Синтаксический разбор простых осложненных предложений
Синтаксический разбор простых осложненных предложений. Урок 5 класс
Цель: повторить и обобщить знания учащихся совершенствовать пунктуационные о классификации предложений по цели высказывания, интонации, наличию главных и второстепенных членов предложения навыки при записи простого осложненного и сложного предложений, предложений с однородными членами, с обращением. ознакомить учащихся с порядком синтаксического разбора простого предложения, отрабатывать умение выполнять синтаксический разбор (устный и письменный) простого осложненного предложения; развивать самостоятельность мышления; воспитывать любовь к родному слову.
Методы и формы обучения: наблюдение над языком, создание проблемных ситуаций; индивидуальная, групповая, фронтальная.
Оборудование: учебник Т.А. Ладыженской, на доске план-схема разбора, раздаточный материал
Тип урока: комбинированный
Ход урока
Организационный момент
Актуализация опорных знаний
Беседа.
1.Что такое предложение?
2.Какие предложения бывают по цели высказывания?
3.По эмоциональной окраске?
4. Какими бывают предложения?
5. Что такое обращение?
6. какие знаки ставим при обращениях?
7. Какие члены называются однородными?
8.Как произносятся однородные члены?
9. Какие члены предложения могут быть однородными?
10. Когда ставится запятая между однородными членами;
11. Когда запятая между однородными членами не ставится.
12. Какие знаки ставим при обобщающих словах?
2. Выполнение тестового задания со взаимопроверкой (учащиеся меняются тетрадями и под диктовку учителя проверяют работы соседа по парте)
Задания теста лежат на каждой парте (раздаточный материал)
Тест
1. Какое из данных предложений осложнено однородными дополнениями:
а) Люди ближних сёл несли на базар овощи, хлеб, птицу, фрукты, мёд.
б) Сосны, берёзы, лиственницы мелькают по сторонам.
в) Ни рыба ни мясо был этот человек.
2. В каком из данных предложений необходимо поставить одну запятую? (Знаки препинания не расставлены.):
а) Метель бушевала всю и ночь и утро и день.
б) Раньше он либо не замечал окружающей природы либо она имела для него чисто практический интерес.
в) Он очень долго говорил с ней то громко то тихо то печально то весело.
3. В каком из данных предложений необходимо поставить только двоеточие? (Знаки препинания расставлены частично.):
а) В числе посуды привозят много глиняных и стеклянных ребячьих игрушек уточек, дудочек и брызгалок.
б) Столы, лавки и кровати выстроганы из чистого белого дерева.
в) Повсюду в клубе, на улицах, на скамейках у ворот, в домах происходили шумные разговоры.
4. Какое из данных предложений побудительное:
а) Ему сейчас казалось, что ничего не было: ни погони за бандитами, ни вьюги, ни мрачной тайги, ничего.
б) В этом лесу есть как лиственные, так и хвойные деревья.
в) Учитесь и познавайте новое.
5. Какое из данных предложений осложнено обращением? (Знаки препинания не расставлены.):
а) Автор этого стихотворения Лермонтов.
б) Между прочим в этом году из всего села из садов целой округи только у нас уродился терновник.
в) Дай Пушкин мне свою певучесть свою раскованную речь свою пленительную участь.
III. Объяснение материала
Работа с учебником. п 41, с. 113-114 выучить правила разбора предложений
Работа с таблицами
IV.Закрепление изученного материала.
Выполнить упражнение 234 (2, 5 предложения)
Творческое задание. Составь предложение.
Из предложения «Купили яркие краски» взять определение.
Из предложения «Синели звезды на рассвете» взять подлежащее.
Добавить сказуемое из предложения «Капли росы блестели на траве».
Взять обстоятельство из предложения «На небе замелькали огоньки».
Запиши предложение, укажите члены предложения. Дайте характеристику данному предложению в скобках.
Упражнение: Запишите предложения, расставьте знаки препинания, выполните синтаксический разбор предложений (схемы не нужно чертить)
Ребята вы любите игры футбол баскетбол волейбол?
Воздух солнце и вода наши лучшие друзья!
Отдай спорту время и получишь здоровье.
V.Итоги урока
VI.Домашнее задание: повторить изученные правила п 41, с. 113-114, составить сочинение-миниатюру (5-6 предложений) «Весна идет», одно из предложений разобрать синтаксически, записать характеристику предложения в скобках.
Приложение 1
Раздаточный материал
Тест
1. Какое из данных предложений осложнено однородными дополнениями:
а) Люди ближних сёл несли на базар овощи, хлеб, птицу, фрукты, мёд.
б) Сосны, берёзы, лиственницы мелькают по сторонам.
в) Ни рыба ни мясо был этот человек.
2. В каком из данных предложений необходимо поставить одну запятую? (Знаки препинания не расставлены.):
а) Метель бушевала всю и ночь и утро и день.
б) Раньше он либо не замечал окружающей природы либо она имела для него чисто практический интерес.
в) Он очень долго говорил с ней то громко то тихо то печально то весело.
3. В каком из данных предложений необходимо поставить только двоеточие? (Знаки препинания расставлены частично.):
а) В числе посуды привозят много глиняных и стеклянных ребячьих игрушек уточек, дудочек и брызгалок.
б) Столы, лавки и кровати выстроганы из чистого белого дерева.
в) Повсюду в клубе, на улицах, на скамейках у ворот, в домах происходили шумные разговоры.
4. Какое из данных предложений побудительное:
а) Ему сейчас казалось, что ничего не было: ни погони за бандитами, ни вьюги, ни мрачной тайги, ничего.
б) В этом лесу есть как лиственные, так и хвойные деревья.
в) Учитесь и познавайте новое.
5. Какое из данных предложений осложнено обращением? (Знаки препинания не расставлены.):
Какое из данных предложений осложнено обращением? (Знаки препинания не расставлены.):
а) Автор этого стихотворения Лермонтов.
б) Между прочим в этом году из всего села из садов целой округи только у нас уродился терновник.
в) Дай Пушкин мне свою певучесть свою раскованную речь свою пленительную участь.
Синтаксический разбор предложения — как его правильно делать
Характеристика анализа
В соответствии с правилами русского языка разобрать текст можно с помощью четырёх видов анализа: морфологического, по составу, фонетического и синтаксического. Последний представляет собой разбор синтаксических единиц, в процессе которого в первую очередь выделяют грамматическую основу. При этом анализ проводится согласно определённому алгоритму действий:
- Соответствующими линиями подчёркиваются члены предложения.
- Осуществляется их характеристика.
- Рисуется схематическое изображение конструкции.


Далее необходимо разобраться с главными членами предложения, составляющими грамматическую основу. Обычно это подлежащее, обозначающее объект либо предмет, а также сказуемое, указывающее на выполненное первым действие. В качестве подлежащего могут выступать местоимения и существительные, а сказуемое представлено глаголом, кратким прилагательным либо существительным.
Кроме этого, чтобы связать основные слова в правильное логическое высказывание, используются второстепенные члены предложения, необходимые для раскрытия целостной картины описываемых событий. К ним относятся определение (местоимение, числительное, прилагательное), дополнение (существительное или местоимение) и обстоятельство (существительное с предлогом и наречие).
На основе перечисленных данных делается общий анализ предложения. Он заключается в подробном разборе связанных в законченную мысль лексем.

Синтаксические единицы
Для составления описания синтаксической конструкции необходимо знать критерии лексем. При анализе предложения определяют несколько характеристик в таком порядке:
- Вид высказывания. Фраза имеет некую эмоционально-экспрессивную окраску, в соответствии с которой является восклицательной или невосклицательной. Также она различается по цели высказывания и может быть побудительной, вопросительной или повествовательной.
- Грамматическая основа. Последовательное описание каждого члена предложения и средств их выражения, а также структуры синтаксической единицы.
- Тип конструкции: простая или сложная. Первая изучается по полноте (с указанием отсутствующего компонента в неполном предложении), распространённости, наличию осложняющих элементов (однородных членов, обращений, местоимений, вводных слов или выражений) и составу (одно- или двусоставная). В односоставных дополнительно устанавливают тип, который бывает личным, безличным, назывным или неопределённо-личным. В сложном предложении выясняют, является ли оно сложносочинённым (ССП), сложноподчинённым (СПП) или бессоюзным (БСП).
- Наличие пунктуационных знаков.
 В односоставных дополнительно устанавливают тип, который бывает личным, безличным, назывным или неопределённо-личным. В сложном предложении выясняют, является ли оно сложносочинённым (ССП), сложноподчинённым (СПП) или бессоюзным (БСП).
В односоставных дополнительно устанавливают тип, который бывает личным, безличным, назывным или неопределённо-личным. В сложном предложении выясняют, является ли оно сложносочинённым (ССП), сложноподчинённым (СПП) или бессоюзным (БСП).Для удобства можно сделать памятку в виде таблицы, где записать общую схему анализа. Это значительно облегчит проработку фраз и позволит довести полученные навыки до автоматизма.
Синтаксический разбор сложного предложения выполняется с расходованием большего количества времени и усилий, поскольку для его анализа потребуется сначала вычленить простые части, а потом уже оценивать каждую из них в отдельности. К тому же в этом случае добавляются дополнительные параметры для исследования.
Если ученику не удаётся быстро освоить правила, стоит воспользоваться размещёнными в интернете программами, которые позволят сделать бесплатно синтаксический разбор предложений онлайн.
Составление схемы
На уроках для получения хорошей оценки не всегда оказывается достаточным сделать простой разбор предложения. Каждому школьнику необходимо научиться придерживаться плана составления схем описываемых единиц:
- Подчеркнуть подлежащее одной сплошной линией, а сказуемое — двумя параллельными.
- Выделить второстепенные члены в соответствии с общепринятыми правилами (например, прилагательное — волнистой линией, определение — пунктиром, обстоятельство — точкой-пунктиром).
- Обозначить, если есть, в конструкции причастный и деепричастный обороты вертикальными чертами, подчеркнуть члены предложения волнистой линией или пунктиром-точкой соответственно.
- Заключить в овал имеющиеся в сложноподчинённых конструкциях союзы и союзные слова, входящие в придаточное предложение. В схеме сложносочинённых фраз эти части речи не обозначаются, а выносятся за рамки основы.

Выполняя упражнение, однородные члены обводят в круг, а обращения, не являющиеся членами синтаксической единицы, отмечают буквой О, отделённой вертикальными линиями. То же самое делают с вводными словами. При составлении схем конструкций, содержащих прямую речь, её отделяют от слов автора с учётом используемых знаков препинания.
Разбор простого предложения
Синтаксический анализ этого типа конструкций лучше всего изучать на основе примеров. Как образец можно взять фразу «Над Москвой розовеют дали». Анализ проводится в несколько этапов:
- Разбор фразы по членам: «над» является предлогом; «Москвой» — дополнением, выраженным существительным; «дали» — подлежащим, выраженным существительным; «розовеют» — сказуемым, выраженным глаголом.
- Определение грамматической основы: в этом предложении она представлена словами «розовеют дали» и указывает на то, что синтаксическая конструкция простая.
- Общая характеристика: предложение по строению — полное, двусоставное и распространённое; по эмоциональной окраске — невосклицательное, в связи с чем в конце ставится точка; по цели высказывания — повествовательное.
- Составление схемы: в этом случае [= -].

Данные, полученные при синтаксическом разборе предложения, к примеру, могут быть записаны следующим образом: если взять конструкцию «Сладость победы стирает горечь терпения», то она состоит из подлежащего «сладость», выраженного существительным, сказуемого «стирает», выраженного глаголом, а также дополнений «победы», «горечь» и «терпения», выраженных существительным. Грамматическая основа — «сладость стирает». Фраза полная, двусоставная, распространённая, невосклицательная, повествовательная. Схема: [- =].
Простое предложение может быть осложнено обособленным деепричастным оборотом, однородными обстоятельствами и т. д. Если разбирать конструкцию «Птичьи голоса звенели повсюду: в степи, в бору, в чаще», можно сделать вывод, что оно невосклицательное, распространённое, двусоставное, повествовательное, полное, осложнённое однородными обстоятельствами. В основе лежит подлежащее «голоса» и сказуемое «звенели». «Всюду» выступает в роли обобщающего слова. [- = ОС: О, О, О].
Простым конструкциям, включающим деепричастный оборот, дополнительно дают объективную оценку. При этом следует указать, каким именно членом предложения он является, после произвести разбор его частей на слова.
В конструкции «Мягко картавя, журчал ручеёк» в качестве грамматической основы выступает «журчал ручеёк», где «журчал» — это сказуемое, а «ручеёк» — подлежащее. Словосочетание «мягко картавя» является обособленным обстоятельством, выраженным деепричастным оборотом. Предложение простое, повествовательное, невосклицательное, двусоставное, полное, распространённое, осложнённое обстоятельством. Схема [| _._._|, = -].
Предложение простое, повествовательное, невосклицательное, двусоставное, полное, распространённое, осложнённое обстоятельством. Схема [| _._._|, = -].
Сложные конструкции
Прежде чем приступать к анализу сложных конструкций, необходимо изначально определить их тип. Существует три вида таких предложений:
- ССП (сложносочинённые) — содержащие в своём составе простые части, соединённые сочинительным союзом.
- СПП (сложноподчинённые) — имеющие главное и придаточное слово.
- БСП (бессоюзные сложные) — состоящие из нескольких простых частей, значение которых можно определить, как последовательность, противопоставление, одновременность и т. п.
Анализируя сложное предложение, изначально необходимо найти его грамматическую основу. После этого определяют главную и придаточную часть. Чтобы провести разбор синтаксических единиц, содержащих несколько придаточных частей, пользуются общим планом.
Образец ССП: «Ночь ушла, и поредел над сопками туман». Характеристика: состоит из двух предложений. В первой части главные члены представлены подлежащим «ночь», выраженным существительным, и сказуемым «ушла», выраженным глаголом; во второй — сказуемым «поредел» и подлежащим «туман». Оценка 1-го предложения — повествовательное, невосклицательное, двусоставное, нераспространённое; 2-го — двусоставное, повествовательное, распространённое, невосклицательное. Вся фраза сложносочинённая, неосложненная, полная, соединённая союзом «и», выражающим одновременность. [- =], и [= -].
Образец СПП: «Класс ничего не понял, когда учитель объяснял по карточкам». Обе части конструкции повествовательные, невосклицательные, распространённые, двусоставные. Вся фраза состоит из главного предложения и придаточного времени (когда?).
Образец БСП: «Подруга собралась уходить — мама убрала со стола». Главные члены первой части — подлежащее «подруга» и однородные сказуемые «собралась уходить»; второй — «мама» (подлежащее) и «убрала» (сказуемое). Обе части повествовательные, невосклицательные, двусоставные. Но, 1-я — нераспространённая, а 2-я — распространённая. Между конструкциями отмечается причинно-следственная связь. [- =] — [- =].
Имея перед собой примеры предложений с описанием разбора и схемами, можно до автоматизма натренировать визуальную память. Благодаря этому любые задания по синтаксическому анализу будут решаться легко.
Анализ зависимостей для малоресурсного языка (тагальский)
D Анализ зависимостей является одним из самых
важные задачи в обработке естественного языка. Это позволяет нам формально
понять структуру и смысл предложения, основанные на отношениях
его слова. В этом блоге я расскажу о том, как мы можем обучать и оценивать
синтаксический анализатор малоресурсного языка, такого как тагальский, мой родной язык.
Это позволяет нам формально
понять структуру и смысл предложения, основанные на отношениях
его слова. В этом блоге я расскажу о том, как мы можем обучать и оценивать
синтаксический анализатор малоресурсного языка, такого как тагальский, мой родной язык.
Разбор предложения требует от нас идентификации его заголовка и иждивенцы . голова обычно самое важное слово, в то время как зависимые существуют только для того, чтобы изменить его. Возьмем это предложение, «Эта девушка — моя сестра», например:
- Каждая стрелка представляет зависимости между словами и то, как они связаны,
т. е. X является $RELATION Y (например,
detдля определителя,possдля притяжательного,nsubjдля именной темы). - Самое важное слово в этом предложении — 9.0018 девушка . Все остальные слова
необязательный; они существуют только для того, чтобы модифицировать это существенное слово. я могу оставить
другие биты и просто скажите «Эта девушка», и это все равно будет относиться к
тот же предмет.
 я могу оставить
другие биты и просто скажите «Эта девушка», и это все равно будет относиться к
тот же предмет.
я могу оставить
другие биты и просто скажите «Эта девушка», и это все равно будет относиться к
тот же предмет.Вы можете многое сделать с этой информацией. Например, вы можете использовать дерево зависимостей, чтобы намекнуть на модель распознавания именованных объектов (NER), где существительное фразы есть. В анализе настроений вы можете использовать голову и ее модификаторы для получить хорошее представление об общей полярности текста. В поиске можно использовать разобранный дерево для улучшения ранжирования результатов. Вы всегда можете увидеть парсер зависимостей как часть конвейера НЛП или как основной компонент приложения НЛП.
На банках деревьев и языках с низким уровнем ресурсов
Какими бы крутыми они ни были, обучение парсера зависимостей требует много
аннотированные данные. Обычно они имеют форму деревьев, и один из их
самые большие запасы — универсальные зависимости
(УД) проект. Однако не все языки
имеют одинаковое количество размеченной информации. Языки с низким ресурсом (LRL)
часто получают более короткий конец палки с точки зрения доступности данных и
объем.
Языки с низким ресурсом (LRL)
часто получают более короткий конец палки с точки зрения доступности данных и
объем.
Для тагальского языка у вас есть только два варианта выбора деревьев: ТРГ 1 (Шахтнер и Отанес, 1983 г., и Самсон С., 2020 г.) и Угнаян (Акино и де Леон, 2020 г.). Первый содержит 128 предложения и 734 токена, а последний имеет 94 предложения и 1011 токенов. Это не так уж и много, особенно если сравнить их с некоторыми английскими деревьями, такими как Атис или ESL, с почти в 50 раз больше токенов, чем у нас. 2
| Берега деревьев | предложений | Жетоны | Источник | Информация на этикетке |
|---|---|---|---|---|
| ТРГ | 128 | 734 | Тагальский справочник по грамматике | Леммы, УПОС, Особенности, Отношения |
| Угнаян | 94 | 1011 | Портал учебных ресурсов DepEd | Леммы, УПОС, Отношения |
Тогда возникает вопрос: как мы можем надежно обучить и оценить модель из малоресурсного языка?
- Для обучение вроде бы можно натренировать парсер и получить приличный
точность примерно со 100 предложениями (Nivre, et al, 2017), поэтому мы будем придерживаться деревьев, которые
у нас есть. Мы будем использовать конфигурацию обучения spaCy по умолчанию, которую вы можете найти
в этом
репозиторий.
- Для оценки мы будем выполнять как одноязычные, так и многоязычные проверки для наши данные. Первый влечет за собой простую 10-кратную перекрестную проверку. для нашей модели (согласно рекомендациям руководства UD), в то время как последняя включает в себя псевдо-переносной подход к обучению, при котором мы обучаем синтаксический анализатор на более крупном языковая модель с тагальским банком деревьев в качестве нашего тестового набора.
 Мы будем использовать конфигурацию обучения spaCy по умолчанию, которую вы можете найти
в этом
репозиторий.
Мы будем использовать конфигурацию обучения spaCy по умолчанию, которую вы можете найти
в этом
репозиторий.Моя общая цель — продемонстрировать, что можно создать достойный тагальский язык. парсер зависимостей с объемом данных, которые у нас были, и выделить пробелы которые мешают нам достичь того же уровня плотности информации, что и другие языки.
Обучение синтаксического анализатора зависимостей с использованием spaCy
Банк дерева универсальных зависимостей (UD) следует определенному формату. Для каждого предложения
обычно вы найдете что-то вроде этого:
Для каждого предложения
обычно вы найдете что-то вроде этого:
# sent_id = schachter-otanes-60-0 # текст = Гумирование анг Бата. # text_en = Ребенок проснулся. 1 Gumising gising ГЛАГОЛ _ Аспект=Исполнение|Настроение=Индия|Голос=Действие 0 корень _ Блеск=пробуждённый 2 ang ADP _ Case=Nom 3 case _ Gloss=the 3 bata bata СУЩЕСТВИТЕЛЬНОЕ _ _ 1 nsubj _ Gloss=child|SpaceAfter=No 4 . . ПУНКТ _ _ 1 пункт _ _
- В первых нескольких строках вы получите некоторые метаданные, такие как уникальный идентификатор предложения, полный текст и его английский перевод.
- Для пронумерованных строк вы увидите лингвистические аннотации для каждого токена (например, «гумизинг», «анг» и др.). Для каждого токена вам обычно предоставляется его лемматизация (базовая форма), часть речи (POS) тег, лексический функции, и другие морфологические информация.
Эти аннотации упакованы в файл .conllu файл
формат, который вы можете открыть, используя
любой текстовый редактор.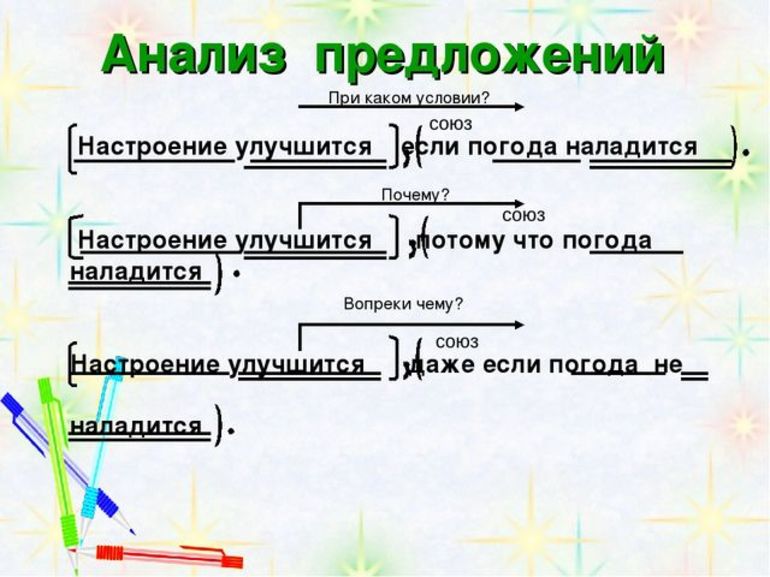 С помощью spaCy мы можем легко разобрать это на
объект Python, которым можно программно управлять:
С помощью spaCy мы можем легко разобрать это на
объект Python, которым можно программно управлять:
python -m spacy convert path/to/annotations.conllu path/to/save/ \
--converter conllu
--n-отправляет 1
--merge-подтокены
Вы могли заметить, что для аннотаций на тагальском языке у нас есть только тестовый набор,
то есть файлы были названы tl_trg-ud-test и tl_ugnayan-ud-test . Этот
рекомендуется
разделить на
проекта универсальных зависимостей и является распространенным сценарием для
языки.
«Если у вас меньше 20 тысяч слов. Вариант A: оставить все как тестовые данные. Пользователям придется пройти 10-кратную перекрестную проверку, если они захотят на ней тренироваться». (UD: выпуск данных Контрольный список)
Существует множество фреймворков для обучения, 3 , но для этого мы будем использовать spaCy.
работа. Мы будем использовать конфиг и проект
система, потому что я лично считаю, что это
удобно и легко. Вы можете найти полный
проект в этом Github
репозиторий.
Вы можете найти полный
проект в этом Github
репозиторий.
spaCy имеет продуманный конвейер для обучения парсера зависимостей, и большая часть он зависит от модели токена-вектора (Tok2Vec) состоит из встраивания и сети CNN. Теггер, морфологизатор и синтаксический анализатор все слушают эту модель Tok2Vec. Возможна замена этой модели Tok2Vec с трансформатором на основе Transformer, но для целей этого блога мы будем использовать опция по умолчанию. Если вы хотите узнать больше об этом шаблоне слушателя, я настоятельно рекомендую посмотреть на разработчика документы
Рисунок : Проект трубопровода spaCy (Источник: веб-сайт spaCy)
Если вы используете этот spaCy
проект, то вы можете обучать
синтаксический анализатор, запустив spacy project run [имя] до команды train .
Это обучает два парсера зависимостей для каждого банка дерева. Вы даже можете увидеть полностью
тренировочная конфигурация в этом
файл.
Наконец, вы должны увидеть обученные модели в /training/${treebank}/model-best каталог. Вы можете получить доступ к этому аналогично тому, как вы получаете доступ к другим моделям spaCy:
Вы можете получить доступ к этому аналогично тому, как вы получаете доступ к другим моделям spaCy:
импортировать пространство nlp = spacy.load («обучение/UD_Tagalog-TRG/модель-лучшая») text = "Накакаин ка на ба?" # ТН: Ты поел? документ = нлп (текст)
Отсюда мы можем использовать displaCy для визуализировать зависимости для данного текста:
от пробела импорта смещения displacy.render(doc,) # https://localhost:5000
(перевод) Ты поел?
Давайте попробуем это на других предложениях вне тренировочного набора):
(перевод) : Вам больше не нужно меня спрашивать.
Проверено! И обратите внимание, что мы используем небольшое количество предложений. (почти сотня) для обучения этого парсера. Конечно, мы не в стране конфет, и есть несколько предложений, где наш парсер работает плохо:
(перевод) : Посмотри мне в глаза, разве ты не видишь?
В этом примере такие слова, как мата (глаз/глаза) и aking (мой) были неправильно
помечен. Первое должно быть существительным, а второе должно быть местоимением.
Но довольно интересно, что помимо этих двух слов, наш парсер
уже достаточно прилично.
Первое должно быть существительным, а второе должно быть местоимением.
Но довольно интересно, что помимо этих двух слов, наш парсер
уже достаточно прилично.
Конечно, нам нужен лучший способ оценить эту модель, а не пробовать случайные фразы. 4 В следующем разделе мы будем использовать как одноязычные, так и межъязыковая оценка для наших двух моделей. Это должно дать нам понимание не только наших моделей, но и наших деревьев.
Одноязычная и межъязыковая оценка
Для оценки наших деревьев мы проведем как одноязычную, так и межъязыковую оценку:
- Одноязычная оценка : мы проведем 10-кратную перекрестную проверку для нашей модели. затем сообщите среднее значение по всем показателям. Ради интереса я также собираюсь проверить, насколько хорошо модель, обученная на другом дереве, работает на другом (и наоборот).
- Межъязыковая оценка : с помощью определенного показателя мы определяем пять (5) языков
которые типологически похожи на тагальский и имеют большие берега деревьев. Мы будем обучать модель
для каждого чужого банка деревьев и использовать TRG и Ugnayan в качестве тестовых наборов.
 Мы будем обучать модель
для каждого чужого банка деревьев и использовать TRG и Ugnayan в качестве тестовых наборов.
Мы будем обучать модель
для каждого чужого банка деревьев и использовать TRG и Ugnayan в качестве тестовых наборов.Что касается наших метрик, мы будем измерять следующее:
-
TOKEN_ACC: точность токенизатора, т. е. насколько хорошо он может определить правильные токены данного текста. -
POS_ACC: точность атрибутов токена. -
MORPH_ACC: общая точность нашего морфологизатора на основе формата Universal Dependencies FEATS. -
DEP_UAS / DEP_LAS: точность анализатора зависимостей. Бывший оценка немаркированного вложения, в то время как последнее называется помеченным вложением оценка (Нивре и Фанг, 2017).
Стоит измерять другие атрибуты нашей модели, даже если нас интересует только
с разбором зависимостей. Я не особо заморачивался с NER, потому что у меня есть
подозреваю, что он не будет работать хорошо, учитывая размер наших данных.
Одноязычная оценка
Я выполнил 10-кратную перекрестную проверку для наборов данных TRG и Ugnayan. я также было любопытно, как каждая модель будет работать с другим набором данных, поэтому я обучил модель для одного и использовал другой в качестве тестового набора.
| TOKEN_ACC | POS_ACC | МОРФ_АКК | ТАГ_АКК | DEP_UAS | DEP_LAS | |
|---|---|---|---|---|---|---|
| Угнаян | 0,998 | 0,819 | 0,995 | 0,810 | 0,667 | 0,409 |
| ТРГ | 1.000 | 0,843 | 0,749 | 0,833 | 0,846 | 0,554 |
| TOKEN_ACC | POS_ACC | МОРФ_АКК | ТАГ_АКК | DEP_UAS | DEP_LAS | |
|---|---|---|---|---|---|---|
| ТРГ на Угнаян | 0,997 | 0,563 | 0,364 | 0,538 | 0,472 | 0,240 |
| Угнаян на ТРГ | 1. 000 000 | 0,789 | 0,424 | 0,779 | 0,793 | 0,572 |
TRG, как банк деревьев, показывает хорошие результаты по большинству показателей по сравнению с Ugnayan. Однако, интересно, что с последним можно обучить довольно приличную модель. Ты можете изучить эти модели, используя демонстрацию ниже.
Межъязыковая оценка
Для межъязыковой оценки я обучил модель на другом языке и использовали наши тагальские деревья в качестве тестового набора. Мои критерии выбора этих языки следующие: они должны быть (1) ближе к тагальскому и (2) должен иметь приличный объем данных (не малоресурсный).
В первом случае я использовал метрику расстояния, чтобы идентифицировать языки, которые
типологически похож на тагальский (Agić, 2017). 5 В этом
случае, это индонезийский (id), вьетнамский (vi), румынский (ro), украинский (uk),
и каталонский (ок. ).
).
Затем я зашел в их репозитории UD и проверил, есть ли в них существующие обучающие и оценочные наборы данных. К счастью, у всех так, поэтому я пошел дальше. и обучили модель анализировать наши тагальские деревья. Результаты интересно: точность токенов хорошая, но точность тегера и парсера оставляет желать лучшего. много лучшего.
TRG Treebank
| TOKEN_ACC | POS_ACC | МОРФ_АКК | ТАГ_АКК | DEP_UAS | DEP_LAS | |
|---|---|---|---|---|---|---|
| ID-GSD | 1.000 | 0,374 | 0,320 | 0,000 | 0,342 | 0,151 |
| ви-втб | 1.000 | 0,306 | 0,423 | 0,000 | 0,309 | 0,143 |
| ро-ррт | 0,999 | 0,392 | 0,198 | 0,000 | 0,304 | 0,098 |
| Великобритания-Ю | 1. 000 000 | 0,185 | 0,177 | 0,000 | 0,539 | 0,188 |
| ка-анкора | 0,999 | 0,284 | 0,057 | 0,015 | 0,261 | 0,081 |
Угнаян Трибанк
| TOKEN_ACC | POS_ACC | МОРФ_АКК | ТАГ_АКК | DEP_UAS | DEP_LAS | |
|---|---|---|---|---|---|---|
| ID-GSD | 0,997 | 0,310 | 0,803 | 0,000 | 0,251 | 0,058 |
| ви-втб | 0,997 | 0,256 | 0,986 | 0,000 | 0,199 | 0,049 |
| ро-ррт | 0,992 | 0,332 | 0,275 | 0,000 | 0,279 | 0,085 |
| Великобритания-Ю | 0,998 | 0,151 | 0,123 | 0,000 | 0,300 | 0,084 |
| ка-анкора | 0,994 | 0,267 | 0,301 | 0,025 | 0,242 | 0,041 |
Что удивительно, так это то, как индонезийские и вьетнамские морфологизаторы
хорошо выступил в Угаяне. Возможно, это связано с их принадлежностью к одному
Австронезийская языковая семья как тагальский? Вы можете исследовать эти модели, используя
демо ниже.
Возможно, это связано с их принадлежностью к одному
Австронезийская языковая семья как тагальский? Вы можете исследовать эти модели, используя
демо ниже.
Демонстрация Streamlit
Вот веб-демонстрация парсера зависимостей и тега POS для всех тагальских и зарубежные модели. Вы можете ввести любое предложение на тагальском, и это даст вам проанализированная информация в удобном именно.
Обратите внимание, что иногда при выборе параметра «Свернуть фразы» возникает ошибка. в языке нет реализации блока существительных. Это так ожидаемо игнорировать это пока. Конечно, вы также можете улучшить языковую поддержку spaCy. внедряя чанкеры существительных в те языки.
Заключение
В этом сообщении мы рассмотрели, как обучить и оценить анализатор зависимостей. для малоресурсного языка, такого как тагальский. Мы также узнали, что:
- Парсеры зависимостей позволяют нам понять структуру и значение
предложения через связь их слов. Эти отношения затем могут
использоваться для нескольких последующих задач обработки естественного языка.
- Можно использовать банк деревьев для обучения парсера зависимостей. Универсальные зависимости (UD) служит хорошим хранилищем для таких. spaCy, это проще и удобнее для анализа и обучения на основе этих наборов данных.
- Языки с низким уровнем ресурсов слишком малы, чтобы в UD они делегировались только как «тестовый набор». Тем не менее, мы все еще можем оценить парсеры из этих деревьев с помощью k-кратной перекрестной проверки или путем сравнения с более крупными зарубежными модели.

Работая над этим проектом, я понял, сколько работы еще предстоит улучшить
лингвистический анализ тагальского языка. Конечно, проще всего сказать, что «мы
нужно больше данных», но аннотирование и маркировка деревьев требует
домен-экспертиза. 6 Если вы использовали spaCy, вам также может понадобиться
Напишите блокировщик существительных, который извлекает базовые словосочетания из парсера. Истинный
достаточно, большая часть этого усилия включает песчаную работу.
Наконец, вы можете рассматривать этот пост в блоге как репродукцию статьи «Анализ в отсутствие родственных языков: оценка малоресурсных парсеров зависимостей на тагальский» (Aquino and de Leon, 2020). Здесь они использовали строфа и UDPipe, но я хочу чтобы проверить, как это работает с spaCy. Это связанные документы график также был полезен в качестве отправной точки для дальнейшего чтения.
Если вам интересно посмотреть код и наборы данных, используемые в этом проекте, тогда не стесняйтесь зайти на Github репозиторий.
Ссылки
- Желько, А. Выбор межъязыкового парсера для Языки с низким ресурсом. В: Материалы семинара NoDaLiDa 2017 по Универсальные зависимости , стр. 1-10, Гётеборг, Швеция, Ассоциация Компьютерная лингвистика.
- Акино, А. и де Леон, Ф. Разбор в
отсутствие связанных языков: оценка парсеров зависимостей с низким уровнем ресурсов на
тагальский. В Материалы четвертого семинара по универсальным зависимостям
(UDW 2020) , стр. 8-15, ACL.
- Драйер, М. и Хаспелмат, М. Атлас мира Языковые структуры онлайн . Институт эволюционной антропологии Макса Планка, Лейпциг.
- Луи, М. и Болдуин, T.langid.py: готовый Инструмент определения языка. В: Труды системы ACL 2012 Демонстрации , страницы 25-30, остров Чеджу, Корея. Ассоциация для Компьютерная лингвистика.
- Нивр, Дж., Земан, Д., Гинтер Ф., Тайерс, Ф. Учебное пособие об универсальных зависимостях: добавление нового языка в UD. Представлено на 15-й конференции Европейского отделения Ассоциации компьютерной лингвистики , 2017.
- Нивр, Дж. и Фанг С-Т. Универсальная зависимость Оценка. In: Proceeding of the NoDaLiDa 2017 Workshop on Universal Зависимости , страницы 86-95, Гетеборг, Швеция. Ассоциация вычислительных Лингвистика
- Schachter, P. and Otanes, F.Tagalog Ссылка Грамматика. University of California Press , 1983.
 8-15, ACL.
8-15, ACL.Сноски
Этот банк деревьев получил свое название от Tagalog Reference Grammar (TRG) автора Шахтер и Отанес.
Большая часть текстов в дереве TRG была удалена.
из этого источника. ↩И мы говорим только о древовидных банках универсальных зависимостей для английского языка. В инвентаре Linguistic Data Consortium у вас есть Penn treebank и OntoNotes с почти более миллиона слов каждый! ↩
Другие наборы инструментов для разбора зависимостей включают UDPipe (который в моем исследовании доступен только для R), и Стэнфорд Станца
деппарструбопровод. ↩Помимо первого предложения, последние два были текстами песен группы. называется Головки-ластики . первый взят из песни Huwag mo nang Itanong , а второй пришли из алапаап . Я определенно испортил перевод, так что прошу прощения за что! ↩
Он основан на инструменте идентификации языка (LangID) Луи и Болдуина.
(2012 г.) в сочетании с некоторыми функциями Атласа мира.
языковых структур (WALS) (Dryer and Haspelmath, 2013). ↩Не говоря уже о том, что эти источники данных должны быть коммерчески выгодными. лицензии: вы хотели бы избегать текстов с авторскими правами и т. п. ↩
 Большая часть текстов в дереве TRG была удалена.
из этого источника. ↩
Большая часть текстов в дереве TRG была удалена.
из этого источника. ↩ (2012 г.) в сочетании с некоторыми функциями Атласа мира.
языковых структур (WALS) (Dryer and Haspelmath, 2013). ↩
(2012 г.) в сочетании с некоторыми функциями Атласа мира.
языковых структур (WALS) (Dryer and Haspelmath, 2013). ↩Новый способ изучения английской грамматики
Иерархия грамматических форм
Грамматическая форма – это слово или группа слов, которые функционируют как единая единица выражения в предложении. Существует четыре ранга грамматических форм. Эти четыре ранга образуют Иерархию грамматических форм:
· слово,
· словосочетание,
· зависимое предложение и
· предложение.
Члены иерархии могут быть показаны в виде треугольника грамматической формы ниже:
Предложение должно иметь полный смысл. Он состоит из слов, начинается с заглавной буквы и заканчивается точкой, знаком вопроса или восклицательным знаком. С точки зрения своих составляющих предложение состоит из ряда основных элементов предложения, необходимых для того, чтобы предложение имело полный смысл.
С точки зрения своих составляющих предложение состоит из ряда основных элементов предложения, необходимых для того, чтобы предложение имело полный смысл.
Всего в предложении может быть семь основных элементов предложения. Это:
1. Подлежащее (S)
2. Глагол (V)
3. Прямое дополнение (dO)
4. Косвенное дополнение (iO)
5. Субъективное дополнение (SC)
9000 2 6. Объективное дополнение (oC) и7. Наречие (A).
Они объясняются в таблице ниже:
В некоторых учебниках по грамматике и прямое дополнение, и косвенное дополнение объединяются просто как дополнение. Точно так же субъективное дополнение и объективное дополнение объединяются просто как дополнение. Таким образом, количество основных элементов предложения становится пятью вместо семи. Это просто другой способ подсчета без каких-либо изменений в содержании.
Остальные два ранга грамматических форм, слов и фраз, обсуждались в уроках с 1 по 3. в качестве элементов статьи .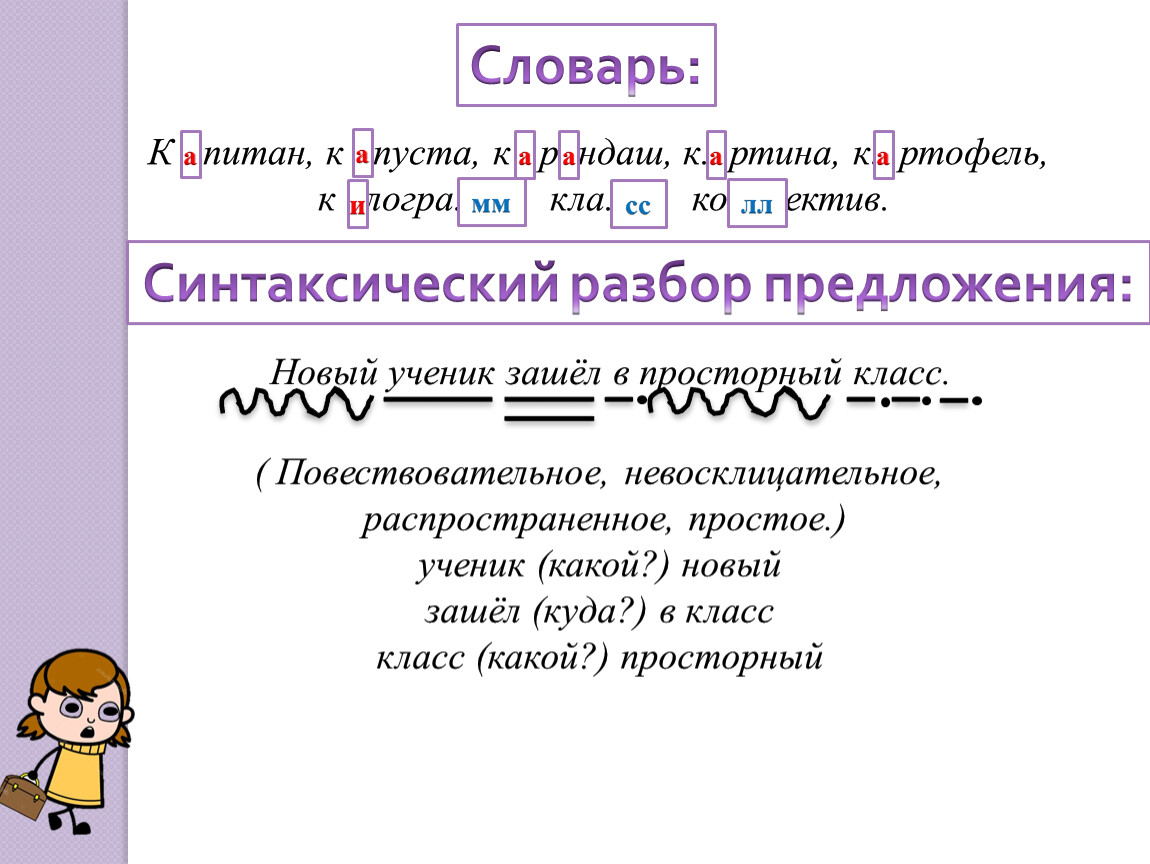
Это правда, что предложение может быть либо независимым предложением, либо зависимым предложением. Чтобы избежать этой двусмысленности, элемента предложения называются элементами предложения, и только зависимые (подчиненные) элементы предложения называются элементами предложения.
Зависимое предложение
Что такое зависимое предложение?
Придаточное предложение состоит из элементов предложения, но отличается от предложения тем, что не дает полного смысла, как это делает предложение.
Придаточные предложения, также называемые придаточными предложениями, занимают третье место в иерархии грамматических форм. Обычно они начинаются с подчинительного союза. Подчинительные союзы в двух зависимых предложениях ниже выделены курсивом.
(a) потому что я устал
(b) до я заснул
Так как они являются зависимыми предложениями, они не являются предложениями. Следовательно, ни один из них не дает полного смысла. Любое из них может быть присоединено к соответствующему простому предложению, чтобы стать частью сложного предложения.
Любое из них может быть присоединено к соответствующему простому предложению, чтобы стать частью сложного предложения.
Три типа предложений
Предложения можно разделить на:
(1) простые предложения.
(2) сложные предложения и
(3) сложные предложения.
Чтобы продемонстрировать, как иерархия грамматических форм работает при составлении предложений, давайте воспользуемся девятью словами, перечисленными в следующей таблице, для образования фраз, зависимых предложений и предложений:
Подводя итог, используя девять данных в таблице слов, мы образовали:
· три фразы,
· одно зависимое предложение, являющееся придаточным предложением, и
· два простых предложения (i) и (ii).
Затем, соединяя зависимое наречие с простым предложением (i), образуется следующее сложное предложение:
· С тех пор, как ты ушел, я думал о тебе.
Два простых предложения (i) и (ii) могут быть объединены в составное предложение:
· Вы ушли; Я думал о тебе.
Это два слова, соединенные точкой с запятой, а не координированным союзом, потому что такой союз не включен в список слов.
Грамматические функции и грамматические формы
Существует множество грамматических форм, принадлежащих к одной и той же категории речи и способных выполнять грамматические функции элементов предложения. Различные грамматические формы перечислены в таблице ниже. Элементы предложения, грамматические функции которых могут быть реализованы грамматическими формами, перечислены в крайнем правом столбце таблицы.
В случае элемента глагола его грамматическая функция может быть реализована только с помощью глагола или фразы с конечным глаголом. Такое глагольное предложение, состоящее из глагольного элемента и всех его дополнений, по существу является сказуемым предложения.
Семь основных моделей повествовательных предложений
С точки зрения грамматических форм предложения можно разделить на три типа: простые, составные и сложные, как мы видели ранее.
По грамматической функции предложения можно разделить на четыре типа: повествовательные, вопросительные, повелительные и восклицательные.
· Повествовательное предложение – это утверждение, оканчивающееся точкой.
· Вопросительное предложение – это вопрос, оканчивающийся знаком вопроса.
· Повелительное наклонение используется для запроса, предупреждения или приказа и заканчивается точкой.
· Восклицательное предложение используется для выражения эмоций и заканчивается восклицательным знаком.
Например:
1. Повествовательное предложение: Я дедушка.
2. Вопросительное предложение: Вы звонили мне?
3. Повелительное наклонение:Будьте осторожны.
4. Восклицательное предложение: Какой сегодня хороший день!
Среди четырех типов предложений повествовательное предложение является наиболее распространенным.
Интересно отметить, что в течение довольно долгого времени существовало только шесть элементов предложения, S, V, dO, iO, sC и oC, которые можно комбинировать, чтобы получить пять основных моделей повествовательных предложений. Это: (1) S + V + sC, (2) S + V, (3) S + V + dO, (4) S + V + iO + dO и (5) S + V + dO + oC. .
Это: (1) S + V + sC, (2) S + V, (3) S + V + dO, (4) S + V + iO + dO и (5) S + V + dO + oC. .
Однако значение некоторых предложений, написанных с некоторыми глаголами, такими как «жить» и «ставить» по двум шаблонам S + V и S + V + dO из пяти основных шаблонов, показанных выше, оказывается неполным. За последние два десятилетия, по-видимому, сложился консенсус в отношении того, что следует включить наречный элемент А, чтобы число основных паттернов увеличилось с пяти до семи, как показано в таблице 4.5 ниже.
В зависимости от времени глагольный элемент V может быть реализован либо
(a) конечным глаголом V f , либо
(b) конечной глагольной фразой VP = AV 1f + RVP.
Нижний индекс f в V f обозначает конечную форму глагола, а нижний индекс 1f в AV 1f обозначает конечную форму первого вспомогательного глагола или единственного вспомогательного глагола в глагольной фразе VP. RVP означает оставшуюся глагольную фразу.
Два набора из семи основных шаблонов повествовательных предложений показаны ниже для элемента глагола (a) или (b):
Все элементы предложения в семи основных шаблонах являются обязательными. Обязательные основные элементы предложения, которые должно иметь предложение, определяются главным глаголом в предложении следующим образом:
· Глагол-связка
Как следует из названия глагола, глагол-связка связывает подлежащее S и субъектное дополнение sC. Итак, sC — это третий элемент предложения, который должен иметь предложение с глаголом-связкой. С тремя элементами предложения S, V и sC значение предложения завершено. Следовательно, предложение с глаголом-связкой в качестве основного глагола имеет только базовую модель предложения (1): S + V + sC.
· Непереходный глагол
Предложения с непереходными глаголами, помимо того, что не имеют субъектного дополнения sC для связи, они не имеют ни прямого объекта dO, ни косвенного iO. Следовательно, они не могут иметь объективного дополнения oC. Так в предложениях с непереходными глаголами нет sC, oC, dO и iO. Некоторые непереходные глаголы должны иметь наречный элемент A, чтобы сделать предложение полным. Следовательно, предложения с непереходными глаголами могут иметь базовую модель повествовательного предложения (2): S + V и базовую модель повествовательного предложения (3): S + В +А.
Так в предложениях с непереходными глаголами нет sC, oC, dO и iO. Некоторые непереходные глаголы должны иметь наречный элемент A, чтобы сделать предложение полным. Следовательно, предложения с непереходными глаголами могут иметь базовую модель повествовательного предложения (2): S + V и базовую модель повествовательного предложения (3): S + В +А.
· Переходный глагол
Переходные глаголы должны иметь прямое дополнение dO. Некоторые переходные глаголы с dO также могут иметь объектное дополнение oC. Некоторые переходные глаголы с dO также должны иметь наречный элемент A. Некоторые переходные глаголы могут иметь как прямое дополнение dO, так и косвенное дополнение iO. Таким образом, предложения с переходными глаголами могут иметь основные модели повествовательных предложений (4): S + V + dO, основные модели повествовательных предложений (5): S + V + dO + A, основные модели повествовательных предложений (6): S + V + iO. + dO и шаблон основного повествовательного предложения (7): S + V + dO + oC.
Таким образом, следует отметить, что, хотя существует семь основных элементов предложения, количество основных элементов предложения, необходимых в Семи Декларативных Базовых Шаблонах, составляет от двух до четырех.
В лингвистике порядок слов в важном понятии. Три из семи основных шаблонов предложений, а именно (4), (5) и (7), имеют три элемента предложения S, V и dO в последовательном линейном порядке. Среди языков мира предложения, включающие эти три элемента предложения, расположены по-разному в шести разных порядках: S + dO + V, S + V + dO, V + S + dO, V + dO + S, dO + V + S и dO + S + V. Оказывается, второй шаблон S + V + dO, который соответствует порядку в Базовом шаблоне (4), является общим для китайского, английского, индонезийского и русского языков, как показано в следующей таблице. По населению около трех миллиардов человек в мире привыкли к линейному порядку S+V+dO.
Порядок элементов предложения в семи основных шаблонах, показанных в таблице выше, является так называемым каноническим порядком.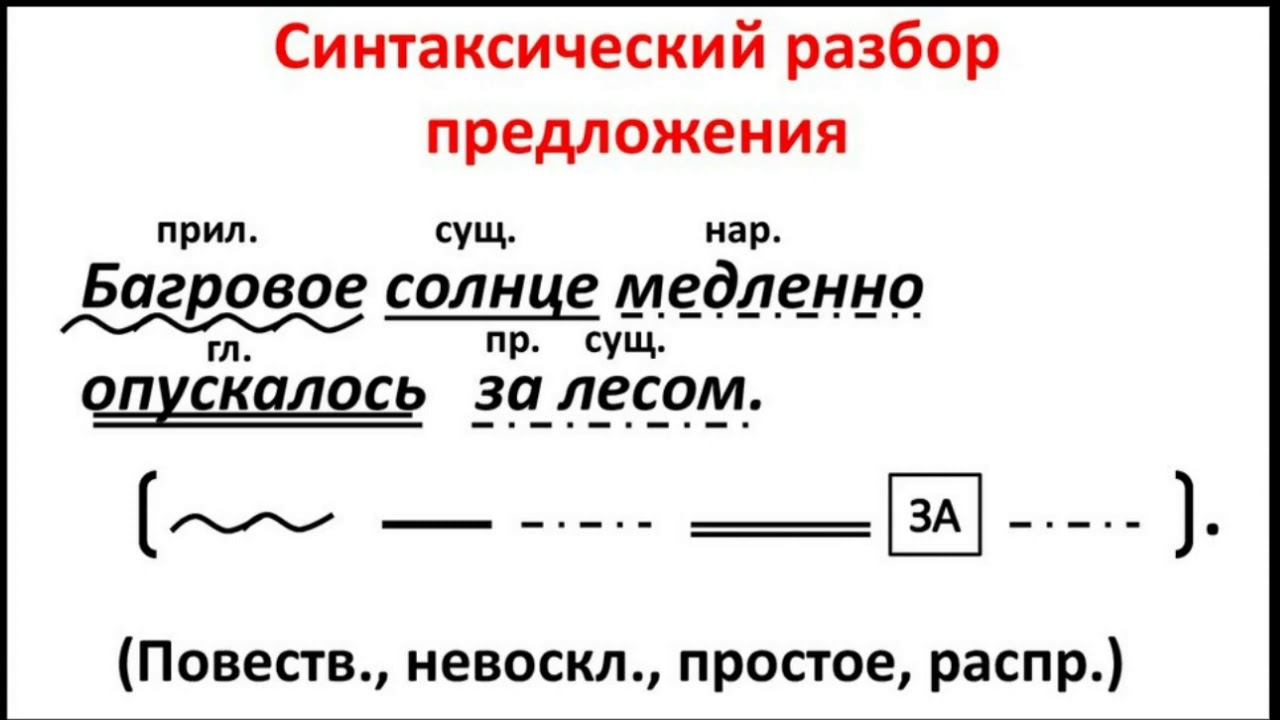 Иногда может быть необходимо или желательно, если это допустимо грамматически и семантически, изменить порядок элементов предложения для достижения определенных коммуникативных эффектов. Однако семь основных паттернов в приведенной выше таблице являются образцом для построения повествовательных предложений.
Иногда может быть необходимо или желательно, если это допустимо грамматически и семантически, изменить порядок элементов предложения для достижения определенных коммуникативных эффектов. Однако семь основных паттернов в приведенной выше таблице являются образцом для построения повествовательных предложений.
Элементы предложения в предложении называются составными частями предложения. Элемент подлежащего и сказуемое в предложении известны как «непосредственные» составляющие предложения. Голова сказуемого — это глагольный элемент, который может быть конечным глаголом или бесконечной глагольной фразой.
Соответственно, семь основных моделей предложений в следующей таблице дают следующие семь основных моделей предикатов повествовательных предложений:
Таким образом, семь основных моделей повествовательных предложений представляют собой план для составления повествовательных предложений.
Диаграммы элементов предложения — слотов (SES)
Диаграммы Рида-Келлога, разработанные в конце 19 90 900 го 90 040 века, использовались в качестве наглядного пособия для разбора предложений.
Ниже приведена диаграмма Sentence Element — Slot (SES), используемая при разборе предложений. Он напоминает трехуровневую полку с несколькими отделениями. Он основан на представлении о том, что составление предложения равносильно вставке соответствующего слова или цепочки слов в несколько слотов. Каждый из трехслойных слотов отображает тройное значение элемента предложения, а именно
(1) формулировка (используемые слова) для элемента предложения, который вносит свою долю значения в
общее значение предложения,
(2) грамматическая форма, которую принимает элемент предложения, и
(3) грамматическая функция, выполняемая элементом предложения.
Возьмем, к примеру, предложение:
· Родители нашли своих детей дома в безопасности».
Шаблон основного повествовательного предложения (7): S + V + dO + oC.
С помощью диаграммы SES предложение можно разобрать следующим образом:
Профессор Массачусетского технологического института Ноам Хомский разработал трансформационную грамматику в 1960-е годы. Основываясь на фазовой структуре и бинарном ветвлении, схематическое представление в форме перевернутого дерева может быть получено, как показано ниже:
Основываясь на фазовой структуре и бинарном ветвлении, схематическое представление в форме перевернутого дерева может быть получено, как показано ниже:
Как видно, после двух бинарных синтаксических анализов на непосредственные составляющие диаграмма перевернутого дерева дает тот же результат, что и показанный ниже. выделено жирным шрифтом, как показано на диаграмме SES.
Примеры основных повествовательных предложений
В этом разделе мы будем использовать диаграммы «Элементы предложения — слоты» (SES) для анализа всех иллюстративных предложений семи основных моделей повествовательных предложений.
· Базовая модель повествовательного предложения (1): S + V + SC
В наборе из трех простых предложений прошедшего времени, приведенных выше, элемент подлежащего первого простого предложения реализуется именной группой «отец того молодого человека». Оно становится антецедентом местоимения третьего лица единственного числа «он» в двух других простых предложениях. Следовательно, в соответствии с соглашением субъект-глагол, их глагол простого прошедшего времени V реализуется
Следовательно, в соответствии с соглашением субъект-глагол, их глагол простого прошедшего времени V реализуется
· либо конечным глаголом-сказуемым прошедшего времени V f = was,
· или от третьего лица, единственного числа, конечного, настоящего совершенного времени, глагольной фразы VP = AV perf + RVP = has was,
Элемент предложения sC в этих трех предложениях реализуется именной группой, an прилагательная фраза и предложная фраза, которые на самом деле являются тремя доступными вариантами.
· Образец основного повествовательного предложения (2): S + V
Подлежащее этого иллюстративного предложения «осенние листья» является составным существительным от третьего лица множественного числа. Итак, конечный вспомогательный глагол AV conf в глагольной фразе есть глагольная фраза настоящего продолженного времени VP есть «являются» в соответствии с соглашением подлежащее-глагол.
· Базовая модель повествовательного предложения (3): S + V + A
Подлежащее – существительное во множественном числе от первого лица. Глагол «жил» в прошедшем времени используется в качестве глагольного элемента предложения. Очевидно, обстоятельственный элемент А в этом примере обязателен, без которого смысл предложения становится неполным или совсем другим.
Глагол «жил» в прошедшем времени используется в качестве глагольного элемента предложения. Очевидно, обстоятельственный элемент А в этом примере обязателен, без которого смысл предложения становится неполным или совсем другим.
· Шаблон основного повествовательного предложения (4): S + V + dO
Субъект этого предложения — существительное во множественном числе «родители». Притяжательное местоимение во множественном числе «их» используется в именной фразе «их дети», потому что его предшествует существительное во множественном числе «родители». Поскольку предложение является констатацией факта, используется простое настоящее время, а глагольный элемент реализуется через V f = любовь.
· Базовая модель повествовательного предложения(5): S + V + dO + A
Подлежащее – это нарицательное существительное во множественном числе «студенты» без артикля перед ним. Это означает, что студенты могут быть любой группой студентов. Вспомогательный глагол настоящего времени AV perf = have in глагольная фраза «have put» используется для соблюдения соглашения между подлежащим и глаголом. Наречный элемент А в этом предложении обязателен, потому что, если его опустить, оставшееся предложение «Студенты поставили свои имена» не имеет полного смысла. См. подробное обсуждение обязательного и необязательного наречного элемента в следующем разделе.
Наречный элемент А в этом предложении обязателен, потому что, если его опустить, оставшееся предложение «Студенты поставили свои имена» не имеет полного смысла. См. подробное обсуждение обязательного и необязательного наречного элемента в следующем разделе.
· Базовая модель повествовательного предложения(6): S + V + iO + dO
Притяжательное местоимение множественного числа «их» в именной фразе «их дети», функционирующей в качестве косвенного объекта, используется, потому что его антецедентом является существительное во множественном числе « родители», глава именной группы, которая выполняет функцию подлежащего элемента. Глагол «принести» соответствует согласованию между подлежащим и глаголом.
· Базовый образец повествовательного предложения (7): S + V + dO + oC
Согласно обычаю, человек, изображающий Санта-Клауса на Рождество, всегда носит белую бороду.
Необязательный элемент наречия
За исключением элемента наречия A, все другие обязательные элементы предложения в простых предложениях семи основных шаблонов ограничены одним в своем роде. Однако один или несколько необязательных наречных элементов могут быть добавлены независимо от того, присутствует ли уже обязательный наречный элемент или нет. Единственная разница между обязательным наречным элементом и необязательным наречным элементом состоит в том, что обязательный наречный элемент всегда помещается в конце предложения, в то время как последний может быть размещен произвольно. В следующих примерах некоторые необязательные наречные элементы помещаются в конце предложений.
Однако один или несколько необязательных наречных элементов могут быть добавлены независимо от того, присутствует ли уже обязательный наречный элемент или нет. Единственная разница между обязательным наречным элементом и необязательным наречным элементом состоит в том, что обязательный наречный элемент всегда помещается в конце предложения, в то время как последний может быть размещен произвольно. В следующих примерах некоторые необязательные наречные элементы помещаются в конце предложений.
Во-первых, давайте рассмотрим основные модели предложений (1), (6) и (7), которые не содержат обязательного наречного элемента.
Основные шаблоны повествовательных предложений (3) и (5) уже содержат обязательный наречный элемент. Дополнительный необязательный наречный элемент или элементы могут быть добавлены, чтобы предоставить дополнительную информацию для обогащения содержания предложения.
Дополнительные наречные элементы могут использоваться для обогащения содержания предложений. Например:
Например:
· Джон купил новую машину.
Шаблон основного повествовательного предложения (4): S + V + dO. В нем нет деепричастного элемента.
В следующем предложении есть три наречных элемента:
· Несколько лет назад Джон приехал на своей новой машине на свадьбу своего племянника в Нью-Йорк.
Результирующий образец предложения A 1 + S + V + dO + A 2 , где
A 1 = несколько лет назад (с указанием времени)
A 2 908 52 = посетить своего племянника свадьба в Нью-Йорке (с указанием цели)
Таким образом, с двумя необязательными наречными элементами полученное предложение предлагает более подробное повествование.
Параллельное строительство
Следующий английский перевод всемирно известного девиза на санскрите также иллюстрирует параллельное строительство:
· Каждое хорошо прожитое сегодня сделает каждое вчера мечтой о счастье, а каждое завтра – видением надежды.
Это простое предложение имеет структуру: S + V + dO + oC + союз координат + dO + oC. Это базовая декларативная модель (7), в которой два последних элемента предложения, dO и oC, повторяются и соединяются сочинительным союзом «и», образуя параллельную конструкцию. Предложение анализируется ниже:
Рекурсия
Различные наборы формулировок могут использоваться для составления предложений одного и того же шаблона предложения. Это называется рекурсией. Известная поговорка в штатах:
· Учиться не думая легкомысленно; думать без изучения опасно.
Предложение имеет базовый шаблон повествовательного предложения (1).
В китайском тексте поговорка выглядит как два простых предложения без какой-либо сочинительной связи между ними. Здесь для соответствия английской грамматике между ними ставится точка с запятой. Его можно разобрать на диаграмме SES следующим образом:
Чтобы увидеть, как можно рекурсивно использовать базовые модели предложений в качестве шаблонов, возьмем, например, следующие три предложения:
1. Фармацевтическая компания нашла новую вакцину от малярии.
Фармацевтическая компания нашла новую вакцину от малярии.
2. Бездомный ребенок нашел дом.
3. Змея проглотила слона.
Эти три повествовательных предложения имеют разные формулировки, но у них один и тот же шаблон основного повествовательного предложения (4): S + V + dO, с N=3 основными элементами предложения. Таким образом, эти два предложения также можно разобрать, вставив разные формулировки в набор из трех одинаковых слотов на диаграмме SES следующим образом:
Все алгебраические уравнения для шаблонов предложений предоставили план и шаблоны для рекурсивного составления предложений.
Рекурсия — это математическая концепция, лежащая в основе арифметической последовательности и геометрической последовательности. Рекурсия в лингвистике — незаменимый и неизбежный инструмент, с помощью которого было составлено бесчисленное количество предложений по всем основным схемам, которые можно найти в этой книге. Вполне возможно, что с помощью рекурсивного использования основных шаблонов будут написаны все предложения во всех книгах на всех библиотечных полках мира.