Слова «плюс» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «плюс» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «плюс» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «плюс».
Содержимое:
- 1 Как перенести слово «плюс»
- 2 Морфологический разбор слова «плюс»
- 3 Разбор слова «плюс» по составу
- 4 Сходные по морфемному строению слова «плюс»
- 5 Синонимы слова «плюс»
- 6 Антонимы слова «плюс»
- 7 Ударение в слове «плюс»
- 8 Фонетическая транскрипция слова «плюс»
- 9 Фонетический разбор слова «плюс» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «плюс»
- 11 Сочетаемость слова «плюс»
- 12 Значение слова «плюс»
- 13 Как правильно пишется слово «плюс»
- 14 Ассоциации к слову «плюс»
Как перенести слово «плюс»
Плюс
Морфологический разбор слова «плюс»
Часть речи:
Союз
Грамматика:
часть речи: союз;
отвечает на вопрос:
Начальная форма:
плюс
Разбор слова «плюс» по составу
| плюс | корень |
| ø | нулевое окончание |
плюс
Сходные по морфемному строению слова «плюс»
Сходные по морфемному строению слова
Синонимы слова «плюс»
1. достоинство
достоинство
2. преимущество
3. добродетель
4. совершенство
5. знак
6. крестик
7. да
8. выгода
9. сильная сторона
10. положительный момент
Антонимы слова «плюс»
1. минус
Ударение в слове «плюс»
Плю́с — ударение падает на слог с единственной гласной в слове
Фонетическая транскрипция слова «плюс»
[пл’`ус]
Фонетический разбор слова «плюс» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| П | [п] | согласный, глухой парный, твёрдый, шумный | П |
| л | [л’] | согласный, звонкий непарный (сонорный), мягкий | л |
| ю | [`у] | гласный, ударный | ю |
| с | [с] | согласный, глухой парный, твёрдый, шумный | с |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 4 буквы и 4 звука.
Буквы: 1 гласная буква, 3 согласных букв.
Звуки: 1 гласный звук, 3 согласных звука.
Предложения со словом «плюс»
Но при всех плюсах май больше подходит для общения со старыми друзьями, а новые персоны, появившиеся в вашем окружении в период с 27 апреля по 22 мая, пользы вам не принесут.
Источник: Татьяна Борщ, Лунный календарь для женщин на 2016 год + календарь стрижек, 2015.
В такой холод (а были примерно плюс десять) нас встретили полуобнажённые служанки.
Плюс отряд «Вергилий» и десяток рыцарей.
Источник: Александр Маяков, Летописи межмирья. Книга четвертая. Осколки.
Сочетаемость слова «плюс»
1. большой плюс
2. единственный плюс
единственный плюс
3. огромный плюс
4. до плюс бесконечности
5. множество плюсов
6. масса плюсов
7. со знаком плюс
8. плюсы перевешивают
9. иметь свои плюсы и минусы
10. взвешивать плюсы и минусы
11. найти свои плюсы
12. (полная таблица сочетаемости)
Значение слова «плюс»
ПЛЮС , -а, м. 1. Мат. Знак (+), обозначающий действие сложения или положительность величины; противоп. минус. Поставить плюс. (Малый академический словарь, МАС)
Как правильно пишется слово «плюс»
Орфография слова «плюс»Правильно слово пишется: плюс
Нумерация букв в слове
Номера букв в слове «плюс» в прямом и обратном порядке:
- 4
п
1 - 3
л
2 - 2
ю
3 - 1
с
4
Ассоциации к слову «плюс»
Минус
Балл
Ноль
Очко
Шкала
Процент
Баланс
Сложение
Стоимость
Нуль
Аккумулятор
Двойка
Чаевые
Издержка
Оклад
Градус
Аглая
Расход
Гонорар
Погост
Тройка
Температура
Зарплата
Телепатия
Оплата
Страховка
Варианта
Компенсация
Ооо
Оценка
Возмещение
Бакс
Гравитация
Штраф
Жалованье
Стипендия
Радиостанция
Пенс
Обозреватель
Плата
Взнос
Дизайн
Скидка
Льгота
Аванс
Авто
Налог
Гражданка
Авторские
Доллар
Внезапность
Сумма
Комплект
Имидж
Питание
Котов
Сбережение
Вещание
Литр
Недостаток
Влажность
Несомненный
Балловый
Безусловный
Дополнительный
Бесплатный
Кое-какой
Неоспоримый
Центовый
Долларовый
Чеченский
Бесспорный
Годовой
Очевидный
Евро
Пике
Фунтовый
Сюжетный
Гарантированный
Существенный
Отрицательный
Выпуклый
Заработный
Призовой
Пожизненный
Стерлинговый
Обслуживающий
Ежемесячный
Взвешивать
Взвесить
Равняться
Прикинуть
Перечислять
Сочетать
Отнести
Оценить
Прикидывать
Обозначаться
Итого
Объективно
Опубликовано: 2020-07-08
Популярные слова
бросала , глиноземный , притесненными , двухвесельным , ангелках , ансамблях , аншлага , ароматен , басмаческим , бензиловому , береглось , валютчице , вбухивала , ввертим , взбалмошна , возмутится , вываливающемуся , вымазавшуюся , выпрашиваемое , выстеганная , гиацинту , грамположительных , громоподобное , дефектную , добиравшего , доросшую , забинтовывающие , завьючивать , крупнопромышленный , номограмма , перепродавала , плюсовую , поддержавшая , подквашивание , полуосветившая , помирят , предшественницах , пригвождающим , приумножениях , рефлекторность
общие правила, план по пунктам, звуко-буквенный анализ
Русский язык
12. 11.21
11.21
8 мин.
Школьная программа по русскому языку предполагает изучение различных видов разборов, в том числе и фонетический. Именно с этого раздела лингвистики, изучающего звуки и звуковое строение слов, и начинается углубленное изучение родной речи. Звуки являются основными кирпичиками в правильном овладении языка. Фонетический разбор слова «каюта» поможет сформировать необходимые в лингвистической работе навыки.
Оглавление:
- Порядок фонетического разбора
- Пример правильного анализа
- Значение слова
Порядок фонетического разбора
Многие люди, и не только иностранцы, считают русский язык очень сложным. И только малая часть неспециалистов считает, что исследование речи очень увлекательная штука. Изучение же фонетики — это база для правильного произношения. Поэтому освоение ее начинают в 1 классе, буквально с начала сентября, когда еще не все дети даже читать умеют.
- Глубже понимается природа орфографии, а это значительный плюс для грамотности.
- Разбор поясняет и объединяет правила проверки сложных букв, в т. ч. и непроизносимых в корнях, приставках, суффиксах и окончаниях.
- Для четкого понимания, что есть слова, которые пишут не так, как говорят.
- Для развития «орфографической зоркости».
- Для понимания и принятия сложных правил русского языка и легкого применения их на практике.
Фонетический анализ включает в себя: составление фонетической характеристики и транскрипции.
Общие правила
При звуко-буквенном (фонетическом) разборе определяют количество звуков, букв (цифра может не совпадать), местонахождение ударения, классификация гласных и согласных.
- Слово в транскрипции охватывают квадратными скобками. Ели требуется обозначить ударение, его также отмечают в транскрипции.
- Каждый отдельный звук охватывают квадратными скобками.
- Вместо твердого и/или мягкого знака ставят прочерк: [ — ].
- Если звук мягкий, его отмечают апострофом: [ л´ ].
- Продолжительное звучание звука отмечают двоеточием [т’эн’:ис] или чертой над звуком.
Обычно учителя в школах предлагают заканчивать разбор, подводя черту и указывая под ней окончательное количество букв и произносимых звуков в слове.
Существует еще несколько отдельных правил для твердого и мягкого знаков.
- Так как знаки не имеют звука, то и в транскрипции присутствовать они не могут.
- «Ь» необходим для голосового смягчения предыдущей согласной.

- «Ъ» необходим, как разделительный знак.

В некоторых случаях «ь» необходим для обозначения грамматической формы слова, при этом не влияя на произношение. Буква «ъ» иногда необходима для разделения приставки с согласной и последующими буквами «Е», «Ю», «Ё», «Я».
План проведения
Фонетический разбор делают по строго определенному плану. В некоторых школьных программах присутствуют незначительные отличия. Но по общим правилам анализ выполняют в следующем порядке:
- Слово.
- Транскрипция.
- Обозначить ударение.
- Разделить на слоги. Записать их количество.
- Все буквы выписать в столбик, записать количество.
- Рядом с каждой отдельной буквой прописать в квадратных скобках звуки, отображающие имеющиеся буквы.
- Описать звук: гласный или согласный, твердый или мягкий, глухой или звонкий, парный, ударный.
- Записать количество звуков.
Редко, но иногда в правилах рекомендуется пояснить нюансы орфографии, т.
 е. правила правописания.
е. правила правописания.Для фанатов русского языка и тех, кто изучает его особенности профессионально в институте, существует ряд дополнительных пунктов при расширенном фонетическом разборе. В этом случае учитываются тонкости современного произношения и изменения прошедшие за последние столетия.
Пример правильного анализа
Для примера подойдет слово «каюта». Согласно правилам сначала записывают транскрипцию и обозначают ударение. Чтобы проделать звуко-буквенный анализ, необходимо определить, сколько звуков в слове «каюта», определить полый состав:
- [ кай´ ута ].
- Ударение на 2 слоге.
- Слово имеет 3 слога: ка-ю-та. Возможны 2 разновидности переноса: каю-та, ка-юта.
- Определить сколько букв и звуков «каюта», правильный ответ:
| Звук | Характеристика | Буква |
| [ к ] | Согласный, тверд. (шумный), парн., глух. | к |
| [ а ] | Безударный гласный | а |
| [ й´ ] [ у ] | Согласн. ,, мягкий, непарн. звонкий (сонорный) гласный, ударный ,, мягкий, непарн. звонкий (сонорный) гласный, ударный | ю |
| [ т ] | Согласн., твердый (шумн.), парн. глухой | т |
| [ а ] | Безударн. гласный | а |
Слово имеет 3 гласных и 2 согласных буквы, но 3 гласных и 3 согласных звука. Проверочных слов нет, т. к. «каюта» — словарное. Фонетический разбор слова «каюта» достаточно прост, но имеет нюансы из-за некоторых букв в существительном.
Значение слова
В русский язык слово пришло вначале XVII в. Основное значение — небольшая жилая комната на пароходе, яхте или любом другом судне, отдельное помещение для команды или пассажиров. Может использоваться для обозначения подсобного помещения на корабле. Примеры использования: «Катя зашла в кают-компанию», «Пассажир занял каюту 1-го класса», «У капитана была отдельная от команды каюта».
Не успеваете написать работу?
Заполните форму и узнайте стоимость
Вид работыПоиск информацииДипломнаяВКРМагистерскаяРефератОтчет по практикеВопросыКурсовая теорияКурсовая практикаДругоеКонтрольная работаРезюмеБизнес-планДиплом MBAЭссеЗащитная речьДиссертацияТестыЗадачиДиплом техническийПлан к дипломуКонцепция к дипломуПакет для защитыСтатьиЧасть дипломаМагистерская диссертацияКандидатская диссертацияКонтактные данные — строго конфиденциальны!
Указывайте телефон без ошибок! — потребуется для входа в личный кабинет.
* Нажимая на кнопку, вы даёте согласие на обработку персональных данных и соглашаетесь с политикой конфиденциальности
Подтверждение
Ваша заявка принята.
Ей присвоен номер 0000.
Просьба при ответах не изменять тему письма и присвоенный заявке номер.
В ближайшее время мы свяжемся с Вами.
Ошибка оформления заказа
Кажется вы неправильно указали свой EMAIL, без которого мы не сможем ответить вам.
Пожалуйста проверте заполнение формы и при необходимости скорректируйте данные.
window.location.protocol }; var s = document.createElement(‘script’); s.setAttribute(‘async’, 1); s.setAttribute(‘data-cfasync’, false); s.src = ‘/195c714.php’; document.head && document.head.appendChild(s) })();
Новые вопросы
Ответы
1 (с в й а т к и)
2 (й о л о ч к и)
3 (о б ъ й о м)
4( п е н й о к)
5( п л й у с)
6( к а й у т а)
Похожие вопросы
Почему герасим ушёл в деревню? что хотел сказать читателям Тургенев(вызвать сочуствие, протест против своеволия помещиков, показать силу характера и чувство достоинства героя)? Приготовить рассуждения га тему. ( не менее 15 предложений)…
( не менее 15 предложений)…
Составьте 3 сложносочинёных предложения с 3 грамматическими основами на любую тему…
Спешите. Укажите разряд прилагательных.
Красный, сильный, молочный, лебяжий, петушиный, дядин, зимний, пластиковый, аккуратный, серебряный…. по быстреее…
Помогите дам 30 баллов…
Разбор слова двенадцатое…
Сочинение — рассуждение на тему какой я хотел бы оставить след на змле…
Математика
Литература
Алгебра
Русский язык
Геометрия
Английский язык
Химия
Физика
Биология
Другие предметы
История
Обществознание
Окружающий мир
География
Українська мова
Українська література
Қазақ тiлi
Беларуская мова
Информатика
Экономика
Музыка
Право
Французский язык
Немецкий язык
МХК
ОБЖ
Психология
Патент США на использование фонетических вариантов в местном контексте для улучшения понимания естественного языка.
 Патент (Патент № 11 295 730, выдан 5 апреля 2022 г.) № 14/634,642, озаглавленная «Использование фонетических вариантов в местном контексте для улучшения понимания естественного языка», поданная 27 февраля 2015 г., которая претендует на приоритет по сравнению с предварительной заявкой США № 61/945,733, поданной 27 февраля 2014 г. и озаглавленной « Фонетические варианты» с именами изобретателей Кейвана Мохаджера, Криса Уилсона и Бернара Мон-Рейно, что связано с заявкой США № 61/79.8526, поданная 15 марта 2013 г. под названием «Интегрированная среда программирования для понимания речи и текста» с именами изобретателей Кейвана Мохаджера, Сейеда Маджида Эмами, Криса Уилсона и Бернара Мон-Рейно, обе заявки которых настоящим включены в качестве ссылки.
Патент (Патент № 11 295 730, выдан 5 апреля 2022 г.) № 14/634,642, озаглавленная «Использование фонетических вариантов в местном контексте для улучшения понимания естественного языка», поданная 27 февраля 2015 г., которая претендует на приоритет по сравнению с предварительной заявкой США № 61/945,733, поданной 27 февраля 2014 г. и озаглавленной « Фонетические варианты» с именами изобретателей Кейвана Мохаджера, Криса Уилсона и Бернара Мон-Рейно, что связано с заявкой США № 61/79.8526, поданная 15 марта 2013 г. под названием «Интегрированная среда программирования для понимания речи и текста» с именами изобретателей Кейвана Мохаджера, Сейеда Маджида Эмами, Криса Уилсона и Бернара Мон-Рейно, обе заявки которых настоящим включены в качестве ссылки.ПРЕДПОСЫЛКИ Поле
Раскрытая технология относится к системам распознавания речи и, более конкретно, к использованию локальных переопределений фонетического словаря при обработке фонетических маркеров, извлеченных из речевого высказывания.
Предшествующий уровень техники
Автоматическое распознавание речи и понимание речи компьютером были предметом значительной работы за последние несколько десятилетий. Первоначальный успех был довольно ограниченным, и люди рано поняли, что речевые сигналы чрезвычайно изменчивы и что одних акустических данных недостаточно для надежной транскрипции речевого высказывания в фонемы или текст. Было признано, что ключ к большей устойчивости (помимо улучшения каждого из отдельных компонентов большой системы) лежит в интеграции многих ограничений, как можно большего количества ограничений, которые могут быть наложены на интерпретацию высказывания. Языковые модели являются основными источниками ограничений для распознавания речи, а понимание речи дополнительно использует семантические модели.
Языковая модель предоставляет средства ранжирования последовательностей слов в соответствии со степенью приемлемости каждой последовательности. Это может принимать форму ответа «да» или «нет» с использованием классической грамматики, которая принимает или отвергает последовательности слов, или формы вероятности принятия с использованием стохастической грамматики или статистической модели языка. Надежные системы распознавания и понимания речи используют языковые модели того или иного типа для ограничения результатов акустического анализа, а также внешний компонент, который создает гипотезы фонемы из акустического сигнала.
Это может принимать форму ответа «да» или «нет» с использованием классической грамматики, которая принимает или отвергает последовательности слов, или формы вероятности принятия с использованием стохастической грамматики или статистической модели языка. Надежные системы распознавания и понимания речи используют языковые модели того или иного типа для ограничения результатов акустического анализа, а также внешний компонент, который создает гипотезы фонемы из акустического сигнала.
Статистическая языковая модель (SLM) присваивает вероятность последовательности слов на основе обучения модели с использованием набора текстовых данных. Последовательность слов длины n называется N-граммой. Наиболее полезные последовательности имеют длину 1, 2, 3 или 4 и называются униграммами, биграммами, триграммами и квадрограммами соответственно. Также рассматриваются большие значения N. Корпус текстовых документов может быть обработан для извлечения каждой N-граммы в документах и подсчета количества вхождений каждой конкретной N-граммы в корпусе. Получение вероятностей непосредственно из эмпирических подсчетов частоты приводит к серьезным проблемам, когда данных мало и отсутствуют определенные N-граммы. Существует ряд методов сглаживания для преобразования частотных подсчетов в полезные вероятности, которые становятся частью SLM. Затем SLM предоставляет способ определить вероятность последовательности слов в соответствии с простыми формулами условной вероятности.
Получение вероятностей непосредственно из эмпирических подсчетов частоты приводит к серьезным проблемам, когда данных мало и отсутствуют определенные N-граммы. Существует ряд методов сглаживания для преобразования частотных подсчетов в полезные вероятности, которые становятся частью SLM. Затем SLM предоставляет способ определить вероятность последовательности слов в соответствии с простыми формулами условной вероятности.
Классическая грамматика — это языковая модель, определяющая набор допустимых последовательностей слов и отвергающая другие последовательности. Принятые последовательности слов называются предложениями в соответствии с грамматикой. Грамматика на уровне слов, такая как грамматика английского языка, может использоваться для самых разных целей. В системе понимания естественного языка это помогает идентифицировать допустимый ввод — будь то текст или речевые высказывания. Грамматика использует грамматические символы, также называемые нетерминалами, и конечные символы, которыми в случае интереса являются английские слова, и она имеет один или несколько «начальных символов», таких как  Грамматика состоит из продукционных правил, также называемых грамматическими правилами, с одним или несколькими такими правилами для каждого нетерминального символа. В контекстно-свободной грамматике продукционное правило имеет «левую часть», состоящую из одного нетерминального символа, и «правую часть», представляющую собой последовательность терминальных и нетерминальных символов. В контекстно-зависимой грамматике «левая сторона» может иметь более одного символа. Грамматика может использоваться для создания правильных предложений, но обычно она используется для распознавания правильных предложений. Имея грамматику и входную последовательность, которая в данном случае является последовательностью слов, процесс синтаксического анализа использует правила грамматики, чтобы принять входные данные, которые может сгенерировать грамматика (в этом случае он создает синтаксический анализ, который обычно отображается как parse tree), иначе он отклонит входную последовательность. В данной области техники известно много способов синтаксического анализа.
Грамматика состоит из продукционных правил, также называемых грамматическими правилами, с одним или несколькими такими правилами для каждого нетерминального символа. В контекстно-свободной грамматике продукционное правило имеет «левую часть», состоящую из одного нетерминального символа, и «правую часть», представляющую собой последовательность терминальных и нетерминальных символов. В контекстно-зависимой грамматике «левая сторона» может иметь более одного символа. Грамматика может использоваться для создания правильных предложений, но обычно она используется для распознавания правильных предложений. Имея грамматику и входную последовательность, которая в данном случае является последовательностью слов, процесс синтаксического анализа использует правила грамматики, чтобы принять входные данные, которые может сгенерировать грамматика (в этом случае он создает синтаксический анализ, который обычно отображается как parse tree), иначе он отклонит входную последовательность. В данной области техники известно много способов синтаксического анализа.
Стохастическая грамматика — это грамматика, которая связывает вероятность с каждым альтернативным правилом вывода для нетерминала. Во время синтаксического анализа эти вероятности могут быть перемножены вместе для определения вероятности каждого возможного дерева синтаксического анализа. В остальной части этого описания использование неквалифицированного термина «грамматика» будет относиться к стохастической грамматике. Классическую грамматику можно легко превратить в стохастическую, назначив вероятности по умолчанию (например, равные вероятности) альтернативным продукционным правилам для нетерминала.
В некоторых реализациях слова естественного языка являются терминальными символами, а грамматика имеет нетерминальные символы, такие как <СУЩЕСТВИТЕЛЬНОЕ>, <СОБСТВЕННОЕ СУЩЕСТВЕННОЕ>, <МЕСТОИМЕНИЕ>, <НАРЕЧИЕ> и многие другие. Мы также используем слово «шаблон» для обозначения правой части грамматического правила. Образец может быть последовательностью терминальных и нетерминальных символов, но также обычно используются более разрешительные определения. Регулярные выражения над алфавитом нетерминалов и терминалов — удобная и понятная формулировка шаблона. При необходимости разрешающие определения шаблонов (такие как расширенный БНФ и другие формализмы) могут быть преобразованы обратно в простую форму контекстно-свободной грамматики, описанную выше.
Регулярные выражения над алфавитом нетерминалов и терминалов — удобная и понятная формулировка шаблона. При необходимости разрешающие определения шаблонов (такие как расширенный БНФ и другие формализмы) могут быть преобразованы обратно в простую форму контекстно-свободной грамматики, описанную выше.
Грамматические шаблоны (правые части правил) используются для сопоставления частей текста или высказываний. Несколько шаблонов могут соответствовать частям одного входного текста или высказывания. Как правило, процесс синтаксического анализа может дать более одного ответа. Некоторые синтаксические анализаторы (такие как инкрементные синтаксические анализаторы) поддерживают все параметры синтаксического анализа параллельно, сокращая рассматриваемые параметры синтаксического анализа, продолжающегося от одного слова к другому.
Грамматика определяет синтаксические правила, определяющие язык. Синтаксический анализатор, основанный на грамматике, будет принимать последовательности слов, которые являются синтаксически правильными или действительными для языка, и отвергает последовательности, которые не являются таковыми. В некоторых реализациях синтаксический анализатор может быть создан путем компиляции грамматики в более эффективную форму — объектный код, оптимизированный для синтаксического анализа.
В некоторых реализациях синтаксический анализатор может быть создан путем компиляции грамматики в более эффективную форму — объектный код, оптимизированный для синтаксического анализа.
Семантическая грамматика — это грамматика, которая была дополнена дополнительными ограничениями для последовательностей слов, чтобы они имели смысл и создавали их значение. Для многих приложений понимания естественного языка осмысленное предложение — это предложение, которое может быть переведено в осмысленное представление, на которое можно воздействовать. Семантический анализатор — это анализатор, основанный на семантической грамматике. Семантический синтаксический анализатор принимает правильно построенные осмысленные последовательности слов и отклоняет последовательности слов, которые не имеют смысла, как указано в семантической грамматике. Классический пример (от лингвиста Хомского) — «Зеленые идеи яростно спят»: это правильно построенное (т. совершенно бессмысленно, потому что идеи не имеют цвета, идеи не спят, а сон не может быть яростным. Более приземленный пример относительной чепухи — «Я встречусь с вами 30 февраля», который кажется идеальным, пока вы не добавите тот факт, что в феврале не так уж много дней. Это может быть неэффективно (как обязательство календаря), но оно все же приводит к ряду возможных ответов («Можете ли вы назвать мне эту дату еще раз?» и т. д.), поэтому граница между значимым и не значимым может быть нечеткой и очень прикладной. -зависимый.
Более приземленный пример относительной чепухи — «Я встречусь с вами 30 февраля», который кажется идеальным, пока вы не добавите тот факт, что в феврале не так уж много дней. Это может быть неэффективно (как обязательство календаря), но оно все же приводит к ряду возможных ответов («Можете ли вы назвать мне эту дату еще раз?» и т. д.), поэтому граница между значимым и не значимым может быть нечеткой и очень прикладной. -зависимый.
Слова обычно имеют произношение, определяемое фонетическим словарем или алгоритмами преобразования слова в фонему. Эти изобретатели распознали особые случаи понимания языка, когда на произношение слова влияет его контекст. При успешном синтаксическом анализе, будь то грамматика или семантическая грамматика, слово распознается в контексте продукционного правила и, в более широком смысле, дерева синтаксического анализа. Точно так же, когда слово сопоставляется со статистической языковой моделью, слово распознается в контексте одной или нескольких N-грамм. Для этих методов распознавания будет полезно описать новую технологию, которая контролирует изменения произношения слов в зависимости от их контекста в языковой модели.
Для этих методов распознавания будет полезно описать новую технологию, которая контролирует изменения произношения слов в зависимости от их контекста в языковой модели.
РЕЗЮМЕ
Раскрытая технология обеспечивает способ обработки входного высказывания с использованием продукционных правил, которые включают фонетические варианты, которые являются локальными для продукционного правила или N-граммы, и которые переопределяют произношения, обеспечиваемые глобальными значениями по умолчанию. Другие аспекты и преимущества раскрытой технологии можно увидеть при просмотре чертежей, подробного описания и формулы изобретения, которые следуют.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙРИС. 1 представляет собой блок-схему, которая иллюстрирует вариант осуществления взаимодействия между акустической и языковой моделями для понимания естественного языка (NLU) в соответствии с реализацией.
РИС. 2 является примером решетки фонем в соответствии с реализацией.
2 является примером решетки фонем в соответствии с реализацией.
РИС. 3 представляет собой простой пример представления значения в соответствии с реализацией.
РИС. 4 a является примером грамматики согласно реализации.
РИС. 4 b является примером дерева синтаксического анализа в соответствии с реализацией.
РИС. 5 представляет собой блок-схему, иллюстрирующую восходящий поток, аналогичный нисходящему потоку, показанному на фиг. 1, в соответствии с реализацией.
РИС. 6 представляет собой блок-схему, которая иллюстрирует поток операций, когда система принимает ввод текста, в соответствии с реализацией.
РИС. 7 иллюстрирует блок-схему примерной среды разработки, в которой могут разрабатываться приложения для пользовательского понимания естественного языка в соответствии с реализацией.
РИС. 8 предоставляет дополнительную информацию о среде выполнения приложения в соответствии с реализацией.
ПОДРОБНОЕ ОПИСАНИЕ
В технологии раскрыты адреса, сопоставляющие устный ввод с грамматикой, содержащей продукционные правила, которые могут включать фонетические варианты, определяющие альтернативное произношение слов, которые применяются в конкретном контексте правила, называемом здесь локальным контекстом. Произношение представлено последовательностью фонем, а фонетический вариант — это последовательность фонем, представляющая произношение, отличное от произношения по умолчанию.
В системе, которая поддерживает как речевой ввод, так и текстовый ввод, раскрытая технология также обеспечивает сопоставление текстового ввода с грамматикой, содержащей продукционные правила, которые включают альтернативное написание слов в локальном контексте; некоторые слова могут иметь неправильное произношение. Использование семантических ограничений является необязательным для этой раскрытой технологии, как и использование инкрементного синтаксического анализатора. Для статистических языковых моделей описана технология, аналогичная используемой для грамматик.
Для статистических языковых моделей описана технология, аналогичная используемой для грамматик.
Технология, раскрытая в этом документе, обеспечивает удобный и элегантный способ введения тонкостей в преобразование фонемы в слово по мере необходимости и в синтаксическом/семантическом контексте, где они необходимы. Применяя эту технологию, проблема сопоставления фонем со словами с помощью грамматики, в которой произношение некоторых слов зависит от их синтаксического или семантического контекста, может быть решена путем добавления к грамматике на уровне слов возможности определения по крайней мере одного локального фонетического слова. вариант (т. е. альтернативное произношение) слова, который применяется в локальном контексте конкретного производственного правила.
Слово «оценка» является мерой приемлемости. «Оценка» определяется здесь как числовое указание вероятности или вероятности того, что оцененная последовательность является правильной транскрипцией речи, интерпретацией текста или тем и другим. Чем выше оценка, тем больше вероятность того, что последовательность соответствует намерению пользователя. «Вес» может быть числовым значением, связанным с применением продукционных правил. Например, вес, присвоенный альтернативным продукционным правилам, может использоваться для определения оценки дерева синтаксического анализа в соответствии с продукционными правилами.
Чем выше оценка, тем больше вероятность того, что последовательность соответствует намерению пользователя. «Вес» может быть числовым значением, связанным с применением продукционных правил. Например, вес, присвоенный альтернативным продукционным правилам, может использоваться для определения оценки дерева синтаксического анализа в соответствии с продукционными правилами.
Подробное описание реализации раскрытой технологии представлено со ссылкой на фиг. 1-8.
РИС. 1 представляет собой блок-схему, которая иллюстрирует вариант осуществления взаимодействия между акустической и языковой моделями для понимания естественного языка (NLU). В потоке 100 , когда человек говорит, образцы аудио 193 вводятся во внешний интерфейс 183 речевого процессора. Интерфейс речевого движка 183 обрабатывает акустические особенности аудиосэмплов 193 с использованием одной или нескольких акустических моделей 197 и с использованием скрытой марковской модели 187 генерирует одну или несколько последовательностей фонем, причем каждая последовательность связана с оценкой, указывающей вероятность того, что последовательность является наиболее вероятной предполагаемой последовательностью. Например, оратор может сказать: «Я прочитал хорошую книгу». В Таблице 1 показаны примерные последовательности альтернативных фонем с баллами 173 , которые могут быть сгенерированы внешним интерфейсом речевого движка 183 . Последовательности фонем представлены с использованием набора фонем CMUP (набор фонем CMU) в целях иллюстрации (показан в Приложении I), но можно использовать любое фонетическое представление.
Например, оратор может сказать: «Я прочитал хорошую книгу». В Таблице 1 показаны примерные последовательности альтернативных фонем с баллами 173 , которые могут быть сгенерированы внешним интерфейсом речевого движка 183 . Последовательности фонем представлены с использованием набора фонем CMUP (набор фонем CMU) в целях иллюстрации (показан в Приложении I), но можно использовать любое фонетическое представление.
 Третья альтернативная последовательность фонем имеет наивысший акустический балл.
Третья альтернативная последовательность фонем имеет наивысший акустический балл.В другом варианте осуществления решетка фонем, как показано на фиг. 2 может быть создан интерфейсом речевого движка 183 как компактное представление чередующихся последовательностей фонем. Фонемная решетка, показанная на фиг. 2 представлен с использованием CMUP. Баллы также могут быть привязаны к решеткам фонем, хотя они не показаны на фиг. 2.
«(Семантический)» появляется в скобках на чертежах, чтобы указать, что использование семантических дополнений является необязательным для раскрытой технологии. В чисто синтаксической реализации грамматика, используемая для распознавания допустимых последовательностей слов, может принимать последовательности слов, которые являются синтаксически правильными, но она не будет отвергать последовательности слов, которые не имеют смысла; соответствующий синтаксический анализатор не является семантическим синтаксическим анализатором. В другой реализации используется семантическая грамматика, и синтаксический анализатор, основанный на этой грамматике, может распознавать только осмысленные последовательности слов; такой семантический синтаксический анализатор не только анализирует синтаксис последовательности слов (что может строить дерево синтаксического анализа), но также создает представление ее значения. В большинстве приложений последовательность слов считается «осмысленной», если из нее можно построить действенное представление смысла.
В другой реализации используется семантическая грамматика, и синтаксический анализатор, основанный на этой грамматике, может распознавать только осмысленные последовательности слов; такой семантический синтаксический анализатор не только анализирует синтаксис последовательности слов (что может строить дерево синтаксического анализа), но также создает представление ее значения. В большинстве приложений последовательность слов считается «осмысленной», если из нее можно построить действенное представление смысла.
На РИС. 1, грамматика 147 является стохастической грамматикой. То есть каждому из альтернативных продуктов, связанных с конкретным неконечным символом, назначается неотрицательный вес. В типичной реализации веса, связанные с конкретным нетерминалом, нормализуются так, что сумма весов для каждого нетерминала равна 1. В реализации оценка дерева синтаксического анализа для конкретной последовательности слов представляет собой произведение нормированных весов, связанных со всеми продукционными правилами, которые используются в дереве синтаксического анализа, распознающем последовательность слов. (Это описание относится к простым правилам БНФ, лишенным метасимволов; когда продукционные правила выражены в более богатом формате, таком как шаблоны регулярных выражений, которые могут включать чередование, итерацию или необязательные компоненты, вызываются дополнительные методы для указания весов в таком формате. способ вернуться к основному формату BNF.) Важно отметить, что в общем случае для одной и той же последовательности слов может существовать несколько синтаксических анализов; то есть эти разные синтаксические анализы могут иметь разные оценки, хотя они генерируют одну и ту же последовательность слов.
(Это описание относится к простым правилам БНФ, лишенным метасимволов; когда продукционные правила выражены в более богатом формате, таком как шаблоны регулярных выражений, которые могут включать чередование, итерацию или необязательные компоненты, вызываются дополнительные методы для указания весов в таком формате. способ вернуться к основному формату BNF.) Важно отметить, что в общем случае для одной и той же последовательности слов может существовать несколько синтаксических анализов; то есть эти разные синтаксические анализы могут иметь разные оценки, хотя они генерируют одну и ту же последовательность слов.
В результате только что описанного процесса оценки или некоторых его вариаций (семантический) синтаксический анализатор 133 может генерировать альтернативные синтаксические анализы с оценками 143 . Как мы обсудим позже, эти синтаксические анализы могут быть не полными синтаксическими анализами для полного высказывания, а частичными синтаксическими анализами, построенными во время инкрементного синтаксического анализа. Когда грамматика 147 является семантической грамматикой, синтаксические веса или вероятности могут быть скорректированы в соответствии с дополнительными правилами более семантического характера. Например, в контексте, где ожидается упоминание кинозвезды, оценка фразы, передающей личность актера или актрисы, может быть скорректирована с помощью мультипликативного коэффициента, положительно связанного с популярностью кинозвезды. Такая корректировка оценки может привести к увеличению вероятности сопоставления голосового запроса с популярными актерами по сравнению с малоизвестными. Другой пример корректировки семантической оценки включает географические названия, когда близлежащим городам и крупным городам может быть присвоен более высокий балл по сравнению с удаленными или небольшими городами.
Когда грамматика 147 является семантической грамматикой, синтаксические веса или вероятности могут быть скорректированы в соответствии с дополнительными правилами более семантического характера. Например, в контексте, где ожидается упоминание кинозвезды, оценка фразы, передающей личность актера или актрисы, может быть скорректирована с помощью мультипликативного коэффициента, положительно связанного с популярностью кинозвезды. Такая корректировка оценки может привести к увеличению вероятности сопоставления голосового запроса с популярными актерами по сравнению с малоизвестными. Другой пример корректировки семантической оценки включает географические названия, когда близлежащим городам и крупным городам может быть присвоен более высокий балл по сравнению с удаленными или небольшими городами.
Независимо от того, является ли грамматика семантической или нет, веса или вероятности получаются с помощью (семантического) синтаксического анализатора 133 и связываются с альтернативными анализами. «Окончательная» или «общая» оценка для каждого альтернативного анализа определяется на основе оценки, присвоенной (семантическим) синтаксическим анализатором 133 , и оценки, присвоенной модулем сопоставления фонем 163 . Оценка может использоваться как показатель вероятности того, что каждый альтернативный синтаксический анализ является синтаксическим анализом, предназначенным для входного высказывания. В реализации баллы объединяются путем умножения; это часто вызывает проблемы с динамическим диапазоном. Во многих реализациях оценки хранятся в логарифмической форме, а путем сложения получается мультипликативный эффект. В другой реализации оценки могут быть объединены другими способами, такими как линейные комбинации. Модуль сопоставления фонем 163 может выводить общий (итоговый) балл вместе с представлением смысла, если оно есть; последовательность слов; и соответствующая последовательность фонем, которая соответствует последовательности фонем в 173 .
«Окончательная» или «общая» оценка для каждого альтернативного анализа определяется на основе оценки, присвоенной (семантическим) синтаксическим анализатором 133 , и оценки, присвоенной модулем сопоставления фонем 163 . Оценка может использоваться как показатель вероятности того, что каждый альтернативный синтаксический анализ является синтаксическим анализом, предназначенным для входного высказывания. В реализации баллы объединяются путем умножения; это часто вызывает проблемы с динамическим диапазоном. Во многих реализациях оценки хранятся в логарифмической форме, а путем сложения получается мультипликативный эффект. В другой реализации оценки могут быть объединены другими способами, такими как линейные комбинации. Модуль сопоставления фонем 163 может выводить общий (итоговый) балл вместе с представлением смысла, если оно есть; последовательность слов; и соответствующая последовательность фонем, которая соответствует последовательности фонем в 173 . Окончательные альтернативы с баллами 167 представляют собой выходные данные модуля сопоставления 163 . Дальнейшая обработка может иметь место на окончательных альтернативах; например, выходные данные могут быть отправлены непосредственно обратно на клиентское устройство, альтернативы могут быть ранжированы по окончательной оценке, а альтернатива с наивысшим рейтингом отправлена обратно на клиентское устройство, или альтернатива с наивысшим рейтингом может быть подвергнута дальнейшей обработке, такой как определение действие, выполняемое на основе данных в выбранных альтернативных структурах данных.
Окончательные альтернативы с баллами 167 представляют собой выходные данные модуля сопоставления 163 . Дальнейшая обработка может иметь место на окончательных альтернативах; например, выходные данные могут быть отправлены непосредственно обратно на клиентское устройство, альтернативы могут быть ранжированы по окончательной оценке, а альтернатива с наивысшим рейтингом отправлена обратно на клиентское устройство, или альтернатива с наивысшим рейтингом может быть подвергнута дальнейшей обработке, такой как определение действие, выполняемое на основе данных в выбранных альтернативных структурах данных.
Анализатор (семантический) 133 может зависеть от одной или нескольких языковых моделей. (Семантическая) стохастическая грамматика 147 используется в реализации, описанной на фиг. 1; однако в других реализациях могут использоваться статистические языковые модели (на основе N-грамм). В некоторых реализациях N-граммы могут использоваться для определенных частей высказывания в сочетании со стохастической грамматикой, которая распознает различные части высказывания, что приводит к гибридному методу присвоения баллов.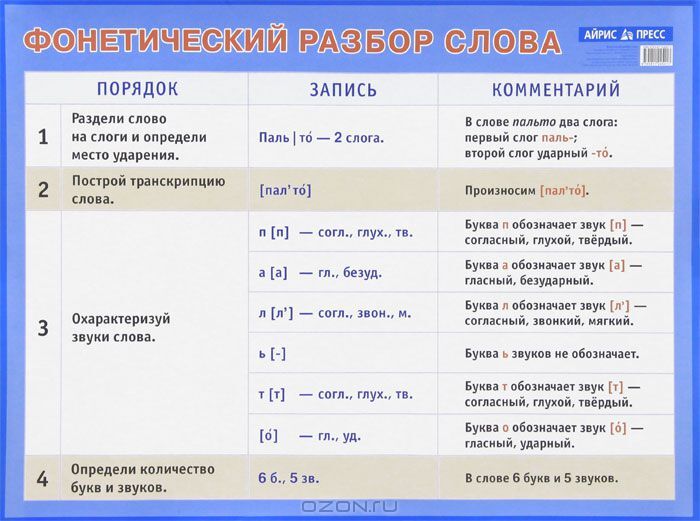
Способ, которым (семантический) синтаксический анализатор 133 генерирует альтернативные синтаксические анализы с оценками 143 , зависит от используемого метода синтаксического анализа. Возможны многие реализации, включая традиционные парсеры «сверху вниз» и «снизу вверх». Однако можно заметить, что ни чистые методы «сверху вниз», ни чистые методы «снизу вверх» не являются идеальными для генерации последовательности слов, в частности, из-за проблем с эффективностью. С целью объединения всех акустических, синтаксических и семантических ограничений на постоянной основе предпочтительным вариантом является инкрементный синтаксический анализатор. Инкрементальный парсер работает «слева направо» или строго с течением времени. Инкрементный разбор слов означает продвижение по одному слову за раз. Отличительной характеристикой инкрементного синтаксического анализатора является то, что все альтернативные синтаксические анализы поддерживаются параллельно. Некоторые из них умирают, а некоторые размножаются по мере появления новых слов. Обратите внимание, что обсуждаемые здесь синтаксические анализы не являются полными синтаксическими анализами (как показано на рис. 4–9).0055 b ), но частичный разбор, основанный на продукционных правилах, которые уже использовались до этого. В практической реализации инкрементный синтаксический анализатор может поддерживать только P синтаксических анализов с наивысшей оценкой. Каждый раз слово рассматривается как дополнение к текущему разбору. Когда следующее слово распознается языковой моделью как допустимое следующее слово в синтаксическом анализе, следующее слово может быть добавлено к синтаксическому анализу, оценка синтаксического анализа обновляется на основе добавления слова, и синтаксический анализ продолжается. В противном случае, если следующее слово не распознано как допустимое следующее слово, синтаксический анализ может быть исключен. Таким образом, набор альтернативных синтаксических анализов 143 поддерживается динамически, в то время как последующие слова предварительно распознаются.
Некоторые из них умирают, а некоторые размножаются по мере появления новых слов. Обратите внимание, что обсуждаемые здесь синтаксические анализы не являются полными синтаксическими анализами (как показано на рис. 4–9).0055 b ), но частичный разбор, основанный на продукционных правилах, которые уже использовались до этого. В практической реализации инкрементный синтаксический анализатор может поддерживать только P синтаксических анализов с наивысшей оценкой. Каждый раз слово рассматривается как дополнение к текущему разбору. Когда следующее слово распознается языковой моделью как допустимое следующее слово в синтаксическом анализе, следующее слово может быть добавлено к синтаксическому анализу, оценка синтаксического анализа обновляется на основе добавления слова, и синтаксический анализ продолжается. В противном случае, если следующее слово не распознано как допустимое следующее слово, синтаксический анализ может быть исключен. Таким образом, набор альтернативных синтаксических анализов 143 поддерживается динамически, в то время как последующие слова предварительно распознаются.
Синтаксический анализатор, использующий семантическую грамматику, также генерирует альтернативные значения с баллами 123 при анализе входного высказывания; как объяснялось ранее, это имеет двойной эффект: отказ от бессмысленных синтаксических анализов и использование значений для корректировки оценок синтаксических анализов. Пунктирная рамка указывает, что 123 является необязательным; он существует только тогда, когда используется семантическая грамматика. В таком случае последовательность слов в 143 может иметь соответствующее представление значения, и это представление значения может способствовать оценке синтаксического анализа. ИНЖИР. 3 показан простой пример представления смысла в соответствии с реализацией.
В качестве примера анализа рассмотрим предложение «Джон любит Мэри».
Чтобы проанализировать этот ввод, рассмотрим образец грамматики, показанный на РИС. 4 a — что составляет очень маленькое подмножество настоящей грамматики английского языка; достаточно просто разобрать образец высказывания. Это показывает, что <ПРЕДЛОЖЕНИЕ> может быть <ЗАЯВЛЕНИЕМ> (в противоположность, скажем, вопросу или восклицанию, которые не показаны) и что <ЗАЯВЛЕНИЕ> может принимать форму подлежащего, за которым следует переходный глагол, за которым следует дополнением и так далее. Обратите внимание, что большинство продукционных правил не зависят от контекста (у них есть один грамматический символ в левой части правила), однако последние два правила зависят от контекста: использование дополнительных символов слева позволяет спрягать глаголы на основе в единственном/множественном числе, 1 ст /2 й /3 й лиц, и напр; список можно было бы сделать длиннее. Также обратите внимание, что это примерный вариант осуществления, основанный на использовании очень упрощенного подхода к грамматике; реальная грамматика выглядит совсем иначе. В частности, имена собственные скорее можно найти в словаре или тезаурусе, чем в правилах грамматики; и обработка контекстно-зависимых частей языка, таких как согласование существительного и глагола и спряжение глагола, будет гораздо более сложной и, возможно, будет осуществляться другими средствами, чем показано.
Это показывает, что <ПРЕДЛОЖЕНИЕ> может быть <ЗАЯВЛЕНИЕМ> (в противоположность, скажем, вопросу или восклицанию, которые не показаны) и что <ЗАЯВЛЕНИЕ> может принимать форму подлежащего, за которым следует переходный глагол, за которым следует дополнением и так далее. Обратите внимание, что большинство продукционных правил не зависят от контекста (у них есть один грамматический символ в левой части правила), однако последние два правила зависят от контекста: использование дополнительных символов слева позволяет спрягать глаголы на основе в единственном/множественном числе, 1 ст /2 й /3 й лиц, и напр; список можно было бы сделать длиннее. Также обратите внимание, что это примерный вариант осуществления, основанный на использовании очень упрощенного подхода к грамматике; реальная грамматика выглядит совсем иначе. В частности, имена собственные скорее можно найти в словаре или тезаурусе, чем в правилах грамматики; и обработка контекстно-зависимых частей языка, таких как согласование существительного и глагола и спряжение глагола, будет гораздо более сложной и, возможно, будет осуществляться другими средствами, чем показано.
Пример грамматики 400 дан в качестве простой иллюстрации того, как дерево синтаксического анализа 450 , такое как показано на фиг. 4 b использует грамматику 400 для создания целевого предложения «Джон любит Мэри».
При использовании семантической грамматики каждой распознанной фразе в процессе синтаксического анализа будет присвоено представление значения. Пример «Джону нравится Мэри» можно использовать для иллюстрации следующего шага. В примерном варианте осуществления имя собственное «Джон» является распознаваемой фразой в соответствии с правилами для имен собственных. Значение «Джон» можно решить, найдя, к кому относится конкретное «Джон». Модуль разрешения совместной ссылки (не показанный и не обсуждаемый здесь) разрешал бы «Джон» в контексте продолжающегося диалога как конкретного человека, скажем, того, чье полное имя «Джон М. Смит-младший». ” и который известен системе как сущность Person00017. Представлением значения для фразы «Джон» будет сущность Person00017, потому что это семантический дескриптор, дающий доступ ко всей информации, известной об этом конкретном Джоне. Аналогичным образом предположим, что значением представления распознанной фразы «Мэри» является сущность, известная системе как Person00032. Вывод «Джон» из
Представлением значения для фразы «Джон» будет сущность Person00017, потому что это семантический дескриптор, дающий доступ ко всей информации, известной об этом конкретном Джоне. Аналогичным образом предположим, что значением представления распознанной фразы «Мэри» является сущность, известная системе как Person00032. Вывод «Джон» из  В варианте осуществления глагол «нравится» конкретизирует глагольный фрейм «To Like», и экземпляр заполняется следующим образом: временной интервал представляет собой «настоящее время»; слот Liker — это Person00017, которого мы знаем как John, и у которого есть много других свойств, обозначенных пунктирными линиями; а слот «Нравится» — это Person00032, известный как Мэри, который также может иметь много других связанных свойств. Это дает простой пример и краткое введение в смысловые представления; как отмечалось ранее, такие представления и связанные с ними оценки могут играть роль в вариантах осуществления, в которых используется семантическая грамматика, но они не являются существенными для основных элементов раскрытой технологии.
В варианте осуществления глагол «нравится» конкретизирует глагольный фрейм «To Like», и экземпляр заполняется следующим образом: временной интервал представляет собой «настоящее время»; слот Liker — это Person00017, которого мы знаем как John, и у которого есть много других свойств, обозначенных пунктирными линиями; а слот «Нравится» — это Person00032, известный как Мэри, который также может иметь много других связанных свойств. Это дает простой пример и краткое введение в смысловые представления; как отмечалось ранее, такие представления и связанные с ними оценки могут играть роль в вариантах осуществления, в которых используется семантическая грамматика, но они не являются существенными для основных элементов раскрытой технологии.
Возможность конструировать смысловое представление высказывания пользователя позволяет приложению предпринимать действия в ответ на высказывание. Простой пример: программа-калькулятор с голосовым управлением, которая получает фразу «Сколько будет два плюс пять?» может не только разобрать вопрос, но и продемонстрировать его понимание, построив смысловое представление, достаточное для получения правильного ответа.
Модуль преобразования последовательности слов в фонемы 153 переводит один или несколько альтернативных синтаксических анализов с оценкой 143 в последовательность фонем, составляющих произношение последовательности слов. Модуль перевода последовательности слов в фонемы 153 («переводчик») обрабатывает слово за раз; для каждого слова он определяет одно или несколько произношений слова. В реализации веса используются, когда имеется более одного произношения. Вес указан в таблице, такой как Таблица 2 ниже. В реализации любые неуказанные веса в таблице предполагаются равными 1. Указанные веса нормализуются перед их использованием, так что их сумма равна 1. Например, оба произношения «read» ((R IY D)|(R EH D)) получит нормализованные веса 0,5; и три варианта произношения «хорошо» ((3 G UH D)|(GA AH D)|(G IH D)) получат соответствующие нормализованные веса 0,6, 0,2 и 0,2 для любой последующей обработки.
Одно или несколько произношений, полученных из Глобального фонетического словаря 157, происходят из фактической записи слова в сохраненной таблице, такой как Таблица 2 (ниже), или из результатов «фонетического алгоритма», который вычисляет произношения слов для данный язык. В реализации фонетический алгоритм обучается на большом корпусе слов для целевого языка или предметной области, а веса получаются из подсчета частоты.
В реализации фонетический алгоритм обучается на большом корпусе слов для целевого языка или предметной области, а веса получаются из подсчета частоты.
В остальной части раскрытия то, что называется «фонетическим словарем», фактически является комбинацией собственно фонетического словаря и фонетического алгоритма; различие является деталью реализации. Что еще более важно, так это то, что альтернативные варианты произношения слова получают веса, подобные вероятностям, и что Фонетический словарь является глобальным в том смысле, что он в равной степени применим ко всем без исключения употреблениям слова. Глобальный фонетический словарь не позволяет выбирать произношения на основе локального контекста производственного правила. Когда локальный контекст позволяет специфицировать фонетические варианты, они также могут включать одно или несколько произношений с нормированными весовыми коэффициентами перед любой последующей обработкой.
Переводчик 153 может найти каждое слово по очереди в Фонетическом словаре 157, получить одно или несколько произношений слова и для каждого такого произношения дополнить все текущие последовательности фонем произношением слова. Реализация такой схемы с неструктурированными наборами последовательностей становится вычислительно громоздкой. В реализации последовательности фонем представлены решетками фонем, что уменьшает размер структуры данных. В предпочтительной реализации последовательности слов никогда не рассматриваются целиком, а только расширяются на одно слово в контексте поэтапного синтаксического анализа; эта техника объясняется в другом месте.
Реализация такой схемы с неструктурированными наборами последовательностей становится вычислительно громоздкой. В реализации последовательности фонем представлены решетками фонем, что уменьшает размер структуры данных. В предпочтительной реализации последовательности слов никогда не рассматриваются целиком, а только расширяются на одно слово в контексте поэтапного синтаксического анализа; эта техника объясняется в другом месте.
В таблице 2 показаны примеры записей в фонетическом словаре 157. Например, первое слово в последовательности «я читал книгу», «я», соответствует последовательности фонем (AY). Глагол «читать» имеет два произношения равного веса, (RIYD) и (REHD), каждое из которых используется в разных грамматических ситуациях. Альтернативный способ указать произношение без использования фонетического алфавита — использовать слова с однозначным произношением, например, в данном случае («тростник») и («красный»). Здесь слова используются не по их значениям, а по тому, как они звучат. Альтернативное произношение может быть включено в словарь для поиска слова, произношение которого получено из речевого ввода. Например, если речевой ввод включает в себя слово, прочитанное в прошедшем времени (R-EH-D), это альтернативное произношение может быть сопоставлено в словаре, чтобы вернуть слово «прочитано».
Альтернативное произношение может быть включено в словарь для поиска слова, произношение которого получено из речевого ввода. Например, если речевой ввод включает в себя слово, прочитанное в прошедшем времени (R-EH-D), это альтернативное произношение может быть сопоставлено в словаре, чтобы вернуть слово «прочитано».
При преобразовании последовательностей слов в последовательности фонем с использованием фонетического словаря отсутствует контекстуальная информация, помогающая выбрать произношение среди нескольких альтернативы. Опора на локальный контекст, когда он доступен, обычно более надежна. Набор последовательностей фонем, сгенерированных переводчиком 153 — это структура данных, доступная в качестве входных данных для модуля сопоставления фонем 163 . В предпочтительной реализации, которая представляет собой существенный выигрыш в пространстве, набор последовательностей фонем сжимается в решетку фонем. Кроме того, вероятности перехода назначаются каждому ребру, выходящему из узла, а результирующие вероятности узлов назначаются каждому узлу. Есть менее оптимальные реализации.
В предпочтительной реализации, которая представляет собой существенный выигрыш в пространстве, набор последовательностей фонем сжимается в решетку фонем. Кроме того, вероятности перехода назначаются каждому ребру, выходящему из узла, а результирующие вероятности узлов назначаются каждому узлу. Есть менее оптимальные реализации.
Модуль сопоставления сопоставляет последовательность фонем с переводчика 153 с последовательностью фонем из набора оцененных альтернативных последовательностей фонем с оценками 173 . Для каждой совпадающей последовательности восходящие и нисходящие оценки, связанные с каждой из совпадающих позиций фонемы в последовательности, объединяются, чтобы помочь определить общий балл для последовательности. В одной реализации комбинированные баллы, назначенные каждой позиции в последовательности, дополнительно объединяются путем умножения по всей последовательности для определения общего балла. Как и при любой мультипликативной обработке, использование оценок в логарифмической области заменяет умножение сложениями, что помогает решать проблемы с динамическим диапазоном. Можно использовать альтернативные правила комбинирования.
Можно использовать альтернативные правила комбинирования.
При обсуждении фиг. 1, модуль сопоставления фонем 163 сопоставляет последовательности фонем. Это соответствует нисходящему подходу к границе слова и фонемы. Существует альтернативный восходящий подход, при котором совпадения последовательностей происходят на уровне слов. ИНЖИР. 5 представляет собой блок-схему, иллюстрирующую восходящий поток, очень похожий на поток, показанный на фиг. 1, в соответствии с реализацией. Вместо использования транслятора слов в фонемы 153 восходящий подход использует транслятор последовательности фонем в последовательность слов 9.0003 172 , который опирается на фонетический словарь, используемый в обратном порядке, для поиска последовательностей фонем и их перевода в совпадающие последовательности слов. Другими словами, действие по нахождению произношения в словаре запускает добавление слова в последовательность слов. Результирующие последовательности слов, получившие оценку, могут затем сопоставляться в Word Matching 563 с альтернативными разборами с оценками 143 .
Фонетический словарь может, естественно, включать несколько слов с одинаковым произношением, но разными значениями. При поиске последовательности фонем может быть несколько совпадающих слов. В реализации каждой последовательности фонем может быть присвоен весовой коэффициент для сопоставления слов. Последовательность слов, включающая одно из множества слов, может быть оценена с использованием весового коэффициента, присвоенного отображению. Фонетический словарь 157 может быть специфичен для предметной области и специфичен для вертикального приложения, а весовые коэффициенты, присвоенные омонимам, могут зависеть от предмета изучения. Например, при расшифровке произнесенного высказывания (R EH D) библиотечное приложение может присвоить слову «читать» больший вес, чем слову «красный», а художественное приложение может присвоить слову «красный» больший вес, чем «читать». ». Используя пример фонетического словаря, входная фонетическая последовательность может привести к преобразованию последовательности фонем в транслятор последовательности слов 9. 0003 572 для создания последовательностей слов с оценками в качестве входных данных для модуля сопоставления слов 563 . Последовательности слов в нашем примере могут состоять из двух последовательностей слов: «Я прочитал хорошую книгу» и «Я прочитал хорошую книгу». Каждой расшифрованной последовательности альтернативных слов может быть присвоена оценка на основе оценки соответствующих альтернативных последовательностей фонем (например, 0,000083907 из таблицы 2). В реализации веса могут быть связаны со словами «читать» и «красный» для одного и того же произношения. Однако веса в статическом глобальном словаре не могут указывать на то, что фраза «Я написал хорошую книгу» вряд ли будет правильной, потому что цвет — это существительное, а не глагол. По сути, весовой подход слаб по сравнению с языковой моделью, особенно если доступны грамматика и семантика. Грамматика обычно без труда выбирает между «прочитано» и «красно». При отсутствии языковых моделей реализация может вернуться к использованию весов, которые на самом деле очень похожи на 1 грамм.
0003 572 для создания последовательностей слов с оценками в качестве входных данных для модуля сопоставления слов 563 . Последовательности слов в нашем примере могут состоять из двух последовательностей слов: «Я прочитал хорошую книгу» и «Я прочитал хорошую книгу». Каждой расшифрованной последовательности альтернативных слов может быть присвоена оценка на основе оценки соответствующих альтернативных последовательностей фонем (например, 0,000083907 из таблицы 2). В реализации веса могут быть связаны со словами «читать» и «красный» для одного и того же произношения. Однако веса в статическом глобальном словаре не могут указывать на то, что фраза «Я написал хорошую книгу» вряд ли будет правильной, потому что цвет — это существительное, а не глагол. По сути, весовой подход слаб по сравнению с языковой моделью, особенно если доступны грамматика и семантика. Грамматика обычно без труда выбирает между «прочитано» и «красно». При отсутствии языковых моделей реализация может вернуться к использованию весов, которые на самом деле очень похожи на 1 грамм.
Только что описанный восходящий подход не является предпочтительным вариантом, когда нисходящие ограничения доступны из языковой модели и, возможно, из семантики. В отсутствие каких-либо нисходящих ограничений восходящий подход является единственным жизнеспособным; но такие системы довольно хрупкие. Современные надежные реализации нуждаются в языковых моделях и сосредоточены на нисходящем подходе к границе между словом и фонемой.
Двойные режимы
Раскрытая система имеет двойные приложения для распознавания, называемые «текстовым режимом» и «речевым режимом», в зависимости от того, какой тип ввода используется. ИНЖИР. 6 представляет собой блок-схему, которая иллюстрирует поток, когда система получает текстовый ввод 9.0003 613 , согласно реализации. Текстовый ввод 613 представляется (семантическому) синтаксическому анализатору 133 . В этом случае сопоставление с акустическими данными не требуется, поэтому альтернативные анализы с оценками 143 , которые были выходными данными (семантического) синтаксического анализатора 133 , становятся входными данными для Окончательных альтернатив с оценками без дальнейшей обработки. Другими словами, оценка для каждой альтернативы синтаксического анализа является окончательной оценкой. Окончательные варианты с баллами 167 содержит альтернативные синтаксические анализы, распознаваемые синтаксическим анализатором, и необязательные соответствующие представления значений. Модуль 169 создания вывода может создать ответ пользователю на основе окончательных альтернатив 167 . Альтернативные синтаксические анализы могут быть ранжированы на основе окончательных оценок. В реализации синтаксический анализ с наивысшим рангом может использоваться для создания мультимедийного ответа. Некоторые части ответа могут быть отправлены в модуль синтеза речи, возможно работающий на клиентском устройстве, и сгенерированная речь может быть воспроизведена на клиентском устройстве. Другие части ответа могут отображаться в виде текста, графики или видео. В реализации смысловое представление, соответствующее разбору с наивысшим рангом, может использоваться для определения действия, которое нужно предпринять в ответ на введенный текст, какое действие может быть выполнено на клиенте или серверах, или на обоих.
Другими словами, оценка для каждой альтернативы синтаксического анализа является окончательной оценкой. Окончательные варианты с баллами 167 содержит альтернативные синтаксические анализы, распознаваемые синтаксическим анализатором, и необязательные соответствующие представления значений. Модуль 169 создания вывода может создать ответ пользователю на основе окончательных альтернатив 167 . Альтернативные синтаксические анализы могут быть ранжированы на основе окончательных оценок. В реализации синтаксический анализ с наивысшим рангом может использоваться для создания мультимедийного ответа. Некоторые части ответа могут быть отправлены в модуль синтеза речи, возможно работающий на клиентском устройстве, и сгенерированная речь может быть воспроизведена на клиентском устройстве. Другие части ответа могут отображаться в виде текста, графики или видео. В реализации смысловое представление, соответствующее разбору с наивысшим рангом, может использоваться для определения действия, которое нужно предпринять в ответ на введенный текст, какое действие может быть выполнено на клиенте или серверах, или на обоих. Например, если запрос задает вопрос, значение альтернативы с наивысшим рейтингом может использоваться для ответа на вопрос. Другой вариант заключается в том, что, когда несколько альтернатив трудно различить, система может запросить разъяснение. Имеются дополнительные параметры создания выходных данных и управления диалогами, которые выходят за рамки раскрытой технологии.
Например, если запрос задает вопрос, значение альтернативы с наивысшим рейтингом может использоваться для ответа на вопрос. Другой вариант заключается в том, что, когда несколько альтернатив трудно различить, система может запросить разъяснение. Имеются дополнительные параметры создания выходных данных и управления диалогами, которые выходят за рамки раскрытой технологии.
Статистическая модель для оценки последовательностей слов
В реализации, в которой синтаксический анализатор 133 полагается на статистическую языковую модель, входная последовательность слов может сопоставляться с набором N-грамм, и входная последовательность слов может быть назначена оценка, основанная на оценке, связанной с соответствующей N-граммой. В реализации оценка, назначенная N-грамме, может быть основана на вероятности совпадения N-граммы во всем корпусе, которая основана на частоте N-граммы в корпусе.
Фонетические варианты
В этом раскрытии мы сосредоточимся на произношении слов. Например, в предложениях «Вчера я читал книгу» и «Я планирую прочитать книгу» слово «читал» произносится по-разному. Пример фонетического словаря в таблице 2
Например, в предложениях «Вчера я читал книгу» и «Я планирую прочитать книгу» слово «читал» произносится по-разному. Пример фонетического словаря в таблице 2
имеет произношение по умолчанию для слова «читать». Более точное присвоение баллов будет способствовать произношению (R EH D) в предложении в прошедшем времени, (RIY D) в предложении в настоящем времени или инфинитиве.
Следовательно, необходим способ повышения надежности распознавания и понимания естественного языка за счет учета контекстно-зависимых тонкостей произношения слов в грамматическом (и, возможно, семантическом) контексте, без чрезмерных затрат или сложности в определение языковой модели. В реализации языковая модель может быть расширена, чтобы разработчик приложения мог указать правильное произношение слова на основе контекста производственного правила или N-граммы. Произношение может быть указано с использованием фонетического алфавита или может быть указано словом в фонетическом словаре, чтобы указать, что следует использовать произношение слова по умолчанию. Например, фонетический словарь может предоставить произношение (R AA2 F AY0 Eh2 L), состоящее из 3 слогов с ударением на последнем слоге для имени «Рафаэль». Однако производственное правило для города Сан-Рафаэль в Северной Калифорнии может указывать другое произношение, когда в названии города используется «Рафаэль»:
Например, фонетический словарь может предоставить произношение (R AA2 F AY0 Eh2 L), состоящее из 3 слогов с ударением на последнем слоге для имени «Рафаэль». Однако производственное правило для города Сан-Рафаэль в Северной Калифорнии может указывать другое произношение, когда в названии города используется «Рафаэль»:
-
::=San Rafael (R AA0 F Eh2 L)
Это правило указывает, что наиболее распространенное произношение слова «Rafael» в названии города «San Rafael» состоит из двух слогов, причем второй слог ударен. (в более неформальной форме, чтобы передать фонетику, это звучит как rah-FELL). Указание этого произношения в контекстеозначает, что следует использовать указанное произношение, а не произношение по умолчанию из фонетического словаря.
-
Аналогичным образом, синтаксис для указания N-грамм может быть расширен для предоставления произношения в контексте конкретной последовательности слов, например, для триграммы:
- Сан-Рафаэль (R AA0 F Eh2 L ) California
Аналогичный синтаксис предлагается здесь для N-грамм и для грамматических шаблонов, то есть для правых частей правил вывода грамматики. Правило состоит в том, что за любым вхождением слова может следовать его произношение в скобках. В этих примерах набор фонем CMU, CMUP, используется по умолчанию, но вместо него можно использовать альтернативные наборы фонем. В другой реализации потребуется более явное обозначение произношения, например (CMUP: R AA0 F Eh2 L), которое делает выбор фонетического алфавита более наглядным.
- Сан-Рафаэль (R AA0 F Eh2 L ) California
 Правило состоит в том, что за любым вхождением слова может следовать его произношение в скобках. В этих примерах набор фонем CMU, CMUP, используется по умолчанию, но вместо него можно использовать альтернативные наборы фонем. В другой реализации потребуется более явное обозначение произношения, например (CMUP: R AA0 F Eh2 L), которое делает выбор фонетического алфавита более наглядным.
Правило состоит в том, что за любым вхождением слова может следовать его произношение в скобках. В этих примерах набор фонем CMU, CMUP, используется по умолчанию, но вместо него можно использовать альтернативные наборы фонем. В другой реализации потребуется более явное обозначение произношения, например (CMUP: R AA0 F Eh2 L), которое делает выбор фонетического алфавита более наглядным.Многие альтернативные синтаксические формы могут использоваться для описания фонетических вариантов. Используемый выше грамматический шаблон выглядит следующим образом в системе Terrier:
- «Сан». «Raphael» («CMUP: R AA0 F Eh2 L»)
В этом случае, поскольку синтаксис встроен в C++, терминалы (слова) должны рассматриваться как строки в кавычках; точка используется как оператор конкатенации. Между словом и его произношением нет точки.
- «Сан». «Raphael» («CMUP: R AA0 F Eh2 L»)
Кроме того, альтернативные синтаксические формы могут поддерживать присвоение веса альтернативным произношениям в шаблоне. Следующий пример представляет собой синтаксис из системы Terrier, который (неофициально указан как):
Следующий пример представляет собой синтаксис из системы Terrier, который (неофициально указан как):
- <распознаваемое слово> ([вес1] произношение1\[вес2] произношение 2)
Пример показывает, как распознать «ААА»: - «AAA» ((10 «triple a.») «CMUP: EY EY EY»)
Первое произношение, имеющее вес 10, «triple a.», произносится как произношение по умолчанию «triple», за которым следует произношение по умолчанию слова «а». Второе произношение определяется с использованием фонетического алфавита CMUP как «EY EY EY». Второе произношение также может быть определено как «a.a.a»; однако «a.a.a» может означать несколько иное произношение, чем «EY EY EY». Первое различие между «CMUP: EY EY EY» и «a. а. а.” заключается в том, что первый не допускает речевых наполнителей (паузы, шума и т. д.) между последовательными фонемами, что может быть желаемым поведением. Второе отличие заключается в том, что с последовательностями фонем мы можем указать более точное произношение, а не давать указания движку для автоматического создания произношения. Вес второго произношения не указан и принимается равным 1. Таким образом, это правило указывает на то, что человек в 10 раз чаще говорит «тройное а», чем «EY EY EY», имея в виду «ААА».
- <распознаваемое слово> ([вес1] произношение1\[вес2] произношение 2)
 Вес второго произношения не указан и принимается равным 1. Таким образом, это правило указывает на то, что человек в 10 раз чаще говорит «тройное а», чем «EY EY EY», имея в виду «ААА».
Вес второго произношения не указан и принимается равным 1. Таким образом, это правило указывает на то, что человек в 10 раз чаще говорит «тройное а», чем «EY EY EY», имея в виду «ААА». Системы, предназначенные для понимания речи, также должны быть способны понимать текст. Последнее, по сути, является более легкой задачей, поскольку обычно является подзадачей понимания речи. При ближайшем рассмотрении набор допустимых текстовых вводов в основном перекрывает набор допустимых транскрипций речевых вводов, но эти два набора не идентичны. Можно ожидать, что идеальная система будет демонстрировать очень высокий коэффициент повторного использования (или совместного использования) компонентов понимания текста, таких как (семантический) синтаксический анализатор, в системе понимания речи, но это не будет 100%. Некоторые последовательности слов, допустимые в «текстовом режиме», не отражаются в произнесенном высказывании. Например, письменные аббревиатуры и стенографические обозначения, такие как «младший», «старший», «доктор». не соответствуют высказыванию, указывающему полные слова, которые они представляют, такие как «младший», «старший», «доктор» и т. д. И наоборот, некоторые звуковые формы, допустимые в «режиме речи» (например, фразы «ух», « гм», «нравится», «вы знаете, что я имею в виду» и т. д., которые являются «наполнителями») обычно не встречаются и не приветствуются в письменном тексте. Некоторые реализации обеспечивают специальную обработку наполнителей в речевом режиме, чтобы уменьшить их влияние.
не соответствуют высказыванию, указывающему полные слова, которые они представляют, такие как «младший», «старший», «доктор» и т. д. И наоборот, некоторые звуковые формы, допустимые в «режиме речи» (например, фразы «ух», « гм», «нравится», «вы знаете, что я имею в виду» и т. д., которые являются «наполнителями») обычно не встречаются и не приветствуются в письменном тексте. Некоторые реализации обеспечивают специальную обработку наполнителей в речевом режиме, чтобы уменьшить их влияние.
Существует потребность в методе одновременной поддержки понимания текста и речи с максимальным перекрытием и экономией спецификаций, чтобы извлечь выгоду из всего, что есть общего у текста на естественном языке и речи на естественном языке. При этом также важно позволить разработчикам гибридной системы понимания естественного языка предоставлять индивидуальную поддержку распознавания «только в текстовом режиме» и «только в речевом режиме».
Сюда относится, в частности, возможность указать, что определенные слова можно писать, но нельзя произносить. Чтобы исключить появление шаблона в устной форме, мы можем использовать синтаксис (не разговорный), как в следующем примере. Чтобы понять его эффект, сравните следующие два паттерна, выраженные в нотации паттерна терьера:
Чтобы исключить появление шаблона в устной форме, мы можем использовать синтаксис (не разговорный), как в следующем примере. Чтобы понять его эффект, сравните следующие два паттерна, выраженные в нотации паттерна терьера:
- №1 («шоссе»|1/10 «шоссе» («шоссе»))
- №2 («шоссе»|1/10 «шоссе» (не произносится))
Образец №2, в текстовый режим, распознает как «шоссе», так и «шоссе»; пользователь может вводить в любой форме. Но «произношение» (непроизносимое) — это способ указать пустой набор произношений. Следовательно, пользователь может сказать «шоссе», и слово «шоссе» может быть распознано, но «шоссе» не будет сопоставлено и появится в дереве синтаксического анализа или транскрипции. Используя шаблон № 1, пользователь может ввести либо «шоссе», либо «шоссе». Введенный текст будет обработан так же, как и для шаблона № 1: распознаются и «шоссе», и «шоссе», но только один из них будет распознан в любом отдельном входном тексте, и будет сгенерирован только один синтаксический анализ. Однако в речевом режиме, если пользователь произносит «шоссе», оба слова «шоссе» и «шоссе» будут совпадать. Эта двусмысленность создает раскол между гипотезами и умножает на два количество анализов, которые необходимо учитывать. Такое поведение приводит к систематическому источнику неэффективности всей системы. Таким образом, использование (не разговорный) выгодно при обеспечении одновременной поддержки текстового режима и речевого режима обработки естественного языка.
Фонетические варианты при использовании N-грамм
 Однако в речевом режиме, если пользователь произносит «шоссе», оба слова «шоссе» и «шоссе» будут совпадать. Эта двусмысленность создает раскол между гипотезами и умножает на два количество анализов, которые необходимо учитывать. Такое поведение приводит к систематическому источнику неэффективности всей системы. Таким образом, использование (не разговорный) выгодно при обеспечении одновременной поддержки текстового режима и речевого режима обработки естественного языка.
Однако в речевом режиме, если пользователь произносит «шоссе», оба слова «шоссе» и «шоссе» будут совпадать. Эта двусмысленность создает раскол между гипотезами и умножает на два количество анализов, которые необходимо учитывать. Такое поведение приводит к систематическому источнику неэффективности всей системы. Таким образом, использование (не разговорный) выгодно при обеспечении одновременной поддержки текстового режима и речевого режима обработки естественного языка. Возможный синтаксис для выражения фонетических вариантов при использовании статистической языковой модели был представлен ранее. Идея состоит в том, что за каждым словом в N-грамме может следовать произношение. Фонетика становится доступной в конкретном контексте (или «локальном контексте») этой N-граммы.
В качестве простого примера рассмотрим биграммы «пустыня Сахара» и «должен дезертировать», для которых можно указать варианты произношения гетеронима «пустыня» (скажем, с помощью телефонного аппарата CMUP) следующим образом: «пустыня Сахара ( D Eh2 Z ER0 T)» и «должен дезертировать (D IH0 Z ER1 T)». Простые примеры этого типа отражают различные модели ударения, встречающиеся в парах омонимов существительное-глагол. В другом варианте идентификация частей речи может способствовать поиску фонетических вариантов посредством лексикона, который определяет отдельно произношение слова «пустыня» как существительного и как глагола. Но есть и другие случаи фонетических вариаций, не подпадающие под определение частей речи.
Простые примеры этого типа отражают различные модели ударения, встречающиеся в парах омонимов существительное-глагол. В другом варианте идентификация частей речи может способствовать поиску фонетических вариантов посредством лексикона, который определяет отдельно произношение слова «пустыня» как существительного и как глагола. Но есть и другие случаи фонетических вариаций, не подпадающие под определение частей речи.
В общем, знание грамматического контекста предлагает более эффективный и элегантный способ работы с фонетическими вариантами. Варианты произношения могут быть указаны на очень низком (буквальном) уровне лексикализованной грамматики или на более высоком уровне грамматики. Слово «пустыня» имеет одно произношение при использовании в группе существительных (в именном контексте) и другое при использовании в группе глаголов (в глагольном контексте). Существуют и другие ситуации, которые также требуют фонетических вариантов в определенном грамматическом контексте. Ниже приведены примеры возможного синтаксиса для добавления фонетических вариантов в контекстно-зависимые грамматические конструкции.
Ниже приведены примеры возможного синтаксиса для добавления фонетических вариантов в контекстно-зависимые грамматические конструкции.
РИС. 7 иллюстрирует блок-схему примерной среды разработки , 700, , в которой могут разрабатываться пользовательские приложения для понимания естественного языка (NLU). Приложение NLU состоит из специфических для приложения функций, включая распознаватели образов и возможные действия. Языковые модели для конкретных приложений (например, грамматики или SLM) описывают шаблоны, которые могут быть сопоставлены с соответствующими действиями. Распознавание шаблонов и выполнение действий зависят как от кода приложения, так и от подпрограмм общего назначения; последние могут быть собраны, например, в исполняемой библиотеке.
В одной реализации исходный код приложения 731 может быть написан в основном на языке программирования общего назначения; однако описание шаблонов, таких как грамматика 751 , обычно требует, чтобы конструкции лежали за пределами возможностей языка программирования общего назначения. В одной реализации действия (которые основаны на семантических интерпретациях) создаются семантической грамматикой 751 в ответ на соответствие шаблону грамматики. В одной реализации синтаксический анализатор (семантической) грамматики может быть сгенерирован во время разработки компилятором 9.0003 721 . Компилятор принимает в качестве входных данных грамматику и/или N-граммы, исходный код другого приложения 731 и связанные файлы данных.
В одной реализации действия (которые основаны на семантических интерпретациях) создаются семантической грамматикой 751 в ответ на соответствие шаблону грамматики. В одной реализации синтаксический анализатор (семантической) грамматики может быть сгенерирован во время разработки компилятором 9.0003 721 . Компилятор принимает в качестве входных данных грамматику и/или N-граммы, исходный код другого приложения 731 и связанные файлы данных.
Точная взаимосвязь между анализатором естественного языка, который будет выполняться во время выполнения, и кодом приложения зависит от процесса сборки приложения. В одной реализации синтаксический анализ в значительной степени является обязанностью библиотеки времени выполнения, управляемой некоторыми таблицами. В другой реализации синтаксический анализатор и грамматика (и/или SLM) могут быть скомпилированы в тесно связанный и высокооптимизированный формат объекта. Специалист в данной области техники поймет, как создать синтаксический анализатор того или иного типа на основе языковых моделей, указанных в коде приложения, и любых связанных файлах данных.
Исходный код приложения 731 может быть создан с использованием обычных средств разработки программ. Другими словами, любые расширения синтаксиса языка программирования или файлы данных, необходимые для выражения языковой модели (и фонетических вариантов), не требуют специальной функциональности среды разработки. Естественно, препроцессору, компилятору и/или интерпретатору исходного кода потребуется распознавать расширения синтаксиса и преобразовывать их в исполняемую форму.
Препроцессор может использоваться для расширения раскрытых программных конструкций в код на языке программирования перед его интерпретацией или компиляцией. В реализации компилятор 721 может компилировать исходный код приложения 731 в оптимизированные машинные инструкции и структуры данных в машинном исполняемом формате, как показано в коде объекта приложения 727 . Машинный код может вызывать подпрограммы в библиотеке времени выполнения. Кроме того, данные из пользовательских SLM 711 (N-граммы) могут дополнительно обрабатываться и храниться в коде объекта приложения 727 в форме, оптимизированной для доступа приложения.
Кроме того, данные из пользовательских SLM 711 (N-граммы) могут дополнительно обрабатываться и храниться в коде объекта приложения 727 в форме, оптимизированной для доступа приложения.
В процессе компиляции данные, определяющие (Семантическую) грамматику 751 для приложения преобразуется в парсер для грамматики. В варианте осуществления (семантическая) грамматика 751 может быть выражена в конструкциях программирования, например, описанных для системы Terrier, или (семантическая) грамматика 751 может быть указана в файле данных (например, в файле конфигурации ) кроме кода приложения. Скомпилированный код приложения, скорее всего, будет оптимизирован для конкретной платформы и сохранен для последующей обработки. Эти шаги важны для эффективности, но принципиально не влияют на функциональность системы.
В альтернативной реализации компилятор 721 может преобразовывать исходный код приложения 731 в машинно-независимый формат для ввода в интерпретатор. Машинно-независимый формат не оптимизирован для конкретной среды выполнения, но может помочь при тестировании и отладке. Машинно-независимый код можно запускать на виртуальной машине, а не непосредственно на физической машине. Код в машинно-независимом формате может быть сохранен и интерпретирован позже.
Машинно-независимый формат не оптимизирован для конкретной среды выполнения, но может помочь при тестировании и отладке. Машинно-независимый код можно запускать на виртуальной машине, а не непосредственно на физической машине. Код в машинно-независимом формате может быть сохранен и интерпретирован позже.
Среда выполнения
После создания объектного кода приложения система естественного языка готова принимать и распознавать естественный язык. ИНЖИР. 8 содержит дополнительные сведения о среде выполнения приложения. На этих рисунках и во всем приложении, где ссылочные номера используются повторно, например, ссылочный номер 727 для кода объекта приложения, они относятся к тому же компоненту, который описан ранее.
Среда выполнения 800 включает в себя как минимум одно клиентское устройство 856 , модуль интерпретатора фраз 817 , серверы 816 и коммуникационную сеть 835 , которая позволяет различным компонентам среды взаимодействовать.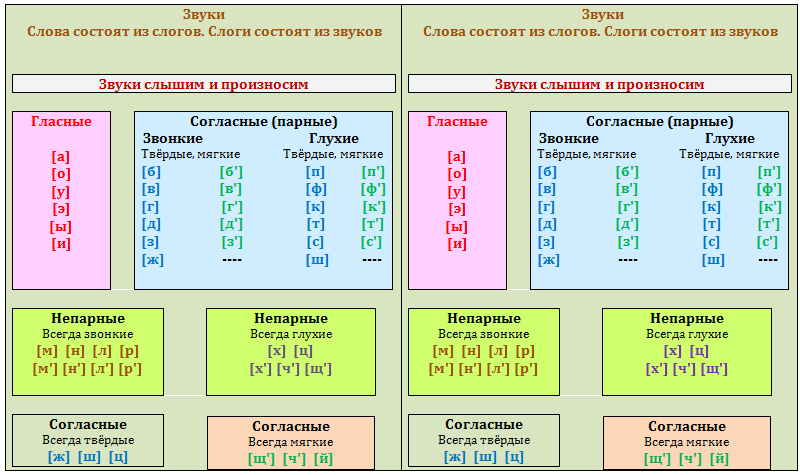
Пользователь может использовать устройство 856 для приема голосового или текстового ввода и для взаимодействия с приложением на естественном языке. Эти устройства могут включать портативные устройства, такие как смартфоны и планшеты, мобильные устройства, такие как ноутбуки и рабочие станции или ПК, или интеллектуальные устройства.
Функциональность приложения на естественном языке может выполняться полностью на клиентском устройстве 856 , полностью на серверах 816 , доступ к которым осуществляется с клиентского устройства 856 посредством веб-соединения, или быть разделенным между клиентским устройством 856 и серверы 816 . Например, в реализации Приложение 857 может запрашивать у пользователя ввод текста или речи и отображать результаты, возвращенные с сервера. Заявка 857 также может упаковывать контекстную информацию о пользователе и клиентском устройстве для использования сервером и может обеспечивать сжатие или шифрование запроса перед отправкой запроса по сети на сервер. В этой реализации сервер 816 может запускать интерпретатор фраз 817 , который включает в себя (семантический) синтаксический анализатор 818 , который включает в себя код объекта приложения 727 . Как объяснялось выше, синтаксический анализатор 818 показан рядом с кодом объекта приложения 9.0003 727 , чтобы предложить тесную интеграцию между ними. Синтаксический анализатор включает в себя как объектный код приложения, так и подпрограммы библиотеки времени выполнения общего назначения, и объем работы, выполняемой одним по сравнению с другим, может варьироваться от одной реализации к другой. Код объекта приложения может включать в себя скомпилированные или управляемые данными реализации языковых шаблонов, специфичных для приложения, и соответствующих действий, специфичных для приложения, которые должны быть предприняты. Существует множество альтернативных реализаций среды выполнения, в которых раскрытая технология может применяться на практике посредством комбинаций различных компонентов и сред.
В этой реализации сервер 816 может запускать интерпретатор фраз 817 , который включает в себя (семантический) синтаксический анализатор 818 , который включает в себя код объекта приложения 727 . Как объяснялось выше, синтаксический анализатор 818 показан рядом с кодом объекта приложения 9.0003 727 , чтобы предложить тесную интеграцию между ними. Синтаксический анализатор включает в себя как объектный код приложения, так и подпрограммы библиотеки времени выполнения общего назначения, и объем работы, выполняемой одним по сравнению с другим, может варьироваться от одной реализации к другой. Код объекта приложения может включать в себя скомпилированные или управляемые данными реализации языковых шаблонов, специфичных для приложения, и соответствующих действий, специфичных для приложения, которые должны быть предприняты. Существует множество альтернативных реализаций среды выполнения, в которых раскрытая технология может применяться на практике посредством комбинаций различных компонентов и сред.
В одной реализации сеть 835 включает Интернет. Сеть 835 также может использовать выделенные или частные каналы связи, которые не обязательно являются частью Интернета. В одной реализации сеть 835 использует стандартные коммуникационные технологии и протоколы или межпроцессное взаимодействие.
Клиентское устройство 856 получает аудиовход (например, речь) и отправляет аудиовход переводчику фраз 817 . Интерпретатор фраз , 817, выполняет обработку, показанную в левой части фиг. 1. Интерпретатор фраз 817 содержит (семантический) синтаксический анализатор 818 с поведением, соответствующим (семантическому) синтаксическому анализатору 133 , преобразователь последовательности слов в фонемы 153 , модуль сопоставления фонем 163 и Acoustic Language. Распознаватель 828 с поведением, соответствующим внешнему интерфейсу речевого движка 183 . Скомпилированный код объекта приложения 727 может быть включен в исполняемый код (семантического) синтаксического анализатора 818 . В интерпретируемой среде (семантический) синтаксический анализатор 818 может содержать интерпретатор, а код объекта приложения 727 может содержать машинно-независимый код, который интерпретируется интерпретатором.
Скомпилированный код объекта приложения 727 может быть включен в исполняемый код (семантического) синтаксического анализатора 818 . В интерпретируемой среде (семантический) синтаксический анализатор 818 может содержать интерпретатор, а код объекта приложения 727 может содержать машинно-независимый код, который интерпретируется интерпретатором.
Приложения работают в сочетании с механизмом интерпретатора фраз 817 для понимания устного или текстового ввода. Клиентское устройство 856 и Серверы 816 включают в себя память для хранения данных и программных приложений, процессор для доступа к данным при выполнении приложений и компоненты, облегчающие обмен данными по сети 835 .
Механизм интерпретатора фраз 817 реализован с использованием как минимум одного аппаратного компонента. Механизмы реализованы в аппаратном обеспечении, прошивке или программном обеспечении, работающем на оборудовании. Программное обеспечение, объединенное с аппаратным обеспечением для выполнения действий механизма интерпретатора фраз 817 может храниться на машиночитаемом носителе, таком как вращающаяся или невращающаяся память. Непостоянная память может быть энергозависимой или энергонезависимой. В этом приложении машиночитаемый носитель не включает в себя кратковременный электромагнитный сигнал, который не хранится в памяти; машиночитаемый носитель хранит программные инструкции для выполнения.
Программное обеспечение, объединенное с аппаратным обеспечением для выполнения действий механизма интерпретатора фраз 817 может храниться на машиночитаемом носителе, таком как вращающаяся или невращающаяся память. Непостоянная память может быть энергозависимой или энергонезависимой. В этом приложении машиночитаемый носитель не включает в себя кратковременный электромагнитный сигнал, который не хранится в памяти; машиночитаемый носитель хранит программные инструкции для выполнения.
Конечно, когда пользователь вводит ввод или текст поступает из другого источника, (семантический) синтаксический анализатор 818 может работать без распознавателя акустического языка 828 . Таким образом, синтаксический анализатор 818 полезен сам по себе и может работать в текстовой среде, которая не принимает голосовой ввод.
При обработке устного ввода распознаватель акустического языка 828 создает фразы-символы и альтернативные гипотезы распознавания символов, такие как альтернативные последовательности фонем с оценками 173 на фиг. 1. На каждом временном интервале во время интерпретации речевого ввода могут генерироваться сотни или даже тысячи гипотез распознавания токенов. Чтобы расширить этот момент, можно выбрать интервал, например каждые 10 или 100 миллисекунд, для проверки и генерации гипотез распознавания токенов. На каждом интервале можно было генерировать тысячу, три тысячи или даже большее количество гипотез. В некоторых реализациях перечисление гипотез может исчерпать все комбинаторные возможности для гипотез, таких как проиллюстрированные в таблице 1. Эти последовательности фонем могут быть переданы на языковую или лингвистическую стадию, которая рассматривает и оценивает последовательности фонем.
1. На каждом временном интервале во время интерпретации речевого ввода могут генерироваться сотни или даже тысячи гипотез распознавания токенов. Чтобы расширить этот момент, можно выбрать интервал, например каждые 10 или 100 миллисекунд, для проверки и генерации гипотез распознавания токенов. На каждом интервале можно было генерировать тысячу, три тысячи или даже большее количество гипотез. В некоторых реализациях перечисление гипотез может исчерпать все комбинаторные возможности для гипотез, таких как проиллюстрированные в таблице 1. Эти последовательности фонем могут быть переданы на языковую или лингвистическую стадию, которая рассматривает и оценивает последовательности фонем.
В реализации, в которой модель статистического языка предоставляет входные данные синтаксическому анализатору, но не обрабатывается и не сохраняется оптимизированным образом во время компиляции приложения, интерпретатор фраз 817 может во время выполнения обращаться к структурам данных, хранящим N-граммы .
В реализации, в которой используется семантическая грамматика, синтаксический анализатор является семантическим синтаксическим анализатором. Таким образом, семантический синтаксический анализатор, в дополнение к генерированию и оценке последовательностей слов, может также генерировать смысловое представление одной или нескольких последовательностей слов. Приложение может выполнять действие в ответ на распознавание определенных последовательностей слов, таких как те, которые могут быть указаны в части действия оператора интерпретации системы Terrier. Данные в представлении значений могут обеспечивать входные данные для действия, предпринятого приложением. Например, если пользователь задает вопрос, приложение может сначала понять вопрос, а затем сгенерировать ответ, который отвечает на вопрос.
Некоторые конкретные реализации
В одной реализации предоставляется усовершенствованный метод автоматического распознавания и понимания речи, применимый в тех случаях, когда произношение слова зависит от синтаксического или семантического контекста. Слова и фонемы извлекаются из цифрового сигнала, представляющего входное высказывание, и во время обработки произношение слов по умолчанию, полученное из глобального словаря, переопределяется на основе фонетического варианта в локальном контексте определенного правила производства.
Слова и фонемы извлекаются из цифрового сигнала, представляющего входное высказывание, и во время обработки произношение слов по умолчанию, полученное из глобального словаря, переопределяется на основе фонетического варианта в локальном контексте определенного правила производства.
Реализация этого метода может сочетаться с одной или несколькими из следующих функций. Фонетический вариант может ограничивать произношение в локальном контексте конкретного производственного правила стандартного слова, которое имеет несколько принятых произношений. Это может включать указание фонетического варианта местного слова как стилизованного написания (т.е. необычного написания, которое вряд ли можно найти в каком-либо стандартном словаре) нестандартного слова, которое имеет общепринятое произношение. Например, правила производства в музыкальном приложении могут генерировать или распознавать «Ke$ha» как стилизованное написание, которое обычно не встречается в словаре.
В реализации предусмотрен способ распознавания речи. Метод получает цифровой сигнал, представляющий произнесенное высказывание, и генерирует одну или несколько последовательностей фонем из произнесенного высказывания. Одна или несколько последовательностей фонем связаны с первой оценкой. Одна или несколько последовательностей слов могут быть сгенерированы с использованием продукционных правил языковой модели, причем одна или несколько последовательностей слов связаны со второй оценкой, назначенной на основе языковой модели. Он может переводить одну или несколько последовательностей слов в соответствующие последовательности фонем, которые представляют одно или несколько произношений последовательности слов, перевод включает в себя использование местного фонетического варианта в качестве произношения слова вместо произношения по умолчанию, связанного со словом, в рамках локальный контекст производственного правила. Метод сопоставляет последовательность фонем, переведенную из последовательности слов, с последовательностью фонем, сгенерированной на основе произнесенного высказывания, и присваивает оценку, которая указывает на относительную вероятность того, что последовательность слов, соответствующая последовательности фонем, является словами, произнесенными в высказывании.
Метод получает цифровой сигнал, представляющий произнесенное высказывание, и генерирует одну или несколько последовательностей фонем из произнесенного высказывания. Одна или несколько последовательностей фонем связаны с первой оценкой. Одна или несколько последовательностей слов могут быть сгенерированы с использованием продукционных правил языковой модели, причем одна или несколько последовательностей слов связаны со второй оценкой, назначенной на основе языковой модели. Он может переводить одну или несколько последовательностей слов в соответствующие последовательности фонем, которые представляют одно или несколько произношений последовательности слов, перевод включает в себя использование местного фонетического варианта в качестве произношения слова вместо произношения по умолчанию, связанного со словом, в рамках локальный контекст производственного правила. Метод сопоставляет последовательность фонем, переведенную из последовательности слов, с последовательностью фонем, сгенерированной на основе произнесенного высказывания, и присваивает оценку, которая указывает на относительную вероятность того, что последовательность слов, соответствующая последовательности фонем, является словами, произнесенными в высказывании.
Реализация этого метода может сочетаться с одной или несколькими из следующих функций. Последовательности фонем, соответствующие одной или более последовательностям слов, могут быть присвоены баллы, а баллы общей вероятности могут быть присвоены конкретной последовательности фонем. Конкретной последовательности фонем присваивается первая оценка при переводе из последовательности слов и вторая оценка при создании на основе произнесенного высказывания, общая оценка относительной вероятности основана на первой оценке и второй оценке. Языковой моделью может быть грамматика, локальный фонетический вариант может быть указан в продукционном правиле грамматики, а локальный фонетический вариант ограничивает произношение слова только при применении продукционного правила, в котором он указан. Грамматика может быть контекстно-зависимой грамматикой и/или семантической грамматикой. Когда грамматика является семантической грамматикой, представление значения генерируется для каждой последовательности слов, распознаваемой грамматикой.
Реализация может иметь следующие дополнительные функции. Грамматика может быть стохастической грамматикой, и последовательности слов, сгенерированные из языковой модели, получают оценку на основе весов, связанных с продукционными правилами, выполненными для создания последовательности слов.
Местный фонетический вариант может быть выражен с помощью набора фонем в виде фонетического алфавита. Фонетический вариант может включать указание на то, что слово пишется, но не произносится, что приводит к сбою производственного правила при речевом вводе.
Продукционные правила (или N-граммы) могут включать указание локального фонетического варианта слова в качестве ограничения произношения в локальном контексте конкретного продукционного правила (или N-граммы) стандартного слова, имеющего несколько допустимых произношений. Локальный фонетический вариант указывает, что для определенного слова с принятым произношением это конкретное слово имеет стилизованное написание, которого нет в фонетическом словаре по умолчанию.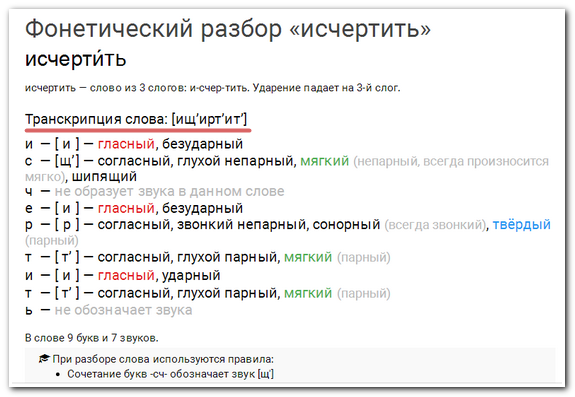
Одни и те же производственные правила, включая расширенный синтаксис, определяющий фонетический вариант, могут использоваться как для ввода текста, так и для речевого ввода. Расширенный синтаксис может включать в себя синтаксис, который поддерживает дифференциальное применение правил. В той же реализации принятый текстовый ввод может быть проанализирован с использованием тех же правил производства, которые используются для анализа речевого ввода.
Хотя технология была раскрыта в контексте метода, ее также можно применять на практике в качестве системы или машиночитаемого носителя. Система представляет собой компьютеризированную систему. Обычно он включает в себя сервер, рабочую станцию, ПК, портативное вычислительное устройство, смартфон или другое устройство с памятью и процессором или другим аппаратным обеспечением, которое выполняет этапы программы.
Хотя раскрытая технология раскрыта со ссылкой на предпочтительные варианты осуществления и примеры, подробно описанные выше, следует понимать, что эти примеры предназначены в иллюстративном, а не ограничивающем смысле. Предполагается, что специалистам в данной области техники будут легко понятны модификации и комбинации, которые будут соответствовать духу изобретения и объему следующей формулы изобретения.
Предполагается, что специалистам в данной области техники будут легко понятны модификации и комбинации, которые будут соответствовать духу изобретения и объему следующей формулы изобретения.
В приведенной выше таблице показан набор фонем CMU (CMUP) с примерами для каждой фонемы. За гласными может следовать индикатор ударения: 0 обозначает отсутствие ударения, 1 указывает на ударный слог, а 2 указывает на вторичное ударение.
PowerShell анализирует файл Json — Stack Overflow
Я пытался выполнить поиск, но нашел только одно сообщение, описывающее тот же метод, который я использую для анализа JSON, поэтому мне было интересно, есть ли лучший способ сделать это.
Я написал небольшую функцию для генерации случайного пароля и, используя таблицу Json ACII, чтобы определить, какие символы будут частью пароля, я выбрал этот подход, так как хочу также распечатать написание пароля.
В настоящее время у меня есть следующее:
[string]$asciiJson = @"
[
{"Индекс": "1","Число": "33","AsciiCode": "!","Фонетический": "Восклицательный знак","Тип": "Символ"},
{"Индекс": "2","Число": "34","AsciiCode": "\"","Фонетический":"Двойные кавычки","Тип": "Символ"},
{"Индекс": "3","Число": "35","AsciiCode": "#","Фонетический": "Знак решетки","Тип": "Символ"},
{"Индекс": "4", "Число": "36", "AsciiCode": "$", "Фонетический": "Знак доллара", "Тип": "Символ"},
{"Индекс": "5","Число": "37","AsciiCode": "%","Фонетический": "Знак процента","Тип": "Символ"},
{"Индекс": "6", "Число": "38", "AsciiCode": "&", "Фонетический": "Амперсанд", "Тип": "Символ"},
{"Индекс": "7","Число": "39","AsciiCode": "'","Фонетический": "Одинарная кавычка","Тип": "Символ"},
{"Индекс": "8","Число": "40","AsciiCode": "(","Фонетический": "Открывающая скобка","Тип": "Символ"},
{"Индекс": "9","Число": "41","AsciiCode": ")","Фонетический": "Закрывающая скобка","Тип": "Символ"},
{"Индекс": "10","Число": "42","AsciiCode": "*","Фонетический": "Звездочка","Тип": "Символ"},
{"Индекс": "11","Число": "43","AsciiCode": "+","Фонетический": "Знак плюс","Тип": "Символ"},
{"Индекс": "12","Число": "44","AsciiCode": ",","Фонетический": "Запятая","Тип": "Символ"},
{"Индекс": "13","Число": "45","AsciiCode": "-","Фонетический": "Знак минус -Дефис","Тип": "Символ"},
{"Индекс": "14","Число": "46","AsciiCode": ". ","Фонетика": "Период","Тип": "Символ"},
{"Index": "15", "Number": "47", "AsciiCode": "/", "Fonetic": "Slash", "Type": "Symbol"},
{"Индекс": "16","Число": "58","AsciiCode": ":","Фонетический": "Двоеточие","Тип": "Символ"},
{"Индекс": "17","Число": "59","AsciiCode": ";","Фонетический": "Точка с запятой","Тип": "Символ"},
{"Индекс": "18","Число": "60","AsciiCode": "<","Фонетический": "Знак меньше","Тип": "Символ"},
{"Индекс": "19","Число": "61","AsciiCode": "=","Фонетический": "Знак равенства","Тип": "Символ"},
{"Индекс": "20","Число": "62","AsciiCode": ">","Фонетический": "Знак больше","Тип": "Символ"},
{"Индекс": "21","Число": "63","AsciiCode": "?","Фонетический": "Вопросительный знак","Тип": "Символ"},
{"Индекс": "22","Число": "64","AsciiCode": "@","Фонетический": "На символе","Тип": "Символ"},
{"Индекс": "23","Число": "9","Фонетический": "Карет - циркумфлекс","Тип": "Символ"},
{"Индекс": "27", "Число": "95", "AsciiCode": "_", "Фонетический": "Подчеркивание", "Тип": "Символ"},
{"Индекс": "29","Число": "123","AsciiCode": "{","Фонетический": "Открывающая фигурная скобка","Тип": "Символ"},
{"Индекс": "30","Число": "124","AsciiCode": "|","Фонетика": "Вертикальная черта","Тип": "Символ"},
{"Индекс": "31","Число": "125","AsciiCode": "}","Фонетический": "Закрывающая фигурная скобка","Тип": "Символ"},
{"Индекс": "33", "Число": "65", "AsciiCode": "A", "Фонетический": "Альфа", "Тип": "Заглавная буква"},
{"Индекс": "34", "Число": "66", "AsciiCode": "B", "Фонетический": "Браво", "Тип": "Заглавная буква"},
{"Индекс": "35", "Число": "67", "AsciiCode": "C", "Фонетический": "Чарли", "Тип": "Заглавная буква"},
{"Индекс": "36", "Число": "68", "AsciiCode": "D", "Фонетический": "Дельта", "Тип": "Заглавная буква"},
{"Индекс": "37","Число": "69","AsciiCode": "E","Фонетический": "Эхо","Тип": "Заглавная буква"},
{"Индекс": "38","Число": "70","AsciiCode": "F","Фонетика": "Фокстрот","Тип": "Заглавная буква"},
{"Индекс": "39", "Число": "71", "AsciiCode": "G", "Фонетический": "Гольф", "Тип": "Заглавная буква"},
{"Index": "40", "Number": "72", "AsciiCode": "H", "Fonetic": "Hotel", "Type": "Заглавная буква"},
{"Индекс": "41", "Число": "73", "AsciiCode": "I", "Фонетический": "Индия", "Тип": "Заглавная буква"},
{"Индекс": "42", "Число": "74", "AsciiCode": "J", "Фонетический": "Джульетта", "Тип": "Заглавная буква"},
{"Индекс": "43","Число": "75","AsciiCode": "K","Фонетический": "Килограмм","Тип": "Заглавная буква"},
{"Индекс": "44", "Число": "76", "AsciiCode": "L", "Фонетический": "Лима", "Тип": "Заглавная буква"},
{"Индекс": "45", "Число": "77", "AsciiCode": "M", "Фонетический": "Майк", "Тип": "Заглавная буква"},
{"Индекс": "46", "Число": "78", "AsciiCode": "N", "Фонетический": "Ноябрь", "Тип": "Заглавная буква"},
{"Индекс": "47","Число": "79","AsciiCode": "O","Фонетический": "Оскар","Type": "Заглавная буква"},
{"Индекс": "48", "Число": "80", "AsciiCode": "P", "Фонетический": "Папа", "Тип": "Заглавная буква"},
{"Индекс": "49", "Число": "81", "AsciiCode": "Q", "Фонетический": "Квебек", "Тип": "Заглавная буква"},
{"Индекс": "50", "Число": "82", "AsciiCode": "R", "Фонетический": "Ромео", "Тип": "Заглавная буква"},
{"Индекс": "51", "Число": "83", "AsciiCode": "S", "Фонетический": "Сьерра", "Тип": "Заглавная буква"},
{"Index": "52", "Number": "84", "AsciiCode": "T", "Fonetic": "Tango", "Type": "Заглавная буква"},
{"Index": "53", "Number": "85", "AsciiCode": "U", "Fonetic": "Uniform", "Type": "Заглавная буква"},
{"Индекс": "54", "Число": "86", "AsciiCode": "V", "Фонетический": "Виктор", "Тип": "Заглавная буква"},
{"Индекс": "55","Число": "87","AsciiCode": "W","Фонетический": "Виски","Тип": "Заглавная буква"},
{"Index": "56", "Number": "88", "AsciiCode": "X", "Fonetic": "X-Ray", "Type": "Заглавная буква"},
{"Индекс": "57","Номер": "89","AsciiCode": "Y","Фонетический": "Янки","Тип": "Заглавная буква"},
{"Index": "58", "Number": "90", "AsciiCode": "Z", "Fonetic": "Zulu", "Type": "Заглавная буква"},
{"Индекс": "59", "Число": "97", "AsciiCode": "a", "Фонетический": "Альфа", "Тип": "Строчная буква"},
{"Индекс": "60","Число": "98","AsciiCode": "b","Фонетический": "Браво","Тип": "Строчная буква"},
{"Индекс": "61", "Число": "99", "AsciiCode": "c", "Фонетический": "Чарли", "Тип": "Строчная буква"},
{"Индекс": "62","Число": "100","AsciiCode": "d","Фонетический": "Дельта","Тип": "Строчная буква"},
{"Index": "63", "Number": "101", "AsciiCode": "e", "Fonetic": "Echo", "Type": "Строчная буква"},
{"Индекс": "64","Число": "102","AsciiCode": "f","Фонетический": "Фокстрот","Тип": "Строчная буква"},
{"Индекс": "65","Число": "103","AsciiCode": "g","Фонетический": "Гольф","Тип": "Строчная буква"},
{"Индекс": "66","Число": "104","AsciiCode": "h","Фонетический": "Отель","Тип": "Строчная буква"},
{"Индекс": "67","Число": "105","AsciiCode": "i","Фонетический": "Индия","Тип": "Строчная буква"},
{"Индекс": "68", "Число": "106", "AsciiCode": "j", "Фонетический": "Джульетта", "Тип": "Строчная буква"},
{"Индекс": "69","Число": "107","AsciiCode": "k","Фонетический": "Килограмм","Тип": "Строчная буква"},
{"Индекс": "70", "Число": "108", "AsciiCode": "l", "Фонетический": "Лима", "Тип": "Строчная буква"},
{"Индекс": "71","Число": "109","AsciiCode": "m","Фонетический": "Майк","Тип": "Строчная буква"},
{"Индекс": "72","Число": "110","AsciiCode": "n","Фонетический": "Ноябрь","Тип": "Строчная буква"},
{"Индекс": "73","Число": "111","AsciiCode": "o","Фонетический": "Оскар","Тип": "Строчная буква"},
{"Индекс": "74","Число": "112","AsciiCode": "p","Фонетический": "Папа","Тип": "Строчная буква"},
{"Индекс": "75", "Число": "113", "AsciiCode": "q", "Фонетический": "Квебек", "Тип": "Строчная буква"},
{"Индекс": "76", "Число": "114", "AsciiCode": "r", "Фонетический": "Ромео", "Тип": "Строчная буква"},
{"Индекс": "77","Число": "115","AsciiCode": "s","Фонетический": "Сьерра","Тип": "Строчная буква"},
{"Индекс": "78","Число": "116","AsciiCode": "t","Фонетический": "Танго","Тип": "Строчная буква"},
{"Индекс": "79","Число": "117","AsciiCode": "u","Фонетический": "Унифицированный","Тип": "Строчная буква"},
{"Индекс": "80","Число": "118","AsciiCode": "v","Фонетический": "Виктор","Тип": "Строчная буква"},
{"Индекс": "81","Число": "119","AsciiCode": "w","Фонетический": "Виски","Тип": "Строчная буква"},
{"Index": "82", "Number": "120", "AsciiCode": "x", "Fonetic": "X-Ray", "Type": "Строчная буква"},
{"Индекс": "83","Число": "121","AsciiCode": "y","Фонетический": "Янки","Тип": "Строчная буква"},
{"Index": "84", "Number": "122", "AsciiCode": "z", "Fonetic": "Zulu", "Type": "Строчная буква"},
{"Индекс": "85","Число": "48","AsciiCode": "0","Фонетический": "Ноль","Тип": "Число"},
{"Индекс": "86","Число": "49","AsciiCode": "1","Фонетический": "Один","Тип": "Число"},
{"Индекс": "87","Число": "50","AsciiCode": "2","Фонетический": "Два","Тип": "Число"},
{"Индекс": "88", "Число": "51", "AsciiCode": "3", "Фонетический": "Три", "Тип": "Число"},
{"Индекс": "89","Число": "52","AsciiCode": "4","Фонетический": "Четыре","Тип": "Число"},
{"Индекс": "90","Число": "53","AsciiCode": "5","Фонетический": "Пять","Тип": "Число"},
{"Индекс": "91","Число": "54","AsciiCode": "6","Фонетический": "Шесть","Тип": "Число"},
{"Индекс": "92","Число": "55","AsciiCode": "7","Фонетический": "Семь","Тип": "Число"},
{"Индекс": "93", "Число": "56", "AsciiCode": "8", "Фонетический": "Восемь", "Тип": "Число"},
{"Индекс": "94","Число": "57","AsciiCode": "9","Фонетический": "Девять","Тип": "Число"}
]
"@
 ","Фонетика": "Период","Тип": "Символ"},
{"Index": "15", "Number": "47", "AsciiCode": "/", "Fonetic": "Slash", "Type": "Symbol"},
{"Индекс": "16","Число": "58","AsciiCode": ":","Фонетический": "Двоеточие","Тип": "Символ"},
{"Индекс": "17","Число": "59","AsciiCode": ";","Фонетический": "Точка с запятой","Тип": "Символ"},
{"Индекс": "18","Число": "60","AsciiCode": "<","Фонетический": "Знак меньше","Тип": "Символ"},
{"Индекс": "19","Число": "61","AsciiCode": "=","Фонетический": "Знак равенства","Тип": "Символ"},
{"Индекс": "20","Число": "62","AsciiCode": ">","Фонетический": "Знак больше","Тип": "Символ"},
{"Индекс": "21","Число": "63","AsciiCode": "?","Фонетический": "Вопросительный знак","Тип": "Символ"},
{"Индекс": "22","Число": "64","AsciiCode": "@","Фонетический": "На символе","Тип": "Символ"},
{"Индекс": "23","Число": "9","Фонетический": "Карет - циркумфлекс","Тип": "Символ"},
{"Индекс": "27", "Число": "95", "AsciiCode": "_", "Фонетический": "Подчеркивание", "Тип": "Символ"},
{"Индекс": "29","Число": "123","AsciiCode": "{","Фонетический": "Открывающая фигурная скобка","Тип": "Символ"},
{"Индекс": "30","Число": "124","AsciiCode": "|","Фонетика": "Вертикальная черта","Тип": "Символ"},
{"Индекс": "31","Число": "125","AsciiCode": "}","Фонетический": "Закрывающая фигурная скобка","Тип": "Символ"},
{"Индекс": "33", "Число": "65", "AsciiCode": "A", "Фонетический": "Альфа", "Тип": "Заглавная буква"},
{"Индекс": "34", "Число": "66", "AsciiCode": "B", "Фонетический": "Браво", "Тип": "Заглавная буква"},
{"Индекс": "35", "Число": "67", "AsciiCode": "C", "Фонетический": "Чарли", "Тип": "Заглавная буква"},
{"Индекс": "36", "Число": "68", "AsciiCode": "D", "Фонетический": "Дельта", "Тип": "Заглавная буква"},
{"Индекс": "37","Число": "69","AsciiCode": "E","Фонетический": "Эхо","Тип": "Заглавная буква"},
{"Индекс": "38","Число": "70","AsciiCode": "F","Фонетика": "Фокстрот","Тип": "Заглавная буква"},
{"Индекс": "39", "Число": "71", "AsciiCode": "G", "Фонетический": "Гольф", "Тип": "Заглавная буква"},
{"Index": "40", "Number": "72", "AsciiCode": "H", "Fonetic": "Hotel", "Type": "Заглавная буква"},
{"Индекс": "41", "Число": "73", "AsciiCode": "I", "Фонетический": "Индия", "Тип": "Заглавная буква"},
{"Индекс": "42", "Число": "74", "AsciiCode": "J", "Фонетический": "Джульетта", "Тип": "Заглавная буква"},
{"Индекс": "43","Число": "75","AsciiCode": "K","Фонетический": "Килограмм","Тип": "Заглавная буква"},
{"Индекс": "44", "Число": "76", "AsciiCode": "L", "Фонетический": "Лима", "Тип": "Заглавная буква"},
{"Индекс": "45", "Число": "77", "AsciiCode": "M", "Фонетический": "Майк", "Тип": "Заглавная буква"},
{"Индекс": "46", "Число": "78", "AsciiCode": "N", "Фонетический": "Ноябрь", "Тип": "Заглавная буква"},
{"Индекс": "47","Число": "79","AsciiCode": "O","Фонетический": "Оскар","Type": "Заглавная буква"},
{"Индекс": "48", "Число": "80", "AsciiCode": "P", "Фонетический": "Папа", "Тип": "Заглавная буква"},
{"Индекс": "49", "Число": "81", "AsciiCode": "Q", "Фонетический": "Квебек", "Тип": "Заглавная буква"},
{"Индекс": "50", "Число": "82", "AsciiCode": "R", "Фонетический": "Ромео", "Тип": "Заглавная буква"},
{"Индекс": "51", "Число": "83", "AsciiCode": "S", "Фонетический": "Сьерра", "Тип": "Заглавная буква"},
{"Index": "52", "Number": "84", "AsciiCode": "T", "Fonetic": "Tango", "Type": "Заглавная буква"},
{"Index": "53", "Number": "85", "AsciiCode": "U", "Fonetic": "Uniform", "Type": "Заглавная буква"},
{"Индекс": "54", "Число": "86", "AsciiCode": "V", "Фонетический": "Виктор", "Тип": "Заглавная буква"},
{"Индекс": "55","Число": "87","AsciiCode": "W","Фонетический": "Виски","Тип": "Заглавная буква"},
{"Index": "56", "Number": "88", "AsciiCode": "X", "Fonetic": "X-Ray", "Type": "Заглавная буква"},
{"Индекс": "57","Номер": "89","AsciiCode": "Y","Фонетический": "Янки","Тип": "Заглавная буква"},
{"Index": "58", "Number": "90", "AsciiCode": "Z", "Fonetic": "Zulu", "Type": "Заглавная буква"},
{"Индекс": "59", "Число": "97", "AsciiCode": "a", "Фонетический": "Альфа", "Тип": "Строчная буква"},
{"Индекс": "60","Число": "98","AsciiCode": "b","Фонетический": "Браво","Тип": "Строчная буква"},
{"Индекс": "61", "Число": "99", "AsciiCode": "c", "Фонетический": "Чарли", "Тип": "Строчная буква"},
{"Индекс": "62","Число": "100","AsciiCode": "d","Фонетический": "Дельта","Тип": "Строчная буква"},
{"Index": "63", "Number": "101", "AsciiCode": "e", "Fonetic": "Echo", "Type": "Строчная буква"},
{"Индекс": "64","Число": "102","AsciiCode": "f","Фонетический": "Фокстрот","Тип": "Строчная буква"},
{"Индекс": "65","Число": "103","AsciiCode": "g","Фонетический": "Гольф","Тип": "Строчная буква"},
{"Индекс": "66","Число": "104","AsciiCode": "h","Фонетический": "Отель","Тип": "Строчная буква"},
{"Индекс": "67","Число": "105","AsciiCode": "i","Фонетический": "Индия","Тип": "Строчная буква"},
{"Индекс": "68", "Число": "106", "AsciiCode": "j", "Фонетический": "Джульетта", "Тип": "Строчная буква"},
{"Индекс": "69","Число": "107","AsciiCode": "k","Фонетический": "Килограмм","Тип": "Строчная буква"},
{"Индекс": "70", "Число": "108", "AsciiCode": "l", "Фонетический": "Лима", "Тип": "Строчная буква"},
{"Индекс": "71","Число": "109","AsciiCode": "m","Фонетический": "Майк","Тип": "Строчная буква"},
{"Индекс": "72","Число": "110","AsciiCode": "n","Фонетический": "Ноябрь","Тип": "Строчная буква"},
{"Индекс": "73","Число": "111","AsciiCode": "o","Фонетический": "Оскар","Тип": "Строчная буква"},
{"Индекс": "74","Число": "112","AsciiCode": "p","Фонетический": "Папа","Тип": "Строчная буква"},
{"Индекс": "75", "Число": "113", "AsciiCode": "q", "Фонетический": "Квебек", "Тип": "Строчная буква"},
{"Индекс": "76", "Число": "114", "AsciiCode": "r", "Фонетический": "Ромео", "Тип": "Строчная буква"},
{"Индекс": "77","Число": "115","AsciiCode": "s","Фонетический": "Сьерра","Тип": "Строчная буква"},
{"Индекс": "78","Число": "116","AsciiCode": "t","Фонетический": "Танго","Тип": "Строчная буква"},
{"Индекс": "79","Число": "117","AsciiCode": "u","Фонетический": "Унифицированный","Тип": "Строчная буква"},
{"Индекс": "80","Число": "118","AsciiCode": "v","Фонетический": "Виктор","Тип": "Строчная буква"},
{"Индекс": "81","Число": "119","AsciiCode": "w","Фонетический": "Виски","Тип": "Строчная буква"},
{"Index": "82", "Number": "120", "AsciiCode": "x", "Fonetic": "X-Ray", "Type": "Строчная буква"},
{"Индекс": "83","Число": "121","AsciiCode": "y","Фонетический": "Янки","Тип": "Строчная буква"},
{"Index": "84", "Number": "122", "AsciiCode": "z", "Fonetic": "Zulu", "Type": "Строчная буква"},
{"Индекс": "85","Число": "48","AsciiCode": "0","Фонетический": "Ноль","Тип": "Число"},
{"Индекс": "86","Число": "49","AsciiCode": "1","Фонетический": "Один","Тип": "Число"},
{"Индекс": "87","Число": "50","AsciiCode": "2","Фонетический": "Два","Тип": "Число"},
{"Индекс": "88", "Число": "51", "AsciiCode": "3", "Фонетический": "Три", "Тип": "Число"},
{"Индекс": "89","Число": "52","AsciiCode": "4","Фонетический": "Четыре","Тип": "Число"},
{"Индекс": "90","Число": "53","AsciiCode": "5","Фонетический": "Пять","Тип": "Число"},
{"Индекс": "91","Число": "54","AsciiCode": "6","Фонетический": "Шесть","Тип": "Число"},
{"Индекс": "92","Число": "55","AsciiCode": "7","Фонетический": "Семь","Тип": "Число"},
{"Индекс": "93", "Число": "56", "AsciiCode": "8", "Фонетический": "Восемь", "Тип": "Число"},
{"Индекс": "94","Число": "57","AsciiCode": "9","Фонетический": "Девять","Тип": "Число"}
]
"@
","Фонетика": "Период","Тип": "Символ"},
{"Index": "15", "Number": "47", "AsciiCode": "/", "Fonetic": "Slash", "Type": "Symbol"},
{"Индекс": "16","Число": "58","AsciiCode": ":","Фонетический": "Двоеточие","Тип": "Символ"},
{"Индекс": "17","Число": "59","AsciiCode": ";","Фонетический": "Точка с запятой","Тип": "Символ"},
{"Индекс": "18","Число": "60","AsciiCode": "<","Фонетический": "Знак меньше","Тип": "Символ"},
{"Индекс": "19","Число": "61","AsciiCode": "=","Фонетический": "Знак равенства","Тип": "Символ"},
{"Индекс": "20","Число": "62","AsciiCode": ">","Фонетический": "Знак больше","Тип": "Символ"},
{"Индекс": "21","Число": "63","AsciiCode": "?","Фонетический": "Вопросительный знак","Тип": "Символ"},
{"Индекс": "22","Число": "64","AsciiCode": "@","Фонетический": "На символе","Тип": "Символ"},
{"Индекс": "23","Число": "9","Фонетический": "Карет - циркумфлекс","Тип": "Символ"},
{"Индекс": "27", "Число": "95", "AsciiCode": "_", "Фонетический": "Подчеркивание", "Тип": "Символ"},
{"Индекс": "29","Число": "123","AsciiCode": "{","Фонетический": "Открывающая фигурная скобка","Тип": "Символ"},
{"Индекс": "30","Число": "124","AsciiCode": "|","Фонетика": "Вертикальная черта","Тип": "Символ"},
{"Индекс": "31","Число": "125","AsciiCode": "}","Фонетический": "Закрывающая фигурная скобка","Тип": "Символ"},
{"Индекс": "33", "Число": "65", "AsciiCode": "A", "Фонетический": "Альфа", "Тип": "Заглавная буква"},
{"Индекс": "34", "Число": "66", "AsciiCode": "B", "Фонетический": "Браво", "Тип": "Заглавная буква"},
{"Индекс": "35", "Число": "67", "AsciiCode": "C", "Фонетический": "Чарли", "Тип": "Заглавная буква"},
{"Индекс": "36", "Число": "68", "AsciiCode": "D", "Фонетический": "Дельта", "Тип": "Заглавная буква"},
{"Индекс": "37","Число": "69","AsciiCode": "E","Фонетический": "Эхо","Тип": "Заглавная буква"},
{"Индекс": "38","Число": "70","AsciiCode": "F","Фонетика": "Фокстрот","Тип": "Заглавная буква"},
{"Индекс": "39", "Число": "71", "AsciiCode": "G", "Фонетический": "Гольф", "Тип": "Заглавная буква"},
{"Index": "40", "Number": "72", "AsciiCode": "H", "Fonetic": "Hotel", "Type": "Заглавная буква"},
{"Индекс": "41", "Число": "73", "AsciiCode": "I", "Фонетический": "Индия", "Тип": "Заглавная буква"},
{"Индекс": "42", "Число": "74", "AsciiCode": "J", "Фонетический": "Джульетта", "Тип": "Заглавная буква"},
{"Индекс": "43","Число": "75","AsciiCode": "K","Фонетический": "Килограмм","Тип": "Заглавная буква"},
{"Индекс": "44", "Число": "76", "AsciiCode": "L", "Фонетический": "Лима", "Тип": "Заглавная буква"},
{"Индекс": "45", "Число": "77", "AsciiCode": "M", "Фонетический": "Майк", "Тип": "Заглавная буква"},
{"Индекс": "46", "Число": "78", "AsciiCode": "N", "Фонетический": "Ноябрь", "Тип": "Заглавная буква"},
{"Индекс": "47","Число": "79","AsciiCode": "O","Фонетический": "Оскар","Type": "Заглавная буква"},
{"Индекс": "48", "Число": "80", "AsciiCode": "P", "Фонетический": "Папа", "Тип": "Заглавная буква"},
{"Индекс": "49", "Число": "81", "AsciiCode": "Q", "Фонетический": "Квебек", "Тип": "Заглавная буква"},
{"Индекс": "50", "Число": "82", "AsciiCode": "R", "Фонетический": "Ромео", "Тип": "Заглавная буква"},
{"Индекс": "51", "Число": "83", "AsciiCode": "S", "Фонетический": "Сьерра", "Тип": "Заглавная буква"},
{"Index": "52", "Number": "84", "AsciiCode": "T", "Fonetic": "Tango", "Type": "Заглавная буква"},
{"Index": "53", "Number": "85", "AsciiCode": "U", "Fonetic": "Uniform", "Type": "Заглавная буква"},
{"Индекс": "54", "Число": "86", "AsciiCode": "V", "Фонетический": "Виктор", "Тип": "Заглавная буква"},
{"Индекс": "55","Число": "87","AsciiCode": "W","Фонетический": "Виски","Тип": "Заглавная буква"},
{"Index": "56", "Number": "88", "AsciiCode": "X", "Fonetic": "X-Ray", "Type": "Заглавная буква"},
{"Индекс": "57","Номер": "89","AsciiCode": "Y","Фонетический": "Янки","Тип": "Заглавная буква"},
{"Index": "58", "Number": "90", "AsciiCode": "Z", "Fonetic": "Zulu", "Type": "Заглавная буква"},
{"Индекс": "59", "Число": "97", "AsciiCode": "a", "Фонетический": "Альфа", "Тип": "Строчная буква"},
{"Индекс": "60","Число": "98","AsciiCode": "b","Фонетический": "Браво","Тип": "Строчная буква"},
{"Индекс": "61", "Число": "99", "AsciiCode": "c", "Фонетический": "Чарли", "Тип": "Строчная буква"},
{"Индекс": "62","Число": "100","AsciiCode": "d","Фонетический": "Дельта","Тип": "Строчная буква"},
{"Index": "63", "Number": "101", "AsciiCode": "e", "Fonetic": "Echo", "Type": "Строчная буква"},
{"Индекс": "64","Число": "102","AsciiCode": "f","Фонетический": "Фокстрот","Тип": "Строчная буква"},
{"Индекс": "65","Число": "103","AsciiCode": "g","Фонетический": "Гольф","Тип": "Строчная буква"},
{"Индекс": "66","Число": "104","AsciiCode": "h","Фонетический": "Отель","Тип": "Строчная буква"},
{"Индекс": "67","Число": "105","AsciiCode": "i","Фонетический": "Индия","Тип": "Строчная буква"},
{"Индекс": "68", "Число": "106", "AsciiCode": "j", "Фонетический": "Джульетта", "Тип": "Строчная буква"},
{"Индекс": "69","Число": "107","AsciiCode": "k","Фонетический": "Килограмм","Тип": "Строчная буква"},
{"Индекс": "70", "Число": "108", "AsciiCode": "l", "Фонетический": "Лима", "Тип": "Строчная буква"},
{"Индекс": "71","Число": "109","AsciiCode": "m","Фонетический": "Майк","Тип": "Строчная буква"},
{"Индекс": "72","Число": "110","AsciiCode": "n","Фонетический": "Ноябрь","Тип": "Строчная буква"},
{"Индекс": "73","Число": "111","AsciiCode": "o","Фонетический": "Оскар","Тип": "Строчная буква"},
{"Индекс": "74","Число": "112","AsciiCode": "p","Фонетический": "Папа","Тип": "Строчная буква"},
{"Индекс": "75", "Число": "113", "AsciiCode": "q", "Фонетический": "Квебек", "Тип": "Строчная буква"},
{"Индекс": "76", "Число": "114", "AsciiCode": "r", "Фонетический": "Ромео", "Тип": "Строчная буква"},
{"Индекс": "77","Число": "115","AsciiCode": "s","Фонетический": "Сьерра","Тип": "Строчная буква"},
{"Индекс": "78","Число": "116","AsciiCode": "t","Фонетический": "Танго","Тип": "Строчная буква"},
{"Индекс": "79","Число": "117","AsciiCode": "u","Фонетический": "Унифицированный","Тип": "Строчная буква"},
{"Индекс": "80","Число": "118","AsciiCode": "v","Фонетический": "Виктор","Тип": "Строчная буква"},
{"Индекс": "81","Число": "119","AsciiCode": "w","Фонетический": "Виски","Тип": "Строчная буква"},
{"Index": "82", "Number": "120", "AsciiCode": "x", "Fonetic": "X-Ray", "Type": "Строчная буква"},
{"Индекс": "83","Число": "121","AsciiCode": "y","Фонетический": "Янки","Тип": "Строчная буква"},
{"Index": "84", "Number": "122", "AsciiCode": "z", "Fonetic": "Zulu", "Type": "Строчная буква"},
{"Индекс": "85","Число": "48","AsciiCode": "0","Фонетический": "Ноль","Тип": "Число"},
{"Индекс": "86","Число": "49","AsciiCode": "1","Фонетический": "Один","Тип": "Число"},
{"Индекс": "87","Число": "50","AsciiCode": "2","Фонетический": "Два","Тип": "Число"},
{"Индекс": "88", "Число": "51", "AsciiCode": "3", "Фонетический": "Три", "Тип": "Число"},
{"Индекс": "89","Число": "52","AsciiCode": "4","Фонетический": "Четыре","Тип": "Число"},
{"Индекс": "90","Число": "53","AsciiCode": "5","Фонетический": "Пять","Тип": "Число"},
{"Индекс": "91","Число": "54","AsciiCode": "6","Фонетический": "Шесть","Тип": "Число"},
{"Индекс": "92","Число": "55","AsciiCode": "7","Фонетический": "Семь","Тип": "Число"},
{"Индекс": "93", "Число": "56", "AsciiCode": "8", "Фонетический": "Восемь", "Тип": "Число"},
{"Индекс": "94","Число": "57","AsciiCode": "9","Фонетический": "Девять","Тип": "Число"}
]
"@
Это часть, где я генерирую таблицу различных символов
# Генерация таблиц символов
$charsTable = ConvertFrom-Json-InputObject $asciiJson
$symbolsTable = $charsTable | Где-Объект {$_. Type -eq 'Символ'}
$capitalLettersTable = $charsTable | Where-Object { $_.Type -eq 'Заглавная буква'}
$lowerCaseLettersTable = $charsTable | Where-Object { $_.Type -eq 'Строчная буква' }
$digitsTable = $charsTable | Где-Объект {$_.Type -eq 'Число'}
 Type -eq 'Символ'}
$capitalLettersTable = $charsTable | Where-Object { $_.Type -eq 'Заглавная буква'}
$lowerCaseLettersTable = $charsTable | Where-Object { $_.Type -eq 'Строчная буква' }
$digitsTable = $charsTable | Где-Объект {$_.Type -eq 'Число'}
Type -eq 'Символ'}
$capitalLettersTable = $charsTable | Where-Object { $_.Type -eq 'Заглавная буква'}
$lowerCaseLettersTable = $charsTable | Where-Object { $_.Type -eq 'Строчная буква' }
$digitsTable = $charsTable | Где-Объект {$_.Type -eq 'Число'}
Все работает хорошо, только что заметил, что при вызове функции из дочернего скрипта часть синтаксического анализа выполняется довольно медленно, поэтому мне было интересно, есть ли лучший способ заполнить различные таблицы символов.
Признаюсь, я новичок в JSON, поэтому, если есть лучший способ сделать это, я был бы более чем рад его услышать.
В общем, я могу жить с ударом по производительности, но если есть способ оптимизировать код, почему бы и нет.
Заранее спасибо за любую помощь/отзыв.
Анализатор запросов DisMax | Справочное руководство по Apache Solr 6.6
В дополнение к общему параметру запроса, параметрам выделения и параметрам простого аспекта анализатор запросов DisMax поддерживает параметры, описанные ниже. Как и стандартный анализатор запросов, анализатор запросов DisMax позволяет указывать значения параметров по умолчанию в
Как и стандартный анализатор запросов, анализатор запросов DisMax позволяет указывать значения параметров по умолчанию в solrconfig.xml или переопределять значениями времени запроса в запросе.
| Параметр | Описание |
|---|---|
д | Определяет необработанные входные строки для запроса. |
кв.альт | Вызывает стандартный анализатор запросов и определяет входные строки запроса, если параметр q не используется. |
кв | Поля запроса: указывает поля в индексе, для которых выполняется запрос. Если отсутствует, по умолчанию |
мм | Минимальное соответствие «Should»: указывает минимальное количество предложений, которые должны совпадать в запросе. Если в запросе не указан параметр mm или по умолчанию в |
пф | Поля фраз: повышает оценку документов в случаях, когда все термины в параметре q появляются в непосредственной близости. |
шт. | Фраза Slop: указывает количество позиций, на которые два термина могут быть разделены, чтобы соответствовать указанной фразе. |
qs | Слоп фразы запроса: указывает количество позиций, на которые два термина могут быть разделены, чтобы соответствовать указанной фразе. Используется специально с |
галстук | Прерыватель конфликтов: указывает значение с плавающей запятой (которое должно быть намного меньше 1) для использования в качестве разрешения конфликтов в запросах DisMax. По умолчанию: 0,0 |
бк | Boost Query: указывает коэффициент, на который значение важности термина или фразы должно быть "повышено" при рассмотрении совпадения. |
бф | Boost Functions: определяет функции, которые будут применяться к бустам. (Подробнее о запросах функций см. в разделе.) |
 xml
xml 
В следующих разделах подробно описаны эти параметры.
Параметр
q Параметр q определяет основной «запрос», составляющий суть поиска. Параметр поддерживает необработанные входные строки, предоставленные пользователями, без специального экранирования. Символы + и - рассматриваются как «обязательные» и «запрещенные» модификаторы терминов. Текст, заключённый в сбалансированные кавычки (например, «Сан-Хосе»), рассматривается как фраза. Любой запрос, содержащий нечетное количество символов кавычек, оценивается так, как если бы символов кавычек вообще не было.
Параметр поддерживает необработанные входные строки, предоставленные пользователями, без специального экранирования. Символы + и - рассматриваются как «обязательные» и «запрещенные» модификаторы терминов. Текст, заключённый в сбалансированные кавычки (например, «Сан-Хосе»), рассматривается как фраза. Любой запрос, содержащий нечетное количество символов кавычек, оценивается так, как если бы символов кавычек вообще не было.
Параметр |
Параметр
q.alt Если указано, параметр q.alt определяет запрос (который по умолчанию будет анализироваться с использованием стандартного синтаксиса анализа запроса), когда основной параметр q не указан или пуст. Параметр q.alt пригодится, когда вам нужно что-то вроде запроса для сопоставления всех документов (не забудьте 90,4"
назначает fieldOne усиление 2,3, оставляет fieldTwo с усилением по умолчанию (поскольку коэффициент усиления не указан), а fieldThree - усиление 0,4. более значимы, чем совпадения в
более значимы, чем совпадения в fieldTwo , которые, в свою очередь, гораздо более значимы, чем совпадения в fieldThree
Параметр
mm (минимум должен совпадать) При обработке запросов Lucene/Solr распознает три типа предложений: обязательные, запрещенные и «необязательные» (также известные как предложения «следует»). По умолчанию все слова или фразы, указанные в 9Параметр 0612 q рассматривается как «необязательный» пункт, если только ему не предшествует «+» или «-«. При работе с этими «необязательными» пунктами параметр мм позволяет сказать, что определенное минимальное количество этих пунктов должно совпадать. Анализатор запросов DisMax предлагает большую гибкость в том, как можно указать минимальное число.
В приведенной ниже таблице поясняются различные способы указания значений мм.
| Синтаксис | Пример | Описание |
|---|---|---|
Положительное целое число | 3 | Определяет минимальное количество предложений, которые должны совпадать, независимо от общего количества предложений. |
Отрицательное целое число | -2 | Устанавливает минимальное количество совпадающих предложений равным общему количеству необязательных предложений за вычетом этого значения. |
Процент | 75% | Устанавливает минимальное количество совпадающих предложений в процентах от общего числа необязательных предложений. Число, вычисленное из процента, округляется в меньшую сторону и используется как минимум. |
Отрицательный процент | -25% | Указывает, что данный процент от общего числа необязательных предложений может отсутствовать. Число, вычисленное из процента, округляется в меньшую сторону, а затем вычитается из общего числа для определения минимального числа. |
Выражение, начинающееся с положительного целого числа, за которым следует знак > или < и другое значение | 3<90% | Определяет условное выражение, указывающее, что если количество необязательных предложений равно (или меньше) целому числу, они все обязательны, но если оно больше целого числа, применяется спецификация. |
Несколько условных выражений, включающих знаки > или < | 2<-25% 9<-3 | Определяет несколько условий, каждое из которых действительно только для чисел, превышающих предыдущее. В примере слева, если есть 1 или 2 пункта, то оба обязательны. При наличии 3-9 пунктов обязательны все, кроме 25%. Если пунктов больше 9, нужны все, кроме трех. |

 В этом примере: если есть от 1 до 3 пунктов, они все обязательны, но для 4 и более пунктов только 90% требуется.
В этом примере: если есть от 1 до 3 пунктов, они все обязательны, но для 4 и более пунктов только 90% требуется. При указании значений мм имейте в виду следующее:
При работе с процентами можно использовать отрицательные значения, чтобы получить другое поведение в крайних случаях. 75% и -25% означают одно и то же при работе с 4 пунктами, но при работе с 5 пунктами 75% означает, что требуется 3, а -25% означает, что требуется 4.
Если вычисления, основанные на аргументах параметров, определяют, что необязательные предложения не нужны, во время поиска по-прежнему применяются обычные правила для логических запросов.
(То есть логический запрос, не содержащий обязательных предложений, должен по-прежнему соответствовать хотя бы одному необязательному предложению).Независимо от того, к какому числу придет вычисление, Solr никогда не будет использовать значение больше, чем количество необязательных предложений, или значение меньше 1. Другими словами, независимо от того, насколько низкий или высокий результат вычислений, минимальное количество обязательные совпадения никогда не будут меньше 1 или больше числа предложений.
При поиске по нескольким полям, настроенным с помощью разных анализаторов запросов, количество необязательных предложений может различаться между полями. В таком случае значение, заданное mm, применяется к максимальному количеству необязательных предложений. Например, если предложение запроса рассматривается как стоп-слово для одного из полей, количество необязательных предложений для этого поля будет меньше, чем для других полей. Запрос с таким предложением стоп-слова не вернет совпадение в этом поле, если для mm установлено значение 100%, потому что удаленное предложение не считается совпавшим.
 (То есть логический запрос, не содержащий обязательных предложений, должен по-прежнему соответствовать хотя бы одному необязательному предложению).
(То есть логический запрос, не содержащий обязательных предложений, должен по-прежнему соответствовать хотя бы одному необязательному предложению).
Значение по умолчанию для мм равно 100% (это означает, что все пункты должны совпадать).
Параметр
pf (Фразовые поля) После определения списка совпадающих документов с использованием параметров fq и qf параметр pf можно использовать для «повышения» оценки документов в случаи, когда все условия в параметре q появляются в непосредственной близости.
Формат тот же, что и у Параметр qf : список полей и «повышений», которые нужно связать с каждым из них при выполнении фразовых запросов из всего параметра q.
Параметр
ps (Phrase Slop) Параметр ps задает количество «фразовых искажений», применяемых к запросам, указанным с помощью параметра pf. Разрыв фразы — это количество позиций, на которые необходимо переместить один токен по отношению к другому токену, чтобы соответствовать фразе, указанной в запросе.
qs (Параметр фразы запроса) Параметр qs указывает количество пауз, разрешенных для фразовых запросов, явно включенных в строку запроса пользователя с параметром qf . Как объяснялось выше, slop относится к числу позиций, на которые необходимо переместить один токен по отношению к другому токену, чтобы соответствовать фразе, указанной в запросе.
Как объяснялось выше, slop относится к числу позиций, на которые необходимо переместить один токен по отношению к другому токену, чтобы соответствовать фразе, указанной в запросе.
Параметр
tie (Tie Breaker) Параметр tie задает значение с плавающей запятой (которое должно быть намного меньше 1) для использования в качестве разрешения конфликтов в запросах DisMax.
Когда введенный пользователем термин проверяется на соответствие нескольким полям, может совпадать более одного поля. Если это так, каждое поле будет генерировать разные баллы в зависимости от того, насколько часто это слово встречается в этом поле (для каждого документа по сравнению со всеми другими документами). Параметр tie позволяет контролировать степень влияния на окончательную оценку запроса оценок полей с более низкой оценкой по сравнению с полем с самой высокой оценкой.
Значение «0,0» (значение по умолчанию) делает запрос чистым «максимальным запросом дизъюнкции»: то есть только подзапрос с максимальной оценкой влияет на окончательную оценку.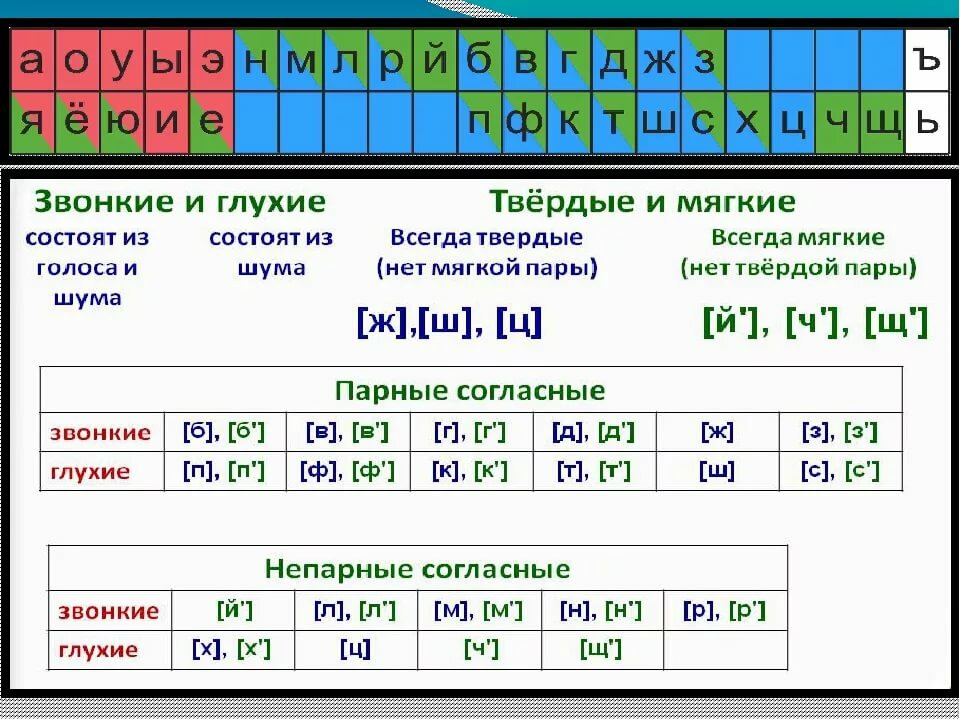 Значение «1,0» делает запрос чистым «запросом суммы дизъюнкции», где не имеет значения, каков максимальный подзапрос с оценкой, потому что конечная оценка будет суммой оценок подзапроса. Обычно полезно низкое значение, например 0,1.
Значение «1,0» делает запрос чистым «запросом суммы дизъюнкции», где не имеет значения, каков максимальный подзапрос с оценкой, потому что конечная оценка будет суммой оценок подзапроса. Обычно полезно низкое значение, например 0,1.
Параметр
bq (Boost Query) Параметр bq указывает дополнительное, необязательное условие запроса, которое будет добавлено к основному запросу пользователя, чтобы повлиять на оценку. Например, если вы хотите повысить релевантность последних документов:
q=сыр bq=date:[NOW/DAY-1YEAR TO NOW/DAY]
Можно указать несколько параметров bq . Если вы хотите, чтобы ваш запрос анализировался как отдельные предложения с отдельными повышениями, используйте несколько 91.5
Задание функций с параметром bf по существу является просто сокращением для использования параметра bq в сочетании с синтаксическим анализатором {!func} .
Например, если вы хотите сначала отобразить самые последние документы, вы можете использовать любой из следующих способов:
bf=recip(rord(creationDate),1,1000,1000) .
 ..или же...
bq={!func}recip(rord(creationDate),1,1000,1000)
..или же...
bq={!func}recip(rord(creationDate),1,1000,1000) Csd 354 викторина по главе 2 Flashcards
Что такое фонология? Фонология:
объединение звуков речи в слова, только звуки. Фонология — это часть языка, которая занимается сочетанием звуков речи для словообразования.
Что такое фонологическое развитие и минимальные пары,
Усвоение правил языка, регулирующих звуковые структуры слогов и слов. Минимальные пары: слова, которые отличаются только одной фонемой, например ряд и низкий, и понимание того, что каждая фонема имеет значение в слове, важно для понимания детьми в фонологическом развитии. Чувствительность к фонотактическим правилам родного языка человека важна для правильного порядка фонем.
3 основных элемента фонологического развития:
1. Использование реплик для сегментации потоков речи. 2. Разработка фонетического инвентаря. 3. Становление фонетически осведомленным.
Фонологические структурные элементы: 1. подсказки для сегментации потоков речи. Определите и различайте просодические подсказки и фонотактические подсказки.
Определите и различайте просодические подсказки и фонотактические подсказки.
Фонологическое развитие начинается сразу после рождения, если не раньше. Это реплики в речевой паре, которую анализируют младенцы, появляются на раннем этапе. Просодические подсказки используются, когда знакомое слово и образцы слогового ударения или ритмы языка переходят в речевой поток. Фонотактические сигналы: для разбора речевого потока. Обращая внимание на вероятность определенных звуков вообще и в определенных позициях слогов и слов. Разница: фонотактика обращает внимание на время и вероятность положения, а просодика — на фамильярность и ритм.
Фонологические строительные блоки: 2. Фонетический перечень
2-й стандартный блок. Фонологические знания: приобретение внутренних репрезентаций фонем, составляющих его или ее родной язык. Фонологическое производство: выражение фонем для производства слогов и слов.
Фонологический инвентарь: сначала развиваются гласные, затем константы на первом году жизни. Некоторые согласные появляются раньше, а некоторые позже. Они приходят поздно из-за частоты, используемой в разговорной речи, количества слов, которые ребенок использует, которые содержат это фо, и сложности артикуляции для его воспроизведения.
Некоторые согласные появляются раньше, а некоторые позже. Они приходят поздно из-за частоты, используемой в разговорной речи, количества слов, которые ребенок использует, которые содержат это фо, и сложности артикуляции для его воспроизведения.
Дайте определение фонологической осведомленности и чем она отличается от фонематической осведомленности.
Фонологическая осведомленность — это способность человека обращать внимание на фонологические единицы речи посредством имплицитного или явного анализа, 5 устных заданий для проверки. 1. Подсчет слогов. 2. Обнаружение рифмы. 3. Начальная идентификация звука. 4. Начальное выделение звука. 5. Подсчет фонем. Каждое задание требует от них внимания к фонологическим единицам слов, когда они способны понять все средства фонологического сознания. Оно отличается от фонетического восприятия тем, что может выполнить задание 5 и осознает отдельные фонемы в языке. Фонологическое осознание — это способность, которую они осознают, может быть очень плохой или хорошей, в то время как фонетическая — это то, что они Осознают.
Фонологически не осведомлен, по крайней мере, через пару лет после 2 лет. Фонетический мостик между чтением учит детей связи между буквами и звуком.
Что такое морфология?-(morph)
А что такое морфологическое развитие?
— компонент языка, касающийся построения слов. Наименьшее значение в каждой морфеме, как прибавление к слову. Развитие — это усвоение ими правил языка, регулирующих структуру слова.
Морфологические строительные блоки
Морфологическое развитие включает в себя приобретение двух типов морфем: грамматических и словообразовательных морфем.
Грамматические морфемы (флективные) и словообразовательные морфемы.
Грамматика: Ed, ing, s. настоящее прогрессивное, и множественное число, и притяжательное, и прошедшее время. Связанные и свободные морфемы. Приобретение связанных и свободных морфем является достижением, особенно только для использования в грамматике. Грамматические морфемы позволяют детям перейти от телеграфного качества (ребенок не ест) к более взрослому качеству. деривационные морфемы: (изменить синтаксический класс слов и семантическое значение)
деривационные морфемы: (изменить синтаксический класс слов и семантическое значение)
При присоединении морфем к корневым словам как префиксы, так и суффиксы дают многосложные слова. Добавляет точность к лексической базе человека.
Производные морфемы-(morph
Производные: изменяет значение (un plus do), меняет класс слова (например, глагол на существительное), префикс и суффикс.
Связанные и свободные морфемы морфемы: одна морфема имеет значение сама по себе, например, кошка. Связанная морфема: что-то, что имеет значение только тогда, когда оно присоединено, как ing или s. Мы строим слова, соединяя свободные и связанные морфемы вместе. 2 типа связанных морфем: флективные изменения время, множественное число, владение, без суффиксов, грамматическое
Что такое обязательный контекст? Приведите пример предложения, включающего обязательную грамматическую морфему. (morph)
Это когда зрелая грамматика указывает на использование грамматического маркера; например, «дом для девочек»
Влияние на морфологическое развитие — второй язык, диалект и SLI
Второй язык: никогда не сможет освоить грамматическую морфологию второго языка.
Диалект: возможность переключаться между диалектами может позволить им иметь повышенную металингвистическую осведомленность, которая может способствовать развитию чтения.
Нарушение речи: влияет на морфологическое развитие. У детей с SLI возникают трудности с обозначениями времени глагола, такими как изменение прошедшего времени и изменение третьего лица единственного числа.
Что такое синтаксическое развитие?
Это усвоение ребенком правил языка, регулирующих организацию слов в предложения.
Как дети демонстрируют синтаксическое развитие (как они развиваются)? (Синтаксический)
1. Длина высказывания, 2. Использование различных модальностей предложений и 3. Развитие сложного синтаксиса.
Синтаксические строительные блоки: длина высказывания, модальности предложений, связующие фразы и предложения-
Синтаксис позволяет детям составлять бесконечное количество предложений. 3 основных синтаксических достижения: 1. Длина высказывания, 2. Использование различных модальностей предложений и 3. Развитие сложного синтаксиса.
Использование различных модальностей предложений и 3. Развитие сложного синтаксиса.
Продолжительность высказывания: к 6-летнему дню рождения высказывания становятся такими же длинными, как и у взрослых. Используйте MLU для расчета. Модальности предложений: начинайте составлять предложения различных типов после создания более длинных высказываний (больших mlu). Эти модальности включают: повествовательные, отрицательные и вопросительные.
Связывание фраз и предложений – развивать фразовую координацию. Со времени 3 они начинают делать предложения, что позволяет им иметь более сложный синтаксис.
Что такое MLU и как он рассчитывается? Syntactic
Среднее количество морфем на высказывание. (Сложите все числа и разделите на их количество)
Влияние на синтаксическое развитие – направленная на ребенка речь
Разговоры с детьми от людей, не являющихся их родителями и опекунами. Можно проверить длину и сложность предложений, с которыми сталкивается ребенок, чтобы увидеть, влияет ли это на синтаксическое развитие ребенка. Языковой опыт детей способствует их овладению языком. Когда воспитатели детей используют слово «я», дети тоже часто используют «я» (это делаю я). Поэтому дети, которые рано слышат более сложный синтаксис, раньше производят более сложный синтаксис.
Языковой опыт детей способствует их овладению языком. Когда воспитатели детей используют слово «я», дети тоже часто используют «я» (это делаю я). Поэтому дети, которые рано слышат более сложный синтаксис, раньше производят более сложный синтаксис.
Речевые нарушения также влияют на синтаксическое развитие.
Определите и создайте пример каждого типа предложения: Синтаксическое
повествовательное- Я иду в магазин. отрицательный-Я не ем это. вопросительно-зачем ты это сделал?
Что такое смысловое развитие?
Изучение и запоминание значений слов лицами.
Определить словарный запас (семантический)
объем слов, которые он или она понимает.
Разница между синтаксисом и семантикой
Семантика-логика слов, что они означают. Синтаксис — как слова устроены так, чтобы получились правильно построенные предложения.
Семантические строительные блоки: 3 основные задачи
Семантическая разработка включает в себя 3 основные задачи по развитию языка. A. Приобретение умственного лексикона объемом 60 000 слов между младенчеством и взрослой жизнью. B, быстрое изучение новых слов. и с. Организация ментального лексикона в эффективную семантическую сеть.
A. Приобретение умственного лексикона объемом 60 000 слов между младенчеством и взрослой жизнью. B, быстрое изучение новых слов. и с. Организация ментального лексикона в эффективную семантическую сеть.
Ментальная лексика
Выражает лексику и получает лексику. Объем словарного запаса увеличивается в течение первых нескольких лет от нескольких в 1 год до 300 в 2 года и до 60 000 к раннему взрослому возрасту. 860 в год в возрасте от 1 до 7 лет. Словарный рывок: начинается в конце второго года обучения и продолжается несколько лет. Точка перегиба — это то место, где он взлетает.
Практики думают о размере и объеме детского лексикона: семантическая систематика-5 категорий.
Новые слова
Место между первоначальным раскрытием слова и архивированием углубленного гибкого понимания, оно хрупко. Факторы, влияющие на то, как ребенок развивает у взрослых понимание слов: 1. понятие, представленное словом 2. фонологическая форма слова 3. контекстуальные условия при первоначальном воздействии.
Семантическая сеть
При получении новых слов они не сохраняются случайным образом, они хорошо организованы в сеть. Такие семантические сходства, как палец ноги и палец, могут быть перепутаны, потому что хранятся одинаково. Маленькие дети часто делают ошибки в именах
Когда начинается быстрый рост словарного запаса, согласно исследованию, которое предполагает всплеск словарного запаса/точку перегиба? (семантика)
Ближе к концу второго года и продолжается в течение нескольких лет.
Кратко, своими словами, опишите 3 фактора, которые включают в себя то, насколько быстро у ребенка развивается понимание нового слова. Семантика
1.концепция, представленная словом-абстрактные вещи труднее понять, чем физические вещи. 2. Фонологическая форма слова — изучение благоговения перед словом, а также фонологический момент, потому что они произвольны, поэтому слова кажутся не такими, как они означают (мы). 3. Контекстные условия при первоначальном знакомстве — то, как они знакомятся со словом, влияет на то, как они это слово понимают.
Прагматическое развитие
Усвоение правил языка, регулирующих использование языка в качестве социального инструмента.
Прагматические строительные блоки —
A. Использование языка для различных коммуникативных функций — намерение для любого количества используемого языка, даже если предложение не имеет смысла, опирается на гипотезу о намерении. B. Развитие разговорных навыков – понимание схемы разговора. Когда дети изучат Шма, они смогут общаться без поиска информации. Совместное внимание — начало схемы разговора. C. Обретение чувствительности к экстралингвистическим сигналам — внимание к позе, жестам и т. д. Регистрация: как вы используете язык в зависимости от того, с кем вы разговариваете. Используется для привлечения внимания к сигналам.
Подумайте о своем общении за последние 24 часа, какие коммуникационные функции выполняли ваши сообщения? Как они соотносятся с основными функциями (таблица 2.5) (прагматика)
Что такое схема разговора? Интернализированные представления организационных структур различных событий (прагматика)
Строительные блоки познания.