Разбор слова по составу, Ушакова О.Д . Тренировочные упражнения. ФГОС , ИД Литера , 9785407007319 2016г. 82,40р.
Ушакова О.Д
Серия: Тренировочные упражнения. ФГОС
Осталось всего 6 шт.
82,40р.
Только в магазинах
В наличии в 4 магазинах
Ангарск, ПродаЛитЪ ТЦ МЕГА
Иркутск, ПродаЛитЪ Европарк
Иркутск, Экспресс
Улан-Удэ, ПродаЛитЪ EuroZone
Цена в магазине может отличаться
от цены, указанной на сайте.
Поделиться ссылкой в:
Издательство:ИД Литера
ISBN:978-5-407-00731-9
Штрих-код:9785407007319
Страниц:32
Тип обложки:Мягкая
Год:2016
НДС:10%
Код:888312
Описание
В книге даны план и образцы разбора слова по составу. Подсказки и памятки помогут школьникам в выполнении одного из самых трудных заданий в контрольных работах.
Подсказки и памятки помогут школьникам в выполнении одного из самых трудных заданий в контрольных работах.
Смотреть все
333,50р.
Определяем части речи и члены предложения 1-4 классы (2021 г.)
Ушакова О.Д
Магазины
267,00р.
Справочник школьника. 1-4 кл.: Русский язык, математика (2020 г.)
Ушакова О.Д
Магазины
186,50р.
Обучающие диктанты: 1-4 классы (2020 г.)
Ушакова О.Д
Магазины
73,50р.
Выучи таблицу умножения. 2-3 классы (2018 г.)
Ушакова О.Д
Магазины
73,50р.
Сложение и вычитание в пределах 100. 1-3 классы (2017 г.)
Ушакова О.Д
Магазины
82,40р.
Секреты умножения и деления. 2-4 классы (2017 г.)
Ушакова О.Д
Магазины
82,40р.
Математика. 2-4 кл.: Магические квадраты (2017 г.)
Ушакова О.Д
Магазины
508,00р.
Литературное чтение. 1-4 классы (2017 г.)
Ушакова О.Д
Магазины
82,40р.
Тренировочные упражнения. Английский язык: Задания на все правила грамматик (2017 г.)
Ушакова О.Д
Магазины
82,40р.
Тренировочные упражнения. Английский язык: Задания для запоминания лексики (2017 г.)
Ушакова О.Д
Магазины
82,40р.
Тренировочные упражнения. Английский язык. 2 год обучения (2017 г.
 )
)Ушакова О.Д
Магазины
73,50р.
Тренировочные упражнения. Английский язык. 1 год обучения (2017 г.)
Ушакова О.Д
Магазины
253,50р.
Грамматика английского языка (2017 г.)
Ушакова О.Д
Магазины
82,40р.
Русский язык. 2-4 кл.: Разбор слова по составу (2016 г.)
Ушакова О.Д
Магазины
82,40р.
Русский язык.
 2-4 кл.: Фонетический разбор
(2016 г.)
2-4 кл.: Фонетический разбор
(2016 г.)Ушакова О.Д
Магазины
82,40р.
Русский язык. 2-4 кл.: Разбор предложений ФГОС (2016 г.)
Ушакова О.Д
Магазины
82,40р.
Тренировочные упражнения. Английский язык. 3 год обучения (2016 г.)
Ушакова О.Д
Магазины
275,90р.
Говори правильно! (2014 г.)
Ушакова О.Д
Магазины
412,30р.
Русский язык для младших школьников: Книжка-подсказка (2014 г.)
Ушакова О.Д
Смотреть все
83,50р.
Проверяем скорость чтения: 1 класс ФГОС (2018 г.)
Крутецкая В.А
Магазины
73,50р.
Тренировочные упражнения. Английский язык. 1 год обучения (2017 г.)
Ушакова О.Д
Магазины
82,40р.
Русский язык. 2-4 кл.: Разбор слова по составу (2016 г.
 )
)Ушакова О.Д
Магазины
82,40р.
Русский язык. 2-4 кл.: Фонетический разбор (2016 г.)
Ушакова О.Д
Магазины
82,40р.
Русский язык. 2-4 кл.: Разбор предложений ФГОС (2016 г.)
Ушакова О.Д
Магазины
82,40р.
Тренировочные упражнения. Английский язык. 3 год обучения (2016 г.)
Ушакова О.Д
Магазины
Смотреть все
202,00р.
Пишем красиво и грамотно. 3 класс (2022 г.)
Горохова Анна Михайловна
Магазины
125,00р.
Русский язык. Научусь писать без ошибок. 1-2 классы (2022 г.)
Сорокина Светлана Павловна
Магазины
156,60р.
Орфографический разбор слова (2014 г.)
Ушакова О.Д.
Магазины
158,00р.
Словарные слова: Кроссворды и головоломки для начальной школы (2022 г.)
Якубова Рамиля Борисовна
Магазины
199,00р.
Правила русского языка. С наклейками, ребусами, кроссвордами (2019 г.)
Матекина Э.
Магазины
232,00р.
Букваренок. 1 кл.: Задания и упражнения к Букварю ФГОС (2021 г.)
Репкин Владимир Владимирович
Магазины
241,00р.
Русский язык. 4 кл.: Тесты (2020 г.)
Гурикова И.В.
Магазины
293,50р.
Литературное чтение. 2 класс: Проверочные и диагностические работы ФГОС /+774666/ (2021 г.
 )
)Кац Э.Э., Миронова Н.А.
Магазины
222,00р.
Учебные таблицы по русскому языку. 1-4 классы (2023 г.)
Алексеев Филипп Сергеевич
Магазины
81,00р.
Русский язык. Выучу все правила. 3 класс (2022 г.)
Шевелёва Наталия Николаевна, Порохня Дмитрий Владимирович
Магазины
131,00р.
Русский язык. 4 класс: Комплексный тренажер (2022 г.)
Барковская Н.Ф.
Магазины
187,50р.
Русский язык в схемах и таблицах. 1-4 класс (2019 г.)
Узорова Ольга Васильевна
Магазины
234,50р.
-20% после регистрации
Литературное чтение. 3 кл.: Проверочные и диагност. работы ФГОС (2020 г.)
Кац Элла Эльханоновна
210,50р.
Читательский дневник. We bare bears (2021 г.)
Магазины
54,00р.
Русский язык. Члены предложения: Рабочая тетрадь младшего школьника (2020 г.
 )
)Бахурова Е.П.
Магазины
170,50р.
10000 заданий и упражнений по русскому языку. 1-4 классы (2020 г.)
Узорова Ольга Васильевна
Магазины
113,00р.
Тренировочные примеры по русскому языку. 1 класс: Задания для повторения из закрепления (2023 г.)
Кузнецова Марта Ивановна
Магазины
113,00р.
Умный блокнот. Начальная школа. Русский язык. Прилагательные без ошибок (2019 г.)
Овчинникова Н. Н.
Н.
Магазины
354,00р.
Литература (2022 г.)
Маланка Т.Г., Захарова Т.А.
Магазины
477,50р.
Тетрадь на выходные.: 3 кл. Давай учиться весело! ФГОС НОО (2020 г.)
Винокурова Н., Зайцева Л.
Магазины
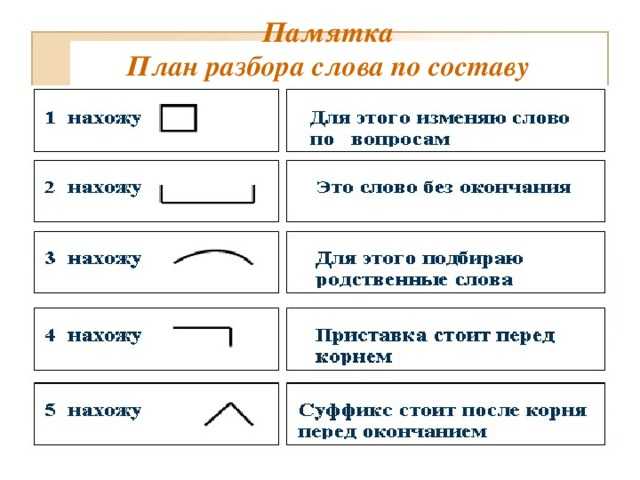
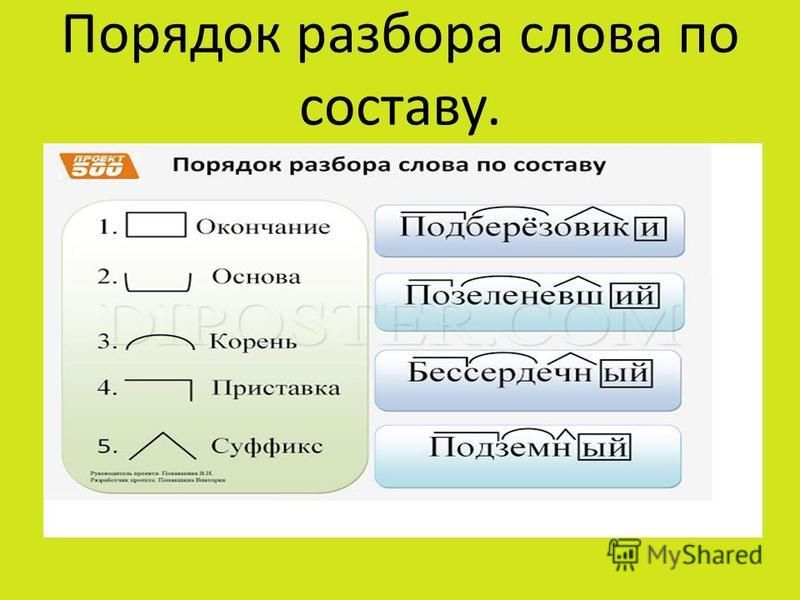
Образование однокоренных слов с помощью суффиксов и приставок. Разбор слова по составу.
Урок 15 | Тема: Образование однокоренных слов с помощью суффиксов и приставок. Разбор слова по составу. | 05.10.21г. |
Цели: развивать умения распознавать однокоренные слова, определять значимые части в слове, выполнять словообразовательный анализ слов.
Планируемые результаты
Предметные: ознакомление с алгоритмом нахождения в слове приставки и суффикса, уточнить представление об окончании и его роли в слове; совершенствовать навыки правописания родовых окончаний прилагательных.
Метапредметные: п. — самостоятельное выделение и формулирование познавательной цели; моделирование; анализ, сравнение, классификация объектов по выделенным признакам; к. — инициативное сотрудничество с учителем и сверстниками; контроль, коррекция, оценка действий партнёра; р. — постановка учебной задачи; сличение способа действия и его результата с заданным эталоном; оценивание качества и уровня усвоения материала; л. — установление связи между целью учебной деятельности и её мотивом.
Тип урока: урок решения учебной задачи.
Ход урока
I. Организационный момент
Организационный момент
II. Проверка домашнего задания
III. Актуализация знаний
Работа на карточках.
— Подберите к данным существительным подходящие по смыслу имена прилагательные с непроизносимыми согласными, а к прилагательным — имена существительные с непроизносимыми согласными.
Писатель, небо, крутая, цветы, горячее, человек, час, сильное, сельская.
(Известный писатель, звёздное небо, крутая лестница, прелестные цветы, горячее сердце, чувствительный человек, поздний час, сильное чувство, сельская окрестность.)
IV. Работа по теме урока
1. Игра «Доскажи словечко»
Знает наша детвора:
Прятки — лучшая… (игра).
Всех ребят хотим собрать,
В прятки будем мы.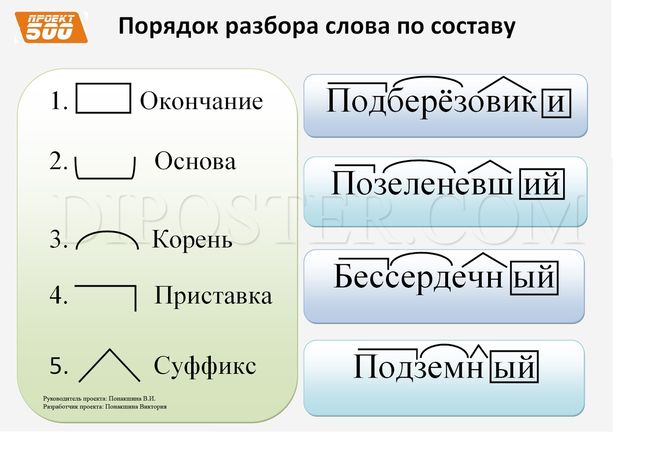 .. (играть).
.. (играть).
Наш щенок такой шалун,
Забияка и… (игрун).
Мой котёнок шаловливый
Очень ласковый,… (игривый).
У малышки погремушка,
Очень шумная… (игрушка).
— Прочитайте слова, которые вы записали. Как они называются?
— Найдите общую часть родственных слов. Как она называется?
— С помощью каких значимых частей образовались эти слова?
— Какие ещё значимые части слова вы знаете? Дайте их определения.
— Как найти корень в слове?
— Как определить, являются ли слова однокоренными?
Работа по учебнику
Упр. 83 (с. 54).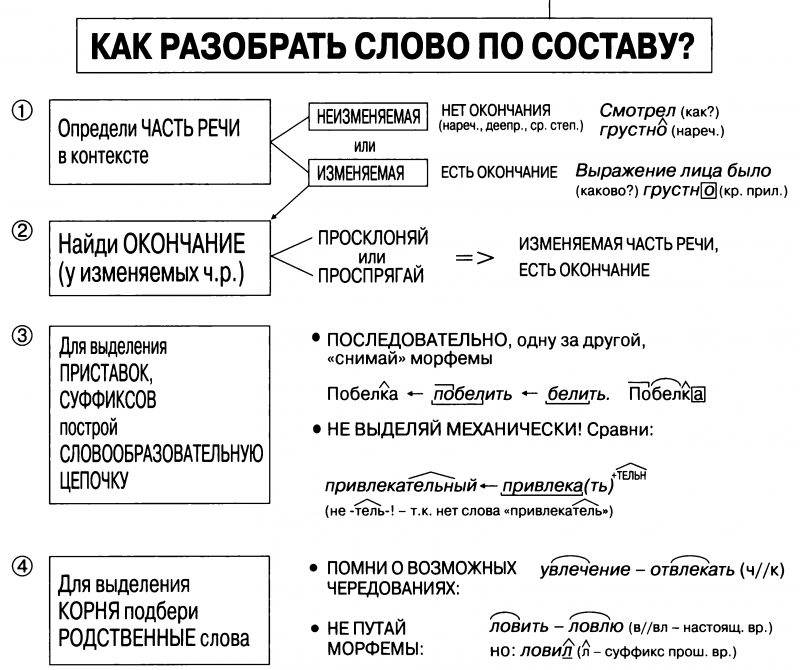
— Прочитайте предложения выразительно.
— Найдите слова, которые употреблены в переносном значении. (Осень ходит, осень развешивает, хрустальные паутины, убирает в золото.)
— Найдите в предложениях грамматические основы.
— Назовите в каждом предложении однородные члены.
— Выполните письменные задания к упражнению.
— Какие окончания вы выделили в словах первого предложения?
— Какую роль играют окончания в словосочетании и предложении?
— Назовите части слова хрустальные.
Упр. 84 (с. 54).
— Прочитайте.
— Какая значимая часть слова служит для связи слов в словосочетании и предложении? (Окончание.)
— Как проверить окончание имени прилагательного? (По имени существительному. )
)
— Выполните задания.
— Прочитайте словосочетания. Объясните правописание окончаний имён прилагательных.
(Самооценка.)
V. Физкультминутка
VI. Закрепление изученного материала
Работа по учебнику
Упр. 86 (с. 55).
— Прочитайте первую группу слов.
— Назовите слова с приставками. (Согреть, поехали, поездка, наушники.)
— Докажите, что это приставки. Найдите корень в этих словах.
— Прочитайте вторую группу слов.
— Назовите слова, в которых выделенная часть не является суффиксом и входит в состав корня. (Чеснок, веник, майка.)
— Назовите однокоренные слова, выделите корни.
— Какое языковое явление мы наблюдаем при образовании однокоренных слов? (Чередование согласных: чеснок — чесночный, майка — маечка, веник — веничек?)
— Выполните письменные задания к упражнению.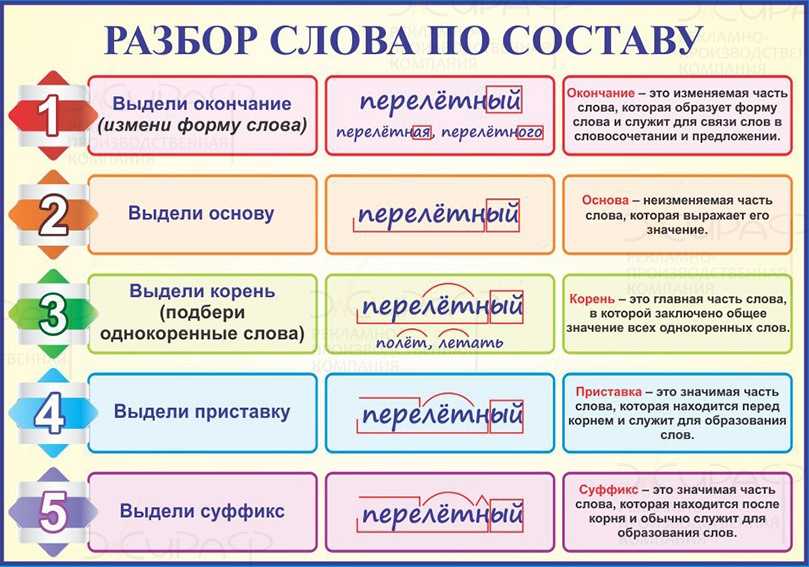
Упр. 87 (с. 55).
— Прочитайте текст.
— Определите его тему. (Животные и их детёныши.)
— Какова главная мысль текста? (Тетёрка — заботливая мама.)
— Сколько частей можно выделить в этом тексте? (Три.)
— Прочитайте первую часть. Определите главную мысль. (Тетёрка с птенцами вышла на прогулку.)
— Прочитайте вторую часть. Определите главную мысль. (Тетеревята разбежались по поляне.)
— Прочитайте третью часть. Определите главную мысль. (Мама следит за птенцами.)
— Придумайте заглавие к каждой части.
— Объясните написание слов с пропущенными буквами.
(Свободный диктант. Учитель читает текст по частям, уча¬щиеся записывают каждую часть по памяти. Самопроверка, самооценка.)
— Выделите в глаголах приставки.
— Подберите слова к первой схеме. (Курочка, тетёрка, тетеревята и т. д.)
— Подберите слова ко второй схеме. (Пёстрая, поляна, куча и т. д.)
VII. Рефлексия
— Разберите слова по составу. Воспользуйтесь памяткой на с. 148 учебника.
Вариант 1
Бессердечный, дубок, подъезд, лень.
Вариант 2
Позолота, розовый, указка, поход.
(Коллективная проверка.)
— Оцените свою работу на уроке.
VIII. Подведение итогов урока
— Из каких значимых частей состоят слова?
— По каким признакам можно определить однокоренные слова? Какова роль окончания в слове?
Домашнее задание
Стр. 54 упр. 85 – составь из слов две скороговорки, запиши их в тетрадь, выучи скороговорки наизусть.
85 – составь из слов две скороговорки, запиши их в тетрадь, выучи скороговорки наизусть.
Передовой ИИ приводит в действие серьезное обновление API рекомендаций контента Parse.ly
Как мы создаем семантические встраивания? Мы потратили последний год на создание и производство языковой модели, которая может преобразовывать фрагмент текста в семантическое вложение. Мы использовали стандартную модель преобразования (своего рода модель глубокого обучения) в качестве отправной точки и точно настроили ее на большом массиве данных, которые мы пометили с помощью неконтролируемого процесса. Мы надеемся раскрыть технические детали в другом посте в будущем.
До сих пор рекомендации Parse.ly основывались на довольно стандартной модели «мешка слов». Этот подход по существу представляет документ как количество слов. Таким образом, документ:
Обама беседует со СМИ в Иллинойсе.
представлен в виде неупорядоченного «мешка слов» следующим образом:
{«the»:1, «говорит»:1, «Обама»:1, «кому»:1, «медиа»:1, «в»:1, «Иллинойс»:1}
Существует много вариантов этого подхода, которые отличаются тем, как они уменьшают влияние общих слов (например, «the» или «as»), так что решающую роль играют редкие, но заметные слова. После применения одной из этих схем взвешивания документ может выглядеть так:
После применения одной из этих схем взвешивания документ может выглядеть так:
{«говорить»: 0,1, «Обама»: 0,4, «медиа»: 0,2, «Иллинойс»: 0,3}
Этот подход (особенно вариант под названием BM25) достаточно эффективен и оставался отраслевым стандартом в течение 15-20 лет. Модель мешка слов можно использовать для рекомендации контента, похожего на документ запроса (т. е. документ, представляющий интерес), путем запроса к базе данных найти документы, наиболее похожие на документ запроса. Сходство двух документов определяется как доля перекрывающихся весов слов.
ElasticSearch — это система баз данных, хлеб с маслом которой обслуживает такие «запросы на сходство документов» как для рекомендательных систем, так и для поисковых систем. Конечная точка Parse.ly /related использует реализацию ElasticSearch BM25 в своем типе запроса More Like This. Конечно, мы добавляем некоторые дополнительные приемы для дальнейшего улучшения стандартного ElasticSearch, но BM25 был в центре наших рекомендаций в течение последних восьми лет или около того.
Возьмите наш первый документ — «Обама говорит со СМИ в Иллинойсе». Теперь представьте, что у нас есть второй документ, который гласит:
Президент приветствует прессу в Чикаго.
Для тех, кто знаком с политикой США, этот документ говорит, по сути, то же самое, что и первый документ, другими словами, они семантически (концептуально) похожи. Однако важные слова в двух документах не совпадают:
Документ 1: (Обама, говорит, СМИ, Иллинойс)
Документ 2: (Президент, приветствует, пресса, Чикаго)
Различный выбор слов в этих двух документах приводит к тому, что модель мешка слов не находит сходства между этими двумя документами, что свидетельствует о серьезной проблеме с этим подходом. Конечно, этот пример (взятый из этой статьи) несколько надуман, и на практике в более длинных документах, которые имеют большое семантическое сходство, часто используется много одних и тех же слов, поэтому модель мешка слов работала достаточно хорошо в течение стольких лет. Тем не менее, вы можете видеть, что есть возможности для улучшения: полагаться на точные совпадения слов — это случайность, которая оставляет слишком много на волю случая.
Тем не менее, вы можете видеть, что есть возможности для улучшения: полагаться на точные совпадения слов — это случайность, которая оставляет слишком много на волю случая.
Ранее мы писали о том, как языковые модели меняют все вокруг — проверьте этот пост, если вы не знакомы с языковыми моделями и хотите узнать больше. Вы можете думать о языковой модели как об огромной модели глубокого обучения, обученной миллионам или миллиардам задач, в которых ей нужно предсказать пропущенное слово в документе. Чтобы хорошо справиться с этой задачей, модель не только изучает, как работает язык, но и учится понимать мир, который мы описываем с помощью языка. Например, модель узнает, что слова Обама и Президент являются синонимами, точно так же, как слова Сенат и законодатели .
Языковые модели стандартно обучаются этой задаче предсказания отсутствующих слов, и без дополнительной настройки они могут брать все слова в документе и преобразовывать их в встраивания слов . Вложение слов представляет слово как точку в «семантическом пространстве». Это немного сложно представить, но ключевой момент заключается в том, что слова, имеющие сходное значение, находятся близко друг к другу в этом пространстве. Итак, если наши векторы слов построены правильно, то слова в нашем документе будут выглядеть так:
Вложение слов представляет слово как точку в «семантическом пространстве». Это немного сложно представить, но ключевой момент заключается в том, что слова, имеющие сходное значение, находятся близко друг к другу в этом пространстве. Итак, если наши векторы слов построены правильно, то слова в нашем документе будут выглядеть так:
В этом случае языковая модель проделала хорошую работу по созданию вложений слов, потому что семантически похожие слова (такие как Обама и Президент, СМИ и пресса ) близки друг к другу.
Теперь давайте посмотрим на рисунок и попробуем придумать схему измерения сходства между двумя документами. Можно было бы просто соединить каждое слово из документа 1 с наиболее похожим на него словом из документа 2 и просуммировать все расстояния между парами. В этом суть подхода, который мы использовали в нашей новой системе. Он концептуально похож на расстояние перемещения слов подход к измерению схожести документов, который мы рассмотрели здесь.
Как оказалось, современные языковые модели хорошо измеряют сходство между двумя словами, , но не очень хороши при измерении сходства между двумя документами . Нам пришлось выполнить значительный объем научно-исследовательских работ, чтобы разработать модель преобразователя, которая могла бы создавать встраивания документов — , мы надеемся подробно рассказать об этой работе в будущих технических постах.
Одним из важных приемов было использование расстояния переноса слов для создания меток для пар документов без присмотра, чтобы наша модель могла научиться преобразовывать встраивания слов документа в встраивание одного документа. Но на данный момент приведенный выше пример дает вам общее представление о нашем подходе.
Как конкретно выглядят улучшения? Чтобы дать вам представление об улучшении, которое вы можете ожидать, давайте рассмотрим конкретный пример от Ars Technica, нашего дружелюбного клиента. Я выбрал статью Дорога к низкоуглеродистому бетону с их домашней страницы сегодня, которую мы будем использовать в качестве «статьи с запросом». Затем мы запросим рекомендации у обеих наших рекомендательных систем: модели набора слов (которая фактически предоставляет рекомендации на странице) и нашего нового подхода, основанного на встраиваниях. Вот результаты:
Я выбрал статью Дорога к низкоуглеродистому бетону с их домашней страницы сегодня, которую мы будем использовать в качестве «статьи с запросом». Затем мы запросим рекомендации у обеих наших рекомендательных систем: модели набора слов (которая фактически предоставляет рекомендации на странице) и нашего нового подхода, основанного на встраиваниях. Вот результаты:
Статья с запросом представляет собой развернутую статью, в которой рассказывается об огромном углеродном следе производства бетона и о возможных способах его уменьшения. Статья довольно техническая, охватывающая детали химии и экономики бетона.
Глядя на контент, рекомендуемый моделью мешка слов, мы видим, что рекомендация с самым высоким рейтингом относится к деталям античного бетона, использовавшегося в Римской империи. Эта рекомендация имеет лишь среднее значение: как и статья с запросом, в ней рассматриваются технические детали бетона, но, в отличие от статьи с запросом, она не касается выбросов углерода и воздействия на окружающую среду. Модель мешка слов, вероятно, получила высокую оценку, потому что в обеих статьях используются редкие слова, такие как кальций , вулканический, и клинкерный. Следующие две статьи более актуальны и посвящены как бетону, так и выбросам углерода, а четвертая статья посвящена инновационной идее, связанной с бетоном, но не выбросам углерода.
Модель мешка слов, вероятно, получила высокую оценку, потому что в обеих статьях используются редкие слова, такие как кальций , вулканический, и клинкерный. Следующие две статьи более актуальны и посвящены как бетону, так и выбросам углерода, а четвертая статья посвящена инновационной идее, связанной с бетоном, но не выбросам углерода.
Новые рекомендации на основе вложений дают более строгие рекомендации: рекомендация с самым высоким рейтингом касается тех же тем, что и статья с запросом: бетон и выбросы углерода. Статья на втором месте также посвящена бетону и углероду, а статья на третьем месте посвящена строительному проекту с низким уровнем выбросов, включающему большое количество бетона. Четвертая статья здесь была самой высоко оцененной статьей в подходе «мешок слов» и имеет лишь умеренную актуальность.
Каких улучшений можно ожидать? Результаты, которые мы видели в приведенном выше примере, являются хорошим представлением ожидаемых улучшений: более релевантные статьи поднимаются в рейтинге, а менее релевантные — понижаются. Часто есть некоторое совпадение.
Часто есть некоторое совпадение.
Улучшение наиболее заметно, когда статья запроса содержит много релевантных связанных статей — в этом случае акцент на семантическом сходстве может иметь большое значение. С другой стороны, если на вашем сайте есть только одна или две статьи, которые имеют отношение к статье запроса, то оба подхода часто будут поднимать их на вершину рейтинга, что приведет к небольшому улучшению.
Попробуйте сами
Клиенты Parse.ly, которые приобрели наш API, могут легко переместить свои запросы из конечной точки /related в конечную точку /similar. Прочтите нашу техническую документацию в нашей базе знаний здесь. Эти два варианта поддерживают одни и те же параметры, используя одни и те же аргументы, вам просто нужно заменить слово «связанный» на «похожий». Например, вы можете запустить командную строку и выполнить следующую команду, чтобы сравнить рекомендации из конечной точки /similar с рекомендациями из конечной точки /related:
> curl ‘https://api.
parsely.com/v2/similar?apikey=[ВАШ_APIKEY]&url=[QUERY_URL]’
> curl ‘https://api.parsely.com/v2/related?apikey=[YOUR_APIKEY]&url=[QUERY_URL]’
 parsely.com/v2/similar?apikey=[ВАШ_APIKEY]&url=[QUERY_URL]’
parsely.com/v2/similar?apikey=[ВАШ_APIKEY]&url=[QUERY_URL]’Анализ межъязыковых зависимостей с помощью POS-управляемого изменения порядка слов
Поделиться этой страницей:
Лу Лю, И Чжоу, Цзяньхан Сюй, Сяоцин Чжэн, Кай-Вэй Чанг и Сюаньцзин Хуан, в
EMNLP-вывод , 2020.Загрузить полный текст
Abstract
Мы предлагаем новый подход к разбору межъязыковых зависимостей, основанный на переупорядочении слов. Слова в каждом предложении корпуса исходного языка переставляются в соответствии с порядком слов в целевом языке под руководством языковой модели на основе частей речи (LM). Чтобы получить наивысшую оценку переупорядочения в соответствии с LM, алгоритм оптимизации на основе популяции и его генетические операторы предназначены для работы с комбинаторной природой такого переупорядочения слов. Затем синтаксический анализатор, обученный на переупорядоченном корпусе, можно использовать для анализа предложений на целевом языке. С помощью обширных экспериментов мы продемонстрировали, что наш подход дает лучшие или сопоставимые результаты на 25 целевых языках (увеличение в среднем на 1,73%) и значительно превосходит базовый уровень на языках, которые сильно отличаются от исходного. Например, при переводе парсера английского языка на хинди и латиницу наш подход превосходит базовый вариант на 15,3% и 6,7% соответственно.
Чтобы получить наивысшую оценку переупорядочения в соответствии с LM, алгоритм оптимизации на основе популяции и его генетические операторы предназначены для работы с комбинаторной природой такого переупорядочения слов. Затем синтаксический анализатор, обученный на переупорядоченном корпусе, можно использовать для анализа предложений на целевом языке. С помощью обширных экспериментов мы продемонстрировали, что наш подход дает лучшие или сопоставимые результаты на 25 целевых языках (увеличение в среднем на 1,73%) и значительно превосходит базовый уровень на языках, которые сильно отличаются от исходного. Например, при переводе парсера английского языка на хинди и латиницу наш подход превосходит базовый вариант на 15,3% и 6,7% соответственно.
Стартовый номер
@inproceedings{liu2020на разных языках,
автор = {Лю, Лу и Чжоу, И и Сюй, Цзяньхань и Чжэн, Сяоцин и Чанг, Кай-Вэй и Хуан, Сюаньцзин},
title = {Синтаксический анализ межъязыковых зависимостей с помощью переупорядочения слов на основе POS},
booktitle = {EMNLP-Находка},
год = {2020}
}
Связанные публикации
Улучшение межъязыкового трансферного обучения Zero Shot с помощью надежного обучения
Куан-Хао Хуан, Васи Ахмад, Нанюн Пэн и Кай-Вэй Чанг в ЕМНЛП , 2021.
Полный текст Код Абстрактный БибТекс ПодробностиПредварительно обученные многоязычные кодировщики, такие как многоязычные кодировщики BERT и XLM-R, демонстрируют большой потенциал для межъязыковой передачи с нулевым выстрелом. Однако эти многоязычные кодировщики не точно выравнивают слова и фразы на разных языках. В частности, изучение выравнивания в многоязычном пространстве встраивания обычно требует параллельных корпусов на уровне предложений или слов, которые дорого получить для языков с низким уровнем ресурсов. В качестве альтернативы можно сделать многоязычные кодировщики более надежными; при точной настройке кодировщика с помощью нисходящей задачи мы обучаем кодировщик допускать шум в контекстных пространствах встраивания, так что даже если представления разных языков не выровнены должным образом, модель все равно может достичь хорошей производительности на межъязыковом нулевом уровне.
передача. В этой работе мы предлагаем стратегию обучения для обучения надежных моделей, проводя связи между состязательными примерами и неудачными случаями межъязыкового переноса с нулевым выстрелом. Мы используем два широко используемых надежных метода обучения, состязательное обучение и рандомизированное сглаживание, чтобы обучить желаемую надежную модель. Экспериментальные результаты показывают, что надежное обучение улучшает межъязыковой перенос с нулевым выстрелом в задачах классификации текста. Улучшение является более значительным в условиях обобщенного межъязыкового переноса, когда пара входных предложений принадлежит двум разным языкам. @inproceedings{huang2021улучшение, title = {Улучшение межъязыкового трансферного обучения Zero Shot с помощью надежного обучения}, автор = {Хуан, Куан-Хао и Ахмад, Васи и Пэн, Наньюнь и Чанг, Кай-Вэй}, презентация_id = {https://underline.io/events/192/posters/7783/poster/40656-improving-zero-shot-cross-lingual-transfer-learning-через-надежное-обучение}, название книги = {EMNLP}, год = {2021} }ДеталиМногоязычный BERT с расширенным синтаксисом для межъязыковой передачи
Васи Ахмад, Хаоран Ли, Кай-Вей Чанг и Яшар Мехдад, ACL , 2021 год.
Полный текст видео Код Абстрактный БибТекс ПодробностиВ последние годы мы наблюдаем колоссальные усилия в предварительном обучении многоязычных текстовых кодировщиков с использованием крупномасштабных корпусов на многих языках для способствовать межъязыковому трансферному обучению. Однако из-за типологических различий между языками межъязыковой перенос затруднен. Тем не менее синтаксис языка, например, синтаксические зависимости, могут преодолеть типологический разрыв. Предыдущие работы показали, что предварительно обученные многоязычные кодировщики, такие как mBERT (Девлин и др., 2019 г.), фиксировать синтаксис языка, помогая межъязыковому переносу. Эта работа показывает, что явное предоставление синтаксиса языка и обучение mBERT с использованием вспомогательного цель кодировать универсальную зависимость Древовидная структура помогает межъязыковому переводу. Мы провести строгие эксперименты над четырьмя НЛП задачи, включая классификацию текста, ответы на вопросы, распознавание именованных сущностей и семантический анализ, ориентированный на задачи.
Результаты эксперимента показывают, что mBERT с расширенным синтаксисом улучшает межъязыковую передачу в популярных тестах, таких как PAWS-X и MLQA, на 1,4.
и 1,6 балла в среднем по всем языкам.
В настройках общего переноса производительность значительно увеличилась, с 3,9и 3.1
баллов в среднем по PAWS-X и MLQA. @inproceedings{ahmad2021синтаксис, title = {Многоязычный BERT с расширенным синтаксисом для межъязыковой передачи}, автор = {Ахмад, Васи и Ли, Хаоран и Чанг, Кай-Вей и Мехдад, Яшар}, название книги = {ACL}, год = {2021} }ДеталиОценка ценности источников в трансферном обучении
Доктор Ризван Парвез и Кай-Вей Чанг, NAACL , 2021 г.
Полный текст видео Код Абстрактный БибТекс ПодробностиТрансферное обучение, которое адаптирует модель, обученную на источниках с большим объемом данных, к целям с низким уровнем ресурсов, широко применяется в обработке естественного языка (NLP).
Однако при обучении модели переноса на нескольких источниках не каждый источник одинаково полезен для цели. Чтобы лучше передать модель, важно понимать значения источников. В этой статье мы разрабатываем SEAL-Shap, эффективную систему оценки источников для количественной оценки полезности источников (например, доменов/языков) в трансферном обучении на основе метода значений Шепли. Эксперименты и всесторонний анализ как междоменных, так и межъязыковых переводов показывают, что наша структура не только эффективна в выборе полезных источников переноса, но и исходные значения соответствуют интуитивному сходству источника и цели. @inproceedings{parvez2021оценка, title = {Оценка ценности источников в трансферном обучении}, автор = {Парвез, Мд Ризван и Чанг, Кай-Вей}, название книги = {NAACL}, id_презентации = {https://underline.io/events/122/sessions/4261/lecture/19707-evaluating-the-values-of-sources-in-transfer-learning}, год = {2021} }ДеталиGATE: кодировщик преобразователя внимания графа для межъязыковой связи и извлечения событий
Васи Ахмад, Наньюн Пэн и Кай-Вэй Чанг в АААИ , 2021.
Полный текст Код Абстрактный БибТекс ПодробностиВ распространенных подходах к межъязыковым отношениям и извлечению событий используются сверточные сети графов (GCN) с универсальными анализами зависимостей для изучения представлений, не зависящих от языка, чтобы модели, обученные на одном языке, можно было применять к другим языкам. Однако GCN не могут моделировать долгосрочные зависимости или несвязанные слова в дереве зависимостей. Чтобы решить эту проблему, мы предлагаем использовать механизм внутреннего внимания, в котором мы явно объединяем структурную информацию для изучения зависимостей между словами на разных синтаксических расстояниях. Мы представляем GATE, \bf Graph \bf Attention \bf Transformer \bf Encoder, и проверяем его межъязыковую переносимость в задачах извлечения отношений и событий. Мы проводим тщательные эксперименты с широко используемым набором данных ACE05, который включает три типологически разных языка: английский, китайский и арабский.
Результаты оценки показывают, что GATE значительно превосходит три недавно предложенных метода. Наш подробный анализ показывает, что благодаря использованию синтаксических зависимостей GATE создает надежные представления, облегчающие перенос между языками. @inproceedings{ahmad2021gate, автор = {Ахмад, Васи и Пэн, Наньюнь и Чанг, Кай-Вэй}, title = {GATE: кодировщик преобразователя внимания графа для межъязыковой связи и извлечения событий}, название книги = {AAAI}, год = {2021} }ДеталиАнализ межъязыковых зависимостей с помощью переупорядочения слов на основе POS
Лу Лю, И Чжоу, Цзяньхан Сюй, Сяоцин Чжэн, Кай-Вэй Чанг и Сюаньцзин Хуан, в EMNLP-вывод , 2020.
Полный текст Абстрактный БибТекс ПодробностиМы предлагаем новый подход к синтаксическому анализу межъязыковых зависимостей, основанный на переупорядочении слов. Слова в каждом предложении корпуса исходного языка переставляются в соответствии с порядком слов в целевом языке под руководством языковой модели на основе частей речи (LM).
Чтобы получить наивысшую оценку переупорядочения в соответствии с LM, алгоритм оптимизации на основе популяции и его генетические операторы предназначены для работы с комбинаторной природой такого переупорядочения слов. Затем синтаксический анализатор, обученный на переупорядоченном корпусе, можно использовать для анализа предложений на целевом языке. С помощью обширных экспериментов мы продемонстрировали, что наш подход дает лучшие или сопоставимые результаты на 25 целевых языках (увеличение в среднем на 1,73%) и значительно превосходит базовый уровень на языках, которые сильно отличаются от исходного. Например, при переводе парсера английского языка на хинди и латиницу наш подход превосходит базовый вариант на 15,3% и 6,7% соответственно. @inproceedings{liu2020на разных языках, автор = {Лю, Лу и Чжоу, И и Сюй, Цзяньхань и Чжэн, Сяоцин и Чанг, Кай-Вэй и Хуан, Сюаньцзин}, title = {Синтаксический анализ межъязыковых зависимостей с помощью переупорядочения слов на основе POS}, booktitle = {EMNLP-Находка}, год = {2020} }ДеталиАнализ межъязыковых зависимостей с помощью немаркированных вспомогательных языков
Васи Ахмад, Чжисон Чжан, Сюэчжэ Ма, Кай-Вэй Чанг и Нанюн Пэн, в CoNLL , 2019.
Полный текст Плакат Код Абстрактный БибТекс ПодробностиМежъязыковое трансферное обучение стало важным оружием в борьбе с недоступностью аннотированных ресурсов для языков с низким уровнем ресурсов. Одним из основных методов переноса между языками является изучение языково-независимых представлений в форме встраивания слов или контекстного кодирования. В этой работе мы предлагаем использовать неаннотированные предложения из вспомогательных языков для помощи в изучении языково-независимых представлений. Мы проводим эксперименты по анализу межъязыковых зависимостей, где мы обучаем парсер зависимостей на исходном языке и переносим его на широкий спектр целевых языков. Эксперименты с 28 целевыми языками показывают, что состязательное обучение значительно улучшает общую производительность перевода в нескольких различных условиях. Мы проводим тщательный анализ, чтобы оценить языково-независимые представления, полученные в результате состязательного обучения.
@inproceedings{ahmad2019на разных языках, автор = {Ахмад, Васи и Чжан, Чжисон и Ма, Сюэчжэ и Чанг, Кай-Вэй и Пэн, Наньюнь}, title = { Межъязыковой анализ зависимостей с помощью немаркированных вспомогательных языков}, название книги = {CoNLL}, год = {2019} }ДеталиОграниченный вывод с учетом целевого языка для анализа межъязыковых зависимостей
Тао Мэн, Наньюнь Пэн и Кай-Вэй Чанг, EMNLP , 2019 г.
Полный текст Плакат Код Абстрактный БибТекс ПодробностиПредыдущая работа по синтаксическому анализу межъязыковых зависимостей часто фокусировалась на выявлении общих черт между исходным и целевым языками и упускала из виду потенциал использования лингвистических свойств языков для облегчения переноса. В этой статье мы показываем, что слабый контроль лингвистических знаний для целевых языков может существенно улучшить межъязыковой синтаксический анализатор зависимостей на основе графов.
В частности, мы изучаем несколько типов корпусной лингвистической статистики и компилируем их в корпусные ограничения, чтобы направлять процесс вывода во время тестирования. Мы адаптируем два метода, лагранжеву релаксацию и апостериорную регуляризацию, для проведения вывода с ограничениями корпусной статистики. Эксперименты показывают, что лагранжева релаксация и вывод апостериорной регуляризации улучшают характеристики в 15 и 17 из 19 случаев.целевые языки соответственно. Улучшения особенно важны для целевых языков, в которых порядок слов отличается от исходного языка. @inproceedings{meng2019target, автор = {Мэн, Тао и Пэн, Наньюнь и Чанг, Кай-Вэй}, title = {Целевой языковой ограниченный вывод для анализа межъязыковых зависимостей}, название книги = {EMNLP}, год = {2019} }ДеталиО трудностях межъязыкового переноса с разницей в порядке: пример разбора зависимостей
Васи Уддин Ахмад, Чжисон Чжан, Сюэчжэ Ма, Эдуард Хови, Кай-Вэй Чанг и Нанюн Пэн, в NAACL , 2019.
Полный текст видео Код Абстрактный БибТекс ПодробностиВ разных языках может быть разный порядок слов. В этой статье мы исследуем межъязыковой перенос и утверждаем, что модель, не зависящая от порядка, будет работать лучше при переносе на далекие иностранные языки. Чтобы проверить нашу гипотезу, мы обучаем синтаксические анализаторы зависимостей на английском корпусе и оцениваем их производительность передачи на 30 других языках. В частности, мы сравниваем кодировщики и декодеры на основе рекуррентных нейронных сетей (RNN) и модифицированных архитектур самоконтроля. Первый основан на последовательной информации, а второй более гибок в моделировании порядка слов. Тщательные эксперименты и подробный анализ показывают, что архитектуры на основе RNN хорошо переносятся на языки, близкие к английскому, в то время как модели с самостоятельным вниманием имеют лучшую общую межъязыковую переносимость и производительность.

 передача. В этой работе мы предлагаем стратегию обучения для обучения надежных моделей, проводя связи между состязательными примерами и неудачными случаями межъязыкового переноса с нулевым выстрелом. Мы используем два широко используемых надежных метода обучения, состязательное обучение и рандомизированное сглаживание, чтобы обучить желаемую надежную модель. Экспериментальные результаты показывают, что надежное обучение улучшает межъязыковой перенос с нулевым выстрелом в задачах классификации текста. Улучшение является более значительным в условиях обобщенного межъязыкового переноса, когда пара входных предложений принадлежит двум разным языкам.
передача. В этой работе мы предлагаем стратегию обучения для обучения надежных моделей, проводя связи между состязательными примерами и неудачными случаями межъязыкового переноса с нулевым выстрелом. Мы используем два широко используемых надежных метода обучения, состязательное обучение и рандомизированное сглаживание, чтобы обучить желаемую надежную модель. Экспериментальные результаты показывают, что надежное обучение улучшает межъязыковой перенос с нулевым выстрелом в задачах классификации текста. Улучшение является более значительным в условиях обобщенного межъязыкового переноса, когда пара входных предложений принадлежит двум разным языкам. 
 Результаты эксперимента показывают, что mBERT с расширенным синтаксисом улучшает межъязыковую передачу в популярных тестах, таких как PAWS-X и MLQA, на 1,4.
и 1,6 балла в среднем по всем языкам.
В настройках общего переноса производительность значительно увеличилась, с 3,9и 3.1
баллов в среднем по PAWS-X и MLQA.
Результаты эксперимента показывают, что mBERT с расширенным синтаксисом улучшает межъязыковую передачу в популярных тестах, таких как PAWS-X и MLQA, на 1,4.
и 1,6 балла в среднем по всем языкам.
В настройках общего переноса производительность значительно увеличилась, с 3,9и 3.1
баллов в среднем по PAWS-X и MLQA.  Однако при обучении модели переноса на нескольких источниках не каждый источник одинаково полезен для цели. Чтобы лучше передать модель, важно понимать значения источников. В этой статье мы разрабатываем SEAL-Shap, эффективную систему оценки источников для количественной оценки полезности источников (например, доменов/языков) в трансферном обучении на основе метода значений Шепли. Эксперименты и всесторонний анализ как междоменных, так и межъязыковых переводов показывают, что наша структура не только эффективна в выборе полезных источников переноса, но и исходные значения соответствуют интуитивному сходству источника и цели.
Однако при обучении модели переноса на нескольких источниках не каждый источник одинаково полезен для цели. Чтобы лучше передать модель, важно понимать значения источников. В этой статье мы разрабатываем SEAL-Shap, эффективную систему оценки источников для количественной оценки полезности источников (например, доменов/языков) в трансферном обучении на основе метода значений Шепли. Эксперименты и всесторонний анализ как междоменных, так и межъязыковых переводов показывают, что наша структура не только эффективна в выборе полезных источников переноса, но и исходные значения соответствуют интуитивному сходству источника и цели. 
 Результаты оценки показывают, что GATE значительно превосходит три недавно предложенных метода. Наш подробный анализ показывает, что благодаря использованию синтаксических зависимостей GATE создает надежные представления, облегчающие перенос между языками.
Результаты оценки показывают, что GATE значительно превосходит три недавно предложенных метода. Наш подробный анализ показывает, что благодаря использованию синтаксических зависимостей GATE создает надежные представления, облегчающие перенос между языками.  Чтобы получить наивысшую оценку переупорядочения в соответствии с LM, алгоритм оптимизации на основе популяции и его генетические операторы предназначены для работы с комбинаторной природой такого переупорядочения слов. Затем синтаксический анализатор, обученный на переупорядоченном корпусе, можно использовать для анализа предложений на целевом языке. С помощью обширных экспериментов мы продемонстрировали, что наш подход дает лучшие или сопоставимые результаты на 25 целевых языках (увеличение в среднем на 1,73%) и значительно превосходит базовый уровень на языках, которые сильно отличаются от исходного. Например, при переводе парсера английского языка на хинди и латиницу наш подход превосходит базовый вариант на 15,3% и 6,7% соответственно.
Чтобы получить наивысшую оценку переупорядочения в соответствии с LM, алгоритм оптимизации на основе популяции и его генетические операторы предназначены для работы с комбинаторной природой такого переупорядочения слов. Затем синтаксический анализатор, обученный на переупорядоченном корпусе, можно использовать для анализа предложений на целевом языке. С помощью обширных экспериментов мы продемонстрировали, что наш подход дает лучшие или сопоставимые результаты на 25 целевых языках (увеличение в среднем на 1,73%) и значительно превосходит базовый уровень на языках, которые сильно отличаются от исходного. Например, при переводе парсера английского языка на хинди и латиницу наш подход превосходит базовый вариант на 15,3% и 6,7% соответственно. 
 В частности, мы изучаем несколько типов корпусной лингвистической статистики и компилируем их в корпусные ограничения, чтобы направлять процесс вывода во время тестирования. Мы адаптируем два метода, лагранжеву релаксацию и апостериорную регуляризацию, для проведения вывода с ограничениями корпусной статистики. Эксперименты показывают, что лагранжева релаксация и вывод апостериорной регуляризации улучшают характеристики в 15 и 17 из 19 случаев.целевые языки соответственно. Улучшения особенно важны для целевых языков, в которых порядок слов отличается от исходного языка.
В частности, мы изучаем несколько типов корпусной лингвистической статистики и компилируем их в корпусные ограничения, чтобы направлять процесс вывода во время тестирования. Мы адаптируем два метода, лагранжеву релаксацию и апостериорную регуляризацию, для проведения вывода с ограничениями корпусной статистики. Эксперименты показывают, что лагранжева релаксация и вывод апостериорной регуляризации улучшают характеристики в 15 и 17 из 19 случаев.целевые языки соответственно. Улучшения особенно важны для целевых языков, в которых порядок слов отличается от исходного языка. 
