Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
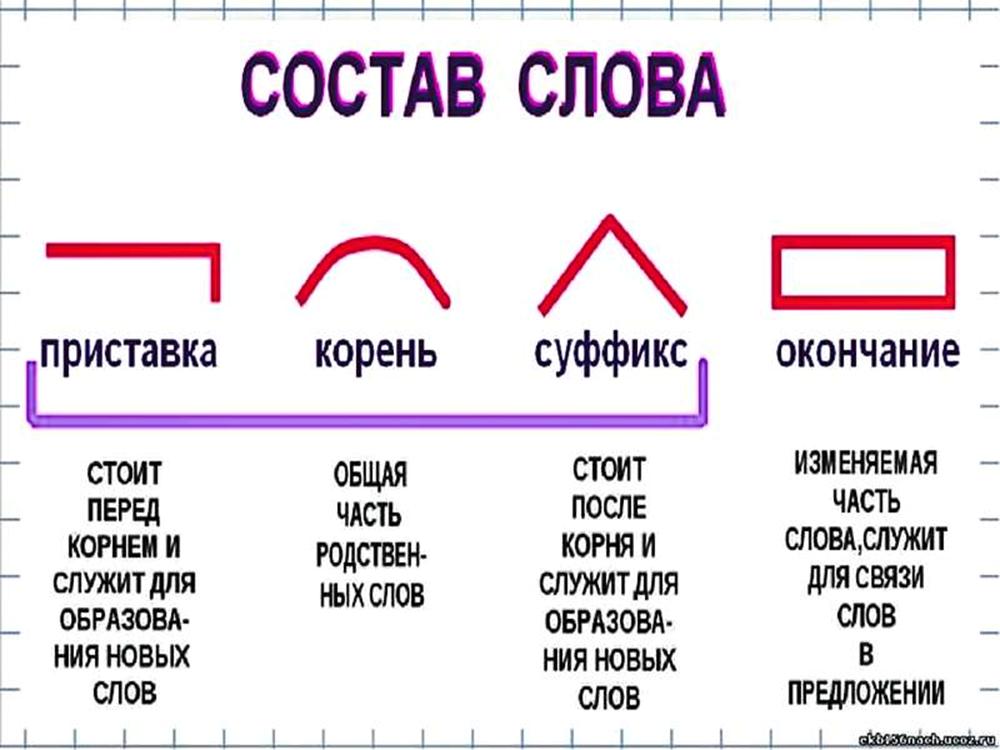
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
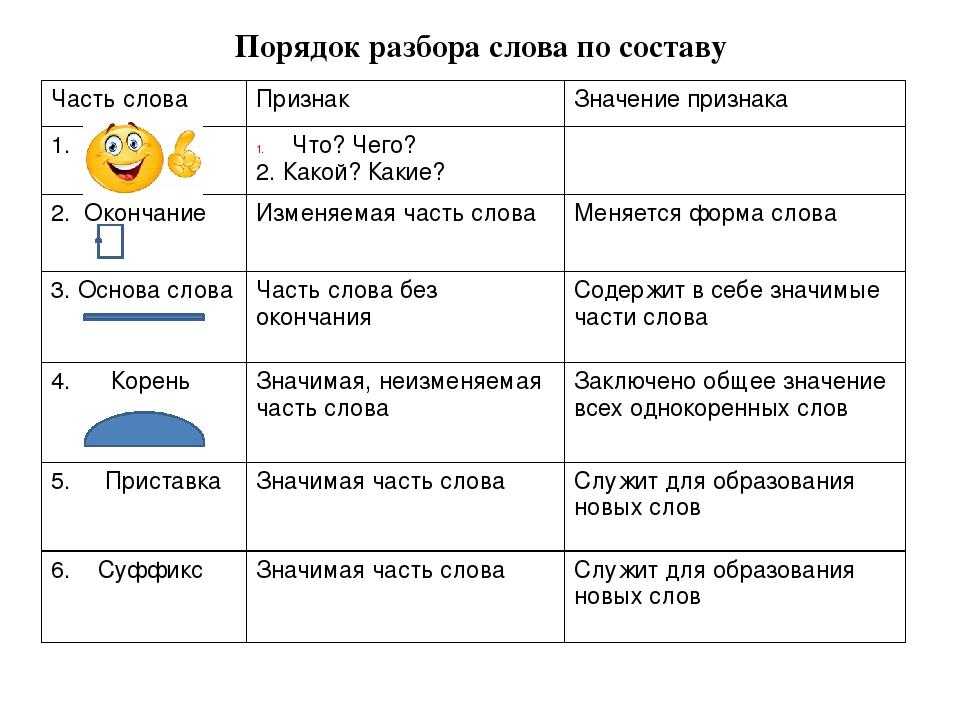
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: жаргон сейчас туалех сейчас разброс сейчас елнйосн сейчас т и н г р е й 1 секунда назад с р и а о т 1 секунда назад мокрота 1 секунда назад с к р и п 2 секунды назад н а е е п с л 2 секунды назад к р н а а 2 секунды назад р а н д е в у 2 секунды назад воюагшти 2 секунды назад лодкаь 2 секунды назад биопленка 2 секунды назад слютар 3 секунды назад
Слова «частота» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «частота» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «частота» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «частота».
Содержимое:
- 1 Слоги в слове «частота» деление на слоги
- 2 Как перенести слово «частота»
- 3 Морфологический разбор слова «частота»
- 4 Разбор слова «частота» по составу
- 5 Сходные по морфемному строению слова «частота»
- 6 Синонимы слова «частота»
- 7 Ударение в слове «частота»
- 8 Фонетическая транскрипция слова «частота»
- 9 Фонетический разбор слова «частота» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «частота»
- 11 Сочетаемость слова «частота»
- 12 Значение слова «частота»
- 13 Как правильно пишется слово «частота»
- 14 Ассоциации к слову «частота»
Слоги в слове «частота» деление на слоги
Количество слогов: 3
По слогам: ча-сто-та
По правилам школьной программы слово «частота» можно поделить на слоги разными способами. Допускается вариативность, то есть все варианты правильные. Например, такой:
Например, такой:
час-то-та
По программе института слоги выделяются на основе восходящей звучности:
ча-сто-та
Ниже перечислены виды слогов и объяснено деление с учётом программы института и школ с углублённым изучением русского языка.
с примыкает к этому слогу, а не к предыдущему, так как не является сонорной (непарной звонкой согласной)
Как перенести слово «частота»
ча—стота
час—тота
часто—та
Морфологический разбор слова «частота»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: женский;
число: единственное;
падеж: именительный;
отвечает на вопрос: (есть) Что?
Начальная форма:
частота
Разбор слова «частота» по составу
| част | корень |
| от | суффикс |
| а | окончание |
частота
Сходные по морфемному строению слова «частота»
Сходные по морфемному строению слова
Синонимы слова «частота»
1. радиочастота
радиочастота
2. видеочастота
Ударение в слове «частота»
частота́ — ударение падает на 3-й слог
Фонетическая транскрипция слова «частота»
[ч’астата]
Фонетический разбор слова «частота» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| ч | [ч’] | согласный, глухой непарный, мягкий, шипящий | ч |
| а | [а] | гласный, безударный | а |
| с | [с] | согласный, глухой парный, твёрдый, шумный | с |
| т | [т] | согласный, глухой парный, твёрдый, шумный | т |
| о | [а] | гласный, безударный | о |
| т | [т] | согласный, глухой парный, твёрдый, шумный | т |
| а | [а] | гласный, ударный | а |
Число букв и звуков:
Буквы: 3 гласных буквы, 4 согласных букв.
Звуки: 3 гласных звука, 4 согласных звука.
Предложения со словом «частота»
В линейном ускорителе электронов электроны впрыскиваются в трубку ускорителя и разгоняются там с помощью электромагнитного поля высокой частоты.
Источник: Коллектив авторов, Полный справочник медицинской аппаратуры.
Важно попасть в резонанс с веществом предмета, правильно настроиться на частоту колебаний его атомов.
Источник: И. С. Прокопенко, Тайны древних цивилизаций, 2015.
В качестве беспроводной связи используются радиоволны конкретного диапазона частот.
Источник: А. И. Ватаманюк, Домашние и офисные сети под Vista и XP, 2008.
Сочетаемость слова «частота»
1. высокие частоты
высокие частоты
2. низкие частоты
3. определённая частота
4. частота сердечных сокращений
5. частота пульса
6. частота колебаний
7. диапазон частот
8. токи высокой частоты
9. изменение частоты
10. работать на частоте
11. настроиться на нужную частоту
12. имеет свою частоту
13. (полная таблица сочетаемости)
Значение слова «частота»
ЧАСТОТА́ , -ы́, мн. -то́ты, ж. 1. Свойство и состояние по знач. прил. частый. (Малый академический словарь, МАС)
Как правильно пишется слово «частота»
Правописание слова «частота»
Орфография слова «частота»
Правильно слово пишется: частота́
Нумерация букв в слове
Номера букв в слове «частота» в прямом и обратном порядке:
- 7
ч
1 - 6
а
2 - 5
с
3 - 4
т
4 - 3
о
5 - 2
т
6 - 1
а
7
Ассоциации к слову «частота»
Диапазон
Процессор
Вещание
Вращение
Усилитель
Передатчик
Спектр
Интенсивность
Излучение
Резонанс
Генератор
Длительность
Радиостанция
Колебание
Настройка
Низка
Ток
Пульс
Производительность
Импульс
Радиосвязь
Фильтр
Сокращение
Вибрация
Регулятор
Громкость
Сдвиг
Сигнал
Коэффициент
Популяция
Электрон
Рация
Мощность
Параметр
Шина
Поглощение
Соотношение
Маятник
Уменьшение
Воспроизведение
Антенна
Коммуникатор
Увеличение
Вала
Мутация
Смещение
Снижение
Фаза
Стандарт
Помеха
Переключатель
Интервал
Шкала
Регулирование
Сканирование
Эфир
Искажение
Телеканал
Усиление
Бит
Биение
Прослушивание
Ядро
Электромагнитный
Звуковой
Переменный
Несущий
Кадровый
Системный
Кровяной
Акустический
Номинальный
Графический
Аварийный
Цифровой
Удвоенный
Сердечный
Динамический
Инфракрасный
Магнитный
Рентгеновский
Эфирный
Квантовый
Максимальный
Голосовой
Настроиться
Прослушивать
Переключиться
Переключить
Вещать
Настроить
Излучать
Вибрировать
Сканировать
Повышаться
Настраивать
Регистрировать
Измерять
Снижать
Уменьшать
python — эффективно вычислять частоту слов в строке
Задавать вопрос
спросил
Изменено 10 месяцев назад
Просмотрено 34к раз
Я разбираю длинную строку текста и вычисляю, сколько раз каждое слово встречается в Python. У меня есть функция, которая работает, но я ищу совета о том, есть ли способы сделать ее более эффективной (с точки зрения скорости) и есть ли даже функции библиотеки Python, которые могли бы сделать это для меня, поэтому я не изобретаю велосипед ?
У меня есть функция, которая работает, но я ищу совета о том, есть ли способы сделать ее более эффективной (с точки зрения скорости) и есть ли даже функции библиотеки Python, которые могли бы сделать это для меня, поэтому я не изобретаю велосипед ?
Можете ли вы предложить более эффективный способ вычисления наиболее часто встречающихся слов в длинной строке (обычно более 1000 слов в строке)?
Также как лучше всего отсортировать словарь в список, где 1-й элемент является наиболее распространенным словом, 2-й элемент является 2-м наиболее распространенным словом и т. д.?
тест = """abc def-ghi jkl abc
абв"""
def calculate_word_частота (ы):
# Сообщение: возвращает список слов, упорядоченных от самых
# от частого к наименее частому
слова = s.split()
частота = {}
для слова словами:
если freq.has_key(слово):
частота[слово] += 1
еще:
частота [слово] = 1
сортировка возврата (частота)
сортировка по определению (d):
# Сообщение: сортировать словарь d в список упорядоченных слов
# от самой высокой частоты к самой низкой частоте
# например: For {"the": 3, "a": 9, "abc": 2} должно быть
# отсортировано в следующий список ["a","the","abc"]
#Я никогда не использовал лямбда-выражения, поэтому я не уверен, что это правильно
вернуть d. sort (cmp = лямбда x, y: cmp (d [x], d [y]))
распечатать calculate_word_frequency (тест)
sort (cmp = лямбда x, y: cmp (d [x], d [y]))
распечатать calculate_word_frequency (тест)
 sort (cmp = лямбда x, y: cmp (d [x], d [y]))
распечатать calculate_word_frequency (тест)
sort (cmp = лямбда x, y: cmp (d [x], d [y]))
распечатать calculate_word_frequency (тест)
- python
- синтаксический анализ
- лямбда
- частота слов
1
Использовать коллекций. Счетчик :
>>> из коллекций импортировать Счетчик
>>> test = 'abc def abc def zzz zzz'
>>> Счетчик(test.split()).most_common()
[('abc', 2), ('zzz', 2), ('def', 2)]
>>>> test = """abc def-ghi jkl abc
абв"""
>>> из коллекций импортировать счетчик
>>> слова = счетчик()
>>>words.update(test.split()) # Обновить счетчик со словами
>>>words.most_common() # Распечатать список от наиболее распространенных до наименее распространенных
[('abc', 3), ('jkl', 1), ('def-ghi', 1)]
Вы также можете использовать NLTK (Natural Language ToolKit). Он предоставляет очень хорошие библиотеки для изучения обработки текстов.
для этого примера вы можете использовать:
из импорта nltk FreqDist текст = "аа бб копия аа бб" fdist1 = FreqDist(текст) # показать 10 наиболее часто встречающихся слов в тексте распечатать fdist1.
 most_common(10)
most_common(10)
результат будет:
[('aa', 2), ('bb', 2), ('cc', 1)]
1
Если вы хотите отображать часто встречающиеся слова и значения количества, а не Список, то вот мой код.
из коллекций Счетчик импорта
str = 'abc def ghi def abc abc'
arr = Счетчик (str.split()).most_common()
для слова, считать в обр:
печатать (слово, количество)
Вывод:
абв 3 защита 2 привет 1
1
Вы можете создать функцию для выполнения своей работы:
частота определения (слово):
лст = слово.split()
результат = {}
для слова в списке:
если слово не в результате:
результат[слово] = 0
результат[слово] += 1
вернуть результат
txt = «Страх ведет к гневу, гнев ведет к ненависти, ненависть ведет к конфликту, конфликт ведет к страданию»
печать (частота (txt))
Вывод:
{'Страх': 1, 'ведет': 4, 'к': 4, 'гнев': 2, 'ненависть': 2, 'конфликт': 2, 'страдание': 1 }
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
1-граммовый набор данных Google
1-граммовый набор данных GoogleПринстонский университет
jhug@cs.
 princeton.edu
princeton.edu Задание разработано для летнего курса программирования для ученых Рокфеллеровского университета
Материалы для задания
Часть 1 (базовый синтаксический анализ и визуализатор набора данных)Часть 2 (инструменты расширенного синтаксического анализа и совокупного анализа наборов данных)
Наборы данных для части 1 и 2
Пакет автоматизированного тестирования, решения и сценарий для создания наборов данных из официального (гораздо большего) набора данных Google, также доступны по запросу по электронной почте.
Обзор
База данных Google Ngram предоставляет около 3 терабайт информации о частотах встречаемости всех наблюдаемых слов и фраз в английском языке (точнее, всех наблюдаемых kgram). Google предоставляет Google Ngram Viewer в Интернете, что позволяет пользователям визуализировать относительную историческую популярность слов и фраз.
В этом задании учащиеся создадут собственную версию Google Ngram Viewer для 1grams. Затем они создадут три дополнительных инструмента визуализации для изучения других аспектов набора данных, которые нельзя решить с помощью Google Ngram Viewer.
Затем они создадут три дополнительных инструмента визуализации для изучения других аспектов набора данных, которые нельзя решить с помощью Google Ngram Viewer.
| Программа просмотра n-грамм Google | Инструмент 1 , созданный учащимися по этому заданию: средство просмотра истории 1 грамм |
Три дополнительных инструмента визуализации включают распределение букв в английском языке, распределение частот всех слов в английском языке и длину среднего слова в английском языке с 1800-х годов. Примеры каждого показаны ниже (с ограниченным набором данных, чтобы избежать спойлеров).
| Инструмент 2 : Распространение писем с использованием очень маленького примера файла | Инструмент 3 : Распределение частот слов слов, начинающихся с Q (закон Ципфа) | Инструмент 4 : Средняя длина слов с 1860 по 1880 год Сюжет с 1800 по настоящее время не показан (во избежание интересного спойлера) |
Назначение задач
- Простой парсер Wordfile . Создайте простой параметризованный синтаксический анализатор CSV для извлечения информации об одном слове из файла CSV и сохранения результатов в ассоциативном массиве, сопоставляющем год и количество слов.
- Простой парсер Totalfile . Создайте простой синтаксический анализатор CSV, который считывает общее количество слов за каждый календарный год и сохраняет результаты в ассоциативном массиве, сопоставляющем слова с общим количеством слов.
- Инструмент 1: Инструмент визуализации истории . Имея список слов, создайте график нормализованной частотности слов для каждого слова. В результате получается инструмент, очень похожий на Google Ngram Viewer (но без веб-интерфейса).
Часть 2
- Сложный парсер Wordfile . Создайте синтаксический анализатор CSV для чтения всей базы данных количества слов, хранящейся в файле Word. Данные будут храниться в ассоциативном массиве, отображающем слово в массив пар (year, count_in_year). При использовании в курсе Python он аккуратно использует большинство наших структур данных первого класса (словари, списки и кортежи).
- Инструмент 2: инструмент частоты букв . Используя word_data, сгенерированный синтаксическим анализатором Wordfile, создайте гистограмму частот английских букв.
- Инструмент 3: Общее количество и ранг . Используя данные word_data, отсортированные по убыванию частоты слов, постройте логарифмический график с количеством каждого слова по оси y и числовым ранжированием по оси x (т. е. наиболее распространенное слово в английском языке будет иметь ранг 1, следующий будет иметь ранг 2 и так далее). При желании включите возможность выделения интересующих слов (например, » вопросы » и « квест » по сюжету показаны в сводке выше).
Студенты увидят примерно линейную зависимость на графике. Удивительно, что частота слов и их ранг должны подчиняться степенному закону. Это известно как закон Ципфа.
- Инструмент 4: Средняя длина слова в год . Используя данные word_data, сгенерированные парсером Wordfile, постройте график средней длины английского слова во всех книгах с 1800 года по настоящее время. Результаты могут (а могут и не) вас удивить! Это довольно сложная задача, и в предоставленных материалах курса предлагаются две вспомогательные функции).
Часть 1
 Создайте простой параметризованный синтаксический анализатор CSV для извлечения информации об одном слове из файла CSV и сохранения результатов в ассоциативном массиве, сопоставляющем год и количество слов.
Создайте простой параметризованный синтаксический анализатор CSV для извлечения информации об одном слове из файла CSV и сохранения результатов в ассоциативном массиве, сопоставляющем год и количество слов.
 Результаты могут (а могут и не) вас удивить! Это довольно сложная задача, и в предоставленных материалах курса предлагаются две вспомогательные функции).
Результаты могут (а могут и не) вас удивить! Это довольно сложная задача, и в предоставленных материалах курса предлагаются две вспомогательные функции).Метаданные
| Резюме | Учащиеся анализируют 1-граммовый набор данных Google и сохраняют информацию в двух разных структурах данных. Используя первую (и более простую) структуру данных, учащиеся создают инструмент для визуализации относительной исторической популярности набора слов (в результате получается инструмент, очень похожий на Google Ngram Viewer). Используя вторую (и более сложную) структуру данных, включающую весь набор данных, учащиеся создают три инструмента, которые имеют дело со агрегированными свойствами данных. В частности, они создают инструменты для визуализации частоты букв в словах английского языка, для наблюдения за распределением популярности всех английских слов (таким образом раскрывая закон Ципфа) и для визуализации средней длины слова в английском языке с 1800-х годов по настоящее время (выявляя интересный результат). |
| Темы | обработка строк, массивы, ассоциативные массивы, файловый ввод-вывод, визуализация |
| Аудитория | КС1 |
| Сложность | Промежуточный. Все задание заняло у студентов от 8 до 12 часов (в течение двух недель). Продолжительность задания можно сократить, удалив из задания один или несколько инструментов визуализации. |
| Сильные стороны | Учащимся понравилось, что они смогли повторить крутой инструмент Google после трех недель опыта программирования. Есть много интересных вещей, которые можно узнать из набора данных с помощью инструментов, разработанных студентами. Исследователи по всему миру активно изучают этот набор данных, что упрощает кражу идей для дополнительных инструментов (дополнительные сведения см. в разделе вариантов ниже), включая невизуальные инструменты. |
| Слабые стороны | Функции описаны на высоком уровне, и более слабым студентам 1-го семестра CS может быть трудно понять, как преобразовать эти функции в хорошо организованный код. Например, при подсчете частот букв в английском языке они должны выяснить, что им нужно хранить 26 счетчиков, и, кроме того, каждый из этих 26 счетчиков должен быть нормализован суммой всех этих счетчиков. Разнообразие типов графиков данных на столь раннем этапе курса приводит к значительному количеству нового синтаксиса. Материалы заданий пытаются решить эту проблему, давая подсказки повсюду. Предоставленный 100-мегабайтный набор данных является лишь небольшим подмножеством полного 1-граммового набора данных, поэтому учащиеся могут быть немного разочарованы, обнаружив, что современные разговорные выражения и нишевые термины могут не появляться. #раскачиваться |
| Библиотечные зависимости | Требуется matplotlib на Python (легко установить с помощью широко доступных двоичных файлов). |
