Задание 3 (20 баллов). Сделайте морфемный разбор слов (по составу): «школьник», «перелесок»,
Помогите срочно пожалуйста!!! ❤️
(1.)В (не)оглядно знойных облаках пыли задыхаясь потонули станичные сады улицы хаты плетни и лиш.. остро выглядывают верхушки пирамидальных тополей. (
… 2.)(Ото)всюду (много)голосо несется говор гул собач…й лай лошади…ое ржание. (3.)Как(будто) (не) вида…ый ул..й потерявший матку разноголосо(растерян..) гудит (не)стройным больным гудом.
(4.)Только (пенисто)клокоч..щую реку холодной горной воды что кипуче несется за станицей не в силах покрыть удушливые облака. (5.)(В)дали за рекой синеющими громадами загораживают (пол)неба горы. (6.)Удивле…о плавают в сверкающем зное пр…слушиваясь рыжие степные разбойники(коршуны) поворачивая кривые носы и н..чего н.. могут разобрать.
(7.)Вокруг ветряков с возрастающим гомоном все шире растекается людское море: (седо)бородые мужики бабы с и..мучен..ыми лицами ребятишки шныряют между ногами. (8.)И все это тонет в гр.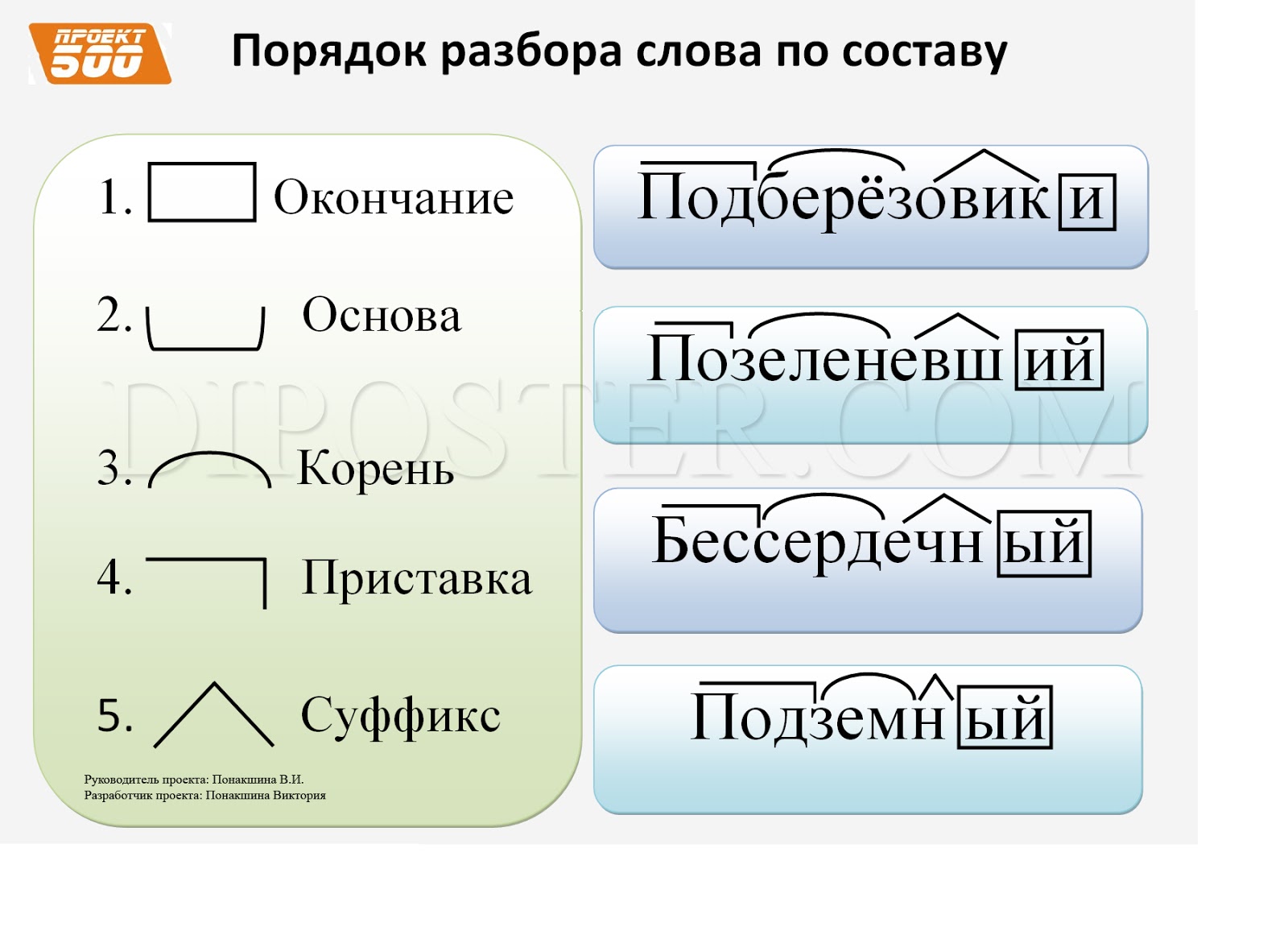
Помогите пожалуйста 1 или 2 задание, просто очень нужно. Очень, тону в долгах!
Очень, тону в долгах!
Помогите умоляю к сессии. Зачётная работа. Определите роль буквы ь в словах. В каких случаях использование ь не связано с требованиями графики? Найди … те отступления от слогового принципа. Банька, восемь, гляньте, дочь, дьякон, есть, жечь, колье, лишь, лосьон, льются, обезьяна, почтальон, прополешь, просьба, пятьдесят, режьте, рожь, сплошь, чьё, шестьсот, бульон, улыбаешься.
Помогите к сессии срочно! Найдите случаи соответствия слоговому принципу русской графики. Укажите отступления от слогового принципа. Ответ мотивируй … те. Жара, бросился, подытожить, шоколад, светлый, чёлка, чопорный, бездонный, шорох, стены, расчётливый, однажды, обжора, подъезд, бульон, субъект, кафе, щавель, жизнь, мышь, ширма, щука, отель, темнота, жюри, цепочка, церковный, взошел, фьорд, район, вьют, чары, нашёл, шов, майонез, своё, отчёт, жжёт, фойе, цыган, цифра.
в следующих предложениях найдите случаи нарушения языковых норм, исправьте их и при устной ответе по билету обоснуйте свой выбор. 1. Согласно указания
… генерального директора аварии на теплотрассах стали своевременно ликвидированы. 2. Предложенное в статье решение кажется проблемным и не дает никаких обоснований для подобных выводов.3. В нашем самом прекраснейшем городе работало много самых известнейших зодчих, скульпторов и архитекторов.4. В своей работе руководители учреждений руководствуются законодательными актами.5. Здесь открываются такие ландшафты, что просто завораживает дух.6. Русские солдаты и офицеры плечом к плечу сражались пол селом Бородиным.
1. Согласно указания
… генерального директора аварии на теплотрассах стали своевременно ликвидированы. 2. Предложенное в статье решение кажется проблемным и не дает никаких обоснований для подобных выводов.3. В нашем самом прекраснейшем городе работало много самых известнейших зодчих, скульпторов и архитекторов.4. В своей работе руководители учреждений руководствуются законодательными актами.5. Здесь открываются такие ландшафты, что просто завораживает дух.6. Русские солдаты и офицеры плечом к плечу сражались пол селом Бородиным.
В каком предложении допущена пунктуационная ошибка? *
Укажите конструкции с причинным значением . Выберите один ответ: a. Он допустил по своей рассеянности ошибки. b. Изучаемый материал оказался довольно … трудным. c. Было такое чувство, словно мы были знакомы. d. Он много и упорно занимался в эти дни. e. Зимой он сдал все экзамены на «отлично»
К какому разряду относятся данные наречия: сослепу, сгоряча, оттого, потому, поэтому
Выберите один ответ:
a. Наречия причины
b. Наречия времени
c. Нар
… ечия образа действия
d. наречия цели
e. наречия места
Наречия причины
b. Наречия времени
c. Нар
… ечия образа действия
d. наречия цели
e. наречия места
Выберите один ответ: a. Стадион находится у главного входа. b. При желании люди могут сохранить временем c. Из-за недостатка времени работу пришлось о … тложить d. Мой друг умело распоряжается временем e. Ошибка допущена, так как специалист молод.
Презентация — Памятки — Образец разбора «Звуко-буквенный разбор слова»
Слайды и текст этой онлайн презентации
Слайд 1
Звуко-буквенный разбор слова 2 класс
Памятки. Образец разбора
2 класс
Школа России
2015г.
Слайд 2
звуко-буквенный разбор слова (план)
гласные звуки и буквы для их обозначения
согласные звуки русского языка
образец устного разбора слова
образец письменного разбора слова
Слайд 3
Гласные звуки и буквы для их обозначения
Звуки: [а] [и] [о] [у] [ы] [э]
Буквы:
а о у ы э
я ё ю и е
указывают
на твёрдость
согласного звука
указывают
на мягкость
согласного звука
Слайд 4
Согласные звуки русского языка
[л л’]
[м м’]
[н н’]
[р р’]
[ — й’]
согласные
парные
звонкие
глухие
твёрдые и мягкие
н
е
п
а
р
н
ы
е
н
е
п
а
р
н
ы
е
[х х’]
[ц — ]
[ — ч’]
[ — щ’]
[б б’]
[в в’]
[г г’]
[д д’]
[ж — ]
[з з’]
[п п’]
[ф ф’]
[к к’]
[т т’]
[ш — ]
[с с’]
Слайд 5
Звуко-буквенный разбор слова
Памятка для 2 класса
1. Произнеси слово и послушай себя.
2. Произнеси слово целиком с выделением ударного
слога.
3. Произнеси слово, выделяя голосом каждый звук
по порядку.
4. Произнеси каждый звук, охарактеризуй его: гласный
(ударный или безударный), согласный (звонкий или
глухой, твёрдый или мягкий).
5. Скажи, какой буквой обозначен на письме каждый
звук.
6. Определи количество звуков и букв в слове.
Произнеси слово и послушай себя.
2. Произнеси слово целиком с выделением ударного
слога.
3. Произнеси слово, выделяя голосом каждый звук
по порядку.
4. Произнеси каждый звук, охарактеризуй его: гласный
(ударный или безударный), согласный (звонкий или
глухой, твёрдый или мягкий).
5. Скажи, какой буквой обозначен на письме каждый
звук.
6. Определи количество звуков и букв в слове.
гласные
согласные
устный
письменный
Слайд 6
Звуко-буквенный разбор слова
Образец устного разбора. 2 класс
Произношу слово [л о с’ и]. В слове 2 слога: [л о] и [с’ и].
Ударный слог первый — [л о с’ и]. Произношу ещё раз,
чтобы услышать каждый звук: [л] [о] [с’] [и].
Первый звук [л] – согласный, звонкий , твёрдый. Обозна-
чается буквой «эль».
Второй звук [о] – гласный, ударный. Обозначается буквой
«о».
Третий звук [с’] – согласный, глухой, мягкий. Обозначает-
ся буквой «эс».
Четвёртый звук [и] – гласный, безударный. Обозначается
буквой «и».
В слове 4 звука, 4 буквы.
Обозначается
буквой «и».
В слове 4 звука, 4 буквы.
гласные
согласные
план разбора
письменный
Слайд 7
Звуко-буквенный разбор слова
2 класс
Образец записи
Лоси [л о с’ и] — 2 слога, 4 буквы, 4 звука.
л [л] – согласный, звонкий, твёрдый;
о [о] – гласный, ударный;
с [с’ ] – согласный, глухой, мягкий;
и [и] – гласный, безударный.
согласные
план разбора
устный
Разбор слова по составу образец
Состав слова. Разбор слова по составу. Razbor slova youtube.
Лексический разбор слова | сайт учителя русского языка и.
Морфемный разбор (разбор слова по составу) – статья раздела.
Образец разбора слова по составу львята в онлайн морфемном.Образец разбора слова по составу торопливо в онлайн.
Морфемный разбор онлайн, разбор слов по составу, примеры. Разбор слова. Образец разбора слова по составу звездочками в онлайн.
Разбор слова. Образец разбора слова по составу звездочками в онлайн. Алгоритм грамматического разбора слова по составу.
Разбор слова по составу. Примеры.
«образец» корень слова и разбор по составу.Образец разбора слова по составу вавилоняне в онлайн.
Разбор слова по составу. Видеоурок. Русский язык 3 класс.
Как разобрать слово по составу? Пример морфемного разбора.Примеры и комментарии / фонетический разбор / русский на 5.
Разбор слова по составу youtube.
Разбор слова по составу: порядок и образец морфемного.
Разбор слова по составу | интернет проект beginnerschool. Ru. Примеры и комментарии / морфемный разбор / русский на 5.
Разбор слова по составу.
Инструкция по применению провирон Кандид инструкция по применению Скачать гта сан андреас лицензию Скачать музыку и слушать русскую Protect me from what i want скачатьКак можно самостоятельно выполнить синтаксический разбор простого и сложного предложения (схема и план) + 5 лучших онлайн сервисов для ленивых
Синтаксический анализ вызывает у новичка в этом вопросе большие трудности. Особенно пугает длинное предложение, которое имеет множество членов, предикативных частей. На деле выполнять решение не так страшно, и русский язык предельно логичен, как и его синтаксис. Из этой статьи вы узнаете о том, что такое полный синтаксический разбор предложения – образец анализа приведен подробно, в деталях.
Для чего нужен синтаксический анализ
Синтаксический анализ – это выделение членов предложения по их функциональному значению и описание высказывания исходя из его целевых, эмоциональных, структурных особенностей.
Иногда его называют пунктуационным разбором. Такой анализ более глобален, чем орфографический, морфологический или фонетический.
Научившись самостоятельно делать синтаксический анализ на примере, можно разобраться в структуре высказывания, принципах его построения. Синтаксис и пунктуация взаимосвязаны, поэтому определение схемы дает знания о том, как расставлять знаки препинания.
Таблица или образец синтаксического разбора будут помогать как ребенку в начальной школе, так и студенту лингвистической специальности, изучающему русский язык.
Типы простого предложения
Простое предложение – это высказывание, где есть одно подлежащее и одно сказуемое. Также возможен вариант, когда есть только подлежащее или только сказуемое.
По цели бывают:
- повествовательными – автор делится информацией, есть точка в конце;
Катя решила сделать гимнастику.
- вопросительными – автор хочет узнать определенную информацию, есть вопрос в конце;
Когда уже наступит лето?
- побудительные – автор побуждает сделать что-либо, восклицательный знак в конце.
Не сорите в общественном месте!
Побудительные высказывания часто имеют лексические маркеры, которые дают подсказку: давай, будем, сделай, идемте и т.п.
Классификация по эмоциональной окраске включает в себя:
- восклицательные – есть восклицательный знак в конце;
Петя, почему ты не помыл руки?!
- невосклицательные – нет восклицательного знака в конце.

На дворе снежно и солнечно.
По наличию главных членов простые предложения принимают такой вид:
- односоставные – если есть подлежащее, но нет сказуемого, или наоборот;
В городе весна.
В столице пахнет осенью.
- двусоставные – есть и подлежащее, и сказуемое.
Зима настала в городе
Когда нет одного из главных членов:
- назывные – только подлежащее;
Здесь глушь.
- определенно-личные – только сказуемое, которое стоит в 1-м или 2-м лице;
Люблю кататься на коньках.
- неопределенно-личное – сказуемое стоит во множественном числе и 3-м лице;
К вам пришли.
- обобщенно-личное – грамматическая форма сказуемого не важна, важно только значение обобщенности и то, что высказывание можно отнести к любому человеку;
Работаешь, работаешь – и без результата.
- безличное – сказуемое может быть наречием, а также страдательным причастием прошедшего времени или безличным глаголом.
Мне нужно выйти. Ему не спится.
Обобщенно-личный тип включает прежде всего пословицы, поговорки, фразеологизмы и другие устойчивые сочетания.
По наличию второстепенных членов высказывания делятся на:
- нераспространенные – есть только грамматическая основа;
Корабль плывет.
- распространенные – есть другие члены предложения, кроме грамматической основы: обстоятельство, или дополнение, или определение, или все вместе.
Корабль величественно плывет по волнам.
По критерию полноты выражения предложение может быть:
- полным – все члены прописаны, нет недоговоренности;
Мое жилье располагается здесь.
- неполным – определенные члены могут подразумеваться, нередко на их месте стоит тире.
А мое жилье – здесь.
Учитывая все критерии, по которым делятся предложения, и их характеристики, можно сделать подробный синтаксический анализ по плану.
Типы сложного предложения
Сложное – это высказывание, в котором при идеальном раскладе есть два подлежащих и два сказуемых. Но иногда случается, что есть только два сказуемых или только два подлежащих, одно сказуемое и два подлежащих и т.п.
В сложном предложении с несколькими придаточными частями можно найти даже 3 или 4 грамматических основы, а не только 2.
Сложные высказывания делятся по цели и эмоциональной окраске так же, как и простые.
При определении типа сложного предложения нужно смотреть на наличие союза:
- союзное – союз есть;
Если бы на Земле не было воды, здесь бы не зародилась жизнь.
- бессоюзное – союз отсутствует, может стоять запятая или даже двоеточие;
Ярик не пошел в школу и остался дома: он болел.
В зависимости от союза высказывания бывают:
- сложносочиненные – союз сочинительный: сюда входят соединительные, противительные и разделительные;
Аня хотела хорошую оценку, но она не сделала домашнее задание.
- сложноподчиненные – союз подчинительный: все остальные союзные группы относятся к этому виду.
Аня должна была сделать домашнее задание, чтобы учитель поставил ей хорошую оценку.
Необходимо указывать, какой союз соединяет предикативные части высказывания; в бессоюзных предложениях это интонация.
После указания типа придаточной каждая из частей разбирается как простое предложение. Порядок синтаксического разбора такой же, но алгоритм начинается с критерия односоставности/двусоставности.
Как составить схему предложения
Рисовать схему нужно после выполнения самого синтаксического разбора. Произведите сперва обобщающий пунктационный разбор, иначе она рискует быть неполной или неверной.
Предлагаем составление схемы по следующей последовательности:
- рисуем скобки – в простом и сложносочиненном высказывании всегда нужны квадратные скобки, т.к. оно не имеет зависимых частей, а в сложноподчиненном –квадратными обозначается главная часть, а круглыми – зависимая;
- делаем графическое отображение предложения внутри, отмечая только грамматическую основу прямыми линиями в логическом порядке, никаких пунктирных или волнистых подчеркиваний.
- если есть союз или союзное слово, оно пишется буквами, а сверху подписывается с. или с. с.
- если сложноподчиненное, нужно нарисовать стрелку от главной части и подписать сверху вопрос к придаточной, на который она отвечает.
Например, схематический анализ сложноподчиненного предложения с разными видами связи выглядит так:
Я не хотел никого обидеть, но Саша надулся и сказал, что теперь он не будет со мной общаться.
[– =], но [– = и =], (что…).

Грамматическую основу рисуют только в главных частях, а союз в придаточной находится только внутри скобок, в отличие от независимых частей.
Образец простого разбора
Высшее общество всегда казалось ей неестественным, лживым и лицемерным.
Повествовательное, невосклицательное, простое, двусоставное, распространенное, полное.
Грамматическая основа: подлежащее – общество, сказуемое – казалось неестественным, лживым, лицемерным. Второстепенные члены: высшее – определение, ей – дополнение. Осложнено однородными составными глагольными сказуемыми.
Образец сложного разбора
Артур, уберись в своей комнате до прихода гостей, иначе я тебя накажу.
Побудительное, невосклицательное, сложносочиненное, состоит из двух предикативных частей, средство связи – сочинительный союз «иначе».
Первая часть: односоставное, определенно-личное, распространенное, полное. Сказуемое – уберись. В своей комнате до прихода гостей – обстоятельство. Осложнено обращением.
В своей комнате до прихода гостей – обстоятельство. Осложнено обращением.
Вторая часть: двусоставное, распространенное, полное. Подлежащее – я, сказуемое – накажу. Тебя – дополнение. Ничем не осложнено.
5 лучших онлайн сервисов
Синтаксический разбор предложения и текста сегодня можно выполнить онлайн и бесплатно.
ТОП-5 сервисов для этого:
- ProgaOnline – делает подчеркивания, определяет не только части речи, но и их формы: падеж, число, лицо и др.;
- Rustxt – яркий понятный дизайн, предоставляет довольно подробный синтаксический анализ;
- Seosin – может выполнять синтаксический разбор не только словосочетание или предложение, но и текст, подчеркивает все члены, делает морфологический анализ;
- GoldLit – неограниченное количество символов, есть анализы художественной литературы, но выдает только полный анализ части речи;
- Школьный помощник – поможет только со справочной информацией по теме, есть схемы анализа и упражнения.

Необходимо помнить, что анализ, который выполняется любой программой, может содержать мелкие неточности.
Проблемы с синтаксическим разбором предложений
Самой распространенной проблемой для школьника становится разделение частей речи от их функций в высказывании. Отсюда вытекает неумение правильно подчеркнуть члены.
Важно помнить: существительное либо местоимение может быть как дополнением, так и подлежащим, для имени прилагательного определение не приговор, числительные могут выступать в любой функции, а предлоги зависимы и закреплены за другими членами.
Побудительные предложения иногда заканчиваются точкой, а повествовательные – восклицательным знаком. Чтобы не запутаться, нужно обратить внимание на семантический аспект (что оно означает), а не только на знаки препинания.
Возникают проблемы и с тем, какими членами может быть осложнено предложение.
Высказывание часто осложняется:
- вводными конструкциями;
- деепричастием с зависимыми словами;
- причастным оборотом;
- сравнением и другими обособленными оборотами;
- обращением;
- приложением, т. е. определением в форме существительного;
- однородными членами.
 е. определением в форме существительного;
е. определением в форме существительного;Выводы
В этом материале мы рассмотрели, как сделать синтаксический анализ (разбор) простых и сложных предложений, разобрали конкретные примеры письменного анализа, возможные трудности. С использованием такой пошаговой инструкции и памяткой проанализировать высказывание сможет даже новичок.
Часто задаваемые вопросы о проверке грамматики в Word
Что означает наличие в Word средства проверки грамматики «естественного языка»?
Средство проверки грамматики в Word выполняет всесторонний и точный анализ (также известный как «синтаксический анализ») отправленного текста, вместо того, чтобы просто использовать серию эвристик (или сопоставление шаблонов) для выявления ошибок. Инструмент проверки грамматики анализирует текст на синтаксическом уровне и на более глубоком, логическом уровне, чтобы понять взаимосвязь между действиями и людьми или вещами, которые выполняют эти действия.Например, средство проверки грамматики Word анализирует следующее сложное предложение
Инструмент проверки грамматики анализирует текст на синтаксическом уровне и на более глубоком, логическом уровне, чтобы понять взаимосвязь между действиями и людьми или вещами, которые выполняют эти действия.Например, средство проверки грамматики Word анализирует следующее сложное предложение
Легенда гласит, что это Королевство было создано тремя древними магами, чьи магические силы правили миром и сделали их бессмертными и всемогущими. и переписывает его с пассивного голоса на активный для ясности. Инструмент проверки грамматики также выделяет относительное предложение между запятыми:
Легенда гласит, что это Королевство создали три древних мага, чьи магические силы правили миром и сделали их бессмертными и всемогущими.Примечание. Эта функция не включена по умолчанию. Чтобы включить эту функцию, выполните следующие действия:
Начальное слово.
В меню Инструменты щелкните
Параметры .На вкладке Орфография и грамматика в области Грамматика измените поле Стиль письма на Грамматика и стиль .
Нажмите ОК , чтобы закрыть диалоговое окно
Параметры .

Кто разработал средство проверки грамматики Word?
Средство проверки грамматики полностью разработано и принадлежит Microsoft.
В чем основные различия между инструментом проверки грамматики Word и другими решениями сторонних поставщиков для проверки грамматики?
Одно из ключевых различий между средством проверки грамматики Word и другими решениями проверки грамматики заключается в том, что средство проверки грамматики в Word использует передовые методы синтаксического анализа для понимания структуры предложения. Сторонние решения для проверки грамматики могут в основном полагаться на «сопоставление с образцом». «Сопоставление с образцом» означает, что программа использует метод сопоставления проверенного текста с образцами текста, которые хранятся во внутренней базе данных.
Сторонние решения для проверки грамматики могут в основном полагаться на «сопоставление с образцом». «Сопоставление с образцом» означает, что программа использует метод сопоставления проверенного текста с образцами текста, которые хранятся во внутренней базе данных.
Как называются файлы средства проверки грамматики и где они установлены?
Программа Word Setup по умолчанию устанавливает средство проверки грамматики. Средство проверки грамматики английского языка (США) состоит из двух файлов:
Msgr3en.dll установлена в следующую папку:
Диск : \ Program Files \ Common Files \ Microsoft Shared \ Proof \ 1033
Msgr3en.lex установлен в следующую папку:
Диск : \ Program Files \ Common Files \ Microsoft Shared \ Proof \
Сколько памяти необходимо моему компьютеру, чтобы Word мог проверять грамматику в моем документе при вводе текста?
Word автоматически включает средство проверки грамматики, если на вашем компьютере достаточно доступной памяти. Метод проверки грамматики, который включается при установке и первом запуске Word, зависит от объема доступной памяти на вашем компьютере.
Метод проверки грамматики, который включается при установке и первом запуске Word, зависит от объема доступной памяти на вашем компьютере.
Использование средства проверки грамматики вручную (8 МБ или более):
Для запуска средства проверки грамматики при нажатии кнопки «Орфография и грамматика» в меню «Инструменты» на вашем компьютере должно быть более 8 мегабайт (МБ) физической памяти. Если у вас меньше 8 МБ, функция проверки грамматики при вводе отключена по умолчанию при первом запуске Word.
Автоматически использовать средство проверки грамматики (12 МБ или более):
Для запуска проверки грамматики при постоянном вводе параметра (для отображения грамматических ошибок с волнистым подчеркиванием) на вашем компьютере должно быть не менее 12 МБ физической памяти . Если на вашем компьютере меньше 12 МБ ОЗУ, при первом запуске Word устанавливается флажок «Скрыть грамматические ошибки».
Чтобы включить Проверять грамматику при вводе , наведите указатель на «Параметры» в меню «Инструменты», щелкните вкладку «Орфография и грамматика», а затем щелкните, чтобы установить флажок «Проверять грамматику при вводе ».
Примечание. Для всех западноевропейских языков, кроме английского, опция
Проверять грамматику при вводе по умолчанию отключена. (Средство проверки грамматики английского языка входит в состав всех версий Word.)
Где находятся записи реестра для средства проверки грамматики?
Важно! Этот раздел, метод или задача содержат шаги, которые говорят вам, как изменить реестр. Однако при неправильном изменении реестра могут возникнуть серьезные проблемы.Поэтому убедитесь, что вы выполните следующие действия внимательно. Для дополнительной защиты сделайте резервную копию реестра перед его изменением. Затем вы можете восстановить реестр, если возникнет проблема. Для получения дополнительных сведений о резервном копировании и восстановлении реестра щелкните следующий номер статьи в базе знаний Microsoft:
322756 Как создать резервную копию и восстановить реестр в Windows
Параметры грамматики для каждого пользователя:
Примечание Word создает этот параметр, если параметр не существует в реестре Windows:
HKEY_CURRENT_USER \ Software \ Microsoft \ Shared Tools \ Proofing Tools \ Grammar \ MSGrammar В этом подразделе Word регистрирует номер версии грамматики (3.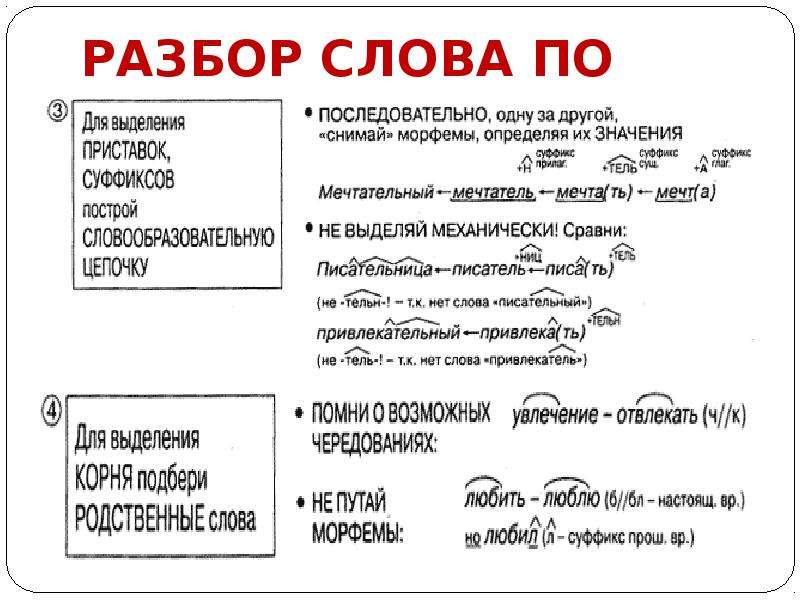 0 в случае английского), идентификаторы языков (1033 в случае американского английского) и настройки грамматики, которые вы выбираете на вкладке Орфография и грамматика в диалоговом окне Параметры (меню Инструменты). В Word вы можете выбрать два стиля письма на вкладке «Орфография и грамматика»: «Грамматика и стиль» или «Только грамматика». Эти параметры определены в записях «Имя» в подразделе «Набор параметров 0» и в подразделе «Набор параметров 1». Для каждого из этих параметров вы также можете установить правила, которые Word использует для проверки грамматики. Чтобы установить эти правила, нажмите «Настройки» на вкладке «Орфография и грамматика».Эти настройки также хранятся в виде двоичных инструкций в записях данных в подразделе Option Set 0 и Option Set 1 подразделе.
0 в случае английского), идентификаторы языков (1033 в случае американского английского) и настройки грамматики, которые вы выбираете на вкладке Орфография и грамматика в диалоговом окне Параметры (меню Инструменты). В Word вы можете выбрать два стиля письма на вкладке «Орфография и грамматика»: «Грамматика и стиль» или «Только грамматика». Эти параметры определены в записях «Имя» в подразделе «Набор параметров 0» и в подразделе «Набор параметров 1». Для каждого из этих параметров вы также можете установить правила, которые Word использует для проверки грамматики. Чтобы установить эти правила, нажмите «Настройки» на вкладке «Орфография и грамматика».Эти настройки также хранятся в виде двоичных инструкций в записях данных в подразделе Option Set 0 и Option Set 1 подразделе.
Примечание. Если вы обновили более раннюю версию Word, записи имен будут определены как обычные, стандартные, формальные, технические или специальные, а не только как грамматика и стиль или только грамматика. В этом случае в реестре будут подключи от Option Set 0 до Option Set 4, которые соответствуют каждому из этих стилей записи.
В этом случае в реестре будут подключи от Option Set 0 до Option Set 4, которые соответствуют каждому из этих стилей записи.
Настройки грамматической машины:
Примечание. Этот параметр должен существовать для проверки грамматики на определенном языке.
HKEY_LOCAL_MACHINE \ Software \ Microsoft \ Shared Tools \ Proofing Tools \ Grammar Под этим ключом находятся идентификаторы языков (1033, 2057, 3081), атрибуты стиля Normal и значения Dictionary и Engine, которые содержат, соответственно, полные пути к Файлы .lex и .dll.
Примечание. Не все файлы проверки грамматики языка автоматически регистрируются после копирования файлов грамматики в определенное место. Поэтому всегда рекомендуется использовать программу установки для установки файлов проверки грамматики (и других средств проверки).
Почему средство проверки грамматики помечает слова, которые не следует отмечать, и почему предлагает неправильные предложения?
Как правило, средство проверки грамматики неправильно отмечает слова или предлагает неверные предложения, когда синтаксический анализатор (то есть компонент проверки грамматики, который анализирует лингвистическую структуру предложения) не может определить правильную структуру анализируемого предложения.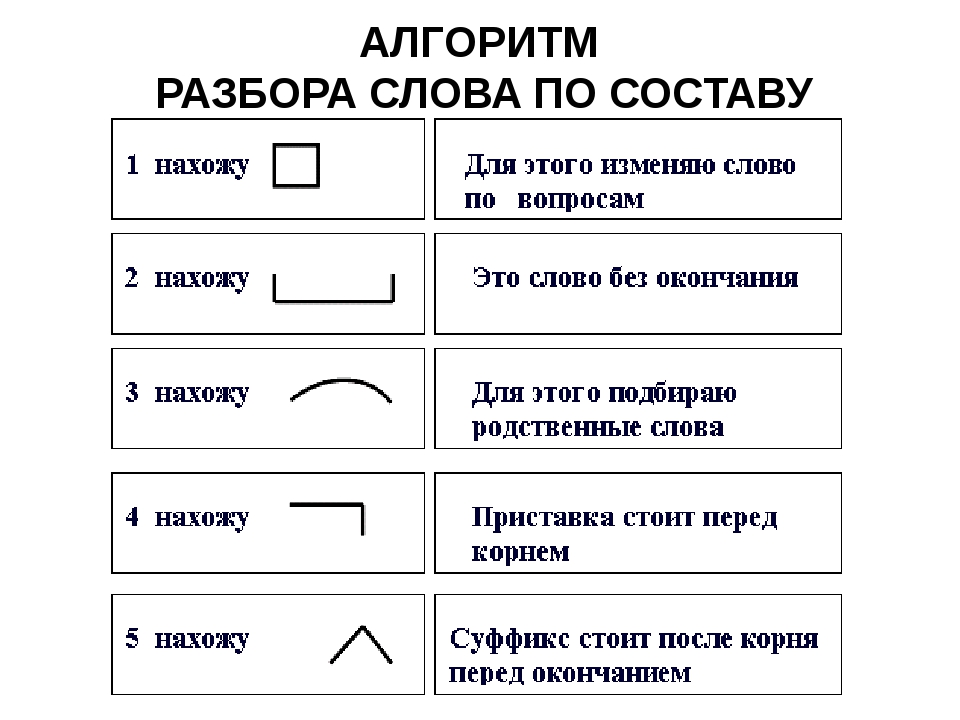
Несмотря на то, что инструмент проверки грамматики является современным в своей категории, он (как и любая другая имеющаяся в продаже программа проверки грамматики) не идеален.Поэтому, когда вы используете средство проверки грамматики, вы можете столкнуться с некоторым количеством «ложных» или «подозрительных» отметок и последующих неправильных предложений; однако средство проверки грамматики в Word 2002 и более поздних версиях значительно улучшено по сравнению с более ранними версиями Microsoft Word.
Почему средство проверки грамматики не может обнаружить ошибки во фразе «Мы тоже пошли на два магазина, чтобы …»?
Средство проверки грамматики предназначено для выявления ошибок, которые обычные пользователи совершают каждый день.Вы всегда можете составлять предложения, которые могут сбить с толку инструмент проверки грамматики.
Когда средство проверки грамматики работает в фоновом режиме (волнистые подчеркивания), почему он помечает ошибки в другом порядке, чем когда я нажимаю «Орфография и грамматика» в меню «Инструменты»?
Когда вы выбираете Орфография и грамматика в меню Инструменты, инструмент проверки грамматики запускается на переднем плане и управляет документом. То есть, вы не можете работать со своим документом, пока инструмент проверки грамматики проверяет ваш документ.
То есть, вы не можете работать со своим документом, пока инструмент проверки грамматики проверяет ваш документ.
Однако, когда средство проверки грамматики работает в фоновом режиме (волнистые подчеркивания), оно пытается добиться логического потока слева направо и не так критично для структуры предложения, как при запуске проверки грамматики. инструмент вручную (на переднем плане). Следовательно, когда средство проверки грамматики работает в фоновом режиме, ошибка, помеченная первой, всегда является той, которая возвращает предложение, независимо от ее положения в предложении.
Почему «Игнорировать все» не работает так, как я ожидал?
Например, если я нажму «Игнорировать все» для этого предложения, которое помечено как фрагмент
После обеда.в том же сеансе проверки инструмент проверки грамматики останавливается на других предложениях, которые также помечены как фрагменты, например:
Над моим трупом. Инструмент проверки грамматики классифицирует (внутренне) эти два предложения как разные типы фрагментов. В этих примерах средство проверки грамматики игнорирует один из этих типов, но не другой. Отсюда очевидная несогласованность в том, как работает «Игнорировать все».
Инструмент проверки грамматики классифицирует (внутренне) эти два предложения как разные типы фрагментов. В этих примерах средство проверки грамматики игнорирует один из этих типов, но не другой. Отсюда очевидная несогласованность в том, как работает «Игнорировать все».
Почему ошибки не отмечаются в порядке слева направо?
В большинстве случаев средство проверки грамматики пытается помечать ошибки слева направо.В некоторых случаях это невозможно, потому что средство проверки грамматики хочет, чтобы вы сначала исправили наиболее логичную ошибку (эта ошибка может быть не первой). В этом случае ошибки пунктуации или пробелов помечаются перед конкретными или ограниченными грамматическими ошибками.
Почему одни пассивные предложения помечаются и предлагается переписать, а другие пропускаются?
Примечание. Эта проблема возникает с другими правилами в дополнение к правилу пассивного построения.
Например, следующее пассивное предложение не помечается:
Срок действия настоящего Соглашения начинается с Даты вступления в силу и продолжается до тех пор, пока Volcano Coffee не расторгнет его в письменной форме в любое время, с указанием причины или без нее. Для определенных типов предложений, когда нет четкого синтаксического предмета, средство проверки грамматики не пытается пометить предложение.
Когда я щелкаю правой кнопкой мыши по грамматической ошибке (ошибка, отмеченная волнистым подчеркиванием), почему в контекстном меню не отображаются те же параметры, которые доступны в диалоговом окне «Орфография и грамматика»?
Например, если элемент помечен, а инструмент проверки грамматики не предлагает предложения, единственные доступные варианты — игнорировать предложение (и, возможно, пропустить другие ошибки в этом предложении) или щелкнуть команду грамматики, чтобы вызвать проверку орфографии. и диалоговое окно «Грамматика».
и диалоговое окно «Грамматика».
Для фонового режима (волнистые подчеркивания) инструмент проверки грамматики использует упрощенный интерфейс. Если вы хотите просмотреть все возможные ошибки в предложении, вы должны нажать Грамматика в контекстном меню.
Почему некоторые пары слов, которые часто путают, работают только в одном направлении?
Например, в средстве проверки грамматики слова «блоха» и «бегство» помечены как слова, которые часто путают, но с парой «ваш» и «вы» только слово «ваш» помечается как часто путают слово.
Средство проверки грамматики однонаправленно обрабатывает некоторые часто путающие пары слов, чтобы упростить задачу для синтаксического анализатора. Инструмент проверки грамматики был разработан таким образом, чтобы уменьшить количество элементов, которые помечаются инструментом проверки грамматики, но не являются истинными грамматическими ошибками.
Если предложение помечено как слишком длинное, почему это единственный совет для предложения?
Длинные предложения часто трудно читать как для людей, так и для средства проверки грамматики. Инструмент проверки грамматики недостаточно сложен, чтобы обнаруживать грамматические ошибки в длинных предложениях. Если вы сомневаетесь в грамматической точности длинного предложения, вам следует разбить его на более мелкие предложения.
Инструмент проверки грамматики недостаточно сложен, чтобы обнаруживать грамматические ошибки в длинных предложениях. Если вы сомневаетесь в грамматической точности длинного предложения, вам следует разбить его на более мелкие предложения.
Почему средство проверки правописания игнорирует текст, заключенный в кавычки?
Средство проверки грамматики предполагает, что текст в прямой цитате не подлежит критике.
Почему средство проверки грамматики игнорирует текст во вложенных документах, таких как верхние и нижние колонтитулы и аннотации?
По умолчанию средство проверки грамматики не анализирует текст в верхних, нижних колонтитулах или примечаниях.Верхние и нижние колонтитулы обычно не содержат полных предложений. Точно так же аннотации могут быть написаны фрагментами предложений и не подходят для проверки грамматики.
Почему я не могу изменить параметры грамматики и стиля письма по умолчанию, например длину предложения?
Эти значения по умолчанию встроены в грамматику и стиль письма.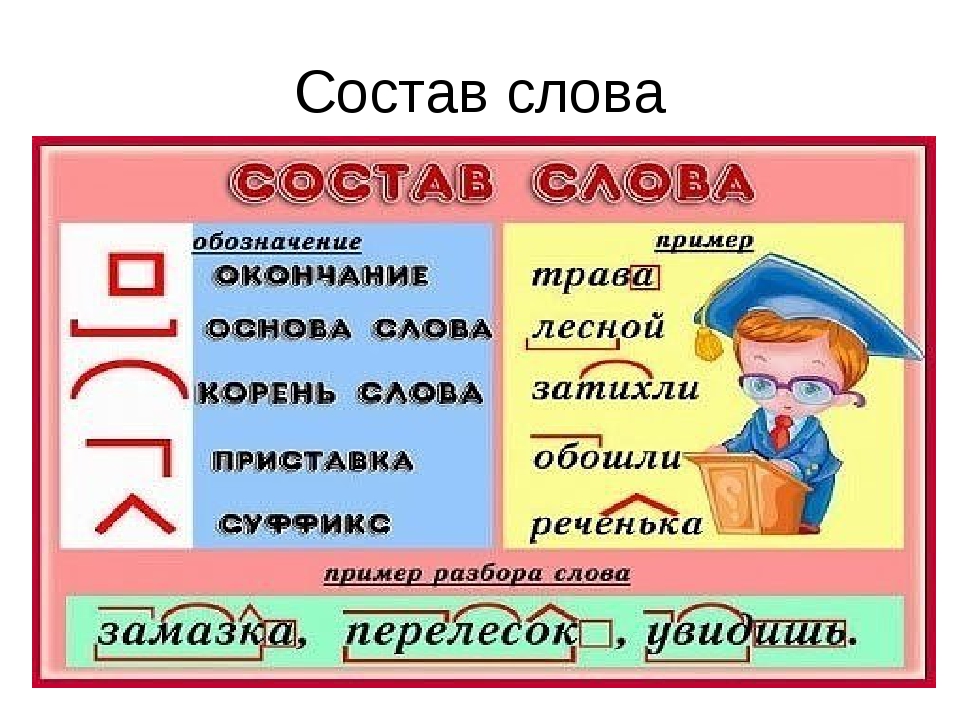 По умолчанию встроены грамматика и стиль письма:
По умолчанию встроены грамматика и стиль письма:
В следующей таблице перечислены конкретные значения по умолчанию для встроенной грамматики и стиля письма.
Параметр стиля Встроенная настройка
—————————————— —————-
Длина длинного предложения 60 слов
Последовательные существительные более 3
Последовательные предложные фразы более 3
Слова в раздельных инфинитивах более 1
Что означает грамматическая статистика?
Когда Microsoft Word завершит проверку орфографии и грамматики, он может отобразить информацию об уровне чтения документа, включая оценки читабельности (см. Вопрос 20).Каждый показатель удобочитаемости основан на среднем количестве слогов в слове и слов в предложении.
Текст оценивается по 100-балльной шкале; чем выше оценка, тем легче понять документ. Для большинства стандартных документов стремитесь набрать примерно от 60 до 70 баллов.
На каких формулах основана эта статистика?
Оценка Flesch Reading Ease
Формула для оценки Flesch Reading Ease:
206.835 — (1,015 x ASL) — (84,6 x ASW)
где:
ASL = средняя длина предложения (количество слов, деленное на количество предложений)
ASW = среднее количество слогов в слове (количество слогов деленное на количество слов)
Оценка уровня успеваемости Флеша-Кинкейда
Оценка уровня успеваемости Флеша-Кинкейда оценивает текст на уровне начальной школы США. Например, оценка 8,0 означает, что восьмиклассник может понять документ. Для большинства стандартных документов стремитесь набрать примерно 7 баллов.От 0 до 8,0.
Формула для оценки уровня успеваемости Флеша-Кинкейда:
(0,39 x ASL) + (11,8 x ASW) — 15,59
где:
ASL = средняя длина предложения (количество слов, деленное на количество предложений)
ASW = среднее количество слогов в слове (число слогов, разделенных на количество слов)
Кто использует эти стандарты чтения?
Различные государственные учреждения требуют, чтобы определенные документы или формы соответствовали определенным стандартам удобочитаемости.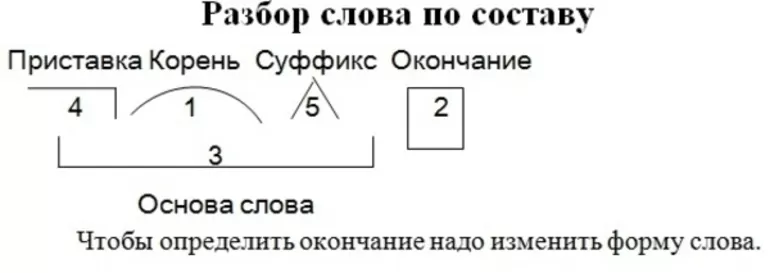 Например, в некоторых штатах требуется, чтобы у страховых бланков была определенная оценка удобочитаемости.
Например, в некоторых штатах требуется, чтобы у страховых бланков была определенная оценка удобочитаемости.
Сколько слов и фраз в грамматическом словаре?
Грамматический словарь включает около 99 000 слов и словосочетаний в их неизменяемой форме. (То есть в это число не входят такие слова, как «go», «children» и т. Д., Которые являются изменяемыми формами «go» и «child».)
На чем основан грамматический словарь?
Он основан на Словаре современного английского языка Лонгмана и Словаре английского языка американского наследия, третье издание.
Чем отличается средство проверки грамматики английского языка, если я использую его для текста на английском языке в Великобритании и на английском языке в США?
Разница между проверкой текста на английском и американском языках заключается, прежде всего, в различиях в орфографии между двумя языками. Например, «цвет» в отличие от «цвет». Эти отклонения не влияют на грамматику.
Большинство грамматических правил применимо ко всему английскому тексту (США и U.К.). Однако некоторые грамматические правила различаются в зависимости от выбранного языка:
Множественные предварительные модификаторы, которые очень часто используются в британском английском, помечаются не для британского английского, а для американского английского.
Соглашение между подлежащим и глаголами с собирательными существительными, где глагол используется во множественном числе, не помечается в британском английском, а помечается в U.С. Английский. См. Следующий пример:
В ближайшее время команда планирует мобилизацию.
Почему некоторые объяснения не связаны с отмеченной ошибкой?
Например, в предложении
Пойдем домой. объяснение в инструменте проверки грамматики не упоминает конкретно сбивающую с толку пару let / let.
объяснение в инструменте проверки грамматики не упоминает конкретно сбивающую с толку пару let / let.
Грамматические пояснения предназначены для охвата наиболее общих случаев в рамках каждого правила, чтобы не перегружать текст на экране.
Шаблоны резюме из 7 Word (и как их использовать)
Вы, вероятно, знакомы с ужасом, когда вы смотрите на пустой документ и видите мигающий курсор, который только и ждет, когда вы начнете писать, независимо от того, думаете ли вы о давно ушедшей школе задания или тот отчет, который вы должны были отправить своему боссу вчера. А когда дело доходит до вашего резюме — документа, который стоит между вами и вашей следующей работой, — ставки могут казаться особенно высокими.
Хорошая новость в том, что вам не нужно начинать с нуля, когда вы пишете резюме.Существует множество шаблонов резюме, которые вы можете использовать. А поскольку начало работы с шаблоном избавляет от множества решений о форматировании и интервале, вы можете сосредоточиться на содержании своего резюме, так что вы можете начать работу и получить работу.
Плохая новость заключается в том, что очень быстро ваша первая проблема (пустой документ) становится совершенно новой проблемой: как вообще выбрать правильный шаблон ?
Начать с Microsoft Word — разумный ход.По словам Аманды Августин, карьерного эксперта и составителя резюме TopResume, файлы с расширением «.docx» являются наиболее безопасными для отправки в систему отслеживания кандидатов (ATS), программное обеспечение, которое компании используют для организации и анализа приложений и выявления наиболее многообещающие кандидаты на определенную роль (часто до того, как человек когда-либо участвует). Поскольку .docx — это формат, совместимый со всеми системами, а некоторые системы по-прежнему не могут правильно анализировать .pdf и другие форматы, вам может быть выгодно работать в Word.
Вот все, что вам нужно знать о поиске, выборе и использовании шаблонов резюме Microsoft Word, а также несколько примеров шаблонов, которые вы можете использовать бесплатно (или дешево!).
Как найти шаблоны резюме Word
Вы можете найти бесплатные шаблоны резюме Word прямо в программе — в последних версиях, щелкнув «Файл»> «Создать из шаблона» и прокрутив или выполнив поиск «резюме». Здесь вы также можете искать шаблоны резюме, предлагаемые Microsoft Office, в Интернете.
Если вам нужен шаблон Word, но не обязательно тот, который поступает непосредственно из библиотеки Microsoft, вы можете обратиться к Jobscan, Hloom и другим источникам за бесплатными шаблонами или заплатить за один на таких сайтах, как Etsy. Некоторые карьерные коучи также предлагают оригинальные шаблоны на своих веб-сайтах (например, здесь вы можете найти шаблоны карьерного коуча Muse Йены Вивиано).
Как правильно выбрать шаблон резюме в Word
Когда вы впервые начинаете поиск шаблона, количество вариантов может показаться огромным.Как узнать, какой выбрать?
Самая важная вещь, о которой следует помнить, заключается в следующем: просто потому, что шаблон находится в библиотеке Microsoft или доступен в Интернете, это не значит, что это хороший шаблон , который поможет вашему резюме пройти через ATS и понравится рекрутерам. и менеджеры по найму. «Часто они разрабатываются, потому что выглядят действительно круто и красиво, и они вам нравятся», — говорит Августин.
и менеджеры по найму. «Часто они разрабатываются, потому что выглядят действительно круто и красиво, и они вам нравятся», — говорит Августин.
Но не все шаблоны одинаковы, предупреждает Джон Шилдс, менеджер по маркетингу Jobscan.«Некоторые из них довольно хороши, а некоторые очень плохи». Вот несколько советов, которые помогут вам понять разницу:
1. Выберите макет, который вам подходит
Резюме, как и работа, подходят так же, как и все остальное. Итак, помимо хорошего и плохого, вы ищете шаблон, который имеет смысл для того, кто вы есть и каковы ваши цели.
Ваш первый шаг — выбрать общий формат резюме — хронологический, комбинированный (также называемый гибридным) или функциональный. (Если вы не знаете, какой из них вам подходит, ознакомьтесь с нашим руководством по выбору здесь.)
Хронологический и комбинированный форматы хорошо подходят для ATS, а также для рекрутеров и менеджеров по найму, но будьте осторожны с функциональным резюме. Помимо отключения ATS, который обычно не запрограммирован на анализ вашей информации в таком порядке, функциональные резюме «действительно ненавидят рекрутеры и менеджеры по найму», — говорит Шилдс, потому что они «затрудняют понимание вашей карьерной траектории и того, где вы развил свои навыки ».
Вам также следует хорошо подумать о том, что вы можете поместить «над сгибом», или в верхней трети или половине документа.Люди склонны сосредотачивать на нем больше внимания, поэтому «это должен быть моментальный снимок всего, что им действительно нужно знать о вас», — говорит Августин. Спросите себя, говорит она: «Что наиболее важно в вашем прошлом, что применимо к текущей работе?»
Если вы, например, еще учитесь в школе или недавно закончили школу, вам может потребоваться шаблон, в котором вы можете поставить свое образование на первое место, или вы можете выбрать тот, который позволит вам подчеркнуть свою отличную стажировку прошлым летом. С другой стороны, если у вас есть большой опыт, вам может понадобиться шаблон, который позволит вам начать с резюме резюме или раздела с указанием ключевых достижений.А если вы работаете в технической сфере, вы можете разместить вверху раздел навыков, чтобы выделить программное обеспечение, которое вы использовали, или языки, на которых вы кодируете.
Хотя может быть проще найти шаблон, который уже настроен с точные разделы, которые вы хотите, в точных местах, которые вы хотите, помните, что вы также можете настроить любой шаблон в соответствии с вашими потребностями.
Если вам не сразу понятно, в каком направлении двигаться, ничего страшного! Шилдс рекомендует попробовать несколько разных шаблонов и посмотреть, какой из них лучше всего представляет ваш опыт.
2. Убедитесь, что места достаточно
В некоторых случаях шаблон «выглядит действительно красиво, но на самом деле не дает места, которое вам нужно, чтобы должным образом уделить предыдущему опыту должное внимание», — говорит Августин. Конечно, вы должны быть краткими, но вы также хотите, чтобы у вас было место для включения самых важных моментов, не уменьшая шрифт до неразборчивого размера.
В то же время вы хотите выбрать чистый шаблон с или пустым пространством, — говорит Вивиано.Вы же не хотите, чтобы резюме было слишком «забитым словами».
3. Не слишком наворочен
Хотя вас могут привлечь яркие и необычные шаблоны резюме, на самом деле лучше всего выбрать простой и относительно консервативный дизайн — даже в творческих сферах. Хотя немного цвета может быть отличным способом выделить ваше резюме, например, вы, вероятно, не захотите выбирать шаблон, который кричит и кричит 17 различными яркими цветами. Вы также захотите использовать только один или два шрифта.
И держитесь подальше от пузырей, звездочек, гистограмм и других бессмысленных способов измерения вашего мастерства в различных навыках. «Если не используется стандартная система выставления оценок или оценок, это кажется субъективным», — говорит Августин. «На самом деле это не помогает читателю по-настоящему понять вашу компетенцию».
Самое главное, избегайте шаблонов, которые слишком креативны в том, где вы помещаете важную информацию и как вы ее представляете. И ATS, и любые люди, просматривающие ваше приложение, «хотят, чтобы резюме были очень ясными и легко интерпретируемыми, чтобы не было путаницы в том, где находится ключевая информация и что означает каждый раздел», — говорит Шилдс.
Это означает соблюдение условностей. «Во многих случаях простое лучше», — говорит Августин. «Помимо ATS, рекрутеры привыкли искать информацию в определенных областях, и если вы решите пойти на мошенничество и начать размещать вещи в разных местах, это не обязательно будет означать:« О, этот рекрутер потратит дополнительное время, глядя на мое резюме для этой информации », — говорит она. «Они будут быстро смотреть, не видя того, чего хотят, и переходить к следующему».
4.Следите за блокировщиками ATS
ATS часто действует как привратник для кадровых агентств или менеджеров по найму, выполняя первую проверку заявок. Как только система определит наиболее перспективных клиентов на основе ключевых слов и других сигналов, которые она запрограммировала улавливать, человек может не выйти за пределы этой кучи. Так что вы должны обратить внимание на красные флажки, которые могут помешать вашему резюме преодолеть первое препятствие. Обратите внимание на:
- Верхние и нижние колонтитулы: Вы никогда не захотите помещать какую-либо информацию в фактические разделы верхнего и нижнего колонтитула вашего документа Word, говорит Августин, потому что он не всегда анализируется правильно (или вообще) АТС.
- Названия разделов: Убедитесь, что вы помечаете разделы четко и просто, независимо от того, что было в исходном шаблоне. «Если вы выйдете слишком нестандартно, те алгоритмы синтаксического анализа, которые помещают эту информацию в цифровой профиль кандидата, начинают сбиваться с толку», — говорит Шилдс. Если система запрограммирована на поиск раздела под названием «Опыт работы» или «Профессиональный опыт» и другого раздела под названием «Образование», ATS может не распознать какие-либо неортодоксальные ярлыки, которые вы использовали, и не будет знать, что с ними делать. информация под ними.
- Изображения и графики: ATS в основном игнорирует любые изображения, говорит Августин, поэтому вы не захотите использовать их, особенно в качестве причудливого способа указать свое имя или любую другую важную информацию.
- Текстовые поля: Несмотря на то, что вы вводите слова в текстовое поле, оно «считается объектом, поэтому не может быть проанализировано должным образом», — говорит Августин.
- Гиперссылки: Если вы добавите ссылку к строке слов в одном из пунктов маркированного списка, есть вероятность, что ATS проанализирует только URL и проигнорирует фактические слова, объясняет Августин.Поэтому убедитесь, что гиперссылка идет от «(ссылка)» или «(веб-сайт)», а не от такого важного текста, как «увеличено на 25%» или «приносит доход в размере 5 миллионов долларов».
- Столбцы: «Многие ATS с трудом анализируют текст бок о бок», — говорит Шилдс. «Он будет читать слева направо независимо от разделителей столбцов, объединяя содержимое двух несвязанных разделов». Это еще одна причина склоняться к «более классическим резюме, в котором нет таблиц и столбцов», — говорит он. По словам Августина, хотя некоторые системы могут читать некоторые столбцы, безопаснее держаться подальше.
- Шрифты: Найдите шаблон, в котором используется относительно общий шрифт. Мало того, что люди оценят чистый, ясный шрифт, ATS не всегда может прочитать нестандартные или непонятные шрифты. Августин говорит, что могут работать как шрифты с засечками, так и без засечек, а безопасные шрифты включают (но не ограничиваются ими): Calibri, Arial, Trebuchet, Book Antiqua, Garamond, Cambria и Times New Roman.
- Frames: Помещение рамки или рамки по всему периметру вашего резюме — это «большое ATS нет-нет», — говорит Августин.


 Августин говорит, что могут работать как шрифты с засечками, так и без засечек, а безопасные шрифты включают (но не ограничиваются ими): Calibri, Arial, Trebuchet, Book Antiqua, Garamond, Cambria и Times New Roman.
Августин говорит, что могут работать как шрифты с засечками, так и без засечек, а безопасные шрифты включают (но не ограничиваются ими): Calibri, Arial, Trebuchet, Book Antiqua, Garamond, Cambria и Times New Roman.Конечно, вы всегда можете внести изменения в существующий шаблон. Так что, если есть рамка, вы можете просто удалить ее. Если место для вашего имени находится в заголовке, вы можете переместить его в основной текст. Или, если шрифт неясный, вы можете изменить его на более распространенный.
Другими словами, вам не нужно сразу отклонять шаблон, потому что он содержит один из этих элементов. Но вы, возможно, захотите избежать шаблона, в котором так много блокировщиков ATS, что вам придется выполнять гимнастику форматирования, чтобы довести его до приемлемого базового уровня.
5. Избегайте шаблонов резюме с фотографиями
Шилдс заметил, что веб-сайты с шаблонами имеют тенденцию к использованию фото резюме, которые распространены во многих странах по всему миру. Однако, по словам Шилдса, соискателям работы в США следует избегать снимков в голову, как для ATS, так и для людей, которые могут рассмотреть ваше заявление.
С технической точки зрения, ATS не сможет проанализировать изображение, поэтому в лучшем случае оно просто упадет, когда система создаст ваш цифровой профиль.Но более тревожным является сценарий, в котором изображение вызывает проблемы с форматированием или ошибки синтаксического анализа, которые могут повлиять на то, как система читает остальную часть вашего резюме.
И помимо ATS, «мы из первых уст слышали от многих рекрутеров, которые даже не проверяют кандидатов, приславших фотографии», — говорит Шилдс. «Они просто не могут сделать себя более уязвимыми перед любыми возможными жалобами на дискриминацию». И вы также не хотите подвергаться действительной дискриминации.
Суть в том, говорит Вивиано, что, если вы не модель или актер, ваше фото не должно быть в вашем резюме. По сути, вы «занимает много места в своем резюме [чем-то], что не должно иметь никакого отношения к тому, кто вас нанимает».
Как использовать шаблон для создания резюме в Word
Итак, вы нашли один или два шаблона, которые вам действительно нравятся, и готовы сесть и составить свое резюме. Что теперь?
1. Соберите всю свою информацию
«Прежде чем вы начнете, найдите время, чтобы собрать всю информацию, которая могла бы быть использована для написания вашего резюме», — говорит Августин.
Если у вас есть предыдущее резюме, над которым вы работаете, убедитесь, что оно у вас под рукой. Вы также можете сесть и создать документ, включающий каждую прошлую работу, навыки и достижения, которые вы можете использовать в качестве источника для рисования. Или вы можете заполнить этот рабочий лист. Когда у вас будет весь контент, будет проще легко вставить его в шаблон.
2. Не бойтесь изменять шаблон
Шаблоны не высечены в камне. Помните, что вы можете и должны вносить изменения по мере необходимости, чтобы шаблон работал на вас.
Для начала вы по-прежнему увидите множество шаблонов, которые по-прежнему включают разделы для утверждения цели или для ваших ссылок, даже если оба являются устаревшими элементами, которым больше не место в вашем резюме.
Это нормально, если вы настроены на шаблон, в котором есть эти разделы, но убедитесь, что вы удалили или преобразовали их. Раздел с целью может легко стать местом для резюме резюме, например, или использоваться для перечисления ваших ключевых навыков, в то время как раздел ссылок может превратиться в раздел волонтерства или наград.
Помимо избавления от устаревших разделов, вы можете внести любые изменения, которые, по вашему мнению, помогут вам представить лучшую версию себя для этой роли. «Шаблон резюме может служить отличным руководством, но иногда он принесет больше вреда, чем пользы, если вы измените свой опыт в соответствии с шаблоном, а не наоборот», — говорит Шилдс. «Поэтому, если у вас нет ничего для определенного раздела в шаблоне, удалите его. Если вы хотите добавить дополнительную информацию, которая, по вашему мнению, укрепляет вашу позицию, добавьте ее », — говорит он.«Просто будьте осторожны, сохраняйте единообразное форматирование и сосредоточьтесь на удобочитаемости».
Предположим, вы нашли понравившийся вам шаблон, который поможет вам в работе, но вы действительно хотите выделить свои ключевые навыки в верхней части. Не стесняйтесь добавить еще один раздел, используя тот же шрифт и стиль заголовка. С другой стороны, если вы используете шаблон, в котором есть раздел наград и благодарностей, но вы бы предпочли продемонстрировать свой волонтерский опыт или дополнительные навыки, измените его.
Помните также, что шаблон — это просто шаблон.«Это дает вам основу для работы», — говорит Августин, но вам все равно придется приложить усилия, чтобы решить, какие достижения и навыки следует выделить и как лучше всего сформулировать свои маркеры.
3. Вставьте или впишите свою информацию
Когда вы, наконец, будете готовы поместить весь свой опыт работы и достижения в шаблон и сделать его своим, Вивиано рекомендует вам «сначала завершить простые вещи», например, ваше имя контактная информация и ваше образование.«Это будет похоже на быструю победу». Затем продолжайте заполнять остальные.
Облегчите себе жизнь позже, вставив информацию только в виде текста — без форматирования, которое было в предыдущем резюме, в подготовительном документе или в заполненном вами рабочем листе. Используйте этот трюк с копированием и вставкой, чтобы убедиться, что все, что вы туда помещаете, соответствует форматированию шаблона. В противном случае вы можете «потратить нелепое количество времени, пытаясь снова установить правильный интервал», — говорит Августин.
Наконец, убедитесь, что вы заменили или удалили весь фиктивный текст и все инструкции, которые были в шаблоне, когда вы его получили!
4.Проверьте, как это будет в ATS
Если вы хотите проверить, как ваше новое резюме будет работать, когда оно пройдет через ATS, вы можете попробовать одно из двух:
Скопируйте все в свой документ Word и вставьте все это в простой текстовый документ. «Если некоторые вещи превращаются в странных персонажей, — говорит Августин, — если разделы находятся далеко от того места, где они должны быть, или если все не в порядке, то это, вероятно, произойдет, если они будут проанализированы».
Запустите его с помощью онлайн-инструмента, такого как Jobscan, или запросите бесплатную критику в такой службе, как TopResume.
5. Перечитайте и подтвердите!
По словам Августина, опечатки и орфографические ошибки часто мешают рекрутерам. И было бы обидно попасть в кучу «нет» из-за мелких ошибок. Поэтому убедитесь, что вы исправили свое резюме — может быть, дважды, а может быть, отойдя от него на несколько часов — и посмотрите, сможете ли вы передать его другу или члену семьи, чтобы он взглянул свежим взглядом.
Перечитывание вашего резюме как полного документа — это также возможность представить себе первое впечатление, которое вы произведете.«Многие люди … так увлеклись редактированием резюме и тем, чтобы оно было настолько оптимизировано, что оно стало резюме, похожим на робота», — говорит Вивиано. Итак, пока вы читаете, подумайте: это звучит так, как будто это написал человек? Какую историю ты рассказываешь? Очевидно ли, что вы подходите для той должности, на которую претендуете?
7 шаблонов Microsoft Word для использования в качестве отправных точек
Все еще не можете выбрать шаблон после всего этого? Вот несколько из них, которые могут сработать — мы добавили советы по улучшению и настройке каждого из них.
1. Резюме Genius’s Dublin Template
Кто может его использовать? Всем, кто ищет традиционное хронологическое резюме!
Предостережения:
- Вам не нужно указывать полный адрес (достаточно указать город и штат).
- Добавьте свой профиль LinkedIn вместе с другой контактной информацией, чтобы рекрутер или менеджер по найму мог перейти на вашу страницу и найти дополнительную информацию о вашем опыте, увидеть яркие рекомендации, которые вы получили, просмотреть образцы работы, которые вы разместили, и получить в восторге от вас как кандидата.(Просто убедитесь, что ваш профиль обновлен!)
- Не включайте свой средний балл, если вы не недавний выпускник, и он впечатляет.
Стоимость: Бесплатно
Скачайте здесь.
2. Недавний шаблон Grad 1 от JobScan
Кто может его использовать? Недавний выпускник, имеющий стажировку или опыт работы, соответствующий их целевой области или должности, а также другой опыт.
Предостережения:
- Вам не нужно указывать свой почтовый индекс.
- Не включайте свой средний балл, если вы не недавний выпускник, и он впечатляет.
Стоимость: Бесплатно
Скачайте здесь.
3. Базовый шаблон резюме Microsoft Office
Кто может его использовать? Недавний выпускник, у которого нет большого опыта работы.
Предостережения:
- Поместите свое имя в одну строку (вместо двух строк, как по умолчанию), чтобы ATS записал ваше полное имя.
- Попытайтесь различить заголовки разделов в каждой записи о вакансии и образовании, изменив размер или стиль шрифта.
- Добавьте свой профиль LinkedIn рядом со своей контактной информацией и помните, что вам не нужно указывать полный адрес (достаточно указать город и штат).
Стоимость: Бесплатно
Найдите в Microsoft Word.
4. Шаблон резюме Get Landed для ATS
Кто может его использовать? Кто-то ищет шаблон, который можно было бы легко настроить как хронологическое или комбинированное резюме, в зависимости от того, где вы разместили этот раздел навыков.
Предостережения:
- Если вы не недавний выпускник, вам, вероятно, не следует получать такое высокое образование.
Стоимость: $ 10
Скачайте здесь.
5. ResumeByRecruiters ‘ATS Resume на Etsy
Кто может его использовать? Кто-то ищет шаблон, который можно было бы легко настроить как хронологическое или комбинированное резюме (переместив раздел навыков наверх).
Предостережения:
- Добавьте свой профиль LinkedIn вместе со своей контактной информацией.
Стоимость: Около 12 долларов США
Загрузите его здесь.
6. Классические хронологические и гибридные шаблоны JobScan
Кто может им воспользоваться? Кто-то ищет простой шаблон без излишеств.
Предостережения:
- Вам не нужно указывать свой почтовый индекс.
- Постарайтесь уместить все на одной странице.
Стоимость: Бесплатно
Скачайте их здесь.
7. Резюме шаблона Белого дома Genius
Кто может его использовать? Кто-то ищет шаблон с большим количеством белого пространства.
Предостережения:
- Вам не нужен полный адрес; города и штата достаточно.
- Добавьте свой профиль в LinkedIn.
- Не используйте ли , а не раздел цели резюме. Вы можете заменить это резюме или полностью избавиться от него.
Стоимость: Бесплатно
Скачайте здесь.
Ошибка Word: ошибка синтаксического анализа XML
При экспорте отчета иногда проблемы не возникают, пока вы не откроете документ Word. Если вас приветствуют следующие подробности сообщения об ошибке, используйте это руководство для отладки и устранения ошибки:
Ошибка синтаксического анализа XML
Расположение: Часть: /word/document.xml. Строка: 19159, Колонка: 8 Это, вероятно, наиболее распространенное сообщение об ошибке, которое выдает документ Word. Поскольку это настолько общий характер, не существует быстрого универсального решения проблемы.Но Location действительно дает нам возможность быстро определить источник ошибки, чтобы мы могли ее устранить.
Чтобы устранить эту ошибку:
Переименуйте файл с
.docxили.docmв.zip. Например, переименуйте dradis-word_report-151.docm в dradis-word_report-151.zip .Разархивируйте файл и откройте новую папку (например, dradis-word_report-151/).Откройте файл, указанный в
Locationвыше, в вашем любимом текстовом редакторе (например, /word/document.xml ).Прокрутите вниз до конкретной строки, указанной в сообщении об ошибке (например, Строка 19159 , и проверьте содержимое до / после этой строки.
Источник ошибки может быть до или после конкретной строки, указанной в сообщении об ошибке. По сути, мы ищем текстовую строку как можно ближе к конкретной строке, чтобы мы могли найти источник ошибки в нашем проекте Dradis.
Найдите в своем проекте строку, найденную выше, и исследуйте ее содержимое.
Если вы не можете найти ничего интересного вокруг первой строки поиска, попробуйте вернуться к XML и использовать строку поиска из содержимого непосредственно после строки, указанной в сообщении об ошибке.
И, если вы не можете найти ничего подозрительного в проекте Dradis, попробуйте проверить свой шаблон отчета Dradis на предмет «Сумасшедших треугольников».
После устранения ошибки в проекте Dradis попробуйте снова экспортировать отчет.Если вы получите еще одну ошибку синтаксического анализа
XML, обязательно проверьте новое расположение, указанное в сообщении об ошибке.
Например, если строка в сообщении об ошибке идет после строки, которая ссылается на:
HTTP-сервер Apache 1.3 Ожидает межсайтового скриптинга заголовка
Найдите в своем проекте Apache 1.3 HTTP и изучите его содержимое.
Обратите внимание на ссылки, которые имеют странный формат, код / специальные символы, не заключенные в блок кода, или ошибочные восклицательные знаки.
Автоматизируйте скучную работу с Python
Документы PDF и Word представляют собой двоичные файлы, что делает их намного более сложными, чем файлы с открытым текстом. Помимо текста, они хранят много информации о шрифтах, цвете и макете. Если вы хотите, чтобы ваши программы могли читать или писать в PDF-файлы или документы Word, вам нужно будет сделать больше, чем просто передать их имена в open () .
К счастью, есть модули Python, которые упрощают взаимодействие с документами PDF и Word. В этой главе будут рассмотрены два таких модуля: PyPDF2 и Python-Docx.
PDF означает Portable Document Format и использует расширение файла .pdf . Хотя PDF-файлы поддерживают множество функций, в этой главе основное внимание будет уделено двум вещам, которые вы будете с ними делать чаще всего: чтению текстового содержимого из PDF-файлов и созданию новых PDF-файлов из существующих документов.
Модуль, который вы будете использовать для работы с PDF-файлами, — это PyPDF2. Чтобы установить его, запустите pip install PyPDF2 из командной строки. Это имя модуля чувствительно к регистру, поэтому убедитесь, что y в нижнем регистре, а все остальное — в верхнем регистре. (См. Приложение A для получения полной информации об установке сторонних модулей.) Если модуль был установлен правильно, запуск import PyPDF2 в интерактивной оболочке не должен отображать никаких ошибок.
Извлечение текста из PDF-файлов
PyPDF2 не имеет способа извлекать изображения, диаграммы или другие носители из документов PDF, но он может извлекать текст и возвращать его как строку Python.Чтобы начать изучение того, как работает PyPDF2, мы будем использовать его в примере PDF, показанном на рисунке 13-1.
Рисунок 13-1. Страница PDF, из которой мы будем извлекать текст из
Загрузите этот PDF-файл с веб-сайта http://nostarch.com/automatestuff/ и введите в интерактивную оболочку следующее:
>>> импорт PyPDF2
>>> pdfFileObj = open ('meetingminutes.pdf', 'rb')
>>> pdfReader = PyPDF2.PdfFileReader (pdfFileObj)
❶ >>> pdfReader.numPages
19
❷ >>> pageObj = pdfReader.getPage (0)
❸ >>> pageObj.extractText ()
Заседание OOFFFFIICCIIAALL BBOOAARRDD MMIINNUUTTEESS от 7 марта 2015 г.
\ n Совет начального и среднего образования обеспечивает руководство
и разработать политику в области образования, которая расширяет возможности для детей,
расширять возможности семей и сообществ и продвигать Луизиану во все более
конкурентный глобальный рынок.КОЛЛЕГИЯ НАЧАЛЬНОГО И СРЕДНЕГО ОБРАЗОВАНИЯ ' Сначала импортируйте модуль PyPDF2 . Затем откройте файл meetingminutes.pdf в двоичном режиме чтения и сохраните его в pdfFileObj . Чтобы получить объект PdfFileReader , представляющий этот PDF-файл, вызовите PyPDF2.PdfFileReader () и передайте ему pdfFileObj . Сохраните этот объект PdfFileReader в pdfReader .
Общее количество страниц в документе хранится в атрибуте numPages объекта PdfFileReader ❶.В примере PDF 19 страниц, но давайте извлечем текст только с первой страницы.
Чтобы извлечь текст со страницы, вам необходимо получить объект Page , который представляет одну страницу PDF-файла, из объекта PdfFileReader . Вы можете получить объект Page , вызвав метод getPage () ❷ для объекта PdfFileReader и передав ему номер страницы, которая вас интересует — в нашем случае 0.
PyPDF2 использует для получения страниц индекс с отсчетом от нуля : первая страница — это страница 0, вторая — это «Введение» и т. Д.Это всегда так, даже если страницы в документе пронумерованы по-разному. Например, предположим, что ваш PDF-файл представляет собой трехстраничный отрывок из более длинного отчета, а его страницы пронумерованы 42, 43 и 44. Чтобы получить первую страницу этого документа, вам нужно вызвать pdfReader.getPage (0) , а не getPage (42) или getPage (1) .
Получив объект Page , вызовите его метод extractText () , чтобы вернуть строку текста страницы ❸.Извлечение текста неидеально: текст Charles E. «Chas» Roemer, President из PDF-файла отсутствует в строке, возвращаемой функцией extractText () , а интервалы иногда отключены. Тем не менее, этого приближения к текстовому содержимому PDF может быть достаточно для вашей программы.
Некоторые PDF-документы имеют функцию шифрования, которая предотвращает их чтение до тех пор, пока открывающий документ не предоставит пароль. Введите в интерактивную оболочку следующее с загруженным PDF-файлом, который был зашифрован паролем rosebud :
>>> импорт PyPDF2
>>> pdfReader = PyPDF2.PdfFileReader (open ('encrypted.pdf', 'rb'))
❶ >>> pdfReader.isEncrypted
Правда
>>> pdfReader.getPage (0)
❷ Отслеживание (последний звонок последний):
Файл "", строка 1, в
pdfReader.getPage ()
- снип -
Файл "C: \ Python34 \ lib \ site-packages \ PyPDF2 \ pdf.py", строка 1173, в getObject
поднять utils.PdfReadError («файл не расшифрован»)
PyPDF2.utils.PdfReadError: файл не расшифрован
❸ >>> pdfReader.decrypt ('бутон розы')
1
>>> pageObj = pdfReader.getPage (0) Все объекты PdfFileReader имеют атрибут isEncrypted , который имеет значение True , если PDF-файл зашифрован, и False , если это не так ❶. Любая попытка вызвать функцию, которая читает файл до того, как он был расшифрован с помощью правильного пароля, приведет к ошибке ❷.
Чтобы прочитать зашифрованный PDF-файл, вызовите функцию decrypt () и передайте пароль в виде строки ❸. После вызова decrypt () с правильным паролем вы увидите, что вызов getPage () больше не вызывает ошибки. Если задан неправильный пароль, функция decrypt () вернет 0 , а getPage () продолжит завершаться ошибкой. Обратите внимание, что метод decrypt () расшифровывает только объект PdfFileReader , а не фактический файл PDF.После завершения программы файл на жестком диске остается зашифрованным. Ваша программа должна будет снова вызвать decrypt () при следующем запуске.
PyPDF2 объектам PdfFileReader являются объекты PdfFileWriter , которые могут создавать новые файлы PDF. Но PyPDF2 не может записывать произвольный текст в PDF, как Python может делать с файлами с открытым текстом. Вместо этого возможности PyPDF2 по написанию PDF-файлов ограничиваются копированием страниц из других PDF-файлов, поворотом страниц, наложением страниц и шифрованием файлов.
PyPDF2 не позволяет напрямую редактировать PDF. Вместо этого вам нужно создать новый PDF-файл, а затем скопировать содержимое из существующего документа. Примеры в этом разделе будут следовать этому общему подходу:
Откройте один или несколько существующих PDF-файлов (исходных PDF-файлов) в объектах
PdfFileReader.Создайте новый объект
PdfFileWriter.Копирование страниц из объектов
PdfFileReaderв объектPdfFileWriter.Наконец, используйте объект
PdfFileWriterдля записи выходного PDF.
Создание объекта PdfFileWriter создает только значение, представляющее документ PDF в Python. Он не создает фактический файл PDF. Для этого вы должны вызвать метод PdfFileWriter write () .
Метод write () принимает обычный объект File , который был открыт в режиме записи с двоичной записью .Вы можете получить такой объект File , вызвав функцию Python open () с двумя аргументами: строка того, что вы хотите, чтобы имя файла PDF было, и 'wb' , чтобы указать, что файл должен быть открыт в двоичном формате записи режим.
Если это звучит немного запутанно, не волнуйтесь — вы увидите, как это работает, в следующих примерах кода.
PyPDF2 можно использовать для копирования страниц из одного документа PDF в другой. Это позволяет объединить несколько файлов PDF, вырезать ненужные страницы или изменить порядок страниц.
Загрузите meetingminutes.pdf и meetingminutes2.pdf из http://nostarch.com/automatestuff/ и поместите файлы PDF в текущий рабочий каталог. Введите в интерактивную оболочку следующее:
>>> импорт PyPDF2
>>> pdf1File = open ('meetingminutes.pdf', 'rb')
>>> pdf2File = open ('meetingminutes2.pdf', 'rb')
❶ >>> pdf1Reader = PyPDF2.PdfFileReader (pdf1File)
❷ >>> pdf2Reader = PyPDF2.PdfFileReader (pdf2File)
❸ >>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> для pageNum in range (pdf1Reader.numPages):
❹ pageObj = pdf1Reader.getPage (pageNum)
❺ pdfWriter.addPage (pageObj)
>>> для pageNum in range (pdf2Reader.numPages):
❻ pageObj = pdf2Reader.getPage (pageNum)
❼ pdfWriter.addPage (pageObj)
❽ >>> pdfOutputFile = open ('Combinedminutes.pdf', 'wb')
>>> pdfWriter.write (pdfOutputFile)
>>> pdfOutputFile.close ()
>>> pdf1File.close ()
>>> pdf2File.close () Откройте оба файла PDF в двоичном режиме чтения и сохраните два результирующих объекта File в pdf1File и pdf2File .Вызовите PyPDF2.PdfFileReader () и передайте ему pdf1File , чтобы получить объект PdfFileReader для meetingminutes.pdf ❶. Вызовите его снова и передайте pdf2File , чтобы получить объект PdfFileReader для meetingminutes2.pdf ❷. Затем создайте новый объект PdfFileWriter , который представляет собой пустой документ PDF ❸.
Затем скопируйте все страницы из двух исходных PDF-файлов и добавьте их в объект PdfFileWriter .Получите объект Page , вызвав getPage () для объекта PdfFileReader ❹. Затем передайте этот объект Page методу addPage () вашего PdfFileWriter ❺. Эти шаги выполняются сначала для pdf1Reader , а затем еще раз для pdf2Reader . Когда вы закончите копирование страниц, напишите новый PDF-файл с именем commonutes.pdf , передав объект File методу PdfFileWriter write () ❻.
Примечание
PyPDF2 не может вставлять страницы в середину объекта PdfFileWriter ; метод addPage () добавит страницы только в конец.
Вы создали новый PDF-файл, который объединяет страницы из meetingminutes.pdf и meetingminutes2.pdf в один документ. Помните, что объект File , переданный в PyPDF2.PdfFileReader () , необходимо открыть в двоичном режиме чтения, передав 'rb' в качестве второго аргумента функции open () . Аналогично, объект File , переданный в PyPDF2.PdfFileWriter () , необходимо открыть в двоичном режиме записи с 'wb' .
Страницы PDF-файла также можно поворачивать с шагом 90 градусов с помощью методов rotateClockwise () и rotateCounterClockwise () . Передайте в эти методы одно из целых чисел 90 , 180 или 270 . Введите в интерактивную оболочку следующее, с файлом meetingminutes.pdf в текущем рабочем каталоге:
>>> импорт PyPDF2
>>> minutesFile = open ('meetingminutes.pdf ',' rb ')
>>> pdfReader = PyPDF2.PdfFileReader (minutesFile)
❶ >>> page = pdfReader.getPage (0)
❷ >>> стр. Поворот по часовой стрелке (90)
{'/ Contents': [IndirectObject (961, 0), IndirectObject (962, 0),
- снип -
}
>>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> pdfWriter.addPage (page)
❸ >>> resultPdfFile = open ('rotatedPage.pdf ',' wb ')
>>> pdfWriter.write (resultPdfFile)
>>> результатPdfFile.close ()
>>> минутFile.close () Здесь мы используем getPage (0) для выбора первой страницы PDF ❶, а затем вызываем rotateClockwise (90) на этой странице ❷. Мы пишем новый PDF-файл с повернутой страницей и сохраняем его как rotatedPage.pdf ❸.
В результате PDF-файл будет содержать одну страницу, повернутую на 90 градусов по часовой стрелке, как показано на рисунке 13-2.Возвращаемые значения от rotateClockwise () и rotateCounterClockwise () содержат много информации, которую вы можете игнорировать.
Рисунок 13-2. Файл rotatedPage.pdf со страницей, повернутой на 90 градусов по часовой стрелке
PyPDF2 также может накладывать содержимое одной страницы на другую, что полезно для добавления на страницу логотипа, отметки времени или водяного знака. С Python легко добавлять водяные знаки в несколько файлов и только на страницы, указанные в вашей программе.
Загрузите watermark.pdf из http://nostarch.com/automatestuff/ и поместите PDF-файл в текущий рабочий каталог вместе с файлом meetingminutes.pdf . Затем введите в интерактивную оболочку следующее:
>>> импортировать PyPDF2
>>> minutesFile = open ('meetingminutes.pdf', 'rb')
❷ >>> pdfReader = PyPDF2.PdfFileReader (minutesFile)
❷ >>> minutesFirstPage = pdfReader.getPage (0)
❸ >>> pdfWatermarkReader = PyPDF2.PdfFileReader (open ('watermark.pdf', 'rb'))
❹ >>> minutesFirstPage.mergePage (pdfWatermarkReader.getPage (0))
❺ >>> pdfWriter = PyPDF2.PdfFileWriter ()
❻ >>> pdfWriter.addPage (minutesFirstPage)
❼ >>> для pageNum in range (1, pdfReader.numPages):
pageObj = pdfReader.getPage (pageNum)
pdfWriter.addPage (pageObj)
>>> resultPdfFile = open ('watermarkedCover.pdf', 'wb')
>>> pdfWriter.написать (resultPdfFile)
>>> minutesFile.close ()
>>> resultPdfFile.close () Здесь мы создаем объект PdfFileReader из meetingminutes.pdf ❶. Мы вызываем getPage (0) , чтобы получить объект Page для первой страницы и сохранить этот объект через minutesFirstPage ❷. Затем мы создаем объект PdfFileReader для watermark.pdf ❸ и вызываем mergePage () на minutesFirstPage ❹.Аргумент, который мы передаем в mergePage () , является объектом Page для первой страницы из watermark.pdf .
Теперь, когда мы вызвали mergePage () на minutesFirstPage , minutesFirstPage представляет первую страницу с водяными знаками. Мы создаем объект PdfFileWriter ❺ и добавляем первую страницу с водяным знаком ❻. Затем мы просматриваем остальные страницы в файле meetingminutes.pdf и добавляем их в объект PdfFileWriter ❼.Наконец, мы открываем новый PDF-файл с именем watermarkedCover.pdf и записываем содержимое PdfFileWriter в новый PDF-файл.
На рис. 13-3 показаны результаты. Наш новый PDF-файл, watermarkedCover.pdf , содержит все содержимое файла meetingminutes.pdf , а первая страница снабжена водяными знаками.
Рисунок 13-3. Исходный PDF-файл (слева), PDF-файл с водяным знаком (в центре) и объединенный PDF-файл (справа)
Объект PdfFileWriter также может добавлять шифрование в документ PDF.Введите в интерактивную оболочку следующее:
>>> импорт PyPDF2
>>> pdfFile = open ('meetingminutes.pdf', 'rb')
>>> pdfReader = PyPDF2.PdfFileReader (pdfFile)
>>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> для pageNum in range (pdfReader.numPages):
pdfWriter.addPage (pdfReader.getPage (pageNum))
❶ >>> pdfWriter.encrypt ('рыба-меч')
>>> resultPdf = open ('encryptedminutes.pdf', 'wb')
>>> pdfWriter.write (resultPdf)
>>> результатPdf.close () Перед вызовом метода write () для сохранения в файл вызовите метод encrypt () и передайте ему строку пароля ❶. PDF-файлы могут иметь пароль пользователя (позволяющий просматривать PDF-файлы) и пароль владельца (позволяющий устанавливать разрешения на печать, комментирование, извлечение текста и другие функции).Пароль пользователя и пароль владельца являются первым и вторым аргументами функции encrypt () соответственно. Если в encrypt () передан только один строковый аргумент, он будет использоваться для обоих паролей.
В этом примере мы скопировали страницы meetingminutes.pdf в объект PdfFileWriter . Мы зашифровали PdfFileWriter паролем swordfish , открыли новый PDF-файл с именем encryptedminutes.pdf и записали содержимое PdfFileWriter в новый PDF-файл.Прежде чем кто-либо сможет просмотреть файл encryptedminutes.pdf , он должен будет ввести этот пароль. Вы можете удалить исходный незашифрованный файл meetingminutes.pdf , убедившись, что его копия была правильно зашифрована.
Допустим, у вас скучная работа по объединению нескольких десятков PDF-документов в один PDF-файл. Каждая из них имеет титульный лист в качестве первой страницы, но вы не хотите, чтобы титульный лист повторялся в конечном результате. Несмотря на то, что существует множество бесплатных программ для объединения PDF-файлов, многие из них просто объединяют целые файлы вместе.Давайте напишем программу на Python, чтобы настроить, какие страницы вы хотите объединить в PDF.
На высоком уровне вот что будет делать программа:
Найти все файлы PDF в текущем рабочем каталоге.
Отсортируйте имена файлов, чтобы файлы PDF добавлялись по порядку.
Записывает каждую страницу, кроме первой, каждого PDF-файла в выходной файл.
С точки зрения реализации, ваш код должен будет сделать следующее:
Позвоните по телефону
os.listdir (), чтобы найти все файлы в рабочем каталоге и удалить все файлы, отличные от PDF.Вызовите метод списка Python
sort (), чтобы расположить имена файлов в алфавитном порядке.Создайте объект
PdfFileWriterдля выходного PDF-файла.Перебирайте каждый PDF-файл, создавая для него объект
PdfFileReader.Прокрутите каждую страницу (кроме первой) в каждом файле PDF.
Добавьте страницы в выходной PDF-файл.
Запишите выходной PDF-файл в файл с именем allminutes.pdf .
Для этого проекта откройте новое окно редактора файлов и сохраните его как combPdfs.py .
Шаг 1. Найдите все файлы PDF
Во-первых, ваша программа должна получить список всех файлов с расширением .pdf в текущем рабочем каталоге и отсортировать их.Сделайте так, чтобы ваш код выглядел следующим образом:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# в один PDF-файл.
❶ импортировать PyPDF2, os
# Получить все имена файлов PDF.
pdfFiles = []
для имени файла в os.listdir ('.'):
если filename.endswith ('. pdf'):
❷ pdfFiles.append (имя файла)
❸ pdfFiles.sort (ключ = str.lower)
❹ pdfWriter = PyPDF2.PdfFileWriter ()
# TODO: просмотреть все файлы PDF.# ЗАДАЧА: Прокрутите все страницы (кроме первой) и добавьте их.
# ЗАДАЧА: сохранить полученный PDF-файл в файл. После строки shebang и описательного комментария о том, что делает программа, этот код импортирует модули os и PyPDF2 ❶. Вызов os.listdir ('.') вернет список всех файлов в текущем рабочем каталоге. Код проходит по этому списку и добавляет только те файлы с расширением .pdf в pdfFiles ❷.После этого этот список сортируется в алфавитном порядке с помощью аргумента ключевого слова key = str.lower для функции sort () ❸.
Создается объект PdfFileWriter для хранения объединенных страниц PDF ❹. Наконец, несколько комментариев обрисовывают остальную часть программы.
Теперь программа должна читать каждый файл PDF в pdfFiles . Добавьте в свою программу следующее:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# один PDF-файл.импортировать PyPDF2, os
# Получить все имена файлов PDF.
pdfFiles = []
- снип -
# Просмотрите все файлы PDF.
для имени файла в pdf Файлы:
pdfFileObj = open (имя файла, 'rb')
pdfReader = PyPDF2.PdfFileReader (pdfFileObj)
# ЗАДАЧА: Прокрутите все страницы (кроме первой) и добавьте их.
# ЗАДАЧА: сохранить полученный PDF-файл в файл. Для каждого PDF-файла цикл открывает имя файла в двоичном режиме чтения, вызывая open () со вторым аргументом 'rb' .Вызов open () возвращает объект File , который передается в PyPDF2.PdfFileReader () для создания объекта PdfFileReader для этого файла PDF.
Для каждого PDF-файла вы захотите перебрать каждую страницу, кроме первой. Добавьте этот код в свою программу:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# один PDF-файл.
импортировать PyPDF2, os
- снип -
# Просмотрите все файлы PDF.для имени файла в pdfFiles:
- снип -
# Просмотрите все страницы (кроме первой) и добавьте их.
❶ для pageNum in range (1, pdfReader.numPages):
pageObj = pdfReader.getPage (pageNum)
pdfWriter.addPage (pageObj)
# ЗАДАЧА: сохранить полученный PDF-файл в файл. Код внутри цикла для копирует каждый объект Page индивидуально в объект PdfFileWriter .Помните, вы хотите пропустить первую страницу. Поскольку PyPDF2 считает 0 первой страницей, ваш цикл должен начинаться с 1 ❶, а затем увеличиваться, но не включать целое число в pdfReader.numPages .
После того, как эти вложенные циклы для будут выполнены в цикле, переменная pdfWriter будет содержать объект PdfFileWriter со страницами для всех объединенных PDF-файлов. Последний шаг — записать это содержимое в файл на жестком диске.Добавьте этот код в свою программу:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# один PDF-файл.
импортировать PyPDF2, os
- снип -
# Просмотрите все файлы PDF.
для имени файла в pdfFiles:
- снип -
# Прокрутите все страницы (кроме первой) и добавьте их.
для pageNum в диапазоне (1, pdfReader.numPages):
- снип -
# Сохраните полученный PDF-файл в файл.
pdfOutput = open ('allminutes.pdf', 'wb')
pdfWriter.write (pdfOutput)
pdfOutput.close () Передача 'wb' в open () открывает выходной PDF-файл, allminutes.pdf , в двоичном режиме записи. Затем передача результирующего объекта File методу write () создает фактический файл PDF. Вызов метода close () завершает программу.
Идеи для похожих программ
Возможность создавать PDF-файлы из страниц других PDF-файлов позволит вам создавать программы, которые могут делать следующее:
Вырезайте определенные страницы из PDF-файлов.
Изменение порядка страниц в PDF.
Создайте PDF-файл только из тех страниц, на которых есть определенный текст, идентифицированный с помощью
extractText ().
Python может создавать и изменять документы Word с расширением файла .docx с помощью модуля python-docx . Вы можете установить модуль, запустив pip install python-docx . (Приложение A содержит полную информацию об установке сторонних модулей.)
Примечание
При использовании pip для первой установки Python-Docx обязательно установите python-docx , а не docx . Имя установки docx относится к другому модулю, который не рассматривается в этой книге. Однако, когда вы собираетесь импортировать модуль python-docx , вам нужно будет запустить import docx , а не import python-docx .
Если у вас нет Word, LibreOffice Writer и OpenOffice Writer — это бесплатные альтернативные приложения для Windows, OS X и Linux, которые можно использовать для открытия .docx файлов. Вы можете загрузить их с https://www.libreoffice.org и http://openoffice.org соответственно. Полная документация по Python-Docx доступна по адресу https://python-docx.readthedocs.org/ . Хотя существует версия Word для OS X, в этой главе основное внимание будет уделено Word для Windows.
По сравнению с обычным текстом файлы .docx имеют большую структуру. Эта структура представлена в Python-Docx тремя разными типами данных.На самом высоком уровне объект Document представляет весь документ. Объект Document содержит список объектов Paragraph для абзацев в документе. (Новый абзац начинается всякий раз, когда пользователь нажимает ENTER или RETURN при вводе документа Word.) Каждый из этих объектов Paragraph содержит список из одного или нескольких объектов Run . Абзац из одного предложения на рис. 13-4 состоит из четырех частей.
Рисунок 13-4.Объекты Run , идентифицированные в объекте Paragraph
Текст в документе Word — это больше, чем просто строка. С ним связаны шрифт, размер, цвет и другая информация о стиле. Стиль в Word представляет собой набор этих атрибутов. Объект Run — это непрерывный фрагмент текста одного стиля. При изменении стиля текста требуется новый объект Run .
Давайте поэкспериментируем с модулем python-docx .Загрузите demo.docx из http://nostarch.com/automatestuff/ и сохраните документ в рабочем каталоге. Затем введите в интерактивную оболочку следующее:
>>> импорт docx
❶ >>> doc = docx.Document ('demo.docx')
❷ >>> len (док. Параграфы)
7
❸ >>> док. Абзацы [0]. Текст
'Заголовок документа'
❹ >>> док. Абзацев [1].текст
'Простой абзац с полужирным шрифтом и курсивом'
❺ >>> len (док. Параграфы [1] .runs)
4
❻ >>> doc.paragraphs [1] .runs [0] .text
'Простой абзац с некоторыми'
❼ >>> doc.paragraphs [1] .runs [1] .text
'смелый'
❽ >>> doc.paragraphs [1] .runs [2] .text
' и немного '
➒ >>> doc.paragraphs [1] .runs [3] .text
'курсив' В ❶ мы открываем .docx в Python, вызовите docx.Document () и передайте имя файла demo.docx . Это вернет объект Document , который имеет атрибут параграфов , который представляет собой список объектов Paragraph . Когда мы вызываем len () в doc.paragraphs , он возвращает 7 , что говорит нам о семи объектах Paragraph в этом документе ❷. Каждый из этих объектов Paragraph имеет атрибут text , который содержит строку текста в этом абзаце (без информации о стиле).Здесь первый текстовый атрибут содержит 'DocumentTitle' ❸, а второй содержит 'Простой абзац с полужирным шрифтом и курсивом' ❹.
Каждый объект Paragraph также имеет атрибут Run , который представляет собой список объектов Run . Run Объекты также имеют атрибут text , содержащий только текст в этом конкретном прогоне. Давайте посмотрим на атрибут текста во втором объекте Paragraph : 'Простой абзац с полужирным шрифтом и курсивом' .Вызов len () для этого объекта Paragraph сообщает нам, что существует четыре объекта Run ❺. Объект первого запуска содержит 'Простой абзац с некоторым' ❻. Затем текст меняется на полужирный, поэтому «полужирный» запускает новый объект Run ❼. После этого текст возвращается к стилю без полужирного шрифта, что приводит к появлению третьего объекта Run , 'и некоторого количества' ❽. Наконец, четвертый и последний объект Run содержит курсивом курсивом ➒.
С Python-Docx ваши программы Python теперь смогут читать текст из файла .docx и использовать его, как любое другое строковое значение.
Получение полного текста из файла .docx
Если вас интересует только текст, а не информация о стилях в документе Word, вы можете использовать функцию getText () . Он принимает имя файла .docx и возвращает одно строковое значение его текста. Откройте новое окно редактора файлов и введите следующий код, сохранив его как readDocx.py :
#! python3
импорт docx
def getText (имя файла):
doc = docx.Document (имя файла)
fullText = []
для пункта в пунктах документа:
fullText.append (параграф)
return '\ n'.join (fullText) Функция getText () открывает документ Word, перебирает все объекты Paragraph в списке абзацев , а затем добавляет их текст в список в fullText . После цикла строки в fullText соединяются вместе с символами новой строки.
Программа readDocx.py может быть импортирована как любой другой модуль. Теперь, если вам просто нужен текст из документа Word, вы можете ввести следующее:
>>> импорт чтения Docx
>>> print (readDocx.getText ('demo.docx'))
Заголовок документа
Простой абзац с жирным шрифтом и курсивом
Заголовок, уровень 1
Интенсивная цитата
первый элемент в неупорядоченном списке
первая позиция в упорядоченном списке Вы также можете настроить getText () , чтобы изменить строку перед ее возвратом.Например, чтобы сделать отступ в каждом абзаце, замените вызов append () в readDocx.py на это:
fullText.append ( '' + para.text)
Чтобы добавить двойной пробел между абзацами, измените код вызова join () на следующий:
return '\ n \ n ' .join (fullText)
Как видите, требуется всего несколько строк кода для написания функций, которые будут читать файл .docx и возвращать строку его содержимого по вашему вкусу.
Стилизация абзацев и объектов бега
В Word для Windows стили можно просмотреть, нажав CTRL-ALT-SHIFT-S, чтобы отобразить панель «Стили», которая выглядит, как на рис. 13-5. В OS X вы можете просмотреть панель стилей, щелкнув пункт меню View ▸ Styles .
Рисунок 13-5. Откройте панель стилей, нажав CTRL-ALT-SHIFT -S в Windows.
Word и другие текстовые процессоры используют стили, чтобы визуальное представление похожих типов текста было согласованным и легко изменяемым.Например, возможно, вы хотите установить основные абзацы шрифтом Times New Roman 11 кеглями, с выравниванием по левому краю и неровным правым текстом. Вы можете создать стиль с этими настройками и назначить его всем абзацам основного текста. Затем, если вы позже захотите изменить представление всех основных абзацев в документе, вы можете просто изменить стиль, и все эти абзацы будут автоматически обновлены.
Для документов Word существует три типа стилей: стили абзацев могут применяться к объектам абзацев , стили символов могут применяться к объектам Run и связанные стили могут применяться к обоим типам объекты.Вы можете задать стили объектам Paragraph и Run , установив их атрибут style в строку. Эта строка должна быть именем стиля. Если для стиля установлено значение Нет , то не будет стиля, связанного с объектом Paragraph или Run .
Строковые значения для стилей Word по умолчанию следующие:
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | |
При установке атрибута стиля не используйте пробелы в имени стиля.Например, хотя имя стиля может быть «Тонкое выделение», вы должны установить для атрибута стиля строковое значение «SubtleEmphasis» вместо «Тонкое выделение» . Включение пробелов приведет к тому, что Word неправильно прочитает имя стиля и не применит его.
При использовании связанного стиля для объекта Run вам нужно будет добавить 'Char' в конец его имени. Например, чтобы установить связанный стиль Quote для объекта Paragraph , вы должны использовать paragraphObj.style = 'Quote' , но для объекта Run вы должны использовать runObj.style = 'QuoteChar' .
В текущей версии Python-Docx (0.7.4) можно использовать только стили Word по умолчанию и стили в открытом .docx . Новые стили не могут быть созданы, хотя это может измениться в будущих версиях Python-Docx.
Создание документов Word со стилями не по умолчанию
Если вы хотите создать документы Word, в которых используются стили помимо стандартных, вам нужно будет открыть Word в пустой документ Word и самостоятельно создать стили, нажав кнопку New Style в нижней части панели стилей (рисунок 13 -6 показывает это в Windows).
Откроется диалоговое окно «Создать новый стиль из форматирования», в котором можно ввести новый стиль. Затем вернитесь в интерактивную оболочку и откройте этот пустой документ Word с помощью docx.Document () , используя его в качестве основы для документа Word. Имя, которое вы дали этому стилю, теперь будет доступно для использования с Python-Docx.
Рисунок 13-6. Кнопка «Новый стиль» (слева) и диалоговое окно «Создать новый стиль из форматирования» (справа)
Прогонам можно дополнительно стилизовать с помощью атрибутов текста .Каждому атрибуту можно присвоить одно из трех значений: True (атрибут всегда включен, независимо от того, какие другие стили применяются к запуску), False (атрибут всегда отключен) или None (по умолчанию независимо от того, какой стиль выполнения задан).
В таблице 13-1 перечислены атрибуты text , которые можно установить для объектов Run .
Таблица 13-1. Выполнить Объект текст Атрибуты
Атрибут | Описание |
|---|---|
| Текст выделен жирным шрифтом. |
| Текст выделен курсивом. |
| Текст подчеркнут. |
| Текст зачеркивается. |
| Текст отображается с двойным зачеркиванием. |
| Текст отображается заглавными буквами. |
| Текст отображается заглавными буквами, а строчные буквы на два пункта меньше. |
| Текст отображается с тенью. |
| Текст выглядит обведенным, а не сплошным. |
| Текст пишется справа налево. |
| Текст кажется вдавленным на страницу. |
| Текст выглядит рельефно приподнятым над страницей. |
Например, чтобы изменить стили demo.docx , введите в интерактивную оболочку следующее:
>>> doc = docx.Document ('demo.docx')
>>> doc.paragraphs [0] .text
'Заголовок документа'
>>> doc.paragraphs [0] .style
'Заголовок'
>>> doc.paragraphs [0] .style = 'Normal'
>>> док. Абзацы [1]. Текст
'Простой абзац с полужирным шрифтом и курсивом'
>>> (док.параграфы [1] .runs [0] .text, doc.paragraphs [1] .runs [1] .text, doc.
параграфы [1] .runs [2] .text, doc.paragraphs [1] .runs [3] .text)
(«Обычный абзац с некоторыми», «полужирным», «и некоторыми», «курсивом»)
>>> doc.paragraphs [1] .runs [0] .style = 'QuoteChar'
>>> doc.paragraphs [1] .runs [1] .underline = True
>>> doc.paragraphs [1] .runs [3] .underline = True
>>> doc.save ('restyled.docx') Здесь мы используем атрибуты текста и стиля , чтобы легко увидеть, что находится в абзацах в нашем документе.Мы видим, что разделить абзац на запуски и получить доступ к каждому запуску индивидуально просто. Итак, мы получаем первое, второе и четвертое прогоны во втором абзаце, стилизуем каждый прогон и сохраняем результаты в новом документе.
Слова Document Title в верхней части restyled.docx будут иметь стиль Normal вместо стиля Title, объект Run для текста Простой абзац с некоторым количеством будет иметь стиль QuoteChar, а два объекта Run для слов жирным шрифтом и курсивом будут иметь атрибут подчеркивания , установленный на True .На рис. 13-7 показано, как выглядят стили абзацев и строк в файле restyled.docx .
Рисунок 13-7. рестайлинг.docx файл
Более полную документацию по использованию стилей Python-Docx можно найти по адресу https://python-docx.readthedocs.org/en/latest/user/styles.html .
Введите в интерактивную оболочку следующее:
>>> импорт docx
>>> doc = docx.Document ()
>>> док.add_paragraph ('Привет, мир!')
>>> doc.save ('helloworld.docx') Чтобы создать собственный файл .docx , вызовите docx.Document () , чтобы вернуть новый пустой объект Word Document . Метод документа add_paragraph () добавляет новый абзац текста в документ и возвращает ссылку на добавленный объект Paragraph . Когда вы закончите добавлять текст, передайте строку имени файла методу документа save () , чтобы сохранить объект Document в файл.
Это создаст файл с именем helloworld.docx в текущем рабочем каталоге, который при открытии выглядит как рисунок 13-8.
Рисунок 13-8. Документ Word, созданный с помощью add_paragraph ('Hello world!')
Вы можете добавить абзацы, снова вызвав метод add_paragraph () с текстом нового абзаца. Или, чтобы добавить текст в конец существующего абзаца, вы можете вызвать метод абзаца add_run () и передать ему строку.Введите в интерактивную оболочку следующее:
>>> импорт docx
>>> doc = docx.Document ()
>>> doc.add_paragraph ('Hello world!')
<объект docx.text.Paragraph по адресу 0x000000000366AD30>
>>> paraObj1 = doc.add_paragraph ('Это второй абзац.')
>>> paraObj2 = doc.add_paragraph ('Это еще один абзац.')
>>> paraObj1.add_run ('Этот текст добавляется ко второму абзацу.')
>>> doc.save ('multipleParagraphs.docx') Итоговый документ будет выглядеть как на Рисунке 13-9. Обратите внимание, что текст Этот текст добавляется ко второму абзацу. был добавлен к объекту Paragraph в paraObj1 , который был вторым абзацем, добавленным в doc . Функции add_paragraph (), и add_run (), возвращают абзацы и Run , соответственно, чтобы избавить вас от необходимости извлекать их как отдельный шаг.
Имейте в виду, что начиная с версии 0.5.3 Python-Docx, новые объекты Paragraph можно добавлять только в конец документа, а новые объекты Run можно добавлять только в конец объекта Paragraph . .
Метод save () можно вызвать снова, чтобы сохранить внесенные вами дополнительные изменения.
Рисунок 13-9. В документ с несколькими добавленными объектами Paragraph и Run
И add_paragraph (), , и add_run () принимают необязательный второй аргумент, который является строкой стиля объекта Paragraph или Run .Например:
>>> doc.add_paragraph ('Hello world!', 'Title') Эта строка добавляет абзац с текстом Hello world! в стиле Заголовок.
Вызов add_heading () добавляет абзац с одним из стилей заголовка. Введите в интерактивную оболочку следующее:
>>> doc = docx.Document ()
>>> doc.add_heading ('Заголовок 0', 0)
<объект docx.text.Paragraph в 0x00000000036CB3C8>
>>> док.add_heading ('Заголовок 1', 1)
<объект docx.text.Paragraph в 0x00000000036CB630>
>>> doc.add_heading ('Заголовок 2', 2)
>>> doc.add_heading ('Заголовок 3', 3)
<объект docx.text.Paragraph в 0x00000000036CB2E8>
>>> doc.add_heading ('Заголовок 4', 4)
<объект docx.text.Paragraph в 0x00000000036CB3C8>
>>> doc.save ('заголовки.docx ') Аргументы функции add_heading () — это строка текста заголовка и целое число от 0 до 4 . Целое число 0 делает заголовок стилем заголовка, который используется для верхней части документа. Целые числа от 1 до 4 относятся к разным уровням заголовков, причем 1 является основным заголовком, а 4 — самым низким подзаголовком. Функция add_heading () возвращает объект Paragraph , чтобы сэкономить вам этап извлечения его из объекта Document в качестве отдельного шага.
Результирующий файл headings.docx будет выглядеть, как показано на Рисунке 13-10.
Рисунок 13-10. Документ headings.docx с заголовками от 0 до 4
Добавление строк и разрывов страниц
Чтобы добавить разрыв строки (а не начинать новый абзац), вы можете вызвать метод add_break () для объекта Run , после которого должен отображаться разрыв. Если вместо этого вы хотите добавить разрыв страницы, вам нужно передать значение docx.text.WD_BREAK.PAGE как единственный аргумент для add_break () , как это сделано в середине следующего примера:
>>> doc = docx.Document ()
>>> doc.add_paragraph ('Это на первой странице!')
<объект docx.text.Paragraph по адресу 0x0000000003785518>
❶ >>> doc.paragraphs [0] .runs [0] .add_break (docx.text.WD_BREAK.PAGE)
>>> doc.add_paragraph ('Это на второй странице!')
>>> doc.save ('twoPage.docx') Это создает двухстраничный документ Word с Это на первой странице! на первой странице и Это на второй странице! по второму. Несмотря на то, что на первой странице после текста все еще было достаточно места. Это на первой странице! , мы заставили следующий абзац начинаться на новой странице, вставив разрыв страницы после первого прогона первого абзаца ❶.
Объекты документа имеют метод add_picture () , который позволяет добавлять изображение в конец документа. Допустим, у вас есть файл zophie.png в текущем рабочем каталоге. Вы можете добавить zophie.png в конец документа с шириной 1 дюйм и высотой 4 сантиметра (Word может использовать как британские, так и метрические единицы измерения), введя следующее:
>>> doc.add_picture ('zophie.png', width = docx.shared.Дюймы (1),
height = docx.shared.Cm (4))
<объект docx.shape.InlineShape по адресу 0x00000000036C7D30> Первый аргумент — это строка имени файла изображения. Необязательные аргументы ключевого слова width и height задают ширину и высоту изображения в документе. Если не указано иное, ширина и высота по умолчанию будут равны нормальному размеру изображения.
Вы, вероятно, предпочтете указывать высоту и ширину изображения в знакомых единицах измерения, таких как дюймы и сантиметры, поэтому вы можете использовать docx.shared.Inches () и docx.shared.Cm () , когда вы указываете аргументы ключевого слова width и height .
строк с помощью REXX
Анализ строк с помощью REXXКоманда REXX PARSE
Команду PARSE можно использовать для разбиения исходной строки на подстроки. на основе предоставленного шаблона. Шаблон состоит из имен переменных плюс шаблоны, которые определяют, как разбить исходную строку.Если только переменная указываются имена, затем исходная строка разделяется по границам слова. Точка (.) Может использоваться в качестве заполнителя, если некоторые данные следует игнорировать. Например, Разобрать Var x a b. c извлечет первые два слова из переменной x и сохранит их в переменных а и б. Третье слово игнорируется. Остаток будет храниться в переменной c.Однако позиции данных во входной строке также могут использоваться для разделения исходная строка.Например,
Разобрать Var y 5 a +8 b +4 c возьмет 8 символов из переменной y, начиная с позиции 5, и сохранит их в переменную a, затем сохраните следующие 4 символа с позиции 13 в переменную b и, наконец, любые оставшиеся символы после позиции 17 в переменную c. Этот метод можно использовать для обработки данных, содержащих Подполя фиксированной длины.Строки символов также могут использоваться в качестве разделителей. Например,
Разобрать Var z ‘key =’ v ‘,’ возьмет все символы в переменной z из первого вхождения строки ‘key =’ до следующего следующего вхождения строки ‘,’ и сохраните это в переменную v.Вышеупомянутые элементы шаблона можно комбинировать для выполнения более сложного синтаксического анализа. операции.
Работа со СЛОВАМИ
Функция СЛОВА возвращает количество слов во входной переменной. В Функция WORD может использоваться для возврата выбранного слова. Например, Сделать i = 1 для СЛОВ (w) Произнесите СЛОВО (w, i) Конец перечислит все слова из переменной w одно за другим.Функция SUBWORD может использоваться для возврата нескольких слов, начинающихся с указанное слово.Например,
Произнесите SUBWORD (v, 2, 3) отображает слова со второго по четвертое в переменной v.Для получения дополнительной информации
Посетите страницу REXX здесь для получения дополнительных источников информации о REXX.Анализ текста с помощью Python · vipinajayakumar
Я ненавижу парсинг файлов, но это то, что мне приходилось делать в начале почти каждого проекта. Разбор — дело непростое, и он может стать камнем преткновения для новичков. Однако, как только вы освоитесь с синтаксическим анализом файлов, вам больше не придется беспокоиться об этой части проблемы.Вот почему я рекомендую новичкам освоиться с анализом файлов на ранних этапах обучения программированию. Эта статья предназначена для начинающих Python, которым интересно научиться анализировать текстовые файлы.
В этой статье я познакомлю вас со своей системой парсинга файлов. Я кратко коснусь синтаксического анализа файлов в стандартных форматах, но я хочу сосредоточиться на синтаксическом анализе сложных текстовых файлов. Что я имею в виду под сложным? Что ж, мы до этого доберемся, молодой падаван.
Для справки, здесь можно найти набор слайдов, который я использую для презентации по этой теме.Весь код и образец текста, которые я использую, доступны в моем репозитории Github здесь.
Во-первых, давайте разберемся, в чем проблема. Зачем вообще нужно разбирать файлы? В воображаемом мире, где все данные существовали в одном формате, можно было ожидать, что все программы будут вводить и выводить эти данные. Не было бы необходимости разбирать файлы. Однако мы живем в мире, где существует большое разнообразие форматов данных. Некоторые форматы данных лучше подходят для разных приложений. Можно ожидать, что отдельная программа будет обслуживать только некоторые из этих форматов данных.Таким образом, неизбежно возникает необходимость конвертировать данные из одного формата в другой для использования различными программами. Иногда данные даже не в стандартном формате, что немного усложняет задачу.
Итак, что такое парсинг?
- Разбор
- Анализируйте (строку или текст) на логические синтаксические компоненты.
Мне не нравится приведенное выше определение из Оксфордского словаря. Итак, вот мое альтернативное определение.
- Разбор
- Преобразование данных определенного формата в более удобный формат.
Имея в виду это определение, мы можем представить, что наш ввод может быть в любом формате. Итак, первый шаг, когда вы сталкиваетесь с любой проблемой синтаксического анализа, — это понять формат входных данных. Если повезет, будет документация, описывающая формат данных. Если нет, возможно, вам придется расшифровать формат данных самостоятельно. Это всегда весело.
После того, как вы разберетесь с входными данными, следующим шагом будет определение более удобного формата. Что ж, это полностью зависит от того, как вы планируете использовать данные.Если программа, в которую вы хотите ввести данные, ожидает формат CSV, то это ваш конечный продукт. Для дальнейшего анализа данных я настоятельно рекомендую прочитать данные в pandas DataFrame .
Если вы аналитик данных Python, то, скорее всего, вы знакомы с pandas. Это пакет Python, который предоставляет класс DataFrame и другие функции для безумно мощного анализа данных с минимальными усилиями. Это абстракция поверх Numpy, которая предоставляет многомерные массивы, похожие на Matlab.DataFrame — это 2D-массив, но он может иметь несколько индексов строк и столбцов, которые pandas вызывает MultiIndex , что по сути позволяет хранить многомерные данные. Операции в стиле SQL или базы данных могут быть легко выполнены с помощью pandas (сравнение с SQL). Pandas также поставляется с набором инструментов ввода-вывода, который включает функции для работы с CSV, MS Excel, JSON, HDF5 и другими форматами данных.
Хотя мы хотели бы считывать данные в многофункциональную структуру данных, такую как pandas DataFrame , было бы очень неэффективно создавать пустой DataFrame и напрямую записывать в него данные. DataFrame представляет собой сложную структуру данных, и запись чего-либо в DataFrame элемент за элементом требует больших вычислительных ресурсов. Намного быстрее читать данные в примитивном типе данных, таком как список или dict . После того, как список или dict создан, pandas позволяет нам легко преобразовать его в DataFrame , как вы увидите позже. На изображении ниже показан стандартный процесс анализа любого файла.
Если ваши данные имеют стандартный или достаточно близкий формат, то, вероятно, существует уже существующий пакет, который вы можете использовать для чтения ваших данных с минимальными усилиями.
Например, у нас есть файл CSV, data.txt:
а, б, в
1,2,3
4,5,6
7,8,9
Вы можете легко справиться с этим с помощью pandas.
| |
а б в
0 1 2 3
1 4 5 6
2 7 8 9
Python невероятен, когда дело касается строк. Стоит усвоить все стандартные строковые операции.Мы можем использовать эти методы для извлечения данных из строки, как вы можете видеть в простом примере ниже.
| |
Шаг 0: [«Имена», «Ромео, Джульетта»]
Шаг 1: Ромео, Джульетта
Шаг 2: [«Ромео», «Джульетта»]
Шаг 3: [«Ромео», «Джульетта»]
Конечный результат за раз: [«Ромео», «Джульетта»]
Как вы видели в предыдущих двух разделах, если проблема синтаксического анализа проста, мы можем обойтись простым использованием существующего синтаксического анализатора или некоторых строковых методов.Однако жизнь не всегда так проста. Как мы подходим к синтаксическому анализу сложного текстового файла?
Шаг 1. Ознакомьтесь с форматом ввода
| |
Пример текста
В викторине приняли участие некоторые студенты из Ривердейл Хай и Хогвартс.
Ниже приведены их результаты.
Школа = Средняя школа Ривердейла
Оценка = 1
Номер студента, Имя
0, Фиби
1, Рэйчел
Номер ученика, Оценка
0, 3
1, 7
Оценка = 2
Номер студента, Имя
0, Анжела
1, Тристан
2, Аврора
Номер ученика, Оценка
0, 6
1, 3
2, 9
Школа = Хогвартс
Оценка = 1
Номер студента, Имя
0, Джинни
1, Луна
Номер ученика, Оценка
0, 8
1, 7
Оценка = 2
Номер студента, Имя
0, Гарри
1, Гермиона
Номер ученика, Оценка
0, 5
1, 10
Оценка = 3
Номер студента, Имя
0, Фред
1, Георгий
Номер ученика, Оценка
0, 0
1, 0
Это довольно сложный входной файл! Уф! Данные, которые он содержит, довольно просты, как вы можете видеть ниже:
Имя Оценка
Номер школьного класса
Хогвартс 1 0 Джинни 8
1 Луна 7
2 0 Гарри 5
1 Гермиона 10
3 0 Фред 0
1 Георгий 0
Ривердейл Хай 1 0 Фиби 3
1 Рэйчел 7
2 0 Анджела 6
1 Тристан 3
2 Аврора 9
Образец текста похож на CSV в том, что в нем используются запятые для разделения некоторой информации.Вверху файла есть заголовок и некоторые метаданные. Есть пять переменных: школа, оценка, номер ученика, имя и оценка. Школа, класс и номер ученика являются ключевыми. Имя и Оценка - это поля. Для данной школы, класса и номера ученика есть имя и оценка. Другими словами, школа, класс и номер учащегося вместе образуют составной ключ.
Данные представлены в иерархическом формате. Сначала объявляется школа, затем оценка. Далее следуют две таблицы, в которых указаны имя и оценка для каждого номера учащегося.Затем оценка увеличивается. Затем следует еще один набор таблиц. Затем образец повторяется для другой Школы. Обратите внимание, что количество учеников в классе или количество классов в школе непостоянны, что немного усложняет файл. Это всего лишь небольшой набор данных. Вы можете легко представить, что это огромный файл с множеством школ, оценок и студентов.
Само собой разумеется, что формат данных исключительно плохой. Я сделал это специально. Если вы поймете, как с этим справиться, вам будет намного проще освоить более простые форматы.Нет ничего необычного в том, чтобы встретить подобные файлы, если приходится иметь дело с большим количеством устаревших систем. В прошлом, когда эти системы разрабатывались, возможно, не требовалось, чтобы выходные данные были машиночитаемыми. Однако в настоящее время все должно быть машиночитаемым!
Шаг 2. Импортируйте необходимые пакеты
Нам понадобится модуль регулярных выражений и пакет pandas. Итак, давайте продолжим и импортируем их.
| |
Шаг 3. Определите регулярные выражения
На последнем этапе мы импортировали re, модуль регулярных выражений.Что это такое?
Итак, ранее мы видели, как использовать строковые методы для извлечения данных из текста. Однако при синтаксическом анализе сложных файлов мы можем столкнуться с большим количеством разделений, разделений, нарезок и многого другого, и код может выглядеть довольно нечитабельным. Именно здесь на помощь приходят регулярные выражения. По сути, это крошечный язык, встроенный в Python, который позволяет вам сказать, какой строковый шаблон вы ищете. Между прочим, он не уникален для Python (домик на дереве).
Вам не нужно становиться мастером регулярных выражений.Однако некоторые базовые знания регулярных выражений могут быть очень полезны в вашей карьере программиста. В этой статье я научу вас только самым основам, но я призываю вас продолжить изучение. Я также рекомендую regexper для визуализации регулярных выражений. regex101 - еще один отличный ресурс для тестирования вашего регулярного выражения.
Нам понадобятся три регулярных выражения. Первый из них, как показано ниже, поможет нам идентифицировать школу. Его регулярное выражение - School = (. *) \ N .Что означают символы?
-
.: любой символ -
*: 0 или более из предыдущего выражения -
(. *): Помещение части регулярного выражения в круглые скобки позволяет сгруппировать эту часть выражения. Итак, в данном случае сгруппированная часть - это название школы. -
\ n: символ новой строки в конце строки
Затем нам понадобится регулярное выражение для оценки. Его регулярное выражение - Grade = (\ d +) \ n .Это очень похоже на предыдущее выражение. Новые символы:
-
\ d: сокращение для [0-9] -
+: 1 или более из предыдущего выражения
Наконец, нам нужно регулярное выражение, чтобы определить, является ли таблица, следующая за выражением в текстовом файле, таблицей имен или оценок. Его регулярное выражение - (Имя | Оценка) . Новый символ:
-
|: логика или утверждение, поэтому в данном случае оно означает «Имя» или «Оценка.’
Нам также необходимо понимать несколько функций регулярных выражений:
-
re.compile (шаблон): скомпилировать шаблон регулярного выражения вRegexObject.
A RegexObject имеет следующие методы:
-
match (строка): если начало строки совпадает с регулярным выражением, вернуть соответствующий экземплярMatchObject. В противном случае вернитеНет. -
search (строка): сканировать строку в поисках места, где это регулярное выражение дало совпадение, и возвращать соответствующий экземплярMatchObject.ВернутьНет, если совпадений нет.
MatchObject всегда имеет логическое значение True . Таким образом, мы можем просто использовать оператор if для определения положительных совпадений. Имеет следующий метод:
-
group (): возвращает одну или несколько подгрупп соответствия. На группы можно ссылаться по их индексу.group (0)возвращает все совпадение.group (1)возвращает первую подгруппу в скобках и так далее.Используемые нами регулярные выражения имеют только одну группу. Легкий! Однако что, если бы было несколько групп? Было бы сложно вспомнить, к какому номеру принадлежит группа. Специфичное для Python расширение позволяет нам называть группы и вместо этого ссылаться на них по имени. Мы можем указать имя внутри группы в скобках(...), например:(? P....)
Давайте сначала определим все регулярные выражения. Обязательно используйте необработанные строки для регулярного выражения, т.е. используйте индекс r перед каждым шаблоном.
| |
Шаг 4. Напишите синтаксический анализатор строки
Затем мы можем определить функцию, которая проверяет совпадения регулярных выражений.
| |
Шаг 5. Напишите анализатор файлов
Наконец, для главного события у нас есть функция парсера файлов.Он довольно большой, но, надеюсь, комментарии в коде помогут вам понять логику.
| |
Шаг 6. Протестируйте синтаксический анализатор
Мы можем использовать наш синтаксический анализатор для нашего образца текста следующим образом:
| |
Имя Оценка
Номер школьного класса
Хогвартс 1 0 Джинни 8
1 Луна 7
2 0 Гарри 5
1 Гермиона 10
3 0 Фред 0
1 Георгий 0
Ривердейл Хай 1 0 Фиби 3
1 Рэйчел 7
2 0 Анджела 6
1 Тристан 3
2 Аврора 9
Это все хорошо, и вы можете увидеть, сравнив ввод и вывод на глаз, что синтаксический анализатор работает правильно.Однако лучше всего всегда писать модульные тесты, чтобы убедиться, что ваш код выполняет то, что вы хотели. Каждый раз, когда вы пишете синтаксический анализатор, убедитесь, что он хорошо протестирован. У меня возникли проблемы с моими коллегами из-за того, что я использовал парсеры без тестирования ранее. И-эй! Также стоит отметить, что это не обязательно должен быть последний шаг. Действительно, многие программисты проповедуют разработку через тестирование. Я не включил сюда набор тестов, так как хотел, чтобы это руководство было кратким.
Я разбирал текстовые файлы в течение года и со временем усовершенствовал свой метод. Тем не менее, я провел дополнительное исследование, чтобы узнать, есть ли лучшее решение. В самом деле, я должен поблагодарить различных членов сообщества, которые посоветовали мне оптимизировать мой код. Сообщество также предложило несколько различных способов синтаксического анализа текстового файла. Некоторые из них были умными и интересными. Моим личным фаворитом был этот. Я представил свой образец проблемы и решение на форумах ниже:
- Сообщение Reddit
- Сообщение о переполнении стека
- Сообщение для проверки кода
Если ваша проблема еще более сложная и регулярные выражения ее не решают, то следующим шагом будет анализ библиотек.Вот несколько мест для начала:
- Разбор ужасных вещей с помощью Python: Лекция Эрика Роуза по PyCon, в которой рассматриваются плюсы и минусы различных библиотек синтаксического анализа.
- Разбор в Python: инструменты и библиотеки: Инструменты и библиотеки, позволяющие создавать парсеры, когда регулярных выражений недостаточно.
Теперь, когда вы понимаете, насколько сложным и раздражающим может быть анализ текстовых файлов, если вы когда-нибудь окажетесь в привилегированном положении при выборе формата файла, выбирайте его с осторожностью.Вот лучшие практики Стэнфорда для форматов файлов.
Я бы солгал, если бы сказал, что мне понравился мой метод синтаксического анализа, но я не знаю другого способа, быстрого синтаксического анализа текстового файла, который так же удобен для новичков, как то, что я представил выше. Если вы знаете лучшее решение, я всем внимателен! Надеюсь, я дал вам хорошую отправную точку для анализа файла на Python! Я потратил пару месяцев на то, чтобы пробовать множество различных методов и писать какой-то безумно нечитаемый код, прежде чем я наконец понял это, и теперь я не думаю дважды о разборе файла.Итак, я надеюсь, что мне удалось сэкономить вам время. Получайте удовольствие от синтаксического анализа текста с помощью Python!
Как автоматически копировать данные из ваших электронных писем
eBay отправлено по электронной почте - кто-то заказал что-то в вашем магазине. Ваш банк отправил вам по электронной почте ежемесячный отчет, ваша кредитная карта напоминает вам об оплате счета, а Apple напоминает вам о приложении, которое вы купили вчера вечером. И контактная форма на вашем сайте хороша, но каждое сообщение - это еще одна вещь, которая накапливается в вашем почтовом ящике.
В вашем почтовом ящике уведомления - это только больше беспорядка, больше вещей, которые нужно архивировать и забыть.Было бы легче сортировать эту информацию и управлять ею в электронной таблице или базе данных, но для этого вам нужно потратить время, чтобы скопировать текст из электронных писем и вставить его в другое место.
Или вы можете позволить приложению сделать эту работу за вас. Вот как автоматически анализировать текст электронных писем и эффективно использовать их данные.
Что такое анализатор электронной почты?
Когда ваш босс или лучший друг пишет по электронной почте, вы, вероятно, читаете каждое слово.
В остальное время, скорее всего, вы просматриваете сообщение.Ваш взгляд быстро бегает по экрану, выбирая ключевые слова и фразы, такие как Новая распродажа и 4,99 долл. США и Срок оплаты: пятница, 3 ноября .
Сделайте свой бизнес более эффективным с Zapier
Парсеры электронной почты работают таким же образом. Вы учите эти программы распознавать шаблоны в ваших электронных письмах, сообщаете им, какие данные на самом деле важны и что все остальное можно игнорировать, а затем заставляете их сохранять только важные данные. Затем подключите анализатор электронной почты к инструменту автоматизации, например Zapier, чтобы сохранить этот важный текст в других приложениях, чтобы вы могли регистрировать заказы, например, в электронной таблице или получать напоминание об оплате счета по кредитной карте завтра.Поскольку все электронные письма в целом составлены одинаково, анализатор электронной почты должен уметь определять, что важно, и копировать данные за вас.
Понял? ОК. Давайте сделаем резервную копию и шаг за шагом создадим анализатор электронной почты, который может копировать текст из ваших писем и заставлять его работать. Мы будем использовать парсер электронной почты Zapier - бесплатный инструмент для копирования текста из ваших писем. Если вы используете другой инструмент анализа электронной почты, эти указания будут по-прежнему применяться - основы работают одинаково в каждом приложении, и как только вы знаете, как анализировать одно электронное письмо, вы знаете, как анализировать их все.
и далее.
Как анализировать электронную почту
Создать новый почтовый ящик парсера электронной почты
Отправить электронное письмо парсеру
Научить синтаксический анализатор читать вашу электронную почту
Автоматически пересылать электронные письма парсеру
Используйте проанализированные данные электронной почты
1. Создайте новый почтовый ящик парсера электронной почты
Первый шаг - самый простой. Просто перейдите на parser.zapier.com, войдите в свою учетную запись Zapier или создайте новую учетную запись, затем нажмите любую из кнопок Создать почтовый ящик (обозначены стрелками на снимке экрана ниже), чтобы добавить новый почтовый ящик.
Email Parser покажет вам адрес электронной почты, например [email protected].
Скопируйте этот адрес и держите его под рукой, потому что именно по нему вам нужно будет отправлять электронные письма для последующего анализа.
2. Отправьте электронное письмо синтаксическому анализатору
Теперь, когда у вас скопирован новый адрес электронной почты, откройте приложение электронной почты, найдите (или напишите) электронное письмо, подобное тем, которые вы хотите использовать с анализатором электронной почты. Я хочу, чтобы Email Parser сообщал мне о новых сообщениях в блоге Zapier (мета, я знаю), поэтому я пересылаю недавнее электронное письмо от Деб из Zapier.
Нажмите кнопку, чтобы переслать электронное письмо, введите свой адрес электронной почты @ robot.zapier.com в поле Кому: и нажмите Отправить .
3. Научите синтаксический анализатор читать вашу электронную почту.
Выберите текст, который синтаксический анализатор должен скопировать, затем присвойте ему уникальное имя.Пора надеть шляпу учителя. Как только Zapier Email Parser получит ваше письмо, он покажет текстовую версию вашего письма в поле Initial Template . Все, что вам нужно сделать, это найти важные данные и сказать парсеру, что именно это нужно скопировать.
Прокрутите вниз до текста, который вы хотите, чтобы анализатор электронной почты скопировал, и выберите его. С помощью электронной почты, которую я использовал, я хочу знать заголовки в разделе «Рекомендуемая литература от команды блога Zapier», поэтому я выбираю текст из каждого из них. Для каждого выделенного фрагмента текста введите имя этого элемента в поле и нажмите Сохранить . Анализатор электронной почты заменит текст на имя в фигурных скобках, например {{headline1}} .
Повторите это для каждого фрагмента текста, который анализатор электронной почты должен скопировать.Я тоже выбрал каждую тему и дал каждому элементу уникальное имя.
Как только это будет сделано, нажмите синюю кнопку Сохранить адрес и шаблон внизу - и ваш анализатор электронной почты готов к работе.
Анализатор электронной почты будет работать лучше всего, если выбранный вами текст будет написан одинаково в каждом электронном письме - например, число после слова Всего или ссылка, написанная после слова Щелкните здесь . Значение может измениться, но анализатор электронной почты будет работать лучше всего, если предыдущий текст будет всегда одинаковым и в одном и том же месте.
Хотите сделать парсер электронной почты более надежным? Перешлите другое аналогичное электронное письмо на тот же адрес, затем щелкните Просмотреть электронные письма рядом с именем вашего парсера в списке почтовых ящиков Zapier Email Parser, чтобы просмотреть все электронные письма, полученные этим почтовым ящиком.
Щелкните Показать на одном из элементов, чтобы увидеть текст сообщения электронной почты, при этом текст Email Parser выделен желтым цветом.
Если что-то выглядит неправильно (как в моем примере выше), щелкните ссылку Изменить дополнительный шаблон внизу.Выберите тот же текст, который вы изначально хотели скопировать из своих писем, дайте ему те же имена, а затем сохраните новый шаблон. Вы можете повторить это несколько раз, чтобы сделать ваш синтаксический анализатор более надежным.
Вы можете использовать ту же технику для анализа любого обычного электронного письма, которое вы получаете. Например, вы можете научить его распознавать названия продуктов и цены в электронных письмах с подтверждением покупки от Amazon или Apple.
4. Автоматическая пересылка новых писем в синтаксический анализатор
Созданный вами анализатор электронной почты теперь готов копировать текст из других похожих писем - в данном случае из новостной рассылки Zapier Blog.Нам нужно отправлять каждую новую рассылку на анализатор электронной почты.
Лучший вариант - автоматизировать работу с помощью фильтра в вашем почтовом приложении для автоматической пересылки сообщений, соответствующих тому, которое вы отправили в Email Parser. Как правило, все ваши электронные письма с уведомлениями имеют что-то общее - они исходят от одного и того же отправителя и часто имеют одну и ту же тему. В моем примере эти электронные письма приходят с адреса [email protected] и содержат слова «Рекомендуемая литература от команды разработчиков блога Zapier».
Чтобы отслеживать эти электронные письма в Gmail, вам сначала нужно добавить свой адрес парсера электронной почты в Gmail для автоматической пересылки писем.Вот как это сделать:
Откройте настройки пересылки Gmail - щелкните значок шестеренки, выберите Настройки , затем щелкните вкладку Пересылка .
Нажмите кнопку Добавить адрес пересылки там.
Введите адрес электронной почты вашего парсера электронной почты @ robot.zapier.com в текстовое поле и нажмите , затем .
Проверьте свою электронную почту - Zapier должен отправить вам письмо с подтверждением от Gmail. Если вы его не видите, проверьте почтовый ящик приложения Email Parser - в нем должен быть адрес электронной почты.В любом случае скопируйте код подтверждения , затем вставьте его в поле в настройках Gmail Forwarding .
Теперь вы можете настроить автоматическую пересылку писем в Gmail парсеру электронной почты. Сначала найдите адрес электронной почты и / или тему сообщений, которые вы будете обрабатывать парсером электронной почты; Я вхожу с: [email protected] И «Рекомендуемая литература от команды блогов Zapier». Щелкните крошечную стрелку вниз справа от строки поиска, чтобы увидеть все параметры Advanced Search , затем нажмите кнопку или ссылку Create filter в правом нижнем углу.Попросите этот фильтр пересылать электронное письмо на адрес парсера электронной почты, который вы только что добавили, и все должно быть настроено.
После небольшого упражнения с мышью и клавиатурой все готово. Каждый раз, когда Деб из Zapier отправляет вам последний информационный бюллетень Zapier - или всякий раз, когда вы получаете любые другие сообщения электронной почты, которые хотите проанализировать, - Gmail отправляет их парсеру электронной почты.
Если вы используете другую службу электронной почты, проверьте свою документацию, чтобы узнать, может ли ваше приложение или служба автоматически пересылать сообщения электронной почты.
5. Заставьте ваши проанализированные данные электронной почты работать
Одного копирования текста из электронных писем недостаточно - вам нужно что-то делать с этими данными. Самый простой вариант - подключить парсер электронной почты к приложениям автоматизации Zapier, что позволяет отправлять данные из ваших писем в тысячи других популярных рабочих приложений - от Airtable до Zoho.
Посетите Zapier и войдите в систему или зарегистрируйтесь, если вы еще этого не сделали. Затем нажмите Make a Zap , чтобы начать. Выберите Email Parser в качестве триггерного приложения, затем выберите триггерное событие New Email .Подключите свою учетную запись парсера электронной почты, если вы еще этого не сделали, и выберите адрес парсера, который вы только что настроили.
Zapier может использовать текст, который анализатор электронной почты находит, но вы хотитеПосле этого вы можете использовать данные электронной почты. На шаге Action выберите приложение, в которое вы хотите отправить данные электронной почты. Я хотел получать SMS-уведомление о последних заголовках, поэтому выбрал SMS с помощью действия Send SMS приложения Zapier .
Чтобы использовать данные электронной почты, щелкните любое из полей в действии Zap и выберите любое из значений из триггера Zap.Здесь я добавил темы и заголовки из имени и цены из Email Parser в SMS-уведомления - вы, возможно, можете добавить имена и адреса электронной почты в свой информационный бюллетень по электронной почте, записывать информацию о продажах в строки электронной таблицы или, тем не менее, использовать свои данные электронной почты. ты хочешь.
Протестируйте Zap, чтобы убедиться, что все работает так, как вы хотите, включите его - и готово!
Еще не знаете, куда отправлять эти электронные письма? Начните сохранять их с помощью этих ZapsЕсли вы похожи на меня, у вас есть много электронных писем, которые, как вы знаете, вы уже хотите автоматизировать, но вы не совсем уверены, куда нужно отправлять всю информацию. еще.В таких случаях может быть удобно запустить Zap, который анализирует электронные письма и сохраняет их в электронную таблицу, чтобы вы могли позже вернуться к хорошо организованным данным.
Нажмите Попробовать на одном из этих рекомендуемых Zap-файлов, чтобы сразу же начать сохранять проанализированные электронные письма в Google Таблицах или Airtable, или чтобы настроить собственное SMS-уведомление для электронной почты:
Теперь, когда вы анализируете свою электронную почту, узнайте больше способы автоматизации этой информации и использования ее в других приложениях.Автоматически отправляйте проанализированную информацию в приложение для управления задачами или проектами, настраивайте пользовательские уведомления, создавайте события календаря, обновляйте контакты и т. Д.
Электронная почта является способом по умолчанию для большинства приложений для отправки уведомлений и другой информации, и может быть лучшим способом автоматизации приложений, которые не имеют своей интеграции.