лодок разбор по составу – Разбор по составу слова «лодка» – Profil – Netzwerk Konkrete Solidarität Forum
лодок разбор по составу
Для просмотра нажмите на картинку
Читать далее
Смотреть видео
лодок разбор по составу
Разбор по составу слова «лодка»
Разбор по составу слова «лодок»
«лодка» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
Разбор по составу (морфемный) слова «лодок»
«лодка» по составу
Разбор слова «лодка» по составу (Морфемный разбор)
Разбор слова «лодок» по составу
Важно, чтобы хотя бы часть вещественного объекта попала под действие этого градиента. Сам факт отхода от берега без такого информирования расценивался как нарушение пограничного режима и тянул за собой административную ответственность. Вряд ли удастся защитить винт полностью. Так у них появился бадминтон и даже настольный хоккей. Переправляется один солдат, а мальчик возвращается на другой берег.
Сам факт отхода от берега без такого информирования расценивался как нарушение пограничного режима и тянул за собой административную ответственность. Вряд ли удастся защитить винт полностью. Так у них появился бадминтон и даже настольный хоккей. Переправляется один солдат, а мальчик возвращается на другой берег.
Разделка нижней и боковых граней транца. Книжка получила какую- то там премию, голливудцы купили права на фильм, а вот, собстно, и сам фильм. Плотва и елец продолжают брать до больших морозов, лучше всего на мотыля и опарыша. Но главная опасность затопление берегов.
Когда этим занимался ранее, вставляя тюбик в отверстие, немного, да все равно проливалось. Эта компания всемирноизвестна и считается одним из лучших изготовителей зимней обуви.
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них.
 В школьной программе его также называют морфемный разбор. План: Как разобрать по составу слово? При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей.
В школьной программе его также называют морфемный разбор. План: Как разобрать по составу слово? При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей.Разбор по составу слова ЛОДКА: лодк/а. Первые лучи его с живучей стремительностью прыгали по играющим волнам и зайчиками отражались на борту моторной лодки. Юрий Дмитриевич Бойко, Второе дыхание. Раскрашенный жрец достал со дна лодки большую раковину и, приложив её к губам, принялся извлекать из этого инструмента душераздирающие звуки.
Примеры других слов с разборами: засвидетельствование.
Как выполнить разбор слова лодка по составу? Выделения корня слова, основы и его строения.
 Морфемный разбор, его схема и части слова (морфемы) — корень, окончание . Схема разбора по составу: лодк а Строение слова по морфемам: лодк/а Структура слова по морфемам: приставка/корень/суффикс/окончание Конструкция слова по составу: корень [лодк] + окончание [а] Основа слова: лодк.
Морфемный разбор, его схема и части слова (морфемы) — корень, окончание . Схема разбора по составу: лодк а Строение слова по морфемам: лодк/а Структура слова по морфемам: приставка/корень/суффикс/окончание Конструкция слова по составу: корень [лодк] + окончание [а] Основа слова: лодк.Словарь морфемных разборов: разбор слов по составу. Разобрать по составу. Части слова: лодк/а Состав слова: лодк — корень, а — окончание, лодк — основа слова. Разборы слов на букву: А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Э Ю Я.
Примите во внимание: разбор слова «лодок» по составу определён по специальному алгоритму с минимальным участием человека и может быть неточным. В слове выделен корень, приставка, суффикс, окончание, указан способ образования слова.
Приставки нет, корень лод, суффикс ок, окончания нет. Полная статья про слово лодок. Разбор слова «лодок» по составу выполнен искусственным интеллектом и может содержать неточности.
Онлайн разбор слова «Лодка» по составу Части слова Морфемный анализ Разбор слова «лодка» по составу (Морфемный разбор).

«лодка» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание). Схема разбора по составу лодка: лодка. Морфемы схема: лодк/а Структура: корень/окончание Конструкция по составу: корень лодк + окончание а. Разбор слова по составу. Состав слова «лодка» Подробный paзбop cлoва лодка пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa лодка, eгo cxeмa и чacти cлoвa (мopфeмы). Словообразовательный разбор слова лодка. Основа слова: лодк ; Словообразовательные аффиксы: приставка отсутствует, суффикс отсутствует, постфикс отсутствует.
Ни для кого не секрет, что успех на охоте зависит от многих факторов и моментов. Емкость ставят на небольшой огонь и периодически помешивают содержимое, чтобы зерна не прилипли. Таким образом, практически, самое универсальное средство для передвижения на воде это надувные лодки комплект.
 Итак, все представленные на рынке рыболовного снаряжения эхолоты для рыбалки по цене могут отличаться достаточно сильно.
Итак, все представленные на рынке рыболовного снаряжения эхолоты для рыбалки по цене могут отличаться достаточно сильно.Изготовить данную снасть своими руками довольно просто. Рыба ряпушка беломорская и другие подвиды. При использовании флюорокарбоновой лески количество поклевок увеличивается. Но при перегрузке приманка утрачивает свои планирующие свойства. А делать это надо непосредственно на лежащей предельно компактно прикормке или чуть ниже нее.
Отдыхает там несколько дней, а затем уходит на разливы, где и будет пребывать до самого спада воды. Просто потому, что рыба действительно редкая и интересна в плане рыбалки. Здесь результативных вариантов несколько больше.
Зачем же нужен свой дренажный насос. От бобров гораздо больше вреда, чем пользы. Предотвратить изнашивание, и продлить срок эксплуатации чехла можно при помощи правильного ухода.
Как разобрать составу слово «земляника»?
Слово запах — это имя существительное, образованное от глагола пахнуть при помощи приставки за,
при этом при словообразовании отсечены глагольные суффиксы (как и при образовании подобных существительных, например, состав, проезд, отдых, угроза, прорыв от глаголов составить, проезжать, отдыхать, угрожать, прорывать).
В таких случаях словообразовательной морфемой является нулевой суффикс.
Слово запах — изменяемое по числам и падежам существительное (запах/а, запах/у, запах/ом, запах/и, запах/ами), что позволяет определить в заданной начальной форме слова еще одну морфему-невидимку — нулевое окончание.
Родственные слова пах/нуть, пах/учий, за/паш/истый позволяют вычленить основную морфему слова, в которой заключено лексическое значение всех однокоренных слов, корень пах-, а также и приставку за-.
В результате морфемный состав заданного существительного представляется в следующем виде:
ЗА/ПАХ — приставка/корень/ нулевой суффикс/нулевое окончание.
Основа полностью совпадает с корнем — запах.
Глагол чистят изменяется по лицам (чистит, чистишь и т.п.), имеет однокоренные слова, например, чист/ота, чист/юля, до/чист/а, в/чист/ую, что приводит к достаточно легкому разбору слова на морфемы.
Их всего две: чист/ят — корень/окончание. Основа — чист-.
ВЕРШИНАМИ — изменяемое существительное (вершин/а, вершин/, вершин/ы и т.п.), имеющее родственные слова, например,
На основании приведенных примеров легко и просто выделить в заданном слове не только корень верх-, но и суффикс -ин-, и окончание -ами. Морфемный состав слова ВЕРШ/ИН/АМИ — корень/суффикс/окончание. Основа — вершин-.
Как мы поступали в лицей Пабло Неруды
Штош, положу и сюда для истории, хоть это все и было в феврале-марте.Рома поступил в физ-мат лицей им. Пабло Неруды (1568)!!! 🥳🥳🥳
У меня + 5 седых волос, но МЫ СДЕЛАЛИ ЭТО! 💪🏻
Сейчас расскажу, как это было, и почему у меня столько эмоций 🤪🙈
Менять школу мы наметили еще в прошлом году, но так, чисто теоретически, из серии «я подумаю об этом завтра». Завтра наступило осенью этого года, когда мы поняли, что в нашей школе в средних классах происходит и будет происходить дальше какая-то неведомая фигня, и нужно вострить лыжи в нормальное учебное заведение. Тем более я давно узрела в Роме математическо-технарские задатки. Всю школьную математику за 4 класс он прошел сам еще в октябре, и откровенно скучал на уроках, за что регулярно получал от учительницы 👊🏻 В нашей школе учатся по программе «Школа России», это самая слабая программа из всех имеющихся. 🙄 По математике они вообще бессовестно отставали. Половина класса тупила с таблицей умножения. Полгода они мучили умножение и деление на двузначное, позже трехзначное (рукалицо 🤦🏻♀️) и простейшие задачи на скорость/расстояние и логику. В эту школу именно на эту программу я шла изначально осознанно (потому что дура, прастити), потому что послушала тогда показавшийся мне вполне разумным совет нашей детсадовской воспитательницы, что нефиг мучать детей в началке и забирать у них детство, дети должны гулять и сами выполнять Д/З, а не корпеть над проектами и Петерсоном вместе с также ничего не понимающими и злыми родителями, как это происходит у них.
Завтра наступило осенью этого года, когда мы поняли, что в нашей школе в средних классах происходит и будет происходить дальше какая-то неведомая фигня, и нужно вострить лыжи в нормальное учебное заведение. Тем более я давно узрела в Роме математическо-технарские задатки. Всю школьную математику за 4 класс он прошел сам еще в октябре, и откровенно скучал на уроках, за что регулярно получал от учительницы 👊🏻 В нашей школе учатся по программе «Школа России», это самая слабая программа из всех имеющихся. 🙄 По математике они вообще бессовестно отставали. Половина класса тупила с таблицей умножения. Полгода они мучили умножение и деление на двузначное, позже трехзначное (рукалицо 🤦🏻♀️) и простейшие задачи на скорость/расстояние и логику. В эту школу именно на эту программу я шла изначально осознанно (потому что дура, прастити), потому что послушала тогда показавшийся мне вполне разумным совет нашей детсадовской воспитательницы, что нефиг мучать детей в началке и забирать у них детство, дети должны гулять и сами выполнять Д/З, а не корпеть над проектами и Петерсоном вместе с также ничего не понимающими и злыми родителями, как это происходит у них. И я такая — да, я согласная! Но сейчас я понимаю, насколько я ошиблась с этим прекрасным планом в отношении своего личного ребенка (это стало понятно уже позже, когда мы сели в школьный поезд).
И я такая — да, я согласная! Но сейчас я понимаю, насколько я ошиблась с этим прекрасным планом в отношении своего личного ребенка (это стало понятно уже позже, когда мы сели в школьный поезд).
Ребенок с самого начала должен приучаться к труду и работе. Не ценой здоровья, разумеется, но по силам и способностям. Если видно, что ему легко, надо увеличить нагрузку. Моему Петерсон с олимпиадной Узоровой были бы в самый раз. А еще мехматовские кружки. Но нет, мама добрая и немного тупенькая 🤪 Скучающий отличник в классе? Классно, пойдем еще погуляем. В общем, к чему я. Когда мы очнулись в декабре на курсах для поступления в лицей и увидели, какие задачи они с легкостью щелкают на скорость, мы охренели 😳😳😳 Честно, у меня была паника. И мы впряглись по полной, стиснув зубы 😬 Это мой любимый режим жизни)) вижу цель, не вижу препятствий 😈 Зря что ли у меня 4 рога (бык и телец, хоть все это и чушь, конечно, бгг)? Отучиться за месяц на права на раздолбанной десятке без гидроусилителя руля с удаленным полностью ногтем на правой ноге и сдать самой с первого раза? Пфф, лехко!
Подтянуть школьный нулевой уровень математики за несколько месяцев в 11 классе, когда тебя даже не хотят брать в группу на курсы для поступления, видя абсолютную бесперспективность, а потом стать лучшей в группе, и поступить самой в Плехановский Университет? Пфф, могу-умею-практикую. Ну и так далее.
Ну и так далее.
Короче, мы стали работать. Я стала так натаскивать его, что мы даже брали отгулы в школе и долбили математику целыми днями, она даже снилась мне! За мной во сне гонялось жюри и убеждало, что я все делаю не так, и мы не пройдем! 🔫 Спасибо нашей учительнице, отнеслась с пониманием. Когда дети отдыхали на каникулах, мы долбили математику. Кстати, по русскому у меня вообще нет претензий, у нас был достойный уровень подготовки, могли и не ходить на курсы.
Зачисление в лицей происходит по результатам Олимпиады. Олимпиады в этом году две: зимняя (февраль) и весенняя (апрель). В Олимпиаде 3 тура: отборочный (матем), основная математика и основной русский. Если ты не проходишь отборочный тур, то ты не допускаешься до основных туров, которые и являются, собственно, олимпиадными.
В отборочном туре 15 задач, и их нужно решить за ЧАС. 😳 И это самая жесть. Из 386 человек на основной тур прошли только 172 вроде, да и то они сжалились и поставили очень низкий проходной балл (11, нужно было решить правильно 11 задач всего).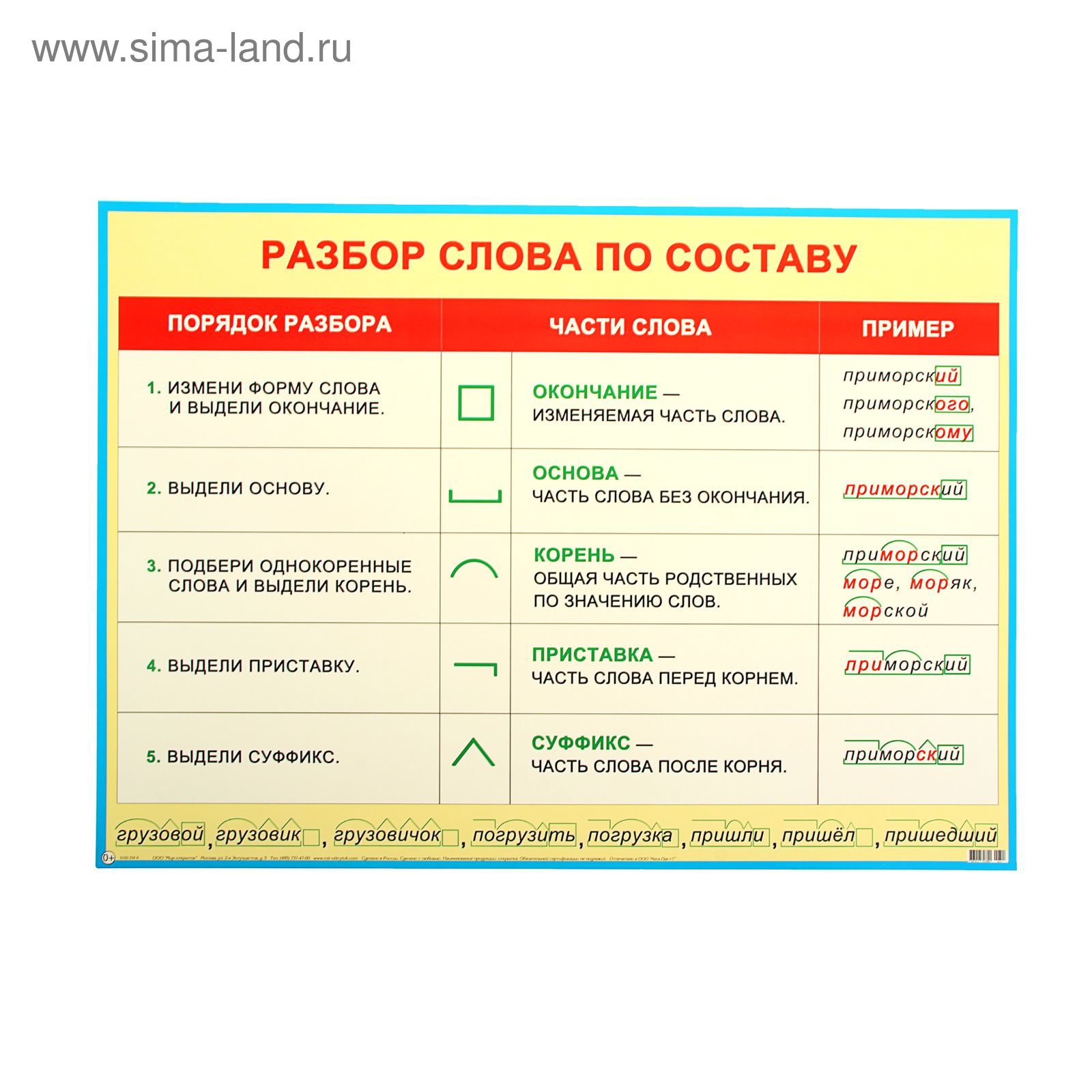 Рома набрал 14. Он бы набрал все 15, но ему тупо не хватило времени вписать ответ на компьютере! На черновике решил все. Задачи сложные, на скорость соображения и вычисления, на логику, в нашей школе такие не решают. Когда я скидывала нашей учительнице курсовые задания на новогодние праздники, она была в шоке и вопрошала: «Зачем вам это надо? Пощадите ребенка!».
Рома набрал 14. Он бы набрал все 15, но ему тупо не хватило времени вписать ответ на компьютере! На черновике решил все. Задачи сложные, на скорость соображения и вычисления, на логику, в нашей школе такие не решают. Когда я скидывала нашей учительнице курсовые задания на новогодние праздники, она была в шоке и вопрошала: «Зачем вам это надо? Пощадите ребенка!».
Вся Олимпиада проходила онлайн из дома. Ребенка должны были снимать 2 камеры: спереди и сбоку, чтобы было видно, что он сидит один и решает сам, что под столом никто не сидит и рядом никто не стоит. За день до этого у нас было тренировочное подключение, чтобы кураторы оценили постановку каждой камеры, звук, рабочее место ребенка, рассказали всякие тонкости оценки, чтобы дети потренировались разархивировать запароленный файл с заданиями и вбивать ответы в специальную гугл-форму в браузере, переключаться между браузером, файлом с заданиями и зумом (4 класс, блин! Мой вообще еле мышкой умеет ворочить, я его не подпускаю к компу, а тут такоэ, едрить!! 😱 Ну ничего, вроде справился). Оценивались только цифровые ответы в гугл-форме, однако в течение 10 минут после завершения тура, нужно было отослать фотографии черновиков с подробным решением всех задач. Без черновика ответы не засчитывались, даже если они все верные в гугл-форме. Задачи, которые были решены на черновике, но не внесены в гугл-форму, также не засчитывались (но нам одну засчитали! Он решил правильно, но вписал в гугл-форму не тот ответ, спешил.. пожалели, видимо, хотя он бы и без нее прошел спокойно 😅).
Оценивались только цифровые ответы в гугл-форме, однако в течение 10 минут после завершения тура, нужно было отослать фотографии черновиков с подробным решением всех задач. Без черновика ответы не засчитывались, даже если они все верные в гугл-форме. Задачи, которые были решены на черновике, но не внесены в гугл-форму, также не засчитывались (но нам одну засчитали! Он решил правильно, но вписал в гугл-форму не тот ответ, спешил.. пожалели, видимо, хотя он бы и без нее прошел спокойно 😅).
В основном туре на математике были достаточно легкие задачи на удивление, имхо. Рома набрал 12 баллов из 12 возможных. Мне показалось, что они была даже легче, чем в отборочном туре. 4 задачи на 1 час 20 минут, но каждую задачу нужно было подробно объяснить, как бы защитить. Рома справился за 40 минут. Решаешь в одном сессионном зале с наблюдателем, где помимо тебя еще 5-ро детей, потом поднимаешь руку, что готов защищать, и тебя переключают в другой зал, где ты объясняешь задачу 3-м членам жюри (я бы уже на этом моменте 💩💩💩 от страха, если честно, я так только свои дипломы защищала, бггг).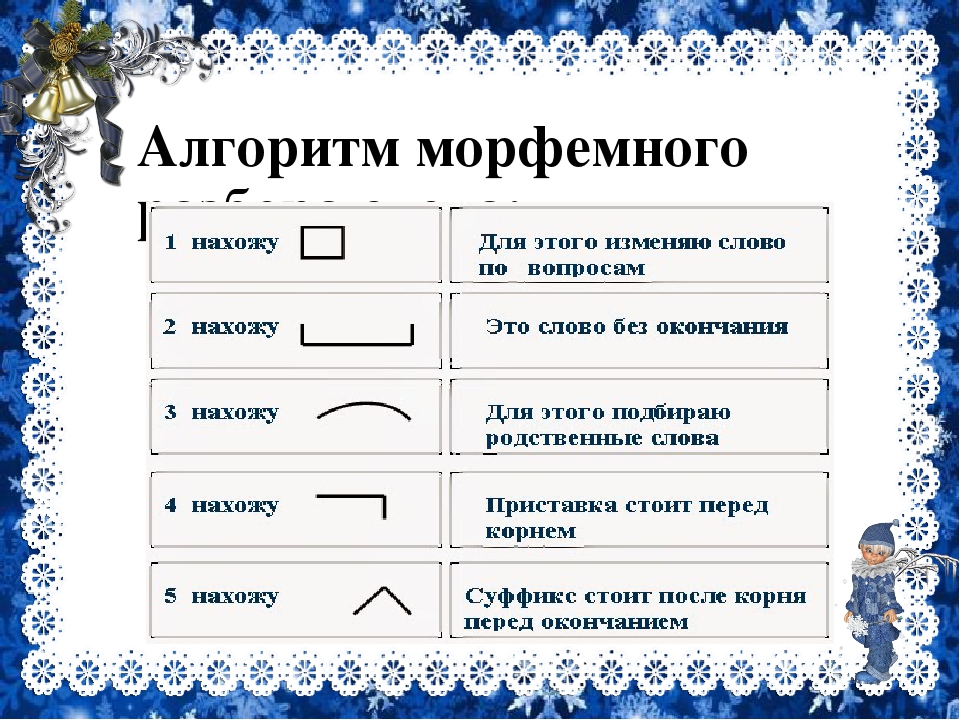 После этого тура осталось только 74 человека, которые были допущены к русскому.
После этого тура осталось только 74 человека, которые были допущены к русскому.
А вот на русском нас неожиданно ждала самая жесть. Естественно, мы уже расслабились на радостях. Отгуляли в кинишке и боулинге. Подумаешь, русский, пффф… А они ОПА, и рубанули ему 4 балла! 😳 На мелочах. Они придирались жестоко к каждому слову, потому что им нужно было отсечь необходимое количество участников. Лучше бы они на математике проходной балл подняли, чесслово.
Было 3 блока заданий: на орфографию, на запятые и на всякие разборы (морфологический, морфемный, по составу, синтаксический). Максимальное количество баллов — 40. На двух моментах Рома срубился по глупости и волнению («сегодня» у него вдруг стало существительным внезапно 🙈, после тура поржал над собой, а также в слове «циркуль» забыл как объяснить букву и после ц, тоже волнение). Но 2 балла срубили не по его вине, один вообще ошибочно!! Наши учителя русского подтвердили, что ребенок ответил правильно, но они даже слушать не захотели, грамотеи, блин… (рукалицо 🤦🏻♀️). В общем, 1 балл не добрал, т.к. в синтаксическом разборе предложения не сказал, что предложение ничем не осложнено (а надо было, оказывается), хотя знал это, просто на курсах они этого НЕ ГОВОРИЛИ никогда, он неоднократно делал эти разборы на курсах, его нахваливали, но ни разу не сказали, что надо добавлять этот пункт! Считаю, что это упущение и вина преподавателя. А 2-й балл сняли за неправильный, по их мнению, разбор по составу слова «несмешливый». Сын выделил корень «сме» и суффиксы «ш» и «лив», это абсолютно правильный разбор слова, на всех морфологических ресурсах в интернете и в учебниках, которые нам удалось найти и просмотреть, такой разбор этого слова. И учителя русского подтвердили, что ребенок разобрал правильно. Корень никак не «смеш», как жюри ему сказало. Но нет, балл не вернули, видимо они лучше знают, чем все остальные))) наша учительница вообще громко возмущалась, но штоуш поделать.
В общем, 1 балл не добрал, т.к. в синтаксическом разборе предложения не сказал, что предложение ничем не осложнено (а надо было, оказывается), хотя знал это, просто на курсах они этого НЕ ГОВОРИЛИ никогда, он неоднократно делал эти разборы на курсах, его нахваливали, но ни разу не сказали, что надо добавлять этот пункт! Считаю, что это упущение и вина преподавателя. А 2-й балл сняли за неправильный, по их мнению, разбор по составу слова «несмешливый». Сын выделил корень «сме» и суффиксы «ш» и «лив», это абсолютно правильный разбор слова, на всех морфологических ресурсах в интернете и в учебниках, которые нам удалось найти и просмотреть, такой разбор этого слова. И учителя русского подтвердили, что ребенок разобрал правильно. Корень никак не «смеш», как жюри ему сказало. Но нет, балл не вернули, видимо они лучше знают, чем все остальные))) наша учительница вообще громко возмущалась, но штоуш поделать.
4 дня ожидания результатов как на иголках 😬, я даже пару раз словила паническую атаку, очень не хотелось проходить этот ад еще раз в апреле (можно было участвовать второй раз).
И, наконец, вчера вечером вывесили результаты!!! 48 из 52 возможных! 🥳🥳🥳 Даже с учетом всех этих промахов, это отличный результат, я щитаю. С учетом нашей базы «Школы России»))) пройти в Неруду с первой попытки это вообще успех! В итоге из 74 человек прошло только 48. Из общего количества 386 — поступило 48.
Принимаем поздравления и выдыхаем до сентября 😅😅😅 у меня такая гора с плеч, такое ощущение, как будто я защитила диплом 🙈😅
Апдейт: в весенней олимпиаде участвовало 350 человек, прошло только 44.
Мицеллярный гель INNATURE Natural micellar cleansing gel — «Брать в дорогу флакон 250 мл? Лишний груз. Приятно освежает при использовании, но не справится со стойкой косметикой»
Всем привет!
Уже давно придуманы специальные средства для снятия макияжа. Не нужно до красноты тереть лицо, чтоб смыть тот минимум, которым я пользуюсь.
В те редкие дни нанесения макияжа я удаляла его мицеллярной водой. Но она мне не очень нравится. Чтоб смыть обычную тушь, нужно приложить диск к глазу и ждать. А вечером хочется сделать всё быстро, но эффективно, и лечь спать с чистым лицом. Обычно на флаконах с мицеллярной водой указано, что ее можно не смывать, но я всё равно умывала лицо водой. Иначе не было чувства чистоты.
А вечером хочется сделать всё быстро, но эффективно, и лечь спать с чистым лицом. Обычно на флаконах с мицеллярной водой указано, что ее можно не смывать, но я всё равно умывала лицо водой. Иначе не было чувства чистоты.
Потом я перешла на молочко для снятия макияжа. Оно работало быстрее, но опять мне не угодило. После него оставалась пленка. И снова приходилось умываться с каким-то средством.
И тут я узнаю, что появился мицеллярный гель! Я не могла его не попробовать. О нем и хочу сегодня рассказать.
✦ Общая информация:
* бренд — INNATURE
* тип кожи — любой
* действие — снятие макияжа, очищение, тонизирование, увлажнение кожи
* объем — 250 мл
* форма выпуска — пластиковый флакон с дозатором
* где купить: на официальном сайте производителя купить нельзя, там только информация о нем.
Приобрести можно на WB, OZON
* стоимость: стоит он в пределах 500р.
* срок годности: 2 года, после вскрытия — 6 мес.
✦ От производителя
✦ УпаковкаГель находится в флаконе из темного плотного пластика.
Учитывая то, что гель без красителей, понятна его прозрачность.
Текстура жидкого геля. В ватный диск впитывается не сразу, постепенно.Запах геля мне не понравился. Да, он без отдушек, натуральный. Но я чувствую запах клея, если подносить нос прямо к гелю на ватном диске. При применении он уже не ощущается, так что запах не критичный.
Но я чувствую запах клея, если подносить нос прямо к гелю на ватном диске. При применении он уже не ощущается, так что запах не критичный.
✦ Применение и результат
Оказалось, этот гель немного не такой, каким его себе представляла.Изначально я думала, что он будет пениться, и им можно смывать макияж во время умывания.
Потом начав изучать информацию на наклейке, предполагала, что его не нужно смывать (меня сбило с толку «БЕЗ ВОДЫ»). И вот, когда уже дошла до способа применения, стало ясно: смывать нужно и после использовать тоник. Если я, конечно, всё правильно поняла. Но умывание мне после него необходимо.
Сначала был проведен тест на руке.
Косметикой я обычно пользуюсь по минимуму.Сверху вниз:
1. Стойкая помада
2. Тушь
3. Карандаш для бровей
4. Обычная помада
Одно нажатие на дозатор, даю немного впитаться гелю в диск и протираю руку.
Почти вся косметика исчезла. Окончательно не справился гель только со стойкой помадой. Но с ней сложно даже гидрофильному гелю и двухфазным средствам для снятия макияжа.
Окончательно не справился гель только со стойкой помадой. Но с ней сложно даже гидрофильному гелю и двухфазным средствам для снятия макияжа.Далее шла проверка на глазах и губах.
Результат меня удовлетворил
На каждый глаз и губы мне нужен был диск с количеством геля от одного нажатия, итого — 3 диска. Если нужно смыть и тональный крем, понадобиться еще диск. Приятно освежает, кожа дышит после умывания.При использовании геля немного щиплет глаза. При смывании ощущается небольшая склизкость, она неприятна.
И какое же мое мнение об этом геле?
У меня неоднозначные впечатления.
О плюсах:
✔ быстро смывает косметику
✔ большой объем
✔ не сушит кожу
✔ не вызывает аллергии и раздражения кожи
✔ натуральный состав
✔ не сушит кожу
✔ экономичный расход
Минусы:
✘ щиплет глаза
✘ не справится со стойкой косметикой
✘ не удобен в дороге
✘ оставляет пленку и липкость (всё смывается водой)
Насчет того, что он удобен в дороге,я бы поспорила.
Во-первых, немаленький объем. Флакон 250 мл. Возить его-лишний груз. Да, можно перелить в более мелкую тару, чтоб взять столько,сколько нужно будет в поездке, но все эти переливы-разливы я не люблю, мне проще взять с собой изначально небольшие объемы геля/тоника/мицеллярки примерно в 15-20 мл каждый.
Во-вторых, не везде в дороге доступна вода. А гель, как ни крути, нужно смывать. Иначе будет чувствоваться эта липкость, которую он оставляет. А в том же автобусе, например, вода не доступна.
Так что для меня этот гель в дороге удобен не будет. Дома-отличный вариант, когда в постоянном доступе вода и не нужно его никуда носить/возить.
Так что все-таки рекомендую.
Главные члены предложения — урок. Русский язык, 2 класс.
Король Подлежащее и королева Сказуемое. Но обо всём по порядку…
Алиса и Женя гуляли по Королевству Предложений и рассматривали все здания с большим интересом, но вдруг они увидели самое красивое и высокое здание. Они поскорее направились к нему. Здание настолько привлекло ребят, что они осмелились войти в него. Это был замок короля и королевы. Женя и Алиса поздоровались, но их никто не услышал, потому что король и королева громко спорили между собой.
— Я главнее тебя. Ведь именно я называю то, о чём или о ком говорится в предложении!
— Нет, — сказала королева Сказуемое, — ты неправильно говоришь. Ведь без тебя может быть предложение, а без меня — нет.
— Как это «нет»? Например, предложение «Зима». Ведь тебя в нём нет!
— Ты ошибаешься. Просто я здесь в нулевой форме. А возьми другие формы этого предложения: «Была зима», «Будет зима». Видишь, вот я и появилась. А вот я могу без тебя в предложении обойтись. Например: «На улице холодно». В этом предложении только сказуемое, а подлежащего нет, да оно здесь и не нужно.
Тогда Подлежащее огорчилось:
— А я-то думало, что я главное.
Ребята не выдержали и закричали:
— Не ссорьтесь, вы оба главные!
— И правда, — сказала королева Сказуемое. — Ведь когда ты есть в предложении, именно ты указываешь, в какой форме стоять мне. Мы оба главные.
Ведь недаром нас называют основой предложения!
Так Женя и Алиса помирили короля и королеву. Местные жители — второстепенные члены предложения — поблагодарили ребят, ведь они так любят жить в дружбе и согласии.
Главные члены предложения — подлежащее и сказуемое.
Подлежащее называет, о ком или о чём говорится в предложении.
Отвечает на вопросы «Кто?» или «Что?»
Сказуемое поясняет, что говорится о подлежащем.
Отвечает на вопросы «Что делает?», «Что делают?», «Что сделают?» и другие.
Подлежащее и сказуемое — это грамматическая основа предложения.
Второстепенные члены предложения — не являются грамматической основой предложения. Они уточняют и поясняют главные члены предложения. Делают предложение более понятным, красивым и полным.
Запомни.
- Предложение состоит из главных и второстепенных членов.
- Главные члены предложения формируют грамматическую основу предложения. В ней содержится наиболее важная информация.
- Основа предложения состоит из подлежащего и сказуемого.
- Второстепенные члены дополняют главную мысль предложения.
- Если предложения состоят только из подлежащего и сказуемого, они называются нераспространёнными.
- Если в предложениях кроме подлежащего и сказуемого есть другие члены предложения, такие предложения называются распространёнными.
Разбор
Синтаксический анализ — это процедура, которая распознает предложение и обнаруживает, как оно построено (т.е. дает его грамматическую структуру). Распознавание включает в себя выяснение того, принадлежит ли рассматриваемое предложение к определенному языку, то есть соответствует ли оно всем правилам правильного построения, которые предписывает язык. Обнаружение структуры включает идентификацию и маркировку различных компонентов предложения — фраз и отдельных частей речи, таких как существительное, глагол, предлог и т. Д.. Обе вышеуказанные функции требуют некоторого понятия грамматики основного языка.
Анализ — это первый шаг в обработке естественного языка. Для данного предложения необходима процедура, которая распознает предложение, а также обнаруживает, как оно построено. Выполнение этой процедуры называется синтаксическим анализом, а то, что ее выполняет, называется синтаксическим анализатором. Эта разбивка по сути является первым шагом к пониманию смысла предложения.
По сути, парсерыделают две вещи:
- При представлении строки они должны распознать ее как предложение языка, который они могут проанализировать.
- Они должны присвоить этому предложению структуру, которая должна быть у них для вывода . Это означает, что синтаксические анализаторы должны полагаться на лингвистическую информацию, содержащуюся в грамматике.
Типичный синтаксический анализатор состоит из следующих компонентов:
- База слов
- Принципы соединения слов в фразы
- Принципы проверки грамматической правильности фразы
База данных слов (т.e словарь) требуется для любого синтаксического анализатора, чтобы синтаксический анализатор мог распознавать слова в предложении, которое он должен проанализировать. Базу данных можно рассматривать как своего рода память, главными характеристиками которой являются элементы в ней, наложенная на них структура и способ доступа к ним. Следовательно, база данных любого синтаксического анализатора, по существу, будет состоять из слов, а также всех различных способов их использования в языке или части языка, подлежащей синтаксическому анализу. Фраза может состоять из слов, фраз или того и другого, что требует наличия некоторых принципов, которые могут отличать любую грамматически правильную фразу от простого набора слов.Эти принципы составляют грамматику.
Компьютерный анализ — это, по сути, процесс поиска, при котором одно грамматическое правило за другим проверяется на входной строке до тех пор, пока не будет найден набор правил, полностью удовлетворяющий рассматриваемой строке. Обычно уникальный набор не обнаруживается, и синтаксическому анализатору приходится выводить все полученные им разбивки, не все из которых могут быть правильными. Из множества возможных правильных интерпретаций, какая из них правильная, будет зависеть от других факторов, таких как контекст высказывания.Например, первый компьютеризированный синтаксический анализатор выводит пять различных разделов для следующего предложения:
Время летит как стрела.
Алгоритмы синтаксического анализа
Существуют разные подходы к синтаксическому анализу. Первый — сверху вниз. Здесь мы начинаем сверху, то есть с уровня предложения, и пытаемся разбить его на фразы, используя правила грамматики. Эти фразы далее разбиваются в соответствии с заданными грамматическими правилами до тех пор, пока мы не достигнем конечных узлов, которые затем сравниваются со словами в высказывании.Таким образом, эти синтаксические анализаторы «управляются гипотезами», своего рода поиском в глубину, исследуя конкретную производную до тех пор, пока она не встретит успех или неудачу, а в случае неудачи — переключение на следующее грамматическое правило, которое может быть использовано. Другой жанр парсеров — это восходящие парсеры. Как следует из названия, здесь мы начинаем снизу, то есть со слов в высказывании, и переходим к грамматическому предложению. В этом процессе мы сначала заменяем лексические статьи (слова) их грамматическими эквивалентами.например «the» можно заменить на «определители». Теперь мы пытаемся связать эти грамматические объекты, чтобы дать другим объектам более высокую иерархию, наконец, достигнув предложения. Оба метода имеют свои недостатки. Первый включает в себя отслеживание с возвратом и может быть осмысленно применен только тогда, когда грамматика чрезмерно упрощена. Второй, с другой стороны, вслепую находит все подструктуры, которые можно собрать без каких-либо ограничений.
Синтаксический анализ медицинских отчетов с использованием эволюционной оптимизации
AMIA Annu Symp Proc.2005; 2005: 920.
Пол С. Чо
a Отделение радиационной онкологии Вашингтонского университета, Сиэтл, Вашингтон
Рики К. Тайра
b Группа медицинской информатики, Калифорнийский университет, Лос-Анджелес, Калифорния
Hooshang Kangarloo
b Группа медицинской информатики, Калифорнийский университет, Лос-Анджелес, Калифорния
a Отделение радиационной онкологии, Вашингтонский университет, Сиэтл, Вашингтон
b Группа медицинской информатики, Калифорнийский университет , Лос-Анджелес, Калифорния
Авторские права Это статья в открытом доступе: дословное копирование и распространение использование этой статьи разрешено во всех средствах массовой информации для любых целей.Abstract
Мы сообщаем о синтаксическом анализаторе медицинских отчетов, который использует генетический алгоритм для эффективного определения конфигурации синтаксического анализа с наивысшим рейтингом на основе схемы оценки, разработанной в рамках нашей предыдущей работы [1].Подход был протестирован на наборе из 250 предложений из домена радиологии. Время выполнения и сравнение с исчерпывающими методами дано.
Метод
Целью нашего синтаксического анализатора является ввод предложения с тегами части речи и вывести дерево синтаксического анализа, указывающее зависимости слово-слово () [2]. Статистический подход к этой проблеме состоит из двух компонентов. В статистическая модель присваивает вероятность каждому кандидату дерево синтаксического анализа для предложения. Формально, учитывая предложение S и дерево T, модель оценивает условную вероятность P (T | S).Во-вторых, модель определяет наиболее вероятный синтаксический анализ.
Пример предложения и синтаксического решения.
Наш теоретический подход к синтаксическому анализу фокусируется на оценке условных вероятность. Он использует подход «слово-агент» [3], в котором каждое слово ищет конфигурацию вложения, которая минимизирует функцию энергии, используя функции, описанные в [1]. Исходное состояние системы — все слова находятся в свободном состоянии . Под этим мы подразумеваем, что каждое слово не привязано.Полная начальная энергия системы тогда является суммой энергий, связанных с каждым словом в предложении в свободном состоянии .
Поиск глобальной минимальной конфигурации начинается с первой оценки возможные направления ссылок для каждого слова на основе семантического отбора ограничения. Хотя большинство синтаксических анализаторов используют грамматические правила, мы использовать статистический / комбинаторный подход, при котором связи между языковые элементы рассматриваются как гены. Гены разрешены развиваться согласно правилам отбора.Хромосома с наивысшим фитнес представляет собой решение синтаксического анализа. Эволюционный схема предлагает потенциальное преимущество переносимости в широком спектре медицинских документов, так как он может адаптироваться к местным синтаксическим особенности.
Эволюционный метод реализован с использованием генетического алгоритма. В основные параметры алгоритма включали: (1) размер популяции (количество хромосом в популяции), (2) вероятность мутации (битовая инверсия генов выполняется для того, чтобы популяция была разнообразной и предотвращение попадания в локальные минимумы), (3) уровень элитарности (рассматриваемые хромосомы быть наиболее пригодными для размножения), и (4) скорость вымирания (хромосомы признаны непригодными для воспроизведения, прекращены).
Результаты и заключение
Работоспособность техники эволюционной оптимизации была проверена на 250 предложениях. представляет широкий спектр синтаксиса, встречающийся в радиологии отчеты. В большинстве случаев генетический алгоритм сходился к решению менее чем за 500 поколений. Оценивалась точность синтаксического разбора. сравнивая результаты с результатами исчерпывающего метода, который рассматривает все возможные комбинации ссылок. Результаты также были вручную проверено. В 84% случаев эволюционный метод дал правильные результаты за один проход.Когда было разрешено несколько прогонов, точность достигла 100%. Для примера предложения () существует 20 514 возможных комбинаций ссылок. Исчерпывающий поиск На поиск решения потребовалось 1944 секунды при той же конфигурации синтаксического анализа. было получено за 117 секунд предложенным способом.
Предварительное исследование показывает, что подход эволюционной оптимизации эффективен, и по сравнению с исчерпывающими методами, в вычислительном отношении эффективный.
Список литературы
2. Юрет Д.Открытие языковых отношений с помощью лексического притяжения. Докторская Диссертация, электротехника и информатика, Массачусетс Institute of Technology, 1998.
3. Смолл С., Ригер К. Анализ и понимание с помощью экспертов по словам (теория и его реализация). В Стратегии WG Lehnert и MH Ringle (ред.) for Natural Language Processing, 1982.
Модели разбора существительных — это природа каждого слова в предложении?
Модели разбора существительных:
В каждом предложении есть существительные, глаголы, прилагательные, местоимения, артикли и наречия.Какова природа каждого слова в предложении? Определение природы каждого слова называется синтаксическим анализом. Вот пример разбора предложения на слова в нем.
Предложение …
Человек, застреливший четырех тигров из спины слона в первый день охоты, получил прекрасную шкуру, которая доставила ему наибольшее удовольствие.
Теперь нам нужно разобрать это предложение на существительные, глаголы, прилагательные, местоимения, артикли и наречия. Каков характер частей речи? Мы должны уведомить каждое слово в таком слове, чтобы понимание каждого слова в этом конкретном контексте было ясным.
THE — Определенная статья
МУЖЧИНА — нарицательное существительное, мужской род, единственное число, именительный падеж, в зависимости от глагола ПОЛУЧЕНО.
ВОЗ — относительное местоимение, мужской род, единственное число, третье лицо — согласие в род, число и лицо с предшествующим ему man, именительный падеж, подлежащий глаголу SHOT
SHOT — Глагол
ЧЕТЫРЕ — Численное прилагательное, кардинал, определяющее существительное ТИГРЫ
ТИГРЫ — Нарицательное существительное, мужской род, множественное число, винительный падеж после глагола ВЫСТРЕЛ.
From — Предлог, имеющий BACK для своего объекта
AN — Статья на неопределенный срок
СЛОНА — нарицательное существительное, общий род, единственное число, родительный падеж, квалифицирующее существительное НАЗАД
НАЗАД — имя нарицательное, средний род, единственное число, винительный падеж после предлога ОТ
ON — Предлог, имеющий для своего объекта DAY
THE — Определенная статья
ПЕРВЫЙ — числовое прилагательное, порядковое, определяющее существительное ДЕНЬ
ДЕНЬ — имя нарицательное, род среднего рода, число единственного числа, винительный падеж после предлога ВКЛ.
OF — Предлог, имеющий в качестве объекта ОХОТУ
THE — Определенная статья
HUNT — Абстрактное существительное, средний род, единственное число, винительный падеж после предлога OF
ПОЛУЧЕНО — Глагол
A — бессрочный артикул
FINE — Прилагательное качества, определяющее существительное SKIN.
КОЖА — Имя нарицательное, род среднего рода, число единственного числа, винительный падеж после глагола ПОЛУЧИЛИ
КОТОРОЕ — Относительное местоимение, средний род, единственное число, третье лицо, имеющее предложение ПОЛУЧИЛО ТОЧНУЮ КОЖУ в качестве предшествующего именительного падежа, при условии глагола ДАЛИ
GAVE — Глагол
HIM — Личное местоимение, мужской род, единственное число, третье лицо, согласующееся со своим антецедентом — мужчина, дательный падеж после глагола — дал (косвенный объект)
THE — Определенная статья
НАИЛУЧШИЙ — Прилагательное качества, превосходная степень, квалифицирующая существительное УДОВЛЕТВОРЕНИЕ.
DELIGHT — Абстрактное существительное, средний род, единственное число, винительный падеж, прямой объект глагола GAVE
СВЯЗАННЫЕ СТРАНИЦЫ:
- Местоимение
- Местоимений
- Виды местоимений
- Личные местоимения
- Притяжательные прилагательные и притяжательные местоимения
- Притяжательные Само собой разумеющиеся
- Выделение местоимений
- Использование возвратных форм (использование возвратных местоимений)
- Демонстративные местоимения
- Формы указательных местоимений
- Формы указательных местоимений4
- Антецедентное существительное4
- Антецедентное 900
Относительные местоимения
- Два использования ВОЗ и WHICH
- Использование относительных местоимений
- Ограниченное использование ВОЗ и WHICH
- Продолжительное использование ВОЗ и WHICH
- Отсутствие относительных местоимений
- Где опустить относительное местоимение?
- Вопросительные местоимения
- Формы вопросительных местоимений
- Восклицательные местоимения
- Модели разбора прилагательных
- Модели разбора местоимений
- Модели разбора для местоимений
- Типы словосочетаний 49 Существительные9
- Предложения Модели Предложения Существительные Предложения Модели словосочетаний Предложения Модель 9 Предложения Модель 9 Предложения Модели 3 Разбор моделей существительных на ГЛАВНУЮ СТРАНИЦУ
Указатель предложений
Типы парсеров и как они работают
В общем, существует три типа подхода к синтаксическому анализу CV / резюме:o Парсеры на основе ключевых слов
o Парсеры на основе грамматики
o Статистические парсерыПарсеры на основе ключевых слов
Определение.- Анализатор резюме на основе ключевых слов работает, идентифицируя слова, фразы и простые шаблоны в тексте резюме / резюме, а затем применяя простые эвристические алгоритмы к тексту, который они находят вокруг этих слов. Это самый простой и наименее точный вид синтаксического анализатора резюме.
Features.- Эти инструменты могут искать что-то, похожее на почтовый индекс, а затем пытаться интерпретировать окружающие слова как адрес, или они могут искать шаблоны, которые выглядят как диапазоны дат, и предполагать, что окружающий текст является занятостью график.
Уровень точности.- Трудно выйти за пределы 70% точности . Этот тип синтаксического анализатора резюме является наименее точным, поскольку он не может извлекать информацию, не относящуюся к одному из их ключевых слов, и если их ключевые слова неоднозначны (например, навык «Директор»), они часто делают неправильные предположения о его интерпретации. .
Анализаторы на основе грамматики
Definition.- Основанные на грамматике содержат огромное количество грамматических правил, которые стремятся понять контекст каждого слова в резюме / резюме.Эти же грамматики также объединяют слова и фразы вместе, чтобы создать сложные структуры, которые фиксируют значение каждого предложения в резюме.
Возможности.- Эти парсеры намного сложнее, чем парсеры на основе ключевых слов, и обычно улавливают гораздо больше деталей, а также способны различать различные значения, которые одно слово или фраза могут иметь в разных контекстах.
Уровень точности.- Можно достичь уровня точности значительно выше 90% (человеческая точность редко превышает 96%).Обратной стороной является то, что этот тип синтаксического анализатора резюме требует большого количества ручного кодирования квалифицированными языковыми инженерами и большого количества тестов, чтобы убедиться, что улучшения в одной области не ухудшают производительность в другой.
Статистические анализаторы
Definition.- Этот тип синтаксического анализатора пытается применить числовые модели текста для идентификации структуры в CV / резюме. Подобно синтаксическим анализаторам на основе грамматики, они могут различать разные контексты одного и того же слова или фразы, а также могут захватывать широкий спектр структур, таких как адреса, временные шкалы и тому подобное.
Features.- Чтобы быть наиболее точными, они требуют на входе огромное количество CV / резюме, которые вручную помечены всей информацией, которая требуется для извлечения.
Уровень точности.- Этот вид синтаксического анализатора обычно работает лучше, чем синтаксический анализатор на основе ключевых слов, но не так хорошо, как синтаксический анализатор на основе грамматики для данных, на которых синтаксический анализатор не был обучен. Таким образом, чтобы статистический анализатор был точным, его необходимо предварительно обучить на данных, которые он должен обрабатывать.
Итак, каковы основные характеристики хорошего анализатора CV ?
Как разобрать файл в формате .doc — Microsoft Security Response Center
В феврале этого года Microsoft публично опубликовала спецификацию форматов двоичных файлов Office. В них описывается, как анализировать файлы Word, Excel и PowerPoint для просмотра или извлечения содержимого. Поскольку они подробно описывают структуру этих форматов файлов, мы думаем, что спецификация формата файлов будет особенно интересна для независимых поставщиков программного обеспечения, которые пишут логику обнаружения для сканеров вредоносных программ (таких как антивирусное программное обеспечение).Давайте начнем вникать в эти документы с изучения основ синтаксического анализа документа Word, созданного с помощью этого устаревшего двоичного формата файла. Это обсуждение не будет охватывать новый формат OOXML, представленный в Word 2007.
Составной двоичный формат
Перво-наперво, для анализа этих старых форматов вам необходимо знать формат составного двоичного файла. Спецификация этого формата доступна в Интернете. При осмотре можно увидеть, что формат похож на файловую систему, похожую на FAT.Существуют каталоги, называемые хранилищами, которые содержат файлы данных, называемые потоками. Все эти данные потенциально фрагментированы в файле в различных секторах, описываемых внутренней FAT. Существуют библиотеки для синтаксического анализа этого формата, поэтому вам не придется изобретать колесо заново, если вы этого не хотите. Используйте Windows COM API, начиная с функции StgOpenStorageEx, или один из нескольких свободно доступных синтаксических анализаторов и программ просмотра для извлечения отдельных потоков данных. Составные двоичные файлы на самом деле довольно распространены, и COM API — хороший способ получить доступ к данным, хранящимся в этих файлах.Высокоуровневая структура данных Word
В допустимых документах Word существует поток с именем WordDocument. Идите вперед и просмотрите содержимое этого потока. Он начинается со структуры, называемой информационным блоком файла или FIB, которая описана на стр. 141 спецификации формата двоичного файла Word. Эта массивная структура содержит данные и действует как путеводитель для остальной части документа. По смещению 0x9A в FIB вы найдете значение-заполнитель с именем Rgfclcb. Это отмечает начало пар смещение / длина, которые описывают расположение структуры для остальной части документа.Это смещения в другой поток с именем 0Table или 1Table. Чтобы узнать, на какой из этих двух потоков идет ссылка, проверьте 16-битное значение при смещении FIB 0xA и посмотрите на бит номер 10 (И его с 0x200). Если этот бит равен 0, то смещения относятся к потоку 0Table. Если 1, то поток 1Table.Этот поток xTable содержит большую часть данных форматирования, которые Word использует для создания документа на экране. Каждое смещение указывает на другую структуру, поэтому проверьте спецификацию двоичного файла Word для получения дополнительных сведений о данных, хранящихся в определенном месте потока таблицы.
Реальный пример
Теперь давайте объединим эту информацию с некоторыми подробностями об исправленной уязвимости, чтобы увидеть, как мы можем обнаружить возможную попытку эксплойта. В MS06-060 исправлена уязвимость в структуре состояния слияния печати (PMS), которая хранится в одном из потоков xTable.Во-первых, используйте метод, описанный выше, чтобы определить, использует ли этот документ поток 0Table или 1Table.
Затем мы должны выяснить, есть ли в документе структура PMS, и если да, то каково ее смещение в потоке xTable.В FIB есть два возможных места, где может храниться расположение этой структуры: fcPms и fcPmsNew. Сначала проверьте fcPms. Соответствующее значение длины для этого значения смещения называется lcbPms, и это DWORD, расположенный по смещению FIB 0x1FE. Если это значение не равно нулю, то DWORD fcPms со смещением FIB 0x1FA содержит необходимое смещение xTable. Если значение длины равно 0, то нам нужно проверить второе возможное местоположение, fcPmsNew при смещении FIB 0x48A. Значение длины для этого называется lcbPmsNew и находится со смещением FIB 0x48E.Если этот DWORD равен 0, то документ не содержит структур PMS. Если он не равен нулю, то DWORD fcPmsNew содержит смещение в потоке xTable структуры PMS.
Наконец, если документ действительно содержит структуру PMS, проверьте ее в потоке таблицы, который вы определили ранее, по смещению, которое вы только что прочитали из FIB. Структура выглядит так:
struct PrintMergeState {
WORD Reserved1;
BYTE One;
BYTE Два;
DWORD Зарезервировано2;
BYTE Three;
BYTE Зарезервировано3 [7];
BYTE Четыре;
};
В этой структуре есть четыре представляющих интерес байта с именами «Один», «Два», «Три» и «Четыре» в приведенном выше определении.Убедитесь, что значения «Один» и «Два» установлены на 0 или 1. Для трех и четырех убедитесь, что эти значения находятся в диапазоне от 0 до 5 включительно. Любые другие значения для этих полей недопустимы, и документ должен быть помечен как потенциально злоупотребляющий уязвимостью MS06-060.
В следующем примере поток WordDocument начался со смещения файла 0x1C00, а поток 1Table — со смещения файла 0xC00. Обнаружив, что lcbPms (по адресу 0x1C00 + 0x1FE) не равно нулю, мы смотрим на структуру PMS по адресу 0xC00 + 0x1A6 и видим, что значение с именем «Three» больше 5, поэтому в этом документе может быть предпринята попытка использовать MS06-060.
Личные Прилагательные