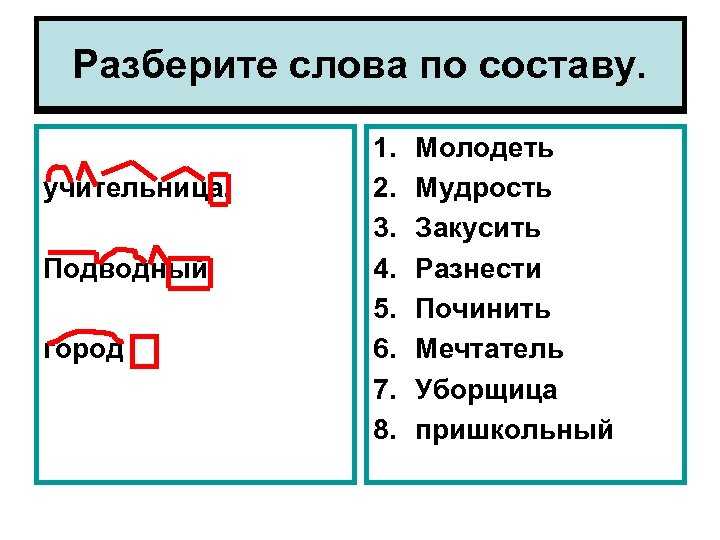
Морфологический разбор слова «правильный»
Часть речи: Прилагательное
ПРАВИЛЬНЫЙ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ПРАВИЛЬНЫЙ»
| Слово | Морфологические признаки |
|---|---|
| ПРАВИЛЬНЫЙ |
|
| ПРАВИЛЬНЫЙ |
|
Все формы слова ПРАВИЛЬНЫЙ
ПРАВИЛЬНЫЙ, ПРАВИЛЬНОГО, ПРАВИЛЬНОМУ, ПРАВИЛЬНЫМ, ПРАВИЛЬНОМ, ПРАВИЛЬНАЯ, ПРАВИЛЬНОЙ, ПРАВИЛЬНУЮ, ПРАВИЛЬНОЮ, ПРАВИЛЬНОЕ, ПРАВИЛЬНЫЕ, ПРАВИЛЬНЫХ, ПРАВИЛЬНЫМИ, ПРАВИЛЕН, ПРАВИЛЬНА, ПРАВИЛЬНО, ПРАВИЛЬНЫ, ПРАВИЛЬНЕЕ, ПРАВИЛЬНЕЙ, ПОПРАВИЛЬНЕЕ, ПОПРАВИЛЬНЕЙ, ПРАВИЛЬНЕЙШИЙ, ПРАВИЛЬНЕЙШЕГО, ПРАВИЛЬНЕЙШЕМУ, ПРАВИЛЬНЕЙШИМ, ПРАВИЛЬНЕЙШЕМ, ПРАВИЛЬНЕЙШАЯ, ПРАВИЛЬНЕЙШЕЙ, ПРАВИЛЬНЕЙШУЮ, ПРАВИЛЬНЕЙШЕЮ, ПРАВИЛЬНЕЙШЕЕ, ПРАВИЛЬНЕЙШИЕ, ПРАВИЛЬНЕЙШИХ, ПРАВИЛЬНЕЙШИМИ
Разбор слова по составу правильный
правильн
ый
| Основа слова | правильн |
|---|---|
| Корень | прав |
| Суффикс | и |
| Суффикс | ль |
| Суффикс | н |
| Окончание | ый |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ПРАВИЛЬНЫЙ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «правильный»
Примеры предложений со словом «правильный»
1
И особливо мне тягостно на тебя глядеть, какой ты правильный, во всем правильный!..
Не герой, Игнатий Потапенко, 1891г.
2
Она тихая, спокойная, и выговор у нее очень правильный, даже правильнееправильного.
Конец сюжетов: Зеленый шатер. Первые и последние. Сквозная линия (сборник), Людмила Улицкая, 2013г.
3
От того, что сделал правильный
выбор – до жути правильный, почти нечеловеческий.
Начало, Дмитрий Босяченко, 2015г.
4
Деловая молодая женщина по имени Анна, в правильной одежде, с правильной сумочкой, на правильном автомобиле, при правильной работе.
Напрямик (сборник), Роман Сенчин, 2016г.
5
Такой светленький, коренастый, плотненький, весь правильный—правильный…
Под прикрытием Пенелопы, Игорь Агафонов
Найти еще примеры предложений со словом ПРАВИЛЬНЫЙ
«Правильный» морфологический разбор слова — ассоциации, падежи и склонение слов
- мужской род
- женский род
- средний род
Существительные к слову правильный
Что или кто бывает правильным? Подбор существительных слов к прилагательному на основе русского языка.
путь
выбор
вопрос
способ
круг
человек
ответ
совет
поиск
наставник
парк
комсомолец
дурачок
район
иероглиф
балласт
сбыт
этап
банкнот
параболоид
мат
крючок
мак
день
хват
взгляд
крест
туман
кирпич
навык
базар
пациент
сенатор
фарватер
тоник
материал
разбойник
угольник
признак
антитоксин
контраст
шмон
слог
чертеж
вуз
снос
гражданин
бинт
носик
мальчик
тип
цилиндр
сбор
игрок
кадр
чижик
фрагмент
лакколит
компресс
блок
дядька
плейер
листочек
заголовок
Глаголы к прилагательному правильный
Что можно сделать правильно? Подбор глаголов на основе русского языка и литературы.
понять
сделать
говорить
делать
понимать
заметить
мыслить
поступить
выбрать
решить
оценить
произносить
ставить
рассудить
воспользоваться
отметить
испугаться
гасить
рисовать
усваивать
закреплять
лишать
нагреть
опровергать
напрячь
яриться
нанести
расшифровывать
упаковать
докончить
вложиться
истолковывать
распылить
подстраивать
уяснить
отождествляться
сплясать
прикалывать
диктовать
существовать
предвидеть
напоминать
осуждать
вздыхать
поменять
шить
вкушать
осмотреться
сформировать
делиться
ходатайствовать
перейти
хранить
усесться
комментировать
издавать
упасть
когтить
научиться
консервировать
воспринимать
зарезать
отделать
Анаграммы
привальный
Гипонимы
справедливый
точный
Какого рода правильный (морфологический разбор)
Разбор слова по части речи, роду, числу, одушевленности и падежу.
Часть речи:
прилагательное
Род:
мужской
Число:
единственное
Степень сравнения:
—
Падеж:
именительный
Склонение прилагательного правильный (какой падеж)
Склонение слова по падежу в единственном и множественном числах.
| Падеж | Вопрос | Единственное | Множ. | ||
|---|---|---|---|---|---|
| Мужской | Средний | Женский | |||
| Именительный | (кто, что?) | правильный | правильное | правильная | правильные |
| Родительный | (кого, чего?) | правильного | правильной | правильных | |
| Дательный | (кому, чему?) | правильному | правильной | правильным | |
| Винительный | (кого, что?) | правильный | правильную | правильные | |
| Творительный | (кем, чем?) | правильным | правильной | правильными | |
| Предложный | (о ком, о чём?) | правильном | правильной | правильных | |
Сфера употребления
Общая лексика Редкое выражение Сельское хозяйство Консервирование РиторикаНапишите свои варианты ассоциаций
Смотрите также
Перевод Ассоциации Анаграммы Синонимы и антонимы Морфологический разбор Склонения Спряжения
Буква в начале Буква в конце
Все связи построены автоматическим анализатором русскоязычного текста.
Синтаксический анализ и выполнение II
Теперь, когда вы понимаете, что такое анонимный глагол/наречие/союз is, вы готовы следить за разбором и выполнением слова по слову. Мы, наконец, откажемся от всех сокращений и обработки предложений точно так же, как это делает переводчик.
На любом скомпилированном языке программа повреждена
в слова (токены)
а затем анализируется, и код генерируется из проанализированного результата. Не так в J: предложение разбито на слова,
но предложение не разобрано полностью; скорее парсинг и выполнение продолжаются
одновременно, сканируя текст справа налево. Парсинг находит
модели в предложении, которые затем выполняются. Исполнение
включает в себя обычную поставку существительных операндов к глаголам для получения результата от
глагол, но и другие действия: предоставление операндов глагола и существительного для
союзы и наречия для создания производных объектов, а также распознавание других
последовательности, которые мы узнаем в ближайшее время.
Выполнение части предложения, которую мы будем называть фрагментом, состоит в замене фрагмента соответствующее одно слово, именно результат выполнения фрагмент. В простом случае, когда фрагмент — это обращение к глаголу (т. е. фрагмент выглядит как

Во всех случаях слово, заменяющее фрагмент, имеет определенная часть речи, а если это глагол, то определенный разряд.
Я хочу повторить, что «исполнение», как здесь используется, не синоним «выполнения существительных операндов». Да, глаголы исполняются именно так. Но выполнение модификатора создает анонимную сущность, и она может вообще не употребляйте существительные (как в примере с +&.>). Выполнение модификатора — это шаг по путь к выполнению производного глагола.
Таблица синтаксического анализа
Исполнение
предложения начинается с разбиения предложения на слова. Слова (с маркером начала строки,
показанные здесь как $ с предварителем) становятся начальным содержимым списка необработанных слов.
Стек push-down также будет использоваться во время
исполнение; он изначально пустой.
Выполнение предложения осуществляется путем повторения этапа синтаксического анализа, который включает в себя: (1) изучение первых 4
элементы стека, чтобы увидеть, соответствуют ли они одному из 9 исполняемых шаблонов;
(2) если совпадение было найдено, выполнение исполняемой части стека (какой
мы назвали исполняемый фрагмент в предыдущей главе), в результате
слово, которое заменяет фрагмент в стеке; (3) если совпадений не найдено,
перемещение самого правого слова необработанного списка слов в крайнее левое
положение стека, сдвигая остальную часть стека вправо.
Чтобы следить за синтаксическим анализом, нам нужно знать, какие шаблоны в вершина стека содержит исполняемый фрагмент. Таблица синтаксического анализа ниже приведен полный список. Больше, чем один символ в прямоугольнике означает, что любой из них соответствует прямоугольнику. имя означает любое допустимое имя переменной, а C, A, V и N обозначают союз, наречие, глагол и существительное соответственно.
самый левый слово стека | прочее стек слов | действие | ||
$ =. | В | Н | что угодно | 0 Монада |
$ =. =: ( А В Н | В | В | Н | 1 Монада |
$ =. =: ( А В Н | Н | В | Н | 2 Диада |
$ =. =: ( А В Н | В Н | А | что угодно | 3 Наречие |
$ =. =: ( А В Н | В Н | С | В Н | 4 соединения |
$ =. | В Н | В | В | 5 Вилка |
$ =. =: ( | К А В N | К А В N | что угодно | 6 Хук/Наречие |
наименование N | =. =: | К А В N | что угодно | 7 Есть |
( | К А В N | ) | что угодно | 8 Парен |
 =: (
=: ( =: ( А В Н
=: ( А В Н Строки в таблице синтаксического анализа обрабатываются в
заказ. Если крайние 4 слова на
стеку соответствует строка в таблице, фрагмент (те слова в стеке, которые
выделены жирным шрифтом в таблице синтаксического анализа) выполняется и заменяется в стеке на
вернулось единственное слово. Поскольку
Фрагмент всегда состоит из двух или трех слов, он официально известен как двузубец или трезубец. Последний столбец таблицы синтаксического анализа дает
описание того, что влечет за собой выполнение фрагмента.
Поскольку
Фрагмент всегда состоит из двух или трех слов, он официально известен как двузубец или трезубец. Последний столбец таблицы синтаксического анализа дает
описание того, что влечет за собой выполнение фрагмента.
Вам будет легче следить за синтаксическим анализом, если вы обратите внимание, что самое левое слово в исполняемом шаблоне обычно является одним из $ =. =: ( AV N . Это означает, что вы можете сканировать справа пока вы не нажмете слово, которое соответствует одному из них, прежде чем вы даже начнете проверять для исполняемого шаблона. Если вы найдете один из $ =. =: ( А В N и он не соответствует исполняемому шаблону, продолжайте искать следующий вхождение.
Обратите внимание, что самое левое слово стека в таблице синтаксического анализа
никогда не союз. Это
первоисточник нашего давно известного правила, согласно которому союзы связывают
слева направо: союз может быть выполнен только тогда, когда он появляется в третьем
позиции стека, но если другая конъюнкция находится в крайнем левом положении, то
стек всегда будет сбрасываться вниз, чтобы проверить, что осталось от этой конъюнкции. аргумент.
аргумент.
Строка 6, определяющая крючки, соответствует любой комбинации CAVN CAVN , кроме Н Д и В А , который совпадают в строке 3. Только комбинации A A , C N , C V , Н С , В С , и В В являются действительный; остальные приводят к синтаксическим ошибкам.
Примеры синтаксического анализа и выполнения
Теперь мы проанализируем несколько предложений. Мы будем представлять анонимные сущности по именам
курсивом с указанием того, как была создана анонимная сущность. До сих пор в этой книге мы едва ли
заметил, что термин «глагол» использовался как для сущности, которая может быть применена к
существительное для получения существительного результата, а также для имя того
сущность. Эта двусмысленность будет
продолжать — быть точным было бы слишком обременительно, — но вы должны знать о
это. Когда мы говорим: «Результат равен av ,
определяется как +/’, это означает, что был создан анонимный глагол, функция которого
описывается как +/,
и прозвище, которое мы ему даем, — слово, то есть то, что идет на казнь
стек для обозначения этого глагола — av .
Предложение: +/2*a, где a равно 1 2 3
необработанный список слов | стопка | строка |
$ + / 2 * |
|
|
$ + / 2 * | 1 2 3 (не исполняемый) |
|
$ + / 2 | * 1 2 3 (не исполняемый) |
|
$+/ | 2 * 1 2 3 (не исполняемый) |
|
$ + | / 2 * 1 2 3 (результат 2 4 6) | 2 |
| $ + / 2 4 6 (результат av , определяется как +/) | 3 |
| $ av 2 4 6 (результат 12) | 0 |
| $ 12 |
|
Столбец с пометкой «линия» указывает, какая строка
таблица синтаксического анализа совпала со стеком. Фрагмент выделен жирным шрифтом и подчеркнут. Обратите внимание, что когда существительное a перемещается на
стек, его значение было перемещено; когда именованный глагол, наречие или союз
перемещается в стек, перемещается только имя . Заметьте также, что значение существительного (1 2 3
здесь) одно слово.
Фрагмент выделен жирным шрифтом и подчеркнут. Обратите внимание, что когда существительное a перемещается на
стек, его значение было перемещено; когда именованный глагол, наречие или союз
перемещается в стек, перемещается только имя . Заметьте также, что значение существительного (1 2 3
здесь) одно слово.
С этого момента мы будем опускать строки, не содержащие исполняемый фрагмент.
Предложение: среднее =: +/% #
необработанный список слов | стопка | строка |
$ означает =: +/% # |
|
|
$ означает | =: + / % # (результат av1 , определяется как +/) | 3 |
$ означает | =: av1 % # (результат av2 , определенный как av1 % #) | 5 |
| $ среднее =: av2 (результат av2 ; среднее значение присваивается ав2 ) | 7 |
| $ av2 |
|
Я хочу подчеркнуть, что назначенное означает
является результатом синтаксического анализа +/ % # . Это , а не последовательность +/ % #,
а скорее один глагол, который выполняет функцию, описанную
вилка. Теперь вы понимаете, почему положить
скобки вокруг определения не имеют значения: av2 будет проанализировано
одинаково в любом случае.
Это , а не последовательность +/ % #,
а скорее один глагол, который выполняет функцию, описанную
вилка. Теперь вы понимаете, почему положить
скобки вокруг определения не имеют значения: av2 будет проанализировано
одинаково в любом случае.
необработанный список слов | стопка | строка |
$ среднее 4 5 6 |
|
|
| $ среднее 4 5 6 (результат 5) | 0 |
| 5 $ |
|
Предложение: среднее 4 5 6
Поскольку среднее значение является результатом синтаксического анализа +/% #,
это выполняется без дальнейших церемоний. Как
вы можете видеть, что один шаг «выполнения» может вызвать каскад обработки, как
каждый глагол, на который ссылается исполнительный глагол, выполняется по очереди. Здесь выполнение среднего делает
всю обработку форка, возвращая результат 5 . Глагол to be execute может быть довольно сложным,
и может иметь смесь именованных и анонимных компонентов, как в следующем
пример. 9. » 1)
Как
вы можете видеть, что один шаг «выполнения» может вызвать каскад обработки, как
каждый глагол, на который ссылается исполнительный глагол, выполняется по очереди. Здесь выполнение среднего делает
всю обработку форка, возвращая результат 5 . Глагол to be execute может быть довольно сложным,
и может иметь смесь именованных и анонимных компонентов, как в следующем
пример. 9. » 1)
4
$ ( среднее значение — ( + / % # ) &.
( av1 ) ) 4 5 6 (результат av1 )
8
$ ( среднее —
( + / % # ) &. ав1 ) 4 5 6 (результат av2 , определено как +/
3
$ ( среднее —
( av2 % # )
&. av1 ) 4 5 6 (результат av3 ,
определяется как av2 % #)
av1 ) 4 5 6 (результат av3 ,
определяется как av2 % #)
5
$ ( среднее —
( av3 ) &. ав1 ) 4 5 6 (результат av3 )
8
$ ( значит
— av3 &. av1 ) 4 5 6 (результат av4 , определено как av3 &. ав1 )
4
$
( среднее — av4 ) 4 5 6 (результат av5, определенный как среднее — av4 )
5
$
( av5 ) 4 5 6 (результат av5 )
8
$ av5 4 5 6 (результат 0,0675759)
0
$ 0,0675759
Опять же, было только одно исполнение глагола. Произошло это в самом конце: после av5 был создан, он был выполнен, и его выполнение включало в себя выполнение
все остальное. av5 выполняется для получения среднего — av4 ;
для этого он выполнил av4 , значит,
затем -,
и так далее по очереди. Каждый выполненный
сущность произвела результат в соответствии со своим определением.
Произошло это в самом конце: после av5 был создан, он был выполнен, и его выполнение включало в себя выполнение
все остальное. av5 выполняется для получения среднего — av4 ;
для этого он выполнил av4 , значит,
затем -,
и так далее по очереди. Каждый выполненный
сущность произвела результат в соответствии со своим определением.
Предложение: inc =: ({.a)&+ где a равно 4 5 6
необработанный список слов | стопка | строка |
$ вкл. =: ({. а) & + |
|
|
$ вкл. =: | ( {. | 0 |
$ вкл. =: | ( 4 ) & + (результат 4) | 8 |
$ вкл. | =: 4 & + (результат av , определяется как 4&+) | 4 |
$ | вкл. =: ав. (результат ав. ; вкл. присваивается ав. ) | 7 |
| $ ср |
|
 4 5 6 ) & + (результат 4)
4 5 6 ) & + (результат 4) Это иллюстрирует важный момент. Даже посреди сложного определения,
глаголы применяются к существительным везде, где это возможно.
И значение существительного в определении — это значение в то время, когда
определение было проанализировано . Если
анализируемое определение относится к глаголу, оно делает это по имени, поэтому значение глагола
это его значение при выполнении .
Даже посреди сложного определения,
глаголы применяются к существительным везде, где это возможно.
И значение существительного в определении — это значение в то время, когда
определение было проанализировано . Если
анализируемое определение относится к глаголу, оно делает это по имени, поэтому значение глагола
это его значение при выполнении .
Остальные примеры представляют собой диковинку, чтобы показать вам, что это стоит ваших усилий, чтобы изучить тонкости синтаксического анализа.
Предложение: а + а =. 5
необработанный список слов | стопка | строка |
$ + а =. 5 |
|
|
$ + | а =. | 0 |
| $ 5 + 5 (результат 10) | 2 |
| 10 долларов |
|
 5 (результат 5;
присваивается 5)
5 (результат 5;
присваивается 5)a присваивается значение непосредственно перед этим значением помещается в стек.
Предложение: 2 +: (2 : ‘&’) -: * 5
необработанный список слов | стопка | строка |
$ 2 +: (2: ‘&’) -: * 5 |
|
|
$ 2 +: | ( 2 : ‘&’ ) -: * 5 (результат ac1 , определяется как 2 : ‘&’) | 4 |
$ 2 +: | ( ac1 ) -: * 5 (результат ac1 ) | 8 |
$ | 2 +: ac1 -: * 5 (результат ac2 , определяется как &) | 4 |
| $ 2 ac2 * 5 (результат av , определяется как 2&*) | 4 |
| $ av 5 (результат 10) | 0 |
| 10 долларов |
|
Посмотрите, что произойдет, если мы опустим круглые скобки:
Предложение: 2 +: 2 : ‘&’ -: * 5
необработанный список слов | стопка | строка |
$ 2 +: 2 : ‘&’ -: * 5 |
|
|
$ 2 +: 2 : | ‘&’ -: * 5 (результат 1) | 1 |
$ 2 | +: 2 : ‘&’ -: 1 (результат ac1 , определяется как 2 : ‘&’) | 4 |
$ | 2 +: ac1 -: 1 (результат ac2 , определяется как &) | 4 |
| $ 2 ac2 1 (ошибка домена: 2&1 недопустимы) | 4 |
Упущение приводит к тонкому, но фатальному изменению в
порядок разбора. Как словарь
говорит: «может быть необходимо заключить в скобки наречное или конъюнктивальное
фраза, которая производит что-либо, кроме существительного или глагола». Теперь вы понимаете, почему.
Как словарь
говорит: «может быть необходимо заключить в скобки наречное или конъюнктивальное
фраза, которая производит что-либо, кроме существительного или глагола». Теперь вы понимаете, почему.
Не определено Words
Если вы попытаетесь выполнить несуществующий глагол, вы получаете сообщение об ошибке:
z 5
|ошибка значения: z
| z 5
Однако эта ошибка возникает во время выполнения имя, а не во время его разбора. В течение разбор, Предполагается, что неопределенное имя быть глаголом бесконечного ранга . Этот позволяет вам писать глаголы, которые относятся друг к другу, и освобождает вас от необходимо быть скрупулезным в отношении порядка, в котором вы определяете глаголы. Например:
a =: z
Получается глагол a, который, когда выполняется, выполнит z.
z =: +
a 5
5
При заданном z выполняется a правильно. Конечно, можно присвоить z к другому глаголу тоже:
b =: z
b 5
5
Теперь не могли бы вы сказать мне, что +/@b 1 2 3
Сделаю? Потратьте минуту, чтобы понять это
(Подсказка: обратите внимание, что я использовал @, а не @:).
+/@b 1 2 3
1 2 3
Поскольку b имеет ранг 0, +/@b также имеет нулевой ранг, поэтому «суммирование» применяется к атомам по отдельности, и мы получить результат списка. Как вы думаете, +/@a 1 2 3 будет тот же результат?
+/@a 1 2 3
6
Даже если a имеет то же значение , что и b, это ранг отличается. как ранг был присвоен при его разборе, и в то время z считался имеют бесконечный ранг. ранг б был присваивается и при разборе, но к тому моменту z уже был определен с рангом 0. Вы можете выиграть много баров ставки с этим, если вы болтаетесь с правильной толпой.
Примечание
Избегайте использования имен параметров x, y,
ты,
в,
м,
и н
для ваших собственных публичных переменных. Те
имена переназначаются всякий раз, когда запускается явно определенная сущность. Кроме того, когда выполняется явное определение,
эти имена всегда оцениваются перед помещением в стек (в других
слов, они передаются по значению, а не по имени, даже если они
глаголы). Поэтому они производят ошибку значения
если они не определены при использовании.
Поэтому они производят ошибку значения
если они не определены при использовании.
Разбор для NLU. NLU был признан невозможным… | Джон Болл | Pat Inc
Упрощать, упрощать, упрощать для понимания языкаNLU считалось невозможным компьютерными лингвистами в 1990-х[i], потому что если это не задача AI-Hard, то она NP-Complete. На этом этапе революция Ноама Хомского в лингвистике потерпела неудачу в практической лингвистике и была заменена «вычислительной» лингвистикой, которая искала статистические решения для замены правил, которые оказались невозможными для реализации.
Проблема в том, что хотя некоторые эксперты сегодня в частном порядке заявляют, что модель Хомского была дискредитирована, его работа продолжает оставаться на высоком уровне: поиск лучших синтаксических анализаторов, создание большего количества аннотированных корпусов с частями речи и эксперименты с другие типы статистических методов, таких как искусственные нейронные сети. Основы компьютерной лингвистики продолжают преследовать формальные системы — синтаксический анализ бессмысленных строк (слов), состоящих из символов (букв), и использование правил для сопоставления частей речи в деревьях. Когда я сравниваю формальную модель Винтнера[ii] в 2013 г., трудно увидеть большие изменения по сравнению с моделью Хомского9.1581 синтаксических структур в 1957 году [iii].
Когда я сравниваю формальную модель Винтнера[ii] в 2013 г., трудно увидеть большие изменения по сравнению с моделью Хомского9.1581 синтаксических структур в 1957 году [iii].
Я утверждал, что для включения NLU[iv] необходим ряд изменений, таких как включение значений, выделение частей речи, удаление деревьев и замена наборами и т. д.[v] ].
Сегодня я покажу, как выделить части речи, оставив только значение, на конкретных примерах английского языка.
Аргумент состоит в том, что наука развивается, когда вводятся лучшие, более простые модели, которые объясняют или предсказывают наблюдения или что-то в этом роде. Я склонен проводить параллели с изобретением, изучая все способы не решать что-то вроде того, как Эдисон не изобрел лампочку.
Удаление частей речи и замена семантической моделью — такое упрощение, которое я с некоторых пор успешно использую для NLU. Я сделал видео, показывающее, как инфинитивные формы и герундии (существительные формы сказуемых) распознаются в разговоре наряду с «обычными» предложениями (глагольными формами сказуемых)[vi].
Части речи — это древняя концепция, примененная в лингвистике для синтаксических анализаторов избирательных округов в 1930-х годах. Хомский оправдывал стремление к синтаксису на основе единственного предложения «бесцветные зеленые идеи яростно спят». Он утверждал, что носитель языка распознает грамматические последовательности в этом предложении независимо от «значимых» предложений[vii].
Я не согласен, потому что синтаксическое представление этого предложения, если исключить значение, допускает неграмматические предложения, такие как «бег, бег, бег, бег, яростный бег», которые используют одни и те же части речи[viii]. В моем анализе использовалась модель Penn Treebank (тэги Penn Treebank P.O.S.)[ix].
Очевидный вопрос: «Что значит для предложения быть грамматическим в языке, если используемая грамматика порождает неграмматические предложения?»
Вместо того, чтобы использовать части речи для моделирования языков, которые впоследствии генерируют неграмматические предложения, давайте искать фразы (шаблоны), которые одновременно распознают предложения в языке и также генерируют правильные предложения (двунаправленная модель).
Мой аргумент состоит в том, что если вы изучаете язык на опыте, а опыт состоит из сенсорного опыта (значимых объектов, качеств и переживаемых действий), то последовательность слов, используемая другими носителями языка, становится образцом фраз этого языка в brain[x] (с использованием теории Патома).
POS в словаре определяет, как слово используется в предложении. Так было долгое время — возможно, потому, что это кажется «научным». Для человека-читателя это, безусловно, полезная система, поскольку форма слова показана с соответствующим определением. Но для машины, возможно, это бесполезно. Вместо того, чтобы показывать разные слова POS, я создаю определение (значение), а затем связываю его со словами. Это консолидирует определения — уменьшает их количество.
Здесь слово «бег» используется с тремя разными частями речи:
- Кот бежит (бег — глагол)
- Бегущий кот быстро (бег — прилагательное)
- Кот бежит быстрый (бег — существительное).

Пока все хорошо. Если мы посмотрим на словарь WordNet, вероятные определения будут в следующем порядке:
- двигаться быстро, используя ноги, не отрывая одной ноги от земли в любой момент времени
- быстро двигаться пешком
- акт о пробеге; Путешествие пешком в быстром темпе
Первая проблема при таком подходе — равенство. Выполняет ли бегущая кошка те же действия, что и «бегущая кошка»? Является ли «бег кота» действием, совершаемым «бегущим котом»? В разговоре это центральное место. Если избранный политик отличается от политика, который был избран, нам нужно знать. Точно так же, как машина узнает, что они одинаковы?
Очевидное решение состоит в том, чтобы объединить определения в одно и обозначить, что используемые словоформы отличаются. Первое письменное определение выше выглядит приемлемым. Это только первый шаг, так как кошки бегают по-разному к людям, а вода течет по-разному к обоим, но объяснение этого с семантической сетью — это другой день.
Если бы в языке было, скажем, 13 000 глаголов, 15 000 прилагательных и 8 000 наречий, общее количество определений могло бы составить примерно 10 000. Есть еще много словарных упрощений, но это ключевая идея.
Проблема дублирования в POS влияет на правила структуры фраз в системе, основанной на правилах. Даже в статистической системе остается выбор правильных частей речи. Давайте посмотрим на правила, необходимые для распознавания синтаксиса следующих трех фраз:
- Кот счастлив NP V ADJ атрибут кота — счастлив (СВК)
2. Кошка животное НП В НП тип кошки (СВК)
Идентификационная фраза, показывающая детали типа кошки (это тип животного)3. Кошка бегает напряженная деятельность (SV)
Прогрессивный аспект бега. В указанное/написанное время кошка выполняет действие. Правила написаны в общепринятой форме. NP — именная группа, ADJ — прилагательное, V — глагол (старая синтаксическая терминология). Здесь фраза 1 связывает существительное с его атрибутом. Фраза 2 указывает на тип упомянутого существительного, а фраза 3 указывает на то, что существительное участвует в прогрессирующем глаголе.
Здесь фраза 1 связывает существительное с его атрибутом. Фраза 2 указывает на тип упомянутого существительного, а фраза 3 указывает на то, что существительное участвует в прогрессирующем глаголе.
Теперь мы можем видеть проблему, созданную без включения значения в теорию формальной лингвистики. Достаточно легко написать правила, которые производят части речи, наблюдаемые в простом примере трех фраз. Но теперь давайте посмотрим на комбинацию беспорядка, который создают наши 3 части речи для слова «бег» при использовании в сочетании с нашими 3 фразами.
Давайте вычислим правильные правила разбора простого предложения: «кот бежит».
- Синтаксический анализатор соответствует фразе 1 (NP V ADJ), так как «бег» — это прилагательное!
- Синтаксический анализатор соответствует фразе 2 (NP V NP), так как «бег» является существительным и может использоваться отдельно, например, «бег — это хорошо».
- Синтаксический анализатор соответствует фразе 3 (NP V V-ing), так как «running» является формой глагола с -ing (причастие настоящего времени).

Возможно ли, что язык просто супер-неоднозначен и не может быть решен для таких примеров? Соответствие всем трем кажется очень плохим.
Несмотря на то, что лингвистам доступны человеческие инструменты для определения правильной части речи в предложении, какой метод мы можем использовать, чтобы решить, какая фраза является правильной? Проблема в том, что если мы получим вопрос вроде: «Бежит ли кошка», у нас будет та же проблема (здесь также могут быть запущены все 3 случая POS).
Одно из решений состоит в том, чтобы сохранить все три, сохранить все в контексте и, когда задается вопрос, сравнить все три с сохраненными копиями-дубликатами. В этом случае будет найдено три совпадения — по одному для каждой части речи. Такой подход и результат кажутся несколько неоптимальными. Это уже начало комбинаторного взрыва, который требует статистики или какого-либо другого инструмента для решения! Проще говоря, это не вычисляет.
Более простая модель наличия трех словарных статей для одного и того же значения состоит в том, чтобы иметь одну статью и применять принцип декомпозиции, чтобы элементы оставались «атомарными». Легко сопоставить атомарные элементы на равенство — проверьте, являются ли они одним и тем же объектом.
Легко сопоставить атомарные элементы на равенство — проверьте, являются ли они одним и тем же объектом.
В мире значений есть только две семантические категории — референты и предикаты. Референты относятся к вещам, а предикаты относятся к вещам.
В приведенном выше примере «выполняемое» определение относится только к предикату. Следовательно, оно не соответствует примеру предложения, кроме прогрессивной формы глагола. Для соответствия атрибутивному предложению необходим еще один атрибут, поскольку прилагательные также являются типом сказуемого.
В английском языке вы можете увидеть сходство значений прилагательных и глаголов (сказуемое), если посмотрите на предложения: «дверь открыта» (ADJ) и «дверь открывается» (V). Одно — это состояние, а другое — достижение, и оба имеют одно и то же значение.
Давайте посмотрим на идею существительного, чтобы увидеть, какая декомпозиция возможна, поскольку она обеспечивает наиболее очевидную комбинацию значений. Существительное смешивает предикатное значение с референтным значением, что приводит к недопустимым фразам в зависимости от значения слова, как мы увидим ниже.
Давайте посмотрим на два существительных: (а) разрушение в значении « разрушение города было плохим» и (б) город в значении « город был грязным». Нуньес [xi] показала в случае существительных-форм глаголов в (а), что они сохраняют значение и доступ к аргументам, как глагол (сказуемое), в то время как (б) не могут (существительные/референты не связаны).
Расширение модели аргумента « подарок Джону вина был оценен по достоинству» является примером, где «Джону» является аргументом «дать», который находится в форме существительного, «подарок». Используя токены POS для их представления, фраза будет иметь вид NP ::= NP ‘to’ NP (шаблон означает, что именное словосочетание состоит из именного словосочетания, слова ‘to’ и еще одного именного словосочетания)
Этот подход неверно, потому что это предложение неверно: « Шпатель в город плохой» не имеет смысла. Это неверно, потому что шпатель не может принимать аргумент «к». А как насчет другого предиката с тремя ролями в «форме существительного», такого как «передача»? Вручение Иоанну шпателя плохо». В этом есть смысл.
А как насчет другого предиката с тремя ролями в «форме существительного», такого как «передача»? Вручение Иоанну шпателя плохо». В этом есть смысл.
Возникающая закономерность заключается в том, что когда существительное является референтом (семантически оно относится к какому-то объекту), оно не соответствует 3-ролевой предикатной фразе NP ::= NP «к» NP. Шаблон соответствует, когда существительное является предикатом с 3 ролями (семантически оно связывает 3 аргумента в своем представлении). Точно так же предикаты с двумя ролями, такие как «разрушение», не соответствуют фразе NP ::= NP «к» NP.
Тесты Facebook в 2017 году использовали эту декомпозицию предикатов вместе с соответствующими проверенными фразами для достижения задокументированных результатов[xii]. В показанных примерах будет только одна фраза, соответствующая показанной (опорная фраза, а не именная фраза):
RP ::= [пред + фраза + 3-ролевая + номинальная] ‘to’ RP
Это означает, что если фраза является сказуемым с 3-ролями и в именной форме, она будет соответствовать со словом «to» после него и еще одной опорной фразой (RP) и ничем другим. Здесь используется правило, необходимое для английского языка, но слишком обобщенное, если его применять только к существительным.
Здесь используется правило, необходимое для английского языка, но слишком обобщенное, если его применять только к существительным.
Используемая здесь номенклатура несколько неуклюжа, но шаблон фразы просто объединяет наборы элементов в список. Дело в том, что только конкретный падеж признается словосочетанием на основании его значимых элементов (он во словосочетании, его значение — сказуемое, он принимает 3-роли и находится в «именной» форме).
Декомпозиция словаря и частей речи показывает, что традиционное существительное может быть семантическим референтом (объектом) или сказуемым (отношением). Возможный синтаксис напрямую связан со значением используемой словоформы, а не с ее POS.
Хотя это и не показано выше, принцип устранения дублирования определений между частями речи доказал свою эффективность при поиске правильного семантического представления предложений.
Хотя это всего лишь один шаг в упрощении словаря для NLU, в целом применяется принцип — сократить шаблоны фраз до значимых элементов слова или фразы, чтобы они соответствовали значению.
[i] https://medium.com/pat-inc/nlu-held-up-by-parts-of-speech-and-fixed-by-meaning-60fb58d5647e Ball, 2018.
[ii] Александр Кларк и др. (ред.), Справочник по вычислительной лингвистике и обработке естественного языка , 2013, с. 11–42.
[iii] Noam Chomsky, Syntactic Structures , Mouton Publishers, Paris, 1957. На странице 4 показаны правила, мало чем отличающиеся от современных вычислительных лингвистических правил. См. Кларк, соч. соч., с. 24 (правило слов) и с. 32 (правило фраз).
[iv] https://medium.com/pat-inc/semantics-not-syntax-creates-nlu-41e2d466567 Ball, 2018.
[v] John S. Ball, Использование NLU в контексте ответов на вопросы : Улучшение задач bAbI Facebook, 21 сентября 2017 г., https://arxiv.org/abs/1709.04558 , P 22. Это краткое изложение рекомендуемых изменений на одной странице.
[vi] https://youtu.be/rWcf17V5BrU Значение без существительных и глаголов, 2019.
[vii] Chomsky, op.