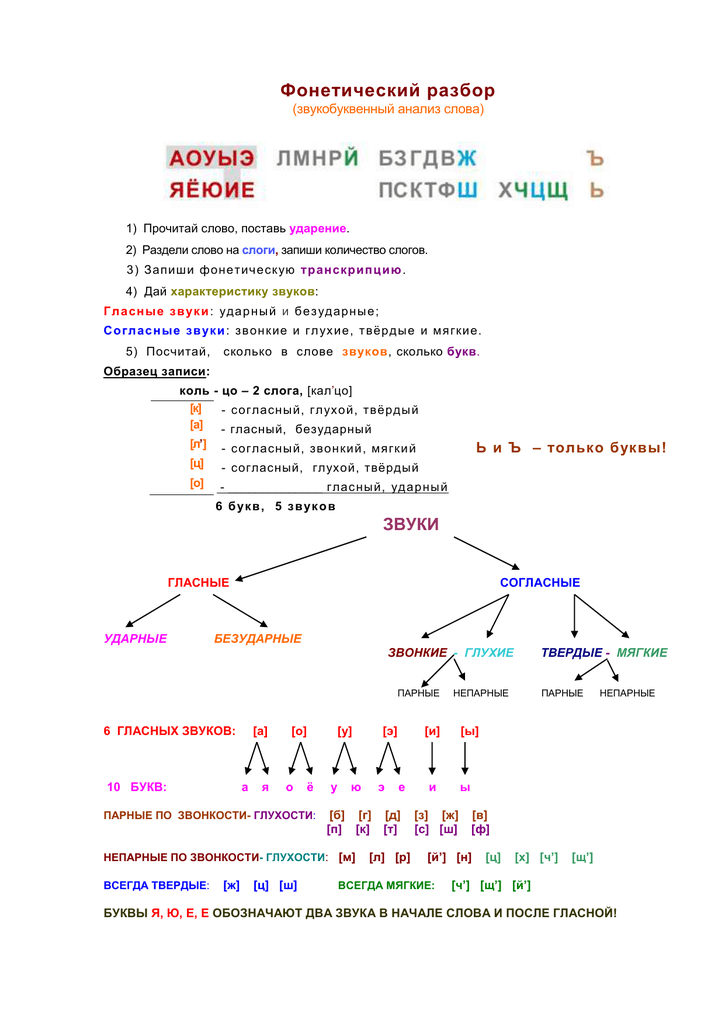
Узнаем как делать звуко-буквенный анализ слова?
Что такое звуко-буквенный анализ слова? Как правильно его делать? На уроках русского языка в начальных классах часто дают подобное задание, однако не все ученики успевают понять во время занятия, как правильно осуществлять разбор. Давайте внимательно изучим этот вопрос.
Для чего это нужно
В отличии от многих европейских языков, где «как слышится, так и пишется», в русском правила написания могут быть достаточно сложными. Почему, например, мы говорим «карова», а пишем «корова»? Вспомним о всеми любимом новогоднем дереве: почему «ёлка», а не «йолка»?
Казалось бы, сочетание букв даст такой же результат. А значит, ученик, не знающий правил написания слов и не понимающий смысла транскрипции, которую мы пишем при звуко-буквенном анализе, будет многие понятия записывать неверно.
Более того, умение писать и читать транскрипции очень пригодится при изучении иностранного языка, в частности — английского. Правила написания слов там весьма сложны — даже запутаннее, чем в нашем родном — а значит, не научившись разбирать содержимое квадратных скобок, вы не сможете и свободно разговаривать!
Первым делом
Первое, что требуется от школьника – написать транскрипцию. Она оформляется в квадратных скобках. Чем ещё она отличается от обычной записи слова? Во-первых, в ней отсутствует мягкий знак. Вместо привычного «ь» мягкость обозначается запятой справа сверху от согласной. Вы же помните, что гласные не обладают таким параметром?
Она оформляется в квадратных скобках. Чем ещё она отличается от обычной записи слова? Во-первых, в ней отсутствует мягкий знак. Вместо привычного «ь» мягкость обозначается запятой справа сверху от согласной. Вы же помните, что гласные не обладают таким параметром?
Некоторые буквы совсем не встречаются в транскрипции: это «я», «ю», «е» и «ё». Вместо них будут использоваться либо обозначения из двух фонем: «й» + гласный, либо только их «парный» гласный. Вы замечали, что эти буквы легко заменить? «Е» — то же, что и «йэ», а «ю» можно представить как «йу». Именно это и требуется в транскрипции.
Пример
Давайте посмотрим на звуко-буквенный анализ слова «моряк». Здесь мы видим сразу несколько характерных деталей. Во-первых, это наличие безударной гласной «о», которая превратится в «а». Что ещё вы замечаете? Правильно, согласный «р» является мягким. Обозначим это запятой над буквой в соответствующем месте. Наконец, сама «я» превратится в «а» — вы же не слышите звука «й», когда произносите это слово?
Итак, напишем «моряк». Звуко-буквенный анализ представим в квадратных скобках справа: [мар’ак]. Вот и всё, первую часть задания мы выполнили!
Звуко-буквенный анализ представим в квадратных скобках справа: [мар’ак]. Вот и всё, первую часть задания мы выполнили!
Забегая вперед, укажем на ещё одну деталь: количество букв и звуков в слове может различаться. Например, в слове «сталь» будет 5 букв, но всего 4 звука. А вот «ящик» покажет с точностью противоположные результаты – четыре против пяти.
Характеристики фонем
Каждый из звуков, представленных в транскрипции, является фонемой. Все они обладают параметрами, которые вы должны научиться выделять.
Согласные могут быть твёрдыми и мягкими, в зависимости от положения в слове. Например, в разобранном нами «моряке» «р’» является мягкой. А вот в слове «ров» та же буква будет представлена в качестве твердого «р».
Ещё одним показателем будет пара «звонкий-глухой». Помните, что такое парные согласные? «Б-п», «в-ф», «г-к» и так далее. Одна из них является звонкой, а вторая – глухой. Некоторые фонемы могут быть только звонкими: это «р», «н», «м», «л». Такие звуки называются сонорными – в их образовании участвует носовая полость.
Обратите внимание, что при проведении звуко-буквенного анализа знаки, обозначающие звонкие фонемы, подвергаются оглушению в конце слова. Например, «гриб» предстанет в виде транскрипции как [гр’ип]. Узнаете омоним – аналогично звучащее слово? Сезонная болезнь – грипп – произносится точно так же.
Оформление
Чтобы преподаватель не придрался к оформлению задания, давайте посмотрим, как это делать в соответствии с правилами.
Запишите слово, которое требуется разобрать, с большой буквы. Теперь поставьте тире, а справа от него – открытую квадратную скобку. Когда вы составите транскрипцию, вы её сюда впишете. Не забудьте закрыть её симметричной квадратной скобкой.
Ниже, под исходным словом нужно вертикально написать все его фонемы – это те знаки, которые составляют транскрипцию. Обратите внимание, что при звуко-буквенном анализе согласная вместе с показателем мягкости составляет единую сущность! Например, в слове «река» — [р’эка] – первой фонемой будет не «р», а «р’». Обязательно запомните это.
Обязательно запомните это.
Напротив каждой полученной фонемы — там, где мы написали их «в столбик» — укажите все их возможные параметры. Сюда относятся и мягкость-твердость, и противопоставление «звонкий-глухой». Напротив каждого знака напишите, соответственно, гласный он или согласный.
Слово «класс»
Давайте разберем ещё один пример. Выберем для проведения звуко-буквенного анализа слово «класс». Наша задача совсем проста. В транскрипции отличаться от оригинальной записи будет только концовка… Но мы ведь и не знаем, как представлять сдвоенные согласные! Ответ прост – вместо двух букв мы напишем одну.
Итак, «класс» предстанет перед нами как [клас]. Здесь «К» — твёрдый глухой согласный, «Л» — твёрдый и звонкий. Вслед за гласной «А» укажем «С» — твёрдый и глухой.
Не забудьте указать количество букв и количество звуков. Например, в последнем разобранном нами слове имеется 5 букв, но всего 4 звука. В целом, это всё, что нужно преподавателю в этом задании! Теперь выберите любой другой пример и сделайте звуко-буквенный анализ слова самостоятельно.
Усложнения
Когда вы подрастете, вы узнаете, что все гласные каждого существующего на планете языка, как и все согласные, сводятся к одной единственной табличке. Они обладают двумя параметрами: подъемом и рядом. Например, гласные «и», «ы» и «у» относятся к одному подъему и различаются рядом – соответственно, передним, средним и задним. И наоборот: «ы» и «а» — гласные одного ряда – среднего, а вот подъемом различаются. В первом случае он верхний, а во втором – нижний.
Если вы хотите связать свою жизнь с изучением языка – стать переводчиком, исследователем родной речи, преподавателем соответствующих предметов, то вам обязательно нужно будет выучить эти тонкости. Впрочем, это кажется сложным лишь на первый взгляд.
Заключение
Правильное выполнение данного задания поможет в дальнейшем разобраться и в иностранных языках. Во-первых, вы будете грамотнее писать. А помимо этого, вы сможете четче разграничивать звуки, что очень важно на первом этапе освоения нового для вас языка.
Выполняйте задания вовремя, и тогда учеба станет приносить больше удовольствия и отнимать меньше времени!
Дошкольник.ruПедагогамПраздникиРукоделиеДошкольник.руДошкольник.ру — сайт воспитателя, логопеда, дефектолога, музыкального руководителя, методиста, инструктора по физической культуре, родителя. Предлагаем педагогам помощь в аттестации. СервисыРазмещаем статьи
Фейсбук |
| Журнал«Дошкольник.РФ» | |||||||||||


 Схема дает возможность определить количество звуков в слове и проконтролировать правильность ее заполнения фишками.
Схема дает возможность определить количество звуков в слове и проконтролировать правильность ее заполнения фишками.
 Таким образом, первый этап работы со словом при звуковом анализе становится ещё и средством воспитания у учащихся культуры устной речи.
Таким образом, первый этап работы со словом при звуковом анализе становится ещё и средством воспитания у учащихся культуры устной речи. Это поможет лучше услышать звук. Вычленяя звук в полном слове, ребёнок контролирует, не искажается ли при этом слово, так как между лексическим значением и звучанием слова существует неразрывная связь. Искажение одного из элементов этой целостной связи разрушает её.
Это поможет лучше услышать звук. Вычленяя звук в полном слове, ребёнок контролирует, не искажается ли при этом слово, так как между лексическим значением и звучанием слова существует неразрывная связь. Искажение одного из элементов этой целостной связи разрушает её. Раздаю карточки:
Раздаю карточки:

 : Мозаика – Синтез, 2005
: Мозаика – Синтез, 2005Выполнить звуко-буквенный (фонетический) разбор слова. Транскрипция
Фонетический разбор слова в русском языке
Текстовод. Фонетика производит фонетический разбор слова онлайн.
Добавьте слово в форму, и программа автоматически произведёт его разбор.
Такой разбор еще называют звуко-буквенный — т. к. в процессе анализа слова подсчитывается количество букв и звуков.
Также, при фонетическом разборе слово делится на слоги и ставится ударение.
Но основная цель — выполнить фонетическую транскрипцию и произвести характеристику всех звуков.
Порядок проведения фонетического разбора:
1. Постановка ударения.
2. Разбивка на слоги.
Здесь предоставляются 2 варианта: слоги для анализа и варианты для переноса слова.
3. Транскрипция слова [в квадратных скобках].
4. Характеристика слова.
5. Транскрипция каждого звука по порядку.
Звук помещается в квадратные скобки.
А) Если он согласный, то определяются следующие его характеристики:
- звонкий/глухой/сонорный, парный/непарный, твёрдый/мягкий.
Мягкость звука обозначается знаком апострофа [«].
Б) Если звук гласный, то устанавливается его ударность.
В) Если у буквы отсутствует звук (ь, ъ и др.), то ставится прочерк [-].
* Не бывает звуков [е], [ё], [ю], [я]. Буквы е, ё, ю, я имеют в разных словах различные звуки.
* Также, нет звука у непроизносимых согласных в корне слова.
Например, солнце — [сонц»э]
6. Подсчёт букв и звуков.
7. Составление цветовой схемы слова.
Наш сервис позволяет сделать звуко-буквенный разбор слова русского языка любой части речи.
В качестве бонуса программа определяет часть речи, число, падеж, категории одушевленности и переходности, род, лицо, время; вид, наклонение, степень и форму (глаголов) и др.
Помните, что е и ё — это две разные буквы, влияющие на результат разбора.
Примите, также, во внимание, что омографы (слова с одинаковым написанием, но разным произношением) будут иметь совершенно разный фонетический разбор.
На сайте textovod. com вы найдёте разбор всех возможных омографов.
Учтите, что последовательность нашего разбора может отличаться от порядка анализа вашей учебной программы.
Учтите, что последовательность нашего разбора может отличаться от порядка анализа вашей учебной программы.
Добавьте слово в форму, и программа автоматически произведёт его разбор.
Textovod. com
22.05.2017 1:25:24
2017-05-22 01:25:24
Источники:
Https://textovod. com/phonetic
Фонетический разбор слов онлайн — правила и примеры » /> » /> .keyword { color: red; }
Фонетический разбор слова в русском языке
Фонетикой называют раздел языкознания, который изучает звуковую систему языка и звуки речи в целом. Фонетика — это наука о сочетании звуков в речи.
Фонетический разбор, или звуко-буквенный, — это анализ строения слогов и звуковой системы слова. Такой анализ предлагается выполнять как упражнение в учебных целях.
Под анализом понимается:
- подсчитывание количества букв; определение числа звуков в слове; постановка ударения; распределение звуков на согласные и гласные; классификация каждого звука; составление транскрипции (графической формы слова).
При разборе важно различать понятия «буква» и «звук». Ведь первые соответствуют орфографическим правилам, а вторые — речевым (то есть звуки анализируются с точки зрения произношения).
Прежде чем приступить к звуко-буквенному разбору, следует запомнить
В русском языке десять гласных звуков:
| [А] | [О] | [У] | [Ы] | [Э] | [ЙА] Буква «Я» | [ЙО] Буква «Ё» | [ЙУ] Буква «Ю» | [И] | [ЙЭ] Буква «Е» |
Первые пять обозначают, что предшествующий согласный является твердым, а вторые — мягким.
И двадцать один согласный звук:
| Звонкие непарные звуки | [Й’] | [Л] | [М] | [Н] | [Р] | |
| Глухие непарные | [Х] | [Ц] | [Ч’] | [Щ’] | ||
| Звонкие парные | [Б] | [В] | [Г] | [Д] | [Ж] | [З] |
| Глухие парные | [П] | [Ф] | [К] | [Т] | [Ш] | [С] |
Звонкими называют согласные, которые образуются с участием звука, а глухие — с помощью шума. Парными называют те согласные, которые образуют пару глухой/звонкий. Например, [Б]/[П], [В]/[Ф], [Г]/[К]. Непарными — те, которые не образуют пары: [Л], [М], [Р].
Парными называют те согласные, которые образуют пару глухой/звонкий. Например, [Б]/[П], [В]/[Ф], [Г]/[К]. Непарными — те, которые не образуют пары: [Л], [М], [Р].
При фонетическом анализе слова стоит помнить, что согласные [Ч’], [Щ’], [Й’] — всегда мягкие, вне зависимости от того, какой гласный образует с ними слог. Согласные [Ж], [Ш] и [Ц] — всегда твердые.
[Й’], [Л], [Л’], [М], [М’], [Н], [Н’], [Р], [Р’] — сонорные звуки. А значит, при произношении этих согласных звук образуется преимущественно голосом, но не шумом. Все сонорные — звонкие звуки.
В русском алфавите есть также буквы Ь, Ъ. Они не образуют звука. Ь (мягкий знак) служит для того, чтобы смягчать согласные, после которых он ставится. Ъ (твердый знак) имеет разделительную функцию.
Правила разбора на звуки
Транскрипция записывается в квадратных скобках: [ ]. Мягкость звука обозначается символом «’». Перед глухими звонкие согласные оглушаются: ногти — [нокт’и]. Звуки [с], [з] в приставках слов смягчаются: разъединить — [раз’й’эд’ин’ит’].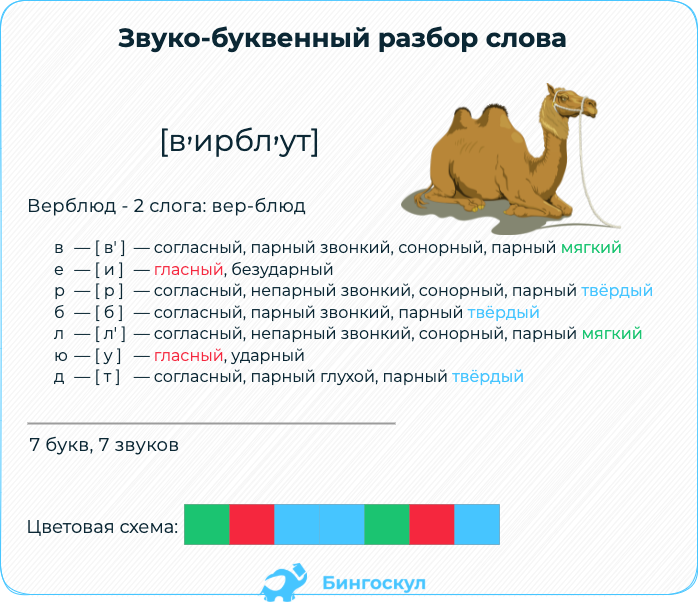 Некоторые согласные в словах не читаются: костный — [косный’]. Сочетание букв «сч», «зч» читаются как «щ»: счастье — [щ’аст’й’э]. Удвоенный согласный обозначается «:»: постепенный — [паст’ип’эн:ый’].
Некоторые согласные в словах не читаются: костный — [косный’]. Сочетание букв «сч», «зч» читаются как «щ»: счастье — [щ’аст’й’э]. Удвоенный согласный обозначается «:»: постепенный — [паст’ип’эн:ый’].
Образец звуко-буквенного разбора слова
Записать слово по правилам орфографии. Разделить слово по слогам. Обозначить ударный слог. Произнести слово вслух и на основании этого выполнить транскрипцию. Описать гласные звуки по порядку, обозначить, какие из них являются ударными, а какие — безударными. Описать согласные. Охарактеризовать их: парные/непарные, звонкие/глухие, твердые/мягкие. Подсчитать количество звуков и букв в слове.
Примеры фонетического разбора
Для примера ниже подобраны слова с наиболее интересными вариантами фонетического разбора: шестнадцатью, яростного, съестного, шестнадцатого, ерошиться, ёжиться, ёжится, ёршится, разъезжаться, съезжаться, для выполнения фонетического разбора других слов воспользуйтесь формой поиска:
Правила разбора на звуки
Транскрипция записывается в квадратных скобках: [ ]. Мягкость звука обозначается символом «’». Перед глухими звонкие согласные оглушаются: ногти — [нокт’и]. Звуки [с], [з] в приставках слов смягчаются: разъединить — [раз’й’эд’ин’ит’]. Некоторые согласные в словах не читаются: костный — [косный’]. Сочетание букв «сч», «зч» читаются как «щ»: счастье — [щ’аст’й’э]. Удвоенный согласный обозначается «:»: постепенный — [паст’ип’эн:ый’]. Записать слово по правилам орфографии. Разделить слово по слогам. Обозначить ударный слог. Произнести слово вслух и на основании этого выполнить транскрипцию. Описать гласные звуки по порядку, обозначить, какие из них являются ударными, а какие — безударными. Описать согласные. Охарактеризовать их: парные/непарные, звонкие/глухие, твердые/мягкие. Подсчитать количество звуков и букв в слове.
Мягкость звука обозначается символом «’». Перед глухими звонкие согласные оглушаются: ногти — [нокт’и]. Звуки [с], [з] в приставках слов смягчаются: разъединить — [раз’й’эд’ин’ит’]. Некоторые согласные в словах не читаются: костный — [косный’]. Сочетание букв «сч», «зч» читаются как «щ»: счастье — [щ’аст’й’э]. Удвоенный согласный обозначается «:»: постепенный — [паст’ип’эн:ый’]. Записать слово по правилам орфографии. Разделить слово по слогам. Обозначить ударный слог. Произнести слово вслух и на основании этого выполнить транскрипцию. Описать гласные звуки по порядку, обозначить, какие из них являются ударными, а какие — безударными. Описать согласные. Охарактеризовать их: парные/непарные, звонкие/глухие, твердые/мягкие. Подсчитать количество звуков и букв в слове.
При фонетическом анализе слова стоит помнить, что согласные Ч, Щ, Й всегда мягкие, вне зависимости от того, какой гласный образует с ними слог.
Wikislovo. ru
06.07.2017 13:48:21
2017-07-06 13:48:21
Источники:
Https://wikislovo. ru/phonetic
ru/phonetic
Фонетический разбор слова. Что это такое? Как его делать? Примеры » /> » /> .keyword { color: red; }
Фонетический разбор слова в русском языке
Если произнести вслух слова «въехать» и «прекрасный», можно заметить, что «е» в них звучит по-разному, хотя это одна и та же буква. И таких примеров в русском языке великое множество. Чтобы разобраться, почему так происходит, придумали фонетический разбор слов. Сейчас расскажем, что это такое, и покажем на примерах, как принято разбирать слова на слоги, звуки и буквы.
О чем эта статья:
Что такое фонетический разбор
Фонетический, или Звуко-буквенный, разбор слова — это анализ звуков и букв, из которых это слово состоит.
В русском языке 33 буквы, из которых мы составляем слова и записываем их на бумаге. Когда мы произносим слово, то слышим звуки — это то, как звучат буквы в его составе. В некоторых словах одна и та же буква может обозначать два звука одновременно либо не звучать вообще. Здесь и пригодится звуко-буквенный разбор: он нужен затем, чтобы мы могли анализировать звуки и буквы, грамотно писать, а также произносить слова.
Здесь и пригодится звуко-буквенный разбор: он нужен затем, чтобы мы могли анализировать звуки и буквы, грамотно писать, а также произносить слова.
Как делается фонетический разбор слова
Звуко-буквенный разбор принято делать по такому алгоритму:
Количество слогов, ударение.
Полная транскрипция слова.
Гласные звуки: ударный или безударный, какой буквой обозначен.
Согласные звуки: звонкий, сонорный или глухой, парный или непарный; твердый или мягкий, парный или непарный; какой буквой обозначен.
Общее количество букв и звуков.
Разбирать слова по звукам и буквам можно устно или письменно. Эти способы немного отличаются друг от друга, поэтому рассмотрим каждый отдельно
Образец письменного фонетического разбора
На письме звуко-буквенный разбор слова делают так:
Транскрипция слова. Записываем слово и все звуки, которые в него входят.
Слоги и ударение. Считаем и записываем количество слогов в слове, обозначаем тот, на который падает ударение.
Звуки. Со следующей строки в столбик переписываем все буквы в том порядке, в котором они стоят в слове. Напротив каждой из них записываем звук и заключаем в квадратные скобки.
Гласные звуки. Рядом с каждым гласным звуком пишем, ударный он или безударный. А после указываем, какой буквой он обозначен.
Согласные звуки. Рядом с каждым согласным звуком указываем, звонкий он или глухой. Далее — парный или непарный по глухости-звонкости. После этого пишем, твердый звук или мягкий, а следом — парный или непарный по мягкости-твердости. В конце нужно указать, какой буквой обозначен звук.
Число букв, звуков. Считаем и записываем количество букв и звуков в слове.
Теперь используем этот алгоритм на примерах.
Пример № 1. Письменный фонетический разбор глагола обыскивать
Обыскивать [абыск’иват’] — 4 слога, 2-й ударный.
О — [а] — гл., безударн.
Б — [б] — согл., зв. парн., тв. парн.
парн., тв. парн.
С — [с] — согл., глух. парн., тв. парн.
К — [к’] — согл., глух. парн., мягк. парн.
И — [и] — гл., безударн.
В — [в] — согл., зв. парн., тв. парн.
А — [а] — гл., безударн.
Т — [т’] — согл., глух. парн., мягк. парн.
Пример № 2. Письменный фонетический разбор прилагательного весенний
Весенний [в’ис’эн’:ий’] — 3 слога, 2-й ударный.
В — [в’] — согл., зв. парн., мягк. парн.
Е — [и] — гл., безударн.
С — [с’] — согл., глух. парн., мягк. парн.
Н — [н’:] — согл., сонорн. непарн., мягк. парн.
И — [и] — гл., безударн.
Й — [й’] — согл., сонорн. непарн., мягк. непарн.
Пример № 3. Письменный фонетический разбор существительного профессор
Профессор [праф’эс:ар] — 3 слога, 2-й ударный.
П — [п] — согл., глух. парн., тв. парн.
Р — [р] — согл., сонорн. непарн., тв. парн.
О — [а] — гл., безударн.
Ф — [ф’] — согл., глух. парн., мягк. парн.
С — [с:] — согл., глух. парн., тв. парн.
О — [а] — гл., безударн.
Р — [р] — согл., сонорн. непарн., тв. парн.
Образец устного фонетического разбора
Если нужно сделать звуко-буквенный разбор устно, придерживайтесь такого алгоритма:
Слоги и ударение. Посчитайте и назовите количество слогов в слове, обозначьте тот, на который падает ударение.
Гласные звуки. Назовите гласные звуки в том порядке, в котором они звучат в слове. Для каждого из них определите, является он ударным или безударным. После уточните буквы, которыми они обозначены.
Согласные звуки. Для каждого из согласных звуков определите, звонкий он или глухой, а затем — парный или непарный по глухости-звонкости. После этого установите, твердый это звук или мягкий, а также парный или непарный по мягкости-твердости. В конце разбора каждого из согласных звуков уточните, какой буквой он обозначен в слове.
Число букв, звуков. Посчитайте и назовите количество букв и звуков в слове.
Посчитайте и назовите количество букв и звуков в слове.
Потренируемся в устном фонетическом разборе на примере тех же слов, что мы разобрали выше.
Пример № 1. Устный фонетический разбор глагола обыскивать
1. В слове обыскивать 4 слога, ударение падает на второй: о-бы-ски-вать.
2. Гласные звуки:
Первый — безударный [а], обозначен буквой о;
Второй — ударный [ы], обозначен буквой ы;
Третий — безударный [и], обозначен буквой и;
Четвертый — безударный [а], обозначен буквой а.
3. Согласные звуки:
[б] — звонкий парный, твердый парный, обозначен буквой б;
[с] — глухой парный, твердый парный, обозначен буквой с;
[к’] — глухой парный, мягкий парный, обозначен буквой к;
[в] — звонкий парный, твердый парный, обозначен буквой в;
[т’] — глухой парный, мягкий парный, обозначен буквой т;
Буква ь не обозначает звука.
4. В слове обыскивать 10 букв и 9 звуков.
Пример № 2. Устный фонетический разбор прилагательного весенний
Устный фонетический разбор прилагательного весенний
1. В слове весенний 3 слога, ударение падает на второй: ве-сен-ний.
2. Гласные звуки:
Первый — безударный [и], обозначен буквой е;
Второй — ударный [э], обозначен буквой е;
Третий — безударный [и], обозначен буквой и.
3. Согласные звуки:
[в’] — звонкий парный, мягкий парный, обозначен буквой в;
[с’] — глухой парный, мягкий парный, обозначен буквой с;
[н’] — звонкий непарный (сонорный), мягкий парный, обозначен буквой н. Вторая н в слове не образует звука;
[й’] — звонкий непарный (сонорный), твердый непарный, обозначен буквой й.
4. В слове весенний 8 букв и 7 звуков.
Пример № 3. Устный фонетический разбор существительного профессор
1. В слове профессор 3 слога, ударение падает на второй: про-фе-ссор.
2. Гласные звуки:
Первый — безударный [а], обозначен буквой о;
Второй — ударный [э], обозначен буквой е;
Третий — безударный [а], обозначен буквой о.
3. Согласные звуки:
[п] — глухой парный, твердый парный, обозначен буквой п;
[р] — звонкий непарный (сонорный), твердый парный, обозначен буквой р;
[ф’] — глухой парный, мягкий парный, обозначен буквой ф;
[с] — глухой парный, твердый парный, обозначен буквой с. Вторая с в слове не образует звука;
[р] — звонкий непарный (сонорный), твердый парный, обозначен буквой р.
4. В слове профессор 9 букв и 8 звуков.
Проверьте себя
Давайте узнаем, насколько хорошо вы поняли, что такое фонетический разбор. Ниже вы найдете три задания, с помощью которых можно потренировать этот навык.
Задание 1
Разберите по звуковому составу следующие слова: занятой, постоялец, вакансия, произносить, говорящий.
Задание 2
Выполните устный фонетический разбор слов: коробочный, больница, идти, союз, морская.
Задание 3
Прочтите короткий текст ниже и выполните письменный фонетический разбор всех существительных в нем.
Мы бродили весной в лесу и наблюдали жизнь дупляных птиц: дятлов, сов. Вдруг в той стороне, где у нас раньше было намечено интересное дерево, мы услышали звук пилы. То была, как нам говорили, заготовка дров из сухостойного леса для стеклянного завода.
Вдруг в той стороне, где у нас раньше было намечено интересное дерево, мы услышали звук пилы. То была, как нам говорили, заготовка дров из сухостойного леса для стеклянного завода.
Впервые делать фонетической разбор слов ученики начинают в 3-м классе начальной школы. Со временем задания на уроках усложняются, поэтому важно вовремя понять тему. Если после прочтения этой статьи у вас еще остались вопросы — приглашаем за знаниями в онлайн-школу русского языка Skysmart. На занятиях преподаватель расскажет, что такое фонетический (звуко-буквенный) разбор слова и как его правильно делать, чтобы повысить оценку в школе.
Считаем и записываем количество слогов в слове, обозначаем тот, на который падает ударение.
Skysmart. ru
09.12.2017 6:45:41
2017-12-09 06:45:41
Источники:
Https://skysmart. ru/articles/russian/foneticheskij-razbor
привет. будет соответствовать всем символам, начинающимся с текста «привет», а затем одному символу. В этой серии мы рассмотрим, как создавать такие регулярные выражения.
Что такое стандарт POSIX?
POSIX , аббревиатура от Portable Operating System Interface , представляет собой набор стандартов, определенных IEEE Computer Society для обеспечения совместимости между операционными системами. Стандарт был реализован для того, чтобы сделать программное обеспечение переносимым между вариантами Unix и другими операционными системами.
Как POSIX повлиял на регулярные выражения Unix?
Регулярные выражения зависят от языков, в которых они реализованы, а также от используемых инструментов. В командной строке раньше было три разных команды для регулярных выражений. grep включал все основные регулярные выражения (BRE), в то время как расширенный grep egrep включал больше обозначений, которые считали его более мощным за счет эффективности. Набор функций, которые он включает, называется расширенными регулярными выражениями (ERE). Кроме того, было fast grep fgrep , что позволяет выполнять несколько фиксированных сопоставлений строк. Эти варианты были объединены в
Эти варианты были объединены в grep POSIX в 1992 году.
Теперь это объединение базовых регулярных выражений (BRE) и расширенных регулярных выражений (ERE) не означало, что их обозначения были объединены. При использовании grep по умолчанию используется нотация BRE, но вы можете легко переключиться на ERE с помощью параметра -E .
Я уже достаточно тебя запутал? Надеюсь, нет… Мы рассмотрим, какие нотации регулярных выражений нуждаются в -E вариант, так что не надо теряться!
Регулярные выражения с помощью grep
В командной строке используется команда grep , что означает печать глобальных регулярных выражений для использования регулярных выражений.
Зачем изучать регулярное выражение и grep?
Знание grep и способов построения регулярных выражений чрезвычайно полезно. Например, вы можете выполнять операции с текстом, такие как поиск и замена, в одной строке. Их можно включить в сценарии оболочки для автоматизации рабочего процесса для быстрой и простой обработки текста. Регулярные выражения также можно использовать в текстовых редакторах, таких как Vim и emacs, средствах просмотра файлов, таких как less и man, а также в таких языках программирования, как awk, python и perl.
Их можно включить в сценарии оболочки для автоматизации рабочего процесса для быстрой и простой обработки текста. Регулярные выражения также можно использовать в текстовых редакторах, таких как Vim и emacs, средствах просмотра файлов, таких как less и man, а также в таких языках программирования, как awk, python и perl.
Пример теста
Для начала попробуем простую команду grep . Мы не будем использовать никаких специальных символов, только буквальные значения.
$ ls /usr/bin | grep 'zip'
bunzip2 bzip2 bzip2recover фанзип ганзип gzip распаковать unzipsfx молния плащ-молния zipdetails zipдетали5.16 zipдетали5.18 zipgrep zipinfo zipnote zipsplit
Здесь мы видим все команды со словом zip в нашей папке /usr/bin . Помните 9В папке 0009 bin все наши команды хранятся в двоичном формате.
Избегайте синтаксического анализа ls
В этой статье объясняется, почему вам не следует анализировать результаты ls . В этом руководстве мы будем анализировать содержимое папки /usr/bin просто в качестве примера. Однако обязательно внимательно прочитайте эту статью и поймите, что синтаксический анализ результатов
В этом руководстве мы будем анализировать содержимое папки /usr/bin просто в качестве примера. Однако обязательно внимательно прочитайте эту статью и поймите, что синтаксический анализ результатов ls может дать неожиданные результаты.
Опции с grep
Вот список полезных опций, которые вы можете использовать с 9Команда 0023 grep .
- -c
- Вывести количество совпадений.
- -E
- Использовать расширенные регулярные выражения.
- -e
- Введите список шаблонов. Возвращает все совпадения из этого списка.
- -F
- Использование фиксированных строк (игнорировать специальные символы).
- -f
- Чтение шаблонов из файла, разделенного новой строкой.
- -h
- Подавить вывод имен файлов.
- -i
- Игнорировать регистр.
- -L
- Печатает имена несопоставленных файлов.
- -l
- Список имен файлов, соответствующих шаблону (вместо вывода совпавших строк).

- -n
- префикс каждой совпадающей строки w номер строки в файле
- -q
- Ничего не печатает, но спокойно завершает работу.
- -r
- Рекурсивный поиск в указанной папке.
- -s
- Подавляет сообщения об ошибках.
- -в
- Распечатайте строки, которые не соответствуют ни одному образцу.

Теперь, когда вы понимаете регулярные выражения, стандарты POSIX и grep, давайте узнаем о двух типах символов в регулярных выражениях.
Буквенные и специальные символы
Существует два типа символов, на которые следует обращать внимание при чтении регулярного выражения: буквальные и специальные символы.
Буквенные символы
Буквенные символы — это именно то, что они звучат так, как они означают — они содержат буквальные значения текста. К ним относятся буквы алфавита; например, если я набрал регулярное выражение проверяет , тогда он будет соответствовать всем вхождениям последовательности t , e , s , t , i , n , g 9009 в нашем запросе.
Использование только буквенных символов имеет ограничения. Мы хотим, чтобы наши поисковые запросы были динамичными и обширными, чтобы мы могли найти больше, чем просто буквальное слово. Например, как мы можем найти все группы символов, содержащие формат ГГГГ/ММ/ДД? Здесь в игру вступают специальные символы.
Специальные символы
Специальные символы , также известные как метасимволы , имеют особое значение и обычно обозначаются пунктуацией.
Следующий текст представляет собой список всех метасимволов, которые мы рассмотрим. Мы начнем с базовых регулярных выражений (BRE), а затем перейдем к расширенной группе (ERE). Просмотрите их, и мы подробно рассмотрим их в следующих уроках.
Основные регулярные выражения (BRE)
Основные регулярные выражения — это 9…]

Обратите внимание, что метасимволы в скобках и фигурных скобках нуждаются в символе обратной косой черты, чтобы экранировать его в BRE.
Расширенные регулярные выражения (ERE)
При использовании расширенных регулярных выражений необходимо ввести параметр -E . Эта группа добавляет в BRE больше метасимволов. Кроме того, им не нужна обратная косая черта перед скобками или круглыми скобками ( {n,m} ).
- {n,m}
- То же, что и BRE, но без \.
- (…)
- Группировки.
- +
- соответствуют одному или нескольким экземплярам предыдущего символа или группы.
- ?
- Совпадение с нулем или более экземпляров предшествующего символа или группы.
- |
- ИЛИ. Сопоставьте любые экземпляры, которые идут до или после канала.

Просмотрел каждый метасимвол? Большой! Давайте перейдем к некоторым примерам и более подробно рассмотрим, как работает каждый специальный символ.
Сопоставление отдельных символов
Использование буквенных символов
Начнем с сопоставления одного символа. Наиболее очевидным способом было бы использование буквенного символа для букв алфавита. Если есть метасимвол, которому вы хотите сопоставить, вы можете экранировать его с помощью обратной косой черты ( \).
$ ls /usr/bin | grep 'c\.d'
creatbyproc.d filebyproc.d newproc.d pidpersec.d runocc.d syscallbyproc.d syscallbysysc.d
Вот простой пример регулярного выражения. Мы ищем шаблоны, которые имеют c , за которыми следует точка (. ), затем d .
Из этого мы можем заметить две вещи:
- Нам нужно использовать обратную косую черту, чтобы экранировать метасимволы (точку).
- Порядок имеет значение.
- Это не «нечеткий поиск», где cat может соответствовать чему-то вроде c omb at .

Использование метасимвола точки
Метасимвола точки ( . ) соответствует любому одиночному символу.
$ ls /usr/bin/ | grep 'ct'
bzcat codesign_allocate colcrt резать генератор gzcat найти инструмент политики tccutil xmlкаталог ypcat zcat
Обратите внимание, что символ должен присутствовать в пределах между с и т . Метасимвол точки не позволяет использовать символ NUL .
В следующем разделе мы узнаем, как использовать раскрытие скобок, что даст вам еще больше возможностей при выборе отдельных символов.
Выражения со скобками
Скобки позволяют указать один символ из группы. Например, если вам нужна одна гласная, вы можете использовать [aeiou] .
$ ls /usr/bin | grep 'b[aeiou]t'
пакет размер укуса.
rwbytype.d
 d
смбутил 9aeiou]t'
d
смбутил 9aeiou]t' Это указывает на некоторый текстовый шаблон, который имеет единственный символ, отличный от [aeiou] между b и t .
Упрощение с диапазоном
Мы можем указать диапазон, если нам нужен диапазон символов или чисел.
$ ls /usr/bin | grep '[a-d][e-g][h-l]' афхаш афида афинфо отменить git-получить-пакет ldapdelete mdfind snmpdelta
С помощью этой команды мы выбрали слова, содержащие первую букву из A , B , C , или D , вторая буква от E , F , или G и третья буква от H , I , J , к или л . Обратите внимание, как эта последовательность из трех букв может появляться в любом месте слова.
Переносимость конфликтует с диапазоном
Серьезным недостатком использования метасимвола - для диапазона является то, что он не переносим из-за другого порядка сопоставления символов. Чтобы объяснить это, нам нужно немного изучить историю.
Чтобы объяснить это, нам нужно немного изучить историю.
Сначала Unix была разработана только с символами ASCII. Это были канонические английские символы, которые имели порядок от 0 до 127, включая такие символы, как управляющие коды, печатные символы и прописные/строчные буквы с цифрами и знаками препинания. Для букв у нас был следующий порядок символов:
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
Когда другие страны начали внедрять Unix, им пришлось освободить место для большего количества символов. Они должны были включать специальные символы, такие как e с акцентом над ним или c с волнистой линией внизу. Таким образом, некоторые сопоставления возникли с таким порядком:
aAbBcCdDeEfFgGhHiIjJkKlLmMnNoOpPqQrRsStTuUvVwWxXyYzZ
Вы, вероятно, уже могли себе представить проблему. Такое выражение, как A-Z , в первом примере захватит все буквы верхнего регистра, а во втором — все буквы, кроме и .
Таким образом, старайтесь не использовать символ диапазона слишком часто. Вместо этого вы можете полагаться на классы символов (ниже), которые являются стандартом POSIX.
Проверка вашей локали
Чтобы проверить вашу текущую локаль, напечатайте переменную $LANG .
$ эхо $ЯЗЫК en_US.UTF-8
Классы символов
Из-за расхождений в порядке сортировки Unix предоставляет несколько классов символов, чтобы сделать сценарии оболочки более переносимыми. Вот список классов символов:
- [:alnum:]
- Буквенно-цифровой
- [:alpha:]
- Алфавитный
- [:blank:]
- Space and Tab
- [:cntrl:]
- Control
- [:digit:]
- Numeric
- [:graph:]
- Non-space
- [:lower:]
- Lowercase
- [ : print:]
- Печата
- [: acpunct:]
- пунктуация
- [: Пространство:]
- пробелы
- [:]
- [: xdigit:]
- [: xdigit:]
- [: xdigit:]
- [: xdigit:]
- .
При использовании классов персонажей вы должен помещать их в скобки.
$ ls /usr/bin/ | grep '[[:цифра:]][[:альфа:]][[:цифра:]]' а2р5.16 а2р5.18 s2p5.16 s2p5.18
Это соответствовало всем файлам, которые имели последовательность, содержащую цифру, символ алфавита, за которым следовала другая цифра.
Использование метасимволов в квадратных скобках
Когда метасимволы помещаются в скобки, они теряют свое особое значение.
Следующий код будет соответствовать любому списку со знаком минус ( - ), точка ( . ) или буква х .
$ ls /usr/bin/ | grep '[-.x]'
... веблатентность.d желание8.4 желание8.5 хар xargs xattr xattr-2.6 xattr-2.7 xcode-выбрать ...Если вы хотите указать скобку ( ] ) или знак минус ( - ), поместите их первыми в списке.
Non-English Environment
В некоторых языках две последовательные буквы могут идентифицировать себя как одну единицу.
Например, если бы мы рассматривали символы 'ts' как единое целое, мы могли бы сделать это, поместив их в скобки и точки [.ц.] .
Кроме того, мы можем указать символы, которые имеют некоторые варианты, такие как знак ударения или тильда. Имея выражение [=a=] , мы можем указать все варианты буквы a . Сюда входят и , и , и и и .
Сопоставление нескольких символов
Со звездочкой
Звездочка ( * ) позволяет сопоставить ноль или кратное число предшествующего символа.
$ ls /usr/bin | grep 'bc*t'
btmmdiagnose ibtool libtool pfbtopsВ этом примере мы сопоставляем команды в нашей папке bin , которые имеют b , любое количество c (включая ни одного), затем t .
Несмотря на удобство, звездочка может оказаться слишком мощной для ваших целей.
Чтобы лучше контролировать количество повторяющихся элементов, мы можем использовать фигурные скобки.Использование фигурных скобок для уточнения
С фигурными скобками ( {...} ) мы можем лучше контролировать, сколько раз встречается элемент. Помните, что в BRE мы должны экранировать символы скобок с помощью обратной косой черты.
- \{n\}
- Соответствует ровно n вхождений предыдущего регулярного выражения.
- \{n,\}
- Соответствует как минимум из вхождений предыдущего регулярного выражения.
- \{n,m\}
- Совпадение между n и m вхождений предыдущего регулярного выражения.
- В ERE нет обратных ссылок, хотя скобки имеют особое значение.
- То же обозначение для сопоставления отдельных символов
- Нет необходимости в управляющих клавишах при использовании фигурных скобок ( {n, m} или круглых скобок. позволяет указывать группы текста в виде регулярных выражений, что полезно для метасимволов для ссылки на группу предыдущих регулярных выражений.0011
Например, (игрушка)* выберет буквы toy ноль или много раз.
Расширенные функции
ERE предлагает три расширенных метасимвола.
Вопросительный знак (?)
? соответствует нулю или одному из предыдущих регулярных выражений.
Знак плюс (+)
Символ плюс ( + ) используется для соответствия одному или нескольким предыдущим регулярным выражениям. Он очень похож на звездочку ( * ), но не допускает значений NUL.
$ ls /usr/bin | grep -E '[[:alpha:]][[:digit:]]+[[:alpha:]]' enc2xs5.16 enc2xs5.18 eqn2graph найти2perl найти2perl5.16 найти2perl5.18 граф2граф h3ph h3ph5.16 h3ph5.18 h3xs h3xs5.16 h3xs5.18 hdxml2manxml заголовокdoc2html ip2cc
Это выделит весь текст с буквой, за которой следует одна или несколько цифр, а затем еще одна буква.
Мы могли бы получить тот же результат с [[:alpha:]][[:digit:]][[:digit:]]*[[:alpha:]] , но предыдущий пример выглядит чище.Чередование (|)
Чередование дает вам гибкость выбора между двумя или более выражениями регулярных выражений.
$ ls /usr/bin/ | grep -E 'zip|pod|enc'
bunzip2 bzip2 bzip2recover enc2xs enc2xs5.16 enc2xs5.18 encode_keychange фанзип генератор ганзип gzip задержка pod2html pod2html5.16 подчекер5.18 подселект подселект5.16 подселект5.18 распаковать unzipsfx uuencode веблатентность.d молния плащ-молния zipdetails zipдетали5.16 zipдетали5.18 zipgrep zipinfo zipnote зипсплитДокументация JDK 19 — Домашняя страница
- Домашняя страница
- Ява
- Java SE
- 19
Обзор
- Прочтите меня
- Примечания к выпуску
- Что нового
- Руководство по миграции
- Загрузить JDK
- Руководство по установке
- Формат строки версии
Инструменты
- Технические характеристики инструментов JDK
- Руководство пользователя JShell
- Руководство по JavaDoc
- Руководство пользователя средства упаковки
Язык и библиотеки
- Обновления языка
- Основные библиотеки
- HTTP-клиент JDK
- Учебники по Java
- Модульный JDK Руководство программиста API бортового регистратора
- Руководство по интернационализации
Технические характеристики
- Документация API
- Язык и ВМ
- Имена стандартных алгоритмов безопасности Java
- банка
- Собственный интерфейс Java (JNI)
- Инструментальный интерфейс JVM (JVM TI)
- Сериализация
- Проводной протокол отладки Java (JDWP)
- Спецификация комментариев к документации для стандартного доклета
- Прочие характеристики
Безопасность
- Руководство по безопасному кодированию
- Руководство по безопасности
Виртуальная машина HotSpot
- Руководство по виртуальной машине Java
- Настройка сборки мусора
Управление и устранение неполадок
- Руководство по устранению неполадок
- Руководство по мониторингу и управлению
- Руководство по JMX
Client Technologies
- Руководство по специальным возможностям Java
Знакомство с ручным редактором регулярных выражений в инструменте синтаксического анализа IDR: Часть 1 idrs-parsing-tool-part-1/
Новичок в написании регулярных выражений? Без проблем.
В этой серии блогов, состоящей из двух частей, мы расскажем об основах регулярных выражений и о том, как писать операторы регулярных выражений (регулярные выражения) для извлечения полей из ваших журналов при использовании пользовательского инструмента синтаксического анализа. Как и в случае с изучением любого нового языка, начало работы может быть самой сложной частью, поэтому мы хотим сделать его максимально простым, чтобы вы могли быстро и беспрепятственно получить максимальную отдачу от этой новой возможности.Возможность анализировать и визуализировать данные журналов — независимо от того, критичны они для аналитики безопасности или нет — уже некоторое время доступна в InsightIDR . Если вы предпочитаете создавать настраиваемые поля из своих журналов нетехническим способом, вы можете просто перейти к пользовательскому инструменту синтаксического анализа , пройти через мастер инструмента синтаксического анализа, чтобы найти шаг «извлечь поля», и перетащить курсор на данные журнала, которые вы хотите извлечь, чтобы начать определение имен полей.
Тенденции
Доступны инстансы Amazon EC2 Trn1 для высокопроизводительного обучения модели
Следующее руководство даст вам базовые навыки и знания, необходимые для написания правил синтаксического анализа с использованием регулярных выражений.
Что такое регулярные выражения?
В технических приложениях вам иногда нужен способ поиска определенных шаблонов в текстовых строках. Например, предположим, что у вас есть следующие строки журнала, которые представляют собой текстовые строки:
10 мая 12:43:12 SECRETSERVERHOST CEF:0|Thycotic Software|Secret Server|10.9.000002|500|Системный журнал|7|msg=С сервером невозможно связаться. rt=10 мая 2021 12:43:12 10 мая 12:43:41 SECRETSERVERHOST CEF:0|Thycotic Software|Секретный сервер|10.9.000002|500|Системный журнал|7|msg=Сервер RPC недоступен. rt=10 мая 2021 12:43:41
Вам нужно найти часть сообщения в строках журнала, то есть все, что находится между «msg=» и «rt=».
С этими двумя строками журнала я мог бы нажать простую кнопку и просто скопировать текст вручную, но очевидно, что этот подход не будет работать, если у меня есть сотни или тысячи строк, из которых мне нужно вытащить поле.Здесь на помощь приходят регулярные выражения, часто сокращаемые до регулярных выражений. Регулярные выражения позволяют выполнять поиск по тексту в соответствии с шаблонами, такими как «msg=», поэтому вы можете легко извлечь нужный текст.
Как это работает?
У меня есть секрет, которым я хочу поделиться с вами о регулярных выражениях: на самом деле это не так уж сложно. Если вы хотите изучить его очень глубоко и понять каждую функцию, это история для другого дня. Однако, если вы хотите узнать достаточно, чтобы разобрать некоторые поля и продолжить свою жизнь, эти простые советы помогут вам сделать это.
Прежде чем мы начнем, вам нужно понять, что регулярное выражение имеет некоторые правила, которым необходимо следовать. Лучший образ мышления, чтобы освоить регулярное выражение, по крайней мере, на некоторое время, — это следовать правилам, не беспокоясь о том, почему.
Вот некоторые из основных правил регулярных выражений:
- Все регулярное выражение заключено в косую черту ("/").
- Совпадения с образцом начинаются с обратной косой черты ("\").
- С учетом регистра.
- Требуется найти соответствие каждому символу искомого текста.
- Требуется, чтобы вы выучили специальный язык для сопоставления символов.
Специальный язык регулярных выражений определяет соответствие искомого текста. Вам нужно начать сопоставление с образцом с обратной косой черты («\»). После этого вы должны использовать специальный символ для обозначения того, что вы хотите сопоставить. Например, буква или «словный символ» соответствует «\w», а число или «цифровой символ» соответствует «\d».
Если мы хотим сопоставить все символы в строке, например:
cat
Мы можем использовать «\w», так как «\w» соответствует любому «символу слова» или букве, поэтому:
\w\w\w
Это соответствует трем символам «c», «a ", и т".
Другими словами, первый «\w» соответствует символу «c»; «\w\w» соответствует «ca»; и «\w\w\w» соответствует «кошке».Как видите, «\w» соответствует любой отдельной букве от «a» до «z», а также соответствует буквам от «A» до «Z». Помните: регулярное выражение чувствительно к регистру.
«\w» также соответствует любому числу. Однако «\w» НЕ соответствует пробелам или другим специальным символам, таким как «-», «:» и т. д. Чтобы соответствовать другим символам, вам нужно использовать их специальные символы регулярных выражений или другие методы, которые мы рассмотрим здесь.
Начало работы с регулярными выражениями
Прежде чем мы продолжим, сейчас самое время потратить несколько минут, чтобы найти «шпаргалку» регулярных выражений, которая вам нравится.
У Rapid7 есть один, который вы можете использовать: https://docs.rapid7.com/insightops/regular-expression-search/, или вы можете использовать совершенно другой, который вы предпочитаете. Как бы то ни было, эти руководства помогут вам отслеживать все варианты соответствия.
Пока мы на этом, давайте также найдем инструмент для тестирования регулярных выражений, который мы можем использовать, чтобы попрактиковаться в нашем регулярном выражении. https://regex101.com/ очень популярен, так как это инструмент и шпаргалка в одном, хотя вы можете найти другой инструмент, который захотите использовать вместо него.
InsightIDR поддерживает версию регулярного выражения под названием RE2, поэтому, если ваш инструмент синтаксического анализа поддерживает вариант Golang/RE2, вы можете выбрать его, чтобы попрактиковаться в конкретном варианте, который использует InsightIDR.
Чтобы следовать за мной, откройте предпочитаемый инструмент для тестирования регулярных выражений. Введите какой-нибудь текст для соответствия и какое-нибудь регулярное выражение, и посмотрите, что произойдет!
Давайте посмотрим на другой способ сопоставления строки «кошка». Вы можете использовать литералы, что означает, что вы просто вводите символ, который хотите сопоставить:
Это означает, что вы буквально хотите сопоставить строку «кошка».
Он соответствует «кошке» и ничему другому.Давайте посмотрим на другой пример. Скажем, мне нужно сопоставить строку:
san-dc01
Как мы видели ранее, вы можете использовать «\w» для сопоставления символов слова. Чтобы сопоставить число, вы можете использовать «\w» или «\d». «\d» будет соответствовать любому числу или «цифре». Однако как вы можете сопоставить «-»?
Дефис («-») не является символом слова, поэтому «\w» ему не соответствует. В этом случае мы можем сказать регулярному выражению, что хотим сопоставить «-» буквально:
\w\w\w-\w\w\d\d
Есть и другие варианты. Символ точки или точки (".") в регулярном выражении означает соответствие любому отдельному символу. Это также работает для разбора строки «san-dc01»:
\w\w\w.\w\w\d\d
Хотя это работает, набирать все эти «\w» утомительно. . Здесь пригодятся подстановочные знаки, иногда называемые квантификаторами регулярных выражений.
Два наиболее распространенных:
* соответствует 0 или более символам
+ соответствует 1 или более символам
«\w*» означает «соответствует 0 или более символам слова», а «\w+» означает «соответствует 1 или более словесных символов».
Давайте воспользуемся этими новыми подстановочными знаками для сопоставления с некоторым текстом. Скажем, у нас есть эти две строки:
cat
san-dc01
Мне нужен один шаблон регулярного выражения, который будет соответствовать обеим строкам . Давайте сначала сопоставим «кот». Регулярное выражение, которое мы использовали ранее:
\w\w\w
соответствует строке, поэтому вы можете видеть, что использование этого подстановочного знака тоже будет работать:
\w+
Теперь давайте посмотрим на соответствие «san-dc01». Я могу использовать это:
\w+-\w+
Это означает «сопоставить столько символов слова, сколько есть, за которым следует тире, а затем столько символов слова, сколько есть». Однако, хотя это соответствует «san-dc01», оно не соответствует «cat». В строке «кошка» нет символов «-», за которыми следуют символы.
Добавленное нами регулярное выражение «-\w+» соответствует строке только в том случае, если символ «-» является частью строки.
Кроме того, «\w+» означает «соответствие одному или нескольким числам». Другими словами, «\w+» означает «сопоставить хотя бы один символ слова с любым их количеством». Таким образом, нам нужно использовать здесь «\w*», чтобы указать, что часть строки «dc01» может не всегда существовать. Нам также нужно использовать «-*», чтобы указать, что «-» может не всегда существовать в строке, которую нам нужно сопоставить.Таким образом, это должно работать для разбора обеих строк:
\w+-*\w*
К настоящему моменту вы, возможно, уже заметили кое-что еще важное о регулярном выражении: обычно существует множество различных шаблонов, которые будут соответствовать одному и тому же тексту.
Иногда я замечаю, что люди высокомерно относятся к своим регулярным выражениям, и эти люди могут насмехаться над вами, если они думают, что вы могли бы создать более короткий шаблон или более эффективный. Оспа в их доме! Не беспокойтесь об этом прямо сейчас. Гораздо важнее, чтобы ваш шаблон регулярного выражения работал, чем чтобы он был коротким или впечатляюще сложным.
Давайте посмотрим на другой способ сопоставления наших строк: вы можете использовать класс символов для сопоставления.
Класс символов определяется с помощью квадратных скобок «[» и «]». Это просто означает, что вы хотите, чтобы регулярное выражение соответствовало всему, что включено в ваш определенный класс.
Это проще, чем кажется! Поскольку наши строки «cat» и «san-dc01» содержат символы, которые соответствуют либо «\w», либо буквальному «-», наш класс символов — «[\w-]».
Теперь мы можем использовать «+», чтобы указать, что наша строка содержит один или несколько символов из класса символов:
[\w-]+
Дополнительные регулярные выражения для разбора журнала
Помимо «\w» и «\d», у меня есть еще несколько регулярных выражений, на которые я хочу обратить ваше внимание. Первый — «\s», так вы сопоставляете пробелы.
«\s» соответствует любому пробельному символу, а «\s+» соответствует одному или нескольким пробельным символам.
Далее, помните, что точка (".") соответствует любому символу. Точка становится особенно мощной, когда вы комбинируете ее со звездой («*»). Помните: звездочка означает совпадение 0 или более символов. Таким образом, «точка-звезда» («.*») будет соответствовать любым символам столько раз, сколько они встречаются, включая отсутствие совпадений. Другими словами, «.*» соответствует чему угодно. 9\d]+» означает сделать наоборот или сопоставить все , кроме для любого цифрового символа!
Примеры синтаксического анализа журнала
Вернемся к тому, с чего мы начали, пытаясь проанализировать поле msg из наших журналов:
10 мая 12:43:12 SECRETSERVERHOST CEF:0|Thycotic Software|Secret Server|10.9.000002| 500|Системный журнал|7|msg=С сервером невозможно связаться. rt=10 мая 2021 12:43:12 10 мая 12:43:41 SECRETSERVERHOST CEF:0|Thycotic Software|Секретный сервер|10.9.000002|500|Системный журнал|7|msg=Сервер RPC недоступен. rt=10 мая 2021 12:43:41
Вы скопировали и вставили эти строки журнала в тестер регулярных выражений? Если нет, то сделайте это сейчас.
Нам нужно разобрать литеральную строку «msg=». Эти литералы в строках журнала часто являются «ключевой» частью пары ключ-значение и иногда называются якорями вместо литералов, поскольку они одинаковы в каждой строке журнала. Чтобы проанализировать их, вы обычно указываете литеральную строку для сопоставления.
Далее нам нужно прочитать следующее значение. У вас есть несколько разных подходов, которые вы можете использовать здесь. Обычный способ анализа значения — прочитать все, что следует, до следующего литерала или привязки. Помните: есть много способов сделать это, но ваше регулярное выражение может выглядеть так:
msg=.*rt=
Кстати, если вы знакомы с регулярными выражениями, вы знаете, что жадная «*» создает неэффективные правила синтаксического анализа, но давайте не будем слишком беспокоиться об этом прямо сейчас. Однако тонкость этого заключается в том, что вы никогда не должны использовать точку («.*») для правил синтаксического анализа. Однако это полезно для поиска и попытки выяснить структуру журнала.
Другой способ прочитать значение — использовать класс символов:
msg=[\w\s\.]+rt=
Давайте разберем класс символов, чтобы точно определить, что указано. «\w» означает совпадение с любым символом слова. «\s» означает соответствие любому пробелу. Нам также нужно сопоставить литеральную точку, так как она появляется в значении msg, но точка или точка имеют особое значение в регулярном выражении. Когда символы имеют особое значение в регулярном выражении, например косая черта, квадратные скобки, точка и т. д., их необходимо «экранировать», что вы делаете, помещая перед ними обратную косую черту («\»). Поэтому, чтобы соответствовать периоду, нам нужно использовать «\». в классе персонажей.
Помните: определение класса символов означает, что вы хотите сопоставить любой символ, определенный в классе, а «+» в конце класса означает «соответствие одному или нескольким из этих символов». В этом случае «[\w\s\.]+» означает «соответствовать любому символу слова, любому пробелу или точке столько раз, сколько встречается».
Сопоставление остановится, когда следующий символ в последовательности не является символом слова, пробелом или точкой ИЛИ, когда будет найдена следующая часть регулярного выражения. Следующая часть регулярного выражения — буквальная строка « rt=" , поэтому регулярное выражение будет извлекать " [\w\s\.]+" символов, пока не дойдет до " rt=" .Наконец, есть еще один синтаксис регулярных выражений, который полезно понимать при использовании регулярных выражений с InsightIDR, — это использование групп захвата. Группа захвата — это то, как вы определяете имена ключей в регулярном выражении. Группы захвата на самом деле гораздо больше, но давайте сузим наше внимание до того, что нам нужно знать для их использования с InsightIDR. Чтобы указать именованную группу захвата для наших целей, используйте следующий синтаксис:
(?P
putyourregexhere) Регулярное выражение, которое вы помещаете в группу захвата, используется для чтения значения, которое будет соответствовать «keyname».
Давайте посмотрим, как это работает с нашими журналами.Допустим, у нас есть несколько журналов в формате пары ключ-значение (KVP), и мы хотим определить и проанализировать ключ «msg». Мы знаем, что это регулярное выражение соответствует нашим журналам: « msg=[\w\s\.]+rt= ». Теперь нам нужно сделать еще один шаг и определить ключ «msg» и его значения. Мы можем сделать это с помощью именованной группы захвата:
msg=(?P
[\w\s\.]+)rt Давайте разберем это. Мы хотим прочитать литеральную строку «msg=», а затем поместить все после нее в группу захвата, остановившись на буквальной строке «rt=». Группа захвата определяет ключ, который вы также можете представить как «имя поля», как «msg»: « (?P
» .Если бы мы хотели проанализировать имя поля как что-то еще, мы могли бы указать это между «<>» Например, если бы мы хотели, чтобы имя поля было «сообщение» вместо «msg», мы бы использовали: « (?P
Следующее регулярное выражение — это то, что мы хотим прочитать для части значения нашей пары ключ-значение.


 Чтобы лучше контролировать количество повторяющихся элементов, мы можем использовать фигурные скобки.
Чтобы лучше контролировать количество повторяющихся элементов, мы можем использовать фигурные скобки. $ ls /usr/bin | grep '[[:alpha:]]{2}'
perlспасибо5.16
perlспасибо5.18
пикв5.16
пикв5.18
14:00 5:16
14:00 5:18
pod2html5.16
pod2html5.18
pod2latex5.16
pod2latex5.18
pod2man5.16
pod2man5.18
pod2readme5.16
pod2readme5.18 Приведенный выше код будет искать строки текста, содержащие двузначное число.
RE_DUP_MAX
Обратите внимание, что значения для n и m должны быть между 0 и RE_DUP_MAX . Эта переменная означает максимальное количество повторений, разрешенных в регулярных выражениях.
Чтобы проверить настройку вашей системы для этого значения, используйте команду getconf .
$ getconf RE_DUP_MAX 255
Обратные ссылки и привязки
Обратные ссылки
При построении регулярного выражения может потребоваться ссылка на некоторый ранее совпавший термин регулярного выражения. Для этого мы можем использовать обратных ссылок .
Фразы, на которые вы хотите сослаться, должны быть заключены в круглые скобки ( \(...\) ). Чтобы сослаться на него, используйте \ цифра , где \1 представляет первую упоминаемую фразу, \2 , вторую и так далее.
Например, регулярное выражение \(foo\)ber\(buzz\)*\2\1 упрощается до (foo)ber(buzz)*buzzfoo . Поскольку звездочка может содержать ноль или много элементов предыдущего регулярного выражения, это будет соответствовать тексту, такому как fooberbuzzbuzzfoo , fooberbuzzbuzzbuzzfoo и так далее.
Поскольку звездочка может содержать ноль или много элементов предыдущего регулярного выражения, это будет соответствовать тексту, такому как fooberbuzzbuzzfoo , fooberbuzzbuzzbuzzfoo и так далее.
Начинается и заканчивается якорями 9[abcd]
. Первый соответствует любому символу, кроме a , b , c или d . Второй ищет текст, начинающийся с a , b , c или d .Расширенные регулярные выражения
До сих пор мы рассмотрели все символы, используемые в базовых регулярных выражениях (BRE). Здесь мы рассмотрим расширенные регулярные выражения (ERE), которые можно использовать с grep 's -E 9.вариант 0024.
Сходства и различия
Вот список сходств и различий между ERE и BRE:
 позволяет указывать группы текста в виде регулярных выражений, что полезно для метасимволов для ссылки на группу предыдущих регулярных выражений.0011
позволяет указывать группы текста в виде регулярных выражений, что полезно для метасимволов для ссылки на группу предыдущих регулярных выражений.0011 Мы могли бы получить тот же результат с [[:alpha:]][[:digit:]][[:digit:]]*[[:alpha:]] , но предыдущий пример выглядит чище.
Мы могли бы получить тот же результат с [[:alpha:]][[:digit:]][[:digit:]]*[[:alpha:]] , но предыдущий пример выглядит чище. В этой серии блогов, состоящей из двух частей, мы расскажем об основах регулярных выражений и о том, как писать операторы регулярных выражений (регулярные выражения) для извлечения полей из ваших журналов при использовании пользовательского инструмента синтаксического анализа. Как и в случае с изучением любого нового языка, начало работы может быть самой сложной частью, поэтому мы хотим сделать его максимально простым, чтобы вы могли быстро и беспрепятственно получить максимальную отдачу от этой новой возможности.
В этой серии блогов, состоящей из двух частей, мы расскажем об основах регулярных выражений и о том, как писать операторы регулярных выражений (регулярные выражения) для извлечения полей из ваших журналов при использовании пользовательского инструмента синтаксического анализа. Как и в случае с изучением любого нового языка, начало работы может быть самой сложной частью, поэтому мы хотим сделать его максимально простым, чтобы вы могли быстро и беспрепятственно получить максимальную отдачу от этой новой возможности.
 С этими двумя строками журнала я мог бы нажать простую кнопку и просто скопировать текст вручную, но очевидно, что этот подход не будет работать, если у меня есть сотни или тысячи строк, из которых мне нужно вытащить поле.
С этими двумя строками журнала я мог бы нажать простую кнопку и просто скопировать текст вручную, но очевидно, что этот подход не будет работать, если у меня есть сотни или тысячи строк, из которых мне нужно вытащить поле.
 Другими словами, первый «\w» соответствует символу «c»; «\w\w» соответствует «ca»; и «\w\w\w» соответствует «кошке».
Другими словами, первый «\w» соответствует символу «c»; «\w\w» соответствует «ca»; и «\w\w\w» соответствует «кошке».
 Он соответствует «кошке» и ничему другому.
Он соответствует «кошке» и ничему другому.
 Кроме того, «\w+» означает «соответствие одному или нескольким числам». Другими словами, «\w+» означает «сопоставить хотя бы один символ слова с любым их количеством». Таким образом, нам нужно использовать здесь «\w*», чтобы указать, что часть строки «dc01» может не всегда существовать. Нам также нужно использовать «-*», чтобы указать, что «-» может не всегда существовать в строке, которую нам нужно сопоставить.
Кроме того, «\w+» означает «соответствие одному или нескольким числам». Другими словами, «\w+» означает «сопоставить хотя бы один символ слова с любым их количеством». Таким образом, нам нужно использовать здесь «\w*», чтобы указать, что часть строки «dc01» может не всегда существовать. Нам также нужно использовать «-*», чтобы указать, что «-» может не всегда существовать в строке, которую нам нужно сопоставить.



 Сопоставление остановится, когда следующий символ в последовательности не является символом слова, пробелом или точкой ИЛИ, когда будет найдена следующая часть регулярного выражения. Следующая часть регулярного выражения — буквальная строка « rt=" , поэтому регулярное выражение будет извлекать " [\w\s\.]+" символов, пока не дойдет до " rt=" .
Сопоставление остановится, когда следующий символ в последовательности не является символом слова, пробелом или точкой ИЛИ, когда будет найдена следующая часть регулярного выражения. Следующая часть регулярного выражения — буквальная строка « rt=" , поэтому регулярное выражение будет извлекать " [\w\s\.]+" символов, пока не дойдет до " rt=" . Давайте посмотрим, как это работает с нашими журналами.
Давайте посмотрим, как это работает с нашими журналами.