Страница не найдена — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Содержание
Разбор слова по составу онлайн (морфемный разбор)
Морфемный разбор: А Б В Г Д Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Э Ю Я.
Морфемный разбор — то же самое, что и разбор слова по составу — выделение частей, из которых состоит слово. Разбор под цифрой 2. На нашем сайте вы можете разобрать нужное слово, воспользовавшись формой выше. Просто введите слово и нажмите на кнопку «Разобрать по составу». Наш сервис отличается большой базой слов в разных формах (более 250 тысяч) и мощной системой поиска с исправлением ошибок. Также у нас есть фонетический разбор слова онлайн.
План морфемного разбора
- Определяем часть речи.
- Выделяем окончание и основу.
- Определяем, есть ли в основе слова приставка и суффикс.
- Убеждаемся, что такие же приставки и суффиксы есть в других словах.
- Выделяем корень.
- Обозначаем все части слова графически.


Примеры разбора
музыковед — существительное, имеющее два корня, соединительную гласную и нулевое окончание.
хорошо — наречие с суффиксом, без окончания.
приграничный — имя прилагательное с четырьмя основными морфемами: приставка, корень, суффикс, окончание.
пол — имя существительное с нулевым окончанием
суши — слово без окончания, неизменяемое существительное
Морфема — значимая минимальная часть слова.
6 видов морфем
- Корень — часть слова, несущая основное значение. Главная морфема.
- Приставка (префикс) — часть слова, стоящая перед корнем, которая дополняет его смысл.
- Суффикс — часть слова после корня.
- Постфикс — часть слова после окончания.
- Окончание — изменяемая часть слова. Выражает грамматические значения рода, лица, числа, падежа.
- Соединительная гласная (интерфикс) — структурный элемент слов, выполняющий соединительную функцию между их частями.
Основа — значащая часть слова без окончания и формообразующих суффиксов и постфиксов. В школьной программе постфикс -ся (сь) входит в основу.
В школьной программе постфикс -ся (сь) входит в основу.
Для каждого разбора на нашем сайте есть текст с наименованием морфем, графическая схема, сходные по составу слова, которые можно использовать для облегчения словообразовательного разбора.
Независимо от того, из какого вы класса, эта страница поможет вам.
Существует множество онлайн-инструментов, которые помогут вам проанализировать состав слова. Это может быть полезно, когда вы хотите понять значение слова или узнать, как оно произносится. Одним из таких инструментов является анализ слова по составу. Этот инструмент позволяет ввести слово, а затем показывает различные части слова и их значения. Это может быть полезно, если вы пытаетесь выучить новый язык или хотите лучше понять значение слова на своем родном языке. Разбор слов помогает учиться языку быстрее и эффективнее, потому что помогает лучше понять слово. Когда вы разбираете слово по составу, вы видите, какое значение имеют отдельные части слова. А также он помогает узнать правильное произношение слова. Понимая, что слово состоит из морфем, вы сможете произносить его правильно. Это полезный инструмент для всех, кто хочет учить русский язык. Попробуйте!
А также он помогает узнать правильное произношение слова. Понимая, что слово состоит из морфем, вы сможете произносить его правильно. Это полезный инструмент для всех, кто хочет учить русский язык. Попробуйте!
Популярное: онлайн, прическа, сколько, замирает, столбов, тихо, известная, постучится, этот, узрю, принакрылась, остановившегося, дружит, листочки, москва, проснулся, съешь, солила, морозцы, вьющиеся, находишься, нашел, показались, наступила, объявил, подорожник, светит, интересная, подсолнечник, начинается, легко, освещает, собирают, остановился, собрались, праздник, называемый, пришел, сотканной, по-белорусски, начинает, каких-нибудь, появляется, жалейщик, вышел, предложил, перелеты, сварился, собираются, весело, учитель, растекается, заморскими, ходит, подъем, люблю, подошел, встречай, сильнее, провисают, чьи-то, отцвели, боится, прилетела, показалось, собирает, любуешься, вьется, снежком, появились, снежинки, пальто, наполняется, открылся, собирались, листьями, разбежались, поезд, салютовать, съел, наполняю, жить, тянулся, открывается, охотники, надвигается, извиваясь, диковатость, отличается, встал, видишь, наступает, природа, затоплял, отправился, приходят, направляющийся, перепрыгнул, весна, преследовать
Поделиться
Пишите, мы рады комментариям
Вверх ↑
«Старый» морфологический разбор слова — ассоциации, падежи и склонение слов
«Старый» морфологический разбор слова — ассоциации, падежи и склонение слов- мужской род
- женский род
- средний род
Гипо-гиперонимические отношения
старый древний латинскийСуществительные к слову старый
Что или кто бывает старым? Подбор существительных слов к прилагательному на основе русского языка.
друг
дом
приятель
солдат
дурак
маг
человек
фильм
пес
город
король
дуб
осел
моряк
пень
колдун
бог
конь
доктор
вояка
болван
развратник
мистер
год
эльф
ворчун
китаец
ботинок
враг
свитер
шрам
сарай
воин
спор
господин
сержант
мудрец
учитель
чудак
саймон
художник
стих
гимн
кирпич
мир
автомобиль
убийца
мак
кусок
глаз
доспех
хомяк
донат
ресторан
вяз
червь
паркет
скиф
швейцар
гроб
вездеход
крестоносец
нрав
квартирмейстер
Глаголы к прилагательному старый
Что можно сделать старо? Подбор глаголов на основе русского языка и литературы.
возложить
коверкать
уходить
выглядеть
дышать
Гипонимы
древний
преклонный
черствый
устаревший
престарелый
престарелый
старинный
архаичный
ветхозаветный
замшелый
доисторический
Какого рода старый (морфологический разбор)
Разбор слова по части речи, роду, числу, одушевленности и падежу.
Часть речи:
прилагательное
Род:
мужской
Число:
единственное
Степень сравнения:
—
Падеж:
именительный
Склонение прилагательного старый (какой падеж)
Склонение слова по падежу в единственном и множественном числах.
| Падеж | Вопрос | Единственное | Множ. | ||
|---|---|---|---|---|---|
| Мужской | Средний | Женский | |||
| Именительный | (кто, что?) | старый | старое | старая | старые |
| Родительный | (кого, чего?) | старого | старой | старых | |
| Дательный | (кому, чему?) | старому | старой | старым | |
| Винительный | (кого, что?) | старый | старую | старые | |
| Творительный | (кем, чем?) | старым | старой | старыми | |
| Предложный | (о ком, о чём?) | старом | старой | старых | |
Сфера употребления
Алюминиевая промышленность Агрохимия Деловая лексика География ТеатрНапишите свои варианты ассоциаций
Смотрите также
Перевод Ассоциации Анаграммы Синонимы и антонимы Морфологический разбор Склонения Спряжения
Буква в начале Буква в конце
Все связи построены автоматическим анализатором русскоязычного текста.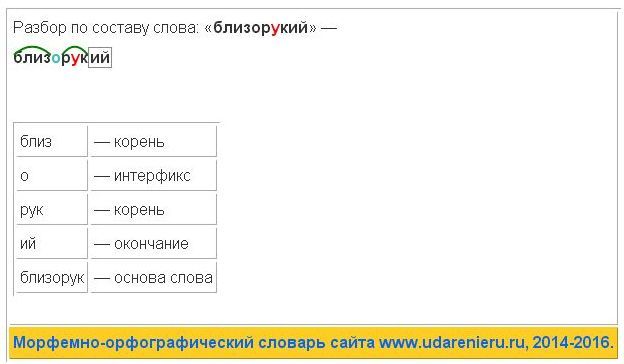
— В: как вы разбираете слово, которое может содержать словосочетание пробелов?
1
Новинка! Сохраняйте вопросы или ответы и организуйте свой любимый контент.
Узнать больше.
Эти журналы почти прибиты гвоздями, но возникают трудности с разделом журнала, который обеспечивает действие fail2ban. Обычно это одно слово, но иногда это два слова с пробелом между ними. Я не уверен, как решить эту проблему, и очень признателен за любую помощь. Я провел немало исследований, но не нашел окончательного ответа, даже пробуя различные решения.
В приведенных ниже примерах вы увидите
Примеры журналов:
2021-10-20 19:50:39,638 fail2ban.actions [31705]: УВЕДОМЛЕНИЕ [sshd] Восстановление запрета 68.183.15.177 2021-10-20 16:08:16,315 fail2ban.actions [6428]: УВЕДОМЛЕНИЕ [sshd] Бан 141.98.10.%MINIFYHTMLb81173a37cbcceb098b1cb51f7b1ec8322%121 2021-10-20 17:21:23,807 fail2ban.
 filter [6428]: INFO [sshd] Found 159.75.130.111 - 2021-10-20 17:21:23
filter [6428]: INFO [sshd] Found 159.75.130.111 - 2021-10-20 17:21:23
Текущая группа:
fail2banRule01 %{date("гггг-ММ-дд ЧЧ:мм:сс,ССС"):Datetime}\s+fail2ban.%{слово}\s+\[%{число:PID }\]\:\s+%{слово:Уровень}\s+\[%{слово:Тюрьма}\]\s+%{слово:ActionType}\s+%{ipv4:ClientIP}(\s+-\s+%{дата ("гггг-ММ-дд ЧЧ:мм:сс"):ActionDate})?
ПРИМЕЧАНИЕ. Это будет в структуре обработки журнала Datadog.
- разбор
- логирование
- datadog
- grok
- fail2ban
Нашел ответ на вопрос. Переход от типа слова к данным.
Вот грок сейчас:
fail2banRule01 %{date(«yyyy-MM-dd HH:mm:ss,SSS»):Datetime}\s+fail2ban.%{word}\s+[%{number :PID}]:\s+%{word:Level}\s+[%{word:Jail}]\s+%{data:ActionType}\s+%{ipv4:ClientIP}(\s+-\s+%{date(» гггг-ММ-дд ЧЧ:мм:сс»):ActionDate})?
Журнал, который был проблемой:
2021-10-20 19:50:39,638 fail2ban. actions [31705]: УВЕДОМЛЕНИЕ [sshd] Восстановление запрета 68.
 183.15.177
183.15.177
Вывод с использованием данных:
{
«Дата и время»: 1634759439638,
"ПИД": 31705,
«Уровень»: «УВЕДОМЛЕНИЕ»,
«тюрьма»: «sshd»,
"ActionType": "Восстановить бан",
"IP-адрес клиента": "68.183.15.177"
}
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
BERTrade: использование контекстных вложений для анализа старофранцузского языка
Loïc Grobol, Матильда Рено, Педро Ортис Суарес, Бенуа Саго, Лоран Ромари, Бенуа Краббе
июнь 2022 г.PDF Зитьерен Код Антология ACL ЛРЭК 2022 ХАЛ
Zusammenfassung
Успехи контекстуального встраивания слов, полученные путем обучения крупномасштабных языковых моделей, хотя и замечательны, в основном произошли для языков, где доступно значительное количество необработанных текстов и где аннотированные данные в последующих задачах имеют относительно правильное написание. И наоборот, пока не совсем ясно, подходят ли эти модели для менее ресурсоемких и более нерегулярных языков. Мы изучаем случай древнефранцузского языка, который находится в интересном положении, имея относительно ограниченный объем доступного необработанного текста, но достаточно аннотированных ресурсов, чтобы оценить актуальность моделей контекстуального встраивания слов для последующих задач НЛП.
И наоборот, пока не совсем ясно, подходят ли эти модели для менее ресурсоемких и более нерегулярных языков. Мы изучаем случай древнефранцузского языка, который находится в интересном положении, имея относительно ограниченный объем доступного необработанного текста, но достаточно аннотированных ресурсов, чтобы оценить актуальность моделей контекстуального встраивания слов для последующих задач НЛП.
BERTrade: использование контекстных вложений для анализа старофранцузского языка
Loïc Grobol, Матильда Рено, Педро Ортис Суарес, Бенуа Саго, Лоран Ромари, Бенуа Краббе
Abstract
Успехи контекстуального встраивания слов, полученные путем обучения крупномасштабных языковых моделей, хотя и замечательны, в основном имели место для языков, где доступны значительные объемы необработанных текстов и где аннотированные данные в последующих задачах имеют относительно регулярный характер. написание. И наоборот, пока не совсем ясно, подходят ли эти модели для менее ресурсоемких и более нерегулярных языков. Мы изучаем случай древнефранцузского языка, который находится в интересном положении, имея относительно ограниченный объем доступного необработанного текста, но достаточно аннотированных ресурсов, чтобы оценить актуальность моделей контекстуального встраивания слов для последующих задач НЛП. В частности, мы используем POS-теги и синтаксический анализ зависимостей для оценки качества таких моделей в большом количестве конфигураций, включая модели, обученные с нуля из небольшого количества необработанного текста, и модели, предварительно обученные на других языках, но настроенные на Medieval. данные Франции.
Мы изучаем случай древнефранцузского языка, который находится в интересном положении, имея относительно ограниченный объем доступного необработанного текста, но достаточно аннотированных ресурсов, чтобы оценить актуальность моделей контекстуального встраивания слов для последующих задач НЛП. В частности, мы используем POS-теги и синтаксический анализ зависимостей для оценки качества таких моделей в большом количестве конфигураций, включая модели, обученные с нуля из небольшого количества необработанного текста, и модели, предварительно обученные на других языках, но настроенные на Medieval. данные Франции. - Антология ID:
- 2022.lrec-1.119
- Том:
- Proceedings of the Thirteenth Language Resources and Evaluation Conference
- Месяц:
- 9 июня 0013
- Год:
- 2022
- Адрес:
- Марсель, Франция
- Место проведения:
- LREC
- SIG:
- Издатель:
- Европейская ассоциация языковых ресурсов
- Примечание:
- Страниц: 9 0011
- 1104–1113
- Язык:
- URL:
- https://aclanthology. org/2022.lrec-1.119
- DOI:
- Bibkey: 9001 0 Ссылка (ACL):
- Лоик Гроболь, Матильда Реньо, Педро Ортис Суарес, Бенуа Саго, Лоран Ромари и Бенуа Краббе. 2022. BERTrade: использование контекстных вложений для анализа старофранцузского языка. In Proceedings of the Thirteenth Language Resources and Evaluation Conference , страницы 1104–1113, Марсель, Франция. Европейская ассоциация языковых ресурсов.
- Процитируйте (неофициально):
- BERTrade: Использование контекстных вложений для анализа старофранцузского языка (Grobol et al., LREC 2022)
- Копия цитирования:
- PDF:
- https://aclanthology.org/2022.lrec-1.119.pdf
 org/2022.lrec-1.119
org/2022.lrec-1.119PDF Процитировать Поиск
- Bibtex
- MODS XML
- КОНДНЯТ
- Преформатированный
@Inprocecendings {grobol-etal-2022-bertrade, @inproceeding
title = "{BERT}rade: использование контекстных вложений для синтаксического анализа {O}ld {F}rench",
автор = {Grobol, Lo{\"\i}c и
Реньо, Матильда и
Ортис Суарес, Педро и
Саго, Бено {\^\i} т и
Ромари, Лоран и
Крэбб, Бенуа,
booktitle = "Материалы Тринадцатой конференции по языковым ресурсам и оценке",
месяц = июнь,
год = "2022",
address = "Марсель, Франция",
издатель = "Европейская ассоциация языковых ресурсов",
url = "https://aclanthology. org/2022.lrec-1.119",
страницы = "1104--1113",
abstract = «Успехи контекстуального встраивания слов, полученные путем обучения крупномасштабных языковых моделей, хотя и замечательны, в основном произошли для языков, где доступно значительное количество необработанных текстов и где аннотированные данные в последующих задачах имеют относительно регулярное написание. И наоборот, это еще не совсем ясно, подходят ли эти модели для менее ресурсоемких и более нерегулярных языков.Мы изучаем случай древнефранцузского языка, который находится в интересном положении, имея относительно ограниченный объем доступного необработанного текста, но достаточно аннотированных ресурсов для оценить релевантность моделей контекстуального встраивания слов для последующих задач НЛП. В частности, мы используем POS-теги и анализ зависимостей для оценки качества таких моделей в большом массиве конфигураций, включая модели, обученные с нуля из небольших объемов необработанного текста и модели, предварительно обученные на других языках, но настроенные на данные средневекового французского языка. ",
}
<моды>
<информация о заголовке>
BERTrade: использование контекстных вложений для анализа древнефранцузского языка
<название типа="личное">
Лоик
Гробол
<роль>
автор
<название типа="личное">
Матильда
Рено
<роль>
автор
<название типа="личное">
Педро
Ортис Суарес
<роль>
автор
<название типа="личное">
Бенуа
Саго
<роль>
автор
<название типа="личное">
Лоран
Ромари
<роль>
автор
<название типа="личное">
Бенуа
Краббе
<роль>
автор
<информация о происхождении>
2022-06
текст
<информация о заголовке>
Материалы Тринадцатой конференции по языковым ресурсам и оценке
<информация о происхождении>
Европейская ассоциация языковых ресурсов
<место>
Марсель, Франция
публикация конференции
Успехи контекстуального встраивания слов, полученные путем обучения крупномасштабных языковых моделей, хотя и замечательны, в основном были достигнуты для языков, в которых доступно значительное количество необработанных текстов и где аннотированные данные в последующих задачах имеют относительно регулярное написание. И наоборот, пока не совсем ясно, подходят ли эти модели для менее ресурсоемких и более нерегулярных языков. Мы изучаем случай древнефранцузского языка, который находится в интересном положении, имея относительно ограниченный объем доступного необработанного текста, но достаточно аннотированных ресурсов, чтобы оценить актуальность моделей контекстуального встраивания слов для последующих задач НЛП. В частности, мы используем POS-теги и синтаксический анализ зависимостей для оценки качества таких моделей в большом количестве конфигураций, включая модели, обученные с нуля из небольшого количества необработанного текста, и модели, предварительно обученные на других языках, но настроенные на Medieval. Данные Франции.
grobol-etal-2022-bertrade
<местоположение>
https://aclanthology.org/2022.lrec-1.119
<часть>
<дата>2022-06
<единица экстента="страница">
1104
1113
%0 Материалы конференции
%T BERTrade: использование контекстных вложений для анализа старофранцузского языка
%A Гроболь, Лоик
% Реньо, Матильда
%A Ортис Суарес, Педро
%A Sagot, Бенуа
%А Ромари, Лоран
% Краббе, Бенуа
%S Материалы Тринадцатой конференции по языковым ресурсам и оценке
%D 2022
%8 июня
%I Европейская ассоциация языковых ресурсов
%C Марсель, Франция
%F grobol-etal-2022-bertrade
%X Успехи контекстуального встраивания слов, полученные путем обучения крупномасштабных языковых моделей, хотя и замечательны, в основном происходили для языков, где доступно значительное количество необработанных текстов и где аннотированные данные в последующих задачах имеют относительно регулярное написание. И наоборот, пока не совсем ясно, подходят ли эти модели для менее ресурсоемких и более нерегулярных языков. Мы изучаем случай древнефранцузского языка, который находится в интересном положении, имея относительно ограниченный объем доступного необработанного текста, но достаточно аннотированных ресурсов, чтобы оценить актуальность моделей контекстуального встраивания слов для последующих задач НЛП. В частности, мы используем POS-теги и синтаксический анализ зависимостей для оценки качества таких моделей в большом количестве конфигураций, включая модели, обученные с нуля из небольшого количества необработанного текста, и модели, предварительно обученные на других языках, но настроенные на Medieval. данные Франции.
%U https://aclanthology.org/2022.lrec-1.119%Р 1104-1113
Уценка (неофициальная)
[BERTrade: использование контекстных вложений для анализа старофранцузского языка] (https://aclanthology.org/2022.lrec-1.119) (Grobol et al., LREC 2022)
 org/2022.lrec-1.119",
страницы = "1104--1113",
abstract = «Успехи контекстуального встраивания слов, полученные путем обучения крупномасштабных языковых моделей, хотя и замечательны, в основном произошли для языков, где доступно значительное количество необработанных текстов и где аннотированные данные в последующих задачах имеют относительно регулярное написание. И наоборот, это еще не совсем ясно, подходят ли эти модели для менее ресурсоемких и более нерегулярных языков.Мы изучаем случай древнефранцузского языка, который находится в интересном положении, имея относительно ограниченный объем доступного необработанного текста, но достаточно аннотированных ресурсов для оценить релевантность моделей контекстуального встраивания слов для последующих задач НЛП. В частности, мы используем POS-теги и анализ зависимостей для оценки качества таких моделей в большом массиве конфигураций, включая модели, обученные с нуля из небольших объемов необработанного текста и модели, предварительно обученные на других языках, но настроенные на данные средневекового французского языка.
org/2022.lrec-1.119",
страницы = "1104--1113",
abstract = «Успехи контекстуального встраивания слов, полученные путем обучения крупномасштабных языковых моделей, хотя и замечательны, в основном произошли для языков, где доступно значительное количество необработанных текстов и где аннотированные данные в последующих задачах имеют относительно регулярное написание. И наоборот, это еще не совсем ясно, подходят ли эти модели для менее ресурсоемких и более нерегулярных языков.Мы изучаем случай древнефранцузского языка, который находится в интересном положении, имея относительно ограниченный объем доступного необработанного текста, но достаточно аннотированных ресурсов для оценить релевантность моделей контекстуального встраивания слов для последующих задач НЛП. В частности, мы используем POS-теги и анализ зависимостей для оценки качества таких моделей в большом массиве конфигураций, включая модели, обученные с нуля из небольших объемов необработанного текста и модели, предварительно обученные на других языках, но настроенные на данные средневекового французского языка. ",
}
",
}
 И наоборот, пока не совсем ясно, подходят ли эти модели для менее ресурсоемких и более нерегулярных языков. Мы изучаем случай древнефранцузского языка, который находится в интересном положении, имея относительно ограниченный объем доступного необработанного текста, но достаточно аннотированных ресурсов, чтобы оценить актуальность моделей контекстуального встраивания слов для последующих задач НЛП. В частности, мы используем POS-теги и синтаксический анализ зависимостей для оценки качества таких моделей в большом количестве конфигураций, включая модели, обученные с нуля из небольшого количества необработанного текста, и модели, предварительно обученные на других языках, но настроенные на Medieval. Данные Франции.
И наоборот, пока не совсем ясно, подходят ли эти модели для менее ресурсоемких и более нерегулярных языков. Мы изучаем случай древнефранцузского языка, который находится в интересном положении, имея относительно ограниченный объем доступного необработанного текста, но достаточно аннотированных ресурсов, чтобы оценить актуальность моделей контекстуального встраивания слов для последующих задач НЛП. В частности, мы используем POS-теги и синтаксический анализ зависимостей для оценки качества таких моделей в большом количестве конфигураций, включая модели, обученные с нуля из небольшого количества необработанного текста, и модели, предварительно обученные на других языках, но настроенные на Medieval. Данные Франции. И наоборот, пока не совсем ясно, подходят ли эти модели для менее ресурсоемких и более нерегулярных языков. Мы изучаем случай древнефранцузского языка, который находится в интересном положении, имея относительно ограниченный объем доступного необработанного текста, но достаточно аннотированных ресурсов, чтобы оценить актуальность моделей контекстуального встраивания слов для последующих задач НЛП. В частности, мы используем POS-теги и синтаксический анализ зависимостей для оценки качества таких моделей в большом количестве конфигураций, включая модели, обученные с нуля из небольшого количества необработанного текста, и модели, предварительно обученные на других языках, но настроенные на Medieval. данные Франции.
%U https://aclanthology.org/2022.lrec-1.119%Р 1104-1113
И наоборот, пока не совсем ясно, подходят ли эти модели для менее ресурсоемких и более нерегулярных языков. Мы изучаем случай древнефранцузского языка, который находится в интересном положении, имея относительно ограниченный объем доступного необработанного текста, но достаточно аннотированных ресурсов, чтобы оценить актуальность моделей контекстуального встраивания слов для последующих задач НЛП. В частности, мы используем POS-теги и синтаксический анализ зависимостей для оценки качества таких моделей в большом количестве конфигураций, включая модели, обученные с нуля из небольшого количества необработанного текста, и модели, предварительно обученные на других языках, но настроенные на Medieval. данные Франции.
%U https://aclanthology.org/2022.lrec-1.119%Р 1104-1113
- BERTrade: использование контекстного Вложения в синтаксический анализ древнефранцузского языка (Grobol et al. , LREC 2022)
 , LREC 2022)
, LREC 2022)ACL
- Лоик Гроболь, Матильда Реньо, Педро Ортис Суарес, Бенуа Саго, Лоран Ромари и Бенуа Краббе. 2022. BERTrade: использование контекстных вложений для анализа старофранцузского языка. В Материалы Тринадцатой конференции по языковым ресурсам и оценке , страницы 1104–1113, Марсель, Франция. Европейская ассоциация языковых ресурсов.
Разбор | Encyclopedia.com
oxford
просмотров обновлено 21 мая 2018 РАЗБОР [От глагола parse , от латинского pars /partis часть, абстрагированная от словосочетания pars orationis часть речи ].1. Разбирать ПРЕДЛОЖЕНИЕ на составные части, более или менее подробно выявляя синтаксические отношения и части речи.
2. Описание СЛОВА в предложении, определение его части речи, словоизменительной формы и синтаксической функции.
Синтаксический анализ прежде был центральным элементом обучения ГРАММАТИКЕ во всем англоязычном мире и широко считался основой использования и понимания письменной речи. Когда многие люди говорят об формальной грамматике в школах, они имеют в виду преподавание разбора и АНАЛИЗА ПУНКТОВ, которое практически прекратилось в начальном и среднем образовании в англоязычном мире в 1960-х годов, а в системе высшего образования на смену лингвистическому анализу пришел лингвистический анализ. Аргумент против традиционного синтаксического анализа состоит из трех частей: он продвигает старомодные описания языка, основанные на ЛАТИНСКИХ грамматических категориях; что студенты не получают от этого пользы; и что это является источником разочарования и скуки как для студентов, так и для учителей. Аргумент в пользу синтаксического анализа состоит из четырех частей: он делает явной структуру речи и письма, дисциплинирует ум, позволяет людям говорить об использовании языка и помогает в изучении и обсуждении иностранных языков. Компромиссная позиция состоит в том, что формальное обсуждение СИНТАКСИСА и функции может быть полезным, но оно должно отходить на второй план по сравнению с беглым выражением и достижением уверенности, а не доминировать в еженедельной рутине.
Когда многие люди говорят об формальной грамматике в школах, они имеют в виду преподавание разбора и АНАЛИЗА ПУНКТОВ, которое практически прекратилось в начальном и среднем образовании в англоязычном мире в 1960-х годов, а в системе высшего образования на смену лингвистическому анализу пришел лингвистический анализ. Аргумент против традиционного синтаксического анализа состоит из трех частей: он продвигает старомодные описания языка, основанные на ЛАТИНСКИХ грамматических категориях; что студенты не получают от этого пользы; и что это является источником разочарования и скуки как для студентов, так и для учителей. Аргумент в пользу синтаксического анализа состоит из четырех частей: он делает явной структуру речи и письма, дисциплинирует ум, позволяет людям говорить об использовании языка и помогает в изучении и обсуждении иностранных языков. Компромиссная позиция состоит в том, что формальное обсуждение СИНТАКСИСА и функции может быть полезным, но оно должно отходить на второй план по сравнению с беглым выражением и достижением уверенности, а не доминировать в еженедельной рутине.

Concise Oxford Companion to the English Language TOM McARTHUR
oxford
просмотров обновлено 18 мая 2018 разбор ( синтаксический анализ 9 0125 ) Процесс определения того, является ли строка входных символов предложением данного языка и, если это так, определение синтаксической структуры строки, как определено грамматикой (обычно контекстно-свободной) для языка. Это достигается с помощью программы, известной как анализатор 9.0065 или синтаксический анализатор . Например, синтаксический анализатор арифметических выражений должен сообщить об ошибке в строке 1–+2, так как недопустимо сопоставление операторов минус и плюс. С другой стороны, строка 1–2–3
является допустимым арифметическим выражением со структурой, заданной утверждением, что его подвыражения равны 1,2,3 и 1–2
(обратите внимание, что 2–3 не является подвыражением. )
Входные данные для синтаксического анализатора представляют собой строку токенов, предоставленную лексическим анализатором.