«Человек» морфологический разбор слова — ассоциации, падежи и склонение слов
- Найти слова начинающиеся на «человек»
- Найти слова содержащие «человек»
- Найти слова заканчивающиеся на «человек»
Гипо-гиперонимические отношения
позвоночное млекопитающее примат человек аланПрилагательные к слову человек
Каким бывает человек? Предлагаем подбор прилагательных на основе литературных произведений и статей.
молодым
другим
хорошим
единственным
любым
нормальным
честным
высоким
добрым
умным
живым
нужным
пожилым
богатым
обычным
порядочным
маленьким
простым
взрослым
прекрасным
сильным
плохим
белым
замечательным
достойным
деловым
худощавым
большим
больным
невысоким
свободным
седым
опасным
неким
серьезным
русским
настоящим
разумным
странным
старым
здравомыслящим
всяким
счастливым
черным
лысым
одетым
ужасным
новым
надежным
милым
коренастым
великим
глупым
смелым
приличным
первым
храбрым
могущественным
благородным
смуглым
чужим
влиятельным
вторым
нехорошим
Глаголы к слову человек
Что может человек? Что можно сделать с человеком? Подбор подходящих глаголов на основе русского языка.
стоять
сказать
знать
пытаться
выглядеть
отправиться
умереть
направиться
чувствовать
приблизиться
говорить
улыбаться
решить
вскочить
сделать
обратиться
показать
являться
достичь
превратиться
повернуть
считатьсяпревращаться
использовать
захотеть
постучать
скользнуть
достать
догадаться
засмеяться
постоять
запустить
открыться
наклониться
держать
пожертвовать
заботиться
подействовать
целовать
измерять
просвистеть
защищать
побеспокоить
озаботить
торопиться
подглядывать
выдрать
напирать
вознести
устранить
перенапрячься
одержать
петь
накликать
уплывать
дотронуться
вытянуть
примолкнуть
выжить
обеспокоиться
жить
оформить
распрямить
отваживаться
Ассоциации к слову человек
Подбор ассоциативного ряда. Слова, которые в той или иной степени ассоциируются с искомым.
Слова, которые в той или иной степени ассоциируются с искомым.
имя
земля
маска
света
мир
форма
плащ
человек
фамилия
плоть
глаз
рука
возраст
состояние
конец
группа
королевство
вид
сорока
зверь
империя
животное
восток
копна
начало
бар
список
тень
униформа
мешок
ал
россия
защита
чувство
свадьба
орбита
сознание
профессия
медведь
гостиная
начальство
колебание
недоумение
весло
папаха
шар
качество
леса
стойка
право
крестьянин
швеция
приход
карта
религия
устройство
плен
таинство
аудитория
британия
виола
мэн
продавец
иванов
Гиперонимы
примат
млекопитающее
существо
прислуга
Гипонимы
чувак
деятель
лыжник
австралиец
нищий
японец
фат
сноб
трус
пианист
дока
шпион
ходок
турист
артист
украинец
налогоплательщик
повеса
распутник
гражданин
особа
американец
пассажир
неврастеник
удалец
родственник
специалист
уродина
левша
балбес
насмешник
пария
донор
курд
героиня
работяга
карлик
болтун
ирод
мерзавец
неудачник
попутчик
хулиган
нарушитель
зомби
мученик
израильтянин
делец
мельник
земляк
преемник
карен
смельчак
персона
беглец
священнослужитель
доносчик
араб
мужчина
американка
атеист
магнат
прототип
священнослужитель
коллега
негр
младенец
палач
алкоголик
подонок
дурак
безбожник
сладкоежка
алкоголичка
невежа
падла
сквалыга
носач
краснобай
замарашка
отморозок
сластолюбец
обалдуй
человечишко
монголоид
позолотчик
тинейджер
жуир
кафир
галлофоб
пиздун
алан
австралоид
европеоид
хипстер
пиздюк
чудак
приказчик
сверстник
питомец
азиат
щеголь
сорвиголова
негроид
дебошир
художник
рабочий
неряха
герой
скупец
мракобес
юноша
пассия
погодок
хват
дылда
однополчанин
усач
пост
ленивец
мальчишка
рабочий
ненавистник
бражник
ребенок
кроманьонец
старик
путаник
интроверт
женщина
друг
муж
товарищ
пиздобол
богочеловек
африканка
мессалина
распутница
сосед
блондин
бабуся
африканец
бородач
армянка
брюнет
афганка
боксер
грузчик
афганец
мошенник
француз
руководитель
адвокат
сосед
лошара
мальчик
девушка
горожанин
плебей
мачеха
рабыня
пророк
итальянец
дева
ворчунья
тесть
грузин
девочка
дворник
преферансист
башибузук
добродетель
сморчок
компьютер
безусый
поэт
глухой
дедушка
сыч
гнида
судья
ангел
тетя
монах
крыса
бирюк
дядя
эквилибрист
морж
заноза
пиявка
марионетка
проститутка
оригинал
гусь
сова
вертушка
пигалица
небожитель
лоб
животное
кровосос
плюшка
жена
удод
фигляр
дистрофик
макака
фрукт
аналитик
громадина
предатель
лошадка
молекула
верста
русый
штатский
хам
сверчок
верующий
известность
пьяный
задница
тряпка
новенький
гвардеец
обыватель
ублюдок
лапоть
провинциал
перебежчик
дубина
божок
авторитет
пень
жук
падаль
сундук
пизда
немец
братишка
канареечник
русский
черный
лиса
тетерев
мурло
ноль
богатырь
огарок
счетчик
дуб
туша
баран
волк
редиска
петушок
козявка
хищник
шкаф
публика
талант
олень
погибший
кремень
нарцисс
желтый
куль
ученый
аэрограф
летун
гиббон
язычник
скорпион
величина
делитель
тормоз
колпак
подснежник
богатый
овощ
мимоза
кошка
лев
симпатия
фигура
Какого рода человек (морфологический разбор)
Разбор слова по части речи, роду, числу, одушевленности и падежу.
Часть речи:
существительное
Род:
мужской
Число:
единственное
Одушевленность:
одушевленное
Падеж:
именительный
Склонение существительного человек (какой падеж)
Склонение слова по падежу в единственном и множественном числах.
| Падеж | Вопрос | Ед.число | Мн. число |
|---|---|---|---|
| Именительный | (кто, что?) | человек | |
| Родительный | (кого, чего?) | человека | |
| (кому, чему?) | человеку | ||
| Винительный | (кого, что?) | человека | |
| Творительный | (кем, чем?) | человеком | |
| Предложный | (о ком, о чём?) | человеке |
Сфера употребления
Общая лексика Оружейное производство Биохимия Автомобильный термин Фамильярное выражениеПредложения со словом человек
Наш робот составил несколько предложений в автоматическом режиме. Оцените его работу, тем самым Вы поможете ему стать более совершенным.
Оцените его работу, тем самым Вы поможете ему стать более совершенным.
1. Человек неспособно говорил с прославленным танцором
0
0
2. Монтано человек стоял на водительском месте
1
1
3. Человек удачно умер от крупного разрыва
3
3Напишите свои варианты ассоциаций
Смотрите также
Перевод Ассоциации Анаграммы Синонимы и антонимы Морфологический разбор Склонения Спряжения
Буква в начале Буква в конце
Все связи построены автоматическим анализатором русскоязычного текста.
Морфемный и словообразовательный разбор слова
Похожие презентации:
Морфемный и словообразовательный разбор слова
Разбор. Фонетический, морфемный, морфологический, синтаксический и словообразовательный разбор
Словообразование. Морфемные способы образования слов
Языковые разборы слов
Методика изучения морфемного состава слов
Словообразовательная морфемика
Методика обучения морфемике и словообразованию
Словообразование. Морфемный состав слова
Морфемный состав слова
Морфемика. Словообразование
Методика морфемики, словообразования
1. Морфемный и словообразовательный разбор слова.
Способы образования словПросушить
Приставочный
Талантливый
Суффиксальный
Приморский
Приставочно суффиксальный
Выход
Бессуффиксный
Первоисточник
Сложение основ
Гласный
Переход из одной части
речи в другую
4. Морфемный разбор
леснойРазберите
эти слова
по
составу:
перелесок
приморский
прогуляться
5. Словообразовательный разбор
леснойлес
(суффиксальный)
+ -н-
перелесок
лес + пере- + -ок(приставочно-суффиксальный)
приморский
море + при- + -ск(приставочно-суффиксальный)
6. Словообразовательный разбор
прогулятьсяпрогулять + ся
(так как прибавляется только
постфикс, такой способ называется
постфиксальный)
7. Назовите способ образования слов:
1. подружка ← подруга ← друг2.
 человечество ← человек
человечество ← человек3. Неуспевающий ← успевающий ←
успе-вать ← успеть
4. переход ← переходить ← ходить
5. наплечный ←плечо
Перед вами
словообразовательные
цепочки
8. Запишем в справочник:
Словообразовательная цепочка — этотакой ряд однокоренных слов, в котором
каждое последующее слово
непосредственно образовано от
предыдущего.
греть → обогреть → обогревать →
обогреватель.
ПРОВЕРЬТЕ СЕБЯ!
1. подружка ← подруга + к (суф.) ←
друг + по (прист.)
2. человечество ← человек + еств
(суф.)
3. Неуспевающий ← успевающий + не
(прист.) ← успевать + ющ (суф.) ←
успеть + ва (суф.)
ПРОВЕРЬТЕ СЕБЯ!
4. переход ← переходить + ᴓ
(бессуффиксный) ← ходить + пере
(прист.)
5. наплечный ← плечо + на + н
(прист.-суф.)
11. Составьте словообразовательные цепочки:
Радостный, радость.Побелка, белый,
побелить.
Накипеть, кипеть,
накипь.
Светлеть, свет,
12.
 ПРОВЕРЬТЕ СЕБЯ!Радостный ← радость + н (суф.)
ПРОВЕРЬТЕ СЕБЯ!Радостный ← радость + н (суф.)Побелка ← побелить + к (суф.)←
белый + по + и (прист.-суф.)
Накипь ← накипеть + ᴓ (бессуф.)
← кипеть + на (прист.)
Посветлеть ← светлеть + по
(прист.) ← свет + е (суф.)
Учимся выполнять
словообразовательный разбор.
Откроем учебник на стр.
190, почитаем порядок
словообразовательного
разбора и выполним
№670
№670
Рассмотреть
Рассвет
№670
Обгонять
Счётчик
№670
Цветной
Ручка
Перейдем к №672, посложнее
слова
Тракторист
Учительница
Дошкольник
Столяр
Столичный
Придорожный
Ёлка
Возьмём дополнительно ещё 3 слова
Лесостепь, паровоз,
темнокожий
Как вы думаете,
в чем особенность этих
слов?
Все эти слова образованы с помощью
сложения
21. Домашнее задание
Выполнитесловообразовательный разбор
слов:
Оглушить,
примирить,
роковой,
уличный,
похудевший,
напильник,
поиск, измерение
English Русский Правила
Корень слова: супер- (префикс) | Membean
Префиксы — это ключевые морфемы английского словаря, с которых начинаются слова. Префикс super- и его вариант sur- означают «над».
Префикс super- и его вариант sur- означают «над».
Все мы знаем, что герой комиксов DC Супермен — это герой, который стоит «над» всеми другими людьми у власти. Он является звездой супер в линейке героев DC Comics или звездой, которая стоит «над» другими героическими звездами, такими как Бэтмен и Чудо-женщина. Говоря о супер звездах, футбольная игра, которая стоит «над» всеми другими футбольными играми, это, вы поняли, Супер Чаша. В Super Bowl участвуют команды super ior из дивизионов AFC и NFC, которые противостоят друг другу, то есть две команды, которые стояли «над» всеми остальными в течение футбольного сезона.
Школьные системы любят, когда члены руководства стоят «над» всеми остальными, например, суперинтенданты , которые несут ответственность за всю школьную систему. Они super визируют или наблюдают за школами в своих округах.
Вариантом префикса супер-, который также означает «выше», является морфема сур-. Например, имя sur — это имя, которое находится «над» семьей и тем самым идентифицирует ее или фамилию семьи. Лицо чего-либо sur этимологически является лицом, лежащим «поверх» того, что оно скрывает. Когда вы на превосходите всех остальных по результатам SAT в вашей школе, вы «перебиваете» их всех, таким образом получая наивысший балл. Тот, кто берет sur Многие люди хотят проверить, что они думают. А вам когда-нибудь приходилось платить на счета за сотовый телефон, эти маленькие подлые платежи, которые «превышают» то, что вы должны заплатить? Иногда вы хотели бы поразить такие заряды «через» голову!
Теперь, когда вы округлили на с помощью супер латентных примеров слов, содержащих префиксы супер- и на , вам больше никогда не придется просматривать эти слова дважды, прежде чем понять, что они означают.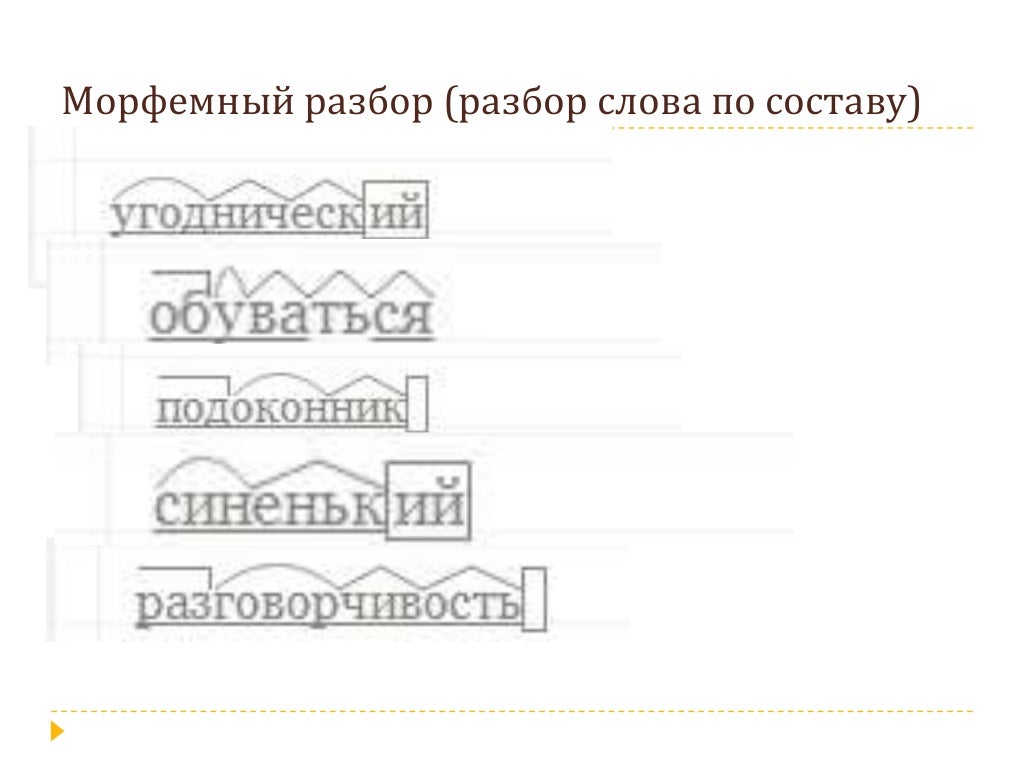 . Это всего лишь супер калифрагилистическийэкспериментальный!
. Это всего лишь супер калифрагилистическийэкспериментальный!
- Супермен : человек «над» всеми остальными
- суперзвезда : звезда «над» всеми другими звездами спорта или музыки
- Суперкубок : футбольный матч «выше» всех остальных
- суперинтендант : администратор всей школьной системы
- руководитель : тот, кто наблюдает «за» другими
- фамилия : имя «над» всем в семье
- поверхность : слой, лежащий «поверх» чего-либо
- превзойти : пройти «над» другими
- опрос : осмотрите что-нибудь
- Надбавка : сбор, превышающий установленную плату
- объемный : волна «над» чем-то, что поглощает его
- превосходная степень : переноса «над» и «над»
Лекции по CS440
Лекции по CS440 CS 440/ECE 448
Margaret Fleck
Естественный язык 3
Боати МакБотфейс (от BBC)
Поиск морфем
Итак, теперь давайте предположим, что у нас есть чистая последовательность слов. Под словом я подразумеваю кусок
размера, удобного для более поздних алгоритмов (например, синтаксический анализ, перевод).
Это может быть вывод распознавателя речи. Или же,
поскольку многие системы естественного языка не начинаются с речи, поток
слов может быть (очищенным) письменным текстом.
Под словом я подразумеваю кусок
размера, удобного для более поздних алгоритмов (например, синтаксический анализ, перевод).
Это может быть вывод распознавателя речи. Или же,
поскольку многие системы естественного языка не начинаются с речи, поток
слов может быть (очищенным) письменным текстом.
Затем эти слова необходимо разделить на морфемы с помощью алгоритма «морфологии». Слова в некоторых языках могут быть очень длинными (например, в турецком), что усложняет задачу. выполнять дальнейшую обработку, если они (по крайней мере, частично) не подразделяются в морфемы. Например:
без ответа —> без ответа
предварительные условия —> предварительные условия
Или рассмотрим следующее известное китайское слово:
Чжун + Го
В современном китайском языке это одно слово («Китай»). И наша система ИИ
вероятно, сможет накопить достаточно информации о Китае за счет
рассматривая его как один двусложный элемент. Но исторически (и в написании
система) состоит из двух морфем («средний» и «кантри»). это то, что
называется
«прозрачное соединение», то есть носитель языка будет
осведомлены об отдельных частях. Это знание внутреннего слова
структура позволила бы человеку угадать
что менее распространенное слово, оканчивающееся на «гуо», также может быть именем
страна.
Но исторически (и в написании
система) состоит из двух морфем («средний» и «кантри»). это то, что
называется
«прозрачное соединение», то есть носитель языка будет
осведомлены об отдельных частях. Это знание внутреннего слова
структура позволила бы человеку угадать
что менее распространенное слово, оканчивающееся на «гуо», также может быть именем
страна.
Иногда родственные слова образуются с помощью процессов, отличных от конкатенации, например. внутренняя смена гласных в английском «фут» против «ноги». Когда это распространено в языке, мы можем захотеть использовать более абстрактное представление на основе признаков, например.
фут —> фут+ЕДИНСТВЕННОЕ ЧИСЛО
фут —> фут+МНОЖЕСТВЕННОЕ ЧИСЛО
Иногда соответствующее разделение зависит от приложения. Итак, английский притяжательный
окончание «s» традиционно пишется как часть предшествующего слова. Однако часто бывает
удобно отделить его как отдельное слово при последующей обработке.
POS-маркировка
Чтобы сгруппировать слова в более крупные единицы (например, предложные фразы), Первым шагом обычно является присвоение тега «части речи» (POS) каждому слову. Вот пример текста из корпуса Брауна, который содержит очень чистые письменный текст.
Северные либералы являются главными сторонниками гражданских прав и интеграция. Они также вели нацию в направлении государство всеобщего благосостояния.
Вот версия с тегами. Например, «либералы» — это ННС, которые является существительным во множественном числе. «Северный» — прилагательное (JJ). Наборы тегов должны различать основные типы слов. (например, существительные и прилагательные) и основные варианты, например. существительные в единственном и множественном числе, глаголы в настоящем и прошедшем времени. Есть также несколько специальных тегов ключевые функциональные слова, такие как HV для «иметь», и знаки препинания (например, точка).
Северные/jj либералы/nns являются/ber the/вождем/jjs сторонники/nns в/в гражданских/жж прав/ннс и/сс/в интеграции/нн ./. Они/ппсс Иметь/hv также/rb привело/vbn the/в нации/nn в/в/в направлении/nn из/в а/в благополучии/нн состояние/нн ./.
 /. Они/ппсс
Иметь/hv также/rb привело/vbn the/в нации/nn в/в/в направлении/nn
из/в а/в благополучии/нн состояние/нн ./.
/. Они/ппсс
Иметь/hv также/rb привело/vbn the/в нации/nn в/в/в направлении/nn
из/в а/в благополучии/нн состояние/нн ./.Большинство слов имеют только одну общую часть речи. Таким образом, мы можем подняться до около 91% точности с использованием простого «базового» алгоритма, который всегда угадывает наиболее распространенную часть речи для каждого слова. Однако некоторые слова имеют более одного возможного тега, например. «либеральный» может быть как существительным, так и прилагательным. Чтобы сделать это правильно, мы можем использовать алгоритмы, подобные скрытым марковским моделям (следующая лекция). На чистом тексте хорошо настроенный POS-тегер может получить около 9точность 7%. Другими словами, POS-теггеры достаточно надежны и в основном используются в качестве стабильной отправной точкой для дальнейшего анализа.
Мелководные системы
Многие полезные системы можно построить, используя только простой локальный анализ.
словесного потока, например слова, словесные биграммы, морфемы, POS-теги,
возможно поверхностный анализ (см. ниже).
Эти алгоритмы обычно делают «марковское предположение», т. е. предполагают, что
только несколько последних пунктов имеют значение для следующего решения. Например.
ниже).
Эти алгоритмы обычно делают «марковское предположение», т. е. предполагают, что
только несколько последних пунктов имеют значение для следующего решения. Например.
- Решаете, вставлять ли границу слова? Посмотрите на последние 5-7 символов.
- Решаете, какой POS-тег поставить на следующее слово? Посмотрите на последние 1-3 слова.
Конкретные методы включают автоматы с конечным числом состояний, скрытые марковские модели (HMM) и рекуррентные нейронные сети (RNN). Позже в этом курсе мы увидим скрытые марковские модели.
Один очень старый тип мелководья
система исправления правописания.
Полезные обновления (которые часто работают)
включать обнаружение грамматических ошибок, добавление гласных или диакритических знаков
в языке (например, арабском), где они часто опускаются.
Передовые исследовательские задачи включают в себя автоматическую оценку
ответы на стандартизированные тесты.
Распознавание речи использовалось для оценки английского языка. беглость речи и дети учатся читать (например, вслух).
Успех зависит от очень сильных ожиданий относительно того, что
скажет человек.
беглость речи и дети учатся читать (например, вслух).
Успех зависит от очень сильных ожиданий относительно того, что
скажет человек.
Перевод часто выполняется с помощью неглубоких алгоритмов. Чтобы научиться переводить, мы могли бы выровнять пары предложений на разных языках, сопоставив соответствующие слова.
Русский: 18-летним нельзя покупать алкоголь.
Французский: Les 18 ans ne peuvent pas acheter d’alcool
| 18 | год | старые | банка | т | купить | спирт | |||
| Лес | 18 | и | пе | пёвент | па | ачетер | д’ | алкоголь |
Обратите внимание, что некоторые слова не имеют соответствий на другом языке. Для других пар языки, могут быть радикальные изменения в порядке слов.
Корпус совпадающих пар предложений можно использовать для создания словарей перевода (для
фразы, а также слова) и извлекать общие сведения об изменениях в порядке слов.
Разбор
Если у нас есть POS-теги для слов, мы можем собрать слова в дерево разбора. Существует множество стилей построения деревьев синтаксического анализа. Здесь представляет собой дерево избирательного округа из пенсильванского дерева (от Митча Маркуса).
Дерево синтаксического анализа в стиле Penn treebank (от Митча Маркуса)
Альтернативой является дерево зависимостей , как показано ниже из Гугл лаборатории. Достаточно свежий парсер от них называется «Парси Макпарсфейс» после Великобритании Boaty McBoatface показан выше.
В этом примере левое дерево показывает правильная приставка для «в своей машине», т.е. модификация «поехала». Дерево справа показывает интерпретацию, в которой улица находится в машине.
Лингвисты (вычислительные и другие) ведут длительные споры о
лучший способ нарисовать эти деревья. Однако закодированная информация
всегда довольно похожи и в основном включают в себя группировку слов
которые образуют связные фразы, например. «государство всеобщего благоденствия». Это довольно похоже
к разбору языков программирования, за исключением того, что программирование
языки были разработаны, чтобы упростить синтаксический анализ.
«государство всеобщего благоденствия». Это довольно похоже
к разбору языков программирования, за исключением того, что программирование
языки были разработаны, чтобы упростить синтаксический анализ.
«Поверхностный синтаксический анализатор» строит только самые нижние части такого дерева. Так что может группировать слова в словосочетания с существительными, предложными словосочетаниями и сложные глаголы (например, «идет»). Извлекать эти фразы намного проще чем построение всего дерева синтаксического анализа, и может быть чрезвычайно полезным для построение неглубоких систем.
Подобно низкоуровневым алгоритмам, синтаксические анализаторы часто принимают решения, используя только
небольшое количество предшествующего (и, возможно, прогнозного) контекста.
Однако «один элемент» контекста может быть целым
кусок дерева синтаксического анализа. Например, «юная леди» может считаться
единое целое. Алгоритмы синтаксического анализа обычно должны учитывать широкий спектр параметров, например. множество вариантов частично построенного дерева. Поэтому они обычно используют
поиск луча, т.е.
оставить только фиксированное количество гипотез с лучшим рейтингом. Более новые методы также
попытаться разделить древовидную структуру между конкурирующими альтернативами (например, динамическое программирование)
чтобы они могли хранить больше гипотез и избегать дублирования работы.
множество вариантов частично построенного дерева. Поэтому они обычно используют
поиск луча, т.е.
оставить только фиксированное количество гипотез с лучшим рейтингом. Более новые методы также
попытаться разделить древовидную структуру между конкурирующими альтернативами (например, динамическое программирование)
чтобы они могли хранить больше гипотез и избегать дублирования работы.
Парсеры делятся на три категории
- Нелексикализованный: используйте только теги POS для построения дерева.
- На основе класса: вне части речи, определите общий тип объект или действие (например, человек против транспортного средства)
- Лексикализованный: также включает некоторую информацию о слове идентичность/значение
Значение лексической информации иллюстрируется предложениями вот так, в котором меняется именное словосочетание изменяет то, что предложное словосочетание изменяет:
Она шла по улице..в ее грузовике.
в новом наряде. (меняет тему)
в Южном Чикаго. (меняет улицу)
 (меняет ход)
(меняет ход) Лучшие синтаксические анализаторы лексикализированы (точность до 94% от Google). Парсер «Parsey McParseface»). Но неясно, сколько информации включать о слова и их значения. Например, должен ли «автомобиль» всегда вести себя как «грузовик»? Более подробная информация помогает принимать решения (особенно приложение) но требует больше обучающих данных.
Подробнее о наборах бирок
Обратите внимание, что набор тегов для корпуса Брауна был несколько специализированным.
для английского языка, в котором формы have и to be
играют важную синтаксическую роль.
Наборы тегов для других языков потребуют одних и тех же тегов (например, для
существительные), но и категории для
типы служебных слов, которые не используются в английском языке.
Например, для набора тегов для китайского языка или языка майя потребуется тег для числа.
классификаторы, которые представляют собой слова, которые идут с числами (например, «три»)
для указания приблизительного типа перечисляемого объекта (например,
«таблице» может потребоваться классификатор для больших плоских объектов). Не ясно, лучше ли иметь специализированные наборы тегов
для конкретных языков или один универсальный набор тегов, включающий
основные функциональные категории для всех языков.
Не ясно, лучше ли иметь специализированные наборы тегов
для конкретных языков или один универсальный набор тегов, включающий
основные функциональные категории для всех языков.
Наборы тегов различаются по размеру в зависимости от теоретических предубеждений люди, делающие аннотированные данные. Меньшие наборы этикеток передают только основная информация о типе слова. Большие наборы содержат информацию о том, какую роль слово играет в окружающем контексте. Образец размеры
- Пенн Трибэнк 36
- Коричневый корпус 87
- «универсальный» 12
Разговорный разговорный язык также включает в себя черты, которых нет в письменном языке.
В приведенном ниже примере (из корпуса Switchboard)
можно увидеть заполненную паузу «ух», а также обломанное слово «т-«.
Кроме того, обратите внимание, что первое предложение разбивается парантетической
комментарий («вы знаете»), и третье предложение обрывается в конце.
Такие особенности затрудняют анализ устной беседы, чем
письменный текст.
Я был бы очень-очень осторожен и, ну, вы знаете, проверил бы их. Э-э, наш, надо было т-, поместить маму в дом престарелых. У нее был довольно массивный инсульт о, ммм, о —
I/PRP ‘d/MD be/VB очень/RB очень/RB осторожный/JJ и/CC ,/, эм/UH ,/, вы /прп знаете/вбп ,/, проверяя/вбг их/прп вых/рп./. Ух/Ух,/, наш/прп$ ,/, имел/вбд т-/к ,/, место/вб мой/прп$ мать/нн в/в а/дт дом престарелых/NN дом/NN ./. Она/PRP имела/VBD a/DT скорее/RB массивная/JJ ход/н.н.о/рб ,/,э/ух ,/,о/рб —/:
Семантика
Представление смысла менее понятно. В современных системах значение индивидуального
основы слов (например, «кошка» или «прогулка») основаны на их наблюдаемом контексте. мы увидим подробности
позже в срок. Но эти значения не связаны или связаны лишь слабо с
Физический мир. Приемы объединения значений отдельных слов в единое
значение (например, «рыжий кот») так же хрупки.
Очень немногие системы пытаются понять
сложные конструкции с использованием кванторов
(«Сколько стрел не попали в цель?»)
или относительные предложения. (Примером относительного предложения является «что дало бы…» в
приведенный выше пример синтаксического анализа Penn treebank.)
(Примером относительного предложения является «что дало бы…» в
приведенный выше пример синтаксического анализа Penn treebank.)
Специфическая проблема даже для простых приложений заключается в том, что отрицание легко для человека, но трудно для него. компьютеры. Например, запрос Google для «Африка, а не франкоязычный» возвращает информацию во франкоязычных частях Африки. И это пример кругового перевода показывает, как Google выполняет следующую конверсию, которая меняет полярность советов.
- Ввод: «так что ой, как пробовать через 3 часа.»
- Вывод: «Попробуйте попробовать через 3 часа.»
Приложения, которые могут хорошо работать с ограниченным пониманием включают
- группировка документов по темам, разделение документов в местах смены темы
- анализ настроений: нравится ли писателю этот фильм или этот ресторан?
Три типа поверхностного семантического анализа оказались полезными и почти в пределах текущих возможностей:
- Классы слов: какие слова похожи друг на друга (например, люди или овощи)?
- значение слова значение значения: какое было предполагаемое прочтение слова с несколькими значениями (например, «банк»)?
- Маркировка семантической роли: мы знаем, что именное словосочетание X относится
к глаголу Y. Является ли X субъектом/действующим лицом? объект, что действие
было сделано? инструмент, используемый, чтобы помочь с действием?
- совместное эталонное разрешение (см. ниже)
 Является ли X субъектом/действующим лицом? объект, что действие
было сделано? инструмент, используемый, чтобы помочь с действием?
Является ли X субъектом/действующим лицом? объект, что действие
было сделано? инструмент, используемый, чтобы помочь с действием?Семантическая ролевая маркировка включает в себя определение того, как основные именные фразы в предложение относится к глаголу. Например, в «Джон вел машину». «Джон» — это субъект/агент, а «машина» — управляемый объект. Эти отношения не всегда являются объектами, т.е. кто ест кого в «мост, пожирающий грузовики»? (Поищи в Гугле.)
В настоящее время наиболее популярным представлением классов слов является «вложение слов». Вложения слов дают каждому слову уникальное местоположение в многомерном евклидовом пространстве, устроенном так, что подобные слова находятся близко друг к другу. Подробности увидим позже. популярный алгоритм word2vec.
Текущий текст содержит ряд «именованных сущностей», т. е. существительных, местоимений и т.
словосочетания, относящиеся к людям, организациям и местам.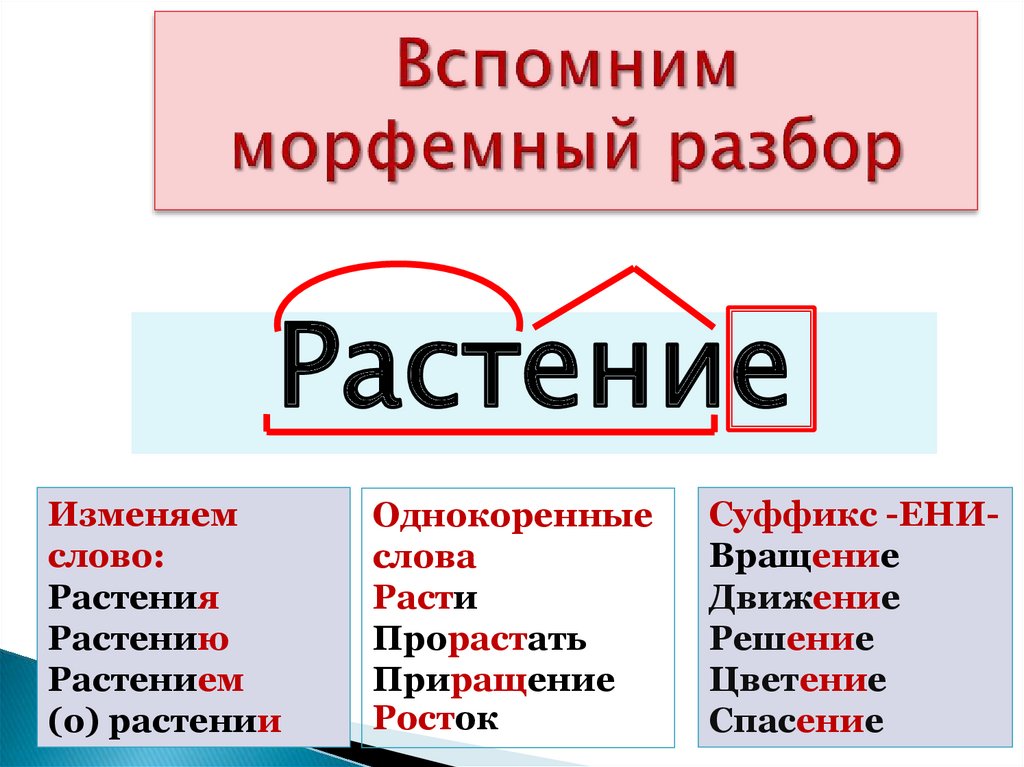 Совместная резолюция пытается идентифицировать
какие именованные сущности относятся к одному и тому же.
Например, в этом тексте из Википедии у нас есть
определил три сущности, относящиеся к Мишель Обаме,
два как Барак Обама и три как места, которые не являются ни тем, ни другим.
их. Одним из источников трудностей являются такие предметы, как
последний «Обама», который внешне выглядит так, как будто это может быть
любой из них.
Совместная резолюция пытается идентифицировать
какие именованные сущности относятся к одному и тому же.
Например, в этом тексте из Википедии у нас есть
определил три сущности, относящиеся к Мишель Обаме,
два как Барак Обама и три как места, которые не являются ни тем, ни другим.
их. Одним из источников трудностей являются такие предметы, как
последний «Обама», который внешне выглядит так, как будто это может быть
любой из них.
[Мишель ЛаВон Робинсон Обама] (родился 17 января 1964 г.) американский юрист, администратор университета и писатель который служил в качестве [Первая леди США] от с 2009 по 2017 год. Замужем за [44-й президент США], [Барак Обама], и была первой афроамериканской первой леди. Выросший на южной стороне [Чикаго, Иллинойс], [Обама] является выпускник [Университет Принстон] и [Гарвардская школа права].
Согласованность диалога
С самого раннего возраста люди обладают сильной способностью управлять
взаимодействия в течение длительного периода времени.