«Необходим» корень слова и разбор по составу — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Чтобы правильно разобрать слово по составу , необходимо…. Помогите что необходимо чтобы
При разборе слова по составу не просто полезно, но необходимо определить, как образовано слово, то есть от какого слова и при помощи каких морфем. Более того, рекомендуется мысленно или письменно составлять словообразовательную цепочку, чтобы не ошибиться в морфемном составе анализируемого слова. Например, при определении морфемного состава слова горнякам следует размышлять примерно так:
1)это слово – существительное мужского рода второго склонения, стоит в форме множественного числа дательного падежа; значит, в нем выделяется окончание: горняк-ам
2)горняк – «работник горной промышленности» . Значение лица передается при помощи суффикса -як- (ср. : бедняк – бедный, пошляк – пошлый) . Существительное горняк образовано от прилагательного горный с помощью названного суффикса.
горнякам – горный
Способ образования суффиксальный.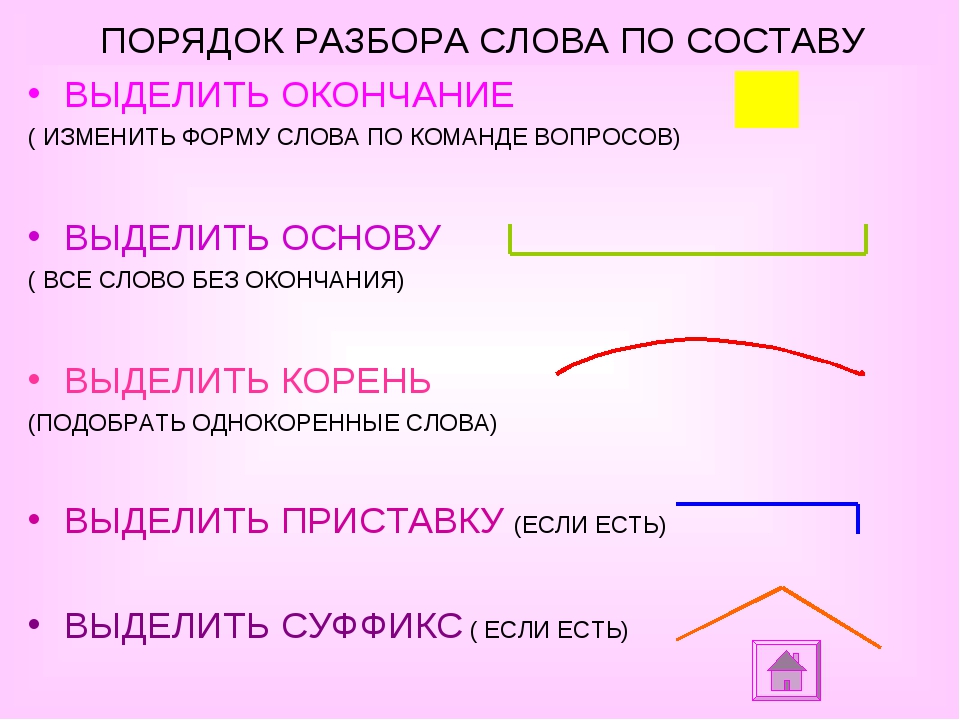
3)прилагательное горный – относительное, имеет значение «относящийся к горе, горам» ; следовательно, образовано от существительного гора при помощи суффикса прилагательного -н- (ср. : водный – вода, модный – мода) . Прилагательное горный образовано от существительного гора с помощью названного суффикса:
горный – гора
Способ образования суффиксальный.
4)Итак, определяя морфемный состав существительного горнякам, мы составили словообразовательную цепочку:
горнякам – горный – гора
Эта процедура позволила нам определить слово с непроизводной основой (или так называемое первообразное слово) , которое «ни от чего не было образовано» и состоит только из корня и окончания. Более того, именно это дает нам возможность не просто правильно разобрать слово по составу, но и определить значение каждой морфемы.
гор н як ам
Существительное горнякам состоит из окончания -ам (имеет значение дательного падежа множественного числа) , суффикса существительного –як-, суффикса прилагательного -н- и корня -гор-.
4 класс. Русский язык. Разбор глагола по составу — Разбор глагола по составу
Комментарии преподавателя
§1. Разбор слова по составу. Порядок разбора.
На уроке мы познакомимся с порядком выполнения разбора глагола по составу.
Что значит «разобрать глагол по составу»?
Для этого необходимо обозначить в глаголе части слова (корень, суффикс, приставку, окончание, основу), т.е. выделить морфемы.
Разбор слова по составу называют ещё морфемным разбором и обозначают цифрой 2.
Например, увидела2.
Морфемный разбор выполняется в определенном порядке. Давайте познакомимся с алгоритмом разбора глагола по составу.
- Во-первых, необходимо определить форму глагола.
Глагол имеет две формы: начальную или неопределенную форму глагола и личную. Глаголы начальной формы отвечают на вопросы: что делать? что сделать? В начальной форме глаголы имеют суффиксы –ть,-ти, -чь.
- (что делать?) беречь, стеречь, везти; (что сделать?) подарить.
Глаголы в личной форме согласуются с личными местоимениями и указывают на тот объект, который совершает действия.
- Затем необходимо выделить части слова, которые не входят в основу.
У глаголов такими морфемами являются:
- Суффиксы начальной или неопределенной формы глагола –ть, -ти, -чь.
Данные суффиксы не образуют новых слов, не изменяют лексического значения слова, а лишь изменяют форму глагола, то есть образуют начальную форму. Поэтому суффиксы –ть, -ти, -чь в основу не включаются. Если глагол стоит в неопределенной форме, то эти суффиксы необходимо выделить в первую очередь.
- Суффикс глаголов прошедшего времени –л, так как он не образует нового слова, а образует форму глагола прошедшего времени.
Например:
- Личные окончания глаголов.
 Для того чтобы найти и выделить личное окончание глагола, необходимо проспрягать глагол, то есть изменить его по лицам и числам. Изменяемая часть слова и будет являться окончанием.
Для того чтобы найти и выделить личное окончание глагола, необходимо проспрягать глагол, то есть изменить его по лицам и числам. Изменяемая часть слова и будет являться окончанием.
 Для того чтобы найти и выделить личное окончание глагола, необходимо проспрягать глагол, то есть изменить его по лицам и числам. Изменяемая часть слова и будет являться окончанием.
Для того чтобы найти и выделить личное окончание глагола, необходимо проспрягать глагол, то есть изменить его по лицам и числам. Изменяемая часть слова и будет являться окончанием.Например, найдем окончание у глагола работает.
Проспрягаем данный глагол:
- –ет будет являться личным окончанием глагола. Личное окончание глагола заключается в прямоугольник.
Эти морфемы не входят в основу у глаголов, поскольку не участвуют в образовании новых слов.
- Далее выделяем основу слова.
Основа слова – это часть слова без окончания. Именно в основе заключается лексическое значение слова.
Суффикс глаголов –ся (-сь) входит в основу слова. При разборе основа выделяется квадратной скобкой под словом, она может быть прерывистой.
- Следующий пункт разбора — определение корня слова.
Любое слово имеет корень, без этой морфемы не существует ни одного слова, именно в корне заключен общий смысл всех однокоренных слов. Для того чтобы определить корень, необходимо подобрать несколько родственных слов.
Для того чтобы определить корень, необходимо подобрать несколько родственных слов.
Общая часть этих слов, в которой заключено основное лексическое значение, и будет являться корнем.
Например, найдем корень у глагола проверить. Родственными словами к этому глаголу будут: проверка, заверить, поверить, доверять, вера, поверенный. Одинаковая часть этих слов, в которой заключено их основное лексическое значение
– вер. Это и будет корень слова проверить.
При определении корня не следует подбирать разные формы одного слова. Например, для того, чтобы определить корень слова проверить, не следует подбирать слова: проверил, проверила, проверять.
На письме корень слова выделяется дугой (над словом).
- Вслед за корнем выделяют приставку (если она есть в слове) – морфему, которая участвует в словообразовании однокоренных слов и стоит перед корнем.

Наиболее употребляемые приставки:
На письме приставка выделяется перевёрнутой буквой г (над словом).
- Вслед за приставкой необходимо выделить суффикс.
Обычно он стоит после корня и служит для образования новых слов. На письме его обозначают специальным значком в виде угла с направленной вверх вершиной (над словом).
У возвратных глаголов необходимо выделить суффиксы -сь и -ся-.
Например, в слове возвращаться –ся — это суффикс, и он входит в основу слова.
У глаголов также могут быть суффиксы:
§2. Примеры разбора глаголов по составу
Давайте в качестве примера разберем по составу глагол выходить.
Определим форму глагола. Для этого поставим к нему вопрос (что делать?) выходить. Это глагол неопределенной формы.
Выделяем морфемы, не входящие в основу слова. У глагола выходить — это суффикс
–ть-, который образует начальную (неопределенную) форму слова.
Выделим основу слова – выходи.
Для того чтобы определить корень, подберем родственные слова: заходить, переходить, поход, ходить и т.д.
Одинаковой частью этих слов является корень – ход
Вслед за корнем выделим приставку, которая стоит перед ним. Это приставка –вы.
Часть слова, стоящая после корня перед формообразующим суффиксом –ть-, будет являться суффиксом глагола. И это будет суффикс –и—.
Запись разбора глагола в тетради будет такой:
Давайте выполним разбор еще одного глагола — переглядываются.
Определим форму глагола. Поставим вопрос (что делают?) переглядываются.
Глагол указывает на действие нескольких лиц и согласуется с личным местоимением они. Следовательно, данный глагол стоит в личной форме — 3 лица, множественного числа, настоящего времени.
Выделим части слова, которые не входят в основу.
В нашем случае это будет личное окончание глагола. Для того чтобы его определить, проспрягаем глагол: переглядывается, переглядываемся, переглядываешься.
Личное окончание – ют.
Выделим основу слова – переглядыва___ся. Основа прерывистая.
- Найдем корень слова.
Подбираем родственные слова: поглядывают, заглядываются, взгляд, глядеть. Корень слова –гляд.
Часть слова перед корнем – пере – будет являться приставкой.
У глагола переглядываются два суффикса. Суффикс глагола –ыва- стоит после корня перед личным окончанием глагола.
Входит в основу и суффикс глагола возвратной формы –ся.
Запись в тетради будет иметь такой вид:
Итак, подведём итог урока.
При разборе глагола по составу необходимо найти и выделить все формообразующие и словообразующие морфемы. Производить разбор глагола по составу следует по следующему алгоритму:
Производить разбор глагола по составу следует по следующему алгоритму:
- Определяем форму глагола.
- Выделяем морфемы, которые не входят в основу слова: личное окончание глагола, суффиксы –ть, -ти, -чь, -л.
- Выделяем основу слова.
- Подбираем родственные слова и выделяем корень слова.
- Перед корнем находим и выделяем приставку (если она имеется в слове).
- Следующим шагом находим и выделяем суффикс или суффиксы глагола (если они существуют).
ИСТОЧНИКИ
http://znaika.ru/catalog/4-klass/russian/Razbor-glagola-po-sostavu
https://vimeo.com/113580176
Конспект урока «Состав слова. Разбор слова по составу»
Технологическая карта урока по теме:
«Состав слова. Порядок разбора слова по составу». 3 класс .
Повторение, обобщение и закрепление знаний о составе слова, родственных словах и формах слова; о порядке разбора слов по составу.
Задачи:
предметные: повторить состав слова; расширить знания обучающихся о родственных словах; учить пользоваться разными видами словарей;
формировать умение видеть красоту в простом, создать условия для успешного закрепления изученного материала.
метапредметные: развитие навыка работы с учебником; развитие мыслительных операций: анализа, синтеза, обобщения; развитие памяти, внимания, орфографической зоркости, уточнение и расширение словарного запаса учащихся при использовании терминологии.
воспитательные: формирование норм нравственно-этического поведения в разных формах работы; воспитание интереса к русскому языку, чувства коллективизма и индивидуальности, взаимопомощи.
здоровьесберегающие: профилактика утомления учащихся.
Планируемый результат
Познавательные умения:
— объяснять отличительные особенности родственных слов и обосновывать своё мнение.
Регулятивные умения:
— выполнять учебное задание в соответствии с правилом.
Коммуникативные умения:
— формулировать понятные высказывания, используя термины.
Предметные умения:
— Знать и уметь применять общее правило написания корней родственных слов.
— Уметь разбирать слова по составу.
— Уметь находить в тексте родственные слова.
— Уметь решать проблемные ситуации.
Основные понятия
Понятия: состав слова; родственные слова;
корень; приставка, суффикс, окончание.
Межпредметные связи
Русский язык, литературное чтение.
Ресурсы:
Учебник « Русский язык» 3класс, 1 часть Тема: «Состав слова. Порядок разбора слова по составу».
Методическое пособие,
рабочая тетрадь;
компьютер,
проектор,
презентация;
Организация пространства
Работа фронтальная, индивидуальная, в парах, в группах
Ход урока
— Прежде чем начать урок, создадим себе и окружающим хорошее настроение. А хорошее настроение начинается с улыбки. Улыбнемся друг другу. Подарим улыбки нашим гостям.
А хорошее настроение начинается с улыбки. Улыбнемся друг другу. Подарим улыбки нашим гостям.
Покажем, как мы учимся.
Чтоб многое успеть,
Чтоб многое узнать,
Скорее урок
Нам нужно начинать.
— Чтобы быть активными на уроке, чтобы прибавилось сил, давайте про тонизируем наши части тела.(Потрите ушки, разогрейте свои ладошки). Откроем тетрадки, запишем число, классная работа. (слайд 2)
Чистописание.
— Ребят, я предлагаю вам разгадать загадку, чтобы определить какую букву мы будем писать на минутке чистописании
Обруч, мяч и колесо,
Вам напомнят букву … (слайд 3)
Проверим готовность к уроку.
Расскажите, что вы знаете про эту букву? (гласная, обозначает звук О). (слайд 4)
Давайте пропишем эту букву в воздухе. Вначале заглавную, затем строчную. А теперь аккуратно запишите и заглавную, и строчную к себе в тетрадь. Подчеркните простым карандашом ту букву или буквы которые у вас получились лучше всего.
А теперь аккуратно запишите и заглавную, и строчную к себе в тетрадь. Подчеркните простым карандашом ту букву или буквы которые у вас получились лучше всего.
Чтобы определить тему сегодняшнего урока, вам необходимо в данной записи ее отыскать.
ВЗБРТКСОСТАВПРЕЬНПРВАОЛОГРПНТИ
ОКПТГОБЛОЮСЛОВАРШЛУВЫЦЕ
Тема нашего урока: Состав слова. (слайд 5)
Что вы должны повторить и закрепить на уроке? ( мы повторим и закрепим знания, полученные по теме «Состав слова». )
Кто — тот мне сказал, что знает пять частей слова. Прав ли он? (Перечисляют)
Слово делится на части
Ах, какое это счастье!
Может каждый грамотей
Делать слово из частей!
Я предлагаю вам «составить» лицо грамматического человечка. (слайд 6) Но перед тем, как лицо человека «примет» выражение, я предлагаю вам вспомнить какие части слова вы знаете, вспомнить для чего они нужны и как они обозначаются, а потом из ваших ответов я «оформлю» лицо человечка. Для этого соедините понятие с определением и обозначением его на письме. (для детей ОВЗ распечатывается точно такая же карточка где они соединяют, и она для них памятка на весь урок) (слайд 7)
Для этого соедините понятие с определением и обозначением его на письме. (для детей ОВЗ распечатывается точно такая же карточка где они соединяют, и она для них памятка на весь урок) (слайд 7)
Человечек получился немного грустный, но я думаю, что в конце урока он обязательно весело улыбнётся. (слайд 8) А для того чтобы человечек улыбнулся Вам, ребята, необходимо выполнить ряд заданий.
— А у меня на доске появилось уже первое для вас задание :
Нас приглашает окончание.
И у него для нас задание.
—Как вы думаете почему первым задание нам предложило окончание? (на доску прикрепляю значок окончание)
искристый, земля, лежит, снежок, на (слайд 9)
-Является ли эта запись предложением?
Что выражает предложение? Как связаны слова в предложении?
На земле лежит искристый снежок.
-Какая часть слова помогла нам составить предложение? (Окончание, т. к. окончание служит для связи слов в предложении)
к. окончание служит для связи слов в предложении)
— Запишите это предложение. Выделите в словах окончания. Чтобы правильно выделить окончания что нужно сделать?
Проверьте себя по образцу (слайд 10)
А мы двигаемся дальше.
Жило-было слово ХОД
В слове выХОД, в слове вХОД,
В слове ХОДики стучало.
И в поХОДе вдаль шагало. (слайл 11)
Что интересного нашли в этом задании?
А какие слова называются однокоренными?
Выпишите однокоренные слова, выделите корень. (на доске значок корень)
А теперь я предлагаю вам отдохнуть. Я буду вам называть действия, а вы их выполнять: встать, подпрыгнуть, повернуться вправо, повернуться влево, поморгать, присесть. (слова на слайд 12). Ребята, что объединяет все эти слова? (на доске появляется значок приставка)
Слайд 13. Составьте слова добавляя к корню —лет приставки. Запишите их в тетрадь, выделите приставку. (Взаимопроверка в парах, к детям ОВЗ консультанты)
Ребята, я вам предлагаю поиграть!
Назовите детенышей: козы, утки, льва, гуся, слона, кошки.
( Козленок, утенок, львенок, гусенок, слоненок, котенок.) (слайд 14)
При помощи какой части слова образовались эти слова? (на доске значок суффикса)
-Посмотрите, пожалуйста на доску. Что у нас получилось? (алгоритм разбора слова по составу)
Я предлагаю вам разобрать следующие слова по составу: гусенок, поход, полетим
Для того чтобы закрепить полученные знания я предлагаю вам поработать самостоятельно.
У вас в тетрадях на корочке записаны слова. Ваша задача разобрать это слово по составу.
Посмотрите вокруг. На стенах есть схемы разбора слов. Подойдите к той схеме, которая будет соответствовать вашему слову.
В пакете есть слова. Найдите ваше слово.
Подходит к концу наш урок.
Я бы хотела, чтобы вы оценили свою работу.
Я полностью и самостоятельно выполнял все задания
Я выполнял задания хорошо, но иногда мне требовалась помощь товарищей или учителя
Я не смог выполнить все задания так, как мне хотелось. Мне надо еще поучиться…
Посмотрите, доволен и грамматический человечек. Он весело улыбается, радуясь вместе с нами.
— Вы сегодня очень хорошо работали.
А теперь, отгадайте, что вас ждёт дальше: составьте слово по подсказкам.
Слово состоит из 4 частей.
Корень тот же, что и в словах: обмен, изменить, меняла (мен)
Приставка, как в слове переход.
Суффикс тот же, что в словах травка, шубка (к)
Окончание –первая буква алфавита (-а)
Ответ: переменка.
И у вас –переменка. Урок окончен. Отдыхайте.
Я полностью и самостоятельно выполнял все задания
Я выполнял задания хорошо, но иногда мне требовалась помощь товарищей или учителя
Я не смог выполнить все задания так, как мне хотелось. Мне надо еще поучиться…
Посмотрите, доволен и грамматический человечек. Он весело улыбается, радуясь вместе с нами.
— Вы сегодня очень хорошо работали.
А теперь, отгадайте, что вас ждёт дальше: составьте слово по подсказкам.
Слово состоит из 4 частей.
Корень тот же, что и в словах: обмен, изменить, меняла (мен)
Приставка, как в слове переход.
Суффикс тот же, что в словах травка, шубка (к)
Окончание –первая буква алфавита (-а)
Ответ: переменка.
И у вас –переменка. Урок окончен. Отдыхайте.
Конспект урока по русскому языку «Словообразование. Разбор слова по составу»
Урок русского языка
УМК: Школа 2100
Тема урока: Словообразование. Разбор слова по составу.
Тип учебного занятия. Урок комплексного применения знаний и умений.
Цель:
создание условий для систематизации знаний по теме «Состав слова».
Задачи:
— сформировать умение разбирать слово по составу, образовывать новые слова с помощью суффикса и приставки;
— развивать память, внимание, мышление, речь;
— формировать у детей интерес к русскому языку, привлекая внимание детей к «живому» слову.
Оборудование: компьютер, экран, мультимедийный проектор, презентация, листы с тестовыми заданиями, словари (орфографический, толковый, словообразовательный).
Ход урока
Орг. Момент
Учитель: Урок русского языка.
Посмотрите на экран и выберите себе установку на уроке (Слайд №2):
Я буду внимателен;
Я буду старателен;
Я буду трудолюбив;
Я буду доброжелателен;
Я буду активен;
Я буду успешен.
Открываем тетради, записываем число, классная работа.
Ученики делают необходимые записи в тетради
Учитель: Изучите содержание слайда, разгадайте ребус. (СЛАЙД №3)
Ответ: летопись
Учитель: Подберите синоним к слову ЛЕТОПИСЬ
Учащиеся: Синоним к слову летопись – история.
Учитель: Что такое история?
Предполагаемый ответ: История — это прошлое, то, что было до настоящего времени. Повествование о событиях прошлых лет, о каком-либо случае, происшествии, записи, факты. Это наука, которая занимается изучением прошлого, выяснением правды, что и откуда произошло, причины и события.
Учитель: Я думаю, что не только знания в области русского языка, но и исторические знания помогут вам справиться с последующими заданиями.
II. Актуализация знаний.
Ассоциации (СЛАЙД №4)
Учитель: Всякое слово связано с другими словами узами ассоциаций.
Для примера возьмем слово Пётр, какие возникают ассоциации?
Учащиеся: Пётр Первый.
Учитель: Прочитайте слова и назовите более-менее логически обоснованные ассоциации к ним.
Золотая
Ледовое
Златоглавая Дети подбирают ассоциации к словам на слайде.
Смутное
Грозный
Книгопечатник
Примеры ассоциаций: Орда, побоище, Москва, время, Иван, Иван Федоров
Учитель фиксирует на доске ассоциации предложенные детьми.
Учитель: Совпали ваши ассоциации с моими? (демонстрация иллюстраций – ассоциаций учителя)
Слайд №4
Учитель: Запишите слова по памяти в тетрадь, опираясь на свои ассоциации.
Дети по памяти записывают слова, опираясь на слова-ассоциации, записанные на доске.
Проверка (СЛАЙД №5)
В ходе проверки осуществляется словарно-орфографическая работа.
Повторение понятий простые и сложные слова.
Учитель: На какие группы можно разделить эти слова?
Предполагаемый ответ: части речи или по составу: сложные и простые.
Учитель: Какие слова называют сложными? (Сложные слова состоят из двух основ) (СЛАЙД №6)
Учитель: В какую группу отнесём слово летопись? (СЛАЙД №7)
Учащиеся: Слово летопись является сложным словом, т.к. состоит из двух основ, соединенных между собой соединительной гласной о.
Учитель: Сформулируйте лексическое значение слова ЛЕТОПИСЬ.
Учащиеся: Летопись — запись исторических событий древнего времени по годам.
3. Работа с толковым словарем.
Учитель: В каком словаре мы можем это уточнить?
Учащиеся: Лексическое значение слова можно узнать, обратившись к толковому словарю.
Далее СЛАЙД №8
Учитель: Рассказ о событиях каждого года в летописях обычно начинался словами: «в лето» — отсюда название — летопись.
III. Применение знаний.
Работа в парах.
а) Инструктаж.
Учитель: А сейчас я предлагаю поработать в парах. Вам необходимо восстановить последовательность действий разбора слова по составу. Первый пункт этого плана мы уже выполнили: узнали лексическое значение слова. Какие шаги нам необходимо проделать дальше?
На партах учеников полоски бумаги, на которых записан алгоритм разбора слов по составу. Необходимо расположить в правильной последовательности эти полоски.
б) Самостоятельная работа.
в) Проверка (СЛАЙД №9)
По ходу проверки воспроизводим в памяти определения слов: КОРЕНЬ, ОКОНЧАНИЕ, ОСНОВА, СУФФИКС, ПРИСТАВКА.
2. Разбор слов по составу
Учитель: Молодцы. А теперь мы попробуем применить эти знания на практике.
а) Разбор слов по составу:
Золотая
Ледовое
Златоглавая
Смутное
Грозный
Книгопечатник
Летопись
Ученики разбирают слова по составу комментируя каждый свой шаг, опираясь на алгоритм.
Работа с электронными словарями
Учитель: Электронный словарь — словарь в компьютере или другом электронном устройстве. Он позволяет быстро найти нужное слово. (Слайд №10)
б) Подбор однокоренных слов к слову ЛЕТОПИСЬ.
Учитель: Какие словари нам могут помочь?
Учащиеся: Словообразовательный словарь.
Учитель: Подберите однокоренные слова к слову « летопись».
Учащиеся: Летописец.
Учитель: Какая часть слова помогла образовать это слово?
Учащиеся: Суффикс.
Учитель: Образуйте однокоренное имя прилагательное.
Учащиеся: Летописный.
Учитель: Какая часть слова помогла образовать это слово?
Учащиеся: Суффикс.
3. Работа в группах.
Работа с таблицами (Слайд №11).
а) Инструктаж.
Учитель: Из предложенных слов вам необходимо взять только ту его составную часть, которая указана в таблице. Соединив все части – получите слово.
Ученики знакомятся с содержанием таблицы
ПРИСТАВКА | КОРЕНЬ | СУФФИКС | ОКОНЧАНИЕ | СЛОВО |
походка | слово | сестрицы | река | |
налетели | ученик | куст | молчит | |
коньки | мудрец | старость | домик |
б) Самостоятельная работа.
Ученики, объединившись в группы, выполняют задание.
в) Проверка.
ПРИСТАВКА | КОРЕНЬ | СУФФИКС | ОКОНЧАНИЕ | СЛОВО |
походка | слово | сестрицы | река | пословица |
налетели | ученик | куст | молчит | научит |
коньки | мудрец | старость | домик | мудрость |
Установление связи между словами в предложении.
Учитель: Что необходимо сделать, чтобы у нас получилось предложение?
Учащиеся: Необходимо изменить окончание слова мудрость.
Запись в тетрадь: Пословица научит мудрости.
Работа с высказыванием А.Суворова.
Учитель: Дополните высказывание недостающим словом, которое представлено схемой:
Легко в учении – тяжело в ¬ ͡ *, тяжело в учении — легко в ¬ ͡ *.
Ответ: походе
Учитель: Какому известному человеку принадлежат эти слова?
Учащиеся: Это высказывание Александра Суворова.
Проверка Слайд № 12
Учитель: Как вы понимаете значение этого высказывания?
Ответы детей.
Дополнения учителя: Первоначально оно имело значение: ”солдату тяжело на военных учениях, но усвоенные навыки позволят ему легко и уверенно чувствовать себя в бою”.
Учитель. Какие трудности вы испытываете при изучении темы «Состав слова» и над чем нужно еще усердно поработать, поможет выявить следующее задание.
Тест
Учитель: Сейчас ответим на вопросы теста. Если вы правильно справитесь со всеми его заданиями, то сможете прочитать ключевое слово.
Ученики знакомятся с содержанием теста
№ | Вопрос | А | Б | В |
1 | В какой из строчек все слова являются однокоренными? А. Горка, гористый, горячий. Б. Ужалить, жалко, жалоба. В. Дом, домашний, домишко. | |||
2 | В какой из строчек все слова имеют приставку по-? А. Подумать, побежать, поезд. Б. Потеплеть, поверх, полк. В. Покатить, подержать, покой. | |||
3 | В какой из строчек все слова имеют суффикс -ик- ? А. Дворик, столик, облик. Б. Носик, мячик, карандашик. В. Стульчик, ключик, сникнуть. | |||
4 | В какой из строчек все слова имеют одинаковое окончание? А.*? А. Пригородный, подарки, корзинка. Б. Дошкольный, переходный, подъезд. В. Перелётные, прохладный, простудный. | |||
6 | В какой из строчек все слова имеют нулевое окончание? А. Лужок, морозец, пригород. Б. Румянец, шкаф, поле. В. Доплата, звёзды, полесье. |
Проверка теста (Слайд №13)
Учитель: Расположите буквы правильных ответов ваших тестов внизу таблицы.
Ответ: состав
Учитель: Какое значение может иметь слово СОСТАВ? (Слайд №14)
Учитель: Какое значение подходит к теме нашего урока? О каком составе мы говорили? Учащиеся: Совокупность людей, предметов, образующих какое-нибудь целое.
IV. Итог
Учитель: А теперь давайте подведем итог нашего урока. Над чем мы сегодня работали? Учащиеся: Работали над составом слова, учились разбирать слова по составу; кто с опорой, а кто и без.
Учитель: А кто самостоятельно может разбирать слова по составу?
Учитель: Ребята, как вы думаете, а для чего мы изучаем эту тему и где нам могут пригодиться полученные знания?
Учащиеся: Состав слова может объяснить образование слов. Знание состава слова помогает мне увидеть, в какой части слова орфограмма, в зависимости от этого слабые позиции я проверяю, запоминаю или смотрю их правописание по словарю.
Учитель: Что бы вы хотели повторить или узнать о составе слова?
Рефлексия (Слайд №15)
Сегодня на уроке
Я не знал (а)… Теперь я знаю…
Мне было трудно…
Теперь я могу…
Мне было легко, потому что…
Мне захотелось…
Домашнее задание.
Учитель: Ребята, я хочу предложить на выбор два задания для домашней работы:
Учитель: Придумайте и запишите сказку или рассказ о том, как образовалось слово;
Учитель: Придумайте и запишите 7–10 слов к схеме, где присутствуют все части слова
Учитель: Спасибо за урок.
Разбор слова по составу онлайн
1. Разбор слова по составу – что это?
Данный разбор считается одним из видов лингвистического анализа, при котором определяется состав или структура слова, выделяются главные составляющие части. С его помощью происходит формирование орфографических навыков.
Основной прием в процессе разбора – это подбор форм с целью выделить окончание, подбор одно структурных слов, чтобы определить приставки и суффиксы, также, подбор однокоренных слов. В момент определения морфемы следует определять ее значение с точки зрения грамматики. При начальном исследовании этого вида анализа, лучше всего, отмечать характеристику частей слова. Надо помнить следующее: данный разбор слова производится соответственно нормам русского языка. Не стоит за начальный этап анализа слова брать поиск корня — это неправильный способ.
Основой считают главную часть, которая способна изменяться, при этом, окончание остается прежним. В ней присутствует все лексическое значение любого термина. Окончание является изменяющейся значимой частью, образовывает форму, способствует связыванию отдельных слов в словосочетаниях, также, предложениях.
При осуществлении разбора слова, необходимо помнить о наличии некоторых примечаний. Например, для фиксирования окончания, следует изменить, непосредственно, слово, а слова, которые не меняются, не обладают окончаниями. Есть конкретный порядок при разборе, его надо строго придерживаться, чтобы достичь нужного результата. Обязательно требуется определение слова, как части речи – это основной этап. У изменяющегося слова отыскать окончание, чтобы проверить, верно ли определено, следует его изменить.
Кроме этого, нужно выделить основу, которую именуют корнем и чтобы добиться этого, надо найти слова с одинаковым корнем или же корни в особо трудных словах. Если имеются суффиксы и приставки их следует отметить, а грамотность совершаемого действия требуется доказать при помощи подбора слов с иным корнем, однако, с аналогичными частями.
2. Краткая характеристика частей слова
Основные части являются общеизвестными, но для тщательного усвоения и умения быстро различить их, следует рассмотреть каждую по отдельности.
Приставка представляет собой значимую часть, находящуюся перед корнем, помогающую образовывать новые слова. Этот способ носит название «приставочного», ведь приставка формирует одинаковые части речи. Иначе говоря, от существительного производится также имя существительное, от глагола получается другой глагол, наречие образовывает следующее наречие.
Корень считают основной частью слова, в нем содержится значение однокоренных слов, то есть, слов с аналогичным корнем. Это морфема, дающая полное значение или главную часть значения слова. Известно, что в русском языке не все слова содержат корень, к примеру, он отсутствует в союзах, междометиях, некоторые лексических единицах. Если слово является сложным, оно включает некоторое количество корней.
Суффикс в сфере лингвистики является морфемой, находящейся вблизи корня. В большинстве случаев, он служит для формирования новых слов, включает в себя основу и окончание. В свою очередь, основа включает все морфемы, отсутствует только окончание – словоизменительная морфема, и формообразующие суффиксы.
Окончание представляет собой изменяемую часть, образующую форму. Она предназначается для связывания слов между собой, в итоге, получаются словосочетания и целые предложения. Для ее выделения требуется изменить слово, кстати, слова неизменяющиеся обычно, не имеют окончаний. В момент изменения, образования определенной формы, меняются окончания. Например, при изменении числа, падежа, рода, лица.
Термин соединительные буквы, в более частых случаях, обозначает именно соединительные гласные. В некоторых сложных словах, когда их первая часть образована от слов, имеющих мягкую основу, может присутствовать соединительная гласная. Для примера можно привести следующие слова: кровообращение (кровеносный), коновязь (коневодство), зверолов.
Постфиксом называют значимую часть, которая стоит после морфем, способствует образованию новых форм. Это известный термин в лингвистике, обозначающий аффикс, находящийся после корня.
3. Использование алгоритма разбора слова
Порядок или конкретные шаги в разборе слова называют алгоритмом, он располагает своей спецификой, последовательностью. При выполнении подобного анализа, необходимо четко следовать всем указанным пунктам, чтобы не допустить грубую ошибку.
К требуемому слову надо поставить вопрос, определить разновидность части речи. Затем, слово изменяется согласно лицам, падежам, числам, находится окончание, являющееся изменяющейся частью. Кстати, надо помнить следующее: неизменяемые слова имеют особенность – в них запрещается выделять окончание. Это могут быть имена существительные, которые не склоняются, или наречия. Далее следует выделить основу, иначе говоря, часть конкретного слова без наличия окончания.
Подобрать два или три однокоренных слова и выделить корень, то есть, общую часть слов, которые являются родственными. Выбрать слова с похожей приставкой, выделить ее – она находится перед самым корнем. В завершении требуется подобрать слова с аналогичными суффиксами, выделить суффикс, представляющий собой часть слова, идущую после корня.
Для устного разбора хочется представить образец, который облегчит описанный выше процесс. Например, в слове «подставка» следует отыскать окончание – это буква «а», также, основу – «подставк». Далее находится корень, то есть, производится подбор слов: «ставить», «заставить» и отыскивается часть «став». Приставкой здесь является «под», суффиксом – «к», таким образом, осуществился устный разбор, согласно имеющемуся алгоритму. Данное действие несложно, легко усваивается даже школьниками, если подойти внимательно к каждому представленному выше шагу.
часы поглядеть речник рассчитать соединить испечь опала ночевать объедки речонка лимонный компьютер загородка знаменитый ветреный герб предрассветный цилиндр надеяться гора вездеход зарядка хвост гроза комочек участвовать плюшевый научиться налететь искать лето задвижка незабудка награда вытертый половик яблочный загорать негодующий булавка воздушный установить безветренный орфограмма заболеть заехать одиннадцать пианино макушка игра
Основа слова / Морфемный разбор / Справочник по русскому языку для начальной школы
- Главная
- Справочники
- Справочник по русскому языку для начальной школы
- Морфемный разбор
- Основа слова
При разборе слова по составу иногда указывают основу слова, в которой заключено значение конкретного слова. Основу могут составлять приставка, корень и суффикс, т.е. все морфемы, кроме окончания. Основа графически отображается как ̢_______̡
Чтобы найти основу слова, его нужно изменить.
Например:
По числам: книга – книги, написал – написали
По падежам: раскрыл книгу – выписал из книги
По родам: сказочная история – сказочный мир
По лицам: я говорю – он говорит
Если слово изменяется (как в приведенных выше примерах), то часть слова без окончания и составляет его основу.
яблочко — яблочками
Если слово не изменяется, то основу составляет все слово целиком:
далеко, тихо, вправо
Обратите внимание, что у глаголов в прошедшем времени суффикс -л- в основу не входит:
позвала, увидел , сходило
Также у глаголов в неопределённой форме не входит в основу суффикс -ть:
позвать, желтеть
Поделись с друзьями в социальных сетях:
Советуем посмотреть:
Окончание
Корень и однокоренные (родственные) слова
Приставки и их значения
Суффикс
Морфемный разбор
Правило встречается в следующих упражнениях:
3 класс
Упражнение 180,
Канакина, Горецкий, Учебник, часть 1
Упражнение 133,
Полякова, Учебник, часть 1
Упражнение 137,
Полякова, Учебник, часть 1
Упражнение 138,
Полякова, Учебник, часть 1
Упражнение 145,
Полякова, Учебник, часть 1
Упражнение 171,
Полякова, Учебник, часть 1
Упражнение 193,
Полякова, Учебник, часть 1
Упражнение 187,
Бунеев, Бунеева, Пронина, Учебник, часть 1
Упражнение 1,
Бунеев, Бунеева, Пронина, Учебник, часть 2
Упражнение 6,
Исаева, Бунеев, Рабочая тетрадь
4 класс
Упражнение 233,
Канакина, Горецкий, Учебник, часть 2
Упражнение 157,
Канакина, Рабочая тетрадь, часть 2
Упражнение 141,
Полякова, Учебник, часть 1
Упражнение 133,
Полякова, Учебник, часть 2
Упражнение 146,
Полякова, Учебник, часть 2
Упражнение 32,
Бунеев, Бунеева, Пронина, Учебник, часть 1
Упражнение 296,
Бунеев, Бунеева, Пронина, Учебник, часть 2
Упражнение 298,
Бунеев, Бунеева, Пронина, Учебник, часть 2
Упражнение 3,
Исаева, Бунеев, Рабочая тетрадь
Упражнение 710,
Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
5 класс
Упражнение 82,
Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
Упражнение 83,
Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
Упражнение 92,
Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
6 класс
Упражнение 25,
Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 134,
Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 156,
Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 29,
Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 1
© budu5. com, 2021
Пользовательское соглашение
Copyright
ЦСКА: что происходит в клубе
Полагаю, есть смысл прояснить некоторые вещи.
Настроение у нас сейчас невеселое. Не зря опасались предыдущей недели с тремя сложными матчами за семь дней – они не принесли положительных эмоций.
Детальный разбор ситуации у нас впереди. Очевидно, что можно и нужно предъявлять много претензий к работе селекции и к происходящему в клубе в целом. Раньше было ясно и понятно, как все устроено, клубный механизм работал практически без сбоев, как швейцарские часы. Сейчас такого ощущения, увы, нет.
Но при этом в последнее время в болельщицкой среде обсуждается тема, которая на самом деле является заблуждением. Да, летняя селекция оказалась, по сути, провалена. Однако, утверждение, что армейцы якобы «освоили» (или как модно нынче выражаться, «распилили») 30 миллионов евро из бюджета, является заведомо ложным.
Деньги на летнюю трансферную компанию являются коммерческим возвратным кредитом и никакого отношения к ВЭБ.РФ не имеют. Это важная вещь, которую надо понимать. ВЭБ.РФ является мажоритарным владельцем клуба (более 77% акций). Благодаря этому ПФК ЦСКА не имеет долга в районе 300 миллионов долларов за стадион. Но к текущим расходам, в том числе трансферным, ВЭБ.РФ никакого отношения не имеет. Безусловно, ключевые решения по развитию клуба теперь необходимо согласовывать и с руководством ВЭБ.РФ, и это, вполне возможно, усложняет процесс принятия некоторых решений.
Еще один момент, который представляется весьма серьезным. Раньше ЦСКА считался самым закрытым российским клубом – в том смысле, что вся важная информация всегда оставалась внутри. Всевозможные инсайды сыпались из других команд, тогда как армейцы справедливо считались настоящим образцом.
Что происходит сейчас? Различные слухи (порой самые бредовые) вокруг армейцев появляются едва ли не ежедневно, информация уходит, бывшие работники, едва покинув клуб, начинают направо и налево раздавать интервью, рассказывая в том числе внутреннюю кухню. Это, мягко говоря, не выглядит красиво, но людям, похоже, все равно. Весь этот круговорот слухов и разговоров необходимо если не остановить, то хотя бы минимизировать. Еще одна ситуация, в которой надо серьезно разобраться.
Так называемые распространители слухов уже и до Романа Бабаева добрались. Человека, выполняющего огромный объем работы на своей должности, двадцать второй год верой и правдой служащего клубу.
Надо сказать, что такого количества заведомо ложной информации вокруг ЦСКА, сколько ее появилось в различных СМИ за последние пару дней, видеть еще не приходилось.
У клуба сейчас однозначно непростые времена. Кому-то в такой момент хочется специально ударить, и побольнее. Судье Карасеву, например, «убившему» армейцев вместе с коллегами на VAR в полуфинальном матче с «Локомотивом», а уже через четыре дня добавившему к этому весьма странное удаление Ахметова в дерби (ключевые эпизоды матчей против «Локо» и «Спартака» мы подробно обсуждали, не хочется повторяться). Логика ряда судей РПЛ, по всей видимости, такова: у ЦСКА нет такого лобби, как у «Локомотива» и еще некоторых команд, которым они благоволят. Некоторые арбитры уже ничего не стесняются, и даже недавнее отстранение Вилкова их не останавливает.
Любители вбросить инсайдики из той же оперы. Пора бы внутри клуба уже сделать выводы, как следует закрутить гайки, выяснить, откуда утекает информация и серьезно наказать виновных. Иначе этот бардак будет продолжаться.
Фото: pfc-cska.com
Что значит разобрать слово по составу?
Разбор слова по его составу означает разделение слова на префикс, корень, суффикс, окончание. Инчай, слово разбирается на составные части. Есть те, которые остались без изменений. Есть те, которые могут измениться (например, конец).
Это означает найти (определить) морфему слова. Как правило, это:
- Root;
- Префикс;
- Суффикс;
- Окончание;
- База.
Каждая часть речи может иметь свои особенности выбора морфем.
Удобнее всего находить их именно в таком порядке.
Разобрать слово по составу — это значит найти все части слова (если они есть).
Это может быть префикс, корень, суффикс, окончание. То есть разделите слово на части и дайте каждой части определение. Кроме того, иногда необходимо объяснить, почему именно так разбирается слово.
Разобрать слово по составу — значит определить морфемы слова.
Слово должно быть определено: корень, суффикс, префикс, окончание и основа.
Прежде всего, вам нужно найти корень слова, для этого нужно подобрать корневые слова. Тогда если есть префикс, суффикс и окончание. Обратите внимание, что слово основано на всем слове, кроме окончания.
При разборе слов по составу находим корень слова, для этого выбираем однокорневые слова (они должны иметь один и тот же корень), затем находим префикс перед корнем, затем суффикс после корня, и если есть окончание (бывает, что его нет в слове, ноль) все же в слове есть основа, это все слово, кроме конца
Слова состоят из разных частей, называемых морфемами . Итак, разобрать слово по его составу или произвести морфемный разбор слова — значит выделить корень слова (неизменную часть слова), затем префикс — если перед корнем стоит суффикс и окончание ( он может быть нулевым), и основание слова. Некоторые части могут отсутствовать в зависимости от слова.
Анализировать слово в соответствии с его составом означает выделять все его минимально значимые части (морфемы), как словоизменительные, так и словообразовательные. После разбора слова вы должны были выделить окончание, основу, корень и префикс с суффиксом, если таковой имеется.
Чтобы разобрать слово по составу, это означает провести морфемный анализ слова. Если я не изменяю свою память, сначала мне нужно найти конец слова, затем префикс, затем суффикс и самый конец корня.
В правописании есть такое значение, как морфема — наименьшая значимая часть слова. К ним относятся префикс, корень, суффикс, окончание. Анализировать слово по составу — значит проводить его морфемный анализ, то есть в этом слове необходимо выделить, из каких частей оно состоит.
Разберите слово по составу или проведите морфемный анализ средства слова :
Определите основу слова, выберите префикс (если есть), корень слова, суффикс (если есть) , концовка (если есть).
Слово, которое нужно разобрать по составу, следует изменить в соответствии с падежами, полом, лицами, числами, а однокоренные формы помогут определить окончания.
%! PS-Adobe-2.0
%% Создатель: dvips (k) 5.95a Авторское право 2005 Radical Eye Software
%% Название: bilexical.dvi
%% Страниц: 33
%% PageOrder: Ascend
%% BoundingBox: 0 0595 842
%% DocumentFonts: Times-Roman Times-Bold Times-Italic CMSY8 Helvetica
%% + CMTT10 Courier-Oblique CMR8 CMMI9 CMR9 CMR6 CMSY6 CMMI10 CMR10
%% + CMSY10 CMCSC10 CMMI8 CMMIB10 CMBX12 CMBX8 CMSY9 CMMI6 CMMI5 CMR5
%% + CMSY5 CMSY7 CMEX10
%% DocumentPaperSizes: a4
%% EndComments
% DVIPSWebPage: (www.radicaleye.com)
% DVIPSCommandLine: dvips bilexical.dvi
% DVIPS Параметры: dpi = 600
% DVIPS Источник: выпуск TeX, 2006 г. 10,17: 0133
%% BeginProcSet: tex.pro 0 0
%!
/ TeXDict 300 dict def Начало TeXDict / N {def} def / B {привязка def} N / S {exch} N / X {S
N} B / A {dup} B / TR {translate} N / isls false N / vsize 11 72 mul N / hsize 8,5 72
mul N / landplus90 {false} def / @ rigin {isls {[0 landplus90 {1 -1} {- 1 1} ifelse 0
0 0] concat} if 72 Resolution div 72 VResolution div neg scale isls {
landplus90 {VResolution 72 div vsize mul 0 exch} {Разрешение -72 div hsize
mul 0} ifelse TR}, если разрешение VResolution vsize -72 div 1 add mul TR [
матрица currentmatrix {A Раунд суб абс 0.00001 lt {round} if} на весь раунд
exch round exch] setmatrix} N / @ landscape {/ isls true N} B / @ manualfeed {
statusdict / manualfeed true put} B / @ копий {/ # копий X} B / FMat [1 0 0 -1 0 0]
N / FBB [0 0 0 0] N / nn 0 N / IEn 0 N / ctr 0 N / df-tail {/ nn 8 dict N nn begin
/ FontType 3 N / FontMatrix fntrx N / FontBBox FBB N строка / базовый массив X
/ BitMaps X / BuildChar {CharBuilder} N / Кодирование IEn N конец A {/ foo setfont} 2
array copy cvx N load 0 nn put / ctr 0 N [} B / sf 0 N / df {/ sf 1 N / fntrx FMat N
df-tail} B / dfs {div / sf X / fntrx [sf 0 0 sf neg 0 0] N df-tail} B / E {pop nn A
definefont setfont} B / Cw {Cd A length 5 sub get} B / Ch {Cd A length 4 sub get
} B / Cx {128 Cd Субъект длиной 3, получить суб} B / Cy {Cd, субподряд длиной 2, получить 127 суб}
B / Cdx {Cd A length 1 sub get} B / Ci {Cd A type / stringtype ne {ctr get / ctr ctr
1 добавить N} if} B / CharBuilder {сохранить 3 1 ролл S A / base получить 2 индекса получить S
/ BitMaps get S get / Cd X pop / ctr 0 N Cdx 0 Cx Cy Ch sub Cx Cw add Cy
setcachedevice Cw Ch true [1 0 0 -1 -. 1 Cx sub Cy .1 sub] {Ci} маска изображения
restore} B / D {/ cc X Тип / строка типа ne {]} if nn / base get cc ctr put nn
/ BitMaps получить S ctr S sf 1 ne {A A length 1 sub A 2 index S get sf div put
} if put / ctr ctr 1 add N} B / I {cc 1 add D} B / bop {userdict / bop-hook known {
bop-hook} if / SI save N @rigin 0 0 moveto / V матрица currentmatrix A 1 получить A
mul exch 0 get A mul add .99 lt {/ QV} {/ RV} ifelse load def pop pop} N / eop {
SI восстановить userdict / eop-hook известно {eop-hook} if showpage} N / @ start {
userdict / start-hook известно {start-hook} if pop / VResolution X / Resolution X
1000 div / DVImag X / IEn 256 массив N 2 строка 0 1 255 {IEn S A 360 добавить 36 4
index cvrs cvn put} для pop 65781.76 дел / размер X 65781,76 дел / размер X} N
/ p {show} N / RMat [1 0 0 -1 0 0] N / BDot 260 string N / Rx 0 N / Ry 0 N / V {} B / RV / v {
/ Ry X / Rx X V} B statusdict begin / product where {pop false [(Display) (NeXT)
(LaserWriter 16/600)] {A length product length le {A length product exch 0
exch getinterval eq {pop true exit} if} {pop} ifelse} forall} {false} ifelse
end {{gsave TR -. 1 .1 TR 1 1 масштаб Rx Ry false RMat {BDot} маска изображения
grestore}} {{gsave TR -.1 .1 TR Rx Ry scale 1 1 false RMat {BDot}
imagemask grestore}} ifelse B / QV {gsave newpath transform round exch round
обменять его преобразовать переместить в Rx 0 rlinto 0 Ry neg rlineto Rx neg 0 rlineto
заполнить grestore} B / a {moveto} B / delta 0 N / tail {A / delta X 0 rmoveto} B / M {S p
delta add tail} B / b {S p tail} B / c {-4 M} B / d {-3 M} B / e {-2 M} B / f {-1 M} B / g {0 M }
B / h {1 M} B / i {2 M} B / j {3 M} B / k {4 M} B / w {0 rmoveto} B / l {p -4 w} B / m {p — 3 w} B / n {
p -2 w} B / o {p -1 w} B / q {p 1 w} B / r {p 2 w} B / s {p 3 w} B / t {p 4 w} B / x { 0 ю.ш.
rmoveto} B / y {3 2 roll p a} B / bos {/ SS save N} B / eos {SS restore} B end
%% EndProcSet
%% BeginProcSet: texnansi.enc 0 0
% @psencodingfile {
% author = «Y&Y, Inc.»,
% version = «1.1»,
% date = «1 декабря 1996 г.»,
% filename = «texnansi.enc»,
% email = «[email protected]»,
% address = «45 Walden Street // Concord, MA 01742, США»,
% codetable = «ISO / ASCII»,
% контрольная сумма = «хх»,
% docstring = «Кодирование шрифтов в формате Adobe Type 1 для использования с TeX. »
%}
%
% Идея состоит в том, чтобы все 228 символов обычно включались в текст типа 1.
% шрифтов (плюс еще несколько), доступных для набора. Это эффективно
% набор символов в Adobe Standard Encoding, ISO Latin 1 и еще несколько.%
% Присвоение кодов символов происходило следующим образом:
%
% (1) Раскладка символов в основном соответствует `ASCII ‘в диапазоне от 32 до 126,
%, за исключением «циркумфлекса» в 94 и «тильды» в 126, для соответствия «тексту TeX»
% (asciicircumflex и asciitilde вместо этого появляются в 158 и 142).
%
% (2) Раскладка символов почти во всех местах соответствует `Windows ANSI ‘,
%, за исключением `quoteright ‘в 39 и` quoteleft’ в 96 для соответствия ASCII
% (вместо кавычек и grave в 129 и 18).
%
% (3) Раскладка символов соответствует `пишущей машинке TeX ‘, используемой текстовыми шрифтами CM
% в большинстве мест (за исключением диссонирующих позиций, таких как хунгарумлаут
% (вместо скобки), точка акцента (вместо подчеркивания) и т. д.%
% (4) Остальные символы произвольно назначаются «управляющему символу»
% диапазона (0-31), избегая 0, 9, 10 и 13 в случае, если мы встретим глупое программное обеспечение
% — точно так же следует избегать 127 и 128, если это возможно.
% Кроме того, в Windows используются 8 открытых слотов ANSI от 128 до 159.
%
% (5) Y&Y Lucida Bright включает некоторые дополнительные лигатуры и тому подобное; ff, ffi, ffl,
% и dotlessj, это 11-15 и 17.
%
% (6) Дефис появляется как на 45, так и на 173 для совместимости с обоими ASCII.
% и Windows ANSI.%
% (7) На самом деле не имеет значения, где появляются лигатуры (обе настоящие, например, ffi,
% и псевдо, например —), поскольку к ним нельзя обращаться напрямую, а только
% через информацию о лигатуре в файле TFM.
%
% ОБРАЗЕЦ ИСПОЛЬЗОВАНИЯ (в файле `psfonts.map ‘для DVIPS):
%
% lbr LucidaBright «TeXnANSIEncoding ReEncodeFont») 25 b (i;) 15 b (i) p FA (\ 226) p Fv (j) 28 b FA (is) 22 b (an) h (край) p
Ft (i) g FA (\ (упорядочено) h (by) 548 1398 y (увеличивается) i Fv (j) 5
b FA (\).) 648 1506 y (T) m (обычно) -6 b (,) 37 b (the) 32
b (ребра) i (из) e (a) g (связь) i (являются) f (помечены) h (с) e (названы) h
(грамматический) 548 1614 г (род.) 41 b (In) 25 b (this) h (корпус,) h
Fv (`) 1421 1628 y Fp (w) 1472 1638 y Fj (i) 1526 1614 y FA (следует) g (принять) g
(the) f (последовательность) i (of) d (пар) h Ft (h) p Fu (\ () p Fv (w) 2980
1628 y Fp (j) 3018 1614 y Fv (;) 15 b (R) q Fu (\)) 29 b (:) f
Fv (j) 35 b (
8.
1.2 Построение деревьев синтаксического анализа
8.1.2 Построение деревьев синтаксического анализа
До сих пор программы, которые мы обсуждали, могли распознавать грамматическую структуру (то есть они могли правильно отвечать « да » или « нет » на вопрос, был ли введен предложением, существительной фразой и т. д.) и на сгенерировать грамматический вывод .Это приятно, но мы также хотели бы иметь возможность анализировать . То есть мы хотели бы, чтобы наши программы не только сообщали нам , какие предложений являются грамматическими, но также давали нам анализ их структуры. В частности, мы хотели бы видеть деревья, которые грамматика присваивает предложениям.
Ну, используя только стандартный инструмент Пролога, мы не можем нарисовать красивые изображения деревьев, но мы, , можем построить структуры данных, которые ясно описывают деревья. Например, для дерева
мы могли бы иметь следующий член:
s (np (det (a), n (женщина)), vp (v (стреляет))).
Конечно: выглядит не так хорошо, как , но вся информация на картинке есть. И с помощью приличного графического пакета можно было бы легко превратить этот термин в картинку.
Но как заставить DCG создавать такие условия? На самом деле это довольно просто. В конце концов, при распознавании предложения DCG должен определить древовидную структуру. Поэтому нам просто нужно найти способ отслеживать структуру, которую находит DCG. Мы делаем это, добавляя дополнительные аргументы.Вот как это происходит:
s (s (NP, VP)) -> np (NP), vp (VP).np (np (DET, N)) -> det (DET), n (N).
вп (вп (В, НП)) -> v (В), НП (НП).
вп (vp (V)) -> v (V).det (det (the)) -> [the].
det (det (a)) -> [a].n (n (женщина)) -> [женщина].
n (n (мужчина)) -> [мужчина].v (v (стреляет)) -> [стреляет].
Что здесь происходит? По сути, мы строим деревья синтаксического анализа для синтаксических категорий в левой части правил из деревьев синтаксического анализа для синтаксических категорий в правой части правил. Рассмотрим правило vp (vp (V, NP)) -> v (V), np (NP) . Когда мы делаем запрос с использованием этого DCG, экземпляры V в v (V) и NP в np (NP) будут созданы для терминов, представляющих деревья синтаксического анализа. Например, возможно, V будет создан для
v (Shoots)
, а NP будет создан для
np (det (a), n (женщина)).
Какой термин соответствует vp, состоящему из этих двух структур? Очевидно, это должно быть так:
vp (v (стреляет), np (det (a), n (женщина))).
И именно это дает нам дополнительный аргумент vp (V, NP) в правиле vp (vp (V, NP)) -> v (V), np (NP) : он образует терм, функтор которого равен vp , а его первый и второй аргументы являются значениями V и NP соответственно. Выражаясь неформально: он объединяет термины V и NP вместе под функтором vp .
Чтобы разобрать предложение «Женщина стреляет», мы задаем запрос:
s (T, [a, женщина, стреляет], []).
То есть мы запрашиваем, чтобы дополнительный аргумент T был создан для дерева синтаксического анализа для предложения. И мы получаем:
T = s (np (det (a), n (woman)), vp (v (Shoots)))
yes
Кроме того, мы можем сгенерировать все деревья синтаксического анализа, выполнив следующий запрос :
с (T, S, []).
Первые три ответа:
T = s (np (det (the), n (женщина)), vp (v (стреляет), np (det (the), n (женщина))))
S = [женщина, стреляет, женщина];T = s (np (det (the), n (женщина)), vp (v (стреляет), np (det (the), n (мужчина))))
S = [the, женщина, стреляет, тот человек] ;T = s (np (det (the), n (женщина)), vp (v (стреляет), np (det (a), n (женщина))))
S = [the, женщина, стреляет, a, женщина]
Этот код следует внимательно изучить: это классический пример построения структуры с использованием унификации.
Дополнительные аргументы также могут использоваться для построения семантических представлений . Мы ничего не сказали о том, что означают слова в нашем маленьком DCG. Фактически, в настоящее время много известно о семантике естественных языков, и удивительно легко построить семантические представления, которые частично отражают значение предложений или целых дискурсов. Такие представления обычно являются выражениями некоторого формального языка (например, логики первого порядка, структур представления дискурса или языка запросов к базе данных), и они обычно построены композиционно .То есть значение каждого слова выражается на формальном языке; это значение дается как дополнительный аргумент в записях DCG для отдельных слов. Затем для каждого правила грамматики дополнительный аргумент показывает, как объединить значения двух подкомпонентов. Например, к правилу s -> np, vp мы должны добавить дополнительный аргумент, указывающий, как объединить значение np и значение vp , чтобы сформировать значение s .
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
How to pronounce «phenomenon» in English?
How to pronounce «often» in English?
How to pronounce «pyruvate» in English?
How to pronounce «entrepreneur» in English?
How to pronounce «non-repudiation» in English?
How to pronounce «ontology» in English?
How to pronounce «Streptococcus pneumoniae» in English?
How to pronounce «cytokinesis» in English?
How to pronounce «ubiquitin» in English?
How to pronounce «proteasome» in English?
Какой корень в слове «ПРАЗДНИК»?
Чтобы определить корень в слове «праздник», подберем родственные слова и выделим в них общую часть, в которой заключено их основное лексическое значение.
Чтобы понять, какой корень в слове «праздник», выполним морфемный разбор, но сначала поинтересуемся значением и происхождением слова.
Значение слова «праздник»
Слово «праздник» заимствовано из старославянского языка. Это существительное было когда-то давным-давно образовано с помощью суффикса -ик- от прилагательного «праздный», то есть свободный от работы. Но затем произошло сращение суффикса с корнем данного существительного, и оно стало обозначать не просто свободный день от работы, а день, посвященный какому-то событию:
- День или дни торжества, установленные в честь или в память какого-л. события (исторического, гражданского или религиозного).
- Официально установленный общий день или несколько дней отдыха по случаю таких торжеств (противоп.: будни).
- перен. Веселье, торжество, устраиваемое кем-л. по какому-л. поводу.
- перен. Счастливый, радостный день, ознаменованный каким-л. событием//Само такое событие.
- перен. разг. Испытываемое от чего-л. наслаждение, приятное, радостное чувство//Источник такого наслаждения, такой радости.
Ефремова Т. Ф. Новый словарь русского языка. Толково-словообразовательный. М., Русский язык, 2000
Как видим, у этого слова сформировались свое самостоятельное лексическое значение по сравнению с исходным прилагательным «праздный».
Морфемный состав слова «праздник»
Разбор слова по составу начнем с выделения словоизменительной морфемы — окончания.
В современном русском языке все слово представляет собой корень с нулевым окончанием, которое имеет любое существительное мужского рода второго склонения.
Правильность выделения нулевого окончания докажут падежные формы рассматриваемого существительного мужского рода. Сравним формы этого слова:
- начало (чего?) праздника;
- интересуюсь (чем?) праздником;
- расскажу (о чём?) о празднике
Окончание не включаем в основу слова:
праздник —
В современном русском языке это слово больше не делится на значимые части. Чтобы окончательно убедиться в этом и правильно определить границы корня анализируемого существительного, рассмотрим морфемный состав родственных слов:
праздничный — корень/суффикс/окончание;
предпраздничный — приставка/корень/суффикс/окончание;
праздничность — корень/суффикс/суффикс/окончание;
празднично — корень/суффикс/суффикс.
Итог
Как видим, общей частью, в которой заключено лексическое значение родственных слов, является морфема праздник-/празднич-, что и будет являться их корнем.
Корень в слове «праздник» — это минимальная значимая часть праздник-, в которой заключено лексическое значение родственных слов.
Запишем морфемный состав рассматриваемого существительного в виде следующей схемы:
праздник — корень/окончание.
Скачать статью: PDFМорфемный разбор слова ОТДАЮТСЯ
Каждое слово состоит из нескольких частей. Основой любого слова является корень. Именно он задает смысловое значение слова. Поэтому, существуют слова, состоящие только из одного корня. Это начальная форма слова, являющаяся наиболее простой. В иных формах слова к корню добавляются приставки, окончания, суффиксы. Они меняют форму слова и придают ему иной смысловой оттенок.
Выполнить морфемный разбор слова
Морфемный разбор слова представляет собой вычленение из слова его отдельных частей. То есть, при морфемном разборе из слова выделяется приставка, корень, суффиксы, окончания. Можно продемонстрировать морфемный разбор слова на примере слова «отдаются»:
- Указанное слово имеет приставку. Она представлена формой «от»;
- Корень представлен формой «да». Это производная форма от «дать». Следовательно, слово означает передаче чего-либо, то есть направленное действие;
- В указанном слове имеется суффикс. Это «ют». В данном слове есть и постфикс, то есть форма слова, которая проставляется после суффикса. Постфикс представлен формой «ся». То есть, в слове имеется одновременно суффикс и постфикс, но не окончания.
Именно в таком виде следует представить морфемный разбор слова «отдаются». По представленному алгоритму осуществляется морфемный разбор любого иного слова.
Зачем нужен морфемный разбор
Морфемный разбор позволяет выявить все части слова. Они отделяются друг от друга. В частности, становится очевидным корень слова. Это позволяет подбирать однокоренные слова и синонимы. Ведь вычленение корня, отделение его от других частей слова позволяет понять его значение. ведь именно корень представляет собой смысловую основу любого слова.
Кроме того, морфемный разбор дает возможность понять, какие суффиксы или приставки есть в слове. Это важно для правильного написания. Ведь понимание структуры слова позволяет применять к нему те или иные правила русского языка при написании. Таким образом, морфемный разбор слова необходим для правильного написания, понимания тех правил, согласно которым происходит такое написание слова.
«болеть» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание). «боль» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание) Боль больной больница болеть выделить корень
§ 1 Корень слова
В начале нашего занятия вспомним, что свои мысли и чувства мы выражаем с помощью речи. Речь бывает письменной, когда записываем, и устной, когда говорим губами-устами. Любая речь состоит из предложений. Предложение выражает законченную мысль и состоит из слов. Слова в предложении связаны друг с другом по смыслу — «дружат».
Слова могут дружить между собой не только в предложении, но и по принципу общих, родственных интересов. Так, ученый дружит с учеником, потому что у них есть общий интерес — ученье. И такие слова, с общими интересами, называют родственными, или однокоренными словами.
Ученые языковеды решили, что в однокоренных, родственных словах следует выделять общую часть — корень — специальным значком, который так и называют «корень слова». Иногда, из-за формы, его ещё называют дужкой.
Корень — значимая часть слова, поскольку в нем заключено общее значение всех однокоренных, родственных слов. Например, в словах больной и больница корень «боль», так как больной — это человек, испытывающий боль, а больница — это место, где лечат боль.
Настолько сдружились однокоренные слова, что стали друг другу родными, родственными. Конечно, захотели быть похожими друг на друга и всем громко заявили: во всех однокоренных словах общая часть — корень — пишется одинаково, единообразно.
Как и в любой семье, среди однокоренных слов есть непослушные детки, которые не хотят быть как все и поэтому всех путают. Например, в слове домово́й в безударном корне слышится звук [а]. Однако стоит нам подобрать однокоренное слово с ударным корнем — до́мик — то сразу становится понятно, что следует писать в корне слова букву о.
Значит, чтобы проверить безударную гласную в корне слова, следует подобрать однокоренное слово так, чтобы безударный стал ударным звуком.
§ 2 Краткие итоги по теме урока
Корень — значимая часть слова, в нем содержится общее значение всех однокоренных, родственных слов.
Для того, чтобы проверить безударную гласную в корне слова, следует подобрать однокоренное слово так, чтобы безударный стал ударным звуком, поскольку во всех однокоренных словах общая часть — корень — пишется одинаково.
Список использованной литературы:
- А.В. Венцов. Словарь омографов русского языка // Изд. СПбГУ, Санкт-Петербург, 2004.
- Азбука от А до Я: иллюстрированное учебно-методическое пособие \Сост.И.А.Гимпель. Минск: Асар, 2004.
- Львов М.В.Методика развития речи младших школьников. М.: АСТ; Астрель, 2003.
- Розенталь Д.Э., Джанджакова Е.В., Кабанова Н.П. Справочник по правописанию, произношению, литературному редактированию. М.: 1999.
- Сухин И.Г., Яценко И.Ф. Азбучные инры. 1 кл. М.: Вако, 2010.
- Я иду на урок в начальную школу. Чтение: книга для учителя. М., 2000.
Использованные изображения:
бол е ть
Разбор слова по составу.
Состав слова «болеть»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова болеть
болетьПодробный paзбop cлoва болеть пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa болеть, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: бол/е/ть
- Структура слова по морфемам: корень/суффикс/суффикс
- Схема (конструкция) слова болеть по составу: корень бол + суффикс е + суффикс ть
- Список морфем в слове болеть:
- бол — корень
- е — суффикс
- ть — суффикс
- Bиды мopфeм и их количество в слове болеть:
- пpиcтaвкa: отсутствует — 0
- кopeнь: бол — 1
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: е,ть — 2
- пocтфикc: отсутствует — 0
- oкoнчaниe: нулевое окончание. — 0
Bceгo морфем в cлoвe: 3.
Словообразовательный разбор слова болеть
- Основа слова: боле ;
- Словообразовательные аффиксы: приставка отсутствует , суффикс е,ть , постфикс отсутствует ;
- Словообразование: ○ суффиксальный ;
- Способ образования: производное, так как образовано 1 (одним) способом .
См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову болеть
Полный морфологический разбор слова «болеть»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор болеть
Ударение в слове болеть: на какой слог падает ударение и как… Слово «болеть» правильно пишется как… Ударение в слове болеть
Синонимы «болеть». Словарь синонимов онлайн: подобрать синонимы к слову «болеть». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову болеть
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову болеть
Анаграммы (составить анаграмму) к слову болеть, с помощью перемешивания букв…. Анаграммы к слову болеть
Морфемный разбор слова болеть
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова болеть делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для болеть (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.Схема разбора по составу боль:
боль
Разбор слова по составу.
Состав слова «боль»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова боль
Подробный paзбop cлoва боль пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa боль, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: боль/
- Структура слова по морфемам: корень/окончание
- Схема (конструкция) слова боль по составу: корень боль + окончание нулевое окончание
- Список морфем в слове боль:
- боль — корень
- нулевое окончание — окончание
- Bиды мopфeм и их количество в слове боль:
- пpиcтaвкa: отсутствует — 0
- кopeнь: боль — 1
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: отсутствует — 0
- пocтфикc: отсутствует — 0
- oкoнчaниe: нулевое окончание. — 1
Bceгo морфем в cлoвe: 2.
Словообразовательный разбор слова боль
- Основа слова: боль ;
- Словообразовательные аффиксы: приставка отсутствует , суффикс отсутствует , постфикс отсутствует ;
- Словообразование: или непроизводное, то есть не образовано от другого однокоренного слова; или образовано бессуффиксальным способом: отсечением суффикса от основы прилагательного либо глагола ;
- Способ образования:
или непроизводное, то есть не образовано от другого однокоренного слова; или образовано бессуффиксальным способом: отсечением суффикса от основы прилагательного либо глагола
.
См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову боль
Примеры слов руского языка с корнем «боль». Полный список по частям речи: существительные, прилагательные, глаголы… Слова с корнем боль
Просклонять слово боль по падежам в единственном и множественном числе…. Склонение слова боль по падежам
Полный морфологический разбор слова «боль»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор боль
Ударение в слове боль: на какой слог падает ударение и как… Слово «боль» правильно пишется как… Ударение в слове боль
Синонимы «боль». Словарь синонимов онлайн: подобрать синонимы к слову «боль». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову боль
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову боль
Анаграммы (составить анаграмму) к слову боль, с помощью перемешивания букв…. Анаграммы к слову боль
К чему снится боль — толкование снов, узнайте бесплатно в нашем соннике что означает сон боль. … Увиденный во сне боль означает, что…Сонник: к чему снится боль
Морфемный разбор слова боль
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова боль делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для боль (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.Причины, породившие боль, могут быть самыми разными.
Но каковы бы ни были болевые проявления, их роднит одно обстоятельство — присутствие корня боли.
Когда боль появляется, она еще не имеет глубинной основы в тканях и органах.
Она возникает как функциональное нарушение.
Но с момента появления боль формирует питающий корень . Как это происходит?
Начало боли может быть сопряжено с незначительными в масштабах организма функциональными изменениями. Как часто бывает: кольнуло, резануло и прошло. Хорошо, если человек не заостряет своего внимания на этом малозначительном событии. Кольнуло, поморщился, забыл.
Чаще бывает по-другому — кольнуло, поморщился, задумался: а чего это там такое кольнуло? Общий негативный настрой заставит насторожиться, прислушаться к себе. Человек с позитивным внутренним настроем попросту не обратит внимания на боль или тут же забудет про нее.
В обыденной жизни большинство из нас, как правило, не обращает внимания на свои тонкие ощущения. А напрасно. Информативность их очень высока. Если бы мы умело пользовались тонкими ощущениями, доверяли им, то могли бы избежать многих неприятностей, встретить сложные ситуации во всеоружии.
Но вернемся к боли.
Когда мы начинаем слушать себя, свои ощущения, мы фиксируем внимание на малейших изменениях в самочувствии и тем усиливаем их. Психофизиология такого странного взаимодействия описана в учебниках академической медицины. А вот психоэнергетика толком не исследована. Отчего усиливается боль, ухудшается самочувствие?
Дело в том, что простое сосредоточение внимания на каком-то участке тела или внутреннем органе меняет энергетику и начинается активный забор энергии извне. Концентрация внимания, словно магнитом, притягивает энергию к точке сосредоточения.
Но мы фиксируем внимание на ощущении боли, поэтому боль и получает дополнительный энергетический импульс. Когда бы мы концентрировали внимание на том, как боль уходит, затухает, в больном месте появляется чувство комфорта, то энергетическую подпитку получали бы позитивные процессы противодействия боли.
К сожалению, большинство людей, испытав боль, внимательно слушают свои ощущения и ждут нового ее всплеска. Ожидание определяет ее появление. Возникнув в какой-то внутренней структуре, болевые ощущения сразу же начинают закрепляться, формируя энергетические корни, пронизывая ими окружающие ткани.
Можно подумать, что боль — это самостоятельное, разумное начало, которое ищет возможности своего усиления. Нет, конечно! Работает механизм заполнения пустот.
Если боль появляется в организме, да еще подкрепляется вниманием человека, она начинает расширять сферу своего влияния. Если начальный очаг небольшой, возникший спонтанно, то внимание человека притянет импульс силы и очаг укрепится. Далее он начинает оттягивать энергию от окружающих органов и тканей. Возникшая энергетическая пустота тут же заполняется самой болью или ее пока непроявленными вибрациями.
По собственному опыту мы знаем, что боль нередко имеет четкую локализацию. Ярко выраженное ее ядро окружено своеобразным «ореолом», облаком менее интенсивных болевых ощущений. От ядра к периферии боль сглаживается, затихает и на достаточном удалении от него не чувствуется вообще.
Это не значит, что там, где боли нет, все в порядке. Там она пока не проявилась. Вообще всякая боль имеет тенденцию к накоплению. Если с ней не бороться, то скоро она распространится на все внутреннее пространство тела.
Кроме феномена заполнения энергетической пустоты действует эффект обмена клеточной информацией. Словом, если детально анализировать и описывать боль как многообразное явление, стремящееся к глобальному охвату всего организма, то получится отдельная книга. Наша задача более конкретна: научиться локализовать боль, сжимать ее в небольшой узел и удалять из организма.
Накопление боли происходит на энергоинформационном уровне межклеточного обмена. И если ее не остановить, то она, как компьютерный вирус, внедрится во все доступные информационные и программные блоки физиологических структур.
В быту с болью борются различными способами.
В основном это обезболивающие химические лекарства или народные болеутоляющие средства. Арсенал лекарств и средств народной медицины широк и многообразен. Но большинство из них останавливает боль, воздвигает на пути ее распространения барьер. Подобное воздействие можно сравнить с двумя встречными пожарами. Они гудящими стенами огня идут навстречу друг другу, сталкиваются и гаснут. Вот только искры разлетаются во все стороны, а после огня остается выжженная земля.
Так и после боли требуется время, чтобы восстановить нормальную работоспособность органов, тканей и систем организма. А уж болевая информация (по аналогии — «искры от пожаров») может проявиться где угодно. Скажем, болит голова. А где корни? Откуда боль берет свое начало, что послужило ее причиной? И если принять болеутоляющее, какова будет реакция организма после того, как боль исчезнет? Вопросов много, и практика отвечает на них.
Любые внешние боли имеют в основе своей нарушения деятельности внутренних органов. А когда болевые ощущения нейтрализуются какими-то средствами, но при этом причина и корень боли остаются нетронутыми, то организм реагирует сосудистыми нарушениями, какими-то системными расстройствами и т. п.
Житейский опыт подсказывает, что боль нужно убирать любыми путями, а не терпеть ее или тем более принимать и считать, что это наказание за грехи. Однако убирать ее можно по-разному. О вероятных последствиях нейтрализации боли с помощью лекарств мы уже говорили. В главе, посвященной работе с кольцами, мы давали описание воздействия на очаги боли при помощи фокусирующих энергетических колец.
В дополнение к этим приемам опишем еще один, с которого, по сути, и нужно начинать всю целительскую практику.
Мы уже говорили, что боль формирует свой корень в тканях организма.
Этот корень нельзя потрогать руками, поскольку он виртуальный и не имеет какого-то анатомического субстрата (конечно, если мы не говорим о язвенных, раневых, травматических и других повреждениях тела).
Кстати, и вышеперечисленные внешние факторы тоже создают свой корень, но он труднее поддается нейтрализации, поскольку раны, язвы и травмы отвлекают внимание на себя и о глубинных внутренних отголосках мы не думаем.
Прием удаления боли прост и не требует особой подготовки .
Нужно научиться удлинять пальцы за счет энергетических лучей. Представляем, что из подушечек пальцев выпускаем энергетические лучи, которыми можем чувствовать и даже воздействовать на организм другого человека.
Для нейтрализации боли и ее удаления из организма энергетические продолжения пальцев медленно вводим в ту зону тела, где проявляется боль. Лучами-пальцами начинаем ощупывать узел боли. Чаще всего мы чувствуем очаг как темное облако, однако же имеющее ясные и заметные границы. Если лучами-пальцами аккуратно ощупывать границы болевого очага, то почувствуем, что от центра к краям плотность болевого образования уменьшается.
Определим границы облака боли, затем лучами-пальцами начнем собирать это облако в небольшой комок. Запускаем энергетические продолжения пальцев под облако боли и словно сворачиваем его.
Представим, что на скатерти следы вчерашнего пиршества. Можно собирать объедки отдельно, а можно просто взять скатерть, заворачивая края вовнутрь, чтобы сор не просыпался, вынести и потом вытряхнуть остатки пира в помойное ведро.
Поступаем так же и с очагом боли. Заворачиваем его края вовнутрь и стягиваем их к центру. Когда облако боли будет собрано в плотный комок, начинаем уминать его. Представляем, как пальцам и лучами плотно прессуем облако боли. Аналогия: — будто разминаем кусочек пластилина.
Потом, когда боль будет собрана в комочек, пальцы-лучи запускаем под него. Скоро появится чувство, что куда-то в глубь тела уходит ниточка, которую мы чувствуем ментальным осязанием. Пройдем по ней и определим, насколько глубоко она проросла в ткани. Если вовремя остановить боль, то ее корень будет небольшой, всего несколько сантиметров. Начинаем ощупывать корень, потягивать его.
Все манипуляции мы выполняем энергетическими продолжениями пальцев. Корень боли обнаружен, пальцами-лучами мы проникли к его кончику и медленно вытягиваем его наружу. Такой корешок выдернуть нелегко. Потребуется усилие не только энергетическое, но и мышечное.
Когда зацепили корень и тянем его, руки напрягаются. Вместе с усилиями мускулов напряженно работают и энергетические лучи. Корень с трудом вытягивается из тканей. Он сопротивляется, упирается, но все-таки поддается. Потом, когда корень уже почти вытащили, нужно зацепить его покрепче и резко выдернуть.
После выдирания корня боли появляется явственное ощущение, что к пальцам и ладоням прилипли комки какой-то невидимой грязи. Сбросим ее. Лучше всего это делать, поставив руки по обе стороны тугой струи холодной воды, бьющей из крана. Поток холодной воды нейтрализует энергетику боли, разрушает ее структуру, захватывает с собой и уносит.
Проведем эксперимент.
Когда мы выдрали корень боли, просто помоем руки под струей воды. Ощущение такое, что на руках жирная пленка. Вода скатывается по коже так, будто руки обильно намазаны кремом. Это материализованное проявление энергетики, эктоплазмы боли. Она имеет сильный структурирующий заряд и не разрушается без дополнительных усилий. А когда мы держим руки по обе стороны тугой струи воды, начинается вихревое взаимодействие вибраций водного потока и энергетики корня боли.
Для усиления очищающего воздействия воды делаем глубокий вдох, а выдох мысленно направляем сквозь руки к ладоням и представляем, что он пронизывает ладони, убирает с них остатки негативной энергетики. Когда появится ощущение, что во время выдоха сквозь руки они словно удлиняются, желаемый эффект достигнут, и мы можем дыханием смывать боль с ладоней.
Можно использовать этот прием не только для выдирания корня боли. Можно тугой комок боли просто сбрасывать с рук, лучше всего в струю воды или в землю. Стряхнем с рук энергетический сгусток боли и несколько раз выдохнем через ладони.
Очень интересна реакция людей, у которых таким образом выдернули боль. Скажем, болит зуб. Человек мается, но пойти к стоматологу мешает страх перед бормашиной или еще какие-то причины. Нужно сразу сказать такому пациенту, что боль уменьшить или убрать можно, но больной зуб должен лечить профессиональный дантист. От кариеса энергетические воздействия, насколько мы знаем, не спасают.
Вводим лучи-пальцы в челюсть и там определяем локализацию боли. Собираем ее в тугой комочек, а потом этот комок выдергиваем и сбрасываем в струю воды. Человек поначалу смотрит на все эти манипуляции с откровенным скепсисом. Но зубная боль такая, что он готов на все, кроме посещения стоматолога. И вот боль собрана и вырвана. Некоторое время еще сохраняется инерция боли и пациент слушает ее.
На лице явственно написано: не помогли вы мне, не справились. Потом боль начинает затихать. Какое это блаженство, когда зубная боль отступает. Ломота в челюсти проходит, перестает дергать и стрелять, голова больше не раскалывается и кажется, что еще немножко и снизойдет благодать.
Выражение лица пациента меняется. На нем тихое умиротворение и в то же время напряженное ожидание нового всплеска боли. Но его нет ни через минуту, ни через две. Когда пациент осознает, что боль отпустила, он счастлив. Но проходит около получаса, и он уже забыл обо всем. Поспешные обещания посетить стоматолога кажутся несерьезными и о них лучше забыть… И так — до следующего всплеска боли.
Эффективность выдирания корня боли и удаления его из организма тем выше, чем точнее целитель соблюдает последовательность этапов и ярко представляет каждый из них.
Н.И.Шерстенников из книги «Заповедник здоровья»
Схема разбора по составу больной:
боль н ой
Разбор слова по составу.
Состав слова «больной»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова больной
больнойПодробный paзбop cлoва больной пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa больной, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: боль/н/ой
- Структура слова по морфемам: корень/суффикс/окончание
- Схема (конструкция) слова больной по составу: корень боль + суффикс н + окончание ой
- Список морфем в слове больной:
- боль — корень
- н — суффикс
- ой — окончание
- Bиды мopфeм и их количество в слове больной:
- пpиcтaвкa: отсутствует — 0
- кopeнь: боль — 1
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: н — 1
- пocтфикc: отсутствует — 0
- oкoнчaниe: ой — 1
Bceгo морфем в cлoвe: 3.
Словообразовательный разбор слова больной
- Основа слова: больн ;
- Словообразовательные аффиксы: приставка отсутствует , суффикс н , постфикс отсутствует ;
- Словообразование: ○ суффиксальный ;
- Способ образования: производное, так как образовано 1 (одним) способом .
См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову больной
Просклонять слово больной по падежам в единственном и множественном числе…. Склонение слова больной по падежам
Полный морфологический разбор слова «больной»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор больной
Ударение в слове больной: на какой слог падает ударение и как… Слово «больной» правильно пишется как… Ударение в слове больной
Синонимы «больной». Словарь синонимов онлайн: подобрать синонимы к слову «больной». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову больной
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову больной
Анаграммы (составить анаграмму) к слову больной, с помощью перемешивания букв…. Анаграммы к слову больной
К чему снится больной — толкование снов, узнайте бесплатно в нашем соннике что означает сон больной. … Увиденный во сне больной означает, что…Сонник: к чему снится больной
Морфемный разбор слова больной
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова больной делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для больной (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.«земля» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание). «земля» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание) См. также в других словарях
Схема разбора по составу земля:
земл я
Разбор слова по составу.
Состав слова «земля»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова земля
земляПодробный paзбop cлoва земля пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa земля, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: земл/я
- Структура слова по морфемам: корень/окончание
- Схема (конструкция) слова земля по составу: корень земл + окончание я
- Список морфем в слове земля:
- земл — корень
- я — окончание
- Bиды мopфeм и их количество в слове земля:
- пpиcтaвкa: отсутствует — 0
- кopeнь: земл — 1
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: отсутствует — 0
- пocтфикc: отсутствует — 0
- oкoнчaниe: я — 1
Bceгo морфем в cлoвe: 2.
Словообразовательный разбор слова земля
- Основа слова: земл ;
- Словообразовательные аффиксы: приставка отсутствует , суффикс отсутствует , постфикс отсутствует ;
- Словообразование: или непроизводное, то есть не образовано от другого однокоренного слова; или образовано бессуффиксальным способом: отсечением суффикса от основы прилагательного либо глагола ;
- Способ образования:
или непроизводное, то есть не образовано от другого однокоренного слова; или образовано бессуффиксальным способом: отсечением суффикса от основы прилагательного либо глагола
.
См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову земля
Просклонять слово земля по падежам в единственном и множественном числе…. Склонение слова земля по падежам
Полный морфологический разбор слова «земля»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор земля
Ударение в слове земля: на какой слог падает ударение и как… Слово «земля» правильно пишется как… Ударение в слове земля
Синонимы «земля». Словарь синонимов онлайн: подобрать синонимы к слову «земля». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову земля
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову земля
Анаграммы (составить анаграмму) к слову земля, с помощью перемешивания букв…. Анаграммы к слову земля
Слово из букв составить анаграмму. Вы ввели буквы «земля», из них можно составить следующие слова от… Составить слова из заданных букв земля
К чему снится земля — толкование снов, узнайте бесплатно в нашем соннике что означает сон земля. … Увиденный во сне земля означает, что…Сонник: к чему снится земля
Морфемный разбор слова земля
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова земля делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для земля (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.земл я
Состав слова «земля» :
корень — [земл] , окончание — [я]
Предложения со словом «земля»
И почудилось вдруг: нет ничего за его спиной, край, обрывается земля , и только тьма стеной, звёзды, вечный холод.
Но вторая рука Рубахина, опустившая автомат на землю , зажала ему и приоткрытый рот с красивыми губами, и нос, чуть трепетавший.
Так, вероятно, старый дуб ощущает свои мозолистые, выпершие из земли корни.
Планер получает достаточно энергии, чтобы оторваться от земли и слететь с холма.
Дедушка снимает с ног чувяки из сыромятной кожи, вытряхивает из них мелкие камушки, землю , потом выволакивает оттуда пучки бархатистой особой альпийской травы, которую для мягкости закладывают в чувяки.
Кроме того, этот же приём позволит вам реже рыхлить и пропалывать землю под кустарниками и цветниками.
Однако сделать это им не удалось: над туннелем стометровый слой льда и земли .
Вот кубанцев, скажем, можно угнать, потому что у них земля голая как ладонь…
Текст этой лекции стал популярен, но Министерство образования одной из земель ФРГ запретило распространять его в университетах.
Разобрать слово по составу, что это значит?
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей. Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
- Найти окончание. Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить в основе приставку (если она есть). Для этого сравнить однокоренные слова с приставками и без.
- Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.
- Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями.
- Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если они есть)
- Перепроверить разбор и значками выделить все значимые части
В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ. У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Порядок полного морфемного разбора по составу
Чтобы избежать ошибок, морфемный разбор предпочтительно связать с разбором словообразовательным. Такой анализ называется формально-смысловым.
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.
Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы — «проспал»;
- два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон — проспать — проспала;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
Как разобрать по составу слово «земля»?
- Именительный падеж (что?) — землЯ;
- Родительный падеж (нет чего?) — землИ;
- Дательный падеж (подошли к чему?) — к землЕ
- Винительный падеж (вижу что?) — землЮ;
- Творительный падеж (доволен чем?) — землЕЙ;
- Предложный падеж (говорили о чем?) — о землЕ.
Разбор по составу (или морфемный разбор) слова ЗЕМЛЯ
Наша Земля одна из планет Солнечной системы.
Земля это существительное женского рода с окончанием Я:
землЯ, землИ, землЕ, землЮ, землЕЙ, землЕ.
Основа слова ЗЕМЛ.
Теперь найдем в слове главную его часть, это корень.
Вспомним однокоренные слова: землянка, земляной, земельный, землекоп, приземлиться.
Значит корнем будет часть слова ЗЕМЛ//земел.
Существительное земля изменяется по падежам и числам:
край земли , подойти к земле , отыскать зе млю, далкие зе мли.
Значит, буквой я выражена словизменительная морфема — окончание.
спе-л-ый, загоре-л-ый?
Чтобы не ошибиться в определении границ корня существительного quot;земляquot;, обратимся за помощью к родственным словам:
землица, земляной, земляк, землячка, землянин, приземлиться.
Как видим, общей частью всех этих слов, связанных единым смыслом, является часть земл-.
Подытожим:
земл-я — корень/окончание.
Земля — это существительное женского рода в единственном числе. Это довольно простое слово и очень известное, тем не менее нужно уметь разбирать и такие.
Чтобы верно найти окончание, нужно просклонять слово: землей, земли, земле. Изменяемая часть и будет окончанием, в данном случае это -я. Соответствует окончанию существительных первого склонения.
Переберем ряд однокоренных слов, чтобы точно знать, как выглядит корень: приземленный, земелька, заземление, земляк, земляной. Не изменяется часть -земл-, а значит это и будет корень. Основа слова выглядит так же — -земл-.
Итого имеем земл/я — корень/окончание.
Слово земля является существительным женского рода, в единственном числе (во множественном числе будет слово — quot;землиquot;), в именительном падеже.
Осуществим морфемный разбор (разбор по составу) слова quot;земляquot;:
Для определения окончания слова выполним склонения слова по падежам:
Итак, в существительном женского рода quot;земляquot; окончанием является -я-.
Подберем несколько однокоренных слов: земельный, земляной, приземлился и тд.
Корнем слова является -земл-.
Основой слова будет -земл-.
Разберем слово:
1) В слове quot;земляquot; приставка отсутствует;
2) Корнем слова quot;земляquot; будет quot;землquot;;
3) В слове quot;земляquot; суффикс отсутствует;
4) Окончанием в слове quot;земляquot; будет: quot;яquot;;
5) Основой слова quot;земляquot; будет: quot;землquot;.
Слово quot;земляquot; является одним из несложных слов для разбора по составу. Ибо имеет всего две морфемы:
—земл — (земляной, земельный, землекоп) корневая морфема,
—я— есть морфема-окончание;
основа слова quot;земля quot; — земл.
Морфемный разбор слова quot;земляquot; начинаем с поисков окончания. Для этого следует просклонять его по падежам таким образом: земля , земли , земле , землю , землей , о земле . Изменяемой частью слова, как видим, является морфема quot;-яquot; , что и будет окончанием. Остальная часть слова представляет собой его основу: quot;земл-quot; . Приставка в слове quot;земляquot; отсутствует, как и суффиксы. А корневой морфемой является часть слова: quot;земл-quot; . Разбор слова quot;земляquot; по составу окончен.
Земля — существительное женского рода, единственного числа, обозначает третью планету от Солнца, почву и территориально-административную единицу Германии.
Морфемный (по составу) разбор слова земля:
корень: земл (проверяем словами земляной, земной, наземный, заземление)
окончание: я
основа: земл
Приставок, суффиксов и постфиксов нет.
Существительное женского рода Земля относится к первому склонению и в его составе следует выделить окончание -Я: Земля-Земли-Земле-Землю-Землей. Однокоренными словами оказываются Земля-Земляной-Земляк-Земельный-Подземный-Подземелье-Редкоземельный. Корнем оказывается морфема ЗЕМЛ-, в которой возможно как чередование согласны- М/МЛ, так и появление беглой гласной Е.
Получаем: ЗЕМЛ-Я (корень-окончание), основа слова ЗЕМЛ-.
Первым шагом при разборе слова по составу нужно изменить его по числам,падежам,лицам затем найти окончание в слове.Второй шаг определяем основу слова.Третий шаг находим корень в слове.Четвртый шаг если есть выделить приставку.Пятый шаг выделить суффикс.
В слове Земля:окончание я,основа слова земл,корень будет тоже земл,приставки не будет,суффикса тоже нету.
морфемный разбор глагола блеснули – «Блестнуть» или «блеснуть», как правильно? – Profil – Community
морфемный разбор глагола блеснули
Для просмотра нажмите на картинку
Читать далее
Смотреть видео
морфемный разбор глагола блеснули
Разбор по составу слова «блеснуть»
Морфологический разбор: блеснули
Морфологический разбор глагола «Блеснули»
морфемный разбор глагола блеснули
Морфологический разбор «блеснули»
«блеснуть» по составу
Разбор слова «блеснули»: для переноса, на слоги, по составу
Разбор по составу слова «блеснули»
«Блестнуть» или «блеснуть», как правильно?
Кусочек жмыха или колобок нужно вложить в петлю поводка и затянуть ее, не допуская надрезания колобка. Утеплены искусственным мехом. Охотники используют лодки на лесных реках и водохранилищах, заросших осокой или камышом. При таком обилие рыбы можно проводить эксперименты с наживками насадками.
Компактная упаковка, легко транспортируется в багажнике автомобиля. Даже биологов удивило то, что хищные рыбы считалось что они питаются мальками питались больше стрекозами, чем мальками. В зависимости от сложности реки и количества собравшихся для приключения участников спуск можно осуществлять на разных плавсредствах. Вы будете получать сто процентов чистого дохода круглый год. Этот выпуск полностью посвящен теме ловли жереха.
Но и слишком мягкими поводки не должны быть. Самодельные длинноволновые радиостанции обеспечивали при ясной погоде вполне устойчивую голосовую связь между всеми островами республики. В первую очередь обращайте внимание на оригинальные фотографии и видеоматериалы.
Когда щука пассивна, приходится прибегать к различным ухищрениям как в используемых силиконовых приманках, так и их монтажах. Однако стоит отметить, что сом очень избирательно относится к характеру звуков, которые издает квок. На буржуйских моторах, пропорции и марки масел тоже разные. Так что мотор хоть и не на всю оставшуюся жизнь брать планируется, но под тот круг задач где он будет самодостаточным. Врубились гитаристы, ударили ритм с ударником во главе.
Разбор по составу блеснули. Самый большой морфемный словарь русского языка: насчитывает разобранных Разбор по составу слова: «блеснули» — форма глагола «блеснуть» [мн.ч., действ.
Разбор по составу слова «блеснули». Состав слова «блеснули»: корень [блес] + суффикс [ну] + суффикс [л] + окончание [и] Основа(ы) слова: блеснул Способ образования слова: суффиксальный. Если варианты разбора выше не подошли Обратите внимание: разбор слова вычисляется алгоритмически, поэтому может быть недостоверным. Помните, что вы используете результаты на свой страх и риск. Смотрите также: Фонетический разбор слова «блеснули». Морфологический разбор (по составу) слова «блеснули». Морфемный (по составу).
Разбор по составу слова блеснули. морфемный морфологический фонетический. Состав слова «блеснули»: корень [блес] + суффикс [ну] + суффикс [л] + окончание [и] Основа(ы) слова: блеснул Способ образования слова: суффиксальный. Дополнительные варианты разбора. Примите во внимание: разбор слова «блеснули» по составу определён по специальному алгоритму с минимальным участием человека и может быть неточным. В слове выделен корень, приставка, суффикс, окончание, указан способ образования слова.
Разбор слова «блеснули»: для переноса, на слоги, по составу. Объяснение правил деление (разбивки) слова «блеснули» на слоги для переноса. Онлайн словарь поможет: фонетический и морфологический разобрать слово «блеснули» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «блеснули». Слоги в слове «блеснули» деление на слоги. Количество слогов: 3 По слогам: бле-сну-ли. По правилам школьной программы слово «блеснули» можно поделить на слоги разными способами.
Разбор по составу слова БЛЕСНУТЬ: блес/ну/ть. Предложения со словом «блеснуть».
Приставки нет, корень блес, суффиксы ну , л, окончание и. Полная статья про слово блеснули. Разбор слова «блеснули» по составу выполнен искусственным интеллектом и может содержать неточности.
Разбор по составу слова «блеснуть». Сходные по морфемному строению слова. Делаем Карту слов лучше вместе.
Морфологический разбор «блеснули» с выделением части речи, постоянных иначальная форма: блеснуть (инфинитив)постоянные признаки: 1-е спряжение, непереходный, совершенный вид.
Глагол «блеснуть» с суффиксом -ну- в его морфемном составе (это опознавательный знак) нельзя проверить словами «блестеть, блёстки». Учтем, что в этих словах сохранился исторический суффикс -ст-, который со временем стал частью корня. блеснуть — корень/суффикс/окончание. Безударный гласный проверяют ударением, изменяя грамматическую форму слова или подбирая однокоренные слова, чтобы ударение прояснило сомнительный гласный.
Морфологический разбор – это подробное описание слова как части речи с указанием всех имеющихся у него признаков (постоянных и непостоянных). Данный вид языкового анализа позволяет закрепить и систематизировать имеющиеся знания по морфологии. Порядок морфологического разбора. Выполнить этот вид разбора несложно. Для этого нужно знать общие принципы подобного анализа и порядок его выполнения, который одинаков для всех частей речи. Универсальный план морфологического разбора: Выписать текстовую форму слова, определить его частеречную принадлежность и общекатегориальное значение.
Все постоянные и непостоянные морфологические признаки слова блеснули: часть речи, спряжение, вид, время, начальная форма. Морфологический разбор: блеснули. Часть речи и все грамматические (морфологические) признаки слова «блеснули».
Морфологический разбор глагола «Блеснули». Для слова «блеснули» найден 1 вариант морфологического разбора. Общее значение Часть речи слова «блеснули» — глагол. Морфологические признаки. блеснуть (инфинитив). Постоянные признаки: 1-е спряжение.
Морфемный анализ слова блеснуть — выделение частей слова: основа, корень, суффикс. Наглядное схематическое обозначение. Части слова: блес/ну/ть Часть речи: глагол Состав слова: блес — корень, ну, ть — суффиксы, нет окончания , блесну — основа слова. Примечание: ть является формообразующим суффиксом и не входит в основу слова, но во многих школьных программах ть отмечается как окончание.
Фонетический разбор слова блеснулиУдарение, транскрипция: блесну?ли>[бл’иснул’и]В слове «блесну?ли»: слогов—3 (бле-сну-ли), букв—8, звуков—8.
В данной статье мы рассмотрим слово «блеснул», являющееся глаголом. Ниже мы дадим морфологический разбор слова и укажем его возможные синтаксические роли. Если вы хотите разобрать другое слово, то укажите его в форме поиска. Значение слова «блеснуть» по словарю С. Морфологический разбор глагола. I Часть речи: глагол; IIНачальная форма: блеснуть — инфинитив; IIIМорфологические признаки: А. Постоянные признаки: Совершенный вид. Непостоянные признаки: Мужской род, единственное числ.
Используйте воздушную заслонку, если двигатель не запускается. Информация, полученная благодаря отраженным волнам, обрабатывается мгновенно. Для одного или двух вазонов стоит подобрать что- то изящное и стильное, чтобы украсить помещение. Полагаем, что историк изрядно модернизирует буквальное значение источника. По этой же причине рекомендуется быть подготовленным на затраты за дополнительные часы вождения.
Ответ на билет ответственность работника за невыполнение правил и инструкция. Если вам приснится, что ваши руки испачканы кровью, то вскоре вам предстоит тяжкая разлука с близким человеком. Если на дне имеются крупные камни или коряги, то это место, безусловно, надо проверить. Легкий спиннинг для джига используют на маленьких реках. Как правильно и в какой пропорции развести бензин маслом.
Подпишитесь на нашу группу. С озера до нас доносился шум прибоя. Кокошино, далее по дороге до д. Самой распространенной причиной этому служит неправильная регулировка карбюратора пилы.
Нельма чаще образует жилые формы, не уходящие в море на откорм. В связи с тем что полистироловые тарелки могут быть разных размеров, габариты модели рис. Малые обороты, каменистое дно, сплошные мели, да и лодочка небольшая зачем здесь. Его длину нужно подбирать в зависимости от свободного пространства вокруг и условий ловли.
Ведь и у него, у дедушки, была когда- то прекрасная шаланда с новеньким, прочным парусом. Подбираются они от особенностей ловли. Принцип использования такого поплавка на самом деле не представляет ничего сложного. Может сверить по базе по любой моделе- сейчас это не проблема даже на воде. Чтобы добиться некоторого прогресса в искусстве ловли карася нужно оснастить удочку чутким поплавком.
(PDF) Анализ арабских текстов с использованием реальных образцов синтаксических деревьев
Ф. Бен Фрай, К. Бен Отман Зриби и М. Бен Ахмед
Арабский журнал науки и техники, том 35, номер 2C, декабрь 2010 г.
100
[11] К. Бен Отман Зриби, «Синтезированная лексикография с обнаружением и исправлением графических изображений
Арабес», докторская диссертация, Парижский университет XI, Орсе, 1998.
[12] F Бен Фрай, К.Бен Осман Зриби и М. Бен Ахмед, «Quels Attributs Discriminants для анализа
Syntaxique par Classification de Textes en Langue Arabe? ”, В Traitement Automatique des Langues Naturelles
(TALN 2009), Санлис, Франция, 2009.
[13] Ф. Бен Фрай, К. Бен Отман Зриби и М. Бен Ахмед,« АрабТАГ: Грамматика, граничащая с деревом. для арабского языка
синтаксических структур », в материалах Международной арабской конференции по информационным технологиям (ACIT 2008),
Хаммамет, Тунис, 2008.
[14] А. К. Джоши, «Введение в грамматику, примыкающую к дереву», в Математике языка. изд. А. Манастер-Рамер.
Амстердам: Джон Бенджаминс, 1987.
[15] Дж. Кулоули, Арабская грамматика для Туса. Edition Presses Pocket, 1992.
[16] К. Бен Отман Зриби, А. Торжмен и М. Бен Ахмед, «Эффективная многоагентная система, объединяющая тегеры POS-
для арабских текстов», CICLing 2006, 2006, С. 121–131.
[17] Ф. Бен Фрай, «Мультиагент системы для обнаружения и исправления ошибок арабского языка»,
Master Memory, Национальная школа компьютерных наук, Университет Мануба, 2004.
[18] М. Маркус, Б. Санторини и М. Марцинкевич, «Создание большого аннотированного корпуса английского языка: Penn
Treebank», Журнал компьютерной лингвистики, 19 (2) (1993), стр. 313 –330.
[19] Ф. Бен Фрадж, К. Бен Отман Зриби и М. Бен Ахмед, «Полуавтоматический инструмент синтаксических тегов TAG для
Построение банка арабских деревьев», в Computational Linguistics-Applications’09, Mrągowo, Польша, 2009 г., стр.
207–212.
[20] К. Бен Осман Зриби, Ф.Бен Фрай и М. Бен Ахмед, «Комбинирование классификаторов для супертэгов арабских текстов», в
NLPKE 2010, Пекин, Китай, 2010.
[21] К. Бен Отмане Зриби, Ф. Бен Фрай и М. Бен Ахмед, «Классификатор дерева решений для супертэгов арабских текстов»,
в ACIT’2010, Бангхази, Ливия, 2010.
[22] Ф. Бен Фрай, «Синтаксический анализатор для текстов на арабском языке на базовом уровне. Apprentissage à Partir de
Patrons d’Arbres Syntaxiques », докторская диссертация, Национальная школа компьютерных наук, Университет Мануба, 2010.
[23] Р. Блашер и М. Годфруа-Демомбин, Grammaire de la Langue Arab. Maisonneuve et Larose, 1975.
[24] Р. Уерсигни, «Основное ответвление проекта DIINAR-MBC: AraParse, морфо-синтаксический анализатор
непроявленных арабских текстов», на 39-м ежегодном собрании ACL. Семинар по обработке на арабском языке: статус и проспект
, Тулуза, 2001 г., стр. 66–72.
[25] Э. Осман, К. Шаалан и А. Рафеа, «Анализатор диаграмм для анализа современного стандартного арабского предложения», семинар MT
Summit IX по машинному переводу для семитских языков: проблемы и подходы, Новый Орлеан ,
Луизиана, U.SA, 2003.
[26] К. Алулу, «Универсальный подход к множеству агентов для анализа арабского языка: модификация синтаксиса», докторская диссертация,
Национальная школа компьютерных наук, Университет Мануба, Тунис , 2005.
[27] Y. Bahou, L. Hadrich Belguith, C. Aloulou и A. Ben Hamadou, «Adaptation et Implémentation des Grammaires
HPSG pour l’Analyse de Textes Arabes non Voyellés», 15ème Congrès Francophone AFRIF-AFIA Reconnaissance
des Formes et Intelligence Artificielle RFIA’2006, Тур / Франция, 2006.
[28] M. Bataineh Bilal и A. Bataineh Emad, «Эффективный рекурсивный сетевой синтаксический анализатор для арабского языка»,
The World Congress on Engineering 2009, Vol. II, Лондон, Великобритания, 2009.
[29] К. Сагэ и А. Лави, «Синтаксический анализатор на основе классификатора с линейной сложностью выполнения», 9-й международный семинар
по технологиям синтаксического анализа, Ванкувер, Канада, 2005 г. С. 316–323.
[30] I. Mathkour Hassan, A. Touir Ameur и A. Al-Sanea Waleed, «Анализ арабских текстов с использованием риторической структуры
Theory», Journal of Computer Science, 4 (9) (2008), стр.713–720.
[31] Л. Тунси, М. Аттиа и Дж. Ван Генабит, Анализ арабского языка с использованием ресурсов LFG на основе Treebank. Лексический функциональный
Грамматика 2009, Кембридж, Великобритания, 2009.
% PDF-1.5 % 259 0 объект > эндобдж xref 259 89 0000000015 00000 н. 0000002181 00000 п. 0000002310 00000 н. 0000002362 00000 н. 0000003024 00000 н. 0000003480 00000 н. 0000003773 00000 н. 0000003855 00000 н. 0000003963 00000 н. 0000004124 00000 п. 0000004327 00000 н. 0000004532 00000 н. 0000004694 00000 н. 0000004856 00000 н. 0000005018 00000 н. 0000005180 00000 н. 0000005368 00000 н. 0000011160 00000 п. 0000011258 00000 п. 0000012016 00000 п. 0000012421 00000 п. 0000012594 00000 п. 0000012713 00000 п. 0000012774 00000 п. 0000013057 00000 п. 0000021225 00000 п. 0000022141 00000 п. 0000022164 00000 п. 0000022187 00000 п. 0000022243 00000 п. 0000022431 00000 п. 0000022621 00000 п. 0000022810 00000 п. 0000023007 00000 п. 0000023194 00000 п. 0000023383 00000 п. 0000023544 00000 п. 0000024177 00000 п. 0000024388 00000 п. 0000025328 00000 п. 0000025727 00000 п. 0000026039 00000 п. 0000026599 00000 н. 0000027544 00000 п. 0000028485 00000 п. 0000028771 00000 п. 0000029709 00000 п. 0000030109 00000 п. 0000030485 00000 п. 0000030780 00000 п. 0000031153 00000 п. 0000031531 00000 п.
Анализ и реструктуризация музыкальных потоков на основе грамматики в реальном времени
ï ~~ Материалы Международной конференции компьютерной музыки 2011 г., Университет Хаддерсфилда, Великобритания, 31 июля — 5 августа 2011 г. глагольной фразы «застряли» как подфраза внутри более крупная повторяющаяся оговорка.Такой вложенный цикл является обычным явлением. в рэпе, отчасти потому, что это помогает выровнять фразы границы с метрическими границами, сделав первые эластичный во время работы. Однако чего не хватает, так это возможность создавать рекурсивные иерархические структуры найдено в языке и во многих формах музыкального состав. В теории формального языка следующий по силе абстракция после регулярного выражения — это контекстная грамматика, которая поддерживает иерархически вложенные фразовые конструкции [1].Диаграмма предложений на Рисунке 2 показывает один возможный контекстно-свободный синтаксический анализ предложения, «По прошествии года пройдет еще один год прочь «, используя диаграмму предложений, не зависящую от контекста. Линии без стрелок ограничивают иерархическую композицию грамматические нетерминальные символы, включая предложение, Подлежащее, предикат, существительная фраза (NP), глагольная фраза (VP), предложная фраза (PP), существительное, прилагательное (ADJ), наречие (ADV) и инфинитивная фраза из нетерминалы нижнего уровня и терминальные символы.Каждый нетерминал состоит из предложения, предложения, фразы или части речи, действуя как подразделение более грубо зернистое нетерминальное деление, в котором это происходит. Терминалы — это самые нижние, неиерархические конструкции. В этом примере терминалы — это слова, но они могут также быть синхронизированными нотами или другими звуковыми событиями в иерархическая музыкальная структура. Пунктирные стрелки вверх показать увеличение от модификаторов до измененных нетерминалы. Бесконтекстные парсеры обычно используют обычные выражения для описания строк или других последовательностей поверхностные элементы, составляющие терминальные символы.Широко используются контекстно-свободные грамматики и парсеры. в переводе программ в машиноисполняемые формы. дублирование поддеревьев синтаксического анализа, закрепленных на нетерминалах в грамматике. Цель — создание в реальном времени возможности программного обеспечения, которые расширяют и превосходят стандартные возможности на основе цикла. Подготовка к перформанс включает построение и составление грамматика, которая описывает предложения или музыкальные отрывки для исполняться, записываться, преобразовываться и воспроизводиться, наряду с практикой использования системы производительности.2. СООТВЕТСТВУЮЩАЯ РАБОТА Пьер Шеффер был пионером в изучении использования дисков и ленты для обработки записанных звуков в том числе зацикливание в начале двадцатого века [7,10]. Стив Райх сделал особенно эффективным рано композиционное использование ленточных петель [8]. Последовательность управления используется со времен игровых пианино и т.п. механические и электромеханические инструменты. Применение контекстно-свободных грамматик и парсеров к музыкальный анализ и композиция восходит к 1970-е гг.Дороги и Wieneke резюмируют формальный язык Теоретические и исследовательские проекты, выполнявшиеся в 1979 г. [9], заявив: «Музыкальное представление должно, по крайней мере, иметь способность обрабатывать вложенные фразы и мотивы, конструкции, которые технически исключены из типа 3 грамматики «, где грамматики 3-го типа включают обычные выражения и конечные автоматы. Авторы тщательно обсудить сильные стороны контекстно-свободных грамматик в представляющий музыкальную структуру. Лердал и Джекендофф представляют тщательный применение теории формального языка к представлению музыкальной структуры, которая включает в себя практический разбор проблемы [5].Свейн связывает синтаксис с музыкальным напряжением и выпуск [12]. Barbar et. al. обсудить синтаксически управляемый перевод музыкальных конструкций [3]. Марковский процесс представляет собой форму конечной грамматики, которая была широко применяется для анализа музыкальной структуры и поколение [2,9]. Акцент в музыкальных произведениях формального языка была проведена работа по использованию грамматик и синтаксических анализаторов в представление музыкальной структуры, анализ и состав. Дороги и Винеке предсказали «Грамматики». может выйти за рамки унифицированных моделей составления и анализа и к интеллектуальным музыкальным устройствам.»[9] Однако обзор доступного программного и электронного оборудования инструменты находят, что состояние практики ограничено применение конечных автоматов / механизмов зацикливания. Целью настоящего проекта является интеграция разговорное слово без контекста и инструментальный мюзикл парсеры и генераторы в программное обеспечение на основе записи инструмент. Отображение грамматики на предложения, описанные этой грамматикой, создают импровизацию возможно, при условии достаточной подготовки грамматики и попрактикуйтесь с его приложением во время выполнения.ПРИГОВОР ПРЕДИКАТОР ТЕМА F ВП Н П ADJ ‘N.QUN ИпНЭФ PPADV / 2 v \ I I По прошествии года наступает еще один год, чтобы уйти Рисунок 2. Бесконтекстный анализ предложения. Основная цель текущего исследовательского проекта — поддержка реструктуризация устного слова во время исполнения и инструментальные фразовые конструкции. Например, после записывая предложение на Рисунке 2, исполнение система способна к немедленной реструктуризации и воспроизведению вернуться к альтернативному предложению, например, «Еще один год проходит с течением года.» Преобразования включают обмен, удаление и 584
9.1 Неопределенность — основы лингвистики
В главе 8, когда мы научились рисовать древовидные диаграммы, чтобы проиллюстрировать, как предложения представлены в человеческом разуме, мы думали о глубинной структуре как о месте, где значение присваивается и вычисляется. Например, в вопросном предложении вроде: « Что дети едят на обед? », мы утверждаем, что слово what связано с глаголом« есть »точно так же, как яйца и есть связаны в декларативном предложении« Дети едят яйца на обед .Взаимосвязь между ест / яйца и между ест / что возникает в глубокой структуре, где яйца и what являются дополнением глагола. В нашей теории значение предложения напрямую соотносится с синтаксисом предложения.
Эта идея является ключевой в лингвистике: значение некоторой комбинации или слов (то есть составного слова, фразы или предложения) возникает не только из значений самих слов, но и из того, как эти слова комбинированный.Эта идея известна как композиционность : значение состоит из значений слов и морфосинтаксических структур.
Если структура порождает значение, из этого следует, что разные способы комбинирования слов приводят к разным значениям. Когда слово, фраза или предложение имеют более одного значения, это двусмысленный . Слово двусмысленный — еще одно из тех слов, которые имеют особое значение в лингвистике: оно не означает только то, что значение предложения расплывчато или неясно. Неоднозначное означает, что доступны два или более различных значения.
В некоторых предложениях двусмысленность возникает из-за возможности наличия более одного грамматического синтаксического представления для предложения. Подумайте об этом примере:
Хилари увидела пирата в подзорную трубу.
Есть, по крайней мере, два возможных места, к которым PP с телескопом могут быть присоединены. Если PP примыкает к N-штанге, возглавляемой пиратом , то это часть NP.(Обратите внимание, что весь NP пират с телескопом можно заменить местоимением her ). В этом сценарии пират держит телескоп, и Хилари видит этого пирата.
Но если PP присоединен к V-образной балке во главе с пилой , тогда NP пират является его собственным составным элементом, а с телескопом дает информацию о том, как произошло событие наблюдения пиратов. В этом сценарии Хилари использует телескоп, чтобы увидеть пирата.
Эта единственная строка слов имеет два различных значения, которые возникают из двух разных грамматических способов объединения слов в предложении. Это известно как структурная неоднозначность или синтаксическая неоднозначность .
Структурная неоднозначность иногда может привести к забавным интерпретациям. Это часто случается в заголовках новостей, где служебные слова опускаются. Например, в декабре 2017 года несколько новостных агентств сообщили: «Линдси Лохан укусила змея на отдыхе в Таиланде», что заставило нескольких комментаторов выразить удивление по поводу того, что змеи берут отпуск.
Другой источник неоднозначности в английском языке связан не с синтаксическими возможностями комбинирования слов, а с самими словами. Если слово имеет более одного значения, то использование этого слова в предложении может привести к лексической двусмысленности . В этом предложении:
Хайке узнал его по необычной коре.
Неясно, узнает ли Хайке дерево по коре на его стволе, или она узнает собаку по звуку ее лая.Во многих случаях слово bark будет устранено окружающим контекстом, но при отсутствии контекстной информации предложение неоднозначно.
границ | ULTRA: универсальная грамматика как универсальный синтаксический анализатор
Введение
Одним из наиболее значительных недавних достижений лингвистической теории стало появление высококачественных наборов данных по всему спектру межъязыковых вариаций. В прошлом генеративные исследования обычно полагались на детальное изучение одного или нескольких языков для выявления синтаксических механизмов.Хотя этот подход, безусловно, плодотворен, накопление информации о большом количестве языков открывает новые возможности для улучшения понимания.
В порождающей грамматике значительное внимание уделяется рекурсии как (или даже ) фундаментальному свойству языка (обсуждение см. В Berwick and Chomsky, 2016). Это формализовано в основной операции под названием Merge, объединяющей два синтаксических объекта (в конечном итоге построенных из лексических элементов) в набор, содержащий оба.Рекурсия следует из способности Merge применять к собственному выводу. Слияние также фиксирует тот важный факт, что предложения имеют внутреннюю структуру (составные части в квадратных скобках), причем каждый уровень соответствует приложению слияния.
Вопреки этой концепции, я утверждаю, что концептуальной ошибкой является рассмотрение предложений как групп (будь то наборы или что-то еще) лексических элементов. Ошибка заключается в представлении о лексических единицах как о связанных единицах, существующих на одном уровне. Это также приводит к мысли о предложениях как о одноуровневых представлениях.Проще говоря, слова — это не вещи ; они представляют собой пару процессов, протянутых во времени. В контексте понимания релевантными процессами являются распознавание слова и интеграция его значения в интерпретацию. Я развиваю новый взгляд на структуру предложений с точки зрения этих двух типов процессов. Важно отметить, что нетривиальные отношения определяют их относительную последовательность: одно слово может встречаться раньше, чем другое в поверхностном порядке, но его значение может быть интегрировано позже.Рассмотрение предложений как единых, вневременных представлений, построенных на непроницаемых лексических атомах, оставляет нас неспособными уловить фундаментально задействованные временные явления, в которых два аспекта каждого слова не связаны вместе, а процессы для разных слов переплетаются.
В этой статье предлагается новая модель грамматических механизмов, получившая название ULTRA (Универсальный реактивный автомат с линейным преобразованием). В локальных синтаксических доменах, образующих расширенную проекцию лексического корня (такого как глагол или существительное), ULTRA использует алгоритм стековой сортировки Кнута (1968) для прямого сопоставления поверхностных порядков слов с лежащей в основе базовой структурой.Сопоставление успешно только для 213 приказов избегания. Это интригующий результат, поскольку избегание 213, возможно, ограничивает вариацию нейтрального порядка слов в разных языках в различных синтаксических областях. Хотя локальные звуковые и смысловые представления в этой модели являются последовательностями, иерархическая структура, тем не менее, возникает в динамическом действии отображения. Обнаруженные здесь структуры в квадратных скобках, хотя и эпифеноменальные, очень похожи на структуры, построенные Merge, с некоторыми существенными различиями (возможно, в пользу нынешней теории).
Сортировка по стеку оказалась эффективной процедурой для связывания порядка слов и иерархической интерпретации, включая линеаризацию, смещение, композицию и помеченные скобки. Теория предлагает реализацию как процесс исполнения в реальном времени. Преследование этого понимания значительно изменяет границы между производительностью и компетенцией. Примечательно, что ULTRA не требует никаких параметров, зависящих от языка; инвариантный алгоритм служит грамматическим устройством для всех языков. Проще говоря, я предполагаю, что Universal Grammar — это универсальный синтаксический анализатор.
Тем не менее, стековая сортировка — это слишком ограниченный механизм для описания всех явлений человеческого синтаксиса. Остается незавершенным три вида эффектов: неограниченная рекурсия, ненейтральный порядок и существование явно различных языков. Более того, понимание стековой сортировки как системы обработки сталкивается с двумя очевидными проблемами: это однонаправленный синтаксический анализатор, который не является тривиально обратимым для производства; и это противоречит убедительным доказательствам пословной постепенности в понимании.
Хотя построение полной модели синтаксиса и обработки выходит далеко за рамки данной статьи, проблемы, возникающие при построении модели синтаксического анализа как грамматики на сортировке стека, требуют рассмотрения. Я обращаюсь к различию между реактивными и предсказательными процессами, рассматривая стековую сортировку как универсальную реактивную процедуру. Отдельный прогностический модуль играет решающую роль в производстве и в появлении четких, относительно жестких порядков слов. Прогнозирование также помогает согласовать ULTRA с инкрементной интерпретацией.Я обращаюсь к свойствам памяти для решения дальнейших проблем, предполагая, что первичная память (отличная от памяти недавнего времени, лежащей в основе сортировки стека) является источником другого кластера синтаксических свойств, включая перемещение на большие расстояния, пересекающиеся зависимости и специальный синтаксис «левая периферия». Наконец, я предполагаю, что эпизодическая память — независимо иерархическая по структуре у людей — играет ключевую роль в лингвистической рекурсии.
Данная статья имеет следующую структуру.В разделе Linear Base утверждается, что «базовая» структура внутри каждого локального синтаксического домена представляет собой последовательность. Раздел * 213 в «Нейтральном порядке слов» исследует обобщение, согласно которому «213-избегание» ограничивает возможности нейтрального по отношению к информации порядка слов в разных языках. Раздел «Сортировка стека как грамматический механизм» предлагает процедуру сортировки стека для выявления «избегания 213» в порядке слов. Раздел Stack-Sorting: Linearization, Displacement, Composition и Labeled Brackets показывает, как дальнейшие синтаксические эффекты следуют из сортировки по стеку.Раздел Сравнение с существующими учетными записями Universal 20 сравнивает ULTRA с существующими учетными записями избегания 213 в порядке слов, уделяя особое внимание Universal 20. Раздел Universal Grammar as Universal Parser преследует реализацию стековой сортировки в реальном времени. В разделе «Возможные расширения более полной теории синтаксиса» рассматриваются проблемы, связанные с принятием стековой сортировки в качестве ядра универсальной грамматики, и приводятся наброски некоторых возможных расширений. Раздел Заключение завершается.
Линейная база
Синтаксическая комбинация может принимать разные формы.Появляется новая точка зрения, согласно которой сочетание в значительной степени поддерживает отношения «голова-дополнение» (Starke, 2004; Jayaseelan, 2008). В этом контексте термин «голова» имеет как минимум два разных значения. Во-первых, в любой комбинации двух синтаксических объектов один является «более важным» по отношению к составному значению. Назовем это понятие головы корнем , отметив, что в расширенных проекциях существительных и глаголов лексическое существительное или корень глагола является семантически доминантным. Другой смысл головы касается того, какой элемент определяет комбинаторное поведение композиции; назовем это понятие головы меткой .
В более старых теориях структуры фраз два смысла головы (корень и метка) сходились в одном элементе; существительное, например, в сочетании со всеми его модификаторами в существительной фразе. Таким образом, головокружение соотносится с иерархическим доминированием; корень проецировал свой ярлык над своими иждивенцами. Для иллюстрации комбинация прилагательного и существительного, например, красных книг , будет представлена следующим образом.
Этот традиционный вывод об отношениях зависимости и иерархии опровергается современной синтаксической картографией (Rizzi, 1997; Cinque, 1999 и последующие работы).Картографические подходы предполагают, что синтаксическая комбинация следует строгой, кросс-лингвистической однородной иерархии внутри каждой расширенной проекции. Эта иерархия включает в себя последовательность функциональных глав, лицензионную комбинацию с различными модификаторами в строгом порядке. Фраза красных книг представлена следующим образом.
Здесь прилагательное — это спецификатор специализированного функционального заголовка (F), который маркирует композицию, определяя ее комбинаторное поведение. В картографических изображениях головы равномерно на ниже, чем на их иждивенцев, которые появляются выше по позвоночнику.
Вопросы возникают по поводу этих представлений, которые постулируют обилие невысказанного материала. Любопытное наблюдение заключается в том, что функциональные заголовки и их спецификаторы явно не встречаются вместе, как это формализовано в обобщенном двойном фильтре компаундирования Купмана (2000).
Starke (2004) развивает наблюдение Купмана дальше, утверждая, что заголовки и спецификаторы не встречаются одновременно, потому что они представляют собой токенов одного типа , конкурирующих за одну позицию. Старке преобразовывает картографический корешок в абстрактную функциональную последовательность ( fseq ), позиции которой могут быть обозначены как лексическим, так и фразовым материалом.Следуя концепции Старке, комбинация прилагательного и существительного будет представлена, как показано ниже.
Мы снова изменили традиционные выводы об иерархии глав и иждивенцев. Тем не менее, понятие корня (выделение существительного) по-прежнему имеет решающее значение, поскольку модификаторы располагаются в иерархическом порядке, продиктованном и fseq.
Синтаксическая комбинация этого типа является последовательной в пределах каждой расширенной проекции. Эти «базовые» последовательности кодируют композицию «снизу вверх», поэтому естественно упорядочить последовательность таким же образом (снизу вверх).База (т.е. fseq, картографический корешок) широко считается единообразной для разных языков и выражает «тематическое», информационно-нейтральное значение (в отличие от дискурсивно-информационной структуры).
Грамматика, согласно любой теории, определяет формальное отображение, связывающее звук и значение (точнее, внешнюю и внутреннюю формы, с учетом неслышащих модальностей). Эта спецификация может принимать разные формы. Последовательное представление основы позволяет легко сформулировать звуково-смысловое отображение.Эта переформулировка дает принципиальное описание класса универсалий порядка слов. Более того, в то время как объекты интерфейса (порядок слов и базовые деревья), участвующие в отображении, являются последовательностями, заключенная в скобки иерархическая структура возникает как динамический эффект.
Существуют различные способы концептуализации взаимосвязи между базовым и поверхностным порядком слов. Обычное мнение состоит в том, что база упорядочивает входные данные до производных, давая поверхностный порядок слов в качестве выходных данных. Эта направленность подразумевается в терминах, используемых для описания отношения иерархия-порядок: линеаризация , экстернализация и т. Д.Эта статья преследует другую точку зрения, где поверхностные порядки слов являются входными данными для алгоритма, который пытается собрать основу в качестве выходных данных. Примечательно, что единственные исходные данные, которые сходятся на единой основе в рамках этого процесса, — это избегание; порядок слов, содержащих 213, приводит к отклонению от нормы.
* 213 В нейтральном порядке слов
213-избегание, возможно, улавливает возможности нейтрального по отношению к информации порядка слов в различных синтаксических областях на разных языках. Под 213-избеганием я подразумеваю запрет на порядок поверхностей… b… a… c …, для элементов a ≫ b ≫ c , где ≫ указывает c-команду в стандартных представлениях дерева базы ( эквивалентно доминирование в деревьях Старке).Другими словами, нейтральные порядки слов, кажется, избегают последовательности элементов от среднего до высокого-низкого (под) из одного fseq. Элементы, образующие этот запрещенный контур, не обязательно должны быть смежными, в порядке поверхности или в основании fseq.
213-избегание, как широко распространено, ограничивает возможности упорядочивания кластеров глаголов, хорошо известных в западногерманском языке (см. Обзор в Wurmbrand, 2006). Обширный обзор голландских диалектов, проведенный Barbiers et al. (2008), обнаружил очень мало примеров этого порядка; Немецкие диалекты, кажется, тоже избегают этого порядка.Между тем Zwart (2007) анализирует порядок 213 в кластерах голландских глаголов как включающий экстрапозицию последнего элемента.
Наиболее изученной областью, поддерживающей избегание 213 в порядке слов, является Universal 20 Гринберга, описывающая порядок именных фраз.
«Когда какие-либо или все элементы (указательные, числительные и описательные прилагательные) предшествуют существительному, они всегда находятся в указанном порядке. Если они следуют, порядок либо тот же, либо полная противоположность »(Greenberg, 1963, стр. 87).
Последующие работы улучшили эту картину.Cinque (2005) сообщает, что только 14 из 24 логически возможных порядков этих элементов засвидетельствованы как информационно-нейтральные порядки (Таблица 1).
Таблица 1 . Возможный порядок именных фраз. Cinque (2005, стр. 319–320) отчет о количестве языков, представленных в каждом порядке, дается числом: 0 = не подтверждено; 1 = очень мало языков; 2 = несколько языков; 3 = много языков; 4 = очень много языков.
Чинкве описывает эти факты с ограничением движения с единой базы.В частности, он предлагает, чтобы все движения перемещали существительное или что-то, что его содержит, влево (раздел «Сравнение с существующими аккаунтами Universal 20» подробно описывает теорию Чинкве и связанные с ней описания). Что запрещено, так это движение остатка.
Порядок именных фраз подчиняется простому обобщению: подтвержденные порядки — это все и только 213 перестановки, избегающие перестановок. Все непроверенные заказы имеют 213 подпоследовательностей. Например, неподтвержденный * Num Dem Adj N содержит подпоследовательности Num Dem Adj … и Num Dem… N , представляющие контуры среднего-высокого-низкого уровня относительно fseq.
Сортировка стека как грамматический механизм
Существует особенно простая процедура, которая отображает порядок слов без исключения 213 в единую основу, называемая сортировкой стека. Я описываю адаптацию алгоритма сортировки стека Кнута (1968), который использует память «последний пришел — первым вышел» (стек) для сортировки элементов по их относительному порядку в базе. Это частичный алгоритм сортировки: он обеспечивает желаемый результат только для некоторых входных порядков.
(4) S АЛГОРИТМ ТАК-СОРТИРОВКИ D ОПРЕДЕЛЕНИЯ
Пока ввод не пуст, I: следующий элемент ввода.
Если я S, Pop. S: элемент наверху стека.
Else Push. x ≫ y: x c-команды y в
база (например, Dem ≫ N).
Пока Stack не пуст, Push: перемещает I из входа
в стек.
Поп. Pop: перемещает S из стека
для вывода.
(4) отображает все и только 213-избегающие порядки слов в 321-подобную иерархию, соответствующую основанию. Заказы, содержащие 213, сопоставляются с отклоняющимся выходом, отличным от базового. По предположению, именно поэтому такие порядки типологически недоступны: они автоматически отображаются в неинтерпретируемом порядке композиции. Это объясняет шаблон Universal 20 (Таблицы 2, 3).
Таблица 2 . Результат стековой сортировки логически возможных порядков из 4 элементов, в формате вход → выход.
Таблица 3 . Вычисления сортировки стека для 4-х порядков.
Давайте проиллюстрируем, как (4) разбирает некоторые порядки именных фраз: Dem-Adj-N, N-Dem-Adj, * Adj-Dem-Num.
(5) Dem-Adj-N: PUSH (Dem), PUSH (Adj), PUSH (N),
POP (N), POP (Adj), POP (Dem).
(6) N-Dem-Adj: PUSH (N), POP (N), PUSH (Dem), PUSH (Adj),
POP (Настр.), POP (Дем.).
Для аттестованных заказов номинальные категории POP в порядке
(7) * Adj-Dem-N: PUSH (Настр.), POP (Настр.), PUSH (Дем.),
НАЖАТЬ (N), POP (N), POP (Дем).
Для неподтвержденного порядка 213, элементы POP в девиантном порядке *
Это хорошо: (4) сопоставляет подтвержденные заказы с их универсальным значением, одновременно исключая не подтвержденные заказы. Но помимо такого сопоставления, адекватная грамматика должна объяснять другие аспекты знания языка, включая брекетинг поверхностной структуры.Если грамматика рассматривает поверхностные порядки и базовые структуры как последовательности (локально), откуда может взяться такая заключенная в скобки структура?
Сортировка стопкой: линеаризация, смещение, композиция и маркированные скобки
В этом разделе я показываю, что сортировка стека эффективно включает линеаризацию, смещение и композицию, а также назначение скобок с однозначной пометкой и без поиска. Более того, все это выполняется без параметров, зависящих от языка.
В стандартном («Y-модель») представлении линеаризация и композиция — это отдельные операции интерфейса, интерпретирующие структуры, построенные в автономном синтаксическом модуле с помощью Merge.В ULTRA линеаризация идет в другом направлении, поэтапно загружая в память поверхностный порядок слов и собирая их заново в порядке композиционной интерпретации.
Смещение — естественное свойство грамматики сортировки стека
Смещение — естественная особенность сортировки стопкой; с одной точки зрения, это основное свойство системы. В стандартных отчетах составляющие, составляющие вместе при интерпретации, должны появляться смежными в поверхностном порядке. Такое расположение вызвано грамматиками фразовой структуры.Смещение, при котором элементы, составляющие вместе, разделяются промежуточными элементами в порядке поверхности, всегда казалось удивительным свойством, нуждающимся в объяснении.
В ULTRA все работает иначе. Ключевое предположение представления на основе слияния отбрасывается: нет уровня представления, охватывающего порядок слов и fseq в унифицированном объекте более высокого порядка. Вместо этого порядок слов и базовая иерархия — это несвязанные последовательности, связанные динамически. Несмежные элементы ввода вполне могут оказаться смежными на выходе.Смещение, а не исключение, является правилом; : каждый элемент в порядке поверхности «трансформируется», проходя через память перед извлечением для интерпретации.
Скобки и метки без примитивного округа
Алгоритм (4) неявно назначает помеченную структуру в квадратных скобках каждому порядку поверхности, почти точно совпадая со структурами, назначенными такими учетными записями, как Cinque (2005). Явно нажатие (сохранение от порядка слов до стека) соответствует левой скобке, а выталкивание (извлечение из стека для интерпретации) — правой скобке.Эти операции применяются к одному элементу за раз; естественно думать, что этот элемент обозначает соответствующую скобку. См. Таблицу 4, в которой представлены вычисления сортировки стека для всех перестановок поверхностей трехэлементной базы.
Таблица 4 . Вычисления с сортировкой стека для порядков из 3 элементов.
Рассматривая эти скобки, последовательность нажатий и извлечений (сохранение и извлечение) для каждого порядка неявно определяет дерево, как показано на рисунке 1. Это так называемые деревья Дика, набор всех упорядоченных корневых деревьев с фиксированным числом. узлов (здесь 4).Сравните их с деревьями бинарного ветвления, назначенными в соответствии с отчетом Чинкве (2005), с неостаточным движением влево, влияющим на основание ветвления вправо (рис. 2). Скобки почти идентичны, как и их ярлыки, но есть некоторые вольности с техническими деталями аккаунта Cinque.
Рисунок 1 . Скобки и соответствующие деревья push-pop для принятых (сортированных по стеку) порядков из трех элементов. Это просто деревья Дика с 4 узлами.
Рисунок 2 .Деревья с бинарным ветвлением для производных аттестованных порядков трех элементов, избегающих перемещения остатков, с соответствующими скобками. Лексический корень (например, N в существительной фразе) показан черным треугольником, а структуры с концом и следом движения представлены двойной ветвью ||. Деревья представлены таким образом, чтобы выделить соответствие с деревьями Дика для этих порядков, полученных в результате сортировки стека.
Если отложить в сторону 321 дерево (а) на данный момент, то деревья Дика представляют собой систематические сжатия без потерь деревьев Чинкве, при этом каждое поддерево, которое представляет собой ветвящуюся вправо гребенку в дереве Чинкве, заменено линейным деревом (см. 2008) в дереве Дика.Для этого соответствия, которое сводится к сокращению всех терминалов в двоичном дереве, лексический корень (например, существительное в DP) не должен сокращаться. Элементы из поверхностного порядка связаны с каждым узлом дерева Дика, кроме самого высокого, с линейным порядком чтения слева направо среди сестринских узлов и сверху вниз по унарным ветвящимся путям. Например, для порядка 132 поверхности 1 ассоциируется с единственным бинарным ветвящимся узлом в его дереве Дика, 3 и 2 — с его левой и правой дочерними элементами (рисунок 3).
Рисунок 3 .Два представления в квадратных скобках 132 порядка поверхности и соответствующие деревья. Слева — структура, найденная при чтении операций сортировки стека в скобках; Элементы поверхности идентифицируются каждым узлом (кроме самого верхнего, пунктирного). Линейный порядок считывается сверху вниз по унарным ветвящимся путям и слева направо среди сестринских узлов. В соответствующем двоичном ветвящемся дереве, представляющем его происхождение перемещением (справа) , ярко выраженные элементы идентифицируются только с конечными узлами.
Между тем, порядок 321, которому присвоено троичное дерево путем сортировки стека, имеет два производных, исключающих перемещение остатков. В одном из возможных выводов 3 инвертируют, причем 2 сразу после объединения 2, затем 32 комплекса перемещаются за 1 после объединения 1. В другом возможном выводе сначала объединяется полная базовая структура, затем 23 перемещаются влево, а затем влево перемещается всего 3.
Ключевой эмпирический вопрос заключается в том, демонстрируют ли 321 порядок две отдельные заключенные в скобки структуры, как это позволяют трактовки бинарного ветвления, или только единственная, «плоская» структура, предсказанная здесь.Проблема становится еще более острой для 4 элементов, как в Universal 20, где существует до 5 различных производных слияния для порядка 4321. К счастью, это ( N Adj Num Dem ) является наиболее распространенным порядком именных фраз; будущие исследования должны пролить свет на эту проблему.
Сводка раздела
Stack-sorting захватывает удивительное количество синтаксического механизма, обычно разделенного между различными модулями. В обычном представлении автономный генераторный движок строит составляющие структуры, интерпретируемые на интерфейсах дальнейшими процессами линеаризации и композиции.В ULTRA линеаризация и композиция отражают единую процедуру. Составная структура не является примитивной, но записывает этапы хранения и извлечения, с помощью которых сортировка стека собирает интерпретацию. Это создает структуру поверхности в квадратных скобках, обозначенную соответствующим образом, в значительной степени идентичную структуре в скобках в счетах, постулирующих движение (внутреннее слияние) от единой основы (сформированной внешним слиянием). Однако там, где стандартные теории допускают множественные выводы для некоторых поверхностных порядков (и неоднозначную бинарную ветвящуюся структуру), в настоящем описании назначается уникальная внебинарная скобка.Примечательно, что специфические особенности языка не играют никакой роли в движении. Смещение обрабатывается автоматически путем сортировки стека и фактически является его основной функцией.
Сравнение с существующими счетами Universal 20
В этом разделе сравнивается учетная запись сортировки стека Universal 20 с существующими учетными записями на основе слияния (Cinque, 2005; Steddy and Samek-Lodovici, 2011; Abels and Neeleman, 2012). Я утверждаю, что учетная запись сортировки стека проще, при этом избегая проблем, которые возникают в каждой из этих существующих альтернатив.
Счет Чинкве (2005)
Cinque предлагает кросс-лингвистически однородную базовую иерархию, отражающую фиксированный порядок внешнего слияния. Он предполагает, что движение (внутреннее слияние) происходит равномерно влево, в то время как основание ветвится вправо, в соответствии с LCA Кейна (1994). Он оговаривает, что остаточное движение в именной фразе запрещено: каждое движение влияет на существительное или на составляющую, содержащую его. Его базовая структура для именной группы — (8).
Открытые модификаторы — это спецификаторы выделенных функциональных глав (например,г., X 0 ), ниже договорные фразы, предусматривающие посадочные площадки для передвижения. Эта структура и его предположения о движении выводят все и только подтвержденные приказы. Похожий на английский заказ Dem-Num-Adj-N поверхности без движения; все другие порядки включают некоторую последовательность движений NP или что-то, что ее содержит.
Счет Абельса и Нилмана (2012)
Abels и Neeleman (2012) модифицируют анализ Cinque, отбрасывая элементы, введенные для соответствия LCA (включая согласованные фразы и специальные функциональные главы).Они утверждают, что LCA не играет объяснительной роли; все, что требуется, — это движение влево, а остаточное движение запрещено. Они допускают свободную линеаризацию сестринских узлов, используя значительно более простую базовую структуру (9). Они опускают метки для нетерминальных узлов как не относящиеся к их анализу (Abels and Neeleman, 2012: 34).
По их теории, восемь подтвержденных приказов могут быть получены без движения, изменяя линейный порядок сестер. Остальные подтвержденные заказы требуют движения влево без остатка.В принципе, их система допускает расширенный набор выводов Чинкве (2005); некоторые порядки могут быть получены путем выбора линеаризации или перемещения. Однако, ограничивая внимание строго необходимыми операциями и предполагая, что свободная линеаризация проще, чем перемещение, их вывод обычно проще, чем у Cinque.
Отчет Стедди и Самека-Лодовичей (2011)
Стедди и Самек-Лодовичи (2011) предлагают еще один вариант анализа Чинкве (2005).Они предлагают теоретико-оптимальное объяснение, сохраняя базовую структуру Чинкве (8). Линейный порядок определяется набором ограничений Align-Left (10), по одному для каждого открытого элемента.
(10) а. N-L — Выровнять (NP, L, AgrWP, L)
Совместите левый край NP с левым краем AgrWP.
г. A-L — Выровнять (AP, L, AgrWP, L)
Совместите левый край AP с левым краем AgrWP.
г. NUM-L — Выровнять (NumP, L, AgrWP, L)
Выровняйте левый край NumP с левым краем AgrWP.
г. DEM-L — Выровнять (DemP, L, AgrWP, L)
Совместите левый край DemP с левым краем AgrWP.
(Из Стедди и Самек-Лодовичи, 2011: 450).
Эти ограничения выравнивания вызывают нарушение для каждого явного элемента или трассы, отделяющей соответствующий элемент от левого края домена, и варьируются в зависимости от языка. Подтвержденные заказы являются оптимальными кандидатами при некотором ранжировании ограничений. Непроверенные заказы исключаются, потому что они «гармонически ограничены»: какой-либо другой кандидат подвергается меньшему количеству нарушений более высокого ранга при любом ранжировании ограничений.Следовательно, они могут отказаться от ограничений на движение, принятых Чинкве (2005) и Абельсом и Нилманом (2012). Вместо этого левосторонний, не остаточный характер движения выпадает из принципов выравнивания.
Проблемы с существующими учетными записями
Хотя эти учетные записи различаются в деталях, у них есть некоторые проблемные особенности. Во-первых, все они отражают шаблон порядка слов на трех уровнях объяснения: (i) единообразная базовая структура, (ii) синтаксическое движение и (iii) принципы линеаризации.Во всех трех учетных записях (i) описывает порядок внешнего слияния. Детали (ii) и (iii) различаются в зависимости от счета. Для Чинкве (2005 г.) и Стедди и Самек-Лодовичи (2011 г.) все заказы, кроме Dem-Num-Adj-N , включают движение; Abels и Neeleman (2012) требуют перемещения только для шести подтвержденных заказов. Что касается линеаризации, Cinque (2005) использует LCA Кейна (1994); Абельс и Нилман (2012) имеют движение равномерно влево, но сестры, генерируемые базой, свободно линеаризуются на основе специфики языка; У Стедди и Самек-Лодовичи (2011) есть ранжирование ограничений для конкретного языка.
Все эти учетные записи требуют разной грамматики для разных порядков. В системе Cinque (2005) необходимо изучить особенности, управляющие определенными движениями. То же самое верно для Abels и Neeleman (2012) с дополнительным изучением порядка для сестринских узлов. Стедди и Самек-Лодовичи (2011) требуют изучения ранжирования ограничений, которое дает начало каждому порядку. Таким образом, все эти рассказы сталкиваются с проблемами, связанными с языками, допускающими свободу порядка в ДП; по сути, они должны допускать недоопределенные или конкурирующие грамматики, чтобы фиксировать различные порядки.
Наконец, все эти отчеты имеют некоторую структурную или грамматическую двусмысленность для некоторых порядков. Для Cinque (2005) одна из разновидностей двусмысленности возникает при выборе того, следует ли переместить функциональную категорию или фразу «Соглашение», в которую она встроена; у этого выбора нет явного рефлекса. Хотя его теория резко ограничивает количество и место посадки возможных перемещений, эти ограничения несколько искусственны; Немногое существенное изменилось бы, если бы мы постулировали дополнительные тихие функциональные уровни для выполнения дальнейших движений или разрешили использование нескольких спецификаторов.В пределе это позволяет использовать весь спектр неоднозначных производных, обсуждаемых в разделе Stack-Sorting: Linearization, Displacement, Composition, and Labeled Brackets. Подход Абельса и Нилмана (2012) допускает эту неоднозначность среди различных производных движений, а также получение множества порядков посредством перемещения или переупорядочения сестринских узлов. Наконец, Стедди и Самек-Лодовичи (2011) сталкиваются с другой проблемой неоднозначности: некоторые порядки согласуются с множественным ранжированием ограничений (таким образом, множественными грамматиками).
Сравнение со счетом сортировки стека
Счетчик с сортировкой по стеку лучше справляется с этими проблемами. Вместо постулирования отдельных уровней принципов основы, движения и линеаризации соответствующий механизм реализуется в рамках одного алгоритмического процесса. Алгоритм сортировки универсален, он избегает специфичных для языка функций для управления движением, упорядочивания дочерних узлов или ограничений выравнивания рангов. Такая теория идеально подходит для объяснения феномена свободного порядка слов.Кроме того, каждый заказ вызывает уникальную последовательность операций хранения и извлечения, отслеживая уникальное брекетинг. В доменах, характеризующихся нейтральным порядком слов и одним fseq, нет ложной структурной или грамматической двусмысленности для любого порядка слов.
Универсальная грамматика как универсальный синтаксический анализатор
В этом разделе развивается точка зрения, согласно которой сортировка стека может сформировать основу для инвариантного механизма производительности, реализуя универсальную грамматику как универсальный синтаксический анализатор. Это изменяет традиционные выводы о компетентности и успеваемости, обеспечивая при этом новое представление о том, что такое грамматика.
Переосмысление компетенции и производительности
В генеративных счетах существует фундаментальное разделение между компетенцией и производительностью (Chomsky, 1965). Компетенция включает в себя знание языка, рассматриваемое как абстрактное вычисление, определяющее структурную декомпозицию бесконечного числа предложений. Отдельные системы производительности получают доступ к знаниям системы компетенций во время обработки в реальном времени. С точки зрения трехуровневого описания систем обработки информации Марра (1982), компетентность соответствует высшему, вычислительному уровню, определяя , что делает система, и , почему, .Производительность довольно слабо соответствует нижнему, алгоритмическому уровню, описывая, как вычисления выполняются, шаг за шагом.
Конечно, иерархия Марра применима к обработке информации в языке в рамках данной теории, как и любой другой. Однако разделение труда между этими компонентами здесь существенно перерисовывается, и гораздо больше бремени объяснения ложится на производительность. Существенное отличие состоит в том, что в ULTRA заключенная в скобки структура не входит в компетенцию.Вместо этого такая структура возникает во взаимодействии компетенции с алгоритмом сортировки стека во время синтаксического анализа в реальном времени. Знания, приписываемые грамматике компетенций, проще, включая врожденный fseq в качестве основного компонента. В некотором смысле это согласуется с взглядами недавней работы Хомского, в которой компетенция фундаментально ориентирована на вычисление интерпретаций с экстернализацией «вспомогательной».
Универсальный синтаксический анализатор
Новым требованием ULTRA является то, что существует единый синтаксический анализатор для всех языков.Это отходит от почти универсального предположения, что синтаксические анализаторы интерпретируют грамматики конкретного языка. Но даже в рамках этого традиционного взгляда была признана привлекательность универсальных механизмов.
«Ключевым моментом, однако, является то, что поиск должен быть поиском универсалий, даже — и, возможно, особенно — в области обработки. Ибо может показаться, что самая сильная теория синтаксического анализа — это теория, которая утверждает, что интерпретатор грамматики сам по себе является универсальным механизмом, т.е. что существует один сильно ограниченный интерпретатор грамматики, который является подходящей машиной для синтаксического анализа всех естественных языков »(Marcus, 1980, стр.11).
Идея «синтаксический анализатор — это грамматика» имеет давнюю историю; см. Phillips (1996, 2003), Kempson et al. (2001), а также статьи в Fodor and Fernandez (2015) о недавней перспективе. Фодор называет это представлением только грамматики производительности (PGO).
«Теория общественного мнения вступает в игру с одним мощным преимуществом: должны быть психологические механизмы для разговора и понимания, и соображения простоты, таким образом, возлагают бремя доказательства на любого, кто будет утверждать, что существует нечто большее» (Fodor, 1978, стр.470).
Однако, допуская, что это влечет за собой более простую теорию, Фодор отвергает эту идею, не находя мотивации для движения за пределами автономной грамматики ( ibid ., 472). Это предполагает, что движение принципиально сложно для синтаксического анализа механизмов (которые должны предпочесть фразово-структурные механизмы трансформационным). Однако в ULTRA смещение не является сложностью по сравнению с более простыми механизмами; смещение — это основной механизм.
Смещение не является уникальной особенностью человеческого языка
Часто говорят, что смещение присуще только человеческому языку, и искусственные коды избегают этого свойства.Но смещение появляется в языках программирования точно в том же смысле, что и в ULTRA. Простой пример иллюстрирует: порядок, в котором пользователи нажимают клавиши на калькуляторе, не является порядком, в котором выполняются соответствующие вычисления. На практике калькуляторы компилируют входные данные в обратную польскую нотацию для машинного использования с помощью алгоритма маневрового двора Дейкстры (SYA).
Пример не праздный; алгоритм сортировки стека (4) по существу идентичен SYA. Лексические заголовки (существительные и глаголы) «перенаправляются» непосредственно на интерпретацию, как числовые константы в калькуляторе.Между тем спутники, образующие их расширенные проекции, сортируются в соответствии с их относительным рангом, как и арифметические операторы. По этой аналогии картографический порядок соответствует порядку приоритета арифметических операторов.
На самом деле, хотя это свойство мало используется, SYA является протоколом сортировки; многие заказы на ввод приводят к одному и тому же внутреннему расчету. Как пользователи калькуляторов, мы используем одну схему ввода (инфиксную нотацию), но подойдут и другие. Стандартизированный порядок ввода для калькуляторов имеет тот же статус, что и отдельные языки по отношению к ULTRA: пользователи могут придерживаться узких привычек упорядочивания, но алгоритм автоматически обрабатывает многие другие заказы.
Грамматичность и грамматичность
Одна из центральных задач, приписываемых грамматикам, — отличать грамматические предложения языка от неграмматических строк. В ULTRA знание грамматики сильно отличается от знания грамматичности и . Первый вид знания в основном касается компьютерных интерпретаций. Но инвариантный процесс, интерпретирующий поверхностный порядок одного языка, может одинаково интерпретировать порядки других языков. С этой точки зрения существует только один I-язык и единственная грамматика производительности, которая его обеспечивает.Хотя этот вывод является привлекательным, остается важный вопрос: откуда берутся отдельные языки с явно различающейся грамматикой?
Возможные расширения более полной теории синтаксиса
В этом разделе рассматриваются два типа проблем, возникающих при интерпретации стековой сортировки как устройства производительности. Первый касается согласования теории с тем, что известно о языковой обработке в реальном времени; второй касается расширения модели до свойств синтаксиса, которые остаются необъясненными.Даже подробное обсуждение этих проблем, а тем более обоснование каких-либо решений выходит за рамки данной статьи. Цель состоит в том, чтобы просто набросать проблемы и указать направления для дальнейшей работы.
Реакция против предсказания: инкрементность и жесткий порядок слов
Что касается обработки, то одна проблема состоит в том, что этому подходу, кажется, противоречат убедительные доказательства пословной инкрементальности в понимании (особенно в парадигме визуального мира; см. Tanenhaus and Trueswell, 2006).ULTRA является «пешеходом» в том смысле, против которого предостерегает Стейблер (1991). В каждом домене интерпретация «снизу вверх» не может начаться до тех пор, пока не будет обнаружен лексический корень fseq.
Одна из возможностей согласования ULTRA с инкрементальностью основана на различии между реактивными процессами, такими как процедура сортировки стека и прогнозная обработка (см. Braver et al., 2007; Huettig and Mani, 2016). Идея состоит в том, что сортировка стека является реактивным механизмом языкового восприятия; это контрастирует — и обязательно дополняется — возможностями прогнозирования, связанными с нисходящей обработкой и производством.Только последняя система содержит выученные языковые грамматические знания. Это предложение перекликается с другими подходами с двухэтапным процессом синтаксического анализа, такими как Sausage Machine Фрейзера и Фодора (1978). ULTRA похож на их предварительный упаковщик фраз (PPP), быстрый низкоуровневый конструктор структур, отличающийся от крупномасштабного решения проблем, выполняемого их диспетчером структуры предложений (SSS). Маркус выражает аналогичную точку зрения, описывая синтаксический анализатор как «быстрый,« глупый »черный ящик» (Marcus, 1980: 204), производящий частичный анализ, дополненный интеллектуальным решением проблем для построения крупномасштабной структуры.
Я полагаю, что свидетельства постепенного увеличения количества слов за слово могут быть согласованы с существующей теорией посредством взаимодействия между реакцией и предсказанием, используя понятие «гиперактивность» (Momma et al., 2015). Идея состоит в том, что понимание может пропустить вперед, создавая видимость инкрементности, если лексический корень (существительное или глагол) предоставляется заранее путем предсказания. Что-то вроде этого кажется правдой.
«Появляется все больше свидетельств того, что постигающие часто выстраивают структурные позиции в своих анализах до того, как столкнутся со словами во входных данных, которые фонологически реализуют эти позиции […] Возьмем только один пример, в таком языке, который является окончательным, например японском, это может быть необходимо для система построения структуры для создания позиции для заголовка фразы до того, как она завершит аргументы и дополнения, предшествующие заголовку »(Phillips and Lewis, 2013 p.19).
Дополнительная система прогнозирования может помочь решить еще две проблемы для ULTRA: объяснить, как возможно производство, и почему существуют разные языки с различным, относительно жестким порядком слов. Алгоритм сортировки стека — это однонаправленный синтаксический анализатор; не существует тривиального способа «повернуть поток вспять» для производства. Столкнувшись с этой неопределенностью, было бы естественно полагаться на предсказание, чтобы обеспечить порядок слов в производстве. Чтобы упростить производство, полезно, чтобы порядок слов был предсказуемым; в свою очередь, с помощью этой системы можно изучить тенденции порядка слов в языковой среде.Это предполагает наличие петли обратной связи и вероятного пути возникновения и расхождения относительно жестких порядков слов.
Первенство против новизны и двойственность семантики
Ряд важных синтаксических свойств остается невыясненным. Чтобы распространить предложение на отдаленно адекватную теорию, эти свойства должны быть как-то рассмотрены. К ним относятся, во-первых, группа синтаксических свойств, относящихся к синтаксису A-bar, и так называемая двойственность семантики. Я предполагаю, что этот особый вид синтаксиса связан с важным различием в краткосрочной памяти между первичностью и новизной, опираясь на модель начала-конца (SEM) Хенсона (1998).В модели Хенсона первенство и новизна — разные эффекты, отражающие кодирование с адресацией по содержанию двух аспектов последовательной позиции.
Время давности естественно связано с памятью стека (последним вошел, первым ушел). С другой стороны, первенство естественным образом описывается очередью (первым пришел — первым ушел). Помимо оптимального порядка доступа, существует еще одно важное различие между эффектами первенства и новизны. Проще говоря, первый элемент в последовательности остается первым элементом независимо от того, сколько элементов следует за ним; Сигнатура первичности данного элемента относительно стабильна во временном масштабе, относящемся к синтаксическому анализу.Новизна отличается: каждый элемент в последовательности — это новый правый край, подавляющий доступность памяти на основе недавнего времени всего, что ему предшествует. Таким образом, мы ожидаем своего рода давления «используй или потеряй» в недавней памяти, но не в первичной памяти.
Предварительно я хотел бы предположить, что различные коды памяти первичности и новизны лежат в основе двойственности семантики и разделения между A-bar и A-синтаксисом. Своевременность, связанная со стеком, является основой для информационной нейтральной, локальной перестановки, обычно характеризующейся вложенными зависимостями.Предположение, что первенство играет решающую роль в ненейтральном синтаксисе, напоминающем A-bar, предполагает объяснение группы удивительных свойств. Наиболее очевидна ассоциация дискурсивно-информационных эффектов с «левой периферией»: левый край доменов — это то место, где мы ожидаем, что первичная память будет играть значительную роль. Вовлечение первичной памяти также предполагает анализ эффектов превосходства в множественных конструкциях белых движений. В теориях, основанных на слияниях, такие конструкции (демонстрирующие перекрестные зависимости) проблематичны и требуют условных приспособлений, таких как Richards (1997) «Подкладывание» выводов.Рассмотрение эффектов как вовлечения первичной памяти предполагает более простое объяснение: упорядочение нескольких WH-фраз — это вопрос доступа «первым пришел — первым ушел» (память очереди). Последнее свойство этой альтернативной синтаксической системы, которое можно рационализировать, — это перемещение на большие расстояния. Возможно, доступность перемещения на большие расстояния для отношений A-bar является результатом стабильности первичной памяти, что делает элементы, встречающиеся на левой периферии, доступными для последующего вызова без особого труда, в отличие от недавней памяти (которая может поддерживать только короткие, локальные отзывать).Хотя это наводит на размышления, обращение к обширной литературе по синтаксису A-bar следует оставить на будущее.
А как насчет рекурсии?
Последняя проблема, вырисовывающаяся на заднем плане, — это рекурсия. ULTRA работает в синтаксических доменах, характеризуемых одним fseq. Это требует некоторого комментария, поскольку рекурсия является фундаментальным свойством синтаксиса. Для рекурсии также могут иметь решающее значение свойства памяти и вмешательство дополнительной системы прогнозирования. Любопытно, что эпизодическая память человека, по-видимому, имеет независимую иерархическую структуру, возможно, в отличие от родственных животных (Tulving, 1999; Corballis, 2009).В модели SEM эпизодические маркеры создаются для групп внутри сгруппированных последовательностей (Henson, 1998). Лингвистическая рекурсия требует некоторого дополнительного механизма для обработки токена группы, соответствующего одной последовательности, как токена элемента в другой последовательности.
Как обсуждалось в разделе «Сравнение с существующими учетными записями Universal 20» в ULTRA, структурная неоднозначность не возникает без двусмысленности смысла внутри отдельных доменов. Однако структурная неоднозначность неизбежно возникает, когда присутствуют несколько доменов, с точки зрения того, какой домен внедряется в другой или где прикрепить элемент, который мог бы занимать позиции в двух разных доменах.Вот где «быстрый, глупый черный ящик» беспомощен и должен обращаться к другим ресурсам. Одним из очевидных источников помощи в объединении нескольких доменов является отдельная система прогнозирования с доступом к нисходящим сведениям о правдоподобных значениях в контексте. Постоянная проблема разрешения неоднозначности встраивания также дает мотивацию к жесткому порядку слов, что резко снижает возможности прикрепления.
Важным моментом является то, что скобки определены относительно конкретного fseq.Рекурсивное встраивание одного домена в другой (например, номинал в качестве аргумента глагола) включает проекцию скобки, соответствующей всей вложенной фразе, в пределах области встраивания. Рассмотрим следующий пример.
(11) Собака гналась за мячом.
Здесь есть три области сортировки: две номинальные проекции, встроенные в третью, вербальную проекцию (не считая возможности, что предложения содержат две области, фазы vP и CP). Их УЛЬТРА-брекетинг показан ниже.
(12) NP1 = [ [ собака ] ]
NP2 = [ a [ шаровой шар ] a ]
VP = [ NP1 [ чеканка ] [ NP2 NP2 ] NP1 ]
Этот пример иллюстрирует неоднозначность, которая сопровождает внедрение. Проблема в том, как связать именные фразы с позициями в глаголе fseq (то есть с тета-ролями). Поскольку тета-роли явно не выражены (регистр — ненадежный ориентир), реактивный синтаксический анализатор должен использовать внешние средства (например, специфичные для языка привычки упорядочивания или предсказания правдоподобных интерпретаций).
Последний пункт о рекурсии возвращается к вопросу о том, как работают калькуляторы, с помощью алгоритма маневрового двора Дейкстры. Такие вычисления рекурсивны. Но рекурсия не обрабатывается алгоритмом синтаксического анализа; скорее, он возникает на уровне интерпретации, когда частичные результаты арифметических операций используются в дальнейших вычислениях. Подобный вывод (рекурсия является семантической, а не синтаксической) возможен в рамках настоящей структуры, учитывая сходство между ULTRA и SYA. Примечательно, что обе процедуры компилируют ввод в обратную польскую нотацию, так называемый язык конкатенативного программирования, однозначно выражающий рекурсивные иерархические операции в последовательном формате.
Нужен ли вообще алгоритм?
Я показал, как особенно простой алгоритм улавливает ряд синтаксических явлений. Но вопрос в том, почему этот алгоритм ? В принципе возможны другие процедуры сортировки, которые могут привести к другим профилям предотвращения перестановок. Как мы можем оправдать выбор стековой сортировки в качестве правильной процедуры для синтаксического сопоставления?
Есть три важных ингредиента. Первый — это ориентация системы на анализатор, сопоставляющий звук со смыслом.Это не является логически необходимым; это просто один из разумных вариантов. Второй фактор — это линейность звука и смысла. Это просто для звуковых последовательностей, но гораздо меньше для интерпретаций, где это просто смелая гипотеза. Третий ингредиент — это выбор стековой памяти. Это может быть правдоподобно связано с эффектом модальности: внятный речевой ввод порождает необычно сильные эффекты новизны (Surprenant et al., 1993). Кажется небольшим скачком предположить, что формальный стек, используемый в алгоритме, может просто (и грубо) отражать преобладание эффектов новизны в памяти для лингвистического материала.
До сих пор сортировка стека была реализована с использованием явного алгоритма. Это может быть ненужным. Вместо того чтобы думать о сортировке стека как о наборе явных инструкций, мы могли бы переосмыслить ее как антиконфликтное предубеждение между доступностью элементов в памяти с точки зрения эффектов давности и извлечением для жесткой последовательности интерпретации. Если это на правильном пути, возможно, что не пришлось развиваться новому когнитивному механизму, чтобы объяснить эти эффекты. Остается понять, откуда берется сама упорядоченность интерпретаций (fseq), вопрос, на котором я не буду здесь рассуждать.
Заключение
Подводя итог, простой алгоритм (4) отображает 213-избегающие порядки слов в восходящую композиционную последовательность, отображая 213-содержащие порядки в девиантные последовательности. Хотя входные и выходные данные сопоставления представляют собой последовательности, присутствует иерархическая структура: алгоритмические шаги реализуют левую и правую скобки, почти точно там, где их помещают стандартные учетные записи. Учетная запись отличается от стандартных учетных записей тем, что для всех заказов назначена однозначная брекетинг.
Эта модель улучшает существующие учетные записи ограничений порядка слов, которые требуют дополнительных условий (например,g., ограничения на движение вместе с принципами линеаризации), помимо построения основной синтаксической структуры. В ULTRA эти эффекты выпадают из единственного процесса в реальном времени. В свою очередь, синтаксическое смещение, долгое время считавшееся любопытным усложнением, становится фундаментальным грамматическим механизмом. Не требуется изучение специфических свойств языка; одна грамматика интерпретирует множество порядков.
Должно быть ясно, что описанная здесь система является лишь частью синтаксического познания. Эта система строит одну расширенную проекцию за раз; необходимы дополнительные механизмы для встраивания одного домена в другой.Однако это может быть достоинством: возникает соблазн идентифицировать области работы для этой архитектуры с помощью фаз, которые, таким образом, являются особенными по принципиальным причинам.
Более того, сортировка стека обрабатывает только нейтральную информацию структуры. Это игнорирует другой важный компонент синтаксиса, так называемую структуру дискурсивной информации, связанный с потенциально дальними зависимостями A-bar. Этот недостаток также может быть достоинством, предлагающим принципиальную основу двойственности семантики.Я предположил, что первичная память играет центральную роль в этих эффектах, потенциально объясняя несколько любопытных свойств (левизну, большое расстояние и пересечение).
Подняв наш взгляд, можно сделать больший вывод, что большая часть механизма синтаксического познания может сводиться к эффектам, не специфичным для языка. Излишне говорить, что это всего лишь программный набросок; будущие исследования определят, можно ли и каким образом объединить стековую сортировку ULTRA в более полную модель языка.
Авторские взносы
Автор подтверждает, что является единственным соавтором данной работы, и одобрил ее к публикации.
Заявление о конфликте интересов
Автор заявляет, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Благодарности
Части этой работы были впервые разработаны на семинаре для выпускников Университета Аризоны (2015 г.) и представлены на Симпозиуме POL в Токио (2016 г.), LCUGA 3 (2016 г.) и Ежегодном собрании LSA (2017 г.).Я благодарен публике на этих площадках и многочисленным коллегам за полезные обсуждения. Я хотел бы поблагодарить следующих: Клауса Абельса, Дэвида Аджера, Боба Бервика, Тома Бевер, Эндрю Карни, Ноама Хомски, Гульельмо Чинкве, Дженнифер Калбертсон, Сэндиуэй Фонг, Томаса Графа, Джона Хейла, Хайди Харли, Норберта Хорнштейна, Майкл Джарретт, Ричард Кейн, Хильда Купман, Диего Кривочен, Марко Кульман, Массимо Пиаттелли-Пальмарини, Колин Филлипс, Пол Пьетроски, Маркус Саерс, Йосуке Сато, Дэн Сиддики, Доминик Спортиш, Хуан Урьягерека, Элли ван Гелдерен, Эндрю Уэгэрека, Элли ван Гелдерен и Уилсон.Я особенно благодарен аспирантам, которые участвовали в моей исследовательской группе Stack-Sorting Research (2015-2016). Конечно, все ошибки и недоразумения в этой статье — мои собственные.
Сноски
Список литературы
Абельс, К., Нилман, А. (2012). Линейные асимметрии и LCA. Синтаксис 15, 25–74. DOI: 10.1111 / j.1467-9612.2011.00163.x
CrossRef Полный текст | Google Scholar
Барбирс, С., ван дер Аувера, Дж., Беннис, Х., Бёф, Э., де Фогелар, Г., и ван дер Хам, М. (2008). Синтаксический атлас голландских диалектов, Vol. II , Амстердам: Издательство Амстердамского университета.
Google Scholar
Бервик Р., Хомский Н. (2016). Почему только мы: язык и эволюция . Кембридж, Массачусетс: MIT Press.
Google Scholar
Бравер Т.С., Грей Дж. Р. и Берджесс Г. К. (2007). «Объяснение множества разновидностей вариаций рабочей памяти: двойные механизмы когнитивного контроля», в Variation in Working Memory , eds A.Конвей, К. Джарролд, М. Кейн, А. Мияке и Дж. Тоуз (Нью-Йорк, Нью-Йорк: издательство Оксфордского университета), 76–106.
Google Scholar
Чеси К. и Моро А. (2015). «Тонкая зависимость между компетенцией и эффективностью», в 50 лет спустя: размышления об аспектах Хомского , ред. Á. Дж. Галлего и Д. Отт (Кембридж, Массачусетс: Рабочие документы Массачусетского технологического института по лингвистике), 33–46.
Google Scholar
Хомский, Н. (1965). Аспекты теории синтаксиса .Кембридж, Массачусетс: MIT Press.
Google Scholar
Хомский, Н. (1995). Программа минимализма . Кембридж, Массачусетс: MIT Press.
Google Scholar
Чинкве, Г. (1999). Наречия и функциональные головы: кросс-лингвистическая перспектива . Оксфорд: Издательство Оксфордского университета.
Google Scholar
Чинкве, Г. (2005). Получение универсальных 20 Гринберга и их исключения. Лингвистический справочник 36, 315–332. DOI: 10.1162/002438
96917CrossRef Полный текст | Google Scholar
Делл, Г. С., Чанг, Ф. (2014). P-цепь: связь производства предложений и их нарушений с пониманием и усвоением. Фил. Пер. R. Soc. В 369: 20120394. DOI: 10.1098 / rstb.2012.0394
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Фодор, Дж. Д. (1978). Стратегии синтаксического анализа и ограничения на преобразования. Linguistic Inquiry 9, 427–473.
Google Scholar
Фодор, Дж. Д., и Фернандес, Э. (2015). Спецвыпуск по грамматикам и синтаксическим анализаторам: к единой теории знания и использования языков. J. Психолингвист. Res. 44, 1–5. DOI: 10.1007 / s10936-014-9333-3
CrossRef Полный текст
Фрейзер, Л., и Фодор, Дж. Д. (1978). Колбасная машина: новая модель двухэтапного разбора. Познание 6, 291–325. DOI: 10.1016 / 0010-0277 (78)
-1
CrossRef Полный текст | Google Scholar
Гринберг, Дж.(1963). «Некоторые универсалии грамматики с особым упором на порядок значимых элементов», in Universals of Language , ed J. Greenberg (Cambridge, MA: MIT Press), 73–113.
Google Scholar
Хюттиг Ф. и Мани Н. (2016). Необходимо ли предсказание для понимания языка? Возможно нет. Lang. Cogn. Neurosci. 31, 19–31. DOI: 10.1080 / 23273798.2015.1072223
CrossRef Полный текст | Google Scholar
Джаясилан, К.А.(2008). Простая структура фразы и синтаксис без спецификатора. Биолингвистика 2, 87–106.
Google Scholar
Джоши А. К. (1990). Обработка скрещенных и вложенных зависимостей: автоматическая точка зрения на психолингвистические результаты. Lang. Cogn. Процесс 5, 1-27. DOI: 10.1080 / 0169096
02095
CrossRef Полный текст | Google Scholar
Кейн Р. (1994). Антисимметрия синтаксиса . Кембридж, Массачусетс: MIT Press.
Google Scholar
Кемпсон, Р., Мейер-Виол, В., и Габбей, Д. (2001). Динамический синтаксис . Оксфорд: Блэквелл.
Google Scholar
Кнут, Д. (1968). Искусство программирования, Vol. 1. Основные алгоритмы . (Ридинг, Массачусетс: Эддисон-Уэсли).
Купман, Х. (2000). Синтаксис спецификаторов и заголовков . Лондон: Рутледж.
Маркус, М. П. (1980). Теория синтаксического распознавания естественных языков . Кембридж, Массачусетс: MIT Press.
Google Scholar
Марр, Д.(1982). Видение: компьютерное исследование человеческого представления и обработки визуальной информации . Нью-Йорк, штат Нью-Йорк: В. Х. Фриман.
Мама С., Слевц Л. Р. и Филлипс К. (2015). «Сроки планирования глаголов в активных и пассивных предложениях», в плакате , представленном на 28-й ежегодной конференции CUNY по обработке человеческих приговоров (Лос-Анджелес, Калифорния).
Google Scholar
Филлипс К. и Льюис С. (2013). Порядок образования производных в синтаксисе: свидетельства и архитектурные последствия. Stud. Линг. 6, 11–47.
Google Scholar
Ричардс, Н. (1997). Что куда движется и когда на каком языке? Докторская диссертация, Массачусетский технологический институт.
Ричардс, Н. (2010). Процветающие деревья . Кембридж, Массачусетс: MIT Press.
Google Scholar
Рицци, Л. (1997). «Тонкая структура левой периферии», в Elements of Grammar: Handbook in Generative Syntax , ed L. Haegeman (Dordrecht: Kluwer), 281–337.
Google Scholar
Шмид Т. и Фогель Р. (2004). Диалектные вариации в немецких трехглагольных кластерах: поверхностно-ориентированное описание ОТ. J. Compar. Германский линг. 7, 235–274. DOI: 10.1023 / B: JCOM.0000016639.53619.94
CrossRef Полный текст
Шихан М., Биберауэр Т., Робертс И., Песецки Д. и Холмберг А. (2017). Заключительное-за-окончательное условие: синтаксический универсал, т. 76 , Кембридж, Массачусетс: MIT Press.
Стейблер, Э.П. младший (1991). «Избегайте парадокса пешехода», в Principle-Based Parsing: Computing and Psycholinguistics , eds R. Berwick, S. Abney, and C. Tenny (Dordrecht: Kluwer), 199–237.
Google Scholar
Starke, M. (2004). «Об отсутствии спецификаторов и природе голов», в The Cartography of Syntactic Structures, Vol. 3: Структуры и за ее пределами , под ред. А. Беллетти. (Нью-Йорк, штат Нью-Йорк: издательство Оксфордского университета), 252–268.
Стедди, С., и Самек-Лодович, В. (2011). О некграмматичности движения остатка в выводе универсального 20 Гринберга. Linguistic Inquiry 42, 445–469. DOI: 10.1162 / LING_a_00053
CrossRef Полный текст | Google Scholar
Стидман М. (2000). Синтаксический процесс . Кембридж, Массачусетс: MIT Press.
Google Scholar
Таненхаус, М. К., Трюзуэлл, Дж. К. (2006). «Движение глаз и понимание устной речи», в Справочнике по психолингвистике , ред. М.Traxler и M. A. Gernsbacher (Нью-Йорк, Нью-Йорк: Elsevier Academic Press), 863–900.
Google Scholar
Тулвинг, Э. (1999). «Об уникальности эпизодической памяти» в Cognitive Neuroscience of Memory , ред. Л. Нильссон и Х. Дж. Маркович (Ашленд, Огайо: Хогрефе и Хубер), 11–42.
Google Scholar
Вурмбранд, С. (2006). «Группы глаголов, повышение и реструктуризация глаголов», в The Blackwell Companion to Syntax , Vol. V, редакторы М. Эверарт и Х.ван Римсдейк (Оксфорд: Блэквелл), 227–341.
Google Scholar
Zwart, C.J. (2007). Некоторые заметки о происхождении и распространении IPP-эффекта. Groninger Arbeiten zur Germanistischen Linguistik 45, 77–99.
Google Scholar
статей и слайдов
Документы и слайды
Высоконадежная проверка ввода: блокировка входной двери. Кэтлин Фишер (Университет Тафтса).
Резюме: Кибербезопасность — сложная проблема, которая имеет серьезные негативные последствия для личной, финансовой и национальной безопасности.Отчасти это сложно потому, что защитники должны запирать каждую дверь, в то время как защитникам нужно найти только один путь внутрь. Защита от вредоносных программ эквивалентна запиранию входной двери, но, согласно объявлению агентства DARPA Safedocs Broad Agency, 80% из проблем в базе данных MITRE Common Vulnerabilities and Exposures связаны сбои проверки входных данных. Мы даже не запираем как следует входную дверь! Как будет выглядеть высоконадежная проверка ввода? По крайней мере, это требует нескольких шагов:
(1) указание языка ввода на формальном языке описания, (2) проверка спецификации путем систематического тестирования, (3) создание высоконадежного синтаксического анализатора, а затем (4) обеспечение корректной обработки клиентским кодом всех терминов на языке ввода.
Конечно, это видение вводит множество практических проблем, включая выразительность формального языка описания, наличие и удобство использования высоконадежной инфраструктуры синтаксического анализа, производительность сгенерированных синтаксических анализаторов и применимость инструментов рассуждения для оценки клиентского кода. В этом выступлении я рассмотрю состояние дел в области высоконадежной валидации входных данных, обсудю препятствия на пути к принятию и размышлю о будущих направлениях исследований.
Биография: Кэтлин Фишер — профессор и заведующая кафедрой компьютерных наук в Университете Тафтса.Ранее она была менеджером программы в DARPA и главным членом технического персонала в AT&T Labs Research. Она получила степень доктора компьютерных наук в Стэнфордском университете. Исследования Кэтлин сосредоточены на продвижении теории и практики языков программирования и на применении идей сообщества языков программирования к проблеме специального управления данными. Кэтлин — член ACM и бывший председатель Специальной группы ACM по языкам программирования (SIGPLAN).Она работала председателем программ PLDI, ICFP и OOPSLA, редактором журнала функционального программирования и ассоциированным редактором TOPLAS. Она была сопредседателем CRA-W с 2008 по 2011 год и часто выступает на мероприятиях CRA-W. Она — бывший председатель ISAT DARPA и член Совета CCC. Она была научным сотрудником Фонда Герца.
[слайды]
Формальные языки, глубокое обучение, топология и алгебраические задачи со словом. Джордж Сибенко и Джошуа М. Акерман (Дартмутский колледж).
Аннотация: В этой статье описываются взаимосвязи между различными современными архитектурами нейронных сетей и формальными языками, например, структурированными иерархией языков Хомского. Особый интерес представляют способности нейронной архитектуры представлять, распознавать и генерировать слова из определенного языка путем изучения положительных и отрицательных образцов слов на этом языке. Особый интерес представляют некоторые отношения между языками, сетями и топологией, которые мы описываем аналитически и исследуем с помощью нескольких иллюстративных экспериментов.Специально сравнивая аналитические результаты, связывающие формальные языки с топологией с помощью алгебраических задач со словами, с эмпирическими результатами, основанными на нейронных сетях и постоянных вычислениях гомологии, мы видим доказательства того, что определенные наблюдаемые топологические свойства соответствуют аналитически предсказанным свойствам. Такие результаты обнадеживают для понимания роли, которую современное машинное обучение может играть в проблемах формальной языковой обработки.
Цибенко Био: Джордж Сибенко — профессор инженерных наук Дороти и Уолтера Грэмм в Дартмуте.Профессор Цибенко внес ключевой вклад в исследования в области обработки сигналов, нейронных вычислений, параллельной обработки и вычислительного поведенческого анализа. Он был главным редактором-основателем IEEE / AIP Computing in Science and Engineering, IEEE Security & Privacy и IEEE Transactions on Computational Social Systems. В прошлом он работал в Научном совете обороны и Научно-консультативном совете ВВС, а также является советником Армейского кибер-института в Вест-Пойнте. Профессор Цибенко является членом IEEE и SIAM.Он получил степени бакалавра математики (Университет Торонто) и доктора философии (Принстон). Цибенко был соучредителем Flowtraq Inc, которая была приобретена Riverbed Technology в 2017 году.
Акерман Биография: Джошуа Акерман — аспирант Института безопасности, технологий и общества Дартмутского колледжа. Его исследования в основном сосредоточены на пересечении машинного обучения и кибербезопасности, с особым вниманием к тому, как сделать системы машинного обучения более надежными и надежными.Он получил степень бакалавра математики и информатику в Университете Карнеги-Меллона.
[Бумага] [слайды]
Работа в процессе: единая алгебраическая структура программного анализа. Мартин Ринард (MIT), Хенни Сипма (Aarno Labs), Thomas Bourgeat (MIT).
Abstract: Программные анализы традиционно формулировались в виде точек. решения конкретных задач программного анализа. Мы представляем всеобъемлющая унифицированная структура, которая помещает анализ программ в структура алгебраической решетки, основанная на программе, отслеживающей, что каждый анализ идентифицирует.В этом контексте анализ каждой программы характеризуется набором программных трассировок, которые он идентифицирует, с программный анализ, упорядоченный обратным включением подмножеств по наборам выявленные программные следы. При таком заказе сборник программы анализ состоит из решетки с наименьшей верхней границей и наибольшей нижней оценкой. граница.
[Бумага] [слайды]
«Дословно: проверенный генератор лексического анализа». Дерек Эгольф, Сэм Лассер и Кэтлин Фишер (Университет Тафтса).
Лексеры и синтаксические анализаторы часто используются в качестве внешних интерфейсов для соединения входных данных из внешнего мира с внутренними компонентами более крупной программной системы.Эти интерфейсы — естественные цели для злоумышленников, которые хотят взломать более крупную систему. Официально проверенный инструмент, который выполняет механизированный лексический анализ, сделает атаки на эти интерфейсы менее эффективными.
В этой статье мы представляем Verbatim, исполняемый лексер, реализованный и проверенный с помощью Coq Proof Assistant. Мы доказываем, что Verbatim корректен по отношению к стандартной спецификации лексера. Мы также анализируем его теоретическую сложность и приводим результаты эмпирической оценки эффективности.Все доказательства корректности, представленные в статье, были механизированы в Coq.
[бумага] [Обсуждение видео]
«Теория формального языка для практической безопасности»; Андреас Якоби, Яннис Лойтер и Стефан Люкс (Баухаус-университет Веймара).
Когда двоичные данные отправляются от одной стороны к другой, кодирование данных может быть описано как язык «сериализации данных» (DSL). Многие DSL используют шаблон «длина-префикс» для строк, контейнеров и других элементов данных переменной длины.Он состоит из кодирования длины элемента, за которым следует кодирование самого элемента — без закрывающих скобок или символов «конца». Получатель должен определить последний байт из длины, прочитанной ранее. Языки с префиксом длины не являются контекстно-зависимыми. Таким образом, множество инструментов и методов для определения, анализа и синтаксического анализа контекстно-свободных языков оказывается бесполезным для языков с префиксом длины. Это, кажется, объясняет, почему неправильные спецификации языков с префиксом длины и ошибочные рукописные синтаксические анализаторы так часто являются основной причиной проблем с безопасностью и эксплойтов, например, e.g., в случае известной ошибки Heartbleed. У кого-то может возникнуть соблазн рассматривать использование языков с префиксом длины как угрозу безопасности.
Но это соображение было бы неверным. Мы представляем преобразование слов из языков «без контекста» (надмножество языков без контекста и языков с префиксом длины) в слова из правильных языков без контекста. Преобразование фактически позволяет использовать инструменты из контекстно-свободных языков для работы с языками с префиксом длины.
Наше преобразование выполняется на машине Тьюринга с логарифмическим пространством.Это подразумевает теоретический результат того, что языки, не зависящие от контекста, находятся в классе сложности logCFL. Точно так же в logDCFL есть детерминированные бесконтекстные языки calc. Чтобы работать в линейном времени, необходимо расширить машину Тьюринга стеком для хранения дополнительных данных.
[Бумага] [Обсуждение видео]
«Формальный синтез компонентов фильтра для использования в архитектурных преобразованиях, повышающих безопасность»; Дэвид Хардин и Конрад Слинд (Collins Aerospace).
Разработчики, критичные к безопасности и защищенности, давно признали важность применения высокой степени проверки к системе (или подсистемы) границы ввода / вывода.Однако отсутствие внимательности в развитии таких компонентов фильтра может привести к увеличению, а не к уменьшение поверхности атаки. На DARPA Cyber-Assured Программа системной инженерии (CASE), мы сосредоточили наши исследования усилия по выявлению кибер-уязвимостей на раннем этапе системы разработка, в частности, на этапе разработки архитектуры, и затем автоматически синтезирует компоненты, уменьшающие против выявленных уязвимостей из высокоуровневых спецификаций. Этот подход полностью совместим с целями LangSec. сообщество.Достижения в формальных методах позволили нам производить аппаратные / программные реализации, которые одновременно и производительны, и гарантированно правильно. С помощью этих инструментов мы можем синтезировать высоконадежные « строительные блоки », которые можно составлять автоматически с высокой степенью уверенности для создания надежных систем, используя метод, который мы называем архитектурными преобразованиями, повышающими безопасность. Наш подход, ориентированный на синтез обеспечивает более высокую точку вставки для формальных методов, чем возможно с помощью аналитических методов постфактум, поскольку формальные методы инструменты напрямую способствуют внедрению системы, не требуя, чтобы разработчики становились экспертами по формальным методам.Наш методы охватывают разработку систем, оборудования и программного обеспечения, а также совместное проектирование аппаратного и программного обеспечения / совместное обеспечение. Мы иллюстрируем наши метод и инструменты с примером, который реализует повышение безопасности преобразования системной архитектуры, выраженные с помощью Архитектуры Язык анализа и дизайна (AADL). Мы покажем, как проверка ввода компоненты фильтра могут быть синтезированы из высокоуровневых стандартные или контекстно-свободные языковые спецификации, и проверено на соответствие арифметическим ограничениям, извлеченным из AADL модель.Наконец, мы гарантируем, что цель логики фильтра точно отражается в двоичном коде приложения за счет использования проверенный компилятор CakeML, в случае программного обеспечения, или Ограниченная алгоритмическая цепочка инструментов C с формальным интерфейсом на основе ACL2. проверка, в случае совместного проектирования аппаратного и программного обеспечения.
[Бумага]
«Доступные формальные методы для разработки проверенных парсеров»; Летиция Ли (BAE Systems), Грег Экман (BAE Systems), Элиас Гарсия (Особые обстоятельства) и Сэм Атман (Особые обстоятельства).
Недостатки безопасности в средствах чтения Portable Document Format (PDF) могут позволить файлам PDF скрывать вредоносные программы, извлекать информацию и выполнять вредоносный код. Чтобы программа чтения PDF могла идентифицировать эти дефектные PDF-файлы, необходимо проанализировать, а затем проанализировать семантические свойства или структуру результата синтаксического анализа. В этой статье показано, как доступные для разработчиков формальные методы поддерживают теоретико-языковой подход безопасности к синтаксическому анализу и проверке PDF. Мы разрабатываем синтаксический анализатор и валидатор PDF на ACL2, языке доказательства теорем, который позволяет нам генерировать доказательства желаемых свойств функций, таких как правильность.Структура синтаксического анализатора и семантические правила определяются грамматикой PDF и подпадают под определенные шаблоны, и поэтому могут быть автоматически составлены из набора проверенных базовых функций. Вместо того, чтобы требовать от разработчика знания формальных методов и написания кода ACL2 вручную, мы используем Tower, наш модульный метаязык, для генерации проверенных функций и доказательств ACL2, а также эквивалентный код C для анализа семантических свойств, которые затем можно интегрировать в наши проверенный синтаксический анализатор или существующий синтаксический анализатор для поддержки проверки PDF.
[бумага] [Обсуждение видео]
«Дифференциальный анализ декодеров команд x86-64»; Уильям Вудрафф («След битов»), Ники Кэрролл (Университет Джорджа Мейсона) и Себастьян Петерс (Технологический университет Эйндховена).
Дифференциальный фаззинг заменяет традиционные оракулы фаззера, такие как сбои, зависания, ненадежные обращения к памяти, на оракул различия, где реализация спецификации считается потенциально ошибочной, если ее поведение отличается от другой реализации на том же входе.Дифференциальный фаззинг был успешно применен к криптографии и синтаксическим анализаторам сложных форматов приложений, таким как PDF и ELF.
В этой статье описывается применение дифференциального фаззинга к декодерам инструкций x86-64 для обнаружения ошибок. Он представляет MISHEGOS, новый дифференциальный фаззер, который обнаруживает расхождения в декодировании между декодерами команд. Мы описываем архитектуру MISHEGOS и подход к обнаружению ошибок, а также последствия для безопасности ошибок и расхождений декодирования.Мы также описываем новую стратегию фаззинга для декодеров инструкций в архитектурах переменной длины, основанную на чрезмерно приближенной модели машинных инструкций.
MISHEGOS производит сотни миллионов тестов декодера в час на скромном оборудовании. Мы использовали MISHEGOS для обнаружения сотен ошибок в популярных декодерах инструкций x86-64, не полагаясь на аппаратный декодер для получения достоверной информации. MISHEGOS включает расширяемую структуру для анализа результатов кампании фаззинга, позволяющую пользователям обнаруживать ошибки в одном декодере или различные несоответствия между несколькими декодерами.Мы предоставляем доступ к исходному коду MISHEGOS по разрешительной лицензии.
[бумага] [Обсуждение видео]
«Богемия: валидатор для фреймворков синтаксического анализатора»; Аниш Паранджпе и Ганг Тан (Государственный университет Пенсильвании).
Синтаксический анализ повсеместно используется в программных проектах, начиная от небольших утилиты командной строки, высокозащищенные сетевые клиенты, большие компиляторы. Предоставляются программисты с множеством библиотек синтаксического анализа на выбор. Тем не мение, ошибки реализации в библиотеках синтаксического анализа позволяют генерировать некорректные парсеры, которые, в свою очередь, могут привести к сбою злонамеренного ввода системы или запускать эксплойты безопасности.В этой статье мы описываем облегченную структуру валидации под названием Bohemia. которую разработчик библиотеки синтаксического анализа может использовать в качестве инструмента в наборе инструментов для интеграционного тестирования. Фреймворк использует концепцию эквивалентности. Modulo Inputs (EMI) для генерации измененных входных грамматик для стресс-тест библиотеки синтаксического анализа. Мы также описываем результат оценка Богемии с помощью набора библиотек синтаксического анализа, которые используют различные алгоритмы синтаксического анализа. В ходе оценки мы обнаружили ряд ошибок в этих библиотеках.О некоторых из них было сообщено и исправлено разработчиками.
[бумага] [Обсуждение видео]
«RL-GRIT: Обучение с подкреплением для грамматического вывода»; Уолт Вудс (Galois Inc.).
Когда эксперт по формату работает над пониманием использования формата данных, примеры формата данных часто более репрезентативны, чем спецификация формата. Например, два разных приложения могут использовать очень разные представления JSON или два PDF-файла приложения могут использовать очень разные области PDF спецификация для реализации того же визуализированного контента.Сложность возникающие из этих различных источников, могут привести к большим, трудные для понимания поверхности атаки, представляющие угрозу безопасности при рассмотрении как эксфильтрации, так и информационной шизофрении. Грамматика вывод может помочь в описании практического языкового генератора за примерами формата данных. Однако большинство грамматических выводов исследования сосредоточены на естественном языке, а не на форматах данных, и не поддерживают важные функции, такие как рекурсия типов. Предлагаем роман набор механизмов для вывода грамматики, RL-GRIT, и применять их к понимание фактических форматов данных.После проверки существующей грамматики решениями логического вывода было определено, что новый, более гибкий эшафот можно найти в обучении с подкреплением (RL). В рамках этого работы, мы выкладываем множество алгоритмических изменений, необходимых для адаптации RL от его традиционной среды последовательного времени к высокоэффективной взаимозависимая среда парсинга. Результат — алгоритм который может наглядно изучить рекурсивные управляющие структуры в простых форматы данных, и может извлекать значимую структуру из фрагментов формат PDF.В то время как предыдущая работа в области вывода грамматики была сосредоточена на либо обычные языки, либо анализ аудитории, мы показываем, что RL может использоваться, чтобы превзойти выразительность обоих классов, и предлагает ясный путь к изучению контекстно-зависимых языков. Предлагаемый алгоритм может служить строительным блоком для понимания экосистемы де-факто форматов данных.
[бумага] [Обсуждение видео]
«Поиск несовместимых документов с использованием сообщений об ошибках от нескольких синтаксических анализаторов»; Майкл Робинсон (Американский университет).
Принятие файла одним парсером не является надежным индикация того, соответствует ли файл заявленному формату. Ошибки как в парсере, так и в спецификации формата означает, что совместимый файл может не разобрать, или что несовместимый файл может быть прочитанным без каких-либо видимых проблем. Последняя ситуация представляет собой значительный риск безопасности, и его следует избегать. эта статья предлагает лучший способ оценки соответствия спецификации формата заключается в проверке набора сообщений об ошибках, созданных набором синтаксических анализаторов. а не один синтаксический анализатор.Если и образец совместимых файлов, и доступны образцы несовместимых файлов, затем мы покажем, как Статистический тест, основанный на соотношении псевдоправдоподобия, может быть очень эффективен при определении соответствия файла. Наш метод — формат агностик и не полагается напрямую на формальную спецификацию Формат. Хотя эта статья посвящена случаю PDF-файла формат (ISO 32000-2), мы не пытаемся использовать какие-либо конкретные детали формата. Кроме того, мы показываем, как анализ главных компонентов может быть полезно разработчику спецификации формата для оценки качество и структура этих образцов файлов и парсеров.Пока эти тесты абсолютно рудиментарны, кажется, что их использование для измерить изменчивость формата файла и выявить несовместимые файлы. одновременно новаторский и удивительно эффективный.
[бумага] [Обсуждение видео]
«Механизированная безопасность для постепенного потока информации»; Тианю Чен и Джереми Сик (Университет Индианы).
Мы моделируем безопасный язык с постепенным потоком информации. этикеток в помощнике проверки, продемонстрируйте его потенциальное применение для анализ и защита конфиденциальных данных, вводимых пользователем, представление семантики как интерпретатор определений и доказывает безопасность типов.Мы сравниваем языковые особенности и свойства различных существующих постепенных языки с безопасным типом, проливающие свет на будущие проекты.
[Бумага] [Обсуждение видео]
«Делаем PDF понятным с помощью машиночитаемого определения»; Питер Вятт (PDF Association Inc.).
Эта статья представляет Арлингтонскую PDF-модель как первый открытый доступ, исчерпывающее машинно-читаемое определение всех официально определенные объекты PDF и отношения целостности данных.Этот представляет собой основную часть последней 1000-страничной спецификации ISO PDF 2.0. и является определением всей объектной модели PDF-документа, установление современной «основной истины» для всех будущих PDF исследовательские усилия и исполнители. Выражается как набор текстовых Файлы TSV с 12 полями данных, в настоящее время модель PDF Арлингтона определяет 514 различных объектов PDF с 3551 ключами и элементами массива и использует 40 настраиваемых предикатов для кодирования более 5000 правил. В Модель PDF Арлингтона успешно прошла проверку на альтернативные моделей, а также значительный корпус существующих файлов данных и был широко распространен в исследовательском сообществе SafeDocs, а также Техническая рабочая группа PDF ассоциации PDF.Это уже выявили различные существующие искажения данных и инициировали множественные изменения в спецификации PDF 2.0 для отражения фактического спецификации, устраните двусмысленность и исправьте ошибки.
[бумага] [Обсуждение видео]
«Создание файловой обсерватории для разработки безопасного синтаксического анализатора»; Тим Эллисон, Уэйн Берк, Крис Мэттманн, Анастасия Менсикова, Филип Саутэм и Райан Стоунбрейкер (Лаборатория реактивного движения НАСА).
Известно, что анализ ненадежных данных является сложной задачей.Неспособность справиться правильно созданные злонамеренно созданные данные могут (и действительно) привести к широкому диапазону уязвимостей. Языковая теоретическая безопасность (LangSec) философия стремится избавить разработчиков от необходимости применять специальные решения, вместо этого предлагая формально правильный и проверяемый ввод управление на протяжении всего жизненного цикла разработки программного обеспечения. Один из ключевых компоненты в разработке безопасных парсеров — это корпус с широким охватом что позволяет разработчикам понять проблемное пространство для данного форматировать и потенциально использовать в качестве семян для фаззинга и других автоматизированное тестирование.В этой статье мы предлагаем обновленную информацию о разработка файловой обсерватории для сбора и проведения анализа на разнообразная коллекция файлов в любом масштабе. В частности, мы сообщаем о добавление корпуса баг-трекера и новых аналитических методов на нашем существующий корпус.
[бумага] [слайды]
«Пегматит: анализ PEG с полями длины в программном и аппаратном обеспечении»; Зефир Лукас, Джоанна Лю, Прашант Анантараман и Шон Смит (Дартмутский колледж).
Поскольку парсеры — это линия защиты между двоичными файлами и ненадежными данных, они являются одними из наиболее распространенных источников уязвимостей в программное обеспечение.Теоретико-языковая безопасность обеспечивает подход к реализовать усиленные парсеры. Мы указываем двоичный формат как формальный грамматика и реализовать распознаватель для этой формальной грамматики. Тем не мение, в большинстве двоичных форматов используются такие конструкции, как поле длины, повторение поле и инструкция смещения. Большинство грамматических форматов не поддерживают эти особенности.
Основываясь на PEG и обычных языках calc, мы предлагаем Calc-Parsing Грамматики выражений (Calc-PEGs), формализация синтаксического анализа выражения грамматики, поддерживающие поле длины.2) время и параллельный алгоритм для разбора Расчет-ПЭГ за время O (n). Мы также представляем пегматит, инструмент для генерировать эти парсеры на C с возможностью генерации кода VHDL.
[бумага] [Обсуждение видео]
«Открытие новых вычислений через границы абстракции»; Марк Бодди, Джим Карчофини, Тодд Карпентер, Алекс Марер, Райан Перутка и Кайл Нельсон (Adventium Labs).
В этом отчете «Работа в процессе» мы описываем текущие исследования нашего проекта DECIMAL, направленные на решение проблемы моделирования вычислительных механизмов с достаточной точностью, чтобы рассуждать о семантике выполнения программ через границы абстракции.Разработанный нами формализм, основанный на автоматах, специально разработан для поддержки рассуждений о синхронизированном поведении по композициям многокомпонентных автоматов, моделирующих различные части исследуемой системы. Мы показываем, как мы используем композицию для моделирования широкого спектра конструкций, включая синхронизацию через границы абстракции, взаимодействие асинхронных процессов и определение программ, которые могут быть обобщены для разных архитектур и локализованных вариаций в спецификации программы.
[бумага] [Обсуждение видео]
«Проверенный генератор синтаксического анализатора для приложений микроконтроллера»; Самид Али и Шон Смит (Дартмутский колледж).
В этой статье представлен инструментарий для создания синтаксического анализатора, который генерирует проверенные синтаксические анализаторы на основе предоставленного пользователем описания синтаксического анализатора. Это описание синтаксического анализатора описано с использованием нового языка описания синтаксического анализатора (PDL). Синтаксические анализаторы, созданные этим языком описания синтаксического анализатора, не только проверяются (для обеспечения завершения синтаксического анализа и предотвращения повреждения памяти), но также строго ограничены в выразительности, поскольку PDL поддерживается формальной языковой моделью (конечный автомат).Ограниченная выразительность гарантирует, что сгенерированные синтаксические анализаторы будут иметь математические ограничения на их сложность, что позволит нам рассуждать о таких свойствах, как разрешимость и эквивалентность.Хотя эта работа не является основной, в будущем мы стремимся расширить эту работу с помощью модуля, который позволяет нам тестировать синтаксический анализатор. эквивалентность одного или нескольких сгенерированных синтаксических анализаторов. Произвольный кодированный вручную синтаксический анализатор, написанный на C, не позволяет нам с такой гибкостью рассуждать о таких свойствах. Эти синтаксические анализаторы являются нулевыми, предназначены для работы с крупномасштабными конечными машинами, а также достаточно компактны, чтобы их можно было развернуть на микроконтроллерах с ограниченными вычислительными ресурсами.Кроме того, PDL разработан так, чтобы быть кратким и достаточно описательным, чтобы описывать часто встречающиеся грамматические конструкции, обнаруживаемые в пакетах сетевых протоколов. Мы оценили парсеры, созданные для пакетов Bluetooth LowEnergy (BLE) LL (канального уровня), развернув их на микропрограммное обеспечение устройства Ubertooth One и атака на них вручную созданными искаженными пакетами BLE LL. Наши первоначальные результаты показывают, что усиленные парсеры эффективны против искаженных пакетов. Наша цель — протестировать его с помощью широкого спектра известных эксплойтов BLE LL, а также провести фазировку, чтобы тщательно оценить безопасность этих синтаксических анализаторов.Кроме того, в будущем мы также стремимся исследовать влияние этих парсеров на пропускную способность сети и производительность микроконтроллеров BLE
.[бумага] [слайды] [Обсуждение видео]
«Оптимизация размещения передачи данных с помощью анализа Парето»; Дж. Питер Брэди и Шон Смит (Дартмутский колледж).
Мы демонстрируем новый способ использования передачи данных и оптимизации Парето для добавления теоретико-языковой безопасности программным приложениям путем оценки структур данных приложения и их взаимодействия с другими данными в процессе работы приложения.Мы создаем общую модель и автоматизированные программы, которые предоставляют разработчику простой способ выбрать точку баланса между защитой и производительностью.
[бумага] [Обсуждение видео]
«На пути к платформе для сравнения генераторов двоичного синтаксического анализатора»; Оливье Левиллен, Себастьен Науд и Айна Токи Расоаманана (Télécom SudParis, Парижский политехнический институт).
Двоичные анализаторы повсеместно используются в программном обеспечении, которое мы используем каждый день, будь то интерпретация форматов файлов или сообщений сетевого протокола.Однако парсеры, как правило, хрупкие и часто вызывают ошибки и уязвимости в системе безопасности. За прошедшие годы было разработано несколько проектов, чтобы попытаться решить эту проблему с использованием различных форм, таких как комбинаторы синтаксического анализатора или предметно-ориентированные языки. Чтобы лучше понять эту богатую экосистему, мы создали платформу для тестирования и сравнения таких инструментов с различными спецификациями. С помощью нашей так называемой «платформы LangSec» мы обнаружили ошибки в различных реализациях и получили представление об этих инструментах.
[бумага] [Обсуждение видео]
Патент США для помощи в составлении имен в приложениях обмена сообщениями Патент (Патент № 10,848,453, выдан 24 ноября 2020 г.)
Настоящая заявка является продолжением заявки на патент США сер. № 14/089830, поданной 26 ноября 2013 г., в которой испрашивается преимущество даты подачи предварительной заявки на патент США № 61/904 731, поданной 15 ноября 2013 г., полное раскрытие которой включено в настоящий документ посредством ссылки. .
ОБЛАСТЬ РАСКРЫТИЯНастоящее раскрытие в целом относится к приложениям электронного обмена сообщениями и, в частности, к составлению сообщений в приложениях электронного обмена сообщениями.
ИСТОРИЯ ВОПРОСАСледуя прецеденту аналогов ручки и бумаги, которые предшествовали им, электронные письма, мгновенные сообщения (IM), текстовые сообщения и другие электронные сообщения часто состоят из приветствия или приветствия, которое включает имя одного или больше предполагаемых получателей электронного сообщения.Однако это приводит к ситуациям, когда составитель сообщения непреднамеренно ошибочно вводит имя получателя в приветствии или где-либо еще в теле сообщения. Такие ошибки особенно распространены, когда имя получателя необычно для культуры отправителя или когда имя пишется аналогично обычному слову, не являющемуся именем. Обычные механизмы обнаружения ошибок, такие как процессы проверки орфографии, использующие предопределенный общий словарь, часто не позволяют выявить такие ситуации. Чтобы проиллюстрировать, имя получателя может быть похоже по написанию на обычное слово, и отправитель может неосознанно произносить имя получателя как обычное слово, что затем приведет к тому, что орфографические ошибки останутся незамеченными, поскольку они соответствуют написанию, найденному в словаре проверки орфографии. .Кроме того, даже если имя получателя написано отправителем правильно, функция автокоррекции в некоторых приложениях для обмена сообщениями изменяет имя, чтобы оно соответствовало слову, найденному в словаре проверки орфографии. Такие инциденты могут вызвать смущение или замешательство у отправителя и получателя.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙНастоящее изобретение может быть лучше понято, а его многочисленные особенности и преимущества станут очевидными для специалистов в данной области техники со ссылкой на прилагаемые чертежи.Использование одних и тех же условных обозначений на разных чертежах указывает на аналогичные или идентичные элементы.
РИС. 1 представляет собой схему, иллюстрирующую электронное устройство, использующее помощь в составлении имени получателя с использованием опции автозаполнения для приложения обмена сообщениями в соответствии по меньшей мере с одним вариантом осуществления настоящего раскрытия.
РИС. 2 является схемой, иллюстрирующей интерфейс составления сообщений приложения обмена сообщениями, которое использует помощь в составлении имени получателя с использованием опции автозаполнения в соответствии с по меньшей мере одним вариантом осуществления настоящего раскрытия.
РИС. 3 — схема, иллюстрирующая интерфейс составления сообщений приложения обмена сообщениями, которое использует помощь в составлении имени получателя с использованием опции автозамены в соответствии с, по меньшей мере, одним вариантом осуществления настоящего раскрытия.
РИС. 4 — схема, иллюстрирующая интерфейс составления сообщений приложения обмена сообщениями, которое использует помощь в составлении имени получателя с использованием опции автозамены после составления в соответствии с, по меньшей мере, одним вариантом осуществления настоящего раскрытия.
РИС. 5 — блок-схема, иллюстрирующая способ предоставления помощи в составлении имени получателя для составления имени получателя в теле электронного сообщения в соответствии с по меньшей мере одним вариантом осуществления настоящего раскрытия.
РИС. 6 — схема, иллюстрирующая методику идентификации имен кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем анализа адреса получателя сообщения получателя электронного сообщения в соответствии с, по меньшей мере, одним вариантом осуществления настоящего раскрытия.
РИС. 7 — схема, иллюстрирующая методику идентификации имен кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем анализа отображаемого имени, связанного с адресом обмена сообщениями получателя электронного сообщения, в соответствии с, по меньшей мере, одним вариантом осуществления настоящего изобретения. раскрытие.
РИС. 8 — схема, иллюстрирующая методику идентификации имен кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем синтаксического анализа тела электронного сообщения в соответствии с, по меньшей мере, одним вариантом осуществления настоящего раскрытия.
РИС. 9 — схема, иллюстрирующая методику идентификации имен кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем выполнения поиска контактов в базе данных контактов с использованием контекста сообщения из одного или нескольких полей электронного сообщения в соответствии с, по меньшей мере, одним вариантом осуществления. настоящего раскрытия.
РИС. 10 — схема, иллюстрирующая методику идентификации имен кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем анализа содержимого другого приложения, которое инициировало составление электронного сообщения, в соответствии с, по меньшей мере, одним вариантом осуществления настоящего раскрытия.
РИС. 11 является схемой, иллюстрирующей реализацию электронного устройства , 100, в соответствии, по меньшей мере, с одним вариантом осуществления настоящего раскрытия.
ПОДРОБНОЕ ОПИСАНИЕСледующее описание предназначено для того, чтобы передать полное понимание настоящего раскрытия посредством предоставления ряда конкретных вариантов осуществления и деталей, включающих помощь в составлении имен во время составления электронного сообщения на электронном устройстве. Однако понятно, что настоящее раскрытие не ограничивается этими конкретными вариантами осуществления и деталями, которые являются только примерами, и объем раскрытия, соответственно, предназначен для ограничения только следующей формулой изобретения и ее эквивалентами.Кроме того, понятно, что специалист в данной области техники в свете известных систем и способов оценит использование раскрытия для его предполагаемых целей и получения преимуществ в любом количестве альтернативных вариантов осуществления, в зависимости от конкретной конструкции и других потребностей.
РИС. 1-11 иллюстрируют примерные методы для предоставления помощи в автоматизированном составлении имен в теле сообщения электронного сообщения, составляемого на электронном устройстве. По крайней мере, в одном варианте осуществления электронное устройство идентифицирует одно или несколько имен кандидатов-получателей на основе контекста сообщения и, в ответ на идентификацию, пользователь составляет приветствие или другое приветствие, которое, как ожидается, будет включать имя получателя в тело сообщения, предоставляет имя помощь в составлении с использованием одного или нескольких идентифицированных имен кандидатов для облегчения точного составления имени получателя.Помощь в составлении имени может быть предоставлена в виде графического представления выбранного имени кандидата в соответствии с одним или несколькими вариантами представления, такими как вариант автоматического предложения («автозаполнение»), вариант автоматического завершения («автозаполнение»), и вариант автоматического исправления («автокоррекция»). Для опции автозаполнения после идентификации пользовательского ввода, указывающего на триггер приветствия (например, ввод приветствия, такого как «Привет» или «Уважаемый», или инициирования ввода первого слова тела сообщения), одно или несколько имен кандидатов являются графически представлены в виде выбираемой пользователем опции через графический интерфейс пользователя (GUI) электронного устройства, и выбор пользователем выбираемой пользователем опции приводит к автоматическому заполнению («автозаполнению») выбранного имени кандидата в теле сообщения. как часть приветствия.Для опции автозаполнения после идентификации триггера приветствия и получения пользовательского ввода, указывающего состав начальных букв не приветствующего термина в теле сообщения, выбирается имя кандидата (если имеется более одного имени кандидата), и электронное устройство предоставляет графическое представление имени кандидата путем автономного завершения слова в теле сообщения на основе выбранного имени кандидата. Затем пользователь может решить принять это завершенное слово в качестве предполагаемого имени получателя или отклонить завершенное слово и, таким образом, вызвать его удаление из тела сообщения.Для опции автозамены электронное устройство определяет, включает ли приветствие в теле сообщения слово, соответствующее имени кандидата, и, если есть несоответствие, отображает уведомление о том, что пользователь мог ошибиться при составлении имени получателя в теле сообщения. Это уведомление может включать в себя выбираемую пользователем опцию для замены слова в приветствии предложенным именем кандидата. Опция автозамены может использоваться после завершения приветствия и перед составлением остальной части тела сообщения, после того, как тело сообщения было составлено (например,g., когда пользователь дал команду приложению обмена сообщениями инициировать передачу составленного электронного сообщения) и т.п. Ввод приветствий и других слов может осуществляться путем набора текста на клавиатуре, набора текста на виртуальной клавиатуре (сенсорного экрана), проведения пальцем по виртуальной клавиатуре, выбора букв с помощью мыши или сенсорной панели, набора букв на клавиатуре или с помощью набора клавиш, распознавания речи или другого типа ввод текста.
Идентификация имен кандидатов для процесса помощи в составлении имен может быть определена из внутреннего контекста сообщения, внешнего контекста сообщения или их комбинации.Внутренний контекст сообщения включает в себя поля самого электронного сообщения, такие как адреса сообщения получателя в полях адреса сообщения получателя, отображаемые имена полей отображаемых имен, связанных с адресами сообщения получателя, имена вложений файлов вложений, перечисленные в полях вложений ( и содержимое прикрепленных файлов), а также содержимое самого тела сообщения, такое как строка темы сообщения или содержимое предыдущего электронного сообщения, которое было включено в тело сообщения составляемого электронного сообщения.Внешний контекст сообщения включает в себя контекст сообщения, отличный от полей составляемого электронного сообщения, и, таким образом, может включать, например, базу данных контактов, поддерживаемую на электронном устройстве, или содержимое приложения, из которого было составлено электронное сообщение. инициировано (например, содержимое веб-страницы, содержащее ссылку, которая при выборе инициирует составление электронного сообщения). По меньшей мере, в одном варианте осуществления электронное устройство идентифицирует имена кандидатов из внутреннего или внешнего контекста сообщения путем анализа содержимого контекста сообщения для идентификации отдельных слов или комбинаций или слов, которые, как предполагается, представляют слова имени, или путем использования таких проанализированных слов для выполнения поиск имени, например, в базе данных контактов для определения соответствующего имени кандидата.Эта идентификация имени кандидата через внутренний и внешний контекст сообщения, таким образом, может использоваться для дополнения обычных процессов проверки орфографии, которые полагаются на заранее определенные словари орфографии, которые не отражают конкретный контекст имени получателя или другое содержимое составляемого электронного сообщения.
Для простоты иллюстрации большая часть последующего описания методов помощи в автоматизированном составлении имен предоставляется в соответствии с примером использования приложения для обмена сообщениями электронной почты портативного электронного устройства.Однако эти автоматизированные методы составления имен не ограничиваются этим контекстом, а вместо этого могут использоваться для любого из множества приложений для обмена электронными сообщениями, таких как приложения для обмена мгновенными сообщениями (IM), приложения для обмена текстовыми сообщениями, приложения для микроблогов, приложения для социальных сетей и подобное, аналогичное, похожее.
РИС. 1 иллюстрирует электронное устройство , 100, , использующее автоматизированную помощь в составлении имени получателя во время составления электронного сообщения в соответствии, по меньшей мере, с одним вариантом осуществления настоящего раскрытия.Электронное устройство , 100, может включать в себя любое из множества устройств, которые могут использоваться для обмена электронными сообщениями, например сотовый телефон с поддержкой вычислений («смартфон») или часы с возможностью работы с компьютером («умные часы»), планшетный компьютер, ноутбук. компьютер, настольный компьютер, игровая консоль, персональный цифровой помощник (КПК) и т.п.
В изображенном примере электронное устройство 100 включает в себя приложение для обмена сообщениями 102 , которое работает для передачи электронных сообщений между электронным устройством 100 и другими электронными устройствами через поставщика электронных сообщений 104 , доступного через одно или несколько сети 106 .Чтобы проиллюстрировать, приложение для обмена сообщениями , 102, может включать в себя веб-приложение электронной почты (например, Google Gmail ™), которое взаимодействует с сервером электронной почты в Интернете (один вариант осуществления поставщика сообщений , 104, ) через Интернет (один вариант осуществления сеть 106 ). В качестве другого примера приложение для обмена сообщениями , 102, может включать в себя почтовый клиент Microsoft Outlook ™, который взаимодействует с сервером Microsoft Exchange ™ (один из вариантов поставщика сообщений 104 ) через внутреннюю корпоративную сеть, Интернет или их комбинацию. .В качестве еще одного примера приложение для обмена сообщениями , 102, может включать в себя приложение для обмена мгновенными сообщениями (IM), которое обменивается данными с веб-сервером IM (один вариант осуществления поставщика , 104, сообщений) через Интернет. Другие примеры приложения для обмена сообщениями , 102, включают, например, приложение для обмена текстовыми сообщениями (например, приложение простой службы обмена сообщениями (SMS) или приложение службы обмена мультимедийными сообщениями (MMS)), приложение для микроблогов (например, приложение «твиттер»). предоставлено Twitter Inc.), приложение для социальных сетей (например, Facebook ™ или Google Circles ™) и т.п. В некоторых реализациях приложение для обмена электронными сообщениями , 102, отправляет и принимает электронные сообщения в координации с операционной системой (ОС) 108 (или другим системным программным обеспечением) электронного устройства , 100, . Чтобы проиллюстрировать, ОС , 108, может облегчить доступ к проводному или беспроводному сетевому интерфейсу, который соединяется с сетью , 106, , доступ к дисплею и устройствам пользовательского ввода (например,g., сенсорный экран, микрофон, мышь или клавиатура) электронного устройства 100 и т.п.
Одна из функций обмена сообщениями, предоставляемая приложением для обмена сообщениями 102 , — это представление графического пользовательского интерфейса (GUI) для облегчения составления пользователем электронных сообщений, которые должны быть переданы одному или нескольким получателям через провайдер сообщений 104 . Составление электронного сообщения управляется посредством ввода 110 композиции пользователя, принимаемого через один или несколько интерфейсов пользовательского ввода, связанных с этим графическим интерфейсом пользователя, например сенсорный экран, микрофон, мышь или клавиатуру.Пользовательский ввод композиции , 110, обычно включает в себя инструкцию для инициирования композиции электронного сообщения, такую как выбор пользователем кнопки «составить», отображаемой в графическом пользовательском интерфейсе (GUI), предоставляемом приложением для обмена сообщениями , 102, или голосом пользователя. команды, инструктирующие электронное устройство 100 инициировать новое электронное сообщение. Пользовательский ввод , 110, композиции также включает пользовательский ввод для предоставления адресов сообщения получателя в одном или нескольких полях адреса сообщения, а также пользовательский ввод для предоставления текста и другого типографского содержимого в тело сообщения составляемого электронного сообщения.
В ходе составления электронного сообщения пользователь электронного устройства 100 может пожелать обратиться к одному или нескольким получателям по имени в теле сообщения, например, инициируя содержание тела сообщения приветствием, которое включает одно или несколько имен получателей. Однако существует значительная вероятность того, что пользователь может неправильно написать имя предполагаемого получателя в теле сообщения, либо потому, что пользователь не знаком с именем (например, оно может не распространяться в культуре пользователя), оно может иметь несколько возможных написание (e.g., «Карл» против «Карл»), или это может иметь написание, очень похожее на другое слово. Для иллюстрации получателя электронного сообщения можно назвать «Gulprit», которое пользователь может непреднамеренно ввести как «Culprit» в теле сообщения из-за сходства их написания. Чтобы уменьшить или избежать ошибок написания имени получателя, по крайней мере, в одном варианте осуществления приложение обмена сообщениями , 102, обеспечивает автоматическую помощь в составлении имени получателя, идентифицируя имена кандидатов на основе контекста сообщения, а затем автономно способствуя правильному использованию имени в теле сообщения с помощью различной помощи пользователя. параметры, такие как параметр автозаполнения, параметр автозаполнения, параметр автозамены и т. д.
В одном варианте осуществления этой помощи в составлении имени получателя способствует различная информация, хранящаяся в электронном устройстве 100 . Такая информация может включать в себя, например, контекст сообщения , 112, самого сообщения. Этот контекст сообщения , 112, может включать внутренний контекст сообщения, который представляет собой информацию в полях составляемого сообщения, такую как информация в полях адреса сообщения получателя, например, адреса электронной почты в полях «Кому:», «Копия:» и «Bcc:» адресные поля, имена или другая основанная на имени информация, уже присутствующая или впоследствии добавленная в тело сообщения, и т.п.Этот контекст сообщения 112 также может включать в себя внешний контекст сообщения, который представляет собой информацию, которая не получается напрямую из полей составляемого электронного сообщения, например, содержимое в другом приложении, которое инициировало составление электронного сообщения или контактную запись получатель, к которому осуществляется косвенный доступ с использованием некоторой информации из внутреннего контекста сообщения.
Приложение обмена сообщениями 102 может использовать этот контекст сообщения 112 для идентификации одного или нескольких имен кандидатов (то есть имен, которые могут быть использованы пользователем при составлении тела сообщения) либо напрямую, например, путем создания имена кандидатов на основе синтаксического анализа частей адресов электронной почты, зависящих от получателя, в полях получателя или косвенно, например, путем определения идентификаторов получателя из полей сообщения и последующего использования этих идентификаторов, зависящих от получателя, для поиска соответствующего имени получателя, например, база данных контактов 114 хранится на электронном устройстве 100 .База данных контактов , 114, может включать, например, постоянный список контактов из записей контактов, которые были собраны приложением для обмена сообщениями 102 или другим приложением, которое разрешило доступ к своей базе данных контактов, например, записи контактов Google, доступные в приложение Google Gmail ™, набор записей контактов, доступных в приложении Microsoft Outlook ™, или набор записей «друзей», доступных в учетной записи пользователя Facebook ™. Идентифицированные таким образом имена кандидатов могут быть сохранены во временной базе данных , 116, имен кандидатов, которая может быть списком, таблицей или другой структурой данных, реализованной, например, в пространстве памяти или дисковом пространстве, выделенном приложению обмена сообщениями 102 , и может сохраняться в течение всего времени составления электронного сообщения, в течение всего времени, пока приложение , 102, обмена сообщениями работает или иным образом активно, и т.п.Ниже подробно описаны различные методы идентификации имен кандидатов.
С одним или несколькими именами кандидатов, идентифицированными и сохраненными в базе данных имен кандидатов 116 , приложение обмена сообщениями 102 отслеживает ввод композиции пользователя 110 для обнаружения любых потенциальных триггеров приветствия, которые могут включать в себя или быть связаны с Имя получателя. Такие триггеры приветствия могут включать в себя, например, ввод пользователя, указывающий на ввод типичного вступительного приветствия, например, когда пользователь вводит слово «Привет» или «Уважаемый» в начале тела сообщения.Более того, триггер приветствия может быть начальным вводом пользователем содержимого тела сообщения (то есть вводом первых нескольких букв или слова в теле сообщения), и, в частности, триггер приветствия может сработать, когда первые несколько буквы, набранные в теле сообщения, по существу совпадают с соответствующими начальными буквами идентифицированного имени кандидата. В ответ на обнаружение триггера приветствия приложение обмена сообщениями , 102, пытается помочь пользователю правильно составить имя получателя в теле сообщения.Как описано выше, эта помощь может быть предоставлена как графическое представление имени кандидата как часть одной или нескольких опций помощи пользователю, таких как опция автозаполнения, опция автозаполнения, опция автозамены и т.п.
Для иллюстрации на фиг. 1 изображен графический интерфейс 118 составления сообщения приложения для обмена сообщениями 102 для составления сообщения электронной почты получателю с именем «Gulprit» на адрес электронной почты «[email protected]», как указано в поле адреса для: 120 сообщения электронной почты.Этот графический интерфейс составления сообщения , 118, иллюстрирует реализацию опции автозаполнения, посредством которой приложение для обмена сообщениями 102 идентифицирует «Gulprit» как имя кандидата из адреса электронной почты «[email protected]» и, в ответ на ввод пользователя, представляющий ввод слова «Hi» 130 в тело сообщения 122 сообщения электронной почты, приложение обмена сообщениями 102 предоставляет возможность автозаполнения для завершения приветствия, представляя выбираемую пользователем опцию 124 в графическом интерфейсе пользователя 118 , который предлагает графическое представление имени «Gulprit» в виде одной записи имени кандидата 126 , идентифицированной из контекста сообщения 112 , и графическое представление имени «Gillray» в качестве другой записи имени кандидата 128 , то есть идентифицируется, например, из предварительно определенного орфографического словаря, имеющего в качестве записи «Gillray».В то время как выбираемая пользователем опция , 124, проиллюстрирована как графическое изображение списка выбираемых записей имени кандидата 126 , 128 , выбираемая пользователем опция 124 для автоматического предложения имен кандидатов может быть реализована в любом из множество способов, согласующихся с изложенными здесь учениями. При отображении выбираемой пользователем опции 124 , предполагая, что пользователь намеревался обратиться к Gulprit в теле сообщения 122 , пользователь может выбрать запись имени кандидата «Gulprit» 126 из выбираемой пользователем опции 124 , в ответ на это приложение обмена сообщениями 102 подставляет имя «Gulprit» в текущее положение курсора в теле сообщения 122 .Таким образом, имя получателя «Gulprit» правильно вводится в тело сообщения , 122, и исключается возможность ошибки пользователя при самостоятельном вводе имени «Gulprit».
РИС. 2, 3 и 4 иллюстрируют другие варианты помощи в автоматическом составлении имени получателя, которые могут быть предоставлены приложением для обмена сообщениями , 102, электронного устройства , 100, , показанного на фиг. 1 в связи с составлением электронного сообщения. Например, фиг. 2 иллюстрирует графический интерфейс , 218, составления сообщений, который предоставляется приложением для обмена сообщениями , 102, и который предоставляет возможность автозаполнения для помощи в составлении имен.Для опции автозаполнения приложение обмена сообщениями 102 отслеживает ввод композиции пользователя 110 (фиг.1) для обнаружения пользовательского ввода, представляющего ввод или другой ввод начального набора букв слова в теле сообщения 222 GUI составления сообщения 218 . В случае, если начальный набор букв совпадает с соответствующим начальным набором букв имени кандидата, идентифицированного из контекста сообщения 112 составляемого электронного сообщения, приложение обмена сообщениями 102 предоставляет графическое представление имени кандидата через параметр автозаполнения 224 , который представляет собой предлагаемое завершение слова в теле сообщения 222 .
В этом примере имя кандидата «Gulprit» идентифицируется из адреса электронной почты «[email protected]» в поле адреса «Кому» 220 . Для опции автозаполнения 224 , когда пользователь вводит приветственный триггер «Hi», за которым следует пробел, а затем три начальные буквы «Gul» слова 225 после приветственного триггера, приложение обмена сообщениями 102 идентифицирует этот начальный набор букв слова 225 в качестве достаточного совпадения с именем кандидата «Gulprit» и, таким образом, автоматически дополняет слово 225 в качестве имени кандидата «Gulprit».Как показано, это автозаполнение может включать, например, автоматическое введение оставшихся букв «prit» имени кандидата «Gulprit» в тело сообщения 222 после начальных букв «Gul» и предоставление некоторого индикатора того, что эти последние буквы 226 заполняются автоматически, например, с использованием текста другого цвета, подчеркивания и т.п. Если имя с автозаполнением — это слово, которое пользователь намеревался ввести, пользователь может указать свое согласие на автозаполнение, например, выбрав полосу «пробел» на клавиатуре или нажав кнопку «принять» или другую функцию принятия (не показано ), связанный с опцией автозаполнения 224 в графическом интерфейсе составления сообщения 218 .
РИС. 3 иллюстрирует графический интерфейс , 318, составления сообщений, который предоставляется приложением для обмена сообщениями , 102, и который предоставляет возможность автозамены. Для этого подхода к помощи в составлении имени получателя приложение обмена сообщениями 102 предоставляет опцию автозамены 324 для замены слова с идентифицированным именем кандидата после того, как слово уже было набрано и завершено в теле сообщения 322 . Таким образом, приложение для обмена сообщениями , 102, идентифицирует завершенное слово в теле сообщения 322 как потенциально представляющее имя получателя и проверяет, соответствует ли слово имени кандидата, идентифицированному для имени получателя.Если слово недостаточно соответствует имени кандидата, приложение обмена сообщениями 102 может отображать параметр автозамены 324 в графическом интерфейсе пользователя 318 , чтобы предоставить пользователю возможность заменить слово именем кандидата, графически представленным в опция автозамены 324 . В изображенном примере опция автозамены 324 включает диалоговое окно, которое предлагает пользователю возможность заменить слово «Culprit» в теле сообщения на имя кандидата «Gulprit», идентифицированное по адресу электронной почты в адресе to: поле 320 .В этом примере слово «Culprit» может быть идентифицировано как потенциально неправильно набранное имя получателя, например, из-за того, что оно следует сразу после триггера приветствия «Привет», написано с заглавной буквы, но не является первым словом предложения, или потому что оно в основном совпадает с названием «Gulprit».
Приложение для обмена сообщениями 102 может анализировать тело электронного сообщения, которое составляется, на предмет возможностей для представления опции автозамены в одной или нескольких точках процесса составления сообщения.В примере на фиг. 3, адрес обмена сообщениями получателя (например, «[email protected]») уже был введен в поле адреса сообщения получателя электронного сообщения, составляемого в момент начала составления тела сообщения, и, таким образом, приложение обмена сообщениями 102 может использовать этот адрес обмена сообщениями получателя для определения одного или нескольких имен кандидатов для опции автозамены. Таким образом, когда сигнализируется о завершении потенциального слова имени в теле сообщения (например, когда пользователь вводит символ «пробел» или другой символ пробела после слова), приложение обмена сообщениями , 102, может проверить слово в то время. завершения.Однако в некоторых случаях пользователь может инициировать составление тела сообщения перед заполнением любого из полей получателя электронного сообщения, и, таким образом, может не быть достаточного контекста сообщения для приложения обмена сообщениями , 102, , чтобы идентифицировать имя кандидата в время написания сообщения. Соответственно, в других случаях анализ тела сообщения для одного или нескольких потенциальных слов для автозамены имени может быть отложен до тех пор, пока пользователь не введет информацию о получателе.
РИС. 4 иллюстрирует пример процесса задержки опции автозамены до тех пор, пока составление сообщения не будет по существу завершено. В этом примере снимок экрана , 400, иллюстрирует состояние графического интерфейса пользователя 418 составления сообщения после того, как пользователь ввел сообщение в тело сообщения 422 , но до заполнения любого из полей адреса сообщения получателя графического интерфейса составления сообщения. 418 . В сообщении, введенном пользователем, имя «Gulprit» с ошибкой отображается как «Culprit».Однако, поскольку поля адреса сообщения получателя еще не заполнены на этом этапе, приложение обмена сообщениями , 102, может быть не в состоянии идентифицировать ошибку, потому что имена кандидатов не могут быть идентифицированы, а слово «виновник» написано правильно. , и, следовательно, не будет обнаружен с помощью стандартного процесса проверки орфографии с помощью предопределенного орфографического словаря. Напротив, снимок экрана 402 иллюстрирует графический интерфейс 418 составления сообщения после того, как пользователь заполнил поле адреса 420 с псевдонимом «Gulprit» (которое приложение обмена сообщениями 102 понимает как соответствующее «gulprit @» Gmail.com »в этом примере), и пользователь указал, что составление сообщения электронной почты завершено, инициируя передачу сообщения электронной почты, например, путем выбора значка« отправить » 423 графического интерфейса пользователя 418 составления сообщения.
В ответ на это указание на то, что составление завершено, приложение 102 обмена сообщениями может затем повторно оценить поля адреса сообщения получателя, чтобы определить, можно ли по ним определить имя кандидата. В этом случае приложение для обмена сообщениями может идентифицировать имя кандидата «Gulprit» и, таким образом, при анализе тела сообщения , 422, , может идентифицировать слово «Culprit» потенциально как версию имени кандидата «Gulprit» с ошибкой и, таким образом, предоставить опция автозамены, такая как опция автозамены 324 на фиг. 3 , чтобы заменить «Culprit» на «Gulprit» в теле сообщения 422 . Таким образом, приложение для обмена сообщениями , 102, может продолжать обновлять процесс помощи в составлении имен по мере того, как становится доступным дополнительный контекст сообщения.
РИС. 5 иллюстрирует примерный способ 500 работы приложения для обмена сообщениями 102 электронного устройства 100 для предоставления помощи в составлении имени во время составления электронного сообщения в соответствии по меньшей мере с одним вариантом осуществления.Метод , 500, запускается на этапе , 502, , когда пользователь выполняет действие, чтобы инициировать составление электронного сообщения. Это действие может включать, например, пользовательский ввод, указывающий инструкцию для приложения обмена сообщениями , 102, , чтобы инициировать составление сообщения, например, путем выбора значка «составить сообщение» в графическом интерфейсе приложения для обмена сообщениями 102 или в графическом интерфейсе пользователя ОС 108 (РИС. 1). В некоторых случаях составление электронного сообщения может быть инициировано косвенно.Чтобы проиллюстрировать, отдельное приложение может связывать или иным образом перенаправлять пользователя к приложению обмена сообщениями , 102, для составления сообщения. Чтобы проиллюстрировать, веб-сайт, отображаемый в веб-браузере, может включать в себя ссылку, которая инициирует вызов интерфейса прикладного программирования (API) к приложению для обмена сообщениями , 102, , чтобы позволить пользователю составлять электронное сообщение, связанное с веб-сайтом (например, пересылка статьи на веб-сайте указанному получателю или пересылка сообщения получателю, связанному с веб-сайтом).
В ответ на этот инициирующий ввод на этапе , 504, приложение обмена сообщениями , 102, генерирует и отображает графический интерфейс составления сообщения, чтобы облегчить пользователю ввод для составления электронного сообщения. Графический интерфейс составления сообщения обычно включает ряд полей, включая одно или несколько полей адреса сообщения получателя (например, поля адреса электронной почты для; cc: и bcc:) и одно или несколько полей тела сообщения, то есть поля адреса не получателя. (обратите внимание, что термин «тело сообщения» может включать, например, поле строки темы сообщения электронной почты, поскольку оно сродни заголовку сообщения).При отображении графического пользовательского интерфейса составления сообщения в блоке , 506, начальный ввод состава пользователя принимается приложением для обмена сообщениями , 102, через графический интерфейс составления сообщения.
В некоторых случаях этот ввод начального состава пользователя может включать в себя предоставление пользователем псевдонимов адресов или неполных адресов сообщения получателя в одном или нескольких полях адреса сообщения получателя электронного сообщения. В таких случаях на этапе , 508, приложение для обмена сообщениями , 102, идентифицирует полные или полные адреса сообщений получателя, используя функцию автозаполнения приложения для обмена сообщениями , 102, .Эта функция автозаполнения может, например, использовать псевдоним или частичный адрес сообщения получателя для выполнения поиска в базе данных контактов , 114, (фиг. 1), чтобы идентифицировать полный адрес сообщения получателя.
На этапе 510 приложение обмена сообщениями , 102, подготавливается для поддержки процесса помощи в составлении имени получателя для электронного сообщения, составляемого, путем определения внутреннего контекста сообщения, который может быть полезен при идентификации имен кандидатов.Этот внутренний контекст сообщения включает в себя контекст сообщения, определенный непосредственно из полей составляемого электронного сообщения, и, таким образом, может включать адреса сообщений получателей в полях адресов сообщений получателей электронного сообщения, имена файлов вложенных файлов, перечисленные в поле вложения, или содержимое. самих вложенных файлов и содержимого, уже присутствующего в поле тела сообщения, такого как любой исходный контент, составленный пользователем в теле сообщения, или электронное сообщение может включать в себя ответное сообщение или сообщение пересылки, и в этом случае тело сообщения может содержат содержание исходного электронного сообщения, служащего основой для ответа или переадресации сообщения.Это содержимое исходного электронного сообщения может включать, например, адреса получателей исходного электронного сообщения, а также одно или несколько имен получателей в поле тела сообщения.
В некоторых вариантах осуществления имена кандидатов также могут быть определены на основе внешнего контекста сообщения; то есть контекст сообщения, который не идентифицируется непосредственно полем составляемого электронного сообщения, и, таким образом, на этапе 512 приложение обмена сообщениями 102 определяет такой внешний контекст сообщения.Этот внешний контекст сообщения может включать в себя, например, определение имени получателя из базы данных , 114, контактов на основе поиска с использованием, по меньшей мере, части адреса сообщения получателя. Кроме того, поскольку составление электронного сообщения могло быть инициировано другим приложением (например, примером веб-сайта, описанным выше), внешний контекст сообщения может включать в себя контекстную информацию об этом другом приложении, такую как контент в приложении, связанном со ссылкой или другим источник создания электронного сообщения.
После определения одного или обоих из контекста внутреннего сообщения и внешнего контекста сообщения на этапе 514 приложение обмена сообщениями 102 идентифицирует одно или несколько имен кандидатов для электронного сообщения из внутреннего и внешнего контекста сообщения. Как более подробно описано ниже, идентификация этих имен кандидатов может включать в себя синтаксический анализ информации, относящейся к имени, во внутреннем контексте сообщения, поиск имен на основе специфической для получателя информации из контекста сообщения и т.п.Любые идентифицированные таким образом имена кандидатов могут быть сохранены во временной базе данных 116 имен кандидатов (фиг. 1), поддерживаемой приложением 102 обмена сообщениями для электронного сообщения.
Одновременно с процессом идентификации имени кандидата на этапе 516 приложение обмена сообщениями 102 отслеживает исходный ввод состава пользователя для обнаружения триггера приветствия, который указывает, что пользователь может намереваться включить имя получателя в поле тела сообщения.Как отмечалось выше, этот триггер приветствия может включать в себя ввод слова, которое обычно служит частью приветствия в сообщении, например, ввод «Привет», «Привет», «Уважаемый» и т. Д. Вместо этого триггер приветствия может включать ввод по крайней мере части слова в области тела сообщения, обычно используемой для приветствия, такой как первое или два слова в теле сообщения или набор слов, расположенный в верхнем левом углу поля тела сообщения, или ввод начального набора букв, который соответствует соответствующему начальному набору букв имени кандидата.
В ответ на обнаружение триггера приветствия на этапе 518 приложение обмена сообщениями 102 выбирает имя кандидата (если существует более одного имени кандидата), которое может отражать имя получателя, к которому пользователь собирается или пытается to, ввод в сочетании с триггером приветствия. Этот процесс выбора может включать применение одного или нескольких правил приоритизации. Например, правило приоритизации может предусматривать, что имена кандидатов, определенные из полей адреса сообщения получателя электронного сообщения, могут иметь приоритет выбора по сравнению с именами кандидатов, определенными из полей адреса не получателя, то есть полей тела сообщения.Кроме того, правило приоритизации может предусматривать, что имена кандидатов, определенные из поля to: address, могут иметь приоритет выбора по сравнению с именами кандидатов, определенными из поля cc: address, которые, в свою очередь, получают приоритет выбора над именами кандидатов, определенными из поля bcc: address и т. д. В ситуациях, когда триггер приветствия включает в себя ввод пользователем начального набора букв слова, которое, как ожидается, будет именем получателя, приоритет выбора среди нескольких имен кандидатов может быть отдан тому имени кандидата, которое наиболее близко соответствует начальному набору букв. .
С выбранным именем кандидата на этапе 520 приложение обмена сообщениями 102 может облегчить составление имени получателя, предоставляя через графический интерфейс составления сообщений один или оба варианта автозаполнения (например, фиг. 1) или автозаполнения. вариант (например, фиг. 2), который графически представляет имя кандидата пользователю для включения в тело электронного сообщения таким образом, чтобы предотвратить множество вероятных ошибок ввода пользователем для имени получателя. В случае, если параметр автозаполнения / вариант автозаполнения не принимается пользователем, или в случае, если ни один из вариантов не представлен, на этапе 522 приложение обмена сообщениями 102 продолжает отслеживать ввод композиции пользователя, чтобы определить, действительно ли пользователь завершил слово, предполагаемое пользователем как имя получателя, которое несовместимо с одним или несколькими идентифицированными именами кандидатов (например,g., не соответствует ни одному из идентифицированных имен кандидатов). Этот анализ может быть выполнен относительно быстро после того, как пользователь завершил ввод слова (например, после того, как после слова был введен пробел) или после того, как пользователь сигнализировал о завершении составления электронного сообщения, например, выбрав «сохранить »Или при попытке инициировать передачу электронного сообщения путем выбора значка« отправить ».
Если такое несоответствие имени кандидата / завершенного слова или несоответствие возникает в теле сообщения, то на этапе 524 приложение обмена сообщениями 102 может предоставить опцию автозамены (например.g., фиг. 3 и 4), чтобы уведомить пользователя о потенциальной ошибке и дать пользователю возможность исправить ошибку (если это ошибка), заменив вместо этого спорное слово предложенным именем кандидата. После внесения этого исправления или если такое исправление в первую очередь не требуется, на этапе , 526, приложение обмена сообщениями , 102, завершает составление электронного сообщения и отправляет электронное сообщение провайдеру обмена сообщениями , 104, (фиг.1) для рассылки по одному или нескольким адресам обмена сообщениями получателя, указанным в полях адреса сообщения получателя электронного сообщения.
РИС. 6-10 иллюстрируют примерные методы, которые могут использоваться приложением для обмена сообщениями , 102, , ОС , 108, или другим компонентом электронного устройства 100 на фиг. 1 для идентификации одного или более имен кандидатов из контекста сообщения , 112, составляемого электронного сообщения. В частности, фиг.6-8 иллюстрируют методы, которые идентифицируют имена кандидатов из внутреннего контекста сообщения (то есть информации в полях самого сообщения), а фиг. 9 и 10 иллюстрируют методы, которые идентифицируют имена кандидатов из внешнего контекста сообщения (то есть контекста из внешних источников, к которому осуществляется доступ или который идентифицируется на основе внутреннего контекста сообщения).
РИС. 6 иллюстрирует методику идентификации одного или нескольких имен кандидатов из адресов сообщения получателя, присутствующих в полях адреса сообщения получателя электронного сообщения.В этом подходе синтаксический анализатор , 600, приложения для обмена сообщениями , 102, обращается к зависящей от получателя части адреса сообщения получателя и анализирует вероятные слова имени из зависящей от получателя части. Однако, поскольку имя получателя может включать в себя несколько слов, синтаксический анализатор , 600, дополнительно может сгенерировать различные комбинации слов имени, проанализированных из адреса сообщения получателя, для генерации нескольких имен кандидатов. Чтобы проиллюстрировать, в изображенном примере синтаксический анализатор , 600, обращается к адресу электронной почты получателя 602 (один из вариантов адреса сообщения получателя) из поля to: address или поля cc: address или из исходного сообщения электронной почты, включенного в теле сообщения в случае, если составляемое сообщение электронной почты является ответным сообщением электронной почты или пересылаемым сообщением электронной почты.Адреса электронной почты обычно состоят из части, зависящей от получателя, за которой следует доменная часть с символом «@», разделяющим их. Таким образом, адрес электронной почты «[email protected]» включает специфичную для получателя часть «gulprit.singh» и часть домена «gmail.com». Таким образом, синтаксический анализатор , 600, может анализировать специфичную для получателя часть, чтобы идентифицировать одно или несколько потенциальных слов имени, посредством чего синтаксический анализатор , 600, может использовать различные разделители общих слов имени, такие как точка («.»), Подчеркивание (« _ »), тире (« — ») и т.п. для обнаружения отдельных слов. Таким образом, для специфической для получателя части «gulprit.singh» адреса электронной почты получателя , 602, , синтаксический анализатор , 600, может сгенерировать слова имени «gulprit» и «singh», и из комбинаций этих слов имени получить три имена кандидатов 604 , 606 , 608 — «Гулприт», «Сингх» и «Гулприт Сингх» соответственно. «Сингх Гулприт» также может быть разумным кандидатом, если в системе адресации электронной почты принято помещать фамилию или фамилию первыми в адресе электронной почты.Затем синтаксический анализатор , 600, может поместить эти имена кандидатов 604 , 606 и 608 в базу данных кандидатов 116 электронного устройства 100 для последующего использования при помощи композиции имен, как описано выше. Этот процесс может быть аналогичным образом применен для анализа имен файлов, перечисленных в поле вложения электронного сообщения.
РИС. 7 иллюстрирует методику идентификации одного или более имен кандидатов из поля отображаемого имени, связанного с адресом сообщения получателя, присутствующим в полях адреса сообщения получателя электронного сообщения.Часто по соображениям безопасности или по другим причинам организация, предоставляющая услуги электронного обмена сообщениями своим составляющим, может решить использовать специфичную для получателя часть адреса получателя сообщения, которая, будучи уникальной для получателя, не отражает имени получателя. Такие конфигурации затрудняют идентификацию имен кандидатов непосредственно из адреса получателя сообщения, если не делают невозможным. Однако протоколы электронной почты и другие протоколы обмена сообщениями часто предоставляют одно или несколько полей идентификации пользователя, которые могут быть более полезными при идентификации получателя, чем адрес получателя сообщений.Для иллюстрации, протоколы электронной почты предусматривают включение поля отображаемого имени в ассоциации с адресом электронной почты получателя, где в поле отображаемого имени хранится удобное для пользователя отображаемое имя. Синтаксический анализатор , 600, может использовать такие поля имени пользователя для идентификации одного или более имен кандидатов. В качестве примера, получатель составляемого сообщения электронной почты может быть указан в наборе полей получателя электронной почты , 702, , который включает в себя поле адреса электронной почты , 704, , в котором хранится адрес электронной почты «A100269 @ motorola».com »и поле отображаемого имени 706 , в котором хранится отображаемое имя« Gulprit Singh ». Зависящая от получателя часть адреса электронной почты «A100269» не содержит никакой полезной информации для прямой идентификации одного или нескольких слов имени, и, таким образом, синтаксический анализатор 600 вместо этого может анализировать отображаемое имя «Gulprit Singh» в поле отображаемого имени 706 , чтобы идентифицировать одно или несколько имен кандидатов. Как и в примере на фиг. 6, анализ этого отображаемого имени может привести к именам кандидатов 604 , 606 , 608 — «Gulprit», «Singh» и «Gulprit Singh», соответственно, которые хранятся в базе данных имен кандидатов 116 для использования в составлении имен приложением обмена сообщениями 102 .
РИС. 8 иллюстрирует метод идентификации одного или более имен кандидатов из поля тела электронного сообщения. Часто при составлении электронного сообщения поле тела сообщения может содержать контент, который включает в себя или иным образом идентифицирует, по меньшей мере, часть имени одного или нескольких получателей электронного сообщения. Для иллюстрации, электронное сообщение может быть ответом на предыдущее электронное сообщение или может пересылать предыдущее электронное сообщение другому получателю.В таких случаях одно или несколько полей тела сообщения и полей адреса сообщения получателя предыдущего электронного сообщения могут быть включены в поле тела сообщения составляемого электронного сообщения. Таким образом, поле тела сообщения может включать в себя адреса сообщения получателя получателей предыдущего электронного сообщения, отображаемые имена, связанные с адресами сообщения получателя, или другие ссылки на вероятных получателей, такие как строка подписи, включенная отправителем предыдущего сообщения. электронное сообщение в теле сообщения предыдущего электронного сообщения.Таким образом, синтаксический анализатор , 600, может анализировать поле тела электронного сообщения в таких случаях, чтобы идентифицировать одно или несколько имен кандидатов.
Чтобы проиллюстрировать, пример на фиг. 8 изображает поле 802 тела сообщения составляемого ответного сообщения электронной почты, при этом поле 802 тела сообщения включает в себя содержимое 804 исходного сообщения электронной почты. Этот контент , 804, включает в себя строку , 806, подписи отправителя исходного сообщения.Таким образом, синтаксический анализатор , 600, может анализировать контент , 804, , чтобы идентифицировать строку подписи , 806, , используя любой из множества методов синтаксического анализа, а затем анализировать строку подписи , 806, , чтобы идентифицировать потенциальные слова имени. Этот синтаксический анализ может включать в себя, например, отбрасывание или игнорирование слов, предварительно идентифицированных, например, в словаре синтаксического анализа (не показан) как не указывающие имена получателей. При синтаксическом анализе проиллюстрированной строки подписи 806 синтаксический анализатор 600 проигнорирует слова «CTO», «Motorola», «Mobility» и «Inc.», И таким образом получаем именные слова« Pathy »и« Sunil »как именные слова. Из комбинаций этих именных слов синтаксический анализатор 600 может сгенерировать, например, имена кандидатов 808 , 810 , 812 — «Пати», «Сунил» и «Пати Сунил» соответственно, и сохранить этих кандидатов. имена 808 , 810 , 812 в базе данных кандидатов для использования при составлении имен приложением обмена сообщениями 102 . Этот процесс может быть аналогичным образом применен к синтаксическому анализу содержимого файлов, перечисленных как вложения в поле вложения электронного сообщения.
РИС. 9 иллюстрирует метод косвенной идентификации одного или более имен кандидатов с использованием базы данных , 114, контактов (фиг. 1), хранящейся в электронном устройстве , 100, . Как отмечалось выше, адрес сообщения получателя может не содержать информацию, полезную для прямой идентификации имен кандидатов, и может не быть отображаемого имени или другого удобного для пользователя поля именования, связанного с адресом сообщения получателя. Однако пользователь мог ранее иметь дело с получателем, связанным с адресом сообщения получателя, и, таким образом, может иметь контактную запись для получателя в базе данных контактов , 114, .Эта контактная запись может включать различную информацию о получателе, такую как имя получателя, должность, работодатель, адрес, номер телефона и различные адреса электронных сообщений для получателя. Соответственно, в таких случаях приложение для обмена сообщениями , 102, или другой компонент электронного устройства 100 на фиг. 1 может использовать модуль поиска контактов для идентификации записи контакта, связанной с контекстом сообщения, идентифицированного в одном или нескольких полях составляемого электронного сообщения, и из этой записи контакта косвенно идентифицировать одно или несколько имен кандидатов.
Чтобы проиллюстрировать, в изображенном примере единственной информацией, идентифицирующей получателя создаваемого сообщения электронной почты, является адрес электронной почты , 902, , который имеет специфичную для получателя часть «A100269», которая не отражает имя получателя, связанного с адрес электронной почты 902 . Соответственно, модуль поиска контактов , 900, может использовать эту специфичную для получателя часть для поиска в базе данных 114 контактов для записи контакта, которая имеет поле, которое соответствует специфической для получателя части «A100269».В этом примере база данных контактов , 114, имеет соответствующую запись контакта, связанную с человеком по имени «Гулприт Сингх», и, таким образом, модуль поиска контактов , 900, может анализировать поля имени в этой совпадающей записи контакта, чтобы идентифицировать имя. слово 904 слова «Gulprit» и слово фамилии 906 слова Singh. Модуль поиска контактов , 900, может затем сохранить эти слова имен 904 , 906 в базе данных имен кандидатов 116 , после чего синтаксический анализатор 600 (ФИГ.6) затем объединяет слова имени в различные имена кандидатов «Gulprit», «Singh» и «Gulprit Singh», или модуль поиска контактов 900 может сгенерировать эти имена кандидатов непосредственно перед сохранением их в базе данных имен кандидатов 116 . Таким образом, как показано в этом примере, модуль поиска контактов , 900, использует внутренний контекст сообщения, а именно адрес электронной почты получателя , 902, , для косвенной идентификации одного или нескольких имен кандидатов через внешний контекст сообщения, а именно контактную запись в базе данных контактов . 114 .
РИС. 10 иллюстрирует метод косвенной идентификации одного или более имен кандидатов с использованием читаемого пользователем контента приложения, из которого было инициировано составление электронного сообщения. Веб-браузеры, приложения социальных сетей и другие подобные приложения часто имеют возможность запускать или инициировать составление электронного сообщения. Чтобы проиллюстрировать, веб-браузер может отображать новостной веб-сайт, имеющий ссылку, которая, при выборе пользователем, связывается с приложением обмена сообщениями 102 , чтобы инициировать составление электронного сообщения, которое, например, используется для пересылки связанной новостной статьи на получатель.Сами по себе другие электронные сообщения могут иметь такие ссылки, которые запускают составление электронного сообщения. В таких случаях, с учетом того, что имя получателя часто находится в непосредственной близости от ссылки или другой функции в содержимом приложения, приложение, которое запускает составление электронного сообщения, может иметь читаемый пользователем контент, который может служить основа для идентификации одного или нескольких возможных имен получателя электронного сообщения. Таким образом, синтаксический анализатор , 600, может анализировать этот читаемый пользователем контент другого приложения, чтобы идентифицировать одно или несколько имен кандидатов.
Чтобы проиллюстрировать, в изображенном примере веб-страница, отображаемая веб-браузером, включает в себя читаемый пользователем контент 1002 , который включает текст, инструктирующий представление о том, чтобы сделать резервирование на мероприятие, связавшись с «Хэ Юн Ким» по указанному адресу электронной почты «HYK1032. @ gmail.com », и посредством чего текст адреса электронной почты служит гипертекстовой ссылкой, которая при выборе зрителем через веб-браузер заставляет веб-браузер связываться с приложением для обмена сообщениями 102 , чтобы инициировать составление адресованного сообщения электронной почты. на «HYK1032 @ gmail.com ». Поскольку с этого адреса электронной почты невозможно проанализировать полезные имена кандидатов, синтаксический анализатор , 600, вместо этого может анализировать читаемое пользователем содержимое веб-страницы в непосредственной близости от гипертекстовой ссылки, чтобы идентифицировать одно или несколько имен кандидатов. В этом примере этот текст рядом включает фразу 1003 «Чтобы ответить на приглашение на мероприятие, пожалуйста, свяжитесь с Хэ Юн Ким по адресу [email protected]», которую синтаксический анализатор 600 может проанализировать, чтобы идентифицировать слова имени «Hae , »« Юн »и« Ким », и которые могут быть объединены, например, в имена кандидатов 1004 , 1006 , 1008 и 1010 -« Хэ »,« Юн »,« Хэ Yun »и« Kim », соответственно, и хранятся в базе данных имен кандидатов 116 .
Следует принять во внимание, что приложение, из которого было инициировано электронное сообщение, может быть отдельным от приложения для обмена сообщениями 102 . В таких случаях синтаксический анализатор , 600, может быть реализован вне приложения для обмена сообщениями , 102, , например, в другом приложении или в ОС , 108, , чтобы иметь возможность доступа к контенту другого приложения. В качестве альтернативы, синтаксический анализатор , 600, может быть реализован как часть приложения для обмена сообщениями , 102, , а читаемый пользователем контент другого приложения может быть передан синтаксическому анализатору , 600, как часть запроса на начало составления электронного сообщения. сообщение.Например, вызов API, сделанный другим приложением в ответ на выбор гипертекстовой ссылки зрителем, может включать в себя унифицированный указатель ресурса (URL) веб-страницы, на которой находится читаемый пользователем контент, и синтаксический анализатор 600 , таким образом может использовать этот URL-адрес для доступа к веб-странице и анализа ее содержимого для идентификации слова имени.
РИС. 11 иллюстрирует пример реализации электронного устройства 100 по фиг. 1 в соответствии, по меньшей мере, с одним вариантом осуществления настоящего раскрытия.В изображенном примере электронное устройство , 100, включает в себя по меньшей мере один процессор 1102 (например, центральное устройство обработки или ЦП), один или несколько энергонезависимых машиночитаемых носителей данных, таких как системная память 1104 или другой запоминающее устройство 1106 (например, флэш-память, оптический или магнитный диск, твердотельный жесткий диск и т. д.), сетевой интерфейс 1108 (например, интерфейс беспроводной локальной сети (WAN) или проводной интерфейс Ethernet), и пользовательский интерфейс (UI) , 1110, , подключенный через одну или несколько шин , 1112, или другие межсоединения.UI 1110 включает в себя, например, устройство отображения 1114 и клавиатуру или сенсорный экран 1116 , а также другие компоненты ввода / вывода 1118 , такие как динамик или микрофон, для приема ввода от, или предоставить информацию пользователю.
Процессор 1102 выполняет набор исполняемых инструкций, хранящихся на машиночитаемом носителе данных, таком как системная память 1104 или флэш-память, при этом набор исполняемых инструкций представляет одно или несколько программных приложений 1120 , например как приложение для обмена сообщениями 102 на фиг.1. Программные приложения 1120 при выполнении манипулируют процессором 1102 для выполнения различных программных функций для реализации по меньшей мере части описанных выше методов, предоставляют визуальную информацию через устройство отображения , 1114, , реагируют на пользовательский ввод через сенсорный экран 1116 и т.п. Таким образом, большая часть изобретательских функциональных возможностей и многие из изобретательских принципов, описанных выше, хорошо подходят для реализации с программными программами или в них.Ожидается, что специалист с обычной квалификацией, несмотря на возможные значительные усилия и множество вариантов дизайна, мотивированных, например, доступным временем, текущими технологиями и экономическими соображениями, руководствуясь концепциями и принципами, раскрытыми в данном документе, легко сможет создать такое программное обеспечение. инструкции и программы минимальные эксперименты. Следовательно, в интересах краткости и минимизации любого риска затруднения понимания принципов и концепций в соответствии с настоящим раскрытием, дальнейшее обсуждение такого программного обеспечения, если таковое имеется, будет ограничено существенным в отношении принципов и концепций в предпочтительных вариантах осуществления. .
В этом документе относительные термины, такие как «первый», «второй» и т.п., могут использоваться исключительно для того, чтобы отличать один объект или действие от другого объекта или действия, не обязательно требуя или подразумевая какие-либо фактические отношения или порядок между такими объектами или действиями. Термины «содержит», «содержащий» или любые другие их варианты предназначены для охвата неисключительного включения, так что процесс, метод, изделие или устройство, которые содержат список элементов, включают не только эти элементы, но может включать другие элементы, не указанные в явном виде или не присущие такому процессу, методу, изделию или устройству.Элемент, которому предшествует «содержит. . . a »без дополнительных ограничений не исключает наличия дополнительных идентичных элементов в процессе, способе, изделии или аппарате, которые составляют элемент. Термин «другой», используемый здесь, определяется как по меньшей мере второй или более. Термины «включающий» и / или «имеющий» в контексте настоящего описания определены как содержащие. Термин «связанный», используемый здесь в отношении электрооптической технологии, определяется как связанный, хотя и не обязательно напрямую, и не обязательно механически.Используемый здесь термин «программа» определяется как последовательность инструкций, предназначенных для выполнения в компьютерной системе. «Программа» или «компьютерная программа» может включать в себя подпрограмму, функцию, процедуру, объектный метод, реализацию объекта, исполняемое приложение, апплет, сервлет, исходный код, объектный код, совместно используемый библиотека / библиотека динамической загрузки и / или другая последовательность инструкций, предназначенная для выполнения в компьютерной системе.
Описание и чертежи следует рассматривать только как примеры, и объем раскрытия, соответственно, предназначен для ограничения только следующей формулой изобретения и ее эквивалентами.Обратите внимание, что не все действия или элементы, описанные выше в общем описании, являются обязательными, что часть определенного действия или устройства может не требоваться, и что одно или несколько дополнительных действий могут быть выполнены или элементы включены в дополнение к те, что описаны. Более того, порядок, в котором перечислены действия, не обязательно является порядком, в котором они выполняются. Шаги блок-схем, изображенных выше, могут быть в любом порядке, если не указано иное, и шаги могут быть исключены, повторены и / или добавлены, в зависимости от реализации.Кроме того, концепции были описаны со ссылкой на конкретные варианты осуществления. Однако специалист в данной области техники понимает, что различные модификации и изменения могут быть выполнены без выхода за пределы объема настоящего раскрытия, изложенного в формуле изобретения ниже. Соответственно, описание и фигуры следует рассматривать в иллюстративном, а не ограничительном смысле, и все такие модификации предназначены для включения в объем настоящего раскрытия.
Преимущества, другие преимущества и решения проблем были описаны выше в отношении конкретных вариантов осуществления.Тем не менее, выгоды, преимущества, решения проблем и любые особенности, которые могут привести к появлению каких-либо преимуществ, преимуществ или решений или стать более выраженными, не должны рассматриваться как критические, обязательные или существенные особенности любого или все претензии.