Тренинг «Морфемный разбор» / Морфемный разбор / Русский на 5
Выполняй морфемный разбор слова. Проверяй себя по ответам:
Задание 1
Слова для разбора:
1) замаскироваться, 2) восток, 3) жгу, 4) жжёшь, 5) вполуха
Ответ:
1) замаскироваться, 2) восток , 3) жгу, 4) жжёшь, 5) вполуха
Задание 2
Слова для разбора:
1) англо-русский, 2) выдохнуться, 3) ждать, 4) жгут (существительное), 5) жгут (глагольная форма)
Ответ:
1) англо-русский, 2) выдохнуться, 3) ждать, 4) жгут , 5) жгут
Задание 3
Слова для разбора:
1) кино, 2) заунывный, 3) заунывно, 4) наследница, 5) бил
Ответ:
1) кино, 2) заунывный, 3) заунывно, 4) наследница, 5) бил
Задание 4
Слова для разбора:
1) насекомое, 2) организационно, 3) спят, 4) пекарня, 5) пилотаж
Ответ:
1) насеком
Задание 5
Слова для разбора:
1) пилотирование, 2) понизу, 3) помимо, 4)мять, 5) мну
Ответ:
1) пилотирование,* 2) понизу, 3) помимо, 4) мять, 5) мну
* Точнее: пилотирова[н’ий’+э], то есть [й] отходит к суффиксу, а [э] — это окончание.
Задание 6
Слова для разбора:
1) справа, 2) пригнать, 3) приворотить, 4) рученька, 5) пять
Ответ:
1) справа, 2) пригнать, 3) приворотить, 4) рученька, 5) пять
Задание 7
Слова для разбора:
1) русифицированный, 2) рядышком, 3) ряби´на (дерево), 4) рябина´ (неровность, пятнистость), 5) русский
Ответ:
1) русифицированный, 2) рядышком, 3) ряби´на (дерево), 4) рябина´ (неровность, пятнистость), 5) русский
Задание 8
Слова для разбора:1) шить, 2) шитьё, 3) бра, 4) мяу, 5) очищу
Ответ:
1) шить, 2) шитьё,* 3) бра, 4) мяу, 5) очищу
* Точнее: шить[й’о], [й’] — суффикс, а [о] — окончание.
Задание 9
Слова для разбора:
1) репетировать, 2) схитрить, 3) вот, 4) сыгранность, 5) сызмальства
Ответ:
1) репетировать, 2) схитрить, 3) вот, 4) сыгранность , 5) сызмальства
Задание 10
Слова для разбора:
1) себя, 2) себялюбец, 3) вру, 4) дал, 5) поучительный
Ответ:
1) себя, 2) себялюбец , 3) вру, 4) дал , 5) поучительный
Смотрите также
— Понравилась статья?:)Мой мир
Вконтакте
Одноклассники
Google+
Морфемный и словообразовательный разбор | Методическая разработка по русскому языку (6 класс) на тему:
1 вариант
Часть А
A1. Что такое морфема?
1) самостоятельная часть речи
2) наименьшая значимая часть слова
3) неизменяемая часть слова
4) корень слова
А2. О какой части слова идёт речь: «Значимая часть слова, стоящая перед корнем и служащая для образования новых слов»?
1) приставка
2) суффикс
3) корень
4) окончание
А3. Укажите ряд, в котором все слова однокоренные:
1) вода, водитель, водный
2) лес, лесной, лесник
3) гора, горный, гореть
4) вести, приведёт, привет
А4. В каком слове нет окончания?
1) тишь
2) озноб
3) выстрел
4) наугад
А5. Слова какого ряда имеют две приставки?
1) предпосылка, предсказание, предубеждение
2) предрассветный, преподнести, преувеличить
3) предыдущий, предшествовать, предусмотреть
4) предъюбилейный, предполагать, предугадать
Часть В. Прочитайте текст, выполните задания В и С.
(1)Пушистые снежинки осторожно ложатся на землю, и она одевается в ослепительный наряд. (2)Побелели дорожки и крыши домов. (3)Под лучами солнца блестят разноцветные искорки инея. (4)На речке среди зарослей камыша темнеет вода.
(4)На речке среди зарослей камыша темнеет вода.
В1. Выпишите слово, состоящее из двух корней.
В2. Из предложений 1-2 выпишите слово, не имеющее окончания.
Часть С
1.Какова тема текста? Озаглавьте текст.
2. Какова основная мысль текста?
3. Каким настроением проникнут текст?
4. Выпишите примеры эпитетов.
2 вариант
Часть А
A1. Какие части слова служат для образования новых слов?
1) корень и окончание
2) корень и суффикс
3) суффикс и приставка
4) приставка и окончание
А2. Какие морфемы входят в основу слова?
1) приставка, корень, суффикс
2) корень, окончание
3) суффикс, окончание, корень
4) приставка, суффикс, окончание
А3. Укажите слово с нулевым окончанием
1) тетрадь
2) тетрадка
3) поставили
4) сном
А4. Слова какой части речи не имеют окончания?
1) глагола
2) наречия
3) существительного
4) прилагательного
А5. Слова какого ряда имеют два суффикса?
1)обидчик, законный, придумал
2) услышал, питание, задержал
3) обещание, выдернул, розовый
4) отцовский, прорежет, усидчивый
Часть В
Прочитайте текст, выполните задания В и С.
(1)Рябину называют осенней красавицей. (2)Она не боится холода, а её ягоды становятся сладкими от мороза. (3)Рябина — полезная ягода. (4)Она обогащает почву своими плодами, привлекает массу птиц, а птицы истребляют вредоносных насекомых.
(По Н. Анучину)
В1. Выпишите слово, состоящие из двух корней.
В2. Выпишите из предложения № 4 слово, состоящие из приставки, корня, суффикса и окончания.
Часть С
1. Какова тема текста? Озаглавьте текст.
2. Определите основную мысль текста.
3. Каким настроением проникнут текст?
4. Выпишите из текста олицетворение.
Урок русского языка «Морфемный и словообразовательный разбор слова» (6 класс)
КОНСПЕКТ УРОКА
Морфемный и словообразовательный разбор слова. Словообразовательный словарь.
Словообразовательный словарь.Школа: ГУ «Средняя школа №7 отдела образования акимата города Костаная»
Дата: 12 неделя 3 урок, 5.12.2016 г.
ФИО учителя: Фатхудинова Аймагуль Мухтарбековна
КЛАСС: 6 А
Количество присутствующих:
Количество отсутствующих:
Цели обучения, которые необходимо достичь на данном уроке
-совершенствовать навык морфемного и словообразовательного разбора слов;
-дифференцировать эти виды разбора слов;
-развивать орфографическую зоркость;
— воспитывать бережное отношение к природе, умение видеть и восхищаться её красотой.
Цели обучения
Все учащиеся смогут: вспомнить теорию данного раздела, производить морфемный и словообразовательный разбор, разграничивать эти два вида разбора.
Большинство учащихся будут уметь: правильно выполнять морфемный и словообразовательный разбор, грамотно и логично составлять новые слова, применять их в устной и письменной речи
Некоторые учащиеся смогут: выполнить все задания верно, самостоятельно сделать вывод, практически использовать полученные в результате анализа знания.
Языковая цель
Учащиеся могут: дать определение морфемам и определение правописанию корней, применять порядок разборов при выполнении заданий.
Ключевые слова и фразы: морфемный разбор, словообразовательный разбор, разграничение, морфемика, морфемы, корень, суффикс, окончание, основа, постфикс, словообразовательная цепочка.
Стиль языка, подходящий для диалога/письма в классе:
Discuss the chart that is created. Which is the most popular fruit choice? Howdoweknow?
Has every learner’s choice been recorded? Howcanwecheck?
Ask learners if they can think of other questions that we might have investigated. If ideas are not forthcoming, ‘lead’ the discussion by suggesting – what else could we have put in the basket? What other things could we try, to see if people have favourites? What other questions could we have asked about our fruit basket?
Take ideas and ask – What do you think the result might be? What would the pictogram look like?
Вопросы для обсуждения:
—
Можете ли вы сказать, почему. ..?
..?
Подсказки:
Предыдущее обучение
Пройдены все темы раздела «Морфемика». Это последний урок по «Словообразованию» перед контрольной работой.
План
Планируемые сроки
Планируемые действия (замените записи ниже запланированными действиями)
Ресурсы
Начало урока
2-5 мин
1. Организационный момент, постановка цели урока и мотивация учебной деятельности учащихся
Цель: Подготовить учащихся к работе на уроке, способствовать
созданию эмоционального настроя на совместную коллективную деятельность
Мотивационное начало урока (дети стоят).
Звучит песня «Снег кружится». Ребята, представьте, что мы с вами снежинки. Вот пошёл сильный снег, снежинки весело кружат в воздухе, постепенно опускаясь на землю. Сначала опустились самые маленькие, хрупкие снежинки (сели девочки), затем снежинки побольше (сели мальчики).
Все снежинки оказались на земле. Тихо вокруг, наступила звёздная ночь.
Но с восходом зимнего солнца снежинки начали просыпаться, они обрадовались морозному утру, улыбнулись солнышку и сказали друг другу: «Доброе утро!»
Тема урока: Морфемный и словообразовательный разбор.
Актуализация знаний.
Цель: актуализировать знания учащихся по теме.
Прием «Круг»
Формативное оценивание
Фрагмент песни «Снег кружится»
Презентация
На доске
Середина урока
5-35 мин
Вызов.
Цель: вспомнить порядок выполнения разборов.
На прошлых уроках мы изучили темы «Морфемика» и «Словообразование». Сегодня мы повторим эти темы, закрепим умение выполнять разные виды разбора слова.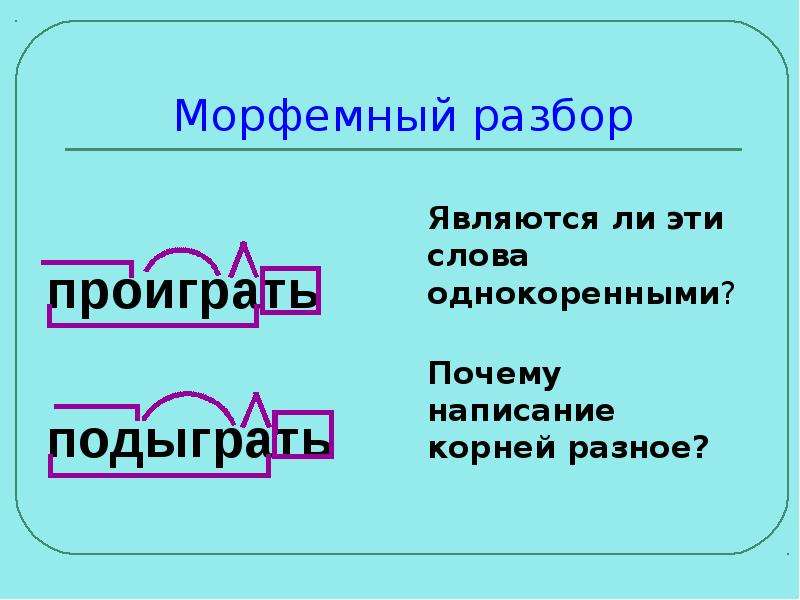
Давайте вспомним этапы анализа слова:
У доски пишет ученик
Морфемный: часть речи
1.окончание
2.основа
3.суффикс(ы)
4.приставка
5.корень
Словообразовательный:
1.Дать толкование лекс.зн-я слова
2.сравнить состав данного слова с однокоренным, выявить ту часть, с помощью которой оно образовалось
4.определить, от чего образовано слово
5.назвать способ образования
Формативное оценивание учащихся
Осмысление
Цель: отработать навык разборов при выполнении заданий; развивать умение работать с текстом; умение отвечать на «толстые и тонкие вопросы» по тексту; развивать логическое мышление, сообразительность.
Работа с текстом.
— А сейчас мы прочитаем текст, из которого узнаем, откуда берется снег.
(Учитель раздает всем уч-ся карточки с текстом и читает его вслух).
Где рождается снег?
(По М. Гумилевской)
Что такое снег? Это много, очень много красивых снежинок: они падают и падают с высоты на землю, на деревья, на крыши домов – чистые, хрупкие, сверкающие.
Раньше думали, что снег – это замерзшие капельки воды. Но снег никогда не родится из капелек воды. Капельки воды могут стать градинками, комочками льда. Но они никогда не превращаются в снежинки.
Водяные пары поднимаются очень высоко над землей, и здесь сразу же из водяных паров образуются крохотные льдинки- кристаллики. Кристаллик все время растет и становится удивительно красивой звездочкой. Снежинки медленно опускаются, собираются хлопьями и падают на землю.
« Толстый и тонкий вопросы». Парная работа
— Из чего рождается снег?
— А что рождается из капелек воды?
— Как автор описывает снежинки?
— Объясните значение словосочетания «хрупкие снежинки».
Взаимооценка в лист успешности.
Задания:
Выписать из текста однокоренные слова и разобрать по составу.
Снег, снежинки; вода, водяные; лед, льдинки.
— А какие еще однокоренные слова можно подобрать к этим словам?
— Как называются части слова?
— Какой мы произвели разбор?
Произвести словообразовательный разбор этих же слов.
Снежинки снег
Водяные вода
Льдинки лед
— Каким способом образованы слова?
Физминутка
Работа по вариантам
1в. Произведите морфемный разбор слов: зимний, снеговик, ледокол, морозец, замерзла, свежий, воздух.
2 в. Произведите морфемный разбор слов, выберите слова, соответствующие схемам
Кукольный (театр) ____________________________________________________
Тонкосуконный (комбинат) ____________________________________________
Октябрьский (район) __________________________________________________
Этнографический (музей) ______________________________________________
Железнодорожный (вокзал) _____________________________________________
Универмаг «Юбилейный»
1. 2. 3.
Самопроверка по компьютеру. Самооценивание.
«Собери россыпи»
А теперь составьте словообразовательную цепочку из этих слов (слова даны вразброс)
Лед, ледниковый, доледниковый, ледник
Разморозить, мороз, морозить, разморозиться
— Каким способом образованы эти слова?
Самооценивание.
На доске ватман
У каждого ученика памятка на парте и тексты с заданиями
Словообразовательный словарь
Конец урока
35-45 мин
— Чем мы занимались на уроке, что нового узнали?
— Для чего нужно знать словообразовательный и морфемный разборы?
Мы изучили темы «Морфемика» и «Словообразование». Словообразование – один из важнейших разделов русского языка, один из важнейших источников пополнения словарного запаса.
Словообразование – один из важнейших разделов русского языка, один из важнейших источников пополнения словарного запаса.
Многие орфографические правила опираются на словообразование. Поэтому, чтобы понять смысл, суть правил, надо хорошо знать состав слова, его строение, находить морфемы и точно определять границы между ними.
Рефлексия
Цель: узнать уровень усвоения
«5»• Кому на уроке было всё понятно, со всеми заданиями справлялись уверенно, повесьте на доску снежинку.
«4»• Если вы затруднялись при выполнении заданий, чувствовали себя неуверенно, повесьте сосульку.
«3»• Кому на уроке было очень трудно, с заданиями не справлялись, повесьте дождик.
Оценивание по листам успешности.
Снежинки, сосульки, дождик.
Листы успешности
Дополнительная информация
Дифференциация.
Как вы планируете поддерживать учащихся?
Как вы планируете стимулировать способных учащихся?
Оценивание.
Как вы планируете увидеть приобретенные знания учащихся?
Межпредметные связи
соблюдение СанПиН
ИКТ компетентность
Связи с ценностями
учащиеся с высоким уровнем мотивации
учащиеся с высоким уровнем мотивации
групповая работа
парная работа
работа по вариантам
наблюдение учителя
результаты работы в тетради
качество ответов учащегося
самооценивание
взаимооценивание
формативное оценивание
русский язык
информатика
ИЗО
Рефлексия
Были ли цели обучения реалистичными?
Что учащиеся сегодня изучили?
На что была направлено обучение?
Хорошо ли сработала запланированная дифференциация?
Выдерживалось ли время обучения?
Какие изменения из данного плана я реализовал и почему?
Используйте пространство ниже, чтобы подвести итоги урока. Ответьте на самые актуальные вопросы об уроке из блока слева.
Ответьте на самые актуальные вопросы об уроке из блока слева.
Итоговая оценка
Какие два аспекта в обучении прошли очень хорошо (с учетом преподавания и учения)?
1:
2:
Какие два обстоятельства могли бы улучшить урок (с учетом преподавания и учения)?
1:
2:
Что узнал об учениках в целом или отдельных лицах?
Морфемный и словообразовательный разбор слова
Морфемный и словообразовательный разбор слова
(урок русского языка с использованием ТРИЗ и РКМ технологии, 6 класс)
Цель: познакомить обучающихся с порядком морфемного и словообразовательного разбора слов; сформировать умение выполнять данные разборы.
Литература: Русский язык: Учебник для 6 класса общеобразовательных учреждений / М.Т.Баранов, Т.А.Ладыженская, Л.А.Тростенцова и др. – М.: Просвещение, 2003.
Оборудование: раздаточный материал, альбомные листы, маркеры.
Форма проведения урока – групповая работа, приём «Зигзаг-2».
Стадия вызова.
Каждая группа (их пять) получает задание:
I. Решить кроссворд.
1. Значимая часть слова, которая находится после корня или после другого суффикса и служит для образования слов.
2. Раздел науки о языке, в котором изучается, от чего и с помощью чего образованы слова.
3. Значимая часть слова, которая образует форму слова и служит для связи слов в словосочетании и предложении.
4. Часть изменяемого слова без окончания.
5. Главная значимая часть слова, в которой заключено общее значение всех однокоренных слов.
Cуффикс
сЛовообразование
окОнчание
осноВа
кОрень
II. «Четвёртое слово – «лишнее».
«Четвёртое слово – «лишнее».
- Морфология, орфография, морфемы, лексика.
? Аргументируйте свой выбор. Дайте определение «лишнему» слову, составьте ТРИЗ-загадку по действиям.
III. Назовите общее понятие для частных: приставочный, суффиксальный, приставочно-суффиксальный, сложение, переход одной части речи в другую. Расскажите о каждом из частных понятий, приведите примеры. (способы образования слов в русском языке)
IV. «Собери слово»
- Приставку возьмите у слова раздуть.
- Корень – у слова бором.
- Окончание – у слова пень. (разбор)
Запишите формы слова и родственные ему слова. Что происходит с гласными в корне однокоренных слов.
V. Запишите предложение, укажите его грамматическую основу: Сегодня на уроке мы будем учиться выполнять морфемный и словообразовательный разборы слова.
— Запишем ключевые слова урока (слово, морфемы, способы образования слов в русском языке, разбор, мы будем учиться). Попробуйте сформулировать цель нашего урока, опираясь на ключевые слова.
— Откройте учебник на стр. 74. Познакомимся с порядком морфемного и словообразовательного разбора.
Выполните разборы предложенных слов, объясните орфограмму:
I. к_ртофелина
II. пр_скучный
III. пар_воз
IV. подоко(н,нн)ик
V. (побежали в) столовую
(группы оформляют разборы на альбомных листах, затем представитель каждой группы прикрепляет работы на доску и комментирует их выполнение)
Стадия осмысления (приём «Зигзаг 2»).
Обучающиеся остаются в своих группах, каждый из них получает карточку с одинаковым дидактическим материалом, но разным заданием (смотри приложение).
По команде учителя обучающиеся переходят в группы «по интересам». Теперь в каждой новой группе собираются обучающиеся, выполнявшие одинаковое задание. Их задача – обсудить полученные результаты, внести, если необходимо, исправления.
Их задача – обсудить полученные результаты, внести, если необходимо, исправления.
Стадия размышления.
Вновь по команде учителя ребята возвращаются в первоначальные группы, и каждый из них предлагает своим «коллегам» выполнить морфемный и словообразовательный разборы одного из своих слов (пусть это будет слово, в котором он хорошо разобрался, потому что на этом этапе урока он «учитель»).
Домашнее задание: выписать из стихотворений А.С.Пушкина, помещённых в учебнике литературы, по одному слову на каждый способ образования, выполнить их морфемный и словообразовательный разборы.
Морфологический разбор имени существительного. 6 класс. Образец разбора
Морфологический разбор имени существительного — это указание его постоянных и непостоянных признаков, полная грамматическая характеристика словоформы.
Имя существительное — это самостоятельная часть речи, которая обозначает предмет и отвечает на вопросы кто? Что?
Кто? Человек, птица, сестра, студент, Вася, Мария, Пушкин.
Что? Дом, дерево, вода, толпа, комедия, счастье, Москва, Россия.Морфологический разбор — это указание признаков, отличающих конкретную часть речи в предложении от других. При морфологическом анализе нужно показать, к какой части речи относится слово, какими постоянными и изменяемыми признаками обладает, в какой форме оно употреблено, какова его роль в предложении.
Постоянные признаки существительного не меняются. Это:
Род: мужской, женский, средний, общий, парный
Склонение: I, II, III, адъективное, несклоняемое, разносклоняемое, склоняемое по местоименному типу
Нарицательность: собственное или нарицательное
Одушевленность: одушевленное или неодушевленное
Группа: конкретное, абстрактное, вещественное или собирательное
Непостоянные признаки меняются в зависимости от места в предложении, грамматической формы:
Число: единственное или множественное
Падеж: именительный, родительный, дательный, винительный, творительный, предложный
Подробнее обо всех этих признаках читайте в статье: Имя существительное в русском языке. Классы, род, число, падежи и склонение
Классы, род, число, падежи и склонение
Также указывается синтаксическая роль — каким членом предложения в данном случае является существительное. Чаще всего существительное бывает подлежащим или дополнением, но может также быть обстоятельством, сказуемым, определением.
План морфологического разбора существительного
Часть речи, общее грамматическое значение и вопрос. Начальная форма: именительный падеж единственного числа.
I. Постоянные признаки
Собственное или нарицательное
Одушевленное или неодушевленное
Конкретное, абстрактное, вещественное или собирательное
Род
Склонение
II. Непостоянные признаки
Число
Падеж
III. Роль в предложении
Образец морфологического разбора существительного
Пример 1. Книга — лучший подарок.
Устный разбор
Книга — существительное; обозначает предмет; отвечает на вопрос что? Начальная форма — книга.
Постоянные морфологические признаки: нарицательное, неодушевленное, женский род, 1-го склонения.
Непостоянные морфологические признаки: употреблено в именительном падеже, в единственном числе.
Синтаксическая роль в предложении: является подлежащим.
Письменный разбор
(Что?) книга. Сущ.
н.ф. — книга
Пост. признаки: нариц., неодуш., ж.р., 1 скл.
Непост. признаки: в Им.п., в ед.ч.
(что?) книга — подлежащее
Пример 2. Я ехал из Петербурга
Петербурга. Существительное; обозначает географический объект; отвечает на вопрос из чего? Начальная форма — Петербург.
Постоянные признаки: собственное, неодушевлённое, мужской род, 2-е склонение.
Не изменяется по числам — имеет форму только единственного числа.
Непостоянные признаки: употреблено в форме родительного падежа.
Синтаксическая роль: в предложении выполняет роль обстоятельства места.
Читайте также:
Морфологический разбор прилагательного. Образец, примеры
Морфологический разбор глагола. Образец и пример разбора
Образец и пример разбора
Морфемный разбор
Разбор слова по составу называют ещё морфемным разбором.
Сначала определяют границы окончания, изменяя форму слова (склоняют или спрягают слово). Затем выясняют часть речи, иначе разбор будет неправильным. Изменяемая часть является окончанием. В нём содержится грамматическое значение слова.
Домик-ом – существительное Т.п. и ед.ч.
Чёрн-ому – прилагательное м.р., ед.ч. и П.п.
Плыл-и – глагол мн.ч.
Окончания могут быть многозначными, одно и то же окончание выражает несколько разных грамматических значений (сравните: стекл-о – сущ. ед.ч. и стекл-о – глаг. ср.р. и ед.ч.).
Полк-а – существительное И.п. и ед.ч.
Знал-а – глагол ж.р. и ед.ч.
Прекрасн-а – прилагательное ж.р. и ед.ч.
Окончание существительного состоит из одной буквы (земл-я, стран-а, арми-я, окн-о, мор-е, собрани-е, подлежаще-е) или бывает нулевым (стол, конь, врач, воробей, гений, мышь, осень).
Окончание прилагательного или причастия в полной форме состоит из двух букв, в краткой форме сокращается на одну букву или становится нулевым в форме мужского рода (син-ий, голуб-ой, син-яя, голуб-ая, син-ее, голуб-ое; нежен, нежн-а, нежн-о, нежн-ы).
Прилагательные синий и лисий внешне похожи, но относятся к разным разрядам (первое качественное, второе притяжательное) и отвечают на разные вопросы. А кроме этого, они еще отличаются своими окончаниями: в слове лисий выделяется суффикс -ий, а окончание нулевое.
Окончание у глаголов выделяется не так просто. Сначала нужно определить его форму. Если это инфинитив (начальная форма), то он не изменяется, то есть не имеет непостоянных признаков, а значит, у него нет никакого окончания. В большинстве случаев он легко узнается по особым приметам: -ть, -ти, -чь (плыть, нести, беречь).
Форма прошедшего времени глагола определяется по суффиксу -л- (пел, пел-а, пел-о, пел-и, смеял-ся, смеял-а-сь, смеял-о-сь, смеял-и-сь). Здесь нужно отбросить постфикс -ся или -сь, потому что окончание стоит перед ним.
Здесь нужно отбросить постфикс -ся или -сь, потому что окончание стоит перед ним.
Формы настоящего и будущего времени глагола легко вспомнить (буквы Е, У, Ю есть в глаголах I спряжения, а буквы И, А, Я – в глаголах II спряжения): делаешь, делаете, делаем, делают; стоишь, стоите, стоим, стоят.
В повелительном наклонении глагола перед окончанием может быть суффикс И, а окончание ТЕ: ид-и-те, пиш-и-те (или режь, режь-те, возь-ми, стой).
Местоимения не разбираем по составу в школе, слишком странно выглядит их корень (к-ого-нибудь, ч-ем-то).
Числительные имеют не одно окончание, а сразу два, причем одно из них находится в середине слова: семьсот, сем-и-сот, семь-ю-ст-ами, сем-и-ст-ах.
В деепричастиях, наречиях, категории состояния, служебных словах, междометиях и звукоподражаниях окончание искать совсем не будем, так как это неизменяемые части речи.
После окончания выделяем основу слова. Она может совпадать с корнем (берег, гор-а), и это непроизводная основа. Она может включать в себя приставку, суффикс (пере-ход, бес-полез-н-ый, дом-ик) и быть производной основой.
Основа простая, если состоит из одного корня (красн-ый), она становится сложной, если имеет несколько корней (пар-о-ход). В основе содержится лексическое значение слова. В основу входят и постфиксы -ся, -сь. Тогда она становится прерывистой (сме-ёшь-ся – основа смеся). В основу не включаются интерфиксы (соединительные гласные О-Е): тепл-о-ход, птиц-е-фабрика.
В каждом слове присутствует корень. Это главная часть слова, в которой заключается общее значение всех однокоренных слов (трав-а, трав-к-а, трав-инк-а, трав-ян-ой, трав-ян-ист-ый). В нём часто видны чередования гласных и согласных звуков (рАсти – срАщение – вырОс; друг – друзья – дружба).
Приставка – знАчимая часть слова, которая находится перед корнем и служит для образования новых слов и форм слов. Приставка состоит из одного звука или нескольких, как гласного, так и согласного (у-нёс, с-петь, по-розовел, при-вкус, сверх-герой). В слове можно найти более одной приставки: без-от-чётный, пере-с-читывать.
В слове можно найти более одной приставки: без-от-чётный, пере-с-читывать.
Каждая приставка имеет своё значение, может быть многозначной, к ней легко подобрать приставку-синоним или антоним.
Приставка бес- имеет значение отсутствия (бес-порядок, бес-конечность).
Приставка вы- имеет синоним по- (вы-мыть и по-мыть).
Приставка в- имеет антоним вы- (в-толкнуть – вы-толкнуть).
Есть даже приставки-омонимы: по-мёрзли, по-бежали, по-сидели, по-стирали.
Новые слова: не-счастье, ис-писать, бес-полезный.
Формы слова: наи-лучший, с-делать.
И по своему происхождению приставки бывают исконными и иноязычными: под-нести, контр-игра.
Суффикс – знАчимая часть слова, которая находится после корня и служит для образования новых слов и форм слов. Одно слово иногда содержит несколько суффиксов: за-бол-е-ва-ем-ость. Некоторые суффиксы выступают в разных вариантах: буфет-чик, стеколь-щик.
Суффиксы, как и приставки, тоже обладают лексическим значением, есть многозначные суффиксы, есть суффиксы-синонимы и омонимы.
Суффиксы -ек, -ик обладают уменьшительно-ласкательным значением: орех – ореш-ек, дом – дом-ик.
Синонимические суффиксы: стакан-чик и газет-чик; учи-тель и выключа-тель.
Суффиксы-омонимы: свин-ин-а, солом-ин-а, голос-ин-а, царап-ин-а, шир-ин-а.
Новые слова: син-ев-а, дожд-лив-ый, капитан-ск-ий.
Формы слов: тиш-е, красив-ее, пе-ть, прыга-л, бежа-вш-ий, увиде-в.
Порядок разбора слова по составу
- Определить часть речи.
- Обозначить окончание слова (если есть).
- Выделить основу.
- Через ряд однокоренных слов найти корень слова, отметить чередование звуков.
- Установить приставку или приставки.
- Установить суффикс или суффиксы.
Образец разбора слова по составу
Переплетение – сущ. ед.ч., И.п., нет переплетени-я или переплетени-ем, окончание Е.
ед.ч., И.п., нет переплетени-я или переплетени-ем, окончание Е.
Основа «переплетени». Однокоренные слова: плету, плеть, плетешь. Корень «плет».
Приставка пере- служит для образования нового слова.
Суффикс -ени[j] служит для образования нового слова.
Пере-плет-ени-е.
Порозовел – глагол, прошедшее время, ед.ч., м.р., окончание нулевое.
Основа «порозове» (-л – формообразующий суффикс). Однокоренные слова: розовый, розоветь. Корень «роз».
Приставка по- обозначает начало действия, служит для образования нового слова.
Суффикс -ов- служит для образования нового слова.
Суффикс -е- служит для образования нового слова.
По-роз-ов-е-л Ø
Выполните разбор по составу следующих слов:
Побеседовать
Беспорядочный
Невосприимчивость
Избранный
Сгнивший
Усмехаясь
Направо
Проверьте себя!
Деятельность учителя | Деятельность учащихся | УУД | |||||
1.Мотивация к учебной деятельности. (3 мин.) Цель:
| 1.Приветствие учащихся. Проверка готовности к уроку. Психологический настрой. Вступительное слово учителя, задающего эмоциональный настрой: Друзья мои! Я очень рада Войти в приветливый ваш класс И для меня уже награда Внимание ваших умных глаз. — Здравствуйте, дорогие ребята! Я желаю вам хорошего настроения. Тема нашего урока: «Морфемный и словообразовательный разбор слова». Сегодня мы с вами повторим различные способы образования слов, и вы должны будете принять активное участие в нашей исследовательской работе и научиться определять способ образования слова, а также строить словообразовательные цепочки. Запишите в тетрадях сегодняшнее число, тему урока и слова классная работа. (Запись на доске числа и названия темы урока) | Приветствуют учителя, друг друга, проверяют готовность к уроку, психологически настраиваются на урок. | Самоопределение (Л1, осуществление гражданской идентификации личности) Целеполагание (Р1, принятие учебной задачи) Планирование учебного сотрудничества с учителем и сверстниками (К1, общение и взаимодействие, планирование учебного сотрудничества (К2, ориентировка на позицию партнера, К5, формулировка) | ||||
2.Актуализация знаний и пробное учебное действие. (10 мин.) Цель:
| 2.Проверка домашнего задания. — Назовите сложные слова (1 ряд) — Какие из них являются сложносокращенными (2 р), что они обозначают (1 р.)? — Запишите на доске, как образовано выделенное слово ( 1 р.) — Постройте схему сложного предложения (2 р.) 3.Актуализация знаний. — На прошлых уроках мы изучили темы «Морфемика» и «Словообразование». Сегодня мы повторим эти темы, закрепим умение выполнять разные виды разбора слова. Давайте вспомним этапы анализа слова: Морфемный:
Забайкальский Словообразовательный:
заснеженные ← снег — Наш урок мы проведем в форме путешествия. Каждый ученик получает рабочий лист, в котором 5 заданий. | Выполняют работу у доски Выполняют анализ слов. Отвечают на вопросы. | Л4, формирование картины мира культуры как порождения предметно-преобразующей деятельности человека, Л7, формирование позитивной самооценки, Р2, планирование своих дйствий, Р5, адекватное восприятие оценки учителя Р7, оценка правильности выполнения действия на уровне адекватной ретроспективной оценки, Р8, внесение необходимых корректив в действие после его завершения на основе оценки и учета характера сделанных ошибок, К5, формулирование собственного мнения, К6, умение договариваться и приходить к общему решению в совместной деятельности, П3, построение речевого высказывания в устной форме. | ||||
Динамическая пауза (2 мин.) Цель: сменить вид деятельности. | Комплекс упражнений для глаз. | Выполняют упражнения. | Личностные: установка на здоровый образ жизни и ее реализация на уроке. | ||||
3. Включение изученного в систему знаний.(25 мин.) Цель: выполнения заданий | Мотивация и координация деятельности учащихся, контроль выполнения задания I этап – Морфемика. — Расскажите, из каких значимых частей состоят слова (1 р) и охарактеризуйте каждую из них (2 р). Задание 1. Выполните морфемный разбор слов Кукольный (театр)
Универмаг «Юбилейный» | Выберите слова, соответствующие схемам:
| Задание 3. Составьте предложения из словосочетаний. 1. Утренняя з…ря 2. возл…жить цветы 3. прик…снуться к чему-то 4. выр…с в саду 5. разг…релся между ребятами | Приставка пре- | |||
1 | 2 | 3 | 4 | Словарные слова | 1 | 2 | Словарные слова |
Учащиеся выполняют упражнение по заданию. При проверке оценивают себя. Выполняют задания в группах Отвечают на вопросы учителя. Выполняют словообразовательный разбор в группах. Работают с орфограммой «корни с чередованием» в парах. Работа с приставками. Работают с правописанием приставок в парах. Работают по рядам. Рассказывают правило. Работают с орфограммой, объясняют. Работают в парах. Делают вывод, обобщают. | Контроль, коррекция, выделение и осознание усвоенного (Р4, осуществление итогового и пошагового контроля по результату, Р5, адекватное восприятие оценки учителя, Р8, внесение необходимых корректив в действие после его завершения на основе его оценки и учета характера сделанных ошибок) Самоопределение (Л6, самооценка личности, Л7, формирование адекватной позитивной самооценки, самоуважения и самопринятия) | ||||||
4.Рефлексия. (5 мин.) Цель: | Рефлексия
— Каким способом? — Какие получили результаты? — Что нужно сделать ещё? — Где можно применить новые знания? — Оцените свою работу на уроке. Работу класса Домашнее задание:
| Отвечают на вопросы учителя. Учащиеся высказывают свое впечатление от урока. Записывают домашнее задание. | Умение выражать свои мысли (К1, понимание возможности различных позиций других людей, отличных от собственной, К3,4, учет разных мнений и стремление к координации различных позиций в сотрудничестве) Рефлексия (П5, структурирование знаний, П16, 17,выдвижение гипотез и их обоснование) Смыслообразование (Л7, формирование адекватной позитивной самооценки, самоуважения и самопринятия) | ||||


 Вы будете выполнять их в течение урока самостоятельно. В конце урока каждый заработает определённое количество баллов, которые мы переведём в оценку. Дополнительные баллы вы сможете получить, отвечая на устные вопросы.
Вы будете выполнять их в течение урока самостоятельно. В конце урока каждый заработает определённое количество баллов, которые мы переведём в оценку. Дополнительные баллы вы сможете получить, отвечая на устные вопросы.


 Каким сегодня был урок?
Каким сегодня был урок?3.2 Морфологический анализ
Цель морфологического анализа — выяснить, из каких морфем построено данное слово. Например, морфологический синтаксический анализатор должен уметь сказать нам, что слово cats является формой множественного числа от основы существительного cat , и что слово mice является формой множественного числа от основы существительного mouse . Таким образом, при вводе строки cats морфологический синтаксический анализатор должен выдать результат, похожий на cat N PL .Вот еще несколько примеров:
мышь | мышь N SG |
мыши | мышь N PL |
fox N PL |
Морфологический анализ дает информацию, которая полезна во многих приложениях НЛП. Например, при синтаксическом анализе это помогает узнать особенности согласования слов.Точно так же специалистам по проверке грамматики необходимо знать информацию о соглашении, чтобы обнаруживать такие ошибки. Но морфологическая информация также помогает специалистам по проверке орфографии решить, является ли что-то возможным словом или нет, и при поиске информации она используется для поиска не только cats , если это вводит пользователь, но и cat .
Чтобы перейти от поверхностной формы слова к его морфологическому анализу, мы сделаем два шага. Во-первых, мы собираемся разделить слова на возможные составляющие.Итак, мы сделаем cat + s из cats , используя + для обозначения границ морфем. На этом этапе мы также учтем правила орфографии, поэтому есть два возможных способа разделить foxes , а именно foxe + s и fox + s . Первый предполагает, что foxe — это ствол, а s — суффикс, а второй предполагает, что стержнем является fox и что e было введено из-за правила правописания, которое мы видели выше.
На втором этапе мы будем использовать словарь основ и аффиксов, чтобы найти категории основ и значения аффиксов. Таким образом, cat + s будет сопоставлено с cat NP PL , а fox + s — с fox N PL . Теперь мы также узнаем, что foxe не является юридической основой. Это говорит нам о том, что разделение foxe + s на foxe + s на самом деле было неправильным способом разделения foxe + s , от которого следует отказаться.Но обратите внимание, что для слова домов правильным является разделение его на домов + s .
Вот изображение, иллюстрирующее два шага нашего морфологического синтаксического анализатора с некоторыми примерами.
Теперь мы построим два преобразователя: один для преобразования формы поверхности в промежуточную форму, а другой — для преобразования промежуточной формы в нижележащую форму.
3.2.1 От поверхности к промежуточной форме
Для выполнения морфологического анализа этот преобразователь должен преобразовать поверхностную форму в промежуточную форму.А пока мы просто хотим рассмотреть случаи английских существительных единственного и множественного числа, которые мы видели выше. Это означает, что преобразователь может или не может вставлять границу морфемы, если слово заканчивается на s . Могут быть слова в единственном числе, оканчивающиеся на s (например, kiss ). Вот почему мы не хотим делать вставку границы морфемы обязательной. Если слово заканчивается на ses , xes или zes , оно может, кроме того, удалить e при введении границы морфемы.Вот преобразователь, который это делает. « Другая » дуга в этом преобразователе обозначает переход, который отображает все символы, кроме s, z, x , на себя.
Могут быть слова в единственном числе, оканчивающиеся на s (например, kiss ). Вот почему мы не хотим делать вставку границы морфемы обязательной. Если слово заканчивается на ses , xes или zes , оно может, кроме того, удалить e при введении границы морфемы.Вот преобразователь, который это делает. « Другая » дуга в этом преобразователе обозначает переход, который отображает все символы, кроме s, z, x , на себя.
Давайте посмотрим, как этот преобразователь работает с некоторыми из наших примеров. На следующих графиках показаны возможные последовательности состояний, через которые может пройти датчик, учитывая, что на входе формируется поверхность кошек и лис .
3.2.2 От промежуточной формы к морфологической структуре
Теперь мы хотим взять промежуточную форму, которую мы создали в предыдущем разделе, и сопоставить ее с базовой формой.Ввод, который должен принимать этот преобразователь, может иметь одну из следующих форм:
корень обычного существительного, например cat
корень существительного + s, например cat + s
корень неправильного существительного единственного числа, например мышь
неправильная основа существительного множественного числа, например мышей
В первом случае преобразователь должен сопоставить все символы стебля с собой, а затем вывести N и SG .Во втором случае он отображает все символы основы на себя, но затем выводит N и заменяет PL на s . В третьем случае он делает то же, что и в первом случае. Наконец, в четвертом случае преобразователь должен сопоставить неправильную основу существительного множественного числа с соответствующей основой единственного числа (например, мышей — мыши ), а затем он должен добавить N и PL . Итак, общая структура этого преобразователя выглядит следующим образом:
Итак, общая структура этого преобразователя выглядит следующим образом:
Что еще нужно указать, так это то, как точно выглядят части между состоянием 1 и состояниями 2, 3 и 4 соответственно.Здесь нам нужно распознать основы существительных и решить, правильные они или нет. Мы делаем это, кодируя лексикон следующим образом. Часть преобразователя, которая распознает cat , например, выглядит следующим образом:
А отображение части преобразователя мышей — мыши можно указать следующим образом:
Подключив эти (частичные) преобразователи к датчику, указанному выше, мы получите преобразователь, который проверяет правильность формы ввода и добавляет информацию о категориях и числовых значениях.
3.2.3 Объединение двух преобразователей
Если теперь мы позволим двум преобразователям для отображения от поверхности к промежуточной форме и для сопоставления от промежуточной формы к нижележащей форме работать каскадом (т.е. мы позволим второму датчику работать на вывод первого), мы можем провести морфологический анализ (некоторых) английских словосочетаний с существительными. Однако мы также можем использовать этот преобразователь для создания формы поверхности из формы, лежащей ниже. Помните, что мы можем изменить направление трансляции при использовании преобразователя в режиме трансляции.
Теперь рассмотрим ввод ягод . Что из этого сделают наши каскадные преобразователи? Первый вернет два возможных разделения, ягод и ягод , но тот, который нам нужен, ягод , не входит в их число. Причина в том, что здесь действует другое правило правописания, которое мы совсем не приняли во внимание. Это правило гласит, что « y меняется на , т.е. до s ».Итак, на первом этапе может быть несколько правил правописания, которые все должны быть применены.
Есть два основных способа справиться с этим. Во-первых, мы можем сформулировать преобразователи для каждого из правил таким образом, чтобы их можно было запускать каскадом. Другая возможность — указать преобразователи таким образом, чтобы их можно было применять параллельно.
Другая возможность — указать преобразователи таким образом, чтобы их можно было применять параллельно.
Существуют алгоритмы объединения нескольких каскадных преобразователей или нескольких преобразователей, которые предполагается использовать параллельно, в один преобразователь.Однако эти алгоритмы работают только в том случае, если отдельные преобразователи подчиняются некоторым ограничениям, поэтому мы должны проявлять осторожность при их указании.
3.2.4 Помещение его в Пролог
Если вы хотите реализовать небольшой морфологический синтаксический анализатор, который мы видели в предыдущем разделе, все, что вам действительно нужно сделать, это перевести спецификации преобразователя в формат Пролога, который мы использовали в последняя лекция. Затем вы можете использовать программу преобразователя из последней лекции, чтобы позволить им работать.
Мы не будем подробно показывать, как преобразователи выглядят в Prolog, но мы хотим быстро взглянуть на вставной преобразователь e , потому что он имеет одну интересную особенность; а именно, другой переход .’): -!.
arc (6,1, X: X): -!.
(PDF) При неконтролируемом морфологическом анализе бенгальского
была получена информация о семантическом родстве между парами слов (см. Schone
и Jurafsky 2001) для улучшения нашего неправильного алгоритма обнаружения прикрепления. Наконец,
, мотивированные работой Сингха и др. (2006) над хинди, мы планируем изучить, как создать теггер части речи
для бенгальского языка, который использует морфологическую информацию
, предоставляемую нашим алгоритмом.
Обработка бенгальского языка все еще находится в зачаточном состоянии. Как упоминалось во введении,
одним из основных препятствий на пути компьютеризации бенгальского языка является нехватка аннотированных корпусов
. В рамках нашего обязательства по разработке высокопроизводительных инструментов и алгоритмов
для автоматического анализа бенгальского языка мы намерены создать аннотированные наборы данных
для различных задач обработки бенгальского языка. Обладая аннотированными данными, мы,
Обладая аннотированными данными, мы,
, надеемся продвинуть вперед современный уровень обработки бенгальского языка, (1) обеспечив возможность
эмпирических оценок систем обработки бенгальского языка и (2) решив
проблем в обработке бенгальского языка с использованием корпусов методы, которые, по данным
, являются наиболее успешными в изучении естественного языка.Прежде всего, мы надеемся, что проект
будет стимулировать интерес к компьютеризации бенгальского языка в сообществе
, занимающемся обработкой естественного языка.
Ссылки
Бхаттачарья, С., Чоудхури, М., Саркар, С., и Басу, А. (2005). Синтез функциональной морфологии для
Бенгальских систем существительных, местоимений и глаголов. В материалах национальной конференции по компьютерной обработке
Bangla (NCCPB 05), стр. 34–43.
Брент, М. Р. (1999). Эффективный вероятностный алгоритм сегментации и поиска слов.
Машинное обучение, 34, 71–106.
Брент, М. Р., Мурти, С. К., и Лундберг, А. (1995). Обнаружение морфемных суффиксов: тематическое исследование индукции минимальной длины описания
. В материалах пятого международного семинара по
искусственному интеллекту и статистике.
Кавар Д., Родригес П. и Шременти Г. (2006). Неконтролируемая индукция морфологии для части —
of-speech-tagging. В рабочих документах Пенна по лингвистике: материалы 29-го ежегодного коллоквиума по лингвистике Penn
, Vol.12.1.
Чаудхури Б. Б., Даш Н. С. и Кунду П. К. (1997). Компьютерный разбор глаголов Bangla. В языкознании
Сегодня, 1 (1), 64–86.
Кройц, М. (2003). Неконтролируемая сегментация слов с использованием априорного распределения длины морфа и частоты
. В материалах 41-го ежегодного собрания ACL, стр. 280–287.
Кройц, М., & Лагус, К. (2005). Неконтролируемая сегментация морфем и индукция морфологии из текстовых корпусов
с использованием Morfessor 1. 0. В области информатики и информатики, Отчет A81, Хельсинки
0. В области информатики и информатики, Отчет A81, Хельсинки
Технологический университет.
Дасгупта, С., и Хан, М. (2004). Унификация функций для морфологического анализа в Bangla. В
Материалы международной конференции по компьютерным и информационным технологиям.
Dasgupta, S., & Ng, V. (2007). Высокопроизводительная морфологическая сегментация, не зависящая от языка. В №
NAACL-HLT 2007: Материалы основной конференции, стр. 155–163.
Даш, Н.С. (2006). Морфодинамика бенгальских соединений с их разложением для лексической обработки
. Язык в Индии (www.languageinindia.com), 6,7.
De
´Jean, H. (1998). Морфемы как необходимые концепции для структур: открытие из немаркированных корпусов. В
Практикум по парадигмам и основам в изучении естественного языка, стр. 295–299.
Фрайтаг, Д. (2005). Индукция морфологии по кластерам терминов. В материалах девятой конференции по компьютерному изучению естественного языка
(CoNLL), стр.128–135.
Голдсмит, Дж. (1997). Изучение морфологии естественного языка без учителя. Университет
Чикаго. http://humanities.uchicago.edu/faculty/goldsmith.
Голдсмит, Дж. (2001). Изучение морфологии естественного языка без учителя. Вычислительный
Лингвистика, 27 (2), 153–198.
Неконтролируемый морфологический анализ бенгальского языка
123
В ответ на Prunet, Beland и Idrissi (2000) и Davis and Zawaydeh (1999, 2001) на JSTOR
Abstract В недавних статьях Prunet, Beland & Idrissi (2000) и Davis & Zawaydeh (1999, 2001) были представлены свидетельства «на полях» арабской морфологии-речевых ошибок, допущенных пациентом с афазией в первом случае, гипокорическое формирование у Иорданский / палестинский диалект во втором, который, как они утверждают, несовместим с основанным на словах анализом семитской морфологии, таким как Махадин (1982), Хит (1987), Бат-Эль (1994), Рэтклифф (1997) или Усишкин ( 1999).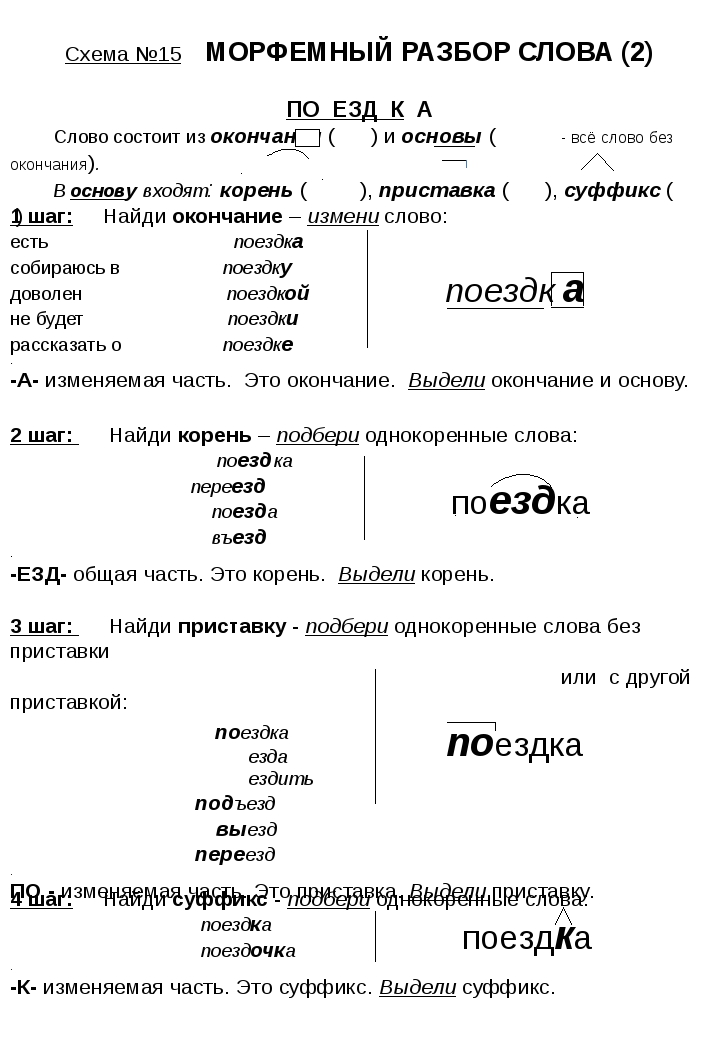 Фактически представленные данные не подтверждают этот вывод. Оба набора данных содержат точки, которые не могут быть предсказаны и не могут быть объяснены с помощью морфемного (коренного) анализа морфологии арабского языка, за который выступают соответствующие авторы. Однако эти документы показывают, что существует потребность в более подробном разъяснении и явной формулировке конкурирующих гипотез, если мы хотим провести значимый эмпирический тест. Ниже я попытаюсь дать такое разъяснение. Затем я покажу, что анализ на основе слов не только обеспечивает лучший эмпирический охват данных, представленных Prunet et.al. и Davis & Zawaydeh, он также обеспечивает основу для принципиального и формально явного анализа этих данных, чего не позволяет подход, основанный на морфемах.
Фактически представленные данные не подтверждают этот вывод. Оба набора данных содержат точки, которые не могут быть предсказаны и не могут быть объяснены с помощью морфемного (коренного) анализа морфологии арабского языка, за который выступают соответствующие авторы. Однако эти документы показывают, что существует потребность в более подробном разъяснении и явной формулировке конкурирующих гипотез, если мы хотим провести значимый эмпирический тест. Ниже я попытаюсь дать такое разъяснение. Затем я покажу, что анализ на основе слов не только обеспечивает лучший эмпирический охват данных, представленных Prunet et.al. и Davis & Zawaydeh, он также обеспечивает основу для принципиального и формально явного анализа этих данных, чего не позволяет подход, основанный на морфемах.
Al-Arabiyya — ежегодный журнал Американской ассоциации учителей арабского языка, обслуживающий ученых в Соединенных Штатах и за рубежом. Аль-Арабийя включает научные статьи и обзоры, которые способствуют изучению, исследованию и преподаванию арабского языка, лингвистики, литературы и педагогики.
Информация для издателейGeorgetown University Press поддерживает академическую миссию Джорджтаунского университета, публикуя научные книги и журналы для самых разных читателей со всего мира. Эти публикации, написанные международной группой авторов, представляющих широкий спектр интеллектуальных перспектив, отражают академические и институциональные преимущества университета. Мы публикуем рецензируемые научные труды с исключительным редакционным и производственным качеством по пяти темам: биоэтика; международные отношения; языки и лингвистика; политология, государственная политика и государственное управление; и религия и этика.
Использование морфологии для обучения лексике
Недавняя запись в блоге Тима Шанахана под названием «Как должна выглядеть инструкция по морфологии?» напомнил мне, насколько важно обучать студентов частям слова (т. е. корням, приставкам, суффиксам) как полезному инструменту для определения значения незнакомых слов и расширения академического словарного запаса.
е. корням, приставкам, суффиксам) как полезному инструменту для определения значения незнакомых слов и расширения академического словарного запаса.
Одним из пяти компонентов нашей программы составления ключевого словаря является Стратегия изучения слов , которая включает в себя поиск подсказок вне слова (использование контекста) и внутри слова (использование частей слова) при встрече неизвестное слово при чтении.Внешние подсказки включают перечитывание предложений до и после слова и использование контекста текста. Внутренние подсказки приходят от распознавания значимых частей слова, то есть с использованием морфологических знаний.
Морфемы и морфологическая осведомленность
Морфемы — это наименьшие единицы значения в языке. Словарь определяет морфему как «слово или часть слова, имеющую значение и не содержащую меньшую часть, имеющую значение.Морфемы включают базовых слов и корневых , префиксов и суффиксов . Их можно комбинировать по-разному, чтобы выражать конкретное значение или выполнять грамматические роли. Некоторые морфемы свободны, — они могут стоять отдельно (например, кошка, прогулка, управление ). Другие морфемы связаны — они не могут стоять отдельно и должны быть присоединены к другой морфеме (например, re-, un-, geo, phon, -ed, -ment). Вот несколько примеров:
- Слово cat содержит одну свободную морфему
- Слово кошки содержит одну свободную морфему (кошка) и одну связанную морфему (и)
- Составное слово песочница содержит две свободные морфемы (песок, ящик)
- Слово непригодный содержит одну связанную морфему (un) и одну свободную морфему (fit)
- Слово переносимый содержит три связанных морфемы (транс, порт, способный)
Морфология означает изучение частей слова, а морфологическая осведомленность относится к способности распознавать наличие морфем в словах. Исследования показывают, что студентов можно обучать различным морфемным элементам, чтобы определять значение новых слов (Edwards et al., 2004). Карлайл (2010) проанализировал 16 исследований о связи обучения морфологической осведомленности с ключевыми компонентами развития грамотности. Результаты показали, что инструкции о частях слова были связаны с улучшением чтения и правописания слов, а также с определением значения незнакомых слов.
Исследования показывают, что студентов можно обучать различным морфемным элементам, чтобы определять значение новых слов (Edwards et al., 2004). Карлайл (2010) проанализировал 16 исследований о связи обучения морфологической осведомленности с ключевыми компонентами развития грамотности. Результаты показали, что инструкции о частях слова были связаны с улучшением чтения и правописания слов, а также с определением значения незнакомых слов.
Academic, School Morphemes
Академическая лексика, которую необходимо выучить после третьего класса, часто состоит из слов, в которых сочетаются корень, префикс и суффикс (e.g., poly + nom + ial = полином ; ману + сценарий = рукопись ). В старших классах начальной школы и выше есть много возможностей найти слова при чтении содержания, содержащие греческие и латинские морфемы. Дети в начальных классах могут начать учиться сочетать морфемы, добавляя общие префиксы и суффиксы к коротким англосаксонским словам, а также составляя их. Например:
- прыжок, прыгает, прыгает, прыгает, прыгун
- чтение, повторное чтение, читатель, не читатель, чтение
- солнце, здание школы, вверх по течению
Морфемный анализ имеет некоторые ограничения.Хотя это полезно, учителя должны также информировать учащихся о том, что это не всегда работает. Это связано с тем, что некоторые префиксы не совпадают по значению (например, в — означает и , а не , и в ). Это также связано с тем, что значение многих греческих и латинских корней существенно изменилось за сотни лет, поэтому они больше не поддаются дословному переводу. Например, дословный перевод осмотрительный должен быть смотреть вокруг ( по кругу означает по кругу, по спектру означает смотреть), в то время как реальное значение — , чтобы быть осторожным, осторожным .
Знакомство с морфологией
Один из способов привить навыки анализа слов — научить студентов, как слова состоят из частей слова и как слова могут быть связаны в семействах слов, например, семейство слов ниже для латинского корня порт (переносить).
Keys to Literacy Преподаватели часто видят примеры учителей, использующих семейства слов, когда мы посещаем классы. Вот несколько примеров:
Другая учебная стратегия состоит в том, чтобы научить студентов создавать семейства слов, задавая основной корень, а затем префиксы и суффиксы, которые можно комбинировать с корнем для создания слов. Word Matrix блоков, таких как примеры ниже, могут быть использованы для этой цели. Дополнительные примеры можно найти на веб-сайте Питера Бауэрса Word Works.
конвой, посланник, конвои, посланники, конвой, конвой, рейс, рейс, рейс, вояж, путешественник, путешественники
повторная попытка, повторная попытка, повторная попытка, невыполненная, ошибка, ошибки, ошибочная, ошибочная, ошибочная, ошибочная, ошибка, прием, приемы, обгон, обгоны, обгон, обгон, предпринять, обязуется, гробовщик, предпринято, обязательство, обязательства , поглощение, захватывает, захватывающее дух, смотритель, забота, берет, берущий, принято, взятие, вынос, захват
Преподавание морфологии
Вот два дополнительных предложения из нашей программы профессионального развития Key Vocabulary Routine:
- Найдите благоприятные моменты: Часто незапланированные моменты возникают во время инструктажа по содержанию, чтобы предоставить примеры анализа слов.Слова из словарных списков содержания могут включать общие части слова, или может возникнуть возможность установить связь между корнем нового слова и словом, ранее охваченным в классе. В частности, преподаватели содержания могут указать примеры слов, содержащих корни, префиксы и суффиксы, из материалов для чтения.
- В центре внимания всей школы: Большинство общих академических слов, которые необходимо выучить учащимся, являются производными словами с частями слова.
 Общешкольный подход к преподаванию академической лексики предполагает, что учителя разных классов и предметов соглашаются уделять внимание нескольким корневым словам и связанным с ними семействам слов каждую неделю или две.
Общешкольный подход к преподаванию академической лексики предполагает, что учителя разных классов и предметов соглашаются уделять внимание нескольким корневым словам и связанным с ними семействам слов каждую неделю или две.
 Общешкольный подход к преподаванию академической лексики предполагает, что учителя разных классов и предметов соглашаются уделять внимание нескольким корневым словам и связанным с ними семействам слов каждую неделю или две.
Общешкольный подход к преподаванию академической лексики предполагает, что учителя разных классов и предметов соглашаются уделять внимание нескольким корневым словам и связанным с ними семействам слов каждую неделю или две.В статье 2015 года, опубликованной в блоге Института мультисенсорного образования, предлагаются следующие стратегии обучения морфологии в классе, основанные на исследовании доктора Нони Лесо:
- Морфологию следует преподавать как отдельный компонент программы улучшения словарного запаса в течение старших классов начальной школы.
- Морфологию следует преподавать как познавательную стратегию, которую необходимо изучить. Чтобы разбить слово на морфемы, ученики должны выполнить следующие четыре шага:
- Признайте, что они не знают этого слова.
- Проанализируйте слово на наличие узнаваемых морфем как в корнях, так и в суффиксах.
- Подумайте о возможном значении, основанном на частях слова.
- Сравните значение слова с контекстом.
- Студентам также необходимо понимать использование префиксов, суффиксов и корней, а также то, как слова преобразуются.
Списки корней, префиксов, суффиксов
Существует значительный объем исследований, показывающих, что обучение префиксов полезно, и многие исследователи лексики рекомендуют обучение наиболее распространенным префиксам как первый и лучший компонент анализа слов (Graves, 2004; Carlisle, 2007).Уайт, Соуэлл и Янагихара (1989) обнаружили, что 20 префиксов составляют почти 97% из 2959 слов с префиксом, которые наиболее часто встречаются в школьных материалах для чтения. Учитывая, как часто встречаются эти 20 префиксов, имеет смысл научить их значению и использованию. Чтобы получить доступ к бесплатному списку этих префиксов, посетите страницу бесплатных ресурсов Keys to Literacy на нашем веб-сайте и перейдите в раздел Словарь . Вы также найдете бесплатные списки следующего:
- Общие числовые префиксы
- Общие и полезные суффиксы
- Общие греческие и латинские корни
Каталожные номера:
Карлайл, Дж. Ф. (2010). Влияние обучения на морфологическое понимание на достижение грамотности: интегративный обзор. Reading Research Quarterly, 45 (4) 464-487.
Ф. (2010). Влияние обучения на морфологическое понимание на достижение грамотности: интегративный обзор. Reading Research Quarterly, 45 (4) 464-487.
Карлайл, Дж. Ф. (2007). Содействие морфологической обработке, развитию словарного запаса и пониманию прочитанного. В R.K. Вагнер А.Э., Муза и К. Танненбаум (ред.). Пополнение словарного запаса: значение для понимания прочитанного . Нью-Йорк: Guilford Press.
Эдвардс, К.Э., Фонт, Г., Бауман, Дж.Ф. и Боланд Э. (2004). Разблокирование значений слов: стратегии и рекомендации по обучению морфемному и контекстному анализу. В Джеймс, Р. Бауман и Эдвард Дж. Каме / ennui (ред.). Словарь инструкций: Изучение на практике . Нью-Йорк: Guilford Press.
Могилы, М.Ф. (2004). Обучающие приставки: насколько хорошо? В Джеймс, Р. Бауман и Эдвард Дж. Каме / ennui (ред.). Словарь инструкций: Изучение на практике . Нью-Йорк: Guilford Press.
Белый, Т.Г., Соуэлл, Дж., И Янагихара, А. (1989). Обучение учеников начальной школы использованию подсказок, состоящих из частей слова. Учитель чтения, 42.
[1] | Д. Аллеманг и Дж. Хендлер, Семантическая сеть для рабочего онтолога: эффективное моделирование в RDFS и OWL, Elsevier, 2011. doi: 10.1016 / c2010-0-68657-3. |
[2] | Д. Бирманн и П.Михайлов, Совместное создание баз данных и совместное использование ресурсов TypeCraft для лингвистов, Языковые ресурсы и оценка 48 (2) (2014), 203–225, Elsevier. DOI: 10.1007 / s10579-013-9257-9. |
[3] | Т. Бернерс-Ли, Проблемы проектирования связанных данных, 2006 г., http://www.w3.org/DesignIssues/LinkedData.html (2011). |
[4] | Дж. Буидж, Грамматика слов: введение в лингвистическую морфологию, Oxford University Press, 2012. |
[5] | С. |
[6] | J. Bosque-Gil, J.Грасиа, Э. Монтьель-Понсода и А. Гомес-Перес, Модели для представления связанных лингвистических данных, Natural Language Engineering 24 (6) (2018), 811–859, Митков, Р., Тайт, Дж. И Богураев, Б.К. (ред.). DOI: 10,1017 / s1351324918000347. |
[7] | К. Чавула и К.М. Кит, Достаточно ли лимона для создания многоязычных онтологий для языков банту ?, в: 11th OWL: Experiences and Directions Workshop (OWLED), C.M. Кит и В. Тамма, ред., 2014 г., стр. 61–72. |
[8] | К. Чиаркос, Онтология лингвистических аннотаций, GLDV — Journal for Computational Linguistics and Language Technology 23 (1) (2008), 1–16, Mönnich, U. and Kühnberger , К. (ред.). |
[9] | К. Чиаркос и С. Хеллманн, Рабочая группа по открытым данным в лингвистике: статус-кво и перспективы, в: Материалы 6-й конференции Open Knowledge Conference (OKCon 2011), S. Хеллманн, П.Фришмут, С. Ауэр и Д. Дитрих, eds, ceur-ws.org, 2011. |
[10] | К. Чиаркос и М. Ионов, Лигт: лексика, родная для LLOD, для представления подстрочный глянцевый текст как RDF, в: 2nd Conference on Language, Data and Knowledge (LDK 2019), M. Eskevich et al., eds, Schloss Dagstuhl-Leibniz-Zentrum Für Informatik, 2019. |
[11] | П. Чимиано, П. Буйтелаар, Дж. МакКрэй и М.Stintek, LexInfo: декларативная модель для интерфейса лексикон-онтология, Журнал веб-семантики 9 (1) (2011), 29–51, Elsevier. DOI: 10.1016 / j.websem.2010.11.001. |
[12] | Б. |
[13] | Б. Комри , M. Haspelmath и B. Bickel, Leipzig Glossing Rules: Conventions for interlinear morpheme-by-morpheme glosses, 2008, доступно в Интернете по адресу https: // www.eva.mpg.de/lingua/pdf/Glossing-Rules.pdf (июль 2016 г.). |
[14] | М. Кройц и К. Лагус, Неконтролируемая сегментация морфем и индукция морфологии из текстовых корпусов с использованием Morfessor 1.0, Хельсинкский технологический университет, Хельсинки, 2005. |
[ 15] | М. Крейтц и К. Лагус, Вызвание морфологической лексики естественного языка из неаннотированного текста, в: Труды Международной и междисциплинарной конференции по адаптивному представлению знаний и мышлению (AKRR’05) 1, T.Хонкела, В. Коненен, М. Пёлля и О. Симула, редакторы, 2005 г., стр. 106–113. |
[16] | Т. Деклерк, Представление информации о полярности элементов составных слов немецкого языка, в: Труды 5-го семинара по связанным данным в лингвистике: Управление, создание и использование связанных языковых ресурсов ( LDL 2016), JP McCrae, C. Chiarcos, E. Montiel Ponsoda, T. Declerck, P. Osenova and S. Hellmann, eds, 2016, pp. 46–49. |
[17] | Т.Эккарт, С. Бош, Д. Голдхан, У. Квастхофф и Б. Климек, Выравнивание словарей на основе переводов для языков банту с ограниченными ресурсами, в: 2-я конференция по языку, данным и знаниям (LDK 2019), М. Эскевич и др. ., ред., Schloss Dagstuhl-Leibniz-Zentrum Fuer Informatik, 2019, стр. 17: 1–17: 11. DOI: 10.4230 / OASIcs.LDK.2019.17. |
[18] | С. Фаррар и Д.Т. Лангендоэн, Реализация золота в OWL-DL, в: Лингвистическое моделирование языков информации и разметки, А.Витт и Д. Метцинг, редакторы, Текст, речь и языковые технологии, Том. |
[19] | М. Форсберг и М. Хулден, Изучение моделей преобразователей для морфологического анализа из примеров перегибов, в: Proceedings of the SIGFSM Workshop on Statistical NLP and Weighted Automata, B. Jurish, A Малетти, К. Вюрцнер и У. Спрингманн, редакторы, 2016 г., стр. 42–50. DOI: 10.18653 / v1 / W16-2405. |
[20] | G. Francopoulo, M. George, N. Calzolari, M. Monachini, N. Bel, M. Pet and C. Soria, Lexical markup framework (LMF), in: Труды Международной конференции по языковым ресурсам и оценке (LREC 2006), Н. Кальцолари, К. Чукри, А. Гангеми и др., Редакторы, 5-е изд., 2006 г., стр. 233–236. |
[21] | Г. Франкопуло и П. Пароубек (редакторы), LMF Lexical Markup Framework, John Wiley & Sons, 2013.DOI: 10.1002 / 9781118712696. |
[22] | Г. Гаэтанель и С. Грейнджер, Как можно использовать обучение, основанное на данных, в преподавании языков ?, в: Справочник по корпусной лингвистике Routledge, A. O’Keeffe and M Маккарти, ред., Рутледж, Лондон, 2010 г., стр. 387–398. DOI: 10.4324 / 9780203856949.ch36. |
[23] | М. Хаспельмат, Сравнительные концепции и описательные категории в кросслингвистических исследованиях, Язык 86 (3) (2010), 663–687, Карлсон, Г.Н. (ред), Лингвистическое общество Америки. DOI: 10.1353 / lan.2010.0021. |
[24] | М. Хаспельмат, Лейпцигские правила лингвистики, Институт эволюционной антропологии Макса Планка, Лейпциг, 2014 г., http://www.uni-regensburg.de/sprache-literatur -kultur / sprache-literatur-kultur / allgemeine-vergleichende-sprachwissenschaft / medien / pdfs / haspelmath_2014_style_rules_linguistics.pdf. |
[25] | М.Хаспелмат и А. Симс, Понимание морфологии, Рутледж, 2013. |
[26] | С. Хеллманн, Интеграция обработки естественного языка (НЛП) и языковых ресурсов с использованием связанных данных, докторская диссертация, Лейпцигский университет, Лейпциг, 2014. |
[27] | С. Хеллманн, С. Моран, М. Брюммер и Дж. МакКрэй (редакторы), Специальный выпуск о многоязычных связанных открытых данных (MLOD), Semantic Web 6 (4) (2015), IOS Press. |
[28] | Н.П. Химмельманн, Документальная и описательная лингвистика, Лингвистика 36 (1) (1998), 161–196, Вальтер де Грюйтер, Берлин. DOI: 10.1515 / ling.1998.36.1.161. |
[29] | К. Янович, П. Хитцлер, Б. Адамс, Д. Колас и К. Вардеман II, Пять звезд использования словаря связанных данных, Семантическая паутина 5 (3) (2014 г.) ), 173–176, IOS Press. DOI: 10.3233 / SW-140135. |
[30] | С.Киров, Р. Коттерелл, Дж. Силак-Глассман, Г. Вальтер, Э. Выломова, П. Ся, М. Фаруки и др., UniMorph 2.0: Универсальная морфология, в: Материалы одиннадцатой Международной конференции по языковым ресурсам и оценке (LREC 2018), N. Calzolari, K. Choukri, C. Cieri, T. Declerck et al., Eds, 2018, pp. 1868–1873. |
[31] | К. Киров, Дж. Силак-Глассман, Р. Ку и Д. Яровски, Очень крупномасштабный анализ и нормализация морфологических парадигм Викислова, в: Proceedings of the Tenth International Конференция по языковым ресурсам и оценке (LREC 2016), Н.Кальцолари, К. Чукри, Т. Деклерк, С. Гогги и др., Ред., 2016 г., стр. 3121–3126. |
[32] | Б. Климек, Предложение согласования OntoLex — MMoOn: На пути к взаимосвязи двух лингвистических моделей предметной области, in: Proceedings of the LDK Workshops: OntoLex, TIAD and Challenges for Wordnets, JP МакКрэй, Ф. Бонд, П. Буйтелаар и др., Ред., 2017, стр. |
[33] | Б. Климек, М. Аккерманн, А.Киршенбаум и С. Хеллманн, Исследование морфологической сложности названных объектов на немецком языке: случай проблемы GermEval NER, в: Материалы 27-й проводимой раз в два года конференции Немецкого общества компьютерной лингвистики и языковых технологий, GSCL 2017: Языковые технологии для решения проблем эпохи цифровых технологий, Г. Рем и Т. Деклерк, редакторы, Springer, Cham, 2017, стр. 130–145. DOI: 10.1007 / 978-3-319-73706-5_11. |
[34] | B.Климек, Н. Арндт, С. Краузе и Т. Арндт, Создание связанных морфологических языковых ресурсов данных с помощью MMoOn — инвентаря морфем иврита, в: Труды Десятой Международной конференции по языковым ресурсам и оценке (LREC 2016), Н. Кальцолари, К. Чукри, Т. Деклерк, С. Гогги и др., Ред., 2016 г., стр. 892–899. |
[35] | Б. Климек, Дж. МакКрэй, Дж. Боске-Гиль, М. Ионов, Дж. К. Таубер и К. Чиаркос, Проблемы представления морфологии в онтологических лексиконах, в: Электронная лексикография в 21 веке.Материалы конференции eLex 2019, И. Косем, Т. Зингано Кун, М. Коррейя и др., Ред., 2019 г., стр. 570–591. |
[36] | К. Леманн, Данные в лингвистике, Лингвистический обзор 21 (3–4) (2004), 175–210, De Gruyter Mouton. DOI: 10.1515 / tlir.2004.21.3-4.175. |
[37] | К. Леманн, Подстрочное морфемное глянцевание, в: Morphologie. Ein Internationales Handbuch zur Flexion und Wortbildung 2, G.Booij, C. Lehmann, J. Mugdan and S. Skopeteas, eds, Walter de Gruyter, 2004, стр. 1834–1857. DOI: 10.1515 / 9783110172782.2. |
[38] | К. Леманн, Лингвистические концепции и категории в описании и сравнении языков, в: Типология, освоение, исследования грамматики, М. Чини и П. Куццолин, ред., Франко Анджели, Милан , 2018, с. 27–50. |
[39] | Дж. |
[40] | JP McCrae, J. Bosque-Gil, J. Gracia, P. Buitelaar и P. Cimiano, The OntoLex-Lemon model: Development and applications, in: Electronic Lexicography in the 21 век: Материалы конференции ELex 2017: Лексикография с нуля, I.Косем, К. Тибериус, М. Якубичек, Й. Каллас, С. Крек и В. Байса, ред., 2017 г., стр. 587–597. |
[41] | JP McCrae, C. Chiarcos, F. Bond, P. Cimiano, T. Declerck, G. De Melo, J. Gracia, S. Hellmann, B. Klimek, S Моран и П. Осенова, Рабочая группа по открытой лингвистике: Разработка облака связанных лингвистических данных, в: Материалы Десятой Международной конференции по языковым ресурсам и оценке (LREC, 2016), Н. Кальцолари, К.Чукри, Т. Деклерк, С. Гогги и др., Ред., 2016 г., стр. 2435–2441. |
[42] | С. Моран, Д. Макклой и Р. Райт, PHOIBLE онлайн, Институт эволюционной антропологии Макса Планка, Лейпциг, 2014 г., http://phoible.org/. |
[43] | Д. Перлмуттер, М. Хаммонд и М. Нунан, Гипотеза морфологии расщепления: данные из идиш, в: Теоретическая морфология: подходы в современной лингвистике, М.Хаммонд и М. Нунан, редакторы, Academic Press, Сан-Диего, 1988, стр. 79–100. |
[44] | М. Рёдер, Р. Усбек, С. Хеллманн и Д. Гербер, N 3 — набор наборов данных для распознавания именованных сущностей и устранения неоднозначности в формате обмена НЛП, в: Материалы Девятой Международной конференции по языковым ресурсам и оценке (LREC 2014), Н. Кальцолари, К. Чукри, Т. Деклерк, Х. Лофтссон и др., ред., 2014 г., стр. 3529–3533. |
[45] | Б. |
[46] | Г. Серассет, Dbnary: Wiktionary как многоязычный лексический ресурс на основе лимона в RDF, специальный выпуск о многоязычных связанных открытых данных (MLOD), Semantic Web 6 (4) (2015 г.) ), 355–361, Hellmann, S., Moran, S., Brümmer, M. и McCrae, J. (eds), IOS Press. DOI: 10.3233 / SW-140147. |
[47] | М. Виганд, А. Балахур, Б. Рот, Д. Клаков и А. Монтойо, Обзор роли отрицания в анализе настроений, в: Материалы семинара об отрицании и спекуляции при обработке естественного языка, Р. Моранте и К. Спорледер, редакторы, 2010 г., стр. 60–68. |
 Бош, Т. Эккарт, Б. Климек, Д. Голдхан и У. Квастхофф, Подготовка и использование лексикографических данных Xhosa для многоязычной федеративной среды, in: Proceedings одиннадцатой Международной конференции по языковым ресурсам и оценке (LREC 2018), Н. Кальцолари, К. Чукри, К. Сиери, Т. Деклерк и др., ред., 2018 г., стр. 4372–4378.
Бош, Т. Эккарт, Б. Климек, Д. Голдхан и У. Квастхофф, Подготовка и использование лексикографических данных Xhosa для многоязычной федеративной среды, in: Proceedings одиннадцатой Международной конференции по языковым ресурсам и оценке (LREC 2018), Н. Кальцолари, К. Чукри, К. Сиери, Т. Деклерк и др., ред., 2018 г., стр. 4372–4378. Комри, Языковые универсалии и лингвистическая типология: синтаксис и морфология, University of Chicago Press, 1989.
Комри, Языковые универсалии и лингвистическая типология: синтаксис и морфология, University of Chicago Press, 1989. 41, Springer, Dordrecht, 2010, стр. 45–66. DOI: 10.1007 / 978-90-481-3331-4_3.
41, Springer, Dordrecht, 2010, стр. 45–66. DOI: 10.1007 / 978-90-481-3331-4_3. DOI: 10.4324 / 9780203776506.
DOI: 10.4324 / 9780203776506. 68–83.
68–83. МакКрэй, Г. Агуадо-де-Сеа, П.Буйтелаар, П. Чимиано, Т. Деклерк, А. Гомес-Перес, Дж. Грасиа и др., Обмен лексическими ресурсами в семантической сети, Языковые ресурсы и оценка 46 (4) (2012), 701–719, Springer Science and Бизнес Медиа (ООО). DOI: 10.1007 / s10579-012-9182-3.
МакКрэй, Г. Агуадо-де-Сеа, П.Буйтелаар, П. Чимиано, Т. Деклерк, А. Гомес-Перес, Дж. Грасиа и др., Обмен лексическими ресурсами в семантической сети, Языковые ресурсы и оценка 46 (4) (2012), 701–719, Springer Science and Бизнес Медиа (ООО). DOI: 10.1007 / s10579-012-9182-3.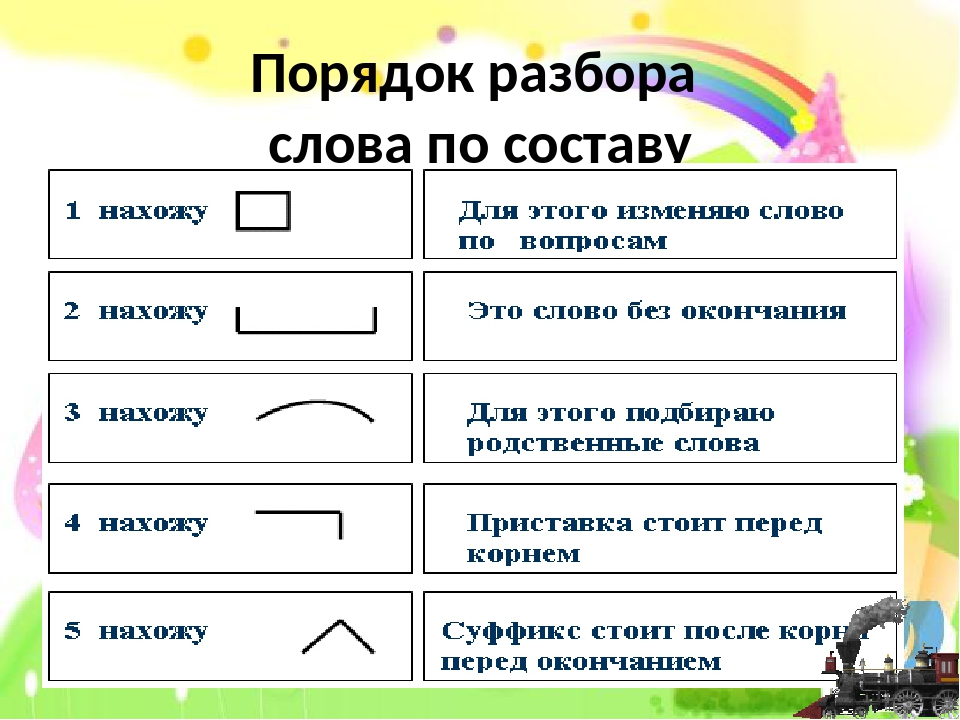 Сагот, The Lefff, свободно доступная морфологическая и синтаксическая лексика с большим охватом для французского языка, в: Материалы 7-й Международной конференции по языковым ресурсам и оценке (LREC 2010 ), Н. Кальцолари, К. Чукри, Б. Маегаард и др., Ред., 2010 г., стр. 2744–2751.
Сагот, The Lefff, свободно доступная морфологическая и синтаксическая лексика с большим охватом для французского языка, в: Материалы 7-й Международной конференции по языковым ресурсам и оценке (LREC 2010 ), Н. Кальцолари, К. Чукри, Б. Маегаард и др., Ред., 2010 г., стр. 2744–2751.Примеры связанных и свободных морфем
Морфемы — это наименьшие единицы языка, которые имеют значение.Их можно классифицировать как свободные морфемы, которые могут стоять отдельно как слова, или связанные морфемы, которые должны быть объединены с другой морфемой, чтобы сформировать полное слово. Связанные морфемы обычно появляются как аффиксы в английском языке.
Примеры свободных морфем
Свободные морфемы считаются базовыми словами в лингвистике. Базовые слова, которые могут стоять отдельно (например, «книга»), известны как свободные основы, в то время как связанные основы (включая латинские корни, такие как «ject») не являются отдельными словами в английском языке.Большинство свободных морфем можно модифицировать с помощью аффиксов для образования сложных слов. Объединение двух свободных морфем создает составное слово (например, «почтовый ящик»), в то время как свободные морфемы, модифицированные аффиксами, являются сложными словами (например, «бегун»).
Есть два типа свободных морфем в зависимости от того, что они делают в предложении: слова содержания и служебные слова.
слов содержимого
Свободные морфемы, составляющие основное значение предложения, являются словами содержимого. Их части речи включают существительные, глаголы и прилагательные.Вот несколько примеров содержательных слов из повседневной речи.
- Существительные : девушка, шляпа, дом, огонь
- Глаголы : ходить, спать, говорить, есть
- Прилагательные : быстро, красиво, весело, большой
Эти слова являются наиболее важными частями предложения. Значение слов содержания может измениться при сочетании с другими морфемами, но их свободные морфемы по-прежнему будут составлять содержание предложения.
Функциональные слова
Свободные морфемы также включают функциональные слова.Эти слова состоят из артиклей, указательных, вспомогательных, количественных, предлогов, местоимений и союзов. Вот несколько примеров свободных морфем как служебных слов.
- Статьи : the, a, an
- Демонстрации : это, то, те, эти
- Вспомогательные глаголы : будет, есть, должен, выполняет
- Кванторы : некоторые, многие, несколько
- Предлоги : под, над, к, от
- Местоимения : он, она, его, ее
- Союзы : для, и, но, или
Функциональные слова служат грамматической связью между содержательные слова.Обычно они не сочетаются с аффиксами, которые меняют их значение.
Примеры связанных морфем
Связанные морфемы не имеют лингвистического значения, если они не связаны с корнем или основным словом или, в некоторых случаях, с другой связанной морфемой. Префиксы и суффиксы — это два типа связанных морфем. В зависимости от того, как они модифицируют корневое слово, связанные морфемы могут быть сгруппированы в две категории: словоизменительные морфемы и словообразовательные морфемы.
Флективные морфемы
Морфемы этого типа изменяют грамматическую функцию слова, будь то время глагола, число, наклонение или склонение другого языка.Восемь флективных морфем организованы в зависимости от того, какую часть речи они изменяют:
- Изменить существительное : -s (или -es), -‘s (или s ‘)
- Изменить прилагательное : -er, -est
- Изменить глагол : -ed, -ing, -en
Эти морфемы представляют собой суффиксы, которые изменяют состояние слова, но не его значение. Когда они изменяют базовое слово, может потребоваться изменение остальной части предложения для правильного согласования подлежащего и глагола. Вот некоторые примеры этих изменений:
- девочка – девочки
- большие – большие
- умные – самые умные
- ходьба – ходьба
- съедено
Деривационные морфемы
Морфема является деривационной, когда она изменяет семантическое значение слова.Большинство деривационных морфем имеют греческие или латинские корни. В отличие от флективных морфем, словообразовательные морфемы могут изменять часть речи слова.
Префиксы:
Суффиксы:
Способ использования морфем также зависит от контекста предложения. Флективные морфемы могут использоваться в деривационных контекстах (например, с использованием -er для создания учитель), что может изменить их классификацию. Вот несколько примеров того, как словообразовательные морфемы могут изменять базовые слова.
- re- + start = restart (чтобы начать заново)
- un- + happy = unhappy (not happy)
- register + -ion = registration (акт регистрации)
- kind + ness = kindness (условие доброты)
Просмотреть и скачать PDF
Подробнее о морфемах
Понимание морфологии языка — первый шаг в его овладении. Узнайте больше о том, как префиксы и суффиксы могут изменять базовые слова, или воспользуйтесь рабочим листом по идентификации морфем, представленным здесь.
Узнайте больше о том, как префиксы и суффиксы могут изменять базовые слова, или воспользуйтесь рабочим листом по идентификации морфем, представленным здесь.
Морфологический анализ суахили с использованием краудсорсинговой лексики
Морфологический анализ суахили с использованием краудсорсинговых лексических ресурсовМорфологический анализ суахили с использованием краудсорсинговых лексических ресурсов Патрик Литтел, Кейтлин Прайс, Лори Левин Университет Британской Колумбии, Оберлинский колледж, Университет Карнеги-Меллона Ванкувер, Британская Колумбия V6T1Z4, Оберлин, Огайо 44074, Питтсбург, Пенсильвания 15213 [защита электронной почты], [защита электронной почты], [защита электронной почты] Абстрактный Мы описываем морфологический анализатор для языка суахили, написанный в расширении XFST / LEXC, предназначенный для простого объявления. морфофонологических паттернов и импорта лексических ресурсов.Наш анализатор был широко дополнен данными из Kamusi Project (kamusi.org), многоязычный словарь, созданный пользователями. Использование этого ресурса позволило нам добиться широкого лексическое покрытие быстро, но неоднородный характер пользовательского контента также создает некоторые проблемы при его адаптации для использования в экспертной системе. Ключевые слова: суахили, морфологический анализ, краудсорсинг. 1. Введение В этой статье описывается морфологический анализатор суахили, предназначенный для использования в статистическом машинном переводе, на основе на лексических ресурсах пользовательского Kamusi Словарь суахили (камуси.org). Адаптация этих ресурсов в нашу систему дала нам значительный выигрыш в типах и токен-покрытие (+ 24,61% и + 15,70% соответственно), но они также создают проблемы, учитывая неоднородный характер контента, добавляемого пользователями. Использование публично предоставленных данных не является чем-то новым. развитие лексикографии - Оксфордский словарь английского языка запросил общественные пожертвования еще в 1859 г..
 (Winchester, 1999) - но появление Интернета сделало возможным «краудсорсинг» (Howe, 2006) словаря в основном
или полностью из онлайн-вкладов (Trap-Jensen, 2013).Хотя недавние попытки краудсорсинга в Интернете крупными
Английские словари, такие как OED (oed.com) и
Словарь Коллинза (collinsdictionary.com)
вызывали споры, большинство языков мира
немного, если вообще есть общедоступные лексические ресурсы в
первое место. В таких случаях краудсорсинг обеспечивает
прекрасная возможность для широкого охвата, но недорогих онлайн-ресурсов, независимо от того, являются ли языки основными языками мира с ограниченными онлайн-ресурсами, такими как суахили, нестандартными диалектами с ограниченными текстовыми данными, такими как филиппинский английский (www.languagecommunities.com/
pinoyenglish.html) или исчезающие языки, например
Инуктитут (livingdictionary.org) или Canadian First
Языки наций (firstvoices.org).
Появление этих новых ресурсов дает потенциально большие преимущества для тех, кто работает над вычислительной техникой.
обработка этих языков (Cristea et al., 2008; Kosem
и др., 2013). Один вопрос, который возникает в отношении
Лексикография сообщества - это то, имеют ли полученные словари достаточное качество для последующей разработки приложений.Что касается словаря Камуси, это
проект предполагает, что ответ, безусловно, «да», хотя
до некоторой степени структура словаря и различная специфика метаданных, предоставляемых пользователем, создают некоторые проблемы для его адаптации.
Целью этой статьи не является критика структуры или
качество словаря Камуси, но чтобы проиллюстрировать это,
возникает необходимое противоречие между следующими двумя вопросами:
1. Какие типы данных нужны разработчикам при создании языковых приложений и экспертных систем?
2.Какие типы данных разумно запрашивать у сообщества
участники?
Ответы на эти вопросы будут зависеть от
потребности приложения и характер сообщества,
но почти неизбежно возникнет несоответствие между тем, чего хотят разработчики, и тем, что «толпа»
могу доставить.
(Winchester, 1999) - но появление Интернета сделало возможным «краудсорсинг» (Howe, 2006) словаря в основном
или полностью из онлайн-вкладов (Trap-Jensen, 2013).Хотя недавние попытки краудсорсинга в Интернете крупными
Английские словари, такие как OED (oed.com) и
Словарь Коллинза (collinsdictionary.com)
вызывали споры, большинство языков мира
немного, если вообще есть общедоступные лексические ресурсы в
первое место. В таких случаях краудсорсинг обеспечивает
прекрасная возможность для широкого охвата, но недорогих онлайн-ресурсов, независимо от того, являются ли языки основными языками мира с ограниченными онлайн-ресурсами, такими как суахили, нестандартными диалектами с ограниченными текстовыми данными, такими как филиппинский английский (www.languagecommunities.com/
pinoyenglish.html) или исчезающие языки, например
Инуктитут (livingdictionary.org) или Canadian First
Языки наций (firstvoices.org).
Появление этих новых ресурсов дает потенциально большие преимущества для тех, кто работает над вычислительной техникой.
обработка этих языков (Cristea et al., 2008; Kosem
и др., 2013). Один вопрос, который возникает в отношении
Лексикография сообщества - это то, имеют ли полученные словари достаточное качество для последующей разработки приложений.Что касается словаря Камуси, это
проект предполагает, что ответ, безусловно, «да», хотя
до некоторой степени структура словаря и различная специфика метаданных, предоставляемых пользователем, создают некоторые проблемы для его адаптации.
Целью этой статьи не является критика структуры или
качество словаря Камуси, но чтобы проиллюстрировать это,
возникает необходимое противоречие между следующими двумя вопросами:
1. Какие типы данных нужны разработчикам при создании языковых приложений и экспертных систем?
2.Какие типы данных разумно запрашивать у сообщества
участники?
Ответы на эти вопросы будут зависеть от
потребности приложения и характер сообщества,
но почти неизбежно возникнет несоответствие между тем, чего хотят разработчики, и тем, что «толпа»
могу доставить. Это особенно верно для ресурсов, таких как
Словари Kamusi, которые создаются перед потенциальными проектами, которые могут в конечном итоге поддерживаться их данными. В разделе 4 мы рассмотрим несколько примеров, в которых данные, имеющие решающее значение для
наше приложение (морфологический стемминг) не всегда
разумно по запросу участников сообщества работающих
независимо.2.
Обзор суахили
Суахили - самый распространенный из языков банту,
является ветвью нигеро-кордофанской языковой семьи и является
используется в качестве лингва-франка в Восточной Африке (Wald, 1990).
Языки банту, включая суахили, хорошо известны.
за их сложную систему классов существительных (Denny and Creider, 1976; Zawawi, 1979; Contini-Morava, 1994). Каждый
существительное на суахили относится к четырнадцати
«Классы» или «пол». Например, большинство существительных, описывающих людей, попадают в класс 1 в единственном числе, где они
начинаются с префикса m- или mw- и попадают в класс 2 во множественном числе, где им предшествует префикс wa-.Самый нечетный
классы имеют четный класс, соответствующий его
множественное число; например, существительные класса 3 имеют множественное число класса 4,
в то время как множественное число класса 10 соответствует существительным класса 9 или 11,
и некоторые существительные класса 11 имеют множественное число класса 6.
К какому классу будет принадлежать конкретное существительное, не совсем
предсказуемо на основе одной только его семантики, хотя там
сильные тенденции - люди склонны попадать в класс 1,
растения и расширенные объекты в классе 3, абстрактные идеи в классе
11/14 и др. Исторически можно реконструировать 22 класса, но
ни один современный язык не сохраняет все 22.Таблица 1 основана на (но,
3333
Особый класс
1 (м-)
3 (м-)
Множественный класс
2 (ва-)
4 (ми-)
5 (0-, ji-)
6 (ма-)
7 (ки)
9 (0-, н-)
11/14 (u-)
15 (ку-)
16, 17, 18 (-ni)
8 (vi-)
10 (0, н-)
10 (0, н-)
Семантическое расширение
люди
растения; расширенный
объекты; естественный
явления
фрукты; круглый,
полые или большие вещи
маленькие вещи
сборник; ссуды
массы; абстракции
герундий
местные жители
Таблица 1: Классы существительных суахили
необходимо, упрощенное из) семантических сетей, заданных
в (Contini-Morava, 1994).
Это особенно верно для ресурсов, таких как
Словари Kamusi, которые создаются перед потенциальными проектами, которые могут в конечном итоге поддерживаться их данными. В разделе 4 мы рассмотрим несколько примеров, в которых данные, имеющие решающее значение для
наше приложение (морфологический стемминг) не всегда
разумно по запросу участников сообщества работающих
независимо.2.
Обзор суахили
Суахили - самый распространенный из языков банту,
является ветвью нигеро-кордофанской языковой семьи и является
используется в качестве лингва-франка в Восточной Африке (Wald, 1990).
Языки банту, включая суахили, хорошо известны.
за их сложную систему классов существительных (Denny and Creider, 1976; Zawawi, 1979; Contini-Morava, 1994). Каждый
существительное на суахили относится к четырнадцати
«Классы» или «пол». Например, большинство существительных, описывающих людей, попадают в класс 1 в единственном числе, где они
начинаются с префикса m- или mw- и попадают в класс 2 во множественном числе, где им предшествует префикс wa-.Самый нечетный
классы имеют четный класс, соответствующий его
множественное число; например, существительные класса 3 имеют множественное число класса 4,
в то время как множественное число класса 10 соответствует существительным класса 9 или 11,
и некоторые существительные класса 11 имеют множественное число класса 6.
К какому классу будет принадлежать конкретное существительное, не совсем
предсказуемо на основе одной только его семантики, хотя там
сильные тенденции - люди склонны попадать в класс 1,
растения и расширенные объекты в классе 3, абстрактные идеи в классе
11/14 и др. Исторически можно реконструировать 22 класса, но
ни один современный язык не сохраняет все 22.Таблица 1 основана на (но,
3333
Особый класс
1 (м-)
3 (м-)
Множественный класс
2 (ва-)
4 (ми-)
5 (0-, ji-)
6 (ма-)
7 (ки)
9 (0-, н-)
11/14 (u-)
15 (ку-)
16, 17, 18 (-ni)
8 (vi-)
10 (0, н-)
10 (0, н-)
Семантическое расширение
люди
растения; расширенный
объекты; естественный
явления
фрукты; круглый,
полые или большие вещи
маленькие вещи
сборник; ссуды
массы; абстракции
герундий
местные жители
Таблица 1: Классы существительных суахили
необходимо, упрощенное из) семантических сетей, заданных
в (Contini-Morava, 1994).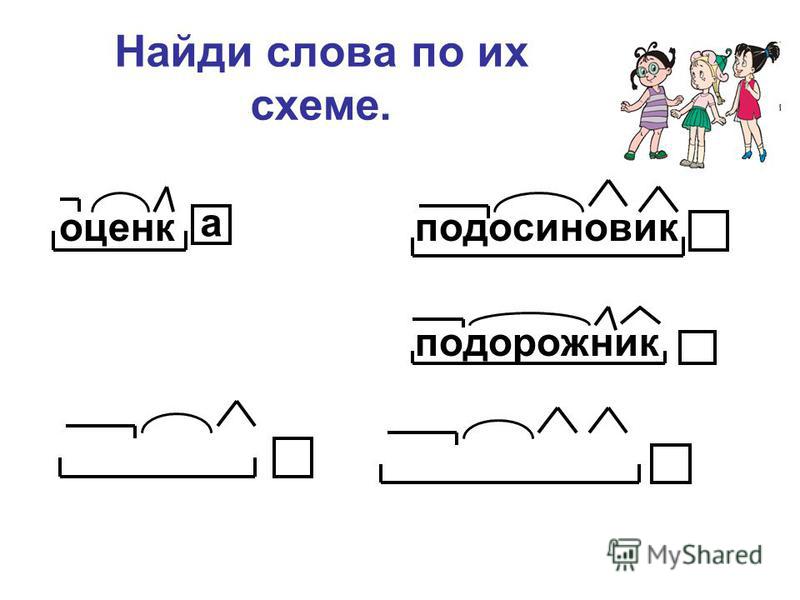 Глаголы, прилагательные, указательные слова, притяжательные маркеры, релятивизаторы и другие элементы также принимают классовые аффиксы,
чтобы указать, с какими номинальными аргументами они связаны.Поэтому идентификация этих префиксов важна для
определение правильных лексических статей и разрешение предложения
зависимости, и это самая важная задача, которую должен выполнить морфологический синтаксический анализатор.
Многие из этих аффиксов соглашения гомофонны. Префикс wap в глаголе, например, может указывать на третье лицо.
множественное число, 2-е единственное число, 3-е единственное число, 3-й класс или класс
11 подлежащее в настоящем времени, либо 2-й или 3-й объект множественного числа. Совместно с другим гомофонным соглашением
префиксы, такие префиксы могут привести к взрыву неоднозначности.Сведение к минимуму такой двусмысленности было первоочередной задачей.
цель разработки нашей системы.
3.
Расширение XFST и LEXC
Наш морфологический синтаксический анализатор служит для взлома
сложное слово, например нинакупенда («Я люблю
вы ») на его составные значимые части, такие как
[SUBJ.1SG] [PRES] [OBJ.2SG] в ожидании [VERB].
Дано
морфологическая сложность глаголов суахили, в частности, это необходимый шаг перед дальнейшей обработкой,
как единственный корень глагола может иметь тысячи возможных
словообразовательные и словоизменительные формы.
Мы реализовали наш парсер с использованием конечного состояния Xerox
инструментарий (Beesley and Karttunen, 2003) 1, написав описание нашего языка в расширении более высокого уровня LEXC и
компилируя это в фактические команды в XFST и
Языки LEXC.XFST и LEXC позволяют построить конечное состояние
преобразователь между, на верхней стороне, морфологическими элементами, такими как [PRES], [SUBJ.1SG] или [VERB], и на
нижняя сторона, соответствующий сегментарный материал, такой как -na-, ni-,
и -a. Морфологическая совместимость в основном ограничена.
в источнике LEXC2, а фонологические правила специфичны1
Более ранний частный синтаксический анализатор суахили, написанный с использованием
Инструментарий конечного состояния TWOLC описан в Huskiarnen (1992).
Глаголы, прилагательные, указательные слова, притяжательные маркеры, релятивизаторы и другие элементы также принимают классовые аффиксы,
чтобы указать, с какими номинальными аргументами они связаны.Поэтому идентификация этих префиксов важна для
определение правильных лексических статей и разрешение предложения
зависимости, и это самая важная задача, которую должен выполнить морфологический синтаксический анализатор.
Многие из этих аффиксов соглашения гомофонны. Префикс wap в глаголе, например, может указывать на третье лицо.
множественное число, 2-е единственное число, 3-е единственное число, 3-й класс или класс
11 подлежащее в настоящем времени, либо 2-й или 3-й объект множественного числа. Совместно с другим гомофонным соглашением
префиксы, такие префиксы могут привести к взрыву неоднозначности.Сведение к минимуму такой двусмысленности было первоочередной задачей.
цель разработки нашей системы.
3.
Расширение XFST и LEXC
Наш морфологический синтаксический анализатор служит для взлома
сложное слово, например нинакупенда («Я люблю
вы ») на его составные значимые части, такие как
[SUBJ.1SG] [PRES] [OBJ.2SG] в ожидании [VERB].
Дано
морфологическая сложность глаголов суахили, в частности, это необходимый шаг перед дальнейшей обработкой,
как единственный корень глагола может иметь тысячи возможных
словообразовательные и словоизменительные формы.
Мы реализовали наш парсер с использованием конечного состояния Xerox
инструментарий (Beesley and Karttunen, 2003) 1, написав описание нашего языка в расширении более высокого уровня LEXC и
компилируя это в фактические команды в XFST и
Языки LEXC.XFST и LEXC позволяют построить конечное состояние
преобразователь между, на верхней стороне, морфологическими элементами, такими как [PRES], [SUBJ.1SG] или [VERB], и на
нижняя сторона, соответствующий сегментарный материал, такой как -na-, ni-,
и -a. Морфологическая совместимость в основном ограничена.
в источнике LEXC2, а фонологические правила специфичны1
Более ранний частный синтаксический анализатор суахили, написанный с использованием
Инструментарий конечного состояния TWOLC описан в Huskiarnen (1992). 2
Поскольку языки банту, в том числе суахили, имеют междугороднюю
ограничения на совместное появление морфем, мы широко использовали
диакритических знаков флага LEXC, аналогично подходу, используемому Преториусом
и Bosch (2003) для зулу, родственного языка банту.указано в источнике XFST.
Описание суахили также требует ряда морфофонологических правил: фонологические преобразования, которые
применяются только к определенным подмножествам основ при наличии
или отсутствие определенных морфологических особенностей. Префиксы классов, такие как m (w) - или ku-, например, могут вести себя по-разному.
в зависимости от морфосинтаксического класса следующих
корень. Некоторые последовательности, такие как отрицательный символ, за которым следует
первое лицо единственного числа ni-, может сливаться в сумку
морфемы, но только в определенных временах.Реализация таких морфофонологических правил в
XFST / LEXC не совсем прост, поскольку
они связаны с низкими преобразованиями фонологических
сегменты по наличию или отсутствию верхней стороны
такие функции, как [ГЛАГОЛ] или [ПРОШЛОЕ]. Есть несколько способов
достижения этого, но у каждого из них есть свои недостатки.
Например, можно ввести непроизносимые «сегменты»
на нижней стороне, которые соответствуют элементам верхней стороны
(скажем, ˆPASTˆ), а затем сделайте ссылку на них в нижних преобразованиях. Можно также использовать композиции XFST для разделения FST на две части, применить нижнее преобразование только к одной из этих частей, а затем
объединить части обратно в один FST.Например, чтобы применить
Правило только для [ПРОШЛОЕ] форм, примерно следующее:
необходимый:
определять
определять
определять
определять
Прошедшие [$ "[ПРОШЛОЕ]" .o. Словарный запас ];
Nonpasts [˜ $ ["ПРОШЛОЕ"] .o. Словарный запас];
Прошлые [Прошедшие .o. <правило>];
Лексикон [Прошедшее | Nonpasts];
В этом коде используется существующий лексикон и, используя
верхние FST композиции, разделяющие их между формами
которые содержат [ПРОШЛОЕ] на своей верхней стороне и формы, которые
нет.
2
Поскольку языки банту, в том числе суахили, имеют междугороднюю
ограничения на совместное появление морфем, мы широко использовали
диакритических знаков флага LEXC, аналогично подходу, используемому Преториусом
и Bosch (2003) для зулу, родственного языка банту.указано в источнике XFST.
Описание суахили также требует ряда морфофонологических правил: фонологические преобразования, которые
применяются только к определенным подмножествам основ при наличии
или отсутствие определенных морфологических особенностей. Префиксы классов, такие как m (w) - или ku-, например, могут вести себя по-разному.
в зависимости от морфосинтаксического класса следующих
корень. Некоторые последовательности, такие как отрицательный символ, за которым следует
первое лицо единственного числа ni-, может сливаться в сумку
морфемы, но только в определенных временах.Реализация таких морфофонологических правил в
XFST / LEXC не совсем прост, поскольку
они связаны с низкими преобразованиями фонологических
сегменты по наличию или отсутствию верхней стороны
такие функции, как [ГЛАГОЛ] или [ПРОШЛОЕ]. Есть несколько способов
достижения этого, но у каждого из них есть свои недостатки.
Например, можно ввести непроизносимые «сегменты»
на нижней стороне, которые соответствуют элементам верхней стороны
(скажем, ˆPASTˆ), а затем сделайте ссылку на них в нижних преобразованиях. Можно также использовать композиции XFST для разделения FST на две части, применить нижнее преобразование только к одной из этих частей, а затем
объединить части обратно в один FST.Например, чтобы применить
Правило только для [ПРОШЛОЕ] форм, примерно следующее:
необходимый:
определять
определять
определять
определять
Прошедшие [$ "[ПРОШЛОЕ]" .o. Словарный запас ];
Nonpasts [˜ $ ["ПРОШЛОЕ"] .o. Словарный запас];
Прошлые [Прошедшие .o. <правило>];
Лексикон [Прошедшее | Nonpasts];
В этом коде используется существующий лексикон и, используя
верхние FST композиции, разделяющие их между формами
которые содержат [ПРОШЛОЕ] на своей верхней стороне и формы, которые
нет. Фонологическое правило применяется только к первым
набор, используя композицию нижней стороны, а затем воссоздает
лексикон, взяв объединение двух FST.Это может
быть сжатым, конечно, но за счет удобочитаемости;
сокращенная версия еще менее интуитивно понятна, и обе
трудно поддерживать в условиях изменений. В частности,
каскад разделов и слияний, выполняющих необходимые
морфофонологические правила отличаются от тех, которые выполняют
необязательное правило, и переход от одного к другому может быть
подвержен ошибкам.
Это разумно, когда всего несколько морфофонологических правил
необходимы, чтобы вручную закодировать каждое такое правило, но суахили
требует десятков таких правил, что потенциально приводит к сотням строк композиций и объединений XFST.Вместо этого мы решили определить очень консервативное расширение для
LEXC, в котором структурированные комментарии позволяют пользователю более просто объявлять морфофонологические преобразования. Эти комментарии позволяют разработчику определять морфологические классы, используя простую булеву алгебру,
и определить преобразования, которые обязательно или необязательно
применить к ним в одной строке файла LEXC. Следующая строка, например, выполняет коалесценцию ха-ни-то на нижней стороне только тогда, когда верхняя сторона содержит
[SUBJ.1SG], но не содержит [COND]:
!? с [SUBJ.1SG] и ˜ [COND]
требуется {haˆniˆ} -> {siˆ}
3334
Все структурированные комментарии в файле LEXC собраны
и скомпилирован в сценарий XFST, который выполняет соответствующее преобразование.
У этого метода есть несколько преимуществ. Во-первых,
значительная экономия строк кода, замена многих строк
трудночитаемого и сложного в обслуживании шаблонного кода. Это позволяет разработчику сохранять морфофонологические объявления в файле LEXC рядом с морфологическими объявлениями.
они ссылаются, а не в отдельный файл.Кроме того, ключевые слова подчеркивают важные различия.
например, является ли правило обязательным («требуется») или необязательным («разрешить») - важное различие, которое трудно вывести из соответствующей серии композиций XFST.
Фонологическое правило применяется только к первым
набор, используя композицию нижней стороны, а затем воссоздает
лексикон, взяв объединение двух FST.Это может
быть сжатым, конечно, но за счет удобочитаемости;
сокращенная версия еще менее интуитивно понятна, и обе
трудно поддерживать в условиях изменений. В частности,
каскад разделов и слияний, выполняющих необходимые
морфофонологические правила отличаются от тех, которые выполняют
необязательное правило, и переход от одного к другому может быть
подвержен ошибкам.
Это разумно, когда всего несколько морфофонологических правил
необходимы, чтобы вручную закодировать каждое такое правило, но суахили
требует десятков таких правил, что потенциально приводит к сотням строк композиций и объединений XFST.Вместо этого мы решили определить очень консервативное расширение для
LEXC, в котором структурированные комментарии позволяют пользователю более просто объявлять морфофонологические преобразования. Эти комментарии позволяют разработчику определять морфологические классы, используя простую булеву алгебру,
и определить преобразования, которые обязательно или необязательно
применить к ним в одной строке файла LEXC. Следующая строка, например, выполняет коалесценцию ха-ни-то на нижней стороне только тогда, когда верхняя сторона содержит
[SUBJ.1SG], но не содержит [COND]:
!? с [SUBJ.1SG] и ˜ [COND]
требуется {haˆniˆ} -> {siˆ}
3334
Все структурированные комментарии в файле LEXC собраны
и скомпилирован в сценарий XFST, который выполняет соответствующее преобразование.
У этого метода есть несколько преимуществ. Во-первых,
значительная экономия строк кода, замена многих строк
трудночитаемого и сложного в обслуживании шаблонного кода. Это позволяет разработчику сохранять морфофонологические объявления в файле LEXC рядом с морфологическими объявлениями.
они ссылаются, а не в отдельный файл.Кроме того, ключевые слова подчеркивают важные различия.
например, является ли правило обязательным («требуется») или необязательным («разрешить») - важное различие, которое трудно вывести из соответствующей серии композиций XFST. Это различие стало очень важным, когда мы интегрировали
лексические элементы из словаря Камуси в нашу систему
и обнаружил, что многие преобразования, описанные на суахили
ссылки как обязательные были фактически необязательными. Изменение «требуется» на «разрешить» было намного быстрее и намного меньше.
подвержены ошибкам, чем ручное редактирование кодовых последовательностей, которые
разделение и отделение ФСТ.Это расширение также вводит ключевые слова для нескольких других
полезные операции. Оператор IF допускает условное
оценка правил, полезная для включения и отключения частей
системы для тестирования. Оператор IMPORT позволяет
импорт лексических ресурсов в файл LEXC.
Однако один недостаток этой конкретной реализации:
в том, что он отделяет код программиста от сообщения об ошибках:
интерпретатор XFST сообщает об ошибках в скомпилированном XFST
код, а не расширенный код LEXC, который программист
работает с, что означает, что он выполняет промежуточный шаг в
случай ошибки, чтобы определить, где ошибка программиста
произошел.Более зрелая система будет работать самостоятельно.
проверка ошибок перед компиляцией.
4.
Проблемы использования данных, предоставленных пользователями
Хотя словарь Камуси позволил нам
достичь обширного лексического охвата, его пользовательский характер, а также некоторые аспекты его построения, которые вытекают из этого, поставили перед проектом определенные задачи.
Каждый из следующих вопросов иллюстрирует напряженность в лексикографии краудсорсинга: та информация, которая может быть полезной
или имеет решающее значение для разработчиков приложений, может быть необоснованным или
проблематично спросить участников.4.1.
Чувства как записи
Смыслы слов суахили и английского языка, конечно, не совсем соответствуют друг другу, но лежат в соответствии "многие-ко-многим".
друг с другом (таблица 2). Это вызывает вопрос
какое слово, суахили или английский, следует считать
базовая запись.
Однако по замыслу словарь Камуси не выделяет слова какого-либо конкретного языка как «базовые» 3; и не
от участников требуется согласовать, какие части отображения
составляют «запись».
Это различие стало очень важным, когда мы интегрировали
лексические элементы из словаря Камуси в нашу систему
и обнаружил, что многие преобразования, описанные на суахили
ссылки как обязательные были фактически необязательными. Изменение «требуется» на «разрешить» было намного быстрее и намного меньше.
подвержены ошибкам, чем ручное редактирование кодовых последовательностей, которые
разделение и отделение ФСТ.Это расширение также вводит ключевые слова для нескольких других
полезные операции. Оператор IF допускает условное
оценка правил, полезная для включения и отключения частей
системы для тестирования. Оператор IMPORT позволяет
импорт лексических ресурсов в файл LEXC.
Однако один недостаток этой конкретной реализации:
в том, что он отделяет код программиста от сообщения об ошибках:
интерпретатор XFST сообщает об ошибках в скомпилированном XFST
код, а не расширенный код LEXC, который программист
работает с, что означает, что он выполняет промежуточный шаг в
случай ошибки, чтобы определить, где ошибка программиста
произошел.Более зрелая система будет работать самостоятельно.
проверка ошибок перед компиляцией.
4.
Проблемы использования данных, предоставленных пользователями
Хотя словарь Камуси позволил нам
достичь обширного лексического охвата, его пользовательский характер, а также некоторые аспекты его построения, которые вытекают из этого, поставили перед проектом определенные задачи.
Каждый из следующих вопросов иллюстрирует напряженность в лексикографии краудсорсинга: та информация, которая может быть полезной
или имеет решающее значение для разработчиков приложений, может быть необоснованным или
проблематично спросить участников.4.1.
Чувства как записи
Смыслы слов суахили и английского языка, конечно, не совсем соответствуют друг другу, но лежат в соответствии "многие-ко-многим".
друг с другом (таблица 2). Это вызывает вопрос
какое слово, суахили или английский, следует считать
базовая запись.
Однако по замыслу словарь Камуси не выделяет слова какого-либо конкретного языка как «базовые» 3; и не
от участников требуется согласовать, какие части отображения
составляют «запись». Скорее, словарь представляет собой
отображение, подобное приведенному выше, в виде серии взаимно однозначных соответствий (Таблица 3).Одно и то же слово на суахили может быть распространено во многих смысловых группах, каждая из которых может быть добавлена разными авторами.
Таблица 2: суахили и английский смысл в соответствии "многие ко многим".
Таблица 3: суахили и английский смысл во взаимно-однозначном соответствии.
Однако это затрудняет определение того, какие наборы
записи должны рассматриваться как единицы в нашей собственной системе.
Рассмотрим узази, который имеет двенадцать смысловых значений (таблица 4). Это
Ясно, что узази не следует рассматривать как подлинную двусмысленность, но при этом он не представляет собой единую концепцию.Скорее, есть как минимум два различных (хотя и связанных)
чувства: деторождение с одной стороны, и более абстрактное понятие семейного происхождения.
Однако на практике мы решили обрабатывать все такие записи
как отдельные записи, если у них есть совместимые части
речь. Вполне вероятно, что в некоторых случаях мы неправильно объединили настоящие гомофонии, но это не влияет на основную цель морфологического стеммера. Когда эти записи
различаются декларациями метаданных, возникает вопрос, что
влияет на морфологический синтаксический анализ; мы подробно расскажем об этом
в разделах 4.3 и 4.4.
4.2.
Отсутствие морфологических разрывов
Фактически, участники Kamusi выполняют некоторое выделение корней, поскольку (в случае глаголов) они вводят глагол
роды
родословная
спуск
родство (степень)
продолжение рода
отношения (степень)
Доставка
заключение
плодородие
отцовство
распространение
воспроизведение
3
Словарь Камуси предназначен для обеспечения соответствия
между многими языками, а не только между суахили и английским.
Таблица 4: Двенадцать смыслов «узази».
3335
стебель, а не глагол с полным изменением формы.Однако помимо этого
стебли рассматриваются как атомные единицы.
В краудсорсинговом проекте неразумно ожидать
все (или даже большинство) участников, чтобы иметь возможность правильно выполнять
морфологический разбор; это особенно верно, когда морфология деривационная (или даже чисто этимологическая).
Скорее, словарь представляет собой
отображение, подобное приведенному выше, в виде серии взаимно однозначных соответствий (Таблица 3).Одно и то же слово на суахили может быть распространено во многих смысловых группах, каждая из которых может быть добавлена разными авторами.
Таблица 2: суахили и английский смысл в соответствии "многие ко многим".
Таблица 3: суахили и английский смысл во взаимно-однозначном соответствии.
Однако это затрудняет определение того, какие наборы
записи должны рассматриваться как единицы в нашей собственной системе.
Рассмотрим узази, который имеет двенадцать смысловых значений (таблица 4). Это
Ясно, что узази не следует рассматривать как подлинную двусмысленность, но при этом он не представляет собой единую концепцию.Скорее, есть как минимум два различных (хотя и связанных)
чувства: деторождение с одной стороны, и более абстрактное понятие семейного происхождения.
Однако на практике мы решили обрабатывать все такие записи
как отдельные записи, если у них есть совместимые части
речь. Вполне вероятно, что в некоторых случаях мы неправильно объединили настоящие гомофонии, но это не влияет на основную цель морфологического стеммера. Когда эти записи
различаются декларациями метаданных, возникает вопрос, что
влияет на морфологический синтаксический анализ; мы подробно расскажем об этом
в разделах 4.3 и 4.4.
4.2.
Отсутствие морфологических разрывов
Фактически, участники Kamusi выполняют некоторое выделение корней, поскольку (в случае глаголов) они вводят глагол
роды
родословная
спуск
родство (степень)
продолжение рода
отношения (степень)
Доставка
заключение
плодородие
отцовство
распространение
воспроизведение
3
Словарь Камуси предназначен для обеспечения соответствия
между многими языками, а не только между суахили и английским.
Таблица 4: Двенадцать смыслов «узази».
3335
стебель, а не глагол с полным изменением формы.Однако помимо этого
стебли рассматриваются как атомные единицы.
В краудсорсинговом проекте неразумно ожидать
все (или даже большинство) участников, чтобы иметь возможность правильно выполнять
морфологический разбор; это особенно верно, когда морфология деривационная (или даже чисто этимологическая). Для
Например, -esh в основе onyesha - это суффикс причинного происхождения,
но участники могут этого не осознавать. Корень -jifunza
(«Учиться») на самом деле есть -funza, ji- это рефлексивный префикс, но
сам по себе корень встречается нечасто.Словарь Камуси
поэтому не требует, чтобы пользователи ограничивали слово за пределами
удаление флективной морфологии.
В записях также не указываются производные соответствия
между чувствами - то есть, хотя -igiza («выполнять») является
причинный от -iga («подражать»), в записи ничего нет
любого из них, чтобы указать, что они связаны. 4 Такая информация, конечно, будет иметь большую ценность для морфологического
парсер.
Морфологический синтаксический анализ часто можно определить по части
речи - начальная буква ny- на существительном 9-го класса, вероятно,
префикс класса 9, а суффикс -ish / -esh в глагольной основе
очень вероятно, что это причинный суффикс, но корень не
всегда однозначно предсказуемо.Некоторые корни случайно начинаются или заканчиваются сегментами, которые можно принять за
аффиксы и другие берут эпентетические сегменты перед определенными суффиксами. Например, некоторые корни принимают эпентетический
-l- перед причинным суффиксом. Если бы кто-то знал соответствующую беспричинную форму, это стало бы очевидным.
является ли l частью корня или нет.
К счастью, такие корни встречаются не особенно часто, и
многие также встречаются в нашем составленном вручную словаре, поэтому для
такие случаи, как эпентетический - мы решили остановить Камуси.
слова жадно, всегда предполагая, что сегменты, которые могут быть
часть аффикса действительно так.4.3.
Специфика тегирования части речи
Чтобы правильно определить слово суахили, необходимо знать
его часть речи. Например, многие корни существительных начинаются с u, но чтобы знать, нужно знать класс существительного.
является ли это префиксом класса или частью самого стебля. В
задача тегирования части речи на суахили - та, которая может быть
выполняется с разной степенью специфичности; некоторые пользователи
используйте широкие категории, такие как «существительное», другие определяют конкретные
класс или даже подкласс.
Для
Например, -esh в основе onyesha - это суффикс причинного происхождения,
но участники могут этого не осознавать. Корень -jifunza
(«Учиться») на самом деле есть -funza, ji- это рефлексивный префикс, но
сам по себе корень встречается нечасто.Словарь Камуси
поэтому не требует, чтобы пользователи ограничивали слово за пределами
удаление флективной морфологии.
В записях также не указываются производные соответствия
между чувствами - то есть, хотя -igiza («выполнять») является
причинный от -iga («подражать»), в записи ничего нет
любого из них, чтобы указать, что они связаны. 4 Такая информация, конечно, будет иметь большую ценность для морфологического
парсер.
Морфологический синтаксический анализ часто можно определить по части
речи - начальная буква ny- на существительном 9-го класса, вероятно,
префикс класса 9, а суффикс -ish / -esh в глагольной основе
очень вероятно, что это причинный суффикс, но корень не
всегда однозначно предсказуемо.Некоторые корни случайно начинаются или заканчиваются сегментами, которые можно принять за
аффиксы и другие берут эпентетические сегменты перед определенными суффиксами. Например, некоторые корни принимают эпентетический
-l- перед причинным суффиксом. Если бы кто-то знал соответствующую беспричинную форму, это стало бы очевидным.
является ли l частью корня или нет.
К счастью, такие корни встречаются не особенно часто, и
многие также встречаются в нашем составленном вручную словаре, поэтому для
такие случаи, как эпентетический - мы решили остановить Камуси.
слова жадно, всегда предполагая, что сегменты, которые могут быть
часть аффикса действительно так.4.3.
Специфика тегирования части речи
Чтобы правильно определить слово суахили, необходимо знать
его часть речи. Например, многие корни существительных начинаются с u, но чтобы знать, нужно знать класс существительного.
является ли это префиксом класса или частью самого стебля. В
задача тегирования части речи на суахили - та, которая может быть
выполняется с разной степенью специфичности; некоторые пользователи
используйте широкие категории, такие как «существительное», другие определяют конкретные
класс или даже подкласс.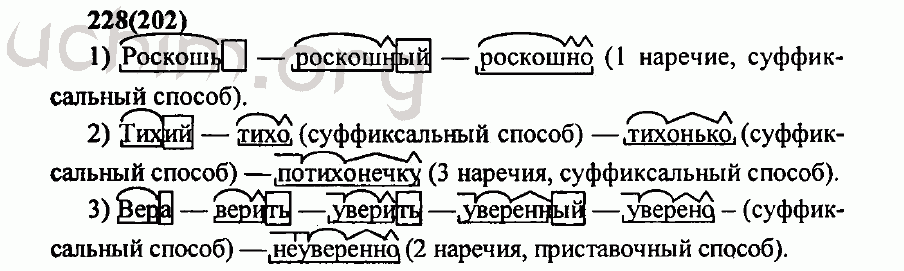 Поэтому часто бывает, что слово на суахили, например узази
выше, имеет некоторые смысловые записи, которые определяют класс существительного
и другие, которые просто помечают это как существительное.На случай, если
узази, три чувства были помечены как «существительное 14», а
девять были помечены как «существительное». Поскольку u- не однозначно
Определите класс существительных узази, существует потенциальная дилемма
здесь: рассматриваем ли мы это как одну запись «существительное 14» (с двенадцатью
чувства), или как одно слово «существительное 14» (с тремя смыслами)
и одна неклассифицированная запись «существительное» (с оставшимися девятью
чувства)? 5
На практике мы рассматривали их как одну запись, если выполнялись следующие критерии:
4
Единственное исключение - пары единственного и множественного числа; их лечат
как одна запись.5
То есть обрабатывают ли синтаксические разборы предложений, содержащих узази, эту форму
как наличие одного потенциального синтаксического анализа (у-зази) или двух (у-зази и узази)?
1. Чтобы предложенные части речи были совместимы.
(То есть они образуют отношения подмножества, такие как «существительное»
и «существительное 14», а не несовместимые декларации
например, «существительное 14» и «существительное 5».)
2. Более специфическая часть речи морфологически совместима с формой. (То есть форма
слова uzazi на самом деле было совместимо с тем, что оно было «существительным
14 ”.)
Некоторые пользователи указали класс дополнительно: не просто «класс существительного»
9/10 », но« существительное класса 9/10 одушевленное ».Большинство существительных, описывающих людей, относятся к классу 1/2, но некоторые - особенно слова
для занятий - находятся в других классах. Эти существительные связаны с их собственными префиксами соглашения о классе в некоторых
парадигмы, но используют префиксы соглашения класса 1/2 в других.
Это полезная информация для синтаксического анализа, но многие пользователи делают это.
не указывать его.6 Следовательно, есть три возможности для
теги существительного «9/10 одушевленного»: «существительное», «существительное 9/10»,
и «существительное 9/10 одушевленное».
Как и для таких записей, как uzazi, мы обрабатываем такие наборы как
наиболее специфическая категория, если она морфологически
последовательные, и не было противоречивых заявлений.Этот
потенциально может внести еще один вид неправильной классификации; если форма правомерно неоднозначна между
одушевленный (то есть принимая морфологию согласования класса 1/2
для некоторых парадигм) и неодушевленный смысл, стеммер
будет рассматривать его как однозначно одушевленное.
4.4.
Критерии тегирования части речи
Авторы также иногда используют несколько иные понятия.
части речи. Например, в определенном смысле суахили «имеет
никаких предлогов как таковых »(Erickson, Gustafsson, 1989),
и выражает предложные значения посредством позиционных существительных, аппликативного суффикса глаголов и других
средства.То есть во многих случаях, когда в английском языке используется
предлог, например «кем», в суахили используется значение существительного
"сторона".
В результате участники могут решить, когда
присваивая такие слова, как kando («сбоку, рядом»), ndani («внутри,
внутри ») или nje (« снаружи, снаружи, из ») в части
речь: идут ли они формальным морфологическим классом
слово (в этих случаях существительные класса 9/10) или функция
слово в предложении? Аналогичная проблема возникает и с прилагательными.
и наречия: многие слова, которые функционируют как прилагательные и
наречия не являются прилагательными или наречиями в формальном морфологическом смысле.Поскольку не все участники будут использовать один и тот же
критерии принятия решения, такие слова могут иметь записи до
четыре разные части речи.
Причина, по которой это проблематично для нас, заключается в том, что это вызывает наши
система для объявления неоднозначности синтаксического анализа там, где на самом деле нет
существует - синтаксический анализ [NOUN], [PREP], [ADJ] и [ADV]
«предложные» существительные на самом деле не разные суахили
слова, но результат того, что участники должны выбирать между формальным и функциональным описанием словоупотребления.
Мы решили использовать только те записи, которые помечены как существительные, и
вместо предлогов, прилагательных и наречий полагались на
составленные вручную списки.6
Это не удивительно, поскольку эта информация не очевидна.
от самой словоформы, но только учитывая договор
возможности его использования в предложении.
3336
Класс Word
Существительные 1/2
Существительные 3/4
Существительные 5/6
Существительные 7/8
Существительные 9/10
Существительные 11/6, 11/10 и 14
Всего классифицированных существительных
Неклассифицированные существительные
Всего существительных
Глаголы происхождения банту
Глаголы арабского происхождения
Всего глаголов
Предлоги
Прилагательные
Вопросительные
Междометия
Союзы
Пунктуация
Итого другое
Всего слов
Пользовательский dict.
48
46
41 год
53
89
36
313
-
313
270
45
315
18
72
8
16
18
35 год
164
792
Камуси дикт.1177
951
1762 г.
1096
3158
748
8892
1860 г.
10752
2442
542
2984
-
-
-
-
-
-
-
13736
по «происхождению» - то есть, где стебель
исходит из и насколько вероятно, что мы полагаем, что мы сделали вывод
подлинный корень суахили. Эти теги предназначены для помощи
более поздние модули в цепочке инструментов выбирают между неоднозначными
разбирает.
• Отсутствие метки происхождения указывает на то, что корень был собран вручную, обычно из учебников или грамматических
ресурсов, о которых мы знали или в достаточной
информация для вывода, фактический корень.• [GUESS1] указывает на корень, полученный от Камуси.
основа словаря, но только когда его префиксы и суффиксы
согласуются с его заявленной частью речи. То есть,
основа увази («открытое пространство, открытость») помечена как
[GUESS1], потому что его префикс класса (u-) совместим
с заявленной частью речи («существительное 14»).
• [GUESS2] указывает на неклассифицированное существительное из словаря Камуси, обозначенное просто как «существительное».
чем, скажем, «существительное 1/2». Мы не пытались пресечь такие
существительные или предсказать их класс.• [GUESS3] указывает возможное английское заимствованное слово.
Таблица 5: Записи слов по классам
5.
• [GUESS4] указывает на полное предположение. Например,
гипотетический жетон куфива угадал бы
root fiv, который является возможным корнем суахили, несмотря на то, что
быть перечисленным в любом из наших лексических ресурсов. [GUESS4]
также содержит отгаданные имена собственные.
Словарный запас
Наш морфологический парсер использовал лексические данные трех
источники:
• Небольшой индивидуальный словарь суахили с корнями
перечисленные в учебниках и грамматиках (и выведенные из них)
как Уилсон (1983) и Адам (1993).• Подмножество словаря суахили Камуси, состоящее из существительных с объявленными классами, неклассифицированных существительных,
и глаголы. Поскольку классификация за пределами этих классов
представляет проблемы анализа (см. раздел 4.4), мы сделали
не включать другие части речи.
• Список английских слов (Loge and Beresford, 1999), чтобы
ловите английские заимствования, которые довольно часто встречаются в речи на онлайн-форуме.
Это количество словарных статей, а не словарных статей Kamusi, поэтому такое слово, как uzazi, считается одной записью.
а не двенадцать.6.
Пометка "происхождение"
Наш морфологический синтаксический анализатор суахили предназначен для
проанализировал входные данные для нескольких проектов на суахили с
различные цели, и поэтому использует различные теги помимо
чисто морфологические признаки.7
Среди них есть теги, предназначенные для передачи сигналов нижестоящим
модули нашей уверенности в конкретном синтаксическом анализе. Поскольку наши лексические ресурсы несколько разнородны, мы помечаем синтаксический анализ
7
Например, чтобы сделать вывод о стилистических свойствах
текст, синтаксический анализатор также помечает слова в соответствии с их этимологическими
происхождение ([АРАБСКИЙ], [ENG] или [ЗАЙМА] с другого языка),
и считается ли конкретная конструкция [СЛУЧАЙНОЙ],
или встречается в [ЗАГОЛОВОК] сек.На рисунках неоднозначности, которые следуют в разделе 7, мы делаем
не считайте синтаксический анализ более неопределенного происхождения как неоднозначный. (Другими словами, если в слове есть два [УГАДАЙ 1]
парсинга, парсинга [GUESS2] и трех парсеров [GUESS4], мы
укажите слово как имеющее два синтаксического анализа.)
7.
Охват и неоднозначность
Исключая [GUESS4] parses8, наша система показывает 90,23%
покрытие токенов и 66,4% покрытие типа 340k токенов
Корпус суахили, полученный из издания на суахили
Global Voices (sw.globalvoicesonline.org).Процент покрытия представлен на Рисунке 1.
Стоит отметить, что включение GUESS уровня 2, состоящего из неклассифицированных существительных, для которых нет более конкретного класса
информация была доступна, внесла очень небольшой вклад в общую
покрытие. То есть включение более качественного
данных было бы достаточно, в то время как включение данных
более сомнительного происхождения мало что повлияло.
Каждый уровень предположений способствует большему охвату, но
также вносит большую степень двусмысленности. Чем больше
уверены, что мы можем быть уверены, что корень подлинный, тем лучше мы сможем
уменьшить недопустимую двусмысленность; на уровне предположения 4, где мы
мало уверены, что корень синтаксического анализа подлинный, это
более вероятно, что любой данный синтаксический анализ является незаконным.На рисунке 2 показаны дополнительные степени неоднозначности, обусловленные
8
С учетом парсинга [GUESS4] система покрывает 99,78%
токены и 98,79% типов. Остальные неанализируемые типы:
в основном имена пользователей или слова на других языках и сценарии.
3337
Рисунок 1: Покрытие токена и типа
Рисунок 2: неоднозначность синтаксического анализа
на каждом уровне предположений.9 Ось X представляет число
разборов, сгенерированных формой, из однозначных (1 разбор)
к более неоднозначному. Ось Y представляет количество
словоформы с заданным количеством разборов; Например,
на уровне GUESS 0 7215 слов являются однозначными, 3160 слов являются двусторонними неоднозначными, 1624
слова с трехзначной двусмысленностью и т. д.8.
Резюме
Лексические данные суахили из онлайн-словаря Камуси оказались неоценимыми в расширении лексических возможностей нашей системы.
покрытия, но требовала особой осторожности при его адаптации в качестве
9
Уровни 2 и 3 GUESS не включены в эту таблицу; как они
состоят из отдельных неразобранных слов, они не вносят вклад в общую двусмысленность, за исключением случаев, когда они случайно соответствуют
УГАДАЙ уровень 0 или 1 слово.
Ресурс LEXC для минимизации двусмысленностей и нелегитимных
разбирает. Мы пытались сдержать их несколькими способами:
исключая лексические формы, которые, по-видимому, противоречат объявленному классу слов, путем разделения лексических данных в соответствии с тем, сколько информации о классе слов было предоставлено, посредством
пополнение лексики подобранными вручную формами, а также
помечая наш уровень уверенности, чтобы клиентские приложения могли
различать качество данных.Наш опыт работы со словарем Камуси показывает, что источники данных, добавленные пользователями, действительно важны при построении экспертных систем, и что преимущества обоих
ресурсы, созданные вручную и краудсорсингом, могут быть сохранены,
а недостатки смягчаются, когда они используются в комбинации.
3338
9.
Благодарности
Эта работа была поддержана Исследовательской лабораторией армии США и Исследовательским управлением армии США по контракту / гранту номер W911NF-10-1-0533.
10.
Завави, С. (1979). Ссудные слова и их влияние на
классификация номиналов суахили.Лейден: Э.Дж. Брилл.
использованная литература
Адам, Х. (1993). Промежуточный курс суахили.
OMIMEE Intercultural Publishers.
Бисли, К. и Карттунен, Л. (2003). Конечная морфология состояния. Публикации CSLI.
Контини-Морава, Э. (1994). Классификация существительных на суахили.
Публикации Института передовых технологий
в гуманитарных науках Университета Вирджинии. Отчеты об исследованиях, вторая серия.
Кристя Д., Форску К., Ршип М. и Зок М.
(2008). Как оценить и повысить качество в
совместный лексикографический подход.В Кальцолари, Н.,
Чукри, К., Маегаард, Б., Мариани, Дж., Одийк, Дж.,
Пиперидис, С., и Тапиас, Д., редакторы, Proceedings of
Шестая международная конференция по языковым ресурсам и оценке (LREC’08). Европейская ассоциация языковых ресурсов (ELRA). http://www.lrecconf.org/proceedings/lrec2008/.
Денни, Дж. П. и Крейдер, К. (1976). Семантика существительного
занятия в прото-банту. Исследования в области африканской лингвистики,
7 (1): 1–30.
Эриксон, Х. и Густафссон, М. (1989). Примечания по грамматике суахили.
Хау, Дж.(2006). Рост краудсорсинга. Проводная, 14 (6).
Хаскиарнен, А. (1992). Двухуровневый компьютерный формализм
для анализа морфологии банту: приложение к
Суахили. Северный журнал африканских исследований, 1 (1): 88–122.
Косем И., Гантар П. и Крек С. (2013). Автоматизация
лексикографическая работа: возможность как для лексикографов, так и для краудсорсинга. В Косем, И., Каллас, Дж., Гантар, П., Крек, С., Лангемец, М., и Туулик, М., редакторы, Электронная лексикография в 21 веке: мышление вне бумаги.Материалы конференции eLex 2013, 17-19 октября 2013 г., Таллинн, Эстония., Стр.
32–48. Любляна / Таллинн: Троина, Институт прикладных наук
Словенистика / Eesti Keele Instituut.
Логе К. и Бересфорд Дж. Р. (1999). Английский открытый
список слов. http://dreamsteep.com/projects/the-englishopen-word-list.html.
Преториус, Л. и Бош, С. Е. (2003). Конечная вычислительная морфология: прототип анализатора для Zulu.
Машинный перевод, страницы 191–212.
Трап-Дженсен, Л. (2013). Изучение лексикографической практики.В Джексоне, Х., редакторе Bloomsbury Companion to
Лексикография, страницы 35–47. Лондон: Bloomsbury Academic.
Вальд Б. (1990). Суахили и языки банту. В
Комри, Б., редактор журнала "Основные языки Южной Азии",
Ближний Восток и Африка, страницы 219–237.
Уилсон, П. (1983). Упрощенный суахили. Longman Group
СОЕДИНЕННОЕ КОРОЛЕВСТВО.
Винчестер, С. (1999). Профессор и сумасшедший.
Нью-Йорк: HarperPerennial.
3339
Поэтому часто бывает, что слово на суахили, например узази
выше, имеет некоторые смысловые записи, которые определяют класс существительного
и другие, которые просто помечают это как существительное.На случай, если
узази, три чувства были помечены как «существительное 14», а
девять были помечены как «существительное». Поскольку u- не однозначно
Определите класс существительных узази, существует потенциальная дилемма
здесь: рассматриваем ли мы это как одну запись «существительное 14» (с двенадцатью
чувства), или как одно слово «существительное 14» (с тремя смыслами)
и одна неклассифицированная запись «существительное» (с оставшимися девятью
чувства)? 5
На практике мы рассматривали их как одну запись, если выполнялись следующие критерии:
4
Единственное исключение - пары единственного и множественного числа; их лечат
как одна запись.5
То есть обрабатывают ли синтаксические разборы предложений, содержащих узази, эту форму
как наличие одного потенциального синтаксического анализа (у-зази) или двух (у-зази и узази)?
1. Чтобы предложенные части речи были совместимы.
(То есть они образуют отношения подмножества, такие как «существительное»
и «существительное 14», а не несовместимые декларации
например, «существительное 14» и «существительное 5».)
2. Более специфическая часть речи морфологически совместима с формой. (То есть форма
слова uzazi на самом деле было совместимо с тем, что оно было «существительным
14 ”.)
Некоторые пользователи указали класс дополнительно: не просто «класс существительного»
9/10 », но« существительное класса 9/10 одушевленное ».Большинство существительных, описывающих людей, относятся к классу 1/2, но некоторые - особенно слова
для занятий - находятся в других классах. Эти существительные связаны с их собственными префиксами соглашения о классе в некоторых
парадигмы, но используют префиксы соглашения класса 1/2 в других.
Это полезная информация для синтаксического анализа, но многие пользователи делают это.
не указывать его.6 Следовательно, есть три возможности для
теги существительного «9/10 одушевленного»: «существительное», «существительное 9/10»,
и «существительное 9/10 одушевленное».
Как и для таких записей, как uzazi, мы обрабатываем такие наборы как
наиболее специфическая категория, если она морфологически
последовательные, и не было противоречивых заявлений.Этот
потенциально может внести еще один вид неправильной классификации; если форма правомерно неоднозначна между
одушевленный (то есть принимая морфологию согласования класса 1/2
для некоторых парадигм) и неодушевленный смысл, стеммер
будет рассматривать его как однозначно одушевленное.
4.4.
Критерии тегирования части речи
Авторы также иногда используют несколько иные понятия.
части речи. Например, в определенном смысле суахили «имеет
никаких предлогов как таковых »(Erickson, Gustafsson, 1989),
и выражает предложные значения посредством позиционных существительных, аппликативного суффикса глаголов и других
средства.То есть во многих случаях, когда в английском языке используется
предлог, например «кем», в суахили используется значение существительного
"сторона".
В результате участники могут решить, когда
присваивая такие слова, как kando («сбоку, рядом»), ndani («внутри,
внутри ») или nje (« снаружи, снаружи, из ») в части
речь: идут ли они формальным морфологическим классом
слово (в этих случаях существительные класса 9/10) или функция
слово в предложении? Аналогичная проблема возникает и с прилагательными.
и наречия: многие слова, которые функционируют как прилагательные и
наречия не являются прилагательными или наречиями в формальном морфологическом смысле.Поскольку не все участники будут использовать один и тот же
критерии принятия решения, такие слова могут иметь записи до
четыре разные части речи.
Причина, по которой это проблематично для нас, заключается в том, что это вызывает наши
система для объявления неоднозначности синтаксического анализа там, где на самом деле нет
существует - синтаксический анализ [NOUN], [PREP], [ADJ] и [ADV]
«предложные» существительные на самом деле не разные суахили
слова, но результат того, что участники должны выбирать между формальным и функциональным описанием словоупотребления.
Мы решили использовать только те записи, которые помечены как существительные, и
вместо предлогов, прилагательных и наречий полагались на
составленные вручную списки.6
Это не удивительно, поскольку эта информация не очевидна.
от самой словоформы, но только учитывая договор
возможности его использования в предложении.
3336
Класс Word
Существительные 1/2
Существительные 3/4
Существительные 5/6
Существительные 7/8
Существительные 9/10
Существительные 11/6, 11/10 и 14
Всего классифицированных существительных
Неклассифицированные существительные
Всего существительных
Глаголы происхождения банту
Глаголы арабского происхождения
Всего глаголов
Предлоги
Прилагательные
Вопросительные
Междометия
Союзы
Пунктуация
Итого другое
Всего слов
Пользовательский dict.
48
46
41 год
53
89
36
313
-
313
270
45
315
18
72
8
16
18
35 год
164
792
Камуси дикт.1177
951
1762 г.
1096
3158
748
8892
1860 г.
10752
2442
542
2984
-
-
-
-
-
-
-
13736
по «происхождению» - то есть, где стебель
исходит из и насколько вероятно, что мы полагаем, что мы сделали вывод
подлинный корень суахили. Эти теги предназначены для помощи
более поздние модули в цепочке инструментов выбирают между неоднозначными
разбирает.
• Отсутствие метки происхождения указывает на то, что корень был собран вручную, обычно из учебников или грамматических
ресурсов, о которых мы знали или в достаточной
информация для вывода, фактический корень.• [GUESS1] указывает на корень, полученный от Камуси.
основа словаря, но только когда его префиксы и суффиксы
согласуются с его заявленной частью речи. То есть,
основа увази («открытое пространство, открытость») помечена как
[GUESS1], потому что его префикс класса (u-) совместим
с заявленной частью речи («существительное 14»).
• [GUESS2] указывает на неклассифицированное существительное из словаря Камуси, обозначенное просто как «существительное».
чем, скажем, «существительное 1/2». Мы не пытались пресечь такие
существительные или предсказать их класс.• [GUESS3] указывает возможное английское заимствованное слово.
Таблица 5: Записи слов по классам
5.
• [GUESS4] указывает на полное предположение. Например,
гипотетический жетон куфива угадал бы
root fiv, который является возможным корнем суахили, несмотря на то, что
быть перечисленным в любом из наших лексических ресурсов. [GUESS4]
также содержит отгаданные имена собственные.
Словарный запас
Наш морфологический парсер использовал лексические данные трех
источники:
• Небольшой индивидуальный словарь суахили с корнями
перечисленные в учебниках и грамматиках (и выведенные из них)
как Уилсон (1983) и Адам (1993).• Подмножество словаря суахили Камуси, состоящее из существительных с объявленными классами, неклассифицированных существительных,
и глаголы. Поскольку классификация за пределами этих классов
представляет проблемы анализа (см. раздел 4.4), мы сделали
не включать другие части речи.
• Список английских слов (Loge and Beresford, 1999), чтобы
ловите английские заимствования, которые довольно часто встречаются в речи на онлайн-форуме.
Это количество словарных статей, а не словарных статей Kamusi, поэтому такое слово, как uzazi, считается одной записью.
а не двенадцать.6.
Пометка "происхождение"
Наш морфологический синтаксический анализатор суахили предназначен для
проанализировал входные данные для нескольких проектов на суахили с
различные цели, и поэтому использует различные теги помимо
чисто морфологические признаки.7
Среди них есть теги, предназначенные для передачи сигналов нижестоящим
модули нашей уверенности в конкретном синтаксическом анализе. Поскольку наши лексические ресурсы несколько разнородны, мы помечаем синтаксический анализ
7
Например, чтобы сделать вывод о стилистических свойствах
текст, синтаксический анализатор также помечает слова в соответствии с их этимологическими
происхождение ([АРАБСКИЙ], [ENG] или [ЗАЙМА] с другого языка),
и считается ли конкретная конструкция [СЛУЧАЙНОЙ],
или встречается в [ЗАГОЛОВОК] сек.На рисунках неоднозначности, которые следуют в разделе 7, мы делаем
не считайте синтаксический анализ более неопределенного происхождения как неоднозначный. (Другими словами, если в слове есть два [УГАДАЙ 1]
парсинга, парсинга [GUESS2] и трех парсеров [GUESS4], мы
укажите слово как имеющее два синтаксического анализа.)
7.
Охват и неоднозначность
Исключая [GUESS4] parses8, наша система показывает 90,23%
покрытие токенов и 66,4% покрытие типа 340k токенов
Корпус суахили, полученный из издания на суахили
Global Voices (sw.globalvoicesonline.org).Процент покрытия представлен на Рисунке 1.
Стоит отметить, что включение GUESS уровня 2, состоящего из неклассифицированных существительных, для которых нет более конкретного класса
информация была доступна, внесла очень небольшой вклад в общую
покрытие. То есть включение более качественного
данных было бы достаточно, в то время как включение данных
более сомнительного происхождения мало что повлияло.
Каждый уровень предположений способствует большему охвату, но
также вносит большую степень двусмысленности. Чем больше
уверены, что мы можем быть уверены, что корень подлинный, тем лучше мы сможем
уменьшить недопустимую двусмысленность; на уровне предположения 4, где мы
мало уверены, что корень синтаксического анализа подлинный, это
более вероятно, что любой данный синтаксический анализ является незаконным.На рисунке 2 показаны дополнительные степени неоднозначности, обусловленные
8
С учетом парсинга [GUESS4] система покрывает 99,78%
токены и 98,79% типов. Остальные неанализируемые типы:
в основном имена пользователей или слова на других языках и сценарии.
3337
Рисунок 1: Покрытие токена и типа
Рисунок 2: неоднозначность синтаксического анализа
на каждом уровне предположений.9 Ось X представляет число
разборов, сгенерированных формой, из однозначных (1 разбор)
к более неоднозначному. Ось Y представляет количество
словоформы с заданным количеством разборов; Например,
на уровне GUESS 0 7215 слов являются однозначными, 3160 слов являются двусторонними неоднозначными, 1624
слова с трехзначной двусмысленностью и т. д.8.
Резюме
Лексические данные суахили из онлайн-словаря Камуси оказались неоценимыми в расширении лексических возможностей нашей системы.
покрытия, но требовала особой осторожности при его адаптации в качестве
9
Уровни 2 и 3 GUESS не включены в эту таблицу; как они
состоят из отдельных неразобранных слов, они не вносят вклад в общую двусмысленность, за исключением случаев, когда они случайно соответствуют
УГАДАЙ уровень 0 или 1 слово.
Ресурс LEXC для минимизации двусмысленностей и нелегитимных
разбирает. Мы пытались сдержать их несколькими способами:
исключая лексические формы, которые, по-видимому, противоречат объявленному классу слов, путем разделения лексических данных в соответствии с тем, сколько информации о классе слов было предоставлено, посредством
пополнение лексики подобранными вручную формами, а также
помечая наш уровень уверенности, чтобы клиентские приложения могли
различать качество данных.Наш опыт работы со словарем Камуси показывает, что источники данных, добавленные пользователями, действительно важны при построении экспертных систем, и что преимущества обоих
ресурсы, созданные вручную и краудсорсингом, могут быть сохранены,
а недостатки смягчаются, когда они используются в комбинации.
3338
9.
Благодарности
Эта работа была поддержана Исследовательской лабораторией армии США и Исследовательским управлением армии США по контракту / гранту номер W911NF-10-1-0533.
10.
Завави, С. (1979). Ссудные слова и их влияние на
классификация номиналов суахили.Лейден: Э.Дж. Брилл.
использованная литература
Адам, Х. (1993). Промежуточный курс суахили.
OMIMEE Intercultural Publishers.
Бисли, К. и Карттунен, Л. (2003). Конечная морфология состояния. Публикации CSLI.
Контини-Морава, Э. (1994). Классификация существительных на суахили.
Публикации Института передовых технологий
в гуманитарных науках Университета Вирджинии. Отчеты об исследованиях, вторая серия.
Кристя Д., Форску К., Ршип М. и Зок М.
(2008). Как оценить и повысить качество в
совместный лексикографический подход.В Кальцолари, Н.,
Чукри, К., Маегаард, Б., Мариани, Дж., Одийк, Дж.,
Пиперидис, С., и Тапиас, Д., редакторы, Proceedings of
Шестая международная конференция по языковым ресурсам и оценке (LREC’08). Европейская ассоциация языковых ресурсов (ELRA). http://www.lrecconf.org/proceedings/lrec2008/.
Денни, Дж. П. и Крейдер, К. (1976). Семантика существительного
занятия в прото-банту. Исследования в области африканской лингвистики,
7 (1): 1–30.
Эриксон, Х. и Густафссон, М. (1989). Примечания по грамматике суахили.
Хау, Дж.(2006). Рост краудсорсинга. Проводная, 14 (6).
Хаскиарнен, А. (1992). Двухуровневый компьютерный формализм
для анализа морфологии банту: приложение к
Суахили. Северный журнал африканских исследований, 1 (1): 88–122.
Косем И., Гантар П. и Крек С. (2013). Автоматизация
лексикографическая работа: возможность как для лексикографов, так и для краудсорсинга. В Косем, И., Каллас, Дж., Гантар, П., Крек, С., Лангемец, М., и Туулик, М., редакторы, Электронная лексикография в 21 веке: мышление вне бумаги.Материалы конференции eLex 2013, 17-19 октября 2013 г., Таллинн, Эстония., Стр.
32–48. Любляна / Таллинн: Троина, Институт прикладных наук
Словенистика / Eesti Keele Instituut.
Логе К. и Бересфорд Дж. Р. (1999). Английский открытый
список слов. http://dreamsteep.com/projects/the-englishopen-word-list.html.
Преториус, Л. и Бош, С. Е. (2003). Конечная вычислительная морфология: прототип анализатора для Zulu.
Машинный перевод, страницы 191–212.
Трап-Дженсен, Л. (2013). Изучение лексикографической практики.В Джексоне, Х., редакторе Bloomsbury Companion to
Лексикография, страницы 35–47. Лондон: Bloomsbury Academic.
Вальд Б. (1990). Суахили и языки банту. В
Комри, Б., редактор журнала "Основные языки Южной Азии",
Ближний Восток и Африка, страницы 219–237.
Уилсон, П. (1983). Упрощенный суахили. Longman Group
СОЕДИНЕННОЕ КОРОЛЕВСТВО.
Винчестер, С. (1999). Профессор и сумасшедший.
Нью-Йорк: HarperPerennial.
3339