Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «звучать», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ЗВУЧАТЬ (чу, чишь, 1 и 2 л. не употр.), чит; несов.
1. Издавать, производить звуки. Струны звучат глухо.
2. О звуках: быть, существовать, слышаться. Звучат детские голоса. Звучат раскаты грома.
3. Выражать что-н. звуками. Голос звучит тревогой.
4. Выражаться, проявляться. В словах звучит радость. В вопросе звучит сомнение.
5. звучит. О том, что важно, престижно, красиво (разг., часто ирон.
| сущ. звучание, я, ср. (к 1, 2 и 3 знач.).
Фонетический (звуко-буквенный) разбор
звуча́ть
звучать — слово из 2 слогов: зву-чать. Ударение падает на 2-й слог.
Транскрипция слова: [звуч’ат’]
з — [з] — согласный, звонкий парный, твёрдый (парный)
в — [в] — согласный, звонкий парный, твёрдый (парный)
у — [у] — гласный, безударный
ч — [ч’] — согласный, глухой непарный, мягкий (непарный, всегда произносится мягко), шипящий
а — [а] — гласный, ударный
т — [т’] — согласный, глухой парный, мягкий (парный)
ь — не обозначает звука
В слове 7 букв и 6 звуков.
Цветовая схема: звучать
Ударение в слове проверено администраторами сайта и не может быть изменено.
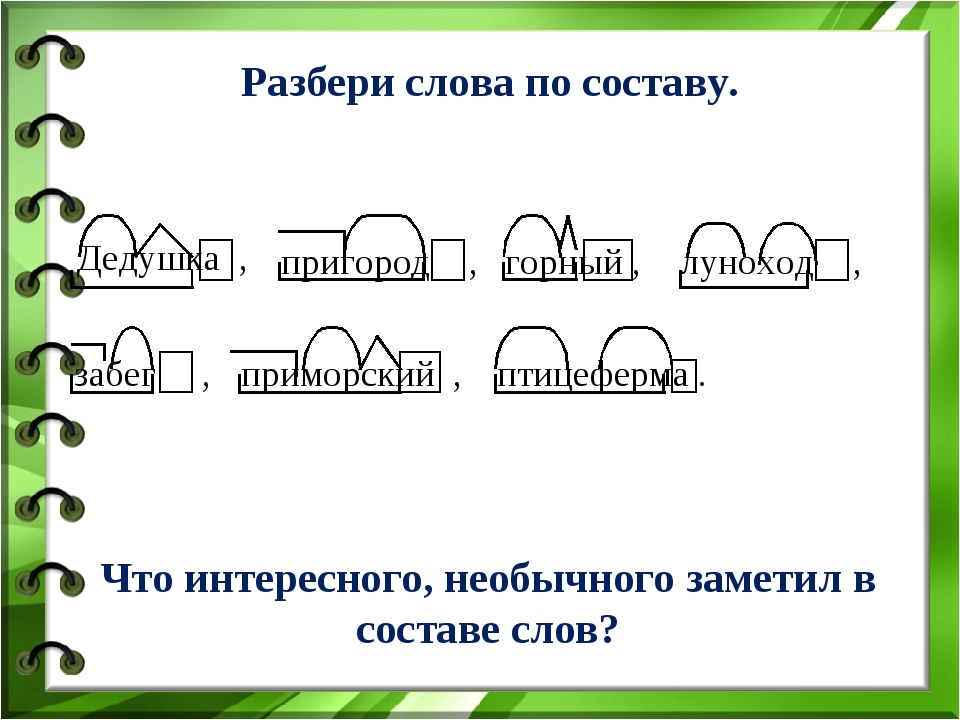
Разбор слова «звучать» по составу
звучать (программа института)
звучать (школьная программа)
Части слова «звучать»: звуч/а/ть
Часть речи: глагол
Состав слова:
а, ть — суффиксы,
нет окончания,
звуча — основа слова.

Примечание: ть является формообразующим суффиксом и не входит в основу слова, но во многих школьных программах ть отмечается как окончание.
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.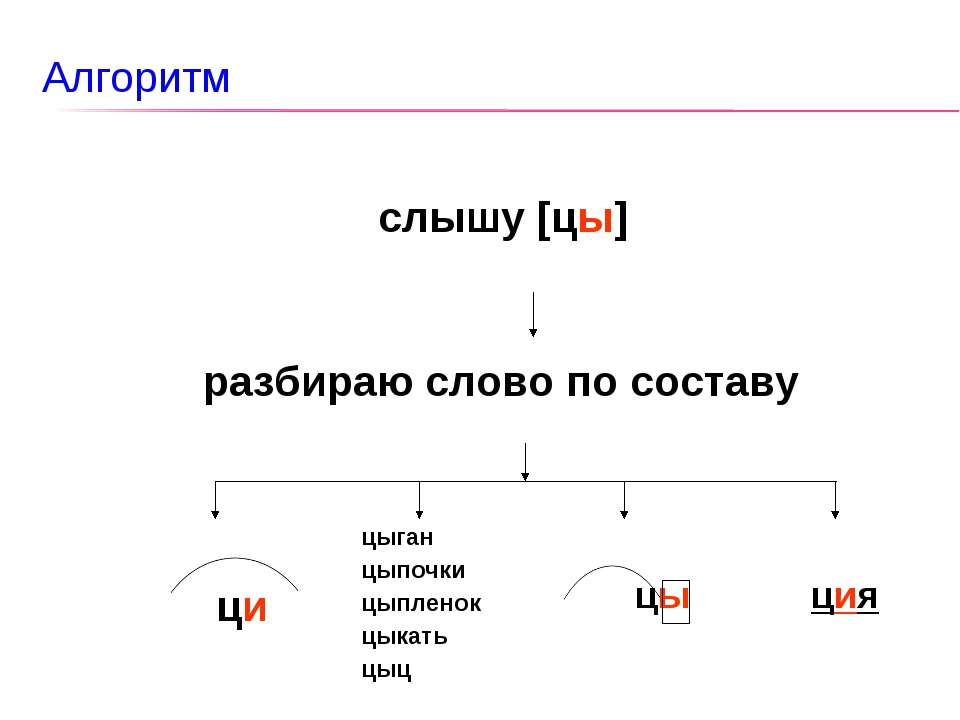
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Яма — фонетический (звуко-буквенный) разбор слова
В слове яма «я» в начале слова всегда обозначает два звука [й’]+гласный. Следует это учесть при оформлении фонетического разбора.
Первый из них – [й’] – всегда имеет одни и те же характеристики, потому что у него нет пары ни среди глухих звуков, ни среди твёрдых. Гласный зависит от ударения: попадая в ударную (сильную) позицию звучит четко — [а́]
Характеристики звуков
В безударной позиции звучание гласных ослаблено. Это называется редукцией. Редуцированный (ослабленный) гласный может произноситься по-разному. Чем дальше от ударения он стоит, тем больше изменяется.
Слово «яма» состоит из 2 согласных и 2 гласных звуков:
- [а́] – ударный – «я»
- [а] – в письменном варианте это «а»
- [й’] – в любой позиции звонкий и мягкий
- [м] – тоже всегда звонкий (не имеет глухой пары), в данном слове звучит твёрдо
Письменный разбор
Разобравшись с характеристиками всех звуков, можно оформлять письменный вариант разбора:
яма — [й’ а́ м а]- 2 слога: я’- ма
я — [й’] – согл., зв., мягк.
[а́] – гласн., уд.
м — [м] – согл., зв., твёрд.
а — [а] – гласн., безуд.
3 б., 4 зв.
Устный ответ
Если потребуется ответить устно, то для характеристики букв прилагательные употребляются в женском роде, а для звуков – в мужском. Например, «а» — гласная, [а] – гласный.
Нельзя забывать о том, что название букв и произношение звуков отличаются. Например, «м»: в алфавите эта буква называется [эм], а звучит в разбираемом слове — [м].
Полный устный ответ должен звучать так:
яма – [й’ а́ м а] – в этом слове 2 слога: я’- ма. Ударение падает на первый слог.
Буква «я» обозначает два звука:
согласный [й’] – звонкий, мягкий
гласный [а́] — ударный
«м» обозначает [м] – согласный, звонкий, твёрдый
«а» в этом слове звучит как [а] – гласный, безударный
В слове «яма» 3 буквы и 4 звука.
Звуко-буквенный разбор слова — Rus-learn.com
Звуко-буквенный разбор слова — это фонетический разбор слова. Чтобы выполнить этот разбор слова, как звучащей единицы языка, пишется транскрипция — запись звукового состава слова. Выполняется точная запись, как звучит слово.
Чтобы выполнить этот разбор слова, как звучащей единицы языка, пишется транскрипция — запись звукового состава слова. Выполняется точная запись, как звучит слово.
Звуко-буквенный разбор — это анализ звукового состава слова и его буквенного отображения на письме.
Часто орфографическая запись слова и его звучание не совпадают. В слове может быть одинаковое количестве звуков, звуков больше, чем букв, и букв больше, чем звуков.
При записи звукового состава слова следует учитывать, что буквы «е», «ё», «ю», «я» могут обозначать два звука в следующих позициях в слове:
1) в начале слова
2) после других гласных звуков
3) после разделительных «ь» и «ъ»
После согласных звуков буквы «е», «ё», «ю», «я» обозначают их мягкость:
- сел [с’ э л]
- нёс [н’ о с]
- люк [л’ у к]
- пять [п’ а т’]
Записывая звучание слова, следует учитывать, что в русском языке происходит фонетический процесс оглушения звонких согласных, находящихся перед глухим согласным и в конце слова, и, наоборот, озвончения глухих согласных перед звонким согласным, кроме «л», «м», «н», «р», «в», «й»
- ложка [ло ш к а]; витязь [в’ и т’a с’]; отблеск [о д б л’ и с к]
- смазка [с м а с к а]; дробь [д р о п’]; сдвинуть [з д в’ и н у т’]
- все [ф с’ э]; пруд [п р у т]; вокзал [в а г з а л]
В словах с буквосочетанием «зж» слышится длинный мягкий звук [ж’]
- брюзжать [б р’ у ж’ а т’]
- мозжечок [м а ж’ и ч’ о к]
Значит, в таких слова букв меньше, чем звуков.
В словах, в которых есть «ь», который обозначает мягкость предыдущего согласного звука или является морфологическим знаком, указывающим на принадлежность слова к женскому роду, букв насчитываем больше, а звуков меньше:
- знать [з н а т’] — 5 букв, 4 звука;
- речь [р ‘э ч’] — 4 буквы, 3 звука.


Мягкие согласные звуки могут смягчать предыдущий согласный звук.
Рейтинг книг Ольги Ушаковой
Теория литературы. Теория и история фольклора. Анализ текста произведения.
- знакомства гурьевск кем обл!
- для секса знакомства казань!
- авито знакомства в алатыре!
- Морфологический разбор «познакомишься»!
- сайт знакомств мегафонпро!
- как добавить фото на сайт знакомств табор!
Интересные факты литературы. ЕГЭ по литературе. Словари сайта. О проекте.
ПОЗНАКОМИТЬСЯ — разбор слова по составу (морфемный разбор)
Задать вопрос. События и новости в мире культуры и образования. Участники сайта.
- Анна Юрьевна Вильчинская!
- знакомства ищу вторую половину!
- познакомиться — разбор по составу, части слова!
Сообщить об ошибке. Поиск информации на сайте. Информация о словаре.
Конспект урока в 3 классе по русскому языку «Основа слова. Разбор слова по составу»
Приемы работы со словарными словами. Русский язык является одним из самых сложных в мире. Немало трудностей возникает, например, с правописанием не Мнемонические методы запоминания словарных сло Мнемонический метод основан на принципе ассоциативного запоминания слов. Слова с трудным написанием следует пр Что такое словарные слова?
2) Морфологический разбор слова «Познакомить»
Правописание словарных слов вызывает многочисленные трудности не только у школьников, но и у взрослых. Так что Класс: 5 класс. Тема: действие , характеристики , все темы. Часть речи: глаголы. Раздел орфографии: не подчиняются правилам. Другие словарные слова, которые не подчиняются правилам:. Популярные темы словарных слов. Словарные слова по частям речи.
Разбор слова «Познакомить»
Словарные слова по разделам орфографии. Все прекрасное.
Все прекрасное.
Классный час Автор — Шартон Т. Сложноподчиненное предложение с придаточным определительным Л. Успанова, учитель русского языка и литературы. Муниципальное образовательное учреждение. Цели урока: Вспомнить известное о сложных предложениях и их видах; Углубить понятие о сложном предложении объяснением средств связи простых предложений. Мы будем вечно прославлять ту женщину, чьё имя Мать Мать Так как Бог не может поспеть повсюду, он создал мать. Арабская пословица.
Смотрите также:
Презентация к уроку по русскому языку 5 класс по теме: Презентация»Синтаксический разбор сложного предложения» экологическое равновесие. Это первое слово, которое произносит человек, и звучит оно на всех языках одинаково нежно. У мамы самые добрые. Строение сложноподчинен ного предложения, знаки препинания СПП включает в себя главное и придаточное ые предложения. Тема урока:. Приложение к уроку Тема: Строение сложноподчиненного предложения. Югорска Бессозное сложное предложение Урок 1 — 9 класс. Придаточные определительные Автор разработки : Милашевская Елена Викторовна, учитель русского языка и литературы школы29 г.
Определите количество грамматических основ в предложениях, составьте их схемы знаки препинания не расставлены. Алая заря скрылась. Еще похожие презентации в нашем архиве:. Загрузить Войти.
Корень мой находится в цен е , В о черке найди приставку мне, Суффикс мой в тетрад к е все встречали, Вся же — в дневнике я и в журнале. Корень тот же, что в слове от да вать , Приставка взята из слов пре града и по сылка, Суффикс и окончание взяты из слова зна ние. Корень извлечь из на чин ки несложно, Приставка в со суде хранится надежно, Суффикс и окончание в гуд ен ие явно услышишь, Вместе — на темы различные пишешь.
Сердюк Валентина Хафизовна , заместитель директора по дополнительному образованию, учитель русского языка. Стадия рефлексии Парная групповая мозговая атака Составление кластера Заполнение таблицы Движение темы. С падежным окончанием С нулевым окончанием Без окончания неизменяемые слова о родин- е Росси- ей патриотизм отличник хорошо наречие сегодня наречие.
Поделиться страницей:. Предложение Словосочетание Слово. Звуки Состав слова Разбор по составу Основа. Морфема Морфемный разбор Лексическое значение Грамматическое значение Нулевое окончание Без окончания.
украинские власти раскритиковали за двойные стандарты по теме русского языка — ИноТВ
После того как пресс-секретарь Владимира Зеленского Юлия Мендель рассказала об «украинском русском языке», в интернете вспомнили о том, какие недавние неоднозначные языковые законы принимались в стране. Также, пишут «Вести», вспомнили и высказывание главы СНБО Алексея Данилова о том, что Донбасса не существует, а украинцы должны окончательно отказаться от русского языка.
После заявления пресс-секретаря Зеленского Юлии Мендель о том, что на Украине есть «украинский русский» язык, который необходимо поддерживать, в сети вспомнили о том, какие недавние неоднозначные языковые законы принимали в Раде. Как пишут «Вести», вспоминают, например, скандальный языковой закон, особенно его последняя статья об обязательном обслуживании на государственном языке с 16 января 2021 года. Мендель и главу МВД Арсена Авакова критиковали за то, что их слова, хоть и звучат логично, однако в итоге ни к чему не приведут.
Как отмечает издание, вспоминали и другие неоднозначные действия и заявления представителей власти по этой теме. Например, недавнее высказывание главы СНБО Алексея Данилова о том, что Донбасса не существует, а украинцы должны окончательно отказаться от русского языка.
Кроме того, «слуги народа» Олег Дунда и Александр Алексийчук в конце марта подали в Раду законопроект о запрете идеологии «русского мира», в котором, помимо статей об осуждении этой концепции, осуждается и «использование языка как механизма манипуляции и способа разжигания вражды». Как отмечает издание, этот неоднозначный законопроект привлёк внимание общества — его в основном критикуют за пункты, которые касаются религии и того же языка. Поэтому «слуги народа», которые не поддерживают такую риторику, стараются максимально отстраниться от законопроекта.
Поэтому «слуги народа», которые не поддерживают такую риторику, стараются максимально отстраниться от законопроекта.
«В «Слуге народа» 245 депутатов. Это инициатива ряда депутатов, моя инициатива будет моей инициативой, она не распространяется на всю партию. А рассматривать детально инициативы отдельных народных депутатов мы будем тогда, когда они будут занесены в комитет, будут внесены в зал — уже тогда мы дадим им оценку», — рассказывает изданию депутат Максим Бужанский, сетуя на то, что законопроект называют инициативой целой партии.
Отдельно, пишут «Вести», есть также вопросы и к языковому омбудсмену Тарасу Креминю, который занимается наблюдением за тем, как работает норма об обслуживании, игнорируя при этом реальные нарушения. Так, в начале марта он заявлял, что на Украине не зафиксировано ни одного случая дискриминации украинцев, которые говорят не на украинском, но, к примеру, представители бизнеса перманентно жалуются на угрозы националистов на почве языка.
«Бомба» в голове. 18-летний футболист умер в Подмосковье во время матча | Футбол | Спорт
В российском спорте произошла трагедия. К сожалению, в последнее время эти слова звучат довольно часто. Рядовой товарищеский матч футбольных команд в Подмосковье обернулся смертью одного из спортсменов.
Упал через пять минут после того, как вышел на поле
«4 апреля произошла трагедия — футболист молодежной команды „Знамя Труда“ Никита Сидоров умер во время матча. Выражаем глубокие соболезнования родным и близким Никиты», — гласит сообщение на странице футбольного клуба в социальной сети.
В воскресенье молодежный состав команды «Знамя Труда» проводил товарищеский матч на стадионе «Торпедо» в Орехово-Зуеве против соперников из Павловского Посада. 18-летний защитник Никита Сидоров был в числе запасных и вышел на поле во втором тайме. По словам очевидцев, Никита успел сыграть всего около пяти минут, и тут ему стало плохо.
Автор блога «Футбольные темы» передает рассказ одного из очевидцев трагедии: «Никита выбил мяч и упал, его затрясло…»
Игру остановили, молодому парню попытались оказать помощь. Генеральный директор МУ ГФК «Знамя Труда» Михаил Пузанов в беседе с телеканалом «360» рассказал о том, что происходило на стадионе: «Получается, он вышел во втором тайме, проиграл пять минут, побежал, и стало плохо. Упал и потерял сознание… Быстро подъехали медики и реанимобиль. Полчаса мы боролись за него. Но, к сожалению, потеряли парня».
«Парень был здоровее всех»
Пузанов отверг возможность того, что Сидоров выходил на поле с выявленными медицинскими патологиями, отметив, что все игроки перед началом сезона прошли диспансеризацию и медицинский осмотр: «Все боролись за него до конца. Парень был здоровее всех».
В спортшколе «Знамя Труда» Никита Сидоров занимался с 2015 года. В прошлом году за второй состав «Знамени Труда», выступающий в Лиге Б чемпионата Московской области, защитник провел 8 матчей, получив одну желтую карточку. Команда в итоге финишировала на 11-м месте.
По данным «Спорт-Экспресса», Сидоров также выступал за мини-футбольный клуб «Мишлен» в лиге Орехово-Зуева.
На официальной странице ФК «Знамя Труда» в Instagram появилось сообщение, в котором говорится: «Предварительным диагнозом врач назвал аневризму. Проблему с кровеносным сосудом в голове. Официального заключения врачей пока нет».
Болезнь, которая убила Андрея Миронова
Аневризма сосуда головного мозга — это патологическое местное расширение просвета артерии головного мозга. Следствием разрыва аневризмы является субарахноидальное или внутримозговое кровоизлияние, которое может привести к смерти либо к неврологическим расстройствам различной степени тяжести, связанных с повреждением тканей головного мозга.
Наиболее эффективный способ борьбы с этой проблемой — ранняя диагностика, которая позволяет врачам вовремя выявить эту «бомбу» в голове и обезвредить ее, приняв соответствующие меры.
Проблема, однако, в том, что выявить аневризму довольно сложно. Человек может десятилетиями жить, даже не догадываясь о ее существовании. В свое время аневризма сосуда головного мозга погубила замечательно актера Андрея Миронова — у него ее разрыв произошел прямо на сцене во время спектакля. Но у Миронова «бомба» сдетонировала в 46 лет, а футболисту из Орехово-Зуева было отпущено всего 18…
«Лопнул сосудик — и все»
Известный спортивный врач Юрий Васильков в беседе со «Спорт-Экспресс» признал, что выявить проблему на том уровне обследования, которое проходят футболисты низшего профессионального и любительского звена, почти невозможно: «Стандартный медосмотр — это одно. А углубленная медицина — это другое, она появляется только в большом футболе. Простой медицинский осмотр не покажет аномалию в черепе, это находка компьютерных врачей. С таким диагнозом играть ни в коем случае нельзя. К сожалению, лопнул сосудик — и все, ушел молодой человек, который даже не успел пожить. Это самая настоящая трагедия. Мы можем лишь склонить головы от печали».
Девушка погибшего футболиста Ангелина Мжельская выложила в Instagram фото и видео с Никитой, написав: «Мой маленький, я тебя очень люблю. Будь всегда рядом… Самый самый. Всё будет замечательно».Российский футбольный союз выразил искренние соболезнования родным и близким Никиты Сидорова.
Не исключено, что на высоком уровне вновь будет поднята тема усиления медицинского контроля в спорте. Однако пока неясно, как можно охватить углубленными медицинскими исследованиями не только профессионалов, но и любителей, а также, что важнее всего, детские спортивные школы.
«Знамя Труда»: успехи и катастрофы
Футбольный клуб «Знамя Труда» считается старейшим в России из тех, что существуют до сих пор — команда была основана в 1909 году. Большую часть времени клуб играл в низших дивизионах, но есть и достижения, которыми по праву можно гордиться. В 1962 году футболисты «Знамени Труда» стали финалистами Кубка СССР по футболу.
Большую часть времени клуб играл в низших дивизионах, но есть и достижения, которыми по праву можно гордиться. В 1962 году футболисты «Знамени Труда» стали финалистами Кубка СССР по футболу.
27 мая 2004 года автобус с футболистами ФК «Знамя Труда» попал в катастрофу на 82-м километре Горьковского шоссе. Команда ехала на очередной матч чемпионата в Щелково. В результате ДТП погибли начальник команды, генеральный директор, водитель, четыре футболиста и один ветеран орехово-зуевского футбола. Еще 10 человек, включая главного тренера, врача и семерых игроков, получили тяжелые травмы.
После этого встал вопрос о том, сможет ли «Знамя Труда» продолжить свое существование, но команда сохранилась.
Летом 2020 года на тренировке ФК «Знамя Труда» молния попала в 16-летнего вратаря Ивана Зборовского. К счастью, оперативно оказанная помощь помогла спасти молодого футболиста.
В интервью «Российской газете» сам Иван впоследствии рассказывал: «Футболка и шорты сгорели, все это дымилось… Остатки одежды выкинули, когда я оказался в больнице. А бутсы сохранились. Правда, они раздроблены…» Кроме того, на шее футболиста расплавилась цепочка.
Зборовский не только выздоровел, но и вернулся в футбол. Пострадавший вратарь был не только знаком и дружен с Никитой Сидоровой. 4 апреля голкипер вместе со вторым составом «Знамени Труда» находился в Москве. О том, что другу повезло меньше, чем ему, он узнал из новостей.
Мрачный 2021-й: трагедии в российском спорте
12 марта 2021 года в Ярославле во время второго матча серии плей-офф Молодежной хоккейной лиги, в котором местный «Локо» встречался с питерским «Динамо», игрок хозяев, вбрасывая шайбу в зону динамовцев, попал в 19-летнего защитника «Динамо» Тимура Файзутдинова.
Несколько дней медики вели борьбу за жизнь Тимура, но прогнозы были неутешительными. Мировые звезды хоккея слали слова поддержки молодому парню и его близким, верили в лучшее, но 16 марта 2021 года Тимур Файзутдинов умер.
Президент ФХР Владислав Третьяк сказал о произошедшем так: «Хочу выразить глубокие соболезнования от ФХР и себя лично. Жалко пацана… Несчастный случай».
30 января 2021 года на школьных соревнованиях по борьбе куреш 13-летний спортсмен Ефим Москвин, проводя прием против соперника по финальной схватке, неожиданно упал на маты. Сначала ребенок был в сознании, успел пожаловаться подошедшему тренеру и врачу на головокружение и тошноту. Крови на ковре не было, и взрослые, вызвав скорую, стали оказывать первую помощь. Но в какой-то момент пострадавший стал хрипеть, а затем потерял сознание.
В Бакалинскую ЦРБ Ефима отвезли, не дожидаясь прибытия бригады скорой помощи. Мальчика поместили в палату интенсивной терапии. Ребенок впал в кому. Впоследствии Ефима перевезли в Республиканскую детскую клиническую больницу в Уфе, где медики продолжили борьбу за его жизнь. Несмотря на все усилия врачей, 23 марта мальчик скончался. Мама погибшего рассказала журналистам: «Сердце не выдержало… Эксперты сказали, что шансов на жизнь у нас не было, полный перерыв мозга спинного от головного. То, что происходило с нами в последнее время, — это остаточные действия, за которые отвечает спиной мозг. Такие случаи — один на миллион, и он случился с нами. Ничего невозможно было сделать».
| Срок | Определение
| ||
Определение
| |||
| Срок | Определение
| ||
Срок
| Определение
| ||
| Срок | |||
 gif»>
Срок
gif»>
Срок  flashcardmachine.com/images/preview_card_back.gif»>
Определение
flashcardmachine.com/images/preview_card_back.gif»>
Определение | Как люди обрабатывают звуки языка; как они понимают слова, предложения и истории, выраженные письмом, речью или языком жестов; и как люди разговаривают друг с другом. |
| Физические и психические процессы, происходящие в процессе формирования речи человеком. |
| Как люди группируют слова во фразы и устанавливают связи между различными частями рассказа. |
| Знание человеком того, что означают слова, как они звучат и как они используются по отношению к другим словам. |
 flashcardmachine.com/images/preview_card_back.gif»>
Срок
flashcardmachine.com/images/preview_card_back.gif»>
Срок | Самый короткий отрезок речи, при изменении которого изменяется значение слова. |
| Наименьшая единица языка, имеющая определяемое значение или грамматическую функцию. Пр. Trucks состоит из нескольких фонем, но только из одной морфемы. |
| Эффект восстановления фонемы |
| Когда фонема в слове слышна, даже если она скрыта шумом, например, кашлем.Обычно это происходит, когда слово является частью предложения. |
 flashcardmachine.com/images/preview_card_back.gif»>
Определение
flashcardmachine.com/images/preview_card_back.gif»>
Определение | Процесс восприятия отдельных слов в непрерывном потоке речевого сигнала. |
| Идея о том, что буквы легче идентифицировать, когда они являются частью слова, чем когда они видны изолированно или в цепочке букв, которые не образуют слово. |
| Относительное употребление слов в определенном языке. Пр. Домой чаще, чем в походе. |
| Явление более быстрого чтения высокочастотных слов по сравнению с низкочастотными словами. |
 flashcardmachine.com/images/preview_card_back.gif»>
Срок
flashcardmachine.com/images/preview_card_back.gif»>
Срок | Процедура, в которой человека просят как можно быстрее решить, является ли конкретный стимул словом или не словом. |
| Прайм, который включает значение слов.Обычно возникает, когда за словом следует другое слово с аналогичным значением. Пр. Ant >> Ошибка реагирует быстрее Ошибка сама по себе будет иметь более медленный ответ. |
| Значения слов и предложений. |
| Правила объединения слов в предложения |
 flashcardmachine.com/images/preview_card_back.gif»>
Срок
flashcardmachine.com/images/preview_card_back.gif»>
Срок | Мысленное группирование слов в предложении по фразам.То, как анализируется предложение, определяет его значение. |
| Ситуация, в которой значение предложения, основанное на его начальных словах, неоднозначно, поскольку в зависимости от того, как предложение разворачивается, возможен ряд значений. Пр. «Мойки Castiron быстро ржавеют» |
| Предложение, в котором значение, которое, кажется, подразумевается в начале предложения, оказывается неверным, на основании информации, представленной позже в предложении. |
| Синтаксис-первый подход к синтаксическому анализу |
 flashcardmachine.com/images/preview_card_back.gif»>
Определение
flashcardmachine.com/images/preview_card_back.gif»>
Определение | Подход к синтаксическому анализу, подчеркивающий роль синтаксиса (интеракционистский подход к синтаксическому анализу) |
| При синтаксическом анализе, когда человек встречает новое слово, синтаксический анализатор предполагает, что это слово является частью текущего синтаксического анализа. |
| Интерактивный подход к синтаксическому анализу |
| Подход к синтаксическому анализу, который учитывает всю информацию — как семантическую, так и синтаксическую — для определения синтаксического анализа, когда человек читает предложение. При таком подходе семантике придается больший вес, чем при синтаксическом анализе. |
 gif»>
Срок
gif»>
Срок | Процесс, с помощью которого читатели создают информацию, которая явно не указана в тексте. |
| Представление текста или рассказа в сознании читателя таким образом, что информация в одной части текста или рассказа связана с информацией в другой части. |
| Вывод, который связывает объект или человека в одном предложении с объектом или человеком в другом предложении. |
Вывод об инструментах или методах, возникающий при чтении текста или прослушивании речи. |
| Вывод, который приводит к выводу, что события, описанные в одном предложении или предложении, были вызваны событиями, которые произошли в предыдущем пункте или предложении. |
| Ментальное представление того, о чем текст. |
| В разговоре говорящий должен строить предложения так, чтобы они содержали как заданную информацию, так и новую информацию. |
 com/images/preview_card_back.gif»>
Определение
com/images/preview_card_back.gif»>
Определение | Прослушивание оператора с определенной синтаксической конструкцией увеличивает шансы того, что следующий оператор будет произведен с той же конструкцией |
Знакомые и незнакомые языки
Фон
Подумайте о том, чтобы послушать кого-то, говорящего на английском (предположительно на том языке, на котором вы свободно владеете, если вы читаете эти слова) и о том, как кто-то говорит на незнакомом вам языке (например,г., телугу, ялунка или сорани). Слушая английский, мы слышим отдельные слова, паузы между словами и затем еще раз слова. Слушая незнакомый язык, часто это звучит как непрерывный звуковой каскад. На языке, который вы изучаете, может быть разница между восприятием слова-паузы-слова и непрерывным звук. В некоторые моменты вы можете правильно разобрать речь на слова, но в других случаях вы не можете.Почему возникает такое восприятие? Оказывается, что восприятие речи зависит от ряда процессов сверху вниз. То есть знания о языке влияет на то, как мы воспринимаем речь.
В этом упражнении вы можете слушать разные языки и испытывать некоторые трудности. разбора некоторых языков на значимые единицы.
Монгольский
Послушайте здесь монгольского.
Валлийский
Послушайте здесь немного валлийского.
Амхарский
Послушайте здесь немного амхарского языка.
Навахо
Послушайте здесь немного навахо.
Венгерский
Послушайте здесь венгерского.
Что это за слово? Используйте Word Type, чтобы узнать!
К сожалению, с текущей базой данных, в которой работает этот сайт, у меня нет данных о том, какие значения ~ term ~ используются чаще всего. У меня есть идеи, как это исправить, но мне нужно найти источник «чувственных» частот. Надеюсь, приведенной выше информации достаточно, чтобы помочь вам понять часть речи ~ term ~ и угадать его наиболее распространенное использование.
Тип слова
Для тех, кто интересуется небольшой информацией об этом сайте: это побочный проект, который я разработал во время работы над описанием слов и связанных слов. Оба этих проекта основаны на словах, но преследуют гораздо более грандиозные цели. У меня была идея для веб-сайта, который просто объясняет типы слов в словах, которые вы ищете — точно так же, как словарь, но сосредоточенный на части речи слов. И так как у меня уже была большая часть инфраструктуры с двух других сайтов, я подумал, что для ее запуска и работы не потребуется слишком много работы.
Словарь основан на замечательном проекте Викисловарь Викимедиа. Сначала я начал с WordNet, но затем понял, что в нем отсутствуют многие типы слов / лемм (определители, местоимения, сокращения и многое другое). Это побудило меня исследовать «Словарь Вебстера» 1913 года, который сейчас находится в открытом доступе. Однако после целого дня работы над его преобразованием в базу данных я понял, что было слишком много ошибок (особенно с тегами части речи), чтобы это было жизнеспособным для Word Type.
Наконец, я вернулся к Викисловарь, о котором я уже знал, но избегал, потому что он неправильно структурирован для синтаксического анализа. Именно тогда я наткнулся на проект UBY — удивительный проект, который требует большего признания. Исследователи проанализировали весь Викисловарь и другие источники и собрали все в один унифицированный ресурс. Я просто извлек записи из Викисловаря и закинул их в этот интерфейс! Так что работы потребовалось немного больше, чем ожидалось, но я счастлив, что продолжил работать после пары первых промахов.
Именно тогда я наткнулся на проект UBY — удивительный проект, который требует большего признания. Исследователи проанализировали весь Викисловарь и другие источники и собрали все в один унифицированный ресурс. Я просто извлек записи из Викисловаря и закинул их в этот интерфейс! Так что работы потребовалось немного больше, чем ожидалось, но я счастлив, что продолжил работать после пары первых промахов.
Особая благодарность разработчикам открытого кода, который использовался в этом проекте: проекту UBY (упомянутому выше), @mongodb и express.js.
В настоящее время это основано на версии викисловаря, которой несколько лет. Я планирую в ближайшее время обновить его до более новой версии, и это обновление должно внести множество новых смысловых значений для многих слов (или, точнее, леммы).
Реверсивная генерация буквы в звук / звук в букву на основе морпологии слова
Аннотация
В этой статье описывается двунаправленная система генерации букв / звука, основанная на стратегии, сочетающей методы, управляемые данными, с основанными на правилах формализм.Наш подход обеспечивает иерархический анализ слова, включая ударение, морфологию и слоговую форму. Генерация достигается с помощью метода вероятностного анализа, при котором вероятности обучаются на основе проанализированного словаря. Наши учебные и тестовые корпуса состояли из написания и произношения для высокочастотной части Коричневого корпуса (10 000 слов). Фонетические метки дополнены маркерами, указывающими на морфологию и ударение. Мы расскажем о двух различных грамматиках, представляющих историческую перспективу.Наша ранняя работа с первой грамматикой вдохновила нас на изменение грамматического формализма, что привело к большему ограничению с меньшим количеством правил. Мы оценили нашу работу по генерации буквы в звук с точки зрения точности всего слова, а также точности фонем. Для невидимого тестового набора мы достигли точности слов 69,3% и точности фонем 91,7% с использованием набора из 52 различных фонем. Хотя в этой статье основное внимание уделяется генерации буквы в звук, наша система также способна генерировать в обратном направлении, как сообщается в другом месте (Meng et al., 1994а). Мы полагаем, что наш формализм будет особенно применим для устного ввода неизвестных слов в систему распознавания.
Хотя в этой статье основное внимание уделяется генерации буквы в звук, наша система также способна генерировать в обратном направлении, как сообщается в другом месте (Meng et al., 1994а). Мы полагаем, что наш формализм будет особенно применим для устного ввода неизвестных слов в систему распознавания.
Zusammenfassung
Dieser Artikel beschreibt ein orthographisch-phonetisches Umsetzungssystem, das in zwei Richtungen arbeitet. Es beruht auf einer Strategie, die die auf Daten basierende Technik mit dem Formalismus eines Regelwerks kombiniert. Unser Ansatz liefert dieierarchische Analyze der Wörter, die die Akzentuierung, die Morphologie und die Silbenstruktur bestimmt.Die Umsetzung wird mit einer auf Wahrscheinlichkeitstechnik beruhenden syntaktischen Анализировать durchgeführt, bei der die Wahrscheinlichkeiten anhand eines Lexikons trainiert werden. Der Training- und Testkorpus besteht aus der Buchstabierung und der Aussprache von den 10 000 meistgebräuchlichen Wörtern des Brown Corpus. Die phonetische Markierung wurde durch morphologische und akzentuelle Marker erweitert. Die Resultate werden von zwei verschiedenen Grammatiken geliefert, die zwei verschieden Entwicklungsstadien der Arbeit entsprechen.Unsere früheren Arbeiten mit der ersten Grammatik haben zu einer Modifizierung des Formalismus geführt, mit gröβeren Einschränkungen und weniger Regeln. Die Leistungsfähigkeit des Systems wurde sowohl auf Wortals auch auf Phonemebene getestet. Bei dem Testkorpus wurde auf Wortebene eine Präzision von 69,3% erreicht und auf Phonemebene 91,7% unter Verwendung von 52 Phonemen. Auch wenn dieser Artikel sich hauptsächlich mit der orthographisch-phonetischen Umsetzung befaβt, поэтому ist unser System doch auch zu der gegensätzliche Umsetzung fähig, wie bei Meng et al.(1994a) berichtet. Unserer Überzeugung nach ist dieses System поддерживает für die mündliche Eingabe unbekannter Wörter in ein Spracherkennungssystem geeignet.
Резюме
Эта статья описывает систему двунаправленной орфографически-фонетической транскрипции, основанную на сочетании стратегий, основанных на принципах работы и формах. Notre Approche fournit une analysis hiérarchique des mots, включая позицию акцента, морфологию и слоговую структуру.Создание является реалистичной техникой вероятностного синтаксического анализа вероятностей, которые не оценивают часть лексики. Nos corpus d’apprentissage et de test sont constitués d’épellations et de произношение 10 000 mots les plus féquents du Brown Corpus. L’étiquetage phonétique a été enrichi par des marqueurs indiquant la morphologie et l’accentuation. Les résultats sont fournis sur deux grammaires distinctes, соответствует à deux stades d’évolution du travail. Notre travail antérieur avec la première grammaire nous a incitéà modifier le formisme de la grammaire, ce qui a abouti à des contraintes plus fortes avec moins de règles, Nous avons évalué les performances de notre système tant au que de motée du motée du motée du motéme eniveau du moténée du motée du motéme eniveau du moténée du motéme eniveau du motée de moté eniveau du mot eniveau du mot eniveau du mot enveau du mot eniveau du mot eniveau du mot eniveau du mot eniveau du mo eniveau du ma des contraintes plus fortes avec moins de règles.Pour le corpus de test, la précision atteinte au niveau du mot est de 69,3%; elle est de 91,7% au niveau du phonème, en utilisant un répertoire de 52 phonèmes. Bien que cet article traite essentielment de la transcription orthographique-phonétique, notre système est également un système de génération dans l’autre sens, comm décrit dans un article antérieur (Meng et al., 1994a). Nous pensons que notre формализм сыворотки, применимый в частности для того, чтобы вводить голосовые движения в системе разведки.
Notre Approche fournit une analysis hiérarchique des mots, включая позицию акцента, морфологию и слоговую структуру.Создание является реалистичной техникой вероятностного синтаксического анализа вероятностей, которые не оценивают часть лексики. Nos corpus d’apprentissage et de test sont constitués d’épellations et de произношение 10 000 mots les plus féquents du Brown Corpus. L’étiquetage phonétique a été enrichi par des marqueurs indiquant la morphologie et l’accentuation. Les résultats sont fournis sur deux grammaires distinctes, соответствует à deux stades d’évolution du travail. Notre travail antérieur avec la première grammaire nous a incitéà modifier le formisme de la grammaire, ce qui a abouti à des contraintes plus fortes avec moins de règles, Nous avons évalué les performances de notre système tant au que de motée du motée du motée du motéme eniveau du moténée du motée du motéme eniveau du moténée du motéme eniveau du motée de moté eniveau du mot eniveau du mot eniveau du mot enveau du mot eniveau du mot eniveau du mot eniveau du mot eniveau du mo eniveau du ma des contraintes plus fortes avec moins de règles.Pour le corpus de test, la précision atteinte au niveau du mot est de 69,3%; elle est de 91,7% au niveau du phonème, en utilisant un répertoire de 52 phonèmes. Bien que cet article traite essentielment de la transcription orthographique-phonétique, notre système est également un système de génération dans l’autre sens, comm décrit dans un article antérieur (Meng et al., 1994a). Nous pensons que notre формализм сыворотки, применимый в частности для того, чтобы вводить голосовые движения в системе разведки.
Ключевые слова
Обратимая генерация букв / звуков
Фонологический синтаксический анализ
Морфология
Рекомендуемые статьиЦитирующие статьи (0)
Полный текстCopyright © 1996 Elsevier B.V. Все права защищены.
Рекомендуемые статьи
Цитирование статей
(PDF) Исследование синтаксического анализа графемы и знания графема-фонемы у двух детей с дислексией
НЕЛЕКСИЧЕСКИЕ ПРОЦЕССЫ ЧТЕНИЯ 31
Graham, S. (1980). Навыки распознавания слов у обучающихся детей с ограниченными возможностями и средних школьников.
(1980). Навыки распознавания слов у обучающихся детей с ограниченными возможностями и средних школьников.
Психология чтения, 2, 23–33. DOI: 10.1080 / 0270271800020106
Джонс, М. Н., и Мьюхорт, Д. Дж. (2004). Чувствительность к регистру букв и биграмм подсчитывается из
больших английских корпусов. Методы исследования поведения, приборы и компьютеры, 36 (3),
388-396.
Кауфман, А., & Кауфман, Н. (2004). Краткий тест на интеллект Кауфмана 2. Серкл-Пайнс, США: AGS.
Коркман М., Кирк У. и Кемп С. (1998). NEPSY: нейропсихологическая оценка развития
. Сан-Антонио, США: Психологическая корпорация.
Ларсен, Л., Конен, С., Никелс, Л., Каслс, А., и МакАртур, Г. (2013). Письмо-звуковой тест
(LeST): надежный и достоверный комплексный критерий знания графемы-фонемы.
Австралийский журнал трудностей обучения, 20 (2), 129-152.
DOI: 10.1080 / 19404158.2015.1037323
Лаксон, В., Галлахер А. и Мастерсон Дж. (2002). Влияние знакомства, плотности расположения букв
, длины букв и сложности графики на точность детского чтения
. Британский журнал психологии, 93 (2), 269-287. DOI: 10.1348 / 000712602162580
Marinus, E., Kohnen, S., & McArthur, G. (2013). Австралийские данные сравнения для теста эффективности чтения слова
. Австралийский журнал трудностей обучения, 18 (2), 199–212.
DOI: 10.1080 / 19404158.2013.852981
Mitchum, C.C., & Berndt, R.S. (1991). Диагностика и лечение нелексического пути
приобретенной дислексии: иллюстрация когнитивного нейропсихологического подхода. Журнал
Нейролингвистика, 6 (2), 103-137. DOI: 10.1016 / 0911-6044 (91)
Ньюкомб Ф. и Маршалл Дж. К. (1984). Разновидности приобретенной дислексии: лингвистический подход. В
Семинарах по неврологии 4 (2), 181-195.
Ньюкомб, Ф.И Маршалл Дж. С. (1985). Чтение и письмо по буквам звучит. В К.Е. Patterson &
J.C. Marshall (Eds.), Поверхностная дислексия: нейропсихологические исследования и когнитивные исследования фонологического чтения
Marshall (Eds.), Поверхностная дислексия: нейропсихологические исследования и когнитивные исследования фонологического чтения
. Хоув, Англия: Эрлбаум.
javascript — извлечение слов из аудиоклипа
javascript — извлечение слов из аудиоклипа — qaruПрисоединяйтесь к Stack Overflow , чтобы учиться, делиться знаниями и строить свою карьеру.
Спросил
Просмотрено 2k раз
Хотите улучшить этот вопрос? Обновите вопрос, чтобы он соответствовал теме Stack Overflow.
Закрыт 3 года назад.
Я хочу создать приложение, которое записывает то, что вы говорите в микрофон, и извлекаю все слова.
Я знаю, что это проблема, над которой работают многие компании и частные лица, но я не совсем уверен, насколько мы далеки от разработки инструментов, которые хороши в этом.
Кроме того, существуют ли какие-либо общедоступные инструменты для достижения этой цели? Я надеюсь, что есть API, предоставляемый Google Assistant, Apple Siri или чем-то еще, что я могу просто использовать, загрузив аудиоклип и затем получив сказанные слова.
задан 31 мая ’17 в 12: 162017-05-31 12:16
Джемзелен8,2912323 золотых знака7777 серебряных знаков184184 бронзовых знака
2 Хотя у Google есть SDK Google Assistant, он в первую очередь предназначен для отправки звука из вашего программного обеспечения или устройства и получения звукового ответа от Ассистента — точно так же, как вы бы получили в Google Home. Точно так же Actions on Google предназначены для обработки всей обработки естественного языка (NLP) и предоставления вам ответа, а не для того, чтобы дать вам именно то, что сказано (хотя это побочный эффект).
Точно так же Actions on Google предназначены для обработки всей обработки естественного языка (NLP) и предоставления вам ответа, а не для того, чтобы дать вам именно то, что сказано (хотя это побочный эффект).
Похоже, вам нужен Cloud Speech API, который представляет собой систему преобразования речи в текст (STT). Вы можете объединить это с чем-то вроде Cloud Natural Language API, который затем может анализировать значение созданного текста.
Создан 31 мая.
Заключенный47.11k 66 золотых знаков4747 серебряных знаков9494 бронзовых знака
lang-js
Stack Overflow лучше всего работает с включенным JavaScriptВаша конфиденциальность
Нажимая «Принять все файлы cookie», вы соглашаетесь с тем, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Принимать все файлы cookie Настроить параметры
Улучшение правописания за счет обучения письму и целому слову у двух многоязычных детей, говорящих на греческом и английском языках | Многоязычное образование
Вмешательства, направленные на улучшение правописания многоязычных детей, важны, потому что 10% населения школьного возраста во всем Европейском Союзе говорят дома на другом языке, чем большинство (Romaine [2004]). До сих пор мероприятия по повышению грамотности традиционно фокусировались на навыках чтения у одноязычных детей (например, Брэдли и Брайант [1983]; Стюарт [1999], [2004]). Исследований по вмешательству в правописание с одноязычными детьми гораздо меньше (например, Brunsdon et al., [2005]; Kohnen et al. [2008a], [2008b]), а исследований, включающих двуязычных детей, немного, особенно для двуязычных, которые приобретают грамотность на языках с разные орфографии, такие как английский и греческий, которые являются языками двух детей, о которых сообщается в данной статье.
До сих пор мероприятия по повышению грамотности традиционно фокусировались на навыках чтения у одноязычных детей (например, Брэдли и Брайант [1983]; Стюарт [1999], [2004]). Исследований по вмешательству в правописание с одноязычными детьми гораздо меньше (например, Brunsdon et al., [2005]; Kohnen et al. [2008a], [2008b]), а исследований, включающих двуязычных детей, немного, особенно для двуязычных, которые приобретают грамотность на языках с разные орфографии, такие как английский и греческий, которые являются языками двух детей, о которых сообщается в данной статье.
Греческая и английская системы письма отличаются прозрачностью соотношения букв и звуков. Английский язык более непрозрачен, чем греческий, как для чтения, так и для правописания. Как мы увидим ниже, у греческого языка есть несогласованные соответствия гласного звука букве (или фонема-графема), тогда как несоответствия английского языка лежат на уровне фонемы-графемы, но также и на более крупных уровнях единиц. Кроме того, для английского языка существуют тысячи соответствий фонема-графема; в то время как для греческого языка их всего несколько, и, что важно, для окончаний слов написание гласных определяется морфологически (например, глаголы в настоящем времени единственного числа от первого лица все оканчиваются на <ω> (/ o /)).
Исследователи провели систематический анализ несоответствий в английской системе письма. Например, Kreiner ([1992]) подсчитал, что 60% написанных слов имеют неправильное написание, а Ziegler et al. ([1997]) сообщил, что 72% односложных слов имеют непоследовательный ритм. Другие исследователи изучали детские тексты, чтобы определить степень несогласованности. Например, Стюарт и др. ([2003]) проанализировали словарный запас детей в раннем чтении и обнаружили, что 50% наиболее часто употребляемых слов пишутся неправильно.Основная трудность в английском языке связана с тем, что один звук (или фонема) может иметь много разных соответствий, и они могут состоять из разных графем. Например, звук / i: / можно записать как
Например, звук / i: / можно записать как
Спенсер ([2007]) проверил 207 учеников 2-6 классов в Великобритании по 120 наиболее часто используемым словам из подсчета слов в детских книгах, Детской базы данных печатных слов (Masterson et al. [2003]). Он сообщил, что неправильное напечатанное слово влияет на орфографические способности учеников — звуки с большим количеством соответствий писать сложнее, чем со звуками с небольшим количеством соответствий. Другие характеристики, такие как частота печатных слов, также были связаны с правильностью написания детьми.
Обращаясь к характеристикам греческой системы письма, Харрис и Джаннулли ([1999]) отмечают, что греческое правописание основано на этимологии слов, а не на их текущем произношении.Хотя греческий язык очень прозрачен для чтения (соответствия между графемами и фонемами почти 1: 1), он несовместим с орфографией. Это связано с тем, что одна и та же гласная фонема может быть записана с помощью разных графем — есть много слов, которые содержат разные графемы, представляющие фонемы / o /, / i / и / e /, поскольку определенные фонематические различия (например, между гласными, представленными < η, ι, υ, οι, ει, υι> и те, которые представлены <ο, ω> или <ε, αι>), больше не присутствуют в языке. Преобладание многосложных слов с открытой слоговой структурой (cvcvcv) в греческом языке означает, что дети часто сталкиваются с непоследовательными графемами гласных. Однако существуют морфосинтаксические правила, которые определяют правильное окончание гласных, поэтому написание гласных не является полностью произвольным. Например, дети учатся, что глаголы первого лица единственного числа оканчиваются на графему гласных <ω> (например, <παίζ-ω> / pezo / (play)), а существительные или прилагательные среднего рода единственного числа имеют грамматический суффикс <ο> (e.г., <νόστιμ-ο> / nostimo / <παγωτ-ό> / payoto / (вкусно) (мороженое)).
Преобладание многосложных слов с открытой слоговой структурой (cvcvcv) в греческом языке означает, что дети часто сталкиваются с непоследовательными графемами гласных. Однако существуют морфосинтаксические правила, которые определяют правильное окончание гласных, поэтому написание гласных не является полностью произвольным. Например, дети учатся, что глаголы первого лица единственного числа оканчиваются на графему гласных <ω> (например, <παίζ-ω> / pezo / (play)), а существительные или прилагательные среднего рода единственного числа имеют грамматический суффикс <ο> (e.г., <νόστιμ-ο> / nostimo / <παγωτ-ό> / payoto / (вкусно) (мороженое)).
Однако не все ясно, если рассматривать основу слова, поскольку основы не могут быть правильно написаны только на основе фонологии или морфологии; знание конкретных слов также важно. Protopapas и Vlahou ([2009]) подсчитали, что соотношение фонема-графема в греческом языке составляет 1,33, что ниже, чем соотношение для английского языка, которое оценивается в 1,7 (Caravolas, [2004]).
По данным Nikolopoulos et al.([2003]) трудности с написанием для греческих детей также происходят из-за того, что греческий язык сильно изменен. Следовательно, начинающий грамотный человек должен выучить множество грамматических и синтаксических правил, чтобы овладеть греческой орфографией. Харрис и Джаннулли ([1999]) провели лонгитюдное исследование, в котором они оценивали правописание в детском саду, затем в 1-м, 2-м и 3-м классе. На основании своих результатов они пришли к выводу, что греческим детям необходимо как минимум три года формального образования, чтобы овладеть основными морфо-синтаксическими правилами.
Правильное написание как на английском, так и на греческом языках будет зависеть от фонологических, семантических и орфографических знаний (Ehri, [1995]; Perfetti and Hart, [2002]; Romani et al. [2005]). Мы также предполагаем, что емкость зрительной памяти будет играть роль в языках с особенно непрозрачной орфографией, таких как английский, из-за несоответствия написания. Описываемые нами программы обучения основаны на этих предположениях. Прежде чем мы представим два тематических исследования, будет изложена принятая теоретическая основа.
Описываемые нами программы обучения основаны на этих предположениях. Прежде чем мы представим два тематических исследования, будет изложена принятая теоретическая основа.
Обзор литературы
Лурия ([1970], стр. 323–324) описал письмо как процесс, включающий различные этапы: «Поток речи разбивается на отдельные звуки. Фонематическое значение этих звуков идентифицируется, и фонемы представлены буквами. Наконец, отдельные буквы объединяются в письменное слово ». «Теория звуковой опосредованности» Лурия оказалась несостоятельной, поскольку когнитивные нейропсихологи сообщили о доказательствах правописания без фонологического опосредствования в случаях фонологической дисграфии (например,г., Шаллис, [1981]). Таким образом, было предложено, что для квалифицированного правописания необходимы две процедуры (например, Barry, [1994]; Ellis and Young, [1988]). Они представлены на рисунке 1. Одна процедура отвечает за поиск знакомых и неправильно написанных слов и часто упоминается как лексический маршрут ( Lex на рисунке 1). Он состоит из хранилища (или словаря) единиц слухового распознавания слов, хранилища значений слов и хранилища представлений целого слова для письменного вывода (орфографический выходной лексикон).
Рис. 1Модель двойного маршрута для написания (воспроизведено с разрешения Barry, [1994] , pp.32).
Во время написания под диктовку, в случае знакомых слов, представленное слово активирует фонологическое представление слова (при слуховом распознавании слова), это, в свою очередь, активирует значение слова (семантику) и написание слова в орфографическая лексика вывода. Что касается второй из двух процедур, она получила название сублексический или собранный, и отвечает за правильное написание новых, незнакомых элементов и слов.Это влечет за собой разбор речевого ввода на его составляющие (фонемы, слоги или другие единицы), отображение фонологических единиц на графемные единицы и, наконец, сборку единиц для вывода. Эта процедура будет успешной с правильными и произносимыми не словами, но не удастся с неправильными словами, что приведет к фонологически правдоподобным орфографическим ошибкам (например, свет → LITE, εκκλησία / eklisia / (церковь) → ΕΚΛΙΣΙΑ). Выходные данные лексического или сублексического маршрута хранятся в графемическом буфере (который является хранилищем краткосрочной памяти) до тех пор, пока не будет предоставлен письменный или устный ответ.
Эта процедура будет успешной с правильными и произносимыми не словами, но не удастся с неправильными словами, что приведет к фонологически правдоподобным орфографическим ошибкам (например, свет → LITE, εκκλησία / eklisia / (церковь) → ΕΚΛΙΣΙΑ). Выходные данные лексического или сублексического маршрута хранятся в графемическом буфере (который является хранилищем краткосрочной памяти) до тех пор, пока не будет предоставлен письменный или устный ответ.
Исследователи изучили орфографические ошибки, которые допускают дети, как средство предоставления информации об используемых ими процессах. Орфографические ошибки можно классифицировать как фонологически и нефонологически подходящие по отношению к целевому слову. Преобладание фонологически подходящих ошибок интерпретировалось как указание на зависимость от сублексической процедуры из-за проблемы с лексическими процессами, тогда как, когда ошибки в основном фонологически неуместны, это интерпретировалось как проблема с сублексическими процедурами.
Межлингвистические групповые исследования и тематические исследования, посвященные изучению навыков правописания и чтения у билингвов, показывают, что трудности, проявляющиеся на одном языке, будут очевидны и на втором языке (см., Например, Geva, [2000]; Geva and Siegel, [ 2000]). Кляйн и Доктор ([1992]) оценили двуязычного ребенка, К.Т., который имел средний интеллект, но страдал дислексией в отношении двух языков, на которых она была грамотна (африкаанс и английский). KT оценивался по чтению слов и неслов на английском и африкаанс; у нее были серьезные трудности с несловами на обоих языках.Несмотря на то, что африкаанс является прозрачным языком, ее субексический маршрут был настолько скомпрометирован, что она не смогла воспользоваться преимуществами прозрачности. Гупта и Джамал ([2007]) исследовали группу из 30 двуязычных детей с дислексией (средний возраст 103 месяца) и сравнили их успеваемость с показателями типично развивающейся двуязычной группы (средний возраст 103 месяца). Дети оценивались по чтению слов на хинди и английском языках. В хинди, как правило, развивающиеся дети совершали преимущественно несловесные ошибки, в то время как в английском они делали более реальные замены слов, что указывает на то, что прозрачность хинди заставляла детей полагаться на сублексические процессы при чтении, в то время как непрозрачность английского заставляла их больше полагаться на слова. основанные процессы.Иная ситуация была с детьми-дислексиками. Казалось, что на них не влияет прозрачность, и они полагаются на сублексические процессы для обоих языков. Это не оптимальная стратегия для английского языка.
Дети оценивались по чтению слов на хинди и английском языках. В хинди, как правило, развивающиеся дети совершали преимущественно несловесные ошибки, в то время как в английском они делали более реальные замены слов, что указывает на то, что прозрачность хинди заставляла детей полагаться на сублексические процессы при чтении, в то время как непрозрачность английского заставляла их больше полагаться на слова. основанные процессы.Иная ситуация была с детьми-дислексиками. Казалось, что на них не влияет прозрачность, и они полагаются на сублексические процессы для обоих языков. Это не оптимальная стратегия для английского языка.
Сообщалось также о тематических исследованиях вмешательства и групповых исследованиях с двуязычными участниками. Например, Broom and Doctor ([1995] a) представили исследование случая вмешательства, проведенное с двуязычным 11-летним мальчиком SP. У SP была фонологическая дислексия развития (особые трудности с сублексическими навыками), а вмешательство было направлено на фонологические навыки.Было обнаружено улучшение процессов сублексического чтения, и на необученные предметы произошло обобщение. Исследователи стремились улучшить только его способность читать по-английски, а не африкаанс.
Стюарт ([1999], [2004]) провел групповое исследование с участием детей приемной и первого класса в Лондоне, и большинство детей изучали английский как дополнительный язык (EAL). Экспериментальной группе была предложена программа, нацеленная на фонологическую осведомленность и фонетику, основанная на схеме Jolly Phonics, а другая группа получила целую языковую программу, основанную на Большой Книге Холдэуэя ([1979]).Акустическая программа оказалась очень эффективной для развития навыков чтения и правописания у EAL и одноязычных детей, и успехи были сохранены при отложенной оценке после вмешательства в конце 2-го года. Такого же улучшения не было обнаружено для интервенционной группы «Большие книги». Сравнения показали 10-месячную разницу в возрасте чтения и 11-месячную разницу в возрасте правописания между двумя группами в пользу группы Jolly Phonics. Тем не менее, последующая оценка в конце 2-го года обучения не выявила значительной разницы в оценках понимания прочитанного между двумя группами, что указывает на то, что фонетической программы недостаточно для повышения уровня понимания прочитанного у детей.
Тем не менее, последующая оценка в конце 2-го года обучения не выявила значительной разницы в оценках понимания прочитанного между двумя группами, что указывает на то, что фонетической программы недостаточно для повышения уровня понимания прочитанного у детей.
Настоящее исследование
Мы описываем коррекцию правописания, проведенную с двумя детьми школьного возраста, LK и ED, которые говорили на английском и греческом языках. Тестирование началось, как только было получено этическое одобрение Института образования, Комитет по этике Лондонского университета и как только были возвращены письма с информированным согласием от родителей и руководства школы. Хотя дети получали обучение на греческом и английском языках, ни один из них не добивался успехов в правописании ни на одном из языков.Для LK описанное ниже изменение правописания нацелено на оба языка; тогда как для ED было предназначено только английское правописание. Первоначально обоим детям было проведено вмешательство по сублексической орфографии. Вмешательство было основано на исследовании, проведенном Brunsdon et al. ([2002a]). Исследователи изучили сублексические процессы чтения восьмилетнего мальчика, страдавшего смешанной дислексией. Они стремились научить соотношениям графема-фонема и обучить сегментации графемы и смешиванию фонем.Вмешательство длилось четыре с половиной месяца. Последующие оценки, проведенные через три месяца после вмешательства, показали, что значительно улучшились знания графемы-фонемы, а также чтение неслов. В настоящем исследовании сублексическое вмешательство использовало аспекты исследования Стюарта ([1999], [2004]) (была принята схема Jolly Phonics) и программы восстановления чтения Клея ([1993]) (использовалась процедура письма). Наконец, из программы Sound Linkage Хэтчера ([1994]) была использована процедура обучения фонологическим способностям.
Чтобы предвидеть результат, в конце сублексического вмешательства и хотя было обнаружено, что орфография LK улучшилась, это не относилось к ED. Затем с ED был проведен тренинг по лексическому правописанию. Вмешательство было основано на предыдущих обучающих исследованиях, посвященных лексическим процессам (например, Behrmann, [1987]; Brunsdon et al., [2005]; De Partz et al., [1992]; Niolaki and Masterson [2012b]; Weekes and Coltheart, [1996]). В частности, Де Парц и др.([1992]) использовали технику визуальных образов в исследовании с 24-летним мужчиной, LP, у которого развилась поверхностная дисграфия. Вмешательство было направлено на неправильные слова с использованием рисунков, встроенных в слова. Производительность LP значительно улучшилась. Берманн ([1987]) использовал технику, связывающую пары омофонов с графическими представлениями, чтобы связать орфографию с семантикой. Было обнаружено улучшение для обученных омофонов и неподготовленных неправильных слов, но не для неподготовленных омофонов. Weekes и Coltheart ([1996]), используя технику графической мнемоники, обнаружили улучшение для обработанных, но не необработанных слов.
Затем с ED был проведен тренинг по лексическому правописанию. Вмешательство было основано на предыдущих обучающих исследованиях, посвященных лексическим процессам (например, Behrmann, [1987]; Brunsdon et al., [2005]; De Partz et al., [1992]; Niolaki and Masterson [2012b]; Weekes and Coltheart, [1996]). В частности, Де Парц и др.([1992]) использовали технику визуальных образов в исследовании с 24-летним мужчиной, LP, у которого развилась поверхностная дисграфия. Вмешательство было направлено на неправильные слова с использованием рисунков, встроенных в слова. Производительность LP значительно улучшилась. Берманн ([1987]) использовал технику, связывающую пары омофонов с графическими представлениями, чтобы связать орфографию с семантикой. Было обнаружено улучшение для обученных омофонов и неподготовленных неправильных слов, но не для неподготовленных омофонов. Weekes и Coltheart ([1996]), используя технику графической мнемоники, обнаружили улучшение для обработанных, но не необработанных слов.
Обращаясь теперь к вмешательствам при дислексике / дисграфике развития, Brunsdon et al. ([2005]) провели исследование с двенадцатилетним ребенком MC, у которого была поверхностная дисграфия развития. Вмешательство было направлено на лексический путь с использованием методов, которые были успешно применены с приобретенными поверхностными дислексиками (карточки с мнемоническими средствами и без них). Улучшение неправильного написания слов MC было обнаружено после четырехнедельного обучения. Что касается мнемонической помощи, они сообщили, что она не дала значительного выигрыша по сравнению с техникой использования карточек без мнемоники.Исследователи обнаружили, что необработанные неправильные слова улучшились в ходе вмешательства, и многие из них показали постепенное улучшение степени сходства с правильным написанием. Ниолаки и Мастерсон ([2012b]) в интервенционном исследовании с многоязычной девушкой, NT, в возрасте 10; 03 лет со смешанной дисграфией, обнаружили, что лексическое обучение значительно улучшило качество правописания, и что методы использования карточек и визуальных образов были одинаково эффективны. NT показал низкий уровень восприимчивого словарного запаса для английского и греческого языков, и анализ достижений, достигнутых во время вмешательства, показал, что большее улучшение наблюдалось для известных целевых слов, чем для неизвестных слов для обоих языков.
NT показал низкий уровень восприимчивого словарного запаса для английского и греческого языков, и анализ достижений, достигнутых во время вмешательства, показал, что большее улучшение наблюдалось для известных целевых слов, чем для неизвестных слов для обоих языков.
Мы хотели дополнительно изучить, были ли признаны успешными вмешательства с монолитными участниками с дисграфией (Brunsdon et al. [2002a], [2002b]; Brunsdon et al., [2005]; Kohnen et al. [2008a], [2008b] достигнет тех же результатов с детьми-полиглотами. Мы стремились изучить, какой тип обучения будет более эффективным для этих детей-полиглотов с проблемами правописания и может ли вмешательство привести к улучшению чтения, а также правописания, в соответствии с выводами из других тематических исследований вмешательства (Brunsdon et al., [2005]; Kohnen et al. [2008a], [2008b]. Для LK, который был двуяграмотным, мы исследовали, будет ли после вмешательства, нацеленного на сублексические процессы, он производить больше фонологически подходящих ошибок в правописании греческого языка, чем английского, поскольку это образец, который сообщается для детей, которые учатся читать и писать в двух алфавитном письме. системы, в которых одна из них более прозрачна, чем другая (см. Hagtvet and Lyster, [2003]; Niolaki and Masterson [2012a]).
Пример из практики: LK
LK был трехъязычным мальчиком, говорящим на греческом, английском и немецком языках, в возрасте 7; 03 лет, когда оценка началась в январе 2010 года.Мать Л.К. — гречанка, а отец — немец, и дома говорят на обоих языках. Он посещал 1-й класс (первый год) греческой независимой школы в Великобритании, где дети получают обучение искусству на греческом языке через греческий язык в течение восьми часов в неделю и английской грамотности, также через посредство греческого языка. по десять часов в неделю. Л.К. был очень общительным мальчиком, который свободно говорил на английском, греческом и немецком языках в устном общении со взрослыми и сверстниками. Исследователю, проводившему вмешательство, родители Л.К. и директор школы сказали, что он опасается индивидуальных занятий.Они объяснили, что этот страх вызван тем фактом, что он может быть заклеймен как больной. LK действительно был застенчивым и стойким на первой встрече, однако исследователь объяснил ему причину, по которой он был вне класса, как долго это продлится, и установил очень хорошие отношения с LK. С тех пор он с радостью присоединился к индивидуальному обучению. LK с большим энтузиазмом воспринял полученную поддержку, потому что он мог наблюдать за прогрессом, которого он добивался, и это также видели его классные учителя и сверстники.
Исследователю, проводившему вмешательство, родители Л.К. и директор школы сказали, что он опасается индивидуальных занятий.Они объяснили, что этот страх вызван тем фактом, что он может быть заклеймен как больной. LK действительно был застенчивым и стойким на первой встрече, однако исследователь объяснил ему причину, по которой он был вне класса, как долго это продлится, и установил очень хорошие отношения с LK. С тех пор он с радостью присоединился к индивидуальному обучению. LK с большим энтузиазмом воспринял полученную поддержку, потому что он мог наблюдать за прогрессом, которого он добивался, и это также видели его классные учителя и сверстники.
В школе формальное обучение английскому и греческому языкам начинается в начале 1 класса, когда детям исполняется 6 лет. До этого дети обычно посещают греческий детский сад, где основное внимание уделяется устным навыкам и некоторым навыкам предварительной грамотности как для английского, так и для греческого языков. LK не посещал греческий детский сад. До первого класса он два года посещал местный детский сад, в котором особое внимание уделялось физическому воспитанию и обучению через игру. Формальное обучение английской грамотности не было включено в их учебную программу, и на этом этапе LK не учился читать по-английски.
В таблице 1 представлены результаты базовых оценок и тестов на чтение, правописание и фонологические способности для английского и греческого языков. Хотя Л.К. свободно говорил по-немецки, он не знал этого языка и не получал никаких инструкций по немецкому языку. Оценка правописания LK на английском языке показала, что он не мог правильно написать свое имя (он написал только первые две буквы), и он не мог написать никаких часто встречающихся слов, кроме слова на . Он умел писать только по-английски буквы для звуков / м /, / а /, / г /, / т / и / с /.Он часто менял буквы. По-гречески он мог написать свое имя и фамилию, но четкого различия между прописными и строчными буквами не было. Он правильно написал только два часто встречающихся слова (μαμά / мама / (мать) и όχι / ohi / (нет)).
Он правильно написал только два часто встречающихся слова (μαμά / мама / (мать) и όχι / ohi / (нет)).
Фонологическая способность LK оценивалась на английском языке с помощью подзадачи смешивания Комплексного теста фонологической обработки (CTOPP, Wagner et al., [1999]). Его работоспособность соответствовала возрасту, но когда его оценивали в задаче сегментации фонем и задаче удаления фонемы из батареи предварительного вмешательства Хэтчера ([1994]), его баллы были 0 из 6 правильных, давая стандартизированный балл 36, и 1 из 6 со стандартизированным баллом 85 соответственно. Фонологические способности в греческом языке оценивались с помощью субтеста смешения из теста Афины (Параскевопулос и др., [1999]). LK получил стандартизованный балл 70.
Стандартизированные баллы не были доступны для оценок чтения и правописания на греческом языке, поэтому показатели LK были сопоставлены с результатами группы сравнения, соответствующей возрасту и невербальным способностям (N = 6, средний возраст = 7; 4, с.d. = .19). Группу сравнения составили двуязычные греко- и англоязычные дети, посещающие тот же класс в школе, что и LK. Оценки для группы сравнения также приведены в Таблице 1.
Обоснование обучения
Было решено провести обучение, направленное на улучшение навыков правописания LK, поскольку было обнаружено, что улучшение правописания в результате обучения распространяется на навыки чтения. (Brunsdon et al., [2005]; Conrad, [2008]; Kohnen et al. [2008a], b; Ouellette, [2010]), в то время как обратное не было обнаружено (Perfetti, [1997] ).Кроме того, орфография — более сложная задача, чем чтение греческой и английской орфографии. LK был ближе к концу 1 класса (весенний семестр — с января по апрель), и он не мог писать, в то время как дети на этом этапе, как правило, могут писать знакомые и незнакомые слова под диктовку и распознавать греческие буквы-звуки. . В английском языке они, как правило, могут составить ряд часто встречающихся неправильных слов, и их научили звукам букв и именам. Таким образом, учителя Л.К. были обеспокоены его способностью справляться со 2-м классом.Сублексический навык LK практически отсутствовал на обоих языках, поэтому было решено, что будет обеспечена поддержка его восприятия букв и звука и его навыков декодирования орфографии. Сублексические процессы были выбраны в качестве цели, поскольку Л.К. не получил пользы от обучения фонетике, которое он получил до сих пор, и казалось важным применить этот навык, прежде чем он перейдет в 2 класс.
LK был ближе к концу 1 класса (весенний семестр — с января по апрель), и он не мог писать, в то время как дети на этом этапе, как правило, могут писать знакомые и незнакомые слова под диктовку и распознавать греческие буквы-звуки. . В английском языке они, как правило, могут составить ряд часто встречающихся неправильных слов, и их научили звукам букв и именам. Таким образом, учителя Л.К. были обеспокоены его способностью справляться со 2-м классом.Сублексический навык LK практически отсутствовал на обоих языках, поэтому было решено, что будет обеспечена поддержка его восприятия букв и звука и его навыков декодирования орфографии. Сублексические процессы были выбраны в качестве цели, поскольку Л.К. не получил пользы от обучения фонетике, которое он получил до сих пор, и казалось важным применить этот навык, прежде чем он перейдет в 2 класс.
Программа обучения
Программа началась в феврале 2010 год и длился девять недель.Занятия проходили в школе Л.К., где первый автор видел его индивидуально один час в неделю. Сессии были разделены на 30 минут, посвященных обучению на греческом языке, и 30 минут на английском языке. Порядок языков менялся каждую неделю. Применяемая процедура была одинаковой для каждого сеанса, и его родителям каждую неделю передавалось письмо с изложением того, что Л.К. должен делать дома.
Процедура
Обучение включало подробное обучение фонетике, в соответствии с программой Хэтчера ([1994]), в ней использовались материалы Jolly Phonics (Lloyd et al.[1992]) и процедуры, использованные Brunsdon et al. ([2002a]) пример вмешательства. Основное различие между исследованием Брансдона и др. И нашим состоит в том, что они обучали чтению, тогда как правописание было целью в настоящем исследовании. Занятия начинались с оценки букв, прочитанных на предыдущей неделе (кроме первого занятия). Каждую неделю изучались шесть букв или диграфов в соответствии с порядком схемы Jolly Phonics. Каждая буква была связана со словом, которое LK произнес и написал в соответствии с процедурой Brunsdon et al.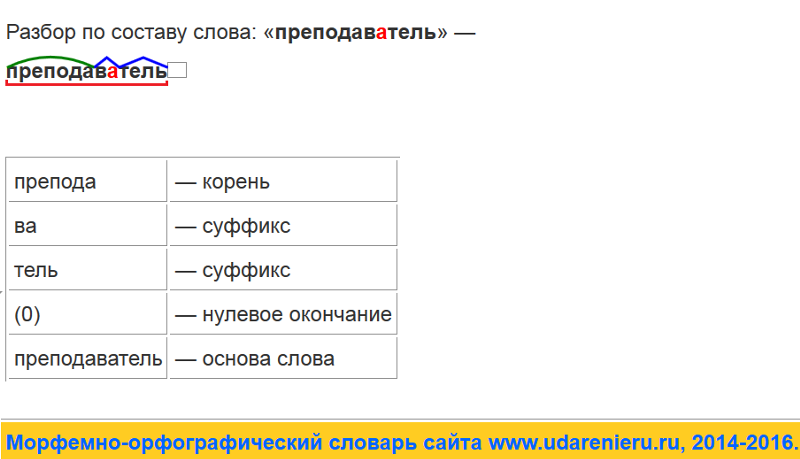 ([2002a]). Например, если целевая буква была U, LK был представлен с буквой, написанной на карточке, и его попросили посмотреть на карточку со словом, начинающимся с этой буквы, написанным на ней (например, < up> ). ЛК попросили прочитать и повторить слово три раза, следуя за тестером. Затем его попросили скопировать букву в верхнем и нижнем регистре и слово. Если он копировал без ошибок, его просили снова написать слово после десятисекундной задержки. Эта процедура выполнялась для каждой новой буквы / орграфа.
([2002a]). Например, если целевая буква была U, LK был представлен с буквой, написанной на карточке, и его попросили посмотреть на карточку со словом, начинающимся с этой буквы, написанным на ней (например, < up> ). ЛК попросили прочитать и повторить слово три раза, следуя за тестером. Затем его попросили скопировать букву в верхнем и нижнем регистре и слово. Если он копировал без ошибок, его просили снова написать слово после десятисекундной задержки. Эта процедура выполнялась для каждой новой буквы / орграфа.
Следующая часть каждой сессии включала фонологические упражнения в соответствии с программой Sound Linkage Хэтчера ([1994]). Фокус занятий менялся каждую неделю и включал в себя работу над концептуализацией слов как частью предложений, осознанием слогов, смешиванием фонем, различением фонем и идентификацией и транспонированием фонем.
После фонологической активности в каждом сеансе LK было предложено написать одно или несколько предложений (структура предложения была субъект-глагол-объект), включая звуки и слова, которым он научился во время вмешательства.На этом этапе, следуя методу, используемому в сеансах интервенции «Восстановление при чтении» (Clay, [1993]), LK попросили разрезать предложение / я на слова, слоги и фонемы, а затем смешать их, чтобы восстановить слова и, наконец, предложения. Затем Л.К. попросили снова написать приговор. Иногда на том же занятии ЛК также просили построить слова, используя пластиковые буквы, помещенные в поля для слов (Эльконин, [1971]). Первый автор разработал фонологические действия на греческом языке, эквивалентные только что описанным.
В конце каждого урока родителям LK передавалось письмо с указаниями и занятиями, и они практиковали с LK каждый день после школы в течение двадцати минут. В этом письме родителям советовали произносить согласные без добавления гласных (например, «солнце» следует произносить / с /, / у /, / н /, а не «сух» «у» «нух»). Их также попросили использовать буквенные звуки и избегать использования буквенных имен, поскольку тренинг был направлен на поддержку знания фонем-графемы. Были предложены следующие мероприятия: «Пожалуйста, попросите Л.К. найти новые буквы в журналах, чтобы вырезать их и наклеить в его / ее блокнот.Пожалуйста, попросите LK вырезать картинки с простыми названиями, которые содержат буквенное обозначение в разных позициях (начало, середина и конец). Под каждой картинкой он должен попытаться написать название объекта на картинке. Если он / она не может написать слово, вы должны помочь, произнеся его растянутым образом. Когда LK закончит упражнение, он / она должен прочитать написанные слова. Таким образом, LK создаст свою собственную звуковую книгу ». Наконец, родителям были даны следующие указания относительно обучения буквам и звукам:
Были предложены следующие мероприятия: «Пожалуйста, попросите Л.К. найти новые буквы в журналах, чтобы вырезать их и наклеить в его / ее блокнот.Пожалуйста, попросите LK вырезать картинки с простыми названиями, которые содержат буквенное обозначение в разных позициях (начало, середина и конец). Под каждой картинкой он должен попытаться написать название объекта на картинке. Если он / она не может написать слово, вы должны помочь, произнеся его растянутым образом. Когда LK закончит упражнение, он / она должен прочитать написанные слова. Таким образом, LK создаст свою собственную звуковую книгу ». Наконец, родителям были даны следующие указания относительно обучения буквам и звукам:
- 1)
Покажите ЛК карточку с письмом.
- 2)
Для каждой карты LK должен произносить звук, который издает буква, а не имя.
- 3)
LK должен произносить слова, содержащие звук (в начале, середине и конце).
- 4)
Удалите карточку и попросите Л.К. написать письмо.
- 5)
Если LK не может вспомнить, как написать письмо, вернитесь к шагу 1.
- 6)
Когда LK сможет правильно озвучить и написать букву, переходите к следующей.

Эту процедуру нужно было выполнять каждый день, и родителей LK попросили одинаково практиковать все шесть букв / диграфов.
Оценка после тренировки
Оценка после тренировки проводилась через одну неделю (сублексический пост-тест 1), а затем через четыре месяца (сублексический пост-тест 2) после окончания обучения, чтобы выявить улучшение правописания. , и сохранялись ли они с течением времени.Используются тесты, которые использовались перед обучением на правописание, чтение и фонологические способности. Результаты представлены в Таблице 2 и показывают, что LK показал улучшение правописания и чтения как для английского, так и для греческого языков. Он также показал улучшение фонологических способностей к греческому языку. Чтобы выяснить, были ли эффекты обучения специфичны для грамотности и фонологических процессов, арифметический субтест из WISC-IV также был повторно проведен сразу после обучения. Результаты не показали изменений (стандартная оценка до тренировки = 100, стандартная оценка после тренировки = 100).
Таблица 2 Результаты до тренировки, немедленные и отсроченные результаты после тренировки для LK и показателей группы сравнения (баллы, выделенные жирным шрифтом, предназначены для оценок, где стандартизованные баллы не были доступны и представляют собой процент правильных ответов)Подробное исследование орфографических процессов
Чтобы более подробно изучить орфографию LK, его эффективность была изучена в неправильном и правильном правописании слов и несловесном правописании (задачи, ориентированные на лексические и сублексические орфографические процессы, соответственно).До обучения LK не умел писать по буквам неправильные и правильные слова и неслова. В таблице 3 представлены его результаты после тренировки. Оценка также проводилась для соответствующей возрастной группы двуязычных англоговорящих и грекоязычных детей (N = 9) из класса LK в школе. Группа сравнения имела средний хронологический возраст 7; 05 (s.d. = 0,29) лет. Дети сравнения были протестированы одновременно с LK, то есть, когда он закончил обучение (немедленная оценка после тренировки, сублексический пост-тест 1), а затем через четыре месяца (отложенная посттренировочная оценка, сублексический пост-тест 2). ).
Группа сравнения имела средний хронологический возраст 7; 05 (s.d. = 0,29) лет. Дети сравнения были протестированы одновременно с LK, то есть, когда он закончил обучение (немедленная оценка после тренировки, сублексический пост-тест 1), а затем через четыре месяца (отложенная посттренировочная оценка, сублексический пост-тест 2). ).
Результаты показали, что сублексические навыки LK, отраженные в несловесном правописании, были лучше, чем лексические процессы как для английского, так и для греческого языков. Преимущество несловесного и правильного написания по сравнению с неправильным написанием слов также было обнаружено для обоих языков в группе сравнения 1 .Значительное улучшение было также отмечено в точности чтения как для греческого, так и для английского языков. Разница между типично развивающимися детьми и LK не была значимой во время субексического пост-теста 2 для чтения английских неправильных слов и несловесных слов, а также для чтения греческих слов и несловесного чтения (для греческого языка различия между неправильными и обычными словами не существует для чтения из-за высокий уровень прозрачности).
Качественный анализ орфографических ошибок
Как отмечалось во введении, исследователи изучили типы орфографических ошибок в качестве средства исследования используемых процессов.В исследовании, в котором использовались те же стимулы, что и в настоящем исследовании, а также дети того же возраста, что и LK, Ниолаки и Мастерсон ([2012a]) сообщили, что одноязычные англоговорящие дети совершали 67% фонологически приемлемых ошибок, а одноязычные грекоязычные дети — 91. % таких ошибок. Мы провели качественный анализ орфографических ошибок, допущенных LK. Проверка типов ошибок, допущенных в неправильном написании слов при оценке с задержкой после вмешательства, показала, что большинство из них были фонологически приемлемыми (60% для английского языка и 88% для греческого).