Становится: какое проверочное слово
RusskiyPro.ru Проверочное слово Становится: проверочное слово
- Определение и морфемный разбор слова «становится»
- Подбор проверочных слов для глагола «становится»
- Примеры для закрепления
Определение и морфемный разбор слова «становится»
Слово «становится» является формой 3-го лица единственного числа глагола «становиться», который означает занимать определённое положение, прекращая движение.
Сделаем морфемный разбор слова, чтобы посмотреть в какой части слова находятся сомнительные буквы:
- станов — корень
- ит — окончание
- ся — постфикс
В данном слове нас интересует гласная буква «а» первого слога в корне слова.
В русском языке для проверки безударной гласной в корне слова необходимо подобрать такое проверочное слово, в котором сомнительная гласная займет ударную позицию.
Подбор проверочных слов для глагола «становится»
В данном случае подобрать проверочное слово не представляется возможным, так как глагол «становится» является словарным словом и его правописание следует запомнить.
стано́вится — словарное слово!
Примеры для закрепления
- Благодаря этим занятиям он становится все смышленее.
- С каждым годом Александр становится все взрослее и умнее.
- Эти тренировки закаляют дух и он становится бесстрашным.
ЧАЩЕ ВСЕГО СМОТРЯТ:
“здравствуйте” или “здраствуйте”
“выберите” или “выберете”
“пожалуйста” или “пожалуста”
“прийти” или “придти”
“как будто” или “как-будто”
“впоследствии” или “в последствии”
“так же” или “также”
“девчонки” или “девчёнки”
ударение в слове “КРАСИВЕЕ”
правописание : “адрес” или “адресс”
“потому что” или “потомучто”
“погода” или “пагода”
“в виду” или “ввиду”
“сделать” или “зделать”
“ничего” или “ни чего”
“нравится” или “нравиться”
“зато” или “за то”
“в принципе” или “впринципе”
“непонятно” или “не понятно”
“ненадолго” или “не надолго”
“всё равно”, “всёравно” или “всё-равно”
“вживую” или “в живую”
“чересчур” или “черезчур”
ударение в слове “СВЕКЛА”
“тем не менее” или “темнеменее”
“благодарю” или “благадарю”
“обожаю” или “обажаю”
“в смысле” или “всмысле”
“сначала” или “с начала”
“вовремя” или “во время”
“лучше” или “лутше”
“тренировка” или “тренеровка”
“то есть” или “тоесть”
ударение в слове “ЖАЛЮЗИ”
“обязательно” или “обезательно”
“картридж” или “катридж”
“конфорка”, “канфорка” или “комфорка”
“не знаю” или “незнаю”
“до скольки”, “доскольки” или “до скольких”
“неважно” или “не важно”
“неправильно” или “не правильно”
“ингредиенты” или “ингридиенты”
“попробовать” или “по пробовать”
“рассчитать” или “расчитать”
“потихоньку”, “по тихоньку” или “по-тихоньку”
ударение в слове “КАТАЛОГ”
“до сих пор” или “досихпор”
“посредством” или “по средством”
заглавных букв, пропущенные знаки препинания: улучшить разделение предложений? — использование
Размер (Дмитрий Беляков)
1
Всем привет.
Я хотел бы применить предварительно обученную модель к своему корпусу.
- Мои тексты ЗАГЛАВНЫМИ БУКВАМИ.
- Пропущено много знаков препинания.
- Текст имеет перенос столбца шириной ±80.
Некоторые символы конца строки (EOL) могут означать конец предложения. Другие EOL просто потому, что есть перенос текста.
Это убивает разделение предложений. Моя гипотеза состоит в том, что исправление синтаксического анализа POS и синтаксического анализа зависимостей может улучшить разделение предложений.
У меня есть несколько вопросов, связанных с этим:
- Я не смог найти достаточно информации о разделении предложений. Есть статьи?
- Я подозреваю, что EOL должен быть добавлен в качестве токена для повышения точности синтаксического анализа зависимостей POS+. Как создать токены EOL?
И наконец: как вы думаете, мой ход мыслей верен и обучение POS и зависимостей (частично) решит проблему?
В качестве резервного сценария можно было бы создать BiLSTM, предсказывающий начало предложения.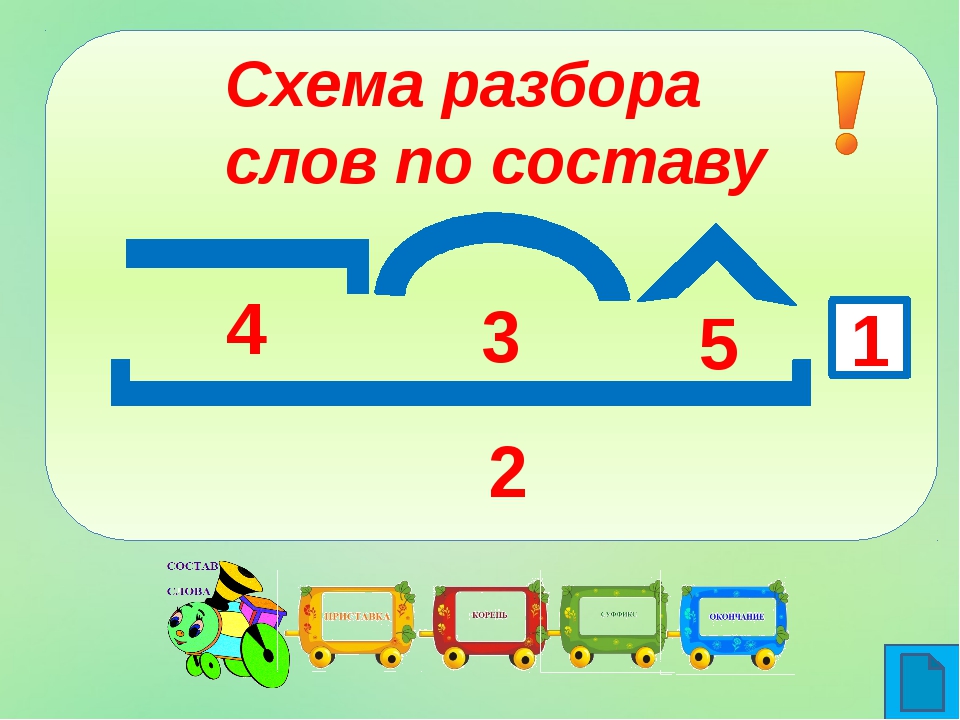 А затем используйте его вместо стандартной стратегии разделения предложений по умолчанию.
А затем используйте его вместо стандартной стратегии разделения предложений по умолчанию.
гоннибал (Мэттью Хоннибал)
2
Я думаю, что модель BiLSTM, вероятно, хорошая идея, хотя у вас могут возникнуть проблемы в зависимости от длины ваших текстов.
Вы можете попробовать преобразовать текст в истинный регистр, выбрав для каждого слова форму с наибольшей вероятностью: строчные, заглавные или прописные. Примерно так:
Def true_case (токен):
формы = [токен.текст.нижний(), токен.текст.верхний(), токен.текст[0].верхний() + токен.текст[1:].нижний()]
probs = [token.vocab[form].prob для формы в формах]
проблема, форма = макс (zip (проблемы, формы))
форма возврата
Это, вероятно, поможет вам повысить производительность тегера и синтаксического анализатора, что может помочь вам в дальнейшей нормализации.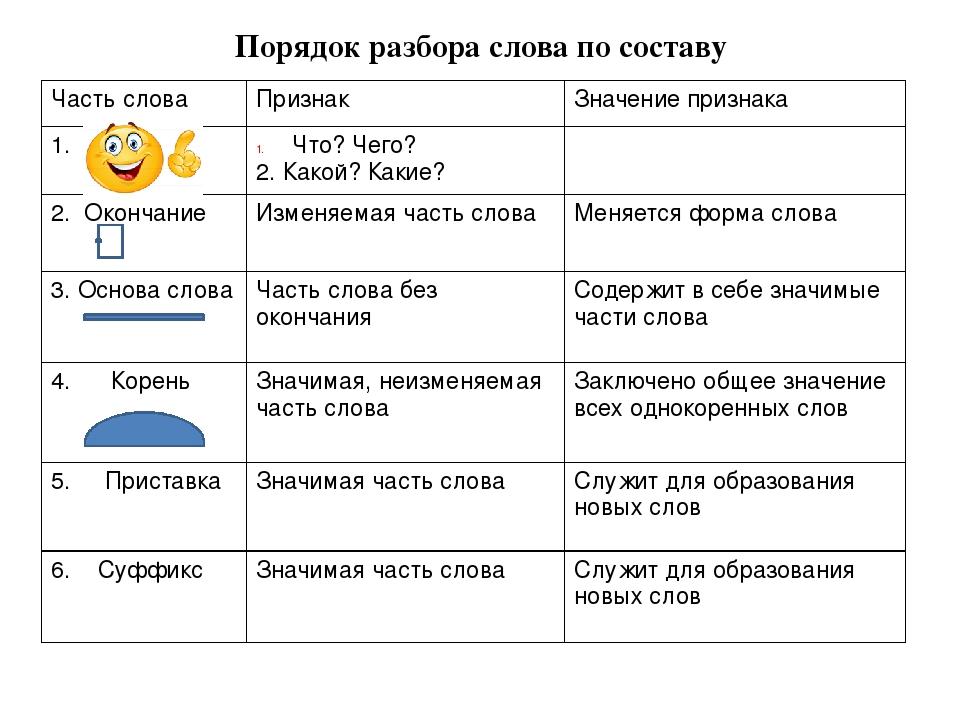
Другая стратегия будет заключаться в том, чтобы запустить spaCy поверх обычного текста, чтобы получить предсказанные теги POS и зависимости, а затем исказить текст, чтобы он был похож на ваш. Затем обучите модель, которая должна предсказать эти синтаксические анализы с учетом поврежденного текста. Затем вы можете запустить эту новую модель над вашими документами, как они есть.
Размер:
Мне не удалось найти достаточно информации о разделении предложений. Есть статьи?
Разделение предложений обычно предполагает, что текст находится в достаточно нормализованной форме, поэтому статьи вряд ли вам помогут.
Размер:
Я подозреваю, что EOL должен быть добавлен в качестве токена для повышения точности синтаксического анализа зависимостей POS+. Как создать токены EOL?
Вероятно, лучше просто нормализовать текст: исправить заглавные буквы, предсказать пунктуацию и добавить ее обратно и т.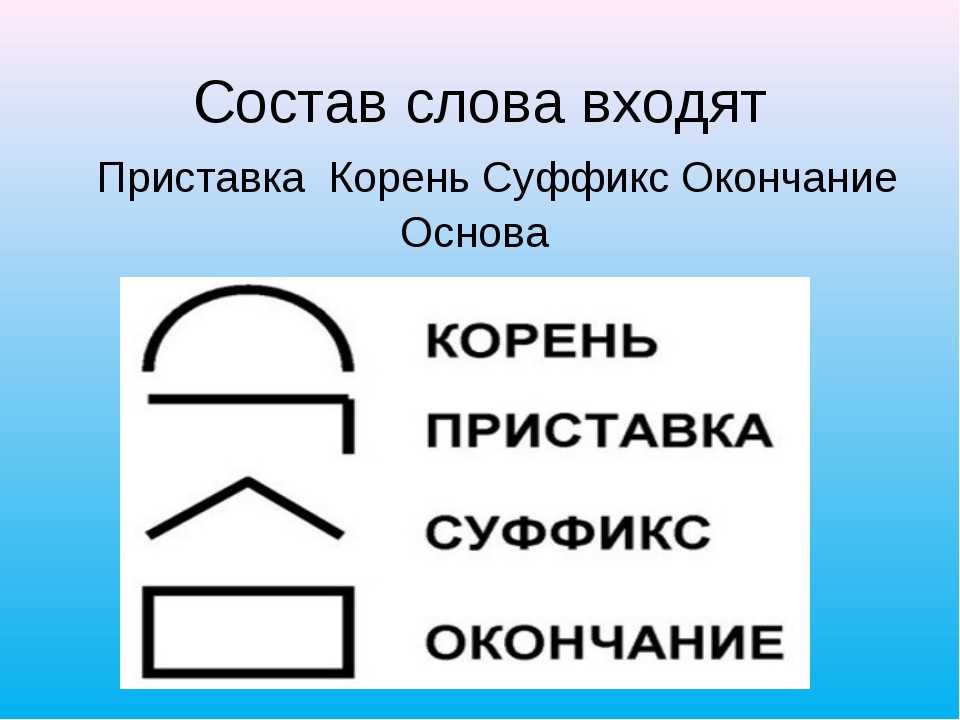 д. Если вы знаете, что слово является концом предложения, вы можете установить следующие токены
д. Если вы знаете, что слово является концом предложения, вы можете установить следующие токены атрибут token.is_sent_start
True . Это заставляет spaCy предсказывать границу предложения в этом токене и не позволяет модели NER предсказывать объект, который охватывает этот токен.Тусклый (Дмитрий Беляков)
3
Привет, Мэтью,
Спасибо за продуманные идеи.
гоннибал:
Вы можете попробовать преобразовать текст в истинный регистр, выбрав для каждого слова форму с наибольшей вероятностью: строчные, заглавные или прописные.
Эта мысль пришла мне в голову. Но я точно не знаю, как работает разделение предложений по умолчанию.
Если я понимаю, как это работает, я могу попытаться обмануть разделитель предложений по умолчанию, чтобы он разделял мой текст как обычный текст.
Насколько я понимаю, для разделения используются 3 основных «функции»: форма, токен пунктуации (.) и зависимости. Я что-то пропустил?
Моя текущая идея состоит в том, чтобы обучить модель лучше распознавать знаки препинания (наряду с другими POS), а затем, возможно, весь текст в нижнем регистре. В зависимости от того, как работает разделение предложений, я могу просто переобучить POS-теги в моем тексте с помощью prodigy.
После этого я реализую разделение предложений на основе правил (есть некоторые правила, которые я могу строго определить) и, наконец, разделение предложений по умолчанию.
Как это звучит?
4
Размер:
Эта мысль пришла мне в голову. Но я точно не знаю, как работает разделение предложений по умолчанию. В этот момент я понял, что это происходит после POS-тегов и, вероятно, внутри трубы «парсера» (так ли это?). Но что именно учитывается, непонятно.
Решение принимается совместно с синтаксической структурой. Итак, он пытается выяснить, где корни двух деревьев, а где они не связаны. Эта точка разделения между двумя деревьями становится границей предложения. Итак, с точки зрения того, что принимается во внимание: многое. Каждое слово получает вектор, определяемый окном до 4 слов с каждой стороны, а затем синтаксический анализатор поддерживает стек и частичный анализ, чтобы определить следующее действие для каждого слова.
Размер:
Насколько я понимаю, для разбиения используются 3 основных «функции»: форма, токен пунктуации (.
) и зависимости. Я что-то пропустил?
 ) и зависимости. Я что-то пропустил?
) и зависимости. Я что-то пропустил?Это функции, используемые при вычислении вектора слов. Но модель синтаксического анализатора — это, по сути, автоматический автомат, который поддерживает состояние и имеет действия, которые он может использовать для манипулирования состоянием, чтобы в конечном итоге вывести дерево. Одним из таких действий является «вставить границу предложения». Текущее состояние автомата используется для расчета признаков для определения следующего действия.
Размер:
Как это звучит?
Ну, трудно сказать! Думаю, это будет довольно трудоемкий процесс, и есть большой риск не получить в итоге ничего полезного. Например, вы, вероятно, должны провести несколько недель, опробуя свои текущие идеи, с вероятностью 20-50% на успех?
Сочинено, сочинение – арабское слово
муаллаф
ﻣُﺆَﻟَّﻒ
сочинено, сочинение – мужской род единственного числа
ﻣُﺆَﻟَّﻒ арабское слово. Смысл состоит, композиция. Вы произносите это муаллаф.
Смысл состоит, композиция. Вы произносите это муаллаф.
Вы хотите помочь arabic.fi?
У нас есть тысячи слов и почти две тысячи фраз с подробной информацией, уроками грамматики и многими другими ресурсами. Все можно использовать бесплатно. С вашей помощью этот сайт может стать еще лучше.
Подробнее здесь
Важные письма: ﺃ ﻝ ﻑ
Корень слова составлено, состав состоит из трех арабских букв: алиф хамза , что пишется ﺃ и произносится ‘ , лям то, что пишется ﻝ и произносится как л и fa , который пишется ﻑ и произносится f . Слова с одинаковыми корневыми буквами часто являются родственными.
Слова, относящиеся к составу, состав
The letters of composed, composition
ﻣُﺆَﻟَّﻒ
ﻣـ
ـﺆ
ﻟـ
ـﻒ
ﻣـ
ـﺆ
ﻟـ
ـﻒ
ﻡ
ﻣـ
ـﻤـ
ـﻢ
ﻝ
ﻟـ
ـﻠـ
ـﻞ
ﻑ
ﻓـ
ـﻔـ
ـﻒ
. (здесь ﻣـ) и произносится m. Краткая гласная u, которая пишется как знак ُ над буквой. Буква, которая пишется ﺅ (здесь ـﺆ) и произносится ‘ и является частью корня слова. Краткая гласная а, которая записывается как знак َ над буквой. Буква лам, которая пишется ﻝ (здесь ﻟـ) и произносится как л, является частью корня слова. Краткая гласная а, которая записывается как знак َ над буквой. Буква фа, которая пишется ﻑ (здесь ـﻒ ) и произносится как f, является частью корня слова. Поэтому слово пишется ﻣُﺆَﻟَّﻒ и произносится муаллаф.
(здесь ﻣـ) и произносится m. Краткая гласная u, которая пишется как знак ُ над буквой. Буква, которая пишется ﺅ (здесь ـﺆ) и произносится ‘ и является частью корня слова. Краткая гласная а, которая записывается как знак َ над буквой. Буква лам, которая пишется ﻝ (здесь ﻟـ) и произносится как л, является частью корня слова. Краткая гласная а, которая записывается как знак َ над буквой. Буква фа, которая пишется ﻑ (здесь ـﻒ ) и произносится как f, является частью корня слова. Поэтому слово пишется ﻣُﺆَﻟَّﻒ и произносится муаллаф.
Арабский язык пишется справа налево. Краткие гласные ставятся над или под буквами, обычно опускаются.
Научитесь писать арабскими буквами
Образец для составления, составления
mufa33al становится муаллаф
Мы видели, что арабское слово, означающее составление, составление, пишется ﻣُﺆَﻟَّﻒ и произносится муаллаф. Он следует образцу формы пассивного причастия 2. Все арабские слова с этим образцом имеют структуру mufa33al, где f, 3 и l заменены корневыми буквами слова.