Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: н а р а м в т сейчас к т о е р е и сейчас б а н к и р сейчас еискра сейчас еьизвмо сейчас поведер сейчас зварот сейчас карамель сейчас тызкоби сейчас плескду 1 секунда назад а к т о р н 1 секунда назад панибратство 1 секунда назад п е с к а р ь 1 секунда назад в а с и л е к 1 секунда назад с е т к а 1 секунда назад
python — Очистите и проанализируйте веб-сайт словаря и получите значение каждого слова в текстовом файле
В дополнение к ответу @Anonymous, у нее есть еще несколько наблюдений.
Selenium — поиск элементов
Получение кнопки перевода, основанной на том, что она является последней кнопкой на странице, довольно хрупкое:
кнопок = driver.find_elements_by_tag_name("button") кнопки[-1].щелчок()
 find_elements_by_tag_name("button")
кнопки[-1].щелчок()
find_elements_by_tag_name("button")
кнопки[-1].щелчок()
Если веб-сайт переупорядочивает вещи (что может сделать дизайнер), это нарушит сценарий. Лучше всего использовать идентификатор или имя, которых, к сожалению, нет на странице вашего парсинга. Но Selenium также может использовать селекторы CSS, например 9.0003
кнопка = driver.find_element_by_css_selector("button[@value='translate']")
Для изменения идентификатора кнопки, имени или значения потребуется изменить внутренний код, что является более значительным изменением. Таким образом, теория состоит в том, что они будут меняться реже.
Циклы
Цикл, который каждый раз выполняет что-то новое, немного напоминает запах кода. Это затрудняет понимание того, что делает код, и на самом деле не сохраняет ни одной строки кода. Если первая строка нуждается в специальной обработке, напишите код для первой строки, а затем цикл для остальных строк. Поместите повторяющийся код в functions:
САНСКРИТ_ЦВЕТ = 0
АНГЛИЙСКИЙ_ЦВЕТ = 2
деф чистый_текст (текст):
вернуть " ". join(col.get_text().split()).strip()
определение scrape_row (строка):
столбец = row.find_all('td')
санскрит = чистый_текст (столбец [SANSKRIT_COL])
английский = чистый_текст (столбец [ENGLISH_COL])
вернуть санскрит, английский
 join(col.get_text().split()).strip()
определение scrape_row (строка):
столбец = row.find_all('td')
санскрит = чистый_текст (столбец [SANSKRIT_COL])
английский = чистый_текст (столбец [ENGLISH_COL])
вернуть санскрит, английский
join(col.get_text().split()).strip()
определение scrape_row (строка):
столбец = row.find_all('td')
санскрит = чистый_текст (столбец [SANSKRIT_COL])
английский = чистый_текст (столбец [ENGLISH_COL])
вернуть санскрит, английский
Затем вложенные циклы можно заменить чем-то вроде этого:
rows = table_body.find_all('tr')
санскрит, английский = очистка_строки (строки [0])
значения = [санскрит, английский]
для строки в строках [1:]:
санскрит, английский = очистка_строки (строки [0])
если санскрит != слово:
перерыв
значения.append(английский)
возвращать значения
попробовать — кроме — еще — наконец
Практически никогда не рекомендуется включать Исключение в предложение кроме . Вдвойне, если вы не печатаете или не регистрируете исключение. Он перехватит каждое исключение, включая KeyboardInterrupt (например, Ctrl-C). Используйте наиболее конкретное исключение, которое вы можете.
В операторе try-except-else-finally предложение else выполняется, если в предложении try нет исключений. 9Предложение 0029 finally выполняется последним, независимо от того, было ли исключение или нет. Таким образом, в вашем коде, если после обработки первой строки возникает исключение, код будет печатать «Смысл не найден…» в предложении , кроме , а затем печатать «значения найдены» в предложении , наконец, .
set.union() set.union() может принимать итерацию, поэтому цикл в remove_duplicates() может быть:
для строки в файле:
unique_words.union(line.split())
с open(...) как файл При использовании open в операторе с (например, в качестве менеджера контекста) файл автоматически закрывается в конце блока, поэтому файл .close() не нужен.
разбор — Является ли слово «лексер» синонимом слова «парсер»?
спросил
Изменено 11 лет, 11 месяцев назад
Просмотрено 656 раз
В заголовке вопрос: Слова «лексер» и «парсер» синонимы или разные? Похоже, что в Википедии эти слова взаимозаменяемы, но английский не мой родной язык, поэтому я не уверен.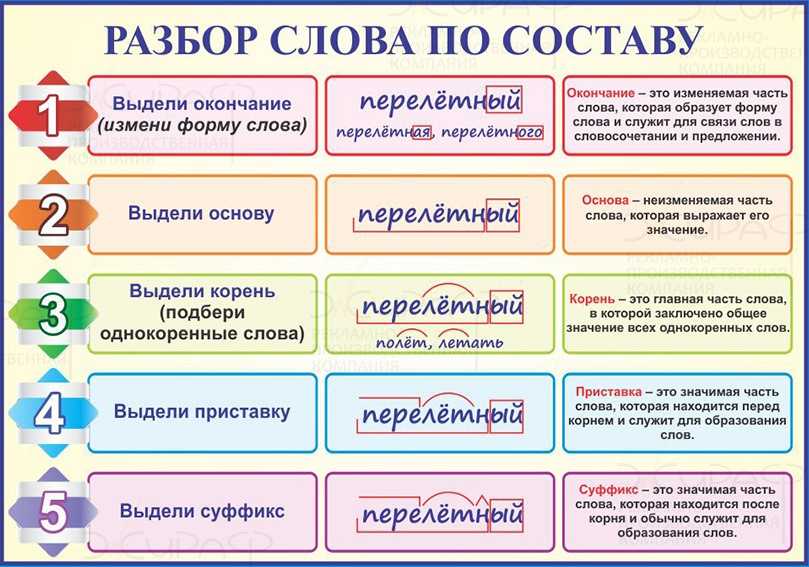
- синтаксический анализ
- независимый от языка
- лексер
- синоним
2
Лексер используется для разделения входных данных на токены, тогда как синтаксический анализатор используется для построения абстрактного синтаксического дерева из этой последовательности токенов.
Теперь вы можете просто сказать, что лексемы — это просто символы и напрямую использовать синтаксический анализатор, но часто бывает удобно иметь синтаксический анализатор, который должен смотреть вперед только на одну лексему, чтобы определить, что он собирается делать дальше. Поэтому лексер обычно используется для разделения ввода на токены до того, как его увидит синтаксический анализатор.
Лексер обычно описывается с помощью простых правил регулярных выражений, которые проверяются по порядку. Существуют инструменты, такие как lex , которые могут автоматически генерировать лексеры из такого описания.
[0-9]+ Номер [A-Z]+ Идентификатор + Плюс
Анализатор, с другой стороны, обычно описывается путем указания грамматики . Опять же, существуют инструменты, такие как yacc , которые могут генерировать синтаксические анализаторы из такого описания.
выражение ::= выражение плюс выражение
| Число
| Идентификатор
Нет. Лексер разбивает входной поток на «слова»; парсер обнаруживает синтаксическую структуру между такими «словами». Например, при вводе:
скорость = путь/время;
вывод лексера:
скорость (идентификатор) = (оператор присваивания) путь (идентификатор) / (бинарный оператор) время (идентификатор) ; (разделитель операторов)
и тогда парсер может установить следующую структуру:
= (назначить)
lvalue: скорость
rvalue: результат
/ (разделение)
дивиденд: содержимое переменной "путь"
делитель: содержимое переменной "время"
Нет. Лексер разбивает исходный текст на лексемы, тогда как синтаксический анализатор соответствующим образом интерпретирует последовательность лексем.