ГДЗ по русскому языку 2 класс учебник Канакина, Горецкий 2 часть
- Тип: ГДЗ, Решебник.
- Автор: В. П. Канакина, В. Г. Горецкий.
- Год: 2021.
- Серия: Школа России.
- Издательство: Просвещение.
Подготовили готовое домашнее задание к упражнениям на 18 странице по предмету русский язык за 2 класс. Ответы на задания: 28, 29.
Учебник 2 часть — Страница 18.
Ответы 2021 года.
Номер 28.
Прочитайте. Спишите.
Нашу речку, словно в сказке,
За ночь вымостил мороз,
Обновил коньки, салазки,
Ёлку из лесу привёз.
С. Маршак
- Какие слова помогают нам представить мороз как живое существо?
Ответ:
Слова «вымостил», «обновил коньки, салазки», «ёлку привёз» помогают нам представить мороз как живое существо – приём олицетворения.
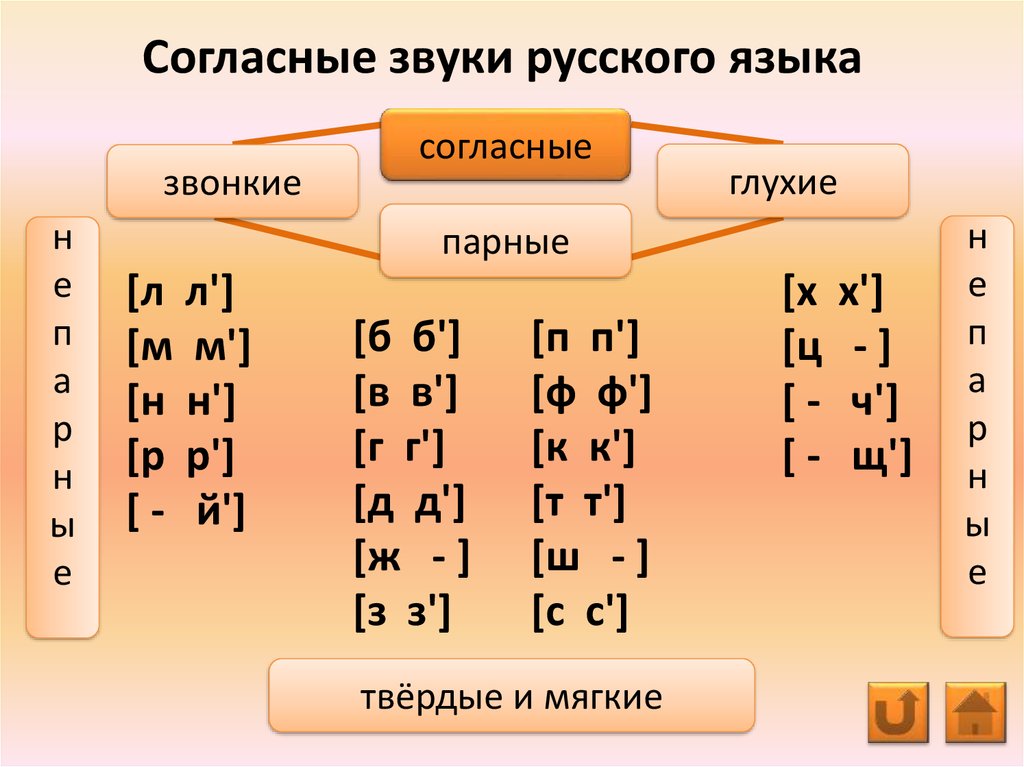
- Подчеркните в словах буквы, которыми обозначены непарные по глухости-звонкости согласные звуки.


Ответ:
Непарные по глухости-звонкости согласные звуки это: [й’], [р], [р’], [л], [л’], [м], [м’], [н], [н’], [ц], [х], [х’], [ч’], [щ’].
Буква ё (ёлка) в начале слова обозначает два звука – [й’о].
Нашу речку, словно в сказке,
За ночь вымостил мороз,
Обновил коньки, салазки,
Ёлку из лесу привёз.
С. Маршак
- Выполните звуко-буквенный разбор слова мороз. При затруднении обратитесь к Памятке 1 «Как провести звуко-буквенный разбор слова» (с. 130–131).
Ответ:
Простой разбор по памятке из учебника:
Моро́з – 2 слога, 5 букв, 5 звуков.
[м] – согл., твёрд.,звон.;
[а] – глас, безудар.;
[р]
[о́] – глас, удар.;
[с] – согл.
 , твёрд.,глух.;
, твёрд.,глух.;Более сложный разбор:
Мо│ро́з [м а р о́ с] – 2 слога, 5 букв, 5 звуков.
М [м] – согл., твёрд. парн. [м-м’],звон. непарн., «эм»;
О [а] – глас, безудар., «о»;
Р [р] – согл., твёрд. парн. [р-р’] ,звон. непарн., «эр»;
О [о́] – глас, удар., «о»;
З [с] – согл., твёрд. парн. [с-с’] ,глух. парн.[с’-з’], «зэ»
Правописание слов с парным по глухости-звонкости согласным звуком на конце слова или перед согласным
Номер 29.
Прочитайте.
суп – зуб круг – звук
год –рот рукав – шкаф
гараж – шалаш
мороз – вопрос
изморозь – изморось
- Какой звук обозначен выделенными буквами в каждой паре слов? Произнесите.
Ответ:
суп – зуб [п] круг – звук [к]
год – рот [т] рукав – шкаф [ф]
гараж – шалаш [ш]
мороз – вопрос [с]
изморозь – изморось [с’]
- Можно ли на слух определить, какой буквой надо обозначить парный по глухости-звонкости согласный звук на конце слова? А какое слово будет проверочным для каждого из данных слов?
Ответ:
Нет, нельзя, происходит оглушение звуков на конце слова. Звук стоит в слабой позиции.
Звук стоит в слабой позиции.
Продолжение номера 49 на следующей странице
Рейтинг
← Выбрать другую страницу ←
Анализ— Как сообщить сканеру синтаксического анализатора языка, что строка является литералом, а не идентификатором, посмотрев на предыдущий токен компиляторы языков программирования.
У меня есть следующий запрос:
статус=подтверждено
И я ожидаю, что статус будет идентификатором переменной, а подтвержден строковым литералом. Единственный способ определить это — посмотреть на = оператор между ними.
Теоретически сканер должен иметь возможность вернуть новый токен, не просматривая предыдущие, но в таком случае как отличить идентификатор от строкового литерала?
Имейте в виду, что я не могу просто добавить двойные кавычки вокруг строки с подтверждением , поскольку мне нужно работать с уже существующим языком запросов, и мне не разрешено вносить в него какие-либо изменения.
Должен ли я просто отслеживать предыдущие N маркеров внутри сканера и действовать соответствующим образом?
Все становится еще более запутанным, если у меня есть что-то вроде этого:
status=acknowledged&visibility=all
тот, который я сейчас разбираю, является оператором, который я должен рассматривать как строковый литерал.
- синтаксический анализ
- компилятор-конструкция
- лексер
3
Вопрос, который вы должны себе задать: «Должен ли мой синтаксический анализатор знать, является ли подтвержденным идентификатором переменной или строковым литералом?»
И я рискну предположить, что ответ таков: «Нет, это не так». Вы можете разобрать такое выражение, как status=acknowledged&visibility=all , ничего не зная о status и подтверждённом (или видимости и all ), кроме того, что они являются операндами. Возможной лексической категорией для таких операндов могут быть «голые слова» (термин пришел из Perl) или «атомы» (Lisp).
Возможной лексической категорией для таких операндов могут быть «голые слова» (термин пришел из Perl) или «атомы» (Lisp).
Конечно, в какой-то момент вам захочется выяснить, что означают эти токены (что по определению является семантическим вопросом), и в этот момент некоторые из них будут разрешены как «имя переменной», а другие — как ( без кавычек) «строковый литерал». Если, например, ваш оператор = настаивает на том, чтобы его левый операнд был именем переменной, а его правый оператор был литералом, вы могли бы легко выполнить соответствующие преобразования во время обхода дерева синтаксического анализа сверху вниз. Я почти уверен, что это подход, используемый большинством подобных парсеров.
В соответствии с принципом разделения задач каждый компонент языкового процессора должен ограничиваться, насколько это возможно, одной частью головоломки. Старайтесь избегать искушения преждевременно провести анализ, который удобнее было бы отложить до соответствующей фазы в будущем.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
python — Разбор вложенных троичных выражений
Продолжением моего квеста PyParsing является разбор вложенных троичных выражений (например, (x == 1 ? true : (y == 10 ? 100 : 200)) ). Таким образом, я построил следующее выражение. Что, как мне кажется, интуитивно понятно. Однако совпадений нет:
Таким образом, я построил следующее выражение. Что, как мне кажется, интуитивно понятно. Однако совпадений нет: any = Word(printables)
условно = Вперед()
sub_exp = (условный | любой)
условное = литеральное ('(') + под_выраж + литеральное ('?') + под_выраж + литеральное (':') + под_выраж + литеральное (')')
для выражения в conditional.scanString(block_str):
распечатать опыт
Сначала я думал, что проблема в том, что печатные формы потребляют все; Я установил excludeChars так, чтобы он не соответствовал :?)( , но это тоже не помогло. Альтернативой было создание вложенных выражений, по одному для »
ОБНОВЛЕНИЕ Используя ответ ниже, но модифицированный для работы со scanString:
Однако при использовании scanString также возвращается много других совпадений (в основном, все, что соответствует атому).
lpar = Литерал('(').подавить()
rpar = Литерал(')').подавить()
любой = Объединить(ОдинИлиБольше(Слово(печатные формы, excludeChars='()?:') | Белый(' ', max=1)))
выражение = Вперед()
атом = любой | Группа (lpar + expr + Literal ('?') + expr + Literal (':') + expr + rpar)
выражение << Литеральное ('(') + атом + ZeroOrMore (выражение) + Литеральное ('?') + атом + ZeroOrMore (выражение) + Литеральное (':') + атом + ZeroOrMore (выражение) + Литеральное (')' )
для ternary_exp в expr.scanString(block_str):
распечатать ternary_exp
- питон
- анализ
8
Я думаю, что ваша проблема двояка: пробелы (которые плохо обрабатываются вашим определением и ) и рекурсия (которая должна использовать оператор << ):
lpar = Literal( ' (').подавить()
rpar = Литерал( ')' ).подавить()
любой = Объединить(ОдинИлиБольше(Слово(печатные формы, excludeChars='()?:') | Белый(' ',max=1)))
выражение = Вперед()
атом = любой | Группа(lpar + expr + Literal('?') + expr + Literal(':') + expr + rpar )
выражение << атом + ZeroOrMore ( выражение )
Например,
t2 = '(x == 1 ? true : (y == 10 ? 100 : 200))' expr.
 parseString(t2)
([(['x == 1 ', '?', 'истина', ':', (['y == 10 ', '?', '100 ', ':', '200'], { })], {})], {})
parseString(t2)
([(['x == 1 ', '?', 'истина', ':', (['y == 10 ', '?', '100 ', ':', '200'], { })], {})], {})
3
Для такого анализа арифметических выражений попробуйте использовать встроенную в pyparsing infixNotation (ранее известную как operatorPrecedence ):
из pyparsing import *
целое число = слово (числа)
переменная = слово (альфа, буквенное обозначение)
boolLiteral = oneOf("истина ложь")
операнд = boolLiteral | переменная | целое число
compare_op = oneOf("== <= >= != < >")
QM,COLON = карта(Литерал,"?:")
expr = infixNotation(операнд,
[
(comparison_op, 2, opAssoc.LEFT),
((QM,COLON), 3, opAssoc.LEFT),
])
print expr.parseString("(x==1? true: (y == 10? 100 : 200) )")
Выводит
[[['x', '==', '1'], '?', 'true', ':', [['y', '==', '10'], '?', '100', ':', '200']]]
infixNotation заботится обо всех рекурсивных выражениях и разрешает приоритет операций и переопределение этого приоритета с помощью ().