существует? — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Как разобрать слово существует по составу
В каком слове правописание суффикса определяется правилом «В бесприставочном причастии совершенного вида пишется «НН»? Укажите правильный вариант отве … та: 1)неизменным 2)брошенная 3)смягчённый 4)постоянный
Помогите пожалуйстаНапишите письмо Лёле. Выразите своё отношение к поступку девочки. Вам помогут следующие вопросы:1.Какие чувства вызывает у вас Куса … ка?2.Как вы оцениваете поступок Лёли?3.Что бы вы сделали на её месте?4.Что бы вы хотели сказать или посоветовать ЛёлеНе меньше 100 слов
стебель тонкий, а ствол____________.
в 5-м предложений найди слово, Состав которого соот-ветствует схеме: корень суфикс , окончанте Выпиши это слово, обозначь его части.предложение: скоро … мой друг рассказал мне,что один охотник продает хорошую взрослую собаку
Составьте и запишите диалог на тему история семьи Краткий диалог 4 класс
Подберите к данным глаголам синонимы и антонимы из слов для выбора.
здравствуйте памагите пожалуйста если не знаете не пешите
Прочитай текст. Определи время глаголов время глаголовВесь мир знаетV) ГалилеоГалилея как выдающегося итальянского астронома. Этотучёный усовершенство … вал (телескоп и с его помощью доказал (м), что мы живём (м) на планете Земля, котораявращается () вокруг Солнца.ВПроверить
замени данные в скобках имена существительные однокоренными именами прилагательными запиши получившиеся словосочетания выдели окончания имен прилагате … льных укажи их род. (тростник) сахар — (гигант) завод — (честь) слово — (доблесть) труд — (известность) артистка — (капуста) лист — (местность) жительница — Помогите пожалуйста!
Упражнение 326 помогитее ответ
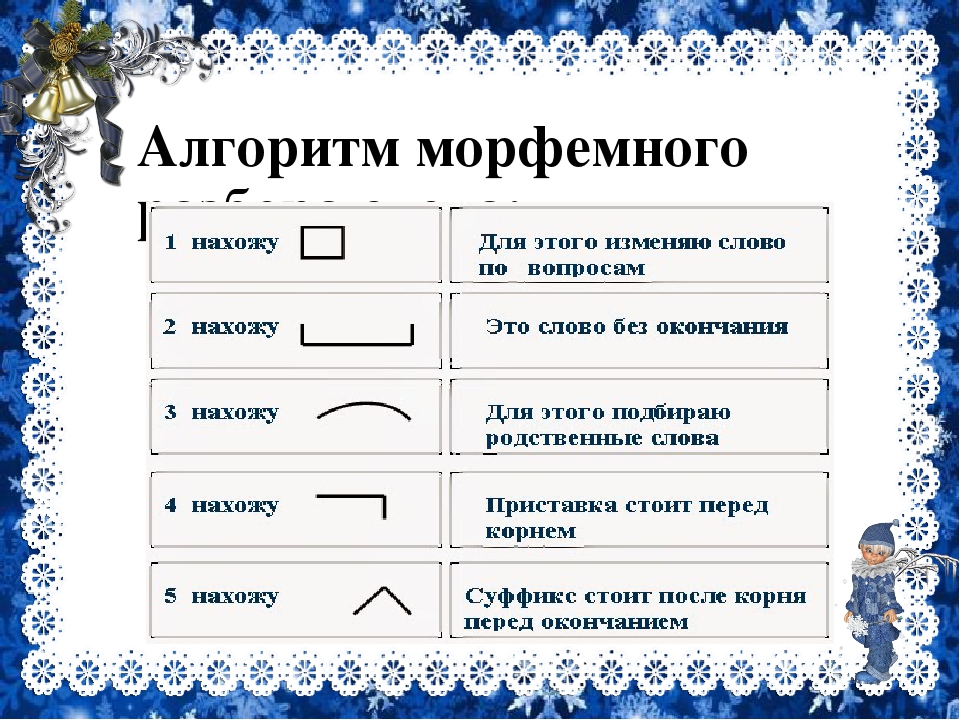
Как разобрать слово по составу? Пример морфемного разбора
Разобрать слово по составу следует, указав следующие морфемы: приставку, корень, суффикс, окончание, соединительную морфему, постфикс.
Окончание в составе слова
Выполнение разбора слова по составу, обычно необходимо начинать с выделения окончания, которое не входит в его основу. Для этого определим, изменяемое ли слово перед нами, есть ли у него окончание. С этой точки зрения важно, к какой части речи относится анализируемая лексема.
Помним, что у неизменяемых частей речи и форм слов нет окончания:
1. у несклоняемых существительных
- драже, метро, такси, рагу, каноэ, боа.
2. У несклоняемых прилагательных
- платье миди;
- юбка гофре;
- язык ханты;
- вес нетто;
- брюки хаки.
3. У наречий на конце вычленим только суффиксы:
- быстро
- неспроста
- врукопашную
- по-польски
4. В морфемном составе деепричастий имеются формообразующие суффиксы:
- гулять — гуляя
- сбежать — сбежав
- открыть — открывши
- нести — нёсши
5. В форме простой сравнительной степени прилагательных и наречий вычленим суффиксы:
В форме простой сравнительной степени прилагательных и наречий вычленим суффиксы:
- ходить тише;
- стало радостнее;
- говорите громче.
Основа слова
Выделив окончание в изменяемом слове, которое склоняется, спрягается или изменяется по родам и числам, остальную часть лексемы обозначим как основу слова.
- создание
- красивый
- двадцатый
- отправим
Помним, что в основу слова не входят формообразующие суффиксы причастий, деепричастий, формы прошедшего времени глагола, постфикс формы повелительного наклонения глагола -те, суффиксы простой сравнительной степени прилагательных и наречий.
Примеры
- лелеющий ребенка
- вылинявшая рубашка
- видимый издали
- задуманный проект
- растертый в порошок
- гуляя по набережной
- открыв книгу
- вычертила график
- нарежьте кусочками
- шагать веселее
- стал слаще
Приставка в составе слова
Затем выделим приставку в слове, если она есть.
сорвать — рвать; оторвать, надорвать, перервать, урвать.
Результативным способом определения приставки в составе слова является подбор лексем с такой же приставкой:
содрать, собрать, совместить, согласиться.
В морфемном составе лексемы может быть несколько приставок, тогда целесообразно составить словообразовательную цепочку и добраться до первого производящего слова:
небезынтересный — безынтересный — интересный.
Суффикс в составе слов
Теперь займемся суффиксом слова. Посмотрим, существует ли слово без такого суффикса:
- седина — седой,;
- вкладчик — вклад;
- бодрость — бодр, бодрый.


Подберем слова с таким же суффиксом и убедимся, что такой суффикс существует:
бодрость — нежность, весёлость, радость.
И теперь после последовательного вычленения всех морфем осталась главная часть слова — корень. Чтобы точно определить границы корня и убедиться, правильно ли мы его выделили, займемся подбором родственных слов. Как известно, общая часть родственных слов, в которой заключено основное лексическое значение слова, и есть корень.
Бодрость — бодрый, бодро (шагать), бодренький, бодриться.
Пример разбора слова по составу
Рассмотрим в качестве примера морфемный разбор слова «безрадостный».
Это изменяемое прилагательное, значит, вычленим окончание -ый, сравнив его формы:
- безрадостная неделя;
- безрадостное настроение;
- безрадостные новости.
Определим основу слова — безрадостн-:
безрадостный
Далее укажем приставку без-, как и в составе слов:
- бездомный
- безработный
Чтобы вычленить суффиксы в слове «безрадостный», восстановим словообразовательную цепочку:
безрадостный ← радостный ← радость ← рад (нет полной формы прилагательного).
Как видим, в составе прилагательного можем выделить суффиксы -ость-, -н-.
Оставшаяся часть слова -рад- является корнем, который прослеживается в родственных словах:
- радость
- радостный
- радовать (ся)
Закончим разбор по составу итоговой записью:
безрадостный — приставка/корень/суффикс/суффикс/окончание
Видеоурок «Разбор глагола по составу»
Скачать статью: PDFРазбор по составу слова существует please
Однажды какой-то человек кинул возле Байкала мусор .Я сказал ему не надо платить не надо кидать возле Байкала мусор пускай он живёт. Потом мы с подругой плавали возле Байкала и увидели что на берегу его ужасно много мусора. мы все убрали решили Живи Байкал пока мы рядом.
мы все убрали решили Живи Байкал пока мы рядом.
ЧАСТИЦА «ПУСКАЙ»
Я думаю, что даже через 50лет русский язык не изменится. Алфавит останется тем же, что и сейчас. Ну а слова, конечно же, будут новые.
Сделать по-другому
Разделить поровну
Поступить по уму
Простить по-дружески
Светить по-летнему
Вести хозяйство по-крестьянски
Дружить по-искренному
Говорить по-немецки
Поступить по-товарищески
Одеваться по-французски
Репортаж с открытия выставки «Современное необычное искусство»
Сегодня мы поведем наш репортаж с выставки, открывшейся в Музее изобразительного искусства. Тема выставки — «Современное искусство». Прямо у входа нас встречает необычная скульптура, изготовленная из пластиковых бутылок. Чуть дальше стоит велосипед, где вместо колес привинчены большие кубы, а вместо руля — шар. Еще одним необычным экспонатом выставки является скульптура человека во весь рост, изготовленная полностью из…вышедших из строя компьютеров!
Тема выставки — «Современное искусство». Прямо у входа нас встречает необычная скульптура, изготовленная из пластиковых бутылок. Чуть дальше стоит велосипед, где вместо колес привинчены большие кубы, а вместо руля — шар. Еще одним необычным экспонатом выставки является скульптура человека во весь рост, изготовленная полностью из…вышедших из строя компьютеров!
На стенах висят картины. Каждая из них — новый взгляд на жизнь, на роль человека в ней. Материал для картин самый разнообразный — от обычных красок и карандашей, до пробок из бутылок и исписанных шариковых ручек.
На выставке много людей. были замечены несколько известных художников и скульпторов.
Эта выставка — новое слово в искусстве. Приходите, не пожалеете!
словообразование — Слова без корня
В русском языке имеется громадное количество слов, в которых нет корня. Но все эти слова, кроме одного-двух, относятся к служебным частям речи.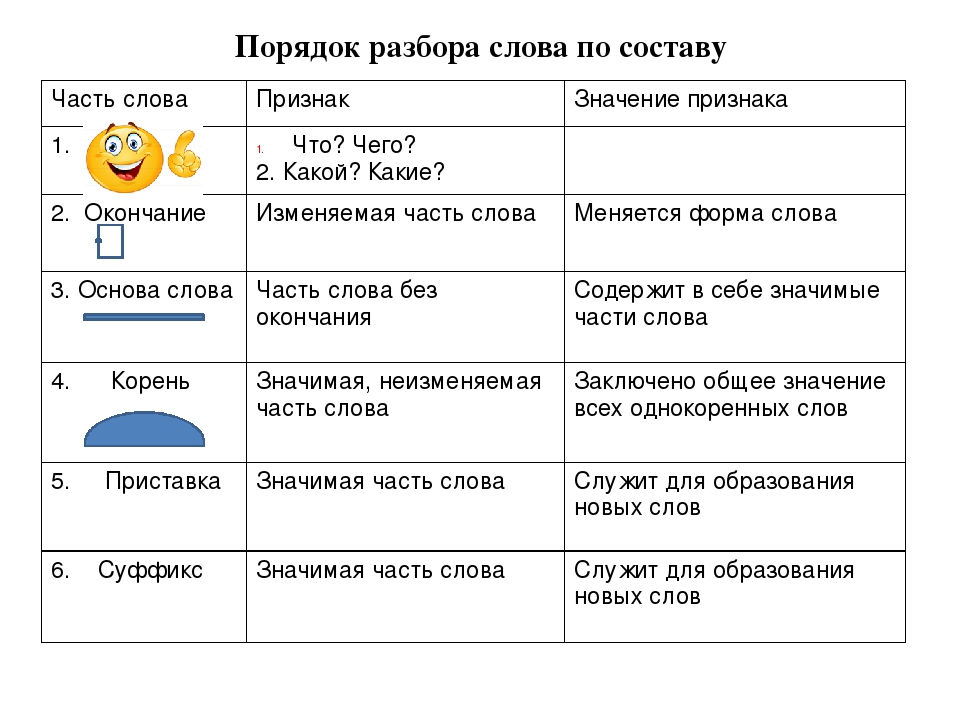 Напомню, что словом в русском языке принято называть не только «слова-названия», но и все служебные слова. В большинстве из них нет корня. Например: «в», «у», «за», «из», «от», «ишь», «и», «ай». Я перечислила лексические единицы. То есть, слова. А попробуйте отыскать в них корень. Не найдёте. Выше я говорила, что в одном-двух самостоятельных словах (точнее, в словоформах) мы тоже не найдём корня. Я не ошиблась. Мы его не найдём по той причине, кто что он нулевой. То есть, он есть формально (потенциально), но «убежал». Подберите однокоренные слова, и он «прибежит» обратно. Например: «вы — 0 — ну — ть» — «вы — ним — ать». Но есть и мнения, что в последнем примере всё-таки имеется зримый корень, состоящий из «Н», наложенном на суффикс. Лингвисты называют такие явления морфемной интерференцией. Спорный случай.
Напомню, что словом в русском языке принято называть не только «слова-названия», но и все служебные слова. В большинстве из них нет корня. Например: «в», «у», «за», «из», «от», «ишь», «и», «ай». Я перечислила лексические единицы. То есть, слова. А попробуйте отыскать в них корень. Не найдёте. Выше я говорила, что в одном-двух самостоятельных словах (точнее, в словоформах) мы тоже не найдём корня. Я не ошиблась. Мы его не найдём по той причине, кто что он нулевой. То есть, он есть формально (потенциально), но «убежал». Подберите однокоренные слова, и он «прибежит» обратно. Например: «вы — 0 — ну — ть» — «вы — ним — ать». Но есть и мнения, что в последнем примере всё-таки имеется зримый корень, состоящий из «Н», наложенном на суффикс. Лингвисты называют такие явления морфемной интерференцией. Спорный случай.
Источник: А может так быть, чтобы в слове не было корня? В каком слове нет корня? | bolshoyvopros.ru.
В русском языке, как ни странно, существуют слова без корня. Это глаголы снять, поднять, принять, занять, вынуть, взять, изъять и т. д. Они образованы таким способом: приставка, суффикс -н (встречается не во всех), глагольный суффикс и окончание. Ко всем этим глаголам можно подобрать пару несовершенного вида, которая будет содержать в себе морфему «-им-«: поднимать, принимать и т. д. Как ни странно, это корень этих слов. Все они образованы от слова «иметь». То есть, хотя эти слова между собой имеют мало общего, они образованы от одного и того же слова. Также от этих слов образуются существительные или прилагательные, имеющие в своём составе морфему «-ём-» или «-йм-«: приём, займ, выемный. Это тот же корень, но здесь происходит чередование.
д. Они образованы таким способом: приставка, суффикс -н (встречается не во всех), глагольный суффикс и окончание. Ко всем этим глаголам можно подобрать пару несовершенного вида, которая будет содержать в себе морфему «-им-«: поднимать, принимать и т. д. Как ни странно, это корень этих слов. Все они образованы от слова «иметь». То есть, хотя эти слова между собой имеют мало общего, они образованы от одного и того же слова. Также от этих слов образуются существительные или прилагательные, имеющие в своём составе морфему «-ём-» или «-йм-«: приём, займ, выемный. Это тот же корень, но здесь происходит чередование.
Источник: Слова без корня в русском языке | pikabu.ru.
В русском языке слов, у которых не было бы корня, нет. Существует лишь одно исключение – это глагол «вынуть», где «вы-» — это приставка, «ну» — это суффикс, а «ть» — это суффикс, характерный для формы инфинитива.
Но и здесь не все так однозначно. Некоторые языковеды относят этот глагол к тем немногим словам, у которых исходного корня в этимологическом плане просто не существует. Правда, это совсем не показатель того, что в его составе корня нет. Основа, которую именуют непроизводной, присуща всем словам без исключения, и она является тем самым компонентом, который мотивирует значение слова. Если говорить об описываемом глаголе, то его корень не совпадает с корнем, выделяемым в слове на момент возникновения этой лексической единицы в языке.
Правда, это совсем не показатель того, что в его составе корня нет. Основа, которую именуют непроизводной, присуща всем словам без исключения, и она является тем самым компонентом, который мотивирует значение слова. Если говорить об описываемом глаголе, то его корень не совпадает с корнем, выделяемым в слове на момент возникновения этой лексической единицы в языке.
Характеризуемое слово образовывается от «яти» путем присоединения приставки «вы-». Это слово является аналогом современного «брать». Таким способом образуется немало и других слов, например: «внять» (с приставкой «вън-»), «взять» (с приставкой «въз-»), «изъять» (с приставкой «изъ-»), «объять» (с приставкой «объ») и т.д.
Исходная форма глагола «выяти» и «выимати», как и родственные слова «сняти» — «снимати», «вняти» — «внимати» со временем приобрела букву «н», которую можно назвать «вставочной». Следствием этого и стало появление таких форм, как «вынять» и «вынимать».
Позже форма «вынять» (совершенный вид) под влиянием звучания глаголов «кинуть», «сдвинуть», «стукнуть», «сгинуть» и др. получила известную всем форму «вынуть». Здесь речь идет не только о таком явлении, как переразложение, но и о процессе аппликации морфем.
получила известную всем форму «вынуть». Здесь речь идет не только о таком явлении, как переразложение, но и о процессе аппликации морфем.
В настоящее время в глаголе «вынуть» (совершенный вид) непроизводной формой основы считается «-н-». Подобный однозвуковой вид является еще и суффиксом, форма выражения которого характеризуется однократностью действия (для сравнения: «вынь», «вынет», «вынут», «вынем»).
В современном русском разбор слова «вынуть» на морфемы будет выглядеть следующим образом: «вы-н-у-ть», где «вы-» — это приставка, «-н-» — это непроизводная форма, которая в других родственных словах чередуется с «-ем-» («выемка»), «-ним-» — («вынимать»), «-н-» — это и суффикс, указывающий на однократность действия, «-у-» — это суффикс, являющийся классовым показателем (аналогично суффиксам «-а-» — «звать», «-е-» — «тереть», «-о-» — «колоть»), «-ть» — элемент инфинитива. Многие лингвисты полагают, что такие морфемы, как корень «-н-» и суффикс «-н-», в этой форме глаголы накладываются друг на друга.
Подытожив все вышесказанное, можно сказать, что с одной стороны, у слова «вынуть» есть корень, если принимать эту морфему за непроизводную форму, которая представляет собой стержень лексического значения слова. Но вместе с тем у этого глагола корня, под которым подразумевают «главный» исходный материал лексической единицы, нет.
Источник: РУССКИЙ ЯЗЫК — ЭТО МЫ | ok.ru.
Разбор по составу слово пулемет
Разбор слова по составу подразумевает деление его на отдельные морфемы: корень, окончание, приставка, суффикс. Существует схема анализа, облегчающая работу.
План морфемного состава слова
- Задать вопрос для определения части речи.
- Окончанием называют изменяемую часть слова. Меняем слово: спрягаем или склоняем, таким образом найдем эту часть.
- Основа — оставшаяся после отделения окончания часть слова. Там будем искать корень, приставку и суффикс.
- Корнем называют общую часть родственных слов. Чтобы корректно выделить, ищем максимально возможное количество однокоренных слов.
- Приставку ищем перед корнем, в начале слова.
- Суффикс находится после корня, перед окончанием.

Не во всех словах присутствуют все морфемы.
Отсутствующее окончание, как в нашем слове «пулемет» называют нулевым. В неизменяемых словах, как наречие, деепричастие, нет окончаний.
Много слов без приставки и без суффикса, как в нашем случае в слове «пулемет». В то же время можно найти и с несколькими приставками, суффиксами и даже корнями. В слове «пуленепробиваемый» два суффикса, две приставки и два корня.
Суффикс «ся» (или «сь») , стоящий после окончания называют постфикс. Основная функция у суффикса — образование новых слов. Суффикс «л» используют для образования прошедшего времени глагола и он не входит в основу. В слове «запылился» постфикс «ся» стоит в конце слова, после окончания. Суффикс «л» образовал прошедшее время, не входит в состав основы.
Морфемный разбор слова «пулемет»
- Вопрос, на который отвечает слово «что?» — существительное.
- «Пулеметом», «пулемету», «пулеметы», «пулеметами» — так определили окончание слова, оно нулевое.
- Основа — все слово «пулемет».
- Однокоренные слова: «бомбометание», «пулеметчица», «пуля», «пулять», «разметаться», «гранатометчик», «противопульный», «бомбомет», «гранатомет», «взметнуться», «пулевой», «пулеметный», «пулька», «минометчик», «миномет»», «минометный», «пуленепробиваемый», «пулелитейный». В нашем слове будет два корня «пул» и «мет».
- Приставки в слове нет.
- Суффикса нет.

haskell — Разбор элемента, который может существовать или не существовать с библиотекой HXT
У меня проблема с HXT. Я хочу разобрать файл совы, и у меня проблема со стрелкой, потому что он не хочет разбирать дерево! Я видел, что проблема в том: Во-первых, код:
import System.Environment --para uso do getArgs
импортировать Data.List.Split (splitOn)
data Class = Class {
имя :: Строка,
subClassOf :: String
} извлечение (Показать, уравнение)
main = делать
[src] >> getClass)
парсер печати
parseClass = ifA (hasAttr "rdf: about") (getAttrValue "rdf: about") (getAttrValue "rdf: ID")
parseSubClass = getAttrValue "rdf: ресурс"
split l = if (length (splitOn "#" l)> 1) then (splitOn "#" l !! 1) else l
atTag tag = deep (isElem >>> hasName tag)
getClass = atTag "сова: класс" >>>
proc l -> делать
className , при этом я должен иметь возможность анализировать файл совы на каждом узле, где он существует, в этом примере:
Но когда я хочу разобрать такое дерево, оно просто не вычисляет и не выбрасывает его!
0
Почему? Потому что узла подкласса не существует! Но я хочу, чтобы класс был доступен там, и поместил его в мои данные, даже если подкласс не существует! Итак, как это возможно?
Моя последняя версия:
Система импорта. Окружающая среда --para uso do getArgs
импортировать Data.List.Split (splitOn)
data Class = Class {
имя :: Строка,
subClassOf :: String
} извлечение (Показать, уравнение)
main = делать
[src] >> getClass)
парсер печати
parseClass = ifA (hasAttr "rdf: about") (getAttrValue "rdf: about") (getAttrValue "rdf: ID")
parseSubClass = (getAttrValue "rdf: resource") `orElse` arr (const" ")
--Test (é Preciso Reesta Definição) uma falha se o nome tiver o "#"
split l = if (length (splitOn "#" l)> 1) then (splitOn "#" l !! 1) else l
atTag tag = deep (isElem >>> hasName tag)
getClass = atTag "сова: класс" >>>
proc l -> делать
className  Окружающая среда --para uso do getArgs
импортировать Data.List.Split (splitOn)
data Class = Class {
имя :: Строка,
subClassOf :: String
} извлечение (Показать, уравнение)
main = делать
[src] >> getClass)
парсер печати
parseClass = ifA (hasAttr "rdf: about") (getAttrValue "rdf: about") (getAttrValue "rdf: ID")
parseSubClass = (getAttrValue "rdf: resource") `orElse` arr (const" ")
--Test (é Preciso Reesta Definição) uma falha se o nome tiver o "#"
split l = if (length (splitOn "#" l)> 1) then (splitOn "#" l !! 1) else l
atTag tag = deep (isElem >>> hasName tag)
getClass = atTag "сова: класс" >>>
proc l -> делать
className
Окружающая среда --para uso do getArgs
импортировать Data.List.Split (splitOn)
data Class = Class {
имя :: Строка,
subClassOf :: String
} извлечение (Показать, уравнение)
main = делать
[src] >> getClass)
парсер печати
parseClass = ifA (hasAttr "rdf: about") (getAttrValue "rdf: about") (getAttrValue "rdf: ID")
parseSubClass = (getAttrValue "rdf: resource") `orElse` arr (const" ")
--Test (é Preciso Reesta Definição) uma falha se o nome tiver o "#"
split l = if (length (splitOn "#" l)> 1) then (splitOn "#" l !! 1) else l
atTag tag = deep (isElem >>> hasName tag)
getClass = atTag "сова: класс" >>>
proc l -> делать
className Dynamic Parsing — Sumo Logic
Dynamic Parsing позволяет автоматически извлекать поля из сообщений журнала JSON при выполнении поиска.Это позволяет просматривать поля из журналов JSON без необходимости вручную указывать логику синтаксического анализа.
Dynamic Parsing извлекает поля JSON при выполнении запроса во время поиска (время выполнения). Динамический синтаксический анализ для JSON можно рассматривать как правило извлечения поля времени выполнения (FER). По умолчанию вашей учетной записи предоставляется один FER времени выполнения, который охватывает все ваши данные.
Если этот FER определен, любой поиск данных JSON будет автоматически анализировать их поля JSON, которые вы затем можете использовать в своем поисковом запросе, как и любое другое поле.
У вас есть выбор из двух режимов на странице поиска, которые позволяют управлять динамическим анализом. Динамический синтаксический анализ активируется, когда поиск выполняется в режиме автоматического анализа , более подробную информацию о режимах можно найти в разделе «Использование динамического синтаксического анализа».
Преимущества использования динамического анализа
- В отличие от FER времени загрузки, где поля являются постоянными, даже когда FER редактируются или удаляются, FER времени выполнения и соответствующие им проанализированные поля могут быть обновлены или удалены в любой момент времени.
- Dynamic Parsing полезен, когда ваша схема журнала часто изменяется, например, если поля часто добавляются или удаляются, что особенно актуально для журналов настраиваемых приложений. Sumo автоматически обнаруживает изменение в вашей схеме и может соответствующим образом корректировать вывод.

Настроить динамический анализ
По умолчанию в вашей учетной записи настроен FER времени выполнения, который применяется ко всем вашим данным. Стандартное время выполнения FER с именем JSON Auto Parsing — All Sources нельзя редактировать или удалять.С этим настроенным FER вам не нужно ничего настраивать для использования динамического анализа. Однако применение одного FER ко всем вашим данным может быть не оптимальным для ваших нужд, поскольку оно будет применяться для каждого поискового запроса (включая те, которые могут не запрашивать какие-либо журналы JSON). Более подробную информацию можно найти в лучших практиках разработки правил.
Для оптимизации производительности поиска вы можете вручную настроить динамический анализ, указав свои собственные FER во время выполнения.
есть область действия, точно такая же, как у FER времени загрузки, которая определяет, какие поиски применимы к динамическому синтаксическому анализу , автоматическому режиму анализа .Для работы динамического синтаксического анализа ваш запрос должен иметь область, определенную в FER времени выполнения, в противном случае Auto Parse Mode не будет применяться.
Перейти к Управление данными > Журналы > Правила извлечения полей .
Нажмите кнопку + Добавить в правом верхнем углу таблицы, чтобы создать FER.
Появляется следующая форма:
Введите следующие параметры:
Название правила .Введите имя, которое упрощает идентификацию правила.
Применяется по номеру . Выберите Время работы .
Объем . Выберите Specific Data и определите объем ваших данных JSON. Вы можете определить свой источник данных JSON как имя раздела (индекс), sourceCategory, имя хоста, имя сборщика или любые другие метаданные, которые описывают ваши данные JSON.Думайте о Scope как о первой части специального поиска перед первой вертикальной чертой (|). Вы будете использовать область действия, чтобы выполнить поиск по правилу. Вы не можете использовать в своей области такие ключевые слова, как «информация» или «ошибка».
Всегда настраивайте автоматическое извлечение JSON (извлечение поля времени выполнения) для определенного имени раздела (рекомендуется) или определенного источника. В противном случае логика автоматического анализа может работать в источниках данных, где она не применима, и приведет к дополнительным накладным расходам, которые могут ухудшить производительность ваших запросов. Лучшие методы для настройки Scope
Ниже приведены рекомендуемые подходы к настройке динамического синтаксического анализа JSON:- Если вы не используете разделы, мы рекомендуем использовать поля метаданных, такие как _sourceCategory, _sourceHost или _collector, для определения области.
- Мы рекомендуем создать отдельный раздел для набора данных JSON и использовать этот раздел в качестве области для извлечения поля времени выполнения. Например, предположим, что у вас есть журналы AWS Cloudtrail, и они хранятся в разделе
_index = cloudtrailв Sumo.Вы можете создать FER времени выполнения с областью действия_index = cloudtrail. Создание отдельного раздела и использование его в качестве области для извлечения поля времени выполнения гарантирует, что логика автоматического анализа применяется только к необходимым разделам.
- Если вы не используете разделы, мы рекомендуем использовать поля метаданных, такие как _sourceCategory, _sourceHost или _collector, для определения области.
Просмотрите данные формы и, когда будете удовлетворены, нажмите Сохранить .


Теперь, когда у вас есть хотя бы один созданный FER среды выполнения, вы можете начать запрашивать данные JSON, и поля внутри этих полезных данных JSON будут автоматически извлечены.
Использовать динамический анализ
Хотя FER времени выполнения настроен на автоматический запуск, вы можете выборочно применить их к своим поисковым запросам на странице поискового запроса журнала.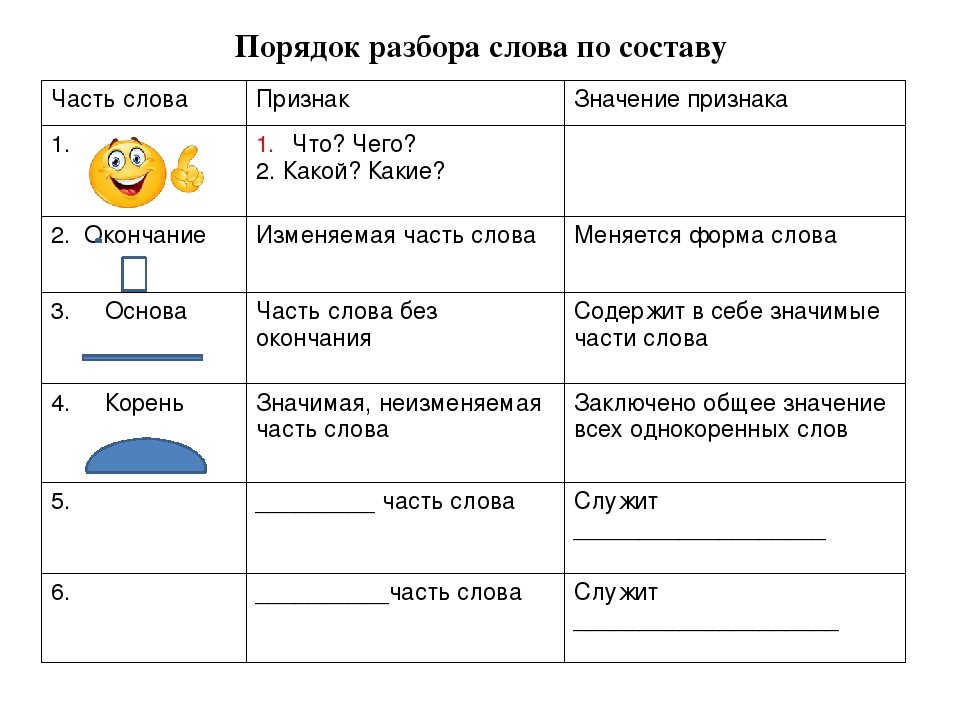 Чтобы использовать динамический анализ, выберите Auto Parse Mode из раскрывающегося списка под полем Time Range, выделенным красным на снимке экрана ниже.
Чтобы использовать динамический анализ, выберите Auto Parse Mode из раскрывающегося списка под полем Time Range, выделенным красным на снимке экрана ниже.
Доступны два режима:
- Режим автоматического анализа
- Будет анализировать все поля, обнаруженные в вашем источнике данных JSON, независимо от того, используете ли вы их в своем запросе или нет.
- Поддерживается в классических панелях мониторинга и поиске по расписанию. Этот режим применим только при поиске источников данных JSON, которые были правильно настроены в среде выполнения FER.
- Ручной режим
- Поля не будут анализироваться автоматически, если они не определены в FER времени загрузки. Пользователи должны вручную указать дальнейшую логику синтаксического анализа.
- Этот режим предназначен для опытных пользователей, которые заинтересованы в максимальной производительности и знают, как разбирать нужные поля.
Ссылка на проанализированные поля JSON
Обозреватель полей и таблица сообщений с результатами поиска имеют несколько полезных функций.
Обозреватель полей:
- Поле ввода для поиска позволяет искать поля по имени.
- структур JSON вложены с опциями разворачивания и сворачивания.
- Кнопка копирования доступна справа от каждого поля, что позволяет легко скопировать имя поля.
Таблица результатов поиска:
- Вы можете копировать имена полей из структур JSON. После выбора (щелкните и выделите) ключ JSON в результатах щелкните правой кнопкой мыши и выберите Копировать имя поля . См. Изменение поиска на вкладке сообщений для получения подробной информации о других предоставляемых параметрах.
При копировании имени поля с использованием этой опции автоматически форматируются имена полей, содержащие специальные символы. Например, имя поля, показанное на снимке экрана, — это общего временного ряда , оно будет автоматически отформатировано до % «общего временного ряда» для правильной работы в поисковом запросе.
- Кнопка копирования доступна справа от имени каждого столбца (поля), что позволяет легко скопировать имя поля.

Основные правила
FER времени выполнения применяются только к журналам, которые соответствуют области запроса. При выполнении поискового запроса сначала определяется, соответствует ли какой-либо из FER времени выполнения области действия запроса. Применяются те FER времени выполнения с совпадающей областью действия. FER во время выполнения применяются для каждой строки журнала, только если журнал содержит элемент JSON.
Например, FER времени выполнения с областью действия:
_sourcecategory = A- Запрос
_sourcecategory = Bне применяется, поскольку область действия не перекрывается областью FER времени выполнения. - Запрос
_sourcecategory = A или _sourcecategory = Bприменяется только к строкам журнала, которые попадают в_sourcecategory = A, в то время как остальные строки журнала не анализируются с помощью этого FER времени выполнения.
- Запрос
Если поле не существует в схеме сообщения журнала, для поля отображаются нулевые результаты (вместо ошибки).
FER времени приема имеют приоритет при назначении полей. FER времени выполнения не отменяет присвоение поля из FER времени приема.
Конфликты между полями загрузки и времени выполнения оцениваются каждой строкой журнала следующими способами:
Если поле «Время загрузки» имеет допустимое значение или пусто, а поле «Время выполнения» не существует, применяется значение из поля «Время загрузки».
Если поле «Время загрузки» не существует или пусто, а поле «Время выполнения» имеет допустимое значение или пусто, применяется значение из поля «Время выполнения».
Если оба поля Ingest и Run Time имеют допустимые значения, применяется значение из поля Ingest Time.
- Пробелы в именах полей автоматически переформатируются в символы подчеркивания.

Ограничения
Ограничения на количество полей
- Динамический анализ извлекает до 100 полей в сообщении. Это 100 полей включает все встроенные и проанализированные поля.
- Итоговые поля, отображаемые в браузере полей, состоят из всех полей, извлеченных по строкам журнала.
- Обозреватель полей отображает количество полей, а также распределение значений каждого поля. Эти вычисления выполняются для первых 200 полей, которые анализируются во время выполнения FER.

pydrake.multibody.parsing — документация pydrake
Разбор SDF и URDF для MultibodyPlant и SceneGraph.
- класс
pydrake.multibody.parsing.AddFrame -
__init__ Самостоятельная инициализация. См. Справку (type (self)) для точной подписи.
-
наименование Имя добавляемого фрейма. Если указана область действия, модель будет переопределена. пример; в противном случае будет использоваться экземпляр `X_PF.base_frame`s.
-
X_PF Поза добавляемой рамы,
F, w.r.t. родительская рамаP(как определяетсяX_PF.). base_frame
-
 base_frame
base_frame -
pydrake.multibody.parsing.GetScopedFrameByName( plant: pydrake.multibody.plant.MultibodyPlant_ [float], full_name: str ) → pydrake.multibody.tree.Frame_ [float] Эквивалент
GetScopedFrameByName Может быть, но выдает, если кадр не найден.
-
pydrake. Многотело.парсинг.GetScopedFrameName( plant: pydrake.multibody.plant.MultibodyPlant_ [float], кадр: pydrake.multibody.tree.Frame_ [float]) → str Создает и возвращает имя кадра с заданной областью для запрошенного кадра.
-
pydrake.multibody.parsing.LoadModelDirectives( имя файла: str ) → pydrake.multibody.parsing.ModelDirectives
- класс
pydrake.multibody.parsing.МодельДиректива Структура верхнего уровня для схемы файла yaml директив модели.
-
__init__ Самостоятельная инициализация. См. Справку (type (self)) для точной подписи.
-

- класс
pydrake.multibody.parsing.ModelInstanceInfo Удобная структура для хранения всей информации для добавления модели экземпляр из файла.
-
__init__ Самостоятельная инициализация. См. Справку (type (self)) для точной подписи.
-
имя_детской_кадры Это имя кадра с незаданной областью, принадлежащее
model_instance.
-
модель_экземпляр
-
название_модели Название модели (возможно, область действия).
-
путь_модели Путь к файлу.
-
имя_ родительского_фрейма ПРЕДУПРЕЖДЕНИЕ — Это родительский кадр с незаданной областью , который считается уникальным.
-
X_PC
-

- класс
pydrake.multibody.parsing.PackageMap Сопоставляет имена пакетов ROS с их полным путем в локальной файловой системе. Это используется парсерами SDF и URDF при синтаксическом анализе файлов, которые ссылаются на Пакеты ROS для ресурсов, таких как файлы сетки.
-
__init__( self: pydrake.multibody.parsing.PackageMap ) → Нет Конструктор, инициализирующий пустую карту.
-
Добавить( self: pydrake.multibody.parsing.PackageMap , имя_пакета: str , путь_пакета: str ) → Нет Добавляет пакет
имя_пакетаи его путь,путь_пакета. Броски еслиpackage_nameуже присутствует в этой PackageMap, или еслипуть_пакетане существует.
-
AddPackageXml( self: pydrake. multibody.parsing.PackageMap , filename: str ) → Нет Добавляет запись в эту PackageMap для данного
не существует или его встроенное имя уже существует на этой карте.package.xmlимя файла. Выдается, еслиfilename
-
Содержит( self: pydrake.multibody.parsing.PackageMap , имя_пакета: str ) → bool Возвращает true тогда и только тогда, когда эта PackageMap содержит
package_name.
-
GetPath( self: pydrake.multibody.parsing.PackageMap , имя_пакета: str ) → str Получает путь, связанный с пакетом
имя_пакета. Отменяет, если в этой PackageMap нет пакета с именемpackage_name.
-
PopulateFromEnvironment( self: pydrake.multibody.parsing.PackageMap , environment_variable: str ) → Нет Получает один или несколько путей из переменной среды
переменная среды. Ползет вниз по каталогу
дерево (-а), начиная с пути (-ов) для поиска файлов package.xml, а значение — это путь к файлуpackage.xml. Можно указать несколько путей, разделив их с помощью символа «:» условное обозначение. Например, переменная среды может содержать [путь 1]: [путь 2]: [путь 3] для поиска трех разных путей.
-
PopulateFromFolder( self: pydrake.multibody.parsing.PackageMap , путь: str ) → Нет Обходит дерево каталогов, начиная с пути
package.xml. Для каждого из этих каталоги, этот метод добавляет новую запись в эту PackageMap, где ключ — это имя пакета, как указано вpackage.xmlи путь к каталогу — это значение.
-
PopulateUpstreamToDrake( self: pydrake. multibody.parsing.PackageMap , model_file: str ) → Нет Сканирует вверх по дереву каталогов от
model_fileдоdrakeпоискpackage. xmlфайлов. Добавляет пакеты, описанные эти файлыpackage.xml. Еслиmodel_fileотсутствует вdrake, этот метод возвращается, ничего не делая.- Параметр
файл_модели: - Файл модели, каталог которого является началом поиска
упаковка.xmlфайлов. Этот файл должен быть файлом SDF или URDF.
- Параметр
-
размер( self: pydrake.multibody.parsing.PackageMap ) → int Возвращает количество записей в этой PackageMap.
-
 multibody.parsing.PackageMap , filename: str ) → Нет
multibody.parsing.PackageMap , filename: str ) → Нет Ползет вниз по каталогу
дерево (-а), начиная с пути (-ов) для поиска файлов
Ползет вниз по каталогу
дерево (-а), начиная с пути (-ов) для поиска файлов  multibody.parsing.PackageMap , model_file: str ) → Нет
multibody.parsing.PackageMap , model_file: str ) → Нет- класс
pydrake.multibody.parsing.Парсер Разбирает входные файлы SDF и URDF в MultibodyPlant и (необязательно) SceneGraph.
-
__init__( self: pydrake. multibody.parsing.Parser, plant: pydrake.multibody.plant.MultibodyPlant_ [float], scene_graph: pydrake.geometry.SceneGraph_ [float] = Нет ) → Нет Создает парсер, который добавляет модели к данному объекту и (необязательно) сцена_граф.
- Параметр
завод: - Указатель на изменяемый объект MultibodyPlant, для которого выполняется синтаксический анализ.
модель (ы) будут добавлены;
plant-> is_finalized ()должно остатьсяНеверно, пока заводэтим. - Параметр
граф_сцены: - Указатель на изменяемый объект SceneGraph, используемый для геометрии. регистрация (для моделирования визуальной или контактной геометрии). Может быть nullptr.
- Параметр
-
AddAllModelsFromFile( self: pydrake.multibody.parsing.Parser , имя_файла: str ) → Список [pydrake.multibody.tree.ModelInstanceIndex] Анализирует файл SDF или URDF с именем
Файлыимя_файлаи добавляет все его модели дозавод.SDF могут содержать несколько элементов
Файлыplantдля каждого тегаURDF содержат один элемент
будет добавлен в завод.- Параметр
имя_файла: - Имя анализируемого файла SDF или URDF. Тип файла будет выводиться из расширения.
Возвращает: Набор индексов экземпляра модели для вновь добавленных моделей. Вызывает: RuntimeError в случае ошибок. - Параметр
-
AddModelFromFile( self: pydrake.multibody.parsing.Parser , имя_файла: str , имя_модели: str = » ) → pydrake.multibody.tree.ModelInstanceIndex Анализирует файл SDF или URDF с именем
имя_файлаи добавляет одну модель кзавод. Было бы ошибкой вызывать это, используя файл SDF с дополнительными
чем один элемент - Параметр
имя_файла: - Имя анализируемого файла SDF или URDF. Тип файла будет выводиться из расширения.
- Параметр
имя_модели: - Имя, данное вновь созданному экземпляру этой модели. Если
пусто, атрибут name из
Возвращает: Индекс экземпляра для вновь добавленной модели. Вызывает: RuntimeError в случае ошибок. - Параметр
-
AddModelFromString( self: pydrake.multibody.parsing.Parser , file_contents: str , file_type: str , имя_модели: str = » ) → pydrake.multibodyIndex.Model Анализирует данные SDF или URDF XML, переданные в
file_contentsи добавляет одну модель кplant. Вызывать это с помощью SDF — ошибка.
с более чем одним элементом - Параметр
file_contents: - Анализируемые XML-данные.
- Параметр
тип_файла: - Формат данных; должно быть либо «sdf», либо «urdf».
- Параметр
имя_модели: - Имя, данное вновь созданному экземпляру этой модели. Если
пусто, атрибут name из
Возвращает: Индекс экземпляра для вновь добавленной модели. Вызывает: RuntimeError в случае ошибок. - Параметр
-
package_map( self: pydrake.multibody.parsing.Parser ) → pydrake.multibody.parsing.PackageMap Получает изменяемую ссылку на PackageMap, используемый этим синтаксическим анализатором.
-
 multibody.parsing.Parser, plant: pydrake.multibody.plant.MultibodyPlant_ [float], scene_graph: pydrake.geometry.SceneGraph_ [float] = Нет ) → Нет
multibody.parsing.Parser, plant: pydrake.multibody.plant.MultibodyPlant_ [float], scene_graph: pydrake.geometry.SceneGraph_ [float] = Нет ) → Нет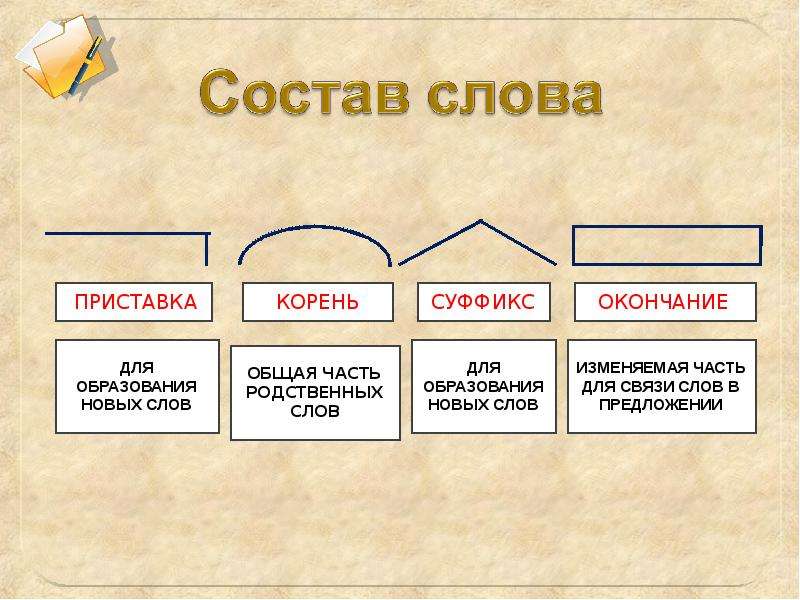
 Было бы ошибкой вызывать это, используя файл SDF с дополнительными
чем один элемент
Было бы ошибкой вызывать это, используя файл SDF с дополнительными
чем один элемент  Вызывать это с помощью SDF — ошибка.
с более чем одним элементом
Вызывать это с помощью SDF — ошибка.
с более чем одним элементом -
pydrake.multibody. parsing. ProcessModelDirectives( директивы: pydrake.multibody.parsing.ModelDirectives, plant: pydrake.multibody.plant.MultibodyPlant_ [float], parser: pydrake.multibody.parsing.Parser .Inbody List [pydrake.multibody.parsing.Parser ) → ] Обрабатывает директивы модели для данного MultibodyPlant.
Примечание
аргумент ModelWeldErrorFunction, описанный выше, скорее всего, исчезнут, когда будет разработан более чистый механизм.Примечание:
pydrake в настоящее время не поддерживает функцию ModelWeldErrorFunction .
 parsing.
parsing. Анализ данных с помощью Jackson с использованием kotlin
Введение в модуль Jackson Kotlin и обнуляемый тип Kotlin для отсутствующих значений в данных
Jackson — одна из известных библиотек для анализа данных XML или JSON, хотя для Kotlin требуются некоторые ключевые факторы чтобы избежать неожиданных проблем.
По умолчанию Java предоставляет конструктор по умолчанию (если нет параметризованного конструктора), который используется Jackson для синтаксического анализа ответа на классы POJO или bean-компонентов.
Kotlin предоставляет функцию классов данных , которые не предоставляют конструктор по умолчанию (вместо этого он использует конструктор параметризации), поэтому синтаксический анализ ответа в Kotlin приведет к исключению InvalidDefinitionException как:
, где Person class это простой data class с двумя свойствами
data class Person (var name: String, var occation: String)
и журнал исключений.
Исключение в потоке "main" com.Fastxml.jackson.databind.exc.InvalidDefinitionException: невозможно создать экземпляр `Person` (не существует создателей, таких как конструктор по умолчанию): невозможно десериализовать из значения объекта (нет создателя на основе делегатов или свойств)
в [Источник: (String ) "{
" имя ":" Павнет ",
" занятие ":" Инженер-программист "
}"
Классы данных имеют ограничение на наличие хотя бы одного параметра первичного конструктора, поэтому конструктор по умолчанию / без аргументов не используется.
 доступно по умолчанию в классах данных.
доступно по умолчанию в классах данных. Джексон не может найти конструктор по умолчанию, поэтому он не может создать объект класса Person и выбросить исключение InvalidDefinitionException .
Эта проблема может быть исправлена с помощью аннотации @JsonProperty , которая проинструктирует Jackson использовать сеттеры и геттеры для синтаксического анализа как:
Исключение также можно исправить, создав нормальный класс вместо data class как:
Внутри компилятор сгенерирует общедоступных установщиков / получателей для доступа к свойствам класса и будет иметь конструктор по умолчанию .
Образец сценария анализа электронной почты Resilient
V32.2 платформы Resilient содержит готовый сценарий Python под названием «Образец сценария: обработка входящей электронной почты (v32.2)». При обновлении до V32.2 любые существующие организации и впоследствии созданные организации будут иметь новый сценарий.
Скрипт предназначен для синтаксического анализа электронной почты на объектах сообщения электронной почты. Он выполняет следующие функции:
Новым инцидентам нужен владелец — либо лицо, указанное по адресу электронной почты, либо по имени группы.В предоставленном сценарии это значение оставлено пустым. Вам необходимо отредактировать скрипт, чтобы добавить устойчивого пользователя в качестве владельца. Например, чтобы изменить владельца на [email protected], найдите строку 8 сценария:
Белый список — это список надежных элементов данных, которые не должны становиться подозрительными артефактами; например, IP-адрес вашего собственного почтового сервера. В скрипте используются две категории белых списков: IP-адрес и URL-домен. Эти белые списки настраиваются путем изменения данных в скрипте.
Первоначально эти белые списки состоят из закомментированных записей, которые служат примерами данных, которые вы, возможно, захотите исключить из рассмотрения. Белые списки не действуют, если вы не раскомментируете записи и не составите грамматически правильный список или не добавите собственные записи.
Белые списки IP-адресов разделены на отдельные списки IPv4 и IPv6. Эти списки применяются к IP-адресам, полученным путем сопоставления с образцом в теле сообщения электронной почты. Если IP-адрес появляется в белом списке, он не добавляется как артефакт к инциденту.
Существует две категории записей в белом списке IP: CIDR (бесклассовая междоменная маршрутизация) и IPRange. Например, в IP V4 IBM владеет сетью 9 класса A. Вы также можете добавить в белый список диапазон IP-адресов, например 12. 0.0.1 — 12.5.5.5 . Чтобы добавить эти критерии в белый список, вы должны добавить следующее в ipV4WhiteList:
"9.0.0.0/8",
"12.0.0.1-12.5.5.5"
Вы также можете добавить в белый список явный IP-адрес, например 13,13.13,13 . Это будет определено следующим образом:
"13.13.13.13"
Белые списки IP v6 работают аналогично. Например, чтобы добавить V6 CIDR aaaa :: / 16 в белый список, вы должны добавить «aaaa :: / 16» в ipV6WhiteList. Например:
Например:
# Белый список для IP-адресов V4
ipV4WhiteList = WhiteList ([
...
])# Белый список для IP-адресов V6
ipV6WhiteList = WhiteList ([
...
])
должен стать:
# Белый список для IP-адресов V4
ipV4WhiteList = WhiteList ([
"9.0.0.0 / 8 ",
" 12.0.0.1-12.5.5.5 ",
" 13.13.13.13 "
])# Белый список для IP-адресов V6
ipV6WhiteList = WhiteList ([
" aaaa :: / 16 "
] )
Белые списки доменов URL
Белый список доменов применяется к URL, найденным в теле письма. Если домен из белого списка обнаружен в потенциальном артефакте URL, он не добавляется к инциденту. Домены могут быть добавлены явно, например mail.businessname.com, или с использованием подстановочного знака, например *.otherbusinessname.com. Например:
# Белый список доменов
domainWhiteList = WhiteList ([
# "*. Ibm.com"
])
станет:
# Белый список доменов
domainWhiteList = WhiteList ([
"mail.
"* .otherbusinessname.com"
])
 businessname.com" ,
businessname.com" , Расширение и настройка
Есть два подхода к расширению и настройке этой функции:
- Запуск нескольких сценариев для одного и того же электронного письма.
- Измените предоставленный сценарий.
По разным причинам добавление большего количества скриптов, как правило, лучше, чем усложнение одного скрипта. Можно ожидать, что платформа Resilient будет принимать несколько категорий сообщений электронной почты из различных интеграций. Некоторая обработка сообщений электронной почты может быть общей, а некоторая обработка может зависеть от категории или интеграции. Сохранение общей обработки в одном сценарии и специализированной обработки в других позволит сделать реализацию более чистой и удобной в обслуживании.
Каждое выполнение сценария выполняется в пределах определенных вычислительных квот — 5 секунд времени выполнения или 50 000 выполняемых строк Python. Обработка регулярных выражений выполняется модулем _re_ Python, выполнение которого считается частью квоты.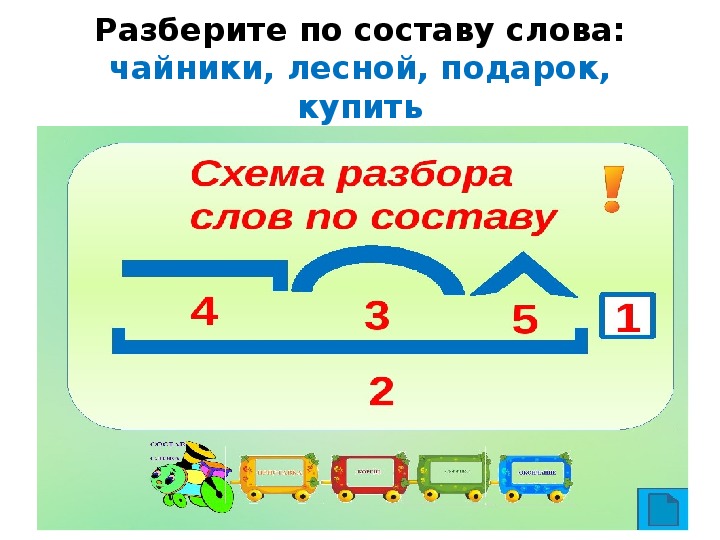 Можно создать сложное регулярное выражение, выполнение которого требует интерпретации большого количества строк Python в конкретном сообщении электронной почты. Выполнение многих таких сложных регулярных выражений может превысить ограничение в 50 000 строк.
Можно создать сложное регулярное выражение, выполнение которого требует интерпретации большого количества строк Python в конкретном сообщении электронной почты. Выполнение многих таких сложных регулярных выражений может превысить ограничение в 50 000 строк.
Примеры
Расширение решения для работы с отчетами о фишингеСценарий: электронные письма, поступающие в определенный почтовый ящик, отражают людей, пересылающих сообщения, подозреваемые в фишинге. Сценарии, работающие с этими сообщениями электронной почты, должны, помимо обычной обработки в образце сценария, записывать адрес электронной почты репортера как возможный объект фишинг-атаки и записывать отправителя переадресованного фишингового сообщения электронной почты как подозрительного.
Решение: добавьте следующий сценарий на платформу Resilient:
import redef addArtifact (regex, artifactType, description):
"" "Этот метод добавляет новые артефакты к инциденту, полученному из совпадений регулярного выражения
параметр в теле письма.
Параметр "regex" - регулярное выражение для сопоставления с содержимым тела письма.
Параметр "artifactType" - тип артефакта (ов).
Параметр "description" - описание артефакта (s).
"" "
dataList = set (re. findall (regex, emailmessage.body.content)) # Использование набора для обеспечения уникальности
if dataList isnotNoneandlen (dataList)> 0:
map (lambda theArtifact: Incident.addArtifact (artifactType , theArtifact, description), dataList)###
# Основная линия начинается здесь
#### Добавьте «Фишинг» в качестве типа инцидента для связанного инцидента
инцидент.incident_type_ids.append («Фишинг»)# Добавить в инцидент информацию об отправителе электронной почты в качестве получателя попытки фишинга
ReportingUserInfo = emailmessage.from.address
, если emailmessage.from.name не None:
reportingUserInfo = u "{0} ". format (emailmessage.from.name, emailmessage.from.address)
инцидент.addArtifact ("Электронная почта Recipient ", reportingUserInfo," Получатель подозрительного письма ")# Извлечь информацию об отправителе электронной почты, исходя из предположения, что пересылается рыболовное письмо
, если не emailmessage.body.content is None:
addArtifact (r" From: (. *. * ) \ n "," Отправитель электронной почты "," Подозрительный отправитель электронной почты ")
addArtifact (r" Reply-To: (.*) \ n ",« Отправитель электронной почты »,« Подозрительный отправитель электронной почты (Reply-To) »)

Важно, чтобы указанный выше сценарий для фишинга запускался после общего сценария, поскольку общий сценарий вызывает инцидент переменная должна быть установлена, и специфичный для фишинга скрипт ожидает, что это уже было сделано. Два самых простых альтернативных способа сделать это:
- Специфичный для фишинга скрипт должен запускаться как второй скрипт правила для нескольких скриптов, которое сначала запускает стандартный сценарий.
- Сценарий для фишинга должен запускаться в отдельном правиле, которое запускается впоследствии.
В любом случае специфичный для фишинга сценарий должен запускаться только при условии, что в созданном сообщении электронной почты указано, что это отчет о фишинге.
Идентификатор кампанииСценарий: одной темы сообщения электронной почты может быть недостаточно для сбора связанных электронных писем в один инцидент.
Может оказаться, что тема сообщения электронной почты недостаточно конкретна или надежна для использования в качестве способа сбора связанных электронных писем.В частности, может иметь место атака, когда несколько векторов атаки используются в одной кампании, что может привести к получению множества различных типов сообщений электронной почты для этой одной кампании.
Одним из решений проблемы является создание нового поля в инциденте, содержащего идентификатор кампании. Этот идентификатор может быть получен из содержимого сообщений электронной почты или выбран из жестко запрограммированного списка, когда кампания распознается сценарием синтаксического анализа.
Решение:
- Создайте новое настраиваемое поле инцидента для идентификатора кампании типа Текст.
- Скопируйте образец сценария синтаксического анализа в новый сценарий.
- Измените новый сценарий, чтобы создать значение для идентификатора кампании, либо выбрав текст из содержимого сообщений электронной почты, либо выбрав из жестко заданного списка идентификаторов кампании, если выполняются определенные критерии.
- Чтобы связать сообщение электронной почты с существующим инцидентом, найдите инциденты, поле идентификатора кампании которых совпадает со значением идентификатора кампании для сообщения электронной почты.Это заменит поиск по теме сообщения электронной почты.
- Если подходящий инцидент не найден, создайте новый инцидент и установите для его поля идентификатора кампании значение идентификатора кампании.
- Измените правила так, чтобы новый сценарий выполнялся вместо примера сценария.
Apache Lucene — синтаксис парсера запросов
Обзор
Хотя Lucene предоставляет возможность создавать свои собственные запросы через свой API, он также предоставляет богатый запрос языка через Query Parser, лексер, который интерпретирует строку в запрос Lucene с помощью JavaCC.
Как правило, синтаксис парсера запросов может отличаться от отпустить к выпуску. На этой странице описан синтаксис по состоянию на текущий выпуск. Если вы используете другой версии Lucene, пожалуйста, обратитесь к копии docs / queryparsersyntax.html, который был распространен с версией, которую вы используете.
Прежде чем использовать предоставленный анализатор запросов, обратите внимание на следующее:
- Если вы программно генерируете строку запроса, а затем анализируя его с помощью парсера запросов, вам следует серьезно подумать о создании ваши запросы напрямую через API запросов.Другими словами, запрос парсер предназначен для текста, вводимого человеком, а не для программного текст.
- Нетокенизированные поля лучше всего добавлять непосредственно в запросы, а не через парсер запросов. Если значения поля генерируются программно приложением, то также следует запросить предложения для этого поля. Анализатор, который использует парсер запросов, предназначен для преобразования введенных человеком текст к условиям.Создаваемые программой значения, такие как даты, ключевые слова и т. Д., должны последовательно генерироваться программой.
- В форме запроса поля, которые представляют собой общий текст, должны использовать запрос парсер. Все остальные, такие как диапазоны дат, ключевые слова и т. Д., Лучше добавлять. напрямую через API запросов. Поле с ограниченным набором значений, которые можно указать в раскрывающемся меню, не следует добавлять в строка запроса, которая впоследствии анализируется, а скорее добавляется как Предложение TermQuery.
Термины
Запрос разбит на термины и операторы. Есть два типа терминов: отдельные термины и фразы.
Отдельный термин — это отдельное слово, например «тест» или «привет».
Фраза — это группа слов, заключенная в двойные кавычки, например «hello dolly».
Несколько терминов можно комбинировать с логическими операторами, чтобы сформировать более сложный запрос (см. Ниже).
Примечание. Анализатор, используемый для создания индекса, будет использоваться для терминов и фраз в строке запроса.Поэтому важно выбрать анализатор, который не будет мешать терминам, используемым в строке запроса.
Поля
Lucene поддерживает полевые данные. При выполнении поиска вы можете указать поле или использовать поле по умолчанию. Имена полей и поле по умолчанию зависят от реализации.
Вы можете выполнить поиск в любом поле, введя имя поля, двоеточие «:» и затем искомый термин.
В качестве примера предположим, что индекс Lucene содержит два поля, заголовок и текст, а текст является полем по умолчанию.Если вы хотите найти документ под названием «Правильный путь», который содержит текст «не ходи этим путем», вы можете ввести:
заголовок: "Верный путь" И текст: иди
или
title: "Делай правильно" И правильно
Поскольку текст является полем по умолчанию, индикатор поля не требуется.
Примечание. Поле действительно только для термина, которому оно предшествует, поэтому запрос
title: Сделай правильно
Найдет только «Do» в поле заголовка.Он найдет «это» и «справа» в поле по умолчанию (в данном случае в текстовом поле).
Модификаторы терминов
Lucene поддерживает изменение условий запроса, чтобы обеспечить широкий диапазон параметров поиска.
Поиск по шаблону
Lucene поддерживает поиск с использованием подстановочных знаков, состоящих из одного и нескольких символов, в рамках одного термина (не внутри фразовых запросов).
Чтобы выполнить поиск с использованием подстановочных знаков, состоящих из одного символа, используйте «?» условное обозначение.
Чтобы выполнить поиск с использованием подстановочных знаков, состоящих из нескольких символов, используйте символ «*».
Поиск с использованием односимвольных подстановочных знаков ищет термины, соответствующие термину с замененным единственным символом. Например, для поиска по запросу «текст» или «тест» можно использовать поиск:
те? Т
При поиске с использованием подстановочных знаков, состоящих из нескольких символов, выполняется поиск 0 или более символов. Например, для поиска теста, тестов или тестировщика можно использовать поиск:
тест *
Вы также можете использовать поиск по шаблону в середине термина.
тэ * т
Примечание: нельзя использовать * или? символ в качестве первого символа поиска.
Нечеткие поиски
Lucene поддерживает нечеткий поиск на основе алгоритма расстояния Левенштейна или алгоритма редактирования расстояния. Чтобы выполнить нечеткий поиск, используйте символ тильды «~» в конце одного слова Term. Например, чтобы найти термин, похожий по написанию на «бродить», используйте нечеткий поиск:
роуминг ~
В этом поиске будут найдены такие термины, как пена и блуждание.
Начиная с Lucene 1.9 дополнительный (необязательный) параметр может указывать необходимое сходство. Значение находится в диапазоне от 0 до 1, при значении, близком к 1, будут сопоставляться только термины с более высоким сходством.Например:
роуминг ~ 0,8
Если параметр не задан, по умолчанию используется 0,5.
Поиск по близости
Lucene поддерживает поиск слов на определенном расстоянии. Чтобы выполнить поиск по близости, используйте символ тильды «~» в конце фразы. Например, для поиска «apache» и «jakarta» в пределах 10 слов друг от друга в документе используйте поиск:
"jakarta apache" ~ 10
Поиск по диапазону
Range Queries позволяют сопоставлять документы, значения полей которых находятся между нижней и верхней границей, указанной в запросе диапазона.Запросы диапазона могут включать или исключать верхнюю и нижнюю границы. Сортировка производится лексикографически.
mod_date: [20020101 TO 20030101]
Это позволит найти документы, поля mod_date которых имеют значения от 20020101 до 20030101 включительно. Обратите внимание, что запросы диапазона не зарезервированы для полей даты. Вы также можете использовать запросы диапазона с полями без даты:
название: {Aida TO Carmen} Здесь находятся все документы, названия которых находятся между Аидой и Кармен, кроме Аиды и Кармен.4 «Apache Lucene»
По умолчанию коэффициент усиления равен 1. Хотя коэффициент усиления должен быть положительным, он может быть меньше 1 (например, 0,2)
Логические операторы
Логические операторы позволяют комбинировать термины с помощью логических операторов. Lucene поддерживает логические операторы AND, «+», OR, NOT и «-» (Примечание: логические операторы должны быть ЗАГЛАВНЫМИ).
Оператор OR является оператором соединения по умолчанию. Это означает, что если между двумя терминами нет логического оператора, используется оператор OR.Оператор OR связывает два термина и находит соответствующий документ, если какой-либо из терминов существует в документе. Это эквивалентно объединению с использованием множеств. Символ || можно использовать вместо слова ИЛИ.
Для поиска документов, содержащих «jakarta apache» или просто «jakarta», используйте запрос:
"jakarta apache" jakarta
или
"Джакарта Апаче" ИЛИ Джакарта
И
Оператор AND сопоставляет документы, в которых оба термина существуют в любом месте текста одного документа.Это эквивалентно пересечению с использованием множеств. Вместо слова AND можно использовать символ &&.
Для поиска документов, содержащих «jakarta apache» и «Apache Lucene», используйте запрос:
"jakarta apache" И "Apache Lucene"
+
Оператор «+» или «обязательный» требует, чтобы термин после символа «+» существовал где-то в поле одного документа. «~ *?: \
Чтобы экранировать эти символы, используйте \ перед символом.Например, для поиска (1 + 1): 2 используйте запрос:
\ (1 \ +1 \) \: 2
Survey123 — Ошибка шаблона отчета
Я разрабатываю шаблон отчета Survey123 и получаю следующее сообщение об ошибке [Ошибка: не удалось проанализировать «$ {RMMAL27_Y_type}». Поле «$ {RMMAL27_Y_type}» не существует или не может быть найдено в текущей области синтаксического анализа. «].
Поле существует в моих данных, и я копирую его прямо из предоставленных примеров того, как работать с полем для отчета шаблон.
- В моем настроенном шаблоне отчета вопрос отформатирован следующим образом:
- Имеются ли в юрисдикции заранее определенные и задокументированные промежуточные области и точки распространения (POD) для получения и распределения ресурсов?
$ {RMMAL27 | selected: «y»} Да
$ {# RMMAL27_Y}
$ {RMMAL27_Y_type}
Тип Имя местоположения: $ {RMMAL27_Y_name}
Тип Местоположение Адрес: $ {RMMAL27_Y_address_}, $ {RMMAL27_Y_MAL_27_Y_city}
$ {/ RMMAL27_Y}
$ {RMMAL27 | выбрано: «n»} №
$ {RMMAL27_N | selected: «no»} Помощь не требуется.
$ {RMMAL27_N | selected: «assist»} Юрисдикции требуется техническая помощь для разработки этого плана / протокола и определения промежуточной зоны и местоположений POD.
Примечания к промежуточному местоположению: $ {RMMAL27_N_notes_stage}
Примечания к расположению POD: $ {RMMAL27_N_notes_pod}
- В загружаемом шаблоне из Survey123 поля показаны как:
Расположение промежуточных и POD (по крайней мере, по одному)
$ {# RMMAL27_Y}
Пожалуйста, выберите тип местоположения
$ {RMMAL27_Y_type}
Расположение промежуточной стадии и POD — Местоположение
$ {RMMAL_27_locality}
Тип местоположения
Тип Расположение Улица Адрес
$ {RMMAL27_Y_address}
Тип Расположение Город
$ {RMMAL27_Y_city}
Тип Местоположение Почтовый индекс
$ 9000_zip2000 $ 9000_zip2000 $ выберите {9MAL272] карта
$ {RMMAL27_Y_geopoint}
————————————— ————————- ——————————
$ {/ RMMAL27_Y}
- Я также получаю сообщение об ошибке «Произошла ошибка при рендеринге механизмом отчетов.
Изучение морфемного состава слова в начальных классах
В статье раскрывается вопрос изучения морфемного состава слова и последовательности организации работы над формированием навыков правильного и, самое главное, осознанного анализа морфемного состава слова.
Ключевые слова:морфемный анализ, орфографический навык, корень, приставка, суффикс, окончание, однокоренные слова.
The question of study of morpheme structure of the word and sequence of organization of work on forming of skills of correct and, the most important thing, conscious analysis of morpheme structure of the word is revealed in the given article.
Key words: morpheme analysis, orthographical, skill, root, prefix, suffix, ending, paranonymous words.
Каждый гражданин нашей страны Республики Узбекистан должен знать свою идеологию, цели своего государства, поэтому необходимо, развитие и изучение русского языка, так как наша страна многонациональна. Поэтому государство проводит реформы в сфере образовательной системы, что даст возможность поднять её на уровень требований нового времени, приблизить прекрасное будущее гармонично развитого поколения.
Учебный предмет «Русский язык» в системе начального образования объединен тремя направлениями. Первое из них связано с развитием у детей дара слова, формированием умения выражать свои мысли, правильно употреблять слова. Речевое развитие детей — основной принцип всех занятий по русскому языку, именно оно содействует воспитывающей и развивающей роли предмета, активизации познавательной деятельности школьников.
Особенно мы обращаем внимание на необходимость рационально проводить работу по развитию образования слов, их морфемному составу и важно обозначить, какое важное место занимают каждая из изученных морфем. Велико также значение занятий словообразованием с точки зрения задач общепедагогического характера, развития мыслительных способностей учащихся, их познавательной деятельности, самостоятельности, навыков решения поисковых задач.
Значение изучения морфемного состава и особенности организации работы в классах с многонациональным составом учащихся состоит, во-первых, в том, что школьники овладевают одним из ведущих способов раскрытия лексического значения слов. Отсюда вытекает задача учителя — создать оптимальные условия для осознания детьми взаимосвязи, существующей в языке между лексическим значением слова и его морфемным составом, целенаправленно руководить на этой основе уточнением словаря учащихся.
Во-вторых, даже элементарные знания об образовании слов очень важны для понимания учащимися основного источника пополнения нашего языка новыми словами.
В-третьих, ознакомление с основами словообразования способствует обогащению знаний школьников об окружающей их действительности. Слова опосредованно (через понятия) соотносятся с предметами, процессами, явлениями. Установление семантико-структурной связи между словами опирается на связь между соотносимыми понятиями.
В-четвертых, осознание роли морфем в слове, а также семантического значения приставок и суффиксов содействует формированию у школьников точности речи. Задача учителя — максимально способствовать не только пониманию учащимися лексического значения слова, но и развитию у них осознанного употребления в контексте слов с определенными приставками и суффиксами.
В-пятых, изучение морфемного состава слова имеет большое значение для формирования орфографических навыков. Обусловлено это тем, что ведущим принципом русского правописания является морфологический. Формирование навыков правописания корня, приставок, суффиксов и окончаний на теоретической основе (а только такое письмо может быть сознательным) требует целенаправленного применения (фонетических, словообразовательных и грамматических знаний). Поэтому одной из важных задач изучения морфемного состава слова является создание основы знаний и умений, необходимых для формирования навыков правописания морфем слова, и, прежде всего, корня.
Без умения выделять в слове его составные части (морфемы): основу, окончание, корень, приставки и суффиксы — невозможно изучение частей речи, усвоение многих орфографических правил, понимание знаний большинства слов, сознательное изучение грамматики. Работа по изучению состава слова ведется в начальных классах и по мере перехода учащихся из класса в класс усложняется. Так, помимо умения выделять в слове значимые части, учащиеся должны научиться подбирать однокоренные слова.
Методика работы по изучению состава слова в начальных классах» значима в современном языкознании, потому что задача пропедевтической работы состоит в подготовке учащихся к пониманию смысловой и структурной соотносимости, которая существует в языке между однокоренными словами. Такая задача обусловлена, во-первых, тем, что понимание семантико-структурной соотносимости слов по своей лингвистической сущности является основой усвоения особенностей однокоренных слов и образования слов в русском языке. Во-вторых, указанная задача продиктована трудностями, с которыми сталкиваются младшие школьники при изучении однокоренных слов и морфем.
При изучении морфемного состава слова многие учителя и учащиеся сталкиваются с проблемой соотношения умения различать разбор по составу слова и разбор словообразовательный, поскольку тот и другой виды разбора выполняют различную роль в усвоении школьниками грамматического строя русского языка. [1.с.154]
Вопрос о роли изучения морфемного состава и последовательности организации работы над формированием навыков правильного и, самое главное, осознанного анализа морфемного состава слова, разработанные как методистами-исследователями прошлого (К. Д. Ушинский, Д. И. Тихомиров, А. Н. Гвоздев, Н. М. Соколов, В. П. Шереметевский), так и учеными-методистами современности (Лебедев В. И., Львов М. Р., Тихонов А. Н.).
В своих трудах профессор В. И. Лебедев рекомендует сочетать упражнения в разборе слова по составу со словообразовательной работой. Эти упражнения представляются в следующем виде:
— выделение морфемы, при помощи которой образовано разбираемое слово от другого;
— мотивированное выделение в слове основы и сравнение её с основой исходного слова;
— самостоятельное составление списка слов, принадлежащих к различным частям речи, но образованных при помощи одноименных суффиксов;
— образование ряда слов, в составе каждого из которых были бы и приставки и суффиксы;
— образование новых слов при помощи:
а) разных приставок;
б) разных суффиксов;
в) соединительных гласных;
г) без соединительных гласных (бессуффиксальный способ). [2, с.264]
Академики Львов М. Р., Шанский Н. М. рекомендуют обучать детей младшего школьного возраста морфемному анализу по принципу «матрешки», снимая последовательно один слой за другим, начиная с конца слова.
Однако в школьной практике существует ещё практика анализа морфемного разбора, начиная с корня.
Тема «Состав слова» злободневна ещё, потому что система изучения морфемного состава слова учитывает не только лингвистические особенности изучаемого материала, возрастные возможности младших школьников, но и такие дидактические принципы, как сознательность, преемственность и перспективность обучения. От ознакомления с особенностями всех морфем учащиеся переходят к изучению каждой морфемы в отдельности, и наконец, в процессе изучения частей речи создаются условия для некоторого углубления знаний о составе слова, поскольку они (знания) вступают в новые, более сложные связи и отношения. Следует заметить, что очень важно в процессе, как подготовительных упражнений, так и тех, которые ставят целью углубить, расширить и упрочить полученные знания, решать грамматические задачи в органической связи с орфографическими.
Усвоение темы «Состав слова» в начальных классах имеет большое значение для дальнейшего изучения русского языка. В ходе занятий по теме осуществляется серьезная подготовка к последующему изучению частей речи. Учащиеся постепенно начинают замечать, что одни и те же суффиксы в разных словах являются показателями определенной части речи; одни и те же приставки, наоборот, присоединяются к разным частям речи, причем новое слово, образованное от данного слова при помощи приставки, относится к той же части речи, что и данное слово. Например, при помощи суффиксов –чик-, -щик-, -ость- и другие образуются только существительные, при помощи суффиксов –ск-, -чив-, -лив- и другие- только прилагательные, при помощи приставки при- образуется и существительное пригород, и прилагательное пригородный, и глагол принести.
Изучение словообразования связано с усвоением орфографии, так как основным принципом русской орфографии является морфологический, согласно которому значимые части слова пишутся всегда одинаково независимо от того, как они произносятся. Так, например, в слове «подходить» гласный о, оказавшись в безударном положении, произносится как [а], звонкий согласный [д] в положении перед глухим [х] произносится как [т]. Тем не менее, руководствуясь морфологическим принципом, мы пишем «подходить».
При составлении рядов однокоренных слов учащиеся сравнивают значение одного слова с другим, находят сходство и различие, приходят к выводу, доказывают, тем самым развивают своё мышление и речь. Применение приема сравнения закономерно вытекает из морфемного разбора, основанного на принципе подбора родственных слов. Каждый раз, когда перед учащимися стоит задача выделить морфемы в данном слове, они могут решить её при условии сравнения данного слова с родственными словами. Чтобы, например, найти корень слова «вестник», учащийся должен, прежде всего, подыскать родственные по звукам и значению слова (вестница, весточка, известить, повестка), сравнить их и найти главную значимую часть (-вест-). При выделении приставки слово сравнивается с однокоренными приставочными словами: прибежать, отбежать, убежать.
Таким образом, прием сравнения сочетается с приемами группировки и обобщения. Следовательно, структурный анализ слов сопровождается различными мыслительными операциями, выделением существенных и несущественных признаков, сравнением их, нахождением сходства и различия между ними, суждением, умозаключением, доказательством, которые оформляются в связное высказывание.
Морфемный анализ обязательно сочетается с работой по лексике и развитию связной речи, поскольку упражнения, заключающиеся главным образом в работе над мотивированными ответами на вопросы, касающиеся морфемного и словообразовательного анализа в составлении словосочетаний и предложений с изучаемыми словами, в выяснении значений выделенных морфем и их правописания, в работе над изложением и сочинением с включением в них анализируемых слов.
Работа по выяснению морфологических частей слова, проводимая из урока в урок, развивает в учащихся интерес к структуре слова, к самому языку. Например, слова «солом-ин-к-а, горош-ин-к-а, жемчуж-ин-к-а» означают: одна из какого-нибудь количества соломы, одна из какого-нибудь количества гороха и т. д. Во всех словах значение единичности заключено в суффиксе –ин-, а суффикс –к- придает значение уменьшительности. Если мы сообщим детям, что –ин- в древнерусском языке означала «один», то они с интересом начинают объяснять значение слов «датчанин, англичанин, крестьянин». Полеченные значения подготавливают ребят к пониманию того, почему –ин- выпадает во множественном числе.
Практическое знакомство с производящей основой развивает интерес к тому, как образовалось и произошло слово. Чем больше сведений получают учащиеся о составе слова и словообразовании, тем яснее становится для них богатство и величие русского языка, тем сильнее пробуждается их желание изучать родной язык.
Данные методические разработки и составленная система упражнений может быть использована учителями в работе с младшими школьниками.
Литература:
1. Lvov M. R. Methods of elementary teaching Russian language — Leningrad 1996 y. P-154.
2. Lebedev V. I. Learning word formation. — in: Barinova E. A. Methods of Russian language. M., 1974. P- 264.
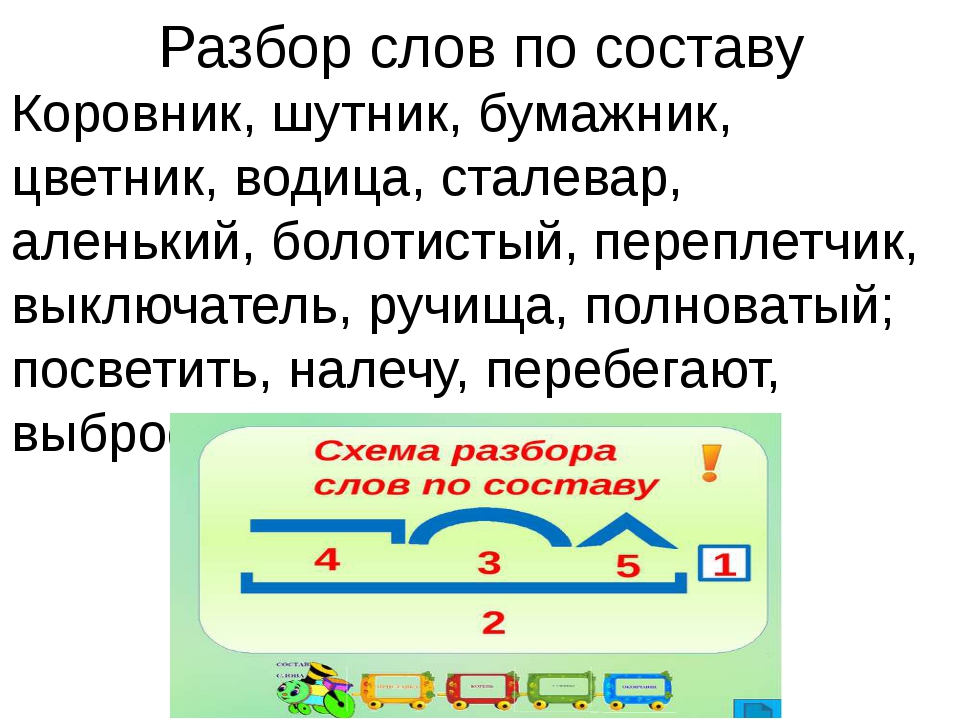
Как разобрать по составу слово попугай
Разбор слов по составу
Разбор слова по составу, или морфемный разбор, — выделение частей, из которых слово состоит. Чтобы научиться делать разборы, необходимо обладать знаниями о частях слова и словообразовании, изучение которых входит в школьную программу. При затруднении с разбором прибегают к словарям морфемных разборов, печатным или электронным. Наш сайт содержит словарь морфемных разборов, включающий популярные в школьной программе слова и сложные слова из обихода. На сайте также содержится справочная информация: даются определения частей слов, объясняются способы словообразования, приводятся примеры. В настоящий момент словарь содержит 100 000 морфемных разборов слов в начальной форме. Знания морфем начальной формы слова (инфинитив, единственное число, мужской род, именительный падеж) в большинстве случаев достаточно для определения морфем слова в разных склонениях, спряжениях, родах и числах. Надеемся, что сайт поможет вам в подготовке домашних заданий.
План разбора
План разбора слова по составу состоит в следующем: Определяем, к какой части речи относится анализируемое слово. Выделяем окончание и основу. Для определения окончания слово изменяют, например, по падежам. Изменяемая часть будет являться окончанием, остальная часть слова без окончания — основой. Следует помнить, что всё слово может являться основой и не иметь окончания, например наречие — неизменяемая часть речи. Определяем, входит ли в основу слова кроме корня также приставка и суффикс. Для этого слово сопоставляется с однокоренными словами. Убеждаемся, что выделенные приставки и суффиксы имеются в других словах. Для проверки подбираются аналогичные слова и сравниваются с анализируемым. Обозначем части слова с помощью графических обозначений.
Примеры разборов
Покажем примеры разбора слов разных частей речи с разной комбинацией морфем: метро — неизменяемое существительное, нет окончания лес — существительное с нулевым окончанием при школь н ый — прилагательное со всеми основными морфемами: приставкой, корнем, суффиксом, окончанием лед о кол — существительное с двумя корнями и соединительной гласной по зв а л а — глагол с приставкой, окончанием, словооразующим суффиксом а и формобращующим суффиксом л, который не входит в основу быстр о — наречие с суффиксом, не имеет окончания Подберите нужные слова с необходимыми частями слова через поиск слов по морфемам.
Особенности разборов
Обратите внимание: морфемные разборы одних и тех же слов могут быть сделаны по-разному в разных словарях, разными учителями и филологами, в школе и в университете. Каждый «источник» аргументирует разбор по-своему и считает свой разбор правильным. Разные учителя придерживаются разных программ определения морфем в словах. Ярким примером служат инфинитивы глаголов. Например в слове жить: в одних школах ть отмечается как суффикс, в других — как окончание, в третьих — как суффикс с последующим нулевым окончанием. Мы выделяем морфемы по первому варианту. Образовательные программы школы и университета в части разбора слов могут различаться. В университетах учитывают этимологию слов, выделяют нулевой суффикс (Азов, бег), рассматривают словообразования от нулевого корня и другие сложные примеры. Мы используем программу, ориентированную на школу, и деление на морфемы по словарю А. Н. Тихонова. Заметим, что есть различия в словаре А. Н. Тихонова и словаре Т. Ф. Ефремовой. Так А. Н. Тихонов части некоторых слов «вносит» в один корень, при этом Т. Ф. Ефремова выделяет в словах приставку, суффиксы, учитывая этимологию. Примеры таких слов: благодарность, превосходство, прекрасный. Современные учёные не могут сойтись во мнении единого верного разбора отдельных слов русского языка, поэтому разные варианты считают допустимыми. При разборе слов следует помнить, что бывают слова, содержащие нулевое окончание (автобус), не имеющие окончания (ателье), имеющие несколько корней (авиапочта) и другие сложные варианты. К сложным вариантам на нашем сайте даны объяснения.
Морфемные словари
Среди печатных изданий словарей морфемных разборов, которые вы найдете в школьной библиотеке, можно выделить следующие: Рацибурская Л. В. Словарь уникальных морфем современного русского языка М.: Флинта: Наука, 2009. — 160 с. Аванесов Р. И., Ожегов С. И. Морфемно-орфографический словарь Около 100 000 слов / А. Н. Тихонов. — М.: АСТ: Астрель, 2002. — 704 с. Тихонов А. Н. Морфемно-орфографический словарь русского языка, 2002. Кузнецова А. И., Ефремова Т. Ф. Словарь морфем русского языка Ок. 52000 слов. — М.: Рус. яз., 1986. — 1132 с. В словарях морфемных разборов обычно деление на морфемы делается с помощью слешей: под/вод/н/ый, гор/а и т. д. В словаре Т. Ф. Ефремовой у группы слов с одинаковым корнем исходное слово записано полностью, а в образованных от него словах корневая морфема обозначается через знак V: лес, V-а, V-н-ой и т. д.
Интернет проект BeginnerSchool. ru
Сайт для детей и их родителей
Как разобрать слово по составу
Продолжим изучать основные правила русского языка и сегодня вспомним, как разбирать Слово по составу.Разобрать слово по составу – значит сделать его морфемный анализ, или указать, из каких морфем слово состоит. Морфема – минимальная значимая часть слова.
Напомним, на какие части можно разбить слово:
Корень
главная значимая часть слова, которую имеют родственные слова.
В русском языке есть слова, которые состоят из одного корня: гриб, метро, пер о, остров, погод а.Также, есть слова состоящие из двух корней: тепл о ход, вод о пад, сам о вар.
Из трех корней: вод о гряз е леч ебница.
Из четырех корней: электр о свет о вод о леч ение.
Суффикс
значимая часть слова, которая стоит после корня и предназначенная для образования новых слов.
В некоторых словах может быть два суффикса: подберез ов ик – суффиксы — ов — и — ик — .Приставка
это значимая часть слова, которая находится перед корнем и предназначена для образования новых слов.
Окончание
это изменяемая часть слова, она служит для связи слов в предложении.
Итак, чтобы разобрать Слово по составу надо найти в слове окончание, для чего надо изменить слово. Например, в слове поездка. Изменяя слово: поездк Ой , или поездк У , то видно – изменяемая часть – А . Обведем её рамочкой, это окончание. Далее найдем корень, для этого подберем однокоренное слово – по Езд , пере Езд . Сравнивая эти слова – видим, что не меняется часть слова Езд . Это и есть корень. Затем найдем приставку, для этого надо опять подобрать однокоренные слова – По езд, Под ъезд. Видно, что приставка стоит перед корнем, т. е. в нашем случае – это часть слова По . И наконец, найдем суффикс, который стоит после корня и предназначен для образования слова, в нашем случае – это часть слова К . У нас получилось: Теперь рассмотрим самые распространенные суффиксы имен существительных:Разбор слова по составу онлайн
Описание
Как разобрать слово по составу
Морфемный разбор слова или разбор по составу — это нахождение всех необходимых частей слова (корень, суффикс, окончание и т. д). Данный принцип является одним из основных в русскоязычной грамматике, поэтому морфемный разбор имеет немаловажное значение. Например, для того, чтобы определить, какая буква пишется в том или ином слове, нужно сначала узнать, в какой части слова она находится. И в зависимости от этого, использовать нужное написание. Грамотный разбор слова является основой правописания. Для осуществления разбора нужно иметь общее представление о морфемах, а также знать определённый порядок действий.
Какие бывают морфемы
Приставка. Это морфема, при помощи которой образовываются новые слова. Приставка находится перед корнем. При помощи приставочного способа образования слов чаще всего получаются одинаковые части речи. Например: ставить — переставить. На примере видно, что от глагола при помощи приставки пере — образовался новый глагол. В русском языке также присутствуют заимствованные от других языков приставки. Например: анти-, де-, суб — и так далее. Корень слова. Корень считается основной частью любого слова. В нем закладывается общее его значение, а также значение однокоренных слов (тех, у которых одинаковый корень). Однокоренных слова не обязательно должны относиться к одной части речи, они могут быть различными (от существительного образовываться в прилагательные и т. д.). Однако встречаются слова, которые имеют созвучные и похожие корни, но в то же время имеют отличные друг от друга значения. В таких случаях слова не считаются однокоренными, а называются омонимами. Для того, чтобы выявить корень слова, необходимо попытаться подобрать к нему однокоренные слова и найти ту общую часть, которая присутствует в каждом слове и остаётся неизменной. Обязательное условие: слова должны иметь похожее лексическое обозначение, а не просто созвучный корень. Например: дом — домик — домашний. Данные слова имеют одинаковую часть слова дом-, а значит она и является корнем. Игра — игровой — играть. В этой цепочке слов общей частью является игр-, значит она также является корнем. Суффикс. Это также одна из части слов, которая помогает образовывать новые слова. Морфема находит свое расположение после корня слова. Кроме того, суффикс помогает менять саму форму того или иного слова, а также образовывать новые части речи. Чаще всего существительное и прилагательные. Например: лес — лесник. Благодаря суффиксу — ник — образовалось новое существительное. Море — морской. При помощи суффикса — ск — от существительного образовалось новое прилагательное. Стоит заметить, что морфема не считается основной частью слова, суффикса попросту может не быть в составе. Чтобы найти данную морфему, нужно для начала определить корень и окончание слова. То, что останется между ними, и будет суффиксом. Важно знать, что оставшаяся часть слова не всегда является цельным суффиксом. Их может быть и несколько. Окончание слова. Окончание является изменяем ой частью слова, которая зависит от рода слова, числа и падежа. Данная морфема обычно идёт после корня либо суффикса. Окончание несёт роль связывание слов в предложениях. Как же его определить? Нужно просто просклонять нужное слово и понять, какой части присуще меняться. Это и будет окончанием слова. Например: трава, травы, траве. Просклоняв слово в разных падежах, можно увидеть, что изменяется только последняя буква, а значит она и является окончанием. Окончание также может иметь и нулевую форму. Для того, чтобы его определить, нужно также просклонять нужное слово по падежам. Если в падежных формах появляются новые буквы, значит начальная форма слова имеет нулевое окончание. Например: дом, дома, дому. В падежных формах слово приобрело окончание, значит изначально оно являлось нулевым. Соединительные буквы. Это буквы, которые соединяют несколько корней в сложнообразованных словах. Наиболее распространены сединительные гласные — о — и — е-. Например: птицелов, кровожадный, самолёт. Основа. Это часть слова, не входящая в состав окончания и остающаяся неизменной.
Основной принцип разбора слова по составу
Определить, с какой частью речи придётся работать. Это можно сделать путем подбора вопроса к слову. Теперь нужно определить окончание имеющегося слова. Для этого стоит просклонять его по числам и падежам. Та часть, которая изменилась, обводится в квадрат. Так обозначается окончание. Первоначальный поиск окончания является обязательным правилом для всех школьников. Ведь некоторые из них начинают морфемный разбор именно с выделения корня. Это является одним из самых ошибочных заблуждений, потому что в некоторых словах определить корень довольно сложно, а где-то его и вовсе нет. Следующее действие — найти основу. Сделать это несложно. Часть слова, оставшаяся после выделения окончания, и является основой. Подчёркивается она одной горизонтальной линией, которая немного приподнимается перед окончанием. Определить корень слова. Чтобы это осуществить, нужно подобрать однокоренные слова к нужному слову. Они должны быть похожи по лексическому значению, то есть быть похожими по смыслу, а не только по звучанию. Та неизменная часть, которая присутствует во всех словах и будет являться корнем. Обозначается он специальной дугой над нужной буквенной частью. Выделить суффиксы. Для этого нужно сопоставить конкретное слово с его прочими формами. А затем создать словообразовательную цепочку, чтобы понять, какое слово было первоначальным, и какой суффикс использовался в процессе. Обозначается морфема формой полуромба над нужной частью слова. Найти приставку. К конкретному слову нужно попытаться подобрать другие приставки. Также можно использовать другие слова с применением имеющейся приставки. Если смысл слова не коверкается, значит эта часть слова является приставкой. Выделяется она горизонтальной линией над словом, которая загинается перед корнем.
Разбор слов по составу
Разбор слова по составу, или морфемный разбор, — выделение частей, из которых слово состоит. Чтобы научиться делать разборы, необходимо обладать знаниями о частях слова и словообразовании, изучение которых входит в школьную программу. При затруднении с разбором прибегают к словарям морфемных разборов, печатным или электронным. Наш сайт содержит словарь морфемных разборов, включающий популярные в школьной программе слова и сложные слова из обихода. На сайте также содержится справочная информация: даются определения частей слов, объясняются способы словообразования, приводятся примеры. В настоящий момент словарь содержит 100 000 морфемных разборов слов в начальной форме. Знания морфем начальной формы слова (инфинитив, единственное число, мужской род, именительный падеж) в большинстве случаев достаточно для определения морфем слова в разных склонениях, спряжениях, родах и числах. Надеемся, что сайт поможет вам в подготовке домашних заданий.
План разбора
План разбора слова по составу состоит в следующем: Определяем, к какой части речи относится анализируемое слово. Выделяем окончание и основу. Для определения окончания слово изменяют, например, по падежам. Изменяемая часть будет являться окончанием, остальная часть слова без окончания — основой. Следует помнить, что всё слово может являться основой и не иметь окончания, например наречие — неизменяемая часть речи. Определяем, входит ли в основу слова кроме корня также приставка и суффикс. Для этого слово сопоставляется с однокоренными словами. Убеждаемся, что выделенные приставки и суффиксы имеются в других словах. Для проверки подбираются аналогичные слова и сравниваются с анализируемым. Обозначем части слова с помощью графических обозначений.
Примеры разборов
Покажем примеры разбора слов разных частей речи с разной комбинацией морфем: метро — неизменяемое существительное, нет окончания лес — существительное с нулевым окончанием при школь н ый — прилагательное со всеми основными морфемами: приставкой, корнем, суффиксом, окончанием лед о кол — существительное с двумя корнями и соединительной гласной по зв а л а — глагол с приставкой, окончанием, словооразующим суффиксом а и формобращующим суффиксом л, который не входит в основу быстр о — наречие с суффиксом, не имеет окончания Подберите нужные слова с необходимыми частями слова через поиск слов по морфемам.
Особенности разборов
Обратите внимание: морфемные разборы одних и тех же слов могут быть сделаны по-разному в разных словарях, разными учителями и филологами, в школе и в университете. Каждый «источник» аргументирует разбор по-своему и считает свой разбор правильным. Разные учителя придерживаются разных программ определения морфем в словах. Ярким примером служат инфинитивы глаголов. Например в слове жить: в одних школах ть отмечается как суффикс, в других — как окончание, в третьих — как суффикс с последующим нулевым окончанием. Мы выделяем морфемы по первому варианту. Образовательные программы школы и университета в части разбора слов могут различаться. В университетах учитывают этимологию слов, выделяют нулевой суффикс (Азов, бег), рассматривают словообразования от нулевого корня и другие сложные примеры. Мы используем программу, ориентированную на школу, и деление на морфемы по словарю А. Н. Тихонова. Заметим, что есть различия в словаре А. Н. Тихонова и словаре Т. Ф. Ефремовой. Так А. Н. Тихонов части некоторых слов «вносит» в один корень, при этом Т. Ф. Ефремова выделяет в словах приставку, суффиксы, учитывая этимологию. Примеры таких слов: благодарность, превосходство, прекрасный. Современные учёные не могут сойтись во мнении единого верного разбора отдельных слов русского языка, поэтому разные варианты считают допустимыми. При разборе слов следует помнить, что бывают слова, содержащие нулевое окончание (автобус), не имеющие окончания (ателье), имеющие несколько корней (авиапочта) и другие сложные варианты. К сложным вариантам на нашем сайте даны объяснения.
Морфемные словари
Среди печатных изданий словарей морфемных разборов, которые вы найдете в школьной библиотеке, можно выделить следующие: Рацибурская Л. В. Словарь уникальных морфем современного русского языка М.: Флинта: Наука, 2009. — 160 с. Аванесов Р. И., Ожегов С. И. Морфемно-орфографический словарь Около 100 000 слов / А. Н. Тихонов. — М.: АСТ: Астрель, 2002. — 704 с. Тихонов А. Н. Морфемно-орфографический словарь русского языка, 2002. Кузнецова А. И., Ефремова Т. Ф. Словарь морфем русского языка Ок. 52000 слов. — М.: Рус. яз., 1986. — 1132 с. В словарях морфемных разборов обычно деление на морфемы делается с помощью слешей: под/вод/н/ый, гор/а и т. д. В словаре Т. Ф. Ефремовой у группы слов с одинаковым корнем исходное слово записано полностью, а в образованных от него словах корневая морфема обозначается через знак V: лес, V-а, V-н-ой и т. д.
Интернет проект BeginnerSchool. ru
Сайт для детей и их родителей
Как разобрать слово по составу
Продолжим изучать основные правила русского языка и сегодня вспомним, как разбирать Слово по составу.Разобрать слово по составу – значит сделать его морфемный анализ, или указать, из каких морфем слово состоит. Морфема – минимальная значимая часть слова.
Напомним, на какие части можно разбить слово:
Корень
главная значимая часть слова, которую имеют родственные слова.
В русском языке есть слова, которые состоят из одного корня: гриб, метро, пер о, остров, погод а.Также, есть слова состоящие из двух корней: тепл о ход, вод о пад, сам о вар.
Из трех корней: вод о гряз е леч ебница.
Из четырех корней: электр о свет о вод о леч ение.
Суффикс
значимая часть слова, которая стоит после корня и предназначенная для образования новых слов.
В некоторых словах может быть два суффикса: подберез ов ик – суффиксы — ов — и — ик — .Приставка
это значимая часть слова, которая находится перед корнем и предназначена для образования новых слов.
Окончание
это изменяемая часть слова, она служит для связи слов в предложении.
Итак, чтобы разобрать Слово по составу надо найти в слове окончание, для чего надо изменить слово. Например, в слове поездка. Изменяя слово: поездк Ой , или поездк У , то видно – изменяемая часть – А . Обведем её рамочкой, это окончание. Далее найдем корень, для этого подберем однокоренное слово – по Езд , пере Езд . Сравнивая эти слова – видим, что не меняется часть слова Езд . Это и есть корень. Затем найдем приставку, для этого надо опять подобрать однокоренные слова – По езд, Под ъезд. Видно, что приставка стоит перед корнем, т. е. в нашем случае – это часть слова По . И наконец, найдем суффикс, который стоит после корня и предназначен для образования слова, в нашем случае – это часть слова К . У нас получилось: Теперь рассмотрим самые распространенные суффиксы имен существительных:Разбор слова по составу онлайн
Описание
Как разобрать слово по составу
Морфемный разбор слова или разбор по составу — это нахождение всех необходимых частей слова (корень, суффикс, окончание и т. д). Данный принцип является одним из основных в русскоязычной грамматике, поэтому морфемный разбор имеет немаловажное значение. Например, для того, чтобы определить, какая буква пишется в том или ином слове, нужно сначала узнать, в какой части слова она находится. И в зависимости от этого, использовать нужное написание. Грамотный разбор слова является основой правописания. Для осуществления разбора нужно иметь общее представление о морфемах, а также знать определённый порядок действий.
Какие бывают морфемы
Приставка. Это морфема, при помощи которой образовываются новые слова. Приставка находится перед корнем. При помощи приставочного способа образования слов чаще всего получаются одинаковые части речи. Например: ставить — переставить. На примере видно, что от глагола при помощи приставки пере — образовался новый глагол. В русском языке также присутствуют заимствованные от других языков приставки. Например: анти-, де-, суб — и так далее. Корень слова. Корень считается основной частью любого слова. В нем закладывается общее его значение, а также значение однокоренных слов (тех, у которых одинаковый корень). Однокоренных слова не обязательно должны относиться к одной части речи, они могут быть различными (от существительного образовываться в прилагательные и т. д.). Однако встречаются слова, которые имеют созвучные и похожие корни, но в то же время имеют отличные друг от друга значения. В таких случаях слова не считаются однокоренными, а называются омонимами. Для того, чтобы выявить корень слова, необходимо попытаться подобрать к нему однокоренные слова и найти ту общую часть, которая присутствует в каждом слове и остаётся неизменной. Обязательное условие: слова должны иметь похожее лексическое обозначение, а не просто созвучный корень. Например: дом — домик — домашний. Данные слова имеют одинаковую часть слова дом-, а значит она и является корнем. Игра — игровой — играть. В этой цепочке слов общей частью является игр-, значит она также является корнем. Суффикс. Это также одна из части слов, которая помогает образовывать новые слова. Морфема находит свое расположение после корня слова. Кроме того, суффикс помогает менять саму форму того или иного слова, а также образовывать новые части речи. Чаще всего существительное и прилагательные. Например: лес — лесник. Благодаря суффиксу — ник — образовалось новое существительное. Море — морской. При помощи суффикса — ск — от существительного образовалось новое прилагательное. Стоит заметить, что морфема не считается основной частью слова, суффикса попросту может не быть в составе. Чтобы найти данную морфему, нужно для начала определить корень и окончание слова. То, что останется между ними, и будет суффиксом. Важно знать, что оставшаяся часть слова не всегда является цельным суффиксом. Их может быть и несколько. Окончание слова. Окончание является изменяем ой частью слова, которая зависит от рода слова, числа и падежа. Данная морфема обычно идёт после корня либо суффикса. Окончание несёт роль связывание слов в предложениях. Как же его определить? Нужно просто просклонять нужное слово и понять, какой части присуще меняться. Это и будет окончанием слова. Например: трава, травы, траве. Просклоняв слово в разных падежах, можно увидеть, что изменяется только последняя буква, а значит она и является окончанием. Окончание также может иметь и нулевую форму. Для того, чтобы его определить, нужно также просклонять нужное слово по падежам. Если в падежных формах появляются новые буквы, значит начальная форма слова имеет нулевое окончание. Например: дом, дома, дому. В падежных формах слово приобрело окончание, значит изначально оно являлось нулевым. Соединительные буквы. Это буквы, которые соединяют несколько корней в сложнообразованных словах. Наиболее распространены сединительные гласные — о — и — е-. Например: птицелов, кровожадный, самолёт. Основа. Это часть слова, не входящая в состав окончания и остающаяся неизменной.
Основной принцип разбора слова по составу
Определить, с какой частью речи придётся работать. Это можно сделать путем подбора вопроса к слову. Теперь нужно определить окончание имеющегося слова. Для этого стоит просклонять его по числам и падежам. Та часть, которая изменилась, обводится в квадрат. Так обозначается окончание. Первоначальный поиск окончания является обязательным правилом для всех школьников. Ведь некоторые из них начинают морфемный разбор именно с выделения корня. Это является одним из самых ошибочных заблуждений, потому что в некоторых словах определить корень довольно сложно, а где-то его и вовсе нет. Следующее действие — найти основу. Сделать это несложно. Часть слова, оставшаяся после выделения окончания, и является основой. Подчёркивается она одной горизонтальной линией, которая немного приподнимается перед окончанием. Определить корень слова. Чтобы это осуществить, нужно подобрать однокоренные слова к нужному слову. Они должны быть похожи по лексическому значению, то есть быть похожими по смыслу, а не только по звучанию. Та неизменная часть, которая присутствует во всех словах и будет являться корнем. Обозначается он специальной дугой над нужной буквенной частью. Выделить суффиксы. Для этого нужно сопоставить конкретное слово с его прочими формами. А затем создать словообразовательную цепочку, чтобы понять, какое слово было первоначальным, и какой суффикс использовался в процессе. Обозначается морфема формой полуромба над нужной частью слова. Найти приставку. К конкретному слову нужно попытаться подобрать другие приставки. Также можно использовать другие слова с применением имеющейся приставки. Если смысл слова не коверкается, значит эта часть слова является приставкой. Выделяется она горизонтальной линией над словом, которая загинается перед корнем.
Что внутри мицеллярной воды Garnier — Wonderzine
Основа состава — вода (aqua/water). На второй позиции — глицерин (glycerin), увлажняющий компонент. Далее — гексиленгликоль (hexylene glycol) — консервант и растворитель. «Сложно сказать, для чего его ввели в состав, — комментирует Агеева. — Предполагаю, что он снижает вязкость, которую может дать полоксамер при низких температурах».
Полоксамеры (poloxamer 184) — неионные мягкие поверхностно-активные вещества, образующие мицеллярные структуры — те самые мицеллы. Их используют в очищающих средствах: в мицеллярной воде, средствах для демакияжа, очищающих эмульсиях, гелях для умывания и продуктах по уходу за волосами. В рецептуре мицеллярной воды выполняет функцию очистителя: эмульгирует жировые загрязнения на коже и удаляет их. Disodium cocoamphodiacetate — мягкое поверхностно-активное вещество, отвечает за очистку кожи. Динатриевая соль (disodium edta) — образует комплексы с катионами металлов, содержащихся в воде, тем самым делая её мягче. Polyaminopropyl biguanide — консервант, работает как предохранитель и отвечает за стабильность формулы: не допускает, чтобы в массе появились микробы.
«Я рекомендую смывать любую мицеллярную воду с лица, — говорит Агеева. — На коже не должно оставаться ничего лишнего. Мицеллярка, по сути, очень жидкое и мягкое мыло. А с мылом что делают? Смывают. С точки зрения химии к жидкому мылу относятся все системы с поверхностно-активными веществами (ПАВ). В мицеллярной воде они в меньшей концентрации и без загустителя. Не калиевые и не натриевые мыла».
Все средства для умывания, шампуни, стиральные порошки и гели для мытья посуды содержат ПАВ. Задача ПАВ в косметике — удалять грязь с поверхности кожи. Они притягивают на себя загрязнения и как бы ловят их в ловушку, облегчая удаление. Мицеллы — одна из форм ПАВ.
ПАВ делают липидный барьер проницаемым и увеличивают скорость потери влаги. Как это происходит? Молекулы ПАВ могут взаимодействовать с липидным барьером кожи и волос и встраиваться в него. Наш липидный барьер и ПАВ чем-то похожи — у них обоих есть два типа участков в молекуле: гидрофильный (который любит воду) и гидрофобный (который воду «боится» и отталкивает её). Молекулы ПАВ, точнее их гидрофобные хвосты, связываются с липидами кожного барьера, захватывают воду и как бы вытягивают её. Кожа теряет способность удерживать влагу, а это приводит к сухости.
«Если в составе мицеллярной воды есть классические эмульгаторы-стабилизаторы PEG или Polysorbate — её обязательно нужно смывать, — объясняет Юлия Агеева. — Эти ПАВ при длительном нахождении на коже могут вызвать сухость, покраснения и сыпь, чувствительность отдельных участков. Мицеллярная вода с Poloxamer (Poloxamer 188, Poloxamer 407) или Lauryl Glucoside (and) Coco Glucoside более мягкая, теоретически её можно оставлять на лице. Эти разновидности ПАВ относятся к классу низкораздражающих и нетоксичных для клеток соединений, которые легко переносятся даже слизистой. Но все реакции будут индивидуальны».
Сержиу Ботелью — о суеверности Руя Витории и опыте побед над «Зенитом»
Продолжаем знакомиться с португальскими помощниками Руя Витории. На очереди — 46-летний Сержиу Ботелью, который отвечает за анализ игры красно-белых и предстоящих соперников.
— Из всех членов тренерского штаба ваша карьера игрока была самой продолжительной. Расскажите о ней подробнее.
— Я начал заниматься футболом в 10 лет. Родители имели скромные возможности, и нужно было пользоваться любым шансом, чтобы выбиться в люди. Для меня таким шансом стал футбол — любовь и страсть всей моей жизни. Играл на профессиональном уровне с 18 до 34 лет. В основном во втором дивизионе, но поднимался и в первый.
— Какие эпизоды карьеры вспоминаете с особой теплотой?
— Как раз те сезоны, когда удавалось подниматься лигой выше. Такое со мной было четыре раза. Но больше всего запомнился последний, когда тренером нашей команды стал Руй Витория. Мне было 33 года, уже собирался переходить на тренерскую работу. Закончил карьеру на мажорной ноте.
— Как работалось с Руем, когда вы еще играли?
— Комфортно, потому что он общается с футболистами на простом языке, это добавляет легкости. К тому моменту я повидал на своем веку уже много тренеров, так что было с кем сравнивать.
— За какие качества Руй предложил вам войти в тренерский штаб?
— Я всегда был достаточно требовательным игроком — и к себе, и к одноклубникам. Меня неоднократно назначали капитаном. Думаю, поэтому Руй меня и приметил. Ему требовался помощник, обладающий большим игровым опытом.
С тех пор мы шаг за шагом шли вместе. Постепенно поднимались с самых низов, нащупывая правильный путь. Совершали ошибки и вместе их исправляли. Теперь мы в «Спартаке» и понимаем, что здесь тоже не будет легко. Но богатый опыт должен помочь.ЦЕЛЬ — БЫТЬ ПЕРВЫМИ
— Уже приступили к изучению соперников по российской лиге?
— Мы начали эту работу сразу после того, как приняли предложение «Спартака». То есть задолго до приезда в Россию. Быстро пришли к общему мнению, что РПЛ — очень непростой, интересный турнир. Семь или восемь команд борются за места в тройке лучших. Будет непросто, но мы готовы биться до конца, чтобы стать первыми.
— Сколько времени занимает разбор ближайшего соперника?
— Такой анализ начинается задолго до матча. К началу микроцикла у нас должна быть собрана вся информация и проработан детальный план подготовки. Например, анализ «Рубина», с которым встретимся в первом туре, а до этого сыграем в товарищеском турнире, начался примерно за месяц до старта сезона.
— Ваш штаб уже имеет опыт побед над конкурентами «Спартака»: в 2016 году вы с «Бенфикой» прошли «Зенит» в 1/8 финала Лиги чемпионов.
— Надеюсь, это поможет нам еще лучше подготовить «Спартак» к матчам с клубом из Санкт-Петербурга. У «Зенита» были сильные исполнители, но мы сумели их переиграть.— После «Бенфики» вы работали в Саудовской Аравии. Каким получилось это приключение?
— В Португалии мы привыкли, что в клубах все разложено по полочкам: четко, профессионально, каждый знает, что делать. В Саудовской Аравии отношение к работе другое. Не только у футболистов, но и в клубе в целом. Поэтому мы должны были принимать тысячу и одно решение одновременно. Было сложно, но это огромный жизненный и тренерский опыт, который сделал нас еще сильнее.
— «Спартак» больше соответствуют стандартам, к которым привыкли в «Бенфике»?
— Не хочу обижать клуб из Саудовской Аравии, но в этом плане, оказавшись в «Спартаке», я снова чувствую себя как дома. Сразу ощутил профессионализм во всех аспектах.
— Вы выиграли с «Аль-Насром» чемпионат страны, но второй сезон сложился не так удачно. Почему?
— Сказалась эпидемия коронавируса. Началось с того, что перед полуфиналом Кубка заразился один игрок. Мы об этом не знали и взяли его в самолет. В раздевалке он тоже был с нами, а после победы летел с командой назад.
Вернулись — и всех стало косить как серпом. Через день выбывало из строя по два–три игрока или члена персонала. Закончилось тем, что к следующему матчу осталось минимальное количество футболистов для стартового состава и всего два тренера.
Обстоятельства были просто безумные: все тренировки и установки проходили по видеосвязи. Когда ситуация стала настолько плохой, что управлять ею было уже невозможно, наш штаб принял решение вернуться домой.«ПАПА, КОГДА МЫ ПОЛЕТИМ В МОСКВУ?»
— В один из вечеров на сборе в Тарасовке Руй удивил всех музыкальностью. Он присоединился к докторам, игравшим на гитарах, потом аккомпанировал им на барабане.
— Это его давнее хобби. В Португалии мы часто устраивали командные ужины. Кто-то брал с собой гитарку, кто-то пел. В какой-то момент Руй сел за барабаны… Ему понравилось, и с тех пор он регулярно совершенствуется.
— А у вас какие увлечения вне футбола?
— С музыкой у меня не сложилось. Люблю путешествовать, заниматься спортом и проводить время с друзьями.
— Уже готовите семью к переезду в Россию?
— Дети и жена каждый день пишут сообщения: «Пап, ну когда мы уже в полетим в Москву? Нашел ли ты нам квартиру?» Приехав в «Спартак», я сразу понял, что в разговорах о хмурости и закрытости русских мало правды. Увидел противоположную картину: эмоциональных, открытых и теплых людей. Сразу рассказал о своих впечатлениях семье, и ей уже не терпится приехать.ПРИМЕТЫ ВИТОРИИ
— Опишите Руя Виторию тремя словами.
— Лидерские качества, интеллект и коммуникабельность.
— Как-то в португальской прессе вы назвали его суеверным.
— Это правда. Например, когда мы работали в «Фатиме», довольно долго не могли победить. В один прекрасный день наш тренерский штаб ехал на игру в микроавтобусе. Я в шутку сказал, что пора бы нам что-то поменять, и сделал два круга на круговой развязке. Тот матч мы выиграли. В итоге Руй всегда просил меня делать так же, когда проезжали это место.
Еще он убежден, что автобус с командой никогда не должен сдавать назад. А в «Витории Гимарайнш» был период, когда перед играми команда обязана была поесть в определенном «счастливом» кафе.
— Уже выбрали в Москве подходящую развязку или ресторан?
— Нет. Будем просто выигрывать.
Про отставку, отсутствие в заявке Смолова и Гилерме, сравнение Евро-2020 и ЧМ-2018, ответ Зареме. Большое интервью Черчесова
Главный тренер сборной России подвел итоги турнира.
- Чемпионат Европы-2020 завершился для сборной России 21 июня после поражения от Дании со счетом 1:4
- На турнире команда Станислава Черчесова набрала 3 очка в трех матчах (победа над Финляндией)
- В плей-офф из группы В прошли Бельгия и Дания
- 30 июня технический комитет РФС признал работу специалиста неудовлетворительной, но выразил Черчесову доверие.
Полная запись пресс-конференции:
Открыть видеоКратко:
- Решение о будущем Черчесова в сборной будет обсуждаться на встрече с Александром Дюковым
- Сборной не хватило вдохновения и куража
- Внутри команды хорошая атмосфера
- Есть игроки, которые могут завершить карьеру в сборной (Жирков, Кудряшов, Дзюба)
- Сильное омоложение состава не было произведено из-за задачи попасть в финальную часть Евро-2020
- Шунин лучше Гилерме, а Дзюба — Смолова
- Черчесов не следит за Заремой, но знаком с ней
Про техком и отставку
— Во-первых, у нас было перед турниром время для подготовки, 24 дня, перед ЧМ — чуть больше. В плане организации у нас вопросов не было, мы три больших турнира провели, тренировались.
Заседание техкома РФС и слова якобы об уровне игроков? Стараюсь не смотреть какие-то вещи, кроме удивления ничего не могло вызвать, об уровне игроков я ничего не говорил, только о том, как была выстроена подготовка. Члены техкома могут выражать любое свое мнение, а игроки знают, когда что-то не то, что мы на собраниях все говорим в глаза.
Ухожу ли я в отставку? Ну, как бы спокойно сформулировать, чтобы это было правильно понятно… Во-первых, мы занимаемся государственным делом, как я понимаю, должность главного тренера, когда я читаю, что меня пригласили… Меня никто не приглашал, это назначение, которое не обсуждается, это приказ к исполнению. Не думал, что буду тренировать сборную, но если зовут и говорят, что надо сделать, моя задача — дать добро, что я готов. Мне дали задание, и я его выполняю. Я так пока бы сформулировал.
Вопрос об отставке мы по-деловому решим. Импульсивных и эмоциональных решений я не должен принимать. Детального разбора Евро с руководителем еще не было, мы сядем и все решим. Мы не в песочнице играем, а представляем страну. Давайте успокоимся, мы попали на большой турнир, но если ЧМ нам подарило государство, то на Евро надо было попасть. На сегодняшний день у меня мысли, как 1 сентября обыграть Хорватию.
Готов ли отказаться от части зарплаты в случае досрочного расторжения контракта? Ребята! Дайте встретиться с руководителем! Я занимаю государственную должность, ее просто так не оставляют. Меня назначили, я делаю свою работу, как только скажут «стоп», — всё.
Что должно произойти, чтобы я подал в отставку? Чтобы какие-то решения принять, надо пообщаться, все войско оставлять на поле боя я не привык. На войне — так на войне, надо воевать. Кто мой руководитель? Сейчас Дюков. Когда пройдет встреча с Дюковым? Не могу сказать, от меня меньше зависит, я каждый день на работе, мы готовились к техкому РФС.
О выступлении на Евро
— Почему не удалось повторить успех ЧМ-2018? Работа признана неудовлетворительной — я бы тут возразил. Работа была выполнена, команда делала то, что мы ей давали. Почему не удалось повторить? Потому что абсолютно четко понимаю, ранее говорил на техкоме: если мы физически были готовы, то чтобы эти кондиции дали результат, нужен кураж, вдохновение чтобы было.
У нас основном составе играли Дивеев, Соболев, Баринов. Жалко, что Захарян и Мостовой покинули нас. Спрашивали, зачем нужен Андрей, ты же его постоянно меняешь. Но он реагировал на это так, как надо, это неприятный момент, нелегкий. Мостовой был на сборе, провел его великолепно, но пандемия опять выкосила.
Какие я допустил личные ошибки на Евро? Когда видишь на поле команду, не соответствующую своей игре… Что я сказал в раздевалке? Был зол за то, что не видел на поле лежащих бельгийцев, мы ни одной карточки даже не получили. Они все это поняли.
Кокорин? Мы за ним не следим, не знаем, где он находится. Из «Сочи» у него было больше шансов попасть в сборную России, чем из «Фиорентины»
Про атмосферу внутри команды
— Под моим руководством игроки себя чувствуют некомфортно? Я не соглашусь с этим, у нас отличная атмосфера в команде, любой подтвердит. На последнем турнире не было веры в определенные вещи — чтобы команда стала командой, какие-то вещи должны происходить, победы на последних секундах. Если Зобнин под моим руководством себя чувствует плохо, то он не смог бы с «Динамо» со мной такой путь пройти. Большой турнир оказывает определенное давление, когда у тебя игроки, которых до конца не знаешь, тогда сложно все ноты знать и правильно играть.
Психологическая готовность? Над этим надо работать, психолога в команде у меня не будет.
Станислав Черчесов / Фото: © РФСО задачах на отбор ЧМ-2022
— Думали, что получили Джикию и Кутепова как связку игроков в обороне. Другое дело, что Илья после прошлого чемпионата не заиграл в своей команде. Теперь у нас есть Дивеев, Евгеньев и так далее. Не знаешь, что, как и куда выльется, недавно звонил Алексею Березуцкому. Не знаю, что мы получим в сентябре. Каждый раз одно и то же: планируешь одно, получаешь другое.
Говорил с Жирковым, его состояние улучшается, (как и у) тех же Кудряшова и Дзюбы. У нас игроки, которые могут завершить карьеру в сборной, принять свое решение. В этом плане предстоит хорошо подумать, на ЧМ-2022 нам нужно квалифицироваться. Это турнир, где надо представлять страну.
Про потолок зарплат в РПЛ
— Главный тренер должен делать свою работу, отвечать за тактику и технику. Если меня в РФС спросят, я отвечу. В невышедшем интервью Нобелю Арустамяну (комментатору «Матч ТВ») он меня спросил об этом, я ему ответил: отбирать правильно, требовать правильно и тренировать правильно. Каждый клуб живет своей жизнью.
Игорь Дивеев / Фото: © REUTERS / Evgenia NovozheninaО появлении футболистов молодежки в главной команде России
— Мы всегда говорили, что молодежная команда должна пробиться на чемпионат Европы, мы их не трогали. Когда начинаешь выдергивать, начинается дисбаланс. Мы очень хотели, чтобы они попали на чемпионат Европы, проявили себя, набрались опыта. И они бы аккуратно, постепенно перешли к нам. Они задачу решили, и на последний сбор из этой команды мы вызвали того же Сафонова.
Почему необходимость омоложения команды стала ясна в течение одной игры Евро, а не в течение трех лет до того? На чемпионат Европы надо попадать? Надо. Нас ругают, что мы не заняли первое место в Лиге наций. Хотя уже там мы начали использовать футболистов, на которых мы рассчитываем. Второе: кто себя как проявил. Говорите — три года. Мухин стал играть три месяца назад. Если бы он три года назад играл, он бы раньше появился. Кстати, подчеркиваю — на каждой тренировке Мухин был одним из лучших, если не лучшим. Чтобы вы понимали, почему он у нас.
Чтобы вот так на кнопку нажимать и как на компьютере все перевернулось — так в футболе не бывает. Должен проходить естественный процесс. Если бы ритм не нарушился отборочный… Но он нарушился. И в этом цейтноте мы должны находить правильные решения, чтобы быть конкурентоспособными.
Про негативный фон вокруг сборной
— Я бы вопрос журналистам передал. Это нормальное явление, с которым ты должен смириться. Я с этим постоянно сталкивался с 15 лет, с критикой, здесь нет проблем, надо мириться. До ЧМ-2018 была критика, мы хотели доказать свою состоятельность. Потом был отбор Евро-2020, опять мы работу сделали.
Вы говорите, что все рады, работаем. Я бы спросил СМИ про негатив — почему? У меня работа — не нравиться всем. У меня нет никакого желания кому-то нравиться.
У меня есть желание, чтобы команда меня слушала. И могу вас заверить: никаких претензий к игрокам у меня не было. Кроме одного. Ни один ни разу не опоздал! Никаких конфликтов. Вот моя претензия к ним. Слишком воспитанными быть не надо — иногда надо быть чуть хулиганами.
Нам нужно друг друга понять. Мы говорим про тактику, которая дает или не дает результат, но я бы хотел посмотреть на вещи по-другому. Чтобы вы нас поняли. Может, мы сегодня разойдемся и каждый придет к каким-то выводам. Вы будете писать, еще и неизвестно, кому больше поверят. Но я вам задаю конкретный вопрос: мы играем дома с финнами, упускаем победу 1:0, проигрываем бельгийцам, потом датчанам. Меня бы выпустили вообще на третий матч? Давайте посмотрим на Данию. Мы приехали к ним, и я не знаю, кому проиграли — трибунам, нации или все же команде?
Маринато Гилерме / Фото: © РИА Новости / Александр ВильфО Гилерме и Смолове, не попавших в состав сборной
— Гилерме провел отборочный цикл, вопрос о нем стал звучать раньше, чем его в команде не стало, от СМИ. Была критика, но мы его не трогали. Были матчи с Бельгией, с Шотландией, где был пропущен курьезный гол. Он одно время неважно играл в клубе, с тем же Сан-Марино вышел Шунин. Потом играем с Турцией, пропускаем три мяча, с Сербией — пропускаем три мяча. Затем Маринато в РПЛ приходит в себя, а потом проигрывает «Зениту» 1:6. Нам нужен вратарь, который будет выручать в определенных моментах. На сегодняшний день Шунин лучше.
Смолов? Федор в сборной не был несколько лет, травмы, переход в «Сельту», еще что-то. После чемпионата мира он был на сборах, 100-й гол он забил у нас в команде. Мы не злопамятные. Другое дело, что есть свой характер и амбиции, если он не был в команде по той или иной причине. Возникает вопрос: несколько лет игрок не был на том уровне, который нкобходим. Выбор стоял между Соболевым и Смоловым, Заболотный был вне конкуренции. Да, Федор себя проявил, мы его знаем. Смотрите, рассказываю четко: сидят тренер и помощники. Моя задача — объяснить решение, я говорю: Смолов — да. Федя заслужил, мы ему даем возможность быть первым номером? Нет, у нас есть капитан. Как с ролью запасного он будет справляться? Мы это видели на чемпионате мира. В нашем понимании — не справляется. Роль основного форварда мы ему не можем дать. А чтобы точно убедиться, прав я или нет, мы внесли его в запасной список, а ответ на мой вопрос он дал сам. Если Смолов к матчу с Хорватией будет номером один — он будет в сборной.
Лунев? Он до сих пор не имеет клуба, и я бы не хотел, чтобы мой футболист после тренировок был на телефоне и решал какие-то вещи. Дюпин и Шунин провели великолепный сезон. Зачем нам рисковать.
Про Зарему и «Спартак»
— Я не слежу за словами Заремы, но когда тебе присылают, что «в «Спартак» Черчесов попадет через мой труп»… Было бы написано иначе — не обратил бы внимания. Тем более что мы с ней знакомы, общались в VIР’е с ней и Леонидом Арнольдовичем [Федуном]. Спасибо Ксении Собчак, которая сделала это интервью с Заремой. И мне мои ребята прислали, я узнал, по какой причине меня не любят. Оказывается, я заменил ее любимого вратаря Плетикосу на Джанаева. Но этого любимого вратаря в «Спартак» притащил я. Я осуществил этот трансфер. И все матчи он у меня играл до того момента, пока меня не уволили. Подчеркиваю: все игры, до секунды. Наверное, меня надо больше любить, раз любимого вратаря привел я. А вот кто его поменял… Как-то все интересно получается.
Попросить Зарему не удалять Telegram-канал? Давайте-ка футбол будет футболом, а цирковой аттракцион — цирковым аттракционом. Давайте не путать одно с другим.
Зарема Салихова / Фото: © Stupnikov Alexander / spartak.com / Global Look PressЧитайте также:
Диетолог и остеопат. Кто работает в тренерском штабе Роберто Манчини в сборной Италии, с которым он дошел до финала Евро
Перформанс Италии не случился бы без Манчини и его тренерского штаба. Рассказываем, кто поможет алленаторе отобрать у Англии первый титул на Евро.
Кто ассистенты Манчини
Альбериго Эвани
Евро-2020
Карасев: «Кьеллини и Бонуччи знают меня по имени»
16 ЧАСОВ НАЗАД
Один из главных помощников Манчини. Иногда заменяет его на тренировках и проводит их самостоятельно. Тот самый стиляга, который стал локальным мемом Евро. Все самые яркие моменты в карьере (как в игровой, так и после) связаны именно с Италией. Год работы в Примавере «Милана», год – в клубе «Сан-Марино». Дальше Эвани завербовал Итальянский футбольный союз, где за семь лет легенда «россонери» спрогрессировал от юношеских команд до основной.
Альбериго Эвани
Фото: Getty Images
В сборной у него особенная роль – Манчини просит Эвани следить за физическим состоянием игроков. У ассистента есть любимчик: «Чиро [Иммобиле] – мой фаворит. Он невероятно выносливый. Чиро бегает 90 минут, после чего говорит: «Давайте уже перейдем от разминки к основному упражнению».
В Италии Эвани знаменит тем, что однажды на тренировки поставил Лоренцо Инсинье отрабатывать борьбу на втором этаже против Джорджо Кьеллини.
Даниэле де Росси
Карьера в сборной у него заканчивалась печально. Италия бодалась со Швецией в стыках перед ЧМ-2018. Первый матч итальянцы проиграли (0:1). Во втором была ничья 0:0. И под конец Вентура попросил помощников подготовить Де Росси к выходу на замену вместо укрепления нападения. Ор и возмущения Де Росси попали на камеру: «*** [блин], нам нужна победа, а не ничья. Почему ты не выпустишь Инсинье? На хрена меня?»
Де Росси против Швеции в 2018 году
Фото: Getty Images
На Де Росси был спрос в Серии В, итальянские медиа писали, что на должность тренера его приглашала «Фиорентина». Но тот выбрал опыт в штабе Манчини.
Аттилио Ломбардо
Помогает с разбором предстоящего соперника. Манчини знает его долгие годы. Вместе они работали в «Галатасарае» и сделали «Ман Сити» чемпионом Англии впервые за 44 года. Вместе приехали и в сборную. Манчини говорил о нем: «Аттилио – самый большой фанат футбола, которого я знаю. Я приезжаю на базу рано, но он уже там. Он всегда что-то читает, что-то записывает и считает. Однажды он сказал мне, что с помощью повторов самостоятельно посчитал количество передач Верратти».
Джулио Нучари
Отвечает за работу с вратарями. Еще один ассистент Манчини, который лишь раз тренировал самостоятельно – «Кальяри» в 2001-м. Неудачно: провел всего восемь матчей и победил лишь дважды. Нучари быстро ушел и даже хотел закончить с футболом.
«Тренерство не приносило удовольствие. У моей семьи есть небольшой бизнес в родной Венеции – мы с отцом долгое время ведем продуктовый магазин. Я хотел углубиться в дело полностью. Но мой друг Роберто позвал меня в «Лацио» тренировать вратарей. Должность ассистента, признаюсь, принесла мне больше счастья».
У Манчини есть диетолог. Он сделал из Лукаку зверя
«В сборную приезжают футболисты и говорят: «Мати, я хочу выглядеть стройнее». Я спрашиваю, что они едят, и начинаю громко ругаться на диетологов из их клубов. Игроки пробуют их защищать, но это бесполезно. Я назначаю им другую диету, и через пять дней сборов они приходят ко мне снова: «Мати, это все ты! Я сбросил два килограмма». Так было всегда».
Эти слова принадлежат диетологу Маттиа Пинселле. Изначально он не хотел становиться врачом. Сразу после школы играл в регби на региональном уровне, а с 2004-го по 2010-й был детским футбольным тренером. Тогда он и получил диплом диетолога. Сначала Пинселла консультировал итальянские команды по регби – так через общих знакомых он познакомился с Антонио Конте. И тот сделал его администратором «Ювентуса», отвечающим за питание основы и Примаверы. Должность администратора – задумка Конте. Пинселла работал не только в расположении команды, но и следил за работой поваров на базе.
Связь с Конте сохранилась даже после переезда Антонио в «Интер». Параллельно Маттиа консультировал Манчини в сборной. Несколько моментов его работы:
Первое. Вывел Лукаку в лучшую форму в его жизни. С диетой Пинселлы Лукаку сбросил балласт из 7 кг, оброс мышцами и стал быстрее на 15%. Ромелу говорил:
«После перехода в «Интер» в моей жизни многое поменялось: теперь я ем много салата, рыбу, куриную грудку, лапшу ширатаки. Я принимаю карнитин, он классно влияет на мои мышцы. На поле я чувствую себя лучше. Углеводы? Люблю сладкий картофель и черный рис, но не ем макароны. Я вышел на другой уровень, физический и ментальный».
Второе. Кстати, о лапше ширатаки – теперь в «Интере» и в Италии питаются только ей. Никакой пасты. Пинселла говорил: «На самом деле видно, когда игрок поел с вечера пасту, а когда – ширатаки. Определяю это по граммам, которые добавились перед утренним взвешиванием».
Третье. В восторге от Пинселлы полузащитник «Ромы» Лоренцо Пеллегрини: «Раньше мой диетолог разрешал мне один день в неделю есть любую вредную пищу. Когда я сказал об этом Маттиа, то, кажется, он хотел меня ударить. Я люблю покушать. И после советов Пинселлы я все так же много ем, но уже не вредную пищу. Вот только я худею, но не толстею».
Остеопат Манчини курирует полицейских
Одно из первых в футболе отделений остеопатии в медицинский штаб ввела «Рома»: несколько профессионалов специализируются исключительно на состоянии костей и их травмах. Они не участвуют в общем медицинском обследовании футболистов – следят только за костями. Такой отдел существует в «Роме» с 2015-го, и все это время им руководит остеопат Вальтер Мартинелли.
Мартинелли – известный персонаж в спортивной медицине. Его главная специализация – футбол. Но он также консультирует команды из мотоспорта и легкой атлетики. В числе тех, с кем он работает, есть команды из общества Gruppi Sportivi Fiamme Gialle – спортивного объединения итальянской полиции. Про них Мартинелли говорит: «Хорошие и спортивные ребята, но постоянно рискующие вылететь из состава команды. Мы готовились к национальным соревнованиям, но один бегун выбыл за день до них – сломал руку на задержании».
Вальтер попал в сборную в 2016-м. Тогда ее тренировал Вентура, который просто захотел узнать состояние Алессандро Флоренци: «Я позвонил в «Рому», но меня соединили с Вальтером, хотя я знал главного физиотерапевта. Флоренци тогда вылечился после травмы бедра, но Вальтер сказал, что он не готов – что-то было не так после обычного ушиба. Он примерно 10 минут рассказывал о неправильной работе ноги Флоренци. Тогда я понял, что такой человек должен быть в сборной».
Каждый раз перед сборами Мартинелли проводит два теста, определяющие общее состояние костей. После сборов делает еще два, после чего передает наблюдения главному физиотерапевту. Основная задача этих тестов – наблюдение за позвоночником. Мартинелли говорит: «Конечно, ноги – главная часть тела для футболистов. Но я всегда слежу в первую очередь за позвоночником. Он должен быть в порядке у каждого игрока – только так у него будет правильная координация».
Еще к финалу:
1-й финал Англии, серия Италии без поражений. Решающий матч ЕвроОт игрока-симулянта до финала Евро. Путь судьи КёйперсаПодписывайтесь на телеграм-канал автора об итальянском футболеЕвро-2020
«Мы хозяева своей судьбы». Речь Манчини перед финалом
14/07/2021 В 19:08
Евро-2020
Кьеллини крикнул проклятие, когда Сака бил пенальти. Какое?
14/07/2021 В 04:39
определение парсинга The Free Dictionary
парсинга
(pärs)v. parsed , pars · ing , pars · es
v. tr. 1.а. Разбивать (предложение) на составные части речи с объяснением формы, функции и синтаксической взаимосвязи каждой части.
б. Для описания (слова), указав его часть речи, форму и синтаксические отношения в предложении.
с. Для обработки (лингвистических данных, таких как речь или письменный язык) в реальном времени во время разговора или чтения, чтобы определить его лингвистическую структуру и значение.
2.а. Внимательно изучить или подвергнуть подробному анализу, особенно путем разбиения на компоненты: «Чего мы упускаем, разбивая поведение шимпанзе на общепринятые категории, распознаваемые в основном на основе нашего собственного поведения?» (Стивен Джей Гулд).
б. Чтобы понять; Поймите: я просто не мог разобрать то, что вы только что сказали.
3. Компьютеры Для анализа или разделения (например, ввода) на более легко обрабатываемые компоненты.
v. внутр.Признать, что анализируются: предложения, которые нелегко разобрать.
[Вероятно, из среднеанглийского pars, часть речи , из латинского pars (ōrātiōnis), часть (речи) ; см. perə- в индоевропейских корнях.]
парсер н.
Словарь английского языка American Heritage®, пятое издание. Авторские права © 2016 Издательская компания Houghton Mifflin Harcourt. Опубликовано Houghton Mifflin Harcourt Publishing Company. Все права защищены.
синтаксический анализ
(pɑːz) vb1. (грамматика) для присвоения составной структуры (предложению или словам в предложении)
2. (грамматика) ( intr ) (из слово или лингвистический элемент), чтобы играть определенную роль в структуре предложения
3. (информатика) вычисление для анализа исходного кода компьютерной программы, чтобы убедиться, что он структурно правильный, прежде чем он будет скомпилирован и преобразован в машинный код
[C16: от латинского pars ( orātionis ) часть (речи)]
ˈparsable adj
ˈparsing n
Словарь английского языка Коллинза — полный и полный, 12-е издание 2014 г. © HarperCollins Publishers 1991, 1994, 1998, 2000, 2003, 2006, 2007 , 2009, 2011, 2014
синтаксический анализ
(pɑrs, pɑrz)v. parsed, pars • ing. в.т.
1. для анализа (предложения) с точки зрения грамматических составляющих, определения частей речи, синтаксических отношений и т. Д.
2. для описания (слова в предложении) грамматически, идентифицируя часть речи, словоизменительная форма, синтаксическая функция и т. д.
vi3. , чтобы признать анализ.
[1545–55;
pars′a • ble, прил.
парсер, п.
Random House Словарь колледжа Кернермана Вебстера © 2010 K Dictionaries Ltd. Авторские права 2005, 1997, 1991, Random House, Inc. Все права защищены.
синтаксического анализа
Past причастие: разобран
герундия: разборе
ImperativePresentPreteritePresent ContinuousPresent PerfectPast ContinuousPast PerfectFutureFuture PerfectFuture ContinuousPresent Идеальный ContinuousFuture Идеальный ContinuousPast Идеальный ContinuousConditionalPast Условное
| Present |
|---|
| я анализирую |
| разбора |
| он / она / оно анализирует |
| мы анализируем |
| вы анализируете |
| они анализируют |
| Preterite |
|---|
| мы проанализировали |
| вы проанализировали |
| они проанализировали |
| Present Continuous |
|---|
| I am parsing | вы разбираете |
| он / она / она анализирует |
| мы разбираем |
| вы разбираете |
| они разбирают |
| вы проанализировали |
| он / она / она проанализировали |
| мы проанализировали |
| вы проанализировали |
| они проанализировали |
| Future | |
|---|---|
| я буду разбирать | |
| он / она / оно проанализирует | |
| мы проанализируем | |
| вы проанализируете | |
| они проанализируют |
| Future Perfect | |
|---|---|
| вы проанализируете | |
| он / она / оно будет проанализировано | |
| мы проанализируем | |
| вы проанализируете | |
| они будут проанализированы | |
| Будущее | |
| Я буду разбирать | |
| вы будете разбирать | |
| он / она / это будет синтаксический анализ | |
| мы будем разбирать | |
| вы будете разбирать | |
| они будут анализировать |
| Present Perfect Continuous |
|---|
| Я анализировал |
| он / она / она анализировал |
| мы анализировали |
| вы анализировали |
| они анализировали |
| Future будет анализировать |
|---|
| вы будете анализировать |
| он / она / она будет анализировать |
| мы будем анализировать |
| вы будете разбирать |
| Прошлое совершенное Непрерывное |
|---|
| вы разбирали |
| он / она / она разбирали |
| мы разбирали |
| вы разбирали |
| они разбирали |
| Условный |
|---|
| Я бы проанализировал |
| вы бы проанализировали |
| он / она / она будет анализировать |
| мы проанализируем |
| Прошлый условный |
|---|
| Я бы проанализировал |
| вы бы проанализировали |
| он / она / она бы проанализировал |
| вы бы проанализировали |
| они бы проанализировали |
Collins English Verb Tables © Harpe rCollins Publishers 2011
parse
Для анализа предложения, разбивая его на составные части и объясняя функцию каждой и их взаимосвязь.
Словарь незнакомых слов по группам Diagram Copyright © 2008 by Diagram Visual Information Limited
Что должны / делать / могут LSTM учиться при синтаксическом анализе конструкций вспомогательных глаголов? | Компьютерная лингвистика
Как и в de Lhoneux, Ballesteros, and Nivre (2019), мы следуем Dyer et al. (2015) при определении композиционной функции. Составленный представительство c i построено конкатенация вектора токена v h головы с вектор зависимого v d присоединяемого, а также вектор r , представляющий метка используется и направление дуги; см. уравнение 4.(В нашем случае, поскольку мы только составляем поддеревья AVC, r могут иметь только два значения: left-aux и right-aux.) Этот конкатенированный вектор передается через аффинный преобразование, а затем нелинейная активация ( tanh ). Первоначально c i — это просто копия токен вектор слова (BiLstm ( x 1: n , i )).vi = [BiLstm (x1: n, i); ci]
(3) Для нашего прогноза эксперименты с использованием этой рекурсивной функции композиции, мы исследуем только что закодировано в c i . Мы называем эта экспериментальная установка рекурсивная установка . Мы ссылаемся на эта рекурсивная композиция функционирует как композиция в оставшаяся часть этой статьи. Обратите внимание, что в де Лонё, Баллестерос и Нивр (2019) мы использовали два разных функции композиции, одна из которых использует простую повторяющуюся ячейку, а другая — Ячейка LSTM.Мы увидели, что тот, который использовал ячейку LSTM, работал лучше. Тем не мение, в этом наборе экспериментов мы делаем рекурсивные композиции только в течение ограниченного часть поддерева: только между вспомогательными и NFMV. Это означает, что LSTM в большинстве случаев проходит только через два состояния, и максимум четыре. 8 Это не позволяют нам узнать правильные веса для входных, выходных и забытых вентилей.An RNN кажется здесь более подходящим, и мы используем только его.Парсинг
ПарсингСледующая: Поколение Up: Обработка Пред .: Обработка
Задача автоматического парсера — взять формальную грамматику и предложение и применить грамматику к предложению, чтобы (а) проверить что он действительно грамматический и (б) учитывая, что он грамматический, показать, как слова объединяются в фразы и как фразы собирать вместе, чтобы сформировать более крупные фразы (включая предложения).Таким образом, для Например, синтаксический анализатор будет использовать приведенные выше правила, чтобы проверить, что предложение Температура повлияла на принтер состоит из существительное, состоящее из существительного Температура , за которым следует вспомогательный глагол, за которым следует глагольная фраза, и что глагольная фраза влияет на принтер состоит из глагола влиять на и существительное словосочетание, состоящее из существительного принтеры . По сути, это дает ту же информацию, что и виды древовидной структуры, которые у нас есть приведено выше, например в Фигура .Таким образом, можно думать о синтаксическом анализаторе как о предложения и создание таких представлений (предполагая, что предложения на самом деле правильно сформированы согласно грамматике).
Как это может быть сделано? Есть много способов применить правила к вход для создания выходного дерева — много разных процедур или алгоритмов синтаксического анализа , с помощью которых входная строка можно присвоить структуру. Вот один из способов:
- Для каждого слова в предложении найдите правило, правая часть которого
совпадает с ним.Это означает, что каждое слово будет помечено
его часть речи (отображается в левой части правила, которое соответствует
Это). Этот шаг в точности эквивалентен поиску слов в
Английский словарь. Учитывая правила типа N
пользователь, принтер N и V clean,
это создаст частичную структуру, как мы можем видеть в верхнем левом углу
угол (этап 0) рисунка.
Рисунок: Анализ с использованием алгоритма снизу вверх - Начиная с левого конца предложения, найдите все правило, правая часть которого будет соответствовать одной или нескольким частям речь (этап 1 рисунка).
- Продолжайте делать шаг 2, сопоставляя все большие и большие части структура фразы до тех пор, пока больше не будут применяться правила. (В нашем примере это будет когда приговор наконец, правило совпадает с существительной и глагольной фразой, которые уже определены). Приговор сейчас проанализирован (этап 2-4 рисунка).
Как правило, можно найти более одного алгоритма для получения данный результат. Как уже упоминалось, это, безусловно, верно для синтаксический анализ: приведенный здесь алгоритм — лишь один из многих возможных варианты, которые отличаются своей способностью эффективно справляться с разные типы грамматики.Тот, который мы дали, начинался с слова предложения, и построил дерево «снизу вверх». Однако мы также могли использовать алгоритм построения дерева «сверху вниз», начиная с узла S. По сути, что будет делать этот алгоритм предположить, что он смотрит на предложение, а затем предположить, что предложение начинается с именной фразы, а затем угадайте, что существительное фраза состоит из существительного, а затем проверьте, действительно ли существительное в начале предложения.Каждый раз есть выбор возможностей (возможно, существительная фраза начинается с определителя) делает первый выбор и, если это окажется неверным, выполняет резервное копирование и пробует следующую альтернативу. В процессе разбора предложения со сложной грамматикой он в конечном итоге получит правильный ответ — возможно, только после множества ошибочных предположений. (Алгоритмы, которые MT и другие системы НЛП более сложные и эффективные, чем эта, конечно). Первые несколько этапов сверху вниз синтаксического анализа показаны на рисунке.
Рисунок: Анализ с использованием алгоритма сверху вниз
Это описание относится только к строительной поверхности, составляющей структурное дерево, конечно. Что касается других уровней представительства (представления грамматических отношений и семантических представлений), как мы отмечали выше, существует два основных подхода. Если информация о других уровнях представительства представлена как аннотации к правилам составляющей структуры, то она должна быть возможно построить эти другие представления одновременно с представление составной структуры.Это немного сложнее, если отношения между уровнями изложены в отдельном сборнике правила. В этом случае лучше всего сначала построить составное представление структуры, и применить эти правила к этому представление.
Простейшая процедура для этого выполняется «рекурсивно» вниз по поверхностное (составляющее) дерево структуры, работающее с каждым узлом по очереди. Начиная с корневого узла, алгоритм ищет правило, lhs которого соответствует этому узлу и его дочерним элементам.В случае следующих правило (которое мы привели выше, но повторим здесь для удобства), это означает, что корневой узел должен быть помечен буквой S, и должно быть три дочери, помеченные как NP, AUX и VP, и VP должны по очереди содержат дочь, обозначенную V, и дочь, обозначенную NP.
NP: 1 доллар, AUX: 2 доллара, V: 3 доллара, NP: 4 доллара
ГОЛОВА: 3 доллара США, ПРЕДМЕТ: 1 доллар США, ОБЪЕКТ: 4 доллара США
Одно толкование такого правила оставляет избирателю структурное дерево нетронутым, и создает новая структура, представляющая грамматические отношения.Это требует от алгоритма создания временного структура, соответствующая правой стороне правила. Он будет отмечен буквой S и будет содержать трех дочерей, одну ГОЛОВА, одна ПРЕДМЕТ и одна ОБЪЕКТ. Конечно, эта структура еще не может быть полным, потому что еще не известно, что это за дочери должны содержать. Однако теперь алгоритм имеет дело с дочерние узлы дерева структуры поверхности точно так же поскольку он имел дело с корневым узлом (отсюда процесс называется рекурсивный).То есть он пытается найти правила, соответствующие каждому из NP, AUX, V и NP и создают соответствующие структуры. Когда он сделал это, это сможет заполнить части временной конструкции созданный первоначально, и представление грамматических отношения будут налажены. Этот можно увидеть на рисунке.
Аналогичную процедуру можно использовать для интерпретации правил, относящихся к грамматические структуры отношения к семантические структуры.Есть количество деталей и уточнений, которые действительно стоит описать, например, как мы гарантируем, что все возможные грамматические отношения структуры, что мы делаем с узлами, упомянутыми на LHS, но не RHS, и так далее. Но это уточнения, и здесь не имеют значения, пока эта основная картина Чисто.
Далее: Поколение Up: Обработка Пред .: Обработка
Арнольд Д Дж
Чт, 21 декабря, 10:52:49 GMT 1995
CS 161 Recitation Notes — синтаксический анализ в Prolog
CS 161 Recitation Notes — синтаксический анализ в PrologОдно из основных направлений исследований естественного языка Обработка (или НЛП) — это область разбора.В смысле НЛП парсинг состоит из присвоения тегов отдельным словам, заключив его в скобки, чтобы указать фразовые границы в приговор. Например, рассмотрим это предложение:
Джон увидел собаку.
В этом предложении Иоанна — существительное собственное, видел — глагол, — определитель , а собака —
существительное. Если теги для существительного, глагола, определителя и существительного
являются PN, V, D и N (соответственно), то мы могли бы пометить слова
как таковой:
Джон - ПН
пила - V
- D
собака - N
Если вы изучали иностранный язык, то условия для
разные грамматические категории слов должны быть знакомы
тебе.Если вы не посещали уроки иностранного языка, тогда
прислушайтесь к своим урокам английского языка в гимназии, где
вы узнали эту информацию об английском языке. Для вашего английского
классы, вероятно, это не казалось вам таким жизненно важным, как ваше
использование языка казалось естественным. Когда вы изучаете
иностранный язык, категории становятся более актуальными, так как
вы более четко замечаете различия в том, как разные
категории слов ведут себя.Для написания компьютерных программ, которые понимают, естественный язык в некотором смысле, синтаксический анализ — критическая задача.Ты должен знать отношения между словами, чтобы выяснить смысл предложения. Например, «Джон увидел собаку». имеет совсем другое значение, чем «собака увидела Джона», несмотря на Дело в том, что у них точно такие же слова. На английском, порядок слов определяет подлежащее в предложении и объект приговора.
Для исходного предложения выше мы могли бы сказать, что оно соответствует к следующему дереву синтаксического анализа:
S
/ \
НП ВП
| / \
ПН В НП
| | / \
Джон видел D N
| |
собака
Из гимназии вы могли помнить, что в предложении
подлежащее и сказуемое.Что ж, это понятие соответствует
ветвление верхнего уровня этого дерева, которое указывает, что
S (или предложение) состоит из NP (именной группы) и VP
(фразовый глагол). Мы могли бы написать это правило так:
[1] С -> НП ВП
что можно было бы прочитать как «предложение переписывается в именную фразу
и глагольную фразу «. Обратите внимание, что это дерево указывает на два разных
способы переписать именную фразу. Его можно было либо переписать на
определитель и существительное (как в «the» и «dog») или
имя собственное. собственное существительное — это имя
человек или место, например Джордж Вашингтон или Детройт, которые
вы обычно видите заглавные буквы.Таким образом, мы могли написать два правила
для именных фраз:
[2] НП -> ПН
[3] НП -> Д Н
Наконец, нам нужно представить правило перезаписи глагольных фраз.
В этом случае глагольная фраза переписывается как глагольная и именная,
Итак, правило выглядит так:
[4] ВП -> В НП
Сложите все это вместе с некоторыми правилами тегов, которые
назначать теги словам, и у нас есть система, которая может анализировать
очень простые предложения. Чтобы разобрать предложение по правилам,
мы сначала помечаем каждое из слов, а затем находим правила, которые соответствуют
какая-то подстрока символов, пока мы не проработаем все
обратный путь к С.Это называется восходящим синтаксическим анализом.
также можно начинать с буквы S, выберите правило с буквой S слева
стороны, а затем поставьте перед собой цель найти что-нибудь
удовлетворяют каждому из условий справа.Например, предположим, что мы хотим разобрать предложение «собака увидела Джон «. Я начинаю с того, что помечаю каждое слово, и они такие же, как они были раньше, но в новом порядке:
Д Н В ПН
собака увидела Джона
Теперь я начну с предложения. Есть только одно правило перезаписи для
предложение, S -> NP VP , так что я его возьму.Теперь я делаю это своим
цель — сначала найти именную фразу, а затем глагольную. у меня есть
два варианта существительной фразы. Сначала пробую правило [2]. Так как я
нет PN в начале предложения, и нет
переписать правило для PN, у меня не получается. Теперь я пробую правило [3], и это происходит
красиво выстроиться. Итак, теперь у меня есть этот частичный синтаксический анализ:
S
/ \
НП ВП
/ \
Д Н
| |
собака
Еще мне осталось разместить следующие слова с тегами:
V PN
видел Джона
Теперь мне нужно найти способ переписать глагольную фразу, чтобы
остальные помеченные слова.есть только одно правило для глагольной фразы,
[4], поэтому выбираю его. Итак, теперь моя цель — найти глагол и
именная фраза из оставшихся помеченных слов. Сначала я ищу
глагол, и, к счастью, видел, есть, поэтому я остаюсь с
это состояние:
оставшиеся условия частичного синтаксического анализа
S
/ \
НП ВП
/ \ / \
Д Н В НП ПН
| | | |
собака увидела Джона
Теперь моя конечная цель — найти именную фразу из оставшихся
срок.Из правила [2] я могу переписать NP в PN, что в точности соответствует
то, что я ищу. Итак, вот мой последний разбор:
S
/ \
НП ВП
/ \ / \
Д Н В НП
| | | |
собака увидела ПН
|
Джон
Итак, теперь давайте подумаем, как это можно представить в Прологе. Ну, для начала теги можно представить как простые конструкции:
определитель
существительное (собака)
глагол (пила)
правильное_ существительное (джон)
На самом деле, чтобы сэкономить много писем (или набора текста, в зависимости от обстоятельств)
Я сокращу эти представления до:
d (the)
п (собака)
v (видел)
пн (джон)
Нет причин, по которым фразы не могут быть просто структурой
как это тоже, например:
np (d (the), n (собака))
нп (пн (джон))
Обратите внимание, как структура вложена, как и вложенные списки в
Лисп.Prolog очень хорошо приспособлен к этому типу структурного вложения.
хорошо. См. Здесь некоторую экспозицию по этому поводу.
Конечно, чем выше в дереве находится структура, тем больше
материал будет вложен в него, пока структура предложения не будет содержать
все:
vp (v (пила), np (pn (john)))
s (np (d (the), n (собака)), vp (v (пила), np (pn (john))))
Если это поможет вам лучше это представить, я мог бы написать это
структурирован так:
s (
нп (
d (в),
п (собака)
),
vp (
v (пила),
нп (
пн (джон)
)
)
)
Хорошо, теперь у нас есть способ представить структуру
синтаксический анализ, поэтому все, что нам нужно, это программа, которая принимает список
слова в предложении (или остатки предложения, вспомните из
пример выше) и выбирает подходящую фразу или тег
строить, вынимает то, что нужно, чтобы строить, строит
его структуру, и вкладывает эту структуру в
представление для всего остального.Звучит немного сложно,
не так ли? Хорошо, давайте по очереди рассмотрим, какие требования:
1. берет список оставшихся частичных предложений
Хорошо, давайте сделаем это первым аргументом
2. выбирает подходящую фразу
определитель ([| L], L, d (the)).
определитель ([a | L], L, d (a)).
правильное_ существительное ([джон | L], L, pn (джон)).
существительное ([мужчина | L], L, n (мужчина)).
существительное ([женщина | L], L, сущ (женщина)).
существительное ([собака | L], L, n (собака)).
существительное ([парк | L], L, n (парк)).существительное ([gun | L], L, n (пистолет)).
существительное ([книга | L], L, n (книга)).
существительное ([телескоп | L], L, n (телескоп)).
глагол ([saw | L], L, v (пила)).
verb_intransitive ([читает | L], L, v (пила)).
предлог ([с | L], L, p (с)).
предлог ([in | L], L, p (in)).
предложение (L0, L, s (NP, VP)): - существительное_фраза (L0, L1, NP),
глагольная_фраза (L1, L, VP).
noun_phrase (L0, L, np (PN)): - собственное_фраза (L0, L, PN).
noun_phrase (L0, L, np (D, N)): - определитель (L0, L1, D),
существительное (L1, L, N).noun_phrase (L0, L, np (D, N, PP)): - определитель (L0, L1, D),
существительное (L1, L2, N),
препозиционная_фраза (L2, L, PP).
verb_phrase (L0, L, vp (V, NP)): - глагол (L0, L1, V),
существительное_фраза (L1, L, NP).
verb_phrase (L0, L, vp (V, NP, PP)): - глагол (L0, L1, V),
существительное_фраза (L1, L2, NP),
препозиционная_фраза (L2, L, PP).
prepositional_phrase (L0, L, pp (P, NP)): - предлог (L0, L1, P),
существительное_фраза (L1, L, NP).
Когнитивная неврология языка
Разбор предложения
Учитывая, что синтаксический анализ кажется чтобы быть частью понимания языка, вопрос о том, как именно читатель или слушатель определяет синтаксическую структуру предложение (предложение разбор ) становится центральной проблемой. Исследователи изучили этот вопрос, представив предложения, которые содержат синтаксическую двусмысленность, то есть ситуацию, в которой больше чем один хорошо сформированный синатктический анализ может быть отнесен к строке слов.Обычно последующие слова указывают правильное анализ. Например:
(1) Юрист обвиняется в том, что ответчик лгал человек.
(2) адвокат обвинен ответчик был лжет.
В (1) мало синтаксических двусмысленность. Напротив, в (2) грамматическая роль существительного фраза ответчик временно двусмысленна между роль «объект глагола» и «подлежащее предстоящего предложения» роль.То, что роль субъекта уместна в этом случай становится ясным только после обнаружения неоднозначного вспомогательный глагол было . Современные теории предсказывают, что в таких ситуаций, читатель назначит роль объекта Ответчик . Это решение приведет к обработке проблема, когда встречается вспомогательный глагол; под объектом анализ, вспомогательное не может быть добавлено к предыдущему предложению материал. Следовательно, эта теория предсказывает, что читатели должен (хотя бы на мгновение) воспринимать вспомогательный глагол как синтаксически аномальный.Таким образом, предсказание состоит в том, что вспомогательный глагол в (2) должен вызывать эффект P600 относительно то же слово в (1). На рисунке показаны ERP для последних трех слов в каждом предложении ( подсудимого лгали ). Стрелки укажите начало каждого слова. В соответствии с предсказание, начиная примерно через 500 мс после начала, вспомогательные глаголы в предложениях вроде (2) вызвали положительный сдвиг, подобный P600. Одна интерпретация этих результатов заключается в том, что читатели совершают к единственному синтаксическому анализу при столкновении с двусмысленность, а не построение всех возможных структур параллельно или ожидая, пока информация, устраняющая неоднозначность, укажет, какой анализ является правильным до присвоения грамматических родов словам. Не менее важно то, что эти результаты показывают, что эффект P600 вызвано не только явной грамматичностью, но и воспринимаются неграммы, которые возникают исключительно из-за того, как люди разбирать предложения.
Артикул:
Остерхаут, Л. (1997). На мозг реакция на синтаксические аномалии: манипуляции с позицией слова и слово класс выявить индивидуальные различия. Мозг и язык , 59 , 494-522.
Остерхаут, Л. и Холкомб, П. Дж. (1992). Связанные с событием потенциалы мозга, выявленные синтаксически. аномалия. Журнал памяти и языка , 31 , 785-806.
Остерхаут, Л., и Холкомб, П. Дж. (1993). Связанные с событием потенциалы и синтаксическая аномалия: свидетельства обнаружение аномалий при восприятии слитной речи. Язык и когнитивные процессы , 8 , 413-438.
Остерхаут, Л., Холкомб, П. Дж., & Суинни, Д. А. (1994). Потенциалы мозга, выявленные садовой дорожкой предложения: свидетельство применения глагольной информации во время парсинг. Журнал экспериментальной психологии: обучение, память и Познание , 20 , 786-803 .
После 46 лет брака анализ скрытого смысла слов жены остается ключом к блаженству
Обозреватель Дэвид Коффелт делится несколькими советами, которые он извлек за 46 лет совместной жизни.Предоставлено Дэвидом КоффельтомОна сказала то, что я думал, она сказала, не так ли?
Мы с Линдой только что отпраздновали 46 лет совместной жизни. Когда в церкви объявили нашу годовщину, наш пастор заметил: «Один из них заслуживает медали». Естественно, я утверждаю, что не имею ни малейшего представления о том, кого он может иметь в виду, и не имею ни малейшего представления о том, почему он так утверждал.
Можно было бы предположить, что после всех этих лет я, возможно, кое-что узнаю о секрете успешных супружеских отношений.Скажем так, я, наверное, должен знать намного больше, чем я. Если бы я утверждал, что всегда был терпеливым, добрым и отличным слушателем, что ж, давайте просто не будем туда идти …
С годами я узнал, что моя любимая жена использует определенные слова и фразы, которые не обязательно означают то, что я будет думать, что они должны иметь в виду. Я не знаю, верно ли это для всех женщин, но могу рассказать только о том, что испытала на собственном опыте.
Первая фраза, которую я, по-видимому, не понимаю должным образом: «Давай.«Я могу поделиться невероятно глубокой идеей о проекте, поездке или подарке только для того, чтобы услышать это простое утверждение из двух слов. Для меня «идти вперед» означает именно это, поэтому я продолжаю.
Я узнал — конечно, на собственном горьком опыте — что это предложение из двух слов — только начало целой главы, которая остается недосказанной. Откуда мне было знать, что после того, как я «пойду вперед», будут невыносимые последствия? Полное предложение фактически должно быть переведено как «Давай, и тебе будет жаль». Ребята, небольшое предупреждение — последние пять слов имеют решающее значение.
Еще одна ловушка — наивно полагать, что «все, что вы думаете», означает, что именно это и рекомендуется делать. На самом деле это означает, что если вы делаете то, что думаете, вы делаете это с большой опасностью для жизни и здоровья.
Следующее ключевое слово, которое стоит прислушаться, — это очень красивое, очень аккуратное маленькое четырехбуквенное слово. Слово «хорошо» подходит практически для любого случая.
Иногда, когда я слышу это слово более одного раза в разговоре, я чувствую себя героем Мэнди Патинкин, Иниго Монтойей из «Принцессы-невесты.Вы можете вспомнить фразу, когда он сказал Визинни: «Ты продолжаешь использовать это слово. Я не думаю, что это означает то, что вы думаете ».
Чем чаще в разговоре используется слово «штраф» и чем выше тональность, тем меньше оно на самом деле означает «хорошо». Это особенно верно, когда он громко повторяется одновременно с хлопком двери. По крайней мере, мне так сказали.
Наконец, еще одно слово, которое нужно добавить в смесь. Когда Линда слышит что-то, во что она может верить, а может и не верить, или заявление, с которым она на самом деле не согласна, она просто говорит: «Да.
Я знаю без тени сомнения, что, когда она говорит «Да», это не означает то же самое, что «Да» или «Я согласен». Фактически, я научился внимательно прислушиваться к интонации голоса, чтобы попытаться определить степень ее несогласия.
Может показаться, что я ищу возможность подразнить жену. Я понимаю, что кое-что делаю, но я также знаю, что она знает, что это весело. Недавно я спросил ее о поддразнивании. Похоже, я неоднократно повторял, что если Линда говорит «да», это не значит «да».
Итак, мне пришлось спросить ее, согласна ли она с этим. Ее ответ? Вы уже догадались — «Ага».
Дэвид Коффелт — житель района Харрисонвилл, его адрес электронной почты: [email protected].
PARSE: синонимы и родственные слова. Что такое другое слово для PARSE?
Требуется другое слово, означающее то же, что и «синтаксический анализ»? Найдите 12 синонимов и 30 связанных слов для слова «синтаксический анализ» в этом обзоре.
Синонимы слова «Анализировать»: интерпретировать, понимать, читать, видеть, принимать, принимать значение, отображать, анализировать, объяснять, разъяснять, глянуть, декодировать
Разобрать как глагол
Определения глагола «Разобрать»
Согласно Оксфордскому словарю английского языка, «parse» как глагол может иметь следующие определения:
- Синтаксический анализ путем присвоения составной структуры (предложению.
- Разложите (предложение) на составные части и опишите их синтаксические роли.
- Анализируйте (строку или текст) на логические синтаксические компоненты.
Синонимы глагола «Разобрать» (12 слов)
| проанализировать | Психоанализ кого-то. Нам нужно проанализировать наши результаты более четко. |
| декодировать | Преобразовать (закодированное сообщение) в понятный язык. Процессоры, используемые для декодирования цифровых аудиосигналов качества CD. |
| прояснить | Избавиться от путаницы или двусмысленности; прояснить. Далее я попытаюсь разъяснить , в чем, по моему мнению, заключаются проблемы. |
| объяснить | быть причиной или мотивирующим фактором для. Они объясняют эд, что их жизнь сосредоточена на религиозных ритуалах. |
| глянец | Придайте блеск или блеск обычно путем втирания. Певица блеск окрасила губы в темно-красный цвет. |
| интерпретировать | Дайте интерпретацию или объяснение. Я согласился интерпретировать для Жан-Клода. |
| прочитал | Обычно читал определенную газету или периодическое издание. Вместо мадам читать сумасшедший. |
| рендеринг | Отказ от сдачи. Они должны были отнести поместье. |
| см. | Посетите место как для развлечения. Элементы обычно классифицируются как металлы или неметаллы см. главу 11. |
| принять | Принять определенный атрибут формы или аспект. Некоторым людям было трудно взять . |
| принять за | Взять силой. |
| поймите | Будьте пониманием. Я понимаю, как вы себя чувствуете. |
Примеры использования глагола «Анализировать»
- Я попросил пару студентов разобрать эти предложения за меня.
- Введенный вопрос пользователя анализируется во внутреннем концептуальном представлении.
Ассоциации «Разбор» (30 слов)
| alliterate | (фразы или строки стиха) содержат слова, начинающиеся с одного звука или буквы. Его имя и фамилия аллитерируют d. |
| алфавит | Набор символов, который включает буквы и используется для написания языка. Фонетический алфавит . |
| анализировать | Разбить на компоненты или основные функции. Проанализируйте предложение. |
| антоним | Слово, которое выражает значение, противоположное значению другого слова, и в этом случае два слова являются антонимами друг друга. Для него антоним гея был подавлен. |
| апостроф | Знак (‘) используется для обозначения пропуска одной или нескольких букв в напечатанном слове. |
| колдовство | Магическое заклинание. |
| словосочетание | Пара или группа слов, которые обычно сопоставляются. Слова имеют аналогичный диапазон словосочетания . |
| исправление | Наказание, особенно в отношении преступников, находящихся в тюрьме, с целью исправления их поведения. Несовместимость правосудия и исправления как уголовно наказуемых целей долгое время оставалась основной нерешенной проблемой уголовно-исполнительной практики. |
| грамматика | Книга по грамматике. Хомский грамматика . |
| грамматик | Лингвист, специализирующийся на изучении грамматики и синтаксиса. |
| омоним | Два слова являются омонимами, если они произносятся или пишутся одинаково, но имеют разные значения. |
| отступ | Пробел, оставленный отступом текста. У нас было отступов для скрепок одна за другой в те дни. |
| углубление | Глубокая выемка или выемка на краю или поверхности чего-либо. Прибрежный вдавливание с. |
| сопоставление | Положение бок о бок. совмещение этих двух изображений. |
| litotes | Преуменьшение риторического эффекта (особенно при выражении утвердительного мнения путем отрицания обратного. Сказать, что я не был немного расстроен, когда вы имеете в виду, что я был очень расстроен, — это пример литов . |
| морфология | Определенная форма, форма или структура. Грамматика организована по двум основным направлениям морфология и синтаксис. |
| орфография | Изучение орфографии и того, как буквы сочетаются для представления звуков и образования слов. Разговорный язык, для которого еще нет санкционированной орфографии . |
| абзац | Разделить на абзацы по тексту. Все ее друзья написали абзац в газете в прошлый понедельник. |
| фраза | Разделите объединение или отметьте на фразы. Они фраза сделаю музыку с удовольствием. |
| пунктуация | Знаки, такие как точка, запятая и квадратные скобки, используемые в письменной форме для разделения предложений и их элементов и для пояснения смысла. Удовлетворительные стандарты грамматики правописания и орфографии и пунктуации . |
| котировка | Регистрация, предоставленная компании, позволяющая официально торговать и торговать ее акциями. Цитата от Марка Твена. |
| риторика | Язык, созданный для того, чтобы оказывать убедительное или впечатляющее воздействие, но который часто считается лишенным искренности или содержательного содержания. Просто риторика . |
| приговор | Вынести приговор кому-либо в суде. Он всегда говорил грамматически предложений с. |
| написание | Способ написания слова. Ее написание было плачевным. |
| синтаксис | Раздел лингвистики, занимающийся синтаксисом. Генеративный синтаксис . |
| опечатка | Опечатка. |
| типографский | Относящийся к типографике, встречающийся или используемый в типографике. Типографский арт. |
| безграмотно | Не соответствует грамматическим правилам. Безграмотное предложение. |
| словарь | Слова, используемые в конкретном предмете или сфере деятельности или в конкретном случае. |