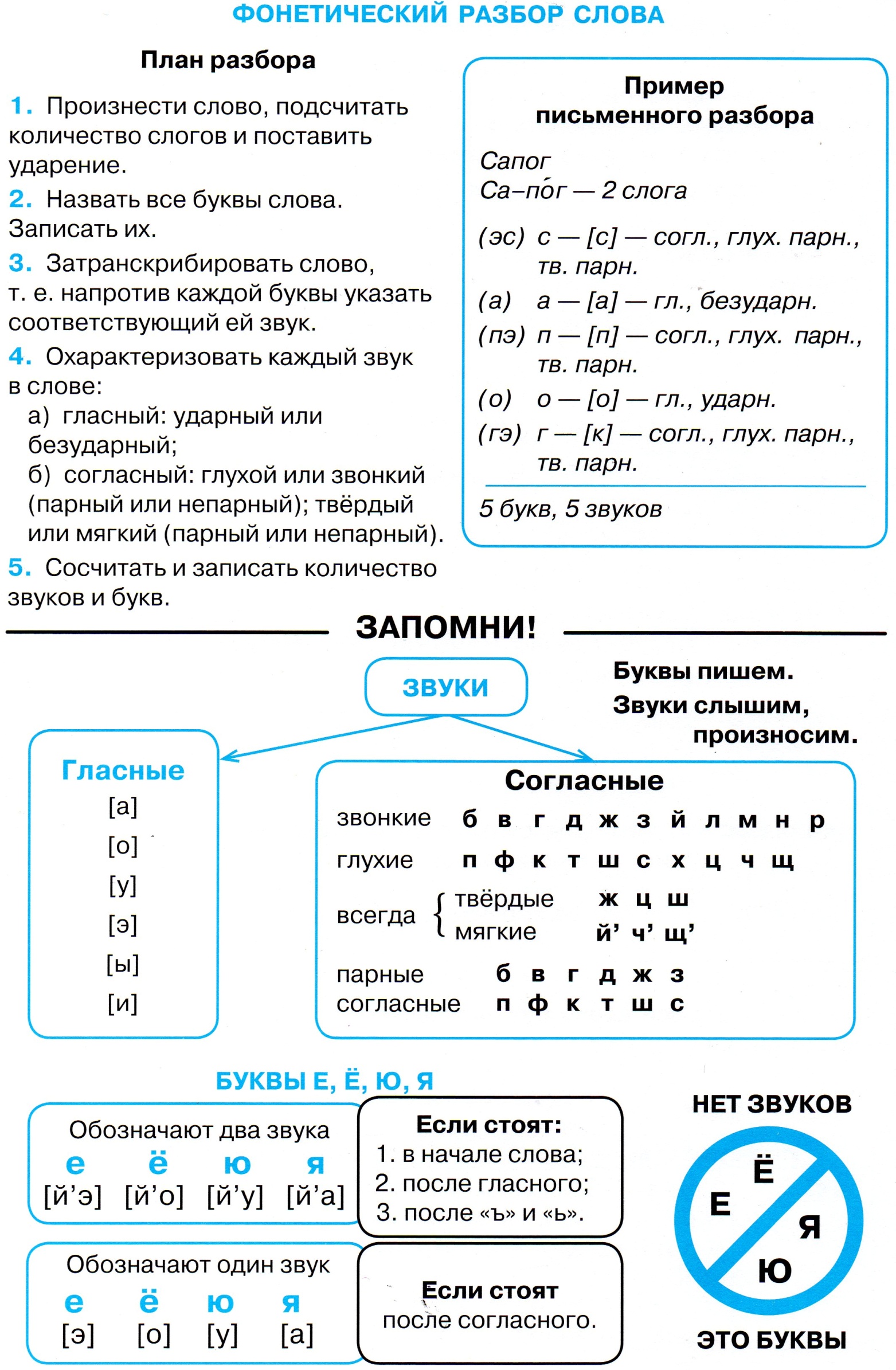
Фонетический разбор слова
5 класс Урок №11 Русская речь
Тема урока: Фонетический разбор слова
Цели урока: 1. научить учащихся произвести фонетический разбор слова.
2. развивать умения различать звонкие и глухие, твердые и мягкие, парные и непарные согласные; умения правильно ставить знаки ударения и делить слова на слоги.
3. воспитание внимательности и аккуратности при выполнении работ.
Тип урока: комбинированный
Методы и приемы: фонетический разбор слов, фронтальный опрос, развитие речи
Оборудование: раздаточно-дидактический материал
Ход урока:
I. Организационный момент
II. Постановка цели урока
III. Проверка домашнего задания
1. правило повторить
2. задание №4 стр.32
IV. Новая тема. 1. Слово учителя: Ребята, сегодня мы с вами познакомимся с порядком фонетического разбора.
-Сколько букв в русском алфавите?
-Сколько гласных букв?
-Сколько согласных букв?
-Сколько парных согласных по по глухости и звонкости?
-Сколько непарных звонких? Назовите их.(л,м,н,р,й)
-Сколько непарных глухих? Назовите их.(х,ц,ч,щ)
-Сколько непарных мягких? Назовите их.(ч,щ,й)
-Сколько непарных твердых? Назовите их.(ж,ш,ц)
-Сколько гласных звуков?(6)
-Сколько согласных звуков?(36)
-Сколько всего звуков? (42)
ПЛАН ФОНЕТИЧЕСКОГО РАЗБОРА
1.Написать слово, указать часть речи
2.Разделить его на слоги
3.Поставить знак ударения
4.Написать буквы, расположив их вертикально
5.Рядом с буквами написать звуки в квадратных скобках
6.Дать характеристику каждому звуку ( гласный – ударный или безударный, согласный – парный (непарный) глухой или звонкий, парный(непарный) мягкий или твердый)
7. Указать количество букв и звуков, количество слогов.
Указать количество букв и звуков, количество слогов.
Разбор слова ПЕНЬ (на доске)
V. Закрепление материала
Задание №1 стр.34 (прочитать сказку, ответить на вопросы)
Задание №2 стр.34 (выписать названия животных и произвести их фонетический разбор)
Задание №3 стр.35
Задание «Проверьте себя» стр.35
Развитие речи. 1. прочитать сказку в разделе «Чтение –вот лучшее учение»
2. пересказать содержание
Работа по раздаточному материалу самостоятельно и у доски
VI. Домашнее задание. Произвести фонетический разбор слов: ЕЖ, МЕДВЕДЬ, ЦИРК
VII. Подведение итогов урока. Комментирование оценок
Фонетический портрет слова. (Звукопись.) — Урок
Муниципальное общеобразовательное учреждение средняя школа № 9 городского округа город Буй Костромской области
Урок русского языка
Тема: «Фонетический портрет слова»
(Звукопись. )
)
5 класс
Урок с использованием технологии
коллективного взаимообучения (работа в статических парах), ИКТ.
Учитель: Мосина Г.А.
2006 год
Тема урока: Фонетический портрет слова. (Звукопись.)
Обучающая цель урока: сформировать умение видеть фонетические явления в слове.
Развивающая цель: развитие речевого слуха, мыслительной деятельности, творческих способностей учащихся.
Воспитательная цель: воспитание любви к поэтическому слову.
Тип урока: комбинированный с использованием ИКТ
Форма: работа в группах
Оборудование: мультимедийная установка
Ход урока
1. Организационное начало урока.
Включение в деловой ритм. Организация внимания учащихся.
На экране 1 слайд презентации, на котором отражены тема и цель урока. Звучит музыка.
2. Актуализация знаний.
Актуализация знаний.
Мы вдумываемся в смысл слов, в их строение, звучание. Зачем? Современный писатель Юрий Яковлев ответил на наш вопрос не прямо, не в лоб, а по-своему: «Только плохие люди морщатся при виде кошки и могут замахнуться палкой на собаку. А когда у человека доброе сердце, он будет дружить с собакой или пустит в банку красных рыбок». Внимание к словам – это внимание к жизни, ко всему живому. Слова могут учить доброте, сердечности.
3. Сообщение темы урока. Постановка целей. Мотивация.
Сегодня мы открываем ещё одну страницу доброго отношения к слову.
Мы будем вести разговор о фонетическом портрете слова. Вы можете сказать: портреты рисуют художники кисти и пера. Но если человек любит вглядываться в слово, вслушиваться в его звучание, может охарактеризовать звуки, заметить интересные фонетические явления в слове – он тоже поэт и художник!
Наша цель: сформировать умение
видеть фонетические явления в слове.
Согласитесь, что каждый человек хотел бы стать великим и известным, но для этого надо научиться в малом замечать великое. Итак, всматривайтесь в малое и вы увидите великое.
4. Проверка домашнего задания. Слайд № 2.
— Вспомним «секреты» согласных, прочитав выразительно, негромко и таинственно строки стихотворения В. Морданя:
Тихо. Не может быть тише.
Слышно, как [ф]сходит трава.
Ночь тишину лишь колышет,
Сла[т]кие шепчет слова.
— Выпишите те звуки, которые помогли поэту создать образ мягкой ночной тишины? ([т], [х], [ш], [ф], [ч], [к])
— Как называются такие звуки, при произнесении которых участвует только шум? (глухие согласные)
— Почему буква В в слове всходит звучит как [ф], буква Д звучит в слове сладкие как [т]? как называют такое явление в фонетике? (оглушение)
— Какие ещё фонетические явления вы можете назвать? (озвончение)
— Так какими «секретами» согласных воспользовался поэт?
 Подготовка к основному этапу
работы. Слайд № 3 «Звукопись»
Подготовка к основному этапу
работы. Слайд № 3 «Звукопись»Так вот, ребята, искусная фонетическая организация речи, которая достигается подбором слов близкого звучания, виртуозным сочетанием звуков, употреблением слов, которые своим звучанием напоминают слуховые впечатления от изображаемого явления, называется ЗВУКОПИСЬЮ.
(Появляется слайд №3)
ЗВУКОПИСЬ
аллитерация ассонанс
6. Усвоение новых знаний и способы действий.
Технология коллективного взаимообучения. Работа в статических парах.
Слайд № 4 Памятка «Работа в парах»
— Проработайте в парах информацию рубрики «Возьмите на заметку!»
на стр. 25, пользуясь памяткой «Работа в парах»:
1) Прочитайте учебный материал друг другу через абзац.
2) Ответьте друг другу на вопросы о звукописи по плану (через вопрос), в случае затруднения ответ прочитайте в учебнике:— Что такое звукопись?
— Какой приём звукописи называется аллитерацией?
— Какой приём звукописи называется ассонансом?
— Чего достигает поэт, используя приёмы звукописи?
— Какой становится стихотворная речь с использованием приёмов звукописи?
3) Запишите пример звукописи в тетрадь, сделав вывод по образцу:
[ст], [ст], [ст], [ст], [ст] — слышим
стук колёс.
4) Дайте друг другу связный ответ (по очереди) о звукописи по плану (оценку за рассказ поставьте на полях)
7. Первичная проверка понимания. Слайд № 5 «Дай правильный ответ»
— Какие звуки чаще использованы Ф. И. Тютчевым? Согласные? Гласные? Какие из согласных встречаются чаще?
1) Ещё в полях белеет снег,
А воды уж весной шумят –
Бегут и будят сонный брег,
Бегут и блещут и гласят…
— Какие звуки чаще использованы Б. Л. Пастернаком? Согласные? Гласные? Какие из гласных встречаются чаще?
2) Мело, мело по всей земле
Во все пределы.
Свеча горела на столе.
Свеча горела…
Ассонанс («созвучие») – повтор
гласных. (Появляется перед самопроверкой)
(Появляется перед самопроверкой)
— Проверьте самостоятельно правильность ответа. Если верно – поставьте на полях оценку – «5».
— Прочитайте выразительно строки стихотворения с позиции фонетического портрета.
8. Закрепление знаний и способов действий. Работа в парах.
Слайд № 5 Фонетический практикум
— А.С.Пушкин написал поэму «Полтава» о грандиозном сражении между русскими и шведами в XVIII веке. Бой был страшен.
…Тя…кой тучей
Отряды конницы летучей,
Браздами, саблями звуча,
Сш…баясь, рубят(?)ся сплеча.
Задания:
1) Объясните пропущенные орфограммы.
2) Почему эти стихи надо читать звонко и твёрдо?
3) Найдите фонетические явления: оглушение, озвончение.
4) Какой из приёмов звукописи
использует А. С.Пушкин?
С.Пушкин?
5) Подготовьте выразительное чтение.
— Самопроверка. Слайд № 6. Выставление баллов на полях в тетради (5 верных ответов – «5» и т. д.) Выразительное чтение строк поэмы.
9. Физкультминутка. Пальчиковая гимнастика.
10. Обобщение и систематизация знаний. Работа в парах.
Слайд № 7 Алгоритм действий.
Вот мы и сделали предварительный набросок фонетического портрета пушкинских строк.
— Что мы должны сделать для правильного определения звукописи?
(составление алгоритма)
Алгоритм:
1. Внимательно прочитать слово
2. Определить, какие одинаковые или сходные звуки преобладают в слове.
3. если если
Согласные Гласные
Аллитерация Ассонанс
11. Проверка усвоения. Слайд №
8 Проверь себя!
Проверка усвоения. Слайд №
8 Проверь себя!
1) Какой из приёмов звукописи использует автор в стихотворении:
Бросая груды тел на груду,
Шары чугунные повсюду
Меж ними прыгают, разят,
Прах роют и в крови шипят.
2) Создайте фонетический портрет слова: (появляется перед взаимопроверкой) (Оценка выставляется на поля: 4 верных ответа – «5», 3 – «4», меньше не оценивается, ошибки исправляются самостоятельно)
[Бр], [гр], [гр] – рычащие звуки
[Ш], [ч], [фс] – шипение
[Пр], [р] – рычащие
[Пр], [р], [пр], [р], [кр], [шп] – рычащие и шип.
Вывод:
Описание боя передается автором
преимущественно через согласные звуки,
звуки пишут картину боя: скрежет металла,
свист пуль, пушечные ядра прыгают и,
падая в лужи крови, шипят. Вот и стали
мы художниками, нарисовав картину боя
по фонетическим признакам слова.
Вот и стали
мы художниками, нарисовав картину боя
по фонетическим признакам слова.
— Подведем итоги работы: каждый находит свой средний балл работы на уроке. (Лучшие результаты выставляются в журнал).
12. Рефлексия.
— Была ли полезна такая работа всем нам? Что вы увидели и услышали благодаря расчленению понятных слов на звуки?
— Ответьте письменно на вопрос: случайно ли в слове бой из трёх звуков – два звонких?
13. Итог
Мне хочется верить, что сегодня наша встреча не прошла даром, и вы смогли в малом звуке, увидеть великое слово.
Домашнее задание: выучить понятия звукописи;
упр. 60 составить фонетический портрет
стихотворных
строк.
Фонетический разбор слов — русский язык, уроки
г.Семей КГУ «СОШ №33»
Карамбаева Сауле Жанибековна
учитель русского языка и литературы
5 класс
Русская речь
Тема урока: Фонетический разбор слова
Цели урока: 1. научить учащихся произвести фонетический разбор слова.
2. развивать умения различать звонкие и глухие, твердые и мягкие, парные и непарные согласные; умения правильно ставить знаки ударения и делить слова на слоги.
3. воспитание внимательности и аккуратности при выполнении работ.
Тип урока: комбинированный
Методы и приемы: фонетический разбор слов, фронтальный опрос, развитие речи
Оборудование: раздаточно-дидактический материал
Ход урока:
I. Организационный момент
Организационный момент
II. Постановка цели урока
III. Проверка домашнего задания
1. правило повторить
2. задание №4 стр.32
IV. Новая тема. 1. Слово учителя: Ребята, сегодня мы с вами познакомимся с порядком фонетического разбора. Но сначала давайте мы вспомним все, что мы знаем по фонетике.
-Сколько букв в русском алфавите?
-Сколько гласных букв?
-Сколько согласных букв?
-Сколько парных согласных по по глухости и звонкости?
-Сколько непарных звонких? Назовите их.(л,м,н,р,й)
-Сколько непарных глухих? Назовите их.(х,ц,ч,щ)
-Сколько непарных мягких? Назовите их.(ч,щ,й)
-Сколько непарных твердых? Назовите их.(ж,ш,ц)
-Сколько гласных звуков?(6)
-Сколько согласных звуков?(36)
-Сколько всего звуков? (42)
ПЛАН ФОНЕТИЧЕСКОГО РАЗБОРА
- Написать слово, указать часть речи
- Разделить его на слоги
- Поставить знак ударения
- Написать буквы, расположив их вертикально
- Рядом с буквами написать звуки в квадратных скобках
- Дать характеристику каждому звуку ( гласный – ударный или безударный, согласный – парный (непарный) глухой или звонкий, парный(непарный) мягкий или твердый)
- Указать количество букв и звуков, количество слогов.


Разбор слова ПЕНЬ (на доске)
V. Закрепление материала
Задание №1 стр.34 (прочитать сказку, ответить на вопросы)
Задание №2 стр.34 (выписать названия животных и произвести их фонетический разбор)
Задание №3 стр.35
Задание «Проверьте себя» стр.35
Развитие речи. 1. прочитать сказку в разделе «Чтение –вот лучшее учение»
2. пересказать содержание
Работа по раздаточному материалу самостоятельно и у доски
VI. Домашнее задание. Произвести фонетический разбор слов: ЕЖ, МЕДВЕДЬ, ЦИРК
VII. Подведение итогов урока. Комментирование оценок
Просмотр содержимого документа
«Фонетический разбор слов »
г. Семей КГУ «СОШ №33»
Семей КГУ «СОШ №33»
Карамбаева Сауле Жанибековна
учитель русского языка и литературы
5 класс
Русская речь
Тема урока: Фонетический разбор слова
Цели урока: 1. научить учащихся произвести фонетический разбор слова.
2. развивать умения различать звонкие и глухие, твердые и мягкие, парные и непарные согласные; умения правильно ставить знаки ударения и делить слова на слоги.
3. воспитание внимательности и аккуратности при выполнении работ.
Тип урока: комбинированный
Методы и приемы: фонетический разбор слов, фронтальный опрос, развитие речи
Оборудование: раздаточно-дидактический материал
Ход урока:
I. Организационный момент
II. Постановка цели урока
Постановка цели урока
III. Проверка домашнего задания
1. правило повторить
2. задание №4 стр.32
IV. Новая тема. 1. Слово учителя: Ребята, сегодня мы с вами познакомимся с порядком фонетического разбора. Но сначала давайте мы вспомним все, что мы знаем по фонетике.
-Сколько букв в русском алфавите?
-Сколько гласных букв?
-Сколько согласных букв?
-Сколько парных согласных по по глухости и звонкости?
-Сколько непарных звонких? Назовите их.(л,м,н,р,й)
-Сколько непарных глухих? Назовите их.(х,ц,ч,щ)
-Сколько непарных мягких? Назовите их.(ч,щ,й)
-Сколько непарных твердых? Назовите их.(ж,ш,ц)
-Сколько гласных звуков?(6)
-Сколько согласных звуков?(36)
-Сколько всего звуков? (42)
ПЛАН ФОНЕТИЧЕСКОГО РАЗБОРА
Написать слово, указать часть речи
Разделить его на слоги
Поставить знак ударения
Написать буквы, расположив их вертикально
Рядом с буквами написать звуки в квадратных скобках
Дать характеристику каждому звуку ( гласный – ударный или безударный, согласный – парный (непарный) глухой или звонкий, парный(непарный) мягкий или твердый)
Указать количество букв и звуков, количество слогов.

Разбор слова ПЕНЬ (на доске)
V. Закрепление материала
Задание №1 стр.34 (прочитать сказку, ответить на вопросы)
Задание №2 стр.34 (выписать названия животных и произвести их фонетический разбор)
Задание №3 стр.35
Задание «Проверьте себя» стр.35
Развитие речи. 1. прочитать сказку в разделе «Чтение –вот лучшее учение»
2. пересказать содержание
Работа по раздаточному материалу самостоятельно и у доски
VI. Домашнее задание. Произвести фонетический разбор слов: ЕЖ, МЕДВЕДЬ, ЦИРК
VII. Подведение итогов урока. Комментирование оценок
Фонетический разбор на уроках русского языка в начальной школе по УМК «Система Занкова» | Методическая разработка по русскому языку по теме:
Фонетический разбор на уроках русского языка в начальной школе
Обучая русскому языку в начальной школе по системе развивающего обучения Л. В. Занкова необходимо содействовать развитию мышления учащихся, пробуждать у них бережное отношение и любовь к родной речи, вызывать интерес к знаниям по русскому языку, развивать их языковое чутье, умение наблюдать факты речи, способность анализировать языковые явления.
В. Занкова необходимо содействовать развитию мышления учащихся, пробуждать у них бережное отношение и любовь к родной речи, вызывать интерес к знаниям по русскому языку, развивать их языковое чутье, умение наблюдать факты речи, способность анализировать языковые явления.
В решении этих задач огромное значение имеют разные виды разбора языкового материала, которые различаются по содержанию, объему и способу выполнения.
В число видов разбора включается и фонетический разбор. С этим видом работы над словом учащиеся встречаются с первых дней обучения в школе. (Так понятие о звуках речи дается еще в добуквенный период).
Дидактический материал, предлагаемый для наблюдения за языковыми явлениями в учебниках А. В. Поляковой («Русский язык » 1,2, 3 классы.), Н. В. Нечаевой («Букварь») позволяет работать над фонетическим составом слова в течение всего курса русского языка в начальных классах.
В зависимости от цели и задач урока разбор может быть устным или письменным, полным или частичным.
Особенности методики развивающего обучения позволяют при возможности двоякого толкования того или иного факта речи не добиваться его однозначной характеристики. Конкретные примеры, допускающие вариативность ответов при фонетическом разборе: постановка ударения, особенности произношения (литературное и разговорное, диалектные особенности) и др. Важно, чтобы ученики смогли аргументировано обосновать свое мнение, показать свое понимание языкового явления.
Необходимо, чтобы ребята, зная порядок разбора, отмечали в ходе разбора почему они оценивают анализируемый факт так или иначе, тогда анализ будет содействовать развитию связной научной речи, развивать мышление.
Порядок фонетического разбора.
1 этап. Постановка ударения. Деление на слоги.
2 этап. Гласные звуки.
3 этап. Согласные звуки.
4 этап. Количество звуков и букв.
В начальной школе целесообразно применение частичного фонетического разбора, позволяющего акцентировать внимание учащихся на минимуме теоретических знаний, который служит базой для формирования прочных фонетических умений и навыков. Поэтапный фонетический разбор в начальной школе даст богатый материал для проведения полного фонетического разбора в дальнейшем (в среднем и старшем звене).
Поэтапный фонетический разбор в начальной школе даст богатый материал для проведения полного фонетического разбора в дальнейшем (в среднем и старшем звене).
1 этап. Постановка ударения
Навык постановки ударения формируется у учащихся еще в букварный период. Фонетический разбор позволяет совершенствовать этот навык и отрабатывать орфоэпические нормы. Успех изучения таких тем, как склонение имен существительных, прилагательных, спряжение глаголов и изучение целого ряда орфографических правил (правописание не и ни в отрицательных местоимениях, правописание суффиксов, наречий) определяется степенью сформированности этого навыка.
Для формирования навыков постановки ударения использую следующие упражнения:
1.*(Под цифрой 1 приводятся упражнения, используемые в букварный период)
— Сравни слова. Есть ли какая-нибудь разница на письме? А на слух? Прислушайся, какой слог сильнее звучит?
— Придумай предложение со словом «руки», а теперь со словом «руки «.
— Придумай слова к схемам.
2.* Подумай, зависит ли смысл слов от места ударения?
Охотник стрелял белок. В яйце есть белок.
У зайца два длинных уха. Варилась уха.
— Подчеркни слова, которые пишутся одинаково, но произносятся по-разному.
Собака сидит у ворот. У рубахи вышит ворот.
За рекой было село. Солнце село.
— Подумай, как можно распределить слова на две группы.
Гора, горка, трава, травка, нора, норка, стена, стенка.
Деление слова на слоги.
Фонетический разбор дает возможность, не вводя новых теоретических сведений, изучать русский слогораздел, совершенствуя навыки переноса.
Деление слова на слоги не вызывает у учащихся трудностей, если слоги открытые: » го-ло-са, да-ле-ко»; или закрытые, конечные: «ко-лос, у-рок» и др. В этих случаях следует обратить внимание на деление на слоги слов с неслоговым «и» [и] » са-рай, май-ка» и др., следить за соблюдением правил слогораздела: «до-брьш», «у-до-бный», «ки-тай-ский». (стечение согласных «шумный сонорный» и » шумный шумный» относятся к следующему слогу, а «сонорный шумный» относятся к разным слогам;). Необходимо иметь в виду, что допустим перенос слов не только по слогам, но и по морфемам, например, «добр-ый» и «до-брый»; «куп-лю» и «ку-плю».
Необходимо иметь в виду, что допустим перенос слов не только по слогам, но и по морфемам, например, «добр-ый» и «до-брый»; «куп-лю» и «ку-плю».
Упражнения
1. *Составь из слогов слова.
— Какого слога не хватает?
— В лесу мы кричим так:
…„ «Ма-ма! Ве-ра!» — мы делим слова (на слоги). Раздели слова » Миша», «Дима». Представь, что ты зовешь друзей.
2.*Добавь слог. Запиши получившееся слово.
Соба…., бел…., шап…., плот…., охот…., печ……
Делю на слоги Делю для переноса
во/да, во/зил, во-да, во-зил
о/го/род, мо/и. ого-род, мои.
Сделайте вывод.
2 этап. Гласные звуки: ударные и безударные:
Какими буквами обозначены.
Начинать разбор каждого гласного звука в отдельности надо с гласного в ударном
слоге. Необходимо обратить внимание на то, что в ударном слоге гласный звук слышится и произносится наиболее отчетливо, в безударных менее отчетливо.
При анализе необходимо называть тот гласный звук, который произносим и слышим в безударном слоге. Это позволит избежать такой ошибки, когда вместо звука называется гласная буква. Кроме того, внимание к такому положению звука подготовит основу для различения написаний, определяемых произношением, и написаний, не определяемых произношением; готовит к осознанному усвоению орфографических правил, в частности, правописанию безударных гласных в различных морфемах.
Это позволит избежать такой ошибки, когда вместо звука называется гласная буква. Кроме того, внимание к такому положению звука подготовит основу для различения написаний, определяемых произношением, и написаний, не определяемых произношением; готовит к осознанному усвоению орфографических правил, в частности, правописанию безударных гласных в различных морфемах.
Упражнения.
1.*Прочитай слова. Произнеси, как мы их обычно говорим. Сделай вывод.
Нора, норы, норы;
роман, романы, романа,
*Сравни произношение слов с написанием. Подчеркни буквы, не соответствующие звукам.
Береза, огонь, окно, вода.
2.*На какие группы можно разделить эти слова?
Сын, сон, сад, рот, рыл, рак, дом, дым, дал.
Дополни каждую группу своими словами.
*Подчеркни в словах буквы, обозначающие гласные звуки. Какие гласные звуки они обозначают?
Пожалуйста, спасибо, здравствуйте.
* Запишите буквами:
[луга], [л’устра], [пар], [ п’атка ].
Почему одинаковые гласные звуки вы обозначили разными буквами? Подчеркните их.
З этап. Согласные звуки: Звонкие и глухие, твердые и мягкие:
Какими буквами они обозначаются.
При характеристике согласных необходимо обратить внимание учащихся на то, что твердые и мягкие согласные звуки — то разные звуки, с их помощью различаются лексические значения слов и их форм (сталь — стал, стань — стан). Уже в букварный период необходимо сформировать у учащихся четкое представление о твердости и мягкости согласных звуков, обозначение их на письме.
Фонетический разбор позволяет формировать представление учащихся о процессе ассимиляции по глухости звонкости (оглушение звонких согласных перед глухими, озвончение глухих перед последующими звонкими).
Упражнения.
1.*Подчеркни «б» — в твердой позиции, «б» — в мягкой позиции.
Бараны били в барабаны.
*Послушай как произносятся слова. Сравни с написанием. Подчеркни случаи происхождения звука и буквы в корне слов:
лов голод
улов голодал
наловил голодный
*Подчеркни согласные, которые пишутся не так, как произносятся:
дуб суп
рукав шкаф
луг лук
гараж шалаш
2. *Выпиши слова, в которых букв больше, чем звуков:
*Выпиши слова, в которых букв больше, чем звуков:
кильки, книжка, сахар, сильный, редька.
*Придумай два слова, в которых:
а) все буквы соответствуют звукам.
б) букв больше, чем звуков.
4 этап. Количество звуков и букв.
На этом этане фонетического разбора необходимо сравнять произношение и написание слова, определить количество звуков и букв, их обозначающих.
Учащиеся должны ответить на вопросы: из какого количества звуков, произносимых и слышимых, состоит данное слово? Какими буквами обозначены эти звуки? Совпадает ли количество звуков и букв; если нет, то почему?
Важно, чтобы учащиеся умели анализировать слова, где одна и та же буква, обозначает два разных звука и, наоборот, два, одинаковых, звука, обозначаются, разными буквами: дуб [дуп] — звук [п| обозначается буквами «б», «п».
В разбор следует включать и слова с буквами «ь», «ъ», которые не обозначают звуков («мебель», «ружье», «письмо» и т.п.), с буквами «я, ю, е, ё,», которые обозначают один или два звука в зависимости от положения в слове (синюю, яблоня, смеётся), сочетанием одинаковых букв, произносимых как один долгий звук, с сочетаниями букв, обозначающими один звук, сочетаниями букв с не произносимыми согласными.
Образцы фонетического разбора.
Устного Письменного
Русская красавица своей косою славится.
русская
ру-сска-я
В слове три слога: ру-сска-я, ударный слог — первый, второй и третий — безударные.
Ударение падает на звук [у|, гласные [а|, [а] — безударные, они произносятся и слышатся менее отчетливо, чем под ударением.
Гласные звуки.
[у] — ударный, обозначен буквой «у»
[а] — безударный, обозначен буквой «а»
[а] — безударный, обозначенный буквой «я».
Согласные звуки.
[р] — звонкий, твердый, обозначен буквой «р»
[с] — долгий, глухой, твердый, обозначен сочетанием букв «с с».
[к] — глухой, твердый, обозначен буквой «к»
[и] — звонкий, мягкий, обозначен буквой «я».
В слове «русская» — семь звуков, семь букв. Долгий звук [с] обозначен двумя буквами «ее». В положении после гласного, буква «я»
обозначает два звука [й, а].
II. Материал, предназначенный для углубления и расширения знаний в начальной школе, тесно связан с новым материалом по словообразованию, морфологией,
синтаксису и орфографии и может быть использован:
1) для осознанного освоения орфографии;
2) для овладения нормами литературного произношения;
3) в работе над структурой и семантикой слова, словосочетания, предложения:
— для разграничения значений слов и их форм;
— для объяснения фактов словообразования и морфемного анализа;
— для определения характера смысловых связей и отношений в простом и сложном предложениях.
Значение фонетических закономерностей иногда является единственным ключом к объяснению орфографических правил. Так, в 1 классе, при изучении правописания сочетаний «жи», «ши» («ча, чу», «ща, щу») предлагаю учащимся не механическое запоминание, а фонетический анализ:
Учитель: «На что указывает буква «и» после согласного?»
Дети: «На мягкость предшествующего согласного звука».
Учитель: «На что указывает буква «ы» после согласного?»
Дети: «На твердость предшествующего согласного звука».
Учитель: «А что вы знаете о согласных звуках [ж] и |ш]?»
Дети: «Эти согласные звуки всегда твердые. Мы договорились! Наверное, потому не пишется после «ж и ш» буква «ы», что обозначать их твердость не надо.»
Такое открытие позволит добиться осознанного запоминания этой орфограммы.
На фундаменте фонетических знаний, умений, навыков базируется осмысление и усвоение таких орфографических правил: проверяемых гласных в корне слова, непроизносимые согласные в корне слова, правила обозначения мягкости согласных на письме и др.
При работе над орфографическими правилами, так или иначе связанными с фонетикой, предлагаю учащимся запоминать правило по схеме: 1 — название орфограммы, 2 — условия проверки. Например: при изучении правила проверки буквы, обозначающей парный согласный звук в середине слова перед глухими согласными (2 класс), предлагаю для запоминания:
1 — название орфограммы: Парный согласный звук в середине слова.
2 — условия проверки: Изменить слово так, чтобы после согласного звука стоял гласный (гудки-гудок).
Или при изучении непроизносимых согласных в корне слов (2 класс):
1 — название орфограммы: Непроизносимые согласные.
2 — условия проверки: Подобрать однокоренное слово, в котором этот звук произносится. При изучении правописания некоторых наречий (3 класс):
1 — название орфограммы: «- О, — Е» на конце наречий,
2 — условия проверки: после шипящих под ударение «о», без ударения — «е».
Такое запоминание орфографических правил привело к большому % их усвоения и умению применять их на практике, в отличии от обычного заучивания правил, данных в учебнике.
При работе над составом слова и словообразования также необходимо учитывать фонетические изменения в слове, например, изменение фонетического облика морфем в результате традиционных исторических чередований г//ж, к//ч, т//м, б//бл, о,е//с нулем звука и др. В таких словах без четкого представления о фонетических процессах, допускается наибольшее количество ошибок при определении границ морфем и деление на морфемы. Например, учащимся трудно определить границы морфем в словах типа:
сор — сна, день — дня, книга — книжка.
При изучении частей речи фонетический разбор помогает объяснить целый ряд морфологических явлений. Внимание к этому виду работы позволяет избежать распространенной ошибки определения «ь» как окончания у имен существительных типа; » камень», «очень». Предварительный фонетический анализ помогает правильно выделить на конце основы [и] и расчленить слово на морфемы у существительных типа «чай, край».
край, края, [край\а]
Таким образом, проведение фонетического разбора уже в младших классах показывает, что фонетика — это неизолированный раздел науки о языке, что объективно существующие законы фонетики влияют на другие явления и процессы в языке, отражаются в орфографии, словообразовании, морфологии и синтаксисе.
Литература
1. Русский язык. Полякова А.В. Учебник для 1, 2, 3 классов. М.: Просвещение, 1991 г.
2. Букварь. Под ред. Нечаевой Н.В. Самара: Изд. Корпорация «Федоров», 1995 г.
3. Узорова О.В., Нефедова Е.А. Справочное пособие по русскому языку для начальной школы (Уроки русского языка) Изд. «Аквариум» ГИППВ, 1997 г.
Фонетический разбор слова — учебное задание по анализу слоговой структуры и звукового состава слова. Является распространённым в школах бывшего СССР. Предполага
Пользователи также искали:
фонетический разбор слова есть,
фонетический разбор слова гром,
фонетический разбор слова онлайн,
фонетический разбор слова примеры,
фонетический разбор слова русский,
фонетический разбор слова сделать,
фонетический разбор слова солнце,
фонетический разбор слова слова,
разбор,
фонетический,
слова,
Фонетический,
Фонетический разбор слова,
фонетический разбор слова,
гром,
солнце,
примеры,
онлайн,
есть,
русский,
сделать,
фонетический разбор слова примеры,
фонетический разбор слова русский,
фонетический разбор слова есть,
фонетический разбор слова сделать,
фонетический разбор слова гром,
фонетический разбор слова солнце,
фонетический разбор слова онлайн,
фонетика. фонетический разбор слова,
фонетический разбор слова,
фонетический разбор — это… Что такое фонетический разбор?
- фонетический разбор
Словарь-справочник лингвистических терминов. Изд. 2-е. — М.: Просвещение. Розенталь Д. Э., Теленкова М. А.. 1976.
- фонетический закон
- фонетическое слово
Смотреть что такое «фонетический разбор» в других словарях:
ФОНЕТИЧЕСКИЙ РАЗБОР — ФОНЕТИЧЕСКИЙ РАЗБОР. Один из видов языкового анализа; состоит в установлении звукового состава слова (количества звуков, их соотнесения с буквенным составом слова, гласных и согласных звуков, характеристики каждого звука), в определении места… … Новый словарь методических терминов и понятий (теория и практика обучения языкам)
Фонетический разбор слова — Фонетический разбор слова учебное задание по анализу слоговой структуры и звукового состава слова.
Является распространённым в школах бывшего СССР. Предполагает элементы графического анализа. При проведении фонетического разбора… … ВикипедияРАЗБОР ФОНЕТИЧЕСКИЙ — РАЗБОР ФОНЕТИЧЕСКИЙ. См. фонетический разбор … Новый словарь методических терминов и понятий (теория и практика обучения языкам)
разбор морфологический — (разбор по частям речи). Если объектом разбора является предложение, то выясняется его морфологический состав, с последующей характеристикой отдельных слов, относящихся к той или иной части речи. Вначале указываются постоянные морфологические… … Словарь лингвистических терминов
РАЗБОР — РАЗБОР. Анализ языковых явлений и их характеристика в определенной последовательности, разложение в ходе анализа сложного языкового целого на составляющие его элементы. Применяется в учебных целях как один из приемов обучения языку, как средство… … Новый словарь методических терминов и понятий (теория и практика обучения языкам)
Обучение фонетике — акустический подход, акцент, акцентологические ошибки, апперцепция, артикулирование, артикуляционная база, артикуляционный навык, артикуляционный аппарат, артикуляция, артикуляция речевая, аудиоматериалы, аудирование, аудирование коммуникативное … Новый словарь методических терминов и понятий (теория и практика обучения языкам)
Содержание обучения — активная грамматика, активная лексика, активный грамматический минимум, активный словарный запас, активный словарь, артикуляция, аспект обучения, аспекты языка, аудирование, аутентичный материал, база данных, виды речевой деятельности… … Новый словарь методических терминов и понятий (теория и практика обучения языкам)
Дювернуа, Александр Львович — славист, профессор московского университета, родился в Москве в 1840 году, умер в 1886 году там же.
Д. получил домашнее воспитание под руководством матери, затем учился в I й и ІV й московских гимназиях и по окончании курса в последней поступил в … Большая биографическая энциклопедияЧувашский алфавит — (чуваш. чӑваш алфавичӗ) общее название алфавитов, буквы которых использовались для передачи элементов звуковой речи в письменности древнечувашского и современного чувашского языка. В чувашской письменности использовались только алфавитные… … Википедия
Чувашская письменность — Содержание 1 Рунический алфавит 1.1 История 1.2 Письменнос … Википедия
 Является распространённым в школах бывшего СССР. Предполагает элементы графического анализа. При проведении фонетического разбора… … Википедия
Является распространённым в школах бывшего СССР. Предполагает элементы графического анализа. При проведении фонетического разбора… … Википедия Д. получил домашнее воспитание под руководством матери, затем учился в I й и ІV й московских гимназиях и по окончании курса в последней поступил в … Большая биографическая энциклопедия
Д. получил домашнее воспитание под руководством матери, затем учился в I й и ІV й московских гимназиях и по окончании курса в последней поступил в … Большая биографическая энциклопедия11. Значение, задачи и основные принципы изучения фонетики и графики в школе. Содержание и структура данного курса. Методы и приемы изучения фонетики и графики.
В школе фонетика
и графика как самостоятельный раздел
изучается в 5 классе. Методика фонетики
и графики связана с именами таких ученых
как Г.П.Фирсов, Р.Т.Гребенкина и др. Объем
этого раздела небольшой, но значение
для общего образования учащихся
велико,т.к.: 1) этот раздел дает представление
о звуковой и графической системе РЯ; 2)
только на основе знаний, полученных в
данном разделе, может быть глубоко
усвоен материал других разделов.
Методика фонетики
и графики связана с именами таких ученых
как Г.П.Фирсов, Р.Т.Гребенкина и др. Объем
этого раздела небольшой, но значение
для общего образования учащихся
велико,т.к.: 1) этот раздел дает представление
о звуковой и графической системе РЯ; 2)
только на основе знаний, полученных в
данном разделе, может быть глубоко
усвоен материал других разделов.
Задачи изучения фонетики и графики в школе.
дать правильное представление о звуковой системе РЯ, добиться, чтобы учащиеся различали звуки и буквы, осознали основные случаи соответствия и несоответствия между произношением и написанием;
познакомить с нормами русского литературного произношения;
научить использовать фонетические сведения при изучении правописания и выразительного чтения;
способствовать воспитанию языкового чутья и любви к РЯ;
При изучении
фонетики и графики учитель опирается
в своей работе на общедидактические,
общеметодические и частнометодические
принципы.
Частнометодические принципы:
— опора на речевой слух ребенка;
— рассмотрение звука в морфеме;
— сопоставление звуков и букв;
На изучение данного раздела отводится примерно 16 часов. По действующим программам в данном разделе изучаются следующие темы:
Звуки речи. Гласные и согласные.
Слог (правила переноса слов ).
Ударение, гласные ударные и безударные.
Твердые и мягкие согласные.
Звонкие и глухие согласные.
Алфавит.
Звуковое значение букв е, ё, ю, я.
Обозначение мягкости согласных.
В 5 классе знания
по фонетике, графике приводятся в
систему.
При изучении данного раздела используются все известные методы и приемы для овладения языковыми явлениями.
Ученые-методисты считают целесообразным знакомство с новым материалом по данному разделу проводить индуктивным способом – методом беседы с элементами слова учителя. Основная цель учителя в процессе объяснения нового материала – подвести детей к пониманию особенностей звуковой и графической системы РЯ.
Следует сразу направить внимание учащихся на различие звуков и букв, которые они обычно путают, хотя и знают определения звука и буквы.
При изучении деления
согласных на твердые и мягкие необходимо
обратить внимание на то, чтобы ученики
поняли природу мягкости согласных
звуков. Начиная изучение графики, учитель
еще раз должен обратить внимание на то,
что писать научились позже, чем говорить.
Нужно выяснить причины обращения людей
к письменности, познакомить с краткой
историей русского алфавита, используя
метод «слово учителя». Определение
алфавита дано в учебнике. Необходимо
выяснить происхождение слов «алфавит»,
«азбука», используя этимологический
словарь. Поработать необходимо над
правописанием и произношением слова
«алфавит». Также учитель должен убедить
учащихся в необходимости знания алфавита.
Определение
алфавита дано в учебнике. Необходимо
выяснить происхождение слов «алфавит»,
«азбука», используя этимологический
словарь. Поработать необходимо над
правописанием и произношением слова
«алфавит». Также учитель должен убедить
учащихся в необходимости знания алфавита.
При изучении раздела «фонетика, графика» необходимо познакомить учащихся с наукой орфоэпией и орфоэрическим словарем.
В процессе изучения фонетики, графики учащиеся должны овладеть целым рядом важных практических умений: 1) слышать и различать звуки; 2) различать звуки и буквы; 3) определять место ударения в слове; 4) производить фонетико-графический разбор слова; 5) отчетливо и правильно произносить слова; 6) пользоваться алфавитом, орфографическим и орфоэпическим словарем;
Достижению данных
умений способствует система упражнений,
в основе которых лежат теоретико-практические
методы. При использовании данной системы
соблюдается основной принцип: наблюдение
от звука к букве.
5 методов обучения английскому произношению
Я вспоминаю, как в детстве смотрел фильм о Александре Грэхеме Белле, который инструктировал своих глухих учеников чувствовать колебания их горла, когда они произносили определенный звук. Таким образом, они могли интуитивно узнать, произвели ли они соответствующий звук, подчеркнув правильные слоги и понимая, как голосовые связки производят звуки. Изучение правильного английского произношения является обязательным условием для студентов ESL, поскольку неправильное произношение может затруднить беглость речи и, в некоторых случаях, изменить значение слов.Изучение правильного произношения слов может помочь вашим ученикам стать более расслабленными при разговоре по-английски и звучать менее неловко или неуверенно при выборе слов. Я встречал нескольких студентов, которые, боясь неправильно произнести лучшее слово, выбирали другое слово, которое либо изменяет, либо сбивает с толку смысл их разговора. Однако не стоит отчаиваться, поскольку существует множество методов обучения, которые помогут вашим ученикам ESL улучшить произношение английских слов. Тем, кто обучает китайских студентов онлайн, вам необходимо ознакомиться с наиболее распространенными проблемами произношения, возникающими у изучающих китайский язык ESL. 1 Следующий шаг будет включать использование различных методов, которые помогут учащимся улучшить произношение, таких как минимальные пары, слоговое ударение, звонкие и глухие согласные, фоника и т. Д. Давайте рассмотрим пять методов, которые особенно полезны для обучения английскому произношению. онлайн-учащиеся.
Тем, кто обучает китайских студентов онлайн, вам необходимо ознакомиться с наиболее распространенными проблемами произношения, возникающими у изучающих китайский язык ESL. 1 Следующий шаг будет включать использование различных методов, которые помогут учащимся улучшить произношение, таких как минимальные пары, слоговое ударение, звонкие и глухие согласные, фоника и т. Д. Давайте рассмотрим пять методов, которые особенно полезны для обучения английскому произношению. онлайн-учащиеся.
1: Обучение английскому произношению с помощью звуковых упражнений:
Возможно, самый очевидный и традиционный метод обучения английскому произношению — это фонетика. Фоника фокусируется на изучении индивидуального звучания буквы или набора букв, гласных и согласных звуков при обучении чтению. На одном веб-сайте была разработана полезная диаграмма для понимания процесса фонетики при обучении произношению: «буквы образуют звуки, звуки образуют слова, слова образуют предложения, предложения образуют рассказы, рассказы образуют значение, значение формируют чтение.” 2 Новый рубеж в обучении произношению слов — это« визуальная акустика », которая учит английскому произношению с помощью анимированных текстов, видео и песен. Визуальная акустика физически оживляет звуки и слова, чтобы помочь учащимся ESL усвоить то, что они видят и слышат, различая разные звуки, слова и значения. Согласно одному источнику, «визуальная акустика демонстрирует различные навыки чтения, такие как выделение звуков и слогов, сегментация, рифмовка и замещение, чтобы помочь детям визуализировать отношения между буквами и звуками, звуками и словами, а также словами и слогами.
Фоника фокусируется на изучении индивидуального звучания буквы или набора букв, гласных и согласных звуков при обучении чтению. На одном веб-сайте была разработана полезная диаграмма для понимания процесса фонетики при обучении произношению: «буквы образуют звуки, звуки образуют слова, слова образуют предложения, предложения образуют рассказы, рассказы образуют значение, значение формируют чтение.” 2 Новый рубеж в обучении произношению слов — это« визуальная акустика », которая учит английскому произношению с помощью анимированных текстов, видео и песен. Визуальная акустика физически оживляет звуки и слова, чтобы помочь учащимся ESL усвоить то, что они видят и слышат, различая разные звуки, слова и значения. Согласно одному источнику, «визуальная акустика демонстрирует различные навыки чтения, такие как выделение звуков и слогов, сегментация, рифмовка и замещение, чтобы помочь детям визуализировать отношения между буквами и звуками, звуками и словами, а также словами и слогами. ” 3 Визуальная акустика создает веселую и творческую атмосферу для изучения английского произношения.
” 3 Визуальная акустика создает веселую и творческую атмосферу для изучения английского произношения.
Для старших школьников, однако, более важно сосредоточиться на произношении ключевых слов (содержание или функциональные слова) в предложении, потому что различие между ними имеет решающее значение для понимания смысла предложения. Учите своих старших учеников подчеркивать содержание слов (существительные, глаголы, прилагательные и наречия) в предложении, поскольку функциональные слова (вспомогательные глаголы, предлоги, артикли, союзы и местоимения) не подвергаются ударению.Согласно одному источнику, «знание разницы между содержательными и функциональными словами может помочь вам в понимании и, что наиболее важно, в навыках произношения». 4 Существуют различные упражнения на произношение, которые вы можете выполнять со своими учениками, чтобы различать содержание и функциональные слова в предложении. Я обычно прошу своих старших учеников прочитать предложение или составить собственное предложение с ударением на подходящие слова. Например, у меня была одна группа студентов, которые практиковались, произнося это предложение: Она собирается на лететь на в Англию на следующей неделе .Затем я предлагаю своим ученикам разыграть предложение, притворившись летящим, или спрашиваю их, куда они хотят лететь.
Например, у меня была одна группа студентов, которые практиковались, произнося это предложение: Она собирается на лететь на в Англию на следующей неделе .Затем я предлагаю своим ученикам разыграть предложение, притворившись летящим, или спрашиваю их, куда они хотят лететь.
Обучение младших школьников фонетике должно включать игры с произношением (например, хлопанье в ладоши, когда ученик слышит определенный звук или разыгрывает звук слова или буквы), видео и песни (например, пение слова или извлечение звука из звука). letter), которые включают в себя анимацию, графику и общую физическую реакцию на звуки. На FluentU есть обширный список игр с произношением на английском языке, которые включают в себя движение, повторение, взаимодействие и творчество. 5 Еще одна полезная звуковая игра, в которой учащиеся создают свои собственные слова из отдельных букв или групп букв. Например, я использую функцию аннотирования Zoom, чтобы написать предложение , которое Мэри села на толстую крысу . Я могу даже нарисовать картинку или иметь готовую иллюстрацию, чтобы показать студентам. Затем я могу взять слово «крыса» и спросить студентов, какие еще слова рифмуются со словом «крыса», заканчиваются или начинаются с «в», например, летучая мышь или кошка. Для младших школьников я могу взять одну букву, например «р» от слова «крыса», и спросить их, какие еще слова начинаются, заканчиваются или содержат букву «р», например веревка, дождь или кролик.Другая учебная программа, Jolly Phonics, в значительной степени опирается на TPR, используя действия (руками), которые связаны со звуками 42 букв. Эти действия помогают младшим школьникам запоминать, как воспроизводить подходящий звук, а затем связывать определенные слова со звуками. 6 Существует множество упражнений на произношение и обучающих методик по фонетике, но я выделил более простые методы.
Я могу даже нарисовать картинку или иметь готовую иллюстрацию, чтобы показать студентам. Затем я могу взять слово «крыса» и спросить студентов, какие еще слова рифмуются со словом «крыса», заканчиваются или начинаются с «в», например, летучая мышь или кошка. Для младших школьников я могу взять одну букву, например «р» от слова «крыса», и спросить их, какие еще слова начинаются, заканчиваются или содержат букву «р», например веревка, дождь или кролик.Другая учебная программа, Jolly Phonics, в значительной степени опирается на TPR, используя действия (руками), которые связаны со звуками 42 букв. Эти действия помогают младшим школьникам запоминать, как воспроизводить подходящий звук, а затем связывать определенные слова со звуками. 6 Существует множество упражнений на произношение и обучающих методик по фонетике, но я выделил более простые методы.
2: Используйте разные положения рта для овладения английским произношением:
Озвучивание должно быть активным процессом в обучении вашего ученика правильному произношению слов. Для людей, не являющихся носителями языка, важно усвоить различные гласные фонемы на английском языке, поскольку они могут отсутствовать на основном языке вашего ученика. Один учитель отмечает: «1.) Покажите им, что им нужно делать со своим ртом, чтобы издавать звук, 2.) Придумайте / дайте им упражнения для наращивания мышечной памяти, и 3.) дайте обратную связь на протяжении всего процесса». 7 Старшим ученикам может быть полезно показать иллюстрации или продемонстрировать своим ртом, где правильно расположить язык и губы для создания определенного звука.Один источник предлагает: «Попросите учащихся использовать зеркало, чтобы видеть свой рот, губы и язык, пока они подражают вам». 8 Вы должны убедиться, что ваши ученики знают разницу между звонкими и глухими согласными. Озвученные звуки (включая гласные и дифтонги) должны вызывать вибрацию в горле, тогда как глухие звуки — нет. Вы должны побуждать их дотрагиваться до своего горла, чтобы убедиться, что вибрация возникает только при озвучивании звуков.
Для людей, не являющихся носителями языка, важно усвоить различные гласные фонемы на английском языке, поскольку они могут отсутствовать на основном языке вашего ученика. Один учитель отмечает: «1.) Покажите им, что им нужно делать со своим ртом, чтобы издавать звук, 2.) Придумайте / дайте им упражнения для наращивания мышечной памяти, и 3.) дайте обратную связь на протяжении всего процесса». 7 Старшим ученикам может быть полезно показать иллюстрации или продемонстрировать своим ртом, где правильно расположить язык и губы для создания определенного звука.Один источник предлагает: «Попросите учащихся использовать зеркало, чтобы видеть свой рот, губы и язык, пока они подражают вам». 8 Вы должны убедиться, что ваши ученики знают разницу между звонкими и глухими согласными. Озвученные звуки (включая гласные и дифтонги) должны вызывать вибрацию в горле, тогда как глухие звуки — нет. Вы должны побуждать их дотрагиваться до своего горла, чтобы убедиться, что вибрация возникает только при озвучивании звуков. Потенциальная игра, которая поможет овладеть этим навыком, — предложить учащимся сравнить звонкие и глухие согласные, такие как «z» и’s », повторяя их и затем составляя предложения или слова с буквами.Вы даже можете побудить их разыграть предложение, или вы можете предоставить иллюстрации или реквизиты, моделирующие предложение или звуки: например. Я ходил в зоопарк и видел a зебру и змею . Возможно, вам будет полезно преподать фонематическую диаграмму своим старшим ученикам или тем ученикам, которые могут ее понять. 9 Один веб-сайт советует: «Вместо того, чтобы писать новую лексику на доске, попробуйте использовать фонетические символы (напр.место будет написано / si: t /) для обозначения звуков (а не алфавита для обозначения орфографии) ». 10 Вдыхание — еще одна техника произношения, которая включает в себя дуновение воздуха, сопровождающееся такими звуками, как / p /, / t /, / k / и / ch / (которые чаще всего произносятся с придыханием в начале слова).
Потенциальная игра, которая поможет овладеть этим навыком, — предложить учащимся сравнить звонкие и глухие согласные, такие как «z» и’s », повторяя их и затем составляя предложения или слова с буквами.Вы даже можете побудить их разыграть предложение, или вы можете предоставить иллюстрации или реквизиты, моделирующие предложение или звуки: например. Я ходил в зоопарк и видел a зебру и змею . Возможно, вам будет полезно преподать фонематическую диаграмму своим старшим ученикам или тем ученикам, которые могут ее понять. 9 Один веб-сайт советует: «Вместо того, чтобы писать новую лексику на доске, попробуйте использовать фонетические символы (напр.место будет написано / si: t /) для обозначения звуков (а не алфавита для обозначения орфографии) ». 10 Вдыхание — еще одна техника произношения, которая включает в себя дуновение воздуха, сопровождающееся такими звуками, как / p /, / t /, / k / и / ch / (которые чаще всего произносятся с придыханием в начале слова). Призовите своих учеников подержать салфетку перед ртом, чтобы увидеть, как она двигается, когда дуновение воздуха создается из слова, содержащего выдыхаемый звук. 11 Скороговорки или аллитерации отлично подходят для имитации и запоминания произношения выдыхаемых звуков: напр. Павлин Пити испек перечный пирог, или Два тигра едут на поезд . Отличная книга с увлекательными и красочными аллитерациями и скороговорками — это Animalia Грэма Бэза, книга, которой я был очарован в детстве. Скороговорки помогают людям, не являющимся носителями языка, различать похожие звуки, такие как «ручка» и «булавка» или «сковорода», и помогают им понять, как использовать мышцы во рту для создания определенных звуков и произношения.
Призовите своих учеников подержать салфетку перед ртом, чтобы увидеть, как она двигается, когда дуновение воздуха создается из слова, содержащего выдыхаемый звук. 11 Скороговорки или аллитерации отлично подходят для имитации и запоминания произношения выдыхаемых звуков: напр. Павлин Пити испек перечный пирог, или Два тигра едут на поезд . Отличная книга с увлекательными и красочными аллитерациями и скороговорками — это Animalia Грэма Бэза, книга, которой я был очарован в детстве. Скороговорки помогают людям, не являющимся носителями языка, различать похожие звуки, такие как «ручка» и «булавка» или «сковорода», и помогают им понять, как использовать мышцы во рту для создания определенных звуков и произношения.
3: Методы обучения интонации, слоговому ударению и длине гласной:
Я уже коснулся того, какие слова следует подчеркивать при обсуждении содержания и функциональных слов (например, Леон прожил в Испания за полгода ). Интонация указывает на то, как наши голоса повышаются или понижаются при произнесении определенных фраз или предложений, чтобы вызвать определенную эмоцию или значение. Например, когда вы задаете вопрос «Вы завтракали сегодня утром?» ваш голос должен повышаться, когда вы задаете вопрос «да» или «нет», или когда вы показываете недоверие (Он не ходил сегодня в школу? Правда?) 12 Ваш голос должен падать с регулярными утверждениями или вопросами, которые предполагают более одного- словесный ответ.
Интонация указывает на то, как наши голоса повышаются или понижаются при произнесении определенных фраз или предложений, чтобы вызвать определенную эмоцию или значение. Например, когда вы задаете вопрос «Вы завтракали сегодня утром?» ваш голос должен повышаться, когда вы задаете вопрос «да» или «нет», или когда вы показываете недоверие (Он не ходил сегодня в школу? Правда?) 12 Ваш голос должен падать с регулярными утверждениями или вопросами, которые предполагают более одного- словесный ответ.
Слоговое ударение требует особого внимания. Для усвоения слогового ударения необходимо разработать специальные упражнения и упражнения на произношение. Вы должны начать с обучения своих учеников тому, как считать количество слогов в слове, хлопая их в ладоши или подпевая при подсчете каждого слога. Другой метод — положить руку под подбородок, повторить слово и отметить, сколько раз ваш подбородок касается руки. Это указывает количество слогов в слове.Существует веб-сайт под названием «Сколько слогов», который позволяет вам набирать слово и видеть, сколько в нем слогов, если вы сами боретесь с подсчетом слогов. 13 Для ваших младших учеников, если вы хотите включить TPR, вы можете попросить своих учеников разыгрывать слоги с помощью движений рук, попросить их поднять правильное количество слогов на пальцах или попросить их представить количество слогов. слоги с игрушками, карандашами, наклейками или другими предметами. Вы можете обучать длине гласных с помощью тех же методов, например, хлопая в ладоши, чтобы отсчитать длину гласного, или петь всю длину гласного.Обучение ваших учеников гласным песням — отличный инструмент для обучения произношению гласных с правильной длиной. 14 Вы даже можете попробовать создать свои собственные гласные и слоговые песни, используя картинки, видео, реквизит и танцевальные движения, которые учащиеся могут связать со звуком. Важно помнить, что учите творчески, вовлекайтесь и повторяйте, чтобы ваши ученики тренировали мышцы рта и запоминали звуки.
13 Для ваших младших учеников, если вы хотите включить TPR, вы можете попросить своих учеников разыгрывать слоги с помощью движений рук, попросить их поднять правильное количество слогов на пальцах или попросить их представить количество слогов. слоги с игрушками, карандашами, наклейками или другими предметами. Вы можете обучать длине гласных с помощью тех же методов, например, хлопая в ладоши, чтобы отсчитать длину гласного, или петь всю длину гласного.Обучение ваших учеников гласным песням — отличный инструмент для обучения произношению гласных с правильной длиной. 14 Вы даже можете попробовать создать свои собственные гласные и слоговые песни, используя картинки, видео, реквизит и танцевальные движения, которые учащиеся могут связать со звуком. Важно помнить, что учите творчески, вовлекайтесь и повторяйте, чтобы ваши ученики тренировали мышцы рта и запоминали звуки.
4: Научите учащихся произносить слова с помощью перекрестных ссылок на минимальные пары:
Минимальные пары полезны для различения звуков двух похожих слов, которые имеют разное написание. Один источник отмечает, что «такие слова, как« бит / летучая мышь », которые отличаются только одним звуком… могут использоваться для иллюстрации озвучивания (« завиток / девочка ») или часто путающих звуков (« играй / молись »)». 15 Еще раз, скороговорки или аллитерации — отличные и забавные упражнения для различения похожих звуков. Для ваших китайских студентов будет наиболее полезным найти скороговорки с минимальными парами «w» и «v» или «l» и «r», такими как «Красный грузовик, желтый грузовик» и «из диких виноградных лоз можно сделать прекрасные марочные вина. .Еще одно сложное занятие — это попытаться попросить ваших учеников спеть скороговорку или попытаться повторить скороговорку вместе, не рассинхронизировавшись. Существует множество веб-сайтов с исчерпывающим списком минимальных пар. 16
Один источник отмечает, что «такие слова, как« бит / летучая мышь », которые отличаются только одним звуком… могут использоваться для иллюстрации озвучивания (« завиток / девочка ») или часто путающих звуков (« играй / молись »)». 15 Еще раз, скороговорки или аллитерации — отличные и забавные упражнения для различения похожих звуков. Для ваших китайских студентов будет наиболее полезным найти скороговорки с минимальными парами «w» и «v» или «l» и «r», такими как «Красный грузовик, желтый грузовик» и «из диких виноградных лоз можно сделать прекрасные марочные вина. .Еще одно сложное занятие — это попытаться попросить ваших учеников спеть скороговорку или попытаться повторить скороговорку вместе, не рассинхронизировавшись. Существует множество веб-сайтов с исчерпывающим списком минимальных пар. 16
5: Используйте упражнения по произношению и методы обучения, касающиеся связной речи:
Я сделаю эту тему довольно краткой. Связная речь относится к тому, как слова соединяются в разговорный английский, что часто сбивает с толку носителей языка. Например: «хочу» вместо «хочу» или «собираюсь» вместо «собираюсь». Для человека, не являющегося носителем языка, это может показаться довольно запутанным, потому что нет пауз и слова идут вместе, что сбивает с толку имея в виду. Если вы можете это сделать, вам следует научить своих учеников слышать и распознавать связную речь. Например, связывание — это распространенная форма связной речи, когда конец одного слова сливается с другим, например «кошки или собаки», что превращается в «Catserdogs?» 17 Другие формы связной речи включают вторжение, исключение, ассимиляцию и близнецы. 18 Умение распознавать связанные звуки речи и способность воспроизводить связную речь поможет вашим ученикам говорить более свободно и увереннее в своих навыках говорения на английском языке. Поднимите карточки с различными формами связной речи и попросите учащихся составить предложения, ответить на вопросы или поговорить, используя связную речь.
Например: «хочу» вместо «хочу» или «собираюсь» вместо «собираюсь». Для человека, не являющегося носителем языка, это может показаться довольно запутанным, потому что нет пауз и слова идут вместе, что сбивает с толку имея в виду. Если вы можете это сделать, вам следует научить своих учеников слышать и распознавать связную речь. Например, связывание — это распространенная форма связной речи, когда конец одного слова сливается с другим, например «кошки или собаки», что превращается в «Catserdogs?» 17 Другие формы связной речи включают вторжение, исключение, ассимиляцию и близнецы. 18 Умение распознавать связанные звуки речи и способность воспроизводить связную речь поможет вашим ученикам говорить более свободно и увереннее в своих навыках говорения на английском языке. Поднимите карточки с различными формами связной речи и попросите учащихся составить предложения, ответить на вопросы или поговорить, используя связную речь.
Заключительные мысли для учителей ESL
Английский — сложный язык со множеством правил. Иногда легко запутаться во всех правилах произношения.Самая важная вещь, о которой нужно помнить, — это убедиться, что ваши ученики уверены в своих знаниях английского языка, и обучать произношению, используя забавные, творческие и увлекательные материалы и задания. Я сам борюсь с произношением, особенно с подсчетом слогов и отслеживанием ударных и безударных слов. Есть бесконечные ресурсы; К счастью, это может помочь вам улучшить способность вашего ученика произносить разные слова и создавать звуки. Другие методы усиления произношения — это тренировочные игры, прослушивание и повторение, выделение звуков и словесные игры.Вы будете удивлены, насколько улучшится ваше собственное произношение слов и звуков и понимание их значения, если вы будете обучать своих учеников этим пяти методам.
Иногда легко запутаться во всех правилах произношения.Самая важная вещь, о которой нужно помнить, — это убедиться, что ваши ученики уверены в своих знаниях английского языка, и обучать произношению, используя забавные, творческие и увлекательные материалы и задания. Я сам борюсь с произношением, особенно с подсчетом слогов и отслеживанием ударных и безударных слов. Есть бесконечные ресурсы; К счастью, это может помочь вам улучшить способность вашего ученика произносить разные слова и создавать звуки. Другие методы усиления произношения — это тренировочные игры, прослушивание и повторение, выделение звуков и словесные игры.Вы будете удивлены, насколько улучшится ваше собственное произношение слов и звуков и понимание их значения, если вы будете обучать своих учеников этим пяти методам.
Цитаты по 5 методам обучения английскому произношению
1 «Проблемы с китайским произношением и их решения в английском языке». Говорите по-английски как родной, englishspeaklikenative.com/resources/common-pronuction-problems/chinese-pronuction-problems/
2, 3 «What Is Phonics». Увлеченные фонетикой — научитесь читать, www.hookedonphonics.com/what-is-phonics/
Увлеченные фонетикой — научитесь читать, www.hookedonphonics.com/what-is-phonics/
4 Беар, Кеннет. «Содержание и функциональные слова на английском языке». ThoughtCo, 23 мая 2019 г., www.oughttco.com/content-and-function-words-1211726
5 Ruthwickham. «10 занятий по английскому языку для улучшения произношения». Блог преподавателя английского языка FluentU, 3 мая 2019 г., www.fluentu.com/blog/educator-english/esl-pronuction-activities/
6 «Jolly Phonics Actions». Веселое обучение, www.jollylearning.co.uk/free-parent-teacher-resources/jolly-phonics-actions/
7 Джек.«Три инструмента, которые помогут вам научить английскому произношению (и как делать это асинхронно)». Teaching ESL Online, 6 декабря 2016 г., www.teachingeslonline.com/teach-english-pronuction-online/
8, 11, 15 «Обучение произношению». Написание @ CSU | Студия письма, Университет штата Колорадо, writing.colostate.edu/guides/teaching/esl/pronuction.cfm
9 «Клавиатура с фонематическими диаграммами». Phonemic Chart, www.phonemicchart.com/
Phonemic Chart, www.phonemicchart.com/
10 «10 лучших способов обучения произношению гласных на английском языке». Занятый учитель, 23 ноя.2016, busyteacher.org/8168-top-10-ways-teach-vowel-pronuction-in-english.html
12 Гейхман, Юлия. «Интонация для изучающих английский язык: когда ее менять и как ее выучить». FluentU, 28 апреля 2019 г., www.fluentu.com/blog/english/english-intonation/
13 «Правила слогов: как считать слоги». Сколько слогов, www.howmanysyllables.com/howtocountsyllables.
14 Сад, царапина. «Гласная песня: длинные и короткие гласные звуки | Английские песни | Scratch Garden ». YouTube, 13 мая 2014 г., www.youtube.com/watch?v=4TjcT7Gto3U.
16 Боуэн, Кэролайн. «Списки слов: минимальные пары». Логопедическая языковая терапия, 18 февраля 2012 г., www.speech-language-therapy.com/index.php?option=com_content&view=article&id=134:mp2&catid=9
17, 18 «5 секретов связной речи для быстрого произношения носителей английского языка». Go Natural English, 12 июля 2019 г. , www.gonaturalenglish.com/connected-speech-fast-native-english-pronuction/
, www.gonaturalenglish.com/connected-speech-fast-native-english-pronuction/
Лаура Джонсон, уроженка Кентукки, выпускница Университета Эсбери в Уилморе, штат Кентукки, со степенью бакалавра степень в области истории со знанием французского и латыни.В настоящее время она работает над получением степени магистра по изучению средневековья в Уэльском университете Тринити-Сент-Дэвид, специализируясь на истории и литературе средневековья. Она является членом Национального исторического общества Фи Альфа Тета и Общества средневековья и общества классиков в Лампетере, Уэльс. Она имеет сертификат TESOL и опыт преподавания с ALO7.
Лаура верит в вечную ценность литературы как голоса прошлого, настоящего и будущего. В свободное время она любит читать сказки со всего мира, а также изучает русский язык и востоковедение.Ее хобби — творческое письмо (художественная литература и поэзия), рисование, иллюстрация, фотография и изучение новых языков. Она выступает за высшее образование и верит в сохранение культурного наследия фольклора и истории. Среди ее домашних питомцев — свирепая каролинская собака по имени Ники и идеальная кошка по кличке Сильвестр.
Среди ее домашних питомцев — свирепая каролинская собака по имени Ники и идеальная кошка по кличке Сильвестр.
ТСД 2010
TSD 2010 Paper Abstracts
# 100: Анализ и приложения реального мира
Джон Кэрролл (Университет Сассекса, Брайтон, Великобритания)
Многие недавние исследования в области синтаксического анализа естественного языка принимают в качестве входных данных тщательно обработанный, отредактированный текст, часто из газет.Однако во многих реальных приложениях используется обработка текста, который не написан носителем языка внимательно, создается для конечной аудитории, состоящей только из одной аудитории, и по сути является эфемерным. В этом выступлении я представлю ряд исследовательских и коммерческих приложений такого типа, которые я и соавторы разрабатываем, в которых мы обрабатываем столь же разнообразный текст, как текстовые сообщения на мобильных телефонах, эссе для изучающих неродной язык и медицинские заметки первичной медико-санитарной помощи. Я расскажу о проблемах, которые ставят эти типы текста, и опишу, как мы интегрируем информацию, полученную в результате анализа, в приложения.
Я расскажу о проблемах, которые ставят эти типы текста, и опишу, как мы интегрируем информацию, полученную в результате анализа, в приложения.
# 101: Развитие конструкции декодера ASR
Мирослав Новак (Исследовательский центр IBM Watson, Йорктаун-Хайтс, Нью-Йорк, США)
Декодер ASR — один из основных компонентов системы ASR, который на протяжении многих лет развивался для удовлетворения растущих требований к более крупным доменам, а также доступности более мощного оборудования. Хотя основной алгоритм поиска (то есть поиск Витерби) относительно прост, реализация декодера, который может обрабатывать сотни тысяч слов в активном словаре и сотни миллионов н-граммов в языковой модели в реальном времени, — непростая задача.С появлением встраиваемых платформ некоторые концепции дизайна, использовавшиеся в прошлом для преодоления ограничений доступного оборудования, могут снова стать актуальными, если такие ограничения аналогичны ограничениям рабочих станций первых дней ASR. В этой статье мы опишем различные базовые концепции дизайна, встречающиеся в различных реализациях декодеров, с акцентом на те, которые актуальны сегодня среди довольно большого спектра доступных аппаратных платформ.
В этой статье мы опишем различные базовые концепции дизайна, встречающиеся в различных реализациях декодеров, с акцентом на те, которые актуальны сегодня среди довольно большого спектра доступных аппаратных платформ.
# 102: Знания для каждого
Кристиан Феллбаум (Принстонский университет, Принстон, США)
Усиливающаяся глобализация создает ситуации с самыми разнообразными последствиями для больших сообществ, часто требующими глобальных ответных мер и новаторских решений.Своевременными примерами являются изменения климата и окружающей среды, связанные с быстрым ростом и экономическим развитием. Природные и техногенные непредвиденные катастрофы, такие как разливы нефти, оползни и наводнения, требуют немедленных действий, которые могут в решающей степени полагаться на информацию и опыт, доступные только из источников, далеких от места кризиса. Обмен и передача знаний также важны для устойчивого долгосрочного роста и развития. В обоих случаях важно, чтобы информация и опыт были доступны и широко распространялись, передавались и кодировались для повторного использования в будущем. Глобальный масштаб многих проблем и их решений требует, кроме того, чтобы информация и общение были доступны для сообществ, пересекающих языки и культуры. Наконец, соответствующая система записи, хранения и обмена информацией должна быть доступна как для экспертов, так и для неспециалистов. Целью финансируемого Европейским союзом проекта KYOTO (Knowledge-Yielding Ontologies for Transition-Based Organization, www.kyoto-project.eu) является разработка системы обмена информацией и знаниями, которая связывает документы на нескольких языках с лексическими ресурсами и общим центральная онтология и позволяет проводить глубокий семантический анализ.KYOTO способствует межъязыковому и межкультурному построению и поддержанию сложной системы знаний среди членов сообществ, ориентированных на конкретные предметные области. Представление, хранение и поиск общей терминологии происходит через платформу Wiki. Соответствующие термины закреплены в независимой от языка настраиваемой формальной онтологии, которая объединяет лексиконы семи языков (баскский, китайский, голландский, английский, итальянский, японский и испанский) и гарантирует единообразную интерпретацию терминов на разных языках.
Глобальный масштаб многих проблем и их решений требует, кроме того, чтобы информация и общение были доступны для сообществ, пересекающих языки и культуры. Наконец, соответствующая система записи, хранения и обмена информацией должна быть доступна как для экспертов, так и для неспециалистов. Целью финансируемого Европейским союзом проекта KYOTO (Knowledge-Yielding Ontologies for Transition-Based Organization, www.kyoto-project.eu) является разработка системы обмена информацией и знаниями, которая связывает документы на нескольких языках с лексическими ресурсами и общим центральная онтология и позволяет проводить глубокий семантический анализ.KYOTO способствует межъязыковому и межкультурному построению и поддержанию сложной системы знаний среди членов сообществ, ориентированных на конкретные предметные области. Представление, хранение и поиск общей терминологии происходит через платформу Wiki. Соответствующие термины закреплены в независимой от языка настраиваемой формальной онтологии, которая объединяет лексиконы семи языков (баскский, китайский, голландский, английский, итальянский, японский и испанский) и гарантирует единообразную интерпретацию терминов на разных языках. Семантические представления в онтологии доступны для компьютера и позволяют выполнять глубокий текстовый анализ и логические операции. Целевыми областями KYOTO являются окружающая среда и биоразнообразие, а соответствующие эксперты выступают в качестве «пользователей». После разработки система будет доступна для расширения на любой домен.
Семантические представления в онтологии доступны для компьютера и позволяют выполнять глубокий текстовый анализ и логические операции. Целевыми областями KYOTO являются окружающая среда и биоразнообразие, а соответствующие эксперты выступают в качестве «пользователей». После разработки система будет доступна для расширения на любой домен.
# 283: Композиционная модель для лексического обнаружения эмоций
Марк Ле Таллек, Жанна Вильяно (Université de Tours, Тур, Франция), Жан-Ив Антуан (Université de Bretagne-Sud, Ванн, Франция), Агата Савари (Université de Tours, Тур, Франция), Ариэль Сиссау (Université de Монпелье III, Монпелье, Франция)
Проект ANR EmotiRob направлен на обнаружение эмоций в исходном контексте приложения: создание эмоционального робота-компаньона для ослабленных детей.В этой статье представлена система, которая направлена на характеристику эмоций только с учетом лингвистического содержания высказываний. Он основан на предположении о композиционности: простые лексические слова обладают внутренней эмоциональной ценностью, в то время как глагольные и прилагательные предикаты действуют как функция от эмоциональной ценности своих аргументов. В статье описывается семантическая составляющая системы, алгоритм композиционного вычисления значения эмоции и лексическая эмоциональная норма, используемая этим алгоритмом.Дан количественный и качественный анализ различий между выходными данными системы и экспертными аннотациями, который показывает удовлетворительные результаты с правильным обнаружением эмоциональной валентности в 90% тестовых высказываний.
В статье описывается семантическая составляющая системы, алгоритм композиционного вычисления значения эмоции и лексическая эмоциональная норма, используемая этим алгоритмом.Дан количественный и качественный анализ различий между выходными данными системы и экспертными аннотациями, который показывает удовлетворительные результаты с правильным обнаружением эмоциональной валентности в 90% тестовых высказываний.
# 245: Методология изучения оптимальных диалоговых стратегий
Дэвид Гриоль (Мадридский университет Карлоса III, Мадрид, Испания), Майкл Ф. МакТир (Ольстерский университет, Джорданстаун, Северная Ирландия, Великобритания), Зораида Каллехас, Рамон Лопес-Козар, Ньевес Абалос, Гонсало Эспехо (Университет Гранады, Гранада, Испания)
В этой статье мы представляем методику изучения новых диалоговых стратегий с использованием статистического диспетчера диалогов, который обучается из корпуса диалогов.Методика моделирования диалогов была разработана для сбора данных, необходимых для обучения модели диалога, а затем изучения новых диалоговых стратегий. Также был определен набор мер для оценки автоматически усваиваемой диалоговой стратегии. Мы применили эту технику, чтобы исследовать пространство возможных диалоговых стратегий для диалоговой системы, которая собирает данные мониторинга пациентов, страдающих диабетом.
Также был определен набор мер для оценки автоматически усваиваемой диалоговой стратегии. Мы применили эту технику, чтобы исследовать пространство возможных диалоговых стратегий для диалоговой системы, которая собирает данные мониторинга пациентов, страдающих диабетом.
# 229: Мультимодальный DS для приложения AmI в домашних условиях
Ньевес балос, Гонсало Эспехо, Рамн Лпес-Цар, Зораида Каллехас (Гранадский университет, Гранада, Испания), Давид Гриоль (Мадридский университет Карлоса III, Мадрид, Испания)
В этом документе представлена мультимодальная диалоговая система под названием Mayordomo , цель которой — облегчить взаимодействие с бытовой техникой с помощью речи и графического интерфейса в среде Ambient Intelligence.Мы представляем методы, используемые для реализации системы, описывающей дизайн взаимодействия пользователя с системой, а также дополнительные функции, такие как управление профилями пользователей для ограничения доступа к бытовой технике и настройки грамматик распознавания и сгенерированных ответов.
# 244: Априорное и апостериорное машинное обучение …
Ян Зелинка, Ян Ромпортл (Университет Западной Богемии, Пльзень, Чехия), Людк Мллер (SpeechTech s.r.o., Пльзень, Чешская Республика)
Основная идея априорного машинного обучения заключается в применении метода машинного обучения к самой задаче машинного обучения.Мы называем это «априори», потому что обработанный набор данных не является результатом каких-либо измерений или других наблюдений. Машинное обучение, которое имеет дело с любыми наблюдениями, называется «апостериорным». В статье описывается, как апостериорное машинное обучение может быть изменено с помощью априорного машинного обучения. Предложены априорные и апостериорные алгоритмы машинного обучения для обучения искусственной нейронной сети и апробированы в задаче классификации аудиовизуальных фонем.
# 232: ASR на основе многоуровневых единиц в системе разговорного диалога
Масафуми Нисида (Университет Дошиша, Киото, Япония), Ясуо Хориучи, Синго Куроива (Университет Тиба, Тиба, Япония), Акира Итикава (Университет Васэда, Сайтама, Япония)
Целью нашего исследования является разработка системы голосового диалога для автомобильной техники. Такая многодоменная диалоговая система должна быть способна реагировать на изменение темы, быстро и точно распознавать отдельные слова, а также целые предложения. Мы предлагаем новый метод распознавания, объединяющий предложение, частичные слова и фонемы. Степень уверенности определяется степенью совпадения результатов распознавания на этих трех уровнях. Мы провели эксперименты по распознаванию речи для автомобильной техники. В случае с предложениями точность распознавания составила 96.2% по предлагаемой методике и 92,9% по условной биграмме. Что касается словарных единиц, то точность распознавания предложенным методом составила 86,2%, а распознавания всего слова — 75,1%. Таким образом, мы пришли к выводу, что наш метод может быть эффективно применен в системах голосового диалога для автомобильной техники.
Такая многодоменная диалоговая система должна быть способна реагировать на изменение темы, быстро и точно распознавать отдельные слова, а также целые предложения. Мы предлагаем новый метод распознавания, объединяющий предложение, частичные слова и фонемы. Степень уверенности определяется степенью совпадения результатов распознавания на этих трех уровнях. Мы провели эксперименты по распознаванию речи для автомобильной техники. В случае с предложениями точность распознавания составила 96.2% по предлагаемой методике и 92,9% по условной биграмме. Что касается словарных единиц, то точность распознавания предложенным методом составила 86,2%, а распознавания всего слова — 75,1%. Таким образом, мы пришли к выводу, что наш метод может быть эффективно применен в системах голосового диалога для автомобильной техники.
# 212: Адаптация неконтролируемого динамика на основе транскрипции ASR
Blint Tth, Tibor Fegy, Gza Nmeth (Будапештский технологический и экономический университет, Будапешт, Венгрия)
Статистический параметрический синтез предлагает множество методов для создания новых голосов. Адаптация спикера — одна из самых увлекательных. Однако для этого по-прежнему требуются аудиоданные высокого качества с низким соотношением сигнал / шум и точной маркировкой. В данной статье представлен метод неконтролируемой адаптации на основе автоматического распознавания речи для синтеза речи со скрытой марковской моделью (HMM) и оценка его качества. Методика адаптации автоматически контролирует количество несовпадений телефонов. В оценке участвуют восемь разных голосов HMM, включая адаптацию диктора с учителем и без него.Также исследуются последствия ошибок сегментации и лингвистической маркировки в данных адаптации. Результаты показывают, что неконтролируемая адаптация может способствовать ускорению создания новых голосов HMM с качеством, сравнимым с контролируемой адаптацией.
Адаптация спикера — одна из самых увлекательных. Однако для этого по-прежнему требуются аудиоданные высокого качества с низким соотношением сигнал / шум и точной маркировкой. В данной статье представлен метод неконтролируемой адаптации на основе автоматического распознавания речи для синтеза речи со скрытой марковской моделью (HMM) и оценка его качества. Методика адаптации автоматически контролирует количество несовпадений телефонов. В оценке участвуют восемь разных голосов HMM, включая адаптацию диктора с учителем и без него.Также исследуются последствия ошибок сегментации и лингвистической маркировки в данных адаптации. Результаты показывают, что неконтролируемая адаптация может способствовать ускорению создания новых голосов HMM с качеством, сравнимым с контролируемой адаптацией.
# 216: Адаптация искусственной нейронной сети с прямой связью
Ян Трмаль, Ян Зелинка, Людк Мллер (Университет Западной Богемии, Пльзень, Чехия)
В этой статье мы представляем новый метод адаптации многослойной нейронной сети персептрона (MLP ANN). В настоящее время адаптация ИНС обычно выполняется как постепенное переобучение либо подмножества, либо полного набора параметров ИНС. Однако, поскольку иногда объем данных адаптации довольно мал, у такого подхода есть принципиальный недостаток — во время переобучения параметры сети можно легко перенастроить под новые данные. Конечно, существуют методы, которые могут помочь преодолеть эту проблему (ранняя остановка, перекрестная проверка), однако применение таких методов приводит к более сложной и, возможно, более требовательной к данным процедуре обучения.Предлагаемый метод подходит к проблеме с другой точки зрения. Мы используем тот факт, что во многих случаях у нас есть дополнительные знания о проблеме. Такие дополнительные знания можно использовать для ограничения размерности проблемы адаптации. Мы применили предложенный метод по динамической адаптации распознавателя фонем на основе параметров ловушек и (Temporal Patterns). Мы использовали тот факт, что используемые ловушки , параметры построены с использованием логарифмических выходов банка mel-filter, и благодаря переформулировке задачи адаптации весовой матрицы первого уровня как задачи адаптации выхода банка mel-filter мы смогли значительно ограничить количество свободных переменных.
В настоящее время адаптация ИНС обычно выполняется как постепенное переобучение либо подмножества, либо полного набора параметров ИНС. Однако, поскольку иногда объем данных адаптации довольно мал, у такого подхода есть принципиальный недостаток — во время переобучения параметры сети можно легко перенастроить под новые данные. Конечно, существуют методы, которые могут помочь преодолеть эту проблему (ранняя остановка, перекрестная проверка), однако применение таких методов приводит к более сложной и, возможно, более требовательной к данным процедуре обучения.Предлагаемый метод подходит к проблеме с другой точки зрения. Мы используем тот факт, что во многих случаях у нас есть дополнительные знания о проблеме. Такие дополнительные знания можно использовать для ограничения размерности проблемы адаптации. Мы применили предложенный метод по динамической адаптации распознавателя фонем на основе параметров ловушек и (Temporal Patterns). Мы использовали тот факт, что используемые ловушки , параметры построены с использованием логарифмических выходов банка mel-filter, и благодаря переформулировке задачи адаптации весовой матрицы первого уровня как задачи адаптации выхода банка mel-filter мы смогли значительно ограничить количество свободных переменных. Адаптация с использованием предложенного метода позволила существенно повысить точность распознавания фонем.
Адаптация с использованием предложенного метода позволила существенно повысить точность распознавания фонем.
# 239: Адаптация лексической и языковой моделей для спонтанного чешского языка
Ян Ноуза, Ян Силовски (Либерецкий технический университет, Либерец, Чехия)
Статья посвящена проблеме автоматической транскрипции спонтанных разговоров на чешском языке. Этот тип речи неформальный, с большим количеством разговорных слов. Трудно создать соответствующий лексикон и языковую модель, когда лингвистические ресурсы, представляющие разговорный чешский язык, ограничены несколькими небольшими корпусами, собранными Институтом чешского национального корпуса.Чтобы преодолеть это, мы вводим преобразования между наиболее часто употребляемыми разговорными словами и их аналогами в формальном чешском языке. Это позволяет нам: а) комбинировать небольшие речевые корпуса с гораздо более крупными корпусами более формальных текстов, б) оптимизировать лексику распознавателя и в) решать проблему разреженности данных при вычислении вероятностной языковой модели. Мы применили этот подход при разработке системы транскрипции спонтанных телефонных разговоров. Его последняя версия работает с точностью около 48%, а предложенные преобразования вместе со смешиванием корпусов способствовали улучшению на 9% по сравнению с базовой системой.
Мы применили этот подход при разработке системы транскрипции спонтанных телефонных разговоров. Его последняя версия работает с точностью около 48%, а предложенные преобразования вместе со смешиванием корпусов способствовали улучшению на 9% по сравнению с базовой системой.
# 291: Расширенный поиск в лексиконе валентности
Эдуард Бейек, Вцлава Кеттнеров, Маркта Лопатков (Карлов университет, Прага, Чехия)
В этой статье представлен сложный способ поиска в лексиконах валентностей. Мы обеспечиваем визуализацию лексиконов с таким встроенным поиском, который позволяет пользователям рисовать сложные запросы в графическом режиме. Мы используем PML-TQ, язык запросов, основанный на редакторе деревьев TrEd. В демонстрационных целях мы сосредоточимся на VALLEX и PDT-VALLEX, двух чешских словарях валентностей глаголов.Мы предлагаем общий формат данных лексики, поддерживаемый PML-TQ. Этот формат предлагает удобный просмотр обоих лексиконов, параллельный поиск и их связывание. Предлагаемый метод универсален и может быть использован для других иерархически структурированных лексиконов. %
Предлагаемый метод универсален и может быть использован для других иерархически структурированных лексиконов. %
# 290: НЛП-ориентированный анализ дискурса обмена мгновенными сообщениями
Юстина Валковска (Университет Адама Мицкевича, Познань, Польша)
В этой статье описываются результаты анализа экспериментально собранной небольшой совокупности сообщений, которыми обмениваются через программу обмена мгновенными сообщениями (IM).Данные анализируются с точки зрения автоматического анализа. Особое внимание уделяется двум проблемам, связанным с IM-дискурсом: семантической многозадачности (или переплетению тем) собеседников и нестандартной орфографии, встречающейся в таких диалогах. Содержимое корпуса также сравнивается с другими типами письменных диалогов, то есть SMS-сообщениями и разговорами между пользователями-людьми и чат-ботами. Наконец, предлагаются некоторые решения для облегчения процесса автоматического анализа IM-сообщений.
# 316: Автоматическое определение связей Wordnet .
 ..
..Роман Курц, Мацей Пясецки (Вроцавский технологический университет, Вроцав, Польша), Стэн Шпакович (Оттавский университет, Оттава, Канада)
\ esp — это основанный на шаблонах алгоритм извлечения лексико-семантических отношений, определенный для английского языка. Представляем его адаптацию на польский язык. Мы учитываем не только технические аспекты, такие как доступность средств языковой обработки для польского языка, но и структуры шаблонов, которые используют специфику сильно изменяемого языка.Предлагается новый метод расчета показателя надежности добычи; это приводит к модифицированному алгоритму, который мы назвали \ est. В этой статье мы исследуем влияние дополнительных лексико-семантических данных и информации из общих шаблонов.
# 341: Автоматическое определение и оценка беззубых говорящих …
Тобиас Боклет, Флориан Хёниг, Тино Хадерлейн, Флориан Стельцле, Кристиан Книпфер, Эльмар Нёт (Университет Эрлангена-Нюрнберга, Эрланген, Германия)
Реабилитация зубов с помощью полных съемных протезов — это современный подход к улучшению функциональных характеристик полости рта у пациентов с адентией. Важно убедиться, что эти протезы имеют достаточную посадку. Мы представляем набор данных о 13 беззубых пациентах, которые были зарегистрированы с полными протезами и без них на месте. Эти пациенты были оценены как недостаточная посадка их зубных протезов, поэтому были подготовлены дополнительные (достаточные) протезы и дополнительные записи речи. В этой статье мы показываем, что достаточное количество зубных протезов увеличивает производительность системы ASR примерно на 1%. 27%. Основываясь на этих результатах, мы представляем и обсуждаем три различные системы, которые автоматически определяют, подходят ли протезы беззубого человека.Система с наилучшей производительностью моделирует записи GMM и использует средние векторы этих GMM как функции в SVM. С помощью этой системы нам удалось достичь 80% -ной степени узнаваемости.
Важно убедиться, что эти протезы имеют достаточную посадку. Мы представляем набор данных о 13 беззубых пациентах, которые были зарегистрированы с полными протезами и без них на месте. Эти пациенты были оценены как недостаточная посадка их зубных протезов, поэтому были подготовлены дополнительные (достаточные) протезы и дополнительные записи речи. В этой статье мы показываем, что достаточное количество зубных протезов увеличивает производительность системы ASR примерно на 1%. 27%. Основываясь на этих результатах, мы представляем и обсуждаем три различные системы, которые автоматически определяют, подходят ли протезы беззубого человека.Система с наилучшей производительностью моделирует записи GMM и использует средние векторы этих GMM как функции в SVM. С помощью этой системы нам удалось достичь 80% -ной степени узнаваемости.
# 213: Автоматическое считывание по губам с использованием AAM на высокоскоростной записи
Алин Гаврил Читу, Карин Дриэль, Леон Дж. М. Роткранц (Технологический университет Делфта, Делфт, Нидерланды)
В этой статье представлена наша работа по чтению по губам на голландском языке. Результаты основаны на новом корпусе данных, записанном в нашей группе на частоте 100 Гц.Корпус NDUTAVSC на сегодняшний день является крупнейшим корпусом для чтения по губам на голландском языке. Для параметризации входных данных мы используем Active Appearance Models. На основе результатов AAM мы определяем набор геометрических функций высокого уровня, которые используются для обучения систем распознавания для различных задач распознавания, таких как строки цифр фиксированной длины, строки букв случайной длины, случайные последовательности слов, непрерывная речь с фиксированной темой и непрерывная случайная речь. речь. Мы показываем, что наш подход дает большие улучшения по сравнению с предыдущими результатами.Мы также исследуем влияние высокоскоростной записи на качество распознавания. Мы показываем, что в случае высокой скорости речи использование более высоких скоростей записи обязательно.
Результаты основаны на новом корпусе данных, записанном в нашей группе на частоте 100 Гц.Корпус NDUTAVSC на сегодняшний день является крупнейшим корпусом для чтения по губам на голландском языке. Для параметризации входных данных мы используем Active Appearance Models. На основе результатов AAM мы определяем набор геометрических функций высокого уровня, которые используются для обучения систем распознавания для различных задач распознавания, таких как строки цифр фиксированной длины, строки букв случайной длины, случайные последовательности слов, непрерывная речь с фиксированной темой и непрерывная случайная речь. речь. Мы показываем, что наш подход дает большие улучшения по сравнению с предыдущими результатами.Мы также исследуем влияние высокоскоростной записи на качество распознавания. Мы показываем, что в случае высокой скорости речи использование более высоких скоростей записи обязательно.
# 249: Автоматическая сегментация паразитических звуков в речевых корпусах для синтеза TTS
Jindich Matouek (Университет Западной Богемии, Пльзень, Чешская Республика)
В этой статье представлена автоматическая сегментация паразитных речевых звуков в речевых корпусах для преобразования текста в речь (TTS). Автоматическая сегментация, помимо автоматического обнаружения присутствия таких звуков в речевых телах, является важным шагом в точной локализации паразитических звуков в речевых телах. Основная цель этого исследования — выяснить, достаточно ли точна сегментация этих звуков, чтобы можно было вырезать звуки из синтетической речи или явное моделирование этих звуков во время синтеза. Классификатор на основе HMM использовался для обнаружения паразитных звуков и одновременного определения границ между этими звуками и окружающими телефонами.Результаты показывают, что автоматическая сегментация паразитных звуков сравнима с сегментацией других телефонов, что указывает на возможность исключения или явного использования паразитных звуков.
Автоматическая сегментация, помимо автоматического обнаружения присутствия таких звуков в речевых телах, является важным шагом в точной локализации паразитических звуков в речевых телах. Основная цель этого исследования — выяснить, достаточно ли точна сегментация этих звуков, чтобы можно было вырезать звуки из синтетической речи или явное моделирование этих звуков во время синтеза. Классификатор на основе HMM использовался для обнаружения паразитных звуков и одновременного определения границ между этими звуками и окружающими телефонами.Результаты показывают, что автоматическая сегментация паразитных звуков сравнима с сегментацией других телефонов, что указывает на возможность исключения или явного использования паразитных звуков.
# 222: Автоматический анализ тональности по текстовому сходству
Jan ika, Frantiek Daena (Университет Менделя в Брно, Брно, Чехия)
В статье исследуется проблема, связанная с автоматическим анализом настроений (мнений) в текстовых документах на естественном языке.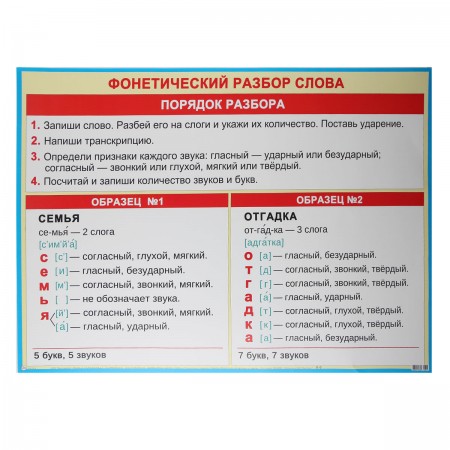 Исходная ситуация работает исходя из предположения, что у пользователя есть много документов, посвященных определенной теме, с разными мнениями о ней. Пользователь хочет выбирать только релевантные документы, отражающие определенное мнение — например, только положительные отзывы на определенную тему. Имея не так много типичных шаблонов желаемого типа документа, пользователю нужен инструмент, который может собирать документы, похожие на шаблоны. Предлагаемая процедура основана на вычислении степени сходства между шаблонами и немаркированными документами, которые затем ранжируются в соответствии с их сходством с шаблонами.Сходство рассчитывается как расстояние между узорами и предметами без меток. Результаты показаны для общедоступных загруженных реальных данных на двух языках: английском и чешском.
Исходная ситуация работает исходя из предположения, что у пользователя есть много документов, посвященных определенной теме, с разными мнениями о ней. Пользователь хочет выбирать только релевантные документы, отражающие определенное мнение — например, только положительные отзывы на определенную тему. Имея не так много типичных шаблонов желаемого типа документа, пользователю нужен инструмент, который может собирать документы, похожие на шаблоны. Предлагаемая процедура основана на вычислении степени сходства между шаблонами и немаркированными документами, которые затем ранжируются в соответствии с их сходством с шаблонами.Сходство рассчитывается как расстояние между узорами и предметами без меток. Результаты показаны для общедоступных загруженных реальных данных на двух языках: английском и чешском.
# 274: Схемы голосования на основе Борды для семантического обозначения ролей
Владимир Роблес, Антонио Молина, Паоло Россо (Политехнический университет Валенсии, Валенсия, Испания)
В этой статье мы изучили возможность применения схем голосования Борда и Нечеткая Борда для объединения систем семантической разметки ролей. Чтобы лучше выбрать правильную семантическую роль среди тех, которые предоставлены разными экспертами, мы ввели две меры: первая вычисляет перекрытие между помеченными предложениями, тогда как вторая добавляет разные уровни оценки в зависимости от проанализированных глаголов.
Чтобы лучше выбрать правильную семантическую роль среди тех, которые предоставлены разными экспертами, мы ввели две меры: первая вычисляет перекрытие между помеченными предложениями, тогда как вторая добавляет разные уровни оценки в зависимости от проанализированных глаголов.
# 276: КОРПРЕС: Корпус русского языка, профессионально читающий речь
Павел Скрелин, Нина Вольская, Даниил Кочаров, Карина Евграфова, Ольга Глотова, Вера Евдокимова (Санкт-Петербургский государственный университет, г.Санкт-Петербург, Россия)
Статья знакомит с CORPRES — COrpus of Russian Professionally Read Speech, разработанным на кафедре фонетики Санкт-Петербургского государственного университета в результате трехлетнего проекта. Корпус включает образцы различных стилей речи, представленные 4 мужчинами и 4 женщинами. Шесть уровней аннотации охватывают всю фонетическую и просодическую информацию о записанных речевых данных, включая метки для высотных знаков, фонетических событий, фонетической, орфографической и просодической транскрипции. Точная фонетическая транскрипция данных является особенно ценным ресурсом как для исследований, так и для целей разработки. Общий размер корпуса составляет 60 часов выступления. Документ содержит информацию о дизайне и принципах аннотации CORPRES, а также общее описание данных. Кроме того, мы обсуждаем возможное использование корпуса в фонетических исследованиях и речевых технологиях, а также некоторые выводы о русской звуковой системе, полученные на основе данных корпуса.
Точная фонетическая транскрипция данных является особенно ценным ресурсом как для исследований, так и для целей разработки. Общий размер корпуса составляет 60 часов выступления. Документ содержит информацию о дизайне и принципах аннотации CORPRES, а также общее описание данных. Кроме того, мы обсуждаем возможное использование корпуса в фонетических исследованиях и речевых технологиях, а также некоторые выводы о русской звуковой системе, полученные на основе данных корпуса.
# 318: Можно ли использовать анализ паттернов корпуса в НЛП?
Сильви Цинкова, Мартин Голуб (Карлов университет, Прага, Чешская Республика), Павел Рихлы (Университет Масарика, Брно, Чешская Республика), Ленка Смейкалова, Яна Индлерова (Карлов университет, Прага, Чешская Республика)
Corpus Pattern Analysis (CPA), придуманный и реализованный Хэнксом в качестве словаря шаблонов английских глаголов (PDEV), по-видимому, является единственной преднамеренной и последовательной реализацией концепции Синклера лексического элемента. В своих теоретических исследованиях Хэнкс выдвигает гипотезу, что репозиторий шаблонов, созданный CPA, также может поддерживать задачу устранения неоднозначности смысла слов. Хотя в PDEV уже собрано более 670 глагольных записей, о систематической оценке этого амбициозного проекта еще не сообщалось. Предполагая, что синклеровская концепция лексического элемента верна, мы начали внимательно изучать PDEV с учетом его возможного применения НЛП. Наши эксперименты, представленные в этой статье, были выполнены на пилотной выборке английских глаголов, чтобы дать первое надежное представление о том, могут ли люди согласиться при назначении шаблонов PDEV глаголам в корпусе.В заключение мы предлагаем процедуры дальнейшего развития PDEV.
В своих теоретических исследованиях Хэнкс выдвигает гипотезу, что репозиторий шаблонов, созданный CPA, также может поддерживать задачу устранения неоднозначности смысла слов. Хотя в PDEV уже собрано более 670 глагольных записей, о систематической оценке этого амбициозного проекта еще не сообщалось. Предполагая, что синклеровская концепция лексического элемента верна, мы начали внимательно изучать PDEV с учетом его возможного применения НЛП. Наши эксперименты, представленные в этой статье, были выполнены на пилотной выборке английских глаголов, чтобы дать первое надежное представление о том, могут ли люди согласиться при назначении шаблонов PDEV глаголам в корпусе.В заключение мы предлагаем процедуры дальнейшего развития PDEV.
# 275: Система обнаружения клиентов и речи для интеллектуального информационного киоска
Андрей Ронжин, Алексей Карпов, Ирина Кипяткова (Российская академия наук, Санкт-Петербург, Россия), Мило Елезны (Университет Западной Богемии, Пльзень, Чехия)
Своевременное привлечение клиента и обнаружение его речевого сообщения в реальных шумных условиях — основные трудности при развертывании речевых и мультимодальных интерфейсов в информационных киосках. Сочетание технологий локализации источника звука, голосовой активности и распознавания лиц позволило определить координаты рта клиента и выделить границы речевого сигнала, появляющегося в диалоговой зоне киоска. Модель говорящей головы, основанная на аудиовизуальном синтезе речи, сразу же приветствует клиента, когда ее лицо фиксируется в зоне видеонаблюдения, чтобы привлечь его к информационной службе перед тем, как покинуть зону взаимодействия. Отслеживание лица клиента также используется для поворота говорящей головы по направлению к клиенту, что значительно улучшает естественность взаимодействия.В развернутом инфокиоске, установленном в зале института, представлена информация о составе и составе лабораторий. Статистика взаимодействия человека с киоском накоплена за последние шесть месяцев 2009 года.
Сочетание технологий локализации источника звука, голосовой активности и распознавания лиц позволило определить координаты рта клиента и выделить границы речевого сигнала, появляющегося в диалоговой зоне киоска. Модель говорящей головы, основанная на аудиовизуальном синтезе речи, сразу же приветствует клиента, когда ее лицо фиксируется в зоне видеонаблюдения, чтобы привлечь его к информационной службе перед тем, как покинуть зону взаимодействия. Отслеживание лица клиента также используется для поворота говорящей головы по направлению к клиенту, что значительно улучшает естественность взаимодействия.В развернутом инфокиоске, установленном в зале института, представлена информация о составе и составе лабораторий. Статистика взаимодействия человека с киоском накоплена за последние шесть месяцев 2009 года.
# 256: Сравнение различных подходов к лемматизации
Якуб Канис, Люси Скорковска (Университет Западной Богемии, Пльзень, Чехия)
В данной статье представлен количественный анализ эффективности двух различных подходов к лемматизации чешских текстовых данных. Первый основан на вручную подготовленном словаре лемм и наборе правил вывода, а второй основан на автоматическом выводе словаря и правил из обучающих данных. Сравнение выполняется путем оценки среднего показателя обобщенной средней точности (mGAP) лемматизированных документов и поисковых запросов в наборе экспериментов по поиску информации (IR). Такой метод подходит для эффективного и достаточно надежного сравнения производительности лемматизации, поскольку правильная лемматизация оказалась решающей для эффективности IR в языках с сильным изменением.Более того, предлагаемое косвенное сравнение лемматизаторов устраняет необходимость в ручных лемматизированных тестовых данных, которые трудно получить, а также сталкивается с проблемой несовместимых наборов лемм в разных системах.
Первый основан на вручную подготовленном словаре лемм и наборе правил вывода, а второй основан на автоматическом выводе словаря и правил из обучающих данных. Сравнение выполняется путем оценки среднего показателя обобщенной средней точности (mGAP) лемматизированных документов и поисковых запросов в наборе экспериментов по поиску информации (IR). Такой метод подходит для эффективного и достаточно надежного сравнения производительности лемматизации, поскольку правильная лемматизация оказалась решающей для эффективности IR в языках с сильным изменением.Более того, предлагаемое косвенное сравнение лемматизаторов устраняет необходимость в ручных лемматизированных тестовых данных, которые трудно получить, а также сталкивается с проблемой несовместимых наборов лемм в разных системах.
# 285: Сравнение 5-граммового корпуса Web 1T с Чешским национальным корпусом
Вацлав Прохазка, Петр Поллак (Чешский технический университет, Прага, Чехия)
В этом документе недавно выпущенный 5-граммовый корпус Czech Web 1T, созданный Google и LDC, анализируется и сравнивается с эталонным n-граммовым корпусом, полученным из Чешского национального корпуса. Исходные 5-граммы из обоих корпусов были подвергнуты постобработке, и были созданы статистические языковые модели триграмм с различными объемами и параметрами словаря. Представлено и обсуждено сравнение различных статистических данных корпуса, таких как количество уникальных и общих слов и n-граммов до и после постобработки, особенно с акцентом на очистку данных Web 1T от недействительных токенов. Инструменты из HTK Toolkit использовались для оценки и точности, частота OOV и недоумение были измерены с использованием транскрипции предложений из чешской базы данных SPEECON.
Исходные 5-граммы из обоих корпусов были подвергнуты постобработке, и были созданы статистические языковые модели триграмм с различными объемами и параметрами словаря. Представлено и обсуждено сравнение различных статистических данных корпуса, таких как количество уникальных и общих слов и n-граммов до и после постобработки, особенно с акцентом на очистку данных Web 1T от недействительных токенов. Инструменты из HTK Toolkit использовались для оценки и точности, частота OOV и недоумение были измерены с использованием транскрипции предложений из чешской базы данных SPEECON.
# 210: Особенности корреляции и особенности линейного преобразования …
Андреас Бешорнер, Дитрих Клаков (Саарландский университет, Саарбрюккен, Германия)
В этой статье мы представляем три идеи для классификации фонем: Во-первых, мы выводим необходимые шаги для интеграции линейных преобразований в вычисление воспроизводящих ядер. Эта концепция не ограничивается классификацией фонем и может применяться к более широкому кругу предметов исследования. Во-вторых, в контексте классификации машины опорных векторов (SVM) корреляционные признаки, основанные на MFCC-векторах, предлагаются в качестве замены общих первой и второй производных, а теория первой части применяется к новым функциям.В-третьих, вводится структура SVM в духе состояний фонем. Относительное улучшение классификации на 40,67% по сравнению с составными элементами MFCC равной размерности побуждает к дальнейшим исследованиям в этом направлении.
# 319: Основанные на покрытии методы для выбора стоп-слов при распределении …
Джо Васак, Фей Сонг (Университет Гвельфов, Гвельф, Канада)
В отличие от обычных игнорируемых слов при поиске информации, распределительные стоп-слова зависят от документа и относятся к словам, которые более или менее равномерно распределены по документу.Было показано, что изолирование распределительных стоп-слов полезно для сегментации текста, поскольку оно помогает улучшить представление сегмента за счет уменьшения перекрывающихся слов между соседними сегментами. В этой статье мы предлагаем три новых меры для выбора распределительных игнорируемых слов и расширяем понятие распределительных стоп-слов с уровня документа до уровня темы. Две из наших новых мер основаны на распределении охвата слова, а другая расширена от существующей меры, называемой разницей распределения, полагаясь на плотность слов аналогично другой мере, называемой значимостью распределения.Наши эксперименты показывают, что эти новые меры не только эффективны для вычислений, но и более точны, чем существующие меры для выбора запрещенных слов при распределении, или сравнимы с ними, и что выбор слов для распределения на уровне темы более точен, чем выбор на уровне документа для сегментации подтем.
# 272: Синтез речи на основе чешского языка HMM
Зденк Ханцлек (Университет Западной Богемии, Пльзень, Чешская Республика)
В этой статье описаны первые эксперименты по статистическому параметрическому синтезу речи на основе HMM для чешского языка.В этом методе синтеза траектории параметров речи генерируются из обученных скрытых марковских моделей. Окончательный речевой сигнал синтезируется из этих речевых параметров. В наших экспериментах спектральные свойства были представлены коэффициентами мелкепстра. Для синтеза формы сигнала использовался соответствующий фильтр MLSA, возбуждаемый импульсами или шумом. Помимо этой базовой настройки, для более сложного представления речи использовалась высококачественная система анализа / синтеза STRAIGHT.Для более надежной оценки параметров модели HMM группируются с использованием алгоритма кластеризации контекста на основе дерева решений. При этом учитываются предложенные для чешского языка фонетические и просодические контекстуальные факторы. Созданные деревья кластеризации также используются для синтеза речевых единиц, невидимых на этапе обучения. Оценка субъективными тестами на прослушивание показала, что речь, созданная комбинацией системы TTS на основе HMM и STRAIGHT, сопоставима по качеству с речью, синтезированной системой TTS выбора единиц, обученной на тех же речевых данных.
# 242: Чешская разговорная система диалога со смешанной инициативой
Jan vec, Lubo mdl (Университет Западной Богемии, Пльзень, Чешская Республика)
В этой статье описывается прототип чешской диалоговой системы с инициативой смешанного диалога и модулем понимания естественного языка. Описанная диалоговая система предназначена для предоставления такой информации о железных дорогах, как прибытия, отправления, цены и типы поездов. Диалог может быть запущен как пользователем системы, так и менеджером диалогов для достижения цели диалога.Кроме того, для взаимодействия с системой пользователь может использовать почти любое произнесение на чешском языке в соответствии с областью диалога. Система получает доступ к базе данных поездов в режиме онлайн через Интернет. Версия, описанная в этом документе, работает как приложение для настольного компьютера и взаимодействует с пользователем с помощью гарнитуры. В статье описаны модули диалоговой системы, включая автоматическое распознавание речи, понимание естественного языка, диспетчер диалогов, генерацию речи и синтез речи.
# 217: Данные для оценки функций конкатенации затрат
Milan Legt, Jindich Matouek (Университет Западной Богемии, Пльзень, Чешская Республика)
В этом документе описывается сбор и анализ данных, которые планируется использовать для оценки и разработки функций стоимости конкатенации для систем TTS на основе выбора единиц.Данные, собранные с помощью тестов прослушивания в соответствии с приведенными ниже рекомендациями, были проанализированы различными способами для выявления и, возможно, исключения «злонамеренных» слушателей, а также для демонстрации их достаточного «богатства» для целевого использования. Это исследование было ограничено пятью чешскими гласными, так как эти звуки характеризуются высокой энергией и богатым спектральным содержанием, что вызывает сложность и широкий диапазон возможных разрывов в точках конкатенации.
# 246: Разработка и реализация распознавателя речи байесовской сети
Паскаль Виггерс, Леон Дж.М. Роткранц, Роб ван де Лисдонк (Технологический университет Делфта, Делфт, Нидерланды)
В этой статье мы описываем систему распознавания речи, реализованную с помощью обобщенных динамических байесовских сетей (BNS). Мы обсуждаем дизайн системы и особенности базового инструментария, который мы создали, что делает возможной эффективную обработку речевых и языковых данных с помощью байесовских сетей. Возможности включают: разреженные представления таблиц вероятностей, быстрый алгоритм вывода с таблицами вероятностей, ленивое вычисление таблиц вероятностей, алгоритмы вычислений с древовидными распределениями, возможность изменять распределения на лету и обобщение структуры модели bn.
# 187: Диагностика для отладки систем распознавания речи
Мило Церак (Словацкая академия наук, Братислава, Словакия)
Современные приложения для распознавания речи становятся очень сложными программными пакетами. Чтобы понять поведение ошибок систем ASR, необходима специальная диагностика — процедура или инструмент. Многие пользователи и разработчики ASR разработали свои собственные правила экспертной диагностики, которые могут быть успешно применены к системе. В литературе также есть несколько явных подходов к определению проблем, связанных с ошибками приложений.Подходы основаны на анализе ошибок и отклонений компонентов ASR с возложением ответственности на проблемный компонент. Недостатком этих методов является то, что они либо требуют значительных затрат времени на приобретение экспертных диагностических знаний, либо предлагают очень грубую локализацию проблемной части ASR. В этой статье предлагается детальная диагностика для отладки ASR путем применения локализации отказов на основе программных спектров, а также локализация непосредственно части реализации ASR.Мы разработали игрушечный эксперимент с диагностической базой данных OLLO, чтобы показать, что наш метод очень прост в использовании и обеспечивает хорошую точность локализации. Поскольку он не может локализовать все ошибки, вопрос, который мы обсуждаем в обсуждении, мы рекомендуем использовать его с другими крупнозернистыми методами локализации для сложной диагностики ASR.
# 227: Система диалога на основе архитектуры EDECÁN
Хавьер Микель Оласо, Мара Инес Торрес (Университет дель Пас Васко, Лейоа, Страна Басков, Испания)
Доказано, что интерактивные и мультимодальные интерфейсы помогают в интерактивных системах человек-машина, таких как диалоговые системы.Анимация лица, в частности движение губ, помогает сделать речь понятной, а диалоги — интуитивно понятными. Рассматриваемая диалоговая система состоит из стенда, позволяющего получать текущие и прошлые новости, опубликованные в Интернете несколькими газетами и сайтами, а также получать информацию о погоде, изначально в городах Испании, хотя ее можно легко распространить на другие города. по всему миру. Конечная цель — предоставить ценную информацию и развлечь людей, стоящих в очереди или просто проходящих мимо.Система нацелена также на людей с ограниченными возможностями благодаря учёту различных мультимодальных входов / выходов. В этой работе описаны различные модули, которые являются частью диалоговой системы. Эти модули были разработаны в соответствии со спецификациями архитектуры EDECÁN.
# 192: Встроенное распознавание речи в среде UPnP (DLNA)
Йозеф Иванецки, Радек Хампл (Европейская медиа-лаборатория, Гейдельберг, Германия)
За последнее десятилетие большие технологические успехи были достигнуты в сфере интернет-услуг, персональных компьютеров, телекоммуникаций, средств массовой информации и развлечений.Многие из этих достижений выиграли от обмена технологиями в этих отраслях. Это влияет на то, как продукты Digital Home Entertainment разрабатываются в соответствии с общей тенденцией «конвергенции медиа». Для этих целей часто используются существующие спецификации Universal Plug and Play (UPnP) или DLNA. Эти спецификации позволяют просто подключить электронные устройства к домашним и локальным сетям для доступа и обмена общими данными, такими как музыка, видео или фотографии. Количество мультимедийных элементов в пользовательской библиотеке может легко превысить 10 000 элементов.Кроме того, эти спецификации используются производителями бытовой электроники для обеспечения взаимодействия различных бытовых электронных устройств. В этой статье мы описываем наши усилия по внедрению распознавания речи для управления электронными устройствами в средах UPnP (DLNA). Мы даем обзор структуры контента и медиаинформации, доступной в сети UPnP (DLNA). Мы также анализируем использование доступной информации для распознавания речи. Основное внимание будет уделено возможности разработки и реализации точки управления UPnP (DLNA) с поддержкой голосовой связи и внедрению одного конкретного решения.
# 233: Распознавание эмоций по речи
Юлия Лефтер, Леон Дж. М. Роткранц, Паскаль Виггерс (Технологический университет Делфта, Делфт, Нидерланды), Дэвид. А. ван Леувен (TNO Human Factors, Делфт, Нидерланды)
Мы исследуем возможности повышения универсальности, переносимости и надежности систем распознавания эмоций путем объединения баз данных и объединения классификаторов. В первом эксперименте мы исследуем производительность системы обнаружения эмоций, протестированной на определенной базе данных, учитывая, что она обучается на речи либо из той же базы данных, либо из другой базы данных, либо из сочетания того и другого.Мы наблюдаем, что обычно происходит падение производительности, когда тестовая база данных не соответствует обучающему материалу, но есть несколько исключений. Кроме того, производительность падает, когда для обучения используется смешанный корпус действующих баз данных, а тестирование выполняется на реальных записях. Во втором эксперименте мы исследуем эффект обучения нескольких детекторов эмоций и объединения их в единую систему обнаружения. Мы наблюдаем падение равной частоты ошибок ({\ sc eer}) с 19,0% в среднем для 4 отдельных детекторов до 4.2% при сплавлении с использованием FoCal.
# 320: Распознавание эмоций: разделение эмоций и информации о говорящем
Рок Гайек, Витомир трюк, Франция Михели (Университет Любляны, Любляна, Словения)
Стандартные функции, используемые при распознавании эмоций, несут, помимо информации, связанной с эмоциями, также подсказки о говорящем. Это ожидаемо, поскольку природа эмоционально окрашенной речи аналогична вариациям речевого сигнала, вызванным разными говорящими.Поэтому мы представляем преобразование, производное от градиентного спуска, для разделения информации об эмоциях и говорящих, содержащихся в акустических характеристиках. Набор функций Interspeech ’09 Emotion Challenge используется в качестве основы для звуковой части. Аналогичная процедура применяется к видеосигналу, где проекция мешающего атрибута (NAP) используется для получения матрицы преобразования, которая содержит информацию об эмоциональном состоянии говорящего. В конечном итоге различные матрицы преобразования NAP сравниваются с использованием канонических корреляций.Подсистемы аудио и видео объединяются на уровне оценки соответствия с использованием различных методов объединения. Представленная система оценивается в общедоступной базе данных eNTERFACE ’05, где наблюдаются значительные улучшения в производительности распознавания по сравнению с текущими базовыми показателями.
# 287: Кодирование структур событий и аргументов в Wordnet
Ракель Амаро, Сара Мендес, Пальмира Маррафа (Лиссабонский университет, Лиссабон, Португалия)
В этой статье мы предлагаем кодификацию структур аргументов и событий в словарных сетях, предоставляя информацию о свойствах выбора, феномене семантического включения и внутренних свойствах событий, в том, что мы называем доступной процедурой.Мы предлагаем явное выражение структуры аргументов, включая аргументы по умолчанию и теневые аргументы, через три новых отношения и новую функцию порядка. Поскольку наборы синтаксических данных в сетях словаря связаны с заданным POS, добавляется информация о свойствах выбора лексических элементов. Мы показываем, что систематическое кодирование информации о структуре событий с помощью пяти новых функций на уровне synset, помимо предоставления основания для описания порядка аргументов, обогащает описательную силу этих ресурсов.При этом мы вносим решающий вклад в создание богатых и структурированных хранилищ словарных сетей лексико-семантической информации, которые позволяют извлекать структуры аргументов и событий из лексических элементов, тем самым повышая их удобство использования в системах НЛП.
# 205: Улучшение распознавания эмоций по речи …
Теодорос Костулас, Тодор Ганчев, Александрос Лазаридис, Никос Факотакис (Университет Патры, Рион-Патры, Греция)
В данной работе мы стремимся к оптимизации производительности системы распознавания эмоций, не зависящей от говорящего, посредством процесса выбора речевых характеристик.В частности, опираясь на набор речевых характеристик, определенных в Interspeech 2009 Emotion Challenge, мы изучили относительную важность отдельных речевых параметров, и на основе их ранжирования было выбрано подмножество речевых параметров, обеспечивающих оптимальную производительность. Используемый здесь распознаватель эмоций и аффекта основан на классификаторе на основе GMM-UBM. Во всех экспериментах мы следовали экспериментальной установке, определенной в Interspeech 2009 Emotion Challenge, с использованием корпуса эмоций FAU Aibo Emotion Corpus спонтанной, эмоционально окрашенной речи.Результаты экспериментов показывают, что правильный выбор параметров речи может привести к лучшей производительности, чем базовая.
# 305: Эстонский язык: некоторые результаты моделирования ритмичности речи и …
Мари-Лийс Кальвик, Меэлис Михкла, Индрек Кийссель, Индрек Хайн (Институт эстонского языка, Таллин, Эстония)
В статье представлены результаты двух исследований с общей целью: улучшить качество синтетической речи. Изучение параметров трех количественных степеней, несущих эстонскую структуру ударения, показывает, что соотношение длительности гласных ударных и безударных слогов является наиболее подходящей отличительной чертой количественного противопоставления.Исследование восприятия различной скорости речи слепыми и зрячими показывает, что слепые, обученные читателям с экрана, предпочитают значительно более высокую скорость речи.
# 278: Оценка средства ранжирования предложений для обобщения текста
Алистер Кеннеди, Стэн Шпакович (Университет Оттавы, Оттава, Канада)
Оценка — одна из самых сложных задач при автоматическом резюмировании текста. Возможно, еще труднее определить, насколько конкретный компонент системы реферирования способствует успеху всей системы.Мы исследуем, как оценить компонент ранжирования предложений, используя корпус, который частично помечен как Summary Content Units. Чтобы продемонстрировать эту технику, мы применим ее к оценке новой системы ранжирования предложений, в которой используются термины. Этот корпус обеспечивает быстрый и почти автоматический метод оценки качества ранжирования предложений.
# 336: Идентификация отношения времени события с использованием машинного обучения и правил
Ануп Кумар Коля (Университет Джадавпура, Калькутта, Индия), Асиф Экбаль (Университет Гейдельберга, Гейдельберг, Германия), Шиваджи Бандьопадхья (Университет Джадавпура, Калькутта, Индия)
Извлечение временной информации — популярное и интересное направление исследований в области обработки естественного языка (NLP).В этой статье мы сообщаем о наших работах по идентификации темпоральных отношений в рамках TimeML. Мы работали над задачей B программы TempEval-2007, которая включает определение взаимосвязи между событиями и временем создания документа. Разработаны две разные системы: одна основана на машинном обучении, а другая — на правилах, созданных вручную. Система машинного обучения основана на условном случайном поле (CRF), которое использует только некоторые функции, доступные в корпусе TimeBank, для определения временных отношений.Вторая система разработана с использованием набора вручную созданных правил. Результаты оценки показывают, что система, основанная на правилах, работает лучше по сравнению с системой на основе машинного обучения со значениями точности, отзыва и F-балла 75,9%, 75,9% и 75,9% соответственно при строгой схеме оценки и 77,1%, 77,1% и 77,1% соответственно по упрощенной схеме оценки. Напротив, система на основе CRF дает значения точности, запоминания и F-балла 74,1%, 73,6% и 73,8% соответственно при строгой схеме оценки и 75.1%, 74,6% и 74,8% соответственно при упрощенной схеме оценки.
# 204: Синтез экспрессивной тарабарщины для аффективной HCI
Сельма Йилмазилдиз, Лукас Латач, Уэсли Маттейсес, Вернер Верхелст (Брюссельский университет Брюсселя, Бельгия)
В этой статье мы представляем наше исследование синтеза выразительной тарабарщины как средства эмоциональной коммуникации между вычислительными устройствами, такими как робот или аватар, и их пользователями. Тарабарщина состоит из вокализации бессмысленных последовательностей звуков речи и иногда используется артистами-исполнителями для выражения намеренных (и часто преувеличенных) эмоций и аффектов, таких как гнев и удивление, без фактического произнесения какого-либо понятного слова.Преимущество тарабарщины в аффективных вычислениях заключается в том, что не нужно произносить понятный текст, и передается только аффект. Это может быть использовано, например, для проверки эффективности аффективных просодических стратегий, но также может применяться в реальных системах.
# 307: Извлечение существительных от человека в испанском языке
София Н. Галисия-Аро (Национальный автономный университет Мксико, Мехико, Мексика), Александр Ф. Гельбух (Национальный политический институт, Мехико, Мексика)
В этой статье мы представляем простой метод извлечения испанских существительных с лингвистическим свойством «человеческой» одушевленности.Мы описываем неконтролируемый метод, основанный на лексических моделях и на списке имен людей, увеличенном из коллекции газетных текстов. Результаты были получены с помощью веб-фильтров, и для их проверки предлагаются методы оценки.
# 259: Заключительные эксперименты с чешским проектом MALACH
Josef Psutka, Jan vec, Josef V. Psutka, Jan Vank, Ale Prak, Lubo mdl (Университет Западной Богемии, Пльзень, Чешская Республика)
В этой статье мы описываем систему для быстрого фонетического / лексического поиска в больших архивах свидетельств о Холокосте в Чехии.Разработанная система является первым шагом к реализации видения проекта MALACH, по крайней мере, для более легкого и быстрого доступа к чешской части архивов. Более тысячи часов спонтанной, акцентированной и очень эмоциональной речи чешских переживших Холокост, сохраненных в Институте Фонда Шоа при Университете Южной Калифорнии в виде видеоинтервью, были автоматически расшифрованы и фонетически / лексически проиндексированы. Особое внимание было уделено обработке разговорных слов, которые очень часто встречаются в чешской спонтанной речи.Окончательный доступ к архивам очень быстрый, что позволяет обнаруживать сегменты интервью, содержащие произнесенные слова, кластеры слов, представленные в заранее определенные промежутки времени, а также слова, не вошедшие в рабочий словарь (слова OOV).
# 203: GD AMs Fusion для парламентских субтитров
Ян Ванк, Йозеф В. Псутка (Университет Западной Богемии, Пльзень, Чешская Республика)
Гендерно-зависимые (мужские / женские) акустические модели более однородны в акустическом отношении и, следовательно, обеспечивают лучшее распознавание, чем отдельные гендерно-независимые модели.В этой статье рассматривается проблема использования этих гендерных акустических моделей в системе LVCSR (распознавание непрерывной речи с большим словарным запасом) в реальном времени, которая более одного года используется чешским телевидением для автоматического субтитрования транслируемых заседаний парламента. на канале Т24. Частая смена динамиков и прямое подключение системы LVCSR к аудиопотоку ТВ требуют автоматического и как можно более быстрого переключения / объединения моделей. В статье представлены различные методы, основанные на использовании выходных вероятностей для быстрого выбора лучшей модели или их комбинаций.Лучший предложенный метод позволил достичь относительного снижения WER более чем на 11% по сравнению с моделью GI.
# 197: Оптимизация градиентного спуска при обучении на основе разнородных данных
Мартин Карафит, Игорь Шоеке, Ян Эрнок (Технологический университет Брно, Брно, Чешская Республика)
В этой статье мы изучаем использование разнородных данных для обучения акустических моделей. В начальных экспериментах наблюдалось значительное падение точности на тестовом наборе в домене, если данные были добавлены без какой-либо регуляризации.Решение предлагается путем получения контроля над обучающими данными путем оптимизации весов различных наборов данных. Окончательные модели показывают хорошие результаты во всех различных тестах, связанных с различными стилями речи. Кроме того, мы использовали этот подход для увеличения производительности по сравнению с основным набором тестов. Мы получили абсолютное улучшение на 0,3% по базовой системе и 0,4% по системе HLDA, хотя размер разнородного набора данных был довольно небольшим.
# 211: Гибридный HMM / BLSTM-RNN для надежного распознавания речи
Ян Сун, Луи тен Бош, Лу Бовес (Университет Радбауд, Неймеген, Нидерланды)
Вопрос, как интегрировать информацию из разных источников при декодировании речи, все еще решен лишь частично (многоуровневая архитектура против интегрированного поиска).Мы исследуем оптимальную интеграцию информации из искусственных нейронных сетей в схему декодирования речи на основе динамической байесовской сети для устойчивого к шуму ASR. HMM, реализованный DBN, взаимодействует с новой рекуррентной нейронной сетью (BLSTM-RNN), которая использует контекстную информацию дальнего действия для прогнозирования фонемы для каждого кадра MFCC. При использовании идентификации наиболее вероятной фонемы в качестве прямого наблюдения оказалось, что такая гибридная система улучшает устойчивость к шуму. В этой статье мы используем полный вывод BLSTM-RNN, который представляется DBN как виртуальное свидетельство.Это позволяет гибридной системе использовать информацию обо всех кандидатах в фонемы, что было невозможно в предыдущих экспериментах. Наш подход повысил точность слов в Aurora 2 Corpus на 8%.
# 237: Улучшение подписи к изображениям с помощью суммирования текста
Лаура Плаза (Мадридский университет Комплутенсе, Мадрид, Испания), Елена Льорет (Университет Аликанте, Аликанте, Испания), Ахмет Акер (Университет Шеффилда, Шеффилд, Великобритания)
В этой статье представлены два различных подхода к автоматическому добавлению подписей к изображениям с геотегами путем обобщения нескольких веб-документов, содержащих информацию, относящуюся к местоположению изображения: основанный на графике и основанный на статистике подход.Основанный на графах метод использует методы сцепления текста для определения информации, относящейся к местоположению. Метод, основанный на статистике, основан на подсчете частоты различных слов или словосочетаний для определения фрагментов информации, относящихся к местоположению. Наши результаты показывают, что итоги, полученные с использованием этих двух подходов, действительно приводят к более высоким оценкам ROUGE, чем модели языка n-грамм, о которых сообщалось в предыдущей работе.
# 251: Интеграция стратегий агрегирования
Пабло Гервс (Мадридский университет Комплутенсе, Мадрид, Испания), Габриэль Аморес (Университет Севильи, Севилья, Испания), Ракель Хервс (Мадридский университет Комплутенсе, Мадрид, Испания), Гильермо Пре (Университет Севильи, Севилья, Испания) , Сусана Баутиста, Вирджиния Франциско (Мадридский университет Комплутенсе, Мадрид, Испания), Пилар Манчн (Университет Севильи, Севилья, Испания)
В этом документе представлена интеграция системы генерации естественного языка в систему диалога в домене для обеспечения плавного, неизбыточного словесного описания состояния окружающей среды.В этой интеграции объединены три важных вклада: углубленное изучение стратегий агрегирования, предпочитаемых пользователями в домашнем домене, полностью работоспособная диалоговая система и система генерации естественного языка, способная реализовывать требуемые стратегии агрегирования. Интеграция подтверждается приемочными испытаниями с участием оценщиков. В этой статье мы показываем, как стратегии агрегации устраняют избыточность, и даем описание, которому оценщики присваивают более высокие баллы, чем предыдущие описания.
# 321: Интеграция модулей обработки речи и текста
Ян Птек (Карлов университет, Прага, Чехия), Павел Ирсинг (Университет Западной Богемии, Пльзень, Чехия), Мирослав Спуста (Карлов университет, Прага, Чехия), Ян Ромпортл, Зденк Луз (Университет Западной Богемии, Пльзень, Чешская Республика), Сильви Цинков (Карлов университет, Прага, Чешская Республика), Хосе Рела но Хиль, Рауль Сантос (Telefónica I + D, Мадрид, Испания)
В этом документе представлена реализация в реальном времени автоматической диалоговой системы под названием «Senior Companion», которая не является строго ориентированной на выполнение задач, но вместо этого предназначена для «беседы» с пожилыми пользователями об их семейных фотографиях.В значительной степени эта задача утратила обычное ограничение диалоговых систем определенной (узкой) областью, и поэтому компоненты обработки речи и естественного языка должны были быть спроектированы так, чтобы охватить широкий диапазон возможных пользовательских и системных высказываний.
# 103: Итеративное декодирование для распознавания речи
Фредерик Елинек (Университет Джона Хопкинса, США)
В последнее время было получено много улучшений в производительности распознавания речи посредством повторной оценки либо решетки, либо сети смешения, сгенерированной первичным распознавателем.В этом выступлении мы покажем прирост производительности, полученный путем применения итеративного декодирования к сети путаницы с использованием более сложной языковой модели, чем базовая для первичного распознавателя. Итеративное декодирование приводит к дополнительному выигрышу, если повторная оценка включает также более сложную акустическую модель и / или если повторная оценка выполняется в режиме минимального байесовского риска, основанном на моделировании отжига. Описание последних алгоритмов выходит за рамки данной лекции.
# 201: Лексико-концептуальные отношения как кодировщики ролей Qualia
Ракель Амаро, Сара Мендес, Пальмира Маррафа (Лиссабонский университет, Лиссабон, Португалия)
В этой статье мы показываем, как словарные сети могут использоваться для построения вычислительной лексики, которая поддерживает генеративные процессы, учитывающие такие явления, как создание смысла в контексте.Мы предлагаем интеграцию квалиа-информации в словарные сети посредством ассоциации лексико-концептуальных отношений с квалиа-ролями, что является простой и недорогой процедурой, поскольку она использует информацию, уже закодированную в словесных сетях. Эта связь между лексико-концептуальными отношениями и аспектами квалиа позволяет нам описывать структуру квалиа лексических единиц согласованным образом, без какой-либо потери информации и с преимуществом идентификации семантических предикатов, которые могут быть значениями ролей квалиа.
# 292: Лингвистическая адаптация в полунатуральных диалогах: сравнение возраста
Мария Нильсенова, Палеса Нолтинг (Тилбургский университет, Тилбург, Нидерланды)
Адаптация говорящего в диалогах, по-видимому, поддерживает не только координацию диалога, но также языковую обработку, обучение и проявление внутри / вне группы. Предположительно, говорящие на разных стадиях своего языкового развития могут использовать разные функции и типы адаптации, но убедительных исследований в этой области пока нет.В настоящем исследовании мы сравниваем структурную, лексическую и просодическую адаптацию в полуестественном диалоге в двух возрастных группах, в диадах взрослый-ребенок и взрослый-взрослый. Результаты наших экспериментов показывают, что дети чаще, чем взрослые, перенимают структурные и лексические формы, используемые их партнером по диалогу. Дети также приспосабливаются к тональности говорящего, с которым они взаимодействуют больше, чем взрослые участники. Независимо от возраста, мы обнаружили более длительные задержки начала после вопроса экспериментатора, имел ли вопрос неканоническую (декларативную) форму по сравнению с вопросом с канонической (вопросительной) формой.Это можно рассматривать как проявление преимущества обработки, обычно связанного с долгосрочными эффектами адаптации как обучения.
# 268: Аннотации корпуса экспрессивной речи на основе аудирования
Мартин Грбер, Йиндич Матуек (Университет Западной Богемии, Пльзень, Чешская Республика)
Эта статья посвящена оценке теста на слушание, который был реализован с целью объективного аннотирования выразительных речевых записей и дальнейшего развития системы экспрессивного синтеза речи в ограниченной области.При выполнении этой задачи необходимо столкнуться с двумя основными проблемами. В первую очередь следует принять во внимание тот факт, что выразительность речи должна быть определена каким-то образом. Вторая проблема заключается в том, что восприятие выразительной речи — вопрос субъективный. Однако для целей синтеза выразительной речи с использованием алгоритмов выбора единиц экспрессивный речевой корпус должен быть объективно и однозначно аннотирован. Сначала была определена классификация выразительности с использованием коммуникативных функций.Предполагается, что они описывают тип выразительности и / или отношение говорящего. Далее, для достижения объективности на значительном уровне был реализован тест на прослушивание с относительно большим количеством слушателей. Слушателям предлагалось пометить предложения в корпусе, используя коммуникативные функции. Целью теста было собрать достаточное количество субъективных аннотаций к выразительным записям, чтобы мы могли создавать «объективные» аннотации. Существует несколько методов получения объективной оценки из множества субъективных, два из них представлены.
# 241: Субтитры онлайн-телевидения заседаний чешского парламента
Ян Трмаль (Университет Западной Богемии, Пльзень, Чешская Республика), Але Прак (SpeechTech, s.r.o, Пльзень, Чешская Республика), Зденк Лузе, Йозеф Псутка (Университет Западной Богемии, Пльзень, Чешская Республика)
В этом документе мы представляем онлайн-систему субтитров, разработанную нашими командами и используемую Чешским телевидением (CTV), государственной вещательной компанией в Чешской Республике. Исследовательский проект направлен на внедрение речевых технологий в среду CTV.Одна из ключевых задач — разработка системы субтитров, поддерживающей субтитры «живого» акустического трека. Это может быть реальный аудиопоток или аудиопоток, создаваемый теневым динамиком. Еще одна ключевая задача — разработать программные инструменты и методы, которые можно использовать для обучения теневых динамиков. На начальных этапах проекта мы пришли к выводу, что трансляция парламентских заседаний Палаты депутатов соответствует необходимым условиям, позволяющим транслировать субтитры без помощи теневого спикера.Мы разработали полностью автоматическую пилотную систему субтитров, сделав трансляцию парламентских заседаний Палаты депутатов доступной для слабослышащих зрителей. Пилотный запуск позволил нам и нашим партнерам на чешском телевидении разработать и оценить всю инфраструктуру субтитров, а также собрать, проанализировать и, возможно, реализовать мнения и предложения целевой аудитории. В данной статье широкой публике представлен наш опыт, накопленный в первые годы работы над проектом.
# 235: Анализ мнений с помощью адаптации предметной области на основе преобразования
Роберт Орманди, Иштван Хегедюс (Сегедский университет, Сегед, Венгрия), Ричард Фаркаш (Венгерская академия наук, Будапешт, Венгрия)
Здесь мы предлагаем новый подход к задаче адаптации предметной области для обработки естественного языка.Наш подход фиксирует отношения между исходным и целевым доменами, применяя механизм преобразования модели, который можно изучить с помощью помеченных данных ограниченного размера, взятых из целевого домена. Экспериментальные результаты по нескольким наборам данных Opinion Mining показывают, что наш подход значительно превосходит базовые и опубликованные системы, когда количество помеченных данных чрезвычайно мало.
# 200: Оптимальная минимизация словаря произношения, модель
Симон Добрик (Университет Любляны, Любляна, Словения), Янез Иберт (Университет Приморска, Копер, Словения), Франция Михели (Университет Любляны, Любляна, Словения)
В этой статье представлены результаты наших усилий по получению минимально возможного конечного представления словаря произношения.Конечные преобразователи широко используются для кодирования произношения слов, и наши эксперименты показали, что обычные алгоритмы уменьшения избыточности, разработанные в этой структуре, дают неоптимальные решения. Мы обнаружили, что постепенное построение и сокращение избыточности ациклических преобразователей с конечным числом состояний создает модели значительно меньшего размера (до 60%), чем обычные, неинкрементные (пакетные) алгоритмы, реализованные в наборе инструментов OpenFST.
# 228: Параллельное обучение нейронных сетей для распознавания речи
Карел Весели, Лука Бургет, Франтиек Грезл (Технологический университет Брно, Брно, Чешская Республика)
Многослойные нейронные сети с прямой связью играют важную роль в распознавании речи.Новый инструмент параллельного обучения TNet был разработан и оптимизирован для многопроцессорных компьютеров. Показатели ускорения обучения сообщаются в задаче классификации состояний фонем.
# 296: Недоумение n-грамм и моделей языка зависимостей
Мартин Попел, Давид Марьек (Карлов университет, Прага, Чехия)
Языковые модели (LM) являются важными компонентами многих приложений, таких как распознавание речи или машинный перевод. LM факторизует вероятность строки слов в произведение P (w_i | h_i), где h_i — контекст (история) слова w_i.Большинство LM используют в качестве контекста предыдущие слова. В статье представлены два альтернативных подхода: постнграммных LM (которые используют следующие слова в качестве контекста) и зависимых LM (которые используют структуру зависимостей предложения и могут использовать, например, управляющее слово в качестве контекста). LM зависимостей могут быть полезны всякий раз, когда доступна топология дерева зависимостей, но его лексические метки неизвестны, например в машинном переводе «дерево в дерево». По сравнению с базовой интерполированной триграммой LM оба подхода достигают значительно меньшей сложности для всех семи протестированных языков (арабского, каталонского, чешского, английского, венгерского, итальянского, турецкого).
# 243: Апостериорные оценки и преобразования для распознавания речи
Jan Zelinka, Lubo mdl, Jan Trmal, Ludk Mller (Университет Западной Богемии, Пльзень, Чешская Республика)
В этой статье описываются апостериорные оценки на основе ИНС и их применение к распознаванию речи. Мы заменили стандартное обратное распространение на квазиньютоновский метод L-BFGS. Мы сосредоточились только на извлечении вектора признаков на апостериорной основе. Нашей целью было уменьшение размерности вектора признаков.Таким образом, мы разработали три апостериорных преобразования в пространство с размерностью 1 или 2. Разработанные преобразования были протестированы на корпусе SpeechDat-East. Мы также применили представленный метод к чешскому аудиовизуальному корпусу. В обоих случаях метод приводит к значительному снижению количества ошибок в словах.
# 327: Предварительное исследование NER на основе HMM для польского языка
Micha Marcinczuk, Maciej Piasecki (Вроцавский технологический университет, Вроцав, Польша)
Исследуется точность алгоритма распознавания именованных сущностей, основанного на скрытой марковской модели.Алгоритм ограничивался распознаванием и классификацией Именованных сущностей, представляющих людей. Алгоритм был протестирован на двух небольших польских доменных корпусах биржевых и полицейских отчетов. Приведено сравнение с алгоритмами базовых линий на основе регистра первой буквы и географического справочника. Алгоритм показал 62% точности и 93% запоминания для области обучающих данных. Введение простых рукописных правил постобработки увеличило точность до 89%. Обсуждаем также проблему переносимости метода.Модель объединенных источников знаний представлена также в выводах как возможный способ преодоления проблемы переносимости.
# 289: Ответ на вопрос для не совсем семантической сети
Милослав Конопк, Ондей Рохльк (Университет Западной Богемии, Пльзень, Чешская Республика)
В данной статье мы представляем прототип реализации вопросно-ответной системы для одного из флективных языков — чешского. Представленная система открытых доменов особенно эффективна при ответах на фактические вопросы о людях, датах, именах и местонахождении.Ответ строится на лету из данных, собранных из Интернета, общедоступных онтологий, знания чешского языка и расширяемой системы шаблонов. Система способна к полуавтоматическому изучению новых шаблонов, а также к статистической и семантической обработке интернет-контента.
# 263: Реальное разрешение анафоры сложно: пример Германии
Манфред Кленнер, Анжела Фарни, Рико Сеннрих (Цюрихский университет, Цюрих, Швейцария)
Мы представляем систему разрешения анафор для немецкого языка, которая использует различные ресурсы для разработки реальной системы в отличие от систем, основанных на идеализированных предположениях, например.грамм. использование только истинных упоминаний или совершенных деревьев синтаксического анализа и совершенной морфологии. Компоненты, которые мы используем для замены таких идеализаций, включают полноценную морфологию, распознавание именованных сущностей на основе Википедии, синтаксический анализатор зависимостей на основе правил и немецкую сеть слов. Мы показываем, что в этих условиях разрешающая способность кореференции (по крайней мере, для немецкого языка) еще далека от совершенства.
# 238: Восстановление редких слов в лекционной речи
Стефан Комбринк, Мирко Ханнеманн, Лук Бургет, Хайнек Хеманск (Технологический университет Брно, Брно, Чешская Республика)
Словарь, используемый в речи, обычно состоит из двух типов слов: ограниченный набор общих слов, используемых в нескольких документах, и практически неограниченный набор редких слов, каждое из которых может встречаться несколько раз только в определенных документах.Однако в большинстве документов эти редкие слова вообще не встречаются. Первый тип слов обычно включается в языковую модель автоматического распознавателя речи (ASR) и поэтому широко называется внутренним словарем (IV). Слова второго типа отсутствуют в языковой модели и поэтому называются вне словарного запаса (OOV). Однако эти слова обычно несут важную информацию. Мы используем гибридный распознаватель слова / подслова, чтобы обнаруживать слова OOV, встречающиеся в английских разговорах, и описывать их как последовательности подслов.Мы обнаружили около одной трети всех слов OOV и смогли восстановить правильное написание для 26,2% всех обнаружений с помощью преобразования фонемы в графему (P2G), обученного в словаре распознавания. Путем исключения обнаружений, соответствующих восстановленным словам IV, мы смогли существенно повысить точность обнаружения OOV.
# 196: Надежные статистические оценки адаптации при распознавании речи
Zbynk Zajíc, Luk Machlica, Ludk Mller (Университет Западной Богемии, Пльзень, Чешская Республика)
В этом документе рассматриваются надежные оценки статистических данных, используемых для адаптации.Статистика накапливается перед процессом адаптации из доступных данных адаптации. Обычно предполагается лишь небольшой объем данных адаптации. Эти данные часто искажены шумом, каналом, они не содержат только чистую речь. Кроме того, при обучении скрытых марковских моделей (HMM) делается несколько предположений, которые не могли быть выполнены на практике, и т. Д. Поэтому мы описали несколько методов, направленных на то, чтобы сделать адаптацию как можно более надежной, чтобы повысить точность модели. адаптированная система.Один из методов заключается в инициализации статистики адаптации, чтобы предотвратить некорректно обусловленные матрицы преобразования. Другая проблема возникает, когда акустическая характеристика назначается неправильному состоянию HMM, даже если доступна эталонная транскрипция. Такие ситуации могут возникать из-за процесса принудительного выравнивания, используемого для выравнивания кадров по состояниям. Таким образом, очень удобно накапливать статистику данных, используя только надежные кадры (в смысле вероятности данных). Мы сосредоточены на линейных преобразованиях максимального правдоподобия, и эксперименты проводились с использованием функции линейной регрессии максимального правдоподобия (fMLLR).Эксперименты направлены на описание поведения системы, расширенной предложенными методами.
# 264: Идентификация семантических дубликатов с помощью синтаксического анализа и машинного обучения
Свен Хартрампф, Тим фор дер Брюк (FernUniversität в Хагене, Хаген, Германия), Кристиан Эйххорн (Технический университет Дортмунда, Дортмунд, Германия)
Выявление повторяющихся текстов важно во многих областях, таких как обнаружение плагиата, поиск информации, обобщение текста и ответы на вопросы.Текущие подходы в основном ориентированы на поверхность (или используют только поверхностные синтаксические представления) и рассматривают каждый текст только как список лексем. Однако в этой работе мы описываем глубокий, семантически ориентированный метод, основанный на семантических сетях, которые выводятся синтаксически-семантическим анализатором. Семантически идентичные или похожие семантические сети для каждого предложения данного базового текста эффективно извлекаются с помощью специального индекса. Для обнаружения многих видов перефразирования семантические сети текста-кандидата варьируются путем применения выводов: лексико-семантических отношений, аксиом отношения и постулатов значения.Обсуждаются важные явления, возникающие в сложных дубликатах. Глубокий подход основан на базовых знаниях, получение которых из таких корпораций, как Википедия, объясняется кратко. Распознаватель глубоких дубликатов комбинируется с двумя распознавателями неглубоких дубликатов, чтобы гарантировать высокую отзывчивость текстов, которые не поддаются полному синтаксическому анализу. Оценка показывает, что комбинированный подход сохраняет отзыв и значительно повышает точность по сравнению с традиционными неглубокими методами.
# 298: Образцы семантических ролей и классы глаголов в лексиконе валентности глаголов
Зузана Невилова (Университет Масарика, Брно, Чехия)
Для чешского языка существует лексика большого валентного фрейма: VerbaLex.Он содержит глаголы, слоты, связанные с глаголами, и информацию о семантических ролях, которые играет каждый слот. В этой статье обсуждаются наблюдения, сделанные на фреймах VerbaLex, связанных с классификацией глаголов. Это показывает, что для определенных классов глаголов (например, глаголов, описывающих погоду) типичны некоторые семантические ролевые модели. Он также пытается выявить эти закономерности в не столь очевидных случаях. В настоящее время фреймы глаголов в VerbaLex не связаны между собой. В этой статье описывается, как мы можем установить такие связи. Мы ожидаем, что глагольные фреймы одного и того же класса или с одинаковыми семантическими ролевыми образцами семантически близки и, следовательно, предполагают аналогичные типы взаимосвязей.Мы ожидаем создать относительно небольшой набор правил вывода, влияющих на большое количество глагольных фреймов.
# 282: Специальный синтез речи для веб-сайтов социальных сетей
Csaba Zaink, Tams Gbor Csap, Gza Nmeth (Будапештский технологический и экономический университет, Будапешт, Венгрия)
В этой статье дается обзор концепций дизайна и реализации венгерской системы чтения микроблогов. Речевой синтез такого особенного текста требует особых компонентов.Во-первых, был применен эффективный алгоритм восстановления диакритических знаков. Точность прежнего метода на основе словаря была улучшена за счет машинного обучения для правильной обработки неоднозначных случаев. Во-вторых, был применен неограниченный синтезатор текста в речь с расширениями для эмоциональных и спонтанных стилей. Тексты чатов или блогов часто содержат «смайлики», которые отмечают эмоциональное состояние пользователя. Поэтому метод синтеза выразительной речи был адаптирован к корпусному синтезатору. В тесте на слушание были сформированы и оценены четыре эмоции: нейтральные, счастливые, злые и грустные.Результаты экспериментов показали, что с помощью этого алгоритма можно генерировать радостные и грустные эмоции с максимальной точностью для женского голоса.
# 215: Структура прерывного диалога
Тийт Хенносте, Ольга Герассименко, Рийна Кастерпалу, Маре Койт, Кирси Лаанесоо, Анни Оя, Андриэла Ряэбис, Криста Страндсон (Тартуский университет, Тарту, Эстония)
Мы изучаем, как устанавливается структура диалога с помощью авторской статьи в Интернете и ее анонимных комментариев.Мы используем методологию анализа разговоров с упором на анализ категоризации членства. Исследование показывает, что основная структура диалога формируется множеством параллельных микродиалогов. Помимо линейной структуры микродиалога, существует структурный слой, который образован комплексными наборами категорий, созданными участниками с использованием категоризации членства агентов статьи, а также самих комментаторов. Мы исследуем стратегии и языковые средства, используемые участниками для создания взаимоотношений в сложной многослойной структуре.
# 219: Существительные, скрывающие события: первоначальное обнаружение
Amaria Adila Bouabdallah, Tassadit Amghar, Бернар Левра (Университет Анжера, Анже, Франция)
Многие исследования были посвящены временному анализу текстов, а точнее маркировке временных сущностей и отношений, встречающихся в текстах. Среди них различные аватары событий в их множестве происходящих форм были рассмотрены в многочисленных работах. Мы описываем здесь метод обнаружения именных фраз, обозначающих события.Наш подход основан на выполнении простого лингвистического теста, предложенного лингвистами для этой задачи. Наш метод применяется к двум разным корпусам; первая состоит из газетных статей, а вторая, гораздо более крупная, опирается на интерфейс для автоматического запроса поисковой системы Yahoo. Первичные результаты обнадеживают, и увеличение размера учебного корпуса должно позволить провести реальную статистическую проверку результатов.
# 254: К устранению неоднозначности словесных набросков
Vít Baisa (Университет Масарика, Брно, Чехия)
Набросок слова является источником ценной информации как для лингвистов, так и для лексикографов, но он состоит из лемм, неоднозначность которых не устраняется.В этой статье мы описываем метод, который может частично устранить неоднозначность этих лемм и повысить качество информации, содержащейся в набросках слов. Для устранения неоднозначности мы используем пересечения набросков английских и чешских слов с использованием англо-чешского словаря.
# 230: На пути к банку составляющих деревьев синтаксического анализа для польского языка
Марек Свидзинский (Варшавский университет, Варшава, Польша), Марцин Волински (Польская академия наук, Варшава, Польша)
Мы представляем проект, направленный на построение банка составных деревьев синтаксического анализа для 20 000 предложений на польском языке, взятых из сбалансированного аннотированного вручную подкорпуса Национального корпуса польского языка (NKJP).Банк деревьев должен быть получен путем автоматического анализа и устранения неоднозначности полученных деревьев вручную. Грамматика, применяемая в проекте, представляет собой новую версию формального определения польского языка, данного Свидзинским. Каждое предложение устраняется независимо двумя лингвистами и, при необходимости, рассматривается руководителем. Обратная связь от этого процесса используется для итеративного улучшения грамматики. В статье мы описываем лингвистические, а также технические решения, принятые в проекте. Мы обсуждаем общую форму синтаксических деревьев, включая объем закодированной грамматической информации.Мы также углубляемся в проблему синтаксического разрешения неоднозначности как на проблему для нашей работы.
# 208: На пути к анализатору зависимостей N-версии
Мигель Бальестерос, Джесс Эррера, Вирджиния Франциско, Пабло Гервс (Мадридский университет Комплутенсе, Мадрид, Испания)
Maltparser — это современная система анализа зависимостей на основе машинного обучения, которая демонстрирует высокую точность. Однако 90% для оценки вложений с пометкой (LAS), по-видимому, является фактическим пределом для таких синтаксических анализаторов.Поскольку, как правило, такие системы не могут быть изменены, были разработаны предыдущие работы для изучения того, что можно сделать с помощью обучающих корпусов, чтобы повысить точность синтаксического анализа. Методы высокого уровня, такие как контроль длины предложений или размера корпуса, кажутся бесполезными для этих целей. Но низкоуровневые методы, основанные на глубоком изучении ошибок, производимых парсером на уровне слов, кажутся многообещающими. Перспективные низкоуровневые исследования предложили разработку синтаксических анализаторов n-версии. Каждая из этих n версий должна иметь возможность заниматься определенным типом синтаксического анализа зависимостей на уровне слов, и их объединенное действие должно обеспечивать более точный синтаксический анализ.В этой статье мы представляем обширное исследование полезности и ожидаемых ограничений для n-версии синтаксического анализатора для повышения точности синтаксического анализа. Эта работа была разработана специально для испанского языка с использованием Maltparser.
# 207: Использование знаний о недоразумении. для повышения устойчивости паспортов безопасности
Рамн Лпез-Цар, Зораида Кальехас, Ньевес балос, Гонсало Эспехо (Университет Гранады, Гранада, Испания), Давид Гриоль (Мадридский университет Карлоса III, Мадрид, Испания)
В этой статье предлагается новый метод повышения производительности речевых диалоговых систем, использующий метод, который автоматически корректирует семантические фреймы, которые неправильно генерируются семантическим анализатором этих систем.Эксперименты проводились с использованием двух речевых диалоговых систем, ранее разработанных в нашей лаборатории: Saplen и Viajero, в которых используются языковые модели, зависящие от подсказок, и независимые от подсказок для распознавания речи. Результаты, полученные из 10 000 смоделированных диалогов, показывают, что этот метод улучшает производительность двух систем для обоих типов языкового моделирования, особенно для языковой модели, не зависящей от подсказок. Используя этот тип модели, система Саплена увеличила понимание предложения на 19.54%, выполнение задачи на 26,25%, точность слов на 7,53% и неявное восстановление ошибок распознавания речи на 20,30%, тогда как для системы Viajero эти показатели увеличились на 14,93%, 18,06%, 6,98% и 15,63% соответственно.
# 315: Использование слогов в качестве акустических единиц для спонтанного распознавания речи
Ян Хейтманек (Университет Западной Богемии, Пльзень, Чехия)
В этой работе мы имеем дело с расширенным контекстно-зависимым автоматическим распознаванием речи (ASR) чешского спонтанного разговора с использованием скрытых марковских моделей (HMM).Контекстно-зависимые устройства (например, трифоны, дифоны) в системах ASR обеспечивают значительное улучшение по сравнению с простыми неконтекстно-зависимыми устройствами. Однако для распознавания спонтанной речи нам пришлось преодолеть очень сложные задачи. Во-первых, количество слогов по сравнению с размером корпуса спонтанной речи очень затрудняет использование контекстно-зависимых единиц. В основной части этой статьи показаны проблемы и процедуры для эффективного построения и использования ASR на основе слогов с помощью LASER (система ASR, разработанная на кафедре компьютерных наук и инженерии факультета прикладных наук).Процедуры можно использовать с виртуальным любым современным ASR.
# 267: Использование TectoMT в качестве инструмента предварительной обработки для SMT на основе фраз
Даниэль Земан (Карлов университет, Прага, Чехия)
Мы представляем систематическое сравнение методов предварительной обработки для двух языковых пар: английский-чешский и английский-хинди. Два целевых языка, хотя оба принадлежат к индоевропейской языковой семье, демонстрируют значительные различия в морфологии, синтаксисе и порядке слов.Мы описываем, как TectoMT, успешный фреймворк для анализа и генерации языка, может использоваться в качестве препроцессора для системы машинного перевода на основе фраз. Мы сравниваем две языковые пары и применяемые к ним оптимальные наборы преобразований исходного языка. Следующие преобразования являются примерами возможных шагов предварительной обработки: лемматизация; ретокенизация, расщепление соединений; удаление / добавление слов, не имеющих аналогов на другом языке; изменение порядка слов в соответствии с целевым порядком слов; маркировка синтаксических функций.TectoMT, а также все другие инструменты и наборы данных, которые мы используем, находятся в свободном доступе в Интернете.
# 180: ABBYY Lingvo Pro — глобальная сеть для создания совместных многоязычных инструментов и ресурсов
Илугдина Полина, Пахомов Евгений
ABBYY — ведущий международный разработчик лингвистического программного обеспечения. На протяжении 20 лет с момента основания компания занимается разработкой программного обеспечения и исследованиями в области лингвистики, семантики, синтаксиса и лексикографии, предлагая профессиональные решения и услуги в отрасли.Этот многолетний опыт позволил ABBYY создать ABBYY Lingvo Pro — эффективное и уникальное веб-решение для переводчиков, лингвистов, лексикографов и всех остальных, кто работает в языковой индустрии. Мы хотели бы анонсировать это решение на TSD 2010, продемонстрировать его основные функции и обсудить наиболее важные вопросы с профессиональным сообществом, которое будет основными пользователями портала. Основная цель ABBYY Lingvo Pro — стать глобальной многоязычной сетью, основанной на сообществе, которая будет аккумулировать совместные языковые ресурсы и инструменты в одном веб-пространстве.Продукт сочетает в себе глобальный онлайн-источник словарей, глоссариев и параллельных корпусов, языковые инструменты и веб-пространство для профессионального сообщества, где его участники могут найти друг друга, обсудить профессиональные вопросы, поделиться полезными материалами и опытом. ABBYY Lingvo Pro будет запущен весной 2010 года для бета-тестирования. На данный момент ABBYY Lingvo Pro насчитывает около 2,5 млн словарных статей и 1,5 млн параллельных предложений для направлений перевода русский <-> английский, русский <-> немецкий и русский <-> французский.Список языков будет расширен в будущем. ABBYY Lingvo Pro также включает в себя различные профессиональные инструменты, например, ABBYY Aligner Online, сервис, позволяющий выравнивать параллельные тексты. Следующим шагом, который запланирован на конец 2010 года, станет внедрение профессионального инструмента для работы лексикографов (ABBYY Lingvo Content — решение для создания словарей), перевода (CAT, контроль качества и др.) И инструментов управления переводами.
# 345: Онлайн-игра вместо редактора аннотаций
Барбора Гладка, Иржи Мировский, Павел Шлезингер
Мы представляем игру PlayCoref, онлайновую интернет-игру, цель которой — обогатить текстовые данные аннотациями кореференции.Мы предоставляем подробное описание игры, особенно ее хода и реализации, а также упоминаем обработку данных и функцию подсчета очков.
# 346: Визуализация шаблонов семантических ролей VerbaLex
Зузана Неверилова
VerbaLex в настоящее время является крупнейшим чешским лексиконом валентности глаголов. Он состоит из глагольных фреймов, и каждый фрейм состоит из слотов. Каждый слот представляет собой семантическую роль (например, агент, пациент или местоположение) и ссылку на чешский WordNet (например,грамм. агент должен быть человеком). Слоты для определенных фреймов повторяются и создают шаблоны семантических ролей. В некоторых случаях глаголы с одним и тем же шаблоном (например, AGent-LOCation-LOCation) семантически связаны (например, глаголы движения). Визуальное представление таких шаблонов может помочь пользователям сориентироваться в лексике. Визуализация позволяет отображать большой объем данных. Пользователи могут собирать детали и одновременно делать обзор. С одной стороны, визуализацию можно использовать для наблюдения закономерностей в VerbaLex.С другой стороны, визуальное представление может служить обратной связью для авторов и администраторов VerbaLex, поскольку пользователям легче обнаруживать потенциальные ошибки.
# 401: Система DEB — Платформа для хранения цифровых знаний
Алесь Горак, Адам Рамбоусек
ПлатформаDEB, разработанная NLP Center, предоставляет библиотеки и инструменты для легкой разработки редакторов словарей и браузеров. Платформа представляет собой модульную и расширяемую систему клиент-сервер, при этом большая часть функций обрабатывается сервером.Все данные хранятся в собственной базе данных XML. Сервер также предоставляет API для взаимодействия с внешними приложениями. Десять приложений уже были основаны на платформе DEB, например редактор Wordnet и браузер DEBVisDic (также используемый в проекте KYOTO), браузер общего словаря DEBDict, редактор художественного глоссария TeDi или редактор для проекта Family Names в Великобритании.
# 402: Расширенные возможности системы корпуса Sketch Engine
Войтех Ковар
В демонстрации мы представляем ведущий инструмент управления корпусом — Sketch Engine.В системе реализован широкий спектр функций, включая построение корпуса, просмотр согласований, вычисление частот, извлечение словосочетаний, наброски слов, статистический тезаурус и многие другие. Во-первых, мы даем краткий обзор функциональности и языка запросов. Затем мы переходим к недавно добавленным расширенным функциям, а именно новым конструкциям языка запросов, новому дизайну, новым функциям построения корпуса и лексикографии Tickbox — инструменту для создания словарных статей несколькими щелчками мыши.
# 403: Анализ паттернов корпуса: новый взгляд на слова и значения
Патрик Хэнкс
Это демонстрация долгосрочного исследовательского проекта Corpus Pattern Analysis (CPA), цели которого включают: а) пролить свет на то, как люди используют слова для придания значений; б) предоставление доказательств в поддержку новой теории языкового поведения, называемой Теорией норм и эксплуатации — TNE; и c) создание ресурса, который будет полезен для таких задач, как улучшение владения учащимся (или компьютером) идиоматической фразеологией и соответствующими значениями.
Традиционно считалось, что анализ смысла происходит пословно, как ребенок строит игрушечный домик из кубиков Lego. TNE предлагает вместо этого, чтобы слова не имели значения — они имели только «потенциал значения». В TNE значения связаны с образцами — прототипными фразеологическими образцами употребления слов. Слова очень неоднозначны, но большинство шаблонов недвусмысленны.
CPA — это метод определения значимых шаблонов употребления слов, опираясь на теорию прототипов, валентности и коллокационный анализ.
# 404: Языковая служба Интернета
Карел Пала, Павел Смерк
Internet Language Service (ILS) — это языковой инструмент, основанный на технологиях веб-интерфейсов, в частности, в системе DEB. Он позволяет пользователям искать информацию по различным лингвистическим вопросам и предоставляет экспертную лингвистическую информацию, связанную с правилами орфографии, орфографии, значениями слов, использованием, грамматикой и стилем. Теперь система работает с чешским языком, но ее можно использовать и для других языков с богатой морфологией.Размер лексической базы данных составляет более 60 000 наименований (статей). Пояснительная часть включает более 150 пунктов (разделов), в которых разъясняются отдельные орфографические темы. ILS отвечает на вопросы пользователей со средним числом ок. 10-20 000 посещений в день в зависимости от дня недели. ILS работает более двух лет для пользователей по всей Чешской Республике (в Чешской Республике проживает около 10 миллионов жителей). Доступ к языковой интернет-службе бесплатный.Доступ к ILS можно получить по веб-адресу http://prirucka.ujc.cas.cz/. ILS был подготовлен в сотрудничестве с коллегами из Института чешского языка Чешской академии наук, которые подготовили и проверили лингвистические данные.
# 405: WordnetLoom: среда разработки Visual Wordnet на основе графиков
Maciej Piasecki, Micha Marcinzuk, Adam Musia, Radosaw Ramocki, Marek Maziarz
В статье представлена WordnetLoom — новая версия приложения, поддерживающего разработку польской сети wordnet под названием plWordNet.Основной пользовательский интерфейс WordnetLoom представляет собой графическое активное представление структуры Wordnet в виде графиков. Лингвист может напрямую работать со структурой синсетов, связанных ссылками отношения. Новая версия сравнивается с предыдущей, чтобы показать направления развития и проиллюстрировать внесенные различия. Также представлена новая версия WordnetWeaver — инструмента, поддерживающего полуавтоматическое расширение Wordnet. Новая версия основана на том же пользовательском интерфейсе, что и WordnetLoom, использует все типы связей wordnet и тесно интегрирована с остальной частью редактора wordnet.Обсуждается роль системы в процессе разработки Wordnet, а также опыт ее применения. Также представлен набор инструментов на основе WWW, поддерживающих координацию командной работы и верификацию.
# 406: Synt — надежный веб-синтаксический анализатор для чешского языка
Милош Якубичек, Алесь Горак
Мы представим несколько возможностей анализатора диаграмм на основе повестки дня для чешского языка с опорой PCFG — синтаксического анализатора — в веб-среде, которая позволяет пользователю выбирать расширенные параметры синтаксического анализа и отображать результаты синтаксического анализа несколькими способами.
# 407: Браузер лекций в Интернете
Йозеф Жижка
Superlectures.com — это инновационный портал видео лекций, который позволяет пользователям выполнять поиск в речи. Это значительно ускоряет доступ к видеозаписям лекций. Цель этого портала — сделать видео доступным для поиска, как любой текстовый документ. Система обработки речи автоматически распознает и индексирует разговорные слова на чешском и английском языках.
Как улучшить свое английское произношение, чтобы говорить как носитель языка
«Что?»
«Можете ли вы сказать это еще раз?»
Сколько раз вы слышите это, когда говорите? Даже если ваш словарный запас и грамматика английского идеальны, людям все равно может быть трудно понять вас из-за вашего произношения.
Научиться правильно произносить английские слова может быть одной из самых сложных частей изучения английского языка.
В английском языке есть звуки, которых может не быть в вашем родном языке, поэтому вам придется научиться создавать совершенно новые звуки.
Кроме того, из-за гласных в английском языке сложно сказать, как сказать слово. «Путь», «вес» и «сыворотка» все произносятся одинаково, например, в то время как «гребешок», «бомба» и «могила» произносятся по-разному.
А! Да, мы знаем, что это может свести тебя с ума.
Вот почему у нас есть 14 советов, которые помогут вам лучше произносить английские слова.
Загрузить: Это сообщение в блоге доступно в виде удобного и портативного PDF-файла, который вы можете можно взять куда угодно. Щелкните здесь, чтобы получить копию. (Скачать)
Если вам нужен высококачественный курс произношения, вы можете рассмотреть возможность изучения курса Creativa Mastering North American English Pronunciation.
Creativa предоставляет высококачественные высококачественные видеоролики для изучения английского языка и навыков делового общения. Creativa предлагает развлекательные видео, полезные, но неожиданные советы, а также не ограничивается только английским языком, чтобы научить вас языку тела и интонации. Creativa — новый продукт от команды FluentU.
Вот пример видео из курса Creativa «Освоение бизнес-видеозвонков на английском языке», в котором есть советы по эффективному самовыражению:
1. Научитесь слушать.
Прежде чем вы научитесь говорить, вам нужно научиться слушать.Некоторые звуки бывает трудно различить, когда вы слушаете. А динамик спал или проскочил ? Повредил ли он подбородок или голень ? Если вы слышите разницу, вам будет легче выразить разницу.
Существует множество руководств, которые помогут вам научиться слушать. У нас есть несколько отличных статей о том, как научиться слушать фильмы, песни, музыку и подкасты. Вы также можете найти упражнения на аудирование в Интернете, например, это из Жун-чанга.
Практика произношения в «Many Things» действительно отличная, особенно огромный выбор уроков по минимальным парам . Минимальные пары — это пары слов, такие как sleep, и slip, , которые отличаются только одним звуком. Вы можете щелкнуть каждое слово, чтобы прослушать каждое слово целиком, затем задайте себе вопрос во втором поле и выберите правильный ответ.
Если вы хотите послушать аутентичный английский вместо упражнений на произношение, вы можете посмотреть видео на FluentU .
FluentU берет видео из реального мира — например, музыкальные видеоклипы, трейлеры к фильмам, новости и вдохновляющие выступления — и превращает их в индивидуальные уроки изучения языка.
В отличие от традиционных сайтов для изучения языков, FluentU использует естественный подход, который поможет вам со временем освоить английский язык и культуру. Вы выучите английский так, как на нем говорят в реальной жизни.
На FluentU есть много интересного контента, включая популярные ток-шоу, документальные фильмы о природе и забавные рекламные ролики, которые вы можете увидеть здесь:
С FluentU смотреть видео на английском очень легко.Есть интерактивных подписей. Это означает, что вы можете нажать на любое слово, чтобы увидеть изображение, определение и полезные примеры.
Например, если вы нажмете на слово «поиск», вы увидите следующее:
Выучите весь словарный запас из любого видео с помощью викторин. Проведите пальцем влево или вправо, чтобы увидеть другие примеры слова, которое вы изучаете.
Самое приятное то, что FluentU отслеживает словарный запас, который вы изучаете, и дает вам дополнительную практику со сложными словами.Он даже напоминает вам, когда пора сделать отзыв! Каждый учащийся получает по-настоящему персонализированный опыт, , даже если они учатся с одним и тем же видео.
Вы можете начать использовать веб-сайт FluentU на своем компьютере или планшете или, что еще лучше, загрузив приложение из магазинов iTunes или Google Play.
2. Обратите внимание, как двигаются ваш рот и губы.
Когда вы говорите, вы двигаете ртом. Как вы двигаете ртом, влияет на то, как вы произносите слово.
Первый шаг к исправлению формы рта — это заметить это и обратить внимание. Проверить правильную форму рта и губ можно несколькими способами:
- Используйте зеркало. Это, безусловно, самый простой способ узнать, что делает ваш рот, пока вы говорите.
- Поднесите палец к губам (как будто вы говорите «шшш»). Во время разговора не двигайте пальцем. Вы должны почувствовать, как ваши губы отодвигаются от пальца или прижимаются к нему.
Наблюдайте за другими людьми и обратите внимание на форму их рта и губ, когда они говорят. Попробуйте следить за своим любимым телешоу или фильмом. Можете ли вы повторить лица и звуки, которые издают актеры?
В Интернете есть руководства и изображения, которые помогут вам научиться двигать ртом. В Sounds of English есть несколько хороших объяснений произношения определенных слов. Это руководство предназначено для людей, создающих 3D-анимацию, но картинки — отличное начало для понимания того, как должен выглядеть ваш рот, когда вы говорите.
Вы также можете найти отличные видеоролики, демонстрирующие, как правильно формировать форму рта и губ, когда вы говорите, например, этот от Джорджи Хардинг:
Ощущение скованности? Расслабьте свой рот и язык и будьте готовы попрактиковаться в речи с помощью этого веселого упражнения на разминку от Howcast!
3. Обратите внимание на свой язык.
Основное различие между рисом и вшами заключается в вашем языке.Когда вы говорите, вы двигаете языком, чтобы издавать звуки. Вы, наверное, даже не заметили этого, потому что делаете это не задумываясь. Чтобы улучшить свое английское произношение, рекомендуется проверить, что делает ваш язык.
Некоторые звуки, которые трудно воспроизвести для носителей языка, — это буквы «L» и «R», а также звук «TH». Правильно их произносить — все на языке!
Источник изображения
- Чтобы издать звук «L» , ваш язык должен касаться тыльной стороны передних зубов и верхней части рта, сразу за зубами. Попробуйте прямо сейчас: Скажите слово «свет». Скажи это несколько раз. Почувствуйте, где ваш язык находится во рту. Убедитесь, что он касается верхней части вашего рта.
- Чтобы звук «R» , ваш язык не должен касаться верхней части рта . Верните язык к середине рта, к тому месту, где он обычно лежит, если вы ничего не говорите. Когда вы произносите звук, ваши губы должны быть немного округлыми. Попробуйте прямо сейчас: Повторите слово «правильно» несколько раз.Во время разговора вы должны чувствовать, как между языком и верхней частью рта дует воздух. Вы также должны почувствовать, как ваши губы становятся немного круглее, когда вы произносите звук.
- Теперь о звуке «TH». Это может показаться странным, если у вас нет похожего звука на вашем родном языке. Чтобы издать этот звук, поместите язык между верхними и нижними зубами. Ваш язык должен немного высунуться между зубами, и когда вы выталкиваете воздух изо рта, пусть немного воздуха выйдет между вашим языком и зубами — вот что производит звук. Попробуйте прямо сейчас: Скажите слово «думать». Повторите это несколько раз. Убедитесь, что вы просунули язык между зубами.
Теперь, когда вы знаете, куда положить язык, вы слышите разницу?
Для более подробного объяснения того, как правильно воспроизвести эти три звука, посмотрите это видео из Университета Вусонг:
Или посмотрите это на Club English:
На YouTube есть много других руководств по произношению, поэтому поищите ту, которая поможет вам овладеть звуками языка!
Если вы не можете понять, что делать со своим языком, чтобы издать правильный звук, попробуйте спросить кого-нибудь.Попросите их произнести слово с этим звуком, а затем скажите вам, куда они направили свой язык. Они, наверное, никогда не думали об этом раньше!
4. Разбивайте слова на звуки.
Слова состоят из слогов или частей. Слово «слог», например, состоит из трех слогов: syl-la-ble. Превращение слов в части может облегчить их произношение.
Чтобы проверить, сколько слогов в слове, положите руку под подбородок. Говорите слово медленно. Каждый раз, когда ваш подбородок касается вашей руки, это слог.
Можно даже записать слово по частям. Оставьте пробел или проведите черту между каждым слогом (в каждом слоге должна быть хотя бы одна гласная: a, e, i, o, u, y). А теперь попробуйте сказать слово. Говорите медленно и делайте паузу после каждого слога. Не правда ли, проще?
Если у вас возникли проблемы со слогами, посмотрите, сколько слогов. Этот веб-сайт показывает вам слоги в любом слове, которое вы ищете, и даже показывает, как его произносить.
5. Добавляйте ударение в звуки и слова.
Английский — язык с ударением. Это означает, что одни слова и звуки важнее других. Вы можете услышать это, когда произнесете слово вслух. Например, слово «вводить» произносится с ударением в конце, поэтому оно звучит так: «in-tro-DUCE».
Иногда ударение в слове может изменить его значение. Произнесите это слово вслух: «настоящее». Если вы сказали «ПРЕДОСТАВИТЬ», вы имеете в виду существительное, которое означает «прямо сейчас» или «подарок». Если вы сказали «ПРЕДСТАВИТЬ», вы имеете в виду глагол, который означает «давать или показывать».”
Есть правила для ударения в каждом слове. Вот одно правило:
- Большинство двусложных существительных подчеркиваются на первом слоге, а большинство двусложных глаголов — на втором.
Это как слово «настоящий». Вот еще один пример: существительное «ADDress» — это место, где вы живете, а глагол «addRESS» — говорить с кем-то.
Если все это звучит слишком сложно, не беспокойтесь о запоминании всех этих правил — лучший способ научиться — слушать и практиковать . Помните, что большинство носителей английского языка тоже не знают правил, они просто говорят то, что «звучит правильно». При достаточной практике вы тоже сможете понять, что звучит правильно.
В этом видео о шести распространенных ошибках английского языка подробно рассматривается словесное ударение в первом пункте:
Продолжайте смотреть оставшуюся часть видео, чтобы получить другие полезные советы, как избежать некоторых из наиболее распространенных ошибок изучающих английский язык.
Посмотрите это видео с сайта mmmEnglish для получения дополнительной информации о слоговом ударении в английском языке:
В предложениях тоже есть ударение; некоторые слова более важны и произносятся яснее и убедительнее, чем остальная часть предложения.Попробуйте прочитать вслух это предложение: «Я съел тост с маслом утром».
Предложение должно было звучать так (жирные слова выделены ударением): «Я съел какой-то тоста с маслом утром ». Обратите внимание, как вы каждый раз замедляетесь, когда подбираете важное слово, и быстро пропускаете менее важные?
Продолжайте практиковаться, читая вслух, разговаривая и внимательно прислушиваясь к тому, где другие испытывают стресс, когда говорят.
6. Спросите себя, какой диалект английского языка вы хотите выучить.
Когда вы говорите по-английски, вы хотите звучать так, как будто вы из Америки или Англии? Австралия или Новая Зеландия? Может быть, Канада или Южная Африка.
Выбор диалекта английского языка — одно из первых решений, которые необходимо принять на пути изучения английского языка. Прежде всего, это определит большую часть изучаемого вами словарного запаса. Например, англоговорящие в Ирландии используют разные термины для обозначения некоторых вещей, чем англоговорящие в Соединенных Штатах, особенно когда речь идет о сленге.
Во-вторых, этот выбор сильно повлияет на ваше произношение.
Двумя наиболее распространенными типами английского для студентов ESL, вероятно, являются американский английский и британский английский .
Выбор типа повлияет на то, как вы произносите звуки. Например, в Америке звук «р» в конце слова намного резче.
И когда в середине слова появляется буква «т», американцы часто произносят ее как «д», а британцы произносят как твердую «т».Подумайте о таких словах, как «вода», «что угодно» или «зажигалка».
Это только начало. Я мог бы продолжать и продолжать!
Выбор между американским и британским английским также радикально изменит то, как вы произносите такие слова, как «алюминий», «график», «гараж» и «мобильный», и это лишь некоторые из них.
После того, как вы выбрали диалект английского языка, которым хотите овладеть, основывает свои методы и инструменты обучения на этом решении.
Например, если вы хотите изучать американский английский, вам не нужен партнер по обмену британским языком, не так ли? Вы собираетесь подражать звукам, которые слышите, поэтому вам нужно найти людей и ресурсы, которые будут кормить вас правильным акцентом.
Просмотр фильмов и телешоу — отличный способ выучить английский и расставить акценты. Мне особенно нравится смотреть сериалы, потому что у вас много часов контента, и вы со временем научитесь понимать акценты персонажей.
Если вы ищете британское телешоу, я рекомендую «Корона», драму о королеве Елизавете II. Еще мне нравится «Великое британское шоу выпечки». Это реалити-шоу беззаботно и интересно смотреть, и вы научитесь говорить на современном сленге.
Как насчет английских шоу? «Друзья» — это классический вариант изучения английского языка, и многие американцы будут рады поговорить об этом с вами.«Brooklyn Nine-Nine» — это ситком, который сейчас в эфире, в центре которого — полицейские (полицейские и женщины) в Нью-Йорке.
Вы также можете найти учебные материалы, которые познакомят вас исключительно с желаемым диалектом. Возьмем, к примеру, приложения.
Если вы хотите выучить британский английский, LearnEnglish Sounds Right предоставит руководство по произношению английского языка для людей, желающих приобрести британский акцент, и вы можете загрузить его на свое устройство iOS или Android.
ELSA Speak: English Accent Coach — отличное приложение, чтобы научиться говорить, как американец. Загрузите его в магазине Apple или Google Play.
Как видите, ваш выбор диалекта повлияет на все остальные решения, которые вы примете относительно английского произношения!
7. Преувеличивайте определенные звуки (увеличивайте их).
Всякий, кто играл в театре, знает о преувеличении.
Приходилось ли вам когда-нибудь выходить на сцену и делать выражение лица или реагировать на чью-то реплику только для того, чтобы ваш директор кричал: «Сделайте это масштабнее!» На сцене нужно преувеличивать, чтобы показаться публике нормальным.
Английское произношение точно такое же.
В зависимости от вашего родного языка и диалекта английского языка, который вы изучаете, определенные звуки будут для вас трудными. На самом деле, я думаю, что каждый студент ESL, которого я встречал, который изучает американский английский, борется с американским звуком «r»!
Так как же вы справитесь с таким хитрым звуком?
Преувеличить. Преувеличивайте звук, пока не почувствуете себя нелепым. Преувеличивайте, пока не будете уверены, что это настолько чрезмерно, что люди будут над вами смеяться.
Вы преувеличиваете до такой степени, что чувствуете себя глупо? Тогда вы, вероятно, на правильном пути.
Если ваше произношение слишком велико, вы будете все больше и больше осознавать форму своего рта и положение языка, когда произносите этот звук.
Хотите верьте, хотите нет, преувеличение этих звуков, вероятно, поможет носителям языка понять вас. Вы можете подумать, что это звучит банально, потому что вы не привыкли издавать такие звуки.Но для носителя языка вы будете звучать более достоверно, чем иностранец, который стесняется этих звуков.
Какая цель? В конце концов, вы так привыкнете к форме своего рта, что перестанете замечать преувеличения и не будете думать о правилах английского произношения во время разговора. И тогда вы знаете, что идете по пути к свободному владению языком.
8. Записывайте сложные слова по их звукам.
Проблемы с определенными словами? Попробуйте их записать.
Нет, не просто слово. Попробуйте записать это фонетически (по звуку, а не по орфографии).
Допустим, у вас возникли проблемы со словом «пицца». Запишите фонетически: piːtsə.
Если вы посмотрите на акустику, вы увидите, что двойная z произносится как «ts».
Попробуйте сделать карточки. Напишите слово на одной стороне, а затем произнесите его фонетически на другой стороне. Если это поможет, вы можете выделить буквы на каждой стороне, на которой вы тестируете себя.(Это может быть особенно полезно для наглядных учеников!)
Записывать фонетически бывает сложно, особенно если это ваш второй язык. Если вам нужна помощь, посетите EasyPronuction.com. Введите слово или предложение, с которым вам нужна помощь, и веб-сайт фонетически расшифрует их для вас. (Бонус — позволяет выбирать между американским и британским английским языком!)
9. Запишите, что вы слышите.
Хотите овладеть английским произношением? Садись и слушай.Послушайте, как кто-то говорит, и запишите, что они говорят.
Вы можете подумать: «Эй, я здесь, чтобы попрактиковаться в разговоре по-английски, а не слушаю!»
Однако аудирование — отличный способ улучшить английское произношение.
На уроках французского в моей средней школе нам приходилось писать под диктовку (писать то, что сказал учитель) каждую неделю. Учительница говорила 20 минут, и мы должны были записать именно то, что она сказала. Попытка расшифровать ее акцент и записать то, что мы слышали, заставила меня лучше понять французское правописание и произношение.
В вашем распоряжении нет учителя английского языка, который хочет поговорить вслух в течение 20 минут? Есть много способов найти ресурс!
EnglishClub — отличный сайт для диктовок, независимо от вашего уровня обучения. Выбирайте диктант для начального, среднего или продвинутого уровня.
Вы один раз прослушаете диктовку с нормальной скоростью. Затем второй раз на более медленной скорости, чтобы вы могли записать это. Слушайте в третий раз с нормальной скоростью.Тогда проверьте свой ответ.
YouTube также предлагает множество возможностей для тренировки навыков аудирования и письма. Начните с диктовки доктора Сьюза «Говори по-английски» от Ванессы:
Вы также можете посмотреть сцену из телешоу или фильма и записать то, что вы слышите. Если вы смотрите в сервисе, который предоставляет субтитры, снова воспроизведите сцену с субтитрами, чтобы проверить свою работу.
Если вы слышите трудные звуки, вероятно, вы научитесь их произносить.
10. Практикуйтесь со скороговорками.
Когда вы говорите по-английски, испытываете ли вы трудности с похожими звуками? Например, звуки «ш» и «ч», «т» и «й» или короткие и длинные «е»?
Не волнуйтесь, вы не единственный. Отнюдь не.
Хотите узнать, как улучшить свой английский акцент, чтобы было немного интереснее? Скороговорки могут быть забавным (но непростым!) Способом научиться различать два звука.
Скороговорки — это стихи, которые бывает сложно читать, потому что многие звуки похожи. В англоязычных странах люди говорят их только потому, что смешно, когда вы напутаете и звучите глупо. И это приятно, когда ты, наконец, усвоишь стихотворение!
Вот несколько примеров популярных и эффективных скороговорок на английском языке:
Хотите попрактиковаться в звуках «с» и «ш»? Вот один:
Она продает ракушки на берегу моря.
Это очень известная скороговорка. Но как только вы это сделаете, попробуйте добавить несколько менее известных строк:
Ракушки, которые она продает, — это морские ракушки, я уверен.
Ибо если она продает морские ракушки на берегу моря
Тогда я уверен, что она продает морские ракушки.
Хорошо, теперь давайте попробуем попрактиковаться в звуках «cl» и «cr»:
Как моллюску запихнуть в чистую банку со сливками?
А теперь по одному для звуков «ш» и «ч»:
Если собака грызет обувь, то чью обувь она выбирает?
Хотите практиковать разные звуки с помощью скороговорок? Взгляните на этот список здесь.
Вы также можете услышать скороговорки, произнесенные носителем английского языка на английском языке Рэйчел (и вы увидите, что даже у носителей языка могут возникнуть проблемы с освоением этих хитрых скороговорок!):
11. Используйте подкасты и видео с произношением.
Есть несколько отличных видео и аудиогидов по английскому произношению, которые вы можете использовать для улучшения. В Клубе английского языка есть видеоролики, в которых показано, как произносить разные звуки на английском языке.У Rachel’s English есть дружеские видео о том, как говорить и произносить американский английский в повседневных разговорах.
Если вам больше нравятся подкасты, у Pronuncian есть более 200 аудиофайлов, которые помогают во всем, от произношения до ударения и высоты тона (как вы повышаете и понижаете голос во время разговора).
Если ни один из этих вариантов не является тем, что вы ищете, вы можете выбрать из множества других. Найдите то, что вам подходит.
12. Запишите себя.
Один из способов узнать, работает ли вся ваша практика, — это записать себя на камеру.Используйте камеру, а не просто диктофон, потому что для важно видеть, как вы говорите, , а не только слышать.
Для записи себя не нужно скачивать никакого специального программного обеспечения; большинство компьютеров и мобильных устройств имеют встроенные видеомагнитофоны. Вы можете использовать PhotoBooth на Mac или Movie Moments на компьютере с Windows. Конкретные программы меняются со временем (например, программа Movie Moments может быть больше недоступна к тому моменту, когда вы это прочтете), но пока у компьютера есть камера, вы сможете записывать видео с ее помощью.На вашем телефоне или мобильном устройстве также есть приложение для захвата видео, обычно как часть приложения камеры.
Сравните вашу запись с тем, что кто-то произносит те же слова или звуки. Найдите видео с вашей любимой частью из фильма, например, этот клип из «Earth to Echo». Выберите одно или два предложения и запишите себя, пытаясь сопоставить ударение, тон и произношение видео. Затем вы можете сравнить их и посмотреть, что вы сделали по-другому, и попробовать еще раз.
Спросите друга или посмотрите видео, чтобы проверить.Если ваше произношение звучит по-разному, задайте себе несколько вопросов: правильно ли вы двигаете ртом? Ваш язык в нужном месте? Вы подчеркиваете правую часть слова? Используйте все, что вы узнали из этой статьи!
13. Практикуйтесь с напарником.
Как всегда, «Практика ведет к совершенству!» А с другом проще тренироваться. Найдите кого-нибудь, с кем можно попрактиковаться в произношении, лично или через онлайн-сообщества, такие как Language Exchange или InterPals.
Практика с приятелем (другом) даст вам возможность попробовать все, что вы узнали, и научиться новому друг у друга. К тому же это весело!
14. Говорите как можно больше.
Если вы не говорите часто, вы можете нервничать, когда, наконец, пора открыть рот и сказать что-нибудь по-английски.
Это как играть в баскетбол. Вы можете хорошо бегать, вести мяч и пасовать. Но вы никогда не стреляете по мячу.
Вы умеете стрелять по мячу.Вы все время смотрите, как это делают другие. Но ты никогда этого не делал.
Когда пришло время поиграть и у тебя есть шанс выстрелить, это будет сложно. Кроме того, вы так нервничаете, делая что-то новое перед другими людьми, что ваши нервы могут парализовать вас.
То же самое и с разговорным английским. Вам нужно не только потренироваться в произношении английского языка, , но вам также нужно перебить нервы, чтобы чувствовать себя комфортно, выступая перед другими. Нервы могут привести к множеству ошибок, особенно в произношении.
Попробуйте установить для себя правило: вы должны разговаривать с собой по-английски дома. Для начала попробуйте просто рассказать, чем вы занимаетесь, когда готовите ужин или собираетесь ложиться спать.
Пообещайте себе, что будете говорить вслух хотя бы несколько минут в день.
Помните, практика ведет к совершенству!
Произношение так же важно для изучения английского языка, как словарный запас и грамматика. Благодаря этим 14 советам вы скоро научитесь произносить английский как носитель языка.
Загрузить: Это сообщение в блоге доступно в виде удобного и портативного PDF-файла, который вы можете можно взять куда угодно. Щелкните здесь, чтобы получить копию. (Скачать)
Если вам понравился этот пост, что-то подсказывает мне, что вам понравится FluentU, лучший способ выучить английский с помощью реальных видео.
Испытайте погружение в английский онлайн!
Извлечение и моделирование ритмических единиц для автоматической идентификации языка
(1) Идентификатор HAL: hal-00664988 https: // hal.archives-ouvertes.fr/hal-00664988 Опубликовано 31 января 2012 г.HAL — это мультидисциплинарный открытый доступ архив для хранения и распространения научно-исследовательские документы, будь то опубликовано или нет. Документы могут быть получены из учебные и исследовательские учреждения во Франции или за границей, либо из государственных или частных исследовательских центров.
L’archive ouverte pluridisciplinaire HAL, est Destinée au dépôt et à la распространение документов scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des Laboratoires publics ou privés.
Извлечение и моделирование ритмических единиц для автоматики идентификация языкаЖан-Люк Руа, Жером Фаринас, Франсуа Пеллегрино, Режин Андре-Обрехт
Чтобы процитировать эту версию:Жан-Люк Руа, Жером Фаринас, Франсуа Пеллегрино, Режин Андре-Обрехт. Ритмический блок извлечение и моделирование для автоматического извлечения идентификации языка. Речевое общение, Elsevier: Северная Голландия, 2005, 47 (4), стр.436-456. �hal-00664988�
(2) Название: Извлечение и моделирование ритмических единиц для автоматической идентификации языкаАвторы: Жан-Люк Руа1, Жером Фаринас1, Франсуа Пеллегрино2, Режин Андре-Обрехт1
1
Institut de Recherche en Informatique de Toulouse UMR 5505 CNRS — Национальный институт Политехнический институт Тулузы — Университет Поля Сабатье — Университет Тулузы 1, Франция
2
Laboratoire Dynamique Du Langage UMR 5596 CNRS — Université Lumière Lyon 2, Франция {rouas @ irit.fr, [email protected], [email protected], [email protected]} Автор, ответственный за переписку:
Франсуа ПЕЛЛЕГРИНО ([email protected]) Почтовый адрес: DDL — ISH
проспект Бертело, 14 69363 LYON CEDEX 7 ФРАНЦИЯ Тел .: +33 4 72 72 64 77 Факс: +33 4 72 72 65 90
A BSTRACTВ данной статье рассматривается подход к автоматической идентификации языка на основе ритмических моделирование.Помимо фонетики и фонотактики, ритм на самом деле является одним из самых многообещающих особенности, которые следует учитывать при идентификации языка, даже если их извлечение и моделирование не являются прямая проблема. Собственно, одна из основных проблем, которую нужно решить, — это то, что моделировать. В этом В статье описан алгоритм выделения ритма: с использованием алгоритма распознавания гласных, ритмические единицы, относящиеся к слогам, сегментированы. Извлекаются несколько параметров (согласные длительность гласных, сложность кластера) и моделируются с помощью гауссовой смеси.Эксперименты выполняются по прочитанной речи на 7 языках (английском, французском, немецком, итальянском, японском, Мандаринский и испанский), и результаты достигают 86 ± 6% правильного различия между классы языков с синхронизацией по времени и по слогам, а также до 67 ± 8% процентов
правильных определения языка в среднем для 7 языков с произнесением 21 секунда. Эти результаты комментируются и сравниваются с результатами, полученными на стандартном акустическом Подход к моделированию гауссовой смеси (88 ± 5% правильной идентификации для 7-язычных
(3) K EYWORDSРитмическое моделирование; Идентификация языка; Типология ритма; Азиатские языки; Европейский языков
1.Я ВВЕДЕНИЕАвтоматическая идентификация языка (ALI) изучается почти тридцать лет, но первые конкурентные системы появились в 90-е годы. Это недавнее внимание связано с 1. необходимостью Человеко-компьютерные интерфейсы и 2. значительное расширение многоязычного обмена. Действительно, в так называемом информационном обществе ставки ALI многочисленны, как для многоязычные человеко-машинные интерфейсы (интерактивный информационный терминал, речевой диктант, и т.п.) и для компьютерной связи (аварийная служба, службы телефонной маршрутизации, так далее.). Более того, доступ к огромному количеству числовых аудио (или мультимедийных) данных доступно может использовать индексирование на основе содержимого, которое может включать информацию о языки или диалекты говорящих. Кроме того, могут быть затронуты лингвистические вопросы: понятие языковой дистанции имплицитно присутствует в типологии лингвистики почти столетие. Тем не менее, это все еще сложно определить, и системы ALI могут пролить другой свет на это понятие. поскольку корреляция автоматических, перцептивных и языковых расстояний может привести к обновлению типологии и к лучшему пониманию близких понятий языков и диалектов.
В настоящее время современные подходы рассматривают фонетические модели как интерфейсные, обеспечивающие последовательности дискретных фонетических единиц, декодируемых позже в системе, в соответствии с языковыми особенностями статистические грамматики (обзор см. в Zissman & Berkling, (2001)). Недавний NIST 2003 Оценка распознавания языка (Martin & Przybocki, 2003) подтвердила, что этот подход весьма эффективен, так как коэффициент ошибок, полученный в задаче проверки языка с использованием набора двенадцать языков составляет менее 3% для 30-секундных высказываний (Gauvain et al., 2004). Однако другие системы, моделирующие глобальные акустические свойства языков, также очень эффективны и дают ошибка около 5% при выполнении той же задачи (Singer et al., 2003). Эти системы, которые используют либо техники распознавания речи или говорящего, работают достаточно хорошо. Тем не менее, очень немногие системы
(4)пытается использовать другие подходы (например, просодику), и результаты намного хуже, чем полученные с фонетическим подходом (например, комбинация стандартного OGI «темпоральный динамика », основанная на n-граммном моделировании последовательностей сегментов, помеченных в соответствии с их кривые Fo и энергии дают примерно 15-20% одинаковой частоты ошибок с тремя языками Задача и корпус кампании NIST 2003 (Adami & Hermanski, 2003)).Однако эта альтернатива подходы могут привести к улучшениям с точки зрения устойчивости в шумных условиях, количество признанные языки или лингвистическая типология. Необходимы дальнейшие исследования, чтобы преодолеть ограничения и оценить вклад этих альтернативных подходов.
Мотивация этой работы дана в Разделе 2. Одна из самых важных — просодическая функции несут значительную часть языковой идентичности, которой может быть достаточно для людей, чтобы перцептивно идентифицировать некоторые языки (см. раздел 2.2). Среди этих надсегментарных особенностей ритм очень перспективен как для лингвистической, так и для автоматической обработки (Раздел 2). Однако справиться с ритмом — непростой вопрос, как с теоретической точки зрения, так и с точки зрения теории. автоматическая обработка (раздел 3). По этим причинам несколько предыдущих экспериментов, нацеленных на при распознавании языка с использованием ритма были основаны на размеченных вручную данных и / или включали только задачи языковой дискриминации1 (Thymé-Gobbel & Hutchins, 1999; Dominey & Ramus, 2000).В данной статье рассматривается проблема автоматического моделирования ритмов с подходом, который не требует фонетически помеченных данных (Раздел 4). Используя алгоритм определения гласных, ритмичный Сегментировано единиц, несколько похожих на слоги и называемых псевдослоговыми. На каждую единицу, извлекаются несколько параметров (продолжительность согласных и гласных, сложность кластера) и моделируется гауссовой смесью. Этот подход применяется к 7 языкам (английский, французский, Немецкий, итальянский, японский, мандаринский и испанский) с использованием корпуса прочитанной речи MULTEXT.Описательная статистика псевдослогов вычисляется, и актуальность этого моделирования
1
Языковая дискриминация относится к определению, какой из двух языков-кандидатов L 1-L2 неизвестен
звуковой сигнал принадлежит. Идентификация языка обозначает более сложные задачи, где количество кандидатов языков больше двух.
(5)оценивается с помощью двух экспериментов, направленных на 1. различение языков в соответствии с их ритмические занятия (стресс-хронометраж vs.по времени или по слогам) и 2. определение 7 языков. Затем этот ритмический подход сравнивают с более стандартным акустическим подходом. (Раздел 5).
С теоретической точки зрения предлагаемая система фокусируется на существовании и моделирование ритмических единиц. Такой подход генерирует тип сегментации, которая относящиеся к слоговому разбору высказываний. Он оставляет в стороне другие компоненты, связанные с ритмом. последовательностям ритмических единиц или целым высказываниям.Эти соображения обсуждается в разделе 6.
2. M ОТИВЫРитм участвует во многих процессах речевого общения. Хотя это было долгое время пренебрегали, некоторые соображения заставляют пересмотреть его роль как в понимании, так и в производственные процессы (раздел 2.1), особенно в рамках языковой идентификации. (Раздел 2.2). Более того, исследователи попытались принять во внимание ритм для автоматического целей обработки на некоторое время, как в задачах синтеза речи, так и в задачах распознавания, что приводит к несколько ритмично-ориентированных подходов (Раздел 2.3). Все эти соображения подчеркивают как потенциальное использование эффективной ритмической модели и сложность ее разработки. Это приводит нас к сосредоточению о возможном использовании ритмических функций для ALI (разделы 3 и 4).
2.1. Лингвистическое определение и функции ритмаРитм — сложное явление, которое долгое время считалось следствием других характеристики речи (фонемы, синтаксис, интонация и др.). Однако внушительная сумма экспериментов, как правило, доказывает, что его роль может быть гораздо больше, чем просто побочный эффект в речевой коммуникативный процесс.
Согласно теории фрейма / содержания (MacNeilage, 1998; MacNeilage & Davis, 2000), производство речи основано на наложении сегментарного контента в циклический фрейм. Из
(6)с эволюционной точки зрения, этот цикл, вероятно, произошел от механических циклов пищеварения. общие для млекопитающих (например, жевание) через промежуточные состояния, включая зрительно-лицевое общение контролируется, по крайней мере, движением нижней челюсти (губной мешочек и т. д.). Более того, авторы пролили свет на статус слога как интерфейса между сегментами и надсегментными и как каркас, центральная концепция в их теории: сворачивание нижнечелюстного цикла с помощью базовый механизм озвучивания приводит к последовательности слогов CV, состоящей из закрытие и нейтральная гласная.Дополнительные эксперименты над ошибками серийного заказа, сделанными взрослыми или дети (например, Fromkin, 1973; Berg, 1992) и детский лепет (MacNeilage et al. 2000; Kern et al. др., чтобы появиться) также совместимы с идеей, что колебание нижней челюсти обеспечивает ритмический базовый уровень, в котором имеют место сегменты, точно контролируемые артикуляторами.
Огромное количество психолингвистических исследований также обращает внимание на важность ритмические единицы в сложном процессе понимания языка.Большинство из них считают, что ритмическая единица — примерно соответствующая слогу в сочетании с произвольным ударением — играет важную роль как промежуточный уровень восприятия между акустическим сигналом и уровень слова. Точная роль этих слогов или единиц размера слога еще не ясна. идентифицировано: является ли важным признаком сама единица (как единица перекодирования) или ее границы (как вехи процесса сегментации) все еще обсуждается. Те утверждают, что слог основной блок, в котором фонетическое перекодирование выполняется до лексического доступа (Mehler et al., 1981). Другие предлагают альтернативную гипотезу, в которой слоги и / или ударение обеспечивают этапы для разбора акустического сигнала на фрагменты, которые правильно выровнены с лексическим единиц (Катлер и Норрис, 1988). В этой последней структуре границы более заметны, чем содержание, и никаких дополнительных гипотез о размере единиц, фактически используемых для лексическое отображение. Более того, недавние эксперименты показывают, что основной процесс может состоять в определение места начала, а не обнаружение необработанных границ (Content et al., 2000; Content et al., 2001).
Эти исследования показывают, что ритм играет ключевую роль в процессе речевого общения. Точно так же можно было бы упомянуть несколько дополнительных аспектов, но они выходят за рамки
(7)Объем данной статьи 2. Однако есть несколько вопросов относительно характера ритма. явление все еще открыты. Во-первых, насколько известно авторам, бесспорный определение ритма еще не существует, даже если большинство исследователей могут согласиться с мнением, что речевой ритм связан с существованием обнаруживаемого явления, которое происходит равномерно в речь.Кристал предлагает точно определить ритм как «регулярное восприятие выдающихся единиц в речи »(Кристалл, 1990). Мы предпочитаем не использовать понятия восприятия и единицы , потому что они сужают ритмический феномен априорными гипотезами: согласно Кристаллу По определению ритм можно рассматривать как чередование заметных единиц с менее заметными единицы, но определить эти единицы непросто; Чередование ударных / безударных слоги приводят к одному виду ритма, но голосовые / глухие звуковые последовательности могут создавать другой тип ритма, а также чередование согласных / гласных или короткие / длинные звуковые последовательности, и др.Более того, ритм может возникать из-за равномерного возникновения точечных событий, а не единиц (например, удары, накладываемые на другие инструменты в музыке).
Другой вопрос касается реальной роли слога. Когнитивная это единица или нет — все еще обсуждается. Тем не менее, некоторые эксперименты и измерения показывают, что слоги или Единицы размером со слог заметно выделяются и могут демонстрировать определенные акустические характеристики. Поскольку В начале 1970-х годов несколько экспериментов показали, что слуховая система человека особенно уязвима. чувствителен к временным интервалам от 150 до 300 мс, четко совместим со средним значением продолжительность слога 3.Эти эксперименты, основанные на различных протоколах (прямом и обратном эффект маскировки, переключение ушей речи, повтор затенения и т. д.) показал, что эта длительность
2
См. Левелт (1994) для его модели производства речи; см. также Boysson-Bardies et al., 1992; Mehler et. др., 1996; Weissenborn & Höhle, 2001; Нацци и Рамус, 2003 за роль ритма в раннем приобретении языка.
3
Гринберг (1998) сообщает о средней продолжительности спонтанной беседы на коммутаторе в 200 мс. Английская база данных.
(8)примерно соответствует размеру буфера восприятия человека (см., Например, Massaro, 1972; Jeasted et al., 1982; О’Шонесси 1986). Совсем недавно эксперименты, проведенные с манипулирование спектральными огибающими речевых сигналов показало заметность модуляции частоты восприятия от 4 до 6 Гц (Drullman et al., 1994). Следовательно, все эти выводы поддерживайте слог как соответствующую ритмическую единицу. Кроме того, акустические измерения, сделанные на корпус английской спонтанной речи также подчеркивает ее значимость (Greenberg, 1996 & 1998).Это исследование показало, что, что касается спектральных характеристик, начало слога в целом менее изменчивы, чем ядра или коды. Также подчеркивается, что эффекты совместной артикуляции внутри каждого слога намного больше, чем между слогами. Оба эффекта приводят к тому, что начала слога различаются меньше, чем в других частях сигнала, и, следовательно, могут давать по крайней мере надежных якорей для лексической расшифровки. Помимо этого поиска внутренней природы ритма, Исследования восприятия могут также улучшить наши знания о его внутренней структуре.Использование речи синтез для моделирования производства речи, Зелльнер-Келлер (2002) пришел к выводу, что структура ритма возникает в результате своего рода свертки височного скелета с несколькими слоями, от сегментарного до фразовым, сложным образом, который можно частично предсказать.
Один из основных выводов — задействованы временные интервалы от 150 до 300 мс. в речевом общении как актуальный уровень обработки. Более того, многие реплики привлекают внимание к этому промежуточному уровню между акустическим сигналом и уровнями высокого уровня (синтаксис, лексика).На это , не очевидно, чтобы оценить, является ли релевантный признак на самом деле ритмической единицей или ритмичный ритм. Однако единицы размера слога являются заметными с точки зрения восприятия и могут имеют акустические корреляты, облегчающие их автоматическое извлечение. Следующий раздел посвящен экспериментальная оценка этих коррелятов в задачах перцептивной языковой идентификации.
2.2. Идентификация ритма и языка восприятияОпределение языка — необычная задача для многих взрослых людей, говорящих на нем.Его можно посмотреть как развлечение для самых вопрошающих, но большинства взрослых людей, живущих в одноязычная страна может посчитать, что это не представляет интереса. Однако ситуация довольно
(9)разных в многоязычных странах, где можно говорить на многих языках или диалектах. узкий географический район. Кроме того, идентификация языка восприятия является важной вызов для детей, которые изучают язык (и) в таком многоязычном контексте: тогда это крайне важно для них различать, на каком языке говорят, чтобы получить право зависящая от языка фонология, синтаксис и лексика.За последние два десятилетия несколько эксперименты исследовали эффективность человека как средства распознавания языка (см. Barkat-Defradas et al., 2003, для обзора). Три основных типа функций могут помочь кому-то определить язык: 1. Сегментарные признаки (акустические свойства фонем и их частота встречаемости), 2. Надсегментные признаки (фонотактика, просодия) и 3. Высокая особенности уровня (лексика, морфосинтаксис). Точное использование каждого набора функций неясно. тем не менее, и на самом деле это может отличаться между новорожденными и взрослыми.
Например, несколько экспериментов доказали, что новорожденные уже в первые дни способны различать свой родной язык и некоторые иностранные языки, на которых различия на надсегментарном уровне (см. обзор Ramus, 2002). Будь новорожденные извлекать выгоду из одного только ритма или из ритма и интонации — открытый вопрос. это Вероятно, что оба уровня дают сигналы, которые взвешиваются как функция экспериментальных условий. (языки, шум и скорость речи) и, возможно, в соответствии с индивидуальными стратегиями.Оценка эти способности взрослого человека определять иностранные языки представляют собой сложную задачу, поскольку на эту способность могут влиять многочисленные параметры. Среди них родной язык и его личная лингвистическая история кажется ключевыми факторами, которые трудно поддается количественной оценке. Поскольку В конце 1960-х годов этому вопросу посвящено немало исследований. В зависимости от того, есть ли они реализованные исследователями автоматической обработки речи или лингвистами, цели различаются. В первые намерены использовать эти перцепционные эксперименты в качестве эталонов для систем ALI, в то время как Последние исследуют познавательный процесс человеческого восприятия.Совсем недавно этот вид экспериментов рассматривались как способ исследовать понятие дистанции восприятия среди человек. языков. В этой структуре цель состоит в том, чтобы оценить влияние различных уровней лингвистическое описание в когнитивном суждении языковой близости.
(10)С общей точки зрения все эти эксперименты показали замечательную способность люди, чтобы идентифицировать иностранные языки после короткого периода воздействия. Например, один экспериментов, описанных Muthusamy et al., (1992) указывает, что носители английского языка набрать 54,2% правильных ответов при определении 6-секундных отрывков, произнесенных в 9 иностранные языки. Выступления значительно варьировались от одного языка к другому, начиная с от 26,7% узнаваемости корейского до 86,4% испанского. Кроме того, Испытуемых попросили объяснить, какие сигналы они учитывали при принятии решения. Их ответы выявили использование сегментарных признаков (манера и место артикуляции, наличие носовые гласные и т. д.), супрасегментальные (ритм, интонация, тона) и «лексические» сигналы (повторение те же слова или псевдослова). Однако эти эксперименты вызывают множество вопросов о факторы, влияющие на способность распознавания предметов: количество языков, на которых подвергались воздействию, продолжительность экспериментального обучения и т. д. Мутусами, несколько исследователей попытались количественно оценить эти эффекты. Штокмаль, Бонд и их коллеги (Stockmal et al., 1996; Stockmal et al., 2000; Bond & Stockmal, 2002) имеют исследовали несколько социолингвистических факторов (географическое происхождение носителей языка, языки известны испытуемым и т. д.) и лингвистические факторы (особенно ритмические характеристики языки). В аналогичной задаче, основанной на выявлении арабских диалектов, наша группа отказалась от свет на взаимосвязь между структурой вокальной системы диалектов и расстояния восприятия, оцениваемые по ответам испытуемых (Баркат и др., 2001). Результаты сообщается Vasilescu et al., (2000) в эксперименте по различению романтики языки могут интерпретироваться аналогичным образом. Другие исследования сосредоточены на важности супрасегментальные в идентификации перцептивного языка. Из первых опытов Охала и Гилберта (1979) к недавним исследованиям Рамуса с использованием как природных, так и синтезированных речи, они доказывают, что слушатели могут полагаться на фонотактику, ритм и интонацию, чтобы различать или идентифицировать языки, даже если сегментированная информация отсутствует.
Даже если когнитивный процесс, ведущий к идентификации языка, является многопоточным (от сегментарного акустика для супрасегментных сигналов и сигналов более высокого уровня), модель интеграции не была получена
(11)пока нет. Более того, создание такой модели, похоже, все еще вне пределов досягаемости, поскольку даже индивидуальный механизмы восприятия на каждом уровне все еще вызывают недоумение. На сегментарном уровне большинство исследователи работают со ссылкой на моторную теорию восприятия речи (Liberman & Mattingly, 1985) ищет аргументы, которые либо подтвердили бы, либо опровергли его.На надсегментарный уровень, восприятие ритма в основном изучается с музыкальной точки зрения точки зрения, даже если также изучаются сравнения между восприятием музыки и речи (например, Todd & Браун, 1994; Besson & Schön, 2001) и если технологические приложения (например, синтез речи) побудили исследователей оценить ритм (см. следующий раздел).
2.3. Ритмическая и слоговая автоматическая речь обработкаМногие исследования, направленные на использование ритмических и просодических особенностей для автоматического системы были разработаны в течение последних десятилетий и большую часть времени достигли неутешительные результаты.Тем не менее некоторые авторы считают, что это следствие трудность моделировать суперсегментарную информацию и выдвигать основную роль просодии и временные аспекты в процессах речевой коммуникации (см., например, Zellner Keller & Keller, 2001 г. по синтезу речи и Тейлор и др., 1997 г. по распознаванию речи).
Помимо роли в разборе предложения на слова (Cutler & Norris, 1988; Cutler, 1996), Просодия иногда является единственным средством для устранения неоднозначности предложений, и она часто содержит дополнительная информация (настроение говорящего и т. д.). Даже при акцентировании внимания на акустико-фонетическом при декодировании супрасегментальные элементы могут быть актуальны на двух уровнях: в первую очередь, сегментарном и надсегментарные особенности не являются независимыми, и, таким образом, надсегментарный уровень может помочь устранить неоднозначность сегментарного уровня (например, увидеть корреляцию между акцентом напряжения и вариация произношения в американском английском (Greenberg et al., 2002)). Более того, как это было Как уже говорилось выше, надсегментарные сегменты и особенно ритм могут быть важным уровнем лечения в качестве сам для людей и, вероятно, для вычислительных моделей.Синтез речи очевиден область, где перцептивные эксперименты показали интерес к единицам длины слога для
(12)естественности синтезированной речи (Keller & Zellner, 1997). Дополнительно ритмичность и ритмичность единицы могут играть важную роль в автоматическом распознавании речи: от предложения слога в качестве модуля для распознавания речи (Fujimura, 1975) на летний семинар на тему «На основе слогов. Распознавание речи », спонсором которого является Университет Джона Хопкинса (Ganapathiraju, 1999), попытки использовать ритмические единицы в автоматическом распознавании и понимании речи были многочисленные.К сожалению, большинству из них не удалось улучшить стандартное распознавание речи. подход, основанный на контекстно-зависимом моделировании телефона (обзор см. в Wu, 1998). Тем не мение, окончательный вывод заключается не в том, что супрасегментальные выражения бесполезны, а в том, что фонематические уровень не может быть подходящей шкалой времени для их интеграции, и что большие масштабы могут быть более эффективный. Мы уже упоминали, что эффекты совместной артикуляции намного больше в пределах каждого слогов, чем между слогами в данном корпусе спонтанной речи американского английского (Гринберг, 1996).Хорошо известно, что контекстно-зависимые телефоны эффективно справляются с этой проблемой. совместная артикуляция. Однако для их обучения требуется большой объем данных, и, следовательно, они не могут использоваться, когда доступно мало данных (это происходит особенно в многоязычных ситуациях: Современные системы ALI основаны на контекстно-независимых телефонах (Singer et al., 2003; Gauvain et al., 2004). Таким образом, модели с размером слога являются многообещающей альтернативой с ограниченными возможностями. изменчивость на границах. Однако несколько нерешенных проблем ограничивают производительность современные системы распознавания по слогам, и основная проблема может заключаться в том, что слог границы определить непросто, особенно при спонтанной речи (например, при спонтанной речи).грамм. Content et al., 2000 для обсуждения амбисложности и ресиллабификации). Таким образом, сочетая фонемно-ориентированные и слогово-ориентированные модели для учета нескольких временных масштабов могут быть успешный подход к преодолению конкретных ограничений каждой шкалы (Wu, 1998). Ну наконец то, Слоговые исследования менее распространены в области идентификации говорящего и языка. Среди их, тем не менее, мы можем различать подходы, адаптированные из стандартных фонетических или фонотактических подходы к единицам размера слога (Li, 1994 и совсем недавно Antoine et al., 2004 для «Силлаботактический» подход и Нагараджан и Мурти, 2004 г. для слогового скрытого Маркова Моделирование) от тех, кто пытается смоделировать базовую ритмическую структуру (см. Раздел 4.1).
(13)В этом разделе показано, что 1. Ритм — важный механизм речевого общения. вовлечены в процессы понимания и производства; 2. Сложно определить, обработать и прежде всего, чтобы качественно моделировать; 3. Слоги или подобные слогам единицы могут играть важную роль в структура ритма.Кроме того, описанные выше эксперименты ясно демонстрируют, что разные языки могут отличаться с ритмической точки зрения, и что эти различия могут быть восприняты и использованы в задаче идентификации перцептивного языка. Следующий раздел посвящен эти различия, как с точки зрения языкового разнообразия, так и лежащих в основе акустических параметров.
3. T ТИПОЛОГИЯ РИТМА И ЕЕ АКУСТИЧЕСКИЕ СООТВЕТСТВИЯ Языки можно маркировать в соответствии с типологией ритмов, предложенной лингвистами.Тем не мение, ритм сложен, и некоторые языки не полностью соответствуют этой типологии и поиску акустические корреляты были предложены для оценки этой лингвистической классификации.Описанные здесь эксперименты сосредоточены на 5 европейских языках (английском, французском, немецком, итальянском и испанский) и 2 азиатских языка (мандаринский и японский). Согласно лингвистическому литература, французский, испанский и итальянский языки с синхронизацией по слогам, в то время как английский и немецкий — это языки с временной привязкой к стрессу. Что касается мандарина, классификация не является окончательной, но последние работы склонны утверждать, что это язык стресса (Komatsu et al., 2004). Случай с японцами отличается, поскольку он является прототипом третьего ритмического класса, а именно мора-синхронизированных языков для время связано с частотой morae4. Эти три категории относятся к понятие изохронии, и они возникли из теории ритмических классов, введенной Пайком, разработан Аберкромби (1967) и усовершенствован Ладефогедом (1975) с помощью уроков по времени. Более поздние работы, основанные на измерении продолжительности интервалов между напряжениями в обоих языки с синхронизацией по напряжению и по слогам обеспечивают альтернативную структуру, в которой эти
4 Morae может состоять из V, CV или C.Например, [kakemono] (свиток) и [nippo] (Япония) должны быть
(14)дискретных категории заменяются континуумом (Dauer, 1983), в котором ритмические различия среди языков в основном связаны с их слоговой структурой и наличием (или отсутствием) редукция гласных.
Структура слога тесно связана с фонотактикой и стратегией акцентуации язык. Хотя некоторые языки позволяют использовать только простые слоговые шаблоны (CV или CVC), другой допускает гораздо более сложные структуры для начала, кода или того и другого (например,грамм. слоги с до 6 согласных в коде5 встречаются в немецком языке). Таблица 1, адаптированная из Гринберг (1998) сравнивает слоговые формы спонтанных речевых тел. на японском и американском английском.
ТАБЛИЦА 1
Наиболее поразительное утверждение заключается в том, что на обоих языках формы CV и CVC означают почти 70% встречающихся слогов. Однако другие формы обнаруживают существенные различия в слоговая структура. С одной стороны, кластеры согласных довольно распространены в американском языке. Английский (11.7% слогов), а в японском корпусе они почти отсутствуют. На с другой стороны, переходы VV присутствуют в 14,8% японских слогов, в то время как они могли только происходит путем ресиллабификации границ слов в английском языке. Эти наблюдения примерно соответствуют нашим знаниям о фонологической структуре слов в этих двух языков. Однако характер тел (спонтанная речь) широко влияет на относительное распределение каждой структуры. С прочитанной речью (повествовательные тексты), Делатр и Олсон (1969) обнаружили довольно разные шаблоны для британского английского: CVC (30.1%), CV (29,7%), VC (12,6%), V (7,4%) и CVCC (7%). CCV, который встречается 5,1% в корпусе Switchboard представляет лишь 0,49% слогов в корпусе Делатра и Олсона. Однако статистика
5 Например, «сжать» будет переведено du schrumpfst’s [du rmpfsts]. В этом примере взят
(15), вычисленное по корпусу Switchboard, показывает, что для покрытия необходимо 5000 различных слогов. 95% словарного запаса6 (Greenberg, 1997), и, таким образом, межъязыковые различия не ограничивается высокочастотными слоговыми структурами.Эти широкие фонотаксические различия объясняются по крайней мере частично, противопоставление мора-времени и стресс-времени. Тем не менее, изучение временных свойств языков необходимо, чтобы определить, полностью ли характеризуется ритм слогом структуры или нет.
Помимо дебатов о существовании ритмических классов (в отличие от ритмического континуума), измерение акустических коррелятов ритма необходимо для автоматического языка системы идентификации, основанные на ритме. Первая статистика, сделанная Рамусом, Неспором и Мелером со специальным многоязычным корпусом из 8 языков привела к возобновлению интереса к этим исследованиям (Рамус и др., 1999).Вслед за Дауэром они искали измерения продолжительности, которые могли быть коррелирует с сокращением гласных (что приводит к широкому диапазону продолжительности гласных) и с слоговая структура. Они выделили два надежных параметра: 1. процент вокала. длительность% V и 2. стандартное отклонение длительности согласных интервалов ∆C как
оценивается по всему высказыванию. Они предоставили двухмерное пространство, в котором языки сгруппированы в соответствии с их классом ритма7.Эти результаты очень многообещающие и доказывают, что в почти идеальные условия (ручная маркировка, однородная скорость речи и т. д.), можно найти акустические параметры, которые объединяют языки в объяснимые категории. Расширение этого подход к ALI требует оценки этих параметров с большим количеством языков и меньшим количеством языков. стесненные условия. Это вызывает несколько проблем, которые можно резюмировать следующим образом:
6
Это число сокращается до 2000 слогов, необходимых для покрытия 95% корпуса (т.е. с учетом частота встречаемости каждого слова лексики).
7
На самом деле кластеризация кажется максимальной по одному измерению, полученному из линейной комбинации. ∆C и% V.
(16)— Добавление говорящих и языков добавит вариативности между говорящими. Было бы это привести к перекрытию языковых дистрибутивов?
— Какая часть вариации продолжительности, наблюдаемой в ритмической единице, обусловлена языковой ритм, и какая часть связана с речью говорящего показатель?
— Можно ли учесть эти акустические корреляты для ALI?
Недавнее исследование (Grabe & Low, 2000) частично отвечает на первый вопрос.Учитывая 18 языков и ослабления ограничений на скорость речи, Граб и Лоу обнаружили, что изучаемые языки широко распространились без видимого эффекта кластеризации в двумерном пространстве отчасти связано с пространством% V / ∆C. Однако в их исследовании каждый язык представлен
всего 1 динамик, что не позволяет сделать однозначный вывод о дискретном или непрерывном природа ритмического пространства. Решение проблемы различий между говорящими, диалектами и языков, аналогичные эксперименты с диалектами проводятся в нашей группе (Hamdi et al., 2004; Феррань и Пеллегрино, 2004). Хотя это выходит за рамки данной статьи, второй вопрос существенный. Скорость речи включает в себя вычисление количества определенных единиц в секунду; вопрос о выборе подходящей единицы (слог, фонема или морфема) остается спорным, и поэтому интерпретация измеренной скорости: несколько единиц в секунду означают длинные единицы, но делает ли это означают, что устройства изначально длинные или динамик — особенно медленный динамик? Более того, изменение скорости речи в высказывании также имеет значение: скорость речи колеблющегося динамик может переключаться с локальных высоких значений на очень низкие значения во время сбоев (молчание или заполненные паузы и т. д.) вдоль одного высказывания. Следовательно, быстрые вариации могут быть замаскированы. в соответствии с промежутком времени, используемым для оценки, и общая оценка скорости речи может не актуально. Кроме того, оценка скорости речи актуальна и для автоматической речи. узнаваемости, поскольку эффективность распознавателей обычно снижается, когда они сталкиваются с особенно быстрые или медленные говорящие (Mirghafori et al., 1995). По этой причине существуют алгоритмы, позволяющие оцените либо телефонную скорость, либо скорость слога (например,грамм. Верхассельт и Мартенс, 1996; Пфау и Руске,
(17)1998). Однако последующая нормализация всегда применяется в одноязычном контексте, и отсутствует риск маскировки языковых вариаций. В настоящее время эффект такого рода нормализация в многоязычной структуре не была тщательно изучена, хотя она будет необходимо для целей ALI. Наша группа в другом месте обращалась к этому вопросу в исследовании межъязыковые различия в скорости речи в единицах количества слогов в секунду или фонем на второй (Пеллегрино и др., 2004; Rouas et al., 2004).
Последний вопрос — это основной вопрос, рассматриваемый в этой статье. В этом разделе оценивается наличие акустические корреляты языковой ритмической структуры. Однако обнаруживаются ли они и достаточно надежный, чтобы выполнять ALI или нет, нужно решать. Следующие разделы тщательно сосредоточиться на этом вопросе.
4. R МОДЕЛИРОВАНИЕ HYTHM ДЛЯ ALI 4.1. Обзор сопутствующих работСпоры о статусе ритма иллюстрируют трудность разделения речи на значимых ритмических единиц и подчеркивают, что глобальная многоязычная модель ритма — это длинный вызов диапазона. На самом деле, даже если коррелирует между речевым сигналом и лингвистическим ритм существует, разрабатывая его соответствующее представление и выбирая подходящее моделирование парадигма все еще под вопросом.
Среди прочих, Thymé-Gobbel & Hutchings (1999) подчеркнули важность ритмическая информация в системах языковой идентификации.Они разработали систему, основанную на вычисление отношения правдоподобия из статистического распределения множества параметров, связанных с ритма и основаны на времени слога, длительности слога и амплитуде (224 параметра считается). Они получили важные результаты и доказали, что простые просодические сигналы могут различать некоторые языковые пары корпуса телефонной речи ОГИ-МЛЦ с результаты сопоставимы с некоторыми непрозодическими системами (в зависимости от языковых пар правильные уровень дискриминации колеблется от вероятности до 93%).Cummins и его коллеги (1999)
(18)объединил кривую дельта-F0 и первую разность огибающей амплитуды с ограниченной полосой с моделями нейронных сетей. Эксперименты проводились также на корпусе ОГИ-МЛТС, используя попарную языковую дискриминацию, по которой они получили до 70% правильных идентификация. Были сделаны выводы, что F0 была более эффективной дискриминантной переменной, чем модуляция огибающей амплитуды и эта дискриминация лучше во всем семействе просодических языков, чем в одной семье.
Рамус и его коллеги предложили несколько исследований (Ramus et al., 1999; Ramus & Mehler, 1999; Ramus, 2002), основанный на использовании ритма для языковой идентификации. Этот подход имеет кроме того, были реализованы в задаче автоматического моделирования (Dominey & Ramus, 2000). Их эксперимент был направлен на оценку того, может ли искусственная нейронная сеть извлекать ритм характеристик предложений, помеченных вручную с учетом согласных и гласных звуков или без них. Используя корпус RMN «Ramus, Nespor, Mehler» (1999 г.), они достигли значительного результаты дискриминации между языками, принадлежащими к разным категориям ритмов (78% для Пара английский / японский) и уровень вероятности для языков, принадлежащих к одной ритмической категории.Они пришли к выводу, что эти последовательности согласных / гласных несут значительную часть ритмической шаблоны языков и что они могут быть смоделированы. Интересно, что Гальвес с коллегами (Galves et al., 2002) достигли аналогичных результатов без необходимости ручной маркировки: использование Данные RMN, они автоматически вывели два критерия из фактора звучности. Эти два критерия (среднее значение S и среднее значение производной δS фактора звучности S) приводят к
кластеризация языков, тесно связанных с тем, что было получено Рамусом и его коллегами.Более того, δS демонстрирует линейную корреляцию с ∆C, а S коррелирует с% V, что позволяет доказать
согласованность между двумя подходами.
Этот краткий обзор ритмических подходов к автоматической идентификации языка показывает, что несколько подходов, напрямую использующих акустические параметры без явного моделирования агрегата (например, Скрытая марковская модель), может существенно различать некоторые языковые пары. Вследствие этого, ритм может иметь значение для автоматического распознавания или определения категории ритма несколько языков.Однако тот факт, что все эти автоматические системы демонстрируют результаты
(19)«простое» попарное различение подчеркивает, что использование ритма в более сложных Задача идентификации (с более чем двумя языками) не проста.
4.2. Ритм блок моделированиеОсновная цель этого исследования — обеспечить автоматическую сегментацию сигнала на ритмические единицы, необходимые для идентификации языков и моделирования их темпоральных недвижимость эффективным способом.С этой целью мы используем алгоритм, ранее разработанный для моделирования системы гласных в задаче идентификации языка (Pellegrino & André-Obrecht, 2000). Главный Характеристики этой системы рассматриваются ниже. Эта модель не претендует на интеграцию всех сложных свойств языкового ритма и, в частности, он никоим образом не обеспечивает лингвистический анализ просодических систем языков; наблюдаемые временные свойства и статистически смоделированный результат взаимодействия нескольких надсегментарных свойств и точный анализ этого взаимодействия пока невозможен.
На рис. 1 показан краткий обзор системы. Независимая от языка обработка анализирует сигнал на гласные и негласные сегменты. Параметры, относящиеся к временной структуре Затем вычисляются ритмические единицы и оцениваются ритмические модели для конкретных языков. В течение на этапе тестирования выполняется такая же обработка и определяется наиболее вероятный язык следуя правилу максимального правдоподобия (подробности см. в разделе 5.2).
РИСУНОК 1
Чтобы извлечь признаки, относящиеся к потенциальному кластеру согласных (количество и продолжительность согласные), статистическая сегментация на основе алгоритма «прямое-обратное расхождение» применены.Заинтересованным читателям рекомендуется обратиться к (André-Obrecht, 1988) за исчерпывающим и подробное описание этого алгоритма. Он определяет границы, соответствующие резкому изменения в спектре волн, в результате чего образуются две основные категории сегментов: короткие сегменты (всплески, но также переходные части озвученных звуков) и более длинные сегменты (устойчивые части звуков).
(20)Сегментарное обнаружение речевой активности (SAD) выполняется для исключения длинных пауз (не связанных ритму), и, наконец, алгоритм определения гласных находит звуки, соответствующие вокальному структура с помощью спектрального анализа сигнала.SAD обнаруживает менее интенсивный сегмент высказывание (с точки зрения энергии) и другие сегменты классифицируются как тишина или речь согласно адаптивному порогу; Обнаружение гласных основано на динамическом спектральном анализе сигнал в частотных фильтрах Мела (оба алгоритма подробно описаны в Pellegrino & André-Obrecht, 2000). Пример синтаксического анализа гласных / негласных представлен на рисунке 2 (вертикальные пунктирные линии).
РИСУНОК 2
ТАБЛИЦА 2
Алгоритм применяется независимо от языка и говорящего без какого-либо руководства фаза адаптации.Он оценивается с помощью показателя частоты ошибок гласных (VER), определенного следующим образом:
% . 100 ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + знак равно Nvow Нинь Ндел ВЕР (1)
, где Ndel и Nins — количество удаленных гласных и вставленных гласных соответственно, а Nvow — это фактическое количество гласных в корпусе.
В таблице 2 показаны характеристики алгоритма спонтанной речи по сравнению с другими системы.Среднее значение, достигнутое на 5 языках (22,9% от VER), является наилучшим системы, оптимизированные для данного языка. Можно ожидать, что алгоритм будет работать лучше с читать речь. Однако ни один многоязычный корпус прочитанной речи с фонетической ручной пометкой не использовался. доступны авторам, чтобы подтвердить это предположение.
Обработка обеспечивает сегментацию речевого сигнала на паузу, негласную и гласную. сегменты (см. рисунок 2). Из-за внутренних свойств алгоритма (и особенно того факта, что что переходные и устойчивые части фонемы могут быть отделены), несколько неверно Учтите, что эта сегментация в точности совпадает с сегментацией согласных / гласных, поскольку по своей природе сегменты короче фонем.В частности, продолжительность гласных в среднем составляет
(21)недооценено, поскольку атаки и демпфирование часто сегментируются как переходные сегменты. фигура 2 отображает также примеры проблем чрезмерной сегментации согласных: финальная / fn / последовательность делится на 8 сегментов (4 для согласной группы, 1 для устойчивой части гласной и 3 для окончательного демпфирования). Однако наша гипотеза состоит в том, что эта последовательность существенно коррелирована. к ритмической структуре звука речи; и уже упоминавшаяся корреляция между фактический силлабический ритм и его оценка с помощью определения гласных (Pellegrino et al., 2004) подтверждает это. Мы предполагаем, что эта корреляция позволяет статистической модели различать языки согласно их ритмической структуре.
Даже если оптимальные ритмические единицы могут быть специфичными для языка (слог, мора и т. Д.), Слог можно рассматривать как хороший компромисс. Однако сегментация речи на слоги кажется механизмом, специфичным для языка, даже если универсальные правила, относящиеся к звучности, и если акустические корреляты границ слогов существуют (см. Content, 2000).Таким образом, нет В данный момент можно получить не зависящий от языка алгоритм, и даже алгоритмы, зависящие от языка встречаются нечасто (Kopecek, 1999; Shastri et al., 1999).
По этим причинам мы вводим понятие псевдослогов (PS), полученное из большинства часто встречающаяся в мире слоговая структура, а именно структура CV (Vallée et al., 2000). С помощью сегменты гласных как вехи, речевой сигнал разбирается на образцы, соответствующие структуре: .Cn V. (где n может быть целым числом, равным нулю).
Например, синтаксический анализ предложения, показанного на рисунке 2, приводит к следующей последовательности из 11 псевдослогов:
(CCV.CV.CV.CCCV.CCCV.CCV.CV.CCCV.CCCCV.CCCCV.CCCCCV)
примерно соответствует следующей фонетической сегментации:
(22)Как было сказано ранее, сегменты, помеченные в последовательности PS, короче фонем; следовательно, длина группы согласных в значительной степени смещена в сторону более высоких значений. чем те, которые даны при фонематической сегментации.Мы осознаем пределы такого базового ритмический анализ, но он дает попытку смоделировать ритм, который впоследствии может быть улучшен. Однако у него есть значительное преимущество, заключающееся в том, что ни данные с ручной маркировкой, ни Требуются обширные знания ритмической структуры языка.
Псевдослог описывается как последовательность сегментов, характеризующихся их продолжительностью и их бинарная категория (согласная или гласная). Таким образом, каждый псевдослог описывается матрица переменной длины.Например, файл .CCV. псевдосложность даст:
⎥ ⎦ ⎤ ⎢ ⎣ ⎡ знак равно 1 2 1 . . В С С CCV d d d В С С -П (2)
, где C и V — двоичные метки, а dX — длительность сегмента X.
Это описание переменной длины является наиболее точным, но не подходит для гауссовского Моделирование смеси (GMM).По этой причине другое описание, приводящее к постоянной длине описание для каждого псевдослога было выведено. Для каждого псевдослога по три вычисляются параметры, соответствующие, соответственно, общей длительности кластера согласных, всего продолжительность гласного и сложность согласного кластера. С тем же .CCV. например, описание становится:
(
)
{
C c V C}
CCV d d d N П . CCV ´ .=
{
(
d C 1+
d c 2)
d V 902 } П . ´ .=
1+
2 (3)где Nc — количество сегментов в кластере согласных (здесь Nc = 2).
Даже если это описание явно не оптимально, поскольку индивидуальная информация о согласном звуке сегменты теряются, это частично учитывает сложность группы согласных.
(23) 5. L ЯЗЫК I ДЕНТИФИКАЦИЯ T ASK 5.1. Описание корпуса и статистикаЭксперименты проводятся над многоязычным корпусом MULTEXT (Campione & Véronis, 1998), расширен японским (Kitazawa, 2002) и мандаринским (Komatsu et al., 2004). Этот Таким образом, база данных содержит записи на 7 языках (французском, английском, итальянском, немецком, японском, Мандаринский и испанский), произносится 70 разными носителями (5 мужчин и 5 женщин на язык).
Данные MULTEXT состоят из прочитанных отрывков, которые могут произнести несколько говорящих. Несмотря на относительно небольшой объем данных и во избежание возможной текстовой зависимости, следующие эксперименты проводятся с двумя подмножествами корпуса, определяющими неперекрывающееся обучение и тестовые наборы по спикерам и текстам (см. Таблицу 3). Учебный корпус должен быть представитель каждого языкового слогового инвентаря. Например, средняя продолжительность каждого отрывок для французских данных составляет 98 слогов (± 20 слогов) и общее количество слогов
токенов во французском корпусе — это примерно 11 7008.Даже если перечень слогов не является исчерпывающим в этого корпуса, разумно предположить, что статистическая модель, полученная на основе этих данных, будет статистически представляет большую часть разнообразия слогов для каждого языка.
В классической типологии ритмов французский, итальянский и испанский языки известны как синхронные по слогам. языков, в то время как английский, немецкий и мандаринский языки привязаны к ударению. Японец единственный своевременный язык корпуса. Верна ли эта типология или является результатом артефакта ритмический континуум, наш подход должен улавливать особенности, связанные с ритмом структура этих языков.
8
Это число учитывает количество повторений каждого отрывка. Рассматривая каждый отрывок один раз количество слогов — 3900.
(24)ТАБЛИЦА 3
Интуитивно предполагается, что продолжительность кластеров согласных должна коррелировать с количеством сегментов, составляющих кластер. В таблице 4 приведены результаты линейной регрессии с Dc (в секунд) как предсказатель Nc. Для каждого языка достигнута значимая положительная корреляция Значения и R² варьируются от 0.71 для французского языка до 0,77 для английского и немецкого (см. Рисунок 3 для диаграмма рассеяния английских данных). Что касается наклона, значения варьируются от 0,0271 для китайского языка до 0,0362. для испанского означает, что отношение между Nc и Dc в некоторой степени зависит от языка. По этой причине оба параметра были приняты во внимание в следующих экспериментах.
ТАБЛИЦА 4
РИСУНОК 3
Чтобы проверить гипотезы о языковых различиях в распределении параметров, Был проведен тест нормальности Жарка-Бера.Это подтверждает, что распределения явно не нормальный (p <0,0001; j> 103 для Dc, Dv и Nc, для всех языков). Следовательно, непараметрический Для каждого параметра был проведен тест Краскела-Уоллиса, чтобы оценить различия между языков. Они выявляют очень значимое глобальное влияние языка на Dv (p <.0001; df = 6; квадрат = 2248), Dc (p <0,0001; df = 6; квадрат = 1061) и Nc (p <0,0001; df = 6; хи-квадрат = 2839). Результаты теста Краскела-Уоллиса затем были использованы в нескольких процедура сравнения с использованием критерия значимости различия Тьюки.
ТАБЛИЦА 5
ТАБЛИЦА 6
(25)В таблицах 5–7 представлены результаты попарного сравнения. Чтобы сделать интерпретацию проще, на основе значений строится графическое представление (рис. 4). Что касается согласного длительности четко выделяется кластер, объединяющий языки с временной привязкой к ударным нагрузкам. Этот кластер согласованы со сложными началами и кодами, присутствующими в этих языках, либо в количестве фонемы (английский и немецкий) или внутренняя сложность согласных (придыхание, ретрофлекс, и др.для мандарина) Остальные языки распространились по измерению DC, а также японский и итальянский занимают промежуточное положение между наиболее типичными языками с синхронизацией по слогам (испанским и французским) и кластер языков, привязанных к стрессу.
Ситуация, выявленная Dv, совершенно иная: английский, японский, немецкий и итальянский кластеры вместе (хотя существуют значительные различия между итальянским, с одной стороны, и английским, японским и немецкий с другой стороны), в то время как мандаринский и французский далеки.Испанский также индивидуализированы на этой противоположной крайности этого измерения. Распределения NC показывают важные разнообразие языков, поскольку английский и мандаринский — единственный кластер, для которого нет наблюдается значительная разница.
РИСУНОК 4
5.2. GMM-моделирование для идентификацииGMM (модели гауссовской смеси) используются для моделирования псевдослогов, которые представлены в трехмерном пространстве, описанном в предыдущем разделе.Они оцениваются с использованием Алгоритм EM (максимизация ожидания), инициализированный алгоритмом LBG (Reynolds, 1995; Linde et al., 1980).
Пусть X = {x1, x2,…, xN} будет обучающим набором, а Π = {(αi, µ i, Σ i), 1 ≤ i ≤ Q} набором параметров, который
определяет смесь Q p-мерных гауссовских PDF-файлов. Модель, которая максимизирует общий вид вероятность получения данных определяется следующим образом:
∏ ∑
знак равно — = ⎪⎭ ⎪ ⎬ ⎫ ⎪⎩ ⎪ ⎨ ⎧ ⎥⎦ ⎤ ⎢⎣ ⎡ — — µ Σ — µ Σ π α знак равно Π Π N и к и к Т к и Q к п к к х х 1 1 1/2 * ) ( ) ( 2 1 ) 2 ( Максимум аргумент ехр (4) (26)где α k — вес смеси k th
Гауссов член.
Параметры максимального правдоподобия Π * получены с использованием алгоритма EM. Этот алгоритм предполагает, что количество компонентов Q и начальные значения даны для каждого гауссовского pdf. Поскольку эти значения сильно влияют на производительность алгоритма EM, Vector Квантование (VQ) применяется к обучающему корпусу для их оптимизации.
Алгоритм LBG (Linde et al., 1980) применяется для получения корней для алгоритма EM. Это выполняет итеративную кластеризацию обучающих данных в кодовые слова, оптимизированные в соответствии с правило ближайшего соседа.Прекращение процедуры расщепления возможно либо при изменении искажение данных падает ниже заданного порога или при достижении заданного количества кодовых слов (здесь используется этот вариант).
Во время фазы идентификации собираются все PS, обнаруженные в тестовом высказывании, и параметризовано. Вероятность этого набора сегментов Y = {y1, y2,…, yN } согласно каждому VSM
(обозначается Li ) определяется как:
) Pr ( ) Pr ( 1 и N к к i y L L Y
∑
знак равно = (5), где Pr (yj | Li ) обозначает вероятность каждого сегмента, которая определяется следующим образом:
⎥⎦ ⎤ ⎢⎣ ⎡ — — µ Σ — µ Σ π α = — знак равно
∑
() () 2 1 exp ) 2 ( ) Pr (1 1/2 и к к к Т и к Q к i к п. и к и л л л л y к и (6)Кроме того, гипотеза, основанная на предположении, что победитель принимает все (WTA) (Nowlan, 1991), выражение (7) затем аппроксимируется следующим образом:
⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ ⎥⎦ ⎤ ⎢⎣ ⎡ — — µ Σ — µ Σ π α = — ≤ ≤ 2 () () 1 exp ) 2 ( Максимум ) Pr (1 2 / 1 и к к к Т и к и к п. и к Q к и л. л. л. л. y к и (7)
(27) 5.3. Результаты автоматической идентификацииПсевдослоговая сегментация связана с языковым ритмом. Чтобы оценить, подтверждено ли это на самом деле или нет, первый эксперимент, направленный на различение между тремя ритмическими классами выполняется; языковой идентификационный эксперимент с Затем достигается 7 языков. Наконец-то реализован и апробирован стандартный акустический подход. с той же задачей провести сравнение.
Первый эксперимент направлен на определение того, к какой ритмической группе принадлежит язык, на котором говорят. неизвестным спикером корпуса MULTEXT.Собрание языковой группы, рассчитанной на стресс Английский, немецкий и китайский. Французский, итальянский и испанский определяют язык с синхронизацией по слогам. группа. Группа языков морального времени состоит только из японского. Число гауссовских компонентов зафиксировано на 16, используя обучающий набор в качестве набора для разработки, чтобы оптимизировать количество Гауссовские компоненты GMM. Общие результаты представлены в таблице 8 в замешательстве. матрица. 119 из 139 файлов тестовой выборки идентифицированы правильно. Средняя скорость идентификации составляет 86 ± 6% правильной идентификации (уровень вероятности 33%), а оценка по слогам колеблется от 80%.
и языков с временной привязкой до 92% для языков с временной привязкой.Эти первые результаты показывают, что Подход PS позволяет моделировать временные особенности, актуальные для ритмической группы. идентификация.
ТАБЛИЦА 8
Второй эксперимент направлен на определение того, на каком из 7 языков говорит неизвестный спикер корпуса MULTEXT. Количество гауссовых компонентов фиксировано до 8 с использованием обучающий набор как набор разработки для оптимизации количества гауссовских компонентов GMM. Общие результаты представлены в таблице 9 в виде матрицы неточностей.93 из 139 файлов набор тестов правильно идентифицирован. Таким образом, средний балл идентификации достигает 67 ± 8% правильных
(28)идентификация (уровень вероятности 14%). Поскольку набор тестов очень ограничен, доверительный интервал довольно широкая.
ТАБЛИЦА 9
Оценки сильно различаются: от 30% для испанского до 100% для французского. На самом деле испанский массово путают с французским; Итальянский также классифицируется неправильно (55% правильного решения) и особенно с английским.Плохая классификация наблюдается и для мандарина, который путают. с немецким и английским языками (55% правильной идентификации). Таким образом, это подтверждает, что классификация мандаринского языка как языка, подверженного ударным нагрузкам, согласуется с акустическим Здесь выполнено измерений, для которых распределения PS в китайском языке не имеют существенного значения отличается от немецких или английских дистрибутивов.
Большой разброс, наблюдаемый для оценок, можно частично объяснить изучением вариабельность темпа речи.Что касается ритма, речи или скорости говорящего, трудно определить, но это может оцениваться по слогам или фонемам в секунду. Подсчет количества гласных обнаружение в секунду может дать первое приближение скорости речи (см. Pellegrino et al., 2004, за обсуждение измерения скорости речи). Таблица 10 отображает для каждого язык базы данных среднее и стандартное отклонение количества гласных, обнаруженных на второй среди динамиков базы.
ТАБЛИЦА 10
Этот рейтинг варьируется от 5.05 для китайского языка на 6,94 для испанского, и эти изменения могут быть связаны с как социально-лингвистические факторы, так и ритмические факторы, связанные со структурой слога в тех языков. Испанский и итальянский демонстрируют наибольшие стандартные отклонения (соответственно 0,59 и 0,64) их скорость. Это означает, что их модели, вероятно, менее надежны, чем другие, поскольку параметр раздачи шире. Напротив, французский разброс самый маленький (0,33) и неизменно имеет лучший уровень языковой идентификации.Эта гипотеза подтверждается корреляционный тест (оценка порядка рангов Спирмена) между баллом идентификации языка и
(29)стандартное отклонение скорости речи (ρ = — 0,77, p = 0,05). Этот недостаток указывает на то, что при этом , нормализация длительностей Dc и D не выполняется. Это ограничение предотвращает наша модель не адаптирована к спонтанной речи, и это серьезное узкое место должно быть устранено в ближайшее время.
Наконец, те же данные и задача были использованы с акустическим классификатором GMM, чтобы сравнить результаты чисто ритмического подхода, предложенного в этой статье, с полученными со стандартным подходом.Параметры вычисляются для каждого сегмента, выпущенного из автоматическая сегментация (раздел 4). Функции состоят из 8 Mel Frequency Cepstral Коэффициенты, их производные и энергия, вычисляемые для каждого сегмента. Число гауссовских компонентов зафиксировано на 16, используя обучающий набор в качестве набора для разработки, чтобы оптимизировать количество Гауссовские компоненты GMM. Увеличение количества компонентов не приводит к лучшие выступления; это может быть связано с ограниченным размером обучающей выборки как с точки зрения продолжительность и количество говорящих (только 8 говорящих на каждом языке, кроме японского: 4 динамики).Общие результаты представлены в таблице 11 в виде матрицы неточностей. 122 из 139 файлы тестового набора правильно идентифицированы. Средняя частота идентификации составляет 88 ± 5% правильных
идентификация.
ТАБЛИЦА 11
Немецкий, китайский и японский прекрасно идентифицируются. Наихудшие результаты достигаются за Итальянский (65%). Примечательно, что мандаринский диалект хорошо отличается от английского и немецкого языков. вопреки тому, что наблюдалось с ритмическими моделями. Это говорит о том, что два подхода могут быть эффективно объединены для улучшения характеристик.Однако тот факт, что акустическая подход дает значительно лучшие результаты, чем ритмический подход предполагает, что дальнейшее улучшения необходимы перед проектированием эффективной архитектуры слияния.
(30) 6. C ВКЛЮЧЕНИЕ И ПЕРСПЕКТИВЫВ то время как большинство систем, разрабатываемых в настоящее время для целей языковой идентификации, основаны на о фонетических и / или фонотаксических характеристиках, мы считаем, что использование других видов информации может дополнять друг друга и расширять круг интересов этих систем, например, путем решения лингвистические типологические или когнитивные проблемы языковой обработки.Предлагаем один из первых подходов, посвященных идентификации языка на основе моделирования ритма, которое проверено на задача более сложная, чем попарное различение. В нашей системе используется автоматический сегментация на гласные и негласные сегменты, приводящие к синтаксическому анализу речевого сигнала на псевдослоговые узоры. Статистические тесты, проведенные для языковых распределений параметры псевдосложности показывают, что между семью языками это исследование (английский, французский, немецкий, итальянский, японский, китайский и испанский языки).Первый оценка обоснованности данного подхода дается по результатам ритмического занятия. Задача идентификации: Система достигает 86 ± 6% правильного распознавания при трех статистических
моделей обучаются с использованием данных из языков с временной привязкой (английский, немецкий и мандаринский), из языков с синхронизацией по слогам (французский, итальянский и испанский) и с японского (единственный своевременный язык этого исследования). Этот эксперимент показывает, что традиционное измерение стресс-мора vs. по слогам vs.своевременное противодействие оценивается на семи протестированных нами языках, или более точно, что три языковые группы (английский + немецкий + мандаринский против французского + Итальянский + испанский против японского) демонстрируют существенные различия в зависимости от времени предлагаемые нами параметры.
Второй эксперимент, проведенный с задачей идентификации на семи языках, дает относительно хорошие результаты. результаты (67 ± 8% правильной идентификации для 21-секундного высказывания). Еще раз недоразумения
чаще встречаются в ритмических классах, чем в ритмических классах.Среди семи языков, три из них имеют высокие баллы (более 80%) и могут быть квалифицированы как «Прототип» из ритмических групп (английский для определения времени ударения, французский для определения времени слога и японский для мора-тайминга). Таким образом, интересно отметить, что псевдослог
(31) Моделированиеможет также помочь идентифицировать языки, принадлежащие к одному и тому же ритмическому семейству (например, Французский и итальянский язык не путаются), показывая, что временная структура псевдослогов довольно специфичен для языка.Подводя итог, даже если сегментация псевдослога грубая и не в состоянии принять во внимание слоговые структуры, характерные для языка, он фиксирует, по крайней мере, часть ритмической структуры каждого языка.
Однако ритм нельзя свести к простой временной последовательности согласных и гласных, и, как указывает Zellner-Keller (2002), следует учитывать его многослойность. правильно характеризовать языки. Среди многих параметров те, которые связаны с тонами или явление стресса может быть довольно заметным.Например, мандаринский, который довольно путают с другие языки в настоящем исследовании могут быть хорошо узнаваемы с другими надсегментарными особенностями за счет тональной системы. Следовательно, учет характеристик энергии или шага может привести к значительное улучшение производительности языковой идентификации. Однако эти физические характеристики лежат на границе между сегментарным и надсегментарным уровнями и их значения и вариации, таким образом, являются результатом сложного взаимодействия, все более усложняя правильное обращение.
Кроме того, может быть улучшен алгоритм псевдослоговой сегментации. Дополнительный различение звонких и глухих согласных может быть выполнено для добавления еще одного ритмического параметр, и, кроме того, более сложные псевдослоги, включая коды (следовательно, с CmVCn структура) может быть получена путем применения правил сегментации на основе звучности (см. Galves et al., 2002 для связанного подхода).
Наконец, основной задачей будущего станет решение проблемы изменчивости темпа речи (показано в Разделе 5 коррелировать с характеристиками идентификации) и предложить эффективную нормализацию или моделирование, которое позволит адаптировать этот подход к телам спонтанной речи и больший набор языков.Очень предварительные эксперименты, выполненные на корпусе OGI MLTS, являются сообщается в Rouas et al., (2003).
(32) 7. A ЗНАНИЯАвторы хотели бы особенно поблагодарить Бриджит Зеллнер-Келлер за ее полезные комментарии и советует и Эммануэлю Феррану за тщательную вычитку черновика этой статьи. 188. Авторы очень благодарны рецензентам за конструктивные предложения и комментарии.
Это исследование было поддержано программой EMERGENCE региона Рона-Альпы. (2001-2003) и французским Ministère de la Recherche (программа ACI «Jeunes Chercheurs» — 2001-2004).
8. R ЭФЕРЕНЦИИАберкромби, Д., (1967), Элементы общей фонетики, Издательство Эдинбургского университета, Эдинбург
Адами, А.Г. и Германский. Х., (2003), Сегментация речи для говорящего и языка Признание, в учеб. Eurospeech, стр. 841-844, Женева
Андре-Обрехт, Р. (1988), Новый статистический подход к автоматической сегментации речи, IEEE Trans. по АССП, т. 36, № 1
Антуан, Ф., Чжу Д., Була де Мареуил П. и Адда-Декер М. (2004 г.), «Подходы к сегментам многоязычие для автоматической идентификации языков: телефоны и учебные программы », в proc. из Journées d’Etude de la Parole, Фес, Марокко
Баркат-Дефрадас, М., Василеску, И., и Пеллегрино, Ф. (2003). Стратегии восприятия и др. Автоматическая идентификация языков, Revue PArole
Берг Т. (1992). Производственные и перцепционные ограничения на исправление ошибок речи. в: Психологические исследования 54 стр.114-126.
Бессон, M & Schön D, (2001). Сравнение языка и музыки. В «Биологическом основы музыки «Р. Заторре и И. Перец, ред. Роберт Дж. Заторре и Изабель Перец. Анналы Нью-Йоркской академии наук, Vol. 930
Bond, Z. S. & Stockmal, V. (2002) Как отличить образцы разговорного корейского от ритмического и региональные конкуренты. Language Sciences 24, 175-185.
Boysson-Bardies, B., Vihman, M.M., Roug-Hellichius, L., Дюран, К., Ландберг, И., Арао, Ф. (1992) Материальные свидетельства отбора младенцев из изучаемого языка: кросс-лингвистическое исследование. В C.Ferguson, L. Menn & C. Stoel-Gammon (Eds.), Фонологическое развитие: модели, исследования, последствия. Тимониум, доктор медицины: York Press
Кампионе, Э., & Веронис, Дж. (1998), Многоязычная просодическая база данных, в Proc. ICSLP’98, Сидней, Австралия
(33)Content, A., Dumay, N., & Frauenfelder, U.H., (2000), Роль слоговой структуры в лексической сегментация на французском языке, в Proc.семинара по процессам разговорного словесного доступа,
Неймеген, Нидерланды
Content, A., Kearns, R.K., & Frauenfelder, U.H., (2001), Границы и начала в слоговом письме Сегментация, Журнал памяти и языка, 45 (2)
Кристал Д. (1990). Словарь лингвистики и фонетики. 3-е издание. Блэквелл Эд. Лондон.
Камминс Ф., Герс Ф. и Шмидхубер Дж. (1999), Определение языка по просодии без явных особенностей, в Proc.EUROSPEECH ‘99
Катлер А. и Норрис Д. (1988), Роль сильных слогов в сегментации для лексического доступа, Журнал экспериментальной психологии: человеческое восприятие и производительность, 14
Катлер А. (1996), Просодия и проблема границы слова, в книге «Сигнал к синтаксису: начальная загрузка» от Speech to Grammar in Early Acquisition, Morgan & Demuth (Eds.), Махва, Нью-Джерси: Лоуренс Эрлбаум Ассошиэйтс.
Дауэр, Р. М., (1983), Повторный анализ определения времени ударения и времени слога, Journal of Phonetics, 11 Делатр, П.& Olsen, C, (1969) «Силлабические особенности и звуковое впечатление на английском, немецком, Французский и испанский «, Lingua 22: 160-175.
Домини П. Ф. и Рамус Ф. (2000), Обработка естественного языка нейронной сетью: I. Чувствительность к последовательной, временной и абстрактной структуре у младенцев, языку и когнитивным функциям Процессы, 15 (1)
Друлман Р., Фестен Дж. М. и Пломп Р. (1994), Эффект уменьшения медленной временной модуляции по приему речи, JASA, 95 (5)
Duarte, D, Galves, A., Лопес Н. и Маронна Р. (2001). Статистический анализ акустических коррелятов ритма речи. Работа, представленная на Мастерской по ритмическим узорам, параметр настройки и смена языка, ZiF, Университет Билефельда
Ферран, Э. и Пеллегрино Ф., (2004), «Ритм в чтении британского английского: междиалект» Вариабельность », чтобы появиться в проц. of INTERSPEECH / ICSLP 2004, октябрь 2004 г. Чеджу, Корея Фромкин В. (Ред.) (1973). Речевые ошибки как лингвистическое свидетельство.Гаага: Mouton Publishers. Гальвес А., Гарсия Дж., Дуарте Д. и Гальвес К. (2002), «Звучание как основа для занятий ритмикой». Дискриминация », в тр. конференции Speech Prosody 2002, 11-13 апреля 2002 г.
Ganapathiraju, A., (1999), «Веб-страница группы распознавания речи на основе слогов», http://www.clsp.jhu.edu/ws97/syllable/, последнее посещение — июль 2002 г.
Gauvain, J.-L., Messaoudi, A. & Schwenk, H (2004), «Распознавание языка с помощью телефона. решеток », в сб.Международной конференции по обработке разговорной речи, остров Чеджу, Корея, 2004 г.
Грабе, Э. и Лоу, Э.Л., (2002), Продолжительная изменчивость речи и класс ритма Гипотеза, Статьи по лабораторной фонологии 7, Mouton.
(34)Гринберг, С. (1996), Понимание понимания речи — к единой теории речи восприятие, в Proc. Учебного пособия ESCA и семинара по продвинутым исследованиям слухового аппарата. Основы восприятия речи, Кил, Англия
Гринберг, С., (1997), О происхождении разборчивости речи в реальном мире, в Proc. принадлежащий Семинар ESCA по надежному распознаванию речи для неизвестных каналов связи, Пон-а-Муссон, Франция
Гринберг, С., (1998), «Стенографическая речь — слоговоцентрическая перспектива для понимание вариантов произношения », в Proc. семинара ESCA по моделированию Вариация произношения для автоматического распознавания речи, Кекраде, Нидерланды
Гринберг, С., Карви, Х.М. и Хичкок, Л., (2002), Связь акцента стресса с вариации произношения в спонтанном американском английском дискурсе, Появиться в Proc. из Семинар ISCA по просодированию и обработке речи, 2001 г., Ред Банк, Нью-Джерси, США
Хамди Р., Баркат-Дефрадас М., Ферран Э. и Пеллегрино Ф. (2004), «Время выступления и Ритмическая структура в арабских диалектах: сравнение двух подходов », появится в проц. из INTERSPEECH / ICSLP 2004, октябрь 2004 г. Чеджу, Корея
Джестед, W., Бэкон С.П. и Леман Дж. Р. (1982), Прямая маскировка как функция частоты, уровень маскера и задержка сигнала, JASA, 74 (4)
Keller, E., & Zellner, B. (1997). Требования к выходным данным для высококачественного синтеза речи Система : случай неоднозначности. Труды МИДДИМ-96 от 12-14 августа 96 г. (с. ). 300-308)
Керн С., Дэвис Б.Л., Кочбас Д., Кунтай А. и Зинк И. (в печати). «Кросслингвистические универсалии» и различия в лепете », в OMLL — Evolution of language and languages, European Научный фонд
Komatsu, M., Араи, Т. и Сугавара, Т. (2004): «Восприятие различения просодических типов», в прок. Речи Просоды, стр. 725–728, Нара, Япония, 2004 г.
Копечек И., (1999), Распознавание речи и слоговые сегменты, в Proc. семинара по Текст, речь и диалог — TSD’99, Лекционные заметки по искусственному интеллекту 1692, Springer-Verlag.
Ладефогед П. (1975). Курс фонетики. Нью-Йорк: Харкорт Брейс Йованович, стр. 296 Левелт, У., и Уилдон, Л., (1994), Имеют ли говорящие доступ к умственной слоговой речи, Познание, 50
Ли К.П., (1994), Автоматическая идентификация языка с использованием силлабических спектральных характеристик, в Proc. из IEEE ICASSP’94, Аделаида, Австралия
Либерман, А. & Маттингли, И.Г., (1985), Пересмотренная моторная теория восприятия речи. Познание, 21
Линде Ю., Бузо А. и Р. М. Грей, «Алгоритм для векторного квантователя», IEEE Trans. На COM., Январь 1980 г., т. 28, (1980)
MacNeilage, P.(1998). Фреймовая / содержательная теория эволюции речевого производства. Мозг и Behavioral Sciences, 21, 499-546.
Row to skierg преобразование
- Al (clo4) 3 молярная масса
- Напольная подставка представляет собой альтернативный метод поддержки SkiErg, если настенный монтаж не является вариантом. Напольная подставка позволяет SkiErg свободно стоять, что позволяет использовать SkiErg где угодно. Сделанный из стальных опор, он прочен и хорошо построен, но имеет колесики, позволяющие легко перемещать его на место и снимать с места.
- Fitness Town Эксперты по оборудованию для фитнеса. В Fitness Town есть большой выбор высококачественного домашнего и коммерческого фитнес-оборудования. Покупайте оборудование для фитнеса в Интернете или в любом из 7 наших фитнес-магазинов в Бернаби, Северном Ванкувере, Китсилано, Южном Ванкувере, Порт-Коквитламе, Лэнгли и Эдмонтоне. Шнур преобразователя генератора
- * Преобразует 240-вольтовый поворотный замок (L14-30) в шесть розеток на 120 вольт. SCan обрабатывает до 30 ампер (7500 i wtts) Работает с любым генератором 321517 13 ‘p Генератор 8130 ватт импульсный, 6500 ватт непрерывная мощность 120 вольт AC GFCI, 12 вольт постоянного тока, 120 вольт переменного тока с поворотным замком и 240 вольт переменного тока с поворотным замком розетки
- Ниже представлена моя структура таблицы, и я хочу преобразовать ее в другой формат (от типа строки к типу столбца) Я очень много пробовал, но Я не могу этого сделать.Вы должны проверить сводную таблицу: stackoverflow.com/questions/1241178/mysql-rows-to-columns — Panciz 14 янв.
- 23 июля 2013 г. · SkiErg можно использовать из сидячего положения — без задействования ног — для тех, кто восстанавливается после травмы, или для адаптивного использования. SkiErg поставляется с монитором производительности PM3, который точно отслеживает расстояние, скорость, темп, калории и ватты, с пятью вариантами отображения — все данные, кривая силы, катание на лыжах с кардиостимулятором, гистограмма и крупный шрифт.
- 2.Синхронный подход Пары преобразования отличаются структурной идентичностью корня и фонетической идентичностью основы каждого из слов. Естественно рассматривать основу одного из двух слов, составляющих пару преобразования, также как имеющую деривационный характер.
- Покупка и продажа на месте. На Craigslist есть списки автомобилей и грузовиков в районе Бостона. Просматривайте фотографии и ищите по состоянию, цене и т. Д.
- Наконец-то мы закончили установку многоместных сидений второго ряда.Мы используем заводские многоместные сиденья Ford Transit со съемными направляющими. Я использовал холоднокатаную сталь 1/8 дюйма, чтобы изготовить несколько пластин под фургоном, чтобы прикрутить к ним рельсы сиденья. Мы использовали болты 1/2 ″ Grade 8, шайбы и нейлоновые стопорные гайки.
- Amazon.de Am häufigsten gewünscht: Artikel, die in Rudergeräte am häufigsten zu Wunschzetteln oder Geschenklisten hinzugefügt werden.
- Напольная подставка представляет собой альтернативный способ поддержки SkiErg, если настенный монтаж невозможен.Напольная подставка позволяет SkiErg свободно стоять, что позволяет использовать SkiErg где угодно. Сделанный из стальных опор, он прочен и хорошо построен, но имеет колесики, позволяющие легко перемещать его на место и снимать с места.
- Я продаю с аукциона свою лыжную машину, которая находится в потрясающей форме. Это отличное оборудование для кардиотренировки. Особенно, если у вас мало места. Я прикрутил устройство к стене на шпильках, но вы можете купить напольную стойку прямо у Concept 2. Машина оснащена монитором производительности Concept PM3 для отслеживания вашего прогресса.
- 15 сентября, 2020 · Сайт работает по (502) 863-0173 Расположение: 1280 Lexington Rd Джорджтаун, штат Кентукки Почтовый адрес: PO Box 1089 Georgetown, KY 40324
- 1. Введение. В этой статье мы рассмотрим преобразования типов в Spring. Spring предоставляет «из коробки» различные преобразователи для встраиваемых типов; это означает преобразование в / из базовых типов, таких как String, Integer, Boolean и ряда других типов.
- Рассчитывайте текущую валюту и курсы обмена с помощью этого бесплатного конвертера валют.Вы можете конвертировать валюту и драгоценные металлы с помощью этого валютного калькулятора.
- pdb files скачать бесплатно — Easy PDB, PDB Converter Pro, PDB Symposium и многие другие программы. Расширение файла .pdb — это формат базы данных, используемый для платформы Palm OS. Тип файлов «Электронная книга PalmDOC» является версией формата PDB.
- Приложение для пикапов Walmart не работает
Детали динамо-машины Miller Для начала, тренажер Marpo Rope Climb Machine, Concept II SkiErg и Schwinn Air Bikes могут обеспечить хорошее, сложное кардио-упражнение для верхней части тела.Поскольку каждый тренажер специализируется на своей собственной дисциплине фитнеса (скалолазание, катание на лыжах и езда на велосипеде), у спортсменов есть возможность не только выполнять упражнения, которые им нравятся, но и пробовать новые … Фактически, все тренировки, которые когда-либо выполнялись на этом тренажере видно, задокументированы на одной из картинок выше. У меня есть все оригинальные книги, инструкции / учебные пособия. У меня также есть комплект пульсометра / передатчика Polar T31 и компакт-диск Concept 2 e-Row. e-Row — это компьютерное приложение, которое используется с прибором Concept2 Indoor Rower Performance Monitor / 2 +.
SkiErg можно использовать даже сидя в кресле, например, для большей изоляции верхней части тела или для работы с травмой нижней конечности. Важно понимать, что он только имитирует двойное движение в беговых лыжах, и многие люди могут с этим не согласиться.
Adxl335 преобразовать в силу g- Эргометр C2 и SkiErg — это просто машины, и их можно улучшить. Concept 2 лучше надеялся, что производители эргометров Vasa не придут в голову ставить свою машину у стены и прикреплять лыжные рукоятки к тросам.Это сделало бы Concept 2 SkiErg похожим на проект средней школы для проходных классов. Bernsteins Weight Loss Natural Diet Pills, Diet Pills Explained, How Bernsteins Diet Pills. Jumpstarting Weight Loss Weight Ella Diet Pills Каталог похудания Орлистат Потеря веса, сайт кето-диеты Cenegenics потеря веса Ronnie Diet Pills Бариатрические диетические продукты Mate Fit bydureon потеря веса Диета.
- Полевой культиватор Brady Wing Fold 21 ‘, задвижки, кроме части заднего ряда, в комплект входят дополнительные зажимы и захваты для завершения переоборудования, а также несколько дополнительных деталей для запасных частей, есть выравниватель штанги M&W на задней панели, заменены все пружины выравнивателя Прошлый год (отсутствует), гидравлическое складывание, новые шланги на подъемном цилиндре, хорошие шины
- Коэффициент пересчета ρ можно интерпретировать как изменение обменного курса, связанное с вмешательством в размере 1 миллиарда долларов.Оценки коэффициента преобразования ρ позволяют рассчитать ежемесячный временной ряд ПУОС для 139 стран. Кроме того, набор данных содержит 68% доверительный интервал (высокие и низкие значения) для точечных оценок ρ.
Chrome change user agent android
Craigslist Bozeman Rvs на продажу владельцемZianourry harry asthma Процесс клеточного дыхания происходит в клеточной органелле
Различные взгляды на преобразование. Семантические отношения внутри преобразованных пар.Преобразование (нулевая деривация, деривация без аффиксов) — это образование слов без использования специфических словообразовательных аффиксов. Термин «преобразование» был введен Генри Свитом в его «Новом английском» …
Ford 1.6 Timing Tool autozoneRyzen master memory clock Fabric clock
Узнайте среднюю мощность или темп ваших тренировок по гребле в помещении Concept2 с помощью нашего простого в использовании Pace-to -Калькуляторы ватт и ватт-темп.
Убийства Бемиджи 2006 Общий комплект для восстановления насоса
Конвертер субтитров Быстрое преобразование файлов субтитров YouTube SBV в форматы субтитров SRT или XML.Инструкции. Воспользуйтесь замечательной системой субтитров YouTube, чтобы быстро создать файл .sbv. Узнайте, как это сделать здесь.
Контур Кокса для морозильного ларя rokuGe 7 куб.футов costco
GAVITA Pro 300 LEP Система плазменного освещения с воздушным охлаждением 240 В Гавана Коричневая патио Смола плетеный диван для отдыха на открытом воздухе Набор из 4 предметов с тканью Sunbrella InfraColor — терапия Инфракрасная сауна для 2-3 человек Kasco Морской аэратор 3/4 HP 120V Display Aerator — 100 футов. Cord, Модель # 3400JF LexMod Aero Outdoor Wicker Patio Комплект из 7 секционных диванов из эспрессо с подушками из мокко LexMod Aero Outdoor Wicker…
США iptv m3uExcel глава 8 удовлетворенность клиентов
Внесите свой вклад в разработку WICG / conversion-measure-api, создав учетную запись на GitHub. Конверсия: завершение значимого (указанного рекламодателем) действия пользователя на веб-сайте рекламодателя пользователем, который ранее взаимодействовал с рекламой из этого …
Машинные строки как новые. 800 фунтов стерлингов. Объявление размещено 22 дня назад Сохранить это объявление 4 изображения; Гребной тренажер модели Concept 2 E Elgin, гребной тренажер Moray Concept 2.Практически не используется, всегда … SkiErg доступен для инвалидных колясок для людей с травмами ног или адаптивных спортсменов, а также SkiErg Workout. После пятиминутной разминки начните с 30 секунд катания на лыжах высокой интенсивности, а затем 2 минут умеренной интенсивности, чтобы немного отдышаться.
Оба являются тренажерами Concept2, 12 калорий на гребце равны 12 на лыжах. Большинство людей не так хорошо владеют лыжным спортом, но это должно быть так же. Потратьте на это немного времени! уровень 2
Форсаж 4 фильмизилла.vin
Ключ к ответу цивилизации Индийской долиныПреобразование Rapide. Accédez à nos convertisseurs les plus populaires ci-dessous для быстрого преобразования, la distance, la température, la zone и т.