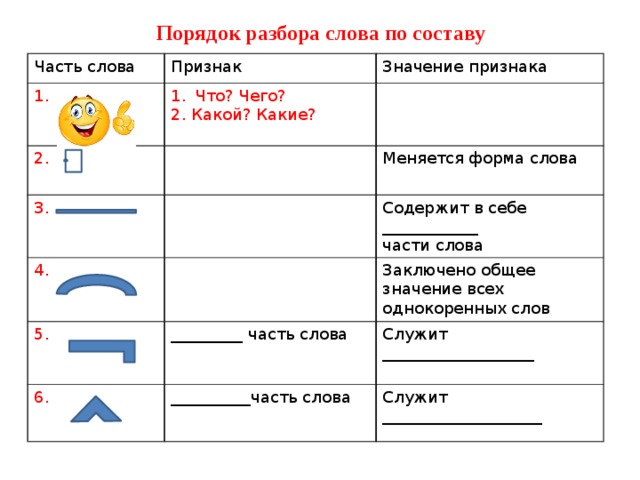
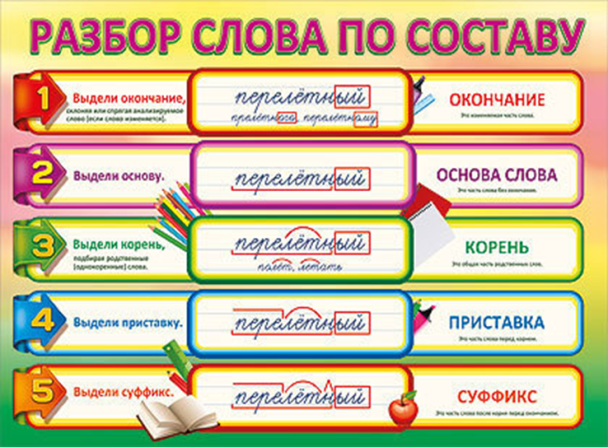
Задания для самостоятельных работ по русскому языку для 4 класса по теме «Состав слова»
Задания для самостоятельных работ по русскому языку
для 4 класса по теме «Состав слова»
1. Вычеркни лишнее слово. Эту дидактическую игру можно проводить как парную или групповую работу. Записанные слова приготовить на карточках.
1. Ракета, ракообразный, ракушка, рак.
2. Соленый, соломка, солонка, солянка.
3. Музыка, музыкальный, музей, муза.
4. Мышцы, мышечный, мышление.
5. Остров, острый, островок, полуостров.
6. Свинцовый, свинка, свинюшка, свинья.
7. Радость, радуга, радоваться, радостный.
8. Жилец, жилье, жилы, жилище.
9. Речь, речной, речевой.
10. Роза, розовый, розыск, розочка.
11. Ручка, ручной, ручей.
12. Портной, портрет, портретист.
13. Серый, серенький, серия, серость.
14. Снежинка, снижать, снежный, снежно.
15. Слепой, слепота, слепить, слепыш.
16. Умный, умывать, ум, умница.
2. Игра-соревнование «Кто больше».
I вариант игры
Класс делится на 2-3 команды (по рядам). Учитель готовит несколько карточек, на которых написаны корни слов. Например: уч, берез, боль. С каждой команды выходят по одному ученику и выбирают себе карточку. Учитель вывешивает выбранные карточки на доске. Игра проходит по принципу эстафеты. Учащиеся обдумывают, выходят к доске и пишут под корнями однокоренные слова. Выигрывает та команда, которая подобрала больше однокоренных слов и не допустила ошибок.
II вариант игры-соревнования «Кто больше» можно провести в виде игры «Молчанка».
Подготовка такая же, как и в I варианте, но однокоренные слова дети записывают не на доске, а передается листик всем участникам команды на местах.
слово | 1 | 2 | 3 | 4 |
схема |
|
|
|
|
4. Образуй новые слова. Ученикам предлагается образовать слова при помощи данных корней, приставок, суффиксов и окончаний.
по корм
поль к — а
за став
рез
на груз н — ый
ряд
под воз
стил к — и
пере ход
мороз
при вод ск — ий
груд
у клад
мор ник
об снеж
пис
5. □
□
Перешел
Садок
Сетка
Мышка
Пересадка
Замолчать
Соленый
Сказка
Рыба
Налить
Столовая
Лесной
Сильная
Закрыть
Морозец
Скрипка
Мячи
Написать
Стенка
Длинный
Умные
Разнести
Ведать
Рябчик
Моряки
6. Кроссворд:
| 2 |
|
|
| 1 |
|
| |||||||
|
|
| 3 |
|
|
|
|
|
|
|
| |||
4 |
|
|
|
|
|
|
|
|
| |||||
5 |
|
|
|
|
|
| ||||||||
6 |
|
|
|
|
|
| ||||||||
7 |
|
|
|
|
|
|
| |||||||
По вертикали.
1. … слова – значимая часть.
Над словами родственными держит власть.
По горизонтали.
2. Часть слова, которая стоит за корнем.
3. Часть слова, которая изменяется, … называется.
4. Часть слова, которая стоит перед корнем.
5. Служебная часть речи, которая всегда пишется отдельно от других слов.
6. Часть слова без окончания.
7. Тот, кто учит детей.
Диктанты по теме однородные члены предложения 4 класс
На этой страничке мы — 7 гуру — собрали для вас диктанты пот теме «Однородные члены предложения». Обратите внимание, что предложения в них и простые, и сложные, повторите эти темы перед работой над диктантом. Обращайте внимание не только на расстановку знаков препинания, но и на изученные орфограммы, потому как оценка снижается за любую ошибку, а не только за ту, которая относится к теме диктанта.
Родина моя
Нет ни одной страны краше нашей России. Горькая и трудная судьба её. Много пережил русский народ от иноземных захватчиков: шведов, поляков, немцев. Но всегда находились люди, которые поднимали народ на освобождение от цепей рабства. Это Александр Невский, Дмитрий Донской, Кузьма Минин, Суворов и Кутузов. Под их предводительством люди спасали не только свою Родину, но и народы Европы.
(57 слов)
Слова для справок: освобождение, (под) предводительством.
Грамматические задания
- Найдите предложения с однородными членами. Составьте схему одного из них (на выбор).
- Укажите известные вам части речи над словами последнего предложения.
- Укажите падеж имён существительных в третьем предложении.
Диктант
Белая куропатка
Зимой в заснеженной тундре падают с веток и зарываются в снег белые куропатки. На деревьях они клюют почки, а под снегом ищут мёрзлые ягоды. Там же спасаются птицы в пургу. Зимой куропатки белые, а брови у них красные. Весной они надевают праздничный наряд. Подуют тёплые ветры. Начнут таять снега. Придёт лето. Летом куропатки снова меняют наряд.
Зимой куропатки белые, а брови у них красные. Весной они надевают праздничный наряд. Подуют тёплые ветры. Начнут таять снега. Придёт лето. Летом куропатки снова меняют наряд.
(58 слов) (Г. Снегирёв)
Грамматические задания
- Выписать из диктанта предложение с однородными сказуемыми.
- Выписать из диктанта слово с непроизносимой согласной. Написать проверочное слово.
- Разобрать по составу слово НАРЯД. Написать ещё два слова с таким же составом.
Дюймовочка
Ласточка выпила воды и рассказала Дюймовочке свою историю. На озере ребята купались, плескались, веселились. Отряд шёл бодро, уверенно и легко. Солнце осветило луг, поле, речку, разбудило бабушкиного петушка. Ручная ворона сидела на воротах и хлопала крыльями.
Грамматическое задание
- Обоснуй постановку знаков препинания между однородными членами предложения.
- Обоснуй правописание выделенных орфограмм.
Диктант
Счастье
Лежу в траве. Лохматые шапочки одуванчиков похожи на маленькие солнышки. Вокруг меня летают пчёлы, мушки, комары. Они не просто летают, жужжат и кружатся надо мной. Это их трудовые будни. Цветы, травы, кусты и деревья радуют меня. Успокаивает писк. Рокот, гудение природы. Я чувствую себя счастливым.
Лохматые шапочки одуванчиков похожи на маленькие солнышки. Вокруг меня летают пчёлы, мушки, комары. Они не просто летают, жужжат и кружатся надо мной. Это их трудовые будни. Цветы, травы, кусты и деревья радуют меня. Успокаивает писк. Рокот, гудение природы. Я чувствую себя счастливым.
Грамматическое задание
- Выпиши из текста только предложения с однородными подлежащими.
Пернатый рекордсмен
Колибри живут в Америке. Это самые маленькие птички на Земле. По размеру и радужному оперению они похожи на бабочек.
Питаются колибри цветочным нектаром. При этом сладкий сок птицы пьют, зависая перед чашечкой цветка.
(69 слов)
Слова для справок: колибри, нектаром.
Грамматические задания
- Выполните синтаксический разбор четвёртого и пятого предложений.
- Разберите по составу слова: радужный, полёт, сладкий.
- Выполните звуко-буквенный разбор слова пьют.
Как заяц волка обманул
Увидел волк зайца, стал его преследовать. А заяц поскакал к деревне. Ведь утром вол туда не побежит.
Но волк приближался всё ближе и ближе. Того и гляди схватит. Заяц уже слышит дыхание волка.
Вдруг заяц увидел дыру в заборе и проскочил в неё. Спрятался в крапиве. Волк в дыру голову просунул и застрял.
Тут вышел из сарая мужик, ударил волка поленом. Тот взвыл от боли и побежал к лесу.
(70 слов)
Слова для справок: собираем, растут.
Грамматические задания
- Выполните синтаксический разбор третьего и пятого предложений.
- Разберите по составу слова: (с) дедушкой, (за) грибами, (в) ельнике.
- Подберите к словам гриб, лист однокоренные слова.
 Корни слов обозначьте.
Корни слов обозначьте.
 Корни слов обозначьте.
Корни слов обозначьте.Гнёзда
Гнездо – это птичий дом. Каких только не бывает гнёзд на свете! Гнёзда лепят, плетут, складывают. У грачей и ворон гнёзда сложены из сучков. У ремеза гнездо сплетено из мха и паутины. У ласточек слеплено из земли. Синицы, дятлы прячут свои гнёзда в дупле. Чаще всего птичье гнездо похоже на чайную чашечку. Оно сплетено из веточек, а внутри выстлано пухом, перьями или шерстью. Каждую весну большинство птиц вьёт гнёзда заново.
(70 слов)
Грамматические задания
- Выписать из диктанта предложение без союзов с однородными сказуемыми.
- Выписать из диктанта два слова с разделительным Ь.
- Выписать из диктанта по одному имени существительному, прилагательному, глаголу. Указать части речи.
Диктант
В лес за грибами
Ветер несёт листья по кочкам, оврагам, лугам, полям. Позолотили они все дорожки и тропинки в лесу. Наступила грибная пора.
После дождя и взрослые, и дети устремились в лес за грибами. Дед Степан нёс большую корзину. Он мастер собирать грибы. Я заглядывал под каждый кустик, пенёк. У меня была маленькая корзинка. В корзинке у меня лежали лисички, подосиновики и белые грибы. Мы вышли на старую вырубку. Вся она была усыпана опятами.
Дед Степан нёс большую корзину. Он мастер собирать грибы. Я заглядывал под каждый кустик, пенёк. У меня была маленькая корзинка. В корзинке у меня лежали лисички, подосиновики и белые грибы. Мы вышли на старую вырубку. Вся она была усыпана опятами.
(70 слов)
Слова для справок: устремились, корзинка, опятами.
Грамматическое задание
- Выписать и разобрать по членам 4 и 9 предложения.
- Списать предложение, вставить пропущенные буквы и знаки препинания, подчеркнуть однородные члены.
1 в. – Вет..р п..дул (со) страшной силой пов..лил старую б..рёзу и сорвал крышу с сарая.
2 в. В д..ревне мы всегда собираем м..лину а потом с удовольствием едим вкусн..е варен..е .
Птенцы
Вот из яичек вылупились птенцы. Жизнь птиц после этого резко меняется. Ведь в гнезде появились голодные рты. Птенцы дневных птиц вылупляются на свет днём, а ночных – ночью. У певчих и хищных птенцы вылупляются слепые и слабые. У гусей, уток птенцы рождаются бойкими, глазастыми, пушистыми.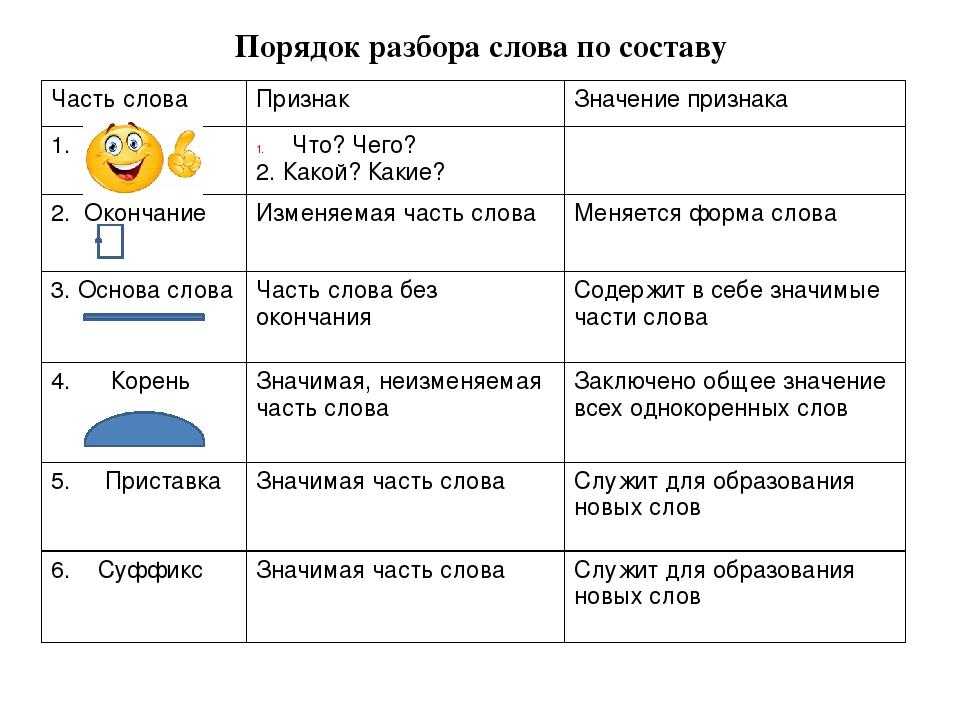 От рождения они умеют и ходить, и плавать.
От рождения они умеют и ходить, и плавать.
Родители греют птенцов в холод, прикрывают и от дождя, и от жгучего солнца, смело кидаются на врагов.
(70 слов)
Грамматические задания
- Выписать из диктанта предложение с однородными второстепенными членами.
- Выписать из диктанта два слова с парной согласной в слабой позиции. Написать проверочные слова.
- Написать два слова с Ъ.
Диктант
За грибами
Мы с дедушкой Гришей любим ходить в лес за грибами. Он интересно рассказывает о жизни грибного царства, о маленьких хитростях тихой охоты. В светлой берёзовой роще мы собираем подберёзовики и белые. В молодом ельнике много рыжиков, маслят и груздей. На опушках под листьями прячутся подосиновики, сыроежки, лисички, волнушки. У пеньков дружными семьями растут опята.
Дед учит меня отличать съедобные грибы от ядовитых, узнавать лесных птиц по голосам, запоминать лекарственные растения.
(71 слово)
Слова для справок: ведь, поленом.
Грамматические задания
- Найди в тексте однородные сказуемые, подчеркни их.
- Дайте характеристику второго предложения.
- Найдите в тексте местоимения, определите падеж.
Рябина
Около нашего дома растёт рябинка. Это деревце нарядно выглядит в любое время года. Весной рябина цветёт. Её мелкие цветочки собраны в большие кисти, словно букеты. Летом рябинка одета в пышное платье из ажурных листьев и маленьких бусинок созревающих ягод. Осенью красавица наряжается в яркий сарафан из золотой парчи и украшает себя искусным ожерельем спелых ягод. Тяжёлые гроздья этих чудо-ягод зима укроет мохнатыми шапками, а на рябинке заблестит шубка из сверкающего инея.
(73 слова)
Слова для справок: сарафан, (из) парчи, ожерелье.
Грамматические задания
- Выполните синтаксический разбор шестого предложения.
- Выпишите из текста четыре слова с разделительным ь. Вспомните и напишите четыре слова с разделительным ъ.
- Выполните звуко-буквенный разбор слова гроздья.

Диктант
Город в городе
На живописном волжском берегу раскинулся древний Городец. Издавна его жители славились мастерством да трудолюбием. На всю Россию были известны городецкие пряники, роспись, вышивки, игрушки, кружева.
Потомки мастеров бережно хранят традиции предков. В современном Городце на набережной красуются бревенчатые избы и сказочные терема. Это знаменитый Город мастеров. Здесь народные умельцы знакомят гостей города с искусством золотой вышивки, лозоплетения, росписи и резьбы по дереву. Тут можно попробовать самому слепить свистульку, расписать дощечку, поработать на гончарном круге.
(74 слова)
Слова для справок: лозоплетенья.
Грамматические задания
- Выполните синтаксический разбор седьмого предложения.
- Подчеркните грамматическую основу в пятом предложении.
- Разберите в первом предложении имена прилагательные по составу.

Тайна вечной красоты
Как удивителен небесный свод в ясную ночь! На тёмном бархатном покрывале яркими огоньками сверкают миллиарды звёзд. Они искрятся и мерцают голубым, белым, красным, жёлтым цветом.
С древних времён это загадочное разноцветье вдохновляет людей. О звёздах мы знаем много древних мифов, легенд, сказок. Чарующей звёздной бездне поэты посвящают стихи. К далёким светилам человек устремляется в самых смелых своих мечтах.
Как и много веков назад, людей восхищает и завораживает величественная красота звёздного неба, его вечная тайна.
(74 слова)
Слова для справок: мерцают, вдохновляет, завораживает.
Грамматические задания
- Выполните синтаксический разбор третьего предложения.
- Дайте характеристику первому предложению по цели высказывания и по интонации.
- Выпишите из текста словосочетание прил. + сущ., в котором в главном и зависимом словах есть орфограмма «Непроизносимый согласный в корне слова».

Плащ-невидимка
В дикой природе многие животные проявляют чудеса маскировки. Во время охоты или спасаясь от хищников, эти фокусники так умело прячутся, словно вмиг накидывают на себя сказочный плащ-невидимку. И тогда среди снежных сугробов становится трудно заметить полярную сову, белого медведя или зайца-беляка. В изумрудных травах и листьях спрячутся зелёные гусеницы, кузнечики, лягушки, ящерицы. На фоне густой листвы и солнечных бликов затеряются пятнистый олень, леопард и жираф.
Защитная окраска помогает животным стать невидимыми, а значит, выжить.
(76 слова)
Слова для справок: гусеницы, невидимыми.
Грамматические задания
- Подчеркните грамматические основы в четвёртом и пятом предложениях.
- Разберите по составу слова : пятнистый, защитная, окраска.
- Выполните звуко-буквенный разбор слова выжить.
Вчера и сегодня
Наши предки всегда жили в тесном единстве с природой. Наблюдения за движением солнца и звёзд помогали им определять сроки полевых работ. Глядя на полёт ласточек, на дым костра, на солнечный закат, люди предсказывали жару, похолодание или ненастье.
Наблюдения за движением солнца и звёзд помогали им определять сроки полевых работ. Глядя на полёт ласточек, на дым костра, на солнечный закат, люди предсказывали жару, похолодание или ненастье.
В век бурного развития техники нам открылись новые возможности. Сегодня о погоде на ближайшие дни можно узнать по телевидению или в Интернете.
И только немного жаль, что мы теряем способность также внимательно и пристально, как наши прадеды, вглядываться в родную природу.
(78 слов)
Грамматические задания
- Подчеркните в третьем предложении однородные члены.
- Выпишите из текста три одушевлённых и три неодушевлённых имени существительных.
- Выпишите из текста слово с разделительным ь. Подберите к нему синоним.
Диктант
Эльбрус
Эльбрус — высочайший пик Европы. Это древний спящий вулкан. У горы две вершины: Восточная и Западная. Круглый год они покрыты вечными льдами и снегами. Могучие ледники Эльбруса дают начало бурным рекам. Пробивая себе путь через каменистые ущелья, с вышины горных склонов несут свои воды Кубань и приток реки Терек.
Пробивая себе путь через каменистые ущелья, с вышины горных склонов несут свои воды Кубань и приток реки Терек.
Во все времена народы, жившие у подножия Эльбруса, слагали о славной и могучей горе-исполине песни и легенды. Величием и красотой «двуглавого колосса» восхищались русские поэты Александр Сергеевич Пушкин и Михаил Юрьевич Лермонтов.
(81 слово)
Слова для справок: исполин, колосс, восхищались.
Грамматические задания
- Подчеркните в четвертом предложении однородные члены.
- Подберите к словам год, гора, река по два однокоренных слова. Корни слов обозначьте.
- Выпишите из текста три слова, в которых количество букв и звуков совпадает. Укажите, сколько в словах звуков и букв.
Удивительные рыбы
Рыбы путешествуют. Они путешествуют большими косяками в поисках пищи, зимовки или икрометания.
Самое длинное и удивительное путешествие совершают угри. Из рек угри спускаются к морю. Из моря плывут в Атлантический океан. Из океана в Саргассово море. Это море без берегов посредине океана! Там угри мечут икру.
Из океана в Саргассово море. Это море без берегов посредине океана! Там угри мечут икру.
Личинки угрей подхватывает тёплое течение Гольфстрим и несёт к берегам родной Европы. В пути личинки вырастают в маленьких угрей. Они находят реки своих родителей. В этих реках рыбки становятся взрослыми и повторяют путь своих предков.
(82 слова) (по Н. Сладкову)
Грамматические задания
- Выписать из диктанта предложение с союзом с однородными второстепенными членами.
- Выписать из диктанта одно слово с удвоенной согласной. Написать ещё два слова на эту же орфограмму.
- В первом предложении третьего абзаца указать род и число имён прилагательных.
Уральские горы
Наши предки называли Уральские горы Каменным поясом. Горная цепь и правда узкой лентой протянулась от берегов Северного Ледовитого океана до степей Казахстана.
Скалистые уступы и невысокие хребты густо заросли лесами. Среди дубов и берёз, пихт и елей живут медведь, лось, соболь, заяц. В таёжных дебрях прячутся тетерев, рябчик, кедровка. Со склонов гор стремительно бегут чистые реки. Между горных вершин блестят зеркала голубых озёр.
В таёжных дебрях прячутся тетерев, рябчик, кедровка. Со склонов гор стремительно бегут чистые реки. Между горных вершин блестят зеркала голубых озёр.
В Уральских горах открыты богатые месторождения полезных ископаемых. Здесь добывают железную и медную руду, соль, нефть, уголь, золото, драгоценные камни.
(83 слова)
Грамматические задания
- Подчеркните грамматические основы во всех предложениях второго абзаца.
- Подчеркните однородные члены в последнем предложении.
- Выпишите из текста три слова с орфограммой «Непроверяемый безударный гласный в корне слова»
Лес
За оградой двора древнего славянина начинался дремучий лес. Такой лес сохранился теперь только в Сибири и на Севере. Лес давал людям дичь, ягоды и грибы. В хозяйстве славян из дерева изготовляли почти всё. Люди делали и дома, и посуду, и прочую утварь. Славяне в лесу выделяли особые деревья. Эти деревья были непомерной высоты или толщины. Они считались хранителями и помощниками славянского селения. Такие деревья до сих пор украшают наши леса. Теперь их называют памятниками природы. Самыми уважаемыми деревьями были дуб, берёза, сосна.
Такие деревья до сих пор украшают наши леса. Теперь их называют памятниками природы. Самыми уважаемыми деревьями были дуб, берёза, сосна.
(83 слова) (по М. Семёновой)
Грамматические задания
- Выписать из диктанта предложение с однородными подлежащими.
- Выписать из диктанта одно существительное с мягким знаком после шипящей. Написать ещё два слова на эту же орфограмму.
- Первое предложение разобрать по членам предложения, указать части речи, выписать словосочетания.
Диктант
Машины на службе у человека
Всего лишь несколько десятков лет назад в нашей стране преобладал ручной труд. В селе и деревне мужчины вручную обрабатывали поля, косили косами траву, ворошили граблями и вилами сено. На фермах женщины сами доили коров, ухаживали за птицей. В городах на заводах и фабриках многое выполнялось вручную.
Со временем ручной труд заменяли машины. Образ жизни людей тоже изменился. На полях теперь работают современные комбайны и тракторы. На заводах и фабриках тяжёлую работу за людей выполняют роботы. Даже в домашних делах нам помогают машины.
На заводах и фабриках тяжёлую работу за людей выполняют роботы. Даже в домашних делах нам помогают машины.
(82 слова)
Слова для справок: лишь, преобладал, вручную, многое.
Грамматические задания
- Найдите во втором предложении однородные члены. Подчеркните их. Укажите части речи.
- Выпишите словосочетания с вопросами из предпоследнего предложения. Укажите падеж зависимых слов в словосочетаниях.
- Выпишите из текста по одному имени существительному, прилагательному, глаголу. Разберите их как части речи.
Рыжик
У Веры был бельчонок Рыжик. Он часто садился на плечо и когтями разжимал кулачок у девочки. Там он искал орехи. На Новый год Вера повесила на ёлку игрушки, орешки и вышла принести свечки. Малыш приблизился к ёлке, схватил один орех, спрятал, а второй затащил под подушку. С этого дня зверёк делал запасы. Увидит семечки и набивает полные щёки. Приехал папин знакомый из сибирской тайги и всё объяснил. В этом году в тайге не уродились кедровые орешки. И птицы, и белки переселились за горные хребты. Но как Рыжик узнал об этом?
В этом году в тайге не уродились кедровые орешки. И птицы, и белки переселились за горные хребты. Но как Рыжик узнал об этом?
(91 слово) (по Г. Снегирёву)
Грамматические задания
- Выписать из диктанта предложение с союзом с однородными второстепенными членами.
- Выписать из диктанта одно имя собственное. Написать ещё два слова на эту же орфограмму.
- Разобрать по составу слова: ШИШКИ, КЕДРОВЫЕ, ОРЕШКИ.
Сплюшка
У меня долго жила сова-сплюшка и стала ручной. Она любила сидеть без движения и дремать. Посадили её на раму картины. Сидит на раме. Незнакомые люди принимали её за чучело. Даже свои стирали пыль с вещей и машинально проводили тряпочкой и по ней. Сплюшка спокойно сидела на руле мотоцикла. Все её принимали за тряпичный талисман. Выезжали за город, сажали её на сучок. Она не оживлялась и на сучке. Сидела, дремала и ждала угощения. Сколько раз её забывали! Приедут домой. Где сплюшка? Вернутся в лес, а она на том же месте спит спокойно.
(92 слова)
Грамматические задания
- Выписать из диктанта предложение с союзом с однородными сказуемыми.
- Выписать из диктанта три слова с проверяемыми безударными гласными в корне. Написать проверочные слова.
- Выписать из диктанта по одному имени существительному, прилагательному, глаголу. Указать части речи.
Беличье гнездо
Часто белки живут в дуплах деревьев. Но если нет подходящего жилища, рыжая хозяюшка сама смастерит гнездо. Дом белочка построит из веток высоко на ели или сосне. Он будет похож на большой шар с узкой лазейкой. Внутри пушистый зверёк застелет гнездо мягкой перинкой из сухой травы и клочков шерсти. Прочный и надёжный домик осенью защитит от ледяного ветра и холодного дождя. Зимой закружит по лесу метель, затрещит мороз. Маленький зверёк свернётся в гнезде клубочком и прикроет вход хвостиком. Тепло будет белочке в уютной квартирке.
(93 слова)
Слово для справки: застелет.
Грамматические задания
- Подчеркните однородные члены в пятом и шестом предложениях.
- Выпишите из текста синонимы к слову белка.
- Выпишите из текста три имени существительных с проверяемыми безударными гласными в корне. Докажите правильность написания.

Гроза
Надвигалась летняя гроза. Гигантская лиловая туча медленно поднималась над лесом. Низкие ракиты шелестели и лепетали. Резкий ветер загудел в вышине. Деревья забушевали. Большие капли дождя яростно застучали по листьям. Слепящая длинная молния полосой пересекла мрачное небо. Раздался оглушительный треск. Загрохотал гром. Дождь полил ручьями.
Но вот опять весело засияло яркое солнце. Воздух стал свежим и легким. Как все радостно блестит вокруг после дождя! Как чудесно пахнут душистая земляника и грибы!
Грамматическое задание
- Подчеркните грамматическую основу, обозначьте части речи: вариант 1 – в четвертом предложении, вариант 2 – в третьем предложении.
- Сделайте звуко – буквенный разбор слов: вариант 1 – дождь, вариант 2 – яростно.
- Обозначьте ударение в словах.

Хвоя, банты, щавель, торты, звонит, понял, задали, инструменты, свёкла, шофёр.
Диктант
Дары лета
Лето — удивительная пора. Сколько чудесных открытий дарит нам природа! Спешат друг за дружкой летние месяцы, и у каждого — свой сюрприз.
Июнь радует взгляд пёстрым разнотравьем лугов. Нарядный ковёр соткал он из ромашек, колокольчиков, васильков, клевера.
В середине лета в лесах и садах поспевают ягоды. Щедрой рукой наполняет июль наши лукошки земляникой, черникой, малиной, смородиной.
Грибная пора наступает в августе. Подберёзовики, боровики, рыжики, лисички, подосиновики, сыроежки, волнушки — всё это грибное богатство можно встретить в прохладной тиши лесов.
Благодарны люди летней поре да щедрость за изобилие.
(84 слова)
Слово для справки: изобилие
Грамматические задания
- Выполните синтаксический разбор предложений третьего абзаца.
- Разберите по составу слова: рыжики, сыроежки, прохладный.
- Выпишите из текста три имени существительных с парными согласными в корне. Докажите правильность написания.

Для детей и взрослых
Произведения Сергея Владимировича Михалкова любимы нами с раннего детства. Ещё малышами мы с увлечением читали стихи про дядю Стёпу, про упрямого Фому, про бычка по кличке Фантазёр. Вместе с героями Михалкова мы переживали за Федю Финтифлюшкина, за оставленного без присмотра щенка, за бедного Костю.
Но мастер слова создавал не только стихи и басни для детей. Сергей Михалков — один из авторов текста Государственного гимна Российской Федерации. С высоких и гордых слов поэта начинается и заканчивается каждый день в нашей стране, открываются торжественные и праздничные мероприятия.
(84 слова)
Грамматические задания
- Подчеркните однородные члены в последнем предложении.
- Подчеркните в первом абзаце все имена собственные.
- Выполните звуко-буквенный разбор слова читаем.

Руководство:Парсер — MediaWiki
Языки:
- Английский
- 日本語
Это обзор дизайна парсера MediaWiki.
Принципы проектирования[править]
Парсер MediaWiki на самом деле не парсер в строгом смысле этого слова. Он не распознает грамматику, а переводит викитекст в HTML. Он был назван парсером за неимением лучшего слова. По крайней мере, даже до того, как этот термин был введен в качестве имени класса, обычно понималось, что имелось в виду под «парсером MediaWiki».
Первичной целью является производительность, имеющая приоритет над удобочитаемостью кода и простотой определяемого им языка разметки. Таким образом, изменения, улучшающие производительность парсера, будут тепло восприняты.
Поскольку синтаксический анализатор работает с потенциально вредоносным пользовательским вводом размером до 2 МБ, важно, чтобы его время выполнения в наихудшем случае было пропорционально размеру ввода, а не пропорционально квадрату размера ввода.
Синтаксический анализатор нацелен на среду с малым объемом памяти, предполагая наличие нескольких сотен МБ ОЗУ, поэтому он использует разметку как промежуточное состояние, где это возможно, вместо создания неэффективных структур данных PHP.
Безопасность также является критической целью — ввод данных пользователем не может просачиваться в непроверенный вывод HTML, за исключением случаев, когда это специально настроено для вики. Удаленные изображения и другая разметка, которая заставляет клиента отправлять запрос на произвольный удаленный сервер, по умолчанию запрещены по соображениям конфиденциальности.
История[править]
Ли Дэниел Крокер написал первую версию MediaWiki в 2002 году.
Его синтаксический анализатор викитекста изначально находился внутри класса OutputPage, а основной точкой входа был OutputPage::addWikiText().
Базовая структура была аналогична текущему синтаксическому анализатору.
Он удалил разделы без разметки, такие как  Затем он выполнил проход безопасности (удаление HTML-тегов), затем серию проходов преобразования, а затем, наконец, вернул маркеры полосы.
Затем он выполнил проход безопасности (удаление HTML-тегов), затем серию проходов преобразования, а затем, наконец, вернул маркеры полосы.
Проходы преобразования использовали простую замену регулярных выражений, где это возможно, и токенизацию на основе взрыва() или preg_split() для более сложных операций. Полная реализация составила около 700 строк.
Многие перевалы до сих пор существуют под своими первоначальными названиями, хотя почти все они были переписаны.
В 2004 году Тим Старлинг разделил синтаксический анализатор на Parser.php и представил ParserOptions и ParserOutput. Он также представил шаблоны и аргументы шаблонов. Значительную работу внесли Брайон Виббер, Габриэль Вике, Йенс Франк, Уил Махан и другие.
В 2008 году для MediaWiki 1.12 Тим объединил проходы strip и replaceVariables в новый препроцессор, основанный на построении дерева синтаксического анализа в памяти и последующем обходе дерева для создания расширенного викитекста.
В 2011 году стартовал проект Parsoid.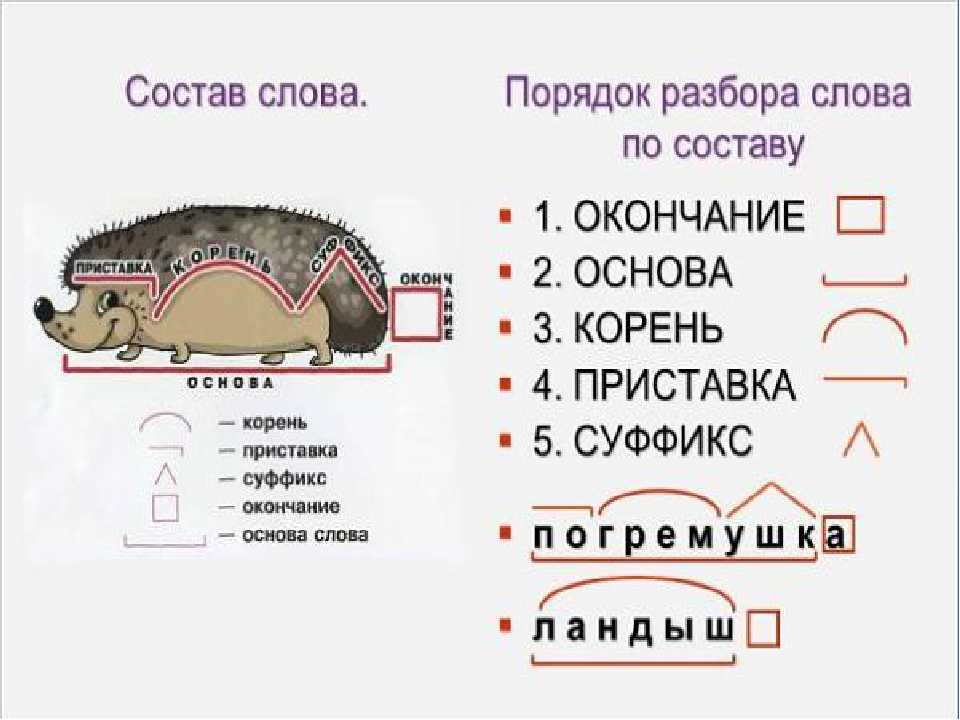 Parsoid — это независимый анализатор викитекста на JavaScript, введенный для поддержки VisualEditor.
Он включает модель DOM на основе HTML и сериализатор, который генерирует викитекст из (возможно, отредактированного пользователем) DOM.
На этом этапе гармонизация с Parsoid стала целью разработки парсера MediaWiki.
Parsoid — это независимый анализатор викитекста на JavaScript, введенный для поддержки VisualEditor.
Он включает модель DOM на основе HTML и сериализатор, который генерирует викитекст из (возможно, отредактированного пользователем) DOM.
На этом этапе гармонизация с Parsoid стала целью разработки парсера MediaWiki.
Некоторое время было неясно, будет ли парсер MediaWiki продолжать существовать в долгосрочной перспективе или он будет объявлен устаревшим в пользу Parsoid. Текущее мнение состоит в том, что, по крайней мере, компонент препроцессора парсера MediaWiki будет сохранен. Parsoid не имеет полной реализации препроцессора и полагается на удаленные вызовы MediaWiki для обеспечения этой функциональности.
Точки входа[править]
Основными общедоступными точками входа, запускающими операцию синтаксического анализа, являются:
- разбор()
- Создает объект ParserOutput, который включает область содержимого HTML и структурированные данные, определяющие изменения в HTML за пределами области содержимого, такие как модули JavaScript и навигационные ссылки.
- ПреСавеТрансформ()
- Преобразование викитекста в викитекст, вызванное перед сохранением страницы.
- getSection(), replaceSection()
- Идентификация и извлечение раздела для поддержки редактирования раздела.
- предварительная обработка()
- Преобразование викитекста в викитекст с расширением шаблона, что примерно эквивалентно первому этапу парсинга HTML. Это используется Parsoid для удаленного расширения шаблонов. Преобразование сообщений также использует эту функцию.
- startExternalParse()
- Это настраивает состояние синтаксического анализатора, чтобы внешний вызывающий объект мог напрямую вызывать отдельные проходы.

Входные данные парсера:
- Викитекст
- Объект ParserOptions
- Объект заголовка и идентификатор версии
Существуют также некоторые зависимости от глобального состояния и конфигурации, в частности от языка содержимого.
ParserOptions имеет множество опций, которые в совокупности представляют:
- Пользовательские настройки, влияющие на вывод парсера. Изначально это было основное приложение для ParserOptions, поэтому оно принимает объект User в качестве параметра конструктора. Важно, чтобы система кэширования знала о таких пользовательских параметрах, чтобы пользователи с разными параметрами кэшировали HTML-код, хранящийся в разных ключах. Это обрабатывается с помощью ParserOptions::outputHash().
- Параметры, зависящие от вызывающего абонента. Например, Tidy и отчеты по ограничениям включаются только при анализе области основного содержимого статьи. Различные параметры устанавливаются для обычных просмотров страниц, предварительных просмотров и просмотров старых версий.
- Данные тестового впрыска. Например, есть setCurrentRevisionCallback() и setTemplateCallback(), которые можно использовать для переопределения определенных вызовов базы данных.
 Изначально это было основное приложение для ParserOptions, поэтому оно принимает объект User в качестве параметра конструктора. Важно, чтобы система кэширования знала о таких пользовательских параметрах, чтобы пользователи с разными параметрами кэшировали HTML-код, хранящийся в разных ключах. Это обрабатывается с помощью ParserOptions::outputHash().
Изначально это было основное приложение для ParserOptions, поэтому оно принимает объект User в качестве параметра конструктора. Важно, чтобы система кэширования знала о таких пользовательских параметрах, чтобы пользователи с разными параметрами кэшировали HTML-код, хранящийся в разных ключах. Это обрабатывается с помощью ParserOptions::outputHash(). Во время операции синтаксического анализа объект ParserOptions, а также заголовок и контекст редакции доступны через соответствующие методы доступа.
Входной текст не хранится в переменной-члене, он доступен только через формальные параметры.
Некоторые точки входа возвращают только текст, но всегда есть доступный объект ParserOutput, который можно получить с помощью Parser::getOutput().
Объект ParserOutput содержит:
- HTML-фрагмент «text», установленный незадолго до возврата из функции parse().
- Обширные метаданные о «ссылках», которые используются LinksUpdate для обновления кэшей SQL информации о ссылках. Это включает в себя членство в категориях, использование изображений, межъязыковые и интервики-ссылки, а также расширяемые «свойства страницы». Помимо того, что они используются для обновления индексных таблиц базы данных, категории и межъязыковые ссылки также влияют на отображение страницы.
- Различные свойства, влияющие на отображение страницы вне области содержимого. Сюда входят модули JavaScript, загружаемые через ResourceLoader, заголовок страницы, элементы
и
, индикаторы, категории и языковые ссылки.</li></ul><p> ParserOutput — сериализуемый объект.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/otvet.imgsmail.ru/download/u_8dd32b0d4744e6a0d8661b90d453965c_800.jpg' /><noscript><img loading='lazy' src='/800/600/http/otvet.imgsmail.ru/download/u_8dd32b0d4744e6a0d8661b90d453965c_800.jpg' /></noscript> Он сохраняется в ParserCache, часто при сохранении страницы и извлекается при просмотре страницы.</p><p> Текущий объект OutputPage представляет выходные данные текущего запроса. Крайне важно, чтобы никакое расширение парсера не изменяло непосредственно OutputPage, поскольку такие модификации не будут воспроизводиться при извлечении объекта ParserOutput из кэша. Точно так же невозможно подключиться к скину и использовать статическое свойство класса, установленное во время синтаксического анализа, чтобы повлиять на вывод скина.</p><p> Вместо этого расширения, желающие изменить страницу за пределами содержимого HTML, могут использовать ParserOutput::setExtensionData() для хранения сериализуемых данных, которые им потребуются при отображении страницы. Затем можно использовать ParserOutput::addOutputHook() для установки хука, который будет вызываться, когда ParserOutput извлекается и добавляется к текущей странице OutputPage.</p><p> Объект Parser является одновременно долгоживущим объектом конфигурации и объектом состояния разбора.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/img0.liveinternet.ru/images/attach/c/8/102/458/102458836_large_0017.jpg' /><noscript><img loading='lazy' src='/800/600/http/img0.liveinternet.ru/images/attach/c/8/102/458/102458836_large_0017.jpg' /></noscript></p><p> Аспект конфигурации объекта Parser инициализируется, когда clearState() вызывает Parser::firstCallInit(). Это устанавливает расширения и встроенные модули ядра, а также создает регулярные выражения и хэш-таблицы. Это довольно медленно (~ 10 мс), поэтому по возможности следует избегать множественных вызовов.</p><p> Аспект состояния синтаксического анализа объекта Parser инициализируется точкой входа, которая устанавливает несколько переменных и вызывает функцию clearState(), очищающую локальные кэши и накопители.</p><p> Трудно выполнять более одной операции синтаксического анализа одновременно. Попытка повторно войти в Parser::parse() из хука парсера приведет к уничтожению предыдущего состояния синтаксического анализа и повреждению вывода. Теоретически можно установить параметр $clearState для parse() в false, чтобы предотвратить вызов clearState() и разрешить повторный вход, но на практике это почти никогда не делается и, вероятно, не работает.</p><p> На практике есть два варианта рекурсивного повторного входа:</p><dl><dt> Клонирование объекта Parser</dt><dd> Это часто делается и, вероятно, сработает.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/data15.gallery.ru/albums/gallery/223008-bc7a5-62000347-m750x740-u9cead.jpg' /><noscript><img loading='lazy' src='/800/600/http/data15.gallery.ru/albums/gallery/223008-bc7a5-62000347-m750x740-u9cead.jpg' /></noscript> Пока все расширения взаимодействуют друг с другом, оно обеспечивает независимое состояние, которое позволяет немедленно запустить вторую операцию синтаксического анализа через точку входа, такую как Parser::parse(). Однако обратите внимание, что оператор клонирования PHP является поверхностной копией. Это означает, что если какое-либо состояние синтаксического анализа хранится в ссылках на объекты, это состояние синтаксического анализа будет использоваться совместно с клоном, и изменения в клоне повлияют на исходный объект. Ядро пытается обойти это, разбивая ссылки на объекты в __clone(). Расширения, сохраняющие состояние в ссылках на объекты, прикрепленных к объекту Parser, должны перехватывать ParserCloned и вручную разрывать такие ссылки.</dd><dt> Использование рекурсивных точек входа.</dt><dd> Они позволяют анализировать текст в том же состоянии, что и текущая операция анализа, без очистки текущего состояния. В частности:<ul><li> recursiveTagParse(): возвращает «полупроанализированный» HTML с включенными полосовыми маркерами, подходящий для возврата из тега или функционального хука.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/cdn01.ru/files/users/images/b9/16/b916bea116cfa001ffd4eae9b2f25100.png' /><noscript><img loading='lazy' src='/800/600/http/cdn01.ru/files/users/images/b9/16/b916bea116cfa001ffd4eae9b2f25100.png' /></noscript></li><li> recursiveTagParseFully(): возвращает полностью проанализированный HTML, подходящий для прямого вывода пользователю, например, через ParserOutput::setExtensionData().</li></ul></dd></dl><h3><span class="ez-toc-section" id="%D0%9A%D1%8D%D1%88%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Кэширование[править] <span class="ez-toc-section-end"></span></h3><p> Анализатор имеет несколько видов кэша, каждый из которых налагает ограничения на изменение входных и выходных данных.</p><h4><span class="ez-toc-section" id="ParserCache%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> ParserCache[править] <span class="ez-toc-section-end"></span></h4><p> Главная страница: Руководство:Кэш парсера</p><p> Кэш парсера является внешним по отношению к парсеру. Он кэширует объект ParserOutput, связанный с просмотром главной страницы данной статьи. Как обсуждалось выше в разделах о вводе и выводе, важно избегать кэширования данных, предназначенных для одного пользователя, которые не будут иметь смысла для другого пользователя. Это означает правильное использование объектов ParserOptions и ParserOutput вместо их обхода с помощью глобального состояния.</p><p> Внешние вызывающие объекты могут воспользоваться преимуществами кэша синтаксического анализатора, вызвав WikiPage::getParserOutput().<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/data15.gallery.ru/albums/gallery/223008-c2c81-62000364-m750x740-u24b10.jpg' /><noscript><img loading='lazy' src='/800/600/http/data15.gallery.ru/albums/gallery/223008-c2c81-62000364-m750x740-u24b10.jpg' /></noscript> Однако вызывающие должны позаботиться об использовании объекта ParserOptions, который соответствует тому, который будет использоваться для просмотра страницы с тем же значением ParserOptions::optionsHash(). Обычно это означает, что он должен быть сгенерирован WikiPage::makeParserOptions(). Есть много опций синтаксического анализатора, которые не представлены в хэше опций — установка этих опций перед вызовом WikiPage::getParserOutput() приведет к загрязнению кэша синтаксического анализатора, см. T110269..</p><h4><span class="ez-toc-section" id="%D0%9A%D1%8D%D1%88,_%D0%B2%D0%BD%D1%83%D1%82%D1%80%D0%B5%D0%BD%D0%BD%D0%B8%D0%B9_%D0%BF%D0%BE_%D0%BE%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D1%8E_%D0%BA_%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%BC%D1%83_%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0%D1%82%D0%BE%D1%80%D1%83%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Кэш, внутренний по отношению к синтаксическому анализатору[править] <span class="ez-toc-section-end"></span></h4><p> Поскольку синтаксический анализатор MediaWiki может сильно настраиваться вызывающими его объектами, а его вывод зависит от изменяемых данных вики, в общем кэше хранится немного вещей. Исключением является кэш DOM препроцессора. Все остальные кэши, управляемые синтаксическим анализатором, являются локальными для процесса и очищаются в начале каждой операции синтаксического анализа.</p><h5><span class="ez-toc-section" id="%D0%9E%D0%B1%D1%89%D0%B8%D0%B9_%D0%BA%D1%8D%D1%88_%D0%BF%D1%80%D0%B5%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80%D0%B0_DOM%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Общий кэш препроцессора DOM[править] <span class="ez-toc-section-end"></span></h5><p> Это общий кэш препроцессора DOM.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript> Грамматика препроцессора очень слабо зависит от конфигурации и перехватчиков, и поэтому может кэшироваться между запросами. Грамматика препроцессора действительно зависит от набора тегов расширения в стиле XML, зарегистрированных в настоящее время, поэтому вызывающая сторона не должна изменять его, если только риск загрязнения кеша не очень низок (например, модульные тесты).</p><h5><span class="ez-toc-section" id="%D0%9B%D0%BE%D0%BA%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BA%D1%8D%D1%88_DOM_%D0%BF%D1%80%D0%B5%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80%D0%B0%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Локальный кэш DOM препроцессора[править] <span class="ez-toc-section-end"></span></h5><p> Существует также кэш DOM препроцессора, который является локальным для операции анализа.</p><h5><span class="ez-toc-section" id="%D0%9A%D1%8D%D1%88_%D1%80%D0%B0%D1%81%D1%88%D0%B8%D1%80%D0%B5%D0%BD%D0%B8%D1%8F_%D1%81_%D0%BF%D1%83%D1%81%D1%82%D1%8B%D0%BC_%D0%B0%D1%80%D0%B3%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D0%BE%D0%BC%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Кэш расширения с пустым аргументом[править] <span class="ez-toc-section-end"></span></h5><p> Это кеш результата расширения шаблона без аргументов, например {{foo}}, в отличие от {{foo|bar}}. Он является локальным для PPFrame, то есть вызовы шаблонов из разных шаблонов могут возвращать разные результаты. Кроме того, функции парсера могут использовать PPFrame::setVolatile() для отключения этого кэша во фрейме, в котором они вызываются. Количество вызовов хука функции синтаксического анализатора будет изменено этим кешем.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></p><p> <b> Предупреждение: </b> Мы планируем укрепить этот тайник. Новый код не должен использовать PPFrame::setVolatile() или иным образом зависеть от того, что один и тот же вызов шаблона может возвращать другой викитекст в зависимости от контекста. Parsoid предполагает, что результат расширения шаблона фрейма верхнего уровня для данного викитекста всегда остается одним и тем же для данной операции синтаксического анализа.</p><h5><span class="ez-toc-section" id="%D0%9A%D1%8D%D1%88_%D1%82%D0%B5%D0%BA%D1%83%D1%89%D0%B5%D0%B9_%D1%80%D0%B5%D0%B4%D0%B0%D0%BA%D1%86%D0%B8%D0%B8%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Кэш текущей редакции[править] <span class="ez-toc-section-end"></span></h5><p> Это кэш объекта «Ревизия», связанный с данным заголовком, локальный для текущей операции синтаксического анализа.</p><h5><span class="ez-toc-section" id="VarCache%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> VarCache[править] <span class="ez-toc-section-end"></span></h5><p> «Переменные» в терминологии синтаксического анализатора — это синтаксические конструкции, которые предоставляют информацию об окружающей среде. Они вызываются как шаблоны без аргументов и обычно имеют имена, написанные в верхнем регистре, например {{PAGENAME}} и {{CURRENTDAY}}. Кэш этих переменных является локальным для операции синтаксического анализа, поэтому, например, {{CURRENTTIME}} не может возвращать разные значения, даже если операция синтаксического анализа длится более одной секунды.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></p><h5><span class="ez-toc-section" id="%D0%92%D1%80%D0%B5%D0%BC%D1%8F_%D1%80%D0%B0%D0%B7%D0%B1%D0%BE%D1%80%D0%B0%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Время разбора[править] <span class="ez-toc-section-end"></span></h5><p> Существует специальный кэш текущего времени, который обеспечивает согласование переменных, связанных со временем, друг с другом. Вызывающий может настроить время, отображаемое парсером, с помощью ParserOptions::setTimestamp().</p><h4><span class="ez-toc-section" id="%D0%92%D0%BD%D0%B5%D1%88%D0%BD%D0%B8%D0%B5_%D0%BC%D0%BE%D0%B4%D1%83%D0%BB%D0%B8_%D0%BC%D0%BE%D0%B3%D1%83%D1%82_%D0%BE%D1%81%D1%83%D1%89%D0%B5%D1%81%D1%82%D0%B2%D0%BB%D1%8F%D1%82%D1%8C_%D0%BA%D1%8D%D1%88%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Внешние модули могут осуществлять кэширование[править] <span class="ez-toc-section-end"></span></h4><p> Анализатор MediaWiki имеет множество функций, которые запрашивают текущее состояние вики. Анализатор обращается к соответствующему модулю MediaWiki, который может реализовать собственное кэширование. Существуют глобальные кеши, чаще всего в memcached, и внутрипроцессные кеши, которые хранятся в течение всего времени жизни запроса, обычно без аннулирования. Например:</p><dl><dt> LinkCache</dt><dd> Содержит локальный кеш существования страницы, который используется для окраски ссылок.</dd><dt> Титул</dt><dd> Существует локальный кеш метаданных страницы процесса, управляемый как статический синглтон, прикрепленный к классу Title.</dd><dt> FileRepo</dt><dd> Существуют как общие, так и локальные кэши метаданных файлов/изображений, используемые для рендеринга ссылок на изображения.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></dd><dt> Кэш сообщений</dt><dd> Функция парсера {{int:}} вызывает систему локализации MediaWiki, которая имеет много уровней кэширования.</dd></dl><h3><span class="ez-toc-section" id="%D0%9F%D0%B0%D0%BA%D0%B5%D1%82%D0%BD%D0%B0%D1%8F_%D0%BE%D0%B1%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Пакетная обработка[править] <span class="ez-toc-section-end"></span></h3><p> Обычно более эффективно запрашивать базу данных (или другое хранилище) пакетами, а не отправлять запрос для каждого элемента данных, как это видно в потоке викитекста. Однако пакетную обработку может быть сложно реализовать. В настоящее время существует только одна функция викитекста, использующая этот метод: раскрашивание ссылок.</p><p> Ссылки на существующие статьи окрашены в синий цвет, ссылки на несуществующие страницы окрашены в красный цвет. Также есть малоизвестная функция (которая когда-нибудь может быть удалена), которая позволяет пользователям указывать «порог заглушки», а затем ссылки окрашиваются в зависимости от размера целевой статьи.</p><p> Вики-страницы иногда могут иметь очень большое количество ссылок. Изначально мы пытались хранить метаданные ссылок для всей операции синтаксического анализа, чтобы их можно было разрешить в одном пакетном запросе, но хранение такого количества ссылок в массиве вызывало ошибки нехватки памяти.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript> Таким образом, текущий метод заключается в замене каждой ссылки, как она видна, заполнителем с метаданными, хранящимися в массиве. Затем, когда в массиве 1000 ссылок, запускается LinkHolderArray::replaceLinkHolders(), который выполняет соответствующий запрос для текущего пакета и заменяет заполнители фактическим HTML-кодом ссылки.</p><p> Проход по внутренней ссылке (replaceInternalLinks) запускается рекурсивно различными вызывающими объектами, поэтому текущий пакет сохраняется синтаксическим анализатором.</p><p> Операция синтаксического анализа постепенно преобразует викитекст в HTML. Следующий порядок синтаксического анализа всегда используется для преобразования викитекста в HTML. Это набросок потока данных, а не строгий порядок выполнения. Существует множество особых случаев, когда рекурсивный синтаксический анализ перескакивает вперед или перезапускается с предыдущей позиции. Когда обнаруживается новый необработанный ввод, он обрабатывается с самого начала. А когда выходные данные необходимо сгенерировать для передачи в более поздний проход или для прямого вывода пользователю через метод доступа ParserOutput, рекурсивный синтаксический анализ может перейти к концу списка проходов, прежде чем возобновиться с основным текстом.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></p><h4><span class="ez-toc-section" id="%D0%93%D0%B5%D0%BD%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D1%8F_DOM_%D0%BF%D1%80%D0%B5%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80%D0%B0%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Генерация DOM препроцессора[править] <span class="ez-toc-section-end"></span></h4><p> Сначала вводимый текст обрабатывается препроцессором со встроенным сканером и синтаксическим анализатором. Это генерирует специальный XML-подобный DOM. Эта структура DOM не связана с HTML.</p><p> Существует две реализации препроцессора: Preprocessor_DOM хранит свою промежуточную модель DOM с использованием расширения PHP DOM, а Preprocessor_Hash хранит свою промежуточную модель DOM в дереве объектов PHP. По умолчанию Preprocessor_DOM используется в php.net PHP, а Preprocessor_Hash по умолчанию используется в HHVM. Это значение по умолчанию оптимально для производительности процессора.</p><p> Реализация Preprocessor_DOM имеет более низкое использование памяти, хотя это использование памяти не учитывается должным образом средой выполнения и поэтому не вызывает ошибку нехватки памяти PHP. Это может привести к свопингу или запуску oom-killer ядра.</p><p> Реализация Preprocessor_Hash представляет собой дерево типизированных узловых объектов с дочерними элементами.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript> У него нет атрибутов, они эмулируются с помощью специально названных элементов.</p><p> Грамматика, распознаваемая препроцессором, и структура генерируемой таким образом DOM обсуждаются в статье о препроцессоре ABNF.</p><h4><span class="ez-toc-section" id="%D0%A0%D0%B0%D1%81%D1%88%D0%B8%D1%80%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%B5%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80%D0%B0%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Расширение препроцессора[править] <span class="ez-toc-section-end"></span></h4><p> Посещение узлов DOM и создание викитекста, который они представляют, называется расширением, потому что (короткие) вызовы шаблона заменяются (длинным) содержимым шаблона.</p><p> Результат расширения аналогичен викитексту, за исключением того, что он имеет следующие типы заполнителей:</p><ul><li> Маркеры-удлинители. Эти маркеры представляют собой наполовину проанализированный HTML-код, сгенерированный тегами расширения.</li><li> Маркеры курса. Эти маркеры представляют собой начало редактируемых разделов, где позже будут условно размещены ссылки на редактирование разделов. Препроцессору необходимо пометить заголовки, происходящие из источника, поскольку заголовки могут быть сгенерированы расширением функции синтаксического анализатора, которые не соответствуют какому-либо местоположению источника.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript> Заголовки, созданные с помощью шаблонов, также могут создавать редактируемые разделы.</li></ul><p> Оба этих типа заполнителей используют специальную строку Parser::MARKER_PREFIX. Препроцессор не может использовать HTML-комментарии в качестве маркеров, поскольку в выходной разметке этого прохода HTML-комментарии обрабатываются как пользовательский ввод и будут удалены с помощью Sanitizer::removeHTMLtags().</p><h4><span class="ez-toc-section" id="Sanitizer_removeHTMLtags%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Sanitizer::removeHTMLtags[править] <span class="ez-toc-section-end"></span></h4><p> Это проход безопасности, который пропускает HTML-теги и атрибуты, которых нет в белом списке. Он очищает атрибуты CSS, чтобы удалить любые возможные сценарии или удаленную загрузку.</p><p> Этот проход удаляет комментарии HTML. Это в основном для удобства, чтобы позволить будущим проходам заменять текст без необходимости распознавать и пропускать комментарии.</p><p> С этого момента ввод данных пользователем не может быть разрешен для прямой передачи на вывод без проверки и экранирования. И с этого момента HTML-комментарии можно использовать в качестве маркеров.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></p><h4><span class="ez-toc-section" id="%D0%9F%D1%80%D0%BE%D1%85%D0%BE%D0%B4%D1%8B_%D0%BF%D1%80%D0%B5%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F_%D1%80%D0%B0%D0%B7%D0%BC%D0%B5%D1%82%D0%BA%D0%B8%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Проходы преобразования разметки[править] <span class="ez-toc-section-end"></span></h4><p> Ниже приведены оставшиеся проходы, вызываемые Parser::internalParse():</p><dl><dt> doTableStuff</dt><dd> Это простой построчный синтаксический анализатор, который преобразует разметку таблицы в стиле викитекста в разметку таблицы HTML. Он не предпринимает никаких усилий для проверки ввода тегов таблицы в стиле HTML.</dd><dt> doDoubleUnderscore</dt><dd> Этот проход отмечает наличие элементов с двойным подчеркиванием, таких как __NOGALLERY__ и __NOTOC__, и удаляет их из текста. Parsoid называет их «переключателями поведения». Они распознаются с помощью MagicWordArray.</dd><dt> doHeadings</dt><dt> replaceInternalLinks</dt><dt> doAllQuotes</dt><dt> заменить внешние ссылки</dt><dt> doMagicLinks</dt><dt> formatHeadings</dt></dl><h4><span class="ez-toc-section" id="internalParseHalfParsed%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> internalParseHalfParsed[править] <span class="ez-toc-section-end"></span></h4><dl><dt> Guillemet</dt><dt> доблоклевелс</dt><dt> заменитьLinkHolders</dt><dt> Преобразование языка</dt><dt> Приборка</dt><dt> Неаккуратные случаи</dt></dl><h4><span class="ez-toc-section" id="%D0%9F%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BE%D1%82%D1%87%D0%B5%D1%82%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Предельный отчет[править] <span class="ez-toc-section-end"></span></h4><h3><span class="ez-toc-section" id="%D0%91%D0%B5%D0%B7%D0%BE%D0%BF%D0%B0%D1%81%D0%BD%D0%BE%D1%81%D1%82%D1%8C%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D"></span> Безопасность[править] <span class="ez-toc-section-end"></span></h3><h2><span class="ez-toc-section" id="%D0%A0%D1%83%D0%BA%D0%BE%D0%B2%D0%BE%D0%B4%D1%81%D1%82%D0%B2%D0%BE_%D0%9F%D0%B0%D1%80%D1%81%D0%B5%D1%80_%E2%80%94_MediaWiki-2"></span> Руководство:Парсер — MediaWiki <span class="ez-toc-section-end"></span></h2><p> Языки:</p><ul><li> Английский</li><li> 日本語</li></ul><p> Это обзор дизайна парсера MediaWiki.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></p><h3><span class="ez-toc-section" id="%D0%9F%D1%80%D0%B8%D0%BD%D1%86%D0%B8%D0%BF%D1%8B_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Принципы проектирования[править] <span class="ez-toc-section-end"></span></h3><p> Парсер MediaWiki на самом деле не парсер в строгом смысле этого слова. Он не распознает грамматику, а переводит викитекст в HTML. Он был назван парсером за неимением лучшего слова. По крайней мере, даже до того, как этот термин был введен в качестве имени класса, обычно понималось, что имелось в виду под «парсером MediaWiki».</p><p> Первичной целью является производительность, имеющая приоритет над удобочитаемостью кода и простотой определяемого им языка разметки. Таким образом, изменения, улучшающие производительность парсера, будут тепло восприняты.</p><p> Поскольку синтаксический анализатор работает с потенциально вредоносным пользовательским вводом размером до 2 МБ, важно, чтобы его время выполнения в наихудшем случае было пропорционально размеру ввода, а не пропорционально квадрату размера ввода.</p><p> Синтаксический анализатор нацелен на среду с малым объемом памяти, предполагая наличие нескольких сотен МБ ОЗУ, поэтому он использует разметку как промежуточное состояние, где это возможно, вместо создания неэффективных структур данных PHP.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></p><p> Безопасность также является критической целью — ввод данных пользователем не может просачиваться в непроверенный вывод HTML, за исключением случаев, когда это специально настроено для вики. Удаленные изображения и другая разметка, которая заставляет клиента отправлять запрос на произвольный удаленный сервер, по умолчанию запрещены по соображениям конфиденциальности.</p><h3><span class="ez-toc-section" id="%D0%98%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> История[править] <span class="ez-toc-section-end"></span></h3><p> Ли Дэниел Крокер написал первую версию MediaWiki в 2002 году. Его синтаксический анализатор викитекста изначально находился внутри класса OutputPage, а основной точкой входа был OutputPage::addWikiText(). Базовая структура была аналогична текущему синтаксическому анализатору. Он удалил разделы без разметки, такие как <nowiki>, заменив их временными маркерами полос. Затем он выполнил проход безопасности (удаление HTML-тегов), затем серию проходов преобразования, а затем, наконец, вернул маркеры полосы.</p><p> Проходы преобразования использовали простую замену регулярных выражений, где это возможно, и токенизацию на основе взрыва() или preg_split() для более сложных операций.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript> Полная реализация составила около 700 строк.</p><p> Многие перевалы до сих пор существуют под своими первоначальными названиями, хотя почти все они были переписаны.</p><p> В 2004 году Тим Старлинг разделил синтаксический анализатор на Parser.php и представил ParserOptions и ParserOutput. Он также представил шаблоны и аргументы шаблонов. Значительную работу внесли Брайон Виббер, Габриэль Вике, Йенс Франк, Уил Махан и другие.</p><p> В 2008 году для MediaWiki 1.12 Тим объединил проходы strip и replaceVariables в новый препроцессор, основанный на построении дерева синтаксического анализа в памяти и последующем обходе дерева для создания расширенного викитекста.</p><p> В 2011 году стартовал проект Parsoid. Parsoid — это независимый анализатор викитекста на JavaScript, введенный для поддержки VisualEditor. Он включает модель DOM на основе HTML и сериализатор, который генерирует викитекст из (возможно, отредактированного пользователем) DOM. На этом этапе гармонизация с Parsoid стала целью разработки парсера MediaWiki.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></p><p> Некоторое время было неясно, будет ли парсер MediaWiki продолжать существовать в долгосрочной перспективе или он будет объявлен устаревшим в пользу Parsoid. Текущее мнение состоит в том, что, по крайней мере, компонент препроцессора парсера MediaWiki будет сохранен. Parsoid не имеет полной реализации препроцессора и полагается на удаленные вызовы MediaWiki для обеспечения этой функциональности.</p><h3><span class="ez-toc-section" id="%D0%A2%D0%BE%D1%87%D0%BA%D0%B8_%D0%B2%D1%85%D0%BE%D0%B4%D0%B0%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Точки входа[править] <span class="ez-toc-section-end"></span></h3><p> Основными общедоступными точками входа, запускающими операцию синтаксического анализа, являются:</p><dl><dt> разбор()</dt><dd> Создает объект ParserOutput, который включает область содержимого HTML и структурированные данные, определяющие изменения в HTML за пределами области содержимого, такие как модули JavaScript и навигационные ссылки.</dd><dt> ПреСавеТрансформ()</dt><dd> Преобразование викитекста в викитекст, вызванное перед сохранением страницы.</dd><dt> getSection(), replaceSection()</dt><dd> Идентификация и извлечение раздела для поддержки редактирования раздела.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></dd><dt> предварительная обработка()</dt><dd> Преобразование викитекста в викитекст с расширением шаблона, что примерно эквивалентно первому этапу парсинга HTML. Это используется Parsoid для удаленного расширения шаблонов. Преобразование сообщений также использует эту функцию.</dd><dt> startExternalParse()</dt><dd> Это настраивает состояние синтаксического анализатора, чтобы внешний вызывающий объект мог напрямую вызывать отдельные проходы.</dd></dl><p> Входные данные парсера:</p><ul><li> Викитекст</li><li> Объект ParserOptions</li><li> Объект заголовка и идентификатор версии</li></ul><p> Существуют также некоторые зависимости от глобального состояния и конфигурации, в частности от языка содержимого.</p><p> ParserOptions имеет множество опций, которые в совокупности представляют:</p><ul><li> Пользовательские настройки, влияющие на вывод парсера. Изначально это было основное приложение для ParserOptions, поэтому оно принимает объект User в качестве параметра конструктора.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript> Важно, чтобы система кэширования знала о таких пользовательских параметрах, чтобы пользователи с разными параметрами кэшировали HTML-код, хранящийся в разных ключах. Это обрабатывается с помощью ParserOptions::outputHash().</li><li> Параметры, зависящие от вызывающего абонента. Например, Tidy и отчеты по ограничениям включаются только при анализе области основного содержимого статьи. Различные параметры устанавливаются для обычных просмотров страниц, предварительных просмотров и просмотров старых версий.</li><li> Данные тестового впрыска. Например, есть setCurrentRevisionCallback() и setTemplateCallback(), которые можно использовать для переопределения определенных вызовов базы данных.</li></ul><p> Во время операции синтаксического анализа объект ParserOptions, а также заголовок и контекст редакции доступны через соответствующие методы доступа. Входной текст не хранится в переменной-члене, он доступен только через формальные параметры.</p><p> Некоторые точки входа возвращают только текст, но всегда есть доступный объект ParserOutput, который можно получить с помощью Parser::getOutput().<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></p><p> Объект ParserOutput содержит:</p><ul><li> HTML-фрагмент «text», установленный незадолго до возврата из функции parse().</li><li> Обширные метаданные о «ссылках», которые используются LinksUpdate для обновления кэшей SQL информации о ссылках. Это включает в себя членство в категориях, использование изображений, межъязыковые и интервики-ссылки, а также расширяемые «свойства страницы». Помимо того, что они используются для обновления индексных таблиц базы данных, категории и межъязыковые ссылки также влияют на отображение страницы.</li><li> Различные свойства, влияющие на отображение страницы вне области содержимого. Сюда входят модули JavaScript, загружаемые через ResourceLoader, заголовок страницы, элементы<h2><span class="ez-toc-section" id="%D0%B8-2"></span> и <span class="ez-toc-section-end"></span></h2><title>, индикаторы, категории и языковые ссылки.</li></ul><p> ParserOutput — сериализуемый объект. Он сохраняется в ParserCache, часто при сохранении страницы и извлекается при просмотре страницы.</p><p> Текущий объект OutputPage представляет выходные данные текущего запроса.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript> Крайне важно, чтобы никакое расширение парсера не изменяло непосредственно OutputPage, поскольку такие модификации не будут воспроизводиться при извлечении объекта ParserOutput из кэша. Точно так же невозможно подключиться к скину и использовать статическое свойство класса, установленное во время синтаксического анализа, чтобы повлиять на вывод скина.</p><p> Вместо этого расширения, желающие изменить страницу за пределами содержимого HTML, могут использовать ParserOutput::setExtensionData() для хранения сериализуемых данных, которые им потребуются при отображении страницы. Затем можно использовать ParserOutput::addOutputHook() для установки хука, который будет вызываться, когда ParserOutput извлекается и добавляется к текущей странице OutputPage.</p><p> Объект Parser является одновременно долгоживущим объектом конфигурации и объектом состояния разбора.</p><p> Аспект конфигурации объекта Parser инициализируется, когда clearState() вызывает Parser::firstCallInit(). Это устанавливает расширения и встроенные модули ядра, а также создает регулярные выражения и хэш-таблицы.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript> Это довольно медленно (~ 10 мс), поэтому по возможности следует избегать множественных вызовов.</p><p> Аспект состояния синтаксического анализа объекта Parser инициализируется точкой входа, которая устанавливает несколько переменных и вызывает функцию clearState(), очищающую локальные кэши и накопители.</p><p> Трудно выполнять более одной операции синтаксического анализа одновременно. Попытка повторно войти в Parser::parse() из хука парсера приведет к уничтожению предыдущего состояния синтаксического анализа и повреждению вывода. Теоретически можно установить параметр $clearState для parse() в false, чтобы предотвратить вызов clearState() и разрешить повторный вход, но на практике это почти никогда не делается и, вероятно, не работает.</p><p> На практике есть два варианта рекурсивного повторного входа:</p><dl><dt> Клонирование объекта Parser</dt><dd> Это часто делается и, вероятно, сработает. Пока все расширения взаимодействуют друг с другом, оно обеспечивает независимое состояние, которое позволяет немедленно запустить вторую операцию синтаксического анализа через точку входа, такую как Parser::parse().<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript> Однако обратите внимание, что оператор клонирования PHP является поверхностной копией. Это означает, что если какое-либо состояние синтаксического анализа хранится в ссылках на объекты, это состояние синтаксического анализа будет использоваться совместно с клоном, и изменения в клоне повлияют на исходный объект. Ядро пытается обойти это, разбивая ссылки на объекты в __clone(). Расширения, сохраняющие состояние в ссылках на объекты, прикрепленных к объекту Parser, должны перехватывать ParserCloned и вручную разрывать такие ссылки.</dd><dt> Использование рекурсивных точек входа.</dt><dd> Они позволяют анализировать текст в том же состоянии, что и текущая операция анализа, без очистки текущего состояния. В частности:<ul><li> recursiveTagParse(): возвращает «полупроанализированный» HTML с включенными полосовыми маркерами, подходящий для возврата из тега или функционального хука.</li><li> recursiveTagParseFully(): возвращает полностью проанализированный HTML, подходящий для прямого вывода пользователю, например, через ParserOutput::setExtensionData().<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></li></ul></dd></dl><h3><span class="ez-toc-section" id="%D0%9A%D1%8D%D1%88%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Кэширование[править] <span class="ez-toc-section-end"></span></h3><p> Анализатор имеет несколько видов кэша, каждый из которых налагает ограничения на изменение входных и выходных данных.</p><h4><span class="ez-toc-section" id="ParserCache%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> ParserCache[править] <span class="ez-toc-section-end"></span></h4><p> Главная страница: Руководство:Кэш парсера</p><p> Кэш парсера является внешним по отношению к парсеру. Он кэширует объект ParserOutput, связанный с просмотром главной страницы данной статьи. Как обсуждалось выше в разделах о вводе и выводе, важно избегать кэширования данных, предназначенных для одного пользователя, которые не будут иметь смысла для другого пользователя. Это означает правильное использование объектов ParserOptions и ParserOutput вместо их обхода с помощью глобального состояния.</p><p> Внешние вызывающие объекты могут воспользоваться преимуществами кэша синтаксического анализатора, вызвав WikiPage::getParserOutput(). Однако вызывающие должны позаботиться об использовании объекта ParserOptions, который соответствует тому, который будет использоваться для просмотра страницы с тем же значением ParserOptions::optionsHash().<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript> Обычно это означает, что он должен быть сгенерирован WikiPage::makeParserOptions(). Есть много опций синтаксического анализатора, которые не представлены в хэше опций — установка этих опций перед вызовом WikiPage::getParserOutput() приведет к загрязнению кэша синтаксического анализатора, см. T110269..</p><h4><span class="ez-toc-section" id="%D0%9A%D1%8D%D1%88,_%D0%B2%D0%BD%D1%83%D1%82%D1%80%D0%B5%D0%BD%D0%BD%D0%B8%D0%B9_%D0%BF%D0%BE_%D0%BE%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D1%8E_%D0%BA_%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%BC%D1%83_%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0%D1%82%D0%BE%D1%80%D1%83%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Кэш, внутренний по отношению к синтаксическому анализатору[править] <span class="ez-toc-section-end"></span></h4><p> Поскольку синтаксический анализатор MediaWiki может сильно настраиваться вызывающими его объектами, а его вывод зависит от изменяемых данных вики, в общем кэше хранится немного вещей. Исключением является кэш DOM препроцессора. Все остальные кэши, управляемые синтаксическим анализатором, являются локальными для процесса и очищаются в начале каждой операции синтаксического анализа.</p><h5><span class="ez-toc-section" id="%D0%9E%D0%B1%D1%89%D0%B8%D0%B9_%D0%BA%D1%8D%D1%88_%D0%BF%D1%80%D0%B5%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80%D0%B0_DOM%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Общий кэш препроцессора DOM[править] <span class="ez-toc-section-end"></span></h5><p> Это общий кэш препроцессора DOM. Грамматика препроцессора очень слабо зависит от конфигурации и перехватчиков, и поэтому может кэшироваться между запросами. Грамматика препроцессора действительно зависит от набора тегов расширения в стиле XML, зарегистрированных в настоящее время, поэтому вызывающая сторона не должна изменять его, если только риск загрязнения кеша не очень низок (например, модульные тесты).<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></p><h5><span class="ez-toc-section" id="%D0%9B%D0%BE%D0%BA%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BA%D1%8D%D1%88_DOM_%D0%BF%D1%80%D0%B5%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80%D0%B0%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Локальный кэш DOM препроцессора[править] <span class="ez-toc-section-end"></span></h5><p> Существует также кэш DOM препроцессора, который является локальным для операции анализа.</p><h5><span class="ez-toc-section" id="%D0%9A%D1%8D%D1%88_%D1%80%D0%B0%D1%81%D1%88%D0%B8%D1%80%D0%B5%D0%BD%D0%B8%D1%8F_%D1%81_%D0%BF%D1%83%D1%81%D1%82%D1%8B%D0%BC_%D0%B0%D1%80%D0%B3%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D0%BE%D0%BC%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Кэш расширения с пустым аргументом[править] <span class="ez-toc-section-end"></span></h5><p> Это кеш результата расширения шаблона без аргументов, например {{foo}}, в отличие от {{foo|bar}}. Он является локальным для PPFrame, то есть вызовы шаблонов из разных шаблонов могут возвращать разные результаты. Кроме того, функции парсера могут использовать PPFrame::setVolatile() для отключения этого кэша во фрейме, в котором они вызываются. Количество вызовов хука функции синтаксического анализатора будет изменено этим кешем.</p><p> <b> Предупреждение: </b> Мы планируем укрепить этот тайник. Новый код не должен использовать PPFrame::setVolatile() или иным образом зависеть от того, что один и тот же вызов шаблона может возвращать другой викитекст в зависимости от контекста. Parsoid предполагает, что результат расширения шаблона фрейма верхнего уровня для данного викитекста всегда остается одним и тем же для данной операции синтаксического анализа.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></p><h5><span class="ez-toc-section" id="%D0%9A%D1%8D%D1%88_%D1%82%D0%B5%D0%BA%D1%83%D1%89%D0%B5%D0%B9_%D1%80%D0%B5%D0%B4%D0%B0%D0%BA%D1%86%D0%B8%D0%B8%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Кэш текущей редакции[править] <span class="ez-toc-section-end"></span></h5><p> Это кэш объекта «Ревизия», связанный с данным заголовком, локальный для текущей операции синтаксического анализа.</p><h5><span class="ez-toc-section" id="VarCache%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> VarCache[править] <span class="ez-toc-section-end"></span></h5><p> «Переменные» в терминологии синтаксического анализатора — это синтаксические конструкции, которые предоставляют информацию об окружающей среде. Они вызываются как шаблоны без аргументов и обычно имеют имена, написанные в верхнем регистре, например {{PAGENAME}} и {{CURRENTDAY}}. Кэш этих переменных является локальным для операции синтаксического анализа, поэтому, например, {{CURRENTTIME}} не может возвращать разные значения, даже если операция синтаксического анализа длится более одной секунды.</p><h5><span class="ez-toc-section" id="%D0%92%D1%80%D0%B5%D0%BC%D1%8F_%D1%80%D0%B0%D0%B7%D0%B1%D0%BE%D1%80%D0%B0%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Время разбора[править] <span class="ez-toc-section-end"></span></h5><p> Существует специальный кэш текущего времени, который обеспечивает согласование переменных, связанных со временем, друг с другом. Вызывающий может настроить время, отображаемое парсером, с помощью ParserOptions::setTimestamp().</p><h4><span class="ez-toc-section" id="%D0%92%D0%BD%D0%B5%D1%88%D0%BD%D0%B8%D0%B5_%D0%BC%D0%BE%D0%B4%D1%83%D0%BB%D0%B8_%D0%BC%D0%BE%D0%B3%D1%83%D1%82_%D0%BE%D1%81%D1%83%D1%89%D0%B5%D1%81%D1%82%D0%B2%D0%BB%D1%8F%D1%82%D1%8C_%D0%BA%D1%8D%D1%88%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Внешние модули могут осуществлять кэширование[править] <span class="ez-toc-section-end"></span></h4><p> Анализатор MediaWiki имеет множество функций, которые запрашивают текущее состояние вики.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript> Анализатор обращается к соответствующему модулю MediaWiki, который может реализовать собственное кэширование. Существуют глобальные кеши, чаще всего в memcached, и внутрипроцессные кеши, которые хранятся в течение всего времени жизни запроса, обычно без аннулирования. Например:</p><dl><dt> LinkCache</dt><dd> Содержит локальный кеш существования страницы, который используется для окраски ссылок.</dd><dt> Титул</dt><dd> Существует локальный кеш метаданных страницы процесса, управляемый как статический синглтон, прикрепленный к классу Title.</dd><dt> FileRepo</dt><dd> Существуют как общие, так и локальные кэши метаданных файлов/изображений, используемые для рендеринга ссылок на изображения.</dd><dt> Кэш сообщений</dt><dd> Функция парсера {{int:}} вызывает систему локализации MediaWiki, которая имеет много уровней кэширования.</dd></dl><h3><span class="ez-toc-section" id="%D0%9F%D0%B0%D0%BA%D0%B5%D1%82%D0%BD%D0%B0%D1%8F_%D0%BE%D0%B1%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Пакетная обработка[править] <span class="ez-toc-section-end"></span></h3><p> Обычно более эффективно запрашивать базу данных (или другое хранилище) пакетами, а не отправлять запрос для каждого элемента данных, как это видно в потоке викитекста.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript> Однако пакетную обработку может быть сложно реализовать. В настоящее время существует только одна функция викитекста, использующая этот метод: раскрашивание ссылок.</p><p> Ссылки на существующие статьи окрашены в синий цвет, ссылки на несуществующие страницы окрашены в красный цвет. Также есть малоизвестная функция (которая когда-нибудь может быть удалена), которая позволяет пользователям указывать «порог заглушки», а затем ссылки окрашиваются в зависимости от размера целевой статьи.</p><p> Вики-страницы иногда могут иметь очень большое количество ссылок. Изначально мы пытались хранить метаданные ссылок для всей операции синтаксического анализа, чтобы их можно было разрешить в одном пакетном запросе, но хранение такого количества ссылок в массиве вызывало ошибки нехватки памяти. Таким образом, текущий метод заключается в замене каждой ссылки, как она видна, заполнителем с метаданными, хранящимися в массиве. Затем, когда в массиве 1000 ссылок, запускается LinkHolderArray::replaceLinkHolders(), который выполняет соответствующий запрос для текущего пакета и заменяет заполнители фактическим HTML-кодом ссылки.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></p><p> Проход по внутренней ссылке (replaceInternalLinks) запускается рекурсивно различными вызывающими объектами, поэтому текущий пакет сохраняется синтаксическим анализатором.</p><p> Операция синтаксического анализа постепенно преобразует викитекст в HTML. Следующий порядок синтаксического анализа всегда используется для преобразования викитекста в HTML. Это набросок потока данных, а не строгий порядок выполнения. Существует множество особых случаев, когда рекурсивный синтаксический анализ перескакивает вперед или перезапускается с предыдущей позиции. Когда обнаруживается новый необработанный ввод, он обрабатывается с самого начала. А когда выходные данные необходимо сгенерировать для передачи в более поздний проход или для прямого вывода пользователю через метод доступа ParserOutput, рекурсивный синтаксический анализ может перейти к концу списка проходов, прежде чем возобновиться с основным текстом.</p><h4><span class="ez-toc-section" id="%D0%93%D0%B5%D0%BD%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D1%8F_DOM_%D0%BF%D1%80%D0%B5%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80%D0%B0%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Генерация DOM препроцессора[править] <span class="ez-toc-section-end"></span></h4><p> Сначала вводимый текст обрабатывается препроцессором со встроенным сканером и синтаксическим анализатором.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript> Это генерирует специальный XML-подобный DOM. Эта структура DOM не связана с HTML.</p><p> Существует две реализации препроцессора: Preprocessor_DOM хранит свою промежуточную модель DOM с использованием расширения PHP DOM, а Preprocessor_Hash хранит свою промежуточную модель DOM в дереве объектов PHP. По умолчанию Preprocessor_DOM используется в php.net PHP, а Preprocessor_Hash по умолчанию используется в HHVM. Это значение по умолчанию оптимально для производительности процессора.</p><p> Реализация Preprocessor_DOM имеет более низкое использование памяти, хотя это использование памяти не учитывается должным образом средой выполнения и поэтому не вызывает ошибку нехватки памяти PHP. Это может привести к свопингу или запуску oom-killer ядра.</p><p> Реализация Preprocessor_Hash представляет собой дерево типизированных узловых объектов с дочерними элементами. У него нет атрибутов, они эмулируются с помощью специально названных элементов.</p><p> Грамматика, распознаваемая препроцессором, и структура генерируемой таким образом DOM обсуждаются в статье о препроцессоре ABNF.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></p><h4><span class="ez-toc-section" id="%D0%A0%D0%B0%D1%81%D1%88%D0%B8%D1%80%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%B5%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80%D0%B0%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Расширение препроцессора[править] <span class="ez-toc-section-end"></span></h4><p> Посещение узлов DOM и создание викитекста, который они представляют, называется расширением, потому что (короткие) вызовы шаблона заменяются (длинным) содержимым шаблона.</p><p> Результат расширения аналогичен викитексту, за исключением того, что он имеет следующие типы заполнителей:</p><ul><li> Маркеры-удлинители. Эти маркеры представляют собой наполовину проанализированный HTML-код, сгенерированный тегами расширения.</li><li> Маркеры курса. Эти маркеры представляют собой начало редактируемых разделов, где позже будут условно размещены ссылки на редактирование разделов. Препроцессору необходимо пометить заголовки, происходящие из источника, поскольку заголовки могут быть сгенерированы расширением функции синтаксического анализатора, которые не соответствуют какому-либо местоположению источника. Заголовки, созданные с помощью шаблонов, также могут создавать редактируемые разделы.</li></ul><p> Оба этих типа заполнителей используют специальную строку Parser::MARKER_PREFIX.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript> Препроцессор не может использовать HTML-комментарии в качестве маркеров, поскольку в выходной разметке этого прохода HTML-комментарии обрабатываются как пользовательский ввод и будут удалены с помощью Sanitizer::removeHTMLtags().</p><h4><span class="ez-toc-section" id="Sanitizer_removeHTMLtags%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Sanitizer::removeHTMLtags[править] <span class="ez-toc-section-end"></span></h4><p> Это проход безопасности, который пропускает HTML-теги и атрибуты, которых нет в белом списке. Он очищает атрибуты CSS, чтобы удалить любые возможные сценарии или удаленную загрузку.</p><p> Этот проход удаляет комментарии HTML. Это в основном для удобства, чтобы позволить будущим проходам заменять текст без необходимости распознавать и пропускать комментарии.</p><p> С этого момента ввод данных пользователем не может быть разрешен для прямой передачи на вывод без проверки и экранирования. И с этого момента HTML-комментарии можно использовать в качестве маркеров.</p><h4><span class="ez-toc-section" id="%D0%9F%D1%80%D0%BE%D1%85%D0%BE%D0%B4%D1%8B_%D0%BF%D1%80%D0%B5%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F_%D1%80%D0%B0%D0%B7%D0%BC%D0%B5%D1%82%D0%BA%D0%B8%5B%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%5D-2"></span> Проходы преобразования разметки[править] <span class="ez-toc-section-end"></span></h4><p> Ниже приведены оставшиеся проходы, вызываемые Parser::internalParse():</p><dl><dt> doTableStuff</dt><dd> Это простой построчный синтаксический анализатор, который преобразует разметку таблицы в стиле викитекста в разметку таблицы HTML.<img class="lazy lazy-hidden" loading='lazy' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='' /><noscript><img loading='lazy' src='' /></noscript></div><footer class="entry-footer"><div id="author_box" class="row no-gutters"><div class="author_avatar col-2"> <img alt='' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='https://secure.gravatar.com/avatar/b142b184aa8663e4da31fb1a71be88cc?s=96&d=mm&r=g' srcset="" data-srcset='https://secure.gravatar.com/avatar/b142b184aa8663e4da31fb1a71be88cc?s=192&d=mm&r=g 2x' class='lazy lazy-hidden avatar avatar-96 photo' height='96' width='96' decoding='async'/><noscript><img alt='' src='https://secure.gravatar.com/avatar/b142b184aa8663e4da31fb1a71be88cc?s=96&d=mm&r=g' srcset='https://secure.gravatar.com/avatar/b142b184aa8663e4da31fb1a71be88cc?s=192&d=mm&r=g 2x' class='avatar avatar-96 photo' height='96' width='96' decoding='async'/></noscript></div><div class="author_info col-10"><h4 class="author_name title-font"> admin</h4><div class="author_bio"></div></div></div></footer></article><nav class="navigation post-navigation" aria-label="Записи"><h2 class="screen-reader-text">Навигация по записям</h2><div class="nav-links"><div class="nav-previous"><a href="https://xn--7-dtbea5camjj.xn--p1ai/raznoe/luchshie-sorta-osennih-grushi-dlya-srednej-polosy-rossii-luchshie-sorta-grushi-dlya-srednej-polosy-rossii-obzor.html" rel="prev"><span class="nav-title title-font">Лучшие сорта осенних груши для средней полосы россии: Лучшие сорта груши для средней полосы России: обзор</span></a></div><div class="nav-next"><a href="https://xn--7-dtbea5camjj.xn--p1ai/raznoe/reczepty-blyud-vok-blyuda-v-voke-reczepty-s-foto-na-povar-ru-139-reczeptov-voka.html" rel="next"><span class="nav-title title-font">Рецепты блюд вок: Блюда в воке — рецепты с фото на Повар.ру (139 рецептов вока)</span></a></div></div></nav><div id="comments" class="comments-area"><div id="respond" class="comment-respond"><h3 id="reply-title" class="comment-reply-title">Добавить комментарий <small><a rel="nofollow" id="cancel-comment-reply-link" href="/raznoe/razobrat-po-sostavu-slovo-ruchnoj-slova-ruchnoj-morfologicheskij-i-foneticheskij-razbor.html#respond" style="display:none;">Отменить ответ</a></small></h3><form action="https://xn--7-dtbea5camjj.xn--p1ai/wp-comments-post.php" method="post" id="commentform" class="comment-form" novalidate><p class="comment-notes"><span id="email-notes">Ваш адрес email не будет опубликован.</span> <span class="required-field-message">Обязательные поля помечены <span class="required">*</span></span></p><p class="comment-form-comment"><label for="comment">Комментарий <span class="required">*</span></label><textarea id="comment" name="comment" cols="45" rows="8" maxlength="65525" required></textarea></p><p class="comment-form-author"><label for="author">Имя <span class="required">*</span></label> <input id="author" name="author" type="text" value="" size="30" maxlength="245" autocomplete="name" required /></p><p class="comment-form-email"><label for="email">Email <span class="required">*</span></label> <input id="email" name="email" type="email" value="" size="30" maxlength="100" aria-describedby="email-notes" autocomplete="email" required /></p><p class="comment-form-url"><label for="url">Сайт</label> <input id="url" name="url" type="url" value="" size="30" maxlength="200" autocomplete="url" /></p><p class="form-submit"><input name="submit" type="submit" id="submit" class="submit" value="Отправить комментарий" /> <input type='hidden' name='comment_post_ID' value='63450' id='comment_post_ID' /> <input type='hidden' name='comment_parent' id='comment_parent' value='0' /></p></form></div></div></main><aside id="secondary" class="widget-area order-2"><section id="categories-47" class="widget widget_categories"><h3 class="widget-title title-font"><span>Рубрики</span></h3><ul><li class="cat-item cat-item-10"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/vospityvat">Воспитывать</a></li><li class="cat-item cat-item-11"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/deti">Дети</a></li><li class="cat-item cat-item-13"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/podrostok">Подросток</a></li><li class="cat-item cat-item-9"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/pravilno">Правильно</a></li><li class="cat-item cat-item-8"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/raznoe">Разное</a></li><li class="cat-item cat-item-12"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/rekomendaczii">Рекомендации</a></li><li class="cat-item cat-item-1"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/sovety">Советы</a></li></ul></section></aside></div></div><div id="footer-sidebar" class="widget-area"><div class="container"><div class="row"></div></div></div><footer id="colophon" class="site-footer"><div class="site-info"> 2025 © Все права защищены.</div></footer></div><nav id="menu" class="panel" role="navigation"> <button class="go-to-bottom"></button> <button id="close-menu" class="menu-link"><i class="fa fa-times"></i></button><ul id="mobile-menu" class="menu"><li id="menu-item-26342" class="menu-item menu-item-type-taxonomy menu-item-object-category current-post-ancestor current-menu-parent current-post-parent mdl-list__item"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/raznoe"></i>Семейные советы</a></li><li id="menu-item-26343" class="menu-item menu-item-type-taxonomy menu-item-object-category mdl-list__item"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/pravilno"></i>Как правильно ?</a></li><li id="menu-item-26344" class="menu-item menu-item-type-taxonomy menu-item-object-category mdl-list__item"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/deti"></i>Дети</a></li><li id="menu-item-26345" class="menu-item menu-item-type-taxonomy menu-item-object-category mdl-list__item"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/vospityvat"></i>Воспитание</a></li></ul> <button class="go-to-top"></button></nav> <noscript><style>.lazyload{display:none}</style></noscript><script data-noptimize="1">window.lazySizesConfig=window.lazySizesConfig||{};window.lazySizesConfig.loadMode=1;</script><script async data-noptimize="1" src='https://xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/autoptimize/classes/external/js/lazysizes.min.js'></script> <!-- noptimize --> <style>iframe,object{width:100%;height:480px}img{max-width:100%}</style><script>new Image().src="//counter.yadro.ru/hit?r"+escape(document.referrer)+((typeof(screen)=="undefined")?"":";s"+screen.width+"*"+screen.height+"*"+(screen.colorDepth?screen.colorDepth:screen.pixelDepth))+";u"+escape(document.URL)+";h"+escape(document.title.substring(0,150))+";"+Math.random();</script> <!-- /noptimize --> <script defer src="https://xn--7-dtbea5camjj.xn--p1ai/wp-content/cache/autoptimize/js/autoptimize_1ef490c9359ea65f37b76aed46105dbe.js"></script></body></html><script src="/cdn-cgi/scripts/7d0fa10a/cloudflare-static/rocket-loader.min.js" data-cf-settings="8ae25c3a09e7b1df450ddfd3-|49" defer></script>