Упражнение 190 — ГДЗ Русский язык 3 класс Канакина учебник часть 1
- Главная
- ГДЗ
- 3 класс
- Русский язык
- Канакина учебник
- Упражнение 190. Часть 1
Вернуться к содержанию учебника
Вопрос
Вариант вопроса #1:
Прочитайте. Объясните, что объединяет слова каждой пары?
Объясните, что объединяет слова каждой пары?
рыбак моряк | холмистый серебристый | перепрыгнул перешагнул | кафе́ ко́фе |
- Нарисуйте схему состава выделенного слова.
Вариант вопроса #2:
Прочитайте. Объясните, что объединяет слова каждой пары?
рыбак моряк | холмистый серебристый | перепрыгнул перешагнул | метро кофе |
- Нарисуйте схему состава выделенного слова.
Ответ
Вариант ответа #1:
Рыбак — моряк. 1. Оба слова служат наименованием людей по тому делу (профессии), которым они занимаются.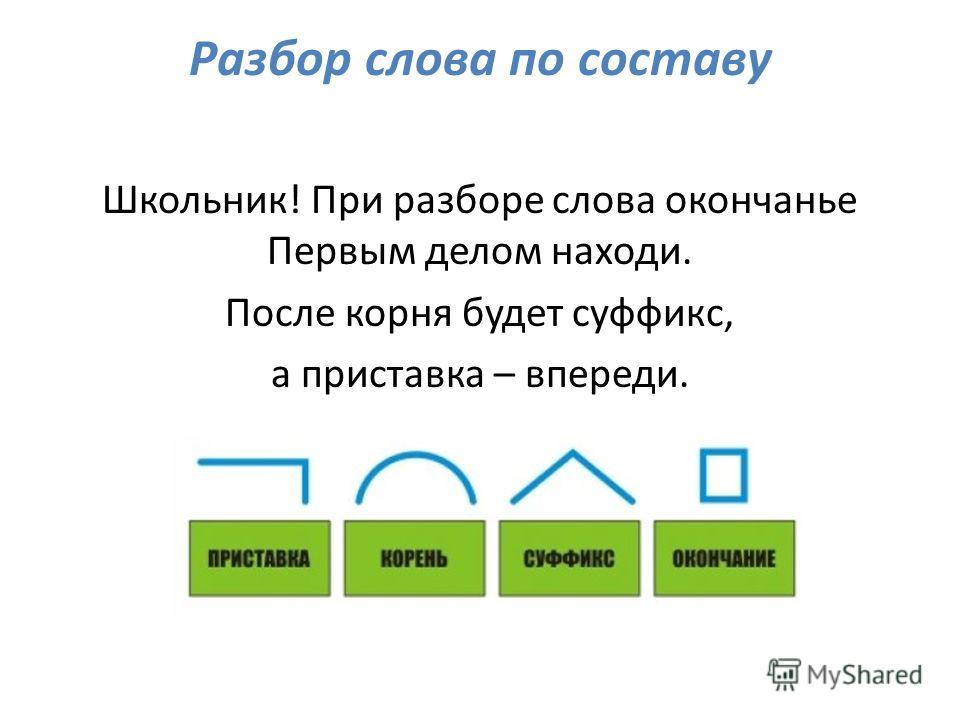 2. Оба слова являются именами существительными 3. Оба слова имеют одинаковый состав —
2. Оба слова являются именами существительными 3. Оба слова имеют одинаковый состав —
Холмистый — серебристый. 1. Оба слова являются именами прилагательными. 2. Оба слова имеют одинаковый состав — .
Перепрыгнул — перешагнул. 1. Оба слова являются глаголами. 2. Оба слова имеют общий оттенок значения — преодолеть препятствие. 3. Оба слова имеют одинаковый состав —
Кафе — кофе. 1. Оба слова являются неизменяемыми именами существительными 2. Оба слова имеют одинаковый состав — .
Серебристый — .
Пояснения:
обратите внимание на задание: вам необходимо составить схему слова, а не разобрать слово по составу, следовательно, вы рисуете значками состав слова, а не обозначаете части слова над самим словом.
Вариант ответа #2:
Слова каждой группы объединены по составу слова.
Серебристый:
Вернуться к содержанию учебника
Канакина. 3 класс. Учебник №1. Проверь себя с. 100
1. Объясните, как найти в словах указанные части слова:
Снежок (корень).
Чтобы найти корень, надо подобрать однокоренные слова и выделить в них общую часть: снеж/ок — снег/, снеж/инка, снеж/ный, за/снеж/енный.
Позвонит (приставка).
Чтобы найти приставку в слове, надо подобрать однокоренное слово без приставки или с другой приставкой. Часть слова, которая стоит перед корнем, и будет приставкой: по/звонит — звонит, пере/звонит, за/звонит.
Медвежонок (суффикс).
Чтобы найти в слове суффикс, надо подобрать однокоренные слова без суффикса или с другими суффиксами. Часть слова, которая стоит после корня перед окончанием, и будет суффиксом: межвеж/онок — медведь, медвеж/ата.
Гроза (окончание).
Чтобы найти окончание в слове, надо изменить форму слова: гроз/а — гроз/ы , за гроз/ой, в гроз/у;
2. Докажите, что слова вязать и вязкий не являются однокоренными.
Слова вязать и вязкий не являются однокоренными, потому что у них разное лексическое значение.
Вязать — вязание, завязать.
Вязкий — тягучий, липкий, клейкий.
Вязкий — вязкость.
3. Найдите лишнее слово в каждой группе слов. Объясните свой ответ.
Берег, берега, береговой, побережье.
Лишнее слово: берега (форма слова), остальные слова — однокоренные.
Дальний, синий, зимний, соседний.
Лишнее слово: синий (отличается от других слов составом слова: корень, окончание), в остальных — корень, суффикс, окончание.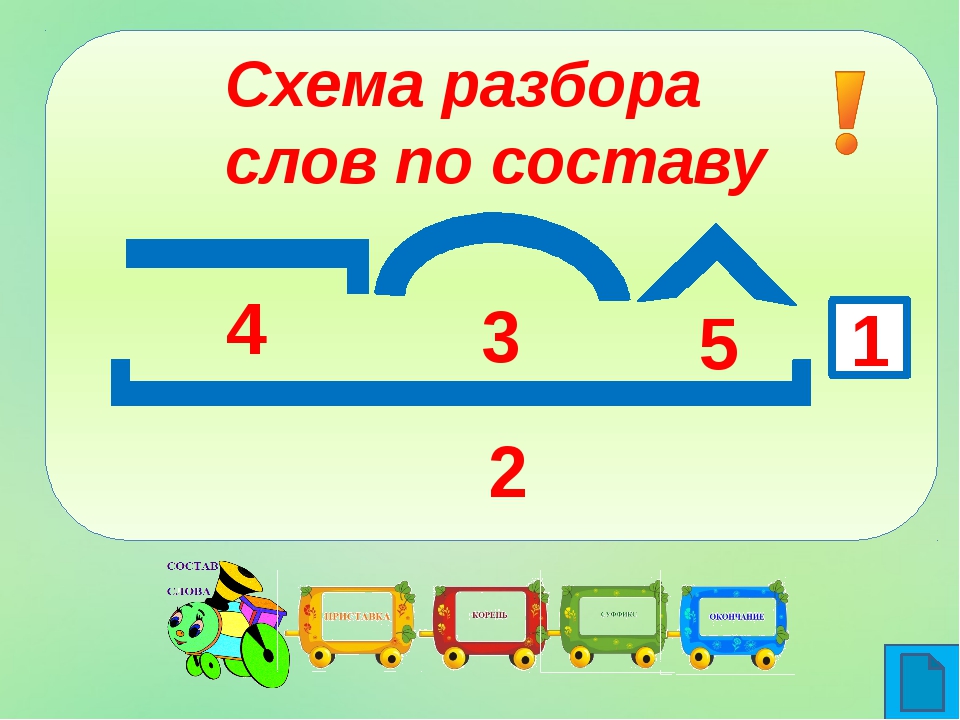
Солнце, пальто, облако, весна.
Лишнее слово: пальто (употребляются только в одной форме).
4. В какие группы по составу можно объединить данные слова? Назовите часть слов, которая их объединяет.
Белый, побелеть, белизна, голубенький, покраснеть, желтизна, беленький, жёлтый.
белый, жёлтый
белизна, желтизна, голубенький, беленький
побелеть, покраснеть
- Нарисуйте схему состава выделенного слова и подберите другое слово с таким же составом.
беленький зёрн/ышк/о
5. Объясните, в каком порядке вы разберёте по составу слова записка и подоконник.
1. Определяем, что слова изменяются, находим окончание (записк/а — окончание -а, подоконник — нулевое).
2. Выделяем в словах основу — часть без окончания (записк-, подоконник-).
3. Находим корень слова, для этого подбираем однокоренные слова (за/пис/ка — пис/ать, под/пис/ать, пере/пис/ать; под/окон/ник — окн/а, окон/ная).
4. Находим приставку. Для этого подбираем однокоренные слова без приставки или с другой приставкой. Часть слова, которая стоит перед корнем, и будет приставкой: за/писка, под/оконник.
5. Находим в слове суффикс. Для этого подбираем однокоренные слова без суффикса или с другими суффиксами. Часть слова, которая стоит после корня перед окончанием, и будет суффиксом: запис/к/а, подокон/ник/.
6. Образуйте от слова дорога слова со следующими значениями:
а) «маленькая узкая дорога»;
дорожка
б) «тот, кто строит дороги»;
дорожник
в) прилагательное к слову дорога;
дорожный
г) «трава, растущая вдоль дороги».
подорожник
7. Назовите слово.
Приставка, суффикс и окончание те же, что и в слове подберёзовик, корень — как в слове осинник.
подосиновик
Ответы по русскому языку. 3 класс. Учебник. Часть 1. Канакина В. П.
Ответы по русскому языку. 3 класс
Корень слова: posit (корень) | Membean
Латинское корневое слово posit означает «помещенный». Хотя в прошлом вы, возможно, оказывались в трудном положении posit , когда видели слова с posit в них, мы надеемся, что этот подкаст posit изменит это!
Скотти из «Звездного пути» неожиданно перенес вас на борт звездолета «Энтерпрайз», а капитан Кирк posit ed или «поместил» перед вами уникальную возможность. Капитан Кирк предлагает вам position ion главного научного сотрудника, или куда вы будете «размещены», если согласитесь присоединиться. Вы рассматриваете эту возможность как такую 
После того, как de posit ed или «поместил» все свои ценности на хранение в банковское хранилище, вы отправляетесь в свое семилетнее путешествие. Вы сразу берете свои пост или место, где «помещены» для несения службы. Капитан Кирк постоянно спрашивает у вас совета о клингонах и ромуланцах, основной операции Федерации posit ion или о тех врагах, которые «поставлены» против них. Вы можете сделать множество проницательных предположений поз ионов или догадок, «размещенных» под этими проблемами, относительно того, что делать с этими подлыми врагами. Sup posit ion вскоре станет работоспособным pro posit ion, или идеями, «предоставленными» экипажу для борьбы с этими врагами.
Однако однажды возникает самая большая опасность из всех — целый флот враждебных боргов теперь «помещен» против или posit e «Энтерпрайз» и вот-вот разнесет всех на борту вдребезги. Во избежание того, чтобы все члены экипажа подверглись разложению posit ion, или их части тела не были «размещены» вдали от того, чтобы быть вместе, вы понимаете, что ap posit e предложение или идея наиболее подходящим образом «размещены» для решения этой ужасной ситуации. заключается в том, чтобы сделать щиты корабля неуязвимыми для атаки противника. Вы создаете новый ком posit e материал из трех секретных веществ, «помещенных» вместе, что делает его таким, что огонь вражеского корабля не имеет никакого эффекта. Чтобы отпраздновать ваше удивительное изобретение, корабельный музыкант создает в вашу честь com
Во избежание того, чтобы все члены экипажа подверглись разложению posit ion, или их части тела не были «размещены» вдали от того, чтобы быть вместе, вы понимаете, что ap posit e предложение или идея наиболее подходящим образом «размещены» для решения этой ужасной ситуации. заключается в том, чтобы сделать щиты корабля неуязвимыми для атаки противника. Вы создаете новый ком posit e материал из трех секретных веществ, «помещенных» вместе, что делает его таким, что огонь вражеского корабля не имеет никакого эффекта. Чтобы отпраздновать ваше удивительное изобретение, корабельный музыкант создает в вашу честь com
Теперь я довольно posit ive, что вы «поместили» в довольно хороший posit ion, когда дело доходит до корня слова posit — и это не журавль в небе sup позиция ион!
- posit : «поместить» идею перед
- позиция : как вы «размещены»
- положительный : настолько уверенный и хороший, что его можно «разместить» в письменной форме
- депозит : действие, когда ценности «помещаются» на финансовый счет
- пост : место, где «размещено» для службы
- противопоставление : состояние или состояние «помещения» против
- предположение : предположение «подложено» под задачу
- предложение : предложение, «выдвинутое» для решения проблемы
- напротив : «размещено» напротив или по направлению к
- разложение : состояние или состояние «размещения»
- подходящий : подходящая идея, «размещенная» рядом с проблемой для ее решения
- композитный : из материалов, «соединенных» вместе
- состав : музыкальное произведение, в котором много нот «помещены» вместе
Parser Combinators: прохождение
04 декабря, 2020 | 14 минут на чтение
Или: Напишите вам парсек во имя великого добра
Большинство людей на пути к Haskell проходят одни и те же первые шаги. Во-первых, вам нужно познакомиться с самим языком, особенно если вы приходите к нему без каких-либо знаний функционального программирования: его необычный синтаксис, лень, отсутствие изменяемого состояния… Оттуда вы можете перейти к функциям и объявлениям типов, ознакомиться освойте функции Prelude (и их известные недостатки) и начните писать свои первые программы. Следующий большой шаг — это, конечно же, монады, печально известное слово на букву «м» 9.0119 [1] и как мы их используем для структурирования наших программ.
Во-первых, вам нужно познакомиться с самим языком, особенно если вы приходите к нему без каких-либо знаний функционального программирования: его необычный синтаксис, лень, отсутствие изменяемого состояния… Оттуда вы можете перейти к функциям и объявлениям типов, ознакомиться освойте функции Prelude (и их известные недостатки) и начните писать свои первые программы. Следующий большой шаг — это, конечно же, монады, печально известное слово на букву «м» 9.0119 [1] и как мы их используем для структурирования наших программ.
Но потом, когда ты начал развивать интуицию для монад… Путь становится неясным. Можно было бы охватить гораздо больше, но ничто из этого не является столь фундаментальным. Есть примерно три категории тем, которые можно изучить:
- Идем дальше с самим языком: изучаем языковые расширения, теорию, лежащую в их основе, и расширенные функции, которые они предоставляют.
- Узнайте больше о различных способах структурирования программы (таких как преобразователи монад или системы эффектов).

- Изучение некоторых из наиболее часто используемых библиотек и понимание того, что делает их такими вездесущими: QuickCheck, Lens… и Parsec.

Сегодня я хочу изучить Parsec, а особенно как работает Parsec . Синтаксический анализ используется повсеместно, и большинство программ на Haskell будут использовать Parsec или один из его вариантов (мегапарсек или аттопарсек). Хотя можно использовать эти библиотеки, не заботясь о том, как они работают, я думаю, интересно разработать мысленную модель их внутреннего устройства; а именно комбинаторы монадических синтаксических анализаторов , так как это простая и элегантная техника, которая полезна не только в случае использования синтаксического анализа необработанного текста. В Hasura мы недавно использовали эту технику, чтобы переписать код, который генерирует схему GraphQL и проверяет по ней входящий запрос GraphQL.
Чтобы лучше понять эту технику, в ходе этой статьи мы сначала повторно реализуем упрощенную версию Parsec , а затем используем ее для написания парсера для значений JSON [2] . Наша цель здесь не будет заключаться в разработке полноценной библиотеки, как раз наоборот: мы реализуем строгий минимум, который нам нужен, чтобы сосредоточиться на основных идеях.
Наша цель здесь не будет заключаться в разработке полноценной библиотеки, как раз наоборот: мы реализуем строгий минимум, который нам нужен, чтобы сосредоточиться на основных идеях.
Выбор представления типа для синтаксических анализаторов
С точки зрения высокого уровня синтаксический анализатор можно рассматривать как функцию перевода: он принимает в качестве входных данных некоторые слабоструктурированные данные (чаще всего это текст) и пытается преобразовать их в структурированные данные, следуя правилам формальная грамматика. Компилятор преобразует последовательность символов в абстрактное синтаксическое дерево, анализатор JSON преобразует последовательность символов в эквивалентное представление значения JSON в Haskell. Есть несколько алгоритмических подходов к этой проблеме; комбинаторы парсера являются примером рекурсивный спуск : мы анализируем каждый термин нашей грамматики, рекурсивно вызывая синтаксические анализаторы для каждого подтермина.
Это означает, что под «парсером» мы оба подразумеваем общее высокоуровневое преобразование и каждый из его отдельных шагов, поскольку каждый парсер рекурсивно выражается как комбинация других парсеров.
Минимальная жизнеспособная реализация
Давайте шаг за шагом разберемся с типом парсера. Во-первых, мы установили, что синтаксический анализатор — это функция от некоторого заданного ввода до того, что мы пытаемся проанализировать. В этом проекте мы будем использовать Строка в качестве ввода, для простоты [3] . Поэтому мы могли бы использовать для представления наших парсеров следующее:
тип Parser a = String -> a
Но этого типа недостаточно для нашего варианта использования. Прежде всего: синтаксический анализатор может дать сбой, если входные данные не соответствуют тому, что диктует наша грамматика. Нам нужно будет определить соответствующий тип для представления ошибок, и синтаксический анализатор должен включить эту возможность на уровне типа.
тип Parser a = String -> либо ParseError a
Кроме того, синтаксический анализ представляет собой последовательную операцию: для анализа объекта JSON необходимо сначала проанализировать открывающую фигурную скобку, затем проанализировать записи, а затем проанализировать закрывающую фигурную скобку; рекурсивно, чтобы проанализировать запись, нужно сначала проанализировать ключ, затем двоеточие, а затем значение. Наш тип синтаксического анализатора будет использоваться для представления каждого из этих шагов, и мы не ожидаем, что каждый шаг будет полностью потреблять входную строку: поэтому каждый синтаксический анализатор должен также возвращать что-то, указывающее, где мы находимся во входном потоке, сколько его было израсходовано или что осталось обработать.
Наш тип синтаксического анализатора будет использоваться для представления каждого из этих шагов, и мы не ожидаем, что каждый шаг будет полностью потреблять входную строку: поэтому каждый синтаксический анализатор должен также возвращать что-то, указывающее, где мы находимся во входном потоке, сколько его было израсходовано или что осталось обработать.
Поскольку мы используем String в качестве нашего входного потока, каждому синтаксическому анализатору достаточно просто вернуть то, что осталось от входной строки [4] . Тип Parser , который мы будем использовать, будет следующим:
Парсер нового типа a = Парсер {
runParser :: String -> (String, либо ParseError a)
}
Написание элементарных парсеров
Как это принято в Haskell, мы начинаем с охвата «аксиоматических» базовых случаев, а затем обобщаем/экстраполируем оттуда. Учитывая, что наш поток String , а наши отдельные токены — это просто символы указанной строки, наши два базовых случая просто соответствуют двум конструкторам списка: во входном потоке остались токены или мы достигли конца. Мы называем эти две функции any и eof соответственно:
Мы называем эти две функции any и eof соответственно:
любой :: Parser Char
any = Parser $ \input -> ввод регистра
-- осталось немного ввода: мы распаковываем и возвращаем первый символ
(x:xs) -> (xs, справа x)
-- ничего не осталось: анализатор не работает
[] -> ("", Left $ ParseError
"любой символ" -- ожидается
"конец ввода" -- встречается
)
eof::Парсер()
eof = Parser $ \input -> регистр ввода
-- никаких входных данных не осталось: синтаксический анализатор прошел успешно
[] -> ("", Право ())
-- оставшиеся данные: синтаксический анализатор не работает
(c:_) -> (ввод, Left $ ParseError
"конец ввода" -- ожидается
[с] -- встречается
)
Это только два основных парсера которые нам нужны! Они охватывают два основных случая: у нас есть символ для разбора или нет. Все остальное можно выразить с помощью этих двух и с помощью комбинаторов.
Синтаксические анализаторы последовательности
Как упоминалось ранее, синтаксический анализ последовательный . Нам часто нужно будет выразить что-то вроде: я хочу применить какой-то парсер A , затем какой-то парсер B и использовать их результаты. Давайте посмотрим, как мы реализуем синтаксический анализатор для записи объекта JSON, например: нам нужно проанализировать строку json, затем двоеточие, затем значение json (мы будем предполагать, что эти отдельные синтаксические анализаторы уже существуют). Полученный код… неоптимален: повторяющийся, подверженный ошибкам и трудно читаемый:
Нам часто нужно будет выразить что-то вроде: я хочу применить какой-то парсер A , затем какой-то парсер B и использовать их результаты. Давайте посмотрим, как мы реализуем синтаксический анализатор для записи объекта JSON, например: нам нужно проанализировать строку json, затем двоеточие, затем значение json (мы будем предполагать, что эти отдельные синтаксические анализаторы уже существуют). Полученный код… неоптимален: повторяющийся, подверженный ошибкам и трудно читаемый:
jsonEntry :: Parser (String, JValue)
jsonEntry = Парсер $\ввод ->
-- разобрать строку json
case runParser jsonString ввод
(вход2, левая ошибка) -> (вход2, левая ошибка)
(вход2, правая клавиша) ->
-- в случае успеха: разобрать одно двоеточие
case runParser (char ':') input2 of
(input3, левая ошибка) -> (input3, левая ошибка)
(вход3, справа _) ->
-- в случае успеха: анализировать значение json
case runParser jsonValue input3 of
(input4, левая ошибка) -> (input4, левая ошибка)
(вход4, правильное значение) ->
-- в случае успеха: вернуть результат
(вход4, справа (ключ, значение))
Это делается довольно громоздким как из-за того, что каждый шаг может завершиться ошибкой, так и из-за того, что каждый шаг возвращает входные данные для следующего. Кроме того, это заставляет нас знать о внутренней структуре парсера, чтобы знать, как их связать. Чтобы упростить задачу, мы можем выделить этот шаблон в отдельную функцию:
Кроме того, это заставляет нас знать о внутренней структуре парсера, чтобы знать, как их связать. Чтобы упростить задачу, мы можем выделить этот шаблон в отдельную функцию:
andThen :: Парсер a -> (a -> Парсер b) -> Парсер b
parserA `andThen` f = Parser $ \input ->
case runParser parserA ввод
(restOfInput, Right a) -> runParser (f a) restOfInput
(restOfInput, Left e) -> (restOfInput, Left e)
Эта функция позволяет нам переписать наш синтаксический анализатор записей JSON таким образом, что больше не требуется явного самоанализа каждого синтаксического анализатора на этом пути.
jsonEntry :: Parser (String, JValue)
jsonEntry =
-- разобрать строку json
jsonString `andThen` \key ->
-- разобрать одно двоеточие
char ‘:’ `иЗатем` \_ ->
-- разобрать значение JSON
jsonValue `andThen` \value ->
-- создать постоянный парсер, который не потребляет входных данных
constParser (ключ, значение)
Силой монад!
Некоторым читателям этот шаблон и затем покажется знакомым; это потому, что andThen в точности совпадает с оператором привязки Monad :
(>>=) :: Парсер a -> (a -> Парсер b) -> Парсер b
Сделав наш Parser тип экземпляром Monad , мы можем использовать мощь всех функций, которые поставляются с ним, и гораздо более удобный синтаксис do notation для наших парсеров [5] . Наконец, нашу функцию jsonEntry можно переписать лаконично и просто:
Наконец, нашу функцию jsonEntry можно переписать лаконично и просто:
jsonEntry :: Parser (String, JValue) jsonEntry = сделать ключ <- jsonString _ <- символ ‘:’ значение <- jsonValue возврат (ключ, значение)
В качестве примечания стоит упомянуть, что, хотя нотация do делает последовательность явной, мы также будем использовать операторы по всему коду (иначе это не был бы «настоящий Haskell» :P). В частности, следующие Functor и Applicative операторы:
(*>) :: Парсер a -> Парсер b -> Парсер b (<*) :: Парсер a -> Парсер b -> Парсер a (<$) :: a -> Парсер b -> Парсер a -- игнорировать начальные пробелы пробелы *> значение -- игнорировать конечные пробелы значение <* пробелы -- подставить значение Истина <$ строка «истина»
Резюме
На данный момент мы определили два наших элементарных парсера и увидели, что цепочка является монадической операцией. Все готово: наши основные потребности удовлетворены.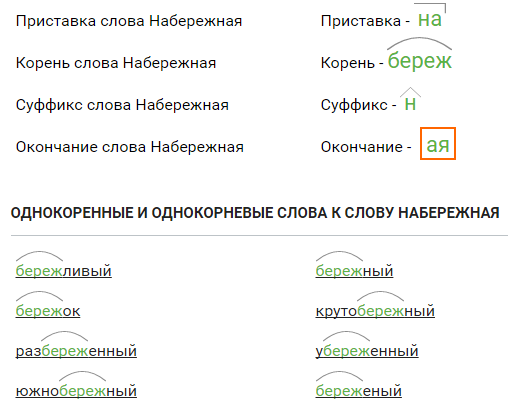 Теперь мы можем начать создавать более интересные парсеры. Для начала представим удовлетворяет : небольшая оболочка вокруг любого , которая позволяет нам проверить, соответствует ли следующий символ во входных данных некоторому произвольному требованию.
Теперь мы можем начать создавать более интересные парсеры. Для начала представим удовлетворяет : небольшая оболочка вокруг любого , которая позволяет нам проверить, соответствует ли следующий символ во входных данных некоторому произвольному требованию.
удовлетворять :: String -> (Char -> Bool) -> Parser Char
выполнить предикат описания = попытаться $ сделать
с <- любой
если предикат c
затем вернитесь с
описание else parseError [c]
Эта функция, хотя и проста, использует другие функции, с которыми мы еще не сталкивались, такие как try . Это наш первый комбинатор!
Объединение парсеров
Формально комбинатор — это функция, которая не полагается ни на что, кроме своих аргументов, например (.) оператор композиции функций:
(ф. г) х = ж (г х)
Но неформально… комбинатор — это то, что объединяет другие вещи . И именно в этом неформальном смысле мы используем его здесь! В нашем контексте комбинаторы синтаксических анализаторов — это функции на синтаксических анализаторах : функции, которые объединяют и преобразуют синтаксические анализаторы в другие синтаксические анализаторы для обработки таких вещей, как поиск с возвратом или повторение.
Выбор, ошибки и возврат
Мы знаем, что синтаксические анализаторы могут дать сбой: именно поэтому у нас есть Либо в их типе. Но не все ошибки фатальны: от некоторых из них можно восстановиться. Представьте, например, что вы пытаетесь проанализировать значение JSON: это может быть объект, или массив, или строка… Чтобы проанализировать такое значение, вы можете попробовать проанализировать открывающие фигурные скобки объекта: если это успешно, вы можете продолжить синтаксический анализ объекта; но если это сразу не удается, вы можете вместо этого попытаться разобрать открывающую скобку массива и так далее. Именно с ошибкой и возвратом мы можем реализовать нашу первую «продвинутую» функцию: выбор.
Чтобы отличить реальную ошибку, которая произошла дальше по линии, или что-то, что просто было неправильным выбором, мы проводим различие между синтаксическими анализаторами, которые терпят неудачу без использования каких-либо входных данных , которые терпят неудачу немедленно, и парсеры, которые терпят неудачу позже: мы предполагаем что если какой-либо ввод был потреблен, то мы были на правильной «ветви». Но взгляда только на один символ вперед не всегда будет достаточно, чтобы решить, верна ли ветвь, и в этом случае нам нужна возможность возврата в случае сбоя ветки: нам нужен комбинатор возврата. вот что try делает: он превращает анализатор в анализатор с возвратом: тот, который не использует входные данные в случае сбоя, который восстанавливает состояние до того, что было. Имеет смысл использовать его для удовлетворения : если предикат не работает, мы не встретили ни одного символа, который можно было бы распаковать, и мы должны оставить входную строку без изменений.
Но взгляда только на один символ вперед не всегда будет достаточно, чтобы решить, верна ли ветвь, и в этом случае нам нужна возможность возврата в случае сбоя ветки: нам нужен комбинатор возврата. вот что try делает: он превращает анализатор в анализатор с возвратом: тот, который не использует входные данные в случае сбоя, который восстанавливает состояние до того, что было. Имеет смысл использовать его для удовлетворения : если предикат не работает, мы не встретили ни одного символа, который можно было бы распаковать, и мы должны оставить входную строку без изменений.
попытка :: Парсер a -> Парсер a try p = Parser $ \state -> case runParser p состояние (_newState, левая ошибка) -> (состояние, левая ошибка) успех -> успех
В этом проекте мы называем наши комбинаторы точно так же, как Parsec. Оператор, который Parsec использует для представления выбора, совпадает с оператором, определенным классом типов Alternative : (<|>) . Его семантика проста: если первый синтаксический анализатор дал сбой, не приняв никаких входных данных [6] , попробуйте второй; в противном случае распространите ошибку:
Его семантика проста: если первый синтаксический анализатор дал сбой, не приняв никаких входных данных [6] , попробуйте второй; в противном случае распространите ошибку:
(<|>) :: Парсер а -> Парсер а -> Парсер а
p1 <|> p2 = Parser $ \s -> case runParser p1 s из
(с', левая ошибка)
| s' == s -> runParser p2 s
| иначе -> (s', левая ошибка)
успех -> успех
С помощью этого оператора мы, наконец, можем реализовать гораздо более удобный комбинатор: выбор . Имея список синтаксических анализаторов, попробуйте их все, пока один из них не добьется успеха.
выбор :: Строка -> [Парсер а] -> Парсер а описание выбора = папка (<|>) noMatch где noMatch = описание parseError "нет совпадения"
Повторение
Последняя группа комбинаторов, которая нам понадобится для нашего проекта, — это комбинаторы повторения. Они не требуют каких-либо внутренних знаний наших Parser и являются хорошим примером того, какую высокоуровневую абстракцию мы теперь можем писать. Как обычно, мы используем те же имена, что и Parsec: many эквивалентно звездочке регулярного выражения и соответствует нулю или более вхождений данного синтаксического анализатора, а many1 эквивалентно плюсу: соответствует одному или нескольким вхождениям:
Как обычно, мы используем те же имена, что и Parsec: many эквивалентно звездочке регулярного выражения и соответствует нулю или более вхождений данного синтаксического анализатора, а many1 эквивалентно плюсу: соответствует одному или нескольким вхождениям:
много, много1 :: Парсер а -> Парсер [а] много p = много1 p <|> вернуть [] много1 р = делать первый <- р остальные <- много р вернуться (первый: отдых)
Благодаря им мы также можем реализовать sepBy и sepBy1 , которые сопоставляют повторяющиеся вхождения данного синтаксического анализатора с заданным разделителем между ними:
sepBy, sepBy1 :: Parser a -> Parser s -> Parser [a] sepBy p s = sepBy1 p s <|> return [] sepBy1 p s = делать первый <- р остальное <- много (s >> p) вернуться (первый: отдых)
Резюме
Вот и все: эти семь комбинаторов — все, что нам нужно для реализации синтаксического анализатора JSON с нуля; на данный момент у нас уже есть достаточно хорошая минимальная повторная реализация библиотеки комбинаторов синтаксических анализаторов, подобной Parsec!
Конечно, полноценная библиотека реализовывала бы гораздо больше: больше примитивов для обработки символов, комбинаторов для необязательных парсеров, более специфичных комбинаторов повторения, поддержки улучшенных сообщений об ошибках… Но это выходит за рамки данного упражнения.
Парсеры на практике: разбор JSON
Чтобы собрать воедино все, что мы видели до сих пор, давайте шаг за шагом рассмотрим процесс построения грамматики парсера JSON. Мы будем делать это снизу вверх: начнем с парсеров для отдельных символов, затем перейдем к парсерам для синтаксиса, затем для скаляров… пока, наконец, мы не сможем написать парсер для произвольного значения JSON. Цель здесь — продемонстрировать, как на каждом этапе мы можем использовать созданные нами более простые абстракции для создания чего-то более сложного. В этом разделе немного больше кода, но я надеюсь, что если вы до сих пор следили за всем, вам будет так же приятно читать, как и мне!
Мы будем использовать следующее представление для значений JSON, которое очень близко к тому, что определяет Aeson [7] :
данные JValue = JObject (JValue строки HashMap) | JArray [JValue] | JString Строка | Двойной номер JNumber | JBool Bool | JNull
Распознавание символов
Используя функции Data. Char , давайте начнем определение нашей грамматики с определения типа символов, которые мы хотим распознавать: это прямое использование нашего удовлетворяет функции :
Char , давайте начнем определение нашей грамматики с определения типа символов, которые мы хотим распознавать: это прямое использование нашего удовлетворяет функции :
char c = выполнить [c] (== c) пробел = удовлетворить "пробел" isSpace цифра = удовлетворить "цифра" isDigit
Синтаксис языка
Чтобы пойти дальше, мы можем определить удобные синтаксические функции, используя вышеупомянутые аппликационные операторы:
строка = символ пересечения
пробелы = много пробелов
символ s = строка s <* пробелы
между открытым закрытым значением = открытым *> значением <* закрытым
скобки = между (символ "[") (символ "]")
фигурные скобки = между (символ "{") (символ "}")
Реализация символа здесь основана на определении Parsec лексемы (в их библиотеке определений языка), которая всегда пропускает конечные пробелы; Таким образом, каждый синтаксический анализатор может быть безопасно написан с предположением, что нет начальных пробелов, которые он должен учитывать. Благодаря такому подходу в нашей грамматике JSON очень мало явных упоминаний о пробелах.
Благодаря такому подходу в нашей грамматике JSON очень мало явных упоминаний о пробелах.
Скаляры
Здесь наша реализация будет отличаться от стандарта JSON. Для простоты наш анализатор чисел будет сопоставлять только натуральные числа:
jsonNumber = читать <$> много1 цифра
Для логических значений мы просто сопоставляем два возможных случая:
jsonBool = выбор "логического значения JSON" [ True <$ символ "true" , Ложь <$ символ "ложь" ]
Что касается строк, мы сопоставляем последовательность символов между двумя двойными кавычками, но мы должны обрабатывать возможность того, что некоторые символы могут быть экранированы. Мы обрабатываем только небольшое подмножество экранированных символов, реализация остальной части спецификации предоставляется читателю в качестве упражнения. 🙂
jsonString =
между (char '"') (char '"') (много jsonChar) <* пробелов
где
jsonChar = выбор "Строковый символ JSON"
[ попробуйте $ '\n' <$ строка "\\n"
, попробуйте $ '\t' <$ строка "\\t"
, попробуйте $ '"' <$ строка "\\\""
, попробуйте $ '\\' <$ строка "\\\\"
, удовлетворять "не кавычки" (/= '"')
]
Массивы и объекты
Значения JSON по определению являются рекурсивными: массивы и объекты содержат другие значения JSON… Чтобы продолжить наш восходящий подход, мы будем предполагать существование верхнего уровня jsonValue парсер, который будет определен последним.
Объект JSON представляет собой группу отдельных записей, разделенных запятыми. Сначала мы анализируем их как список, используя наш комбинатор повторений, а затем преобразуем указанный список ассоциаций в HashMap :
. jsonObject = сделать
assocList <- фигурные скобки $ jsonEntry `sepBy` символ ","
вернуть $ fromList asocList
где
jsonEntry = сделать
к <- jsonString
символ ":"
v <- jsonValue
возврат (к, в)
Наконец, массив — это просто группа значений, заключенных в скобки и разделенных запятыми:
jsonArray = скобки $ jsonValue `sepBy` символ ","
Собираем все вместе
Наконец, мы можем выразить анализатор верхнего уровня для значения JSON:
jsonValue = выбор "значение JSON" [JObject <$> jsonObject , JArray <$> jsonArray , JString <$> jsonString , JNumber <$> jsonNumber , JBool <$> jsonBool , JNull <$ символ "нуль" ]
И… все!
Завершение
Эта статья является результатом моего личного опыта попыток понять внутреннюю работу Parsec после многих лет его использования. Я попробовал свои силы в написании небольшого синтаксического анализатора JSON с нуля, на стороне, когда я изучал, что заставляет Parsec работать, чтобы лучше понять, применив его на практике. Когда я это сделал, я был поражен тем, насколько маленьким и лаконичным был результирующий код, и насколько простой была грамматика JSON. Я искренне надеюсь, что это пошаговое руководство окажется для вас полезным и даст вам представление о красоте комбинаторов парсеров!
Я попробовал свои силы в написании небольшого синтаксического анализатора JSON с нуля, на стороне, когда я изучал, что заставляет Parsec работать, чтобы лучше понять, применив его на практике. Когда я это сделал, я был поражен тем, насколько маленьким и лаконичным был результирующий код, и насколько простой была грамматика JSON. Я искренне надеюсь, что это пошаговое руководство окажется для вас полезным и даст вам представление о красоте комбинаторов парсеров!
Весь код в этой статье можно найти в этом списке GitHub.
Для более сложного примера использования комбинаторов синтаксического анализатора, если вы хотите узнать больше о том, как мы использовали эту технику для повторной реализации нашего поколения схемы GraphQL, вы можете взглянуть на описание PR, которое представило ее.
Хасура, конечно же, нанимает. Если обсуждения, подобные приведенным выше, кажутся вам убедительными, посмотрите на наши открытые роли и подайте заявку. Если вы хотите следить за тем, что строит команда, где мы говорим, и время от времени получать гифки с детёнышами животных. .. Информационный бюллетень сообщества Hasura — это ежемесячная рассылка без традиционного маркетингового спама.
.. Информационный бюллетень сообщества Hasura — это ежемесячная рассылка без традиционного маркетингового спама.
Спасибо за прочтение!
От себя лично: холм, за который я готов умереть, заключается в том, что монады не сложны, но часто плохо преподаются или преподаются способом, который не предназначен должным образом для аудитории. Я серьезно рассматриваю возможность запуска какой-нибудь программы «интуиция для монад, если вы уже знаете хотя бы один другой язык программирования менее чем за 15 минут или вам вернут деньги». ↩︎
Для простоты код в этой статье не будет полностью соответствовать стандарту: мы будем обрабатывать только натуральные числа и сокращенный набор экранируемых символов. ↩︎
Библиотеки комбинаторов синтаксического анализатора не используют напрямую String в качестве входных данных; отчасти потому, что для представления текста доступны лучшие типы, такие как Text , но также и потому, что синтаксический анализатор не всегда является первым шагом перевода: часто, например, в случае компилятора, лексер или токенизатор уже преобразовывают вводимый текст в последовательность лексем или токенов.
Для синтаксического анализатора важно, чтобы входные данные можно было линейно повторять; Парсек называет это Stream : String представляет собой поток Char , и вывод токенизатора также будет потоком токенов. ↩︎Большинство библиотек предпочитают передавать запись State , которая упаковывает входные потоки и несет дополнительную информацию, такую как текущая позиция, что позволяет (помимо других преимуществ) гораздо лучше отображать сообщения об ошибках. ↩︎
Хотя Parsec и его производные используют этот монадический подход, можно создавать синтаксические анализаторы, которые полагаются только на Прикладной . Это компромисс: монадические синтаксические анализаторы более мощные, поскольку синтаксический анализ может разветвляться в зависимости от того, что было проанализировано ранее, но более ограниченные аппликативные синтаксические анализаторы допускают статическую интроспекцию значений. ↩︎
Выполнение сравнения строк для проверки того, не смог ли синтаксический анализатор использовать какие-либо входные данные, крайне неэффективно и является нежелательным следствием нашего упрощенного дизайна.
Если вместо того, чтобы просто передавать String в качестве состояния, мы должны были использовать правильный Запись состояния , мы могли бы реализовать это более эффективно, например, сравнив значение, которое представляет нашу позицию во входном потоке. ↩︎Aeson — наиболее широко используемая библиотека Haskell для работы с JSON. ↩︎
 Для синтаксического анализатора важно, чтобы входные данные можно было линейно повторять; Парсек называет это Stream : String представляет собой поток Char , и вывод токенизатора также будет потоком токенов. ↩︎
Для синтаксического анализатора важно, чтобы входные данные можно было линейно повторять; Парсек называет это Stream : String представляет собой поток Char , и вывод токенизатора также будет потоком токенов. ↩︎ Если вместо того, чтобы просто передавать String в качестве состояния, мы должны были использовать правильный Запись состояния , мы могли бы реализовать это более эффективно, например, сравнив значение, которое представляет нашу позицию во входном потоке. ↩︎
Если вместо того, чтобы просто передавать String в качестве состояния, мы должны были использовать правильный Запись состояния , мы могли бы реализовать это более эффективно, например, сравнив значение, которое представляет нашу позицию во входном потоке. ↩︎Antoine Leblanc
Похожие статьи
Чему мы научились при переходе с CircleCI на Buildkite
23 ноября 2021 г.0011
Создание компилятора GraphQL to SQL на Postgres, MS SQL и MySQL
29 апреля 2021 г.
By
Фил Фримен
Создание Hasura — CI/CD и история монорепозитория
21 09 21 апреля 22 апреляVishnu Bharathi
Hasura 2.0 Обзор инженерной системы
18 марта, 2021
по
Фил Фриман
Аналогичные теги
Инжиниринг
Haskell
Поделитесь этой статьей
.