Слова «вверху» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «вверху» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «вверху» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «вверху».
Содержимое:
- 1 Слоги в слове «вверху» деление на слоги
- 2 Как перенести слово «вверху»
- 3 Морфологический разбор слова «вверху»
- 4 Разбор слова «вверху» по составу
- 5 Сходные по морфемному строению слова «вверху»
- 6 Синонимы слова «вверху»
- 7 Антонимы слова «вверху»
- 8 Ударение в слове «вверху»
- 9 Фонетическая транскрипция слова «вверху»
- 10 Фонетический разбор слова «вверху» на буквы и звуки (Звуко-буквенный)
- 11 Предложения со словом «вверху»
- 12 Значение слова «вверху»
- 13 Как правильно пишется слово «вверху»
- 14 Ассоциации к слову «вверху»
Слоги в слове «вверху» деление на слоги
Количество слогов: 2
По слогам: вве-рху
р — непарная звонкая согласная (сонорная), примыкает к текущему слогу
Как перенести слово «вверху»
вве—рху
ввер—ху
Морфологический разбор слова «вверху»
Часть речи:
Предлог
Грамматика:
часть речи: предлог;
отвечает на вопрос:
Начальная форма:
вверху
Разбор слова «вверху» по составу
| в | приставка |
| верх | корень |
| у | суффикс |
вверху
Сходные по морфемному строению слова «вверху»
Сходные по морфемному строению слова
Синонимы слова «вверху»
1. наверху
наверху
2. на высоте
3. над головой
Антонимы слова «вверху»
1. внизу
Ударение в слове «вверху»
вверху́ — ударение падает на 2-й слог
Фонетическая транскрипция слова «вверху»
[в’ ирх`у]
Фонетический разбор слова «вверху» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| в | [в’] | согласный, глухой парный, твёрдый, долгий | в |
| в | — | не образует звука | в |
| е | [и] | гласный, безударный | е |
| р | [р] | согласный, звонкий непарный (сонорный), твёрдый | р |
| х | [х] | согласный, глухой непарный, твёрдый, шумный | х |
| у | [`у] | гласный, ударный | у |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 6 букв и 5 звуков.
Буквы: 2 гласных буквы, 4 согласных букв.
Звуки: 2 гласных звука, 3 согласных звука.
Предложения со словом «вверху»
Источник: Т. В. Коган, Остеопатия. Уникальный массаж для связок, костей и мышц, 2016.
Вертикальная пластинка имеет вверху клиновидную нёбную вырезку, имеющую по краям передний глазничный отросток и задний клиновидный.
Источник: Т. В. Коган, Остеопатия. Уникальный массаж для связок, костей и мышц, 2016.
Если ладонь или рука широкая вверху, направленность энергии может быть разной, человек беспокоен, активен и оригинален.
Источник: В. В. Калюжный, Большая книга хиромантии, 2015.
Значение слова «вверху»
ВВЕРХУ́ , нареч.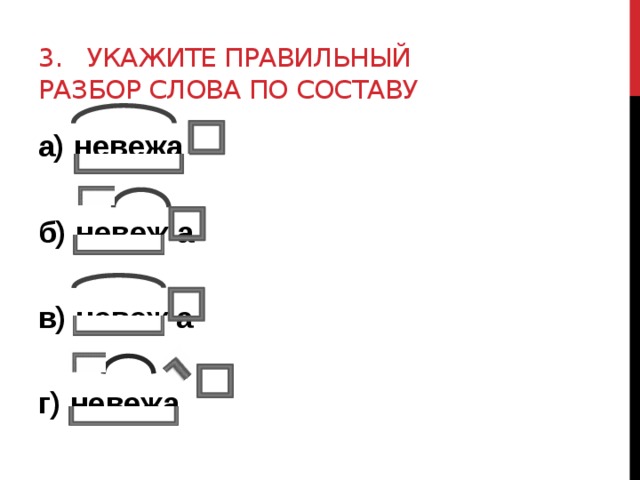 На высоте (в воздухе, в небе), над кем-, чем-л., выше кого-, чего-л.; противоп. внизу. (Малый академический словарь, МАС)
На высоте (в воздухе, в небе), над кем-, чем-л., выше кого-, чего-л.; противоп. внизу. (Малый академический словарь, МАС)
Как правильно пишется слово «вверху»
Орфография слова «вверху»Правильно слово пишется: вверху́
Нумерация букв в слове
Номера букв в слове «вверху» в прямом и обратном порядке:
- 6
в
1 - 5
в
2 - 4
е
3 - 3
р
4 - 2
х
5 - 1
у
6
Ассоциации к слову «вверху»
Полотнище
Колос
Кайма
Герб
Ширин
Зубец
Оконечность
Логотип
Крон
Древко
Крона
Отверстие
Свод
Кровля
Перевязь
Стебель
Карниз
Просвет
Окружность
Купол
Овал
Перекладина
Полукруг
Синева
Голубизна
Ширина
Арка
Прямоугольник
Серп
Выемка
Венок
Ветвь
Балка
Брус
Сноп
Орнамент
Кумир
Вымпел
Жердь
Полумесяц
Заголовок
Надпись
Небосвод
Небо
Облако
Окошечко
Выпуклость
Конус
Геральдический
Прямоугольный
Зелёный
Волнистый
Жёлтый
Полукруглый
Горизонтальный
Продольный
Переходящий
Остроконечный
Зубчатый
Наклонный
Цилиндрический
Вертикальный
Поперечный
Треугольный
Решетчатый
Лицевой
Отвесный
Смыкаться
Сужаться
Сопроводить
Сплетаться
Оканчиваться
Гласить
Светлеть
Голубеть
Сходиться
Зашуршать
Громоздиться
Переплетаться
Обрамить
Парить
Соединяться
Расширяться
Проплывать
Виднеться
Клубиться
Вписать
Шелестеть
Кружить
Зеленеть
Внизу
Высоко
Справа
Слева
Где-то
Посередине
Посредине
Вертикально
Снизу
Сообразно
Русско-английский словарь, перевод на английский язык
wordmap
Русско-английский словарь — показательная эрудиция
Русско-английский словарь — прерогатива воспользоваться вариативным функционалом, насчитывающим несколько сотен тысяч уникальных английских слов. Чтобы воспользоваться сервисом, потребуется указать предпочтенное слово на русском языке: перевод на английский будет отображен во всплывающем списке.
Чтобы воспользоваться сервисом, потребуется указать предпочтенное слово на русском языке: перевод на английский будет отображен во всплывающем списке.
Русско-английский словарь — автоматизированная система, которая отображает результаты поиска по релевантности. Нужный перевод на английский будет в верхней части списка: альтернативные слова указываются в порядке частоты их применения носителями языка. При нажатии на запрос откроется страница с выборкой фраз: система отобразит примеры использования искомого слова.
Русско-английский словарь содержит строку для поиска, где указывается запрос, а после запускается непосредственный поиск. Система может «предлагать» пользователю примеры по использованию слова: «здравствуйте» на английском языке, «хризантема» на английском языке. Дополнительные опции системы — отображение частей речи (будет выделена соответствующим цветом). В WordMap русско-английский словарь характеризуется наличием функции фильтрации запросов, что позволит «отсеять» ненужные словосочетания.
Применение сервиса и достоинства
Перевод на английский язык с сервисом WordMap — возможность улучшить словарный запас учащегося. Дополнительные преимущества в эксплуатации WordMap:
- Слова с различным значением, которые оптимизированы под любой уровень владения английским языком;
- Русско-английский словарь содержит примеры, позволяющие усовершенствовать практические навыки разговорного английского;
- В списке результатов указаны всевозможные синонимы и паронимы, которые распространены в сложном английском языке.
Онлайн-сервис WordMap предлагает пространство для совершенствования интеллектуальных способностей, способствует результативной подготовке к сдаче экзамена. Быстрый перевод на английский может быть использован с игровой целью: посоревноваться с коллегой или одноклубником; бросить вызов преподавателю, превзойдя ожидания собственного ментора.
Только что искали:
досин 2 секунды назад
надсыпали 3 секунды назад
козодон 5 секунд назад
рилмопаа 6 секунд назад
завуалированный 8 секунд назад
теян 12 секунд назад
двужилых 16 секунд назад
посвятивший себя всецело 16 секунд назад
нам, татарам, всё равно 17 секунд назад
нарюпеь 17 секунд назад
сизанова 20 секунд назад
риврхаат 20 секунд назад
сильнейшие 25 секунд назад
гардина 28 секунд назад
идентичные близнецы 29 секунд назад
Ваша оценка
Закрыть
Спасибо за вашу оценку!
Закрыть
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | кот | 0 слов | 4 часа назад | 95. 54.241.87 54.241.87 |
| Игрок 2 | город | 0 слов | 6 часов назад | 158.181.234.21 |
| Игрок 3 | идилличность | 24 слова | 7 часов назад | 79.132.117.234 |
| Игрок 4 | кокичи ома молодец!политик лидер и боец!наш президент страну поднял!россию ома не предал! | 0 слов | 12 часов назад | 89.178.65.183 |
| Игрок 5 | кокичи ома молодец!политик лидер и боец!наш президент страну поднял!россию ома не предал! | 0 слов | 12 часов назад | 89.178.65.183 |
| Игрок 6 | я отчим хисоки | 0 слов | 12 часов назад | 89.178.65.183 |
| Игрок 7 | лох | 0 слов | 12 часов назад | 89. 178.65.183 178.65.183 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | трико | 50:49 | 2 часа назад | 213.87.163.240 |
| Игрок 2 | поляк | 47:55 | 2 часа назад | 78.132.170.10 |
| Игрок 3 | атлантизм | 196:184 | 5 часов назад | 188.190.88.4 |
| Игрок 4 | эммер | 0:0 | 5 часов назад | 95.152.2.247 |
| Игрок 5 | метоп | 54:56 | 7 часов назад | 95.153.160.59 |
| Игрок 6 | штосс | 53:54 | 8 часов назад | 95. 153.160.59 153.160.59 |
| Игрок 7 | джемпер | 8 часов назад | 79.132.117.234 | |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| Аниса | На одного | 10 вопросов | 15 часов назад | 5.128.126.42 |
| Соня | На одного | 10 вопросов | 15 часов назад | 5.128.126.42 |
| Блблбл | На одного | 10 вопросов | 15 часов назад | 5.128.126.42 |
| Гусь | На одного | 5 вопросов | 15 часов назад | 5.128.126.42 |
| Ооооооо | На одного | 10 вопросов | 15 часов назад | 5. 128.126.42 128.126.42 |
| Пррнрппшд7еикгм5колгштл | На одного | 10 вопросов | 15 часов назад | 5.128.126.42 |
| Рататуй | На одного | 10 вопросов | 15 часов назад | 5.128.126.42 |
| Играть в Чепуху! | ||||
Как разобрать слово по составу?
Существует чёткое правило, которое надо выполнять, чтобы сделать разбор слова по составу без ошибок. Для этого надо строго следовать порядку разбора, не пропуская ни одного шага, и помнить об указанных ниже особых и трудных случаях.
АЛГОРИТМ РАЗБОРА СЛОВА ПО СОСТАВУ
Алгоритм разбора слова по составу — пошаговая последовательность. Она помогает правильно выполнить работу. Используемый приём сравнения развивает логическое мышление.
Обязательная поэтапность разбора любого слова по составу:
- Выделение окончания
- Определение основы
- Подбор однокоренных слов, выделение корня.

- В последнюю очередь выделение приставок и суффиксов

ОСОБЕННОСТИ ОПРЕДЕЛЕНИЯ ОКОНЧАНИЯ НА ПРИМЕРЕ РАЗНЫХ ЧАСТЕЙ РЕЧИ
Разбор по составу существительного
Например, слово «пеналом». Образуя форму слова, изменяем падеж: «пеналу». Изменилась часть –ом. Значит, это окончание.
Образовывать форму слова необходимо, чтобы не ошибиться в трудных случаях: сравним слова «коров» и «столов». В первом слове окончание нулевое, а –ов — часть корня («корова»), во втором — -ов окончание.
Важно помнить о наречии «домой», где — ой — суффикс: у существительных 2 склонения («дом — 2 склонение») нет окончания –ой. Наречия не изменяются, значит, у него вообще нет окончания. Всё слово — основа.
Имя прилагательное
Слово «волшебными» поставим в форму женского рода единственного числа: «волшебная». Сравниваем формы слова, изменяется часть –ыми. Это окончание.
Примеры
Бесполезный — то, в чём нет никакой пользы
полезный
польза
Общая часть — корень — польз- . Приставка бес- стоит перед корнем, после него — суффикс –н.
Приставка бес- стоит перед корнем, после него — суффикс –н.
Парашютист — человек, спускающийся с парашютом
парашют
Состав слова: корень, суффикс -ист и нулевое окончание.
Глагол «повторяете» настоящего времени. Попробуем изменить лицо: «повторяют». Вывод: окончание –ете.
«Заставили» — «заставила»: в первом глаголе окончание –и.
ПРИМЕРЫ РАЗБОРА СЛОВ ПО СОСТАВУ
Разбор слова Настенный
- Изменяем форму слова: настенная. Окончание –ый.
- Основа настенн-.
- Подбираем однокоренные слова: стена, пристенок. Находим корень: -стен-
- Сопоставляем все родственные слова: видим приставку на-, суффикс –н-.
- Доказываем наличие этих морфем в других словах: на-поль-н-ый, на-столь-н-ый.
Разбор слова Сползает
- Изменяем форму слова: сползают. Окончание –ет.
- Основа сполза-.
- Подбираем однокоренные слова: ползёт, заползал, ползание. Находим корень: -полз-
- Сопоставляем все однокоренные слова: видим приставку с-, суффикс –а-.
- Доказываем наличие этих морфем в других словах: с-бивают, с-пис-а-ть, прочит-а-ть.
 Находим корень: -полз-
Находим корень: -полз-Разбор слова Запевает
- Изменяем форму слова: запеваю. Окончание –ет.
- Основа запева-.
- Подбираем однокоренные слова: петь, пение, запевала. Находим корень: -пе-
- Сопоставляем все родственные слова: видим приставку за-, суффикс –ва-.
Разбор слова Повторяла
- Изменяем форму слова: повторяли. Окончание –а.
- Основа повторя-.
- Подбираем однокоренные слова: вторить, второй. Находим корень: -втор-
- Сопоставляем все однокоренные слова: видим приставку по-, суффикс –я-.
Разбор слова Преподаватель
- Изменяем форму слова: преподавателю. Окончание нулевое.
- Основа преподаватель.
- Подбираем однокоренные слова: преподавать, подавать, давать (знания), дать. Находим корень: -да-.
- Сопоставляем все родственные слова: видим приставки пре-, по-, суффикс –ва-.
 Находим корень: -да-.
Находим корень: -да-.Разбор слова Вверху
- Это наречие. Неизменяемое слово. У неизменяемых слов вообще нет окончания.
- Основа всё слово вверху.
- Подбираем однокоренные слова: наверху, верховный, верх. Находим корень: -верх-.
- Сопоставляем все однокоренные слова: видим приставку в-, суффикс –у.
Разбор слова Разноцветный
- Изменяем форму слова: разноцветное. Окончание -ый.
- Основа разноцветн-.
- Подбираем однокоренные слова: разный, разница, различие, цветной, цвет. Находим два корня: разн-, -цвет-. Это сложное прилагательное.
- Сопоставляем все однокоренные слова: видим соединительную гласную –о-, суффикс –н-.
Изучение состава слова играет значительную роль при формировании орфографической зоркости.
Дети начинают понимать и запоминают: все части слова неизменны в написании и не зависят от произношения.
ТРУДНЫЕ СЛУЧАИ ПРИ РАЗБОРЕ СЛОВА ПО СОСТАВУ
Проводя анализ слов, школьники не всегда обращают внимание на лексическое значение разбираемого слова. Это часто приводит к ошибкам, особенно при выделении суффиксов.
- слова оканчиваются на -чик-, –щик-, -ист, -ушк.
В словах с такими суффиксами подбор однокоренных слов обязателен. (Мяч-ик — мяч, ключ-ик— ключ, рез-чик — резать, ящик, хрящ-ик — хрящ, камен-щик — камень; аист, лист; ушко, нес-ушк-а).
Анализируя состав слова «каменщик», находим существительное, от которого оно образовано: камень; «плащик» — это небольшой плащ. Соответственно видим в словах суффиксы –щик, -ик.
Необходимо обучить детей разграничению понятий «оканчивается на…» и «окончание». Слово «автобус» оканчивается на –бус (-ус, -с), но окончание нулевое.
Непонимание разницы в значениях приводит к частым ошибкам при морфемном анализе глаголов в неопределённой форме.
- элемент –ть (читать, считать)
в учебных пособиях разных авторов рассматриваются или как суффикс, или как окончание. В любом случае предшествующий гласный в эту часть слова не входит.
В любом случае предшествующий гласный в эту часть слова не входит.
Рассмотрим –ть как окончание неопределённой формы. Слово «ускорять» оканчивается на –ять (это важно при определении спряжения глагола), здесь –я- — суффикс и окончание –ть. «Побороть» оканчивается на –оть: -о- — суффикс, окончание –ть.
Умение разбирать последовательно слово по составу приобретается при постоянной работе по алгоритму. Нарушение последовательности или игнорирование приводит к ошибкам. Внимание к слову — основа успеха.
Вся информация взята из открытых источников.
Если вы считаете, что ваши авторские права нарушены, пожалуйста,
напишите в чате на этом сайте, приложив скан документа подтверждающего ваше право.
Мы убедимся в этом и сразу снимем публикацию.
Страница не найдена — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Содержание
Морфологический разбор слова «сверху»
Слово можно разобрать в 2 вариантах, в
зависимости от того, в каком контексте оно используется.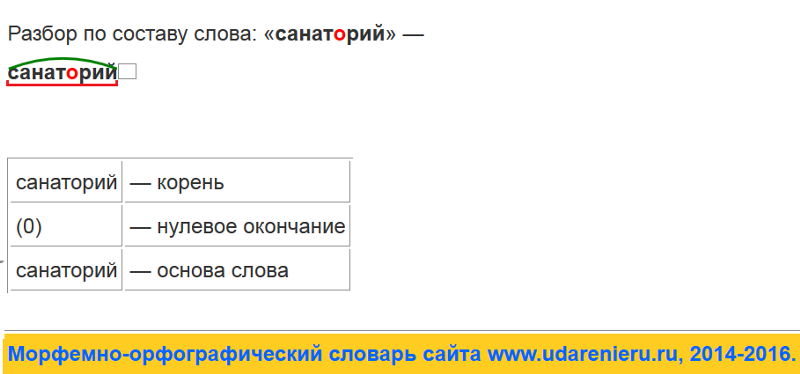
1 вариант разбора
Часть речи: Наречие
2 вариант разбора
Часть речи: Предлог
Разбор слова по составу сверху
| Основа слова | сверху |
|---|---|
| Приставка | с |
| Корень | верх |
| Суффикс | у |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «СВЕРХУ» в конкретном предложении или тексте, то лучше использовать морфологический разбор текста.
Найти синонимы к слову «сверху»
Примеры предложений со словом «сверху»
1
Справа, слева, сверху, сверху, сверху рубят шашки без передышки, звенит сталь беспрерывным звоном.
Самои. Сборник рассказов и повестей, Анатолий Агарков
2
Сверху спустили фотографа с камерой и стали снимать страшный багаж с боков и сверху.
В поисках убийцы, А. Е. Зарин, 1915г.
3
Мне сверху надо говорить, – сверху-то лучше!
Сказки об Италии и не только… (сборник), Максим Горький, 2011г.
4
Островский – не миф, насажденный сверху (хотя и сверху насаждали).
Как закалялась сталь, Николай Островский, 2005г.
5
Сверху, как отец, который сейчас смотрел на все это сверху вниз.
Патрик Мелроуз. Книга 1 (сборник), Эдвард Сент-Обин, 1998г.
Найти еще примеры предложений со словом СВЕРХУ
Страница не найдена — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
- Части слова или морфемы слова — названия, виды, обозначения
- Морфемный разбор онлайн, разбор слов по составу, примеры
- План разбора
- Как разобрать по составу слово русский?
- Что такое состав слова? Примеры состава слов: «повторение», «помогать», «подснежник»
- Общие сведения о разборе состава слова
- Состав слова
- Что такое морфема?
- Нулевые морфемы
- Разбор слова по составу — морфемный разбор, правила, примеры
- Алгоритм разбора слова по составу
- Особенности определения окончания на примере разных частей речи
- «читать» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
- Как сделать словообразовательный разбор слова в русском языке
- Немного теории
- Сложение двух основ
- «кровать» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
- «Разбор слова по составу и словообразовательный разбор»
- Что такое морфемный разбор 🚩 зачастую морфемный разбор слова 🚩 Лингвистика
- Словообразование: примеры и способы
- Словообразование как раздел языка
- Фонетический разбор слова онлайн примеры бесплатно, словарь полного фонетического разбора
- Морфемный разбор слова онлайн
- Тест Разбор слова по составу по русскому языку онлайн
- Морфемный анализ 5 класс онлайн-подготовка на Ростелеком Лицей
- Вы пьете корень. «Питьевой»
- Автоматическая сегментация морфем (Открытые проблемы в лингвистике компьютерного разнообразия 1)
- Тщательный анализ слова в композиции. «Прилежно»
- Морфология 1 Введение Морфология Морфологический анализ (MA)
- Страница не найдена | MIT
- Что такое морфология? — Введение в лингвистику
 «Питьевой»
«Питьевой»Части слова или морфемы слова — названия, виды, обозначения
Слово состоит из частей: приставки, корня, суффикса, окончания. Их также называют морфемами. Приставка, корень и суффикс составляют основу слова, они являются значимыми частями слова. Говоря иначе: слово состоит из основы и окончания. Раздел науки, который изучает строение слов и способы их образования, называет словообразованием. Следует разделять понятия морфемного и словообразовательного разбора.
Названия и обозначения
Каждая часть слова имеет название и визуальное обозначение (начертание). Обозначения — как бы «маркеры», которые пририсовывают к соответствующей части слова сверху, снизу или обводкой.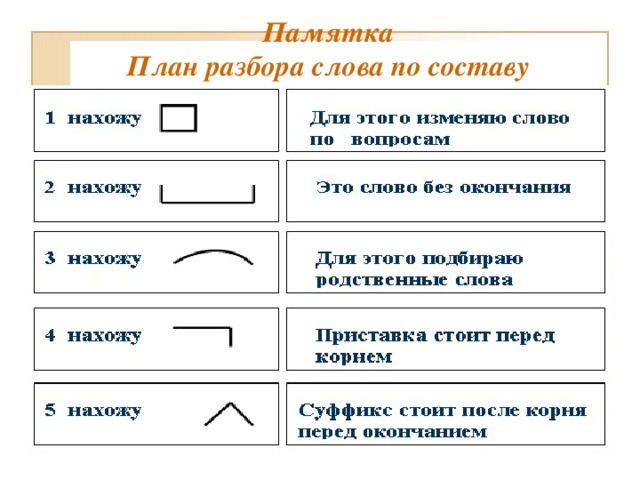
— приставка (или префикс)
— корень
— суффикс и постфикс
— окончание
— основа и соединительная гласная (или интерфикс)
Покажем обозначение морфем на примерах: авангардный,
абзац,
безвыходный
В тетрадных листах обычно слова пишут шариковой ручкой, а части слов выделяют карандашом или шариковой ручкой другого цвета. На школьных досках части слов выделяют мелком или маркером цветом, отличающимся от цвета слова. Наш сайт содержит краткий словарь морфемных разборов с наглядным обозначением морфем.
Группы морфем
Морфемы разделяются на три группы:
- корневая морфема — корень;
- словообразующие морфемы — приставка, словообразующий суффикс;
- формообразующие морфемы — окончание, формообразующий суффикс.
В основу слова входят корень и словообразующие морфемы.
Рис 1. Схематическое представление частей слова
Вне рамок школьной программы используется иная терминология для некорневых морфем — аффиксы. Существуют и другие морфемы и их комбинации, но они не входят в школьную программу, поэтому мы их подробно не рассматриваем.
Существуют и другие морфемы и их комбинации, но они не входят в школьную программу, поэтому мы их подробно не рассматриваем.
Любая из морфем может отсутствовать в слове, в том числе корень. Однако некоторые учёные считают, что отсутствие корня в действительности является наличием нулевого корня.
Видоизменение морфем
Части слова могут подвергаться выпадению звука либо замене одного звука другим. Такие видоизменения могут возникнуть в однокоренных словах и в разных формах одного и того же слова:
• в приставках: отрезать — оторвать, разделить — расписать;
• в корнях: оросить — орошение, просит — упрашивает, беречь — берегу — бережный;
• в суффиксах: сучок — сучка — сучочек;
• в окончаниях: водой — водою, в лесу — о лесе.
Морфемный разбор онлайн, разбор слов по составу, примеры
Разбор слова по составу (или морфемный разбор) — выделение частей, из которых слово состоит.
Чтобы научиться делать разборы, необходимо обладать знаниями о частях словаи словообразовании , изучение которых входит в школьную программу. При затруднении с разбором прибегают к словарям морфемных разборов, печатным или электронным. Наш сайт содержит словарь морфемных разборов, включающий популярные в школьной программе слова и сложные слова из обихода. На сайте также содержится справочная информация: даются определения частей слов, объясняются способы словообразования, приводятся примеры.
При затруднении с разбором прибегают к словарям морфемных разборов, печатным или электронным. Наш сайт содержит словарь морфемных разборов, включающий популярные в школьной программе слова и сложные слова из обихода. На сайте также содержится справочная информация: даются определения частей слов, объясняются способы словообразования, приводятся примеры.
В настоящий момент словарь содержит 100 000 морфемных разборов слов в начальной форме. Знания морфем начальной формы слова (инфинитив, единственное число, мужской род, именительный падеж) в большинстве случаев достаточно для определения морфем слова в разных склонениях, спряжениях, родах и числах. Надеемся, что сайт поможет вам в подготовке домашних заданий.
План разбора
План разбора слова по составу состоит в следующем:
Определяем, к какой части речи относится анализируемое слово.
Выделяем окончание и основу. Для определения окончания слово изменяют, например, по падежам. Изменяемая часть будет являться окончанием, остальная часть слова без окончания — основой.
Следует помнить, что всё слово может представлять собой основу без окончания, например у наречия — неизменяемой части речи.
Определяем, входит ли в основу слова кроме корня также приставка и суффикс. Для этого слово сопоставляется с однокоренными словами.
Убеждаемся, что выделенные приставки и суффиксы имеются в других словах. Для проверки подбираются аналогичные слова и сравниваются с анализируемым.
Обозначем части слова с помощью графических обозначений.
Как разобрать по составу слово русский?
Морфемный анализ, или разбор по составу, слова РУССКИЙ
Слово русский может быть как существительным, так и прилагательным, но в любом случае состав его одинаков.
ЫЙ это окончание (русск-ий, русск-ого, русск-им и т. д.),
основа слова РУССК,
корневая морфема вычленяется с помощью слов с тем же корнем: Русь, орусевший и др. Корень РУС.
Остается в этом слове выделить суффикс СК, благодаря которому слово пишется, и это надо запомниь, с двумя С.
автор вопроса выбрал этот ответ лучшим
В русском языке, слово «русский» может быть как прилагательным, причем полным, так и существительным, но в любом случае, состав слова от этого никоим образом не изменится, поэтому: неодушевленное, мужской род, единственное число, может быть как в именительном, так и в винительном падежах.
Слово «русский» согласно морфемного разбора, выглядит следующим образом:
1) РУС — корень данного слова,
2) СК — суффикс данного слова,
3) ИЙ — окончание данного слова.
Основу слова составляет: русск
Вычисленный способ образования данного слова «русский» является суффиксальным
В слове «русский» имеются:
два слога (ру-сский),
семь букв,
шесть звуков.
Слово » русский »
, относится к имени прилагательному, потому что отвечает на вопрос » какой? «, имеет русский род и находится в единственном числе.
Что такое состав слова? Примеры состава слов: «повторение», «помогать», «подснежник»
Состав слова особенно часто просят разобрать учеников средней школы. Ведь благодаря таким занятиям ребята намного лучше усваивают материал словообразования и правописание различных выражений. Но, несмотря на легкость данной задачи, школьники не всегда выполняют ее правильно. С чем это связано? Об этом мы расскажем далее.
Ведь благодаря таким занятиям ребята намного лучше усваивают материал словообразования и правописание различных выражений. Но, несмотря на легкость данной задачи, школьники не всегда выполняют ее правильно. С чем это связано? Об этом мы расскажем далее.
Общие сведения о разборе состава слова
В филологической науке разбор слова по составу называют «морфемным анализом». Считается, что это самая сложная аналитическая работа, которую следует осуществлять с лексическими единицами нашего родного языка. Но если придерживаться определенного алгоритма, данную процедуру можно провести очень легко, быстро и верно.
Состав слова
Как известно, все слова в русском языкесостоят из окончания и основы. В последнюю часть входят: суффикс, корень и приставка. Обычно их называют морфемами.
Что такое морфема?
«Морфема» с греческого языка переводится как «форма». То есть это — значимая и минимальная часть слова, которая не может расчленяться на более мелкие единицы.
Морфема обладает грамматическим значением и грамматической формой. Она способна передавать совершенно разные типы значений, а именно:
Она способна передавать совершенно разные типы значений, а именно:
Нулевые морфемы
Следует также отметить, что помимо материально выраженных, в русском языке встречаются и нулевые морфемы, которые также обладают грамматическим значением. Приведем пример: в слове «дом» не выражено материальное окончание, а в слове «нёс» — суффикс и окончание прошедшего времени.
Разбор слова по составу — морфемный разбор, правила, примеры
Существует чёткое правило, которое надо выполнять, чтобы сделать разбор слова по составу без ошибок. Для этого надо строго следовать порядку разбора, не пропуская ни одного шага, и помнить об указанных ниже особых и трудных случаях.
Алгоритм разбора слова по составу
Алгоритм разбора слова по составу — пошаговая последовательность. Она помогает правильно выполнить работу. Используемый приём сравнения развивает логическое мышление.
Обязательная поэтапность разбора любого слова по составу:
Выделение окончания
Определение основы
Подбор однокоренных слов, выделение корня.
В последнюю очередь выделение приставок и суффиксов
Чтобы правильно, безошибочно выделить окончание, необходимо образовать другую словоформу. Сопоставить две формы одного и того же слова. Изменившаяся часть слова — окончание. Оставшаяся без изменения — основа.
Особенности определения окончания на примере разных частей речи
Разбор по составу существительного
Например, слово «пеналом». Образуя форму слова, изменяем падеж: «пеналу». Изменилась часть –ом. Значит, это окончание.
Образовывать форму слова необходимо, чтобы не ошибиться в трудных случаях: сравним слова «коров» и «столов». В первом слове окончание нулевое, а –ов — часть корня («корова»), во втором — -ов окончание.
Важно помнить о наречии «домой», где — ой — суффикс: у существительных 2 склонения («дом — 2 склонение») нет окончания –ой. Наречия не изменяются, значит, у него вообще нет окончания. Всё слово — основа.
Имя прилагательное
Слово «волшебными» поставим в форму женского рода единственного числа: «волшебная».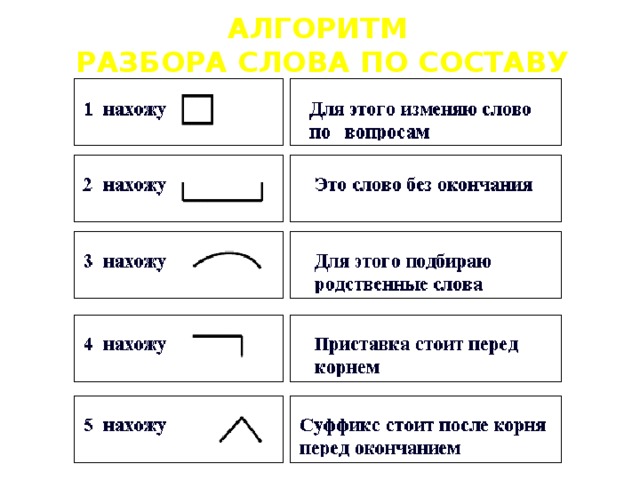 Сравниваем формы слова, изменяется часть –ыми. Это окончание.
Сравниваем формы слова, изменяется часть –ыми. Это окончание.
Чтобы правильно выделить корень в слове, обязательно требуется подбирать родственные слова. Важно помнить: приставки, а также суффиксы изменяют лексическое значение. Подбор однокоренных слов помогает без ошибок определить эти морфемы.
Примеры
Бесполезный — то, в чём нет никакой пользы
полезный
польза
Общая часть — корень — польз- . Приставка бес- стоит перед корнем, после него — суффикс –н.
Парашютист — человек, спускающийся с парашютом
парашют
Состав слова: корень, суффикс -ист и нулевое окончание.
Глагол «повторяете» настоящего времени. Попробуем изменить лицо: «повторяют». Вывод: окончание –ете.
«Заставили» — «заставила»: в первом глаголе окончание –и.
«читать» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
Умение правильно находить общий корень — важный навык, помогающий в изучении крайне сложного русского языка.
Чем нужно руководствоваться, чтобы подобрать правильные однокоренные слова к слову читать? Успешно справиться с этим заданием — найти однокоренные / однокорневые слова для читать — невозможно без знания определений морфемы, приставки, корня, суффикса, окончания. Мы поможем научиться основным принципам поиска однокоренных слов, узнав, что такое корень и какое значение при поиске однокоренных слов к читать играют другие морфемы, или подобрать родственные части речи к слову читать из нашего онлайн-словаря с функцией автоматического определения корня.
В нашем онлайн словаре однокоренных слов мы поможем Вам разобрать слово читать по составу. Выделяем корень читать , суффикс, приставку и окончание, а так же однокоренные слова для читать .
Как сделать словообразовательный разбор слова в русском языке
Словообразование – неотъемлемая часть языка. Без него не было бы новых слов, профессиональныхжаргонов, названий новых изобретений и многого другого. Без словообразования современный язык не был бы настолько богат и удобен для общения, многие слова не канули бы в лету, не стали бы историзмами. Благодаря этому процессу наша повседневная речь усложняется и совершенствуется. Именно поэтому нужно знать законы словообразования и уметь делать словообразовательный разбор слова.
Без словообразования современный язык не был бы настолько богат и удобен для общения, многие слова не канули бы в лету, не стали бы историзмами. Благодаря этому процессу наша повседневная речь усложняется и совершенствуется. Именно поэтому нужно знать законы словообразования и уметь делать словообразовательный разбор слова.
Немного теории
Словообразование (деривация) – процесс создания новых, зачастую более сложных слов из более простых. Этот процесс является неотъемлемой составляющей такой науки, как лингвистика. В разделе словообразования словаделятся на первичные (из которых получают новое слово) и производные (которые получаются при помощи словообразования). Словообразование — сложный процесс, и именно поэтому для него есть несколько методов. О них (или некоторых из них) мы и поговорим в этой статье, а в итоге узнаем, как произвести словообразовательный разбор слова и многое другое. Кроме того, мы узнаем намного больше того, что говорили нам в школе, на уроках русского языка. И, может быть, вы сможете объяснить ребёнку то, что не смог доходчиво объяснить учитель.
И, может быть, вы сможете объяснить ребёнку то, что не смог доходчиво объяснить учитель.
Сложение двух основ
В современном мире из-за обилия слов и их спецификации всё чаще используется такой метод словообразования, как сложение двух основ. Чаще всего это сложение происходит так: у двух слов, например, «вода» и «проводить», выделяется корень. Получается: «вод» и «провод». Эти корни соединяются при помощи соединительной гласной «о». Получается новое слово: «водопровод», означающее систему сооружений, чаще всего находящуюся под землёй, доставляющую воду от места «добычи» в места её потребления. Это один из самых простых методов словообразования.
«кровать» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
Умение правильно находить общий корень — важный навык, помогающий в изучении крайне сложного русского языка.
Чем нужно руководствоваться, чтобы подобрать правильные однокоренные слова к слову кровать? Успешно справиться с этим заданием — найти однокоренные / однокорневые слова для кровать — невозможно без знания определений морфемы, приставки, корня, суффикса, окончания. Мы поможем научиться основным принципам поиска однокоренных слов, узнав, что такое корень и какое значение при поиске однокоренных слов к кровать играют другие морфемы, или подобрать родственные части речи к слову кровать из нашего онлайн-словаря с функцией автоматического определения корня.
Мы поможем научиться основным принципам поиска однокоренных слов, узнав, что такое корень и какое значение при поиске однокоренных слов к кровать играют другие морфемы, или подобрать родственные части речи к слову кровать из нашего онлайн-словаря с функцией автоматического определения корня.
В нашем онлайн словаре однокоренных слов мы поможем Вам разобрать слово кровать по составу. Выделяем корень кровать , суффикс, приставку и окончание, а так же однокоренные слова для кровать .
«Разбор слова по составу и словообразовательный разбор»
учителя
русского языка и литературы Плетневой
Н.С.
Предварительная
подготовка к уроку
Ученикам
предлагается повторить темы
« Словообразование »
и « Состав
слова »,
а также выполнить ряд упражнений,
рассчитанных на отработку перечисленных
тем.
Цели:
повторить
темы «Состав слова» и «Словообразование»;
воспитывать
у учеников интерес к процессу
словообразования, воспитать умение
грамотно и логично составлять новые
слова и применять их в устной и письменной
речи;
развивать
практические навыки словообразовательного
анализа состава слова; научить практически
использовать полученные в результате
анализа знания.
Оборудование: учебник,
выполненные на листе ватмана схемы
словообразовательного разбора и разбору
по составу слова, карточки с баллами –
несколько штук от 1 до 5 баллов.
Ход
урока
I.
Организационный момент.
II.
Проверка домашнего задания.
III.
Работа над новым материалом.
Данный
урок предполагается провести в виде
соревнования: ученики, правильно отвечая
на вопросы и выполняя задания, зарабатывают
карточки с баллами – на каждой карточке
от1 до 5 баллов, в зависимости от сложности
от сложности вопроса и полноты ответа.
В конце урока подводится подсчет карточек
и поощрение – например, три ученика,
набравшие наибольшее количество баллов,
получают зачет «автоматом», остальные,
в зависимости от полученных на уроке
баллов, некоторые «поблажки» на зачете
либо другое поощрение.
Учитель: На
прошлых уроках мы изучили, а затем
повторили темы « Состав
слова »
и « Словообразование ».
Данные темы относятся к более крупной
части системы наук о языке –
словообразованию. Как и другие части
языкознания – морфология, орфография,
лексика, — словообразование также имеет
ряд типов разборов слова. В частности,
это разбор слова по составу и
словообразовательный разбор. Обратимся
к таблице и повторим этапы того и другого
анализа.
Что такое морфемный разбор 🚩 зачастую морфемный разбор слова 🚩 Лингвистика
Морфема — минимальная неделима значимая часть слова, которая служит для образования новых слов и форм. Проанализировать состав и назначение морфем в составе конкретного слова позволяет морфемный разбор .
1. Морфемный разборпроизводится над той формой слова, которая присутствует в тексте-задании. Слово выписывается без изменений, определяется, к какой части речи оно относится, является ли эта часть речи изменяемой или неизменяемой.
2. Если слово изменяемое, определяется флексия или окончание слова . Чтобы определить окончание, нужно изменить слово (подвергнуть склонению, спряжению). Необходимо помнить, что окончание – это изменяемая часть слова, у неизменяемых частей речи, таких как деепричастие, наречие , некоторые имена существительные и имена прилагательные , а также служебные части речи, окончания быть не может!
Необходимо помнить, что окончание – это изменяемая часть слова, у неизменяемых частей речи, таких как деепричастие, наречие , некоторые имена существительные и имена прилагательные , а также служебные части речи, окончания быть не может!
3. Определяется и выделяется основа слова – часть слова без окончания.
4. Выделяется корень слова . К слову подбираются однокоренные (родственные) слова. Следует помнить, что корни могут быть омонимичными, и необходимо внимательно следить, какое именно значение имеет слово. Так, к слову «коса» в значении «женская прическа » нельзя указывать в качестве однокоренных такие слова, как «косарь» и «косить». В этом значении однокоренными словами будут являться «косонька», «косичка» и даже «космы».
5. Выделяются другие словообразующие и формообразующие части слова: приставки (префиксы), суффиксы (аффиксы и постфиксы), соединительные гласные (интерфиксы). С каждым из них подбираются слова, образованные тем же способом.
Некоторые источники указывают морфемный разбор и разбор словапо составу как идентичные. Но это не совсем так. При проведении этих двух разборов есть ряд существенных отличий.
Но это не совсем так. При проведении этих двух разборов есть ряд существенных отличий.
— Для морфемного разбора форма слова берется без изменений, для разбора по составу используется начальная форма слова. Например, для глагола «делали» начальная форма «делать».
— При словообразовательном разборе указывается, является ли слово производным, т.е. образованным от другого или нет, при морфемном разборе этого не требуется.
— При словообразовательном разборе необходимо указать способ образования слова , а не подбирать слова, образованные при помощи тех же приставок и суффиксов, как в морфемном.
Иногда путают морфемный и морфологический разбор . Это грубая ошибка. При морфологическом разборе рассматривается слово как часть речи, анализируются грамматические категории, свойственные ему. При морфемном же анализу подвергаются только морфемы, составляющие слово.
Морфемный разбор – это разбор слова по составу. Порядок действий следующий: сначала выделяется окончание, формообразующий суффикс, затем основа слова (не путать с корнем), приставка, суффикс и в самом конце выделяется корень.
Словообразование: примеры и способы
Образование новых слов – очень важный процесс. Он говорит о том, что язык не стоит на месте, он развивается, находится в движении. Процесс становления слова частицей языка весьма длительный, ведь носители должны привыкнуть к нему. Новые слова называются неологизмами. А наука, изучающая способы их появления, – словообразованием.
Словообразование как раздел языка
У любого слова есть значимые части, морфемы. Этокасается не только русского, но и всех остальных языков. Значимыми эти части называются потому, что участвуют в образовании новых слов, они не изменяются при склонении или спряжении. Такими морфемами являются приставка, суффикс и основа. Отсюда – и способы словообразованияслов: приставочный и суффиксальный.
Также в появлении новых слов участвует и основа. Обычно она отвечает за образование сложных слов, потому что основы, взаимодействуя между собой, складываются.
Стоит отметить, что иногда сложно проследить, что было истоками того или иного слова. В таком случае поможет словообразовательный словарь. Он есть в каждом языке. Также можно заглянуть в этимологический, ведь зачастую морфемы, с помощью которых слово было когда-то образовано, срастаются с корнем.
В таком случае поможет словообразовательный словарь. Он есть в каждом языке. Также можно заглянуть в этимологический, ведь зачастую морфемы, с помощью которых слово было когда-то образовано, срастаются с корнем.
В качестве примера можно привести слово память. В процессе исторического развития это слово потеряло приставку па-, с помощью которой произошло. В настоящее время при морфемном разборемы выделяем в этом слове только корень, основу и окончание.
Фонетический разбор слова онлайн примеры бесплатно, словарь полного фонетического разбора
Русский язык сложен не только для изучающих его иностранцев, зачастую и носители сталкиваются с определенными трудностями. Кажется, что сложного в обычном фонетическом разборе, ведь все мы учились в школе, где эта тема была преподнесена весьма доступно. Но когда пытаемся помочь отпрыскам с домашним заданием по русскому языку, сталкиваемся с рядом трудностей. Начинаем звонить друзьям, знакомым, учителям, но можно поступить намного проще и не искать информацию в школьных учебниках и всевозможных шпаргалках на бумажных носителях.
Здесь на помощь придет фонетический разбор слова онлайн бесплатно. Очень удобная система алфавитного поиска позволяет сразу же найти слово, вызвавшее затруднение при разборе.
Словарь полного фонетического разбора представляет анализ слов, который на каждой странице сделан в соответствие со всеми необходимыми требованиями. То есть последовательно выполнены все шаги, которые предполагает разбор слова онлайн.
Во-первых, дана запись слова в соответствие с орфографическими нормами. Затем определен ударный звук, что, кстати, позволяет использовать данный фонетический словарь при неуверенности в орфоэпических характеристиках. То есть если у вас есть сомнения в верной постановке ударения, развейте их, зайдя на страницу, посвященную сложному для вас слову.
Немаловажным является и деление слова на слоги. Если вы не знаете, как правильно перенести слово, используйте звукобуквенный анализ слова онлайн, где есть все необходимые сведения. Зайдя на сайт, найдите искомую страницу и проверьте – правильно ли был вами сделан слогораздел.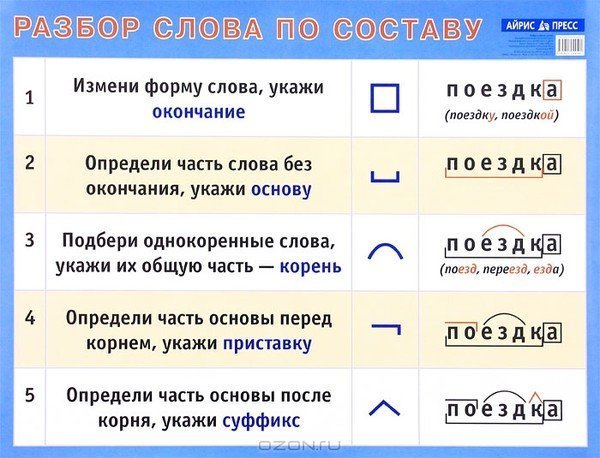
Фонетическая транскрипция слова пригодится и школьникам, но в большей степени студентам, углубленно изучающим современный русский язык и пытающимся постичь его фонетические и орфоэпические нормы.
И непосредственно звуковой анализ слова онлайн заключается в последовательной характеристике всех звуков в слове. Каждый из них записывается с новой строчки, определяется гласный он или согласный, а после этого рядом подробно описываются его свойства с точки зрения глухости/звонкости, твердости/мягкости. Для гласных звуков выделяются ударная или безударная позиции. Причем если слог в слове один, запись об ударности звука опускается, так как это очевидно. После того, как дана характеристика каждого из звуков, составляющих слово, подсчитывается и записывается количество букв и звуков.
Кроме того, в конце каждой статьи словаря дается ряд ссылок, направляющих посетителей в другие словари для ознакомления со статьями, касающимися данного слова.
Морфемный разбор слова онлайн
Морфемный разбор – это деление слова на составные его части. Часть речи разбирается на корень, приставку, суффикс, основу, префикс и т. д. Это очень важно для понимания принципа правописания. Многие правила русского языка строятся на определении того, в какой части слова пишется та или иная буква. Например, приставка «Пре» пишется в слове, когда оно обозначает высокую степень качества («Презабавный», «Премудрая»).
Часть речи разбирается на корень, приставку, суффикс, основу, префикс и т. д. Это очень важно для понимания принципа правописания. Многие правила русского языка строятся на определении того, в какой части слова пишется та или иная буква. Например, приставка «Пре» пишется в слове, когда оно обозначает высокую степень качества («Презабавный», «Премудрая»).
Правила также строятся на основе того, в какой его части находится буква, с которой возникают трудности. Так, чтобы точно определить какую именно букву нам употребить в слове (ё или о), нужно понять, в какой части она стоит. В корне мы напишем ё (черный), не беря в счет исключения, а в окончаниях существительных, наречий и прилагательных под ударением поставим о. Вот поэтому очень важно делать морфемный разбор слова. В этом деле вам будет хорошим помощником словообразовательный словарь Тихонова (печатный или в онлайн формате). Для того чтобы владеть в совершенстве русским языком, необходимо привить в себе привычку разбирать слова со словарем.
Выполнение морфемного разбора по плану
Порядок действий:
- Для начала определите к какой части речи относится слово, которое предполагается разобрать.
- Теперь выделим основу и окончание. Чтобы определить окончание, нужно слово изменить по роду или падежам. Часть, которая будет изменяться – есть окончание, остальное – основа. Нужно не забывать, что все слово может являться основой и не иметь окончания, например, наречие является неизменяемой частью речи.
- Теперь определим наличие приставки и суффикса. Чтобы это сделать нужно часть речи сравнить с однокоренными.
- Удостоверимся, что суффиксы и приставки есть также и в других словах. Для этого нужно подобрать аналогичные слова и сравнить их.
- Выделяем части, используя специальные графические обозначения.
План разбора слова на морфемы
Читайте также: Синтаксический разбор слова.
Несколько примеров деления части речи по составу
- Лесной – прилагательное, с корнем «Лес», суффиксом – «Н» и окончанием «Ой».
- Безработица – существительное, с приставкой «Без», корнем – «Работ», суффиксом – «Иц» и окончанием «А».
- Больной – существительное, прилагательное, с корнем – «Боль», суффиксом – «Н», с окончанием – «Ой».

Разобрать состав любого слова также могут помочь различные бесплатные online-сервисы.
Морфемный разбор слова
Это может быть полезным: Лексический разбор слова.
Основные положения при морфемном разборе слова онлайн
Чтобы выполнить грамотно разбор слова по составу, необходимо последовательно выполнять действия. Прежде чем это сделать, необходимо усвоить некоторый порядок:
- Найти окончание. Найдем для начала окончание слова там, где это можно сделать. Чтобы найти окончание необходимо изменить слово: пирог – пирогу, окончание «У». Часто в школе дети ошибочно начинают разбор с определения корня. Это неверный способ, потому что есть слова, в которых это сделать достаточно сложно, например – съем, вынуть. К примеру, в слове «Вынуть» н – корень замаскировался под суффикс ну, определить это можно изменив на другую форму вынимать, здесь корень – ним. Для того чтобы определить части слова и выполнить разбор без ошибок можно воспользоваться словарем морфем.
- Определение основы. Основа слова – это часть изменяемого слова, которая останется после того, как мы отбросим от него окончание. В деепричастии и наречии основой является все слово, потому что они являются неизменяемыми. Морфемный разбор любой части речи онлайн даст возможность определить ее происхождение.
- Определение суффикса. В первую очередь определяют формообразующие суффиксы. Чтобы это сделать нужно часть речи сравнить с подобными формами. Затем определяют словообразовательные суффиксы, чтобы стало ясно от какого источника и при помощи какого суффикса оно сформировалось. Например, в словах воспитатель и учитель слова образованы с помощью суффикса «тель». Используя словарь морфемного разбора слова, вы не сможете ошибиться в определении суффикса. Он поможет понять смысл и законы образования в русском языке.
- Нахождение приставки. Для того чтобы это сделать, необходимо заменить приставку на подобную. Если вы не можете определить приставку самостоятельно, вам поможет специальный словарь или online-сервисы.
- Следующей частью, которую нужно определить, будет корень. Для этого подберите несколько однокоренных слов, чтобы убедиться в правильности определенной морфемы: волк – волку – волчок.
- Каждая морфема слова имеет свое графическое обозначение. Чтобы определить соответствие графических обозначений можно воспользоваться словарем. При различных затруднениях при разборе слова вам поможет морфемно-орфографический онлайн-словарь.
 К примеру, в слове «Вынуть» н – корень замаскировался под суффикс ну, определить это можно изменив на другую форму вынимать, здесь корень – ним. Для того чтобы определить части слова и выполнить разбор без ошибок можно воспользоваться словарем морфем.
К примеру, в слове «Вынуть» н – корень замаскировался под суффикс ну, определить это можно изменив на другую форму вынимать, здесь корень – ним. Для того чтобы определить части слова и выполнить разбор без ошибок можно воспользоваться словарем морфем. Он поможет понять смысл и законы образования в русском языке.
Он поможет понять смысл и законы образования в русском языке.Также вы можете посмотреть видео по этой теме:
Женя Птушкин
10/10
Sunnat Ishpulatov
10/10
Рейтинг теста
Средняя оценка: 3.6. Всего получено оценок: 516.
А какую оценку получите вы? Чтобы узнать — пройдите тест.
Морфемный анализ 5 класс онлайн-подготовка на Ростелеком Лицей
Морфемный анализ
Один из видов лингвистического анализа — определение состава слова. Он играет значительную роль в формировании грамотности письма.
Он играет значительную роль в формировании грамотности письма.
Необходимо помнить, что разбор слова по составу следует производить в соответствии с нормами современного русского языка. Так, в современном русском языке слово «богатый» не имеет суффикса, который выделялся по правилам прошлого и имел то же значение, что и в прилагательном «полосатый», а именно: наличие соответствующего признака, предмета.
В настоящее время прилагательное «полосатый» имеет отношение к слову «полоса», т. е. мотивировано им, и, следовательно, содержит суффикс -ат, прилагательное же «богатый» утратило древнее отношения с существительным «бог», поэтому его основа состоит лишь из корня.
Никогда не следует начинать анализ слова с поиска корня, каким бы «прозрачным» он ни казался!
Основным приемом при разборе слова:
1. Подбор его форм для выделения окончания.
2. Подбор одноструктурных слов для определения суффиксов и приставок
3. Подбор однокоренных слов для нахождения корня.
4. Основа — часть слова без окончания.
Как уже говорилось, корень является последней морфемой, которая выделяется в слове. Этому правилу надо следовать неукоснительно, особенно если принять во внимание то, что один и тот же корень может выступать в словах в различных видах, например: веду, водить, вести; шла, шел, пришедший.
Слово может иметь в своем составе один (вода, лес) и более корней (водовоз, лесоруб).
Порядок разбора
1. Определить, какой частью речи является анализируемое слово, в какой форме оно употреблено.
2. Если слово изменяется, выделить формообразовательные морфемы.
3. Выделить основу.
4. В основе выделить корень.
5. Выделить словообразовательные морфемы (если есть).
Образец разбора
Городской — прилагательное в форме мужского рода именительного падежа единственного числа.
Окончание –ой.
Основа городск-.
Корень город-.
Словообразовательный суффикс –ск-
Вы пьете корень. «Питьевой»
Схема разбора по составу напитка:
напиток е
Разбор слова состав.
Состав слова «напиток»:
Соединительная гласная: отсутствует
Постфикс: отсутствует
Морфемы — части слова питьевой
напиток
Подробная разбивка слова напиток по составу. Слово cope, префикс, суффикс и окончание слова.Мофемный состав слова напиток, его рисунок и части слова (морфология).
- Схема морфем: pi / th / e
- Структура слова по морфемам: корень / корень / окончание
- Схема (построение) слова drink по составу: корень пи + корень t + окончание е
- Список морфем в слове drink:
- Типы морфов и их количество в слове drink:
- доставка: отсутствует — 0
- королева: напиток — 2
- соединительный ледник: отсутствует — 0
- cyffix: отсутствует -0
- постфикс: отсутствует -0
- конец: e -1
Все морфемы в слове: 3.
Словообразование разбор слова пить
- Основа слова: напиток ;
- Словообразовательные аффиксы: префикс отсутствует , суффикс отсутствует , постфикс отсутствует ;
- Словообразование: ○ сложение или сращивание основы (или целого слова), неправильное сложение, так как образовано без соединительной гласной ;
- Способ обучения: производная, так как образуется в 1 (один) способ .
См. Также другие словари:
Однокорневые слова… это слова, имеющие корень … принадлежащие к разным частям речи, и в то же время близкие по значению … Слова с одним корнем пить
Какое слово означает пить множественное число …. Что пьет напиток?
Полный морфологический анализ слова «пить»: часть речи, начальная форма, морфологические особенности и формы слова. Направление науки о языке, где изучается слово … Морфологический разбор питья
Ударение в слове питье: на какой слог ударение и как… Слово «пить» правильно пишется как … Ударение в слове пить
Синонимы к слову «пить». Онлайн-словарь синонимов: найдите синонимы к слову «пить». Слова-синонимы, похожие слова и похожие выражения в … Синонимы питья
Онлайн-словарь синонимов: найдите синонимы к слову «пить». Слова-синонимы, похожие слова и похожие выражения в … Синонимы питья
Анаграммы (составить анаграмму) к слову пить, смешивая буквы … Анаграммы для напитка
К чему снится пить — толкование снов, узнать для бесплатно в нашем соннике к чему снится пить. … Виденный во сне напиток означает это… Сонник: к чему снится пить
Морфемный разбор слова пить
Морфемный разбор слова принято называть разбором слова по составу — это поиск и анализ морфем (частей слова), входящих в состав данное слово.
Морфемный разбор слова выпивка очень прост. Для этого достаточно соблюдать все правила и порядок разбора.
Давайте сделаем синтаксический анализ морфем правильным, но для этого достаточно пройти 5 шагов:
- определение части речи слова — первый шаг;
- второй — выбираем окончание: для изменчивых слов спрягаем или раздуваем, для неизменяемых (герундий, наречия, некоторые существительные и прилагательные, официальные части речи) — окончаний нет;
- дальше ищем основу. Это самая легкая часть, потому что вам просто нужно отрезать конец, чтобы определить стержень. Это будет основой слова;
- Следующий шаг — поиск корня слова. Подбираем родственные слова для питья (их еще называют однокорневыми), тогда корень слова будет очевиден;
- Мы находим остальные морфемы, выбирая другие слова, образованные таким же образом.
 Это самая легкая часть, потому что вам просто нужно отрезать конец, чтобы определить стержень. Это будет основой слова;
Это самая легкая часть, потому что вам просто нужно отрезать конец, чтобы определить стержень. Это будет основой слова;Как вы видите, разбор морфемы выполняется просто. Теперь давайте определим основные морфемы слова и проанализируем их.
* Морфемный синтаксический анализ слова (синтаксический анализ слов) — поиск корня, префиксов, суффиксов, окончаний и основных слов
Парсинг слова по составу на сайте производится по словарю морфемного разбора.
напиток
Состав слова «напиток» :
корень — [пи], формирующий суффикс — [th]
Предложения со словом «пить»
Единственное шампанское, которое можно пить из маленького Бутылка 200 мл через соломинку прямо на дискотеке.
После плодотворной работы можно было полностью расслабиться, на время забыть о рутинных заботах, выпить молодого вина и спеть озорные песни.
Ей запретили пить и почти курить.
Маленькие капризничали, просили выпить, а большие дрались и играли в фантики.
Лариса погладила его по голове, потому что он рос и умнел, Марина снисходительно улыбнулась детской наивности, Степан вообще проигнорировал его, а Алексей Тихонович вместо того, чтобы пить больше стаканов и спрашивать других, лучше ли жить в такой квартире или в собственном доме, встал, подошел к окну и подумал.
Вечером пошел к старушке Клавдии Петровне попить чаю.
Он сохранил свою жизнь и себя аккуратно; когда он перестал пить, то не мог сдвинуться с места.
И подумал, как хорошо сидеть в таком буфете, слушать тонкие свистки проезжающих электричек, греться у плиты и пить пиво из кружки.
Разбери слово по составу, что оно означает?
Анализ слова по составу один из видов лингвистических исследований, цель которого — определить структуру или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе это еще называется разбор морфемы … Сайт с практическими рекомендациями поможет правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, причастие, наречие, числительное.
В школьной программе это еще называется разбор морфемы … Сайт с практическими рекомендациями поможет правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, причастие, наречие, числительное.
План: Как разобрать слово?
При синтаксическом разборе морфем соблюдайте определенную последовательность выделения значимых частей. Начните с того, чтобы «убрать» морфемы с конца, используя метод «раздевания корня». Подходите к анализу осмысленно, избегайте необдуманных разделений.Определите значения морфем и выберите одинаковые корневые слова, чтобы подтвердить правильность анализа.
- Запишите слово так же, как и в домашнем задании. Прежде чем приступить к разборке композиции, выясните лексическое значение (значение).
- Определите из контекста, к какой части речи он относится. Вспомните особенности слов, относящихся к этой части речи:
- изменчивый (имеет окончание) или неизменный (не имеет окончания)
- есть ли у него формирующий суффикс?
- Найдите концовку. Для этого склоняйтесь по регистру, меняйте число, пол или человека, спрягайте — вариативная часть будет окончанием. Помните о изменяемых словах с нулевым окончанием, обязательно обозначьте, если оно есть: sleep (), friend (), audibility (), gratitude (), ate ().
- Чтобы выделить основу слова, используется часть без окончания (и формирующего суффикса).
- Обозначьте префикс в базе (если есть). Для этого сравните одинаковые корневые слова с префиксами и без них.
- Определите суффикс (если есть).Чтобы проверить, выберите слова с разными корнями и с одним и тем же суффиксом, чтобы они выражали одно и то же значение.
- Найдите корень у основания. Для этого сравните несколько связанных слов. Их общая часть — это корень. Запомните одни и те же корневые слова с чередующимися корнями.
- Если в слове два (или более) корня, обозначьте соединяющую гласную (если есть): листопад, звездолет, садовник, пешеход.
- Отметьте формирующие суффиксы и постфиксы (если есть)
- Еще раз проверьте синтаксический анализ и выделите все важные части значками
 Для этого склоняйтесь по регистру, меняйте число, пол или человека, спрягайте — вариативная часть будет окончанием. Помните о изменяемых словах с нулевым окончанием, обязательно обозначьте, если оно есть: sleep (), friend (), audibility (), gratitude (), ate ().
Для этого склоняйтесь по регистру, меняйте число, пол или человека, спрягайте — вариативная часть будет окончанием. Помните о изменяемых словах с нулевым окончанием, обязательно обозначьте, если оно есть: sleep (), friend (), audibility (), gratitude (), ate (). В первичных классах разобрать слово — означает выделить окончание и основу, затем обозначить префикс суффиксом, подобрать одинаковые корневые слова и затем найти их общую часть: корень, и все.
* Примечание: Минобрнауки России рекомендует для общеобразовательных школ три учебных комплекса по русскому языку в 5-9 классах. У разных авторов разбор морфем по составу отличается подходом. Чтобы избежать проблем с выполнением домашнего задания, сравните приведенный ниже порядок синтаксического анализа с вашим учебником.
Порядок полного синтаксического анализа морфем по составу
Во избежание ошибок предпочтительно связывать синтаксический анализ морфем с деривационным синтаксическим анализом.Такой анализ называется формально-семантическим.
- Определите часть речи и проведите графический морфемный анализ слова, то есть обозначьте все доступные морфемы.
- Запишите окончание, определите его грамматическое значение … Укажите суффиксы словоформы (если есть)
- Запишите основу слова (без формирующих морфем: окончаний и формирующих суффиксов)
- Найдите морфемы. Выпишите суффиксы и префиксы, обоснуйте их выбор, объясните их значение
- Корень: свободный или связанный. Для слов со свободными корнями составьте цепочку словообразования: «напиши-то → напиши-напиши → напиши-ое», «dry (oh) → dry-ar () → dry-ar-nits» -(а также)». Для слов со связанными корнями выберите слова с единой структурой: «платье-раздевание-переодевание».
- Запишите корень, возьмите те же коренные слова, укажите возможные варианты, чередование гласных или согласных в корнях.
 Для слов со свободными корнями составьте цепочку словообразования: «напиши-то → напиши-напиши → напиши-ое», «dry (oh) → dry-ar () → dry-ar-nits» -(а также)». Для слов со связанными корнями выберите слова с единой структурой: «платье-раздевание-переодевание».
Для слов со свободными корнями составьте цепочку словообразования: «напиши-то → напиши-напиши → напиши-ое», «dry (oh) → dry-ar () → dry-ar-nits» -(а также)». Для слов со связанными корнями выберите слова с единой структурой: «платье-раздевание-переодевание».Как найти морфему в слове?
Пример полного морфемного синтаксического анализа глагола «спал»:
- окончание «а» указывает на форму глагола женский, номера единиц, прошедшее время, сравните: проспал;
- основание гандикапа «проспал»;
- два суффикса: «а» — суффикс основы глагола, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставку «про» — действие со значением потери, неудобства, ср.: просчитаться, проиграть, упустить;
- словообразовательная цепочка: сон — проспал — проспал;
- корень «cn» — в родственных словах возможны чередования cn // cn // sleep // syp. Однокорневые слова: сон, засыпание, сонливость, недосыпание, бессонница.
 Однокорневые слова: сон, засыпание, сонливость, недосыпание, бессонница.
Однокорневые слова: сон, засыпание, сонливость, недосыпание, бессонница.Схема разбора состава напитков:
drink em
Разбор слова композиция.
Состав слова «напитки»:
Соединительная гласная: отсутствует
Постфикс: отсутствует
Морфемы — части слова напитки
напитки
Подробная разбивка слова напитки по составу.Слово cope, префикс, суффикс и окончание слова. Мофема расположение слова напитки, его рисунок и часть слова (морфология).
- Схема морфемы: p / e
- Структура слова по морфемам: корень / окончание
- Схема (построение) слова drinks по составу: корень pt + окончание em
- Список морфем в слове drinks:
- Типы морфов и их количество в слове drink:
- доставка: отсутствует — 0
- королева: p — 1
- соединительный ледник: отсутствует — 0
- cyffix: отсутствует — 0
- постфикс: отсутствует -0
- конец: нет -1
Все морфемы в слове: 2.
Анализ словообразования слова drink
См. Также другие словари:
Полный морфологический анализ слова «напитки»: часть речи, начальная форма, морфологические особенности и формы слова. Направление науки о языке, где изучается слово … Морфологический разбор напитков
Ударение в слове напитки: на какой слог падает ударение и как . .. Слово «напитки» правильно пишется как .. Ударение в слове напитки
Анаграммы (составьте анаграмму) к слову напитки, смешивая буквы… Анаграммы для слова напитки
Морфемный разбор слова drink
Морфемный разбор слова обычно называется разбором слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово .
Морфемный разбор слова пить очень просто. Для этого достаточно соблюдать все правила и порядок разбора.
Давайте проведем морфемный синтаксический анализ правильно, и для этого нам достаточно пройти 5 шагов:
- определение части речи слова — первый шаг;
- второй — выбираем окончание: для изменчивых слов спрягаем или раздуваем, для неизменяемых (герундий, наречия, некоторые существительные и прилагательные, официальные части речи) — окончаний нет;
- дальше ищем основу. Это самая легкая часть, потому что вам просто нужно отрезать конец, чтобы определить стержень. Это будет основой слова;
- Следующий шаг — поиск корня слова. Подбираем родственные слова для напитков (их еще называют однокорневыми), тогда корень слова будет очевиден;
- Мы находим остальные морфемы, выбирая другие слова, образованные таким же образом.
 Это самая легкая часть, потому что вам просто нужно отрезать конец, чтобы определить стержень. Это будет основой слова;
Это самая легкая часть, потому что вам просто нужно отрезать конец, чтобы определить стержень. Это будет основой слова;Как вы видите, разбор морфемы выполняется просто. Теперь давайте определим основные морфемы слова и проанализируем их.
* Морфемный синтаксический анализ слова (синтаксический анализ слов) — поиск корня, префиксов, суффиксов, окончаний и основных слов
Парсинг слова по составу на сайте производится по словарю морфемного разбора.
Автоматическая сегментация морфем (Открытые проблемы в лингвистике компьютерного разнообразия 1)
| Число | Слово | Малые данные | Большие данные | Онлайн |
|---|---|---|---|---|
| 1 | рука | рука | рука | рука |
| 2 | ручной щиток | рука-сч-ну | ручной щиток | ручная работа |
| 3 | hantel | ч-а-н-т-эль | Хан-Эль | han-tel |
| 4 | голод | h-u-n-g-er | голод | голод |
| 5 | lauf-en | l-a-u-f-en | лауфен | lauf-en |
| 6 | geh-en | gehen | gehen | gehen |
| 7 | lieg-en | l-i-e-g-en | лиген | лиген |
| 8 | schlaf-en | Ш-лафен | шланг | schlaf-en |
| 9 | kind-er-arzt | вид-эр-а-р-з-т | kind-er-arzt | киндер-арзт |
| 10 | grund-schule | g-rund-sch-u-l-e | grund-schule | grundschule |
Что ясно видно из таблицы, где все формы, отклоняющиеся от моего анализа, выделены красным шрифтом, так это то, что ни одна из моделей не работает убедительно в
сегментируя мои десять тестовых слов. Но что еще более важно, мы можем ясно видеть
Но что еще более важно, мы можем ясно видеть
что проблемы алгоритма резко возрастают при работе с небольшими обучающими данными. Поскольку сегментирование, предложенное в столбце Small data , явно
худшее — разбиение слов на буквы, казалось бы, случайным образом.
В этом контексте интересно то, что подготовленные лингвисты редко терпят неудачу.
в этой задаче, даже когда все, что им было дано, — это небольшой список данных для обучения. Что они делают , а не
Неудача подтверждается многочисленными исследованиями, в которых лингвистические полевые исследователи
исследовали до сих пор недостаточно изученные языки и быстро выяснили
как работает морфология.
Почему так сложно найти границы морфем?
Что делает определение границ морфем таким трудным, в том числе для людей, так это то, что они по своей сути неоднозначны. Заключительный -s может обозначать множественное число в немецком языке, особенно по заимствованиям, как в Job-s , но он также может обозначать короткий вариант es «it», где гласная удаляется, как в ist «это», и во многих других случаях он может просто ничего не отмечать, а вместо этого быть частью более крупной морфемы, например Haus «дом». Может ли определенная подстрока звуков в языке функционировать как морфема, зависит от значения слова, а не от самой подстроки. Мы можем — еще раз — увидеть одно из больших различий между последовательностями в биологии и последовательностями в лингвистике: лингвистические последовательности выводят свою «функцию» (то есть свое значение) из контекста, в котором они используются, а не только из их структуры.
Может ли определенная подстрока звуков в языке функционировать как морфема, зависит от значения слова, а не от самой подстроки. Мы можем — еще раз — увидеть одно из больших различий между последовательностями в биологии и последовательностями в лингвистике: лингвистические последовательности выводят свою «функцию» (то есть свое значение) из контекста, в котором они используются, а не только из их структуры.
Если говорящие больше не могут четко понимать морфологическую структуру данного слова, они могут даже начать изменять ее, чтобы сделать ее более «прозрачной» в своем значении.Примерами этого являются многочисленные случаи народной этимологии , где говорящие переосмысливают морфемы в слове, с английским ham-burger в качестве яркого примера, так как слово первоначально, кажется, происходит от города Hamburg , что не имеет ничего общего с ветчиной.
Как люди находят морфемы?
В
Причины, по которым человеческие лингвисты могут относительно легко находить морфемы в разреженных данных, в то время как машины не могут, все еще не
мне совершенно ясно (т. е.люди хороши в распознавании образов и
е.люди хороши в распознавании образов и
машин нет). Однако у меня есть некоторые основные идеи о том, почему люди
во многом
превосходят машины, когда дело доходит до сегментации морфем; и я думаю
что будущие подходы, которые пытаются учесть эти идеи, могут
резко улучшить производительность автоматической сегментации морфем
методы.
Во-первых, учитывая важность значения для определения морфемической структуры, мне кажется почти абсурдным пытаться идентифицировать морфемы в данном языковом корпусе на основе чистого анализа последовательностей, не принимая во внимание их значение.Если мы сталкиваемся с двумя словами
как испанский hermano «брат» и hermana «сестра», это понятно — если мы знаем что
они означают — что -o vs. -a , скорее всего, обозначает различие между
Пол. Пока машины сравнивают потенциальные сходства внутри слов
независимо от семантики, люди всегда будут начинать с тех пар, где
они думают, что могут ожидать найти интересные изменения. Так долго как
Так долго как
значения предоставлены, лингвист-человек — даже если он не знаком с
заданном языке — может легко предложить более или менее убедительную сегментацию
список всего 500 слов.
Второй момент, который игнорируется в современных автоматических подходах, — это тот факт, что морфологические структуры сильно различаются между языками. Например, в китайском и многих языках Юго-Восточной Азии почти правилом является то, что каждый слог представляет одну морфему (с минимальными исключениями, которые подтверждаются и обсуждаются в литературе). Поскольку в этих языках снова легко найти слоги, поскольку слова часто могут оканчиваться только на определенное количество звуков, алгоритм для обнаружения слов на этих языках не будет нуждаться в какой-либо статистике n-граммов, а только в теории слоговых структур.Вместо глобальных стратегий нам, возможно, придется использовать локальные стратегии сегментации морфем, в которых мы идентифицируем различные типов языков , для которых данный алгоритм кажется подходящим.
Это подводит нас к третьему пункту. Особенность языковых последовательностей в разговорных языках состоит в том, что они построены на определенных фонотаксических правилах , которые управляют их общей структурой. Допускается ли язык более трех согласных в начале слова, зависит от его фонотактики , его набора правил, по которым набор звуков объединяется для образования морфем и слов.Сама фонотактика также может указывать на границы морфем, поскольку они могут запрещать комбинации звуков внутри морфем, которые могут возникать, когда морфемы объединяются в слова. Немецкий Ur-instinkt «основной инстинкт», например, произносится с голосовой остановкой после Ur -, что может встречаться только в начале немецких слов и морфем, таким образом выделяя слово как составное (в противном случае слово может быть проанализировано как Urin-stinkt «запах мочи».
Четвертый момент, который также обычно игнорируется в современных подходах к
автоматическая сегментация морфем — это кросс-лингвистических свидетельств. В
В
во многих случаях носители данного языка могут сами больше не знать
оригинальной морфологической сегментации некоторых их слов, в то время как
сравнение с близкородственными языками все еще может выявить это. Если у нас есть
потенциально мультиморфемное слово на одном языке, например, и только одно из
две потенциальные морфемы, отраженные как нормальное слово на другом языке,
это явное свидетельство того, что потенциально мультиморфемное слово действительно
состоят из нескольких морфем.
Предложения
Лингвисты регулярно используют разные типы доказательств, пытаясь понять
в
морфологический состав слов данного языка. Если мы хотим
к
продвинуть область автоматической сегментации морфем, как мне кажется
Необходимо отказаться от идеи определения морфологии языка, просто взглянув на распределение букв по словоформам. Вместо этого мы
должен
использовать семантическую, фонотаксическую и сравнительную информацию. В дальнейшем нам следует отказаться от идеи разработки универсальных алгоритмов сегментации морфем, а лучше изучить, какой подход лучше всего работает с каким морфологическим типом. Как
В дальнейшем нам следует отказаться от идеи разработки универсальных алгоритмов сегментации морфем, а лучше изучить, какой подход лучше всего работает с каким морфологическим типом. Как
эти аспекты могут
быть объединенными в единую структуру, однако до сих пор не совсем понятно
мне; и это также причина, по которой я перечисляю автоматические морфемы
сегментация как первая из десяти моих открытых проблем в вычислительной
лингвистика разнообразия.
Однако даже более важным, чем стратегии решения проблемы, является то, что мы начинаем работать с обширными наборами данных для тестирования и обучения новых алгоритмов, которые стремятся идентифицировать границы морфем на разреженных данных.На данный момент таких наборов данных не существует. Такие подходы, как Morfessor, были разработаны для определения границ морфем в письменных языках, они почти не работают с фонетической транскрипцией. Но если бы у нас были доступные наборы данных для тестирования и обучения, будь то всего около 20 или 40 языков из разных языковых семей, вручную аннотированные экспертами, сегментированные как по фонетике, так и по морфемам, это позволило бы нам исследовать как существующие и новые подходы гораздо более основательно, и я ожидаю, что это может дать реальный импульс нашей дисциплине и значительно помочь нам в разработке передовых решений проблемы.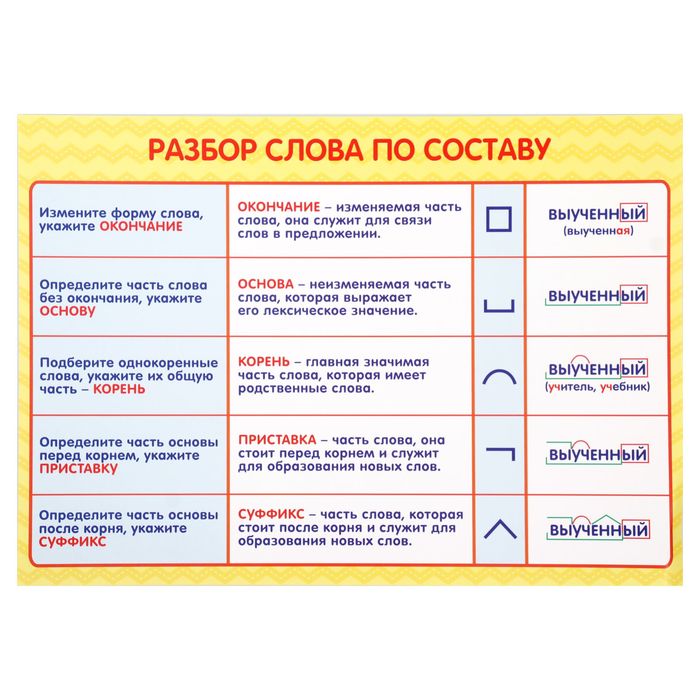
Список литературы
Баайен Р. Х. и Пипенброк Р. и Гуликерс Л. (ред.) (1995) Лексическая база данных CELEX. Версия 2 . Филадельфия.
Бенден, Кристоф (2005) Автоматическое обнаружение морфем с использованием
распределительные измерения. В: Клаус Вейхс и Вольфганг Галл (ред.):
Классификация — вездесущий вызов . Берлин и
Гейдельберг: Springer. С. 490-497.
Бордаг, Стефан (2008) Неконтролируемая и свободная от знаний морфема
сегментация и анализ.В: Кэрол Питерс, Валентин Джиджкун,
Томас Мандл, Хеннинг Мюллер, Дуглас В. Оард, Ансельмо Пеньас, Вивьен Петрас и Диана Сантос (ред.): Достижения в области многоязычного и мультимодального поиска информации . Берлин и Гейдельберг: Springer, стр.
881-891.
Кройц, М. и Лагус, К. (2005) Неконтролируемая сегментация морфем
и индукция морфологии из корпусов текстов с помощью Morfessor 1.0.
Технический отчет . Хельсинкский технологический университет.
Голдсмит, Джон А. и Ли, Джексон Л. и Ксантос, Арис (2017) Вычислительное обучение морфологии. Ежегодный обзор языкознания 3.1: 85-106.
и Ли, Джексон Л. и Ксантос, Арис (2017) Вычислительное обучение морфологии. Ежегодный обзор языкознания 3.1: 85-106.
Хаммарстрём, Харальд (2006) Наивная теория аффиксации и
Алгоритм извлечения. В: Материалы восьмого заседания
Специальная группа ACL по компьютерной фонологии и морфологии в
HLT-NAACL 2006, с. 79–88.
Харрис, Зеллиг С. (1955) От фонемы до морфемы. Язык 31.2: 190-222.
Лист, Иоганн-Маттис (2014) Сравнение последовательностей в исторической лингвистике .Дюссельдорф: издательство Дюссельдорфского университета.
Вирпиоя, Сами, Смит, Петер, Гронроос, Стиг-Арне и Куримо,
Mikko (2013) Morfessor 2.0: реализация Python и расширения для
Базовый уровень Морфессора . Хельсинки: Университет Аалто.
Тщательный анализ слова в композиции. «Прилежно»
Разбор слова по составу.
Состав слова «прилежный»:
Добросовестный морфемный синтаксический анализ
Морфемный синтаксический анализ слова обычно называется синтаксическим анализом слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный разбор слова прилежный очень прост. Для этого достаточно соблюдать все правила и порядок разбора.
Будет правильно выполнять морфемный синтаксический анализ, но для этого мы просто пройдем через 5 шагов:
- Определение части речи слова прилежный — первый шаг;
- второй — выберите окончание: для сопряженных слов спрягаем или склоняем, для неизменяемых (наречие, наречие, некоторые существительные и прилагательные, служебные части речи) — окончаний нет;
- дальше, ищем основу.Это самая легкая часть, потому что для определения основы вам просто нужно отрезать концовку. Это будет основой слова;
- Следующий шаг — поиск корня слова. Подбираем родственные слова для усердия (их еще называют родственными), тогда корень слова будет очевиден;
- Мы находим оставшиеся морфемы для усердного, выбирая другие слова, образованные таким же образом, как и усердный.
,
Как видите, усердный анализ морфем делается просто.Теперь давайте определим основные морфемы слова прилежный и проведем их анализ.
См. Также в других словарях:
Отклонить слово прилежный в падежах в единственном и множественном числе …. Усердие слова прилежный в падежах
Полный морфологический разбор слова «прилежный»: Часть речи, начальная форма , морфологические особенности и словоформы. Направление науки о языке, в котором изучается слово … Морфологический анализ прилежный
Акцент в слове прилежный: на какой слог падает ударение и как… Правильно пишется слово «прилежный» как… Ударение в слове прилежный
Синонимы слова «прилежный». Словарь синонимов онлайн: выберите синонимы к слову «прилежный». Синонимы, похожие слова и родственные выражения в … Синонимы к слову прилежный
Разбор слова по составу Одно из лингвистических исследований видов, цель которого — определить структуру или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них.В школьной программе также называется морфемным синтаксическим анализом . Сайт с практическими рекомендациями поможет правильно проанализировать любую часть речи по составу онлайн: существительное, прилагательное, глагол, местоимение, причастие, причастие, наречие, числительное.
План: Как по составу разобрать слово?
При проведении морфемического анализа соблюдайте определенную последовательность выделения значимых частей. Начните с того, чтобы «убрать» морфемы с конца, используя метод «раздевания корня». Подходите к анализу осмысленно, избегайте необдуманных разделений.Определите значения морфем и выберите родственные слова, чтобы подтвердить правильность анализа.
- Напишите слово в той же форме, что и в домашнем задании. Прежде чем приступить к анализу сочинения, выясните его лексическое значение (значение).
- Определите из контекста, к какой части речи он относится. Вспомните особенности слов, относящихся к этой части речи:
- изменчивый (есть окончание) или неизменный (не имеет окончания)
- есть ли у него формирующий суффикс?
- Найдите концовку.Для этого откажитесь от падежей, измените число, пол или человека, спрягите — вариативная часть будет концом. Помните о изменяемых словах с нулевым окончанием, обязательно укажите, есть ли оно: dream (), friend (), audibility (), gratitude (), eaten ().
- Выделение основы слова — это часть без окончания (и формирующего суффикса).
- Обозначьте префикс в основании (если есть). Для этого сравните корневые слова с приставками и без.
- Определите суффикс (если есть).Для проверки подберите слова с разными корнями и с одним и тем же суффиксом, чтобы они выражали одно и то же значение.
- Найдите корень root. Для этого сравните несколько связанных слов. Их общая часть — это корень. Помните о корневых словах с чередующимися корнями.
- Если слово имеет два (или более) корня, укажите соединительную гласную (если есть): листопад, звездолет, садовник, пешеход.
- Отметьте формообразующие суффиксы и постфиксы (если есть)
- Еще раз проверьте синтаксический анализ и выделите все соответствующие части значками

В младших классах разобрать слово — это означает выделить окончание и основание, после обозначить приставку суффиксом, выделить слова с одним корнем и затем найти их общую часть: корень — это все.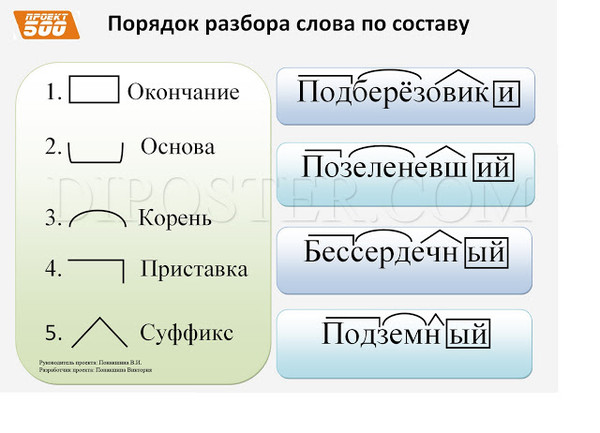
* Примечание: Минобрнауки России рекомендует для общеобразовательных школ три учебных комплекса на русском языке в 5–9 классах. Разные авторы морфемного анализа состава разный подход. Чтобы избежать проблем с производительностью в домашнем задании, сравните приведенную ниже процедуру синтаксического анализа с вашим учебным пособием.
Порядок полного морфемного анализа композиции
Во избежание ошибок синтаксический анализ морфем предпочтительно связан с синтаксическим анализом слов.Такой анализ называется формально-семантическим.
- Для установления части речи и графического морфемического анализа слова, то есть для обозначения всех имеющихся морфем.
- Выпишите окончание, определите его грамматическое значение. Укажите суффиксы, образующие слово (если есть)
- Запишите основу слова (без морфемных морфем: окончания и морфирующие суффиксы)
- Найдите морфемы. Запишите суффиксы и префиксы, обоснуйте их выбор, объясните их значение
- Корень: свободный или связанный. Для слов со свободными корнями составьте словообразовательную цепочку: «write-ab → write-ab → write-abb», «dry» (b) → dry-b () → dry-bb — (и) ». слова со связанными корнями, выберите слова с единой структурой: «одеть-раздеть-переодеться»
- Запишите корень, подберите коренные слова, укажите возможные варианты, чередование гласных или согласных в корнях
 Для слов со свободными корнями составьте словообразовательную цепочку: «write-ab → write-ab → write-abb», «dry» (b) → dry-b () → dry-bb — (и) ». слова со связанными корнями, выберите слова с единой структурой: «одеть-раздеть-переодеться»
Для слов со свободными корнями составьте словообразовательную цепочку: «write-ab → write-ab → write-abb», «dry» (b) → dry-b () → dry-bb — (и) ». слова со связанными корнями, выберите слова с единой структурой: «одеть-раздеть-переодеться»Как найти морфему в слове?
Пример полного морфемного анализа глагола «проспал»:
- окончание «а» указывает на форму глагола женского рода, одно число, прошедшее время, давайте сравним: проспал;
- основание гандикапа «проспал»;
- два суффикса: «а» — суффикс основы глагола, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставку «про» — действие со значением потери, неудобства, ср.: просчитаться, проиграть, упустить;
- словообразовательная цепочка: сон — проспал — проспал;
- «cn» корень — в связанных словах возможны чередования cn // cn // sleep // rash. Бандитские слова: сон, засыпание, сонливость, недосыпание, бессонница.
 Бандитские слова: сон, засыпание, сонливость, недосыпание, бессонница.
Бандитские слова: сон, засыпание, сонливость, недосыпание, бессонница.Разбор слова по составу.
Состав слова «усердно»:
Морфемный анализ слова усердно
Разбором слова обычно называют разбор слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный синтаксический анализ выполняется очень просто. Для этого достаточно соблюдать все правила и порядок разбора.
Мы проведем морфемный анализ правильно, а для этого просто пройдем 5 шагов:
- Прилежное определение части речи — первый шаг;
- второй — выберите окончание: для сопряженных слов спрягаем или склоняем, для неизменяемых (наречие, наречие, некоторые существительные и прилагательные, служебные части речи) — окончаний нет;
- дальше, ищем основу.Это самая легкая часть, потому что для определения основы вам просто нужно отрезать концовку. Это будет основой слова;
- Следующий шаг — поиск корня слова. Мы старательно подбираем родственные слова для (их еще называют родственными), тогда корень слова будет очевиден;
- Мы находим оставшиеся морфемы для усердно, выбирая другие слова, которые сформированы таким же образом, как усердно.
,

Как видите, старательно морфемный анализ, делается просто.А теперь внимательно определимся с основными морфемами слова и проведем его анализ.
См. Также в других словарях:
Уклоняй слово усердно в единственном и множественном числе …. Склонение слова старательно по падежам
Полный морфологический разбор слова «усердно»: Часть речи, начальная форма, морфологические особенности и формы слова. Направление науки о языке, в котором изучается слово … Прилежно морфологический анализ
Ударение в слове старательное: на какой слог падает ударение и как… Слово «усердно» правильно пишется как … Ударение в слове усердно
Морфология 1 Введение Морфология Морфологический анализ (MA)
Презентация на тему: «Морфология 1 Введение Морфология Морфологический анализ (МА)» — стенограмма презентации:
ins [data-ad-slot = «4502451947»] {display: none! important;}}
@media (max-width: 1000 пикселей) {# place_14> ins: not ([data-ad-slot = «4502451947»]) {display: none! important;}}
@media (max-width: 1000 пикселей) {# place_14 {width: 250px;}}
@media (max-width: 500 пикселей) {# place_14 {width: 120px;}}
]]>
1
Морфология 1 Введение Морфология Морфологический анализ (MA)
Использование методов FS в MA Автоматическое изучение морфологии языка Введение: marc general i la motivació d’aquest treball
2
Морфология 2 Морфология Результат морфологического анализа
Структура слова как состав морфем Связанные с правилами словообразования Функции Флексия Деривация Состав Результат морфологического анализа Морфосинтаксическая категоризация (POS) e. грамм. Набор тегов Parole (VMIP1S0), более 150 категорий для испанского, например Набор тегов Penn Treebank (VBD), около 30 категорий для английского языка Морфологические особенности Число, падеж, род, лексические функции
грамм. Набор тегов Parole (VMIP1S0), более 150 категорий для испанского, например Набор тегов Penn Treebank (VBD), около 30 категорий для английского языка Морфологические особенности Число, падеж, род, лексические функции
3
Морфология 3 Морфологический анализ Проблемы
Разложение слова на конкатенацию морфем Обычно некоторые морфемы содержат значение Один (корень или основа) в сгибании и образовании Более одного в составе Другие (аффиксы) обеспечивают морфологические особенности Проблемы Фонологические изменения в конкатенации морфем Морфотактика Какие морфемы могут быть объединены с какими другими
4
Морфология 4 Проблемы Аффиксы гибкие аффиксы производные аффиксы
Суффиксы, префиксы, инфиксы, интерфиксы гибкие аффиксы производные аффиксы Производные иногда подразумевают семантическое изменение, не всегда предсказуемое Расширения значений Лексические правила За производным суффиксом может следовать гибкий суффикс love => lover => lovers Сгибание не меняет POS, иногда производное сгибание влияет на другие слова в соглашении предложения
5
Морфология 5 Морфотактика Фонологические изменения (морфофонология)
Правила образования слов Допустимые комбинации между морфемами Простая конкатенация Корень / образец сложных моделей Регулярность зависит от языка Фонологические изменения (морфофонология) Изменения при конкатенации морфем Источник: переменные фонологии, морфологии и сложности орфографии . грамм. вокальная гармония
грамм. вокальная гармония
6
Морфология 6 1 морфема: 2 морфемы: 3 морфемы: 4 морфемы: evitar
evitable = evitar +able 3 морфемы: inevitable = in + evitar +able 4 морфемы: inevitabilidad = in + evitar +able + idad
7
Морфология 7 число глагольная форма пол дом дома cheval chevaux
Flexive Морфология число дом дома cheval chevaux casa casas словесная форма прогулка ходьба ходьба ходьба амо амас аман… пол niño niña
8
Морфология 8 Форма Исходная производная Морфология
Без изменений barcelonés Префикс неизбежный Суффикс importantísimo Исходный глагол => прилагательное tardar => глагол tardío => существительное sufrir => sufrimiento существительное => существительное актер => прилагательное atletao => прилагательное atleta => прилагательное rojo => rojizo прилагательное => наречие alegre => alegremente
9
Морфологический анализ 1
Типы морфологических анализаторов Формальные словари Словари эффективности словоформ Языки с несколькими вариантами (напр. грамм. Английский язык) расширяемость Возможность создания и обслуживания с помощью морфологического генератора. Языки с высокой степенью гибкости, деривация, композиция FS методы FSA 1 анализаторы уровня FST> 1 анализаторы уровня
грамм. Английский язык) расширяемость Возможность создания и обслуживания с помощью морфологического генератора. Языки с высокой степенью гибкости, деривация, композиция FS методы FSA 1 анализаторы уровня FST> 1 анализаторы уровня
10
Морфологический анализ 2
Двухуровневые морфологические анализаторы Общая модель для языков с конкатенацией морфем Независимость между лингвистическим ПО и анализатором Допустимо для анализа и генерации Различие между лексическим и поверхностным уровнями Параллельные правила для морфофонологии Простая реализация
11
Морфологический анализ 3
Морфологические правила Определите отношения между символами (поверхностью) и морфемами и сопоставьте строки символов и морфемную структуру слова.Правила правописания Выполняются на уровне букв, образующих слово. Может использоваться для определения достоверных фомологических изменений. Ричи, Пульман, Блэк, Рассел, 1987
12
Морфологический анализ 4
ввод: форма вывода лемма + морфологические признаки Входные данные Вывод cat cat + N + sg cats cat + N + pl города city + N + pl слияние слияние + V + pres_part поймано (catch + V + past) или ( catch + V + past_part)
13
Морфологический анализ 5
reg_noun irreg_pl_noun irreg_sg_noun множественное число лиса овца овца -s кошка мышь мышь собака 1 2 reg_noun множественное число irreg_pl_noun irreg_sg_noun Морфотактика
14
Морфологический анализ 6
f o x s c a t d g n e y m u i туман кошка собака осел мышь мышь Письмо преобразователи
15
Морфологический анализ 7
лексика верхнего уровня cat + N cat + N + pl нижний уровень кошка кошки c: c a: a t: t + N: + pl: s
16
Морфологический анализ 8
Использование FST в качестве распознавателя На основе пары входных строк (одна лексическая, а другая поверхностная) и отвечает, если одна является преобразованием другой. : ___ s #
: ___ s #
22
Морфологический анализ 14
epenthesis +: e { s: sx: xz: z} — s: s context => контекстное ограничение
23
Морфологический анализ 15
e-делеция e: 0 =: C или — или — или l:: 0 или c: c mov e + ed mov ed согласовано e + ed согласовано
24
Морфологический анализ 16
a-делеция a: 0 — t: t редукция иона редукция ионного контекста izdo foco context.s правила правописания FST1 FST2 … FSTn поверхностный уровень f o x e s
26 год
Морфологический анализ 18
Lexicon-FST Lexicon-FST Lexicon-FST • FSTA FST1 … FSTn FSTA = FST1 … FSTn композиция пересечения
27
Автоматическое изучение морфологии 1
Проблема Основа парадигмы + affixea Получение основы Классификация основ в моделях Изучение части морфологии (например,грамм. деривационный) Два подхода Предыдущие морфологические знания отсутствуют Goldsmith, 2001 Brent, 1999 Snover, Brent, 2001, 2002 Морфологические знания могут быть использованы Oliver et al, 2002
28 год
Автоматическое изучение морфологии 2
Автоматический морфологический анализ Идентификация границ между морфемами Зеллиг Харрис {префикс, суффикс} условная энтропия биграммы и триграммы с высокой вероятностью образования морфемы Изучение шаблонов или правил сопоставления между парами слов Глобальный подход (вверху- вниз) Golsdmith, Brent, de Marcken
29
Автоматическое изучение морфологии 3
Система Голдсмита, основанная на MDL (минимальная длина описания) Начальное разделение: слово -> основа + суффикс, разделение всех слов Хороший кандидат для разбиения на {основы, суффикс} в слове должен быть хорошим кандидатом другими словами стратегия MI (взаимная информация) Более быстрая конвергенция Learning Signatures {подписи, основа, суффиксы} MDL
30
Автоматическое изучение морфологии 4
Полуавтоматический морфологический анализ Оливер, 2004 Начинается с набора морфологических правил, написанных вручную TL: TF: Desc lemma end form окончание POS Списки негибких классов, закрытых классов и неправильных слов Корпорация сербо-хорватских 9 МВт Русский 16 МВт
Страница не найдена | MIT
Перейти к содержанию ↓
- Образование
- Исследовать
- Инновации
- Прием + помощь
- Студенческая жизнь
- Новости
- Выпускников
- О MIT
- Подробнее ↓
- Прием + помощь
- Студенческая жизнь
- Новости
- Выпускников
- О MIT
Меню ↓
Поиск
Меню
Ой, похоже, мы не смогли найти то, что вы искали!
Попробуйте поискать что-нибудь еще!
Что вы ищете?
Увидеть больше результатов
Предложения или отзывы?
Что такое морфология? — Введение в лингвистику
Морфология — это изучение слов. Морфемы — это минимальные единицы слов, которые имеют значение и не могут быть далее подразделены. Есть два основных типа: свободный и связанный. Свободные морфемы могут встречаться отдельно, а связанные морфемы должны встречаться с другой морфемой. Пример свободной морфемы — «плохой», а пример связанной морфемы — «ly». Он связан, потому что, хотя он имеет значение, он не может существовать отдельно. Он должен быть присоединен к другой морфеме, чтобы образовалось слово.
Свободная морфема: плохо
Связанная морфема: -ly
Слово: плохо
Когда мы говорим о словах, есть две группы: лексические (или содержательные) и функциональные (или грамматические) слова.Лексические слова называются словами открытого класса и включают существительные, глаголы, прилагательные и наречия. В эту группу можно регулярно добавлять новые слова. Функциональные слова или слова закрытого класса — это союзы, предлоги, артикли и местоимения; и новые слова не могут быть (или очень редко) добавлены в этот класс.
Аффиксы часто являются связанной морфемой. В эту группу входят префиксы, суффиксы, инфиксы и циркумфиксы. Префиксы добавляются в начало другой морфемы, суффиксы добавляются в конец, инфиксы вставляются в другие морфемы, а циркумфиксы присоединяются к другой морфеме в начале и в конце.Ниже приведены примеры каждого из них:
Префикс: re- добавлен, чтобы делать, производит повтор
Суффикс: -или добавлен для редактирования, производит редактор
Инфикс: -um- добавлен в fikas (сильный) производит фумика (чтобы быть сильным) в Bontoc
Circumfix: ge- и -t to lieb (любовь) производит geliebt (любимый) на немецком языке
Есть две категории аффиксов: словообразовательные и словоизменительные. Основное различие между ними состоит в том, что словообразовательные аффиксы добавляются к морфемам для образования новых слов, которые могут быть, а могут и не быть одной и той же частью речи, а флективные аффиксы добавляются в конец существующего слова по чисто грамматическим причинам. Всего в английском языке всего восемь флективных аффиксов:
| -с | настоящее время в единственном числе от третьего лица | она ждет |
| -ed | прошедшее время | он ходил |
| -ing | прогрессивный | она смотрит |
| -en | причастие прошедшего времени | она съела |
| -с | множественное число | три стола |
| -х | притяжательный | Кот Холли |
| -er | сравнительный | ты выше |
| -ест | превосходная | ты самый высокий |
Другой тип связанных морфем называется связанными корнями.Это морфемы (а не аффиксы), которые должны быть присоединены к другой морфеме и не имеют собственного значения. Некоторые примеры приведены в разделе «Воспринимать» и приведены в «Отправить».
Английские морфемы
- Бесплатно
- Открытый класс
- закрытый класс
- Связанный
- Приложение
- Производное
- Инфлекционный
- Корень
- Приложение
Есть шесть способов образовывать новые слова.Составные слова — это комбинация слов, аббревиатуры образуются из инициалов слов, обратные образования создаются из удаления того, что ошибочно считается аффиксом, сокращения или вырезки сокращают более длинные слова, эпонимы создаются из имен собственных (имен), а смешение — это объединение частей слов в одно.
Чӣ гуна калимаи «маҷалла» -ро аз рӯи таркибаш муайян кардан мумкин аст?
Чӣ гуна калимаи «маҷалла» -ро аз рӯи таркибаш муайян кардан мумкин аст?
Калима маҷалла аз забони фаронсавӣ гирифта шудааст, бинобар ин ягон морфемаи (суффикси) дигарро дар он ҷудо кардан ғайриимкон аст ва тамоми калима решаест, ки дар калимаҳои ҳосилшуда пайгирӣ кардан мумкин аст:
маҷалла, маҷалла, рӯзноманигор, рӯзноманигор.
Азбаски ин як исми тағирёбандаи ҷинси мук ҷинси дуюмдараҷаи дуюм аст, дар охир мо сифри сифрро интихоб мекунем, ки ҳангоми тағир ёфтани калима дар ҳолатҳо ва рақамҳо амалӣ мешавад:
маҷалла_ — маҷалла, маҷалла, маҷалла, маҷалла.
Асоси калима маҷаллаи он аст — бе хотима.
Дар натиҷа, мо таркиби морфемии ин калимаро менависем:
log_ — root / end.
Маҷалла — ва агар, журнал + пули нақд. иқтибос; Zhur quot; — ин тарҷумаи кӯҳнаи желе аст, ки дар овони кӯдакӣ онро волидон сохтаанд ва quot; nalquot; танҳо пули нақд аст. .
Дар калимаи маҷалла хотима нест. Аз ин рӯ, мо як майдони холиро тарк мекунем. Асоси калима маҷалла мебошад. Ин маънои онро дорад, ки дар ин ҷо ягон пешванд ё пасванд нест. Пас ин исм зуд ҷудо карда мешавад. Боқӣ мондааст, ки калимаро дар боло давр занед, то решаро қайд кунед.
Пеш аз ҳама, мо қисми нутқро муайян мекунем. ЖУРНАЛ — ин калима исм хоҳад буд, калима тағирёбанда аст, бинобар ин мо таҳлилро бо равшан кардани охири он ва поя оғоз мекунем.
Маҷаллаи-Y, маҷалла-U, маҷалла -_. ОХИР — НОЛ.
Боқимонда дар калимаи BASIC ҷойгир аст.
Баъд, мо бо пойгоҳ кор мекунем. Magazine-ny, маҷалла-ист, маҷалла-ҷануб, VS WORD — ин РЕШ хоҳад буд.
ЖУРНАЛ-_.
Калимаи Quote; Journalquot; он ашёи беҷон аст ва ба саволи «чӣ?» ҷавоб медиҳад. Маҷалла исми мардона аст.
Таҳлили ин калима дар таркиб, quot; маҷалла; квота; он ҳам реша ва ҳам пойгоҳ аст.
Он на пешванд дорад, на суффикс ва на охири.
Ман боварӣ дорам, ки калимаи quot; journalquot;, ки ба савол чӣ ҷавоб медиҳад? як исм бо охири сифр (квадрати холӣ) ва решаи калимаи quot; journalquot; — —Журнал—, яъне тамоми калима реша аст, поя рӯзнома.
Маҷалла калимаи пайдоиши забони хориҷӣ буда, дурусттараш дар асри 17 аз забони фаронсавӣ ба мо омадааст.Ин калима ба қонунҳои забони русӣ итоат кард, исми мардона шуд. Реша ва пойгоҳ маҷалла аст. Анҷоми сифр
Исми мардона Journal дар ҷудогона аст ва ба таназзули дуввум ишора мекунад. Дар таркиби он, мо охири сифрро ҷудо хоҳем кард: Journal-Journal-Journal-Journal-Journal-Journal. Як калимаи реша чунин хоҳад буд: Journal-Journalist-Journalist-Journalist-Journalism. Решаи калима морфемаи JOURNAL мебошад.
Мо ба даст меорем: JOURNAL_ (хотимаи реша-сифр), асоси калимаи JOURNAL.
Дар ин калима, реша ва пойгоҳ маҷалла, хотима сифр аст. Намедонам, шояд ҳоло дар барномаи таълимии забони русӣ аллакай қоидаҳои нав мавҷуданд, аммо понздаҳ сол пеш мо онҳоро бо ин роҳ ҷобаҷо мекардем.
Калимаи калима; маҷалла quot; дорои морфемҳо ё қисмҳои зерин мебошанд:
Префикс гум шудааст.
Реша — иқтибос; -ҷурнал- НОҲИЯИ ДАНҒАР
Суффикс сифр аст.
Анҷом сифр аст.
Ва охирин чизе, ки бояд дар ёд дошт, пойгоҳ аст — quot; маҷалла НОҲИЯИ ДАНҒАР
Барори кор
Тест по русскому языку по теме «Морфемика» (5 класс)
Морфемика 5 класс
1 вариант
1. Подчеркните слова, имеющие нулевое окончание.
Спелый, шарфы, мышь, повторял, перекресток, медведь, облако, вверх.
2. Выделите окончания
Пишем, умного, лыжня, сани, сверху.
3. Выберите пары слов, в которых представлены формы одного и того же слова.
1) художник – художница;
2) берег – береговой;
3) спать – спал;
4) белый – беловатый;
5) читать – читают,
6) грубое – грубая.
4. В каком ряду верно перечислены все морфемы, входящие в основу слова?
1) приставка, корень, окончание
2) корень, суффикс
3) приставка, корень, суффикс, окончание
4) приставка, корень, суффикс
5. Выделите корень
Заплетать, вкусненький, записался, подлокотник, желтоватый, налево.
6. Закончи предложение: «Главная значимая часть слова, в которой заключено общее лексическое значение всех однокоренных слов – это…»
1) Приставка;
2) корень;
3) суффикс;
4) окончание;
5) основа.
7. Выберите в каждой строчке лишнее слово, подчеркните его
1. Приморский, уморить, море.
2. Росток, растение, растерять.
3. Губа, загубить, губастый.
4. Утихнет, тихий, утешать.
5. Развевается, развитие, веять.
8. Обозначьте приставки
Сверхзвуковой, наименьший, перезагрузка, пробираться, антифашист.
9. Образуйте слова с уменьшительно-ласкательным значением, используя суффиксы -ушк-, -к-, -ок, -ышк-, -ёк, -ик.
Зуб___________, гнездо____________, зонт________, тетрадь_________, зерно___________, парень______________
10. Выделите уменьшительно-ласкательные суффиксы.
Деревушка, гвоздик, ящик, осинка, сынок, лепесток, пенёк.
11. Разберите по составу слова и сделайте цепочку из слов, от которых оно образовано
Учительская, налево, присоединила, пришкольный, заоблачный.
Морфемика 5 класс
2 вариант
1. Выберите слова, имеющие нулевое окончание.
Слева, завтрак, легкий, читаешь, взрыв, днем, пень, учился.
2. Выделите окончания
Бегают, красивым, улицу, вприпрыжку, мысли.
3. Выберите пары слов, в которых представлены формы одного и того же слова.
1) красивый – красив;
2) решаем – решаете;
3) ресницы – ресниц;
4) бумага – бумажный,
5) делать – сделать;
6) ходить – переходить.
4. Какая часть слова служит для образования форм слова?
1) окончание
2) приставка
3) корень
4) суффикс
5. Выделите корень
Забирать, справа, преподнести, хитрющий, бельчонок, поздороваться.
6. Закончи предложение: «Значимая часть слова, которая находится после корня и служит для образования новых слов – это…»
1) Приставка;
2) корень;
3) суффикс;
4) окончание;
5) основа.
7. Выберите в каждой строчке однокоренные слова. Обозначьте корень
1. Переселить, пересилить, сильный.
2. Город, горожанин, загородка.
3. Липовый, липнет, липа.
4. Любитель, любовь, любой.
5. Нос, переносить, переносица.
8. Обозначьте приставки
Бесполезный, отрывать, суперскачки, алогичный, приступить.
9. Образуйте слова с уменьшительно-ласкательным значением, используя суффиксы -юшк-, -инк, -еньк-, -ик, -чик.
Белый___________, хозяйка____________, заяц________, пароход_________, снег___________, добрый______________
10. Выделите уменьшительно-ласкательные суффиксы.
Девушка, ключик, ластик, рябинка, доченька, потолок, паренёк.
11. Разберите по составу слова и сделайте цепочку из слов, от которых оно образовано
Настольный, приморский, справа, подорожник, парашютистка.
ОТВЕТЫ
1 вариант
1. Подчеркните слова, имеющие нулевое окончание.
Спелый, шарфы, мышь, повторял, перекресток, медведь, облако, вверх.
2. Выделите окончания
Пишем, умного, лыжня, сани, сверху.
3. Выберите пары слов, в которых представлены формы одного и того же слова.
1) художник – художница;
2) берег – береговой;
3) спать – спал;
4) белый – беловатый;
5) читать – читают,
6) грубое – грубая.
4. В каком ряду верно перечислены все морфемы, входящие в основу слова?
1) приставка, корень, окончание
2) корень, суффикс
3) приставка, корень, суффикс, окончание
4) приставка, корень, суффикс
5. Выделите корень
Заплетать, вкусненький, записался, подлокотник, желтоватый, налево.
6. Закончи предложение: «Главная значимая часть слова, в которой заключено общее лексическое значение всех однокоренных слов – это…»
1) Приставка;
2) корень;
3) суффикс;
4) окончание;
5) основа.
7. Выберите в каждой строчке лишнее слово, подчеркните его
1. Приморский, уморить, море.
2. Росток, растение, растерять.
3. Губа, загубить, губастый.
4. Утихнет, тихий, утешать.
5. Развевается, развитие, веять.
8. Обозначьте приставки
Сверхзвуковой, наименьший, перезагрузка, пробираться, антифашист.
9. Образуйте слова с уменьшительно-ласкательным значением, используя суффиксы -ушк-, -к-, -ок, -ышк-, -ёк, -ик.
Зуб – зубок (ик), гнездо — гнездышко, зонт — зонтик, тетрадь — тетрадка, Егор – Егорушка (ка), парень – паренёк.
10. Выделите уменьшительно-ласкательные суффиксы.
Деревушка, гвоздик, ящик, осинка, сынок, лепесток, пенёк.
11. Разберите по составу слова и сделайте цепочку из слов, от которых оно образовано
Учительская, налево, присоединила, пришкольный, петербуржец, заоблачный.
учитель учить
левый
присоединить соединить единый
школьный школа
облачный облако
ОТВЕТЫ
2 вариант
1. Выберите слова, имеющие нулевое окончание.
Слева, завтрак, легкая, читаешь, взрыв, днем, пень, учился.
2. Выделите окончания
Бегают, красивым, улицу, вприпрыжку, мысли.
3. Выберите пары слов, в которых представлены формы одного и того же слова.
1) красивый – красив;
2) решаем – решаете;
3) ресницы – ресниц;
4) бумага – бумажный,
5) делать – сделать;
6) ходить – переходить.
4. Какая часть слова служит для образования форм слова?
1) окончание
2) приставка
3) корень
4) суффикс
5. Выделите корень
Забирать, справа, преподнести, хитрющий, бельчонок, поздороваться.
6. Закончи предложение: «Значимая часть слова, которая находится после корня и служит для образования новых слов – это…»
1) Приставка;
2) корень;
3) суффикс;
4) окончание;
5) основа.
7. Выберите в каждой строчке однокоренные слова. Обозначьте корень
1. Переселить, пересилить, сильный.
2. Город, горожанин, загородка.
3. Липовый, липнет, липа.
4. Любитель, любовь, любой.
5. Нос, переносить, переносица.
8. Обозначьте приставки
Бесполезный, отрывать, суперскачки, алогичный, приступить.
9. Образуйте слова с уменьшительно-ласкательным значением, используя суффиксы -юшк-, -инк, -еньк-, -ик, -чик.
Белый — беленький, хозяйка — хозяюшка, заяц – заинька (чик), пароход — пароходик, снег — снежинка, добрый — добренький
10. Выделите уменьшительно-ласкательные суффиксы.
Девушка, ключик, ластик, рябинка, доченька, потолок, паренёк.
11. Разберите по составу слова и сделайте цепочку из слов, от которых оно образовано
Настольный, подорожник, справа, приморский, парашютистка.
стол
море
правый
дорожник дорожный дорога
парашютист парашют
Глава 15. Анализ
.
REBOL / Core Руководство пользователя
Основное содержание
Отправьте нам отзыв
В комплекте:
1. Обзор
2. Простое разбиение
3. Правила грамматики
4. Пропуск ввода
5. Типы соответствия
6. Рекурсивные правила
7. Оценка
7.1 Возвращаемое значение
7.2 Выражения в правилах
7.3 Копирование ввода
7.4 Маркировка входных данных Вход
7.5 Изменение строки
7.6 Использование объектов
7.7 Отладка
8.Работа с пробелами
9. Блоки синтаксического анализа и диалекты
9.1 Соответствующие слова
9.2 Сопоставление типов данных
9.3 Запрещенные символы
9.4 Примеры диалектов
9.5 Подблоки синтаксического анализа
10. Сводка операций синтаксического анализа
10.1 Общие формы
10. 2 Определение количества
Пропуск значений
10.4 Получение значений
10.5 Использование слов
10.6 Соответствие значений (только анализ блоков)
10.7 Слова типа данных
1. Обзор
При синтаксическом анализе последовательность символов или значений разбивается на более мелкие. части.Его можно использовать для распознавания символов или значений, которые происходят в определенном порядке. Помимо предоставления мощного, читаемый и удобный подход к регулярному выражению сопоставление с образцом, синтаксический анализ позволяет вам создавать свои собственные языки для конкретных целей.
Функция parse имеет общий вид:
правила серии синтаксического анализаАргумент серии — это входные данные, которые анализируются и могут быть строкой. или блок. Если аргумент является строкой, он анализируется по символам.Если Аргумент — это блок, он разбирается по значению.
Аргумент правила определяет, как аргумент серии разобраны.
Функция parse также принимает два уточнения: / all и / ящик . Уточнение / all анализирует все символы внутри строки, включая все разделители, такие как пробел, табуляция, перевод строки, запятая и точка с запятой.Уточнение / case анализирует строка в зависимости от регистра. Если / регистр не указан, верхний и строчные буквы обрабатываются одинаково.
2. Простое разделение
Простая форма parse предназначена для разделения строк:
строка синтаксического анализа нетФункция parse разделяет входной аргумент, строку, в блок из нескольких строк, разбивая каждую строку везде, где встречается разделитель, например пробел, табуляция, новая строка, запятая, или точка с запятой.Аргумент none указывает на то, что никакие другие разделители кроме этих. Например:
зондовый синтаксический анализ "Поездка займет 21 день" нет ["" "Поездка" "" займет "" "21" "день"]Аналогично
зондирующий синтаксический анализ "здесь, там, везде; хорошо" нет ["здесь" "там" "везде" "хорошо"]Обратите внимание, что в приведенном выше примере были удалены запятые и точки с запятой.
Вы можете указать свои собственные разделители во втором аргументе для parse .Например, следующий код анализирует номер телефона с тире (-) разделители:
анализ зонда "707-467-8000" "-" ["707" "467" "8000"]В следующем примере в качестве разделители:
анализ зонда {= "} ["IMG" "SRC" "test.gif" "WIDTH" "123"]В следующем примере строка анализируется только на основе запятых; любые другие разделители игнорируются. Следовательно, пробелы внутри строк не удаляются:
Обычно при синтаксическом анализе строк любые пробелы (пробел, табуляция, строки) автоматически обрабатываются как разделители. (ноль)»
3.Правила грамматики
Функция parse принимает грамматические правила, написанные на диалект REBOL. Диалекты — это суб-языки REBOL, которые используют та же лексическая форма для всех типов данных, но допускает различный порядок значения внутри блока.
Чтобы определить правила, используйте блок, чтобы указать последовательность входных данных. Для например, если вы хотите проанализировать строку и вернуть символы » телефон », вы можете использовать правило:
строка синтаксического анализа ["телефон"]Чтобы разрешить любое количество пробелов или отсутствие пробелов между словами, напишите правило как это:
строка синтаксического анализа ["телефон"]Вы можете указать альтернативные правила с помощью вертикальной черты (|). Например:
["телефон" | "радио"]принимает строки, которые соответствуют любому из следующего:
телефон радиоПравило может содержать блоки, которые рассматриваются как вспомогательные правила.
[["а" | "the"] ["phone" | "радио"]]принимает строки, которые соответствуют любому из следующего:
телефон радио телефон радиоДля повышения удобочитаемости запишите подправила в отдельный блок и дайте им имя, которое поможет указать их цель:
статья: ["а" | "the"] устройство: ["телефон" | "радио"] строка синтаксического анализа [устройство статьи]В дополнение к сопоставлению одного экземпляра строки вы можете предоставить count или диапазон, который повторяет совпадение.В следующем примере представлен кол-во:
[3 "а" 2 "б"], который принимает строки, соответствующие:
aaabbВ следующем примере представлен диапазон:
[1 3 «а» «б»], который принимает строки, соответствующие любому из следующего:
ab aab aaabНачальной точкой диапазона может быть ноль, что означает, что он не является обязательным.
[0 3 «а» «б»]принимает строки, которые соответствуют любому из следующего:
b ab aab aaabИспользуйте или , чтобы указать, что один или несколько символов совпадают.
[немного "а" "б"]принимает строки, содержащие один или несколько символов a и b:
ab aab aaab aaaabВ следующем примере используется any:
[любой "а" "б"], который принимает строки, содержащие ноль или более символов a или б:
b ab aab aaab aaaabСлова некоторые и любые также могут использоваться на блоки.Например:
[некоторые ["а" | "b"]]принимает строки, содержащие любую комбинацию символов a и б.
Другой способ выразить необязательность символа — это указать альтернативный выбор — нет:
["а" | "б" | никто]В этом примере принимаются строки, содержащие a, b или никто.
Отсутствует полезно для указания дополнительных шаблонов или для перехвата случаи ошибок, когда не совпадает ни один шаблон.
4. Пропуск ввода
пропускает , — и — слова позволяют пропускать ввод.
Используйте skip , чтобы пропустить один символ, или используйте его с повторите , чтобы пропустить несколько символов:
["а" пропустить "б"] ["a" 10 пропусков "b"] ["a" 1 10 skip]Чтобы пропустить, пока не будет найден конкретный символ, используйте до:
[от "а" до "б"]Предыдущий пример начинает синтаксический анализ с a и заканчивается на b, но не включает b.
Чтобы включить конечный символ, используйте через:
[от "а" до "б"]Предыдущий пример начинает синтаксический анализ в a, заканчивается в b и включает b.
Следующее правило находит заголовок HTML-страницы и печатает его:
страница: читать http://www.rebol.com/ проанализировать страницу [через скопировать текст в ] печатать текст REBOL TechnologiesПервые – находят тег заголовка и сразу проходят Это.
5. Типы соответствий
При синтаксическом анализе строк эти типы данных и слова могут использоваться для сопоставления символов во входной строке:
Тип соответствия
Описание
«abc»
соответствует всей строке
# «c»
соответствует одному символу
тег
соответствует строке тега
конец
соответствует концу ввода
(битовый набор )
соответствует любому указанному символу в наборе
Чтобы использовать все эти слова (кроме битового набора, который объясняется ниже) в единое правило, используйте:
[ ["отлично" | "невероятный"] #"!" конец]В этом примере анализируются входные строки:
отлично! невероятно!Конец указывает, что во входном потоке ничего не следует.
Битовый набор Тип данных заслуживает более подробного объяснения. Битовые наборы используется для эффективного задания наборов символов. В charset Функция позволяет указывать отдельные символы или диапазоны символов. Например, строка:
цифра: кодировка "0123456789"определяет набор символов, содержащий цифры.Это позволяет использовать такие правила, как:
[3 цифры »-« 3 цифры »-« 4 цифры], который может анализировать телефонные номера в форме:
707-467-8000Чтобы принять любое количество цифр, обычно пишут правило:
цифры: [некоторая цифра]Набор символов также может указывать диапазоны символов. Например, набор символов можно было бы записать как:
цифра: charset [# "0" - # "9"]В качестве альтернативы вы можете комбинировать определенные символы и диапазоны персонажей:
the-set: charset ["+ -.Чтобы расширить это, вот буквенно-цифровой набор символов:
alphanum: charset [# "0" - # "9" # "A" - # "Z" # "a" - # "z"]Наборы символов также могут быть изменены с помощью вставки и удалить функций или комбинации наборов могут быть созданы с помощью объединение и пересекает функций. Эта линия копирует набор символов цифр и добавляет к нему точку:
цифра-точка: вставить копию цифры "."Следующие строки определяют полезные наборы символов для синтаксического анализа:
цифра: charset [# "0" - # "9"] альфа: кодировка [# "A" - # "Z" # "a" - # "z"] alphanum: объединение альфа-цифры
6.Рекурсивные правила
Вот пример набора правил, который анализирует математические выражения и дает приоритет (приоритет) используемых математических операторов:
expr: [термин ["+" | "-"] expr | срок] термин: [коэффициент ["*" | "/"] термин | фактор] фактор: [первичный «**» фактор | начальный] первичный: [некоторая цифра | "(" выражение ")"] цифра: кодировка "0123456789"Теперь мы можем анализировать многие типы математических выражений.
пробный синтаксический анализ "1 + 2 * (3 - 2) / 4" выражение правда анализ пробы "4/5 + 3 ** 2- (5 * 6 + 1)" expr правдаОбратите внимание, что в примерах некоторые правила относятся к самим себе.Для Например, правило expr включает выражение expr. Это полезный метод определения повторяющихся последовательностей и комбинаций. Правило рекурсивный — относится к самому себе.
При использовании рекурсивных правил необходимо соблюдать осторожность, чтобы предотвратить бесконечную рекурсию. Например:
выражение: [выражение ["+" | "-"] срок]создает бесконечный цикл, потому что первое, что делает expr — использует expr снова.
7. Оценка
Обычно вы анализируете строку, чтобы получить какой-то результат.Вы хотите сделать больше, чем просто убедитесь, что строка действительна, вы хотите что-то сделать во время ее анализа. Например, вы можете выбрать подстроки из разных частей строка, создать блоки связанных значений или вычислить значение.
7.1 Возвращаемое значение
Примеры в предыдущих главах показали, как анализировать строки, но безрезультатно. были произведены. Это делается только для проверки того, что строка имеет указанный грамматика; значение, возвращаемое из синтаксического анализа , указывает на его успех.Следующие примеры показывают это:
пробный синтаксический анализ "a b c" ["a" "b" "c"] правда пробный синтаксический анализ "a b" ["a" "c"] ложныйФункция parse возвращает истину, только если она достигает конец входной строки. Неудачное совпадение останавливает анализ ряд. Если синтаксический анализ исчерпывает значения для поиска раньше достигнув конца ряда, он не проходит через ряд и возвращает ложь :
пробный синтаксический анализ "a b c d" ["a" "b" "c"] ложный пробный синтаксический анализ "a b c d" [от "b" до "d"] правда пробный синтаксический анализ "a b c d" [до "b" до конца] правда
7.
2 Выражения в правилахВнутри правила вы можете включить выражение REBOL, которое будет оцениваться, когда parse достигает этой точки в правиле. Круглые скобки используются для укажите такие выражения:
строка: "в этом предложении есть телефон" строка анализа зонда [ к "а" на «телефон» (распечатайте «найденный телефон») до конца ] нашел телефон правдаВ приведенном выше примере анализируется строка телефона и выводится сообщение. нашел телефон после завершения матча. Если строки a или телефон отсутствует и разбор не может быть выполнен, выражение нет оценен.
Выражения могут появляться в любом месте правила, и несколько выражений могут встречаются в разных частях правила. Например, следующий код печатает разные строки в зависимости от того, какие входы были найдены:
строка синтаксического анализа [ "а" | "the" на «телефон» (печать «ответ») | на «радио» (печать «слушать») | на «телевизор» (печать «смотреть») ] отвечать строка: "на полке радио" строка синтаксического анализа [ "а" | "the" на «телефон» (печать «ответ») | на «радио» (печать «слушать») | на «телевизор» (печать «смотреть») ] СлушатьВот пример, который подсчитывает, сколько раз тег предварительного форматирования HTML появляется в текстовой строке:
количество: 0 страница: прочтите http: // www.(count: count + 1)]] количество отпечатков 777
7.3 Копирование ввода
Наиболее частым действием, выполняемым с помощью parse , является сбор деталей. анализируемой строки. Это делается с копией , и это за которым следует имя переменной, в которую вы хотите скопировать строку. В В следующем примере анализируется заголовок веб-страницы:
проанализировать страницу [через скопировать текст в ] печатать текст REBOL / Основной словарьПример работает путем пропускания текста до тех пор, пока не будет найден & LT; название & GT; тег.Вот где он начинает копировать ввод stream и установив переменную с именем text для его хранения. Копия операция продолжается до закрытия & LT; title & GT; тег найден.
Действие копирования также можно использовать с целыми блоками правил. Например, для правило:
[скопировать заголовок ["H" ["1" | «2» | «3»]]строка заголовка содержит все h3, h4 или строка h5.
7.4 Маркировка входа
Действие copy создает копию найденной подстроки, но это не всегда желательно.В некоторых случаях лучше сохранить текущая позиция входного потока в переменной.
ПРИМЕЧАНИЕ. Слово копия , используемое при синтаксическом анализе, отличается от copy функция, используемая в выражениях REBOL. Parse использует диалект REBOL, а копия имеет другое значение внутри этого диалект.
В следующем примере переменная begin содержит ссылку на строка ввода страницы сразу после & LT; title & GT ;. В окончание относится к строке страницы непосредственно перед .Эти переменные можно использовать так же, как и будет использоваться с любой другой серией.
проанализировать страницу [ через begin: to окончание: (изменение / начало части "Справочное руководство по Word", окончание) ]Вы можете видеть, что приведенное выше выражение синтаксического анализа фактически изменило содержимое название:
проанализировать страницу [через скопировать текст в ] печатать текст Справочное руководство по WordВот еще один пример, который отмечает позицию каждого тега таблицы в HTML.
страница: прочтите http: // www.rebol.com/index.html таблицы: сделать блок! 20 проанализировать страницу [ любой [до знака "" (добавить индекс таблиц? пометить) ] ]Блок таблиц теперь содержит позицию каждого тега:
таблицы таблицы foreach [ print ["таблица найдена по индексу:" таблица] ] таблица найдена по индексу: 836 таблица найдена по индексу: 2076 таблица найдена по индексу: 3747 таблица найдена по индексу: 3815 таблица найдена по индексу: 4027 таблица найдена по индексу: 4415 таблица найдена по индексу: 6050 таблица найдена по индексу: 6556 таблица найдена по индексу: 7229 таблица найдена по индексу: 8268ПРИМЕЧАНИЕ. Текущая позиция во входной строке также может быть изменен.В следующем разделе объясняется, как это делается.
7.5 Изменение строки
Теперь, когда вы знаете, как получить позицию входной серии, вы также может использовать на нем другие функции серии, в том числе вставку , удалить , а изменить .
str: «Где индейка? Ты индейку не видел?» разобрать str [некоторые [на "?" отметка: (поменять отметку "!") пропустить]] печать str Где индейка! Вы видели индейку!Пропуск в хвосте продвигает ввод по сравнению с новым характер, что в данном случае необязательно, но это хорошая практика.
В качестве другого примера, чтобы вставить текущее время везде, где слово время появляется в каком-то тексте, напишите:
str: "в это время я бы хотел увидеть изменение времени" синтаксический анализ str [ некоторые [ко "времени" отметка: (удалить / разделить метку 4: вставить метку сейчас / время) :отметка ] ] печать str в 14:42:12 я бы хотел увидеть изменение 14:42:12Обратите внимание на слово: mark, использованное выше. Он устанавливает вход в новый должность. Функция insert возвращает новую позицию просто мимо вставки текущего времени.
7.6 Использование объектов
При разборе большой грамматики из набора правил переменные используются для создания грамматика более читабельна. Однако переменные являются глобальными и могут стать перепутаны с другими переменными, имеющими такое же имя где-то еще в программа.
Решение этой проблемы состоит в том, чтобы использовать объект, чтобы сделать все слова правила локально в контексте. Например:
парсер тегов: создать объект! [ теги: сделать блок! 100 текст: сделать строку! 8000 html-код: [ скопировать тег [""] (добавить тег тегов) | скопировать txt в "
7.7 Отладка
По мере написания правил иногда требуется отладка. В частности, вы может захотеть узнать, как далеко вы продвинулись в разборе правила.
Функция trace может использоваться для наблюдения за операцией синтаксического анализа.
Лучше всего вставить отладочные выражения в правила синтаксического анализа. Как Например, для отладки правила:
[к ""]вставьте функцию print после ключевых разделов для мониторинга ваш прогресс по правилу:
[в ""]В этом примере печатаются 1, 2 и 3, как правило обработанный.
Другой подход — распечатать часть входной строки как синтаксический анализ бывает:
[ на "" ]Если это делается часто, вы можете создать для этого правило:
здесь: [где: (распечатать где)] [ в "" ]Функция copy также может использоваться для указания того, что подстроки были проанализированы во время обработки правила.
8. Работа с пространствами
Функция parse обычно игнорирует все промежуточные пробелы между сканируемыми шаблонами. Например, правило:
["а" "б" "в"]возвращает строки, которые соответствуют:
abc до н.и другие комбинации с аналогичным интервалом.
Чтобы обеспечить соблюдение определенного соглашения об интервале, используйте parse с / все доработки. В предыдущем примере это уточнение заставляет синтаксический анализ соответствовать только первому регистру (abc).
parse / all "abc" ["a" "b" "c"]При указании / все уточнения заставляют каждый символ в обрабатываемый входной поток, включая разделители по умолчанию, такие как пробел, табуляция, новая строка.
Чтобы обрабатывать пробелы в ваших правилах, создайте набор символов, определяющий допустимые пробелы:
spacer: charset reduce [tab newline # ""]Если вы хотите, чтобы между каждой буквой был один пробел, напишите:
["a" распорка "b" распорка "c"]Чтобы разрешить использование нескольких пробелов, напишите:
пробелы: [некоторые пробелы] ["a" пробелы "b" пробелы "c"]Для более сложной грамматики создайте набор символов, который позволяет сканировать строка до символа пробела.
без пробела: дополнительная прокладка в пространство: [некоторые непространственные | конец] слова: сделать блок! 20 разобрать / весь текст [ некоторые [скопировать слово в пробел (добавить слово слово) пробел] ]В предыдущем примере строится блок из всех его слов. В Дополнение Функция инвертирует набор символов. Теперь он содержит все , кроме пробелов, которые вы определили ранее. Набор символов без пробела содержит все символы, кроме пробела символы. Правило пространственного размещения принимает один или несколько символов до пробел или конец входного потока.Главное правило ожидает начала со словом, скопируйте это слово до пробела, затем пропустите пробел и начать следующее слово.
9. Блоки синтаксического анализа и диалекты
Блоки анализируются аналогично строкам. Набор правил определяет порядок ожидаемые значения. Однако, в отличие от парсинга строк, парсинг блоков не касается символов или разделителей.
Блочный синтаксический анализ — это самый простой способ создания REBOL диалектов . Диалекты — это подъязыки REBOL, которые используют одну и ту же лексическую форму для всех данных. типы, но допускают другой порядок значений в блоке. Ценности делают нет необходимости соответствовать нормальному порядку, требуемому аргументами функции REBOL. Диалекты могут обеспечить большую выразительную силу для определенных областей использовать. Например, сами правила парсера указаны как диалект.
9.1 Соответствующие слова
При синтаксическом анализе блока для сопоставления со словом укажите слово как буквальный:
'название 'когда 'пустой
9.2 Соответствие типов данных
Вы можете сопоставить значение любого типа данных, указав данные введите слово. См. Раздел «Соответствие типов данных» ниже.
Тип данных Word
Описание
строка!
соответствует любой строке в кавычках
раз!
соответствует в любое время
дата!
соответствует любой дате
кортеж!
соответствует любому кортежу
ПРИМЕЧАНИЕ. Не забывайте «!» это часть имени или ошибка будет сгенерирован.
9.3 Запрещенные символы
Разбор операций, разрешенных для блоков, — это те, которые имеют с конкретными персонажами. Например, нельзя указать совпадение с первым буква слова или строки, а также пробелы или символы новой строки.
9.4 Примеры диалектов
Несколько кратких примеров помогают проиллюстрировать разбор блоков:
блок: [когда 10:30] распечатать блок синтаксического анализа ['когда 10:30] распечатать блок синтаксического анализа ['когда время!] parse block ['когда установлено время time! (время печати)]Обратите внимание, что конкретное слово можно сопоставить, используя его буквальное слово в правило (как в случае «когда»).Тип данных может быть указан скорее чем значение, как в строках выше, содержащих времени! . В Кроме того, переменной можно присвоить значение с помощью набора операция.
Как и в случае со строками, при синтаксическом анализе блоков могут быть указаны альтернативные правила:
правило: [некоторые [ 'когда установленное время! | 'где установить строку! | 'которые устанавливают людей [слово! | блокировать!] ]]Эти правила позволяют вводить информацию в любом порядке:
синтаксический анализ [ кто Фред где "Даунтаун Центр" когда 9:30 ] правило печать [время, место, люди]В этом примере можно было бы использовать присвоение переменных, но он показывает, как обеспечить альтернативный порядок ввода.
Вот еще один пример, который оценивает результаты синтаксического анализа:
правило: [ установить счетчик целое! установить строку str! (количество циклов [print str]) ] синтаксический анализ [3 "отличная работа"] правило parse [3 "хижина" 1 "поход"] [какое-то правило]И, наконец, более сложный пример:
правило: [ установить действие ['купить | 'продавать] установить целое число! "акции" в установить цену в деньгах! (либо действие = 'продать [ print [цена "доход" * число] итого: итого + (цена * число) ] [ печать ["себестоимость" цена * число] итого: итого - (цена * количество) ] ) ] всего: 0 анализ [продать 100 акций по 123 доллара.45] правило печать ["всего:" всего] всего: 0 синтаксический анализ [ продать 300 акций по 89,08 доллара купить 100 акций по $ 120,45 продать 400 акций по $ 270,89 ] [какое-то правило] печать ["всего:" всего]Следует отметить, что это один из способов, как выражения, использующие диалект концепция, впервые описанная в главе 4, может быть оценена .
9.5 Подблоки синтаксического анализа
При синтаксическом анализе блока, если подблок найден, он рассматривается как один значение блока ! тип данных.Однако, чтобы разобрать субблок, вы должны вызвать синтаксический анализатор рекурсивно для этого субблока. В в слов обеспечивает эту возможность. Ожидается, что следующий значение во входном блоке — это подблок, который нужно проанализировать. Это как если бы блок! Был предоставлен тип данных . Если следующее значение не является блок! Тип данных , совпадение не выполняется и в ищет альтернативы или выходит из правила. Если следующее значение — блок, парсер правило, которое следует за в слово , используется для начала синтаксического анализа подблок.Он обрабатывается так же, как и подправило.
правило: [дата! в [строку! время!]] данные: [10-янв-2000 ["Ukiah" 10:30]] распечатать правило синтаксического анализа данныхВсе обычные операции синтаксического анализатора могут применяться к в .
правило: [ установить дату дату! установить информацию в [строка! время!]] ] данные: [10-янв-2000 ["Ukiah" 10:30]] распечатать правило синтаксического анализа данных информация для печати правило: [дата! скопируйте элементы 2 в [строку! время!]] данные: [10-янв-2000 ["Ukiah" 10:30] ["Rome" 2:45]] распечатать правило синтаксического анализа данных зонды
10.Сводка операций синтаксического анализа
10.1 Общие формы
Оператор
Описание
|
альтернативное правило
[блок]
подправило
(парен)
оценить выражение REBOL
10.
2 Указанное количество
Оператор
Описание
нет
ничего не найдено
опт
ноль или один раз
какой-то
один или несколько раз
любой
ноль или более раз
12
повторить узор 12 раз
1 12
повторить узор от 1 до 12 раз
0 12
повторить узор от 0 до 12 раз
10.
3 значения пропуска
Оператор
Описание
пропустить
пропустить значение (или несколько, если задано повторение)
С по
предварительный ввод значения или типа данных
С по
предварительный ввод через значение или тип данных
10.4 Получение значений
Оператор
Описание
комплект
установить следующее значение переменной
копия
скопировать следующую последовательность совпадений в переменную
10.
5 Использование слов
Оператор
Описание
слово
поисковое значение слова
слово:
отметить текущую позицию входной серии
: слово
установить текущую позицию серии ввода
‘слово
соответствует слову буквально (блок синтаксического анализа)
10.6 совпадений значений (только анализ блоков)
Оператор
Описание
«Фред»
соответствует строке «fred»
% данные
совпадает с именем файла% data
10:30
совпадает со временем 10:30
1.
соответствует кортежу 1.2,3
10,7 слов типа данных
Слово
Описание
Тип !
соответствует чему-либо с заданным типом данных
Как извлечь первое слово из текстовой строки в Excel (3 простых способа)
В Excel есть несколько замечательных формул, которые помогут вам разрезать текстовые данные на части.
Иногда, когда у вас есть текстовые данные, вам может потребоваться извлечь первое слово из текстовой строки в ячейке.
Есть несколько способов сделать это в Excel (используя комбинацию формул, используя поиск и замену и использование Flash Fill)
В этом уроке я покажу вам несколько действительно простых способов извлечь первое слово из текстовая строка в Excel .
Извлечь первое слово с помощью текстовых формул
Предположим, у вас есть следующий набор данных, в котором вы хотите получить первое слово из каждой ячейки.
Следующая формула сделает это:
= ЕСЛИОШИБКА (LEFT (A2, FIND ("", A2) -1), A2) Позвольте мне объяснить, как работает эта формула.
Часть формулы НАЙТИ используется для поиска позиции символа пробела в текстовой строке. Когда формула находит позицию символа пробела, функция LEFT используется для извлечения всех символов перед этим первым символом пробела в текстовой строке.
Хотя одной формулы LEFT должно быть достаточно, она выдаст ошибку, если в ячейке есть только одно слово и нет пробелов.
Чтобы справиться с этой ситуацией, я заключил формулу LEFT в формулу IFERROR, которая просто возвращает исходное содержимое ячейки (поскольку нет пробелов, указывающих, что она пуста или содержит только одно слово).
В этом методе есть одна хорошая черта: результат является динамическим. Это означает, что если вы измените исходную текстовую строку в ячейках в столбце A, формула в столбце B автоматически обновится и даст правильный результат.
Если вам не нужна формула, вы можете преобразовать ее в значения.
Извлечение первого слова с помощью функции «Найти и заменить»
Еще один быстрый метод извлечения первого слова — использование функции «Найти и заменить» для удаления всего, кроме первого слова.
Предположим, у вас есть набор данных, как показано ниже:
Ниже приведены шаги по использованию функции «Найти и заменить», чтобы получить только первое слово и удалить все остальное:
- Скопируйте текст из столбца A в столбец B. чтобы убедиться, что у нас есть и исходные данные.
- Выберите все ячейки в столбце B, в которых вы хотите получить первое слово
- Щелкните вкладку «Главная»
- В группе редактирования щелкните «Найти и выбрать», а затем щелкните «Заменить».Откроется диалоговое окно «Найти и заменить».
- В поле «Найти» введите * (один пробел, за которым следует звездочка)
- Оставьте поле «Заменить на» пустым.
- Нажмите кнопку «Заменить все».
Приведенные выше шаги удаляют все, кроме первого слова в ячейках.
Вы также можете использовать сочетание клавиш Control + H , чтобы открыть диалоговое окно «Найти и заменить».
Как это работает?
В поле «Найти» мы использовали пробел, за которым следует звездочка.Знак звездочки (*) — это подстановочный знак, который представляет любое количество символов.
Итак, когда мы просим Excel найти ячейки, содержащие пробел, за которым следует знак звездочки, и заменить его пробелом, он находит первый пробел и удаляет все после него, оставляя нам только первое слово.
И если у вас ячейка, в которой нет текста или только одно слово без пробелов, вышеуказанные шаги не повлияют на нее.
Извлечь первое слово с помощью Flash Fill
Еще один действительно простой и быстрый способ извлечь первое слово с помощью Flash Fill.
Flash Fill был представлен в Excel 2013 и доступен во всех последующих версиях. Он помогает при манипулировании текстом, определяя шаблон, которого вы пытаетесь достичь, и заполняет его для всего столбца.
Например, предположим, что у вас есть набор данных ниже, и вы хотите извлечь только первое слово.
Ниже приведены шаги для этого:
- В ячейке B2, которая является соседним столбцом наших данных, вручную введите «Маркетинг» (что является ожидаемым результатом)
- В ячейке B3 введите «HR»
- Выберите диапазон B2: B10
- Щелкните вкладку «Главная».
- В группе «Редактирование» щелкните раскрывающийся список «Заливка».
- Выберите параметр «Флэш-заливка»
При выполнении описанных выше шагов все ячейки будут заполнены первым. слово из соседнего столбца (столбец A).
Осторожно : В большинстве случаев Flash Fill работает нормально и дает правильный результат, но в некоторых случаях может не дать правильного результата. Просто не забудьте еще раз убедиться, что результаты соответствуют ожиданиям.
Примечание. При вводе ожидаемого результата во второй ячейке столбца B вы можете увидеть весь текст во всех ячейках светло-серым цветом. Это результат, который вы получите, если сразу нажмете клавишу ввода. Если вы не видите серую линию, используйте опцию Flash Fill на ленте.
Итак, это три простых метода извлечения первого слова из текстовой строки в Excel.
Надеюсь, вы нашли этот урок полезным!
Другие руководства по Excel, которые могут вам понравиться:
Как анализировать данные в Excel (разделить столбец на несколько)
Excel: как анализировать данные (разделить столбец на несколько)
В Excel (2016, 2013, 2010) можно анализировать данные из одного столбца на два или более столбца. И вы можете сделать это за несколько простых шагов.Предположим, что столбец A содержит «Фамилия, имя». Выполните следующие действия, чтобы разделить данные из столбца A на столбец «Фамилия» и столбец «Имя». Нет необходимости в резке и вставке!
Откройте электронную таблицу Excel, содержащую данные, которые вы хотите разделить, затем:
- Выделите столбец, содержащий объединенные данные (например, фамилию, имя), щелкнув букву непосредственно над столбцом.
- Щелкните вкладку «Данные» на ленте, затем найдите группу «Инструменты для работы с данными» и щелкните «Текст в столбцы».Появится «Мастер преобразования текста в столбцы».
- На шаге 1 мастера выберите «С разделителями»> щелкните [Далее].
- Разделитель — это символ или пробел, разделяющий данные, которые вы хотите разделить. Например, если в вашем столбце написано «Смит, Джон», вы должны выбрать «Запятая» в качестве разделителя. Выберите разделитель в ваших данных.
- Установите флажок «Обрабатывать последовательные разделители как один».
- Щелкните [Далее].
- В разделе «Формат данных столбца» выберите «Общие».«
- Щелкните значок красной стрелки / электронной таблицы в дальнем правом углу текстового поля «Место назначения».
- Выделите столбцы, которые вы хотите содержать разделенные данные, щелкнув буквы прямо над столбцами (вы можете выбрать столбцы из любого места в электронной таблице). Или вручную щелкните и перетащите, чтобы выбрать продажи, которые вы хотите содержать разделенные данные.
- Еще раз щелкните значок красной стрелки / электронной таблицы, чтобы вернуться к мастеру.
- Щелкните [Готово].
Примечание:
Если данные, которые вы хотите разделить, НЕ содержат разделителя (тире, запятой, табуляции и т. Д.) Для разделения данных, выберите «Фиксированная ширина» на первом шаге мастера «Преобразовать текст в столбец». . Эта опция позволяет вам вручную создавать подразделения в ваших данных, перетаскивая линию разрыва.
Ключевые слова: разделение столбцов, анализ данных, разделение ячейки, отдельная информация
Опубликовано в Компьютерная помощь
Мое резюме прочитано неправильно.Что мне делать? — Резюме по адресу
Если вам было показано сообщение об ошибке
Если после загрузки резюме в Score My Resume вам было показано следующее сообщение об ошибке, мы не смогли правильно обработать ваше резюме:
Это могло быть по разным причинам и обычно легко ремонтируется , так что не волнуйтесь! Чтобы наша система могла правильно проанализировать и проанализировать ваше резюме, убедитесь, что загруженное вами резюме:
- на английском языке
- содержит раздел «Опыт работы» — вы также можете включить раздел «Проекты» или «Действия»! Просто убедитесь, что вы назвали раздел что-то вроде «Опыт», «Проекты», «Действия» или «Опыт работы» и убедитесь, что заголовок раздела написан с заглавной буквы
- находится в формате PDF, а не защищен паролем
- использует общий шрифт (например,грамм. Calibri, Times New Roman, Arial)
- содержит текст и не является сканированным документом или изображением (например, созданным в Photoshop) — экспортируйте его с помощью Microsoft Word или Google Docs! Убедитесь, что текст в PDF-файле выделяется.
- — это не более 2 МБ в размере файла и не более 4 страниц (обратите внимание, что ваше резюме должно содержать не более 2 страниц!)
После того, как вы подтвердите вышеизложенное, попробуйте повторно загрузить свое резюме — вы должны получить свое резюме! Если у вас возникли проблемы, напишите нам!
Если вышеуказанное не работает, используйте этот шаблон Word
Если вы выполнили указанные выше действия, и наша система не может проанализировать ваше резюме, вероятно, ваше резюме несовместимо с ATS.ATS (системы отслеживания кандидатов) — это автоматизированное программное обеспечение, которое работодатели используют для электронного анализа и обработки вашего резюме (подробнее).
Убедитесь, что вы используете шаблон резюме, совместимый с ATS, например этот шаблон резюме (документ Word). Мы оцениваем только содержание вашего резюме (так как это наиболее важно!), Поэтому любой шаблон, который вы используете, даст такой же результат.
Если вам не отображалось сообщение об ошибке
Если вам показали обзор вашего резюме, но ваше резюме не было прочитано или отображено правильно, возможно, вы используете нестандартный шаблон резюме (например.грамм. многоколоночные, созданные в Photoshop или использующие разные шрифты).
Если маркированный список был прочитан неправильно, убедитесь, что вы озаглавили раздел о своем опыте работы чем-то вроде «Опыт», «Опыт работы» и т. Д. Попробуйте использовать стандартный шрифт (например, Arial, Helvetica и т. Д.).
Если вы можете избежать использования многоколоночного макета, сделайте это! Современное программное обеспечение для отслеживания кандидатов (например, ATS, автоматизированные инструменты, которые анализируют резюме и ранжируют их) становится лучше при чтении многоколоночного макета, но есть еще много других инструментов, которые по-прежнему не могут читать многоколоночные резюме так, как вам хотелось бы. это к.
По всем остальным вопросам используйте контактную форму ниже, и мы свяжемся с вами в ближайшее время (обычно
Основы интеллектуального анализа текста в R
Так что же такое интеллектуальный анализ текста? Проще говоря: интеллектуальный анализ текста — это процесс извлечения полезных идей из текста. В этой статье мы будем иметь дело с так называемым пакетом слов, то есть подходом BoW к интеллектуальному анализу текста.
Я большой поклонник того, что сначала нужно делать, чем говорить о подходе к обучению, поэтому давайте сразу перейдем к простым практическим примерам и на их основе построим историю интеллектуального анализа текста.
Попробуйте интеллектуальный анализ текста:
qdap и счетные термины
По сути, набор слов интеллектуальный анализ текста представляет собой способ подсчета терминов или н-граммов в коллекции документов. Рассмотрим следующие предложения, которые мы сохранили в текст и сделали доступными в рабочей области:
text
Ручной подсчет слов в предложениях выше — это боль! К счастью, пакет qdap предлагает лучшую альтернативу. Вы можете легко найти 3 наиболее часто встречающихся термина (включая связи) в тексте, вызвав функцию freq_terms и указав 3.
библиотека (qdap) common_terms
Объект partial_terms хранит все уникальные слова и их количество. Затем вы можете создать столбчатую диаграмму, просто вызвав функцию построения графика для объекта partial_terms .
участок (частые_термы)
Первым шагом исследования текста является, конечно, загрузка самих текстовых данных, которые предполагается анализировать.
библиотека (читатель)
пакет 㤼 㸱 readr 㤼 был собран под R версии 3.3.2
# Импортировать текстовые данные tweets
Отсутствуют имена столбцов, заполненные: 'X1' [1] Анализируется с учетом спецификации столбца: cols ( X1 = col_integer (), дата = col_character (), id = col_double (), ссылка = col_character (), retweet = col_character (), текст = col_character (), author = col_character () )
# Просмотр структуры твитов str (твиты)
Классы «tbl_df», «tbl» и «data.
# Распечатать количество строк в твитах nrow (твиты)
[1] 2428
# Изолировать текст от твитов: tweets_text tweets_text
chr [1: 2428] "Тень Луны выходит на берег Орегона, пересекает США со скоростью 1800 миль в час, выезжает из Скаролины.
Построение корпуса
Давайте теперь построим корпус из этого вектора строк. Корпус — это набор документов, но также важно знать, что в домене tm R распознает его как отдельный тип данных.
Существует два типа данных корпуса: постоянный корпус, то есть PCorpus, и изменчивый корпус, то есть VCorpus. По сути, разница между ними связана с тем, как коллекция документов хранится на вашем компьютере.Мы будем использовать энергозависимый корпус, который хранится в оперативной памяти компьютера, а не сохраняется на диск, просто для большей эффективности памяти.
Чтобы создать изменчивый корпус, R должен интерпретировать каждый элемент в нашем векторе текста, tweets_text , как документ. И пакет tm предоставляет для этого так называемые функции Source! В этом упражнении мы будем использовать функцию Source с именем VectorSource () , потому что наши текстовые данные содержатся в векторе. Выход этой функции называется Исходным объектом .
библиотека (tm) tweets_source
Теперь, когда мы преобразовали наш вектор в объект Source, мы передаем его другой функции tm , VCorpus () , для создания нашего изменчивого корпуса. Объект VCorpus — это вложенный список или список списков. В каждом индексе объекта VCorpus есть объект PlainTextDocument , который по сути представляет собой список, содержащий фактические текстовые данные ( содержимое ), а также некоторые соответствующие метаданные ( мета ), которые могут помочь визуализировать объект VCorpus и концептуализировать все это.
# Сделать изменчивый корпус: tweets_corpus tweets_corpus
> Метаданные: для конкретного корпуса: 0, уровень документа (индексированный): 0 Содержимое: документы: 2428
# Распечатать данные 15 твита в tweets_corpus tweets_corpus [[15]]
> Метаданные: 7 Содержимое: символов: 117
# Распечатать содержание 15-го твита в tweets_corpus tweets_corpus [[15]] [1]
$ содержимого [1] «Более 300 метрических тонн этого вещества заключено в каждом 500-метровом металлическом астероиде, вращающемся вокруг Солнца.
str (tweets_corpus [[15]])
Список из 2 $ content: chr "В каждом 500-метровом металлическом астероиде, вращающемся вокруг Солнца, содержится более 300 метрических тонн этого вещества. #ThatsGold" "| __truncated__ $ meta: Список из 7 .. $ author: chr (0) .. $ datetimestamp: POSIXlt [1: 1], формат: «2017-03-07 16:00:13» .. $ description: chr (0) .. $ заголовок: chr (0) .. $ id: chr "15" .. $ language: chr "en" .. $ origin: chr (0) ..- attr (*, "класс") = chr "TextDocumentMeta" - attr (*, "класс") = chr [1: 2] "PlainTextDocument" "TextDocument"
Поскольку другим распространенным источником текста является фрейм данных, существует функция Source с именем DataframeSource () . Функция DataframeSource () обрабатывает всю строку как полный документ, поэтому будьте осторожны, чтобы не получить нетекстовые данные, такие как идентификаторы клиентов, при поиске документа таким образом.
example_text
> Метаданные: для конкретного корпуса: 0, уровень документа (индексированный): 0 Содержимое: документов: 3
ул.(df_corpus)
Список из 3 $ 1: список из 2 .. $ content: chr [1: 2] «Анализ текста - прекрасное время». «R - отличный язык» .. $ meta: Список из 7 .. .. $ author: chr (0) .. .. $ datetimestamp: POSIXlt [1: 1], формат: «2017-03-07 16:00:14» .. .. $ description: chr (0) .. .. $ заголовок: chr (0) .. .. $ id: chr "1" .. .. $ language: chr "en" .. .. $ origin: chr (0) .. ..- attr (*, "класс") = chr "TextDocumentMeta" ..- attr (*, "класс") = chr [1: 2] "PlainTextDocument" "TextDocument" $ 2: список из 2 .. $ content: chr [1: 2] «Анализ текста дает понимание» «R имеет множество применений» .. $ meta: Список из 7 .. .. $ author: chr (0) .. .. $ datetimestamp: POSIXlt [1: 1], формат: «2017-03-07 16:00:14» .. .. $ description: chr (0) .. .. $ заголовок: chr (0) .. .. $ id: chr "2" .. .. $ language: chr "en" .. .. $ origin: chr (0) .. ..- attr (*, "класс") = chr "TextDocumentMeta" ..- attr (*, "класс") = chr [1: 2] "PlainTextDocument" "TextDocument" $ 3: список из 2 .
# Создайте VectorSource в столбце 3: vec_source vec_source
> Метаданные: для конкретного корпуса: 0, уровень документа (индексированный): 0 Содержимое: документов: 3
ул. (vec_corpus) Список из 3 $ 1: список из 2 .. $ content: chr "R - отличный язык" .. $ meta: Список из 7 .. .. $ author: chr (0) .. .. $ datetimestamp: POSIXlt [1: 1], формат: «2017-03-07 16:00:14» .. .. $ description: chr (0) .
Очистка и предварительная обработка текста
После получения корпуса, как правило, следующим шагом будет очистка и предварительная обработка текста.Для этого мы в основном будем использовать функции из пакетов tm и qdap . В области интеллектуального анализа текста слов очистка помогает агрегировать термины. Например, имеет смысл считать слова «майнер», «добыча полезных ископаемых» и «шахта» одним термином. Конкретные шаги предварительной обработки зависят от проекта. Например, слова, используемые в твитах, сильно отличаются от слов, используемых в юридических документах, поэтому процесс очистки также может быть совершенно другим.
Общие функции предварительной обработки включают:
-
tolower (): Сделать все символы строчными -
removePunctuation (): удалить все знаки препинания -
removeNumbers (): удалить числа -
stripWhitespace (): удалить лишние пробелы
Обратите внимание, что tolower () является частью базового R , тогда как остальные три функции взяты из пакета tm .
Давайте проверим, как эти функции работают на небольшом фрагменте обычного текста:
# Создать объект: текст text Она проснулась в 6 утра. Это так рано! Она проснулась всего на 10% и начала пить кофе перед своим компьютером." # Все строчные tolower (текст)
[1] « она проснулась в 6 утра, это так рано! Она проснулась всего на 10% и начала пить кофе за компьютером."
# Удалить знаки препинания removePunctuation (текст)
[1] «bSheb проснулась в 6 утра. Это так рано. Она проснулась всего в 10 и начала пить кофе перед своим компьютером»
# Удалить числа removeNumbers (текст)
[1] « Она проснулась в полночь. Это так рано! Она проснулась всего на% и начала пить кофе перед своим компьютером».
# Удалить пробелы stripWhitespace (текст)
[1] " Она проснулась в 6 А.М. Так рано! Она проснулась всего на 10% и начала пить кофе за компьютером ».
Пакет qdap предлагает другие функции очистки текста. Каждый по-своему полезен и особенно эффективен в сочетании с другими.
-
скобкаX (): удалите весь текст в скобках (например, «Это (так) круто» заменяется «Это круто») -
replace_number (): заменить числа их эквивалентами слов (например, «2» становится «два») -
replace_abbreviation (): заменить сокращения их полными текстовыми эквивалентами (например,грамм. «Sr» становится «Senior») -
replace_contraction (): преобразовать сокращения обратно в их базовые слова (например, «не следует» становится «не следует») -
replace_symbol ()Заменить общие символы их эквивалентами слов (например, «$» превращается в «доллар»)
Давайте попробуем некоторые из этих функций на строке text , которую мы определили в предыдущем примере:
# Удалить текст в квадратных скобках скобка X (текст)
[1] "Она проснулась в 6 часов утра.М. Так рано! Она проснулась всего на 10% и начала пить кофе за компьютером ».
# Заменить числа на слова replace_number (текст)
[1] « Она проснулась в шесть утра. Это так рано! Она проснулась всего на десять процентов и начала пить кофе перед своим компьютером».
# Заменить сокращения replace_abbreviation (текст)
[1] « Она проснулась в 6 утра. Это так рано! Она проснулась всего на 10% и начала пить кофе за компьютером."
# Заменить схватки replace_contraction (текст)
[1] « Она проснулась в 6 утра, это так рано! Она проснулась всего на 10% и начала пить кофе перед своим компьютером».
# Заменить символы словами replace_symbol (текст)
[1] « Она проснулась в 6 утра. Это так рано! Она проснулась всего на 10 процентов и начала пить кофе перед компьютером."
Стоп-слова
Следующая проблема, которую мы рассмотрим, — это так называемые стоп-слова . Это слова, которые встречаются часто, но дают мало информации. Так что вы можете удалить их. Некоторые распространенные английские стоп-слова включают «I», «she’ll», «the» и т. Д. В пакете TM в этом общем списке 174 стоп-слова. Фактически, когда вы проводите анализ, вам, вероятно, нужно будет что-то добавить к этому списку. Если оставить некоторые частые слова, которые не добавляют понимания, при частотном анализе им будет уделяться слишком много внимания, что обычно приводит к ошибочной интерпретации результатов.
Использование функции c () позволяет добавлять новые слова (через запятую) в список стоп-слов. Например, следующее добавит «word1» и «word2» к списку английских стоп-слов по умолчанию:
all_stops
Когда у вас есть список стоп-слов, которые имеют смысл, вы будете использовать функцию removeWords () для своего текста. removeWords () принимает два аргумента: текстовый объект, к которому он применяется, и список слов, которые нужно удалить.
# Список стандартных английских стоп-слов
стоп-слова ("ru") [1] «я» «я» «мой» «я» «мы» «наш» «наш» «мы» [9] "вы" "ваш" "ваш" "себя" "себя" "он" "его" "его" [17] "сам" "она" "ее" "ее" "сама" "она" "ее" "сама" [25] "они" "их" "их" "их" "сами" "что" "что" "кто" [33] "кто" "это" "то" "эти" "те" "есть" "есть" "есть" [41] «было» «было» «быть» «было» «быть» «иметь» «было» «было» [49] "имея" "делать" "делает" "сделал" "делаю" "будет" "должен" "мог" [57] "должен" "я" "ты" "он" "она" "это" "мы" "они" [65] "у меня" "у" "у" "у них есть" "я бы" "ты бы" "он бы" "она" [73] "мы бы" "они бы" "я" "вы" "он" "она" "мы" "они" [81] «не» «не» «не было» «не было» «не было» «не было» «не было» «не было» [89] «не» «не» «не буду» «не буду» «не буду» «не должен» «не могу» «не могу» [97] "не мог" "не должен" "давайте" "это" "кто" "что" "здесь" "есть" [105] "когда" "где" "почему" "как" "а" "ан" "то" "и" [113] "но" "если" "или" "потому что" "как" "до" "пока" "из" [121] "at" "by" "for" "с" "about" "против" "между" "в" [129] "через" "во время" "до" "после" "выше" "ниже" "к" "от" [137] "вверх" "вниз" "внутрь" "за" "на" "выкл" "над" "под" [145] "снова" "далее" "затем" "один раз" "здесь" "там" "когда" "где" [153] "почему" "как" "все" "любые" "оба" "каждый" "несколько" "больше" [161] "большинство" "другие" "некоторые" "такие" "нет" "ни" "не" "только" [169] "свой" "такой же" "так" "чем" "слишком" "очень"
# Печатать текст без стандартных стоп-слов
removeWords (текст, игнорируемые слова ("ru")) [1] " Она проснулась в 6 А.
# Добавить в список «кофе» и «зерно»: new_stops new_stops
[1] « Она проснулась в 6 утра. Рано! Она на 10% проснулась и начала пить перед компьютером».
Введение в определение основы слова и завершение основы
Еще один полезный шаг предварительной обработки включает выделение корня слова и завершение основы.Пакет tm предоставляет функцию stemDocument () для доступа к корню слова. Эта функция либо принимает вектор символов и возвращает вектор символов, либо принимает PlainTextDocument и возвращает PlainTextDocument.
Еще один полезный этап предварительной обработки включает выделение основы и завершение основы . Пакет tm предоставляет функцию stemDocument () для доступа к корню слова. Эта функция либо принимает вектор символов и возвращает вектор символов, либо принимает документ PlainTextDocument и возвращает документ PlainTextDocument . Например,
stemDocument (c («вычисления», «компьютеры», «вычисления»))
возвращает «вычислить» «вычислить» «вычислить». Но поскольку «вычислить» — не настоящее слово, мы хотим дополнить слова так, чтобы «вычислительные», «компьютеры» и «вычисления» относились к одному и тому же слову, скажем, «компьютер», в нашем текущем анализе. .
Мы можем легко сделать это с помощью функции stemCompletion () , которая принимает вектор символов и аргумент для словаря завершения.Словарь завершения может быть вектором символов или объектом Corpus. В любом случае словарь завершения для нашего примера должен содержать слово «компьютер» для всех слов, которые к нему относятся.
# Создать сложный усложнить
сложный сложный сложный «усложнять» «усложнять» «усложнять»
Основание слова и завершение корня в предложении
Давайте рассмотрим следующее предложение как наш документ для этого упражнения:
«В сложной спешке Том бросился исправлять новую проблему, слишком сложно.
Это предложение содержит те же три формы слова «усложнять», которые мы видели в предыдущем упражнении. Разница здесь в том, что даже если вы вызовете stemDocument () для этого предложения, оно вернет предложение, не прерывая никаких слов.
stemDocument («В сложной спешке Том бросился исправлять новое затруднение, слишком сложно.»)
[1] «В сложной спешке Том бросился исправлять новое осложнение, слишком сложно."
Это происходит потому, что stemDocument () обрабатывает все предложение как одно слово. Другими словами, наш документ представляет собой символьный вектор длины 1 вместо длины n, где n — количество слов в документе. Чтобы решить эту проблему, мы сначала удаляем знаки препинания с помощью функции removePunctuation () , затем strsplit () этот вектор символов от длины 1 до длины n, unlist () , затем переходим к основанию и повторно полный.
text_data
[1] «В» «a» «сложный» «hast» «Tom» «спешка» «, чтобы« исправить »« a »« новый » [11] «сложный» «слишком» «сложный»
# Создать словарь завершения: comp_dict comp_dict
В сложной ситуации Том спешит исправить
«В» «а» «усложнять» «спешить» «Том» «спешить» «, чтобы» «исправить»
новое усложнение слишком сложное
«а» «новый» «усложняют» «слишком» «усложняют» Применение шагов предварительной обработки к корпусу
Пакет tm предоставляет специальную функцию tm_map () для применения функций очистки к корпусу. Сопоставление этих функций со всем корпусом позволяет очень легко масштабировать шаги очистки.
Для экономии времени (и строк кода) рекомендуется использовать настраиваемую функцию, поскольку вы можете применять одни и те же функции в нескольких корпусах. Вы, наверное, догадались, что делает функция clean_corpus () . Он принимает один аргумент, корпус, применяет к нему ряд функций очистки по порядку, а затем возвращает окончательный результат.
Обратите внимание, что функциям пакета tm не требуется content_transformer () , но функции base R и qdap нужны.
Обязательно проверьте результаты своей функции. Если вы хотите снять денежные суммы, то removeNumbers () использовать нельзя! Кроме того, порядок этапов очистки имеет значение. Например, если вы removeNumbers () , а затем replace_number () , вторая функция не найдет ничего, что можно было бы изменить!
Проверить, проверить и еще раз проверить!
# Давайте найдем самые частые слова в нашем tweets_text и посмотрим, стоит ли избавляться от некоторых common_terms
# Ну ничем особо не выделяется, кроме галстуков и статей, поэтому стандартный словарь стоп-слов # на английском подойдет.
$ содержимого [1] "спасибо именинникам, доброжелателям twitterverse, родившимся в 1958 году, но еще не чувствую дня 57"
# Распечатать тот же твит в исходном виде твиты $ text [227]
[1] «Спасибо всем доброжелателям Дня Рождения в Twitterverse.Родился в 1958 году, но чувствую себя и на день старше 57 ».
Составление матрицы документов-терминов
Матрица «документ-термин» используется, когда вы хотите, чтобы каждый документ был представлен в виде строки. Это может быть полезно, если вы сравниваете авторов в строках или данные расположены в хронологическом порядке и вы хотите сохранить временные ряды.
# Создаем dtm из корпуса: tweets_dtm
> Нестандартные / редкие записи: 26328/20383440 Редкость: 100% Максимальный срок: 107 Взвешивание: частота слагаемого (тс)
# Преобразовать tweets_dtm в матрицу: tweets_m tweets_m
[1] 2428 8406
# Проверить часть матрицы tweets_m [148: 150, 2587: 2590]
Термины Документы, умирающие раньше, раньше 148 0 0 0 0 149 0 0 0 0 150 0 0 0 0
# Так как разреженность слишком велика, т.
> Нестандартные / редкие записи: 3258/93862 Редкость: 97% Максимальный срок: 8 Взвешивание: частота слагаемого (тс)
# Преобразовать tweets_dtm в матрицу: tweets_m tweets_m
[1] 2428 40
# Проверить часть матрицы tweets_m [148: 158, 10:22]
Термины Docs full fyi get good happy just know life like moon never new night 148 0 1 0 0 0 1 0 0 0 0 0 0 0 149 0 0 0 0 0 0 0 0 0 1 0 0 0 150 0 0 0 0 0 0 0 0 0 0 0 0 0 151 0 0 0 0 0 0 0 0 0 0 0 0 0 152 0 1 0 0 1 0 0 0 0 0 0 1 0 153 0 0 0 0 0 0 1 0 0 0 0 0 0 154 0 0 0 0 0 0 0 0 0 0 0 0 0 155 1 0 0 0 0 0 0 0 0 1 0 0 0 156 0 1 0 0 0 0 0 0 0 0 0 0 0 157 0 0 0 0 0 0 0 0 0 0 0 0 0 158 0 0 0 0 0 0 0 0 0 0 0 0 0
Составление термодокументной матрицы
TDM часто является матрицей, используемой для языкового анализа. Это потому, что у вас, вероятно, больше терминов, чем авторов или документов, и жизнь, как правило, легче, когда у вас больше строк, чем столбцов. Простой способ начать анализ информации — это преобразовать матрицу в простую, используя as.matrix () на TDM.
# Создаем tdm из корпуса: tweets_tdm
> Нестандартные / редкие записи: 26328/20383440 Редкость: 100% Максимальный срок: 107 Взвешивание: частота слагаемого (тс)
# Преобразовать tweets_tdm в матрицу: tweets_m tweets_m
[1] 8406 2428
# Проверить часть матрицы tweets_m [148: 158, 126: 138]
Документы Условия 126 127 128 129 130 131 132 133 134 135 136 137 138 12м 0 0 0 0 0 0 0 0 0 0 0 0 0 12середина 0 0 0 0 0 0 0 0 0 0 0 0 0 12-й 0 0 0 0 0 0 0 0 0 0 0 0 0 12x4 0 0 0 0 0 0 0 0 0 0 0 0 0 130200pm 0 0 0 0 0 0 0 0 0 0 0 0 0 130 миль / ч 0 0 0 0 0 0 0 0 0 0 0 0 0 132pm 0 0 0 0 0 0 0 0 0 0 0 0 0 137-я 0 0 0 0 0 0 0 0 0 0 0 0 0 138 0 0 0 0 0 0 0 0 0 0 0 0 0 1382 0 0 0 0 0 0 0 0 0 0 0 0 0 13эпизод 0 0 0 0 0 0 0 0 0 0 0 0 0
# Поскольку разреженность очень высока, т.
> Нестандартные / редкие записи: 6196/311872 Редкость: 98% Максимальный срок: 15 Взвешивание: частота слагаемого (тс)
# Преобразовать tweets_dtm в матрицу: tweets_m tweets_m
[1] 131 2428
# Проверить часть матрицы tweets_m [14:28, 10:22]
Документы Условия 10 11 12 13 14 15 16 17 18 19 20 21 22 лучший 0 2 0 0 0 0 0 0 0 0 0 0 0 большой 0 0 0 0 0 0 0 0 0 0 0 0 0 мозг 0 0 0 0 0 0 0 0 0 0 0 0 0 звонок 0 0 0 0 0 0 0 0 0 0 0 0 0 вызывается 0 0 0 0 0 0 0 0 0 0 0 0 0 банка 0 0 0 0 0 0 1 0 0 0 0 0 0 прохладно 0 0 0 0 0 0 0 0 0 0 0 0 0 космический 0 0 0 0 0 0 0 0 0 0 0 0 0 космос 0 0 0 0 0 0 0 0 0 0 0 0 0 любопытный 0 0 0 0 0 0 0 0 0 0 0 0 0 день 0 0 1 0 0 0 0 0 0 0 0 0 0 дней 0 0 0 0 0 0 0 0 0 0 0 0 0 не 0 0 0 0 0 0 0 0 0 0 0 0 0 земля 0 0 1 0 0 0 0 0 0 0 0 0 0 земли 0 0 0 0 0 0 0 0 0 0 0 0 0
LS0tDQp0aXRsZTogIkJhc2ljcyBvZiBUZXh0IE1pbmluZyBpbiBSIC0gQmFnIG9mIFdvcmRzIg0Kb3V0cHV0OiANCiAgaHRtbF9ub3RlYm9vazogDQogICAgdG9jOiB5ZXMNCi0tLQ0KDQojIEludHJvZHVjdGlvbg0KDQpTbyB3aGF0IGlzIHRleHQgbWluaW5nPyBUbyBwdXQgaXQgc2ltcGxlOiBUZXh0IG1pbmluZyBpcyB0aGUgcHJvY2VzcyBvZiBkaXN0aWxsaW5nIGFjdGlvbmFibGUgaW5zaWdodHMgZnJvbSB0ZXh0LiBJbiB0aGlzIGFydGljbGUgd2UnbGwgYmUgZGVhbGluZyB3aXRoIHRoZSBzbyBjYWxsZWQgQmFnIG9mIFdvcmRzLCBpLmUuIEJvVyBhcHByb2FjaCB0byB0ZXh0IG1pbmluZy4gDQoNCkknbSBhIGJpZyBmYW4gb2YgZmlyc3QgZG8gdGhhbiB0YWxrIGFib3V0IGFwcHJvYWNoIGluIGxlYXJuaW5nIHNvIGxldCdzIGp1bXAgcmlnaHQgaW50byBlYXN5IHByYWN0aWNhbCBleGFtcGxlcyBhbmQgYnVpbGQgdGhlIHN0b3J5IG9mIHRleHQgbWluaW5nIGZyb20gdGhlcmUuDQoNCiMjIEdldCBhIGJpdCBvZiB0YXN0ZSBvZiB0ZXh0IG1pbmluZzogYHFkYXBgIGFuZCBjb3VudGluZyB0ZXJtcw0KDQpBdCBpdHMgaGVhcnQsICoqYmFnIG9mIHdvcmRzKiogdGV4dCBtaW5pbmcgcmVwcmVzZW50cyBhIHdheSB0byBjb3VudCB0ZXJtcywgb3IgKipuLWdyYW1zKiosIGFjcm9zcyBhIGNvbGxlY3Rpb24gb2YgZG9jdW1lbnRzLiBDb25zaWRlciB0aGUgZm9sbG93aW5nIHNlbnRlbmNlcywgd2hpY2ggd2UndmUgc2 F2ZWQgdG8gYHRleHRgIGFuZCBtYWRlIGF2YWlsYWJsZSBpbiB0aGUgd29ya3NwYWNlOg0KDQpgYGB7cn0NCnRleHQgPC0gIlRleHQgbWluaW5nIHVzdWFsbHkgaW52b2x2ZXMgdGhlIHByb2Nlc3Mgb2Ygc3RydWN0dXJpbmcgdGhlIGlucHV0IHRleHQuIFRoZSBvdmVyYXJjaGluZyBnb2FsIGlzLCBlc3NlbnRpYWxseSwgdG8gdHVybiB0ZXh0IGludG8gZGF0YSBmb3IgYW5hbHlzaXMsIHZpYSBhcHBsaWNhdGlvbiBvZiBuYXR1cmFsIGxhbmd1YWdlIHByb2Nlc3NpbmcgKE5MUCkgYW5kIGFuYWx5dGljYWwgbWV0aG9kcy4iDQpgYGANCk1hbnVhbGx5IGNvdW50aW5nIHdvcmRzIGluIHRoZSBzZW50ZW5jZXMgYWJvdmUgaXMgYSBwYWluISBGb3J0dW5hdGVseSwgdGhlIGBxZGFwYCBwYWNrYWdlIG9mZmVycyBhIGJldHRlciBhbHRlcm5hdGl2ZS4gWW91IGNhbiBlYXNpbHkgZmluZCB0aGUgdG9wIDMgbW9zdCBmcmVxdWVudCB0ZXJtcyAoaW5jbHVkaW5nIHRpZXMpIGluIHRleHQgYnkgY2FsbGluZyB0aGUgYGZyZXFfdGVybXNgIGZ1bmN0aW9uIGFuZCBzcGVjaWZ5aW5nIDMuDQoNCmBgYHtyLCBtZXNzYWdlPUZBTFNFLCB3YXJuaW5nPUZBTFNFfQ0KbGlicmFyeShxZGFwKQ0KZnJlcXVlbnRfdGVybXMgPC0gZnJlcV90ZXJtcyh0ZXh0LCAzKQ0KYGBgDQoNClRoZSBgZnJlcXVlbnRfdGVybXNgIG9iamVjdCBzdG9yZXMgYWxsIHVuaXF1ZSB3b3JkcyBhbmQgdGhlaXIgY291bnRzLiBZb3UgY2FuIHRoZW4gbWFrZSBhIGJhciBjaG FydCBzaW1wbHkgYnkgY2FsbGluZyB0aGUgcGxvdCBmdW5jdGlvbiBvbiB0aGUgYGZyZXF1ZW50X3Rlcm1zYCBvYmplY3QuDQoNCmBgYHtyfQ0KcGxvdChmcmVxdWVudF90ZXJtcykNCmBgYA0KDQojIEZyb20gbG9hZGluZyB0aGUgdGV4dHVhbCBkYXRhIHRvIFRETSBhbmQgRFRNOiBzaG9ydCBleGFtcGxlcw0KDQpUaGUgZmlyc3Qgc3RlcCBvZiB0ZXh0IG1pbmluZyBlbmRlYXZvdXIgaXMgb2YgY291cnNlIGxvYWRpbmcgdGhlIHZlcnkgdGV4dHVhbCBkYXRhIHRoYXQgaXMgc3VwcG9zZWQgdG8gYmUgYW5hbHl6ZWQuDQoNCmBgYHtyLCBtZXNzYWdlPVRSVUV9DQoNCmxpYnJhcnkocmVhZHIpDQoNCiMgSW1wb3J0IHRleHQgZGF0YQ0KdHdlZXRzIDwtIHJlYWRfY3N2KCJkYXRhL05laWxkZUdyYXNzZVR5c29uVHdlZXRzLmNzdiIpDQoNCiMgVmlldyB0aGUgc3RydWN0dXJlIG9mIHR3ZWV0cw0Kc3RyKHR3ZWV0cykNCg0KIyBQcmludCBvdXQgdGhlIG51bWJlciBvZiByb3dzIGluIHR3ZWV0cw0KbnJvdyh0d2VldHMpDQoNCiMgSXNvbGF0ZSB0ZXh0IGZyb20gdHdlZXRzOiB0d2VldHNfdGV4dA0KdHdlZXRzX3RleHQgPC0gdHdlZXRzJHRleHQNCg0Kc3RyKHR3ZWV0c190ZXh0KQ0KYGBgDQojIyBCdWlsZGluZyBhIGNvcnB1cw0KDQpMZXQncyBub3cgYnVpbGQgYSBjb3JwdXMgb3V0IG9mIHRoaXMgdmVjdG9yIG9mIHN0cmluZ3MuICBBIGNvcnB1cyBpcyBhIGNvbGxlY3Rpb24gb2YgZG9jdW1lbnRzLCBidXQgaXQncyBhbHNvIG ltcG9ydGFudCB0byBrbm93IHRoYXQgaW4gdGhlIGB0bWAgZG9tYWluLCBSIHJlY29nbml6ZXMgaXQgYXMgYSBzZXBhcmF0ZSBkYXRhIHR5cGUuDQoNClRoZXJlIGFyZSB0d28ga2luZHMgb2YgdGhlIGNvcnB1cyBkYXRhIHR5cGUsIHRoZSBwZXJtYW5lbnQgY29ycHVzLCBpLmUuIFBDb3JwdXMsIGFuZCB0aGUgdm9sYXRpbGUgY29ycHVzLCBpLmUuIFZDb3JwdXMuIEluIGVzc2VuY2UsIHRoZSBkaWZmZXJlbmNlIGJldHdlZW4gdGhlIHR3byBoYXMgdG8gZG8gd2l0aCBob3cgdGhlIGNvbGxlY3Rpb24gb2YgZG9jdW1lbnRzIGlzIHN0b3JlZCBpbiB5b3VyIGNvbXB1dGVyLiBXZSB3aWxsIHVzZSB0aGUgdm9sYXRpbGUgY29ycHVzLCB3aGljaCBpcyBoZWxkIGluIGNvbXB1dGVyJ3MgUkFNIHJhdGhlciB0aGFuIHNhdmVkIHRvIGRpc2ssIGp1c3QgdG8gYmUgbW9yZSBtZW1vcnkgZWZmaWNpZW50Lg0KDQpUbyBtYWtlIGEgdm9sYXRpbGUgY29ycHVzLCBSIG5lZWRzIHRvIGludGVycHJldCBlYWNoIGVsZW1lbnQgaW4gb3VyIHZlY3RvciBvZiB0ZXh0LCBgdHdlZXRzX3RleHRgLCBhcyBhIGRvY3VtZW50LiBBbmQgdGhlIGB0bWAgcGFja2FnZSBwcm92aWRlcyB3aGF0IGFyZSBjYWxsZWQgU291cmNlIGZ1bmN0aW9ucyB0byBkbyBqdXN0IHRoYXQhIEluIHRoaXMgZXhlcmNpc2UsIHdlJ2xsIHVzZSBhIFNvdXJjZSBmdW5jdGlvbiBjYWxsZWQgYFZlY3RvclNvdXJjZSgpYCBiZWNhdXNlIG91ciB0ZXh0IGRhdGEgaXMgY29udGFpbm VkIGluIGEgdmVjdG9yLiBUaGUgb3V0cHV0IG9mIHRoaXMgZnVuY3Rpb24gaXMgY2FsbGVkIGEgKlNvdXJjZSBvYmplY3QqLg0KDQpgYGB7ciwgbWVzc2FnZT1GQUxTRSwgd2FybmluZz1GQUxTRX0NCmxpYnJhcnkodG0pDQoNCnR3ZWV0c19zb3VyY2UgPC0gVmVjdG9yU291cmNlKHR3ZWV0c190ZXh0KQ0KDQpgYGANCk5vdyB0aGF0IHdlJ3ZlIGNvbnZlcnRlZCBvdXIgdmVjdG9yIHRvIGEgU291cmNlIG9iamVjdCwgd2UgcGFzcyBpdCB0byBhbm90aGVyIGB0bWAgZnVuY3Rpb24sIGBWQ29ycHVzKClgLCB0byBjcmVhdGUgb3VyIHZvbGF0aWxlIGNvcnB1cy4NClRoZSBgVkNvcnB1c2Agb2JqZWN0IGlzIGEgbmVzdGVkIGxpc3QsIG9yIGxpc3Qgb2YgbGlzdHMuIEF0IGVhY2ggaW5kZXggb2YgdGhlIGBWQ29ycHVzYCBvYmplY3QsIHRoZXJlIGlzIGEgYFBsYWluVGV4dERvY3VtZW50YCBvYmplY3QsIHdoaWNoIGlzIGVzc2VudGlhbGx5IGEgbGlzdCB0aGF0IGNvbnRhaW5zIHRoZSBhY3R1YWwgdGV4dCBkYXRhIChgY29udGVudGApLCBhcyB3ZWxsIGFzIHNvbWUgY29ycmVzcG9uZGluZyBtZXRhZGF0YSAoYG1ldGFgKSB3aGljaCBjYW4gaGVscCB0byB2aXN1YWxpemUgYSBgVkNvcnB1c2Agb2JqZWN0IGFuZCB0byBjb25jZXB0dWFsaXplIHRoZSB3aG9sZSB0aGluZy4NCg0KYGBge3J9DQojIE1ha2UgYSB2b2xhdGlsZSBjb3JwdXM6IHR3ZWV0c19jb3JwdXMNCnR3ZWV0c19jb3JwdXMgPC0gVkNvcnB1cyh0d2VldHNfc291cm NlKQ0KDQojIFByaW50IG91dCB0aGUgdHdlZXRzX2NvcnB1cw0KdHdlZXRzX2NvcnB1cw0KDQojIFByaW50IGRhdGEgb24gdGhlIDE1dGggdHdlZXQgaW4gdHdlZXRzX2NvcnB1cw0KdHdlZXRzX2NvcnB1c1tbMTVdXQ0KDQojIFByaW50IHRoZSBjb250ZW50IG9mIHRoZSAxNXRoIHR3ZWV0IGluIHR3ZWV0c19jb3JwdXMNCnR3ZWV0c19jb3JwdXNbWzE1XV1bMV0NCg0Kc3RyKHR3ZWV0c19jb3JwdXNbWzE1XV0pDQpgYGANCg0KQmVjYXVzZSBhbm90aGVyIGNvbW1vbiB0ZXh0IHNvdXJjZSBpcyBhIGRhdGEgZnJhbWUsIHRoZXJlIGlzIGEgU291cmNlIGZ1bmN0aW9uIGNhbGxlZCBgRGF0YWZyYW1lU291cmNlKClgLiBUaGUgYERhdGFmcmFtZVNvdXJjZSgpYCBmdW5jdGlvbiB0cmVhdHMgdGhlIGVudGlyZSByb3cgYXMgYSBjb21wbGV0ZSBkb2N1bWVudCwgc28gYmUgY2FyZWZ1bCBub3QgdG8gcGljayB1cCBub24tdGV4dCBkYXRhIGxpa2UgY3VzdG9tZXIgSURzIHdoZW4gc291cmNpbmcgYSBkb2N1bWVudCB0aGlzIHdheS4NCg0KYGBge3J9DQpleGFtcGxlX3RleHQgPC0gZGF0YS5mcmFtZShudW0gPSBjKDEsMiwzKSwgQXV0aG9yMSA9IGMoIlRleHQgbWluaW5nIGlzIGEgZ3JlYXQgdGltZS4iLCAiVGV4dCBhbmFseXNpcyBwcm92aWRlcyBpbnNpZ2h0cyIsICJxZGFwIGFuZCB0bSBhcmUgdXNlZCBpbiB0ZXh0IG1pbmluZyIpLCBBdXRob3IyID0gYygiUiBpcyBhIGdyZWF0IGxhbmd1YWdlIiwgIlIgaGFzIG1hbnkgdXNlcy IsICJSIGlzIGNvb2whIiksIHN0cmluZ3NBc0ZhY3RvcnMgPSBGQUxTRSkNCg0KIyBDcmVhdGUgYSBEYXRhZnJhbWVTb3VyY2Ugb24gY29sdW1ucyAyIGFuZCAzOiBkZl9zb3VyY2UNCmRmX3NvdXJjZSA8LSBEYXRhZnJhbWVTb3VyY2UoZXhhbXBsZV90ZXh0WywgMjozXSkNCg0KIyBDb252ZXJ0IGRmX3NvdXJjZSB0byBhIGNvcnB1czogZGZfY29ycHVzDQpkZl9jb3JwdXMgPC0gVkNvcnB1cyhkZl9zb3VyY2UpDQoNCiMgRXhhbWluZSBkZl9jb3JwdXMNCmRmX2NvcnB1cw0Kc3RyKGRmX2NvcnB1cykNCg0KIyBDcmVhdGUgYSBWZWN0b3JTb3VyY2Ugb24gY29sdW1uIDM6IHZlY19zb3VyY2UNCnZlY19zb3VyY2UgPC0gVmVjdG9yU291cmNlKGV4YW1wbGVfdGV4dFssIDNdKQ0KDQojIENvbnZlcnQgdmVjX3NvdXJjZSB0byBhIGNvcnB1czogdmVjX2NvcnB1cw0KdmVjX2NvcnB1cyA8LSBWQ29ycHVzKHZlY19zb3VyY2UpDQoNCiMgRXhhbWluZSB2ZWNfY29ycHVzDQp2ZWNfY29ycHVzDQpzdHIodmVjX2NvcnB1cykNCmBgYA0KDQojIyBDbGVhbmluZyBhbmQgcHJlcHJvY2Vzc2luZyBvZiB0aGUgdGV4dA0KDQpBZnRlciBvYnRhaW5pbmcgdGhlIGNvcnB1cywgdXN1YWxseSwgdGhlIG5leHQgc3RlcCB3aWxsIGJlIGNsZWFuaW5nIGFuZCBwcmVwcm9jZXNzaW5nIG9mIHRoZSB0ZXh0LiBGb3IgdGhpcyBlbmRlYXZvciB3ZSBhcmUgbW9zdGx5IGdvaW5nIHRvIHVzZSBmdW5jdGlvbnMgZnJvbSB0aGUgYHRtYCBhbmQgYHFkYXBgIH BhY2thZ2VzLg0KSW4gYmFnIG9mIHdvcmRzIHRleHQgbWluaW5nLCBjbGVhbmluZyBoZWxwcyBhZ2dyZWdhdGUgdGVybXMuIEZvciBleGFtcGxlLCBpdCBtYXkgbWFrZSBzZW5zZSB0aGF0IHRoZSB3b3JkcyAibWluZXIiLCAibWluaW5nIiBhbmQgIm1pbmUiIHNob3VsZCBiZSBjb25zaWRlcmVkIG9uZSB0ZXJtLiBTcGVjaWZpYyBwcmVwcm9jZXNzaW5nIHN0ZXBzIHdpbGwgdmFyeSBiYXNlZCBvbiB0aGUgcHJvamVjdC4gRm9yIGV4YW1wbGUsIHRoZSB3b3JkcyB1c2VkIGluIHR3ZWV0cyBhcmUgdmFzdGx5IGRpZmZlcmVudCB0aGFuIHRob3NlIHVzZWQgaW4gbGVnYWwgZG9jdW1lbnRzLCBzbyB0aGUgY2xlYW5pbmcgcHJvY2VzcyBjYW4gYWxzbyBiZSBxdWl0ZSBkaWZmZXJlbnQuDQoNCkNvbW1vbiBwcmVwcm9jZXNzaW5nIGZ1bmN0aW9ucyBpbmNsdWRlOg0KDQotIGB0b2xvd2VyKClgOiBNYWtlIGFsbCBjaGFyYWN0ZXJzIGxvd2VyY2FzZQ0KLSBgcmVtb3ZlUHVuY3R1YXRpb24oKWA6IFJlbW92ZSBhbGwgcHVuY3R1YXRpb24gbWFya3MNCi0gYHJlbW92ZU51bWJlcnMoKWA6IFJlbW92ZSBudW1iZXJzDQotIGBzdHJpcFdoaXRlc3BhY2UoKWA6IFJlbW92ZSBleGNlc3Mgd2hpdGVzcGFjZQ0KDQpOb3RlIHRoYXQgYHRvbG93ZXIoKWAgaXMgcGFydCBvZiBiYXNlIGBSYCwgd2hpbGUgdGhlIG90aGVyIHRocmVlIGZ1bmN0aW9ucyBjb21lIGZyb20gdGhlIGB0bWAgcGFja2FnZS4gDQoNCkxldCdzIGNoZWNrIGhvdyB0aGlzIG Z1bmN0aW9ucyB3b3JrIG9uIGEgc21hbGwgY2h3bmsgb2YgcGxhaW4gdGV4dDoNCg0KYGBge3J9DQoNCiMgQ3JlYXRlIHRoZSBvYmplY3Q6IHRleHQNCnRleHQgPC0gIjxiPlNoZTwvYj4gd29rZSB1cCBhdCAgICAgICA2IEEuTS4gSXRcJ3Mgc28gZWFybHkhICBTaGUgd2FzIG9ubHkgMTAlIGF3YWtlIGFuZCBiZWdhbiBkcmlua2luZyBjb2ZmZWUgaW4gZnJvbnQgb2YgaGVyIGNvbXB1dGVyLiINCg0KIyBBbGwgbG93ZXJjYXNlDQp0b2xvd2VyKHRleHQpDQoNCiMgUmVtb3ZlIHB1bmN0dWF0aW9uDQpyZW1vdmVQdW5jdHVhdGlvbih0ZXh0KQ0KDQojIFJlbW92ZSBudW1iZXJzDQpyZW1vdmVOdW1iZXJzKHRleHQpDQoNCiMgUmVtb3ZlIHdoaXRlc3BhY2UNCnN0cmlwV2hpdGVzcGFjZSh0ZXh0KQ0KDQpgYGANCg0KVGhlIGBxZGFwYCBwYWNrYWdlIG9mZmVycyBvdGhlciB0ZXh0IGNsZWFuaW5nIGZ1bmN0aW9ucy4gRWFjaCBpcyB1c2VmdWwgaW4gaXRzIG93biB3YXkgYW5kIGlzIHBhcnRpY3VsYXJseSBwb3dlcmZ1bCB3aGVuIGNvbWJpbmVkIHdpdGggdGhlIG90aGVycy4NCg0KLSBgYnJhY2tldFgoKWA6IFJlbW92ZSBhbGwgdGV4dCB3aXRoaW4gYnJhY2tldHMgKGUuZy4gIkl0J3MgKHNvKSBjb29sIiBiZWNvbWVzICJJdCdzIGNvb2wiKQ0KLSBgcmVwbGFjZV9udW1iZXIoKWA6IFJlcGxhY2UgbnVtYmVycyB3aXRoIHRoZWlyIHdvcmQgZXF1aXZhbGVudHMgKGUuZy4gIjIiIGJlY29tZXMgInR3byIpDQotIGByZXBsYWNlX2 FiYnJldmlhdGlvbigpYDogUmVwbGFjZSBhYmJyZXZpYXRpb25zIHdpdGggdGhlaXIgZnVsbCB0ZXh0IGVxdWl2YWxlbnRzIChlLmcuICJTciIgYmVjb21lcyAiU2VuaW9yIikNCi0gYHJlcGxhY2VfY29udHJhY3Rpb24oKWA6IENvbnZlcnQgY29udHJhY3Rpb25zIGJhY2sgdG8gdGhlaXIgYmFzZSB3b3JkcyAoZS5nLiAic2hvdWxkbid0IiBiZWNvbWVzICJzaG91bGQgbm90IikNCi0gYHJlcGxhY2Vfc3ltYm9sKClgIFJlcGxhY2UgY29tbW9uIHN5bWJvbHMgd2l0aCB0aGVpciB3b3JkIGVxdWl2YWxlbnRzIChlLmcuICIkIiBiZWNvbWVzICJkb2xsYXIiKQ0KDQpMZXQncyB0cnkgb3V0IHNvbWUgb2YgdGhlc2UgZnVuY3Rpb25zIG9uIHRoZSBgdGV4dGAgc3RyaW5nIHdlJ3ZlIGRlZmluZWQgaW4gdGhlIHByZXZpb3VzIGV4YW1wbGU6DQoNCmBgYHtyfQ0KIyBSZW1vdmUgdGV4dCB3aXRoaW4gYnJhY2tldHMNCmJyYWNrZXRYKHRleHQpDQoNCiMgUmVwbGFjZSBudW1iZXJzIHdpdGggd29yZHMNCnJlcGxhY2VfbnVtYmVyKHRleHQpDQoNCiMgUmVwbGFjZSBhYmJyZXZpYXRpb25zDQpyZXBsYWNlX2FiYnJldmlhdGlvbih0ZXh0KQ0KDQojIFJlcGxhY2UgY29udHJhY3Rpb25zDQpyZXBsYWNlX2NvbnRyYWN0aW9uKHRleHQpDQoNCiMgUmVwbGFjZSBzeW1ib2xzIHdpdGggd29yZHMNCnJlcGxhY2Vfc3ltYm9sKHRleHQpDQpgYGANCg0KIyMgU3RvcCB3b3Jkcw0KDQpUaGUgbmV4dCBpc3N1ZSB0aGF0IHdlJ2xsIGRlYWwgd2l0aC BhcmUgdGhlIHNvLWNhbGxlZCAqc3RvcCB3b3JkcyouIFRoZXNlIHRoZSBhcmUgd29yZHMgdGhhdCBhcmUgZnJlcXVlbnQgYnV0IHByb3ZpZGUgbGl0dGxlIGluZm9ybWF0aW9uLiBTbyB5b3UgbWF5IHdhbnQgdG8gcmVtb3ZlIHRoZW0uIFNvbWUgY29tbW9uIEVuZ2xpc2ggc3RvcCB3b3JkcyBpbmNsdWRlICJJIiwgInNoZSdsbCIsICJ0aGUiLCBldGMuIEluIHRoZSBgdG1gIHBhY2thZ2UsIHRoZXJlIGFyZSAxNzQgc3RvcCB3b3JkcyBvbiB0aGlzIGNvbW1vbiBsaXN0LiBJbiBmYWN0LCB3aGVuIHlvdSBhcmUgZG9pbmcgYW4gYW5hbHlzaXMgeW91IHdpbGwgbGlrZWx5IG5lZWQgdG8gYWRkIHRvIHRoaXMgbGlzdC4gTGVhdmluZyBjZXJ0YWluIGZyZXF1ZW50IHdvcmRzIHRoYXQgZG9uJ3QgYWRkIGFueSBpbnNpZ2h0IHdpbGwgY2F1c2UgdGhlbSB0byBiZSBvdmVyZW1waGFzaXplZCBpbiBhIGZyZXF1ZW5jeSBhbmFseXNpcyB3aGljaCB1c3VhbGx5IGxlYWRzIHRvIHdyb25nbHkgYmlhc2VkIGludGVycHJldGF0aW9uIG9mIHJlc3VsdHMuDQoNClVzaW5nIHRoZSBgYygpYCBmdW5jdGlvbiBhbGxvd3MgeW91IHRvIGFkZCBuZXcgd29yZHMgKHNlcGFyYXRlZCBieSBjb21tYXMpIHRvIHRoZSBzdG9wIHdvcmRzIGxpc3QuIEZvciBleGFtcGxlLCB0aGUgZm9sbG93aW5nIHdvdWxkIGFkZCAid29yZDEiIGFuZCAid29yZDIiIHRvIHRoZSBkZWZhdWx0IGxpc3Qgb2YgRW5nbGlzaCBzdG9wIHdvcmRzOg0KDQogICAgYWxsX3N0b3 BzIDwtIGMoIndvcmQxIiwgIndvcmQyIiwgc3RvcHdvcmRzKCJlbiIpKQ0KDQpPbmNlIHlvdSBoYXZlIGEgbGlzdCBvZiBzdG9wIHdvcmRzIHRoYXQgbWFrZXMgc2Vuc2UsIHlvdSB3aWxsIHVzZSB0aGUgYHJlbW92ZVdvcmRzKClgIGZ1bmN0aW9uIG9uIHlvdXIgdGV4dC4gYHJlbW92ZVdvcmRzKClgIHRha2VzIHR3byBhcmd1bWVudHM6IHRoZSB0ZXh0IG9iamVjdCB0byB3aGljaCBpdCdzIGJlaW5nIGFwcGxpZWQgYW5kIHRoZSBsaXN0IG9mIHdvcmRzIHRvIHJlbW92ZS4NCg0KYGBge3J9DQojIExpc3Qgc3RhbmRhcmQgRW5nbGlzaCBzdG9wIHdvcmRzDQpzdG9wd29yZHMoImVuIikNCg0KIyBQcmludCB0ZXh0IHdpdGhvdXQgc3RhbmRhcmQgc3RvcCB3b3Jkcw0KcmVtb3ZlV29yZHModGV4dCwgc3RvcHdvcmRzKCJlbiIpKQ0KDQojIEFkZCAiY29mZmVlIiBhbmQgImJlYW4iIHRvIHRoZSBsaXN0OiBuZXdfc3RvcHMNCm5ld19zdG9wcyA8LSBjKCJjb2ZmZWUiLCAiYmVhbiIsIHN0b3B3b3JkcygiZW4iKSkNCg0KIyBSZW1vdmUgc3RvcCB3b3JkcyBmcm9tIHRleHQNCnJlbW92ZVdvcmRzKHRleHQsIG5ld19zdG9wcykNCmBgYA0KIyMgSW50cm8gdG8gd29yZCBzdGVtbWluZyBhbmQgc3RlbSBjb21wbGV0aW9uDQoNClN0aWxsIGFub3RoZXIgdXNlZnVsIHByZXByb2Nlc3Npbmcgc3RlcCBpbnZvbHZlcyB3b3JkIHN0ZW1taW5nIGFuZCBzdGVtIGNvbXBsZXRpb24uIFRoZSB0bSBwYWNrYWdlIHByb3ZpZGVzIHRoZSBzdGVtRG 9jdW1lbnQoKSBmdW5jdGlvbiB0byBnZXQgdG8gYSB3b3JkJ3Mgcm9vdC4gVGhpcyBmdW5jdGlvbiBlaXRoZXIgdGFrZXMgaW4gYSBjaGFyYWN0ZXIgdmVjdG9yIGFuZCByZXR1cm5zIGEgY2hhcmFjdGVyIHZlY3Rvciwgb3IgdGFrZXMgaW4gYSBQbGFpblRleHREb2N1bWVudCBhbmQgcmV0dXJucyBhIFBsYWluVGV4dERvY3VtZW50Lg0KDQpTdGlsbCBhbm90aGVyIHVzZWZ1bCBwcmVwcm9jZXNzaW5nIHN0ZXAgaW52b2x2ZXMgKndvcmQgc3RlbW1pbmcqIGFuZCAqc3RlbSBjb21wbGV0aW9uKi4gVGhlIGB0bWAgcGFja2FnZSBwcm92aWRlcyB0aGUgYHN0ZW1Eb2N1bWVudCgpYCBmdW5jdGlvbiB0byBnZXQgdG8gYSB3b3JkJ3Mgcm9vdC4gVGhpcyBmdW5jdGlvbiBlaXRoZXIgdGFrZXMgaW4gYSBjaGFyYWN0ZXIgdmVjdG9yIGFuZCByZXR1cm5zIGEgY2hhcmFjdGVyIHZlY3Rvciwgb3IgdGFrZXMgaW4gYSBgUGxhaW5UZXh0RG9jdW1lbnRgIGFuZCByZXR1cm5zIGEgYFBsYWluVGV4dERvY3VtZW50YC4NCkZvciBleGFtcGxlLA0KDQogICAgc3RlbURvY3VtZW50KGMoImNvbXB1dGF0aW9uYWwiLCAiY29tcHV0ZXJzIiwgImNvbXB1dGF0aW9uIikpDQoNCnJldHVybnMgImNvbXB1dCIgImNvbXB1dCIgImNvbXB1dCIuIEJ1dCBiZWNhdXNlICJjb21wdXQiIGlzbid0IGEgcmVhbCB3b3JkLCB3ZSB3YW50IHRvIHJlLWNvbXBsZXRlIHRoZSB3b3JkcyBzbyB0aGF0ICJjb21wdXRhdGlvbmFsIiwgImNvbXB1dGVycyIsIGFuZCAiY2 9tcHV0YXRpb24iIGFsbCByZWZlciB0byB0aGUgc2FtZSB3b3JkLCBzYXkgImNvbXB1dGVyIiwgaW4gb3VyIG9uZ29pbmcgYW5hbHlzaXMuDQoNCldlIGNhbiBlYXNpbHkgZG8gdGhpcyB3aXRoIHRoZSBgc3RlbUNvbXBsZXRpb24oKWAgZnVuY3Rpb24sIHdoaWNoIHRha2VzIGluIGEgY2hhcmFjdGVyIHZlY3RvciBhbmQgYW4gYXJndW1lbnQgZm9yIHRoZSBjb21wbGV0aW9uIGRpY3Rpb25hcnkuIFRoZSBjb21wbGV0aW9uIGRpY3Rpb25hcnkgY2FuIGJlIGEgY2hhcmFjdGVyIHZlY3RvciBvciBhIENvcnB1cyBvYmplY3QuIEVpdGhlciB3YXksIHRoZSBjb21wbGV0aW9uIGRpY3Rpb25hcnkgZm9yIG91ciBleGFtcGxlIHdvdWxkIG5lZWQgdG8gY29udGFpbiB0aGUgd29yZCAiY29tcHV0ZXIiIGZvciBhbGwgdGhlIHdvcmRzIHRvIHJlZmVyIHRvIGl0Lg0KDQpgYGB7cn0NCiMgQ3JlYXRlIGNvbXBsaWNhdGUNCmNvbXBsaWNhdGUgPC0gYygiY29tcGxpY2F0ZWQiLCAiY29tcGxpY2F0aW9uIiwgImNvbXBsaWNhdGVkbHkiKQ0KDQojIFBlcmZvcm0gd29yZCBzdGVtbWluZzogc3RlbV9kb2MNCnN0ZW1fZG9jIDwtIHN0ZW1Eb2N1bWVudChjb21wbGljYXRlKQ0KDQojIENyZWF0ZSB0aGUgY29tcGxldGlvbiBkaWN0aW9uYXJ5OiBjb21wX2RpY3QNCmNvbXBfZGljdCA8LSAoImNvbXBsaWNhdGUiKQ0KDQojIFBlcmZvcm0gc3RlbSBjb21wbGV0aW9uOiBjb21wbGV0ZV90ZXh0IA0KY29tcGxldGVfdGV4dCA8LSBzdGVtQ29tcGxldG lvbihzdGVtX2RvYywgY29tcF9kaWN0KQ0KDQojIFByaW50IGNvbXBsZXRlX3RleHQNCmNvbXBsZXRlX3RleHQNCmBgYA0KIyMjIFdvcmQgc3RlbW1pbmcgYW5kIHN0ZW0gY29tcGxldGlvbiBvbiBhIHNlbnRlbmNlDQoNCkxldCdzIGNvbnNpZGVyIHRoZSBmb2xsb3dpbmcgc2VudGVuY2UgYXMgb3VyIGRvY3VtZW50IGZvciB0aGlzIGV4ZXJjaXNlOg0KDQo + ICJJbiBhIGNvbXBsaWNhdGVkIGhhc3RlLCBUb20gcnVzaGVkIHRvIGZpeCBhIG5ldyBjb21wbGljYXRpb24sIHRvbyBjb21wbGljYXRlZGx5LiINCg0KVGhpcyBzZW50ZW5jZSBjb250YWlucyB0aGUgc2FtZSB0aHJlZSBmb3JtcyBvZiB0aGUgd29yZCAiY29tcGxpY2F0ZSIgdGhhdCB3ZSBzYXcgaW4gdGhlIHByZXZpb3VzIGV4ZXJjaXNlLiBUaGUgZGlmZmVyZW5jZSBoZXJlIGlzIHRoYXQgZXZlbiBpZiB5b3UgY2FsbGVkIGBzdGVtRG9jdW1lbnQoKWAgb24gdGhpcyBzZW50ZW5jZSwgaXQgd291bGQgcmV0dXJuIHRoZSBzZW50ZW5jZSB3aXRob3V0IHN0ZW1taW5nIGFueSB3b3Jkcy4gDQoNCmBgYHtyfQ0Kc3RlbURvY3VtZW50KCJJbiBhIGNvbXBsaWNhdGVkIGhhc3RlLCBUb20gcnVzaGVkIHRvIGZpeCBhIG5ldyBjb21wbGljYXRpb24sIHRvbyBjb21wbGljYXRlZGx5LiIpDQpgYGANCg0KVGhpcyBoYXBwZW5zIGJlY2F1c2UgYHN0ZW1Eb2N1bWVudCgpYCB0cmVhdHMgdGhlIHdob2xlIHNlbnRlbmNlIGFzIG9uZSB3b3JkLiBJbiBvdGhlciB3b3Jkcywgb3VyIG RvY3VtZW50IGlzIGEgY2hhcmFjdGVyIHZlY3RvciBvZiBsZW5ndGggMSwgaW5zdGVhZCBvZiBsZW5ndGggbiwgd2hlcmUgbiBpcyB0aGUgbnVtYmVyIG9mIHdvcmRzIGluIHRoZSBkb2N1bWVudC4gVG8gc29sdmUgdGhpcyBwcm9ibGVtLCB3ZSBmaXJzdCByZW1vdmUgdGhlIHB1bmN0dWF0aW9uIG1hcmtzIHdpdGggdGhlIGByZW1vdmVQdW5jdHVhdGlvbigpYCBmdW5jdGlvbiwgd2UgdGhlbiBgc3Ryc3BsaXQoKWAgdGhpcyBjaGFyYWN0ZXIgdmVjdG9yIG9mIGxlbmd0aCAxIHRvIGxlbmd0aCBuLCBgdW5saXN0KClgLCB0aGVuIHByb2NlZWQgdG8gc3RlbSBhbmQgcmUtY29tcGxldGUuDQoNCmBgYHtyfQ0KDQp0ZXh0X2RhdGEgPC0gIkluIGEgY29tcGxpY2F0ZWQgaGFzdGUsIFRvbSBydXNoZWQgdG8gZml4IGEgbmV3IGNvbXBsaWNhdGlvbiwgdG9vIGNvbXBsaWNhdGVkbHkuIg0KDQojIFJlbW92ZSBwdW5jdHVhdGlvbjogcm1fcHVuYw0Kcm1fcHVuYyA8LSByZW1vdmVQdW5jdHVhdGlvbih0ZXh0X2RhdGEpDQoNCiMgQ3JlYXRlIGNoYXJhY3RlciB2ZWN0b3I6IG5fY2hhcl92ZWMNCm5fY2hhcl92ZWMgPC0gdW5saXN0KHN0cnNwbGl0KHJtX3B1bmMsIHNwbGl0ID0gJyAnKSkNCg0KIyBQZXJmb3JtIHdvcmQgc3RlbW1pbmc6IHN0ZW1fZG9jDQpzdGVtX2RvYyA8LSBzdGVtRG9jdW1lbnQobl9jaGFyX3ZlYykNCg0KIyBQcmludCBzdGVtX2RvYw0Kc3RlbV9kb2MNCg0KIyBDcmVhdGUgdGhlIGNvbXBsZXRpb24gZGljdGlvbm FyeTogY29tcF9kaWN0DQpjb21wX2RpY3QgPC0gYygiSW4iLCAiYSIsICJjb21wbGljYXRlIiwgImhhc3RlIiwgIlRvbSIsICJydXNoIiwgInRvIiwgImZpeCIsICJuZXciLCAidG9vIikNCg0KIyBSZS1jb21wbGV0ZSBzdGVtbWVkIGRvY3VtZW50OiBjb21wbGV0ZV9kb2MNCmNvbXBsZXRlX2RvYyA8LSBzdGVtQ29tcGxldGlvbihzdGVtX2RvYywgY29tcF9kaWN0KSANCg0KIyBQcmludCBjb21wbGV0ZV9kb2MNCmNvbXBsZXRlX2RvYw0KDQpgYGANCg0KIyMgQXBwbHlpbmcgcHJlcHJvY2Vzc2luZyBzdGVwcyB0byBhIGNvcnB1cw0KDQpUaGUgYHRtYCBwYWNrYWdlIHByb3ZpZGVzIGEgc3BlY2lhbCBmdW5jdGlvbiBgdG1fbWFwKClgIHRvIGFwcGx5IGNsZWFuaW5nIGZ1bmN0aW9ucyB0byBhIGNvcnB1cy4gTWFwcGluZyB0aGVzZSBmdW5jdGlvbnMgdG8gYW4gZW50aXJlIGNvcnB1cyBtYWtlcyBzY2FsaW5nIHRoZSBjbGVhbmluZyBzdGVwcyB2ZXJ5IGVhc3kuDQoNClRvIHNhdmUgdGltZSAoYW5kIGxpbmVzIG9mIGNvZGUpIGl0J3MgYSBnb29kIGlkZWEgdG8gdXNlIGEgY3VzdG9tIGZ1bmN0aW9uLCBzaW5jZSB5b3UgbWF5IGJlIGFwcGx5aW5nIHRoZSBzYW1lIGZ1bmN0aW9ucyBvdmVyIG11bHRpcGxlIGNvcnBvcmEuIFlvdSBjYW4gcHJvYmFibHkgZ3Vlc3Mgd2hhdCB0aGUgYGNsZWFuX2NvcnB1cygpYCBmdW5jdGlvbiBkb2VzLiBJdCB0YWtlcyBvbmUgYXJndW1lbnQsIGNvcnB1cywgYW5kIGFwcGxpZXMgYSBzZXJpZX Mgb2YgY2xlYW5pbmcgZnVuY3Rpb25zIHRvIGl0IGluIG9yZGVyLCB0aGVuIHJldHVybnMgdGhlIGZpbmFsIHJlc3VsdC4NCg0KTm90aWNlIGhvdyB0aGUgYHRtYCBwYWNrYWdlIGZ1bmN0aW9ucyBkbyBub3QgbmVlZCBgY29udGVudF90cmFuc2Zvcm1lcigpYCwgYnV0IGJhc2UgYFJgIGFuZCBgcWRhcGAgZnVuY3Rpb25zIGRvLg0KDQpCZSBzdXJlIHRvIHRlc3QgeW91ciBmdW5jdGlvbidzIHJlc3VsdHMuIElmIHlvdSB3YW50IHRvIGRyYXcgb3V0IGN1cnJlbmN5IGFtb3VudHMsIHRoZW4gYHJlbW92ZU51bWJlcnMoKWAgc2hvdWxkbid0IGJlIHVzZWQhIFBsdXMsIHRoZSBvcmRlciBvZiBjbGVhbmluZyBzdGVwcyBtYWtlcyBhIGRpZmZlcmVuY2UuIEZvciBleGFtcGxlLCBpZiB5b3UgYHJlbW92ZU51bWJlcnMoKWAgYW5kIHRoZW4gYHJlcGxhY2VfbnVtYmVyKClgLCB0aGUgc2Vjb25kIGZ1bmN0aW9uIHdvbid0IGZpbmQgYW55dGhpbmcgdG8gY2hhbmdlISANCg0KKipDaGVjaywgY2hlY2ssIGFuZCByZS1jaGVjayEqKg0KDQpgYGB7cn0NCiNMZXQncyBmaW5kIHRoZSBtb3N0IGZyZXF1ZW50IHdvcmRzIGluIG91ciB0d2VldHNfdGV4dCBhbmQgc2VlIHdoZXRoZXIgd2Ugc2hvdWxkIGdldCByaWQgb2Ygc29tZQ0KZnJlcXVlbnRfdGVybXMgPC0gZnJlcV90ZXJtcyh0d2VldHNfdGV4dCwgMzApDQpwbG90KGZyZXF1ZW50X3Rlcm1zKQ0KDQojIFdlbGwgbm90aGluZyBzdGFuZHMgb3V0IGluIHBhcnRpY3VsYXIsIGV4ZXBjdC B0aWVzIGFuZCBhcnRpY2xlcywgc28gdGhlIHN0YW5kYXJkIHdvY2FidWxhcnkgb2Ygc3RvcHdvcmRzDQojIGluIEVuZ2xpc2ggd2lsbCBkbyBqdXN0IGZpbmUuDQoNCiMgQ3JlYXRlIHRoZSBjdXN0b20gZnVuY3Rpb24gdGhhdCB3aWxsIGJlIHVzZWQgdG8gY2xlYW4gdGhlIGNvcnB1czogY2xlYW5fY291cHVzDQpjbGVhbl9jb3JwdXMgPC0gZnVuY3Rpb24oY29ycHVzKXsNCiAgY29ycHVzIDwtIHRtX21hcChjb3JwdXMsIHN0cmlwV2hpdGVzcGFjZSkNCiAgY29ycHVzIDwtIHRtX21hcChjb3JwdXMsIHJlbW92ZVB1bmN0dWF0aW9uKQ0KICBjb3JwdXMgPC0gdG1fbWFwKGNvcnB1cywgY29udGVudF90cmFuc2Zvcm1lcih0b2xvd2VyKSkNCiAgY29ycHVzIDwtIHRtX21hcChjb3JwdXMsIHJlbW92ZVdvcmRzLCBzdG9wd29yZHMoImVuIikpDQogICAgcmV0dXJuKGNvcnB1cykNCn0NCg0KIyBBcHBseSB5b3VyIGN1c3RvbWl6ZWQgZnVuY3Rpb24gdG8gdGhlIHR3ZWV0X2NvcnA6IGNsZWFuX2NvcnANCmNsZWFuX2NvcnAgPC0gY2xlYW5fY29ycHVzKHR3ZWV0c19jb3JwdXMpDQoNCiMgUHJpbnQgb3V0IGEgY2xlYW5lZCB1cCB0d2VldA0KY2xlYW5fY29ycFtbMjI3XV1bMV0NCg0KIyBQcmludCBvdXQgdGhlIHNhbWUgdHdlZXQgaW4gb3JpZ2luYWwgZm9ybQ0KdHdlZXRzJHRleHRbMjI3XQ0KYGBgDQoNCiMjIE1ha2luZyBhIGRvY3VtZW50LXRlcm0gbWF0cml4DQoNClRoZSBkb2N1bWVudC10ZXJtIG1hdHJpeCBpcyB1c2VkIH doZW4geW91IHdhbnQgdG8gaGF2ZSBlYWNoIGRvY3VtZW50IHJlcHJlc2VudGVkIGFzIGEgcm93LiBUaGlzIGNhbiBiZSB1c2VmdWwgaWYgeW91IGFyZSBjb21wYXJpbmcgYXV0aG9ycyB3aXRoaW4gcm93cywgb3IgdGhlIGRhdGEgaXMgYXJyYW5nZWQgY2hyb25vbG9naWNhbGx5IGFuZCB5b3Ugd2FudCB0byBwcmVzZXJ2ZSB0aGUgdGltZSBzZXJpZXMuDQoNCmBgYHtyfQ0KIyBDcmVhdGUgdGhlIGR0bSBmcm9tIHRoZSBjb3JwdXM6IA0KdHdlZXRzX2R0bSA8LSBEb2N1bWVudFRlcm1NYXRyaXgoY2xlYW5fY29ycCkNCg0KIyBQcmludCBvdXQgdHdlZXRzX2R0bSBkYXRhDQp0d2VldHNfZHRtDQoNCiMgQ29udmVydCB0d2VldHNfZHRtIHRvIGEgbWF0cml4OiB0d2VldHNfbQ0KdHdlZXRzX20gPC0gYXMubWF0cml4KHR3ZWV0c19kdG0pDQoNCiMgUHJpbnQgdGhlIGRpbWVuc2lvbnMgb2YgdHdlZXRzX20NCmRpbSh0d2VldHNfbSkNCg0KIyBSZXZpZXcgYSBwb3J0aW9uIG9mIHRoZSBtYXRyaXgNCnR3ZWV0c19tWzE0ODoxNTAsIDI1ODc6MjU5MF0NCg0KIyBTaW5jZSB0aGUgc3BhcnNpdHkgaXMgc28gaGlnaCwgaS5lLiBhIHByb3BvcnRpb24gb2YgY2VsbHMgd2l0aCAwcy8gY2VsbHMgd2l0aCBvdGhlciB2YWx1ZXMgaXMgdG9vIGxhcmdlLA0KIyBsZXQncyByZW1vdmUgc29tZSBvZiB0aGVzZSBsb3cgZnJlcXVlbmN5IHRlcm1zDQoNCnR3ZWV0c19kdG1fcm1fc3BhcnNlIDwtIHJlbW92ZVNwYXJzZVRlcm1zKHR3ZWV0c19kdG 0sIDAuOTgpDQoNCiMgUHJpbnQgb3V0IHR3ZWV0c19kdG0gZGF0YQ0KdHdlZXRzX2R0bV9ybV9zcGFyc2UNCg0KIyBDb252ZXJ0IHR3ZWV0c19kdG0gdG8gYSBtYXRyaXg6IHR3ZWV0c19tDQp0d2VldHNfbSA8LSBhcy5tYXRyaXgodHdlZXRzX2R0bV9ybV9zcGFyc2UpDQoNCiMgUHJpbnQgdGhlIGRpbWVuc2lvbnMgb2YgdHdlZXRzX20NCmRpbSh0d2VldHNfbSkNCg0KIyBSZXZpZXcgYSBwb3J0aW9uIG9mIHRoZSBtYXRyaXgNCnR3ZWV0c19tWzE0ODoxNTgsIDEwOjIyXQ0KYGBgDQojIyBNYWtpbmcgYSB0ZXJtLWRvY3VtZW50IG1hdHJpeA0KDQpUaGUgVERNIGlzIG9mdGVuIHRoZSBtYXRyaXggdXNlZCBmb3IgbGFuZ3VhZ2UgYW5hbHlzaXMuIFRoaXMgaXMgYmVjYXVzZSB5b3UgbGlrZWx5IGhhdmUgbW9yZSB0ZXJtcyB0aGFuIGF1dGhvcnMgb3IgZG9jdW1lbnRzIGFuZCBsaWZlIGlzIGdlbmVyYWxseSBlYXNpZXIgd2hlbiB5b3UgaGF2ZSBtb3JlIHJvd3MgdGhhbiBjb2x1bW5zLiBBbiBlYXN5IHdheSB0byBzdGFydCBhbmFseXppbmcgdGhlIGluZm9ybWF0aW9uIGlzIHRvIGNoYW5nZSB0aGUgbWF0cml4IGludG8gYSBzaW1wbGUgbWF0cml4IHVzaW5nIGBhcy5tYXRyaXgoKWAgb24gdGhlIFRETS4NCg0KYGBge3J9DQojIENyZWF0ZSB0aGUgdGRtIGZyb20gdGhlIGNvcnB1czogDQp0d2VldHNfdGRtIDwtIFRlcm1Eb2N1bWVudE1hdHJpeChjbGVhbl9jb3JwKQ0KDQojIFByaW50IG91dCB0d2VldHNfdGRtIGRhdGENCn R3ZWV0c190ZG0NCg0KIyBDb252ZXJ0IHR3ZWV0c190ZG0gdG8gYSBtYXRyaXg6IHR3ZWV0c19tDQp0d2VldHNfbSA8LSBhcy5tYXRyaXgodHdlZXRzX3RkbSkNCg0KIyBQcmludCB0aGUgZGltZW5zaW9ucyBvZiB0d2VldHNfbQ0KZGltKHR3ZWV0c19tKQ0KDQojIFJldmlldyBhIHBvcnRpb24gb2YgdGhlIG1hdHJpeA0KdHdlZXRzX21bMTQ4OjE1OCwgMTI2OjEzOF0NCg0KIyBTaW5jZSB0aGUgc3BhcnNpdHkgaXMgc28gaGlnaCwgaS5lLiBhIHByb3BvcnRpb24gb2YgY2VsbHMgd2l0aCAwcy8gY2VsbHMgd2l0aCBvdGhlciB2YWx1ZXMgaXMgdG9vIGxhcmdlLA0KIyBsZXQncyByZW1vdmUgc29tZSBvZiB0aGVzZSBsb3cgZnJlcXVlbmN5IHRlcm1zDQoNCnR3ZWV0c190ZG1fcm1fc3BhcnNlIDwtIHJlbW92ZVNwYXJzZVRlcm1zKHR3ZWV0c190ZG0sIDAuOTkpDQoNCiMgUHJpbnQgb3V0IHR3ZWV0c19kdG0gZGF0YQ0KdHdlZXRzX3RkbV9ybV9zcGFyc2UNCg0KIyBDb252ZXJ0IHR3ZWV0c19kdG0gdG8gYSBtYXRyaXg6IHR3ZWV0c19tDQp0d2VldHNfbSA8LSBhcy5tYXRyaXgodHdlZXRzX3RkbV9ybV9zcGFyc2UpDQoNCiMgUHJpbnQgdGhlIGRpbWVuc2lvbnMgb2YgdHdlZXRzX20NCmRpbSh0d2VldHNfbSkNCg0KIyBSZXZpZXcgYSBwb3J0aW9uIG9mIHRoZSBtYXRyaXgNCnR3ZWV0c19tWzE0OjI4LCAxMDoyMl0NCmBgYA0KDQo =
900 04
|
|
Первый синтаксический анализ
Дело
Первый синтаксический анализ берет загруженные тексты и разбивает каждый на составляющие истории, а также анализирует структуру каждой истории и помещает соответствующие поля в заголовки.
Как это сделать
Вы будете обрабатывать ваши данные папка за папкой. В подпапках каждой из этих входных папок могут быть файлы, если хотите, программа обработает их автоматически.Данные на разных языках должны находиться в разных папках.
Первый процесс синтаксического анализа будет выполняться двумя способами в зависимости от собранных вами данных:
a) разные загрузки поисковых запросов в разных папках.
Если вы загружали несколько раз по разному каждый раз, ища другой поисковый запрос, то выполните этот процесс первого синтаксического анализа несколько раз, по одному разу для каждого поискового запроса. Используйте одну папку для каждого типа данных поискового слова.Например, будет папка, полная данных об изменении климата, и отдельные папки для парникового эффекта или глобального потепления и т. Д.
Английский
Поисковое слово Папка и любые подпапки
Папка с поисковым словом B и подпапки
и т. Д.
Китайский
Поисковое слово F Папка и подпапки
Папка с поисковым словом G и подпапки
и т. Д.
b) один или несколько загрузок поискового запроса все в одной папке
В этом случае вы можете запустить процесс первого синтаксического анализа один раз для каждого языка
Английский
данные в папке X и любых подпапках
Китайский
данные в папке Y и любых подпапках
Для каждого прогона выберите
• Папка загруженных файлов
• Язык
• Введите слово
и нажмите «Загрузить набор для загрузки».Это покажет вам, какие загруженные файлы были найдены. Он проверит, нет ли случаев, когда одно и то же содержимое находится в двух файлах (в таком случае он предложит удалить один). Затем он перечислит все загруженные файлы. Нажмите «Обработать их».
Исходные статьи анализируются на предмет признаков даты, автора и т. Д. Это a) направляет структуру папок и имена файлов результатов, b) содержит информацию заголовка в скобках в верхней части каждого текстового файла.
Дата выходного файла Windows также устанавливается в соответствии с датой публикации его содержимого, если это 1980 год или более поздняя версия (невозможно управлять ранее).
Ваши исходные текстовые файлы для загрузки будут преобразованы в Unicode, если еще не в Unicode. (Если они пришли с Mac, лучше сначала использовать WordSmith Text Converter на них. Компьютеры Mac обычно добавляют некоторые ненужные файлы и папки.)
Процесс синтаксического анализа использует список полей документа, перечисленных в настройках поиска, при определении заголовков для каждой статьи.
Если этот процесс работает удовлетворительно, список загруженных файлов будет очищен и готов для анализа следующей папки.
Контрольно-измерительные материалы по русскому языку. 9 класс
Контрольный диктант в 9 классе № 1
Цель:
проверить соответствие знаний, умений и
навыков учащихся требованиям государственного
стандарта и программы по русскому языку.
Содержание контрольного диктанта направлено на выявление качества усвоения учебного материала за 8-й класс и направлено на повторение предыдущего:
— правописание проверяемых безударных гласных;
— правописание непроверяемых безударных гласных;
— правописание окончаний прилагательных и причастий;
— написание не с наречиями и глаголами;
-правильное написание наречий;
— написание н-нн в прилагательных и наречиях;
— дефисное написание местоимений и наречий.
Знаки препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении;
— запятые при причастном и деепричастном обороте.
— запятые при уточнении и вводных словах.
Грамматические задания направлены на выявления умений:
1. Фонетического разбора;
2. разбора по составу;
3. синтаксического разбора предложения;
4. работа по схеме.
Незнакомая усадьба
Однажды, возвращаясь домой, я нечаянно
забрёл в какую-то незнакомую усадьбу.
Солнце уже пряталось, и на цветущей ржи
растянулись вечерние тени. Два ряда старых,
тесно посаженных елей стояли, образуя
красивую аллею. Я перелез через изгородь
и пошёл по ней, скользя по еловым
иглам. Было тихо и темно, и только
на вершинах кое-где дрожал яркий золотой
свет и переливался радугой в сетях
паука. Я повернул на длинную липовую аллею.
Здесь тоже запустение и старость. Прошлогодняя
листва шелестела под ногами. Направо,
в фруктовом саду, нехотя, слабым
голосом пела иволга, должно быть, тоже
старая. Но вот липы кончились. Я
прошёл мимо дома с террасой, и передо
мной неожиданно открылся чудесный вид:
широкий пруд с купальней, деревня на
том берегу, высокая узкая колокольня. На
ней горел крест, отражая заходившее солнце.
На миг на меня повеяло очарованием чего-то
родного, очень
знакомого
(138 слов)
Грамматические задания.
1. Сделать фонетический разбор слова:
Солнце (1-й вариант) Старая (1-й вариант)
2. Разобрать слова по составу:
Посаженных, растянулись (1-й вариант) заходившее, переливался (2-й вариант)
3. Из текста диктанта выписать по одному словосочетанию на все виды подчинительной связи.
4. Выписать из текста по 3 слова:
1-й вариант: прилагательные, указать разряд
2-й вариант: причастия, указать время
5. Сделать синтаксический разбор предложения:
Однажды, возвращаясь домой, я нечаянно забрёл в какую-то незнакомую усадьбу.
(1-й вариант)
Два
ряда старых, тесно посаженных елей стояли,
образуя красивую аллею. (2-й
вариант)
6. Выписать из диктанта предложения по схеме:
1-й вариант: [ ], и [ ]. 2-й вариант: [ __O и O, |-.-.-.-.| ].
Контрольный диктант в 9 классе № 2
Цель: проверить знания, умения и навыки учащихся на начало учебного года за курс 5- 8 классов.
Содержание контрольного диктанта направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные;
— непроверяемые безударные гласные;
— правописание окончаний имён существительных;
— написание непроизносимых согласных:
— правописание корней с чередованием;
— н-нн в прилагательных;
— не с прилагательными, наречиями и глаголами;
— написание производных предлогов;
— дефисное написание приложений.
Постановки знаков препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении;
— запятые при причастном и деепричастном обороте;
— запятая при уточнении.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— синтаксического разбора предложения;
— разбора по составу слова;
— умения подбирать проверочные слова.
Диктант
Чуткое ухо ловит знакомые звуки весны. Вот вверху, почти над головой, послышалась барабанная трель, звонкая, радостная. Нет, это не скрип старого дерева, как обычно думают городские неопытные люди, оказавшись в лесу ранней весной. Это, выбрав сухое дерево, по-весеннему барабанит лесной музыкант. — пёстрый дятел. Всюду: в лесу, ближе и дальше — торжественно звучат, как бы перекликаясь, барабаны. Так дятлы приветствуют весну..
Вот, пригретая лучами
мартовского солнца, свалилась с макушки
дерева, рассыпавшись снежной пылью, тяжёлая
снежная шапка. И, точно живая, долго
ещё колышется, как бы машет рукой, зелёная
ветка, освобождённая от зимних оков.
Стайка клестов-еловиков, весело пересвистываясь, красно-брусничным ожерельем рассыпалась по увешанным шишками вершинам елей. Лишь немногие знают, что эти птички, весёлые, общительные, всю зиму проводят в хвойных лесах, искусно устраивая в густых сучьях тёплые гнёзда. Опершись на лыжные палки, долго любуешься, как шустрые птички клювиками теребят шишки, выбирая из них семена, как, кружась в воздухе, тихо сыплются на снег лёгкие шелушинки.
(149 слов) (По И. Соколову – Микитову)
Грамматические задания
1. Фонетический разбор слова:
Лесной — 1-й вариант старого — 2-й вариант
2. Сделать разбор слова по составу:
Городские, перекликаясь, освобождённая — 1-й вариант
Радостная, оказавшись, увешанным — 2-й вариант
3. Найти в тексте односоставные предложения и
указать их тип.
4. Выполнить синтаксический разбор предложения:
Вот вверху, почти над головой, послышалась барабанная трель, звонкая, радостная. — 1-й вариант.
Стайка клестов-еловиков, весело пересвистываясь, красно-брусничным ожерельем рассыпалась по увешанным шишками вершинам елей. — 2-й вариант.
Контрольный диктант в 9 классе № 3
Цель: проверить общий уровень сформированности орфографической и пунктуационной грамотности учащихся за курс 8 класса в соответствии с требованиями государственного стандарта.
Содержание контрольного диктанта направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные;
— непроверяемые безударные гласные;
— правописание окончаний имён существительных;
— написание непроизносимых согласных:
— правописание корней с чередованием;
— н-нн в причастиях;
— не с прилагательными, наречиями и глаголами;
— написание производных предлогов;
Постановки знаков препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении;
— запятые при обособлении определений.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— синтаксического разбора предложения;
— определять типы односоставных предложений;
— определять способ связи слов в словосочетании;
— группировать орфограммы.
Звёзды
Летом звёзд не увидишь. Когда бы Серёжа ни проснулся, когда бы ни лёг — на дворе светло. Если даже тучи и дождь, всё равно светло, потому что за тучами солнце. В чистом небе иногда можно заметить прозрачное пятнышко, похожее на осколок стекла. Это месяц, дневной, ненужный, он висит и тает в солнечном сиянии, тает и исчезает.
Зимой дни короткие. Темнеет рано. Задолго до ужина Дальнюю улицу, с её тихими заснеженными садами и белыми крышами, обступают звёзды. Их тысячи, а может, и миллионы.
Посреди неба
звёзды, мелкие и крупные, звёздный песок
— всё сбито воедино в морозно
сверкающий плотный туман, в причудливо – неровную
полосу, переброшенную будто через улицу,
как мост. Этот мост называется Млечный
Путь.
Прежде Серёжа не обращал внимания на звёзды, они его не интересовали, потому что он не знал, что у них есть названия. Но мама показала ему Млечный Путь. И Сириус. И Большую Медведицу. И красный Марс. Сережа хотел знать все названия, но мама не помнила, зато она показала ему горы на Луне, и он как будто прикоснулся к ним.
(170 слов) (По В. Пановой)
Грамматические задания
1. Сгруппировать слова по видам орфограмм.
2. Определить типы односоставных предложений:
Из первого абзаца — 1-й вариант из второго абзаца — 2-й вариант
3. Выписать из текста по два словосочетания на каждый способ подчинительной связи. Разберите словосочетания.
4. Выполните полный синтаксический разбор предложения:
В
чистом небе иногда можно заметить
прозрачное пятнышко, похожее на осколок стекла. —
1-й вариант
Это месяц, дневной, ненужный, он висит и тает в солнечном сиянии, тает и исчезает. — 2-й вариант
Контрольный диктант в 9 классе № 4
Цель: проверить общий уровень сформированности орфографической и пунктуационной грамотности учащихся за курс 8 класса в соответствии с требованиями государственного стандарта.
Содержание контрольного диктанта направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные;
— непроверяемые безударные гласные;
— правописание окончаний имён существительных;
— написание непроизносимых согласных:
— разделительные Ь и Ъ;
— буквы О-Ё после шипящих в корне слова;
— н-нн в суффиксах прилагательных и причастий;
— не с прилагательными, наречиями и глаголами;
— различение не и ни;
Постановки знаков препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении;
— запятые при обособлении определений, приложении;
— запятые при уточняющих членах предложении;
— при прямой речи.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— синтаксического разбора предложения;
-способ образования слов;
— определять способ связи слов в словосочетаниях;
— группировать орфограммы.
Зимние испытания природы
Ни облака на туманном беловатом небе, ни малейшего ветра на снежных равнинах. Красное, но неяркое солнце, своротило с невысокого полдня к недалёкому закату. Жестокий крещенский мороз сковал природу, сжимал, палил всё живое.
Небольшой обоз тянулся по узенькой проселочной неторной дорожке. Пронзительно скрипели, визжали полозья.
Обоз поднялся на возвышение и
въехал в берёзовую рощу — единственный
лесок на большом степном пространстве.
Чудное, печальное зрелище представляла
бедная роща! Как будто ураган или
громовые удары тешились над нею долгое
время. Всё было исковеркано. Молодые
деревья, согнутые в разновидные дуги, воткнули
гибкие вершины свои в сугробы и как
будто силились вытащить их. Деревья постарее,
пополам изломанные, торчали высокими пнями, а
иные, разодранные надвое, лежали, развалясь
на обе стороны. «Кто это так
исковеркал берёзник?» — сказал молодой
мужик. «Иней, — отвечал старик, —
глянь-ка, сколько его нальнуло к сучьям.
Ведь под инеем – то лёд толщиной в руку.
Это бывает после оттепелей, случается не
каждый год и вещует урожай».
(155 слов) (По С. Аксакову)
Грамматические задания
1. Найдите два – три слова с проверяемой безударной гласной в корне слова и подберите к ним проверочные слова:
В первом, втором абзацах — 1-й вариант в третьем абзаце — 2-й вариант
2. Укажите, как образованы слова: Беловатом,
своротило, просёлочной — 1-й вариант
;
въехал, единственный, надвое — 2-й вариант
3. Выпишите два словосочетания и произведите их разбор.
4. Произведите синтаксический разбор предложения:
Жестокий крещенский мороз сковал природу, сжимал, палил всё живое. — 1-й вариант
Небольшой обоз тянулся по узенькой проселочной неторной дорожке. — 2-й вариант
Контрольный диктант в 9 классе № 5
Цель: проверить общий уровень сформированности орфографической и пунктуационной грамотности учащихся на конец 1-й четверти в соответствии с требованиями государственного стандарта.
Содержание контрольного диктанта направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные;
— непроверяемые безударные гласные;
— правописание окончаний имён существительных;
— написание непроизносимых согласных:
— написание з – с на конце приставок;
— буквы О – Ё после шипящих в корне слова;
— н-нн в прилагательных и причастиях;
— не в местоимениях и наречиях.
Постановки знаков препинания:
— запятая при однородных членах предложения;
— запятая в сложносочинённом предложении;
— запятые при обособлении определений, обстоятельстве;
— запятая при уточняющих членах предложения.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— синтаксического разбора предложения;
— определять типы односоставных предложений;
— определять способ связи слов в предложении;
— объяснять написание н-нн в словах.
Осенние воспоминания
Вспоминается мне ранняя погожая осень.
Воздух так чист, точно его совсем нет. В поредевшем саду далеко видна дорога к большому шалашу, усыпанная соломой. Около шалаша вечером греется самовар, и по саду, между деревьями, расстилается длинной полосой голубоватый дым.
Надышавшись на гумне ржаным
ароматом новой соломы и мякины, бодро идёшь
домой к ужину.
Темнеет. В саду горит костёр, и крепко тянет душистым дымом вишнёвых сучьев. Пылает багровое пламя, окружённое мраком, и чьи-то чёрные, точно вырезанные из чёрного дерева, силуэты двигаются вокруг костра, меж тем как гигантские тени от них ходят по яблоням. То по всему дереву ляжет чёрная рука в несколько аршин, то чётко нарисуются две ноги. Вдруг все это скользнёт с яблони — и тень упадёт по всей аллее.
Поздней ночью, шурша по сухой траве, как слепой, доберёшься до шалаша. Там на поляне немного светлее, а над головой белеет Млечный Путь. Долго глядишь в тёмно-синюю глубину неба, переполненную созвездиями.
Как холодно, росисто, и как хорошо жить на свете!
(160 слов) (По И. Бунину)
Грамматические задания
1. Найти сложносочинённое предложение, составить его схему, графически объяснить пунктуацию:
в котором оба простых предложения двусоставные — 1-й вариант
в котором хотя бы одно из простых предложений односоставное — 2-й вариант
2. Выпишите по одному словосочетанию на все
виды подчинительной связи, разберите их.
3. Выпишите 2 слова разных частей речи, в суффиксах которых имеется н или нн, обозначьте условия выбора того или иного написания.
4. Произведите синтаксический разбор предложения:
Около шалаша вечером греется самовар, и по саду, между деревьями, расстилается длинной полосой голубоватый дым. — 1-й вариант
В саду горит костёр, и крепко тянет душистым дымом вишнёвых сучьев. — 2-й вариант
Контрольный диктант в 9 классе № 6
Цель: проверить общий уровень сформированности орфографической и пунктуационной грамотности учащихся на конец 1-й четверти в соответствии с требованиями государственного стандарта.
Содержание контрольного диктанта направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные;
— непроверяемые безударные гласные;
— правописание окончаний имён существительных;
— написание непроизносимых согласных:
— правописание корней с чередованием;
— з-с на конце приставок;
— написание -тся -ться в глаголах;
— написание н-нн в прилагательных и причастиях;
Постановки знаков препинания:
— запятая при однородных членах предложения;
— запятая в сложносочинённом предложении;
— запятые при обособлении обстоятельств.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— синтаксического разбора предложения;
-фонетического разбора слова;
-разбора слова по составу;
— умение работать с простым осложнённым предложением.
Диктант
Сквозь чащу черёмухи пробираемся к берегу. Конец июня, а она только-только оделась по-весеннему. Запоздалым сиреневым цветом горит багульник, а берёзка, не поверив лету, стоит голая.
Тайга, увидев простор Байкала, катится к нему по сопкам ярусами зелени и у самой воды замирает. Пощупав корнями воду, лиственницы, берёзы и сосны раздумали купаться, остановились, а тайга напирает сзади, остановиться не может. Оттого на берегу лежат поваленные деревья – великаны, загородив дорогу к озеру.
Удивительно видеть здесь апрель
и июнь сразу. За спиной запахи леса,
а на Байкале — точь-в-точь Волга в
разливе. То же безбрежное водное
пространство, те же льдины стадами.
Байкал вскрывается поздно, и до конца мая носятся по воде ледяные стада. В июне они пристают к берегу и тут, у валуна, медленно оседают, неожиданным шорохом пугая зверей у водопоя.
Чистая, как слеза, вода Байкала не терпит мусора, и в штормовую погоду он швыряет на берег обломки лодок, коряги. Ни соринки в воде!
Дальние синие сопки сливаются с закатными полосами, и их медленно заволакивает вечерняя дымка.
(165 слов) (По В. Пескову)
Грамматические задания.
1. Произвести фонетический разбор слова:
Голая — 1-й вариант июня — 2-й вариант
2. Сделать разбор слова по составу:
Пробираемся, запоздалым, загородив — 1-й вариант
остановиться, безбрежное, по-весеннему — 2-й вариант
3. Осложнить предложение обособленным определением —
1-й вариант
Обстоятельством — 2-й вариант
Сквозь чащу черёмухи пробираемся к берегу.
4. Сделать синтаксический разбор сложносочинённого предложения:
Запоздалым сиреневым цветом горит багульник, а берёзка, не поверив лету, стоит голая. — 1-й вариант
Байкал вскрывается поздно, и до конца мая носятся по воде ледяные стада. — 2-й вариант
Контрольный диктант в 9 классе № 7
Цель: проверить общий уровень сформированности орфографической и пунктуационной грамотности учащихся на конец 1-й четверти в соответствии с требованиями государственного стандарта.
Содержание контрольного диктанта направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные;
— непроверяемые безударные гласные;
— правописание окончаний имён существительных;
— написание непроизносимых согласных:
— правописание корней с чередованием;
— з-с на конце приставок;
— н-нн в прилагательных и причастиях;
— написание падежных окончаний существительных;
Постановки знаков препинания:
— запятая при однородных членах предложения и тире при обобщающем слове;
— запятая в сложносочиненном предложении;
— запятые при обособлении определений и
обстоятельств.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— синтаксического разбора предложения;
-умение разбирать слова морфологически;
-работать с простым осложнённым предложением;
-умение объяснять написание н-нн в прилагательных и причастиях.
Диктант
Под лёгким дуновением
знойного ветра море вздрагивало, и,
покрываясь мелкой рябью, ослепительно ярко
отражавшей солнце, оно улыбалось голубому
небу тысячами серебряных улыбок. В
пространстве между морем и небом
носился весёлый плеск волн, набегавших
на пологий берег песчаной косы. Всё
было полно живой радости: звук и
блеск солнца, ветер и солёный аромат
воды, жаркий воздух и жёлтый песок. Узкая
коса, вонзаясь острым шпилем в безграничную
пустыню играющей солнцем воды, терялась
где-то вдали. Вёсла, корзина да бочки
беспорядочно валялись на песке. В этот день
даже чайки истомлены зноем. Они сидят
на песке, раскрыв клювы и опустив
крылья, или лениво качаются на волнах.
Солнце начинает спускаться в море, и неугомонные волны играют весело и шумно, плескаясь о берег. Солнце садится, и на жёлтом песке ложится розовый отблеск его лучей. И жалкие кусты ив, и перламутровые облака, и волны, набегавшие на берег, — всё готовится к ночному покою. Ночные тени ложатся не только на море, но и на берег. Вокруг только безмерное море, посеребренное луной, и синее, усеянное звёздами небо.
(165 слов) (По М. Горькому)
Грамматические задания
1. Объяснить написание н-нн в словах.
2. Выполнить морфологический разбор слов:
Играют — 1-й вариант садится — 2-й вариант
3. В тексте диктанта найти простое осложнённое
предложение, выписать его и графически
показать знаки препинания , указывая, чем
осложнено предложение.
В первом абзаце — 1-й вариант во втором абзаце — 2-й вариант
4. Синтаксический разбор предложения:
Солнце начинает спускаться в море, и неугомонные волны играют весело и шумно, плескаясь о берег. — 1-й вариант.
Солнце садится, и на жёлтом песке ложится розовый отблеск его лучей. — 2-й вариант
Контрольный диктант в 9 классе № 8
Цель: проверить общий уровень сформированности орфографической и пунктуационной грамотности учащихся на конец 1-й четверти в соответствии с требованиями государственного стандарта.
Содержание контрольного диктанта направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные;
— непроверяемые безударные гласные;
— правописание окончаний имён существительных;
— написание непроизносимых согласных:
— написание з – с на конце приставок;
— буквы О – Ё после шипящих в корне слова;
— н-нн в прилагательных и причастиях;
— не в местоимениях и наречиях.
Постановки знаков препинания:
— запятая при однородных членах предложения;
— запятая в сложносочинённом предложении;
— запятые при обособлении определений, обстоятельстве;
— запятая при уточняющих членах предложения.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— синтаксического разбора предложения;
-разбирать слова по составу;
— определять способ связи слов в словосочетании;
-фонетический разбор слова.
Лес поздней осенью
И как этот же самый лес хорош поздней
осенью! Ветра нет, и нет ни солнца,
ни света, ни тени, ни движения,
ни шума; в мягком воздухе разлит
осенний запах, подобный запаху вина; тонкий
туман стоит вдали над жёлтыми полями.
Сквозь обнажённые, бурые сучья деревьев
мирно белеет неподвижное небо; кое-где на
липах висят последние золотые листья. Сырая земля
упруга под ногами; высокие сухие былинки
не шевелятся; длинные нити блестят на
побледневшей траве. Спокойно дышит грудь, а
на душу находит странная тревога. Идёшь
вдоль опушки, глядишь за собакой, а
между тем любимые образы, любимые лица,
живые и мёртвые, приходят на память,
давно-давно заснувшие впечатления неожиданно
просыпаются; воображение реет и носится,
как птица, и всё так ясно движется
и стоит перед глазами. Сердце то
вдруг задрожит и забьётся, страстно бросится вперёд,
то безвозвратно потонет в воспоминаниях.
Вся жизнь развёртывается легко и быстро,
как свиток; всем своим прошедшим, всеми
чувствами, силами, всею своею душой владеет
человек. И ничего кругом ему не
мешает — ни солнца нет, ни ветра,
ни шуму.
(168 слов) (По И. Тургеневу)
Грамматическое задание
1. Сделать фонетический разбор слова:
Поздней — 1-й вариант движения — 2-й вариант
2. Выписать по два словосочетания на все виды подчинительной связи и разобрать их.
3. Разобрать слова по составу:
Движения, обнажёнными, заснувшие — 1-й вариант
Неподвижное, просыпаются, побледневшей — 2-й вариант
4. Сделать синтаксический разбор предложения:
Спокойно дышит грудь, а на душу находит странная тревога. — 1-й вариант
Сердце то вдруг задрожит и забьётся, страстно бросится вперёд, то безвозвратно потонет в воспоминаниях. — 2-й вариант
Контрольный диктант в 9 классе № 9
Цель: проверить соответствие знаний, умений и навыков учащихся требованиям учебной программы на конец 2-й четверти по теме «СПП с придаточными определительными и изъяснительными» и 1-го полугодия
Содержание контрольной работы направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные в корне слова;
-непроверяемые безударные гласные;
-правописание окончаний существительных;
-написание о- после шипящих и ц;
— н-нн в прилагательных;
-написание производных предлогов
Постановка знаков препинания:
— запятая в ССП;
-запятая в СПП;
-запятая при однородных членах предложения;
-Запятая
при причастном и деепричастном оборотах.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— синтаксического разбора предложения;
-умение разбирать слова морфологически;
-фонетического разбора слова
Андрей Рублёв
В продолжение долгих часов Андрей остаётся наедине со своим учителем Даниилом Чёрным, который открывает юному художнику тайны живописи.
Даниил был живописцем первой величины. Однако самая большая заслуга его в том, что он не только увидел одарённость Рублёва, но и воспитал в нём самостоятельную творческую мысль и манеру, не подавлял своим авторитетом, понимая, что каждый должен идти своим путём.
Поступать так — значит проявлять поистине большой
ум, поразительное уважение к личности,
неиссякаемую любовь к жизни. Ведь мастеру
не просто примириться с тем, что собственный
ученик заводит с тобой споры, и не
только не делать попытки оборвать его, а
всячески поощрять к продолжению этого спора.
Рублёву повезло, что возле него с самых первых шагов оказался такой душевный и опытный старший товарищ. Андрей оценил это и бережно пронёс признательность и уважение к своему учителю через всю жизнь.
От того далёкого времени сохранилась миниатюра, на которой Рублёв запечатлён с гордо поднятой головой. Неизвестный автор в Рублёве увидел не гордыню, которая на Руси считалась величайшим грехом, а заслуживающее уважения достоинство.
(167 слов) (По В. Прибыткину)
Грамматические задания.
1. Синтаксический разбор предложения:
1-й вариант: Рублёву повезло, что возле него с самых первых шагов оказался такой душевный и опытный старший товарищ.
2-й
вариант: От того далёкого времени
сохранилась миниатюра, на которой Рублёв
запечатлён с гордо поднятой головой.
2. Фонетический разбор слова.
1-й вариант: юному 2-й вариант: большая
3. Морфологический разбор слова.
1-й вариант: глагола 2-й вариант: прилагательного
4. Выписать из текста словосочетания на все виды подчинительной связи.
Контрольный диктант в 9 классе № 10
Цель: проверить соответствие знаний, умений и навыков учащихся требованиям учебной программы на конец 2-й четверти по теме «СПП с придаточными определительными и изъяснительными» и 1-го полугодия
Содержание контрольной работы направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные в корне слова;
-непроверяемые безударные гласные;
— написание собственных имён существительных;
-правописание окончаний существительных;
-дефисное написание наречий;
— н-нн в прилагательных;
-написание производных предлогов
Постановка знаков препинания:
— запятая в ССП;
-запятая в СПП;
-запятая при однородных членах предложения;
-запятая при причастном и деепричастном оборотах;
—
знаки препинания в предложениях с прямой речью.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— фонетический разбор слова;
— умение трансформировать предложения с прямой речью;
— синтаксического разбора предложения;
-умение работать со словосочетаниями.
Диктант
Первая встреча Пушкина с Николаем I произошла в Москве, куда царь вызвал поэта из Михайловской ссылки. Это было через два месяца после расправы над декабристами, многие из которых были друзьями поэта. Пушкин знал, что в делах почти всех осуждённых декабристов находили его вольнолюбивые стихи, что стихи эти были широко распространены в армии и что сам он у царя на подозрении. Когда Николай не добился от арестованных показаний о прямой связи с ними поэта, он приказал сжечь его «возмутительные» стихи.
Ещё в Михайловском Пушкин
тщательно пересматривает свои бумаги и уничтожает
наиболее опасные страницы драгоценных записок
о выдающихся современниках, которые он вёл
в продолжение пяти лет. Поэт боялся,
что записи его могут многим повредить,
а может, и умножить число жертв.
Царь спросил Пушкина, переменился ли за годы ссылки его образ мыслей и даёт ли он слово думать и действовать иначе. Поэт не мог, однако, сделаться другим и по-прежнему вёл себя свободно и независимо. Об этом говорит хотя бы стихотворение «Арион», в котором Пушкин провозглашает свою верность друзьям-декабристам: «Я гимны прежние пою…»
(169 слов) (Из книги А. Гессена «Набережная Мойки, 12 »)
Грамматические задания
1. Сделать фонетический разбор слова:
Первая — 1-й вариант армия — 2-й вариант
2. выписать из диктанта по одному словосочетанию на все виды подчинительной связи:
Из первого абзаца — 1-й вариант из второго, третьего абзаца — 2-й вариант
3. Найти предложение с косвенной речью и
заменить его предложением с прямой речью.
4. Синтаксический разбор предложения:
Когда Николай не добился от арестованных показаний о прямой связи с ними поэта, он приказал сжечь его «возмутительные» стихи. — 1-й вариант
Поэт боялся, что записи его могут многим повредить, а может, и умножить число жертв. — 2- вариант
Контрольный диктант в 9 классе № 11
Цель: проверить соответствие знаний, умений и навыков учащихся требованиям учебной программы на конец 2-й четверти по теме «СПП с придаточными определительными и изъяснительными» и 1-го полугодия
Содержание контрольной работы направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные в корне слова;
-непроверяемые безударные гласные;
-правописание окончаний существительных;
-написание слов с пол-;
— написание приставок пре-, при-;
— н-нн в прилагательных;
-написание
сложных наречий.
Постановка знаков препинания:
— запятая в ССП;
-запятая в СПП;
-запятая при однородных членах предложения;
-Запятая при обособленных членах предложения.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— синтаксического разбора предложения;
-умение разбирать слова морфологически
— разбора слова по составу;
— работы со словосочетаниями.
Диктант
Затопив в
землянке печурку, Поля сварила чай и,
как только стемнело, легла спать. Первые
полчаса было как-то тревожно и неуютно. Всё
казалось, что кто-то крадётся к землянке.
Вот-вот откроется дверь — и войдут
чужие люди. Потом поднимала голову,
прислушивалась. Оказывается, это похрустывало
сено под её телом. В конце концов Поля
убедила себя, что тайга пустынна в
зимнее время и ничто ей не грозит.
Вся тревога от возбуждения и мнительности,
и нечего всякими пустяками голову забивать.
Она уснула крепко, проспав без сновидений
всю ночь напролёт.
С рассветом Поля, встав на лыжи, пошла дальше. Шла, как вчера, легко, излишне не торопилась, но и не мешкала зря на остановках. Посидит где-нибудь на валежнике, похрустит сухарями — и снова в путь.
Тайга лежала, закутанная в снега, притихшая, задумчивая. День выдался светлее вчерашнего. Несколько раз выглядывало солнышко, и тогда макушки деревьев со своими белыми пушистыми шапками становились золотыми и светились, как горящие свечи. Виднее становились и затёсы на стволах, за которыми Поля следила в оба глаза, чтобы не сбиться с пути.
(167 слов) (По Г. Маркову)
Грамматические задания
1. Разобрать слова по составу:
Похрустывало, закутанная, затопив — 1-й вариант;
притихшая, проспав, прислушивалась — 2-й вариант
2. Выполнить морфологический разбор слова:
Закутанная — 1-й вариант притихшая — 2-й вариант
3. Сделать синтаксический разбор предложения:
Всё казалось, что кто-то крадётся к землянке. — 1-й вариант
Виднее становились и затёсы на стволах, за которыми Поля следила в оба глаза. — 2-й вариант.
4. Выписать по одному словосочетанию на все виды подчинительной связи:
Из первого абзаца — 1-й вариант из остального текста — 2-й вариант
Контрольный диктант в 9 классе № 12
Цель: проверить соответствие знаний, умений и навыков учащихся требованиям учебной программы на конец 3-й четверти по теме «Сложные бессоюзные предложения»
Содержание контрольной работы направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные в корне слова;
-непроверяемые безударные гласные;
-правописание окончаний существительных;
-написание о после шипящих и ц;
— н-нн в прилагательных;
-написание производных предлогов
Постановка знаков препинания:
— запятая в ССП;
-запятая в СПП;
-запятая при однородных членах предложения;
-Запятая
при причастном и деепричастном оборотах.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— умение озаглавливать текст;
— разбирать слова по составу;
— знать фонетический разбор слова;
— делать разбор словосочетаний;
— синтаксического разбора предложения.
Диктант
В Подмосковье есть у меня заветное место — лесная поляна вдали от дорог.
Особенно хорошо здесь ранней осенью. На
рябину прилетают кормиться дрозды, в сухих
листьях ежевики шуршат ежи, и самое главное
— осенью сюда приходят лоси. Я не сразу
догадался, почему под вечер почти всегда вижу тут
двух-трёх лосей. Однажды всё прояснилось:
они приходили пожевать яблоки. Поляна
упирается в заполненный рыжим бурьяном
брошенный сад. Деревья в нём выродились, и
плоды дают только растущие от корней
ветки. Охотников до нестерпимо кислых яблок
в лесу, кажется, не было, но однажды,
присев на краю сада, я услышал: яблоки
похрустывали на чьих – то зубах. Я приподнялся
и увидел: один лось, задирая голову,
мягкой губой захватывал яблоки, другой
собирал яблоки, лежащие на земле.
Такие картины память наша хранит как лекарство на случай душевной усталости. Сколько раз после трудового дня я приходил в себя и, успокоенный, засыпал, стоило только закрыть глаза и вспомнить рябины со снующими в них дроздами, запах грибов и двух лосей, жующих кислые яблоки.
(167 слов) (По И. Бильфельду)
Грамматические задания
1. Озаглавить текст диктанта.
2. Сделать фонетический разбор слова:
Лесная — 1-й вариант ежевики — 2-й вариант
3.
Выписать по одному словосочетанию на все
виды подчинительной связи и разобрать их.
4. Разобрать слова по составу:
Заполненный, брошенный — 1-й вариант выродились, похрустывали — 2-й вариант
5. Сделать синтаксический разбор предложения:
Однажды всё прояснилось: они приходили пожевать яблоки. — 1-й вариант
Я приподнялся и увидел: один лось, задирая голову, мягкой губой захватывал яблоки. — 2-й вариант
Контрольный диктант в 9 классе № 13
Цель: проверить соответствие знаний, умений и навыков учащихся требованиям учебной программы на конец 3-й четверти по теме «Сложные бессоюзные предложения»
Содержание контрольной работы направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные в корне слова;
-непроверяемые безударные гласные;
-правописание окончаний существительных;
-написание о- после шипящих и ц;
— н-нн в прилагательных;
-написание производных предлогов
Постановка знаков препинания:
— запятая в ССП;
-запятая в СПП;
-запятая при однородных членах предложения;
-Запятая
при причастном и деепричастном оборотах.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— умение озаглавливать текст;
— определять смысловые отношения между частями в БСП;
— делать синтаксический разбор словосочетаний;
— синтаксического разбора предложения;
Диктант
Деревня была где-то за лесом. Если идти в неё по большой дороге, нужно отмахать не один десяток километров; если пойти лесными тропинками, путь урежется вдвое. Толстые корни обхватили извилистую тропу. Лес шумит, успокаивает. В стылом воздухе кружатся жухлые листья. Тропинка, петляя среди деревьев, поднимается на пригорки, спускается в ложбинки, забираясь в чащобу осинника, выбегает на зарастающие ельником поляны, и кажется, что она так и не выведет тебя никуда.
Но вот вместе с листьями начинают
кружиться снежинки. Их становится больше и
больше, и в снежном хороводе не видно
уже ничего: ни падающих листьев, ни тропы.
Осенний день как свеча: тлеет – тлеет тусклым огнём и угаснет. На лес наваливаются сумерки, и дороги совсем не видно; не знаешь, куда идти.
Жутко и страшно в темноте, а Марина совсем одна. Идти дальше рискованно: осенью северные леса страшны волками. Марина забирается на дерево и решает переждать длинную ночь в лесу.
Мокрый снег напоил влагой пальто. Холодно, и ноют обмороженные ноги. Наконец в промозглом рассвете неожиданно закричали петухи. Деревня, оказывается, была совсем рядом.
(168 слов) (По Л. Фролову)
Грамматические задания
1. Озаглавить текст диктанта.
2. Найти в тексте БСП и определить смысловые отношения между частями БСП.
3. Выписать по одному словосочетанию на все виды подчинительной связи и разобрать их:
в 1, 2 абзацах — 1-й вариант в остальном тексте — 2-й вариант
4. Сделать синтаксический разбор предложения:
Идти дальше рискованно: осенью северные леса страшны волками. 1- вариант
Жутко и страшно в темноте, а Марина совсем одна. — 2- вариант
Контрольный диктант в 9 классе № 14
Цель: проверить соответствие знаний, умений и навыков учащихся требованиям учебной программы на конец 3-й четверти по теме «Сложные бессоюзные предложения»
Содержание контрольной работы направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные в корне слова;
-непроверяемые безударные гласные;
-правописание окончаний существительных;
-написание о- после шипящих и ц;
— н-нн в прилагательных;
-написание производных предлогов
Постановка знаков препинания:
— запятая в ССП;
-запятая в СПП;
-запятая при однородных членах предложения;
-Запятая
при причастном и деепричастном оборотах.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— умение работать со СБП;
— определять смысловые отношения между частями СБП;
— синтаксического разбора предложения.
Летние дни
Хороши летние
туманные дни, хотя охотники их не любят.
В такие дни нельзя стрелять: птица,
вспорхнув у вас из-под ног, тотчас же
исчезает в беловатой мгле неподвижного
тумана. Но тихо, как невыразительно тихо
кругом! Всё проснулось, и всё молчит.
Вы проходите мимо дерева — оно не
шелохнётся: оно нежится сквозь тонкий пар,
ровно разлитый в воздухе, чернеется
перед вами длинная полоса. Вы принимаете
её за близкий лес; вы подходите —
лес превращается в высокую гряду полыни
на меже. Над вами, кругом вас — всюду
туман… Но вот ветер слегка
шевельнётся — клочок бледно-голубого неба
смутно выступит сквозь редеющий, словно
задымившийся пар, золотисто-жёлтый луч ворвётся
вдруг, заструится длинным потоком, ударит по
полям, упрётся в рощу, — и вот
опять всё заволоклось. Долго продолжается борьба;
но как нескладно великолепен и ясен
становится день, когда свет наконец
восторжествует и последние волны согретого
тумана то скатываются и расстилаются
скатертями, то извиваются и исчезают в
голубой, нежно сияющей тишине…
(144 слова) (По И.С. Тургеневу)
Грамматические задания
1. Выписать СБП, произвести синтаксический разбор.
2. Определить смысловые отношения между частями СБП.
3. Найти в тексте СПП, построить схемы, определить вид придаточных предложений.
Годовой контрольный диктант в 9 классе № 15
Цель:
проверить соответствие знаний, умений и
навыков учащихся требованиям государственного
стандарта и программы по русскому языку.
Содержание контрольного диктанта направлено на выявление качества усвоения учебного материала за 9-й класс и направлено на повторение предыдущего:
— правописание проверяемых безударных гласных;
— правописание непроверяемых безударных гласных;
— написания з-с на конце приставок;
— правописание окончаний прилагательных и причастий;
— гласные в приставках пре- и при;
— написание не с наречиями и глаголами;
-правильное написание наречий;
— написание н-нн в прилагательных и причастиях;
— дефисное написание сложных прилагательных.
Знаки препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении
-обособленных определениях, обстоятельствах, дополнениях с предлогом.
Грамматические задания направлены на выявления умений:
1.находить и подбирать синонимы;
2. разбора слова по составу;
3.находить орфограммы и приводить примеры;
4.синтаксического разбора предложения.
Перевал
Ночь давно, а я всё ещё бреду по горам к перевалу, бреду под ветром, среди холодного тумана, и безнадёжно, но покорно идёт за мной в поводу мокрая, усталая лошадь, звякая пустыми стременами.
В сумерки, отдыхая у подножия сосновых лесов, за которыми начинается этот голый, пустынный подъём, я смотрел в необъятную глубину подо мною с тем особым чувством гордости и силы, с которым всегда смотришь с большой высоты.
Ещё можно было различить огоньки в темнеющей долине далеко внизу, на побережье тесного залива, который всё расширялся и обнимал полнеба.
Но в горах уже наступила
ночь. Темнело быстро, я шёл, приближаясь
к лесам, — и горы вырастали всё
мрачней и величавее, а в пролёты
между их отрогами с бурной стремительностью
валился косыми, длинными облаками густой
туман, гонимый бурей сверху. Он срывался с
плоскогорья, которое окутывал гигантской рыхлой
грядой, и своим падением как бы
увеличивал хмурую глубину пропастей
между горами. Он уже задымил лес,
надвигаясь на меня вместе с глухим,
глубоким и нелюдимым гулом сосен. Повеяло
зимней свежестью, понесло снегом и ветром.
(167 слов) (По И. Бунину)
Грамматические задания
1. Найдите в тексте 2-3 орфограммы, назовите их, приведите другие примеры.
2. Найдите в тексте синонимы, подберите к ним ещё 2-3 синонима.
3. Разберите слова по составу:
Приближаясь, (в) темнеющей, вырастали — 1-й вариант
Срывался, надвигаясь, мрачней — 2-й вариант
4. Произведите синтаксический разбор анализ предложения:
Ещё
можно было различить огоньки в темнеющей
долине далеко внизу, на побережье тесного
залива, который всё расширялся и обнимал
полнеба. — 1-й вариант
Он срывался с плоскогорья, которое окутывал гигантской рыхлой грядой, и своим падением как бы увеличивал хмурую глубину пропастей между горами. — 2-й вариант
Годовой контрольный диктант в 9 классе № 16
Цель: проверить соответствие знаний, умений и навыков учащихся требованиям государственного стандарта и программы по русскому языку.
Содержание контрольного диктанта направлено на выявление качества усвоения учебного материала за 9-й класс и направлено на повторение предыдущего:
— правописание проверяемых безударных гласных;
— правописание непроверяемых безударных гласных;
— написания з-с на конце приставок;
— правописание окончаний прилагательных и причастий;
— гласные в приставках пре- и при;
— написание не с наречиями и глаголами;
-правильное написание наречий;
— написание н-нн в прилагательных и причастиях;
— дефисное написание сложных прилагательных.
Знаки препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении
-обособленных определениях, обстоятельствах, дополнениях с предлогом.
Грамматические задания направлены на выявления умений:
1.фонетического разбора слова;
2. разбора слова по составу;
3.находить орфограммы и приводить примеры;
4. синтаксического разбора предложения.
Перевал
Вопреки предсказанию моего спутника, погода прояснилась и обещала нам тихое утро; хороводы звёзд чудными узорами сплетались на далёком небосклоне и одна за другой гасли по мере того, как бледноватый отблеск востока разливался по тёмно-лиловому своду, озаряя крутые отголоски гор, покрытые лесами.
Направо и налево чернели
мрачные, таинственные пропасти, и туманы,
клубясь и извиваясь, как змеи, сползали
туда по морщинам соседних скал, будто
чувствуя и пугаясь приближения дня. Тихо
было на небе и на земле, только
изредка набегал прохладный ветер с востока,
приподнимая гриву лошадей, покрытую инеем.
Мы тронулись в путь; с трудом пять худых кляч тащили наши повозки по извилистой дороге на Гуд-Гору; мы шли пешком сзади, подкладывая камни под колёса, когда лошади выбивались из сил; казалось, дорога вела на небо, потому что, сколько глаз мог разглядеть, она всё поднималась и наконец пропадала в облаке, которое ещё с вечера отдыхало на вершине Гуд-Горы, как коршун, ожидающий добычу. Снег хрустел под ногами; воздух становился так редок, что было больно дышать, кровь поминутно приливала в голову.
(63 слова) (По М. Лермонтову)
Грамматические задания
1.Найдите
в тексте 2-3 орфограммы, назовите их,
приведите другие примеры.
2. Сделать фонетический разбор слова:
Инеем — 1-й вариант озаряя — 2-й вариант
3. Разобрать слова по составу:
Предсказанию, хороводы, поднималась — 1-й вариант
Сплетались, приближения, небосклоне — 2-й вариант
4. Сделать синтаксический разбор предложения:
Направо и налево чернели мрачные, таинственные пропасти, и туманы, клубясь и извиваясь, как змеи, сползали туда по морщинам соседних скал, будто чувствуя и пугаясь приближения дня. –1-й вариант.
Тихо было на небе и на земле, только изредка набегал прохладный ветер с востока, приподнимая гриву лошадей, покрытую инеем. — 2-й вариант.
Годовой контрольный диктант в 9 классе № 17
Цель:
проверить соответствие знаний, умений и
навыков учащихся требованиям государственного
стандарта и программы по русскому языку.
Содержание контрольного диктанта направлено на выявление качества усвоения учебного материала за 9-й класс и направлено на повторение предыдущего:
— правописание проверяемых безударных гласных;
— правописание непроверяемых безударных гласных;
— написания непроизносимых согласных в корне слова;
— правописание окончаний прилагательных и причастий;
— написание не с наречиями и глаголами;
-правильное написание наречий;
— написание н-нн в прилагательных и причастиях;
— написание сложных существительных.
Знаки препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении
— при обособленных членах предложения.
Грамматические задания направлены на выявления умений:
1.делать фонетический разбор слова;
2. разбора слова по составу;
3.производить морфологический разбор прилагательного;
4. синтаксического разбора предложения
Утро в тайге
Тайга дышала, просыпалась, росла.
Сердце моё трепыхнулось и замерло от радости: на каждом листике, на каждой хвоинке, травке, в венцах соцветий и на живых стволах деревьев — повсюду мерцали, светясь и играя, капли росы.
И каждая роняла крошечную блёстку света, но, слившись вместе, эти блёстки заливали сиянием торжествующей жизни всё вокруг.
Ещё ни единый луч солнца не прошил острой иглой овчину тайги, но по небу во всю ширь расплылась размоина, и белёсая глубь небес всё таяла, таяла, обнажая блёклую, прозрачно-льдистую голубизну, в которой всё ощутимей глазу виднелась несмелая, силы пока не набравшая теплота.
Живым духом пополнились леса,
кусты, травы, листья. Снова защёлкали о
стволы деревьев и о камни железнолобые
жуки и божьи коровки; бурундук умывался
лапками на коряге и беззаботно удрал
куда-то; костёр наш, едва тлевший, воспрял,
щёлкнул раз-другой, разбрасывая угли, и
сам собой занялся огнём.
Солнце во всём сиянии поднялось над лесом, пробив его из края в край пучками ломких спиц, раскрошившихся в быстро текущих водах речонки.
(160 слов) (По В. Астафьеву)
Грамматические задания
1.Разобрать слова по составу:
Хвоинке, крошечную, железнолобые — 1-й вариант
размоина, раскрошившихся, речонки — 2-й вариант
2. Выписать из текста по два словосочетания на все виды подчинительной связи и разобрать их:
Из 1,2,3-го абзацев — 1-й вариант из остального текста — 2-й вариант
3. Сделать морфологический разбор прилагательного:
Ломких — 1-й вариант текущих — 2-й вариант
4. Произвести синтаксический разбор предложения:
Солнце
во всём сиянии поднялось над лесом, пробив
его из края в край пучками ломких
спиц, раскрошившихся в быстро текущих водах
речонки.
Годовой контрольный диктант в 9 классе № 18
Цель: проверить соответствие знаний, умений и навыков учащихся требованиям государственного стандарта и программы по русскому языку.
Содержание контрольного диктанта направлено на выявление качества усвоения учебного материала за 9-й класс и направлено на повторение предыдущего:
— правописание проверяемых безударных гласных;
— правописание непроверяемых безударных гласных;
— написания непроизносимых согласных в корне слова;
— правописание окончаний прилагательных и причастий;
— написание не с наречиями и глаголами;
-правильное написание наречий;
— написание н-нн в прилагательных и причастиях;
— написание сложных существительных.
Знаки препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении
—
при обособленных членах предложения.
Грамматические задания направлены на выявления умений:
1.делать фонетический разбор слова;
2. разбора слова по составу;
3.производить морфологический разбор прилагательного;
4. синтаксического разбора предложения
Критерии оценки знаний учащихся
Диктант
• «5» – за работу, в которой нет ошибок.
• «4» – за работу, в которой допущено 1 – 2 ошибки.
• «3» – за работу, в которой допущено 3 – 4 ошибки.
• «2» – за работу, в которой допущено более 5 ошибок.
Грамматическое задание
«5» — безошибочное выполнение всех заданий;
«4» — если учеником выполнено 4 задания с небольшими погрешностями;
«3» — правильно выполнил не менее 3-х заданий с небольшим недочетами
«2» — если ученик не справляется с большинством грамматических заданий.
В городе
Я снял комнату на окраине, на верху
старого дома. Хозяин мой был вечно
занятый, молчаливый человек. Внизу у него было
три комнаты, но он редко заходил
туда, обедал и спал на террасе, а
в комнатах было сумрачно, пахло пылью
и старыми обоями.
Окно моей комнаты выходило в одичавший сад, заросший смородиной, малиной, лопухом и крапивой. По утрам за окном возились воробьи, тучами налетали дрозды клевать смородину. На забор взлетали соседские куры с петухом. Петух громко, гласно пел, вытягивая кверху шею, и с любопытством смотрел в сад.
Я жил в городе уже две недели, но всё никак не мог привыкнуть к тихим улицам с деревянными тротуарами, к редким гудкам пароходов по ночам.
Это был небольшой город. Почти всё
лето в нём стояли белые ночи. Ночью
наш сад пах смородиной и росой, а
на берегу бубнил мотором катер. Возле
домов раздавался отчётливый дробный стук —
это шли рабочие со смены. Казалось,
что у домов чуткие стены и город,
притаившись, вслушивается в шаги своих обитателей.
(163 слова) (По Ю. Казакову)
Грамматические задания
1. Сделать фонетический разбор слова:
Пылью — 1-й вариант обоями — 2-й вариант
2. Разобрать слова по составу:
Одичавший, пел, взлетали, пароходов — 1-й вариант
Заросший, соседские, смотрел, деревянными — 2-й вариант
3. Сделать морфологический разбор слова:
Смородиной — 1-й вариант (на) реке — 2-й вариант
4. Сделать синтаксический разбор предложения:
По утрам за окном возились воробьи, тучами налетали дрозды клевать смородину. — 1-й вариант
Ночью
наш сад пах смородиной и росой, а
на берегу бубнил мотором катер.
— 2-й вариант
Годовой контрольный диктант в 9 классе № 19
Цель: проверить соответствие знаний, умений и навыков учащихся требованиям государственного стандарта и программы по русскому языку.
Содержание контрольного диктанта направлено на выявление качества усвоения учебного материала за 9-й класс и направлено на повторение предыдущего:
— правописание проверяемых безударных гласных;
— правописание непроверяемых безударных гласных;
— написания непроизносимых согласных в корне слова;
— правописание окончаний прилагательных и причастий;
— написание не с наречиями и глаголами;
-правильное написание наречий;
— написание н-нн в прилагательных и причастиях;
— написание сложных существительных.
Знаки препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении
—
при обособленных членах предложения.
Грамматические задания направлены на выявления умений:
1.делать фонетический разбор слова;
2. разбора слова по составу;
3.производить морфологический разбор прилагательного;
4. синтаксического разбора предложения
В городе
Я снял комнату на окраине, на верху старого дома. Хозяин мой был вечно занятый, молчаливый человек. Внизу у него было три комнаты, но он редко заходил туда, обедал и спал на террасе, а в комнатах было сумрачно, пахло пылью и старыми обоями.
Окно моей комнаты выходило в одичавший сад, заросший смородиной, малиной, лопухом и крапивой. По утрам за окном возились воробьи, тучами налетали дрозды клевать смородину. На забор взлетали соседские куры с петухом. Петух громко, гласно пел, вытягивая кверху шею, и с любопытством смотрел в сад.
Я жил в городе уже две недели, но
всё никак не мог привыкнуть к тихим
улицам с деревянными тротуарами, к редким
гудкам пароходов по ночам.
Это был небольшой город. Почти всё лето в нём стояли белые ночи. Ночью наш сад пах смородиной и росой, а на берегу бубнил мотором катер. Возле домов раздавался отчётливый дробный стук — это шли рабочие со смены. Казалось, что у домов чуткие стены и город, притаившись, вслушивается в шаги своих обитателей.
(163 слова) (По Ю. Казакову)
Грамматические задания
1. Сделать фонетический разбор слова:
Пылью — 1-й вариант обоями — 2-й вариант
2. Разобрать слова по составу:
Одичавший, пел, взлетали, пароходов — 1-й вариант
Заросший, соседские, смотрел, деревянными — 2-й вариант
3. Сделать морфологический разбор слова:
Смородиной — 1-й вариант (на) реке — 2-й вариант
4. Сделать синтаксический разбор предложения:
По утрам за окном возились воробьи, тучами налетали дрозды клевать смородину. — 1-й вариант
Ночью наш сад пах смородиной и росой, а на берегу бубнил мотором катер. — 2-й вариант
Разбор слова по составу. (Закрепление). – оқушыларға және студенттерге арналған bilimland.kz білім беру платформасы
| Цели обучения, которые достигаются на данном уроке (ссылка на учебную программу): | <p>2.1.1.1 определять с помощью учителя опорные слова, фиксировать их; отвечать на закрытые вопросы, закрепление знаний учащихся по изученной теме. 2.2.3.1 формулировать вопросы с опорой на ключевые слова, отвечать на вопросы по содержанию прочитанного 2.3.8.2 обощить и систематизировать знания учащихся о частях слова, </p><p> </p> |
Сабақ барысы
| Сабақ кезеңдері | Жоспарланған іс-әрекет | Ресурстар |
|---|---|---|
Начало урока 0-4 (5-10 мин Середина урока 11-20 мин 21-22 мин 23-26 мин 27-28 мин 29-35 мин Конец урока 36-37 мин 38-40) | <p>Создание положительного эмоционального настроя</p><p> Повернитесь все друг другу, </p><p>И пожмите руку другу. </p><p> Руки вверх все поднимите, </p><p> И вверху пошевелите. </p><p>Крикнем весело: «Ура!» </p><p>Урок наш начинать пора! </p><p>Вы друг другу помогайте, </p><p>На вопросы отвечайте. </p><p>Всю работу, что вам дам поделите пополам</p><p>.Отрабатывать умение разбор слова по составу </p><p>Актуализация знаний. </p><p> Цель: создать мотивацию к включению в учебную деятельность. </p><p> Учитель. – Ребята, на данном уроке послушайте отрывок из одного литературного произведения и скажите, как оно называется, и кто его написал? </p><p>« В одном сказочном городе жили коротышки Коротышками их называли потому, что они были очень маленькие. Каждый коротышка был ростом с небольшой огурец. В городе у них было очень красиво». </p><p>Учитель. – А как зовут самого умного и начитанного героя этой сказки? </p><p>Минутка чистописания. Ученики записывают имя Знайка. </p><p> Учитель. – К сегодняшнему уроку русского языка </p><p> Знайка приготовил для вас разные задания!</p><p> Постараемся с ними справиться? </p><p> Работа по теме урока. </p><p> Цель: согласовать тему и цель урока.</p><p> Учитель. – Итак, первое задание от Знайки: расшифруйте запись и назовите тему урока. SCOFCTVAWB ZCRЛOLBDNA -<span> </span></p><p><span><br></span>Тема урока « Состав слова»</p><p> Закрепление. -<span> </span>Знайка приготовил для вас следующее задание. -<span> </span></p><p><span><br></span> Из каких частей могут состоять слова? Деление на группы: /</p><p> От Знайки конверт/ «Найди свое место» </p><p> У каждого ребенка на парте лежит конверт с карточками с частями слова. </p><p> Каждый ребенок читает что написано на карточке и садятся в нужном порядке.</p><p> Затем каждая группа вспоминает определение каждой части слова. </p><p> Учитель. Знайка приготовил для вас тест. </p><p> 1 гр. Что такое окончание? </p><p> 2гр. Что такое корень? </p><p> 3 гр. Что такое суффикс? </p><p>4 гр. Что такое приставка? </p><p> Работа над темой урока. Цель: усвоение содержание темы.</p><p> Учитель. – Знайка ребята приготовил для вас загадки.</p><p> Отгадайте загадки.</p><p> 1 гр. Линию прямую, ну-ка, </p><p>Сам нарисовать сумей-ка!</p><p> Это сложная наука! </p><p>Пригодится здесь —-/ линейка/ </p><p>2гр. В снежном поле по дороге </p><p>Мчится конь мой одногий </p><p>И на много-много лет О . / ручка/ </p><p> 3 гр. Если ей работу дать – Зря трудился карандаш. /ластик/ </p><p> 4 гр. Новый дом несу в руке, </p><p>Дверца дома на замке </p><p>Тут жильцы бумажные, </p><p>Все ужасно важные / портфель/ </p><p>Учащиеся записывают отгадки в тетрадь. </p><p> -Ребята , как одним словом можно назвать эти слова. </p><p> Школьные принадлежности . -Как нужно относиться к школьным приналежностям? — Сегодня мы продолжим изучать историю школьных принадлежностей. (Д, К) Физминутка </p><p>Руки подняли и покачали </p><p> — Это деревья в лесу. </p><p> Руки согнули, кисти встряхнули</p><p> — Ветер сбивает росу. </p><p>В стороныруки, плавно помашем </p><p> — Это кнам птицы летят. </p><p> Как они тихо садятся, покажем</p><p> — Крылья сложили назад. </p><p>Работа по теме урока Цель: выполнение практических заданий. </p><p> Работа по учебнику. </p><p>Учитель. — А сейчас Знайка предлагает вам поработать в группе.</p><p> Каждая группа должна текст об истории школьных принадлежностей. ( Г.)</p><p> Упр. 16 1 гр. История линейки. </p><p> Упр 9 2 гр. История ручки </p><p> Упр 11 3 гр. Ластик </p><p>Упр 18 4 гр . Портфель. . </p><p>Ученики читают текст узнают об истории школьных принадлежностей. </p><p>Каждая группа работает по учебнику выполняют задания. </p><p> Читают , составляют вопросы, выписывают из каждого текста выделенные слова и разбирают их по составу. </p><p>Из каждой группы выходят по одному ученику об истории школьных вещей. </p><p> Что интересного узнали.</p><p> (Д, К) Динамическая пауза </p><p> Для начала мы с тобой крутим только головой корпусом вращаем тоже </p><p> Это мы конечно можем. </p><p> Руки прямо протянули </p><p> Вверх и в стороны прогнули </p><p>От разминки раскраснелись </p><p>И за парты все уселись.</p><p> Работа по теме урока Цель: выполнение практических заданий. </p><p> -Ребята , Знайка предлагает вам игру! Крестики – нолики» Поле для игры находится у каждого из вас на парте. -<span> </span></p><p><span><br></span>А игра заключается в следующем: -<span> </span></p><p><span><br></span>Я буду читать вам утверждение и если вы с ними согласны , в клеточке ставите Х, если не согласны О</p><p> Отвечать начнем с той клеточки, в которой стоит точка.</p><p> И так , начнем: </p><p>1.<span> </span>Корень – ‘то главная часть предложения /о/</p><p> 2.<span> </span>Родственные слова еще называют однокоренными?/х/ </p><p> 3.<span> </span>Верно ли, что у слов носик и носильщик одинаковый корень?/о/ </p><p> 4.<span> </span>Корни в родственных словах пишутся одинаково?/х/ </p><p>5.<span> </span>Окончание – это изменяемая часть слова /х/</p><p> 6.<span> </span>Суффикс помогает образовывать новые слова /х/ </p><p>7. <span> </span>Приставка часть слова, которая стоит после корня и служит для образования новых слов/о / </p><p>8.<span> </span>Корень – это общая часть родственных слов/х/ </p><p> 9.<span> </span>Суффикс это часть речи. /о/ </p><p>Проверим ваши ответы . Для этого каждая группа меняется с заданием</p><p>. Сравните рисунок в вашем задание с рисунком Знайки. </p><p> Если у вас получился такой же рисунок, значит все ответы верны.</p><p> Вам необходимо себя оценить. </p><p> Формативная работа на группу</p><p> - <span> </span>Ребята , Знайка предлагает каждой группе работать по учебнику . стр 35 упр 17. Подобрать слова по схемам по три слова. </p><p> При завершении работ каждая группа выходит к доске и приклепляют слова к схемам. Работа в тетради «Что я знаю и умею»</p><p> Цель: оценка уровня усвоения навыка по теме. </p><p>Итог урока. </p><p> Рефлексия. Чтобы разобрать слова по составу , нужно выделить ….., ….., …….. </p><p> Оцените свою работу на уроке . </p><p>Продолжи фразу. </p><p>Мне понравилось на уроке ………………………………… . </p><p> На уроке мне было интересно …… . </p><p>Мне было трудно на уроке ….. . </p><p>Я хотел бы чтобы на уроке …… . </p><p> Домашнее задание стр 37-38 выполнить устно</p> |
Пікірлер(0)
Патент США на помощь в составлении имен в приложениях для обмена сообщениями.
Патент (Патент № 11 283 752, выданный 22 марта 2022 г.)Настоящая заявка является продолжением заявки на патент США Сер. № 16/559,808, поданной 4 сентября 2019 г., которая является продолжением заявки на патент США Сер. № 14/089,830, поданной 26 ноября 2013 г., в которой испрашивается преимущество даты подачи предварительной заявки на патент США № 61/904,731, поданной 15 ноября 2013 г., полное раскрытие которой настоящим включено в настоящий документ посредством ссылки .
ОБЛАСТЬ РАСКРЫТИЯ
Настоящее изобретение в целом относится к приложениям для обмена электронными сообщениями и, более конкретно, к составлению сообщений в приложениях для обмена электронными сообщениями.
ИСХОДНАЯ ИНФОРМАЦИЯ
Следуя прецеденту предшествующих им бумажных аналогов, электронные письма, мгновенные сообщения (IM), текстовые сообщения и другие электронные сообщения часто состоят из приветствия или приветствия, которое включает имя одного или нескольких предполагаемых получателей электронного сообщения. Однако это приводит к ситуациям, когда составитель сообщения непреднамеренно ошибается в написании имени получателя в приветствии или в другом месте в теле сообщения. Такие ошибки особенно распространены, когда имя получателя необычно в культуре отправителя или если имя пишется так же, как обычное слово без имени. Обычные механизмы обнаружения ошибок, такие как процессы проверки орфографии, использующие предопределенный общий словарь, часто не могут уловить такие ситуации. Чтобы проиллюстрировать это, имя получателя может быть похоже по написанию на обычное слово, и отправитель может неосознанно написать имя получателя как обычное слово, что затем приведет к тому, что опечатка останется незамеченной, поскольку она соответствует написанию, найденному в словаре проверки орфографии. . Кроме того, даже если имя получателя правильно написано отправителем, функция автокоррекции в некоторых приложениях для обмена сообщениями изменяет имя в соответствии со словом, найденным в словаре проверки орфографии. Такие инциденты могут вызвать смущение или замешательство как у отправителя, так и у получателя.
Настоящее раскрытие может быть лучше понято специалистами в данной области техники, а его многочисленные особенности и преимущества станут очевидными для специалистов в данной области техники при обращении к сопровождающим чертежам. Использование одних и тех же условных обозначений на разных чертежах указывает на сходные или идентичные элементы.
РИС. 1 представляет собой схему, иллюстрирующую электронное устройство, использующее помощь в составлении имени получателя с использованием опции автоматического предложения для приложения обмена сообщениями в соответствии по меньшей мере с одним вариантом осуществления настоящего раскрытия.
РИС. Фиг.2 представляет собой схему, иллюстрирующую интерфейс составления сообщения приложения для обмена сообщениями, которое использует помощь в составлении имени получателя с использованием опции автозаполнения в соответствии по меньшей мере с одним вариантом осуществления настоящего раскрытия.
РИС. 3 представляет собой схему, иллюстрирующую интерфейс составления сообщений приложения для обмена сообщениями, которое использует помощь в составлении имен получателей с использованием опции автокоррекции в соответствии по меньшей мере с одним вариантом осуществления настоящего раскрытия.
РИС. Фиг.4 представляет собой схему, иллюстрирующую интерфейс составления сообщения приложения для обмена сообщениями, которое использует помощь в составлении имени получателя с использованием опции автокоррекции после составления в соответствии по меньшей мере с одним вариантом осуществления настоящего раскрытия.
РИС. 5 представляет собой блок-схему, иллюстрирующую способ предоставления помощи в составлении имени получателя для составления имени получателя в теле сообщения электронного сообщения в соответствии по меньшей мере с одним вариантом осуществления настоящего раскрытия.
РИС. 6 представляет собой схему, иллюстрирующую способ идентификации имен-кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем синтаксического анализа адреса сообщения получателя электронного сообщения в соответствии по меньшей мере с одним вариантом осуществления настоящего раскрытия.
РИС. 7 представляет собой схему, иллюстрирующую способ идентификации имен-кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем анализа отображаемого имени, связанного с адресом получателя сообщения получателя электронного сообщения, в соответствии по меньшей мере с одним вариантом осуществления настоящего изобретения. раскрытие.
РИС. 8 представляет собой схему, иллюстрирующую способ идентификации имен-кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем анализа тела электронного сообщения в соответствии по меньшей мере с одним вариантом осуществления настоящего раскрытия.
РИС. 9 представляет собой схему, иллюстрирующую способ идентификации имен-кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем выполнения поиска контактов в базе данных контактов с использованием контекста сообщения из одного или нескольких полей электронного сообщения в соответствии по меньшей мере с одним вариантом осуществления. настоящего раскрытия.
РИС. 10 представляет собой схему, иллюстрирующую способ идентификации имен-кандидатов для помощи в составлении имени получателя во время составления электронного сообщения путем синтаксического анализа содержимого другого приложения, которое инициировало составление электронного сообщения, в соответствии по меньшей мере с одним вариантом осуществления настоящего раскрытия.
РИС. 11 представляет собой схему, иллюстрирующую реализацию электронного устройства , 100, в соответствии по меньшей мере с одним вариантом осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
Следующее описание предназначено для того, чтобы передать полное понимание настоящего раскрытия путем предоставления ряда конкретных вариантов осуществления и деталей, включающих помощь в составлении имени во время составления электронного сообщения на электронном устройстве. Однако следует понимать, что настоящее раскрытие не ограничивается этими конкретными вариантами осуществления и деталями, которые являются только примерами, и соответственно предполагается, что объем раскрытия ограничивается только следующей формулой изобретения и ее эквивалентами. Кроме того, понятно, что специалист в данной области, в свете известных систем и способов, оценит использование раскрытия по назначению и преимущества в любом числе альтернативных вариантов осуществления, в зависимости от конкретной конструкции и других потребностей.
РИС. 1-11 иллюстрируют примерные методы предоставления помощи в автоматизированном составлении имени в теле сообщения электронного сообщения, составленного на электронном устройстве. По меньшей мере в одном варианте осуществления электронное устройство идентифицирует одно или несколько имен потенциальных получателей на основе контекста сообщения и в ответ на идентификацию того, что пользователь составляет приветствие или другое приветствие, которое, как ожидается, будет включать имя получателя в тело сообщения, предоставляет имя помощь в составлении с использованием одного или нескольких идентифицированных имен-кандидатов для облегчения точного составления имени получателя. Помощь в составлении имени может предоставляться в виде представления графического представления выбранного имени-кандидата в соответствии с одним или несколькими вариантами представления, такими как вариант автоматического предложения («самопредложение»), вариант автоматического завершения («автозаполнение»), и вариант автоматического исправления («автокоррекция»). Для варианта автозаполнения при идентификации пользовательского ввода, указывающего на триггер приветствия (например, при вводе приветственного термина, такого как «Привет» или «Уважаемый», или инициировании ввода первого слова тела сообщения), одно или несколько имен-кандидатов графически представлен как выбираемый пользователем вариант через графический пользовательский интерфейс (GUI) электронного устройства, и выбор пользователем выбираемого пользователем параметра приводит к автоматическому заполнению («автозаполнение») выбранного имени кандидата в теле сообщения как часть приветствия. Для варианта автозаполнения, после идентификации приветственного триггера и получения пользовательского ввода, указывающего состав начальных букв не приветственного термина в теле сообщения, выбирается имя-кандидат (если имеется более одного имени-кандидата), и электронное устройство предоставляет графическое представление имени кандидата путем автономного завершения слова в теле сообщения на основе выбранного имени кандидата. Затем пользователь может принять это завершенное слово в качестве предполагаемого имени получателя или отклонить завершенное слово и, таким образом, вызвать его удаление из тела сообщения. Для варианта автозамены электронное устройство определяет, включает ли приветствие в теле сообщения слово, совпадающее с именем-кандидатом, и, если есть несоответствие, отображает уведомление о том, что пользователь мог ошибиться при составлении имени получателя в теле сообщения. Это уведомление может включать в себя выбираемую пользователем опцию замены слова в приветствии предлагаемым именем кандидата. Опцию автозамены можно использовать после завершения приветствия и до составления остальной части тела сообщения, после составления тела сообщения (например, когда пользователь поручил приложению обмена сообщениями инициировать передачу составленного электронного сообщения), и тому подобное. Ввод приветствий и других слов может осуществляться путем набора текста на клавиатуре, набора текста на виртуальной клавиатуре (с сенсорным экраном), проведения пальцем по виртуальной клавиатуре, выбора букв мышью или сенсорной панелью, набора аккордов на клавиатуре или наборе клавиш, распознавания речи или другого типа текстовая запись.
Идентификация имен-кандидатов для процесса помощи в составлении имен может быть определена из внутреннего контекста сообщения, внешнего контекста сообщения или их комбинации. Внутренний контекст сообщения включает в себя поля самого электронного сообщения, такие как адреса сообщения получателя в полях адреса сообщения получателя сообщения, отображаемые имена полей отображаемого имени, связанных с адресами сообщения получателя, имена вложений файлов вложений, перечисленных в полях вложений ( и содержание вложенных файлов), а также содержание самого тела сообщения, такое как строка темы сообщения или содержание предыдущего электронного сообщения, которое было включено в тело сообщения составляемого электронного сообщения. Внешний контекст сообщения включает в себя контекст сообщения, отличный от полей составляемого электронного сообщения, и, таким образом, может включать, например, базу данных контактов, поддерживаемую на электронном устройстве, или содержимое приложения, из которого была составлена композиция электронного сообщения. срабатывает (например, содержимое веб-страницы, содержащей ссылку, при выборе которой инициируется составление электронного сообщения). По меньшей мере в одном варианте осуществления электронное устройство идентифицирует имена-кандидаты из внутреннего или внешнего контекста сообщения, анализируя содержимое контекста сообщения для идентификации отдельных слов или комбинаций или слов, которые, по прогнозам, представляют слова имени, или используя такие проанализированные слова для выполнения поиск имени, например, в базе данных контактов для определения соответствующего имени-кандидата. Эта идентификация имени-кандидата посредством внутреннего и внешнего контекста сообщения, таким образом, может использоваться в дополнение к обычным процессам проверки орфографии, которые полагаются на предопределенные словари правописания, которые не отражают конкретный контекст имени получателя или другое содержимое составляемого электронного сообщения.
Для простоты иллюстрации, большая часть следующего описания методов помощи при автоматизированном составлении имен предоставлена в соответствии с примером использования приложения для обмена сообщениями электронной почты на портативном электронном устройстве. Однако эти автоматизированные методы составления имен не ограничиваются этим контекстом, а вместо этого могут использоваться для любого из множества приложений для обмена электронными сообщениями, таких как приложения для обмена мгновенными сообщениями (IM), приложения для обмена текстовыми сообщениями, приложения для микроблогов, приложения для социальных сетей и т. подобное, аналогичное, похожее.
РИС. 1 показано электронное устройство , 100, , использующее автоматизированную помощь в составлении имени получателя во время составления электронного сообщения в соответствии по меньшей мере с одним вариантом осуществления настоящего раскрытия. Электронное устройство 100 может включать в себя любое из множества устройств, которые могут использоваться для обмена электронными сообщениями, например мобильный телефон с вычислительной функцией («смартфон») или часы с вычислительной функцией («умные часы»), планшетный компьютер, ноутбук. компьютер, настольный компьютер, игровая консоль, персональный цифровой помощник (КПК) и т. п.
В показанном примере электронное устройство 100 включает в себя приложение для обмена сообщениями 102 , предназначенное для обмена электронными сообщениями между электронным устройством 100 и другими электронными устройствами через поставщика электронных сообщений 104 , доступного через один или несколько сети 106 . Для иллюстрации приложение обмена сообщениями 102 может включать в себя веб-приложение электронной почты (например, Google Gmail™), которое взаимодействует с сервером электронной почты в Интернете (один вариант осуществления поставщика 9 сообщений).0005 104 ) через Интернет (один из вариантов сети 106 ). В качестве другого примера, приложение обмена сообщениями 102 может включать в себя клиент электронной почты Microsoft Outlook™, который взаимодействует с сервером Microsoft Exchange™ (один вариант осуществления поставщика сообщений 104 ) через внутреннюю корпоративную сеть, Интернет или их комбинацию. . В качестве еще одного примера приложение 102 для обмена сообщениями может включать в себя приложение для обмена мгновенными сообщениями (IM), которое обменивается данными с веб-сервером IM (один вариант осуществления поставщика 9 обмена сообщениями).0005 104 ) через Интернет. Другие примеры приложения для обмена сообщениями 102 включают, например, приложение для обмена текстовыми сообщениями (например, приложение службы простого обмена сообщениями (SMS) или приложение службы обмена мультимедийными сообщениями (MMS)), приложение для ведения микроблогов (например, приложение для «твитинга»). предоставленный Twitter Inc.), приложение для социальных сетей (например, Facebook™ или Google Circles™) и т.п. В некоторых реализациях приложение для обмена электронными сообщениями 102 отправляет и получает электронные сообщения в координации с операционной системой (ОС) 108 (или другое системное программное обеспечение) электронного устройства 100 . Для иллюстрации, ОС 108 может облегчить доступ к проводному или беспроводному сетевому интерфейсу, который подключается к сети 106 , доступ к дисплею и пользовательским устройствам ввода (например, сенсорному экрану, микрофону, мыши или клавиатуре) электронного устройство 100 и т.п.
Одной из функций обмена сообщениями, обеспечиваемой приложением обмена сообщениями 102 , является представление графического пользовательского интерфейса (GUI) для облегчения составления пользователем электронных сообщений, которые должны быть переданы одному или нескольким получателям через провайдера обмена сообщениями 104 . Композиция электронного сообщения управляется с помощью ввода пользовательской композиции 110 , полученного через один или несколько интерфейсов пользовательского ввода, связанных с этим графическим интерфейсом пользователя, таких как сенсорный экран, микрофон, мышь или клавиатура. Пользовательский ввод 110 состава обычно включает в себя инструкцию для инициирования составления электронного сообщения, например, выбор пользователем кнопки «составить», отображаемой в графическом пользовательском интерфейсе (GUI), предоставляемом приложением обмена сообщениями 102 или с помощью голосовых команд пользователя, предписывающих электронному устройству 100 инициировать новое электронное сообщение. Пользовательский ввод 110 состава также включает в себя пользовательский ввод для предоставления адресов сообщения получателя в одном или нескольких полях адреса сообщения и пользовательский ввод для предоставления текста и другого типографского содержимого в тело сообщения составляемого электронного сообщения.
При составлении электронного сообщения пользователь электронного устройства 100 может потребоваться обратиться к одному или нескольким получателям по имени в теле сообщения, например, инициировав содержимое тела сообщения приветствием, которое включает одно или несколько имен получателей. Однако существует значительная вероятность того, что пользователь может неправильно написать имя предполагаемого получателя в теле сообщения либо из-за того, что пользователь не знаком с этим именем (например, оно может быть непривычным для культуры пользователя), написания (например, «Карл» против «Карл»), или оно может иметь написание, очень похожее на другое слово. Чтобы проиллюстрировать это, получатель электронного сообщения может быть назван «Gulprit», что пользователь может непреднамеренно ввести как «Culprit» в теле сообщения из-за сходства их правописания. Чтобы уменьшить количество ошибок при написании имени получателя или избежать их, по меньшей мере, в одном варианте осуществления приложение 9 обмена сообщениями0005 102 обеспечивает автоматическую помощь в составлении имени получателя, определяя имена-кандидаты на основе контекста сообщения, а затем автономно облегчая правильное использование имени в теле сообщения с помощью различных параметров помощи пользователю, таких как параметр автозаполнения, параметр автозаполнения, параметр автозамены и подобное, аналогичное, похожее.
В одном варианте осуществления этой помощи в составлении имени получателя способствует различная информация, хранящаяся в электронном устройстве 100 . Такая информация может включать, например, контекст сообщения 112 самого сообщения. Этот контекст сообщения 112 может включать в себя внутренний контекст сообщения, который является информацией в полях составляемого сообщения, такой как информация в полях адреса сообщения получателя, такая как адреса электронной почты в полях «to:», «cc:» и адресные поля «скрытая копия:», имена или другая информация на основе имен, уже присутствующая или впоследствии добавленная в тело сообщения, и т.п. Контекст этого сообщения 112 также может включать внешний контекст сообщения, то есть информацию, которая не получена напрямую из полей составляемого электронного сообщения, например, содержимое другого приложения, которое инициировало составление электронного сообщения, или контактную запись получателя, которая осуществляется косвенно, используя некоторую информацию из внутреннего контекста сообщения.
Приложение для обмена сообщениями 102 может использовать этот контекст сообщения 112 для определения одного или нескольких имен-кандидатов (т. имена кандидатов из анализа частей адресов электронной почты, специфичных для получателя, в полях получателя или косвенно, например, путем определения идентификаторов, специфичных для получателя, из полей сообщения, а затем использования этих идентификаторов, специфичных для получателя, для поиска соответствующего имени получателя из, например, база контактов 114 сохраняется на электронном устройстве 100 . База данных контактов 114 может включать, например, постоянный список записей контактов, который был собран приложением обмена сообщениями 102 или другим приложением, которое разрешило доступ к своей базе данных контактов, например к записям контактов Google, доступным в приложение Google Gmail™, набор записей контактов, доступных в приложении Microsoft Outlook™, или набор записей «друзей», доступных в учетной записи пользователя Facebook™. Идентифицированные таким образом имена-кандидаты могут быть сохранены во временной базе данных имен-кандидатов 9.0005 116 , который может быть списком, таблицей или другой структурой данных, реализованной, например, в пространстве памяти или дисковом пространстве, выделенном для приложения обмена сообщениями 102 , и может сохраняться в течение всего времени составления электронного сообщения, на время, пока приложение обмена сообщениями 102 работает или иным образом активно, и т.п. Ниже подробно описаны различные методы идентификации имен-кандидатов.
С одним или несколькими именами-кандидатами, идентифицированными и сохраненными в базе данных имен-кандидатов 116 , приложение обмена сообщениями 102 отслеживает ввод 110 состава пользователя для обнаружения любых потенциальных триггеров приветствия, которые могут включать в себя имя получателя или быть связаны с ним. Такие триггеры приветствия могут включать в себя, например, пользовательский ввод, указывающий на ввод типичного вводного приветствия, такого как ввод пользователем слова «Привет» или «Уважаемый» в начале тела сообщения. Кроме того, триггер приветствия может быть начальным вводом пользователем содержимого тела сообщения (то есть вводом первых нескольких букв или слов в теле сообщения), и, в частности, триггер приветствия может сработать, когда первые несколько буквы, напечатанные в теле сообщения, по существу совпадают с соответствующими начальными буквами идентифицированного имени кандидата. В ответ на обнаружение триггера приветствия приложение обмена сообщениями 102 пытается помочь пользователю правильно составить имя получателя в теле сообщения. Как описано выше, эта помощь может предоставляться как графическое представление имени кандидата как часть одной или нескольких опций помощи пользователю, таких как опция автозаполнения, опция автозаполнения, опция автозамены и т.п.
Для иллюстрации на РИС. 1 показан состав сообщения GUI 118 приложения для обмена сообщениями 102 для составления сообщения электронной почты получателю с именем «Gulprit» на адрес электронной почты «gulprit@gmail. com», как указано полем «Кому: адрес» 120 сообщения электронной почты. Этот графический интерфейс 118 составления сообщения иллюстрирует реализацию опции автоматического предложения, посредством которой приложение обмена сообщениями 102 идентифицирует «Gulprit» как имя-кандидат из адреса электронной почты «[email protected]» и в ответ на ввод пользователя, представляющий ввод слова «Привет» 130 в тело сообщения 122 сообщения электронной почты, приложение для обмена сообщениями 102 предоставляет опцию автоматического предложения для завершения приветствия, предоставляя выбираемую пользователем опцию 124 в графическом интерфейсе пользователя 118 , который предлагает графическое представление имени «Gulprit» в качестве одного имени-кандидата 126 , идентифицированного из контекста сообщения 112 , и графическое представление имени «Gillray» в качестве другого имени-кандидата запись 128 , которая идентифицируется, например, из предопределенного орфографического словаря, содержащего «Gillray» в качестве записи. В то время как выбираемая пользователем опция 124 проиллюстрирована как графическое изображение списка выбираемых записей имен-кандидатов 126 , 128 , выбираемая пользователем опция 124 для автоматического предложения имен-кандидатов может быть реализована любым из множества способов, согласующихся с изложенными здесь идеями. С отображаемой таким образом выбираемой пользователем опцией 124 , предполагая, что пользователь намеревался обратиться к Gulprit в теле сообщения 122 , пользователь может выбрать запись имени-кандидата «Gulprit» 126 из выбираемой пользователем опции 124 , в ответ на что приложение обмена сообщениями 102 вставляет имя «Gulprit» в текущую позицию курсора в теле сообщения 122 . Таким образом, имя получателя «Gulprit» правильно вводится в тело сообщения 122 , и исключается возможность ошибки пользователя при самостоятельном вводе имени «Gulprit».
РИС. 2, 3 и 4 иллюстрируют другие варианты помощи в автоматизированном составлении имени получателя, которые могут предоставляться приложением , 102, обмена сообщениями электронного устройства 9.0005 100 на фиг. 1 в сочетании с составом электронного сообщения. Например, фиг. 2 иллюстрирует GUI 218 составления сообщения, который предоставляется приложением 102 для обмена сообщениями и который предоставляет вариант автозаполнения для помощи в составлении имени. Для варианта автозаполнения приложение 102 для обмена сообщениями отслеживает пользовательский ввод 110 состава (фиг. 1) для обнаружения пользовательского ввода, представляющего ввод или другой ввод начального набора букв слова в теле 9 сообщения.0005 222 состава сообщения GUI 218 . В случае, если начальный набор букв совпадает с соответствующим начальным набором букв имени-кандидата, идентифицированного из контекста сообщения 112 составляемого электронного сообщения, приложение обмена сообщениями 102 предоставляет графическое представление имени-кандидата через параметр автозаполнения 224 , который представляет собой предлагаемое завершение слова в теле сообщения 222 .
В этом примере имя кандидата «Gulprit» определяется по адресу электронной почты «[email protected]» в поле «Кому: адрес» 220 . Для опции автозаполнения 224 , когда пользователь вводит приветственный триггер «Привет», за которым следует пробел, а затем три начальные буквы «Гул» слова 225 после приветственного триггера, приложение обмена сообщениями 102 идентифицирует этот начальный набор букв слова 225 как достаточное совпадение с именем-кандидатом «Gulprit» и, таким образом, автоматически дополняет слово 225 в качестве имени-кандидата «Gulprit». Как показано, это автозаполнение может включать, например, автоматическое включение оставшихся букв «prit» имени-кандидата «Gulprit» в тело сообщения 222 после начальных букв «Gul» и предоставление некоторого индикатора того, что эти последние буквы 226 заполняются автоматически, например, с использованием текста другого цвета, подчеркивания и т. п. Если автозаполненное имя представляет собой слово, которое пользователь намеревался ввести, пользователь может выразить свое согласие на автозаполнение, например, нажав клавишу «пробел» на клавиатуре или выбрав кнопку «принять» или другую функцию принятия (не показана). ), связанный с параметром автозаполнения 224 в составе сообщения GUI 218 .
РИС. 3 иллюстрирует GUI , 318, составления сообщения, который предоставляется приложением , 102, для обмена сообщениями и который обеспечивает опцию автокоррекции. Для этого подхода к помощи в составлении имени получателя приложение для обмена сообщениями 102 предоставляет параметр автозамены 324 для замены слова идентифицированным именем-кандидатом после того, как слово уже было введено и заполнено в теле сообщения 322 . Таким образом, приложение , 102, обмена сообщениями идентифицирует законченное слово в теле , 322, сообщения как потенциально представляющее имя получателя и проверяет, соответствует ли это слово имени-кандидату, идентифицированному для имени получателя. Если слово недостаточно соответствует имени-кандидату, приложение обмена сообщениями 102 может отобразить опцию автозамены 324 в графическом пользовательском интерфейсе 318 , чтобы предоставить пользователю возможность заменить слово именем-кандидатом, графически представленным в автозамена вариант 324 . В показанном примере параметр автозамены 324 включает в себя диалоговое окно, которое предоставляет пользователю возможность заменить слово «Преступник» в теле сообщения именем-кандидатом «Гулприт», определенным по адресу электронной почты в поле «Кому:». поле 320 . В этом примере слово «Преступник» может быть идентифицировано как потенциально неправильно набранное имя получателя, например, из-за того, что оно сразу следует за триггером приветствия «Привет», пишется с заглавной буквы, но не является первым словом предложения, или потому что оно по существу соответствует названию «Гулприт».
Приложение для обмена сообщениями 102 может анализировать тело составляемого электронного сообщения на предмет возможностей предоставления опции автозамены в одном или нескольких точках процесса составления сообщения. В примере на фиг. 3, адрес получателя для обмена сообщениями (например, «[email protected]») уже введен в поле адреса получателя электронного сообщения, составляемого в момент начала составления тела сообщения, и, таким образом, приложение для обмена сообщениями 102 может использовать этот адрес для обмена сообщениями получателя, чтобы идентифицировать одно или несколько имен-кандидатов для опции автозамены. Таким образом, когда сообщается о завершении потенциального слова имени в теле сообщения (например, когда пользователь вводит символ «пробел» или другой символ пробела после слова), приложение обмена сообщениями 102 может проверить слово в момент завершения. Однако в некоторых случаях пользователь может инициировать составление тела сообщения до заполнения любого из полей получателя электронного сообщения, и, таким образом, может не хватить контекста сообщения для приложения обмена сообщениями 9. 0005 102 для идентификации имени кандидата во время составления сообщения. Соответственно, в других случаях анализ тела сообщения на наличие одного или нескольких потенциальных слов для автозамены имени может быть отложен до тех пор, пока пользователь не введет информацию о получателе.
РИС. 4 иллюстрирует пример процесса задержки опции автокоррекции до тех пор, пока составление сообщения не будет по существу завершено. В этом примере снимок экрана 400 иллюстрирует состояние графического интерфейса 9 состава сообщения.0005 418 после того, как пользователь набрал сообщение в теле сообщения 422 , но до заполнения любого из полей адреса получателя сообщения графического пользовательского интерфейса 418 . Сообщение, введенное пользователем, содержит ошибочное представление имени «Gulprit» как «Culprit». Однако, поскольку поля адреса сообщения получателя еще не заполнены на этом этапе, приложение для обмена сообщениями 102 может быть не в состоянии идентифицировать ошибку, поскольку имена кандидатов не могут быть идентифицированы, а «виновник» — это правильно написанное слово. , и, следовательно, не будет обнаружен с помощью стандартного процесса проверки орфографии с предопределенным орфографическим словарем. Напротив, скриншот 402 иллюстрирует состав сообщения GUI 418 после того, как пользователь заполнил поле адреса 420 с псевдонимом «Gulprit» (который приложение обмена сообщениями 102 понимает как соответствующее «[email protected]» в этом примере), и пользователь указал, что составление сообщения электронной почты завершено, например, инициировав передачу сообщения электронной почты, выбрав значок «отправить» 423 графического интерфейса 9 состава сообщения.0005 418 .
В ответ на это указание о том, что составление завершено, приложение обмена сообщениями 102 может затем повторно оценить поля адреса сообщения получателя, чтобы определить, можно ли определить из них имя-кандидат. В этом случае приложение обмена сообщениями может идентифицировать имя-кандидат «Gulprit» и, таким образом, при анализе тела сообщения 422 может идентифицировать слово «Culprit» потенциально как вариант имени-кандидата «Gulprit» с ошибкой и, таким образом, предоставить вариант автозамены, например вариант автозамены 324 на фиг. 3, заменить «Culprit» на «Gulprit» в теле сообщения 422 . Таким образом, приложение обмена сообщениями , 102, может продолжать обновлять процесс помощи при составлении имени по мере того, как становится доступным дополнительный контекст сообщения.
РИС. 5 иллюстрирует примерный способ 500 работы приложения 102 обмена сообщениями электронного устройства 100 для предоставления помощи в составлении имени во время составления электронного сообщения в соответствии по меньшей мере с одним вариантом осуществления. Способ 500 инициируется в блоке 502 , когда пользователь выполняет действие, чтобы инициировать составление электронного сообщения. Это действие может включать, например, пользовательский ввод, указывающий инструкцию для приложения обмена сообщениями 102 инициировать составление сообщения, например, путем выбора значка «создать сообщение» в графическом пользовательском интерфейсе приложения обмена сообщениями 102 или в графическом пользовательском интерфейсе ОС 108 (фиг. 1). В некоторых случаях составление электронного сообщения может быть инициировано косвенно. Для иллюстрации отдельное приложение может связать или иным образом перенаправить пользователя в приложение для обмена сообщениями 9.0005 102 для составления сообщения. Для иллюстрации веб-сайт, отображаемый в веб-браузере, может включать ссылку, которая инициирует вызов интерфейса прикладного программирования (API) к приложению обмена сообщениями 102 , чтобы позволить пользователю составить электронное сообщение в связи с веб-сайтом (например, пересылка статьи на веб-сайте указанному получателю или пересылка сообщения получателю, связанному с веб-сайтом).
В ответ на этот инициирующий ввод в блоке 504 приложение для обмена сообщениями 102 генерирует и отображает графический интерфейс пользователя для составления сообщения, чтобы облегчить ввод данных пользователем для составления электронного сообщения. Графический интерфейс состава сообщения обычно включает в себя несколько полей, в том числе одно или несколько полей адреса сообщения получателя (например, поля адреса электронной почты «Кому», «Копия:» и «Скрытая копия») и одно или несколько полей тела сообщения, т. е. адрес, не являющийся получателем. поля (обратите внимание, что термин «тело сообщения» может включать, например, поле строки темы сообщения электронной почты, поскольку это сродни заголовку сообщения). С отображаемым графическим интерфейсом состава сообщения в блоке 506 исходный пользовательский ввод состава получен приложением обмена сообщениями 102 через графический интерфейс состава сообщения.
В некоторых случаях этот первоначальный ввод состава пользователя может включать в себя предоставление пользователем адресных псевдонимов или неполных адресов сообщения получателя в одном или нескольких полях адреса сообщения получателя электронного сообщения. В таких случаях в блоке 508 приложение обмена сообщениями 102 идентифицирует полные или полные адреса получателя сообщения, используя функцию автозаполнения приложения обмена сообщениями 9.0005 102 . Эта функция автозаполнения может, например, использовать псевдоним или частичный адрес сообщения получателя для выполнения поиска в базе данных контактов 114 (фиг. 1) для идентификации полного адреса сообщения получателя.
На этапе 510 приложение обмена сообщениями 102 готовится к поддержке процесса помощи в составлении имени получателя для составляемого электронного сообщения путем определения внутреннего контекста сообщения, который может быть полезен при идентификации имен-кандидатов. Этот внутренний контекст сообщения включает в себя контекст сообщения, определенный непосредственно из полей составляемого электронного сообщения, и, таким образом, может включать в себя адреса получателя сообщения в полях адреса сообщения получателя электронного сообщения, имена файлов вложенных файлов, перечисленных в поле вложения, или содержание самих вложенных файлов, а также содержимое, уже присутствующее в поле тела сообщения, например любое начальное содержимое, составленное пользователем в теле сообщения, или электронное сообщение может включать ответное сообщение или сообщение пересылки, и в этом случае тело сообщения может содержать содержимое исходного электронного сообщения, служащего основой для ответа или пересылаемого сообщения. Это содержимое исходного электронного сообщения может включать в себя, например, адреса получателей исходного электронного сообщения, а также одно или несколько имен получателей в поле тела сообщения.
В некоторых вариантах осуществления имена-кандидаты также могут определяться на основе внешнего контекста сообщения; то есть контекст сообщения, который не идентифицируется непосредственно полем составляемого электронного сообщения, и, таким образом, на этапе 512 приложение обмена сообщениями 102 определяет такой внешний контекст сообщения. Этот внешний контекст сообщения может включать в себя, например, определение имени получателя из базы данных контактов 114 на основе поиска с использованием по меньшей мере части адреса сообщения получателя. Кроме того, поскольку составление электронного сообщения могло быть инициировано другим приложением (например, описанным выше примером веб-сайта), контекст внешнего сообщения может включать контекстную информацию об этом другом приложении, например содержимое приложения, связанное со ссылкой или другим источник происхождения электронного сообщения.
После определения одного или обоих внутреннего контекста сообщения и внешнего контекста сообщения на этапе 514 приложение обмена сообщениями 102 идентифицирует одно или несколько имен-кандидатов для электронного сообщения из внутреннего и внешнего контекста сообщения. Как более подробно описано ниже, идентификация этих имен-кандидатов может включать в себя синтаксический анализ информации, относящейся к имени, во внутреннем контексте сообщения, поиск имени на основе информации, специфичной для получателя, из контекста сообщения и т.п. Любые имена-кандидаты, идентифицированные таким образом, могут быть сохранены во временной базе данных имен-кандидатов 9.0005 116 (фиг. 1), поддерживаемый приложением обмена сообщениями 102 для электронного сообщения.
Одновременно с процессом идентификации имени-кандидата на этапе 516 приложение для обмена сообщениями 102 отслеживает исходный ввод данных пользователем для обнаружения триггера приветствия, который указывает, что пользователь может намереваться включить имя получателя в поле тела сообщения. Как отмечалось выше, этот триггер приветствия может включать ввод слова, которое обычно служит частью приветствия в сообщении, например ввод «Привет», «Привет», «Уважаемый» и т. д. Вместо этого триггер приветствия может включать ввод по крайней мере части слова в область тела сообщения, обычно используемую для приветствий, например, первое или два слова в теле сообщения, или набор слов, расположенный в самом верхнем левом углу поля тела сообщения, или ввод начального набора букв, совпадающего с соответствующим начальным набором букв имени-кандидата.
В ответ на обнаружение триггера приветствия в блоке 518 приложение для обмена сообщениями 102 выбирает имя-кандидат (если существует более одного имени-кандидата), которое может отражать имя получателя, к которому направляется пользователь или пытается to, ввод в сочетании с триггером приветствия. Этот процесс выбора может включать применение одного или нескольких правил определения приоритетов. Например, правило приоритизации может предусматривать, что имена-кандидаты, определенные из полей адреса сообщения получателя электронного сообщения, могут иметь приоритет выбора над именами-кандидатами, определенными из полей, не являющихся адресами получателя, то есть полей тела сообщения. Кроме того, правило приоритизации может предусматривать, что имена-кандидаты, определенные из поля адреса «кому», могут иметь приоритет выбора над именами-кандидатами, определенными из поля «копия: адрес», которые, в свою очередь, имеют приоритет выбора над именами-кандидатами, определенными из поля «скрытая копия: адрес». и т. д. В ситуациях, когда триггер приветствия включает в себя ввод пользователем начального набора букв слова, которое, как ожидается, будет именем получателя, приоритет выбора среди нескольких имен-кандидатов может быть отдан тому имени-кандидату, которое наиболее точно соответствует начальному набору букв. .
При выборе имени-кандидата в блоке 520 приложение для обмена сообщениями 102 может облегчить составление имени получателя, предоставив через графический интерфейс составления сообщений один или оба варианта автозаполнения (например, на рис. 1) или автозаполнения. вариант (например, фиг. 2), который графически представляет имя-кандидат пользователю для включения в тело электронного сообщения таким образом, чтобы исключить многие вероятные ошибки ввода пользователем имени получателя. В случае, если опция автозаполнения/опция автозаполнения не принимается пользователем, или в случае, если ни одна из опций не представлена, в блоке 522 приложение для обмена сообщениями 102 продолжает отслеживать введенные пользователем данные, чтобы определить, завершил ли пользователь слово, которое, по прогнозам, предназначалось пользователем в качестве имени получателя, которое несовместимо с одним или несколькими идентифицированными именами-кандидатами. (например, не соответствует ни одному из идентифицированных имен-кандидатов). Этот анализ может быть выполнен относительно быстро после того, как пользователь завершит ввод слова (например, после ввода символа пробела после слова) или после того, как пользователь просигнализировал о завершении составления электронного сообщения, например, выбрав «сохранить». ” или попытавшись инициировать передачу электронного сообщения, выбрав значок «отправить».
Если такое несоответствие или несоответствие имени-кандидата/полного слова возникает в теле сообщения, то на этапе 524 приложение обмена сообщениями 102 может предоставить опцию автозамены (например, фиг. 3 и 4), чтобы уведомить пользователя потенциальной ошибки и дать пользователю возможность исправить ошибку (если это ошибка), заменив слово, о котором идет речь, предложенным именем кандидата. После внесения этой коррекции или, если такая коррекция вообще не требуется, в блоке 526 приложение для обмена сообщениями 102 завершает составление электронного сообщения и отправляет электронное сообщение провайдеру обмена сообщениями 104 (фиг. 1) для распространения по одному или нескольким адресам обмена сообщениями получателя, указанным в полях адреса сообщения получателя электронное сообщение.
РИС. 6-10 иллюстрируют примерные методы, которые могут использоваться приложением 102 обмена сообщениями, ОС 108 или другим компонентом электронного устройства 9.0005 100 на фиг. 1 для идентификации одного или нескольких имен-кандидатов из контекста сообщения 112 составляемого электронного сообщения. В частности, фиг. 6-8 иллюстрируют методы, которые идентифицируют имена-кандидаты из внутреннего контекста сообщения (то есть информации в полях самого сообщения), а фиг. 9 и 10 иллюстрируют методы, которые идентифицируют имена-кандидаты из внешнего контекста сообщения (то есть контекста из внешних источников, доступ к которым осуществляется или которые идентифицируются на основе внутреннего контекста сообщения).
РИС. 6 иллюстрирует способ идентификации одного или более имен-кандидатов из адресов сообщения получателя, присутствующих в полях адреса сообщения получателя электронного сообщения. В этом подходе синтаксический анализатор , 600, приложения , 102 обмена сообщениями осуществляет доступ к специфичной для получателя части адреса сообщения получателя и анализирует вероятные слова имени из специфичной для получателя части. Однако, поскольку имя получателя может включать несколько слов, синтаксический анализатор 600 дополнительно может генерировать различные комбинации слов имени, проанализированных из адреса сообщения получателя, для генерирования нескольких имен-кандидатов. Чтобы проиллюстрировать, в изображенном примере синтаксический анализатор 600 получает доступ к адресу электронной почты получателя 602 (один вариант осуществления адреса сообщения получателя) из поля «Кому: адрес» или поля «Копия: адрес» или из включенного исходного сообщения электронной почты. в теле сообщения в случае, если составляемое сообщение электронной почты является ответным сообщением электронной почты или пересылаемым сообщением электронной почты. Адреса электронной почты обычно состоят из части, относящейся к получателю, за которой следует часть домена, с символом «@», разделяющим их. Таким образом, адрес электронной почты «[email protected]» включает в себя часть, относящуюся к получателю, «gulprit.singh» и часть домена, «gmail.com». Парсер 9Таким образом, 0005 600 может анализировать часть, относящуюся к получателю, для идентификации одного или нескольких потенциальных слов имени, посредством чего анализатор 600 может использовать различные разделители слов общего имени, такие как точка («.»), подчеркивание («_») , тире («-«) и т.п. для обнаружения отдельных слов. Таким образом, для специфичной для получателя части «gulprit.singh» адреса электронной почты получателя 602 синтаксический анализатор 600 может генерировать слова имени «gulprit» и «singh», и из комбинаций этих слов имени получаются три имена кандидатов 604 , 606 , 608 — «Гулприт», «Сингх» и «Гулприт Сингх» соответственно. «Сингх Гулприт» также может быть разумным кандидатом на имя, если соглашение системы адресации электронной почты заключается в том, чтобы ставить фамилию или фамилию первыми в адресе электронной почты. Затем синтаксический анализатор 600 может поместить эти имена-кандидаты 604 , 606 и 608 в базу данных 116 имен-кандидатов электронного устройства 100 для последующего использования в помощи при составлении имен, как описано выше. Этот процесс может быть аналогичным образом применен для разбора имен файлов, перечисленных в поле вложения электронного сообщения.
РИС. 7 иллюстрирует способ идентификации одного или более имен-кандидатов из поля отображаемого имени, связанного с адресом сообщения получателя, присутствующим в полях адреса сообщения получателя электронного сообщения. Часто из соображений безопасности или по другим причинам организация, предоставляющая услугу обмена электронными сообщениями своим членам, может решить использовать специфичную для получателя часть адреса сообщения получателя, которая, хотя и уникальна для получателя, не отражает имя получателя. Такие конфигурации затрудняют, если не делают невозможным, идентификацию имен-кандидатов непосредственно из адреса получателя сообщения. Однако протоколы электронной почты и другие протоколы обмена сообщениями часто предоставляют одно или несколько полей идентификации пользователя, которые могут быть более полезными для идентификации получателя, чем адрес получателя для обмена сообщениями. Для иллюстрации протоколы электронной почты предусматривают включение поля отображаемого имени в связь с адресом электронной почты получателя, где поле отображаемого имени хранит удобное для пользователя отображаемое имя. Парсер 600 могут использовать такие поля имени пользователя для идентификации одного или нескольких имен-кандидатов. Например, получатель составляемого сообщения электронной почты может быть указан в наборе полей получателя электронной почты 702 , который включает поле адреса электронной почты 704 , в котором хранится адрес электронной почты «A100269@motorola. com» и поле отображаемого имени. 706 , в котором хранится отображаемое имя «Gulprit Singh». Часть адреса электронной почты «A100269», относящаяся к получателю, не содержит какой-либо полезной информации для прямой идентификации одного или нескольких слов имени, и, таким образом, синтаксический анализатор 600 вместо этого может проанализировать отображаемое имя «Gulprit Singh» в поле отображаемого имени 706 , чтобы определить одно или несколько имен-кандидатов. Как и в примере на фиг. 6, анализ этого отображаемого имени может привести к именам-кандидатам 604 , 606 , 608 — «Гулприт», «Сингх» и «Гулприт Сингх» соответственно, которые хранятся в базе данных имен-кандидатов . 116 для помощи в составлении имени приложением для обмена сообщениями 102 .
РИС. 8 иллюстрирует способ идентификации одного или нескольких имен-кандидатов из поля тела сообщения электронного сообщения. Часто при составлении электронного сообщения поле тела сообщения может содержать содержимое, которое включает в себя или иным образом идентифицирует по меньшей мере часть имени одного или нескольких получателей электронного сообщения. Для иллюстрации, электронное сообщение может быть ответом на предыдущее электронное сообщение или может пересылать предыдущее электронное сообщение другому получателю. В таких случаях одно или более полей тела сообщения и полей адреса сообщения получателя предыдущего электронного сообщения могут быть включены в поле тела сообщения составляемого электронного сообщения. Таким образом, поле тела сообщения может включать в себя адреса сообщений получателей предыдущего электронного сообщения, отображаемые имена, связанные с адресами сообщений получателей, или другие ссылки на вероятных получателей, такие как строка подписи, включенная отправителем предыдущего электронного сообщения. электронное сообщение в теле сообщения предыдущего электронного сообщения. Парсер 9Таким образом, в таких случаях 0005 600 может анализировать поле тела сообщения электронного сообщения для идентификации одного или нескольких имен-кандидатов.
Для иллюстрации примера на фиг. 8 показано поле , 802, тела сообщения составляемого ответного сообщения электронной почты, при этом поле , 802, тела сообщения включает в себя содержимое , 804 исходного сообщения электронной почты. Это содержимое 804 включает строку подписи 806 отправителя исходного сообщения. Таким образом, анализатор 600 может проанализировать содержимое 804 , чтобы идентифицировать строку подписи 806 , используя любой из множества методов анализа, а затем проанализировать строку подписи 806 , чтобы идентифицировать потенциальные слова имени. Этот синтаксический анализ может включать, например, отбрасывание или игнорирование слов, предварительно идентифицированных, например, в словаре синтаксического анализа (не показан) как не указывающие на имена получателей. При анализе иллюстрированной строки подписи 806 синтаксический анализатор 600 проигнорирует слова «CTO», «Motorola», «Mobility» и «Inc. » и, таким образом, получит слова имени «Pathy» и «Sunil». как название слова. Из комбинаций этих именных слов парсер 600 может генерировать, например, имена-кандидаты 808 , 810 , 812 — «Пэти», «Сунил» и «Пэти Сунил» соответственно, и сохранять эти имена-кандидаты 808 , 8 , 812 в базе данных имен-кандидатов для использования в качестве помощи при составлении имен приложением обмена сообщениями 102 . Этот процесс может быть аналогичным образом применен к разбору содержимого файлов, перечисленных как вложения в поле вложения электронного сообщения.
РИС. 9 иллюстрирует метод косвенной идентификации одного или нескольких имен-кандидатов с использованием базы данных 114 контактов (фиг. 1), поддерживаемой в электронном устройстве 100 . Как отмечалось выше, адрес сообщения получателя может не содержать информации, полезной для прямой идентификации имен-кандидатов, и может не быть отображаемого имени или другого удобного для пользователя поля именования, связанного с адресом сообщения получателя. Однако пользователь мог ранее иметь дело с получателем, связанным с адресом сообщения получателя, и, таким образом, может иметь контактную запись для получателя в базе данных контактов 9.0005 114 . Эта контактная запись может включать в себя различную информацию о получателе, такую как имя получателя, должность, работодатель, адрес, номер телефона и различные электронные адреса получателя. Соответственно, в таких случаях приложение , 102, для обмена сообщениями или другой компонент электронного устройства , 100, по фиг. 1, может использовать модуль поиска контактов для идентификации записи контакта, связанной с контекстом сообщения, идентифицированным в одном или нескольких полях составляемого электронного сообщения, и из этой записи контакта косвенно идентифицировать одно или несколько имен-кандидатов.
Чтобы проиллюстрировать, в изображенном примере единственная информация, идентифицирующая получателя составляемого сообщения электронной почты, — это адрес электронной почты 902 , который имеет специфичную для получателя часть «A100269», которая не отражает имя получателя, связанного с адрес электронной почты 902 . Соответственно, модуль 900 поиска контактов может использовать эту часть, специфичную для получателя, для поиска в базе данных контактов 114 записи контакта, которая имеет поле, соответствующее части, специфичной для получателя, «A100269».». В этом примере база данных контактов 114 имеет совпадающую запись контакта, связанную с человеком по имени «Гулприт Сингх», и, таким образом, модуль поиска контактов 900 может анализировать поля имени в этой совпадающей записи контакта, чтобы идентифицировать имя. слово 904 «Гулприт» и слово фамилии 906 «Сингх». Затем модуль поиска контактов 900 может сохранить эти имена имен 904 , 906 в базе данных имен кандидатов 9.0005 116 , после чего синтаксический анализатор 600 (фиг. 6) затем объединяет слова имени в различные имена-кандидаты «Гулприт», «Сингх» и «Гулприт Сингх», или модуль поиска контактов 900 может генерировать эти кандидаты имена непосредственно перед их сохранением в базе данных имен кандидатов 116 . Таким образом, как показано в этом примере, модуль 900 поиска контактов использует внутренний контекст сообщения, а именно адрес электронной почты получателя 902 , для косвенной идентификации одного или нескольких имен-кандидатов через внешний контекст сообщения, а именно запись контакта в базе данных 9 контактов.0005 114 .
РИС. 10 иллюстрирует метод косвенной идентификации одного или нескольких имен-кандидатов с использованием читаемого пользователем содержимого приложения, из которого было инициировано составление электронного сообщения. Веб-браузеры, приложения социальных сетей и другие подобные приложения часто имеют возможность инициировать или инициировать составление электронного сообщения. Для иллюстрации веб-браузер может отображать новостной веб-сайт со ссылкой, которая при выборе пользователем связывается с приложением обмена сообщениями 9.0005 102 , чтобы инициировать составление электронного сообщения, которое, например, используется для пересылки соответствующей новостной статьи получателю. Сами другие электронные сообщения могут иметь такие ссылки, которые инициируют составление электронного сообщения. В таких случаях, с учетом того, что имя получателя часто находится рядом со ссылкой или другой функцией в содержимом приложения, приложение, которое инициирует составление электронного сообщения, может иметь читаемый пользователем контент, который может служить в качестве основу для идентификации одного или нескольких имен-кандидатов получателя электронного сообщения. Таким образом, анализатор 600 может проанализировать этот читаемый пользователем контент другого приложения, чтобы идентифицировать одно или несколько имен-кандидатов.
Чтобы проиллюстрировать, в изображенном примере веб-страница, отображаемая веб-браузером, включает читаемый пользователем контент 1002 , который включает в себя текст, инструктирующий вид сделать резервирование на событие, связавшись с «Хэ Юн Ким» по указанному адресу электронной почты «HYK1032». @gmail.com», и при этом текст адреса электронной почты служит гипертекстовой ссылкой, которая при выборе зрителем через веб-браузер заставляет веб-браузер связываться с приложением обмена сообщениями 102 , чтобы инициировать составление сообщения электронной почты на адрес «[email protected]». Поскольку с этого адреса электронной почты нельзя проанализировать полезные имена-кандидаты, синтаксический анализатор 600 вместо этого может проанализировать читаемый пользователем контент веб-страницы рядом с гипертекстовой ссылкой, чтобы идентифицировать одно или несколько имен-кандидатов. В этом примере этот текст в близи включает фразу 1003 «Чтобы ответить на приглашение на мероприятие, свяжитесь с Хэ Юн Ким по адресу [email protected]», которую анализатор 600 может анализировать слова имени «Хэ», «Юн» и «Ким», которые могут быть объединены, например, в имена-кандидаты 1004 , 1006 , 1008 и 1010 — «Хэ», «Юн», «Хэ Юн» и «Ким» соответственно и хранятся в базе данных имен кандидатов 116 .
Следует понимать, что приложение, из которого было инициировано электронное сообщение, может быть отделено от приложения 102 обмена сообщениями. В таких случаях синтаксический анализатор 600 может быть реализован вне приложения 102 обмена сообщениями, например, в другом приложении или в ОС 108 , чтобы иметь возможность доступа к содержимому другого приложения. Альтернативно, синтаксический анализатор 600 может быть реализован как часть приложения 102 обмена сообщениями, а читаемый пользователем контент другого приложения может быть передан синтаксическому анализатору 600 как часть запроса на инициирование составления электронного сообщения. сообщение. Например, вызов API, сделанный другим приложением в ответ на выбор зрителем гипертекстовой ссылки, может включать в себя унифицированный указатель ресурса (URL) веб-страницы, на которой находится читаемый пользователем контент, и синтаксический анализатор 9. 0005 600 , таким образом, можно использовать этот URL-адрес для доступа к веб-странице и анализа ее содержимого для идентификации слова имени.
РИС. 11 иллюстрирует пример реализации электронного устройства , 100, по фиг. 1 в соответствии по меньшей мере с одним вариантом осуществления настоящего раскрытия. В изображенном примере электронное устройство 100 включает в себя по меньшей мере один процессор 1102 (например, центральное устройство обработки или ЦП), один или несколько энергонезависимых машиночитаемых носителей данных, таких как системная память 1104 или другое запоминающее устройство 1106 (например, флэш-память, оптический или магнитный дисковод, твердотельный жесткий диск и т. д.), сетевой интерфейс 1108 (например, интерфейс беспроводной локальной сети (WAN) или проводной интерфейс Ethernet) и пользовательский интерфейс (UI) 1110 , подключенный через одну или несколько шин 1112 или другие межсоединения. UI 1110 включает в себя, например, устройство отображения 1114 и клавиатуру или сенсорный экран 1116 , а также другие компоненты ввода/вывода 1118 , такие как динамик или микрофон, для приема ввода или предоставления информации пользователю.
Процессор 1102 выполняет набор исполняемых инструкций, хранящихся на машиночитаемом носителе данных, таком как системная память 1104 или флэш-память, при этом набор исполняемых инструкций представляет собой одно или несколько программных приложений 1120 , например как приложение для обмена сообщениями 102 на фиг. 1. Программные приложения 1120 при выполнении манипулируют процессором 1102 для выполнения различных программных функций для реализации, по крайней мере, части описанных выше методов, предоставляют визуальную информацию через устройство отображения 1114 , отвечают на пользовательский ввод через сенсорный экран 1116 и т. п. Таким образом, большая часть изобретательских функциональных возможностей и многие изобретательские принципы, описанные выше, хорошо подходят для реализации с программами или в них. Ожидается, что специалист с обычными навыками, несмотря на возможные значительные усилия и множество вариантов дизайна, мотивированных, например, наличием времени, современной технологией и экономическими соображениями, руководствуясь концепциями и принципами, раскрытыми в настоящем документе, сможет легко создать такое программное обеспечение. инструкции и программы минимум экспериментов. Следовательно, в интересах краткости и сведения к минимуму любого риска затемнения принципов и концепций согласно настоящему раскрытию, дальнейшее обсуждение такого программного обеспечения, если таковое имеется, будет ограничено существенными элементами в отношении принципов и концепций в рамках предпочтительных вариантов осуществления. .
В этом документе относительные термины, такие как первый и второй и т. п., могут использоваться исключительно для того, чтобы отличить один объект или действие от другого объекта или действия, не обязательно требуя или подразумевая какие-либо фактические отношения или порядок между такими объектами или действиями. Термины «включает», «содержащий» или любой другой их вариант предназначены для охвата неисключительного включения, такого, что процесс, метод, изделие или устройство, которые включают список элементов, включают не только эти элементы, но и могут включать другие элементы, не указанные явно или присущие такому процессу, методу, изделию или устройству. Элемент, которому предшествует «содержит . . . а» без дополнительных ограничений не исключает существования дополнительных идентичных элементов в процессе, методе, изделии или устройстве, которые содержат элемент. Термин «другой», используемый здесь, определяется как по меньшей мере второй или более. Термины «включающий» и/или «имеющий», используемые в данном документе, определяются как содержащие. Термин «связанный», как он используется здесь в отношении электрооптической технологии, определяется как связанный, хотя и не обязательно напрямую, и не обязательно механически. Используемый здесь термин «программа» определяется как последовательность инструкций, предназначенных для выполнения в компьютерной системе. «Программа» или «компьютерная программа» может включать в себя подпрограмму, функцию, процедуру, объектный метод, реализацию объекта, исполняемое приложение, апплет, сервлет, исходный код, объектный код, общий библиотека/библиотека динамической загрузки и/или другая последовательность инструкций, предназначенная для выполнения в компьютерной системе.
Спецификацию и чертежи следует рассматривать только как примеры, и, соответственно, предполагается, что объем раскрытия ограничивается только следующей формулой изобретения и ее эквивалентами. Обратите внимание, что не все действия или элементы, описанные выше в общем описании, являются обязательными, что часть конкретного действия или устройства может не требоваться, и что одно или несколько дополнительных действий или элементы могут быть включены в дополнение к описанные. Более того, порядок перечисления действий не обязательно соответствует порядку их выполнения. Шаги блок-схем, изображенных выше, могут быть в любом порядке, если не указано иное, и шаги могут быть исключены, повторены и/или добавлены, в зависимости от реализации. Кроме того, концепции были описаны со ссылкой на конкретные варианты осуществления. Однако специалисту в данной области техники понятно, что различные модификации и изменения могут быть выполнены без отклонения от объема настоящего изобретения, изложенного в приведенной ниже формуле изобретения. Соответственно, описание и чертежи следует рассматривать в иллюстративном, а не ограничительном смысле, и предполагается, что все такие модификации включены в объем настоящего раскрытия.
Преимущества, другие преимущества и решения проблем были описаны выше в отношении конкретных вариантов осуществления. Однако выгоды, выгоды, решения проблем и любые свойства, которые могут привести к появлению или усилению каких-либо выгод, преимуществ или решений, не должны рассматриваться как критические, требуемые или существенные свойства любого или все претензии.
parslet — конструкция синтаксического анализатора
синтаксический анализатор — это не что иное, как класс, производный от Parslet::Parser . Самый простой синтаксический анализатор, который можно было бы написать,
выглядеть так:
класс SimpleParser < Parslet::Parser
правило (: a_rule) { ул ('simple_parser') }
корень (: a_rule)
конец
Язык, распознаваемый этим синтаксическим анализатором, представляет собой просто строку «simple_parser». Правила парсера очень похожи на методы и определяются с помощью
.
правило(имя) {определение_блока}
За кулисами это действительно определяет метод, который возвращает все, что вы вернуться из него.
У каждого парсера есть корень. Это указывает, где должен начинаться синтаксический анализ. Это похоже на точка входа в ваш парсер. С корнем, определенным следующим образом:
корень(:мой_корень)
вы создаете метод #parse в своем синтаксическом анализаторе, который начнет синтаксический анализ
вызвав метод #my_root . У вас также будет #root (экземплярный) метод, который является псевдонимом корневого метода. Следующие вещи
действительно один и тот же:
SimpleParser.new.parse(строка) SimpleParser.new.root.parse(строка) SimpleParser.new.a_rule.parse(строка)
Знание этих вещей дает вам большую гибкость; Я объясню, почему в конец главы. А пока просто позвольте мне указать, что, поскольку все это Ruby, ваш любимый редактор отлично подсветит синтаксис кода парсера.
Атомы: внутренняя часть анализатора
Совпадающие строки символов
Анализатор состоит из атомов анализатора (или парлетов, отсюда и название). атомы - это то, что появляется внутри ваших правил (и, возможно, где-то еще). мы уже встретил атом, строка атом:
ул('простой_парсер')
Это возвращает экземпляр Parslet::Atoms::Str . Эти атомы парсера
все они происходят от Parslet::Atoms::Base и, по сути, имеют только
один метод, который вы можете вызвать: #parse . Так это работает:
str('foobar').parse('foobar') # => "foobar"@0
Атомы — это небольшие синтаксические анализаторы, которые могут распознавать языки и выдавать ошибки, просто
как настоящие подклассы Parslet::Parser .
Совпадение диапазонов символов
Второй атом парсера, о котором вам нужно знать, позволяет вам сопоставлять диапазоны символов:
совпадение('[0-9a-f]')
Приведенный выше атом соответствует числам от нуля до девяти и буквам «а».
на «f» — да, вы угадали — например, шестнадцатеричные числа. Внутри
такого парслета сопоставления, по сути, является регулярным выражением, которое соответствует
один символ ввода. Поскольку мы будем так часто использовать диапазоны с #match и поскольку печатать ('[]') утомительно, вот еще один способ
написать выше #match атом:
матч ['0-9a-f']
Совпадения символов являются экземплярами Parslet::Atoms::Re . Здесь
еще несколько примеров диапазонов символов:
match['[:alnum:]'] # буквы и цифры
match['\n'] # новые строки
match('\w') # символы слова
match('.') # любой символ
The wild wild
#any Последний пример выше соответствует регулярному выражению /./ , который соответствует
любой один символ. Для этого есть специальный атом:
Любые
Состав атомов
Из этих основных атомов можно составить сложные грамматики. Следующее несколько разделов расскажут вам о различных способах составления атомов.
Простые последовательности
Соответствие «foo» и затем «bar»:
str('foo') >> str('bar') # то же, что и str('foobar')
Последовательности соответствуют экземплярам класса Parslet::Atoms::Sequence .
Повторение и его особые случаи
Для моделирования повторяющихся атомов следует использовать #repeat :
ул('foo'). повторить
Это позволит foo повторяться любое количество раз, включая ноль. если ты
смотрим подпись для #повторяем в Parslet::Atoms::Base ,
вы увидите, что на самом деле у него два аргумента: min и max . Итак, следующее
код все понятно:
str('foo').repeat(1) # соответствует 'foo' хотя бы один раз
str('foo').repeat(1,3) # не менее одного и не более 3 раз
str('foo').repeat(0, nil) # по умолчанию: то же, что и str('foo').repeat
Повторение имеет особый случай, который часто используется: соответствие чему-либо
один раз или совсем не может быть достигнуто с помощью repeat(0,1) , но также
через красивое:
str('foo').maybe # то же, что и str('foo').repeat(0,1)
Все они соответствуют Parslet::Atoms::Repetition . Обратите внимание на это
небольшой поворот к #возможно :
str('foo').maybe.as(:f).parse('') # => {:f=>nil}
str('foo'). repeat(0,1).as(:f).parse('') # => {:f=>[]}
Нулевое значение #возможно равно нулю. Это обслуживание
интуиция, что foo.maybe либо дает мне foo , либо
вообще ничего, не пустой массив. Но будь по-твоему!
Чередование
Наиболее важным методом построения грамматик является чередование. Без то ваши грамматики будут различаться только количеством совпадающих вещей, но не в содержании. Вот как это выглядит:
ул('foo') | str('bar') # соответствует 'foo' ИЛИ 'bar'
Обычно это читается как «foo» или «bar».
Приоритет оператора
Операторы, которые мы выбрали для комбинации атомов парслета, имеют оператор приоритет, который вы ожидаете. Скобки не нужны, чтобы выразить чередование последовательностей:
str('s') >> str('последовательность') |
str('se') >> str('quence')
И многое другое
Атомы парслета не так красивы, как атомы верхушки дерева. Ну вот, мы сказали это. Однако кажется, что в них есть другая эстетика; Oни
являются чистым Ruby и хорошо интегрируются с остальной частью вашей среды. Иметь
посмотри на это:
# Также занимает место после важных элементов, таких как ';' или же ':'. Назовите это
# указав символ, который вы хотите сопоставить, в качестве аргумента:
#
# arg >> (spaced(',') >> arg).repeat
#
def с интервалом (символ)
строка (символ) >> соответствует ['\s']
конец
или даже так:
# Превращает любой атом в выражение, соответствующее левой скобке,
# атом, а затем правая скобка.
#
# в квадратных скобках (сумма)
#
def в квадратных скобках (атом)
с интервалом ('(') >> атом >> с интервалом (')')
конец
Вы могли бы сказать, что, поскольку parslet — это просто старые объекты Ruby (PORO ™), это позволяет создавать очень плотный код. Включение модулей, наследование классов,… все ваши инструменты должны хорошо работать с parslet.
Построение дерева
По умолчанию parslet просто возвращает вам те строки, которые вы ему вводите. Parslet не будет генерировать парсер для вас и не будет генерировать ваш
абстрактное синтаксическое дерево для вас. Метод #as(name) позволяет вам
чтобы точно указать, как вы хотите, чтобы ваше дерево выглядело:
str('foo').parse('foo') # => "foo"@0
str('foo').as(:bar).parse('foo') # => {:bar=>"foo"@0}
Итак, вы думаете: #as(name) позволяет мне создать хеш, большое дело.
Это не все. Вы заметите, что аннотирование всего, что вы хотите сохранить
в вашей грамматике с #as(name) автоматически создает разумное дерево
состоит из хэшей, массивов и строк. Это действительно немного волшебно: Parslet
имеет набор умных правил, которые объединяют аннотированный вывод ваших атомов в
дерево. Вот еще несколько примеров с атомом слева и результирующим
дерево (при условии успешного синтаксического анализа) справа:
# Обычные строки просто отображаются в строки
ул('а').Повторить "ааа"@0
# Массивы фиксируют повторение не строк
str('a'). repeat.as(:b) {:b=>"aaa"@0}
str('a').as(:b).repeat [{:b=>"a"@0}, {:b=>"a"@1}, {:b=>"a"@2} ]
# Поддеревья объединяются - немаркированные строки отбрасываются
str('a').as(:a) >> str('b').as(:b) {:a=>"a"@0, :b=>"b"@1}
str('a') >> str('b').as(:b) >> str('c') {:b=>"b"@1}
# #возможно вернет nil, а не пустой массив
ул('а').maybe.as(:а) {:а=>"а"@0}
ул('а').maybe.as(:а) {:а=>ноль}
Захват ввода
Расширенный материал для чтения — не стесняйтесь пропустить это.
Иногда синтаксическому анализатору необходимо сопоставить что-то, что уже было сопоставлено против. Подумайте о документах Ruby, например:
.
ул = <<- ЗДЕСЬ
Это часть heredoc.
ЗДЕСЬ
Ключом к сопоставлению документов такого типа является захват части входных данных сначала, а затем построить остальную часть парсера на основе захваченной части. Вот как это выглядит в простейшем виде:
match['ab'].capture(:capt) >> # создаем захват
динамический { | с, с | str(c. captures[:capt]) } # и сопоставить с использованием захвата
Этот синтаксический анализатор соответствует либо «aa», либо «bb», но не смешанным формам «ab» или «ba».
В последнем примере представлены два новых понятия для такого сложного синтаксического анализатора: #capture(name) Метод и код dynamic { ... } блокировать.
Добавление #capture(name) к любому синтаксическому анализатору захватит эти синтаксические анализаторы
приводит к получению хэша в контексте синтаксического анализа. Тогда и только тогда, когда парсер match['ab'] успешно, он сохраняет либо «a», либо «b» в context.captures[:capt] .
Единственный способ получить этот хеш в процессе синтаксического анализа — это динамический { ... } кодовый блок. (по причинам, не зависящим от
рамки этого документа) В таком блоке можно:
динамический { |источник, контекст|
# создавать парсеры, используя случайность
ранд < 0,5 ? ул('а'): ул('б')
# Или используя контекстную информацию
ул(контекст. захваты[:захват])
# Или .. выполняя другую работу (потребляет 100 символов, а затем 'a')
источник.потребить(100)
ул('а')
}
Scopes
Что делать, если вы хотите проанализировать heredocs, содержащиеся внутри heredocs? это все черепашки
путь вниз, в конце концов. Чтобы иметь возможность вспомнить, какая строка использовалась для
построить внешний heredoc, вы должны использовать #scope { ... } блок, который был введен в parslet 1.5. Подобно открытию блока Ruby, он позволяет
вам записывать результаты (присваивать значения переменным) тем же именам, которые вы
уже используется во внешней области видимости — без уничтожения значений внешней области видимости для
эти захваты! .
Вот пример:
str('a').capture(:a) >> область {str('b').capture(:a) } >>
динамический { | с, с | ул(c.captures[:a]) }
Это анализирует «аба» — если вы понимаете это, вы понимаете области действия и
захватывает. Поздравляю.
И многое другое
Теперь вы точно знаете, как создавать парсеры с помощью Parslet. Ваши парсеры будет выводить сложные структуры, состоящие из бесконечных массивов, сложных хэшей и несколько остатков струн. Но ваши навыки программирования подводят вас, когда вы пытаетесь чтобы использовать все эти данные. Выбирая ключи за ключами в хеше за хешем, вы чувствовать себя тараканом, только что прочитавшим произведения Кафки. Это не весело. Этот это не то, на что вы подписались.
Пришло время познакомить вас с Parslet::Transform и его работой.
AMUSE: многоязычный семантический анализ для ответов на вопросы по связанным данным
1 Введение
Задаче ответов на вопросы по связанным данным (QALD) в последние годы уделяется повышенное внимание (см. опросы [14] и [36] ).
Задача состоит в отображении вопросов на естественном языке в исполняемую форму, например. в частности, запрос SPARQL, который позволяет получить ответы на вопрос из заданной базы знаний. Рассмотрим вопрос: Кто создал Википедию?, который можно интерпретировать как следующий запрос SPARQL по отношению к DBpedia 9.0941 1 1 1Префиксы dbo и dbr обозначают пространства имен http://dbpedia.org/ontology и http://dbpedia.org/resource/ соответственно.:
SELECT DISTINCT ?uri WHERE { dbr:Wikipedia dbo:author ?uri .}
Важная проблема при сопоставлении вопросов на естественном языке с запросами SPARQL заключается в преодолении так называемого «лексического пробела» (см. [13] , [14] ). Лексический пробел затрудняет правильную интерпретацию вышеупомянутого вопроса, поскольку нет никакой поверхностной связи между созданной строкой запроса и локальным именем автора URI. Чтобы преодолеть лексический разрыв, системам необходимо сделать вывод, что в приведенном выше случае create следует интерпретировать как автор.
Лексический разрыв только усугубляется при рассмотрении нескольких языков, поскольку мы сталкиваемся с межъязыковым разрывом, который необходимо преодолеть. Рассмотрим, например, вопрос: Wer hat Wikipedia gegründet?, который включает сопоставление gründen с автором для успешной интерпретации вопроса.
Устраняя лексический пробел в ответах на вопросы по связанным данным, мы представляем новую систему, которую мы называем AMUSE, которая опирается на вероятностный вывод для выполнения структурированного прогнозирования в пространстве поиска возможных запросов SPARQL для прогнозирования запроса, который имеет наибольшую вероятность быть правильным. интерпретация заданной строки запроса. В качестве основного вклада в статью мы представляем новый подход к ответам на вопросы по связанным данным, который опирается на вероятностный вывод для определения наиболее вероятного значения вопроса с учетом модели.
Параметры модели оптимизированы для заданного обучающего набора данных, состоящего из вопросов на естественном языке с соответствующими запросами SPARQL, как это предусмотрено эталонным тестом QALD. Процесс вывода основан на приближенных методах вывода, в частности на методе Монте-Карло цепи Маркова, для присвоения идентификаторов базы знаний (KB), а также смысловых представлений каждому узлу в дереве зависимостей, представляющем структуру синтаксической зависимости вопроса. На основе этих назначенных смысловых представлений каждому узлу можно вычислить полное семантическое представление, опираясь на восходящую семантическую композицию по дереву синтаксического анализа. В качестве новинки наша модель может обучаться на разных языках, полагаясь на универсальные зависимости.
Насколько нам известно, это первая система для ответов на вопросы по связанным данным, которую можно обучить для работы на разных языках (в нашем случае на трех) без необходимости реализации какой-либо эвристики или знаний, специфичных для языка.
Чтобы преодолеть межъязыковой лексический разрыв, мы экспериментируем с автоматически переведенными метками и полагаемся на подход встраивания для извлечения похожих слов в пространстве встраивания. Мы показываем, что с помощью встраивания слов можно эффективно способствовать сокращению лексического разрыва по сравнению с базовой системой, в которой используются только известные метки.
2 Подход
Наша интуиция в этой статье заключается в том, что интерпретация вопроса на естественном языке с точки зрения запроса SPARQL представляет собой композиционный процесс, в котором частичные семантические представления комбинируются друг с другом восходящим образом вдоль дерева зависимостей, представляющего синтаксическую структуру заданный вопрос. Вместо того, чтобы полагаться на созданные вручную правила, определяющие композицию, мы полагаемся на подход к обучению, который может вывести такие «правила» из обучающих данных. Мы используем модель факторного графа, которая обучается с использованием цели ранжирования и SampleRank в качестве процедуры обучения, чтобы изучить модель, которая учится предпочитать хорошие интерпретации вопроса плохим. По сути, интерпретация вопроса, представленного в виде дерева зависимостей, состоит из присвоения нескольких переменных: i) идентификатора базы знаний и семантического типа для каждого узла в дереве синтаксического анализа и ii) индекса аргумента (1 или 2) для каждого узла. край в дереве зависимостей, указывающий, к какому слоту родительского узла, субъекта или объекта должен быть применен дочерний узел. Таким образом, входными данными для нашего подхода является набор пар (q,sp) вопроса q и запроса SPARQL sp. В качестве примера рассмотрим следующие вопросы на английском, немецком и испанском языках: Кто создал Википедию? Wer hat Wikipedia gegrundet? ¿Quién creó Википедия? соответственно. Независимо от языка, на котором они выражены, три вопроса можно интерпретировать как один и тот же запрос SPARQL из введения.
Наш подход состоит из двух уровней вывода, которые мы называем L2KB и QC. Каждый из этих слоев состоит из различных графов факторов, оптимизированных для разных подзадач общей задачи. Первый уровень вывода обучается с использованием цели связывания объектов, которая учится связывать части запроса с идентификаторами базы знаний. В частности, на этом шаге вывода идентификаторы KB присваиваются словам открытого класса, таким как существительные, имена собственные, прилагательные, глаголы и т. д. В нашем случае базой знаний является DBpedia. Мы используем универсальные зависимости 2 2 2http://universaldependencies.org/v2, 70 банков деревьев, 50 языков [28] для получения деревьев анализа зависимостей для 3 языков.
Второй уровень вывода — это уровень построения запросов, который берет k лучших результатов из уровня L2KB и присваивает семантические представления словам закрытого класса, таким как вопросительные местоимения, определители и т. д., чтобы получить логическое представление полного вопроса. Подход обучается на наборе данных поезда QALD-6 для вопросов на английском, немецком и испанском языках для оптимизации параметров модели. Модель изучает сопоставления между деревом синтаксического анализа зависимостей для заданного текста вопроса и узлами RDF в запросе SPARQL. На выходе наша система создает исполняемый SPARQL-запрос для заданного вопроса NL. Все данные и исходный код находятся в свободном доступе 3 3 3https://github.com/ag-sc/AMUSE. В качестве семантических представлений мы полагаемся на DUDES, которые описаны в следующем разделе.
2.1 Чуваки
DUDES ( Недоопределенные структуры представления дискурса на основе зависимостей ) [9] - это формализм для определения смысловых представлений и их композиции. Они основаны на Теории репрезентации недоопределенного дискурса (UDRT) [33, 10] и полученных в результате репрезентациях смысла. Формально DUDE определяется следующим образом:
Определение 1
A DUDE состоит из 5 кортежей (v,vs,l,drs,slots), где
v - это основная переменная в DUDES
.vs - это (возможно, пустой) набор переменных, переменные проекции
л это маркировка основного DRS
drs - это DRS (основное смысловое наполнение DUDE)
слотов — это (возможно, пустой) набор семантических зависимостей
Таким образом, ядром DUDES является Структура представления дискурса (DRS) [15] . Основная переменная представляет собой переменную, которая должна быть объединена с переменными в слотах других ЧУВАКОВ, в которые вставлен рассматриваемый ЧУВАК. Каждый DUDE собирает информацию о том, какие семантические аргументы необходимы для того, чтобы DUDE был завершен в том смысле, что все слоты были заполнены. Эти обязательные аргументы моделируются как набор слотов, которые заполняются через (функциональное) применение других ЧЕЛОВЕКОВ. Проекционные переменные важны для представления вопросов; они указывают, какая сущность запрашивается. При преобразовании DUDES в запросы SPARQL они будут напрямую соответствовать переменным в предложении SELECT запроса. Наконец, слоты собирают информацию о том, какие синтаксические элементы соответствуют каким семантическим аргументам в DUDE.
В качестве основных единиц композиции мы рассматриваем 5 предопределенных типов DUDES, которые соответствуют элементам данных в наборах данных RDF.
Мы рассматриваем Resource DUDES , которые представляют ресурсы или отдельных лиц, обозначаемых именами собственными, такими как Wikipedia (см. 1st DUDES на рисунке 1). Мы рассматриваем Класса ПИВАНОВ, которым соответствуют наборы элементов, т.е. классы, например класс Лица (см. 2-й ПИВАН на Рисунке 1). Мы также рассматриваем недвижимость DUDES , которые соответствуют свойствам объекта или типа данных, таким как автор (см. 3-й DUDES на рисунке 1). Далее мы рассматриваем классы ограничений, которые представляют значение интерсективных прилагательных, таких как , шведский, (см. 4-й DUDES на рис. 1). Наконец, для определения значения вопросительных местоимений можно использовать специальный тип DUDES, например: Who или What (см. 5-й ЧУВЧИК на рис. 1).
При применении ЧУВСТВА d2 к d1, где d1 разделяет на подкатегории ряд семантических аргументов, нам нужно указать, какой аргумент d2 заполняет. Например, применение 1-го ЧУВАНА на рис. 1 к 3-му ЧУВАНУ на рис. 1 с индексом аргумента 1 дает следующий ЧУВАН:
v:- vs:{} l:1 1: \tt dbo:автор(dbr:Wikipedia,y) (у, а2, 2)
2.2 Императивно определенные графы факторов
В этом разделе мы вводим понятие графов факторов [19] , следуя обозначениям [41] и [17] . Факторный граф G
— это двудольный граф, определяющий распределение вероятностей
π. Граф состоит из переменных V и факторов Ψ. Переменные можно дополнительно разделить на наборы наблюдаемых переменных X и скрытых переменных Y. Фактор Ψi соединяет подмножества наблюдаемых переменных xi и скрытых переменных yi
и вычисляет скалярную оценку на основе экспоненты скалярного произведения вектора признаков
fi(xi,yi) и набора параметров θi: Ψi= efi(xi,yi)⋅θi. Вероятность скрытых переменных при наблюдаемых переменных является произведением отдельных факторов:
| π(y|x;θ)=1Z(x)∏Ψi∈GΨi(xi,yi)=1Z(x)∏Ψi∈Gefi(xi,yi)⋅θi | (1) |
где Z(x) — статистическая сумма.
Для заданных входных данных, состоящих из проанализированного на основе зависимостей предложения, граф факторов разворачивается путем применения шаблонных процедур, которые сопоставляют части входных данных и генерируют соответствующие факторы. Таким образом, шаблоны представляют собой императивно заданные процедуры, разворачивающие граф.
Шаблон Tj∈T определяет подмножества наблюдаемых и скрытых переменных (x′,y′) с x′∈Xj и y′∈Yj, для которых он может генерировать факторы, и функцию fj(x′,y′) для генерирования признаков для этих переменных.
Кроме того, все факторы, созданные данным шаблоном Tj, имеют одни и те же параметры θj.
С этим определением мы можем переформулировать условную вероятность следующим образом:
| π(y|x;θ)=1Z(x)∏Tj∈T∏(x′,y′)∈Tjefj(x′,y′)⋅θj | (2) |
Входными данными для нашего подхода является пара (W,E), состоящая из последовательности слов W={w1,…,wn} и набора ребер зависимости E⊆W×W, образующих дерево.
Состояние (W,E,α,β,γ) представляет собой частичную интерпретацию ввода в терминах частичных семантических представлений.
Частичные функции α:W→KB, β:W→{t1,t2,t3,t4,t5} и γ:E→{1,2} отображают слова в идентификаторы KB, слова в пять основных типов DUDES и ребра. индексам семантических аргументов, где 1 соответствует субъекту свойства, а 2 соответствует объекту соответственно.
На рис. 2 показана схематическая визуализация вопроса вместе с его графом факторов. Факторы измеряют совместимость между различными назначениями наблюдаемых и скрытых переменных. Интерпретация вопроса — это та, которая максимизирует апостериорную модель с параметрами θ: y∗=argmaxyπ(y|x;θ).
2.3 Вывод
Мы полагаемся на приближенную процедуру вывода, в частности на цепь Маркова Монте-Карло [1] .
Метод выполняет итеративный вывод для изучения пространства состояний возможных интерпретаций вопросов, предлагая конкретные изменения в наборах переменных, которые определяют распределение предложений. Процедура вывода выполняет итеративный локальный поиск и может быть разделена на (i) создание возможных состояний-преемников для данного состояния путем применения изменений, (ii) оценку состояний с использованием оценки модели и (iii) принятие решения о том, какое предложение принять в качестве преемника. государство. Предложение принимается с вероятностью, пропорциональной вероятности, заданной распределением π. Чтобы вычислить логическую форму вопроса, мы запускаем две процедуры вывода, используя две разные модели.
Первая модель L2KB обучается с использованием цели связывания, которая учится сопоставлять слова открытого класса с идентификаторами KB.
Процесс выборки MCMC выполняется за m шагов для модели L2KB; верхние k состояний используются в качестве входных данных для второй модели вывода, называемой QC, которая присваивает значения словам закрытого класса, чтобы получить полноценное семантическое представление вопроса. Обе стратегии вывода генерируют последующие состояния путем исследования на основе ребер в дереве синтаксического анализа зависимостей. Мы исследуем только следующие типы ребер: основные аргументы, неосновные зависимые элементы, номинальные зависимые элементы, определенные универсальными зависимостями 9.0941 4 4 4http://universaldependencies.org/u/dep/index. html и узлы со следующими тегами POS: NOUN, VERB, ADJ, PRON, PROPN, DET.
В обеих моделях вывода мы чередуем итерации между использованием вероятности состояния, заданного моделью, и объективной оценкой, чтобы решить, какое состояние принять. Изначально все частичные присваивания α0,β0,γ0. пусты.
Мы полагаемся на инвертированный индекс, чтобы найти все идентификаторы базы знаний для данного термина запроса. Инвертированный индекс сопоставляет термины с кандидатами в идентификаторы базы знаний для всех трех языков. Он создан с учетом ряда ресурсов: названий ресурсов DBpedia, анкорных текстов и ссылок Википедии, названий классов DBpedia, синонимов классов DBpedia из WordNet 9.0937 [26, 16] , а также лексикализации свойств и классов ограничений из DBlexipedia [40] . Записи в указателе сгруппированы по типу DUDES, так что он поддерживает поиск по типу. Индекс хранит частоту упоминаний в паре с идентификатором базы знаний. Во время поиска индекс возвращает нормализованную оценку частоты для каждого кандидата в идентификатор базы знаний.
2.3.1 L2KB: ссылка на базу знаний
Генерация предложений: Генерация предложений L2KB предлагает изменения в заданном состоянии, рассматривая ребра одной зависимости и изменяя: i) идентификаторы KB родительских и дочерних узлов, ii) тип DUDES родительских и дочерних узлов и iii) индекс аргумента. прикреплен к краю. Переменные семантического типа варьируются в пределах 5 определенных основных типов DUDES, в то время как переменная индекса аргумента находится в диапазоне {1,2}. Результирующие частичные семантические представления ребра зависимости проверяются на выполнимость по отношению к базе знаний, сокращая предложение, если оно не выполнимо. На Рисунке 3 показано местное исследование добж -край между Википедия и создал . Левое изображение показывает начальное состояние с пустыми присваиваниями для всех скрытых переменных. На правом изображении показано предложение, в котором изменены идентификаторы KB и типы DUDE узлов, подключаемых ребром dobj . Процесс вывода присвоил идентификатор базы знаний dbo:author и тип Property DUDES созданному узлу . Узлам Wikipedia присваивается тип Resource DUDES, а также идентификатор базы знаний dbr:Wikipedia. Ребро зависимости получает индекс аргумента 1, означающий, что dbr:Wikipedia должен быть вставлен в позицию субъекта свойства dbo:author. Частичное семантическое представление, представленное этим ребром, изображено в конце раздела 2.2. Поскольку это выполнимо, оно не обрезается. Напротив, состояние, в котором ребру присваивается индекс аргумента 2, даст следующее невыполнимое представление, соответствующее вещам, автором которых является 9.0807 Википедия вместо вещей, созданных Википедия :
| v:- vs:{} l:1 | ||
1:
| ||
(у, а2, 2) |
Рисунок 3: Слева: исходное состояние на основе синтаксического анализа зависимостей, где каждый узел имеет пустой идентификатор базы знаний и семантический тип.
Справа: Предложение, созданное при генерации предложения LKB для вопроса 9.0807 Кто создал Википедию? Целевая функция:
В качестве цели для модели L2KB мы полагаемся на цель связывания, которая вычисляет перекрытие между предполагаемыми ссылками на сущности и ссылками на сущности в золотом стандартном запросе SPARQL.
Все сгенерированные состояния ранжируются по целевому показателю. Состояния Top-k передаются на следующий шаг выборки. На следующей итерации вывод выполняется для этих k состояний. Выполнение этой процедуры для m итераций дает последовательность состояний (s0,…,sm), которые выбираются из распределения, определяемого лежащими в основе факторными графами.
2.3.2 Контроль качества: конструкция запроса
Генерация предложения: Предложения на этом уровне вывода состоят из назначений типа QueryVar DUDES узлам для слов класса, в частности определителей, которые могут заполнить позицию аргумента родителя неудовлетворенными аргументами.
Объективная функция:
В качестве цели мы используем целевую функцию, которая измеряет сходство (график) между предполагаемым запросом SPARQL и запросом SPARQL золотого стандарта.
На рис. 4 показано состояние ввода и состояние выборки для уровня вывода QC нашего примера запроса: Кто создал Википедию? . Исходное состояние (см. слева) имеет слот 1, назначенный ребру dobj . Свойство ЧУВЧИКИ имеют 2 слота по определению. На правом рисунке показано предлагаемое состояние, в котором слот аргумента 2 назначен ребру nsubj, а тип QueryVar DUDES назначен узлу Who . Это соответствует представлению и запросам SPARQL ниже:
| v:- vs:{y} l:1 | ||
1:
| ||
SELECT DISTINCT ?y WHERE {dbr:Wikipedia dbo:author ?y .}
Рисунок 4: Слева: состояние входа; Справа: Предложение, созданное генерацией предложения QC для вопроса Кто создал Википедию? 2.
4 ОсобенностиВ качестве признаков для факторов мы используем конъюнкции следующей информации: i) лемма родительского и дочернего узлов, ii) идентификаторы KB родительского и дочернего узлов, iii) POS-теги родительского и дочернего узлов, iv) тип DUDE родительского узла и дочерний, v) индекс аргумента на краю, vi) отношение зависимости края, vii) нормализованный показатель частоты для извлеченных идентификаторов КБ, viii) сходство строк между идентификатором КБ и леммой узла, ix) ограничения rdfs:domain и rdfs:range для родительского идентификатора базы знаний (в случае, если он является свойством).
2.5 Параметры модели обучения
Для оптимизации параметров θ мы используем реализацию алгоритма SampleRank [41] . Алгоритм SampleRank получает градиенты для этих параметров из пар последовательных состояний в цепочке на основе функции предпочтения P, определенной через целевую функцию O следующим образом:
| P(s′,s)={1, если O(s′)>O(s)0, иначе | (3) |
Мы заметили, что принятие предложений только на основе оценки модели требует большого количества шагов логического вывода. Это связано с тем, что пространство для исследования огромно, учитывая все ресурсы-кандидаты, предикаты, классы и т. д. в DBpedia. Чтобы направить поиск к хорошим решениям, мы переключаемся между оценкой модели и объективной оценкой, чтобы вычислить вероятность принятия предложения. Как только процедура обучения переключает функцию оценки на следующем шаге выборки, модель использует параметры из предыдущего шага для оценки состояний.
2.6 Устранение лексического пробела
Ключевым компонентом предлагаемого конвейера ответов на вопросы является уровень L2KB. Этот уровень отвечает за предложение возможных идентификаторов KB для частей вопроса. Рассмотрим вопрос Кто автор Голодных игр? Кажется тривиальной задачей связать слово запроса , писатель , с соответствующим идентификатором dbo:author, однако для этого по-прежнему требуются предварительные знания о семантике слова запроса и записи в базе знаний (например, что автором книги является Автор).
Чтобы устранить лексический пробел, мы полагаемся, с одной стороны, на лексикализации свойств DBpedia, извлеченных M-ATOLL. [39, 40] для нескольких языков 5 5 5M-ATOLL в настоящее время предоставляет лексикализации для английского, немецкого и испанского языков.
Однако, в частности, для испанского и немецкого языков M-ATOLL дает очень скудные результаты. Мы предлагаем два решения для преодоления лексического пробела: использование машинного перевода для перевода английских меток на другие языки, а также использование встраивания слов для получения свойств-кандидатов для данного текста упоминания.
Машинные переводы
Мы полагаемся на онлайн-словарь Dict.cc 6 6 6http://www.dict.cc в качестве нашего механизма перевода. Мы запрашиваем у веб-службы каждую доступную английскую метку и целевой язык и сохраняем полученные кандидаты на перевод в качестве новых меток для соответствующего объекта и языка.
Хотя эти переводы могут быть зашумлены без надлежащего контекста, мы получаем разумную отправную точку для создания кандидатов на лексикализации, особенно в сочетании с подходом встраивания слов.
Поиск встраивания слов
Было показано, что многие методы встраивания слов, такие как метод пропуска грамм [25] , кодируют полезные семантические и синтаксические свойства. Цель метода пропуска грамм состоит в том, чтобы изучить представления слов, которые полезны для предсказания контекстных слов. В результате изученные вложения часто отображают желаемую линейную структуру, которую можно использовать с помощью простого сложения векторов. Руководствуясь композицией векторов слов, мы предлагаем меру семантической связи между упоминанием m и записью e 9 в БДпедии.0003
, используя косинусное сходство между соответствующими представлениями векторов
→ vm и → ve.
Для этого мы следуем подходу [5] для получения векторов встраивания сущностей из векторов слов:
Определим вектор упоминания m как сумму векторов его токенов 7 7 7 Мы опускаем все токены стоп-слов. →vm=∑t∈m→vt, где →vt — необработанные векторы из набора предварительно обученных векторов скип-грамм. Точно так же мы получаем векторное представление записи DBpedia e, добавляя отдельные векторы слов для соответствующей метки le для e, таким образом, →ve=∑t∈le→vt.
Например, вектор для текста упоминания кинорежиссер составлен как →vmovie director = →vmovie+→vdirector. Запись DBpedia dbo:director имеет метку режиссер фильма и, таким образом, состоит из →vdbo:director=→vfilm+→vdirector.
Чтобы сгенерировать потенциальных кандидатов на связывание с учетом текста упоминания, мы можем вычислить косинусное сходство между →vm и каждым возможным →ve
как меру семантической связанности и, таким образом, произвести ранжирование всех записей-кандидатов. Сокращая ранжирование по выбранному порогу, мы можем контролировать точность и полноту создаваемого списка кандидатов.
Для этой работы мы обучили 3 экземпляра модели skip-gram с каждыми 100 измерениями в английской, немецкой и испанской Википедии соответственно. Следуя этому подходу, записи DBpedia с самым высоким рейтингом для текста упоминания общая численность населения перечислены ниже:
Более подробная оценка проводится в разделе 3, где мы исследуем поиск кандидатов по сравнению с базовым уровнем M-ATOLL.
3 Эксперименты и оценка
Мы представляем эксперименты, проведенные с набором данных QALD-6, состоящим из вопросов на английском, немецком и испанском языках. Обучаем и тестируем на многоязычной подзадаче. Это дает набор обучающих данных, состоящий из 350 и 100 тестовых экземпляров. Мы обучаем модель с 350 обучающими экземплярами для каждого языка из набора данных обучения QALD-6, выполняя 10 итераций по набору данных со скоростью обучения, установленной на 0,01, для оптимизации параметров. Мы устанавливаем k равным 10. Мы выполняем шаг предварительной обработки дерева синтаксического анализа зависимостей перед запуском конвейера. Этот шаг состоит из слияния узлов, соединенных составными ребрами. Это приводит к тому, что для составных имен используется один узел, что снижает время прохождения и сложность модели. Подход оценивается по двум задачам: задача связывания и задача ответа на вопрос. Задача связывания оценивается путем сравнения предлагаемых ссылок базы знаний с элементами базы знаний, содержащимися в вопросе SPARQL, с точки зрения F-меры. Задача ответа на вопрос оценивается путем выполнения созданного запроса SPARQL по базе знаний DBpedia и сравнения полученных ответов с ответами, полученными для золотого стандартного запроса SPARQL, с точки зрения F-меры.
Перед оценкой всего конвейера задачи контроля качества мы оцениваем влияние использования различных лексических ресурсов, включая встраивание слов, для вывода неизвестных лексических отношений.
3.1 Оценка Lexicon Generation
Мы оцениваем предлагаемые методы генерации лексикона с использованием машинного перевода и встраивания в отношении лексикона ручных аннотаций, полученных из обучающего набора набора данных QALD-6.
Ручной лексикон представляет собой сопоставление упоминания с ожидаемой записью в базе знаний, полученной из пар (вопрос-запрос) в наборе данных QALD-6.
Поскольку M-ATOLL предоставляет только свойства онтологии DBpedia, мы ограничиваем наш подход к встраиванию слов, чтобы также создавать только это подмножество сущностей KB. Аналогичным образом ручной лексикон фильтруется таким образом, что он содержит только записи свойств слова для свойств онтологии DBpedia, чтобы предотвратить ненужное искажение результатов оценки из-за неразрешимых терминов запроса.
Оценка выполняется по количеству сгенерированных кандидатов на термин запроса с использованием показателя Recall@k. Сосредоточение внимания на воспоминании является разумной оценочной метрикой, поскольку рассматриваемый ручной лексикон далеко не исчерпывающий, а отражает лишь небольшое подмножество возможных лексикализации свойств базы знаний в вопросах на естественном языке. Кроме того, компонент L2KB отвечает за создание набора связанных состояний-кандидатов, которые служат отправными точками для второго уровня вывода, уровня контроля качества. Предоставление компонента с высокой степенью отзыва на этом этапе конвейера имеет решающее значение для компонента построения запроса.
На рис. 5 визуализирована производительность поиска с использованием метрики Recall@k. Мы можем наблюдать значительное увеличение отзыва на разных языках при создании кандидатов с использованием метода встраивания слов. Сочетание кандидатов M-ATOLL с кандидатами на встраивание слов дает наилучшую производительность припоминания. Наибольший абсолютный прирост наблюдается для немецкого языка.
| (а) Английский | (б) немецкий | (с) испанский |
Чтобы контекстуализировать наши результаты, мы обеспечиваем верхнюю границу для нашего подхода, который состоит из прогона всех экземпляров в тесте с использованием 1 эпохи и принятия состояний только в соответствии с объективной оценкой, что дает подход, подобный оракулу. Мы сообщаем макро-F-меры для этого оракула в таблице
1 вместе с фактическими результатами теста при оптимизации параметров обучающих данных. Мы оцениваем различные конфигурации нашей системы, в которых мы рассматриваем i) словарь имен, полученный только из меток DBpedia (DBP), ii) дополнительные словарные записи, полученные из DBLexipedia (DBLex), iii) словарь, созданный вручную (Dict), и iv) записи, выведенные с использованием косинусного сходства в пространстве встраивания (Embed).
Важно отметить, что даже оракул не дает идеальных результатов, что связано с тем, что лексический разрыв все еще сохраняется, и некоторые записи не могут быть сопоставлены с правильными идентификаторами базы знаний. Кроме того, ошибки в тегах POS или в дереве зависимостей не позволяют стратегии логического вывода генерировать правильные предложения.
Мы видим, что во всех конфигурациях результаты явно улучшаются при использовании дополнительных записей из DBLexipedia (DBLex) по сравнению с использованием только меток из DBpedia. Результаты еще больше улучшаются при добавлении лексических элементов, выведенных на основе сходства в пространстве встраивания (+ Embed), но все еще далеки от результатов с созданным вручную словарем (Dict), что показывает, что устранение лексического пробела является важной проблемой для повышения производительности ответов на вопросы. системы над связанными данными.
В задаче связывания, несмотря на то, что использование внедрений повышает производительность, как видно из условия DBP + DBLex + Embed по сравнению с условием DBP + DBLex, по-прежнему существует явный запас по сравнению с условием DBP + DBLex + Dict (английский 0,16 против 0,22, немецкий 0,10 против 0,27, испанский 0,04 против 0,30).
В задаче контроля качества добавление вложений поверх DBP + DBLex также оказывает положительное влияние, но также ниже по сравнению с условием DBP + DBLex + Dict (английский 0,26 против 0,34, немецкий 0,16 против 0,37, испанский 0,20 против 0,42). Очевидно, можно заметить, что разница между изученной моделью и оракулом уменьшается по мере того, как в систему добавляется больше лексических знаний.
Таблица 1: Макро-баллы F1 по тестовым данным для задач связывания и ответов на вопросы с использованием различных конфигураций3.3 Анализ ошибок
Анализ ошибок выявил следующие четыре распространенные ошибки, которые мешали системе найти правильную интерпретацию: i) неверный ресурс (30% тестовых вопросов), как в . Когда состоялось Бостонское чаепитие? , где Бостонское чаепитие не сопоставлен ни с одним ресурсом, ii) неправильное свойство (48%), как в вопросе Кто написал песню Hotel California? , где наша система выводит свойство dbpedia:musicalArtist для песни вместо свойства dbpedia:writer, iii) неправильный слот (10%), как в Сколько людей живет в Польше? , где предполагается, что Польша заполнит 2-й слот вместо 1-го слота dbepdia:populationTotal и iv) неверный тип запроса (12%), как в . Где начинается Пикадилли? , где наш подход ошибочно предполагает, что это ASK-запрос.
4 Связанная работа
Существует значительный объем работы по семантическому разбору ответов на вопросы. В более ранней работе проблема решалась с использованием методов статистического машинного перевода [42] или создания синхронных грамматик [43] . В недавней работе задача была сформулирована как создание статистических лексикализованных грамматик; большая часть этой работы опиралась на CCG как теорию грамматики и лямбда-исчисление для семантического представления и семантической композиции [35, 4, 46, 21, 3, 18, 20, 2, 22] . В отличие от приведенной выше работы, мы предполагаем, что доступен синтаксический анализ ввода в виде дерева зависимостей, и мы изучаем модель, которая присваивает семантические представления каждому узлу в дереве. Большая часть ранних работ по семантическому анализу была сосредоточена на очень специфических областях с очень ограниченным семантическим словарем. Совсем недавно ряд исследователей рассмотрели эту проблему и сосредоточились на наборах данных QA с открытым доменом, таких как WebQuestions, которые основаны на Freebase 9.0937 [6, 7, 30, 34, 45, 8, 31, 44, 32] .
Наш подход имеет некоторое отношение к работе Reddy et al. [31] в том смысле, что мы оба начинаем с дерева зависимостей (или необоснованного графа в их терминологии) и цель состоит в том, чтобы обосновать необоснованные отношения в базе знаний. Мы используем другой подход к обучению и модель, а также другой формализм семантического представления (ЧУВЧИКИ против лямбда-выражений). Совсем недавно Reddy et al. [32] расширили свой метод для создания общих логических форм, основанных на универсальных зависимостях, независимых от приложения, то есть ответов на вопросы. Они оценивают свой подход как к веб-вопросам, так и к графическим запросам. Хотя наборы данных, которые они используют, содержат тысячи обучающих примеров, мы показали, что можем обучить модель, используя только 350 вопросов в качестве обучающих данных.
Работа Freitas et al. [12] использует распределенное структурированное векторное пространство, τ-пространство, для преодоления лексического разрыва между запросами и базой знаний, чтобы сопоставить условия запроса с соответствующими свойствами и классами в базовой базе знаний. Кроме того, Фрейтас и соавт. [11] изучал различные семантические модели распределения в сочетании с машинным переводом. Их результаты показывают, что сочетание машинного перевода с подходом Word2Vec обеспечивает наилучшую производительность для измерения семантической связи между несколькими языками.
Луковников и др. [23]
предложили сквозную модель QALD, использующую нейронные сети. Этот подход хорошо подходит для ответов на простые вопросы и был обучен на наборе данных со 100 000 обучающих экземпляров. Напротив, тесты QALD-6 содержат меньше данных (350 экземпляров), а вопросы включают более сложные вопросы, требующие агрегирования и сравнения. Нилакантан и др.
[27] предложили подход, основанный на нейронной модели, который дает результаты, сравнимые с современными ненейронными семантическими анализаторами на WikiTableQuestions [29] набор данных, который включает вопросы с агрегированием.
Лучшей системой в тесте QALD-6 [36] была система [24] , достигшая F-меры 89%. Однако этот подход основан на подходе с контролируемым естественным языком, в котором запросы переформулированы вручную, чтобы этот подход мог их анализировать. Единственная система, способная работать на трех языках, как наша, — это система UTQA [38]
. Система UTQA достигает гораздо более высоких результатов по сравнению с нашей системой, достигая F-мер 75% (EN), 68% (ES) и 61% (Persian). Подход основан на конвейере из нескольких классификаторов, выполняющих извлечение ключевых слов, связывание отношений и объектов, а также определение типа ответа. Все эти шаги выполняются совместно в нашей модели.
Höffner et al. [14] Компания провела недавно обзор опубликованных подходов к эталонным тестам QALD, проанализировала различия и выявила семь проблем. Наш подход решает четыре из этих семи проблем: многоязычие, двусмысленность, лексический пробел и шаблоны. Наша вероятностная модель выполняет неявное устранение неоднозначности и выполняет семантическую интерпретацию, используя традиционную восходящую семантическую композицию, используя самые современные формализмы семантического представления и, таким образом, не опираясь на какие-либо фиксированные шаблоны. Мы предложили, как преодолеть лексический пробел, используя подход для создания лексических отношений между поверхностными упоминаниями и объектами в базе знаний, используя подход к репрезентативному обучению. Многоязычие достигается за счет использования универсальных зависимостей и нашей методологии, которая позволяет обучать модели для разных языков.
5 Заключение
Мы представили многоязычную модель графа факторов, которая может преобразовывать входные данные на естественном языке в логическую форму, опираясь на DUDES как на семантический формализм. Учитывая входные данные, проанализированные на основе зависимостей, наша модель выводит как семантический тип, так и сущность базы знаний для каждого узла в дереве зависимостей и вычисляет общую логическую форму с помощью восходящей семантической композиции. Мы применили наш подход к задаче ответа на вопрос по связанным данным, используя набор данных QALD-6. Мы показываем, что наша модель может научиться преобразовывать вопросы в запросы SPARQL, обучая только 350 экземпляров. Мы показали, что наш подход работает для нескольких языков, в частности для английского, немецкого и испанского. Мы также показали, как можно преодолеть лексический разрыв с помощью встраивания слов, повышающего производительность по сравнению с использованием явной лексики, созданной подходами индукции лексики, такими как M-ATOLL. В будущем мы расширим наш подход для обработки вопросов с помощью других операций фильтрации. Мы также сделаем нашу систему доступной на GERBIL 9.0937 [37] для прямого сравнения с другими системами.
Благодарности
Эта работа была поддержана Кластером передовых технологий когнитивного взаимодействия «CITEC» (EXC 277) в Университете Билефельда, который финансируется Немецким исследовательским фондом (DFG).
Каталожные номера
- [1]
Андриё, К., де Фрейтас, Н., Дусе, А., Джордан, М.И.: Введение в MCMC для машинного обучения. Машинное обучение 50, 5–43 (2003)
- [2] Арци, Ю., Ли, К., Зеттлемойер, Л.: Семантический разбор CCG с широким охватом АМР. Труды EMNLP, стр. 1699–1710 (2015).
- [3] Арци, Ю., Зеттлемойер, Л.С.: Начальная загрузка семантических парсеров из Разговоры. Труды ACL, стр. 421–432 (2011 г.)
- [4]
Baldridge, J., Kruijff, GJM: Связь ccg и гибридной логической зависимости
семантика. В: Труды ACL. стр. 319–326. Ассоциация для
Компьютерная лингвистика (2002)
- [5] Базиле В., Джеббара С., Кабрио Э., Чимиано П.: Наполнение базы знаний с отношениями объект-местоположение с использованием дистрибутивной семантики. В: Учеб. из ЭКАВ. стр. 34–50 (2016)
- [6] Берант Дж., Чоу А., Фростиг Р., Лян П.: Семантический анализ на Freebase из пар вопрос-ответ. Труды EMNLP (октябрь), 1533–1544 гг. (2013)
- [7] Берант Дж., Лян П.: Семантический разбор с помощью перефразирования. ACL (рис. 1), 1415–1425 (2014 г.)
- [8]
Берант, Дж., Лян, П.: Имитационное обучение семантических анализаторов на основе повестки дня. Труды Ассоциации компьютерной лингвистики 3, 545–558. (2015)
- [9] Чимиано, П.: Гибкая смысловая композиция с чуваками. В: Материалы 8-я Международная конференция по вычислительной семантике (IWCS). стр. 272–276 (2009 г.)
- [10]
Чимиано, П., Франк, А., Рейл, У.: Построение семантики на основе UDRT для
LTAG — и что это говорит нам о роли дополнения в LTAG. В:
Материалы 7-го Международного семинара по вычислительной семантике
(ИВКС). стр. 41–52 (2007 г.)
- [11]
Фрейтас, А., Барзегар, С., Сейлз, Дж. Э., Хандшу, С., Дэвис, Б.: Семантика родство для всех (языки): сравнительный анализ многоязычных семантическое родство с помощью машинного перевода. В: Инженерия знаний и Управление знаниями: 20-я международная конференция, EKAW 2016, Болонья, Италия, 19 ноября-23, 2016, Материалы 20. С. 212–222. Спрингер (2016)
- [12] Фрейтас, А., Карри, Э.: Запросы на естественном языке к разнородным связанным данным графики: дистрибутивно-композиционный семантический подход. В: Материалы 19-я международная конференция по интеллектуальным пользовательским интерфейсам. стр. 279–288. АКМ (2014)
- [13]
Хакимов, С., Унгер, К., Вальтер, С., Чимиано, П.: Применение семантического разбора к
ответ на вопрос по связанным данным: устранение лексического пробела. В:
Международная конференция по применению естественного языка к информации
Системы. стр. 103–109. Спрингер (2015)
- [14] Хёффнер К., Вальтер С., Маркс Э., Усбек Р., Леманн Дж., Нгонга Нгомо, А.К.: Обзор проблем, связанных с ответами на вопросы в семантической сети. Семантическая сеть (препринт), 1–26 (2016 г.)
- [15] Камп, Х., Рейл, У.: От дискурса к логике; Введение в Теоретико-модельная семантика естественного языка. Клувер, Дордрехт (1993)
- [16] Килгаррифф, А., Феллбаум, К.: Wordnet: электронная лексическая база данных (2000 г.)
- [17]
Клингер, Р., Чимиано, П.: Совместные и конвейерные вероятностные модели для детальный анализ настроений: извлечение аспектов, субъективных фраз и их отношения. Труды ICDMW стр. 937–944 (2013)
- [18] Кришнамурти, Дж., Митчелл, Т.М.: Совместный синтаксический и семантический анализ с Комбинаторная категориальная грамматика. Труды ACL, стр. 1188–1198 (2014 г.)
- [19]
Кшишанг, Ф.Р., Фрей, Б.Дж., Лелигер, Х.А.: Графики факторов и суммарное произведение
Алгоритм. IEEE Transactions по теории информации 47 (2), 498–519 (2001)
- [20] Квятковски Т., Чой Э., Арци Ю., Зеттлемойер Л.: Семантика масштабирования Парсеры с сопоставлением онтологий на лету. Труды EMNLP (октябрь), 1545–1556 (2013 г.)
- [21] Квятковски Т., Зеттлемойер Л., Голдуотер С., Стидман М.: Индуцирование Вероятностные грамматики CCG из логической формы с унификацией высшего порядка. Труды EMNLP (октябрь), 1223–1233 (2010 г.)
- [22] Ли, К., Льюис, М., Зеттлемойер, Л.: Глобальный нейронный анализ CCG с оптимизацией Гарантии. Труды EMNLP, стр. 2366–2376 (2015 г.).
- [23]
Луковников Д., Фишер А., Леманн Дж., Ауэр С.: На основе нейронных сетей ответы на вопросы по графикам знаний на уровне слов и символов. В: Материалы 26-й Международной конференции по всемирной паутине. стр. 1211–1220 гг. Руководящий комитет международных конференций по всемирной паутине (2017)
- [24]
Маццео, Г.М., Заниоло, К.: Ответы на контролируемые вопросы на естественном языке на
Базы знаний RDF. В: Материалы 19-й Международной конференции.
по расширению технологии баз данных. стр. 608–611 (2016).
- [25]
Миколов Т., Суцкевер И., Чен К., Коррадо Г.С., Дин Дж.: Распределено представления слов и фраз и их композиционность. В: Достижения в нейронных системах обработки информации. стр. 3111–3119 (2013 г.)
- [26] Миллер, Г.А.: Wordnet: лексическая база данных для английского языка. Коммуникации АКМ 38(11), 39–41 (1995)
- [27] Нилакантан, А., Ле, К.В., Абади, М., Маккаллум, А., Амодей, Д.: Изучение интерфейс на естественном языке с нейронным программистом. Международная конференция по обучающим представлениям (2017)
- [28] Nivre, J.e.a.: Универсальные зависимости 2.0 (2017 г.), http://hdl.handle.net/11234/1-1983, электронная библиотека LINDAT/CLARIN в Институте формальной и прикладной лингвистики Карлова университета
- [29] Пасупат, П., Лян, П.: Композиционно-семантический анализ полуструктурированных столы. АКЛ (2015)
- [30]
Редди, С. , Лапата, М., Стидман, М.: Крупномасштабный семантический анализ без
Пары вопрос-ответ. Сделки ACL 2, 377–392 (2014)
- [31] Редди С., Тэкстрем О., Коллинз М., Квятковски Т., Дас Д., Стидман, М., Лапата, М.: Преобразование структур зависимостей в логические Формы для семантического анализа. Сделки ACL 4, 127–140 (2016)
- [32] Редди С., Тэкстрем О., Петров С., Стидман М., Лапата М.: Универсальный семантический разбор. В: Труды EMNLP (2017).
- [33] Рейле, У.: Работа с неопределенностями путем занижения спецификации: конструкция, Представление и дедукция. Журнал семантики 10 (2), 123–179 (1993).
- [34] Рокт, Т., Ридель, С.: Внедрение логических фоновых знаний во встраивания для извлечения отношений. NAACL, стр. 1119–1129 (2014)
- [35] Стидман, М.: Синтаксический процесс. Компьютерная лингвистика 131(1), 146–148 (2000)
- [36]
Унгер, К., Нгомо, ACN, Кабрио, Э.: 6-е открытое задание по ответу на вопрос
по связанным данным (qald-6). В: Задача по оценке семантической паутины. стр.
171–177. Спрингер (2016)
- [37] Усбек Р., Рёдер М., Нгонга Нгомо А.С., Барон С., Оба А., Брюммер М., Чеккарелли Д., Корнолти М., Черикс Д., Эйкманн Б., и др.: Gerbil: общая система сравнительного анализа аннотаторов сущностей. В: Материалы 24-й Международной конференции по всемирной паутине. стр. 1133–1143 гг. Руководящий комитет международных конференций по всемирной паутине (2015)
- [38] Вейсех, А.П.Б.: Ответы на межъязыковые вопросы с использованием общего семантического пространства. В: TextGraphs @ NAACL-HLT. стр. 15–19(2016)
- [39] Вальтер, С., Унгер, К., Чимиано, П.: М-атолл: основа для лексикализации онтологий на нескольких языках. В: Международная семантическая сеть Конференция. стр. 472–486. Спрингер (2014)
- [40]
Вальтер, С., Унгер, К., Чимиано, П.: Dblexipedia: ядро для многоязычного
лексико-семантическая сеть. В: Материалы 3-го Международного семинара по НЛП.
и DBpedia, совместно с 14-й Международной семантической веб-конференцией. (ISWC 2015), 11-15 октября, США (2015)
- [41] Вик, М., Роханиманеш, К., Кулотта, А., МакКаллум, А.: SampleRank. Обучение предпочтения от атомарных градиентов. Семинар NIPS по продвижению в рейтинге, стр. 1–5 (2009)
- [42] Вонг, Ю.В., Муни, Р.Дж.: Обучение семантическому анализу со статистическими данными. машинный перевод. В: Материалы основной конференции по человеческому языку. Технологическая конференция Североамериканского отделения ACL. стр. 439–446. АКЛ (2006)
- [43] Вонг, Ю.В., Муни, Р.Дж.: Изучение синхронных грамматик для семантического анализа с лямбда-исчислением. В: Труды ACL. об. 45, с. 960 (2007)
- [44] Сюй К., Редди С., Фэн Ю., Хуанг С., Чжао Д.: Ответы на вопросы Freebase через извлечение отношений и текстовые доказательства. Труды ACL стр. 2326–2336 (2016).
- [45]
Yih, W.T., Chang, M.W., He, X., Gao, J.: Семантический анализ с помощью поэтапного запроса
Создание графика: ответы на вопросы с помощью базы знаний. ACL, стр. 1321–1331.
(2015)
- [46]
Zettlemoyer, L.S., Collins, M.: Обучение преобразованию предложений в логическую форму: Структурированная классификация с вероятностными категориальными грамматиками. 21-й Конференция по неопределенности в искусственном интеллекте (2005 г.)
TASK-- Обработка китайского языка
1. Введение
Первая и вторая оценки синтаксического анализа китайского языка (CIPS-ParsEval-2009[1] и CIPS-SIGHAN-ParsEval-2010[2]) были успешно проведены в 2009 и 2010 гг. соответственно. Результаты оценки на уровне предложений и предложений китайского языка показывают, что анализ сложных предложений по-прежнему представляет собой серьезную проблему для китайского языка. На этот раз мы сосредоточимся на задаче разбора предложений, предложенной вторым CIPS-ParsEval, чтобы выявить подробные трудности разбора сложных предложений китайского языка в отношении двух типичных схем сложности предложений: сочетания событий на уровне предложения и композиции понятий на уровне предложения. уровень. Мы введем в оценку новую схему аннотаций на основе лексикона Комбинаторная категориальная грамматика (CCG) ([3],[4]) и проведем параллельное сравнение производительности синтаксического анализатора с традиционной грамматикой фразовой структуры (PSG), используемой в Банк китайских деревьев Цинхуа (TCT).
Эта оценка включает две подзадачи, т. е. оценку синтаксического анализа PSG и оценку синтаксического анализа CCG. Для каждой подзадачи есть две дорожки. Одним из них является дорожка Close, в которой оценка параметров модели проводится исключительно на основе данных поезда. Другой - это открытый трек, в котором любые наборы данных, кроме данных обучения, могут использоваться для оценки параметров модели. Мы возьмем отдельные оценки для этих двух треков.
Кроме того, мы оценим следующие два вида методов отдельно в тесном треке.
1) Единая система: синтаксические анализаторы, использующие единую модель синтаксического анализа для завершения задачи синтаксического анализа.
2) Комбинация систем: участники могут комбинировать несколько моделей для повышения производительности. Совместные методы декодирования будут рассматриваться как комбинированные методы.
2. Оценочные задачи
Задание 1: Оценка синтаксического анализа CCG
Входные данные: китайское предложение с правильной аннотацией сегментации слов. Количество слов больше 2. Пример:
- 小型(маленький) 木材(дерево) 加工场(фабрика) 在(есть) 忙(занят) 着(-модальность) 制作(строить) 各(несколько) 种(-классификатор) 木制品(деревообработка) 。(точка ) (Небольшая деревообрабатывающая фабрика занята строительством нескольких столярных изделий. )
Цель синтаксического анализа: назначить соответствующие теги категории CCG словам и сгенерировать дерево вывода CCG для предложения.
Выходные данные: Дерево вывода CCG с тегами категории CCG для предложения.
- (S{decl} (S (NP (NP/NP 小型) (NP (NP/NP 木材) (NP 加工场) )) (S\NP ([S\NP]/[S\NP] 在) (S{Cmb=LW}\NP (S\NP (S\NP 忙) ([S\NP]\[S\NP] 着)) (S\NP ([S\NP]/NP 制作) ( NP (NP/NP ([NP/NP]/M 各) (M 种) ) (NP 木制品) ) ) ) ) ) (wE 。) )
Задание 2: Оценка синтаксического анализа PSG
Входные данные: китайское предложение с правильной аннотацией сегментации слов. Число слов больше 2. Пример:
- 小型(маленький) 木材(дерево) 加工场(фабрика) 在(есть) 忙(занят) 着(-модальность) 制作(строить) 各(несколько ) 种(-классификатор) 木制品(изделия из дерева) 。(точка) (Небольшая деревообрабатывающая фабрика занята строительством нескольких изделий из дерева.)
Цель синтаксического анализа: присвоить словам соответствующие теги части речи (POS) и сгенерировать Дерево структуры фразы для предложения.
Вывод: Дерево структуры фразы с POS-тегами для фразы.
- (zj (dj (np (b 小型) (np (n 木材) (n 加工场)) ) ) (vp (d 在) (vp-LW (ap (a 忙) (uA 着) ) (vp ( v 制作) (np (mp (m 各) (qN 种) ) (n 木制品) ) ) ) ) ) (wE 。) )
парсеры. Одним из них является этап присвоения синтаксической категории, включая тег POS и категорию CCG. Другой этап — это этап генерации дерева синтаксического анализа, включая дерево синтаксического анализа PSG и дерево вывода CCG. Поэтому мы разрабатываем для них два разных набора метрик.
3.1 Показатели оценки синтаксической категории
Основными показателями являются точность тегирования синтаксической категории (SC_P), полнота (SC_R) и оценка F1 (SC_F1).
- SC_P= (количество правильно помеченных слов) / (количество автоматически помеченных слов) * 100%
- SC_R= (количество правильно помеченных слов) / (количество слов по золотому стандарту) * 100%
- SC_F1= 2*SC_P*SC_R / (SC_P + SC_R)
Правильно помеченные слова должны иметь те же синтаксические категории, что и слова золотого стандарта.
Чтобы получить подробные результаты оценки для различных синтаксических категорий, мы можем классифицировать все слова с тегами в разные наборы и вычислить для них разные SC_P, SC_R и SC_F1. Условие классификации следующее.
Если (SC_Token_Ratio >=10%), то синтаксический тег будет одного класса со своим тегом SC, в противном случае все остальные низкочастотные слова с тегами SC будут классифицироваться специальным классом с тегом Oth_SC. Где SC_Token_Ratio= (токен слова одного специального SC в наборе тестов) / (токен слова # в наборе тестов) * 100%.
3.2 Метрики оценки дерева синтаксического анализа
Базовые метрики помечены как составная точность (LC_P), полнота (LC_R) и F1-оценка (LC_F1).
- LC_P = (количество правильно помеченных составляющих) / (количество автоматически проанализированных составляющих) * 100%
- LC_R = (количество правильно помеченных составляющих) / (количество составляющих по золотому стандарту) * 100%
F1= 2*LC_P*LC_R / (LC_P+LC_R)
Правильно помеченные составляющие должны иметь одинаковые синтаксические теги и левая и правая границы с золотыми стандартами.
Чтобы получить подробные результаты оценки различных синтаксических составляющих, мы можем классифицировать их по 5 наборам и вычислить для них разные LC_P, LC_R и LC_F1.
(1) Компоненты сложного события
(2) Составные компоненты понятия
(3) Клаузальные и фразовые компоненты
(4) Одноузловые компоненты
(5) Все остальные компоненты
Классификация основана на синтаксическая составляющая и теги грамматических отношений, аннотированные в TCT. Пожалуйста, обратитесь к следующему разделу для получения более подробной информации.
Мы вычисляем средневзвешенное значение оценок F1 первых четырех наборов (Tot4_F1), чтобы получить окончательные ранжированные оценки для различных предлагаемых систем синтаксического анализатора. Формула расчета следующая: Tot4_F1 = ∑LC_F1i * LC_Ratioi,i∈[1,4].
LC_Ratioi — коэффициент распределения для i-го набора компонентов в тестовом наборе. Формула расчета: LC_Ratioi= (количество компонентов в i-м наборе) / (количество всех компонентов) * 100%
Для сравнительного анализа мы все вычисляем средневзвешенное значение F1-показателей всех пяти наборов для ранжирования.
Чтобы оценить возможную верхнюю границу производительности автоматических парсеров, мы также разрабатываем следующие дополнительные показатели:
(1) Точность немаркированных составляющих (ULC_P) = (количество составляющих с правильными границами) / (количество автоматически проанализированных составляющих) * 100%
(2) Отзыв немеченого компонента (ULC_R)= (количество компонентов с правильными границами) / (количество компонентов золотого стандарта) * 100%
(3) Оценка F1 немеченого компонента (ULC_F1) = 2* NLC_P*NLC_R / (NLC_P + NLC_R)
(4) Точность непересекающихся составляющих (NoCross_P)= (количество составляющих, не пересекающихся с составляющими золотого стандарта) / (количество составляющих, проанализированных автоматически) * 100%
4.
Оценочные данныеВсе новости и академические статьи, аннотированные в TCT версии 1.0[6], выбираются в качестве основных обучающих данных для оценки. Он состоит примерно из 480 000 китайских слов. В качестве базовых тестовых данных можно использовать 1000 предложений, извлеченных из версии TCT-2010. На их основе могут быть построены окончательные обучающие и тестовые наборы данных посредством следующих процедур автоматического преобразования.
Во-первых, мы делаем бинарные файлы для всех деревьев аннотаций TCT и получаем новую бинаризованную версию TCT. Добавлены два новых тега грамматических отношений RT и LT для описания вставленных фиктивных узлов с левой и правой структурой комбинации пунктуации. Они могут предоставлять базовые древовидные структуры синтаксического анализа для оценок синтаксического анализа PSG и CCG.
Во-вторых, мы классифицируем все составляющие TCT на 5 групп в соответствии с тегами синтаксической составляющей (SynC) и грамматической связи (GR), аннотированными в TCT 9. 0003
1. Составные части комплексного события, если выполняется одно из следующих условий.
a) TCT SynC tag=fj и TCT GR tag ∈{BL, LG, DJ, YG, MD, TJ, JS, ZE, JZ, LS}
b) TCT SynC tag=jq
2. Составная концепция составляющих, если соблюдены все следующие два условия
a) TCT GR tag ∈{LH, LW, SX, CD, FZ, BC, SB}
b) TCT Sync tag ∈{np, vp, ap, bp, dp, mp, sp, tp, pp}
3. Клаузальные и фразовые составляющие, если соблюдены все следующие два условия
a) Тег TCT GR ∈ {ZW, PO, DZ, ZZ, JY, FW, JB, AD}
b) Тег TCT Sync ∈ {dj, np, sp, tp, mp, vp, ap, dp, pp, mbar, bp}
4. Одноузловые составляющие, если TCT SynC tag=dlc
5. Все остальные составляющие
Они предоставят базовую информацию для расчета метрик детальной оценки дерева синтаксического анализа.
Наконец, мы создаем наборы данных оценки для двух задач синтаксического анализа с помощью следующих подходов:
1. Для оценки синтаксического анализа PSG мы автоматически преобразуем данные аннотации TCT посредством:
а) Для синтаксических составляющих, принадлежащих к вышеуказанным классам 1-2 и 5, мы сохраняем исходные ТСТ два тега;
b) Для синтаксической составляющей, принадлежащей к вышеуказанному классу 3-4, мы сохраняем только оригинальные теги TCT SynC.
2. Для оценки синтаксического анализа CCG мы автоматически преобразуем данные аннотации TCT в формат CCG с помощью инструмента TCT2CCG [7].
Чтобы оценить влияние разного масштаба обучающего корпуса на производительность парсера, мы разделили все обучающие данные на N частей. В каждом тренировочном цикле n частей (n∈[1,10]) корпусов аннотаций можно использовать для обучения N различных моделей синтаксического анализа. На их основе можно получить N различных результатов тестирования на одном и том же наборе тестовых данных. Таким образом, можно построить несколько диаграмм трендов вариаций различных видов оценочных метрик на разных обучающих корпусах. При оценке мы установим N=10.
5. Процедура оценки
Каждому участнику закрытого трека будет предоставлено 10 различных тренировочных данных. Их просят предоставить 10 различных результатов тестирования, выведенных 10 различными моделями синтаксического анализа, обученными на вышеупомянутых 10 различных обучающих данных.
Все участники должны указать стандартное имя документа для каждого предоставленного результата в соответствии со следующим форматом номинации:
(1) <Идентификатор участника> представляет собой идентификатор участника, полученный при онлайн-регистрации.
(2) <Имя задачи> представляет имя участвующей задачи синтаксического анализа: PSG или CCG.
(3) <Тренировочный режим> представляет различные тренировочные треки: Закрыть или Открыть.
(4) <Модель синтаксического анализа> представляет различные методы построения модели синтаксического анализа, используемые участниками: одиночный или множественный (комбинация систем).
(5) <Имя системы> представляет собой сокращенное имя, данное участниками для своей системы, состоящее не более чем из 5 символов.
(6) <Шкала данных обучения> представляет различные данные обучения, используемые в процедуре обучения: [1-10].
Вот пример номинации: 01-PSG-Closed-Single-CCP-1.CPT. Он может предоставить следующую информацию: Участник с идентификатором 01 принимает участие в близком отслеживании задачи оценки синтаксического анализа PSG. Он использует единую модель синтаксического анализа для обучения своего синтаксического анализатора. Сокращенное название его системы парсера — CCP. Он использует 10% обучающих данных для получения результатов теста. Вся эта информация может обеспечить хорошую поддержку для окончательного анализа и обобщения данных.
Ссылки
[1]. Цян Чжоу, Юэмэй Ли. Отчет об оценке CIPS-ParsEval-2009. В проц. первого семинара по оценке синтаксического анализа китайского языка, Пекин, Китай, ноябрь 2009 г., стр. III—XIII. (2009)
[2]. Цян Чжоу, Цзинбо Чжу. Оценка синтаксического анализа китайского языка. проц. Совместной конференции CIPS-SIGHAN по обработке китайского языка (CLP-2010), Пекин, август 2010 г., стр. 286-295. (2010)
[3]. Стидман, Марк. Поверхностная структура и интерпретация. MIT Press, Кембридж, Массачусетс. (1996).
[4]. Стидман, Марк. Синтаксический процесс. MIT Press, Кембридж, Массачусетс. (2000)
[5]. Кларк С., Копестейк А., Карран Дж.Р., Чжан Ю., Гербелот А., Хаггерти Дж., Ан Б.Г., Вик С.В., Рознер Дж., Куммерфельд Дж., Доуборн Т. .: Крупномасштабная синтаксическая обработка: Парсинг в сети. Заключительный отчет семинара JHU CLSP 2009 г. (октябрь 2009 г.)
[6]. Цян Чжоу. Схема аннотации китайских деревьев. Журнал китайской информации, 18 (4), стр. 1-8. (2004)
[7]. Цян Чжоу. Автоматическое преобразование данных TCT в банк CCG: спецификация обозначений версии 3.0. Технический отчет CSLT-20110512, Центр речевых и языковых технологий, Научно-исследовательский институт информационных технологий, Университет Цинхуа. (2011).
Определение состава и значение | Английский словарь Коллинза
Видео: произношение
композиция
Примеры употребления слова «композиция» в предложении
композиция
Как мы могли пропустить эти блестящие композиции?
Это также сила тщательной композиции.
Вот шесть его ключевых композиций.
В средней школе мы использовали черновики для первых набросков сочинений.
Ее звучание основано на перкуссионной андеграундной танцевальной музыке, эмбиенте и современной классической композиции.
Опять же, это была по существу критическая работа, а не часть конструктивной композиции.
Он работает над кларнетсонатой в рамках своего обучения музыкальной композиции.
Движение звезд спорта по всему миру привело к трансформации в составе национальных сборных.
Их усилия также проливают свет на роль женщин в классической музыке, как исторической, так и современной.
Мы должны писать сочинения в полевые дни, и я пишу лучшие из них.
Цитаты
В школе сочинение проверяет вашу выносливость, тогда как перевод требует сообразительности. Но в дальнейшей жизни можно поиздеваться над теми, кто преуспел в сочинении. Гюстав Флобер. Словарь полученных идей
Тенденции
состав
На других языках
композиция
британский английский: композиция /ˌkɒmpəˈzɪʃən/ СУЩЕСТВИТЕЛЬНОЕ
Состав чего-либо — это вещи, из которых они состоят, и то, как они расположены.
Посмотрите состав субботней команды.
- Американский английский: композиция / kɒmpəˈzɪʃən/
- Арабский: تَرْكِيب
- Бразильский португальский: составной
- Китайский: 构成成分
- Хорватский: sastav
- Чехия: skladba
- Датский: состав
- Голландский: композит
- Европейский испанский: состав
- Финский: koostaminen
- Французский язык: состав
- Немецкий: Состав
- Греческий: σύνθεση
- Итальянский: композиция
- Японский: 構成
- Корейский: 구성
- Норвежский: состав
- Польский: kompozycja budowa
- Европейский португальский: composição
- Румынский: compoziție
- Русский: состав
- Испанский: состав
- Шведский: состав
- Thai: สิ่ง ที่ มา มา จัด วาง องค์ ประกอบ, วิธี จัด วาง ประกอบ ประกอบ
- Турции: Беста
- Украинский: склад
- Вьетнамский: sự tập hợp
Связанные условия
композиция
Быстрое задание
Обзор викторины
Вопрос: 1
-
Оценка: 0 / 5
чили
чили
Был полдень.
мужской
почта
Большинство людей в аудитории были .
блоха
блоха
Болезнь передается от крыс к человеку через укусы.
Ваш счет:
Слово дня
королевская семья
Королевская семья страны – это король, королева или император и все члены их семьи.
Подпишитесь на нашу рассылку
Получайте последние новости и получайте доступ к эксклюзивным обновлениям и предложениям
Зарегистрируйтесь
В чем разница между объявлением и рекламой?
На этой неделе мы рассмотрим два слова, которые иногда путают: объявление и реклама. Улучшите свой английский с Collins. Подробнее
Учебные пособия для каждого этапа вашего обучения
Ищете ли вы кроссворд, подробное руководство по завязыванию узлов или советы по написанию идеального эссе для колледжа, Harper Reference предоставит вам все необходимое для учебы. Подробнее
Угадывая отличительные черты готической литературы
С приближением сезона ужасов ничто не знаменует смену времен года лучше, чем День Франкенштейна 30 августа. Подробнее
Collins English Dictionary Apps
Загрузите наши приложения English Dictionary, доступные как для iOS, так и для Android. Подробнее
Collins Dictionaries for Schools
Наши новые онлайн-словари для школ обеспечивают безопасную и подходящую среду для детей. И самое главное, это приложение не содержит рекламы, так что зарегистрируйтесь сейчас и начните использовать его дома или в классе. Подробнее
Списки слов
У нас есть почти 200 списков слов из самых разных тем, таких как виды бабочек, куртки, валюты, овощи и узлы! Удивите своих друзей своими новыми знаниями! Подробнее
Обновление нашего использования
Существует множество различных факторов, влияющих на то, как английский язык используется сегодня во всем мире. Мы рассмотрим некоторые способы изменения языка. Прочтите нашу серию блогов, чтобы узнать больше.
Подробнее
Area 51, Starship и Harvest Moon: слова сентября в новостях
Уверен, многие согласятся, что мы живем в странные времена. Но должны ли они быть настолько странными, чтобы Зона 51 попала в заголовки газет? А при чем здесь рыбы, похожие на инопланетян. Сентябрьские слова в новостях объясняют все. Подробнее
Оценка Scrabble
за «композицию»:
17
Быстрое задание
Обзор викторины
Вопрос: 1
-
Оценка: 0 / 5
Ваша оценка:
Создайте учетную запись и войдите, чтобы получить доступ к этому БЕСПЛАТНОМУ контенту
Зарегистрируйтесь сейчас или войдите, чтобы получить доступ
Упрощение разработки пакетов Crossplane
Как мы объясняли в посте с объявлением об альфа-версии, основной проблемой, о которой мы слышали от сообщества и наших клиентов, является то, насколько сложно создавать инфраструктуру, что, если быть честным, не ужасно удивительно. Сегодня отдельному создателю пакета Crossplane в основном предоставляется возможность редактирования простого текста, что далеко от опыта разработки с помощью IDE, к которому многие из нас привыкли (подумайте о WYSIWYG в сравнении с Google Docs или Microsoft Word).
В этом посте мы расскажем, почему это так, и начнем погружаться в то, что мы сделали, чтобы попытаться облегчить часть этой боли. Прежде всего, мы углубимся в то, как мы предоставляем автору механизм для рендеринга проверки/диагностики линтера, пока они создают/редактируют свою составную инфраструктуру.
Фон
Большая часть того, что мы обсудим, будет в контексте кода Visual Studio; однако я хотел бы подчеркнуть, что темы не ограничиваются VS Code. Как мы увидим, многое из того, что мы рассмотрим, можно применить к Atom, Goland, Vim и т. д.
Отлично, помня об этом, давайте приступим.
Сегодня, когда нам нужно создать/отредактировать манифест ресурса Kubernetes, многие из нас начинают с добавления следующих расширений в ваш экземпляр VS Code:
- YAML поддержка языка
- Поддержка Kubernetes
Возможно, в большинстве случаев этого будет достаточно. Благодаря расширению поддержки языка YAML вы получите множество замечательных функций:
- Проверка YAML
- Автозаполнение
- Форматирование
- и т. д.
А из расширения Kubernetes вы сможете:
- Просматривать репозитории Helm.
- Файлы Lint YAML для потенциальных проблем/предложений.
- Отредактируйте манифесты ресурсов и примените их к своему кластеру.
- Просмотр различий текущего состояния ресурса с манифестом ресурса в репозитории Git.
- Получение и отслеживание журналов.
- и т. д.
В общем, оба расширения отлично справляются с проверкой/анализом манифестов ресурсов по соответствующей схеме ресурса. Однако, не по своей вине, оба расширения терпят неудачу при представлении манифеста `Composition`.
Почему? Пожалуй, самый простой способ ответить на этот вопрос — посмотреть на схему Composition .
Если вы никогда не углублялись в него раньше, тип Composition определяется как CustomResourceDefinition в Kubernetes. Как и в случае с любым CRD, вам необходимо определить схему openAPIv3Schema , которая сообщает Kubernetes, какой будет форма вашего нового API. Из этого следует, что чем выразительнее схема API, тем проще будет указывать ошибки при проверке данного файла по вашей схеме.
Например (используя пример CronTab CRD):
Если в вашем CR вы указали:
Когда вы примените этот ресурс к своему кластеру, Kubernetes вернет ошибку, указывающую, что cronSpec должен был иметь тип string, но вы предоставил логическое значение.
Однако, если вместо этого вы измените приведенную выше схему CRD на:
, теперь вы сможете свободно определить cronSpec, если он находится в объекте. Это означает, что все нижеследующие пройдут проверки:
Выше мы подошли к корню нашей проблемы. Возвращаясь к Composition CRD, мы можем видеть здесь, что там, где мы определяем ресурсы, составляющие Composition, то есть шаблоны ресурсов, в base тип определяется как объект.
Теперь, прежде чем мы начнем делать поспешные выводы, т.е. «давайте определим более ограничительную схему для spec.resources[*].base , проблема решена», нам нужно сделать шаг назад. Сила Состав — это возможность составить любой ресурс , будь то автономный, где вы хотите определить более ограниченный API для своих потребителей или составленный из других ресурсов, например. база данных с политикой доступа. Если бы мы определили более ограничительную схему для spec.resources[*].base , это фактически подорвало бы нашу способность в общем «составлять любой ресурс».
Так что же нам делать?
Language Server
Ранее мы кратко обсуждали расширение поддержки языка YAML. Если вы когда-нибудь изучали, что входит в это расширение, вы можете быть удивлены, обнаружив, что большая часть мощности, стоящей за ним, на самом деле исходит от соответствующего yaml-language-server, а не от расширения JS, установленного в самом VS Code.
Итак, что такое «языковой сервер».
Краткая история
От самих Microsoft:
Языковой сервер — это особый вид расширения Visual Studio Code, который расширяет возможности редактирования для многих языков программирования. С помощью языковых серверов вы можете реализовать автозаполнение, проверку ошибок (диагностику), переход к определению и многие другие языковые функции, поддерживаемые в VS Code.
Однако при реализации поддержки языковых функций в VS Code мы обнаружили три общие проблемы:
Во-первых, языковые серверы обычно реализуются на своих родных языках программирования, и это создает трудности при их интеграции с VS Code, который имеет среду выполнения Node.js.
Кроме того, языковые функции могут требовать больших ресурсов. Например, чтобы правильно проверить файл, Language Server должен проанализировать большое количество файлов, построить для них абстрактные синтаксические деревья и выполнить статический анализ программы.
Наконец, интеграция многоязыковых инструментов с несколькими редакторами кода может потребовать значительных усилий. С точки зрения языковых инструментов им необходимо адаптироваться к редакторам кода с различными API. С точки зрения редакторов кода, они не могут ожидать какого-либо единого API от языковых инструментов. Это делает реализацию языковой поддержки для M языков в N редакторах кода работой M * N. Чтобы решить эти проблемы, Microsoft определила протокол Language Server, который стандартизирует связь между языковыми инструментами и редактором кода. Таким образом, языковые серверы могут быть реализованы на любом языке и работать в своем собственном процессе, чтобы избежать снижения производительности, поскольку они взаимодействуют с редактором кода через протокол языкового сервера. Кроме того, любые языковые инструменты, совместимые с LSP, можно интегрировать с несколькими редакторами кода, совместимыми с LSP, а любые редакторы кода, совместимые с LSP, могут легко подобрать несколько языковых инструментов, совместимых с LSP.
Учитывая вышеизложенное, то, что сделали ребята из Red Hat, внедрив языковой сервер для обеспечения всесторонней поддержки YAML, сами позиционируют себя для предоставления мощных языковых функций любому клиенту , который может общаться по протоколу языкового сервера. На самом деле мы упомянули некоторые из этих клиентов в начале раздела «История» — Atom, IntelliJ (а также другие редакторы JetBrains), Vim и многие другие.
Если бы мы могли последовать их примеру и написать языковой сервер для ответа на события от данного клиента, совместимого с LSP, мы могли бы:
- Потенциально решить ряд проблем, с которыми авторы сталкиваются в настоящее время при создании/редактировании ресурсов Crossplane.
- Решите один раз. Написание сервера означает, что его можно использовать с любым совместимым клиентом.
Именно это мы и сделали.
Проверка шаблона ресурса с помощью
xplsДо этого момента мы обсуждали проблему, которую пытаемся решить, и почему это проблема. Мы также кратко обсудили архитектурное решение того, как мы собираемся настроить себя для решения проблемы (используя языковой сервер). Давайте теперь углубимся в то, как мы предоставляли проверочную диагностику клиентам LSP.
Примечание: мы собираемся сосредоточиться в первую очередь на самой проверке и не касаться того, как мы реализовали обработчики языкового сервера для ответа на запросы от клиентов LSP. В мире существует довольно много примеров того, как люди реализовывали обработчики LSP. Так что, если вам интересно углубиться в это, я настоятельно рекомендую ознакомиться с этими примерами.
Примечание. Реализация обработчиков LSP для
xplsможно найти здесь.
Давайте начнем с того, что мы пытаемся сделать. Начиная с хорошо известного примера, взятого прямо из документации crossplane. io, приведенный ниже Composition описывает ресурсы, из которых состоит XPostgreSQLInstance :
. проверки схемы на всем пути вниз, пока мы не достигнем (если мы использовали одно из расширений, упомянутых ранее):
по адресу spec.resources[0].base (на языке пути YAML).
Здесь у нас есть манифест для v1beta1/RDSInstance из группы database.aws.crossplane.io , т.е. упаковка. Если бы у нас был способ использовать CRD для RDSInstance И способ получить только манифест `RDSInstance` из `Composition`, мы потенциально могли бы использовать те же механизмы, которые API-сервер Kubernetes использует для проверки пользовательских запросов ресурсов перед созданием ресурса. .
Как Kubernetes проверяет запросы пользовательских ресурсов на соответствие CRD
Несколько месяцев назад мой коллега Дэниел Мангам написал в блоге подробное описание того, как Kubernetes проверяет пользовательские ресурсы. Вкратце о том, что он обнаружил, было то, что в apiextensions-apiserver есть функция с именем NewSchemaValidator , которая принимает в качестве аргумента apiextensions.CustomResourceValidation и возвращает:
- Новый объект validate.SchemaValidator, созданный на основе OpenAPIV3Schema из CustomResourceValidation.
- Преобразованная спец.Схема из OpenAPIV3Schema.
- И ошибка, если она есть.
Фрагмент выглядит следующим образом:
После создания validate.SchemaValidator каждый раз, когда на сервер API поступает новый запрос пользовательского ресурса, неупорядоченное представление передается Validate() , который затем возвращает результаты проверки (ошибки и предупреждения) в виде validate.Result .
Наконец, Validate.Result Участники выглядят как:
, в то время как они имеют тип Ошибка , они также имеют тип Ошибки 66666666666666666. . Строка пути YAML, где произошла ошибка/предупреждение проверки, например. что-то вроде спец.ресурсы[0].connectionDetails[1].fromConnectionSecretKey . Это, в сочетании с деталями, добавленными в поле message , и вы получите сообщение, подобное следующему, если вы отправили число в качестве значения для fromConnectionSecretKey :
Как мы можем изолировать ресурс манифест шаблона в композиции
Учитывая все «тонкие» ссылки на использование пути YAML выше, в идеале, если бы мы могли найти способ проанализировать Композиция файла в YAML AST и впоследствии иметь возможность перемещаться по дереву с использованием нотации пути YAML, у нас будет две части нашей головоломки: использование нотации пути YAML теоретически упрощает поиск части файла, которую мы хотим для проверки, а также для изоляции части файла, в которой произошла ошибка проверки.
К счастью, существует отличный проект с открытым исходным кодом под названием goccy/go-yaml, который делает именно это. Используя API, предоставляемые go-yaml, мы можем:
- Прочитать каждый файл из файловой системы рабочей области.
- Разобрать файл в AST.
- Сохраните AST для быстрого поиска позже.
Затем, учитывая AST, мы можем отфильтровать Node в дереве, используя строку пути YAML, например. используя наш пример выше, учитывая AST, представляющий
. Мы можем сделать что-то подобное, чтобы получить узел, соответствующий манифесту RDSInstance :
Как получить CustomResourceDefinition для нашего шаблона ресурса
Те, кто ранее создавал пакет Crossplane, знают, что необходимо определить файл crossplane.yaml . Этот файл используется для того, чтобы указать Crossplane, как устанавливать компоненты, из которых состоит ваш пакет. Пример этого, опять же с использованием хорошо известного пакета Getting-start-with-aws , выглядит так:0005 спец. зависит от поля . Мы определили, что этот пакет «зависит» от API-интерфейсов, которые исходят от crossplane/provider-aws , в частности версии `v0.18.2`.
Подробнее об управлении зависимостями мы поговорим в одном из последующих постов этой серии. На данный момент мы используем это объявление для извлечения внешнего CustomResourceDefinition, который соответствует RDSInstance в нашем примере.
Все вместе
В последних нескольких разделах мы рассмотрели критические компоненты, которые мы можем использовать вместе, чтобы информировать автора композиции о любых ошибках в их шаблонах ресурсов. Давайте рассмотрим, как это выглядит, приведя события, полученные языковым сервером:
- Пользователь сохраняет свой файлcomposition. yaml, который содержит композицию xpostgresqlinstances.aws.database.example.org из нашего примера выше.
- xpls , Crossplane Language Server, получает соответствующие textDocument/didSave событие от клиента LSP, которое включает URI пути к файлу, который изменился.
- Внутри сервер считывает содержимое файла композиция.yaml , который был только что сохранен, и этот файл анализируется в его представление AST.
- Тип групповой версии (GVK) составного ресурса
5. Затем узел AST, соответствующий составному ресурсу, передается в SchemaValidator Validate() метод для получения проверки Результат .
Наконец, на шаге 6 для каждой ошибки в проверке Результат , Имя и Сообщение Извлечено:
- . Узел AST , соответствующий заданной строке пути YAML. Кроме того, позиции курсора получаются из маркера, соответствующего полученному Узел .
- Сообщение используется для предоставления дополнительного контекста для ошибки.
- Вместе они передаются новому событию textDocument/publishDiagnostics , которое включает в себя начальную и конечную позиции, полученные из токена в 1, сообщение, указывающее на удобочитаемую ошибку, а также серьезность ошибки (это определяет, будет ли пользователь видит прочитанную или желтую волнистую линию)
- Затем диагностика отправляется клиенту LSP для отображения пользователю.
Резюме
В этом посте мы рассмотрели, почему существует пробел в существующих инструментах для проверки композиции, что такое языковой сервер и почему он был хорошим выбором для включения наших циклов обратной связи проверки, мы дали обзор того, как Kubernetes проверяет запросы пользовательских ресурсов на соответствие CustomResourceDefinition и, наконец, то, как мы объединили все эти концепции, чтобы приступить к устранению пробелов в рабочем процессе автора при работе с ресурсами Crossplane.