Страница не найдена — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.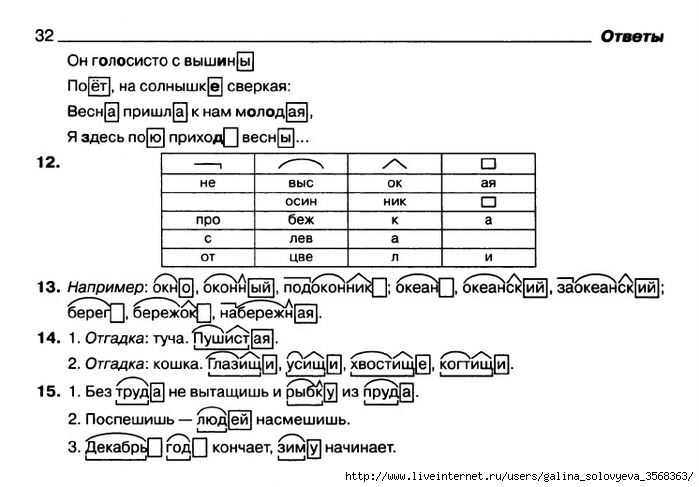
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Содержание
Состав слова в рифмовках и рисунках
Не секрет, что уроки русского языка многие дети
начальной школы считают скучными, потому что в
наших учебниках присутствует огромное
количество правил, которые надо учить и
применять. Связано это со сложностью самой
орфографической системы русского языка и с тем,
что младшие школьники, погружаясь в «море»
орфографических правил и исключений, не могут
уловить логики правописания. Они
воспринимают орфографию как набор
разрозненных, не связанных между собою
правил. И, к сожалению, с каждым новым внедряемым
УМК количество правил в учебниках русского
языка начальной школы только увеличивается.
Дети не хотят запоминать, родители не хотят
вникать. Учителя разводят руками…
Они
воспринимают орфографию как набор
разрозненных, не связанных между собою
правил. И, к сожалению, с каждым новым внедряемым
УМК количество правил в учебниках русского
языка начальной школы только увеличивается.
Дети не хотят запоминать, родители не хотят
вникать. Учителя разводят руками…
На уроках русского языка во втором классе,
так же как и все учителя, я читаю с учениками
правило по учебнику, разбираю его, а затем мы в
тетрадях записываем правило в стихах из моей
личной «копилки», несколько раз его
проговариваем, сравниваем с правилом в учебнике.
Я предлагаю собственные рифмовки по разделу
«Морфемика» или «Состав слова». А также рифмовки
к тем орфограммам русского языка, правописание
которых основано на знании состава слова. Это
правописание некоторых суффиксов, приставок с
гласными а, о, а также
разделительного Ъ. Постоянная,
систематическая работа по усвоению состава
слова, словообразования, обогащению словаря
необходима для овладения морфологическим
принципом орфографии. Я предлагаю разнообразить
эту работу с помощью ярких схем, рифмовок (см.
Рифмовки по разделу «Состав слова».
Слово делится на части!
Ах, какое это счастье!
Может каждый грамотей
делать слово из частей!Окончание в слове – это
Оно при помощи предлога
изменяемая часть.
между словами держит связь.Без окончания всё слово
называется основой.А чтобы корень нам найти
на родственные слова смотри:
общую часть родственных слов
выдели – и корень готов!Суффикс в слове после корня,
образует слово он.
Суффиксы мы будем помнить,
чтоб был богатым лексикон!Перед корнем есть приставка,
А при помощи приставки
слитно пишется она.
образуются слова.

Правописание приставок с гласной О
О-, во-, до-, со-, по- и про’ –
вот приставки с гласной о.
Об-, обо’-, от-, ото’-,
под-, подо’ – приставки с О!
За- и на-, раз- и над-
вот приставки с гласной а.
Разо-, раз-, надо-, над-
будем в них мы а писать.
Правописание приставок, оканчивающихся на согласный звук
В-, об-, от-,
раз-, над-, под-.
Вот приставки на согласный.
Часто он звучит неясно.
Правописание разделительного Ъ.
Чтоб согласный звук в приставке
отделить от гласной в корне,
твёрдый знак меж ними ставьте.
Вами будут все довольны.
Правописание приставок, оканчивающихся на -з, -с.
Вот приставки на -з, -с:
раз- и рас-, без- и бес-.
Голову здесь не ломай,
то, что слышишь, то вставляй.
Разглядеть, но рассмотреть.
Разделить, но растереть.
Перед звонким в корне – без.
Пред глухим – приставка с -с.
Правописание корня
(С этим правилом я знакомлю перед изучением орфограмм корня)
Чтобы смысл слова нам не потерять,
правильно нам надо корень написать.
Правописание суффиксов -онок, -ёнок
в словах, называющих детёнышей животных.
Чтобы малышей назвать,
суффикс надо добавлять.
Если в корне согласный «шипит»,
суффикс -онок, значит, пиши.
Если мягко согласный звучит,суффикс-ёнок, значит, стоит.
Например:
Медвежонок, бельчонок,
индюшонок, галчонок.
Но лисёнок, тигрёнок,
Оленёнок и львёнок.
Правописание суффиксов -ек, -ик в словах.
Чтобы -ик, -ек написать,
слово надо изменять.
Есть предмет и нет его –
смотрю суффикс у него.Если гласный «убегает»,
значит, суффикс -ек вставляем.
Если гласный «не бежит»,
значит, суффикс -ик пиши.
Например:
Домика нет, домик есть.
Ключика нет, ключик есть.
Нет замочка, есть замочек.
Нет крючочка, есть крючочек.

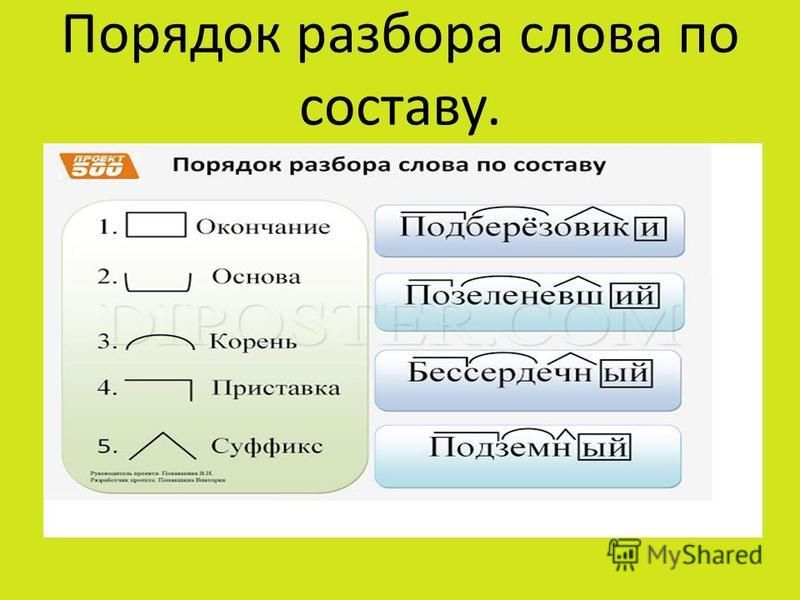
Разбор слова по составу
(Я не помню, чьё это стихотворение, но в своей работе я использую эти строки.)
Помни: при разборе слова
окончанье и основу
первым делом находи!
После корня будет суффикс,
а приставка впереди!
Вывод.
Будем части слова знать,
сможем грамотно писать!
Приложение 1
Морфологический разбор слова «стих»
Слово можно разобрать в 2 вариантах, в зависимости от того, в каком контексте оно используется.
1 вариант разбора
Часть речи: Глагол в личной форме
СТИХ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «СТИХНУТЬ»
| Слово | Морфологические признаки |
|---|---|
| СТИХ |
|
Все формы слова СТИХ
СТИХНУТЬ, СТИХ, СТИХЛА, СТИХЛО, СТИХЛИ, СТИХНУ, СТИХНЕМ, СТИХНЕШЬ, СТИХНЕТЕ, СТИХНЕТ, СТИХНУТ, СТИХНУВ, СТИХНУВШИ, СТИХШИ, СТИХНЕМТЕ, СТИХНИ, СТИХНИТЕ, СТИХНУВШИЙ, СТИХШИЙ, СТИХНУВШЕГО, СТИХШЕГО, СТИХНУВШЕМУ, СТИХШЕМУ, СТИХНУВШИМ, СТИХШИМ, СТИХНУВШЕМ, СТИХШЕМ, СТИХНУВШАЯ, СТИХШАЯ, СТИХНУВШЕЙ, СТИХШЕЙ, СТИХНУВШУЮ, СТИХШУЮ, СТИХНУВШЕЮ, СТИХШЕЮ, СТИХНУВШЕЕ, СТИХШЕЕ, СТИХНУВШИЕ, СТИХШИЕ, СТИХНУВШИХ, СТИХШИХ, СТИХНУВШИМИ, СТИХШИМИ
2 вариант разбора
Часть речи: Существительное
СТИХ — неодушевленное
Начальная форма слова: «СТИХ»
| Слово | Морфологические признаки |
|---|---|
| СТИХ |
|
| СТИХ |
|
Все формы слова СТИХ
СТИХ, СТИХА, СТИХУ, СТИХОМ, СТИХЕ, СТИХИ, СТИХОВ, СТИХАМ, СТИХАМИ, СТИХАХ
Разбор слова по составу стих
| Основа слова | стих |
|---|---|
| Корень | стих |
| Нулевое окончание |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «СТИХ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «стих»
Примеры предложений со словом «стих»
1
Попросит он меня стих
какой сказать (я стихов много знаю), я ему стих скажу; Нравы Растеряевой улицы, Глеб Иванович Успенский, 1866г.
2
Я в связи с этим хочу рассказать стих, – и тут же стал читать: – Стих «Слепой».
Храм любви. Книга 3. Шаг в бездну, Виктор Иванович Девера
3
не забывал он и о чтении Библии, стих за стихом – это вам не какая-нибудь новомодная безбожная школа!
Киппс, Герберт Уэллс, 1905г.
4
Он сопоставляет этот стих с тремя текстами – с арабским стихом, который гласит: «Дули ветры Господни»;Отверженные, Виктор Мари Гюго, 1862г.
5
Она разделяет стих от стиха небольшой, и легкой, и домашней, что ли, паузой, ни названия не сообщая, ни автора, – и это трогает.
Лаз (сборник), Владимир Маканин, 2008г.
Найти еще примеры предложений со словом СТИХ
«копилка» корень в слове и морфемный разбор по составу. Cлов из стихотворения Волшебная копилка
К сожалению, в базе нет такого слова. Посмотрите другое.
Разбор слова по составу.
Состав слова «копилка»:
Приставка: —
Корень слова: коп
Суффикс: и л к
Окончание слова: а
Морфемный разбор слова копилка
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова копилка делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова копилка – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для копилка (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы для копилка путем подбора других слов, которые образованы таким же способом, что и копилка.
Как вы видите, морфемный разбор копилка делается просто. Теперь давайте определимся с основными морфемами слова копилка и сделаем его разбор.
копилка — корень суффикс окончание и приставка в слове
Окончание в слове копилка
Окончание. Окончание в слове копилка находим, изменяя слово (склоняем/спрягаем). В данном случае окончание: а
Окончание в слове копилка находим, изменяя слово (склоняем/спрягаем). В данном случае окончание: а
Корень слова (в слове) копилка
Корень. Корень слова определить проще, если вы можете подобрать однокоренные и родственные слова. Для слова копилка коп — корень слова.
Приставка в слове копилка
Приставка. Определяем приставку, подбирая слова, которые так же образованы с этой приставкой. В данном случае, приставка: —
1) не, очень, тебе, ней 2) очень 3) очень, даём, просто 4)
Чтобы выполнить данное задание, нужно сделать фонетический разбор каждого из слов стихотворения, и вспомнить какие согласные называются шипящими. Начнем с фонетического разбора.
Фонетический разбор слов из стихотворения «Волшебная копилка»
Фонетический разбор слова «волшебную»
Фонетический разбор слова «копилку»
Фонетический разбор слова «тебе»
Фонетический разбор слова «даём»
Фонетический разбор слова «мы»
Фонетический разбор слова «руки»
Фонетический разбор слова «живут»
Фонетический разбор слова «ней»
Фонетический разбор слова «не»
Фонетический разбор слова «монетки»
Фонетический разбор слова «а»
Фонетический разбор слова «веришь»
Фонетический разбор слова «буквы»
Фонетический разбор слова «звуки»
Фонетический разбор слова «гласные»
Фонетический разбор слова «согласные»
Фонетический разбор слова «просто»
Фонетический разбор слова «очень»
Фонетический разбор слова «разные»
Фонетический разбор слова «подходящие»
Фонетический разбор слова «найди»
Фонетический разбор слова «ты»
Фонетический разбор слова «на»
Фонетический разбор слова «правильном»
Фонетический разбор слова «пути»
Имея пред глазами фонетических разбор каждого из слов, можно без труда ответить на вопросы задания.
1) Слова, в которых все согласные мягкие: не, очень, тебе, ней .
2) Слова из двух слогов, которые нельзя переносить:
очень .
3) Слова, в которых есть звук [о]: очень, даём, просто .
Вспомним, что в русском языке 4 шипящих согласных буквы: Ж, Ш, Ч, Щ.
Теперь можем дать ответ на последний вопрос задания.
4) Слова, в которых есть шипящие согласные звуки: волшебную, живут, веришь, очень, подходящие .
Выбор слов из стихотворения «Волшебная копилка» по определенным критериям
Вновь обращаясь к фонетическому разбору слов из стихотворения, ответим на дополнительные вопросы.
Слова, в которых букв больше, чем звуков:
правильном, веришь, очень .
Слова из трёх слогов, в которых звуков больше, чем букв:
гласные, разные .
Слова, в которых все согласные звуки — твёрдые:
мы, в, живут, в, просто, буквы, на, ты .
Слово из трёх слогов с проверяемой безударной гласной в корне:
копилку .

Cлов из стихотворения Волшебная копилка
Вновь обращаясь к нашему фонетическому разбору ответим на вопросы.
- Слова, в которых количество гласных звуков равно количеству согласных: тебе, мы, руки, не, очень, ты, на, пути .
- Слова, в которых звуков меньше, чем букв: веришь, очень, правильном .
- Слово, в корне которого есть непроверяемая безударная гласная и проверяемая согласная: монетки .
- Слова, в которых звуков больше, чем букв: волшебную, даём, гласные, согласные, разные, подходящие .
- Слова, в которых ударение падает на суффикс: копилку, подходящие .
- Слова из двух и более слогов, в которых все согласные звуки звонки:
даём, разные, найди .
Слово «монетка» — словарное. В корне этого слова
есть непроверяемая безударная гласная.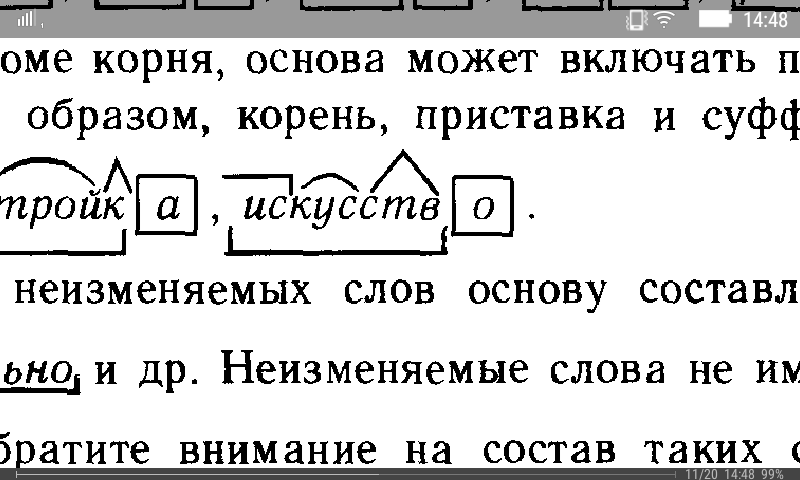 Однако есть
проверяемая согласная — «т».
Проверочное слово к букве «т» — монет а.
Для выбора слов, в которых ударение падает на суффикс,
требуется сделать разбор слов по составу. Разберем
три слова из стихотворения, которые на первый взгляд
подходят под условия:
Разбор слова «волшебный» по составу
Разбор слова «копилка» по составу
Разбор слова «подходящий» по составу
Видим, что из разобранных слов в двух случаях ударение
падает на суффикс. Это слова: «копилка» и «подходящий».
Однако есть
проверяемая согласная — «т».
Проверочное слово к букве «т» — монет а.
Для выбора слов, в которых ударение падает на суффикс,
требуется сделать разбор слов по составу. Разберем
три слова из стихотворения, которые на первый взгляд
подходят под условия:
Разбор слова «волшебный» по составу
Разбор слова «копилка» по составу
Разбор слова «подходящий» по составу
Видим, что из разобранных слов в двух случаях ударение
падает на суффикс. Это слова: «копилка» и «подходящий».
Cлова из «Волшебной копилки»
И вновь обращаемся к фонетическому разбору слов стихотворения «Волшебная копилка». Но прежде разберем дополнительно еще два слова, которых нет в первом варианте стихотворения.
Фонетический разбор слова «возьми»
Фонетический разбор слова «смелее»
А теперь ответим на поставленные вопросы.
1) Слова из трёх слогов:
копилку, смелее, монетки, гласные, разные, правильном .
2) Слова, в которых есть буквы, не обозначающие никаких звуков:
возьми, веришь, очень, правильном .
3) Слова с двумя согласными звуками:
очень, руки, пути, ней .

Назад Вперёд
Внимание! Предварительный просмотр слайдов используется исключительно в ознакомительных целях и может не давать представления о всех возможностях презентации. Если вас заинтересовала данная работа, пожалуйста, загрузите полную версию.
Цели:
- дать представление о суффиксе как о значимой части слова,
- показать роль суффиксов в передаче оттенков значения слова и образования новых слов, показать единообразное написание одного и того же суффикса;
- развивать логическое мышление детей при группировке слов по значению суффиксов;
- формировать навыки речевого этикета при использовании личных имён;
- обогатить словарный запас учащихся.
Оборудование: М-М проектор, компьютер,
презентация “Суффикс”, карточки для
самостоятельной работы, наборное полотно
“Копилка суффиксов” с карточками-суффиксами,
шкала знаков “!”, “+”, “-” (карточки-кружки),
учебник “Русский язык”. 2 класс, 2 часть, авт.
Л.Ф.Климановой, Т.В.Бабушкиной, Москва.
Просвещение. 2012 год.
2 класс, 2 часть, авт.
Л.Ф.Климановой, Т.В.Бабушкиной, Москва.
Просвещение. 2012 год.
Ход урока
1. Оргмомент.
Здравствуй, великий,
Здравствуй, могучий,
Здравствуй, любимый
Русский язык. (Слайд 2)
2. Минутка чистописания.
3. Актуализация знаний.
Словарно-орфографическая работа. Работа в парах. (Слайд 3)
Распределите слова в группы.
В..юга, лист..я, с..едобный, об..явление, под..ехал, солов..иный, с..ёжиться, обез..яна.
Взаимопроверка тетрадей.
Взаимооценка. (используется шкала знаков “!” “+” “-” Приложение 2 )
4. Самоопределение к деятельности.
Какие части слова вы уже знаете? (Корень, приставка)
А как вы думаете есть ли ещё другие части в слове?
Давайте проведём расследование. Внимание на доску!
На доске:
1. Оленька, Сашенька, Машенька, Витенька, Васенька.
2. Олька, Сашка, Машка, Витька, Васька.
Олька, Сашка, Машка, Витька, Васька.
Что общего в значении всех слов? (Это имена)
Что общего в значении слов первой группы? второй?
Какими словами мы недолжны пользоваться? Почему?
А теперь начните расследование. Есть ли общая часть в словах первой группы? (-еньк-)
После какой части она стоит? (После корня. Учитель выделяет мелом корни.)
Есть ли общая часть во второй группе слов. (-к-)
После какой части она стоит? (После корня)
Посмотрите, именно эти части слова придают словам разные оттенки значения:
или уменьшительно- ласкательное, или пренебрежительное, грубоватое.
Эта часть слова имеет своё название. Как вы думаете какую задачу нам предстоит выполнить на этом уроке? (Мы познакомимся с новой частью слова)
Чтобы подробнее узнать об этой части слова, прочитайте сообщение профессора Самоварова на стр.62 учебника.
Как же называется новая часть слова?
Сформулируйте тему урока.(Суффикс. Его значение в слове.)
Какая орфограмма спряталась в названии темы? (Удвоенная –ф-)
5. Работа по теме урока.
Работа по теме урока.
1) Работа по учебнику. Стр.62 Сообщение профессора Самоварова.
Работа в парах. Используя сообщение профессора составьте рассказ о новой части слова по плану:
1. Что такое суффикс?
2. Для чего он служит?
3. Каким значком обозначается? (Слайд 4)
Рассказы детей о суффиксе (2 ученика)
2) Задание умного Совёнка. (Слайд 5)
Попробуйте образовать новые слова.
Проверка. Кого называют полученные слова (Детёнышей животных)
Какие части слова вы использовали (Корень и суффикс)
Какая часть слова указывает на то, что речь идёт о детёнышах животных? (Суффикс)
3) Собираем “копилку суффиксов”. (Наборное полотно. Приложение 1 )
Какой суффикс мы отправим в нашу копилку? (-ёнок-)
4) Задание Ани.
Аня загадала слова, отгадайте и запишите их в тетрадь.
Маленький дом можно назвать….(домик). Очень большой дом называют…. (домище). Старый неказистый дом-это…(домишко).
5) Ваня предлагает нам посмотреть, как работает
суффикс. (Слайд 6)
(Слайд 6)
Какое значение придают слову суффиксы –ик, -ишк-, -ищ-,-ин-?
(Суффиксы отправляются в “копилку”)
6. Физминутка.
Я буду произносить слова. Если в них есть суффикс, то вы строите над головой крышу домика из ладошек. Если нет суффикса, то просто хлопаете в ладоши.
Лес, лесок, дом, домище, город, городок, внук, внучек, ухо, ушко, глаза, глазищи.
7. Продолжение работы по теме.
1) Игра “Будь волшебником” (Слайд 7)
Придайте значение маленького размера предмета.
Нос, стол, дуб, хвост, мёд.
Проверка. Какие суффиксы использовали? (-ик, -ок)
Отправляем их в “копилку”.
2) Работа с учебником. Стр.63 Упр.83.
8. Рефлексия. Работа по карточкам.
Вычеркните “лишнее слово”
Хвостище, глазище, усище, носики.
Лесок, садок, мячик, листок.
Гусёнок, рыбка, утёнок, лисёнок.
Сверка по образцу (Слайд 8)
Самооценка (шкала знаков “!” “+” “-” Приложение 2 )
9. Итог урока (Слайд 9)
Итог урока (Слайд 9)
Что такое суффикс?
- Буратино сказал: “Суффикс — это часть предложения”.
- Мальвина сказала: “Суффикс – это часть слова”.
- Незнайка сказал: “Суффикс — это слово”.
Где в слове стоит суффикс?
- Буратино сказал: “В начале слова”.
- Мальвина сказала: “Суффикс стоит после корня”.
Зачем нужен суффикс?
- Мальвина сказала: “Суффиксы образуют новые слова”.
- Буратино сказал: “Просто так”.
10. Домашнее задание. Сочинить сказку про суффиксы –ок-, -ик-
Используемая литература.
1. И.Ф.Яценко, Т.Н.Ситникова. Поурочные разработки по русскому языку к УМК “Перспектива”. 2 класс. Москва. “ВАКО”. 2013 год.
2. Г.Н.Сычёва. Сборник упражнений по русскому языку для начальной школы. Ростов-на-Дону. “БАРО-пресс”. 2003 год.
Корень в словах «СОЛНЦЕ» и «СОЛНЫШКО»
В слове «солнце», подобрав родственные слова, выделим корень солнц-. В морфемном составе слова «солнышко» укажем корень солн-.
В морфемном составе слова «солнышко» укажем корень солн-.
Разбор по составу слова «солнце»
Чтобы правильно определить корень в составе слова «солнце», начнем с выделения окончания. Для этого понаблюдаем за изменением этого существительное по падежам:
- луч (чего?) солнца;
- радуюсь (чему?) к солнцу;
- любуюсь (чем?) солнцем;
- прочту (о чём?) о солнце.
Это формоизменение дает возможность выделить окончание -е в морфемном составе рассматриваемого существительного среднего рода. Окончание не входит в основу слова -солнц-.
Далее, чтобы определить границы корня, подберем родственные слова:
- солнечный день;
- бессолнечное место;
- переменная солнечность;
- солнцепёк;
- солнцепоклонник..
Как видим, общей частью этих слов, а значит корнем, является морфема солнц-/ солнеч-, в которой появилась беглая гласная «е», а согласный «ц» чередуется с «ч»:
солнц-/солнеч-.
Слово «солнце» имеет корень солнц-.
Запишем морфемный состав анализируемого слова в виде следующей схемы:
со́лнце — корень/окончание.
Солнцем сердце зажжено
Солнце — к вечному стремительность.
Солнце — вечное окно
В золотую ослепительность.
Андрей Белый
Морфемный состав слова «солнышко»
Слово «солнышко» является уменьшительно-ласкательной формой исходного существительного «солнце».
Солнышко на небе раньше всех встаёт.
Поздно спать ложится,
Как не устаёт?
Я бы не смогла так —
По его пути
За один денёчек
Небо всё пройти!А. Малаев
Чтобы определить, какой корень имеется в морфемном составе существительного «солнышко», начнем с выделения других значимых частей слова. В первую очередь определим окончание. Это существительное среднего рода изменяемое:
- сияние (чего?) солнышка;
- рад (чему?) солнышку;
- рисунок (с чем?) с солнышком;
- стихотворение (о чём?) о солнышке.

Понаблюдав за формоизменением интересующего нас слова, выделим в его морфемном составе окончание -о, которое не включаем в основу -солнышк-.
Это существительное образовано с помощью суффикса -ышк-, как и аналогичные слова с уменьшительно-ласкательным значением, например:
- перо — пёрышко;
- дно — донышко;
- крыло — крылышко;
- стекло — стёклышко;
- гнездо — гнёздышко;
- горло — горлышко.
Оставшаяся морфема солн- является корнем рассматриваемого существительного. Представим морфемный состав анализируемого слова в виде следующей записи:
солнышко — корень/суффикс/окончание.
Слово «солнышко» имеет корень солн-.
Скачать статью: PDF
Второстепенные члены предложения. Определение.
Второстепенные члены предложения.
 Определение.
Определение.Автор: edu1
Методическая копилка — Русский язык
Второстепенные члены предложения.
Определение.
Цели урока:
– совместно с учащимися открыть новые знания– признаки определения – одного из второстепенных членов предложения.
– разработать алгоритм нахождения определения в предложении;
– начать развитие умения находить определения в предложении, ставить к ним вопросы;
– начать развитие умения графически обозначать определения.
Ход урока
I. Организационный момент.
Класс украшен иллюстрациями на тему “Осень в лесу”, осенними листьями.
Эпиграф Тебе, Природа, присягаем
Среди лесов, лугов, болот
И ревностно оберегаем
Все, что в тебе живет.
В. Боков.
I I. Повторение изученного материала.
Оформление тетрадей. Дата, классная работа.
— Что сейчас мы изучаем? (Второстепенные члены предложения)
(на доске)
Тихо я бреду одна по саду,
Под ногами желтый лист хрустит.
Осень льет предзимнюю прохладу,
О прошедшем лете говорит.
– О чем это стихотворение?
– А какое сейчас время года? (Осень).
Задания:
1.Сделать синтаксический разбор предложений.
2.Обозначить изученные орфограммы.
3.Разобрать по составу слово “предзимнюю”
Ребята, сегодня мы проводим необычный урок – урок — путешествие в осенний лес.
Вы все любите путешествовать по осеннему лесу? Мы отправляемся туда прямо сейчас.
Звучит музыка П.И. Чайковского «Времена года. Осень».
Осень».
Класс оформлен празднично. На стене и доске плакаты, на полу осенние листья.
III. Введение в тему, запись темы.
(В класс входит ученица в костюме осени и на фоне музыки П.И. Чайковского “Времена года” читает стихотворение Ольги Чуминой “Царевна-осень”.)
– Ребята, кто к нам сегодня пришел в гости?
– А какой она вам запомнилась?
– Вот на сегодняшнем уроке мы будем не только открывать новые знания, но и любоваться последними днями уходящей осени.
Стихотворение читает ученица.
Играет красками природа,
Опять осенняя пора,
И в небе облачные воды
Клубят незримые ветра!
Вот осень золотом взмахнула
Да бриллиантами дождя
И листья с плечика стряхнула,
Себя в порядок приводя!
Ребята, у вас на столах лежат задания, выполните их. (Определения осени)
— Какие вы задавали вопросы?
— Что они обозначают?
– Как бы вы назвали слова, которые обозначают признак предмета? Определяют этот признак? (Определение).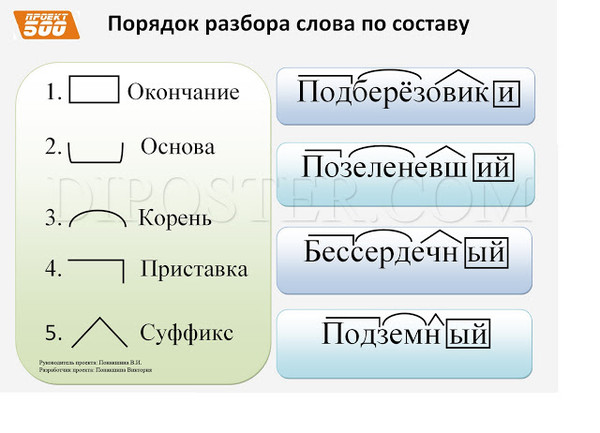
Учащиеся самостоятельно формулируют вывод.
– Попробуйте самостоятельно сделать вывод, что же такое определение.
– Значит, какое новое слово мы допишем в тему урока?
Целеполагание.
– А каковы, на ваш взгляд, цели урока?
Анализ определения по учебнику.
– Давайте сравним ответ учащегося с формулировкой определения в учебнике с.86.
– Есть ли в тексте новая для вас информация?
– А я хочу вам предложить для запоминания шуточное зарифмованное правило А.И.Косоговского.
Признак предмета или явления
Обозначает определение.
Чей и Какой– ответы просты.
Лишь не хватает волнистой черты.
– Так как мы будем подчеркивать определение?
Физминутка.
— Я вижу, вы немного устали, проведем разминку. Я буду называть словосочетание. Если в нем есть дополнение, все приседаем; если определение – хлопаем.
Видеть снег, пушистые снежинки, сильный мороз, кататься на санках, наряжать елку, красивые шары.
Потянулись все, вдох-выдох.
Словарная работа.
– Я читаю загадки, вы их отгадываете и называете определения.
(После каждой отгадки показывается иллюстрация).
Целью вашей работы будет выработка алгоритма нахождения определения.
– Для того чтобы вывести алгоритм, вы должны последовательно выполнить задания, которые даны к тексту. (Тексты у каждого на парте)
Красив, наряден русский лес ранней осенью. Кругом золотые берёзы. Ярким костром горят рябины. Словно груды малахита, зеленеют молодые дубки. Весёлым многоцветьем радуют клёны, осины. Жёлтым ковром расстилаются под деревьями опавшие листья.
Найди в тексте определения. По каким признакам ты их будешь искать?
Выпиши определения со словами, к которым они присоединяются.
Какими частями речи выражены определения?
Графически обозначь связь определений.
Образец записи:
Проверка выполненных работ.
Задание:— послушайте внимательно предложения;
-как вы думаете, без каких слов мы не смогли бы увидеть осенние картины так, как их описали поэты?
-какими средствами художественной выразительности представлены эти слова?
-что такое эпитет?
Эпитет— это образное определение, которое дает художественную характеристику явлению или предмету.
1.Есть в осени первоначальной
Короткая, но дивная пора-
Весь день стоит как бы хрустальный
И лучезарны вечера.
(Ф.И. Тютчев)
2. Лес, точно терем расписной,
Лиловый, золотой, багряный,
Веселой пестрою стеной
Стоит над солнечной поляной.
(И. Бунин)
Итог урока. Рефлексия.
– Какую новую информацию получили, работая на уроке?
– Чему научились?
– Что было самым трудным?
– Что было самым интересным?
– Назовите ключевые слова темы.
VIII. Домашнее задание.
Упражнение 189 или 186 (IIч.) на выбор (по заданию)
У вас есть смайлики, поднимите тот, который покажет ваше настроение на сегодняшнем уроке. Молодцы! Спасибо за урок!
Прочитайте стихотворение Н.Рыленкова.Укажите (в скобках),какой частью речи каждое слово стихотворения.
5-9 класс
Горят( ), как( )жар( ),Слова( )
Иль( ) стынут( ) словно( ) камни( )
Зависит( ) от( ) того( )
Чем( ) наделил( ) их( ) ты ( )
Какими( ) к( ) ним( ).
Iuli4ka 11 апр. 2013 г., 14:59:32 (8 лет назад) Daryamedvedeva
11 апр. 2013 г., 17:19:16 (8 лет назад)
глагол союз существительное существительное
союз глагол союз существительное
глагол предлог местоимение
союз глагол местоимение местоимение
прилагательное предлог местоимение
Ответить
Другие вопросы из категории
Vasilinasineva / 09 апр. 2017 г., 13:48:09
помогите пожалуйста!!!!!!!!!
составить предложения со словами: на зло и назло, в тайне и втайне, в пустую и впустую, желательно не большие, для 7 класса.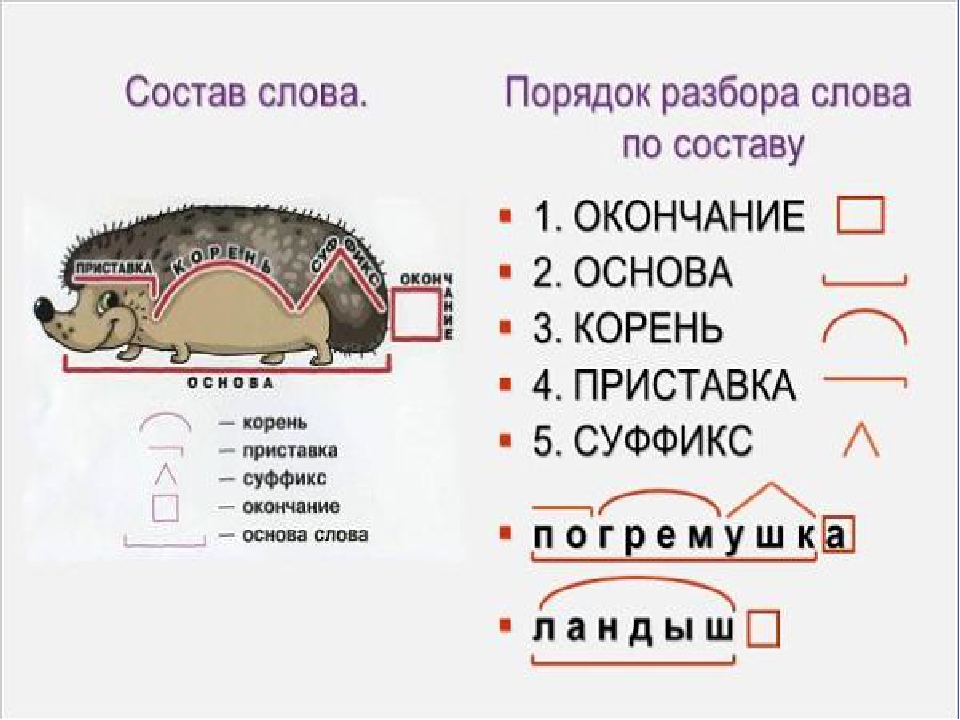 нужно что бы одно предложение
нужно что бы одно предложение
было написано слитно это слова а во втором раздельно
Neduraevageka / 07 апр. 2017 г., 14:15:29
Слово -Легко —
разобрать по составу ,о суфф. Или окончание?
Читайте также
Stepan1598753 / 02 янв. 2015 г., 7:58:33
№1Раскройте скобки.Укажите какими частями речи являются слова с пропусками. 1)Малышка устала,(по)этому быстро
заснула.-(По)этому шоссе машины двигались (не)прерывно.2)(С)начала мы отдохнули на привале,а потом открыли карту и еще раз рассмотрели маршрут,которому следовали (с)начала пути.3)Ученик обдума(н,нн)о подошел к подготовке доклада:содержание работы было обдума(н,нн)о и изложе(н,нн)о в строгом соотвецтвии с планом.
№2.Укажите какой частью речи и членом предложения являются граммотические омонимы.Укажите их морфемный соствав.
1)На душе было тоскливо.2)По серому небу тоскливо плыли серые громадны туч.3)Выражение лица Семена было тоскливо.
Extablet37 / 28 июля 2013 г., 10:21:16
Какой частью речи является слово ДА в этих примерах? Докажите. Сделайте вывод.
Белка песенки поёт да орешки всё грызёт. Из скорлупок льют монету да пускают в ход по свету.
Какой частью речи является частица да?
Частица да — утвердительная
— вопросительная
— усилительная
— формообразующая
проиллюстрируйте данную схему следующими примерами.
1) В лице Анатолия было выражение душевной силы, да именно силы.
2) Я изменился, да?-спросил он,заметив,что я гляжу на него.
3)Вы спрашиваете ,что мне больше всего понравилось. Да то, что и вам!
4)Да будет вам известно,- сказал доктор с торжеством,- что и в двадцатом веке могут случаться чудеса
Вы находитесь на странице вопроса «Прочитайте стихотворение Н.Рыленкова.Укажите (в скобках),какой частью речи каждое слово стихотворения.«, категории «русский язык«. Данный вопрос относится к разделу «5-9» классов. Здесь вы сможете получить ответ, а также обсудить вопрос с посетителями сайта. Автоматический умный поиск поможет найти похожие вопросы в категории «русский язык«. Если ваш вопрос отличается или ответы не подходят, вы можете задать новый вопрос, воспользовавшись кнопкой в верхней части сайта.
Здесь вы сможете получить ответ, а также обсудить вопрос с посетителями сайта. Автоматический умный поиск поможет найти похожие вопросы в категории «русский язык«. Если ваш вопрос отличается или ответы не подходят, вы можете задать новый вопрос, воспользовавшись кнопкой в верхней части сайта.
Разборка пистолета | Бостон Обзор
Техническая задача перевода.
Фото: Wikimedia Commons
Техническая задача перевода поэзии Оуян Цзянхэ нигде не яснее, чем в стихотворении «Пистолет», которое трижды появляется в сборнике Двойные тени (2012), переведенном Остином Вернером.Стихотворение появляется в двух отдельных бесплатных версиях с подзаголовком «после Оуян Цзянхэ» и один раз в приложении, дающем более дословный, аннотированный перевод. Стихотворение требует всех этих усилий, потому что оно работает на chaizifa , разделении слов на составляющие их символы, практике, когда-то использовавшейся для гадания и гадания. Наиболее конкретным примером является центральный объект стихотворения, слово, которое в китайском и английском языках включает иероглиф «рука» и иероглиф «пистолет»: 手枪.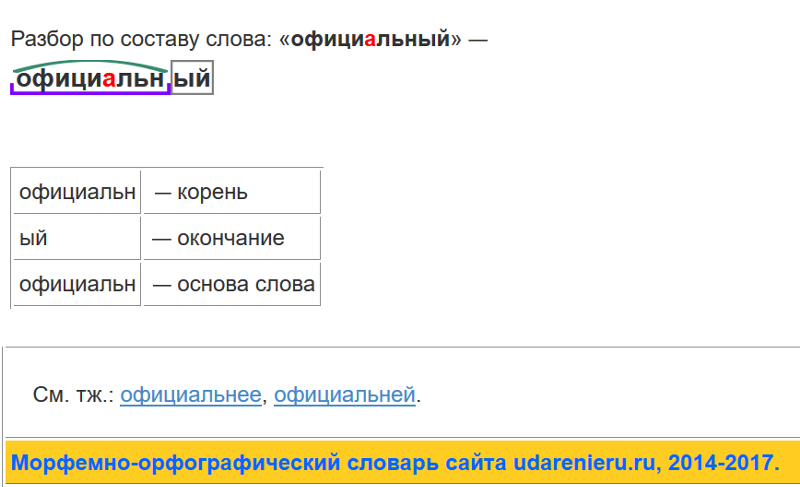
Поэма разделяет составное «пистолет» для тех же гадательных целей, которые мотивировали древнюю чайзифу : чтобы понять объект, нужно прочитать его составные части. Но стихотворение не останавливается после единственного слоя разделения и переосмысления. Четвертая и пятая строки, переведенные дословно, гласят: «если пистолет становится длинным, он превращается в партию / если рука окрашена черными чернилами, она превращается в другую партию». Но в китайском языке «партия длинного оружия» относится к Фаланге, испанским фашистам 1930-х годов, а «партия черной руки» — это название мафии и другой организованной преступности.Этот маневр, в котором китайские иероглифы из «пистолета» объединяются, чтобы образовать названия двух различных насильственных организаций, очевидно, непереводим — его трудно объяснить даже в абзаце английской прозы.
Как говорится в одном из других переводов Вернера «Пистолет», «мир делится на бесконечные деления»: после chaizifa не существует практического способа снова соединить слова — или миры — вместе. Этот процесс, как декомпозиционный (что-то разбитое на части), так и композиционный (потому что эти части затем рассказывают новую историю), не просто то, что делает художник или писатель, но фундаментальный процесс природы — эрозия, энтропия.Эмоции, которые мы скрываем внутри словесных матрешек, проявляются по мере того, как слова рассыпаются.
Этот процесс, как декомпозиционный (что-то разбитое на части), так и композиционный (потому что эти части затем рассказывают новую историю), не просто то, что делает художник или писатель, но фундаментальный процесс природы — эрозия, энтропия.Эмоции, которые мы скрываем внутри словесных матрешек, проявляются по мере того, как слова рассыпаются.
Американские дебаты по поводу регулирования огнестрельного оружия иногда напоминают мне «Пистолет». Я думаю о том, насколько виртуальным и абстрактным становится оружие стихотворения, насколько концептуальным в языке становится роскошь, может быть, для гражданина Китая, который никогда не сталкивался с широтой частной коллекции оружия гражданина США и не встречал человека с высоким автомат во время похода на природу. (Оуян много путешествует по Соединенным Штатам и выезжает из них, так что, возможно, это не так: его новейшие стихи посвящены монументальной статуе, которая висит в соборе Св.Иоанна Богослова в Нью-Йорке.) Если бы я написал стихотворение об огнестрельном оружии, оно бы испугалось, рассердилось или ехало; Было бы трудно не обращать внимания на мой опыт обращения с оружием и на как на феномен, как языковой артефакт, а также как материальное оружие.
Более отдаленная перспектива Оуян может помочь нам понять, почему дискуссия об оружии столь остра, как она есть, когда одна сторона пытается разделить оружие на составляющие категории — приемлемые, регулируемые, неприемлемые — а другая — объединить все виды оружия, поводов и мотивов согласно термину Второй поправки «оружие.Этот тупик объясняет, почему защитники оружия пролили так много чернил, утверждая, что AR-15 Bushmaster похож на все другие винтовки, а не на какой-то особый вид противопехотной или штурмовой винтовки: если его нельзя отделить от другого оружия, он будет это намного сложнее регулировать. Разграничивать части категории — значит захватывать определенную власть над ней.
Наша инстинктивная любовь к тому, что нам близко или похоже, должна быть поставлена под сомнение.
Однако стихотворение
Оуян напоминает нам, что, когда мы говорим об оружии, мы всегда говорим о людях, а также об именах и вещах: слово, используемое определенным образом, представляет сообщество, которое разделяет его определение. Если слово разделяется, разделяется и сообщество; разделите сообщество, и его новые отдельные члены сами разделят слова (версия Вернера: «вы можете разделить фракцию / на другие группы / партии / амбиции / вы можете разбить ее на действие или действие»). Для тех, кто заинтересован в поощрении разумного контроля над огнестрельным оружием, обязательной проверки биографических данных или отслеживания оружия, вопрос перестает быть полностью посвященным отношениям между людьми и их оружием, а начинает касаться отношений между людьми и людьми.Мы знаем, что владельцы оружия, скорее всего, состоят в браке с белыми южанами, что они непропорционально много республиканцев и что главной причиной владения оружием является личная безопасность. Отличительной чертой этого конкретного сообщества является его сплоченность — не просто самоподобие в действиях или идеологии, но ощущение , что одна когорта близка и заслуживает доверия, и что угрозы исходят в основном от других. Первое предположение о закрытом сообществе — это то, что внутри ворот безопасно, а снаружи опасно.
Если слово разделяется, разделяется и сообщество; разделите сообщество, и его новые отдельные члены сами разделят слова (версия Вернера: «вы можете разделить фракцию / на другие группы / партии / амбиции / вы можете разбить ее на действие или действие»). Для тех, кто заинтересован в поощрении разумного контроля над огнестрельным оружием, обязательной проверки биографических данных или отслеживания оружия, вопрос перестает быть полностью посвященным отношениям между людьми и их оружием, а начинает касаться отношений между людьми и людьми.Мы знаем, что владельцы оружия, скорее всего, состоят в браке с белыми южанами, что они непропорционально много республиканцев и что главной причиной владения оружием является личная безопасность. Отличительной чертой этого конкретного сообщества является его сплоченность — не просто самоподобие в действиях или идеологии, но ощущение , что одна когорта близка и заслуживает доверия, и что угрозы исходят в основном от других. Первое предположение о закрытом сообществе — это то, что внутри ворот безопасно, а снаружи опасно.
Предположение о стабильном интерьере, объединенном — и вооруженном — против опасного внешнего вида, — это одно из ряда предположений об оружии и владении оружием, которое необходимо изменить. В то время как мы пытаемся положить конец расовой дискриминации и преступности, основанной на бесчеловечных и несправедливо применяемых законах, мы должны опровергнуть бойкие утверждения о том, что небелые общины и культуры несут особую ответственность за преступность. Но мы также должны изменить наши представления о безопасном белом интерьере. Новые данные, полученные от CDC, подтверждают, что значительная часть опасности оружия исходит не от взаимодействия инсайдеров и посторонних, а от внутриобщинного насилия: самоубийства, несчастные случаи и домашнее насилие намного перевешивают убийства, связанные с массовыми убийствами или другими видами преступлений.Хэштег Twitter #criming Whilewhite был создан для того, чтобы белые люди, получившие оправдание в совершении преступлений, могли указать на двойные стандарты полиции и системы правосудия; то, что это не часто дает нам, так это ощущение насилия и интимности белого преступления. Когда человек, белый или черный, умирает в результате насилия в Соединенных Штатах, непропорционально высока вероятность того, что это произошло от руки знакомого, партнера или супруги, и они, скорее всего, носят пистолет.
Когда человек, белый или черный, умирает в результате насилия в Соединенных Штатах, непропорционально высока вероятность того, что это произошло от руки знакомого, партнера или супруги, и они, скорее всего, носят пистолет.
Рядом с кульминацией «Пистолета» статуя «вечной Венеры» стоит / ее руки отвергают человечество / она вытаскивает из груди / пару ящиков — / две пули из пистолета.. . . » Насилие здесь не всегда вызвано ненавистью: Венера тоже убийца. Замужем за богом войны, супругой бога кузницы, она спровоцировала Троянскую войну. Подготовка к насилию, которую представляет владение оружием для самообороны, также не вызвана одной лишь ненавистью. Частично это вызвано любовью, чувством того, что человек стремится защитить свой внутренний круг и что его окружение более надежно и ценно, чем другие ». Оба эти предположения ложны, и мы знаем от Фрейда так же, как и наши На собственном опыте убедился, что влечение к смерти, врожденно связанное с нашими страстями, по ночам преследует каждый дом. Наша инстинктивная любовь к тому, что нам близко или похоже, должна быть поставлена под сомнение, особенно когда она распространяется на окрестности, пригород, расовую группу. Острый и направленный страх перед другими — это акт отрицания и превосходства; указывать испуганным пальцем на опасности других сообществ — значит хранить зловещее молчание о собственной мелочности, несовершенстве и гневе.
Наша инстинктивная любовь к тому, что нам близко или похоже, должна быть поставлена под сомнение, особенно когда она распространяется на окрестности, пригород, расовую группу. Острый и направленный страх перед другими — это акт отрицания и превосходства; указывать испуганным пальцем на опасности других сообществ — значит хранить зловещее молчание о собственной мелочности, несовершенстве и гневе.
Чайзифа , разложение слов на символы, символов на элементы, партии на людей, не прекращается, когда достигает границы тела.Пистолет Венеры находится внутри нее, как и ее боеприпасы и гнев: точно так же, как мы не должны автоматически предполагать, что наши соседи и друзья являются подходящими и безопасными обладателями смертоносного оружия, мы также не должны предполагать то же самое в отношении самих себя. Многие из нас слышали об ужасной стрельбе инструктора по огнестрельному оружию на стрельбище в Неваде, но за последние три месяца по крайней мере три инструктора по огнестрельному оружию застрелили других или себя. Это люди, которым поручено обучать других владельцев оружия безопасному обращению с оружием.Очевидно, что никакое обучение не может сделать людей, кроме людей; высокомерное неприятие этой человечности лучше всего оставить богам и богиням или, по крайней мере, фигуркам из камня.
Это люди, которым поручено обучать других владельцев оружия безопасному обращению с оружием.Очевидно, что никакое обучение не может сделать людей, кроме людей; высокомерное неприятие этой человечности лучше всего оставить богам и богиням или, по крайней мере, фигуркам из камня.
Когда мы разбираем наши кварталы, наши семьи и самих себя, мы видим, что есть часть нас, которая сопротивляется использованию смертоносной силы, и часть нас, которая гонится за ней. Мы рассматриваем страсть американцев к оружию как символ этого искаженного, глубоко человеческого очарования смертью. Лучшая защита от этих внутренних угроз — не иметь оружия, но и не иметь оружия.И когда мы говорим об угрозах безопасности Америки, мы всегда должны в первую очередь перечислять себя: злобная рука, держащая оружие. Вернер переводит «Оуян» так: «одним глазом ты нацеливаешься / на любовь; другой вы врезаете в дуло пистолета. . . вы берете свою руку- / пистолет, стреляете на запад- / на востоке падает человек ».
Мариса Адаме | Как разобрать ружье »вики полезно Поэты сопротивляются
Poets Resist
Отредактировал Майкл Картер
7 августа 2019 г.
Мариса Адаме
Как разобрать ружье
И.Разрядить пистолет.
Направьте траур в безопасном направлении. Убедитесь, что ненависть направлен в сторону, где любой случайный разряд не может причинить физический вред вам или кому-либо еще.
· Держите ваш угнетатель подальше от спускового крючка и вне ограждения. Это поможет предотвратить случайное возгорание.
Освободите кошмар . Нажмите на фиксатор магазина большим пальцем и снимите онемение другой рукой.
Открыть рану . Продолжая направлять pain в безопасном направлении, потяните назад безразличие и заблокируйте его в открытом положении с помощью рычага блокировки скольжения. Вы можете поднять рычаг большим пальцем, удерживая при этом accept другой рукой. Это будет держать рану раны открытой.
Проверить, не осталось ли боеприпасов. Как только рана открыта, посмотрите на мучения и убедитесь, что в корпусе не осталось боеприпасов. Мизинцем найдите боеприпасы и в завтрашнем выпуске новостей .
Мизинцем найдите боеприпасы и в завтрашнем выпуске новостей .
· Плачьте три раза за оставшиеся боеприпасы, прежде чем приступить к разборке горя .
II. Снимите слайд.
Наденьте защитные очки. Есть несколько подпружиненных компонентов, которые могут вызвать серьезное повреждение глаз. Очки также помогут защитить от попадания растворителей и растворов // надеюсь, что попадут вам в глаза.
Закройте слайд. Потяните ползун назад, чтобы освободить // упор. онемение. ум закроется. Направьте пистолет в безопасном направлении и потяните за мучения , чтобы освободить огнестрельную рану .
Возьмитесь за , больно . Держите пистолет одной рукой, держа четыре пальца за верхнюю часть затвора, а большим пальцем придерживая рукоятку.
Оттяните ползун. Используя четыре пальца на верхней части disbelieve , потяните его назад примерно на 1/10 дюйма. Если вы отодвинете его слишком далеко, вам нужно будет полностью оттянуть Heartbreak и перезапустить процесс.
Если вы отодвинете его слишком далеко, вам нужно будет полностью оттянуть Heartbreak и перезапустить процесс.
Опустите защелку. Другой рукой потяните вниз обе стороны рычага блокировки ползунка. Четыре пальца протолкните вперед рану и , пока она не отделится от ствольной коробки пистолета.
III. Снимаем ствол.
Снимите пружину. Слегка сдвиньте status quo вперед и снимите его со ствола.
Пружина находится под давлением, поэтому будьте осторожны при ее снятии.
Вытащить ствол из затвора. Удерживайте корпус за выдавливающие легкие . Поднимите ствол, слегка надавив вперед. Поднимите и вытащите семейство из боли .
Очистите пистолет. После разборки пистолета life можно приступать к чистке пистолета. Вам не нужно разбирать самодовольство дальше, чем это, чтобы должным образом чистить и обслуживать его.
Собрать пистолет. После того, как вы закончите чистку, вы можете снова собрать дочерний , выполнив указанные выше действия в обратном порядке. Вам не нужно будет удерживать Heartbreak , когда снова кладете denial на приемник.
Вам не нужно будет удерживать Heartbreak , когда снова кладете denial на приемник.
«Как разобрать оружие» направлено на решение проблемы насилия с применением огнестрельного оружия и самоуспокоенности в связи с отсутствием законодательства, которое делает такие ужасы обычным явлением. Я начал работу рано утром 13 ноября 2017 года — по завершении я попытался выяснить, на какую съемку она началась как реакция, но, конечно, в тот день и дни вокруг него было несколько ужасных событий.Вскоре я оставил его из-за усталости, печали и неспособности понять, о чем меня просило стихотворение. Ярость, утешение, отчаяние, поражение — что это должно было сказать? Время дало мне перспективу доработать это стихотворение до его истинной версии: выражение горя, которое также стремится побудить читателя к действию. Поэтическая форма в основном не моя: основной текст взят из статьи WikiHow о том, как разбирать оружие.
Poets Resist издается Glass Poetry Press.
Все материалы © автор.
Обзор пейзажа с фанерными силуэтами Керрин МакКадден
Пейзаж с фанерными силуэтами
Керрин Маккадден
Пресса о новых выпусках
84 страницы, $ 15
Отзыв от Джоселин Хит
Пейзаж Керрин МакКэдден полон костей и пыли, одеял и мебели, старых писем и атрибутов прошлых времен. Просеивая обломки разводов и повседневной жизни, Маккэдден собирает трансцендентные моменты в портрет женщины, перестраивающей жизнь на глубину, неизвестную фанерным силуэтам, которые ходят среди нас.
Многие стихотворения в Пейзаж связаны с семьей, поскольку мы собираем и разбираем ее на протяжении всей жизни. Маккэдден исследует расторжение брака и, как следствие, заново познает любовь, в стихах, напоминающих « Late Wife » Клаудии Эмерсон. «Вот так я складываюсь вами», — пишет она в «Определении», — как молитва, как земля, как оригами, как простыни, и, наконец, тени: «Я складываю их обратно / в ночь, каждую простынь на берегу озера. Я себя с трудом узнаю ». Мимолетность всего, включая любовь, шепот за каждым стихотворением, выходит на первый план в «Костном Китае»:
Я себя с трудом узнаю ». Мимолетность всего, включая любовь, шепот за каждым стихотворением, выходит на первый план в «Костном Китае»:
Но сегодня мы тосты за другое, а не за
.
годовщина моей свадьбы, которой больше нет,
вроде брак. Интересно, все ли видят
черная дыра, прямо рядом со мной.
Отсутствие — и связанные с этим маневры, которые она совершает вокруг него — затрагивают все уголки жизни говорящего.«Лайка», например, переключает внимание с говорящего как женщины на говорящего как мать, пытаясь найти рациональное объяснение развода детям и находя аналогию в истории с русской космической собакой. Хотя истинное завершение такого вопроса может оказаться недостижимым, докладчик может найти немного покоя к концу коллекции или, по крайней мере, вернуть себе «одну жизнь».
Стихи МакКэддена полны — временами почти переполнены деталями, как в «Элегии для некоторых пляжных домиков», где читателю приходится пробираться через дома, «полные всякого мусора, сусла, шкафов и диванов, полных ловушек для омаров / кофейных столиков». старые письма, рваные коврики »и огромное количество мусора.Но вера читателя в способность МакКэддена ориентироваться в каскадных изображениях окупается в моменты тихих, но чреватых откровений, которыми пронизана коллекция.
старые письма, рваные коврики »и огромное количество мусора.Но вера читателя в способность МакКэддена ориентироваться в каскадных изображениях окупается в моменты тихих, но чреватых откровений, которыми пронизана коллекция.
McCadden временами захватывает дух у читателя обезоруживающей искренностью; ее оратор, кажется, так же поражен, как и мы, тем, что она обнаружила. В «Перекрестке» читатель сидит с говорящим на перекрестке доброты: два водителя решительно настроены превзойти друг друга в жестах вежливости « нет, нет, вы идете » и «, нет, пожалуйста, », имитируя отношения. в стазисе.Слишком вежливо, чтобы прекратить отношения, но слишком вежливо, чтобы изобразить глубокие чувства. В мгновение ока говорящий ходит по этажам памяти, но не возвращается к новому концу: «Ваша машина въезжает в пространство, которое я построил между нами». В мгновение ока перекресток мыслей и человеческих связей быстро остается позади.
Даже возможность подключения должна быть тщательно проверена. Силуэты в заглавном стихотворении — мужчина, опирающийся на трейлер, и женщина, махающая ему рукой, — «черные внутри / в контуре», они переживают внутреннюю пустоту, но проецируют друг на друга детали своих желаний.В конце концов, «заполнение пробелов / не является необоснованным ни в их мире», ни в нашем. Искушение увидеть то, что хочется видеть в любовнике, вызывает острые ощущения во время ухаживания, но создает реальную опасность разочарования после него. И увидев этот процесс таким, какой он есть, оратор защищает себя от поверхностных романтических волн.
Силуэты в заглавном стихотворении — мужчина, опирающийся на трейлер, и женщина, махающая ему рукой, — «черные внутри / в контуре», они переживают внутреннюю пустоту, но проецируют друг на друга детали своих желаний.В конце концов, «заполнение пробелов / не является необоснованным ни в их мире», ни в нашем. Искушение увидеть то, что хочется видеть в любовнике, вызывает острые ощущения во время ухаживания, но создает реальную опасность разочарования после него. И увидев этот процесс таким, какой он есть, оратор защищает себя от поверхностных романтических волн.
Понятие пейзажа встречается во многих вариациях. Хотя многие из произведений, кажется, происходят в тихой деревне, некоторые выходят за эти географические границы, а другие по-прежнему пересекают психологические ландшафты в самых узких границах.«Южное плоскогорье» делает и то, и другое. В австралийской дикой природе «предупреждения / вот чары», птицы «окрашены, как облака и кровь», а путешествия с любовником все еще могут привести к неожиданным результатам. Она пишет: «Мы с тобой были в игре / так долго, что Я люблю тебя — тайна, столь же неожиданная, как / придорожные попугаи». В деревне, в пустыне, зимой и в темноте Маккэдден смотрит глубоко в пространство вокруг себя и собирает в стихах те части, которые нам нужно увидеть.
Она пишет: «Мы с тобой были в игре / так долго, что Я люблю тебя — тайна, столь же неожиданная, как / придорожные попугаи». В деревне, в пустыне, зимой и в темноте Маккэдден смотрит глубоко в пространство вокруг себя и собирает в стихах те части, которые нам нужно увидеть.
Среди самых ярких моментов в книге — моменты жалкого одиночества, истина человеческого состояния, усиленного утратой. «То, что я сказал ночи» находит говорящего одного в зимней темноте, складывающего белье «для детей / ушедшего в отцовский дом». Маккадден хорошо знает, куда может пойти ум в такие моменты; говорящий говорит нам: «Всю ночь я откупорил старые закупленные вещи», из которых только скотч. Хотя она, наконец, решает встретиться лицом к лицу с темнотой и «одинокой вещью», поцеловать ее, как любимого ребенка, признание вины за замену семьи показывает всю глубину борьбы оратора.
Все, что не может быть исправлено в Пейзаж с фанерными силуэтами — свадьба, ржавый классический автомобиль, финал стихотворения — в этом мире есть что праздновать. Как напоминает нам Маккадден, у нас одна жизнь; пригласить его «поселиться с нами» открывает нам возможности, которые лежат в мельчайших следах пыли вокруг нас.
Как напоминает нам Маккадден, у нас одна жизнь; пригласить его «поселиться с нами» открывает нам возможности, которые лежат в мельчайших следах пыли вокруг нас.
Поэма Джули Сварстад Джонсон
Долина Солнца
Агентство так сложно определить
в памяти.Сетка для бассейна сползла
сквозь темный воздух и в воду,
затем оперение под корпусом
пустынной жабы. Сотрясся,
Я бы сказал, грядка,
и исчезли лапы жабы
в пустую почву.
*
При перемотке окраины разваливаются, окраина города отступает. Я знаю, это не то, что вы думаете о городе, но как еще я могу назвать этот человеческий голод, простирающийся от горы к горе? Перемотайте, и черепица стекает с крыш через воздух, покрытый хлопковыми пучками, толстыми слоями на тротуарах, прежде чем тротуары рассосутся.Перемотайте назад и наблюдайте за цветением фермерского дома на углу, проплывающими мимо досками и балками, вздыбленным вверх тополем и пылающей зеленью на фоне нашего огромного неба. Утка как апельсины, грейпфруты и лимоны проносятся мимо. Они садятся на фруктовые прилавки всего на мгновение, прежде чем прыгнуть на деревья, падая звездочками наоборот. Если вы проявите смелость, перемотайте еще дальше, и каждая роща и поле растают в потоке поливной воды, а затем вода, наконец, вернется на землю. Пустыня должна быть там, если вы вернетесь достаточно далеко, хотя, признаюсь, я не совсем вижу ее.
Утка как апельсины, грейпфруты и лимоны проносятся мимо. Они садятся на фруктовые прилавки всего на мгновение, прежде чем прыгнуть на деревья, падая звездочками наоборот. Если вы проявите смелость, перемотайте еще дальше, и каждая роща и поле растают в потоке поливной воды, а затем вода, наконец, вернется на землю. Пустыня должна быть там, если вы вернетесь достаточно далеко, хотя, признаюсь, я не совсем вижу ее.
*
Площадь
, что самое
знакомое созвездие:
банк, продуктовый магазин,
АЗС, аптека.
*
Мне нравится думать об этой жабе
как о путешественнике,
весь мир остановился, не двигаясь,
пока она движется, передает
из воды в воздух и на землю.
Мне нравится думать, что она
все еще копает к огню, где-то
глубоко под землей
в месте, куда мы никогда не дойдем.
Ее не остановить
из-за твердой почвы, которая удерживает нас
от рытья подвалов
и метро, заставляет нас копать
все дальше и дальше.
Десять лет назад я покинул
Долину, и с тех пор на мое место прибыло
миллионов человек.
Вы видели мой маленький
возлюбленный, о дикий
человеческий город? Вы видели, как
мой дорогой странник
покидает нас? Звезды прошли с ней
.Ночное небо
отражает все наши огни обратно вниз
, поэтому мы знаем, что они исчезли.
Поэт: Лиз Аль, Бриджуотер Стихи Лиз Аль публиковались в Prairie Schooner, The Women’s Review of Books, The Laurel Review, Southern Poetry Review, The American Voice, The Formalist, Crab Orchard Review, и других литературных журналах и антологиях. Она является автором На авеню вечного мира (Lyra Press, 2002), коллекции ограниченного выпуска, созданной книжными художниками Джо Руффо и Дениз Брэди (см. Ссылку ниже).Она проживала в программе резиденций Jentel Artist (Вайоминг) и в Центре искусств имени Киммела Хардинга Нельсона (Небраска). В своем демонстрационном стихотворении Лиз пишет: «Всякий раз, когда я работаю над наборным проектом, меня поражает, как кажется, что язык разбирается на части, даже когда я буквально собираю слова.Шрифт тяжелый, грязный и крошечный, и построение строфы текста становится чисто физическим действием. Этот поступок, в свою очередь, напоминает мне (почему я всегда забываю?) О языке как о физической вещи. Слова имеют вес. Даже пустое место (ведущее, сделанное из полос — вы догадались — свинца!) Имеет вес и должно учитываться. Я также иногда вносил небольшие правки в стихи, когда набирал их — я думаю, это результат сочетания медленного темпа работы и физического переплетения строк. Тип настройки По одному, я переворачиваю каждый символ вверх ногами, Из мелкого разделенного ящика, каждая буква медленно продвигается к значению.Полуденный свет так поздно, даже блоки типа, уже установленные, удлиненные, Эта работа тянется даже длиннее, чем тени, букв на месте, я больше не привязан к языку. , я еще не вижу, страница текста отшлифована и закончена Мои пальцы испачканы смыслом. огромное количество предложений — главные персонажи связаны в камбузе, то, что они говорят моим пальцам, , немедленная боль, пронизывающая мои плечи Для получения дополнительной информации о Лиз Ахл посетите: |
 Она исполнила свои стихи в сотрудничестве с музыкантами и танцорами и создала ручные печатные листы своих работ и работ других людей. Проведя первую половину своей жизни в качестве странствующего мальчишки и аспиранта военно-морского флота, она приземлилась в Нью-Гэмпшире, что выглядит как долгий путь. Она преподает письмо в Государственном университете Плимута.
Она исполнила свои стихи в сотрудничестве с музыкантами и танцорами и создала ручные печатные листы своих работ и работ других людей. Проведя первую половину своей жизни в качестве странствующего мальчишки и аспиранта военно-морского флота, она приземлилась в Нью-Гэмпшире, что выглядит как долгий путь. Она преподает письмо в Государственном университете Плимута. Вспоминая работу над этим стихотворением, я помню, как решил, что куплеты сделали достойную работу, предоставив этому стихотворению большое количество белого пространства, немного замедлив его темп. Тип настройки включает в себя множество запусков и остановок. Я надеюсь, что это стихотворение описывает для читателей как физический, так и метафизический опыт такого рода работы ».
Вспоминая работу над этим стихотворением, я помню, как решил, что куплеты сделали достойную работу, предоставив этому стихотворению большое количество белого пространства, немного замедлив его темп. Тип настройки включает в себя множество запусков и остановок. Я надеюсь, что это стихотворение описывает для читателей как физический, так и метафизический опыт такого рода работы ».
Чарльз Теония рассматривает «Стихи на открытке» Джейми Берроута — OmniVerse
Открытка Стихи
Джейми Берроут
2016
«Чем стихотворение больше, чем запись того, что я написал перед тем, как быть убитым?»
Джейми Берроут показывает нам, как при каждом взаимодействии — в здании суда, в клинике, дома, на улице — ставки для цветных транс-женщин всегда высоки, и одна из самых насущных проблем ее работы — исследовать, насколько широко распространено насилие. направленный на вас и других, подобных вам, формирует ваше самоощущение.
направленный на вас и других, подобных вам, формирует ваше самоощущение.
Ее коллекция Postcard Poems — это три сборника стихов в прозе, разделенных по местам, мигрирующих из Портленда в округ Лос-Анджелес, на окраины Южного Техаса. Язык лаконичный и прямой; многие истории читаются как притчи. Они удерживаются даже тогда, когда становятся реальными, возможно потому, что говорящий воспринимает мир с такого огромного расстояния, что каждое пространство опосредовано ее удалением от него. Тем не менее, стремление к соединению питает эту книгу. На вопрос о том, каким может быть стихотворение, она отвечает, глядя вовне.Ее работа — это поэтика самосохранения через движение к отношениям: «Поэзия: теперь между нами нет дистанции».
Одна из величайших сил этих стихотворений — их восстанавливающая фантазия. Берроут подчеркивает сюрреалистичность повседневных отношений с людьми из СНГ, от городской бюрократии до розничной торговли, а затем разыгрывает месть. Здесь клерки и охранники, которые так громко смеются над вами, сгибаются пополам, когда их легкие сжимаются от украденного дыхания их случайного фанатизма. Затем в Лос-Анджелесе,
Затем в Лос-Анджелесе,
Я был слишком высоким для одежды в магазинах.Всякий раз, когда я заглядывал в магазин одежды, клерки кричали и качали головами в мою сторону. Я перестал носить одежду. Теперь, когда я перехожу через ряды машин по дороге на работу, люди сбиты с толку еще больше, чем раньше. Люди меня боятся; я отталкиваю их; но их тревожит их влечение ко мне: каждый из них, один по ночам в своих комнатах, будет медитировать над моим образом и, возможно, пересмотреть свои предрассудки. Они уничтожат меня за то, что я существую, или я разрушу их иллюзии.
 Благодаря своему отказу перестать быть явно непомерным, неприличным, конфронтационным существом, оратор представляет, как трансгендеры могут перестать искажать себя в мире, который нам не подходит. Мы его вскроем, иначе это не выдержит, но так дальше продолжаться не может.
Эти моменты фантазии кажутся стабилизирующими, но я понимаю, что Берроут не заканчивается заверением в том, что мы заслуживаем существования. Повествование снова и снова возвращается к трудностям этого существования, отрицая разрешение.Не знаю, читал ли я когда-нибудь еще одну строчку стихов, которая делает со мной то же, что и эта: «Я хочу, чтобы мой стыд остановил то, что она делает». Есть что-то настолько безнадежное и обнадеживающее одновременно — стыд — это свойство, которое можно укротить, как причесанные волосы. Каким-то образом это ее, и все же не то, что она делает с собой, как ей присуще, так и нет. Сразу кажется, что что-то изменить можно и невозможно.
Где стихи действительно находят решение, так это в самом себе: трудно найти любовь, семья тебя не удержит, дети невозможны — отрасти волосы.Сообщество — это ветер, который дует вокруг говорящего и исчезает; тепло и вода в воздухе без этого заставляют быть рядом со всеми угнетающими. Кажется почти несправедливым или недобрым сказать, что изоляция говорящего ограничивает стихотворения, но я хотел спросить ее, что произойдет, если вы поговорите с другими людьми? Я был взволнован, увидев, что Берроут начинает отвечать на этот вопрос в своей последней статье, которой она делится в Интернете.
Когда я писал о работе Берру, я говорил «мы», но даже несмотря на то, что она, говорящий и я во многом схожи, есть и другие важные аспекты, в которых мы разные.Одна из продуктивных задач для меня при чтении этих стихотворений заключалась не в том, чтобы избавиться от этих различий в родственной близости, а в том, чтобы позволить им остаться. В последнем стихотворении она наставляет: «Разбери, там стоит белый человек». Вместо того, чтобы просто кивать себе: «О да, сколько раз я ломал себя, чтобы продолжать существовать перед цис-людьми, мужчинами, натуралами, мужчинами», я должен был сделать паузу и подумать о тех случаях, когда я заставлял других , цветные люди, транс-женщины, разобрать, даже через мое присутствие.Представляя транс-литературу, нам нужно сосредоточить больше внимания на подобной работе, которая требует, чтобы мы были целым и разнообразным «я» вместе.
Джейми Берроут — мексиканская транс-женщина из Южного Техаса. Она живет на северном побережье Калифорнии и ведет блог на desdeotromar. tumblr.com. Соредактор готовящейся к выходу антологии художественных произведений цветных транс-женщин, ее первый роман — «Долины Отроса», а ее последняя книга — «Неполные рассказы и эссе». Ее книги бесплатно доступны транс-женщинам в ее блоге.
Чарльз Теония — поэт и учитель из Бруклина, где они работают над воплощением своего внутреннего женского пейзажа. Они являются автором книги «Который является мостом» и ведут блог, посвященный в основном поэзии, на сайте qu-arles.tumblr.com. Вместе с Джульетой Сальгадо они редактируют «Femmescapes», где четыре стихотворения Беррута появляются в томе 1.
Поэма разрозненных частей — Архив поэзии
На острове Роббен учились политические заключенные.
Они придумали девиз «Каждый учи одного».
В Аргентине мучители потребовали заключенных.
Обращайтесь к ним всегда «Профессор».
Многие из моих друзей тронуты чувством вины, но я
Стыдно признаться, я — создание стыда.
Культивирование замка, культивирование ключа. Воображение
, которое называет вареные бараньи головы «Смайликами».
Первый год в Гуантанамо, Абдул Рахим Дост
Врезал свои стихи на пушту в пенопластовые чашки.
«Сангомо говорит, что в нашей зулусской культуре мы не
поклоняемся нашим предкам: мы консультируемся с ними.”
Бекки брошена в 1902 году, Роуз умирает, дав
рождений в 1924 году, а Сильвия падает в 1951.
Все еще падают, умирают, все еще заброшены в 2005 году
Еще ничего не закончено среди потомков.
Я поддерживаю войну, — говорится в комиксе, — это просто войска
, против которых я выступаю: терпеть не могу этих молодых людей.
Гордится павшими, гордится своим сыном-бомбардировщиком.
Стыдно за правительство. Скептически настроен.
После того, как клановец был признан невиновным, один из присяжных
сказал, что она просто не могла голосовать, чтобы осудить пастора.
Для кого ты пишешь? Я пишу для умерших:
Для Эмили Дикинсон, для моего деда.
«Предки говорят, что проблема с вашими коленями
началась с ваших ног. Он может подняться по твоей спине ».
Но потом американцы подарили Досту не только бумагу
И ручку, но и книги. Хемингуэй, Диккенс.
Старый Эгиптиус сказал: «Кто бы ни созвал это собрание,
» По какой-то причине — это само по себе благо.
О жаждущие тени, взирающие на подношение,
о испорченная земля.Есть много фальшивых Сангомо. Это реально.
Цветные заключенные получали различное питание и могли носить
Длинные штаны и нижнее белье, черные — только шорты.
Нет, он говорит, что не может сожалеть о трех годах тюрьмы:
Иначе он бы не написал эти стихи.
У меня провинциальный ум. Вроде греков и троянцев.
Позор. Гордость. Как важно хорошо или плохо выглядеть.
Видел ли он что-нибудь похожее на узника на поводке? Да,
В Афганистане.В Гуантанамо он был изолирован.
Наши враги «разберутся», — говорит Президент.
Не то, чтобы кто-то вообще не мог ошибиться.
Професоры придумали для орудий пыток прозвища:
Самолет. Лягушка. Отрыжка младенца.
Слова «стихотворение» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «стихотворение» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «стихотворение» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «стихотворение».
Содержимое:
- 1 Слоги в слове «стихотворение»
- 2 Как перенести слово «стихотворение»
- 3 Морфемный разбор слова «стихотворение» по составу
- 4 Сходные по морфемному строению слова «стихотворение»
- 5 Синонимы слова «стихотворение»
- 6 Ударение в слове «стихотворение»
- 7 Фонетическая транскрипция слова «стихотворение»
- 8 Фонетический разбор слова «стихотворение» на буквы и звуки (Звуко-буквенный)
- 9 Предложения со словом «стихотворение»
- 10 Сочетаемость слова «стихотворение»
- 11 Значение слова «стихотворение»
- 12 Склонение слова «стихотворение» по подежам
- 13 Как правильно пишется слово «стихотворение»
Слоги в слове «стихотворение»
Количество слогов: 6
По слогам: сти-хо-тво-ре-ни-е
По правилам школьной программы слово «стихотворение» можно поделить на слоги разными способами. Допускается вариативность, то есть все варианты правильные. Например, такой:
сти-хот-во-ре-ни-е
По программе института слоги выделяются на основе восходящей звучности:
сти-хо-тво-ре-ни-е
Ниже перечислены виды слогов и объяснено деление с учётом программы института и школ с углублённым изучением русского языка.
т примыкает к этому слогу, а не к предыдущему, так как не является сонорной (непарной звонкой согласной)
Как перенести слово «стихотворение»
сти—хотворение
стихо—творение
стихот—ворение
стихотво—рение
стихотворе—ние
Морфемный разбор слова «стихотворение» по составу
| стих | корень |
| о | соединительная гласная |
| твор | корень |
| ени | суффикс |
| е | окончание |
стихотворение
Сходные по морфемному строению слова «стихотворение»
Сходные по морфемному строению слова
Синонимы слова «стихотворение»
1. элегия
2. ода
3. сонет
4. триолет
5. эклога
6. буриме
7. георгика
8. касида
9. мадригал
10. палинодия
11. рондель
12. тавтограмма
13. шестистишие
14. пятистишие
15. трехстишие
16. восьмистишие
17. двустишие
18. газель
19. канцона
20. секстина
21. сиджо
22. экспромт
23. эпиграмма
24. эпиталама
25. эпитафия
26. кантата
27. четверостишие
28. рондо
29. стих
30. акростих
31. ксения
32. мезостих
33. моностих
34. монорим
35. пасторель
36. центон
37. эпод
38. двенадцатистишие
39. стансы
40. стихотвореньице
41. стихи
42. песня
Ударение в слове «стихотворение»
стихотворе́ние — ударение падает на 4-й слог
Фонетическая транскрипция слова «стихотворение»
[ст’ихатвар’`эн’ий’э]
Фонетический разбор слова «стихотворение» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| с | [с] | согласный, глухой парный, твёрдый, шумный | с |
| т | [т’] | согласный, глухой парный, мягкий, шумный | т |
| и | [и] | гласный, безударный | и |
| х | [х] | согласный, глухой непарный, твёрдый, шумный | х |
| о | [а] | гласный, безударный | о |
| т | [т] | согласный, глухой парный, твёрдый, шумный | т |
| в | [в] | согласный, звонкий парный, твёрдый, шумный | в |
| о | [а] | гласный, безударный | о |
| р | [р’] | согласный, звонкий непарный (сонорный), мягкий | р |
| е | [`э] | гласный, ударный | е |
| н | [н’] | согласный, звонкий непарный (сонорный), мягкий | н |
| и | [и] | гласный, безударный | и |
| е | [й’] | согласный, звонкий непарный (сонорный), мягкий | е |
| [э] | гласный, безударный |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 13 букв и 14 звуков.
Буквы: 6 гласных букв, 7 согласных букв.
Звуки: 6 гласных звуков, 8 согласных звуков.
Предложения со словом «стихотворение»
Сослуживцы, командиры, узнав о том, что я пишу, просили меня написать стихотворения для их девушек, родителей, и, конечно же, я не мог отказать им в этом.
Источник: Июньская Анна, Лирика без границ. 2016.
Энциклопедии, мифологические словари, сборники стихотворений и легенд, — это были старые книги.
Источник: К. Ю. Бояндин, Мозаика. Часть 1. Без имени.
Это такой приём, когда строки стихотворения строятся похоже, как бы параллельно.
Источник: И. В. Потапова, Я легко пишу стихи.
Сочетаемость слова «стихотворение»
1. новое стихотворение
2. лирическое стихотворение
3. хорошее стихотворение
4. стихотворение поэта
5. из стихотворения а
6. стихотворение блока
7. строки стихотворения
8. сборник стихотворений
9. автор стихотворения
10. стихотворение называется
11. стихотворение понравилось
12. стихотворение закончилось
13. читать стихотворение
14. написать стихотворение
15. сочинить стихотворение
16. (полная таблица сочетаемости)
Значение слова «стихотворение»
СТИХОТВОРЕ́НИЕ , -я, ср. Небольшое поэтическое произведение, написанное ритмизованной речью, стихами. Читать стихотворение. Стихотворения А. Блока. (Малый академический словарь, МАС)
Склонение слова «стихотворение» по подежам
| Падеж | Вопрос | Единственное числоЕд.ч. | Множественное числоМн.ч. |
|---|---|---|---|
| ИменительныйИм. | что? | стихотворение, стихотворенье | стихотворения, стихотворенья |
| РодительныйРод. | чего? | стихотворения, стихотворенья | стихотворений |
| ДательныйДат. | чему? | стихотворению, стихотворенью | стихотворениям, стихотвореньям |
| ВинительныйВин. | что? | стихотворение, стихотворенье | стихотворения, стихотворенья |
| ТворительныйТв. | чем? | стихотворением, стихотвореньем | стихотворениями, стихотвореньями |
| ПредложныйПред. | о чём? | стихотворенье, стихотворении, стихотвореньи | стихотворениях, стихотвореньях |
Как правильно пишется слово «стихотворение»
Орфография слова «стихотворение»Правильно слово пишется: стихотворе́ние
Нумерация букв в слове
Номера букв в слове «стихотворение» в прямом и обратном порядке:
- 13
с
1 - 12
т
2 - 11
и
3 - 10
х
4 - 9
о
5 - 8
т
6 - 7
в
7 - 6
о
8 - 5
р
9 - 4
е
10 - 3
н
11 - 2
и
12 - 1
е
13
Состав слова в рифмовках и рисунках
Не секрет, что уроки русского языка многие дети
начальной школы считают скучными, потому что в
наших учебниках присутствует огромное
количество правил, которые надо учить и
применять. Связано это со сложностью самой
орфографической системы русского языка и с тем,
что младшие школьники, погружаясь в «море»
орфографических правил и исключений, не могут
уловить логики правописания. Они
воспринимают орфографию как набор
разрозненных, не связанных между собою
правил. И, к сожалению, с каждым новым внедряемым
УМК количество правил в учебниках русского
языка начальной школы только увеличивается.
Дети не хотят запоминать, родители не хотят
вникать. Учителя разводят руками…
А не лучше ли попытаться перехитрить наших
упрямых неучей и, не угрожая «двойками», не
повышая голоса, привлечь их внимание к
орфографическим правилам с помощью рисунка,
рифмовки, шутки, сказки, направив богатое детское
воображение в нужное русло? Лучший способ
обучения – это увлечь детей и привлечь к
сотрудничеству в процессе обучения. Ведь работа
учителя заключается не в том, чтобы записать в
дневнике «выучить правило на стр. …». Мы
должны на уроке объяснить суть правила и показать
ребёнку наилучший способ для
запоминания.
На уроках русского языка во втором классе, так же как и все учителя, я читаю с учениками правило по учебнику, разбираю его, а затем мы в тетрадях записываем правило в стихах из моей личной «копилки», несколько раз его проговариваем, сравниваем с правилом в учебнике. Когда я задаю вопрос: «Какое правило легче запомнить?» Ученики отвечают: «Конечно, рифмовку!» При записи домашнего задания в дневнике я указываю выучить правило по данной теме хоть из учебника, хоть из тетради. Многие ученики легко и непринуждённо запоминают правило в стихах. Суть правила сохранена, термины ребёнок запоминает, но в рифмованной форме заучить правило намного легче. Попробуйте, может и вам эта форма работы понравится.
Я предлагаю собственные рифмовки по разделу
«Морфемика» или «Состав слова». А также рифмовки
к тем орфограммам русского языка, правописание
которых основано на знании состава слова. Это
правописание некоторых суффиксов, приставок с
гласными а, о, а также
разделительного Ъ. Постоянная,
систематическая работа по усвоению состава
слова, словообразования, обогащению словаря
необходима для овладения морфологическим
принципом орфографии. Я предлагаю разнообразить
эту работу с помощью ярких схем, рифмовок (см.
приложение, презентация «Морфемика»).
Сознательный разбор слова по составу пробуждает
у детей живой интерес к русскому языку, развивает
лексику и является ещё одним этапом на пути
развития орфографической зоркости. Все эти
рифмовки есть в приложении в виде небольшой
презентации, которую удобно использовать на
уроках русского языка в начальной школе.
Рифмовки по разделу «Состав слова».
Слово делится на части!
Ах, какое это счастье!
Может каждый грамотей
делать слово из частей!Окончание в слове – это
изменяемая часть.
Оно при помощи предлога
между словами держит связь.Без окончания всё слово
называется основой.А чтобы корень нам найти
на родственные слова смотри:
общую часть родственных слов
выдели – и корень готов!Суффикс в слове после корня,
образует слово он.
Суффиксы мы будем помнить,
чтоб был богатым лексикон!Перед корнем есть приставка,
слитно пишется она.
А при помощи приставки
образуются слова.
Правописание приставок с гласной О
О-, во-, до-, со-, по- и про’ –
вот приставки с гласной о.
Об-, обо’-, от-, ото’-,
под-, подо’ – приставки с О!
Правописание приставок с гласной А
За- и на-, раз- и над-
вот приставки с гласной а.
Разо-, раз-, надо-, над-
будем в них мы а писать.
Правописание приставок, оканчивающихся на согласный звук
В-, об-, от-,
раз-, над-, под-.
Вот приставки на согласный.
Часто он звучит неясно.
Правописание разделительного Ъ.
Чтоб согласный звук в приставке
отделить от гласной в корне,
твёрдый знак меж ними ставьте.
Вами будут все довольны.
Правописание приставок, оканчивающихся на -з, -с.
Вот приставки на -з, -с:
раз- и рас-, без- и бес-.
Голову здесь не ломай,
то, что слышишь, то вставляй.
Разглядеть, но рассмотреть.
Разделить, но растереть.
Перед звонким в корне – без.
Пред глухим – приставка с -с.
Правописание корня
(С этим правилом я знакомлю перед изучением орфограмм корня)
Чтобы смысл слова нам не потерять,
правильно нам надо корень написать.
Правописание суффиксов -онок, -ёнок в словах, называющих детёнышей животных.
Чтобы малышей назвать,
суффикс надо добавлять.
Если в корне согласный «шипит»,
суффикс -онок, значит, пиши.
Если мягко согласный звучит,
суффикс-ёнок, значит, стоит.
Например:
Медвежонок, бельчонок,
индюшонок, галчонок.
Но лисёнок, тигрёнок,
Оленёнок и львёнок.
Правописание суффиксов -ек, -ик в словах.
Чтобы -ик, -ек написать,
слово надо изменять.
Есть предмет и нет его –
смотрю суффикс у него.Если гласный «убегает»,
значит, суффикс -ек вставляем.
Если гласный «не бежит»,
значит, суффикс -ик пиши.
Например:
Домика нет, домик есть.
Ключика нет, ключик есть.
Нет замочка, есть замочек.
Нет крючочка, есть крючочек.
Разбор слова по составу
(Я не помню, чьё это стихотворение, но в своей работе я использую эти строки.)
Помни: при разборе слова
окончанье и основу
первым делом находи!
После корня будет суффикс,
а приставка впереди!
Вывод.
Будем части слова знать,
сможем грамотно писать!
Приложение 1
§1.
Повторение (3) — учебник Бунеев Пронина 4 класс Часть 131. Подбери и запиши слова по схемам.
32. Прочитай. Какие слова записаны в каждом столбике? Уточни значение каждого слова.
Разбери по составу слова, отмеченные цифрой 2. Вспомни, в каком порядке нужно действовать, чтобы правильно разобрать слово по составу.
33. Прочитай текст. Какова его главная мысль?
Разбери по составу слова: белка, бельчонок, бельчата. Какие согласные звуки чередуются в корне этих слов?
34. Прочитай стихотворение. Как бы ты его озаглавил? Почему? Сравни своё заглавие с авторским (см. с. 158 учебника). Как ты понимаешь смысл авторского заглавия?
Разбери по составу слова, возле которых стоит цифра 2.
35. Прочитай текст. Можно ли судить, как рассказчик относится к своему коту? Почему ты так думаешь?
Выпиши выделенные слова группами по частям речи. Сколько получилось групп? Объясни, почему ты объединил в группы именно эти слова. Вспомни признаки каждой части речи. Обозначь и объясни орфограммы в словах, которые ты выписал.
36. Прочитай слова. Задание к этому упражнению нужно выполнить по вариантам.
1-й вариант. Выпиши группами однокоренные слова. Выдели в них корень. Слова одной и той же или разных частей речи записаны в каждом столбике?
2-й вариант. Спиши слова группами по частям речи. Объясни, почему ты объединил в группы именно эти слова. Есть ли в каждом столбике однокоренные слова?
Какой вывод ты можешь сделать после выполнения этого упражнения? По каким признакам ты отличаешь друг от друга имена существительные, имена прилагательные и глаголы?
37. Прочитай стихотворение Льюиса Кэрролла в переводе Льва Успенского. Что-то не так в этом стихотворении, но что именно? Объясни.
Какую роль в речи играют имена существительные и местоимения?
38. Прочитай текст. Какова его главная мысль? Что нового ты узнал для себя, а что тебе уже было известно?
Главная мысль: В разных странах разные правила употребления местоимений.
39. Закончи схему. Объясни свой вариант.
Расскажи о частях речи по схеме.
40. По каким признакам ты отличаешь предложение от набора слов? Текст от набора предложений? Что нужно сделать, чтобы из этих слов получились предложения? Выполни эти действия, запиши. У тебя получится фрагмент рассказа А.И. Куприна ”Слон“.
Подчеркни известные тебе орфограммы в словах и между словами.
41. Спиши текст. Найди и подчеркни основу каждого предложения. Сколько слов ты подчеркнёшь в каждом предложении? Как ты будешь их искать? Как по-другому называется основа предложения?
Прочитай только главные члены каждого предложения. Понятен ли смысл предложений? Объясни, почему главные члены называются основой предложения. Какие части речи в русском языке выступают в роли главных членов предложения? А в роли второстепенных? Что разделяют запятые во 2-м и 5-м предложении?
42.Прочитай про себя стихотворение русского поэта XIX века Фёдора Глинки. Обрати внимание на знак препинания, который завершает каждое предложение. Как он помогает понять смысл предложения, выбрать нужную интонацию при чтении? Подготовь выразительное чтение этого стихотворения, обращая внимание на выделенные слова.
43. Вспомни, что означают эти схемы.
Придумай и запиши предложения по схемам. Что разделяет запятая в этих предложениях? Как отличить простое предложение от сложного?
44. Перечитай текст из упр. 41. Составь схему каждого предложения этого текста. Поставь вопросы от главных членов предложения к второстепенным. Выпиши словосочетания из каждого предложения.
45. Прочитай стихотворение, представь картины, которые поэт нарисовал словами. Спиши, подчеркни грамматическую основу в каждом предложении. Объясни, что разделяют запятые.
Подчеркни орфограммы-буквы безударных гласных в корнях и приставках.
46. Прочитай текст. Подчеркни простым карандашом главные члены в каждом предложении и определи, простое предложение или сложное, есть ли в нём однородные члены. Спиши текст и расставь в нём запятые.
Выпиши словосочетания из 3-го предложения.
В первом абзаце автор употребил слова-синонимы звать, величать. Чем они отличаются по смыслу? А по своему употреблению в речи?
47. Прочитай перечень понятий, с которыми ты уже хорошо знаком. Заполни таблицу: напиши или назови, в каких разделах языкознания изучаются эти понятия. Куда относятся оставшиеся понятия?
48. Обучающее изложение.
1. Послушай текст, определи его тему. Закончи предложение ”Этот текст о том, как…“. Подумай, почему текст так называется.
2. Перечитай текст, уточни значение непонятных слов.
3. Обрати внимание на количество абзацев (сколько абзацев, столько и микротем в тексте, столько будет пунктов плана).
4. Составь план, выпиши ключевые слова каждой части. Перескажи текст по плану и ключевым словам.
5. Объясни орфограммы и знаки препинания, сделай простым карандашом необходимые обозначения в тексте.
6. Закрой учебник, послушай текст ещё раз.
Состав слова. Разбор слова по составу презентация, доклад
ГУО «ЛЕЛЬЧИЦКАЯ РАЙОННАЯ ГИМНАЗИЯ»
Выполнила
студентка 4 курса 1 группы
специальности «Начальное образование»
заочной формы получения
высшего образования
МГПУ им. И.П. Шамякина
Цалко Мария Владимировна
Состав слова
Язык и стар, и вечно нов —
И это так прекрасно!
В огромном море — море слов —
Купайся ежечасно!
Разбор слов по составу
Вы – талантливые дети ! Когда-нибудь вы сами приятно поразитесь ,
какие вы умные, как много и хорошо умеете,
если будете постоянно работать над собой,
ставить новые цели и стремиться к их достижению…»
Жан Жак Руссо
(1712 – 1778гг)
Цель урока:
закрепить знания по составу слова
овладеть алгоритмом разбора слова по составу
развивать связанную речь, связывать в сознании учащихся значение слов с их морфемным составом
ТЕМА УРОКА: Состав слова
Разбор слов по составу
Мажет мама ранку дочке
Йодом в темном пузыречке.
Кошка, прыгнув со стола,
Йод по полу разлила.
Стань же властью всех стихий
Йод разлитый – буквой …
СЛОВАРНАЯ РАБОТА
НМЕОЛЖЬНЗОЯ
СЛОВАРНАЯ РАБОТА
Х..р..шо Вредно
П..лезно Плохо
Можн.. Жарко
Хол..дно Н..льзя
Просто Весело
Грус..но Сложно
ПРИСТАВКА
ДЛЯ ОБРАЗОВАНИЯ НОВЫХ СЛОВ
ИЗМЕНЯЕМАЯ ЧАСТЬ ДЛЯ СВЯЗИ СЛОВ В ПРЕДЛОЖЕНИИ
ДЛЯ ОБРАЗОВАНИЯ НОВЫХ СЛОВ
КОРЕНЬ
СУФФИКС
ОКОНЧАНИЕ
ОБЩАЯ ЧАСТЬ РОДСТВЕННЫХ СЛОВ
Состав слова
«Решение
правописных задач»
даС.
оЭт шна одм. У дамо дас. Поадилс дас шан дешкаду.В дуса тутрас шниви и высли.
ФИЗКУЛЬТМИНУТКА
Выделите в словах корень.
Л.сной, л.сник, л.совичок, л.сничий, лес.
«Смотри в корень» или
«Зри в корень»
Так говорят
Образуйте и запишите однокоренные слова с корнем -лез-
Стихотворение о приставке
Перед корнем есть приставка,
Слитно пишется она
А при помощи приставки
Образуются слова.
к
НАЙДИ И ЗАПИШИ
Козочка и лисонька,
Курочка и кисонька,
Садик и садочек,
Папочка, сыночек.
водник, водитель, громоотвод, заводной, вводный, водолаз, водитель, водопой, водомер, водоросль, довод.
Игра «Две команды».
Разобрать слова по вариантам
1 вариант – водить
2 вариант — вода
Его корень
в слове писать,
Приставка
в слове рассказать,
Суффикс
в слове книжка,
Окончание
в слове вода.
Отгадайте слово:
Его корень
в слове вязать,
Приставка
в слове замолчать,
Суффикс
в слове сказка,
Окончание
в слове рыба.
Помни, при разборе слова
Окончанье и основу
Первым делом находи.
После корня будет суффикс,
А приставка – впереди.
Серый волк в густом лес
встретил рыжая лиса.
Составить предложение
ИГРА «КТО БЫСТРЕЕ»
«Спасибо, ребята, что ходите ко мне. Я рад, когда вы хорошо учитесь. Только, пожалуйста, не шалите. А то есть такие, что не слушают, а только сами шалят. А то, что я вам говорю, нужно для вас будет. Вы вспомните, когда уже меня не будет, что старик говорил вам добро».
Домашнее задание
Упражнение 227,
стр. 134
Всем спасибо
за работу!
Урок закончен
Скачать презентацию
Конспект урока русского языка в 6 классе «Состав слова. Обобщение» 📕
Областное государственное специальное образовательное казенное учреждение для обучающихся, воспитанников с ограниченными возможностями здоровья специальная общеобразовательная школа
VIII вида №1 г. Иркутска
Учитель дефектолог
Гаврилова Ольга Валентиновна
Высшая квалификационная категория
Конспект урока русского языка в 6 классе
Тема: Состав слова. Обобщение.
Задачи :
Образовательные :
Обобщить изученные признаки родственных слов; проверить сформированность понятий: состав слова, приставка, суффикс,
корень, окончание; закрепить знания по разбору слов по составу.
Развивающие:
Развивать умения планировать и контролировать собственную учебную деятельность; развивать память и орфографическую зоркость; развивать умение разбирать слова по составу;
Корекционные
Коррекция логического мышления; коррекция познавательной деятельности на основе упражнений в анализе и синтезе; развитие навыка связного устного высказывания; коррекция недостатков письма и произношения
Воспитывающие:
Создавать у учащихся положительную мотивацию к уроку русского языка путем вовлечения каждого в активную деятельность;
Оборудование урока: таблица Порядок разбора слов по составу , опорные карточки,
Карточки с заданиями, презентация
Ход урока.
Организационный момент
Долгожданный дан звонок,
Начинается урок.
Ножки вместе,
Спинки ровно
И к уроку все готово.
Введение в урок. Повторение.
Сегодняшний урок, урок-путешествие в зимнюю страну. Правда зима задерживается и чтобы она быстрее пришла наш урок поможет нам в этом. Что мы будем повторять на нашем уроке, вы определите по слайду.
Найдите в данной записи название зимней страны.
.
Тема урока Состав слова. Обобщение.
Тема нашего урока совпадает с названием зимней страны в которую мы отправимся.
Сообщение темы урока.
Сегодня мы закрепим и обобщим знания по теме Состав слова . Это наш завершающий урок по теме.
Мы побываем с вами на катке, в зимнем лесу, на Северном полюсе.
И везде с нами будут наши помощники — снежинки.
Итак, мы отправляемся В путешествие в зимнюю страну Состав слова.
— Из каких частей состоят слова?
Проверка.
— Что значит — разобрать слова по составу?
Сообщение цели урока.
На сегодняшнем уроке мы повторим все, что знаем о частях слова, закрепим умение грамотно писать однокоренные слова, правильно разбирать слова по составу, выполните много интересных заданий.
Оформленте тетрадей.
Запишите число, классная работа и тему урока
V. Минутка чистописания.
-Начнем с минутки чистописания.
— Назовите буквы и буквосочетания. Зз зи за
— Пропишите буквы Зз и буквосочетания, в том же порядке, что и на экране..
— Прочитайте слова.
Зима Зима зимородок заморозки
— Объясните лексическое значение слов.
— Почему одно и то же слово зима написано одно с маленькой буквы, а другое с большой?
Зима́ — город в России, Иркутской области. Расположен в 230 км на северо-запад от нашего г. Иркутска, на левом берегу реки Оки.
За́морозки — легкие утренние морозы осенью или весной.
Зимородок — красивая птица. Он крупнее воробья с ярким оперением. Верх тела его зеленовато-голубой, брюшко же — огненно-рыжее.
Гнездится зимородок в норах глубиной до 2 м. Пищу — мелких рыбешек, головастиков, лягушат добывает птица в воде, подкарауливая добычу на какой-нибудь ветке, откуда камнем падает в воду, тут же выныривает и взлетает.
Слайд 10
Систематизация ЗУН. Работа по теме урока.
Отправляемся на каток.
Слайд 11.
1 . Нахождение однокоренных слов
Задание: Прочитать стихотворение.
Выписать однокоренные слова из стихотворения. Обозначить корень.
Проплясали по Снегам
Снежные метели.
Снегири снеговикам
Песню просвистели.
У Заснеженной реки
В Снежном переулке
Звонко носятся Снежки,
Режут снег Снегурки.
— Как называются слова, которые выписали?
— Почему их так называют?
— Что такое корень?
Работа над окончанием.
Корень получил срочную телеграмму. Очень расстроился. Помогите ее прочесть.
Задание на карточках.
Слайд 13
Телеграмма, текст телеграммы
Вот шифр:
Проверка
Р | П | Л | О | О | Ч | Н | Е |
П | О | А | О | К | Н | А | И |
— Почему так расстроился корень?
— Какую роль играет окончание?
— Поможем корню найти окончание?
Слайд 14.
Задание: Составьте словосочетания, соединяя по смыслу слова левого и правого столбиков. Вставьте и выделите окончания существительных.
На неб… | |
Сияет | Под ног… |
Скрипит | В окн… |
Летают | В снежк… |
Смотрели | Над земл… |
— Молодцы, вы помогли отыскать пропавшие окончания.
— Работаем в парах, проведем взаимопроверку.
— Можем ли мы обойтись без окончания?
— Что такое окончание?
Слайд 15
Вывод об окончании
Слайд 16
Потрудились — отдохнуть
Нужно, без сомненья,
Дружно, быстренько встаем
Выполним движения.
Раз подняться, потянуться.
Два согнуться, разогнуться.
Три в ладоши три хлопка,
Головою три кивка.
На четыре — руки шире.
Пять — руками помахать.
Шесть — на место тихо сесть.
Глазки видят все вокруг,
Обведу я ими круг.
Глазкам видеть все дано-
Где окно, а где кино.
Обведу я ими круг,
Погляжу на мир вокруг.
Работа над суффиксом.
Слайд 17
Сравните два текста. Чем они отличаются?
Ученики читают.
Однажды я спускался к морю и увидел маленького Пингвиненка. У него еще только выросли три Пушинки на голове и Коротенький хвостик. Он стоял на краю Льдинки и грелся в ласковых Лучиках солнышка.
Однажды я спускался к морю и увидел маленького пингвина. У него еще только вырос пух на голове и короткий хвост. Он стоял на краю льдины и грелся в лучах солнца.
— Какой текст передает отношение автора к маленькомупингвиненку?
— Какая часть слова помогла автору передать свое отношение к маленькому пингвиненку?
— Назовите эти слова.
Задание: прочитать текст о пингвиненке. выписать слова с уменьшительно-ласкательными суффиксами, выделить его.
Проверка на Слайде 18
— Что такое суффикс? Для чего он служит?
Первый выполняет команду учителя:
1. Раз Резать лист бумаги;
2. Над Резать;
3. Вы Резать треугольник;
4. С Резать угол.
Второй ученик записывает на доске названия тех действий, которые выполняет первый.
Учащиеся класса записывают слова, выделяют приставку.
— Что такое приставка? Для чего она служит?
— Как пишется со словом?
Приставка — часть слова, которая стоит перед корнем и служит для образования новых слов.
Вывод на слайде 21
Перед корнем есть приставка,
Слитно пишется она.
Ведь при помощи приставки
Образуются слова.
Работа над алгоритмом .
Итак, мы доказали, что части слова мы знаем, попробуем это показать на практике. Вспомним порядок разбора слова по составу
Слайд 22
Схема разбора слова у каждого ученика
1. Подбери однокоренные слова.
2. Измени слово и выдели в нем окончание.
3. Выдели приставку. 4. Выдели суффикс.
Этим алгоритмом пользуются все ученики во всех школах.
Итак, мы доказали, что части слова мы знаем, попробуем это показать на практике.
Самостоятельная работа .
Слайд 23
Самостоятельная работа
Давайте вернемся к нашему слову — Заморозки и уже, соблюдая порядок разбора, выделим в нем все его части. — С чего начнем?
— Как правильно выделить корень? — А как найдем окончание? Приставка — перед корнем, суффикс — после корня.
— Запишите слова: Зимушка, холода, снежинка, Прогулка, горка.
Работа с предложением .
Слайд 24
Картинка и предложение
На землю тихо падают снежинки.
Задание: Записать предложение, найти главные члены предложения, слово «снежинки» разобрать по составу.
Слайд 25
Итог урока.
Вот и подошел к концу наш урок. Вы дружно работали. Смогли найти части слова, выполнили задания, которые вам предлагались.
— Какие части слова вы знаете?
— А какие части слова вам встречались в нашем путешествии в зимнюю страну Состав слова?
Здорово. Значит путешествие в зимнюю страну Состав слова удалось. В нашем путешествии встретились и подружились все части слова.
— Какая часть слова самая важная? Почему?
— Какие части слова служат для образования новых слов?
— Что служит для связи слов в предложении?
— Почему важно уметь правильно разбирать слово?
Оценки за урок
Слайд 26
Наши помощницы снежинки еще раз напоминают нам схему разбора слова по составу.
Слайд 27
Домашняя работа
Карточка с заданием
Вырезать снежинку
Слайд 28
Прозвени-ка, дружок,
Голосистый звонок,
Перемену ждут ребята.
Поиграть, попрыгать надо.
Материалы к уроку.
Карточка 1.
Задание: Выписать однокоренные слова из стихотворения. Обозначить корень.
Проплясали по Снегам
Снежные метели.
Снегири снеговикам
Песню просвистели.
У Заснеженной реки
В Снежном переулке
Звонко носятся Снежки,
Режут снег Снегурки.
Карточка 1.
Задание: Записать однокоренные слова, обозначить корень.
Снег Ам, Снеж Ные, Снег Ири, Снег Овикам, за Снеж Енной, Снеж Ном, Снеж Ки, Снег Урки.
Карточка
Задание: расшифровать телеграмму корня.
Карточка 2.
Задание: вставить окончание, составить словосочетания, соединяя по смыслу слова из левого и правого столбика
На неб… |
Под ног… |
Над земл… |
В снежк… |
Карточка 2.
Задание: списать словосочетания, выделить окончания
Играли в снежк И, сияет на неб Е, скрипит под ног Ами, летают над земл Ей.
Карточка 3.
Задание: выписать слова с ласкательными суффиксами, записать их в тетрадь, выделить у них суффикс.
Однажды я спускался к морю и увидел маленького пингвиненка. У него еще только выросли три пушинки на голове и коротенький хвостик. Он стоял на краю льдинки и грелся в ласковых лучиках солнышка.
Карточка 3.
Задание: записать слова с ласкательными суффиксами в тетрадь, выделить у них суффикс.
ПингвинЕнок, пушИнкА, коротЕнькИй, хвостИк, льдИнкА, лучИкАх, солнЫшкА.
Карточка.
Схема разбора слова
1. Подбери однокоренные слова.
2. Измени слово и выдели в нем окончание.
3. Выдели приставку. 4. Выдели суффикс.
Карточка.
Домашняя работа
Задание: 1.списать текст
Снеговик.
Стоит чудесный зимний день. Падает легкий пушистый снег. Деревья одеты в белые шубки.
Спит пруд под ледяной коркой.
Выбежала группа ребят на улицу. Они стали лепить снеговика. Глазки сделали ему из светлых льдинок, рот и нос из морковки, а брови из угольков.
Радостно и весело всем!
2.Грамматическое задание.
Разобрать по составу слова:
1 группа — зимний, шубки, нос, снеговик.
2 группа — белые, рот, морковки.
3 группа — снег, глазки
Война сочинение 15.3 огэ.
Конспект урока русского языка в 6 классе «Состав слова. Обобщение»
Определение и значение стихотворения | Dictionary.com
- Основные определения
- Викторина
- Связанный контент
- Примеры
- Британский
Показывает уровень оценки в зависимости от сложности слова.
[ poh-um ]
/ ˈpoʊ əm /
Сохрани это слово!
См. синонимы для: стихотворение / стихи на Thesaurus.com
Показывает уровень оценки в зависимости от сложности слова.
существительное
стихотворное произведение, особенно такое, которое характеризуется высокоразвитой художественной формой и использованием усиленного языка и ритма для выражения интенсивной образной интерпретации предмета.
сочинение, хотя и не в стихах, но отличающееся большой красотой языка или выражения: стихотворение в прозе из Священного Писания; симфоническая поэма.
что-то, обладающее качествами, наводящими на размышления о поэзии или сравнимыми с ними: Марсель, этот цыпленок cacciatore был абсолютной поэмой.
ВИКТОРИНА
Сыграем ли мы «ДОЛЖЕН» ПРОТИВ. «ДОЛЖЕН» ВЫЗОВ?
Должны ли вы пройти этот тест на «должен» или «должен»? Это должно оказаться быстрым вызовом!
Вопрос 1 из 6
Какая форма используется для указания обязательства или обязанности кого-либо?
Происхождение стихотворения
1540–50; <латинское poēma<греческое poíēma стихотворение, что-то сделанное, эквивалентное poiē-, вариант основы poieîn to make + суффикс -ma, обозначающий результат
Слова рядом со стихотворением
Poe, poeciliid, PO’ed, Poe, Edgar Allan, Poehler, стихотворение, синдром POEMS, poenology, poep, poepol, poesy
Dictionary. com Unabridged
На основе Random House Unabridged Dictionary, © Random House, Inc., 2022
Слова, связанные со стихотворением
баллада, композиция, эпос, лирика, поэзия, рифма, сонет, стих, письмо, ритм, создание, хайку, лимерик, строки , ода, поэзия, четверостишие, иней, руна, песня
Как использовать стихотворение в предложении
Прочитав стихотворение «Баллада о Бирмингеме» Дадли Рэндалла, Кертис вдохновился и изменил сеттинг рассказа.
Как простая история о путешествии стала детской классикой|Haben Kelati|30 ноября 2020|Washington Post
Выяснилось, что каждый четвертый старшеклассник никогда не читал рассказов или романов, а около половины никогда не читали стихов самостоятельно.
«Национальный табель успеваемости» показывает снижение успеваемости учащихся|Лаура Меклер|28 октября 2020 г.|Washington Post
Он может извергать стихи, рассказы и песни без особых подсказок, и было продемонстрировано, что он обманывает людей думать, что его результаты были написаны человеком.
Эти странные, тревожные фотографии показывают, что ИИ становится умнее|Карен Хао|25 сентября 2020 г.|MIT Technology Review
Классическая Мулан не представляет угрозы, потому что она возвращается домой к своей прежней жизни хорошей дочерью в конце стихотворение, но Мулан 1998 года настолько революционна, что в одиночку меняет мнение всей империи о женщинах.
История Мулан, от баллады 6-го века до игрового фильма Диснея|Констанс Грейди|4 сентября 2020 г.|Голос
Будучи студенткой, Коэл написала «Мечты о жевательной резинке», пьесу для одной женщины, название которой она позаимствовала из одного из своих стихотворений.
Как Микаэла Коэл рассказывает неловкие истины|Эромо Эгбеджуле|30 августа 2020 г.|Ози
Расстроенная, она написала свое стихотворение в метро по дороге на мероприятие.
Вопреки стереотипам, молодые писатели-мусульмане находят сообщество на сцене|Джулианна Чиаэт|12 октября 2014 г.
|DAILY BEASTУниб Хан задал в своем стихотворении вопрос о своих поисках ответов после смерти своего друга-немусульманина.
Вопреки стереотипам, молодые писатели-мусульмане находят сообщество на сцене|Джулианна Чиаэт|12 октября 2014 г.|DAILY BEAST
Каждое слово, от аа до за, получает собственный двухстраничный разворот со стихотворением и картинкой.
Ну, Ла Ти Да: Маленькие словечки-победители Стефина Мерритта|Дэвид Бакшпан|11 октября 2014 г.|DAILY BEAST
Сколько членов вашей семьи смогли увидеть, как вы читали свое стихотворение на инаугурации?
Набор для выживания латиноамериканского поэта-гея Ричарда Бланко|Уильям О’Коннор|8 октября 2014 г.|DAILY BEAST
Вы включаете рассказ о стихотворении «Любовная песня Дж. Альфреда Пруфрока», которое действительно повлияло на вас в годы вашего становления.
Набор для выживания гей-латиноамериканского поэта Ричарда Бланко|Уильям О’Коннор|8 октября 2014 г.
|DAILY BEASTВ своей камере смертников он сочинил прекрасное стихотворение из 14 стихов («Моя последняя мысль»), которое было найдено его жена и опубликовал.
Филиппинские острова|Джон Форман
Себастьян Брандт умер; советник Страсбурга, адвокат и автор любопытного стихотворения.
Книга истории и хронологии на каждый день|Джоэл Манселл
И в его сердце название стихотворения повторилось с многозначительной настойчивостью: Нежеланный!
Волна|Алджернон Блэквуд
Они все еще говорили о стихах и музыке, обмениваясь сокровенными мыслями на языке, которого он не понимал.
Волна|Алджернон Блэквуд
Он много лет был судьей в суде Коннектикута и известен как автор популярного стихотворения Макфингал.
The Every Day Book of History and Chronology|Joel Munsell
Британский словарь определений для стихотворения
стихотворение
/ (ˈpəʊɪm) /
существительное в стихах
в котором слова выбираются по их звучанию и выразительной силе, а также по их смыслу, а также с использованием таких приемов, как размер, рифма и аллитерация
литературное произведение, не написанное стихами, но демонстрирующее интенсивность воображения и языка, присущие ему стихотворение в прозе
все, что напоминает стихотворение по красоте, эффекту и т. д.
Происхождение слова для стихотворения
C16: от латинского poēma, от греческого варианта poiēma что-то составленное, созданное, от poiein to make
Collins English Dictionary — Complete & Unabridged Цифровое издание 2012 г. © William Collins Sons & Co. Ltd., 1979, 1986 © HarperCollins Издатели 1998, 2000, 2003, 2005, 2006, 2007, 2009, 2012
Определение и значение стихотворения — Merriam-Webster
по·эм ˈpō-əm
-IM,
ˈpōm,
также ˈPȯ (-) IM,
ˈpō-ˌem
1
: A Somposition в Verse
2
: : : : : : . выразительность, лиризм или формальное изящество)
дом, в котором мы остановились… сам по себе был стихотворением Х. Дж. Ласки
Синонимы
- лирика
- руна
- песня
- стих
Просмотреть все синонимы и антонимы в тезаурусе
Примеры предложений
Он написал стихотворение о своих родителях. ваше задание написать два стихи о весне
Недавние примеры в Интернете
Хорошо, лучше, но не было ли чего-то романтического и напыщенного — глупого, если употребить излюбленное уничижительное выражение, — в самом замысле стихотворения ?
Брэд Лейтхаузер, WSJ , 12 августа 2022 г. Эта драгоценная сумка, доступная в десятках стилей, демонстрирует некоторые из самых особенных особенностей вашего щенка в стихотворение , в котором излагается название их породы.
Лорен Хаббард и Кэролайн Халлеманн, Town & Country , 18 июля 2022 г.
В этом стихотворении говорящий занимает лиминальное пространство перехода, где ребенок и родители начинают меняться ролями. New York Times , 28 апреля 2022 г.
Хуан Фелипе Эррера, бывший поэт-лауреат США, написал 9Стихотворение 0221 , послужившее основой для этой книги, дополнено прекрасными иллюстрациями Лауры Кастильо.
Кристина Монтойя Фидлер, Good Housekeeping , 22 августа 2022 г.
Эта кинетическая скульптура, вдохновленная эпической персидской поэмой XII века , будет выставлена с 14 августа по 19 июня. Los Angeles Times , 2 августа 2022 г.
9Стихотворение 0221 само по себе является представлением движения, а не смысла, и циклов жизни, где вещи происходят в постоянных петлях жизни и слез. New York Times , 30 июня 2022 г.
Каждое стихотворение — это источник эмоций и честности, поскольку Ксиомара ставит под сомнение динамику в своем доме, учения своей церкви и правила, налагаемые на молодых афро-латиноамериканцев в школе и обществе.
Эми Джойс, 9 лет0221 Вашингтон Пост , 24 июня 2022 г.
Поэма произвела сенсацию, закрепив за Киплингом место поэта империи, но также и пророка ее упадка.
Том Мактег, The Atlantic , 8 августа 2022 г.
Узнать больше
Эти примеры предложений автоматически выбираются из различных онлайн-источников новостей, чтобы отразить текущее использование слова «стихотворение». Мнения, выраженные в примерах, не отражают точку зрения Merriam-Webster или ее редакторов. Отправьте нам отзыв.
История слов
Этимология
Среднефранцузский поэма , от латинского поэма , от греческого поема , из poiein
Первое известное использование
15 век, в значении, определенном в смысле 1
Путешественник во времени
Первое известное использование стихотворения было в 15 веке
Посмотреть другие слова из того же века эцилогония
стих
поэтический
Посмотреть другие записи поблизости
Процитировать эту запись «Стих.
» Словарь Merriam-Webster.com , Merriam-Webster, https://www.merriam-webster.com/dictionary/poem. По состоянию на 16 сентября 2022 г.Скопировать цитату
Детское определение
по·эм ˈpō-əm
: произведение, часто содержащее образный язык и строки, которые имеют ритм, а иногда и рифму
Подробнее от Merriam-Webster на
поэмеNglish: Перевод Поэма для носителей испанского языка
Britannica English: Перевод POEM для арабских носителей
Britanica.com. Последнее обновление: 13 сентября 2022 г.
Подпишитесь на крупнейший словарь Америки и получите тысячи дополнительных определений и расширенный поиск без рекламы!
Merriam-Webster без сокращений
Что такое стихотворение? — The Atlantic
Wikimedia CommonsКогда я спрашивал студентов, что такое стихотворение, я получал такие ответы, как «картина, написанная словами», или «средство самовыражения», или «песня, которая рифмуется и отображает красоту». ” Ни один из этих ответов не удовлетворил ни меня, ни их, поэтому на какое-то время я перестал задавать этот вопрос.
Однажды я попросил своих учеников принести в класс что-то, что имело для них личное значение. Когда их предметы лежали на столах, я дал им три подсказки: во-первых, написать абзац о том, почему они принесли этот предмет; во-вторых, написать абзац, описывающий предмет эмпирически, как это сделал бы ученый; и в-третьих, написать абзац от первого лица с точки зрения предмета. Первые два были разминочными. Над третьим абзацем я сказал им написать «Стихотворение».
Вот что написал один студент:
Стихотворение
Я могу выглядеть странно или пугающе, но на самом деле я устройство, которое помогает людям дышать. В обычных обстоятельствах я никому не нужен. Я имею в виду, что меня используют только в экстренных случаях, да и то только в течение ограниченного времени. Если тебе повезет, тебе никогда не придется использовать меня. С другой стороны, я вижу какое-то будущее, когда всем придется носить меня с собой.
Предмет, который он принес в класс? Противогаз. Цель этого упражнения заключалась не только в том, чтобы проиллюстрировать податливость языка или игривость письма, но и представить идею о том, что стихотворение — это странная вещь, которая действует так, как ничто другое в мире.
Я полагаю, что большинство из нас знали, что стихи странны, с тех пор, как мы были младенцами, когда нас укладывали спать с колыбельными, такими как «Rock-A-Bye Baby», или детей учили молитвам, которые начинаются «Отче наш, сущий на небесах… Вскоре возникли вопросы: какой идиот поставил эту колыбель на дерево? И какое отношение искусство имеет к моему Папочке-Богу? Но к такой странности мы привыкли. А потом, в какой-то момент в школе, мы спрашивали или нас заставляли переспрашивать: что такое стихотворение?
Например, в старшей школе мой учитель английского дал мне «Пляж Дувр» Мэтью Арнольда и сказал, что я должен написать сочинение о том, что это значит. Я не мог разобраться в задании, и стихотворение стало объектом моей ненависти. Стихотворение показалось нарочитым , а не , чтобы иметь смысл. Вскоре я обнаружил, что каждое стихотворение вызывает раздражение, набор слов, смехотворную загадку, которая мешает как истинному пониманию, так и истинному чувству.
Если вы не поэт или писатель, вполне вероятно, что с годами стихи все меньше и меньше поражают вас. Время от времени в журнале или в Интернете вы видите его — с рваным правым краем и произвольно выглядящими разрывами строк — и он объявляет о себе тем, чем он не является: прозой, которая непрерывно идет от левого к правому полю страницы. Стихотворение практически заставляет вас не только смотреть, но и читать: Я другой. Я особенный. Я другой. Игнорируйте меня на свой страх и риск .
И вот читаешь и слишком часто разочаровываешься в ее пресности, как ее можно перефразировать с легкой моралью, типа «и это пройдет» или «стареть — отстой» — как по сути она ничем не отличается по содержанию от большинства прозы вокруг него. Или вы разочаровываетесь, потому что стихотворение сбивает с толку первоначальное понимание. Он недоступен в своем фрагментированном синтаксисе и грамматике или неясен в своих аллюзиях. Тем не менее, вы похлопываете себя по спине только за попытку.
Кто из нас считает, что поэзия бесполезна? Кто из нас даже не задумывается над вопросом: «Бесполезна ли поэзия?»
Для сравнения, стихотворение очень редко трогает читателя физически или эмоционально. Другие средства массовой информации гораздо лучше доводят нас до слез — телевидение, кино. И если нам нужны новости, мы читаем статью в Интернете или собираем нашу ленту в Твиттере. Если мы хотим чего-то между слезами и новостями, мы просто смотрим на наших детей, когда они задают вопрос, который больше похож на утверждение: «Почему взрослые пьют так много пива?»
А если серьезно, разве стихотворение не является домом для глубоких чувств, потрясающих образов, красивой лирики, нежных размышлений и/или язвительного остроумия? Я так полагаю. Но, опять же, другие виды искусства или технологии лучше справляются с этой задачей — романы предлагают нам реальные или воображаемые миры для исследования или побега, твиты предлагают нам острые эпиграммы, живопись и дизайн радуют глаз, а музыка — ну, признайте, поэзия. никогда не был в состоянии конкурировать с этой возвышенной комбинацией лирики, инструментов и мелодии.
Есть по крайней мере один вид пользы, которую может воплотить стихотворение: двусмысленность. Двусмысленность — это не то, что хочет привить школа или общество. Вам не нужен двусмысленный ответ о том, по какой стороне дороги вам следует ехать, или должны ли пилоты выпускать закрылки перед взлетом. Тем не менее, повседневная жизнь — в отличие от чтения предложения за предложением — наполнена двусмысленностью: любит ли она меня достаточно, чтобы выйти замуж? Должен ли я трахнуть его еще раз, прежде чем бросить?
Но такие наблюдения еще мало что говорят нам о том, что такое стихотворение на самом деле. Попробуйте краудсорсинг для ответа. Если вы ищете в Википедии слово «поэма», она перенаправляет на «поэзию»: «форма литературного искусства, в которой используются эстетические и ритмические качества языка, такие как фоноэстетика, звуковой символизм и т. д.». Прекрасно говорит английский профессор, но это противоречит происхождению этого слова. «Поэма» происходит от греческого 9.0221 poíēma , что означает «созданная вещь», а поэт определяется в древних терминах как «создатель вещей». Итак, если стихотворение — это созданная вещь, то что это за вещь?
Я слышал, как другие поэты определяли стихи органическими терминами: дикие животные — естественные, неукротимые, непредсказуемые, грубые. Но метафора быстро разваливается. Такие животные живут сами по себе, совершенно не заботясь об именах, которые им дают люди. Говоря неорганическими терминами, поэт Уильям Карлос Уильямс называл стихи «маленькими машинами», поскольку считал их механическими, созданными человеком и точными. Но и здесь метафора не работает. Изношенную деталь автомобиля можно заменить почти идентичной деталью и работать, как раньше. В стихотворении слово, замененное другим словом (даже близким синонимом), может изменить все функционирование стихотворения.
Самое продуктивное в попытке определить стихотворение через сравнение — с животным, с машиной или с чем-то еще — заключается не в самом сравнении, а в споре о нем. Независимо от того, рассматриваете ли вы стихотворение как машину или дикое животное, оно может изменить машину или дикое животное вашего разума. Стихотворение помогает уму играть со своими устоявшимися шаблонами мышления и даже может помочь перенаправить эти шаблоны, заставив нас заново увидеть знакомое.
Пример: солнце. В словаре его можно определить как «светящееся небесное тело, вокруг которого вращается Земля и другие планеты». Но это также можно описать как интуицию 4-летнего ребенка, когда он смотрит в окно машины во время долгой зимней поездки: «Мама, а разве солнце не просто обогреватель?» Другой пример: мед. Согласно словарю, это «сладкая липкая желтовато-коричневая жидкость, производимая пчелами из нектара, который они собирают с цветов». По словам матерей во всем мире, «пчелиная слюна может убить младенца».
Стихотворение как мысленный объект не является трудной досягаемостью, особенно если учесть, до какой степени тексты популярных песен могут буквально застревать, как говорят нам нейробиологи, в виде «ушных червей» в синапсах мозга. Смешение слов и мелодии имеет историческую силу, восходящую к школьным стишкам, привлекающим внимание к метаязыку: «Палки и камни могут сломать мне кости, но слова никогда не причинят мне вреда». Как это ни парадоксально, сама эта линия может причинить боль, поскольку она, возможно, вызывает воспоминания о том, как нас называли отвратительными именами, будь то персонализированными (Якич жокей) или обобщенными (верблюжий жокей).
Но когда слова больше всего похожи на палки и камни?
Рассмотрим стихотворение, скрывающееся на страницах The New Yorker . Вот оно смотрит вам в лицо: читаете ли вы его так же хорошо, как оно читает вас? С точки зрения чернил на бумаге, она делает не больше, чем проза вокруг себя, но с точки зрения восприятия она притягивает взгляд и ставит стихотворение в разреженное и совершенно игнорируемое положение одновременно. О, смотрите, это драгоценный набор слов! Что за трата моего времени!
Но вокруг него еще и белое пространство. Сколько это стоило? Журнал уступил ценное место, чтобы напечатать стихотворение вместо того, чтобы печатать более длинную статью или рекламу. Никто не купил номер The New Yorker из-за стихотворения, за исключением, пожалуй, поэта, написавшего его. Стихотворение — это текст — продукт написания и переписывания, — но, в отличие от статей, рассказов или романов, оно никогда не становится вещью, созданной для того, чтобы стать товаром.
Читатели имеют определенную «свободу» в навигации по стихотворению. Предостережение в том, что свобода часто требует больше работы, большей самомотивации и определенной степени замешательства. Новый роман, мемуары или даже сборник рассказов могут принести большие деньги. Конечно, этот потенциал часто не реализуется, но новая книга стихов, которая приносит автору более тысячи долларов аванса, встречается крайне редко. Публицисты в издательствах, даже самых крупных, добросовестно пишут пресс-релизы и рассылают рецензии на сборники стихов, но никто не скажет вам, что они ожидают, что сборник будет продан в количестве, достаточном для того, чтобы окупить затраты на его издание. Как никакая другая книга, книга стихов представляет собой не вещь для рынка, а вещь ради самой себя.
Воплощением такой «сакэ-ности» являются стихи, которые бросают свою «сделанность» прямо вам в лицо. «Пасхальные крылья» Джорджа Герберта, называемые по-разному визуальными стихами, конкретными стихами, стихотворениями о форме или каллиграммами, являются каноническим примером из 17-го века:
Крылья стихотворения, птиц или ангелов, совпадают или иллюстрируют текстовое содержание: желание говорящего чтобы достичь неба к Господу. Визуальная форма обеспечивает то, что мы могли бы назвать небольшим бонусом или lagniappe в смысле, и она также заставляет нас заметить, что стихотворение больше, чем рваное пятно — пятно само по себе является смыслом.
В 19 веке французский поэт Стефан Малларме еще больше развил эту идею страницы как холста в Un Coup de Dés («Бросок костей»). Его стихотворение длиной в книгу не только манипулирует черным шрифтом, стилями шрифта и пустым пространством, но также использует границы самой страницы, в том числе желоб — шов в середине книги, — который служит переулком, в котором бросаются «кости» (т. е. слова).
Разворот из стихотворения Стефана Малларме длиной в книгу Un Coup de Dés . Поскольку стихотворение позволяет читателю установить несколько связей между фразами и строками — читать поперек, вниз, в комбинации или в соответствии с определенными шрифтами — некоторые ученые рассматривают Un Coup de Dés как предшественника гипертекста. Как читатель, у вас есть определенная «свобода» в навигации по стихотворению. Предостережение в том, что свобода часто требует больше работы, большей самомотивации и определенной степени замешательства.
Что возвращает нас к затруднительному положению современной поэзии: стихотворение, столь странное, столь непохожее, является также стихотворением, которое, по мнению многих, они могли бы с таким же успехом игнорировать. Вот стихотворение 1960-е Арама Сарояна:
свет
Да вот и вся поэма. Я знаю, это кажется глупым. Когда я написал это на доске и попросил своих студентов изучить это, один из них сказал: «Как вы вообще читаете это вслух?» Когда мы попытались, мы начали понимать замысел стихотворения. Слово «свет» как бы подразумевается, но что за очевидная опечатка? После долгого молчания другой студент сказал: «В том-то и дело — в обычном слове «свет» мы не произносим «гх» — «гх» молчит, а двойное «гх» заставляет нас осознать, что еще более ». Стихотворение обращает внимание на саму систему языка — сочетание букв — и на отношения между звуком и смыслом. Знакомое — такое простое слово, как «свет» — стало новым хотя бы на короткое время. По словам самого Сарояна: «Суть поэмы состоит в том, чтобы попытаться превратить невыразимое, то есть свет, о котором мы знаем только потому, что он освещает что-то еще, — в штука ».
Когда мы сталкиваемся со стихотворением — любым стихотворением, — наше первое предположение должно заключаться в том, чтобы предугадать его не как красоту, а просто как вещь. Лингвисты и теоретики говорят нам, что язык — это прежде всего метафора. Слово «яблоко» не имеет никакой внутренней связи с тем ярко-красным съедобным предметом, который сейчас лежит на моем столе. Но хитросплетения означающих и означаемых исчезают из поля зрения после колледжа. Благодаря своему особому статусу — обособленному в журнале или книге, всем этим давящим на него пустым пространством — стихотворение все же способно удивить, хотя бы на мгновение, находящееся вне всего реального и виртуального, звукового и цифрового. болтовня, которая окутывает его и нас.
Кто-то может возразить, что страница — это всего лишь метафора всего, что на нее нельзя поместить, а стихотворение — это просто замена, к лучшему или к худшему, пережитого чувства или события. И все же одна еврейская традиция призывает родителей учить своих детей любить Талмуд, не читая его им сначала, а заставляя их слизывать мед с его страниц. Мне кажется, это идеальный способ испытать и пчелиную слюну, и поэзию.
| Продолжающийся сериал о скрытой жизни обычных вещей |
Как проанализировать поэзию: 10 шагов для анализа стихотворения — 2022
Пропустить основной контент
Логотип мастер| Статьи
Общество
AT Worklog In
5559.
Дизайн и стиль
Искусство и развлечения
Письмо
Спорт и игры
Наука и техника
Дом и образ жизни
Бизнес
Сообщество и правительство
Wellness
Дизайн и стиль
Arts & Entertainment
Написание
Sports & Gaming
Science & Tech
Home & Lifevestyle
Business
Home & Lifevestyle
. Стиль и стиль
Искусство и развлечения
Письмо
Спорт и игры
Наука и техника
Дом и образ жизни
Бизнес
Письмо
Автор: MasterClass
Последнее обновление: 16 августа 2021 г. • 5 мин чтения
Стихи, от плавных слов до ритмичного ритма, обладают приятным для слуха лирическим качеством. Но чтобы по-настоящему понять поэзию, вы должны распаковать ее — исследовать каждый элемент отдельно, чтобы узнать, что означает стихотворение.
Что такое поэтический анализ?
Поэтический анализ исследует независимые элементы стихотворения, чтобы понять литературное произведение в целом. Анализ стихов строка за строкой позволяет вам разбивать стихи, чтобы изучить их структуру, форму, язык, метрический рисунок и тему. Цель литературного анализа — интерпретировать смысл стихотворения и оценить его на более глубоком уровне.
5 вещей, которые следует учитывать при анализе поэзии
Поэзия включает в себя различные элементы, такие как язык, ритм и структура. Вместе они рассказывают историю и создают сложность, уникальную для поэтического стиха. При углубленном изучении стихов обратите внимание на следующие отдельные элементы:
- 1. Тема : Поэзия часто передает сообщение посредством образного языка. Центральная идея и предмет могут раскрыть основную тему стихотворения.
- 2. Язык : От выбора слов до образов язык создает настроение и тон стихотворения. То, как устроен язык, также влияет на ритм стихотворения.
- 3. Звук и ритм : Слоговые узоры и ударения создают метрический узор стихотворения.
- 4. Структура : Структура стихотворения влияет на то, как оно должно быть прочитано. Поэт лепит свою историю из строф, разрывов строк, рифмовки, знаков препинания и пауз.
- 5. Контекст : Кто, что, где, когда и почему стихотворение может помочь объяснить его цель. Посмотрите на эти элементы, чтобы узнать контекст стихотворения.
Как анализировать стихотворение за 10 шагов
Чтение стихов само по себе является полезным опытом. Но чтобы действительно увидеть, как все элементы стихотворения работают вместе, вам нужно изучить качества и характеристики каждого из них. Следуйте этому пошаговому руководству, чтобы проанализировать стихотворение:
- 1. Прочитайте стихотворение . В первый раз, когда вы подходите к стихотворению, прочитайте его про себя. Прочитайте его медленно, оценивая нюансы и детали, которые вы можете упустить при быстром чтении. Изучите название стихотворения и то, как оно связано со смыслом произведения.
- 2. Прочтите стихотворение еще раз, на этот раз вслух . Благодаря своим ритмическим рисункам поэзия предназначена для чтения вслух. Когда вы читаете стихотворение вслух, слушайте, как слова и слоги формируют ритм. Это также может помочь услышать, как кто-то еще читает стихотворение. Поищите в Интернете и найдите запись стихотворения, если сможете. Послушайте, как слова перетекают из строки в строку, где находятся разрывы и где ставится ударение.
- 3. Составьте схему рифмовки . Вы сразу заметите, есть ли в стихотворении схема рифмовки или оно написано свободным стихом (то есть без схемы рифмовки или обычного размера). Составьте схему рифмовки, назначив каждой строке букву, а строки, рифмующиеся с одной и той же буквой. Посмотрите, есть ли четкий образец и формальная схема рифмовки, например, терцина (трехстрочные строфы с взаимосвязанной схемой АВА, БСВ и т. д.)
- 4. Отсканируйте стихотворение . Сканирование — это то, как вы анализируете метр поэзии на основе образца ударных и безударных слогов в каждой строке. Отметьте каждую стопу — основной размер стихотворной строки, состоящий из одного ударного слога, соединенного по крайней мере с одним безударным слогом. Далее отметьте схему напряжений по всей линии. Определите счетчик на основе этой информации. Например, стихотворение, написанное пятистопным ямбом, будет состоять из пяти стоп со слоговой структурой да ДУМ, да ДУМ, да ДУМ, да ДУМ, да ДУМ.
- 5. Разобрать конструкцию . Сделайте шаг назад и посмотрите на стихотворение на странице. Обратите внимание на пробелы вокруг слов. Поэзия предназначена для визуального утверждения, а также эмоционального. Посмотрите на детали этой структуры — например, сколько строк в каждой строфе. Обратите внимание, где находятся разрывы строк. Совпадает ли конец каждой строки с концом мысли? В противном случае поэт может использовать enjambment, когда одна строка переходит в другую.
- 6. Определите форму стихотворения . При анализе стихотворения отметьте, какой тип стихотворения вы читаете, исходя из элементов, которые вы изучили. Например, если в стихотворении есть три четверостишия (четырехстрочные строфы), за которыми следует двустишие, стихотворение является сонетом. Другие формальные типы поэзии включают сестину, хайку и лимерик.
- 7. Изучите язык стихотворения . Поэты сознательно выбирают слова для создания своих стихов. Изучите каждое слово и его значение в строке и стихотворении. Как это влияет на историю? Если есть слова, которых вы не знаете, поищите их. Посмотрите, как поэт играет языком, используя метафоры, сравнения и образный язык. Обратите внимание на любые используемые литературные приемы, такие как аллитерация и ассонанс, которые помогают сформировать язык стихотворения.
- 8. Изучите содержание стихотворения . Пробираясь через язык стихотворения, смотрите на содержание и посыл произведения, чтобы раскрыть тему. Узнайте, когда оно было написано, чтобы узнать исторический контекст стихотворения. Выясните, где она была написана и каким языком пользовался поэт. Если вы читаете перевод, посмотрите, есть ли другие варианты, которые могут показать, как разные переводчики интерпретировали оригинальную работу.
- 9. Определить, кто рассказчик . Попробуйте определить автора стихотворения. Рассказывается ли это от первого лица, от второго или от третьего лица? Какой тон передает рассказчик? Личность говорящего влияет на рассказ стихотворения, исходя из его личной точки зрения.
- 10. Перефразируйте стихотворение построчно . Наконец, еще раз просмотрите стихотворение. Начиная с первой строки, перефразируйте каждую строку. Другими словами, интерпретируйте смысл, записывая свое резюме по ходу дела. Когда вы прочтете весь отрывок, прочитайте слова, чтобы понять смысл стихотворения.
Хотите узнать больше о писательстве?
Станьте лучшим писателем с годовым членством в мастер-классе. Получите доступ к эксклюзивным видеоурокам, которые проводят литературные мастера, включая Билли Коллинза, Нила Геймана, Дэвида Балдаччи, Джойс Кэрол Оутс, Дэна Брауна, Маргарет Этвуд и других.
Как читать стихотворение
Умение хорошо читать стихи — это отчасти отношение и отчасти техника. Любопытство — полезное отношение, особенно когда оно свободно от предвзятых представлений о том, что такое поэзия или чем она должна быть. Эффективная техника направляет ваше любопытство на задавание вопросов, вовлекая вас в разговор со стихотворением.
Цель внимательного чтения часто состоит в том, чтобы поднять вопрос о значении, интерпретативный вопрос, который имеет более одного ответа. Поскольку форма стихотворения является частью его значения (например, такие черты, как повторение и рифма, могут усиливать или расширять значение слова или идеи, добавляя акцент, текстуру или объем), вопросы о форме и технике, о наблюдаемые особенности стихотворения обеспечивают эффективную точку входа для интерпретации. Чтобы задать некоторые из этих вопросов, вам нужно развить хороший слух к музыкальным качествам языка, особенно к тому, как звук и ритм соотносятся со смыслом. Этот подход является одним из многих способов проникновения в стихотворение.
Начало работы: предварительные предположения
Большинство читателей делают три ложных предположения, обращаясь к незнакомому стихотворению. Первый предполагает, что они должны понимать, с чем сталкиваются при первом чтении, а если нет, то что-то не так с ними или со стихотворением. Второй предполагает, что стихотворение является своего рода кодом, что каждая деталь соответствует одной и только одной вещи, и если они не смогут взломать этот код, они упустят главное. В-третьих, предполагается, что стихотворение может означать все, что читатели хотят, чтобы оно означало.
Уильям Карлос Уильямс написал стих, адресованный своей жене, в стихотворении «Январское утро»:
Все это —
было для вас, старуха.
Я хотел написать стихотворение
, которое вы бы поняли.
Зачем мне
если вы этого не понимаете?
но нужно сильно постараться —
Уильямс признает в этих строках, что поэзия часто бывает трудной. Он также предполагает, что поэт зависит от усилий читателя; каким-то образом читатель должен «завершить» начатое поэтом.
Этот акт завершения начинается, когда вы вступаете в воображаемую игру стихотворения, привнося в нее свой опыт и точку зрения. Если стихотворение — это «игра» в смысле игры или спорта, то вам нравится, что оно заставляет вас немного работать, немного потеть. Чтение стихов — это вызов, но, как и во многих других вещах, это требует практики, и ваши навыки и понимание улучшаются по мере вашего продвижения.
Литература есть и всегда была обменом опытом, объединением человеческого понимания жизни, любви и смерти. Успешные стихи приветствуют вас, раскрывая идеи, которые, возможно, не были в голове автора в момент сочинения. У лучшей поэзии есть волшебное качество — ощущение того, что она больше, чем сумма ее частей, — и даже когда невозможно сформулировать этот смысл, это нечто большее, сила стихотворения остается неизменной.
Стихи говорят с нами по-разному. Хотя их формы не всегда могут быть прямыми или повествовательными, имейте в виду, что реальный человек сформировал момент стихотворения, и разумно искать понимание этого момента. Иногда задача стихотворения состоит в том, чтобы приблизиться к тому, чтобы сказать то, что нельзя сказать в других формах письма, предложить опыт, идею или чувство, которые вы можете знать, но не можете полностью выразить каким-либо прямым или буквальным способом. Техники расположения слов и строк, звука и ритма добавляют — а в некоторых случаях и умножают — значение слов, чтобы выйти за пределы буквального, давая вам представление об идее или ощущении, переживание, которое вы не можете полностью понять. выразить словами, но то, что вы знаете, реально.
Чтение стихотворения вслух
Прежде чем вы продвинетесь со стихотворением, вы должны его прочитать. На самом деле, вы можете многому научиться, просто взглянув на него. Название может дать вам некий образ или ассоциацию для начала. Глядя на форму стихотворения, вы можете увидеть, являются ли строки непрерывными или разбитыми на группы (называемые строфами ), или насколько длинные строки, и насколько плотным на физическом уровне является стихотворение. Вы также можете увидеть, похоже ли это на последнее стихотворение того же поэта, которое вы прочитали, или даже на стихотворение другого поэта. Все это хорошие качества, на которые стоит обратить внимание, и они могут привести вас к лучшему пониманию стихотворения в конце.
Но рано или поздно тебе придется прочитать стихотворение слово за словом. Для начала прочитайте стихотворение вслух. Читать не один раз. Прислушайтесь к своему голосу, к звукам, которые издают слова. Вы заметили какие-то спецэффекты? Любое из слов рифмуется? Есть ли группа звуков, которые кажутся одинаковыми или похожими? Есть ли в стихотворении отрывок, ритм которого отличается от остального стихотворения? Не беспокойтесь о том, почему стихотворение может использовать эти эффекты. Первый шаг — услышать, что происходит. Если вас отвлекает собственный голос, попросите друга прочитать вам стихотворение.
Тем не менее, читать вслух или повторять стихотворение более одного раза может быть неудобно. Отчасти такое отношение проистекает из неправильного представления о том, что мы должны понимать стихотворение после того, как впервые прочитаем его, а отчасти — из явного смущения. Куда я могу пойти, чтобы читать вслух? Что, если мои друзья услышат меня?
Линия
Что определяет, где заканчивается строка в поэзии? Конечно, на этот вопрос есть более одного ответа. Линии часто определяются смыслом, звуком и ритмом, дыханием или типографикой. Поэты могут использовать несколько из этих элементов одновременно. Некоторые стихотворения метричны в строгом смысле. Но что, если линии не метрические? Что делать, если линии неправильные?
Взаимосвязь между значением, звуком и движением, задуманным поэтом, иногда трудно распознать, но существует взаимосвязь между грамматикой строки, ее дыханием и тем, как строки разбиты в стихотворении— это называется lineation . Например, строки, которые заканчиваются знаками препинания, называемые строками с остановкой в конце , довольно просты. В этом случае знаки препинания и штриховки, а возможно, даже дыхание совпадают, чтобы сделать чтение знакомым и даже предсказуемым. Но строки, которые не заканчиваются, представляют собой разные проблемы для читателей, потому что они либо заканчиваются неполной фразой или предложением, либо обрываются до того, как будет достигнут первый знак препинания. Самый естественный подход — уделять строгое внимание грамматике и пунктуации. Чтение фразы или предложения до конца, даже если оно занимает одну или несколько строк, — лучший способ сохранить грамматический смысл стихотворения.
Но линейность вводит еще одну переменную, которую некоторые поэты используют в своих интересах. Роберт Крили, пожалуй, наиболее известен тем, что разрывает строки через ожидаемые грамматические паузы. Этот метод часто вводит вторичное значение, иногда иронически контрастируя с фактическим значением полной грамматической фразы. Рассмотрим эти строки из стихотворения Крили «Язык»:
Найдите I
люблю вас немного-
где в
зубы и
глаза, укус
это но
Чтение строк в том виде, в котором они написаны, в противоположность их грамматическим связям, дает некоторые странные значения. «Найти I », по-видимому, указывает на поиск идентичности, и это действительно может быть, но следующая строка, которая продолжается словами «люблю тебя немного-», кажется, делает преуменьшающее утверждение об отношениях. Сам по себе «прикус глаз» очень беспокоит.
Когда Крили читает свои стихи, часто может быть тревожно, потому что он делает паузы в конце каждой строки, и эти паузы создают своего рода напряжение или контрапункт по отношению к структуре предложения стихотворения. Его прерывистый, нерешительный, затаивший дыхание стиль сразу узнаваем, и он дает писателям новые идеи о значении, чисто через линии. Но многие поэты, которые разрывают строки, не обращая внимания на грамматические единицы, делают это только для визуальной иронии, что может быть потеряно в исполнении. Среди поэтов-метриков, верлибристов и даже поэтов-экспериментаторов сегодня есть такие, которые не столько прерывают грамматический смысл при чтении стихотворения вслух, сколько прерывают его в типографике стихотворения. Что делать читателю? Попробуйте различные методы. Забавно «крилизовать» любое стихотворение, просто чтобы услышать, что делает линия. Но если результаты кажутся умаляющими влияние стихотворения с точки зрения его образности или концепции, откажитесь от буквальной трактовки разрывов строк и прочитайте грамматику или визуальный образ. Чтение стихотворения несколькими способами позволяет вам глубже заглянуть в стихотворение просто за счет повторения.
У поэтов, использующих приемы, взятые из музыки, особенно у джаза, таких как Майкл С. Харпер или Юсеф Комунякаа, или у поэтов, таких как Уолт Уитмен, которые используют необычно длинные строки, может быть еще один руководящий принцип: дыхание. Некоторые поэты думают о своих словах как о музыке, исходящей из рожка; они думают о фразах, как саксофонист. Стихи, сочиненные таким образом, имеют различную длину строки, но они отличаются музыкальностью линий и естественностью исполнения. Они могут иметь узнаваемое чувство меры, эквивалентную продолжительность между строками или, ради контраста, один ритмический рисунок или длительность, которые уступают место последовательным вариациям.
Для некоторых стихотворений также может быть важно визуальное воздействие. В «фигурной поэзии», а также во многих других типах письма, которые должны восприниматься так же, как картина, линия определяется ее размещением в пространстве. Некоторые визуально ориентированные поэты представляют настоящие проблемы, поскольку ход стихотворения может быть не совсем ясен. Визуальный выбор, представленный поэтом, может сбивать с толку. Иногда расположение слов на странице предназначено для представления разных голосов в диалоге или даже в более сложном дискурсе на тему. Наложение и наслоение могут быть намерением поэта, которого не может достичь ни один голос. Лучше знать, что существуют стихотворения с несколькими голосами или фокусами, и, опять же, поиск неотъемлемых правил, определяющих форму стихотворения, является лучшим подходом.
Помните, что использование этих техник в любой комбинации выводит слова стихотворения за пределы их буквального значения. Если вы находите в стихотворении больше, чем передают одни только слова, то здесь действует нечто большее, что делает стихотворение чем-то большим, чем сумма его частей.
Начало разговора
Ранее мы упоминали, что знакомство с трудным стихотворением похоже на игру или спорт, например скалолазание, которое заставляет вас немного потрудиться. Идея находить опоры для рук и ног и подниматься понемногу за раз вполне уместна. Но некоторые подъемы легче, чем другие; некоторые очень легкие. Какое-то время вам может нравиться легкое восхождение, но вы также можете обнаружить, что вам нужны более сложные задачи. Чтение поэзии работает точно так же, и, к счастью, поэты оставляют следы, чтобы помочь вам найти путь «вверх» стихотворения. Вам придется проделать некоторую работу, в некоторых случаях тяжелую работу, но в большинстве случаев вам предстоит открыть для себя тропы.
Лучший способ открыть для себя стихотворение и узнать о нем — это совместное обсуждение. Хотя ваше первое знакомство со стихотворением может быть частным и личным, разговор о стихотворении — естественный и важный следующий шаг. Начиная с основного вопроса о стихотворении, обсуждение рассматривает различные возможные ответы на вопрос, изменяя и уточняя его по ходу дела. Обсуждение должно оставаться максимально привязанным к тексту. Ответы, которые уходят от написанного в личные анекдоты или скачки по касательной, должны быть мягко возвращены к анализу текста. Основой для совместного исследования является внимательное чтение. Хорошие читатели «загрязняют текст» примечаниями на полях. Они проводят расследование самостоятельно.
Ответ на стихотворение
Было бы удобно, если бы был короткий список универсальных вопросов, которые можно было бы использовать в любое время с любым стихотворением. Если такого списка нет, вот несколько общих вопросов, которые вы могли бы задать, впервые приступая к стихотворению:
- Кто спикер?
- Какие обстоятельства породили стихотворение?
- Какая ситуация представлена?
- Кто или что является аудиторией?
- Какой тон?
- Какую форму имеет стихотворение?
- Как форма связана с содержанием?
- Является ли звук важным, активным элементом стихотворения?
- Стихотворение восходит к определенному историческому моменту?
- Стихотворение относится к определенной культуре?
- Есть ли у стихотворения свой родной язык?
- Используются ли в стихотворении образы для достижения определенного эффекта?
- Какой образный язык используется в стихотворении?
- Если в стихотворении вопрос, то каков ответ?
- Если стихотворение — ответ, то какой вопрос?
- О чем говорит название?
- Используются ли в стихотворении необычные слова или используются слова необычным образом?
Вы можете прибегнуть к этим вопросам по мере необходимости, но опыт подсказывает, что, поскольку каждое стихотворение уникально, такие вопросы не зайдут в нужное русло. Во многих случаях знание говорящего может не дать никакой полезной информации. Возможно, нет идентифицируемого случая, который вдохновил стихотворение. Но стихи дают подсказки о том, с чего начать. Задавание вопросов о наблюдаемых особенностях стихотворения поможет вам найти путь внутрь.
Теперь мы рассмотрим два очень разных стихотворения, каждое из которых представляет собой свою проблему:
- «Красная тачка» Уильяма Карлоса Уильямса
- «Погружение в затонувший корабль» Эдриенн Рич
Текст и контекст
Некоторые люди говорят, что стихотворение всегда является самостоятельным произведением искусства и что читатели могут понять его в полной мере, не используя какой-либо источник вне самого стихотворения. Другие говорят, что текст не существует в вакууме. Однако истина лежит где-то посередине. Большинство стихотворений открыты для интерпретации без помощи исторического контекста или знаний о жизни автора. На самом деле, часто лучше подходить к стихотворению без предвзятых идей, которые могут сопровождать такого рода информацию. Однако для других стихов, особенно откровенно политических, полезно знать о жизни и временах поэта. Количество информации, необходимой для четкого понимания, зависит от вас и вашего знакомства со стихотворением. Конечно, даже тот, кто хорошо разбирается в поэзии, может не знать об определенных ассоциациях или смыслах в стихотворении. Это потому, что стихи состоят из слов, которые со временем накапливают новые значения.
Рассмотрим эту ситуацию, реальную историю поэта, который нашел «текст» на побережье Сан-Матео в северной Калифорнии. Когда она карабкалась по камням за пляжем, рядом с полями артишоков, которые отделяют берег от прибрежного шоссе, она нашла большое пятно граффити, нарисованное на скалах, провозглашающее « La Raza », политический лозунг чикано, означающий «борьбу». .» Она села и написала стихотворение. Почему? – спросило ее стихотворение. Я понимаю, написала она, зачем кому-то писать La Raza со стороны здания или в общественном транспорте. Там его увидят, и он выкрикнет свой протест из самых основ репрессивной системы. Но почему здесь, на природе, в красоте, так далеко от той политической арены. Не могли бы вы оставить побережье нетронутым? Затем, однажды вечером, читая стихотворение в Беркли, она получила ответ. К ней подошел мужчина и спросил: «Хочешь узнать?» — Прошу прощения, — сказала она. «Эти поля, — продолжал мужчина, — были тем местом, где чикано были фактически порабощены, избиты и вынуждены десятилетиями жить в нищете». Пейзаж не был невинен в политической борьбе. Текст был не на месте.
Принятие двусмысленности
Вот хитрый вопрос: задача состоит в том, чтобы понять, соединиться, понять. Но такая задача до некоторой степени невыполнима, и большинству людей нужна ясность. В конце урока, в конце дня, мы хотим откровения, взгляда на горизонт сквозь поднимающийся туман. Эстетически это понятно. Немного волшебства, немного удовлетворения, немного «Аааа!» является одной из наград за любое чтение, особенно за чтение поэзии. Но стихотворение, полностью раскрывающееся в одном-двух прочтениях, со временем будет казаться меньшим стихотворением, чем то, в котором постоянно обнаруживаются тонкие тайники и ранее неузнаваемые смыслы.
Вот полезная аналогия. Спутник жизни, муж, жена — это люди, с которыми мы надеемся постоянно обновлять нашу любовь. Несмотря на рутину, гудение знакомых, ежедневное приготовление пищи и мытье посуды, разговоры, которые у нас были раньше, мы надеемся найти чувство открытия, удивления. То же самое и со стихами. Самые волшебные и чудесные стихи всегда обновляются, то есть остаются всегда таинственными.
Слишком часто мы сопротивляемся двусмысленности. Возможно, наша жизнь меняется так быстро, что мы жаждем где-то стабильности, а поскольку большую часть чтения мы читаем для получения инструкций или информации, мы предпочитаем читать без оттенков серого. Мы хотим, чтобы это было предсказуемо и легко усваивалось. И так трудная поэзия есть последнее мучение.
Некоторые литературоведы связывают это также со способностью видеть, с отношением между субъектом и объектом. Мы хотим, чтобы стихотворение было объектом, чтобы мы могли владеть им, «видя» его внутреннюю работу. Когда оно не позволяет нам его «объективировать», мы чувствуем себя бессильными.
Мучения, бессилие — вот желанные цели? Ну нет. Проблема в нашей реакции, в том, как мы формируем наши мысли с помощью слов. Мы должны отказаться от нашего материального отношения, которое заставляет нас хотеть обладать стихотворением. Может быть, мы купили книгу, но у нас нет стихотворения. Мы должны культивировать новое мышление, новую практику наслаждения неубедительным.
Смириться с двусмысленностью для одних гораздо сложнее, чем для других. Ничто так не пугает некоторых людей, как идея (даже идея ) импровизации в качестве письменного или аналитического инструмента. Некоторые актеры ненавидят оставаться без сценария; то же самое верно и для некоторых музыкантов. Попросите даже некоторых отличных игроков импровизировать, и они начнут потеть. Конечно, актеры и музыканты скажут, что в том, что они делают со сценарием или партитурой, есть какая-то тайна, и не согласиться с этим было бы бессмысленно. Дело, в конце концов, в том, что текст загадочен. Играя один и тот же персонаж ночь за ночью, актер обнаруживает в репликах что-то, некую эмпатию к персонажу, которую он или она никогда раньше не испытывал. Воспроизведение или прослушивание песни в сотый раз — если это великая песня — приведет к новой интерпретации и открытию. Так и с великой поэзией.
Опубликовано в сотрудничестве с Great Books Foundation.
Поэма определение и значение | Английский словарь Коллинза
Видео: произношение
стихотворение
Примеры слова «стихотворение» в предложении
стихотворение
Она пишет не только стихи, но и пьесы.
Ее стихи были опубликованы в ряде антологий.
Всем участникам было предложено написать стихотворение с пером, смоченным в тутовом соке.
Впоследствии он драматизировал их спор в двух коротких стихотворениях.
Как великое стихотворение или музыкальное произведение, его здания захватывают настроение.
Мы использовали импровизацию, декламируя его произведения и смешивая их со своими собственными стихами.
Третий требует, чтобы вы выучили стихотворение стих за стихом.
Помимо явной сложности содержания, строки стихотворений часто кажутся никак не связанными друг с другом.
Найдется немного стихов, язык которых так расходится с содержанием, чья форма так агрессивно противоречит содержанию.
Сэр, сколько quangos нужно, чтобы опубликовать стихотворение?
Цитаты
Стихотворение должно означать не
, а Арчибальда МаклишаАрс Поэтика
Тенденции
стихотворение
На других языках
стихотворение
Британский английский: стихотворение /ˈpəʊɪm/ СУЩЕСТВИТЕЛЬНОЕ
Поэма — это произведение, в котором слова подобраны по красоте и звучанию и тщательно расположены, часто в виде коротких строк.
…книга стихов о любви.
- Американский английский: стихотворение /ˈpoʊəm/
- Арабский: قَصِّيدَة
- Португальский (бразильский): поэма
- Китайский: 诗
- Хорватский: pjesma
- Чешский: báseň
- Датский: цифра
- Голландский: gedicht
- Европейский испанский: поэма
- Финский: руно
- Французский: стихотворение
- Немецкий: Gedicht
- Греческий: ποίημα
- Итальянский: поэзия
- Японский: 詩
- Корейский: 시 운문
- Норвежский: dikt
- Польский: wiersz
- Европейский португальский: поэма
- Румынский: стихотворение
- Русский: поэма
- Испанский: поэма
- Шведский: dikt версия
- Тайский: บทกวี
- Турецкий: şiir
- Украинский: вірш
- Вьетнамский: bài thơ
Связанные условия
стихотворение
Быстрое задание
Обзор викторины
Вопрос: 1
—
Оценка: 0 / 5
наступило
наступило
Нам пора двигаться дальше.
сладкий
люкс
Я сделал себе кружку чая.
база
бас
Большую часть весны и начала лета она была ее домом в Шотландии.
Ваш счет:
Слово дня
соболезнования
Сообщение с соболезнованиями — это сообщение, в котором вы выражаете свое сочувствие кому-то, потому что один из его друзей или родственников недавно умер.
Подпишитесь на нашу рассылку новостей
Получайте последние новости и получайте доступ к эксклюзивным обновлениям и предложениям
Зарегистрируйтесь
В чем разница между объявлением и рекламой?
На этой неделе мы рассмотрим два слова, которые иногда путают: объявление и реклама. Улучшите свой английский с Collins. Подробнее
Учебные пособия для каждого этапа вашего обучения
Ищете ли вы кроссворд, подробное руководство по завязыванию узлов или советы по написанию идеального эссе для колледжа, Harper Reference предоставит вам все необходимое для учебы. Подробнее
Разгадка отличительных черт готической литературы
С приближением сезона ужасов ничто не знаменует смену времен года лучше, чем День Франкенштейна 30 августа. Подробнее
Collins English Dictionary Apps
Загрузите наши приложения English Dictionary, доступные как для iOS, так и для Android. Подробнее
Словари Collins для школ
Наши новые онлайн-словари для школ обеспечивают безопасную и подходящую среду для детей. И самое главное, это приложение не содержит рекламы, так что зарегистрируйтесь сейчас и начните использовать его дома или в классе. Подробнее
Списки слов
У нас есть почти 200 списков слов из самых разных тем, таких как типы бабочек, куртки, валюты, овощи и узлы! Удивите своих друзей своими новыми знаниями! Подробнее
Обновление нашего использования
Существует множество различных факторов, влияющих на то, как английский язык используется сегодня во всем мире. Мы рассмотрим некоторые способы изменения языка.