Морфологический разбор слова «рассчитывать»
Слово можно разобрать в 2 вариантах, в зависимости от того, в каком контексте оно используется.
1 вариант разбора
Часть речи: Инфинитив
РАССЧИТЫВАТЬ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «РАССЧИТЫВАТЬ»
| Слово | Морфологические признаки |
|---|---|
| РАССЧИТЫВАТЬ |
|
Все формы слова РАССЧИТЫВАТЬ
РАССЧИТЫВАТЬ, РАССЧИТЫВАЮ, РАССЧИТЫВАЕМ, РАССЧИТЫВАЕШЬ, РАССЧИТЫВАЕТЕ, РАССЧИТЫВАЕТ, РАССЧИТЫВАЮТ, РАССЧИТЫВАЛ, РАССЧИТЫВАЛА, РАССЧИТЫВАЛО, РАССЧИТЫВАЛИ, РАССЧИТЫВАЯ, РАССЧИТЫВАВ, РАССЧИТЫВАВШИ, РАССЧИТЫВАЙ, РАССЧИТЫВАЙТЕ, РАССЧИТЫВАЮЩИЙ, РАССЧИТЫВАЮЩЕГО, РАССЧИТЫВАЮЩЕМУ, РАССЧИТЫВАЮЩИМ, РАССЧИТЫВАЮЩЕМ, РАССЧИТЫВАЮЩАЯ, РАССЧИТЫВАЮЩЕЙ, РАССЧИТЫВАЮЩУЮ, РАССЧИТЫВАЮЩЕЮ, РАССЧИТЫВАЮЩЕЕ, РАССЧИТЫВАЮЩИЕ, РАССЧИТЫВАЮЩИХ, РАССЧИТЫВАЮЩИМИ, РАССЧИТЫВАВШИЙ, РАССЧИТЫВАВШЕГО, РАССЧИТЫВАВШЕМУ, РАССЧИТЫВАВШИМ, РАССЧИТЫВАВШЕМ, РАССЧИТЫВАВШАЯ, РАССЧИТЫВАВШЕЙ, РАССЧИТЫВАВШУЮ, РАССЧИТЫВАВШЕЮ, РАССЧИТЫВАВШЕЕ, РАССЧИТЫВАВШИЕ, РАССЧИТЫВАВШИХ, РАССЧИТЫВАВШИМИ
2 вариант разбора
Часть речи: Инфинитив
РАССЧИТЫВАТЬ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «РАССЧИТЫВАТЬ»
| Слово | Морфологические признаки |
|---|---|
| РАССЧИТЫВАТЬ |
|
Все формы слова РАССЧИТЫВАТЬ
РАССЧИТЫВАТЬ, РАССЧИТЫВАЮ, РАССЧИТЫВАЕМ, РАССЧИТЫВАЕШЬ, РАССЧИТЫВАЕТЕ, РАССЧИТЫВАЕТ, РАССЧИТЫВАЮТ, РАССЧИТЫВАЛ, РАССЧИТЫВАЛА, РАССЧИТЫВАЛО, РАССЧИТЫВАЛИ, РАССЧИТЫВАЯ, РАССЧИТЫВАВ, РАССЧИТЫВАВШИ, РАССЧИТЫВАЙ, РАССЧИТЫВАЙТЕ, РАССЧИТЫВАЮЩИЙ, РАССЧИТЫВАЮЩЕГО, РАССЧИТЫВАЮЩЕМУ, РАССЧИТЫВАЮЩИМ, РАССЧИТЫВАЮЩЕМ, РАССЧИТЫВАЮЩАЯ, РАССЧИТЫВАЮЩЕЙ, РАССЧИТЫВАЮЩУЮ, РАССЧИТЫВАЮЩЕЮ, РАССЧИТЫВАЮЩЕЕ, РАССЧИТЫВАЮЩИЕ, РАССЧИТЫВАЮЩИХ, РАССЧИТЫВАЮЩИМИ, РАССЧИТЫВАВШИЙ, РАССЧИТЫВАВШЕГО, РАССЧИТЫВАВШЕМУ, РАССЧИТЫВАВШИМ, РАССЧИТЫВАВШЕМ, РАССЧИТЫВАВШАЯ, РАССЧИТЫВАВШЕЙ, РАССЧИТЫВАВШУЮ, РАССЧИТЫВАВШЕЮ, РАССЧИТЫВАВШЕЕ, РАССЧИТЫВАВШИЕ, РАССЧИТЫВАВШИХ, РАССЧИТЫВАВШИМИ, РАССЧИТЫВАЕМЫЙ, РАССЧИТЫВАЕМОГО, РАССЧИТЫВАЕМОМУ, РАССЧИТЫВАЕМЫМ, РАССЧИТЫВАЕМОМ, РАССЧИТЫВАЕМАЯ, РАССЧИТЫВАЕМОЙ, РАССЧИТЫВАЕМУЮ, РАССЧИТЫВАЕМОЮ, РАССЧИТЫВАЕМА, РАССЧИТЫВАЕМОЕ, РАССЧИТЫВАЕМО, РАССЧИТЫВАЕМЫЕ, РАССЧИТЫВАЕМЫХ, РАССЧИТЫВАЕМЫМИ, РАССЧИТЫВАЕМЫ
Разбор слова по составу рассчитывать
рассчитыва
ть
| Основа слова | рассчитыва |
|---|---|
| Приставка | рас |
| Корень | счит |
| Суффикс | ыва |
| Глагольное окончание | ть |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «РАССЧИТЫВАТЬ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «рассчитывать»
1
Асов привык рассчитывать только на себя, ему просто не на кого было рассчитывать.
Мародёры, Александр Ансуз, 2009г.
2
Решайтесь, я должен понять, на кого и на что мне рассчитывать, или мне ни на кого не рассчитывать, как это всегда и было.
Что сказал Бенедикто. Часть 2, Татьяна Витальевна Соловьева, 2013г.
3
Просили, просили приказчика, четвертый день прошел, а рассчитывать нас не рассчитывает…
На горах, Павел Мельников-Печерский, 1875-1881г.
4
«Положим, – продолжал мысленно рассчитывать Рикс, – теперь, ввиду отношения к нему императора, есть кому заплатить долги.
5
Но ведь если он уедет, то мы лишимся одного из главных помощников в этом деле, на которого мы можем рассчитывать.
Тайна герцога, Михаил Волконский, 1912г.
Найти еще примеры предложений со словом РАССЧИТЫВАТЬ
«РаСчитывать» или «раССчитывать» как правильно пишется слово
Краткое описание
В русском языке есть правила, которые разъясняют, как пишется «рассчитывать». Изучаемый глагол был образован от слова «считать» путём прибавления префикса «рас». Среди распространённых однокоренных слов можно назвать «считать», «счёт», из-за чего правильно писать «рассчитывать». Такая норма написания изучаемого примера сложилась исторически. Если убрать букву -с из корня, то в итоге изменится первоначальное значение глагола.
Среди распространённых однокоренных слов можно назвать «считать», «счёт», из-за чего правильно писать «рассчитывать». Такая норма написания изучаемого примера сложилась исторически. Если убрать букву -с из корня, то в итоге изменится первоначальное значение глагола.
При выборе однокоренных слов не нужно опираться на существительное «расчёт», основное отличиекоторого в том, что корень утратил согласный «с», из-за чего стал производным безаффиксного способа и перегласовки. Слово «расчёт» пишется только с одной буквой -с. «Рассчитано», «рассчитать» (причастия), а также «рассчитывается» (возвратный глагол) сохранили своё морфологическое строение. Изучаемые примеры объединяет только тот факт, что они были образованы благодаря добавлению приставки -рас.
Лучше запомнить нормы правописания можно в том случае, если выполнить морфологический и морфемный анализ слова, а также составить правильную транскрипцию.
Основные примеры предложений:
- Все родственники пытались доказать, что она может рассчитывать на поддержку близких, но Марина будто не слышала их и ничего вокруг не замечала.

- Его внешность и обаятельная улыбка добавляли ему уверенности, а также давали основание рассчитывать на свои силы и целеустремлённость.
- Дорога была широкой, благодаря чему можно было спокойно передвигаться, а также рассчитывать на свободную полосу.
- Научись правильно рассчитывать свои силы, и тогда ты точно будешь всё успевать.
- В жизни можно рассчитывать только на себя.
- В этом месяце следует рассчитывать на получение вознаграждения за приложенные усилия.
Для проверки нельзя использовать следующие слова: расчитывать, расчитать, расчитаться, ращитывать, ращитать, подрасчитать, рассчетный, расчитаться. В противном случае будет допущена грубая ошибка. Только ответственный подход к изучению правописания позволяет повысить итоговый уровень языкознания. Благодаря этому можно точно знать, когда нужно писать слова слитно или раздельно, а также использовать удвоение согласных.
Фонетический анализ
По условиям школьной программы ученикам предстоит изучить сразу несколько разделов о родном языке. В каждом случае возникает необходимость произвести развёрнутый анализ определённой языковой единицы согласно действующим правилам. Одним из таких разделов является фонетика. Фонетический анализ определённого слова подразумевает то, что в итоге человек будет знать всё о том, что такое звуки речи, какими они бывают, а также как соотносятся с буквами.
В каждом случае возникает необходимость произвести развёрнутый анализ определённой языковой единицы согласно действующим правилам. Одним из таких разделов является фонетика. Фонетический анализ определённого слова подразумевает то, что в итоге человек будет знать всё о том, что такое звуки речи, какими они бывают, а также как соотносятся с буквами.
Звуко-буквенный разбор должен быть выполнен по чёткому плану и с разработанной последовательностью действий. Нарушение этих правил чревато серьёзными ошибками. В начальной школе схема фонетического анализа выглядит так:
- Правильная запись изучаемого слова (с точки зрения орфографии).
- Постановка ударения. Этот этап может содержать дополнительное задание, которое связано с тем, что ученик должен уметь правильно произносить лексему. К примеру: в слове «договор» нужно поставить ударение на последний слог, а не на первый.
- Следует разбить пример на слоги и написать точное их количество.
- Транскрипцию выполняют в квадратных скобках. Учащемуся необходимо изобразить такой вариант лексемы, который он слышит и произносит.
- Каждый звук записывают в столбик. Должно присутствовать развёрнутое описание характеристик согласных и гласных.
- На финальном этапе остаётся подсчитать количество звуков и букв.
Чтобы хорошо разбираться в том, что значит фонетический анализ, необходимо понимать принципы графического изображения информации. Важно записывать не сами звуки, а морфемы.
В соответствии с требованиями звуко-буквенного анализа «рассчитывать» состоит из четырёх слогов: ра-ссчи-ты-вать. Ударение падает на второй слог. Транскрипция: [рас:ч’итыват’]. Фонетический разбор:
- Р [р] — согласн., звонк. непарн., твёрд.
- А [а] — гласн., безударн.
- С [с:] — согласн., глух. парн., твёрд.
- С — не образовывает звука в этом примере.
- Ч [ч’] — согласный, глухой непарный, шипящий.
- И [и] — гласный, ударный.
- Т [т] — согласн., глух. парн., твёрд.
- Ы [ы] — гласн., безударн.
- В [в] — согласный, звонкий парный, твёрдый.
- А [а] — гласный, безударный.
- Т [т’] — согласный, глухой парный, мягкий.
- Ь — не обозначает звука.

Всего в рассматриваемом слове 12 букв и 10 звуков.
Морфологический разбор
Когда возникает необходимость разобраться с тем, как правильно писать — «рассчитывается» или «расчитывается», можно провести морфологический разбор этого глагола — один из самых известных видов анализа. Если ученик не постарается максимально изучить морфологию, то он не сможет сдать экзамен по русскому языку. Эта тема содержит много интересных правил и исключений, которые позволяют повысить уровень грамотности учащихся.
Морфологический анализ основан на разборе слова как части речи. Классический морфологический разбор состоит всего из трёх этапов:
- Выписать в тетрадь слово именно в той форме, в которой оно было употреблено в предложении. Важно определить часть речи. Слово должно быть поставлено в начальную форму.
- Следует перечислить все присутствующие грамматические признаки.
- На финальном этапе остаётся указать, каким именно членом предложения является слово.
По описанной схеме разбираются абсолютно все части речи русского языка. Но так как в каждом случае действуют свои грамматические признаки, то определённый план анализа прилагательного, существительного или глагола будет незначительно отличаться.
Изучаемое слово «рассчитывать» может быть проанализировано двумя способами. Наиболее подходящий вариант напрямую зависит от того, в составе какого словосочетания либо предложения оно находится.
Во втором случае «рассчитывать» тоже выступает в роли глагола. Начальная форма — «рассчитывать». Постоянные признаки: первое спряжение, переходной, несовершенный вид. Непостоянные признаки — изъявительное наклонение. Может быть разным членом предложения, из-за чего нужно предварительно изучить смысл изложенной информации.
Морфемный состав слова
Распространённое в русском языке слово «рассчитать» пишется только с двумя буквами -с. Развёрнутый морфемный разбор — это анализ присутствующих в слове морфем. В этом случае действуют свои правила, которые нельзя оставлять без внимания. Морфема представляет собой минимальную неделимую значимую часть слова, которая нужна в русском языке для образования совершенно новых слов и форм. Только качественный разбор позволяет в полном объёме проанализировать состав морфем и их назначение.
В этом случае действуют свои правила, которые нельзя оставлять без внимания. Морфема представляет собой минимальную неделимую значимую часть слова, которая нужна в русском языке для образования совершенно новых слов и форм. Только качественный разбор позволяет в полном объёме проанализировать состав морфем и их назначение.
Именно морфемный разбор помогает учащимся разобраться в том, какие именно морфемы входят в состав анализируемого глагола. Специалисты рекомендуют придерживаться стандартной схемы, чтобы итоговый результат соответствовал всем требованиям:
- Первым делом выписывают слово для морфемного анализа без изменений. Следует определить часть речи.
- Окончание определяют только в том случае, если слово может быть изменено. Глагол следует склонять либо спрягать. У неизменяемых слов (наречие, деепричастие, некоторые имена существительные, прилагательные, служебные части речи) окончания нет.
- Определить основу.
- Выделить корень. Для избежания ошибок следует подобрать однокоренные слова, но нельзя забывать, что можно столкнуться с омонимичными корнями.
- Нужно выделить оставшиеся морфемы: суффиксы, приставки, соединительные гласные.

В некоторых учебниках можно встретить ошибочную информацию о том, что морфемный анализ и разбор слова по составу является одним и тем же, но это совершенно не так. В первом случае используют определённую словоформу без внесения изменений. А вот для анализа по составу следует применить начальную форму (например: ходили — ходить). Для морфемного разбора не указывают тот факт, является ли слово производным, а при словообразовательном анализе этот пункт обязателен.
Анализируемое слово «рассчитывать» является глаголом. Основа разбираемого примера — «рассчитыва». Корректный морфемный анализ: приставка (рас) + корень (счит) + суффикс (ыва) + суффикс (ть). Этот разбор позволяет корректно использовать глагол во время изложения информации в письменном виде. Существует проверочное слово для «рассчитать»: пересчитывание, досчитаться, рассчитывать, подсчитываться.
Этот разбор позволяет корректно использовать глагол во время изложения информации в письменном виде. Существует проверочное слово для «рассчитать»: пересчитывание, досчитаться, рассчитывать, подсчитываться.
Именно языкознанию каждый человек должен уделять повышенное внимание, так как от усвоенных правил и примеров предложений напрямую зависит уровень устной и письменной грамотности. Для корректного написания изучаемого глагола следует ознакомиться с основными синонимами к слову «рассчитывать»: собираться, думать, предполагать, надеяться, планировать, расчётный, расчётливый, анализировать, решать, предусматривать, полагаться, обдумывать, намереваться, сокращать, посчитать, просчитать, пересчитать. Выбор определённого примера зависит от контекста предложения, а также от посыла, который нужно передать конечному читателю.
Если ученик увлекается стихами, тогда собственные идеи и мысли можно изложить при помощи правильно подобранной рифмы: отсчитывать, высчитывать, прочитывать, перевоспитывать, подпитывать, считывать, дочитывать, учитывать, воспитывать, почитывать, впитывать, отчитывать. Во время написания текстов может пригодиться склонение слова по падежам:
Во время написания текстов может пригодиться склонение слова по падежам:
- Именительный — рассчитывающий.
- Родительный — рассчитывающего.
- Винительный — рассчитывающего.
- Творительный — рассчитывающим.
- Предложный — рассчитывающем.
Все нюансы должны быть максимально учтены, так как русский язык является весьма интересной, многогранной и сложной наукой. Лучше усвоить все описанные правила помогут примеры сложных предложений:
- Впрочем, основные средства фирма рассчитывает получить благодаря размещению своих акций на крупных иностранных биржевых площадках, которых сегодня много.
- По правде говоря, Диана никак не рассчитывала увидеть здесь членов семьи, она вчера думала насчёт того, что распрощается с жизнью в одиночестве.
- Дайте ей понять, что она в любой ситуации может рассчитывать на нас, мы всегда, независимо ни от чего, будем с ней.
- Лучше заранее рассчитаться за выбранные товары, перепроверив их реальную стоимость.

Если ответственно подойти к изучению изложенного материала, то в итоге можно существенно повысить уровень языкознания, чтобы не допускать ошибки в элементарных словах.
Еще слова со сложным написанием:
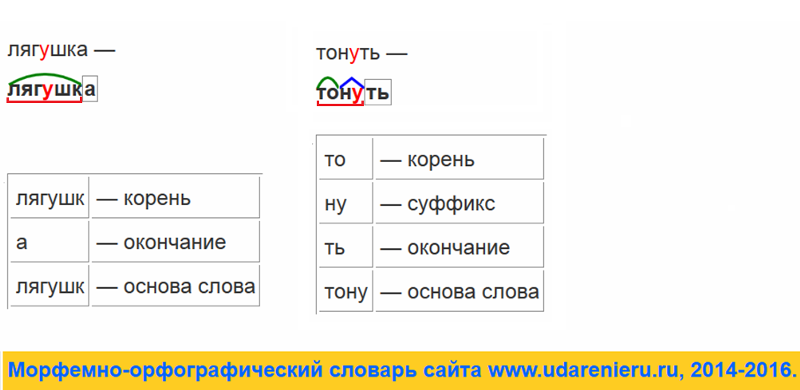
- рассчитана
| Приставка — раз | |
Корень слова разделить | Корень — дел |
Суффикс слова разделить | Суффикс — и,ть |
Окончание слова разделить | Окончание — нулевое окончание. |
Основа слова разделить | Основа — раздели |
 – 0
– 0 Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;| раз | приставка |
| дел | корень |
| и | суффикс |
| ть | глагольное окончание |
Сходные по морфемному строению слова
Делаем Карту слов лучше вместе
Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов.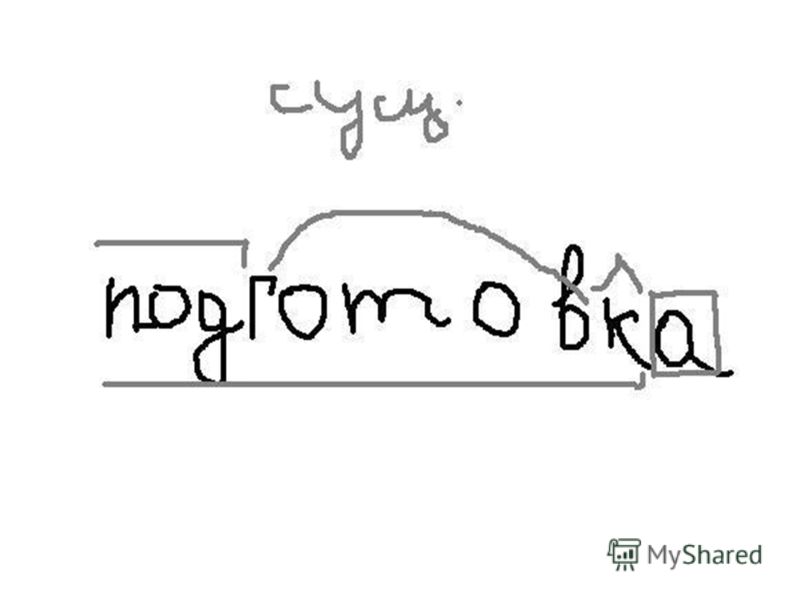 Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Я обязательно научусь отличать широко распространённые слова от узкоспециальных.
Насколько понятно значение слова иссыхать (глагол), иссыхает:
Ассоциации к слову «разделить»
Синонимы к слову «разделить»
Предложения со словом «разделить»
- Мы что, сами безработные или опасаемся, что вскоре можем разделить их судьбу?
- Ты хотел разделить чистоту своего пламени, но разделить её было не с кем.
- Скоро студию пришлось разделить на три помещения, и сама жизнь поддержала идею объединения.
- (все предложения)
Цитаты из русской классики со словом «разделить»
- – Ах какие они все глупые, и рыбки и птички! А я бы разделила все – и червячка и краюшку, и никто бы не ссорился. Недавно я разделила четыре яблока… Папа приносит четыре яблока и говорит: «Раздели пополам – мне и Лизе». Я и разделила на три части: одно яблоко дала папе, другое – Лизе, а два взяла себе.
 Я и разделила на три части: одно яблоко дала папе, другое – Лизе, а два взяла себе.
Я и разделила на три части: одно яблоко дала папе, другое – Лизе, а два взяла себе.Сочетаемость слова «разделить»
Значение слова «разделить»
РАЗДЕЛИ́ТЬ , –делю́, –де́лишь; прич. страд. прош. разделённый, –лён, –лена́, –лено́; сов., перех. 1. (несов. разделять и делить). Произвести деление чего-л. на части, распределить по частям. Разделить яблоко на пять частей. Разделить землю на участки. Разделить книгу на главы. (Малый академический словарь, МАС)
Отправить комментарий
Дополнительно
Значение слова «разделить»
РАЗДЕЛИ́ТЬ , –делю́, –де́лишь; прич. страд. прош. разделённый, –лён, –лена́, –лено́; сов., перех. 1. (несов. разделять и делить). Произвести деление чего-л. на части, распределить по частям. Разделить яблоко на пять частей. Разделить землю на участки. Разделить книгу на главы.
Предложения со словом «разделить»:
Мы что, сами безработные или опасаемся, что вскоре можем разделить их судьбу?
Ты хотел разделить чистоту своего пламени, но разделить её было не с кем.
Скоро студию пришлось разделить на три помещения, и сама жизнь поддержала идею объединения.
Синонимы к слову «разделить»
Ассоциации к слову «разделить»
Сочетаемость слова «разделить»
Морфология
Карта слов и выражений русского языка
Онлайн-тезаурус с возможностью поиска ассоциаций, синонимов, контекстных связей и примеров предложений к словам и выражениям русского языка.
Справочная информация по склонению имён существительных и прилагательных, спряжению глаголов, а также морфемному строению слов.
Сайт оснащён мощной системой поиска с поддержкой русской морфологии.
Сегментация сублексических морфем в обучении английскому языку 15-месячных детей
Введение
В большинстве человеческих языков важные компоненты лингвистической структуры переносятся аффиксами или связанными морфемами. Аффиксы в языке составляют относительно небольшой, но часто встречающийся набор форм, которые появляются как части слов, но никогда не встречаются без основы. Хотя связанные морфемы всегда встречаются как часть более крупного слова, они рассматриваются как имеющие независимый статус в силу того факта, что они продуктивно сочетаются с основами и другими грамматическими элементами систематическим и предсказуемым образом. Например, любой корень английского глагола, который изменяется с суффиксом -ing , которому предшествует форма вспомогательного глагола, be , приводит к форме глагола, отмеченной особым временем и аспектом: настоящее прогрессивное (например, она читает ). Таким образом, овладение морфологической системой языка предполагает приобретение обобщений об отношениях между формальными элементами (например, вспомогательное-— и -ing ), а также о семантических и функциональных свойствах языка, которые представлены в морфологической форме. система (например, наклонение, вид, число и т.
Аффиксы в языке составляют относительно небольшой, но часто встречающийся набор форм, которые появляются как части слов, но никогда не встречаются без основы. Хотя связанные морфемы всегда встречаются как часть более крупного слова, они рассматриваются как имеющие независимый статус в силу того факта, что они продуктивно сочетаются с основами и другими грамматическими элементами систематическим и предсказуемым образом. Например, любой корень английского глагола, который изменяется с суффиксом -ing , которому предшествует форма вспомогательного глагола, be , приводит к форме глагола, отмеченной особым временем и аспектом: настоящее прогрессивное (например, она читает ). Таким образом, овладение морфологической системой языка предполагает приобретение обобщений об отношениях между формальными элементами (например, вспомогательное-— и -ing ), а также о семантических и функциональных свойствах языка, которые представлены в морфологической форме. система (например, наклонение, вид, число и т. д.). Однако, прежде чем учащиеся смогут получить морфологические факты о своем языке, они должны сначала идентифицировать подлексические комбинаторные единицы: они должны идентифицировать связанные морфемы.
д.). Однако, прежде чем учащиеся смогут получить морфологические факты о своем языке, они должны сначала идентифицировать подлексические комбинаторные единицы: они должны идентифицировать связанные морфемы.
Первое продуктивное использование детьми связанных морфем (и функциональных категорий в более широком смысле, включая служебные слова) задерживается по сравнению с их первоначальным производством содержательных слов. Например, дети обычно произносят свои первые слова примерно в 12 месяцев, но только в возрасте от 18 до 24 месяцев, когда они начинают комбинировать слова, дети, изучающие английский язык, начинают производить морфемы, когда они необходимы (Brown, 1973; de Villiers and de Villiers, 1973), и даже в этом случае мастерство может ограничиваться небольшим числом форм.
Из исследований восприятия и понимания также получены доказательства того, что младенцы, изучающие английский язык, начали формировать представление о сублексических морфемах и узнали кое-что о паттернах, в которых морфемы обычно встречаются, к тому времени, когда они начинают произносить двухсловные слова. комбинации (Santelmann and Jusczyk, 1998; Golinkoff et al., 2001; Soderstrom et al., 2002). Например, Santelmann и Jusczyk (1998) показали, что 18-месячные младенцы предпочитали слушать грамматические предложения, в которых слово оканчивается на морфему 9.0005 -ing следует за служебным словом — это (1a), над неграмматическими предложениями, в которых слово следует за служебным словом может (1b).
комбинации (Santelmann and Jusczyk, 1998; Golinkoff et al., 2001; Soderstrom et al., 2002). Например, Santelmann и Jusczyk (1998) показали, что 18-месячные младенцы предпочитали слушать грамматические предложения, в которых слово оканчивается на морфему 9.0005 -ing следует за служебным словом — это (1a), над неграмматическими предложениями, в которых слово следует за служебным словом может (1b).
(1) а. В пекарне все пекут хлеб.
б. *В пекарне каждый может печь хлеб.
Однако Santelmann и Jusczyk не обнаружили такого дифференцированного предпочтения у 15-месячных детей. Точно так же для словоизменения -s (множественное число и третье лицо единственного числа) Soderstrom (2003) и Soderstrom et al. (2002) показали, что 19Месячные замечали, когда нарушались нормальные зависимости между аффиксом и соседними служебными словами, а 16-месячные — нет. Однако Содерстром и соавт. (2007) сообщили о некоторых условиях, при которых даже 16-месячные дети проявляют чувствительность к неуместному аффиксу -s . В совокупности эти эксперименты показывают, что к 18 месяцам младенцы, изучающие английский язык, усваивают морфосинтаксические паттерны, включающие ряд сублексических морфем, и предполагают, что чувствительность младенцев к некоторым из этих паттернов развивается в 16 месяцев. Как следствие, эти исследования также предоставляют данные о том, когда учащиеся представляют аффиксы в виде отдельных форм, то есть отдельно от основ, к которым они прикреплены, поскольку младенцы должны сначала сегментировать аффиксы как отдельные единицы, прежде чем изучать модели, в которые они вносят свой вклад.
В совокупности эти эксперименты показывают, что к 18 месяцам младенцы, изучающие английский язык, усваивают морфосинтаксические паттерны, включающие ряд сублексических морфем, и предполагают, что чувствительность младенцев к некоторым из этих паттернов развивается в 16 месяцев. Как следствие, эти исследования также предоставляют данные о том, когда учащиеся представляют аффиксы в виде отдельных форм, то есть отдельно от основ, к которым они прикреплены, поскольку младенцы должны сначала сегментировать аффиксы как отдельные единицы, прежде чем изучать модели, в которые они вносят свой вклад.
Аналогичные эксперименты с младенцами, изучающими немецкий язык (Höhle et al., 2006), голландский (van Heugten and Johnson, 2010) и французский язык (van Heugten and Shi, 2010; Nazzi et al., 2011), в целом подтвердили вывод о том, что младенцы в возрасте от 17 до 24 месяцев становятся чувствительными к морфосинтаксическим паттернам, включающим аффиксы, и к функциональным элементам в более широком смысле (van Heugten and Shi, 2009; Shi and Melançon, 2010). В то же время эти кросс-лингвистические исследования позволили глубже понять дистрибутивные и лингвистические факторы, влияющие на то, как младенцы обрабатывают морфосинтаксические зависимости. Однако эти исследования оставляют открытым вопрос о репрезентации младенцами сублексических морфем в период развития до того, как они проявят чувствительность к зависимостям между морфосинтаксическими единицами. То есть непонятно точно , почему 15-месячных детей не реагировали по-разному на (1a) и (1b) в исследовании Сантельмана и Ющика (1998). Имеются данные о том, что между 11 и 14 месяцами младенцы приобретают представление о служебных словах (Shi et al., 2006a,b), поэтому поведение 15-месячных детей вряд ли связано с неспособностью различать на в (1а) из банки в (1б). Однако может случиться так, что 15-месячные дети просто не представляют — как дискретную единицу и, следовательно, не имеют возможности представить паттерны и зависимости, включающие эту морфему.
В то же время эти кросс-лингвистические исследования позволили глубже понять дистрибутивные и лингвистические факторы, влияющие на то, как младенцы обрабатывают морфосинтаксические зависимости. Однако эти исследования оставляют открытым вопрос о репрезентации младенцами сублексических морфем в период развития до того, как они проявят чувствительность к зависимостям между морфосинтаксическими единицами. То есть непонятно точно , почему 15-месячных детей не реагировали по-разному на (1a) и (1b) в исследовании Сантельмана и Ющика (1998). Имеются данные о том, что между 11 и 14 месяцами младенцы приобретают представление о служебных словах (Shi et al., 2006a,b), поэтому поведение 15-месячных детей вряд ли связано с неспособностью различать на в (1а) из банки в (1б). Однако может случиться так, что 15-месячные дети просто не представляют — как дискретную единицу и, следовательно, не имеют возможности представить паттерны и зависимости, включающие эту морфему. С другой стороны, они могут иметь дискретное представление -ing , но еще не изучили шаблоны зависимостей, в которых участвует -ing . Решение этого вопроса важно для понимания динамики морфосинтаксического развития младенцев, а также для обеспечения основы для дальнейшего изучения механизмов морфосинтаксического усвоения младенцев.
С другой стороны, они могут иметь дискретное представление -ing , но еще не изучили шаблоны зависимостей, в которых участвует -ing . Решение этого вопроса важно для понимания динамики морфосинтаксического развития младенцев, а также для обеспечения основы для дальнейшего изучения механизмов морфосинтаксического усвоения младенцев.
Недавнее исследование младенцев, изучающих французский язык, имеет отношение к этому вопросу. Marquis and Shi (2012) познакомили 11-месячных детей, изучающих французский язык, с псевдокорнем (то есть бессмысленным слогом). Затем они записали время прослушивания младенцами отрывков, содержащих псевдокорень, «измененный» с настоящим французским суффиксом /e/, и предложений с незнакомым псевдокорнем, также заканчивающимся на /e/. Младенцы дольше слушали предложения, содержащие измененный фамильярный псевдокорень, что позволяет предположить, что младенцы отделили окончание /e/ от остальной части слова и узнали знакомую основу. Различные младенцы, которые тестировались на знакомых и незнакомых псевдокорнях, склоняемых с /u/, который не является французским аффиксом, не слушали предпочтительно ни один тип стимула. Таким образом, реакцию младенцев, предпочитающих фамильярные или незнакомые основы с суффиксом /е/, нельзя объяснить фонетическим сходством знакомой и тестируемой форм; скорее, поведение младенцев, по-видимому, определялось факторами, связанными со статусом /е/ как морфемы. Исследование Маркиза и Ши предоставляет самые ранние доказательства сегментации подлексических морфем у младенцев.
Таким образом, реакцию младенцев, предпочитающих фамильярные или незнакомые основы с суффиксом /е/, нельзя объяснить фонетическим сходством знакомой и тестируемой форм; скорее, поведение младенцев, по-видимому, определялось факторами, связанными со статусом /е/ как морфемы. Исследование Маркиза и Ши предоставляет самые ранние доказательства сегментации подлексических морфем у младенцев.
Результаты Marquis and Shi (2012) показывают, что у младенцев к концу первого года жизни начинают формироваться представления о связанных морфемах, по крайней мере, в случае младенцев, изучающих французский язык. При рассмотрении вопроса о репрезентации -ing учащимися английского языка возникает искушение распространить этот вывод на английский язык и сделать вывод, что английские 15-месячные дети должны поэтому представлять -ing как дискретную форму. Однако между французским и английским языками есть важные различия, которые могут повлиять на то, как выводы Маркиза и Ши из французского обобщаются на английский язык. Прежде всего, флективная система французского языка в целом богаче, чем английская. Во французском языке отмечаются как грамматический род, так и число, а также согласование рода и числа между существительными, местоимениями, определителями и прилагательными. Эти свойства могут привести к тому, что младенцы, изучающие французский язык, будут обращать внимание, обнаруживать и обрабатывать суффиксы в более раннем возрасте по сравнению с младенцами, изучающими английский и другие языки, в которых открытая морфология относительно бедна. Поэтому важно проверить находку на других языках.
Прежде всего, флективная система французского языка в целом богаче, чем английская. Во французском языке отмечаются как грамматический род, так и число, а также согласование рода и числа между существительными, местоимениями, определителями и прилагательными. Эти свойства могут привести к тому, что младенцы, изучающие французский язык, будут обращать внимание, обнаруживать и обрабатывать суффиксы в более раннем возрасте по сравнению с младенцами, изучающими английский и другие языки, в которых открытая морфология относительно бедна. Поэтому важно проверить находку на других языках.
Существуют также методологические соображения, которые ограничивают возможность обобщения выводов Marquis and Shi (2012). В их экспериментах младенцев знакомили с предварительно сегментированной основой, и им нужно было обрабатывать и распознавать эту основу только в сочетании с суффиксом. Если ранние представления младенцев о сублексических формах неустойчивы, их способность обнаруживать и обрабатывать связанные морфемы может быть ограничена. Требования к обработке для отслеживания одной предварительно сегментированной основы в ходе эксперимента могут быть достаточно простыми для обнаружения морфемы и последующей сегментации основы, но сублексическая обработка может быть затруднена в более сложных ситуациях. Воспроизведение результатов с различными экспериментальными планами, особенно с теми, которые предъявляют более высокие требования к ресурсам обработки и памяти, важно для установления надежности ранних представлений морфологии младенцев. В каждом эксперименте настоящего исследования младенцы подвергались воздействию множества стеблей, изогнутых с помощью -ing . Чтобы показать признаки морфологической сегментации, они должны были отделить основы от этих форм, запомнить их в течение периода ознакомления, а затем распознать их в ходе тестовых проб. Хотя младенцам не нужно было бы сегментировать и сохранять каждый стебель, чтобы продемонстрировать надежный эффект сегментации, им пришлось бы отслеживать несколько, что увеличивало сложность и потребность в ресурсах.
Требования к обработке для отслеживания одной предварительно сегментированной основы в ходе эксперимента могут быть достаточно простыми для обнаружения морфемы и последующей сегментации основы, но сублексическая обработка может быть затруднена в более сложных ситуациях. Воспроизведение результатов с различными экспериментальными планами, особенно с теми, которые предъявляют более высокие требования к ресурсам обработки и памяти, важно для установления надежности ранних представлений морфологии младенцев. В каждом эксперименте настоящего исследования младенцы подвергались воздействию множества стеблей, изогнутых с помощью -ing . Чтобы показать признаки морфологической сегментации, они должны были отделить основы от этих форм, запомнить их в течение периода ознакомления, а затем распознать их в ходе тестовых проб. Хотя младенцам не нужно было бы сегментировать и сохранять каждый стебель, чтобы продемонстрировать надежный эффект сегментации, им пришлось бы отслеживать несколько, что увеличивало сложность и потребность в ресурсах. Кроме того, требование к младенцам выполнять сегментацию на этапе ознакомления, а не во время теста, — противоположность метода Маркиза и Ши, — также может увеличить сложность задачи. Когда голая основа дается первой, это может помочь младенцам в обнаружении соответствующих слов в тестовых отрывках, что несколько облегчает задачу обнаружения основы в измененной форме. Однако, когда флективные формы даются первыми (особенно когда они находятся в пассажах, как в экспериментах 2–4), младенцы не имеют этого дополнительного ориентира для морфологической сегментации.
Кроме того, требование к младенцам выполнять сегментацию на этапе ознакомления, а не во время теста, — противоположность метода Маркиза и Ши, — также может увеличить сложность задачи. Когда голая основа дается первой, это может помочь младенцам в обнаружении соответствующих слов в тестовых отрывках, что несколько облегчает задачу обнаружения основы в измененной форме. Однако, когда флективные формы даются первыми (особенно когда они находятся в пассажах, как в экспериментах 2–4), младенцы не имеют этого дополнительного ориентира для морфологической сегментации.
Таким образом, выводы Marquis and Shi (2012) предоставляют важные доказательства того, что младенцы могут представлять сублексические морфемы задолго до того, как они смогут отслеживать модели зависимости, в которых они встречаются. Однако типологические различия между английским и французским языками, а также единый методологический контекст результатов дают лишь косвенные доказательства в отношении морфологических представлений у изучающих английский язык. Таким образом, вопрос о том, лечат ли 15-месячные дети, изучающие английский язык, -ing как отдельная форма [и, таким образом, их кажущаяся нечувствительность к нарушению в (1b)] остается открытым. Настоящее исследование обеспечивает более прямую оценку морфологических представлений 15-месячных детей, изучающих английский язык. В экспериментах 1–3 используются несколько дизайнов и наборов стимулов, чтобы предоставить сходящиеся доказательства того, что 15-месячные дети, изучающие английский язык, рассматривают -ing как отдельную единицу. Доказательства дискретной репрезентации выводятся из способности младенцев сегментировать -ing , в отличие от неморфемных суффиксов, от концов новых слов. Основанный на формальном сходстве сублексической сегментации и сегментации слов, Эксперимент 4 продолжает проверку доказательств сублексической сегментации у 8-месячных детей, которые, как было показано, выделяют слова из непрерывной речи (Jusczyk and Aslin, 19).95; Саффран и др.
Таким образом, вопрос о том, лечат ли 15-месячные дети, изучающие английский язык, -ing как отдельная форма [и, таким образом, их кажущаяся нечувствительность к нарушению в (1b)] остается открытым. Настоящее исследование обеспечивает более прямую оценку морфологических представлений 15-месячных детей, изучающих английский язык. В экспериментах 1–3 используются несколько дизайнов и наборов стимулов, чтобы предоставить сходящиеся доказательства того, что 15-месячные дети, изучающие английский язык, рассматривают -ing как отдельную единицу. Доказательства дискретной репрезентации выводятся из способности младенцев сегментировать -ing , в отличие от неморфемных суффиксов, от концов новых слов. Основанный на формальном сходстве сублексической сегментации и сегментации слов, Эксперимент 4 продолжает проверку доказательств сублексической сегментации у 8-месячных детей, которые, как было показано, выделяют слова из непрерывной речи (Jusczyk and Aslin, 19).95; Саффран и др. , 1996; Ющик и др., 1999; Пелуччи и др., 2009).
, 1996; Ющик и др., 1999; Пелуччи и др., 2009).
Эксперимент 1
В этом эксперименте проверялась гипотеза о том, что 15-месячные дети, изучающие английский язык, представляют суффикс — ing как отдельную единицу и что представление в виде отдельной формы влияет на синтаксический анализ и представление слов младенцами.
Младенцы были ознакомлены с новыми словами, произносимыми в одиночестве. Некоторые слова оканчивались английской морфемой -ing (например, lerjoving ), а другие заканчивались последовательностью фонем /ɑt/ ( -ot , например, jemontot ), в то время как другие систематически не имели общего окончания. Прогноз заключался в том, что если 15-месячные дети будут представлять суффикс -ing как отдельную сущность, то они с большей вероятностью будут сегментировать -ing от концов новых слов, чем псевдосуффикс -. от . В результате процесса сегментации младенцы сохраняли представление о полученных в результате изолированных новых «стеблях» (9). 0005 -ing основы , например, lerjov , в приведенном выше примере). Так как, согласно гипотезе, младенцы не будут выполнять такого рода сублексическую сегментацию со словами, оканчивающимися на — от (или будут делать это значительно реже), они не должны формировать сублексические репрезентации основ слов, оканчивающихся на . -от ( -от стволов ). В результате младенцы должны найти — основ более знакомыми, чем -из основ после ознакомления. Различия в ответах проверялись с использованием версии процедуры предпочтения поворота головы (HPP; Kemler Nelson et al., 19).95).
0005 -ing основы , например, lerjov , в приведенном выше примере). Так как, согласно гипотезе, младенцы не будут выполнять такого рода сублексическую сегментацию со словами, оканчивающимися на — от (или будут делать это значительно реже), они не должны формировать сублексические репрезентации основ слов, оканчивающихся на . -от ( -от стволов ). В результате младенцы должны найти — основ более знакомыми, чем -из основ после ознакомления. Различия в ответах проверялись с использованием версии процедуры предпочтения поворота головы (HPP; Kemler Nelson et al., 19).95).
Материалы и методы
Испытуемые
Все эксперименты, описанные в этой статье, были одобрены Институциональным наблюдательным советом Университета Южной Калифорнии. Субъекты были набраны по телефону из базы данных родителей, которые выразили заинтересованность в том, чтобы их дети участвовали в исследованиях в нашей лаборатории. По крайней мере, один родитель каждого младенца дал информированное согласие до того, как младенец участвовал в эксперименте. В конце каждой тестовой сессии мы дарили родителю футболку для своего ребенка с надписью «Выпускник Лаборатории языкового развития Университета Южной Калифорнии» в знак нашей признательности.
В конце каждой тестовой сессии мы дарили родителю футболку для своего ребенка с надписью «Выпускник Лаборатории языкового развития Университета Южной Калифорнии» в знак нашей признательности.
Были проанализированы данные по 24 15-месячным детям, изучающим английский язык (средний возраст 14:25, диапазон 14:15–15:10). Были протестированы еще 15 младенцев, но они были исключены из анализа данных из-за невыполнения эксперимента (6), непосещения в течение более 1 с как минимум трех тестовых проб в блоке (5), чрезмерной суетливости (2), вмешательство родителей (1), младенец ушел из поля зрения (1). Двенадцать испытуемых были случайным образом распределены в ознакомительную группу А; остальные 12 были отнесены к группе ознакомления Б.
Стимулы и дизайн
Ознакомительные и тестовые стимулы были записаны женщиной, коренной американкой, говорящей на английском языке, которая не знала цели исследования. Запись производилась в звукопоглощающей кабине с использованием микрофона Shure SM58. Стимулы оцифровывались непосредственно на компьютер с частотой дискретизации 44,1 кГц. Было записано по три экземпляра каждого из ознакомительных и тестовых заданий. Все стимулы регистрировались в течение одного и того же сеанса записи.
Стимулы оцифровывались непосредственно на компьютер с частотой дискретизации 44,1 кГц. Было записано по три экземпляра каждого из ознакомительных и тестовых заданий. Все стимулы регистрировались в течение одного и того же сеанса записи.
Ознакомительные стимулы. Ознакомительные стимулы состояли из двух наборов, А и В, каждый из которых состоял из 16 одноразовых слов. В каждом наборе пять слов оканчивались английским суффиксом -ing , пять заканчивались неморфологическим окончанием -ot (/ɑt/), а остальные шесть слов были «неизменяемыми», то есть оканчивались на a. последовательность фонем, которой не было в других словах-ознакомителях. Целью включения неизмененных наполнителей было внести некоторое разнообразие в ознакомительный материал, чтобы поддержать участие младенцев в эксперименте. Что касается плана эксперимента, слова, оканчивающиеся на -ing и -ot рассматривались как псевдооснова плюс суффикс -ing или — ot . Псевдоосновы в -ing слов называются -ing основами , а псевдоосновы в -ing слов называются -ot основами . Наборы A и B были разработаны для уравновешивания стеблей и окончаний, так что из стеблей в одном наборе были из стеблей в другом наборе. «Неинфлективные» слова в обоих наборах были одинаковыми. В таблице 1 показан полный набор ознакомительных стимулов для эксперимента 19.0015
Псевдоосновы в -ing слов называются -ing основами , а псевдоосновы в -ing слов называются -ot основами . Наборы A и B были разработаны для уравновешивания стеблей и окончаний, так что из стеблей в одном наборе были из стеблей в другом наборе. «Неинфлективные» слова в обоих наборах были одинаковыми. В таблице 1 показан полный набор ознакомительных стимулов для эксперимента 19.0015
Таблица 1 . Ознакомительный материал для эксперимента 1 .
Четыре псевдоосновы были двусложными, а остальные односложными. Длина основы была включена в качестве переменной, чтобы увеличить разнообразие ознакомительного материала, а также исследовать влияние сложности слова на способность младенцев обнаруживать суффиксы. Для двусложных основ ударение контролировалось таким образом, чтобы хорейные и ямбические основы встречались одинаково часто с -ing и -ot окончания (см. табл. 1).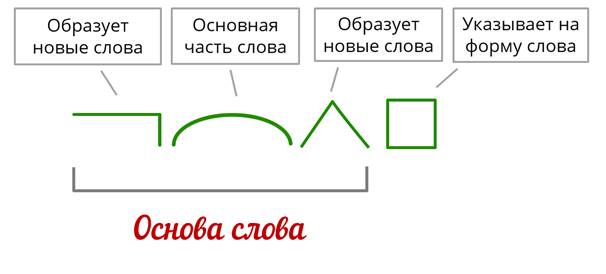
Тестовые стимулы. Тестовые стимулы состояли из 10 псевдооснов, которые были «изменены» в ознакомительных наборах, но теперь без суффиксов (например, gorp, rimp, gemónt и т. д.). Было четыре уникальных типа тестовых основ, характеризующихся их ценностью по двум параметрам: количеству слогов и статусу основы. Основы были либо односложными, либо двусложными (производными от двухсложных и трехсложных ознакомительных слов соответственно), и их было либо 9, либо 9 слов.0005 -ing стеблей или -ot стеблей. В то время как тестовые стимулы были идентичны для всех младенцев, статус стержня — то есть был ли он -ин стеблем или — или стеблем — зависел от ознакомительной установки младенца. Эта конструкция имеет статус уравновешенного штока для каждого испытательного штока. В таблице 2 показаны тестовые основы, упорядоченные по количеству слогов и статусу основы.
Таблица 2 . Тестовые стимулы для эксперимента 1 .
Акустические свойства. Чтобы гарантировать, что любые различия в способности младенцев сегментировать -ing и -ot не могут быть связаны с акустическими различиями между окончаниями, средняя амплитуда и продолжительность -ing и -ot в токенах ознакомительных материалов измеряли с помощью Praat (Boersma and Weenink, 2009). Поскольку каждое слово было реализовано в трех токенах, акустические измерения усреднялись по трем токенам для каждого слова. В таблице 3 представлены средние значения для каждого суффикса, организованные по основе слова. На рис. 1 эти средства изображены графически с указанием типа аффикса. Как показывают таблица и рисунок, окончания систематически не различаются ни в зависимости от измерения, ни от простой комбинации измерений.
Таблица 3 . Измерения длительности и интенсивности английского аффикса и псевдо-аффикса, использованных в эксперименте 1 .
Рисунок 1. График зависимости длительности (с) от амплитуды (дБ) суффиксов в эксперименте 1 . Каждая точка данных представляет собой среднее значение длительности и амплитуды аффикса, усредненное по трем токенам ознакомительного слова.
Процедура и оборудование
Каждый младенец тестировался отдельно, когда сидел на коленях у воспитателя в центре звукоизолированной комнаты. Смотритель слушал маскирующую музыку через плотно прилегающие наушники, чтобы не слышать экспериментальный материал. Экспериментатор наблюдал за поведением младенца через встроенный телевизионный монитор в соседней комнате. Экспериментатор регистрировал реакцию младенца на поворот головы в компьютер, который контролировал все аспекты эксперимента.
В начале фазы ознакомления красный свет, расположенный на уровне глаз на стене прямо перед младенцем, неоднократно мигал. Когда младенец ориентировался на свет, ознакомительный материал проигрывался на двух громкоговорителях, установленных на стенах слева и справа от младенца. Когда начался ознакомительный поток, центральный свет погас и замигал свет, установленный над одним из громкоговорителей. Он продолжал мигать, пока младенец сначала не посмотрел на него, а затем отвернулся в течение двух секунд подряд. Затем боковой свет гас, а центральный свет снова замигал до тех пор, пока младенец не сориентировался в нейтральное центральное положение. Этот процесс повторялся на протяжении этой фазы, рандомизируя сторону, на которой вспыхивал свет. Взаимодействие со светом поддерживало интерес младенцев и устанавливало непредвиденные обстоятельства между их поведением взгляда и активацией света.
Когда начался ознакомительный поток, центральный свет погас и замигал свет, установленный над одним из громкоговорителей. Он продолжал мигать, пока младенец сначала не посмотрел на него, а затем отвернулся в течение двух секунд подряд. Затем боковой свет гас, а центральный свет снова замигал до тех пор, пока младенец не сориентировался в нейтральное центральное положение. Этот процесс повторялся на протяжении этой фазы, рандомизируя сторону, на которой вспыхивал свет. Взаимодействие со светом поддерживало интерес младенцев и устанавливало непредвиденные обстоятельства между их поведением взгляда и активацией света.
Ознакомительный материал воспроизводился непрерывно в течение всей фазы ознакомления и не зависел от ориентации младенцев после начала испытания. 16 ознакомительных слов были представлены в пяти блоках, причем порядок слов был случайным в каждом блоке, а также в другом случайном порядке для каждого младенца. Между каждым словом была пауза в 300 мс. Поскольку было записано три варианта каждого слова (см. раздел «Стимулы и дизайн»), компьютер случайным образом выбирал один из трех жетонов на каждой презентации. Половина испытуемых слышала слова из набора слов А, а другая половина слышала слова из набора В. Общий период ознакомления длился около 80 с.
раздел «Стимулы и дизайн»), компьютер случайным образом выбирал один из трех жетонов на каждой презентации. Половина испытуемых слышала слова из набора слов А, а другая половина слышала слова из набора В. Общий период ознакомления длился около 80 с.
За фазой ознакомления сразу же последовала краткая фаза обучения на случай непредвиденных обстоятельств. Здесь представление слуховых стимулов также зависело от ориентации младенца на мигающий боковой свет. Слуховой стимул всегда представлял собой чистый тон частотой 440 Гц продолжительностью 1 с. Презентация начиналась, когда младенец ориентировался на мигающий боковой свет, и тон повторялся до тех пор, пока младенец не отводил взгляд в течение двух последовательных секунд. Этот этап состоял из четырех таких испытаний. Его цель состояла в том, чтобы подготовить младенца к непосредственно следующей фазе тестирования, в которой предъявление слухового стимула также зависело от ориентации на мигающий свет.
Фаза тестирования была аналогична фазе обучения в непредвиденных обстоятельствах, за исключением того, что в каждом испытательном испытании проигрывалась последовательность стеблей. В таблице 2 показаны четыре типа проб, которые определяли, какие именно последовательности стеблей игрались. Типы проб определялись длиной в слогах основ и окончанием, которое ассоциировалось с основами при ознакомлении. Стемы воспроизводились в указанном порядке с ISI 300 мс. Последовательность повторялась в тестовом испытании до тех пор, пока младенец не отводил взгляд в течение двух секунд подряд или после 15 повторений последовательности. Тестовые испытания были представлены в двух блоках с рандомизированным порядком испытаний внутри блоков, всего восемь тестовых испытаний на ребенка. Компьютер записывал продолжительность каждого испытания. Переход от одного испытания к другому не отличался для испытаний внутри блока по сравнению с переходами от первого ко второму блоку.
В таблице 2 показаны четыре типа проб, которые определяли, какие именно последовательности стеблей игрались. Типы проб определялись длиной в слогах основ и окончанием, которое ассоциировалось с основами при ознакомлении. Стемы воспроизводились в указанном порядке с ISI 300 мс. Последовательность повторялась в тестовом испытании до тех пор, пока младенец не отводил взгляд в течение двух секунд подряд или после 15 повторений последовательности. Тестовые испытания были представлены в двух блоках с рандомизированным порядком испытаний внутри блоков, всего восемь тестовых испытаний на ребенка. Компьютер записывал продолжительность каждого испытания. Переход от одного испытания к другому не отличался для испытаний внутри блока по сравнению с переходами от первого ко второму блоку.
На всех этапах эксперимента сторона предъявления стимула в данной пробе выбиралась случайным образом. Однако выбор был ограничен таким образом, чтобы стимулы не предъявлялись к одной и той же стороне более чем в трех последовательных испытаниях.
Если младенцы сегментируют суффикс -ing из ознакомительных слов, то основы -ing должны быть им относительно знакомы, поскольку они являются результатом процесса сегментации. Если младенцы не сегментируют псевдосуффикс, -ot , то основы -ot должны быть относительно менее знакомыми. Предполагается, что различия в знакомстве приведут к разнице во времени прослушивания двух типов стимулов.
Результаты
Время прослушивания менее 1 с было заменено временем прослушивания для тех же стимулов в альтернативном блоке. Этот критерий использовался для выявления испытаний, в которых младенцы отводили взгляд до того, как услышали хотя бы один полный стебель в испытании, поскольку такие испытания не считались информативными в отношении представлений об интересе. Это привело к одной замене двусложной -ot проба основы и одна замена односложной пробы -ing . Однако, как описано в разделе, посвященном выбору субъектов, младенцы, сохранявшие поворот головы менее 1 с в более чем одном испытании на блок, не были включены в анализ данных.
Данные сначала подвергались дисперсионному анализу (ANOVA) с типом основы ( -ing или -ot ) и длиной в слогах (1 или 2) как внутрисубъектные факторы, а группа ознакомления (A или Б) как межсубъектный фактор. Поскольку не было значительного основного эффекта или взаимодействий с участием ознакомительной группы, все дальнейшие анализы объединяли группы А и В для увеличения мощности. В полученном дисперсионном анализе 2 × 2 не было основных эффектов, но было значительное взаимодействие между типом основы и количеством слогов в основе [9].0005 F (1,23) = 4,47, р = 0,046].
Чтобы понять это взаимодействие, среднее время прослушивания младенцами -ing основ и -ot основ сравнивали отдельно для односложных и двусложных основ. Для односложных основ среднее время прослушивания младенцами — и -из основ составляло 12,70 с (SE = 1,18) и 11,60 с (SE = 1,27) соответственно. Парный тест t показал, что эти времена прослушивания существенно не отличались [9]. 0005 t (23) = 0,79, p = 0,44]. Однако для двухсложных основ младенцы значительно дольше слушают – основ ( M = 14,1 с, SE = 1,3) по сравнению с — основ [ M = 10,9 с, SE = 1,1; t (23) = 2,42, p = 0,024, d = 0,56]. 16 из 24 младенцев дольше слушали двусложные -от стеблей. На рисунке 2 показано время прослушивания каждого типа основы, организованное по длине слогов.
0005 t (23) = 0,79, p = 0,44]. Однако для двухсложных основ младенцы значительно дольше слушают – основ ( M = 14,1 с, SE = 1,3) по сравнению с — основ [ M = 10,9 с, SE = 1,1; t (23) = 2,42, p = 0,024, d = 0,56]. 16 из 24 младенцев дольше слушали двусложные -от стеблей. На рисунке 2 показано время прослушивания каждого типа основы, организованное по длине слогов.
Рисунок 2. Среднее время прослушивания для Эксперимента 1, упорядоченное по длине основы в слогах и статусу основы . Столбики погрешностей показывают стандартные ошибки.
Обсуждение
В целом, этот эксперимент свидетельствует о том, что к 15 месяцам дети, изучающие английский язык, обращаются с -ing особым образом, так что когда они слышат слово, оканчивающееся в этой последовательности, они отделяют его от остальной части. слово. Доказательства получены в результате сравнения тестовых испытаний, в которых испытуемые слышали основы, с которыми они были знакомы, в словах, оканчивающихся на 9. 0005 -ing против слов, оканчивающихся на -ot . Когда основы были двусложными, испытуемые дольше слушали — или основ. Если предположить, что младенцы много раз сегментировали морфемные основы во время ознакомления и, таким образом, воспринимали их как сущность, отличную от более крупного слова, то различия в слуховом восприятии согласуются с предпочтением новизны — от основ, которые, согласно гипотезе, испытуемые ранее не отделялись от ознакомительных слов.
0005 -ing против слов, оканчивающихся на -ot . Когда основы были двусложными, испытуемые дольше слушали — или основ. Если предположить, что младенцы много раз сегментировали морфемные основы во время ознакомления и, таким образом, воспринимали их как сущность, отличную от более крупного слова, то различия в слуховом восприятии согласуются с предпочтением новизны — от основ, которые, согласно гипотезе, испытуемые ранее не отделялись от ознакомительных слов.
Непонятно, почему такая разница не наблюдалась для односложных основ. Одна из возможностей заключается в том, что более длинные слова были более заметными на этапе ознакомления и выделялись на фоне более коротких слов. Младенцы, возможно, не обрабатывали слова с односложными основами в той же степени, что и слова с двусложными основами, и, следовательно, не могли отделить от этих слов ни — , ни — . В целом переменная длина новых слов могла нарушать способность младенцев сегментировать морфемы во всех словах (Johnson and Tyler, 2010), а более длинные трехсложные слова (т. внимание 1 . Способность младенцев сегментировать -ing из односложных основ исследуется далее в эксперименте 3.
внимание 1 . Способность младенцев сегментировать -ing из односложных основ исследуется далее в эксперименте 3.
Как показывают измерения, представленные на рис. таким образом, который привел бы к результатам, наблюдаемым в эксперименте 1. Тем не менее, стоит воспроизвести открытие с другими стимулами. Имея это в виду, эксперимент 2 повторяет общий результат эксперимента 1 с другим псевдо-аффиксом и слегка измененным дизайном.
Эксперимент 2
Эксперимент 1 предоставил доказательства, которые согласуются с интерпретацией того, что 15-месячные дети предпочтительно сегментируют -ing (в отличие от неморфемных окончаний) от слов, указывая на то, что они представляют -ing как отдельная сущность. Однако в ходе эксперимента -ing противопоставлялось только одному псевдо-аффиксу, -ot . Возможно, младенцам было легче сегментировать —, чем —, хотя акустические измерения не подтверждают эту возможность (см. Таблицу 3). Тем не менее, чтобы быть уверенным, что результаты не были обусловлены каким-то идиосинкразическим свойством -от . Эксперимент 2 повторял общий дизайн, но с псевдо-аффиксом — дут . Наиболее очевидная разница между двумя псевдоаффиксами заключается в том, что -дут начинается со смычного согласного, тогда как -от (как и -инг ) начинается с гласного. На фонологическом уровне наличие начала делает -dut более полным слога по сравнению с -ot (и -ing ) и, следовательно, может увеличить вероятность того, что псевдосуффикс будет отделен от слога. остальное слово (Хейс, 2009 г.). Акустические свойства -дут и -инг в Эксперименте 2 представлены и обсуждаются ниже.
Таблицу 3). Тем не менее, чтобы быть уверенным, что результаты не были обусловлены каким-то идиосинкразическим свойством -от . Эксперимент 2 повторял общий дизайн, но с псевдо-аффиксом — дут . Наиболее очевидная разница между двумя псевдоаффиксами заключается в том, что -дут начинается со смычного согласного, тогда как -от (как и -инг ) начинается с гласного. На фонологическом уровне наличие начала делает -dut более полным слога по сравнению с -ot (и -ing ) и, следовательно, может увеличить вероятность того, что псевдосуффикс будет отделен от слога. остальное слово (Хейс, 2009 г.). Акустические свойства -дут и -инг в Эксперименте 2 представлены и обсуждаются ниже.
Чтобы сделать опыт младенцев более похожим на обычный языковой контекст, в ознакомительном материале были представлены новые слова в английских предложениях – например, I see you lérjoving! , а не изолированно, как в эксперименте 1. Расположение новых слов в простых предложениях сделало стимулы для ознакомления более естественными, чем список изолированных слов. Естественные контексты могут привести к более активному использованию механизмов языковой обработки, например, таких, как сегментация слов, синтаксическая и семантическая обработка. Затем обнаружение и сегментация сублексических форм может быть улучшена за счет большей общей лингвистической обработки. С другой стороны, естественные контексты также более сложны, с большим количеством материала для обработки в данном высказывании и большей потребностью в ресурсах (при условии, что субъекты в некоторой степени выполняют обработку на этих других языковых уровнях). Таким образом, мы могли бы отметить преимущество сублексической сегментации форм, более знакомых младенцам на основе их опыта английского языка, таких как суффикс 9.0005 -ing .
Расположение новых слов в простых предложениях сделало стимулы для ознакомления более естественными, чем список изолированных слов. Естественные контексты могут привести к более активному использованию механизмов языковой обработки, например, таких, как сегментация слов, синтаксическая и семантическая обработка. Затем обнаружение и сегментация сублексических форм может быть улучшена за счет большей общей лингвистической обработки. С другой стороны, естественные контексты также более сложны, с большим количеством материала для обработки в данном высказывании и большей потребностью в ресурсах (при условии, что субъекты в некоторой степени выполняют обработку на этих других языковых уровнях). Таким образом, мы могли бы отметить преимущество сублексической сегментации форм, более знакомых младенцам на основе их опыта английского языка, таких как суффикс 9.0005 -ing .
Материалы и методы
Субъекты
Процедуры набора субъектов были идентичны тем, которые использовались в Эксперименте 1.
В эксперименте участвовали 30 младенцев в возрасте 15 месяцев (средний возраст 15 месяцев 3 дня, диапазон 14:15–15: 18). Пятнадцать испытуемых были случайным образом распределены в ознакомительную группу А, а остальные испытуемые были отнесены к ознакомительной группе В. Были протестированы еще 28 испытуемых, но они были исключены из исследования из-за невыполнения эксперимента (15), неспособности ориентироваться в течение как минимум 2 не менее трех попыток на блок (2), вмешательство родителей (3), чрезмерная суетливость (6), отказ оборудования (1) и ошибка экспериментатора (1).
Стимулы и дизайн
Бессмысленные слова представляли собой трехсложные слова из Эксперимента 1. Каждое одноразовое слово встречалось в двух разных предложениях, что давало в общей сложности восемь уникальных ознакомительных предложений. Во всех предложениях одноразовое слово было последним словом в предложении и находилось в синтаксической позиции глагола. Были созданы два уравновешенных набора ознакомительных предложений (набор А и набор Б). Предложения в наборе A приведены в таблице 4. Набор B был создан из набора A путем обмена -dut и -ing окончания одноразовых слов в предложениях в таблице 4. Например, предложению I see you lérjoving в наборе A соответствует I see you lérjovdut в наборе B.
Предложения в наборе A приведены в таблице 4. Набор B был создан из набора A путем обмена -dut и -ing окончания одноразовых слов в предложениях в таблице 4. Например, предложению I see you lérjoving в наборе A соответствует I see you lérjovdut в наборе B.
Таблица 4 . Ознакомительные предложения для испытуемых группы А в эксперименте 2 .
Предложения для ознакомления были записаны женщиной, для которой английский язык является родным, и которая была слепа к предсказаниям эксперимента. Говорящего обучали произносить предложения с нормальной просодией, подходящей для простого повествовательного предложения или вопроса. Предложения были собраны в три списка, каждый из которых перечислял предложения в разном случайном порядке. Было записано, как говорящий читает каждый список, в результате чего было получено три отдельных экземпляра каждого ознакомительного предложения, из которых для использования в эксперименте была выбрана наиболее естественно звучащая версия.
Объектами тестирования были четыре основы nonce: lérjov, gemónt , káftee, jivánt . Для данного испытуемого половина тестовых стеблей была — стеблей, а половина стеблей была -dut стеблей. Благодаря процедуре уравновешивания — основ для испытуемых в группе А были — основ для испытуемых в группе В, и наоборот. Следовательно, любые общие различия в ответах младенцев на -ing основ и -dut основ не могут быть связаны с идиосинкразией самих тестовых заданий, а скорее должны быть связаны с различиями в распределении тестовых заданий при ознакомлении. струны.
Напомним, что ударение было хореическим (сильное-слабое) для половины номентальных основ и ямбическим (слабое-сильное) для другой. Известно, что стресс является фактором обработки детской речи (Jusczyk et al., 1993; Echols et al., 1997; Thiessen and Saffran, 2003; Curtin et al., 2005; среди прочих) и, следовательно, может влиять на сублексическую речь. сегментация. Следовательно, схема стресса была включена в экспериментальный план в качестве контролируемой переменной. Образец ударения для одного одноразового корня из каждой категории корней ( -ing и -dut ) был хореическим, а другой — ямбическим.
Следовательно, схема стресса была включена в экспериментальный план в качестве контролируемой переменной. Образец ударения для одного одноразового корня из каждой категории корней ( -ing и -dut ) был хореическим, а другой — ямбическим.
Тестовые задания были записаны тем же обученным диктором, который записал ознакомительные предложения. Основы производились со списочной интонацией, каждое слово записывалось трижды и оцифровывалось на компьютере, управлявшем экспериментом. При воспроизведении тестовых элементов компьютер случайным образом выбирал один из трех экземпляров элемента для воспроизведения.
Акустические свойства. Хотя экземпляров -от и -ing в эксперименте 1 в целом не различались по параметрам интенсивности и длительности (см. табл. 3), возможно, что какие-то другие факторы делали -от особенно устойчивыми к сегментации. Используемый здесь псевдоаффикс -dut более правильно сформирован как слог, чем -ot , из-за наличия начала (Hayes, 2009) и не должен быть устойчивым к сегментации по фонологическим признакам. Для сравнения акустическая мощность — дут и -ing , средняя интенсивность двух окончаний измерялась в каждом ознакомительном предложении с использованием программного пакета Praat (Boersma and Weenink, 2009). Каждое новое слово встречалось в двух ознакомительных предложениях, поэтому измерения для каждого слова усреднялись по двум его токенам. В таблице 5 представлены эти средние значения для каждого слова, а на рисунке 3 показаны окончания в двух измерениях. (Также показаны элементы из эксперимента 3.) Ясно, что по этим акустическим измерениям0005 -dut систематически не различаются. Таким образом, псевдосуффикс не только является слогом CVC, но и соответствует -ing по длительности и интенсивности. Таким образом, с акустико-фонетической точки зрения псевдосуффикс должен быть так же легко отделим от псевдоосновы, как и собственно английский суффикс.
Для сравнения акустическая мощность — дут и -ing , средняя интенсивность двух окончаний измерялась в каждом ознакомительном предложении с использованием программного пакета Praat (Boersma and Weenink, 2009). Каждое новое слово встречалось в двух ознакомительных предложениях, поэтому измерения для каждого слова усреднялись по двум его токенам. В таблице 5 представлены эти средние значения для каждого слова, а на рисунке 3 показаны окончания в двух измерениях. (Также показаны элементы из эксперимента 3.) Ясно, что по этим акустическим измерениям0005 -dut систематически не различаются. Таким образом, псевдосуффикс не только является слогом CVC, но и соответствует -ing по длительности и интенсивности. Таким образом, с акустико-фонетической точки зрения псевдосуффикс должен быть так же легко отделим от псевдоосновы, как и собственно английский суффикс.
Таблица 5 . Измерения продолжительности и интенсивности для -ing и псевдосуффиксов в целевых словах в экспериментах 2–4 .
Рис. 3. График зависимости длительности (с) от амплитуды (дБ) суффиксов в экспериментах 2–4 . Каждая точка данных представляет собой два измерения аффикса (типа, обозначенного меткой) токена ознакомительного слова.
Процедура и аппаратура
Аппаратура, использовавшаяся в эксперименте 1, использовалась и в эксперименте 2, однако процедура несколько различалась. Во-первых, ознакомительные стимулы предъявлялись шестью блоками, а не пятью. Таким образом, испытуемые слышали дополнительное повторение каждого нового слова в этом эксперименте. Общая продолжительность ознакомительного этапа составила примерно 90 с. Ознакомительные высказывания предъявлялись с ISI 200 мс.
Этап тестирования также отличался от эксперимента 1 тем, что здесь в каждом тестовом испытании повторялся только один стебель, а не несколько стеблей одного типа. Таким образом, было проведено четыре уникальных тестовых испытания, вместе составляющих каждую комбинацию типа основы ( -ing против -dut ) и формы ударения (хорея против ямбического). Из-за уравновешенного дизайна — из стеблей для испытуемых группы А были — из стеблей для субъектов группы B, и наоборот. Как и в эксперименте 1, тестовые испытания были представлены в двух блоках с рандомизированным порядком внутри блоков.
Из-за уравновешенного дизайна — из стеблей для испытуемых группы А были — из стеблей для субъектов группы B, и наоборот. Как и в эксперименте 1, тестовые испытания были представлены в двух блоках с рандомизированным порядком внутри блоков.
Все остальные аспекты процедуры были идентичны эксперименту 1.
Результаты и обсуждение
Тестовые пробы с временем прослушивания менее 1 с были заменены временем прослушивания того же стимула в другом блоке. Таким образом были изменены данные для одного испытания ствола -ing и одного испытания ствола -dut .
Данные были сначала представлены для 2 × 2 × 2 ANOVA с типом основы ( -ing или -dut ) и характером напряжения ствола (хорея или ямбического) в качестве внутрисубъектных факторов и группой противовеса (A или Б) как межсубъектный фактор. Поскольку групповая переменная не взаимодействовала с какой-либо другой переменной, данные двух групп были объединены в последующих анализах для увеличения мощности. Был выполнен ANOVA 2 × 2 с типом основы ( -ing или -dut ) и характером ударения (хорея или ямбического) в качестве внутрисубъектных переменных. Как и предполагалось, основным эффектом был стволовой тип: младенцы слушали в среднем в течение 9 часов.0,02 с (SE = 0,34) до -ing стеблей по сравнению с 8,04 с (SE = 0,33) до -dut стеблей ] 2 . У 22 из 30 младенцев была такая картина. Других значительных основных эффектов или взаимодействий не наблюдалось. На рис. 4 показано среднее время прослушивания – 90 006 веток и 90 005 – 90 006 веток.
Был выполнен ANOVA 2 × 2 с типом основы ( -ing или -dut ) и характером ударения (хорея или ямбического) в качестве внутрисубъектных переменных. Как и предполагалось, основным эффектом был стволовой тип: младенцы слушали в среднем в течение 9 часов.0,02 с (SE = 0,34) до -ing стеблей по сравнению с 8,04 с (SE = 0,33) до -dut стеблей ] 2 . У 22 из 30 младенцев была такая картина. Других значительных основных эффектов или взаимодействий не наблюдалось. На рис. 4 показано среднее время прослушивания – 90 006 веток и 90 005 – 90 006 веток.
Рисунок 4. Среднее время прослушивания -ing стеблей и -дут стеблей в опытах 2–4 .
Как и в эксперименте 1, младенцы по-разному реагировали на основы, с которыми они были знакомы в словах, оканчивающихся на английский суффикс -ing , по сравнению с основами, с которыми они были знакомы в словах, оканчивающихся псевдосуффиксом. Однако здесь младенцы дольше слушали -ing основ по сравнению с псевдосуффиксными основами, тогда как в Эксперименте 1 младенцы дольше слушали псевдосуффиксные основы. Предпочтение знакомства здесь по сравнению с новизной в эксперименте 1 неудивительно, если учесть различия в дизайне двух экспериментов. В эксперименте 1 младенцы были ознакомлены с изменчивыми словами изолированно, тогда как в этом эксперименте слова были встроены в английские предложения. Разумно предположить, что 15-месячные дети в какой-то степени обрабатывали дополнительную богатую структуру вводных данных для ознакомления – сегментируя слова (Aslin et al., 19).98), классификации слов (Höhle et al., 2004; Gerken et al., 2005; Mintz, 2006; Shi and Melançon, 2010) и доступа к значениям слов. Было высказано предположение, что сложность стимула оказывает важное влияние на предпочтение младенцами новизны или знакомства в экспериментальных парадигмах, таких как HPP: более высокая сложность на этапах ознакомления и обучения связана с предпочтением более знакомого тестового материала, если эта сложность находится в пределах. область того, что младенцы могут обрабатывать и представлять (Hunter et al.
Предпочтение знакомства здесь по сравнению с новизной в эксперименте 1 неудивительно, если учесть различия в дизайне двух экспериментов. В эксперименте 1 младенцы были ознакомлены с изменчивыми словами изолированно, тогда как в этом эксперименте слова были встроены в английские предложения. Разумно предположить, что 15-месячные дети в какой-то степени обрабатывали дополнительную богатую структуру вводных данных для ознакомления – сегментируя слова (Aslin et al., 19).98), классификации слов (Höhle et al., 2004; Gerken et al., 2005; Mintz, 2006; Shi and Melançon, 2010) и доступа к значениям слов. Было высказано предположение, что сложность стимула оказывает важное влияние на предпочтение младенцами новизны или знакомства в экспериментальных парадигмах, таких как HPP: более высокая сложность на этапах ознакомления и обучения связана с предпочтением более знакомого тестового материала, если эта сложность находится в пределах. область того, что младенцы могут обрабатывать и представлять (Hunter et al. , 1983; Хантер и Эймс, 1988 г .; Кидд и др., 2012). Таким образом, увеличение сложности и разнообразия ознакомительного материала от эксперимента 1 к эксперименту 2 согласуется со сдвигом от предпочтения новизны в эксперименте 1 к предпочтению знакомства в эксперименте 2.
, 1983; Хантер и Эймс, 1988 г .; Кидд и др., 2012). Таким образом, увеличение сложности и разнообразия ознакомительного материала от эксперимента 1 к эксперименту 2 согласуется со сдвигом от предпочтения новизны в эксперименте 1 к предпочтению знакомства в эксперименте 2.
Таким образом, результаты эксперимента 2 дополнительно подтверждают гипотеза о том, что 15-месячные дети воспринимают суффикс -ing как отдельный элемент. Эксперименты 1 и 2 сравнивали сублексическую сегментацию с -ing и два разных псевдосуффикса. В обоих случаях результаты показали, что младенцы по-разному сегментировали основы и окончания, когда окончание было английским суффиксом по сравнению с неанглийскими псевдосуффиксами.
Однако в эксперименте 1 различия в сегментации были обнаружены только для двусложных основ. Младенцы не демонстрировали признаков другого паттерна сублексической сегментации с односложными основами. Одним из объяснений было то, что при прослушивании списка изолированных слов трехсложные слова (с двусложными основами) могли выделяться на фоне одно- и двусложных слов и привлекали внимание младенцев больше, чем двусложные слова. В отличие от относительно неестественного сценария ознакомления в эксперименте 1 (длинный список отдельных слов), в эксперименте 2 дети знакомились с новыми словами в гораздо более естественном контексте, что могло бы более полно задействовать механизмы языковой обработки и, в свою очередь, облегчить обнаружение новых слов. знакомые суффиксы в двусложных словах. Эксперимент 3 проверяет это предсказание, подвергая 15-месячных детей двухсложным бессмысленным словам в экспериментальной схеме, аналогичной эксперименту 29.0015
В отличие от относительно неестественного сценария ознакомления в эксперименте 1 (длинный список отдельных слов), в эксперименте 2 дети знакомились с новыми словами в гораздо более естественном контексте, что могло бы более полно задействовать механизмы языковой обработки и, в свою очередь, облегчить обнаружение новых слов. знакомые суффиксы в двусложных словах. Эксперимент 3 проверяет это предсказание, подвергая 15-месячных детей двухсложным бессмысленным словам в экспериментальной схеме, аналогичной эксперименту 29.0015
Эксперимент 3
Материалы и методы
Субъекты
Процедуры набора субъектов были идентичны тем, которые использовались в предыдущих экспериментах.
Были проанализированы данные о 34 младенцах в среднем возрасте 15 месяцев (средний возраст 15 месяцев 1 день, диапазон от 14 месяцев 13 дней до 15 месяцев 14 дней). Данные от 19 дополнительных младенцев были исключены из-за невыполнения эксперимента (13), чрезмерной суетливости (3), вмешательства родителей (2) и ошибки экспериментатора (1).
Стимулы и дизайн
Ознакомительный и тестовый стимулы готовили так же, как и в эксперименте 2. Структура ознакомительного материала соответствовала структуре в эксперименте 2, за исключением того, что одноразовые слова были двусложными, а не трехсложными, а ударение шаблон для всех одноразовых слов был хореическим. Как и в эксперименте 2, имелось два уравновешенных набора для ознакомления, А и В, так что 90 005 – 90 006 стеблей-вкладышей А были 90 005-dut 90 006 стеблей-вкладышей В, и наоборот. Ознакомительные задания для набора А приведены в таблице 6. Тестовыми заданиями были только четыре одноразовых слова: фем, горп, сиб и риз . Fem и gorp были -ing стеблей для субъектов группы A и -dut стеблей для субъектов группы B. Аналогично, sib и riz были -ing основ для субъектов группы B, но -dut основ для субъектов группы A.
Таблица 6 . Ознакомительные предложения для испытуемых группы А в эксперименте 3 .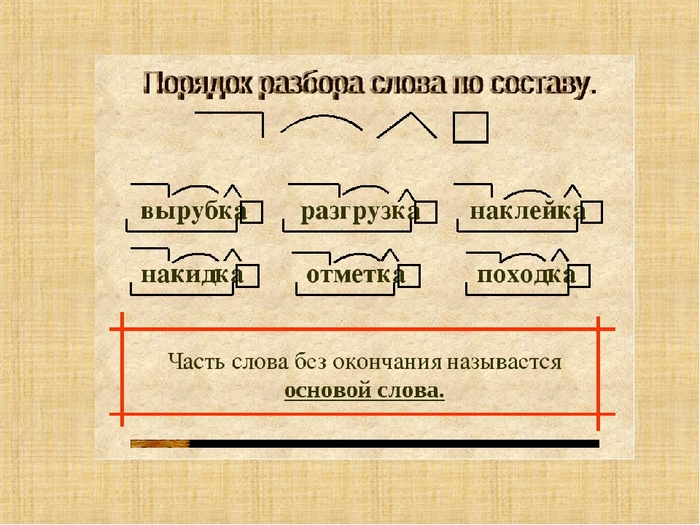
Процедура
Процедура была идентична процедуре в эксперименте 2, за исключением того, что блоков ознакомления было семь, а не шесть. Это связано с тем, что ознакомительные предложения были немного короче по продолжительности, а общая продолжительность ознакомительного периода сохранялась примерно на уровне 90 с.
Результаты и обсуждение
Как и в предыдущих исследованиях, тестовые пробы с временем ориентации менее 1 с были заменены временем ориентации испытуемого на тот же стимул в другом блоке. Данные на троих 9Таким образом были модифицированы стволовых опытов.
Для каждого испытуемого среднее время ориентации для стеблей было рассчитано путем усреднения времени ориентации для всех испытаний стеблей по тестовым блокам. Среднее время ориентации на — стеблей рассчитывали аналогичным образом, в результате чего на одного испытуемого приходилось две точки данных.
Субъекты в ознакомительных группах A и B не различались по своим общим образцам ответов на -ing против — стеблей [ t (32) = 1,33, p = 0,19], поэтому баллы для двух групп были объединены. Как и в эксперименте 2, младенцы значительно дольше слушали — стеблей по сравнению с -dut стеблей. Среднее время прослушивания составило 8,7 с (SE = 0,35) и 7,7 с (SE = 0,334) для -ing и -dut стеблей соответственно [ t (33) = 2,34, p = 0,026 , d = 0,47]. У 22 из 34 младенцев была такая картина. На рис. 4 показано среднее время прослушивания для двух типов основы.
Как и в эксперименте 2, младенцы значительно дольше слушали — стеблей по сравнению с -dut стеблей. Среднее время прослушивания составило 8,7 с (SE = 0,35) и 7,7 с (SE = 0,334) для -ing и -dut стеблей соответственно [ t (33) = 2,34, p = 0,026 , d = 0,47]. У 22 из 34 младенцев была такая картина. На рис. 4 показано среднее время прослушивания для двух типов основы.
Младенцы, таким образом, вели себя здесь при проверке односложных основ так же, как и в эксперименте 2 при проверке двусложных основ: они достоверно дольше слушали -ing основ по сравнению с -dut основ. Таким образом, как и в экспериментах 1 и 2, младенцы отделяли основы знакомых им слов с английским суффиксом, но не основы с псевдосуффиксом. Однако здесь младенцы показали эту разницу в сегментации двухсложных слов, тогда как в эксперименте 1 этого не произошло. Как обсуждалось ранее, структура ознакомительного материала могла сфокусировать внимание младенцев на более отчетливых трехсложных словах, чтобы они с меньшей вероятностью могли обнаружить и распознать сегмент 9. 0005 -ing от односложных основ. Кроме того, знакомство младенцев с одноразовыми словами в нормальных английских предложениях могло привести к большей вовлеченности и активации механизмов и репрезентаций нормальной речи, включая обработку знакомых аффиксов, таких как -ing .
0005 -ing от односложных основ. Кроме того, знакомство младенцев с одноразовыми словами в нормальных английских предложениях могло привести к большей вовлеченности и активации механизмов и репрезентаций нормальной речи, включая обработку знакомых аффиксов, таких как -ing .
Таким образом, этот эксперимент подтверждает гипотезу о том, что 15-месячные дети, изучающие английский язык, обращаются с английским суффиксом -ing привилегированным образом при обработке речи. Эти результаты согласуются с выводами Marquis and Shi (2012), которые показали, что младенцы, изучающие французский язык, уже к 11 месяцам представляют элементы связанной морфологии. Маркиз и Ши предположили, что младенцы формируют отчетливые репрезентации связанных морфем, по крайней мере вначале, просто потому, что эти формы очень часто встречаются у них на входе. Этого объяснения может быть достаточно, чтобы объяснить разницу в сегментации между -ing и используемые здесь псевдосуффиксы. Однако механизм, который учитывает внутреннюю предсказуемость форм, возможно, в дополнение к их частоте, также согласуется с настоящими выводами. Например, механизм сегментации слов, предложенный Saffran et al. (1996) сегментирует последовательности на стыках с низкой вероятностью перехода между слогами. Последовательности с высокой вероятностью перехода также могут иметь относительно высокую частоту, но две последовательности могут быть одинаковыми по частоте, но различаться внутренней вероятностью перехода. Младенцы в возрасте 8 месяцев, по-видимому, чувствительны к вероятности перехода, а не только к частоте (Aslin et al., 19).98).
Однако механизм, который учитывает внутреннюю предсказуемость форм, возможно, в дополнение к их частоте, также согласуется с настоящими выводами. Например, механизм сегментации слов, предложенный Saffran et al. (1996) сегментирует последовательности на стыках с низкой вероятностью перехода между слогами. Последовательности с высокой вероятностью перехода также могут иметь относительно высокую частоту, но две последовательности могут быть одинаковыми по частоте, но различаться внутренней вероятностью перехода. Младенцы в возрасте 8 месяцев, по-видимому, чувствительны к вероятности перехода, а не только к частоте (Aslin et al., 19).98).
Функциональное сходство между сегментацией слов и сублексической сегментацией связанных морфем, то есть выделением предсказуемых последовательностей из более крупных последовательностей, может быть отражено сходством в механизмах обработки. Поскольку 8-месячные младенцы демонстрируют статистически обоснованную сегментацию слов, вполне возможно, что они также могут обнаруживать очень регулярные паттерны в пределах слов. Эксперимент 4 исследует этот вопрос, повторяя процедуры и схему эксперимента 2, но тестируя 8-месячных младенцев.
Эксперимент 4 исследует этот вопрос, повторяя процедуры и схему эксперимента 2, но тестируя 8-месячных младенцев.
Эксперимент 4
Материалы и методы
Субъекты
Процедуры набора субъектов были идентичны тем, которые использовались в предыдущих экспериментах.
Были протестированы 36 младенцев в возрасте 8 месяцев (средний возраст 8 месяцев 3 дня, диапазон от 7 месяцев 18 дней до 8 месяцев 20 дней). Младенцы были случайным образом распределены в одну из двух ознакомительных групп, А или В, состоящих из 18 младенцев в каждой. Были проанализированы данные всех 36 младенцев.
Стимулы и дизайн
Стимулы и схема эксперимента были идентичны эксперименту 2.
Процедура и аппаратура
Аппаратура и методика тестирования были идентичны эксперименту 2.
Результаты и обсуждение
Как и в предыдущих экспериментах, время ориентации менее 1 с заменяли временем ориентации испытуемого на тот же стимул в другом блоке. Таким образом были изменены данные для одного испытания ствола -ing .
Таким образом были изменены данные для одного испытания ствола -ing .
Данные сначала были представлены для 2 × 2 × 2 ANOVA с типом ствола ( -ing или -dut ) и структурой напряжения ствола (хорея или ямбом) в качестве внутрисубъектных факторов и группой противовеса (A или B). ) как межсубъектный фактор. Поскольку групповая переменная не взаимодействовала ни с какой другой переменной, данные двух групп были объединены для увеличения мощности. Был выполнен ANOVA 2 × 2 с типом основы ( -ing или -dut ) и характером ударения (хорея или ямбического) в качестве внутрисубъектных переменных. Ни главный эффект, ни взаимодействие не были значительными (все F с < 1). Как показано на рисунке 4, время прослушивания младенцами стеблей -ing и -dut составляло 9,0 с (SE = 0,37) и 9,0 с (SE = 0,26) соответственно.
В отличие от предыдущих опытов с 15-месячными детьми, не было выявлено, что 8-месячные особенным образом обращались с -инъекциями при обработке ознакомительного материала. В принципе, механизмы, задействованные в лабораторных демонстрациях сегментации слов у детей в возрасте 7,5–8 месяцев, могут сегментировать предсказуемые подлексические паттерны, такие как связанные морфемы. Однако этот эксперимент не дает никаких доказательств того, что 8-месячные дети проводят такие анализы. Конечно, план эксперимента оценивает сегментацию суффиксов косвенно, измеряя реакцию младенцев на основы. Возможно, у младенцев сегментировано -ing (но не -dut ) во время ознакомления, но не имел достаточного контакта с полученными стеблями, чтобы быть в состоянии распознать их на этапе тестирования. По сравнению с экспериментами по сегментации слов, в экспериментах, описанных здесь, младенцы подвергаются гораздо меньшему воздействию отдельных тестовых элементов. Например, в исследовании Saffran et al. (1996) младенцев тестировали на слова, которые они слышали 45 раз. Количество экспозиций в настоящем исследовании могло быть достаточным для 15-месячных, но не для 8-месячных.
В принципе, механизмы, задействованные в лабораторных демонстрациях сегментации слов у детей в возрасте 7,5–8 месяцев, могут сегментировать предсказуемые подлексические паттерны, такие как связанные морфемы. Однако этот эксперимент не дает никаких доказательств того, что 8-месячные дети проводят такие анализы. Конечно, план эксперимента оценивает сегментацию суффиксов косвенно, измеряя реакцию младенцев на основы. Возможно, у младенцев сегментировано -ing (но не -dut ) во время ознакомления, но не имел достаточного контакта с полученными стеблями, чтобы быть в состоянии распознать их на этапе тестирования. По сравнению с экспериментами по сегментации слов, в экспериментах, описанных здесь, младенцы подвергаются гораздо меньшему воздействию отдельных тестовых элементов. Например, в исследовании Saffran et al. (1996) младенцев тестировали на слова, которые они слышали 45 раз. Количество экспозиций в настоящем исследовании могло быть достаточным для 15-месячных, но не для 8-месячных. С другой стороны, возможно также, что 8-месячные еще не начали формировать долговременные представления о сублексических формах.
С другой стороны, возможно также, что 8-месячные еще не начали формировать долговременные представления о сублексических формах.
План этого эксперимента можно изменить, чтобы увеличить количество одноразовых слов. Тем не менее, это может привести к тому, что младенцы получат доказательства того, что псевдо-аффиксы также являются аффиксами, и тогда младенцы могут начать сегментировать и псевдо-аффиксы. Действительно, в одном эксперименте Marquis and Shi (2012) продемонстрировали, что при достаточном знакомстве с псевдосуффиксом /u/ 11-месячные дети, изучающие французский язык, начали относиться к окончанию так же, как к реальному французскому суффиксу /e/. в своей экспериментальной задаче.
Общее обсуждение
В совокупности эксперименты в этом исследовании показывают, что 15-месячные дети, изучающие английский язык, представляют суффикс -ing как дискретную единицу. Таким образом, хотя в предыдущих экспериментах не удалось найти доказательства того, что 15-месячные дети приобрели морфосинтаксические зависимости, включающие — (Santelmann and Jusczyk, 1998), младенцы, тем не менее, могут находиться в процессе обучения этим зависимостям в этом возрасте. В частности, наличие дискретного представления аффикса позволяет младенцам замечать зависимости между этим аффиксом и другими формами.
В частности, наличие дискретного представления аффикса позволяет младенцам замечать зависимости между этим аффиксом и другими формами.
Важно отметить, что, хотя это исследование подтверждает гипотезу о том, что младенцы воспринимают -ing как дискретную сущность в возрасте 15 месяцев, было бы преждевременно делать вывод о том, что они усвоили форму qua суффикса английского языка. То есть нет данных о том, что эти формы вполне морфологичны в том смысле, что младенцы представляют их как элементы, участвующие в зависимостях и связанные с определенными семантическими свойствами. (Действительно, результаты Сэнтельманна и Юскика показывают, что младенцы еще не усвоили основные паттерны и зависимости, включающие -ing .) Первоначально младенцы могли представлять связанные морфемы как отдельные объекты просто в силу того факта, что они часто встречаются в словах, как предположили Marquis and Shi (2012). Результаты настоящего исследования полностью согласуются с этим предложением. При изучении ввода ребенка Питера в корпусе Блума (Bloom et al., 1974, 1975) базы данных CHILDES (MacWhinney, 2000) было обнаружено, что 2,2% словесных токенов и 6,9% типов слов, произнесенных взрослыми для Петр оканчивался на /Iŋ/ (независимо от того, было ли окончание морфемой или нет, как в пой ). Напротив, только 0,6% токенов и 0,5% типов слов оканчивались на /ɑt/, и не было слов, оканчивающихся на последовательность /dʌt/ 3 .
При изучении ввода ребенка Питера в корпусе Блума (Bloom et al., 1974, 1975) базы данных CHILDES (MacWhinney, 2000) было обнаружено, что 2,2% словесных токенов и 6,9% типов слов, произнесенных взрослыми для Петр оканчивался на /Iŋ/ (независимо от того, было ли окончание морфемой или нет, как в пой ). Напротив, только 0,6% токенов и 0,5% типов слов оканчивались на /ɑt/, и не было слов, оканчивающихся на последовательность /dʌt/ 3 .
Хотя Marquis и Shi (2012) обсуждают ранние представления младенцами связанных морфем с точки зрения частоты сублексических паттернов, разумно предположить, что обнаружение сублексических форм может также зависеть от переходных вероятностей. То есть, когда часто встречающаяся форма встречается во многих различных контекстах, она с большей вероятностью будет идентифицирована как отдельная форма, чем форма с одинаковой частотой, встречающаяся в более ограниченном наборе контекстов. Тогда механизмы сегментации сублексических форм будут вычислительно подобны механизмам, которые были предложены для обнаружения слов в беглой речи (Saffran et al. , 19).96; Аслин и др., 1998 г.; Пелуччи и др., 2009). Хотя это может быть и так, эксперимент 4 не обнаружил свидетельств того, что 8-месячные дети обнаруживали и сегментировали — из бессмысленных слов, хотя младенцы относительно редко встречались с новыми формами по сравнению с другими экспериментами по сегментации слов. Будущие исследования с использованием различных методов могут дополнительно изучить, как ранние младенцы начинают сегментировать и представлять связанные морфемы в виде отдельных форм.
, 19).96; Аслин и др., 1998 г.; Пелуччи и др., 2009). Хотя это может быть и так, эксперимент 4 не обнаружил свидетельств того, что 8-месячные дети обнаруживали и сегментировали — из бессмысленных слов, хотя младенцы относительно редко встречались с новыми формами по сравнению с другими экспериментами по сегментации слов. Будущие исследования с использованием различных методов могут дополнительно изучить, как ранние младенцы начинают сегментировать и представлять связанные морфемы в виде отдельных форм.
Помимо свойств распределения, таких как частота и вероятность перехода, фонологические факторы также могут влиять на раннее представление аффиксов младенцами. В той мере, в какой аффиксы в данном языке имеют фонотактические тенденции, которые младенцы могут обнаружить, как только младенцы сегментируют достаточное количество аффиксов, чтобы обнаружить паттерны, они могут использовать эти тенденции в качестве сигналов для дальнейшей сегментации и открытия новых аффиксов. Эта возможность вызывает потенциальную озабоченность в данном исследовании: хотя, как только что сообщалось, частота использования /ɑt/ и /dʌt/ на концах слов при вводе детьми очень низкая или практически отсутствует, эти два псевдоаффикса не параллельны в сравнение с реальными английскими аффиксами при анализе на более общем уровне. В частности, ни один флективный суффикс английского языка не имеет структуры CVC, такой как / dʌt / (хотя некоторые производные аффиксы имеют, например, -tion ), но часто встречаются аффиксы со структурой VC, например /ɑt/ (например, /Iŋ/, /әz/, /әd/). В принципе, если младенцы чувствительны к этим более широким фонотаксическим свойствам английских флективных аффиксов, нетипичная структура -dut могла заставить младенцев отвергнуть -dut в качестве возможного суффикса в экспериментах 2 и 3. 4 Такая возможность предлагает другое объяснение различающихся результатов в отношении односложных основ в эксперименте 1 по сравнению с экспериментом 3: младенцы могут быть относительно более склонны относиться к -ot в качестве возможного суффикса из-за его фонологической структуры и, учитывая более простую общую структуру двусложных слов, в эксперименте 1 были сегментированы как -ing , так и -ot из более коротких слов. предназначен для проверки этих более широких обобщений фонологической формы.
В частности, ни один флективный суффикс английского языка не имеет структуры CVC, такой как / dʌt / (хотя некоторые производные аффиксы имеют, например, -tion ), но часто встречаются аффиксы со структурой VC, например /ɑt/ (например, /Iŋ/, /әz/, /әd/). В принципе, если младенцы чувствительны к этим более широким фонотаксическим свойствам английских флективных аффиксов, нетипичная структура -dut могла заставить младенцев отвергнуть -dut в качестве возможного суффикса в экспериментах 2 и 3. 4 Такая возможность предлагает другое объяснение различающихся результатов в отношении односложных основ в эксперименте 1 по сравнению с экспериментом 3: младенцы могут быть относительно более склонны относиться к -ot в качестве возможного суффикса из-за его фонологической структуры и, учитывая более простую общую структуру двусложных слов, в эксперименте 1 были сегментированы как -ing , так и -ot из более коротких слов. предназначен для проверки этих более широких обобщений фонологической формы. Тем не менее, чтобы рассмотреть эту возможность, было проведено последующее исследование со взрослыми; эксперимент был разработан, чтобы оценить, показывают ли опытные англоязычные пользователи преимущество в сегментировании -ot , который соответствует английской структуре словоизменения, происходит от одноразовых словоформ, по сравнению с -dut , который не соответствует. Пятнадцать носителей английского языка прослушали те же одноразовые слова, которые заканчивались на — dut и — ot , которые использовались в этих исследованиях, но слова были представлены в быстрой последовательности, с 1,1 с между началами слов. Время от времени два слова подряд заканчивались либо на -дут , либо оба на -от . Участники должны были нажимать клавишу всякий раз, когда они слышали слово, которое рифмуется со словом перед ним. Интересующий вопрос заключался в том, различались ли участники по точности определения рифм с -от по сравнению с рифмами с -дут .
Тем не менее, чтобы рассмотреть эту возможность, было проведено последующее исследование со взрослыми; эксперимент был разработан, чтобы оценить, показывают ли опытные англоязычные пользователи преимущество в сегментировании -ot , который соответствует английской структуре словоизменения, происходит от одноразовых словоформ, по сравнению с -dut , который не соответствует. Пятнадцать носителей английского языка прослушали те же одноразовые слова, которые заканчивались на — dut и — ot , которые использовались в этих исследованиях, но слова были представлены в быстрой последовательности, с 1,1 с между началами слов. Время от времени два слова подряд заканчивались либо на -дут , либо оба на -от . Участники должны были нажимать клавишу всякий раз, когда они слышали слово, которое рифмуется со словом перед ним. Интересующий вопрос заключался в том, различались ли участники по точности определения рифм с -от по сравнению с рифмами с -дут . Логистическая регрессия с окончанием ( -дут vs. -от ) в качестве внутрисубъектной переменной не выявила разницы в точности определения рифм с -дут (в среднем 78% обнаруженных) по сравнению с рифмами с -от (в среднем выявлено 68%; р = 0,336). Таким образом, для взрослых, по-видимому, нет преимущества той или иной формы в отношении простоты обнаружения. Интересно, что у 9 было небольшое преимущество во времени реакции.0005 -dut рифм (607 мс, измерено от начала суффикса) по сравнению с -ot рифм [653 мс; t (14) = 2,20, p < 0,05]. Хотя эти данные, полученные от взрослых, едва ли можно считать убедительными в отношении знаний младенцев об интонациях, они, по крайней мере, предполагают, что младенцы не будут предубеждены против сегментации -dut по сравнению с -ot из псевдостеблей, несмотря на тот факт, что первый нетипичен. в отношении флективных суффиксов в английском языке.
Логистическая регрессия с окончанием ( -дут vs. -от ) в качестве внутрисубъектной переменной не выявила разницы в точности определения рифм с -дут (в среднем 78% обнаруженных) по сравнению с рифмами с -от (в среднем выявлено 68%; р = 0,336). Таким образом, для взрослых, по-видимому, нет преимущества той или иной формы в отношении простоты обнаружения. Интересно, что у 9 было небольшое преимущество во времени реакции.0005 -dut рифм (607 мс, измерено от начала суффикса) по сравнению с -ot рифм [653 мс; t (14) = 2,20, p < 0,05]. Хотя эти данные, полученные от взрослых, едва ли можно считать убедительными в отношении знаний младенцев об интонациях, они, по крайней мере, предполагают, что младенцы не будут предубеждены против сегментации -dut по сравнению с -ot из псевдостеблей, несмотря на тот факт, что первый нетипичен. в отношении флективных суффиксов в английском языке.
Небольшое, но надежное преимущество в скорости обнаружения -dut по сравнению с -ot у взрослых может быть связано с тем, что — dut является полным слогом, тогда как ot не имеет начала и подвергается повторному слогу с сегменты на конце стебля. Действительно, мотивирующим фактором для использования — dut в экспериментах 2–4 было использование псевдоаффикса, который было относительно легко сегментировать по структурным основаниям, что обеспечило более сильную проверку обращения с младенцами в возрасте 9 лет.0005 -ing как привилегированная форма. Однако, выходя за рамки методологических соображений этого исследования, факторы восприятия, связанные со структурой слога аффикса, являются еще одним способом, которым фонологические переменные могут играть роль в усвоении аффиксов младенцами: обнаружить и получить больше времени, чем аффиксы, которые не являются. Кросс-лингвистически, есть некоторая поддержка этого понятия. Например, турецкие морфемы обычно слоговые и содержат нередуцированные гласные, а многие имеют начало. Дети, изучающие турецкий язык, демонстрируют продуктивное использование морфем несколько раньше, чем дети, изучающие английский язык (Aksu Koç and Ketrez, 2003). В настоящем исследовании, хотя -ing не имеет начала, оно выделяется среди большинства других флективных морфем английского языка тем, что имеет полную гласную.
Действительно, мотивирующим фактором для использования — dut в экспериментах 2–4 было использование псевдоаффикса, который было относительно легко сегментировать по структурным основаниям, что обеспечило более сильную проверку обращения с младенцами в возрасте 9 лет.0005 -ing как привилегированная форма. Однако, выходя за рамки методологических соображений этого исследования, факторы восприятия, связанные со структурой слога аффикса, являются еще одним способом, которым фонологические переменные могут играть роль в усвоении аффиксов младенцами: обнаружить и получить больше времени, чем аффиксы, которые не являются. Кросс-лингвистически, есть некоторая поддержка этого понятия. Например, турецкие морфемы обычно слоговые и содержат нередуцированные гласные, а многие имеют начало. Дети, изучающие турецкий язык, демонстрируют продуктивное использование морфем несколько раньше, чем дети, изучающие английский язык (Aksu Koç and Ketrez, 2003). В настоящем исследовании, хотя -ing не имеет начала, оно выделяется среди большинства других флективных морфем английского языка тем, что имеет полную гласную. Это также, как правило, первая флективная морфема, которая надежно воспроизводится, когда это требуется детям, изучающим английский язык. Таким образом, возможно, что хотя 15-месячные дети идентифицировали эту «устойчивую» морфему как отдельную форму, они еще не сформировали независимые представления о других английских морфемах. Изучение этого вопроса путем тестирования различных морфем прояснит роль перцептивных свойств суффиксов, которые могут влиять на то, как сначала представляются связанные морфемы.
Это также, как правило, первая флективная морфема, которая надежно воспроизводится, когда это требуется детям, изучающим английский язык. Таким образом, возможно, что хотя 15-месячные дети идентифицировали эту «устойчивую» морфему как отдельную форму, они еще не сформировали независимые представления о других английских морфемах. Изучение этого вопроса путем тестирования различных морфем прояснит роль перцептивных свойств суффиксов, которые могут влиять на то, как сначала представляются связанные морфемы.
Наконец, в дополнение к потенциальной роли частоты в приобретении младенцами аффиксов (Marquis and Shi, 2012), более общие дистрибутивные свойства флективной системы языка могут влиять на обнаружение младенцами связанных морфем. Как упоминалось ранее, можно было бы ожидать, что время развития первых репрезентаций морфем будет зависеть от богатства явных морфологических обозначений языка. Изучающие языки с богатой морфологической маркировкой (например, французский) могут начать обнаруживать и представлять сублексические формы раньше, чем их сверстники, изучающие более «бедные» морфологически языки (например, английский). Приобретение турецкого языка, опять же, подтверждает эту точку зрения. В турецком языке широко используется морфологическая маркировка, и дети демонстрируют продуктивное использование морфем уже в 17 месяцев (Аксу Коч и Кетрез, 2003). Однако такие сравнения осложняются фонологическими и перцептивными факторами, обсуждавшимися ранее.
Приобретение турецкого языка, опять же, подтверждает эту точку зрения. В турецком языке широко используется морфологическая маркировка, и дети демонстрируют продуктивное использование морфем уже в 17 месяцев (Аксу Коч и Кетрез, 2003). Однако такие сравнения осложняются фонологическими и перцептивными факторами, обсуждавшимися ранее.
Заключение
Важным компонентом языка как по структуре, так и по содержанию являются подлексические комбинаторные единицы – связанные морфемы. При овладении языком учащиеся должны усвоить семантические и структурные свойства связанных морфем, но перед этим они должны определить, какие соответствующие подлексические единицы есть в их языке. Описанные здесь эксперименты показывают, что 15-месячные дети, изучающие английский язык, представляют -ing как отдельную форму. При обработке новых слов, оканчивающихся на -ing , они отделяют суффикс от основы. Это позволяет им замечать морфосинтаксические и морфосемантические паттерны, которые включают эту форму, и которые станут частью их приобретенных грамматических знаний. Кроме того, представляя основы слов в виде отдельных форм, младенцы могут затем обнаруживать морфосинтаксические паттерны, включающие основу, такие как другие флективные парадигмы. Таким образом, в том возрасте, когда многие учащиеся еще не комбинируют слова в своей речи, и до того, как они продуктивно используют связанные морфемы, у младенцев начинают формироваться представления о морфологии их языка.
Кроме того, представляя основы слов в виде отдельных форм, младенцы могут затем обнаруживать морфосинтаксические паттерны, включающие основу, такие как другие флективные парадигмы. Таким образом, в том возрасте, когда многие учащиеся еще не комбинируют слова в своей речи, и до того, как они продуктивно используют связанные морфемы, у младенцев начинают формироваться представления о морфологии их языка.
Заявление о конфликте интересов
Автор заявляет, что исследование проводилось в отсутствие каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов.
Благодарности
Я хотел бы поблагодарить Лауру Стинберг и Кристи Харди за их помощь в сборе и кодировании данных о младенцах, Феликса Ванга и Калин Редди за проведение эксперимента для взрослых, а также многих родителей и семьи, которые вызвались сделать это исследование возможным. . Предварительные данные некоторых из этих экспериментов были представлены на Международной конференции по изучению младенчества и на конференции Бостонского университета по языковому развитию. Это исследование было частично поддержано грантом Национального института здравоохранения (NICHD-R01HD040368). 9 В этом и последующих экспериментах количество испытуемых, участвовавших в анализе данных, было больше, чем в эксперименте 1. Это связано с тем, что мы ожидали относительно высокий уровень отсева на основе пилотных исследований, поэтому ассистентам исследователей была предоставлена высокая квота на количество участников. субъектов для тестирования в данном эксперименте. В результате мы получили больше испытуемых, чем в первоначальном исследовании. Однако ограничение анализа данных первыми 12 испытуемыми на условие уравновешивания в экспериментах 2–4 (как и в эксперименте 1) дает ту же картину результатов, что и сообщаемые результаты, которые включают дополнительных младенцев. 9 Эта возможность была предложена анонимным рецензентом.
Это исследование было частично поддержано грантом Национального института здравоохранения (NICHD-R01HD040368). 9 В этом и последующих экспериментах количество испытуемых, участвовавших в анализе данных, было больше, чем в эксперименте 1. Это связано с тем, что мы ожидали относительно высокий уровень отсева на основе пилотных исследований, поэтому ассистентам исследователей была предоставлена высокая квота на количество участников. субъектов для тестирования в данном эксперименте. В результате мы получили больше испытуемых, чем в первоначальном исследовании. Однако ограничение анализа данных первыми 12 испытуемыми на условие уравновешивания в экспериментах 2–4 (как и в эксперименте 1) дает ту же картину результатов, что и сообщаемые результаты, которые включают дополнительных младенцев. 9 Эта возможность была предложена анонимным рецензентом.
Ссылки
Аксу Коч, А., и Кетрез, Ф. Н. (2003). «Ранняя словесная морфология в турецком языке: появление флексий», в Mini-Paradigms and the Emergence of Verb Morphology , eds D. Bittner, WU Dressler, and Kilani-Schoch (Berlin: Walter de Gruyter), 27–52.
Bittner, WU Dressler, and Kilani-Schoch (Berlin: Walter de Gruyter), 27–52.
Аслин, Р. Н., Саффран, Дж. Р., и Ньюпорт, Э. Л. (1998). Вычисление статистики условной вероятности у 8-месячных младенцев. Псих. науч. 9, 321–324.
CrossRef Полный текст
Блум, Л., Худ, Л., и Лайтбаун, П. (1974). Подражание в развитии речи: если, когда и почему. Познан. Психол. 6, 380–420.
CrossRef Полный текст
Блум Л., Лайтбаун П. и Худ Л. (1975). Структура и вариации в детском языке. Моногр. соц. Рез. Детский Дев. 40, 1–97.
Опубликован Аннотация | Опубликован полный текст | Полный текст CrossRef
Бурсма, П., и Венинк, Д. (2009 г.). Praat: компьютерная фонетика (Версия 5.1.43) [Компьютерная программа] . Доступно по адресу: http://www.praat.org/.
Браун, Р. (1973). Первый язык: ранние стадии . Кембридж, Массачусетс: Издательство Гарвардского университета.
Куртин, С., Минц, Т. Х., и Кристиансен, М. Х. (2005). Стресс меняет репрезентативный ландшафт: свидетельство сегментации слов. Познание 96, 233–262.
Х. (2005). Стресс меняет репрезентативный ландшафт: свидетельство сегментации слов. Познание 96, 233–262.
Опубликован Аннотация | Опубликован полный текст | Полнотекстовая перекрестная ссылка
де Вильерс, Дж. Г., и де Вильерс, П. А. (1973). Поперечное исследование усвоения грамматических морфем в детской речи. Ж. Психолингвист. Рез. 2, 267–278.
CrossRef Полный текст
Эколс, Ч. Х., Кроухерст, М. Дж., и Чайлдерс, Дж. Б. (1997). Восприятие ритмических единиц речи младенцами и взрослыми. Дж. Мем. Ланг. 36, 202–225.
Полный текст CrossRef
Геркен Л., Уилсон Р. и Льюис В. (2005). Младенцы могут использовать сигналы распределения для формирования синтаксических категорий. Дж. Чайлд Ланг. 32, 249–268.
Опубликован Аннотация | Опубликован полный текст | Полный текст CrossRef
Голинкофф, Р. М., Хирш-Пасек, К., и Швайсгут, М. А. (2001). «Переоценка знаний маленьких детей о грамматических морфемах», в Подходы к начальной загрузке: фонологические, лексические, синтаксические и нейрофизиологические аспекты раннего овладения языком , Vol. 1, ред. Дж. Вайссенборн и Б. Хёле (Амстердам: Джон Бенджаминс), 167–188.
1, ред. Дж. Вайссенборн и Б. Хёле (Амстердам: Джон Бенджаминс), 167–188.
Хейс, Б. (2009 г.). Введение в фонологию . Молден, Массачусетс: Уайли-Блэквелл.
Хёле, Б., Шмитц, М., Сантельманн, Л.М., и Вайссенборн, Дж. (2006). Распознавание прерывистых вербальных зависимостей немецкими 19-месячными детьми: свидетельство лексического и структурного влияния на ранние способности детей к обработке данных. Ланг. Учиться. Дев. 2, 277–300.
CrossRef Полный текст
Хёле, Б., Вайссенборн, Дж., Кифер, Д., Шульц, А., и Шмитц, М. (2004). Функциональные элементы в обработке речи младенцев: роль детерминантов в синтаксической категоризации лексических элементов. Младенчество 5, 341–353.
Полный текст CrossRef
Хантер, М. А., и Эймс, Э. У. (1988). Многофакторная модель предпочтений младенцев в отношении новых и знакомых стимулов. Доп. Младенчество Res. 5, 69–95.
Хантер, Массачусетс, Эймс, Э.В., и Купман, Р. (1983). Влияние сложности стимула и времени ознакомления на предпочтения младенцев в отношении новых и знакомых стимулов. Дев. Психол. 19, 338.
Влияние сложности стимула и времени ознакомления на предпочтения младенцев в отношении новых и знакомых стимулов. Дев. Психол. 19, 338.
CrossRef Full Text
Johnson, E.K., and Tyler, MD (2010). Проверка пределов статистического обучения для сегментации слов. Дев. науч. 13, 339–345.
Опубликован Аннотация | Опубликован полный текст | Полный текст CrossRef
Ющик П.В. и Аслин Р.Н. (1995). Распознавание младенцами звуковых образов слов в беглой речи. Познан. Психол. 29, 1–23.
Опубликован Аннотация | Опубликован полный текст | CrossRef Full Text
Jusczyk, P.W., Cutler, A., and Redanz, N.J. (1993). Предпочтение младенцев преобладающим образцам ударения английских слов. Детская разработка. 64, 675–687.
Опубликовано Резюме | Опубликован полный текст | Полный текст CrossRef
Ющик, П. В., Хьюстон, Д. М., и Ньюсом, М. (1999). Начало сегментации слов у детей, изучающих английский язык. Познан. Психол. 39, 159–207.
Психол. 39, 159–207.
Опубликован Аннотация | Опубликован полный текст | CrossRef Полный текст
Кемлер Нельсон, Д.Г., Ющик, П.В., Мандель, Д.Р., Майерс, Дж., Терк, А., и Геркен, Л. (1995). Процедура предпочтения поворота головы для проверки слухового восприятия. Поведение младенцев. Дев. 18, 111–116.
CrossRef Полный текст
Кидд, К., Пиантадоси, С.Т., и Аслин, Р.Н. (2012). Эффект Златовласки: человеческие младенцы обращают внимание на визуальные последовательности, которые не являются ни слишком простыми, ни слишком сложными. PLoS ONE 7:e36399. doi:10.1371/journal.pone.0036399
CrossRef Full Text
MacWhinney, B. (2000). Проект CHILDES: инструменты для анализа разговоров: база данных . 3-е издание, Vol. 2. Махва, Нью-Джерси: Lawrence Erlbaum Associates.
Маркиз А. и Ши Р. (2012). Начальное морфологическое обучение у довербальных младенцев. Познание 122, 61–66.
Опубликован Аннотация | Опубликован полный текст | Полный текст CrossRef
Mintz, TH (2006). «Нахождение глаголов: подсказки распределения по категориям, доступные младшим учащимся», в «Действие встречает слово: как дети изучают глаголы », редакторы Р. М. Голинкофф и К. Хирш-Пасек (Нью-Йорк: издательство Оксфордского университета), 31–63.
«Нахождение глаголов: подсказки распределения по категориям, доступные младшим учащимся», в «Действие встречает слово: как дети изучают глаголы », редакторы Р. М. Голинкофф и К. Хирш-Пасек (Нью-Йорк: издательство Оксфордского университета), 31–63.
Нацци Т., Барьер И., Гойе Л., Креш С. и Лежандр Г. (2011). Отслеживание неправильных морфофонологических зависимостей в естественном языке: свидетельство приобретения согласия субъекта и глагола во французском языке. Познание 120, 119–135.
Опубликован Аннотация | Опубликован полный текст | Полный текст CrossRef
Пелуччи, Б., Хэй, Дж. Ф., и Саффран, Дж. Р. (2009). Статистическое обучение естественному языку у 8-месячных младенцев. Детская разработка. 80, 674–685.
Опубликован Аннотация | Опубликован полный текст | Полный текст CrossRef
Сафран, Дж. Р., Аслин, Р. Н., и Ньюпорт, Э. Л. (1996). Статистическое обучение 8-месячных младенцев. Наука 274, 1926–1928.
Опубликовано Резюме | Опубликован полный текст | Полный текст CrossRef
Сантельманн, Л. М., и Ющик, П.В. (1998). Чувствительность к прерывистым зависимостям у изучающих язык: свидетельство ограничений в пространстве обработки. Познание 69, 105–134.
М., и Ющик, П.В. (1998). Чувствительность к прерывистым зависимостям у изучающих язык: свидетельство ограничений в пространстве обработки. Познание 69, 105–134.
Опубликован Аннотация | Опубликован полный текст | Полный текст CrossRef
Ши, Р., Катлер, А., Веркер, Дж., и Круикшенк, М. (2006a). Частота и форма как детерминанты функторной чувствительности у младенцев, осваивающих английский язык. Дж. Акуст. соц. Являюсь. 119, EL61–EL67.
Полный текст CrossRef
Ши, Р., Веркер, Дж. Ф., и Катлер, А. (2006b). Распознавание и представление служебных слов у детей, изучающих английский язык. Младенчество 10, 187–198.
Полный текст CrossRef
Ши Р. и Мелансон А. (2010). Синтаксическая категоризация у детей, изучающих французский язык. Младенчество 15, 517–533.
CrossRef Full Text
Soderstrom, M. (2003). Приобретение морфологии словоизменения в раннем перцептивном знании синтаксиса . Докторская диссертация, Университет Джона Хопкинса. [Получено из диссертаций и тезисов ProQuest. (УМИ № 3068215)].
[Получено из диссертаций и тезисов ProQuest. (УМИ № 3068215)].
Содерстром, М., Векслер, К., и Ющик, П. В. (2002). «Чувствительность детей ясельного возраста, изучающих английский язык, к морфологии согласования в рецептивной грамматике», в материалах 26-й ежегодной конференции Бостонского университета по языковому развитию , редакторы Б. Скарабела, С. Фиш и А. Х.-Дж. До (Сомервилль: Cascadilla Press), 643–652.
Содерстром, М., Уайт, К.С., Конуэлл, Э., и Морган, Дж.Л. (2007). Рецептивное грамматическое знание слов знакомого содержания и словоизменения у 16-месячных детей. Младенчество 12, 1–29.
CrossRef Полный текст
Тиссен, Э. Д., и Саффран, Дж. Р. (2003). Когда сигналы сталкиваются: использование стресса и статистических сигналов для определения границ слов 7–9-месячными младенцами. Дев. Психол. 39, 706–716.
Опубликован Аннотация | Опубликован полный текст | Полный текст CrossRef
van Heugten, M., and Johnson, EK (2010). Связь способностей к распределенному обучению младенцев с овладением естественным языком. Дж. Мем. Ланг. 63, 197–209.
Связь способностей к распределенному обучению младенцев с овладением естественным языком. Дж. Мем. Ланг. 63, 197–209.
CrossRef Full Text
van Heugten, M., and Shi, R. (2009). Малыши, изучающие французский язык, используют информацию о поле в определителях во время распознавания слов. Дев. науч. 12, 419–425.
Опубликован Аннотация | Опубликован полный текст | Полный текст CrossRef
van Heugten, M., and Shi, R. (2010). Чувствительность младенцев к несмежным зависимостям через границы фонологических фраз. Дж. Акус. соц. Являюсь. 128, EL223–EL228.
Опубликован Аннотация | Опубликован полный текст | Полнотекстовая перекрестная ссылка
[PDF] На основе слов или морфем? Стратегии аннотации для современной еврейской клитики
- Идентификатор корпуса: 15270289
@inproceedings{Tsarfaty2008WordBasedOM,
title={На основе слов или морфем? Стратегии аннотаций для современных еврейских клитик},
автор={Реут Царфати и Йоав Голдберг},
название книги={LREC},
год = {2008}
} - Реут Царфати, Йоав Голдберг
- Опубликовано в LREC 1 мая 2008 г.
- Лингвистика

Морфологически богатые языки бросают вызов аннотаторам древовидных банков в отношении статуса орфографических (разделенных пробелами) парных слов . [] Ключевой результат Наши результаты, в свою очередь, поднимают новые вопросы, касающиеся взаимодействия морфологической и синтаксической обработки, исследование которых облегчается параллельным банком деревьев, который мы сделали доступным.
Просмотр на ACL
CS.BGU.AC.ILМорфологический анализ и неоднозначности для морфологически богатых языков и универсальных зависимостей
- A. More, RUT TSARFATY
Лингвистика, компьютерная наука
4
Лингвистика, компьютерная наука
4
, лингвистика.
- 2016
Представлена новая, независимая от языка структура для MA&D, основанная на системе перехода с двумя вариантами — на основе слов и на основе морфем — и специальном переходе для смягчения предвзятости последовательностей морфем переменной длины.
Универсальный морфо-синтаксический анализ и вклад Lexica: анализ материалов лаборатории ONLP для совместного задания CoNLL 2018
- Амит Секер, А. Мор, Реут Царфати
Информатика
CoNLL0015
- 2018
Представлен вклад лаборатории ONLP Открытого университета Израиля в общую задачу UD по многоязычному синтаксическому анализу необработанного текста в универсальные зависимости на основе синтаксического анализатора на основе перехода под названием yap, который включает автономный морфологическая модель, автономная модель зависимости и совместная морфосинтаксическая модель.
Морфологическое устранение неоднозначности на основе переходов
- Реут Царфати
Лингвистика, информатика
- 2015
Эксперименты показывают, что MD на основе перехода на основе морфем последовательно превосходит основанный на словах вариант морфологического устранения неоднозначности MRL, обеспечивая при этом новые современные результаты по MD на иврите.
Представление морфосинтаксических единиц и координационных структур в турецком дереве зависимостей
- У. Сулубаджак, Г. Эрийгит
Лингвистика
SPMRL@EMNLP 70015
- 81385 817851023
Новое синтаксическое представление морфосинтаксических подслов в турецком языке позволяет с идеальной точностью определять отношения между ИГ без необходимости скрывать лексическую информацию.
A Single Generative Model for Joint Morphological Segmentation and Syntactic Parsing
- Yoav Goldberg, Reut Tsarfaty
Linguistics
ACL
- 2008
A single joint model for performing both morphological segmentation and syntactic disambiguation which bypasses the предлагается связанная цикличность.
A morph-based and a word-based treebank for Beja
- Sylvain Kahane, M. Vanhove, Rayan Ziane, B. Guillaume
Computer Science
TLT
- 2021
The paper presents the first Банк деревьев UD для беджа, кушитского языка, на котором говорят в Судане, построен на основе преобразования и улучшения межстрочного глоссированного текста (IGT) и объясняет выбор использования аннотаций на основе морфинга и его последствия.
Реляционно-реализационный анализ
- Реут Царфати, К. Симаан
Информатика
COLING
- 2008
допускают вариативность структуры фразы и морфологически-синтаксическое взаимодействие.
Универсальная совместная морфо-синтаксическая обработка: Представление Открытого университета Израиля для совместного задания CoNLL 2017 г.
- А. Море, Реут Царфаты
Информатика
CoNLL
- 2017
Представление Открытого Университета в CoNLL 2017 Shared Task от мультизависимой утилиты парсинга текста и зависимостей Показан поддерживаемый лексикой морфологический анализатор для MRL современного иврита.
Синтаксические парсеры на основе Penn Treebank для южнодравидийских языков с использованием подхода машинного обучения
- Дж. ЭнтониП.
Информатика
- 2010
Представлена разработка статистических синтаксических парсеров на основе Penn Treebank для двух южнодравидийских языков, а именно каннада и малаялам, и производительность систем значительно высока и достигается очень конкурентоспособная точность.
Синтаксические синтаксические анализаторы южнодравидийских языков на основе Penn Treebank с использованием подхода машинного обучения
- P. Antony, Nandini J. Warrier, K. Soman
Информатика
- 2010
Представлена разработка статистических синтаксических парсеров на основе Penn Treebank для двух южнодравидийских языков, а именно каннада и малаялам, и производительность систем значительно высока и достигается очень конкурентоспособная точность.
ПОКАЗЫВАЕТСЯ 1-10 ИЗ 28 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантности Наиболее влиятельные документыНедавность
Неконтролируемый HMM на основе морфем для морфологической неоднозначности иврита
- М. Адлер, Майкл Эльхадад
Лингвистика, информатика
ACL
- 2006
Алгоритмы HMM для изучения и поиска в этом текстовом представлении таким образом, что сегментация и тегирование могут быть изучены параллельно за один шаг.
Выбор оптимальной архитектуры для сегментации и POS-тегов современного иврита
- Рой Бар-Хаим, К. Симаан, Ю. Винтер
Информатика
SEMITIC@ACL
- 2005
HMM), который демонстрирует наилучшую общую производительность как при тегировании POS, так и при сегментации.
Морфология, основанная на словах
В этой статье рассматриваются две противоположные точки зрения на морфологический анализ, рассматриваются флективные паттерны, связанные с выбором между этими альтернативами, и предлагаются преимущества абстрактной модели, вытекающие из того факта, что наборы слов часто предсказывают другие слова. форм и определяют морфотактический анализ их частей.
Создание дерева-банка текстов на современном иврите
- Ю. Винтер, Алон Альтман, К. Симаан, А. Итаи, Н. Натив
Информатика
- 2001
A полуавтомат описана процедура будущего расширения банка деревьев, которая начинается с ручной сегментации слов на последовательности морфем, затем продолжается автоматическим тегированием POS и анализом с последующей ручной коррекцией результирующих деревьев разбора.
Трехмерная параметризация для разбора морфологически богатых языков
- Реут Царфати, К. Симаан
Информатика
IWPT
- 2007
к улучшенной производительности.
Единая порождающая модель для совместной морфологической сегментации и синтаксического анализа
- Йоав Голдберг, Реут Царфати
Лингвистика
ACL
- 2008
Предлагается единая совместная модель для выполнения как морфологической сегментации, так и синтаксического устранения неоднозначности, которая обходит связанную цикличность.
Морфология на уровне слов: психолингвистический взгляд на линейное формирование имен в иврите
- Д. Равид
Лингвистика
- 2006
Иврит является широко известным синтетическим семитическим языком. линейная корневая морфология. В данной статье обсуждается менее известная сторона иврита — линейные операции…
The Penn Arabic Treebank: создание крупномасштабного аннотированного арабского корпуса
- M. Maamouri, Ann Bies, Tim Buckwalter, Wigdan Mekki
Информатика
- 2004
Адрес этой статьи на арабском языке поскольку они относятся к выбору методологии, объясняют выбор в пользу использования стиля руководств Penn English Treebank и показывают несколько способов, в которых человеческие аннотации важны, а автоматический анализ затруднен.
Integrated Morphological and Syntactic Disambiguation for Modern Hebrew
- Reut Tsarfaty
Linguistics, Computer Science
ACL
- 2006
This work represents a first attempt at modeling morphological-syntactic interaction in a generative probabilistic framework to позволяют анализировать MH и показывают, что морфологическая информация, выбранная в тандеме с синтаксическими категориями, полезна для анализа семитских языков.
Penn Treebank: аннотирующая структура аргументов предиката
- M. Marcus, Grace Kim, Britta Schasberger
Компьютерная наука
HLT
- 1994
. более последовательная обработка широкого круга грамматических явлений обеспечивает набор совмещенных нулевых элементов в том, что можно рассматривать как «основное» положение для таких явлений, как wh-движение, пассив и подлежащие инфинитивных конструкций. - Проверка орфографии — это приложение, которое используется для определения правильности написания слова. Функциональность проверки орфографии можно разделить на две части: обнаружение ошибок проверки орфографии и исправление ошибок проверки орфографии. На этапе обнаружения ошибок проверки орфографии обнаруживается только ошибка, в то время как исправление ошибок проверки орфографии также предоставляет некоторые предложения по исправлению ошибки, обнаруженной на этапе обнаружения ошибок проверки орфографии. Еще одно преимущество использования средства проверки орфографии на основе морфологии заключается в том, что оно может справиться с проблемой сущности имени. Если какое-то слово не входит в лексикон, его можно легко добавить.
Обработка естественного языка. Название:- Морфологический анализ | Рагвендра Заркар
Название:- Морфологический анализ
ВВЕДЕНИЕ
Обработка естественного языка (НЛП) является одной из наиболее быстро развивающихся областей исследований. Результаты морфологического анализа и морфологической генерации можно считать очень важными для большинства приложений обработки естественного языка. Поскольку морфологический анализ является методом распознавания слова, его результат можно использовать на более позднем этапе. Имея это в виду, данное исследование объясняет, как морфологический анализ и генерация могут быть продемонстрированы как критические компоненты нескольких областей обработки естественного языка, таких как средства проверки орфографии и машинный перевод.
Морфологический анализ — это область языкознания, изучающая структуру слов. Он определяет, как слово образуется с помощью морфем. Морфема – это основная единица английского языка. Морфема - это наименьший элемент слова, который имеет грамматическую функцию и значение. Свободная морфема и связанная морфема - это два типа морфем. Одна свободная морфема может стать полным словом.
Например, автобус, велосипед и т.д. Связанная морфема, с другой стороны, не может стоять отдельно и должна быть соединена со свободной морфемой, чтобы образовать слово. примерами являются ing, un и другие связанные морфемы.
Инфлективная морфология и деривационная морфология — это два типа морфологии. Оба этих типа имеют собственное значение в различных областях, связанных с обработкой естественного языка.
• Что такое морфологический анализатор?
Во флективных языках слова образуются посредством морфологических процессов, таких как аффиксация. Например, добавляя суффикс «-s» к глаголу «танцевать», мы образуем «танцы» третьего лица единственного числа.Морфологический анализатор присваивает атрибуты данному слову, оценивая, какие морфологические процессы претерпела форма. Если вы дадите ему слово «bailaré» на испанском языке, он скажет вам, что это первое лицо, единственное число, простое будущее, изъявительное наклонение форма глагола «байлар».
Морфологический разбор.
Это процесс определения морфенов, из которых состоит данное слово. Морфены — это наименьшие осмысленные слова, которые нельзя разделить дальше. Морфены могут быть стволовыми или афиксными. Основа - это корень слова, тогда как афикс может быть префиксом, суффиксом или инфиксом. Например:
Неудачный → неуспешный
(префикс) (основа) (суффикс)
Порядок слов также определяет морфологический синтаксический анализатор. Чтобы спроектировать морфологический синтаксический анализатор, нам потребуются три вещи: лексикон, морфптактика и орфографические правила.
• Инфлективная морфология
модификация слова для выражения различных
грамматических категорий.
Инфлективная морфология — это изучение процессов, включая аффиксацию и изменение гласных, которые различают формы слов в определенных грамматических категориях. Инфлективная морфология состоит из: не менее пяти категорий, представленных в следующем отрывке из Language Typology и Syntactic Description: Grammatic Categories and the Lexicon . Как поясняется в тексте, словообразовательную морфологию не так легко классифицировать, потому что словообразование не так предсказуемо, как флексия. Примеры: кошки, мужчины и т. д. лексемы либо путем изменения синтаксической категории (части речи) основы, либо путем добавления содержательного, неграмматического значения, либо того и другого. С одной стороны, деривацию можно отличить от флективной морфологии, которая обычно не меняет категорию, а скорее модифицирует лексемы, чтобы они соответствовали различным синтаксическим контекстам; флексия обычно выражает такие различия, как число, падеж, время, вид, лицо и другие. С другой стороны, деривацию можно отличить от соединения, которое также создает новые лексемы, но путем объединения двух или более основ, а не путем аффиксации, редупликации, вычитания или внутренней модификации различного рода. Хотя различия в целом полезны, на практике применять их не всегда легко.• Морфология, основанная на морфемах:
В этих словах анализируются сочетания морфем. Морфология на основе слов (обычно) представляет собой подход, основанный на словах и парадигмах . Теория принимает парадигмы в качестве центрального понятия. Вместо того, чтобы устанавливать правила объединения морфем в словоформы или образования словоформ из основ, морфология, основанная на словах, устанавливает обобщения, которые сохраняются между формами флективных парадигм.
• Морфология на основе лексем:
Морфология, основанная на лексемах, обычно использует так называемый подход «элемент-и-процесс».
Вместо того, чтобы анализировать словоформу как набор морфем, расположенных в последовательности, говорят, что словоформа является результатом применения правил, которые изменяют словоформу или пару, чтобы произвести новую.• Морфология, основанная на словах:
Морфология, основанная на словах, обычно представляет собой подход, основанный на словах и парадигмах. Вместо установления правил объединения морфем в словоформы.
В большинстве систем НЛП для морфологического анализа используются простые лингвистические теории. Слова связаны друг с другом по правилам аналогии. Слова можно классифицировать на основе шаблона, в который они вписываются. Применимо как к существующим словам, так и к новым. Применение образца, отличного от того, который был использован, дает начало новому слову. Примеры: более старое заменяет старейшее.
Процедура и алгоритм:
Специалист по языку предоставляет различные таблицы слов для всего языка.
Корни следуют шаблону, заложенному в таблице, для создания своего слова.Алгоритм:Формирование таблицы парадигм
Назначение:Сформировать таблицу парадигм из таблицы словоформ для корня
Вход:Корень r, Таблица форм слов Wft(с метками для строк и столбцов) Выход:Таблица парадигм Pt Алгоритм:
1. Создайте пустую таблицу PT той же размерности, размера и меток, что и таблица словоформ WFT.
2. для каждой записи w в WTF выполните, если w=r затем сохраните (0,0) в соответствующей позиции в PT, иначе начните пусть i будет позицией первых символов w и r, которые отличаются, сохраните (размер( r)-i+1, суффикс(i,w)) в соответствующей позиции в PT
3.return PT
В наши дни люди в основном зависят от технических средств, таких как компьютеры, мобильные телефоны для своих повседневных нужд. Но когда мы говорим о людях, не знакомых с технологиями, и об инвалидах, они сталкиваются с большими трудностями при взаимодействии этих сред. Поэтому для этого требуется синтез текста в речь.
Морфологический анализ может быть использован для уменьшения размера лексики, а также играет важную роль в определении произношения омографа. Это также помогает в удалении Schwa и его рассмотрении. В случае сложных слов этот анализатор можно использовать для выделения сложного слова в основную форму, а затем этот основной корень можно объединить с помощью морфологического генератора для получения результата.Машинный перевод.
Машинный перевод в основном помогает людям, которые принадлежат к разным сообществам и хотят взаимодействовать с данными, представленными на разных языках, поскольку этот машинный перевод является одним из важных решений. Для нескольких языков был разработан машинный перевод, но для нескольких других языков работа продолжается.
Из-за отсутствия морфологического анализа нам необходимо хранить все словоформы, это увеличит размер базы данных и потребует больше времени для поиска. Еще одним преимуществом этого анализатора является то, что он предоставляет информацию о таких словах, как число, род.
Эта информация может быть использована в целевом языке для создания правильной формы слова.Преимущество этого анализатора в том, что он предоставляет информацию о слове, таком как число, род. Эта информация может быть использована в целевом языке для создания правильной формы слова.
. Проверка орфографии
Поисковая система — это прикладная программа, используемая для поиска определенного документа в Интернете с использованием World Wide Web. Мы должны предоставить входные данные движку, после чего он предоставит результат на основе введенных данных. Морфологический анализ и генерация улучшают результат поисковой системы.
Предположим, что если в качестве входных данных указано слово, но этого слова нет в лексиконе, это повлияет на выходные данные. В этом случае проводится морфологический анализ этого слова.
Синтаксические выражения различных семантических элементов выражаются отдельными и независимыми словами. морфологические, фонологические, определенные автономно в 1970-х годах, и остальная часть работ по синтаксису показали, что синтаксические системы могут использовать морфологию. исследователи, использующие синтаксис, в котором синтаксические и морфологические
структуры могут быть получены из семантических представлений, должны показать словообразование без использования двух типов морфем, а именно лексических морфем и грамматических морфем .
Английские слова обычно состоят из основы и дополнительного набора аффиксов.Синтаксические процессы.
машинный перевод между двумя языками, база данных слов играет важную роль. … Еще одним важным преимуществом может быть то, что Морфологический анализ предоставляет информацию о слове, таком как номер
Морфологические факты.
мы используем его в нашей повседневной жизни, например, используя слова во множественном числе, то есть добавляя s к его префиксу, и все это зависит от обработки токена ex Я ем одну дыню в день.
Индонезийский: я ем две фруктовые дыни каждый день
Этот язык не использует морфологическое множественное число в формулировках
одно предложение из инаугурационной речи Джона Ф. Кеннеди
Два метода морфологии, аналитический и синтетический, являются двумя двумя .
Пункт 1
Формы с одинаковым значением и одинаковой звуковой формой во всех случаях их появления являются экземплярами одной и той же морфемы.
Пункт 2
Формы с одинаковым значением, но разными звуковыми формами могут быть экземплярами одной и той же морфемы, если их распределения не перекрываются.
Точка 3
Не все морфемы сегментарны.
Пример:
run run в этом глагол и прошедшее время не являются
говорить, говорить, сегментировать, а главное смотреть
есть, ели, как в формах настоящего, так и в прошедшем времени этих глаголов
, потому что это контраст между ними, что важно.
Как различать или разбивать слова Aztec, на которых говорят в Мексике,
Пример
ikalwewe 'его большой дом'
ikalsosol 'его старый дом' Итак, здесь ikal- означает 'его дом' ikalmeh 'его дома' -wewe означает «большой» ikalci·n «его маленький дом»
Резюме
Мы представили некоторые наши основные убеждения, лежащие в основе того, что ни один язык не является совершенным, кроме санскрита, так как нет правильного деления, а также с помощью пример того, как обработка естественного языка будет работать или поможет в мл отличать или переводить слово из его собственного существующего словаря.