Морфологический разбор слова «бесполезный»
Часть речи: Прилагательное
БЕСПОЛЕЗНЫЙ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «БЕСПОЛЕЗНЫЙ»
| Слово | Морфологические признаки |
|---|---|
| БЕСПОЛЕЗНЫЙ |
|
| БЕСПОЛЕЗНЫЙ |
|
Все формы слова БЕСПОЛЕЗНЫЙ
БЕСПОЛЕЗНЫЙ, БЕСПОЛЕЗНОГО, БЕСПОЛЕЗНОМУ, БЕСПОЛЕЗНЫМ, БЕСПОЛЕЗНОМ, БЕСПОЛЕЗНАЯ, БЕСПОЛЕЗНОЙ, БЕСПОЛЕЗНУЮ, БЕСПОЛЕЗНОЮ, БЕСПОЛЕЗНОЕ, БЕСПОЛЕЗНЫЕ, БЕСПОЛЕЗНЫХ, БЕСПОЛЕЗНЫМИ, БЕСПОЛЕЗЕН, БЕСПОЛЕЗНА, БЕСПОЛЕЗНО, БЕСПОЛЕЗНЫ, БЕСПОЛЕЗНЕЕ, БЕСПОЛЕЗНЕЙ, ПОБЕСПОЛЕЗНЕЕ, ПОБЕСПОЛЕЗНЕЙ
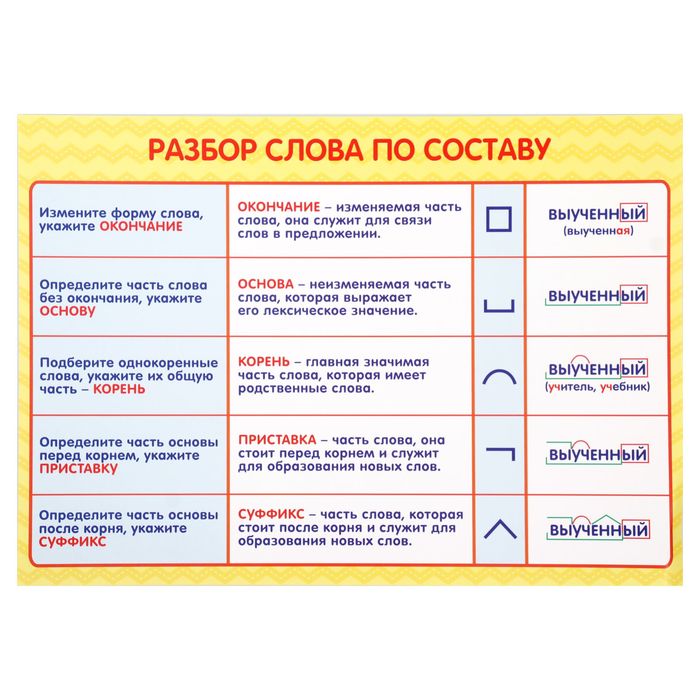
Разбор слова по составу бесполезный
бесполезн
ый
| Основа слова | бесполезн |
|---|---|
| Приставка | бес |
| Корень | полез |
| Суффикс | н |
| Окончание | ый |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «БЕСПОЛЕЗНЫЙ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «бесполезный»
Примеры предложений со словом «бесполезный»
1
Гомес направился к окну, прильнул лбом к раскаленному стеклу, посмотрел на улицу, на это бесполезное солнце, на этот бесполезный день.
Смерть в душе, Жан-Поль Сартр, 1949г.
2
Но Тельман привык бороться с этим бесполезным чувством: что может тут дать бесполезный гнев?
Поджигатели. «Но пасаран!», Ник. Шпанов, 1949г.
3
Когда же приходил бесполезный
врач – до еще более бесполезной тети Муси или позже.
Похороны кузнечика, Николай Кононов, 1999г.
4
Бесполезный человек в бесполезном и злом мире, – подумалось ему.
Кадиш по Розочке, Леонид Бляхер
5
Полковник, вы – бесполезны, – мир брюнета рухнул за одну секунду, а его самого придавило бетонной плитой с надписью «Бесполезный».
Алхимия vs Магия, Amor Corte
Найти еще примеры предложений со словом БЕСПОЛЕЗНЫЙ
Как правильно пишется слово «сдесь» или «здесь»?
Содержание
- 1 Введение
- 2 История происхождения слова «здесь»
- 3 Правило написания «з» в словах
- 4 Как правильно пишется «здесь»
- 5 Разбор слова «здесь» по составу
- 6 Примеры предложений
- 7 Заключение
- 8 Полезное видео
Введение
В русском языке слова далеко не всегда пишутся так, как слышатся. Можно выделить ряд случаев, в которых по этой причине чаще всего допускаются ошибки. Одним из них является слово «здесь».
Можно выделить ряд случаев, в которых по этой причине чаще всего допускаются ошибки. Одним из них является слово «здесь».
Не зная правил или же путая их, люди часто пишут через букву «с» — «сдесь», что совсем не верно. Как же правильно писать слово «здесь»?
История происхождения слова «здесь»
Первоначальное «сьдесе» можно встретить в летописях с 14-го века. С течением времени оно приобрело свой современный вид.
Правило написания «з» в словах
Приставки, которые заканчиваются на буквы «з» и «с», пишутся также, как и слышатся: перед звонкими согласными через «з», перед глухими согласными через «с». Например, «з» пишется в случаях беЗдомный, раЗжечь. «С» — в раСсчитать, беСсовестный.
Важно! Запомни правило: здесь, здание, здоровье пишутся с буквой «з» и не имеют приставки.
Как правильно пишется «здесь»
При этом, в памяти закрепилось правило, в котором говорится, что приставки «з» не существует, и из этого якобы следует написание через букву «с».
Есть и другое правило русского языка, которое хоть и приводит к верному написанию, но не подходит этому случаю.
Справка! Перед глухими согласными в конце приставки буква «с», а перед звонкими — «з».
Рассмотрим на примерах:
- беЗоблачный, беЗжалостный, раЗдавить, иЗделие; беСполезный,
- раСпаковать, иСцарапиться, воСпламениться.
Таким образом, делается вывод, что в наречии «здесь» перед согласной «Д» должна стоять звонкая «З». Ошибка состоит в том, что первую букву считают приставкой, в то время, как в слове «здесь» приставки вовсе нет. В нём, более того, нет ни суффиксов, ни окончаний — есть только один корень.
Разбор слова «здесь» по составу
Итак, уже было обозначено, что приставки нет. Чтобы проверить это, следует разобрать выражение «здесь» по частям. Точнее попытаться сделать это, как в случаях с заехал, вошёл, сделал, принёс.
Отделив приставки получим соответственно слова ехал, шёл, делал, нёс. Они существуют и имеют своё значение. Если отделить от слова «здесь» предполагаемую приставку «з», то останется «десь».
Они существуют и имеют своё значение. Если отделить от слова «здесь» предполагаемую приставку «з», то останется «десь».
В русском языке такого выражения нет и эта часть не имеет никакого смысла. Соответственно, «з» — не приставка, а слово «здесь» состоит только из корня.
Примеры предложений
«Здесь» используется в значении «в этом месте» или «при этих обстоятельствах», к примеру:
- Здесь это всё по-другому: звёздное небо ярче, воздух чище, трава зеленее.
- Ситуация усложняется, причем здесь не обойтись без помощи верных друзей.
- Новый дом отличается тем, что здесь находится комфортно и безопасно.
Заключение
Для того, чтобы писать грамотно, необходимо не только знать правила грамматики русского языка, но и уметь правильно использовать их, зная в каком случае какое правило подходит. Таким образом, понимая, что слово «здесь» состоит из корня и не имеет приставок, проще и быстрее получится сделать вывод о правописание слова через «з».
Полезное видео
(PDF) Настройка веса функций для рекурсивных нейронных сетей. (2014) | Jiwei Li
Размещенный контент•
Jiwei Li
11 декабря 2014-arXiv: Neural and Evolutionary Computing-
TL;DR: В этом документе рассматривается, как модель рекурсивной нейронной сети может автоматически отбрасывать бесполезную информацию и выделять важные доказательства, другими словами, выполнить «настройку веса» для получения представления более высокого уровня.
…читать дальшечитать меньше
Аннотация: В этой статье рассматривается, как модель рекурсивной нейронной сети может автоматически отбрасывать бесполезную информацию и выделять важные доказательства, другими словами, выполнять «настройку веса» для получения представления более высокого уровня. Мы предлагаем две модели: взвешенную нейронную сеть (WNN) и нейронную сеть с бинарным ожиданием (BENN), которые автоматически контролируют вклад одной конкретной единицы в представление более высокого уровня. Предлагаемую модель можно рассматривать как включающую более мощную композиционную функцию для встраивания сбора данных в рекурсивные нейронные сети. Экспериментальные результаты демонстрируют значительное улучшение по сравнению со стандартными нейронными моделями.
Мы предлагаем две модели: взвешенную нейронную сеть (WNN) и нейронную сеть с бинарным ожиданием (BENN), которые автоматически контролируют вклад одной конкретной единицы в представление более высокого уровня. Предлагаемую модель можно рассматривать как включающую более мощную композиционную функцию для встраивания сбора данных в рекурсивные нейронные сети. Экспериментальные результаты демонстрируют значительное улучшение по сравнению со стандартными нейронными моделями.
…читать дальшеЧитать меньше
Темы: Нейронная сеть с временной задержкой (67%), Рекуррентная нейронная сеть (64%), Нейронная сеть прямого распространения (64%), Сетевые модели нервной системы (60%), Искусственная нейронная сеть ( 58%) …читать дальше
Цитаты
Открытый доступ
Дополнительные фильтры
Труды Статья•DOI•
0 Document Modeling with Gated Recurent Network Classification3 9 Sentiment ]
Duyu Tang 1 , Bing Qin 1 , Ting Liu 1 • Институты (1)
Институт технологии Харбин 1
01 Sep 2015
TL; DR: A Neural Network — это сеть Neular. для изучения векторного представления документов унифицированным восходящим образом и значительно превосходит стандартную рекуррентную нейронную сеть в моделировании документов для классификации настроений.
для изучения векторного представления документов унифицированным восходящим образом и значительно превосходит стандартную рекуррентную нейронную сеть в моделировании документов для классификации настроений.
…читать дальшечитать меньше
Аннотация: Классификация настроений на уровне документа остается проблемой: кодирование внутренних отношений между предложениями в семантическом значении документа. Чтобы решить эту проблему, мы вводим модель нейронной сети для обучения векторному представлению документов унифицированным восходящим образом. Сначала модель изучает представление предложений с помощью сверточной нейронной сети или долговременной кратковременной памяти. После этого семантика предложений и их отношения адаптивно кодируются в представлении документа с помощью закрытой рекуррентной нейронной сети. Мы проводим классификацию настроений на уровне документов по четырем крупномасштабным наборам данных обзоров из IMDB и Yelp Dataset Challenge. Экспериментальные результаты показывают, что: (1) наша нейронная модель демонстрирует превосходные характеристики по сравнению с несколькими современными алгоритмами; (2) закрытая рекуррентная нейронная сеть значительно превосходит стандартную рекуррентную нейронную сеть в моделировании документов для классификации настроений. 1
Экспериментальные результаты показывают, что: (1) наша нейронная модель демонстрирует превосходные характеристики по сравнению с несколькими современными алгоритмами; (2) закрытая рекуррентная нейронная сеть значительно превосходит стандартную рекуррентную нейронную сеть в моделировании документов для классификации настроений. 1
…читать дальшеЧитать меньше
1,160 цитирований
Методы цитирования из статьи «Настройка весовых коэффициентов для рекурсивных…» …]
Мохит Ийер 1 , Варун Манджунатха 1 , Джордан Бойд-Грабер 1 , Хал Дауме 2 • Учреждения (2)
Университет Мэриленда 1
Колледж Парк 1 9 903 Колледж Парк 1 9 903 Университет Мэриленда0037 , Университет Колорадо в Боулдере 2
01 июля 2015 г.
TL;DR: В этой работе представлена простая глубокая нейронная сеть, которая конкурирует с такими моделями, а в некоторых случаях даже превосходит их по результатам анализа настроений и ответов на вопросы, основанные на фактах. лишь часть времени обучения.
лишь часть времени обучения.
…читать дальшечитать меньше
Аннотация: Многие существующие модели глубокого обучения для задач обработки естественного языка сосредоточены на изучении композиционности их входных данных, что требует большого количества дорогостоящих вычислений. Мы представляем простую глубокую нейронную сеть, которая конкурирует с такими моделями, а в некоторых случаях даже превосходит их в анализе настроений и задачах с ответами на фактические вопросы, занимая лишь часть времени обучения. Хотя наша модель синтаксически невежественна, мы демонстрируем значительные улучшения по сравнению с предыдущими моделями мешка слов, углубляя нашу сеть и применяя новый вариант отсева. Более того, наша модель работает лучше, чем синтаксические модели, на наборах данных с высокой синтаксической дисперсией. Мы показываем, что наша модель делает те же ошибки, что и модели с учетом синтаксиса, указывая на то, что для рассматриваемых нами задач нелинейное преобразование входных данных важнее, чем адаптация сети для учета порядка слов и синтаксиса.
…читать дальшеЧитать меньше
705 цитирований
Цитаты из статьи «Настройка весовых коэффициентов для рекурсивных…»
[…]
Дую Тан 1 , Бин Цинь 1 , Тинг Лю 1 •Учреждения (1)
Харбинский технологический институт 1 5
Июль 20003TL;DR: за счет объединения данных на уровне пользователя, продукта и документа в единой нейронной структуре предлагаемая модель обеспечивает самые современные характеристики в наборах данных IMDB и Yelp1.
…читать дальшечитать меньше
Аннотация: Методы нейронных сетей дали многообещающие результаты для классификации текста по тональности. Однако эти модели используют только семантику текстов, игнорируя при этом пользователей, которые выражают настроение, и продукты, которые оцениваются, оба из которых имеют большое влияние на интерпретацию настроения текста. В этой статье мы решаем эту проблему путем включения информации об уровне пользователя и продукта в нейросетевой подход для классификации тональности на уровне документа. Пользователи и продукты моделируются с использованием моделей векторного пространства, представления которых отражают важные глобальные подсказки, такие как индивидуальные предпочтения пользователей или общие качества продуктов. Такие глобальные доказательства, в свою очередь, облегчают встраивание процедуры обучения на уровень документа, обеспечивая лучшее текстовое представление. Объединяя данные на уровне пользователя, продукта и документа в единой нейронной структуре, предлагаемая модель обеспечивает самые современные характеристики в наборах данных IMDB и Yelp1.
В этой статье мы решаем эту проблему путем включения информации об уровне пользователя и продукта в нейросетевой подход для классификации тональности на уровне документа. Пользователи и продукты моделируются с использованием моделей векторного пространства, представления которых отражают важные глобальные подсказки, такие как индивидуальные предпочтения пользователей или общие качества продуктов. Такие глобальные доказательства, в свою очередь, облегчают встраивание процедуры обучения на уровень документа, обеспечивая лучшее текстовое представление. Объединяя данные на уровне пользователя, продукта и документа в единой нейронной структуре, предлагаемая модель обеспечивает самые современные характеристики в наборах данных IMDB и Yelp1.
…читать дальшечитать меньше
296 цитирований
Методы цитирования из «Настройка веса признаков для рекурсивного…»
Материалы статьи•
Упоминание, контекст и сущность моделирования с помощью нейронных сетей для устранения неоднозначности сущности
43 [.
 ..]
..]Yaming Sun 1 , Lei Lin 1 , Duyu Tang 1 , Nan Yang 2 , Zhenzhou Ji 1 , Xiaolong Wang 2 (2)
Харбинский технологический институт 1 , Microsoft 2
25 июля 2015 г.
TL;DR: представлен новый подход нейронной сети, который учитывает семантические представления упоминания, контекста и объекта, кодирует их в непрерывном векторное пространство и эффективно использует их для устранения неоднозначности сущностей.
…читать дальшеЧитать меньше
Аннотация: Для запроса, состоящего из упоминания (строки имени) и справочного документа, устранение неоднозначности сущности требует связывания упоминания с сущностью из справочной базы знаний, такой как Википедия. В существующих исследованиях обычно используются созданные вручную функции для представления упоминания, контекста и сущности, что является трудоемким и слабым для обнаружения объяснительных факторов данных. В этой статье мы решаем эту проблему, представляя новый подход нейронной сети. Модель учитывает семантические представления упоминания, контекста и сущности, кодирует их в непрерывном векторном пространстве и эффективно использует для устранения неоднозначности сущности. В частности, мы моделируем контексты переменного размера с помощью сверточной нейронной сети и встраиваем позиции контекстных слов, чтобы учесть расстояние между контекстным словом и упоминанием. Кроме того, мы используем нейронную тензорную сеть для моделирования семантических взаимодействий между контекстом и упоминанием. Мы проводим эксперименты по устранению неоднозначности сущностей на двух эталонных наборах данных из TAC-KBP 2009.и 2010. Экспериментальные результаты показывают, что наш метод обеспечивает самые современные характеристики для обоих наборов данных.
В этой статье мы решаем эту проблему, представляя новый подход нейронной сети. Модель учитывает семантические представления упоминания, контекста и сущности, кодирует их в непрерывном векторном пространстве и эффективно использует для устранения неоднозначности сущности. В частности, мы моделируем контексты переменного размера с помощью сверточной нейронной сети и встраиваем позиции контекстных слов, чтобы учесть расстояние между контекстным словом и упоминанием. Кроме того, мы используем нейронную тензорную сеть для моделирования семантических взаимодействий между контекстом и упоминанием. Мы проводим эксперименты по устранению неоднозначности сущностей на двух эталонных наборах данных из TAC-KBP 2009.и 2010. Экспериментальные результаты показывают, что наш метод обеспечивает самые современные характеристики для обоих наборов данных.
…читать дальшеЧитать меньше
174 цитирования
Цитаты из статьи «Настройка весовых коэффициентов для рекурсивных.
 ..» al., 2013a], разбор дискурса [Li et al., 2014], классификация отношений [Zeng et al., 2014], анализ настроений [Socher et al., 2013c; Танг и др., 2014; Li, 2014], определение частей речи и распознавание именованных объектов [Collobert et al., 2011]….
..» al., 2013a], разбор дискурса [Li et al., 2014], классификация отношений [Zeng et al., 2014], анализ настроений [Socher et al., 2013c; Танг и др., 2014; Li, 2014], определение частей речи и распознавание именованных объектов [Collobert et al., 2011]….[…]
Материалы статьи •
Моделирование пользователей с помощью нейронной сети для предсказания рейтинга отзывов
[…]
Duyu Tang 1 , Bing Li 6 Qin
6 1 1 , Yuekui Yang 2 • Институты (2)Харбинский технологический институт 1 , Tencent 2
25 июля 2015
TL; введена модель (UWCVM), которая эффективно фиксирует действия пользователя как функцию, влияющую на представление непрерывного слова.
…читать дальшечитать меньше
Аннотация: В этой статье мы представляем метод нейронной сети для прогнозирования рейтинга отзывов. Существующие нейросетевые методы прогнозирования тональности обычно фиксируют только семантику текстов, но игнорируют пользователя, который выражает тональность. Это нежелательно для прогнозирования рейтинга обзора, поскольку каждый пользователь влияет на то, как интерпретировать текстовое содержание обзора. Например, одно и то же слово (например, «хороший») может указывать на разную силу тональности, когда оно написано разными пользователями. Мы решаем эту проблему, разрабатывая новую нейронную сеть, которая учитывает информацию о пользователях. Интуиция заключается в том, чтобы учитывать пользовательскую модификацию значения определенного слова. В частности, мы расширяем модели лексико-семантической композиции и вводим векторную модель композиции пользовательских слов (UWCVM), которая эффективно фиксирует действия пользователя как функцию, влияющую на представление непрерывного слова. Мы интегрируем UWCVM в контролируемую среду обучения для прогнозирования рейтинга отзывов и проводим эксперименты с двумя наборами контрольных обзоров.
Существующие нейросетевые методы прогнозирования тональности обычно фиксируют только семантику текстов, но игнорируют пользователя, который выражает тональность. Это нежелательно для прогнозирования рейтинга обзора, поскольку каждый пользователь влияет на то, как интерпретировать текстовое содержание обзора. Например, одно и то же слово (например, «хороший») может указывать на разную силу тональности, когда оно написано разными пользователями. Мы решаем эту проблему, разрабатывая новую нейронную сеть, которая учитывает информацию о пользователях. Интуиция заключается в том, чтобы учитывать пользовательскую модификацию значения определенного слова. В частности, мы расширяем модели лексико-семантической композиции и вводим векторную модель композиции пользовательских слов (UWCVM), которая эффективно фиксирует действия пользователя как функцию, влияющую на представление непрерывного слова. Мы интегрируем UWCVM в контролируемую среду обучения для прогнозирования рейтинга отзывов и проводим эксперименты с двумя наборами контрольных обзоров. Экспериментальные результаты демонстрируют эффективность нашего метода. Он демонстрирует превосходные характеристики по сравнению с несколькими сильными базовыми методами.
Экспериментальные результаты демонстрируют эффективность нашего метода. Он демонстрирует превосходные характеристики по сравнению с несколькими сильными базовыми методами.
… Прочитайте Moreread Less
135 Цитаты
СПИСОК ЛИТЕРАТУРЫ
Открытый доступ
Подробнее фильтры
Журнальная статья • DOI •
Long Comptrummer Memory 9000
[DOI •
Long Long Trome-Trmer Memory 9000
[… ].0003
01 ноября 1997 г. — Нейронные вычисления
TL;DR: Представлен новый эффективный метод на основе градиента, называемый долговременной кратковременной памятью (LSTM), который может научиться преодолевать минимальные временные задержки, превышающие 1000 шагов дискретного времени. за счет обеспечения постоянного потока ошибок через постоянные карусели ошибок в специальных подразделениях.
…читать дальшечитать меньше
Аннотация: Обучение хранению информации в течение длительных интервалов времени с помощью рекуррентного обратного распространения занимает очень много времени, в основном из-за недостаточного, затухающего обратного потока ошибок. Мы кратко рассмотрим работу Хохрайтера (1991) проанализируйте эту проблему, а затем решите ее, внедрив новый эффективный метод на основе градиента, называемый долгой кратковременной памятью (LSTM). Обрезая градиент там, где это не наносит вреда, LSTM может научиться преодолевать минимальные временные задержки, превышающие 1000 шагов дискретного времени, обеспечивая постоянный поток ошибок через постоянные карусели ошибок в специальных единицах. Блоки мультипликативных вентилей учатся открывать и закрывать доступ к постоянному потоку ошибок. LSTM локален в пространстве и времени; его вычислительная сложность на временной шаг и вес равны O. 1. Наши эксперименты с искусственными данными включают локальные, распределенные, вещественные и зашумленные представления паттернов. По сравнению с рекуррентным обучением в реальном времени, обратным распространением во времени, рекуррентной каскадной корреляцией, сетями Элмана и фрагментацией нейронной последовательности, LSTM приводит к гораздо более успешным запускам и обучается намного быстрее. LSTM также решает сложные, искусственные задачи с большой задержкой, которые никогда не решались предыдущими рекуррентными сетевыми алгоритмами.
По сравнению с рекуррентным обучением в реальном времени, обратным распространением во времени, рекуррентной каскадной корреляцией, сетями Элмана и фрагментацией нейронной последовательности, LSTM приводит к гораздо более успешным запускам и обучается намного быстрее. LSTM также решает сложные, искусственные задачи с большой задержкой, которые никогда не решались предыдущими рекуррентными сетевыми алгоритмами.
…читать дальшеЧитать меньше
49 735 цитирований
«Настройка весовых коэффициентов для рекурсивных вычислений…» относится к методам в этой статье
Proceeding Article•DOI•
Glove: Global Vectors for Word Representation 9000 9000 …]
Джеффри Пеннингтон 1 , Ричард Сочер 2 , Кристофер Д. Мэннинг 1 •Учреждения (2)
Стэнфордский университет 1 , Колорадский университет в Боулдере 2 9
60003 01 октября 2014 г.
TL;DR: Новая модель глобальной логбилинейной регрессии, которая сочетает в себе преимущества двух основных семейств моделей, описанных в литературе: глобальной матричной факторизации и методов окна локального контекста, и создает векторное пространство со значимой подструктурой.
…читать дальшечитать меньше
Аннотация: Современные методы изучения представлений слов в векторном пространстве позволили уловить мелкие семантические и синтаксические закономерности с помощью векторной арифметики, но происхождение этих закономерностей оставалось неясным. Мы анализируем и определяем свойства модели, необходимые для появления таких закономерностей в векторах слов. Результатом является новая глобальная модель логбилинейной регрессии, которая сочетает в себе преимущества двух основных семейств моделей, описанных в литературе: глобальной матричной факторизации и методов локального контекстного окна. Наша модель эффективно использует статистическую информацию, обучая только ненулевые элементы в матрице совпадения слов, а не всю разреженную матрицу или отдельные контекстные окна в большом корпусе. Модель создает векторное пространство со значимой подструктурой, о чем свидетельствует ее эффективность 75% в недавней задаче аналогии слов. Он также превосходит связанные модели в задачах подобия и распознавании именованных объектов.
Модель создает векторное пространство со значимой подструктурой, о чем свидетельствует ее эффективность 75% в недавней задаче аналогии слов. Он также превосходит связанные модели в задачах подобия и распознавании именованных объектов.
…читать дальшеЧитать меньше
23 307 цитирований
«Настройка веса признаков для рекурсивного…» относится к методам в этой статье
Размещенный контент•
Эффективная оценка представлений слов в векторном пространстве
43
3. ..]
Томас Миколов 1 , Кай Чен 2 , Грег С. Коррадо 3 , Джеффри Дин 3 •Учреждения (3)
Брненский технологический университет
Телекоммуникации 2 , Google 3
16 января 2013-arXiv: вычисления и язык
Аннотация: Мы предлагаем две новые модели архитектуры для вычисления непрерывных векторных представлений слов из очень больших наборов данных. Качество этих представлений измеряется в задаче на сходство слов, а результаты сравниваются с ранее наиболее эффективными методами, основанными на различных типах нейронных сетей. Мы наблюдаем значительное улучшение точности при гораздо меньших вычислительных затратах, т. е. требуется меньше дня, чтобы изучить высококачественные векторы слов из набора данных из 1,6 миллиарда слов. Кроме того, мы показываем, что эти векторы обеспечивают современную производительность на нашем тестовом наборе для измерения синтаксического и семантического сходства слов.
Качество этих представлений измеряется в задаче на сходство слов, а результаты сравниваются с ранее наиболее эффективными методами, основанными на различных типах нейронных сетей. Мы наблюдаем значительное улучшение точности при гораздо меньших вычислительных затратах, т. е. требуется меньше дня, чтобы изучить высококачественные векторы слов из набора данных из 1,6 миллиарда слов. Кроме того, мы показываем, что эти векторы обеспечивают современную производительность на нашем тестовом наборе для измерения синтаксического и семантического сходства слов.
… Прочитайте Moreread Less
20 046 Цитатов
Статья по разбирательствам • DOI •
ПРЕДЛОЖЕНИЯ ОБУЧЕНИЯ Фразы с использованием RNN Encoder-декодер для статистической машины
[…]
Kyunghyun Cho 1 ,
Kyunghyun CHO 1 ,
Kyunghyun CHO 1 ,
Kyunghyun CHO 1 , Kyunghyun CHO 1 , Kyunghyun CHO 1 [. Kyunghyun CHO 1 . Bart van Merriënboer 2 , Caglar Gulcehre 2 , Дмитрий Богданау, Fethi Bougares, Holger Schwenk, Yoshua Bengio 3 , Yoshua Bengio 4 , Yoshua Bengio , Yoshua 7 -Institution 5 • подробнее Aalto University 1 , Université de Montréal 2 , AT&T 3 , École Polytechnique de Montréal 4 , Alcatel-Lucent 5 01 Jan 2014 Abstract: In this paper, we propose a новая модель нейронной сети под названием RNN Encoder-Decoder, которая состоит из двух рекуррентных нейронных сетей (RNN). Одна RNN кодирует последовательность символов в векторное представление фиксированной длины, а другая декодирует представление в другую последовательность символов. Кодер и декодер предлагаемой модели совместно обучаются максимизировать условную вероятность целевой последовательности при заданной исходной последовательности. …читать дальшечитать меньше 14 140 цитирований Недурно? Классификация настроений с использованием методов машинного обучения […] Bo Pang, Lillian Lee, Shivakumar Vaithyanathan 01 января 2002 Аннотация: Рассматривается задача классификации документов не по теме, а по общему настроению, например, определить, является ли отзыв положительным или отрицательным. Используя обзоры фильмов в качестве данных, мы обнаружили, что стандартные методы машинного обучения определенно превосходят базовые показатели, созданные человеком. …читать дальшеЧитать меньше 6,980 цитирований Свернуть Майкл Брайан, 16 лет, использовал это слово на заседании Специального комитета молодежи в июле, говоря о деньгах, потраченных на психическое здоровье. Согласно Оксфордскому словарю английского языка, пневмоноультрамикроскопический кремнийвулканокониоз — это «выдуманное длинное слово, означающее заболевание легких, вызванное вдыханием очень тонкой золы и песчаной пыли». Хотите использовать такое красивое слово, чтобы произвести впечатление на своих друзей и семью? Сводка новостей поможет вам в этом… Getty Images Быть полутораногим может быть весьма полезно, если вы разгадываете кроссворд Слово: Sesquipedalian Значение: Loveing of long words Произносится: Sess-kwi-peh-day-leean Предложение для использования: Как человек, который выполняет свою миссию, я делаю это полуторным, я делаю это полуторным использовать множество длинных слов во всех моих разговорах. Getty Images СТОП с длинными словами, говорите покороче Слово: гиппопотомонстросескипедалиофобный Означает: кто-то, кто боится длинных слов Произносится: Hippoh-poh-toh-mon-stroh-sess-kwi-ped-ah-lee-oh-foe-bik Предложение для его использования в: Любые гиппопотомонстросесквипедалиофобы действительно возненавидят меня с моим новым запас слов. Getty Images Один билет в… э… сюда, пожалуйста Слово: Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch Означает: это название валлийской деревни и самое длинное название места в Великобритании! ..]
..] Эмпирически установлено, что производительность системы статистического машинного перевода улучшается за счет использования условных вероятностей пар фраз, вычисленных кодером-декодером RNN, в качестве дополнительной функции в существующей логарифмической линейной модели. Качественно мы показываем, что предложенная модель обучается семантически и синтаксически осмысленному представлению лингвистических фраз.
Эмпирически установлено, что производительность системы статистического машинного перевода улучшается за счет использования условных вероятностей пар фраз, вычисленных кодером-декодером RNN, в качестве дополнительной функции в существующей логарифмической линейной модели. Качественно мы показываем, что предложенная модель обучается семантически и синтаксически осмысленному представлению лингвистических фраз. Однако три использованных нами метода машинного обучения (наивный байесовский метод, классификация с максимальной энтропией и метод опорных векторов) не так хорошо работают с классификацией настроений, как с традиционной тематической категоризацией. В заключение мы рассмотрим факторы, усложняющие задачу классификации настроений.
Однако три использованных нами метода машинного обучения (наивный байесовский метод, классификация с максимальной энтропией и метод опорных векторов) не так хорошо работают с классификацией настроений, как с традиционной тематической категоризацией. В заключение мы рассмотрим факторы, усложняющие задачу классификации настроений. 13 причудливых словечек, чтобы сбить с толку людей


 n3w519j8ta.1.4.2.0.0.0.$19″> Произносится: Llan-vire-pooll-gwin-gill-goh-gare-uh-win-drorb-ooll-llanty-sillyoh-gohgohgoh
n3w519j8ta.1.4.2.0.0.0.$19″> Произносится: Llan-vire-pooll-gwin-gill-goh-gare-uh-win-drorb-ooll-llanty-sillyoh-gohgohgoh
Предложение для его использования в: Хотите съездить в Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch этим летом?
Getty Images
Эти новые пять фунтов означают, что Банк Англии решил, что старые пятерки ничего не стоят. Это одно из самых длинных слов в английском языке, поэтому любому полуторному человеку будет полезно знать его.
Произносится: флок-сих-нау-киних-хиллих-пиллих-фик-ай-шун
Предложение, в котором можно использовать это: Я очень оскорблен тем, что мой друг флокцинауцинифилилифицирует мой удивительный новый словарный запас.
Getty Images
Менеджер «Ливерпуля» Юрген Клопп известен тем, что с хорошим юмором отвечает на некоторые вопросы о своей команде с неуместными шутками или юмором.
Произносится: fah-see-shush-lee
Предложение для его использования: Вы никогда не должны вести себя шутливо, когда речь идет о важных и серьезных вещах, таких как использование красивых слов.
Слово: Антидисистеблишментарианство
Значение: Первоначально это означало, когда люди были против лишения англиканской церкви статуса, но теперь это может использоваться для обозначения движения против правительства, лишающего их поддержки определенной церкви или религия.
Произносится: anti-dis-est-ab-lish-men-tare-rian-ism Предложение для его использования в: Знаете ли вы, что антидисистеблишментарианство было исключено из 10-го издания Краткого Оксфордского словаря по ошибке? ? Нет, но вы делаете сейчас.
Getty Images
Этот 100-каратный бриллиант кажется нам идеальным
Слово: Quintessential
Означает: идеальный пример чего-то
Произносится: Kwin-teh-sen-shul 3 30508 Предложение, в котором это можно использовать: Я типичный полутораногий человек.
Слово: Boondoggle
Произносится: Как это выглядит — это не так уж сложно произнести!
Предложение, в котором это можно использовать: Вы можете подумать, что моя миссия выучить больше длинных слов — полная бесполезность, но на самом деле это чрезвычайно интересно.
Getty Images
Зачем использовать много слов, когда можно использовать только одно?
Слово: Иноречие
Означает: Использование большого количества слов там, где на самом деле нужно меньшее количество слов.
Произносится: Sir-cum-loh-cue-shunПредложение для его использования в: Моя любовь к многословию означает, что вы можете подумать, что мои предложения излишне длинные, но я не согласен.
Getty Images
Эти большие лодки немного хвастливы?
Слово: Gasconade
Значение: Экстравагантно похвастаться
Произносится: Gas-con-ayde
 n3w519j8ta.1.4.2.0.0.0.$53″> Употребление в предложении: Я не люблю газконад, но мой словарный запас после прочтения этой статьи совершенно исключительный.
n3w519j8ta.1.4.2.0.0.0.$53″> Употребление в предложении: Я не люблю газконад, но мой словарный запас после прочтения этой статьи совершенно исключительный.Бробдингнегский футболист (мы не говорим о Майкле Оуэне)
Слово: Бробдингнегский
Означает: Огромный или гигантский. Оно написано с большой буквы, так как это слово происходит от названия земли в «Путешествиях Гулливера», где все огромно.
Произносится: Brob-ding-nag-ian
Предложение, в котором следует его использовать: У меня словарный запас в пропорциях Бробдингнега!
Getty Images
Стена. Буквально просто фото на стене.
Слово: Lateritious