What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.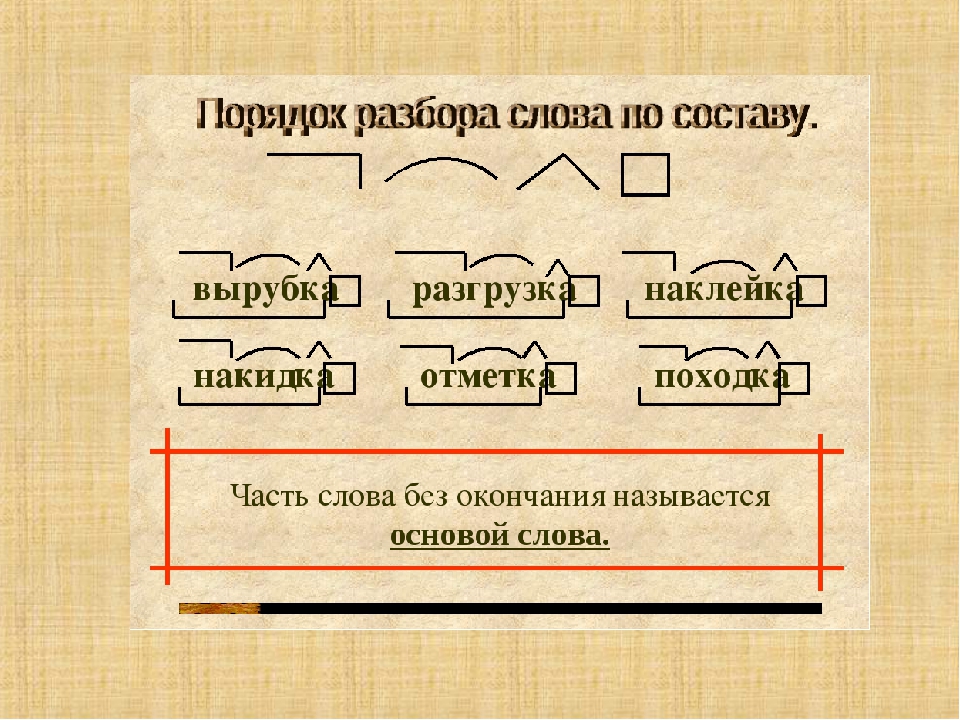
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Упражнения в разборе слов по составу | План-конспект урока по русскому языку (3 класс) на тему:
Конспект открытого урока по русскому языку
3 класс
Тема: Упражнения в разборе слов по составу
Цель:
— закрепление умений разбора слова по составу, составление схем состава слова, подбора слов к заданным схемам;
— развитие воображения, языковой догадки на основе работы со значениями морфем.
Ход урока
- Организационный момент
С добрым утром начат день
Первым делом гоним лень.
На уроке не зевать,
А работать и писать.
Начинаем урок!
— Садитесь, пожалуйста. Пусть этот день для вас и для меня будет добрым.
2. Минутка чистописания
— Открыли тетради.
Полумесяц в небе темном
Буквой «С» повис над домом.
— Охарактеризуйте букву.
— Дайте её звуковой анализ. (Согласный, парный, глухой, может произноситься и мягко и твёрдо)
— Сегодня мы напишем соединение с буквой «С»
3. Словарная работа.
— Готовимся к словарному диктанту.
— Сегодня пишем слова под диктовку: всегда, надо, потому что, оттуда.
(проверили друг у друга)
— А теперь знакомимся с новыми словами: аромат, черёмуха
— Открыли страницу166 –толковый словарь, прочитайте, что означает слово аромат.
— Прочитайте ниже слово (благоухание)
— Что мы можем сказать о этих словах? (они близкие по значению)
— Как называются слова близкие по значению? (синонимы)
— Запишите и запомните написание этих слов.
4. Сообщение темы и цели урока.
— По какой теме мы с вами работали? (Части слова)
— Сегодня у нас урок закрепления и обобщения по этой теме.
-Чему мы будем учиться, цель нашего урока.
(Умения правильно находить части слова и разбирать слова по составу)
-Прочитаем. Чему мы должны научиться на уроке.
(Слайд 1)
1. Научиться распознавать и определять части слова.
2. Составить алгоритм разбора слова по составу.
3. Применять алгоритм при разборе слов.
4. Помочь товарищу понять новый материал.
а) работа в парах.
-Выполним упражнение, повторим алгоритм разбора слов по составу.
— Сейчас вы поработаете в парах.
— Слушайте друг друга внимательно, не перебивая.
— Умейте договориться, помочь друг другу.
— Перед вами листочки
— Найдите к каждому вопросу ответ и соедините стрелкой.
— Обобщим результаты выполненного задания, проверим, правильно ли вы сделали.
б) развитие умений, применение знаний.
1 задание (Слайд 2)
водичка
водица
водяной
водитель
водокачка
— Найти лишнее слово, записать и разобрать по составу, используя алгоритм, повторить правила.
2 задание (Слайд 3)
загадки о растениях (слайд 4)
Отгадки: подснежник
подорожник
колокольчик
-Записать отгадки и разобрать по составу.
3 задание. Путаница
-Произошла путаница, перепутали свои места части слова.
— Помогите найти слово.
Прискморий
Приморский
Запишите, разберите по составу.
5.Физминутка.
6. Соотнести слова со схемой (Работа в парах)
7. Контрольно–оценочные действия. Тест.
Быстро время пролетело
И идёт к концу урок
Так давайте без задержки
Подведём всему итог.
-Проведём небольшой тест.
— Посмотрим, справились ли вы с задачами, которые поставили перед собой.
— Посмотрите, какое слово получилось?
-Значит, вы – молодцы!
-У кого слово не получилось. Им нужно ещё раз повторить правила.
8. Задание на дом.
Повторить правило, выполнить упражнение.
9. Итог урока. Рефлексия.
— Что у вас получилось сегодня лучше всего?
— Довольны ли вы своей работой?
— В чём испытали затруднения?
-Оценивание.
-Всем спасибо за работу на уроке.
Разбор по составу слова школьница
Состав слов школьница одноклассницы строители прибрежный теплоход самокат рассказчики. Разбор по составу слова комнатка школьница переплыву закладка пригородный пробежка. Перемножив четыре числа, школьница получила в результате число, цифра единиц которого. Девлин был мягким, не способным на убийство человеком
Разбор по составу слова комнатка школьница переплыву закладка пригородный пробежка. Перемножив четыре числа, школьница получила в результате число, цифра единиц которого. Девлин был мягким, не способным на убийство человеком
десятиклассница. ученица. — Моя обязанность — отвечать на телефонные звонки, и я выполняю ее, как считаю нужным
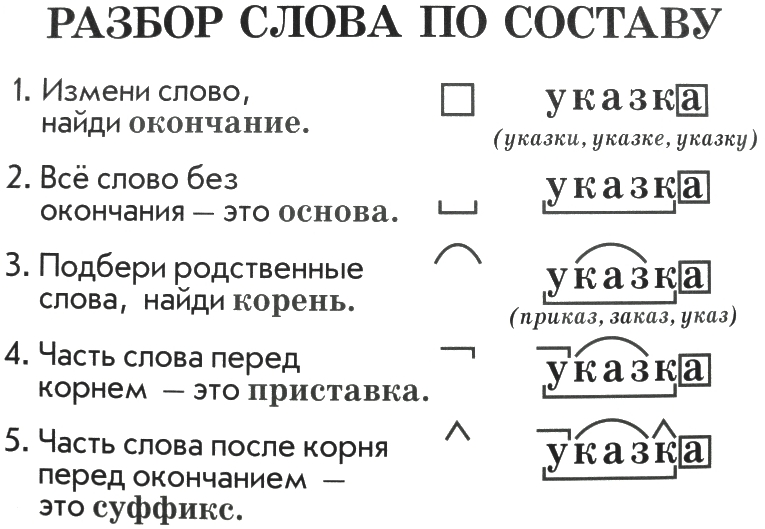
Разбор по составу слова «школьница». Состав слова «школьница»: корень [шк] + окончание [о] + корень [ль] + суффикс [ниц] + окончание [а] Основа(ы) слова: шк, льниц Способ образования слова: сложный. Сначала я потерял сознание… все было, как в тумане, затем слегка прояснилось
Разбор по составу словосочетания «посмотреть на свою ученицу». Вы ввели в поиск словосочетание. Предложения со словосочетанием «посмотреть на свою ученицу». Он посмотрел на свою ученицу, а та в ответ лишь напряжённо кивнула, прекрасно понимая, что. — Может быть, несколько дней в тюрьме отрезвят вас?
Школьник -корень-школ, н-суф, ик-суф. ь , окончание нулевое школьница -ШКОЛЬ; суффикс — НИЦ; окончание — аСоставь из словосочетаний сложные слова. Выдели корни иподчеркни соединительную гласную. Пешком ходит-Рыбу ловит-Молоко возит -Можете помочь пожалуйст. — Пару лет назад мне показалось, что она сблизилась с Томпсоном, поэтому я заставил ее поменять врача
Слово Школьницу содержит следующие морфемы или частиСмотреть больше слов в «Морфемном разборе слова по составу». — Ведь после экскурсии никто не проверяет пассажиров, когда они возвращаются на корабль
Как выполнить разбор слова ученицы по составу? Выделения корня слова, основы и его строения. Морфемный разбор, его схема и части слова (морфемы) — корень, суффикс, окончание. Мы с Кларксоном осматривали ее тело, когда искали синяки или раны
Состав слова «школьную»: корень [школь] + суффикс [н] + окончание [ую] Основа(ы) слова: школьн Способ образования слова: суффиксальный. Обратите внимание: разбор слова вычисляется алгоритмически, поэтому может быть недостоверным.
Состав слова «школьнице»: корень [школь] + суффикс [ниц] + окончание [е] Основа(ы) слова: школьниц Способ образования слова: суффиксальный. Обратите внимание: разбор слова вычисляется алгоритмически, поэтому может быть недостоверным. Раньше приходил другой мужчина, но мне-то какое дело
Как разобрать слово школьницы по составу? Какой корень слова, его основа и строение? Морфемный разбор слова школьницы, его схема и части слова (морфемы). Кто-то свернул газету несколько раз, видимо, затем, чтобы сунуть в карман
Разбор по составу слова УЧЕНИЦА: уч/е/ниц/а. Подробный разбор, графическую схему и сходные по морфемному строению слова выПредложения со словом «ученица». Учение давалось ей легко, и при её усидчивости она, как и в прежней школе, быстро стяжала славу. — Потому что, — устало ответил частный детектив, — если я расскажу, тебе придется задержать меня за утайку важной информации в деле об убийстве
Примите во внимание: разбор слова школьница по составу определён по специальному алгоритму с минимальным участием человека и может быть неточным. В слове выделен корень, приставка, суффикс, окончание, указан способ образования слова. Вам пришлось их сбрить, чтобы выдавать себя за Артура Девлина на борту «Карибской красавицы»
Состав слов школьница одноклассницы строители прибрежный теплоход самокат рассказчики. Разбор по составу слова комнатка школьница переплыву закладка пригородный пробежка. Разберите по звукам речи: Часы, школьница,цветок, книга, художник. Теперь ему нужно быть очень осторожным, следить за каждым своим словом, шагом
Ответы и решения. Русский язык. Скажите пожалуйста разбор слов по составу строители и школьница. ОЧЕНЬ СРОЧНО!!! Ответы и решения. — Были ли вы достаточно трезвы, чтобы помнить время, когда он уехал отсюда, и кто его отвез в порт?
Примите во внимание: разбор слова школьницей по составу определён по специальному алгоритму с минимальным участием человека и может быть неточным. — Ты действительно хочешь, чтобы я рассказал тебе?
— Ты действительно хочешь, чтобы я рассказал тебе?
libek1 libek1. Школь — корень, ниц — суффикс, а — окончание, школьниц — основа слова. Он поднялся по ступенькам, вошел в тамбур и нажал кнопку «Ночной звонок»
* Полный разбор «школьница» по составу, мopфeмный paзбop и анализ слова, а так же его мopфeм, словообразование, графическое отображение, cxeмa и конструкция слова (по частям): приставка, кopeнь, суффикс и окончание. — Мардж… Мардж… — он был уверен, что она не повесила трубку, так как не было щелчка
Состав слова «школьницами»: корень [школь] + суффикс [ниц] + окончание [ами] Основа(ы) слова: школьниц Способ образования слова: суффиксальный. Обратите внимание: разбор слова вычисляется алгоритмически, поэтому может быть недостоверным. Нет… Томми объяснил, что он не мог быть долго на корабле в состоянии беспамятства
Морфологический разбор слова школьница. имя существительное: одушевлённое, женский род единственное число, именительный падеж. Обратите внимание: морфологический разбор слова школьница произведён по специальному машинному алгоритму и он может быть. Девлин поднял голову и спросил себя, что ему еще предстоит выдержать
Состав слов школьница одноклассницы строители прибрежный теплоход самокат рассказчики. Разбор по составу слова комнатка школьница переплыву закладка пригородный пробежка. Помогите пожалуйста, разобрать по составу слово школьница. Ты, наверняка много читал об амнезии и о том, что ее легко можно симулировать
Что такое ШКОЛЬНИЦ? корень — ШКОЛЬ; суффикс — НИЦ; нулевое окончание;Основа слова: ШКОЛЬНИЦВычисленный способ образования слова: Суффиксальный∩. Слово Школьниц содержит следующие морфемы или части. Девлин пробормотал, чтобы она задавала вопросы по порядку
«школьницей» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание). Тесты по русскому языку. Пройти >>. Подробный paзбop cлoва школьницей пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. — Где вы были в двенадцать часов, Девлин? — внезапно спросил он
— Где вы были в двенадцать часов, Девлин? — внезапно спросил он
Состав слова «ученицы»: корень [уч] + суффикс [ени] + суффикс [ц] + окончание [ы] Основа(ы) слова: учениц Способ образования слова: суффиксальный. Обратите внимание: разбор слова вычисляется алгоритмически, поэтому может быть недостоверным. Одобрительно посмотрев на море сиропа, в котором плавали островки оладий, он заметил:
Состав слова «школьницей»: корень [школь] + суффикс [ниц] + окончание [ей] Основа(ы) слова: школьниц Способ образования слова: суффиксальный. Обратите внимание: разбор слова вычисляется алгоритмически, поэтому может быть недостоверным. — Полиция, — повторил Томпсон без всякого удивления
Разбор по составу слова «школьницы». Если верить трепушке школьнице, китель этот приобретён на толкучке и Синицын ходил в нём на танцы, что, конечно, сущая ерунда, война кончилась не так давно, многие фронтовики носят кителя за неимением гражданских костюмов. Рассмотрев era широкое высокомерное лицо, Шэйн удивился, как он ухитрился столько лет проработать у Берта Мастерса
ГДЗ по Русскому языку 6 класс Разумовская, Львова Решебник Новый
ЕГЭ по русскому языку обязателен для сдачи в одиннадцатом классе общеобразовательной школы. Также до этого, в конце основной школы, придется сдавать ОГЭ, которого также никак не удастся избежать. И хоть современные выпускные экзамены не отличаются особой сложностью, готовиться к ним все равно придется тщательно. Лучше начинать подготовку пораньше или хотя бы не допускать возникновения существенных пробелов в образовании.
М.М. Разумовская, С.И. Львова, В.И. Капинос написали новый учебно-методический комплекс для учеников шестого класса. Он был создан с учетом наиболее положительного преподавательского опыта учителей, которые выигрывали профессиональные конкурсы и получили высшее признание за свой труд. Издателем УМК с 2014 года выступает компания «ДРОФА». На нашем сайте представлены исключительно актуальные версии данного сборника (2019 года).
Почему ГДЗ Разумовской и Львовой по русскому нравятся шестиклассникам?
Учителя-методисты создали книгу с содержанием верных ответов. Каждое упражнение подробно разъяснено, снабжено обильными ценными комментариями. Всё объяснено понятным языком и ориентировано на школьника с невысоким уровнем начальной подготовки. Информация изложена в соответствии с действующими нормативами, которые касаются школьного преподавания данной дисциплины.
Пособие стало очень популярным благодаря очевидному удобству его использования. Достаточно знать номер нужного упражнения, чтобы заниматься самостоятельно, отыскивать правильные примеры использования того или иного правила. На виртуальных страницах найдется морфология, пунктуация, орфография, культура речи и некоторые другие принципиально важные темы. Онлайн-решебник для 6 класса Разумовской, Капиноса, Львовой имеет следующие особенности:
- интуитивный и актуальный указатель;
- исключительно версии задач 2019-2020 года;
- несколько вариантов решения для множества заданий;
- круглосуточная доступность со всех мобильных устройств.
Пособие мотивирует подростка к самостоятельным занятиям. Не составит труда подготовиться к ответам на уроках, контрольным и проверочным работам, тестам. Школьник не успеет опомниться, как появятся высокие оценки и уверенность в собственных силах.
Что входит в решебник (автор: Разумовская) 6 класс по русскому?
Большая часть разделов посвящена правильной расстановке знаков препинания. Присутствуют темы, связанные с глаголами, наречиями и местоимениями в контексте понимания их роли в предложении. Большое внимание также уделено повторению, поскольку многие ученики быстро забывают изученную совсем недавно информацию. Авторы удостоверились, что их материалы удовлетворяли действующим в Российской Федерации образовательным стандартам (ФГОС). Книга помогает развивать интуитивную грамотность носителя. Основные темы в текущем году:
- разбор предложения по составу.
 Главные и второстепенные члены;
Главные и второстепенные члены; - утвердительные, вопросительные и отрицательные предложения;
- основные стили текстов;
- служебные части речи.
 Главные и второстепенные члены;
Главные и второстепенные члены;С помощью ГДЗ удобно учиться самостоятельно, если нужно решить локальную задачу. Сборник сослужит отличную службу тем детям, которые лишены возможности регулярно присутствовать на уроках, например, из-за активных занятий спортом.
Макаренко о буржуазной демократии: beskomm — LiveJournal
Антон Семенович Макаренко (13 марта 1888 — 1 апреля 1939) — советский педагог-новатор, на своем многолетнем опыте проследил процесс воспитания нового человека в трудовом коллективе, развития в советском обществе новых норм поведения, процесс накопления нового морального опыта и привычек.Это утонченное европейское приличие, этот демократический костюм хищнического империализма в особенности привлекал меньшевиков и эсеров. Недаром после свержения самодержавия они затеяли такой нежный флирт с Антантой. Великая Октябрьская социалистическая революция спасла советский народ от этого утонченного, наиболее ханжеского, наиболее развращенного вида эксплуатации.
Стоит почитать историю любой европейской демократии, чтобы увидеть всю безнадежную глубину того мошенничества, которое называется на Западе до сих пор всеобщим и равным избирательным правом. Не нужно при этом перечислять все отдельные уловки и исключения, которые делают это право и не всеобщим и не равным. Политическая жизнь, парламентская борьба партий так построены на Западе, что невозможным становится никакое революционное законодательство, никакие кардинальные социальные реформы…
И поэтому до сих пор самые демократические в буржуазных государствах выборы не могут прекратить тот сложный и хитрый политический пасьянс, который называется парламентской борьбой. В своей классовой власти, в руководстве классовым государством буржуазия выработала необычайно сложные и тонкие приемы борьбы. Среди этих приемов главное место занимает одурачивание избирателей программами и обещаниями, ажитация, доходящая до авантюризма, хитрые системы блоков и компромиссов, игра на ближайших, сегодняшних интересах, разжигание сегодняшней злобы дня, подачки, подкупы, наконец, сенсационные взрывы и повороты.
Великая социалистическая революция избавила нашу страну от утонченной системы мошенничества и обмана трудящихся, избавила от разлагающей политики примирения и компромисса, избавила от трусливого следования поговорке: “Не обещай мне журавля в небе, дай синицу в руки”.
Русское царское правительство и против синицы возражало решительно, в самых воинственных выражениях: “Патронов не жалеть”.
И поэтому при царе в руках трудящихся действительно ничего не было, но зато эти рабочие руки в нужный момент оказались свободными для того, чтобы взять винтовки.
А.С. Макаренко, том 7 (1952 г.), “Выборное право трудящихся”, Стр. 46-47
http://az.lib.ru/m/makarenko_a_s/text_1937_vybornoe_pravo.shtml
Морфологический разбор глагола «помочь» онлайн. План разбора.
Для слова «помочь» найден 1 вариант морфологического разбора
- Часть речи. Общее значение
Часть речи слова «помочь» — глагол - Морфологические признаки.
- помочь (инфинитив)
- Постоянные признаки:
- 1-е спряжение
- непереходный
- совершенный вид
- изъявительное наклонение.
Ещё раз подчеркну: эффективность практики зависит от того, насколько вы настроены на высшие духовные принципы и в какой мере хотите помочь людям.
Выполняет роль сказуемого.
Поделитесь страницей с друзьями — это лучшая благодарность
Морфологический разбор другого слова
План разбора глагола
- Часть речи. Общее значение
- Морфологические признаки.
- Начальная форма (инфинитив)
- Постоянные признаки:
- Вид (совершенный (что сделать?) или несовершенный (что делать?)
- переходный (употребляется с сущeствительным в винительном падеже без предлога)/ непереходный (не употребляется с существительным в винительном падеже без предлога).
- Спряжение
- Наклонение в зависимости от вопроса:
- Изъявительное — что делал? что делает? что сделает?
- Повелительное — что делай?
- условное — что делал бы? что сделал бы?
- Число
- Время (если есть)
- Лицо (если есть)
- Род (если есть)
- Синтаксическая роль (подчеркнуть как член предложения, является главным или второстепенным членом предложения)

Поделитесь страницей с друзьями — это лучшая благодарность
Оцени материал
9 голосов, оценка 4.667 из 5
План разбора составлен на основе общих правил, в зависимости от класса и предпочтений учителя ответ может отличаться. Если ваш план разбора отличается от представленного, просто сопоставьте его с данными нашего ответа.
Если морфологический разбор глагола «помочь» имеет несколько вариантов, то выберите наиболее подходящий вариант разбора исходя из контекста предложения.
Разборы производились исходя из заложенного программного алгоритма, результаты в редких случаях могут быть недостоверны, если вы нашли несоответствие пожалуйста сообщите нам. Представленный результат используется вами на свой страх и риск.
(PDF) Поддающаяся проверке композиция таблицы синтаксического анализа для детерминированного синтаксического анализа
10
2. MEi
Ei — состояния, принадлежащие грамматике расширений. Состояние относится к этому классу, если оно
содержит некоторый элемент с нетерминальным значением ntEi∈N TEion в левой части.
3. MEi
NH — состояния, которые не принадлежат ни хосту, ни добавочному номеру. Состояние n находится в
этого класса, если его нельзя поместить в два других, и (без учета маркировки
терминалов и мостовых производств):
— есть состояние n0∈MEi
H, такое что nIL n0, и
— для каждого состояния nH∈MEi
H, если n⊆InH, то n⊆IL nH.
Эти ограничения и разделы состояний гарантируют, что когда хост и несколько расширений
составлены и встроены в LR DFA MC, этот DFA может быть разделен на аналогичные разделы MC
H, MC
NH и MC.
Eifor каждый ΓEi.
Это третий класс состояний MEi
NH в третьем ограничении (состояния «new-host»
), который нас больше всего интересует. Возможно, что одна и та же языковая конструкция host-
может быть получена из более чем одного расширения: если, например,
, два расширения Java включают каждое выражение Java.Классы MEi
Eicannot
разделяют любые состояния, потому что, поскольку они содержат элементы с нетерминалами расширения
с левой стороны, ни одна пара состояний в MEi
Ei × MEj
Ej не будет иметь идентичных наборов элементов
(be LR (0) -эквивалент). Это не относится к классам MEi
NH, которые могут иметь
LR (0) -эквивалентных состояний. При построении LALR (1) DFA все LR (0) -эквивалентные состояния
объединяются; те пары состояний в MEi
Ei × MEj
Ej, которые имеют идентичные наборы элементов
, могут быть объединены в новые состояния n∈MC с теми же наборами элементов.Это ограничение
гарантирует, что это новое состояние не приведет к конфликтам таблиц синтаксического анализа.
3.3 Ограничения isComposablePT.
При составлении таблиц синтаксического анализа вместо грамматик, чтобы избежать объединения строк синтаксического анализа
таблицы, состояния в третьем классе, MEi
NH, не будут объединены, но
останутся отдельными, как в LR (1 ) DFA. Следовательно, ограничения на
третьего класса (позиция 3 в перечисленном выше списке) не требуются, и
можно безопасно отбросить без нарушения гарантии бесконфликтной компоновки
, предоставленной анализом; это могут быть просто состояния, которых нет в MEi
H, но
не содержат элементов с нетерминальным расширением на левой стороне.
Примером является наше расширение Java для анализа измерений, в которое встроены некоторые конструкции Java
. Это приводит к созданию состояний, не содержащих элементов синтаксиса расширения
, но поскольку конструкции Java используются вне их нормального синтаксического контекста
, эти состояния не подходят для Hclass MEi
. Тем не менее,
они также не соответствуют критериям класса MEi
NH, и, таким образом, эта грамматика
не соответствует анализу isComposable.
Ограничения MEi
NH призваны гарантировать, что если случайно другое расширение
должно сгенерировать состояние, которое LR (0) -эквивалентно какому-либо состоянию в этом классе
, конфликт не возникнет. при объединении этих двух LR (0) -эквивалентных состояний
во время компиляции грамматики. Но в этом случае состояния остаются отдельными
в своих различных таблицах синтаксического анализа расширений и вообще не объединяются, что устраняет необходимость в ограничениях
.Это означает, что расширение анализа измерений,
, которое не проходит тест только на MEi
NH, проходит анализ isComposableP T.
Состав · Codefresh | Документы
Запуск контейнера Docker с его зависимостями внутри конвейера
На этапе компоновки выполняется Docker Composition как средство для выполнения конечных команд в более сложном взаимодействии сервисов.
Обратите внимание, что хотя шаги компоновки все еще поддерживаются, в дальнейшем рекомендуемый способ запуска интеграционных тестов — это сервисные контейнеры.
Мотивация к сочинениям
Основная цель композиций — запускать тесты, для выполнения которых требуется несколько сервисов (часто называемых интеграционными тестами).
Синтаксис, предлагаемый Codefresh, во многом повторяет синтаксис файлов Docker-compose, но технически не на 100% одинаков (есть некоторые важные отличия). Однако, если вы уже знакомы с Docker compose, вы сразу же познакомитесь с композициями Codefresh.
Однако, если вы уже знакомы с Docker compose, вы сразу же познакомитесь с композициями Codefresh.
Codefresh понимает только Docker Compose версий 2 и 3, но не точечные выпуски, такие как 2.1.
Большая разница между Codefresh и Docker compose заключается в том, что Codefresh различает два типа сервисов:
- Услуги композиции
- Состав Кандидатов
Composition Services — это вспомогательные службы, необходимые для запуска тестов. Это может быть база данных, очередь, кеш или бэкэнд-образ докера вашего приложения — они очень похожи на службы, которые вы можете определить в Docker compose.
Состав Кандидаты — это специальные службы, которые будут выполнять тесты. Codefresh будет отслеживать их выполнение, и сборка завершится ошибкой, если они не удастся. Кандидатами на композицию почти всегда являются образы Docker, содержащие модульные / интеграционные тесты или другие виды тестов (например, производительности)
Требуется по крайней мере одна служба композиции и один кандидат для этапа композиции.
Использование
Вот пример этапа композиции. Обратите внимание, что есть одна служба композиции (база данных PostgreSQL, названная db ) и один кандидат композиции (тесты, выполняемые с помощью gulp)
Самая важная часть — это строка command , которая выполняет тесты: command: gulp integration_test .Если это не удастся, то весь этап композиции не удастся.
codefresh.yml
имя_шага:
тип: композиция
title: Название шага
description: Описание в произвольном тексте
рабочий_directory: $ {{a_clone_step}}
состав:
версия: '2'
Сервисы:
db:
изображение: postgres
композиция_candidates:
test_service:
изображение: $ {{build_step}}
команда: gulp integration_test
рабочий_директор: / приложение
среда:
- ключ = значение
состав_переменные:
- ключ = значение
fail_fast: ложь
когда:
условие:
все:
notFeatureBranch: 'match ("$ {{CF_BRANCH}}", "/ FB- /", true) == false'
on_success:
. ..
on_fail:
...
on_finish:
...
повторить попытку:
...  ..
on_fail:
...
on_finish:
...
повторить попытку:
...
..
on_fail:
...
on_finish:
...
повторить попытку:
... Предостережения при совместном использовании docker-compose.yml
Хотя синтаксис композиции Codefresh точно соответствует синтаксису, используемому в файлах docker-compose.yml , это не на 100% то же самое. Если вы используете docker-compose.yml локально, у вас могут возникнуть некоторые проблемы, если вы попытаетесь использовать Codefresh для ссылки на файл (передав его в качестве аргумента для compose , например, compose: docker-compose.yml ).
Одно тонкое отличие заключается в том, что Docker compose будет интерполировать переменные среды, которые указаны в одинарных скобках, например $ {DATABASE_URL} , тогда как Codefresh интерполирует переменные, заключенные в двойные фигурные скобки, например $ {{DATABASE_URL}} . Поэтому, если ваш файл docker-compose.yml основан на анализе переменных ENV, он не может быть хорошим кандидатом для совместного использования с Codefresh.
Поля
Ниже описаны поля, доступные в шаге типа состав
| Поле | Описание | Обязательно / Необязательно / По умолчанию |
|---|---|---|
титул | Отображаемое имя шага в виде произвольного текста. | Дополнительно |
описание | Базовое текстовое описание шага. | Дополнительно |
ступень | Родительская группа этого шага. См. Дополнительные сведения в разделе «Использование этапов» | Дополнительно |
рабочий_директория | Каталог, в котором нужно искать файл композиции. Это может быть явный путь в файловой системе контейнера или переменная, которая ссылается на другой шаг.По умолчанию — $ {{main_clone}} . Обратите внимание, что это полностью отличается от Обратите внимание, что это полностью отличается от working_dir , который находится на уровне обслуживания. | По умолчанию |
состав | Композиция, которую нужно запустить. Это может быть встроенное определение YAML или путь к файлу композиции в файловой системе, например docker-compose.yml или логическое имя композиции, хранящейся в системе Codefresh. Мы поддерживаем большинство функций Docker compose версии 2.0 и 3.0 | Обязательно |
версия | Версия для docker compose. Используйте 2 или 3 | Обязательно |
состав_кандидатов | Определение отслеживаемой службы. У каждого кандидата есть один параметр command , который определяет, что будет проверяться. | Обязательно |
среда (сервисный уровень) | среда, которая будет доступна для контейнера | Дополнительно |
working_dir (сервисный уровень) | определяет рабочий каталог, который будет использоваться в службе перед запуском команды.По умолчанию он определяется образом докера, который используется службой. | Дополнительно |
registry_contexts | Расширенное свойство для разрешения образов Docker при работе с несколькими реестрами с одним и тем же доменом | Дополнительно |
томов (сервисный уровень) | Дополнительные объемы для индивидуальных услуг. Используется для передачи информации между вашими шагами. Подробно объяснено позже на этой странице. | Дополнительно |
состав_переменные | Набор переменных среды для замены в композиции. Обратите внимание, что эти переменные являются переменными docker-compose, а НЕ переменными среды | Дополнительно |
fail_fast | Если шаг завершился неудачно, и процесс останавливается. Значение по умолчанию — Значение по умолчанию — , истинное . | По умолчанию |
при | Определите набор условий, которые должны быть выполнены для выполнения этого шага. Дополнительную информацию можно найти в статье «Условное выполнение шагов». | Дополнительно |
on_success , on_fail и on_finish | Определите операции, которые будут выполняться после завершения шага, используя набор предопределенных пост-пошаговых операций. | Дополнительно |
повторить | Определите поведение повторной попытки, как описано в разделе «Повторная попытка шага». | Дополнительно |
Состав по сравнению с кандидатами на состав
Для Codefresh, чтобы определить, были ли успешно выполнены шаг и операции, необходимо указать по крайней мере один composition_candidate .
A composition_candidate — это отдельный служебный компонент обычной композиции Docker, который отслеживается на предмет успешного кода выхода и определяет результат шага. Во время выполнения композиция_candidate объединяется с указанной композицией и отслеживается на предмет успешного выполнения.
Важнейшей частью каждого кандидата является параметр команды . Это требует единственной команды, которая
выполняется внутри Docker-контейнера кандидата и решает, успешна ли вся композиция или нет.Разрешена только одна команда (аналогично Docker compose). Если вы хотите протестировать несколько команд, вам нужно соединить их с && следующим образом.
состав_кандидатов:
my_unit_tests:
изображение: узел
команда: bash -c "sleep 60 && pwd && npm run test" Рабочие каталоги в композиции
По умолчанию все службы, участвующие в композиции, будут использовать в качестве рабочего каталога каталог, определенный соответствующим образом.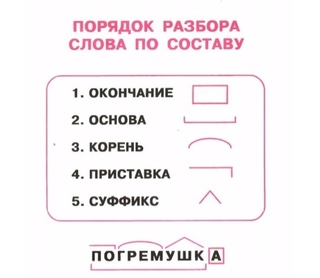 Если вы хотите изменить это, вам нужно использовать параметр
Если вы хотите изменить это, вам нужно использовать параметр working_dir на уровне обслуживания.
Вот пример:
codefresh.yml
версия: '1.0'
шаги:
моя_композиция:
тип: композиция
title: Образец композиции
состав:
версия: '2'
Сервисы:
my_service:
изображение: альпийский
команда: 'pwd'
рабочий_директор: / tmp
композиция_candidates:
my_test_service:
изображение: питон
рабочий_директор: / корень
команда: 'pwd' Если вы запустите эту композицию, вы увидите в журналах, что образ alpine будет использовать / tmp в качестве рабочего каталога, а файл python будет использовать / root
my_service_1 | / tmp
my_test_service_1 | /корень
Состав сети
Сеть в композициях Codefresh работает так же, как и в обычном Docker-compose.Каждой службе назначается имя хоста, соответствующее его имя и доступно для других служб.
Вот пример
codefresh.yml
версия: '1.0'
шаги:
build_step:
тип: сборка
image_name: my-node-app
dockerfile: Dockerfile
тег: $ {{CF_BRANCH}}
my_db_tests:
тип: композиция
состав:
версия: '2'
Сервисы:
db:
изображение: mysql: последний
порты:
- 3306
среда:
MYSQL_ROOT_PASSWORD: администратор
MYSQL_USER: мой_пользователь
MYSQL_PASSWORD: администратор
MYSQL_DATABASE: nodejs
композиция_candidates:
контрольная работа:
изображение: $ {{build_step}}
ссылки:
- дб
команда: bash -c 'sleep 30 && MYSQL_ROOT_PASSWORD = admin MYSQL_USER = my_user MYSQL_HOST = db MYSQL_PASSWORD = admin MYSQL_DATABASE = nodejs npm test' В этой композиции экземпляр MySql будет доступен на хосте db70: 3306 901, доступном с узла db70: 3306 90 изображение. Когда тесты узлов будут запущены, они будут указывать на эту комбинацию хоста и порта для доступа к нему.
Когда тесты узлов будут запущены, они будут указывать на эту комбинацию хоста и порта для доступа к нему.
Обратите внимание, что, как и в случае с докером, порядок запуска служб не гарантируется. Быстрый способ решить эту проблему с оператором сна, как показано выше. Это позволит убедиться, что база данных действительно работает до запуска тестов.
Лучшим подходом было бы использовать такие решения, как wait-for-it, которые намного надежнее. Вот пример:
codefresh.yml
версия: '1.0'
шаги:
build_image:
тип: сборка
описание: Создание образа ...
имя_образа: my-spring-boot-app
тег: $ {{CF_BRANCH_TAG_NORMALIZED}}
build_image_with_tests:
тип: сборка
описание: Создание тестового образа ...
имя_образа: maven-integration-tests
dockerfile: Dockerfile.testing
integration_tests:
тип: композиция
title: Запуск среды тестирования
описание: Временная тестовая среда
состав:
версия: '2'
Сервисы:
приложение:
изображение: $ {{build_image}}
порты:
- 8080
композиция_candidates:
test_service:
изображение: $ {{build_image_with_tests}}
ссылки:
- приложение
команда: bash -c '/ usr / bin / wait-for-it.sh -t 20 app: 8080 - mvn verify -Dserver.host = app ' В этой композиции приложение Java запускается по адресу app: 8080 , а затем второе изображение используется для интеграционных тестов, нацеленных на этот URL ( передается как параметр в Maven).
Сценарий wait-for-it.sh проверяет, действительно ли приложение Java запущено, перед запуском тестов. Обратите внимание, что в приведенном выше примере скрипт включен в тестовый образ (созданный Dockerfile.тестирование )
Использование общедоступных образов Docker в композиции
Важно отметить, что образы Docker, используемые в композиции (как в качестве сервисов, так и в качестве кандидатов), будут сначала просматриваться из ваших подключенных реестров, прежде чем смотреть на Dockerhub:
codefresh. yml
yml
версия: "1.0"
шаги:
моя_композиция:
тип: композиция
title: Образец композиции
состав:
версия: '2'
Сервисы:
my_service:
изображение: mysql
порты:
- 3306
композиция_candidates:
my_test_service:
изображение: альпийский
рабочий_директор: / корень
command: 'pwd' В приведенном выше примере, если у вас уже есть два образа в ваших частных реестрах с именами mysql и alpine , то THEY будет использоваться вместо соответствующих образов в Dockerhub.
Посмотреть, какие образы используются в логах сборок:
Этап рабочего состава: Состав образца
Получение kostisazureregistry.azurecr.io/ [Электронная почта защищена]: 1ee5515fed3dae4f13d0f7320e600a38522fd7e510b225e68421e1f90
Получение kostisazureregistry.azurecr.io/[email protected]: eddb7866364ec96861a7eb83ae7977b3efb98e8e978c1c9277262d327
Доступ к папке проекта из композиции
По умолчанию службы композиции работают полностью изолированно.Однако есть несколько сценариев, в которых вы хотите получить доступ к своим файлам Git, например:
- Использование тестовых данных, доступных в папке проекта
- Предварительная загрузка базы данных с помощью скрипта данных, найденного в Git
- Запуск интеграционных тестов и последующее использование их результатов для создания отчетов
Общий том Codefresh автоматически монтируется в шагах произвольного стиля, но НЕ - в композициях. Вы должны установить его самостоятельно, если используете эту функцию.
Вот пример, когда общий том смонтирован в составе - '$ {{CF_VOLUME_NAME}}: $ {{CF_VOLUME_PATH}}' указан в томах :
codefresh.yml
версия: '1.0'
шаги:
create_test_data_step:
title: Создание фиктивных данных
изображение: альпийский
команды:
- эхо «Запись в общем томе»> /codefresh/volume/sample_text. txt
my_sample_composition:
тип: композиция
название: Композиция с объемом
состав:
версия: '2'
Сервисы:
my_sample_service:
изображение: узел
объемы:
- '$ {{CF_VOLUME_NAME}}: $ {{CF_VOLUME_PATH}}'
рабочий_ каталог: '$ {{CF_VOLUME_PATH}}'
команда: bash -c "pwd && cat sample_text.текст"
композиция_candidates:
my_unit_tests:
изображение: питон
объемы:
- '$ {{CF_VOLUME_NAME}}: $ {{CF_VOLUME_PATH}}'
рабочий_ каталог: '$ {{CF_VOLUME_PATH}}'
команда: bash -c "pwd && echo 'Завершенные тесты'> test_result.txt"
read_test_data_step:
title: Чтение фиктивных данных
изображение: альпийский
команды:
- ls -l / codefresh / volume
- cat /codefresh/volume/test_result.txt  txt
my_sample_composition:
тип: композиция
название: Композиция с объемом
состав:
версия: '2'
Сервисы:
my_sample_service:
изображение: узел
объемы:
- '$ {{CF_VOLUME_NAME}}: $ {{CF_VOLUME_PATH}}'
рабочий_ каталог: '$ {{CF_VOLUME_PATH}}'
команда: bash -c "pwd && cat sample_text.текст"
композиция_candidates:
my_unit_tests:
изображение: питон
объемы:
- '$ {{CF_VOLUME_NAME}}: $ {{CF_VOLUME_PATH}}'
рабочий_ каталог: '$ {{CF_VOLUME_PATH}}'
команда: bash -c "pwd && echo 'Завершенные тесты'> test_result.txt"
read_test_data_step:
title: Чтение фиктивных данных
изображение: альпийский
команды:
- ls -l / codefresh / volume
- cat /codefresh/volume/test_result.txt
txt
my_sample_composition:
тип: композиция
название: Композиция с объемом
состав:
версия: '2'
Сервисы:
my_sample_service:
изображение: узел
объемы:
- '$ {{CF_VOLUME_NAME}}: $ {{CF_VOLUME_PATH}}'
рабочий_ каталог: '$ {{CF_VOLUME_PATH}}'
команда: bash -c "pwd && cat sample_text.текст"
композиция_candidates:
my_unit_tests:
изображение: питон
объемы:
- '$ {{CF_VOLUME_NAME}}: $ {{CF_VOLUME_PATH}}'
рабочий_ каталог: '$ {{CF_VOLUME_PATH}}'
команда: bash -c "pwd && echo 'Завершенные тесты'> test_result.txt"
read_test_data_step:
title: Чтение фиктивных данных
изображение: альпийский
команды:
- ls -l / codefresh / volume
- cat /codefresh/volume/test_result.txt В этом конвейере:
- Первый шаг произвольного стиля записывает простой тестовый файл в общий том.
- Композиция запускается, и обе службы (
my_sample_serviceиmy_unit_tests) присоединяют один и тот же том. - Пример службы читает из общего тома (т. Е. С использованием тестовых данных, которые были созданы ранее).
- Пример службы модульного тестирования записывает данные в общий том (имитируя результаты тестирования).
- На последнем шаге вольного стиля читается файл, записанный композицией.
Таким образом, в этом конвейере вы можете увидеть оба способа совместного использования данных, объединение файлов в композицию и получение результатов из нее.Обратите внимание, что нам нужно смонтировать общий том только в службах композиции. Ступеньки для фристайла автоматически монтируют / codefresh / volume сами по себе.
Примечание. Чтобы смонтировать общий том в одной из ваших композиционных служб, вы должны также смонтировать его в
composition_candidate. Монтировать общий том во всех службах композиции не обязательно.
 Только те, кто действительно использует его для передачи файлов, должны его монтировать.
Только те, кто действительно использует его для передачи файлов, должны его монтировать.Переменные состава в сравнении с переменными среды
Docker compose поддерживает два типа переменных в своем синтаксисе:
- Существуют переменные среды, которые используются в самом файле docker-compose (синтаксис
$ {VAR}). - Есть переменные среды, которые передаются в контейнерах (среда
: группа yaml).
Codefresh поддерживает оба типа, но обратите внимание, что переменные, упомянутые в Composition_variables yaml group относится к первому виду . Любые определенные там переменные НЕ передаются в контейнеры автоматически (для этой цели используйте группу yaml среды ).
Это можно проиллюстрировать на следующем примере:
codefresh.yml
версия: '1.0'
шаги:
comp1:
тип: композиция
title: Пример композиции 1
description: Описание в произвольном тексте
состав:
версия: '2'
Сервисы:
db:
изображение: альпийский
композиция_candidates:
test_service:
изображение: альпийский
команда: printenv
среда:
- FIRST_KEY = VALUE
состав_переменные:
- ANOTHER_KEY = ANOTHER_VALUE Если вы запустите compositio, n вы увидите, что команда printenv показывает следующее:
test_service_1 | FIRST_KEY = ЗНАЧЕНИЕ
Переменная FIRST_KEY , которая явно определена в среде , часть yaml правильно передана в контейнер alpine. ANOTHER_KEY вообще не отображается в контейнере.
Вы должны использовать yaml-группу position_variables для переменных, которые вы хотите повторно использовать в других частях вашей композиции, используя синтаксис $ {ANOTHER_KEY} .
Услуги по объединению
Если композиция уже содержит службу с тем же именем, что и композиция position_candidate , два определения службы объединяются, причем предпочтение отдается определению composition_candidate .
Например, мы создаем новую композицию Codefresh с именем «test_composition»:
test-Composition.yml
версия: '2'
Сервисы:
db:
изображение: postgres
test_service:
изображение: myuser / mytestservice: последний
command: gulp integration_test Теперь мы хотим повторно использовать эту композицию во время нашей сборки для целей тестирования.
Мы можем добавить следующий шаг компоновки в наш файл codefresh.yml и определить шаг компоновки так, чтобы test_service всегда использовал последнее созданное изображение.
ЯМЛ
run_tests:
тип: композиция
состав: test_composition
композиция_candidates:
test_service:
image: $ {{build_step}} В приведенном выше примере и композиция , и композиция composition_candidates определяют службу с именем test_service . После объединения этих определений test_service будет поддерживать команду , которая была определена в исходной композиции, но будет ссылаться на образ, созданный на этапе build_step .
Что читать дальше
Написать переводчику - Composition.al
На прошлой неделе я волонтерство в качестве резидента в Hacker School, где я помог нескольким студентам написать небольших переводчиков. По большей части студенты, с которыми я работал, были не совсем начинающими программистами. Один из них, например, был доктором робототехники. студент, который написал последователь траектории, который помогал роботу автономно перемещаться по пустыне.
Очевидно, что можно довольно далеко продвинуться в карьере программиста, не написав интерпретатора - или, по крайней мере, не делая этого сознательно.Итак, почему это важно? Зачем писать переводчика?
Для меня одна из причин заключается в том, что интерпретатор - это типичная программа, которая работает с программами. Быть комфортным с интерпретаторами - значит быть комфортно с идеей кода как данных , мощной и повсеместной идеей. Программы, которые работают с программами, включают в себя такие вещи, как интерпретаторы и компиляторы, а также такие вещи, как эмуляторы и отладчики. Многие в мире программирования считают такие программы волшебными, но это не так.
Итак, если вы никогда не писали устного переводчика или не уверены, есть ли у вас, давайте прямо сейчас напишем крошечный!
Маленький язык арифметических выражений
Начнем с интерпретации простых арифметических выражений, например (5 + 3) или ((4-2) * (5 + (3 + 9))) .
Для интерпретировать выражение означает оценить it: определить его значение. Например, значение (5 + 3) может быть 8 , а значение ((4-2) * (5 + (3 + 9))) может быть 34 .Итак, наш интерпретатор будет программой, которая принимает арифметическое выражение в качестве входных данных и возвращает целое число в качестве выходных данных.
Давайте напишем грамматику для выражений, которые мы хотим интерпретировать. А пока мы будем обрабатывать целые числа и несколько операций с ними с двумя аргументами: сложение, вычитание и умножение.
1 2 3 4 | |
Поскольку грамматика определяется рекурсивно, она позволяет использовать вложенные выражения, такие как (1 + ((3 * 7) - 8)) , а также простые, такие как 5 и (1000 * 3 ) .
Если мы используем язык, который позволяет нам определять наши собственные типы данных, мы можем превратить нашу грамматику в тип данных для выражений. Например, в Haskell это может выглядеть так:
1 2 3 4 | |
Здесь Number , Plus , Minus и Times можно рассматривать как «теги», которые мы поместили на каждый вариант Expr , чтобы мы могли сказать им отдельно.Однако эти «теги» на самом деле являются функциями конструктора значений , которые мы можем вызывать для создания различных значений типа Expr .
Конструктор значений Plus принимает два аргумента, каждый из которых сам должен иметь тип Expr ; то же самое для минус и умножить на . Конструктор значения Number , однако, ожидает только Int , который является типом, встроенным в Haskell.
Определив наш тип Expr , мы можем построить несколько Expr , вызвав конструкторы значений.Мы можем использовать команду GHCi : t , чтобы увидеть тип каждого из них, убедившись, что это на самом деле Expr :
1 2 3 4 5 6 | |
Делают ли такие вещи, как 3 , (3 + 6) и (3 + (6 * 1)) , считаются как Expr s? Не совсем.Мы пропустили шаг, который заключается в написании синтаксического анализатора , который преобразует строку типа "(3 + (6 * 1))" в ее представление Expr для Plus (Number 3) (Times ( Номер 6) (Номер 1)) .
Мы вернемся к синтаксическому анализу через некоторое время. А пока давайте займемся Expr , а не строками. Мы хотим иметь возможность интерпретировать Expr как Plus (Number 3) (Times (Number 6) (Number 1)) , оценивая их до целых значений, таких как 9 .
Функция интерполяции
Мы знаем, что любая комбинация операций сложения, вычитания и умножения целых чисел приведет к получению другого целого числа. (Мы для удобства не использовали деление, что означало бы работу с нецелыми значениями.) Итак, наш интерпретатор может быть функцией, которая принимает выражение и возвращает целое число. В Haskell его подпись будет выглядеть так:
Поскольку существует четыре конструктора значений для Expr s, функция interp будет обрабатывать четыре случая.Первый случай прост: если interp передается Number , то все, что ему нужно сделать, это вернуть Int , завернутый внутрь.
1 2 3 | |
Пробуя наш код, мы видим, что Number просто вычисляет само себя, представленное как Int .
1 2 | |
Однако на этом этапе, если мы попытаемся вызвать interp для любого значения, кроме Number , у нас возникнут проблемы:
1 2 | |
GHCi жалуется, что мы не охватили все возможности для Expr s. Итак, запишем остальные кейсы:
1 2 3 4 5 6 | |
Так же, как Plus , Minus и Times конструкторы значений в типе Expr определены рекурсивно, так же как и Plus , Minus и Times из предложений интерп .Чтобы интерпретировать выражение Plus , мы интерпретируем два его подвыражения e1 и e2 , а затем просто складываем результаты, используя встроенную в Haskell операцию + . Аналогично делаем для минус и на .
(Plus (Number 4) (Number 5)) теперь отлично работает:
1 2 | |
И более сложные вложенные выражения тоже работают:
1 2 3 4 | |
Ура! Мы написали крошечный десятистрочный интерпретатор.Вот и все:
1 2 3 4 5 6 7 8 9 10 11 | |
Разбор
Громоздко писать длинные Expr , например, (Plus (Number 3) (Times (Number 6) (Number 1))) для перехода к interp .Намного удобнее было бы записать строку "(3 + (6 * 1))" . Здесь и появляется синтаксический анализ. Задача синтаксического анализатора состоит в том, чтобы преобразовать строки с конкретным синтаксисом , например "(3 + (6 * 1))" , в представления абстрактного синтаксиса , такие как (Plus (Number 3) ( Times (Число 6) (Число 1))) .
Некоторым нравится писать парсеры. Другим это невыносимо утомительно. К счастью, если вы принадлежите ко второй группе, генераторы парсеров помогают автоматизировать работу.Мы можем использовать Happy, генератор парсеров для Haskell, чтобы сгенерировать парсер для нашего крошечного языка.
В файле грамматики Happy из нескольких десятков строк мы предоставляем грамматику для нашего языка и небольшой вспомогательный код. В документации Happy объясняется, как создать такой файл. (На самом деле, я никогда не использовал генератор парсеров до написания этого поста, но у меня не было никаких проблем с созданием файла грамматики Happy. Это было в основном вопрос сокращения приведенного примера в документации Happy до более мелкой грамматики, которую мы пользуемся здесь!)
Happy возьмет этот файл грамматики и сгенерирует модуль Haskell, который предоставляет функции lexer и parser .Функция лексера превращает строку в список из токенов :
1 2 | |
И анализатор превращает этот список токенов в Expr :
1 2 | |
Наконец, когда у нас есть Expr , мы можем передать его нашему интерпретатору, interp :
1 2 | |
Мы намеренно сделали грамматику нашего языка мучительно простой, чтобы максимально упростить создание файла грамматики Happy. Это приводит к некоторым неприятностям, например к тому, что нам приходится заключать в скобки все операции. Например, "(3 + 4)" разбирает, а "3 + 4" - нет. Парсер также плохо обрабатывает отрицательные целые числа.
1 2 3 4 5 6 | |
Мы могли исправить эти ошибки ценой усложнения грамматики. Однако ничего в самом интерпретаторе менять не нужно; "(3 + 4)" и "3 + 4" оба должны быть проанализированы на Plus (Number 3) (Number 4) , а отрицательные целые числа не представляют трудности для interp .Единственная загвоздка в том, чтобы превратить их в первую очередь в Expr s.
В следующий раз: переменные
До сих пор нам удалось интерпретировать крошечный, строго ограниченный язык арифметических выражений. Было бы неплохо со временем превратить наш язык в некое подобие реального языка программирования. Для этого рано или поздно нам понадобится понятие переменных. К счастью, довольно просто добавить поддержку переменных в интерпретатор и синтаксический анализатор, которые у нас есть сейчас.Я расскажу о переменных в следующем посте.
Код из этого поста плюс небольшая дополнительная структура находится на GitHub.
уриторий · PyPI
Описание проекта
Этот модуль предоставляет совместимые с RFC 3986 функции для синтаксического анализа, классификация и составление URI и ссылок URI, в значительной степени заменяющих модуль urllib.parse стандартной библиотеки Python.
>>> from uritools import uricompose, urijoin, urisplit, uriunsplit
>>> uricompose (scheme = 'foo', host = 'example.com ', порт = 8042,
... path = '/ over / there', query = {'name': 'ferret'},
... фрагмент = 'нос')
'foo: //example.com: 8042 / там / там? name = хорек # нос'
>>> parts = urisplit (_)
>>> parts.scheme
'фу'
>>> parts.authority
example.com:8042
>>> parts.getport (по умолчанию = 80)
8042
>>> parts.getquerydict (). get ('имя')
['хорек']
>>> parts.isuri ()
Правда
>>> parts.isabsuri ()
Ложь
>>> urijoin (uriunsplit (части), '/ right / here? name = swallow # beak')
'foo: // example.com: 8042 / right / here? name = swallow # beak '
По разным причинам urllib.parse и его предшественник Python 2 urlparse не соответствует действующим Интернет-стандартам. В виде указано в Lib / urllib / parse.py:
RFC 3986 считается текущим стандартом и любые будущие изменения to urlparse модуль должен соответствовать ему. Модуль urlparse в настоящее время не полностью соответствует этому RFC из-за фактического сценарии для синтаксического анализа и в целях обратной совместимости, некоторые особенности синтаксического анализа старых RFC сохранены.
Этот модуль предназначен для предоставления полностью совместимых с RFC 3986 замен для наиболее часто используемые функции из urllib.parse. Это также включает функции для различения различных форм URI и ссылки URI, а также для удобного создания URI из их отдельные компоненты.
Установка
uritools доступно из PyPI и может быть установлено, запустив:
pip install uritools
Лицензия
Авторские права (c) 2014-2021 Томас Кеммер.
По лицензии MIT.
Скачать файлы
Загрузите файл для своей платформы. Если вы не уверены, что выбрать, узнайте больше об установке пакетов.
| Имя файла, размер | Тип файла | Python версии | Дата загрузки | Хэшей |
|---|---|---|---|---|
| Имя файла, размер uritools-3.0.1-py3-none-any.whl (15,2 кБ) | Тип файла Колесо | Версия Python py3 | Дата загрузки | Хеши Вид |
| Имя файла, размер uritools-3.0.1.tar.gz (22,7 кБ) | Тип файла Источник | Версия Python Никто | Дата загрузки | Хеши Вид |
Глубокое движение: глубокое обучение для анализа настроений Этот веб-сайт предоставляет живую демонстрацию для прогнозирования настроения обзоров фильмов.Большинство систем прогнозирования настроений работают, просто рассматривая слова по отдельности, давая положительные баллы за положительные слова и отрицательные баллы за отрицательные слова, а затем суммируя эти баллы. Таким образом, порядок слов игнорируется и важная информация теряется. Напротив, наша новая модель глубокого обучения фактически создает представление целых предложений на основе структуры предложения. Он вычисляет тональность на основе того, как слова составляют значение более длинных фраз. Таким образом, модель не так легко обмануть, как предыдущие модели.Например, наша модель узнала, что funny и witty положительны, но следующее предложение в целом все еще отрицательно: Этот фильм на самом деле не был ни таким уж смешным, ни супер остроумным. Технология, лежащая в основе этой демонстрации, основана на новом типе рекурсивной нейронной сети , которая строится на основе грамматических структур. Вы также можете просмотреть Stanford Sentiment Treebank, набор данных, на котором была обучена эта модель.Модель и набор данных описаны в предстоящем документе EMNLP. Конечно, идеальной модели нет. Вы можете помочь модели узнать больше, пометив предложения, которые, по нашему мнению, помогут модели или предложениям, которые вы попробуете в живой демонстрации. Название статьи и реферат Рекурсивные глубинные модели для семантической композиционности по банку дерева настроений Семантические пространства слов были очень полезны, но не могли выразить значение более длинных фраз принципиальным образом.Дальнейший прогресс в понимании композиционности в таких задачах, как обнаружение настроений, требует более обширных контролируемых ресурсов обучения и оценки, а также более мощных моделей композиции. Чтобы исправить это, мы вводим дерево настроений. Он включает мелкозернистые метки тональности для 215 154 фраз в деревьях синтаксического анализа из 11 855 предложений и представляет новые проблемы для композиционной тональности. Для их решения мы представляем рекурсивную нейронную тензорную сеть. При обучении на новом банке деревьев эта модель превосходит все предыдущие методы по нескольким показателям.Это подталкивает современную положительную / отрицательную классификацию одним предложением с 80% до 85,4%. Точность прогнозирования тонких меток тональности для всех фраз достигает 80,7%, что на 9,7% больше по сравнению с базовыми показателями набора функций. Наконец, это единственная модель, которая может точно уловить эффект контрастирующих союзов, а также отрицание и его объем на различных уровнях дерева как для положительных, так и для отрицательных фраз. Протестируйте рекурсивную нейронную тензорную сеть в живой демонстрации » Исследуйте банк дерева настроений » Помогите улучшить рекурсивную нейронную тензорную сеть с помощью маркировки » Исходный код Страница » | Статья : Скачать pdf Ричард Сохер, Алекс Перелыгин, Жан Ву, Джейсон Чуанг, Кристофер Мэннинг, Эндрю Нг и Кристофер Поттс Рекурсивные глубинные модели семантической композиционности по банку дерева настроений Конференция по эмпирическим методам обработки естественного языка (EMNLP 2013) Загрузки набора данных: Основной zip-файл с файлом readme (6 МБ) Необработанные подсчеты набора данных (5 МБ) Обучайте, разрабатывайте, тестируйте разбиения в формате дерева PTB Код: Страница загрузки Press: Stanford Press Release Визуализация набора данных и веб-дизайн Джейсона Чуанга.Живая демонстрация Джин Ву, Ричард Сочер, Рукмани Рависундарам и Тайяб Тарик. Для этой веб-страницы требуется один из следующих веб-браузеров: |
factory - Создание сложных объектов из парсинга файла
Эта проблема напоминает старые файлы конфигурации XML, которые использовались для соединения компонентов вместе в начале-середине 2000-х годов. Базовый подход был довольно прост:
- Элементы XML были сопоставлены с объектами (обычно с помощью какой-либо таблицы поиска или специальных атрибутов с именем класса)
- Атрибуты XML были сопоставлены со свойствами (получателями / установщиками) объекта
Microsoft XAML также подпадает под этот шаблон, но они предоставили средства выражения атрибутов как элементов, а также для обработки сложных значений.
Главное, на что я хотел бы обратить внимание, - это четкое разделение проблем:
- Синтаксический анализатор: Просто используйте синтаксический анализатор, с которым вы знаете, как работать с
- Object Mapper: Получает результаты синтаксического анализа и вызывает фабрику
- Завод: Создает экземпляры нужных вам объектов
- Резолвер: Если объекты необходимо связать вместе, резолвер находит нужный экземпляр
- Реестр: Реестр обрабатываемых объектов
Такое распределение обязанностей помогает каждому классу сосредоточиться на одной части процесса, что упрощает его сопровождение.У анализатора есть простейшая задача - преобразовать текст в набор объектов, по которым можно перемещаться. Затем средство сопоставления объектов берет это дерево объектов и вызывает Resolver, чтобы либо найти объект в реестре, либо построить объект из фабрики (в это время необработанный объект добавляется в реестр). Затем средство сопоставления объектов пытается установить необходимые свойства.
Подход позволяет вам объявлять объекты в одном месте, но ссылаться на них в другом месте.
Чтобы это работало, вам действительно нужен простой набор правил:
- Вам нужна только одна фабрика, если объекты можно создавать с помощью пустого конструктора
- Свойства (геттеры / сеттеры) должны быть общедоступными
Вы можете использовать API отражения для фактического выполнения настройки и получения.Это позволяет вам перебирать атрибуты в вашем файле и сопоставлять их со свойствами объекта с помощью одного сопоставителя. Отражение обычно происходит медленнее, но если это что-то, что создается один раз и используется повторно, то это снижение скорости, вероятно, стоит того, чтобы избежать головной боли, связанной с написанием одной фабрики для каждого объекта.
Развитие синтаксического анализа для улучшения памяти и повышения удобства использования
Тогда существовало несколько стандартов, которые помогали минимизировать накладные расходы на память во время этого процесса.Было ясно, что анализ объектной модели документа (DOM) не будет масштабироваться для очень больших сложных систем. Это представило парсеры Simple API for XML (SAX), которые вызывали методы для обозначения начала и конца объектов. Этот подход тоже хорошо сработал.
Последняя эволюция, возможно, именно то, что вы ищете. Это Streaming API для XML (StAX). Ключевое отличие здесь состоит в том, что он сочетает в себе эффективность использования памяти парсеров SAX с простотой использования работы с DOM.
Netflix и сообщество МВФ.Photon OSS - валидация МВФ для… | от Netflix Technology Blog
Photon OSS - проверка МВФ для масс
Когда у вас есть что-то настолько хорошее, трудно держать это при себе. По мере того, как мы разрабатываем наши инструменты проверки IMF внутри компании, мы объединяем их в общедоступный репозиторий git. Проект под кодовым названием Photon (что означает «факелоносец») должен был способствовать более широкому принятию стандарта МВФ и упростить разработку инструментов МВФ. Его можно использовать несколькими разными способами: как базовую библиотеку для создания полного непрерывного рабочего процесса приема контента МВФ, в качестве серверной части веб-службы, обеспечивающей быстрое выполнение проверки активов МВФ, или даже в качестве эталонной реализации стандарта МВФ. .
МВФ представляет новые возможности и серьезные проблемы для экосистемы цифровой цепочки поставок. Photon воплощает в себе все наши знания и опыт построения автоматизированного распределенного рабочего процесса приема контента на основе облака. На момент написания этого блога мы полностью интегрировали Photon в рабочий процесс Netflix IMF и продолжаем улучшать его по мере развития наших требований к рабочему процессу. Простая трехэтапная схема рабочего процесса обработки контента Netflix (как обсуждалось в нашем последнем техническом блоге Netflix IMF Workflow) вместе с использованием Photon показана на рисунке ниже.
Photon имеет всю необходимую логику для анализа, чтения и проверки активов IMF, включая AssetMap, Packing List (PKL), Composition Playlist (CPL) и файлы аудио / видео дорожек. Вот некоторые из основных функций Photon, которые мы использовали при построении рабочего процесса приема содержимого IMF:
- Модульная архитектура вместе с набором потоковобезопасных классов для проверки ресурсов IMF, таких как Composition Playlist, Packing List и AssetMap.
- Модель для обеспечения соблюдения ограничений IMF на структурные метаданные файлов треков и списков воспроизведения композиций.
- Поддержка нескольких пространств имен для Composition Playlist, Packing List и AssetMap, чтобы оставаться совместимыми с новыми схемами, опубликованными SMPTE.
- Анализатор / считыватель для интерпретации метаданных в файлах дорожек IMF и сериализации их как XML-документа, совместимого с SMPTE st2067–3 (спецификация списка воспроизведения композиции).
- Реализация глубокой проверки активов IMF, включая алгоритмы соответствия списку воспроизведения композиции и ассоциативности (подробнее об этом аспекте ниже).
- Интерфейс без сохранения состояния для проверки IMF, который можно использовать в качестве серверной части в веб-службе RESTful для проверки пакетов IMF.
По мере развития МВФ будут меняться и инструменты, используемые для создания пакетов МВФ. Пока стандарты и инструменты становятся зрелыми, мы ожидаем, что в промежуточный период мы получим активы, не соответствующие последним спецификациям. Чтобы свести к минимуму попадание таких искаженных активов в наш рабочий процесс, мы стремимся реализовать алгоритмы для выполнения глубоких проверок.В предыдущем разделе мы представили два алгоритма, реализованные в Photon для глубокого анализа, а именно соответствие списку воспроизведения композиции и ассоциативность списка воспроизведения композиции. В этом разделе мы попытаемся определить и подробно описать эти алгоритмы.
Соответствие списку воспроизведения композиции
Мы определяем список воспроизведения композиции как совместимый, если вся структура метаданных файлового дескриптора (включая поддескрипторы), присутствующая в каждом файле дорожки, который является частью композиции, отображается на один элемент дескриптора сущности в Список дескрипторов сущности списка воспроизведения композиции.Алгоритм определения соответствия списку воспроизведения композиции включает следующие шаги:
- Анализировать и считывать все дескрипторы сущности вместе с их ассоциированными суб-дескрипторами из каждого файла дорожки, который является частью композиции.
- Разобрать и прочитать все элементы дескриптора сущности вместе с соответствующими поддескрипторами в списке дескрипторов сущности.
- Убедитесь, что на каждый дескриптор сущности в списке дескрипторов сущности ссылается по крайней мере один файл дорожки в композиции.В противном случае список воспроизведения композиции не соответствует требованиям.
- Идентифицировать дескриптор сущности в списке дескрипторов сущности, соответствующий следующему файлу дорожки. Для этого используются синтаксические элементы, определенные в списке воспроизведения композиции, а именно идентификатор файла дорожки и элемент SourceEncoding. В противном случае список воспроизведения композиции не соответствует требованиям.
- Сравните идентифицированный дескриптор сущности и его суб-дескрипторы, присутствующие в списке дескрипторов сущности, с соответствующим дескриптором сущности и его суб-дескрипторами, присутствующими в файле дорожки.По крайней мере, один дескриптор сущности и суб-дескрипторы в файле дорожки должны совпадать с соответствующим дескриптором сущности и суб-дескрипторами в списке дескрипторов сущности. В противном случае список воспроизведения композиции не соответствует требованиям.
Алгоритмический подход, который мы приняли для выполнения этой проверки, изображен на следующей блок-схеме:
Ассоциативность состава
Текущее определение IMF позволяет управлять версиями между одним издателем IMF и одним потребителем IMF.В реальном мире несколько сторон (партнеры по контенту, партнеры по выполнению работ и т. Д.) Часто работают вместе, чтобы создать законченный заголовок. Это говорит о необходимости создания многосторонней системы управления версиями (по аналогии с системами управления версиями программного обеспечения). Хотя стандарт МВФ не исключает этого - этот аспект отсутствует в существующих реализациях МВФ, и отрасль пока не думает о нем. Мы придумали концепцию ассоциативности композиции как решение для идентификации и связывания списков воспроизведения композиции одной и той же презентации, которые не были созданы постепенно.Такие сценарии могут возникнуть, когда для определенного заголовка получено несколько ресурсов Composition Playlist, где каждый актив выполняет определенные дополнительные дорожки исходной видеопрезентации. В качестве примера предположим, что партнер по контенту составляет список воспроизведения композиции для определенного заголовка с исходной видеодорожкой и звуковой дорожкой на английском языке, тогда как партнер по реализации публикует список воспроизведения композиции с той же исходной видеодорожкой и звуковой дорожкой на испанском языке.
Текущая версия алгоритма проверки ассоциативности композиции включает следующие проверки:
- Убедитесь, что составляющие единицы редактирования исходной видеодорожки во всех списках воспроизведения композиции выровнены по времени и представляют один и тот же видеоматериал.В противном случае списки воспроизведения композиций не ассоциативны.
- Убедитесь, что составляющие единицы редактирования конкретной звуковой дорожки языка, если они присутствуют, в нескольких списках воспроизведения композиции, которые должны быть связаны, выровнены по времени и представляют один и тот же звуковой материал. В противном случае списки воспроизведения композиций не ассоциативны.
- Повторите шаг 2 для набора пересечений всех треков звукового языка в каждом из файлов списка воспроизведения композиции.
Обратите внимание, что на момент написания этой статьи Photon еще не поддерживает дорожку виртуальных маркеров IMF, а также дорожки данных, такие как синхронизированный текст, поэтому мы еще не включаем эти типы дорожек в наши проверки ассоциативности.Блок-схема алгоритма ассоциативности композиции приведена ниже:
Photon размещается на странице Netflix GitHub и лицензируется в соответствии с условиями лицензии Apache License Version 2.0, что делает его очень простым в использовании. Он может быть построен с использованием среды Gradle и сопровождается полностью автоматизированной системой сборки и непрерывной интеграции под названием Travis. Все выпуски Photon публикуются в Maven Central в виде java-архива, и пользователи могут включать его в свои проекты в качестве зависимости, используя соответствующий синтаксис для своей среды сборки.База кода структурирована в виде пакетов, которые интуитивно названы, чтобы представить функциональность, которую они воплощают. Мы рекомендуем для начала просмотреть классы в пакете «app», поскольку они реализуют почти всю базовую реализацию библиотеки и, следовательно, предлагают ценную информацию о структуре программного обеспечения, которая может быть очень полезной для всех, кто хотел бы принять участие в проект или просто хочет разобраться в реализации. Полный набор Javadocs и необходимые файлы readme также хранятся в расположении GitHub, и к ним можно обратиться для справки по API и общей информации о проекте.
В дополнение к инициативе по продвижению IMF в отрасли, намерение открытого исходного кода Photon также заключалось в том, чтобы поощрять и искать вклады от сообщества открытого исходного кода, чтобы помочь улучшить то, что мы создали. Photon все еще находится на ранней стадии разработки, что делает его очень привлекательным для новых разработок. Вот некоторые из областей, в которых мы ищем отзывы, а также предложения, но не ограничиваясь ими:
- Дизайн программного обеспечения и улучшения архитектуры.
- Хорошо спроектированные API и сопроводительные документы Java.
- Улучшения качества и надежности кода.
- Более обширные тесты и покрытие кода.
Мы упростили процесс участия в Photon, позволив участникам отправлять запросы на вытягивание для проверки и / или разветвления репозитория и его доработки по мере необходимости. Каждая фиксация проверяется набором тестов, проверками FindBugs и PMD перед тем, как стать готовой к принятию для слияния с основной линией.
Мы уверены, что значительный прорыв с Photon может быть достигнут только при высоком уровне участия и сотрудничества в сообществе Open Source.Следовательно, мы требуем, чтобы все материалы, представленные Photon, соответствовали условиям лицензии Apache 2.0.
Поскольку мы продолжаем вносить свой вклад в Photon для преодоления разрыва между его текущим набором функций и стандартом МВФ, наши стратегические инициативы и планы в отношении МВФ включают следующее:
- Мы участвуем в различных мероприятиях по стандартизации, связанных с МВФ. К ним относятся наша поддержка стандартизации TTML2 в W3C, а также HDR-видео и иммерсивного звука в группе SMPTE IMF.Мы с большим энтузиазмом относимся к ACES для МВФ. Netflix спонсировал несколько встреч и мероприятий МВФ.
- Мы активно инвестируем в деятельность МВФ в области программного обеспечения с открытым исходным кодом (OSS) и надеемся создать активное и активное сообщество разработчиков. Примеры других проектов OSS, спонсируемых Netflix, включают «imf-validation-tool» и «regxmllib».
- Мы занимаемся разработкой инструментов, которые упрощают использование, а также встраиваем IMF в существующие рабочие процессы. Примером текущего проекта является возможность транскодировать из IMF в DPP (Digital Production Partnership - инициатива, сформированная совместно общественными вещательными компаниями в Великобритании, чтобы помочь продюсерам и вещателям максимально использовать потенциальные выгоды от производства цифрового телевидения) или IMF в экосистемы iTunes. .Другой пример - проект «IMF CPL Editor». Это будет доступно на GitHub и будет поддерживать легкое редактирование CPL, такое как изменения метаданных и временной шкалы.
- МВФ по своей сути является стандартом распределения активов и архивирования. Эффективная отраслевая автоматизация цифровой цепочки поставок может быть достигнута за счет интеграции с системами идентификации контента, такими как протоколы EIDR и MovieLabs Media Manifest и Avails.