Морфологический разбор слова «зависеть»
Часть речи: Инфинитив
ЗАВИСЕТЬ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ЗАВИСЕТЬ»
| Слово | Морфологические признаки |
|---|---|
| ЗАВИСЕТЬ |
|
Все формы слова ЗАВИСЕТЬ
ЗАВИСЕТЬ, ЗАВИШУ, ЗАВИСИМ, ЗАВИСИШЬ, ЗАВИСИТЕ, ЗАВИСИТ, ЗАВИСЯТ, ЗАВИСЕЛ, ЗАВИСЕЛА, ЗАВИСЕЛО, ЗАВИСЕЛИ, ЗАВИСЕВ, ЗАВИСЕВШИ, ЗАВИСЬТЕ, ЗАВИСЯЩИЙ, ЗАВИСЯЩЕГО, ЗАВИСЯЩЕМУ, ЗАВИСЯЩИМ, ЗАВИСЯЩЕМ, ЗАВИСЯЩАЯ, ЗАВИСЯЩЕЙ, ЗАВИСЯЩУЮ, ЗАВИСЯЩЕЮ, ЗАВИСЯЩЕЕ, ЗАВИСЯЩИЕ, ЗАВИСЯЩИХ, ЗАВИСЯЩИМИ, ЗАВИСЕВШИЙ, ЗАВИСЕВШЕГО, ЗАВИСЕВШЕМУ, ЗАВИСЕВШИМ, ЗАВИСЕВШЕМ, ЗАВИСЕВШАЯ, ЗАВИСЕВШЕЙ, ЗАВИСЕВШУЮ, ЗАВИСЕВШЕЮ, ЗАВИСЕВШЕЕ, ЗАВИСЕВШИЕ, ЗАВИСЕВШИХ, ЗАВИСЕВШИМИ
Разбор слова по составу зависеть
| Основа слова | зависе |
|---|---|
| Корень | завис |
| Суффикс | е |
| Глагольное окончание | ть |
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ЗАВИСЕТЬ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.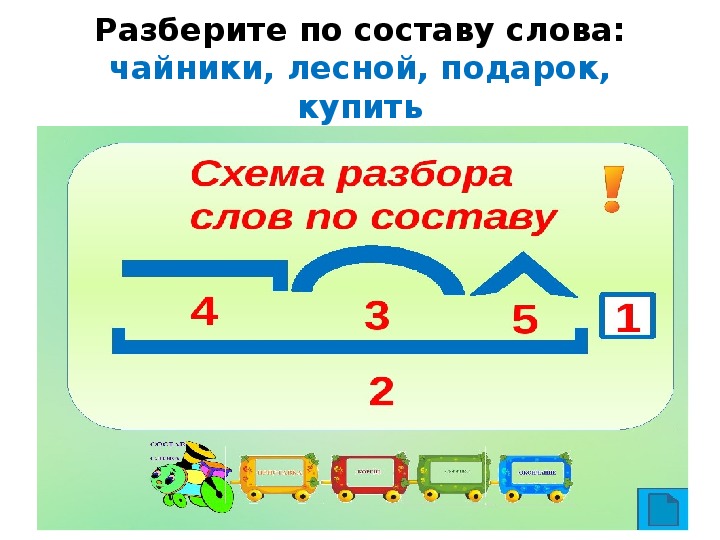
Примеры предложений со словом «зависеть»
1
От нас будет, конечно, зависеть развить в нем те или другие склонности.
Две жизни, Михаил Волконский, 1914г.2
От меня будет зависеть даже, может быть, до некоторой степени судьба России.
Две жизни, Михаил Волконский, 1914г.3
Самое для вас верное: пригнать сюда колонну и ни от кого не зависеть.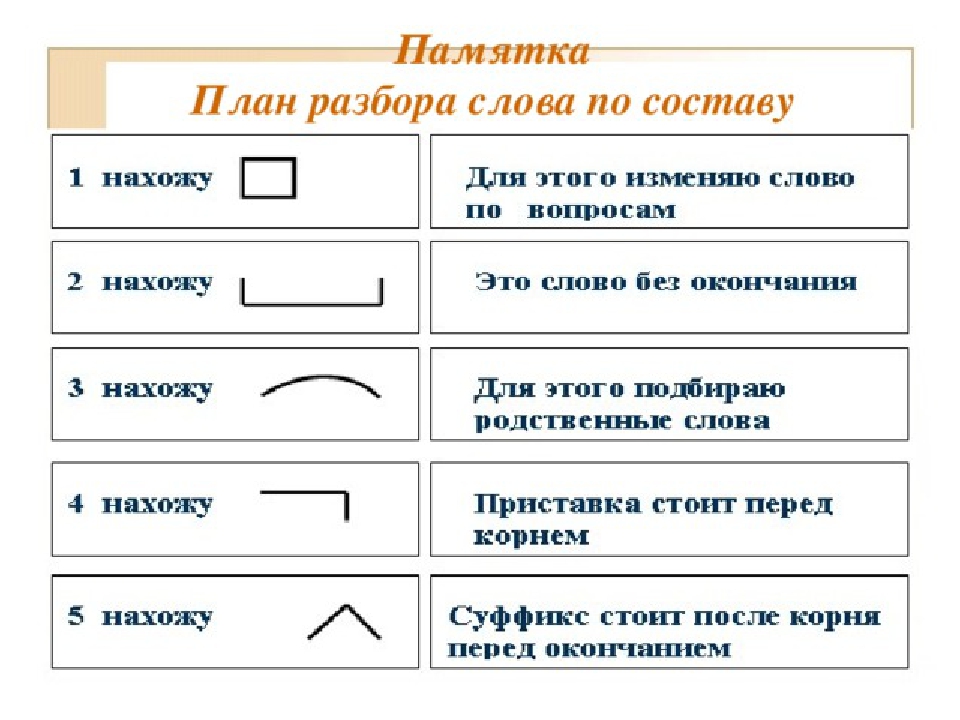
4
А что касается до времени – отчего я от него зависеть буду?
Отцы и дети, Иван Тургенев, 1862г.5
все будет зависеть от материала, который вольешь в нее.
Найти еще примеры предложений со словом ЗАВИСЕТЬ
What is Google Sans Text?
Browse Eckher Glossary and expand your business and technology vocabulary.
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
How to pronounce «featurize» in English?
How to pronounce «Onehunga» in English?
How to pronounce «Takapuna» in English?
How to pronounce «İzmir» in English?
How to pronounce «Coronaviridae» in English?
How to pronounce «Whanganui» in English?
How to pronounce «Chlöe Swarbrick» in English?
How to pronounce «Kohimarama» in English?
How to pronounce «Tua Tagovailoa» in English?
How to pronounce «Craig Federighi» in English?
How to pronounce «Stefanos Tsitsipas» in English?
How to pronounce «Jacob deGrom» in English?
How to pronounce «myocarditis» in English?
How to pronounce «SZA» in English?
How to pronounce «Cassie Kozyrkov» in English?
Разбери слова по — Школьные Знания.
 com
comтравка: корень (∩) ТРАВ + суффикс (∧) К + окончание (☐) А. Основа слова: травк.
кормушка: корень (∩) КОРМ + суффикс (∧) УШК + окончание (☐) А. Основа слова: кормушк.
холмистый: корень (∩) ХОЛМ + суффикс (∧) ИСТ + окончание (☐) ЫЙ. Основа слова: холмист.
беленький: корень (∩) БЕЛ + суффикс (∧) ЕНЬК + окончание (☐) ИЙ. Основа слова: беленьк.
красноватый: : корень (∩) КРАСН + суффикс (∧) ОВАТ + окончание (☐) ЫЙ. Основа слова: красноват.
заморский: приставка (¬) ЗА + корень (∩) МОР + суффикс (∧) СК + окончание (☐) ИЙ. Основа слова: заморск.
подоконник☐: приставка (¬) ПОД + корень (∩) ОКОН + суффикс (∧) НИК + нулевое окончание. Основа слова: подоконник.
осинник☐: корень (∩) ОСИН + суффикс (∧) НИК + нулевое окончание. Основа слова: осинник.
подберёзовик☐: приставка (¬) ПОД + корень (∩) БЕРЁЗ + суффикс (∧) ОВ, ИК + нулевое окончание. Основа слова: подберёзовик.
Основа слова: подберёзовик.
зависеть: корень (∩) ЗАВИС + суффикс (∧) Е + окончание (☐) ТЬ. Основа слова: зависе.
поджарить: приставка (¬) ПОД + корень (∩) ЖАР + суффикс (∧) И + окончание (☐) ТЬ. Основа слова: поджари.
перебежать: приставка (¬) ПЕРЕ + корень (∩) БЕЖ + суффикс (∧) А + окончание (☐) ТЬ. Основа слова: перебежа.
маленький: корень (∩) МАЛ + суффикс (∧) ЕНЬК + окончание (☐) ИЙ. Основа слова: маленьк.
медведица: корень (∩) МЕДВЕД + суффикс (∧) ИЦ + окончание (☐) А. Основа слова: медведиц.
тигрята: корень (∩) ТИГР + суффикс (∧) ЯТ + окончание (☐) А. Основа слова: тигрят.
карандашик☐: корень (∩) КАРАНДАШ + суффикс (∧) ИК + нулевое окончание. Основа слова: карандашик.
домишко☐: корень (∩) ДОМ + суффикс (∧) ИШК + окончание (☐) О. Основа слова: домишк.
маслёнка: корень (∩) МАСЛ + суффикс (∧) ЁНК + окончание (☐) А. Основа слова: маслёнк.
Основа слова: маслёнк.
«Зависить» или «зависеть» как правильно пишется?
Жизненные ситуации часто диктуют свои обстоятельства, от которых зависит тот или иной человеческий выбор. В разговорной речи актуальна тема зависимости от каких-либо событий, действий, страхов… Но как быть с письменной речью?
Русский язык проявляет свое коварство в отображении лексем на письме. Слуховое восприятие не всегда соответствует нормам правописания. Необходимо осознавать, как правильно пишется та или иная бытовая лексическая единица. Зависить или зависеть: как правильно пишется?
Правильно пишется
Нормы русского правописания задают тон культуре речи. Активно употребляемые слова иногда вызывают смятение из-за незнания правил их написания или неумения на практике применять теорию. Кроме того, производные формы лексических единиц вызывают не меньше вопросов. Например: зависишь, как пишется, зависевший как пишется? Некоторые производные могут подпадать под разные правила.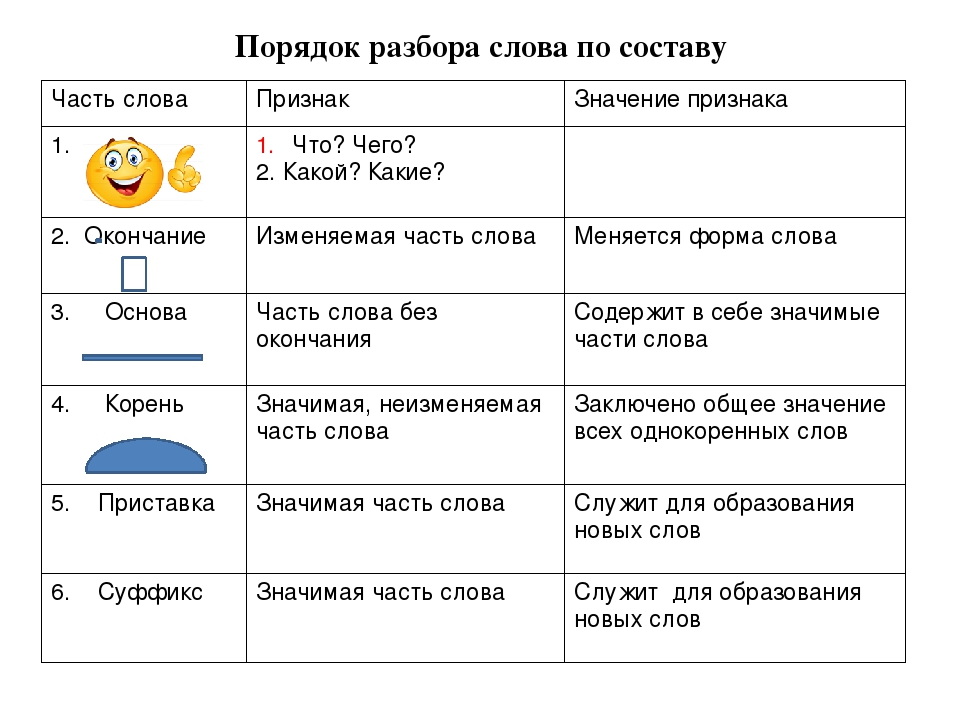 К примеру, чтобы понять прилагательное “завистливый”, как пишется, нужно вспомнить норму сокращения согласных.
К примеру, чтобы понять прилагательное “завистливый”, как пишется, нужно вспомнить норму сокращения согласных.
В русском языке корректным написанием изучаемой словоформы считаются: глагол зависеть, имя прилагательное завистливый, но зависишь в виде исключения.
Какое правило?
Нормы русского языка основываются на исключения, подтверждающие правила. Изучаемая лексема подлежит запоминанию так, как относится к глаголу второго спряжения.
В производных словах сохраняется суффикс Е: зависел, зависевший, зависев, но инфинитив “зависишь” писаться должен через гласную И. .
Морфологические и синтаксические свойства
Морфологический разбор изучаемой лексемы: инфинитивная форма глагола несовершенного вида, второго спряжения. К непостоянным признакам указанного глагола относятся: изъявительное наклонение и невозвратный вид.
В зависимости от контекста синтаксическая роль видоизменяется.
Разбор по составу
Морфемный разбор способствует пониманию сухой теоретической части в правописании:
- корень – завис;
- суффикс – е;
- окончание – ть;
- основа – зависе.
зависеть
Значение
Умение грамотно толковать слова – фундамент любых взаимоотношений. Корректно донести мысль можно только с правильно подобранными лексическими единицами. Некоторые могут применяться в разных значениях. К примеру, исследуемая словоформа используется в двух пониманиях:
- Нахождение в чьей-то власти или подчинении.
- Обусловленность определенными обстоятельствами, причинная связь определенных последствий.
Синонимы
Смятение в связи с незнанием правильного написания определенного понятия решается подбором схожего по смыслу слова. Таким образом, выражение не потеряет смысл, и не придется краснеть из-за досадных ошибок.
Синонимический ряд к изучаемой лексеме в зависимости от желаемого смыслового наполнения: уступать, подчиняться, находиться во власти, обусловливать, плясать под чужую дудку.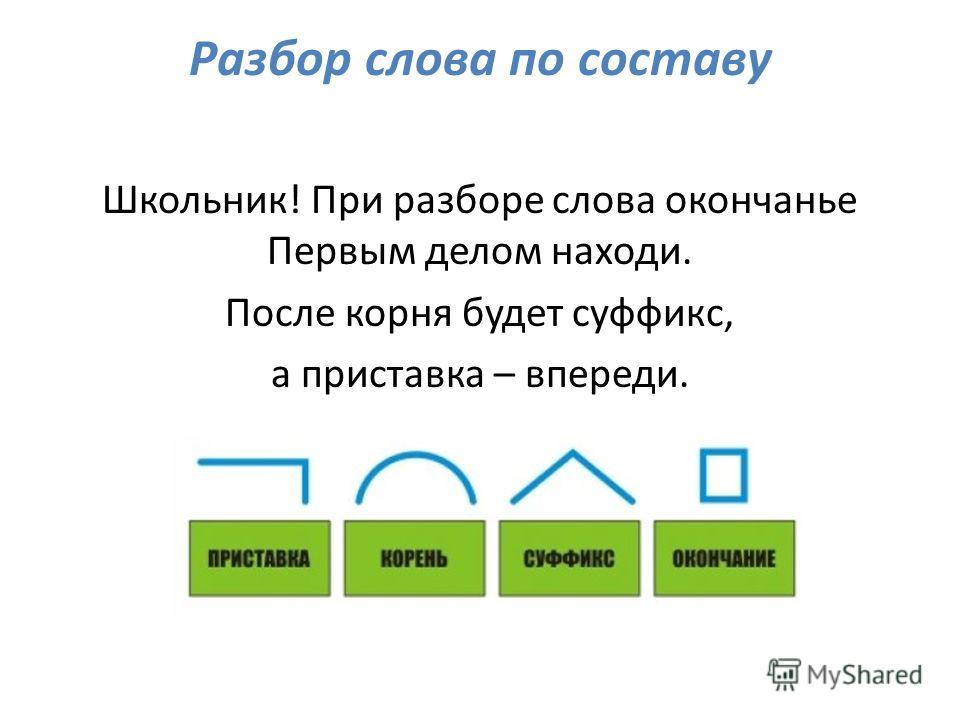
Примеры предложений
- Ему надоело зависеть от чужих решений, и чрезмерной родительской опеки. Он решился переехать в другой город и начать все с чистого листа.
- Зависевший от мнения окружающих никогда не сможет стать самодостаточной реализованной личностью.
- Красота городского парка будет зависеть от сознательности отдыхающих граждан.
- Сложно не зависеть финансово от родителей, если нет хорошо оплачиваемой работы.
- Он зависимый от хобби: во всем видит прекрасное и всегда находит время и место для необычного кадра.
Неправильно пишется
Распространенные ошибки во время написания исследуемой лексической единицы и производных словоформ: зависить, зависила, зависивший, зависливый, зависил, зависешь, зависиш, зависеш.
Заключение
Грамотность – показатель культуры речи. Умение оперировать своим словарным запасом на практике располагает к себе окружающих. Гораздо приятней поддерживать беседу с образованным человеком, чья речь обогащена синонимами, оборотами. Главное – уметь точно и лаконично излагать свою мысль. В случае проблем с запоминанием теории, можно опираться на доступные примеры ее практического применения.
Главное – уметь точно и лаконично излагать свою мысль. В случае проблем с запоминанием теории, можно опираться на доступные примеры ее практического применения.
Написание о/е после шипящих в суффиксах и окончаниях существительных, прилагательных и наречий
Написание букв «о» или «е» после шипящих в суффиксах и окончаниях существительных, прилагательных и наречий зависит от ударения. Укажем алгоритм написания о/е после шипящих в суффиксах и окончаниях слов этих частей речи согласно правилу русского языка.
Алгоритм выбора букв о/е после шипящих
Чтобы выбрать букву «о» или «е» после шипящего, действуем пошагово, используя следующий алгоритм.
- Первый шаг — определение части речи, к которой принадлежит слово.
- Второй шаг — разбор слова по составу (морфемный разбор), чтобы выяснить, в какой его части находится орфографическая проблема.

- Третий шаг — поставить ударение в слове.
- Четвёртый шаг — написать букву «о» или «е»/»ё» в соответствии с правилом орфографии.

Разобрав слово по составу, убедимся, что это суффикс или окончание существительного, прилагательного или наречия. Тогда, чтобы правильно написать после шипящего согласного букву «е» или «о» в суффиксе или окончании слов этих частей речи, руководствуемся орфографическим правилом:
В суффиксах и окончаниях существительных, прилагательных и наречий после шипящих основы «ж», «ш», «ч», «щ» под ударением пишется буква «о», без ударения — «е».
Рассмотрим, как действует это правило, на примерах слов указанных частей речи.
Написание букв о/е после шипящих у существительных
У существительных под ударением после шипящих корня в суффиксах и окончаниях форм творительного падежа напишем букву «о».
Примеры:
слушо́к, сундучо́к, прыжо́к;
девчо́нка, деньжо́нки, рубашо́нка;
с силачо́м, борщо́м, под стеллажо́м, тиражо́м;
с врачо́м, грачо́м, свечо́й, саранчо́й, плащо́м.
Без ударения напишем букву — «е»:
ре́ченька
но́женька
ту́чей
ку́чей
афи́шей
о́вощем
плю́шем
ла́ндышем
В заимствованных существительных с суффиксом -ёр- и в русском слове «ухажёр» после шипящих корня пишется буква «ё»:
дирижёр
монтажёр
стажёр
массажёр
Отличаем эти написания от слова «мажор» и производного прилагательного, в морфемном составе которых нет указанного суффикса:
мажор — корень/окончание;
мажорный — корень/суффикс/окончание.
Имеем в виду, что существительные, образованные от глаголов, сохраняют суффикс этой части речи и пишутся после шипящих корня с буквой «ё»:
ночевать — ночёвка;
корчевать — корчёвка;
межевать — межёвка;
растушевать — растушёвка;
перекочевать — перекочёвка.
Написание букв о, е после шипящих в суффиксах и окончаниях прилагательных
У прилагательных аналогично под ударением в суффиксах -ов-, -он и окончаниях после шипящих согласных корня пишется буква «о».
Примеры:
- моржо́вый
- камышо́вый
- парчо́вый
- грошо́вый
- ежо́вый
- холщо́вый
- смешо́н (беглое «о»)
- большо́й
- чужо́й
но рыжему, хорошей.
Написание суффиксов наречий после шипящих
В соответствии с указанным орфографическим правилом в суффиксах наречий после шипящих согласных основы под ударением пишется буква «о», без ударения — «е»:
- горячо́
- свежо́
- общо́
- голышо́м
- нагишо́м,
но ти́ше, бли́же, да́льше, неуклю́же
Видеоурок
Скачать статью: PDFОпределение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова « случиться», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
СЛУЧИТЬСЯ, чусь, чишься; сов.
1. (1 и 2 л. не употр.). Произойти, совершиться. Что случилось? Случилась неприятность.
2. безл., с неопр. Прийтись, выпасть на чьюн. долю (разг.). Случилось ночевать в лесу. Приятелям снова случилось встретиться. Приедешь снова? Как случится (т. е. будет зависеть от обстоятельств).
3. Случайно оказаться, обнаружиться (разг.). У меня не случилось (безл.) денег. Если случишься в городе, позвони. Приятеля не случилось
| несов. случаться, аюсь, аешься.
Фонетический (звуко-буквенный) разбор
случи́ться
случиться — слово из 3 слогов: слу-чи-ться. Ударение падает на 2-й слог.
Транскрипция слова: [случ’иц:а]
с — [с] — согласный, глухой парный, твёрдый (парный)
л — [л] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
у — [у] — гласный, безударный
ч — [ч’] — согласный, глухой непарный, мягкий (непарный, всегда произносится мягко), шипящий
и — [и] — гласный, ударный
т — [ц:] — согласный, глухой непарный, твёрдый (непарный, всегда произноится твёрдо)
ь — не обозначает звука
с — не образует звука в данном слове
я — [а] — гласный, безударный
В слове 9 букв и 7 звуков.
При разборе слова используются правила:
- Сочетание букв -тьс- обозначает длинный звук [ц:]
Цветовая схема: случиться
Разбор слова «случиться» по составу
случиться (программа института)
случиться (школьная программа)
Части слова «случиться»: случ/и/ть/ся
Часть речи: глагол
Состав слова:
случ — корень,
и, ть, ся — суффиксы,
нет окончания,
случи + ся — основа слова.
Примечание: ть является формообразующим суффиксом и не входит в основу слова, но во многих школьных программах ть отмечается как окончание. ся является словообразующим суффиксом (постфиксом) и входит в основу слова.
Урок 9. какие бывают главные и второстепенные члены предложения — Русский язык — 4 класс
Русский язык, 4 класс
Урок № 9.
Тема: Какие бывают главные и второстепенные члены предложения.
ОРГАНИЗАЦИОННЫЙ МОМЕНТ:
Цель нашего урока – научиться разбирать предложение по составу.
Задачи:
- Узнать, какие бывают члены предложения, какая у них функция и как они выделяются при разборе.
- Научиться находить основу предложения.
- Порассуждать, какие бывают предложения.
Результаты:
- Узнаем, что такое основа предложения, главные и второстепенные члены.
- Научимся находить и выделять члены предложения, определять, какой частью речи они выражены.
- Потренируемся выделять предложения в тексте.
Тезаурус
Главные члены предложения – это грамматическая основа предложения.
Подлежащее – это главный член предложения, который обозначает, о ком или о чём говорится в предложении, и отвечает на вопросы: кто? или что?
Сказуемое – это главный член предложения, который связан с подлежащим и отвечает на вопросы: что делает предмет? каков предмет? что такое предмет? кто такой?
Второстепенными называют все члены предложения, кроме подлежащего и сказуемого.
Определение – это второстепенный член предложения, который обозначает признак предмета и отвечает на вопросы какой? чей?
Дополнение – это второстепенный член предложения, который отвечает на вопросы косвенных падежей.
Обстоятельство – это второстепенный член предложения, который обозначает место (где? куда? откуда?), время (когда? с каких пор? до каких пор?), причину (почему? отчего?), образ действия (как? каким образом?) и пр.
Список литературы
Основная литература
- Канакина В. П., Горецкий В. Г. Русский язык. 4 класс: учеб. для общеобразоват. организаций. В 2 ч. Ч. 1 — М.: Просвещение, 2018. – 160 с.
- Канакина В. П., Горецкий В. Г. Русский язык. 4 класс: учеб. для общеобразоват. организаций. В 2 ч. Ч. 2 — М.: Просвещение, 2018. – 160 с.
Дополнительная литература
- Канакина В. П. Русский язык. Рабочая тетрадь. 4 класс. В 2 ч. Ч. 1. — М.: Просвещение, 2018.
- Канакина В. П. Русский язык. Рабочая тетрадь. 4 класс. В 2 ч. Ч. 2. — М.: Просвещение, 2018.
- Канакина В. П. и др. Русский язык. 4 класс. Электронное приложение. — М.: Просвещение, 2011.
ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
Сегодня на уроке мы поговорим о строительстве. Но не домов, а предложений. В качестве строительных материалов мы будем использовать члены предложения.
- Какие члены предложения вы помните?
Подлежащее, сказуемое, определение, дополнение, обстоятельство.
Чтобы построить дом, сначала нужно залить фундамент – главную часть, на которой будет держаться вся постройка. В предложении роль такого фундамента выполняет грамматическая основа: подлежащее и сказуемое. Подлежащее обозначает человека или предмет, о котором говорится в предложении. Сказуемое обозначает действие в предложении.
Дома бывают разные: высокие и малоэтажные, большие и маленькие. Это зависит от стен. В предложении стены – это второстепенные члены предложения: определение характеризует предмет или человека, обстоятельство рассказывает о времени, месте, причине и способе действия, дополнение сообщает дополнительную информацию.
Чтобы дом был готов нужна ещё крыша. В предложении крыша – это знаки препинания: точка, восклицательный знак, вопросительный знак. Многоточие.
- Вспомните, от чего зависит выбор знака?
Конечно, от интонации.
Подлежащее и сказуемое называются основой предложения, а определение, дополнение и обстоятельство – второстепенными членами предложения.
Давайте подставим в схему реальные слова:
Умные ребята быстро строят предложения.
Посмотрите, как они связаны между собой. Подлежащее обычно выражено именем существительным обязательно в именительном падеже. Сказуемое зависит от подлежащего и обычно выражено глаголом, определение может зависеть от любого существительного и обычно выражено прилагательным или притяжательным местоимением, обстоятельство зависит от сказуемого и обычно выражено наречием или существительным с предлогом, дополнение часто зависит от сказуемого или других членов предложения и обычно выражено существительным в косвенном падеже.
ДОПОЛНИТЕЛЬНО
Предложения, которые состоят только из подлежащего и сказуемого называются нераспространенными: Наступила зима.
Предложения, которые состоят из главных и второстепенных членов называются распространёнными: Сегодня наступила настоящая снежная зима.
Познакомьтесь со схемой разбора предложения на странице 149 учебника:
Пользуясь этой схемой, сделайте разбор предложения в тетради:
Скоро в саду распустятся красивые белые лилии.
ПРАКТИЧЕСКАЯ ЧАСТЬ
Задание 1.
Соедините члены предложения и части речи, которыми они чаще всего выражены.
- Подлежащее 1. Глагол
- Сказуемое 2. Наречие
- Определение 3. Прилагательное
- Обстоятельство 4. Существительное
Задание 2. Разгадайте кроссворд:
- Главный член предложения, обозначающий действие.
- Второстепенный член предложения, обозначающий признак действия.
- Второстепенный член предложения, обозначающий предмет, поясняет сказуемое
- Главный член предложения, обозначающий предмет.
- Второстепенный член предложения, обозначающий признак предмета.
1 |
|
|
|
|
|
|
|
|
|
| 4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Задание 3. Отделите части речи от членов предложения:
Существительные, определение, дополнение, глагол, прилагательное, сказуемое, наречие, подлежащее, местоимение, предлог, союз, обстоятельство
Части речи | Члены предложения |
Задание 4. Выделите цветом вопросы косвенных падежей
Как? Когда? Кого? Кому? О чем? Кто? Зачем? Что делать? О ком? Кем? Что? Где?
Задание 5. Выделите в тексте грамматические основы предложений:
Летели и летели осеннее листья. Ветер подхватил их и погнал к речке. По зеркальной воде поплыли золотые монетки. На краю деревни заиграл рожок. Это пастух собирал стадо. Я выхожу из дома, беру весла и иду к речке. Восток светлеет, розовеет. Река словно похорошела, выпрямилась. Под первыми лучами солнца засверкали, заискрились капельки воды. Стояла чудесная пора осени.
Задание 6. Составьте из слов и знаков препинания предложения, чтобы получился текст.
Слова: осени, дни, холодные, наступили;
в, плавали. жёлтые, лужах, листья;
небу, низкие, ползли, по, тучи;
Знаки: . . .
Задание 7. Соотнесите предложения и схемы.
- Ребята по лесной тропинке вышли на поляну.
- Анна и Инна угостили ребят печеньем.
- Радостные вернулись ребята с прогулки!
- [_______ _________].
- [_______ и _______ _________].
- [________ ___________]!
Задание 8. Соедините название второстепенного члена предложения и его обозначение в схеме:
Определение
Дополнение
Обстоятельство
Сказуемое
________
________
________
Задание 9. Спишите предложение в тетрадь и выпишите грамматическую основу предложения.
В воздухе кружатся белые снежинки.
Задание 10. Подчеркните второстепенные члены предложения:
Покраснели осинки, пожелтели берёзки. Гроздья ягод созрели на рябинах. Кругом растёт пушистый ельник. Зеленеют молодые елочки. Из земли бьёт чистый родник.
Задание 11. Вставьте пропущенные буквы.
Ясное в..сеннее утро. Развернулись на ни..ких кустиках м..л..дые л..сточки. Из з..мли выглядывают у..кие стрелки свежей тра..ки. Покачиваются на бере..ке лё..кие серё..ки.
Задание 12. Зачеркните лишнее слово в каждом ряду. Объясните свой выбор.
- Определение, подлежащее, дополнение, обстоятельство.
- Существительное, прилагательное, сказуемое, наречие.
- Подлежащее, сказуемое, определение, союз
Задание 13.
Определите член предложения, который повторяется в предложении:
- В саду растут яблоки, груши и персики. ____________________________
- Я был в Москве, в Таганроге и во Владивостоке. ____________________________
- Девочка бежала и смеялась. ____________________________
Задание 14* Составьте рассказ по картинке и выделите в нём второстепенные члены предложения.
КОНТРОЛЬНЫЙ МОДУЛЬ
Вариант 1
1. Главные члены предложения — это …
- Словосочетание
- Подлежащее и сказуемое
- Подлежащее и глагол
2. Какой член предложения отвечает на вопросы КАКОЙ? КАКАЯ? КАКОЕ? КАКИЕ?
- Подлежащее
- Определение
- Сказуемое
3. Каким членом предложения является выделенное слово:
Мама мыла пол в комнате брата.
- Сказуемое
- Подлежащее
- Дополнение
Вариант 2.
1. Главные члены предложения это…
- Подлежащее и сказуемое
- Существительное и глагол
- Словосочетание
2. Какой член предложения отвечает на вопросы: Как? Когда? Где? Куда?
- Подлежащее
- Обстоятельство
- Сказуемое
3. Я слушала музыку, и не слышала, как мама вошла
- Подлежащее
- Обстоятельство
- Сказуемое
ОТВЕТЫ:
Задание 1.
1-4, 2-1, 3-3, 4-2
Задание 2.
|
|
|
|
|
|
|
| 2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
1 | с | к | а | з | у | е | м | о | е |
| 4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| б |
|
| п |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| с |
| 5 | о | п | р | е | д | е | л | е | н | и | е |
|
|
|
|
|
|
|
| т |
|
| д |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 | д | о | п | о | л | н | е | н | и | е |
|
|
|
|
|
|
|
|
|
|
|
|
| я |
|
| е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| т |
|
| ж |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| е |
|
| а |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| л |
|
| щ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ь |
|
| е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| с |
|
| е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| в |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| о |
|
|
|
|
|
|
|
|
|
|
|
|
|
Задание 3.
Части речи: существительное, глагол, прилагательное, наречие, предлог, союз, местоимение
Члены предложения: определение, дополнение, сказуемое, подлежащее, обстоятельство
Задание 4.
Кого? Кому? О чём? О ком? Кем?
Задание 5.
Летели и летели осеннее листья. Ветер подхватил их и погнал к речке. По зеркальной воде поплыли золотые монетки. На краю деревни заигралрожок. Это пастух собирал стадо. Я выхожу из дома, беру весла и иду к речке. Восток светлеет, розовеет. Река словно похорошела, выпрямилась. Под первыми лучами солнца засверкали, заискрились капельки воды. Стояла чудесная пора осени.
Задание 6.
Наступили холодные дни осени. В лужах плавали жёлтые листья. По небу ползли низкие тучи.
Задание 7.
1-1, 2-2, 3-3
Задание 8.
________ дополнение
________ определение
________обстоятельство
Сказуемое — лишнее
Задание 9.
Снежинки кружатся.
Задание 10.
Покраснели осинки, пожелтели берёзки. Гроздья ягод созрели на рябинах/ на рябинах. Кругом растёт пушистый ельник. Зеленеют молодые ёлочки. Из земли бьёт чистый родник.
Задание 11.
Ясное весеннее утро. Развернулись на низких кустиках молодые листочки. Из земли выглядывают узкие стрелки.
Задание 12.
- обстоятельство. (Подлежащее – это главный член предложение, а остальные – второстепенные)
- Существительное, прилагательное,
сказуемое, наречие. (Сказуемое – это член предложения, а остальные – части речи) - Подлежащее, сказуемое, определение,
союз (Союз –это часть речи, а остальные – члены предложения)
Задание 13.
- Подлежащее
- Обстоятельство
- Сказуемое
Контрольный модуль
В-1
1. 2
2. 2
3. 3
В-2
1. 1
2. 2
3.3
границ | Доказательства морфологического состава сложных слов с использованием MEG
1. Введение
Некоторые слова простые, а некоторые нет. Поначалу это звучит как очень банальная тавтология, но споры о том, хранятся ли мультиморфемные слова просто в виде целой словоформы (Butterworth, 1983; Giraudo and Grainger, 2001) или всегда строятся из их морфемных частей (Taft, 2004). ) был развлекательным, провокационным и спорным в области лексической обработки в течение последних 40 лет.Комплексная модель того, как слова сохраняются и извлекаются, требует понимания того, как связаны форма и значение и как эта связь разворачивается во времени в естественной речи.
Потенциальный контраст между хранением целого слова и хранением морфем впервые обсуждался в классической модели удаления аффиксов (Taft and Forster, 1975), которая предполагала, что лексический доступ включает доступ к основе морфологически сложных слов. Это исследование показало, что псевдосложные слова с реальной основой (например,g., de- juvenate ) потребовалось больше времени для отклонения в задаче лексического решения (и часто неправильно выбирались как слова), чем псевдосложные слова с реальными префиксами и несуществующими основами (например, de- pertoire ). Это было воспринято как доказательство того, что к морфемам обращались до лексического доступа, и они способствуют поиску лексического элемента в памяти. При использовании различных парадигм прайминга накопились доказательства в пользу доступности морфем во время лексического доступа (Marslen-Wilson et al., 1994; Растл и Дэвис, 2003; Тафт, 2004). Это привело к появлению моделей обработки, в которых морфологическая декомпозиция является автоматическим и необходимым этапом обработки сложных слов (Rastle et al., 2004). В недавних исследованиях (Fiorentino et al., 2014; Semenza and Luzzatti, 2014) изучались этапы разложения, чтобы увидеть, как значение морфемы интегрируется в значение сложного слова. Результаты электрофизиологии (Fiorentino et al., 2014) выявили большую отрицательность для лексикализованных соединений (например,g., teacup) и новые соединения (например, tombnote) по сравнению с мономорфемными словами во временном окне 275–400 мс, что указывает на стадию, на которой значения морфем объединяются в английских соединениях. Эти психологические модели дают четкие прогнозы относительно стадий и динамики лексического доступа, но в настоящее время отсутствуют доказательства привязки этих стадий к определенным областям мозга. Это исследование направлено на выявление области, ответственной за состав значений морфем. Исследования из литературы по именованию картинок (Dohmes et al., 2004) предполагает, что на этом этапе должна быть большая активация для семантически прозрачных сложных слов, поскольку они демонстрируют большую концептуальную активацию и конкуренцию лемм в дополнение к эффекту морфологического перекрытия. Следовательно, эта область должна быть чувствительной только к составу сложных слов, значение морфемы которых имеет семантически прозрачное отношение к общему значению по сравнению со сложными словами, морфемы которых не разделяют семантические отношения, непрозрачный .
Один из способов взглянуть на лексическую обработку сложных слов — посмотреть, может ли активация морфологической структуры модулировать доступность сложного слова. Некоторые исследования кросс-модального прайминга (Marslen-Wilson et al., 1994) показали, что праймирование в лексическом решении между словами, имеющими общую основу, происходило только тогда, когда простое число и цель имели связанные значения (например, , исход , штрих , исход , но , отдел — нет), в то время как другие исследования (Zwitserlood, 1994) с использованием прайминга с частичным повторением показали, что прайминг не зависит от семантических отношений между простым числом и целью.Однако исследования с использованием замаскированного прайминга, парадигмы сублиминального прайминга, в котором простому слову предшествует прямая маска и следует за ним целевое слово (Forster and Davis, 1984), обнаружили, что при манипулировании семантической прозрачностью эффекты облегчения возникали для сложных слов независимо от имеют ли прайм и мишень один и тот же морфологический корень (Longtin et al., 2003; Rastle et al., 2004; Fiorentino and Poeppel, 2007; McCormick et al., 2008). Эти эффекты не проявлялись для морфологически простых слов (например,г., публичный дом ). Было обнаружено более быстрое лексическое время принятия решений для сложных слов, которые можно сегментировать на существующие морфемы, что означает, что замаскированные простые / немаскированные целевые пары без семантических отношений, такие как corner-corn и bootleg-boot , показали ускоренное распознавание целевых слов с помощью величины, неотличимые от пар с семантическими отношениями, такими как очиститель-очиститель и чашка-чай .
Поскольку общепринято, что морфологическая декомпозиция выполняется для каждого сложного слова, которое может быть исчерпывающим образом разобрано на существующие морфемы, исследования визуального распознавания слов должны сместить акцент с декомпозиции на последующие механизмы, задействованные для активации фактического значения сложного целевого слова. .Менье и Лонгтин (2007) предположили, что активация слова вступает в игру поэтапно, которые включают по крайней мере одну раннюю стадию морфологической декомпозиции и более позднюю стадию семантической интеграции морфологических частей. Fiorentino et al. (2014) представили доказательства основанного на морфемах пути активации слова, который включает разложение на морфологические составляющие и комбинаторные процессы, действующие на эти представления. Поскольку предыдущие исследования показали, что ранняя декомпозиция, вызванная морфологической структурой, происходит автоматически для прозрачных и непрозрачных слов, разница между этими двумя типами слов может проявиться на более позднем этапе комбинаторных операций.
Другой способ взглянуть на лексическую обработку сложных слов — это посмотреть, как форма отображается на значение. Это очень важно при обработке морфологически сложных слов, чтобы отделить то, как мозг воспринимает прозрачные слова от того, как он воспринимает непрозрачные. Это можно исследовать, посмотрев, как значения морфем складываются в мозгу. Существуют модели общего механизма связывания в построении предложений (Friederici et al., 2000) и в базовой композиции именных фраз (Bemis and Pylkkänen, 2011), которые вовлекают левую переднюю височную долю (LATL) в состав слов во фразы. .В парадигме минимальной композиции Bemis и Pylkkänen (2011) обнаружили, что два составных элемента во фразе прилагательное-существительное (например, красная лодка ) вызывают большую активацию в левой передней височной доле, LATL, примерно на 225 мс, чем два. несоставные элементы (например, xkq boat , случайная последовательность букв и слова). Это было воспринято как доказательство того, что базовая комбинаторная обработка данных поддерживается LATL. В сложных словах есть особый подкласс слов, которые имеют структуру, параллельную существительным фразам, известным как составные слова.Сложные слова обладают уникальным свойством состоять только из свободных морфем (отдельных слов). Составные слова также различаются по измерению семантической прозрачности , степени, в которой комбинация значений морфем соответствует общему значению слова. Это означает, что мы можем варьировать вклад морфем в композицию значения. Эти свойства делают составные слова отличным кандидатом для исследования морфологического состава сложных слов, поскольку они могут обеспечивать аналогичную структуру для работы, выполняемой на уровне фразы.Эти параллели приводят к тому, что LATL является кандидатом на композицию внутри слова, и это обеспечивает интересную основу для изучения эффектов внутрилексической семантической композиции как аналога композиции на уровне фразы.
Таким образом, семантически прозрачные составные слова (например, почтовый ящик) должны вызывать большую активность в этой области, чем простые слова, поскольку их значения происходят из состава их морфемических частей, тогда как семантически непрозрачные составные слова (например,, бутлег) не должны вызывать большей активности, поскольку между их частями и значениями нет связи. В общем, модель сложного распознавания слов потребует, по крайней мере, этих двух этапов обработки: разбора на базовые единицы (декомпозиция) и композиции этих словоформ в сложное значение. Чтобы распаковать эти этапы, мы предлагаем использовать два типа парадигм грунтования: грунтовку с частичным повторением (например, ДОРОГА-обочина), аналогичные парадигмам, используемым в исследованиях замаскированного грунтования, которые будут использоваться для исследования эффектов разложения в соединениях, и грунтовка с полным повторением (например,g., ROADSIDE-roadside), которые будут использоваться для исследования композиционных эффектов их морфем. Штрихи условия повторения прайминга использовали для оценки эффекта композиции в отсутствие поведенческой реакции. В этом отношении метод анализа аналогичен принятому Zweig и Pylkkänen (2009), в котором авторы напрямую сравнивают сложные (производные) слова, таким образом стремясь найти эффекты разложения, которые не зависят от прайминга. В этом исследовании используется задача создания именования слов для изучения этих этапов, связанных с лексической обработкой, поскольку она обеспечивает сопоставимые эффекты с задачами лексического принятия решений (Neely, 1991) и не требует пробного заполнения.Эта задача была выполнена, пока активность мозга регистрировалась с помощью МЭГ, чтобы исследовать, есть ли в левой височной доле область, отвечающая за морфологический состав. Это исследование вносит свой вклад в работу по характеристике нейронных основ лексической обработки сложных слов, предоставляя доказательства композиции в составных словах и связывая их с их нейронными коррелятами. Учитывая предшествующую литературу, мы ожидаем найти доказательства разложения для сложных слов, но не для симплексных слов.Это открытие согласуется с литературой по визуальному распознаванию слов, особенно с литературой по замаскированному праймингу, где есть облегчающие эффекты при прайминге морфологически сложных слов, но не морфологически простых слов. Однако мы не ожидаем увидеть это общее преимущество морфологической сложности в составе. Поскольку состав смысла регулируется семантически, мы ожидаем обнаружить влияние композиции на активность мозга только для прозрачных соединений.
2.Материалы и методы
2.1 Участники
Восемнадцать правшей, носителей английского языка в возрасте от 18 до 30 лет, с нормальным или исправленным зрением, дали информированное согласие и приняли участие в этом эксперименте. Исследование было одобрено Университетским комитетом по деятельности с участием людей (UCAIHS) Нью-Йоркского университета. Данные MEG от трех участников были исключены из-за большого количества отказов от испытаний, вызванных шумовыми помехами (> 25%). Подробности отказа описаны в процедуре.
2.2. Материал
Все стимулы состояли из английских би-морфемных соединений (например, чашка) и морфологически простых существительных (например, шпинат), сопоставленных по длине и поверхностной частоте. Мы манипулировали семантической прозрачностью, включая полностью семантически прозрачные (например, чайная чашка) слова, в которых обе составляющие морфемы имеют семантическое отношение к значению всего соединения, и полностью семантически непрозрачные слова (например, фигня), в которых ни один из составляющих морфемы имеют семантическое отношение к составному значению.
311 английских словосочетаний были собраны из предыдущих исследований (Juhasz et al., 2003; Fiorentino and Poeppel, 2007; Fiorentino and Fund-Reznicek, 2009; Drieghe et al., 2010) и классифицированы с точки зрения семантической прозрачности с помощью семантики. задача на соответствие, выполняемая с помощью инструмента Amazon Mechanical Turk. В этом задании 20 участникам было предложено оценить по шкале от 1 до 7, насколько каждый компонент соединения относится к целому слову. По шкале 1 соответствует несвязанному, а 7 — очень близкому.Каждому участнику случайным образом представили один из компонентов каждого соединения. Соединения классифицировались как семантически непрозрачные (далее , непрозрачные, ), если сумма баллов их составляющих находилась в интервале 2–6, и как семантически прозрачные (далее , прозрачные ), если сумма была в интервале 10–14. Например, непрозрачный состав deadline получил суммарный рейтинг 3,76 с dead , что дает рейтинг прозрачности 1.44 и строка дает рейтинг 2.32. Точно так же составной кукольный домик получил суммарную оценку 11,79, где кукла внесла рейтинг прозрачности 6,47, а дом дал оценку 5,32. Для каждого типа слова было выбрано шестьдесят словосочетаний. Этот метод нормирования семантической прозрачности соответствовал методам, использованным в упомянутых предыдущих исследованиях. Морфологически простые слова (далее simplex : например, шпинат) были объединены из Rastle et al.(2004) и English Lexicon Project отбирали слова, закодированные на наличие только одной морфемы (Balota et al., 2007). Симплексные слова (например, бордел ) были выбраны так, чтобы они имели неморфологическую связь формы с их простыми числами (например, бульон ). Кроме того, эти слова были ограничены и выбраны таким образом, чтобы простое слово нельзя было разбить на более мелкие части без создания недопустимых морфем.
2.3. Типовой проект дома
Три разных типа слов были сопоставлены в двух условиях прайминга: полное повторение и частичное (составляющее) повторение (см. Таблицу 1).Для условия повторного прайминга в качестве прайма и мишени использовали одно и то же соединение (например, чашка TEACUP). Для прайминга с частичным повторением мы использовали первый компонент соединения в качестве праймера (например, чайную чашку TEA). Для симплексного условия неморфологическая родственная форма использовалась в качестве составляющей в условии частичного повторения прайминга (например, SPIN-шпинат). Эти два условия прайминга были объединены для управления условиями, в которых прайм не имел семантического отношения к цели (например,г., DOORBELL-чашка; ДВЕРЬ-чашка).
Таблица 1. Матрица расчета .
2,4. Процедура
Все участники прочитали все элементы во всех условиях (всего 720), которые были разделены на три списка по 240 слов и рандомизированы в каждом списке. Порядок представления списков был сбалансирован между испытуемыми. Экспериментальной задачей было наименование слов: испытуемым предлагались пары слов, и их просили прочитать вслух второе слово каждой пары.Стимулы были представлены белым шрифтом Courier размером 30 пунктов на сером фоне с помощью PsychToolbox (Brainard, 1997). Каждое испытание начиналось с предъявления фиксирующего креста, затем штриховки, затем мишени. Каждая из этих визуальных презентаций была представлена в течение 300 мс с последующим пропуском 300 мс (см. Рисунок 1). Мы записали начальную латентность речи и высказывания каждого испытуемого для поведенческого анализа.
Рис. 1. Структура эксперимента .
Перед экспериментом форма головы каждого участника была оцифрована с использованием системы Polhemus Fastscan вместе с пятью точками индикатора положения головы, которые используются для совместной регистрации положения головы по отношению к датчикам MEG во время сбора данных.Электромагниты, прикрепленные к этим точкам, локализуются после того, как участники лежат внутри массива датчиков МЭГ, что обеспечивает совместную регистрацию систем координат головы и датчика. Форма головы используется во время анализа для совместной регистрации головы на МРТ участников. Половине участников МРТ не проводились; поэтому мы масштабировали общий эталонный мозг, который предоставляется в FreeSurfer, чтобы он соответствовал размеру голов этих участников.
Во время эксперимента участники оставались лежать в комнате с магнитным экраном, а реакцию их мозга контролировали градиентометры MEG.Экспериментальные элементы проецировались на экран, чтобы участник мог прочитать и выполнить задание. Данные МЭГ были собраны с использованием аксиальной системы градиентометра для всей головки с 157 каналами и тремя опорными каналами (Канадзавский технологический институт, Ноноичи, Япония). Запись проводилась в режиме постоянного тока, то есть без фильтра верхних частот, с фильтром нижних частот 300 Гц и режекторным фильтром 60 Гц.
2,5. Анализ
Мы исследовали латентность начала, время реакции на наименование слова, чтобы оценить эффекты морфологического разложения на основе Фиорентино и Поппеля (2007).Поскольку время реакции чувствительно к лексическим свойствам слов (Fiorentino and Poeppel, 2007), составные слова должны обрабатываться быстрее при праймировании, чем симплексные слова, из-за остаточной активации ранее активированных морфем. Недекомпозиционная учетная запись не предсказывает никаких различий из-за структуры слова, если слова правильно сопоставлены по релевантным свойствам всего слова. Таким образом, начальная задержка может использоваться, чтобы понять, есть ли эффект разложения. Поведенческие данные были проанализированы с использованием традиционного дисперсионного анализа для типа слова с помощью модели взаимодействия с частичным повторением.Прайминг с частичным повторением в задачах лексического решения использовался, чтобы продемонстрировать доступность морфем в сложных словах (Rastle et al., 2004). Подобные поведенческие эффекты были также обнаружены при использовании именования слов (см. Neely, 1991 для сравнительного обзора лексического решения и именования слов). Таким образом, свидетельство эффектов разложения можно наблюдать во времени реакции, чтобы говорить, , задержка начала . Предыдущие исследования привели к предсказанию, что должен быть стимулирующий эффект более короткой задержки начала из-за прайминга для соединений по сравнению с их эквивалентами из симплексных слов, поскольку сегментация на морфемы приводит к более быстрому доступу к сложному слову.
После сбора данных мозга мы применили метод непрерывно скорректированных наименьших квадратов (Adachi et al., 2001), процедуру снижения шума в программном обеспечении MEG160 (Yokogawa Electric Corporation и Eagle Technology Corporation, Токио, Япония), которая вычитает шум из Градиометры МЭГ основаны на измерениях шума в опорных каналах, удаленных от головы. Данные подвергались полосовой фильтрации в диапазоне 1–40 Гц с использованием БИХ-фильтра. Запись всего эксперимента была сегментирована на интересующие эпохи, от -200 мс до до 600 мс после визуального отображения основного слова.Мы отклонили испытания, в которых максимальная амплитуда размаха превышала предел 4000fT, и уравняли испытания, чтобы иметь равное количество испытаний для каждого условия и для каждого типа слова для правильного сравнения. Средний процент отклоненных испытаний среди субъектов составлял 1,9%, а для каждого типа слова: 1,3% для непрозрачных, 2,2% для симплексных, 1,8% для прозрачных. Каналы датчиков были отмечены как плохие и отбрасывались для каждого испытуемого, если полное отклонение канала превышало 10%.
Матрица ковариации шума была вычислена для каждого участника с использованием процедуры автоматического выбора модели (Engemann and Gramfort, 2015) на случайном выборе базовых эпох (120 эпох) от -200 мс до начала представления креста фиксации.Для участников с МРТ кортикальные реконструкции были сгенерированы с помощью FreeSurfer, в результате чего пространство источника составляло 5124 вершины (CorTechs Labs Inc., Ла-Хойя, Калифорния и MGH / HMS / MIT Центр биомедицинской визуализации Athinoula A. Martinos, Чарльстон, Массачусетс). Метод модели граничных элементов (БЭМ) использовался для моделирования активности в каждой вершине для расчета прямого решения. Обратное решение было сгенерировано с использованием этой прямой модели и матрицы ковариации шума и вычислено с ограничением фиксированной ориентации, требующим, чтобы дипольные источники были перпендикулярны кортикальной поверхности.Затем данные датчиков для каждого испытуемого проецировались в их индивидуальное исходное пространство с использованием оценки минимальной нормы с корковыми ограничениями (все анализы проводились с использованием MNE-Python: Gramfort et al., 2013, 2014), в результате чего получались нормализованные по шуму карты динамических статистических параметров. (dSPM: Dale et al., 2000).
Для этого анализа наш дизайн (таблица 2) сводится к простому сравнению между составными (например, TEACUP) и симплексными словами (например, SPINACH) одного и того же размера, которые служили простыми числами в условии повторения (например,g., TEACUP-teacup), описанный выше в разделе «Дизайн». Поскольку для этого анализа мы используем нейрофизиологические данные, относящиеся к молчаливому чтению слов, которые служили простыми числами, поведенческих данных для этих слов нет. Таким образом, мы также избегаем артефактов, связанных с произвольными движениями, которые могут поставить под угрозу анализ эффектов, представляющих интерес для исследования (Hansen et al., 2010).
Таблица 2. Анализ простых чисел .
Мы исследовали нервную активность, локализованную во всей левой височной доле.Этот регион был выбран на основе композиционных эффектов, обнаруженных в предложениях (Friederici et al., 2000) или фразах прилагательное-существительное (Bemis and Pylkkänen, 2011). Чтобы проверить, была ли повышена активность соединений в этой области, был проведен тест t на остаточную активацию типа составного слова (непрозрачный, прозрачный) после удаления активации из симплексного контрольного слова от 100 до 600. мс после появления стимула. Карта мозга с p была сгенерирована для временных рядов, а пространственно-временные кластеры были идентифицированы для смежных пространственно-временных кластеров, у которых значение p было меньше 0.05 и длительностью не менее 10 мс. Значения t были суммированы для тех точек в кластере, которые соответствовали этим критериям. Затем сначала был выполнен тест непараметрической перестановки путем перетасовки меток типов слов, а затем вычисления кластеров, образованных новыми метками. Распределение, сгенерированное из 10 000 перестановок, было вычислено путем вычисления значимых уровней наблюдаемого кластера. Скорректированное значение p было определено из процента кластеров, которые были больше, чем исходный вычисленный кластер (Maris and Oostenveld, 2007).Эти тесты были рассчитаны с использованием пакета статистического анализа данных MEG, Eelbrain (https://pythonhosted.org/eelbrain/).
3. Результаты
3.1. Морфологическая декомпозиция
С точки зрения поведения мы обнаружили значительный эффект прайминга с частичным повторением [ F (1, 17) = 25,91, p <0,001], но, что наиболее важно, взаимодействие типа слова с помощью прайминга [ F ( 2, 17) = 9,24, p <0,001] (рисунок 2).Этот эффект показывает, что именование составных слов упрощается в большей степени, чем для морфологически простых слов, когда они начислены. В запланированных сравнениях были обнаружены достоверные различия между непрозрачными соединениями и симплексными словами [ F (1, 17) = 5,93, p <0,03], а также прозрачными соединениями и симплексными словами [ F (1, 17) = 14,46, p <0,005], но не между прозрачными и непрозрачными соединениями [ F (1, 17) = 2.84, p. > 0,1]. Эти результаты показывают, что даже в словообразовании существует чувствительность к морфологической структуре помимо орфографического и фонологического перекрытия, но этот этап обработки нечувствителен к значению морфем по отношению к составному слову, что согласуется с предыдущим литература по морфологическому разложению (Rastle et al., 2004; McCormick et al., 2008).
Рисунок 2. Средство разницы задержки начала частичного повторения прайминга .
3.2. Морфологический состав
Результаты показывают надежные эффекты большей активации прозрачных соединений по сравнению с их симплексными контролями в височной доле. С этим различием связаны два значимых кластера: первый кластер был локализован в передней средней височной извилине от 250 до 470 мс ( t = 4552,3, p <0,05, рисунок 3), а второй кластер активности был локализуется в задней верхней височной извилине от 430 до 600 мс ( t = 5654, p <0.05, рисунок 4). Однако не было обнаружено надежных кластеров для различия непрозрачных соединений и симплексных слов в височной доле.
Рис. 3. Разница между прозрачностью и симплексом в левой передней височной доле (LATL) .
Рис. 4. Разница между прозрачностью и симплексом в задней верхней височной мышце (pSTG) .
4. Обсуждение
Анализ разных типов слов по отдельности выявил очень последовательные доказательства того, что существует разница в том, как простые и сложные слова обрабатываются в мозгу.Поведенческие результаты подтвердили, что существует стадия лексического доступа, которая чувствительна к морфологическим формам в сложных словах, и продемонстрировали, что эти эффекты также могут наблюдаться в других модальностях тестирования, а именно, в именовании слов. Эффект начального латентного взаимодействия, когда составные слова создавались быстрее, чем морфологически простые слова, когда они начинались с их составной морфемы, в значительной степени согласуется с результатами в литературе по замаскированному праймингу по распознаванию слов и дает дополнительные доказательства того, что в лексическом доступе есть стадия декомпозиции где сложные слова разбираются на свои морфемы (Rastle et al., 2004; Тафт, 2004; Моррис и др., 2007; Маккормик и др., 2008; Fiorentino и Fund-Reznicek, 2009). Операция синтаксического анализа происходит независимо от семантических отношений между составляющими морфемами и их сложным словом. Поскольку ранняя активация составляющих посредством морфологического разложения происходит независимо от семантической прозрачности, то, что отличает прозрачное и непрозрачное соединение, должно происходить, таким образом, на более поздней стадии морфемного состава. Повышенная активность прозрачных соединений в передней височной доле с 250 до 470 мс свидетельствует о стадии лексического доступа, на которой значения морфемы играют роль в доступе к общему значению слова.Bemis и Pylkkänen (2011) показывают комбинаторные эффекты в LATL для прилагательных слов примерно через 225 мс после предъявления критического слова. Разницу во времени можно объяснить разными моментами времени, когда мы фиксируем начало действия стимула. В Bemis и Pylkkänen (2011) начало совпадает с началом существительного boat во фразе red boat , тогда как в нашем исследовании критическим стимулом является весь состав sailboat .
Повышенная активация в задней височной доле прозрачных соединений с 430 до 600 мс, которая следует за активностью в LATL, согласуется с тем фактом, что эта область участвует в лексическом поиске (Hickok and Poeppel, 2007; Lau et al., 2008). Lau et al. (2008) предположили, что задняя область височной доли является лучшим кандидатом для лексического хранения слов. Поскольку LATL отвечает за составление значения составляющих морфем, задняя височная доля будет отвечать за извлечение информации из хранимого в ней лексико-семантического представления. Эта область также участвует в преобразовании звука в значение (Binder et al., 2000), которое включает поиск фонологической информации. Это исследование согласуется с моделями декомпозиции из литературы по визуальному распознаванию слов и обеспечивает нейронную основу для этапа лексического доступа, участвующего в композиции значения в составных словах, тем самым помогая распутать когнитивные процессы, которые нечеткие, когда время реакции является единственной мерой. .Объединяя результаты психолингвистических исследований с записями МЭГ активности мозга, полученные результаты предполагают, что распознавание соединений включает в себя отдельные стадии: стадию декомпозиции, которая не зависит от семантики, и стадию композиции, которая регулируется семантикой. Мы показали, что ход активации различается по сложности слова и семантической прозрачности.
Авторские взносы
Авторы TB и DC являются первыми авторами, поскольку оба они в равной степени внесли свой вклад в работу.
Финансирование
Эта работа поддержана Национальным научным фондом в рамках гранта № BCS-0843969 и Исследовательским советом Нью-Йоркского университета в Абу-Даби в рамках гранта № G1001 Института NYUAD Нью-Йоркского университета Абу-Даби. Работа по туберкулезу была поддержана исследовательской стипендией Национального научного фонда под номером DGE-1342536. Работа DC была поддержана Координацией повышения квалификации кадров высшего образования и Комиссией Фулбрайта в соответствии с Законом о взаимном образовательном обмене, спонсируемой Государственным департаментом Соединенных Штатов Америки, Бюро по вопросам образования и культуры.
Заявление о конфликте интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Благодарности
Мы хотели бы поблагодарить Алека Маранца за его поддержку и руководство этим проектом. Мы также хотели бы поблагодарить Машу Вестерлунд и Фиби Гастон за критические отзывы для этой статьи. Мы также хотели бы поблагодарить Джеффа Уокера из NYU MEG Lab за его помощь во время тестирования участников.
Список литературы
Адачи Ю., Симогавара М., Хигучи М., Харута Ю. и Очиаи М. (2001). Снижение непериодического магнитного шума окружающей среды при измерении МЭГ методом наименьших квадратов с постоянной корректировкой. заявл. Сверхпроводимость. IEEE Trans . 11: 669–672. DOI: 10.1109 / 77.919433
CrossRef Полный текст | Google Scholar
Балота Д. А., Яп М. Дж., Кортезе М. Дж., Хатчисон К. А., Кесслер Б., Лофтис Б. и др. (2007). Проект английской лексики. Behav. Res. Методы 39, 445–459. DOI: 10.3758 / BF03193014
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Бемис, Д. К., и Пюлкканен, Л. (2011). Простая композиция: магнитоэнцефалографическое исследование понимания минимальных языковых фраз. Дж. Neurosci . 31, 2801–2814. DOI: 10.1523 / JNEUROSCI.5003-10.2011
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Биндер, Дж.R., Frost, J. A., Hammeke, T. A., Bellgowan, P. S., Springer, J. A., Kaufman, J. N., et al. (2000). Активация височной доли человека речью и неречевыми звуками. Cereb. Cortex 10, 512–528. DOI: 10.1093 / cercor / 10.5.512
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Баттерворт, Б. (1983). «Лексическое представление», в Language Production , Vol. 2, изд Б. Баттерворт (Лондон: Academic Press), 257–294.
Дейл, А.М., Лю, А. К., Фишл, Б. Р., Бакнер, Р. Л., Белливо, Дж. У., Левин, Дж. Д. и др. (2000). Динамическое статистическое параметрическое картирование: комбинирование ФМРТ и МЭГ для визуализации корковой активности с высоким разрешением. Neuron 26, 55–67. DOI: 10.1016 / S0896-6273 (00) 81138-1
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Фиорентино, Р., Фунд-Резничек, Э. (2009). Маскированная морфологическая грунтовка составных компонентов. Ment. Лексикон 4, 159–193.DOI: 10,1075 / мл. 4.2.01fio
CrossRef Полный текст | Google Scholar
Фиорентино, Р., Найто-Биллен, Ю., Бост, Дж., И Фунд-Резничек, Э. (2014). Электрофизиологические доказательства комбинаторной обработки английских соединений на основе морфем. Cogn. Neuropsychol . 31, 123–146. DOI: 10.1080 / 02643294.2013.855633
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Фиорентино, Р., Поппель, Д. (2007). Сложные слова и структура в лексике. Lang. Cogn. Процесс . 22, 953–1000. DOI: 10.1080 / 016
7011
CrossRef Полный текст | Google Scholar
Форстер К. И. и Дэвис К. (1984). Прайминг повторения и ослабление частоты в лексическом доступе. J. Exp. Psychol. Учить. Mem. Cogn . 10, 680–698. DOI: 10.1037 / 0278-7393.10.4.680
CrossRef Полный текст | Google Scholar
Friederici, A. D., Wang, Y., Herrmann, C. S., Maess, B., and Oertel, U. (2000). Локализация ранних синтаксических процессов в лобных и височных областях коры: магнитоэнцефалографическое исследование. Hum. Brain Mapp . 11, 1–11. DOI: 10.1002 / 1097-0193 (200009) 11: 1 <1 :: AID-HBM10> 3.0.CO; 2-B
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Gramfort, A., Luessi, M., Larson, E., Engemann, D.A., Strohmeier, D., Brodbeck, C., et al. (2013). Анализ данных МЭГ и ЭЭГ с помощью MNE-python. Фронт. Neurosci . 7: 267. DOI: 10.3389 / fnins.2013.00267
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Грамфорт, А., Луесси, М., Ларсон, Э., Энгеманн, Д. А., Стромайер, Д., Бродбек, К. и др. (2014). Программное обеспечение МНЭ для обработки данных МЭГ и ЭЭГ. Neuroimage 86, 446–460. DOI: 10.1016 / j.neuroimage.2013.10.027
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Хансен, П. К., Крингельбах, М. Л., и Салмелин, Р. (2010). MEG: Введение в методы . Нью-Йорк, Нью-Йорк: Издательство Оксфордского университета.
Google Scholar
Юхас, Б.Дж., Старр, М. С., Инхофф, А. В., и Плак, Л. (2003). Влияние морфологии на обработку составных слов: свидетельства от именования, лексических решений и фиксации взгляда. руб. Дж. Психол . 94, 223–244. DOI: 10.1348 / 000712603321661903
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Longtin, C.-M., Segui, J., and Hallé, P.A. (2003). Морфологическая грунтовка без морфологической взаимосвязи. Lang. Cogn. Процесс . 18, 313–334.DOI: 10.1080 / 016
244000036
CrossRef Полный текст | Google Scholar
Марслен-Уилсон, В., Тайлер, Л. К., Вакслер, Р., и Олдер, Л. (1994). Морфология и значение в английской ментальной лексике. Psychol. Ред. . 101, 3–33. DOI: 10.1037 / 0033-295X.101.1.3
CrossRef Полный текст | Google Scholar
Маккормик, С. Ф., Растл, К., и Дэвис, М. Х. (2008). Есть ли в слове «фетиш» праздник? влияние орфографической непрозрачности на морфо-орфографическую сегментацию при визуальном распознавании слов. J. Mem. Lang . 58, 307–326. DOI: 10.1016 / j.jml.2007.05.006
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Нили, Дж. Х. (1991). «Эффекты семантического прайминга в визуальном распознавании слов: выборочный обзор текущих результатов и теорий», в Basic Processes in Reading: Visual Word Recognition , ред. Д. Беснер и Г. У. Хамфрис (Хиллсдейл, штат Нью-Джерси: L. Erlbaum Associates), 264 –336.
Google Scholar
Растл, К.и Дэвис М. Х. (2003). Чтение морфологически сложных слов . Нью-Йорк, Нью-Йорк: Психология Пресс.
Google Scholar
Тафт М. и Форстер К. И. (1975). Лексическое хранение и поиск слов с префиксом. J. Verb. Учить. Глагол. Поведение . 14, 638–647. DOI: 10.1016 / S0022-5371 (75) 80051-X
CrossRef Полный текст | Google Scholar
Цвейг, Э., Пюлкканен, Л. (2009). Визуальный эффект m170 морфологической сложности. Lang.Cogn. Процесс . 24, 412–439. DOI: 10.1080 / 016
802180420
CrossRef Полный текст | Google Scholar
Zwitserlood, P. (1994). Роль семантической прозрачности в обработке и представлении нидерландских словосочетаний. Lang. Cogn. Процесс . 9, 341–368. DOI: 10.1080 / 016
408402123CrossRef Полный текст | Google Scholar
% PDF-1.4 % 1 0 объект > эндобдж 7 0 объект /Заголовок /Предмет / Автор /Режиссер / Ключевые слова / CreationDate (D: 20210623172849-00’00 ‘) / ModDate (D: 201
105339 + 02’00 ‘) / В ловушке / Ложь / PTEX.FullBanner (это LuaTeX, версия 1.0.4 \ (TeX Live 2017 / Debian \)) >> эндобдж 2 0 obj > эндобдж 3 0 obj > эндобдж 4 0 obj > эндобдж 5 0 obj > эндобдж 6 0 obj > эндобдж 8 0 объект > эндобдж 9 0 объект > эндобдж 10 0 obj > эндобдж 11 0 объект > эндобдж 12 0 объект > эндобдж 13 0 объект > эндобдж 14 0 объект > эндобдж 15 0 объект > эндобдж 16 0 объект > эндобдж 17 0 объект > эндобдж 18 0 объект > эндобдж 19 0 объект > эндобдж 20 0 объект > эндобдж 21 0 объект > эндобдж 22 0 объект > эндобдж 23 0 объект > эндобдж 24 0 объект > эндобдж 25 0 объект > эндобдж 26 0 объект > эндобдж 27 0 объект > эндобдж 28 0 объект > эндобдж 29 0 объект > эндобдж 30 0 объект > эндобдж 31 0 объект > эндобдж 32 0 объект > эндобдж 33 0 объект > эндобдж 34 0 объект > эндобдж 35 0 объект > эндобдж 36 0 объект > эндобдж 37 0 объект > эндобдж 38 0 объект > эндобдж 39 0 объект > эндобдж 40 0 объект > эндобдж 41 0 объект > эндобдж 42 0 объект > эндобдж 43 0 объект > эндобдж 44 0 объект > эндобдж 45 0 объект > эндобдж 46 0 объект > эндобдж 47 0 объект > эндобдж 48 0 объект > эндобдж 49 0 объект > эндобдж 50 0 объект > эндобдж 51 0 объект > эндобдж 52 0 объект > эндобдж 53 0 объект > эндобдж 54 0 объект > эндобдж 55 0 объект > эндобдж 56 0 объект > эндобдж 57 0 объект > эндобдж 58 0 объект > эндобдж 59 0 объект > эндобдж 60 0 объект > эндобдж 61 0 объект > эндобдж 62 0 объект > эндобдж 63 0 объект > эндобдж 64 0 объект > эндобдж 65 0 объект > эндобдж 66 0 объект > эндобдж 67 0 объект > эндобдж 68 0 объект > эндобдж 69 0 объект > эндобдж 70 0 объект > эндобдж 71 0 объект > эндобдж 72 0 объект > эндобдж 73 0 объект > эндобдж 74 0 объект > эндобдж 75 0 объект > эндобдж 76 0 объект > эндобдж 77 0 объект > эндобдж 78 0 объект > эндобдж 79 0 объект > эндобдж 80 0 объект > эндобдж 81 0 объект > эндобдж 82 0 объект > эндобдж 83 0 объект > эндобдж 84 0 объект > эндобдж 85 0 объект > эндобдж 86 0 объект > эндобдж 87 0 объект > эндобдж 88 0 объект > эндобдж 89 0 объект > эндобдж 90 0 объект > эндобдж 91 0 объект > эндобдж 92 0 объект > эндобдж 93 0 объект > эндобдж 94 0 объект > эндобдж 95 0 объект > эндобдж 96 0 объект > эндобдж 97 0 объект > эндобдж 98 0 объект > эндобдж 99 0 объект > эндобдж 100 0 объект > эндобдж 101 0 объект > эндобдж 102 0 объект > эндобдж 103 0 объект > эндобдж 104 0 объект > эндобдж 105 0 объект > эндобдж 106 0 объект > эндобдж 107 0 объект > эндобдж 108 0 объект > эндобдж 109 0 объект > эндобдж 110 0 объект > эндобдж 111 0 объект > эндобдж 112 0 объект > эндобдж 113 0 объект > эндобдж 114 0 объект > эндобдж 115 0 объект > эндобдж 116 0 объект > эндобдж 117 0 объект > эндобдж 118 0 объект > эндобдж 119 0 объект > эндобдж 120 0 объект > эндобдж 121 0 объект > эндобдж 122 0 объект > эндобдж 123 0 объект > эндобдж 124 0 объект > эндобдж 125 0 объект > эндобдж 126 0 объект > эндобдж 127 0 объект > эндобдж 128 0 объект > эндобдж 129 0 объект > эндобдж 130 0 объект > эндобдж 131 0 объект > эндобдж 132 0 объект > эндобдж 133 0 объект > эндобдж 134 0 объект > эндобдж 135 0 объект > эндобдж 136 0 объект > эндобдж 137 0 объект > эндобдж 138 0 объект > эндобдж 139 0 объект > эндобдж 140 0 объект > эндобдж 141 0 объект > эндобдж 142 0 объект > эндобдж 143 0 объект > эндобдж 144 0 объект > эндобдж 145 0 объект > эндобдж 146 0 объект > эндобдж 147 0 объект > эндобдж 148 0 объект > эндобдж 149 0 объект > эндобдж 150 0 объект > эндобдж 151 0 объект > эндобдж 152 0 объект > эндобдж 153 0 объект > эндобдж 154 0 объект > эндобдж 155 0 объект > эндобдж 156 0 объект > эндобдж 157 0 объект > эндобдж 158 0 объект > эндобдж 159 0 объект > эндобдж 160 0 объект > эндобдж 161 0 объект > эндобдж 162 0 объект > эндобдж 163 0 объект > эндобдж 164 0 объект > эндобдж 165 0 объект > эндобдж 166 0 объект > эндобдж 167 0 объект > эндобдж 168 0 объект > эндобдж 169 0 объект > эндобдж 170 0 объект > эндобдж 171 0 объект > эндобдж 172 0 объект > эндобдж 173 0 объект > эндобдж 174 0 объект > эндобдж 175 0 объект > эндобдж 176 0 объект > эндобдж 177 0 объект > эндобдж 178 0 объект > эндобдж 179 0 объект > эндобдж 180 0 объект > эндобдж 181 0 объект > эндобдж 182 0 объект > эндобдж 183 0 объект > эндобдж 184 0 объект > эндобдж 185 0 объект > эндобдж 186 0 объект > эндобдж 187 0 объект > эндобдж 188 0 объект > эндобдж 189 0 объект > эндобдж 190 0 объект > эндобдж 191 0 объект > эндобдж 192 0 объект > эндобдж 193 0 объект > эндобдж 194 0 объект > эндобдж 195 0 объект > / ProcSet [/ PDF / Text / ImageC / ImageB / ImageI] >> эндобдж 196 0 объект > поток x ڝ XɎ6 + MdAr32 i + O «) f4) X˫WE-_XsK% jJ] ^> į | -., O, ۸ \ M & jdYs ଅ + .8 * | Sf’i’LQƾ \ z} MR6T ֫ & DO $ @: ԞIw dow, ZDE4 (ݧ v $ 6 梐 ~ Ͱ8kds & @ l6xzlxfDӾgHGPh, ڞ jgKrdAhBM (OpJnWȫ ‘$ «ώ5Hz» tWa $! R% z & FuUu1 ƑI269 + @ Pb; 6n3vA @ vg24 ~ DVUc1 примечания: *https://zhuanlan.zhihu.com/p/147321515
https://zhuanlan.zhihu.com/p/66268929
Очень важной частью задач обработки естественного языка является анализ структуры языка. Существует два основных метода анализа синтаксической структуры
- Анализ округа
- Анализ зависимостей
Первый в основном касается того, как формируются предложения и как слова образуют фразы.Таким образом, изучение Постоянного округа в основном касается «грамматик без содержания», которые игнорируют семантику.
Последнее, отношение зависимости, в основном связано с тем, от каких других слов зависит каждое слово в предложении.
При синтаксическом анализепостоянных групп в основном используется грамматик структуры фраз, то есть грамматика фраз для непрерывной организации слов во вложенные компоненты, также известные как грамматики контекстного дерева. Основным этапом является выполнение для каждого слова Части речи, сокращенно POS , а затем объединение их во фразы, а затем рекурсивно рекурсивно формировать более крупные фразы.
пример: милый котик у двери.
| предложение | приятный | кот | по | дверь | ||
| Анализ POS | Det Квалификаторы определитель | Adj прилагательное | N существительное | P Предлог | Det Квалификаторы (определитель | N (имя существительное) |
| Составьте фразу | NP именная фраза Существительная фраза Det + Adj + N | NP, фраза существительного | ||||
Фраза предлога PP Предлог pharse P + NP | ||||||
| Объединить фразу | НП + ПП | |||||
На изображении ниже используется инструмент визуализации анализа всей композиции. Результат согласуется с анализом в таблице выше (за исключением того, что он также проанализировал пунктуацию)
Зависимость, основная проблема заключается в том, что каждое слово в предложении зависит от другого слова.Например, следующее предложение:
«Посмотри на этого милого дурачка!»
- «Дурак» — это объект действия «взгляд», поэтому «дурак» зависит от «взгляда»;
- И «Милый», и «маленький» видоизменяют «дурака». Следовательно, эти два прилагательных зависят от слова «дурак»;
- «Это» также указывает на «дурак», поэтому это также зависит от «дурак».
Таким образом, мы проясняем все зависимости в этом предложении, построение графа зависимостей выглядит так:
Обратите внимание, что на рисунке мы добавили корневой узел «Root», чтобы у слова «look» также были зависимые объекты.
Конечно, есть много правил анализа реляционных зависимостей, которые более сложны и меня это не интересует, поэтому я не буду здесь больше писать.
Давайте познакомимся с тем, как позволить машине автоматически помогать нам анализировать структуру предложений.
2.1 Традиционный анализ на основе переходов
Эта статья в основном знакомит с методом «жадного детерминированного анализа на основе переходов», предложенным Nivre в 2003 году, который когда-то стал стандартным методом анализа зависимостей.Здесь я кратко расскажу, как это работает.
Мы строим триплет, а именно стек, буфер и набор зависимостей.
- Вначале стек хранит только один корневой узел;
- Buffer содержит предложение, которое нам нужно проанализировать;
- Набор сохраняет проанализированные нами зависимости, который сначала пуст.
Что нам нужно сделать, так это непрерывно проталкивать слова из буфера в стек и определять, есть ли отношения зависимости со словами в стеке, и выводить их в набор, пока все слова в буфере не будут вытолкнут, а также в стеке.Если остался только один корень, анализ завершен.
Ниже я использую очень простой пример, чтобы продемонстрировать этот процесс. На этот раз мы проанализировали предложение:
.Процесс анализа выглядит следующим образом:
Вторая строка: [root, i] в стеке не является зависимостью. Выполняется действие shift, что означает, что первое слово в буфере помещается в стек.
Третья строка: [root, i, love] в стеке, которая составляет отношение зависимости: любовь указывает на I, отношение, указывающее влево, выполняемое действие — это левая дуга, то есть зависимое слово I удаляется из стека, и зависимость помещается в набор зависимостей.
Четвертая строка: [root, love] в стеке не является зависимостью. Выполняется сдвиг, что означает, что первое слово (WUHAN) в буфере помещается в стек.
Пятая строка: стек — это [корень, любовь, ухань], который составляет отношения зависимости: любовь указывает на ухань, право относится к отношениям, а предпринятые действия — это правая дуга, то есть удалить зависимое слово ухань из стек и поместите зависимость в установленную зависимость.
Шаг 6: Стек равен [root, love], а буфер пуст, что составляет отношение зависимости: root указывает на любовь, а действие, выполняемое отношением правого пальца, является правой дугой, поместите зависимость в набор зависимостей
Шаг 7: В стеке остается только корень, анализ завершается
Вышеупомянутый процесс не должен быть трудным для понимания, но я уверен, что у вас определенно возникнут вопросы в это время:
❝ Как позволить аппарату определять текущее действие? То есть как машина узнает, сформированы ли отношения зависимости в стеке?
❞
В эпоху Nivre здесь использовались методы машинного обучения, что требовало серьезной функциональной инженерии.Функции здесь часто имеют двоичную функцию, то есть бесчисленное количество индикаторных условий в качестве функций для обучения модели. Вы можете себе представить такие высокоширотные особенности очень редко. Таким образом, около 95% времени анализа этой модели уходит на вычисления. Это также самая важная проблема традиционных методов.
2.1 Анализ нейронных зависимостей
Метод анализа нейронной зависимости является результатом исследования команды Стэнфорда в 2014 году. Он в основном использует метод нейронной сети для замены традиционного метода машинного обучения и использует низкоразмерное распределенное представление для замены сложного многомерного разреженного представления признаков. традиционного метода.Весь процесс анализа по-прежнему основан на предыдущем методе, основанном на переходах.
Прежде всего, ясно, что наша задача прогнозирования — это «В соответствии с текущим состоянием, то есть текущим состоянием стека, буфера, набора, построить функции, а затем спрогнозировать следующее действие». 。
Как строятся наши характеристики в анализе нейронной зависимости? Информация, которую мы можем использовать, включает слова (Word), часть речи (postag) и метку зависимости (метку) .Мы выполняем низкоразмерные распределенные представления для этих трех, то есть с помощью метода встраивания дискретные слова, метки и теги преобразуются в низкоразмерные векторные представления.
Для состояния мы можем выбрать определенные слова и отношения в стеке, буфере и множестве, чтобы сформировать набор, а затем объединить все их векторы внедрения, чтобы сформировать характеристическое представление состояния. После прохождения нескольких нелинейных скрытых слоев, наконец, добавляется слой softmax, чтобы получить вероятность каждого класса.
Что касается того, какие слова и отношения выбрать, это один «Опыт» Вы можете узнать больше об этом в статье Стэнфорда. Сетевая структура всей модели также очень проста:
Оценка
В отличие от задач общей классификации, существуют две метрики для оценки модели анализа зависимостей.
- LAS (обозначенная оценка прикрепления) является правильным, только если направление стрелки и грамматические отношения дуги верны.
- UAS (немаркированная оценка крепления) означает, что до тех пор, пока направление дуги стрелки правильное.
Как показано на рисунке ниже: стрелки с правильным направлением — 1,2,4,5; стрелки и грамматика действительно правильные только 1,
На этом заканчивается краткое введение в анализ зависимостей. Анализ зависимостей — не самая распространенная задача в нашем НЛП. Мы редко видим применение анализа зависимостей напрямую. Наши более общие задачи — это классификация, распознавание сущностей, понимание прочитанного и диалог.Однако анализ зависимостей как базовая технология обработки естественного языка пытается заставить машины понимать внутреннюю структуру языка. После понимания структуры становится возможным NLU (понимание естественного языка).
Лингвистические проблемы и сложности можно разделить на лексические, синтаксические или семантические в зависимости от их контекста. Лексические проблемы связаны с интерпретация отдельных слов или фраз, а не целых классов.Эти проблемы существуют независимо от контекста, хотя они очевидны только в Это. Синтаксические проблемы включают структурные отношения между словами или фразами; они часто выражаются семантически (т.е. неоднозначно), но это симптом а не причину.Семантические проблемы подразделяются на лексические, синтаксические и дискурсивные типы. Хотя как лексические, так и семантические лексические проблемы связаны с отдельными словами или фразы, семантические проблемы скорее синкатегорические, чем специфические. Семантический проблемы в синтаксисе возникают, когда синтаксис конструкции правильный, но его смысл неправильно сформирован или неоднозначен, или наоборот.Семантические случаи дискурса включают контекст дискурса высказывания и, поскольку высказывания этого типа являются синтаксически и семантически правильно сформированы, описывают языковые сложности а не проблемы.
Некоторые из этих случаев могут быть обработаны существующими методами обработки, в то время как другие остаются несговорчивыми. Несколько примеров не являются проблемой, но включены просто потому, что они дают представление о природе английского языка. Большинство заимствованы или адаптированы из других источников (Hirst, 1987; Leech, 1981; Marcus, 1978; Милн, 1986; Перейра и Уоррен, 1980; Перро, 1985; Реттиг, 1988; Росс, 1967; Виноград, 1983).Обсуждению предшествуют примеры, к которым ссылка может быть сделана указателем в скобках.
Лексическая двусмысленность
в синтаксической категории (часть речи)
«раковина», «пила», «дубинка», «кольцо»Раковина — это существительное и глагол, означающий -исчезнуть-под водой-. Синтаксически неоднозначные слова дополнительно могут быть семантически неоднозначно в рамках данной категории. Как существительное, клуб является омонимом. как для -балтывания-оружия-, так и-развлекательной-ассоциации-; внутри последнего смысл, он многозначен, потому что может означать как рекреационно-социальную-группу, так и -здоровье-.Взятые в совокупности примеры предполагают, что синтаксически или семантически неоднозначные слова часто бывают общими и короткими.
в словесном значении
«Бейкер», «Квебек»Эти слова обозначают человека или роль (1), или город или провинцию (2). Неопределенность обозначений может повлиять на количественную оценку; пекарь — обычная роль, но Бейкер — конкретный человек.
в обозначении аббревиатуры
«Ян», «Массачусетс», «BC»Соответственно, эти частицы обозначают имя или месяц, градус или градус. государство, провинция или период исторического времени.Сокращения различаются от слов в возможности использовать знаки препинания и заглавные буквы, которые может помочь различить их разные значения. Однако эти средства могут быть недостающими, частичными или нестандартными.
2. Лексические пробелы
«притеснение», «агрессия»; «угнетать», * «агрессию»Первые два слова выглядят как номинализация, но не в форме «агрессия» существует, чтобы соответствовать глаголу «угнетать». Это явление нехватки слово, выражающее понятие, называется лексическим пробелом.Лексические пробелы обычно понимается применительно к легко понимаемым концепциям, имеющим дополнительное концепции, которые воплощаются на словах.
3. Нераспознанные слова
«бливит», «снуд», «чела».Люди обычно сталкиваются со словами, которых они не знают или которые бессмысленно.
4. Идиомы
«красный глаз», «галстук», «возить угли в Ньюкасл», «яппи», «аятолла» популярная культура »,« ксерокопия »Идиомы бывают всех размеров — слова, фразы и предложения.Они могут включать монеты (1, 4) и имена собственные (3) и могут иметь относительно короткую продолжительность жизни (4, 5). Идиомы, которые выживают достаточно долго, переходят в язык навсегда (6).
5. Субидиоматические выражения
`about ‘,« Мы собирались уходить »; «достаточно» + инф, «достаточно стар, чтобы лучше знаю, но достаточно молод, чтобы сделать это ».В дополнение к идиомам, основанным на существительных и глаголах или имеющим существенное В конкретном смысле существует класс субидиоматических выражений, которые действуют как фасилитаторы выражения или лингвистические сокращения.Эти выражения обычно основаны на модификаторах (3) и могут иметь сопутствующие части речи (4). Смысл субидиомы ограничен и гомологичен смыслу модификатора или часть, с которой это происходит.
6. Встраивание центра
«Обои, которые предложил поставить ваш сын, кривые», «Крыса, которую укусила собака, съела сыр».Это правильно составленное предложение трудно понять, потому что встреча с придаточным предложением вынуждает читателя приостановить свое частичное понимание всего предложения.Возможность запутать контексты возникает, как только два сложены.
7. Приговоры Garden Path
«Конь проехал мимо ворот сарая упал», «Человек, который насвистывает мелодии. пианино »,« Старик в лодке »,« Хлопчатобумажная одежда, из которой растет в Миссисипи «,» Попросите студентов, не сдавших экзамен, сдать дополнительная ».В предложениях по садовой дорожке используются слова, которые можно понять как нечто большее, чем одна часть речи. Эти категорично-неоднозначные слова встречаются как внутри пункты (3 и 5) и между пунктами (1, 2 и 4).Пунктуация и относительные вводные местоимения, которые однозначно идентифицируют клаузальный чтение опущено. Рассматривая примеры по порядку, «гонка» может выступать в роли головы. прилагательного и причастия прошедшего времени, мелодии и человек могут быть существительными или глагол, существительное или прилагательное «хлопка» и главный или вспомогательный глагол «иметь» в повелительные или вопросительные конструкции.
Садовые дорожки часто содержат промежуточные фразы или предложения, откладывающие пересмотр читателем его неверной интерпретации и, следовательно, поощрение недоразумение.Удаление промежуточной конструкции иногда может устранить альтернативное прочтение и всегда облегчает понимание основного предложения. Когда это будет выполнено на четырех примерах такого рода: «Попросите учащихся возьмите дополнительную »,« Мужчина настраивает пианино »и« Хлопок растет в Миссисипи »сразу становится недвусмысленным.« Конь упал »становится неграмотный; только наличие вставленной предложной фразы `прошедшее дверь сарая ‘позволяет прилагательному быть размещенным на законных основаниях.После перефразируя это, получается: «Скачавшая лошадь упала», что недвусмысленно.
8. Распространение предложений с расширенными предложениями (продолжающиеся предложения)
«Это кошка, которая укусила крысу, съевшую сыр, который купил Джек», «Они пришли на ужин, и они остались всю ночь, и они ушли сразу после завтракали, но они все еще опаздывали и были наказаны, когда добрались до школа ».Формальных трудностей в обработке этих предложений нет, но в Практика, с которой справиться по мере продолжения становится все более обременительной.Кажется что мы используем знаки препинания в конце предложения как сигнал, понимание. Когда предложение заканчивается, мы знаем, что можем перестать следить за целый класс возможных синтаксических отношений переключает наше внимание на следующий ряд слов.
9. Синтаксическая двусмысленность
в область действия модификатора
«Старики и бабы»Только контекст может сказать, означает ли эта фраза «старики и старушки», или «старики и женщины неустановленного возраста».
в ссылка на фразу
«Я видел его на холме в подзорную трубу»; «Он работал над столом на бумага »,« Работал на бумаге на столе ».Первое предложение имеет три чтения, которые зависят от того, как последнее предложная фраза интерпретируется. Если «с телескопом» читать как аккомпанемент, он может модифицировать «его» или «холм» и производить «он и телескоп» были замечены на холме »или« его видели на холме, на котором установлен телескоп. Это».Если фраза используется для обозначения инструмента, используемого для зрения, она производит «его видели на холме в телескоп».
Второе и третье предложения показывают, как возникает двусмысленность, когда предложение содержит более одной фразы, которая может играть более одной доступной роли. Выбор одной роли для первой фразы автоматически назначает вторую другая фраза. Таким образом, любое предложение можно интерпретировать как указание на то, что бумага пишет кто-то, сидящий за столом, или что стол покрашенный или отшлифованный поверх расстеленной бумаги.`At ‘можно заменить на` on’ в любом месте.
в согласованное соединение
«мужчины и женщины или мальчики»В зависимости от того, как интерпретируется объем союзов, это фраза может означать «либо мужчины и женщины, либо мужчины и мальчики», либо «мужчины и женщины или мальчики.
в косвенное объектное чувство
«Иоанн написал Марии письмо», «Мы завидуем твоему богатству».Косвенный объект по своей сути семантически неоднозначен.Это почти всегда выражает чувство направленности к и от имени и является перефразировано как `to ‘+ indobj или` for’ + indobj. Хотя контекст внутри предложение обычно устанавливает смысл, этот пример доказывает, что можно делать неоднозначные заявления; неясно, было ли это письмо было написано Мэри или от ее имени.
Второе предложение — это пример предложения, которое нельзя перефразировать на любым из двух стандартных способов.Чтение «кому» не имеет смысла. «Мы тебе завидуем для вашего богатства «имеет смысл, но это не совсем правильно. Завидовать кому-то за богатство — это не то же самое, что желание владеть самим богатством, а это то, что второй пример действительно значит.
в договорное владение
«У меня есть фотография Джона»Это говорит о том, что либо у меня есть фотография, принадлежащая Джону, либо я иметь его фотографию. Неоднозначность возникает, если форма выражает два разных ощущается благодаря сокращению и исчезает, когда сокращение расширен.Таким образом, «У меня есть фотография Джона» и «У меня есть фотография Джона». каждый недвусмысленно выражает одно из прочтений примера.
в часть речи
«Джон исполнил женские движения в народном танце после того, как научил женщину переходит в начальный номер. Посмотрите, как быстро движется женщина сейчас «;» Они готовим яблоки »;« Время летит как стрела »;« Я знаю, что мальчик плохой »,« Я знаю что мальчики плохие »;« Какие мальчики это сделали? »,« Чем мальчики занимаются, не мое дело »; «Мусор может быть вонючим», «Мусорный бак был вонючим»; «Я сказал девушке, что я понравилась история »,« Я рассказал девушке, которой мне понравилась история »,« Я рассказал девушке, что история, которая мне понравилась ».По сути, это та же проблема, что и лексическая двусмысленность в синтаксической дело. Однако эти примеры выходят за рамки выявления проблемы, чтобы продемонстрировать Это. Каждое словосочетание «девочка движется» в первом предложении состоит из разные части речи; ? adj + существительное, существительное + существительное, существительное + глагол. «Кулинария» действует как настоящее причастие и прилагательное (2). Третий пример — классический с пять измерений, только четыре из которых я могу идентифицировать: мухи должны быть рассчитаны на определенным образом, тип мух любит стрелы, время летит быстро, и? пора что летает понравилась стрелка.
10. Многоточие
«Она танцует лучше, чем он», «Я сделала это, а он нет».Буквальное прочтение любого предложения задает вопрос: чем он это делает? какие? Многоточие в предложении часто можно определить по присутствию согласования союзов или пунктуации между эллиптическим предложением и его референт. Эллиптическая ссылка между предложениями часто полагается на структурная симметрия между двумя родственными выражениями.
11. Межсерийное соглашение
«Можно ожидать, что эту землю и эти леса сдадут в аренду и продадут. себя соответственно »,« Последние два человека на этом снимке живут в Колумбусе. и Чикаго «Предложения, в которых используется `соответственно ‘, явно или неявно координируются с кросс-серийная основа (а не на основе встраивания центра). В кросс-сериале координации, каждый конъюнкт в серии связан со своим аналогом в такая же позиция в другой серии.Конструкция сбивает с толку, когда число конъюнктов не согласен. Можно согласовать более двух серий; (1) есть все еще легко понять, если добавить «в 1989 и 1990 годах».
12. Анафора
«делай это», «такие дела», «делаю так»;«Джейн дала Джоан леденец, потому что она была голодна», «Джейн дала Джоан леденец, потому что она не была голодна»;
«У женщины и девушки были шляпы, и женщина отдала свою девушке».
Хотя анафора обычно включает ссылки на существительные («это»), они могут также применимы к прилагательным («такой») или наречиям («так»).Ссылка в следующем Пример может быть определен только прагматическим знанием того, кто был голоден. В в терминах последнего примера, какая шляпа была перенесена в каждом из следующих предложения: 1) «Девушка отдала свое женщине»; 2) «Девушка отдала свой женщина «; 3)» Девушка отдала женщине «?
13. Существительные с несколькими словами и соединения слитных существительных
«Трубный ключ», «шпатель», «рожок для обуви», «офисная мебель по налогу на имущество», «конский ошейник».Фразы, которые содержат в своей голове более одного существительного, можно разделить. на два типа.В составах существительных, состоящих из нескольких слов, последнее существительное обеспечивает доминантные элементы смысла фразы и каждое предшествующее существительное определяет и расширяет его (1, 2, 4). Объединенные существительные — это соединения существительных, которые вызывают новое чувство, в значительной степени не связанное с его компонентами (3, 5).
14. Предлагаемые фразы
«Каждому там был подарок».Эта несколько необычная конструкция подчеркивает вступительную фразу.Там нет проблем в обработке, тем более что наличие структурных пунктуация сигнализирует о вероятности зависимости расстояния (между «имел» и `для ‘).
15. Синтаксически неправильно сформированный ввод
«Мальчики здесь». «Эй. Ты. Да, ты. Сделай это. Верно. Верно. № Окей «Неграмматические высказывания всегда будут с нами. Они найдены особенно в речи, где параллельные визуальный и слуховой моды действуют на интегрировать всю коммуникацию и заменить сломанную фразеологию и неполное выражение.Некорректно оформленные утверждения можно разделить на те, которые полностью, но неправильно сформированы, а те, которые гораздо менее полны чем обычное эллиптическое утверждение.
16. Номиналы
«Я пожалел, что он ушел», «Он меня удивил»,? «После его ухода мы нанял спортсмена. «, ??» Главным результатом его ухода было прекращение вражды «Номиналы становятся более неудобными по мере того, как конструкция, в которой они появляются. становится более сложным.Росс приписывает эту неловкость «существительному» которую номинальная форма приобретает в результате своей трансформации (Ross, 1967 в Винограде, 1983).
17. Недействительные преобразования
вопросительный
«Мерри хотел видеть Барбару», «Кого хотел видеть Мерри?»; «У Мерри есть книга, которая понравилась Барбаре », *« Кому у Мерри есть книга, которая понравилась? »Преобразование первого предложения во второе не представляет проблемы, однако выполнение параллельного преобразования третьего оператора генерирует неправильно составленное предложение.Третье предложение необходимо перефразировать, чтобы объединить придаточное предложение в главном предложении, генерируя «Барбара была довольна Книга Мерри », прежде чем ее можно будет преобразовать в эквивалентный вопросительный вопрос. конструкция «Кому понравилась книга Мерри?».
рефлексивный
«Я кричал, чтобы Гарри открыл дверь», * «Я пытался открыть дверь. дверь », ??« Я сам пытался открыть дверь »,« Я пытался открыть дверь для я ».Первое предложение является законным, но аналогичная конструкция включение рефлексивных отношений плохо сформировано.Остальные предложения — это перефразирование второго оператора, направленное на правильный синтаксис, в то время как сохраняя рефлексивный элемент и тот же смысл. Эти примеры кажутся выделить немотивированную сложность синтаксиса английского языка.
18. Эргативные глаголы
«Мужчина открывает дверь», «Мужчина смеется над шуткой»; «Тот человек готовит обед »,« Мужчина готовит »,« Мясо готовит »;« Вода. плохой вкус »,« Я чувствую вкус воды »Чтобы установить контекст для оценки этих необычных глаголов, рассмотрите первые два неэргативных предложения, которые являются соответственно переходными и непереходный.Усечение дает один удовлетворительный результат: «Мужчина смеется «и сомнительный?» Человек открывается «(если контекст не ранее было установлено).
Теперь рассмотрим следующие три предложения. Хотя поверхностный синтаксис этих Примеры показывают, что `cook ‘является битрейтранзитивным, беря или оставляя объект также хорошо, что в действительности глагол, кажется, имеет врожденную транзитивность. Выполнение того же усечения на (3) для получения (4) меняет его смысл; (4) является неоднозначный, его разные смыслы — «готовить-что-то» и-быть-приготовлены-.Это изменение значения не произошло с первыми двумя усечениями.
Глаголы такого типа называются эргативными. Кажется, у них такая большая потребность
для объекта, который, если не указан синтаксически, действие может быть
интерпретируется как отскок от агента. Эргативный глагол может значимо заполнять
два кадра «Что-то есть
Вкус, запах и другие глаголы, описывающие процессы восприятия, являются эргативными. Ментальная сфера, в частности эмоциональная, изобилует примерами своего рода ситуация, которую выражают эргативные глаголы.Рассмотрим «страх» и «испуг». Хотя оба высказывания в паре «Он напугал меня», «Я боялся его» являются активные, они относятся к одному действию, а не к двум. Факторы, действующие здесь, кажутся в некотором роде с двумя типами речевого акта, локутивным («Я боялся его «) и перлокутивным (» он напугал меня «), обобщенным из случаев умышленное действие ко всем действиям.
19. Гомоморфность (похожий синтаксис, разная семантика)
«Падение самолетов может быть опасно», «Полет самолетов может быть опасным», «Покупка. самолеты могут быть опасными »;« Уоррен хочет доставить удовольствие »,« Уоррен легко пожалуйста». В первом наборе примеров используются эргативные глаголы для иллюстрации гомоморфности.
а второй набор показывает, что это нечто иное, чем эргирование. (1) и (3)
можно недвусмысленно перефразировать как «Падающие самолеты могут быть
опасно «и» <Быть> покупка самолетов может быть опасной «. Второй
предложение можно читать двояко: «Летящие самолеты могут быть опасными» и
«<быть> летающими самолетами может быть опасно». Кажется, не хватает
составляющая, которая будет различать два смысла.Парафразы
предполагают, что путаница возникает из-за разных значений эргативных глаголов;
«Самолеты, которыми управляют, могут быть опасными» — это почти пересказ «
Такое же различие проявляется во втором примере без присутствия
двусмысленность. Перефразируя (4), «Уоррен» становится прямым объектом в «
20. Ссылка на большие расстояния
«Мужчина вышел из дома. Светило солнце. Было тепло и безветренно. A пела птица. Ему было хорошо »,« Это тот человек, который в свое время и после говорить со всеми нами, кто интересуется этими вопросами, когда проблема становится важным сделал это «.В первом примере правильная ссылка на «он» должна быть найдена через три промежуточных предложения.Предложения часто ссылаются на соседние или более удаленные операторы, и эти ссылки могут быть легко неправильно понятый. Во втором примере ссылка на дальнее расстояние происходит в пределах предложение через 24 слова между «кто» и «сделал это».
Ссылки могут также встречаться между существительным и существительным; ожидается, что мы узнаем сущности, которые ранее были введены в повествование. Имя нарицательное справиться труднее, чем местоимение, потому что последнее, очевидно, требует референта, тогда как первое может быть представлением нового актера.Проблема усугубляется, когда ссылка не прямая, а через синоним.
21. Сравнение
«Прилив лучше», «Прилив лучше, чем ABC», «Прилив лучше любого мыла. продается в этой стране »;« Tide — лучшее мыло, которое продается в этой стране. страна ».Все сравнения, будь то сравнительные (1) или превосходные (4), должны указать их контекст. В сравнительном случае это означает выявление конкретное лицо (2) или группа лиц, к которым относится объект сравниваются (3).Когда проводится сравнительная оценка с набором, полученное утверждение легко перефразировать в превосходное сравнение. Таким образом (3) является перефразированием (4).
22. Буквальное и идиоматическое употребление
«Включаю диас», «Включаю кран»;«Мужчины согласились играть в мяч»,
«Мужчины согласились играть в мяч во вторник вечером»,
«Признавая свои различия, мужчины согласились играть в мяч. по этому вопросу ».
Каждое слово в первом предложении выполняет традиционный синтаксис. функция; `on ‘начинается с предложной фразы, которая указывает, где вращение происходит.Во втором предложении «включить» — это идиома, в которой частица `on ‘указывает направление вращения. (4) и (5) показывают, как одно и то же предложение можно изменить, чтобы выбрать между буквальным и идиоматическим чувства.
Здесь возникает дилемма. Синтаксический анализатор, который обрабатывает (2) как глагол + преп, будет неправильно понять это, всегда беря максимально длинную строку из ввода (т.е. идиоматическое использование) означает, что (1) никогда не будет правильно распознан.
23. Интенсивное и широкое использование
«Президент находится в Кэмп-Дэвиде»,«Президент избирается каждые четыре года».
Иногда название роли предназначено для идентификации человека, который в данный момент заполняю его, а иногда и саму роль. Это аналогично различие между содержанием термина и его продолжением.
24. Универсальная и специфическая количественная оценка
«Ищу мужчину»,«Золотой тамаринд меньше кошки, но вдвое милее»,
«Я держу мужчину»,
«Мужчина, увидевший меня, вышел из комнаты»,
« человек, который видел меня, вышел из комнаты ».
Первый пример иллюстрирует проблему; неясно, является ли искомый человек — это конкретная личность или вообще любой мужчина.Второй и третий примеры демонстрируют, что как определенные, так и неопределенные кванторы могут испытайте такую двусмысленность. «Кошка» — универсальный, а «тамаринд» может быть; «мужчина», однако, следует толковать конкретно, потому что никто не может держите всех мужчин. Четвертое и пятое предложения показывают, что количественные двусмысленность может возникнуть в напряженных глаголах. Учитывая, что я нахожусь в комнате, мужской Увидение меня должно предшествовать его выходу из комнаты. Следовательно, «видит» может быть только понимается как общее видение на регулярной основе, а не как конкретное одиночный акт зрения.Поскольку оба глагола в пятом предложении — прошедшее время, временной порядок не установлен, и слово «пила» может относиться к количественная оценка.
Не было обнаружено никакого общего метода разрешения количественной неоднозначности. Однако, если количественная фраза строго определена по определению или через В контексте, разумно предположить, что ссылка относится к определенной сущности. Таким образом, при отсутствии противоположного контекста (например, при чтении тематических объявлений) «Я ищу красный Мустанг 1977 года» предполагает, что говорящий ищет конкретная машина себе известная.Точно так же «Человек, который видел меня в течение трех недели в 9 часов вышел из комнаты «предполагает, что осмотр — это акт не имеет отношения к отъезду.
25. Двусмысленность
присущий (многозначность и омонимия)
«правый»Слова могут быть как многозначными, так и омонимичными. «Право» имеет одноименное название чувства праведности и правши. Каждое из этих чувств само по себе многозначный. Когда используется в «правильных поступках» и «поступать правильно», -righteous- имеет гомологи правильных-при-обстоятельствах и -абсолютно правильно-.Гомологи -правой- демонстрируются в правая »и« моя правая рука ». Они где-то справа и на правой стороне моего тела.
«Правильно» также может занимать разные синтаксические категории: «Могущество делает правильным». (существительное), «я выпиваю бутылку» (глагол), `правильная вещь ‘(прилагательное) и« делай правильно «(наречие)
автоантонимия
«пример»Подмножество неоднозначных слов несут пары смыслов, которые являются анотными. Этот Это явление известно под разными названиями, включая аутоантонимию.См. Обсуждение списка LINGUIST с начала 1995 г. и далее.
в количественном смысле
«Перечислить поезда, которые ходят в каждый город», «Не все приехали», «Все не делает этого ».Эти предложения вводят двусмысленность, потому что «каждый» означает как универсальный квантор all и экзистенциальный квантор some. Как результат из первого примера остается неясным, должны ли поезда ехать во все города или только один из них для включения в список. Следующие примеры показывают, что отрицание может взаимодействовать с неоднозначностью квантификатора.«Не все» экзистенциально один ‘и, следовательно, кто-то, и повсеместно’ не все ‘и, следовательно, нет один.
26. Грамматичность. (для помощи в общении)
«Все любят свою жену»,«Хотя было предсказано, что Голдуотер не выиграет»,
«Человек, который покажет, что хочет, получит приз, которого заслуживает».
В каждом из этих примеров структура подчинена коммуникация; каждый из них легко понять, хотя он нарушает правила грамматика.Первый пример правильнее было бы сформулировать как «Все любят их жен «, что внесет синтаксическую двусмысленность в число жены есть у каждого человека.
Ссылка на «это» в (2) — это опущенная фраза «его победа» или «что он оговорка о выигрыше. Наличие любого из них создает неудобную конструкцию: «Хотя было предсказано, что он выиграет, Голдуотер не (выиграл) »;« Хотя его победа было предсказано, Голдуотер не (выиграл) ». Третий случай аналогичен второй. Его можно перефразировать так: «Если мужчина заслуживает награды и показывает, что он хочет, он получит приз «, но это не отражает необходимости показать желание подчеркнуто в (3).
27. Эффект пассивизации.
«Мало кто читает много книг», «Многие книги мало кто читает»;«Некоторые книги мало кто читает», «Некоторые книги мало кто читает»;
«Ни одна книга не читается всеми людьми», «Все люди не читают книг».
В первом примере (1) подчеркивается нехватка прожорливых читателей. в то время как его пассивное преобразование (2) подчеркивает изобилие плохо читаемых книги. Кажется, что первая фраза предложения занимает важное место.(1) и (2) делать разные заявления, потому что акцент смещается с «книги» в «читатели», когда голос превращается из пассивного в активный. Хотя проблема исчезает, когда количественная оценка смещается к нейтральной `some ‘во втором примере (3, 4),` some’ в этом случае оказывается квалификатор идентичности, а не количественный показатель меры, потому что проблема сохраняется, когда кванторы универсальны (5, 6).
28. Ссылочная непрозрачность / наклонность
«Росс считает, что собака Нади потеряна»,«Росс считает, что спаниель Нади потерялся».
(2) не может быть выведено из (1), потому что первое предложение не прямо сказать, что Росс знает породу собаки Нади. Индивидуальный личные знания обязательно ограничены, и нельзя предполагать, что объективные факты субъективно известны каждому. Ссылка на субъективное знание встречается в таких словах, как «верить», «говорить», «думать», что сообщать косвенно дискурс и умственная деятельность.
29. Обычная двусмысленность
«Куры готовы к употреблению»,«Бостонский поезд идет по девятому пути»,
«человеческое потомство», «человеческая раса», «человеческая собака», «человеческое потребление», «человеческие эксперименты»;
«собачье мясо».
Оба первых двух примера содержат неоднозначные элементы. `Готов к есть ‘может быть истолковано как идиома, означающая «полностью приготовленный», или как конструкция означает -голодный-. Во втором примере изменение train с помощью «Бостон» оставляет неясным, идет ли поезд или оттуда. город. Эти двусмысленности возникают из-за условностей, которые мы обычно предполагаем из контекст, когда мы читаем любое из утверждений. Однако первый пример должен вообще не быть двусмысленным.Его полностью подготовленный смысл может быть только понимается из-за неправильного прочтения; сделать это утверждение в правильной грамматике быть «Цыплята готовы к употреблению». Рекламная практика сделала «готов к употреблению» означает «готов к употреблению».
Путаница -to- или -from- во втором примере основана на аналогичном предположение, но то, которое формально не преподается через СМИ. «Бостон» в данном случае также может означать -сделано-в-Бостоне-, названо в честь Бостона или даже -владельцем-корпорацией-метро Бостона.Направленные чувства выбраны как те, которые следует запутать, потому что движение и путешествие — это Первое, что у большинства людей ассоциируется с поездами. Приходит неоднозначность (если это делает) через знание расписания.
Все пять «человеческих» примеров используют прилагательное для обозначения различных отношения между его объектом и людьми: потомки людей, расы, состоящие из людей, потребление людьми, эксперименты на людях, собаки с человеческими чертами. Точно так же, хотя оба слова в последнем примере индивидуально недвусмысленно, при совместном использовании неясно, означают ли они мясо в корм собаке или мясо собаки.
30. Дополнительные или копулятивные глаголы.
«Джон спокоен».Двадцать связок — это особый случай отношений. Они используются в заявление, позволяющее квалифицировать объект потенциально сложным образом а не для выражения официальных отношений. Несмотря на это, эти глаголы делают уточнять наличие их дополнения.
Достаточно исчерпывающий список копулятивных глаголов: субъективные дополнения: `быть ‘,` становиться’, `расти ‘,` получать’, `чувствовать ‘,` казаться’, `проявляться ‘,` вкушать’, `звучать ‘, «запах», «смотри», «оставаться», «действовать», «идти», «поворачивать», «делать»; объективные дополнения: «сделать», «доказать», «представить», «рассмотреть».
31. Необоснованная ссылка
«Они всегда смотрят»,«Вчера шел дождь».
Референты для «они» и «оно» предоставляются по соглашению, а не контекст; ничего не будет найдено в повествовании.
32. Значение «Сдвиг через расширение»
«Осциллограф, который Том использовал для установки»,«Осциллограф, который Том использовал для установки радиоприемника»
В этом примере есть элементы садовой дорожки и идиомы, но конструкция, на которой он основан, может быть уникальной.В первом предложении «осциллограф» — прямой объект; во втором — инструмент и «радио» — это прямой объект. Виноград (1983) полагает, что разные смыслы «привыкшие» используются. В первом предложении фраза, которую он представляет как useta, идиоматически выражает прошедшее время; во втором — инструментальность.
33. Ссылка через синоним
«Дети моей сестры снова в магазине. Этим трем мальчикам точно нравится конфета »,« Мужчина вышел из дома.Солнце светило. Было тепло и безветренно. Пела птица. Ему было хорошо ».
Мы понимаем, что «эти три мальчика» означает «дети», потому что двое словосочетания с существительными в высшей степени синонимичны (хотя и не совсем так; маленькие девочки могут быть дети тоже). Менее синонимичные пары и ссылки через отрицательные антонимы являются труднее понять.
Синонимы и длинный диапазон вместе — рецепт дорогостоящей обработки в случаях ссылки. Если `мужчина ‘или` Мистер Смит заменяется на «он» в последнем предложении второго примера предыдущие четыре предложения или 15 слов будут необходимо протестировать, чтобы поймать намеченную ссылку.
34. Диексис в диалоге
«« Это тот человек. Он положил это туда »»,«Джон указал на свою поврежденную машину и сказал:« Посмотри на это! Как ты думаешь, я могу видеть сквозь это? Он будет работать, но эта шина разорвется в клочья через милю, если Я делаю. ‘».
Первое заявленное утверждение невозможно понять без контекста. В во втором мы делаем вывод, что лобовое стекло автомобиля было непрозрачным из-за трещин и звезды, и что, хотя шины не спущены, часть крыла или рама прижимается к одному из них.
Произнесенные слова могут идентифицировать вещи в сцене, которые не упоминаются в высказывание. Тот же эффект может быть достигнут в письменном повествовании, только если идентифицированный элемент явно или неявно вводится в непосредственной близости от диалог.
35. Диалог Атрибуция
«Я сделал это». «Нет, ты этого не сделал». «Да, он сделал!»Содержание этих трех предложений подразумевает трех говорящих, а не два человека по очереди, что в противном случае можно было бы предположить.
Письменный английский ни разу не идентифицирует носителей напрямую цитируемого диалога они были представлены. Кавычки используются для разграничения высказываний и предполагается, что выступающие по очереди. Это соглашение становится проблематичным, когда в разговоре участвует более двух человек; тогда мы должны полагаться на наши модели интересы, мотивации и перспективы участников для определения атрибуции. В диалоге существует явный риск неправильного толкования. среди трех и более человек.
36. Речевые акты.
«Не могли бы вы передать солонку?» ,«Она повернулась к двум своим женихам, которые стояли там с подарком в руке, и сказала: «Я возьму цветы».
Речевые акты можно разделить на те, в которых языковой смысл несовместим с контекстом и с теми, в которых он совпадает. Первое Случай, проиллюстрированный (1), охватывает то, что обычно известно термином Остина (1962). Интерес локатора к физическим возможностям одитора не имеет отношения к его физическим возможностям. текущая активность приема пищи.
Второй случай более контекстный. В (2) все стороны знают, что женщина выражая предпочтение чему-то большему, чем подарок. Хотя второе высказывание внешне похож на метонимию (в том, что речевой акт состоит из цветы понимаются как символ мужчины, который их предлагает), это отличается в этом смысле подразумевается буквально; без сомнения, женщина действительно ожидает и получает цветы. Следовательно, ее высказывание не является исключительно образным.
37.de re vs de dicto Scope
«Он уверенно шел по садовой дорожке»,«По всей видимости, шел по садовой дорожке».
«Уверенно» относится к действию хождения в рамках утверждения и развивает его смысл; «очевидно» относится ко всему утверждению и квалифицирует предложение, которое он сообщает. Первый — это de re , а последний de dicto . Рамка для различения этих два падежа переводят слова-кандидаты в их родственную форму существительного: «Это очевидно, что… «. Любое утверждение, которое можно разумно перефразировать таким образом это de dicto.
37. Модальное и гипотетическое существование
«Может снег»,«Он должен прийти»,
«Будь он здесь, он бы не согласился».
Модальные глаголы — это замкнутый набор, определяющий возможность, способность и необходимость совершения определенного действия или класса действий (1). Кроме того, модальные параметры определяют волю, намерение, предсказание, разрешение и обязательство живого агента для выполнения действия (2).
Слагательное наклонение используется для выражения утверждений, которые имеют воображаемый или гипотетическое существование (3).
38. Необходимое против случайного следствия.
«Том вошел в комнату. Яблоко упало со стола»,«Том ударил кулаком по столу. Яблоко с него упало»,
«Том посмотрел на реку. Яблоко упало со стола»,
«Том на работе. Яблоко упало со стола».
В отсутствие явных коннекторов, таких как «потому что», «однако» и «поскольку» (разговорный) мы должны использовать здравый смысл, чтобы сделать вывод о том, что причинно-следственная связь следствие сопровождает временную последовательность.Первый пример открыт для любого необходимое или случайное толкование. На мой взгляд, он слегка наклоняется в сторону причинности, потому что это приводит к трудностям упоминания событий. В Второй пример, очевидно, следует понимать причинно. Третий и четвертый Примеры включают события, а также состояние и событие соответственно. Читатели вряд ли можно подумать, что падение яблока в любом случае произошло из-за удара Тома действие или состояние.
39. Неопределенное членство в множестве
«Семья пошла на спектакль.Он был так неудачно поставлен, что некоторые аудитория освистала. Остальные ушли, и некоторые люди начали разговаривать между самих себя ».Прочитав приведенные выше предложения, невозможно узнать, какие из члены семьи освистали, ушли, начали разговаривать между собой или продолжили смотреть спектакль. Языковые высказывания обычно определяют группы и выполняют операции над ними: 1) конъюнкция («банда и я»), 2) дизъюнкция («Это они или мы «), 3) член и 4) идентификация и выбор подмножества (» все семья была среди зрителей… «,` один из сотрудников ‘. Результатом этих операций в спецификации групп или индивидуумов, идентичность которых неизвестна. Пользователи языка верят, что им сообщат состав группы, когда это важно.
haskell — Каковы преимущества аппликативного анализа над монадическим?
Основное различие между монадическим и аппликативным синтаксическим анализом заключается в том, как обрабатывается последовательная композиция. В случае аппликативного синтаксического анализатора мы используем (<*>) , тогда как с монадой мы используем (>> =) .
(<*>) :: Parser (a -> b) -> Parser a -> Parser b
(>> =) :: Parser a -> (a -> Parser b) -> Parser b
Монадический подход более гибкий, потому что он позволяет грамматике второй части зависеть от результата первой, но на практике нам редко нужна эта дополнительная гибкость.
Вы могли подумать, что дополнительная гибкость не повредит, но на самом деле это может. Это мешает нам выполнять полезный статический анализ парсера без его запуска.Например, предположим, что мы хотим знать, может ли синтаксический анализатор соответствовать пустой строке или нет, и какие возможные первые символы могут быть в совпадении. Нам нужны функции
empty :: Parser a -> Bool
first :: Parser a -> Set Char
С помощью аппликативного синтаксического анализатора мы можем легко ответить на этот вопрос. (Я здесь немного обманываю. Представьте, что у нас есть конструкторы данных, соответствующие (<*>) и (>> =) в «языках» нашего синтаксического анализатора-кандидата).
пусто (f <*> x) = пусто f && пусто x
первый (f <*> x) | пусто f = первое f, `объединение`, первое x
| в противном случае = первая f
Однако с монадическим синтаксическим анализатором мы не знаем, какова грамматика второй части, не зная входных данных.
пусто (x >> = f) = пусто x && пусто (f ???)
первый (x >> = f) | пустой x = первый x, сначала `union` (f ???)
| в противном случае = первый x
Позволяя больше, мы меньше рассуждаем.Это похоже на выбор между системами динамического и статического типов.
Но какой в этом смысл? Для чего мы можем использовать это дополнительное статическое знание? Что ж, мы можем, например, использовать его, чтобы избежать возврата при синтаксическом анализе LL (1), сравнивая следующий символ с первым набором каждой альтернативы. Мы также можем статически определить, будет ли это неоднозначным, проверив, перекрываются ли первых наборов двух альтернатив.
Другой пример — то, что его можно использовать для исправления ошибок, как показано в статье Детерминированные анализаторы комбинаторов с исправлением ошибок С.Доаитсе Свиерстра и Люк Дюпоншель.
Однако обычно выбор между аппликативным и монадическим анализом уже был сделан авторами библиотеки синтаксического анализа, которую вы используете. Когда библиотека, такая как Parsec, предоставляет оба интерфейса, выбор того, какой из них использовать, является чисто стилистическим. В некоторых случаях прикладной код легче читать, чем монадический, а иногда наоборот.
Обработка естественного языка + Google Translate
Языковой перевод сложнее, чем простой метод дословной замены.Как видно из материалов для чтения и видеороликов к этому модулю, для перевода текста на другой язык требуется больше контекста, чем может предоставить словарь. Этот «контекст» в языке известен как грамматика. Поскольку компьютеры не понимают грамматики, им нужен процесс, в котором они могут деконструировать предложения и реконструировать их на другом языке так, чтобы это имело смысл. Слова могут иметь несколько разных значений, а их смысл зависит от их структуры в предложении. Обработка естественного языка решает эту проблему сложности и неоднозначности языкового перевода.Видео об ускоренном курсе PBS показывает, как компьютеры используют методы НЛП.
Разбиение предложений на более мелкие части, которые можно было бы легко обработать:
- Чтобы компьютеры могли разбирать предложения, необходима грамматика
- Разработка правил структуры фраз, которые инкапсулируют грамматику языка
Используя структуры фраз, компьютеры могут создавать деревьев синтаксического анализа
* Изображение получено с: https: // www.youtube.com/watch?v=fOvTtapxa9c
Деревья синтаксического анализа: свяжите каждое слово с вероятной частью речи + показать построение предложения
- Это помогает компьютерам обрабатывать информацию более легко и точно
Видео PBS также объясняет, каким образом Siri может разбирать простые словесные команды. Кроме того, приложения для распознавания речи с максимальной точностью используют глубокие нейронные сети .
Рассматривая работу нейронной сети Google Translate, видео Code Emportium описывает нейронную сеть как средство решения проблем.В случае Google Translate задача или проблема нейронных сетей, которую необходимо решить, — это взять английское предложение (ввод ) и превратить его в перевод на французский (вывод , ).
Как мы узнали из модуля структур данных, компьютеры не обрабатывают информацию так, как это делает наш мозг. Они обрабатывают информацию с помощью чисел (векторов). Итак, первым шагом всегда будет преобразование языка в компьютерный. Для этой конкретной задачи будет использоваться рекуррентная нейронная сеть (нейронная сеть специально для предложений).
Шаг 1. Возьмите английское предложение и преобразуйте его в компьютерный язык (вектор ) с помощью рекуррентной нейронной сети
Шаг 2. Преобразование вектора во французское предложение (с помощью другой рекуррентной нейронной сети)
Изображение получено с: https://www.youtube.com/watch?v=AIpXjFwVdIE
Согласно исследованию из статьи 2014 года о нейронном машинном переводе, модель архитектуры кодировщика-декодера, изображенная выше, лучше всего работает для предложений средней длины из 15-20 слов (Чо и др.).Видео Code Emporium протестировало метод LSTM-RNN Encoder на более длинных предложениях и обнаружило, что переводы также не работают. Это связано с отсутствием сложности в этом методе. Рекуррентные нейронные сети используют прошлую информацию для генерации текущей информации. На видео показан пример:
«При создании 10-го слова французского предложения он смотрит на первые девять слов в английском предложении». Рекуррентная нейронная сеть просматривает только прошедшие слова, а не слова, которые идут после текущего слова.В языке слова, стоящие перед и после, важны для построения предложения. Следовательно, двунаправленная нейронная сеть способна делать именно это.
Изображение получено с: https://www.youtube.com/watch?v=AIpXjFwVdIE
Двунаправленные нейронные сети (смотрит на слова, стоящие до и после) Vs. Нейронная сеть (смотрит только на слова, стоящие перед ней)
Использование модели BiDirectional — на каких словах (в исходном источнике) следует сосредоточить внимание при создании перевода?
Теперь переводчику нужно научиться согласовывать с входом и выходом.Это изучает дополнительный модуль, называемый механизмом внимания (, какие французские слова будут генерировать какие английские слова) .
Это тот же процесс, который использует Google Translate — в большем масштабе
Google Translate Процесс и архитектура / разбивка по слоям
Изображение получено из видео: https://www.youtube.com/watch?v=AIpXjFwVdIE
Английский перевод передается на кодировщик , переводит предложение в вектор (каждому слову присваивается номер), затем механизм внимания используется для определения английских слов, на которых нужно сосредоточиться, поскольку он генерирует французское слово , то декодер будет переводить французский перевод по одному слову за раз (фокусируясь на словах, определенных механизмом внимания).
цитируемых работ
Ускоренный курс. Структуры данных: ускоренный курс по информатике № 14 . YouTube , https://www.youtube.com/watch?v=DuDz6B4cqVc.Как написать идеальное синтезированное эссе для экзамена по языку AP
Если вы планируете сдавать экзамен AP Language (или AP Lang), вы, возможно, уже знаете, что 55% вашей общей оценки за экзамен будет основано на трех эссе. Первое из трех эссе, которое вам нужно будет написать на экзамене AP Language, называется «обобщающим эссе».»Если вы хотите заработать полные баллы на этой части экзамена AP Lang, вам необходимо знать, что такое обобщающее эссе и какие навыки оцениваются в обобщающем эссе AP Lang.
В этой статье мы объясним различные аспекты синтезирующего эссе AP Lang, , включая то, какие навыки вам необходимо продемонстрировать в своем ответе на синтезирующее эссе, чтобы получить хорошую оценку. Мы также дадим вам полный анализ реальной подсказки AP Lang Synthesis Essay, предоставим анализ примера синтезирующего эссе AP Lang и дадим вам четыре совета по написанию синтезирующего эссе.
Давайте начнем с подробного рассмотрения того, как работает синтезное эссе AP Lang!
2021 AP Test Changes из-за COVID-19
В связи с продолжающейся пандемией коронавируса COVID-19 тесты AP теперь будут проводиться в течение трех разных сессий с мая по июнь. Даты ваших экзаменов, а также то, будут ли они проводиться онлайн или в бумажной форме, будут зависеть от вашей школы. Чтобы узнать больше о том, как все это будет работать, а также получить самую свежую информацию о датах испытаний, онлайн-обзоре AP и о том, что эти изменения значат для вас, обязательно ознакомьтесь с нашей статьей часто задаваемых вопросов о AP COVID-19 на 2021 год.
Synthesis Essay AP Lang: Что это такое и как это работает
Synthesis Essay — первое из трех эссе, включенных в раздел Free Response экзамена AP Lang.
Часть эссе, посвященная синтезу AP Lang в разделе «Свободный ответ», длится в общей сложности один час . Этот час состоит из рекомендованного 15-минутного периода чтения и 40-минутного периода письма. Имейте в виду, что эти временные рамки являются просто рекомендациями, и что экзаменуемые могут анализировать отведенные 60 минут для завершения обобщающего эссе по своему усмотрению.
А вот как выглядит структура реферата AP Lang. Экзамен представляет от шести до семи источников, которые организованы по определенной теме (например, альтернативная энергия или выдающаяся область, которые являются прошлыми темами сводного экзамена).
Из этих шести-семи источников по крайней мере два являются визуальными , включая по крайней мере один количественный источник (например, график или круговую диаграмму). Остальные четыре-пять источников основаны на печатном тексте, и каждый из них содержит примерно 500 слов.
В дополнение к шести-семи источникам экзамен AP Lang предоставляет письменные подсказки, состоящие из трех абзацев. В подсказке будет кратко объяснена тема эссе, а затем представлено утверждение, на которое студенты ответят в сочинении, в котором синтезируется материал по крайней мере из трех из предоставленных источников.
Вот пример подсказки, предоставленной Советом колледжа:
Указания : Следующая подсказка основана на шести сопутствующих источниках.
Этот вопрос требует, чтобы вы объединили различные источники в связное, хорошо написанное эссе. Обратитесь к источникам, подтверждающим вашу позицию; избегайте простого пересказа или резюме. Ваш аргумент должен быть центральным; источники должны поддержать этот аргумент .
Не забудьте указать как прямые, так и косвенные ссылки.
Введение
Телевидение оказало влияние на президентские выборы в США с 1960-х годов. Но что это за влияние и как оно повлияло на избранных? Сделал ли он выборы более справедливыми и доступными, или он переместил кандидатов от решения проблем к преследованию имиджа?
Переуступка
Внимательно прочтите следующие источники (включая любую вводную информацию). Затем в эссе, объединяющем по крайней мере три источника поддержки, займите позицию, которая защищает, оспаривает или квалифицирует утверждение о том, что телевидение оказало положительное влияние на президентские выборы.
Источники называются «Источник A», «Источник B» и т. Д .; заголовки включены для вашего удобства.
Источник A (Кэмпбелл)
Источник B (Харт и Трис)
Источник C (Менанд)
Источник D (диаграмма)
Источник E (Ранни)
Источник F (Коппел)
Как мы упоминали ранее, в этом приглашении приводится тема, которая в нем кратко объясняется, а затем предлагается занять позицию.В этом случае вам придется выбрать позицию относительно того, положительно или отрицательно повлияло телевидение на выборы в США. Вам также дается шесть источников для оценки и использования в своем ответе. Теперь, когда у вас есть все необходимое, ваша задача — написать потрясающее обобщающее эссе.
Но что именно означает «синтезировать»? Согласно CollegeBoard, когда в подсказке к эссе вас просят синтезировать, это означает, что вы должны «комбинировать различные точки зрения из источников, чтобы сформировать поддержку последовательной позиции» в письменной форме.Другими словами, сводное эссе просит вас изложить свое утверждение по теме, а затем выделить связи между несколькими источниками, которые поддерживают ваше утверждение по этой теме. Кроме того, вам нужно будет привести конкретные свидетельства из ваших источников, чтобы подтвердить свою точку зрения.
За обобщающее эссе вы набираете шесть баллов на экзамене AP Lang . Студенты могут получить 0–1 балл за написание тезиса в эссе, 0–4 балла за включение доказательств и комментариев и 0–1 балл за сложность мысли и продемонстрированное сложное понимание темы.
Ваша оценка будет зависеть от того, насколько эффективно вы выполните следующие задачи в своем эссе по синтезу AP Lang:
Напишите диссертацию, которая отвечает на приглашение экзамена с защитной позицией
Предоставьте конкретные доказательства, подтверждающие все утверждения в вашей аргументации из как минимум трех из предоставленных источников, и четко и последовательно объясните, как доказательства, которые вы включаете, подтверждают вашу аргументацию
Продемонстрировать изощренность мышления, придумав продуманный аргумент, поместив аргумент в более широкий контекст, объяснив ограничения аргумента
Делайте риторический выбор, укрепляющий ваши аргументы, и / или используйте яркий и убедительный стиль в своем эссе.
Если ваше синтетическое эссе соответствует критериям, приведенным выше, , то есть хорошие шансы, что вы хорошо наберетесь в этой части экзамена AP Lang!
Если вы ищете еще больше информации о выставлении оценок, совет колледжей разместил на своем веб-сайте рубрику оценок AP Lang Free Response. (Вы можете найти его здесь.) Мы рекомендуем внимательно изучить его, поскольку он включает в себя дополнительные сведения о выставлении оценок за синтез эссе.
Не бойтесь…. мы собираемся научить вас, как разобрать даже сложнейшую подсказку для сочинения по синтезу AP.
Полная разбивка реальной подсказки для сочинения по синтезу языка AP
В этом разделе, мы научим вас анализировать и отвечать на подсказки для синтезирующего сочинения, выполнив пять простых шагов, включая предлагаемые временные рамки для каждого шага процесса.
Шаг 1. Проанализируйте подсказку
Самое первое, что нужно сделать, когда часы начнут работать, — это прочитать и проанализировать подсказку. Чтобы продемонстрировать, как это сделать, мы рассмотрим образец подсказки для эссе по синтезу AP Lang ниже. Эта подсказка пришла прямо из экзамена AP Lang 2018:
.Известный домен — это власть, которой обладают правительства для приобретения собственности у частных владельцев для общественного пользования. Обоснование выдающихся владений состоит в том, что правительства обладают большей юридической властью над землями в пределах их владений, чем частные собственники. Известные владения так или иначе создавались по всему миру на протяжении сотен лет.
Внимательно прочтите следующие шесть источников, включая вводную информацию по каждому источнику. Затем синтезируйте материал по крайней мере из трех источников и включите его в связное, хорошо разработанное эссе, которое защищает, оспаривает или уточняет представление о том, что выдающаяся область является продуктивной и полезной.
Ваш аргумент должен быть в центре вашего эссе. Используйте источники, чтобы развить свой аргумент и объяснить его обоснование. Избегайте простого суммирования источников.Четко укажите, из каких источников вы черпаете, с помощью прямой цитаты, перефразирования или резюме. Вы можете цитировать источники как Источник A, Источник B и т. Д. Или используя описания в круглых скобках.
При первом чтении вы можете нервничать, не зная, как ответить на этот запрос … особенно если вы не знаете, что такое выдающийся домен! Но если вы разделите подсказку на части, вы сможете сразу понять, что подсказка просит вас сделать.
Чтобы получить полное представление о том, что вам нужно сделать в этом запросе, вам необходимо указать наиболее важные детали в этом запросе, абзац за абзацем. Вот что просит вас сделать каждый абзац:
- Параграф 1: Приглашение представляет и кратко объясняет тему , по которой вы будете писать свое синтезирующее эссе. Эта тема — концепция выдающейся области.
- Параграф 2: Приглашение представляет конкретное утверждение о концепции выдающегося домена в этом абзаце: Выдающийся домен является продуктивным и выгодным. Этот абзац инструктирует вас решить, хотите ли вы защитить, оспорить или квалифицировать это утверждение в своем обобщающем эссе , и использовать для этого материалы как минимум из трех из предоставленных источников.
- Параграф 3: В последнем параграфе подсказки экзамен дает вам четкие инструкции о том, как подойти к написанию вашего синтетического эссе . Во-первых, сделайте ваши аргументы в центре эссе. Во-вторых, используйте материал как минимум из трех источников для развития и объяснения своих аргументов. В-третьих, предоставьте комментарии к включенному вами материалу и предоставьте надлежащие цитаты, когда вы включаете цитаты, пересказы или резюме из предоставленных источников.
Таким образом, вам придется согласиться, не согласиться с заявлением, изложенным в подсказке, или уточнить его, а затем использовать по крайней мере три источника для обоснования своего ответа. Поскольку вы, вероятно, мало что знаете о выдающемся домене, вы, вероятно, определитесь с вашей позицией после того, как вы прочитали предоставленные источники.
Чтобы эффективно использовать свое время на экзамене , вам следует потратить около 2 минут на чтение подсказки и запоминание того, что вас просят сделать.У вас будет достаточно времени, чтобы прочитать предоставленные источники, что станет следующим шагом к написанию обобщающего эссе.
Шаг 2. Внимательно прочтите исходный код
После того, как вы внимательно прочитали подсказку и отметили наиболее важные детали, вам необходимо прочитать всех предоставленных источников. Заманчиво пропустить один или два источника, чтобы сэкономить время, но мы не рекомендуем этого делать. Это потому, что вам необходимо доскональное понимание темы, прежде чем вы сможете точно ответить на запрос!
Для примера приглашения к экзамену, приведенного выше, предоставлено шесть источников.Мы не собираемся включать все источники в эту статью, но вы можете просмотреть шесть источников из этого вопроса на экзамене AP Lang 2018 здесь. Источники включают пять источников печатного текста и один визуальный источник — мультфильм.
Читая источники, важно читать быстро и внимательно. Не торопитесь! Держите карандаш в руке, чтобы быстро отметить важные отрывки, которые вы, возможно, захотите использовать в качестве доказательства в своем синтезе. Пока вы читаете источники и отмечаете отрывки, вы хотите подумать о том, как информация, которую вы читаете, влияет на вашу позицию по проблеме (в данном случае — на выдающейся сфере).
Когда вы закончите чтение, потребуется несколько секунд, чтобы резюмировать в фразе или предложении, защищает ли источник, оспаривает или квалифицирует, является ли выдающийся домен выгодным (что является заявлением в подсказке) . Хотя может показаться, что у вас нет на это времени, важно дать себе эти заметки о каждом источнике, чтобы вы знали , как вы можете использовать каждый в качестве доказательства в своем эссе.
Вот что мы имеем в виду: допустим, вы хотите оспорить идею о том, что выдающаяся область полезна.Если вы записали заметки о каждом источнике и о том, что в нем говорится, вам будет легче включить соответствующую информацию в свой план и свое эссе.
Итак, сколько времени вам следует потратить на чтение предоставленных источников? Экзамен AP Lang рекомендует уделить 15 минут чтению источников. . Если вы потратите около двух из этих минут на чтение и разбиение подсказки для эссе, имеет смысл потратить оставшиеся 13 минут на чтение и аннотирование источников.
Если вы закончите читать и аннотировать раньше, вы всегда можете перейти к составлению сводного эссе.Но убедитесь, что вы не торопитесь и внимательно читаете! Лучше потратить немного больше времени на чтение и понимание источников сейчас, чтобы вам не пришлось возвращаться и перечитывать источники позже.
Сильный тезис сделает много тяжелой работы в вашем эссе. (Видите, что мы там делали?)
Шаг 3. Напишите сильный тезис
После того, как вы проанализировали подсказку и внимательно прочитали источники, следующее, что вам нужно сделать, чтобы написать хорошее синтезирующее эссе, — это написать сильное тезисное изложение .
Хорошая новость о написании тезиса для этого обобщающего эссе заключается в том, что у вас есть все необходимые инструменты для этого под рукой. Все, что вам нужно сделать, чтобы написать свой тезис, — это решить, как ваша позиция относится к указанной теме.
В приведенном ранее примере подсказки вам, по сути, дается три варианта оформления вашего тезисного утверждения: вы можете защитить, оспорить или квалифицировать претензию, предоставленную подсказкой, , что выдающийся домен является продуктивным и выгодно .Вот что это означает для каждого варианта:
Если вы решите отстаивать претензию, ваша задача будет заключаться в том, чтобы доказать, что претензия верна . В этом случае вам нужно будет показать, что выдающийся домен — это хорошо.
Если вы решите оспорить претензию, вы будете утверждать, что претензия неверна. Другими словами, вы будете утверждать, что выдающийся домен не продуктивен. или выгодны.
Если вы решите соответствовать требованиям, это означает, что вы согласны с частью претензии, но не согласны с другой частью претензии. Например, вы можете утверждать, что выдающийся домен может быть продуктивным инструментом для правительств, но не выгоден для владельцев собственности. Или, может быть, вы утверждаете, что выдающаяся область полезна в определенных обстоятельствах, но не в других.
Когда вы решаете, хотите ли вы, чтобы ваше синтетическое эссе защищало, оспаривало или уточняло это утверждение, вам необходимо четко выразить эту позицию в своем тезисе. Вы не хотите просто повторять утверждение, представленное в подсказке, резюмировать проблему без последовательного утверждения или писать тезис, не отвечающий на подсказку.
Вот пример тезиса, получившего полные баллы за выдающееся эссе по синтезу предметной области:
Хотя выдающееся владение может быть использовано неправомерно в личных интересах за счет граждан, оно является жизненно важным инструментом любого правительства, которое намеревается иметь какое-либо влияние на землю, которой оно управляет, помимо письменного закона.
Этот тезис получил полные баллы, потому что он излагает оправданную позицию и устанавливает линию рассуждений по вопросу о выдающейся области. В нем излагается позиция автора (что одни части выдающейся области хороши, а другие плохи), а затем объясняется , почему так думает автор (это хорошо, потому что позволяет правительству выполнять свою работу, но это плохо потому что правительство может злоупотребить своей властью.)
Поскольку в этом примере тезиса излагается обоснованная позиция и устанавливается линия рассуждений, его можно развить в основной части эссе с помощью дополнительных утверждений, подтверждающих доказательств и комментариев.И веский аргумент является ключом к получению шести баллов за ваше обобщающее эссе для AP Lang!
Ищете помощь в подготовке к экзамену AP?
Наши индивидуальные онлайн-услуги по обучению AP могут помочь вам подготовиться к экзаменам AP. Найдите лучшего репетитора, получившего высокие баллы на экзамене, на который вы готовитесь!
Шаг 4: Создайте набросок эссе для обнаженных костей
После того, как вы составили проект тезисов, у вас есть основа, необходимая для разработки краткого плана вашего обобщающего эссе.Разработка плана может показаться пустой тратой вашего драгоценного времени, но , если вы хорошо разработаете план, на самом деле сэкономит ваше время, когда вы начнете писать свое эссе.
Имея это в виду, мы рекомендуем потратить от 5 до 10 минут на написание вашего синтезирующего эссе . Если вы используете краткую схему, подобную приведенной ниже, помечая каждый фрагмент содержания, который вам необходимо включить в черновик эссе, вы сможете разработать наиболее важные фрагменты синтеза еще до того, как начнете составлять собственное сочинение.
Чтобы помочь вам увидеть, как это может работать в день тестирования, мы создали для вас образец схемы. Вы даже можете запомнить этот план, чтобы помочь вам в день теста! В схеме ниже вы найдете места для заполнения тезисов, тематических предложений основного абзаца, доказательств из предоставленных источников и комментариев :
- Введение
- Представьте контекст, окружающий тему эссе, в двух предложениях (это хорошее место, чтобы использовать то, что вы узнали об основных мнениях или разногласиях по этой теме из чтения ваших источников).
- Напишите прямое, ясное и краткое изложение тезиса, в котором излагается ваша позиция по теме
- Кузов
- Основной абзац №1
- Тематическое предложение, представляющее первую опорную точку или пункт формулы
- Доказательства № 1
- Комментарий к показаниям № 1
- Доказательство № 2 (при необходимости)
- Комментарий к доказательству № 2 (при необходимости)
- Основной абзац № 2
- Тематическое предложение, представляющее вторую опорную точку или пункт формулы
- Доказательства № 1
- Комментарий к показаниям № 1
- Доказательство №2 (при необходимости)
- Комментарий к доказательству № 2 (при необходимости)
- Основной абзац № 3
- Тематическое предложение, представляющее три опорных пункта или претензии
- Доказательства № 1
- Комментарий к показаниям № 1
- Доказательство №2 (при необходимости)
- Комментарий к доказательству № 2 (при необходимости)
- Основной абзац №1
- Заключительный абзац
- Обобщает основную линию рассуждений, которую вы развили и отстаивали на протяжении всего эссе.
- Повторяет тезис
Потратив время на разработку этих важнейших частей синтеза в виде скроенного наброска, вы получите карту для вашего последнего эссе.Если у вас есть карта, писать сочинение будет намного проще.
Шаг 5. Напишите ответ на эссе
Самое замечательное в том, чтобы потратить несколько минут на разработку плана, состоит в том, что вы можете развить его в свой черновик эссе. После того, как вы потратите от 5 до 10 минут на набросок вашего синтезирующего эссе, вы можете использовать оставшиеся 30-35 минут, чтобы составить свое сочинение и просмотреть его.
Поскольку вы обрисовываете в общих чертах свое эссе до того, как приступите к составлению черновика, написание эссе должно быть довольно простым.Вы уже будете знать, сколько абзацев вы собираетесь написать, какова будет тема каждого абзаца и какие цитаты, пересказы или резюме вы собираетесь включить в каждый абзац из предоставленных источников. Вам просто нужно будет заполнить одну из самых важных частей вашего синтеза — ваш комментарий.
Комментарии — это ваше объяснение того, почему ваши доказательства подтверждают аргумент, который вы изложили в своей диссертации. Ваш комментарий — это то место, где вы на самом деле приводите свои аргументы, поэтому это такая важная часть вашего синтезирующего эссе.
Размышляя о том, что сказать в своем комментарии, помните одну вещь, которую указывает напоминание AP Lang к синтезу эссе: не просто резюмируйте источники. Вместо этого, комментируя доказательства, которые вы включаете, вам необходимо объяснить, как эти доказательства поддерживают или опровергают ваш тезис . Вы должны включить комментарий, который предлагает вдумчивый или новый взгляд на доказательства из ваших источников, чтобы развить вашу аргументацию.
Одна очень важная вещь, которую следует помнить при составлении эссе, — это цитировать свои источники.В приглашении к синтезу экзамена AP Lang указано, что вы можете использовать общие ярлыки для предоставленных источников (например, «Источник 1», «Источник 2», «Источник 3» и т. Д.). В приглашении к экзамену будет указано, какая метка соответствует какому источнику, поэтому вам необходимо внимательно процитировать источники. Вы можете процитировать свои источники в предложении, в котором вы вводите цитату, резюме или перефразирование, или можете использовать цитату в скобках. Цитирование ваших источников влияет на вашу оценку синтезируемого эссе, поэтому важно помнить об этом.
Одна из самых важных частей вашего заявления в колледж — это то, какие уроки вы выбираете в старшей школе (в сочетании с тем, насколько хорошо вы успеваете в этих классах). Наша команда экспертов по поступлению в PrepScholar объединила свои знания в это единственное руководство по планированию расписания вашего школьного курса. Мы посоветуем вам, как сбалансировать ваше расписание между обычными курсами и курсами с отличием / AP / IB, как выбрать дополнительные уроки и какие классы вы не можете позволить себе не посещать.
Продолжайте читать, чтобы увидеть реальный пример отличного ответа на эссе по синтезу AP!
Реальный пример и анализ синтеза AP
Если вам все еще интересно, как написать обобщающее эссе, примеры реальных эссе из прошлых экзаменов AP Lang могут прояснить ситуацию. Эти ответы на реферативное эссе для учащихся могут помочь вам понять, как написать обобщающее эссе, которое сбьет с толку учащихся.
Хотя в Интернете есть множество примеров сочинений, мы выбрали один, чтобы рассмотреть его поближе. Мы собираемся дать вам краткий анализ одного из этих примеров обобщающих эссе студентов из экзамена AP Lang 2019 ниже!
Пример синтезированного эссе Ответ А.П. Ланга
Для начала давайте посмотрим на официальную подсказку для обобщающего эссе 2019 года:
В ответ на растущий спрос нашего общества на энергию, крупномасштабная ветроэнергетика привлекла внимание правительств и потребителей как потенциальная альтернатива традиционным материалам, которые питают наши электросети, таким как уголь, нефть, природный газ, вода или даже более новые. источники, такие как ядерная или солнечная энергия.Тем не менее, создание крупномасштабных ветряных электростанций коммерческого класса часто является предметом споров по разным причинам.
Внимательно прочтите шесть источников, найденных на экзамене AP по английскому языку и композиции 2019 (вопрос 1), включая вводную информацию по каждому источнику. Напишите эссе, в котором синтезируется материал по крайней мере из трех источников и раскрывается ваша позиция по наиболее важным факторам, которые следует учитывать при принятии решения о создании ветряной электростанции частному лицу или агентству.
Источник A (фотография)
Источник B (Лейтон)
Источник C (Селтенрих)
Источник D (коричневый)
Источник E (Правило)
Источник F (Molla)
В своем ответе вы должны сделать следующее:
- Ответьте на запрос с тезисом, представляющим оправданную позицию.
- Выберите и используйте доказательства как минимум из 3 предоставленных источников для подтверждения своей аргументации. Четко укажите использованные источники с помощью прямой цитаты, перефразирования или резюме. Источники могут упоминаться как Источник A, Источник B и т. Д., или используя описание в круглых скобках.
- Объясните, как доказательства подтверждают вашу линию рассуждений.
- Используйте правильную грамматику и пунктуацию в своих аргументах.
Теперь, когда вы точно знаете, что подсказка просила студентов сделать в синтезирующем эссе AP Lang 2019 года, вот пример синтезирующего эссе AP Lang, написанный настоящим студентом на экзамене AP Lang в 2019 году:
[1] Ситуация была известна в течение многих лет, и до сих пор делается очень мало: альтернативная энергия — единственный способ надежно обеспечить энергией меняющийся мир.Энергия, поступающая от промышленности и частной жизни, является подавляющим источником невозобновляемых источников энергии, и с сокращающимися запасами ископаемого топлива прекращение эксплуатации угольных и газовых топливных электростанций является лишь вопросом времени. Таким образом, одна из жизнеспособных альтернатив — энергия ветра. Но, как и во всем, есть свои плюсы и минусы. Основными факторами, которые должны учитывать энергетические компании при строительстве ветряных электростанций, являются экологические, эстетические и экономические факторы.
[2] Экологические преимущества использования энергии ветра хорошо известны и доказаны.Ветровая энергия, согласно оценке источника B, несомненно, чистая и возобновляемая. От того, что для их производства требуется очень мало опасных материалов, до недостатка топлива, помимо того, что происходит естественным образом, энергия ветра на сегодняшний день является одним из наименее вредных для окружающей среды доступных источников энергии. Кроме того, энергия ветра посредством коробки передач и современных материалов лопастей имеет самый высокий процент удержания энергии. Согласно источнику F, энергия ветра сохраняет 1164% энергии, вложенной в систему, а это означает, что она увеличивает энергию, преобразованную из топлива (ветра) в электричество, в 10 раз! Ни один другой метод производства электроэнергии не может быть эффективнее даже наполовину.Важно учитывать эффективность и экологичность ветровой энергии, особенно потому, что они вносят экономический вклад в энергетические компании.
[3] С экономической точки зрения энергия ветра является одновременно благом и костью для электрических компаний и других пользователей. Для потребителей энергия ветра очень дешевая, что приводит к более низким счетам, чем из любого другого источника. Потребители также получают косвенное возмещение в виде налогов (источник D). В одном техасском городке Маккейми налоговые поступления увеличились на 30% за счет строительства ветряной электростанции.Это помогает финансировать улучшения города. Но нет никаких сомнений в том, что ветроэнергетика наносит ущерб и энергетическим компаниям. Хотя с точки зрения возобновляемой энергии ветер невероятно дешев, он все же значительно дороже ископаемого топлива. Таким образом, хотя он помогает сократить выбросы, он обходится электроэнергетическим компаниям дороже, чем традиционные электростанции, работающие на ископаемом топливе. Хотя общая экономическая тенденция является положительной, есть некоторые препятствия, которые необходимо преодолеть, прежде чем энергия ветра станет действительно более эффективной, чем ископаемое топливо.
[4] Эстетика может стать самым большим препятствием для энергетических компаний. Хотя ветроэнергетика может принести значительную экономическую и экологическую выгоду, люди всегда будут бороться за сохранение чистой, нетронутой земли. К сожалению, для улучшения внешнего вида турбин мало что можно сделать. Белая краска — самый распространенный выбор, потому что она «ассоциируется с чистотой». (Источник E). Но это может сделать его заметным, как больной большой палец, и сделать гигантские машины более неуместными.Сайт также не может быть изменен, потому что это влияет на генерирующую мощность. Звук вызывает еще большее беспокойство, потому что он нарушает личную продуктивность, нарушая режим сна людей. Энергетическим компаниям следует подумать о том, чтобы работать с производством турбин, чтобы сделать машины менее эстетичными, чтобы получить большую общественную поддержку.
[5] Как и в большинстве случаев, у ветровой энергии нет простого ответа. Компании, создающие их, обязаны взвесить преимущества и последствия.Но, уравновешивая экономику, эффективность и эстетику, энергетические компании могут создать решение, которое уравновешивает влияние человека с сохранением окружающей среды.
И это полный пример эссе по синтезу AP Lang, написанный в ответ на настоящую подсказку экзамена AP Lang! Важно помнить, что подсказки для эссе синтеза на экзамене AP Lang всегда одинаково структурированы и сформулированы, и студенты часто отвечают примерно в том же количестве абзацев, что и в приведенном выше примере ответа на эссе.
Далее, давайте проанализируем это эссе в качестве примера и поговорим о том, что в нем эффективно, что можно улучшить и какие оценки давали ему прошлые экзамены.
Анализ
Чтобы начать анализ образца эссе синтеза, давайте посмотрим на оценочный комментарий, предоставленный Советом колледжа:
- За разработку диссертации реферат получил 1 из 1 возможных баллов
- За доказательства и комментарии эссе получило 4 из 4 возможных баллов
- За изощренность мысли эссе получило 0 баллов из 1 возможных.
Это означает, что окончательная оценка за этот пример эссе составила 5 из 6 возможных баллов . Давайте более внимательно посмотрим на содержание эссе-примера, чтобы выяснить, почему оно получило такую разбивку баллов.
Разработка диссертации
Тезисы — одна из трех основных категорий, которые принимаются во внимание , когда вам присуждаются баллы на этой части экзамена. Это примерное эссе получило 1 балл из 1.
И вот почему: тезис ясно и кратко излагает позицию по теме, представленной в подсказке — альтернативная энергия и энергия ветра — и определяет наиболее важные факторы, которые энергетические компании должны учитывать при принятии решения о создании ветряной электростанции. .
Доказательства и комментарии
Вторая ключевая категория, принимаемая во внимание при оценке сводных экзаменов, — это включение доказательств и комментариев. Этот образец получил 4 из 4 возможных баллов за эту часть обобщающего эссе.Как минимум, этот образец эссе соответствует упомянутому в приглашении требованию о том, чтобы автор использовал доказательства как минимум из трех из предоставленных источников.
Вдобавок к этому автор хорошо справляется со связью включенных доказательств с утверждением, сделанным в тезисе, посредством эффективных комментариев. Комментарий в этом образце эссе эффективен, потому что он выходит за рамки простого резюмирования того, что говорят предоставленные источники. Вместо этого он объясняет и анализирует доказательства, представленные в отобранных источниках, и связывает их с подтверждающими пунктами, которые автор делает в каждом основном абзаце.
Наконец, автор эссе также получил баллы за доказательства и комментарии, потому что автор развил и поддержал последовательную линию рассуждений на протяжении всего эссе . Эти рассуждения резюмируются в четвертом абзаце в следующем предложении: «Энергетическим компаниям следует учесть одну вещь — работать с производством турбин, чтобы сделать машины менее эстетичными, чтобы получить большую общественную поддержку».
Поскольку автор проделал хорошую работу, последовательно развивая свои аргументы и объединяя доказательства, они получили полные оценки в этой категории.Все идет нормально!
Утонченность мысли
Итак, мы знаем, что это эссе получило 5 баллов из 6, а место, где писатель потерял балл, было связано с изощренностью мысли, за что автор получил 0 баллов из 1. Это потому, что в этом образце эссе делается несколько обобщений и расплывчатых утверждений, вместо которых можно было бы сделать конкретные утверждения , поддерживающие более сбалансированный аргумент.
Например, в следующем предложении из 5-го абзаца образца эссе автор упускает возможность указать конкретные возможности, которые энергетические компании должны учитывать в отношении энергии ветра .Вместо этого автор двусмысленно и уклончиво говорит: «Как и на большинство вещей, ветроэнергетика не имеет простого ответа. Компании, создающие их, должны взвесить выгоды и последствия».
Если автор этого эссе был заинтересован в том, чтобы попытаться получить этот 6-й балл в ответе на обобщающее эссе, он мог бы подумать о более конкретных утверждениях. Например, они могут указать конкретных преимуществ и последствий , которые следует учитывать энергетическим компаниям при принятии решения о создании ветряной электростанции.Сюда могут входить такие вещи, как воздействие на окружающую среду, экономическое воздействие или даже плотность населения!
Несмотря на потерю одного балла в последней категории, это эссе-пример синтеза является сильным. Он хорошо разработан, продуманно написан и развивает аргументы по теме экзамена, используя доказательства и поддержку.
4 совета по написанию синтетического эссе
AP Lang — это ограниченный по времени экзамен, поэтому вам нужно выбрать, на чем вы хотите сосредоточиться, в то ограниченное время, которое вам дается на написание обобщающего эссе.Продолжайте читать, чтобы получить совет наших экспертов о том, на чем вам следует сосредоточиться во время экзамена.
Совет 1. Прочтите сначала подсказку
Это может показаться очевидным, но когда у вас мало времени, легко растеряться. Просто помните: , когда придет время писать сводное эссе, сначала прочтите подсказку !
Почему так важно прочитать подсказку перед чтением исходных текстов? Потому что, когда вы знаете, на какой вопрос вы пытаетесь ответить, вы сможете читать источники более стратегически. Подсказка поможет вам понять, какие утверждения, моменты, факты или мнения следует искать при чтении источников.
Чтение источников, не прочитав сначала подсказку, похоже на попытку водить машину с завязанными глазами: вы, вероятно, сможете это сделать, но, скорее всего, это плохо закончится!
Совет 2: делайте заметки во время чтения
В течение 15-минутного периода чтения в начале обобщающего эссе вы будете читать источники как можно быстрее.В конце концов, вам, вероятно, не терпится начать писать!
Хотя определенно важно эффективно использовать свое время, также важно читать достаточно внимательно, чтобы понимать свои источники. Внимательное чтение позволит вам определить части источников, которые также помогут вам поддержать ваше тезисное изложение в вашем эссе.
Читая источники, подумайте о том, чтобы пометить полезные отрывки звездочкой или галочкой на полях экзамена , чтобы вы знали, какие части текста нужно быстро перечитывать при составлении сводного эссе.Вы также можете подумать о суммировании ключевых моментов или положения каждого источника в предложении или нескольких словах, когда вы закончите читать каждый источник во время периода чтения. Это поможет вам узнать позицию каждого источника по данной теме и выбрать три (или больше!), Которые поддержат ваш аргумент о синтезе.
Совет 3. Начните с тезиса
Если вы не начнете свое сочинение-синтез с сильного тезисного утверждения, будет сложно написать эффективное сочинение-синтез. Как только вы закончите читать и комментировать предоставленные источники, вам нужно сделать следующее — написать сильное тезисное заявление.
Согласно руководству CollegeBoard по оценке синтезируемого эссе AP Lang, сильное тезисное изложение будет отвечать на запрос — , а не , переформулируйте или перефразируйте подсказку. Хорошая диссертация займет четкую, обоснованную позицию по теме, изложенной в подсказке и источниках.
Другими словами, чтобы написать твердое тезисное изложение, которым будет руководствоваться остальная часть вашего синтезирующего эссе, вам нужно подумать о вашей позиции по рассматриваемой теме, а затем заявить о ней на основе вашего должность. Эта позиция будет либо защищать, либо оспаривать, либо квалифицировать утверждение, сделанное в подсказке к эссе.
Обоснованная позиция, которую вы заняли в своем тезисе, будет определять вашу аргументацию в остальной части эссе, поэтому важно сначала сделать это . Когда у вас будет сильное тезисное изложение, вы можете приступить к составлению наброска своего эссе.
Совет 4. Сосредоточьтесь на своем комментарии
Написание вдумчивых, оригинальных комментариев, объясняющих ваши аргументы и источники, очень важно.Фактически, если вы сделаете это хорошо, вы получите четыре очка (из шести)!
AP Lang предоставляет вам от шести до семи источников на экзамене, и вы должны будете включить цитаты, перефразирование или резюме по крайней мере из трех из этих источников в свое обобщающее эссе и интерпретировать эти доказательства для читателя.
Хотя включение доказательств очень важно, чтобы получить дополнительный балл за «сложность мысли» в обобщающем эссе, важно потратить больше времени на обдумывание вашего комментария к доказательствам, которые вы решили включить.Комментарий — это ваш шанс продемонстрировать оригинальное мышление, сильные риторические навыки и четко объяснить , как включенные вами доказательства подтверждают позицию, изложенную в вашем тезисе.
Чтобы заработать 6-й возможный балл за сводное эссе, убедитесь, что ваш комментарий демонстрирует тонкое понимание исходного материала, объясняет это тонкое понимание и помещает доказательства, взятые из источников, в беседу друг с другом.Для этого старайтесь избегать неопределенных формулировок. По возможности будьте конкретны и всегда связывайте свой комментарий с тезисом!
Что дальше?
Экзамен по языку AP — это гораздо больше, чем просто сводное эссе. Обязательно ознакомьтесь с нашим экспертным руководством по всему экзамену, а затем узнайте больше о сложном разделе с несколькими вариантами ответов.
Сложен ли экзамен AP Lang … или это легко? Посмотрите, как он сочетается с другими тестами AP в нашем списке самых сложных экзаменов AP.
Знаете ли вы, что технически существует два экзамена AP по английскому языку? Вы можете узнать больше о втором тесте AP по английскому, экзамене AP Literature, в этой статье.