает три (3) первых тематических ролевых последовательности , 202, . Каждая первая последовательность тематических ролей из множества последовательностей первых тематических ролей показана на фиг. 2 с соответствующим правилом грамматики, 214 .
Пример отображения, показанный на РИС. 2 раскрывает примерный способ, используемый для перевода каждого из трех предикативных выражений , 208, естественного языка в такое же предикативное выражение 210 искусственного языка. В примерном способе одна из трех первых тематических ролевых последовательностей , 202, используется для каждого из примерных трех предикативных выражений естественного языка , 208, и одной и той же второй тематической ролевой последовательности 9.1180 204 может использоваться один раз для каждого из трех предикативных выражений естественного языка 208 . Результатом применения любой из трех первых тематических ролевых последовательностей 202 и одной второй тематической ролевой последовательности 204 является определение последовательности аргументов 212 предикативного выражения искусственного языка в предикативном выражении искусственного языка 210 , в котором последовательность аргументов выражения, предикативных на искусственном языке, 212 не зависит от того, какая из первых последовательностей тематических ролей 202 применяется.
Продолжая ссылаться на фиг. 2 каждое из трех предикативных выражений , 208, на естественном языке показано как содержащее первое соответствующее подмножество множества частей , 200, предикативных выражений на естественном языке. Каждая из множества частей , 200, предикативного выражения на естественном языке содержит по меньшей мере один токен. Примеры токенов могут включать слова и знаки препинания.
Продолжая ссылаться на фиг. 2, примерное предикативное выражение 210 на искусственном языке частично содержит последовательность аргументов 212 предикативного выражения на искусственном языке. Каждый из двух примерных аргументов выражения предиката искусственного языка представляет собой символ «ne». Символ «ne» означает «не выражен», это указывает на то, что для каждого «ne» нет предикативной части выражения в естественном языке 200 , соответствующей аргументу место 206 занято «ne». Каждый из аргументов 212 предикативного выражения искусственного языка, кроме аргументов предикативного выражения искусственного языка, каждый из которых является «ne», является структурой данных. Каждый из аргументов , 212, предикативного выражения искусственного языка задает по меньшей мере частичное значение по меньшей мере одной из множества частей 200 предикативного выражения естественного языка. По крайней мере, одна из множества частей 9 выражений, предикативных на естественном языке.1180 200 соответствует одному из мест 206 аргумента предикативного выражения искусственного языка, которому назначается структура данных в соответствии с иллюстративными соответствиями, показанными на фиг. 2. Каждая из структур данных может быть аргументом 212 предикативного выражения искусственного языка в силу того, что она назначена одному из мест 206 аргумента предикативного выражения искусственного языка.
РИС. 3 представляет собой блок-схему примерного способа использования множества последовательностей тематических ролей 9.1180 202 204 для перевода предикатного выражения на естественном языке 208 в предикативное выражение на искусственном языке 210 , примером которого является предикативное выражение на искусственном языке 210 . Блок 300 на фиг. 3 представляет собой этап получения предикативного выражения 208 на естественном языке, содержащего по меньшей мере один токен. Токены могут включать слова и знаки препинания. Пример предикативного выражения на естественном языке 208 , содержащий один токен, представляет собой команду, такую как «Go», в которой единственный аргумент-предикат-выражение на искусственном языке соответствует тематической роли, называемой «агент», и где значением аргумента-предиката-выражения на искусственном языке является лицо или лица, которым произносится команда. Аргумент предикативного выражения искусственного языка, который не соответствует какому-либо первому элементу последовательности тематических ролей 202 , может быть присвоен месту аргумента 9 аргумента предикативного выражения искусственного языка1180 206 , в котором место 206 аргумента выражения, определяющего искусственный язык, соответствует тематической роли, и где тематическая роль указана отдельно от спецификации любой первой последовательности тематических ролей 202 . В блоке 302 находится этап получения множества последовательностей тематических ролей 202 204 , где каждая из множества последовательностей тематических ролей 204 соответствует последовательности аргументов-предикатов 212 . Затем способ применяет множество последовательностей тематических ролей 202 204 к предикативному выражению естественного языка 208 (блок 304 ). Наконец, способ переводит предикативное выражение естественного языка 208 в предикативное выражение искусственного языка 210 на основе применения множества последовательностей тематических ролей 204 к предикативному выражению естественного языка 208 (блок 306 ).
РИС. 4 представлена блок-схема примерного способа применения первой последовательности 202 тематических ролей из множества последовательностей 202 204 тематических ролей к предикативному выражению 208 на естественном языке (блок 400 ). Кроме того, способ применяет вторую последовательность тематических ролей , 204, из множества последовательностей тематических ролей , 202, , , 204, для перевода предикативного выражения естественного языка 9.1180 208 в предикативное выражение искусственного языка 210 (блок 402 )
Что касается фиг. 5 представлена блок-схема примерного способа разбора предикативного выражения 208 естественного языка на множество частей 200 предикативного выражения естественного языка с использованием грамматического правила 214 (блок 500 ). Затем метод определяет соответствие по меньшей мере одной первой тематической ролевой последовательности 202 элемент и, по крайней мере, одна из частей выражения 200 предикатов естественного языка (блок 502 ). Затем в блоке 504 метод получает соответствие между по меньшей мере одним вторым элементом последовательности 204 тематических ролей и по меньшей мере одним аргументом места 206 предикативного выражения искусственного языка. Наконец, в блоке 506 метод определяет порядок, по крайней мере, одного аргумента выражения 9 предиката искусственного языка.1180 212 на основе определения соответствия между по крайней мере одним элементом первой тематической ролевой последовательности 202 и по крайней мере одной из частей выражения, предикативной на естественном языке 200 , и на основе получения соответствия между по крайней мере одной второй тематической ролевой последовательностью 204 элемент и по крайней мере один искусственный язык предикативного аргумента выражения место 206 .
Продолжая ссылаться на фиг. 5, первая структура данных, представляющая, по меньшей мере, частичное значение для каждой из, по меньшей мере, одной из частей 9 выражений, предикативных на естественном языке.1180 200 можно получить. Одна такая принятая первая структура данных может соответствовать тематической роли, которая является элементом последовательности 202 первой тематической роли. В этом случае отображение, иллюстрируемое отображением, показанным на фиг. 2, может использоваться для определения места 206 аргумента предикативного выражения искусственного языка, которому назначена одна такая принятая первая структура данных. В блоке 506 метод определяет порядок, по крайней мере, одного аргумента выражения 9 предиката искусственного языка.1180 212 . В только что описанном примере, в котором полученная первая структура данных соответствует тематической роли, которая является элементом первой последовательности тематических ролей 202 , которая получила первую структуру данных, является аргументом выражения 212 предикативного выражения искусственного языка, назначенным определенный искусственный язык предикативное выражение аргумент место 206 .
В примере, где полученная первая структура данных представляет по крайней мере частичное значение для каждой из по крайней мере одной из частей выражения предиката естественного языка 200 не соответствует тематической роли, которая является элементом какой-либо первой последовательности тематических ролей 202 , может быть получена вторая структура данных, представляющая по крайней мере частичное значение для каждого из по крайней мере одного из предикативных выражений естественного языка части 200 и спецификацию идентичности элемента второй последовательности тематических ролей 204 , которая соответствует этой второй структуре данных. В этом примере вторая структура данных может быть назначена соответствующему месту 9 аргумента предикативного выражения искусственного языка.1180 206 без использования всего сопоставления, показанного в качестве примера на фиг. 2.
РИС. 6 состоит из двух (2) фигур, фиг. 6А и фиг. 6Б. ИНЖИР. 6А показаны примерные соответствия между одним из по меньшей мере одного первого элемента , 602, грамматического правила первого грамматического правила , 604, , где первый элемент , 602, грамматического правила идентифицирован как примерное начало перемещающегося элемента. Кроме того, на фиг. 6A показаны примерные соответствия между вышеизложенным и одним по меньшей мере одним вторым элементом 9 правила грамматики.1180 606 второго грамматического правила 608 идентифицировал первые значения 610 перемещающегося признака, получил идентифицированные существующие вторые значения перемещающегося признака 612 , связанного с одним по меньшей мере одним элементом 602 первого грамматического правила, и получили идентифицированные существующие третьи значения перемещающегося признака 614 , связанные с одним по меньшей мере одним вторым элементом 606 правила грамматики.
РИС. 6В показан примерный этап построения первого узла 9.1180 616 на основе применения процесса расчета значения функции перемещения. ИНЖИР. 6B дополнительно иллюстрирует ассоциирование определенных идентифицированных первых значений , 610, подвижного элемента, определенных идентифицированных вторых значений , 612, подвижного элемента и определенных идентифицированных третьих значений , 614, подвижного элемента с первым построенным узлом , 616 . . Как показано на фиг. 6B, значения каждого соответствующего «списка» значений 610 612 614 , связанные с первым узлом, представляют собой весь список, в отличие от любого определенного подмножества соответствующего списка, который не содержит всех значений списка.
РИС. 6B показан пример контекста, который может существовать для шага построения первого узла , 616, и соответствующих шагов связывания определенных идентифицированных первых значений , 610, движущегося объекта, определенных идентифицированных вторых значений 612 подвижного элемента и определенные идентифицированные третьи значения 614 подвижного элемента с первым узлом 616 . Этот иллюстративный контекст может существовать в ситуации, когда строится диаграмма синтаксического анализатора диаграмм. В таком контексте первое частичное дерево синтаксического анализа , 618, может соответствовать первому ребру, связанному с создаваемой диаграммой, второе частичное дерево синтаксического анализа , 620 может соответствовать второму ребру, связанному с создаваемой диаграммой, и третье частичное дерево синтаксического анализа 622 может быть результатом комбинации первого частичного дерева синтаксического анализа 618 и второго частичного дерева синтаксического анализа 620 . Результирующее третье частичное дерево синтаксического анализа , 622, может быть связано с вновь построенным ребром, связанным с диаграммой синтаксического анализатора диаграмм. В примерном контексте, показанном на фиг. 6В, построенный первый узел , 616, помещается в результирующее третье частичное дерево , 622, синтаксического анализа в то место, где находится первое частичное дерево 9 синтаксического анализа. 1180 618 и второе частичное дерево синтаксического анализа 620 соединены. По меньшей мере, один узел может быть связан с каждым элементом первого грамматического правила 604 и с каждым элементом второго грамматического правила 608 . В показанном примере первые значения 610 и вторые значения 612 связаны с узлом a*, поскольку первый элемент правила грамматики 602 соответствует a*. В показанном примере третьи значения 614 связаны с узлом a’, поскольку второй элемент правила грамматики 606 .
РИС. 7 представлена блок-схема примерного способа построения первого узла , 616, на основе применения процесса вычисления значения полученного признака к одному из идентифицированных по меньшей мере одному первому элементу правила грамматики , 602, и к соответствующей части выражения естественного языка для идентификацию любых первых значений , 610, перемещающегося элемента, где принимается идентификация по меньшей мере одного первого элемента , 602 правила грамматики в качестве источника перемещающегося элемента.
Принята идентификация по меньшей мере одного первого элемента 602 правила грамматики первого правила 604 грамматики в качестве источника перемещающегося элемента (этап 700 ). Принимается процесс вычисления значения перемещающегося признака, связанный по меньшей мере с одним первым элементом , 602, правила грамматики (этап , 702, ). Любой из элементов первого правила грамматики может быть идентифицирован как соответствующее происхождение элемента перемещения. Каждое такое идентифицированное происхождение элемента перемещения может иметь отдельный процесс вычисления значения связанного элемента перемещения. В примерах, где есть несколько элементов первого правила грамматики 602 , идентифицированные как соответствующие источники перемещающегося элемента, первые значения 610 перемещающегося элемента, идентифицированные посредством применения множества соответствующих процессов вычисления значений движущегося элемента, могут накапливаться и связываться с дополнительными элементами связанных правил грамматики.
Часть выражения на естественном языке связана с одним из по меньшей мере одного первого элемента правила грамматики 602 (блок 704 ). Любой процесс вычисления значения перемещающегося признака может использовать ассоциированную часть выражения на естественном языке любым способом в качестве входных данных для этого процесса вычисления. Процесс вычисления значения перемещающегося признака применяется к одному из, по меньшей мере, одного первого элемента 9 правила грамматики.1180 602 и к части выражения естественного языка для идентификации любых первых значений 610 функции перемещения (блок 706 ).
Первый узел 616 построен на основе применения процесса вычисления значения движущегося признака (блок 708 ). Результирующие значения перемещающихся признаков, если таковые имеются, могут быть связаны с построенным первым узлом , 616, любым способом. В некоторых случаях может быть полезно просто связать любые накопленные значения перемещающихся признаков с дополнительными элементами грамматических правил таким образом, чтобы они появлялись в нужных местах в деревьях синтаксического анализа, где эти деревья синтаксического анализа являются результатом любого соответствующего процесса.
РИС. 8 представляет собой блок-схему примерного способа, включающего этапы, ведущие к присвоению по меньшей мере одного определенного значения для каждого из по меньшей мере одного модифицирующего выражения на естественном языке , 812 по меньшей мере одного определенного значения для каждого из по меньшей мере одного модифицирующего выражения. выражение на естественном языке 814 . Присвоение определенных значений происходит, когда оба, по меньшей мере, одно определенное значение для каждого из, по меньшей мере, одного выражения-модификатора на естественном языке 812 и по меньшей мере одно модифицированное выражение 814 на естественном языке содержатся в полученном первом выражении на естественном языке 816 .
Получено первое выражение на естественном языке 816 (блок 800 ). Первое выражение на естественном языке 816 является выражением на естественном языке, значение которого по меньшей мере частично определяется путем присвоения по меньшей мере одного определенного значения каждому из по меньшей мере одного модифицирующего выражения на естественном языке 9.1180 812 к по меньшей мере одному определенному значению для каждого из по меньшей мере одного модифицированного выражения на естественном языке 814 .
Идентифицируется по меньшей мере одно выражение 812 модификатора на естественном языке, содержащееся в полученном выражении на естественном языке (блок 802 ). По крайней мере, для одного из модифицирующих выражений на естественном языке 812 анализатор естественного языка идентифицирует по меньшей мере одно модифицированное выражение на естественном языке 814 , содержащееся в первом выражении на естественном языке 9. 1180 816 , где каждое из по меньшей мере одного модифицируемого выражения на естественном языке 814 может быть изменено по меньшей мере одним модифицирующим выражением на естественном языке 812 (блок 804 ). Этот шаг можно использовать для идентификации по меньшей мере одного модифицируемого выражения на естественном языке , 814, , которому может быть разрешено модифицировать по меньшей мере одно из модифицирующих выражений на естественном языке , 812, по любым исходным критериям.
По крайней мере, одно значение для каждого из по крайней мере одного выражения модификатора на естественном языке 812 и определяется по меньшей мере одно значение для каждого из по меньшей мере одного модифицированного выражения естественного языка 814 (блок 806 ).
По крайней мере, одно модифицированное выражение на естественном языке 814 , синтаксически разрешенное для модификации по крайней мере одним выражением на естественном языке-модификатором 812 , связано по меньшей мере с одним выражением на естественном языке-модификатором 812 (блок 808 ). Этот шаг может по существу отражать выбор по крайней мере одного модифицированного выражения на естественном языке 9.1180 814 , который может быть изменен по крайней мере одним модификатором выражения на естественном языке 812 на основе синтаксических критериев.
Продолжая ссылаться на фиг. 8, по меньшей мере одно определенное значение для каждого из по меньшей мере одного модифицирующего выражения на естественном языке 812 назначается по меньшей мере одному определенному значению для каждого из по меньшей мере одного модифицированного выражения на естественном языке 814 на основе семантических критериев ( блок 810 ). Комбинация последних двух шагов (блоки 808 810 ), может ассоциировать по меньшей мере одно модифицирующее выражение на естественном языке 812 с по меньшей мере одним присвоенным определенным значением по меньшей мере с одним модифицированным выражением на естественном языке 814 также с по меньшей мере одним назначенным определенным значением. Поскольку эта ассоциация создается для каждого из, по крайней мере, одного выражения-модификатора на естественном языке , 812, , отражается частичная интерпретация полученного первого выражения на естественном языке , 816, в целом, хотя дополнительные факторы могут способствовать любой общей интерпретации первого выражения. получил естественно-языковое выражение.
РИС. 9 представляет собой блок-схему, иллюстрирующую способ связывания по меньшей мере одного модифицируемого выражения на естественном языке 814 , синтаксически разрешенного для изменения по меньшей мере одним модифицирующим выражением на естественном языке 812 , с по меньшей мере одним модифицирующим выражением на естественном языке 812. (блок 808 ) на фиг. 8, и присвоения по меньшей мере одного определенного значения каждому из по меньшей мере одного модификатора выражения на естественном языке 812 , по меньшей мере, к одному определенному значению для каждого из по меньшей мере одного модифицированного выражения , 814, естественного языка на основе семантических критериев (блок , 810, ) на ФИГ. 8.
РИС. 9 представлена блок-схема одного из двух примерных способов, которые могут соответствовать двум соответствующим процедурам, одна из которых частично содержит или вызывает другую. Способ на фиг. 9 включает способ, показанный на фиг. 10. Фиг. 9 и фиг. 10 может применяться к примерному случаю, когда только одно модифицированное выражение на естественном языке 814 связан с каждым модификатором выражения на естественном языке 812 .
РИС. 9 отражает предположение, что для каждого из по меньшей мере одного из выражений на естественном языке-модификаторе 812 по меньшей мере одно модифицированное выражение на естественном языке 814 содержится в первом выражении на естественном языке 816 , при этом каждое из по меньшей мере одного выражения на естественном языке выражение на естественном языке 814 разрешено модифицировать хотя бы одним модификатором выражения на естественном языке 812 . Другими словами, фиг. 10 отражает предположение, что этап (этап 804 ) на фиг. 8 уже взят для примерного случая на фиг. 9 и фиг. 10. Фиг. 9 также отражает предположение, что этап (этап 806 ) на фиг. 8 взят для примерного случая на фиг. 9 и фиг. 10. Следовательно, предполагается, что одно или несколько значений уже определены для идентифицированных модификаторов и для идентифицированных модификаций, содержащихся в первом выражении на естественном языке.1180 816 .
Блок 902 на фиг. 9 раскрывает этап связывания по меньшей мере одного модифицируемого выражения на естественном языке 814 , синтаксически разрешенного для модификации по меньшей мере одним выражением на естественном языке-модификатором 812 , по меньшей мере с одним выражением на естественном языке-модификатором 814 для примерного случая ИНЖИР. 9 и фиг. 10. Блок , 902, по фиг. 9 также раскрывает этап присвоения, по меньшей мере, одного определенного значения каждому из, по меньшей мере, одного выражения-модификатора на естественном языке 9.1180 812 к по меньшей мере одному определенному значению для каждого из по меньшей мере одного модифицированного выражения на естественном языке 814 на основе семантических критериев для примерного случая на фиг. 9 и фиг. 10.
Для примерного случая на фиг. 9 и фиг. 10 блок 902 соответствует этапам блока 808 и блока 810 на фиг. 8, где один модификатор связан с одним модификатором, и по крайней мере одно определенное значение выражения модификатора на естественном языке 812 присвоен по крайней мере одному определенному значению модифицированного выражения на естественном языке 814 . Блок 902 также соответствует этапу приведенного в качестве примера способа на фиг. 9, который детализирован на фиг. 10 для примерного случая на фиг. 9 и фиг. 10.
Условная ветвь 904 проверяет метод на неудачу на текущем уровне рекурсии, если для первого модификатора (для текущего уровня рекурсии) не найдена совместимая пара модификатор-модификатор в списке, содержащем все модификатор выражений на естественном языке 812 , найденный в блоке 802 на фиг. 8.
Этап блока 906 раскрывает саморекурсивный вызов примерной процедуры, отраженной на фиг. 9, где этот вызов пытается найти совместимые пары модификатор-модификатор для всех, кроме первого (для текущего уровня рекурсии) выражения модификатора на естественном языке 812 . Если условная ветвь 908 терпит неудачу, то способ по фиг. 9 пытается найти альтернативную совместимую пару модификатор-модификатор для первого выражения модификатора на естественном языке 812 .
РИС. 10 представлена блок-схема примерного способа ассоциирования по меньшей мере одного модифицируемого выражения на естественном языке 814 , синтаксически разрешенного для модификации по меньшей мере одним выражением на естественном языке-модификатором 812 , с по меньшей мере одним выражением на естественном языке-модификатором 814 для примерный случай на фиг. 9 и фиг. 10. Блок-схема на фиг. 10 также раскрывает этап присвоения, по меньшей мере, одного определенного значения для каждого из, по меньшей мере, одного выражения-модификатора на естественном языке 9.1180 812 к по меньшей мере одному определенному значению для каждого из по меньшей мере одного модифицированного выражения на естественном языке 814 на основе семантических критериев для примерного случая на фиг. 9 и фиг. 10.
Шаг 1002 пытается получить представление значения для выражения модификатора на естественном языке 812 . Если шаг 1002 завершается успешно в соответствии с условным переходом 1004 , то шаг 1006 извлекает список всех модифицированных выражений естественного языка 814 , которые разрешено модифицировать выражением модификатора на естественном языке 812 , определенным на этапе 804 на фиг. 8.
Этап 1008 выбирает следующий или первый элемент, модифицированное выражение на естественном языке, 814 из списка модифицированных, извлеченных на этапе 1006 . Шаг 1008 завершается успешно, как определено условной ветвью 1010 , если только список, полученный на шаге 1006 , не пуст. Если полученный список пуст, то метод возвращается, чтобы попробовать альтернативное значение представления выражения модификатора на естественном языке, 812 .
Этап 1012 извлекает представление значения для модифицированного выражения 814 на естественном языке, выбранного из списка на этапе 1006 . Если поиск завершается успешно, как определено условной ветвью 1014 , то на шаге 1016 предпринимается попытка найти способ, с помощью которого текущий выбранный модификатор выражения 812 на естественном языке может изменить выбранный в данный момент модификатор выражения на естественном языке 814 . По сути, постулируется некоторая связь между модифицирующим выражением на естественном языке 812 и модифицируемым выражением на естественном языке 814 , которое «объясняет», как первое может изменить последнее.
Если на шаге 1016 связь не была успешно постулирована, как определено в условном переходе 1018 , то метод возвращается к шагу 1012 , чтобы получить следующее представление значения для модифицированного выражения на естественном языке 814 . Примерный способ, показанный на фиг. 9 и фиг. 10 завершается успешно, как определено условной ветвью 1018 , когда все модифицирующие выражения на естественном языке 812 имеют ассоциированное модифицируемое выражение на естественном языке 814 , как более широко раскрыто на этапе 808 на фиг. 8, и, по крайней мере, одно представление значения (по крайней мере, одно определенное значение) для каждого модификатора выражений на естественном языке 812 назначается по крайней мере одному соответствующему представлению значения (по крайней мере, одному определенному значению) связанного модифицированного выражения на естественном языке 9. 1180 814 , как более широко отражено в шаге 810 на ФИГ. 8.
РИС. 11 представляет собой блок-схему, иллюстрирующую способ построения первого узла , 616, . Построение первого узла , 616, основано на применении процесса вычисления значения принятого признака к одному из идентифицированных, по меньшей мере, одного второго элемента , 606, правил грамматики для фиг. 11. Конструкция первого узла 616 также основана на соответствующей части выражения естественного языка для идентификации любых первых значений 610 элемента перемещения, где идентификация по меньшей мере одного второго элемента 606 правила грамматики для фиг. 11, как источник функции перемещения. Это отличается от примера, показанного на фиг. 6, поскольку дочерний узел (a’ на фиг. 6) соответствует элементу правила грамматики , 606, , который идентифицирован как источник перемещающегося элемента для примера, показанного на фиг. 11.
Для примера, показанного на фиг. 11 каждая функция перемещения используется для обработки информации о неявных путях от узла к узлу в деревьях синтаксического анализа или частичных деревьях синтаксического анализа, неявных в содержимом синтаксического анализатора диаграммы. Значение каждой подвижной функции является спецификацией идентичности завершенного компонента (узла). Завершенный узел — это узел, все дочерние узлы которого назначены в соответствии с соответствующим правилом грамматики.
Блок 1100 присваивает («устанавливает») значение каждого движущегося объекта списку, содержащему спецификацию завершенного узла, соответствующего элементу правила грамматики 606 на фиг. 6, который идентифицируется как источник каждого такого соответствующего движущегося объекта.
Для примера, показанного на РИС. 11, а’ соответствует только что завершенному узлу. Этап , 1102, обновляет значение каждого движущегося объекта до списка «вычисленных» значений, в этом примере списка, содержащего одно значение, которое является спецификацией идентичности завершенного компонента (узла) и любых существующих значений, уже связанных с родительский узел, который соответствует узлу а* на фиг. 6.
Дочерний узел a’ может иметь существующие значения функции перемещения. Эти значения соответствуют третьим значениям элемента перемещения, , 614, на фиг. 6. Этапы , 1104, задают значение функции перемещения как объединение значений, связанных с родительским узлом, что соответствует a* на фиг. 6 и эти существующие значения функции перемещения. Для примера, показанного на фиг. 11 вычисленные значения функции перемещения уже включены в значения, связанные с родительским узлом до шага 9.1180 1104 .
РИС. 12 показаны примерные шаги, предпринятые для стандартизации порядка, в котором аргументы появляются в каждом логическом предикате, используемом как часть представления знаний, независимо от порядка, в котором эти аргументы выражены в выражении на естественном языке, к которому применяется предикат. Основным преимуществом использования исчисления предикатов для представления знаний является то, что оно может напрямую поддерживать вывод и анализ. Ключевой возможностью системы NLU является определение выражений на естественном языке, которые имеют сходное значение или имеют одинаковое значение, даже если они выражены с использованием разных слов или с использованием разного порядка слов. Можно также использовать процессы логического вывода, но в конечном счете желательно установить стандартную форму для представления знаний, чтобы выражения на естественном языке, которые приводят к тому же самому выражению на языке представления знаний, имели одинаковое значение.
Подход, описанный на фиг. 12 используется для построения выражений исчисления предикатов, в частности, предикатов, которые являются базовыми выражениями в исчислении предикатов, из которых состоят более сложные выражения. Предикаты, построенные в этом подходе, учитывают множество аспектов значения, которые применяются к NLU, смысл слова (как для предикативных, так и для непредикативных слов), типы сущностей, на которые может ссылаться каждое конкретное слово, и типы сущностей. которые могут соответствовать определенным тематическим ролям в сочетании со смыслами предикативных слов (когда это применимо). Один из способов указать, какие комбинации тематических ролей и типов сущностей совместимы для определенных значений предикативных слов (часто глаголов), — это использовать факты Пролога в следующей форме.
predArgTypes(<Предикативное слово>,<Синтаксическая категория>,<Целочисленный идентификатор>,<Список смыслов>,<Спецификация типов>),
где
1. (<Предикативное слово> — это слово естественного языка, которое либо модификатор или глагол,
2. <Синтаксическая категория> — это одна синтаксическая категория естественного языка, для которой может использоваться предикатное слово,
3. <Целочисленный идентификатор> — это идентификатор последовательности тематических ролей, которая использоваться в качестве «главной» ролевой последовательности для построения предикатного представления предикатного выражения естественного языка (например, предложения, прилагательного, наречия и т. д.),
4.
5.
Соответствие между тематическими ролями и выражениями на естественном языке определяется использованием грамматических правил, каждое из которых определяет последовательность тематических ролей, которая будет использоваться в качестве «главной» последовательности тематических ролей, и последовательность тематических ролей, которая отражает фактически выраженные тематические роли, когда используется это грамматическое правило. Показанный ниже пример используется для дальнейшего пояснения этого подхода и пояснения фиг. 12.
Ниже приводится грамматическое правило для английского предложения в форме «X было оценено с использованием Y», где X и Y могут быть любыми простыми или сложными английскими выражениями. Это грамматическое правило такое же, как показано выше, и повторено здесь для удобства.
Функция [mID, [0, 2], [10] ] используется для указания последовательности тематических ролей, которая будет использоваться в качестве основной последовательности тематических ролей с этим правилом грамматики. Идентифицирующее целое число равно 10. Пролог-факт roleSeq(10, [eWhen, genAgent, way, vg, theme, inst, ben, target_purp, priorCause_mot]) перечисляет тематические роли в конкретной показанной последовательности. Эта информация в любой адекватной форме извлекается в блоке , 1200, на фиг. 12. Функция [roleSeq, [0], [11]] в грамматическом правиле используется для извлечения последовательности тематических ролей, которые фактически выражены в английском выражении, санкционированном этим грамматическим правилом, в данном случае это факт, roleSeq( 11, [тема, вг, инст]). Это шаг, который соответствует блоку 1202 на РИС. 12. Элемент «мкг» в списке означает «verbGroup» и является заполнителем, не соответствующим какой-либо тематической роли. Компонент verbGroup английского предложения устанавливает предикацию этого предложения и не соответствует какому-либо дополнению в предложении. Следовательно, в логическом предикате, построенном в соответствии с этой группой глаголов, нет аргумента.
Предикативное слово для любого примерного предложения формы «X было оценено с использованием Y» является корневой формой слова «оценка», то есть «оценка». В блоке 1204 на РИС. 12 идентифицирует это предикатное слово, которое используется в блоке , 1206, для извлечения соответствующего факта Пролога, описанного далее. Данные, извлеченные в этом примере, которые соответствуют данным, упомянутым в блоке , 1206, на фиг. 12 является фактом формы
predArgTypes(<Предикативное слово>,<Синтаксическая категория>,<Целочисленный идентификатор>,<Список значений>,<Спецификация типов>),
, как указано выше. В этом случае полученный факт равен
predArgTypes(оценка,’основной глагол’,10,[1],[ [время],[сущность],[сущность],na,[сущность],[сущность],
- [сущность],[ сущность],[сущность]]).
Использование типа entity позволяет избежать каких-либо ограничений на тип объекта или объектов, которые могут быть обозначены соответствующим аргументом создаваемого предиката. В реализации системы NLU ограничения должны быть выражены в пятом элементе пятого аргумента факта Prolog predArgTypes(estimate,’main verb’, 10, [1], — — -), который показан выше, чтобы отразить это ограничение. Первый аргумент этого факта predArgTypes, «оценка», — это предикатное слово, найденное в блоке 9.1180 1204 на фиг. 12. Третий аргумент, «10», является идентификатором последовательности тематических ролей, которая будет использоваться в качестве основной последовательности тематических ролей. Четвертый аргумент — это список идентификаторов, каждый из которых имеет значение предикатного слова. Любой смысл, определяемый идентификатором в этом списке, может использоваться с другой информацией, заданной фактом predArgType Prolog. Пятый аргумент, как объяснялось выше, указывает допустимые типы сущностей, на которые может ссылаться соответствующий аргумент в конструируемом предикате.
Возможны различные этапы построения предиката для представления значения английского выражения, санкционированного грамматическим правилом. Один из способов начинается с построения «шаблона» предиката, который имеет предикатное имя, основанное на предикатном слове и смысле, в котором оно используется. В этом случае смысл в том, что с идентификацией целого числа 1, поэтому имя предиката — «оценка [1]». В этом примере предикату требуется столько аргументов, сколько длина пятого аргумента факта predArgTypes(—) Prolog минус 1 для учета присутствия «na». Результатом этой конструкции является тело шаблона предиката ‘(ne,ne,ne,ne,ne,ne,ne,ne)’. Эта конструкция упоминается в блоке 1208 на фиг. 12. блок , 1210, по фиг. 12 может быть реализован путем построения выражения «оценка [1]», где «1» — это идентификатор смысла предикатного слова, который может использоваться с другой информацией, заданной прологовым фактом predArgType. Этап, соответствующий блоку , 1212, на фиг. 12 — это шаг, обеспечивающий размещение аргументов предиката в стандартном порядке, определяемом последовательностью тематических ролей (номер 10), заданной в качестве мастера. В этом примере [theme, vg, inst] — это выраженная последовательность ролей, а [eWhen, genAgent, way, vg, theme, inst, ben, target_purp, PriorCause_mot] — последовательность главных ролей. Поскольку «тема» появляется как пятый элемент последовательности главной роли, аргумент (который представляет собой любое английское выражение, соответствующее X в «X было оценено с использованием Y») помещается на пятое место аргумента шаблона предиката. . Точно так же аргумент, соответствующий «inst», помещается на шестое место аргумента. Если arg1, arg2 и т. д. обозначают фактические представления знания аргументов предиката, результирующее представление значения английского выражения будет следующим: ‘estimate[1](ne,ne,ne,ne,arg1,arg2, ne,ne), где arg1 — тема, а arg2 — инструмент. Все аргументы, кроме пятого и шестого, не имеют выражения ни в одном предложении, санкционированном этим грамматическим правилом, поэтому все их места в сказуемом занимают «ne» (не выражено) в соответствии с шагом блока 9. 1180 1214 на РИС. 12.
Независимый анализ каждой отдельной серии последовательных модифицирующих выражений (независимых от остальной части выражения на естественном языке, частью которого они являются, за исключением одной точки «присоединения» — и независимых друг от друга) может быть выполнен с использованием спецификация того, какие выражения и слова могут изменять какие другие выражения и слова, и список для каждого узла в диаграмме, который включает смысл этого узла, вычисленный из всех комбинаций смыслов всех альтернативных упорядоченных дочерних наборов этого узла. Данные, дающие спецификацию пар модификатор-модификатор-кандидат, могут быть получены из самой грамматики естественного языка, когда известно с уверенностью, основанной на структуре грамматики, что конкретный узел является модификатором конкретного одного из своих братьев и сестер. Функции перемещения могут использоваться для сбора данных, необходимых для определения пар модификатор-модификатор, когда они синтаксически более отдаленно связаны. Сложные существительные имеют имплицитную регулярную синтаксическую структуру, которую можно охарактеризовать как бинарное дерево вплоть до уровня отдельных существительных или конкретных именных словосочетаний. Комбинация этих трех синтаксических индикаторов возможных пар модификатор-модификатор обеспечивает широкий охват (возможно, исчерпывающий охват в зависимости от конструкции грамматики) всех возможных пар. Хотя правила грамматики могут предоставить данные о многих парах модификатор-модификатор, удобно использовать перемещающиеся атрибуты для сбора данных модификатор-модификатор, которые можно собрать из отдельных грамматических правил, в дополнение к данным о более отдаленных синтаксических отношениях между потенциальными модификаторами и модификаторами.
РИС. 9 изображен рекурсивный подход для нахождения комбинации пар модификатор-модификатор, [X,Y], соответствующих смыслов для X и Y, и спецификации того, «как» X может модифицировать Y при наличии этих смыслов для входного списка модификаторов. Вычисление совместимых комбинаций пар модификатор-модификатор принимает во внимание синтаксические отношения членов выражений естественного языка, значения слов (как предикативных слов, таких как глаголы), так и непредикативных слов, семантические отношения, которые «объясняют» или «объясняют». «учитывать», как каждый модификатор может изменить модификатор, с которым он связан, и гарантирует, что любые результирующие связанные сети выражений, которые являются членами пар модификатор-модификатор, используют либо одинаковые, либо совместимые смыслы для всех вхождений всех этих слов и выражений. . Блок 902 на фиг. 9 вызывает процедуру (изображенную на фиг. 10 и описанную ниже), которая находит модификацию, соответствующие смыслы для X (один заданный модификатор) и Y и способ, которым X может модифицировать Y с учетом этих смыслов.
Процедура по фиг. 9 является рекурсивным, потому что он вызывает себя в блоке 906 со всеми модификаторами, кроме первого, из списка, который ему дается на каждом уровне рекурсии. Когда в качестве входных данных задан пустой список, это указывает на то, что все модификаторы были успешно обработаны (каждый из них имеет назначенный модификатор, и элементы каждой пары модификатор-модификатор имеют назначенные смыслы и способ, которым X может изменить Y). Если тест 904 терпит неудачу, тогда никакое решение для сокращенного списка (содержащего все, кроме первого модификатора X) для любой комбинации [X, Y], смыслов для X и Y и способа X, изменяющего Y, завершается, и вся процедура терпит неудачу. Когда такая комбинация была найдена в блоке 902 для X и в блоке 906 для всех модификаторов в данном списке, кроме X, то было найдено полное решение. Требуется возврат (здесь указанный для рекурсивной процедуры), а не поиск решения для каждого модификатора независимо, потому что модификаторы и модификации могут участвовать более чем в одном отношении модификации, поэтому может потребоваться, чтобы присвоенные смыслы были одинаковыми или дополняющими для все модификаторы и модификации в данном списке.
РИС. 10 показан один из способов организации этого вычисления для каждого модификатора. Блок 1002 на фиг. 10 извлекает значение модификатора и назначает его как текущее значение X. Тест , 1004, на фиг. 10 терпит неудачу, когда нет больше чувств X, чтобы попробовать. Блок 1006 на фиг. 10 одновременно извлекает всех кандидатов-модификаторов для текущего модификатора, назначенного X. Блок 1008 на фиг. 10 выбирает один из модификаторов-кандидатов (по одному) для текущего модификатора, назначенного X, из этого списка. Если тест 1010 терпит неудачу, то все комбинации смыслов для Y и способы, которыми X может изменить Y, были опробованы для текущей комбинации X и назначенного смысла X, и процедура возвращается, чтобы попробовать другой смысл X. Шаг 1012 , если успешно, извлекает смысл для Y. Если тест 1014 терпит неудачу, то X не может изменить Y для текущей комбинации X, Y и их соответствующих в настоящее время назначенных смыслов, поэтому процедура возвращается, чтобы попробовать другой кандидат-модификатор Y. Шаг 1016 использует процедуру X_Can_Modify_Y(X,Y), которой даются два значения X и Y и которая определяет по критериям, характерным для конкретных входных аргументов X и Y, как X может изменить Y. Каждый временной шаг 1016 на фиг. 10 используется для того же модификатора, того же модификатора и тех же соответствующих смыслов для них, он пытается найти другую «причину», почему X может модифицировать Y в этих смыслах. Есть много способов, как это можно реализовать для использования знаний в базе знаний.
Например, фраза «на холме» может изменить слово «телескоп», потому что любой физический объект может физически опираться на холм под действием силы тяжести, и любой физический объект может быть прикреплен к холму, если часть этого объекта будет погружена в материал. того холма. Любая из этих причин сама по себе достаточна для интерпретации «телескопа на холме». Кроме того, они являются совместимыми «дополнительными» смыслами, которые могут быть верны для одной и той же ситуации. Фраза «тень на холме» будет иметь другую интерпретацию, другое отношение между «тенью» и «холмом», потому что «тень» — это не физический объект, а скорее относительное отсутствие света по сравнению с прилегающими участками поверхности на земле. холм. Такие «объяснения» могут быть чрезмерными упрощениями для конкретных приложений системы NLU или настолько сложными, насколько это необходимо.
Смысл этого примера в том, что разные такие объяснения приводят к разным значениям предикативного слова «на». Это типично для предлогов, которые могут иметь самые разные интерпретации в зависимости от типов сущностей, которые они принимают в качестве аргументов. Если условная ветвь 1018 терпит неудачу, это указывает на то, что невозможно найти больше способов объяснить, как X может изменить Y для данного модификатора и модификатора и их соответствующих смыслов. В этом случае процедура возвращается, чтобы попробовать другой смысл для Y. Если условный переход 1018 завершается успешно, затем была найдена модификация Y, комбинация соответствующих смыслов для X и Y и способ, с помощью которого X может изменить Y, и процедура завершается успешно. Процедура, реализованная на Прологе, может быть «возвращена назад» таким образом, что она ведет себя так, как если бы условная ветвь 1018 не удалась, даже если ответ был успешно возвращен. Это может привести к дополнительным ответам, при этом процедура действует как «генератор» нескольких ответов, пока больше не будет найдено. В качестве альтернативы, если процедура «вызывается» снова, она начинается с «старта».
Как упоминалось в Резюме в разделе «Функции для путешествий», основное использование функций для путешествий в текущей системе заключается в определении английских слов и фраз, которые являются потенциальными модификаторами других слов и фраз строго в силу синтаксических соображений. Это полезно, потому что позволяет упростить грамматику естественного языка, что, в свою очередь, уменьшает количество деревьев синтаксического анализа, которые обычно необходимо построить. В общем, перемещающиеся признаки могут использоваться для указания того, что любые конкретные узлы или типы узлов или узлы с любыми конкретными свойствами находятся ниже общего предка в дереве синтаксического анализа «до того, как это дерево синтаксического анализа будет построено». Значения бегущих признаков определяются при построении карты. Конвейерная система NLU, которая создает одно дерево синтаксического анализа за раз, а затем передает это дерево синтаксического анализа в качестве входных данных на этап обработки, связанный с семантическим анализом, строит столько деревьев синтаксического анализа, сколько необходимо для различения всех комбинаций «прикрепления модификатора», таких как предложные словосочетания и зависимые предложения. При таком и подобных подходах структура дерева синтаксического анализа полностью отвечает за отображение того, какие узлы изменяют какие другие узлы. Одни и те же варианты построения альтернативных поддеревьев, отражающих эту модификацию, можно встретить много раз при построении деревьев синтаксического анализа.
Если эти варианты встречаются K раз при построении нескольких деревьев синтаксического анализа и имеется N комбинаций модификаций, то общее количество деревьев синтаксического анализа увеличивается в [N x (K−1)]) раз. Поскольку во входном выражении может возникнуть несколько ситуаций, требующих альтернативных шаблонов модификации, это может резко увеличить общее количество деревьев синтаксического анализа. В текущей системе функции перемещения позволяют серии «постноминальных модификаторов», таких как предложные фразы и зависимые фразы, интерпретировать каждую из них независимо от остальных деревьев синтаксического анализа, в которых они встречаются, и независимо друг от друга. Примером может служить именное словосочетание «Человек на холме с телескопом и коричневым пятном». Есть три предложных фразы: «на холме», «с телескопом» и «с коричневым пятном». Есть шесть вероятных интерпретаций этой фразы, в зависимости от того, какие предлоги изменяют какие именное словосочетание. Пять альтернативных деревьев синтаксического анализа показаны на фиг. 13. Если эти пять деревьев синтаксического анализа необходимо построить хотя бы два раза из-за другой структуры деревьев синтаксического анализа, частью которых могут быть эти деревья синтаксического анализа, общее количество деревьев синтаксического анализа будет увеличено на 8, а другие поддеревья с альтернативной модификацией шаблоны могут нуждаться в построении большего количества раз, что усиливает эту неэффективность. Сообщалось, что некоторые предложения в известных публикациях длиной от 20 до 30 слов могут по отдельности давать тысячи деревьев синтаксического анализа. Кроме того, использование путешествующих атрибутов обеспечивает удобство указания более простой и интуитивно понятной грамматики. Например, грамматическое правило, такое как
np2—>[typeNameOrS, seriesPostNominalMods]
может использоваться там, где категория seriesPostNominalMods представляет собой последовательный ряд предложных фраз или зависимых предложений. Деревья синтаксического анализа, построенные при использовании этого правила, являются «плоскими» под узлом категории seriesPostNominalMods. Такой узел просто имеет один дочерний элемент для каждого номинального модификатора записи вместо одной из альтернативных структур в поддереве, как показано на фиг. 13. Это делает грамматику более простой и интуитивно понятной, а также уменьшает количество деревьев синтаксического анализа, которые необходимо построить, как описано ранее. Функции перемещения поддерживают этот процесс, предоставляя список потенциальных модификаторов для каждого модификатора во время построения диаграммы. ИНЖИР. 11 показаны основные этапы, предпринятые для определения значений структур перемещающихся элементов. Функции добавляются в грамматику, чтобы указать, в каких узлах создается значение для структуры функций. Обратите внимание, что на фиг.1 узлы упоминаются как «компоненты». 11. В настоящее время в разрабатываемом прототипе системы используются три функции перемещения: modt, ntar и pmod. Modt имеет значения, которые определяют узлы в диаграмме любой синтаксической категории, которая действует как модификатор номинальных выражений и появляется слева от выражения, которое они модифицируют.
Примером этих синтаксических категорий являются прилагательные, которые появляются слева от своих модификаций (как и большинство прилагательных). Ntar принимает в качестве своих значений узлы, принадлежащие к какой-либо номинальной категории (не предикативному слову), такие как существительные и именные словосочетания. Pmod принимает в качестве значений узлы, которые являются модификаторами номинальных выражений и могут появляться справа от выражения, которое они модифицируют. Примерами являются предлоги и зависимые предложения. В примере, описанном выше, использовались три предложных словосочетания, которые обрабатываются как значения путевого признака типа pmod. Значение движущегося объекта может исходить из узла, соответствующего компоненту (узлу) на только что завершенной диаграмме. Узел завершен, когда его последний дочерний элемент используется для его расширения. В анализаторе диаграммы сверху вниз, который использует текущая система, может потребоваться, чтобы дочерний компонент сам уже был полным компонентом (узлом), чтобы его можно было использовать для расширения другого незавершенного узла. Когда узел расширяется, результатом считается отдельный узел, следовательно, ряд полных дочерних узлов расширяет узлы (производя новые узлы), пока не будут добавлены все дочерние узлы и не получится полный «родительский» узел.
Атрибуты перемещения обрабатываются, когда узлы расширяются, независимо от того, приводит ли это расширение к полному узлу или нет. Однако значения перемещаемых атрибутов собираются и сохраняются для последующего извлечения только тогда, когда последнее расширение приводит к полному родительскому узлу. Все потенциальные деревья синтаксического анализа, построенные из узлов диаграммы, состоят только из полных узлов. Каждый из этих процессов, обработка перемещаемых атрибутов на всех расширениях узлов, их сбор и сохранение при создании полных узлов, подробно описан ниже. Создание значения движущегося объекта, которое «путешествует» вверх от только что завершенного узла, может быть указано с помощью нотации [ATT, [0, — -], [начало]], где ATT — тип атрибута перемещения, такой как modt. Он «путешествует вверх», передаваясь от каждого потомка к родителю дочернего элемента, родителю этого родителя и т. д. по мере расширения узлов на диаграмме. Как описано в блоке 1102 на фиг. 11 значение, созданное для ATT, представляет собой некоторую спецификацию только что завершенного узла. В текущей системе [ATT, [0, — -], [origin]], заменяется на [ATT, [0, — -], [[[Cat,S,E, ID]]]], где ID идентификатор только что завершенного узла.
Например, [modt, [0], [origin]] будет заменено на [modt, [0], [[[preNounMod, 5, 9, 77]]]], если только что завершенный узел относится к категории preNounMod с идентификатором 77 и встречается во входном выражении между позициями 5 и 9. Есть еще один способ, которым может возникнуть значение движущегося объекта. Оно может исходить из узла, соответствующего одному из элементов правой части грамматического правила. В настоящее время для этого используется нотация [ATT, [N1,N2,N3 — -], [[org, Ni]]], где ATT — тип перемещающегося атрибута, а Ni — член списка [N1,N2,N3 — -]. Например, если родительский узел имеет признак [modt,[1,2],[[org,1]]], то этот признак изначально заменяется на [modt,[1,2],[[[preNounMod,1 ,4,436]]]], где дочерний узел [preNounMod,1,4,436] является единственным (пока что) значением атрибута modt, область действия которого в родительском узле равна [1,2]. Вокруг спецификации узла в реализации, из которой был взят этот пример, так много круглых скобок из-за деталей текущей реализации, специфичных для этой реализации. В принципе, для указания списка значений необходимы только две пары скобок, когда каждое значение представлено одной парой. В этом случае узел представлен одной парой. В этом примере идентификатор узла равен 436, а выражение на естественном языке, соответствующее этому узлу категории preNounMod, находится между позициями 1 и 4 входного выражения на естественном языке.
Родительскому узлу разрешено иметь как спецификацию происхождения путешествующего атрибута, так и другую спецификацию для того же самого атрибута, который имеет свою собственную указанную область действия. Блок 1104 обрабатывает случай, когда оба присутствуют, если область действия неисходной спецификации содержит целое число 0. Целое число 0 указывает, что любое значение, полученное из расширения любого k-го дочернего элемента родителя, где целое число k находится в рамках этой спецификации, передается родителю родителя. Например, если и [modt, [0], [origin]] и [modt, [0,2,4], [[[cat1,2,3,77],[cat2,5,8,78]]] ] появляются в родительском узле, а родительским узлом является [catp,1,9,55], то две спецификации modt объединяются в [modt, [0,2,4],[[[catp,1,9,55],[cat1,2,3,77],[cat2,5, 8,78]]]].
Блок 1106 завершает создание атрибутов перемещения для узла путем объединения атрибутов перемещения каждого дочернего узла, используемого для расширения родительского узла на диаграмме, с атрибутами перемещения, которые уже находятся в родительском узле непосредственно перед этим расширением. . Если целое число k находится в области действия перемещаемого атрибута ATT родительского узла, а 0 находится в области действия того же самого атрибута k-го дочернего элемента, используемого для расширения родительского узла, то значение родительского ATT становится объединением любых значений родительского узла для ATT до расширения и k-го дочернего значения ATT. Например, если у родителя [modt, [2,4], [[[cat1,1,3,55],[cat2,7,8,56]]]], а у второго потомка [modt,[0 ,2,4],[[[cat3,6,10,80],[cat4,17,18,81]]]] тогда результирующее значение modt для расширенного родителя после его расширения этим дочерним узлом равно
[modt,[2,4],[[[cat1,1,3,55],[cat2,7,8,56],[cat3,6,10,80],[cat4,17,18, 81]]]].
Эта комбинация имеет место, потому что ‘2’ в [2,4], область ATT для родителя указывает, что значения modt второго дочернего элемента должны быть объединены со значениями modt родителя, если дочерний элемент «хочет ” передать любой up. То, что дочерний элемент должен отказаться от них, обозначается «0» в [0,2,4], область действия для modt в дочернем элементе.
Когда узел N завершен (все дочерние элементы, которые он может иметь в соответствии с применимым правилом грамматики, были использованы для расширения этого узла), тогда может существовать множество перемещающихся атрибутов с соответствующими списками значений для каждого из них в этом узел. Тот факт, что они «прибыли» в N, указывает на то, что путь от источника каждого значения до N существует. Тот факт, что значения двух или более атрибутов достигают узла, указывает на синтаксическую связь между их исходными точками. Например, modt означает, что каждое из его значений является потенциальным модификатором, а ntar указывает, что каждое из его значений является словом или выражением, которое может быть изменено модификатором. При правильном расположении разрешенных путей, когда любое значение modt достигает того же завершенного узла, что и любое значение ntar, это указывает на то, что значение modt может изменить значение ntar. Ценность этого вытекает из того факта, что деревья синтаксического анализа еще не построены. Их строительство еще даже не началось; однако в этот момент доступна информация, которая указывает, какие модификаторы могут модифицировать какие модификаторы строго на основе их синтаксического отношения. Метод использования перемещающихся атрибутов при построении диаграмм может иметь множество других применений, кроме того, когда используются разные значения (а не только узлы в диаграмме). Нет ограничений на типы информации, которая может быть включена в «значения» атрибутов путешествия. По сути, любая информация, доступная в одной точке (одном узле) при построении диаграммы, может быть передана по желанию ее предкам. Кроме того, перемещающиеся элементы также могут передаваться от родителя к дочернему при создании узлов «нулевой длины». Например, как описано выше, когда создаются узлы 1, 2, 5 и 10, может быть организована передача атрибутов перемещения от родительского узла, который впоследствии должен быть расширен до первого дочернего узла, используемого для расширения этого родителя. Это может не потребоваться при использовании движущихся объектов для идентификации пар модификатор-модификатор.
Настоящее изобретение может представлять собой систему, способ и/или компьютерный программный продукт. Компьютерный программный продукт может включать в себя машиночитаемый носитель (или носители), содержащий машиночитаемые программные инструкции, заставляющие процессор выполнять аспекты настоящего изобретения.
Машиночитаемый носитель данных может представлять собой материальное устройство, которое может сохранять и хранить инструкции для использования устройством выполнения инструкций. Машиночитаемый носитель данных может быть, например, но не ограничиваясь этим, электронным устройством хранения данных, магнитным устройством хранения данных, оптическим устройством хранения данных, электромагнитным устройством хранения данных, полупроводниковым устройством хранения данных или любой подходящей комбинацией вышеперечисленного. Неисчерпывающий список более конкретных примеров машиночитаемого носителя данных включает в себя следующее: переносная компьютерная дискета, жесткий диск, оперативная память (ОЗУ), постоянное запоминающее устройство (ПЗУ), стираемое программируемое считываемое устройство. только память (EPROM или флэш-память), статическая оперативная память (SRAM), портативный компакт-диск с постоянной памятью (CD-ROM), цифровой универсальный диск (DVD), карта памяти, дискета, механический закодированное устройство, такое как перфокарты или выпуклые структуры в канавке с записанными на них инструкциями, и любая подходящая комбинация вышеперечисленного. Считываемый компьютером носитель данных, используемый здесь, не должен рассматриваться как преходящий сигнал сам по себе, такой как радиоволны или другие свободно распространяющиеся электромагнитные волны, электромагнитные волны, распространяющиеся по волноводам или другим передающим средам (например, световые импульсы, проходящие через оптоволоконный кабель) или электрические сигналы, передаваемые по проводу.
Описанные здесь машиночитаемые программные инструкции могут быть загружены в соответствующие вычислительные/обрабатывающие устройства с машиночитаемого носителя данных или на внешний компьютер или внешнее запоминающее устройство через сеть, например, Интернет, локальную сеть, глобальную сеть сети и/или беспроводной сети. Сеть может включать медные кабели передачи, оптические волокна передачи, беспроводную передачу, маршрутизаторы, брандмауэры, коммутаторы, шлюзовые компьютеры и/или пограничные серверы. Карта сетевого адаптера или сетевой интерфейс в каждом вычислительном/обрабатывающем устройстве принимает машиночитаемые программные инструкции из сети и пересылает машиночитаемые программные инструкции для хранения на машиночитаемом носителе данных в соответствующем вычислительном/обрабатывающем устройстве.
Машиночитаемые программные инструкции для выполнения операций по настоящему изобретению могут быть инструкциями ассемблера, инструкциями архитектуры набора инструкций (ISA), машинными инструкциями, машинно-зависимыми инструкциями, микрокодом, инструкциями встроенного программного обеспечения, данными установки состояния или любым исходным кодом или объектный код, написанный в любой комбинации одного или нескольких языков программирования, включая объектно-ориентированный язык программирования, такой как Java, Smalltalk, C++ или тому подобное, и обычные процедурные языки программирования, такие как язык программирования «C» или подобные языки программирования. Машиночитаемые программные инструкции могут выполняться полностью на компьютере пользователя, частично на компьютере пользователя, в виде автономного программного пакета, частично на компьютере пользователя и частично на удаленном компьютере или полностью на удаленном компьютере или сервере. В последнем случае удаленный компьютер может быть подключен к компьютеру пользователя через сеть любого типа, включая локальную сеть (LAN) или глобальную сеть (WAN), или подключение может быть выполнено к внешнему компьютеру (для например, через Интернет с помощью интернет-провайдера). В некоторых вариантах осуществления электронные схемы, включая, например, программируемые логические схемы, программируемые пользователем вентильные матрицы (FPGA) или программируемые логические матрицы (PLA), могут выполнять машиночитаемые программные инструкции, используя информацию о состоянии машиночитаемых программных инструкций для персонализации. электронная схема для реализации аспектов настоящего изобретения.
Аспекты настоящего изобретения описаны здесь со ссылкой на блок-схемы и/или блок-схемы способов, устройств (систем) и компьютерных программных продуктов в соответствии с вариантами осуществления изобретения. Следует понимать, что каждый блок иллюстраций блок-схем и/или блок-схем и комбинации блоков в иллюстрациях блок-схем и/или блок-схем могут быть реализованы машиночитаемыми программными инструкциями.
Эти машиночитаемые программные инструкции могут быть предоставлены процессору компьютера общего назначения, компьютера специального назначения или другого программируемого устройства обработки данных для создания машины, так что инструкции, которые выполняются через процессор компьютера или другое программируемое устройство устройства обработки данных, создавать средства для реализации функций/действий, указанных в блок-схеме и/или блок-схеме или блоках блок-схемы. Эти машиночитаемые программные инструкции также могут быть сохранены на машиночитаемом носителе данных, который может указывать компьютеру, программируемому устройству обработки данных и/или другим устройствам функционировать определенным образом, так что машиночитаемый носитель данных, содержащий инструкции, хранящиеся на нем, содержит изделие, включающее в себя инструкции, которые реализуют аспекты функции/действия, указанные в блок-схеме и/или блоке или блоках блок-схемы.
Машиночитаемые программные инструкции также могут быть загружены в компьютер, другое программируемое устройство обработки данных или другое устройство, чтобы обеспечить выполнение ряда рабочих шагов на компьютере, другом программируемом устройстве или другом устройстве для создания реализуемого компьютером процесса , так что инструкции, которые выполняются на компьютере, другом программируемом устройстве или другом устройстве, реализуют функции/действия, указанные в блок-схеме и/или блок-схеме или блоках блок-схемы.
Блок-схемы и блок-схемы на рисунках иллюстрируют архитектуру, функциональные возможности и работу возможных реализаций систем, способов и компьютерных программных продуктов в соответствии с различными вариантами осуществления настоящего изобретения. В связи с этим каждый блок на блок-схеме или блок-схеме может представлять модуль, сегмент или часть инструкций, которые содержат одну или несколько исполняемых инструкций для реализации указанной логической функции (функций). В некоторых альтернативных реализациях функции, отмеченные в блоке, могут выполняться не в порядке, указанном на фигурах. Например, два последовательно показанных блока фактически могут выполняться по существу одновременно, или иногда блоки могут выполняться в обратном порядке, в зависимости от задействованной функциональности. Следует также отметить, что каждый блок на блок-схемах и/или блок-схемах, а также комбинации блоков на блок-схемах и/или блок-схемах могут быть реализованы аппаратными системами специального назначения, которые выполняют указанные функции или действия или выполнять комбинации специального оборудования и компьютерных инструкций.
Хотя варианты осуществления были описаны в связи с различными вариантами осуществления на различных фигурах, следует понимать, что могут использоваться другие аналогичные варианты осуществления или могут быть внесены модификации и дополнения в описанный вариант осуществления для выполнения той же функции без отклонения от него. . Следовательно, раскрытые варианты осуществления не должны ограничиваться каким-либо одним вариантом осуществления, а скорее должны толковаться по широте и объему в соответствии с прилагаемой формулой изобретения.
Родители: Как «тренировать» английское сочинение? — По моему скромному мнению (ИМХО)
Джинкс
#1
К средней школе английский становится труднее! Я помню, как в 7-м классе со слезами на глазах! Сейчас я нахожусь в этой точке с моей дочерью. Итак, как родитель может научить хорошему письму… не написав его для ребенка?!? Кажется, я не могу найти золотую середину.
В частности, как написать сильное введение, сильный тезис, сильное тематическое предложение и сильные выводы?
Fretful_Porpentine
#2
Я не родитель, но я преподаватель английского языка, который многому учит первокурсников. Честно говоря, я не думаю, что вам нужно учить писать. Это работа школы, и, кроме того, это чертовски близко к необучаемому. Люди учатся писать, читая — чертовски много — и сочиняя, и сочиняя, и сочиняя очень плохую прозу, и получая отзывы о своих произведениях, и сочиняя еще, и, наконец, сочиняя что-то наполовину приличное. Легких путей НЕТ, и ученикам приходится выбрасывать из своей системы много плохих эссе, прежде чем они смогут написать хорошее. В значительной степени только думаю, что вы может сделать это: а) стоять в стороне и позволять ребенку совершать собственные ошибки; и б) иметь дом, полный книг, и читать их часто, в присутствии ребенка и с явным удовольствием. (Я бы хотел, чтобы хотя бы у одного из ста моих учеников был родитель, который мог бы смоделировать вторую часть. )
kbear
#3
Как же трудно оставаться в стороне. Мои дети даже могут позволить себе роскошь 16 детей в классе, и я все еще думаю, что учителя не проводят достаточно времени с каждым учеником, чтобы разобраться с ошибками в его письме.
Одна из вещей, которую делает школа, и я считаю, что это здорово, это то, что они позволяют учащимся сдать черновик за несколько дней до установленного срока. Учителя не предлагают столько конструктивной критики, как я думаю, они должны, но это полезно. Мой муж постоянно пытается заставить их давать мне свои задания для корректировки, но они очень злятся на мой вклад!
Я на собственном горьком опыте научился не слишком сильно вмешиваться. В 6 классе моя дочь получила «отлично» за сочинение, которое я почти переписал, потому что оно было таким ужасным. Так что да, они должны делать свои собственные ошибки. Я научился помогать им только с орфографией и грамматикой, потому что этому не учат, поэтому эти ошибки на самом деле не их вина, и пусть учитель занимается стилем и композицией.
Также трудно понять, каким должен быть стандарт в определенном возрасте. Мы можем подумать, что сочинение довольно плохое, но для их возраста оно может быть довольно хорошим.
Бенганмо
#4
Я пытаюсь научить своего 8-летнего ребенка писать письма. (и я ищу для нее друзей по переписке, если кому-то интересно)
Я также попрошу ее рассказать мне истории и ее день… и я скажу ей сначала рассказать мне, а затем написать.
Лично я считаю, что все решает практика, и все дело в том, чтобы не бояться излагать свои мысли на бумаге.
Я поправлю только грамматику и орфографию, постараюсь не трогать структуру предложения или что-то еще.
Мандаджо
#5
Я преподаю английский язык для младших школьников на интенсивном курсе письма, и мой лучший совет — придерживаться низких стандартов, работать только над несколькими вещами одновременно и сосредоточиться на том, что у них получается хорошо. Писать трудно , и поскольку всегда есть место для совершенствования, очень легко заставить ребенка уходить с каждого урока с чувством, что он просто отстой, и все, что он делает, — это катастрофа. Кроме того, вы можете с пользой пересматривать вещи лишь столько раз, прежде чем они вам так надоест, что вас захочется вырвать.
Думаю, я имею в виду, что то, что вы считаете «недостаточной обратной связью», может быть более «целевым фокусом на конкретных навыках», что, по моему мнению, является гораздо лучшим способом работы.
На тысячах совещаний, которые я провел, я узнал две удивительные вещи:
Дети не способны определить, хорошо ли они пишут, или отличить хороший текст от плохого. Им нужно указать хорошее.
Дети обычно не перечитывают свои сочинения: в лучшем случае они лишь бегло просматривают их. Они не понимают, как плохо звучат пассажи: как у певца в душе, то, что происходит в их голове, действительно отличается от того, что на самом деле производится.
Итак, что я могу предложить:
Прочтите им вслух их черновики, и пусть они прочитают черновики вам в ответ. Не поддавайтесь желанию редактировать/исправлять. Позвольте им услышать то, что там есть, что научит их слышать это для себя.
Убедитесь, что вы хвалите то, что сделано хорошо.
Сообщите им, в каких строках есть грамматические ошибки, и пусть они исправят их. Обсудите правило, которое применяется только после того, как они найдут пятно, и при необходимости исправьте исправление.
Если вы не знаете правил, вы просто знаете, что нужно, вам либо нужно их выучить, либо дурачиться: вы не можете научить их принципам, если не знаете.
псевдотритон_ruber_ruber
#6
Вам нужны мотивированные дети. Вы не можете просто засунуть им грамматику в глотку, если они не хотят глотать грамматику.
Если у них есть мотивация, они будут читать. Жадно. И хотят повторить прочитанное. Если они это сделают, вы можете попросить их сделать упражнения по моделированию — мне повезло, моя старшая дочь читала Шекспира, когда училась в начальной школе, и решила написать пародию на Гамлета для развлечения. Когда она это сделала, я рассыпался в ее комплиментах (и подавил смех над комичными попытками 7-летнего ребенка подражать Шекспиру) и указал на несколько вещей, сделанных Шекспиром, которые она не совсем поняла. Она переписала свою пьесу и приблизила эти элементы.
Итак, выясните, что вашему ребенку нравится читать, и посмотрите, захочет ли он/она попробовать свои силы в подражании этой модели. Я адаптировал метод Бена Франклина по обучению письму, в котором используется моделирование, которое я кратко описываю здесь, и вы тоже можете это сделать.
Мандаджо
#7
псевдотритон_ruber_ruber:
Вам нужны мотивированные дети. Вы не можете просто засунуть им грамматику в глотку, если они не хотят глотать грамматику.
Если у них есть мотивация, они будут читать. Жадно. И хотят повторить прочитанное. Если они это сделают, вы можете попросить их сделать упражнения по моделированию — мне повезло, моя старшая дочь читала Шекспира, когда училась в начальной школе, и решила написать пародию на Гамлета для развлечения.
Итак, выясните, что вашему ребенку нравится читать, и посмотрите, захочет ли он/она попробовать свои силы в подражании этой модели. Я адаптировал метод Бена Франклина по обучению письму, в котором используется моделирование, которое я кратко описываю здесь, и вы тоже можете это сделать.
Моделирование предложений — действительно хорошая идея: Дон Киллгаллон написал кучу книг/учебников для всех уровней по этому вопросу. Вы можете найти элементарные предметы достойным местом для начала, если ваши дети борются.
кормак262
#8
Бенганмо:
Я пытаюсь научить своего 8-летнего ребенка писать письма.
Я также попрошу ее рассказать мне истории и ее день… и я попрошу ее сначала рассказать мне, а потом написать.
Лично я считаю, что разница заключается в практике, и все дело в том, чтобы не бояться излагать свои мысли на бумаге.
Я буду исправлять только грамматику и орфографию, постараюсь не трогать структуру предложения или что-то еще.
Абсолютно согласен! Практика письма — это то, что будет иметь значение. Я репетитор младший. дети старшей и старшей школы, и большая часть письма довольно плоха. Но те, кто ведут блоги, пишут много электронных писем и т. д., явно опережают игру.
Помню, когда я учился в 7-м классе, мне приходилось писать в дневнике каждый день. Я не видел смысла и думал, что это пустая трата времени. Но теперь я вижу ценность.
К 7-му классу дети уже довольно хорошо умеют устно выражаться. Но есть «препятствие», которое нужно преодолеть, излагая свои мысли на бумаге. Практика письма — ЛУЧШИЙ способ научить детей выражать себя словами, ИМХО. Чтение поможет расширить их словарный запас, но я думаю, что простое письмо — лучший способ улучшить навыки письма.
фука
#9
Написание рубрик может быть большим подспорьем, если они хорошие. Они дают определенные вещи, к которым нужно стремиться и проверять, и анализируют их по категориям оценок, которые большинство читателей могут последовательно назначать, когда они знают систему. Оттуда вы можете посмотреть, какие части требуют наибольшей работы — грамматика, использование слов, структура, аудитория, формальности и так далее. В седьмом классе я не думаю, что уместно ругать их за логику или риторику, если только не ясно, что они просто вытаскивают чушь из головы.
Также важно найти что-то, что может заинтересовать студента. Достаточно сложно написать убедительное эссе из пяти абзацев на тему, которая вам нравится. К тому времени, когда вы проведете все свои исследования, систематизируете информацию и отредактируете свою диссертацию, вы в конечном итоге возненавидите этот материал. Если вы уже ненавидите это, вы никогда не дойдете до конца процесса.
Хитрость, однако, в том, что вам нужно указывать как минимум в два раза больше хороших вещей, чем плохих.
Еще одна вещь, которую я считаю полезной, — это найти примеры письменной речи из реальной жизни — редакционные статьи, колонки, блоги, письма редактору, даже сообщения на доске объявлений — и предложить ученику прочитать и критически оценить их. Посредственные примеры лучше, чем хорошие, потому что они дают учащемуся возможность найти то, что нужно исправить.
блины3
#10
Это зависит от того, чем вы хотите им помочь.
Грамматика: Трудно сделать. Это работа школы. Вам нужны рабочие листы.
Стиль: Трудно сделать. Они должны читать, и читать разнообразно, чтобы уловить нюансы стиля.
Формат: простой. Подчеркните контур. Тезис. 3 подтверждающих утверждения. Вывод. Вы можете попрактиковаться в этом, погуглив подсказки для эссе. Затем проработайте несколько вместе с ребенком — напишите только набросок. Просто очень грубо спросите «Как вы относитесь к этой теме? Почему? Поместите это в предложение, и вы получите свой тезис. Можете ли вы привести 3 примера, подтверждающих то, что вы только что сказали? Можете ли вы придумать предложение, которое резюмирует то, что вы пытаетесь сказать?» и БУМ. Набросок сделан. Переходите к следующей теме. Вы можете легко пройти 3-5 из них за относительно короткий период времени.
Несмотря на то, что это в основном относится к эссе, логическое мышление и разбивка на части подходят для более организованного письма в других формах.
даже_свен
#11
У меня был учитель 9-го класса, который действительно привел нас в форму. Он заставил нас писать стандартное эссе из пяти абзацев каждый день в течение месяца.
У него был список правил… подчеркнутые тезисы, без использования «я», без орфографических ошибок, без использования «вещи», даже как «все» или «что-то» и т. д. Если вы нарушили правило, ваш бумага была публично скомкана и выброшена. Если вы написали то, что похоже на эссе, и не нарушили правила, вы получили высшие баллы. Мы делали это день за днем в течение месяца.
В конце месяца мы избавились от наших вредных привычек и могли написать стандартное сочинение по структуре во сне.
Позже мы, конечно, узнали о стиле и исключениях из правил. Но сначала вы должны быть в состоянии написать разумное эссе из пяти абзацев, не задумываясь об этом.
Атомы Кино
СледующийПредыдущий
В этой главе представлено общее введение в атомы фильмов QuickTime, а также конкретные сведения о расположении и использовании этих атомов. Каждый тип атома, обсуждаемый в этой главе, показан с сопроводительной иллюстрацией, содержащей информацию о смещении, за которой следуют описания полей.
Эта глава разделена на следующие основные разделы:
Обзор атомов фильмов обсуждает атомы фильмов QuickTime, которые действуют как контейнеры для информации, описывающей данные фильма. Предоставляется концептуальная иллюстрация, показывающая организацию простого однодорожечного фильма QuickTime. Также обсуждаются атомы таблицы цветов и атомы пользовательских данных.
Атомы дорожки описывает атомы дорожки, которые определяют одну дорожку фильма. Также обсуждаются атомы данных пользователя и треки подсказок.
Атомы мультимедиа обсуждает атомы мультимедиа, которые определяют данные фильма дорожки, такие как тип мультимедиа и шкала времени мультимедиа.
Sample Atoms обсуждает атомы таблицы образцов, которые указывают, где расположены образцы мультимедиа, их продолжительность и т.
д. Раздел также включает примеры того, как вы используете эти атомы.Примечание: Атомы носителя и атомы выборки , а не содержат фактические данные выборки, такие как кадры видео или аудио. Они содержат метаданные, используемые для обнаружения и интерпретации таких образцов.
Compressed Movie Resources обсуждает сжатые ресурсы фильмов, в которых алгоритм сжатия без потерь используется для сжатия содержимого атома фильма, включая любую дорожку, мультимедиа или атомы сэмпла. Содержимое должно быть распаковано перед анализом атома фильма.
Reference Movies обсуждает фильмы, содержащие атом эталонного фильма (список ссылок на альтернативные фильмы, а также критерии выбора правильного фильма из списка альтернатив). Атомы фильма, которые содержат эталонный атом фильма, не обязательно содержат атомы дорожки, носителя или образца.
Обзор Movie Atoms
атома фильма QuickTime имеют тип атома 'moov' . Эти атомы действуют как контейнер для информации, описывающей данные фильма. Эта информация или метаданные хранятся в различных типах атомов. Вообще говоря, в атоме фильма хранятся только метаданные. Образцы данных для фильма, такие как аудио- или видеосэмплы, упоминаются в атоме фильма, но не содержатся в нем.
Атом кино, по существу, является вместилищем других атомов. Эти атомы, взятые вместе, описывают содержание фильма. На самом высоком уровне атомы фильмов обычно содержат атомы дорожек, которые, в свою очередь, содержат атомы медиа. На самом нижнем уровне находятся листовые атомы, которые содержат неатомарные данные, обычно в форме таблицы или набора элементов данных. Например, атом дорожки содержит атом редактирования, который, в свою очередь, содержит атом списка редактирования , листовой атом, который содержит данные в форме таблицы списка редактирования. Все эти атомы обсуждаются далее в этом документе.
На рис. 2-1 представлен концептуальный вид организации простого однодорожечного фильма QuickTime. Каждое вложенное поле на иллюстрации представляет собой атом, который принадлежит его родительскому атому. На рисунке не показаны области данных ни для одного из атомов. Эти области описаны в следующих разделах.
Обратите внимание, что на этом рисунке показана организация стандартного атома фильма. Можно сжать метаданные фильма, используя алгоритм сжатия без потерь. В таких случаях атом фильма содержит только один дочерний атом — сжатый атом фильма ( 'cmov' ). Когда этот дочерний атом не сжат, его содержимое соответствует структуре, показанной на следующем рисунке. Дополнительные сведения см. в разделе Ресурсы сжатых фильмов
Также можно создать эталонный фильм, который ссылается на другие фильмы; в этом случае атом фильма может содержать только эталонный атом фильма ( 'rmra' ). Подробнее см. в разделе «Эталонные фильмы». В конечном счете цепочка должна заканчиваться либо стандартным атомом фильма, таким как на рис. 2-1, либо сжатым атомом фильма, который можно распаковать для получения той же структуры.
Примечание. В однодорожечном видеофайле QuickTime могут присутствовать дополнительные атомы, которые не показаны на рис. 2-1.
Кино Атом
Вы используете атомы фильма, чтобы указать информацию, которая определяет фильм, то есть информацию, которая позволяет вашему приложению интерпретировать демонстрационные данные, хранящиеся в другом месте. Атом фильма обычно содержит атом заголовка фильма, который определяет масштаб времени и информацию о продолжительности для всего фильма, а также характеристики его отображения. Существующие фильмы могут содержать атом профиля фильма, в котором обобщаются основные характеристики фильма, такие как необходимые кодеки и максимальная скорость передачи данных. Кроме того, атом фильма содержит атом дорожки для каждой дорожки в фильме.
Атом фильма имеет тип атома 'moov' . Он содержит другие типы атомов, в том числе по крайней мере один из трех возможных атомов — атом заголовка фильма ( 'mvhd' ), сжатый атом фильма ( 'cmov' ) или эталонный атом фильма ( 'rmra').). Несжатый атом фильма может содержать как атом заголовка фильма, так и атом ссылки на фильм, но он должен содержать по крайней мере один из них. Он также может содержать несколько других атомов, таких как отсеченный атом ( 'clip' ), один или несколько атомов дорожек ( 'trak' ), атом таблицы цветов ( 'ctab' ) и атом пользовательских данных ( 'udta' ).
Сжатые атомы фильма и эталонные атомы фильма обсуждаются отдельно. В этом разделе описываются обычные несжатые атомы фильма.
На рис. 2-2 показана схема типичного киноатома.
Примечание: Как упоминалось ранее, атомы листа отображаются в виде белых прямоугольников, а атомы-контейнеры — в виде серых прямоугольников.
Рисунок 2-2 Схема атома фильмаАтом фильма может содержать следующие поля:
- Размер
Количество байтов в этом атоме фильма.
- Тип
Тип атома фильма; в этом поле должно быть установлено значение
'moov'.- Профиль атома
Для получения дополнительной информации см. The Movie Profile Atom.
- Атом заголовка фильма
Дополнительную информацию см. в разделе Атомы заголовка фильма.
- атом вырезки из фильма
Дополнительную информацию см. в разделе Отсечение атомов.
- Трек атомов
Подробную информацию о трековых атомах и связанных с ними атомах см. в разделе Track Atoms.
- Атом данных пользователя
Дополнительную информацию об атомах пользовательских данных см. в разделе Атомы пользовательских данных.
- Таблица цветов атом
См. Атомы таблицы цветов для обсуждения атома таблицы цветов.
- Сжатый фильм атом
См. Ресурсы по сжатым фильмам для обсуждения атомов сжатых фильмов.
- Эталонный атом фильма
См. Справочные фильмы для обсуждения атомов эталонного фильма.
Атом профиля фильма
Примечание. Атомы профиля устарели в формате файла QuickTime. Следующая информация предназначена для документирования существующего контента, содержащего атомы профиля, и не должна использоваться для новой разработки.
Атом профиля фильма суммирует характеристики и сложность фильма, такие как требуемые кодеки и максимальная скорость передачи данных, чтобы помочь приложениям или устройствам проигрывателя быстро определить, есть ли у них необходимые ресурсы для воспроизведения фильма.
Функции для фильма обычно включают максимальную скорость передачи видео и аудио, список типов аудио и видео кодеков, размеры видео, а также любые применимые профили и уровни MPEG-4. Это вся информация, которую также можно получить, более детально изучив содержимое файла фильма. Эта сводка предназначена для того, чтобы приложения или устройства могли быстро определить, могут ли они воспроизвести фильм. Он не предназначен для хранения информации, которой нет больше нигде в фильме, и не должен использоваться как таковой.
Примечание: Тот факт, что функция не отображается в атоме профиля, не означает, что ее нет в ролике. Сам атом профиля может отсутствовать или может отображать только подмножество функций фильма. Все функции, перечисленные в атоме профиля, присутствуют, но список не обязательно является полным.
При создании атома профиля допустимо опускать некоторые функции, присутствующие в ролике, но при этом требуется полностью указать любые функции, которые включены в профиль. Например, фильм, содержащий видео, может иметь или не иметь функцию типа видеокодека в атоме профиля, но если какая-либо функция типа видеокодека включена в атом профиля, каждый требуемый видеокодек должен быть указан в атоме профиля.
Атом профиля фильма — это атом профиля ( 'prfl' ), родителем которого является атом фильма. Это отличается от атома профиля дорожки, родительским элементом которого является атом дорожки. Структура атома профиля идентична в обоих случаях, но содержимое атома профиля фильма описывает фильм в целом, а содержимое атома профиля дорожки специфично для конкретной дорожки.
Атом профиля содержит список функций. В атоме профиля фильма эти функции обобщают фильм в целом. В атоме профиля дорожки эти функции описывают конкретную дорожку.
Каждая запись в списке функций состоит из четырех 32-битных полей:
Первое поле зарезервировано и должно быть установлено равным нулю.
Второе поле — это идентификатор детали, который определяет функцию как специфичную для бренда или универсальную. Особенности, характерные для бренда, характерны для конкретного бренда. Универсальные функции можно найти в файлах любого типа, в которых используется атом профиля. Универсальные функции имеют идентификатор части из четырех пробелов ASCII (0x20202020). Специфические для бренда функции имеют идентификатор части, который является одним из кодов Compatible_Brand для этого типа файла, как указано в атоме типа файла (
'ftyp'). Например, идентификатор части для функций, специфичных для QuickTime, —'qt '. Однако все функции, описанные в этом документе, являются универсальными.Третье поле — это код объекта или имя, 32-разрядное целое число без знака, которое обычно лучше всего интерпретируется как четыре символа ASCII. Пример: функция максимального битрейта видео имеет код или имя функции
'mvbr'. Допустимо использовать нулевое значение кода функции (0x00000000, , а не 9).0095 четыре нулевых символа ASCII) в качестве заполнителя в одной или нескольких парах «имя-значение». Читатель должен игнорировать коды объектов с нулевым значением.Четвертое поле — это значение, которое также является 32-битным полем. Значение может быть целым числом со знаком или без знака, или значением с фиксированной точкой, или содержать подполя, или состоять из упакованного массива; его можно интерпретировать только по отношению к конкретному признаку.
Подробнее о структуре и содержании атомов профиля см. в Руководстве по использованию атомов профиля.
Атомы заголовка фильма
Вы используете атом заголовка фильма для указания характеристик всего фильма QuickTime. Данные, содержащиеся в этом атоме, определяют характеристики всего фильма QuickTime, такие как шкала времени и продолжительность. Он имеет значение типа атома 'mvhd' .
На рис. 2-3 показано расположение атома заголовка фильма. Атом заголовка фильма является листовым атомом.
Рисунок 2-3 Схема атома заголовка фильмаВы определяете атом заголовка фильма, указав следующие элементы данных.
- Размер
32-разрядное целое число, указывающее количество байтов в этом атоме заголовка фильма.
- Тип
32-разрядное целое число, определяющее тип атома; должен быть установлен на
'mvhd'.- Версия
1-байтовая спецификация версии этого атома заголовка фильма.
- Флаги
Три байта пространства для будущих флагов заголовка фильма.
- Время создания
32-разрядное целое число, указывающее календарную дату и время (в секундах с полуночи 1 января 1904 г.), когда был создан атом фильма. Настоятельно рекомендуется указывать это значение с использованием универсального глобального времени (UTC).
- Время модификации
32-разрядное целое число, указывающее календарную дату и время (в секундах с полуночи 1 января 1904 г.), когда атом фильма был изменен. BooleanНастоятельно рекомендуется, чтобы это значение задавалось с использованием всемирного координированного времени (UTC).
- Шкала времени
Значение времени, указывающее шкалу времени для этого фильма, т. е. количество единиц времени, проходящих в секунду в его системе координат времени. Система координат времени, которая измеряет время в шестидесятых долях секунды, например, имеет шкалу времени 60.
- Продолжительность
Значение времени, указывающее продолжительность фильма в единицах шкалы времени.
Обратите внимание, что это свойство получено из дорожек фильма. Значение этого поля соответствует продолжительности самой длинной дорожки в фильме.- Предпочтительная ставка
32-битное число с фиксированной точкой, указывающее скорость воспроизведения этого фильма. Значение 1,0 указывает на нормальную скорость.
- Предпочтительный том
16-битное число с фиксированной точкой, указывающее, насколько громко воспроизводить звук этого фильма. Значение 1,0 указывает на полный объем.
- Зарезервировано
Десять байт зарезервированы для использования Apple. Установите на 0.
- Матричная структура
Матричная структура, связанная с этим фильмом. Матрица показывает, как отображать точки из одного координатного пространства в другое. См. Матрицы для обсуждения того, как матрицы отображения используются в QuickTime.
- Время предварительного просмотра
Значение времени в фильме, с которого начинается предварительный просмотр.
- Продолжительность предварительного просмотра
Продолжительность предварительного просмотра фильма в единицах шкалы времени фильма.
- Постерное время
Значение времени постера фильма.
- Время выбора
Значение времени для начала текущего выбора.
- Длительность выбора
Продолжительность текущего выделения в единицах шкалы времени фильма.
- Текущее время
Значение времени для текущей временной позиции в фильме.
- Идентификатор следующей дорожки
32-битное целое число, указывающее значение, используемое в качестве идентификатора дорожки следующей дорожки, добавленной в этот фильм. Обратите внимание, что 0 не является допустимым значением идентификатора дорожки.
Примечание. Дата создания и изменения должна быть установлена с использованием всемирного координированного времени (UTC). В предыдущих версиях формата файла QuickTime это не указывалось, и в этих полях обычно устанавливалось местное время для часового пояса, в котором был создан фильм.
Таблица цветов Атомы
Атомы таблицы цветовопределяют список предпочтительных цветов для отображения фильма на устройствах, поддерживающих только 256 цветов. Список может содержать до 256 цветов. Эти необязательные атомы имеют значение типа 9.2603 ктаб . Атом таблицы цветов содержит структуру данных таблицы цветов Macintosh.
На рис. 2-4 показано расположение атома таблицы цветов.
Рисунок 2-4 Схема атома таблицы цветовАтом таблицы цветов содержит следующие элементы данных.
- Размер
32-битное целое число, указывающее количество байтов в этом атоме таблицы цветов.
- Тип
32-разрядное целое число, определяющее тип атома; это поле должно быть установлено на
ктаб.- Семя таблицы цветов
32-битное целое число, которое должно быть равно 0.
- Флаги таблицы цветов
16-разрядное целое число, которое должно быть равно 0x8000.
- Размер таблицы цветов
16-разрядное целое число, указывающее количество цветов в следующем массиве цветов. Это относительное значение нуля; установка этого поля в 0 означает, что в массиве есть один цвет.
- Массив цветов
Набор цветов. Каждый цвет состоит из четырех 16-битных целых чисел без знака. Первое целое число должно быть установлено равным 0, второе — красное значение, третье — зеленое значение, четвертое — синее значение.
Атомы пользовательских данных
Атомы данных пользователя позволяют вам определять и хранить данные, связанные с объектом QuickTime, например фильм 'moov' , дорожка 'trak' или медиа 'mdia' . Сюда входит как информация, которую ищет QuickTime, например информация об авторских правах или необходимость зацикливания фильма, так и произвольная информация, предоставляемая вашим приложением и для него, которую QuickTime просто игнорирует.
Атом пользовательских данных, непосредственным родителем которого является атом фильма, содержит данные, относящиеся к фильму в целом. Атом пользовательских данных, родителем которого является атом дорожки, содержит информацию, относящуюся к этой конкретной дорожке. Файл фильма QuickTime может содержать множество атомов пользовательских данных, но только один атом пользовательских данных может быть непосредственным потомком любого заданного атома фильма или атома дорожки.
Атом пользовательских данных имеет тип атома 'udta' . Внутри атома пользовательских данных находится список атомов, описывающих каждую часть пользовательских данных. Пользовательские данные предоставляют простой способ расширить информацию, хранящуюся в фильме QuickTime. Например, атомы пользовательских данных могут хранить позицию окна фильма, характеристики воспроизведения или информацию о создании.
В этом разделе описываются атомы данных, распознаваемые QuickTime. Вы можете создавать новые типы атомов данных, которые распознает ваше собственное приложение. Приложения должны игнорировать любые типы атомов данных, которые они не распознают.
На рис. 2-5 показан макет пользовательского атома данных.
Рисунок 2-5 Схема атома данных пользователяАтом данных пользователя содержит следующие элементы данных.
- Размер
32-разрядное целое число, указывающее количество байтов в этом пользовательском атоме данных.
- Тип
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'udta'.- Список данных пользователя
Список пользовательских данных, отформатированный как последовательность атомов. Каждый элемент данных в списке пользовательских данных содержит информацию о размере и типе вместе с полезными данными. По историческим причинам список данных необязательно завершается 32-битным целым числом, равным 0. Если вы пишете программу для чтения атомов пользовательских данных, вы должны разрешить завершающий 0.
Однако, если вы пишете программу для создания пользовательские атомы данных, вы можете смело опустить завершающий 0,В таблице 2-1 перечислены определенные в настоящее время типы записей списка.
Тип записи списка | Описание | Для сортировки |
|---|---|---|
| Имя организатора | |
| Ключевые слова для аранжировщика | Х |
| Ключевые слова для композитора | Х |
| Имя композитора | |
| Заявление об авторских правах | |
| Дата создания фильма | |
| Имя режиссера фильма | |
| Изменить даты и описания | |
| Указание формата фильма (сгенерированный компьютером, оцифрованный и т. | |
| Информация о фильме | |
| Код ISRC | |
| Название звукозаписывающей компании | |
| URL звукозаписывающей компании | |
| Имя создателя файла | |
| URL создателя или создателя файла | |
| Ключевые слова заголовка содержания | Х |
| Название содержимого | |
| Ключевые слова для производителя | Х |
| Заявление об авторских правах на запись, которому обычно предшествует символ | |
| Наименование производителя | |
| Имена исполнителей | |
| Ключевые слова главного художника и исполнителя | Х |
| URL основного артиста и исполнителя | |
| Специальные требования к оборудованию и программному обеспечению | |
| Ключевые слова субтитров содержания | Х |
| Подзаголовок контента | |
| Кредиты для тех, кто предоставил исходный контент фильма | |
| Имя автора песен | |
| Ключевые слова для автора песен | Х |
| Название и номер версии программного обеспечения (или оборудования), с помощью которого был создан этот фильм | |
| Имя сценариста фильма | |
| Воспроизвести все кадры — байт, указывающий, что все кадры видео должны воспроизводиться независимо от времени | |
| Информация о треке-подсказке — статистические данные для потоковой передачи определенного трека в реальном времени. | |
| Информационный атом подсказки — данные, используемые для потоковой передачи фильма или дорожки в реальном времени. Дополнительные сведения см. в разделах «Информационный атом подсказки о фильме» и «Атом пользовательских данных отслеживания подсказок». | |
| Имя объекта | |
| 'ТАНМ' | |
| | Характеристика мультимедиа, необязательно присутствующая в данных пользователя дорожки — специальный текст, описывающий что-то интересное в дорожке. | |
| |
Длинное целое число, указывающее стиль зацикливания. Этот атом отсутствует, если фильм не зациклен. Значения: 0 для нормального цикла, 1 для палиндромного цикла. |
|
| |
Печать в видео — отображение фильма в полноэкранном режиме. Этот атом содержит 16-байтовую структуру, описанную в разделе Печать на видео (полноэкранный режим). |
|
| |
Воспроизвести только выбор — байт, указывающий, что должна воспроизводиться только выбранная область фильма |
|
| |
Расположение окна по умолчанию для фильма — два 16-битных значения, {x,y} |
Элементы пользовательских данных, помеченные как «ключевые слова» и помеченные как «Для сортировки», предназначены для использования, когда отображаемый текст не имеет заранее определенного порядка сортировки (например, в восточных языках, когда сортировка зависит от контекстного значения). Эти ключевые слова можно отсортировать алгоритмически, чтобы расположить соответствующие элементы в правильном порядке.
Положение окна, зацикливание, воспроизведение только выбранного, воспроизведение всех кадров и печать на видеоатомы управляют тем, как QuickTime отображает фильм. Эти атомы интерпретируются только , если непосредственным родителем атома пользовательских данных является атом фильма ( 'moov' ). Если они включены как часть пользовательских данных атома дорожки, они игнорируются.
Текстовые строки данных пользователя и коды языков
Все записи списка пользовательских данных, тип которых начинается с символа © (ASCII 169), определяются как международный текст. Эти записи списка должны содержать список текстовых строк с соответствующими кодами языков. Сохраняя несколько версий одного и того же текста, один текстовый элемент пользовательских данных может содержать переводы для разных языков.
Список текстовых строк использует формат небольшого целочисленного атома, который идентичен формату атома QuickTime, за исключением того, что он использует 16-битные значения для размера и типа вместо 32-битных значений. Первое значение — это размер строки, включая размер и тип, а второе значение — это код языка для строки.
Текстовые строки пользовательских данных могут использовать либо текстовую кодировку Macintosh, либо текстовую кодировку Unicode. Формат кода языка определяет формат кодирования текста. За кодами языка Macintosh следует текст, закодированный Macintosh. Если код языка указан с использованием языковых кодов ISO, перечисленных в спецификации ISO 639-2/T, текст использует кодировку Unicode. Когда используется Unicode, текст находится в UTF-8, если только он не начинается с метки порядка байтов (BOM, 0xFEFF), и в этом случае текст находится в UTF-16. И спецификация, и текст UTF-16 должны быть с обратным порядком байтов. Несколько версий одного и того же текста могут использовать разные схемы кодирования.
Важно:
Значения языкового кода меньше 0x400 являются языковыми кодами Macintosh. Значения языкового кода, большие или равные 0x400, являются языковыми кодами ISO. Исключением из этого правила является код языка 0x7FFF, который указывает на неуказанный язык Macintosh.
ISO представляют собой трехсимвольные коды. Чтобы поместиться в 16-битном поле, символы должны быть упакованы в три 5-битных подполя. Эта упаковка описана в «Коды языков ISO» .
Метки характеристик среды
Атом пользовательских данных дорожки ( 'trak' ) может содержать ноль или более атомов метки характеристики среды ( 'tagc' ).
Данные полезной нагрузки атома тега характеристики носителя — это тег, указывающий на что-то интересное в дорожке. Это специальная строка, состоящая из подмножества символов US-ASCII (7 бит плюс чистый старший бит) и соответствующая структуре, описанной в следующих параграфах. Это не строка C; нет завершающего нуля, поэтому количество символов определяется размером атома. Допустимые символы: буквы (A-Z, a-z), цифры (0-9), тире (-), точка (.), подчеркивание (_) и тильда (~).
Любая дорожка файла QuickTime может быть связана с одним или несколькими тегами, указывающими характеристики носителя. Теги указывают на что-то интересное в треке. Например, тег может указывать назначение дорожки (это комментарий), абстрактную характеристику дорожки (требуется аппаратное декодирование) или указание на то, что дорожка содержит разборчивый текст (дорожка главы и дорожка субтитров могут быть обеими). читается пользователем).
Сравнение тегов чувствительно к регистру; два тега совпадают, если байты строк совпадают точно. Не следует использовать две строки тегов, отличающиеся только регистром, чтобы избежать возможной путаницы для разработчиков или создателей контента.
Повторяющиеся теги в одной дорожке разрешены, но не приветствуются. Дублирование не имеет особого значения.
Строки тегов не локализованы и предназначены для машинной интерпретации; однако мнемонические строки приветствуются.
Тег является общедоступным или частным:
Строки тегов имеют следующую структуру:
-
Общедоступный тег начинается с префикса «public.
», за которым следует один или несколько сегментов, разделенных точками. Примерами (не определены) могут быть public.subtitle или public.commentary.director. Примечание. Общие теги являются общедоступными, поскольку они задокументированы в этой спецификации или доступны в API Apple. Другие определения тегов с пометкой «public». префикс запрещен; вместо этого используйте приватные теги.
-
Частный тег начинается с домена частного объекта с использованием обратного соглашения об именах DNS. Например, apple.com становится com.apple. Далее следует один или несколько сегментов, разделенных точками. Примерами (не определены) могут быть com.apple.this-is-a-tag, com.apple.video.includes-sign-language и org.w3c.html5.referenced-video.
-
Единственными разрешенными префиксами являются «общедоступные». и обратные домены. Все остальные префиксы зарезервированы для использования в будущем.
Примечание: Поддерживаются общие домены верхнего уровня, отличные от «общедоступных» (если они должны быть назначены). Строка «общедоступные» зарезервирована для обозначения тегов характеристик общедоступных медиа.
Эта спецификация определяет следующие теги характеристик общедоступных носителей. Другие общедоступные и частные теги могут быть определены вне спецификации; нераспознанные теги следует игнорировать.
-
public.auxiliary-content (действителен для всех типов медиа)
Указывает, что содержимое дорожки было отмечено автором содержимого как вспомогательное для представления медиафайла. Например, этим тегом может быть отмечен аудиокомментарий или дорожка субтитров, поскольку они не являются содержимым программы. Если этот тег отсутствует, можно сделать вывод, что дорожка помечена этой характеристикой, если дорожка является членом альтернативной группы и дорожка исключена из автовыбора с помощью атома исключения дорожки из автовыбора; см. Отслеживание исключения из атомов автовыбора.
-
public.accessibility.transscribes-spoken-dialog (действительно для разборчивых носителей)
Указывает, что дорожка включает разборчивый контент на языке локали дорожки, который расшифровывает разговорный диалог.
-
public.accessibility.describes-music-and-sound (действительно для разборчивых носителей)
Указывает, что дорожка включает разборчивое содержимое на языке локали дорожки, которое описывает музыку и звуковые эффекты, встречающиеся в аудиопрограмме.
-
public.accessibility.describes-video (действительно для звуковых носителей)
Указывает, что дорожка включает звуковое содержимое, описывающее визуальную часть презентации.
-
public.easy-to-read (действительно для разборчивых носителей)
Указывает, что дорожка предоставляет разборчивое содержимое на языке указанной локали, которое было отредактировано для облегчения чтения.
Имя дорожки
Атом пользовательских данных фильма может содержать атом имени дорожки ( 'тнам' ).
Данные полезной нагрузки атома имени дорожки состоят из следующих данных.
-
Зарезервировано: 32-разрядное целое число, которое должно быть установлено равным нулю.
-
Язык: 16-битное целое число, содержащее упакованный код ISO 639-2/T, как описано в разделе Текстовые строки данных пользователя и коды языков.
-
Имя: Оканчивающаяся нулем строка UTF-8 или UTF-16, содержащая название дорожки. Если это строка UTF-16, она должна начинаться с метки порядка байтов (0xFEFF).
Трек может иметь несколько атомов 'tnam' с разными языковыми кодами. Обычно для каждой дорожки достаточно иметь один атом 'tnam' на том же языке, что и содержимое дорожки. Альтернативные треки также могут иметь 92 603 «tnam» 92 604 атома; их наличие подразумевает только то, что название является хорошей удобочитаемой меткой для трека.
Печать на видео (полноэкранный режим)
Атом пользовательских данных атома фильма может содержать атом печати в видео ( 'птв' ). Обратите внимание, что четвертый символ — это пробел ASCII (0x20). Если присутствует атом печати на видео, QuickTime воспроизводит фильм в полноэкранном режиме, без окна и без видимого контроллера. Любая часть экрана, не занятая фильмом, становится черной. Пользователь должен нажать клавишу Esc (Escape), чтобы выйти из полноэкранного режима.
Этот атом часто временно добавляется и удаляется для управления режимом отображения фильма для одной презентации, но его также можно сохранить как часть постоянного файла фильма.
Данные полезной нагрузки для печати на видеоатоме состоят из следующего.
- Размер дисплея
-
16-битное целое число с прямым порядком байтов , указывающее размер экрана для фильма: 0 указывает, что фильм должен воспроизводиться в нормальном размере; 1 означает, что фильм должен воспроизводиться в двойном размере; 2 означает, что фильм следует воспроизводить в половинном размере; 3 указывает, что фильм должен быть масштабирован для заполнения экрана; 4 указывает, что фильм должен воспроизводиться с его текущим размером (это последнее значение обычно используется, когда атом печати на видео вставлен временно и размер фильма был временно изменен).
- Зарезервировано1
-
16-разрядное целое число, значение которого должно быть равно 0.
- Зарезервировано2
-
16-разрядное целое число, значение которого должно быть равно 0.
- Слайд-шоу
-
8-битное логическое значение со значением 1 для показа слайдов. В режиме слайд-шоу фильм продвигается на один кадр при каждом нажатии клавиши со стрелкой вправо. Звук отключен.
- Играть в открытую
-
8-битное логическое значение, значение которого обычно равно 1, указывающее, что фильм должен воспроизводиться при открытии. Поскольку в полноэкранном режиме нет видимого контроллера, приложения всегда должны устанавливать это поле равным 1, чтобы не запутать пользователя.
Трековые атомы
Атомы дорожки определяют одну дорожку фильма. Фильм может состоять из одной или нескольких дорожек. Каждая дорожка не зависит от других дорожек фильма и несет собственную временную и пространственную информацию. Каждый атом дорожки содержит связанный с ним медиа-атом.
Гусеницы используются специально для следующих целей:
-
Для содержания ссылок и описаний мультимедийных данных (дорожек мультимедиа).
-
Для содержания треков-модификаторов (tweens и т. д.).
-
Содержит информацию о пакетировании для потоковых протоколов (дорожки подсказок). Дорожки подсказок могут содержать ссылки на данные образцов мультимедиа или копии данных образцов мультимедиа. Дополнительные сведения о дорожках подсказок см. в разделе Носители подсказок.
Примечание: Видео QuickTime не может состоять только из дорожек подсказок или дорожек модификаторов; должна быть хотя бы одна дорожка мультимедиа. Кроме того, дорожки мультимедиа не могут быть удалены из фильма с подсказками, даже если дорожки подсказок содержат копии данных образцов мультимедиа — в дополнение к дорожкам подсказок должен остаться весь фильм без подсказок.
На рис. 2-6 показано расположение атома дорожки. Атомы трека имеют значение типа атома 'trak' . Атом дорожки требует атома заголовка дорожки ( 'tkhd' ) и атома носителя ( 'mdia' ). Другие дочерние атомы являются необязательными и могут включать атом отсечения дорожки ( 'clip' ), атом матовой дорожки ( 'matt' ), атом редактирования ( 'edts' ), атом ссылки дорожки ( 'tref' ), атом настроек загрузки дорожки ( 'load' ), атом карты ввода дорожки ( 'imap' ) и атом пользовательских данных ( 'udta' ).
Примечание: Рисунок 2-6 содержит необязательный атом профиля дорожки ‘prfl’ . Атомы профиля дорожки устарели в текущей версии QuickTime, но могут присутствовать в существующих файлах QuickTime. Включение сюда предназначено для документирования существующего контента, содержащего атомы профиля, их не следует использовать для новой разработки.
Атомы дорожки содержат следующие элементы данных.
- Размер
-
32-битное целое число, указывающее количество байтов в этом атоме дорожки.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'trak'. - Профиль гусеницы атом
-
Подробнее см. в разделе Track Profile Atom.
- Атом заголовка дорожки
-
Подробнее см. в разделе Атомы заголовка дорожки.
- Размеры режима апертуры дорожки атом
-
Подробнее см. в разделе Отслеживание атомов измерения режима апертуры.
- Отсечение атома
-
Дополнительную информацию см. в разделе Отсечение атомов.
- Трек матовый атом
-
Дополнительную информацию см. в разделе Отслеживание матовых атомов.
- Редактировать атом
-
Подробнее см.
в разделе Редактирование атомов. - Ссылочный атом дорожки
-
Подробности см. в разделе «Отслеживание эталонных атомов».
- Исключение дорожки из атома автовыбора
-
Дополнительные сведения см. в разделе Отслеживание исключения из атомов автоматического выбора.
- Отслеживание параметров загрузки атома
-
Дополнительные сведения см. в разделе Отслеживание параметров загрузки атомов.
- Отслеживание атома входной карты
-
Дополнительные сведения см. в разделе «Отслеживание входных атомов карты».
- Media Atom
-
Дополнительные сведения см. в разделе Media Atoms.
- Определяемый пользователем атом данных
-
Дополнительную информацию см. в разделе Атомы пользовательских данных.
Профиль гусеницы Atom
Примечание. Атомы профиля устарели в формате файла QuickTime. Следующая информация предназначена для документирования существующего контента, содержащего атомы профиля, и не должна использоваться для новой разработки.
Атомы профиля могут быть дочерними атомами фильма или атомами трека. Для получения дополнительной информации об атомах профиля см. Атом профиля фильма.
Атомы заголовка дорожки
Атом заголовка дорожки указывает характеристики одной дорожки в фильме. Атом заголовка дорожки содержит поле размера, указывающее количество байтов, и поле типа, указывающее формат данных (определяемый типом атома 9).2603 'тхд' ).
На рис. 2-7 показана структура атома заголовка дорожки.
Рисунок 2-7 Схема атома заголовка дорожкиАтом заголовка дорожки содержит характеристики дорожки для дорожки, включая временную, пространственную и объемную информацию.
Атомы заголовка дорожки содержат следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме заголовка дорожки.
- Тип
-
32-разрядное целое число, определяющее тип атома; это поле должно быть установлено на
'tkhd'. - Версия
-
1-байтовая спецификация версии этого заголовка дорожки.
- Флаги
-
Три байта, зарезервированные для флагов заголовка дорожки. Эти флаги указывают, как дорожка используется в фильме. Допустимы следующие флаги (все флаги включены, если установлено значение 1).
- Отслеживание включено
-
Указывает, что трек включен. Значение флага 0x0001.
- Трек в фильме
-
Указывает, что этот трек используется в фильме. Значение флага 0x0002.
- Дорожка в предварительном просмотре
-
Указывает, что дорожка используется в предварительном просмотре фильма. Значение флага 0x0004.
- Дорожка в афише
-
Указывает, что дорожка используется в афише фильма. Значение флага 0x0008.
- Время создания
-
32-разрядное целое число, указывающее календарную дату и время (выраженное в секундах с полуночи 1 января 1904 г.
), когда был создан заголовок дорожки. Настоятельно рекомендуется указывать это значение с использованием универсального глобального времени (UTC). - Время модификации
-
32-разрядное целое число, указывающее календарную дату и время (выраженное в секундах с полуночи 1 января 1904 г.) момента изменения заголовка дорожки. Настоятельно рекомендуется указывать это значение с использованием универсального глобального времени (UTC).
- Идентификатор дорожки
-
32-битное целое число, однозначно идентифицирующее дорожку. Значение 0 использовать нельзя.
- Зарезервировано
-
32-битное целое число, зарезервированное для использования Apple. Установите в этом поле значение 0.
- Продолжительность
-
Значение времени, указывающее продолжительность этой дорожки (в системе временных координат фильма). Обратите внимание, что это свойство получено из правок дорожки. Значение этого поля равно сумме длительностей всех правок трека.
Если списка редактирования нет, то продолжительность представляет собой сумму длительностей выборок, преобразованную в шкалу времени фильма. - Зарезервировано
-
8-байтовое значение, зарезервированное для использования Apple. Установите в этом поле значение 0.
- Слой
-
16-битное целое число, указывающее пространственный приоритет этой дорожки в ее фильме. QuickTime Movie Toolbox использует это значение, чтобы определить, как дорожки накладываются друг на друга. Дорожки с более низкими значениями слоя отображаются перед дорожками с более высокими значениями слоя.
- Альтернативная группа
-
16-битное целое число, идентифицирующее набор дорожек фильма, которые содержат альтернативные данные друг для друга. Этот же идентификатор появляется в каждом
'тхд'атом остальных треков в группе. QuickTime выбирает одну дорожку из группы, которая будет использоваться при воспроизведении фильма. Выбор может основываться на таких соображениях, как качество воспроизведения, язык или возможности компьютера. Нулевое значение указывает, что дорожка не находится в альтернативной группе дорожек.
Наиболее распространенная причина использования альтернативных дорожек — предоставление версий одной и той же дорожки на разных языках. На рис. 2-8 показан пример нескольких дорожек. Идентификатор альтернативной группы видеодорожки равен 0, что означает, что она не входит в альтернативную группу (и ее языковые коды пусты; обычно видеодорожки должны иметь соответствующие языковые теги). Три звуковые дорожки имеют одинаковый идентификатор группы, поэтому они образуют одну альтернативную группу, а дорожки субтитров имеют разные идентификаторы группы, поэтому они образуют другую альтернативную группу. Дорожки не будут соседствовать в реальном файле QuickTime; это всего лишь список примеров значений полей дорожки.
Рисунок 2-8 Пример чередования дорожек в двух чередующихся группах - Том
-
16-битное значение с фиксированной точкой, указывающее, насколько громко должен воспроизводиться звук этой дорожки.
Значение 1,0 указывает на нормальную громкость. - Зарезервировано
-
16-битное целое число, зарезервированное для использования Apple. Установите в этом поле значение 0.
- Матричная структура
-
Матричная структура, связанная с этой дорожкой. См. Рисунок 2-3 для иллюстрации матричной структуры.
- Ширина гусеницы
-
32-битное число с фиксированной точкой, указывающее ширину этой дорожки в пикселях.
- Высота гусеницы
-
32-битное число с фиксированной точкой, указывающее высоту этой дорожки в пикселях.
Исключить дорожку из атомов автовыбора
Некоторые альтернативные дорожки содержат не прямой перевод (или непереведенную письменную форму) основного содержимого. Следы комментариев являются одним из примеров. Эти треки не должны выбираться автоматически. Наличие в дорожке атома Track Exclude From Autoselection указывает на то, что эта дорожка не должна выбираться автоматически.
Такие треки должны иметь удобочитаемые имена, которые помогают пользователям определить назначение трека. Эти имена хранятся в одном или нескольких атомах имени дорожки ( 'tnam' ), каждый из которых переведен на другой язык, в атоме пользовательских данных ( 'udta' ) внутри атома 'trak' .
Тип атома Track Exclude From Autoselection: 'txas' . Этот атом, если он используется, должен быть где-то после атома 'tkhd' .
Исключение трека из автовыбора атомов, содержащих следующие элементы данных.
- Размер
-
32-битное целое число, указывающее количество байтов в дорожке, исключаемой из атома автовыбора. Это должно быть 8, так как этот атом не должен содержать данных.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'txas'.
Атомы измерения режима апертуры дорожки
Видеодорожка в фильме QuickTime может сигнализировать чистую информацию об апертуре и соотношении сторон пикселя через расширения описания изображения. Чистая апертура определяет отображаемую часть закодированных пикселей. Соотношение сторон пикселя — это соотношение сторон закодированных пикселей. Концептуально закодированные пиксели распаковываются, растягиваются (или сжимаются) в зависимости от соотношения сторон пикселя, а лишние пиксели обрезаются в соответствии с чистой апертурой.
Примечание. Дорожки QuickTime определяют простые измерения для своего содержимого в измерениях заголовков дорожек. При отсутствии атома размеров режима апертуры дорожки размеры в заголовке дорожки используются для всех режимов.
В этом контексте размеры, записанные в описании изображения, определяют размеры закодированных пикселей (закодированные размеры). То, что на самом деле отображается, является результатом применения соотношения сторон пикселя и чистой апертуры (размеры дисплея).
Несмотря на то, что результат применения чистой апертуры и соотношения сторон пикселя является тем, что предназначено для окончательного отображения, бывают случаи, когда полезно отображать все пиксели, существующие в содержимом, для различных целей. Читателям, анализирующим фильмы QuickTime, требуется информация, позволяющая использовать эти различные режимы отображения, чтобы обеспечить эту гибкость:
- Чистый режим
-
В этом режиме применяются как чистая апертура, так и соотношение сторон пикселей. Размеры дорожки становятся равны чистым размерам, которые равны размерам дисплея (с соответствующим содержанием).
- Производственный режим
-
В этом режиме применяется соотношение сторон пикселей, но не чистая апертура. Изображение представлено с правильным соотношением сторон, но дополнительные пиксели за пределами изображения, существующие в исходном материале, будут представлены. Размеры дорожки равны результату применения соотношения сторон пикселя.
- Классический режим
-
В этом режиме изображение отображается без применения пропорций пикселей или чистой апертуры. Изображение отображается с использованием размеров заголовка дорожки, что означает, что распакованное изображение масштабируется в соответствии с размерами заголовка дорожки, если закодированные размеры отличаются.
- Закодированные пиксели
-
В этом режиме закодированные пиксели отображаются без изменений. В этом режиме размеры дорожки равны закодированным размерам. Никакого масштабирования или преобразования не происходит.
Информация, необходимая для каждого из этих режимов представления, представлена в дополнительных атомах размеров режима апертуры дорожки.
Примечание: Старые приложения, созданные до QuickTime 7, будут продолжать использовать значения измерений, хранящиеся в заголовке дорожки.
Атом размеров апертуры дорожки
Атом-контейнер, в котором хранится информация для коррекции видео в виде трех необходимых атомов. Этот атом необязательно включается в атом дорожки. Тип атома размеров режима апертуры дорожки — ‘tap’ .
На рис. 2-9 показано расположение атома размеров режима апертуры дорожки.
Рисунок 2-9 Схема атома размеров режима апертуры дорожки- Размер
-
32-битное целое число, указывающее количество байтов в атоме размеров режима апертуры дорожки.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
«нажмите». - Трековая размерность чистой апертурой атом
-
См. Размеры очистки диафрагмы. Атом
Размер чистой апертуры дорожки Atom
Этот атом содержит размеры чистой апертуры дорожки в пикселях. Тип атома размеров чистой апертуры дорожки — ‘clef’ .
На рис. 2-10 показано расположение атома размеров апертуры дорожки.
Рисунок 2-10 Компоновка атома размеров апертуры дорожки- Размер
-
32-битное целое число, указывающее количество байтов в атоме размеров режима апертуры дорожки.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
«ключ». - Версия
-
1-байтовая спецификация версии этого атома.
- Флаги
-
Три байта, зарезервированные для флагов атома.
- Ширина
-
32-битное число с фиксированной запятой, указывающее ширину чистой апертуры дорожки в пикселях.
- Высота
-
32-битное число с фиксированной точкой, указывающее высоту чистой апертуры дорожки в пикселях.
Атом размеров производственной апертуры дорожки
Этот атом содержит размеры производственной апертуры дорожки в пикселях. Тип атома размеров производственной апертуры дорожки: ‘prof’ .
На рис. 2-11 показано расположение атома размеров апертуры производства дорожки.
Рисунок 2-11 Схема расположения апертуры производства дорожки с размерами атома- Размер
-
32-разрядное целое число, указывающее количество байтов в атоме размеров режима апертуры дорожки.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'prof'. - Версия
-
1-байтовая спецификация версии этого атома.
- Флаги
-
Три байта, зарезервированные для флагов атома.
- Ширина
-
32-битное число с фиксированной точкой, указывающее ширину рабочей апертуры дорожки в пикселях.
- Высота
-
32-битное число с фиксированной точкой, указывающее высоту рабочей апертуры дорожки в пикселях.
Размеры закодированных пикселей дорожки Атом
Этот атом содержит размеры закодированных пикселей дорожки в пикселях. Тип атома размеров закодированных пикселей дорожки — ‘enof’ .
На рис. 2-12 показано расположение этого атома.
Рисунок 2-12 Атом размеров закодированных пикселей дорожки- Размер
-
32-битное целое число, указывающее количество байтов в атоме размеров режима апертуры дорожки.
- Тип
-
32-разрядное целое число, определяющее тип атома; это поле должно быть установлено на
‘enof’. - Версия
-
1-байтовая спецификация версии этого атома.
- Флаги
-
Три байта, зарезервированные для флагов атома.
- Ширина
-
32-битное число с фиксированной запятой, указывающее ширину размеров закодированных пикселей дорожки в пикселях.
- Высота
-
32-битное число с фиксированной запятой, указывающее высоту размеров закодированных пикселей дорожки в пикселях.
Отсечение атомов
Атомы отсечения задают области отсечения для фильмов и дорожек. Атом отсечения имеет значение типа атома 9.2603 'зажим' .
На рис. 2-13 показано расположение этого атома.
Рисунок 2-13 Схема атома отсеченияАтомы отсечения содержат следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом отсеченном атоме.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'clip'. - Область отсечения, атом
-
См. Атомы области отсечения.
Атомы области отсечения
Атом области отсечения содержит данные, определяющие область отсечения, включая ее размер, ограничивающую рамку и область. Атомы области отсечения имеют значение типа атома 'crgn' .
Расположение атома области отсечения показано на рис. 2-13.
Атомы области отсечения содержат следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме области отсечения.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'crgn'. - Размер области
-
Поля данных размера области, поля границы области и области отсечения составляют область QuickDraw.
- Рамка границы региона
-
Поля данных размера области, поля границы области и области отсечения составляют область QuickDraw.
- Данные области отсечения
-
Поля данных размера области, поля границы области и области отсечения составляют область QuickDraw.
Трековые матовые атомы
Матовые атомы дорожки используются для визуального смешивания изображения дорожки при ее отображении.
Атомы матовой дорожки имеют значение типа атома 'матовая' .
На рис. 2-14 показано расположение атомов матовой дорожки.
Рисунок 2-14 Компоновка матовой дорожки атомаАтомы матовой дорожки содержат следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме подложки дорожки.
- Тип
-
32-разрядное целое число, определяющее тип атома; это поле должно быть установлено на
'матовый'. - Сжатый матовый атом
-
Фактические данные матового материала.
Подробнее см. в разделе «Сжатые матовые атомы».
Сжатые матовые атомы
Сжатый атом подложки указывает структуру описания изображения и данные подложки, связанные с конкретным атомом подложки. Сжатые атомы штейна имеют значение типа атома 'kmat' .
Схема сжатого матового атома показана на рис. 2-14.
Сжатые атомы штейна содержат следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом сжатом матовом атоме.
- Тип
-
32-разрядное целое число, определяющее тип атома; это поле должно быть установлено на
'kmat'. - Версия
-
1-байтовая спецификация версии этого сжатого матового атома.
- Флаги
-
Три байта пространства для флагов. Установите в этом поле значение 0.
- Структура описания матового изображения
-
Структура описания изображения, связанная с данными подложки. Описание изображения содержит подробную информацию, которая определяет, как используются данные подложки.
См. описание образца видео для получения дополнительной информации об описаниях изображений. - Матовые данные
-
Сжатые данные подложки переменной длины.
Редактировать Атомы
Вы используете атомы редактирования для определения частей медиа, которые должны использоваться для создания дорожки для фильма. Сами правки содержатся в таблице списка правки, которая состоит из значений смещения по времени и длительности для каждого сегмента. Атомы редактирования имеют значение типа атома 'edts'.
На рис. 2-15 показано расположение атома редактирования.
При отсутствии списка редактирования презентация трека начинается сразу. Пустое редактирование используется для смещения времени начала дорожки.
Примечание: Если атом редактирования или атом списка редактирования отсутствует, можно предположить, что весь носитель используется дорожкой.
Рисунок 2-15 Схема атома редактирования Атомы редактирования содержат следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме редактирования.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'edts'. - Редактировать список атомов
-
См. Атомы списка редактирования.
Редактировать список атомов
Вы используете атом списка редактирования, также показанный на рис. 2-15, для отображения времени в фильме на время в медиа и, в конечном счете, в медиа данные. Эта информация представлена в виде записей в таблице списка редактирования, показанной на рис. 2-16. Атомы списка редактирования имеют значение типа атома 'эльст' .
Атомы списка редактирования содержат следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме списка редактирования.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'elst'. - Версия
-
1-байтовая спецификация версии этого атома списка редактирования.
- Флаги
-
Три байта пространства для флагов. Установите в этом поле значение 0.
- Количество записей
-
32-разрядное целое число, указывающее количество записей в следующем атоме списка редактирования.
- Редактировать таблицу списка
-
Массив 32-битных значений, сгруппированных в записи, содержащие по 3 значения в каждой. На рис. 2-16 показано расположение записей в этой таблице.
Запись таблицы списка редактирования содержит следующие элементы.
- Продолжительность трека
-
32-битное целое число, указывающее продолжительность этого сегмента редактирования в единицах временной шкалы фильма.
- Медиа время
-
32-битное целое число, содержащее время начала в медиафайлах этого сегмента редактирования (в единицах шкалы медиавремени).
Если в этом поле установлено значение –1, это пустое редактирование. Последнее редактирование в треке никогда не должно быть пустым. Любая разница между продолжительностью фильма и продолжительностью дорожки выражается как неявное пустое редактирование. - Скорость носителя
-
32-битное число с фиксированной точкой, указывающее относительную скорость воспроизведения мультимедиа, соответствующего этому сегменту редактирования. Это значение скорости не может быть 0 или отрицательным.
Отслеживание настроек загрузки атомов
Атомы настроек загрузки дорожки содержат информацию, указывающую, как дорожка должна использоваться в ее фильме. Приложения, которые читают файлы QuickTime, могут использовать эту информацию для более эффективной обработки данных фильмов. Атомы настроек загрузки дорожки имеют значение типа атома 'загрузка' .
На рис. 2-17 показано расположение этого атома.
Рисунок 2-17 Схема атома настроек загрузки дорожки Атомы настроек загрузки дорожки содержат следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме параметров загрузки дорожки.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'load'. - Время начала предварительной загрузки
-
32-битное целое число, указывающее время начала в системе временных координат фильма сегмента дорожки, который должен быть предварительно загружен. Используется в сочетании с продолжительностью предварительной загрузки.
- Продолжительность предварительной загрузки
-
32-битное целое число, указывающее продолжительность в системе временных координат фильма сегмента дорожки, который должен быть предварительно загружен. Если для длительности установлено значение –1, это означает, что сегмент предварительной загрузки простирается от времени начала предварительной загрузки до конца дорожки. Все медиаданные в сегменте дорожки, определяемом значениями времени начала и продолжительности предварительной загрузки, должны быть загружены в память при воспроизведении фильма.
- Флаги предварительной загрузки
-
32-битное целое число, содержащее флаги, управляющие операцией предварительной загрузки. Определены только два флага, и они взаимоисключающие. Если этот флаг установлен в 1, дорожка должна быть предварительно загружена независимо от того, включена ли она. Если этот флаг установлен на 2, дорожка будет предварительно загружена, только если она включена.
- Подсказки по умолчанию
-
32-битное целое число, содержащее подсказки воспроизведения. Может быть включено более одного флага. Флаги включаются установкой их в 1. Определены следующие флаги.
- Двойной буфер
-
Этот флаг указывает, что дорожка должна воспроизводиться с использованием ввода-вывода с двойной буферизацией. Значение этого флага равно 0x0020.
- Высокое качество
-
Этот флаг указывает на то, что дорожка должна отображаться в максимально возможном качестве, без учета соображений производительности в реальном времени.
Значение этого флага равно 0x0100.
Отслеживание эталонных атомов
Ссылочные атомы дорожек определяют отношения между дорожками. Ссылочные атомы дорожки позволяют одной дорожке указать, как она связана с другими дорожками. Например, если в фильме есть три видеодорожки и три звуковые дорожки, ссылки на дорожки позволяют идентифицировать связанные звуковые и видеодорожки. Ссылочные атомы дорожки имеют значение типа атома 'треф' .
Ссылки на дорожки являются однонаправленными и указывают от дорожки-получателя к дорожке-источнику. Например, видеодорожка может ссылаться на дорожку временного кода, чтобы указать, где хранится ее временной код, но дорожка временного кода не будет ссылаться на видеодорожку. Дорожка временного кода является источником информации о времени для видеодорожки.
Одна дорожка может ссылаться на несколько дорожек. Например, видеодорожка может ссылаться на звуковую дорожку, чтобы указать, что они синхронизированы, и на дорожку временного кода, чтобы указать, где хранится ее временной код.
На один трек также могут ссылаться несколько треков. Например, и звуковая, и видеодорожка могут ссылаться на одну и ту же дорожку временного кода, если они используют одинаковую информацию о времени.
Если этот атом отсутствует, дорожка никоим образом не ссылается ни на какую другую дорожку. Обратите внимание, что размер массива атомов ссылочного типа дорожки соответствует размеру ссылочного атома дорожки. Ссылки на дорожки с индексом ссылки 0 разрешены. Это указывает на отсутствие ссылки.
Дополнительные сведения о ссылках на дорожки см. в разделе Ссылки на дорожки.
На рис. 2-18 показано расположение ссылочного атома дорожки.
Рисунок 2-18 Схема атома ссылки дорожкиАтом ссылки дорожки содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме ссылки на дорожку.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'tref'. - Отслеживание атомов эталонного типа
-
Список атомов типа ссылки на дорожку, содержащий информацию о ссылке на дорожку. Эти атомы описаны далее.
Каждый атом ссылки на дорожку определяет отношения с дорожками определенного типа. Ссылочный тип подразумевает тип дорожки. В Таблице 2-2 показаны типы ссылок на дорожки и их описания.
| Тип ссылки |
Описание |
|---|---|
| | Ссылка на дорожку содержится в дорожке метаданных с синхронизацией (дополнительную информацию см. в разделе Носитель метаданных с синхронизацией) и предоставляет ссылки на дорожки, для которых она содержит описательные характеристики. Примечание. Если дорожка синхронизированных метаданных описывает характеристики всего фильма, между ней и другой дорожкой не будет ссылки на дорожку типа |
| |
Список глав или сцен. Обычно ссылается на текстовую дорожку. |
| | Субтитры. В любой дорожке это идентифицирует дорожку с закрытыми субтитрами, которая содержит текст, подходящий для направляющей дорожки. Дополнительные сведения см. в разделе «Медиа со скрытыми субтитрами». |
| | В звуковой дорожке это ссылка на дорожку в другом формате, но с идентичным содержанием, если таковая существует; например, дорожка AC3 может ссылаться на дорожку AAC с идентичным содержимым. См. Альтернативные звуковые дорожки. |
| | В звуковой дорожке это ссылка на дорожку субтитров, которая должна использоваться в качестве дорожки субтитров звуковой дорожки по умолчанию. Если дорожка субтитров является частью пары дорожек субтитров, это должно ссылаться на принудительную дорожку субтитров пары. |
| | Принудительная дорожка субтитров. В обычной дорожке пары дорожек субтитров это ссылается на принудительную дорожку. Для получения дополнительной информации см. Пример данных субтитров. |
| | Упомянутые дорожки содержат исходный носитель для этой дорожки подсказок. |
| |
Стенограмма. Обычно ссылается на текстовую дорожку. |
| |
Непервичный источник. Указывает, что указанная дорожка должна отправлять свои данные на эту дорожку, а не представлять их. Ссылочная дорожка будет использовать данные для изменения способа представления своих данных. Дополнительную информацию см. |
| | Синхронизация. Обычно между видео и звуковой дорожкой. Указывает, что две дорожки синхронизированы. Ссылка может быть с любой дорожки на другую, или может быть две ссылки. |
| | Временной код. Обычно ссылается на дорожку временного кода. |
Каждый атом типа ссылки на дорожку содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме типа ссылки на дорожку.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено одно из значений, показанных в таблице 2-2.
- Идентификаторы дорожек
-
Список значений идентификаторов дорожек (32-разрядные целые числа), указывающих связанные дорожки.
Обратите внимание, что это один из случаев, когда значения идентификатора дорожки могут быть установлены на 0. Неиспользуемые записи в атоме могут иметь значение идентификатора дорожки, равное 0. Установка идентификатора дорожки на 0 может быть более удобной, чем удаление ссылки.
Вы можете определить количество ссылок на дорожки, хранящихся в атоме типа ссылки на дорожку, вычитая размер его заголовка из общего размера, а затем разделив на размер идентификатора дорожки в байтах.
Отслеживание входных атомов карты
Атомы входной карты дорожки определяют, как должны интерпретироваться данные, отправляемые на эту дорожку из ее неосновных источников. Ссылки на дорожки типа 'ssrc' определяют вторичные источники данных дорожки. Эти источники предоставляют дополнительные данные, которые необходимо использовать при обработке трека. Атомы входной карты дорожки имеют значение типа атома 'imap' .
На рис. 2-19 показано расположение входного атома дорожки. Этот атом содержит один или несколько входных атомов дорожки. Обратите внимание, что атом карты ввода дорожки является структурой атома QT.
Каждый атом карты ввода дорожки содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме входной карты дорожки.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'imap'. - Отслеживание входных атомов
-
Список входных атомов отслеживания, указывающий, как использовать входные данные.
Карта ввода определяет все вторичные входы дорожки. Каждый вторичный вход определяется с использованием отдельного атома входа дорожки.
Каждый входной атом дорожки содержит следующие элементы данных.
- Размер
-
32-битное целое число, указывающее количество байтов во входном атоме этой дорожки.
- Тип
-
32-разрядное целое число, определяющее тип атома; это поле должно быть установлено на
'in'(обратите внимание, что два начальных байта должны быть установлены на 0x00). - Идентификатор атома
-
32-битное целое число, связывающее этот входной атом дорожки с его вторичным входом. Значение этого поля соответствует индексу вторичного входа в эталонном атоме дорожки. То есть первый вторичный вход соответствует входному атому дорожки со значением идентификатора атома, равным 1; второй для отслеживания входного атома с идентификатором атома 2 и так далее.
- Зарезервировано
-
16-разрядное целое число, которое должно быть равно 0.
- Число детей
-
16-разрядное целое число, указывающее количество дочерних атомов в этом атоме.
- Зарезервировано
-
32-битное целое число, которое должно быть установлено равным 0.
Атом ввода дорожки, в свою очередь, может содержать атомы двух других типов: атомы типа ввода и атомы идентификатора объекта. Требуется атом типа ввода; он указывает, как данные должны интерпретироваться.
Атом типа ввода содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме входного типа.
- Тип
-
32-разрядное целое число, определяющее тип атома; это поле должно быть установлено на
'ty'(обратите внимание, что два начальных байта должны быть установлены на 0x00). - Тип ввода
-
32-разрядное целое число, указывающее тип данных, которые должны быть получены из вторичного источника данных. В Таблице 2-3 перечислены допустимые значения для этого поля.
| Идентификатор ввода |
Значение |
Описание |
|---|---|---|
| |
1 |
Матрица преобразования 3 × 3 для преобразования местоположения дорожки, масштабирования и т. |
| |
2 |
Область отсечения QuickDraw для изменения формы дорожки. |
| |
3 |
Значение с фиксированной точкой 8,8, указывающее относительную громкость звука. Это используется для затухания громкости. |
| |
4 |
16-битное целое число, указывающее уровень звукового баланса. Это используется для панорамирования местоположения звука. |
| |
5 |
Запись графического режима (32-битное целое число, указывающее графический режим, за которым следует цвет RGB) для изменения графического режима дорожки для визуального затухания. |
| |
6 |
Матрица преобразования 3 × 3 для преобразования объекта в пределах местоположения дорожки, масштабирования и т. |
| |
7 |
Запись графического режима (32-битное целое число, указывающее графический режим, за которым следует цвет RGB) для изменения объекта в графическом режиме дорожки для визуального затухания. |
| |
|
Сжатые данные изображения для объекта на дорожке. Обратите внимание, что это было |
Если вход работает с объектом внутри дорожки (например, спрайт внутри дорожки спрайта), атом идентификатора объекта должен быть включен в атом ввода дорожки, чтобы идентифицировать объект.
Атом идентификатора объекта содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме идентификатора объекта.
- Тип
-
32-битное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'obid'. - Идентификатор объекта
-
32-битное целое число, идентифицирующее объект.
Атомы носителя
Атомы мультимедиа описывают и определяют тип мультимедиа дорожки и данные выборки. Атом носителя содержит информацию, которая указывает:
-
Тип носителя, такой как звук, видео или синхронизированные метаданные
-
Компонент обработчика мультимедиа, используемый для интерпретации выборочных данных
-
Шкала времени мультимедиа и продолжительность трека
-
Информация о мультимедиа и треке, такая как громкость звука или графический режим
-
Атомы таблицы сэмплов, которые для каждого семпла мультимедиа указывают описание сэмпла, продолжительность и смещение в байтах от ссылки на данные
Атом медиа имеет тип атома 'мдиа' . Он должен содержать атом заголовка носителя ( 'mdhd' ) и может содержать атом ссылки на обработчик ( 'hdlr' ), атом информации о носителе ( 'minf' ) и пользовательские данные ( 'udta' ) атом.
Примечание: Не путайте атом носителя ( 'mdia' ) с атомом носителя data ( 'mdat' ). Атом носителя содержит только ссылки на данные носителя; атом данных мультимедиа содержит фактические образцы мультимедиа.
На рис. 2-20 показано расположение атома среды.
Рисунок 2-20 Схема атома средыАтомы среды содержат следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме носителя.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'mdia'. - Атом заголовка носителя
-
Этот атом содержит стандартную информацию о носителе.
См. Атомы заголовка носителя. - Atom расширенного языкового тега
-
Этот атом содержит расширенный языковой тег, описывающий язык мультимедиа. См. Atom расширенного языкового тега.
- Ссылочный атом обработчика
-
Этот атом идентифицирует компонент обработчика мультимедиа, который должен использоваться для интерпретации данных мультимедиа. Дополнительные сведения см. в разделе Ссылочные атомы обработчика.
Обратите внимание, что атом ссылки обработчика сообщает вам, какой тип мультимедиа содержит этот атом мультимедиа, например, видео или звук. Компоновка атома информации о мультимедиа зависит от обработчика мультимедиа, который должен интерпретировать мультимедиа. Media Information Atoms обсуждает, как данные могут храниться на носителе, используя в качестве примера видеоформат, определенный Apple.
- Атом информации о носителе
-
Этот атом содержит данные, относящиеся к типу мультимедиа, которые используются компонентом обработчика мультимедиа.
См. Атомы информации о носителях. - Атом данных пользователя
-
См. Атомы пользовательских данных.
Атомы заголовка мультимедиа
Атом заголовка мультимедиа определяет характеристики мультимедиа, включая шкалу времени и продолжительность. Атом заголовка носителя имеет тип атома 'mdhd' .
На рис. 2-21 показана структура атома заголовка носителя.
Рисунок 2-21 Схема атома заголовка носителяАтомы заголовка носителя содержат следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме заголовка носителя.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'mdhd'. - Версия
-
Один байт, указывающий версию этого атома заголовка.
- Флаги
-
Три байта пространства для флагов заголовка носителя.
Установите в этом поле значение 0. - Время создания
-
32-битное целое число, указывающее (в секундах с полуночи 1 января 1904 г.), когда был создан атом носителя. Настоятельно рекомендуется указывать это значение с использованием универсального глобального времени (UTC).
- Время модификации
-
32-битное целое число, указывающее (в секундах с полуночи 1 января 1904) при изменении атома носителя. Настоятельно рекомендуется указывать это значение с использованием универсального глобального времени (UTC).
- Шкала времени
-
Значение времени, указывающее шкалу времени для этого носителя, то есть количество единиц времени, проходящих в секунду в его системе координат времени.
- Продолжительность
-
Продолжительность этого медиа в единицах его временной шкалы.
- Язык
-
16-битное целое число, указывающее код языка для этого носителя. См. Значения языковых кодов для допустимых языковых кодов.
Также см. Atom расширенного языкового тега для предпочтительного кода для использования здесь, если расширенный языковой тег также включен в атом мультимедиа. - Качество
-
16-битное целое число, указывающее качество воспроизведения носителя, то есть его пригодность для воспроизведения в данной среде.
Расширенный языковой тег Atom
Расширенный языковой тег Atom представляет информацию о языке мультимедиа на основе отраслевого стандарта RFC 4646 (Best Common Practices (BCP) #47). Это необязательный аналог атома заголовка мультимедиа, и он должен соответствовать определению атома заголовка мультимедиа в фильме QuickTime. На атом носителя и, в свою очередь, на дорожку приходится не более одного атома расширенного языкового тега. Расширенный атом тега языка имеет тип атома 9.2603 'эльнг' .
До введения этого типа атома QuickTime поддерживал языки с помощью кодов, основанных либо на ISO 639, либо на классических языковых кодах Macintosh. Эти языковые коды связаны с мультимедиа (для каждой дорожки) в фильме QuickTime и упоминаются как язык мультимедиа .
Чтобы отличить расширенную языковую поддержку от старой системы, она называется расширенной языковой меткой , а не кодом языка 9009.5 . Основное преимущество расширенного языкового тега заключается в том, что он включает в себя дополнительную информацию, такую как регион, сценарий, вариант и т. д., в виде частей (или вложенных тегов). Например, эта дополнительная информация позволяет отличить контент на французском языке, на котором говорят в Канаде, от контента на французском языке, на котором говорят во Франции.
На рис. 2-22 показано расположение этого атома.
Рисунок 2-22 Схема атома расширенного языкового тегаАтомы расширенного языкового тега содержат следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме заголовка носителя.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'elng'. - Версия
-
Один байт, указывающий версию этого атома заголовка.
- Флаги
-
Три байта пространства для флагов заголовка носителя. Установите в этом поле значение 0.
- Строка тега языка
-
Строка C с завершающим нулем, содержащая строку языкового тега, совместимую с RFC 4646 (BCP 47), в кодировке ASCII, например "en-US", "fr-FR" или "zh-CN".
Дополнительные примечания:
-
Тег расширенного языка переопределяет язык мультимедиа, если они не совпадают.
-
Расширенный атом тега языка является необязательным, и если он отсутствует, следует использовать язык мультимедиа.
-
Проверка строки языкового тега не выполняется. Приложения, обрабатывающие фильмы QuickTime, должны быть готовы к недопустимому языковому тегу и должны вести себя так, как если бы информация не была найдена.
-
Для лучшей совместимости с более ранними проигрывателями, если указан расширенный языковой тег, наиболее совместимый языковой код должен быть указан в поле языка атома 'mdhd' (например, "eng", если расширенный языковой тег "ан-АУ"). Если нет разумно совместимого тега, упакованная форма 'und' может быть указана в коде языка атома 'mdhd'.
Ссылочные атомы обработчика
Ссылочный атом обработчика указывает компонент обработчика мультимедиа, который должен использоваться для интерпретации данных мультимедиа. Ссылочный атом обработчика имеет значение типа атома 9.2603 'hdlr' .
Исторически атом ссылки обработчика также использовался для ссылок на данные. Однако это использование больше не актуально, и теперь его можно безопасно игнорировать.
Атом обработчика внутри атома мультимедиа объявляет процесс, с помощью которого могут быть представлены медиаданные в потоке, и, таким образом, характер медиа в потоке. Например, обработчик видео будет обрабатывать видеодорожку.
На рис. 2-23 показано расположение ссылочного атома обработчика.
Рисунок 2-23 Макет ссылочного атома обработчикаСсылочные атомы обработчика содержат следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме ссылки обработчика.
- Тип
-
32-разрядное целое число, определяющее тип атома; это поле должно быть установлено на
'hdlr'. - Версия
-
1-байтовая спецификация версии информации об этом обработчике.
- Флаги
-
3-байтовое пространство для информационных флагов обработчика. Установите в этом поле значение 0.
- Тип компонента
-
Четырехзначный код, определяющий тип обработчика. Для этого поля допустимы только два значения:
'mhlr'для обработчиков мультимедиа и'dhlr'для обработчиков данных. - Подтип компонента
-
Четырехзначный код, определяющий тип обработчика мультимедиа или обработчика данных.
Для обработчиков мультимедиа это поле определяет тип данных, например, 9.2603 «видео» для видеоданных, «звук»для звуковых данных или«субт»для субтитров. Информацию об определенных типах мультимедийных данных см. в разделе Типы атомов мультимедийных данных.Для обработчиков данных это поле определяет тип ссылки на данные; например, значение подтипа компонента
'alis'идентифицирует псевдоним файла. - Производитель компонентов
-
Зарезервировано. Установите на 0.
- Флаги компонентов
-
Зарезервировано. Установите на 0,
- Маска флагов компонентов
-
Зарезервировано. Установите на 0.
- Название компонента
-
Строка (подсчитанная), указывающая имя компонента, то есть обработчик носителя, использованный при создании этого носителя. Это поле может содержать строку нулевой длины (пустую).
Атомы информации о носителях
Атомы информации о медиа (определяемые типом атома 'minf' ) хранят специфичную для обработчика информацию для медиаданных дорожки. Обработчик мультимедиа использует эту информацию для сопоставления времени мультимедиа с данными мультимедиа и для обработки данных мультимедиа.
Эти атомы содержат информацию, относящуюся к типу данных, определяемому носителем. Кроме того, формат и содержимое атомов мультимедийной информации диктуются обработчиком мультимедийных данных, который отвечает за интерпретацию потока мультимедийных данных. Другой обработчик СМИ не знал бы, как интерпретировать эту информацию.
В этом разделе описываются атомы, в которых хранится мультимедийная информация для видео ( 'vmhd' ), звука ( 'smhd' ) и базовых ( 'gmhd' ) частей фильмов QuickTime.
Примечание: В разделе "Использование атомов образцов" обсуждается, как обработчик видеоматериалов находит образцы в видеоносителях.
Атомы информации о видео носителях
Информационные атомы видеоносителей являются атомами высшего уровня в видеоносителях. Эти атомы содержат ряд других атомов, которые определяют специфические характеристики видеоданных. На рис. 2-24 показана структура атома видеоинформации о носителе.
Атом информации о носителе видео содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме информации о носителе видео.
- Тип
-
32-разрядное целое число, определяющее тип атома; это поле должно быть установлено на
'minf'. - Информационный атом видеоносителя
-
См. Атомы заголовка информации о носителе видео.
- Ссылочный атом обработчика
-
См. Ссылочные атомы обработчика.
- Информационный атом данных
-
См. Атомы информации о данных.
- Образец таблицы атомов
-
См. образец таблицы атомов.
Атомы заголовка информации о видео
Атомы заголовка информации о видеоносителях определяют конкретную информацию о цвете и графическом режиме.
На рис. 2-25 показана структура атома заголовка информации о носителе видео.
Рисунок 2-25 Схема атома заголовка информации о носителе для видеоАтом заголовка информации о носителе видео содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме заголовка информации о носителе видео.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'vmhd'. - Версия
-
1-байтовая спецификация версии этого атома заголовка информации о носителе видео.
- Флаги
-
3-байтовое пространство для флагов информации о видеоносителях. Есть один определенный флаг.
- Без наклона вперед
-
Это флаг совместимости, который позволяет QuickTime различать фильмы, созданные с помощью QuickTime 1.0, и более новые фильмы. Вы должны всегда устанавливать этот флаг равным 1, если только вы не создаете фильм, предназначенный для воспроизведения, с использованием версии 1.
0 QuickTime. Значение этого флага равно 0x0001.
- Графический режим
-
16-разрядное целое число, указывающее режим передачи. Режим передачи указывает, какую логическую операцию должен выполнять QuickDraw при рисовании или переносе изображения из одного места в другое. См. Графические режимы для списка графических режимов, поддерживаемых QuickTime.
- Opcolor
-
Три 16-битных значения, определяющие красный, зеленый и синий цвета для режима передачи, указанного в поле графического режима.
Звуковые носители информации Атомы
Информационные атомы звуковых носителей являются атомами высшего уровня в звуковых носителях. Эти атомы содержат ряд других атомов, которые определяют специфические характеристики звуковых мультимедийных данных. На рис. 2-26 показано расположение атома звуковой информации о носителях.
Рисунок 2-26 Схема атома информации о носителе для звука Атом информации о носителе звука содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом звуковом атоме информации о носителе.
- Тип
-
32-разрядное целое число, определяющее тип атома; это поле должно быть установлено на
'minf'. - Атом заголовка информации о звуковом носителе
-
См. Атомы заголовка информации о звуковом носителе.
- Ссылочный атом обработчика
-
См. Ссылочные атомы обработчика.
- Информационный атом данных
-
См. Атомы информации о данных.
- Образец таблицы атомов
-
См. Пример таблицы атомов.
Атомы заголовка информации о звуковом носителе
Атом заголовка информации о звуковом носителе хранит управляющую информацию о звуковом носителе, такую как баланс.
На рис. 2-27 показано расположение этого атома.
Рисунок 2-27 Схема атома заголовка информации о звуковом носителе Атом заголовка звуковой информации о носителе содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом звуковом атоме заголовка информации о носителе.
- Тип
-
32-разрядное целое число, определяющее тип атома; это поле должно быть установлено на
'smhd'. - Версия
-
1-байтовая спецификация версии этого звукового атома заголовка информации о носителе.
- Флаги
-
3-байтовое пространство для звуковых флагов информации о носителе. Установите в этом поле значение 0.
- Весы
-
16-битное целое число, указывающее звуковой баланс этого звукового носителя. Баланс звука — это параметр, который управляет микшированием звука между двумя динамиками компьютера. В этом поле обычно установлено значение 0. Дополнительные сведения о значениях баланса см. в разделе Баланс.
- Зарезервировано
-
Зарезервировано для использования Apple. Установите в этом поле значение 0.
Базовые информационные атомы носителя
Базовый атом информации о медиа (показан на рис. 2-28) хранит медиаинформацию для таких типов медиа, как синхронизированные метаданные, текст, MPEG, временной код и музыка.
Типы носителей, производные от базового обработчика носителей, могут добавлять другие атомы в базовый атом информации о носителях, если это необходимо. В настоящее время единственным типом носителя, который определяет дополнительные атомы, является носитель с временным кодом. Дополнительные сведения об этих типах носителей см. в разделах Носители метаданных с синхронизацией и Носители с временным кодом.
Рисунок 2-28 Схема базового атома информации о носителеБазовый атом информации о носителе содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом базовом атоме информации о носителе.
- Тип
-
32-разрядное целое число, определяющее тип атома; это поле должно быть установлено на
'minf'. - Базовый атом заголовка информации о носителе
-
См. Базовые атомы заголовка информации о носителях.
Базовые атомы заголовка информации о носителе
Базовый атом заголовка информации о носителе указывает, что этот атом информации о носителе относится к базовому носителю.
На рис. 2-29 показано расположение этого атома.
Рисунок 2-29 Схема базового атома заголовка информации о носителеБазовый атом заголовка информации о носителе содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом базовом атоме заголовка информации о носителе.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'gmhd'. - Базовый информационный атом носителя
-
См. Базовый информационный атом носителя.
- Атом информации о текстовом носителе
-
См.
Атом информации о текстовом носителе.
Базовые информационные атомы носителя
Базовый атом информации о носителе, содержащийся в атоме заголовка базовой информации о носителе ( 'gmhd' ), определяет управляющую информацию о носителе, включая графический режим и информацию о балансе.
На рис. 2-30 показана структура базового информационного атома носителя.
Рисунок 2-30 Схема базового информационного атома носителяБазовый информационный атом носителя содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом базовом информационном атоме носителя.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'gmin'. - Версия
-
1-байтовая спецификация версии этого базового атома заголовка информации о носителе.
- Флаги
-
3-байтовое пространство для флагов базовой информации о носителе.
Установите в этом поле значение 0. - Графический режим
-
16-разрядное целое число, указывающее режим передачи. Режим передачи указывает, какую логическую операцию должен выполнять QuickDraw при рисовании или переносе изображения из одного места в другое. См. Графические режимы для получения дополнительной информации о графических режимах, поддерживаемых QuickTime.
- Opcolor
-
Три 16-битных значения, определяющие красный, зеленый и синий цвета для режима передачи, указанного в поле графического режима.
- Весы
-
16-битное целое число, указывающее звуковой баланс этого носителя. Баланс звука — это параметр, который управляет микшированием звука между двумя динамиками компьютера. В этом поле обычно установлено значение 0. Дополнительные сведения о значениях баланса см. в разделе Баланс.
- Зарезервировано
-
Зарезервировано для использования Apple. Установите в этом поле значение 0.
Data Information Atoms
Ссылочный атом обработчика (описанный в разделе Ссылочные атомы обработчика) содержит информацию, указывающую компонент обработчика данных, который обеспечивает доступ к медиаданным. Компонент обработчика данных использует информационный атом данных для интерпретации данных мультимедиа. Атомы информации данных имеют значение типа атома 'dinf' .
На рис. 2-31 показано расположение информационного атома данных.
Рисунок 2-31 Схема информационного атома данныхИнформационный атом данных содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом информационном атоме данных.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'dinf'. - Атом ссылки на данные
-
См. Атомы ссылки на данные.
Атомы ссылки на данные
Атомы ссылки на данные содержат табличные данные, которые указывают компоненту обработки данных, как получить доступ к данным носителя. На рис. 2-31 показан атом ссылки на данные.
Атом ссылки на данные содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме ссылки на данные.
- Тип
-
32-разрядное целое число, определяющее тип атома; это поле должно быть установлено на
'дреф'. - Версия
-
1-байтовая спецификация версии этого атома ссылки на данные.
- Флаги
-
3-байтовое пространство для флагов ссылки на данные. Установите в этом поле значение 0.
- Количество записей
-
32-разрядное целое число, содержащее количество последующих ссылок на данные.
- Ссылки на данные
-
Массив ссылок на данные.
Каждая ссылка на данные форматируется как атом и содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в ссылке на данные.
- Тип
-
32-разрядное целое число, указывающее тип данных в ссылке на данные. В Таблице 2-4 перечислены допустимые значения типов.
- Версия
-
1-байтовая спецификация версии ссылки на данные.
- Флаги
-
3-байтовое пространство для флагов ссылки на данные. Есть один определенный флаг.
- Собственная ссылка
-
Этот флаг указывает, что данные мультимедиа находятся в том же файле, что и атом фильма. В Macintosh и других файловых системах с файлами с несколькими ответвлениями установите этот флаг в 1, даже если данные находятся в другом ответвлении от атома фильма. Значение этого флага равно 0x0001.
- Данные
-
Справочная информация по данным.
В таблице 2-4 показаны определенные в настоящее время типы ссылок на данные, которые могут храниться в атоме заголовка.
| Тип ссылки на данные |
Описание |
|---|---|
| |
Ссылка на данные является псевдонимом Macintosh. Псевдоним содержит информацию о файле, на который он ссылается, включая его полное имя пути. |
| |
Ссылка на данные является псевдонимом Macintosh. К концу псевдонима добавляется тип ресурса (хранится как 32-битное целое число) и идентификатор (хранится как 16-битное целое число со знаком) для использования в указанном файле. Этот тип ссылки на данные устарел в формате файла QuickTime. Эта информация предназначена для документирования существующего контента, содержащего ссылки на данные «rsrc», и не должна использоваться для новой разработки. |
| |
Строка C, указывающая URL-адрес. После строки C могут быть дополнительные данные. |
Образцы атомов
QuickTime хранит мультимедийные данные в семплах. Выборка — это отдельный элемент в последовательности данных, упорядоченных по времени. Сэмплы хранятся на носителе и могут иметь различную продолжительность.
Сэмплы хранятся в виде серии фрагментов на носителе. Фрагменты — это набор выборок данных на носителе, обеспечивающий оптимизированный доступ к данным. Чанк может содержать один или несколько сэмплов. Фрагменты в медиа могут иметь разные размеры, а отдельные сэмплы внутри фрагмента могут отличаться друг от друга по размеру, как показано на рис. 2-32.
Рисунок 2-32 Сэмплы на носителе Один из способов описать сэмпл — использовать атом таблицы сэмплов. Атом таблицы образцов действует как хранилище информации об образцах и содержит ряд различных типов атомов. Различные атомы содержат информацию, которая позволяет обработчику мультимедиа анализировать образцы в правильном порядке. Этот подход обеспечивает упорядочение выборок, не требуя, чтобы данные выборки сохранялись последовательно относительно времени фильма в фактическом потоке данных.
В следующем разделе обсуждается пример атома таблицы. В последующих разделах обсуждается каждый из атомов, которые могут находиться в образце атома таблицы.
Образец таблицы атомов
Атом таблицы сэмплов содержит информацию для преобразования времени мультимедиа в номер сэмпла и местоположение семпла. Этот атом также указывает, как интерпретировать образец (например, следует ли распаковывать видеоданные и, если да, то каким образом). В этом разделе описывается формат и содержимое примера атома таблицы.
Тип атома таблицы примера 'stbl' . Он может содержать атом описания выборки, атом времени до выборки, атом синхронизации выборки, атом выборки-фрагмента, атом размера выборки, атом смещения фрагмента и атом теневой синхронизации. Недавние дополнения к списку типов атомов, которые может содержать атом таблицы сэмплов, — это необязательное описание группы сэмплов и атомы сэмпл-к-группе, включенные в Приложение G: Подготовка аудио — обработка задержки кодировщика в AAC.
Атом таблицы сэмплов содержит все индексы времени и данных сэмплов мультимедиа в дорожке. Используя таблицы, можно найти образцы во времени, определить их тип и определить их размер, контейнер и смещение в этом контейнере.
Если дорожка, содержащая атом таблицы сэмплов, не ссылается на данные, то атом таблицы сэмплов не должен содержать никаких дочерних атомов (не очень полезная дорожка мультимедиа).
Если дорожка, в которой содержится атом таблицы сэмплов, ссылается на данные, то требуются следующие дочерние атомы: описание семпла, размер сэмпла, сэмпл в чанке и смещение чанка. Все подтаблицы выборочной таблицы используют одно и то же общее количество выборок.
Атом описания образца должен содержать хотя бы одну запись. Атом описания образца необходим, так как он содержит поле индекса ссылки на данные, которое указывает, какой атом ссылки на данные использовать для извлечения образцов мультимедиа. Без описания образца невозможно определить, где хранятся образцы мультимедиа. Атом образца синхронизации является необязательным. Если атом синхронизации сэмпла отсутствует, все сэмплы неявно являются сэмплами синхронизации.
На рис. 2-33 показана структура примера атома таблицы.
Рисунок 2-33 Схема атома таблицы примераАтом таблицы примера содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом образце атома таблицы.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'stbl'. - Пример описания атома
-
См. описание образца Атомы.
- Атом времени до выборки
-
См.
Атомы времени до выборки. - Атом смещения композиции
-
См. Атом смещения композиции.
- Сдвиг состава Наименьший наибольший атом
-
См. Сдвиг состава Наименьший наибольший атом.
- Пример синхронизации атома
-
См. Атомы образца синхронизации.
- Пример атома частичной синхронизации
-
См. Пример атома частичной синхронизации.
- Образец-фрагмент атома
-
См. Атомы Sample-to-Chunk.
- Размер выборки атом
-
См. Атомы размера образца.
- Атом смещения фрагмента
-
См. Атомы смещения фрагмента.
- Пример флагов зависимостей atom
-
См. пример флагов зависимостей Atom.
- Теневой синхронизирующий атом
-
Зарезервировано для использования в будущем.
Образец Описание Атомы
В атоме описания сэмпла хранится информация, позволяющая декодировать сэмплы на носителе. Данные, хранящиеся в описании образца, различаются в зависимости от типа носителя. Например, в случае видеоносителей примеры описания представляют собой структуры описания изображения. Образец описания информации для каждого типа носителя объясняется в Типы атомов данных носителя
На рис. 2-34 показано расположение атома описания примера.
Рисунок 2-34 Схема примера описания атома Атом описания образца имеет тип атома 'stsd' . Атом описания образца содержит таблицу описаний образцов. Носитель может иметь одно или несколько образцов описания, в зависимости от количества различных схем кодирования, используемых в носителе, и от количества файлов, используемых для хранения данных. Атом выборки-в-фрагмент идентифицирует описание семпла для каждого образца в носителе, указывая индекс в этой таблице для соответствующего описания (см. Атомы выборки-в-фрагмент).
Атом описания образца содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом образце атома описания.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'stsd'. - Версия
-
1-байтовая спецификация версии атома описания этого примера.
- Флаги
-
3-байтовое пространство для флагов описания образца. Установите в этом поле значение 0.
- Количество записей
-
32-разрядное целое число, содержащее количество приведенных ниже образцов описания.
- Таблица описания образцов
-
Массив описаний образцов. Подробнее см. в разделе Общая структура описания образца.
Общая структура образца Описание
Хотя точный формат описания образца зависит от типа носителя, первые четыре поля описания каждого образца одинаковы.
- Размер описания образца
-
32-битное целое число, указывающее количество байтов в описании выборки.
Важно: При разборе описаний образцов в атоме ‘stsd’ помните о значении размера описания образца, чтобы правильно читать каждую запись таблицы. Некоторые примеры описания заканчиваются четырьмя нулевыми байтами, которые не указаны иначе.
- Формат данных
-
32-разрядное целое число, указывающее формат сохраняемых данных. Это зависит от типа носителя, но обычно это либо формат сжатия, либо тип носителя.
- Зарезервировано
-
Шесть байтов, которые должны быть установлены на 0.
- Индекс ссылки на данные
-
16-битное целое число, содержащее индекс ссылки на данные, используемой для извлечения данных, связанных с выборками, которые используют эту выборку описание. Ссылки на данные хранятся в атомах ссылок на данные.
За этими четырьмя полями могут следовать дополнительные данные, относящиеся к типу носителя и формату данных. Дополнительные сведения о конкретных типах и форматах носителей см. в разделе Типы атомов данных носителей.
Время выборки атомов
Атомы времени до выборки хранят информацию о продолжительности выборок носителя, обеспечивая сопоставление времени в среде с соответствующей выборкой данных. Атом времени до выборки имеет тип атома 'stts' .
Вы можете определить соответствующую выборку для любого времени в носителе, изучив таблицу атомов времени до выборки, которая содержится в атоме времени до выборки.
Атом содержит компактную версию таблицы, которая позволяет индексировать от времени до номера образца. Другие таблицы предоставляют размеры выборки и указатели от номера выборки. Каждая запись в таблице дает количество последовательных отсчетов с одинаковой временной дельтой и дельту этих отсчетов. Добавляя дельты, можно построить полную карту времени до выборки.
Атом содержит временные дельты: DT(n+1)
= DT(n) + STTS(n) , где STTS(n) — это (несжатая) запись таблицы для выборки n, а DT — время отображения для выборки (n). Образцы записей упорядочены по отметкам времени; поэтому все дельты неотрицательны. Ось DT имеет нулевое начало; DT(i) = SUM ( для j=0 до i-1 из delta(j) ), а сумма всех дельт дает длину носителя в дорожке (не сопоставленную с общая временная шкала и без учета какого-либо списка редактирования). Атом списка редактирования предоставляет начальное значение DT, если оно непустое (ненулевое).
На рис. 2-35 показано расположение атома времени до выборки.
Рисунок 2-35 Схема атома времени до выборкиАтом времени до выборки содержит следующие элементы данных.
- Размер
-
32-разрядное целое число, указывающее количество байтов в этом атоме времени до выборки.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'stts'. - Версия
-
1-байтовая спецификация версии этого атома времени выборки.
- Флаги
-
3-байтовое пространство для флагов времени выборки. Установите в этом поле значение 0.
- Количество записей
-
32-разрядное целое число, содержащее количество записей в таблице времени выборки.
- Таблица времени до выборки
-
Таблица, определяющая продолжительность каждой выборки на носителе.
Каждая запись таблицы содержит поле количества и поле длительности. Структура таблицы времени до выборки показана на рис. 2-36.
Вы определяете запись таблицы времени до выборки, указав следующие поля:
- Количество проб
-
32-битное целое число, указывающее количество последовательных выборок одинаковой продолжительности.
- Длительность выборки
-
32-разрядное целое число, указывающее длительность каждой выборки.
Записи в таблице описывают образцы в соответствии с их порядком в носителе и их продолжительностью. Если последовательные выборки имеют одинаковую продолжительность, одна запись в таблице может использоваться для определения более одной выборки. В этих случаях поле счетчика указывает количество последовательных выборок одинаковой продолжительности. Например, если видеоноситель имеет постоянную частоту кадров, в этой таблице будет одна запись, а счетчик будет равен количеству выборок.
На рис. 2-37 представлен пример таблицы времени до выборки, основанной на фрагментированных мультимедийных данных, показанных на рис. 2-32. Этот поток данных содержит в общей сложности девять выборок, которые по количеству и продолжительности соответствуют записям в таблице, показанной здесь. Несмотря на то, что сэмплы 4, 5 и 6 находятся в одном фрагменте, сэмпл 4 имеет продолжительность 3, а сэмплы 5 и 6 имеют продолжительность 2.
Рисунок 2-37 Пример таблицы времени до выборкиComposition Offset Atom
Образцы видео в закодированных форматах имеют порядок декодирования и порядок представления (также называемый состав заказа или дисплей заказ ). Атом смещения композиции используется при наличии неупорядоченных видеосэмплов.
-
Если порядок декодирования и представления совпадают, атома смещения композиции не будет. Атом времени до выборки обеспечивает порядок декодирования и представления видеопотока, а также позволяет вычислять время начала и окончания.
-
Если видеосэмплы хранятся не в порядке представления, атом времени до сэмпла обеспечивает порядок декодирования, а атом смещения композиции обеспечивает время представления для декодированных семплов, выраженное как дельта для каждого семпла основа.
Примечание: Время декодирования напрямую не влияет на время представления при работе с неупорядоченными образцами видео. Порядок существенный.
Атом смещения композиции содержит пошаговое отображение времени от декодирования до представления. Каждая запись в таблице смещения композиции представляет собой дельту времени от декодирования до времени представления: CT(n) = DT(n) + CTTS(n), где CTTS(n) — (несжатая) запись таблицы для выборки n DT — время декодирования время, а CT — время композиции (или отображения). Дельта, выраженная в таблице смещения состава, может быть положительной или отрицательной.
Когда присутствуют атом времени до выборки и атом смещения композиции, считыватель, анализирующий неупорядоченные видеосэмплы, имеет всю информацию, необходимую для вычисления времени начала и окончания, а также минимального и максимального смещения между ними. время декодирования и время представления. Образцы таблиц сканируются для получения этих значений.
Примечание: В последнем отображаемом кадре продолжительность декодирования используется в качестве продолжительности презентации.
Тип атома смещения композиции ‘ctts’ .
На рис. 2-38 показано расположение этого атома.
Рисунок 2-38 Схема атома смещения композиции- Размер
-
32-разрядное целое число, указывающее количество байтов в атоме смещения композиции.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
‘ctts’. - Версия
-
1-байтовая спецификация версии этого атома.
- Флаги
-
3-байтовое пространство, зарезервированное для флагов смещения. Установите в этом поле значение 0.
- Количество записей
-
32-разрядное целое число без знака, указывающее количество выборочных чисел в следующем массиве.
За счетчиком записей следует таблица композиционного смещения, показанная на рис. 2-39.
Рисунок 2-39 Схема записи таблицы композиционного смещения- sampleCount
-
32-битное целое число без знака, которое обеспечивает количество последовательных выборок с рассчитанным композиционным смещением в поле.
- CompositionOffset
-
32-разрядное целое число со знаком, указывающее значение вычисленного CompositionOffset.
Наименьший наибольший атом сдвига композиции
Необязательный наименьший атом сдвига композиции суммирует рассчитанные минимальное и максимальное смещения между временем декодирования и композицией, а также время начала и окончания для всех выборок. Это позволяет читателю определить минимальное время, необходимое для декодирования, чтобы получить правильный порядок представления без необходимости сканирования таблицы образцов для диапазона смещений. Тип композиционного сдвига наименьшего атома равен 9. 2603 'cslg' .
На рис. 2-40 показано расположение этого атома.
Рисунок 2-40 Схема наименьшего наибольшего атома сдвига композиции- Размер
-
32-битное целое число, указывающее количество байтов в наименьшем атоме сдвига композиции.
- Тип
-
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
‘cslg’. - Версия
-
1-байтовая спецификация версии этого атома.
- Флаги
-
3-байтовое пространство, зарезервированное для флагов. Установите для этого поля значение 0.
- композицияOffsetToDisplayOffsetShift
-
32-разрядное целое число без знака, указывающее вычисляемое значение.
- lastDisplayOffset
-
32-разрядное целое число со знаком, указывающее вычисляемое значение.
- GreatDisplayOffset
-
32-разрядное целое число со знаком, указывающее вычисляемое значение.
- displayStartTime
-
32-разрядное целое число со знаком, указывающее вычисляемое значение.
- displayEndTime
-
32-разрядное целое число со знаком, указывающее вычисляемое значение.
Использование смещения композиции и сдвига композиции наименьшие наибольшие атомы
При сохранении таблицы сэмплов неупорядоченного видеопотока необходимо вычислить сдвиг смещения.
lessDisplayOffset = min {отображать смещения всех выборок}
GreatDisplayOffset = max {отображает смещения всех образцов}
если( минимумDisplayOffset < 0 )
композицияOffsetToDisplayOffsetShift = наименьшее смещение дисплея;
еще
композицияOffsetToDisplayOffsetShift = 0; |
Эти значения хранятся в составе сдвига наименьшего наибольшего атома в пределах атома таблицы образцов.
Затем следует написать атом таблицы смещений композиции, в котором хранятся смещения отображения, настраивая каждое смещение путем вычитания сдвига композицииOffsetToDisplayOffsetShift:
композицияOffset[n] = displayOffset[n] - композицияOffsetToDisplayOffsetShift; |
Примечание: Если наименьший атом сдвига состава отсутствует, читатель должен предположить, что композицияOffsetToDisplayOffsetShift = 0 . Таблицы примеров необходимо будет просмотреть, чтобы найти наименьшее и наибольшее смещения, а также время начала и окончания презентации, чтобы определить смещение времени декодирования, необходимое для презентации.
Синхронизация образцов атомов
Атом выборки синхронизации идентифицирует ключевые кадры в медиа. В носителе, который содержит сжатые данные, ключевые кадры определяют начальные точки для частей временно сжатой последовательности. Ключевой кадр является автономным, то есть он не зависит от предыдущих кадров. Последующие кадры могут зависеть от ключевого кадра.
Атом выборки синхронизации обеспечивает компактную маркировку точек произвольного доступа в потоке. Таблица составлена строго в порядке возрастания номера образца. Если эта таблица отсутствует, каждая выборка неявно является точкой произвольного доступа.
Атомы образца Sync имеют тип атома 'stss' . Атом синхронизации выборки содержит таблицу номеров выборок. Каждая запись в таблице идентифицирует образец, который является ключевым кадром для мультимедиа. Если атома выборки синхронизации не существует, то все выборки являются ключевыми кадрами.
На рис. 2-41 показано расположение атома выборки синхронизации.
Рисунок 2-41 Схема атома выборки синхронизацииАтом выборки синхронизации содержит следующие элементы данных.
- Размер
32-разрядное целое число, указывающее количество байтов в этом атоме выборки синхронизации.
- Тип
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'stss'.- Версия
1-байтовая спецификация версии этого атома образца синхронизации.
- Флаги
3-байтовое пространство для флагов выборки синхронизации. Установите в этом поле значение 0.
- Количество записей
32-разрядное целое число, содержащее количество записей в таблице образцов синхронизации.
- Пример таблицы синхронизации
Таблица номеров образцов; каждый номер выборки соответствует ключевому кадру.
На рис. 2-42 показан макет таблицы примера синхронизации.
Образец частичной синхронизации
В этом атоме перечислены образцы частичной синхронизации. Поскольку такие выборки не являются выборками полной синхронизации, их также не следует указывать в атоме выборки синхронизации.
Тип атома выборки частичной синхронизации: ‘stps’ .
На рис. 2-43 показано расположение этого атома.
Рисунок 2-43 Схема атома частичной синхронизации- Размер
32-разрядное целое число, указывающее количество байтов в атоме выборки частичной синхронизации.
- Тип
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
‘stps’.- Версия
1-байтовая спецификация версии этого атома.
- Флаги
3-байтовое пространство, зарезервированное для флагов.
Установите в этом поле значение 0.- Количество записей
32-разрядное целое число без знака, указывающее количество выборочных чисел в следующем массиве.
- Таблица образцов частичной синхронизации
Таблица номеров образцов. На рис. 2-44 показан макет таблицы примера частичной синхронизации.
. Рисунок 2-44.Когда сэмплы добавляются на носитель, они собираются в фрагменты, что обеспечивает оптимизированный доступ к данным. Чанк содержит один или несколько сэмплов. Фрагменты в медиа могут иметь разные размеры, а сэмплы внутри фрагмента могут иметь разные размеры. Атом выборки-фрагмента хранит информацию о фрагментах для сэмплов на носителе.
Атомы от выборки к фрагменту имеют тип атома
'stsc'. Атом выборки-к-фрагменту содержит таблицу, которая сопоставляет сэмплы с фрагментами в потоке мультимедийных данных. Исследуя атом от образца к фрагменту, вы можете определить фрагмент, который содержит конкретный образец.На рис. 2-45 показано расположение атома образец-кусок.
Рисунок 2-45 Схема атома «выборка-фрагмент»Атом «выборка-фрагмент» содержит следующие элементы данных.
- Размер
32-разрядное целое число, указывающее количество байтов в этом атоме выборки-фрагмента.
- Тип
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'stsc'.- Версия
1-байтовая спецификация версии этого атома преобразования выборки в фрагмент.
- Флаги
3-байтовое пространство для флагов преобразования выборки в фрагмент. Установите в этом поле значение 0.
- Количество записей
32-разрядное целое число, содержащее количество записей в таблице преобразования выборки в фрагмент.
- Таблица преобразования выборки в фрагмент
Таблица, которая отображает сэмплы в чанки.
На рис. 2-46 показана структура записи в таблице преобразования выборки в фрагмент. Каждый атом от сэмпла к фрагменту содержит такую таблицу, которая идентифицирует фрагмент для каждого семпла в носителе. Каждая запись в таблице содержит поле первого фрагмента, поле образцов на фрагмент и поле идентификатора описания образца. Из этой информации вы можете установить, где находятся сэмплы в медиаданных.
Вы определяете запись таблицы выборки в фрагмент, указав следующие элементы данных.
- Первый блок
Номер первого фрагмента, использующего эту запись таблицы.
- выборок на блок
Количество выборок в каждом фрагменте.
- Пример описания ID
Идентификационный номер, связанный с описанием образца для образца. Дополнительные сведения об атомах описания образца см. в разделе Атомы описания образца.
На рис.
Рисунок 2-47 Пример таблицы выборки-фрагмента 2-47 показан пример таблицы преобразования выборки в фрагмент, основанной на потоке данных, показанном на рис. 2-32.Каждая запись таблицы соответствует набору последовательных фрагментов, каждый из которых содержит одинаковое количество образцов. Кроме того, каждый из образцов в этих фрагментах должен использовать одно и то же описание образца. Всякий раз, когда изменяется количество сэмплов на порцию или описание сэмпла, вы должны создать новую запись в таблице. Если все фрагменты имеют одинаковое количество сэмплов на фрагмент и используют одно и то же описание сэмпла, в этой таблице будет одна запись.
Размер выборки Атомы
Вы используете атомы размера выборки, чтобы указать размер каждой выборки в носителе. Атомы размера выборки имеют тип атома
'stsz'.Атом размера выборки содержит число выборок и таблицу с размером каждой выборки. Это позволяет самим медиаданным быть без фреймов.
Общее количество образцов в среде всегда указывается в количестве образцов. Если указан размер по умолчанию, то таблица не следует.На рис. 2-48 показано расположение атома размера выборки.
Рисунок 2-48 Схема атома размера выборкиАтом размера выборки содержит следующие элементы данных.
- Размер
32-разрядное целое число, указывающее количество байтов в этом атоме размера выборки.
- Тип
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'stsz'.- Версия
1-байтовая спецификация версии этого атома размера выборки.
- Флаги
3-байтовое пространство для флагов размера выборки. Установите в этом поле значение 0.
- Размер образца
32-битное целое число, указывающее размер выборки. Если все выборки имеют одинаковый размер, это поле содержит значение этого размера.
Если в этом поле установлено значение 0, то выборки имеют разные размеры, и эти размеры сохраняются в таблице размеров выборки.- Количество записей
32-битное целое число, содержащее количество записей в таблице размера выборки.
- Таблица размеров образцов
Таблица, содержащая информацию о размере выборки. Таблица размеров выборки содержит запись для каждой выборки в потоке данных мультимедиа. Каждая запись таблицы содержит поле размера. Поле размера содержит размер рассматриваемого образца в байтах. Таблица индексируется по номеру выборки — первая запись соответствует первой выборке, вторая запись — второй выборке и так далее.
На рис. 2-49 показана структура таблицы произвольного размера выборки.
Рисунок 2-49 Пример таблицы размера выборкиАтомы смещения фрагментов
Атомы смещения фрагмента определяют местоположение каждого фрагмента данных в потоке данных мультимедиа.
Атомы смещения фрагмента имеют тип атома 'stco'.Таблица смещений фрагментов дает индекс каждого фрагмента в содержащем файле. Есть два варианта, позволяющие использовать 32-битные или 64-битные смещения. Последнее полезно при работе с очень большими фильмами. Только один из этих вариантов встречается в любом отдельном экземпляре атома таблицы образца.
Обратите внимание, что смещения — это смещения в файле, а не смещение в какой-либо атом в файле (например, атом
'mdat'). Это позволяет ссылаться на мультимедийные данные в файлах без какой-либо атомарной структуры. Однако будьте осторожны при создании автономного файла QuickTime с его метаданными (атом фильма) в начале, потому что размер атома фильма влияет на смещения фрагментов медиаданных.Примечание: Атом таблицы примера может содержать 64-битный атом смещения фрагмента (
STChunkOffset64AID = 'co64'). Когда появляется этот атом, он используется вместо исходного атома смещения фрагмента, который может содержать только 32-битные смещения. Когда QuickTime записывает видеофайлы, он использует 64-битный атом смещения фрагмента только в том случае, если есть фрагменты, использующие старшие 32 бита смещения фрагмента. В противном случае для обеспечения совместимости с предыдущими версиями QuickTime используется исходный 32-битный атом смещения фрагмента.На рис. 2-50 показано расположение атома смещения фрагмента.
Рисунок 2-50 Схема атома смещения фрагментаАтом смещения фрагмента содержит следующие элементы данных.
- Размер
32-разрядное целое число, указывающее количество байтов в этом атоме смещения фрагмента.
- Тип
32-разрядное целое число, определяющее тип атома; в этом поле должно быть установлено значение
'stco'.- Версия
1-байтовая спецификация версии этого атома смещения фрагмента.
- Флаги
3-байтовое пространство для флагов смещения фрагмента.
Установите в этом поле значение 0.- Количество записей
32-разрядное целое число, содержащее количество записей в таблице смещения фрагментов.
- Таблица смещения кусков
Таблица смещения фрагмента, состоящая из массива значений смещения. Для каждого фрагмента в носителе существует одна запись в таблице. Смещение содержит смещение в байтах от начала потока данных до фрагмента. Таблица индексируется по номеру чанка — первая запись таблицы соответствует первому чанку, вторая запись таблицы — второму чанку и так далее.
На рис. 2-51 показана структура произвольной таблицы смещения фрагментов.
Рисунок 2-51 Пример таблицы смещения фрагментовSample Dependency Flags Atom
Sample Dependency Flags Atom использует один байт на образец в качестве битового поля, описывающего информацию о зависимости. Пример атома флагов зависимостей имеет тип
'sdtp'.На рис.
Рисунок 2-52 Схема примера флагов зависимостей атома 2-52 показано расположение этого атома.- Размер
32-разрядное целое число, указывающее количество байтов в образце атома флагов зависимостей.
- Тип
32-разрядное целое число, определяющее тип атома; это поле должно быть установлено на
‘sdtp’.- Версия
1-байтовая спецификация версии этого атома.
- Флаги
3-байтовое пространство, зарезервированное для флагов. Установите в этом поле значение 0.
- Пример таблицы флагов зависимостей
Таблица 8-битных значений, указывающих настройки флага выборки. Количество записей в таблице получается из поля количества выборок соответствующего атома размера выборки. На рис. 2-53 показан макет произвольной таблицы флагов зависимостей.
Рисунок 2-53 Пример таблицы флагов зависимостейЗначения флагов указаны следующим образом:
enum {// зарезервирован бит 0x80; битовые комбинации 0x30, 0xC0 и 0x03 зарезервированы
kQTSampleDependency_EarlierDisplayTimesAllowed = 1<<6, // mediaSampleEarlierDisplayTimesAllowed
kQTSampleDependency_SampleDoesNotDependOnOthers = 1<<5, // ie: an I picture
kQTSampleDependency_SampleDependsOnOthers = 1<<4, / / т.
е.: не картинка I kQTSampleDependency_NoOtherSampleDependsOnThisSample = 1<<3, // mediaSampleDroppable
kQTSampleDependency_OtherSamplesDependOnThisSample = 1<<2,
kQTSampleDependency_ThereIsNoRedundantCodingInThisSample = 1<<1,
kQTSampleDependency_ThereIsRedundantCodingInThisSample = 1<<0
};
Использование образцов атомов
В этом разделе представлены примеры с использованием только что описанных атомов. Эти примеры призваны помочь вам понять отношения между этими атомами.
В первом разделе «Поиск семпла» описываются шаги, которые обработчик мультимедиа использует для поиска семпла, содержащего мультимедийные данные для определенного времени на носителе. Во втором разделе, «Поиск ключевого кадра», описываются шаги, которые обработчик мультимедиа использует для поиска подходящего ключевого кадра для определенного момента времени в фильме.
Поиск образца
Когда QuickTime отображает фильм или дорожку, он указывает соответствующему обработчику мультимедиа получить доступ к данным мультимедиа для определенного времени. Обработчик мультимедиа должен правильно интерпретировать поток данных, чтобы получить запрошенные данные. В случае видеоносителей обработчик мультимедиа проходит через несколько атомов, чтобы найти местоположение и размер выборки для заданного времени мультимедиа.
Обработчик мультимедиа выполняет следующие шаги:
Определяет время в системе координат времени мультимедиа.
Проверяет атом времени до выборки, чтобы определить номер выборки, которая содержит данные за указанное время.
Сканирует атом от образца к фрагменту, чтобы обнаружить, какой фрагмент содержит рассматриваемый образец.
Извлекает смещение фрагмента из атома смещения фрагмента.
Находит смещение внутри фрагмента и размер выборки, используя атом размера выборки.
Поиск ключевого кадра
Поиск ключевого кадра для указанного времени в фильме немного сложнее, чем поиск выборки для указанного времени. Обработчик мультимедиа должен использовать атом синхронизирующей выборки и атом времени до выборки вместе, чтобы найти ключевой кадр.
Обработчик мультимедиа выполняет следующие шаги:
Проверяет атом времени до выборки, чтобы определить номер выборки, которая содержит данные за указанное время.
Сканирует атом синхронизирующей выборки, чтобы найти ключевой кадр, предшествующий номеру выборки, выбранному на шаге 1.
Сканирует атом от образца к фрагменту, чтобы обнаружить, какой фрагмент содержит ключевой кадр.
Извлекает смещение фрагмента из атома смещения фрагмента.
Находит смещение внутри фрагмента и размер выборки, используя атом размера выборки.
Сжатые видеоресурсы
Большинство фильмов QuickTime содержат метаданные в дополнение к данным мультимедиа.
Медиаданные могут быть сжаты с использованием различных алгоритмов сжатия видео и звука. Начиная с QuickTime 3 также стало возможным сжимать метаданные, более известные как ресурс фильма. Однако ресурс фильма нельзя сжать с помощью алгоритма сжатия с потерями, поскольку он содержит важную информацию, такую как используемые типы сжатия видео и аудио, смещения отдельных кадров и информацию о времени. Следовательно, для сжатия ресурса фильма необходимо использовать алгоритмы сжатия данных без потерь.Сжатие ресурсов фильма с помощью сжатия данных обычно уменьшает размер ресурса фильма на 50 % или более. Для фильмов QuickTime, которые транслируются через Интернет, это может существенно сократить задержку запуска фильма и, следовательно, имеет ряд явных преимуществ.
Разрешение QuickTime сжимать ресурс фильма
Большинству разработчиков приложений не нужно знать подробности того, как сжимаются ресурсы фильма. Набор инструментов для фильмов
FlattenMovieиФункции FlattenMovieDataсжимают ресурс фильма, если это требуется приложением. Для этого приложениям достаточно установить флаг flattenCompressMovieResourceпри вызове любой функции. Компонент экспорта фильма QuickTime также предоставляет пользователям возможность сжатия ресурса фильма при экспорте или создании нового фильма посредством экспорта.Структура сжатого ресурса фильма
Ресурс сжатого фильма, аналогичный ресурсу несжатого фильма, состоит из группы атомов QuickTime, расположенных в иерархии.
Как и несжатый ресурс фильма, самый внешний атом — это атом фильма. Внутри атома фильма есть один сжатый атом фильма, который содержит все остальные необходимые атомы. Сжатый атом фильма имеет два субатома. Первый — это атом сжатия данных, который содержит одно 32-битное целое число, определяющее, какой алгоритм сжатия данных без потерь использовался для сжатия ресурса фильма. Второй дочерний атом — это сжатые данные фильма, которые содержат сам сжатый ресурс фильма. Первое 32-битное целое число в атоме сжатых данных фильма указывает несжатый размер ресурса фильма, а затем следуют сжатые данные ресурса фильма.
Содержание полного сжатого фильма показано в таблице 2-5. Константы, определяющие типы атомов, определены в файле
MoviesFormat.h. Также показаны четырехзначные коды для каждого типа атома.Таблица 2-5 Содержимое полного сжатого фильма Тип атома
Четырехзначный код
Фильм
"движение"Сжатый фильм
'смов'Атом сжатия данных
"дком"Сжатые данные фильма
'ЦМВД'32-битное целое число
Размер без сжатия
Справочные фильмы
Фильм QuickTime может выступать в качестве контейнера для набора альтернативных фильмов, которые должны отображаться при определенных условиях.
Один из этих фильмов может содержаться в одном и том же файле; любые другие включены по ссылке.Например, фильм QuickTime может содержать список ссылок на фильмы с разной скоростью передачи данных, что позволяет приложению выбирать наиболее привлекательный фильм, который может плавно воспроизводиться при загрузке через Интернет, в зависимости от скорости подключения пользователя.
Фильм, содержащий ссылки на альтернативные фильмы, называется эталонным фильмом.
Эталонный фильм содержит атом эталонного фильма (
Рисунок 2-54 Атом фильма, содержащий атом'rmra') на верхнем уровне атома фильма, как показано на рис. 2-54. Атом фильма может также содержать атом заголовка фильма или может содержать только ссылочный атом фильма.'rmra'вместо атома'mvhd'Атом эталонного фильма содержит один или несколько атомов дескриптора эталонного фильма, каждый из которых описывает альтернативный фильм.
Каждый ссылочный атом дескриптора фильма содержит ссылочный атом данных, который указывает местоположение фильма.
Примечание. Местоположения фильмов указываются с использованием ссылок на данные QuickTime. QuickTime поддерживает несколько типов ссылок на данные, но альтернативные фильмы обычно указываются с использованием типов ссылок на данные любого URL-адреса (
'адрес ') или псевдоним файла ('alis').Ссылочный атом дескриптора фильма может содержать другие атомы, которые определяют системные требования фильма и качество фильма. Если да, то будет атом соответствующего типа для каждого требования, которое должно быть выполнено для воспроизведения фильма, а также может быть атом качества.
Приложения должны воспроизводить фильм самого высокого качества, требования которого удовлетворяет система пользователя. Если ссылка данных на выбранный фильм не может быть разрешена — например, из-за того, что файл не может быть найден — приложение должно рекурсивно пытаться воспроизвести фильм следующего самого высокого качества, пока не добьется успеха или не исчерпает список фильмов, требования которых удовлетворяются.
.Если фильм содержит атом ссылочного фильма и атом заголовка фильма, приложения должны воспроизводить соответствующий фильм, указанный атомом ссылочного фильма.
Если система пользователя не соответствует ни одному из критериев альтернативных фильмов или ни одна из квалификационных ссылок на данные не может быть разрешена, приложения должны воспроизводить фильм, определенный в атоме заголовка фильма. (Фильм, определенный в атоме заголовка фильма, также может быть указан одной из альтернативных ссылок на фильм.)
Атом заголовка фильма иногда используется для предоставления резервного фильма для приложений, которые могут воспроизводить старые фильмы QuickTime, но не понимают эталонные фильмы.
При синтаксическом анализе эталонного фильма читатель должен рассматривать URL-адрес или ссылку на файл в атоме эталонного фильма как новую отправную точку, не делая предположений о том, что ссылка является допустимым URL-адресом, существующим файлом или правильно сформированным и воспроизводимым файлом.
Фильм Quick Time.Эталонный фильм Atom
Атом ссылочного фильма содержит ссылки на один или несколько фильмов, как показано на рис. 2-55. При желании он может содержать список системных требований для воспроизведения каждого фильма и рейтинг качества для каждого фильма. Обычно он используется для указания списка альтернативных фильмов, которые будут воспроизводиться в различных условиях.
Родителем опорного атома фильма всегда является атом фильма (
Рисунок 2-55 Атом'moov'). В данном атоме фильма допускается только один эталонный атом фильма.'rmra'с несколькими атомами'rmda'Справочный атом фильма может содержать следующие поля:
- Размер
Количество байтов в этом эталонном атоме фильма.
- Тип
Тип этого атома; это поле должно быть установлено на
'рмра'.- Справочный дескриптор фильма атом
Атом эталонного фильма должен содержать по крайней мере один атом дескриптора эталонного фильма и обычно содержит более одного.
Дополнительную информацию см. в разделе Справочный дескриптор фильма Atom.
Справочный дескриптор фильма Atom
Каждый атом эталонного дескриптора фильма содержит другие атомы, описывающие, где можно найти конкретный фильм, и, при необходимости, системные требования для воспроизведения этого фильма, а также необязательный рейтинг качества для этого фильма.
Родителем атома дескриптора фильма всегда является атом ссылки на фильм (
'rmra'). В данном атоме ссылки на фильм допускается несколько атомов дескриптора фильма, и обычно присутствует более одного.На рис. 2-56 показано расположение этого атома.
Рисунок 2-56 Эталонный атом дескриптора фильмаЭталонный атом дескриптора фильма может содержать следующие поля:
- Размер
Количество байтов в этом эталонном атоме дескриптора фильма.
- Тип
Тип этого атома; в этом поле должно быть установлено значение
'rmda'.- Атом ссылки на данные
Каждый атом ссылки на фильм должен содержать ровно один атом ссылки на данные. Дополнительную информацию см. в разделе Атомы ссылок на данные.
- Атом скорости передачи данных
Атом эталонного фильма может содержать необязательный атом скорости передачи данных. Может присутствовать только один атом скорости передачи данных. Дополнительную информацию см. в разделе Атом скорости передачи данных.
- атом скорости процессора
Атом эталонного фильма может содержать необязательный атом скорости процессора. Может присутствовать только один атом скорости процессора. См. Atom скорости процессора для получения дополнительной информации.
- Проверка версии атома
Атом эталонного фильма может содержать необязательный атом проверки версии. Могут присутствовать несколько атомов проверки версии. Дополнительную информацию см. в разделе Проверка версии Atom.
- Компонент обнаруживает атом
Атом эталонного фильма может содержать необязательный атом обнаружения компонента.
Могут присутствовать несколько атомов обнаружения компонентов. Дополнительную информацию см. в разделе Обнаружение атома компонента.- Качественный атом
Атом эталонного фильма может содержать необязательный атом качества. Может присутствовать только один качественный атом. Дополнительную информацию см. в разделе «Качественный атом».
Ссылка на данные Атом
Атом ссылки на данные содержит информацию, необходимую для поиска фильма, потока или файла, который может воспроизводить QuickTime, обычно в виде URL-адреса или псевдонима файла.
В данном атоме дескриптора ссылки на фильм допускается только один атом ссылки на данные.
Атом ссылки на данные может содержать следующие поля:
- Размер
Число байтов в этом атоме ссылки на данные.
- Тип
Тип этого атома; в этом поле должно быть установлено значение
'rdrf'.- Флаги
32-битное целое число, содержащее флаги.
В настоящее время определен один флаг.- Фильм является автономным
Если младший бит равен 1, фильм является автономным. Для этого требуется, чтобы родительский фильм содержал атом заголовка фильма, а также атом эталонного фильма. Другими словами, текущие
'moov'атом должен содержать как'rmra'атом, так и'mvhd'атом. Чтобы разрешить эту ссылку на данные, приложение использует фильм, определенный в атоме заголовка фильма, игнорируя остальные поля в этом атоме ссылки на данные, которые используются только для указания внешних фильмов.
- Тип ссылки на данные
Тип ссылки на данные. Значение
'alis'указывает на запись псевдонима файловой системы. Значение'urlуказывает на строку, содержащую унифицированный указатель ресурса. Обратите внимание, что четвертый символ в'url '- это пробел ASCII (0x20).- Размер ссылки на данные
Размер ссылки на данные в байтах, выраженный в виде 32-разрядного целого числа.
- Ссылка на данные
Ссылка на данные фильма QuickTime, потока или файла, которые может воспроизводить QuickTime. Если тип ссылки
'alis', это поле содержит содержимоеОбработчик псевдонима. Если тип ссылки'url', это поле содержит строку с завершающим нулем, которую можно интерпретировать как URL. URL-адрес может быть абсолютным или относительным и может указывать любой протокол, который поддерживает QuickTime, включаяhttp://,ftp://,rtsp://,file:///иdata. :.
Атом скорости передачи данных
Атом скорости передачи данных определяет минимальную скорость передачи данных, необходимую для воспроизведения фильма. Обычно это сравнивается с настройкой скорости соединения в пользовательской панели управления QuickTime Settings. Приложения должны воспроизводить фильм с максимальной скоростью передачи данных, меньшей или равной скорости соединения пользователя.
Если скорость соединения ниже, чем скорость передачи данных любого фильма, приложения должны воспроизводить фильм с самой низкой скоростью передачи данных. Предполагается, что фильм с самой высокой скоростью передачи данных имеет самое высокое качество.В данном опорном атоме дескриптора фильма допускается только один атом скорости передачи данных.
Атом скорости передачи данных может содержать следующие поля:
- Размер
Количество байтов в этом атоме скорости передачи данных.
- Тип
Тип этого атома; в этом поле должно быть установлено значение
'rmdr'.- Флаги
32-битное целое число, которое в настоящее время всегда равно 0.
- Скорость передачи данных
- 931, кратно 100.
Приложения должны воспроизводить фильм с максимальной указанной скоростью ЦП, которая меньше или равна скорости пользователя. Если скорость пользователя ниже, чем скорость процессора любого фильма, приложения должны воспроизводить фильм с наименьшими требованиями к скорости процессора.
Фильм с самой высокой скоростью процессора считается самым качественным.В данном эталонном атоме дескриптора фильма допускается только один атом скорости процессора.
Атом скорости процессора может содержать следующие поля:
- Размер
Количество байтов в этом атоме скорости процессора.
- Тип
Тип этого атома; в этом поле должно быть установлено значение
'rmcs'.- Флаги
32-битное целое число, которое в настоящее время всегда равно 0.
- Скорость процессора
Относительный рейтинг требуемой скорости компьютера, выраженный в виде 32-разрядного целого числа, кратного 100, где большие числа указывают на более высокую скорость.
Проверка версии Atom
Атом проверки версии указывает пакет программного обеспечения, например QuickTime или QuickTime VR, и версию этого пакета, необходимую для отображения фильма. Пакет указан с использованием гештальт-типа Macintosh, такого как
'qtim'для QuickTime (QuickTime обеспечивает поддержку этих гештальт-тестов в вычислительной среде Windows).Вы можете указать минимальную требуемую версию, которая должна быть возвращена проверкой гештальта, или вы можете потребовать, чтобы определенное значение возвращалось после выполнения двоичной
Иоперация над битовым полем Гештальт и маской.Несколько атомов проверки версии разрешены в пределах данного эталонного атома дескриптора фильма. Приложения не должны пытаться воспроизвести фильм, если все проверки версии не пройдены успешно.
Атом проверки версии может содержать следующие поля:
- Размер
Количество байтов в этой версии проверочного атома.
- Тип
Тип этого атома; это поле должно быть установлено на
'рмвк'.- Флаги
32-битное целое число, которое в настоящее время всегда равно 0.
- Программный пакет
32-битный гештальт-тип, например
'qtim', указывающий программный пакет для проверки.- Версия
32-разрядное целое число без знака, содержащее либо минимальную требуемую версию, либо требуемое значение после двоичной операции
И.- Маска
Маска для бинарной операции
Инад битовым полем Gestalt.- Тип чека
Тип выполняемой проверки, выраженный 16-разрядным целым числом. Установите 0 для проверки минимальной версии, установите 1 для требуемого значения после двоичных
Ибитового поля Gestalt и маски.
Компонент Обнаружение атома
Атом обнаружения компонента указывает компонент QuickTime, например конкретный декомпрессор видео, необходимый для воспроизведения фильма. Можно указать тип компонента, подтип и другие обязательные атрибуты, а также минимальную версию.
В пределах данного эталонного атома дескриптора фильма разрешены атомы обнаружения нескольких компонентов. Приложения не должны пытаться воспроизвести фильм, если не присутствуют хотя бы минимальные версии всех необходимых компонентов.
Атом обнаружения компонента может содержать следующие поля:
- Размер
Количество байтов в этом компоненте обнаруживает атом.
- Тип
Тип этого атома; это поле должно быть установлено на
'rmcd'.- Флаги
32-битное целое число, которое в настоящее время всегда равно 0.
- Описание компонента
Запись описания компонента. Дополнительные сведения см. в разделе Запись описания компонента.
- Минимальная версия
32-разрядное целое число без знака, содержащее минимальную требуемую версию указанного компонента.
Запись описания компонента
Описывает класс компонентов по их атрибутам. Поля, для которых установлено значение 0, рассматриваются как «безразличные».
struct ComponentDescription {OSType componentType;
OSType componentSubType;
Компонент OSTypeПроизводитель;
unsigned long componentFlags;
unsigned long componentFlagsMask;
};
-
тип компонента Четырехзначный код, определяющий тип компонента.
-
компонентПодтип Четырехзначный код, определяющий подтип компонента. Например, подтип компонента сжатия изображения указывает алгоритм сжатия, используемый компрессором. Значение 0 соответствует любому подтипу.
-
компонент Производитель Четырехзначный код, идентифицирующий производителя компонента. Компоненты, предоставляемые Apple, имеют значение производителя
'appl'. Значение 0 соответствует любому производителю.-
компонентФлаги 32-битное поле, содержащее флаги, описывающие требуемые возможности компонента. Старшие 8 бит должны быть установлены на 0. Младшие 24 бита зависят от каждого типа компонента. Эти флаги можно использовать для обозначения наличия функций или возможностей в данном компоненте.
-
компонентFlagsMask 32-битное поле, указывающее, какие флаги в поле
componentFlagsотносятся к данной операции. Для каждого флага в поле componentFlags, который должен рассматриваться как критерий поиска, установите соответствующий бит в этом поле на 1. Чтобы игнорировать флаг, установите бит на 0.
Флаги компонентов импортера фильмов
-
canMovieImportInPlace Установите этот бит, если компонент импорта фильма должен иметь возможность создавать фильм из файла без необходимости записи в отдельный файл на диске. Примеры включают компоненты импорта MPEG и AIFF.
-
фильмИмпортПодтипИсфилеРасширение Установите этот бит, если подтип компонента является расширением файла, а не типом файла Macintosh. Например, если вам требуется компонент импорта, который открывает файлы с расширением
.doc, установите этот флаг и установите для подтипа компонента значение 9.2603 'ДОК .
-
canMovieImportFiles Установите этот бит, если компонент импорта фильмов должен импортировать файлы.
Качественный атом
Атом качества описывает относительное качество фильма. Это действует как тай-брейк, если более одного фильма соответствует указанным требованиям, и в противном случае не очевидно, какой фильм следует воспроизвести.
Это может быть в том случае, если два подходящих фильма имеют одинаковые требования к скорости передачи данных и скорости ЦП, например, или если для одного фильма требуется более высокая скорость передачи данных, а для другого — более высокая скорость ЦП, но оба они могут воспроизводиться в текущей системе. В этих случаях приложения должны воспроизводить фильм с максимальным качеством, указанным в атоме качества.
В данном эталонном атоме дескриптора фильма допускается только один атом качества.
Атом качества может содержать следующие поля:
- Размер
Количество байтов в этом атоме качества.
- Тип
Тип этого атома; в этом поле должно быть установлено значение
'rmqu'.- Качество
Относительное качество фильма, выраженное в виде 32-битного целого числа. Большее число указывает на более высокое качество. Каждому фильму должно быть присвоено уникальное значение.
СледующийПредыдущий
Copyright © Apple Inc., 2004, 2016. Все права защищены. Условия использования | Политика конфиденциальности | Обновлено: 2016-09-13
AP English Literature Multiple Choice: Complete Expert Guide
Вас пугает мысль о том, что вам придется тратить час на ответы на вопросы с несколькими вариантами ответов о сложных отрывках из прозы и поэзии? Задача множественного выбора AP Literature достаточна, чтобы вызвать крапивницу даже у самых опытных читателей, но не напрягайтесь! Это полностью обновленное руководство послужит вашей полной дорожной картой к успеху в разделе множественного выбора AP English Literature and Composition.
Во-первых, мы рассмотрим, как выглядит раздел множественного выбора — гайки и болты.
Затем я расскажу о восьми типах вопросов с несколькими вариантами ответов, с которыми вы можете столкнуться, и о том, как преуспеть в них. Далее следуют советы по обучению, практические ресурсы с несколькими вариантами ответов и, наконец, то, что нужно помнить для успешной сдачи экзамена!AP Литература с несколькими вариантами ответов Обзор
AP English Literature and Composition Первый раздел — это раздел с несколькими вариантами ответов. У вас будет 60 минут, чтобы ответить на 55 вопросов о четырех-пяти отрывках из литературной прозы и поэзии.
Дата составления отрывков AP Lit может варьироваться от 16-го до 21-го века, однако, как правило, вам не будут предоставлены автор, дата или название для каких-либо отрывков (поэзия является случайным исключением в отношении заглавие). Большинство отрывков взяты из произведений, первоначально написанных на английском языке, хотя иногда могут встречаться переведенные отрывки из известных литературных произведений на иностранном языке.
Раздел с несколькими вариантами ответов оценивается в 45% от общего балла за экзамен. Вы получаете балл за каждый правильный ответ на вопрос. Поскольку на этом экзамене нет штрафа за угадывание, вы должны отвечать на каждый вопрос с несколькими вариантами ответов, даже если вам приходится угадывать. Однако вы должны строить догадки только после того, как исключите все ответы, которые, как вы знаете, неверны. Это общий обзор. Но какие вопросы вы можете ожидать увидеть?
8 типов освещенных вопросов AP с множественным выбором
Существует восемь типов вопросов, с которыми вы можете столкнуться на экзамене AP Lit. В этом разделе я расскажу о каждом типе вопросов и о том, как на них ответить. Все вопросы взяты из примеров вопросов в «Описании курса и экзамена AP». Отрывки для этих вопросов также доступны там.
#1: Понимание прочитанного
Вопросы на понимание прочитанного проверяют, поняли ли вы смысл отрывка на буквальном, конкретном уровне.
Здесь вам не нужно напрягать мускулы интерпретации или анализа — просто сообщите, о чем говорится в отрывке.Вы легко узнаете эти вопросы, поскольку в них обычно используются такие слова и фразы, как «согласно», «утверждая» и «упоминается». Лучшая стратегия для этих вопросов — вернуться и перечитать часть текста , связанную с вопросом, чтобы быть абсолютно уверенным, что вы читаете его правильно. Возможно, вам придется немного прочитать до и/или после упомянутого момента, чтобы сориентироваться и найти наиболее правильный ответ.
Пример:
Объяснение:
Строки, на которые ссылается отрывок, говорят: «Избавьте нас всех от слов об оружии, его силе и дальности / Длинные числа, которые взрывают разум / Наши медлительные, безрассудные сердца останутся позади, / Неспособные бояться того, что слишком странный."
Этот вопрос спрашивает, почему люди не слушают пророка, когда он говорит об опасности оружия. Какой из ответов наиболее логичен?
Вариант (А) «люди интересуются оружием» может показаться заманчивым просто потому, что это общая тема и идея многих работ.
Но нигде в отрывке не сказано, что людей интересует оружие! Устраните это.Варианты (B) и (C) также можно исключить, потому что в этой части отрывка ничего не говорится о природе или любви, даже косвенно.
Вариант (D) также может быть заманчивым просто потому, что это еще одна распространенная тема в литературе — люди не прислушиваются к повторяющимся предупреждениям. Но опять же, в отрывке нет ничего, что подтверждало бы это.
Это оставляет (E), "люди не могут понять абстрактные решения власти". Это прекрасно согласуется с отрывком, в котором говорится, что «сердца» людей «неспособны бояться того, что слишком необычно». (Е) правильный ответ.
У людей в этом стихотворении каменные сердца.
#2: Вывод
Эти вопросы выводят вас на один шаг дальше простого понимания прочитанного и просят вас сделать вывод, основанный на доказательствах в отрывке — вас могут спросить о подразумеваемом мнении персонажа или рассказчика, авторе отношение и т.
д. Это будет то, о чем прямо не говорится в отрывке, но что вы можете предположить, основываясь на том, что на самом деле сказано в отрывке. В этих вопросах обычно используются такие слова, как «выводить» и «подразумевать».Есть два ключа к ответам на эти вопросы: во-первых, как всегда, вернитесь назад и прочитайте ту часть отрывка, к которой относится вопрос. Во-вторых, пусть вас не смущает тот факт, что вы делаете вывод — лучший ответ будет больше всего подкреплен тем, что на самом деле написано в отрывке . Вопросы на вывод подобны вопросам на понимание прочитанного второго уровня: вам нужно знать не только то, о чем говорится в отрывке, но и то, что он означает.
Пример:
Объяснение:
Первое предложение отрывка гласит: «Конечно, религиозные и моральные идеи Додсонов и Талливеров были слишком специфичны, чтобы их можно было вывести дедуктивно из утверждения, что они были частью протестного населения.
Великобритании».Какой выбор является наиболее разумным выводом о религиозных идеях Додсона и Талливера, основанным на первом предложении?
Выбор (A) говорит, что «рассказчик не может описать их с полной точностью». Это может быть правдой, но в первом предложении нет ничего, что подтверждало бы этот вывод — рассказчик говорит, что их идеи «слишком специфичны», а не то, что рассказчик не может их точно описать. Исключите выбор (A).
Вариант (B), «у них нет реальной логической основы» также может быть верным, но не может быть выведен из предложения, которое не указывает на то, логичны ли их убеждения или нет.
Вариант (С) может показаться заманчивым — мысль о том, что их не может оценить тот, кто их не разделяет, может показаться прекрасно согласующейся с тем фактом, что они «слишком специфичны» для основного протестантского населения. Но лучший ли это выбор, который больше всего поддерживается проходом? Давайте запомним это, но рассмотрим остальные ответы.
Выбор (D) утверждает, что убеждения Додсонов и Талливеров «происходят из фундаментального отсутствия терпимости». Это скачок, который не подтверждается тем, что на самом деле говорит первое предложение; устранить его.
Choice (E) говорит, что их верования «не типичны для британских протестантов в целом». В предложении говорится, что их верования «слишком специфичны», чтобы их можно было узнать просто потому, что Додсоны и Талливеры идентифицируют себя как британские протестанты, что подразумевает, что их верования на самом деле «не совпадают» с основными британскими протестантскими верованиями.
Вариант (E) является выводом, наиболее подкрепляемым отрывком, а затем — даже более подкрепляемым, чем вариант (C). Итак, (Е) является ответом. Помните, несколько ответов могут показаться правильными, , но только лучший ответ является правильным.
Как вы думаете, важны ли для Додсонов и Талливеров церкви, украшенные соответствующим образом?
#3: Интерпретация образного языка
В этих вопросах вам предлагается интерпретировать смысл образного языка в контексте отрывка.
Их можно идентифицировать, потому что они либо прямо упоминают образный язык или образное устройство, либо в самом вопросе будет образная языковая фраза.Еще раз повторю, что самое важное, что вы можете сделать, чтобы успешно ответить на эти вопросы, — это вернуться и перечитать! Для образного языка значение очень сильно зависит от контекста фразы в отрывке. Подумайте, что говорится вокруг образной фразы и к чему эта фраза относится.
Пример:
Объяснение:
В этом вопросе вам предлагается интерпретировать образное выражение «этот живой язык». Чтобы сориентировать вас в стихотворении, эти строфы советуют пророку «говорить о собственном изменении мира» (13).
В поэме говорится: «Чем бы мы были без / Дуги дельфина, возвращения голубя / этих вещей, в которых мы видели себя и говорили? Спроси нас, пророк, как мы будем вызывать / нашу природу, когда этот живой язык это все / Рассеяно, это стекло затемнено или разбито».
В контексте стихотворения, справа рассказчик спрашивает, что мы без «этого живого языка», стихотворение говорит о том, как мы «видим себя» в «дуге дельфина» и «возвращении голубя». Это изображения природы. Таким образом, лучшая интерпретация «того живого языка» — это ответ (А) как метафора природы. По сути, строфа означает: «Спроси нас, пророк, как мы познаем себя, когда природа будет уничтожена».
Дуга дельфина.
#4: Литературная техника
Эти вопросы позволяют узнать, почему автор использует те или иные слова, фразы или структуры. По сути, какой цели служит такой выбор в литературном смысле? Какой эффект создается? Эти вопросы часто включают такие слова, как «служит в основном для», «эффект», «вызывает» и «для того, чтобы».
Конечно, чтобы подойти к этим вопросам, перечитайте упомянутую часть отрывка. Но также спросите себя, почему автор использовал именно эти слова или именно эту структуру? Что совершается этим специфическим литературным «ходом»?
Пример:
Объяснение:
Эта строфа, содержащая повторение «спроси нас», гласит: «Спроси нас, спроси нас, с безмирной розой / Наши сердца подведут нас; приди, требуя / Будет ли возвышенное или давние / Когда закрываются бронзовые летописи дуба».
Итак, каков эффект от повторения «спросите нас, спросите нас»? Вариант (А) предполагает, что пророк является причиной многих страданий мира. Ни в строфе, ни даже во всем стихотворении нет ничего, что могло бы предложить это, поэтому мы можем исключить это.
Вариант (B) говорит, что это саркастический вызов. Эта строфа, однако, читается не как саркастическая, а как очень серьезная — устраните (Б).
Вариант (C) означает, что говорящий уверен в ответе, который даст пророк. На самом деле это не имеет смысла, потому что говорящий на самом деле не задает вопросы пророку, а говорит пророку, какие вопросы задавать. Устранить (С).
Выбор (D) говорит, что он превращает строку в идеальный пятистопный ямб. Вы можете исключить его, даже не беспокоясь о том, какие слоги выделены ударением, потому что в идеальной строке пятистопного ямба 10 слогов, а в этой строке 11. Остается (E) — эффект заключается в обеспечении «тона умоляющей серьезности». Учитывая, что говорящий, кажется, умоляет пророка задать конкретные вопросы, это подходит.
(Е) правильный ответ.Нужна помощь в подготовке к экзамену AP?
Наши индивидуальные услуги онлайн-репетиторов AP помогут вам подготовиться к экзаменам AP. Найди лучшего репетитора, получившего высокий балл на экзамене, к которому ты готовишься!
#5: Анализ персонажа
В вопросах анализа характера вам будет предложено узнать что-то о персонаже — его мнения, взгляды, убеждения, отношения с другими персонажами и т. д.
Во многих отношениях это особый тип вопросов на вывод, потому что вы делаете вывод о более широких чертах персонажа на основе свидетельств, представленных в отрывке. Как и следовало ожидать, вопросы о персонажах задают гораздо чаще по прозаическим отрывкам, чем по стихам.
Здесь важно обращать внимание на все, что прямо сказано о персонаже(ах) в соответствующих частях прохождения. Как и в вопросе на вывод, будет ответом, который лучше всего соответствует доказательствам в отрывке.
Пример:
Объяснение:
Эти строки гласят: «Их религия была простой, полуязыческой, но в ней не было ереси — если под ересью собственно подразумевается выбор — ибо они не знали существовала любая другая религия, кроме религии прихожан, которая, казалось, передавалась по наследству, как астма».
Вариант (A) подразумевает, что эта часть отрывка привлекает внимание к преданности сестер Додсон определенным ритуалам. Здесь не упоминаются никакие ритуалы; (А) можно исключить.
Выбор (B) говорит, что эти линии указывают на их «безмятежное самодовольство». В отрывке говорится, что они не знали никакой другой религии. Если они не знают, мы можем обоснованно заключить, что их не беспокоит их собственная религия. Держите (B) в бегах.
Вариант (C) означает, что они имеют «глубокие религиозные убеждения». Это похоже на скачок; все, что на самом деле говорится в отрывке, это то, что их религии «полуязыческие», но не еретические, потому что они просто не знают никакой другой религии, кроме «поклонников часовни», которая, кажется, связана с семейным происхождением.
Мы не можем разумно заключить, что у них есть сильные религиозные убеждения из этого. Устранить (С).Вариант (D) заявляет, что у них "потревоженная совесть". Опять же, ничто в отрывке не делает этого разумного вывода; если они не знают, что могут быть и другие религиозные традиции, зачем им мешать своим собственным?
Выбор (E) говорит, что у них есть «чувство истории и традиций». Это может быть заманчивым выбором, потому что они указывают на тот факт, что религия «посетителей часовни… казалось, передавалась по наследству». Но это не их религия, так что это не очень хорошо подкрепленный вывод.
Таким образом, вариант (B) дает наиболее разумный вывод о сестрах Додсон и является правильным ответом.
Довольно характер.
#6: Общие вопросы по отрывку
Эти вопросы потребуют от вас взглянуть на отрывок «с высоты птичьего полета» и определить или описать характеристику отрывка в целом: его цель, тон, жанр, и так далее.
Это может быть сложно, потому что вы не можете просто вернуться к определенному месту в отрывке, чтобы найти лучший ответ; нужно рассматривать прохождение в целом.Рассмотрим общую картину, созданную мелкими деталями. Я настоятельно рекомендую размечать тексты для основных тем, цели, тона и т. д. при первом чтении, чтобы вы могли свериться с обозначениями на полях для подобных вопросов.
Пример:
Объяснение:
Даже при беглом просмотре этого отрывка становится ясно, что рассказчик подробно рассказывает о Додсонах, поэтому мы можем предположить, что рассказчика больше всего интересует что-то о Додсоны. Тогда мы можем исключить (B) и (C), так как они ничего не говорят о Додсонах.
Так что о Додсонах больше всего волнует рассказчика? В первом предложении упоминаются их «религиозные и нравственные идеи», а затем описывается их «полуязыческая», но не еретическая религия. Затем мы видим, что «религия Додсонов состояла в почитании всего, что было обычным и респектабельным» (22–23), за которым следует длинный список того, что это такое.
Остальная часть отрывка аналогичным образом описывает то, что Додсоны считают важным, от «быть богаче, чем предполагалось» до поступать правильно «по отношению к родственникам». Таким образом, ясно, что рассказчик больше всего озабочен описанием значений Додсонов, что соответствует выбору (А).
#7: Структура
Эти вопросы касаются конкретных структурных элементов прохода. Часто вас будут спрашивать об изменениях тона, отступлениях или конкретной форме стихотворения. Иногда эти вопросы будут указывать на определенную часть отрывка/стихотворения и просят вас определить, что эта часть отрывка выполняет в пределах в большом отрывке.
Это еще один тип вопросов, в котором будет очень полезно отметить отрывок при первом прочтении — обязательно отмечайте любые изменения в структуре, тоне, жанре и т. д. во время чтения, а также любые структурные элементы, которые кажутся необычными или значительными.
Пример:
Объяснение:
Строки 1-34 описывают образ рассказчика, играющего на лютне ради своей любви.
В строках 34-43 установлено, что рассказчик собирается ввести праздную мысль (да, это болтливое стихотворение). Строки 44-48 гласят: «А что, если вся одушевленная природа / Будь всего лишь органическими арфами, разнообразно обрамленными, / Которые трепещут в мысли, когда над ними проносится / Пластичный и обширный, один интеллектуальный ветерок, / Сразу Душа каждого и Бог всех?»Так что здесь говорит рассказчик? Он задается вопросом, не является ли «вся одушевленная природа» (то есть все живые существа) просто арфами, а мысль — струнами, на которых играют. Это явно метафора, и третья сноска к отрывку говорит нам, что «лютня» является синонимом «арфы». Итак, ответ (D) — эта часть отрывка функционирует как «метафорическое применение образа лютни».
Это арфа! Нет, это лютня! Нет, и то, и другое!
#8: Грамматика/Гайки и болты
Очень редко вам будут задавать вопрос о грамматике части отрывка — например, определить, какое слово изменяет прилагательное.
Очень специфические вопросы о метре стихотворения (например, пятистопном ямбе) также попадают в эту категорию. Эти вопросы касаются не столько литературного мастерства, сколько сухой техники, необходимой для беглого владения английским языком.Пример:
Пояснение:
Соответствующая часть стихотворения гласит: «В полдень я протягиваю члены вон там, на холме, / Сквозь полузакрытые веки я смотрю / Солнечные лучи танцуют, как алмаз, на главной , / И спокойная муза на спокойствии».
Какая прелесть! Если мы сможем распутать это предложение, выяснить, что изменяет слово «спокойствие», будет довольно легко. Во-первых, мы можем исключить все ответы, в которых слово «спокойный» называется наречием, потому что форма наречия «спокойный» — «спокойно». Устраните (B) и (E).
В предложении мы видим, что говорящий ("Я") наблюдает за танцующими солнечными лучами. Затем у нас есть «и», за которым следует еще один глагол в «музе». Откуда мы знаем, что «муза» здесь является глаголом? Потому что в противном случае в предложении «и спокойная муза на спокойствии» нет глагола и нет смысла.
Поскольку «муза» — это глагол, его нельзя изменить с помощью прилагательного, поэтому исключите вариант выбора (D). Остаются (А) и (С). Есть ли смысл «солнечным лучам» размышлять о спокойствии? Не особенно; для говорящего (I) гораздо больше смысла размышлять о спокойствии. Вариант (А) является правильным ответом.Так танцуют эти солнечные лучи?
Как подготовиться к AP Literature Multiple Choice
У меня есть несколько советов о том, как лучше всего подготовиться к успеху в разделе множественного выбора AP Lit.
Прочтите разнообразные литературные произведения и стихи
Поскольку отрывки в разделе множественного выбора AP Literature относятся к разным эпохам, жанрам, авторам и стилям, важно ознакомиться с широким спектром Английские литературные стили , чтобы вы чувствовали себя комфортно с отрывками и могли анализировать то, что они говорят, не перегружаясь.
Читать много всего: прозу, конечно, но особенно поэзию, так как многие студенты уже менее знакомы с поэзией, а поэзия может быть довольно непрозрачной и трудной для анализа.
В качестве отправной точки для того, что вы могли бы прочитать, ознакомьтесь с нашим руководством по списку чтения AP Lit.Когда вы начнете чувствовать себя комфортно на языке многих эпох и стилей, самое время поработать над оттачиванием навыков внимательного чтения.
Оттачивайте свои навыки внимательного чтения
Ваша способность внимательно читать — читать отрывки не только для понимания, но и с учетом того, как автор использует литературную технику, — имеет первостепенное значение в разделе с несколькими вариантами ответов. Вы будете практиковаться в внимательном чтении прозы и стихов на уроках, но дополнительная практика может вам только помочь.
Когда вы читаете все свое чтение из разных эпох и жанров, подумайте о том, что делает автор и почему он или она это делает. Какие методы используются? Какие мотивы и темы существуют? Как изображены персонажи?
Если вы не знаете, как это сделать, вот некоторые ресурсов для чтения прозы:
- Вы можете получить руководства по внимательному чтению в Интернете в центре письма Университета Висконсин-Мэдисон и в Гарвардском колледже. Центр письма.
- В Purdue OWL также есть статья о том, как избегать «подводных камней» при близком чтении.
Вот некоторые ресурсов для чтения поэзии:
- Вот руководство по чтению поэзии от Университета Висконсин-Мэдисон.
- Вам обязательно следует ознакомиться с этим действительно превосходным руководством по чтению стихов от Poets.org, которое включает в себя два поэтических чтения.
Изучите литературные и поэтические приемы
Вы должны быть знакомы с литературными терминами , чтобы любые вопросы о них имели для вас смысл. Опять же, вы, вероятно, изучите большинство из них в классе, но освежить их в памяти не помешает. Ознакомьтесь с нашим руководством по 31 литературному приему, которые вам нужно знать, с определениями и примерами.
Заполните практические вопросы и попрактикуйтесь в разделах с несколькими вариантами ответов
Чтобы преуспеть в разделе с несколькими вариантами ответов, попрактикуйтесь в ответах на вопросы с несколькими вариантами ответов! Это может показаться легкой задачей, но, тем не менее, это очень важно.
Каждую неделю выделяйте время на ответы на большое количество практических вопросов. Следите за тем, какие вопросы даются вам легко — вы каждый раз определяете тему? — и какие сложные — запутанные сравнениями? Это поможет вам выяснить, есть ли какие-либо навыки или концепции, которые вам нужно освежить.
Вы также должны пройти полный практический раздел с несколькими вариантами ответов по крайней мере один раз, дважды, если сможете. Вы можете сделать это как часть полного практического теста (который я рекомендую) или сделать это отдельно. Но прохождение раздела с несколькими вариантами ответов в условиях, подобных AP, поможет вам чувствовать себя подготовленным, спокойным и собранным в день теста.
Как красавица эпохи Регентства, поймавшая офицера!
AP Литература Ресурсы для практики множественного выбора
Существует множество доступных практических ресурсов, которые вы можете использовать, чтобы отточить свои навыки множественного выбора для экзамена AP по английской литературе и сочинению.
Золотым стандартом лучших практических вопросов с несколькими вариантами ответов является College Board. Это потому, что они пишут экзамен AP, поэтому их практические вопросы больше всего похожи на настоящие вопросы AP с несколькими вариантами ответов, которые вы увидите в день экзамена. Они предлагают как полные выпущенные экзамены, так и примеры вопросов.Даже когда у вас закончатся официальные практические вопросы College Board, вы все равно можете использовать неофициальные ресурсы, чтобы отточить свои навыки множественного выбора. В этом разделе я рассмотрю оба.
Официальные ресурсы
См. ниже три потенциальных источника официальных вопросов Совета колледжей.
Выпущены экзамены College Board
Выпущены три официальных экзамена College Board. Каждый из них имеет полный раздел с множественным выбором из 55 вопросов. Вот ссылки!
- 1987 AP Экзамен по английской литературе и сочинению
- 1999 г. Экзамен AP по английской литературе и сочинению
- 2012 AP Экзамен по английской литературе и сочинению
Примеры вопросов из описания курса и экзамена
Описание курса английской литературы и экзамена AP содержит 19 практических вопросов с несколькими вариантами ответов!
Ваш учитель
У вашего учителя AP также могут быть копии старых экзаменов AP, которые вы можете использовать на практике. Спроси и увидишь!
На мой взгляд, все учителя английского языка выглядят так, будто они родом из 19 века.
Неофициальные ресурсы
В дополнение к практическим вопросам с несколькими вариантами ответов, предоставленным Советом колледжей, в Интернете также есть несколько мест, где вы можете получить неофициальные практические вопросы с несколькими вариантами ответов. Однако не все они стоят вашего времени с точки зрения качества. Я пройдусь по лучшим здесь.
Чтобы получить еще более надежный список, ознакомьтесь с нашим полным списком.Albert AP Викторины по английской литературе
Albert предлагает викторины с несколькими вариантами ответов, разделенные на категории прозы, поэзии и драмы. Вам дается название, дата и автор работы, которых вы не получите на настоящем экзамене AP. Как викторины Varsity Tutors, Альберт предлагает вопросы, которые проверяют те же навыки, что и на экзамене AP, но вопросы сформулированы по-другому . Кроме того, вам нужно будет заплатить за учетную запись, чтобы получить доступ к большинству материалов.
Еще один надежный способ попрактиковаться в ответах на вопросы с несколькими вариантами ответов — это хорошая книга отзывов. Вы хотите убедиться, что это высокое качество — я рекомендую Barron's, в частности, для экзамена AP по литературе, поскольку их вопросы действительно напоминают настоящие вопросы AP по сложности и стилю написания.
Однако атмосферной картины обстановки вы не получите.
Советы в день тестирования для AP Lit Multi-Choice Success
Не полагайтесь на свою память отрывка, отвечая на вопросы. Всегда оглядывайтесь на проход, , даже если вам кажется, что ответ очевиден!
Взаимодействуйте с отрывками — обводите, отмечайте, подчеркивайте, делайте заметки, делайте все, что угодно. Это поможет вам сохранить информацию и активно участвовать в прохождении. Особенно отметьте области, где, как кажется, есть какие-то переходы или изменения, так как велика вероятность, что вам будут задавать вопросы об этих переходах!
Вам также может быть полезно сделать несколько быстрых заметок по общей теме или мотиву отрывка/стихотворения, как только вы дойдете до конца. Это поможет вам в вопросах прохождения в целом.
Если у вас возникли проблемы с пониманием отрывка, пропустите его и перейдите к следующему.
Скорее всего, когда вы вернетесь к этому позже, вы обнаружите, что это намного легче понять. А если нет, то, по крайней мере, вы не тратили слишком много времени на то, чтобы разобраться в этом, прежде чем ответить на вопросы о других, более простых отрывках.
Acing the AP Lit Multiple Choice: Key Takeaways
Первый раздел экзамена AP English Literature and Composition Exam представляет собой часовой тест из 55 вопросов с несколькими вариантами ответов на четыре-пять литературных и прозаических отрывков. Этот раздел оценивается в 45% от общего балла за экзамен.
Существует восемь типов вопросов, которые вы можете увидеть в разделе с несколькими вариантами ответов:
#1: Понимание прочитанного
#2: Вывод
#3: Определение и интерпретация образного языка
#4: Литературная техника
#5 : Анализ персонажей
№ 6: Общие вопросы прохождения
№ 7: Структура
№ 8: Грамматика/основыВот как лучше всего подготовиться к разделам с несколькими вариантами ответов:
№1 : Прочитайте различные литературные произведения и стихи всех эпох и жанров, охватываемых тестом!
#2 : Оттачивайте свои навыки внимательного чтения, чтобы понимать, что делают писатели и почему они это делают.
#3 : Изучите литературные приемы и термины, а также способы их определения и применения!
#4 : Подготовьтесь к экзамену, выполнив практические разделы и практические вопросы.
Существует множество официальных и неофициальных ресурсов для практики. Лучшие из них являются официальными советами колледжей, но как только они закончатся, вам также будут доступны высококачественные неофициальные ресурсы.
Вот несколько советов для тестового дня, которые помогут вам добиться хоумрана по английскому языку:
#1 : Всегда оглядывайтесь на отрывок, когда отвечаете на вопросы — не полагайтесь на память!
#2 : взаимодействуйте с отрывками по мере их чтения, в том числе отмечайте важные моменты и структурные или тональные сдвиги в тексте.
#3 : Вы также можете написать пару кратких заметок об общей теме (темах) и мотивах отрывка в конце, чтобы ссылаться на них при ответах на общие вопросы отрывка.
#4 : Если язык отрывка трудно разобрать, пропустите его и вернитесь позже. Скорее всего, во второй раз это будет иметь гораздо больше смысла, а если нет, по крайней мере, вы не тратите время впустую, которое могли бы потратить на ответы на более простые вопросы.
И тогда вы жили долго и счастливо.
Что дальше?
Нужны дополнительные ресурсы для AP English Literature? См. наше полное руководство по экзамену AP по литературе, наш полный список практических тестов AP по английской литературе и наш список для чтения AP по английской литературе.
Также принимаете AP Language and Composition? У нас есть экспертное руководство по AP Lang and Comp, полный список практических тестов AP Language и Composition, а также список из 55 терминов AP English Language, которые вы должны знать.
Если вы сдаете другие экзамены AP, ознакомьтесь с нашим пятиступенчатым планом обучения AP, узнайте, когда начинать подготовку к экзаменам AP и как найти лучшие практические тесты AP.