What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.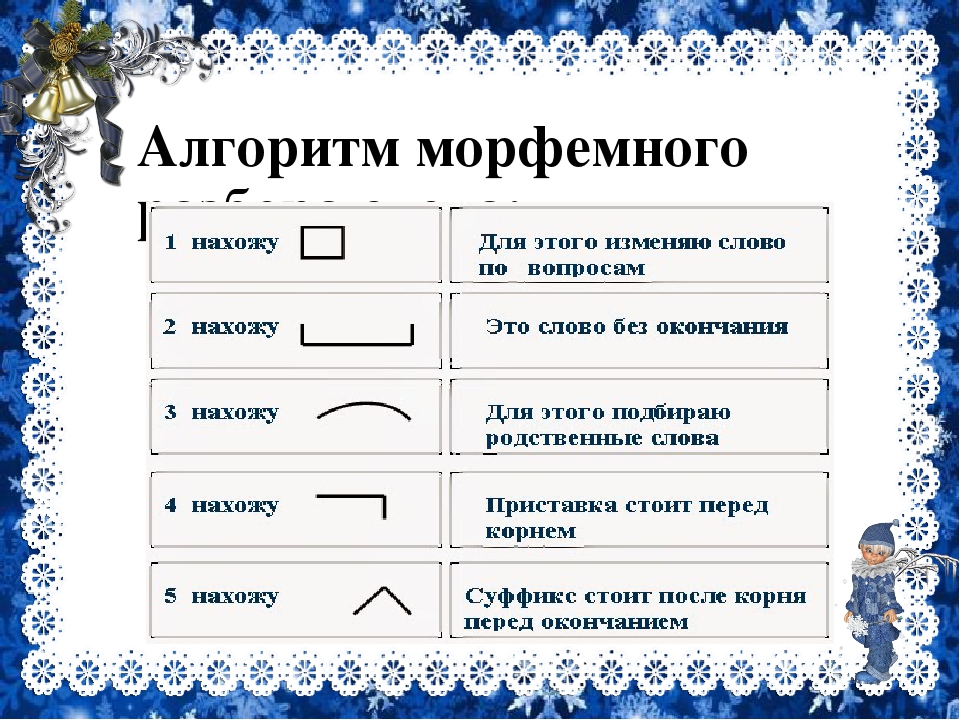
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «удержаться», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
УДЕРЖАТЬСЯ, ержусь, ержишься; сов.
1. Сохранить определённое положение, не упасть. У. на ногах. У. за перила. У. на краю обрыва.
2. Остаться на месте, не отступить. У. на завоёванном рубеже. У. на прежних позициях.
3. от чего. Не дать обнаружиться чему-н., заставить себя не сделать что-н. У. от смеха. У. от упрёков.
4. Сохраниться, сберечься. В народе удержались старые обычаи.
|
Фонетический (звуко-буквенный) разбор
удержа́ться
удержаться — слово из 4 слогов: у-дер-жа-ться. Ударение падает на 3-й слог.
Транскрипция слова: [уд’иржац:а]
у — [у] — гласный, безударный
д — [д’] — согласный, звонкий парный, мягкий (парный)
е — [и] — гласный, безударный
р — [р] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
ж — [ж] — согласный, звонкий парный, твёрдый (непарный, всегда произноится твёрдо), шипящий
а — [а] — гласный, ударный
т — [ц:] — согласный, глухой непарный, твёрдый (непарный, всегда произноится твёрдо)
ь — не обозначает звука
с — не образует звука в данном слове
я — [а] — гласный, безударный
В слове 10 букв и 8 звуков.
При разборе слова используются правила:
- Сочетание букв -тьс- обозначает длинный звук [ц:]
Цветовая схема: удержаться
Ударение в слове проверено администраторами сайта и не может быть изменено.
Разбор слова «удержаться» по составу
удержаться (программа института)
удержаться (школьная программа)
Части слова «удержаться»: у/держ/а/ть/ся
Часть речи: глагол
Состав слова:
у — приставка,
держ — корень,
а, ть, ся — суффиксы,
нет окончания,
удержа + ся — основа слова.
Примечание: ть является формообразующим суффиксом и не входит в основу слова, но во многих школьных программах ть отмечается как окончание. ся является словообразующим суффиксом (постфиксом) и входит в основу слова.
ся является словообразующим суффиксом (постфиксом) и входит в основу слова.
Морфологический разбор слова «дернуться»
Часть речи: Инфинитив
ДЕРНУТЬСЯ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ДЕРНУТЬСЯ»
| Слово | Морфологические признаки |
|---|---|
| ДЕРНУТЬСЯ |
|
Все формы слова ДЕРНУТЬСЯ
ДЕРНУТЬСЯ, ДЕРНУЛСЯ, ДЕРНУЛАСЬ, ДЕРНУЛОСЬ, ДЕРНУЛИСЬ, ДЕРНУСЬ, ДЕРНЕМСЯ, ДЕРНЕШЬСЯ, ДЕРНЕТЕСЬ, ДЕРНЕТСЯ, ДЕРНУТСЯ, ДЕРНУВШИСЬ, ДЕРНЕМТЕСЬ, ДЕРНИСЬ, ДЕРНИТЕСЬ, ДЕРНУВШИЙСЯ, ДЕРНУВШЕГОСЯ, ДЕРНУВШЕМУСЯ, ДЕРНУВШИМСЯ, ДЕРНУВШЕМСЯ, ДЕРНУВШАЯСЯ, ДЕРНУВШЕЙСЯ, ДЕРНУВШУЮСЯ, ДЕРНУВШЕЮСЯ, ДЕРНУВШЕЕСЯ, ДЕРНУВШИЕСЯ, ДЕРНУВШИХСЯ, ДЕРНУВШИМИСЯ
Разбор слова по составу дернуться
| Основа слова | дёрну |
|---|---|
| Корень | дёр |
| Суффикс | ну |
| Глагольное окончание | ть |
| Постфикс | ся |
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ДЕРНУТЬСЯ» в конкретном предложении или тексте, то лучше использовать морфологический разбор текста.
Примеры предложений со словом «дернуться»
1
Если ты попробуешь дернуться, то узнаешь вкус этого лезвия.
2
Повернув к нему лицо, Джессика не смогла удержаться, чтобы не дернуться от смеха, видя, как струи дождя бурным потоком стекают с кончика его носа.
История матери, Аманда Проуз, 2015г.3
Он уже вставил было ключ в замок, когда металлический щелчок заставил его дернуться.
Мы против вас, Фредрик Бакман, 2017г.4
Хотя Лидия и Лука ждали официанта с завтраком, стук в дверь заставил их дернуться.
Американская грязь, Дженин Камминс, 2019г.5
Стоило мне дернуться, вздыбиться, поддать снизу, чтобы войти в нее поглубже, как она карала за это:
Россия в постели, Эдуард ТопольНайти еще примеры предложений со словом ДЕРНУТЬСЯ
Поурочные разработки по русскому языку: 9 класс
Егорова Н. В. Поурочные разработки по русскому языку: 9 класс.
Цель пособия — помочь учителю в организации уроков русского языка в выпускном классе основной школы.
Итоговая аттестация традиционно проводится в форме изложения с творческим заданием (элементами сочинения) по открытым текстам. В связи с этим в пособии значительное внимание уделяется работе с изложениями и выполнению творческих заданий к ним.
Поурочное планирование составлено в соответствии с программой общеобразовательных учреждений по русскому языку авторов М. Т. Баранова, Т. А. Ладыженской, Н. М. Шанского.
Пособие включает подробное описание хода уроков с указанием их цели и методических приемов, рекомендации домашних заданий и разбор наиболее сложных вопросов.
В структуре уроков учтена необходимость систематического повторения разделов языкознания, изученных с 5-го по 8-й класс; даны разные типы заданий: словарные, творческие, объяснительные и другие диктанты, сочинения, все виды лингвистического разбора, вопросы по теории языка, практические работы, тесты, лингвистические задачи различной сложности, работы со словарями и т. д. даются рекомендации по подготовке к изложениям и сочинениям, ответы к заданиям, ключи к тестам.
Примеры по стилистике и другим разделам языкознания выбраны с учетом их актуальности.
Кроме того, пособие включает дополнительные материалы для уроков; учитывает разную степень подготовки учащихся, их возрастные особенности (материалы по занимательной лингвистике, истории языка, лингвистические игры).
В приложениях приведены варианты индивидуальных заданий, контрольных диктантов, тестов, тексты тренировочных изложений, варианты выполнения творческих заданий к экзаменационным изложениям, материалы для предэкзаменационных консультаций, в том числе критерии оценки качества знаний.
При работе с пособием учитель может воспользоваться как полным планом проведения уроков, так и отдельными материалами и заданиями. Пособие пригодится и учителям, работающим в старших классах, для подготовки учеников к школьным выпускным экзаменам. . Определять тип и стиль текста, создавать тексты разных стилей и типов речи. Подготовить и сделать доклад на историко-литературную тему по одному источнику. Составлять тезисы или конспект небольшой литературно-критической статьи (или фрагмента большой статьи). Писать сочинения публицистического характера. Писать заявление, автобиографию. Совершенствовать содержание и языковое оформление сочинения, находить и исправлять различные языковые ошибки в своем тексте. Свободно и грамотно говорить на заданные темы. Соблюдать при общении с собеседниками соответствующий речевой этикет.
. Определять тип и стиль текста, создавать тексты разных стилей и типов речи. Подготовить и сделать доклад на историко-литературную тему по одному источнику. Составлять тезисы или конспект небольшой литературно-критической статьи (или фрагмента большой статьи). Писать сочинения публицистического характера. Писать заявление, автобиографию. Совершенствовать содержание и языковое оформление сочинения, находить и исправлять различные языковые ошибки в своем тексте. Свободно и грамотно говорить на заданные темы. Соблюдать при общении с собеседниками соответствующий речевой этикет.
Авторы программы В. В. Бабайцева, А. П. Еремеева,
А. Ю. Купалова, Г. К. Лидман-Орлова, С. Н. Молодцова,
Е. И. Никитина, Т. М. Пахнова, С. Н. Пименова, Ю. С. Пичугов,
Л. Ф. Талалаева, Л. Д. Чеснокова
NLU удерживаются частями речи и фиксируются смыслом | Джона Болла | Pat Inc
AI нуждается в понимании естественного языка (NLU)Сегодня мы завершаем обзор проблем, вызванных текущими научными моделями, чтобы мы могли перейти к решению в следующий раз. Сопутствующее видео находится на YouTube здесь: https://youtu.be/ZwdAr8kvkj8.
Итак, мы поставили под сомнение гипотезу о том, что фундаментальная цель лингвистического анализа — понять его грамматику и структуру. Хотя это могло быть отличной идеей для объединения с бихевиористами 1930-х, 40-х и 50-х годов, исключение смысла было препятствием на пути к NLU.
Синтаксический анализ и NLU называется AI-Complete — то, что невозможно сделать, пока все проблемы AI не будут решены вместе, потому что реальный язык очень неоднозначен и требует больших вычислений. Мы видели, как профессор из Стэнфорда Дэниел Джурафски сообщил, что синтаксический анализ является NP-полной проблемой [i] в применении к полноценным человеческим языкам. Это означает, что синтаксический анализ для NLU невозможен.
Сегодня мы рассмотрим другую важную проблему синтаксического анализа: связанные строительные блоки, которые создают опасный и неразрешимый комбинаторный взрыв. Предлагается решение: добавление словаря без неоднозначности определений, вызванной частями речи. Это позволяет избежать потери данных, вызванной правилами.
Предлагается решение: добавление словаря без неоднозначности определений, вызванной частями речи. Это позволяет избежать потери данных, вызванной правилами.
Считает ли мейнстрим — и под мейнстримом я имею в виду формальные и компьютерные лингвисты — все еще верят, что языки построены на грамматических элементах, таких как части речи? Да, это так. Как мы видели в прошлый раз, это был один из элементов, который Блумфилд привнес в лингвистику для непосредственного анализа составляющих в 1930-х годах на основе его исследования.
Вот изображение из выступления профессора Криса Мэннинга [ii] в Стэнфорде в 2017 году. Крис — австралиец, лингвист, а также гуру машинного обучения. Обратите внимание, что на его диаграмме есть фиксированная последовательность обработки — проработать слова, затем синтаксис (разобрать!), Затем значение, затем контекст.
Проблема в том, что значение слова или фразы часто определяется контекстом. И некоторые языки не так дружелюбны, как английский со своей системой. Вот 3 представления фраз на разных языках, которые, как мне кажется, подтверждают идею о том, что три шага (слово-фраза-значение) на самом деле являются одним шагом.Мой опыт показывает, что последний шаг также должен быть включен для NLU, поскольку это позволяет использовать одну систему для многих языков (мы тестировали 9 до сих пор в лаборатории), и он согласуется с алгоритмом связывания RRG от синтаксиса к семантике и обратно [ iii].
Разбивка предложений на английском языке по RRG, синтаксис без алгоритма связыванияЗдесь, на английском языке, основной предикат, speared, имеет референтные фразы (NP на диаграмме), связывающие роли актера и подчиненного и добавляющие вокруг него предикат местоположения (где).
Разбивка австралийского языка дирбал с помощью RRG Обратите внимание на то, что на этом австралийском языке аборигенов элементы референтных фраз (NP) распределены в предложении, но основной предикат по-прежнему связывает своего актера и субъекта с предикатом местоположения, обертывающим его на периферии.
И в этом языке обозначения головы из Грузии синтаксис предложения: «мужчина дал книгу женщине» является частью сказуемого (отдельное слово) и, следовательно, имеет место в уровень морфологии. Итак, здесь морфология выполняет роль синтаксиса фразы.
Как я покажу в другой раз, теория Патом всегда предполагает, что языковой анализ будет объединен для автоматизации обучения.
Дело в том, что по мере того, как анализируются все более разнообразные языки, решением проблемы NLU становится интеграция синтаксиса, семантики и дискурс-прагматики.Решение становится RRG.
Я называю анализ человеческого языка сопоставлением с образцом. Шаблон не может быть разложен на недостающую информацию, блокирующую разрешение смысла.
Я знаю, что есть много компьютерных лингвистов, и все будут сомневаться в том, как их модель подрывается реальным NLU. Но, как сказал Галилей, выступая против скептиков его наблюдений за спутниками Юпитера, «в вопросах науки авторитет тысячи не стоит скромных рассуждений отдельного человека» [iv].
Лексические категории (части речи или pos) являются частью древней модели языковой композиции. Pos — это основа наших словарей. К сожалению, одно только pos приводит к ненужному увеличению количества повторяющихся определений, поскольку значения воспроизводятся во всех частях речи, что приводит к множеству других комбинаторных проблем, особенно если рассматривать фразы.
Текущая модель имеет изъяны для NLU, но мы исправляем это, добавляя значения.
В то время как словари с удовольствием используют заглавные слова для введения флективных слов (например, кот / кошки как существительные, счастливый / счастливый / самый счастливый как прилагательные и бег / бег / бег / бег / бег как глаголы), они кропотливо копируют определения между этими частями речи.
В таблице ниже все словоформы отражают одно определение. Вариация формы отражает другие смысловые элементы (лицо, время и т. Д.). В некоторых распространенных словах, таких как «быть» и «идти», вариация формы является экстремальной, при этом предоставленная форма заменяет стандартную вариацию (например, be-is-was / go-go). Эта концепция известна как дополнение [v], но принцип работает без изменений, поскольку форма сохраняет одно определение плюс добавляет семантическое содержание.
Д.). В некоторых распространенных словах, таких как «быть» и «идти», вариация формы является экстремальной, при этом предоставленная форма заменяет стандартную вариацию (например, be-is-was / go-go). Эта концепция известна как дополнение [v], но принцип работает без изменений, поскольку форма сохраняет одно определение плюс добавляет семантическое содержание.
Это кажется разумным подходом к построению словаря.Сохраняя единое определение для нескольких форм одного и того же слова, определение записывается только один раз — или это так?
В отличие от одного заглавного слова для одного определения выше (представляющего одно определение для нескольких форм), значение «бега» (ниже) копируется между формой прилагательного, формой существительного и формой глагола в словаре.
Таблица 2. Бегущая словоформа, несколько определенийДля ранних систем, основанных на правилах, эта неоднозначность определений привела к ужасному взрыву правил и разобранных древовидных структур в дополнение к заботе о поддержке словаря.
Существует третий случай, когда слова с разными «манерами» могут оперировать одним основным определением. Такой подход позволяет таким заглавным словам, как «дать», «взять», «забрать» + «вверх», «переносить» и «захватить», чтобы использовать одно определение [vi]. Мы рассмотрим это позже.
Правила синтаксического анализа также приводят к потере данных, поскольку такой символ, как NP (именная фраза), теряет значение лежащего в основе слова во время применения правила.
Синтаксическая модель берет предложение конечных символов, таких как «путешествие» и «кошка», и превращает их в нетерминальный символ, NP.Модель, основанная на значении, берет первое и делает его «p: путешествие» (предикат, означающий путешествие), а второй — «r: cat» (референт, означающий кошку), плюс некоторые атрибуты. Когда предложения расширяются с помощью «to Princeton», синтаксическая система добавляет символ PP (так что теперь у нас есть NP PP), в то время как система, основанная на значениях, добавляет «цель» к «p: путешествие» и ничего к «r: кошка », поскольку это не имеет смысла.
В системе, основанной на значении, есть разница между «путешествием» и «кошкой»: один является предикатом, а другой — референтом.Это смысловые (семантические) термины. Путешествие — это занятие, а кошка — это вещь. И да, я знаю, что есть двусмысленные термины, которые делают это введение неадекватным. Следующим шагом в NLU является проверка предиката с его аргументами для исключения недопустимых случаев. Эта проверка сначала выполняется со словарем, а затем с контекстом.
Чтобы упростить модель, мы можем предположить, что языки построены на значении слов, а не только на грамматических категориях. Помимо знания значения слова, то, как оно представлено, не менее важно для системы, которая его использует.Наука о мозге также говорит нам, что локализованы различные типы сенсорных представлений, такие как такие качества, как цвет, визуальное движение, распознавание лиц и элементы речи. Это важно для автоматического изучения языка. Научный метод должен уточнить модель, чтобы отразить, как языки мира трактуют определение.
Контекст — это единственный способ подтвердить определенные типы двусмысленности, и это делается с помощью вопросов, когда говорящий неясен.
В конце концов, значение слова каким-то образом связано с реальным миром, а не только с произвольным знаком, который с ним связан.Значение также не зависит от языка. Ловля мяча на одном языке по-прежнему является действием, при котором мяч пойман, независимо от слов или фраз, используемых для его описания.
В следующий раз мы рассмотрим, как дублирование определений в частях речи разрешается с помощью терминов, основанных на значении, и копирования описанного выше словарного метода. Это создает набор бессмысленных словоформ, связанных с независимым от языка определением на каком-то уровне.
Мы начали эту серию с обзора того, где мы находимся, и некоторых демонстраций, демонстрирующих NLU в действии, преодолевая ограничения текущего научного подхода. В этой серии предстоит пройти долгий путь, поскольку мы переключаем фокус с того, что не сработало, на то, что работает.
В этой серии предстоит пройти долгий путь, поскольку мы переключаем фокус с того, что не сработало, на то, что работает.
В одном предложении NLU препятствует желание анализировать предложения независимо от контекста и значения на основе частей речи.
Мы видели, как это было идентифицировано как NP-полная проблема в 1996 году. Решение состоит в том, чтобы вернуть части языка в более простую модель, которая может быть изучена мозгом. По мере продвижения вперед мы увидим, как теория патома позволяет изучать язык и как это возможно, используя обширные наблюдения зрелой лингвистической модели, ролевой и справочной грамматики, из широкого спектра различных языков.
(далее — изменение словаря для устранения ключевого фактора комбинаторного взрыва синтаксического анализа)
[i] Daniel Jurafsky, Вероятностная модель лексического и синтаксического доступа и устранения неоднозначности , Cognitive Science 20, 1996, P 142.
[ii] Школа инженерии Стэнфордского университета, профессор Кристофер Мэннинг, YouTube, https://youtu.be/OQQ-W_63UgQ, 3 апреля 2017 г.
[iii] Роберт Д. Ван Валин младший, Изучение Интерфейс синтаксиса и семантики, Cambridge University Press, 2005, P 128–158.
[iv] Приписывается Галилео Галилею, Диалог о двух главных системах мира , 1632.
[v] Эмма Л. Пейви, Структура языка: введение в грамматический анализ , Cambridge University Press , 2010, P 29.
[vi] Джон С. Болл, Использование NLU в контексте для ответов на вопросы: улучшение задач Facebook bAbI, 21 сентября 2017 г., https://arxiv.org/abs/1709.04558 , С 11–12.
Определение удержания в словаре.com
иметь или держать (предмет) в руках, руках и т. д. или в них; застежка
(tr) для поддержки или удержания головы утопающего над водой
для поддержания или поддержания в определенном состоянии или состоянии для сдерживания эмоций; держать твердо
(tr), чтобы отложить или зарезервировать они будут держать наши билеты до завтра
(когда intr, обычно используется в командах), чтобы удерживать или удерживать от движения, действия, отъезда, удерживать этого человека, пока не приедет полиция
(внутреннее), чтобы оставаться быстрым или неразрывным, что кабель не продержится намного дольше
(внутреннее) (из-за погоды), чтобы оставаться сухим и ярким, как долго продержится погода?
(tr), чтобы привлечь внимание к своему пению, удерживал аудиторию
(tr), чтобы участвовать или проводить собрание
(tr), чтобы иметь право собственности, владения и т. Д., Он имеет юридическое образование в Лондоне; у кого пик пик?
Д., Он имеет юридическое образование в Лондоне; у кого пик пик?
(tr), чтобы использовать или нести ответственность за должность директора
(tr), чтобы иметь место или емкость для картонной коробки, будет содержать только восемь книг
(tr), чтобы иметь возможность контролировать внешние эффекты употребление пива, спиртных напитков и др. может хорошо удерживать напиток
(часто следуют за или мимо), чтобы остаться или побудить его оставаться верным своему обещанию; он придерживался своих взглядов, несмотря на возражения
(tr; принимает пункт как объект), чтобы утверждатьон считает, что теория неверна
(intr), чтобы оставаться актуальной, действительной или истинной, старые философии не верны в настоящее время
(tr) держать в умеподдерживать привязанность к кому-то
(tr) рассматривать или рассматривать в определенной манере Я очень дорожу им
(tr) для охраны или защиты успешно удерживать форт от нападения
(intr) для продолжать идти своим путем
(иногда следуют дальше) музыка, чтобы поддерживать звук (ноты) в течение указанного времени, чтобы удерживать полубрев до его полного значения
(tr) вычисление для сохранения (данных) на устройстве хранения после копирования на другое запоминающее устройство или в другое место на том же устройстве Очистить сравнение (деф.49)(tr) иметь при себе незаконные наркотики
хранить или сохранять в силе, чтобы применять или иметь отношение к тем же правилам, которые действуют для всех
держит большой палец Южноафриканец держит большой палец одной руки другой, в надежда на удачу
держи!- стоп! ждать!
- оставайся на прежнем месте! как при фотографировании
держать голову высоко, чтобы вести себя гордым и уверенным образом
держаться самостоятельно, чтобы сохранить свое положение или положение, особенно несмотря на сопротивление или трудности
молчать или молчать, чтобы молчать
доказывать достоверность, логичность или непротиворечивость
его нельзя удерживать, он настолько энергичен или решителен, что его невозможно удержать
(PDF) Разбор фраз арабского глагола с использованием предгрупповых грамматик
International Journal on Natural Language Computing (IJNLC) Том. 7, № 3, июнь 2018 г.
7, № 3, июнь 2018 г.
27
ахмад », система отклоняет это предложение, поскольку оно не принадлежит к языку, сгенерированному предгрупповой грамматикой
, определенной в лексиконе. Основным ограничением этой системы является отсутствие лексики арабского языка
, чтобы включить больше глагольных времен, таких как будущее время. Кроме того, отсутствие визуального инструмента для
представляет график сокращения ссылок после процесса синтаксического анализа.
9.
C
ВКЛЮЧЕНИЯ
Основным вкладом этой работы является разработка первой фазы синтаксического анализатора предгрупповой грамматики для арабского языка
на основе формального анализа арабских предложений, введенного Ламбеком.Эта работа
создает арабский мини-лексикон, содержащий глаголы в настоящем и прошедшем времени, и применяет алгоритм
, основанный на линейном подходе, для проверки правильности фраз арабских глаголов. В будущем
мы стремимся завершить арабский синтаксический анализатор, чтобы анализировать больше арабских грамматических фраз
, таких как дважды переходные глаголы, двойные сопряжения и полный анализ движения клитики
в арабском языке.Кроме того, мы добавим визуальный инструмент, представляющий график сокращения ссылок после процесса синтаксического анализа
.
R
ЭФЕРЕНЦИИ
[1] Иоахим, Ламбек, (2006) «Предварительная группа и обработка естественного языка», Springer Science, Vol. 28, No.
2, pp41-48.
[2] Садрзаде, Мехрнуш, (2007) «Анализ предгрупп персидских предложений», В Клаудиа Касадио и
Иоахим Ламбек, редакторы, Вычислительные алгебраические подходы к естественному языку, Polimetrica,
Милан, Италия, стр.
[3] Даниэле, Барджелли и Иоахим, Ламбек, (2001) «Алгебраический подход к структуре арабских предложений»,
Лингвистический анализ, Том. 31, стр. 301–315.
[4] Мороз, Катажина, (2010) «Алгоритм синтаксического анализа в стиле Саватеева для предгрупповых грамматик»,
InProceedingsof Formal Grammar14, Lecture Notes in Computer Science, Vol. 5591.
5591.
[5] Ричард, Эрле, (2004) «Алгоритм синтаксического анализа для предгрупповых грамматик», In Proceedings of Category
Grammar, pp59-75.
[6] Денис, Беше, (2007) «Анализ предгрупповых грамматик и исчисления ламбека с использованием частичной композиции»,
Studia Logica, Vol. 87, pp199-224.
[7] Юрий, Саватеев, (2010) «Однонаправленные грамматики Ламбека за полиномиальное время», Теория вычислений
систем, Вып. 46, pp662-672.
[8] Энн, Преллер, (2007) «Линейная обработка с предварительными группами», Studia Logica. Vol. 87, стр. 171–197.
[9] Иоахим, Ламбек, (2001) «Грамматики типов как предварительные группы», Grammars, Vol.4. С. 21–39.
[10] Иоахим, Ламбек, (2005) «Что такое прегруппы?», В Клаудиа, Касадио, Роберт Сили и Филип Скотт, редакторы
, Язык и грамматика: Исследования по математической лингвистике и естественному языку, публикации CSLI
Стэнфорд, стр 129-136.
[11] Ареф, Абу Авад и Эссам Хананде, (2016) «Разработка анализатора перехода для арабского языка»,
International Journal of Advanced Computer Science and Applications, Vol.7. С. 173-175.
[12] Энн Преллер и Виолэн Принс, (2008) «Грамматики предгрупп с линейным синтаксическим анализом фразы французского глагола
», Клаудиа Касадио и Иоахим Ламбек, редакторы, Вычислительные алгебраические подходы к естественному языку
, Polimetrica, Монца , Италия, стр. 53–84.
Обработка естественного языка — скачать видео на ppt онлайн
Презентация на тему: «Обработка естественного языка» — стенограмма:
ins [data-ad-slot = «4502451947»] {display: none! important;}} @media (max-width: 1000 пикселей) {# place_14> ins: not ([data-ad-slot = «4502451947»]) {display: none! important;}} @media (max-width: 1000 пикселей) {# place_14 {width: 250px;}} @media (max-width: 500 пикселей) {# place_14 {width: 120px;}} ]]> 1 Обработка естественного языка
Машинный перевод Структуры аргументов предикатов Синтаксический синтаксический анализ Лексическая семантика Вероятностный синтаксический анализ Неоднозначности в интерпретации предложений CSE391 — 2005 NLP
2 Одно из первых приложений для компьютеров
Машинный перевод Одно из первых приложений для компьютеров Двуязычный словарь> Перевод слова в слово Хороший перевод требует понимания! Война и мир, звук и ярость? Что мы можем сделать? Подъязыки.
 технические области, статический словарь Метео в Канаде, Руководства по эксплуатации тракторов Caterpillar, Ботанические описания, Военные сообщения CSE391 — 2005 NLP
технические области, статический словарь Метео в Канаде, Руководства по эксплуатации тракторов Caterpillar, Ботанические описания, Военные сообщения CSE391 — 2005 NLP3 Пример перевода CSE391 — 2005 NLP
4 Проблемы перевода: с корейского на английский
— Порядок слов — Пропущенные аргументы — Лексическая двусмысленность — Структура и морфология CSE391 — 2005 NLP
5 Общий поток Структура предиката-аргумента Составляющие Отношения
Основные составляющие предложения и их связь друг с другом Составляющие Джон, Мэри, собака, удовольствие, магазин.Отношения Любит, кормит, иди, принеси, принеси CSE391 — 2005 НЛП
6 Абстрагирование от поверхностной структуры
CSE391 — 2005 НЛП
7 Перенос лексиконов CSE391 — 2005 NLP
8 Машинный перевод Лексический выбор — устранение неоднозначности смысла
Ирак проиграл битву.Ilakuka centwey ciessta. [Ирак] [битва] [проиграна]. Джон потерял свой компьютер. John-i computer-lul ilepelyessta. [Джон] [компьютер] [неуместно]. CSE391 — 2005 НЛП
9 Обработка естественного языка
Синтаксические грамматики, синтаксические анализаторы, синтаксические деревья, структуры зависимостей Семантика Кадры подкатегории, семантические классы, онтологии, формальная семантика Прагматика Местоимения, справочное разрешение, модели дискурса CSE391 — 2005 NLP
10 Синтаксические категории Существительные, местоимения, существительные собственные
Глаголы, непереходные глаголы, переходные глаголы, непереходные глаголы (фреймы подкатегории) Модификаторы, прилагательные, наречия Предлоги Союзы CSE391 — 2005 NLP
11 Синтаксический анализ Кот сел на циновку. Det Существительное Глагол Prep Det Существительное
Det Существительное Глагол Prep Det Существительное
Время летит, как стрела. Существительное Глагол Prep Det Существительное Фрукт летит, как банан. Существительное Существительное Глагол Det Существительное CSE391 — 2005 NLP
12 Parses Кот сел на циновку S NP VP Det PP N V кот сел NP Prep N
CSE391 — 2005 NLP
13 Разборы Время летит, как стрела.S NP VP N раз V PP летает Prep NP
Det N arrow an CSE391 — 2005 NLP
14 Разборы Время летит, как стрела. S NP VP N раз V NP N как мухи N
Также [вы] время летит, как стрелы, с глаголом «время». N раз V NP N как мухи N Det arrow an CSE391 — 2005 NLP
15 Рекурсивные переходные сети для CFG
NP VP S S1 S2 S3 pp det noun NP S4 S5 adj S6 существительное местоимение s: — np, vp.нп: — местоимение; существительное; det, прил, существительное; нп, стр. CSE391 — 2005 НЛП
16 Лексикон существительное (кошка). существительное (мат). det (в). det (а). глагол (сат). подготовка (на).
сущ. (Летает). существительное (время). существительное (стрелка). det (ан). глагол (летает). глагол (время). приготовить (вроде). чего-нибудь не хватает? существительное ([fly | T], T), глагол ([fly | T], T). глагол ([сидеть | Т], Т). CSE391 — 2005 НЛП
17 Лексикон с корнями существительное (летает, летает).существительное (кошка, кошка). существительное (время, время).
существительное (стрелка, стрелка). дет (ан, ан). глагол (летает, летает). глагол (время, время). приготовить (нравится, нравится). существительное (кошка, кошка). существительное (мат, мат). det (the, the) det (а, а). глагол (сидеть, сидеть). приготовить (дальше, дальше). чего-нибудь не хватает? существительное ([fly | T], T), глагол ([fly | T], T). глагол ([сидеть | Т], Т). CSE391 — 2005 НЛП
глагол (время, время). приготовить (нравится, нравится). существительное (кошка, кошка). существительное (мат, мат). det (the, the) det (а, а). глагол (сидеть, сидеть). приготовить (дальше, дальше). чего-нибудь не хватает? существительное ([fly | T], T), глагол ([fly | T], T). глагол ([сидеть | Т], Т). CSE391 — 2005 НЛП
18 Разборы Старая банка может удержать воду. S NP VP Det NP aux the V can
Делайте лексику на борту! det NP aux the V can adj N hold can old det N the water CSE391 — 2005 NLP
19 Структурная неоднозначность
Эта фабрика может консервировать тунца.Эта фабрика занимается консервированием тунца и лосося. Ученики cse91 сдали экзамен в 212. Студенты cse91 сдали экзамен в 212? CSE391 — 2005 НЛП
20 Lexicon Старая банка может удержать воду.
Существительное (can, can) Существительное (can, can) Существительное (вода, вода) Существительное (удерживать, удерживать) Существительное (удерживать, удерживать) Det (the, the) Глагол (удерживать, удерживать) Глагол (держать, удерживать) Aux (может, может) Adj (старый, старый) чего-нибудь не хватает? существительное ([fly | T], T), глагол ([fly | T], T).глагол ([сидеть | Т], Т). CSE391 — 2005 НЛП
21 год Простая контекстно-свободная грамматика в нотации BNF
S → NP VP NP → Местоимение | Существительное | Det Adj Существительное | NP PP PP → Prep NP V → Глагол | Aux Verb VP → V | V НП | В НП НП | В НП ПП | Вице-президент ПП CSE391 — 2005 НЛП
22 Выполняется нисходящий синтаксический анализ [Старый, can, can, hold, the, water]
S → NP VP NP → NP? NP → Местоимение? Местоимение? fail NP → Существительное? Существительное? fail NP → Det Adj Noun? Дет? ADJ? старое существительное? Может добиться успеха. ВП? CSE391 — 2005 НЛП
ВП? CSE391 — 2005 НЛП
23 Выполняется синтаксический анализ сверху вниз [можно, подержать, вода]
VP → VP? V → Глагол? Глагол? fail V → Aux Verb? Aux? может глагол? удерживать удачно неудачно [the, water] CSE391 — 2005 NLP
24 Выполняется синтаксический анализ сверху вниз [can, hold, the, water]
VP → VP NP V → Verb? Глагол? fail V → Aux Verb? Aux? может глагол? удерживайте NP → Местоимение? Местоимение? fail NP → Существительное? Существительное? fail NP → Det Adj Noun? Дет? ADJ? провал CSE391 — 2005 NLP
25 Лексикон Глагол (удерживать, удерживать) Существительное (can, can) Глагол (удерживать, удерживать) Существительное (can, can)
Aux (can, can) Adj (старое, старое) Adj (,) Существительное (can, can) Существительное (банки, банка) Существительное (вода, вода) Существительное (удерживать, удерживать) Существительное (удерживать, удерживать) Det (the, the) что-то отсутствует? существительное ([fly | T], T), глагол ([fly | T], T).глагол ([сидеть | Т], Т). CSE391 — 2005 НЛП
26 Выполняется синтаксический анализ сверху вниз [can, hold, the, water]
VP → V NP? V → Глагол? Глагол? fail V → Aux Verb? Aux? может глагол? удерживайте NP → Местоимение? Местоимение? fail NP → Существительное? Существительное? fail NP → Det Adj Noun? Дет? ADJ? Существительное? вода SUCCEED CSE391 — 2005 NLP
27 Лексикон Глагол (удерживать, удерживать) Существительное (can, can) Глагол (удерживать, удерживать) Существительное (can, can)
Aux (can, can) Adj (стар., Стар.) Adj (,) Существительное (банки, банка) Существительное (вода, вода) Существительное (удерживать, удерживать) Существительное (удерживать, удерживать) Det (the, the) Существительное (старое, старое) чего-то не хватает? существительное ([fly | T], T), глагол ([fly | T], T). глагол ([сидеть | Т], Т). CSE391 — 2005 НЛП
глагол ([сидеть | Т], Т). CSE391 — 2005 НЛП
28 год Подход «сверху вниз» Начните с цели предложения
S → NP VP S → Wh-слово Aux NP VP Попытаемся найти NP 4 разными способами, прежде чем пытаться разобрать, где глагол стоит первым. О чем это вам напоминает? поиск Что было бы лучше? CSE391 — 2005 НЛП
29 Подход снизу вверх Начните со слов в предложении.
Каким структурам они соответствуют? После того, как структура построена, сохраняется в ДИАГРАММЕ. CSE391 — 2005 НЛП
30 Выполняется анализ снизу вверх
det adj существительное aux verb det noun. Старая банка может удерживать воду. det существительное aux / глагол существительное / глагол существительное det существительное. CSE391 — 2005 НЛП
31 год Выполняется анализ снизу вверх
det adj существительное aux verb det noun.Старая банка может удерживать воду. det существительное aux / глагол существительное / глагол существительное det существительное. CSE391 — 2005 НЛП
32 Выполняется анализ снизу вверх
det adj существительное aux verb det noun. Старая банка может удерживать воду. det существительное aux / глагол существительное / глагол существительное det существительное. CSE391 — 2005 НЛП
33 Сверху вниз vs.Снизу вверх Помогает с неоднозначностью POS — учитывайте только релевантные POS Повторно перестраивает одну и ту же структуру Тратит много времени на невозможный синтаксический анализ Необходимо учитывать каждую POS Строит каждую структуру один раз Тратит много времени на бесполезные структуры Что было бы лучше? CSE391 — 2005 НЛП
34 Гибридный подход Сверху вниз с диаграммой
Используйте прогноз и эвристику для выбора наиболее вероятного типа предложения. Используйте вероятности для тегов pos, вложений pp и т. Д.CSE391 — 2005 НЛП
Используйте вероятности для тегов pos, вложений pp и т. Д.CSE391 — 2005 НЛП
35 год Особенности C для случая, субъективное / объективное
Она посетила ее. P для личного соглашения, (1-й, 2-й, 3-й) он мне нравится, он нравится вам, он нравится ему, N для согласования номера, тема / глагол Он ему нравится, он нравится им. G для гендерного согласия, предмет / глагол английский, возвратные местоимения. Он умылся. Романские языки, det / существительное T для времени, вспомогательные, сентенциальные дополнения и т. Д.* будет закончено плохо CSE391 — 2005 NLP
36 Примеры словарных статей с использованием признаков: регистр, число, пол, лицо
местоимений (subj, sing, fem, third, she, she). местоимение (obj, петь, fem, третий, ее, ее). местоимение (obj, Num, Gender, second, you, you). местоимение (subj, петь, Gender, first, I, I). существительное (падеж, множественное число, род, третий, летает, летает). CSE391 — 2005 НЛП
37 Language to Logic Как мы туда попали?
Джон пошел в книжный магазин. Джон store1, иди (John, store1) Джон купил книгу. купить (Джон, книга1) Джон дал книгу Мэри. дай (Джон, книга1, Мэри) Мэри положила книгу на стол. положить (Мэри, книга1, таблица1) CSE391 — 2005 НЛП
38 Лексическая семантика То же событие — разные предложения
Джон разбил окно молотком. Джон разбил окно трещиной. Молоток разбил окно. Окно разбилось. CSE391 — 2005 НЛП
39 То же событие — разные синтаксические фреймы
Джон разбил окно молотком.SUBJ VERB OBJ MODIFIER Джон разбил окно трещиной. Молоток разбил окно. SUBJ VERB OBJ Окно разбилось. SUBJ ГЛАГОЛ CSE391 — 2005 NLP
40 Семантика — аргументы предикатов
break (АГЕНТ, ИНСТРУМЕНТ, ПАЦИЕНТ) АГЕНТ ПАЦИЕНТ ИНСТРУМЕНТ Джон разбил окно молотком. ИНСТРУМЕНТ ПАЦИЕНТА. Молотком разбилось окно. ПАЦИЕНТ Окно разбито. Fillmore 68 — Кейс для кейса CSE391 — 2005 NLP
41 год Джон разбил окно молотком.МОДИФИКАТОР SUBJ OBJ
АГЕНТ ПАЦИЕНТ ИНСТРУМЕНТ Джон разбил окно молотком. SUBJ OBJ MODIFIER INSTRUMENT ПАЦИЕНТ. Молотком разбилось окно. СУБЪЕКТ ОБЪЕКТ ПАЦИЕНТ Окно разбито. SUBJ CSE391 — 2005 НЛП
42 Удовлетворение ограничений
break (Агент: анимация, Инструмент: инструмент, Пациент: физический объект) Агент <=> subj Инструмент <=> subj, with-pp Пациент <=> obj, subj ACL81, ACL85, ACL86, MT90, CUP90, AIJ93 CSE391 — 2005 NLP
43 год Взаимодействие синтаксиса и семантики
Синтаксические анализаторы будут производить синтаксически допустимые синтаксические анализы для семантически аномальных предложений Лексическая семантика может использоваться для их исключения CSE391 — 2005 NLP
44 год Удовлетворение ограничений
give (Agent: animate, Patient: Physical-object Recipient: animate) Agent <=> subj Patient <=> object Recipient <=> косвенный объект, to-pp CSE391 — 2005 NLP
45 Подкатегория Частоты
Женщины держали собак на пляже.Где держать? Держитесь на пляже 95% NP XP 81% Какие собаки? Собаки на пляже 5% НП 19% Женщины обсуждали собак на пляже. Где обсудить? Обсудить на пляже 10% NP PP 24% Какие собаки? Собаки на пляже 90% NP 76% CSE391 — 2005 Ford, Bresnan, Kaplan 82, Jurafsky 98, Roland, Jurafsky 99 NLP
46 Время чтения NP-bias (время медленнее выделяется жирным шрифтом)
Официант подтвердил, что заказ был сделан вчера.Подсудимый согласился, что приговор будет вынесен в ближайшее время. CSE391 — 2005 НЛП
47 Время чтения S-образное смещение (не медленнее, чем жирное слово)
Официант настаивал, что заказ был сделан вчера. Подсудимый выразил надежду, что приговор будет вынесен в ближайшее время. Трюзуэлл, Таненхаус и Келло, 93 Трюзуэлл и Ким 98 CSE391 — 2005 НЛП
48 Вероятностные контекстно-свободные грамматики
Добавление вероятностей Лексикация вероятностей CSE391 — 2005 NLP
49 Простая контекстная свободная грамматика в BNF
S → NP VP NP → Местоимение | Существительное | Det Adj Существительное | NP PP PP → Prep NP V → Глагол | Aux Verb VP → V | V НП | В НП НП | В НП ПП | Вице-президент ПП CSE391 — 2005 НЛП
50 Простой вероятностный CFG
S → NP VP NP → Местоимение [0.10] | Существительное [0.20] | Det Adj Существительное [0.50] | NP PP [0.20] PP → Prep NP [1.00] V → Глагол [0.20] | Aux Verb [0.20] VP → V [0.10] | В НП [0,40] | В НП НП [0.10] | В НП ПП [0.20] | Вице-президент PP [0.20] CSE391 — 2005 NLP
51 Простой вероятностный лексикализованный CFG
S → NP VP NP → Местоимение [0.10] | Существительное [0.20] | Det Adj Существительное [0.50] | NP PP [0.20] PP → Prep NP [1.00] V → Глагол [0.20] | Aux Verb [0.20] VP → V [0.87] {спать, плакать, смеяться} | В НП [0,03] | В НП НП [0,00] | В НП ПП [0,00] | Вице-президент PP [0,10] CSE391 — 2005 NLP
52 Простой вероятностный лексикализованный CFG
VP → V [0.30] | V NP [0.60] {сломать, расколоть, сломать ..} | В НП НП [0,00] | В НП ПП [0,00] | ВП ПП [0.10] ВП → В [0.10] а как насчет | В НП [0,40] оставить? | V NP NP [0.10] leave1, leave2? | В НП ПП [0.20] | Вице-президент PP [0.20] CSE391 — 2005 NLP
53 Предложение TreeBanked S (S (аналитики NP-SBJ) (VP имеют (VP было
(VP ожидают (NP (NP пакт GM-Jaguar)) (SBAR (WHNP-1, что) (S (NP-SBJ * T * -1) (VP даст (VP даст (NP, производитель автомобилей из США) (NP (NP — возможная (ADJP 30%) доля)) (PP-LOC в (NP, британская компания))))))))) )) Вице-президент был вице-президентом, был вице-президентом NP-SBJ Аналитик ожидает НП Вот пример из Wall Street Journal Treebank II.Предложение находится в светло-синем поле в нижнем левом углу, синтаксическая структура в виде дерева синтаксического анализа находится посередине, фактическая аннотация находится в светло-сером поле. что SBAR WHNP-1 пакт GM-Jaguar NP S VP NP-SBJ VP даст * T * -1 NP PP-LOC Аналитики ожидали пакта GM-Jaguar, который даст американскому автопроизводителю в конечном итоге 30% акций британская компания. американский автопроизводитель NP, в конечном итоге 30% акций NP британская компания NP в CSE391 — 2005 NLP
54 То же самое предложение, PropBanked
ожидали (S Arg0 (аналитики NP-SBJ) (VP имеют (VP было (VP ожидало Arg1 (NP (NP пакт GM-Jaguar) Arg0 (NP-SBJ * T * -1) (VP даст (VP даст Arg2 (NP — U.S. производитель автомобилей) Arg1 (NP (NP (возможная доля (ADJP 30%))) (PP-LOC в (NP, британская компания))))))))))) Arg0 Arg1 Аналитик в пакте GM-Jaguar Здесь та же аннотация по-прежнему находится в сером поле с добавленными метками аргументов. Дерево представляет собой структуру зависимостей, которая порождает предикаты в голубом поле. Обратите внимание, что трассировка связана с соглашением GM-Jaguar Pact. Заметьте также, что с такой же легкостью можно было бы сказать: «пакт GM-Jaguar, который даст в конечном итоге… долю американскому автопроизводителю.», Где это будет« ARG0: пакт GM-Jaguar, который предоставит ARG1: в конечном итоге… долю ARG2: американскому автопроизводителю ». Это работает точно так же для китайского и корейского языков, как и для английского (и, предположительно, будет работать и для арабского), что даст * T * -1 американскому автопроизводителю в конечном итоге 30% акций британской компании Arg0 Arg2 Arg1. ожидаем (аналитики, пакт GM-J) дают (пакт GM-J, производитель автомобилей в США, 30% акций) CSE391 — 2005 NLP
55 Заголовки Заголовки Полиция начинает кампанию по преследованию сбежавших с дороги
Глава Ирака ищет оружие Учитель забастовывает праздных детей Шахтеры отказываются работать после смерти Суд по делам несовершеннолетних пытается застрелить обвиняемого CSE391 — 2005 NLP
56 События Из лекции КРР CSE391 — 2005 NLP
57 Контекстная чувствительность Языки программирования не зависят от контекста
Естественные языки зависят от контекста? Особенности движения, соответственно, Джон, Мэри и Билл ели персики, груши и яблоки соответственно.CSE391 — 2005 НЛП
58 Иерархия грамматики Хомского
Регулярные грамматики, aabbbb S → aS | ноль | bS Контекстно-свободные грамматики, aaabbb S → aSb | nil Контекстно-зависимые грамматики, aaabbbccc xSy → xby Машины Тьюринга CSE391 — 2005 NLP
59 Рекурсивные переходные сети для CFG
NP VP S S1 S2 S3 pp det noun NP S4 S5 adj S6 существительное местоимение s: — np, vp.нп: — местоимение; существительное; det, прил, существительное; нп, стр. CSE391 — 2005 НЛП
60 Большинство синтаксических анализаторов — это машины Тьюринга.
Для более естественной и понятной обработки движения. Для более эффективной обработки функций. Не потому, что соответственно — большинство синтаксических анализаторов не справляются с этим. CSE391 — 2005 НЛП
61 Вложенные зависимости и пересекающиеся зависимости
CF Собака гналась за кошкой, укусившей бегущую мышь.CF Мышь, за которой гналась собака, побежала. К.С. Джон, Мэри и Билл ели персики, груши и яблоки соответственно CSE391 — 2005 NLP
62 Движение Что Иоанн дал Марии? * Где Джон дал Марии?
Джон дал Мэри печенье. Джон дал <что> Мэри. CSE391 — 2005 НЛП
63 Обработка движения: регистры удержания / категории косой черты
S: — Wh, S / NP S / NP: — VP S / NP: — NP VP / NP VP / NP: — Глагол CSE391 — 2005 NLP
% PDF-1.5 % 216 0 объект > эндобдж 217 0 объект > поток DOI: 10.1073 / pnas.17015
application / pdf10.1073 / pnas.17015
http://dx.doi.org/10.1073/pnas.17015
2017-04-12false10.1073/pnas.17015
2017-04-12false
NEWCAT: Анализ естественного языка с использованием левоассоциативной грамматики (Книга)
Хауссер, Р. NEWCAT: Анализ естественного языка с использованием левоассоциативной грамматики . США: Н. П., 1986.
Интернет.
Хауссер, Р. NEWCAT: Анализ естественного языка с использованием левоассоциативной грамматики . Соединенные Штаты.
Хауссер, Р.Мы б .
«NEWCAT: Разбор естественного языка с использованием левоассоциативной грамматики». Соединенные Штаты.
@article {osti_6721611,
title = {NEWCAT: Анализ естественного языка с использованием левоассоциативной грамматики},
author = {Hausser, R},
abstractNote = {Эта книга показывает, что анализ структурных составляющих порождает нерегулярный порядок линейной композиции, что является прямой причиной крайней вычислительной неэффективности.Он предлагает альтернативную левоассоциативную грамматику, которая работает с регулярным порядком линейных композиций. Левоассоциативная грамматика основана на наращивании и отмене валентностей. Левоассоциативные синтаксические анализаторы отличаются от всех других систем тем, что история синтаксического анализа дублирует лингвистический анализ. Левоассоциативная грамматика проиллюстрирована двумя левоассоциативными синтаксическими анализаторами естественного языка: одним для немецкого и одним для английского.},
doi = {},
url = {https: // www.osti.gov/biblio/6721611},
journal = {},
number =,
объем =,
place = {United States},
год = {1986},
месяц = {1}
}
Определения, примеры и обсуждения грамматики английского языка
Грамматика языка включает основные аксиомы, такие как времена глаголов, артикли и прилагательные (и их правильный порядок), формулировку вопросов и многое другое.Язык не может функционировать без грамматики. В этом просто не было бы смысла — людям нужна грамматика для эффективного общения.
Ораторы и слушатели, авторы и их аудитория должны функционировать в одинаковых системах, чтобы понимать друг друга. Другими словами, язык без грамматики подобен груде кирпичей без раствора, скрепляющего их. В то время как основные компоненты присутствуют, они для всех целей и целей бесполезны.
Краткие факты: происхождение и определение грамматических слов
Слово грамматика происходит от греческого языка, означающего «искусство письма».»Это подходящее описание. На любом языке грамматика:
Мы учим грамматику с рождения
Британский лингвист, академик и писатель Дэвид Кристал говорит нам , что «грамматика — это изучение всех контрастов значений, которые можно выразить в предложениях.» Правила «грамматики говорят нам, как это сделать. на английском языке существует около 3500 таких правил ».
Конечно, это пугает, но носителям языка не нужно беспокоиться об изучении каждого правила.Даже если вы не знакомы со всеми лексикографическими терминами и педантичными мелочами, связанными с изучением грамматики, возьмите их у известного писателя и эссеиста Джоан Дидион: «То, что я знаю о грамматике, — это ее безграничная сила. Изменение структуры предложения меняет смысл этого предложения «.
Грамматика — это то, чему все мы начинаем учиться в первые дни и недели жизни, общаясь с другими. С того момента, как мы родились, язык — и грамматика, из которой он состоит, — окружают нас повсюду.Мы начинаем изучать его, как только слышим, как это говорят вокруг нас, даже если мы еще не полностью понимаем его значение.
Хотя ребенок не имеет понятия о терминологии, он начинает улавливать и усваивать, как составляются предложения (синтаксис), а также выяснять, из каких частей складываются эти предложения (морфология).
«Молчаливое знание грамматики дошкольником сложнее, чем самое толстое руководство по стилю», — объясняет когнитивный психолог, лингвист и научно-популярный автор Стивен Пинкер.«[Грамматику] не следует путать с указаниями о том, как« следует »говорить».
Использование грамматики в реальном мире
Конечно, любой, кто хочет быть эффективным оратором или писателем, должен иметь хотя бы базовые знания грамматики. Чем дальше вы выйдете за рамки основ, тем эффективнее и понятнее вы сможете общаться практически в любой ситуации.
«Есть несколько применений грамматики:
(1) Распознавание грамматических структур часто необходимо для пунктуации
(2) Изучение родной грамматики полезно, когда кто-то изучает грамматику иностранного языка
(3) Знание грамматики помогает в интерпретации литературных, а также нелитературных текстов, поскольку интерпретация отрывка иногда в решающей степени зависит от грамматического анализа
(4) Изучение грамматических ресурсов английского языка полезно для композиции: в частности, оно может поможет вам оценить варианты, доступные вам, когда вы придете для редактирования ранее написанного черновика. — Из Введение в грамматику английского языка Сидни Гринбаум и Джеральд Нельсон
В профессиональной среде глубокие знания грамматики могут помочь вам эффективно и легко взаимодействовать с коллегами, подчиненными и начальством. Даете ли вы указания, получаете обратную связь от своего начальника, обсуждаете цели конкретного проекта или создаете маркетинговые материалы, умение эффективно общаться чрезвычайно важно.
Типы грамматики
Учителя следуют курсу педагогической грамматики при обучении изучающих английский язык.В то время как студентам в основном приходится разбираться с тонкостями предписывающей традиционной грамматики (например, проверять соответствие глаголов и подлежащих и где ставить запятые в предложении), лингвисты сосредотачиваются на бесконечно более сложных аспектах языка.
Они изучают, как люди овладевают языком, и обсуждают, рождается ли каждый ребенок с концепцией универсальной грамматики, исследуя все, от того, как разные языки сравниваются друг с другом (сравнительная грамматика), до разнообразия перестановок в пределах одного языка (описательная грамматика) и способа в котором слова и их употребление взаимосвязаны для создания смысла (лексикограмма).