Морфологический разбор слова «понимая»
Часть речи: Деепричастие
ПОНИМАЯ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ПОНИМАТЬ»
| Слово | Морфологические признаки |
|---|---|
| ПОНИМАЯ |
|
Все формы слова ПОНИМАЯ
ПОНИМАТЬ, ПОНИМАЮ, ПОНИМАЕМ, ПОНИМАЕШЬ, ПОНИМАЕТЕ, ПОНИМАЕТ, ПОНИМАЮТ, ПОНИМАЛ, ПОНИМАЛА, ПОНИМАЛО, ПОНИМАЛИ, ПОНИМАЯ, ПОНИМАВ, ПОНИМАВШИ, ПОНИМАЙ, ПОНИМАЙТЕ, ПОНИМАЮЩИЙ, ПОНИМАЮЩЕГО, ПОНИМАЮЩЕМУ, ПОНИМАЮЩИМ, ПОНИМАЮЩЕМ, ПОНИМАЮЩАЯ, ПОНИМАЮЩЕЙ, ПОНИМАЮЩУЮ, ПОНИМАЮЩЕЮ, ПОНИМАЮЩЕЕ, ПОНИМАЮЩИЕ, ПОНИМАЮЩИХ, ПОНИМАЮЩИМИ, ПОНИМАВШИЙ, ПОНИМАВШЕГО, ПОНИМАВШЕМУ, ПОНИМАВШИМ, ПОНИМАВШЕМ, ПОНИМАВШАЯ, ПОНИМАВШЕЙ, ПОНИМАВШУЮ, ПОНИМАВШЕЮ, ПОНИМАВШЕЕ, ПОНИМАВШИЕ, ПОНИМАВШИХ, ПОНИМАВШИМИ, ПОНИМАЕМЫЙ, ПОНИМАЕМОГО, ПОНИМАЕМОМУ, ПОНИМАЕМЫМ, ПОНИМАЕМОМ, ПОНИМАЕМАЯ, ПОНИМАЕМОЙ, ПОНИМАЕМУЮ, ПОНИМАЕМОЮ, ПОНИМАЕМА, ПОНИМАЕМОЕ, ПОНИМАЕМО, ПОНИМАЕМЫЕ, ПОНИМАЕМЫХ, ПОНИМАЕМЫМИ, ПОНИМАЕМЫ
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ПОНИМАЯ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.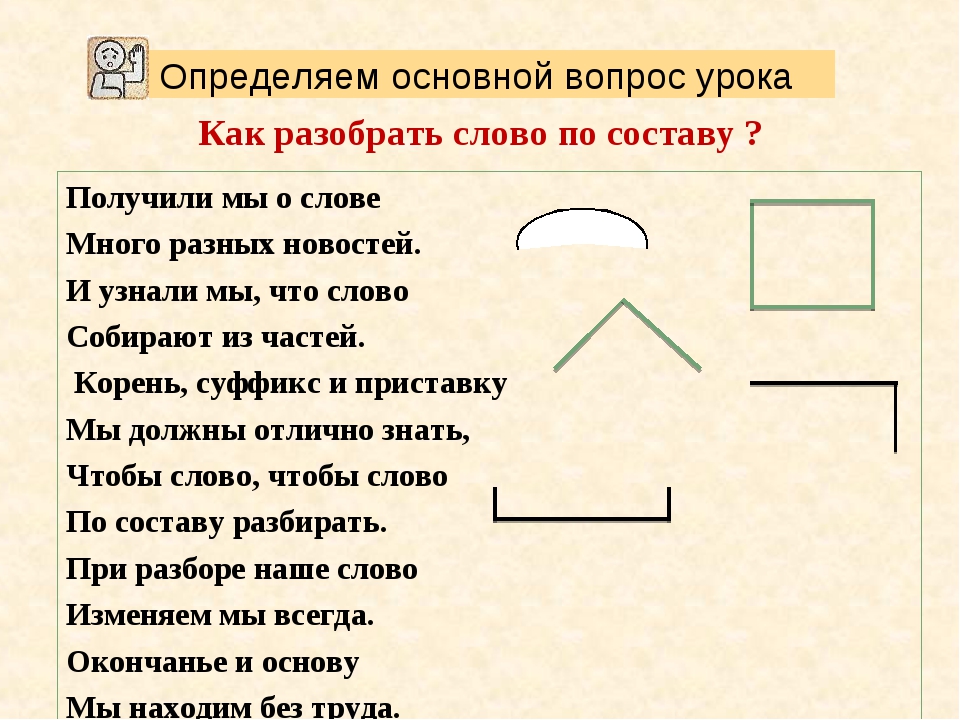
Примеры предложений со словом «понимая»
1
Ты всегда так, – отвечала она, как будто совершенно не понимая его и изо всего того, что он сказал, умышленно понимая только последнее.
Анна Каренина, Лев Толстой, 1878г.2
Не понимая, что происходит, но понимая, что какое-то ЧП, мы сели на койку и уставились на этих двух безобразно орущих людей.
Звездный билет (сборник), Василий Аксенов3
Слушал все это Георгий с оторопью, вроде понимая и не понимая Володю Першинова, но отступать и каяться было поздно – прощание неминуемо надвигалось…
Смертельный любовный треугольник, Георгий Баженов, 2006г.
4
Очнувшись, Коляй долго лежал, не то что не понимая, наоборот – со стыдом понимая
5
Завтра, доктор сказал, что завтра, – не понимая или не желая понимать эти взгляды, дрожащим голосом ответил Сергей.
Дневники мотоциклиста, Данни Грек, 2014г.Найти еще примеры предложений со словом ПОНИМАЯ
88 | Фонетика: статьи на gramota.
 me
meФонетический разбор слова “жизнь” поможет выяснить характер лексемы с точки зрения основных признаков её звукового состава. Таким образом, звуко-буквенный разбор слова – это тот звуковой набор, из которого и состоит само слово. Фонетический разбор Проведение фонетического анализа, необходимо начать с разбивания слова по… Читать »
Раздел: Фонетика ПодробнееВ фонетическом разборе слова “блюде” основное место занимают буквы и звуки, составляющие слово. Звуко-буквенный разбор слова характеризует его звуковые свойства и различия в буквенном и звуковом составе. Фонетический разбор Для грамотного проведения фонетического анализа, необходимо следовать определенному плану, по которому… Читать »
Раздел: Фонетика Подробнее Звуко-буквенный разбор слова помогает сравнить количество букв и звуков, а также выявляет их основные признаки. Фонетический разбор Для грамотного проведения фонетического анализа, необходимо начать с разбивания… Читать » Раздел: Фонетика Подробнее
Звуко-буквенный разбор слова помогает сравнить количество букв и звуков, а также выявляет их основные признаки. Фонетический разбор Для грамотного проведения фонетического анализа, необходимо начать с разбивания… Читать » Раздел: Фонетика ПодробнееСейчас мы готовы сделать фонетический разбор слова «чайка». Для этого потребуется звуко-буквенный разбор, к которому нам нужно приступить именно теперь. Рассмотрим его в следующих абзацах. Фонетический разбор Приступить нам стоит с понимания, сколько звуков и букв в слове «чайка» и, конечно, с правильного определения его слогов: Увидим,… Читать »
Раздел: Фонетика ПодробнееВ это время нас ожидает фонетический разбор слова «звонишь». Мы хотим осуществления его по всем правилам русского языка и нам потребуется звуко-буквенный разбор, к которому будем приступать сейчас. Рассмотрим его ниже. Фонетический разбор Начинать нам стоит с понимания, сколько звуков и букв в слове «звонишь» и, конечно, с верного определения… Читать »
Мы хотим осуществления его по всем правилам русского языка и нам потребуется звуко-буквенный разбор, к которому будем приступать сейчас. Рассмотрим его ниже. Фонетический разбор Начинать нам стоит с понимания, сколько звуков и букв в слове «звонишь» и, конечно, с верного определения… Читать »
Сейчас нас ждет фонетический разбор слова «юбка». Для этого потребуется звуко-буквенный разбор слова «юбка», к которому нам нужно приступить теперь. Рассмотрим его в следующих пунктах. Фонетический разбор Приступать нам стоит с понимания, сколько звуков и букв в слове «юбка» и, конечно, с верного определения его слогов: Смотрите, какое… Читать »
Для этого потребуется звуко-буквенный разбор слова «юбка», к которому нам нужно приступить теперь. Рассмотрим его в следующих пунктах. Фонетический разбор Приступать нам стоит с понимания, сколько звуков и букв в слове «юбка» и, конечно, с верного определения его слогов: Смотрите, какое… Читать »
В этот момент нас ждет фонетический разбор слова «рожь». Для проведения его по правилам русского языка требуется звуко-буквенный разбор, к которому нам нужно приступить прямо сейчас. Рассмотрим его далее. Фонетический разбор Начинать нам стоит с определения, сколько звуков и букв в слове «рожь» и, конечно, с правильного определения его слогов:… Читать »
Раздел: Фонетика Подробнее«Мне бы хотелось превзойти или хотя бы достичь уровня s1mple» — большое интервью с sh2ro | CS:GO
Состав Gambit Esports по CS:GO уже более пяти недель подряд возглавляет мировой рейтинг команд по версии HLTV.
Статус лучшей команды мира, тренировки в Gambit
— Последние месяцы для вашей команды были выдающимися. Поделись эмоциями, каково это — быть лучшей командой мира?
— Хорошо быть тир-1 командой, которая выходит в финалы на трех крупных турнирах подряд. Обидно, конечно, было проиграть последние два ивента и занять второе место… Но для нас это уже большое достижение, что мы дошли до такого уровня.
Мы пытаемся абстрагироваться от этого статуса, никогда не подходим к матчу как фавориты. Если мы играем против команд из топ-10 или топ-20, то готовимся к ним точно так же, как раньше. Нет недооценки соперника.
— С приходом HObbit вы стали очень стремительно прогрессировать. Что такого он привнес в команду?
Что такого он привнес в команду?
— Он добавил уверенности в официальных играх, которой нам не хватало. У нас было пять неопытных игроков, и нам нужна была свежая кровь. Хоть Абаю и 26 лет, он играет на суперуровне, и у него много опыта за спиной. Он нам стал объяснять, как лучше поступать в той или иной ситуации, и мы все это запоминали. Поначалу у нас что-то могло не получаться, но по итогу мы дошли до нашего текущего уровня.
Gambit Esports— Когда вы играете официалки, вашим тренером выступает CEO клуба. Он какую-то тренерскую работу по ходу игры выполняет или же nafany справляется один?
— У нас каждый что-то делает в плане тактики, и большую часть работы выполняет тренер — подготовка к матчу, разбор. И ему помогает аналитик. Они вдвоем много работы делают, не только nafany.
— Если заходишь смотреть матч NAVI, то можешь быть уверен, что первую строчку в таблице займет s1mple. Когда заходишь смотреть ваш матч, то не знаешь, чего ждать — на топ-1 настрелять может любой. Почему так получается? И на что вы делаете ставку при подготовке — на тактику или индивидуальное мастерство?
Когда заходишь смотреть ваш матч, то не знаешь, чего ждать — на топ-1 настрелять может любой. Почему так получается? И на что вы делаете ставку при подготовке — на тактику или индивидуальное мастерство?
— Мы долго и много тренировались, чтобы попасть сюда, поэтому, наверное, и набрали такую индивидуальную форму. После Нового года мы сели очень плотно задротить и месяц, наверное, только пракки и играли. Когда игра идет, мы можем сказать: «Давай, у тебя всё хорошо летит. Дропнем AK-47 — пойдешь убьешь». Так даже в официальных матчах бывало.
Но в большинстве случаев, я считаю, мы выигрываем в тактическом плане. Может, и не видно, что мы какую-то информацию знаем по карте, но когда мы в игре, мы как будто читаем соперника, и нам легче становится от этого.
— Насколько я могу судить, вы все матчи за последний год сыграли с буткемпа. Я вообще не помню лайв-камов из ваших домов. Сейчас Абай уехал. А вы как, остаетесь?
— Я уехал домой на четыре дня. Не знаю, отсюда я буду играть групповую стадию EPIC CIS League Spring 2021 или нет. Если там московские серверы будут, то, наверное, дома ещё чуть-чуть посижу. А так у нас все разъехались, кроме nafany. Он на буткемпе остался.
Не знаю, отсюда я буду играть групповую стадию EPIC CIS League Spring 2021 или нет. Если там московские серверы будут, то, наверное, дома ещё чуть-чуть посижу. А так у нас все разъехались, кроме nafany. Он на буткемпе остался.
— Можешь рассказать, как у вас обычно проходит день на буткемпе? Когда у вас нет официалок, вы просыпаетесь и… что происходит дальше?
— Подъем, условно, в 11. Просыпаемся, нам готовят завтрак, мы едим и сразу садимся за компьютеры — разминаемся, что-то разбираем, демки смотрим, обсуждаем, работаем над тактикой, а после этого играем шесть пракков. Вот примерно так любой день проходит. С двух до восьми или с двух до девяти мы играем.
— А после пракков? Не устаешь смотреть в экран?
— Последнее время лично я после тренировок отхожу от ПК. Иду отдохнуть, полежать. Но так я стал делать после DreamHack. До этого после каждого игрового дня я пытался смотреть демки, больше анализировать матчи, играть в CS, находить какие-то фишки — и все в Gambit так делали. Сейчас я выключаю компьютер и иду отдыхать, прогуляться по улице или что-то вроде.
Сейчас я выключаю компьютер и иду отдыхать, прогуляться по улице или что-то вроде.
— Давай немного заглянем в прошлое. Вы почти три года играли под тегом Youngsters. Когда ещё не было очевидно, что вы прорветесь наверх, вот этот статус «второго состава» давил на вас?
— Когда результаты основного состава пошли на спад, стало очевидно, что ростер вот-вот распадется. В тот момент все понимали, что нам еще предстоит очень много работы, но организация очень сильно нас поддерживала. Никто не ставил перед нами задачи начать выигрывать здесь и сейчас.
— Давай поговорим про твою команду. Можешь буквально по паре слов про каждого тиммейта рассказать? Кто какой человек, кто как в игре себя проявляет, как вы взаимодействуете с ребятами?
— Серега Ax1Le спокойный, больше рассудительный в мыслях. Тимофей interz тоже спокойный и рассудительный, много думает, в игре, в жизни — без разницы. Абай HObbit веселый, может поддержать, разрядить обстановку, опыта много. Nafany энергичный, вспыльчивый в каком-то роде.
Абай HObbit веселый, может поддержать, разрядить обстановку, опыта много. Nafany энергичный, вспыльчивый в каком-то роде.
— Давай представим ситуацию: идет третья карта гранд-финала мейджора, вы проигрываете 14:15. Кто в этот момент возьмет тайм-аут и заведет команду?
— Скорее всего, nafany. В критических ситуациях я могу поставить паузу. Я не заводила, но могу сказать нужные слова.
Поражение в финале DreamHack, конкуренция с NAVI
— Переместимся в настоящее. DreamHack — что случилось в финале?
— Хочу отдать должное NAVI за победу над нами. Они ведь проиграли нам последние три встречи. Впрочем, когда ты играешь ещё раз против команды, которую побеждал, она уже знает так или иначе твои фишки, ей становится легче, она может подстроиться. Мы же готовились к NAVI так же, как и раньше, ничего не поменяли. Мы хотели выиграть и не настраивались на поражение, но что-то пошло не так. Они нас как-то передавили.
Не скажу, что у нас что-то в игре получалось плохо. Мы играли в свой Counter-Strike, но где-то поспешили, где-то были на нервах чуть-чуть. В общем, нас просто переиграли на первой карте. На второй мы проиграли много клатчей, счет мог бы быть другой за сторону защиты. За террористов мы уже начали входить во вкус игры и камбечить, но у нас не получилось додавить. Train была нашей картой, мы могли её выиграть. Тоже не додавили, не доиграли. Будем это фиксить всё, потому что обычно мы доигрываем все моменты, которые форсы, антиэко, а тут не доиграли, и получился просто развал по экономике. Я там бегал без AWP шесть-семь раундов, плохо получилось.
Мы играли в свой Counter-Strike, но где-то поспешили, где-то были на нервах чуть-чуть. В общем, нас просто переиграли на первой карте. На второй мы проиграли много клатчей, счет мог бы быть другой за сторону защиты. За террористов мы уже начали входить во вкус игры и камбечить, но у нас не получилось додавить. Train была нашей картой, мы могли её выиграть. Тоже не додавили, не доиграли. Будем это фиксить всё, потому что обычно мы доигрываем все моменты, которые форсы, антиэко, а тут не доиграли, и получился просто развал по экономике. Я там бегал без AWP шесть-семь раундов, плохо получилось.
— Вернемся к Natus Vincere. В медиа, обсуждениях фанатов чувствуется, что между вами зарождается такой спортивный конфликт. Два гиганта из СНГ, две большие команды. А вы считаете NAVI принципиальным соперником?
— Лично мне без разницы, против кого играть. С другой стороны, NAVI дольше всех из СНГ держатся в топе, поэтому они своего рода принципиальный соперник. Всегда охота их победить, всегда стараемся против них.
— Как только результаты Gambit пошли в гору, тебя, разумеется, сразу стали сравнивать с s1mple. Как ты к этому относишься? У тебя есть желание обойти его в каких-то моментах?
— Я за s1mple следил всю свою карьеру. Это феноменальный игрок — у него все аспекты игры на лучшем уровне. Конечно, мне бы хотелось в индивидуальном плане превзойти или, может, достичь хотя бы его уровня, но я немного иначе интерпретирую роль снайпера, поэтому сравнивать нас не очень уместно. Хотя, может, местами у меня что-то «симпловское» и проскакивает.
— А можешь рассказать, чем различаются ваши роли, плейстайл? Условно, что делаешь ты и чего не делает он, и наоборот?
— Я не хочу вдаваться в детали. У меня ещё нет настолько сильной уверенности в каких-то мувах во время матчей. Когда я пересматриваю свои демки, то регулярно отмечаю, что в том или ином моменте мог сыграть лучше. Всегда можно сыграть лучше, лучшее решение принять в игре.
Когда ты в стрессовой ситуации, тебя давят с трех сторон — справа, слева и снизу, ты, чаще всего, ошибаешься. S1mple же всегда принимает лучшее решение, которое может. Он может из этой ситуации выйти с двумя фрагами. Не всегда, конечно, но в большинстве случаев он находит именно то решение, которое будет оптимальным для команды. Я ещё не на том уровне, поэтому в ответственных ситуациях порой допускаю ошибки — примерно в половине случаев. Вот этого умения мгновенно ориентироваться в ситуации мне не хватает.
S1mple же всегда принимает лучшее решение, которое может. Он может из этой ситуации выйти с двумя фрагами. Не всегда, конечно, но в большинстве случаев он находит именно то решение, которое будет оптимальным для команды. Я ещё не на том уровне, поэтому в ответственных ситуациях порой допускаю ошибки — примерно в половине случаев. Вот этого умения мгновенно ориентироваться в ситуации мне не хватает.
— В последние годы к гонке за титул лучшего игрока года приковано особое внимание. А тебя посещают мысли о ней? Или твой приоритет — командные трофеи?
— Я думаю, каждый игрок, который хорошо выступает на профессиональной сцене, хочет выигрывать турниры — охота показать лучший результат. И точно так же все, наверное, хотят получить медаль MVP, но это желание уже не настолько сильное. Все равно радость победы с командой будет сильнее. Лучше победить, чем получить какую-то медаль, показать хорошую статистику, но остаться лишь финалистом.
— У вас впереди RMR-турнир. Какая цель стоит перед командой? Только первое место?
Какая цель стоит перед командой? Только первое место?
— Конечно! Когда ты топ-1 команда мира, цель может быть только одна — победить.
Успехи команд из СНГ, спад Astralis и Vitality
— Много лет у нас было полторы команды в регионе, а сейчас СНГ в топе всех турниров. Как так вышло?
— У нас сильный регион, все набрали хорошие составы и много тренировались. Я думаю, что из-за того, что сейчас спад у Team Vitality, Astralis, а device перешел в Ninjas in Pyjamas, многие европейские команды просели. Это позволило Gambit, Team Spirit и Virtus.pro со временем выстрелить. В Катовице все наши команды были в плей-офф именно из-за того, что это старание, это рвение, которого многим не хватает, у наших все-таки есть. Надеюсь, все клубы из СНГ, которые сейчас в топе, не растеряют форму, потому что потерять свое место среди лучших легко, а вернуться — тяжело.
— В прошлом году Team Vitality и Astralis входили в «большую тройку» команд, которые разыгрывали большинство трофеев. Что думаешь об их неожиданном спаде?
Что думаешь об их неожиданном спаде?
— В Team Vitality просто возрастные игроки были, а теперь убрали RpK, решили сделать ставку на молодняк, но пока выходит не очень. Они, наверное, недотренировались, может быть, нить в игре какую-то потеряли. У них там ZywOo — лучший игрок прошлого года по версии HLTV.org, поэтому, я думаю, все у них будет в порядке. Молодые игроки — misutaaa и Kyojin — будут выступать лучше. У них ничего, по идее, не поменялось. ApEX так же коллит, shox выполняет свою роль, ZywOo — свою. Игрокам нужно время, чтобы наиграть позиции. Надеюсь, они это сделают и в Европе будет тир-1 команда.
Ростер Astralis тоже может очень даже легко выстрелить, учитывая то, какое рвение способны демонстрировать игроки команды. Они могут заходить в топ-3, топ-4, топ-2 и выигрывать турниры. Другой вопрос, кому они отдадут «палку» — я так вижу, что они не особо поделили AWP. За террористов её может Magisk взять, gla1ve иногда за CT берет, dupreeh — тоже. Датчане — это все-таки те игроки, которые задрали планку тир-1 сцены и на протяжении двух лет доминировали на ней. Я думаю, что у них тоже может все пойти к лучшему. С этим надо разобраться.
Я думаю, что у них тоже может все пойти к лучшему. С этим надо разобраться.
Device в NiP тоже, я думаю, заиграет. Это будет как у нас, скорее всего (не уверен): придет опытный игрок, и молодняк, который сейчас в NiP, что-то почерпнет и заиграет более уверенно на турнирах, начнет занимать призовые места.
device. Фото: Ninjas in Pyjamas— В начале года после турнира в Катовице многие команды из СНГ взлетели в топ-10 HLTV.org, но потом их дела пошли на спад. Как думаешь, с чем это связано?
— Virtus.pro до этого выиграла Flashpoint и DreamHack. Я думаю, она чуть-чуть устала, давно ничего не обновляла в своей игре. Игроки VP сами говорили, что не будут ничего кардинально менять, только вносить мелкие правки. Поэтому, наверное, к ним все просто привыкли, к их стилю игры, и им стало тяжело побеждать. Но игроки VP прошли долгий путь от топ-40 до финала мейджора, у них очень много опыта, и именно Virtus.pro останется в топ-10 и будет показывать на протяжении года хороший CS. Да и Team Spirit тоже — в этой команде индивидуально сильные киберспортсмены, они просто найдут нужный подход и вскоре снова будут претендовать на хорошие места на турнирах.
Да и Team Spirit тоже — в этой команде индивидуально сильные киберспортсмены, они просто найдут нужный подход и вскоре снова будут претендовать на хорошие места на турнирах.
— Как тебе игра degster?
— Degster — очень крутой чувак. Я познакомился с ним года три назад, наверное. С того момента он очень сильно прогрессировал. У него было желание играть, и поэтому он достиг таких результатов — сейчас он один из лучших снайперов. У него есть все, чтобы стать лучшим игроком в мире.
Jame в роли кумира, Ancient в маппуле, первая большая покупка
— Когда ты начинал играть, какие три игрока были для тебя кумирами?
— Именно когда я начал играть в CS:GO в 2013-м, в топе были другие игроки. Когда я стал играть на десятом уровне FACEIT, в FPL, получил профиль на HLTV.org, то учился на демках у Jame — именно пониманию игры и подобным аспектам. Я знал какие-то основы, но не понимал каких-то мувов, поэтому сидел анализировал.
Мне был очень интересен путь, который проделала его AVANGAR.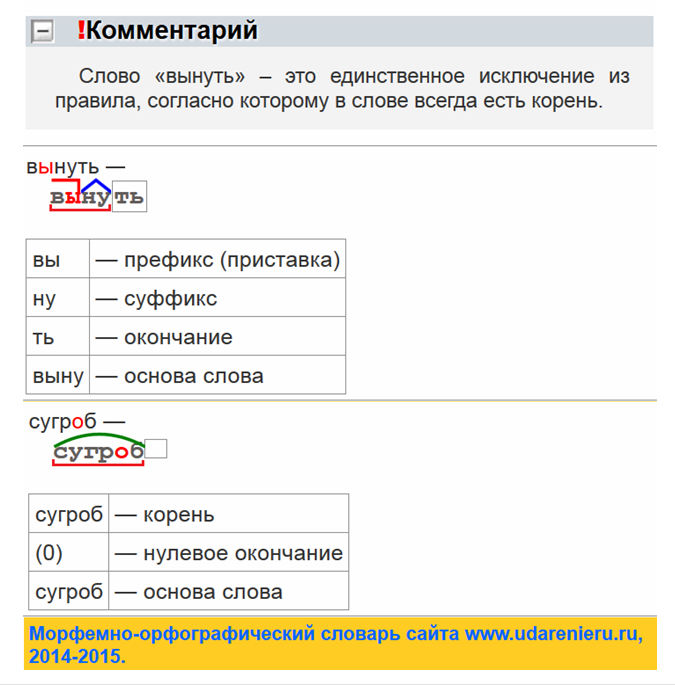 Команда же вращалась в своих кругах, на мировой сцене ее не знали, но в итоге она выстрелила, стала хорошо играть, попала в топ-20, топ-15, стала проходить на крупные турниры, потом — финал мейджора, и все эти два года игроки сидели на буткемпе и задрачивали CS!
Команда же вращалась в своих кругах, на мировой сцене ее не знали, но в итоге она выстрелила, стала хорошо играть, попала в топ-20, топ-15, стала проходить на крупные турниры, потом — финал мейджора, и все эти два года игроки сидели на буткемпе и задрачивали CS!
Поэтому я выбрал для себя Jame и начал у него учиться. Учился, смотрел много демок. Больше всего я следил за AVANGAR — это была моя любимая команда на тот момент. А потом, когда меня подписала Gambit, мне все это помогло, и я начал еще активнее работать над своей игрой: уже стал анализировать матчи device, s1mple, потом ZywOo появился, GuardiaN, cadiaN — все лучшие снайперы. У всех учился и добавлял что-то в свою игру, что-то менял и вот так потихоньку, помаленьку находил свой стиль игры.
— Что думаешь по поводу обновления маппула?
— Не ту карту убрали, я думал, уберут Mirage. Лишаться Train нам не очень хотелось. По поводу Ancient ничего не могу сказать — я на нее еще даже толком не заходил, бегал максимум минут пять. Думаю, это так или иначе освежит маппул, все команды ее рано или поздно подготовят. А разработчики будут фиксить карту, как это было с Vertigo, — она выглядит сыровато, на самом деле. Там такие тона зелёные — не очень нравится, очень тяжело с AWP в прицел смотреть. Но что поделать — будем играть, тренировать. Наверное.
Думаю, это так или иначе освежит маппул, все команды ее рано или поздно подготовят. А разработчики будут фиксить карту, как это было с Vertigo, — она выглядит сыровато, на самом деле. Там такие тона зелёные — не очень нравится, очень тяжело с AWP в прицел смотреть. Но что поделать — будем играть, тренировать. Наверное.
— Разумеется, ты не скажешь, сколько получаешь, но очевидно, что для среднестатистического 19-летнего парня из России это колоссальные суммы. Стал ли ты больше тратить, когда выбился в топ, или, может быть, совершил какую-то большую покупку?
— По большей части я коплю на квартиру. Из больших покупок есть разве что PS5 — стоит вот, но я еще даже не поиграл ни разу. Ни на что другое деньги я особо не трачу.
— Есть ли у тебя вообще какие-нибудь мечты или грандиозные планы? Может, у тебя есть мысли в будущем поехать в другой регион или что-то такое?
— Если говорить именно о CS:GO, то главная задача — стать более стабильным игроком. Хочу фиксить свою игру, улучшить ее. А мечта — наверное, выиграть мейджор.
Хочу фиксить свою игру, улучшить ее. А мечта — наверное, выиграть мейджор.
— Спасибо тебе большое за интервью! Хочешь передать что-то болельщикам или хейтерам?
— Спасибо всем, кто нас поддерживает и болеет за нас! Любите Gambit! Алга, Gambit!
Ближайшие семинары учебного центра
|
|
 Хотелось бы провести семинар с большей практикой (особенно для заполнения первых частей для строительных организаций).
Хотелось бы провести семинар с большей практикой (особенно для заполнения первых частей для строительных организаций). Уровень знаний отличный. Единственное для меня, хотелось бы, чтобы была привязка к наглядному материалу (рабочая тетрадь). Т.е. информация на экране перекликалась с информацией в рабочей тетради. Уровень организации отличный. Все понравилось. У меня произошло четкое структурирование системы работы на ЭП. Многие вопросы нашли ответы данным семинаром. Большое спасибо!
Уровень знаний отличный. Единственное для меня, хотелось бы, чтобы была привязка к наглядному материалу (рабочая тетрадь). Т.е. информация на экране перекликалась с информацией в рабочей тетради. Уровень организации отличный. Все понравилось. У меня произошло четкое структурирование системы работы на ЭП. Многие вопросы нашли ответы данным семинаром. Большое спасибо! Спасибо за помощь! Желаю дальнейшего процветания! Очень грамотный лектор. Приятно было беседовать, задавать вопросы. Надеюсь на дальнейшее сотрудничество.
Спасибо за помощь! Желаю дальнейшего процветания! Очень грамотный лектор. Приятно было беседовать, задавать вопросы. Надеюсь на дальнейшее сотрудничество. Лектору также огромное спасибо. Единственное, как для новичка было труднее понимать какие-то фразы и действия.
Лектору также огромное спасибо. Единственное, как для новичка было труднее понимать какие-то фразы и действия. Доступное изложение информации. Спасибо.
Доступное изложение информации. Спасибо. Очень много узнала нового, закрепила старое, а главное получила навыки использования ЭТП “Сбербанк-АСТ”, что было моим пробелом. Лекторы ответили на все интересующие вопросы.
Очень много узнала нового, закрепила старое, а главное получила навыки использования ЭТП “Сбербанк-АСТ”, что было моим пробелом. Лекторы ответили на все интересующие вопросы. Узнаешь много нового и получишь ответы на имеющиеся у тебя вопросы.
Узнаешь много нового и получишь ответы на имеющиеся у тебя вопросы. Материал был подан интересно и профессионально. Заметно у Антона широкое знание темы, выходящее за грани непосредственно семинара. Организация семинара была также на должном уровне.
Материал был подан интересно и профессионально. Заметно у Антона широкое знание темы, выходящее за грани непосредственно семинара. Организация семинара была также на должном уровне.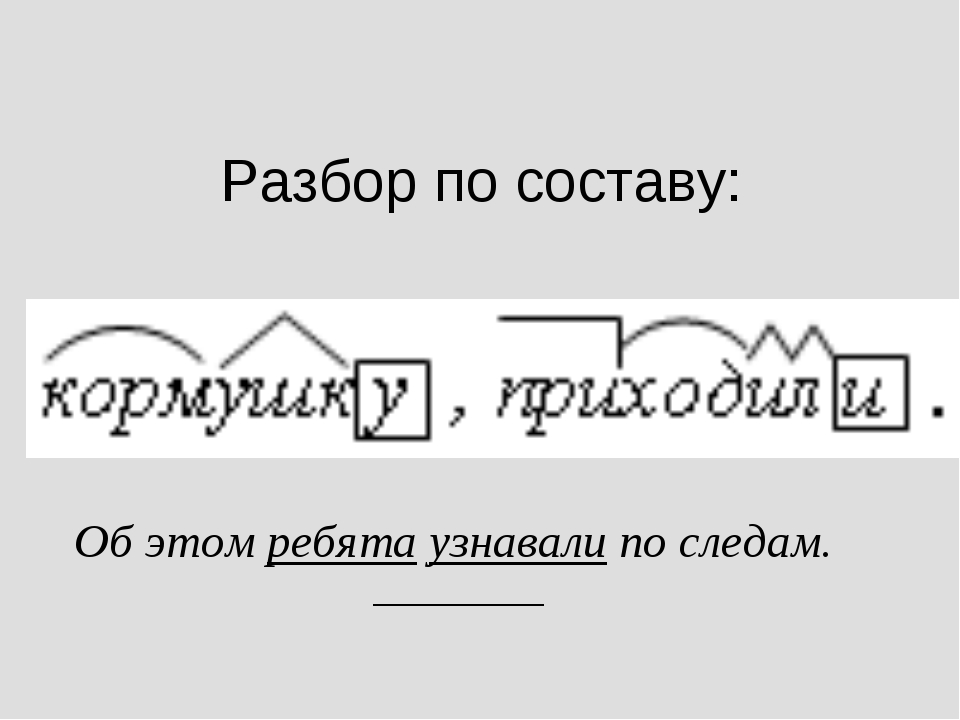 почте, но и по телефону для того, чтобы убедиться в том, что информация точно дошла (о переносе даты и места проведения обучающего семинара). Пришлось дважды приезжать на семинар.
почте, но и по телефону для того, чтобы убедиться в том, что информация точно дошла (о переносе даты и места проведения обучающего семинара). Пришлось дважды приезжать на семинар.  к. ранее не было таких знаний, чтобы можно было спокойно участвовать.
к. ранее не было таких знаний, чтобы можно было спокойно участвовать. Хотелось бы улучшить техническую часть – чтобы не висла компьютерная техника. В целом семинар очень полезный для меня, спасибо!
Хотелось бы улучшить техническую часть – чтобы не висла компьютерная техника. В целом семинар очень полезный для меня, спасибо! Лектору — огромное спасибо!
Лектору — огромное спасибо! Если бы знали о ВАС – обратились бы сразу, а теперь придется ВСЕ переделывать.
Если бы знали о ВАС – обратились бы сразу, а теперь придется ВСЕ переделывать.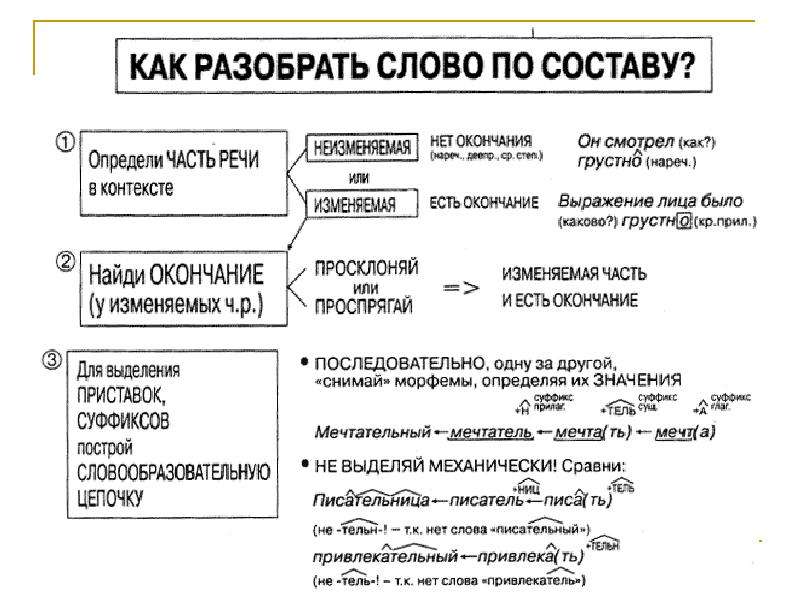 Вся информация была актуальна и очень полезна. Некоторые моменты, в которых ранее были провисания, стали просты и понятны.
Вся информация была актуальна и очень полезна. Некоторые моменты, в которых ранее были провисания, стали просты и понятны.
 В целом семинар очень понравился, лектору огромное спасибо!
В целом семинар очень понравился, лектору огромное спасибо! Организация семинара хорошо подготовлена!
Организация семинара хорошо подготовлена! Организация семинара — оценка отлично. Работы лекторов — оценка хорошо.
Организация семинара — оценка отлично. Работы лекторов — оценка хорошо. Обучение проходило в полном объеме , доступным языком. Получила много полезной информации. Все понравилось!
Обучение проходило в полном объеме , доступным языком. Получила много полезной информации. Все понравилось!
 Отличное сочетание практического и теоретического курса. Плюс высококлассные специалисты, которые на протяжении длительного времени работают в данной теме.
Отличное сочетание практического и теоретического курса. Плюс высококлассные специалисты, которые на протяжении длительного времени работают в данной теме. Спасибо за семинар!
Спасибо за семинар!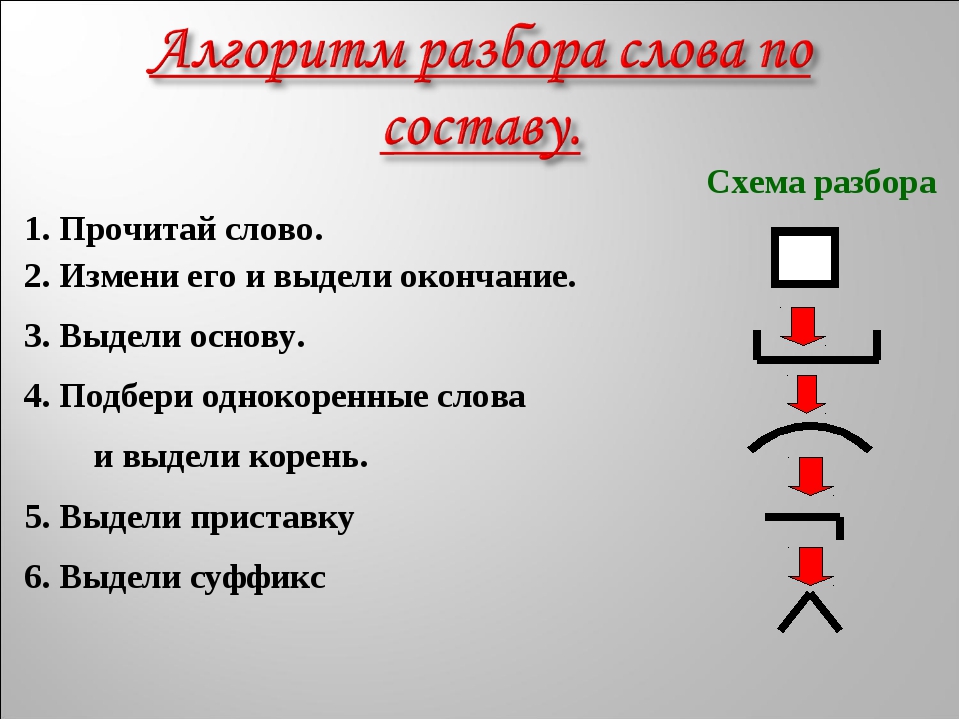 Важно, что лекторы обращают внимание на изменения в законодательстве, произошедшие в последнее время и на перспективу развития госзакупок.
Важно, что лекторы обращают внимание на изменения в законодательстве, произошедшие в последнее время и на перспективу развития госзакупок. Хотелось бы семинар по 223ФЗ на ЭТП ОТС-Тендер. А именно – практика торгов на ЭТП.
Хотелось бы семинар по 223ФЗ на ЭТП ОТС-Тендер. А именно – практика торгов на ЭТП. В. и Валиуллиной И.Г, за профессиональное чтение лекций и хорошо организованное ведение семинара. Отдельное спасибо Асановой М. в консультировании и координировании.
В. и Валиуллиной И.Г, за профессиональное чтение лекций и хорошо организованное ведение семинара. Отдельное спасибо Асановой М. в консультировании и координировании. Лектору пожелание — больше примеров из практики. На практическом занятии, на мой взгляд, лучше тренироваться на одном аукционе, а не на 4-х сразу. Произошла небольшая путаница. Спасибо!
Лектору пожелание — больше примеров из практики. На практическом занятии, на мой взгляд, лучше тренироваться на одном аукционе, а не на 4-х сразу. Произошла небольшая путаница. Спасибо! Понравилась дикция, манера подачи и ответы на вопросы.
Понравилась дикция, манера подачи и ответы на вопросы. к. законы очень сложные для их понимания.
к. законы очень сложные для их понимания.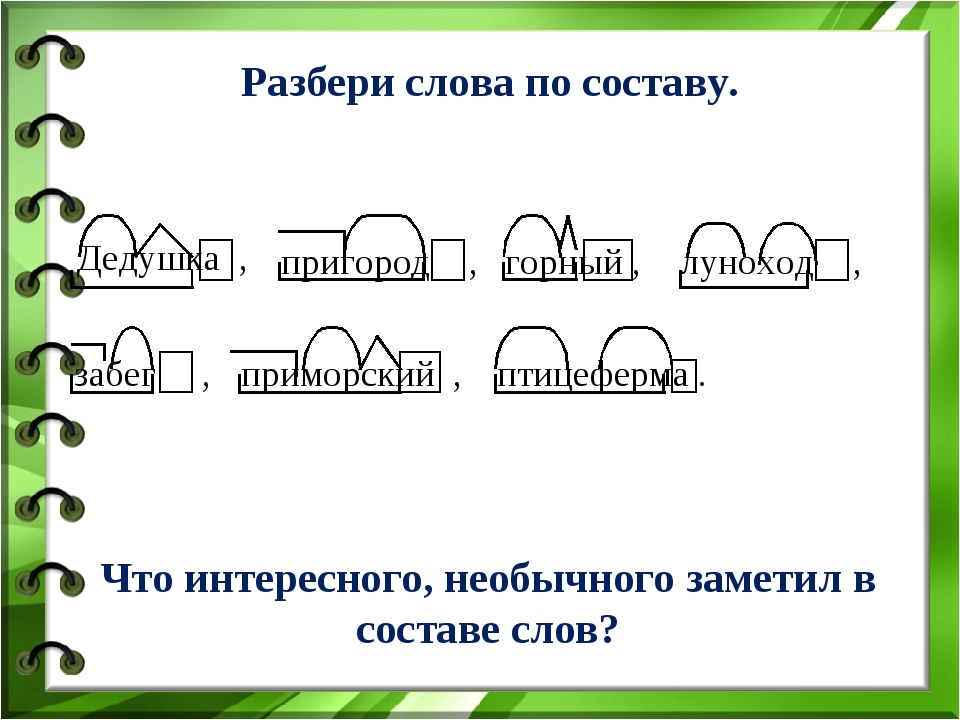 В общем и целом материал дается доступным языком. Хорошо подготовлен методический материал. Продуманы паузы с приемом кофе, чая и также обеды. Единственное, что все же два дня недостаточно для того, чтобы более детально рассмотреть и подать информацию слушателям. Возможно, стоит добавить еще один день.
В общем и целом материал дается доступным языком. Хорошо подготовлен методический материал. Продуманы паузы с приемом кофе, чая и также обеды. Единственное, что все же два дня недостаточно для того, чтобы более детально рассмотреть и подать информацию слушателям. Возможно, стоит добавить еще один день. Организаторам спасибо за организацию обучения. За четкие, слаженные действия, своевременные уведомления о начале, месте обучения.
Организаторам спасибо за организацию обучения. За четкие, слаженные действия, своевременные уведомления о начале, месте обучения. Спасибо.
Спасибо. Лектор излагает материал понятно и компетентно. Желаю организаторам и лектору финансовых и личностных успехов!
Лектор излагает материал понятно и компетентно. Желаю организаторам и лектору финансовых и личностных успехов! Огромное спасибо лекторам и организаторам!
Огромное спасибо лекторам и организаторам! Пожелание: организаторам плодотворной работы. Пожелание лектору: удачи в работе!
Пожелание: организаторам плодотворной работы. Пожелание лектору: удачи в работе!
 То, что надо для участия в торгах.
То, что надо для участия в торгах. Материал выдан доступно, лаконично.
Материал выдан доступно, лаконично.
 Наиболее актуально было узнать позицию, обжалование ФАС России, заключение контрактов, нарушения со стороны заказчиков. К тому же получила новые контакты! Обменялись опытом, знаниями!
Наиболее актуально было узнать позицию, обжалование ФАС России, заключение контрактов, нарушения со стороны заказчиков. К тому же получила новые контакты! Обменялись опытом, знаниями! Считаю, что для проведения данного семинара предложенных два дня обучения мало. Тяжело воспринимается лекционный материал. Одного дня практических занятий также не достаточно.
Считаю, что для проведения данного семинара предложенных два дня обучения мало. Тяжело воспринимается лекционный материал. Одного дня практических занятий также не достаточно. Отдельное спасибо Валиулиной Инне за полные и развернутые ответы на наши вопросы.
Отдельное спасибо Валиулиной Инне за полные и развернутые ответы на наши вопросы. В целом все понятно, доступно, но очень много для осознания. Второй день — “ох уж это несовершенство техники, но все доступно” 🙂
В целом все понятно, доступно, но очень много для осознания. Второй день — “ох уж это несовершенство техники, но все доступно” 🙂
 Практическое занятие, конечно, интереснее. Практика есть практика. Надеюсь, полученные знания помогут в работе на ЭП, Желаю Антону и всем организаторам здоровья, успехов в работе и новых достижений.
Практическое занятие, конечно, интереснее. Практика есть практика. Надеюсь, полученные знания помогут в работе на ЭП, Желаю Антону и всем организаторам здоровья, успехов в работе и новых достижений. Во-вторых, хотелось бы, чтобы где-то через полгода был проведен еще один семинар — разбор ошибок и практические советы. В-третьих, вкусно накормили. Спасибо!
Во-вторых, хотелось бы, чтобы где-то через полгода был проведен еще один семинар — разбор ошибок и практические советы. В-третьих, вкусно накормили. Спасибо!
 Спасибо за сотрудничество!
Спасибо за сотрудничество! 
Как харассмент влияет на экономику
Вадим Ковалев― 13 часов 12 минут в российской столице. Здравствуйте! Всех приветствую на волнах «Эха Москвы» и на YouTube-канале «Общество». Вернулись с праздников, и для кого-то встреча с коллегами в офисе, общение, корпоративной кофе, в общем, всё то, почему мы так, знаю точно, соскучились на удалёнке, это приятное такое событие. Ну, для кого-то возвращение в офис не будет таким радостным. И причина тому harassment. И пусть не волнуются коллеги по «Эхо Москвы» Маргарита Ставнийчук и Ирина Воробьёва, которые эту тему подробно разбирают. Мы не будем отнимать хлеб, а рассмотрим тему в контексте экономики. Собственно чему программа «Бизнес-ланч»-то и посвящена. Как harassment влияет на климат в трудовых коллективах и на успех целых компаний? Какие риски влечёт недостаточное внимание к этой теме для корпораций? Об этом поговорим с нашими потрясающими гостями сегодня. Александр Цыпкин, председатель комитета по внутрикорпоративным коммуникациям Ассоциации менеджеров, консультант по стратегическим коммуникациям, публицист и сценарист. Александр Цыпкин с нами на связи. Здравствуйте, Александр!
Александр Цыпкин― Да. Приветствую. Приветствую.
В. Ковалев― И Юлия Андреева, сопредседатель Комиссии по бизнес-этике Ассоциации менеджеров, партнер практики частных клиентов, адвокат S&K Вертикаль. Здравствуйте, Юлия!
Юлия Андреева― Добрый день!
В. Ковалев― Меня зовут Вадим Ковалёв. Ну, что ж, дорогие друзья? Давайте начинать. Так что же такое harassment? Данные ВЦИОМ показывают, что большинство россиян об этом не знают, об этом термине. Означает ли это, что с этим явлением не сталкивались, Александр?
А. Цыпкин― Ну, нет, конечно. Я… Кстати, мне кажется, важно отметить, почему у нас такой здесь состав. Мы как раз до майских праздников, до, так сказать, разгула загородного харассмента проводили круглый стол на эту тему. И вот там было интересное как раз, мне кажется, выступление на тему влияния харассмента на экономику. Вот я соответственно могу это рассмотреть с точки зрения внутрикорпоративной коммуникации. Вот Юля с точки зрения права и этики. Вот. А действительно были цифры достаточно неожиданные, из которых следовало, что про harassment в России особо-то не знают. А я предполагаю, что не знают про слово harassment. А про слово «домогательства» или любые другие вариации на тему… В основном, кстати, думаю у нас harassment ассоциируется с сексуальным какими-то вопросами, вот, конечно, знают многие и по-другому относятся. Ну, я до эфира говорил, что то же самое можно провести опрос по поводу буллинга в школе и спросить, кто подвергался. А потом сказать, часто ли вас били головой об дверь. Вот. И соответственно будет совершенно другой ответ. Вот. Поэтому, мне кажется, проблема есть. Но опять же, конечно, она не настолько артикулирована чётко, насколько в западном мире, где граница, может быть, даже сейчас несколько сдвинута радикально в сторону того, что любое проявление внимания может рассматриваться как harassment. У нас всё нужно определить, где российский человек средний вот эту границу проводит, где оказать знак внимания, может быть, такой шуткой двусмысленной, и это вроде бы нормально. Да? И даже когда этого не делает, начинают все вокруг обижаться девушки, как же так, на нас внимания не обращают. А где начинается реальный harassment, реальные домогательства с последствиями и так далее. вот. Но вот это исследование было для меня действительно удивительным. Да.
В. Ковалев― Юль, вот Саша уже затронул тему, что традиционно в России, наверное, воспринимается harassment как некие сексуальные домогательства. Да? Но термин на самом деле шире. Так вот что же юристы понимают под этим термином? Заплатить за девушку в ресторане – это harassment?
Ю. Андреева― Ну, давайте начнём с того, что, во-первых, термина, определения в принципе ни харассмента, ни сексуальных домогательств в российской законодательстве нет. Мы можем судить как бы вообще да, в принципе о термине harassment, исключительно основываясь на зарубежном опыте и плюс на исследованиях психологов, социологов, других экспертов из разных областей. Начнём с того, что harassment – это в принципе термин, который определяет нарушение границ чужого… другого человека. Да? То есть условно, что это границы как психологические, так и физические. И вот отсутствие уважения и притеснение этих границ – это и есть harassment, это если говорить о самом широком поле как бы определения харассмента.
А. Цыпкин― То есть сейчас… Извини. Можно вопрос короткий? А как бы эхо бы убрать? Что сделать для этого?
В. Ковалев― «Эхо» не надо убирать, Александр.
А. Цыпкин― Да? Это хорошо. Смешно. Скажи, пожалуйста, Юль, дедовщина попадает в понятие харассмента? Если мы говорим, дедовщина…
Ю. Андреева― Да, безусловно.
А. Цыпкин― … не сексуального свойства. Дедовщина, когда заставляют выполнять какую-то работу чёрную и так далее. Вот такая прямая дедовщина.
Ю. Андреева― Да. Мы должны понимать, что harassment… Зачастую в основе харассмента вообще не лежит сексуального подтекста. Harassment – это проявление власти и как бы своего рода там отношения власти – подчинения. То есть когда сильный пол довлеет над слабым и использует для этого своё положение – да? – соответственно. Поэтому с точки зрения того, что может подпадать под действие харассмента, то есть это и шутки оскорбительные, ну, и пошлые. Да? Там фотографии, которые высылаются через мессенджеры, соцсети, с сексуальным подтекстом в том числе. Это и неприятные высказывания в целом о внешности человека. Ну, понятно, что все действия, которые в принципе направлены против воли другого лица. Безусловно в законодательстве, например, если мы говорим о крайних видах харассмента, то есть это и изнасилование, и принуждение к действиям сексуального характера. Эти вещи есть. Но это прямо крайняя-крайняя степень урегулирования. Да? Есть НРЗБ характера.
В. Ковалев― Юля, скажи, пожалуйста, собственно вот платить за девушку в кафе, в ресторане на бизнес-ланче, так это же harassment или нет? Вот ответь на вопрос.
Ю. Андреева― Если девушка активно сопротивляется и хочет заплатить сама… сама за себя, то да, это своего рода harassment, но ответственности за него не будет.
В. Ковалев― Вот как оно бывает.
А. Цыпкин― Но… Вот и на самом деле еще один момент, который касается нашего менталитета, как вот только что Вадик, понятно, задал этот вопрос в некой шутливой форме. А слово harassment у нас моментально вызывает приступ желания пошутить. Ой, а вот это? Ну, на самом деле это же не harassment. Да что вы так к этому относитесь? А заплатить за девушку? А сказать, что у неё там, не знаю, задница красивая – это harassment – не harassment? Да? То есть у нас, конечно, сдвинута в обществе эта граница чуть-чуть. И более того я как раз не раз выступал насчёт того, что как, мне кажется, сегодня на западе она в другую сторону сдвинута чрезвычайно. Я общался со своими коллегой американскими, которые сказали, слушай, ну, вообще-то говоря, сейчас вот человеку пригласить кого-то на свидание уже становится несколько так затруднительно, потому что до приглашения на свидание, нужно какие-то два слова сказать, а если скажешь слово на работе и, не дай бог, этот человек еще находится в каком-то подчинении, то ты можешь после этого такое вообще получить себе cancel culture. Ну, вот мне кажется важно говорить, что мы действительно потратили наше время сейчас именно на экономику, потому что, конечно, для меня вот в нашей той беседе было интересно, чем судить, как реально это может повлиять просто на финансовое состояние той или иной компании, наличие у них корпоративных каких-то правил культуры и ограничение с харассментом.
В. Ковалев― Ну, вот абсолютно точно, Саш, вряд ли может человек эффективно и полноценно работать, – да? – если у него в коллективе есть какие-то проблемы, если он кого-то опасается. И вот как harassment влияет на экономику, собственно на успех и развитие компании? Юль, почему вот международные компании именно озаботились этой темой?
Ю. Андреева― Ну, почему? Потому что понятно, что на западе, ну, в других странах в принципе – да? – как бы есть примеры того, насколько сильно урегулирована эта область взаимоотношения людей и само собой за это предусмотрена ответственность. Ну, во-первых, это штрафы для компании. Во-вторых, это падение производительности труда. То есть психологическая обстановка в компании падает на низкий уровень весьма. Плюс это токсичные отношения, развитие токсичных отношений внутри компании. Ну, и было достаточно много исследований, которые показывали, что 80% девушек, которые подвергались харассменту на рабочих местах, они в течение 2-х лет увольнялись с работы после этого инцидента. Кроме того есть исследования, которые говорят о том, что если в руководстве компании одни мужчины представлены, то эта компания зарабатывает гораздо меньше, чем та компания, в руководстве которой представлена женщины. Но к чему я это говорю? К тому, что большинство женщин, которые узнают о том, что в этой компании в принципе есть ситуации с харассментом, либо они могут быть подвергнуты харассменту, они уходят с этих рабочих мест и в принципе отказываются в дальнейшем строить карьеру. И мы понимаем, что эта компания фактически уходит от возможности заработать гораздо больше. Ну, и опять же те скандалы, которые уже не один раз поднимались в СМИ и были, мы знаем достаточное количество примеров: и Uber, и Google. Акции этих компаний очень сильно падают – да? – после того, как мы узнаем о таком скандале. И дальнейшая перспектива. То есть то как компания реагирует в принципе на эту ситуацию, очень во многом влияет на то, сколько будут стоить акции, ну, и какой… какой будет доход вообще в принципе у компании.
В. Ковалев― Скажи… Да. Саш, а как…
А. Цыпкин― Да. Угу.
В. Ковалев― … компании пытаются противодействовать вот такому поведению отдельных сотрудников? Существует ли какая-то распространенная практика? Что? Кодексы пишут? Уставы?
А. Цыпкин― Ну, смотри, вот здесь как раз мы вновь неожиданно попали в ситуацию, когда западные компании стали серьезно отличается от российских. Последний раз такое было в 90-е. Они были совершенно разные. Да? Потом как-то более-менее друг к другу приблизились. И тут вдруг вот западное общество рвануло в сторону новой этики вот со всеми там, может, и перегибами, но тем не менее это направление благое, и естественно эти правила и конструкции перекочевали в российские представительства этих компаний. И, ну, в большинстве, насколько я знаю, западных сегодня структур есть четкий кодекс, что запрещает, что разрешает. Есть профилактические меры. Есть возможность анонимно сообщить о ситуации, связанной с харассментом. Есть психологи. То есть эта работа ведется системно. И в итоге, конечно, получается какая ситуация? Если сегодня выбирает человек работу и понимает, что у него там девушка, допустим, которая не может защитить там себя от харассмента. Разные же девушки бывают. К которой подойдешь, и она тебе быстро объяснит, что нужно делать. А есть которые, ну, себя защитить не в силах, но от этого не менее эффективные сотрудники. Они смотрят, а, ну, вот в российских компаниях этого нет, а в западных это есть, пойду я туда работать. Соответственно более эффективные в какой-то мере трудовые ресурсы, они перетекают в те компании, в которых это защищается. Ведь опять же речь не только о харассменте в отношении женщин, сексуальной ориентацию, просто национальный harassment. Да? Когда приходит человек, а под него как следует забуллят просто по его национальности. Ну, вот. И компании что? Они занимаются в основном информационно-профилактической работой, потому что… Как бы сказать? Проблема-то в том, что новая этика не предполагает презумпции невиновности в чем-то. И соответственно если всплывет проблема харассмента, то компания огребет до того, как разбирательство произойдет. И, в общем-то, акции могут упасть в целом даже по ложному доносу одного сотрудника на другого. Мы, правда, на этом мероприятии обсуждали… спрашивал я, а сколько было ложных доносов, ну, там потому что замечательно, возможность для шантажа. Написать и сказать, а ко мне директор подходил, вот предложил за повышение такое-то. И вот сразу начинается разборка, а подходил или нет, вообще-то неизвестно. А говорят, что ложных доносов мало, там это, не знаю, доли процента. Вот. Но тем не менее проблемы для компании есть. Репутация моментально начинает подгорать. Понятно, что в России с репутацией в целом пока не так, как на западе. У нас репутационные риски чуть ниже. Но и они, очевидно, придут. И никому не нужна эта заморочка, особенно если у тебя контакты с зарубежными поставщиками, или ты сам зарубежная компания здесь.
В. Ковалев― Спасибо, Саша. Юль, а вот у тех сообщений, анонимных сообщений, о которых Александр вот только что сказал… У нас, кстати, в стране есть отдельная культура – да? – такая анонимных сообщений. Вот у них есть какая-то юридическая сила? И как их разбирать работодателю?
Ю. Андреева― … это зависит от того, что прописано в принципе кодексе этики или в ином документе, который касается этого вопроса у самой компании. Поэтому кто-то реагирует, кто-то нет. Практика совершенно разная. И опять же там способы того, каким образом профилактируют и борются с харассментом на рабочих местах, у всех компаний совершенно отличается. Ну, где-то есть естественно точка соприкосновения, но тем не менее это и горячие линии, это и, ну, понятно, наличие самого кодекса, это и какие-то группы разбора. Кто-то там позволяет себе из руководителей просто напрямую разбираться в ситуации, связанной с харассментом. Это зависит от корпоративной культуры самой компании.
А. Цыпкин― А, Юль, я правильно понимаю, что с точки зрения законодательства невозможно уволить человека за то, что… ну, по закону уволить за то, что он нарушил некий кодекс, прописанный внутри компании, которые запрещает, допустим, комментарии сексуального свойства в отношении сотрудника другого? Вот конкретно за это уволить его нельзя. Он… Это решение будет обжаловано в суде. Правильно?
Ю. Андреева― Да, да. Совершенно точно. У нас нет ни одного судебного прецедента, который можно подвести под статью о дискриминации, которая запрещена Трудовым кодексом. Ну, это опять же нужно понимать обстоятельства конкретные, что было сказано, что было сделано. Если говорить прямо, то уволить за harassment на рабочем месте невозможно.
В. Ковалев― Вот приехали.
А. Цыпкин― Ну, да. Повторюсь, мне кажется, если на эту тему как-то рассуждать, то исключительно нужно доказывать акционерам по сути дела, прежде всего акционерам, то, что невыгодно быть уже компанией, в которой этим вопросом никто не занимается. У нас, кстати, интересно вот на этом нашем круглом столе был пример двух совершенно диаметрально противоположных позиций. Одна компания, в которой НРЗБ, по-моему, у нас акционер присутствовал или, ну, по крайней мере руководитель, который говорит, что вот у нас вообще в компании запрещены любые взаимоотношения между сотрудником… сотрудниками гендерного свойства. То есть хоть по любви, хоть замуж, то есть всё – это запрещено и всё, чтоб даже не разбираться. В других компаниях там, по-моему, были западные представители – да? – говорят, ну, у нас, конечно, по любви можно, брак может состояться. А почему нет? Где людям ещё знакомиться? Вот две разные интересные позиции. Я, честно говоря, даже не знаю, какая более правильная. По-человечески кажется, что более правильная 2-я, конечно. С другой стороны вот для собственника понятно, он просто сказал: ничего нельзя и всё. Ни на каких корпоративах никто никого за задницу не берёт. Всех, кто взяли, все уволены. Всё. И люди такие поняли, хорошо, работаем так, как работаем.
В. Ковалев― Слушай, ну, практика показывает, что люди если друг друга полюбят, то, конечно, они найдут способы так, чтобы работодатель об этом никогда не узнал и будет просто больше тратить время на переписывание в каких-то там анонимных чатиках и так далее, и там подобное, которых там…
А. Цыпкин― Да.
В. Ковалев― … опять-таки хватает. Вот здесь ещё одна тонкая грань. Как можно защитить право человека на какую-то личную жизнь там, – да? – потому что где ещё сейчас человеку средних лет знакомиться-то, кроме как не на работе, Юль?
Ю. Андреева― Ну, смотри, да, вот здесь вот как раз то, что Саша сказал, две крайние противоположности. Но исследование как раз доказывают то, что нельзя полностью запрещать отношения на рабочих местах. Ну, во-первых, – да? – в 1-ю очередь то, что у нас действительно там 90% своего времени люди проводят на работе, им реально негде больше знакомиться кроме как на работе. А второй момент – то, что там, где будет жесткий запрет, там будут тайные отношения, которые ещё… с которыми ещё тяжелее разбираться… с последствиями которых еще тяжелее разбираться нежели, чем когда это разрешено. Но есть определенные правила, ограничения либо ситуации, которые когда они начинают мешать работе, – да? – то есть они могут быть разрешены с помощью как раз там представителей тех отделов, которые отвечают за этику внутри компании. И если есть сложности, то их можно разобрать. Но по сути как бы личная жизнь, она на то и личная, что она должна оставаться между двух людей, – да? – как бы по сути не выливаться куда-либо и разбираться уж тем более публично там среди… на всю компанию рассказывать о том, какие, у кого отношения были, как бы это не приемлемо. Это может в принципе нарушать основные, базовые права человека.
В. Ковалев― Юль, а вот ты сказала, что существуют некоторые комиссии, которые разбирают подобные кейсы. Кто туда входит помимо руководства? Или наоборот руководство туда не входит принципиально?
Ю. Андреева― Да нет, это по-разному опять же. Да? То, что зависит от самой компании. Обязательно там есть человек, который отвечает… Ну, это скорее всего HR. Плюс это тот человек, который отвечает за этику. То есть, ну, зависит от масштабом компании. Да? Если это крупная компания, международная корпорация, то очевидно, что там есть отдел, сформированный, где… которое возглавляется определенным лицом, обладающим навыками, который проводит тренинги, который писал кодекс для этой компании и способен разобраться в такой ситуации. Вот. Как правило, это вот либо руководство, либо HR и плюс ещё вот представитель комиссии по этике внутри компании.
В. Ковалев― Ну, что…
А. Цыпкин― Мне, кстати, кажется… А мы уходим на рекламу, да?
В. Ковалев― Да, мы сейчас уходим на короткие новости. Ну, что ж, дорогие друзья? Совсем скоро мы вернемся и тему дообсуждаем. У нас сегодня в студии программы «Бизнес-ланч» Александр Цыпкин, председатель комитета по внутрикорпоративным коммуникациям Ассоциации менеджеров, консультант по стратегическим коммуникациям, публицист, сценарист, и Юлия Андреева, сопредседатель Комиссии по бизнес-этике Ассоциации менеджеров, партнёр практики частных клиентов, адвокат S&K Вертикаль. Скоро вернемся.
**********
В. Ковалев― После новостей и небольшой паузы снова в эфире «Эха Москвы» программа «Бизнес-ланч». Меня зовут Вадим Ковалёв. Сегодня в студии, к сожалению, виртуально, виртуально из «Москва-сити», из прекрасного Санкт-Петербурга Александр Цыпкин, председатель комитета по внутрикорпоративных коммуникаций Ассоциации менеджеров, консультант по стратегическим коммуникациям, публицист и сценарист и Юлия Андреева, сопредседатель Комиссии по бизнес-этике Ассоциации менеджеров, партнер практики частных клиентов, адвокат S&K Вертикаль. Меня зовут Вадим Ковалев. Ну, что ж? Продолжаем обсуждать, как harassment влияет на экономику. И собственно поговорили, что нет юридических последствий пока – да? – харассмента, и как противодействуют этому компании. А вот есть ли в России громкие случаи влияния на репутацию отдельных лиц или компаний подобного поведения? Или пока это продолжает быть табуированной темой? Юля?
Ю. Андреева― Ну, пока что у нас естественно такого же влияния, как это происходит в других странах, нет безусловно. Мы слышим о громких скандалах, которые были замечены, но тем не менее сказать о том, что были какие-то существенные последствия, это вряд ли. Все мы наслышаны… Ну, я не буду приводить фамилии, наверное, в эфире как бы вспоминая эти ситуации, но тем не менее это единичные истории. У нас даже как бы если мы вспомним компанию, например, «Сбербанк», уж это упоминание я себе позволю, то акции компании даже не упали в принципе – да? – там после того, как это случилось. И все эти НРЗБ скандал. И эти вещи затихают. Но тем не менее то, что мы понимаем, что harassment безусловно оказывает влияние на репутацию, потому что раньше этого не было вообще. Это так. Скажем, ну, можно, наверное, в кавычки поставить, но тем не менее интерес к этой теме растет. Люди начинают понимать то, о чем они имеют право говорить, о чём они раньше молчали. И поэтому как бы эта проблема, она действительно становится проблемой для компаний.
В. Ковалев― Саш…
А. Цыпкин― Ну, вот я да, как раз…
В. Ковалев― Да.
А. Цыпкин― Как раз и хотел бы сказать, что хорошо, что мы эту тему сегодня поднимаем, потому что если б меня спросили исключительно как специалиста по репутации, я сказал, да вообще не волнуйтесь. Ничего не будет. Реально ничего не произойдёт. Продажи не остановится. Люди пойдут покупать кефир тот же самый, даже если узнают, что начальник кефирного завода приставал к секретарше. Ничего не будет. А акции тоже никуда особо не денутся. Мы… мы не запал. Это если б я рассуждал исключительно как пиарщик. Это плохо. Но это так на сегодняшний момент. Это изменится, но не сегодня и не через год, и даже не через 2, я думаю. Но повторюсь, с точки зрения репутации, скорее бренда эйчаровского понятно, что человек перед тем, как прийти на работу, зайдёт на соответствующий ресурс и почитает, что там происходит. И он там узнает, что начальник на корпоративе или вообще у нас без этого дела ты никуда не пройдёшь, или ребят, здесь людям из Средней Азии делать нечего, потому что такого можете наслушаться. И квалифицированный, хороший сотрудник, а в России дефицит кадров, не придёт. Либо человек, который подвергается внутри своей компании вот такому сейчас, узнает, что а другой компании по-другому, потому что сегодня всё открыто, и просто уволиться и перейдет работать, может даже за меньшие деньги. Вот это может сильно по компании ударить, потому что вот это отсутствие репутационных последствий, оно обманчиво. Оно не влияет на вот, повторюсь, на продажу, наверное, товаров и на рыночную стоимость, но на настроение, на эффективность работы сотрудников влияет безусловно, 100%.
В. Ковалев― А вот…
Ю. Андреева― Я еще можно добавлю?
В. Ковалев― Да, Юль, пожалуйста.
Ю. Андреева― Что у нас… На самом деле мы часто забываем о том, ну, наверное, мы растем в своем поколении, оцениваем там своих… одного возраста – да? – категорию, но тем не менее мы должны понимать то, что то молодое поколение, которое сейчас готовится выйти, новые рабочие кадры, они уже совершенно по-другому воспринимают…
В. Ковалев― Да.
Ю. Андреева― … эту проблему. Они активно поднимают и обсуждают эту проблему в вузах. Мне как представителю – да? – проекта, который занимается в принципе харассментом практически, ну, раз там в 2 недели точно приходят запросы из вузов с просьбой дать свою оценку, свои комментарии, там помочь разработать какой-то кодекс. Поэтому действительно для них эта проблема уже важная, и они обращают на это внимание. Поэтому рассматривая вакансии в крупных компаниях для себя, в принципе пытаясь идти работать, они будут выбирать те компании, где этот вопрос урегулирован должным образом.
В. Ковалев― Саш, вот пандемия…
А. Цыпкин― Мне кажется…
В. Ковалев― Саш, можно короткий вопрос? Вот…
А. Цыпкин― Давай.
В. Ковалев― Вот пандемия оставляет свой след. Да? Работы становится меньше в целом. Да? И люди заработают цепляются, за неё держатся. Вот нет ожидания, что большее количество людей будут терпеть просто подобные выходки, подобное поведение, чтобы не лишиться работы, особенно учитывая, что её особо и нет вокруг?
А. Цыпкин― К сожалению, ты, конечно, прав. И дело даже не только в пандемии. А в целом нельзя сказать, что наша экономика вообще летит вперед на всех парах и… Если мы говорим о Москве, в Москве работы много. А если мы говорим о регионах за пределами Садового кольца, то да, там и с работой похуже и менталитет иной. Но повторюсь, мы же говорим об эффективности компании, а значит о самых лучших сотрудниках. Поэтому те, кто боятся потерять работу, зная, что они ее не найдут, они… Они, наверное, не пойдут заявление писать в этической комитет. А профессионалы настоящие, те, кто в России всегда работу найдут, потому что… Ну, что обманывать-то? Люди на рынке известны. Если у тебя репутация серьёзного профессионала, ты… у тебя всегда три-четыре предложения о работе есть, даже если это пока ещё там должность среднего звена или начальной какая-то. Либо ты в стартап какой-то уйдёшь. Поэтому лучших можно потерять. А так да. Понимаешь, надо еще менталитет, чтобы наконец стал исправляться. И люди стали понимать, что использование служебного положения в сексуальных целях, давай хотя бы про это, это просто адское западло. Ну, просто, что это свидетельство о тебе как о не очень состоятельном мужчине в целом, не в смысле денег, а в смысле внутреннего содержания. Ну, то есть хоть это… А это моментально сегодня благодаря соцсетям рассылается, репутация разлетается. Всё, через 5 секунд об этом уже все знают. И ты начинаешь портить себе свою чисто человеческую репутацию, которая может иметь значение и уж точно будет иметь значение через несколько лет, когда всё это вспомнят, и когда к нам cancel culture придёт. А она придёт и придёт во всех их худших проявлениях, когда ты… задним числом тебя сделают виноватым за те грехи, которые 10 лет назад ещё не считались грехами. Вот тогда у нас тут такой «Me too» начнется! Вот и если у нас действительно будут… все тенденции к нам придут, то у людей начнутся проблемы очень серьезные и репутационные, и акции начнут падать и так далее, то, что всё это вылетит. Поэтому готовиться нужно сейчас.
В. Ковалев― Спасибо, Саша. Юля?
Ю. Андреева― Да, я совершенно согласна. У нас на самом деле сейчас уже мы понимаем, что у нас происходит становление тех социальных норм, которые потом перерастут в законодательные нормы, и поэтому меняется отношение общества. Общество зреет, скажем так, в этом направлении. Понятно, что уже есть ряд вещей, за которые, ну, в принципе там 90% людей проголосуют, то, что да, эти вещи должны быть запрещены на законодательном уровне. Так поступать нельзя. И бояться того, что у нас здесь… руку, когда девушка выходит из такси или придержать дверь, этого не произойдет, но ближайшие, не знаю, 50-100 лет точно. Мы не дорастем так быстро до этого. Но…
А. Цыпкин― Произойдет.
Ю. Андреева― В ближайшие 50 лет, думаешь…
А. Цыпкин― Раньше.
В. Ковалев― Мне… мнения разделились. Кстати, вот знаете, интересный вывод из опроса ВЦИОМ также коллеги делают, что мнение «Сама виновата» не распространено среди россиян. Его поддерживают всего 4% опрошенных. Согласны с этим?
Ю. Андреева― Согласна с чем, ты имеешь в виду?
В. Ковалев― С тем, что всего 4% россиян считают, вот у тебя слишком короткая юбка, или какие-то…
А. Цыпкин― Нет, у нас, говоря западным эвфемизмом victim blaming, прости, Господи, это когда все говорят, сама виновата, у нас, конечно, распространён. Я вообще так не очень бы доверял опросам общественного мнения, потому что человек склонен говорить чуть-чуть лучше, чем он думает и представить позицию, которая, как ему кажется, благородна, особенно когда ещё это вопрос о политике, экономике – ладно. А когда ты так… Как так… Так делаешь? Нет, конечно, не делаю. Ни в коем случае. На самом деле это большая проблема нашей страны, что говорят, сама виновата или сам виноват, не так поступил. Вот. Но опять же почему я считаю, что это будет гораздо быстрее? Деньги за этим придут. Очень будет выгодно проезжаться на теме харассмента. Выгодно будет записать заявление в комитет по этике. Выгодно будет скандал в прессе устраивать, что он ко мне подошёл. Да? Потому что компания будет пытаться это быстренько замять и сказать, слушай, ладно, на вот возьми деньги, только… только не кричи везде в «Твиттере» или в «Инстаграме», что у тебя за жопу взял. И дальше все будут думать, так, окей, чтоб меня уж точно не обвинили, я вообще буду за километр всех обходить. На корпоратив не пойду. А если пойду, то пить не буду, потому что из того, что я просто где-то в углу стоял и разговаривал, потом этот человек напишет на меня такой цифровой дорос, сетевой, и независимо… Это вообще не про право будет. Это будет по социальную… социальные последствия. А они к нам безусловно придут. Они безусловно придут.
Ю. Андреева― Так вот мы с тобой говорим о разных вещах. Я говорю о том, что на законодательном уровне мы не будем регулировать эти вещи в ближайшие 50 лет точно.
А. Цыпкин― Это да. Конечно.
Ю. Андреева― Да. А с точки зрения социальных норм безусловно, ну, потому что даже если взять пример, что у нас в принципе, – да? – хоть мы и говорим, что мы там не ориентируемся на Америку, и зачем нам здесь ее НРЗБ, у нас все равно очень много международных компаний. Люди, которые впитывают в себя культуру поведения внутри этой компании.
В. Ковалев― Юль, скажи, пожалуйста, маленький совет руководителям бизнеса, которые нас сейчас слушают, какие первые шаги, чтобы противодействовать харассменту стоит предпринять, если в компании еще нет такой идеологии, что называется. Это что? Комитет по этике? Кодекс этики? Протоколы реагирования?
Ю. Андреева― Да, безусловно разработать ту систему процедурную, которая будет приемлема для вашей компании, разработать кодекс корпоративной этики. Ведь не всегда… Как бы не обязательно туда включать только harassment, есть много других разных, отличающихся от нормы, – да? – скажем так, девиантных форм поведения, которые тоже неприемлемы в компании. Опираться на уважение чести и достоинства. Разработать и понять систему, куда могут присылать эти сообщения, как вы будете реагировать. Да? То есть какие возможные шаги для того, чтобы устранить то нарушение, которое произошло. Как будут разбираться эти ситуации. То есть нужно… Ну, в любом случае это важно для компании, потому что это отражает ценность компании, ее ДНК. Да? То есть то, чем живут сотрудники. И в принципе это влияет положительно на развитие самой компании, потому что даже при приеме на работу вы уже будете понимать, подходит человек вам по корпоративному духу, или это вообще не ваш человек, с которым вы расстанетесь, там вложив в него силы, деньги, через полгода – да? – или, может быть, быстрее, понимая, что вы не можете дальше с ним работать. Поэтому нельзя просто не обращать вообще внимание на эти ситуации. То есть я считаю, что уже все компании там от мала до велика должны как бы принимать эти вещи у себя внутри.
А. Цыпкин― Тут… Тут еще главное только себе не врать, потому что есть компании…
Ю. Андреева― Да.
А. Цыпкин― … где уже понятно, что акционер определенным образом относится к определенным социальным группам или национальным группам, или каким-то ещё, и все остальные… его ближайшее окружение точно так же. И тут они начитают играть в ускоренной толерантности. И когда приходит у ним человек из этой социальной группы, допустим, читает этот кодекс, приходит, а внутри компании совершенно другая культура. Вот здесь лучше сразу на входе каким-то образом сказать, слушай, ну, вот у нас вот так это всё происходит. Давай вот врать не будем. Мы видим, что ты вот такой. Что-то мне кажется, не получится у тебя здесь. Ну, по крайней это будет как-то честнее, и придёт меньшее количество конфликтов. А это не очень, наверное, этично, но пока надо смотреть правде в глаза и… Или начинать действительно на уровне акционеров и первых лиц перекраивать свое собственное сознание и понимать, что вот так нельзя больше. Я так делать не хочу. Вот. Но чтобы это было честным. Очень большая проблема у нас и страны в целом – это такое повсеместное лицемерие. Мы верим в одну идею, а реализуем другую.
В. Ковалев― Ну, что ж, дорогие друзья? На этой, как говорится, оптимистичной ноте диалог безусловно этот продолжим. Спасибо большое нашим потрясающим спикерам программы «Бизнес-ланч» сегодня. У нас в гостях был Александр Цыпкин, председатель комитета по внутрикорпоративным коммуникациям Ассоциации менеджеров, консультант по стратегическим коммуникациям, публицист, сценарист, и Юлия Андреева, сопредседатель Комиссии по бизнес-этике Ассоциации менеджеров, партнер практики частных клиентов, адвокат S&K Вертикаль. В студии был Вадим Ковалёв. Слушайте «Бизнес-ланч» каждый вторник на «Эхо Москвы».
Скучаю по ударам сзади Новости Брянска
На портале SOVSPORT.RU состоялась видеоконференция с Егором Титовым, который поддержал давнюю традицию – общаться с читателями в преддверии Нового года.
«ПОЧТИ ВСЕГДА СОГЛАСЕН С ЛОВЧЕВЫМ»
– Не сочтите за лукавство, но я практически всегда соглашаюсь с оценками Евгения Ловчева в «Советском спорте». В том числе и с резкими выводами. Видимо, мы смотрим на футбол со схожих позиций. Когда Евгений Серафимович начал писать, что Карпин не тренер для «Спартака», у меня возникли схожие мысли. Но в случае с молодыми тренерами ситуация может меняться. Очевидно, что Валерий быстро учится, уже по ходу сезона ему удалось многое исправить. Я наконец увидел систему в игре «Спартака» и понял, чего хочет тренер. Новички вливаются в состав безболезненно. Это уже другой «Спартак». Случись отставка Карпина, то эта мера была бы ошибочной.
Картинка года для меня – это праздник в ложе для почетных гостей после матча с «Локомотивом» (3:0). Я видел, как радовались и обнимались випы. Но я хорошо помню, как раньше некоторые из них публично выбрасывали абонементы, плевались и обещали, что больше не придут. «Спартак» заставил болельщика вновь поверить в себя. И я верю, что по итогам чемпионата команда будет в тройке.
– А вылет из еврокубков на чьей совести?
– Вина за поражение «Легии» лежит полностью на футболистах. Просто не проявили характер в концовке и позволили себя переиграть.
– В первый год в «Спартаке» Карпин то и дело обращался к вам за советом. А как сейчас?
– Как таковых отношений с Карпиным нет. Когда видимся, общаемся нормально. Негатива нет. В 2008‑м я очень хорошо знал «Спартак», и Валерий это понимал. Сейчас с точностью до наоборот – нет человека, который бы знал «Спартак» лучше Карпина. К чему мои советы?
«ПРОТИВ ПРИБАВКИ В ВЕСЕ – НЕ ВОЗРАЖАЮ!»
– Чуть ли не треть посетителей интересуются проектами, в которых вы принимаете участие, – команда «Артист», тульский «Арсенал» из любительской лиги…
– Наверное, это потому, что команда «Артист» – детище Коли Трубача – набирает обороты. А «Арсенал»» созвал множество известных футболистов.
Благодаря «Артисту» я с другой стороны начал узнавать Россию. Во времена «Спартака» что мы видели: самолет – отель – стадион. Общения и чего-то познавательного было минимум. Куда нас только не зовут на следующий год! Правда, в «Артисте» огромная потеря: Аленичев теперь будет тренировать тульский «Арсенал» и не сможет выбираться в поездки. Зато мы будем ездить играть за Тулу по возможности.
– Вы уверены, что готовы больно получать по ногам от соперников в любительской лиге?
– Готов! Соскучился я по этим ударам сзади. Уже готовлю щитки. Главное – вовремя расставаться с мячом. Как учил нас Георгий Ярцев: «Соперник к тебе прилетел, а мяч уже улетел». Контролирует меня теперь как тренер Петрович (Владимир Пресняков-старший. – Прим. ред.). После тренировок и игр он непременно оценивает меня: «Что-то Егорушка не слишком хорош». Это задевает, в следующий раз играю в полную мощь. Так что и к матчам за «Арсенал» подойду в полной готовности. К счастью, не склонен к лишнему весу. Сколько ни ем после окончания карьеры, килограммов так и не прибавилось, хотя я бы не возражал.
«ДОЧКА НАПОМИНАЕТ МНЕ… ЕВСЕЕВА»
– Когда мы увидим на кортах международных турниров Анну Титову?
– До профи дочке еще далеко по возрасту. Да и работы впереди много. Если заниматься делом, то заниматься серьезно. Поэтому в ближайшее время вопрос будет поставлен жестко: если не вырисовывается хороших перспектив, если на фоне ведущих теннисисток она окажется на плохих позициях, то лучше оставить это занятие. Но я больше оптимист. Радует, что у дочери есть характер. Не раз обыгрывала более сильных соперниц – на морально-волевых, ломая тактический рисунок и озадачивая тем самым соперниц. С первой ракеткой города Сочи сражалась недавно четыре часа. Проиграла первый сет, но затем вырвала победу. И тогда я ей сказал: «Ты можешь». Аня как спортсмен напоминает мне Вадика Евсеева. Вадик иногда говорил: «Я в футбол не очень играю, зато работяга и не сдамся!».
«ЖДУ НЕ ДОЖДУСЬ НОВОГОДНЕГО ВЫПУСКА ВАШЕГО ЕЖЕНЕДЕЛЬНИКА!»
– В одном из предновогодних выпусков «Советского спорта – Футбола» ждите сюрприз. Редакция пригласила нас с Андреем Тихоновым провести матч на обычной «коробке» в районе Отрадное с местными жителями. Пока играли, я ужасно замерз. Зато отогрелись с Андреем на посиделках с болельщиками – они втянули нас в дискуссию. Самому не терпится репортаж прочитать – в таких «народных акциях» участвовать еще не приходилось…
Почему Центробанк хочет ограничить выдачу кредитов с плавающими ставками? | Личные деньги | Деньги
Центральный банк России предлагает ограничить выдачу гражданам кредитов с плавающими ставками.
Как пишет РБК со ссылкой на соответствующий законопроект ЦБР, речь идет о займах сроком до одного года или более 20 лет, а также о кредитах с нефиксированным процентом.
Доля кредитов с переменными ставками в РФ невелика — порядка 0,1%. Но она может вырасти, поскольку банки заинтересованы в выдаче таких кредитов (денежно-кредитная политика в России ужесточается, Центробанк повышает ключевую ставку, деньги для банков становятся дороже, с плавающими ставками это можно переложить на плечи заемщиков).
Напомним, в марте президент РФ Владимир Путин поручил правительству и Банку России разработать меры для снижения рисков заемщиков от роста плавающих ставок по кредитам. ЦБР тогда опубликовал шесть возможных способов ограничений, в том числе и полный запрет подобных кредитов.
Поправки коснутся законов «О Центральном банке», «О потребительском кредите», «О кредитных историях».
Ожидается, что большинство из них могут вступить в силу уже с 1 января следующего года.
Помимо ограничений на кредиты с плавающими ставками Банк России предлагает ограничить и параметры таких займов: ввести максимально допустимое значение переменного процента и установить срок возможного «удлинения» кредита, а срок продления не должен превышать три года. Дело в том, что длинные ссуды «очень чувствительны к изменению таких параметров», говорится в пояснительной записке к законопроекту.
Кроме того, ЦБР собирается усилить информированность должников. «Предполагается, что банки будут обязаны указывать на своих сайтах информацию о том, как теоретически могут вырасти расходы клиента после коррекции ставки по ссуде. Кредитор должен будет предупредить заемщика об изменении значения ставки за 15 дней до события, предоставить новый график платежей и информацию о полной стоимости кредита», — отмечается в сообщении Банка России.
Как замечает президент Межотраслевой ассоциации саморегулируемых организаций в области строительства и проектирования «Синергия», Александра Белоус, плавающие процентные ставки очень выгодны для банкиров, но их широкое применение, особенно при выдаче ипотечных займов, может привести к негативным последствиям и даже социальным проблемам.«Плавающая ставка страхует в первую очередь риски кредитора, но при этом ставит заемщика в заведомо неравноправное положение. Фактически его обязывают компенсировать банку упущенную прибыль, даже когда ухудшение экономической конъюнктуры никак не связано с действиями самого заемщика и он не причастен к ситуации, из-за которой ему увеличили процент. Простой человек не может отвечать за макроэкономику, стабильность национальной валюты, рост или спад производства.
Теоретически, конечно, плавающая ставка для заемщика может быть пересмотрена банком в меньшую сторону. Однако практически это маловероятно. Финансовые организации заинтересованы в максимизации прибыли и повышении дивидендных выплат своим акционерам, поэтому лишать себя дохода в пользу заемщиков добровольно они никогда не станут.
Кредиты с плавающими ставками слишком трудны для понимания неподготовленного потребителя. В случае плавающей ставки заемщики рискуют неверно оценить реальную сумму ежемесячного платежа и объем переплаты по кредиту. В результате люди в какой-то момент сталкиваются с таким увеличением объема платежей, который не могут осилить. Например, специалисты Центробанка просчитали, что при увеличении ставки кредита на 15 лет с 6,5% до 9% ежемесячный платеж возрастет на 12,5%, а общая переплата по кредиту увеличится примерно на треть.
Даже при фиксированной процентной ставке заемщик часто не учитывает ряд нюансов и после подписания кредитного договора бывает неприятно удивлен реальным размером выплат. В условиях же продолжающегося седьмой год подряд снижения реальных располагаемых доходов населения любое непредвиденное увеличение ставки по кредиту наверняка вызовет серьезные проблемы с обслуживанием долгов. А это в конце концов невыгодно и самим банкам. Ведь если заемщики массово не смогут обслуживать свои кредиты, в том числе ипотеку, это серьезно увеличит размеры проблемных активов банка. В свою очередь проблемы банков могут дестабилизировать экономику в целом и вызвать рост социальной напряженности. Поэтому лучше избегать массового применения такого высокорискового инструмента, как плавающие процентные ставки по кредиту, тем более в области ипотеки», — рассказала Белоус АиФ.ru.
(PDF) Понимание разговорного языка
90. Р. Пьераччини, Э. Левин и К. Х. Ли (1991). Стохастическое представление концептуальной структуры в
задаче ATIS. Труды, 1991 г., семинар
, посвященный речи и естественному языку, 121-124, Лос-Анджелес
Альтос, Калифорния.
91.
Р. Пьераччини, Э. Левлин, Э. Видаль. (1993) Изучение языка. Eurospeech, стр.
1407-1412. Берлин, Германия
92.
A.Потамианос, С. Нараянан и Г. Риккарди, (2005) Адаптивное категориальное понимание для
систем разговорного диалога
IEEE Trans; по обработке речи и звука, SAP-13 (2): 321-329
93.
S. S. Pradhan, H. Ward, K. Hacioglu, J.H. Мартин и Д. Джурафски (2004) Shallow Semantic
Parsing using Support Vector Machines. HLT-NAACL, Бостон, Массачусетс, США, стр. 233-240.
94.
С. С. Прадхан, Х. Уорд и Дж. Х. Мартин (2007) К надежной семантической маркировке ролей.
NAACL HLT, Рочестер, штат Нью-Йорк, США, стр. 556–563,
95.
Н. Прието, Э. Санчис и Л. Палмеро (1994) Непрерывное понимание речи на основе автоматического
изучения акустических и семантических моделей. ICSLP, Иокогама, Япония
96.
М. Пурвер, Ф. Ратиу, Л. Каведон (2006) Надежная интерпретация в диалоге путем объединения
оценок уверенности с контекстными характеристиками. ICSLP, Питтсбург, Пенсильвания, США, стр. 1-4
97.
O.Рамбоу, С. Бангалор, Т. Батт, А. Наср, Р. Спроут (2002) Создание синтаксического анализатора конечного состояния с использованием семантики приложения
. COLING, Taipei
98.
C. Raymond, F. Bechet, N. Camelin, R. De Mori, G. Damnati (2005) Семантическая интерпретация
с исправлением ошибок IEEE ICASSP, Филадельфия, Пенсильвания, США
99
К. Раймонд, Ф. Бешет, Р. де Мори и Г. Дамнати, (2006) Об использовании преобразователей конечного состояния
для семантической интерпретации,
Речевая коммуникация, 48 (3): 288-304.
100.
К. Раймонд, Ф. Беше, Н. Камелин, Р. Де Мори и Г. Дамнати (2007) Последовательное решение
стратегии машинной интерпретации речи
, IEEE Trans. по обработке речи и звука,
15 (1): 162-171.
101.
G. Riccardi, R. Pieraccini и E. Bocchieri (1996) Стохастические автоматы для языкового моделирования.
Компьютерная речь и язык, 10 (4): 265-293.
102.
Г. Риккарди и Д.Хаккани-Тур (2005) Активное обучение: теория и приложения к автоматике
Распознавание речи
IEEE Trans. по обработке речи и звука, SAP-13 (4): 534-545
103.
S.D. Ричардсон, В. Б. Долан и Л. Вандервенде. (1998). MindNet:
«Получение и структурирование семантической информации из текста». ACL-COLING, Монреаль, Канада, стр. 1098-1102.
104.
М. Ричардсон и П. Домингос (2006) Марковские логические сети, машинное обучение, 62: 107-
136.
105.
К. Райс (1999) Обнаружение речевого акта на основе HMM и нейронных сетей. IEEE ICASSP Phoenix,
AZ, США.
106.
Б. Рорк (2001) Вероятностный нисходящий синтаксический анализ и языковое моделирование. Вычислительная
Лингвистика
27 (2), 2–28.
107.
Р. Сарикая, Ю. Гао и М. Пичени (2004) Сравнение основанных на правилах и статистических
Методы семантического моделирования языка и измерения уверенности.HLT-NAACL, Бостон,
Масса, США, стр. 65-68
108.
Р. Сарикая, Ю. Гао, М. Пичени и Х. Эрдоган. (2005) Измерение семантической уверенности
для голосовых диалоговых систем
IEEE Trans. по обработке речи и звука, 13 (4): 534-545.
109.
R. E. Schapire, M. Rochery, M. Rahim, and N. Gupta (2005) BoostingWith Prior Knowledge for
Call Classification
IEEE Trans. по обработке речи и звука, САП-13 (2): 174-182
110.
Э. Шриберг, А. Столке, Д. Хаккани-Тур и Г. Тур, (2000) Автоматическая сегментация речи на основе Prosody
на предложения и темы,
Речевая коммуникация, стр. 127–154, 2000 .
Дебют семейства парсеров Google
Мы уже встречались с Parsey McParseface, а также с новыми моделями SyntaxNet в мае, когда Google их представил. SyntaxNet является частью Tensor Flow, фреймворка Google с открытым исходным кодом для глубокого обучения, а вместе с Parsey они, в свою очередь, помогают заложить основу для понимания естественного языка (NLU).Сегодня компания Google представила семью Парси с его 40 двоюродными братьями, которые являются предварительно обученными моделями с открытым исходным кодом для синтаксического анализа текста на 40 языках.
Для тех из вас, кто не знаком с Parsey McParseface и синтаксическим анализом в целом, позвольте нам рассказать вам, что это такое. Анализ включает разбиение предложения и определение его компонентов как существительных, глаголов, прилагательных, наречий и т. Д. Он просто обозначает части речи, присутствующие в составе предложения.Это делается для того, чтобы компьютерные системы могли понимать и «читать» человеческий язык, чтобы разумно обрабатывать его как команду. Это может показаться несущественным, но Mc Parseface работает в Google в огромных масштабах и помогает разбивать и понимать запросы веб-поиска, выполняемые пользователями. Теперь Google сделал эту технологию доступной на 40 языках, тем самым помогая множеству исследователей по всему миру.
Свободное владение несколькими языками было не только тем параметром, над которым работал Google, кроме того, они усилили базовую библиотеку SyntaxNet NLU.Parsey теперь может определять разные значения на основе различий в написании, что более известно как морфология. В английском размещении буквы «s» после слова обычно получается множественное число, однако это не относится к другим языкам, например, немецкому и русскому языкам, которые сильно трансформированы. С помощью Parsey Google стремится улучшить глубокое обучение, которое представляет собой тип искусственного интеллекта, включающий огромное количество данных, передаваемых через искусственные нейронные сети, в попытке научить их понимать выводы, связанные с новыми данными и обрабатывать строки слов.
Parsey и глубокое обучение вызвали немало изменений в сфере совместного использования, одним из которых стала волна чат-ботов. Благодаря расширению синтаксического анализа за счет преодоления языковых барьеров платформа On-Demand может серьезно пострадать. Поскольку на платформе On-Demand размещение заказа требует подробного описания того, что требуется, и требует больше времени, альтернативой этому является интеграция API, что опять же является сложным процессом для непрофессионала. Парсинг обеспечит простоту общения на естественном языке.Поскольку компьютер поймет заявление, сделанное в чате, и проанализирует, что это за команда, без использования подробного оператора или ключа API, тем самым заменяя On-Demand чатами и позволяя таким платформам, как Fugu, расти.
Что нового в Swift — WWDC 2017 — Видео
Скачать
Добрый день всем.
Спасибо.
Добро пожаловать в раздел новых возможностей Swift.
Меня зовут Дуг Грегор. Я здесь с некоторыми из моих коллег из команды Swift, чтобы поговорить о некоторых замечательных вещах, которые мы привносим в Swift 4.
Теперь, если вы следите за разработчиком iOS и автором Оле Бегеманном, вы на самом деле знаете все, что уже есть в Swift 4.
Это то, что мне очень нравится в сообществе Swift.
Что здесь сделал Оле, он просмотрел все предложения, что входило в Swift 4 и что он сделал? Он построил игровую площадку, чтобы продемонстрировать, как работают эти функции, и поделился ею со всем миром, чтобы мы все могли извлечь из нее уроки.
Это круто.
И это возможно, потому что в любой момент вы можете перейти на Swift.org, наш дом с открытым исходным кодом, и загрузите снимок последнего и лучшего компилятора Swift.
Этот снимок представляет собой набор инструментов, который вы можете установить в Xcode.
Предоставляет новый компилятор, отладчик, исходный код, все. Таким образом, вы можете создать свое приложение с использованием новейших инструментов. Попробуйте некоторые из новых функций, проверьте, исправили ли мы вашу любимую ошибку. Конечно, все это возможно, потому что Swift имеет открытый исходный код. Мы разрабатываем все открыто на GitHub, чтобы вы могли следить за ними.
Вы можете участвовать, если хотите.
А также, как развивается Swift. Стандартная библиотека, язык — это открытый процесс эволюции, в ходе которого мы оцениваем индивидуальные предложения.
Усовершенствуйте их, улучшите их, чтобы сделать Swift лучше для всего сообщества разработчиков.
Как вы уже, несомненно, слышали, Xcode 9 представляет поддержку рефакторинга для Swift.
Итак, все биты уровня языка, которые заставляют работать рефакторинг для Swift, фактически остались в проекте Swift.Так что скоро мы откроем исходный код.
Самое замечательное в этом то, что вы можете проверить и собрать исходный код Swift, создать свои собственные рефакторинги, а затем с помощью механизма цепочки инструментов, о котором я только что говорил, опробовать их в Xcode.
Хорошо, это способ действительно работать с вашими инструментами разработки.
Теперь также частью нашей экосистемы с открытым исходным кодом является менеджер пакетов Swift.
Итак, это поддерживает растущую экосистему с более чем 7000 пакетов на GitHub.
Это чрезвычайно популярно для серверного Swift, где Swift PM позволяет очень легко получить серверные компоненты, необходимые для создания серверного приложения Swift в Linux.
В этом году Swift Package Manager претерпел множество улучшений. В лучшем манифестном API, лучшем рабочем процессе разработки и так далее. Кроме того, мы добились значительного прогресса в достижении нашей конечной цели первоклассной поддержки пакетов Swift в среде Xcode IDE. И мы приближаемся к этому с использованием Swift PM в качестве библиотеки и, конечно же, новой системы сборки Xcode, полностью построенной на Swift.
Итак, сегодня у нас много работы.
Я расскажу о нескольких небольших улучшениях и дополнениях к самому языку, прежде чем мы углубимся в историю совместимости исходного кода, мы собираемся поговорить о том, как мы можем использовать весь код, который вы создали на Swift. , с Swift 4 и Xcode 9.
Мой коллега Боб расскажет об инструментах Swift и улучшениях производительности, прежде чем Бен погрузится в строки, коллекции и некоторые общие функции Swift.
Наконец, Джон расскажет об эксклюзивном доступе к памяти.
Это семантическое ограничение, которое мы вводим в язык Swift, чтобы построить его в будущем.
Итак, начнем с одной маленькой особенности.
Контроль доступа. Итак, вот я определил эту простую структуру даты.
И он похож на тот, что в фундаменте. Он будет использовать secondsSinceReferenceDate как внутреннее представление, но я делаю его закрытым, потому что это не лучший API для предоставления моим пользователям.
Я хочу, чтобы этот тип был хорошим гражданином ценного типа, чтобы он был равноправным и сопоставимым.
Но этот код уже кажется немного загроможденным и беспорядочным. Мне действительно следует разбить это на отдельные расширения; по одному на каждую задачу, верно? Это хороший стиль кодирования Swift, но Swift 3 не очень хорошо его поддерживает, потому что вы получите эту ошибку, которую не сможете передать в частное объявление из другой лексической области видимости.
Вы можете исправить это с помощью fileprivate.
Но это означало, что весь файл мог видеть этого члена, а это не совсем так. Это слишком широко.
Итак, Swift 4 уточняет это так, что мы расширяем объем того, что означает частное, чтобы охватить только объявления во всех расширениях определенного типа в том же исходном файле.
Это гораздо лучше соответствует идее использования расширений для организации вашего кода.
И с этим изменением давайте больше никогда не будем говорить об управлении доступом.
Во-вторых, я хочу поговорить о составлении классов и протоколов.
Итак, здесь я представил этот протокол встряхивания для элемента пользовательского интерфейса, который может давать небольшой эффект встряхивания, чтобы привлечь к себе внимание.
И я пошел дальше и расширил некоторые классы UIKit, чтобы фактически обеспечить эту функциональность встряхивания. А теперь я хочу написать что-нибудь простое. Я просто хочу написать функцию, которая принимает кучу элементов управления, которые можно встряхнуть, и встряхивает те, которые могут привлекать к ним внимание.
Какой тип я могу написать здесь в этом массиве? Это на самом деле неприятно и сложно.
Итак, я мог бы попробовать использовать элемент управления пользовательского интерфейса. Но не все элементы управления пользовательского интерфейса в этой игре подвижны.
Я мог бы попробовать встряхнуть, но не все встряхиваемые элементы являются элементами управления пользовательским интерфейсом. И на самом деле нет хорошего способа представить это в Swift 3.
Swift 4 вводит понятие создания класса с любым количеством протоколов.
Это небольшая функция, но она прекрасно вписывается в общий набор Swift. Теперь, если вы пришли из опыта Objective-C, вы уже знаете все о том, что он делает, потому что Objective-C действительно имеет эту функцию в течение очень долгого времени.
Вот API Touch Bar, где клиент находится в NSView, который также соответствует NSTextInputClient.
В Swift 3 мы фактически не могли представить этот тип, поэтому мы импортировали его как NSView, что немного смущало.
Итак, Swift 4 исправляет это, и теперь мы можем фактически импортировать тип, используя NSView, который является NSTextInputClient, чтобы сопоставить все API и соответствующим образом.
Итак, сегодня мы поговорим об огромном количестве замечательных функций. Я хочу выделить несколько особенностей в области улучшения вещей, которые мы считаем идиомами какао. KeyPaths, Key-Value Coding, Archival & Serialization — большие новые функции Swift, которые будут обсуждаться в этой другой сессии «Что нового в Foundation» в среду.
И эти функции прекрасно работают с типами значений Swift. Таким образом, вы можете использовать их во всем своем коде Swift.
На этом занятии они также ответят на старый вопрос: как разобрать JSON в Swift.
Хорошо, поговорим о совместимости источников.
Итак, по своей природе Swift 4 в значительной степени совместим с исходным кодом Swift 3.
Причина в том, что язык не сильно изменился. Мы внесли некоторые улучшения. Как и переход на управление осью.
Мы внесли некоторые дополнения. Как и изменение состава классов и протоколов.
Также были улучшены способы сопоставления существующих API в SDK с Swift. Они предоставляют более качественные API Swift, чем раньше.
Но масштаб таких изменений намного, намного меньше, чем, скажем, от Swift 2 до 3 или даже от Swift 1 до 2.
Итак, переход от Swift 3 к 4 не так уж и серьезен для кода. база, как раньше.
И многие из функций, о которых мы говорим, являются чисто аддитивными.Итак, они в каком-то новом синтаксическом пространстве. Введение этих новых функций не нарушает код.
Тем не менее, нам нужен плавный путь миграции.
Итак, мы также представляем Swift 3.2.
Самое главное в Swift 3.2 — это не отдельный компилятор или другой набор инструментов.
Это режим компиляции компилятора Swift 4, который имитирует поведение Swift 3.
Итак, если какой-то синтаксис или семантика изменится с Swift 3 на 4, это обеспечит поведение Swift 3.
Более того, он понимает изменения, внесенные в новый SDK. Итак, если API-интерфейс в Swift 4 проектируется иначе, чем в Swift 3, он фактически откатит эти изменения в представление Swift 3.
Конечным результатом здесь является то, что когда вы открываете свой проект Swift 3 в Xcode 9 и строите его с помощью Swift 3.2, почти все должно просто строиться и работать так, как раньше.
И это отличный путь к освоению новых функций Swift 4, потому что большинство из них доступно также в Swift 3.2, а также все замечательные новые API и фреймворки в SDK этого года. Теперь, когда вы готовы перейти на Swift 4, а затем, в предыдущие годы, мы всегда предоставляли мигратора, чтобы взять ваш код из Swift 3 и переместить его на Swift 4.
Теперь, в отличие от предыдущих лет, это усилия по миграции не останавливают мир, больше ничего не нужно делать, пока весь стек не будет перемещен вперед.
Причина в том, что Swift 3.2 и Swift 4 могут сосуществовать в одном приложении.
Итак, вы можете установить, какую версию.
Вы можете установить, какую версию языка вы собираетесь использовать для каждой цели.
Итак, если вы хотите перейти на Swift 4, вы можете перенести целевое приложение, но оставить все свои фреймворки и все другие зависимости в Swift 3.2. Это хорошо.
Когда ваши зависимости обновляются и переходят на Swift 4, это прекрасно, они могут работать с вашим приложением, будь то Swift 3.2 или Swift 4.
Менеджер пакетов Swift также понимает это.
Итак, он будет собирать пакеты с той версией инструментов, которая использовалась для разработки пакета, и если пакет поддерживает несколько языковых версий Swift, которые могут быть описаны в манифесте, поэтому Swift Package Manager будет делать правильные вещи.
Теперь мы думаем, что при сосуществовании Swift 3.2 и Swift 4, с меньшим количеством изменений от Swift 3 к Swift 4, вы получите хороший плавный путь миграции на Swift 4.
И с этим, Я бы хотел поговорить с Бобом об улучшениях в сборке.
Поскольку размер и сложность ваших приложений Swift продолжают расти, мы инвестируем в улучшения системы сборки, чтобы не отставать от этого роста.
Xcode 9 имеет совершенно новую реализацию системы сборки.
Конечно, он написан на Swift и построен на основе движка LLBuild с открытым исходным кодом.
Он действительно быстро вычисляет зависимости между различными этапами вашей сборки.
Вы, скорее всего, заметите это, выполняя инкрементную сборку большого проекта.
Это предварительная версия технологии в Xcode 9. Мы хотели бы, чтобы вы ее опробовали. Итак, перейдите в настройки проекта или рабочей области в меню файлов и выберите новую систему сборки.
Помимо более быстрой системы сборки, еще один способ более эффективного использования вашей системы — это избегать дублирования работы.
И Xcode 9 делает это несколькими разными способами.
Предварительно скомпилированный заголовок моста ускоряет сборку больших проектов со смешанным исходным кодом.
Заголовок моста описывает интерфейсы в вашем коде Objective-C, поэтому их можно использовать в вашем коде Swift.
Если у вас много Objective-C, заголовок моста может быть очень большим и медленным для компиляции.
И повторный синтаксический анализ содержимого этого заголовка для каждого из ваших файлов Swift является расточительным.
У компилятора Apple LLVM есть отличное решение для этого, предварительно скомпилированные заголовки.
Xcode 9 теперь будет использовать предварительно скомпилированную версию заголовка моста, поэтому его нужно проанализировать только один раз.
Музыкальное приложение Apple — отличный пример, когда это очень помогает. Музыка — действительно большой проект, и он поровну разделен между Objective-C и Swift.
Использование предварительно скомпилированного заголовка моста, который используется по умолчанию в Xcode 9, ускоряет отладочную сборку музыки примерно на 40%.
Тестирование покрытия кода — еще один мощный инструмент, но в Xcode 8 он также может быть источником избыточных усилий.
Рассмотрим распространенный сценарий, когда вы вносите некоторые изменения в свой код, получаете его для сборки, а затем хотите запустить тесты с покрытием.
Вот как это выглядит в навигаторе отчетов Xcode.
Обратите внимание, что есть дополнительная сборка.
Почему это там? Тестирование покрытия реализовано в компиляторе путем допуска дополнительного кода инструментария для подсчета количества запусков каждого фрагмента кода.
В Xcode 8 обычная сборка не включает этот инструментарий.Итак, прежде чем вы сможете запускать тесты с покрытием, необходимо перестроить весь проект.
В Xcode 9 мы объединяем эти сборки.
Если у вас включено покрытие для тестирования, обычная сборка будет включать инструменты.
Это очень небольшая цена.
Менее 3% для одного проекта, который мы измерили.
Но вы получаете огромную выгоду, потому что теперь вам нужно создать свой проект только один раз в этом сценарии.
Следующее изменение на самом деле не связано с ускорением сборки.
Речь идет о том, чтобы этого избежать.
Итак.
Индексирование отличное. Это ключ к некоторым из самых мощных функций Xcode, таким как новый глобальный рефакторинг переименования, но индексация в фоновом режиме тратит усилия.
Всякий раз, когда вы строите свой проект, компилятор должен искать всю ту же символьную информацию, которая необходима для символьного индекса.
Итак, теперь в Xcode 9 мы будем автоматически обновлять индекс всякий раз, когда вы создаете свой проект.
Для этого есть очень небольшие накладные расходы во время сборки, но тогда нет необходимости повторять всю эту работу снова в фоновом режиме.
Итак, у нас есть новая система сборки и несколько различных способов более эффективного использования системы, что особенно для тех из вас, кто работает с большими проектами Swift, мы думаем, что это будет большим улучшением.
А теперь обратимся и посмотрим на производительность во время выполнения.
Создание высокопроизводительного кода всегда было одной из ключевых целей Swift. И с каждым новым выпуском Swift производительность увеличивалась.
Следующий шаг — сделать эту производительность более предсказуемой и стабильной.
Давайте посмотрим на пример со Swift 3.
Здесь у меня есть простой протокол, заказанный с функцией сравнения, и другая функция, которая будет проверять это путем сортировки массива значений с использованием сравнения.
Код написан в очень общем виде. Он должен работать с любым значением, которое соответствует заказанному протоколу.
Даже разные элементы в массиве могут быть разных типов.
Давайте посмотрим на производительность этого.
На этом графике показано время в секундах на сортировку 100 000 массивов по 100 элементов в каждом.
И это измерения для разных размеров элементов массива. Итак, для структуры, состоящей из одной работы, выполнение таких операций занимает чуть меньше 2 секунд.
Если по какой-то причине размер значений увеличивается до 2 слов, время увеличивается незначительно. И если он вырастет до трех слов, он продолжит свою траекторию.
А если у нас есть четыре слова.
Мы достигли пика производительности.
Это в девять раз медленнее.
Что здесь только что произошло? Чтобы понять это падение производительности, нам нужно углубиться в реализацию Swift.
Если вам это интересно, я рекомендую вам посмотреть «Понимание производительности Swift» за прошлый год.
А пока я дам краткое резюме.
Для представления значения неизвестного типа компилятор использует структуру данных, которую мы называем экзистенциальным контейнером.
Внутри экзистенциального контейнера есть встроенный буфер для хранения небольших значений.
В настоящее время мы переоцениваем размер этого буфера, но для Swift 4 он остается теми же тремя словами, что и раньше.
Если значение слишком велико для размещения во встроенном буфере, оно размещается в куче.
А хранение в куче может быть очень дорогим.
Вот что привело к падению производительности, которую мы только что видели.
Итак, что мы можем с этим поделать? Ответ — коровьи буферы, экзистенциальные коровьи буферы. Нет, не такая корова.
КОРОВА — это сокращение от «копия справа».
Возможно, вы слышали, как мы говорили об этом раньше, потому что это ключ к высокой производительности с семантикой значений.
В Swift 4, если значение слишком велико для размещения во встроенном буфере, оно выделяется в куче вместе со счетчиком ссылок.
Несколько экзистенциальных контейнеров могут совместно использовать один и тот же буфер, если они только читают из него.
И это позволяет избежать большого количества дорогостоящего выделения кучи.
Буфер нужно копировать с отдельным выделением только в том случае, если он изменен, хотя на него есть несколько ссылок.
И Swift теперь полностью автоматически справляется со всем этим за вас.
Какое влияние на производительность? Это намного стабильнее.
Вместо 18 секунд на сортировку этих прямых структур теперь осталось чуть больше 4 секунд.
Вместо крутого обрыва это пологий спуск.
Это улучшение относится к случаю, когда компилятор имеет дело со значениями, тип которых он вообще не знает.
Но аналогичная проблема возникает с общим кодом, в котором тип параметризован.
Давайте посмотрим на это.
Во многих случаях компилятор может быстро сделать общий код, используя специализированные версии для определенных типов.
Но иногда компилятор не может видеть определенные типы, и тогда ему необходимо использовать неспециализированный универсальный код.
Это может быть намного медленнее.
Это еще одна форма падения производительности.
До сих пор Swift использовал выделение кучи для общих буферов в неспециализированном коде. И, как мы только что видели, выделение кучи может быть очень медленным.
Swift 4 теперь использует общие буферы, выделенные стеком.
Итак, мы получаем аналогичное улучшение для неспециализированного универсального кода. Сейчас мы постоянно стремимся сделать производительность Swift действительно предсказуемой.
Но Swift 4 добился больших успехов, чтобы исправить некоторые из худших из этих проблем с производительностью.
Еще одним параметром производительности является размер.
По мере того, как ваши приложения становятся все больше и больше, размер кода становится все более важным.
Один из способов уменьшить размер кода — избегать использования неиспользуемого кода.
Вернемся к примеру Дуга со структурой даты.
Как и любой тип значения, рекомендуется привести его в соответствие с эквивалентными и сопоставимыми протоколами.
Но что, если окажется, что ваше приложение не использует один из них.
Вам не нужно платить за код, который вы не используете. В Swift 4 компилятор автоматически оптимизирует используемые соответствия, так что вы не платите за это цену.
И обратите внимание, что это взаимодействует с другими оптимизациями, такими как де-виртуализация и встраивание, что предоставляет компилятору другие возможности для удаления неиспользуемых соответствий.
Итак, это оптимизация, которую компилятор может выполнить полностью автоматически.
Это не всегда возможно.
Давайте посмотрим на еще один.
Здесь у меня очень простой класс с двумя функциями.
Компилятор сгенерирует эти функции, и поскольку в Swift 3 это подкласс NSObject, язык автоматически определит, что компилятор определит атрибут objc.
Это означает, что эти функции должны быть доступны из Objective-C.
Итак, компилятор сгенерирует функции преобразования, которые совместимы с соглашениями Objective-C и переадресовывают функции Swift.
Теперь функции в Swift по-прежнему вызываются напрямую.
В моем примере показывать печать вызовов.
Это означает, что функции преобразователя часто оказываются неиспользованными.
Но поскольку они доступны для среды выполнения Objective-C, компилятор не может определить, что они не используются.
Чтобы исправить это, необходимо изменить языковую модель.
Итак, в Swift 4 атрибут objc используется только в тех случаях, когда он явно необходим. Например, когда вы переопределяете метод Objective-C или соответствуете протоколу Objective-C.
Это изменение позволяет избежать многих неиспользуемых переходных каналов.
Когда мы внедрили это в Apple Music App, размер кода уменьшился почти на 6%.
Если у вас есть набор функций, которые вы хотите сделать доступными, и Objective-C, мы рекомендуем вам поместить их в расширение и пометить расширение атрибутом objc.
Это гарантирует, что все эти функции будут доступны для вашего кода Objective-C.
И если по какой-то причине это невозможно, компилятор сообщит вам об ошибке.
Итак, что нужно сделать, чтобы принять это изменение? Дуг упомянул инструмент миграции, который поможет вам перенести код в Swift 4.
С помощью вывода objc мигратор предлагает вам выбор.
Если вас не слишком заботит размер кода, средство миграции может легко сопоставить поведение Swift 3, просто вставив атрибут objc туда, где он ранее был бы выведен.
Но приложив немного больше усилий, вы можете воспользоваться преимуществами улучшения размера кода, используя минимальный логический вывод.
Если вы выберете эту опцию для минимального вывода, мигратор начнет с поиска всех мест, где он может определить, что атрибут objc определенно необходим. И он это сделает, он вставит это автоматически.
Этого может быть недостаточно, поскольку средство миграции не может обнаружить проблемы в отдельных модулях Swift или в вашем коде Objective-C.
Итак, чтобы помочь вам найти эти места, программа миграции пометит функции преобразователя, которые считаются устаревшими.
Затем вы можете собрать свой код, запустить его и посмотреть предупреждения об устаревании.
Давайте посмотрим на это повнимательнее.
Вот пример предупреждения сборки.
У меня есть функция Swift для отображения состояния моего контроллера представления.
И я вызываю это из моего кода Objective-C.
Но поскольку я все еще полагаюсь на вывод objc, я получаю предупреждение о том, что он устарел.
Чтобы исправить это, мне нужно найти место в моем коде Swift, где определена функция, и добавить атрибут objc.
Некоторые проблемы могут быть не видны во время сборки. В Objective-C можно ссылаться на функцию способами, которые не могут быть обнаружены до выполнения.
Итак, по этой причине также важно запускать ваш код, запускать все ваши тесты, выполнять как можно большую часть кода и искать в консоли в области отладки Xcode сообщения, подобные этому.Сообщая вам, что вам нужно добавить атрибут objc.
Обратите внимание, что сообщение показывает точное местоположение источника, в котором определена функция. Итак, вы можете просто перейти в это место и добавить атрибут. После того, как вы исправили все предупреждения сборки и времени выполнения, перейдите к настройкам сборки для вашего проекта.
Измените настройку вывода Swift 3 objc на значение по умолчанию. На этом миграция завершена.
Это действительно не так уж и сложно.
Мы сделали это для Apple Music App, всего около 40 мест, где нужно было добавить атрибут objc в действительно большом проекте.
Более 30 из них могут быть обработаны мигратором полностью автоматически.
Это изменение для ограничения вывода objc, а также оптимизация удаления неиспользуемых соответствий протоколов помогают уменьшить размер кода. Сейчас я расскажу вам еще об одном изменении, которое еще больше повлияло на общий размер вашего приложения.
Помимо инструкций и данных, из которых состоит приложение для компиляции Swift, таблицы символов в платформах Swift занимают много места.
Swift использует много символов, а имена часто довольно длинные. Например, в Swift 3.1 почти половина стандартной библиотеки занята символами.
Как показано здесь более темной синей полосой.
В Swift 4 для символов требуется гораздо меньше места. Итак, хотя в стандартной библиотеке намного больше контента.
Фактически уменьшился общий размер.
Мы добились этого, сделав имя короче, а также убрав символы.
Как статический компоновщик, так и динамический компоновщик используют отдельную структуру данных попытки для быстрого поиска символов.
Итак, это означает, что символы Swift редко нужны в таблице символов.
Xcode 9 имеет новую настройку сборки, Strip Swift Symbols, которая включена по умолчанию.
Вы можете отключить это, если это вызовет проблемы для вашего рабочего процесса.
Но Xcode обычно выполняет удаление символов как часть архивации вашего проекта. Таким образом, эта функция не влияет на более ранние стадии разработки.В частности, это не должно мешать нормальной отладке или профилированию.
Если по какой-то причине вы хотите проверить символы, которые присутствуют в двоичном файле, после его удаления.
Вы можете использовать инструмент DYLD info с опцией экспорта для просмотра экспортированных символов.
Этот параметр сборки применяется к коду, который вы создаете в своем проекте.
Стандартные библиотеки Swift обрабатываются отдельно.
Они удаляются как часть Утончения приложений.
Это важно понимать, потому что если вы хотите измерить размер своего приложения, вам действительно нужно пройти через рабочий процесс распространения Xcode и экспортировать свое приложение.
И когда вы это сделаете, вы увидите новую настройку, которую вы можете использовать для управления тем, следует ли удалять символы из стандартных библиотек.
Вы можете отключить его, но мы рекомендуем в большинстве случаев оставлять его включенным, так как это значительно уменьшит размер вашего приложения.
Затем Бен собирается подойти и рассказать о том, что нового в строках, коллекциях и дженериках.
Спасибо, Боб.
Итак, в этом выпуске у нас есть несколько действительно замечательных функций в стандартной библиотеке и универсальных библиотеках. И я начну со струнных.
Строки в Swift 4 ускоряют и упрощают обработку символов, сохраняя при этом ту же цель, которую они всегда преследовали, — помочь вам написать правильный код Unicode. Итак, что мы подразумеваем под правильным Юникодом? Что ж, во многом это зависит от того, что мы имеем в виду, когда говорим о персонаже.
В большинстве языков программирования символ — это просто число и некоторая кодировка.
В старых системах это может быть ASCII.
В наши дни это, вероятно, одна из кодировок Unicode.
Так почему это имеет значение. Давайте посмотрим на пример.
Итак, одиночная буква é с острым ударением в Юникоде может быть закодирована двумя разными способами.
Один способ — с одним скейлером Unicode, E9.
Другой способ — следовать простой букве E с комбинированным модификатором острого акцента.
Эти два способа кодирования одной и той же буквы — это то, что Unicode называет каноническим эквивалентом.
Вы должны иметь возможность использовать любой из них без какой-либо разницы.
Итак, что это может означать в коде.
Хорошо, когда язык по умолчанию смотрит на строки, глядя на отдельные единицы кода в строке. Вы можете получить очень странное поведение.
Этот пример написан на Ruby, но мы видим аналогичное поведение на других языках, таких как Java или C.
Мы можем создать две строки двумя разными способами, которые должны быть в точности эквивалентными.
Для пользователя они выглядят одинаково.
Но если мы сделаем что-то вроде подсчета количества символов, мы получим разные результаты.
И если мы используем операцию сравнения по умолчанию, они не равны.
Это может вызвать некоторые действительно трудные для понимания и диагностики проблемы.
И поэтому строгий Swift использует несколько иной подход.
В Swift символ — это то, что Unicode охлаждает графему.
Графема — это то, что большинство пользователей подумает как об одном символе, когда они увидят его на экране.
А в Swift, независимо от того, как вы составляете конкретную графему, это один символ, и две эквивалентные графемы с разным составом сравниваются как равные.
Теперь логика разбиения строки на графемы может стать довольно сложной.
Например, семейный смайлик состоит из смайликов взрослых и детей.
А в Swift 4, поскольку мы используем разбиение графиков Unicode 9, встроенное в операционную систему, это считается одним символом.
Но за эту сложную логику приходится платить. А в предыдущих версиях Swift вы платили за каждого обработанного персонажа. Еще более простые.
В этом выпуске мы добавили быстрый путь для этих более простых символов на многих разных языках.
Это означает, что обработка этих более простых символов в строке по мере ее прохождения должна занимать примерно треть времени, чем в предыдущих версиях.
Эти быстрые пути устойчивы к присутствию более сложных символов.
Итак, например, если вы обрабатывали сообщения в социальных сетях, это был в основном простой текст, но с добавлением некоторых смайликов, мы выбираем только более медленный и более сложный путь для обработки смайлов. А теперь давайте снова посмотрим на этот пример смайлика. Об этом стоит обратить внимание на две вещи.
Во-первых, графемы могут иметь переменную ширину.
Итак, мы явно не можем иметь произвольный доступ к определенной графеме в строке.
У нас может быть произвольный доступ к определенной кодовой единице, и вы все равно можете получить ее в строках Swift.
Но что это значит? В этом примере ничего не значит для доступа к пятой кодовой единице.
Это уж точно не пятый символ.
Еще одна вещь, на которую следует обратить внимание, — это немного необычное поведение. Мы добавили в строку шесть элементов, но когда мы закончили, счетчик не увеличился. И это обычно не то, что можно ожидать от других коллекций, таких как массивы. И именно из-за таких крайних случаев было сочтено, что строки не должны быть коллекциями в предыдущих версиях Swift.Вместо этого вам приходилось обращаться к символам как к набору свойств символа в строке.
Но на самом деле это никому не помогло понять проблемы, которых пытались избежать.
Все, что он делал, — это загромождение кода. Это отговаривало людей от мышления в терминах символов и от использования стандартной библиотеки для обработки строк.
Итак, в Swift 4 строки представляют собой набор символов. И это очень помогает очистить подобный код.
Есть еще одна вещь, которую мы можем упростить. При обработке строк очень часто требуется разрезать от индекса до конца строки.
В Swift 4 для этого есть сокращение. Вы можете оставить конец диапазона всякий раз, когда вы нарезаете коллекцию, то есть от индекса до конца коллекции. И есть аналогичный синтаксис для перехода от начала до индекса. Создание коллекций строк означает, что у них есть все свойства, которые вы используете в других коллекциях, поэтому вы можете архивировать их, отображать их, искать или фильтровать их.
Это значительно упрощает построение обработки строк.
Рассмотрим пример.
Предположим, вы хотите определить, есть ли флаг страны в сообщении в вашем приложении, чтобы задействовать некоторую логику.
Флаги стран в Unicode состоят из пар специальных региональных индикаторов, которые обозначают код страны флага ISO. Так, например, японский флаг — это JNP. Мы можем добавить расширение к скалеру Unicode, чтобы иметь возможность определять, является ли он одним из этих специальных региональных индикаторов.
Затем мы можем расширить символ, чтобы определить, является ли символ флагом.
Здесь используется новое свойство, доступное в Swift 4, которое позволяет получить доступ к базовым модулям масштабирования Unicode, составляющим графику.
Это действительно полезная вещь, с которой можно поиграть, если вы хотите больше узнать о том, как работает Unicode, особенно на игровой площадке Swift.
Теперь, когда у нас есть это, мы можем использовать его со всеми знакомыми API коллекций. Итак, мы можем искать, содержит ли строка флаг.
Или мы можем отфильтровать только флаги в новую строку. Итак, теперь, когда строки являются коллекциями, вы могли заметить, что у них появился новый метод split. Это уже существующий метод сбора.
Разбивает строку на массив фрагментов.
Но если вы запустите его на Swift в Swift 4, вы заметите, что он не возвращает массив строк.
Тип фрагмента в Swift 4 для строк — это подстрока.
Итак, почему мы дали ему другой тип? Что ж, есть некоторые фундаментальные инженерные компромиссы, которые нужно сделать при принятии решения о том, как должна работать нарезка коллекций.
Когда вы нарезаете коллекцию, должна ли она делать копию элементов, которые вы нарезаете, или должна возвращать представление во внутреннее хранилище исходной коллекции. С точки зрения производительности, совместное использование хранилища явно будет быстрее.
Как упоминал ранее Боб, выделение и отслеживание кучи памяти может быть очень дорогостоящим.
Вы могли бы легко провести как минимум половину времени в такой операции, как Split, делая копии.
Более того, если нарезка занимает линейное время, потому что мы делаем копии элементов, тогда цикл, который выполнял операции нарезки, может случайно оказаться квадратичным, вместо того, чтобы выполняться в линейное время, которое вы могли бы ожидать.
Итак, нарезка любой коллекции в Swift должна происходить в постоянное время.
Но у того подхода к общему хранилищу, который мы используем вместо этого, есть и обратная сторона. И чтобы понять, что это такое, давайте посмотрим на внутреннюю реализацию string.
Итак, в настоящее время в Swift внутренние строки состоят из трех свойств.
У них есть указатель на начало буфера.
У них есть счетчик количества кодовых единиц в буфере, и у них есть ссылка на объект-владелец.
Объект-владелец отвечает за отслеживание и управление буфером. И это знакомая закономерность, если вы знаете, как писать работы в других коллекциях.
Когда исходная строковая структура уничтожается, счетчик ссылок и объект-владелец сбрасываются до нуля, а класс на классе освобождает буфер.
Теперь давайте посмотрим, что происходит, когда мы создаем подстроку.
Итак, предположим, что мы отрезали только слово из исходной строки.
Подстрока теперь имеет начало, указывающее на букву W, счетчик — пять, а владельцем является общая ссылка на первоначального владельца строки.
Теперь, что происходит, когда исходная строка выходит за пределы области видимости.
Счетчик ссылок владельца уменьшается, но он не уничтожается, потому что он используется подстрокой. Итак, буфер не освобожден.
И это хорошо, потому что подстрока полагается на буфер. Но весь буфер остается. Не только часть, но и подстрока, на которую она опирается.
Теперь в этом случае нет ничего страшного, это всего лишь несколько символов.
Но это может быть настоящей проблемой.
Предположим, вы загрузили из Интернета гигантский кусок текста, а затем вырезали лишь небольшую часть этого текста и назначили ее какой-то долговременной переменной, такой как метка пользовательского интерфейса.
Это выглядит как утечка памяти.
Потому что исходный гигантский кусок текстового буфера никогда не освобождается.
На самом деле это была такая большая проблема в Java, что несколько лет назад они изменили поведение нарезки строк, чтобы заставить их делать копии.
Но, как мы видели, у этого есть недостаток производительности, и мы не обязательно хотим идти на такой компромисс.
Естественным решением такой проблемы в Swift является использование типа.
Вот почему подстроки — это другой тип, чем строки.
Теперь, когда вы выполняете операцию нарезки исходной большой строки, вы в конечном итоге захотите назначить подстроку строке, и компилятор сообщит вам об этом.
Если вы примените исправление, оно предложит вам создать новую строку, которая скопирует только ту часть буфера, которую вы нарезали.
И это позволяет исходному буферу выйти за рамки и освободить.
Итак, у нас есть два разных типа. Вы можете задать вопрос, когда мне следует использовать подстроку в моем коде. И ответ таков: вы, вероятно, не должны часто делать это явно.
При определении интерфейсов, таких как методы для типов или свойств, вы должны предпочесть использовать строку, чтобы избежать проблем с утечкой памяти, о которых мы только что говорили, а также потому, что строка — это то, что мы называем общим типом валюты.Это тот тип, который все ожидают увидеть в API.
В большинстве случаев единственный раз, когда вы сталкиваетесь с типом подстроки, — это когда вы выполняете операцию нарезки.
И поскольку Swift использует вывод типа, вы вообще не будете называть тип подстроки.
Подстроки имеют многие из тех же методов и свойств, что и обычные строки.
Таким образом, даже если вы не называете тип как подстроку, большая часть кода будет работать так же, как если бы он работал со строкой.
И если вам на самом деле не нужно создавать строку, потому что вы выполняете только локальные операции, то этого можно вообще избежать.
Вот и все, что касается струнных.
И еще одна особенность, о которой мы хотим поговорить. И это многострочные строковые литералы.
Раньше писать об этом было очень сложно. Вам нужно было написать один большой длинный строковый литерал со встроенными в него косыми чертами.
Swift 4 вводит синтаксис тройных кавычек.
Вы начинаете многострочную строку с тройной кавычки.
И заканчиваете тройной кавычкой.
Отступ заключительной тройной кавычки определяет отступ для каждой строки многострочной строки.
Вы можете видеть здесь, поскольку мы поместили наш литерал внутрь функции, мы хотим, чтобы он имел хороший отступ, чтобы соответствовать форматированию остальной части нашего кода.
Правило состоит в том, что независимо от того, какой отступ вы используете в закрывающей кавычке, вы должны включать как минимум такой же отступ в каждую строку строки.
Затем, когда код компилируется, этот отступ удаляется.
Это действительно приятная функция. И одна из замечательных вещей, которые стоит упомянуть об этом, заключается в том, что она одновременно предлагается и реализуется внешними членами сообщества Swift с открытым исходным кодом.
Итак, строка. Теперь поговорим о некоторых новых функциях дженериков.
С каждой версией Swift мы улучшали общую систему. Как для того, чтобы сделать его более мощным, так и для того, чтобы сделать его более удобным и доступным.
Например, с расширениями протокола, которые появились в Swift 2.
В этом выпуске мы представляем две функции.
Предложения Where для связанных типов и общие индексы.
И я покажу вам пару примеров того, как мы использовали их в стандартной библиотеке, чтобы дать вам представление о том, как вы могли бы использовать их в своем коде.
Итак, предположим, вы хотите определить, равен ли каждый элемент последовательности определенному значению.
Это можно сделать с помощью метода contains, который уже существует в последовательности.
Но этот код немного неуклюжий.
Вы должны написать, что последовательность не содержит ни одного элемента, не равного значению.
Если вы пишете это снова и снова, это может сильно раздражать, а расширения протокола дают вам действительно хороший способ обернуть подобный код вспомогательными методами, которые упрощают ваш код.
Итак, мы можем заключить этот код в расширение по последовательности, которое дает нам что-то более читаемое для вызова.
Теперь, когда вы расширяете последовательность таким образом, есть одна вещь, которая немного раздражает.И это то, что вам приходилось писать Iterator.Element для обозначения типа элементов последовательности.
В Swift 4 можно удалить Итератор. потому что последовательность имеет собственный тип элемента.
Теперь может показаться, что это действительно простые функции, которые мы добавили. Но на самом деле мы не смогли бы этого сделать без возможности ограничивать связанные типы. И я покажу вам, как это сделать.
Итак, в Swift 3 у нас была последовательность протокола, с ней был связанный итератор типа.
И итератор имел связанный тип для элемента.
В Swift 4 мы добавили связанный тип Element, а затем добавили предложение where к типу, связанному с Iterator, чтобы требовать, чтобы его элемент был таким же, как элемент последовательности.
В противном случае они могут рассинхронизироваться, что вызовет трудности.
Мы использовали это в нескольких местах стандартной библиотеки.
Так, например, ранее не было гарантии, что элементы подпоследовательности принадлежат к тому же типу, что и элементы последовательности.
Никто и никогда не захочет писать последовательность, если это не так.
Использовать было бы невозможно. Но компилятор все равно не гарантировал этого, потому что у нас нет способа выразить это на языке.
Теперь, с предложениями where для связанных типов, мы можем дать эту гарантию.
Итак, что это значит для вашего кода? Что ж, если вы даже сами расширили последовательность или коллекцию, вы, вероятно, обнаружили, что вам нужно добавить все эти, казалось бы, ненужные предложения where к вашему расширению, чтобы гарантировать, что оно будет скомпилировано, потому что тело полагалось на то, что протокол не гарантировал.
Теперь, поскольку мы сделали то, что вы видели на предыдущих слайдах, это может гарантировать. Итак, вы получите предупреждения о том, что теперь у вас есть избыточные ограничения.
Это просто предупреждения как в режиме Swift 3, так и в Swift 4, и все, что они говорят вам, это то, что они не нужны, и вы можете улучшить свой код, что вы можете сделать в своем собственном темпе.
Теперь есть еще одна вещь, которую нужно знать об этих новых ограничениях, которые мы добавили. И это то, что это одна из немногих вещей, которая обратно несовместима в Swift 3.2 режим.
Потому что производительность протокола должна быть одинаковой во всей программе.
Итак, если вы написали свои собственные типы коллекций, которые могут нарушить некоторые из этих ограничений, вам придется решить эти проблемы, прежде чем вы сможете скомпилировать с новым компилятором.
Мы думаем, что такое случается редко. Обычно это недосмотр, и его легко разрешить. Но об этом нужно помнить, если вы это сделали.
Итак, наконец, поговорим об общих индексах.
Ранее мы видели пример синтаксиса одностороннего диапазона.
Итак, как мы на самом деле реализовали это внутри стандартной библиотеки? Ну, во-первых, есть частичный диапазон нового типа от.
Он очень похож на обычный диапазон, но имеет только нижнюю границу.
Далее следует выражение диапазона протокола, которое мы использовали для объединения всех различных типов типов диапазонов.
У него есть метод, который принимает коллекцию и использует ее для преобразования любого выражения диапазона в конкретный тип диапазона, который можно использовать для нарезки.
Например, частичный диапазон от использует конечный индекс коллекций для заполнения отсутствующей верхней границы.
Теперь, когда у нас есть этот протокол, мы можем расширить строку с помощью универсального индекса, который будет принимать любое выражение диапазона и использовать это выражение диапазона для нарезки подстроки.
Но поскольку строки теперь являются коллекциями, мы фактически можем поместить эту функцию непосредственно в коллекцию. И это включает в себя любые пользовательские коллекции, которые вы, возможно, написали, которые получают эту функцию автоматически через протокол.
Таким образом мы действительно смогли очистить большой объем кода в стандартной библиотеке, потому что мы могли удалить все повторяющиеся операции нарезки, которые нам приходилось жестко кодировать для каждого типа диапазона, который мы хотели поддерживать, и заменить их одним универсальным нижний индекс.
И мы надеемся, что вы сможете найти аналогичные способы использования дженериков для очистки вашего кода.
Итак, есть множество новых функций, о которых мне не удалось рассказать сегодня, например, некоторые новые числовые протоколы.
И несколько действительно интересных улучшений типа словаря.
Одна из вещей, которые мы добавили, — это новый метод для коллекций, который позволяет вам менять местами два элемента в коллекции, учитывая два индекса, вместо использования глобальной функции, которая принимает два аргумента.
И это было сделано для поддержки новой функции эксклюзивного доступа к памяти, о которой Джон собирается поговорить с вами подробнее.
Спасибо, Бен.
Спасибо, Бен.
Эксклюзивный доступ к памяти — это новое правило, которое мы добавляем в Swift 4.
Это действительно первая часть гораздо более крупной функции, которую мы называем владением.
Право собственности — это облегчение понимания эффективности вашей программы.
Это упростит вам оптимизацию вашей программы, удалив ненужные копии и сохраняя, когда вам это необходимо. Но это также позволит нам сделать Swift быстрее по умолчанию в ряде случаев.
И, в конечном итоге, он позволит включить некоторые действительно мощные новые языковые функции для создания безопасных и оптимально эффективных абстракций, прежде чем мы сможем сделать что-либо из того, что нам нужно, чтобы упростить рассуждения о памяти.
А это означает принудительный монопольный доступ к памяти.
Итак, что я имею в виду?
Давайте рассмотрим пример.
Часто бывает, что я перебираю подобную коллекцию и хочу изменять каждый элемент по ходу.
Это довольно распространенный образец. Итак, я собираюсь извлечь это в метод.
Теперь, когда у меня есть этот метод, у меня есть общая операция, которую я могу использовать для изменения любой изменяемой коллекции.
Каждый элемент за раз.Эта операция выполняет итерацию по набору индексов, которые она фиксирует в начале итерации.
Итак, это действительно работает, только если ничто в этой операции не изменяет набор индексов путем добавления или удаления элементов из коллекции.
Но я довольно ясно вижу, что в этом методе ничто не изменяет коллекцию. Верно? Хорошо, хорошо, я называю это закрытие, которое было передано. А закрытие — это произвольный код.
Но опять же, я смотрю на этот метод и думаю про себя: ОК, я даю закрытие доступа только к определенному элементу коллекции, а не ко всей коллекции.
Итак, я должен знать, что ничто не может изменять коллекцию, пока эта операция выполняется.
К сожалению, в Swift 3 язык работает не так.
Давайте вернемся к тому коду, который у меня был, где я вызывал свой метод.
Что делать, если вместо простого умножения элемента на 2 я попытаюсь получить доступ к переменной чисел.
Мне ничего не мешает сделать это. Я могу просто в любой момент этого закрытия что-то удалить или добавить что-то в переменную, в массив, пока я повторяю это в другом методе.
Как только я это делаю, мне сразу бросается в глаза одна вещь.
Намного труднее рассуждать о том, что происходит с этим массивом чисел. Раньше было так, что я мог просто смотреть на каждую отдельную функцию в моей программе и думать о том, что она индивидуально делает с каждой переменной, к которой у нее есть доступ.
И это здорово. Это одно из лучших свойств того, что мы называем семантикой значений. Что вы получаете такую изоляцию в каждой программе, в каждой части вашей программы.
Все складывается вместе, и вам не нужно рассуждать обо всем сразу.
Но, к сожалению, поскольку мы можем делать такие вещи, мы получаем своего рода эталонную семантику вроде аффекта, когда вам внезапно приходится рассуждать обо всей своей программе вместе, чтобы понять, что происходит.
Здесь, когда я делаю такие вещи, я собираюсь пробежать конец массива.
Теперь мне довольно легко пойти дальше и попытаться исправить это в моем методе, вместо того, чтобы перебирать набор индексов в начале коллекции, я собираюсь перезагружать индекс каждый раз, и сравните то и другое, если я что-то сдвину с конца, все будет работать.
Но, о, должен быть другой способ. Способ получше.
Потому что я сделал свой код намного уродливее и немного медленнее. И вы знаете, если бы этого было достаточно, это был бы разумный компромисс, верно.
Вы знаете, потерять немного в производительности и сделать код немного уродливее — это нормально, если это приведет к тому, что он станет более правильным.
Но здесь этого недостаточно.
Давайте еще раз вернемся к этому закрытию.
Что, если вместо того, чтобы удалить что-то одно в конце цикла, я на самом деле просто стер весь массив, прежде чем я получу доступ к элементу.
Что это вообще за доступ на данный момент? Куда это идет? Я назначаю то, чего на самом деле больше не существует, потому что в массиве нет никаких элементов.
Это действительно хороший вопрос, и чтобы ответить на него, нам нужно немного углубиться в реализацию массива. Массив — это копия при записи типа значения, реализованная с помощью буфера с подсчетом ссылок.
В начале цикла числа указывают именно на этот буфер. Для повышения производительности Swift действительно хочет привязать переменную элемента, переданную в замыкание, непосредственно к памяти в этом буфере.
Но это создает проблему, потому что, когда мы выполняем это присваивание, числа больше не указывают на этот буфер, а это означает, что он больше не поддерживает его.
Swift должен быть безопасным языком. Мы не хотим оставлять это как висящую ссылку.
Итак, что-то должно поддерживать этот буфер в рабочем состоянии, чтобы это не привело к сбою программы.
Как это может работать? Что ж, это работает так: Swift фактически неявно создает ссылку на буфер на время операции с индексом.
И это позволяет избежать сбоев.
Но это приводит к дополнительному снижению производительности, которое, как мы надеемся, оптимизатор будет очищать каждый раз, когда мы добавляем индекс в массив.
Итак, такой неисключительный доступ к памяти создает проблемы на нескольких уровнях. Каскадирование проблем в вашей программе.
Это затрудняет рассуждение.
Это делает ваш код менее общим и труднее доказать его правильность.
И это создает проблемы с производительностью как в вашей части программы, так и для Swift, когда он пытается оптимизировать эти общие структуры данных.
Решение в том, что у нас должен быть монопольный доступ к памяти.
Что я подразумеваю под эксклюзивом? Что ж, это нормально, когда две разные части программы одновременно читают одну и ту же переменную.
Но, когда у меня есть что-то, что записывает в переменную, очень важно, чтобы ни к чему другому вообще не было доступа.
То, что записывает в переменную, должно быть эксклюзивным.
И все.
Это правило. Это новое правило, которое мы добавляем в Swift 4.
Итак, как мы можем добиться этого? Что ж, в большинстве случаев, как в нашем исходном примере, Swift действительно способен обеспечить это во время компиляции. Здесь я вызываю метод изменения чисел. Это инициирует право на него на время разговора. Когда я приду позже в рамках этого вызова и вызову для него другой метод мутации.
У меня конфликтующее право, которое нарушает правило.
И Swift может просто видеть, что это происходит во время компиляции, и немедленно сообщать вам об этом.
Так вот, это обычно будет верным в самых распространенных ситуациях, связанных с семантикой значений.
Но есть ситуации, когда это невозможно, как правило, из-за какой-то ссылочной семантики. Либо глобальная переменная, либо какая-то разделяемая память, например свойство класса.
Итак, вернемся к нашему исходному примеру.
Здесь числа были локальной переменной.
Но что, если бы это была собственность класса? Что ж, ситуация в основном такая же.Здесь я вызываю метод изменения свойства класса.
И в закрытии я вызываю изменяющий метод для того же свойства класса.
Но они относятся к объектам, которые компилятор не может определить, являются ли они одним и тем же объектом или нет.
В общем, смысл типов классов в том, что вы можете перемещать их, копировать, совместно использовать во всей программе.
И используйте их где угодно.
Но это означает, что компилятор больше не может окончательно сказать вам, действительно ли какая-либо конкретная функция полностью или с таким доступом обращается к одному и тому же объекту.
Итак, компилятор должен быть консервативным.
Было бы недопустимо, если бы мы постоянно запрещали все подобные вещи. Итак, вместо этого мы выполняем проверку динамически.
Это означает, что мы получим такую ошибку во время выполнения.
Но только если это один и тот же объект. Конечно, если это разные объекты, они считаются двумя свойствами класса на них, считающимися разной памятью.
И конфликта нет.
Теперь это принудительное исполнение, которое мы делаем, по соображениям производительности выполняется только в одном потоке.
Однако инструмент дезинфекции потоков, который мы делаем доступным в Xcode, будет улавливать такого рода проблемы даже между потоками.
На этой неделе будет отличное занятие.
Я настоятельно рекомендую любому из вас заняться поиском подобных ошибок с помощью Xcode.
Это правило Swift 4.
Как мы сказали вчера в State of Union, Swift 3.2 предназначен для того, чтобы ваш существующий код продолжал работать.
Итак, в Swift 3.2 это просто предупреждение.
Однако, поскольку Swift 4 и Swift 3 должны взаимодействовать в будущей версии Xcode, нам придется сделать это ошибкой даже в режиме Swift 3.
Итак, мы настоятельно рекомендуем вам обратить внимание на эти предупреждения и исправить их.
Поскольку это просто предупреждения, вы можете исправить их в удобное для вас время. И в своем собственном темпе, но вы должны отнестись к ним серьезно.
Мы действительно с нетерпением ждем мощи, которую это принесет. Так будет намного проще рассуждать о коде.Это позволит сделать множество действительно потрясающих оптимизаций как в библиотеке, так и в компиляторе. И это также поможет нам гораздо проще предоставлять инструменты, которые вы можете использовать для оптимизации своего собственного кода способами, которые будут действительно отличными.
Если вам интересно узнать больше о том, что мы планируем с этим делать, на веб-сайте Swift есть манифест о праве собственности, который я бы посоветовал вам проверить. Теперь один нюанс. Предварительная версия для разработчиков, которую мы предоставили вам на этой неделе, некоторые из этих вещей все еще находятся в разработке.