Склонение имен существительных по падежам
Склонение — это словоизменение формы имен существительных по падежам. Введите ваше слово и нажмите кнопку «Просклонять» и в результате вы увидите полный разбор вашего слова, окончание, число и род.
В русском языке имя существительное изменяет свою форму по падежам и числам, в результате разбора вы получите постоянный признак существительного — это мужской, женский или средний род.
Склонение имен существительных
Склонение имен существительных может быть трех типов — это 1, 2, 3 склонение.
Для того чтобы определить к какому типу склонения относится ваше слово, нужно выполнить
разбор слова по составу
и выделить окончания слова.
1 склонение существительных
Существительные женского и мужского рода с окончанием -а или -я в форме именительного падежа относятся к первому склонению.
2 склонение существительных
Существительные с нулевым окончанием мужского рода и среднего рода с окончанием -о или -е относятся к второму склонению.
2 склонение существительных
Остается третье склонение — это существительные с нулевым окончанием женского рода относятся к третьему склонению.
Окончание склонений имен существительных:
| Падежи | Слово помощник | Вопросы | 1 скл | 2скл | 3скл | Мн. ч ч |
| Именительный | Есть | Кто? Что? | -а -я | □ -о -е | □ | а я и ы |
| Родительный | Нет | Кого? Чего? | -а -я | -и | ов ев ей □ | |
| Дательный | Рад | Кому? Чему? | -е | -у -ю | -и | ам ям |
| Винительный | Вижу | Кого? Что? | -у -ю | □ -о -е -а -я | □ | а я и ы ов ев ей □ |
| Творительный | Любуюсь | Кем? Чем? | -ой -ей | -ом -ем | -ю | ами ями |
| Предложный | Говорю | О ком? О чем? | -е | -е | -и | ах ях |
Если у вас есть вопросы или пожелания, можете обратиться к нам по электронной почте
admin@rustxt.
ГДЗ по русскому языку 4 класс учебник Канакина, Горецкий 2 часть – стр 5
- Тип: ГДЗ, Решебник.
- Автор: Канакина В. П., Горецкий В. Г.
- Год: 2019.
- Издательство: Просвещение.
Подготовили готовое домашнее задание к упражнениям на 5 странице по предмету русский язык за 4 класс. Ответы на вопросы к заданиям 2 и 3.
Учебник 2 часть – Страница 5.
Ответы 2022 года.
Обратите внимание!
Некоторые имена прилагательные могут быть употреблены в полной и краткой форме:
Широкие (реки) — (реки) широки; долгий (путь) — (путь) долог; родная (картина) — (картина) родна.
Имя прилагательное в краткой форме употребляется в предложении как сказуемое.
Номер 2.
Прочитайте. О какой птице идёт речь?
У . .. по бокам пёрышки совсем белые. Голова, крылья, хвост чёрные, как у вороны. Очень красивый у птицы хвост. Он длинный, прямой, будто стрела. Перья на хвосте зеленоватые. … — птица очень нарядная, ловкая, подвижная.
.. по бокам пёрышки совсем белые. Голова, крылья, хвост чёрные, как у вороны. Очень красивый у птицы хвост. Он длинный, прямой, будто стрела. Перья на хвосте зеленоватые. … — птица очень нарядная, ловкая, подвижная.
Г. Скребицкий
Ответ:
В данном тексте идет речь о сороке.
- Слова какой части речи помогли вам узнать птицу? Спишите, вставляя пропущенное слово — название птицы.
Ответ:
У сороки по бокам пёрышки совсем белые. Голова, крылья, хвост чёрные, как у вороны. Очень красивый у птицы хвост. Он длинный, прямой, будто стрела. Перья на хвосте зеленоватые. Сорока — птица очень нарядная, ловкая, подвижная.
Слова белые, чёрный, красивый, длинный, зеленоватые, нарядная, ловкая. Имена прилагательные помогают узнать птицу, ведь указывают на ее качества.
- Подчеркните волнистой линией имена прилагательные. Какие из них помогают описать внешний вид птицы, её поведение, отношение к ней автора?
Ответ:
У сороки по бокам пёрышки совсем белые. Голова, крылья, хвост чёрные, как у вороны. Очень красивый у птицы хвост. Он длинный, прямой, будто стрела. Перья на хвосте зеленоватые. Сорока — птица очень нарядная, ловкая, подвижная.
Голова, крылья, хвост чёрные, как у вороны. Очень красивый у птицы хвост. Он длинный, прямой, будто стрела. Перья на хвосте зеленоватые. Сорока — птица очень нарядная, ловкая, подвижная.
Разбор слова по составу
Пёрышки — сущ.
Разбор слова как части речи
На хвосте — имя существительное, обозначает предмет и отвечает на вопрос «на чём?». Н. ф. — хвост. Ед. ч., П. п.
Номер 3.
Прочитайте.
Кость — костистый, автомобиль — автомобильный, январь, тень, разговор, Русь, счастье, шум, правда, лень, длина, сон, луч, обида, привет, конь.
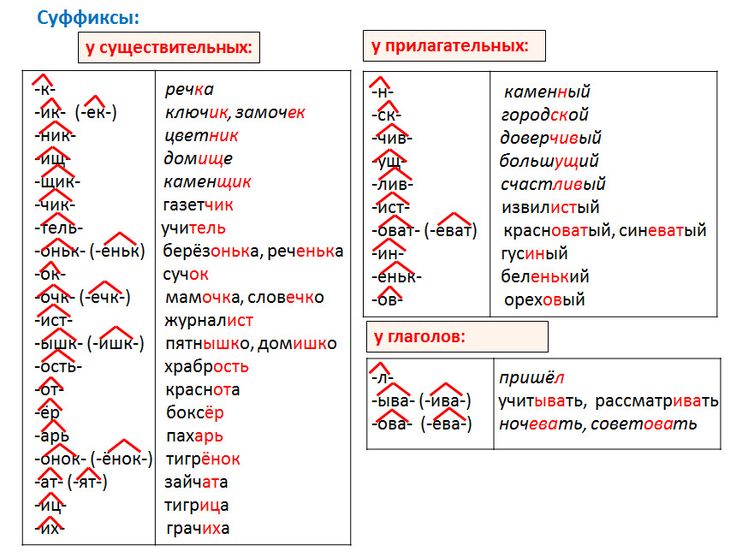
- Образуйте от данных имен существительных однокоренные имена прилагательные с помощью одного из суффиксов: -ист-, -лив-, -ив-, -ск-, -н-, -чив-. Запишите слова парами. Выделите суффиксы в именах прилагательных.
Ответ:
Кость — костистый, автомобиль — автомобильный, январь — январский, тень — тенистый, разговор — разговорный, Русь — русский, счастье — счастливый, шум — шумный, правда — правдивый, лень — ленивый, длина — длинный, сон — сонный, луч — лучистый, обида — обидчивый, привет — приветливый, конь — конный.
- Составьте и запишите предложение с любым именем прилагательным.
Ответ:
Мама сказала, что рыба очень костистая.
Рейтинг
← Выбрать другую страницу ←
In Nuce: Грамматика: Порядок разбора существительных
Грамматика: Порядок разбора существительных
Parse : [из L. pars , часть .] В грамматике , чтобы разложить предложение на его элементы . Разбор часто становится упражнением в логике .
Порядок анализа
Из Новая английская грамматика для школ , по Томас Харви :
Парсинг состоит из
1. Называние части речи
Существительное, а почему?
2.
Рассказывая его свойства
 Рассказывая
его свойства
Рассказывая
его свойстваа. Обычное или правильное, и почему?
б. Пол и почему?
в. Человек, а почему?
д. Номер и почему?
3. Указание на его отношение к другим словам
Дело, а зачем?
4. Указание правила его построения
Правило построения.
Модели для разбора существительных
Мэри поет.
«Мэри» — это существительное ; это имя; собственно , это имя конкретного человека; женский пол , обозначает женский пол; третье лицо , обозначает человек, о котором идет речь; единственное число ,
обозначает только один; именительный падеж , используется как подлежащее предложение «Мария поет».
 Правило I . — «Предметом
предложение стоит в именительном падеже».
Правило I . — «Предметом
предложение стоит в именительном падеже».Лошади животных.
«Животные» — это существительное; общий , это может применяться к любому классу или виду; общий род , это обозначает мужчин или женщин; третье лицо ; множественное число , оно обозначает более одного; именительный падеж , используется как сказуемое предложения «Лошади — животные». Правило II .— «Существительное или местоимение, употребляемое в качестве сказуемого предложения, стоит в именительном падеже».
Поэт Милтон был слеп.
«Милтон» — это существительное; правильный; мужской род , ит обозначает мужчину; третье лицо; единственное число; именительный падеж , в приложение со словом «поэт».
 Правило IV . — «Существительное или местоимение,
ограничить значение существительного или местоимения, обозначая одно и то же
человек, место или вещь находятся в одном и том же падеже».
Правило IV . — «Существительное или местоимение,
ограничить значение существительного или местоимения, обозначая одно и то же
человек, место или вещь находятся в одном и том же падеже».Генри усвоил урок .
«У Генри» — существительное ; правильный; мужской род; третье лицо; единственное число; притяжательный случай , это обозначает владения и модифицирует «урок». Правило III . — «Существительное или местоимение, используемое для ограничения значения существительного, обозначающего другой вещь, находится в притяжательном падеже».
Джон изучает грамматику.
«Грамматика» — это существительное; общий; средний род; третье лицо; единственное число; объективный случай , используется как объект переходного глагола «учиться». Правило VI . — «Дополнение переходного глагола в действительном залоге, или его причастий, находится в объектном падеже».

Книга лежит на столе .
«Стол» — существительное ; общий; средний род; в третьих человек; единственное число; объектив case , используется как объект предлога «на». Правило VII . — «Объект предлог стоит в объектном падеже».
Уильям, открыть дверь.
«Уильям» — это существительное; правильный; мужской род; второе лицо; единственное число; абсолютный case , это имя адресата. Правило V . — «А существительное или местоимение, используемые независимо друг от друга, стоят в именительном абсолютном падеже дело.»
Предыдущий Harvey’s A New English Grammar Next
#grammar
#writing #English #ESL #englishasasecondlanguage #languagearts #education #homeschool
#существительные #parsing #orderofparsingnouns #grammarrules #teachingenglish
Новое сообщение Старый пост Главная
!–боковая панель>
Разбор фразы существительного
Разбор фразы существительногоДалее: Полный анализ Up: Парсинг Предыдущий: Идентификация пункта
Разбор именных словосочетаний похож на разбиение именных словосочетаний, но на этот раз
цель состоит в том, чтобы найти именное словосочетание на всех уровнях. Это означает, что, как и в задаче идентификации предложения, нам нужно
уметь распознавать встроенные фразы.
Следующий пример предложения проиллюстрирует это:
Это означает, что, как и в задаче идентификации предложения, нам нужно
уметь распознавать встроенные фразы.
Следующий пример предложения проиллюстрирует это:
В (ранние торги) в (Гонконге) (понедельник) котировалось (золото)
в (($366,50) (унция)).
Это предложение содержит семь именных словосочетаний, из которых одно, содержащее последние четыре слова предложения состоят из двух встроенных существительных фразы. Если мы используем тот же подход, что и для идентификации предложения, получение скобки всех уровней фразы за один шаг и балансируя их, мы будем вероятно, не обнаружит это словосочетание, потому что оно начинается и заканчивается вместе с другими словосочетаниями. Поэтому здесь мы будем использовать другой подход.
Мы будем восстанавливать словосочетания существительных на разных уровнях, выполняя
повторяющиеся фрагменты [Tjong Kim Sang (2000a)].
Мы начнем с данных, содержащих слова и теги частей речи, и
определить основные словосочетания существительных в этих данных с помощью методов, используемых в
наша работа по разбивке именных фраз. После этого заменим фразы, которые были найдены главой
слова и их теги.
Это создаст сводку предложений со словами и смешанным
поток данных тегов POS и тегов фрагментов.
Мы можем еще раз применить к этим данным наши методы разбивки именных фраз.
время и найти именные фразы на один уровень выше базового уровня.
Шаги сжатия и разделения будут повторяться, чтобы
получить фразы на более высоких уровнях.
Процесс остановится, когда новые фразы не будут найдены.
После этого заменим фразы, которые были найдены главой
слова и их теги.
Это создаст сводку предложений со словами и смешанным
поток данных тегов POS и тегов фрагментов.
Мы можем еще раз применить к этим данным наши методы разбивки именных фраз.
время и найти именные фразы на один уровень выше базового уровня.
Шаги сжатия и разделения будут повторяться, чтобы
получить фразы на более высоких уровнях.
Процесс остановится, когда новые фразы не будут найдены.
Описанный здесь подход кажется тривиальным расширением нашего существительного
работа по фрагментации фраз.
Однако осталось обсудить некоторые детали.
Во-первых, это выбор заглавного слова во фразе.
процесс подведения итогов.
В то время, когда мы проводили эти эксперименты, у нас не было доступа к
набор правил Магермана/Коллинза для определения заглавных слов и
поэтому мы использовали правило, созданное нами самими: заглавное слово существительного
фраза — это последнее слово первой группы существительных во фразе или
последнее слово фразы, если оно не содержит группу существительных.
Второй факт, который мы должны упомянуть, заключается в том, что данные, которые мы использовали, содержат
другой формат фрагментов именной фразы, чем данные, которые мы ранее
работали с.
В этой задаче мы используем набор данных, который был разработан для существительного
фраза, заключающая в скобки общую задачу CoNLL-99 [Osborne (1999)].
Это было извлечено из Wall Street Journal, части Penn.
Treebank [Marcus et al. (1993)] без дополнительных модификаций, а это означает,
например, что притяжательные формы между двумя словосочетаниями существительных были
присоединен к первому, в отличие от именной группы данных.
Это и другие различия приводят к тому, что мы не можем быть уверены, что
Методы, которые мы разработали для другого формата словосочетаний с основными существительными,
очень хорошо работают здесь.
Действительно, в части фрагментации нашего неглубокого
синтаксический анализатор по сравнению с работой с фрагментами (F из 92,77
по сравнению с 93,34).
Однако мы решили не заморачиваться поиском лучшего
конфигурации для нашего чанкера именных фраз и обучили существующий
чанкер с данными, доступными для этой задачи.
Возникла непредвиденная проблема, когда мы попытались использовать чанкер для определение именных словосочетаний выше основного уровня. Выход нашего чанкера — это большинство голосов пяти систем, использующих разные представления данных. В нашей оценочной работе с данными настройки (раздел 21 WSJ) мы заметил, что общий вывод чанкера на небазовом уровне был хуже, чем производительность лучшей отдельной системы [Тьонг Ким Сан (2000a)]. Причина этого в том, что система, которая использовала данные O+C представительство, превзошло остальные четыре системы с большим отрывом. Из-за этого и, вероятно, из-за того, что остальные четыре системы допустил аналогичные ошибки, ошибки четверки отменили некоторые из правильный анализ наилучшей системы и привело к тому, что большинство голосов хуже, чем лучшая индивидуальная система. По этой причине мы решили использовать только кронштейн представления при обработке именных словосочетаний выше базовых уровней.
Главный открытый вопрос в этом исследовании — какие обучающие данные использовать. при обработке неосновных именных словосочетаний.
Чтобы найти ответ на этот вопрос, мы проверили несколько
конфигурации при обработке данных настройки, раздел 21 WSJ, с
обучающие данные для общей задачи CoNLL-99.
Мы протестировали шесть конфигураций обучающих данных для прогнозирования открытых
и закрыть позиции скобок: используя все позиции скобок, позиции
только базовые фразы, те из всех фраз, кроме базовых фраз, те из
фразы только текущего уровня, фразы текущего уровня и
предыдущего, а также текущего уровня и следующего.
На всех уровнях использование скобок текущего уровня только доказало свою эффективность.
быть лучшим или близким к лучшему.
На шестом уровне новых именных словосочетаний обнаружено не было.
Поэтому мы решили использовать только скобки одного уровня фразы в
обучающие данные для небазовых фраз и идентификация стоп-фраз после
шесть уровней.
при обработке неосновных именных словосочетаний.
Чтобы найти ответ на этот вопрос, мы проверили несколько
конфигурации при обработке данных настройки, раздел 21 WSJ, с
обучающие данные для общей задачи CoNLL-99.
Мы протестировали шесть конфигураций обучающих данных для прогнозирования открытых
и закрыть позиции скобок: используя все позиции скобок, позиции
только базовые фразы, те из всех фраз, кроме базовых фраз, те из
фразы только текущего уровня, фразы текущего уровня и
предыдущего, а также текущего уровня и следующего.
На всех уровнях использование скобок текущего уровня только доказало свою эффективность.
быть лучшим или близким к лучшему.
На шестом уровне новых именных словосочетаний обнаружено не было.
Поэтому мы решили использовать только скобки одного уровня фразы в
обучающие данные для небазовых фраз и идентификация стоп-фраз после
шесть уровней.
Мы применили именную фразу chunker с фиксированным симметричным контекстом.
размеры к данным словосочетания существительного общей задачи CoNLL-99
[Тьонг Ким Сан (2000a)]. Чанкер сгенерировал большинство голосов открытых и закрытых скобок, поставленных
вперед пятью системами, каждая из которых использовала другое представление
основных словосочетаний (IOB1, IOB2, IOE1, IOE2 и O или C).
Все системы использовали окно из четырех левых и четырех правых слов и
Теги POS (18 функций) и четыре системы, использующие представления ввода-вывода
дополнительно выполняется и дополнительный проход с окном из трех левых и
три справа для слов и POS-тегов и окно из двух левых и двух
прямо без тега фокуса для тегов фрагментов (также 18 функций).
Выход чанкера был представлен каскаду из шести чанкеров,
каждый из которых состоял из пары предикторов открытой и закрытой скобок
которые тренировались со скобками с одного из уровней с 1 по 6.
После каждой фазы чанка найденные фразы заменялись заголовком.
слово фразы и тег фиксированного фрагмента.
Чанкер сгенерировал большинство голосов открытых и закрытых скобок, поставленных
вперед пятью системами, каждая из которых использовала другое представление
основных словосочетаний (IOB1, IOB2, IOE1, IOE2 и O или C).
Все системы использовали окно из четырех левых и четырех правых слов и
Теги POS (18 функций) и четыре системы, использующие представления ввода-вывода
дополнительно выполняется и дополнительный проход с окном из трех левых и
три справа для слов и POS-тегов и окно из двух левых и двух
прямо без тега фокуса для тегов фрагментов (также 18 функций).
Выход чанкера был представлен каскаду из шести чанкеров,
каждый из которых состоял из пары предикторов открытой и закрытой скобок
которые тренировались со скобками с одного из уровней с 1 по 6.
После каждой фазы чанка найденные фразы заменялись заголовком.
слово фразы и тег фиксированного фрагмента.
Система получила общую скорость F 83,79 (точность
90,00% и отзыв 78,38%) для идентификации произвольного существительного
фразы. 9 Немного лучше, чем у нас на CoNLL-99 (82,98,
получено без системной комбинации), которая была лучшей из двух записей
представлены для общего задания на этом семинаре.
Производительность нашего именного словосочетания chunker можно рассматривать как
базовая оценка для этого набора данных.
Этот показатель уже достаточно высок: F = 79,70, и кажется
что чанкеры небазового уровня не внесли большого вклада в
производительность этого мелкого парсера.
Из любопытства мы также проверили, насколько хорошо полный синтаксический анализатор работает на
задание на выявление произвольных именных словосочетаний.
Для этого мы посмотрели выходные данные парсера, описанного
[Коллинз (1999)], который был предоставлен с кодом парсера (раздел WSJ
23, модель 2).
Парсер получил F = 89,8 (точность 89,3% и полнота).
90,4%) для этой задачи.
Это намного лучше, чем наш неглубокий парсер, но мы должны отметить, что
по сравнению с нашим приложением парсер Collins имеет доступ к более
части речи теги и больше обучающих данных с более сложными
аннотацию, а не только границы именной фразы.
9 Немного лучше, чем у нас на CoNLL-99 (82,98,
получено без системной комбинации), которая была лучшей из двух записей
представлены для общего задания на этом семинаре.
Производительность нашего именного словосочетания chunker можно рассматривать как
базовая оценка для этого набора данных.
Этот показатель уже достаточно высок: F = 79,70, и кажется
что чанкеры небазового уровня не внесли большого вклада в
производительность этого мелкого парсера.
Из любопытства мы также проверили, насколько хорошо полный синтаксический анализатор работает на
задание на выявление произвольных именных словосочетаний.
Для этого мы посмотрели выходные данные парсера, описанного
[Коллинз (1999)], который был предоставлен с кодом парсера (раздел WSJ
23, модель 2).
Парсер получил F = 89,8 (точность 89,3% и полнота).
90,4%) для этой задачи.
Это намного лучше, чем наш неглубокий парсер, но мы должны отметить, что
по сравнению с нашим приложением парсер Collins имеет доступ к более
части речи теги и больше обучающих данных с более сложными
аннотацию, а не только границы именной фразы.