Урок русского языка. «Состав слова. Алгоритм разбора слова по составу». 2-й класс
Цель: Учить разбирать слова по составу используя алгоритм
Задачи:
- Формировать умение подбирать однокоренные слова и развивать умения находить в словах корень, приставки, суффиксы, окончание, основу.
- Учить их видеть орфограммы в разных частях слова, выделять их графически.
- Развивать орфографическую зоркость, речь, наблюдательность.
- Воспитывать бережное отношение к природе.
Настрой на хорошую работу.
Вдохните… Как хорошо, что мы вместе. Мы все счастливы и здоровы. Мы помогаем друг другу. Мы дополняем друг друга. Мы нужны друг другу. Пусть этот день несёт нам радость общения, наполнит сердце благородными чувствами. И, подобно этим цветам, раскроются ваши души, даря окружающим свет, тепло и любовь. Улыбнитесь друг другу.
И, подобно этим цветам, раскроются ваши души, даря окружающим свет, тепло и любовь. Улыбнитесь друг другу.
Вот с таким настроением мы и начнём наш урок.
II. Чистописание.— Откройте тетради и запишите число и предложение «Классная работа».
— Назовите буквы и буквосочетания.
Зз зи за
— Назовите буквосочетания, в котором буква з обозначает мягкий согласный звук.
— Пропишите буквы Зз и буквосочетания.
— Прочитайте слова.
зима Зима зимородок заморозки
— Объясните лексическое значение слов.
Зима́ — город в России, Иркутской области. Расположен в 230 км на северо-запад от областного центра г. Иркутска, на левом берегу реки Оки.
Зимородок — это удивительно красивая птица. Он немного крупнее воробья с необычайно ярким оперением. Верх тела его зеленовато-голубой, брюшко же — огненно-рыжее. Гнездится зимородок по береговым обрывам в норах глубиной до 2 м.
За́морозки — легкие утренние морозы осенью или весной. (С.И. Ожегов, Н.Ю. Шведова «Толковый словарь русского языка»)
— Что заметили? Разделите слова на группы.
— Какие слова называются однокоренными?
— Что общего? Признаки какой части речи называли?
— Что вы знаете об именах существительных?
— Подчеркните ошибкоопасные буквы в словах.
— Как проверить ошибкоопасные буквы в слове заморозки? Подобрать проверочные слова.
— Какую букву нельзя проверить?
— Как называются слова написание надо запомнить? (словарные слова)
— Запишите слова.
III. Актуализация.— Подберите однокоренные слова к слову заморозки. Мороз, заморозка, мороженое,
морозец, морозилка, морозильник, Морозко, морозная.
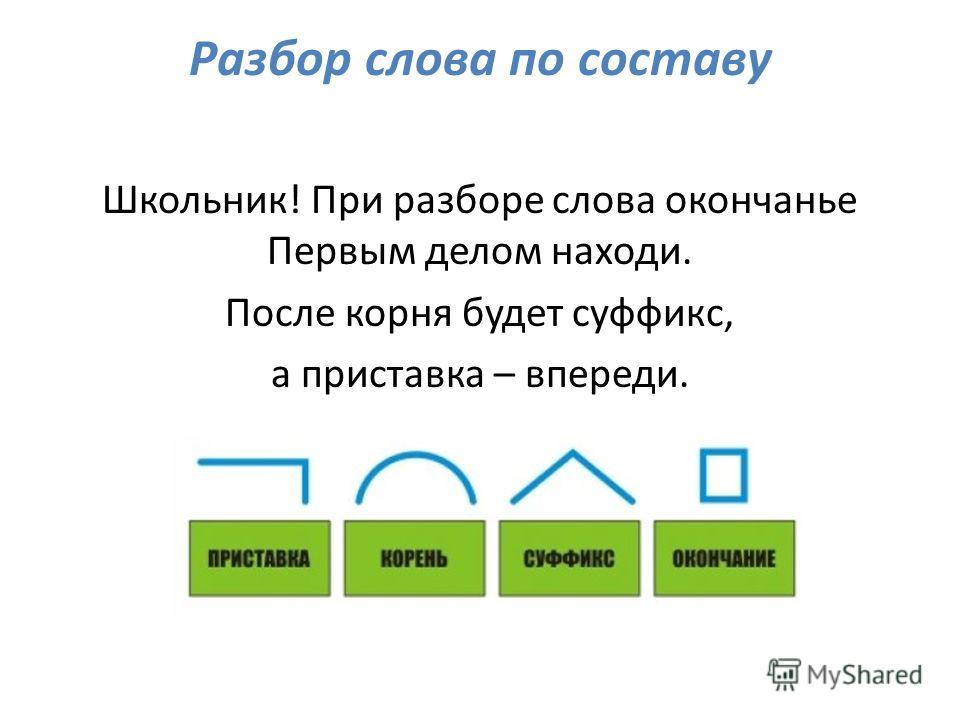
— Что знаете о частях слова?
Корень — это общая (одинаковая) часть однокоренных слов.
Окончание — это изменяемая часть слова, которая образует форму слова и служит для связи слов в предложении и словосочетании.
Основа — это часть изменяемого слова без окончания.
Приставка — это часть слова, которая стоит перед корнем и служит для образования новых слов.
Суффикс — это часть слова, которая стоит после корня и служит для образования новых слов.
IV. Проблемная ситуация— Так какую часть слова надо находить первой, какую следующей и почему? А в какой последовательности нужно выполнять разбор слова по составу? Сформулируйте тему урока? (Ученики формулируют тему и цель урока).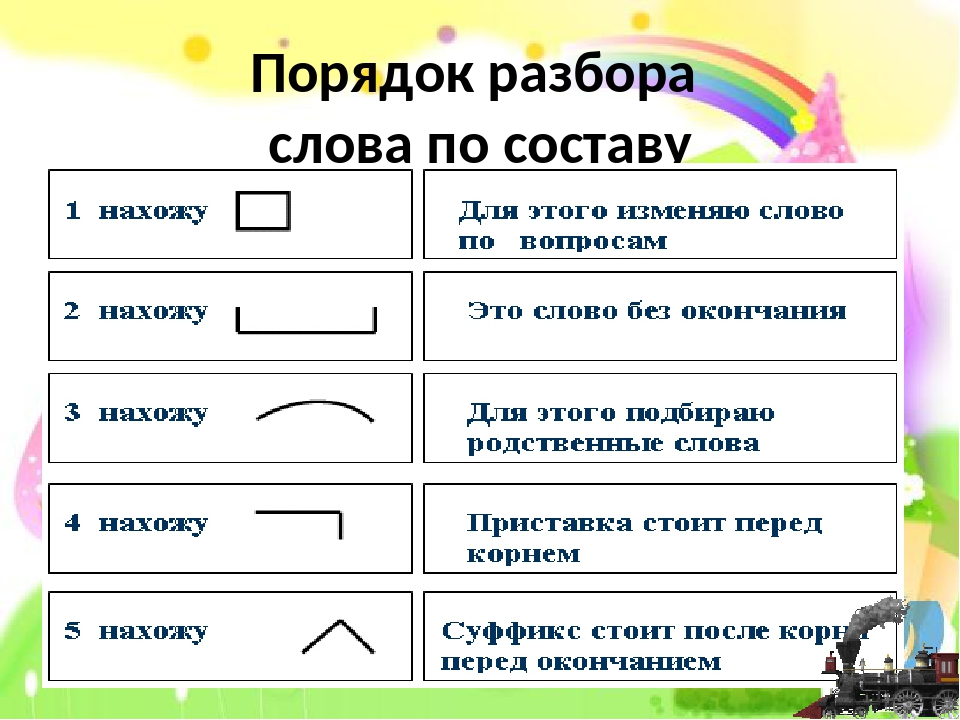
— Какие задачи поставим перед собой и будем решать на уроке?
Тема урока: Состав слова. Алгоритм разбора слова по составу.
Цели урока: научить определять части слова, разбирать слова по составу; развивать орфографическую зоркость, внимание, речь, наблюдательность; воспитывать бережное отношение к природе, интерес к процессу познания.
Задача: на основании полученных знаний о частях слова, провести самостоятельное выведение алгоритма разбора слова по составу.
V. Открытие нового.Вывод:
VI. Физминутка.Слово по составу верно разбирай:
Первым, окончание всегда выделяй,
На основу внимательно смотри,
Корень, поскорее, ты у нее найди,
Приставку и суффикс в конце определи.

Пускай снегами все заносит,
(Руки через стороны вверх, опустили)
Пускай лютуют холода,
(Руки на пояс, повороты туловища влево – вправо)
Зима меня не заморозит,
Не напугает никогда.
(Левой рукой плавное движение вверх – вниз, правая на поясе)
Зимою белые снежинки
Танцуют за моим окном.
(Правой рукой плавное движение вверх-вниз, левая на поясе)
А Дед Мороз свои картинки рисует на стекле ночном.
(Плавные движения двумя руками вверх-вниз перед собой)
— Запишите слова: зимушка, холода, снежинка, прогулка, горка. (Выполняют ученики разбор слов по составу с комментированием)
— А в какой последовательности нужно выполнять разбор слова по составу?
— Какие части слова входят в основу?
Вывод: Начинать разбор по составу нужно с окончания, затем, зная окончание слова, будем выделять основу, потом корень и только после этого приставку и суффикс.
На дереве висит кормушка. На ветку села синичка. Над елкой закружила стайка дроздов.
— Прочитайте предложения.
— Запишите предложение под диктовку.
— Найдите, подчеркните ошибкоопасные буквы в предложениях.
—
— Какое время года трудное для животных? Почему?
Птицам трудно приходится зимой. Нередко они голодают. Во время метелей и сильных морозов много птиц погибает от голода. Особенно часто птицы погибают в конце зимы, когда почти весь корм повсюду съеден. Действительно, зима – очень трудное время для птиц, особенно, если она морозная и снежная. Не найти птицам под снегом корма. Голодная птица сильно страдает от холода. Зимой день короткий, а чтобы выжить, не замерзнуть, пищи нужно съесть больше, чем летом.
ПОКОРМИТЕ ПТИЦ
Покормите птиц зимой!
Будет им зима.
Пусть со всех концов
К вам слетятся, как домой,
Стайки на крыльцо.
Не богаты их корма,
Горсть зерна нужна,
Горсть одна – и не страшна
(Александр Яшин)
— Подберите к существительному зима подходящие прилагательные. Зима, какая? (Холодная, морозная, сказочная, суровая, снежная, вьюжная, студеная, белая и т.д.)
— Составьте cинквейн на тему «Зима».
— Прочитайте cинквейн. Запишите.
Х. Итог урока.— Подведем итог нашего урока. Какое открытие сделали? (Алгоритм разбора состава слова)
ЛитератураСлово по составу верно разбирай:
Первым, окончание всегда выделяй,
На основу внимательно смотри,
Корень, поскорее, ты у нее найди,
Приставку и суффикс в конце определи.

- С.И. Ожегов, Н.Ю. Шведова «Толковый словарь русского языка»)
- http://www.inpic.ru/tag/зимородок
- http://birds-altay.ru/2009/10/goluboj-zimorodok/
- http://www.liveinternet.ru/users/3872837/post142442036
- http://free-extras.com/search/1/winter.htm
- http://www.redbook.ru/article483.html
- https://urok.1sept.ru/articles/517799/
Разбор слова по составу — начальные классы, уроки
Конспект урока русского языка в 4 классепо теме: «Разбор слова по составу».
Образовательные:
-уточнить понятия «корень», «основа», «приставка»,
«суффикс», «окончание»;
-создать с учащимися алгоритм разбора слова по составу;
Развивающие:
— развивать умения выделять части слова, способствовать развитию орфографического навыка.
— развивать речь учащихся, обогащать словарный запас детей;
-развивать сообразительность, мышление, память.
Воспитательные:
-создавать у учащихся положительную мотивацию к уроку русского языка путём вовлечения каждого в активную деятельность;
-воспитывать культуру речи, любовь к слову, родному языку;
-воспитывать внимание, доброе отношение друг к другу.
Оборудование: ноутбук, мультимедийный проектор, экран, слайды по теме, картинки с рисунками.
Формирование УУД:
— личностные действия: уметь создавать благоприятную дружескую атмосферу вокруг себя, принимать активное участие на уроке, быть вежливым, воспитанным, корректным.
— регулятивные действия: уметь планировать свою деятельность, ставить перед собой задачи, делать выводы, контролировать свои действия, быть внимательным;
— познавательные действия: уметь определять глаголы, изменять их по вопросу, согласовать с именами существительными, использовать их в речи и письме.
— коммуникативные действия: уметь работать в группе, в паре, принимая равное участие; уметь выслушать и помочь товарищу, обогащать связную речь посредством глаголов.
Оборудование урока:
-карточки индивидуального опроса;
Тип урока: изучение нового материала.
Формы работы: фронтальная, индивидуальная, групповая.
Методы обучения: словесно-наглядный, проблемно-поисковый (эвристический), самостоятельная работа, иллюстративный.
Ход урока.
1.Организационный момент. Хай Файв!(сигнал тишины)
— Добрый день.
Дети. Мы рады приветствовать вас в классе,
Возможно, есть классы и лучше и краше.
Но пусть в нашем классе вам будет светло,
Пусть будет уютно и очень легко,
Поручено нам вас сегодня встречать,
Ну начнем же урок, не будем зря время терять.
– Спасибо, будем надеяться, что настроение наших гостей хорошее, а будет ещё лучше. Я желаю вам успешной работы и приятного общения на уроке. Посмотрите, друг на друга, улыбнитесь и пожелайте своему соседу удачи. И так, начнем наш урок.
Я желаю вам успешной работы и приятного общения на уроке. Посмотрите, друг на друга, улыбнитесь и пожелайте своему соседу удачи. И так, начнем наш урок.
На партах лежат цветные полоски. Выберите из 4 один себе цвет. Прикрепите в бэйджиках. Пусть каждому из вас этот выбранный цвет принесет отличное настроение для усвоения новых знаний.
Внимание на экран. Здесь эпиграф к нашему уроку. (Я читаю)
Слайд 2
Слово делится на части,
Как на дольки апельсин.
Может каждый грамотей
Строить слово из частей.
(Таймд Раунд Робин) Как вы понимаете эти слова? Обсудите у себя в группе, проговаривая каждый по очереди по кругу за определенное время. Начинает участник № 1 по сигналу.
1) (по 10секунд 4 раза)
Кто хочет поделиться с своей мыслью? Стол 3- участник 3 и т.д.
Как вы думаете о чём мы с вами сегодня будем говорить на уроке?
Чем мы сегодня будем заниматься?
Какую поставим цель? (Научиться разбирать слова по составу) Слайд 3
Всё на свете из чего-нибудь состоит: облака из капелек, лес из деревьев.
Слова тоже сделаны из своего материала.
Слово делится на части
Как на дольки апельсин.
И у каждой части слова есть своё название.
Над которыми мы сегодня и будем работать.
2. Актуализация знаний.
Ну а чтобы собрать наше внимание, проведём «Разминку для ума».
Глазки на меня. Отвечаем хором, быстро.
называется…
— Как называется третий зимний месяц?
Какие буквы не употребляются в начале русских слов?
Во что превращается вода зимой….
Часть слова без окончания называется …
Назовите слово, противоположное слову враг.
Самый короткий месяц в году?
— Сколько гласных звуков в русском алфавите?
-Какие части речи мы с вами знаем?
Молодцы!
Ну и конечно, какой урок без словарной работы!
Окрываем тетради , записываем число. Классная работа.
3. Словарная работа.
Конверт № 1.
Для каждого участника в конверте лежат карточки для словарной работы.
Слайд 4
Задание. Прочитайте текст, вставьте пропущенные буквы
Зимой ру .. кий лес сказоч..ный и ч.. десный.
Сне.. украшает пуш.. стые ветки деревьев.
Смолистые шишки в.. сят (на) елях.
В серебряном уборе стоят красавицы — б.. рёзки.
(20секунд)
Кто готов покажите это (чир — фейервек)
Обменялись листочками с партнером по лицу.
Слайд 5 Взаимопроверка по экрану, с объяснением орфограмм.
4. Разминка.
Сейчас мы должны вспомнить все части слова.
Релли Робин -два участника поочередно обмениваются короткими ответами в виде списка)
Конверт № 2.
Вам нужно на этих листочках написать о каких понятиях части слова идет речь. Работаете с партнером по плечу, по очереди. Начинают партнер под буквой Б.
Работаете с партнером по плечу, по очереди. Начинают партнер под буквой Б.
Слайд 6 (30 секунд)
1) Изменяемая часть слова это — ……….
2) Часть слова без окончания это — ………….
3) Часть слова, которая стоит перед корнем и служит для образования новых слов это — ……….
4) Часть слова, которая стоит после корня и служит для образования новых слов это — ……….
5) Главная часть слова это — …….
Кто готов покажите это (чир — фейервек)
Вы вспомнили все, что касается состава слова. Применим это на практике. Сейчас вы работаете с партнером по лицу.
Слайд 7(Приставка,корень, предлог,окончание;
Приставка, корень, суффикс, союз)
Возьмите конверт № 3 . На листочках слова. Назовите 4 — е лишнее слово запишите лишнее слово в тетрадях. Затем поменяйтесь с партнерами листочками и опять найдите 4 – е лишнее. У вас должны получиться 2 слова.
Затем поменяйтесь с партнерами листочками и опять найдите 4 – е лишнее. У вас должны получиться 2 слова.
по 20 секунд два раза
Посовещавшись, скажите, какие слова у вас получились лишними?
Стол № 1 участник 2.
Стол № 4 участник 4. Слайд 8
Хорошо, спасибо!
Вывод разминки. Микс Пэа Шэа-звучит музыка, ученики молча смешиваются, двигаясь по кабинету.
— Встаньте, задвиньте стульчики. Возьмите в руки тетради и карандаши. Когда музыка остановится, вы должны образовать пару с ближайшими к вам учениками и «дать пять» (взяться в воздухе за руки), затем я задаю вопрос , а вы должны будете поделится ответом своим партнером и наоборот.
1 – й вопрос. Почему лишними оказались слова предлог и союз.
(Начинает тот, у кого волосы светлее)
(по 15 секунд два раза)
Музыка!!!
(Музыка останавливается, ученики находят другую пару. )
)
2 – й вопрос. Чем предлоги отличаются от приставок?.
(Начинает тот, у кого волосы длиннее.)
Ученики делятся ответом со своими партнерами
(по 15 секунд два раза)
Поблагодарите своего партнера.
— А теперь на этот вопрос ответит… (Ceer!)
Музыка!!!
(Музыка останавливается, ученики находят другую пару.)
3 – й вопрос. Для чего необходимо знать состав слова? (Состав слова может объяснить образование слов. Знание состава слова помогает мне увидеть, в какой части слова орфограмма)
(Начинает тот, кто ниже ростом.)
(Ученики делятся своими партнерами
(по 15 секунд два раза)
Поблагодарите своего партнера.
— А теперь на этот вопрос ответит… (Ceer!)
Спасибо, ребята, молодцы! Пройдите на свои места.
— Молодцы!
III. Основная часть.
1.Раунд Тэйбл (письменная работа по очереди, по кругу на одном листе– по часовой стрелке.)
Конверт № 4 Работа на листочках.
— На карточках к словам из левого столбика подберите правильную схему состава слова из правого столбика и рядом запишите цифру. письменная работа по очереди, по кругу на одном листе– по часовой стрелке
Начинает ученик под номером 2.
Слова……………. Схемы состава слова…………………
Слайд 9
Песенка 1)
Пенал 2)
Подруга 3)
Подсказка 4)
1 минута
Кто готов покажите это (чир — фейервек)
— А теперь на этот вопрос ответит… (Ceer!) Слайд10
Спасибо, ребята, молодцы!
2 . Углы. Конэрс (распределяются по углам от выбранного ими ответа)
Углы. Конэрс (распределяются по углам от выбранного ими ответа)
Конверт № 5
Слайд 11.Каждый из вас должен выбрать одно слово. Запишите в тетрадях. Подберите к нему однокоренные слова. Запишите их.
1. Море
2. Город
3. Лес
4. Сад
2 минуты
Кто готов покажите это (чир — фейервек)
Кто выбрал для себя слово лес – пройдите в тот угол, где нарисован рисунок леса, город – в другой угол и т.д. море в свой угол, сад в свой угол.
— Идите к вашему углу комнаты и найдите партнера для разговора не из вашей команды.
— Обсудите в парах, какие положительные эмоции вызывают данные слова и картинки?
(по 15 секунд два раза).
…! Поделись мнением своего партнера. (Ceer!)
(Ceer!)
( Из каждого угла по 1 человеку.)
— Теперь в вашем же углу найдите другого партнера, с кем вы еще не общались и вместе составьте однокоренные слова с используемым словом на стене вашего угла .
(По 15 секунд два раза ).
Спасибо.
Давайте поблагодарим своего партнера.
Посмотрите на свои бейджики. Образуйте команду, собравшись по цветам .
3. Работа над своими однокоренными словами.
— Сядьте на новые места. Давайте посмотрим, какие же однокоренные слова у вас получились. Стол № 1. У кого слово –море. Прочитай свои слова. Остальные столы дополняют и записывают.
И остальные слова. А для чего мы подбирали однокоренные слова?
Физминутка!!!!!!!!!!!!!!!!!!!!
4. Творческое задание 1.
Слайд 12Что оно означает? КОНСТРУКТОР – тот, кто конструирует что-либо, создает конструкцию чего-либо; это набор частей, деталей, из которых строят разные сооружения.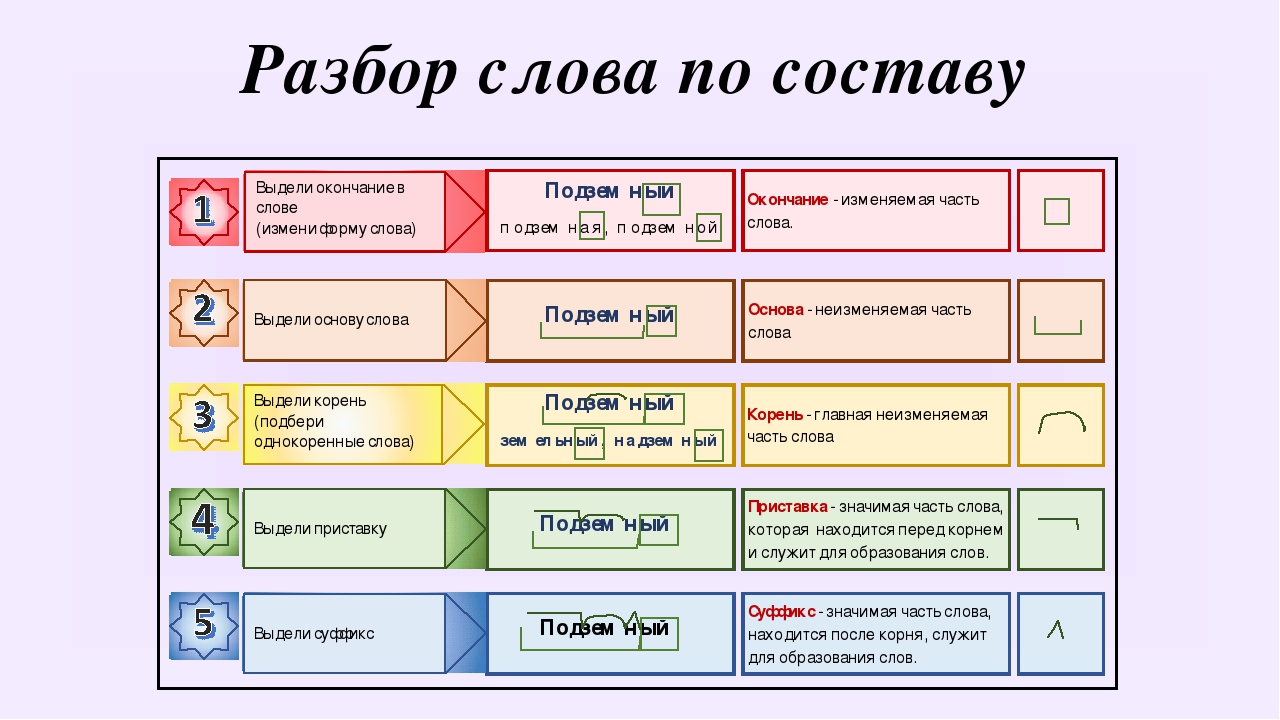
Вам приходилось собирать что-нибудь из деталей конструктора? Вот и мы с вами сейчас будем конструировать слова.
Конверт № 6
Слайд 13Вы берете ту часть слова, которая указана в таблице. И у вас должно получится новое слово. Каждый работает сам.
ПРИСТАВКА | КОРЕНЬ | СУФФИКС | ОКОНЧАНИЕ | СЛОВО |
походка | слово | сестрицы | река | пословица |
налетели | ученик | куст | молчит | научит |
коньки | мудрец | старость | домик | мудрость |
Кто готов покажите это (чир — фейервек)
Проверка Слайд 14
Можно ли детали, изображённые на карточках, отнести к «словесному конструктору»? Докажите.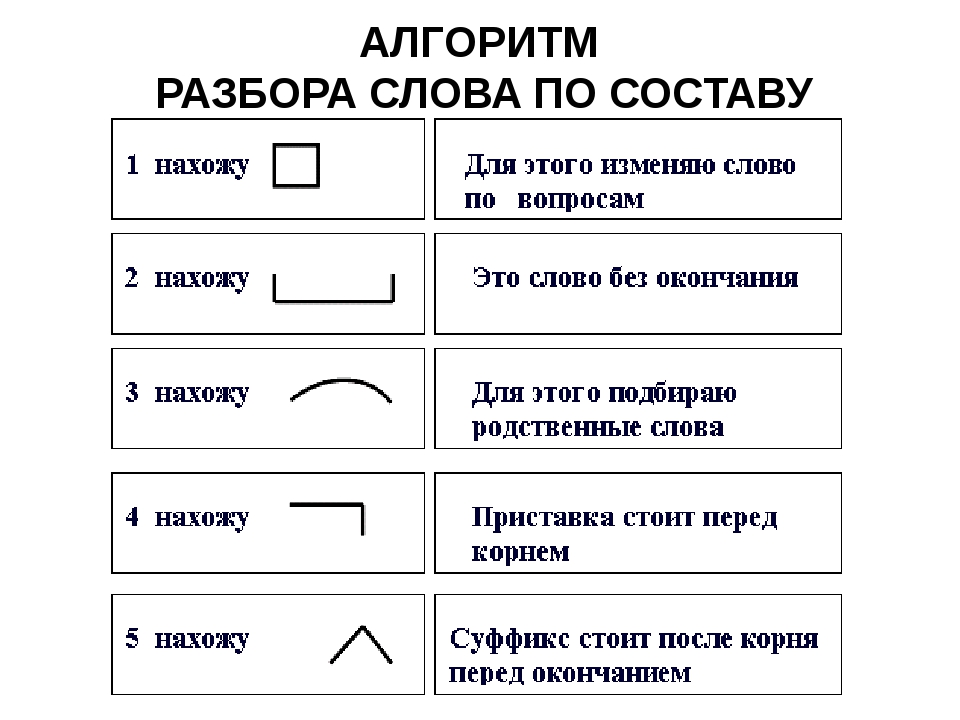
(Работа по учебнику с. 157 упр.198 – запас)
Вывод , как нужно правильно действовать при разборе слов по составу?
Слайд 15
Сравним с выводом по книге.
Закрепление. Работа в группе.
Конверт № 7.
Соберите слова из слогов, составленные слова представители групп напишите на доске. По очереди выходим и правильно выделяем части слова, используя алгоритм.
Подберёзовик, добродушная, подосиновик, одноклассники
Как образовались данные слова? Молодцы!
Минутка отдыха слайды 16,17,18
7. Итог урока.
Слайд 19
Урок наш заканчивается, давайте подведём итог.
Над какой темой мы сегодня начали работу на уроке?
Могут ли существовать приставки и суффиксы в речи самостоятельно,
отдельно от слова?
А кто самостоятельно может разбирать слова по составу?
Достаточно одного урока?
Действовали вместе и работали хорошо
А сейчас каждый подумает и оценит свою деятельность на уроке на лесенке успеха.
Что бы вы хотели повторить или узнать о составе слова? На этот вопрос напишите на стикерах, и прикрепите на парковку, это будет ваш билетик на выход с урока.
IХ. Домашнее задание
Стр.158 упр.200
А в заключении хочется показать вам небольшую сказку.
«Кто главнее и важнее»
— Живут на свете удивительные морфемы. Имя у них тоже удивительное и загадочное – суффиксы. Иногда могут звенеть, как колокольчики: оньк, еньк, знь; стучать каблучками: ек, ик, чик, ник; петь, как птички: чив, лив, чив, лив! Суффиксы и приставки поначалу очень дружили и никогда не ссорились. Они много времени проводили вместе. Но однажды они поспорили о том, кто из них лучше помогает корню выражать значение слова.
Приставки. Ну как вы не понимаете?! Возьмём слово выиграть, это совсем не то, что проиграть! А написать самой – это вам не списать у кого-нибудь. И всё это благодаря нам, приставкам! Ну что, нужны после этого ещё какие-нибудь слова?
И всё это благодаря нам, приставкам! Ну что, нужны после этого ещё какие-нибудь слова?
Суффиксы. Конечно, нужны и очень много (выступают вперёд) Мы привели сюда целую семью слов: лесок, лесовик, лесник.
Смотрите, как могущественны в этих словах мы – суффиксы! Захотим — и лес превращается в лесок. А вот и человек, который охраняет лес. И все эти превращения совершили мы – суффиксы.
Прист. Зато, если захотят сказать что-то просто очень-преочень, то на помощь приходим мы, приставки. И тогда говорят прекрасный, прелестный, и вообще: не хорошенький, а прехорошенький, не огромный, а преогромный! Так что да здравствуем мы, приставки!
Суф. Зато мы можем приласкать! И сказать не мама, а мамочка, не Оля, а Оленька!
Уч. Спорили приставки и суффиксы, спорили – чуть не подрались! Спасибо, вовремя корень вмешался – встал между ними.
Корень. Что вы тут расшумелись? Вы попробуйте хоть вместе, хоть порознь что-нибудь без меня, без корня, сказать!
Уч. Приставки и суффиксы пробовали- пробовали, старались-старались, и так и эдак – ничего у них не вышло. С тех пор корень как главный в слове решил так.
Корень. За то, что вы раздор учинили, никогда больше друг друга не увидите, друг до дружки не дотронетесь, а будете стоять от меня по разные стороны: вы, приставки, – слева, а вы, суффиксы, — справа. И станете вы во веки веков меня охранять и мне помогать. А за службу вашу верную я подарю вам дома-терема, и, чтобы вас никто не путал, крыши на них будут разные. У приставок вот такие: , а у суффиксов – совсем другие: . А себе я выберу крышу самую красивую, на месяц в небе похожую. Вот такую: .
Уч. Тут всем спорам конец пришёл. Да и некогда: слов на свете много, работы всем морфемам хватает.
К.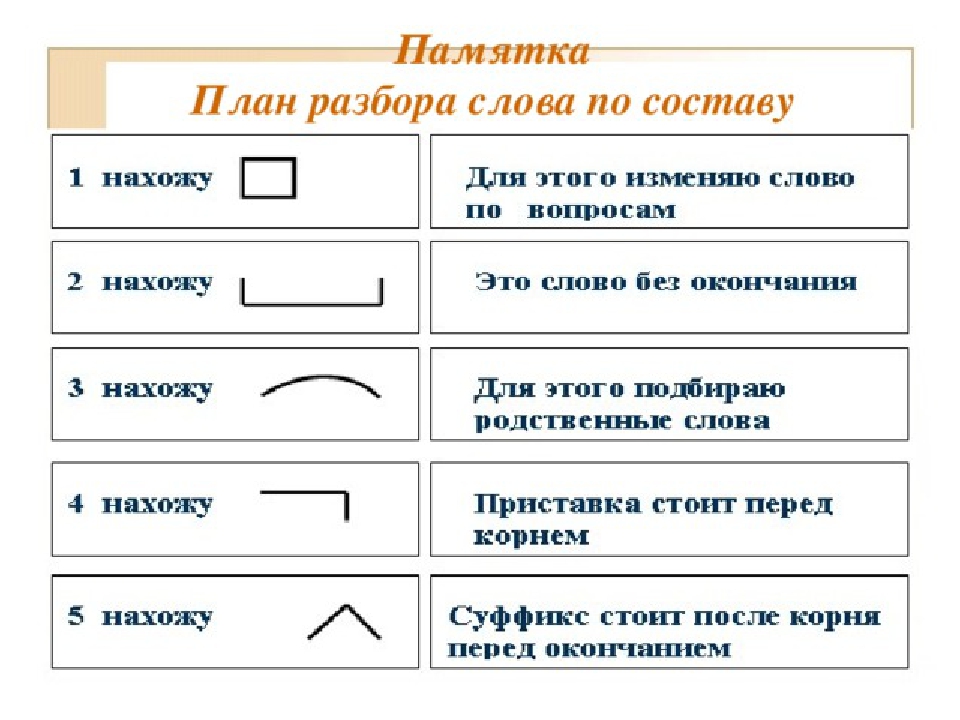 В корне смысл, но не весь
В корне смысл, но не весь
Главный, но не полный.
Пр. Потому приставка есть-
Смысл она дополнит.
Суф. — Рад я в этом ей помочь.
После корня встать не прочь!
Ну и что ж, что после корня, —
Всё равно я всех проворней!
Уч. А о какой морфеме ни слова не было сказано в сказке?
Дети. –Об окончании.
Уч. –А вот спешит к нам уже и окончание.
Окон. И на род укажу,
И про время скажу,
И слова все свяжу, хоть и временно.
Ведь недаром всю жизнь
Беззаветно служу
Я родному морфемному племени!
Уч. –Вот и сказке конец, а кто слушал …
Дети. МОЛОДЕЦ
МОЛОДЕЦ
Тест “Состав слова”.
1. Подчеркните части слова, которые ты знаешь.
Союз, корень, знак, окончание, предлог, речь, приставка, слово, текст, суффикс, предмет.
2. Какая часть слова может изменяться? _______________
3.Устно разберите слова по составу. Впиши в нужный столбик слово по схеме.
Лесок, сады, дом, работник, ледяной, день, березка, городок, походы, смелый, поезда, конь, цветник, осенний, погода, дожди.
4. Какая часть слова служит для образования новых слов? _______________________________________________
5. Разбери однокоренные слова по составу.
Соль, подсолнечник, солить, солнце, пересолить.
Карточки с заданиями по русскому языку по теме «Разбор слова по составу»
Карточки для индивидуальной работы по русскому языку
для учащихся 3 класса
Карточки
можно использовать на этапе закрепления и диагностики темы «Разбор слова по
составу». Задания в карточках предложены двух уровней: (1)- базовый, (2)-
повышенный.
Задания в карточках предложены двух уровней: (1)- базовый, (2)-
повышенный.
Карточка №1
1(1) Разобрать слова по составу.
Снежинка, переносить, заморозить, рыбка, мореход, лётчик, кустик, корешок.
2(2) Распределите слова в соответствующие столбики, соответственно схемам. Разберите слова по составу.
Банька, снежный, добежать, учение, ответить, разговор, ночь, черный.
____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
Карточка №2
1(2)Разбери слова по составу. Запиши слова в соответствующие столбики.
Сад , переход, медовый, улететь, залез,
выходной, белый.
слова, называющие предметы | слова, называющие действия | слова, называющие признаки |
|
|
|
|
|
|
|
|
|
|
|
|
2(2) Разбери слова по составу. Найди слова с одинаковым составом и выпиши их ниже парами.
Прибрежный, ключик, небесный, подушка, подосиновик, осиная, читать, учить, дорисовать, кленовый.
____________________________________________________________________________________________________________________________________
Карточка №3
1(2) Разбери слова по составу.
Листочек, школьник, держать, бой, купить, снежок, подорожник, учение, долететь.
Придумайте слово с таким же составом как слово- ПОДОРОЖНИК.
____________________________________________________________________________________________________________________________________
2(2) Отгадайте слово и разберите его по составу.
| Приставка как, в слове …
| Корень как, в слове …
| Суффикс как, в слове …
| Окончание как, в слове … | Получилось слово… |
1 | понес | бегать | читать | летать |
|
2 |
| посадить | мостовая | серая |
|
3 | залетать | полёт | смотреть | ходить |
|
4 | почитать | дорожка | подснежник | конь |
|
5 |
| ветреная | снежок | стул |
|
Карточка №4
1(1)
Разобрать слова по составу.
Дубовый, длинный, мяч, перелётная, подбежать, осмотреться, подъехать, улей.
2(2) Распределите слова в соответствующие столбики, соответственно схемам. Разберите слова по составу.
Стена, ручной, море, ключик, звонкий, подвозить, зимушка, осенняя, переход, школьный.
____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
Карточка №5
1(2)Разбери слова по составу. Запиши слова в соответствующие столбики.
Стройка, цветник, ворона, кочка, снеговой, бежать, дубовая, стульчик, слоненок, береговая.
слова, называющие предметы | слова, называющие действия | слова, называющие признаки |
|
|
|
|
|
|
|
|
|
|
|
|
2(2) Разбери слова по составу.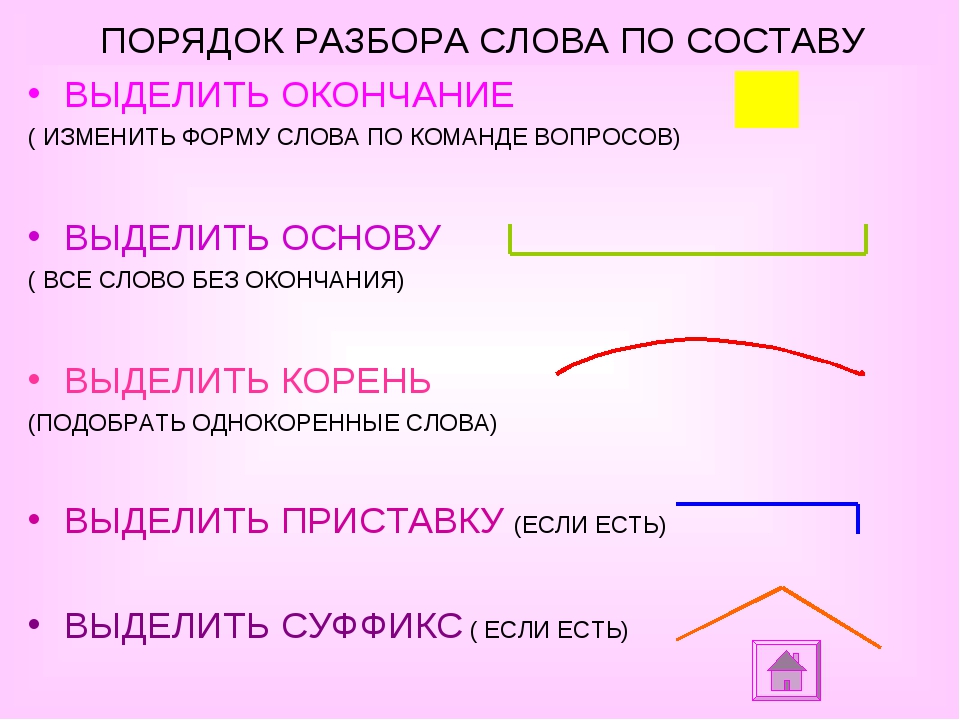 Найди слова
с одинаковым составом и выпиши их ниже парами.
Найди слова
с одинаковым составом и выпиши их ниже парами.
Стенка, травяной, бумажка, прибрежная, город, глазик, лесник, посадить, листовой, чай , кофе.
____________________________________________________________________________________________________________________________________
Карточка №6
1(2) Разбери слова по составу.
Крот, девица, ученик, весёлый, листочек, ученица, молочный, метро, желтый.
Придумайте слово с таким же составом как слово- молочный.
____________________________________________________________________________________________________________________________________
2(2) Отгадайте слово и разберите его по составу.
| Приставка как, в слове …
| Корень как, в слове …
| Суффикс как, в слове …
| Окончание как, в слове … | Получилось слово… |
1 | донести | бежать | читать | учить |
|
2 |
| садик | медовый | белая |
|
3 | захочет | летчик | смотреть | ходить |
|
4 | порулить | дорожная | подснежник | лес |
|
5 |
| круглый | дружок | пень |
|
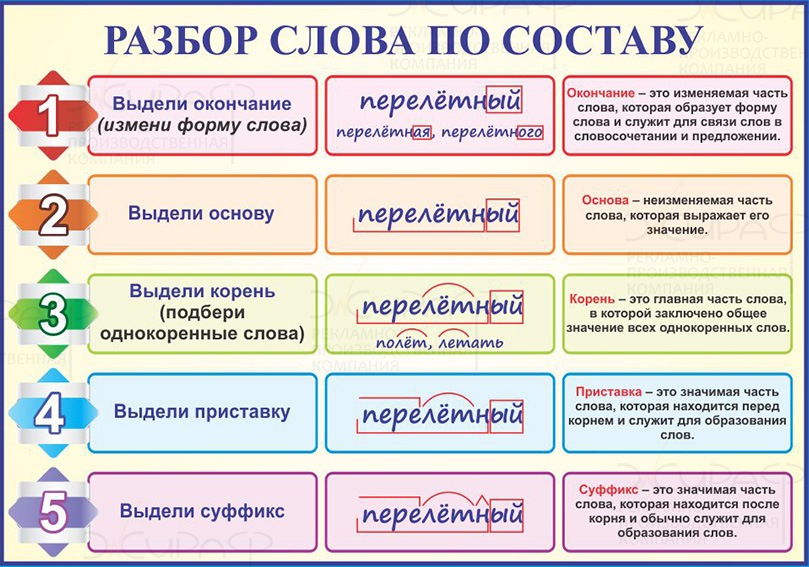
Морфемный разбор (разбор слова по составу)
При морфемном разборе слова (разборе слова по составу) сначала в слове выделяется окончание и формообразующий суффикс (если они есть), подчёркивается основа.
После этого основа слова разбивается на морфемы.
Как мы уже говорили, возможны два противоположных подхода к морфемному членению основы: формально-структурный и формально-смысловой.
Суть формально-структурного морфемного разбора состоит в том, что в основе в первую очередь выделяется корень как общая часть родственных слов. Затем то, что идёт до корня, учеником должно быть осознано как приставка (приставки) в соответствии с представлениями ученика о том, встречались ли ему подобные элементы в других словах. Аналогично с суффиксами. Иначе говоря, главным при разборе становится эффект узнаваемости учеником морфем, внешнее сходство каких-то частей разных слов. И это способно привести к массовым ошибкам, причина которых — игнорирование того факта, что морфема является значимой языковой единицей. Отсутствие работы по определению значения морфем приводит в ошибкам двух типов, имеющих разную природу:
Ошибки в определении корня слова связаны с неразличением синхронного морфемного и исторического (этимологического) состава слова. Причём комплекс 2 неразличение современного и исторического морфемного состава слов берёт за установку, помогающую иногда в определении правильности написания, что вполне соответствует общей орфографико-пунктуационной направленности курса и учебника в целом. Так, в учебнике по теории в качестве иллюстративного материала приведён такой пример морфемного разбора слова искусство (ис-кус-ств-о). Очевидно, что такой подход не может способствовать корректному выделению корня в современной структуре слова и приводит к выделению в основе незначимых сегментов.
Причём комплекс 2 неразличение современного и исторического морфемного состава слов берёт за установку, помогающую иногда в определении правильности написания, что вполне соответствует общей орфографико-пунктуационной направленности курса и учебника в целом. Так, в учебнике по теории в качестве иллюстративного материала приведён такой пример морфемного разбора слова искусство (ис-кус-ств-о). Очевидно, что такой подход не может способствовать корректному выделению корня в современной структуре слова и приводит к выделению в основе незначимых сегментов.
Ошибки в выделении приставок и суффиксов связаны с алгоритмом морфемного членения — с представлением большинства учащихся о слове как о веренице морфем, которые должны быть «опознаны» как уже встречавшиеся в других словах. Крайнее выражение разборов такого рода — случаи типа клю-чик (ср.: лёт-чик), я-щик (обой-щик). Но и при правильно определённом корне очень часто приходится сталкиваться с неправильным определением количества и состава приставок и суффиксов, если этих морфем в слове больше двух. Это связано, во-первых, с алгоритмом морфемного членения и, во-вторых, с тем, что в учебниках слова, имеющие более одной приставки и/или суффикса, практически не приводятся.
Это связано, во-первых, с алгоритмом морфемного членения и, во-вторых, с тем, что в учебниках слова, имеющие более одной приставки и/или суффикса, практически не приводятся.
Формально-структурный подход к морфемному членению слова не является исключительно принадлежностью школьной практики. Аналогичный подход осуществлён в ряде научных изданий, например в «Словаре морфем русского языка» А. И. Кузнецовой и Т. Ф. Ефремовой, где утверждается, что «морфемный анализ мало зависит от словообразовательного, так как обычно при членении слова используется сопоставительный метод, при котором практически не учитывается, что от чего образуется».
Формально-структурному подходу противопоставлен подход формально-смысловой (формально-семантический). Главная установка данного подхода и алгоритм морфемного разбора выходят из трудов Г. О. Винокура и состоят в неразрывности морфемного членения и словообразовательного разбора. О том, что этот подход является целесообразным и даже единственно возможным, писали многие учёные и методисты на протяжении многих десятилетий.
Подход учебных комплексов к вопросу о принципах и алгоритме морфемного членения различен: учебные комплексы 1 и 3 предлагают формально-смысловой подход к морфемному членению слова (комплекс 3 в большей степени, чем комплекс 1), комплекс 2 — формально-структурный.
Алгоритм морфемного разбора основы состоит в построении словообразовательной цепочки «наоборот»: со слова как бы «снимаются» приставки и суффиксы, корень же выделяется в последнюю очередь. При разборе постоянно необходимо соотнесение значения производного и значения его производящего; производящая основа в современном русском языке — основа мотивирующая. Если между значением производного и значением производящего (в нашем представлении) слова нет отношения мотивированности, производящее выбрано неверно.
Таким образом, порядок разбора слова по составу таков:
1) выделить окончание, формообразующий суффикс (если они есть в слове),
2) выделить основу слова — часть слова без окончаний и формообразующих суффиксов,
3) выделить в основе слова приставку и / или суффикс через построение словообразовательной цепочки,
4) выделить в слове корень.
Примеры :
1) плотничал
Образец рассуждения :
плотничал — форма глагола плотничать; глагол стоит в форме прошедшего времени изъявительного наклонения, что выражено формообразующим суффиксом -л—, мужского рода единственного числа, что выражено нулевым кончанием (сравним: плотничал-и).
Основа — плотнича—.
Глагол плотничать образован от существительного плотник, мотивируется через него: плотничать — «быть плотником»; разница между основой плотничаи плотник — суффикс -а—, в основах представлено чередование к / ч.
Существительное плотник в современном языке непроизводно, так как не может быть мотивировано через слово плот. Следовательно, плотник /плотнич — корень.
Таким образом, словоформа плотничал имеет нулевое окончание со значением мужского рода единственного числа, формообразующий суффикс -л— со значением прошедшего времени изъявительного наклонения, словообразующий суффикс -а— со значением являться тем, что названо в мотивирующей основе, корень плотнич. Основа слова плотнича-.
Основа слова плотнича-.
Словообразование в английском языке. Способы и правила построения новых слов
Для знания иностранного языка богатство словарного запаса ничуть не менее важно, чем понимание грамматики. Чем большим количеством слов владеет человек, тем свободнее он себя чувствует в иноязычной среде.
Многообразие лексики во многом определяется богатством словообразования в английском языке. Построение новых слов основано на общих принципах. И тот, кто знает эти принципы, чувствует себя среди незнакомой лексики гораздо увереннее.
Структура слова и ее изменение
Новые слова усваиваются постепенно. Чаще всего, сначала мы только понимаем их в текстах или чужой речи, а уже потом начинаем активно использовать в своей. Поэтому освоение новой лексики – процесс длительный и требует от ученика терпения, активной практики чтения, слушания и работы со словарем.
Один из методов быстро расширить свой словарный запас – освоить способы словообразования в английском языке. Поняв принципы, по которым строятся слова, можно из уже известного слова вывести значения его однокоренных слов.
Поняв принципы, по которым строятся слова, можно из уже известного слова вывести значения его однокоренных слов.
Строительный материал для каждого слова – это корень, приставки и суффиксы. Корень – это та часть слова, которая несет основной смысл. Слово без корня не может существовать. Тогда как приставки и суффиксы – необязательная часть, однако прибавляясь к корню, именно они помогают образовать новые слова. Поэтому, описывая словообразование в английском, мы будем разделять приставочные и суффиксальные способы.
Все приставки и суффиксы обладают собственным значением. Обычно оно довольно размыто и служит для изменения основного значения слова. Когда к корню добавляется приставка или суффикс (или же оба элемента), то их значение прибавляется к значению корня. Так получается новое слово.
Образование новых слов может приводить не только к изменению значения, но и менять части речи. В этой функции чаще выступают суффиксы. Прибавляясь к корню, они переводят слово из одной части речи в другую, например, делают прилагательное из глагола или глагол из существительного.
Так, от одного корня может образоваться целая группа, все элементы которой связаны между собой. Поэтому словообразование помогает изучающим английский видеть смысловые отношения между словами и лучше ориентироваться в многообразии лексики.
Получить новое слово можно не только за счет приставок и суффиксов. Еще один способ – это словосложение, при котором в одно слово объединяются два корня, образуя новый смысл. Кроме того, к словообразованию относится сокращение слов и создание аббревиатур.
Приставки как способ словообразования в английском
Приставка (также употребляется термин «префикс») – элемент слова, который ставится перед корнем. Приставочное словообразование английский язык редко использует для смены частей речи (в качестве исключения можно назвать префикс «en-» / «em-» для образования глаголов). Зато приставки активно используются для изменения значения слова. Сами префиксы могут иметь различные значения, но среди них выделяется большая группа приставок со схожей функцией: менять смысл слова на противоположный.
1. Приставки с отрицательным значением:
- un-: unpredictable (непредсказуемый), unable (неспособный)
- dis-: disapproval (неодобрение), disconnection (отделение от)
- im-, in-, il -,ir-: inactive (неактивный), impossible (невозможный), irregular (нерегулярный), illogical (нелогичный). То, какая из этих приставок будет присоединяться к слову, зависит от следующего за ней звука. «Im-» ставится только перед согласными «b», «p», «m» (impatient — нетерпеливый). «Il-» возможно только перед буквой «l» (illegal — незаконный), «ir-» – только перед «r» (irresponsible — безответственный). Во всех остальных случаях употребляется приставка «in-» (inconvenient – неудобный, стесняющий).
- mis-: misfortune (несчастье, беда). Приставка «mis-» может использоваться не только для образования прямых антонимов, но и иметь более общее значение отрицательного воздействия (misinform — дезинформировать, вводить в заблуждение, misunderstand — неправильно понять).


2. Другие приставочные значения
- re-: rebuild (отстроить заново, реконструировать). Приставка описывает повторные действия (rethink — переосмыслить) или указывает на обратное направление (return — возвращаться).
- co-: cooperate (сотрудничать). Описывает совместную деятельность (co-author – соавтор).
- over-: oversleep (проспать). Значение префикса — избыточность, излишнее наполнение (overweight — избыточный вес) или прохождение определенной черты (overcome — преодолеть).
- under-: underact (недоигрывать). Приставку можно назвать антонимом к приставке «over-», она указывает на недостаточную степень действия (underestimate — недооценивать). Кроме того, приставка используется и в изначальном значении слова «under» — «под» (underwear — нижнее белье, underground — подземка, метро).
- pre-: prehistoric (доисторический). Приставка несет в себе идею предшествования (pre-production — предварительная стадия производства).
- post-: post-modern (постмодернизм). В отличие от предыдущего случая, приставка указывает на следование действия (postnatal – послеродовой).
- en-, em-: encode (кодировать). Префикс служит для образования глагола и имеет значение воплощения определенного качества или состояния (enclose — окружать). Перед звуками «b», «p», «m» приставка имеет вид «em-» (empoison — подмешивать яд), в остальных случаях – «en-» (encourage — ободрять).
- ex-: ex-champion (бывший чемпион). Используется для обозначения бывшего статуса или должности (ex-minister — бывший министр).

Образование новых слов при помощи суффиксов
Суффиксы занимают позицию после корня. За ними может также следовать окончание (например, показатель множественного числа «-s»). Но в отличие от суффикса окончание не образует слова с новым значением, а только меняет его грамматическую форму (boy – мальчик, boys – мальчики).
По суффиксу часто можно определить, к какой части речи принадлежит слово. Среди суффиксов существуют и такие, которые выступают только как средство образования другой части речи (например, «-ly» для образования наречий). Поэтому рассматривать эти элементы слова мы будем в зависимости от того, какую часть речи они характеризуют.
Среди суффиксов существуют и такие, которые выступают только как средство образования другой части речи (например, «-ly» для образования наречий). Поэтому рассматривать эти элементы слова мы будем в зависимости от того, какую часть речи они характеризуют.
Словообразование существительных в английском языке
Среди суффиксов существительных можно выделить группу, обозначающую субъектов деятельности и группу абстрактных значений.
1. Субъект деятельности
- -er, -or: performer (исполнитель). Такие суффиксы описывают род занятий (doctor — доктор, farmer — фермер) или временные роли (speaker — оратор, visitor — посетитель). Могут использоваться и в качестве характеристики человека (doer — человек дела, dreamer — мечтатель).
- -an, -ian: magician (волшебник). Суффикс может участвовать в образовании названия профессии (musician — музыкант) или указывать на национальность (Belgian — бельгийский / бельгиец).
- -ist: pacifist (пацифист). Этот суффикс описывает принадлежность к определенному роду деятельности (alpinist – альпинист) или к социальному течению, направлению в искусстве (realist — реалист).
- -ant, -ent: accountant (бухгалтер), student (студент).
- -ee: employee (служащий), conferee (участник конференции).
- -ess : princess (принцесса). Суффикс используется для обозначения женского рода (waitress – официантка).
 Этот суффикс описывает принадлежность к определенному роду деятельности (alpinist – альпинист) или к социальному течению, направлению в искусстве (realist — реалист).
Этот суффикс описывает принадлежность к определенному роду деятельности (alpinist – альпинист) или к социальному течению, направлению в искусстве (realist — реалист).2. Абстрактные существительные
Основа этой группы значений – обозначение качества или состояния. Дополнительным значением может выступать объединение группы людей и обозначение определенной совокупности.
- -ity: activity (деятельность), lability (изменчивость).
- -ance, -ence, -ancy, -ency: importance (важность), dependence (зависимость), brilliancy (великолепие), efficiency (эффективность).
- -ion, -tion, -sion: revision (пересмотр, исправление), exception (исключение), admission (допущение), information (информация).
- -ism: realism (реализм). В отличие от суффикса «-ist» обозначает не представителя некоторого течения, а само течение (modernism — модернизм) или род занятий (alpinism — альпинизм).
- -hood: childhood (детство). Может относиться не только к состоянию, но и описывать группу людей, форму отношений: brotherhood (братство).
- -ure: pleasure (удовольствие), pressure (давление).
- -dom: wisdom (мудрость). Также используется при обозначении группы людей, объединения по некоторому признаку: kingdom (королевство).
- -ment: announcement (объявление), improvement (улучшение).
- -ness: darkness (темнота), kindness (доброта).
- -ship: friendship (дружба). К дополнительным значениям относится указание на титул (lordship — светлость), умение (airmanship — лётное мастерство) или на объединение круга людей определенными отношениями (membership — круг членов, partnership — партнерство).
- -th: truth (правда), length (длина).

Словообразование прилагательных в английском языке
- -ful: helpful (полезный). Указывает на обладание определенным качеством (joyful — радостный, beautiful — красивый).
- -less: countless (бессчетный). Значение суффикса близко к отрицанию и характеризует отсутствие определенного качества, свойства (careless — беззаботный). Этот суффикс можно определить как антоним для «-ful» (hopeless — безнадежный, а hopeful — надеющийся).
- -able: comfortable (комфортный). «Able» (способный) существует и как самостоятельное прилагательное. Оно определяет значение суффикса – возможный для выполнения, доступный к осуществлению (acceptable – приемлемый, допустимый, detectable – тот, который можно обнаружить).
- -ous: famous (знаменитый), dangerous (опасный).
- -y: windy (ветреный), rusty (ржавый).
- -al: accidental (случайный), additional (добавочный).
- -ar: molecular (молекулярный), vernacular (народный).
- -ant, -ent: defiant (дерзкий), evident (очевидный).
- -ary, -ory: secondary (второстепенный), obligatory (обязательный).
- -ic: democratic (демократический), historic (исторический).
- -ive: creative (творческий), impressive (впечатляющий).
- -ish: childish (детский, ребяческий). Суффикс описывает характерный признак с негативной оценкой (liquorish – развратный) или с ослабленной степенью качества (reddish — красноватый). Кроме того, суффикс может отсылать к национальности (Danish — датский).
- -long: livelong (целый, вечный). Такой суффикс обозначает длительность (lifelong — пожизненный) или направление (sidelong — косой, вкось) и может принадлежать не только прилагательному, но и наречию.

Словообразование глаголов
Для глагольных суффиксов сложно определить конкретные значения. Основная функция таких суффиксов — перевод в другую часть речи, то есть само образование глагола.
- -ate: activate (активизировать), decorate (украшать).
- -ify, -fy: notify (уведомлять), verify (проверять).
- -ise, -ize: summarize (суммировать), hypnotize (гипнотизировать).
- -en: weaken (ослабевать), lengthen (удлинять).
- -ish: demolish (разрушать), embellish (украшать).

Словообразование наречий
- -ly: occasionally (случайно).
- -wise: otherwise (иначе). Обозначает способ действия (archwise — дугообразно).
- -ward(s): skyward/skywards (к небу). Обозначает направление движения (northward — на север, shoreward — по направлению к берегу).
Суффиксы: таблица словообразования по частям речи
Приведенный список суффиксов – это далеко не все возможности английского языка. Мы описали наиболее распространенные и интересные случаи. Для того чтобы разобраться в этом множестве вариантов и лучше усвоить образование слов в английском языке, таблица резюмирует, для каких частей речи какие суффиксы характерны.
Поскольку суффиксальное преобразование слов в английском языке различается по частям речи, таблица разбита на соответствующие группы. Одни и те же суффиксы могут добавляться к разным частям речи, но в результате они определяют, к какой части речи принадлежит новое слово.
Одни и те же суффиксы могут добавляться к разным частям речи, но в результате они определяют, к какой части речи принадлежит новое слово.
Объединение суффиксов и приставок
Важная характеристика словообразования – это его продуктивность. От одного корня можно образовать целую группу слов, добавляя разные приставки и суффиксы. Приведем несколько примеров.
- Для possible словообразование может выглядеть следующим образом: possible (возможный) — possibility (возможность) — impossibility (невозможность).
- Цепочка переходов для слова occasion: occasion (случай) — occasional (случайный) — occasionally (случайно).
- Для слова agree словообразование можно выстроить в цепочки с приставкой и без приставки: agree (соглашаться) — agreeable (приемлемый / приятный) — agreeably (приятно) — agreement (соглашение, согласие).
agree (соглашаться) — disagree (противоречить, расходиться в мнениях) — disagreeable (неприятный) — disagreeably (неприятно) — disagreement (разногласие).

Словосложение и сокращение слов
Словосложение — еще один способ образовать новое слово, хотя и менее распространенный. Он основан на соединении двух корней (toothbrush — зубная щетка, well-educated — хорошо образованный). В русском языке такое словообразование тоже встречается, например, «кресло-качалка».
Если корень активно используется в словосложении, то он может перейти в категорию суффиксов. В таком случае сложно определить, к какому типу – суффиксам или словосложению – отнести некоторые примеры:
- -man: fireman (пожарный), spiderman (человек-паук)
- -free: sugar-free (без сахара), alcohol-free (безалкогольный)
- -proof: fireproof (огнестойкий), soundproof (звукоизолирующий)
Помимо объединения нескольких корней, возможно также сокращение слов и создание аббревиатур: science fiction — sci-fi (научная фантастика), United States of America – USA (Соединенные Штаты Америки, США).
Новые слова без внешних изменений
К особенности словообразования в английском языке относится и то, что слова могут выступать в разных частях речи без изменения внешнего вида. Это явление называется конверсией:
I hope you won’t be angry with me — Надеюсь, ты не будешь на меня злиться (hope – глагол «надеяться»).
I always had a hope to return to that city — У меня всегда оставалась надежда вернуться в этот город (hope – существительное «надежда»).
The sea is so calm today — Море так спокойно сегодня (calm – прилагательное «спокойный»).
With a calm she realized that her life was probably at its end — Со спокойствием она осознала, что ее жизнь, вероятно, подходила к концу (calm – существительное «спокойствие, невозмутимость»).
I beg you to calm down — Я умоляю тебя успокоиться (calm – глагол «успокоиться»).
Конспект урока по русскому языку «Разбор слова по составу»
Тема. Разбор слова по составу.
Разбор слова по составу.
Педагогическая задача: Выявить уровень сформированности умений выполнять разбор слов по составу с целью устранения ошибок на следующих уроках.
Планируемые результаты:
Предметные: знают части слова (корень, приставку, суффикс, окончание), алгоритм разбора слов по составу; умеют выделять корень слова, образовывать однокоренные слова, подбирать слова к схемам, разграничивать понятия «части слова» и «части речи».
Метапредметные:
Регулятивные: выполнять разбор слов по алгоритму, сравнивать своё задание с образцом.
Познавательные: находят ответы на свои вопросы в ходе анализа выполненных заданий.
Коммуникативные: доносят свою позицию до всех участников образовательного процесса, оформляют свои мысли в устной и письменной речи (на листочках самостоятельной работы), умеют обмениваться мнениями в паре, слушать друг друга, понимать позицию партнёра.
Личностные УУД: имеют целевую установку на отработку алгоритма разбора слов по составу, ориентируются на понимание причин успеха в учёбе в ходе самооценки и взаимооценки работы.
Ход урока:
Организационный этап
Давайте создадим хороший эмоциональный настрой: улыбнёмся друг другу руки, поделимся хорошим настроением и пожелаем удачи.
2) Проверка домашнего задания, воспроизведение и коррекция опорных знаний учащихся. Актуализация знаний.
«Разминка для ума»
Отвечаем, быстро.
называется…(окончание)
— Как называется второй зимний месяц?-январь
Часть слова без окончания называется …основой
Назовите слово, противоположное слову враг.-друг
Чем кончается лето и начинается осень?-о
— Сколько гласных букв в русском алфавите?-10
3) Постановка цели и задач урока. Мотивация учебной деятельности учащихся.
Мотивация учебной деятельности учащихся.
1. На слайде дана схема:
мороз
— Составьте слова по схеме.
— Какие слова составили? Как эти слова называются?
— Какой «секрет» есть у всех однокоренных слов?
(одинаковый корень и близкое значение)
Мороз, морозец, морозный, заморозки
— Из каких частей состоят слова?
— Что такое корень? Приставка? Суффикс? Окончание?
— Какие части слова служат для образования новых слов?
— Расскажите порядок разбора слова по составу.
Какова же будет тема урока?
РАЗБОР СЛОВА ПО СОСТАВУ.
— Какие задачи поставим? (Упражняться в разборе слов по составу, определять части слова)
— Значит, мы должны выяснить, что у каждого из вас получается, а что нет. Над чем нам предстоит ещё поработать?
— Как будем работать? ( С учителем, сами, в паре)
— Что вы должны знать и уметь, чтобы безошибочно выполнять разбор слова по составу?
-А что нам может помочь действовать организованно и научиться быстро
и грамотно разбирать слова по составу? (План действия, алгоритм).
-Следовательно, какова же цель нашего урока? (Составить алгоритм разбора слова
по составу).
У детей на партах пошаговый план алгоритма. Учащиеся работают в парах.
-Составим алгоритм разбора слова по составу.
-Запиши слово.
-Измени слово и выдели окончание.
-Отдели окончание от основы и выдели основу.
-Подбери однокоренные слова и выдели корень.
-Найди и обозначь приставку и суффикс.
Проверка:
-Какой первый шаг?
-Что нужно сделать потом?
-Мы составили свой алгоритм. Давайте убедимся в правильности его
построения. Откройте учебник на стр.123.
-Чем отличается наш алгоритм от предоставленного в учебнике?
(Для устного разбора, а наш для письменного).
4) Первичное закрепление
-в знакомой ситуации (типовые)
Практическое применение
На доске записаны слова в 4 слова.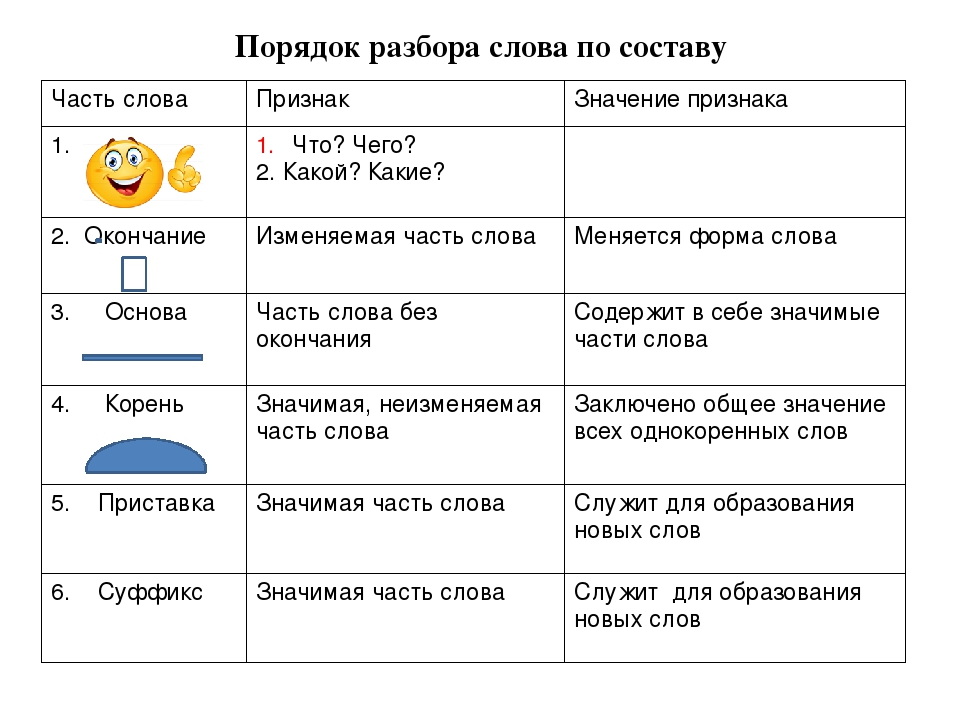 Выделяют части слова, используя алгоритм.
Выделяют части слова, используя алгоритм.
перегородка ореховый побег соседка
-Вы научились разбирать слова по составу. Молодцы!
-в изменённой ситуации (конструктивные)
Самостоятельная работа.
Задания на карточке:
Определи верно ли выделен корень в словах:Снежный, ледок, посадка
Умение определять корень слова.
+ если верно выполнено всё задание, т.е. найдены 2 слова
Укажи порядок разбора слова по составу:
__ Найди корень: подбери несколько однокоренных слов.
__ Прочитай слово.
__ Измени слово и выдели окончание.
__ Выдели основу слова.
__ Найди и обозначь приставку и суффикс
(если они есть)
Знание алгоритма разбора слова по составу.
Правильно ли выбраны слова к схеме. Поможет тебе выполнить это задание алгоритм разбора слов по составу.

медный снежок медовый
подружка дерево подводник
Находить соответствие слова схеме
5. Сформулируй задание к упражнению:
_______________________________________________
фокус
мель ник=___________
лес
Умение сформулировать задание
Проверь, верно ли указаны части слова:
Золотые (прил.) осинки(сущ.) шумят (глагол) листьями (сущ.).
А) Да.
Б) Нет.
Если нет, исправь ошибки.
+ 1.Умение видеть соответствие или несоответствие заданию.
+2. Умение разбирать слова по составу.
8. Анализ результатов. Проверяем вместе
УменияТвоя оценка
1.Умение определять корень слова.
2. Знание алгоритма разбора слова по составу.
3. Находить соответствие слова схеме
4. Умение сформулировать задание
5. а) Умение видеть соответствие или несоответствие заданию.
Б) Умение разбирать слова по составу.
5. Физкультминутка. слайд
Учебник с.123 упр.50
5) Творческое применение и добывание знаний в новой ситуации (проблемные задания)
На слайде – шарады оценка расписание
6) Информация о домашнем задании, инструктаж по его выполнению
Придумайте 5 слов и разобрать их по алгоритму, который мы сегодня составили.
7) Рефлексия (подведение итогов занятия)- слайд
Сегодня на уроке: Мы составили…
Мы научились…
— В каких заданиях не было ошибок?
— Над чем надо поработать?
— Это будет задачей на следующий урок.
— На следующем уроке будете выполнять те задания, в которых допустили сегодня ошибки.
зация зна-
ний и фик-
сация за-
труднений в
деятельно-
сти.
-Прочитайте, пожалуйста, слова и озаглавьте, объединив данные слова одной темой.
Слайд 1
-Что можно сказать о словах первого столбика?
-Докажите
-Как озаглавим слова второго столбика?
-Давайте выделим составные части данных родственных слов, прокомментируем и запишем в тетради.
-Снег снежный
снега снежинка
снегу подснежник
Деятельность учителя
Деятельность учащих-
ся
УУД
1.Органи-
зационный
момент
Учитель приветствует детей, мотивирует на учебную деятельность.
Учащиеся настраиваются на урок.
Коммуникативные: планирование учебного сотрудничества с учителем и сверстниками; личностные: наличие мотивации к труду, работе на результат
о снеге снежки
-Это однокоренные слова.
-Это разная форма одного и того же слова «снег».
-Здесь изменяется только окончание
(дети выделяют окончание и корень данных слов)
-Однокоренные или родственные слова.
Коллективный разбор слов, фронтальная работа.
Коммуникативные: планирование учебного сотрудничества с учителем и сверстниками; регулятивные:
контролировать процесс результаты своей деятельности; познавательные:
строить рассуждения, устанавливать причинно-следственные связи;
личностные: развитие самостоятельности
3.Самооп-
ределение к
деятельно-
сти.
— Откройте, пожалуйста, учебник на станице 73, рассмотрим схему. Со всеми ли частями слова мы познакомились?
-Назовите часть слова, с которой мы еще не знакомы.
-Сформулируйте тему урока
(Ответы детей)
-Основа
-Тема нашего урока «Основа слова»
Регулятивные:
осуществлять анализ с выделением существенных признаков, делать самостоятельно простые выводы; коммуникативные:
оформлять свои мысли в устной форме для решения коммуникативных задач;
познавательные:
строить рассуждения, устанавливать причинно-следственные связи ; личностные: развитие самостоятельности
4. Постановка
Постановка
учебной за-
дачи.
-Сейчас, ребята я выделю в данных словах основу. Вы, наблюдая и анализируя мои действия, должны сделать вывод: что называется основой
-Какую задачу мы ставим себе на данный урок?
— Мы видим надстрочный знак над словом, что он может обозначать?
Слайд 2
— В конце урока мы разберем по составу данные слова, выделив все его составные части, в том числе и основу, таким образом, проверив себя.
Дети высказывают свои предположения и приходят к выводу:
-Основа – это составная часть слова, в которую входит корень, приставка, суффикс. Т.е. все слово без окончания и является основой.
-Научится выделять основу слова.
(Дети находят в условных обозначениях этот знак)
— Этот знак обозначает, что данное слово мы должны разобрать по составу.
Регулятивные:
осуществлять анализ с выделением существенных признаков, делать самостоятельно выводы; познавательные:
строить рассуждения, устанавливать причинно-следственные связи
5. Построение
Построение
проекта вы-
хода из за-
труднения.
Первичное
закрепление
каждого по-
няти
Откройте учебник на странице 95 и прочитайте правило тётушки Совы. Всё ли мы правильно сказали про основу слова? Что дополнительно сообщила нам тётушка Сова?
-Найдите упражнение 181 на странице 96.
Мы работаем парами.
— А сейчас немного отдохнем вместе с Машей из мультфильма «Маша и медведь».
-Мы сделали правильные выводы. Но тётушка Сова нас дополнила, что в основе слова заключено его лексическое значение.
Работа детей. Взаимопроверка.
Физкультминутка
Коммуникативные: планирование учебного сотрудничества со сверстниками; Регулятивные:
осуществлять анализ с выделением существенных признаков, делать самостоятельно простые выводы; коммуникативные:
оформлять свои мысли в устной форме для решения коммуникативных задач;
познавательные:
строить рассуждения, устанавливать причинно-следственные связи; личностные: развитие самостоятельности
6. Самостояте
Самостояте
льная работа
с самопроверкой
по эталону
-Работаем на нэтбуках.
К нам в гости пришла Маша из мультфильма «Маша и медведь». Она решила поиграть в «Поле чудес». Слайд 4
Ваша задача – помочь Маше отгадать слово, а также составить свои слова, состоящие из таких же частей, как у Маши. Все свои слова пишете у себя на открытой странице, определенным цветом выделяя все составные части слова. Основу мы выделяем подчеркиванием.
В процессе отгадывания я могу открыть одну или две значимые части слова. Вы можете найти подсказку в упр. 183 на стр.97.
Затем мы сверяемся с доской и смотрим, угадали ли вы заданные слова и сумели оказать помощь Маше. Так же мы проверяем, какие слова, состоящие из таких же частей, вы написали. Слайды 5-10
Самостоятельная работа
с самопроверкой
по эталону.
Приложение 1
Коммуникативные: планирование учебного сотрудничества с учителем;
Регулятивные: контролировать процесс и результаты своей деятельности;
осуществлять анализ с выделением существенных признаков, делать самостоятельно простые выводы; познавательные:
строить рассуждения, устанавливать причинно-следственные связи; личностные: развитие самостоятельности и личной ответственности;
7. Рефлексия
Рефлексия
деятельности
(итог урока)
-Ребята, что нового мы сегодня узнали? Чему мы учились на уроке?
— Ребята, а сейчас мы возвращаемся к тем словам, при помощи которых мы должны себя проверить, как мы научились выделять основу и другие составные части слова и оценить свои успехи цветом. Слайд 12
-Кто хочет выставить свою оценку в классный журнал, может со своей тетрадью подойти к учителю для анализа оценки и своей классной работы.
— Домашнее задание: прочитать памятку № 5 на стр.146, упр. 185.
-Мы узнали, что называется основой слова, и научились ее выделять в словах.
Разбор слов по составу. Слайд 11
Взаимопроверка.
Самооценка на полях тетради при помощи цвета.
Регулятивные:
контролировать процесс и результаты своей деятельности;
делать самостоятельно выводы; познавательные:
строить рассуждения, устанавливать причинно-следственные связи; личностные: развитие самостоятельности и личной ответственности.
|
Этапы урока |
Содержание учебного материала каждого этапа |
Деятельность обучающихся |
Деятельность учителя |
|
Самоопределение. Цель – настроить на позитивную коллективную работу, положительную мотивацию учения. |
Приветствие учащихся. Проверка готовности к уроку. Чистописание (цепочка из букв м, р, ф и петли с закруглением вверху и внизу).
|
Приветствуют учителя. Организуют свое рабочее место, проверяют наличие индивидуальных учебных принадлежностей на столе. Выполняют письмо по образцу. Разгадывают шараду. |
Создает эмоциональный настрой на работу. Организует письмо по образцу. |
|
Актуализация знаний |
Разгадать какое слово спряталось (морфема). |
Вспоминают, что такое морфема, морфология. |
|
|
Постановка учебной задачи, целей урока. Цель – закрепить знания о составе слова. |
Сегодня мы совершим путешествие по океану Знаний в страну по имени «Морфема». Эта страна интересна тем, что состоит из островов. Мы сегодня посетим эти острова и пообщаемся с их жителями. Вы готовы к этому? В путешествие мы отправимся на волшебном корабле. Давайте запишем дату нашего путешествия. Тетрадь — это наш бортовой журнал, туда будем делать все записи о путешествии. Чтобы попасть на волшебный корабль, выполним словарную работу.
|
Дети записывают число и классная работа, словарь. (Берег, до свидания, весело, вместе, интересный, погода, коллектив, ветер). |
Организует работу, управляет диалогом и ведет к верному ответу на вопросы. Управляет процессом определения уровня знаний. |
|
Работа по теме урока 1 остров. |
В стране «Морфема» живут части слова. Догадайтесь, какой первый островок? С чего начнем, друзья, урок? Нас приглашает окончание? И у него для нас задание? А что такое окончание? (Ответы детей) Что такое окончание? Какую роль окончание выполняет в нашей речи?
— А ну-ка, ребята, внимание! В каждом ли слове есть окончание?
— Когда вы будете постарше, окончание расскажет вам все свои секреты. — Жители острова «Окончание» задали вам задачу.
В, гости, хорошо, а, дом, лучше.
— Прочитайте. Получилась ли у вас пословица?
— Что нужно сделать, чтобы связать слова в предложении? ( Ответы детей и составление пословицы)
Молодцы, ребята! Справились с первой задачей. Запишите в тетрадь эту пословицу. Выделите те части слова, которые помогли связать слова по смыслу. ( Работа в тетради). |
Дети отвечают на вопросы и выполняют задания 1.Выделить в словах окончания. Вода, море, палуба, земля. 2.Корабль, ветер, мотор. 3.Радио, кино, пальто. (Индивидуальная работа). |
Через подводящий диалог приводит в формулировке понятий. |
|
2 остров. |
Представьте, что мы опять на нашем корабле, который плывет к следующему острову. Жило-было слово ХОД В слове выХОД, в слове вХОД, В слове ХОДики стучало. И в поХОДе вдаль шагало
Кто догадался, к какому острову мы приближаемся? Что такое корень слова? (Ответы детей)
А вот и новая задачка от местных жителей. От данных слов образуйте однокоренные слова. |
1 ряд: Лень – (ленивый, леность, лентяй.) 2 ряд: Боль — (больной, заболеть, переболеть. 3 ряд: Соль –( соленый, посолить, пересолить.) Что такое однокоренные слова? Запишите эти слова и выделите корень. ( Работа в малых группах).
|
Через подводящий диалог приводит в формулировке понятий. |
|
Физкультминутка. |
«Морская звезда».
|
(Руки поднимаем вверх, сжимая и разжимая пальцы, опускаем руки вниз). |
|
|
3 остров. |
А теперь глаза закрыли! С вами дальше мы поплыли.
Прислушайтесь, что с палубы кричит матрос?
«Приплыли? Причаливаем! Выходите!» Как вы думаете, на каком острове мы оказались? Почему так решили? Что такое приставка? Какую роль выполняет приставка? А вот и следующее задание от островитян. Какие слова получились? Запишите их в тетрадь и выделите приставку. ( Работа в тетради) Молодцы, и с этим заданием вы справились!
|
Ответы детей. Выполнение задания. Какие прставки вы знаете?
(Работа в парах). |
Через подводящий диалог приводит в формулировке понятий. |
|
4 остров. |
Продолжается наше путешествие. Закрыли глаза. Мы приближаемся к следующему острову.
Водичка тепленькая Погодка чудесненькая. А не сбились мы в пути? Что за остров впереди?
Почему вы так решили? А что такое суффикс? Давайте поиграем! Назовите детенышей: козы, утки, льва, гуся, слона, кошки.
( Козленок, утенок, львенок, гусенок, слоненок, котенок.) При помощи какой части слова образовались эти слова? Какой оттенок дал слову суффикс? (Ответы детей) Запишите в тетрадь слова, записанные на доске, и выделите суффикс. ( Работа в тетради) Ребята, жители последних островов спрашивают, для чего нужны суффиксы и приставки? (Ответы детей)
|
Ответы детей на вопрос « Для чего нужны суффиксы? Какие суффиксы вы знаете?».
|
Через подводящий диалог приводит в формулировке понятий. |
|
Определение задачи на следующий урок. |
Молодцы, справились и с этой задачей! Но мы ещё должны узнать одну морфему, чтобы правильно выполнять морфемный анализ слова. |
|
|
|
Этап самостоятельной работы. |
Вот мы и вернулись домой. Мы повторили все, что знали о частях слова.
разборе слов по составу.
Горка, полет, слово, садик, расписка. ( Работа в тетради) 2.Составьте новые слова, используя выделенные части данных слов.
|
|
Контролирует выполнение задания. |
|
Рефлексии. Оценивание. |
Молодцы, ребята! Вы показали, чему научились! Что вам понравилось на уроке? А что не понравилось? Что бы вы хотели изменить? Не ленитесь, старайтесь как можно больше узнать обо всем на свете — и тогда каждый урок будет для вас не скучным, а веселым.
|
Участвуют в учебном диалоге. |
|
|
Домашнее задание. |
Карточка.
|
|
|

 У него еще много тайн.
У него еще много тайн.
 )
)



Патент США для помощи в составлении имен в приложениях обмена сообщениями Патент (Патент № 10,848,453, выдан 24 ноября 2020 г.
 )
)Настоящая заявка является продолжением заявки на патент США сер. № 14/089830, поданной 26 ноября 2013 г., в которой испрашивается преимущество даты подачи предварительной заявки на патент США № 61/904 731, поданной 15 ноября 2013 г., полное раскрытие которой включено в настоящий документ посредством ссылки. .
ОБЛАСТЬ РАСКРЫТИЯНастоящее раскрытие в целом относится к приложениям электронного обмена сообщениями и, в частности, к составлению сообщений в приложениях электронного обмена сообщениями.
ИСТОРИЯ ВОПРОСА Следуя прецеденту аналогов ручки и бумаги, которые предшествовали им, электронные письма, мгновенные сообщения (IM), текстовые сообщения и другие электронные сообщения часто состоят из приветствия или приветствия, которое включает имя одного или больше предполагаемых получателей электронного сообщения. Однако это приводит к ситуациям, когда составитель сообщения непреднамеренно ошибочно вводит имя получателя в приветствии или где-либо еще в теле сообщения. Такие ошибки особенно распространены, когда имя получателя необычно для культуры отправителя или когда имя пишется аналогично обычному слову, не являющемуся именем.Обычные механизмы обнаружения ошибок, такие как процессы проверки орфографии, использующие предопределенный общий словарь, часто не позволяют выявить такие ситуации. Чтобы проиллюстрировать, имя получателя может быть похоже по написанию на обычное слово, и отправитель может неосознанно произносить имя получателя как обычное слово, что затем приведет к тому, что орфографическая ошибка останется незамеченной, поскольку она соответствует написанию, найденному в словаре проверки орфографии. . Кроме того, даже если имя получателя написано отправителем правильно, функция автокоррекции в некоторых приложениях для обмена сообщениями изменяет имя, чтобы оно соответствовало слову, найденному в словаре проверки орфографии.Такие инциденты могут вызвать смущение или замешательство у отправителя и получателя.
Такие ошибки особенно распространены, когда имя получателя необычно для культуры отправителя или когда имя пишется аналогично обычному слову, не являющемуся именем.Обычные механизмы обнаружения ошибок, такие как процессы проверки орфографии, использующие предопределенный общий словарь, часто не позволяют выявить такие ситуации. Чтобы проиллюстрировать, имя получателя может быть похоже по написанию на обычное слово, и отправитель может неосознанно произносить имя получателя как обычное слово, что затем приведет к тому, что орфографическая ошибка останется незамеченной, поскольку она соответствует написанию, найденному в словаре проверки орфографии. . Кроме того, даже если имя получателя написано отправителем правильно, функция автокоррекции в некоторых приложениях для обмена сообщениями изменяет имя, чтобы оно соответствовало слову, найденному в словаре проверки орфографии.Такие инциденты могут вызвать смущение или замешательство у отправителя и получателя.
Настоящее изобретение может быть лучше понято, а его многочисленные особенности и преимущества станут очевидными для специалистов в данной области техники со ссылкой на прилагаемые чертежи. Использование одних и тех же условных обозначений на разных чертежах указывает на аналогичные или идентичные предметы.
Использование одних и тех же условных обозначений на разных чертежах указывает на аналогичные или идентичные предметы.
РИС. 1 представляет собой диаграмму, иллюстрирующую электронное устройство, использующее помощь в составлении имени получателя с использованием опции автозаполнения для приложения обмена сообщениями в соответствии, по меньшей мере, с одним вариантом осуществления настоящего раскрытия.
РИС. 2 — схема, иллюстрирующая интерфейс составления сообщений приложения обмена сообщениями, которое использует помощь в составлении имени получателя с использованием опции автозаполнения в соответствии с по меньшей мере одним вариантом осуществления настоящего раскрытия.
РИС. 3 — схема, иллюстрирующая интерфейс составления сообщения приложения обмена сообщениями, которое использует помощь в составлении имени получателя с использованием опции автозамены в соответствии с по меньшей мере одним вариантом осуществления настоящего раскрытия.
РИС. 4 — схема, иллюстрирующая интерфейс составления сообщения приложения обмена сообщениями, которое использует помощь в составлении имени получателя с использованием опции автозамены после составления в соответствии с, по меньшей мере, одним вариантом осуществления настоящего раскрытия.
РИС. 5 — блок-схема, иллюстрирующая способ предоставления помощи в составлении имени получателя для составления имени получателя в теле электронного сообщения в соответствии с по меньшей мере одним вариантом осуществления настоящего раскрытия.
РИС. 6 — схема, иллюстрирующая методику идентификации имен кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем анализа адреса получателя электронного сообщения в соответствии с по меньшей мере одним вариантом осуществления настоящего раскрытия.
РИС. 7 — схема, иллюстрирующая методику идентификации имен кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем анализа отображаемого имени, связанного с адресом обмена сообщениями получателя электронного сообщения, в соответствии с, по меньшей мере, одним вариантом осуществления настоящего изобретения. раскрытие.
раскрытие.
РИС. 8 — схема, иллюстрирующая методику идентификации имен кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем синтаксического анализа тела электронного сообщения в соответствии с, по меньшей мере, одним вариантом осуществления настоящего раскрытия.
РИС. 9 — схема, иллюстрирующая методику идентификации имен кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем выполнения поиска контактов в базе данных контактов с использованием контекста сообщения из одного или нескольких полей электронного сообщения в соответствии по меньшей мере с одним вариантом осуществления. настоящего раскрытия.
РИС. 10 — схема, иллюстрирующая методику идентификации имен кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем анализа содержимого другого приложения, которое инициировало составление электронного сообщения, в соответствии с, по меньшей мере, одним вариантом осуществления настоящего раскрытия.
РИС. 11 — схема, иллюстрирующая реализацию электронного устройства , 100, в соответствии, по меньшей мере, с одним вариантом осуществления настоящего раскрытия.
ПОДРОБНОЕ ОПИСАНИЕ Нижеследующее описание предназначено для передачи полного понимания настоящего раскрытия посредством предоставления ряда конкретных вариантов осуществления и деталей, включающих помощь в составлении имени во время составления электронного сообщения на электронном устройстве. Однако понятно, что настоящее раскрытие не ограничивается этими конкретными вариантами осуществления и деталями, которые являются только примерами, и объем раскрытия, соответственно, предназначен для ограничения только следующей формулой изобретения и ее эквивалентами.Кроме того, понятно, что специалист в данной области техники в свете известных систем и способов оценит использование раскрытия для его предполагаемых целей и получения преимуществ в любом количестве альтернативных вариантов осуществления, в зависимости от конкретной конструкции и других потребностей.
РИС. 1-11 иллюстрируют примерные методы для предоставления помощи в автоматизированном составлении имен в теле сообщения электронного сообщения, составляемого на электронном устройстве. По крайней мере, в одном варианте осуществления электронное устройство идентифицирует одно или несколько имен кандидатов-получателей на основе контекста сообщения и, в ответ на идентификацию, пользователь составляет приветствие или другое приветствие, которое, как ожидается, будет включать имя получателя в тело сообщения, предоставляет имя помощь в составлении с использованием одного или нескольких идентифицированных имен кандидатов для облегчения точного составления имени получателя.Помощь в составлении имени может быть предоставлена в виде графического представления выбранного имени кандидата в соответствии с одним или несколькими вариантами представления, такими как вариант автоматического предложения («автозаполнение»), вариант автоматического завершения («автозаполнение»), и возможность автоматического исправления («автокоррекция»). Для опции автозаполнения после идентификации пользовательского ввода, указывающего на триггер приветствия (например, ввод приветствия, такого как «Привет» или «Уважаемый», или инициирования ввода первого слова тела сообщения), одно или несколько имен кандидатов являются графически представлены в виде выбираемой пользователем опции через графический интерфейс пользователя (GUI) электронного устройства, и выбор пользователем выбираемой пользователем опции приводит к автоматическому заполнению («автозаполнению») выбранного имени кандидата в теле сообщения. как часть приветствия.Для опции автозаполнения после идентификации триггера приветствия и получения пользовательского ввода, указывающего состав начальных букв не приветствующего термина в теле сообщения, выбирается имя кандидата (если имеется более одного имени кандидата), и электронное устройство предоставляет графическое представление имени кандидата путем автономного завершения слова в теле сообщения на основе выбранного имени кандидата.
Для опции автозаполнения после идентификации пользовательского ввода, указывающего на триггер приветствия (например, ввод приветствия, такого как «Привет» или «Уважаемый», или инициирования ввода первого слова тела сообщения), одно или несколько имен кандидатов являются графически представлены в виде выбираемой пользователем опции через графический интерфейс пользователя (GUI) электронного устройства, и выбор пользователем выбираемой пользователем опции приводит к автоматическому заполнению («автозаполнению») выбранного имени кандидата в теле сообщения. как часть приветствия.Для опции автозаполнения после идентификации триггера приветствия и получения пользовательского ввода, указывающего состав начальных букв не приветствующего термина в теле сообщения, выбирается имя кандидата (если имеется более одного имени кандидата), и электронное устройство предоставляет графическое представление имени кандидата путем автономного завершения слова в теле сообщения на основе выбранного имени кандидата. Затем пользователь может решить принять это завершенное слово в качестве предполагаемого имени получателя или отклонить завершенное слово и, таким образом, вызвать его удаление из тела сообщения.Для опции автозамены электронное устройство определяет, включает ли приветствие в теле сообщения слово, соответствующее имени кандидата, и, если есть несоответствие, отображает уведомление о том, что пользователь мог ошибиться при составлении имени получателя в теле сообщения. Это уведомление может включать в себя выбираемую пользователем опцию для замены слова в приветствии предложенным именем кандидата. Опция автозамены может использоваться после завершения приветствия и перед составлением остальной части тела сообщения, после того, как тело сообщения было составлено (например,g., когда пользователь дал команду приложению обмена сообщениями инициировать передачу составленного электронного сообщения) и т.п. Ввод приветствий и других слов может осуществляться путем набора текста на клавиатуре, набора текста на виртуальной клавиатуре (сенсорного экрана), проведения пальцем по виртуальной клавиатуре, выбора букв с помощью мыши или сенсорной панели, набора текста с помощью клавиатуры или набора клавиш, распознавания речи или другого типа ввод текста.
Затем пользователь может решить принять это завершенное слово в качестве предполагаемого имени получателя или отклонить завершенное слово и, таким образом, вызвать его удаление из тела сообщения.Для опции автозамены электронное устройство определяет, включает ли приветствие в теле сообщения слово, соответствующее имени кандидата, и, если есть несоответствие, отображает уведомление о том, что пользователь мог ошибиться при составлении имени получателя в теле сообщения. Это уведомление может включать в себя выбираемую пользователем опцию для замены слова в приветствии предложенным именем кандидата. Опция автозамены может использоваться после завершения приветствия и перед составлением остальной части тела сообщения, после того, как тело сообщения было составлено (например,g., когда пользователь дал команду приложению обмена сообщениями инициировать передачу составленного электронного сообщения) и т.п. Ввод приветствий и других слов может осуществляться путем набора текста на клавиатуре, набора текста на виртуальной клавиатуре (сенсорного экрана), проведения пальцем по виртуальной клавиатуре, выбора букв с помощью мыши или сенсорной панели, набора текста с помощью клавиатуры или набора клавиш, распознавания речи или другого типа ввод текста.
Идентификация имен кандидатов для процесса помощи в составлении имен может быть определена из внутреннего контекста сообщения, внешнего контекста сообщения или их комбинации.Внутренний контекст сообщения включает в себя поля самого электронного сообщения, такие как адреса сообщения получателя в полях адреса сообщения получателя сообщения, отображаемые имена полей отображаемых имен, связанных с адресами сообщения получателя, имена вложений файлов вложений, перечисленные в полях вложений ( и содержимое прикрепленных файлов), а также содержимое самого тела сообщения, такое как строка темы сообщения или содержимое предыдущего электронного сообщения, которое было включено в тело сообщения составляемого электронного сообщения.Внешний контекст сообщения включает в себя контекст сообщения, отличный от полей составляемого электронного сообщения, и, таким образом, может включать, например, базу данных контактов, поддерживаемую на электронном устройстве, или содержимое приложения, из которого было составлено электронное сообщение. инициировано (например, содержимое веб-страницы, содержащее ссылку, которая при выборе инициирует составление электронного сообщения). По меньшей мере, в одном варианте осуществления электронное устройство идентифицирует имена кандидатов из внутреннего или внешнего контекста сообщения путем анализа содержимого контекста сообщения для идентификации отдельных слов или комбинаций или слов, которые, как предполагается, представляют слова имени, или путем использования таких проанализированных слов для выполнения поиск имени, например, в базе данных контактов для определения соответствующего имени кандидата.Эта идентификация имени кандидата через внутренний и внешний контекст сообщения, таким образом, может использоваться для дополнения обычных процессов проверки орфографии, которые полагаются на заранее определенные словари орфографии, которые не отражают конкретный контекст имени получателя или другое содержимое составляемого электронного сообщения.
инициировано (например, содержимое веб-страницы, содержащее ссылку, которая при выборе инициирует составление электронного сообщения). По меньшей мере, в одном варианте осуществления электронное устройство идентифицирует имена кандидатов из внутреннего или внешнего контекста сообщения путем анализа содержимого контекста сообщения для идентификации отдельных слов или комбинаций или слов, которые, как предполагается, представляют слова имени, или путем использования таких проанализированных слов для выполнения поиск имени, например, в базе данных контактов для определения соответствующего имени кандидата.Эта идентификация имени кандидата через внутренний и внешний контекст сообщения, таким образом, может использоваться для дополнения обычных процессов проверки орфографии, которые полагаются на заранее определенные словари орфографии, которые не отражают конкретный контекст имени получателя или другое содержимое составляемого электронного сообщения.
Для простоты иллюстрации большая часть нижеследующего описания методов помощи в автоматизированном составлении имен предоставляется в соответствии с примером использования приложения для обмена сообщениями электронной почты портативного электронного устройства. Однако эти автоматизированные методы составления имен не ограничиваются этим контекстом, а вместо этого могут использоваться для любого из множества приложений для обмена электронными сообщениями, таких как приложения для обмена мгновенными сообщениями (IM), приложения для обмена текстовыми сообщениями, приложения для микроблогов, приложения для социальных сетей и подобное, аналогичное, похожее.
Однако эти автоматизированные методы составления имен не ограничиваются этим контекстом, а вместо этого могут использоваться для любого из множества приложений для обмена электронными сообщениями, таких как приложения для обмена мгновенными сообщениями (IM), приложения для обмена текстовыми сообщениями, приложения для микроблогов, приложения для социальных сетей и подобное, аналогичное, похожее.
РИС. 1 иллюстрирует электронное устройство , 100, , использующее автоматизированную помощь в составлении имени получателя во время составления электронного сообщения в соответствии с, по меньшей мере, одним вариантом осуществления настоящего раскрытия.Электронное устройство 100 может включать в себя любое из множества устройств, которые могут быть использованы для обмена электронными сообщениями, например сотовый телефон с поддержкой вычислений («смартфон») или часы с возможностью вычислений («умные часы»), планшетный компьютер, ноутбук. компьютер, настольный компьютер, игровая консоль, персональный цифровой помощник (КПК) и т. п.
п.
В изображенном примере электронное устройство 100 включает в себя приложение обмена сообщениями 102 , которое работает для передачи электронных сообщений между электронным устройством 100 и другими электронными устройствами через поставщика электронных сообщений 104 , доступного через одно или несколько сети 106 .Чтобы проиллюстрировать, приложение обмена сообщениями , 102, может включать в себя веб-приложение электронной почты (например, Google Gmail ™), которое взаимодействует с сервером электронной почты в Интернете (один вариант осуществления поставщика сообщений 104 ) через Интернет (один вариант осуществления сеть 106 ). В качестве другого примера приложение обмена сообщениями 102 может включать в себя почтовый клиент Microsoft Outlook ™, который взаимодействует с сервером Microsoft Exchange ™ (один из вариантов поставщика сообщений 104 ) через внутреннюю корпоративную сеть, Интернет или их комбинацию. .В качестве еще одного примера приложение для обмена сообщениями , 102, может включать в себя приложение для обмена мгновенными сообщениями (IM), которое обменивается данными с веб-сервером IM (один вариант осуществления поставщика 104 обмена сообщениями) через Интернет. Другие примеры приложения для обмена сообщениями 102 включают в себя, например, приложение для обмена текстовыми сообщениями (например, приложение службы простых сообщений (SMS) или приложение службы обмена мультимедийными сообщениями (MMS)), приложение для микроблогов (например, приложение «твиттер»). предоставлено Twitter Inc.), приложение для социальных сетей (например, Facebook ™ или Google Circles ™) и т.п. В некоторых реализациях приложение для обмена электронными сообщениями , 102, отправляет и принимает электронные сообщения в координации с операционной системой (ОС) 108 (или другим системным программным обеспечением) электронного устройства 100 .
.В качестве еще одного примера приложение для обмена сообщениями , 102, может включать в себя приложение для обмена мгновенными сообщениями (IM), которое обменивается данными с веб-сервером IM (один вариант осуществления поставщика 104 обмена сообщениями) через Интернет. Другие примеры приложения для обмена сообщениями 102 включают в себя, например, приложение для обмена текстовыми сообщениями (например, приложение службы простых сообщений (SMS) или приложение службы обмена мультимедийными сообщениями (MMS)), приложение для микроблогов (например, приложение «твиттер»). предоставлено Twitter Inc.), приложение для социальных сетей (например, Facebook ™ или Google Circles ™) и т.п. В некоторых реализациях приложение для обмена электронными сообщениями , 102, отправляет и принимает электронные сообщения в координации с операционной системой (ОС) 108 (или другим системным программным обеспечением) электронного устройства 100 . Чтобы проиллюстрировать, ОС 108 может облегчить доступ к проводному или беспроводному сетевому интерфейсу, который соединяется с сетью 106 , доступ к дисплею и устройствам пользовательского ввода (например.g., сенсорный экран, микрофон, мышь или клавиатура) электронного устройства 100 и т.п.
Чтобы проиллюстрировать, ОС 108 может облегчить доступ к проводному или беспроводному сетевому интерфейсу, который соединяется с сетью 106 , доступ к дисплею и устройствам пользовательского ввода (например.g., сенсорный экран, микрофон, мышь или клавиатура) электронного устройства 100 и т.п.
Одна из функций обмена сообщениями, предоставляемая приложением обмена сообщениями 102 , — это представление графического пользовательского интерфейса (GUI) для облегчения составления пользователем электронных сообщений, которые должны быть переданы одному или нескольким получателям через провайдер обмена сообщениями 104 . Составление электронного сообщения управляется посредством пользовательского ввода 110 композиции, принимаемого через один или несколько пользовательских интерфейсов ввода, связанных с этим графическим интерфейсом пользователя, например сенсорный экран, микрофон, мышь или клавиатуру.Пользовательский ввод композиции , 110, обычно включает в себя инструкцию для инициирования композиции электронного сообщения, такую как выбор пользователем кнопки «составить», отображаемой в графическом пользовательском интерфейсе (GUI), предоставляемом приложением обмена сообщениями 102 или через голос пользователя. команды, инструктирующие электронное устройство 100 инициировать новое электронное сообщение. Пользовательский ввод состава , 110, также включает пользовательский ввод для предоставления адресов сообщения получателя в одном или нескольких полях адреса сообщения, и пользовательский ввод для предоставления текста и другого типографского содержимого в тело сообщения составляемого электронного сообщения.
В ходе составления электронного сообщения пользователь электронного устройства 100 может пожелать обратиться к одному или нескольким получателям по имени в теле сообщения, например, инициируя содержимое тела сообщения приветствием, которое включает одно или несколько имен получателей. Однако существует значительная вероятность того, что пользователь может неправильно написать имя предполагаемого получателя в теле сообщения, либо потому, что пользователь не знаком с именем (например, оно может не распространяться в культуре пользователя), оно может иметь несколько возможных написание (e.g., «Карл» против «Карл»), или это может иметь написание, очень похожее на другое слово. Для иллюстрации получателя электронного сообщения можно назвать «Gulprit», которое пользователь может непреднамеренно ввести как «Culprit» в теле сообщения из-за сходства их написания. Чтобы уменьшить или избежать ошибок написания имени получателя, по крайней мере, в одном варианте осуществления приложение обмена сообщениями , 102, обеспечивает автоматическую помощь в составлении имени получателя, идентифицируя имена кандидатов на основе контекста сообщения, а затем автономно содействуя правильному использованию имени в теле сообщения с помощью различной помощи пользователя. параметры, такие как параметр автозаполнения, параметр автозаполнения, параметр автозамены и т. д.
В одном варианте осуществления этой помощи в составлении имени получателя способствует различная информация, хранящаяся в электронном устройстве 100 . Такая информация может включать в себя, например, контекст сообщения , 112, самого сообщения. Этот контекст сообщения 112 может включать внутренний контекст сообщения, который представляет собой информацию в полях составляемого сообщения, например информацию в полях адреса получателя сообщения, например адреса электронной почты в полях «Кому:», «Копия:» и «Bcc:» адресные поля, имена или другая основанная на имени информация, уже присутствующая или впоследствии добавленная в тело сообщения, и т.п.Этот контекст сообщения 112 также может включать в себя внешний контекст сообщения, который представляет собой информацию, которая не получается напрямую из полей составляемого электронного сообщения, например, содержимое в другом приложении, которое инициировало составление электронного сообщения или контактную запись получатель, к которому осуществляется косвенный доступ с использованием некоторой информации из внутреннего контекста сообщения.
Приложение обмена сообщениями 102 может использовать этот контекст сообщения 112 для идентификации одного или нескольких имен кандидатов (то есть имен, которые могут быть использованы пользователем при составлении тела сообщения) либо напрямую, например, путем создания имена кандидатов на основе синтаксического анализа частей адресов электронной почты, зависящих от получателя, в полях получателя или косвенно, например, путем определения идентификаторов получателя из полей сообщения и последующего использования этих идентификаторов, зависящих от получателя, для поиска соответствующего имени получателя, например, база данных контактов 114 хранится на электронном устройстве 100 .База данных контактов , 114, может включать, например, постоянный список контактов с записями контактов, которые были собраны приложением обмена сообщениями 102 или другим приложением, которое разрешило доступ к своей базе данных контактов, например, записи контактов Google, доступные в приложение Google Gmail ™, набор записей контактов, доступных в приложении Microsoft Outlook ™, или набор записей «друзей», доступных в учетной записи пользователя Facebook ™. Имена кандидатов, идентифицированные таким образом, могут быть сохранены во временной базе данных имен кандидатов , 116, , которая может быть списком, таблицей или другой структурой данных, реализованной, например, в пространстве памяти или дисковом пространстве, выделенном приложению обмена сообщениями 102 , и может сохраняться в течение всего времени составления электронного сообщения, в течение всего времени, пока приложение 102 обмена сообщениями работает или иным образом активно, и т.п.Ниже подробно описаны различные методы идентификации имен кандидатов.
Когда одно или несколько имен кандидатов идентифицированы и сохранены в базе данных имен кандидатов 116 , приложение обмена сообщениями 102 отслеживает ввод состава пользователя 110 для обнаружения любых потенциальных триггеров приветствия, которые могут включать в себя или быть связаны с Имя получателя. Такие триггеры приветствия могут включать в себя, например, ввод пользователя, указывающий на ввод типичного вступительного приветствия, например, когда пользователь вводит слово «Привет» или «Уважаемый» в начале тела сообщения.Более того, триггер приветствия может быть начальным вводом пользователем содержимого тела сообщения (то есть вводом первых нескольких букв или слова в теле сообщения), и, в частности, триггер приветствия может сработать, когда первые несколько буквы, набранные в теле сообщения, по существу совпадают с соответствующими начальными буквами идентифицированного имени кандидата. В ответ на обнаружение триггера приветствия приложение обмена сообщениями 102 пытается помочь пользователю правильно составить имя получателя в теле сообщения.Как описано выше, эта помощь может быть предоставлена как графическое представление имени кандидата как часть одной или нескольких опций помощи пользователю, таких как опция автозаполнения, опция автозаполнения, опция автозамены и т.п.
Для иллюстрации на фиг. 1 изображен графический интерфейс составления сообщения 118 приложения обмена сообщениями 102 для составления сообщения электронной почты получателю с именем «Gulprit» на адрес электронной почты «[email protected]», как указано в поле адреса «to:» 120 сообщения электронной почты.Этот графический интерфейс составления сообщений , 118 иллюстрирует реализацию опции автозаполнения, посредством которой приложение обмена сообщениями 102 идентифицирует «Gulprit» как имя кандидата из адреса электронной почты «[email protected]» и в ответ на ввод пользователя, представляющий ввод слова «Hi» 130 в тело сообщения 122 сообщения электронной почты, приложение обмена сообщениями 102 предоставляет возможность автозаполнения для завершения приветствия, представляя выбираемую пользователем опцию 124 в графическом интерфейсе пользователя 118 , который предлагает графическое представление имени «Gulprit» в виде одной записи имени кандидата 126 , идентифицированной из контекста сообщения 112 , и графическое представление имени «Gillray» в качестве другой записи имени кандидата 128 , то есть идентифицируется, например, из предварительно определенного орфографического словаря, имеющего в качестве записи «Gillray».В то время как выбираемая пользователем опция 124 проиллюстрирована как графическое изображение списка выбираемых записей имени кандидата 126 , 128 , выбираемая пользователем опция 124 для автоматического предложения имен кандидатов может быть реализована в любом из множество способов, согласующихся с изложенными здесь учениями. При отображении выбираемой пользователем опции 124 , предполагая, что пользователь намеревался обратиться к Gulprit в теле сообщения 122 , пользователь может выбрать запись имени кандидата «Gulprit» 126 из выбираемой пользователем опции 124 , в ответ на это приложение обмена сообщениями 102 подставляет имя «Gulprit» в текущее положение курсора в теле сообщения 122 .Таким образом, имя получателя «Gulprit» правильно вводится в тело сообщения 122 и исключается возможность ошибки пользователя при самостоятельном вводе имени «Gulprit».
РИС. 2, 3 и 4 иллюстрируют другие варианты помощи при автоматическом составлении имени получателя, которые могут быть предоставлены приложением обмена сообщениями 102 электронного устройства 100 на фиг. 1 в связи с составлением электронного сообщения. Например, фиг. 2 иллюстрирует графический интерфейс 218 составления сообщений, который предоставляется приложением обмена сообщениями 102 и который предоставляет возможность автозаполнения для помощи в составлении имен.Для опции автозаполнения приложение обмена сообщениями 102 отслеживает ввод композиции пользователя 110 (фиг.1), чтобы обнаружить ввод пользователя, представляющий ввод или другой ввод начального набора букв слова в теле сообщения 222 GUI составления сообщений 218 . В случае, если начальный набор букв совпадает с соответствующим начальным набором букв имени кандидата, идентифицированного из контекста сообщения 112 составляемого электронного сообщения, приложение обмена сообщениями 102 предоставляет графическое представление имени кандидата через параметр автозаполнения 224 , который представляет собой предлагаемое завершение слова в теле сообщения 222 .
В этом примере имя кандидата «Gulprit» идентифицируется по адресу электронной почты «[email protected]» в поле адреса «Кому» 220 . Для опции автозаполнения 224 , когда пользователь вводит приветственный триггер «Hi», за которым следует пробел, а затем три начальные буквы «Gul» слова 225 после приветственного триггера, приложение обмена сообщениями 102 идентифицирует этот начальный набор букв слова 225 в качестве достаточного совпадения с именем кандидата «Gulprit» и, таким образом, автоматически дополняет слово 225 в качестве имени кандидата «Gulprit».Как показано, это автозаполнение может включать, например, автоматическое введение оставшихся букв «prit» имени кандидата «Gulprit» в тело сообщения 222 после начальных букв «Gul» и предоставление некоторого индикатора того, что эти последние буквы 226 заполняются автоматически, например, с использованием текста другого цвета, подчеркивания и т.п. Если имя с автозаполнением — это слово, которое пользователь намеревался ввести, пользователь может указать свое согласие на автозаполнение, например, выбрав полосу «пробел» на клавиатуре или нажав кнопку «принять» или другую функцию принятия (не показано ), связанный с опцией автозаполнения 224 в графическом интерфейсе составления сообщений 218 .
РИС. 3 иллюстрирует графический интерфейс 318 составления сообщения, который предоставляется приложением обмена сообщениями 102 и который предоставляет возможность автозамены. Для этого подхода к помощи в составлении имени получателя приложение обмена сообщениями 102 предоставляет опцию автозамены 324 для замены слова с идентифицированным именем кандидата после того, как слово уже было набрано и заполнено в теле сообщения 322 . Таким образом, приложение обмена сообщениями , 102, идентифицирует завершенное слово в теле сообщения 322 как потенциально представляющее имя получателя и проверяет, соответствует ли слово имени кандидата, идентифицированному для имени получателя.Если слово недостаточно соответствует имени кандидата, приложение обмена сообщениями 102 может отображать параметр автозамены 324 в графическом интерфейсе пользователя 318 , чтобы предоставить пользователю возможность заменить слово на имя кандидата, графически представленное в опция автокоррекции 324 . В изображенном примере опция автозамены 324 включает в себя диалоговое окно, которое предлагает пользователю возможность заменить слово «Culprit» в теле сообщения на имя кандидата «Gulprit», идентифицированное из адреса электронной почты в адресе to: поле 320 .В этом примере слово «Culprit» может быть идентифицировано как потенциально неправильно набранное имя получателя, например, из-за того, что оно следует сразу после триггера приветствия «Привет», написано с заглавной буквы, но не является первым словом предложения, или потому что оно в основном совпадает с названием «Gulprit».
Приложение обмена сообщениями 102 может анализировать тело создаваемого электронного сообщения на предмет возможности представить параметр автозамены в одной или нескольких точках процесса составления сообщения.В примере на фиг. 3, адрес обмена сообщениями получателя (например, «[email protected]») уже был введен в поле адреса сообщения получателя электронного сообщения, составляемого в момент начала составления тела сообщения, и, таким образом, приложение обмена сообщениями 102 может использовать этот адрес обмена сообщениями получателя для определения одного или нескольких имен кандидатов для опции автозамены. Таким образом, когда сигнализируется завершение потенциального слова имени в теле сообщения (например, когда пользователь вводит символ «пробел» или другой символ пробела после слова), приложение обмена сообщениями 102 может проверить слово в то время завершения.Однако в некоторых случаях пользователь может инициировать составление тела сообщения до заполнения любого из полей получателя электронного сообщения, и, таким образом, может быть недостаточно контекста сообщения для приложения обмена сообщениями 102 , чтобы идентифицировать имя кандидата в время написания сообщения. Соответственно, в других случаях анализ тела сообщения для одного или нескольких потенциальных слов для автозамены имени может быть отложен до тех пор, пока пользователь не введет информацию о получателе.
РИС. 4 иллюстрирует пример процесса задержки опции автозамены до тех пор, пока составление сообщения не будет по существу завершено. В этом примере снимок экрана 400 иллюстрирует состояние графического пользовательского интерфейса составления сообщения 418 после того, как пользователь ввел сообщение в тело сообщения 422 , но до заполнения любого из полей адреса сообщения получателя графического интерфейса составления сообщения. 418 . В сообщении, введенном пользователем, имя «Gulprit» с ошибкой отображается как «Culprit».Однако, поскольку поля адреса сообщения получателя еще не заполнены на этом этапе, приложение обмена сообщениями 102 может быть не в состоянии идентифицировать ошибку, потому что имена кандидатов не могут быть идентифицированы, а «Culprit» — это правильно написанное слово. , и, следовательно, не будет обнаружен с помощью стандартного процесса проверки орфографии с предопределенным орфографическим словарем. Напротив, снимок экрана 402 иллюстрирует графический интерфейс составления сообщения 418 после того, как пользователь заполнил поле адреса 420 с псевдонимом «Gulprit» (которое приложение обмена сообщениями 102 понимает как соответствующее «gulprit @» Gmail.com »в этом примере), и пользователь указал, что составление сообщения электронной почты было завершено, например, инициируя передачу сообщения электронной почты, выбрав значок« отправить » 423 графического интерфейса пользователя 418 составления сообщения.
В ответ на это указание на то, что составление завершено, приложение обмена сообщениями 102 может затем повторно оценить поля адреса сообщения получателя, чтобы определить, можно ли по ним определить имя кандидата. В этом случае приложение обмена сообщениями может идентифицировать имя кандидата «Gulprit» и, таким образом, при анализе тела сообщения 422 , может идентифицировать слово «Culprit» потенциально как версию имени кандидата «Gulprit» с ошибкой и, таким образом, предоставить опция автозамены, такая как опция автозамены 324 на фиг. 3 , заменить «Culprit» на «Gulprit» в теле сообщения 422 . Таким образом, приложение обмена сообщениями , 102, может продолжать обновлять процесс помощи в составлении имен по мере того, как становится доступным дополнительный контекст сообщения.
РИС. 5 иллюстрирует примерный способ 500 работы приложения обмена сообщениями 102 электронного устройства 100 для предоставления помощи в составлении имени во время составления электронного сообщения в соответствии по меньшей мере с одним вариантом осуществления.Метод 500 запускается в блоке 502 , когда пользователь выполняет действие, чтобы инициировать составление электронного сообщения. Это действие может включать в себя, например, ввод пользователя, указывающий инструкцию для приложения обмена сообщениями 102 , чтобы инициировать составление сообщения, например, путем выбора значка «составить сообщение» в графическом интерфейсе приложения обмена сообщениями 102 или в графическом интерфейсе пользователя ОС 108 (РИС. 1). В некоторых случаях составление электронного сообщения может быть инициировано косвенно.Чтобы проиллюстрировать, отдельное приложение может связывать или иным образом перенаправлять пользователя к приложению обмена сообщениями 102 для составления сообщения. Чтобы проиллюстрировать, веб-сайт, отображаемый в веб-браузере, может включать в себя ссылку, которая инициирует вызов интерфейса прикладного программирования (API) к приложению обмена сообщениями 102 , чтобы позволить пользователю составлять электронное сообщение, связанное с веб-сайтом (например, пересылка статьи на веб-сайте указанному получателю или пересылка сообщения получателю, связанному с веб-сайтом).
В ответ на этот инициирующий ввод в блоке 504 приложение обмена сообщениями 102 генерирует и отображает графический интерфейс составления сообщения, чтобы облегчить пользователю ввод для составления электронного сообщения. Графический интерфейс составления сообщения обычно включает в себя несколько полей, включая одно или несколько полей адреса сообщения получателя (например, поля адреса электронной почты для; cc: и bcc:) и одно или несколько полей тела сообщения, то есть поля адреса, не являющегося получателем. (обратите внимание, что термин «тело сообщения» может включать, например, поле строки темы сообщения электронной почты, поскольку оно сродни заголовку сообщения).При отображении графического пользовательского интерфейса составления сообщения в блоке 506 начальный ввод состава пользователя принимается приложением 102 обмена сообщениями через графический интерфейс составления сообщения.
В некоторых случаях этот ввод начального состава пользователя может включать в себя предоставление пользователем псевдонимов адресов или неполных адресов сообщения получателя в одном или нескольких полях адреса сообщения получателя электронного сообщения. В таких случаях в блоке 508 приложение обмена сообщениями 102 идентифицирует полные или полные адреса сообщений получателя, используя функцию автозаполнения приложения обмена сообщениями 102 .Эта функция автозаполнения может, например, использовать псевдоним или частичный адрес сообщения получателя для выполнения поиска в базе данных контактов 114 (фиг. 1), чтобы идентифицировать полный адрес сообщения получателя.
В блоке , 510, приложение обмена сообщениями 102 подготавливается для поддержки процесса поддержки составления имени получателя для электронного сообщения, составляемого путем определения внутреннего контекста сообщения, который может быть полезен при идентификации имен кандидатов.Этот внутренний контекст сообщения включает в себя контекст сообщения, определенный непосредственно из полей составляемого электронного сообщения, и, таким образом, может включать адреса сообщений получателей в полях адресов сообщений получателей электронного сообщения, имена файлов вложенных файлов, перечисленные в поле вложения, или содержимое. самих вложенных файлов и содержимого, уже присутствующего в поле тела сообщения, такого как любой исходный контент, составленный пользователем в теле сообщения, или электронное сообщение может включать в себя ответное сообщение или сообщение пересылки, и в этом случае тело сообщения может содержат содержание исходного электронного сообщения, служащего основой для ответа или переадресации сообщения.Это содержимое исходного электронного сообщения может включать, например, адреса получателей исходного электронного сообщения, а также одно или несколько имен получателей в поле тела сообщения.
В некоторых вариантах осуществления имена кандидатов также могут быть определены на основе внешнего контекста сообщения; то есть контекст сообщения, который непосредственно не идентифицируется полем составляемого электронного сообщения, и, таким образом, на этапе 512 приложение обмена сообщениями 102 определяет такой внешний контекст сообщения.Этот внешний контекст сообщения может включать в себя, например, определение имени получателя из базы данных контактов , 114, на основе поиска с использованием, по меньшей мере, части адреса сообщения получателя. Кроме того, поскольку составление электронного сообщения могло быть инициировано другим приложением (например, примером веб-сайта, описанным выше), внешний контекст сообщения может включать в себя контекстную информацию об этом другом приложении, такую как контент в приложении, связанный со ссылкой или другим источник создания электронного сообщения.
С определением одного или обоих из контекста внутреннего сообщения и внешнего контекста сообщения на этапе 514 приложение обмена сообщениями 102 идентифицирует одно или несколько имен кандидатов для электронного сообщения из внутреннего и внешнего контекста сообщения. Как более подробно описано ниже, идентификация этих имен кандидатов может включать в себя синтаксический анализ информации, относящейся к имени, во внутреннем контексте сообщения, поиск имен на основе информации о получателе из контекста сообщения и т.п.Любые идентифицированные таким образом имена кандидатов могут быть сохранены во временной базе данных 116 имен кандидатов (фиг. 1), поддерживаемой приложением 102 обмена сообщениями для электронного сообщения.
Одновременно с процессом идентификации имени кандидата в блоке 516 приложение обмена сообщениями 102 отслеживает ввод исходной композиции пользователя для обнаружения триггера приветствия, который указывает, что пользователь может намереваться включить имя получателя в поле тела сообщения.Как отмечалось выше, этот триггер приветствия может включать в себя ввод слова, которое обычно служит частью приветствия в сообщении, например, ввод «Привет», «Привет», «Уважаемый» и т. Д. Вместо этого триггер приветствия может включать ввод по крайней мере части слова в области тела сообщения, обычно используемой для приветствия, такой как первое или два слова в теле сообщения или набор слов, расположенный в верхнем левом углу поля тела сообщения, или ввод начального набора букв, который соответствует соответствующему начальному набору букв имени кандидата.
В ответ на обнаружение триггера приветствия на этапе 518 приложение обмена сообщениями 102 выбирает имя кандидата (если существует более одного имени кандидата), которое может отражать имя получателя, к которому пользователь собирается или пытается к, вход в сочетании с триггером приветствия. Этот процесс выбора может включать применение одного или нескольких правил приоритизации. Например, правило приоритизации может предусматривать, что имена кандидатов, определенные из полей адреса сообщения получателя электронного сообщения, могут иметь приоритет выбора по сравнению с именами кандидатов, определенными из полей адреса не получателя, то есть полей тела сообщения.Кроме того, правило приоритизации может предусматривать, что имена кандидатов, определенные из поля to: address, могут иметь приоритет выбора по сравнению с именами кандидатов, определенными из поля cc: address, которые, в свою очередь, получают приоритет выбора над именами кандидатов, определенными из поля bcc: address и т. д. В ситуациях, когда триггер приветствия включает в себя ввод пользователем начального набора букв слова, которое, как ожидается, будет именем получателя, приоритет выбора среди нескольких имен кандидатов может быть отдан тому имени кандидата, которое наиболее близко соответствует начальному набору букв. .
С выбранным именем кандидата в блоке 520 приложение обмена сообщениями 102 может облегчить составление имени получателя, предоставляя через графический интерфейс составления сообщений один или оба варианта автозаполнения (например, фиг. 1) или автозаполнения. вариант (например, фиг. 2), который графически представляет имя кандидата пользователю для включения в тело электронного сообщения таким образом, чтобы предотвратить множество вероятных ошибок ввода пользователем для имени получателя. В случае, если параметр автозаполнения / вариант автозаполнения не принимается пользователем, или в случае, если ни один из вариантов не представлен, на этапе 522 приложение обмена сообщениями 102 продолжает отслеживать ввод композиции пользователя, чтобы определить, действительно ли пользователь завершил слово, предполагаемое пользователем как имя получателя, которое несовместимо с одним или несколькими идентифицированными именами кандидатов (например,g., не соответствует ни одному из идентифицированных имен кандидатов). Этот анализ может выполняться относительно быстро после того, как пользователь завершил ввод слова (например, после того, как после слова был введен пробел) или после того, как пользователь сигнализировал о завершении составления электронного сообщения, например, выбрав «сохранить »Или при попытке инициировать передачу электронного сообщения путем выбора значка« отправить ».
Если такое несоответствие имени кандидата / завершенного слова или несоответствие возникает в теле сообщения, то на этапе 524 приложение обмена сообщениями 102 может предоставить опцию автозамены (например.g., фиг. 3 и 4), чтобы уведомить пользователя о потенциальной ошибке и дать пользователю возможность исправить ошибку (если это ошибка), заменив вместо этого спорное слово предложенным именем кандидата. После внесения этого исправления или, если такое исправление в первую очередь не требуется, на этапе 526 приложение обмена сообщениями 102 завершает составление электронного сообщения и отправляет электронное сообщение провайдеру обмена сообщениями 104 (фиг.1) для рассылки по одному или нескольким адресам обмена сообщениями получателя, указанным в полях адреса сообщения получателя электронного сообщения.
РИС. 6-10 иллюстрируют примерные методы, которые могут использоваться приложением обмена сообщениями 102 , OS 108 или другим компонентом электронного устройства 100 на фиг. 1 для идентификации одного или нескольких имен кандидатов из контекста сообщения 112 составляемого электронного сообщения. В частности, фиг.6-8 иллюстрируют методы, которые идентифицируют имена кандидатов из внутреннего контекста сообщения (то есть информации в полях самого сообщения), а фиг. 9 и 10 иллюстрируют методы, которые идентифицируют имена кандидатов из внешнего контекста сообщения (то есть контекста из внешних источников, к которому осуществляется доступ или который идентифицируется на основе внутреннего контекста сообщения).
РИС. 6 иллюстрирует методику идентификации одного или нескольких имен кандидатов из адресов сообщения получателя, присутствующих в полях адреса сообщения получателя электронного сообщения.В этом подходе синтаксический анализатор 600 приложения обмена сообщениями 102 обращается к зависящей от получателя части адреса сообщения получателя и анализирует вероятные слова имени из части, зависящей от получателя. Однако, поскольку имя получателя может включать в себя несколько слов, синтаксический анализатор , 600 дополнительно может генерировать различные комбинации слов имени, анализируемых из адреса сообщения получателя, для генерации нескольких имен кандидатов. Чтобы проиллюстрировать, в изображенном примере синтаксический анализатор , 600 обращается к адресу электронной почты получателя 602 (один из вариантов адреса сообщения получателя) из поля to: address или поля cc: address, или из включенного исходного сообщения электронной почты. в теле сообщения в случае, если составляемое сообщение электронной почты является ответным сообщением электронной почты или пересылаемым сообщением электронной почты.Адреса электронной почты обычно состоят из части, зависящей от получателя, за которой следует доменная часть с символом «@», разделяющим их. Таким образом, адрес электронной почты «[email protected]» включает специфичную для получателя часть «gulprit.singh» и часть домена «gmail.com». Таким образом, синтаксический анализатор , 600 может анализировать специфичную для получателя часть, чтобы идентифицировать одно или несколько потенциальных слов имени, посредством чего синтаксический анализатор , 600 может использовать различные разделители общих слов имени, такие как точка («.»), Подчеркивание (« _ »), тире (« — ») и т.п. для обнаружения отдельных слов. Таким образом, для специфической для получателя части «gulprit.singh» адреса электронной почты получателя 602 синтаксический анализатор 600 может генерировать слова имени «gulprit» и «singh», и из комбинаций этих слов имени получить три имена кандидатов 604 , 606 , 608 — «Гулприт», «Сингх» и «Гулприт Сингх» соответственно. «Сингх Гулприт» также может быть разумным кандидатом на имя, если в системе адресации электронной почты принято помещать фамилию или фамилию первыми в адресе электронной почты.Затем синтаксический анализатор 600 может поместить эти имена кандидатов 604 , 606 и 608 в базу данных кандидатов 116 электронного устройства 100 для последующего использования при помощи композиции имен, как описано выше. Этот процесс может быть аналогичным образом применен для анализа имен файлов, перечисленных в поле вложения электронного сообщения.
РИС. Фиг.7 иллюстрирует методику идентификации одного или более имен кандидатов из поля отображаемого имени, связанного с адресом сообщения получателя, присутствующим в полях адреса сообщения получателя электронного сообщения.Часто по соображениям безопасности или по другим причинам организация, предоставляющая услуги электронного обмена сообщениями своим составляющим, может решить использовать специфичную для получателя часть адреса получателя сообщения, которая, будучи уникальной для получателя, не отражает имени получателя. Такие конфигурации затрудняют идентификацию имен кандидатов непосредственно из адреса получателя сообщения, если не делают невозможным. Однако протоколы электронной почты и другие протоколы обмена сообщениями часто предоставляют одно или несколько полей идентификации пользователя, которые могут быть более полезными при идентификации получателя, чем адрес получателя сообщений.Чтобы проиллюстрировать, протоколы электронной почты предусматривают включение поля отображаемого имени в ассоциации с адресом электронной почты получателя, где поле отображаемого имени хранит удобное для пользователя отображаемое имя. Анализатор , 600, может использовать такие поля имени пользователя для идентификации одного или нескольких имен кандидатов. В качестве примера, получатель составляемого сообщения электронной почты может быть указан в наборе полей получателя электронной почты 702 , который включает в себя поле адреса электронной почты 704 , в котором хранится адрес электронной почты «A100269 @ motorola».com »и поле отображаемого имени 706 , в котором хранится отображаемое имя« Gulprit Singh ». Специфическая для получателя часть адреса электронной почты «A100269» не содержит никакой полезной информации для прямой идентификации одного или нескольких слов имени, и, таким образом, синтаксический анализатор 600 вместо этого может проанализировать отображаемое имя «Gulprit Singh» в поле отображаемого имени . 706 для идентификации одного или нескольких кандидатов. Как и в примере на фиг. 6, анализ этого отображаемого имени может привести к именам кандидатов 604 , 606 , 608 — «Gulprit», «Singh» и «Gulprit Singh», соответственно, которые хранятся в базе данных имен кандидатов 116 для использования в составлении имен приложением обмена сообщениями 102 .
РИС. 8 иллюстрирует метод идентификации одного или более имен кандидатов из поля тела электронного сообщения. Часто при составлении электронного сообщения поле тела сообщения может содержать контент, который включает в себя или иным образом идентифицирует, по меньшей мере, часть имени одного или нескольких получателей электронного сообщения. Для иллюстрации электронное сообщение может быть ответом на предыдущее электронное сообщение или может пересылать предыдущее электронное сообщение другому получателю.В таких случаях одно или несколько полей тела сообщения и полей адреса сообщения получателя предыдущего электронного сообщения могут быть включены в поле тела сообщения составляемого электронного сообщения. Таким образом, поле тела сообщения может включать в себя адреса сообщения получателя получателей предыдущего электронного сообщения, отображаемые имена, связанные с адресами сообщения получателя, или другие ссылки на вероятных получателей, такие как строка подписи, включенная отправителем предыдущего сообщения. электронное сообщение в теле сообщения предыдущего электронного сообщения.Таким образом, синтаксический анализатор , 600 может анализировать поле тела электронного сообщения в таких случаях, чтобы идентифицировать одно или несколько имен кандидатов.
Чтобы проиллюстрировать, пример на фиг. 8 изображает поле 802 тела сообщения составляемого ответного сообщения электронной почты, при этом поле 802 тела сообщения включает в себя содержимое 804 исходного сообщения электронной почты. Это содержимое 804 включает строку подписи 806 отправителя исходного сообщения.Таким образом, синтаксический анализатор , 600, может анализировать контент , 804, , чтобы идентифицировать строку подписи , 806, , используя любой из множества методов синтаксического анализа, а затем анализировать строку подписи , 806, для идентификации потенциальных слов имени. Этот синтаксический анализ может включать, например, отбрасывание или игнорирование слов, предварительно идентифицированных, например, в словаре синтаксического анализа (не показан) как не указывающие имена получателей. При синтаксическом анализе проиллюстрированной строки подписи 806 анализатор 600 проигнорирует слова «CTO», «Motorola», «Mobility» и «Inc.», И таким образом получаем именные слова« Pathy »и« Sunil »как именные слова. Из комбинаций этих именных слов синтаксический анализатор 600 может сгенерировать, например, имена кандидатов 808 , 810 , 812 — «Pathy», «Sunil» и «Pathy Sunil» соответственно, и сохранить этих кандидатов. имена 808 , 810 , 812 в базе данных кандидатов для использования при составлении имен приложением обмена сообщениями 102 . Этот процесс может быть аналогичным образом применен к синтаксическому анализу содержимого файлов, перечисленных как вложения в поле вложения электронного сообщения.
РИС. 9 иллюстрирует метод косвенной идентификации одного или нескольких имен кандидатов с использованием базы данных контактов , 114, (фиг. 1), хранящейся в электронном устройстве , 100, . Как отмечалось выше, адрес сообщения получателя может не содержать информацию, полезную для прямой идентификации имен кандидатов, и может не быть отображаемого имени или другого удобного для пользователя поля именования, связанного с адресом сообщения получателя. Однако пользователь мог ранее иметь дело с получателем, связанным с адресом сообщения получателя, и, таким образом, может иметь контактную запись для получателя в базе данных контактов , 114, .Эта контактная запись может включать в себя различную информацию о получателе, такую как имя получателя, должность, работодатель, адрес, номер телефона и различные адреса электронных сообщений для получателя. Соответственно, в таких случаях приложение обмена сообщениями 102 или другой компонент электронного устройства 100 на фиг. 1 может использовать модуль поиска контактов для идентификации записи контакта, связанной с контекстом сообщения, идентифицированного в одном или нескольких полях составляемого электронного сообщения, и из этой записи контакта косвенно идентифицировать одно или несколько имен кандидатов.
Для иллюстрации, в изображенном примере единственной информацией, идентифицирующей получателя создаваемого сообщения электронной почты, является адрес электронной почты 902 , который имеет специфичную для получателя часть «A100269», которая не отражает имя получателя, связанного с электронный адрес 902 . Соответственно, модуль поиска контактов , 900, может использовать эту специфичную для получателя часть для поиска в базе данных контактов 114 записи контакта, которая имеет поле, которое соответствует специфической для получателя части «A100269».В этом примере база данных контактов , 114, имеет соответствующую запись контакта, связанную с человеком по имени «Гулприт Сингх», и, таким образом, модуль поиска контактов 900 может анализировать поля имени в этой совпадающей записи контакта, чтобы идентифицировать имя. слово 904 слова «Gulprit» и слово фамилии 906 слова Singh. Модуль поиска контактов 900 может затем сохранить эти слова имен 904 , 906 в базе данных имен кандидатов 116 , после чего синтаксический анализатор 600 (РИС.6) затем объединяет слова имени в различные имена кандидатов «Gulprit», «Singh» и «Gulprit Singh», или модуль поиска контактов 900 может сгенерировать эти имена кандидатов непосредственно перед их сохранением в базе данных имен кандидатов 116 . Таким образом, как показывает этот пример, модуль поиска контактов 900 использует внутренний контекст сообщения, а именно адрес электронной почты получателя 902 , для косвенной идентификации одного или нескольких имен кандидатов через внешний контекст сообщения, а именно контактную запись в базе данных контактов 114 .
РИС. 10 иллюстрирует метод косвенной идентификации одного или более имен кандидатов с использованием читаемого пользователем контента приложения, из которого было инициировано составление электронного сообщения. Веб-браузеры, приложения социальных сетей и другие подобные приложения часто имеют возможность запускать или инициировать составление электронного сообщения. Для иллюстрации веб-браузер может отображать новостной веб-сайт, имеющий ссылку, которая, при выборе пользователем, связывается с приложением обмена сообщениями 102 , чтобы инициировать составление электронного сообщения, которое, например, используется для пересылки связанной новостной статьи на получатель.Сами по себе другие электронные сообщения могут иметь такие ссылки, которые запускают составление электронного сообщения. В таких случаях, с учетом того, что имя получателя часто находится в непосредственной близости от ссылки или другой функции в содержимом приложения, приложение, которое запускает составление электронного сообщения, может иметь читаемый пользователем контент, который может служить основа для идентификации одного или нескольких возможных имен получателя электронного сообщения. Таким образом, синтаксический анализатор , 600, может анализировать этот читаемый пользователем контент другого приложения, чтобы идентифицировать одно или несколько имен кандидатов.
Чтобы проиллюстрировать, в изображенном примере веб-страница, отображаемая веб-браузером, включает в себя читаемый пользователем контент 1002 , который включает в себя текст, инструктирующий представление о необходимости резервирования на мероприятии, связавшись с «Хэ Юн Ким» по указанному адресу электронной почты «HYK1032» @ gmail.com », и при этом текст адреса электронной почты служит гипертекстовой ссылкой, которая при выборе пользователем через веб-браузер заставляет веб-браузер связываться с приложением обмена сообщениями 102 , чтобы инициировать составление адресованного электронного сообщения. на «HYK1032 @ gmail.com ». Поскольку с этого адреса электронной почты невозможно проанализировать полезные имена кандидатов, синтаксический анализатор 600 вместо этого может анализировать читаемое пользователем содержимое веб-страницы в непосредственной близости от гипертекстовой ссылки, чтобы идентифицировать одно или несколько имен кандидатов. В этом примере этот текст поблизости включает фразу 1003 «Чтобы ответить на приглашение на мероприятие, пожалуйста, свяжитесь с Хэ Юн Ким по адресу [email protected]», которую синтаксический анализатор 600 может проанализировать, чтобы идентифицировать слова имени «Hae , »« Юн »и« Ким », и которые могут быть объединены, например, в имена кандидатов 1004 , 1006 , 1008 и 1010 -« Хэ »,« Юн »,« Хэ Юн »и« Ким », соответственно, и хранятся в базе данных имен кандидатов 116 .
Следует принять во внимание, что приложение, из которого было инициировано электронное сообщение, может быть отдельным от приложения обмена сообщениями 102 . В таких случаях синтаксический анализатор , 600, может быть реализован вне приложения обмена сообщениями , 102, , например, в другом приложении или в ОС 108 , чтобы иметь возможность доступа к контенту другого приложения. В качестве альтернативы, синтаксический анализатор , 600, может быть реализован как часть приложения обмена сообщениями , 102, , а читаемый пользователем контент другого приложения может быть передан синтаксическому анализатору , 600 как часть запроса на инициирование составления электронного сообщения. сообщение.Например, вызов API, сделанный другим приложением в ответ на выбор гипертекстовой ссылки зрителем, может включать в себя унифицированный указатель ресурса (URL) веб-страницы, на которой находится читаемый пользователем контент, и синтаксический анализатор 600 , таким образом может использовать этот URL-адрес для доступа к веб-странице и анализа ее содержимого для идентификации слова имени.
РИС. 11 иллюстрирует пример реализации электронного устройства 100 по фиг. 1 в соответствии, по меньшей мере, с одним вариантом осуществления настоящего раскрытия.В изображенном примере электронное устройство 100 включает в себя по меньшей мере один процессор 1102 (например, центральное устройство обработки или ЦП), один или несколько энергонезависимых машиночитаемых носителей, таких как системная память 1104 или другой запоминающее устройство 1106 (например, флэш-память, оптический или магнитный диск, твердотельный жесткий диск и т. д.), сетевой интерфейс 1108 (например, интерфейс беспроводной локальной сети (WAN) или проводной интерфейс Ethernet), и пользовательский интерфейс (UI) 1110 , подключенный через одну или несколько шин 1112 или другие межсоединения.UI 1110 включает в себя, например, устройство отображения 1114 и клавиатуру или сенсорный экран 1116 , а также другие компоненты ввода / вывода 1118 , такие как динамик или микрофон, для приема ввода от, или предоставить информацию пользователю.
Процессор 1102 выполняет набор исполняемых инструкций, хранящихся на машиночитаемом носителе данных, таком как системная память 1104 или флэш-память, при этом набор исполняемых инструкций представляет одно или несколько программных приложений 1120 , например как приложение обмена сообщениями 102 на фиг.1. Программные приложения , 1120, при выполнении манипулируют процессором , 1102, для выполнения различных программных функций для реализации по меньшей мере части описанных выше методов, предоставляют визуальную информацию через устройство отображения , 1114, , реагируют на пользовательский ввод через сенсорный экран 1116 и т.п. Таким образом, большая часть изобретательских функциональных возможностей и многие из изобретательских принципов, описанных выше, хорошо подходят для реализации с программными программами или в них.Ожидается, что специалист с обычной квалификацией, несмотря на возможные значительные усилия и множество вариантов дизайна, мотивированных, например, доступным временем, текущими технологиями и экономическими соображениями, руководствуясь концепциями и принципами, раскрытыми в данном документе, легко сможет создать такое программное обеспечение инструкции и программы минимальные эксперименты. Следовательно, в интересах краткости и минимизации любого риска затруднения понимания принципов и концепций в соответствии с настоящим раскрытием, дальнейшее обсуждение такого программного обеспечения, если таковое имеется, будет ограничено существенным в отношении принципов и концепций в предпочтительных вариантах осуществления. .
В этом документе относительные термины, такие как первый, второй и т.п., могут использоваться исключительно для того, чтобы отличать один объект или действие от другого объекта или действия, не обязательно требуя или подразумевая какие-либо фактические отношения или порядок между такими объектами или действиями. Термины «содержит», «содержащий» или любые другие их варианты предназначены для охвата неисключительного включения, так что процесс, метод, изделие или устройство, которые содержат список элементов, включают не только эти элементы, но может включать другие элементы, не указанные в явном виде или не присущие такому процессу, методу, изделию или устройству.Элемент, которому предшествует «содержит. . . a »без дополнительных ограничений не исключает наличия дополнительных идентичных элементов в процессе, способе, изделии или аппарате, которые составляют элемент. Термин «другой», используемый здесь, определяется как по меньшей мере второй или более. Термины «включающий» и / или «имеющий» в контексте настоящего описания определены как содержащие. Термин «связанный», используемый здесь в отношении электрооптической технологии, определяется как связанный, хотя и не обязательно напрямую, и не обязательно механически.Используемый здесь термин «программа» определяется как последовательность инструкций, предназначенных для выполнения в компьютерной системе. «Программа» или «компьютерная программа» может включать в себя подпрограмму, функцию, процедуру, объектный метод, реализацию объекта, исполняемое приложение, апплет, сервлет, исходный код, объектный код, совместно используемый библиотека / библиотека динамической загрузки и / или другая последовательность инструкций, предназначенная для выполнения в компьютерной системе.
Описание и чертежи следует рассматривать только как примеры, и объем раскрытия, соответственно, ограничивается только следующей формулой изобретения и ее эквивалентами.Обратите внимание, что не все действия или элементы, описанные выше в общем описании, являются обязательными, что часть определенного действия или устройства может не требоваться, и что одно или несколько дополнительных действий могут быть выполнены или элементы включены в дополнение к те, что описаны. Более того, порядок, в котором перечислены действия, не обязательно является порядком, в котором они выполняются. Шаги блок-схем, изображенных выше, могут быть в любом порядке, если не указано иное, и шаги могут быть исключены, повторены и / или добавлены, в зависимости от реализации.Кроме того, концепции были описаны со ссылкой на конкретные варианты осуществления. Однако специалист в данной области техники понимает, что различные модификации и изменения могут быть выполнены без выхода за пределы объема настоящего раскрытия, изложенного в формуле изобретения ниже. Соответственно, описание и фигуры следует рассматривать в иллюстративном, а не ограничительном смысле, и все такие модификации предназначены для включения в объем настоящего раскрытия.
Выгоды, другие преимущества и решения проблем были описаны выше в отношении конкретных вариантов осуществления.Тем не менее, выгоды, преимущества, решения проблем и любые особенности, которые могут привести к появлению каких-либо преимуществ, преимуществ или решений, или стать более выраженными, не должны рассматриваться как критические, обязательные или существенные особенности любого или все претензии.
(PDF) Синтаксические ядра в разборе зависимостей — многоязычное исследование
Дж. Нивр. Эффективный алгоритм анализа проективной зависимости
. In Proceedings of the VIII Inter-
national Conference on Parsing Technologies, pages
149–160, Nancy, France, Apr.2003.
J. Nivre. Инкрементальность в детерминированной зависимости
синтаксический анализ. In Proceedings of the Workshop on Incre-
mental Parsing: Bringing Engineering and Cogni-
tion Вместе, страницы 50–57, Барселона, Испания, июль
2004. Ассоциация компьютерной лингвистики.
J. Nivre. Непроективный анализ зависимостей в ожидаемом линейном времени. В материалах совместной конференции
47-го ежегодного собрания ACL и
4-й Международной совместной конференции по обработке естественного языка
AFNLP (ACL-IJCNLP),
страниц 351–359, 2009.
J. Nivre and C.-T. Клык. Универсальная оценка зависимости
. In Proceedings of the NoDaLiDa 2017
Workshop on Universal Dependencies (UDW 2017),
pages 86–95, 2017.
J. Nivre, M.-C. de Marneffe, F. Ginter, Y. Goldberg,
J. Hajiˇ
c, C. D. Manning, R. McDonald, S. Petrov,
S. Pyysalo, N. Silveira, R. Tsarfaty, and D. Zeman.
Универсальные зависимости v1: многоязычная коллекция treebank
.In Proceedings of the 10th International
Conference on Language Resources and Evaluation
(LREC), 2016.
J. Nivre, M. Abrams, ˇ
Z. Agi´
c, L. Ahrenberg, L. An —
tonsen, K. Aplonova, MJ Aranzabe, G. Arutie,
M. Asahara, L. Ateyah, M. Attia, A. Atutxa, L. Au-
gustinus, E. Badmaeva, M. Ballesteros, E. Banerjee,
S. Bank, V. Barbu Mititelu, V. Basmov, J. Bauer,
S. Bellato, K.Bengoetxea, Y. Berzak, IA Bhat,
RA Bhat, E. Biagetti, E. Bick, R. Blokland, V. Bo-
bicev, C. B¨
orstell, C. Bosco, G. Bouma, С. Боу —
человек, А. Бойд, А. Бурхардт, М. Кандито, Б. Карон,
Г. Карон, Г. Себиро ˘
glu Eryi˘
git, FM Cecchini,
GGA Celano , S. ˇ
C´
epl¨
o, S. Cetin, F. Chalub,
J. Choi, Y. Cho, J. Chun, S. Cinkov´
a, A.Collomb,
C¸. C¸ ¨
oltekin, M. Connor, M. Courtin, E. Davidson,
M.-C. de Marneffe, V. de Paiva, A. Diaz de Ilarraza,
C. Dickerson, P. Dirix, K. Dobrovoljc, T. Dozat,
K. Droganova, P. Dwivedi, M. Eli, A. Elkahky,
B. Ephrem, T. Erjavec, A. Etienne, R. Farkas, H. Fer-
nandez Alcalde, J. Foster, C. Freitas, K. Gajdoˇ
sov´
a,
D. Гэлбрейт, М. Гарсия, М. G¨
ardenfors, S.Garza,
K. Gerdes, F. Ginter, I. Goenaga, K. Gojenola,
M. G¨
okırmak, Y. Goldberg, X. G´
omez Guinovart,
B. Gonz´
ales Saavedra, M. Grioni, N. Gr ¯
uz¯
ıtis,
B. Guillaume, C. Guillot-Barbance, N. Habash,
J. Hajiˇ
c, J. Hajiˇ
c jr., L. H`
a M˜
y, N.-R. Han, K. Har-
ris, D. Haug, B. Hladk´
a, J.Hlav´
aˇ
cov´
a, F. Hociung,
P. Hohle, J. Hwang, R. Ion, E. Irimia, O
.. Ishola,
T. Jel´
Инек, А. Йоханссен, Ф. Йоргенсен, Х. Касликара,
С. Кахане, Х. Канаяма, Дж. Канерва, Б. Кац,
Т. Каяделен, Дж. Кенни, В. Кеттнеров
a, J. Kirch-
ner, K. Kopacewicz, N. Kotsyba, S. Krek, S. Kwak,
V. Laippala, L. Lambertino, L. Lam, T. Lando,
S.Д. Ларасати, А. Лаврентьев, Дж. Ли, П. Lˆ
e H`ˆ
ong,
A. Lenci, S. Lertpradit, H. Leung, CY Li, J. Li,
K. Ли, К. Лим, Н. Любэ
si´
c, О. Логинова, О. Ля-
шевская, Т. Линн, В. Макетанц, А. Макажанов,
М. Мандл, К. Мэннинг , R. Manurung, C. M˘
ar˘
anduc,
D. Mareˇ
cek, K. Marheinecke, H. Mart´
ınez Alonso,
A. Martins, J.Maˇ
sek, Y. Matsumoto, R. McDon-
ald, G. Mendonc¸a, N. Miekka, M. Misirpashayeva,
A. Missil¨
a, C. Mititelu, Y. Miyao, S . Montemagni,
A. More, L. Moreno Romero, KS Mori, S. Mori,
B. Mortensen, B. Moskalevskyi, K. Muischnek,
Y. Murawaki, K. M ¨
u¨
urisep, P. Nainwani, JI
Navarro Hor˜
niacek, A. Nedoluzhko, G. Neˇ
spore-
B¯
erzkalne, L.Nguy˜ˆ
en Thi
., H. Nguy˜ˆ
en Thi
.Minh,
V. Николаев, R. Nitisaroj, H. Nurmi, S. Ojala,
A. Ol´
u`
okun, M. Omura, P. Osenova, R. ¨
Ostling,
L. Ovrelid, N. Partanen, E. Pascual, M. Passarotti,
A. Patejuk, G. Paulino- Пассос, С. Пэн, К.-А.
Perez, G. Perrier, S. Petrov, J. Piitulainen, E. Pitler,
B. Plank, T. Poibeau, M. Popel, L. Pretkalnin¸a,
S.Pr´
evost, P. Prokopidis, A. Przepi´
orkowski, T. Puo-
lakainen, S. Pyysalo, A. R¨
a¨
abis, A. Rademaker,
L. Рамасами, Т. Рама, К. Рамиш, В. Равишанкар,
Л. Реал, С. Редди, Г. Рем, М. Рисслер, Л. Ри-
налди, Л. Ритума, Л. Роча, М. Романенко, Р. Роза,
Д. Ровати, В. Рос
, ca, О. Рудина, Дж. Рутер, С. Садде,
Б. Сагот, С. Салех, Т. Самардо
zi´
с, с.Samson, M. San-
guinetti, B. Saul¯
ıte, Y. Sawanakunanon, N. Schnei-
der, S. Schuster, D. Seddah, W. Seeker, M. Seraji,
M. Шен, А. Шимада, М. Шохибуссирри, Д. Сичи
нава, Н. Сильвейра, М. Сими, Р. Симионеску, К. Симк
о,
М. ˇ
Симков
а , К. Симов, А. Смит, И. Соарес-
Бастос, К. Спадин, А. Стелла, М. Страка, J. Str-
nadov´
a, A. Suhr, U. Sulubacak, Z .Sz´
ant´
o, D. Taji,
Y. Takahashi, T. Tanaka, I. Tellier, T. Trosterud,
A. Trukhina, R. Tsarfaty, F. Tyers, S. Uematsu,
Z. Ureˇ
sov´
a, L. Uria, H. Uszkoreit, S. Vajjala,
D. van Niekerk, G. van Noord, V. Varga, E. Ville-
monte de la Clergerie, V. Vincze, L. Wallin, JX
Wang, JN Washington, S. Williams, M. Wir´
en,
T. Woldemariam, T.-s. Вонг, К.Ян, М. М.
Яврумян, З. Ю., З. №
Забокртск
л, А. Зельдес, Д. Зе-
человек, М. Чжан, Х. Чжу. Универсальная зависимость —
cies 2.3, 2018. URL http://hdl.handle.net/
11234 / 1-2895. LINDAT / CLARIAH-CZ digital li-
brary в Институте формального и прикладного лингвизма
tics (´
UFAL), факультет математики и физики,
Карлов университет.
J. Nivre, M.-C. де Марнеф, Ф.Ginter, J. Hajiˇ
c, C. D.
Manning, S. Pyysalo, S. Schuster, F. Tyers и
D. Zeman. Универсальные зависимости v2: постоянно растущая коллекция многоязычных банков деревьев. В Pro-
ceedings 12-й Международной конференции по языковым ресурсам и оценке
(LREC), 2020.
К. Самуэльссон. Статистическая теория зависимости син-
налога. В COLING 2000 Volume 2: 18-я Международная конференция по компьютерной лингвистике
,
2000.
Ф. Сангати и К. Мацца. Английское дерево зависимости —
bank `
a la tesni`
ere. В материалах 8-го Международного семинара по деревьям и лингвистическим теориям
ries, страницы 173–184, ноябрь 2009 г.
Синтаксических ядер в разборе зависимостей — многоязычное исследование
@inproceedivre- nproceedings {basirat-n 2021-синтаксический,
title = "Синтаксические ядра в разборе зависимостей {-} Многоязычное исследование",
author = "Басират, Али и
Нивр, Иоаким ",
booktitle = "Труды 16-й конференции Европейского отделения Ассоциации компьютерной лингвистики: основной том",
месяц = апр,
год = "2021",
address = "Онлайн",
publisher = "Ассоциация компьютерной лингвистики",
url = "https: // аклантология.org / 2021.eacl-main.117 ",
pages = "1376--1387",
abstract = "Стандартные модели синтаксического анализа зависимостей принимают слова за элементарные единицы, которые вступают в отношения зависимости. В этой статье мы исследуем, есть ли какие-либо преимущества от обогащения этих моделей более абстрактным понятием ядра, предложенным Тесни {\` e} re. Мы делаем это, показывая, как понятие ядра может быть определено в рамках универсальных зависимостей и как мы можем использовать функции композиции, чтобы сделать синтаксический анализатор зависимостей на основе переходов осведомленным об этой концепции.Эксперименты на 12 языках показывают, что состав ядра дает небольшие, но значительные улучшения в точности синтаксического анализа. Дальнейший анализ показывает, что улучшение в основном касается небольшого числа отношений зависимости, включая номинальные модификаторы, отношения координации, основные предикаты и прямые объекты. ",
}
<моды> Синтаксические ядра в разборе зависимостей - многоязычное исследование Али Базират <роль>автор Иоаким Нивр <роль>автор 2021-апр текст Труды 16-й конференции Европейского отделения Ассоциации компьютерной лингвистики: основной том Ассоциация компьютерной лингвистики <место>В сети публикация конференции Стандартные модели синтаксического анализа зависимостей принимают слова как элементарные единицы, которые вступают в отношения зависимости.В этой статье мы исследуем, есть ли какие-либо преимущества от обогащения этих моделей более абстрактным понятием ядра, предложенным Теснером. Мы делаем это, показывая, как концепция ядра может быть определена в рамках универсальных зависимостей и как мы можем использовать функции композиции, чтобы сделать синтаксический анализатор зависимостей на основе переходов осведомленным об этой концепции. Эксперименты на 12 языках показывают, что состав ядра дает небольшие, но значительные улучшения в точности синтаксического анализа. Дальнейший анализ показывает, что улучшение в основном касается небольшого числа отношений зависимости, включая номинальные модификаторы, отношения координации, основные предикаты и прямые объекты. basirat-nivre-2021-syntactic <местоположение>https://aclanthology.org/2021.eacl-main.117 2021-апр 1376 1387
% 0 Материалы конференции Синтаксические ядра% T при разборе зависимостей - многоязычное исследование % А Басират, Али % A Nivre, Иоаким % S Труды 16-й конференции Европейского отделения Ассоциации компьютерной лингвистики: основной том % D 2021 г. % 8 апр % I Ассоциация компьютерной лингвистики % C в сети % F basirat-nivre-2021-синтаксис % X Стандартные модели синтаксического анализа зависимостей принимают слова за элементарные единицы, которые вступают в отношения зависимости.В этой статье мы исследуем, есть ли какие-либо преимущества от обогащения этих моделей более абстрактным понятием ядра, предложенным Теснером. Мы делаем это, показывая, как концепция ядра может быть определена в рамках универсальных зависимостей и как мы можем использовать функции композиции, чтобы сделать синтаксический анализатор зависимостей на основе переходов осведомленным об этой концепции. Эксперименты на 12 языках показывают, что состав ядра дает небольшие, но значительные улучшения в точности синтаксического анализа. Дальнейший анализ показывает, что улучшение в основном касается небольшого числа отношений зависимости, включая номинальные модификаторы, отношения координации, основные предикаты и прямые объекты.% U https://aclanthology.org/2021.eacl-main.117 % П 1376-1387
Написание сочинения о будущем
Каждая композиция имеет начала, , , середину, и конец . Середина, безусловно, самая длинная, но не менее важны начало и конец.
Если ваша композиция посвящена какой-то прогулке, нет необходимости писать полстраницы о раннем вставании, завтраке, приготовлении обеденной корзины или вывозе машины из гаража. начало должно быть кратким, и нет причин, по которым композиция о прогулке, например, не должна начинаться с фактического места на пляже, в парке, зоопарке, гавани или где бы то ни было.
Точно так же , заканчивающееся , должно закончить Композицию быстро, четко и точно. Это не только завершает вашу историю, но часто может добавить тот «последний штрих», который отличает обычную композицию от хорошей.
Неожиданные концовки придают неожиданный поворот истории, и этот вид завершающего штриха часто используется в творческой композиции.Обычно он состоит не более чем из двух или трех предложений, которые не длиннее, чем начальный абзац, который устанавливает сцену или приводит историю в движение.
средний Композиции составляет основную часть рассказа или описания и может состоять из трех или четырех абзацев. Он не должен содержать ничего, что не касается конкретной рассказываемой истории, и должен переходить от одного пункта к другому по мере того, как каждый происходит или описывается.
Чтобы избежать ошибок и использовать лучшие слова и фразы, каждое предложение следует тщательно продумать, прежде чем писать пером.Старайтесь не писать первое, что приходит вам в голову, но не ждите слишком долго, пока появятся идеи. Как только вы начнете, продолжайте, пока история не закончится. Не делайте фальстартов, вычеркивая или исключая и начиная все сначала.
Когда вы закончите сочинение, прочтите его до конца и посмотрите, как оно звучит для вас. Исправьте грамматические или пунктуационные ошибки. Не бойтесь использовать какое-либо громкое или незнакомое слово просто потому, что вы не можете его написать. Используйте свой словарь.
Перепишите свою Композицию после того, как вы ее закончили, где вы можете сказать что-то лучше. Вырежьте части, которые не нужны для вашего рассказа или описания.
Только написание множества Композиций поможет вам в этом преуспеть. Чтение и прослушивание рассказов, замечание в них хороших слов и фраз, их заимствование и использование некоторых хороших идей улучшат вашу способность писать сочинения.
Запомните свои абзацы.Несколько предложений составляют абзац, а несколько абзацев составляют композицию. Подобно тому, как предложение говорит вам определенную сумму и не более того, так и абзац. Когда достигается новая часть истории или описания, начинайте новый абзац.
ПРОШЛОЕ, НАСТОЯЩЕЕ ИЛИ БУДУЩЕЕ
Вот абзац о прошлом :
В прошлом году я ходил в школу каждый день. Я так регулярно посещал занятия, что получил за это сертификат. Я был не только постоянным, но и всегда пунктуальным, ни разу не опаздывая.Я гордился этим своим достижением.
Вот абзац о подарке :
Я люблю добираться до школы задолго до того, как прозвенит звонок, чтобы пойти в класс. Я могу поиграть со своими товарищами на детской площадке и пообщаться с ними перед началом уроков. Сейчас мы тренируемся со своими йо-йо и говорим о футболе и крикете в этом году.
Вот абзац о будущем :
В наступающем футбольном сезоне постараюсь попасть в школьную команду.Когда пройдут пробы, я буду настолько хорошо обучен, что у меня будут хорошие шансы на продажу товара
.действие. Я начну тренироваться еще до окончания сезона крикета. Сверчок закончится не раньше апреля или мая.
Если вы сложите эти три абзаца, вы получите Композицию, написанную о прошлом, настоящем и будущем. В любой одной композиции могут быть все эти периоды времени. С другой стороны, вы можете написать Композицию, которая все в прошлом, все в настоящем или все в будущем.
Даже в одном абзаце у вас могут быть предложения о разных временах, прошлом, настоящем или будущем. Но никогда не используйте более одного раза в одном предложении.
ПИСЬМО О БУДУЩЕМ
Помните, что ничего не произошло, и — это не , что они происходят; они будут или могут произойти , будет происходящим или происходящим, и так далее.
Каким будет мир через сто лет.
Пунктов:
- Больше всего — людей, домов, магазинов, автомобилей, заводов, ферм, плотин, электростанций и так далее.
- Различия в моде — одежда, прически, дизайн автомобилей, строительные конструкции — широкие дороги — надземные пешеходные переходы и пешеходные дорожки на уровне первого этажа высоких зданий в городах и т. Д.
- Новые города и предприятия в стране — новые ирригационные схемы, основанные на новых плотинах и каналах — новые гидроэлектрические системы — больше людей в деревне и более близкие фермерские поселения.
- Развитие и продвижение [более бедных] стран [и]… увеличение торговли и путешествий между странами.
- То, что может привести к войне и спорам — вещи, которые могут привести к миру и соглашению — общение и переговоры, встречи и игры — богатые страны и бедные — образование, медицина, религии и верования.
Вот еще несколько тем, о которых вы можете писать:
- Что я планирую на следующий отпуск.
- Что сделает папа, если выиграет в лотерею.
- Что сделает мама на вечеринке.
- Что бы мы сделали, если бы пришла война.
Лейк, W.G. ок. 1965 г. Запланированная композиция, книга 3. Сидней: Aidmasta Productions, стр. 3, 13, 18.
Как разбирать предложения | Синоним
Анализ предложения включает определение функции каждого слова. Раньше в школе регулярно преподавали формальную грамматику английского языка в надежде, что это улучшит правильное использование языка учащимися. Однако исследования показали, что выполнение формальных упражнений по грамматике оказывает минимальное положительное влияние на письменные сочинения учащихся.Разбор предложений вышел из моды. Сегодня преподаватели говорят, что классное время лучше проводить за письмом в контексте. Тем не менее, учащимся полезно уметь определять части речи и понимать их функции в предложениях. Умение разбирать предложение может быть полезным для студентов, изучающих английский как второй язык.
1 Выберите короткое предложение из газеты
Выберите короткое предложение из газеты, журнала или книги. Скопируйте предложение в тетрадь.Между каждой строкой текста оставляйте пустую строку.
2 Прочтите предложение вслух
Прочтите предложение вслух. Визуализируйте значение предложения.
3 Определите основное действие
Определите, какое действие является основным в предложении. Например, в предложении «Молодой человек, укравший деньги, быстро побежал по улице», основное действие — это бег, поэтому слово «побежал» является основным предикатом предложения.
4 Изучите предложение
Изучите предложение, чтобы определить, есть ли слова, которые добавляют дополнительное описание к основному предикату. В этом примере дескрипторы «быстро перейдут по улице». Попробуйте задать себе вопросы «как?» «где?» и почему?» Что касается основного предиката, то в этом примере «run» поможет вам найти дескрипторы.
5 Проведите двойную линию
Проведите двойную линию под всеми словами в полном предикате.В этом примере «быстро побежал по улице». Обратите внимание, что этот предикат сообщает вам действие — «бег», а также место и способ запуска. Карандашом другого цвета нарисуйте линию под словом «run», чтобы определить его как основное сказуемое.
6 Определите исполнителя
Определите исполнителя действия основного предиката. Задайте себе вопрос «кто совершил действие?» В этом примере вы спросите: «Кто бегал?» или «кто сбежал?» Проведите единственную линию под исполнителем действия или предметом.В этом примере основной предмет — «мужчина».
7 Изучите предложение-2
Изучите предложение, чтобы определить, есть ли слова, которые добавляют дополнительное описание к основному предмету. В этом примере дескрипторы — «молодой человек, укравший деньги». Попробуйте задать себе вопросы «что за?» или «какой?» о главном предмете, в этом примере «человек», чтобы помочь вам найти дескрипторы.
8 Нарисуйте еще одну линию
Нарисуйте еще одну линию под всем объектом, используя перо другого цвета.В этом примере тема полностью: «Молодой человек, укравший деньги».
9 Повторите шаги
Повторите шаги с 1 по 8 для дополнительных предложений, чтобы получить больше практики. Имейте в виду, что синтаксический анализ предложений состоит из определения основного и полного подлежащего, а также основного и полного предиката предложения. Кроме того, синтаксический анализ включает идентификацию слов, которые изменяют или описывают подлежащее и сказуемое.
10 Разработайте цветовую систему
Разработайте цветовую систему символов, которая поможет вам различать изменяемые слова при синтаксическом анализе предложений.Используйте разные цвета или отметки, такие как круглые или квадратные скобки, для обозначения прилагательных, таких как «молодой», и таких фраз, как «кто украл деньги».
Модель композиции символов со сверточными нейронными сетями для анализа зависимостей на морфологически богатых языках — arXiv Vanity
Сян Юй Нгок Тханг Ву
Institut für Maschinelle Sprachverarbeitung
Universität Stuttgart
Аннотация
Мы представляем анализатор зависимостей на основе переходов, который использует сверточную нейронную сеть для составления представлений слов из символов.Модель состава символов демонстрирует значительное улучшение по сравнению с моделью поиска слов, особенно для синтаксического анализа агглютинативных языков. Эти улучшения даже лучше, чем использование предварительно обученных встраиваний слов из дополнительных данных. По наборам данных SPMRL наша система превосходит предыдущий лучший жадный анализатор (Ballesteros et al., 2015) в среднем на 3%. 1 1 1 Парсер доступен по адресу http://www.ims.uni-stuttgart.de/institut/mitarbeiter/xiangyu/index.en.html
1 Введение
Как и многие другие задачи НЛП, синтаксический анализ зависимостей также страдает от проблемы вне словарного запаса (OOV), и, вероятно, в большей степени, чем другие, поскольку обучающих данных с синтаксической аннотацией обычно мало. Эта проблема особенно серьезна, когда целью является морфологически богатый язык. Например, в наборах данных общих задач SPMRL (Seddah et al., 2013, 2014) 4 из 9 древовидных банков содержат более 40% типов слов в наборе разработки, которые никогда не встречаются в обучающем наборе.
Один из способов решить проблему OOV — это предварительно обучить вложения слов, например, word2vec (Mikolov et al., 2013) , из большого набора немаркированных данных. Это дает два основных преимущества: (1) больше типов слов, что означает, что словарь расширяется за счет немаркированных данных, так что некоторые из слов OOV теперь имеют заученное представление; (2) больше токенов слов для каждого типа, что означает, что синтаксическое и семантическое сходство слов моделируется лучше, чем с использованием только данных обучения парсера.
Предварительно обученные вложения слов могут облегчить проблему OOV за счет расширения словарного запаса, но он не моделирует морфологическую информацию. Вместо того, чтобы искать вложения слов, многие исследователи предлагают составить представление слова из символов для различных задач, например, тегирование части речи (душ Сантуш и Задрозный, 2014; Планк и др., 2016) , распознавание именованных сущностей (душ Сантуш и Гимарайнш, 2015) , языковое моделирование (Линг и др., 2015) , машинный перевод (Коста-Жусса и Фоноллоса, 2016) .В частности, Ballesteros et al. (2015) используют символьную модель двунаправленной долгосрочной краткосрочной памяти (LSTM) для анализа зависимостей. Kim et al. (2016) представляет модель символов сверточной нейронной сети (CNN) для моделирования языка, но не сравнивает модели персонажей и заявляет, что «остается открытым вопрос о том, какая модель композиции персонажей (например, LSTM или CNN) работает лучше» .
Мы предлагаем применить модель CNN по Kim et al. (2016) в жадном анализаторе зависимостей на основе переходов с нейронными сетями с прямой связью (Chen and Manning, 2014; Weiss et al., 2015) . Эта модель не требует дополнительных немаркированных данных, но работает лучше, чем использование предварительно обученных встраиваний слов. Кроме того, его можно комбинировать с встраиванием слов из справочной таблицы, поскольку они отражают различные аспекты сходства слов.
Экспериментальные результаты показывают, что модель CNN особенно хорошо работает на агглютинативных языках, где частота OOV высока. На других морфологически богатых языках модель CNN также работает не хуже, чем модель поиска слов.
Более того, наша модель CNN превосходит как исходную, так и нашу повторную реализацию двунаправленной модели LSTM, разработанную Ballesteros et al. (2015) с большим отрывом. Он предоставляет эмпирические доказательства вышеупомянутого открытого вопроса, предполагая, что CNN является лучшей моделью композиции персонажей для анализа зависимостей.
4 Заключение
В этой статье мы предлагаем использовать CNN для составления представлений слов из символов для анализа зависимостей.Эксперименты показывают, что модель CNN постоянно улучшает точность синтаксического анализа, особенно для агглютинативных языков. При внешнем сравнении наборов данных SPMRL наша система превосходит предыдущий лучший жадный анализатор.
Мы также предоставляем эмпирические данные и анализ, показывающие, что модель CNN действительно решает проблему OOV и что он лучше подходит для анализа зависимостей, чем LSTM.
Приложение B Предварительная обработка ввода символов
Для ввода CNN мы используем список символов с фиксированной длиной до для пакетной обработки.Мы добавляем некоторые специальные символы помимо обычных алфавитов, цифр и знаков препинания:
Например, если мы ограничим длину ввода до 9, короткое слово ein будет преобразовано в
Анализ важности слов
После завершения Краткого Оксфордского словаря Генри Ватсон Фаулер предложил Oxford University Press создать словарь, в котором не будут очевидны очевидные слова, а вместо этого сосредоточиться на сбивающих с толку и неточных, а также на вызывающих беспокойство идиомах и устаревших правилах. Оксфордский редактор назвал его «утопическим словарем», «который будет очень хорошо продаваться в Утопии».Книга, опубликованная в 1926 году под названием «Словарь современного английского языка», на самом деле была скромным бестселлером и впоследствии выдержала несколько изданий и два пересмотра.
Успех книги был полностью обеспечен ее автором Х.В. Фаулер, бывший учитель английской государственной школы, неудачливый литературный журналист и выдающийся лексикограф. Фаулер был авторитетным и здравомыслящим, чрезвычайно знающим и сдержанно остроумным, грамматическим моралистом, ненависть которого к обману сделала его моралистом на стороне здравого смысла.
Радикал в свое время, Фаулер считал, что заканчивать предложение предлогом не является преступлением, что лучше разделить инфинитив, чем написать неудобное предложение, пытаясь этого избежать, что общие слова должны быть предпочтительнее иностранные и многосложные. Фаулер, как писал Эрнест Гауэрс, автор «Полных простых слов», «был освободителем от оков грамматических педантов, которые так долго сковывали нас».
Словарь современного английского языка проникнут индивидуальностью и особенностями его автора, возможно, даже больше, чем знаменитый Словарь Сэмюэля Джонсона.Фаулер любил рискованные, но забавные обобщения. В своей статье о «Дидактике», например, он отмечает, что «мужчины в такой же степени одержимы дидактическим импульсом, как женщины — материнским инстинктом». Он также учил хорошим манерам. Его запись «Французские слова» начинается так: «Демонстрация превосходных знаний — такая же вульгарность, как и демонстрация превосходного богатства — более того, поскольку знание должно более определенно, чем богатство, приводить к осмотрительности и хорошим манерам».