Транскрипция слов примеры русский язык
Содержание
- Примеры фонетического разбора
- Йотированная гласная + ь
- Йотированная гласная + чередование согласной
- Сдвоенная согласная — долгий звук
- Сдвоенная согласная — обычный звук
- Фонетическая транскрипция слова
- Транскрипция – что это?
- Зачем нужна транскрипция?
- Частичная транскрипция
- Как записать транскрипцию
- Примеры транскрипции слов
- Что мы узнали?
- Транскрипция слова. Фонетический разбор слова
- Основные понятия
- План фонетического разбора
- Фонетическая транскрипция видео
- Таблицы соответствия букв и звуков для фонетического разбора
- Примеры фонетического разбора
- Примеры заданий с элементами фонетического разбора
- Фонетическая транскрипция – примеры, правила (5 класс, русский язык)
- Транскрипция – что это?
- Зачем нужна транскрипция?
- Частичная транскрипция
- Как записать транскрипцию
- Примеры транскрипции слов
- Что мы узнали?
- Фонетический разбор слова
- Правила разбора на звуки
- Образец звуко-буквенного разбора слова
- Примеры фонетического разбора
- Видео
Примеры фонетического разбора
Приведём примеры простых и сложных случаев фонетических разборов слов. К каждому примеру дано объяснение разбора.
К каждому примеру дано объяснение разбора.
Покажем примеры фонетических разборов для йотированных гласных. Определение йотированных гласных дано на странице звуков. В русском слове много слов с удвоенными согласными: классно, баллон, сумма, ванна и другие. В звуко-буквенном разборе следует обращать особое внимание на позицию удвоенной согласной, так как может образовываться долгий звук. Покажем на примерах два случая.
Йотированная гласная + ь
Слово: е́ль
Транскрипция: [й’эл’]
е → [ й’ ] — согласный, звонкий непарный (сонорный), мягкий непарный
[ э ] — гласный, ударный
л → [ л’ ] — согласный, звонкий непарный (сонорный), мягкий парный
ь — не обозначает звука
В этом примере гласная е стоит в начале слова, поэтому является йотированной и образует два звука [й’] + [э]. Мягкий знак не означает звука, но смягчает согласную л. В итоге 3 буквы и 3 звука.
Йотированная гласная + чередование согласной
Слово: его́
Транскрипция: [й’иво]
е → [ й’ ] — согласный, звонкий непарный (сонорный), мягкий непарный
[ и ] — гласный, безударный
г → [ в ] — согласный, звонкий парный, твёрдый парный
о → [ о ] — гласный, ударный
Гласная е является йотированной и обозначает два звука.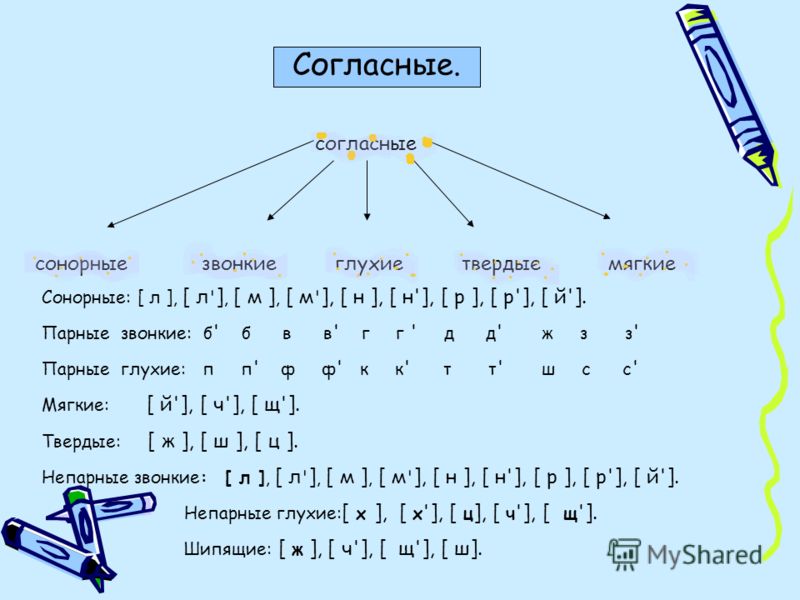 Но в отличие от первого примера буква не под ударением, поэтому она означает звуки [й’] + [и]. Обратите внимание, что буква г в слове произносится как «в». Так как в слове нет случаев «пропадания» звуков, поэтому 3 буквы и 4 звука.
Но в отличие от первого примера буква не под ударением, поэтому она означает звуки [й’] + [и]. Обратите внимание, что буква г в слове произносится как «в». Так как в слове нет случаев «пропадания» звуков, поэтому 3 буквы и 4 звука.
Сдвоенная согласная — долгий звук
Слово: те́ннис
Транскрипция: [т’э н ис] или [т’эн:ис]
т → [ т’ ] — согласный, глухой парный, мягкий парный
е → [ э ] — гласный, ударный
н → [ н: ] — согласный, глухой парный, твёрдый парный
н — не образует звука
и → [ и ] — гласный, безударный
с → [ с ] — согласный, глухой парный, твёрдый парный
Сдвоенная согласная н образует долгий звук [н:], так как ударение в слове идёт до этой согласной. Допустимы оба обозначения долгого звука — 1) черта над звуком, 2) двоеточие справа. Долгий звук также называют длинным, тянущимся.
Сдвоенная согласная — обычный звук
Слово: хокке́й
Транскрипция: [хакэй’]
х → [ х ] — согласный, глухой непарный, твёрдый парный
о → [ а ] — гласный, безударный
к → [ к ] — согласный, глухой парный, твёрдый парный
к — не образует звука
е → [ э ] — гласный, ударный
й → [ й’ ] — согласный, звонкий непарный (сонорный), мягкий непарный
В отличие от примера со словом теннис здесь сдвоенная согласная к не образует долгого звука, так как ударение в слове идёт сразу после согласной. Произнесите вслух оба слова и почувствуйте, что в слове хоккей букву к получается произносить быстро, а в слове теннис букву н можно произнести с небольшой задержкой.
Произнесите вслух оба слова и почувствуйте, что в слове хоккей букву к получается произносить быстро, а в слове теннис букву н можно произнести с небольшой задержкой.
На сайте можно сделать фонетический разбор любого русского слова в режиме онлайн — введите слово в форму поиска и нажмите кнопку.
Источник
Фонетическая транскрипция слова
Транскрипция – что это?
Когда мы записываем что-то под диктовку, мы записываем не то, что мы слышим, а то, что мы понимаем. То есть записываем слова не так, как услышали (вада), а так, как пишется по правилам понятое нами слово (вода). И это понятно. Ведь диктующий может говорить неразборчиво, обладать плохой дикцией. Но мы его все равно понимаем. И пишем, например, не “гхуша”, а “груша”.
Но мы можем записать слово не только так, как оно пишется, но и так, как оно произносится. Вот эта запись и называется “транскрипция”.
Зачем нужна транскрипция?
Фонетическая транскрипция слова выполняет ряд функций:
Из вышесказанного понятно, что транскрипции могут быть разные. Одни передают норму, другие – реальное произношение.
Одни передают норму, другие – реальное произношение.
Точно в соответствии с произносительной нормой говорят разве что дикторы из прошлого века.
Школьникам интересна транскрипция как основа для фонетического разбора при изучении курса русского языка. Иногда к транскрипции прибегают составители орфоэпических словарей для передачи правильного произношения.
Частичная транскрипция
Иногда прибегают к частичной транскрипции. Это обычно бывает, если надо указать правильное произношение отдельных звуков.
Например, мо[дэ]ль. Это значит, что Д перед Е не мягкий.
Как записать транскрипцию
Транскрипцию в школах на уроках русского языка выполняют в квадратных скобках с помощью букв современного русского алфавита с использованием отдельных особых транскрипционных знаков: ударение, апостроф, иногда j.
В редких случаях учителя просят пользоваться знаками “ъ” и “ь” для обозначения гласных в заударной позиции, знаками “и склонное к э”, “крышечка” и т. п. Однако обычно такие знаки используют только студенты-филологи, тогда как школьники ими не пользуются и обозначают безударные а и о в любой позиции знаком [а], а и, я и е в безударной же позиции в любом месте слова знаком [и].
п. Однако обычно такие знаки используют только студенты-филологи, тогда как школьники ими не пользуются и обозначают безударные а и о в любой позиции знаком [а], а и, я и е в безударной же позиции в любом месте слова знаком [и].
Транскрипция записывается в квадратных скобках.
Даже если транскрибируется имя собственное, заглавная буква не пишется.
Можно транскрибировать слово “на слух”, если есть возможность прочесть его несколько раз вслух, протягивая каждый звук. Поскольку это бывает редко, транскрибируют обычно “по правилам”.
Основные правила:
Примеры транскрипции слов
Что мы узнали?
Транскрипция – это запись слова по звукам так, как оно произносится, или так, как оно должно произноситься. При транскрибировании школьники используют обычные буквы русского алфавита за некоторым исключением и особые знаки. Существует ряд правил, которым надо следовать, записывая транскрипцию. Транскрипция помогает производить фонетический разбор и является его обязательной частью.
Источник
Транскрипция слова. Фонетический разбор слова
Основные понятия
Умение анализировать слово с точки зрения его произношения поможет школьнику понять случаи несоответствия того, что мы слышим, тому, что мы пишем, поможет систематизировать знания о фонетике и орфографии (в частности, о принципах орфографии), научит правильно произносить и правильно писать слова. Наиболее распространённым видом такого анализа является фонетический разбор, для которого необходимы сведения о звуках речи.
Фонетический разбор начинается с правильной записи слова, деления его на слоги, постановки ударения.
Затем нужно записать слово так, как оно звучит, то есть сделать его транскрипцию.
Чтобы не ошибиться, нужно произносить слово вслух, обращая внимание на то, как оно и помнить основные правила:
Например, слово МОРОЗ:
мо-рОз, ударение падает на второй слог.
Осталось посчитать количество звуков и букв.
В этом слове оно одинаково: букв 5 и звуков 5.
План фонетического разбора
Таким образом, фонетический разбор делается по следующему плану:
Фонетическая транскрипция видео
Таблицы соответствия букв и звуков для фонетического разбора
С помощью фонетического разбора можно проиллюстрировать случаи оглушения и озвончения согласных, объяснить необходимость проверки безударных гласных постановкой их в сильную позицию (под ударение), рассмотреть примеры несовпадения количества звуков и букв и т. д.
Примеры фонетического разбора
7 букв, 8 звуков; буква Я обозначает 2 звука, так как находится после гласной.
5 букв, 4 звука; звуки Д и Т сливаются в долгий [т¯], происходит оглушение звука Д.
Примеры заданий с элементами фонетического разбора
Возможны занимательные задания, помогающие пробудить интерес школьников к фонетике и орфоэпии, внимательное отношение к орфографии.
Например: определите, какие слова получатся, если произнести в обратном порядке звуки, из которых они состоят? Код, араб, ель, рай, лёд.
(Ответы: ток, пара, лей, яр, толь).
Для выполнения задания детям нужно записать транскрипцию слова и затем прочитать её наоборот: рай — [рай] — [йар] – яр.
Или задание такого типа: определите, сколько раз в предложении «Не трудиться – так и хлеба не добиться» встречаются мягкие согласные.
(Ответ 5: [н’] – 2 раза, [д’] [л’] [б’] – по 1 разу).
Для выполнения этого задания ученикам нужно записать транскрипцию всего предложения. Необходимо помнить, что в потоке речи звуки влияют друг на друга, изменяются. Например, КАК БЫ будет звучать [кагбы], то есть происходит озвончение звука [к] под влиянием последующего звонкого [б]. Подобные задания могут встретиться в олимпиадах по русскому языку.
Правила транскрибирования текста
Правильное деление на слоги помогает переносить слова с одной строки на другую, но необходимо помнить, что деление на слоги не всегда совпадает с делением слова на части для переноса. Правила переноса представлены в таблице:
Правила переноса слов
Источник
Фонетическая транскрипция – примеры, правила (5 класс, русский язык)
Устная речь – это речь звучащая. Она первична, так как появилась раньше. Если хотим, мы можем что-то записать на бумаге – это будет уже письменная речь. Но есть возможность записать и звучащую речь.
Она первична, так как появилась раньше. Если хотим, мы можем что-то записать на бумаге – это будет уже письменная речь. Но есть возможность записать и звучащую речь.
Транскрипция – что это?
Когда мы записываем что-то под диктовку, мы записываем не то, что мы слышим, а то, что мы понимаем. То есть записываем слова не так, как услышали (вада), а так, как пишется по правилам понятое нами слово (вода). И это понятно. Ведь диктующий может говорить неразборчиво, обладать плохой дикцией. Но мы его все равно понимаем. И пишем, например, не “гхуша”, а “груша”.
Но мы можем записать слово не только так, как оно пишется, но и так, как оно произносится. Вот эта запись и называется “транскрипция”.
Зачем нужна транскрипция?
Фонетическая транскрипция слова выполняет ряд функций:
Из вышесказанного понятно, что транскрипции могут быть разные. Одни передают норму, другие – реальное произношение.
Точно в соответствии с произносительной нормой говорят разве что дикторы из прошлого века.

Школьникам интересна транскрипция как основа для фонетического разбора при изучении курса русского языка. Иногда к транскрипции прибегают составители орфоэпических словарей для передачи правильного произношения.
Частичная транскрипция
Иногда прибегают к частичной транскрипции. Это обычно бывает, если надо указать правильное произношение отдельных звуков.
Например, мо[дэ]ль. Это значит, что Д перед Е не мягкое.
Как записать транскрипцию
Транскрипцию в школах на уроках русского языка выполняют в квадратных скобках с помощью букв современного русского алфавита с использованием отдельных особых транскрипционных знаков: ударение, апостроф; иногда j.
В редких случаях учителя просят пользоваться знаками “ъ” и “ь” для обозначения гласных в заударной позиции, знаками “и склонное к э”, “крышечка” и т.п. Однако обычно такие знаки используют только студенты-филологи, тогда как школьники ими не пользуются и обозначают безударные а и о в любой позиции знаком [а], а и, я и е в безударной же позиции в любом месте слова знаком [и].
Транскрипция записывается в квадратных скобках.
Даже если транскрибируется имя собственное, заглавная буква не пишется.
Можно транскрибировать слово “на слух”, если есть возможность прочесть его несколько раз вслух, протягивая каждый звук. Поскольку это бывает редко, транскрибируют обычно “по правилам”.
Основные правила:
Примеры транскрипции слов
Что мы узнали?
Транскрипция – это запись слова по звукам так, как оно произносится, или так, как оно должно произноситься. При транскрибировании школьники используют обычные буквы русского алфавита за некоторыми исключениями и особые знаки. Существует ряд правил, которым надо следовать, записывая транскрипцию. Транскрипция помогает производить фонетический разбор и является его обязательной частью.
Источник
Фонетический разбор слова
Фонетикой называют раздел языкознания, который изучает звуковую систему языка и звуки речи в целом. Фонетика — это наука о сочетании звуков в речи.
Фонетический разбор, или звуко-буквенный, — это анализ строения слогов и звуковой системы слова. Такой анализ предлагается выполнять как упражнение в учебных целях.
Под анализом понимается:
При разборе важно различать понятия «буква» и «звук». Ведь первые соответствуют орфографическим правилам, а вторые — речевым (то есть звуки анализируются с точки зрения произношения).
Прежде чем приступить к звуко-буквенному разбору, следует запомнить
В русском языке десять гласных звуков:
| [А] | [О] | [У] | [Ы] | [Э] | [ЙА] буква «Я» | [ЙО] буква «Ё» | [ЙУ] буква «Ю» | [И] | [ЙЭ] буква «Е» |
Первые пять обозначают, что предшествующий согласный является твердым, а вторые — мягким.
И двадцать один согласный звук:
| звонкие непарные звуки | [Й’] | [Л] | [М] | [Н] | [Р] | |
| глухие непарные | [Х] | [Ц] | [Ч’] | [Щ’] | ||
| звонкие парные | [Б] | [В] | [Г] | [Д] | [Ж] | [З] |
| глухие парные | [П] | [Ф] | [К] | [Т] | [Ш] | [С] |
Звонкими называют согласные, которые образуются с участием звука, а глухие — с помощью шума. Парными называют те согласные, которые образуют пару глухой/звонкий. Например, [Б]/[П], [В]/[Ф], [Г]/[К]. Непарными — те, которые не образуют пары: [Л], [М], [Р].
Парными называют те согласные, которые образуют пару глухой/звонкий. Например, [Б]/[П], [В]/[Ф], [Г]/[К]. Непарными — те, которые не образуют пары: [Л], [М], [Р].
При фонетическом анализе слова стоит помнить, что согласные [Ч’], [Щ’], [Й’] — всегда мягкие, вне зависимости от того, какой гласный образует с ними слог. Согласные [Ж], [Ш] и [Ц] — всегда твердые.
[Й’], [Л], [Л’], [М], [М’], [Н], [Н’], [Р], [Р’] — сонорные звуки. А значит, при произношении этих согласных звук образуется преимущественно голосом, но не шумом. Все сонорные — звонкие звуки.
В русском алфавите есть также буквы Ь, Ъ. Они не образуют звука. Ь (мягкий знак) служит для того, чтобы смягчать согласные, после которых он ставится. Ъ (твердый знак) имеет разделительную функцию.
Правила разбора на звуки
Образец звуко-буквенного разбора слова
Примеры фонетического разбора
Для примера ниже подобраны слова с наиболее интересными вариантами фонетического разбора: шестнадцатью, яростного, съестного, шестнадцатого, ерошиться, ёжиться, ёжится, ёршится, разъезжаться, съезжаться, для выполнения фонетического разбора других слов воспользуйтесь формой поиска:
Источник
Видео
Учимся составля ть транскрипцию слова (русский язык)
Фонетическая транскрипция | uchim. org
org
Правила транскрипции гласных звуков в русском языке
Русский язык. Фонетика: Фонетическая транскрипция. Центр онлайн-обучения «Фоксфорд»
Русский язык. Транскрипция
Фонетика. Фонетический разбор слова | Русский язык ЕГЭ, ЦТ
Транскрипция в русском языке. Правила написания транскрипции в русском языке.
Фонетическая транскрипция
Фонетический разбор слова | Русский язык | TutorOnline
Транскрипция для 1 класса
Презентация к уроку русского языка в 5 классе на тему : «Фонетический разбор слова»
Тема: «Фонетический разбор слова»
Цель: — научить учащихся производить фонетический разбор слова.
Задачи: — развивать умения различать звонкие и глухие, твердые и мягкие, парные и непарные согласные; умения правильно ставить ударение и делить слова на слоги.
Ход урока:
I.Организационный момент
— Здравствуйте, ребята. Сегодня на урок к нам пришли гости. Поздоровайтесь. Садитесь.
— Открываем тетради, записываем число, классная работа.
II.Проверка домашнего задания
— Спишите слова с доски, расставьте ударение, запишите транскрипцию.
Получается:
Земля — [з,и м л,а]
лев — [л,э ф]
цветок — [ц в,и т о к]
открыть — [а т к р ы т,]
мороз — [м а р о с,]
очки — [а ч,к,и]
— Молодцы! Вы очень хорошо справились с заданием. А теперь в середине новой строки запишем тему нашего урока «Фонетический разбор слова».
III.Изучение нового материала
— Итак, тема нашего урока «Фонетический разбор слова».
— Какую цель мы поставили перед собой на этот урок?
— Какие задачи необходимо решить для достижения нашей цели?
- Фонетический опрос
— Каждый правильный ответ +5 б. , неправильный ответ -5 б.
, неправильный ответ -5 б.
— Как называется раздел науки о языке изучающий звуки речи? (фонетика)
— На какие группы делятся звуки речи? (гласные, согласные)
— Какие звуки являются гласными? (которые состоят только из голоса)
— Какие звуки являются согласными? (которые состоят из голоса и шума)
— Какими бывают гласные звуки? (ударные и безударные)
— Каким буквам отведена двойная роль? (е, ё, ю, я)
— Сколько букв в русском алфавите?
— Сколько гласных?
— Сколько согласных?
— В чем разница между буквой и звуком?
— Сколько парны согласных по глухости – звонкости?
— Сколько непарных глухих? (4)
— Назовите. [х, ц, ч, щ]
— Сколько непарных мягких согласных? (3)
— Назовите. [ч,, щ,, й,]
— Сколько непарных твердых согласных? (3)
— Назовите. [ж, ш, ц]
— Сколько глысных звуков? (6)
— Сколько согласных звуков? (36)
— Сколько всего звуков? (42)
— Молодцы, ребята!
2. Физминутка
— Вышла мышка как-то раз (ходьба на месте). Поглядеть который час (повороты влево, вправо, пальцы «трубочкой» перед глазами).
Поглядеть который час (повороты влево, вправо, пальцы «трубочкой» перед глазами).
— Мышки дернули за гири (руки вверх и приседание с опусканием рук). Раз, два, три, четыре (хлопки над головой).
— Вдруг раздался страшный звон (хлопки перед собой).
— Убежали мышки вон (бег на месте).
— Отдохнули. Теперь сел ровно. Спинки выпрямили. Теперь перейдем к изучению нового материала.
Сочетание чн как правило, произносится в соответствии с написанием.
Например: Античный, дачный, качнуть.
Но в некоторых сочетаниях букв чн не так, как пишется, а по-другому [шн], например: коне[ш]но, ску[ш]но, наро[ш]но, праче[ш]ная.
В некоторых словах допускается двоякое произнашение.
Например: булочная, гречневый, сливочный.
В конце XIX – начале XX века многие слова произносились с [шн], а не с [чн]. Произношение [шн] старой московской орфоэпической нормы.
3. Объяснения учителя
— Открываем учебники на стр. смотрим план фонетического разбора.
— А теперь я покажу вам как надо выполнять фонетический разбор.
— С красной строки, с большой буквы записываем предложение:
На лесной поляне стоял старый пень1.
Пень – 1 слог.
п [п?] – согл., парн., глух., мягк.
е [э] – гл., ударн.
н [н?] – согл., непарн., сонор., мягк.
ь [-]
4 б., 3 зв. [п, э н,]
— Ребята, кому не понятно, как выполнять фонетический разбор?
IV. Закрепление изученного.
– Разгадать ребусы и выполнить фонетический разбор слов. (учащийся у доски)
воро′та – 3 слога
в [в] – согл., парн., зв., тв.
о [а] – гл., безуд.
р [р] – согл., непарн., сон., тв.
о [о] – гл., ударн.
т [т] – согл., парн., глух., тв.
а [а] – гл., безуд.
6 б., 6 зв. в а р о т а
ры′бка – 2 слога
р [р] – согл., парн., сон., тв.
ы [ы] – гл., ударн.
б [п] – согл., парн., глух., тв.
к [к] – согл., парн., глух., тв.
а [а] – гл., безуд.
5 б., 5 зв. р ы п к а
ты′ква – 2 слога
т [т] — согл. , парн., глух., тв.
, парн., глух., тв.
ы [ы] — гл., ударн.
к [к] — согл., парн., глух., тв.
в [в] — согл., парн., зв., тв.
а [а] — гл., безуд.
5 б., 5 зв. [т ы к в а]
камы?ш – 2 слога
к [к] — согл., парн., глух., тв.
а [а] — гл., безуд.
м [м] — согл., непарн., сон., тв.
ы [ы] — гл., ударн.
ш [ш] — согл., парн., глух., тв.
5 б., 5 зв. [к а м ы ш]
— Правильно произнесите записанные слова.
Что, чтобы, скучный, конечно, скворечник, яичница, гречневый, пустячный.
— Команда, все члены которого быстро и правильно справились с заданием получаете 20 баллов.
V. Подведение итогов.
VI. Домашнее задание.
— Итак, ребята, наш урок заканчивается.
— Чему мы научились сегодня на уроке?
— Достигли ли мы цели, которую поставили перед собой в начале урока?
— Что на уроке понравилось больше всего?
— Выставили оценки, заработанные вами на уроке.
— Открыли дневники, записываем домашнее задание все, кроме команды С. Боброва, выполнить фонетический разбор слов: ёж, медведь, цирк.
Боброва, выполнить фонетический разбор слов: ёж, медведь, цирк.
— Команда Семена составит связанный рассказ на тему: «Что я знаю о фонетике?»
Просмотр содержимого документа
«Презентация к уроку русского языка в 5 классе на тему : «Фонетический разбор слова» »
Презентация к уроку русского языка в 5 классе:
«Фонетический разбор слова»
Подготовила: учитель русского языка и литературы МБУ СОШ №46 Устивицкая Алёна Валерьевна
Спишите слова с доски, расставьте ударение, запишите транскрипцию .
Земля, Лев, Цветок, Открыть, Мороз, Очки
Проверь себя
[ з , и м л , а ] [ л , э ф ] [ ц в , и т о к ] [ а т к р ы т , ]
[ м а р о с , ] [ а ч , к , и ]
Фонетический опрос
— Как называется раздел науки о языке изучающий звуки речи?
— На какие группы делятся звуки речи?
— Какие звуки являются гласными?
— Какие звуки являются согласными?
— Какими бывают гласные звуки?
Фонетический опрос
— Каким буквам отведена двойная роль?
— Сколько букв в русском алфавите?
— Сколько гласных?
— Сколько согласных?
— В чем разница между буквой и звуком?
— Сколько парны согласных по глухости – звонкости?
Фонетический опрос
— Сколько непарных глухих? Назовите их.
— Сколько непарных мягких согласных? Назовите их.
— Сколько непарных твердых согласных? Назовите их.
— Сколько гласных звуков?
— Сколько согласных звуков?
— Сколько всего звуков?
Физминутка
Вышла мышка как-то раз (ходьба на месте).
Поглядеть, который час (повороты влево, вправо, пальцы
«трубочкой» перед глазами).
Мышки дернули за гири (руки вверх и приседанье с опусканием рук).
Раз, два, три, четыре (хлопки над головой).
Вдруг раздался страшный звон (хлопки перед собой).
Убежали мышки вон (бег на месте).
Сочетание чн
Сочетание чн как правило, произносится в соответствии с написанием.
Например: Античный, дачный, качнуть.
Но в некоторых сочетаниях букв чн не так, как пишется, а по-другому [шн], например: коне[ш]но, ску[ш]но, наро[ш]но, праче[ш]ная.
В некоторых словах допускается двоякое произношение.
Например: булочная, гречневый, сливочный.
Интересный факт
В конце XIX – начале XX века многие слова произносились с [шн], а не с [чн]. Произношение [шн] старой московской орфоэпической нормы.
Выполнение фонетического разбора
Пень – 1 слог.
п [п᾽] – согл., парн., глух., мягк..
е [э] – гл., ударн..
н [н᾽] – согл., непарн., сонор., мягк..
ь [-]
4 б., 3 зв.. [п, э н,]
Разгадайте ребусы и выполните фонетический разбор слов
Проверьте себя
воро′та – 3 слога
в [в] – согл., парн., зв., тв..
о [а] – гл., безуд..
р [р] – согл., непарн., сон., тв..
о [о] – гл., ударн..
т [т] – согл., парн., глух., тв..
а [а] – гл., безуд..
6 б., 6 зв.. [в а р о т а]
ры′бка – 2 слога
р [р] – согл., парн., сон., тв..
ы [ы] – гл., ударн..
б [п] – согл. , парн., глух., тв..
, парн., глух., тв..
к [к] – согл., парн., глух., тв..
а [а] – гл., безуд..
5 б., 5 зв.. [р ы п к а]
Проверьте себя
ты′ква – 2 слога
т [т] — согл., парн., глух., тв..
ы [ы] — гл., ударн..
к [к] — согл., парн., глух., тв..
в [в] — согл., парн., зв., тв..
а [а] — гл., безуд..
5 б., 5 зв.. [т ы к в а]
камы´ш – 2 слога
к [к] — согл., парн., глух., тв..
а [а] — гл., безуд..
м [м] — согл., непарн., сон., тв..
ы [ы] — гл., ударн..
ш [ш] — согл., парн., глух., тв..
5 б., 5 зв.. [к а м ы ш]
Задание 1 и 2 ВПР-5 класс. Перепишите текст, выполните разборы
ВПР по русскому языку — 5 класс. Задание 1, 2. Переписывание текста. Виды разборов: фонетический, морфемный, морфологический разборы слов, синтаксический разбор предложения.
ВАРИАНТ 1
Задание 1. Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Текст 1
Без с..ниц зимн.. лес зам..ра..т(2). С..сновая ветка заскр..пит снежная ша(б/п)ка обруш..т..ся с ёлки(1). Но нал..тит стайка с..ниц и лес вновь ож..ва..т.
С..ниц.. с писком перел..тают с ветки на ветку, с дер..ва на дер..во. Они осматрива..т кажд.. трещинку(3) в к..ре ищ..т вкус..ные семеч..ки.
С..ниц.. (не)ул..тают на зиму в тёпл.. края, как другие птиц.. . Они звонко перекл..кают..ся в зимн.. л..су. Летом лес нап..лня..т..ся и радос..но звенит птич..ими г..л..сами. А с..ниц (не)слыхать с их скромн.. пес..нкой. В лют.. стужу с..ниц.. прил..тают к избам.(4) Ребята сыпл..т для них в к..рмушки семеч..ки п..дсолнуха.
Ответ
Задание 2. Выполните обозначенные цифрами в тексте 1 языковые разборы:
(1) Фонетический разбор
(2)Морфемный разбор
(3)Морфологический разбор
(4) Синтаксический разбор
ВАРИАНТ 2
Задание 1. Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Текст 1
Кр..сив и п..чален русский лес ранн.. осен..ю. На з..л..том фон.. пож..лтевшей листвы выд..ляют..ся яркие пятна красно-ж..лтых клёнов(1) осин. Медленно кружат..ся в воздух.. и тихо л..жат..ся на землю лист..я.(4) От дер..ва к дер..ву прот..нулись бл..стящие с..р..бристые нити лё(г/х)кой паутины. Отцв..тают(2) поз..ние цв..ты.
Пр..зрачен и чист осенний воздух пр..зрач..на в..да в л..сных канавах овра(ж/ш)ках и руч..ях.
Тихо в осенн..м л..су, лишь ш..лестит под н..гами опавшая листва. Иногда тонко просв..стит где-то в кустах ря(б/п)чик протенька..т с..ница(3) пром..лькнёт среди сосен дроз(д/т).
Ле(г/х)ко и привольно дыш..т..ся в осенн..м л..су. И долго (не)хоч..т..ся ух..дить из него.
Ответ
Задание 2. Выполните обозначенные цифрами в тексте 1 языковые разборы:
(1) Фонетический разбор
(2)Морфемный разбор
(3)Морфологический разбор
(4) Синтаксический разбор
ВАРИАНТ 3
Задание 1. Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Текст 1
В..сенн..е со..нце буд..т пч..л и соб..ра..т(2) их на п..лянах.(4) Да и как им (не)проснут..ся, когда вокру(г/к) р..стёт столько цв..тов! А когда цв..тут фруктовые д..рев..я, для пч..л праз..ник. Вишня яблони груша крыж..вник см..родина – настоящ..е раздол..е для пч..линого войска. Больше всего мёда получа..т..ся из пыльц.. липы акац..и донника.
В средн..х ш..ротах к этому списку добавля..т..ся белый(3) клевер. Его пуш..стые г..ловки ра(з/с)сыпались по п..лянам и опушкам на открытых со..нцу м..стах. Утром пч..ла трудит..ся на одном из м..доносов, пока это р..стение (не)прекраща..т выр..батывать нектар. А к обеду(1) она переход..т на другой ви(д/т).
Ответ
Задание 2. Выполните обозначенные цифрами в тексте 1 языковые разборы:
(1) Фонетический разбор
(2)Морфемный разбор
(3)Морфологический разбор
(4) Синтаксический разбор
ВАРИАНТ 4
Задание 1. Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Текст 1
В (А,а)зи.. обита..т птица-портниха. Но эта мал..нькая швея (не)ш..ёт плат..я и ю(б/п)ки.
Когда приход..т п..ра размн..жения, она сш..ва..т два листа. Тонкий клю(в/ф) зам..ня..т(2) ей иголку. (З/с)делав клювом дыроч..ку в листе, портниха прод(е/и)ва..т заранее скрученную из хлопка или паутины ниточ..ку. Таких сте(ж/ш)ков она дела..т иной раз около д..сятка, проч..но сшивая два листоч..ка. Внутри з..лёной к..лыбельки птич..ка в..ёт гн..здо из хлопка пуха и ш..рстинок.
Птица-портниха живёт(1) вбл..зи от нас..лённых мест, в садах на плантациях. Иногда даже пос..ляет..ся на веранд.. дома и в..ёт гн..здо в ветвях комнатных(3) р..стений. Пита..т..ся птица мурав..ями но подб..ра..т и разные зёрнышки.(4)
Ответ
Задание 2. Выполните обозначенные цифрами в тексте 1 языковые разборы:
(1) Фонетический разбор
(2)Морфемный разбор
(3)Морфологический разбор
(4) Синтаксический разбор
ВАРИАНТ 5
Задание 1. Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Текст 1
Резн..ми, ажурн..ми, игольчат..ми появляют..ся в..сной на свет первые тр..винки. Сразу и (не)различиш.., какое р..стение проклюнулось пок..залось из влажной земли. Скоро ра(з/с)пуст..т..ся ра(з/с)прав..т..ся нежные листоч..ки.(4) И уже можно будет узнать по ним тысячелис..ник одуван..ч..к р..машку и к..локольчик.
Но самое настоящее ч..до прои(з/с)ход..т тогда, когда р..стения зацв..тают(2). И ра(з/с)цвечивают..ся з..лёные луга опушки(1) к..согоры п..ляны необыкновенными цв..точ..ными(3) узорами. Ж..лтые одуван..чики белые р..машки синие к..л..кольч..ки сразу броса..т..ся в глаза: и стебли у них высокие, и цв..тки крупные. Но среди пёстрого разнотрав..я есть и такие, вроде бы совсем неприметные, скромные, но по-своему оч..ровательные. И над этой кр..сотой разд..ют..ся птич..и трели.
Ответ
Задание 2. Выполните обозначенные цифрами в тексте 1 языковые разборы:
Выполните обозначенные цифрами в тексте 1 языковые разборы:
(1) Фонетический разбор
(2)Морфемный разбор
(3)Морфологический разбор
(4) Синтаксический разбор
ВАРИАНТ 6
Задание 1. Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Текст 1
Пе(в/ф)чие птиц.. уже ул..тели в тёплые края. Слышно, как в орехов..й рощ.. л..сток пересч..тыва..т каждый сучок, пока (не)уп..дёт на землю.
Вдру(г/к) на тр..пе я услышал необыч..н..ю песню. Кто-то скр..жетал клювом булькал горлом даже соб..рался св..стеть. Я ост..новился у орешины(2) и прислушался к ре(з/с)ким звукам.(4) И тут ра(з/с)гл..дел в..рону. Т..ж..лая(3) птица ра(з/с)качивалась на ветк.., будто на к..челях. Ра(з/с)пев(1) у в..роны вых..дил плохой но она пела радос. .но и (не)обр..щала на меня внимания.
.но и (не)обр..щала на меня внимания.
Может, без других птиц она почу..ствовала себя сол..в..ём Кто в рощ.. до в..сны смож..т оспорить это её право.
Ответ
Задание 2. Выполните обозначенные цифрами в тексте 1 языковые разборы:
(1) Фонетический разбор
(2)Морфемный разбор
(3)Морфологический разбор
(4) Синтаксический разбор
ВАРИАНТ 7
Задание 1. Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Текст 1
Причина нашего праз..нич..ного настр..ения краски ру(с,сс)кого леса.
Бе(з/с)конеч..но р..знообразны они летом. Со всех ст..рон в..днеют..ся оранжевые(3) ств..лы сосен соч..ная зел..нь елей и б.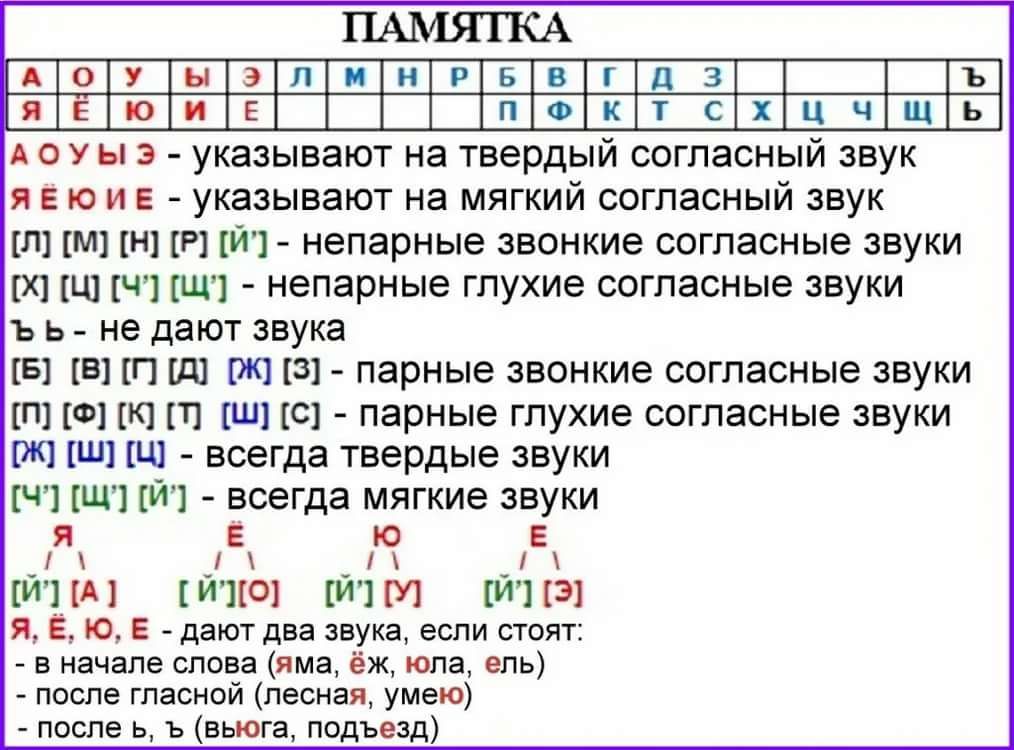 .лоснежный наря(д/т)(1) б..рёзок. Проступают снизу г..лубые полутона мха.(4) Гл..за ск..льзят по гла(д/т)кой тр..ве п..лянк.. и вдру(г/к) на барх..тном её к..вре вспыхива..т яркая бусинка. З..мл..ника!
.лоснежный наря(д/т)(1) б..рёзок. Проступают снизу г..лубые полутона мха.(4) Гл..за ск..льзят по гла(д/т)кой тр..ве п..лянк.. и вдру(г/к) на барх..тном её к..вре вспыхива..т яркая бусинка. З..мл..ника!
Алый цвет яго(д/т) сразу броса..т..ся в гл..за. Соб..ра..шь з..мл..нику и вид..шь, что много неспелой. Если бы вся она была з..лёной, мы бы прошли мимо. З..лёные ягоды на з..лёном фон.. (не)найдёшь. А спелая яго(д/т)ка(2) сама прос..т..ся в к..рзинку. Как р..зумно всё устроено в природ..!
Ответ
Задание 2. Выполните обозначенные цифрами в тексте 1 языковые разборы:
(1) Фонетический разбор
(2)Морфемный разбор
(3)Морфологический разбор
(4) Синтаксический разбор
ВАРИАНТ 8
Задание 1. Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Текст 1
Ч..дес..ны лунные мартовские ночи! Сказоч..ным каж..т..ся н..чной(1) лес. Иные, н..чные, слыш..т..ся звуки и г..л..са. Гугукнула сова и от..звались ей где-то д..леко другие нев..димки-совы. Пискнув тихонько, л..сная мыш.. проб..жала по снегу скрылась под пнём в сугроб.. . Опушкой леса проб..жала ост..рожная л..сица. В светл.. ночи выход..т к..рмит..ся на п..ля зайц.. .
Ещё спят в св..их тёплых(3) норах и б..рлогах б..рсуки и м..дведи. Но в мартовские днивсё чаще просыпа..т..ся м..дведь. Подр..стают(2) в б..рлогах р..дившиеся з..мой м..двежата.
Настоящая в..сна приход..т в с..р..дин.. марта. Радос..но, по-в..сеннему ч..рикают вороб..и. На л..сных тр..пинках провалива..т..ся под н..гами сне(г/к).(4)
Ответ
Задание 2. Выполните обозначенные цифрами в тексте 1 языковые разборы:
(1) Фонетический разбор
(2)Морфемный разбор
(3)Морфологический разбор
(4) Синтаксический разбор
ВАРИАНТ 9
Задание 1. Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Текст 1
Кр..сив и п..чален русский лес ранн.. осен..ю. На з..л..том фон.. пож..лтевшей листвы выд..ляют..ся яркие пятна красно-ж..лтых клёнов(1) осин. Медленно кружат..ся в воздух.. и тихо л..жат..ся на землю лист..я.(4) От дер..ва к дер..ву прот..нулись бл..стящие с..р..бристые нити лё(г/х)кой паутины. Отцв..тают(2) поз..ние цв..ты.
Пр..зрачен и чист осенний воздух пр..зрач..на в..да в л..сных канавах овра(ж/ш)ках и руч..ях.
Тихо в осенн..м л..су, лишь ш..лестит под н..гами опавшая листва. Иногда тонко просв..стит где-то в кустах ря(б/п)чик протенька..т с..ница(3) пром..лькнёт среди сосен дроз(д/т).
Ле(г/х)ко и привольно дыш..т..ся в осенн..м л..су. И долго (не)хоч..т..ся ух..дить из него.
Ответ
Задание 2. Выполните обозначенные цифрами в тексте 1 языковые разборы:
(1) Фонетический разбор
(2)Морфемный разбор
(3)Морфологический разбор
(4) Синтаксический разбор
ВАРИАНТ 10
Задание 1. Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Текст 1
Белая куропатка ж..тельница м..ховых болот и обш..рных низин. Такие м..ста обыч..но покрыты мхами брус..никой и клюквой. Ко́рм..т..ся эти птиц.. на земле и (не)взл..тают на д..рев..я. Когда на болот.. вып..да..т сне(г/к) и скрыва..т весь корм, куропатки переб..рают..ся на л..сные(3) опушки(1).
Цел..ю зиму стайки куропаток корм..т..ся поч..ками с..рё(ж/ш)ками побегами м..л..дых б..рёзок. Быва..т, что всё в нижн..й части кустов уже общипано, а до более высок..х побегов куропаткам (не)дот..нут..ся. Птиц.. перел..тают(2) и ищ..т корм на другой опушк.. .(4) Вот и в..ют..ся их д..ро(ж/ш)ки вокру(г/к) зар..слей кустарников. До сумерек стайка ещё не ра(з/с) облюбу..т нов..е место.
Ответ
Задание 2. Выполните обозначенные цифрами в тексте 1 языковые разборы:
(1) Фонетический разбор
(2)Морфемный разбор
(3)Морфологический разбор
(4) Синтаксический разбор
- Демоверсия ВПР по русскому языку 5 класс 2020
- ВПР по русскому — 5 класс
Фонематический контекст, например, правила произношения, фонотактические ограничения, фонемные N-граммы и т.
 д. (epo) Патенты и патентные заявки (класс 704/E15.02)
д. (epo) Патенты и патентные заявки (класс 704/E15.02)Фонематический контекст, например, правила произношения, фонотактические ограничения, фонема N- граммы и т.д. (epo) Патенты (Класс 704/E15.02)
ФОНЕТИЧЕСКИЕ КЛЮЧИ ДЛЯ ЯПОНСКОГО ЯЗЫКА
Номер публикации: 20120004901
Резюме: Здесь описаны различные варианты фонетических ключей для японского языка. Набор правил кана применяется к символам кана, предоставленным пользователем. Символы Кана определены в алфавитном языке на основе звучания символов Кана. Затем создается полный фонетический ключ на основе определенных символов Кана. Фонетический ключ с замененной гласной создается путем замены гласной в полном фонетическом ключе, а фонетический ключ без гласной создается путем удаления гласной из полного фонетического ключа.
 Затем записи кана в базе данных обрабатываются для определения соответствующей записи кана, которая имеет фонетический ключ, идентичный по меньшей мере одному из полного фонетического ключа, фонетического ключа с замещенными гласными и фонетического ключа без гласных. Соответствующие записи Kana затем представляются пользователю.
Затем записи кана в базе данных обрабатываются для определения соответствующей записи кана, которая имеет фонетический ключ, идентичный по меньшей мере одному из полного фонетического ключа, фонетического ключа с замещенными гласными и фонетического ключа без гласных. Соответствующие записи Kana затем представляются пользователю.Тип: Заявка
Подано: 30 июня 2010 г.
Дата публикации: 5 января 2012 г.
Изобретатель: ХОЗУМИ НАКАНО
Устройство и способ построения модели фонетической вариации и система фонетического распознавания и ее способ
Номер публикации: 20110119051
Аннотация: Предусмотрен аппарат построения фонетической вариационной модели, имеющий базу данных фонем для записи по меньшей мере стандартной фонетической модели языка и множества нестандартизированных фонем языка.
Идентификатор фонетического варианта идентифицирует множество фонетических вариантов между нестандартизированными фонемами и стандартной фонетической моделью. Калькулятор фонетического преобразования вычисляет множество коэффициентов функции фонетического преобразования на основе фонетических вариаций и функции фонетического преобразования. Генератор модели фонетической вариации генерирует по меньшей мере модель фонетической вариации на основе стандартной фонетической модели, функции фонетического преобразования и ее коэффициентов.Тип: Заявка
Подано: 15 декабря 2009 г.
Дата публикации: 19 мая 2011 г.
Заявитель: ИНСТИТУТ ИНФОРМАЦИОННОЙ ИНДУСТРИИ
Изобретатели: Хуан-Чунг Ли, Чун-Сянь Ву, Хань-Пин Шен, Чун-Кай Ван, Чиа-Синь Се
Поиск разговорных медиа по фонемам, полученным из расширенных понятий, выраженных в виде текста
Номер публикации: 20110040774
Реферат: Согласно одному варианту осуществления поиск медиа включает в себя прием поискового запроса, содержащего условия поиска.
По крайней мере один поисковый термин расширяется, чтобы получить набор концептуально эквивалентных терминов. Набор концептуально эквивалентных терминов преобразуется в набор поисковых фонем. Файлы, в которых записаны фонемы, ищутся в соответствии с набором поисковых фонем. Файл, содержащий фонему, совпадающую хотя бы с одной фонемой поиска, выбирается и выводится клиенту.Тип: Заявка
Подано: 14 августа 2009 г.
Дата публикации: 17 февраля 2011 г.
Заявитель: Компания Raytheon
Изобретатели: Брюс Э. Пиплс, Майкл Р. Джонсон, Кристофер Д. Барр
Неконтролируемая маркировка акцента на уровне предложения
Номер патента: 7844457
Реферат: Раскрываются способы автоматической маркировки ударениями без маркировки данных вручную.
Методы предназначены для использования распределения ударения между функциональными и содержательными словами.Тип: Грант
Подано: 20 февраля 2007 г.
Дата патента: 30 ноября 2010 г.
Правопреемник: Корпорация Microsoft
Изобретатели: Инин Чен, Фрэнк Као-пин Сун, Мин Чу
Система проверки орфографии, включая фонетический орфограф
Номер патента: 7831911
Резюме: Система проверки правописания включает механизм проверки правописания букв.
Механизм правописания букв сконфигурирован для выбора множества строк-кандидатов целевых букв, которые точно соответствуют исходной строке с ошибкой. Система проверки орфографии включает механизм проверки правописания фонем. Механизм написания фонем сконфигурирован для выбора множества возможных целевых строк фонем, которые точно соответствуют исходной строке с ошибкой. Модуль ранжирования сконфигурирован так, чтобы объединять целевые строки-кандидаты букв и целевые строки-кандидаты фонемы в комбинированный список целевых строк-кандидатов. Модуль ранжирования также сконфигурирован для ранжирования списка возможных целевых строк, чтобы предоставить список лучших целевых строк-кандидатов для исходной строки с ошибками.Тип: Грант
Подано: 8 марта 2006 г.
Дата патента: 9 ноября 2010 г.
Правопреемник: Корпорация Microsoft
Изобретатель: Уильям Д. Рэмси
Система и способ распознавания многоязычной речи
Номер патента: 7761297
Реферат: Система распознавания многоязычной речи. Изобретаемая система включает в себя механизм моделирования речи, механизм поиска речи и механизм принятия решений. Механизм моделирования речи принимает и преобразует смешанный многоязычный речевой сигнал в речевые характеристики. Механизм поиска речи находит и сравнивает наборы данных-кандидатов. Механизм принятия решений выбирает результирующие речевые модели из речевых моделей-кандидатов и генерирует речевую команду.
Тип: Грант
Подано: 18 февраля 2004 г.
Дата патента: 20 июля 2010 г.
Правопреемник: Delta Electronics, Inc.
Изобретатель: Юн-Вен Ли
МЕТОД И УСТРОЙСТВО ДЕКОДЕРА MELODIS CRYSTAL
Номер публикации: 20100121643
Реферат: Раскрытая технология относится к системе и способу быстрого, точного и распараллеливаемого речевого поиска, называемому кристаллическим декодером.
Это особенно полезно для поисковых приложений, в отличие от диктовки. Он может достигать как скорости, так и точности, не жертвуя одним ради другого. Он может искать различные варианты записей в справочной базе данных без значительного увеличения времени обработки. Даже основную часть декодирования можно распараллелить по мере увеличения количества слов, чтобы поддерживать быстрое время отклика.Тип: Заявка
Подано: 2 ноября 2009 г.
Дата публикации: 13 мая 2010 г.
Заявитель: Melodis Corporation
Изобретатели: Кейван Мохаджер, Сейед Маджид Эмами, Джон Гроссман, Джо Чжо Со Аунг, Сина Сохангир
СИСТЕМА ОБРАБОТКИ РЕЧИ, МЕТОД ОБРАБОТКИ РЕЧИ И ПРОГРАММА ОБРАБОТКИ РЕЧИ
Номер публикации: 200
401ПРЕОБРАЗОВАНИЕ ГРАФЕМ В ФОНЕМЫ С ИСПОЛЬЗОВАНИЕМ АКУСТИЧЕСКИХ ДАННЫХ
Номер публикации: 200
153
Abstract: Описано использование акустических данных для улучшения преобразования графемы в фонему для распознавания речи, например, для более точного распознавания произносимых имен в системе голосового набора.
Описана совместная модель акустики и графемы (акустические данные, последовательности фонем, последовательности графем и выравнивание между последовательностями фонем и последовательностями графем), а также переобучение с помощью обучения максимального правдоподобия и дискриминационного обучения адаптации параметров модели графонемы с использованием акустических данных. Также описан неконтролируемый сбор графемных меток для полученных акустических данных, что позволяет автоматически получать значительное количество фактических выборок, которые можно использовать при переобучении. Речевой ввод, который не соответствует порогу достоверности, может быть отфильтрован, чтобы не использоваться повторно обученной моделью.Тип: Заявка
Подано: 7 декабря 2007 г.
Дата публикации: 11 июня 2009 г.
Заявитель: MICROSOFT CORPORATION
Изобретатели: Сяо Ли, Асела Дж. Р. Гунавардана, Алехандро Асеро
СПОСОБ И УСТРОЙСТВО, ОТНОСЯЩИЕСЯ К ОБРАБОТКЕ ВЫБРАННОГО АУДИОКОНТЕНТА С ИСПОЛЬЗОВАНИЕМ ПОИСКОВОГО ПРОЦЕССА РАСПОЗНАВАНИЯ РЕЧИ С МНОЖЕСТВЕННЫМ РАЗРЕШЕНИЕМ
Номер публикации: 20080162129
Abstract: Предоставляется (101) множество кадров дискретизированного аудиоконтента, а затем обрабатывается (102) это множество кадров с использованием процесса поиска распознавания речи, который включает, по меньшей мере частично, поиск не менее двух из границ состояний, границ подслов и границ слов с использованием разных разрешений поиска.
Тип: Заявка
Подано: 29 декабря 2006 г.
Дата публикации: 3 июля 2008 г.
Заявитель: MOTOROLA, INC.
Изобретатель: Ян Мин Ченг
СИНХРОННЫЙ ПЕРЕВОД ЛЕКЦИЙ И ВЫСТУПЛЕНИЙ В ОТКРЫТОМ ОБЛАСТИ
Номер публикации: 20080120091
Резюме: Открытая система речевого перевода в режиме реального времени для синхронного перевода устной презентации, которая представляет собой устный монолог, состоящий из лекции, выступления, презентации, коллоквиума и семинар.
Система включает в себя блок автоматического распознавания речи, сконфигурированный для приема звука, содержащего устное представление на первом языке, и для непрерывного создания словесных гипотез, и блок машинного перевода, который получает гипотезы, при этом блок машинного перевода выводит перевод на второй язык. , из устной презентации.Тип: Заявка
Подано: 26 октября 2007 г.
Дата публикации: 22 мая 2008 г.
Изобретатели: Александр Вайбель, Кристиан Фюген
Система и метод использования таблицы соответствий для сжатия руководства по произношению
Номер патента: RE40458
Резюме: Подпрограммы синтаксического анализа извлекают из обычного словаря произношения запись, которая включает словарное слово и словарные фонемы, представляющие произношение словарного слова.
Таблица соответствий используется для сжатия словаря произношения. Таблица соответствий включает в себя наборы соответствий для конкретного языка, каждый набор имеет запись текста соответствия, запись фонемы соответствия, представляющую произношение записи текста соответствия, и уникальный символ, идентифицирующий набор соответствий. Система сопоставления сравнивает словарную статью с наборами соответствий и заменяет словарную статью символами, представляющими наилучшие совпадения. При отсутствии совпадения могут использоваться символы, представляющие немой текст или несопоставленные фонемы. Символы соответствия, представляющие наилучшие совпадения, представляют собой сжатые записи словаря произношения. Система сопоставления также генерирует наборы кодов декодера для последующего преобразования наборов символов.Тип: Грант
Подано: 13 января 2003 г.
Дата патента: 12 августа 2008 г.
Правопреемник: Apple Inc.
Изобретатель: Тимоти Фреденбург
 Затем записи кана в базе данных обрабатываются для определения соответствующей записи кана, которая имеет фонетический ключ, идентичный по меньшей мере одному из полного фонетического ключа, фонетического ключа с замещенными гласными и фонетического ключа без гласных. Соответствующие записи Kana затем представляются пользователю.
Затем записи кана в базе данных обрабатываются для определения соответствующей записи кана, которая имеет фонетический ключ, идентичный по меньшей мере одному из полного фонетического ключа, фонетического ключа с замещенными гласными и фонетического ключа без гласных. Соответствующие записи Kana затем представляются пользователю. Идентификатор фонетического варианта идентифицирует множество фонетических вариантов между нестандартизированными фонемами и стандартной фонетической моделью. Калькулятор фонетического преобразования вычисляет множество коэффициентов функции фонетического преобразования на основе фонетических вариаций и функции фонетического преобразования. Генератор модели фонетической вариации генерирует по меньшей мере модель фонетической вариации на основе стандартной фонетической модели, функции фонетического преобразования и ее коэффициентов.
Идентификатор фонетического варианта идентифицирует множество фонетических вариантов между нестандартизированными фонемами и стандартной фонетической моделью. Калькулятор фонетического преобразования вычисляет множество коэффициентов функции фонетического преобразования на основе фонетических вариаций и функции фонетического преобразования. Генератор модели фонетической вариации генерирует по меньшей мере модель фонетической вариации на основе стандартной фонетической модели, функции фонетического преобразования и ее коэффициентов. По крайней мере один поисковый термин расширяется, чтобы получить набор концептуально эквивалентных терминов. Набор концептуально эквивалентных терминов преобразуется в набор поисковых фонем. Файлы, в которых записаны фонемы, ищутся в соответствии с набором поисковых фонем. Файл, содержащий фонему, совпадающую хотя бы с одной фонемой поиска, выбирается и выводится клиенту.
По крайней мере один поисковый термин расширяется, чтобы получить набор концептуально эквивалентных терминов. Набор концептуально эквивалентных терминов преобразуется в набор поисковых фонем. Файлы, в которых записаны фонемы, ищутся в соответствии с набором поисковых фонем. Файл, содержащий фонему, совпадающую хотя бы с одной фонемой поиска, выбирается и выводится клиенту. Методы предназначены для использования распределения ударения между функциональными и содержательными словами.
Методы предназначены для использования распределения ударения между функциональными и содержательными словами. Механизм правописания букв сконфигурирован для выбора множества строк-кандидатов целевых букв, которые точно соответствуют исходной строке с ошибкой. Система проверки орфографии включает механизм проверки правописания фонем. Механизм написания фонем сконфигурирован для выбора множества возможных целевых строк фонем, которые точно соответствуют исходной строке с ошибкой. Модуль ранжирования сконфигурирован так, чтобы объединять целевые строки-кандидаты букв и целевые строки-кандидаты фонемы в комбинированный список целевых строк-кандидатов. Модуль ранжирования также сконфигурирован для ранжирования списка возможных целевых строк, чтобы предоставить список лучших целевых строк-кандидатов для исходной строки с ошибками.
Механизм правописания букв сконфигурирован для выбора множества строк-кандидатов целевых букв, которые точно соответствуют исходной строке с ошибкой. Система проверки орфографии включает механизм проверки правописания фонем. Механизм написания фонем сконфигурирован для выбора множества возможных целевых строк фонем, которые точно соответствуют исходной строке с ошибкой. Модуль ранжирования сконфигурирован так, чтобы объединять целевые строки-кандидаты букв и целевые строки-кандидаты фонемы в комбинированный список целевых строк-кандидатов. Модуль ранжирования также сконфигурирован для ранжирования списка возможных целевых строк, чтобы предоставить список лучших целевых строк-кандидатов для исходной строки с ошибками.

 Это особенно полезно для поисковых приложений, в отличие от диктовки. Он может достигать как скорости, так и точности, не жертвуя одним ради другого. Он может искать различные варианты записей в справочной базе данных без значительного увеличения времени обработки. Даже основную часть декодирования можно распараллелить по мере увеличения количества слов, чтобы поддерживать быстрое время отклика.
Это особенно полезно для поисковых приложений, в отличие от диктовки. Он может достигать как скорости, так и точности, не жертвуя одним ради другого. Он может искать различные варианты записей в справочной базе данных без значительного увеличения времени обработки. Даже основную часть декодирования можно распараллелить по мере увеличения количества слов, чтобы поддерживать быстрое время отклика. Резюме: Предусмотрена система перевода речи для приема исходной речи на первом языке, перевода входного содержания на второй язык и вывода результата перевода в виде речь, включающая в себя: часть обработки ввода для приема ввода исходной речи и генерирования из исходной речи текста на исходном языке и просодической информации исходной речи; часть перевода для генерирования переведенного предложения путем перевода первого языка на второй язык; информацию о преобразовании просодических признаков, включающую в себя ассоциированную просодическую информацию между первым языком и вторым языком; часть преобразования просодических признаков для преобразования просодической информации исходной речи в просодическую информацию речи, которая должна быть выведена; и часть синтеза речи для вывода переведенного предложения в виде речи, синтезированной на основе просодической информации речи, которая должна быть выведена.
Тип: Заявка
Подано: 13 ноября 2008 г.
Дата публикации: 13 августа 2009 г.
Изобретатель: Шехуэй Бу
 Описана совместная модель акустики и графемы (акустические данные, последовательности фонем, последовательности графем и выравнивание между последовательностями фонем и последовательностями графем), а также переобучение с помощью обучения максимального правдоподобия и дискриминационного обучения адаптации параметров модели графонемы с использованием акустических данных. Также описан неконтролируемый сбор графемных меток для полученных акустических данных, что позволяет автоматически получать значительное количество фактических выборок, которые можно использовать при переобучении. Речевой ввод, который не соответствует порогу достоверности, может быть отфильтрован, чтобы не использоваться повторно обученной моделью.
Описана совместная модель акустики и графемы (акустические данные, последовательности фонем, последовательности графем и выравнивание между последовательностями фонем и последовательностями графем), а также переобучение с помощью обучения максимального правдоподобия и дискриминационного обучения адаптации параметров модели графонемы с использованием акустических данных. Также описан неконтролируемый сбор графемных меток для полученных акустических данных, что позволяет автоматически получать значительное количество фактических выборок, которые можно использовать при переобучении. Речевой ввод, который не соответствует порогу достоверности, может быть отфильтрован, чтобы не использоваться повторно обученной моделью.

 Система включает в себя блок автоматического распознавания речи, сконфигурированный для приема звука, содержащего устное представление на первом языке, и для непрерывного создания словесных гипотез, и блок машинного перевода, который получает гипотезы, при этом блок машинного перевода выводит перевод на второй язык. , из устной презентации.
Система включает в себя блок автоматического распознавания речи, сконфигурированный для приема звука, содержащего устное представление на первом языке, и для непрерывного создания словесных гипотез, и блок машинного перевода, который получает гипотезы, при этом блок машинного перевода выводит перевод на второй язык. , из устной презентации. Таблица соответствий используется для сжатия словаря произношения. Таблица соответствий включает в себя наборы соответствий для конкретного языка, каждый набор имеет запись текста соответствия, запись фонемы соответствия, представляющую произношение записи текста соответствия, и уникальный символ, идентифицирующий набор соответствий. Система сопоставления сравнивает словарную статью с наборами соответствий и заменяет словарную статью символами, представляющими наилучшие совпадения. При отсутствии совпадения могут использоваться символы, представляющие немой текст или несопоставленные фонемы. Символы соответствия, представляющие наилучшие совпадения, представляют собой сжатые записи словаря произношения. Система сопоставления также генерирует наборы кодов декодера для последующего преобразования наборов символов.
Таблица соответствий используется для сжатия словаря произношения. Таблица соответствий включает в себя наборы соответствий для конкретного языка, каждый набор имеет запись текста соответствия, запись фонемы соответствия, представляющую произношение записи текста соответствия, и уникальный символ, идентифицирующий набор соответствий. Система сопоставления сравнивает словарную статью с наборами соответствий и заменяет словарную статью символами, представляющими наилучшие совпадения. При отсутствии совпадения могут использоваться символы, представляющие немой текст или несопоставленные фонемы. Символы соответствия, представляющие наилучшие совпадения, представляют собой сжатые записи словаря произношения. Система сопоставления также генерирует наборы кодов декодера для последующего преобразования наборов символов.
Фонологическая и фонематическая осведомленность: на практике
Эти упражнения будут эффективными для большинства учащихся, но дети по-разному реагируют на них. Некоторым студентам потребуется гораздо больше практики, чем другим, и то, что хорошо работает для большинства студентов, не обязательно будет эффективным для всех.
Упражнения на понимание языка
В этом разделе
Подсчет слов в предложении
Подсчет слов в предложении может показаться простым. Но когда мы говорим, мы произносим слова вместе. Маленьким детям важно знать, что поток речи состоит из отдельных слов. Для детей с низким уровнем владения языком или детей, изучающих английский язык, это занятие особенно важно.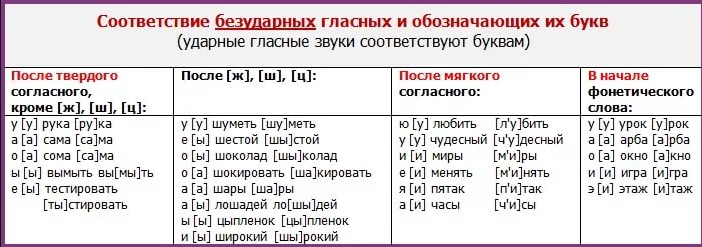 Совершенно нормально брать предложения из рассказа. Язык должен быть близок к общеупотребительной речи.
Совершенно нормально брать предложения из рассказа. Язык должен быть близок к общеупотребительной речи.
Шаги:
- Дайте каждому ребенку манипуляцию или манипуляции, с помощью которых можно считать слова в предложении.
- Продиктуйте предложение. Предложения должны быть четко сформулированы, но не запинаясь, искусственно. Слова должны идти вместе, как в естественной речи.
- Не диктуйте сбивчиво: «Мама [пауза] пошла [пауза] в [пауза] магазин [пауза]».
- Будьте осторожны, когда диктуете такие фразы, как «собирается», «будет», «используется», чтобы произносить два слова. Не говорите «собираюсь», «буду», «усета» и т. д.
- Все учащиеся повторяют предложение.
- Один ученик использует манипуляции для подсчета слов.
- Все учащиеся используют манипуляции для подсчета слов в одном предложении.
Повторите эти шаги с 10 предложениями.
Следуя этим шагам, учащиеся проходят индивидуальную и групповую практику, чтобы обеспечить максимальное количество практики в кратком упражнении.
Один из использованных манипуляторов — бумажный кролик, вырезанный и прикрепленный к деревянной палочке. Учащиеся «прыгают за кроликом» для каждого слова в предложении. Другими манипуляциями являются фишки для бинго или крышки от бутылок, которые подсчитываются за каждое слово.
Предложения должны начинаться с двух-пяти слов, затем должны становиться немного длиннее, но обычно не должны превышать восьми слов.
Вернуться к началу
Фонологические занятия
Подсчет слогов
Подсчет слогов требует, чтобы учащийся знал, что такое слог. Познакомить со словарным словом: слог. Слоги можно объяснить детям следующим образом:
«Слова состоят из слогов. В некоторых словах 1 слог. В некоторых словах много слогов. Наш рот знает, где находятся слоги. Давайте используем рот, чтобы чувствовать слоги. Смотри на меня. Я буду использовать нечто, называемое сжатыми губами, чтобы чувствовать слоги. Я крепко сомкну губы и прокричу слово «класс».
Плотно закройте губы и крикните «класс». Студенты услышат два приглушенных крика.
«Я услышал два крика. Я почувствовал два толчка воздуха. Я хотел открыть рот 2 раза. Это означает, что в слове «класс» два слога. Я поднимаю два пальца, чтобы показать, сколько слогов в слове «класс». Сделай это со мной». Затем проведите группу через два примера.
Шаги:
- Диктуем слова естественным образом.
- Избегайте сбивчивой диктовки: «mon [pause] ster»
- Диктуйте слова так, как они произносятся, а не как пишутся. Например, скажите «DOC-ter», а не «doct-OR».
- Все учащиеся повторяют слово.
- Все ученики выкрикивают это слово с зажатыми губами.
- Все учащиеся пальцами показывают, сколько слогов.
Повторите эти шаги с 15 словами. Первые уроки должны включать слова с одним и двумя слогами. Затем включите слова с тремя слогами. Когда учащиеся овладеют навыками, введите несколько сложных слов из четырех или более слогов. Не забудьте также включить одно-, двух- и трехсложные слова.
Не забудьте также включить одно-, двух- и трехсложные слова.
Потренировавшись, избавьтесь от сжатых губ:
Шаги:
- Диктуем слова в естественной манере.
- Все учащиеся повторяют слово.
- Все учащиеся пальцами показывают, сколько слогов.
Вернуться к началу
Сегментация слогов
Сегментация слогов легко осваивается после того, как учащиеся могут использовать сжатые губы для подсчета слогов. Лучше всего ограничить это занятие словами, состоящими из трех или менее слогов.
«Я могу произнести слово, затем произнести каждый слог в слове. Как я говорю каждый слог, я кладу карту. Раскладываю карты слева направо. Смотри на меня. Я говорю все слово: «Арахис». Я произношу каждый слог и кладу карточку: «горох» [положить карточку] «орех» [положить карточку так, чтобы ученики видели ее слева направо]. Теперь я провожу пальцем под карточками и произношу слово целиком: «арахис» [провожу пальцем под карточками слева направо]. Сделай это со мной». Затем мы проводим группу через два примера.
Сделай это со мной». Затем мы проводим группу через два примера.
Шаги:
- Мы диктуем слова в естественной манере.
- Все учащиеся повторяют слово.
- Один ученик использует манипуляторы для сегментации слогов.
- Все учащиеся используют манипуляции для разделения слогов.
Повторите эти шаги с 10–15 словами. Первые уроки должны включать слова с одним и двумя слогами. Затем включите слова с тремя слогами.
Следуя этим шагам, учащиеся проходят индивидуальную и групповую практику, чтобы обеспечить максимальное количество практики в кратком упражнении.
Манипуляторами могут быть карты, войлок, фишки для бинго, крышки от бутылок или другие предметы.
Вернуться к началу
Определение первого, последнего и среднего слогов
Определение слогов требует от учащегося сегментации слова, а затем произнесения только целевого слога. Лучше всего ограничить это занятие словами, состоящими из трех или менее слогов..jpg) Для этой задачи достаточно первого, среднего и последнего. Когда учащиеся переходят к печати, учащиеся могут использовать этот навык для произношения более длинных слов для правописания и чтения.
Для этой задачи достаточно первого, среднего и последнего. Когда учащиеся переходят к печати, учащиеся могут использовать этот навык для произношения более длинных слов для правописания и чтения.
«Я могу произнести каждый слог в слове. Тогда я могу сказать только первый слог. Как я говорю каждый слог, я кладу карту. Смотри на меня. Я говорю все слово: «закат». Я произношу каждый слог и кладу карточку: «солнце» [положите карточку] «закат» [положите карточку так, чтобы ученики видели ее слева направо]. Я произношу слово целиком: «закат» [проведите пальцем под карточками слева направо]. Я касаюсь и произношу только первый слог: «солнце» [дотроньтесь до первой карты]. Сделай это со мной». Затем мы проведем группу через два примера.
Шаги:
- Диктуем слова в естественной манере.
- Все учащиеся повторяют слово.
- Один ученик использует манипуляторы для сегментации слогов.
- Представьте это, сказав: «Один ученик будет нашим голосом, все остальные будут молча сегментировать слоги».
- [Имя], сегмент [слово].

- Все учащиеся (молча) используют манипуляции для сегментации слогов.
- Другой ученик называет только первый слог.
- Все, какой первый слог?
- Все учащиеся касаются и произносят первый слог.
Повторите эти шаги с 15 словами. Начните с одно- и двухсложных слов. Начните с определения первого слога. Познакомить с определением последнего слога. Комбинируйте определение первого и последнего слога с одно-, двух- и трехсложными словами. Добавьте трехсложные слова. Познакомить с определением среднего слога.
Следуя этим шагам, учащиеся проходят индивидуальную и групповую практику, чтобы обеспечить максимальное количество практики в кратком упражнении.
Вернуться к началу
Смешанные слоги
Смешанные слоги следует преподавать после того, как учащиеся смогут сегментировать. Лучше всего ограничить это занятие словами, состоящими из трех или менее слогов.
«Я могу произнести каждый слог в слове, а затем я могу соединить слоги, чтобы произнести слово. Как я говорю каждый слог, я кладу карту. Раскладываю карты слева направо. Смотри на меня. Я произношу каждый слог и кладу карточку: «на коленях» [положить карточку] «сверху» [положить карточку так, чтобы она показывалась слева направо для учащихся]. Теперь я провожу пальцем под карточками и произношу слово целиком: «ноутбук» [провожу пальцем под карточками слева направо]. Сделай это со мной». Затем мы проводим группу через два примера.
Как я говорю каждый слог, я кладу карту. Раскладываю карты слева направо. Смотри на меня. Я произношу каждый слог и кладу карточку: «на коленях» [положить карточку] «сверху» [положить карточку так, чтобы она показывалась слева направо для учащихся]. Теперь я провожу пальцем под карточками и произношу слово целиком: «ноутбук» [провожу пальцем под карточками слева направо]. Сделай это со мной». Затем мы проводим группу через два примера.
Шаги:
- Диктуем слоги.
- Все учащиеся повторяют слоги и раскладывают карточки.
- Один ученик смешивает слоги.
- Все учащиеся смешивают слоги.
Повторите эти шаги с 15 словами. Первые уроки должны включать слова с одним и двумя слогами. Затем включите слова с тремя слогами.
Следуя этим шагам, учащиеся проходят индивидуальную и групповую практику, чтобы обеспечить максимальное количество практики в кратком упражнении.
Вернуться к началу
Манипулирование слогами (добавление, удаление, замена)
Добавление
Манипуляции со слогами обычно следует обучать в такой последовательности: добавление, удаление, замена. Добавление слогов очень похоже на смешивание слогов. Учащиеся уже знают, что делать с карточками. Таким образом, это самая простая манипуляция.
Добавление слогов очень похоже на смешивание слогов. Учащиеся уже знают, что делать с карточками. Таким образом, это самая простая манипуляция.
«Я могу добавлять слоги, чтобы получилось новое слово. Смотри на меня. Я произношу первый слог и кладу карточку: «на коленях» [положить карточку]. Я добавляю последний слог: «сверху» [поместите карточку так, чтобы она отображалась слева направо для учащихся]. Я касаюсь и произношу слоги: «круг», «верх», «ноутбук» [проводит пальцем под карточками слева направо]. Сделай это со мной». Затем мы проводим группу через два примера.
Шаги:
- Диктуем первый слог и кладем карточку.
- Все учащиеся повторяют слог и кладут карточку.
- Диктуем второй слог и кладем карточку.
- Все учащиеся повторяют слог и кладут карточку.
- Все учащиеся касаются и говорят, а затем смешивают слоги, чтобы произнести слово.
Повторите эти шаги с 15 двусложными словами.
Удаление
«Смотрите, как я убираю слог из слова. Слово: «карандаш». «Ручка», «цил» [поместите карточку для каждого слога так, чтобы учащиеся читали его слева направо]. «Карандаш» [проведите пальцем по слогам и произнесите слово]. Я убираю «цил» [убрать карточку]. «Ручка» осталась [коснитесь оставшейся карты]. Сделай это со мной.»; Затем мы проведем группу через два примера.
Слово: «карандаш». «Ручка», «цил» [поместите карточку для каждого слога так, чтобы учащиеся читали его слева направо]. «Карандаш» [проведите пальцем по слогам и произнесите слово]. Я убираю «цил» [убрать карточку]. «Ручка» осталась [коснитесь оставшейся карты]. Сделай это со мной.»; Затем мы проведем группу через два примера.
Шаги:
- Диктуем слово и раскладываем карточки.
- Все учащиеся повторяют слово и кладут карточки.
- Все учащиеся касаются и говорят, а затем смешивают слоги, чтобы произнести слово.
- Диктуем удаляемый слог, чередуя первый и последний.
- Все учащиеся дотрагиваются и произносят оставшийся слог.
Повторите эти шаги с 15 двусложными словами.
Замена
«Я могу изменить один слог в слове, чтобы получилось новое слово. Смотри на меня. Я заменю «загар» на «закат». Какой слог различается в словах «загар» и «закат»? Я буду использовать карты. Первое слово — «загар» [произнести по слогам, выложить карты, коснуться и произнести по слогам, смешать слово]. Я хочу изменить «загар» на «закат». [Дотроньтесь до карточек, произнесите новые слоги, смешайте новое слово]. Второй слог другой. Я поменяю карты на и скажу новый слог: [возьми вторую карту и скажи «тан», отложи новую карту и скажи «сет»]. Я дотронусь и скажу новое слово: [проговорить слоги, выложить карты, дотронуться и сказать слоги, смешать слово].
Я хочу изменить «загар» на «закат». [Дотроньтесь до карточек, произнесите новые слоги, смешайте новое слово]. Второй слог другой. Я поменяю карты на и скажу новый слог: [возьми вторую карту и скажи «тан», отложи новую карту и скажи «сет»]. Я дотронусь и скажу новое слово: [проговорить слоги, выложить карты, дотронуться и сказать слоги, смешать слово].
Шаги:
- Диктуем старое слово на новое слово.
- Все учащиеся повторяют старое слово за новым словом и выкладывают карточки на каждый слог.
- Все учащиеся касаются и говорят, а затем смешивают старое слово.
- Повторяем новое слово.
- Под карточками все учащиеся касаются и говорят, а затем смешивают новое слово.
- Спрашиваем: слог выходит?
- Все учащиеся касаются и говорят слог, убирая карточку.
- Спрашиваем: слог входит?
- Все учащиеся касаются и говорят слог, добавляя карточку.
- Все учащиеся касаются и говорят, а затем смешивают новое слово.

Повторите эти шаги с 15 словами.
Вернуться к началу
Смешение начала и изморози
Начало — это начальная согласная или группа согласных односложного слова. Иней — это гласная и любые согласные, следующие за началом. Таким образом, в слове «карта» /m/ — начало, а /ap/ — изморозь.
В отличие от слогов, нам не нужно учить словарные термины начала времени. Этот навык является опорой для навыков фонематического восприятия, а не навыком с длительной полезностью. Смешению начала и времени легче обучаться после того, как учащиеся научились смешивать слоги. Используйте только слова с одним начальным звуком. Смеси можно преподавать на фонетических инструкциях.
Мы моделируем лица студентов. Мы работаем справа налево, поэтому для учащихся это выглядит слева направо.
«Я могу смешать две части слога, чтобы получилось слово. Смотри на меня. /M/ [кладем правый кулак на стол], /ap/ [кладем левый кулак на стол], ‘карта’ [сводим кулаки вместе, чтобы коснуться перед ней]. Сделай это со мной». Затем мы проводим группу через два примера.
Сделай это со мной». Затем мы проводим группу через два примера.
Шаги:
- Мы диктуем время начала [паузы] иней, используя кулаки для представления начала и времени.
- Все учащиеся повторяют звуки и изображают их кулаками.
- Один ученик смешивает начало и время, чтобы произнести слово.
- Все учащиеся смешивают начало и время, чтобы произнести слово.
Повторите эти шаги с 10 словами. Не забывайте использовать слова только с одним начальным звуком. Например, используйте /ch/ /in/, но избегайте /sw/ /im/.
Следуя этим шагам, учащиеся проходят индивидуальную и групповую практику, чтобы обеспечить максимальное количество практики в кратком упражнении.
Вернуться к началу
Завершение начального периода
Как и во всех действиях начального периода, используйте только слова с одним начальным звуком.
Мы моделируем лица студентов. Мы работаем справа налево, поэтому для учащихся это выглядит слева направо.
«Я скажу слово и дам вам первую часть. Затем вы говорите последнюю часть. Смотри на меня. Слово «лента». Первая часть — /t/ [кладем правый кулак на стол]. Что за остальная часть слова? /Ape/ [кладем левый кулак на стол]. Слово «лента» [мы сводим кулаки вместе, чтобы коснуться перед ней]. Сделай это со мной.»; Затем мы проводим группу через два примера.
Шаги:
- Мы диктуем начало, используя кулак для представления звука начала.
- Все учащиеся повторяют начальный звук и опускают кулак.
- Один ученик добавляет иней и опускает правый кулак, затем смешивает начало и иней, чтобы произнести слово.
- Все учащиеся смешивают начало и время, чтобы произнести слово.
Повторите эти шаги с 10 словами.
Следуя этим шагам, учащиеся проходят индивидуальную и групповую практику, чтобы обеспечить максимальное количество практики в кратком упражнении.
Наверх
Эти слова рифмуются?
Чтобы учащиеся могли узнать, рифмуются ли слова, и составить рифмующиеся слова, они должны понимать, что такое рифмование. Познакомить со словарным словом: рифма. Рифмование можно объяснить детям так:
Познакомить со словарным словом: рифма. Рифмование можно объяснить детям так:
Лепим лицом к учащимся. Мы работаем справа налево, поэтому для учащихся это выглядит слева направо.
«Слова рифмуются, когда они заканчиваются одинаковыми звуками. Например, я могу проверить, рифмуются ли слова «сделать» и «взять». Смотри на меня. Я смешиваю две части каждого слова. /M/ [кладем правый кулак на стол], /ake/ [кладем левый кулак на стол], ‘make’ [сводим кулаки вместе, чтобы коснуться перед ней]. /T/ [кладем правый кулак на стол], /ake/ [кладем левый кулак на стол], ‘take’ [сводим кулаки вместе, чтобы соприкоснуться перед собой]. Окончания обоих слов были одинаковыми: /ake/ [поднимите левый кулак, повернувшись лицом к ученикам, чтобы показать, что окончания совпадают]. Я сделаю несколько, а ты скажешь мне, рифмуются ли они».
Затем мы показываем группе еще два примера: один без рифмы, а другой с рифмой. Мы предлагаем учащимся показать большой палец вверх или вниз, чтобы указать, рифмуются ли слова.
Шаги:
- Диктуем два слова. Не говорите ничего между словами; короткой паузы будет достаточно.
- Все учащиеся повторяют слова.
- Все учащиеся показывают кулаками две части первого слова.
- Все ученики кулаками показывают две части второго слова.
- Все учащиеся показывают большой палец вверх или вниз, чтобы указать, рифмуются ли слова.
Потренировавшись, убираем эшафот сегментации начала и изморози:
Шаги:
- Диктуем два слова.
- Один учащийся показывает большой палец вверх или вниз, чтобы указать, рифмуются ли слова.
- Все учащиеся показывают большой палец вверх или вниз, чтобы указать, рифмуются ли слова.
Это задание можно расширить, включив в него три слова. Мы спрашиваем учащихся, какие два слова рифмуются.
Повторите эти шаги с 10 наборами слов.
Вернуться к началу
Придумывание рифмующихся слов
Для учащихся с плохим фонологическим слухом придумывание слов, которые рифмуются, является сложной задачей. Другим учащимся будет трудно удержаться от выбалтывания рифмующихся слов. Чтобы облегчить задачу, разрешите бессмысленные слова, а также настоящие слова.
Другим учащимся будет трудно удержаться от выбалтывания рифмующихся слов. Чтобы облегчить задачу, разрешите бессмысленные слова, а также настоящие слова.
«Я могу сказать два рифмующихся слова. Смотри на меня. «Смотреть» «выемка». Они рифмуются. Я могу сказать слово, которое рифмуется. Это не обязательно должно быть настоящее слово. «Смотреть» «Зотч». «Зотч — это не настоящее слово, но оно рифмуется со словом «часы», потому что оба слова заканчиваются одним и тем же звуком».
Затем мы проведем группу еще по двум примерам. Затем мы диктуем слово и просим отдельных учащихся назвать слова, которые рифмуются. Если учащийся испытывает затруднения, мы можем предоставить новый начальный звук и попросить учащегося смешать его для создания рифмы.
Повторите эти шаги с 10 словами.
Вернуться к началу
Обучение одной фонеме
Новые согласные звуки
Мы должны убедиться, что они правильно артикулируют согласные звуки, прежде чем начинать обучение. Обязательно произносите согласный звук без завершающего звука /э/ в конце. Например, первый звук в слове «фут» — /fffff/, а не /fuh/. Добавление завершающего звука /uh/ мешает смешиванию звуков для произнесения слов. Очень важно, чтобы мы правильно артикулировали звуки, чтобы они могли правильно их выучить. См. Ehri (2020): Подключенная фонация более эффективна, чем сегментированная фонация, для обучения начинающих читателей декодированию незнакомых слов.
Обязательно произносите согласный звук без завершающего звука /э/ в конце. Например, первый звук в слове «фут» — /fffff/, а не /fuh/. Добавление завершающего звука /uh/ мешает смешиванию звуков для произнесения слов. Очень важно, чтобы мы правильно артикулировали звуки, чтобы они могли правильно их выучить. См. Ehri (2020): Подключенная фонация более эффективна, чем сегментированная фонация, для обучения начинающих читателей декодированию незнакомых слов.
Вот список из 44 звуков (фонем) английского языка. Ниже посмотрите видео, показывающее, как произносится каждый из звуков.
Обучение звукам в изоляции можно начинать с детей в возрасте 4 лет, но артикуляция может мешать повторению некоторых звуков. Согласные звуки можно познакомить так:
Шаги:
- Мы говорим: «Вы выучите новый согласный звук. Звук: [звук]. Послушайте еще раз: [звук]».
- Учащиеся повторяют звук 4 или 5 раз, пока мы ходим по комнате и слушаем.
 Звук: [звук]. Послушайте еще раз: [звук]».
Звук: [звук]. Послушайте еще раз: [звук]».- Убедитесь, что все учащиеся произносят звук правильно и не добавляют /uh/ в конце согласного.
- Для исправления опишите, как образуется звук (губы, зубы, язык), используйте ручные зеркала, чтобы учащиеся могли видеть, как они произносят звуки.
- Мы призываем от 6 до 10 учеников произнести звук.
- Все учащиеся произносят звук.
Вернуться к началу
Новые гласные звуки
Опять же, мы должны убедиться, что они правильно артикулируют гласные звуки, прежде чем начинать обучение.
Гласные звуки можно ввести так:
Шаги:
Новый звук
- Мы говорим: «Вы выучите новый гласный звук. Звук: /ăăăă/. Послушайте еще раз: /ăăăă/».
- Студенты повторяют звук 4 или 5 раз, пока мы ходим по комнате и слушаем. Убедитесь, что все учащиеся произносят звук правильно.
- Для исправления опишите, как образуется звук (губы, зубы, язык), используйте ручные зеркала, чтобы учащиеся могли видеть, как они произносят звуки.
- Мы призываем от 6 до 10 учеников произнести звук.
- Все учащиеся произносят звук.
 Убедитесь, что все учащиеся произносят звук правильно.
Убедитесь, что все учащиеся произносят звук правильно.Научите ярлык
- Мы говорим: «Ярлык — это то, что мы называем чем-то. Обозначение звука /ăăăă/ — короткое а».
- Все учащиеся повторяют этикетку.
- Мы вызываем от 6 до 10 учеников и задаем 2 вопроса в другом порядке: «Что такое короткий звук? Как называется звук /ăăăă/?»
- Все учащиеся произносят звук.
- Все учащиеся произносят этикетку.
Вернуться к началу
Сопоставление нового звука в исходной позиции
После изучения нового звука (согласного или гласного) научите учащихся слышать новый звук в исходной позиции. Представьте упражнение:
Теперь вы будете слушать [звук] в начале слов. Ты скажешь мне, начинается ли слово со звука [звук]. Смотри на меня. Я скажу слово. Я покажу большой палец вверх, если слово начинается со звука [звук]. Я покажу большой палец вниз, если слово не начинается со звука [звук]».
Ты скажешь мне, начинается ли слово со звука [звук]. Смотри на меня. Я скажу слово. Я покажу большой палец вверх, если слово начинается со звука [звук]. Я покажу большой палец вниз, если слово не начинается со звука [звук]».
[Мы произносим слово, которое начинается с целевого звука, делает паузу, затем показывает большой палец вверх. Мы произносим другое слово, которое не начинается с целевого звука, делает паузу, затем показывает большой палец вниз.]
«Давайте сделаем кое-что вместе».
[Мы проводим группу через два примера, один со словом, которое начинается с целевого звука, а другой не начинается с целевого звука.]
Шаги:
- Мы говорим учащимся слушать слова, которые начни со звука [звук].
- Диктуем слово.
- Все учащиеся повторяют слово.
- Все учащиеся показывают большой палец вверх или вниз, чтобы указать, начинается ли слово с целевого звука.
Повторите эти шаги для всех 15 слов в уроке. Начните с согласных, затем переходите к кратким гласным, затем к долгим гласным. Не используйте слова со смесями в начале.
Начните с согласных, затем переходите к кратким гласным, затем к долгим гласным. Не используйте слова со смесями в начале.
Вернуться к началу
Соответствие новому звуку в конечной позиции
Сразу после прослушивания нового звука в исходной позиции учащиеся могут прослушать тот же целевой звук в конечной позиции. Разумеется, это невозможно сделать с краткими гласными, поскольку английские слова не оканчиваются краткими гласными звуками. Представьте занятие:
«Теперь вы будете слушать [звук] в конце слов. Ты мне скажешь, оканчивается ли слово на звук [звук]. Смотри на меня. Я скажу слово. Я покажу большой палец вверх, если слово оканчивается на звук [звук]. Я покажу большой палец вниз, если слово не оканчивается звуком [звук]».
[Мы произносим слово, оканчивающееся на целевой звук, делаем паузу, затем показываем большой палец вверх. Мы произносим еще одно слово, которое не заканчивается на нужный звук, делаем паузу, затем показываем большой палец вниз. ]
]
«Давай сделаем что-нибудь вместе».
[Мы проводим группу через два примера, один со словом, которое заканчивается на целевой звук, а другой не заканчивается на целевой звук.]
Шаги:
- Мы говорим учащимся слушать слова, которые заканчиваться звуком [звук].
- Диктуем слово.
- Все учащиеся повторяют слово.
- Все учащиеся показывают большой палец вверх или вниз, чтобы указать, заканчивается ли слово нужным звуком.
Повторите эти действия, если в уроке используется не более 15 слов
Начните с согласных, возобновите упражнение при обучении долгим гласным. Не используйте слова со смесями в начале.
Вернуться к началу
Фонематическая осведомленность
Несмотря на то, что сегментировать звуки сложнее, чем просто определить первый или последний звук, это разумный следующий шаг, если учащиеся освоили время начала. Эта деятельность начинается с сегментации, а затем включает в себя определение отдельных звуков.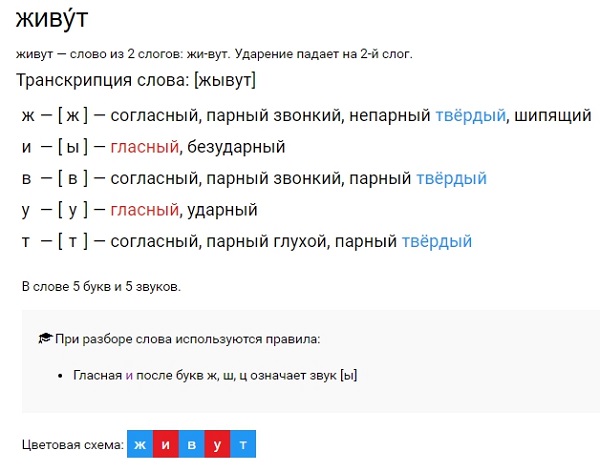
Членение звуков в слоге
«Слова можно разбивать на отдельные звуки. Мы называем это сегментацией звуков. Сегмент – это часть чего-либо. Мы будем разбивать слова на части или сегменты».
[Раздать каждому учащемуся по 3 манипулятора — в данном примере пробки от бутылок.]
Когда мы моделируем, нам, возможно, придется работать справа налево, чтобы учащимся казалось, что слева направо. Если мы работаем на доске, мы можем работать слева направо.
«Сначала я покажу вам, как пользоваться колпачками. Я буду считать 1, 2, 3 и над каждым числом поставлю шапку. Смотри на меня. 1 [сдвиньте кепку вперед], 2 [сдвиньте кепку, работая от студентов слева направо], 3 [сдвиньте кепку, работая от студентов слева направо]. Ты делаешь это.»
[Сдвиньте заглавные буквы в стопку, чтобы показать начало нового слова.]
«Сейчас я разделю звуки в слове на сегменты и буду использовать заглавные буквы, чтобы показать каждый звук. Смотри на меня. Слово «ноги», /f/ [сдвиньте колпачок], /ee/ [сдвиньте колпачок], /t/ [сдвиньте колпачок], foot [проведите пальцем под колпачком, смешивая звуки]. Я сделаю еще один».
Я сделаю еще один».
Мы моделируем еще одно или два слова, затем проводим группу по двум примерам. Не используйте слова, содержащие букву «x» или «qu», потому что каждое из них представляет 2 фонемы (x=ks; qu=kw). Используйте слова с одним, двумя или тремя звуками. Не используйте слова со смесями, пока все учащиеся не освоят сегментацию трех звуковых слов. Не используйте слова с контролируемым r или сильными дифтонгами (oy и ou), пока учащиеся не выучат эти звуки изолированно.
Шаги:
- Диктуем слово.
- Все учащиеся повторяют слово.
- Один учащийся разделяет звуки на сегменты, сдвигая колпачок для каждого звука и проводя пальцем ниже, чтобы смешать звуки обратно в слово.
- Все учащиеся сегментируют звуки, сдвигая колпачок для каждого звука и проводя пальцем ниже, чтобы смешать звуки обратно в слово.
- Другой ученик показывает пальцем и произносит первый звук.
- [после освоения этого навыка добавить:]
- Другой ученик показывает пальцем и произносит последний звук.
- [после освоения этого навыка добавить:]
- Другой ученик показывает и произносит гласный звук (например, /ă/).
- Другой учащийся показывает и произносит метку гласной (т. е. короткую а)

Повторите эти шаги для всех 15 слов в уроке.
Мы можем согласовать это упражнение с изучением гласных звуков отдельно. Мы, возможно, научили короткометражку звуку и ярлыку ранее в тот же день. Затем мы выбираем короткие слова для сегментации. Таким образом, учащиеся осваивают гласные звуки и обозначения в контексте произносимых слов. Требуется больше усилий для выбора слов. Это дает мощные результаты, обеспечивая прочную основу для правописания и чтения.
Смотрите и учитесь
Доктор Луиза Моутс помогает воспитателю детского сада освоить технику обучения фонематической сегментации с помощью чипов, чтобы помочь учащимся научиться определять отдельные звуки в слове. Буквы можно вводить позже.
 youtube.com/embed/hbOpKUapsNY»>
youtube.com/embed/hbOpKUapsNY»> Вернуться к началу
Смешивание звуков
[Раздайте каждому учащемуся по три манипулятора — в данном примере крышки от бутылок.]
«Мы можем смешивать звуки, чтобы сказать слово. Смотри на меня. Звуки: /s/ [сдвинь шапку], /ō/ [сдвинь шапку], /p/ [сдвинь кепку]. Я коснусь и скажу, затем смешать. /s/ [дотронуться до первой заглавной], /ō/ [дотронуться до средней заглавной], /p/ [дотронуться до последней заглавной буквы], мыло [проводить пальцем под заглавными буквами]. Сделай это со мной».
Когда мы моделируем, нам, возможно, придется работать справа налево, чтобы ученикам казалось, что слева направо. Если мы работаем на доске, мы можем работать слева направо.
[Сдвиньте заглавные буквы в стопку, чтобы показать начало нового слова.]
Мы проводим группу по двум примерам. Помните, не используйте слова, содержащие букву «x» или «qu», потому что каждое из них представляет 2 фонемы. Используйте слова с одним, двумя или тремя звуками. Не используйте слова со смесями, пока все учащиеся не освоят сегментацию трех звуковых слов. Не используйте слова с контролируемым r или сильными дифтонгами (oy и ou), пока учащиеся не выучат эти звуки изолированно.
Не используйте слова со смесями, пока все учащиеся не освоят сегментацию трех звуковых слов. Не используйте слова с контролируемым r или сильными дифтонгами (oy и ou), пока учащиеся не выучат эти звуки изолированно.
Шаги:
- Диктуем звуки, используя прописные буквы для обозначения звуков.
- Все учащиеся повторяют звуки, используя заглавные буквы для обозначения звуков.
- Один учащийся касается звуков и произносит их, а затем проводит пальцем ниже, чтобы объединить звуки в слово.
- Все учащиеся касаются и произносят звуки, а затем проводят пальцем ниже, чтобы объединить звуки в слово.
- Другой ученик показывает пальцем и произносит первый звук.
- [после освоения этого навыка добавить:]
- Другой ученик показывает пальцем и произносит последний звук.
- [после освоения этого навыка добавить:]
- Другой ученик показывает и произносит гласный звук (например, /ō/).
- Другой учащийся указывает и произносит метку гласной (т. е. долгий о)

Повторите эти шаги для всех 15 слов в уроке. Как и в случае сегментации, можно выбрать слова, которые усиливают звуки, изучаемые изолированно.
Вернуться к началу
Управление звуками (добавление, замена, удаление)
Это упражнение на фонематическое осознание является самым сложным из всех занятий по фонологическому осознанию. Это вершина мастерства. Имейте в виду, что плохая фонологическая осведомленность является наиболее распространенной слабостью трудных читателей. Учащиеся, которые овладевают этим навыком, имеют прочную основу для успеха в чтении.
Добавление звуков
Как правило, имеет смысл обучать манипулированию звуками в такой последовательности: добавить, заменить, удалить, из прагматических соображений. Для удаления нужны звуки, поэтому добавление и замена должны происходить перед удалением. Манипулирование звуками похоже на манипулирование слогами.
Помните, что не используйте слова, содержащие буквы «x» или «qu», поскольку каждое из них представляет 2 фонемы. Используйте слова с одним, двумя или тремя звуками. Не используйте слова со смесями, пока все учащиеся не освоят сегментацию трех звуковых слов. Не используйте слова с
r-контролируемыми или сильными дифтонгами (oy и ou), пока учащиеся не выучат эти звуки изолированно.
«Я могу добавлять звуки, чтобы составить новое слово. Смотри на меня. Я произношу первый звук и сдвигаю заглавную букву: /ī/ [заглавная буква]. Я добавляю последний звук: /s/ [сдвиньте заглавную букву так, чтобы она отображалась слева направо для учащихся]. Я касаюсь и произношу слоги: /ī/, /s/, «лед» [проведите пальцем под капителями слева направо]. Первый звук — /ī/ [дотронься до первой заглавной буквы]. Гласный звук /ī/ [дотронься до первой заглавной буквы]. Метка гласной длинная i [коснитесь первой заглавной буквы]. Последний звук — /s/ [дотронься до последней заглавной буквы]. Сделай это со мной». Затем мы проводим группу через два примера.
Затем мы проводим группу через два примера.
Примечание. Мы можем добавлять звуки следующим образом: /m/ /ĭ/, /m/ /ĭ/ /s/ или /ĭ/ /s/, /m/ /i/ /s/. Единственное изменение в процедуре — объявить, добавляется ли звук в начале или в конце слова.
[Сдвиньте заглавные буквы в стопку, чтобы показать начало нового слова.]
Шаги:
- Произносим звук и сдвигаем заглавную букву.
- Все учащиеся повторяют звук и сдвигают шапку.
- Говорим то ли добавляем начальный или конечный звук, то диктуем звук и сдвигаем шапку.
- Все учащиеся повторяют.
- Все учащиеся касаются и говорят, а затем смешивают звуки в слово.
- Все учащиеся касаются и говорят, а затем смешивают слоги, чтобы произнести слово.
- Один ученик касается и произносит первый звук.
- Другой ученик касается и произносит последний звук.
- Другой ученик касается и произносит гласный звук.
- Другой ученик касается и произносит этикетку с гласной.

Повторите эти шаги с 15 словами
Замена звуков
«Я могу заменить один звук в слове, чтобы получилось новое слово. Смотри на меня. Я заменю «сделать» на «выпечь». Какой звук различается в словах «сделать» и «выпечь»? Я буду использовать заглавные буквы, чтобы найти звук, который меняется».
[Мы используем колпачки, чтобы коснуться и сказать, а затем смешать «сделать». Под заглавными буквами мы касаемся и произносим, затем смешиваем «выпекать».]
«Первый звук в make — /m/. Первый звук в слове Bake — /b/. Я снимаю первую крышку и надеваю новую».
[Снимаем первую шапку, говоря /m/. Надеваем новую кепку, произнося /b/.]
«Не буду трогать и говорить новое слово. /b/ [дотроньтесь до первой заглавной], /ā/ [дотроньтесь до средней заглавной], /k/ [дотроньтесь до последней заглавной], ‘выпекать’ [проведите пальцем под заглавной]».
Мы моделируем еще один пример, затем проводим группу через два примера.
Шаги:
Начальное слово
- Диктуем начальное слово.
- Все учащиеся повторяют слово.
- Все учащиеся сдвигают заглавные буквы, чтобы показать каждый звук, затем проводят пальцем ниже, чтобы объединить звуки в слово.

Замена звука
- Мы говорим: «Замени [старое слово] на [новое слово]. Повторение.»
- Все учащиеся повторяют «Замените [старое слово] на [новое слово]».
- Все учащиеся касаются и говорят, а затем смешивают старое слово.
- Все учащиеся касаются и говорят, а затем смешивают новое слово [указывая под заглавными буквами].
- Мы просим учащихся указать на изменяющийся звук.
- Один ученик снимает колпачок, говоря, что звук пропадает.
- Другой ученик вставляет новую крышку, говоря, что звук входит.
- Все учащиеся касаются и говорят, а затем смешивают новое слово.
Повторите эти шаги с 4-6 словами в уроке.
Замените только первый звук на несколько уроков. Замените первый и последний звуки на несколько уроков.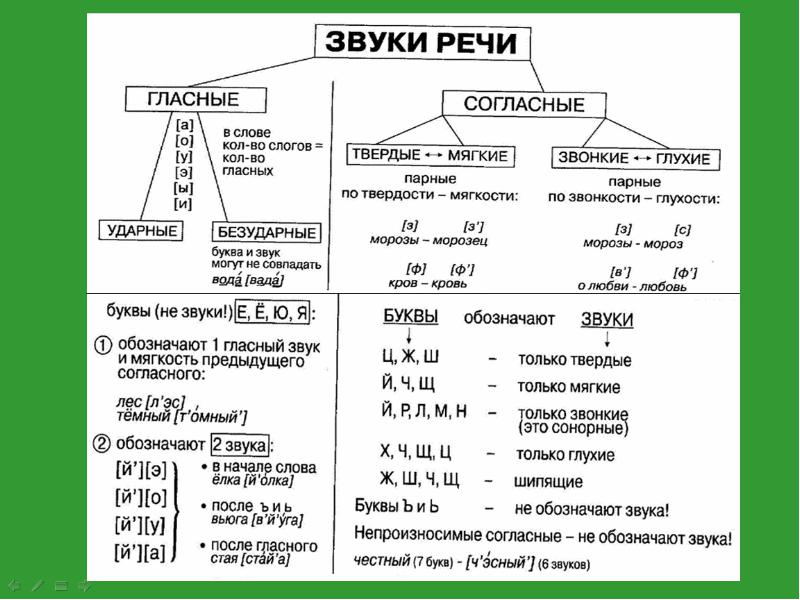 Наконец, учите заменять средний звук. Попрактикуйтесь в замене звуков на нескольких уроках. Затем снова введите добавление звуков. Попрактикуйтесь в добавлении и замене звуков в течение нескольких уроков, прежде чем начинать удалять звуки.
Наконец, учите заменять средний звук. Попрактикуйтесь в замене звуков на нескольких уроках. Затем снова введите добавление звуков. Попрактикуйтесь в добавлении и замене звуков в течение нескольких уроков, прежде чем начинать удалять звуки.
Удаление звуков
«Я могу удалить один звук в слове, чтобы образовать новое слово. Смотри на меня. Я заменю «велосипед» на «на». Какой звук в слове «велосипед» заменен на «по»? Я буду использовать заглавные буквы, чтобы найти удаленный звук».
[Мы используем колпачки, чтобы коснуться и сказать, а затем смешать «велосипед». Под заглавными буквами мы касаемся и произносим, затем смешивается «by».]
«Последний звук в слове «bike» — /k/. Последний звук в слове «by» — /ī/. Я сниму последнюю кепку».
[Снимаем последнюю заглавную букву, говоря /к/.]
«Сейчас я коснусь и скажу новое слово. /b/ [коснуться первой заглавной], /ī/ [коснуться последней заглавной], ‘by’ [провести пальцем под заглавной]».
Моделируем пример удаления первого звука и последнего звука. Мы проводим группу через два примера, один раз удаляя первый звук и один раз удаляя последний звук.
Мы проводим группу через два примера, один раз удаляя первый звук и один раз удаляя последний звук.
Шаги:
Начальное слово
- Диктуем начальное слово.
- Все учащиеся повторяют слово.
- Все учащиеся сдвигают заглавные буквы, чтобы показать каждый звук, затем проводят пальцем ниже, чтобы объединить звуки в слово.
Удаление звука
- Мы говорим: «Замени [старое слово] на [новое слово]. Повторение.»
- Все учащиеся повторяют «Замените [старое слово] на [новое слово]».
- Все учащиеся касаются и говорят, а затем смешивают старое слово.
- Все учащиеся касаются и говорят, а затем смешивают новое слово [указывая под заглавными буквами].
- Мы просим учащихся указать на звук, который будет удален.
- Один ученик снимает колпачок, говоря, что звук пропадает.
- Все учащиеся касаются и говорят, а затем смешивают новое слово.
Повторите эти шаги с 6-8 словами в уроке. Удалить звуки для нескольких уроков. Затем снова введите добавление и замену звуков.
Удалить звуки для нескольких уроков. Затем снова введите добавление и замену звуков.
Эти добавления, замены и удаления образуют звуковых цепочек — не орфографических цепочек. Например: тошнить, лизать, нравиться, лаймить, копейки, умирать, к I.
После того, как вы освоите навыки добавления, замены и удаления звуков, вы можете продолжать предлагать учащимся практиковать эти навыки.
Вернуться к началу
Ссылки
Ehri, L. C. (2004). Обучение фонематическому восприятию и фонетике: объяснение метаанализа Национальной группы по чтению. В P. McCardle & V. Chhabra (Eds.), Голос доказательства в исследовании чтения (стр. 153-186). Балтимор, Мэриленд: Brookes Publishing Co.
O’Connor, RE (2011). Знание фонемы и алфавитный принцип. В RE O’Connor & PF Vadasy (Eds.), Справочник по интервенциям чтения (стр. 9-26). Нью-Йорк: Гилфорд.
Правил правописания и 44 фонемы, миссис Джуди Араужо, доктор медицинских наук, CAGS
VectorStock Image
44 фонемы
Пожалуйста, загляните на мою страницу Sound Wall!
ТЕЛЕФОНМА | ПРИМЕР | ГРАФЕМА |
/б/ | бита, резина | б, бб |
/с/ | кот, утка, воздушный змей, аккорд, вопрос, признание, фолк, букет | с, ск, к, гл, д, куб. |
/д/ | собака, средняя, наполненная | д, дд, изд |
/ф/ | жир, вафля, кашель, телефон, теленок, часто | f, ff, gh, ph, lf, ft |
/г/ | получить, хихикать, призрак, гость | г, гг, гх, гу |
/ч/ | горячий, кто | ч, белый |
/к/ | кувшин, край, клетка, драгоценный камень, жираф, спортзал, солдат, преувеличение | j, -dge, -ge, g (рядом с e, i, y), di, gg |
/л/ | пусть, холм, участок, маленький, ископаемый, сельский | л, лл, эл, ле, ил, ал |
/м/ | коврик, мама, большой палец, осень, ладонь | м, мм, мб, мн, лм |
/н/ | не, зайка, знать, грызть, пневмония | н, нн, кн, жн, пн |
/стр/ | горшок, счастливый | с, стр |
/р/ | крыса, спеши, пиши, стишок, сюда | р, рр, право, право, ре |
/с/ | набор, беспорядок, лошадь, цент, город, тарелка, сцена, психология, слушай | с, сс, сб, в (рядом с е, и, у), сбн, пс, ст |
/т/ | загар, погремушка, Томас, прыгнул, сомнение, птеродактиль | т, тт, т, ед, бт, пт |
/в/ | фургон, у, Стефан | в, ве, ф, тел. |
/с | прогулка, кит, вопрос, хор | ш, б, у, о |
/х/ | лиса | х |
/г/ | желтый, мнение, аллилуйя | г, и, й |
/г/ | зебра, жужжание, изумление, роза, изгибы, ножницы, ксилофон, деление, мера | z, zz, ze, se, s, ss, x, si |
/а/ | яблоко, плед, смех | а, ай, ав |
/д/ | слон, хлеб, хоронить, друг, сказал, много, леопард, эстетика, телка | е, еа, у, т. |
/я/ | иглу, тренажерный зал, Англия, женщины, занят, построить, сито, определенные | я, у, е, о, у, уи, то есть, ай |
/о/ | осьминог, ва ш, все, честный, кашель, купил, нарисовал, возил, поймал | o, wa, al, ho, ou, ough, aw, au, авг |
/у/ | зонт, достаточно, обезьяна, наводнение, действительно, Аляска/экстра, приходите | u, ou, o, oo, oe, /a/ слог, o_e |
Длинный | дождь, поднос, восемь, вена, выпечка, они, бифштекс, фартук, прямой, калибр, крокет, где, варьируются | ай, ай, эй, эй, а-е, эй, еа, а, ай, ау, эт, эре, ар |
Длинный е | дерево, мясо, начальник, потолок, быть, счастливый, обезьяна, Пит, феникс, люди, маленькая, Мария | ee, ea, ie, ei, e, y, ey, ee-e, oe, eo, i-e, i |
Длинный и | велосипед, ночь, мой, привет, галстук, тип, ф инд, дикий , купить, ржаной, глаз, проход, остров, высота | i-e, igh, y, i, ie, y-e, ind , ild, уй, йе, глаз, ай, ис, эй |
Длинный или | лодка, лук, идти, халат, г старый, призрак, болт , шить, хотя, замок, брошь, Джо | oa, ow, o, o-e, old, ost, olt , ew, ough, eau, oo, oe |
Лонг у | трубка, вырос, клей, ботинок, эму, суп, сквозной, кто, туфелька, вид, красота, вражда, очередь | ue, ew, ue, oo, u, ou, ough, o, oe, iew, eau, eu, eue |
| оо | крутой, новый, потерять, флейта, синий, костюм, ты, обувь, через, грипп книга, можно, положить | оо, эв.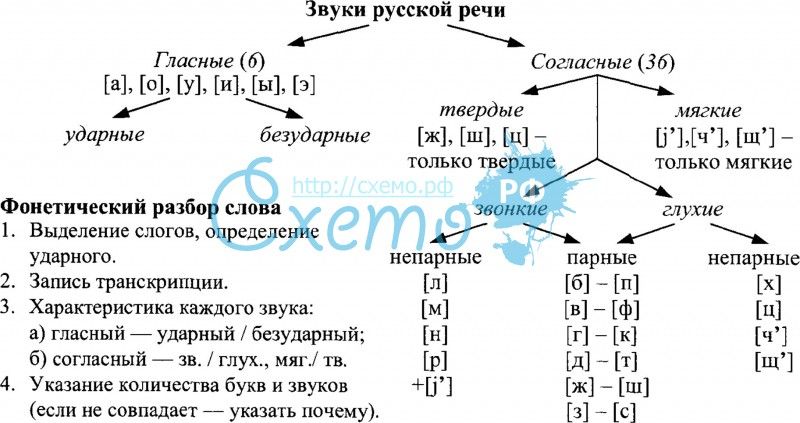 о-э. у-е, уе, уи, оу, оэ, о, тьфу, у о-э. у-е, уе, уи, оу, оэ, о, тьфу, у_____________________ оо, оул, у
|
или | дом, корова, сук | оу, оу, оу |
или | мальчик, масло, буй | ой, ой, уо |
ар | звезда, сердце, квадрат, сержант, гвардеец | ар, ухо, ар, эр, уар |
или | кукуруза, храп, доска, бедная, наливная, теплая | или, руда, весло, пол, наш, ар |
или | ее, поворот, первый, зеркало, услышал, слово, путешествие, доллар, сироп | э, ур, ир, ирр, ухо или, наш, ар |
или | тащить, учил, сырой, кашлять, думать, мяч | ау, ау, ау, ау, ау, а |
ш | обувь, шеф-повар, телевидение, заверить, дополнение, океан, конечно, особенный, совесть | sh, ch, si, ss, ti, ce, su, ci, sci |
ч | стул, спичка, будущее, вопрос, праведник | ч, -тч, ту, ти, тэ |
-й | моль | -й |
-й | мать | -й |
нк | затонул, тонул, гудок, кусок склеенные звуки | нк |
нг | пели, пели, песня, пели, склеенные звуки язык | нг, нге |
 см, лк, кве
см, лк, кве
 е., ай, а, эо, ае, еи
е., ай, а, эо, ае, еиПравила правописания и 44 фонемы
В этом списке, взятом из Обернского университета, указана частота каждого написания, например, длинного /A/. Наиболее часто длинное «а» пишется в конце открытых слогов, как в слове «бекон»; вторым по частоте является a_e, как в выпечке.
Наиболее часто длинное «а» пишется в конце открытых слогов, как в слове «бекон»; вторым по частоте является a_e, как в выпечке.
| Фонема | Основные варианты написания в порядке частотности (Ханна, Фрай) и примеры слов |
| /а/ | а ( мешок ), 97%; a_e ( есть ), 3% |
| /А/ | а ( бекон ), 45%; a_e ( запечь ), 35%; ай ( рейд ), 9%; ай ( играть ), 6% |
| /Ар/ | ар ( притча ), 29%; являются ( голые ), 23%; воздух ( ярмарка ), 21%; до ( там ), 15%; ухо ( медведь ), 6% |
| /ар/ | бар ( бар ), 89%; есть ( есть ), 5%; ухо ( сердце ), 3% |
| /ав/ | o ( потеряли ), 41%; а (шар ), 22%; а.е. ( выборка ), 19%; ав ( пила ) 10% |
| /б/ | б ( большой ), 97% |
| /ч/ | ч ( стул ), 55%, т ( черта ), 31%; тч ( поймать ), 11% |
| /д/ | д ( до ), 98% |
| / у / (шва) | о ( другое ), 24%; у (вверх), 20%; а ( тревога ), 19%; я ( паника ), 18%; е ( достаточно ), 11%; ou ( известный ), 5% |
| /e/ | э ( пласт ), 91%; шт ( хлеб ) 4% |
| /Э/ | г ( очень ), 41%; е ( берегитесь ), 40%; ее ( фут ), 6%; шт. ( место ), 6% ( место ), 6% |
| /Эр/ | эр ( опыт ), 32%; ухо ( страх ), 25%; олени ( олени ), 18%; e_e ( здесь ), 14%; уровень ( уровень ), 7% |
| /ул/ | файл ( таблица ), 95% |
| /эр/ | эр ( молоток ), 77%; или ( запах ), 12%; ар ( подвал ), 8% |
| /ф/ | f ( лиса ), 78%; тел ( телефон ), 12%; ff ( материал ), 9% |
| /г/ | г ( девочка ), 88%; гг ( яйцо ), 5%; х ( выход ), 3% |
| /ч/ | ч ( горячий ), 98% |
| /вх/ | бел.ч ( белый ), 100% |
| /я/ | 91 896 и (90 781 попали в 90 782), 92 %; т. е. ( дают ), 6% [у ( тренажерный зал ), 2%]|
| /I/ | и_е ( труба ), 37%; я ( Библия ), 37%; у ( на ), 14%; высокий ( правый ), 6% |
| /к/ | г. э. ( возраст г.), 66%; j ( струя ), 22%; дгэ ( кромка ), 5%; г ( солдат ), 3% э. ( возраст г.), 66%; j ( струя ), 22%; дгэ ( кромка ), 5%; г ( солдат ), 3% |
| /к/ | c ( автомобиль ), 73%; к ( комплект ), 13%; ск ( больных ), 6%; ч ( хор ), 3% |
| /кс/ | х ( шесть ), 90%; кс ( набат ), 10% |
| /кВт/ | qu ( бросить ), 97% |
| /л/ | л ( ножка ), 91%; ll ( расскажи ), 9% |
| /м/ | м ( м ), 94%; мм ( диммер ), 4% |
| /н/ | n ( нет ), 97% [kn ( знаю )<1%] |
| /нг/ | нг ( пой ), 59%; п ( обезьяна ), 41% |
| /о/ | о ( горячий ), 94%; а ( хочу ), 5% |
| /О/ | о ( фокус ), 73 %; о_е ( надежда ), 14%; оа ( лодка ), 5%; вл ( ряд ), 5% |
| /у/ | ой ( масло ), 62%; ой ( игрушка ), 32% |
| /оо/ | у ( куст ), 61%; оо ( крючок ), 35%; о ( женщина ), 5% |
| /или/ | или ( вместо ), 97%; руда ( ядро ), 3% |
| /вл/ | оу ( крик ), 56%; вл ( вой ), 29%; ou_e ( дом ), 13% |
| /стр/ | p ( пин ), 96%, pp ( случается ), 4% |
| /р/ | r ( запуск ), 97% |
| / с / | с ( скажем ), 73%, с ( крупа ), 17%; сс ( подбросить ), 7% |
| /л/ | ти ( действие ), 53%; ш ( застенчивый ), 26%; ci ( спец. ), 5%; ssi ( деление ), 3% ), 5%; ssi ( деление ), 3% |
| /т/ | т ( топ ), 97% |
| /й/ | й ( баня ) 100% |
| /у/ | u ( шина ) 86%; о ( тонн ), 8% |
| /U/ или /OO/ | u ( человек ), 59%; u_e ( использовать ), 19%; оо ( луна ), 11%; эу ( несколько ) 4% |
| /v/ | в ( очень ), 99,5% |
| /с | ш ( путь ), 92%; у ( замша ), 7,5% |
| /г/ | i ( лук ), 55%; у ( да ), 44% |
| / г / | с ( было ), 64%; г ( ноль ), 23%; эс ( мухи ), 4%, х ( ксилофон ), 4% |
| /ж/ | si ( надрез ), 49%; с ( удовольствия ), 33%; г ( гараж ), 15% |
Правила правописания и 44 фонемы
Этот список, взятый из Обернского университета, показывает вероятность того, что когда вы видите слово, например, с a_e, оно произносит длинное /A/ в 78% случаев. (в 22% случаев там написано что-то другое, например, /a/ в слове have.)
(в 22% случаев там написано что-то другое, например, /a/ в слове have.)
| Корреспонденция | Фонема, пример слова и процент достоверности в общеупотребительных словах |
| а_е | /A/ ( торт ) 78% |
| и | /А/ ( дождь ) 75% |
| или | /A/ ( воспроизвести ) 96% |
| е_е | /E/ ( эти ) 17% |
| ее | /E/ ( футов ) 96% |
| Шт. | /E/ ( место ) 64%; /e/ ( голова ) 17% |
| или | /А/ ( ) 50%; /E/ ( или ) 25% |
| эй | /E/ ( обезьяна ) 77% |
| т.е. | /E/ ( поле ) 49%; /I/ ( связано с ) 27% |
| i_e | /I/ ( пять ) 74% |
| о_е | /O/ ( плита ) 58% |
| или | /O/ ( слой ) 95% |
| вл | /O/ ( снег ) 68%; / вл / ( как ) 32% |
| ое | /O/ ( т. н.э. ) 44%; /OO/ (обувь ) 33%; /u/ ( делает ) 22% [всего 9 слов в образце] н.э. ) 44%; /OO/ (обувь ) 33%; /u/ ( делает ) 22% [всего 9 слов в образце] |
| или | / вл/ ( из ) 43 %; /u/ ( коснуться ) 18%; /U/ ( ваш ) 7% |
| u_e | /OO/ или /U/ (правило , отказ ) 77% |
| оо | /OO/ ( загрузочный ) 50 %; /оо/ ( книга ) 40% |
| ев | /OO/ ( взорвал ) 88%; /U/ ( несколько ) 19% [некоторое совпадение, например, новый ] |
| или | /i/ ( сборка ) 53 %; /U/ ( фрукт ) 24% |
| или | /aw/ ( причина ) 79% |
| ав | /aw/ ( увидел ) 100% |
| или | /ой/ ( присоединиться к ) 100% |
| и | /ой/ ( мальчик ) 100% |
| иа | /E/a/ ( фортепиано ) 54 %; / u / ( Азия ) 46% |
| y (безударный слог) | /E/ ( повезло ) 100% |
Каталог наиболее частых написаний каждой фонемы – Брюс Мюррей, Педагогический колледж (auburn. edu)
edu)
Правила правописания и 44 фонемы
Согласные
звонкие и глухие звуки Звонкость возникает при вибрации голосовых связок. Вот КРУТОЙ трюк. Попросите учащихся плотно заткнуть уши и произнести все звуки букв. Ухо должно быть расплющено и заблокировано непосредственно рукой – длинные волосы должны быть убраны в сторону. При произнесении этих звонких звуков присутствует вибрация/звон!
сочетания согласных образуют 2-3 звука: br, cl, spl, sp, thr, sq, gl, pl. . .
wh слова – h молчит: кит, колесо, кнут
ck или k: ck употребляется в конце односложных слов после 1 короткой гласной: back, deck, clock; c используется для финального звука /k/, когда слово состоит из 2 или более слогов: музыка, движение, Атлантика, исторический
tch слова – t молчит: поймать, зацепить, растянуть
«t» здесь касается короткой гласной. Иначе нам это не нужно:
Иначе нам это не нужно:
марш бранч дюйм хруст
дгэ слова – д молчит: . Это нужно для того, чтобы коснуться одной короткой гласной. Если это длинное гласное слово, нам не нужна стадия d: , огромная. Если согласная соприкасается с гласной, нам не нужна d: выпад, петля; «j» НИКОГДА не используется в конце слова.
c обычно звучит как s рядом с e, i и y: цент, город, тарелки – получить и дать являются исключениями
гу издает жесткий звук г: гость, гитара, гид. В противном случае ge и gi звучат как /j/; u держит g тяжело.
слова никогда не заканчиваются только на v: иметь, смелый, верить
слова никогда не заканчиваются только на j: age, gouge
в середине слов звук /j/ обычно представлен ge, gi, gy: (маржа), за исключением слова: пижама.
GH в конце слов/pH имеет/F/Sound: Кашель, Телефон
CH может издать 3 звука: Чейз, Рождество, Chef
Silent Late , большой палец, нож, грызть
Правило FLoSS — двойное f, l, s (и z): если в слове 1 слог ~ пух, холм, беспорядок (Есть некоторые исключения, например, bus , или когда s звучит как z, как в было или f звучит как v как в из .)
вопросительные слова: кто** – звучит иначе, чем другие wh вопросы , что, где, когда, почему, как, мог, должен, бы (заклинание, говоря «о, счастливая собака», что означает «старый»), делать, делает, делал
Произношение
Когда s стоит после глухого согласного , это произносится как /s/ – шапки, смех, что, мотыльки.
Когда буква стоит после гласной, другой буквы s или звонких согласных, она произносится как /z/ – бревна, трубы, проходы.
Диграфы – могут быть орграфы согласных и гласных
Диграфы согласных и гласных – это 2 буквы, которые составляют 1 звук: , оо. . .
Пожалуйста, посетите мою домашнюю страницу для получения дополнительной информации! Документ доступен при пожертвовании в размере 10 долларов.
Гласные
Безмолвный e заставляет гласный произносить свое имя, а не звук.
торт Пит Худа Одинокая трубка
Подробнее о Silent E
- Silent E помогает держать несколько слов от появления множества, как, пожалуйста, не просьба, а не дома.
- v не появляется в конце слов, поэтому безмолвное e придает этим словам орфографическую правильность, например, dove, love, shove, have.
- e указывает, когда буква g или c обозначает ее мягкий звук, как в слове клетка или гонка.
- Удалите немой e при добавлении суффикса, который начинается с гласной, например, ed или ing , но НЕ, если суффикс начинается с согласной:
al звучит как «ол»: мяч, падение, зал, высокий, звонок, прогулка, разговор, соль
слитные или склеенные звуки: группы букв, отдельные звуки которых трудно разделить при членении слов. ank, ink, onk, unk, ang, ing, ong, ung, am, an, all
ank, ink, onk, unk, ang, ing, ong, ung, am, an, all
нетипичные долгие гласные: old (холодный, золотой), ind (найти, слепой), ild (дикий , ребенок), ost (призрак, самый), olt (болт, жеребенок), old (холодный, жирный)
Группа гласных Обобщения
- За ai обычно следует буква n или l: парус, грот
- oa почти всегда используется ТОЛЬКО в 1-сложных словах: лодка, жаркое
- т.е. переворачивается после c:receive. Запомните i перед e, кроме как после c, или когда оно звучит как a, как в соседе, и взвешивайте: начальник, потолок
- eigh встречается очень редко. Эта мнемоника включает в себя самые распространенные восемь слов: Восемь соседей весят столько же, сколько груз саней.
- oe редко встречается для длинного звука oo. Наиболее распространенными словами являются обувь и каноэ. Запомните эту мнемонику: Джо ударил противника носком ботинка, находясь в каноэ.
- е добавляется к следующим словам замерзнуть, чихнуть, дом, подняться из-за долгих гласных звуков или иметь дифтонг (ou в доме).

diphthongs make 2 vowel sounds in 1 syllable: au/aw, ew/oo, oi/oy, ow/ou
Generalizations About Diphthongs
- oi is used in the middle слов: почва Правила правописания и 44 фонемы
- oy используется в конце слога: oyster, boy
- а.е. используется в середине слов: причина
- augh очень редко встречается для au. Следующая мнемоника включает в себя наиболее распространенные аугги: Надменная непослушная дочь поймала кота и научила его забивать.
- aw используется в конце слова или в середине, если слово оканчивается на одну букву n или l: лужайка, ползание
- ou используется в середине слов: дом
- , когда за ough следует t, произносится звук /aw/, как в слове buy, если нет, то звучит долгий звук o, как в слове тесто
- ow используется в конце слов или в середине, если слово оканчивается на одиночное n, l, er: down, рычание, душ
- ew стоит в конце слога: жевать
- уе стоит в конце слога; ue — редкое написание длинного звука oo. Вот мнемосхема с наиболее распространенными словами: Сью заклеила синее платье.
- ui — редкое написание длинного звука oo. Вот мнемоника с самыми распространенными словами: Официант в круизе пролил фруктовый сок на мужской костюм и получил синяк под глазом.
 Вот мнемосхема с наиболее распространенными словами: Сью заклеила синее платье.
Вот мнемосхема с наиболее распространенными словами: Сью заклеила синее платье.2 звука оо: школа, лось, книга, повар — Долгий звук оо в слове «сапог» встречается чаще, чем короткий звук в слове «книга». Итак, если ребенок застрял на слове «оо», попросите его сначала попробовать длинный звук!
2 звука вл: снег, плуг
3 звука у: желтый, небо, малыш е в конце двухсложных слов)
r-управляемая гласная или босси r ~ r рядом с гласной управляет гласной: car, corn
ir, ur, er производит тот же звук! H er t ur n f ir st! Ее птица рыгает.
WA: Вода, часы, желание, мыть
Правописание – префиксы и суффиксы Правописание r улей и 44 фонемы
Прошедшее время ed имеет 3 звука: после t или d оно производит звук ed и образует слог ed: нарисовано, требуется, переполнено, звучно3
Когда глагол оканчивается на звонкий звук, отличный от /d/, окончание произносится как /d/, как и в глаголах call, cryed, yelled, listened
Когда глагол оканчивается на глухой согласный, отличный от /t/, окончание произносится как /t/ как в спрашивал, смеялся, исправлял, натыкался
Удваивается? Удвоить конечную согласную, если:
- слово односложное
- слово оканчивается на одну согласную
- перед согласной стоит только 1 гласная
- 1 гласная начинает суффикс, например, ing, ed
большой, большой er , bigness лад, лад ing , раздражительный
если существительное оканчивается на s, ss, x, z, ch, sh и их больше 1: 90d – ad 90d звучит как /ez/
автобусы, скамейки, лисы, кусты, жужжание
если существительное/глагол оканчивается на y: изменить y на i и добавить es или ed, ЕСЛИ перед y стоит согласная
пенни, младенцы, несли, торопили, а не тогда, когда есть только гласная, касающаяся у: мальчики, играет
Конечная у после гласной остается неизменной при добавлении любого суффикса: остался, оплата, подлежащий оплате НО, если перед у стоит согласная, замените у на я : жалко, скопировано Правила правописания и 44 фонемы
если существительное оканчивается на f: Замените f на v и добавьте es
листья, ножи, но в других случаях не нужно: fifes, крыши
некоторые формы множественного числа неправильные: 2 90men , зубы, ноги, мыши, рыбы, олени. Притяжательные множественное число для букв и цифр: Используйте ‘s ~ 8, t, расставьте все точки над i множественное число для существительных, оканчивающихся на o: Существительные, оканчивающиеся на o после гласной s: studios морфология: Prefix_Suffix_Root_list_chart_R1 Проверьте этот суффикс PDF: Суффиксы Суффикс Ful: Ful имеет один L ~ Jogiful Суффикс LY: . Правила правописания и 44 фонемы Документ Word на этой странице доступен после пожертвования в размере 10 долларов США на оплату обслуживания моего веб-сайта. Нет графики из-за законов об авторском праве. Благодарю вас! 9 Ссылка Мнемонические предложения взяты из Project Read. Copyscape предупреждает меня о дублировании контента. Пожалуйста, уважайте мою работу. генеративные модели выравнивания слов. Предварительные знания играют роль вероятностных мягких ограничений между парами двуязычных слов, которые должны использоваться для обучения модели выравнивания слов. Мы исследуем знания, которые могут быть получены автоматически из принципа энтропии и двуязычного латентного семантического анализа, и покажем, как их можно применить для улучшения качества перевода. Мы представляем глобальную дискриминативную статистическую модель порядка слов для машинного перевода. Наша модель сочетает в себе информацию о синтаксическом движении и поверхностном движении и обучена избирательно выбирать из возможных порядков слов. Мы показываем, что сочетание дискриминационного обучения с функциями для обнаружения этих двух разных видов явлений движения приводит к существенному улучшению показателей порядка слов по сравнению с сильными базовыми показателями. Интеграция этой модели порядка слов в базовую систему машинного перевода приводит к улучшению BLEU на 2,4 пункта для перевода с английского на японский. Извлечение правил преобразования дерева для систем синтаксического машинного перевода может быть затруднено из-за ошибок выравнивания слов, которые нарушают синтаксические соответствия. Системы статистического машинного перевода обычно обучаются на больших объемах двуязычного текста (для изучения моделей перевода) и одноязычного текста на целевом языке (для языковых моделей). ). В этой статье мы исследуем использование трансдуктивных полууправляемых методов для эффективного использования одноязычных данных с исходного языка с целью улучшения качества перевода. Для этой цели мы предлагаем несколько алгоритмов и представляем сильные и слабые стороны каждого из них. Мы представляем подробные экспериментальные оценки французско-английского набора данных EuroParl и данных китайско-английского отслеживания больших данных NIST 2006. Недавние исследования представляют противоречивые данные о том, могут ли системы устранения неоднозначности слов (WSD) помочь улучшить производительность статистического машинного перевода (МП) системы. В этой статье мы успешно интегрируем современную систему WSD в современную иерархическую систему машинного перевода на основе фраз Hiero. Мы впервые показываем, что интеграция системы WSD повышает производительность современной статистической системы машинного перевода при выполнении реальной задачи перевода. Кроме того, улучшение является статистически значимым. Мы представляем новый подход к проблеме устранения неоднозначности смысла слова, который использует основанные на корпусе доказательства в сочетании с фоновыми знаниями. Когда система устранения неоднозначности смысла слов (WSD) обучается в одном домене, но применяется к другому домену, часто наблюдается падение точности . Категоризация человека не является ни бинарным, ни контекстно-зависимым процессом. Скорее, одни понятия являются лучшими примерами категории, чем другие, в то время как критерии принадлежности к категории могут в разной степени удовлетворяться разными понятиями в разных контекстах. В свете этих эмпирических фактов статическая структура категорий WordNet кажется одновременно чрезмерно жесткой и чрезмерно хрупкой для обработки реальных текстов. Стандартной формой анализа лингвистической типологии является универсальное следствие. Эти последствия констатируют факты о ряде существующих языков, например, «если объекты идут после глаголов, то прилагательные идут после существительных». В этой статье мы предлагаем новую модель различительного языка, которую можно использовать для общих приложений. В отличие от хорошо известных языковых моделей с N-граммами, дискриминационные языковые модели могут обеспечить более точное различение, поскольку они могут использовать перекрывающиеся функции и нелокальную информацию. Однако дискриминационные языковые модели использовались только для повторного ранжирования в конкретных приложениях, потому что мы не можем получить отрицательные примеры. В данной статье исследуется проблема выявления ошибочных/правильных предложений. У этой проблемы есть важные приложения, например, обеспечение обратной связи для авторов английского как второго языка, контроль качества параллельных двуязычных предложений, извлеченных из Интернета, и оценка результатов машинного перевода. Распознавание речи во многих морфологически богатых языках страдает от очень высокого коэффициента внесловаря (OOV). Более ранние работы показали, что методы декомпозиции словаря могут практически решить эту проблему для подмножества этих языков. В этой статье сравниваются различные подходы к распознаванию речи с открытой словарной декомпозицией, используя в качестве эталона распознавание эстонской речи. Сравнения выполняются с использованием больших моделей из 60000 лексических единиц и меньших словарей из 5000 единиц. Показано, что большая словарная модель, основанная на созданном вручную морфологическом тегере, дает самый низкий уровень ошибок в словах, в то время как неконтролируемый метод обнаружения морфологии Morfessor Baseline дает несколько более слабые результаты. Преобразование графемы в фонему (g2p) является основным компонентом любой системы преобразования текста в речь. Мы показываем, что добавление простых ограничений по слогам и назначению ударения, а именно одного ядра на слог и одного главного ударения на слово, к совместной модели n-грамм для преобразования g2p приводит к резкому повышению точности преобразования. Во-вторых, мы оценили морфологическую предварительную обработку для преобразования g2p. Хотя морфологическая информация была включена в некоторые прошлые системы, ее вклад, если таковой вообще был, никогда не оценивался количественно. Мы сравнили актуальность морфологической предварительной обработки по отношению к методу морфологической сегментации, размеру обучающей выборки, алгоритму преобразования g2p и двум языкам, английскому и немецкому. звуковой инвентарь языков мира. Путем тщательного статистического анализа мы обнаруживаем, что эта избыточность является неизменным свойством инвентаря согласных. Далее статистический анализ показывает, что инвентарь гласных не обладает таким свойством, что, в свою очередь, указывает на тот факт, что принципы организации инвентаря гласных и согласных совершенно различны по своей природе. В этой статье мы исследуем транслитерацию именованных объектов с использованием фонетического метода оценки. Фонетический метод вычисляется с использованием фонетических характеристик и псевдофункций, тщательно разработанных на основе данных об ошибках произношения изучающих английский язык как второй язык. Слова иностранного происхождения называются заимствованными словами или заимствованными словами. Заимствованное слово обычно импортируется в китайский язык путем фонетической транслитерации, если перевод недоступен. Семантическая транслитерация рассматривается как хорошая традиция, передающаяся из поколения в поколение при введении иностранных слов в китайский язык. Он не только сохраняет то, как слово звучит в исходном языке, но и сохраняет исходные семантические атрибуты слова. В этой статье впервые делается попытка автоматизировать процесс семантической транслитерации. Мы проводим исследование возможности семантической транслитерации и предлагаем вероятностную модель транслитерации личных имен с латиницы на китайский язык. Мы представляем новый метод прогнозирования изменчивых словоформ для создания морфологически богатых языков в машинном переводе. Мы используем богатый набор источников синтаксических и морфологических знаний как из исходных, так и из целевых предложений в вероятностной модели и оцениваем их вклад в создание русских и арабских предложений. Наши результаты показывают, что предлагаемая модель существенно превосходит обычно используемую базовую модель триграммного целевого языка; в частности, использование морфологических и синтаксических признаков приводит к очень большому выигрышу в точности предсказания. Мы также показываем, что предложенный метод эффективен при относительно небольшом количестве данных. Мы представляем разработку и оценку переводчика amenuensis, который использует сопоставимые корпуса для предложения и ранжирования небуквальных решений перевода выражений. из общего лексикона. Используя дистрибутивное сходство и двуязычные словари, этот метод превосходит установленные методы извлечения переводных эквивалентов из параллельных корпусов. Эффективное декодирование было фундаментальной проблемой машинного перевода, особенно с интегрированной языковой моделью, которая необходима для достижения хорошего качества перевода. Мы разрабатываем более быстрые подходы к этой проблеме на основе алгоритмов синтаксического анализа k-best и демонстрируем их эффективность как в системах машинного перевода, основанных на фразах, так и на основе синтаксиса. Машинный перевод предложения на исходном языке включает в себя выбор соответствующих слов целевого языка и упорядочивание выбранных слов для формирования правильно сформированного целевого языка приговор. Большая часть предыдущей работы по статистическому машинному переводу основывалась на (em local) ассоциациях целевых слов/фраз с исходными словами/фразами для лексического отбора. Напротив, в этой статье мы представляем новый подход к лексическому отбору, при котором целевые слова связаны со всем исходным предложением (em global) без необходимости вычисления локальных ассоциаций. Далее мы представляем технику восстановления предложения целевого языка из выбранных слов. Представления синтаксиса естественного языка на основе зависимостей требуют тонкого баланса между структурной гибкостью и вычислительной сложностью, и в недавней работе было предложено несколько ограничений для определения классов структуры зависимости, которые хорошо сбалансированы в этом смысле. Все эти ограничения сформулированы для полностью определенных структур, что затрудняет их интеграцию в модели, в которых структуры состоят из лексической информации. В этой статье мы показываем, как можно лексикализировать два эмпирически релевантных структурных ограничения и как объединение полученных словарей с обычными средствами композиции приводит к возникновению иерархии языков с умеренной контекстно-зависимой зависимостью. В этой статье показано, как использовать преобразование Unfold-Fold для преобразования проективных билексических грамматик зависимостей (PBDG) в сохраняющие неоднозначность слабо эквивалентные Бесплатные грамматики (CFG). Эти CFG могут быть проанализированы за время O(n 3 ) с использованием CKY и других стандартных алгоритмов с соответствующей индексацией, а не за время O(n 5 9 ).3302 ) время, требуемое наивным кодированием. Неформально использование алгоритма CKY с такой CFG имитирует шаги алгоритма синтаксического анализа Eisner-Satta O (n 3 ) PBDG. Это преобразование делает все методы, разработанные для CFG, доступными для PBDG. Мы демонстрируем это, описывая декодер максимального апостериорного разбора для PBDG. Мы показываем, что проблемы синтаксического анализа и поверхностной реализации для грамматических формализмов с «бесконтекстными» выводами в сочетании с семантикой Монтегю (при определенных ограничениях) могут быть сведены к единый способ оценки запроса Datalog. Помимо предоставления алгоритма с полиномиальным временем для вычисления всех деревьев вывода (в форме общего леса) из входной строки или входной логической формы, это сокращение имеет следующие теоретико-сложностные следствия для всех таких формализмов: (i) решение задачи распознавания грамматичности (поверхностной реализуемости) входной строки (логической формы) в LOGCFL; и (ii) задача поиска одной логической формы (поверхностной строки) из входной строки (логической формы) находится в функциональном LOGCFL. Более того, переписывание программы Datalog с помощью обобщенных дополнительных магических наборов в результате сокращения дает эффективные алгоритмы в стиле Эрли как для синтаксического анализа, так и для генерации. Мы исследуем проблему выбора порядка слов для набора деревьев зависимостей, чтобы минимизировать общую длину зависимостей. Мы представляем алгоритм вычисления оптимального расположения одного дерева, а также численный метод оптимизации грамматики упорядочения по набору типов зависимостей. Было обнаружено, что грамматика, созданная путем минимизации длины зависимостей в неупорядоченных деревьях из Penn Treebank, на удивление хорошо согласуется с английским порядком слов, что позволяет предположить, что минимизация длины зависимостей повлияла на эволюцию английского языка. Большие корпуса проанализированных предложений с метками семантических ролей (например, PropBank) предоставляют обучающие данные для использования при создании высокопроизводительных систем автоматической маркировки семантических ролей. Ядро дерева свертки показало очень многообещающие результаты в маркировке семантической роли (СРЛ). Однако этот метод учитывает меньше лингвистических знаний и выполняет только жесткое сопоставление между подструктурами, что может привести к переобучению и менее точной мере сходства. В этой статье представлено новое применение оптимизации чередующейся структуры (ASO) для задачи маркировки семантической роли (SRL) именных предикатов в NomBank. ASO — это недавно предложенный линейный алгоритм многозадачного обучения, который извлекает общие структуры нескольких задач для повышения точности за счет использования вспомогательных задач. В этой статье мы исследуем ряд различных вспомогательных задач, и мы можем значительно повысить точность задачи NomBank SRL, используя этот подход. Насколько нам известно, предложенный нами подход обеспечивает самую высокую точность, опубликованную на сегодняшний день в задаче NomBank SRL на английском языке. Мы предлагаем новую простую модель для автоматического определения предпочтений выбора с использованием показателей семантического сходства на основе корпуса. Мы изучаем проблему переноса известного метода НЛП на язык с небольшими существующими ресурсами НЛП, в частности, фрагментацию на основе SVM на иврите. Мы представляем два основанных на SVM метода подделки модели и закрепленного обучения. Это позволяет проводить детальный анализ изученных моделей SVM, что дает рекомендации по выявлению ошибок в обучающем корпусе, определению роли и взаимодействия лексических признаков и, в конечном итоге, созданию модели с уменьшением ошибок на 15%. Показано, что получившийся блокировщик устойчив к наличию шума в обучающем корпусе, полагается на меньшее количество лексических признаков, чем предполагалось ранее, и достигает производительности по F-мере 9. Мы представляем метод веб-анализа для обнаружения и улучшения отношений, в которых участвует указанный концепт. Мы обнаруживаем целый ряд отношений, ориентированных на данную концепцию, а не общие известные отношения, как в большинстве предыдущих работ. Наш метод основан на шаблонах кластеризации, которые содержат понятийные слова и другие слова, связанные с ними. Мы оцениваем метод по трем различным богатым концепциям и обнаруживаем, что в каждом случае метод создает широкий спектр отношений с хорошей точностью. Penn Treebank не аннотирует фразы с основными существительными (NP), придерживаясь только плоских структур, которые игнорируют сложность английских NP. Ключевой вопрос, стоящий перед сообществом синтаксических анализаторов, заключается в том, как сравнивать синтаксические анализаторы, которые используют разные формализмы грамматики и выдают разные результаты. Оценка синтаксического анализатора на том же ресурсе, который использовался для его создания, может привести к несопоставимым показателям точности и чрезмерно оптимистичному представлению о производительности синтаксического анализатора. Мы описываем подход к адаптации предметной области, который подходит именно в том случае, когда имеется достаточно «целевых» данных, чтобы добиться большего успеха, чем просто использование только «исходных» данных. Наш подход невероятно прост, его легко реализовать как этап предварительной обработки (10 строк Perl!) и он превосходит современные подходы к целому ряду наборов данных. Адаптация предметной области является важной проблемой обработки естественного языка (НЛП) из-за отсутствия размеченных данных в новых предметных областях. В этой статье мы изучаем проблему адаптации предметной области с точки зрения взвешивания экземпляров. Мы формально анализируем и характеризуем проблему адаптации домена с точки зрения распределения и показываем, что существуют две различные потребности в адаптации, соответствующие разным распределениям экземпляров и функций классификации в исходном и целевом доменах. Затем мы предлагаем общую структуру взвешивания экземпляров для адаптации предметной области. Наши эмпирические результаты по трем задачам NLP показывают, что включение и использование большего количества информации из целевой области посредством взвешивания экземпляров является эффективным. Исторически так сложилось, что в методах неконтролируемого обучения отсутствовал принципиальный метод выбора количества невидимых компонентов. Исследования непараметрических априорных оценок, таких как процесс Дирихле, позволили вместо этого использовать бесконечные модели, в которых количество скрытых категорий не фиксировано, а вместо этого может расти с объемом обучающих данных. В этой работе мы разрабатываем модель бесконечного дерева, новый тип бесконечной модели, которая способна представлять рекурсивную ветвящуюся структуру в произвольно большом наборе скрытых категорий. В частности, мы разрабатываем три модели бесконечного дерева, каждая из которых реализует различные предположения о независимости, и для каждой модели мы также определяем простые процедуры вывода выборки с прямым назначением, подходящие для обучения без учителя. Мы демонстрируем полезность наших моделей неконтролируемым изучением тегов части речи из структуры скелета зависимостей банка дерева, достигая точности 71%, и неконтролируемым разделением тегов части речи, что повышает точность разбора с 85,11% до 87,40% при использовании в генеративном анализаторе зависимостей. За последние несколько лет двумя основными направлениями исследований в области машинного обучения обработки естественного языка были изучение полу — контролируемые алгоритмы обучения как способ обучения классификаторов, когда размеченных данных мало, и изучение способов использования знаний и глобальной информации в структурированных задачах обучения. В этой статье мы предлагаем включить знания предметной области в полууправляемые алгоритмы обучения. Мы используем ограничения в качестве общей структуры для представления знаний, основанных на здравом смысле, и разрабатываем новый протокол обучения, который объединяет и может использовать несколько видов ограничений. Экспериментальные результаты, представленные в области извлечения информации, показывают, что применение ограничений помогает модели генерировать лучшую обратную связь во время обучения, и, следовательно, структура обеспечивает высокоэффективное обучение со значительно меньшим количеством обучающих данных, чем это было возможно раньше для этих задач. До недавнего времени расширение статистического машинного перевода на основе фраз (PBSMT) с помощью синтаксической структуры приводило к ухудшению производительности системы. В этой работе мы показываем, что лексические синтаксические описания в форме супертэгов могут привести к значительно лучшим системам PBSMT. Мы описываем новую модель PBSMT, которая включает супертэги в модель целевого языка и целевую сторону модели перевода. Используются два типа супертегов: лексикализированная грамматика, примыкающая к дереву (LTAG), и комбинаторная категориальная грамматика (CCG). Несмотря на различия между супертеггерами LTAG и CCG, они дают схожие улучшения. Помимо супертегирования, мы также исследуем полезность поверхностной глобальной меры грамматичности, основанной на комбинаторных операторах. Мы проводим различные эксперименты с арабско-английским тестовым набором NIST 2005, обращаясь к таким вопросам, как разреженность, масштабируемость и полезность системных подкомпонентов. Большинство показателей автоматической оценки для машинного перевода (МП) основаны на сравнении с переводами, сделанными человеком. Однако ссылки на людей не всегда могут быть доступны. В этой статье мы представляем подход машинного обучения, который сочетает в себе широкий спектр показателей беглости и адекватности, полученных из более слабых источников псевдоссылок сравнений, чтобы сформировать составную метрику, которая оценивает результаты машинного перевода на уровне предложений. Мы показываем, что регрессионное обучение, которое оптимизирует метрику для корреляции с оценкой человека на обучающих примерах, является ключом к использованию этой более слабой формы ссылок. Мы представляем простой метод упаковки слов для статистического выравнивания слов. Наша цель — упростить задачу автоматического выравнивания слов, объединяя несколько последовательных слов, когда мы считаем, что они соответствуют одному слову в противоположном языке. Это делается с помощью самого слова выравнивателя, т. е. путем начальной загрузки на его выходе. Мы оцениваем эффективность нашего подхода при выполнении задачи машинного перевода с китайского на английский и сообщаем об относительном увеличении оценки BLEU на 12,2 % по сравнению с современной системой SMT на основе фраз. В последнее время в системах машинного перевода применяется декодирование сети путаницы. Мы исследуем факторы, определяющие порядок составляющих в немецких предложениях, и предлагаем алгоритм, который выполняет задачу в два этапа: во-первых, лучший кандидат на начальное положение предложения выбран. Поверхностные реализаторы делятся на те, которые используются для генерации (редукторы NLG), и те, которые отражают процесс синтаксического анализа (обратимые реализаторы). В то время как первые полагаются на грамматики, которые нелегко использовать для синтаксического анализа, неясно, как второй тип реализаторов может быть параметризован для получения из набора возможных перефраз, перефразирования, соответствующего данному контексту генерации. В этой статье мы представляем поверхностный реализатор, который сочетает в себе обратимую грамматику (используемую для синтаксического анализа и построения семантики) с символическим средством выбора парафраз. В этой статье мы переводим генерацию предложений из TAG-грамматик с семантической и прагматической информацией в задачу планирования путем декларативного и явного кодирования вклада каждого слова. Это позволяет нам использовать недавние улучшения производительности в готовых планировщиках. Это также открывает новые перспективы в отношении генерации референтных выражений и отношений между языком и действием. исходный контент с беглостью результирующего текста. В этой статье мы разрабатываем метрику автоматической оценки только для оценки беглости путем изучения использования выходных данных синтаксического анализатора в качестве метрик и показываем, что они коррелируют с человеческими суждениями о беглости сгенерированного текста. Затем мы разрабатываем машинное обучение на их основе и показываем, что он работает лучше, чем выходные показатели отдельного синтаксического анализатора, приближаясь к нижней границе производительности человека. Невербальные модальности, такие как жесты, могут улучшить обработку спонтанной устной речи. Например, похожие жесты рук, как правило, предсказывают семантическое сходство, поэтому функции, которые количественно определяют сходство жестов, могут улучшить такие задачи, как разрешение кореферентности. Однако не все движения рук являются информативными жестами; Психологические исследования показали, что говорящие с большей вероятностью жестикулируют, когда их речь двусмысленна. В идеале можно было бы обращать внимание на жесты только в таких обстоятельствах и игнорировать другие движения рук. Мы представляем условное слияние модальностей, которое формализует эту интуицию, рассматривая информативность жеста как скрытую переменную, которую нужно изучать вместе с меткой класса. В этой статье мы исследуем полезность навигационной карты (NM), графического представления структуры дискурса. Мы проводим исследование пользователей, чтобы выяснить, воспринимают ли пользователи NM как полезную систему обучения разговорному диалогу. С точки зрения пользователей, наши результаты показывают, что присутствие NM позволяет им лучше идентифицировать и следовать плану обучения, а также лучше интегрировать инструкции. Пользователям также было легче концентрироваться и учиться у системы, если присутствовал NM. Наш предварительный анализ объективных показателей еще больше подтверждает эти выводы. Руководствуясь психолингвистическими открытиями о том, что взгляд тесно связан с человеческим языком, мы в настоящее время изучаем использование естественно одновременно встречающихся взгляд и речевые высказывания во время человеко-машинного разговора для автоматического приобретения и интерпретации словарного запаса в мультимодальных разговорных системах. В частности, мы разработали неконтролируемый подход, основанный на моделях перевода, для автоматического изучения сопоставлений между словами и объектами на графическом дисплее. Экспериментальные результаты показывают, что взгляд пользователя может предоставить достоверную информацию для установления таких сопоставлений, которые имеют многообещающие последствия для автоматического получения и интерпретации пользовательских словарей для диалоговых систем. нужны более естественные интерфейсы. В этом документе описывается добавочный синтаксический анализатор и алгоритм обучения без учителя для создания этого синтаксического анализатора из обычного текста. Синтаксический анализатор использует представление синтаксической структуры, похожее на ссылки зависимостей, которые хорошо подходят для поэтапного анализа. В этом документе представлен анализатор зависимости максимальной энтропии, основанный на эффективном k-лучшем алгоритме максимального связующего дерева (MST). Хотя в недавней работе предполагается, что ограничения алгоритма MST с краевым фактором значительно снижают точность синтаксического анализа, мы показываем, что генерация 50 лучших синтаксических анализов в соответствии с моделью с краевым фактором имеет производительность оракула намного выше производительности 1-наилучшей зависимости. Как далеко мы сможем продвинуться в неконтролируемом синтаксическом анализе, если увеличим наш обучающий корпус на несколько порядков по сравнению с тем, что мы пытались делать до сих пор? Мы представляем новый эффективный алгоритм неконтролируемого синтаксического анализа с использованием модели всего поддерева. В то время как предыдущие неконтролируемые модели всех поддеревьев зависели от случайной выборки поддеревьев из набора всех возможных двоичных деревьев, назначенных предложениям (Bod 2006), наш алгоритм преобразует упакованный лес всех двоичных деревьев непосредственно в компактную PCFG. Хотя средняя производительность статистических синтаксических анализаторов постепенно улучшается, они по-прежнему добавляют ко многим предложениям аннотации довольно низкого качества. Определение полярности и силы мнений является важной темой исследований, привлекающей значительное внимание в течение последних нескольких лет. Многие существующие подходы полагаются на людей-аннотаторов для оценки полярности и силы мнений, что является трудоемкой и подверженной ошибкам задачей. Мы используем другой подход, рассматривая экономический контекст, в котором оценивается мнение. Мы исходим из того, что текст в онлайн-системах влияет на поведение читателей, и этот эффект можно наблюдать с помощью некоторых легко измеряемых экономических переменных, таких как доходы или цены на продукты. Затем, обращая логику, мы делаем вывод о семантической направленности и силе мнения, отслеживая изменения соответствующей экономической переменной. По сути, мы объединяем эконометрику с алгоритмами интеллектуального анализа текста, чтобы определить «экономическую ценность текста» и присвоить «долларовую стоимость» каждой фразе мнения, эффективно измеряя настроение и без необходимости ручной маркировки. В этой статье представлено применение PageRank, модели случайного блуждания, первоначально разработанной для ранжирования результатов веб-поиска, для ранжирования WordNet synsets с точки зрения того, насколько сильно они обладают данным семантическим свойством. Семантические свойства, которые мы используем для иллюстрации подхода, — это позитивность и негативность, два свойства, имеющие центральное значение в анализе настроений. В этой статье мы исследуем структурированную модель для совместной классификации тональности текста на различных уровнях детализации. Вывод в модели осуществляется снизу вверх и основан на стандартных методах классификации последовательностей с выводом Витерби с ограничениями для обеспечения согласованных решений. Основное преимущество такой модели состоит в том, что она позволяет классификационным решениям на одном уровне текста влиять на решения на другом. Автоматическая классификация настроений широко изучалась и применялась в последние годы. Однако настроение выражается по-разному в разных областях, и аннотирование корпусов для каждой возможной области интересов нецелесообразно. Мы исследуем доменную адаптацию для классификаторов настроений, уделяя особое внимание онлайн-обзорам различных типов продуктов. Во-первых, мы расширили классификацию настроений недавно предложенного алгоритма обучения структурным соответствиям (SCL), уменьшив относительную ошибку из-за адаптации между доменами в среднем на 30% по сравнению с исходным алгоритмом SCL и на 46% по сравнению с контролируемым базовым уровнем. Во-вторых, мы определяем меру сходства доменов, которая хорошо коррелирует с потенциалом адаптации классификатора из одного домена в другой. В последнее время возрос интерес к неконтролируемому обнаружению высокоуровневых семантических отношений, включающих сложные единицы, такие как фразы и целые предложения. . Обычно такие подходы сталкиваются с двумя основными препятствиями: разреженностью данных и правильным обобщением примеров. В этой работе мы описываем представление Clustered Clause, которое использует информационную кластеризацию и зависимости между предложениями для создания упрощенного и обобщенного представления грамматического предложения. Мы реализуем алгоритм, использующий это представление для обнаружения предопределенного набора отношений высокого уровня, и демонстрируем эффективность нашей модели в преодолении обеих упомянутых проблем. Получение больших объемов знаний о выводе, таких как правила следования, стало основным фактором в достижении надежной семантической обработки. Несмотря на то, что были проведены серьезные исследования алгоритмов обучения таким знаниям, методология их оценки была проблематичной, что препятствовало дальнейшим исследованиям. Мы предлагаем новую методологию оценки правил следствия, которая явно рассматривает их семантические свойства и обеспечивает удовлетворительный уровень согласия между людьми. Методология используется для сравнения двух современных алгоритмов обучения, выявляя критические проблемы для будущего прогресса. В этом документе представлен новый подход к расширению запроса при поиске ответов, использующий методы статистического машинного перевода (SMT). Мы предлагаем вычислительную модель повторного использования текста, адаптированную для древних литературных текстов, часто доступную нам только в небольших и зашумленных образцах. Тематическая сегментация и идентификация часто решаются как отдельные проблемы, тогда как обе они являются частью тематического анализа. В этой статье мы изучаем, как идентификация темы может способствовать улучшению сегментатора темы на основе повторения слов. Сначала мы представляем неконтролируемый метод для обнаружения тем текста. Затем мы подробно описываем, как эти темы используются при сегментации для поиска тематических сходств между текстовыми сегментами. Наконец, мы показываем результаты оценки, проведенной как для французского, так и для английского языков, интерес к предлагаемому нами методу. Мы исследуем различные наборы функций для выполнения автоматической сегментации дискурса на уровне предложений в рамках общего подхода к машинному обучению, включая функции, полученные из любого конечного состояния или контекстно-свободные аннотации. За последние пятьдесят лет модель личностных черт «Большой пятерки» стала стандартной в психологии, и исследования систематически документировали корреляции между широким спектром лингвистических переменные и черты Большой пятерки. Отдельное направление исследований изучало методы автоматического создания языка, который варьируется в зависимости от параметров личности. Хотя эта работа предполагает очевидную полезность для создания языка, богатого личностью: (1) эти системы генерации не оценивались, чтобы увидеть, производят ли они узнаваемые личностные вариации; (2) они в основном были основаны на генерации на основе шаблонов с ограниченным пересказом для различных личностных параметров; (3) использование психологических данных было скорее эвристическим, чем систематическим. Мы решаем задачу неконтролируемой тематической сегментации речевых данных, опираясь только на первичную акустическую информацию. В отличие от существующих алгоритмов сегментации речи по темам, наш подход не требует входных расшифровок. Наш метод предсказывает смену тем, анализируя распределение повторяющихся акустических паттернов в речевом сигнале, соответствующем одному говорящему. Фильтр Блума (BF) — это рандомизированная структура данных для запросов на членство в множестве. Его требования к пространству значительно ниже нижних границ теории информации без потерь, но он дает ложные срабатывания с некоторой постоянной вероятностью. Здесь мы исследуем использование БФ для языкового моделирования в статистическом машинном переводе. Мы предлагаем новый подход к адаптации межъязыковой языковой модели (LM), основанный на двуязычном латентном семантическом анализе (bLSA). Представлена модель bLSA, которая позволяет эффективно передавать скрытые распределения тем между языками, обеспечивая взаимное соответствие тем во время обучения. Используя предложенную структуру bLSA, межъязыковая адаптация LM может быть выполнена путем, во-первых, вывода апостериорного распределения темы исходного текста, а затем применения предполагаемого распределения к N-грамме LM целевого языка посредством маргинальной адаптации. Семантическая связанность является очень важным фактором для задачи разрешения кореференции. Чтобы получить эту семантическую информацию, подходы, основанные на корпусе, обычно используют шаблоны, которые могут выражать конкретное семантическое отношение. Шаблоны, однако, разрабатываются вручную и поэтому не обязательно являются самыми эффективными с точки зрения точности и широты. Чтобы решить эту проблему, в этой статье мы предлагаем подход, который может автоматически находить эффективные шаблоны для разрешения кореферентности. В этом документе рассматривается вопрос о том, можно ли улучшить преобразователь корреференции на основе обучения, используя знания семантического класса, которые автоматически извлекаются из версии Penn Treebank, в которой словосочетания существительных помечены символом Их семантические классы. Эксперименты с тестовыми данными ACE показывают, что преобразователь кореференции, который использует такое индуцированное знание семантического класса, значительно превосходит (на 2% по F-мере) тот, который использует эвристически вычисленное знание семантического класса. Что еще более важно, индуцированное знание повышает точность разрешения имен нарицательных на 2-6%. В этом документе представлен метод автоматического создания оглавления. Этот тип резюме может служить эффективным средством навигации для доступа к информации в длинных текстах, таких как книги. Чтобы сгенерировать согласованное оглавление, нам нужно зафиксировать как глобальные зависимости между различными заголовками в таблице, так и локальные ограничения внутри разделов. Наш алгоритм эффективно обрабатывает эти сложные зависимости, разбивая модель на локальные и глобальные компоненты и постепенно формируя выходные данные модели. Результаты автоматической оценки и ручной оценки подтверждают преимущества этой схемы: наша система постоянно оценивается выше, чем неиерархические базовые модели. Хотя и обобщение документов, и извлечение ключевых слов нацелены на получение кратких представлений из документов, эти две задачи обычно исследуются независимо друг от друга. Мы описываем новую архитектуру нейронной сети для решения проблемы семантической маркировки ролей. Многие текущие решения сложны, состоят из нескольких этапов и функций, созданных вручную, и слишком медленны для применения в составе реальных приложений, требующих таких семантических меток, отчасти из-за использования в них синтаксического анализатора. В этом документе рассматривается автоматическая классификация семантических отношений в словосочетаниях с существительными на основе кросс-лингвистических данных из пяти романских языков: испанского, итальянского, французского. , португальский и румынский. Набор новых семантических и контекстуальных признаков англо-романского НП получен на основе эмпирических наблюдений за распределением синтаксиса и значения именных словосочетаний в двух разножанровых корпусах (Europarl и CLUVI). Эти функции были использованы в алгоритме машин опорных векторов, который достиг точности 76,9.% (Europarl) и 74,31% (CLUVI). Мы представляем новый подход к извлечению связей, который требует лишь нескольких обучающих примеров. Имея несколько пар именованных сущностей, которые, как известно, проявляют или не проявляют определенное отношение, пакеты предложений, содержащих эти пары, извлекаются из сети. Мы расширяем существующий метод извлечения отношений, чтобы справиться с этой более слабой формой наблюдения, и представляем экспериментальные результаты, демонстрирующие, что наш подход может надежно извлекать отношения из веб-документов. Описана структура машинного обучения с минимальным учителем для извлечения отношений различной сложности. Извлечение отношений между сущностями является важной частью IE для произвольного текста. Предыдущие методы в основном основаны на статистической корреляции и отношениях зависимости между сущностями. В этой статье проблема пересматривается на многоуровневых слоях фраз, предложений и предложений с использованием отношений зависимости и дискурса. Наша структура с несколькими разрешениями использует клаузальные отношения двумя способами: 1) для фильтрации зашумленных путей зависимости; и 2) повысить надежность извлечения пути зависимости. Полученная система превосходит предыдущие подходы на 3%, 7%, 4% на доменах MUC4, MUC6 и ACE RDC соответственно. Многие ошибки, возникающие в системах неуправляемого и полууправляемого извлечения отношений (RE), происходят из-за неправильного распознавания участвующих сущностей в отношениях. Анализ зависимостей естественного языка приобрел важность в связи с его применимостью к задачам НЛП. Создание больших объемов аннотированных данных для обучения статистических анализаторов PCFG является дорогостоящим, и производительность таких анализаторов снижается при обучении и тестовые данные берутся из разных доменов. Мы представляем новую структуру, которая сочетает в себе сильные стороны поверхностного синтаксического анализа и глубокого синтаксического анализа для повышения точности глубокого анализа, в частности, за счет сочетания зависимостей и HPSG. Мы представляем структуру для синтаксического анализа со скрытыми переменными на основе динамических сигмовидных сетей доверия. Мы демонстрируем, что предыдущую модель синтаксического анализа нейронной сети с прямой связью можно рассматривать как грубое приближение к выводу с помощью этого класса графических моделей. Построив более точную, но все же податливую аппроксимацию, мы значительно повысили точность синтаксического анализа, предполагая, что SBN обеспечивают хорошую идеализацию для синтаксического анализа. Системы машинной транслитерации принимают исходное слово в качестве входных данных и производят целевое слово на другом языке, имеющем то же произношение, что и исходное . Большинство современных систем транслитерации используют корпус известных пар исходных и целевых слов для обучения своей системы и обычно оценивают свои системы на аналогичном корпусе. В этой статье мы исследуем производительность систем транслитерации на корпусах, которые варьируются контролируемым образом. В частности, мы контролируем количество и предшествующее знание языка транслитераторов-людей, используемых для построения корпусов, а также происхождение исходных слов, из которых состоят корпуса. для работы с неизвестными словами, включая машинный перевод, поиск информации на разных языках и ответы на вопросы на разных языках. В этой статье мы предлагаем новый алгоритм транслитерации с английского на персидский. Предыдущие методы, предложенные для этой языковой пары, применяют инструмент выравнивания слов для обучения. Измерение сходства на основе символов является важным компонентом многих систем обработки естественного языка, включая подходы к транслитерации, кореферентности, выравниванию слов, исправлению правописания и выявление однокоренных слов в родственных словарях. Мы предлагаем дискриминационную основу на основе выравнивания для сходства строк. Мы собираем признаки из пар подстрок, согласующихся с выравниванием двух строк по символам. Текущие исследования в области анализа текста отдают предпочтение количеству текстов, а не их качеству. Но для анализа двуязычной терминологии и для многих языковых пар большие сопоставимые корпуса недоступны. Что еще более важно, поскольку термины определяются по отношению к конкретной области с ограниченным регистром, ожидается, что качество, а не количество корпуса имеет большее значение при анализе терминологии. Адаптация языковой модели (LM) важна как для речи, так и для языковой обработки. Часто это достигается путем объединения общего LM с моделью для конкретной темы, которая более актуальна для целевого документа. В отличие от предыдущей работы по неконтролируемой адаптации LM, в этой статье исследуется, насколько эффективно использование информации об именованных объектах (NE) вместо рассмотрения всех слов помогает адаптации LM. В этой статье мы оцениваем два подхода к анализу скрытых тем, а именно кластеризацию и скрытое распределение Дирихле (LDA). Кроме того, предлагается новая динамически адаптируемая схема взвешивания для смешанных тематических моделей на основе тематического анализа LDA. В этой статье мы представляем методы улучшения устранения неоднозначности именной фразы (NP) в рамках модели генеративного синтаксического анализа на основе истории. Помимо уменьшения шума в данных, мы рассматриваем моделирование двух основных источников информации для устранения неоднозначности: симметрии в конъюнктивной структуре и зависимости между конъюнктивными лексическими заголовками. Мы также изменили правила нахождения заголовков для групп с основными существительными, чтобы лексическая единица, выбранная для заглавия всей фразы, больше напоминала лексическую единицу, выбранную для других типов координатных NP. В этом документе рассматривается проблема нормализации текста, важная, но часто упускаемая из виду проблема обработки естественного языка. Под нормализацией текста мы подразумеваем преобразование неформально введенного текста в каноническую форму путем устранения шумов в тексте и определения границ абзацев и предложений в тексте. Раньше вопросы нормализации текста часто решались от случая к случаю или изучались отдельно. В этой статье сначала дается формализация всей проблемы. Затем он предлагает унифицированный подход к тегированию для выполнения задачи с использованием условных случайных полей (CRF). В работе показано, что при введении небольшого набора тегов большинство задач по нормализации текста можно выполнить в рамках подхода. Закон Ципфа регулирует распределение извлечений. Таким образом, даже в таком массивном корпусе, как Интернет, значительная часть извлечений появляется нечасто. В этой статье показано, как оценить правильность таких разреженных извлечений с помощью неконтролируемых языковых моделей. Система REALM, которая сочетает в себе языковые модели на основе HMM и N-грамм, ранжирует извлечения-кандидаты по вероятности их правильности. Эксперименты над несколькими отношениями показывают, что REALM уменьшает ошибку извлечения на 39%, в среднем, по сравнению с предыдущей работой. В этой статье мы предлагаем правила преобразования леса в строку для повышения выразительности моделей преобразования дерева в строку. Правило преобразования леса в строку способно фиксировать несинтаксические пары фраз, описывая соответствие между несколькими деревьями синтаксического анализа и одной строкой. Чтобы интегрировать эти правила в модели преобразования дерева в строку, вводятся вспомогательные правила, обеспечивающие уровень обобщения. В этом документе представлено основанное на функциональном слове и основанное на синтаксисе (FWS) решение для упорядочивания фраз. Руководствуясь наблюдением, что служебные слова часто кодируют грамматические отношения между фразами в предложении, мы предлагаем вероятностную синхронную грамматику для моделирования порядка служебных слов и их левых и правых аргументов. Мы также расширяем стандартный ITG для размещения одиночных зазоров. Путем лексикализации результирующих правил ITG с одним пробелом в небольшом количестве случаев, соответствующих служебным словам, мы улучшаем эффективность упорядочения фраз. В этой статье, вдохновленной предыдущими подходами предварительной обработки к SMT, предлагается новый , вероятностный подход к переупорядочиванию, который сочетает в себе достоинства синтаксиса и SMT на основе фраз. Учитывая исходное предложение и его дерево синтаксического анализа, наш метод генерирует с помощью операций с деревом n-лучший список переупорядоченных входных данных, которые затем передаются стандартному декодеру на основе фраз для получения оптимального перевода. Эксперименты показывают, что для задачи NIST MT-05 по переводу с китайского на английский это предложение приводит к улучшению BLEU на 1,57%. Современные системы SMT на основе фраз плохо работают при использовании небольших обучающих наборов. Это является следствием ненадежных оценок перевода и плохого охвата исходных и целевых фраз. В данной статье представлен метод, облегчающий эту проблему за счет использования нескольких переводов одной и той же исходной фразы. Центральное место в нашем подходе занимает триангуляция, процесс перевода с исходного на целевой язык через промежуточный третий язык. Это позволяет использовать для обучения гораздо более широкий спектр параллельных корпусов и может комбинироваться со стандартной таблицей фраз с использованием обычных методов сглаживания. Экспериментальные результаты демонстрируют улучшения BLEU для триангулированных моделей по сравнению со стандартной системой на основе фраз. Задачи маркировки двоичных последовательностей часто возникают при обработке естественного языка. Изучение лингвистической структуры без учителя представляет собой сложную проблему. Общий подход состоит в том, чтобы определить генеративную модель и максимизировать вероятность скрытой структуры с учетом наблюдаемых данных. Как правило, это делается с использованием оценки максимального правдоподобия (MLE) параметров модели. логлинейные модели на произвольных функциях. Функцию потерь можно рассматривать как (генеративную) альтернативу оценке максимального правдоподобия с интересной теоретико-информационной интерпретацией, и она статистически непротиворечива. В этой статье мы предлагаем управляемое обучение, новую структуру обучения для двунаправленной классификации последовательностей. Задачи изучения порядка вывода и обучения локального классификатора динамически включаются в единый алгоритм обучения, подобный персептрону. Мы применяем этот новый алгоритм обучения к маркировке POS. Он получает коэффициент ошибок 2,67% на стандартном тестовом наборе PTB, что представляет собой снижение относительной ошибки на 3,3% по сравнению с предыдущим лучшим результатом с меньшим количеством функций в том же наборе данных. . .
. . Базовое слово щипля надеюсь, безопасно, мягко
Базовое слово щипля надеюсь, безопасно, мягко Правила правописания и 44 фонемы
Основная программа конференции – тезисы • ACL 2007, Прага
Руководящие статистические модели выравнивания слов на основе предварительных знаний
Юнган Дэн и Юцин Гао

Дискриминационная модель синтаксического порядка слов для машинного перевода
Пи-Чуан Чанг и Кристина Тутанова
Адаптация выравнивания слов к синтаксическому машинному переводу
Джон ДеНеро и Дэн Кляйн
 Мы предлагаем новую модель для неконтролируемого выравнивания слов, которая явно учитывает составную структуру целевого языка во время обучения, сохраняя при этом надежность и эффективность модели HMM. Прогнозы модели повышают производительность системы извлечения трансдукции дерева без ущерба для качества выравнивания.
Мы предлагаем новую модель для неконтролируемого выравнивания слов, которая явно учитывает составную структуру целевого языка во время обучения, сохраняя при этом надежность и эффективность модели HMM. Прогнозы модели повышают производительность системы извлечения трансдукции дерева без ущерба для качества выравнивания. Трансдуктивное обучение для статистического машинного перевода
Никола Уэффинг, Голамреза Хаффари и Ануп Саркар
 Мы показываем значительное улучшение качества перевода для обоих наборов данных.
Мы показываем значительное улучшение качества перевода для обоих наборов данных. Устранение неоднозначности смысла слов улучшает статистический машинный перевод
Йи Сенг Чан, Хви Тоу Нг и Дэвид Чианг
Изучение экспрессивных моделей для устранения неоднозначности смысла слова
Лючия Специа, Марк Стивенсон и Мария дас Граас Вольпе Нуньес
 Используя алгоритм индуктивного логического программирования, этот подход генерирует выразительные правила устранения неоднозначности, которые используют несколько источников знаний, а также могут моделировать отношения между ними. Подход оценивается в двух задачах: определение правильного перевода для набора глаголов с высокой степенью неоднозначности в англо-португальском переводе и устранение неоднозначности глаголов из задачи лексического образца Senseval-3. Средняя точность, полученная для многоязычной задачи, превосходит другие исследованные методы машинного обучения. В одноязычной задаче подход работает так же хорошо, как современная система, которая сообщает результаты для того же набора глаголов.
Используя алгоритм индуктивного логического программирования, этот подход генерирует выразительные правила устранения неоднозначности, которые используют несколько источников знаний, а также могут моделировать отношения между ними. Подход оценивается в двух задачах: определение правильного перевода для набора глаголов с высокой степенью неоднозначности в англо-португальском переводе и устранение неоднозначности глаголов из задачи лексического образца Senseval-3. Средняя точность, полученная для многоязычной задачи, превосходит другие исследованные методы машинного обучения. В одноязычной задаче подход работает так же хорошо, как современная система, которая сообщает результаты для того же набора глаголов. Адаптация домена с активным обучением для устранения неоднозначности смысла слов
Йи Сенг Чан и Хви Тоу Нг
 Это подчеркивает важность адаптации предметной области для устранения неоднозначности смысла слова. В этой статье мы впервые показываем, что подход активного обучения может быть успешно использован для адаптации систем WSD к предметной области. Затем, используя преобладающий смысл, предсказанный максимизацией ожидания (EM), и применяя технику слияния счетов, мы повышаем эффективность исходного процесса адаптации, достигнутого с помощью основного активного подхода к обучению.
Это подчеркивает важность адаптации предметной области для устранения неоднозначности смысла слова. В этой статье мы впервые показываем, что подход активного обучения может быть успешно использован для адаптации систем WSD к предметной области. Затем, используя преобладающий смысл, предсказанный максимизацией ожидания (EM), и применяя технику слияния счетов, мы повышаем эффективность исходного процесса адаптации, достигнутого с помощью основного активного подхода к обучению. Создание функциональных и контекстно-зависимых лексических онтологий
Тони Вил и Янфен Хао
 В этой статье мы описываем синтагматический, основанный на корпусе подход к переопределению категорий WordNet функциональным, градуируемым и контекстно-зависимым способом. Мы описываем, как диагностические свойства для этих определений автоматически приобретаются из Интернета, и как повышенная гибкость категоризации, возникающая в результате этих переопределений, предлагает надежное объяснение понимания метафор в форме теории включения категорий Глюксберга (2001). Кроме того, мы демонстрируем, как эта способность к образной категоризации может эффективно управляться автоматически сгенерированными онтологическими ограничениями, также полученными из Интернета.
В этой статье мы описываем синтагматический, основанный на корпусе подход к переопределению категорий WordNet функциональным, градуируемым и контекстно-зависимым способом. Мы описываем, как диагностические свойства для этих определений автоматически приобретаются из Интернета, и как повышенная гибкость категоризации, возникающая в результате этих переопределений, предлагает надежное объяснение понимания метафор в форме теории включения категорий Глюксберга (2001). Кроме того, мы демонстрируем, как эта способность к образной категоризации может эффективно управляться автоматически сгенерированными онтологическими ограничениями, также полученными из Интернета. Байесовская модель для обнаружения типологических следствий
Хэл Даум III и Лайл Кэмпбелл
 Такие последствия обычно обнаруживаются путем кропотливого ручного анализа небольшой выборки языков. Мы предлагаем вычислительную модель для помощи в этом процессе. Наша модель способна обнаружить как хорошо известные следствия, так и некоторые новые следствия, которые заслуживают дальнейшего изучения. Более того, благодаря тщательному применению иерархического анализа мы можем справиться с известной проблемой выборки: языки не являются независимыми.
Такие последствия обычно обнаруживаются путем кропотливого ручного анализа небольшой выборки языков. Мы предлагаем вычислительную модель для помощи в этом процессе. Наша модель способна обнаружить как хорошо известные следствия, так и некоторые новые следствия, которые заслуживают дальнейшего изучения. Более того, благодаря тщательному применению иерархического анализа мы можем справиться с известной проблемой выборки: языки не являются независимыми. Модель различительного языка с псевдоотрицательными образцами
Дайсуке Оканохара и Дзюнъити Цудзи
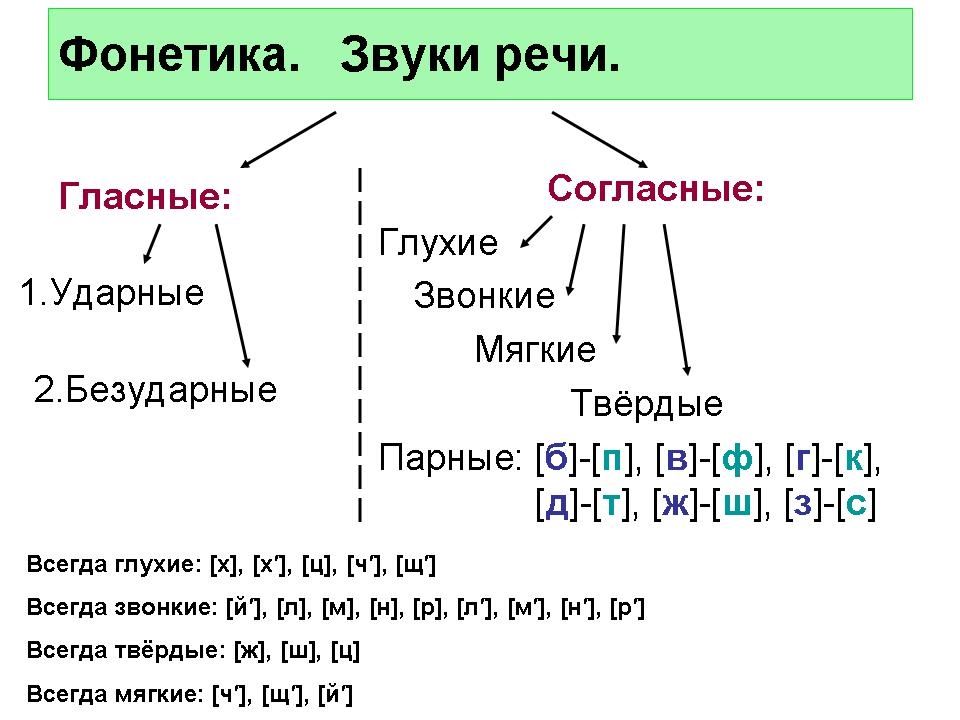 Мы предлагаем взять псевдоотрицательные примеры из языковых моделей с N-граммами. Эта формулировка, однако, требует непомерно больших вычислительных затрат для обработки довольно большого количества функций и обучающих выборок. Мы решаем проблему, оценивая скрытую информацию предложений, используя полумарковскую модель классов, а затем извлекаем из них признаки. Мы также используем онлайн-алгоритм максимальной маржи с эффективным вычислением ядра. Экспериментальные результаты показывают, что псевдоотрицательные примеры можно рассматривать как настоящие отрицательные примеры, и наша модель может правильно различать эти предложения.
Мы предлагаем взять псевдоотрицательные примеры из языковых моделей с N-граммами. Эта формулировка, однако, требует непомерно больших вычислительных затрат для обработки довольно большого количества функций и обучающих выборок. Мы решаем проблему, оценивая скрытую информацию предложений, используя полумарковскую модель классов, а затем извлекаем из них признаки. Мы также используем онлайн-алгоритм максимальной маржи с эффективным вычислением ядра. Экспериментальные результаты показывают, что псевдоотрицательные примеры можно рассматривать как настоящие отрицательные примеры, и наша модель может правильно различать эти предложения. Обнаружение ошибочных предложений с использованием автоматически найденных последовательных шаблонов
Гуйхуа Сун, Сяохуа Лю, Гао Цун, Мин Чжоу, Чжунъян Сюн, Джон Ли и Чин-Ю Лин
 В этой статье мы предлагаем новый подход к обнаружению ошибочных/ исправлять предложения, объединяя обнаружение паттернов с моделями обучения под наблюдением. Экспериментальные результаты показывают, что наши методы перспективны.
В этой статье мы предлагаем новый подход к обнаружению ошибочных/ исправлять предложения, объединяя обнаружение паттернов с моделями обучения под наблюдением. Экспериментальные результаты показывают, что наши методы перспективны. Декомпозиция словарного запаса для эстонского открытого словаря Распознавание речи
Антти Пуурула и Микко Куримо
 Показано, что только подход, основанный на Морфессоре, адекватно масштабируется для меньших размеров словарного запаса.
Показано, что только подход, основанный на Морфессоре, адекватно масштабируется для меньших размеров словарного запаса. Фонологические ограничения и морфологическая предварительная обработка для преобразования графемы в фонему
Вера Демберг, Гельмут Шмид и Грегор Млер

Коэффициент избыточности: неизменное свойство запасов согласных языков мира
Анимеш Мукерджи, Моноджит Чоудхури, Анупам Басу и Нилой Гангули
Многоязычная транслитерация с использованием фонетического метода на основе признаков
Su-Youn Yoon, Kyoung-Young Kim и Richard Sproat
 Линейный классификатор на основе фонетических признаков обучается с использованием алгоритма машинного обучения Winnow. Предлагаемый метод тестируется на четырех языках: арабском, китайском, хинди и корейском, а также на исходном английском языке с использованием сопоставимых корпусов. На хинди и арабском языке наблюдается заметное улучшение по сравнению с базовой системой, которая была создана вручную с использованием фонетических знаний, но без данных обучения. Предлагаемый метод может быть обучен с использованием небольшого количества данных и, таким образом, полезен в ситуациях, когда данные для обучения ограничены. Более того, для некоторых редко используемых языков практически невозможно собрать достаточно обучающих данных. Мы также демонстрируем, что метод эффективен при обучении на языковых парах, отличных от целевой языковой пары. Таким образом, метод может применяться как с минимальными данными, так и без данных о целевом языке, и может достигать сопоставимых результатов для разных языков.
Линейный классификатор на основе фонетических признаков обучается с использованием алгоритма машинного обучения Winnow. Предлагаемый метод тестируется на четырех языках: арабском, китайском, хинди и корейском, а также на исходном английском языке с использованием сопоставимых корпусов. На хинди и арабском языке наблюдается заметное улучшение по сравнению с базовой системой, которая была создана вручную с использованием фонетических знаний, но без данных обучения. Предлагаемый метод может быть обучен с использованием небольшого количества данных и, таким образом, полезен в ситуациях, когда данные для обучения ограничены. Более того, для некоторых редко используемых языков практически невозможно собрать достаточно обучающих данных. Мы также демонстрируем, что метод эффективен при обучении на языковых парах, отличных от целевой языковой пары. Таким образом, метод может применяться как с минимальными данными, так и без данных о целевом языке, и может достигать сопоставимых результатов для разных языков. Это возможно, потому что метод использует независимые от языка фонетические признаки, а также независимые от языковых пар признаки, которые моделируют распространенные ошибки межъязыковой замены.
Это возможно, потому что метод использует независимые от языка фонетические признаки, а также независимые от языковых пар признаки, которые моделируют распространенные ошибки межъязыковой замены. Семантическая транслитерация личных имен
Хайчжоу Ли, Кхе Чай Сим, Джин-Ши Куо и Минхуэй Донг
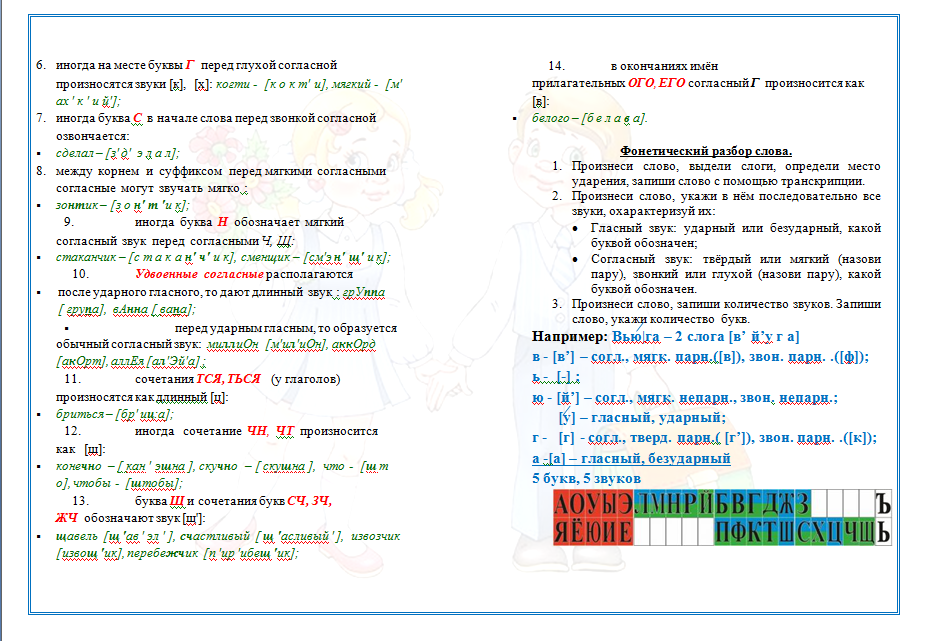 Результаты показывают, что семантическая транслитерация значительно и постоянно повышает точность по сравнению с фонетической транслитерацией во всех экспериментах.
Результаты показывают, что семантическая транслитерация значительно и постоянно повышает точность по сравнению с фонетической транслитерацией во всех экспериментах. Генерация сложной морфологии для машинного перевода
Эйнат Минков, Кристина Тутанова и Хисами Судзуки

Помощь переводчикам в непрямом лексическом переводе
Богдан Бабич, Энтони Хартли, Серж Шарофф и Ольга Мудрая
Восстановление леса: более быстрое декодирование с помощью интегрированных языковых моделей
Лян Хуанг и Дэвид Чианг
 В обоих случаях наши методы обеспечивают ускорение на порядок по сравнению с обычным методом поиска луча при тех же уровнях ошибки поиска и точности перевода, что и измеренные BLEU.
В обоих случаях наши методы обеспечивают ускорение на порядок по сравнению с обычным методом поиска луча при тех же уровнях ошибки поиска и точности перевода, что и измеренные BLEU. Статистический машинный перевод с помощью глобального лексического отбора и реконструкции предложений
Сринивас Бангалор, Патрик Хаффнер и Стефан Кантак
 Мы сравниваем результаты этого подхода с результатами, полученными из системы статистического машинного перевода с конечным числом состояний, которая опирается на локальные лексические ассоциации.
Мы сравниваем результаты этого подхода с результатами, полученными из системы статистического машинного перевода с конечным числом состояний, которая опирается на локальные лексические ассоциации. Контекстно-зависимые языки с умеренной зависимостью
Марко Кульманн и Матиас Мхл
 Наши результаты обеспечивают фундаментальное понимание связи между структурными свойствами представлений зависимостей и понятиями формальной власти.
Наши результаты обеспечивают фундаментальное понимание связи между структурными свойствами представлений зависимостей и понятиями формальной власти. Преобразование проективных билексических грамматик зависимостей в эффективно анализируемые CFG с помощью Unfold-Fold
Марк Джонсон
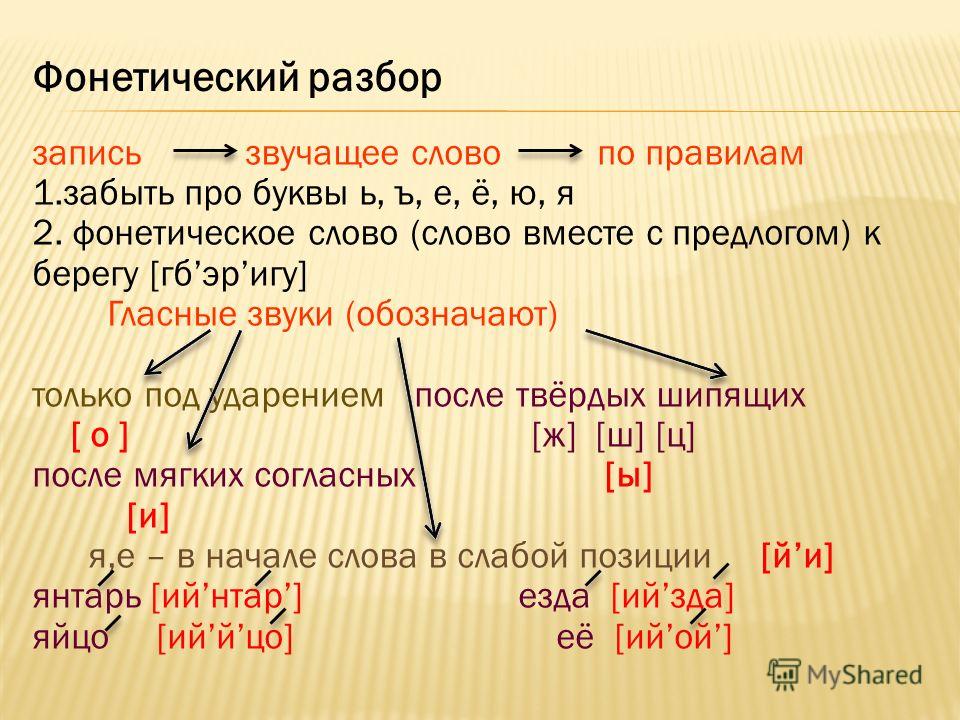
Синтаксический анализ и генерация как запросы к журналу данных
Макото Канадзава

Оптимизация грамматик для минимальной длины зависимостей
Дэниел Гилдеа и Дэвид Темперли
Обобщение аннотаций семантических ролей для синтаксически сходных глаголов
Эндрю Гордон и Рейд Суонсон
 Несмотря на размер этих корпусов, отдельные глаголы (или наборы ролей) часто имеют лишь несколько экземпляров в этих корпусах, и только часть английских глаголов имеет хотя бы одну аннотацию. В этой статье мы описываем подход к решению этой проблемы разреженных данных, позволяющий точно маркировать семантические роли для глаголов (наборов ролей) только с одним обучающим примером. Наш подход включает идентификацию синтаксически похожих глаголов, найденных в PropBank, выравнивание аргументов в их соответствующих наборах ролей и использование соответствующих им аннотаций в PropBank в качестве суррогатных обучающих данных.
Несмотря на размер этих корпусов, отдельные глаголы (или наборы ролей) часто имеют лишь несколько экземпляров в этих корпусах, и только часть английских глаголов имеет хотя бы одну аннотацию. В этой статье мы описываем подход к решению этой проблемы разреженных данных, позволяющий точно маркировать семантические роли для глаголов (наборов ролей) только с одним обучающим примером. Наш подход включает идентификацию синтаксически похожих глаголов, найденных в PropBank, выравнивание аргументов в их соответствующих наборах ролей и использование соответствующих им аннотаций в PropBank в качестве суррогатных обучающих данных. Ядро дерева свертки на основе грамматики для классификации семантических ролей
Мин Чжан, Ваньсян Че, Аити Ау, Чу Лим Тан, Годонг Чжоу, Тинг Лю и Шэн Ли
 Чтобы снять ограничения, в этой статье предлагается управляемое грамматикой ядро дерева свертки для классификации семантических ролей путем введения в ядро дерева свертки дополнительных лингвистических знаний. Предложенная управляемая грамматикой свертка демонстрирует два преимущества по сравнению с предыдущей: 1) приближенное сопоставление подструктур, управляемое грамматикой, и 2) приближенное сопоставление узлов дерева, управляемое грамматикой. Два улучшения позволяют предложенному ядру исследовать больше лингвистически мотивированных функций подструктуры, чем предыдущее. Эксперименты над общей задачей CoNLL-2005 SRL показывают, что предложенное ядро дерева, управляемое грамматикой, значительно превосходит предыдущее ядро, не основанное на грамматике, в классификации семантических ролей. Кроме того, мы представляем составное ядро для интеграции методов, основанных на функциях и древовидных ядрах. Экспериментальные результаты показывают, что составное ядро превосходит ранее известные методы.
Чтобы снять ограничения, в этой статье предлагается управляемое грамматикой ядро дерева свертки для классификации семантических ролей путем введения в ядро дерева свертки дополнительных лингвистических знаний. Предложенная управляемая грамматикой свертка демонстрирует два преимущества по сравнению с предыдущей: 1) приближенное сопоставление подструктур, управляемое грамматикой, и 2) приближенное сопоставление узлов дерева, управляемое грамматикой. Два улучшения позволяют предложенному ядру исследовать больше лингвистически мотивированных функций подструктуры, чем предыдущее. Эксперименты над общей задачей CoNLL-2005 SRL показывают, что предложенное ядро дерева, управляемое грамматикой, значительно превосходит предыдущее ядро, не основанное на грамматике, в классификации семантических ролей. Кроме того, мы представляем составное ядро для интеграции методов, основанных на функциях и древовидных ядрах. Экспериментальные результаты показывают, что составное ядро превосходит ранее известные методы.
Изучение предиктивных структур для маркировки семантических ролей в NomBank
Чанг Лю и Хви Тоу Нг
Простая модель выбора предпочтений на основе подобия
Катрин Эрк
 Сосредоточившись на задаче маркировки семантических ролей, мы вычисляем селективные предпочтения для семантических ролей. Новая модель тщательно оценивается и сравнивается как с моделями WordNet, так и с моделями кластеризации выборочных предпочтений на основе EM.
Сосредоточившись на задаче маркировки семантических ролей, мы вычисляем селективные предпочтения для семантических ролей. Новая модель тщательно оценивается и сравнивается как с моделями WordNet, так и с моделями кластеризации выборочных предпочтений на основе EM. Фальсификация модели SVM и привязанное обучение: пример на иврите NP Chunking
Йоав Голдберг и Майкл Эльхадад
 2.2 в тексте с автоматической маркировкой PoS. Методы анализа SVM также дают общее представление о фрагментации на основе SVM.
2.2 в тексте с автоматической маркировкой PoS. Методы анализа SVM также дают общее представление о фрагментации на основе SVM. Полностью неконтролируемое обнаружение взаимосвязей концепций с помощью веб-анализа
Дмитрий Давыдов, Ари Раппопорт и Моше Коппел
Добавление структуры словосочетаний существительных в Penn Treebank
Дэвид Вадас и Джеймс Карран
 Это означает, что инструменты, обученные на данных Treebank, не могут изучить правильную внутреннюю структуру NP. В этой статье подробно описывается процесс добавления брекетинга золотого стандарта в каждое именное словосочетание в Penn Treebank. Затем мы проверяем согласованность и надежность наших аннотаций. Наконец, мы используем этот ресурс для определения структуры NP с использованием нескольких статистических подходов, тем самым демонстрируя полезность корпуса. Это добавляет подробности в Penn Treebank, которые необходимы для многих приложений НЛП.
Это означает, что инструменты, обученные на данных Treebank, не могут изучить правильную внутреннюю структуру NP. В этой статье подробно описывается процесс добавления брекетинга золотого стандарта в каждое именное словосочетание в Penn Treebank. Затем мы проверяем согласованность и надежность наших аннотаций. Наконец, мы используем этот ресурс для определения структуры NP с использованием нескольких статистических подходов, тем самым демонстрируя полезность корпуса. Это добавляет подробности в Penn Treebank, которые необходимы для многих приложений НЛП. Независимая от формализма оценка синтаксического анализатора с помощью CCG и DepBank
Стивен Кларк и Джеймс Р. Карран
 В этой статье мы оцениваем синтаксический анализатор CCG в DepBank и демонстрируем трудности преобразования выходных данных синтаксического анализатора в грамматические отношения DepBank. Кроме того, мы представляем метод измерения эффективности преобразования, который обеспечивает верхнюю границу точности синтаксического анализа. Синтаксический анализатор CCG получает F-оценку более 81 % для помеченных зависимостей по сравнению с верхней границей 84,8 %. Мы сравниваем парсер CCG с парсером RASP, превосходя RASP более чем на 5% в целом и по большинству типов зависимостей.
В этой статье мы оцениваем синтаксический анализатор CCG в DepBank и демонстрируем трудности преобразования выходных данных синтаксического анализатора в грамматические отношения DepBank. Кроме того, мы представляем метод измерения эффективности преобразования, который обеспечивает верхнюю границу точности синтаксического анализа. Синтаксический анализатор CCG получает F-оценку более 81 % для помеченных зависимостей по сравнению с верхней границей 84,8 %. Мы сравниваем парсер CCG с парсером RASP, превосходя RASP более чем на 5% в целом и по большинству типов зависимостей. Разочаровывающе простая адаптация предметной области
Hal Daume III
 Техника поставляется с несколькими простыми теоретическими гарантиями. Более того, это тривиально распространяется на проблему многодоменной адаптации, где есть данные из множества разных доменов.
Техника поставляется с несколькими простыми теоретическими гарантиями. Более того, это тривиально распространяется на проблему многодоменной адаптации, где есть данные из множества разных доменов. Взвешивание экземпляров для адаптации предметной области в НЛП
Цзин Цзян и ЧенгСян Чжай

Бесконечное дерево
Дженни Роуз Финкель, Тронд Гренагер и Кристофер Д. Мэннинг

Направляющая полусупервизия с обучением, управляемым ограничениями
Минг-Вей Чанг, Лев Ратинов и Дэн Рот

Статистический машинный перевод на основе фраз с супертегами
Хани Хассан, Халил Симаан и Энди Уэй
 %Используя учебные материалы разного размера, мы показываем, что наш подход не страдает особыми проблемами %разреженности или масштабируемости. Наш лучший результат (0,4688 BLEU) улучшается на 6,1% по сравнению с современной системой PBSMT и выгодно отличается от лучших систем в задаче NIST 2005.
%Используя учебные материалы разного размера, мы показываем, что наш подход не страдает особыми проблемами %разреженности или масштабируемости. Наш лучший результат (0,4688 BLEU) улучшается на 6,1% по сравнению с современной системой PBSMT и выгодно отличается от лучших систем в задаче NIST 2005. Регрессия для оценки машинного перевода на уровне предложений с псевдоссылками
Джошуа С. Альбрехт и Ребекка Хва
 Наши экспериментальные результаты показывают, что предлагаемая структура создает метрики, которые конкурируют со стандартными эталонными метриками с точки зрения корреляции с человеческими суждениями о новых экземплярах тестов.
Наши экспериментальные результаты показывают, что предлагаемая структура создает метрики, которые конкурируют со стандартными эталонными метриками с точки зрения корреляции с человеческими суждениями о новых экземплярах тестов. Начальное выравнивание слов с помощью упаковки слов
Янджун Ма, Николас Строппа и Энди Уэй
Улучшенная комбинация систем на уровне слов для машинного перевода
Антти-Вейкко Рости, Спирос Мацукас и Ричард Шварц
 Из-за ошибок в выравнивании гипотез декодирование может привести к получению неграмматических комбинаций. В этом документе описывается усовершенствованный метод на основе сети путаницы для объединения выходных данных из нескольких систем машинного перевода. В этом подходе произвольные функции уровня предложения могут быть добавлены логарифмически линейно в целевую функцию, что позволяет повторно оценивать языковую модель. Кроме того, предлагается новый метод автоматического выбора гипотезы, против которой согласуются другие гипотезы. Общий алгоритм настройки веса может использоваться для оптимизации различных показателей автоматической оценки, включая TER, BLEU и METEOR. Эксперименты с использованием задач NIST MT05 с переводом с арабского на английский и с китайского на английский показывают значительные улучшения в оценках BLEU по сравнению с более ранними методами декодирования на основе сети путаницы.
Из-за ошибок в выравнивании гипотез декодирование может привести к получению неграмматических комбинаций. В этом документе описывается усовершенствованный метод на основе сети путаницы для объединения выходных данных из нескольких систем машинного перевода. В этом подходе произвольные функции уровня предложения могут быть добавлены логарифмически линейно в целевую функцию, что позволяет повторно оценивать языковую модель. Кроме того, предлагается новый метод автоматического выбора гипотезы, против которой согласуются другие гипотезы. Общий алгоритм настройки веса может использоваться для оптимизации различных показателей автоматической оценки, включая TER, BLEU и METEOR. Эксперименты с использованием задач NIST MT05 с переводом с арабского на английский и с китайского на английский показывают значительные улучшения в оценках BLEU по сравнению с более ранними методами декодирования на основе сети путаницы. Создание порядка составляющих в немецких предложениях
Катя Филиппова и Михаэль Штрубе
 Затем определяется порядок остальных составляющих. Первое задание сложнее второго из-за свойств немецкого предложения в начале предложения. Эксперименты показывают значительное улучшение по сравнению с несколькими базовыми и конкурирующими подходами. Кроме того, наш алгоритм значительно эффективнее этих.
Затем определяется порядок остальных составляющих. Первое задание сложнее второго из-за свойств немецкого предложения в начале предложения. Эксперименты показывают значительное улучшение по сравнению с несколькими базовыми и конкурирующими подходами. Кроме того, наш алгоритм значительно эффективнее этих. Символический подход к почти детерминированной реализации поверхности с использованием грамматики примыкания к дереву
Клэр Гарден и Эрик Коу

Генерация предложений как проблема планирования
Александр Коллер и Мэтью Стоун
GLEU: автоматическая оценка беглости на уровне предложений
Эндрю Маттон, Марк Драс, Стивен Ван и Роберт Дейл
 Наконец, мы рассмотрим различные языковые модели для генерации предложений и покажем, что, хотя отдельные метрики синтаксического анализатора можно «обмануть» в зависимости от метода генерации, машинное обучение обеспечивает последовательную оценку беглости.
Наконец, мы рассмотрим различные языковые модели для генерации предложений и покажем, что, хотя отдельные метрики синтаксического анализатора можно «обмануть» в зависимости от метода генерации, машинное обучение обеспечивает последовательную оценку беглости. Слияние условной модальности для разрешения кореференции
Джейкоб Эйзенштейн и Рэндалл Дэвис
 Применительно к разрешению кореферентности условное слияние модальностей значительно превосходит как раннее, так и позднее слияние модальностей, которые в настоящее время являются современными методами комбинирования модальностей.
Применительно к разрешению кореферентности условное слияние модальностей значительно превосходит как раннее, так и позднее слияние модальностей, которые в настоящее время являются современными методами комбинирования модальностей. Полезность графического представления структуры дискурса в системах разговорного диалога
Михай Ротару и Диана Дж. Литман
Автоматизированный набор словарного запаса и его интерпретация в мультимодальных разговорных системах
Йи Лю, Джойс Й.
 Чай и Ронг Джин
Чай и Ронг Джин Мультимодальный интерфейс для доступа к домашнему контенту
Майкл Джонстон, Луис Фернандо Д’Аро, Мишель Левин и Бернар Ренгер
 В этой статье мы исследуем применение технологий мультимодального интерфейса для поиска и просмотра базы данных фильмов. В результате система позволяет пользователям получать доступ к фильмам с помощью речи, пера, дистанционного управления и динамических комбинаций этих способов. Представлена экспериментальная оценка с более чем 40 пользователями, в которой сравниваются два варианта системы: один, сочетающий речь с традиционным вводом данных с пульта дистанционного управления, и второй, где у пользователя есть дисплей планшета, поддерживающий голосовой ввод и ввод с помощью пера.
В этой статье мы исследуем применение технологий мультимодального интерфейса для поиска и просмотра базы данных фильмов. В результате система позволяет пользователям получать доступ к фильмам с помощью речи, пера, дистанционного управления и динамических комбинаций этих способов. Представлена экспериментальная оценка с более чем 40 пользователями, в которой сравниваются два варианта системы: один, сочетающий речь с традиционным вводом данных с пульта дистанционного управления, и второй, где у пользователя есть дисплей планшета, поддерживающий голосовой ввод и ввод с помощью пера. Быстрый добавочный синтаксический анализ без учителя
Йоав Сегинер
 В отличие от предыдущих неконтролируемых синтаксических анализаторов, синтаксический анализатор не использует теги частей речи, а обучение и синтаксический анализ являются локальными и быстрыми, не требующими явной кластеризации или глобальной оптимизации. Синтаксический анализатор оценивается путем преобразования его вывода в эквивалентные скобки и улучшает ранее опубликованные результаты для неконтролируемого синтаксического анализа простого текста.
В отличие от предыдущих неконтролируемых синтаксических анализаторов, синтаксический анализатор не использует теги частей речи, а обучение и синтаксический анализ являются локальными и быстрыми, не требующими явной кластеризации или глобальной оптимизации. Синтаксический анализатор оценивается путем преобразования его вывода в эквивалентные скобки и улучшает ранее опубликованные результаты для неконтролируемого синтаксического анализа простого текста. K-лучший анализ связующего дерева
Кит Холл
 парсеры. Это мотивирует наш подход к синтаксическому анализу, который основан на переранжировании k-лучших синтаксических анализов, сгенерированных моделью с краевыми факторами. Мы представляем описание алгоритма k-best MST вместе с эмпирическими результатами для реранжера, основанного на признаках дерева. Мы представляем результаты точности синтаксического анализа оракула для модели с краевыми факторами и 1-лучшие результаты для реранжера на восьми языках (семь из CoNLL-X и английский).
парсеры. Это мотивирует наш подход к синтаксическому анализу, который основан на переранжировании k-лучших синтаксических анализов, сгенерированных моделью с краевыми факторами. Мы представляем описание алгоритма k-best MST вместе с эмпирическими результатами для реранжера, основанного на признаках дерева. Мы представляем результаты точности синтаксического анализа оракула для модели с краевыми факторами и 1-лучшие результаты для реранжера на восьми языках (семь из CoNLL-X и английский). Не за горами ли конец контролируемого синтаксического анализа?
Ренс Бод
 Мы тестируем две модели: оценщик U-DOP*, который извлекает поддеревья из деревьев, сгенерированных кратчайшими производными, и UML-DOP, который обучает полной редукции PCFG на задержанном корпусе. Известно, что обе оценки статистически непротиворечивы. Хотя UML-DOP немного превосходит U-DOP*, только последний можно протестировать на данных NANC WSJ и LA Times (которые на два порядка больше, чем у Penns WSJ), показывая, что возможно значительное улучшение неконтролируемого синтаксического анализа. В этой статье представлены первые эксперименты с неконтролируемой моделью всех поддеревьев без какой-либо априорной выборки. В этом документе также сообщается о первых неконтролируемых результатах стандартного набора тестов WSJ (раздел 23), достигающих 70,7% немаркированного f-показателя.
Мы тестируем две модели: оценщик U-DOP*, который извлекает поддеревья из деревьев, сгенерированных кратчайшими производными, и UML-DOP, который обучает полной редукции PCFG на задержанном корпусе. Известно, что обе оценки статистически непротиворечивы. Хотя UML-DOP немного превосходит U-DOP*, только последний можно протестировать на данных NANC WSJ и LA Times (которые на два порядка больше, чем у Penns WSJ), показывая, что возможно значительное улучшение неконтролируемого синтаксического анализа. В этой статье представлены первые эксперименты с неконтролируемой моделью всех поддеревьев без какой-либо априорной выборки. В этом документе также сообщается о первых неконтролируемых результатах стандартного набора тестов WSJ (раздел 23), достигающих 70,7% немаркированного f-показателя. Ансамбльный метод отбора высококачественных синтаксических анализаторов
Рой Райхарт и Ари Раппопорт
 Количество таких предложений растет, когда обучающие и тестовые данные берутся из разных доменов, что характерно для основных веб-приложений, таких как поиск информации и ответы на вопросы. В этой статье мы представляем алгоритм Sample Ensemble Parse Assessment (SEPA) для определения качества синтаксического анализа. Мы используем функцию согласования между несколькими копиями парсера, каждая из которых обучена на разных выборках из обучающих данных, для оценки качества синтаксического анализа. Мы экспериментировали как с генеративными, так и с реранжирующими парсерами (Collins, Charniak и Johnson соответственно). Мы показываем превосходные результаты по сравнению с несколькими базовыми уровнями как в том случае, когда обучающие и тестовые данные относятся к одному и тому же домену, так и когда они относятся к разным доменам. Для тестовой настройки, использованной в предыдущей работе, мы показываем снижение ошибки на 31% по сравнению с их 20%.
Количество таких предложений растет, когда обучающие и тестовые данные берутся из разных доменов, что характерно для основных веб-приложений, таких как поиск информации и ответы на вопросы. В этой статье мы представляем алгоритм Sample Ensemble Parse Assessment (SEPA) для определения качества синтаксического анализа. Мы используем функцию согласования между несколькими копиями парсера, каждая из которых обучена на разных выборках из обучающих данных, для оценки качества синтаксического анализа. Мы экспериментировали как с генеративными, так и с реранжирующими парсерами (Collins, Charniak и Johnson соответственно). Мы показываем превосходные результаты по сравнению с несколькими базовыми уровнями как в том случае, когда обучающие и тестовые данные относятся к одному и тому же домену, так и когда они относятся к разным доменам. Для тестовой настройки, использованной в предыдущей работе, мы показываем снижение ошибки на 31% по сравнению с их 20%. Анализ мнений с использованием эконометрики: пример систем репутации
Аниндья Гхош, Панайотис Г.
Ипейротис и Арун Сундарараджан Мы утверждаем, что, интерпретируя мнения в эконометрических рамках, мы получаем первую объективную, измеримую и контекстно-зависимую оценку мнений. Мы делаем обсуждение более конкретным, представляя результаты по системе репутации торговой площадки Amazon.com. Мы показываем, что отзывы пользователей влияют на ценообразование продавцов, и, измеряя их ценообразование, мы можем сделать вывод о полярности и силе основных текстовых оценок, публикуемых покупателями. PageRanking WordNet Synsets: приложение для сбора мнений
Андреа Эсули и Фабрицио Себастьяни
Обоснование применения PageRank для определения семантических свойств синсетов заключается в том, что пространство синсетов WordNet можно рассматривать как граф, в котором синсеты связаны бинарным отношением «терм, принадлежащий синсетам s 9».3499 k встречается в толковании synset s i «. Данные для этого отношения могут быть получены из Extended WordNet, общедоступной смысловой версии WordNet. Мы утверждаем, что это отношение структурно родственно отношению между гиперссылками. Веб-страницы и, таким образом, поддаются анализу PageRank. Мы сообщаем об экспериментальных результатах, подтверждающих нашу интуицию.3173 Эксперименты показывают, что этот метод может значительно уменьшить ошибку классификации по сравнению с моделями, обученными изолированно. Биографии, Болливуд, бумбоксы и блендеры: адаптация предметной области для классификации настроений
Джон Блитцер, Марк Дредзе и Фернандо Перейра
Эту меру можно использовать, например, для выбора небольшого набора доменов для аннотирования, чьи обученные классификаторы будут хорошо переноситься во многие другие домены. Кластеризация предложений для обнаружения высокоуровневых отношений: теоретико-информационный подход
Сэмюэл Броуди
Экземплярная оценка извлечения правила следствия
Идан Шпектор, Эял Шнарч и Идо Даган
Статистический машинный перевод для расширения запроса при поиске ответов
Стефан Ризлер, Александр Вассерман, Иоаннис Цочантаридис, Вибху Миттал и Йи Лю
устранить лексический разрыв между вопросами и ответами. Расширение запроса на основе SMT выполняется путем i) применения перефразирования полного предложения к запросу для введения синонимов в глобальный контекст запроса и ii) путем перевода условий запроса в условия ответа с использованием модели SMT полного предложения, обученной на парах вопрос-ответ. . Мы сравниваем эти глобальные, контекстно-зависимые методы расширения запроса с моделью tfidf и локальным расширением запроса в базе данных из 10 миллионов пар вопросов и ответов, извлеченных из страниц часто задаваемых вопросов. Экспериментальные результаты показывают значительное улучшение расширения запросов на основе SMT по сравнению с обоими базовыми показателями. Вычислительная модель повторного использования текста в древних литературных текстах
Джон Ли
Модель учитывает шаблоны чередования источников, чтобы иметь возможность выравнивать даже предложения с низким поверхностным сходством. Мы демонстрируем его способность характеризовать повторное использование текста в Новом Завете на греческом языке. Поиск тем документа для улучшения сегментации тем
Olivier Ferret
Полезность функций, полученных на основе синтаксического анализа, для автоматической сегментации дискурса
Сигер Фишер и Брайан Роарк
Мы добились наилучшей производительности в этой задаче и демонстрируем, что наши контекстно-свободные функции, вдохновленные SPADE, имеют решающее значение для достижения такого уровня точности. Это противоречит недавним результатам, предполагающим, что чисто подходы с конечным числом состояний могут работать конкурентоспособно. PERSONAGE: Генерация личности для диалога
Франсуа Мересс и Мэрилин Уокер
Мы представляем PERSONAGE (PERSONAlity GENerator), языковой генератор с 29Ранее было показано, что параметры коррелируют с экстраверсией, важным аспектом личности. Мы исследуем два метода создания языка, богатого личностью: (1) прямое создание с определенными настройками параметров, предложенными в литературе по психологии; и (2) сверхгенерация и отбор с использованием статистических моделей, обученных на основе рейтингов судей. Оценка показывает, что оба метода надежно генерируют высказывания, которые варьируются по измерению экстраверсии, по мнению людей. Осмысление звука: неконтролируемая сегментация темы по акустическому входу
Игорь Малютов, Алекс Парк, Регина Барзилай и Джеймс Гласс
Алгоритм надежно обрабатывает шум, присущий сопоставлению на основе акустического сходства, путем интеллектуального агрегирования информации о сходстве распределения из нескольких локальных сравнений. Наши эксперименты показывают, что сегментация на основе звука выгодно отличается от сегментации на основе транскриптов, вычисляемой по зашумленным транскриптам. Эти результаты демонстрируют полезность нашего метода для приложений, где распознаватель речи недоступен или его выходные данные имеют высокий уровень ошибок в словах. Рандомизированное языковое моделирование для статистического машинного перевода
Дэвид Талбот и Майлз Осборн
Мы исследуем, как BF, содержащий n-граммы, извлеченные из большого корпуса, может дополнить стандартную n-грамму LM в системе SMT, и рассмотрим (i) как эффективно включить приблизительную информацию о частоте и (ii) как уменьшить эффективную частоту ошибок за счет первая проверка подпоследовательностей более низкого порядка в n-граммах-кандидатах. Наши решения в обоих случаях сохраняют односторонние гарантии ошибок стандартного BF, используя при этом особые характеристики статистики естественного языка для уменьшения требований к пространству. Адаптация LM на основе двуязычного LSA для перевода разговорной речи
Yik-Cheung Tam, Ian Lane и Tanja Schultz
Предлагаемая структура также обеспечивает быструю загрузку моделей LSA для новых языков на основе исходной модели LSA из другого языка. При переводе речи и текста с китайского на английский предложенная структура bLSA успешно уменьшила путаницу слов в английском LM более чем на 27% для unigram LM и до 13,6% для 4-граммового LM. Кроме того, предложенный подход постоянно улучшал качество машинного перевода. Разрешение кореференции с использованием информации о семантической связанности из автоматически обнаруженных шаблонов
Сяофэн Ян и Цзянь Су
Мы изучаем, как автоматически обнаруживать и оценивать шаблоны, а также как использовать шаблоны для получения информации о семантической связности. Оценка набора данных ACE показывает, что семантическая информация, основанная на шаблонах, полезна для разрешения кореферентности. Индукция семантического класса и разрешение кореферентности
Винсент Нг
Создание оглавления
С. Р. К. Бранаван, Паван Дешпанде и Регина Барзилай
На пути к итеративному подходу к одновременному обобщению документов и извлечению ключевых слов
Сяоцзюнь Ван, Цзяньву Ян и Цзяньгуо Сяо
В этой статье предлагается новый подход с итеративным подкреплением для одновременного извлечения резюме и ключевых слов из одного документа при условии, что резюме и ключевые слова документа могут быть взаимно усилены. Подход, естественно, может в полной мере использовать подкрепление между предложениями и ключевыми словами, объединяя однородные отношения между предложениями, однородные отношения между словами и разнородные отношения между предложениями. Экспериментальные результаты показывают значительное улучшение по сравнению с несколькими базовыми уровнями для обеих задач. Подход, основанный на корпусе, проверен, чтобы работать почти так же хорошо, как подход, основанный на знаниях, для вычисления семантики слов. Быстрое семантическое извлечение с использованием новой архитектуры нейронной сети
Ронан Коллоберт и Джейсон Уэстон
Вместо этого наш метод изучает прямое сопоставление исходного предложения с семантическими тегами для данного предиката без помощи синтаксического анализатора. Наша результирующая система обеспечивает точность, сравнимую с современным уровнем развития техники, за долю вычислительных затрат. Улучшение интерпретации словосочетаний с использованием межъязыковой информации
Роксана Гирью
Результаты сравнивались с двумя современными моделями, описанными в литературе: контролируемой моделью и веб-моделью без учителя. Обучение извлечению связей из Интернета с использованием минимального контроля
Разван Бунеску и Рэймонд Муни
Управляемая начальными числами платформа машинного обучения «снизу вверх» для извлечения отношений различной сложности
Фейю Сюй, Ханс Ушкорейт и Хун Ли
Начальная загрузка начинается с небольшого набора n-мерных экземпляров отношения в качестве начальных значений, чтобы автоматически изучать правила шаблона из проанализированных данных, которые затем могут извлекать новые экземпляры отношения и его проекции. Мы предлагаем новую модель представления правил, которая позволяет комбинировать n-мерные правила отношений поверх правил проекций отношения. Композиционный подход к построению правил поддерживается методом извлечения шаблонов снизу вверх. Поскольку мы рассматриваем только лингвистические структуры, которые содержат аргументы в начальных отношениях, извлечение шаблона не страдает от вычислительных проблем модели поддерева (Sudo et al., 2003). По сравнению с другими автоматическими подходами наши правила не только локализуют аргументы отношения, но и назначают их точные целевые роли аргументов. Метод оценивается по двум задачам: получение Нобелевских премий и управление событиями преемственности. Выполнение новой задачи Нобелевской премии является сильным. Для задачи преемственности управления результаты выгодно отличаются от результатов существующих подходов к приобретению шаблонов. Платформа с несколькими разрешениями для извлечения информации из произвольного текста
Мстислав Масленников и Тат-Сенг Чуа
Использование корпусной статистики по сущностям для улучшения полууправляемого извлечения отношений из Интернета
Бенджамин Розенфельд и Ронен Фельдман
Это особенно верно для систем, которые не используют отдельные компоненты распознавания именованных объектов, а вместо этого полагаются на неглубокий синтаксический анализ общего назначения. Такие системы имеют большую применимость, поскольку способны извлекать отношения, содержащие атрибуты неизвестного типа. Однако за эту общность приходится платить точностью. В этой статье мы покажем, как использовать статистику корпуса для проверки и исправления аргументов извлеченных экземпляров отношения, улучшая общую производительность RE. Мы тестируем методы на SRES, самоконтролируемой системе извлечения веб-отношений. Мы также сравниваем производительность методов на основе корпуса с эффективностью методов проверки и исправления, основанных на контролируемых компонентах NER. За пределами проективности: многоязычная оценка ограничений и мер для непроективных структур
Джи Хавелка
Непроективные структуры распространены в анализе зависимостей, поэтому нам нужны детализированные средства их описания, особенно для целей подходов, ориентированных на машинное обучение, таких как синтаксический анализ. Мы представляем оценку двенадцати языков, в которой исследуются некоторые ограничения и меры непроективных структур. Мы придерживаемся подхода, основанного на ребрах, концентрируясь на свойствах отдельных ребер, а не на свойствах целых деревьев. В нашу оценку мы включили ранее не зарегистрированные меры, учитывающие уровни узлов в деревьях зависимостей. Наши эмпирические результаты подтверждают теоретические результаты и показывают, что подход на основе ребер с использованием уровней узлов обеспечивает точные и в то же время выразительные средства для захвата непроективных структур в естественном языке. Самообучение для усовершенствования и адаптации статистических анализаторов, обученных на небольших наборах данных
Рой Рейхарт и Ари Раппопорт
В этой статье мы используем самообучение, чтобы улучшить качество синтаксического анализатора и адаптировать его к другой области, используя лишь небольшое количество начальных данных, аннотированных вручную. Мы сообщаем о значительном улучшении как тогда, когда исходные и тестовые данные находятся в одном домене, так и в сценарии адаптации вне домена. В частности, мы добились снижения стоимости аннотации на 50 % для случая внутри предметной области, что дало улучшение на 66 % по сравнению с предыдущей работой и снижение на 20–33 % для случая адаптации предметной области. Самообучение с небольшими размеченными наборами данных впервые успешно применяется к этим задачам. Мы также смогли дать характеристику того, когда самообучение является ценным. Синтаксический анализ HPSG с поверхностными ограничениями зависимостей
Кендзи Сагае, Юсуке Мияо и Дзюнъити Цудзии
разбор. Мы показываем, что, используя поверхностные зависимости для ограничения применения правил HPSG с широким охватом, мы можем извлечь выгоду из ряда методов синтаксического анализа, разработанных для высокоточного анализа зависимостей, при этом фактически выполняя глубокий синтаксический анализ. Наша структура обеспечивает абсолютное улучшение на 1,4% по сравнению с современным подходом к анализу HPSG с широким охватом. Составной анализ с инкрементными сигмовидными сетями доверия
Иван Титов и Джеймс Хендерсон
Эта генеративная модель синтаксического анализа обеспечивает самые современные результаты для текста WSJ и снижение ошибок на 8% по сравнению с базовым синтаксическим анализатором нейронной сети. Влияние корпуса на оценку автоматических систем транслитерации
Сарвназ Карими, Эндрю Терпин и Фальк Шолер
Мы обнаружили, что точность слов автоматических систем транслитерации может изменяться до 30% (в абсолютном выражении) в зависимости от корпуса, на котором они работают. Мы пришли к выводу, что для построения корпусов для оценки автоматизированных систем транслитерации следует использовать не менее четырех человек-транслитераторов; и что, хотя метрики абсолютной точности слов могут не переноситься в разные корпуса, относительные рейтинги производительности системы остаются стабильными в разных корпусах. Модели свернутых согласных и гласных: новые подходы к англо-персидской транслитерации и обратной транслитерации
Сарвназ Карими, Фальк Шолер и Эндрю Терпин
Напротив, мы представляем алгоритм выравнивания, специально разработанный для транслитерации. Наша новая модель повышает точность транслитерации с английского на персидский на 14,2% по сравнению с базовым уровнем в n-граммах. Мы также исследуем обратную транслитерацию для этой языковой пары, ранее не изученную проблему. Мы предлагаем новый метод обратной транслитерации. Экспериментальные результаты показывают, что наш алгоритм приводит к абсолютному улучшению на 25,1% по сравнению со стандартными подходами к транслитерации. Различающее сходство строк на основе выравнивания
Шейн Бергсма и Гжегож Кондрак
Этот подход обеспечивает исключительную производительность; в девяти отдельных экспериментах по идентификации родственных слов с использованием шести разных языковых пар мы более чем в два раза превышаем среднюю точность традиционных орфографических показателей, таких как отношение длиннейшей общей подпоследовательности и коэффициент Дайса. Мы также демонстрируем улучшение по сравнению с другими недавними дискриминационными и эвристическими функциями подобия. Изучение двуязычной терминологии — с использованием мозга, а не сопоставимых корпусов
Эммануэль Морен, Батрис Дайле, Коити Такеучи и Кё Кагэура
Таким образом, наша гипотеза состоит в том, что качество корпуса важнее количества и обеспечивает качество приобретенных терминологических ресурсов. Мы показываем, насколько важен тип дискурса как характеристика сопоставимого корпуса. Неконтролируемая адаптация языковой модели, включающая информацию об именованном объекте
Фейфан Лю и Ян Лю
Наши экспериментальные результаты показывают, что структура адаптации LM, основанная на NE, превосходит базовую универсальную LM. Кроме того, в подходе на основе LDA расширение именованных сущностей с помощью синтаксически отфильтрованных слов вместе с увеличением количества тем приводит к снижению недоумения на 14,23% по сравнению с базовым общим LM. Координация устранения неоднозначности именной фразы в модели генеративного синтаксического анализа
Дейдре Хоган
Наши изменения в базовой модели приводят к увеличению f-показателя зависимости координации NP с 690,9% до 73,8%, что представляет собой относительное снижение ошибки f-показателя на 13%. Унифицированный подход тегов к нормализации текста
Conghui Zhu, Jie Tang, Hang Li, Hwee Tou Ng и Tiejun Zhao
Точность предлагаемого метода высока, так как подзадачи нормализации взаимообусловлены и должны выполняться вместе. Экспериментальные результаты по очистке данных электронной почты и распознаванию именованных сущностей показывают, что предложенный метод значительно превосходит подход с использованием каскадных моделей и подход с использованием независимых моделей. Извлечение разреженной информации: неконтролируемые языковые модели на помощь
Дуг Дауни, Стефан Шенмакерс и Орен Эциони
Поскольку REALM предварительно вычисляет языковые модели на основе своего корпуса и не требует помеченных вручную начальных значений, он гораздо более масштабируем, чем предыдущие подходы, которые изучают модели для каждого отдельного отношения на основе помеченных вручную данных. Таким образом, REALM идеально подходит для открытого извлечения информации, когда отношения интересов заранее не указаны и их количество потенциально велико. Правила статистического преобразования леса в строку
Yang Liu, Yun Huang, Qun Liu и Shouxun Lin
Экспериментальные результаты показывают, что на китайско-английском тестовом наборе NIST 2005 модель преобразования дерева в строку, дополненная правилами преобразования леса в строку, обеспечивает относительное улучшение на 4,3% с точки зрения оценки BLEU по сравнению с исходной моделью, которая допускает преобразование дерева в строку. только правила to-string. Упорядочивание фраз с функциональными словами
Хендра Сетиаван, Мин-Йен Кан и Хайчжоу Ли
Эксперименты показывают, что подход FWS неизменно превосходит базовую систему как в упорядочении слов по функциям, так и в общем балле BLEU в сценариях идеального и зашумленного выравнивания слов. Вероятностный подход к переупорядочению на основе синтаксиса для статистического машинного перевода
Чи-Хо Ли, Минхуэй Ли, Донгдонг Чжан, Му Ли, Мин Чжоу и И Гуань
Машинный перевод с помощью триангуляции: эффективное использование многопараллельных корпусов
Тревор Кон и Мирелла Лапата
Максимальная ожидаемая полезность маркировки двоичных последовательностей
Мартин Янше
Прогнозный вывод по F-оценке как полезности сводится к поиску последовательности двоичных меток с максимальным ожидаемым F-оценкой по сравнению с простой вероятностной моделью маркировки последовательностей. Мы показываем, что количество гипотез, для которых необходимо оценить ожидаемую F-оценку, линейно зависит от длины последовательности, и представляем основу для эффективной оценки ожиданий многих общих функций потерь/полезности, включая F-оценку. Эта структура включает в себя как точные, так и более быстрые неточные методы расчета. Полностью байесовский подход к неконтролируемой маркировке частей речи
Шэрон Голдуотер и Том Гриффитс
Мы показываем, используя тегирование частей речи, что полностью байесовский подход может значительно повысить производительность. Байесовский подход не оценивает один набор параметров, а интегрирует все возможные значения параметров. Это различие гарантирует, что изученная структура будет иметь высокую вероятность в диапазоне возможных параметров, и позволяет использовать априорные предположения, благоприятствующие разреженным распределениям, типичным для естественного языка. Наша модель имеет структуру стандартной триграммы HMM, но обеспечивает точность тегирования, сравнимую с точностью современной дискриминационной модели (Smith and Eisner, 2005), что на 15 процентных пунктов выше, чем у MLE. Более того, наш байесовский HMM можно успешно обучить только на данных, без словаря тегов. Вычислительно эффективная М-оценка логлинейных структурных моделей
Ноа А. Смит, Дуглас Л. Вейл и Джон Д. Лафферти
Это значительно быстрее, чем оценка максимального (условного) правдоподобия условных случайных полей (Lafferty et al., 2001; nocitelafferty-01 порядок или более). Мы сравниваем его производительность и время обучения с HMM и CRF в задаче поверхностного синтаксического анализа. Эти эксперименты четко выделяют вклад богатых функций и дискриминационного обучения, которые, как показано, являются более чем аддитивными. Управляемое обучение для классификации двунаправленных последовательностей
Либин Шен, Джорджио Сатта и Аравинд К. Джоши
Различные структуры для оценки ответов на сложные вопросы: пирамиды не рухнут, как и люди-оценщики. на основе методологии, используемой для оценки ответов на сложные вопросы в треках TREC QA. В этой работе исследуются данные из трека TREC 2006 QA, первого крупномасштабного применения метода пирамиды самородков, и показано, что этот метод объединения суждений о важности самородков от нескольких оценщиков повышает стабильность и дискриминационную способность оценки, вводя только небольшая дополнительная стоимость ручной оценки. Мы обращаемся к желанию поддерживать модель реальных пользователей для задачи ответов на вопросы, исследуя различные способы, которыми можно комбинировать мнения оценщиков. Мы показываем, что оценка пирамиды самородков сильно коррелирует с другими оценками, поддерживающими пользовательскую модель, и, следовательно, является подходящим методом для оценки задачи конечного пользователя, такой как ответ на вопрос.
Использование синтаксических и поверхностных семантических ядер для классификации вопросов и ответов
Алессандро Москитти, Сильвия Куартерони, Роберто Базили и Суреш Манандхар
В этой статье мы изучаем влияние синтаксической и поверхностной семантической информации на автоматическую классификацию и переупорядочение вопросов и ответов. . Мы определяем (а) новые древовидные структуры, основанные на неглубокой семантике, закодированной в структурах аргументов предикатов (PAS), предоставленных PropBank, и (б) новые функции ядра, чтобы использовать репрезентативную силу таких структур. Наши эксперименты с машинами опорных векторов и приведенными выше моделями показывают, что синтаксическая информация помогает в конкретных задачах, таких как классификация вопросов и ответов, и что неглубокая семантика приводит к значительному улучшению, когда можно извлечь надежный набор PAS, например. из ответов.
Независимая от языка вероятностная ранжировка ответов на вопросы
Чонву Ко, Теруко Митамура и Эрик Нюберг
В этом документе представлена схема вероятностного ранжирования ответов для многоязычных ответов на вопросы. Структура оценивает вероятность отдельного варианта ответа с учетом степени релевантности ответа и количества подтверждающих доказательств, представленных в наборе вариантов ответа на вопрос. Наш подход оценивался путем сравнения наборов ответов-кандидатов, сгенерированных экстракторами ответов на китайском и японском языках, с повторно ранжированными наборами ответов, созданными системой ранжирования ответов. Эмпирические результаты тестирования фактоидных вопросов NTCIR показывают улучшение производительности при выборе ответов на китайском языке на 40% и улучшение выбора ответов на японском языке на 45%.
Обучение составлению эффективных стратегий на основе библиотеки компонентов диалога
Мартин Спиттерс, Марко Де Бони, Якуб Заврел и Ремко Боннема
В этом документе описывается метод автоматического обучения эффективным стратегиям диалога, созданным на основе библиотеки содержимого диалога с использованием обучение с подкреплением на основе отзывов пользователей. Эта библиотека включает в себя приветствия, социальный диалог, болтовню, шутки и построение отношений, а также более обычные компоненты разъяснения и проверки диалога. Мы проверили этот метод с помощью системы мотивационного диалога, которая побуждает к выполнению упражнений, и показали, что его можно использовать для создания хороших стратегий диалога без особых усилий.
О роли контекста и просодии в интерпретации «хорошо»
Агустин Гравано, Стефан Бенус, Гектор Чавес, Джулия Хиршберг и Лорен Уилкокс
прагматические функции слова «хорошо». Результаты исследования восприятия показывают, что контекстуальные сигналы являются более сильными предикторами дискурсивной функции, чем акустические сигналы. Тем не менее, акустические особенности, отражающие изменение высоты тона на правом краю слова «хорошо», играют важную роль в устранении неоднозначности, независимо от того, присутствуют ли другие контекстуальные сигналы или нет.
Предсказание успеха в диалоге
Дэвид Рейтер и Джоанна Д. Мур
Решение задач в диалоге зависит от языкового выравнивания собеседников, которое, как предполагается, основано на механистических эффектах повторения (Pickering & Garrod 2004). В статье мы ищем подтверждение этой гипотезы, рассматривая повторение в корпусах — и коррелирует ли повторение с успехом задачи. Мы показываем, что релевантная тенденция к повторению основана на медленной адаптации, а не на краткосрочной подготовке, и демонстрируем, что лексическое и синтаксическое повторение является надежным предиктором успеха задачи, учитывая первые пять минут диалога, ориентированного на задачу.
Решение этого, этого и того в неограниченном многостороннем диалоге
Кристоф Мюллер
Мы представляем реализованную систему для разрешения этого, этого и того в расшифрованном многостороннем диалоге. Система обрабатывает NP-анафоры, а также дискурсивно-дейктические анафоры, то есть местоимения с антецедентами VP. Выборочные предпочтения для предшественников NP или VP определяются на основе подсчета корпуса. Первоначальные результаты показывают, что система работает лучше, чем базовый уровень, основанный на давности.
Сравнительное исследование методов оценки параметров для статистической обработки естественного языка
Цзяньфэн Гао, Гален Эндрю, Марк Джонсон и Кристина Тутанова
В этой статье представлено сравнительное исследование пяти алгоритмов оценки параметров для четырех задач НЛП. Три из пяти алгоритмов хорошо известны в сообществе компьютерной лингвистики: оценка максимальной энтропии (ME) с регуляризацией L2, усредненный персептрон и бустинг. Мы также исследуем оценку ME с помощью все более популярной регуляризации L1 с использованием нового алгоритма оптимизации и BLasso, который представляет собой версию Boosting с регуляризацией Lasso (L1). Сначала мы исследуем все наши оценщики на двух задачах переранжирования: задаче выбора синтаксического анализа и задаче адаптации языковой модели. Затем мы применяем лучшие из этих оценщиков к двум дополнительным задачам, связанным с моделями условной последовательности: условной марковской модели (CMM) для маркировки частей речи (POS) и условного случайного поля (CRF) для сегментации китайских слов. Наши эксперименты показывают, что три из оценщиков, оценка ME с регуляризацией L1 или L2 и усредненный персептрон, находятся на первом месте почти со статистической связью.
Аппроксимация грамматики репрезентативным подъязыком: новая модель изучения языка
Смаранда Муресан и Оуэн Рэмбоу
Мы предлагаем новую модель изучения языка, которая изучает синтаксико-семантические грамматики из небольшого числа строк естественного языка, аннотированных с их семантикой, наряду с основными предположениями о синтаксисе естественного языка. Мы показываем, что пространство поиска для грамматической индукции представляет собой полную грамматическую решетку, которая гарантирует уникальность изученной грамматики.
Сегментация китайского языка с помощью алгоритма персептрона на основе слов
Юэ Чжан и Стивен Кларк
Стандартные подходы к сегментации китайских слов рассматривают проблему как задачу тегирования, присваивая метки символам в последовательности, указывающие, отмечает ли символ границу слова . Дискриминационно обученные модели, основанные на местных характеристиках символов, используются для принятия решений о тегировании, а декодирование Витерби находит сегментацию с наивысшей оценкой. В этой статье мы предлагаем альтернативный сегментатор на основе слов, который использует функции, основанные на полных словах и последовательностях слов. Алгоритм персептрона используется для различительного обучения. Поскольку декодирование Витерби больше не применимо, мы используем декодер с поиском луча. Закрытые тесты на первом и втором тестах SIGHAN показывают, что наша система конкурентоспособна с лучшими в литературе, достигая самых высоких зарегистрированных F-баллов для ряда корпусов.
Разрешение кореференции без учителя в непараметрической байесовской модели
Ария Хагиги и Дэн Кляйн
Мы представляем неконтролируемый непараметрический байесовский подход к разрешению кореференции, который моделирует как глобальные ссылки на объекты в корпусе, так и последовательную анафорическую структуру в каждом документе. В то время как большая часть существующей работы управляется парными решениями, наша модель является полностью генеративной, производя каждое упоминание из комбинации глобальных свойств объекта и локального состояния внимания. Несмотря на то, что наша система работает без присмотра, она обеспечивает удивительно конкурентоспособную производительность наборов данных ACE и MUC. В частности, наша лучшая система достигает 70,3 MUC F1 на тестовом наборе MUC-6, что в целом находится в диапазоне некоторых недавних контролируемых результатов.
Подход с опорным языком для статистического машинного перевода на основе фраз
Хуа Ву и Хайфэн Ван
В этой статье предлагается новый метод статистического машинного перевода на основе фраз с использованием сводного языка. Для осуществления перевода между языками Lf и Le с небольшим двуязычным корпусом мы вводим третий язык Lp, который называется опорным языком. Для Lf-Lp и Lp-Le существуют большие двуязычные корпуса. Используя только двуязычные корпуса Lf-Lp и Lp-Le, мы можем построить модель перевода для Lf-Le. Преимущество этого метода заключается в том, что мы можем выполнять перевод между Lf и Le, даже если для этой языковой пары нет двуязычного корпуса. Используя BLEU в качестве метрики, наш метод сводного языка обеспечивает абсолютное улучшение на 0,06 (относительное значение 22,13%) по сравнению с моделью, непосредственно обученной с 5000 пар предложений Lf-Le для франко-испанский перевод. Кроме того, при наличии небольшого двуязычного корпуса Lf-Le наш метод может дополнительно улучшить качество перевода за счет использования дополнительных двуязычных корпусов Lf-Lp и Lp-Le.
Начальная загрузка стохастического преобразователя для извлечения арабо-английской транслитерации
Тарек Шериф и Гжегож Кондрак
Мы предлагаем начальный подход к обучению стохастического преобразователя без памяти для извлечения транслитераций из англо-арабского битекста. Он узнает свою метрику подобия из данных в битексте и, таким образом, может работать непосредственно со строками, написанными в разных сценариях письма, без каких-либо дополнительных знаний языка. Мы показываем, что этот преобразователь с самонастройкой работает так же хорошо или даже лучше, чем модель, специально разработанная для обнаружения транслитераций арабского и английского языков.
Преимущества Massively Parallel Rosetta Stone: межъязыковой поиск информации на более чем 30 языках
Peter A. Chew и Ahmed Abdelali
В этой статье мы описываем наш опыт в расширении стандартного межъязыкового поиска информации ( CLIR), который использует параллельно выровненные корпуса и скрытое семантическое индексирование. Большинство, если не все предыдущие работы, которые следовали этому подходу, были сосредоточены на двуязычном поиске; два примера связаны с использованием французско-английских или англо-греческих параллельных корпусов. Наше расширение подхода в значительной степени параллельно в двух смыслах: лингвистическом и вычислительном. Во-первых, мы используем параллельно выровненный корпус, состоящий почти из 50 параллельных переводов на более чем 30 различных языков, каждый из которых содержит более 30 000 документов. Учитывая размер этого набора данных, массивно-параллельный подход был также необходим в более обычном вычислительном смысле. Наши результаты показывают, что лингвистический параллелизм не только не добавляет больше шума, но и лучше, когда речь идет о точности межъязыкового поиска, в дополнение к очевидному преимуществу, заключающемуся в том, что CLIR можно выполнять на большем количестве языков.
Пересмотр подходов к машинному обучению для оценки машинного перевода на уровне предложений
Джошуа С.
Альбрехт и Ребекка ХваВ прошлом методы машинного обучения предлагались как средство разработки автоматических метрик для оценки качества машинно переведенных предложений. . В данной статье эта идея исследуется дополнительно, анализируются аспекты обучения, влияющие на производительность. Мы показываем, что ранее предложенные подходы к обучению классификатора человеческого сходства не так хорошо коррелируют с человеческими суждениями о качестве перевода. Вместо этого мы утверждаем, что обучение на основе регрессии дает более надежные показатели. Мы демонстрируем осуществимость метрик на основе регрессии посредством эмпирического анализа кривых обучения и исследований обобщения. Наши результаты показывают, что метрики на основе регрессии могут достигать более высокой корреляции с человеческими суждениями, чем некоторые стандартные автоматические метрики.
Автоматическое получение ранжированных структур квалиа из Интернета
Филипп Чимиано и Йоханна Вендерот
В этой статье представлен подход к автоматическому изучению структур квалиа для существительных из Интернета и, таким образом, открывается возможность исследовать влияние структур квалиа на естественный язык. обработка в более крупном масштабе. Этот подход основан на более ранней работе, основанной на идее сопоставления конкретных лексико-синтаксических шаблонов, передающих определенное семантическое отношение во Всемирной паутине, с использованием стандартных поисковых систем. В нашем подходе элементы квалиа фактически ранжируются для каждой роли квалиа по некоторому показателю. Конкретный вклад статьи заключается в обширном анализе и количественном сравнении различных показателей ранжирования элементов квалиа. Кроме того, мы впервые представляем количественную оценку такого подхода к изучению структур квалиа по отношению к созданному вручную золотому стандарту.
Модель последовательности для классификации ситуационных сущностей
Алексис Палмер, Элиас Понверт, Джейсон Болдридж и Карлота Смит
Ситуационные сущности (СЭ) — это события, состояния, общие высказывания и встроенные факты и пропозиции, вводимые в дискурс с помощью предложений текст. Мы сообщаем о первых управляемых данными моделях для классификации SE, которая представляет собой маркировку предложений в соответствии с типом сущности ситуации, которую они представляют. Классификация SE важна для идентификации режима дискурса и полезна для разбора дискурса. Мы используем последовательный подход к задаче, который превосходит простой классификатор на основе высказываний. Лингвистически мотивированные признаки совпадения и информация о грамматических отношениях из глубокого синтаксического анализа повышают точность классификации. Кроме того, мы сообщаем о жанровых эффектах, наблюдаемых в классификации SE, которые поддерживают анализ модусов дискурса, имеющих характерное распределение SE и последовательностей SE. Наконец, мы показываем, что классификация SE помогает точному анализу дискурса.
Слова и отголоски: оценка и смягчение проблемы неслучайности в моделировании частотного распределения слов
Барони Марко и Эверт Стефан
Модели частотного распределения, настроенные на слова и другие лингвистические события, могут предсказывать количество и частотное распределение типов в выборках слов. произвольные размеры. Мы впервые проводим тщательную оценку этих моделей на основе перекрестной проверки и разделения обучающих и тестовых данных. Наши эксперименты показывают, что точность предсказания моделей омрачена серьезными проблемами переобучения из-за нарушений предположения о случайной выборке в корпусных данных. Затем мы предлагаем простой метод предварительной обработки для решения проблем неслучайности. Дальнейшая оценка подтверждает эффективность метода, которая выгодно отличается от более сложных методик коррекции.
Система крупномасштабного сбора вербальных, именных и адъективных фреймов подкатегоризации из корпусов
Джудита Прейсс, Тед Бриско и Анна Корхонен
использоваться для приобретения исчерпывающих словарей для глаголов, существительных и прилагательных. Система включает в себя обширный классификатор на основе правил, который идентифицирует 168 словесных, 37 прилагательных и 31 именную структуру из грамматических отношений, выводимых надежным синтаксическим анализатором. Система обеспечивает высочайшую производительность на всех трех установках.
Независимая от языка неконтролируемая модель морфологической сегментации
Вера Демберг
Было показано, что морфологическая сегментация полезна для ряда задач НЛП, таких как машинный перевод, распознавание речи, синтез речи и поиск информации. Недавно был предложен ряд подходов к неконтролируемой морфологической сегментации. В этой статье описывается алгоритм, основанный на предыдущих подходах и объединяющий их в простую модель морфологической сегментации, которая превосходит другие подходы на английском и немецком языках, а также дает хорошие результаты на агглютинативных языках, таких как финский и турецкий. Мы также предлагаем метод обнаружения вариаций внутри стеблей без присмотра. Мы показываем, что качество сегментации, достигнутое с помощью нового алгоритма, достаточно хорошее, чтобы улучшить задачу синтеза речи.
Использование языков трассировки Мазуркевича для морфологии на основе разделов
Франсуа Бартелеми
Морфология на основе разделов — это подход к морфологии с конечным числом состояний, где грамматика описывает особый вид регулярных отношений, которые разбивают все строки данного кортежа на одинаковое количество подстрок. Они компилируются в конечном автомате. В этой статье мы рассматриваем вопрос о слиянии грамматик, использующих различные разбиения, в один конечный автомат. Затем можно получить морфологическое описание путем параллельного или последовательного применения ограничений, выраженных в отношении различных понятий раздела (например, морфемы, фонемы, графемы). Теория языков следов Мазуркевича, хорошо известная семантика параллельных систем, обеспечивает способ представления и составления такого описания.
Много шума из ничего: Модель социальной сети русских парадигматических пробелов
Роберт Даланд, Андреа Д. Симс и Джанет Пьеррумбер
В ряде русских глаголов отсутствуют формы непрошедшего времени 1sg. Сохранение этих парадигматических пробелов, по-видимому, противоречит высокопродуктивной природе флективных систем. Мы моделируем сохранение и распространение пробелов в русском языке с помощью мультиагентной модели. Мы провели три симуляции: без изучения грамматики, с произвольным аналоговым давлением и с морфофонологически обусловленным обучением. Результаты и предельное поведение сравниваются с засвидетельствованным историческим развитием гэпов. Мы предполагаем, что сохранение пробелов можно объяснить отсутствием морфологической конкуренции.
Транслитерация на основе подстроки
Тарек Шериф и Гжегож Кондрак
Транслитерация — это задача преобразования слова из одного алфавитного алфавита в другой. Мы представляем новый подход к транслитерации на основе подстрок, вдохновленный моделями машинного перевода на основе фраз. Мы исследуем две реализации транслитерации на основе подстрок: алгоритм динамического программирования и преобразователь с конечным числом состояний. Мы показываем, что наш преобразователь на основе подстрок не только значительно превосходит современный подход на основе букв, но и на несколько порядков быстрее.
Итерация конвейера
Кристи Холлингсхед и Брайан Роарк
В этом документе представлена итерация конвейера, подход, который использует выходные данные более поздних этапов конвейера для ограничения более ранних этапов того же конвейера. Мы демонстрируем значительные улучшения в современном конвейере синтаксического анализа PCFG с использованием ограничений базовой фразы, полученных либо из более поздних этапов конвейера синтаксического анализа, либо из неглубокого синтаксического анализатора с конечным состоянием. Наилучшая производительность достигается путем переранжирования объединения неограниченных синтаксических анализов и относительно сильно ограниченных синтаксических анализов.
Изучение синхронных грамматик для семантического анализа с помощью лямбда-исчисления
Юк Вах Вонг и Рэймонд Дж. Муни
В этой статье представлены первые эмпирические результаты изучения синхронных грамматик, генерирующих логические формы. Используя методы статистического машинного перевода, семантический синтаксический анализатор, основанный на синхронной контекстно-свободной грамматике, дополненной лямбда-операторами, изучается с учетом набора обучающих предложений и их правильных логических форм. Полученный синтаксический анализатор показал себя как наиболее производительную систему в области запросов к базе данных.
Обобщение древовидных преобразований для индуктивного синтаксического анализа зависимостей
Йенс Нильссон, Йоаким Нивр и Йохан Холл
Предыдущие исследования управляемого данными синтаксического анализа зависимостей показали, что древовидные преобразования могут повысить точность синтаксического анализа для определенных синтаксических анализаторов и наборов данных. Мы исследуем, в какой степени это можно обобщить для языков/деревьев и синтаксических анализаторов, уделяя особое внимание псевдопроективному анализу как способу захвата непроективных зависимостей и преобразованиям, используемым для облегчения анализа координатных структур и групп глаголов. Результаты показывают, что положительный эффект псевдопроективного синтаксического анализа не зависит от стратегии синтаксического анализа, но зависит от конкретных свойств языка или банка деревьев. Напротив, преобразования, специфичные для конструкции, кажутся более чувствительными к стратегии синтаксического анализа, но имеют постоянный положительный эффект на нескольких языках.
Изучение многоязычного субъективного языка с помощью межъязыковых проекций
Рада Михалча, Кармен Банеа и Дженис Вибе
В этом документе рассматриваются методы создания ресурсов для анализа субъективности на новом языке с использованием инструментов и ресурсов, доступных на английском языке. Учитывая мост между английским и выбранным целевым языком (например, двуязычный словарь или параллельный корпус), методы можно использовать для быстрого создания инструментов для анализа субъективности на новом языке.
Определение полярности настроений в финансовых новостях: подход, основанный на сплоченности
Энн Девитт и Хуршид Ахмад
Текст не является чистым фактом. Сообщение может заставить вас смеяться или плакать, но может ли оно также заставить вас продать без покрытия акции компании А и скупить опционы компании Б? Исследования в области финансов убедительно свидетельствуют о том, что это возможно. Исследования показали, что как информационные, так и аффективные аспекты текста новостей глубоко воздействуют на рынки, влияя на объемы сделок, цены акций, волатильность цен и даже будущие доходы компаний. Эта статья направлена на исследование вычислимой метрики положительной или отрицательной полярности в тексте финансовых новостей, которая согласуется с человеческими суждениями о полярности в таких текстах и может использоваться в количественном анализе влияния новостей на финансовые рынки.
Слабо контролируемое обучение для классификации хеджирования в научной литературе
Бен Медлок и Тед Бриско
Мы исследуем автоматическую классификацию спекулятивного языка, или «хеджирование», в научной литературе из биомедицинской области, используя слабо контролируемое машинное обучение. Наш вклад включает точное описание задачи с рекомендациями по аннотации, анализ и обсуждение, вероятностную формулировку парадигмы самообучения, а также теоретическую и практическую оценку представленных моделей обучения и классификации. Мы экспериментально демонстрируем, что классификация хеджирования возможна с использованием слабо контролируемого машинного обучения, указывая при этом направления для будущих исследований.
Анализ текста для автоматического комментирования изображений
Коэн Дешахт и Мари-Франсин Моэнс
Мы представляем новый подход к автоматическому комментированию изображений с использованием ассоциированного текста. Мы обнаруживаем и классифицируем все сущности (лица и объекты) в тексте, после чего определяем значимость (важность сущности в тексте) и визуальность (степень визуального восприятия сущности) этих сущностей. Мы объединяем эти меры, чтобы вычислить вероятность того, что объект присутствует на изображении. Пригодность нашего подхода была успешно проверена на 50 парах изображение-текст Yahoo! Новости.
Анализ требований пользователей для поиска информации о собраниях на основе запроса
Винченцо Паллотта, Виолета Серетан и Марита Айломаа
Мы представляем исследование требований пользователей к ответам на вопросы по записям собраний, которое оценивает сложность вопросов пользователей с точки зрения того, какие типы информация и методы поиска необходимы для того, чтобы дать правильные ответы. Мы основываем нашу работу на эмпирическом анализе запросов пользователей. Мы обнаружили, что большинство полученных запросов относятся к спорным процессам и результатам (около 60%). Наш анализ также показывает, что стандартный поиск информации на основе ключевых слов может успешно обрабатывать менее 20% запросов и что его необходимо дополнять другими типами метаданных и выводов.
Объединение нескольких источников знаний для сегментации диалогов в мультимедийных архивах
Пей-Юн Сюэ и Джоанна Д. Мур
Автоматическая сегментация важна для обеспечения понятности мультимедийных архивов, а также для разработки последующих модулей поиска и извлечения информации. В этом исследовании мы изучаем подходы, которые могут сегментировать разговорную речь путем интеграции различных источников знаний (например, слов, аудио- и видеозаписей, намерений говорящего и контекста). В частности, мы оцениваем производительность подхода максимальной энтропии и оцениваем эффективность различных мультимодальных функций в задаче автоматической сегментации разговоров. Мы также предоставляем количественный отчет об эффекте использования транскрипции ASR в отличие от человеческих транскриптов.
Тематический анализ для поиска психиатрических документов
Лян-Чи Ю, Чунг-Сянь Ву, Чин-Ю Лин, Эдуард Хови и Чиа-Линг Лин
Попытки поиска психиатрических документов помочь людям эффективно и действенно найти соответствующие консультационные документы к своим депрессивным проблемам. Люди могут понять, как облегчить свои симптомы в соответствии с рекомендациями в соответствующих документах. В этой работе предлагается использовать информацию высокого уровня, извлеченную из консультационных документов, для повышения точности результатов поиска. Тематическая информация, принятая здесь, включает в себя негативные жизненные события, депрессивные симптомы и семантические отношения между симптомами, которые полезны для лучшего понимания запросов пользователей. Экспериментальные результаты показывают, что предлагаемый подход обеспечивает более высокую точность, чем модели поиска на основе слов, а именно модель векторного пространства (VSM) и модель Окапи, использующие только информацию на уровне слов.
Кем быть? — Электронная профориентация на основе семантического родства
Ирина Гуревич, Кристоф Мллер и Торстен Зеш
Мы представляем исследование, направленное на изучение использования семантической информации в новом приложении НЛП, Электронной профориентации (ЭКГ), на немецком языке. ЭКГ формулируется как информационно-поисковая (ИП) задача, в соответствии с которой текстовые описания профессий (документы) ранжируются по релевантности естественно-языковым описаниям профессиональных интересов человека (теме). Мы сравниваем эффективность двух семантических моделей IR: (IR-1) с использованием мер семантической связанности (SR), основанных либо на wordnet, либо на Википедии, и наборе эвристик, и (IR-2) с измерением сходства между темой и документами на основе Явный семантический анализ (ESA) (Габрилович и Маркович, 2007). Мы оцениваем эффективность показателей SR по существу в задачах (T-1) вычисления семантической связанности и (T-2) решения задач Reader’s Digest Word Power (RDWP). Мы обнаружили, что мера, основанная на словесной сети, лучше подходит для определения семантического сходства, в то время как мера, основанная на Википедии, очень хороша для определения семантической связанности и неклассических семантических отношений. Он также работает значительно лучше как с точки зрения охвата, так и с точки зрения корректности для задач RDWP. Мы обнаружили, что (IR-2) работает значительно лучше для более длинных тем, в то время как (IR-1) с использованием меры SR на основе Википедии значительно лучше для коротких тем как в MAP, так и в P10.
Извлечение социальных сетей и биографических фактов из стенограмм разговорной речи
Хунъян Цзин, Нанда Камбхатла и Салим Рукос
Мы представляем общую схему автоматического извлечения социальных сетей и биографических фактов из стенограммы разговорной речи. Наш подход основан на объединении выходных данных нескольких модулей извлечения информации, включая распознавание и обнаружение сущностей, обнаружение отношений и обнаружение событий. Мы описываем особенности и алгоритмические усовершенствования, эффективные для транскриптов разговорной речи. Эти улучшения повышают производительность извлечения из социальных сетей с 0,06 до 0,30 для набора для разработки и с 0,06 до 0,28 для тестового набора, что измеряется f-мерой связей внутри сети. Та же структура может быть применена к другим жанрам текста. Мы создали систему автоматического создания биографии для текста общей предметной области, используя тот же подход.
Financial Times 17204 Steerpike – Fifteensquared
Спасибо Steerpike. Определения подчеркнуты в подсказках.
через
8. Возврат аппетита в середине урока Jiu-Jits урок джиу-джитсу».
9. Оказывается, партнер беспокоится об обществе (10)
TRANSPIRES : Анаграмма (… обеспокоенный) ПАРТНЕР ЕСТЬ , содержащий (о) S (аббревиатура от «Общество»).
10. Арабские ополченцы, игнорирующие старого инструктора, первоначально (6)
ЙЕМЕНИ : «йомены» (исторически члены добровольческого ополчения, выросшие из гражданских йоменов/мужчин, владевших небольшими поместьями) минус (игнорируя) «о» (аббревиатура от «старый») + 1-я буква (…, изначально) «инструктор».
Defn: …, конкретно из Йемена.
11. Предупреждение о звонке университетская больница гниль (8)
ЯЗЫК : Реверс (…о) СИГНАЛ (предупреждение/указание, возможно, на опасность в ситуации) (звонок) U (сокращение от «университет») + H (сокращение от «больница»).
Defn: …/испортиться в результате небрежности.
12. Устья рек, разделенные большими шлюзами (8)
КОЛЬЦА : R (аббревиатура от «река») + ВХОДЫ (устья/узкие полосы воды из моря или озера в сушу) , содержащие (разделенные) /тысяча долларов или фунтов).
Defn: … волос.
14. Скульптура чрезвычайно красивой скачущей лошади (6)
МРАМОР : 1-я и последняя буквы (чрезвычайно) «красивая» 7 2
Defn: А… сделанный, ну, из мрамора.
16. Барбарская свиней, отступающая через Центральное плато (4)
Goth : Обращение (… отступает) свинья (свиней/свиней, который был одомашнен) , содержащий (по всему) , содержащий (по всему) 1111111111111111111111111 (по всему) , содержащей (по всему) . средняя буква (центральная) «плато».
17. Дерево образует полые побеги (5)
ПОЖАРЫ : ПИХТА (вечнозеленое хвойное дерево) + «эволюционирует» минус все его средние буквы (пустые).
18. Эта женщина написала о судье (4)
СЛУШАТЬ : ЕЕ(притяжательное местоимение этой женщины/третьей стороны для женщины) , содержащее (написано о) A.
Defn: … в суде.
19. Более убежденный вымогателем из высшего сословия (6)
Ростовщик : SURER (более убежденный/уверенный) ставится после (от) U (имеющий характеристики высшего сословия).
Определ.: …, например. ростовщик, который взимает непристойные / грабительские процентные ставки.
21. Нота давления на учителя (8)
ГОСПОЖА : МИ(нота в гамме сольфа) + НАПРЯЖЕНИЕ(надавливание/сила на материальный объект).
Defn: A (женщина) … кто преподает определенный предмет.
23. Отключите электроэнергию после того, как городская церковь была осаждена разъяренной толпой (4,4)
БАРАНЬЯ ОТДЕЛКА : P(символ «сила» в физике) ставится после (после) { LA (аббревиатура от Лос-Анджелес, американский город) + [ CH (аббревиатура от «церковь») содержится в (осажден) анаграмма ( злая толпа] }.
Defn: Толстый … кусок мяса ягненка, вокруг и часто с ребром.
26. Государственный департамент штата произвольно нанимает женщин (6)
ВСЕГДА : A + NY (аббревиатура от штата Нью-Йорк в США) + HO (аббревиатура от «Home Office», правительственный департамент в Великобритании) плюс (принимает) W (аббревиатура от «женщины»).
27. Благословенные типы, отвергающие первые электронные имплантаты (10)
СТИМУЛЫ : «миротворцы» (благословенные, которые договариваются о мире между конфликтующими сторонами) минус (отклонение) 2 902 19011 9012 ) «электронный».
Defn: … в организм для регулирования сердцебиения.
28. Родился и умер в нищете (4)
NEED : NEE (родился, используется в отношении девичьей фамилии замужней женщины) плюс (и) D (аббревиатура от «умерла»).
Defn: …/состояние бедности/отсутствия вещей.
Down
1. Журналисты ездят на автобусе до заброшенной столицы Сумер (10)
. Полудиторы : Анаграмма (… отброшенные) автобус + 1 -й буквы (… отброшенная) автобус + 81 1ST (… отброшен). столица) «Шумер».
2. Может столкнуться с неприятными джентльменами на окраинах Тинмута (8)
СИЛА : R (аббревиатура от «бег» в крикетных очках) содержится в (в) анаграмма 2 80790 (противный) GENTS размещен над (на, в нижней подсказке) 1-я и последняя буквы (окраина) «Teignmouth».
3. Волнения начинают распространяться на общий (6)
БОРЬБА : 1-е буквы соответственно из (начинает) «распространяться на» + RIFE (общий/широкий).
4. Все подавлены Мальчишником (4)
ШАР : ВСЕ(все) помещены ниже (подавлены, в ключе вниз) B (аббревиатура от «Холостяк»).
5. Совместная статья о британском писателе, поднимающем волны (8)
TSUNAMIS : T (прямоугольный стык в дереве, скажем, в форме буквы «T») + SUN (британский таблоид) выше (включено, в подсказке) AMIS (Кингсли или Мартин, отец и сын британских писателей).
Определение: Гигантский ….
6. Большой остров, где Латинский квартал в основном обеспечивает алкоголь (6)
ЛИКЕР : L (аббревиатура от «большой») + I (аббревиатура от «остров») + QUO (латинское «где») + средняя буква (… по существу) «четверть».
7. Сбор стандартных членских взносов для религиозной группы (4)
ЕВРЕИ : Гомофон (Получение) «взносов» (стандартных членских взносов, таких как «профсоюзные взносы»).
Я полагаю, вы могли слышать, как некоторые люди произносят «d» как «dj».
13. Схватка подонков, окружающих королеву (5)
SCRUM : SCUM(подонки/бесполезные или презренные люди) содержащие (окружающие) «R» (аббревиатура от «Regina»/Queen).
Defn: …/борьба или потасовка с участием толпы.
15. Привлекательные предметы старший сын разбросаны по территории (10)
МАГНИТНЫЕ КАМНИ : Анаграмма (… разбросаны) СТАРШИЙ СЫН содержащий ab (вокруг) ab. .
Ответ: … или магнитные камни/кусочки минерала, которые естественным образом намагничиваются/притягиваются к другим магнитным материалам.
17. Элемент поддержки европейской вершины (8)
ЛБ : FOR(поддерживающий/второй) + E(аббревиатура от «европейский») + ГОЛОВА(вершина/верхний конец).
Defn: …на лицо.
18. Racing, подвешенная вокруг пустынной взлетно-посадочной полосы в Род-Айленде (8)
HURRYING : HUNG(подвешенная/прикрепленная к более высокой точке) содержащая 2 (вокруг) [
1 8 0 удалены все внутренние буквы (пустая) «взлетно-посадочная полоса» , содержащаяся в (в) RI (аббревиатура от Род-Айленд)].
20. Полироль, наносимая на мелкие камни (6)
РУБИНЫ : Руб(полировать, протирая/двигая, например, тряпкой по поверхности) + IE(аббревиатура от «id est»/что есть) помещается над (надевается в нижнем ключе) S (аббревиатура от «маленький»).
Сырье:
22. Нечастые драки из-за наркотиков (6)
РЕДКИЙ : СПАРЗ (бои/боксы как форма тренировки) подсказка) E (аббревиатура от «Экстази», наркотик).