Шестой разбор в русском языке
Содержание
- что означает разбор 6?землетрясение и прибрежных-эти слова надо разобрать этим разбором
- Что такое разбор под цифрой 6 и как его делать?
- Морфологический разбор «шестой»
- «Шестой» (имя прилагательное)
- Значение слова «шестой» по словарю С. И. Ожегова
- Морфологический разбор имени прилагательного
- Склонение имени прилагательного по падежам
- «Шестой» (имя существительное)
- Значение слова «шестой» по словарю С. И. Ожегова
- Морфологический разбор имени существительного
- Склонение имени существительного по падежам
- «Шестой» (числительное)
- Морфологический разбор числительного
- Склонение числительного по падежам
- Разобрать другое слово
- Морфологический разбор слова с примерами и онлайн
- Морфологический разбор онлайн
- Морфологический разбор существительного
- План разбора прилагательного
- Морфологический разбор глагола
- Видео
- Фонетический разбор слова «шестой»
- Фонетический разбор «шестой»:
- «Шестой»
- Характеристики звуков
- Смотрите также:
- Морфологический разбор слова «шестой»
- Фонетический разбор слова «шестой»
- Значение слова «шестой»
- Разбор по составу слова «шестой»
- Карточка «шестой»
- Предложения со словом «шестой»
- Звуко буквенный разбор слова: чем отличаются звуки и буквы?
- Что такое фонетический разбор?
- Фонетическая транскрипция
- Как сделать фонетический разбор слова?
- Пример фонетического разбора слова
- Фонетика и звуки в русском языке
- Гласные звуки в словах русского языка
- Фонетика: характеристика ударных гласных
- Безударные гласные буквы и звуки в словах русского языка
- Звуко буквенный разбор: йотированные звуки
- При фонетическом разборе гласные е, ё, ю, я образуют 2 звука:
- Фонетический разбор слов, когда гласные «Ю» «Е» «Ё» «Я» образуют 1 звук
- Фонетический разбор: согласные звуки русского языка
- Звуко-буквенный разбор: какими бывают согласные звуки?
- Позиционные изменения согласных звуков в русском языке
- Позиционное оглушение/озвончение
- Мягкие согласные в русском языке
- Позиционные изменения парных звонких-глухих перед шипящими согласными и их транскрипция при звукобуквенном разборе
- Шпаргалка по уподоблению согласных звуков по месту образования
- Непроизносимые согласные звуки в словах русского языка
- Видео
что означает разбор 6?землетрясение и прибрежных-эти слова надо разобрать этим разбором
Схема орфографического разбора слова
1. Выписать контрольное слово.
Выписать контрольное слово.
2. Вставить пропущенные буквы или раскрыть скобки.
3. Подчеркнуть в слове место орфограммы.
4. Назвать орфограмму и объяснить (устно или письменно) условия правильного написания.
5. Указать проверочное слово (если возможно) и привести примеры слов с данной орфограммой.
Образец орфографического разбора слова:
Трава, рядами — безударная проверяемая гласная в корне слова; проверяется ударением:
трава — травы, рядами — ряд; вода — воды, леса — лес.
По этой схеме и примерым нужно разобрать ваши слова. Вот орфограммы, которые нужно объяснить:
— безударная в корне, проверяемая ударением
— соединительная гласная после мягкого согласного
— безударная гласная в корне, проверяемая ударением
— в приставке пишем И, так как обозначает близость
Схема орфографического разбора слова
1. Выписать контрольное слово.
2. Вставить пропущенные буквы или раскрыть скобки.
3. Подчеркнуть в слове место орфограммы.
4. Назвать орфограмму и объяснить (устно или письменно) условия правильного написания.
5. Указать проверочное слово (если возможно) и привести примеры слов с данной орфограммой.
Образец орфографического разбора слова:
Трава, рядами — безударная проверяемая гласная в корне слова; проверяется ударением:
трава — травы, рядами — ряд; вода — воды, леса — лес.
По этой схеме и примерым нужно разобрать ваши слова. Вот орфограммы, которые нужно объяснить:
— безударная в корне, проверяемая ударением
— соединительная гласная после мягкого согласного
— безударная гласная в корне, проверяемая ударением
— в приставке пишем И, так как обозначает близость
Схема орфографического разбора слова
1. Выписать контрольное слово.
2. Вставить пропущенные буквы или раскрыть скобки.
3. Подчеркнуть в слове место орфограммы.
4. Назвать орфограмму и объяснить (устно или письменно) условия правильного написания.
5. Указать проверочное слово (если возможно) и привести примеры слов с данной орфограммой.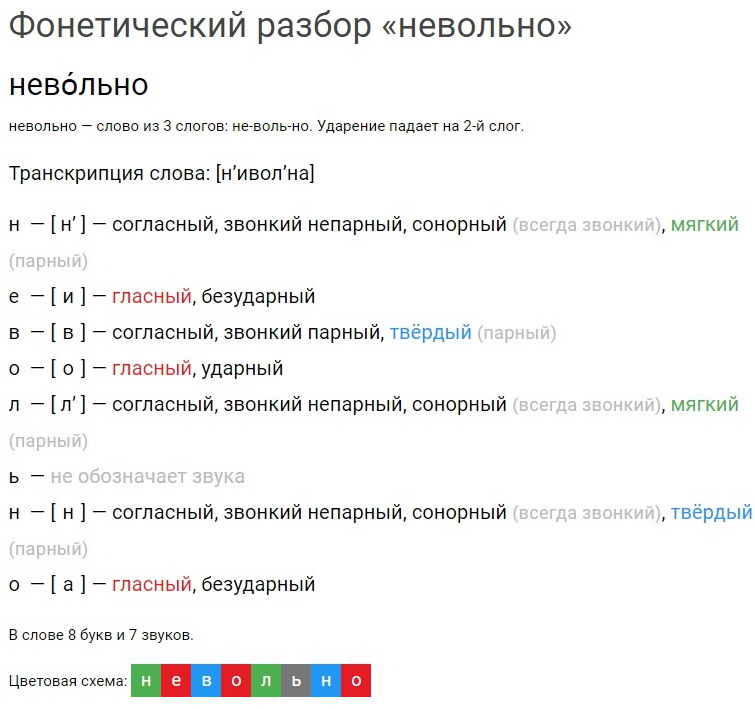
Образец орфографического разбора слова:
Трава, рядами — безударная проверяемая гласная в корне слова; проверяется ударением:
трава — травы, рядами — ряд; вода — воды, леса — лес.
По этой схеме и примерым нужно разобрать ваши слова. Вот орфограммы, которые нужно объяснить:
— безударная в корне, проверяемая ударением
— соединительная гласная после мягкого согласного
— безударная гласная в корне, проверяемая ударением
— в приставке пишем И, так как обозначает близость
Источник
Что такое разбор под цифрой 6 и как его делать?
Чтобы грамотно писать, нужно либо обладать врожденной грамотностью, либо много читать (а лучше и то и другое), ну либо хорошо учить правила русского языка, например, уметь делать все эти разборы, в частности, орфографический.
Да, цифра шесть предусматривает необходимость разбора орфографического. Сейчас мы выберем с вами какое-нибудь предложение, будем искать в нем орфограмму, а потом будем искать проверочные слова к слову с этой орфограммой и определять правило, по которому это слово нужно писать так или иначе.
Например, у нас есть предложение:
Вчера в книжный магазин поступила очень интересная новинка.
Выберем орфограмму в слове «новинка», это написание безударной гласной, в данном случае, гласной «о». Есть правило проверки таких гласных подбором однокоренных слов, в которых данная гласная будет стоять под ударением. Подбираем такие слова: новь, новый.
Разбор слова, который в учебнике обозначен цифрой 6, помогает школьникам учиться грамотно писать, не допуская орфографических ошибок. В русском языке очень много слов, написание которых вызывает сомнения. Ошибки допустить очень легко, поэтому важно запоминать правила и слова, а также учиться анализировать их, чтобы меньше ошибаться при их написании.
Под цифрой 6 подразумевается орфографический разбор слова.
Чтобы его выполнить, нужно выписать само слово.
Далее вставить пропущенные буквы, определив, какую букву необходимо вставить, опираясь на изученное правило.
Выделить орфограмму, подчеркнув ее.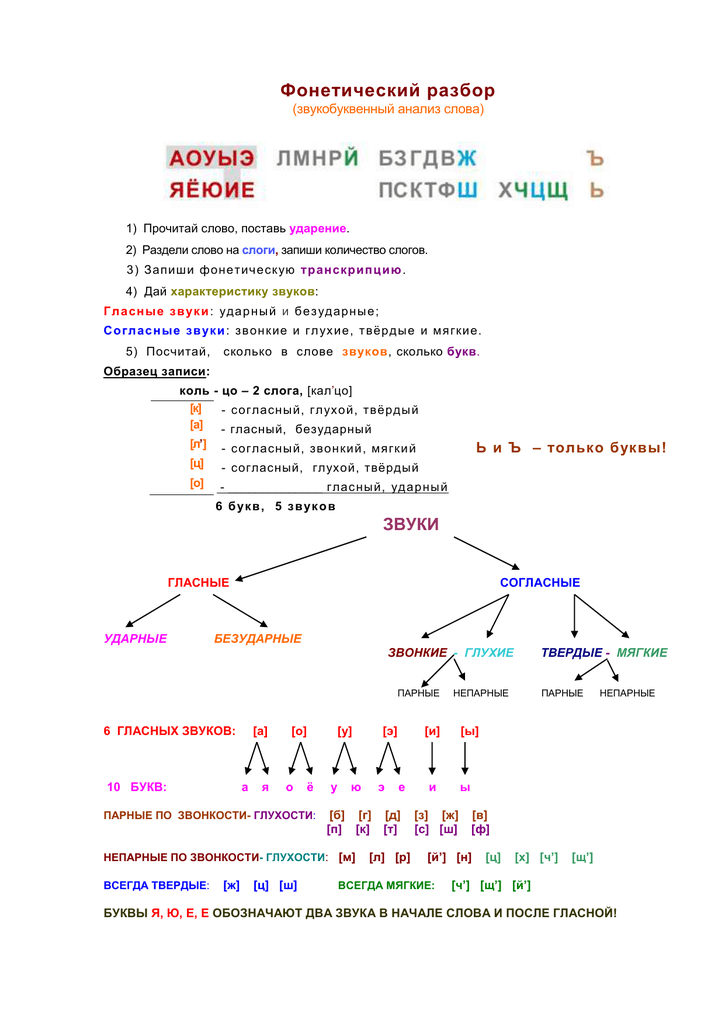
Назвать орфограмму, объяснить, какое правило применимо в данном случае.
Если можно подобрать проверочное слово, требуется его назвать.
Подсказка, которая поможет правильно выполнить орфографический разбор слова:
Пример подобного разбора:
Если мы видим циферку шесть, то это значит орфографический разбор.
Для начала мы должны найти орфограмму.
Дальше нужно подобрать нужное правило.
После этого нам нужно найти проверочное слово, также нужно объяснить почему это слово будет проверочным.
Смотрим на орфографический разбор такого слова как «дорожка»:
В учебниках можно встретить в конце слова в скобках или в индексе справа от слова цифры имеющие свою специфическую кодировку. Цифра 3 указывает что нужно сделать орфограмму слова и найти проверочное к нему.
Как это сделать можно прочитать здесь и ниже.
Нужно найти орфограмму слова, затем написать правило русского языка, согласно которому слово нужно писать именно так. Далее ищем проверочное слово.
Далее ищем проверочное слово.
Ниже представлена таблица, как правильно делать орфографический разбор слова.
Да, вам вполне может попасться задание с цифрой шесть, если вам попалось такое задание, значит нужно сделать орфографический разбор. Делается он просто.
Вначале находим орфограмму в этом слове и обозначаем ее. После этого нужно понять, почему это слово нужно проверять.
Далее находим проверочное слово, приводим обоснование, почему оно является проверочным. Остается еще привести примеры с такой же орфограммой.
Что значит цифра 6, какой это разбор?
Разбор под цифрой 6 это орфографический разбор.
Если кратко, то нужно найти в слове орфограмму и проверочное слово к нему.
Орфографический разбор делаем по следующему плану (схеме):
Цифра шесть ставиться после слова в предложении. Это будет означать, что следует сделать орфографический разбор данного слова. В одном предложении может ставиться не одна цифра 6, а несколько, что будет означать, что надо сделать орфографический разбор нескольких слов.
Напомним, что именно подразумевается под орфографическим разбором слова. Чаще всего в таких словах пропущены буквы, т.е. на место точек надо вставить букву и определить орфограмму. Потом следует выделить морфему графически. Указать проверочное слово.
Орфограммы могут быть в приставках, в корнях слова и т.д.
Примерный образец орфографического разбора слова.
Разбор под цифрой 6 подразумевает орфографический разбор слова. Применяется он в первую очередь для того, чтобы проверить правильность написания того или иного слова.
Первым делом, нам нужно установить орфограмму, то есть понять, правописание каких букв требует проверок. Обычно проверяются приставки и безударные гласные в корне, реже суффиксы или окончания.
После этого каждую сомнительную букву мы проверяем по стандартным правилам. Безударные гласные мы проверяем с помощью других однокоренных слов, если это невозможно, значит перед нами словарное слово, проверяем по словарю. Приставки и суффиксы проверяем по простым правилам, для определения окончания смотрим, в каком падеже задано слово и проверяем по окончанию падежей.
В итоге мы получаем правильное слово, в котором все буквы проверены, это и есть разбор под цифрой 6.
Для его правильного выполнения, нам необходимо выявить орфограмму в слове, а затем ее выделить.
После этого нам необходимо произвести объяснение выявленной нами орфограммы. После чего необходимо подобрать то слово, которое является проверочным и записать его. Если проверочное слово отсутствует в принципе, то мы заменяем его примерами к тому правилу, которое касается данной орфограммы.
Получаем: НОВ-УЮ, НОВ-ОМУ (корень-окончание), основа слова НОВ-
Эта словоформа отвечает на вопрос «что сделает?“ и является формой будущего времени совершенного вида третьего лица единственного числа глагола «встретить». В предложении может быть простым глагольным сказуемым.
Определим какой частью речи является слово «переулок«.
Теперь разберём слово «переулок» по составу ( морфемный разбор ):
Схематически это выглядит следующим образом:
Слово «драгоценных» ( прилагательное, каких? ). Разберем его по составу, то есть выделим все морфемы, которые есть в данном слове:
Разберем его по составу, то есть выделим все морфемы, которые есть в данном слове:
—драг— первый корень слова;
—о— соединительная гласная слова;
—цен— второй корень слова;
—н— суффикс слова;
—ых— окончание слова;
основа слова: драгоценн.
Однокоренными словами оказываются: Мелочь-Мелочный-Мелочиться-Мелкий.
Следовательно корнем слова будет морфема МЕЛОЧЬ, причем этот корень может выглядеть и как МЕЛК или МЕЛОЧ. Реже выделяют корень МЕЛ-.
Получаем: МЕЛОЧЬ_ (корень-нулевое окончание), основа слова: МЕЛОЧЬ.
Выделим здесь тот же корень МЕЛОЧ-.
Получаем: МЕЛОЧ-Н-ЫЙ (корень-суффикс-окончание), основа слова: МЕЛОЧН-.
Источник
Морфологический разбор «шестой»
В данной статье мы рассмотрим слово «шестой». В зависимости от контекста, оно может быть: именем прилагательным, именем существительным, числительным. Ниже мы подробно разберём каждый из этих случаев, дадим морфологический разбор слова и укажем его возможные синтаксические роли.
Ниже мы подробно разберём каждый из этих случаев, дадим морфологический разбор слова и укажем его возможные синтаксические роли.
Если вы хотите разобрать другое слово, то укажите его в форме поиска.
«Шестой» (имя прилагательное)
Значение слова «шестой» по словарю С. И. Ожегова
Морфологический разбор имени прилагательного
1) шестой – мужской род, единственное число, полная форма, положительная степень, именительный падеж
2) шестой – мужской род, единственное число, полная форма, положительная степень, винительный падеж
3) шестой – женский род, единственное число, полная форма, положительная степень, родительный падеж
4) шестой – женский род, единственное число, полная форма, положительная степень, дательный падеж
5) шестой – женский род, единственное число, полная форма, положительная степень, творительный падеж
6) шестой – женский род, единственное число, полная форма, положительная степень, предложный падеж
Склонение имени прилагательного по падежам
| Падеж | Мужской род | Средний род | Женский род | Множественное число |
|---|---|---|---|---|
| Именительный падеж | Какой? шестой | Какое? шестое | Какая? шестая | Какие? шестые |
| Родительный падеж | Какого? шестого | Какого? шестого | Какой? шестой | Каких? шестых |
| Дательный падеж | Какому? шестому | Какому? шестому | Какой? шестой | Каким? шестым |
| Винительный падеж | Какого? Какой? шестой, шестого | Какого? Какое? шестое | Какую? шестую | Каких? Какие? шестые, шестых |
| Творительный падеж | Каким? шестым | Каким? шестым | Какой? шестою, шестой | Какими? шестыми |
| Предложный падеж | О каком? шестом | О каком? шестом | О какой? шестой | О каких? шестых |
«Шестой» (имя существительное)
Значение слова «шестой» по словарю С.
 И. Ожегова
И. ОжеговаМорфологический разбор имени существительного
1) шестой – единственное число, именительный падеж
2) шестой – единственное число, винительный падеж
3) шестой – единственное число, родительный падеж
4) шестой – единственное число, дательный падеж
5) шестой – единственное число, творительный падеж
6) шестой – единственное число, предложный падеж
Склонение имени существительного по падежам
| Падеж | Единственное число | Множественное число |
|---|---|---|
| Именительный падеж кто? что? | шестой, шестая | шестые |
| Родительный падеж кого? чего? | шестого, шестой | шестых |
| Дательный падеж кому? чему? | шестому, шестой | шестым |
| Винительный падеж кого? что? | шестого, шестой, шестую | шестых, шестые |
| Творительный падеж кем? чем? | шестым, шестою, шестой | шестыми |
| Предложный падеж о ком? о чём? | шестом, шестой | шестых |
«Шестой» (числительное)
Морфологический разбор числительного
Склонение числительного по падежам
| Падеж | Мужской род | Средний род | Женский род | Множественное число |
|---|---|---|---|---|
| Именительный падеж | Какой? шестой | Какое? шестое | Какая? шестая | Каковы? шестые |
| Родительный падеж | Какого? шестого | Какого? шестого | Какой? шестой | Каких? шестых |
| Дательный падеж | Какому? шестому | Какому? шестому | Какой? шестой | Каким? шестым |
| Винительный падеж | Какого? шестой, шестого | Какое? шестое | Какую? шестую | Какие? шестые, шестых |
| Творительный падеж | Каким? шестым | Каким? шестым | Какой? шестою, шестой | Какими? шестыми |
| Предложный падеж | О каком? шестом | О каком? шестом | О какой? шестой | О каких? шестых |
Разобрать другое слово
Введите слово для разбора: Найти
Относительными называются прилагательные, которые обозначают:
Относительные прилагательные не имеют антонимов и синонимов, степеней сравнения и кратких форм.
Отвечают на вопросы «какой?», «какая?», «какое?», «какие?».
Полные прилагательные отвечают на вопросы «какой?», «какая?», «какое?», «какие?» и могут склоняться по родам, числам и падежам.
Качественные и относительные прилагательные: отвечает на вопросы «какой?», «какая?», «какое?», «какие?»
Притяжательные прилагательные: отвечает на вопросы «чей?», «чья?», «чьё?», «чьи?»
Качественные и относительные прилагательные: отвечает на вопросы «какого?», «какой?», «какое?», «какую?», «каких?», «какие?»
Притяжательные прилагательные: отвечает на вопросы «чьего?», «чей?», «чьё?», «чью?», «чьих?», «чьи?»
Качественные и относительные прилагательные: отвечает на вопросы «какого?», «какой?», «каких?»
Притяжательные прилагательные: отвечает на вопросы «чьего?», «чьей?», «чьих?»
Качественные и относительные прилагательные: отвечает на вопросы «какому?», «какой?», «каким?»
Притяжательные прилагательные: отвечает на вопросы «чьему?», «чьей?», «чьим?»
Качественные и относительные прилагательные: отвечает на вопросы «каким?», «какой?», «какими?»
Притяжательные прилагательные: отвечает на вопросы «чьим?», «чьей?», «чьими?»
Качественные и относительные прилагательные: отвечает на вопросы «о каком?», «о какой?», «о каких?»
Притяжательные прилагательные: отвечает на вопросы «о чьём?», «о чьей?», «о чьих?»
К неодушевлённым существительным относятся названия предметов и явлений, которые не являются живыми существами:
Такие существительные отвечают на вопрос «что?». При склонении по падежам во множественном числе форма винительного падежа совпадает с формой именительного.
При склонении по падежам во множественном числе форма винительного падежа совпадает с формой именительного.
К нарицательным существительным относятся слова, обозначающие обобщённые названия предметов, явлений, состояний и действий:
Такие существительные пишутся со строчной буквы.
Ко второму склонению относятся имена существительные мужского рода (кроме тех, что оканчиваются на -а (-я)) и среднего рода:
Источник
Морфологический разбор слова с примерами и онлайн
Морфологический разбор онлайн
Введите слово без ошибок:
Введите любое слово, затем нажмите «разобрать». После этого вы получите разбор, в котором будет написана часть речи, падеж, род, время и всё остальное. Т.к. разбор производится вне контекста, то может быть предложено несколько вариантов разбора, среди которых вам нужно будет выбрать правильный. Разбор выполняется компьютером автоматически, поэтому иногда могут быть ошибки. Будьте внимательны, онлайн разбор предназначен для помощи, а не для бездумного переписывания. Замечание про букву Ё: не заменяйте её на Е.
Замечание про букву Ё: не заменяйте её на Е.
Нажмите Ctrl+D, чтобы добавить сервис в закладки и пользоваться им в будущем.
Для того, чтобы не испытывать трудности в схеме морфологического разбора слова или в порядке разбора, не следует автоматически запоминать последовательность и принцип разбора. Эффективнее всего ориентироваться на выделение общих признаков частей речи, а затем перейти на частные признаки этой формы. При этом общая логика разбора должна быть сохранена. Также вам помогут Части речи.
Следующие примеры морфологического разбора позволят понять схему разбора слов предложения в русском языке. Однако следует помнить, что наличие текста – обязательное условие правильного разбора частей речи, ведь морфологический разбор – это характеристика слова (как части речи), учитывающая специфику его использования.
Рассмотрим примеры морфологического разбора.
Морфологический разбор существительного
Существительное (образец разбора):
Текст: Малыши любят пить молоко.
Молоко – существительное, начальная форма – молоко, нарицательное, неодушевленное, среднего рода, 2-го склонения, в винительном падеже, единственном числе (множественного не имеет), прямое дополнение.
Прилагательное (образец разбора):
Текст: Полное лукошко грибов собрала Аленушка.
Полное – имя прилагательное, начальная форма – полный; качественное: полное; в положительной (нулевой) степени сравнения, в среднем роде, винительном падеже, является дополнением.
Числительное (порядок разбора):
Числительное (образец разбора):
Текст: Пролетело четыре дня.
Четыре – числительное, начальная форма – четыре, количественное, простое, в именительном падеже, не имеет числа и рода, является подлежащим.
Местоимение (порядок разбора):
Местоимение (образец разбора):
Текст: С нее капали хрустальные дождинки.
Нее – местоимение, начальная форма – она, личное, 3-е лицо, женский род, родительный падеж, единственное число, обстоятельство места.
Морфологический разбор глагола
Глагол (образец разбора):
Текст: Сказали правду, не побоявшись осуждения.
Сказали – глагол, начальная форма – сказать, невозвратный, непереходный, совершенного вида, 1-го спряжения, в изъявительном наклонении, прошедшем времени, множественном числе, является сказуемым.
Причастие (порядок разбора):
Причастие (образец разбора):
Текст: Гляжу на опадающую листву и грущу.
Опадающую – причастие, начальная форма – опадающий, от глагола опадать, несовершенного вида, настоящего времени, невозвратное, непереходное, в женском роде, винительном падеже, единственном числе, согласованное определение.
Деепричастие (порядок разбора):
Деепричастие (образец разбора):
Текст: Уезжая за границу, ты грустишь о доме.
Уезжая – деепричастие, от глагола «уезжать», несовершенного вида, невозвратное, непереходное, обстоятельство образа действия.
Наречие (порядок разбора):
Наречие (образец разбора):
Текст: Солнце взошло выше, и тучи рассеялись.
Выше – наречие, обстоятельственное места, является обстоятельством места, сравнительная степень.
Видео
Что-то непонятно? Есть хорошее видео по теме для прилагательных:
Порядок разбора в вашем классе может отличаться от предложенного, поэтому советуем уточнить у вашего учителя требования к разбору.
Всё для учебы » Русский язык » Морфологический разбор слова с примерами и онлайн
Чтобы добавить страницу в закладки, нажмите Ctrl+D.
Если страница помогла, сохраните её и поделитесь ссылкой с друзьями:
Источник
Фонетический разбор слова «шестой»
Фонетический разбор «шестой»:
«Шестой»
Характеристики звуков
Смотрите также:
Морфологический разбор слова «шестой»
Фонетический разбор слова «шестой»
Значение слова «шестой»
Разбор по составу слова «шестой»
Карточка «шестой»
Предложения со словом «шестой»
Звуко буквенный разбор слова: чем отличаются звуки и буквы?
Прежде чем перейти к выполнению фонетического разбора с примерами обращаем ваше внимание, что буквы и звуки в словах — это не всегда одно и тоже.
Буквы — это письмена, графические символы, с помощью которых передается содержание текста или конспектируется разговор. Буквы используются для визуальной передачи смысла, мы воспримем их глазами. Буквы можно прочесть. Когда вы читаете буквы вслух, то образуете звуки — слоги — слова.
Список всех букв — это просто алфавит
Почти каждый школьник знает сколько букв в русском алфавите. Правильно, всего их 33. Русскую азбуку называют кириллицей. Буквы алфавита располагаются в определенной последовательности:
| Аа | «а» | Бб | «бэ» | Вв | «вэ» | Гг | «гэ» |
| Дд | «дэ» | Ее | «е» | Ёё | «йо» | Жж | «жэ» |
| Зз | «зэ» | Ии | «и» | Йй | «й» | Кк | «ка» |
| Лл | «эл» | Мм | «эм» | Нн | «эн» | Оо | «о» |
| Пп | «пэ» | Рр | «эр» | Сс | «эс» | Тт | «тэ» |
| Уу | «у» | Фф | «эф» | Хх | «ха» | Цц | «цэ» |
| Чч | «чэ» | Шш | «ша» | Щщ | «ща» | ъ | «т. з.» з.» |
| Ыы | «ы» | ь | «м.з.» | Ээ | «э» | Юю | «йу» |
| Яя | «йа» |
Всего в русском алфавите используется:
Звуки — это фрагменты голосовой речи. Вы можете их услышать и произнести. Между собой они разделяются на гласные и согласные. При фонетическом разборе слова вы анализируете именно их.
Звуки в фразах вы зачастую проговариваете не так, как записываете на письме. Кроме того, в слове может использоваться больше букв, чем звуков. К примеру, «детский» — буквы «Т» и «С» сливаются в одну фонему [ц]. И наоборот, количество звуков в слове «чернеют» большее, так как буква «Ю» в данном случае произносится как [йу].
Что такое фонетический разбор?
Звучащую речь мы воспринимаем на слух. Под фонетическим разбором слова имеется ввиду характеристика звукового состава. В школьной программе такой разбор чаще называют «звуко буквенный» анализ. Итак, при фонетическом разборе вы просто описываете свойства звуков, их характеристики в зависимости от окружения и слоговую структуру фразы, объединенной общим словесным ударением.
Фонетическая транскрипция
Для звуко-буквенного разбора применяют специальную транскрипцию в квадратных скобках. К примеру, правильно пишется:
В схеме фонетического разбора используются особые символы. Благодаря этому можно корректно обозначить и отличить буквенную запись (орфографию) и звуковое определение букв (фонемы).
Ниже приводятся подробные правила для орфоэпического, буквенного и фонетического и разбора слов с примерами онлайн, в соответствии с общешкольными нормами современного русского языка. У профессиональных лингвистов транскрипция фонетических характеристик отличается акцентами и другими символами с дополнительными акустическими признаками гласных и согласных фонем.
Как сделать фонетический разбор слова?
Провести буквенный анализ вам поможет следующая схема:
Данная схема практикуется в школьной программе.
Пример фонетического разбора слова
Вот образец фонетического разбора по составу для слова «явление» → [йивл’э′н’ийэ]. В данном примере 4 гласных буквы и 3 согласных. Здесь всего 4 слога: я-вле′-ни-е. Ударение падает на второй.
В данном примере 4 гласных буквы и 3 согласных. Здесь всего 4 слога: я-вле′-ни-е. Ударение падает на второй.
Звуковая характеристика букв:
Теперь вы знаете как сделать звуко-буквенный анализ самостоятельно. Далее даётся классификация звуковых единиц русского языка, их взаимосвязи и правила транскрипции при звукобуквенном разборе.
Фонетика и звуки в русском языке
Какие бывают звуки?
Все звуковые единицы делятся на гласные и согласные. Гласные звуки, в свою очередь, бывают ударными и безударными. Согласный звук в русских словах бывает: твердым — мягким, звонким — глухим, шипящим, сонорным.
— Сколько в русской живой речи звуков?
Правильный ответ 42.
Делая фонетический разбор онлайн, вы обнаружите, что в словообразовании участвуют 36 согласных звуков и 6 гласных. У многих возникает резонный вопрос, почему существует такая странная несогласованность? Почему разнится общее число звуков и букв как по гласным, так и по согласным?
Всё это легко объяснимо. Ряд букв при участии в словообразовании могут обозначать сразу 2 звука. Например, пары по мягкости-твердости:
Ряд букв при участии в словообразовании могут обозначать сразу 2 звука. Например, пары по мягкости-твердости:
А некоторые не обладают парой, к примеру [ч’] всегда будет мягким. Сомневаетесь, попытайтесь сказать его твёрдо и убедитесь в невозможности этого: ручей, пачка, ложечка, чёрным, Чегевара, мальчик, крольчонок, черемуха, пчёлы. Благодаря такому практичному решению наш алфавит не достиг безразмерных масштабов, а звуко-единицы оптимально дополняются, сливаясь друг с другом.
Гласные звуки в словах русского языка
Гласные звуки в отличии от согласных мелодичные, они свободно как бы нараспев вытекают из гортани, без преград и напряжения связок. Чем громче вы пытаетесь произнести гласный, тем шире вам придется раскрыть рот. И наоборот, чем громче вы стремитесь выговорить согласный, тем энергичнее будете смыкать ротовую полость. Это самое яркое артикуляционное различие между этими классами фонем.
Ударение в любых словоформах может падать только на гласный звук, но также существуют и безударные гласные.
— Сколько гласных звуков в русской фонетике?
В русской речи используется меньше гласных фонем, чем букв. Ударных звуков всего шесть: [а], [и], [о], [э], [у], [ы]. А букв, напомним, десять: а, е, ё, и, о, у, ы, э, я, ю. Гласные буквы Е, Ё, Ю, Я не являются «чистыми» звуками и в транскрипции не используются. Нередко при буквенном разборе слов на перечисленные буквы падает ударение.
Фонетика: характеристика ударных гласных
Главная фонематическая особенность русской речи — четкое произнесение гласных фонем в ударных слогах. Ударные слоги в русской фонетике отличаются силой выдоха, увеличенной продолжительностью звучания и произносятся неискаженно. Поскольку они произносятся отчетливо и выразительно, звуковой анализ слогов с ударными гласными фонемами проводить значительно проще. Положение, в котором звук не подвергается изменениям и сохранят основной вид, называется сильной позицией. Такую позицию может занимать только ударный звук и слог. Безударные же фонемы и слоги пребывают в слабой позиции.
Разбор по звукам ударных гласных
Гласная фонема [о] встречается только в сильной позиции (под ударением). В таких случаях «О» не подвергается редукции: котик [к о´ т’ик], колокольчик [калак о´ л’ч’ык], молоко [малак о´ ], восемь [в о´ с’им’], поисковая [паиск о´ вайа], говор [г о´ вар], осень [ о´ с’ин’].
Исключение из правила сильной позиции для «О», когда безударная [о] произносится тоже отчётливо, представляют лишь некоторые иноязычные слова: какао [кака’ о ], патио [па’ти о ], радио [ра’ди о ], боа [б о а’] и ряд служебных единиц, к примеру, союз но. Звук [о] в письменности можно отразить другой буквой «ё» – [о]: тёрн [т’ о´ рн], костёр [кас’т’ о´ р]. Выполнить разбор по звукам оставшихся четырёх гласных в позиции под ударением так же не представит сложностей.
Безударные гласные буквы и звуки в словах русского языка
Сделать правильный звуко разбор и точно определить характеристику гласного можно лишь после постановки ударения в слове. Не забывайте так же о существовании в нашем языке омонимии: за’мок — замо’к и об изменении фонетических качеств в зависимости от контекста (падеж, число):
Не забывайте так же о существовании в нашем языке омонимии: за’мок — замо’к и об изменении фонетических качеств в зависимости от контекста (падеж, число):
В безударном положении гласный видоизменяется, то есть, произносится иначе, чем записывается:
Подобные изменения гласных в безударных слогах называются редукцией. Количественной, когда изменяется длительность звучания. И качественной редукцией, когда меняется характеристика изначального звука.
Одна и та же безударная гласная буква может менять фонетическую характеристику в зависимости от положения:
Так, различается 1-ая степень редукции. Ей подвергаются:
Примечание: Чтобы сделать звукобуквенный анализ первый предударный слог определяют исходя не с «головы» фонетического слова, а по отношению к ударному слогу: первый слева от него. Он в принципе может быть единственным предударным: не-зде-шний [н’из’д’э´шн’ий].
(неприкрытый слог)+(2-3 предударный слог)+ 1-й предударный слог ← Ударный слог → заударный слог (+2/3 заударный слог)
Любые другие предударные слоги и все заударные слоги при звуко разборе относятся к редукции 2-й степени. Ее так же называют «слабая позиция второй степени».
Ее так же называют «слабая позиция второй степени».
Редукция гласных в слабой позиции так же различается по ступеням: вторая, третья (после твердых и мягких соглас., — это за пределами учебной программы): учиться [уч’и´ц:а], оцепенеть [ацып’ин’э´т’], надежда [над’э´жда]. При буквенном анализе совсем незначительно проявятся редукция у гласного в слабой позиции в конечном открытом слоге (= в абсолютном конце слова):
Звуко буквенный разбор: йотированные звуки
Фонетически буквы Е — [йэ], Ё — [йо], Ю — [йу], Я — [йа] зачастую обозначают сразу два звука. Вы заметили, что во всех обозначенных случаях дополнительной фонемой выступает «Й»? Именно поэтому данные гласные называют йотированными. Значение букв Е, Ё, Ю, Я определяется их позиционным положением.
При фонетическом разборе гласные е, ё, ю, я образуют 2 звука:
◊ Ё — [йо], Ю — [йу], Е — [йэ], Я — [йа] в случаях, когда находятся:
Как видите, в фонематической системе русского языка ударения имеют решающее значение. Наибольшей редукции подвергаются гласные в безударных слогах. Продолжим звука буквенный разбор оставшихся йотированных и посмотрим как они еще могут менять характеристики в зависимости от окружения в словах.
Наибольшей редукции подвергаются гласные в безударных слогах. Продолжим звука буквенный разбор оставшихся йотированных и посмотрим как они еще могут менять характеристики в зависимости от окружения в словах.
◊ Безударные гласные «Е» и «Я» обозначают два звука и в фонетической транскрипции и записываются как [ЙИ]:
Примечание: Для петербургской фонологической школы характерно «эканье», а для московской «иканье». Раньше йотрованный «Ё» произносили с более акцентированным «йэ». Со сменой столиц, выполняя звуко-буквенный разбор, придерживаются московских норм в орфоэпии.
Некоторые люди в беглой речи произносят гласный «Я» одинаково в слогах с сильной и слабой позицией. Такое произношение считается диалектом и не является литературным. Запомните, гласный «я» под ударением и без ударения озвучивается по-разному: ярмарка [ йа ´рмарка], но яйцо [ йи йцо´].
Фонетический разбор слов, когда гласные «Ю» «Е» «Ё» «Я» образуют 1 звук
По правилам фонетики русского языка при определенном положении в словах обозначенные буквы дают один звук, когда:
Фонетический разбор: согласные звуки русского языка
Согласных в русском языке абсолютное большинство. При выговаривании согласного звука поток воздуха встречает препятствия. Их образуют органы артикуляции: зубы, язык, нёбо, колебания голосовых связок, губы. За счет этого в голосе возникает шум, шипение, свист или звонкость.
При выговаривании согласного звука поток воздуха встречает препятствия. Их образуют органы артикуляции: зубы, язык, нёбо, колебания голосовых связок, губы. За счет этого в голосе возникает шум, шипение, свист или звонкость.
Сколько согласных звуков в русской речи?
В алфавите для их обозначения используется 21 буква. Однако, выполняя звуко буквенный анализ, вы обнаружите, что в русской фонетике согласных звуков больше, а именно — 36.
Звуко-буквенный разбор: какими бывают согласные звуки?
В нашем языке согласные бывают:
Определить звонкость-глухость или сонорность согласного можно по степени шума-голоса. Данные характеристики будут варьироваться в зависимости от способа образования и участия органов артикуляции.
Примечание: В фонетике у согласных звуковых единиц также существует деление по характеру образования: смычка (б, п, д, т) — щель (ж, ш, з, с) и способу артикуляции: губно-губные (б, п, м), губно-зубные (ф, в), переднеязычные (т, д, з, с, ц, ж, ш, щ, ч, н, л, р), среднеязычный (й), заднеязычные (к, г, х). Названия даны исходя из органов артикуляции, которые участвуют в звукообразовании.
Названия даны исходя из органов артикуляции, которые участвуют в звукообразовании.
Подсказка: Если вы только начинаете практиковаться в фонетическом разборе слов, попробуйте прижать к ушам ладони и произнести фонему. Если вам удалось услышать голос, значит исследуемый звук — звонкий согласный, если же слышится шум, — то глухой.
Подсказка: Для ассоциативной связи запомните фразы: «Ой, мы же не забывали друга.» — в данном предложении содержится абсолютно весь комплект звонких согласных (без учета пар мягкость-твердость). «Степка, хочешь поесть щец? – Фи!» — аналогично, указанные реплики содержат набор всех глухих согласных.
Позиционные изменения согласных звуков в русском языке
Согласный звук так же как и гласный подвергается изменениям. Одна и та же буква фонетически может обозначать разный звук, в зависимости от занимаемой позиции. В потоке речи происходит уподобление звучания одного согласного под артикуляцию располагающегося рядом согласного. Данное воздействие облегчает произношение и называется в фонетике ассимиляцией.
Позиционное оглушение/озвончение
В определённом положении для согласных действует фонетический закон ассимиляции по глухости-звонкости. Звонкий парный согласный сменяется на глухой:
В русской фонетике глухой шумный согласный не сочетается с последующим звонким шумным, кроме звуков [в] — [в’]: вз битыми сливками. В данном случае одинаково допустима транскрипция как фонемы [з], так и [с].
При разборе по звукам слов: итого, сегодня, сегодняшний и тп, буква «Г» замещается на фонему [в].
По правилам звуко буквенного анализа в окончаниях «-ого», «-его» имён прилагательных, причастий и местоимений согласный «Г» транскрибируется как звук [в]: красного [кра´снава], синего [с’и´н’ива], белого [б’э´лава], острого, полного, прежнего, того, этого, кого. Если после ассимиляции образуются два однотипных согласных, происходит их слияние. В школьной программе по фонетике этот процесс называется стяжение согласных: отделить [ад:’ил’и´т’] → буквы «Т» и «Д» редуцируются в звуки [д’д’], бе сш умный [б’и ш: у´мный]. При разборе по составу у ряда слов в звукобуквенном анализе наблюдается диссимиляция — процесс обратный уподоблению. В этом случае изменяется общий признак у двух стоящих рядом согласных: сочетание «ГК» звучит как [хк] (вместо стандартного [кк]): лёгкий [л’о′х’к’ий], мягкий [м’а′х’к’ий].
При разборе по составу у ряда слов в звукобуквенном анализе наблюдается диссимиляция — процесс обратный уподоблению. В этом случае изменяется общий признак у двух стоящих рядом согласных: сочетание «ГК» звучит как [хк] (вместо стандартного [кк]): лёгкий [л’о′х’к’ий], мягкий [м’а′х’к’ий].
Мягкие согласные в русском языке
В схеме фонетического разбора для обозначения мягкости согласных используется апостроф [’].
Примечание: буква «Ь» после согласного непарного по твердости/мягкости в некоторых словоформах выполняет только грамматическую функцию и не накладывает фонетическую нагрузку: учиться, ночь, мышь, рожь и тд. В таких словах при буквенном анализе в квадратных скобках напротив буквы «Ь» ставится [-] прочерк.
Позиционные изменения парных звонких-глухих перед шипящими согласными и их транскрипция при звукобуквенном разборе
Чтобы определить количество звуков в слове необходимо учитывать их позиционные изменения. Парные звонкие-глухие: [д-т] или [з-с] перед шипящими (ж, ш, щ, ч) фонетически заменяются шипящим согласным.
Явление, когда две разных буквы произносятся как одна, называется полной ассимиляцией по всем признакам. Выполняя звуко-буквенный разбор слова, один из повторяющихся звуков вы должны обозначать в транскрипции символом долготы [:].
Шпаргалка по уподоблению согласных звуков по месту образования
Непроизносимые согласные звуки в словах русского языка
Во время произношения целого фонетического слова с цепочкой из множества различных согласных букв может утрачиваться тот, либо иной звук. Вследствие этого в орфограммах слов находятся буквы, лишенные звукового значения, так называемые непроизносимые согласные. Чтобы правильно выполнить фонетический разбор онлайн, непроизносимый согласный не отображают в транскрипции. Число звуков в подобных фонетических словах будет меньшее, чем букв.
В русской фонетике к числу непроизносимых согласных относятся:
Примечание: В некоторых словах русского языка при скоплении согласных звуков «стк», «нтк», «здк», «ндк» выпадение фонемы [т] не допускается: поездка [пайэ´стка], невестка, машинистка, повестка, лаборантка, студентка, пациентка, громоздкий, ирландка, шотландка.
Если вы затрудняетесь выполнить фонетический разбор слова онлайн по обозначенным правилам или у вас получился неоднозначный анализ исследуемого слова, воспользуйтесь помощью словаря-справочника. Литературные нормы орфоэпии регламентируются изданием: «Русское литературное произношение и ударение. Словарь – справочник». М. 1959 г.
Теперь вы знаете как разобрать слово по звукам, сделать звуко буквенный анализ каждого слога и определить их количество. Описанные правила объясняют законы фонетики в формате школьной программы. Они помогут вам фонетически охарактеризовать любую букву.
Источник
Видео
Задание 6. ЕГЭ по русскому языку 2020. Поиск лексических ошибок.
Урок по подготовке к ВПР 6 кл.Синтаксический разбор
ЛАЙФХАК для задания №6 / Русский язык ЕГЭ 2022 / Лексические ошибки
РУССКИЙ ЯЗЫК 6 класс: Словообразовательный разбор слова
ЗАДАНИЕ 6 В ЕГЭ // РАЗБОР И ЛАЙФХАКИ
Морфологический разбор глагола
ВПР 6 класс. Русский язык 2019 . Подробный разбор . Вариант 1.
Подробный разбор . Вариант 1.
Синтаксический разбор предложения | Русский язык | TutorOnline
РУССКИЙ ЯЗЫК 6 класс: Морфологический разбор глагола
Морфологический разбор глагола (6 класс)
Как выполнить звуковой разбор слова
В процессе школьного обучения русскому языку ученики знакомятся с разными видами разборов. Это и лексический анализ слова, и разбор по составу и способам образования. Дети учатся разбирать предложение по членам, выявлять его синтаксические и пунктуационные особенности. А также производить многие другие языковые операции.
Обоснование темы
После повторения материала, пройденного в начальной школе, учащиеся 5-х классов приступают к первому крупному разделу языкознания – фонетике. Завершением его изучения является разбор слова по звукам. Почему именно с фонетики начинается серьёзное и глубокое знакомство с родной речью? Ответ прост. Текст состоит из предложений, предложения – из слов, а слова – из звуков, которые и являются теми кирпичиками, строительным материалом, первоосновой языка, причем не только русского, а любого. Вот почему разбор слова по звукам – начало формирования практических навыков и умений школьников в лингвистической работе.
Вот почему разбор слова по звукам – начало формирования практических навыков и умений школьников в лингвистической работе.
Понятие фонетического разбора
Что именно включает он в себя, и что нужно знать школьникам, чтобы успешно справляться с заданиями фонетического характера? Во-первых, хорошо ориентироваться в слоговом членении. Во-вторых, разбор слова по звукам не может производиться без чёткого различения гласных и согласных фонем, парных и непарных, слабых и сильных позиций. В-третьих, если оно (слово) включает йотированные, мягкие или твёрдые элементы, удвоенные буквы, ученик тоже должен уметь ориентироваться, какая литера используется для обозначения того или иного звука на письме. И даже такие сложнейшие процессы, как аккомодация или ассимиляция (уподобление) и диссимиляция (расподобление), тоже должны быть ими хорошо изучены (хотя указанные термины и не упоминаются в учебниках, тем не менее, дети знакомятся с этими понятиями). Естественно, что разбор слова по звукам не может производиться, если ребёнок не умеет транскрибировать, не знает элементарных правил транскрипции. Поэтому учитель должен серьёзно и ответственно подойти к преподаванию раздела «Фонетика».
Поэтому учитель должен серьёзно и ответственно подойти к преподаванию раздела «Фонетика».
Теоретические рекомендации
Что представляет собой схема разбора слова по звукам? Какие этапы она включает? Разберёмся в этом подробно. Для начала лексема выписывается из текста, ставится знак «тире», после чего она пишется снова, только уже разделённая на слоги. Проставляется ударение. Затем открываются квадратные скобки, и ученик должен слово затранскрибировать – записать так, как оно слышится, т. е. выявить его звуковую оболочку, обозначить мягкость фонем, если таковые имеются, и т. д. Далее под вариантом транскрипции нужно пропустить строчку, провести вниз вертикальную черту. Перед ней в столбик записываются все буквы слова, после – в квадратных скобках звуки и даётся их полная характеристика. В конце разбора проводится небольшая горизонтальная черта и, как подведение итогов, отмечается количество буквы и звуков в слове.
Пример первый
Как всё это выглядит на практике, т. е. в школьной тетрадке? Произведём вначале пробный разбор слова по звукам. Примеры анализа дадут возможность понять многие нюансы. Записываем: покрывало. Делим на слоги: по-кры-ва´-ло. Транскрибируем: [пакрыва´ла]. Анализируем:
е. в школьной тетрадке? Произведём вначале пробный разбор слова по звукам. Примеры анализа дадут возможность понять многие нюансы. Записываем: покрывало. Делим на слоги: по-кры-ва´-ло. Транскрибируем: [пакрыва´ла]. Анализируем:
- п – [п] – это звук согласный, он глухой, парный, пара — [б], твердый;
- о – [а] – это гласный звук, безударный;
- к – [к] – звук согл., он глух., парн., [пара — г], твёрд.;
- р – [р] — звук согласный, сонорный, поэтому непарный по звонкости, твёрдый;
- ы – [ы] – это гласный, в данной позиции безударный;
- в – [в] – звук этот согл., является звонким, пара его — [ф], твёрдый;
- а — [а´] – гласный звук, в ударной позиции;
- л – [л] – это звук согл., относится к сонорным, поэтому непарн., твёрдый;
- о – [а] – согласный, безударный.
Итого: 9 букв в слове и 9 звуков; количество их полностью совпадает.
Пример второй
Посмотрим, как произвести разбор слова «друзья» по звукам. Действуем по уже намеченной схеме. Делим его на слоги, выставляем ударение: дру-зья´. Теперь записываем в транскрибируемом виде: [друз’й’а´]. И анализируем:
Действуем по уже намеченной схеме. Делим его на слоги, выставляем ударение: дру-зья´. Теперь записываем в транскрибируемом виде: [друз’й’а´]. И анализируем:
- д – [д] – согласный, он звонкий и является парным, пара — [т], твёрдый;
- р – [р] – согл., звонкий, сонорный, непарный, твёрдый;
- у – [у] – гласный, безударный;
- з – [з’] – согл., является звонким, имеет глухую пару — [с], мягкий и тоже парный: [з];
- ь – звука не обозначает;
- я – [й’] – полугласный, звонкий всегда, поэтому непарный, всегда мягкий;
- [а´] – гласный, ударный.
В данном слове 6 букв и 6 звуков. Их количество совпадает, т. к. Ь звука не обозначает, а буква Я после мягкого знака обозначает два звука.
Пример третий
Показываем, как следует делать разбор слова «язык» по звукам. Алгоритм вам знаком. Выписывайте его и делите на слоги: я-зык. Затранскрибируйте: [й’изы´к]. Разберите фонетически:
- я – [й’] – полугласный, звонкий, непарный всегда, только мягкий;
- [а] – этот звук гласный и безударный;
- з – [з] – согл.
 , звонкий, парный, пара — [с], твёрдый;
, звонкий, парный, пара — [с], твёрдый;
 , звонкий, парный, пара — [с], твёрдый;
, звонкий, парный, пара — [с], твёрдый;- ы – [ы´] – гласный, ударный;
- к – [к] – согласный, глухой, парный, [г], твёрдый.
Слово состоит из 4 букв и 5 звуков. Их количество не совпадает потому, что буква Я стоит в абсолютном начале и обозначает 2 звука.
Пример четвёртый
Посмотрим, как выглядит разбор слова «белка» по звукам. После выписки его произведите слогоделение: бел-ка. Теперь затранскрибируйте: [б’э´лка]. И произведите буквенно-звуковой анализ:
- б – [б’] – согл., звонкий, парный, [п], мягкий;
- е – [э´] – гласный, ударный;
- л – [л] – согл., сонорный, непар., в данном случае твёрдый;
- к – [к] – согл., глух., парный, [г], твёрдый;
- а – [а] – гласный, безударный.
В данном слове одинаковое количество букв и звуков – по 5. Как видите, производить фонетический разбор этого слова достаточно просто. Важно только обращать внимание на нюансы его произношения.
Пример пятый
Теперь давайте сделаем разбор слова «ель» по звукам. Пятиклассникам это должно быть интересно. Он поможет повторить и закрепить фонетические особенности йотированных гласных. Состоит слово из одного слога, что тоже непривычно ученикам. Транскрибируется оно так: [йэ´л’]. Теперь произведем анализ:
- е – [й’] – полугласный, звонкий, непарный, мягкий;
- [э´] – гласный, ударный;
- л – [л´] – согласный, сонорный, поэтому непарный, в данном слове мягкий;
- ь – звука не обозначает.
Таким образом, в слове «ель» 3 буквы и 3 звука. Буква Е обозначает 2 звука, т. к. стоит в начале слова, а мягкий знак звуков не обозначает.
Делаем выводы
Мы привели примеры фонетического разбора слов, состоящих из разного количества слогов и звуков. Учитель, объясняя тему, обучая своих школьников, должен стараться наполнить их словарный запас соответствующей терминологией. Говоря о звуках «Н», «Р», «Л», «М», следует называть их сонорными, попутно указывая, что они всегда звонкие и потому не имеют пары по глухости. [Й] сонорным не является, но тоже только звонкий, и по этому параметру примыкает к 4 предыдущим. Более того, раньше считалось, что этот звук относится к согласным, однако его справедливо называть полугласным, т. к. он очень близок к звуку [и]. Как лучше запомнить их? Запишите с детьми предложение : «Мы не увидели подругу». В неё и входят все сонорные.
[Й] сонорным не является, но тоже только звонкий, и по этому параметру примыкает к 4 предыдущим. Более того, раньше считалось, что этот звук относится к согласным, однако его справедливо называть полугласным, т. к. он очень близок к звуку [и]. Как лучше запомнить их? Запишите с детьми предложение : «Мы не увидели подругу». В неё и входят все сонорные.
Особые случаи разбора
Для того чтобы правильно определить фонетическую структуру слова, важно уметь в него вслушаться. Например, словоформа «лошадей» будет иметь такой вид в транскрипции: [лашыд’э´й’], «дождь» — [до´щ’]. Разобраться самостоятельно пятиклассникам с такими и подобными случаями довольно сложно. Поэтому учитель должен на уроках стараться анализировать интересные примеры и обращать внимание учеников на некоторые языковые тонкости. Касается это и таких слов, как «праздник», «дрожжи», т. е., содержащих удвоенные или непроизносимые согласные. На практике оно выглядит следующим образом: празд-ник, [пра´з’н’ик]; дрож-жи, [дро´жы]. Над «ж» следует провести черту, указывающую на длительность звука. Нестандартна тут и роль буквы И. Здесь она обозначает звук Ы.
Над «ж» следует провести черту, указывающую на длительность звука. Нестандартна тут и роль буквы И. Здесь она обозначает звук Ы.
О роли транскрипции
К вопросу о слогоделении
Слогоделение — тоже вопрос довольно сложный для пятиклассников. Обычно учитель ориентирует детей на такое правило: сколько в слове гласных букв, столько и слогов. Ре-ка: 2 слога; по-душ-ка: 3 слога. Это так называемые простые случаи, когда гласные находятся в окружение согласных. Несколько сложнее для детей другая ситуация. Например, в слове «синяя» наблюдается стечение гласных. Школьники затрудняются, как делить на слоги подобные варианты. Следует им объяснить, что и тут правило остаётся неизменным: си-ня-я (3 слога).
Вот такие особенности наблюдаются при фонетическом разборе.
Как только родители начинают задумываться о том, как обучить свое чадо навыкам чтения, кроме букв и слогов появляется понятие «звуковой анализ слова». Однако не каждый понимает, зачем необходимо обучать ребенка, не умеющего читать, его делать, ведь это может только вызвать путаницу. Но, как оказывается, от умения правильно разбираться слова на звуки зависит в будущем умение правильно писать.
Но, как оказывается, от умения правильно разбираться слова на звуки зависит в будущем умение правильно писать.
Звуковой анализ слова: что это
Прежде всего, стоит дать определение. Итак, звуковым анализом слова называют определение по порядку их размещения звуков в конкретном слове и характеристика их особенностей.
Зачем же детям нужно учиться выполнять звуковой анализ слова? Для разработки фонематического слуха, то есть умения четко различать звучащие звуки и не путать слова, например: Тима — Дима. Ведь если ребенок не научен четко различать на слух слова, он не сможет их правильно записывать. А данное умение может пригодиться не только при изучении грамматики родного языка, но и при изучении языков других стран.
Порядок разбора слова по звукам
При выполнении звукового анализа любого слова необходимо в первую очередь поставить ударение, далее разделить его на слоги. Потом выяснить, сколько букв в слове и сколько звуков. Следующим шагом будет постепенный анализ каждого звука. После этого подсчитывается, сколько в анализируемом слове гласных и сколько согласных. Поначалу детям лучше давать для анализа простые односложные или двухсложные слова, например их имена: Ваня, Катя, Аня и другие.
После этого подсчитывается, сколько в анализируемом слове гласных и сколько согласных. Поначалу детям лучше давать для анализа простые односложные или двухсложные слова, например их имена: Ваня, Катя, Аня и другие.
Когда ребенок понемногу разобрался с тем, как правильно проводить анализ на простых примерах, стоит усложнять разбираемые примеры слов.
Звуковой анализ слова: схема
При работе с самыми маленькими детьми для лучшего усвоения информации используются специальные цветные карточки.
Карточка алого цвета используется для обозначения гласных звуков. Синяя — твердых согласных, зеленая — мягких. Для обозначения слогов используют двухцветные карточки в той же цветовой гамме. С их помощью можно учить ребенка характеризовать звуки и целые слоги. Также необходимы карточка для обозначения ударения и карточка, показывающая разделение слова на слоги. Все эти обозначения, помогающие учить ребенка делать звуковой анализ слова (схема играет вэтом не последнюю роль), утверждены официальной школьной учебной программой России.
Гласные звуки их краткая характеристика. Дифтонги
Прежде чем начать анализировать слово, важно знать, какими особенностями обладают все фонетические звуки (гласные/согласные). При обучении детей на ранних этапах необходимо давать информацию только о самым простых свойствах, все остальное ребенок будет изучать в старших классах.
Гласные звуки (их шесть: [о], [а], [э], [ы], [у], [и]) бывают ударными/безударными.
Также в русском в наличии есть буквы, которые в определенной позиции могут давать пару звуков — ё [йо], ю [йу], я [йа], е [йэ].
Если они следуют за согласными — звучат как один звук и придают мягкости предшествующему звуку. В других позициях ( начало слова, после гласных и «ъ» и «ь») звучат как 2 звука.
Краткая характеристика согласных
Согласных звуков в нашем языке тридцать шесть, но графически их обозначает всего двадцать один знак. Согласные быват твердыми и мягкими, а также звонкими и глухими. Также они могут/не могут образовывать пары.
В таблице ниже перечислены звонкие и глухие звуки, способные образовывать пары, и те, которые не обладают такой способностью.
Мягкий и твердый знаки не дают звуков. Мягкий знак делает предыдущий согласный мягким, а твердый знак играет роль разделителя звуков (к примеру, в украинском подобную роль играет апостроф).
Примеры звукового анализа слов: «язык» и «группа»
Разобравшись с теорией, стоит попробовать попрактиковаться.
1) В данном примере два слога «я-зык». 2 слог является ударным
2) Первый слог образован с помощью дифтонга «я», который стоит в начале слова, а следовательно, состоит из 2 звуков [й`а]. Звук [й`] — это согласный (согл.), мягкий (мягк.) (карточка зеленого цвета), второй звук [а] — гласный, безударный (алая карточка). Для обозначения этого слога в схеме можно взять также двухцветную зелено-красную карточку.
3) В схеме ставится карточка, обозначающая разделение слогов.
4) Слог 2 «зык». Он состоит из трех звуков [з], [ы], [к]. Согласный [з] — тверд., звонкий (карточка синего цвета). Звук [ы] — гласн., ударный (карточка красного цвета). Звук [к] — согл., тверд., глух. ( карточка синего цвета).
Согласный [з] — тверд., звонкий (карточка синего цвета). Звук [ы] — гласн., ударный (карточка красного цвета). Звук [к] — согл., тверд., глух. ( карточка синего цвета).
5) Ставится ударение и проверяется путем изменения анализируемого слова.
6) Итак в слове «язык» два слога, четыре буквы и пять звуков.
Стоит учитывать один момент: в данном примере слово «язык» разбиралось как для учеников первого класса, которым еще не известно, что некоторые гласные в безударной позиции могут давать другие звуки. В старших классах, когда ученики будут углублять свои познания в фонетике, они узнают что в слове «язык» безударная [а] произносится как [и] — [йизык].
Звуковой анализ слова «группа».
1) В анализируемом примере 2 слога: «гру-ппа». 1 слог является ударным.
2) Слог «гру» составляют три звука [гру]. Первый [г] — согл., тверд., звонк. ( карточка синего цвета). Звук [р] — согл., тверд., звонк. (карточка синего цвета). Звук [у] — гласн., ударн. (карточка алого цвета).
3) В схеме ставится карточка, обозначающая разделение слогов.
4) Во втором слоге «ппа» три буквы, но они производят всего 2 звука [п:а]. Звук [п:] — согл., тверд., глух. (карточка синего цвета). Также он является парным и произносится длинно (синяя карточка). Звук [а] — гласн., безударный (алая карточка).
5) Ставится ударение в схеме.
6) Итак, слово «группа» состоит из 2 слогов, шести букв и пяти звуков.
Умение делать простейший звуковой анализ слова не является чем-то сложным, на самом деле это довольно простой процесс, но от него зависит многое, особенно если у ребенка проблемы с дикцией. Если разобраться, как правильно его делать, это поможет произносить слова на родном языке без ошибок и будет способствовать развитию умения грамотно их записывать.
Звуко-буквенный разбор слова — это характеристика звукового и буквенного состава слова. Чтобы его выполнить, пишется транскрипция — точная запись звукового состава слова.
Звуко-буквенный разбор слова необходим для осознанного овладения русским языком, грамотного написания слов, особенно в тех случаях, когда в словах есть безударные гласные, непроизносимые согласные, буквы, обозначающие два звука, буквы, не обозначающие звуков и пр.
Фонетический разбор выполняется в несколько этапов. Звуко-буквенный разбор предполагает деление слова на слоги в соответствии с количеством гласных звуков, постановку ударения, запись звучания слова. Затем проводится фонетический анализ каждого звука. Фонетический разбор завершается подсчетом количества букв и звуков.
Буквы и звуки
Чтобы правильно выполнить звуко-буквенный разбор слова, научимся различать, что на бумаге мы видим буквы, а когда произносим слово, то слышим звуки. Буквы — это графические знаки, с помощью которых можно обозначить звуки речи.
В русском языке различают гласные и согласные звуки.
Гласные буквы и звуки
Гласные звуки образуются при свободном прохождении воздуха изо рта. Они состоят только из голоса. В русском языке имеются
6 гласных звуков: [а], [о], [у], [э], [и], [ы]
и 10 гласных букв: а, о, у, э, и, ы, я, е, ё, ю, я.
Гласные звуки [а], [о], [у], [э], [ы] звучат после твердых согласных звуков, а буквы «и», «е», «ё», «ю», «я» и «ь» обозначают, что предыдущий согласный звук является мягким. Эта фонетическая мягкость обозначается специальным значком — апострофом:
- лён [л’ о н]
- редис [р’ и д’ и с]
- соль [с о л’]
Для выполнения звуко-буквенного разбора следует поставить в слове ударение.
Под ударением гласные звуки звучат отчетливо, а без ударения они искажаются:
до́мик [д о м’ и к], окно́ [а к н о]
- после согласных буквы «е», «я» без ударения соответствует звуку [и]
cтена́ [с т’ и н а] , ряби́на [р’ и б’ и н а]
Каждый гласный звук в одиночку или в сочетании с одним или с несколькими согласными согласными образует фонетический слог:
Согласные буквы и звуки
В русской речи звучат 36 согласных звуков. При их произношении выдыхаемый воздух трется об губы, язык и щеки, в результате чего возникает шум.
Всегда звонкие согласные [л], [м], [н], [р] произносятся с участием голоса и минимальным шумом.
Если согласные звуки произносятся с бо́льшей долей голоса и шума, то образуются звонкие согласные:
Каждому звонкому согласному соответствует парный глухой согласный, который произносится с большей долей шума, чем голоса:
Буквы «х», «ц», «ч», «щ» обозначают глухие согласные [х], [ц], [ч’], [щ’], у которых нет парных звонких согласных.
Согласные звуки бывают твердые и мягкие:
[б] — [б’], [в] — [в’], [г] — [г’], [д] — [д’], [з] — [з’], [к] — [к’], [л] — [л’], [м] — [м’], [н] — [н’], [п] — [п’], [р] — [р’], [с] — [с’], [т] — [т’], [ф] — [ф’], [х] — [х’];
Выполняя звуко-буквенный анализ, учитываем, что буквы «й», «ч» и «щ» обозначают всегда мягкие звуки [й’], [ч’], [щ’],
Как научиться делать звуко-буквенный разбор
Для того, чтобы научиться делать звуко-буквенный разбор слова, важно понимать, что часто орфографическая запись слова и его звучание не совпадают.
- одинаковое количество звуков;
- звуков больше, чем букв;
- букв больше, чем звуков.
Примеры
- не́бо [н’ э б а] — 4 буквы, 4 звука
- ярлы́к [й ‘а р л ы к] — 5 букв, 6 звуков
- купа́ть [к у п а т’] — 6 букв, 5 звуков
При записи звукового состава слова следует учитывать, что буквы «е», «ё», «ю», «я» могут обозначать два звука в следующих позициях в слове:
1. в начале слова:
- е́ дкий [ й’ э т к’и й’]
- ё мкий [ й’ о м к’ и й’]
- ю́ ный [ й’ у н ы й’]
- я́ сли [ й’ а с’ л’ и]
2. после других гласных звуков:
- по е зди́ть [п а й’ э з’ д’ и т’]
- по ё м [п а й’ о м]
- ка ю́ та [к а й’ у т а]
- ма я́ к [м а й’ а к]
3. после разделительных «ь» и «ъ»:
- жуль е́ н [ж у л’ й э’ н]
- въ е́ хать [в й ‘э х а т’]
- курь ё з [к у р’ й’ о с]
- отъ ё м [а т й’ о м]
- рь я́ ный [р’ й’ а н ы й’]
- изъ я́ н [и з’ й’ а н]
- вь ю́ нок [в’ й’ у н о к]
- предъ ю биле́йный [п р’ и д й’ у б’ и л’ э й’ н ы й’]
Как видим, в таких словах всегда больше звуков, чем букв.
После согласных звуков буквы «е», «ё», «ю», «я» обозначают их мягкость:
- с е л [с’ э л]
- н ё с [н’ о с]
- л ю к [л’ у к]
- п я ть [п’ а т’]
Записывая звучание слова, следует учитывать, что в русском языке происходит фонетический процесс оглушения звонких согласных, находящихся перед глухим согласным и в конце слова, и, наоборот, озвончения глухих согласных перед звонким согласным, кроме «л», «м», «н», «р», «в», «й»
- ло́жка [ло ш к а], ви́тязь [в’ и т’a с’ ], о́тблеск [о д б л’ и с к];
- сма́зка [с м а с к а], дробь [д р о п’ ], сдви́нуть [ з д в’ и н у т’];
- все [ ф с’ э], пруд [п р у т ], вокза́л [в а г з а л].
В словах с буквосочетанием «зж» слышится длинный мягкий звук [ж’]
- брю зж а́ть [б р’ у ж’ а т’]
- мо зж ечо́к [м а ж’ и ч’ о к]
В конце глаголов буквосочетания -тся и -ться звучат как [ца]:
- бои́тся [б а и ц а];
- стели́ться [с’ т’ и л и ц а].

В словах, в которых есть «ь», который обозначает мягкость предыдущего согласного звука или является морфологическим знаком, указывающим на принадлежность слова к женскому роду, букв насчитываем больше, а звуков меньше:
- знать [з н а т’] — 5 букв, 4 звука;
- речь [р ‘э ч’] — 4 буквы, 3 звука.
Мягкие согласные звуки могут смягчать предыдущий согласный звук.
Послушаем, как звучат слова:
- све́чка [ с’ в’ э ч’ к а]
- гво́зди [г во з’ д’ и]
- жизнь [ж ы з’ н’]
- зо́нтик [з о н’ т’ и к]
Образец фонетического разбора
Источник изображения: fedsp.com
Пример звуко-буквенного разбора
Чтобы выполнить звуко-буквенный разбор, запишем слово и поставим в нем ударение. Разделим его на фонетические слоги. Учитывая все фонетические изменения в слове, запишем по вертикали буквы и соответствующие им звуки слова в квадратных скобках. Дадим фонетическую характеристику каждому звуку.
Дадим фонетическую характеристику каждому звуку.
Например, выполним фонетический разбор слова «ёлочный»:
ёлочный [й’ о л а ч’ н ы й’]
ё-ло-чный — 3 слога. Первый слог ударный.
- буква «ё» — [й’] — согласный, звонкий непарный, мягкий непарный;
- [о] — гласный ударный;
- буква «л» — [л] — согласный звонкий непарный, твердый парный;
- буква «о» — [а] — гласный безударный;
- буква «ч» — [ч’] — согласный, глухой непарный, мягкий непарный;
- буква «н»— [н] — согласный звонкий непарный, твердый парный;
- буква «ы» — [ы] — гласный безударный;
- буква «й» — [й’] — согласный, звонкий непарный, мягкий непарный.
В слове «ёлочный» 7 букв, 8 звуков.
Видеоурок «Фонетический разбор слов»
Для закрепления материала посмотрите видео по теме урока.
Как делать звуко-буквенный разбор слова? » Kupuk.net
Звуко-буквенный разбор слова — это характеристика звукового и буквенного состава слова. Чтобы его выполнить, пишется транскрипция — точная запись звукового состава слова.
Звуко-буквенный разбор — это анализ звукового состава слова и его буквенного отображения на письме.
Звуко-буквенный разбор слова необходим для осознанного овладения русским языком, грамотного написания слов, особенно в тех случаях, когда в словах есть безударные гласные, непроизносимые согласные, буквы, обозначающие два звука, буквы, не обозначающие звуков и пр.
Фонетический разбор выполняется в несколько этапов. Звуко-буквенный разбор предполагает деление слова на слоги в соответствии с количеством гласных звуков, постановку ударения, запись звучания слова. Затем проводится фонетический анализ каждого звука. Фонетический разбор завершается подсчетом количества букв и звуков.
Затем проводится фонетический анализ каждого звука. Фонетический разбор завершается подсчетом количества букв и звуков.
Буквы и звуки
Чтобы правильно выполнить звуко-буквенный разбор слова, научимся различать, что на бумаге мы видим буквы, а когда произносим слово, то слышим звуки. Буквы — это графические знаки, с помощью которых можно обозначить звуки речи.
В русском языке различают гласные и согласные звуки.
Гласные буквы и звуки
Гласные звуки образуются при свободном прохождении воздуха изо рта. Они состоят только из голоса. В русском языке имеются
6 гласных звуков: [а], [о], [у], [э], [и], [ы]
и 10 гласных букв: а, о, у, э, и, ы, я, е, ё, ю, я.
Гласные звуки [а], [о], [у], [э], [ы] звучат после твердых согласных звуков, а буквы «и», «е», «ё», «ю», «я» и «ь» обозначают, что предыдущий согласный звук является мягким. Эта фонетическая мягкость обозначается специальным значком — апострофом:
Эта фонетическая мягкость обозначается специальным значком — апострофом:
- лён [л’ о н]
- редис [р’ и д’ и с]
- соль [с о л’]
Для выполнения звуко-буквенного разбора следует поставить в слове ударение.
Под ударением гласные звуки звучат отчетливо, а без ударения они искажаются:
- буква «о» обозначает звук [а];
до́мик [д о м’ и к], окно́ [а к н о]
- после согласных буквы «е», «я» без ударения соответствует звуку [и]
cтена́ [с т’ и н а] , ряби́на [р’ и б’ и н а]
Каждый гласный звук в одиночку или в сочетании с одним или с несколькими согласными согласными образует фонетический слог:
- бо-ло-то
- кра-со-та
- у-ди-ви-тель-ный
- ли-ни-я
Согласные буквы и звуки
В русской речи звучат 36 согласных звуков. При их произношении выдыхаемый воздух трется об губы, язык и щеки, в результате чего возникает шум.
Всегда звонкие согласные [л], [м], [н], [р] произносятся с участием голоса и минимальным шумом.
Если согласные звуки произносятся с бо́льшей долей голоса и шума, то образуются звонкие согласные:
[б], [в], [г], [д], [ж], [з].
Каждому звонкому согласному соответствует парный глухой согласный, который произносится с большей долей шума, чем голоса:
- [б] — [п];
- [в] — [ф];
- [г] — [ к];
- [д] — [т];
- [ж] — [ш];
- [з] — [с].
Буквы «х», «ц», «ч», «щ» обозначают глухие согласные [х], [ц], [ч’], [щ’], у которых нет парных звонких согласных.
Согласные звуки бывают твердые и мягкие:
[б] — [б’], [в] — [в’], [г] — [г’], [д] — [д’], [з] — [з’], [к] — [к’], [л] — [л’], [м] — [м’], [н] — [н’], [п] — [п’], [р] — [р’], [с] — [с’], [т] — [т’], [ф] — [ф’], [х] — [х’];
Выполняя звуко-буквенный анализ, учитываем, что буквы «й», «ч» и «щ» обозначают всегда мягкие звуки [й’], [ч’], [щ’],
а буквы «ж», «ш», «ц» — твердые звуки [ж], [ш], [ц].
Как научиться делать звуко-буквенный разбор
Для того, чтобы научиться делать звуко-буквенный разбор слова, важно понимать, что часто орфографическая запись слова и его звучание не совпадают. В слове может быть:
- одинаковое количество звуков;
- звуков больше, чем букв;
- букв больше, чем звуков.
Примеры
- не́бо [н’ э б а] — 4 буквы, 4 звука
- ярлы́к [й ‘а р л ы к] — 5 букв, 6 звуков
- купа́ть [к у п а т’] — 6 букв, 5 звуков
При записи звукового состава слова следует учитывать, что буквы «е», «ё», «ю», «я» могут обозначать два звука в следующих позициях в слове:
1. в начале слова:
- е́дкий [й’ э т к’и й’]
- ёмкий [й’ о м к’ и й’]
- ю́ный [й’ у н ы й’]
- я́сли [й’ а с’ л’ и]
2. после других гласных звуков:
- поезди́ть [п а й’ э з’ д’ и т’]
- поём [п а й’ о м]
- каю́та [к а й’ у т а]
- мая́к [м а й’ а к]
3. после разделительных «ь» и «ъ»:
после разделительных «ь» и «ъ»:
- жулье́н [ж у л’ й э’ н]
- въе́хать [в й ‘э х а т’]
- курьёз [к у р’ й’ о с]
- отъём [а т й’ о м]
- рья́ный [р’ й’ а н ы й’]
- изъя́н [и з’ й’ а н]
- вью́нок [в’ й’ у н о к]
- предъюбиле́йный [п р’ и д й’ у б’ и л’ э й’ н ы й’]
Как видим, в таких словах всегда больше звуков, чем букв.
После согласных звуков буквы «е», «ё», «ю», «я» обозначают их мягкость:
- сел [с’ э л]
- нёс [н’ о с]
- люк [л’ у к]
- пять [п’ а т’]
Записывая звучание слова, следует учитывать, что в русском языке происходит фонетический процесс оглушения звонких согласных, находящихся перед глухим согласным и в конце слова, и, наоборот, озвончения глухих согласных перед звонким согласным, кроме «л», «м», «н», «р», «в», «й»
- ло́жка [ло ш к а], ви́тязь [в’ и т’a с’], о́тблеск [о д б л’ и с к];
- сма́зка [с м а с к а], дробь [д р о п’], сдви́нуть [з д в’ и н у т’];
- все [ф с’ э], пруд [п р у т], вокза́л [в а г з а л].
В словах с буквосочетанием «зж» слышится длинный мягкий звук [ж’]
- брюзжа́ть [б р’ у ж’ а т’]
- мозжечо́к [м а ж’ и ч’ о к]
В конце глаголов буквосочетания -тся и -ться звучат как [ца]:
- бои́тся [б а и ц а];
- стели́ться [с’ т’ и л и ц а].
В словах, в которых есть «ь», который обозначает мягкость предыдущего согласного звука или является морфологическим знаком, указывающим на принадлежность слова к женскому роду, букв насчитываем больше, а звуков меньше:
- знать [з н а т’] — 5 букв, 4 звука;
- речь [р ‘э ч’] — 4 буквы, 3 звука.
Мягкие согласные звуки могут смягчать предыдущий согласный звук.
Послушаем, как звучат слова:
- све́чка [с’ в’ э ч’ к а]
- гво́зди [г во з’ д’ и]
- жизнь [ж ы з’ н’]
- зо́нтик [з о н’ т’ и к]
Образец фонетического разбора
Источник изображения: fedsp. com
Пример звуко-буквенного разбора
Чтобы выполнить звуко-буквенный разбор, запишем слово и поставим в нем ударение. Разделим его на фонетические слоги. Учитывая все фонетические изменения в слове, запишем по вертикали буквы и соответствующие им звуки слова в квадратных скобках. Дадим фонетическую характеристику каждому звуку.
Например, выполним фонетический разбор слова «ёлочный»:
ёлочный [й’ о л а ч’ н ы й’]
ё-ло-чный — 3 слога. Первый слог ударный.
- буква «ё» — [й’] — согласный, звонкий непарный, мягкий непарный;
- [о] — гласный ударный;
- буква «л» — [л] — согласный звонкий непарный, твердый парный;
- буква «о» — [а] — гласный безударный;
- буква «ч» — [ч’] — согласный, глухой непарный, мягкий непарный;
- буква «н»— [н] — согласный звонкий непарный, твердый парный;
- буква «ы» — [ы] — гласный безударный;
- буква «й» — [й’] — согласный, звонкий непарный, мягкий непарный.
В слове «ёлочный» 7 букв, 8 звуков.
Если у вас возникнут трудности при проведении звуко-буквенного (фонетического) разбора слова, то всегда можно проверить себя на сайте phoneticonline.ru.
Видеоурок «Фонетический разбор слов»
Для закрепления материала посмотрите видео по теме урока.
Разбираемся в порядке проведения фонетического анализа слова, произведения, текста с примерами *
Написание профессионального текста в любом жанре требует тотального подхода и анализа материалов, корректной переработке и грамотному изложению. Притом все эти качества будут представлены не просто в отсутствии грамматических, лексических или иных нареканий. Важно, чтобы новосозданный текст соответствовал основным критериям: информативность, читабельность, полезность и пр. Сегодня мы поговорим о таком критерии при оценке произведений, как фонетический анализ.
СОДЕРЖАНИЕ
Что это такое?
Фонетический анализ представляет собой разновидность аналитической мысли, когда эксперт или пользователь (читатель) изучает звуковой состав слова или произведения в целом.
Фонетика – это раздел лингвистической и филологической науки, который занимается разбором слов на составные части с оцениванием произношения: сочетание звуков, правильность их употребления, специфика написания и произношения отдельных категорий и пр.
Данная технология изучается еще со школьной скамьи, но в профессиональном русле она пригодна лишь в отдельных сегментах: в преподавательской деятельности, коррекционной деятельности (логопед, дефектолог и пр.), лингвистической (важна для корректоров, редакторов, лингвистов, филологов) и пр.
Основные функции фонетического анализа слов и текстаВ студенческой среде фонетический анализ курсовых и дипломных работ фактически не применяется. Для них достаточно грамотно и аргументированно раскрыть тему в рамках научного стиля. Созвучия, оценка сочетаний слов и прочих нюансов не входит в число обязательных требований при подготовке студенческих и научно-исследовательских проектов. К данному нюансу чаще всего обращаются более опытные ученые, авторы художественных произведений, поэты, работники издательств и пр.
Но для того, чтобы заниматься фонетическим анализом слова и текста, важно иметь соответствующие знания и навыки, а это значит, что за плечами должно быть соответствующее образование. Проводить качественный фонетический анализ текста и вырабатывать рекомендации относительно совершенствования произведения может только квалифицированный и компетентный эксперт!
Зачем нужен фонетический анализ слова или текста?
Фонетический анализ слова позволяет разобраться в звуковых сочетаниях и облегчает процесс постановки речи, ее коррекции при необходимости (выявлении дефектов и их коррекции). Поэтому в первую очередь, фонетический анализ слова позволяет восстановить речь индивида, сделать ее понятной и правильной, грамотной.
Фонетический анализ в рамках изучения языка способствует также развитию соответствующего (фонематического) слуха, то есть правильному восприятию и усвоению информации: что человек услышал и как он понял суть услышанного текста. Порой из-за дефектов в фонетическом восприятии у учащихся портится успеваемость: в диктантах наблюдается масса глупых и нелепых ошибок и пр. Более того, если неправильно воспринять слово, то и тема не будет усвоена на должном уровне, что не менее важно как для школьников, так и для студентов. Поэтому фонетический анализ текста способствует устранению всех недопониманий и конкретизации основного смысла.
Фонетический разбор слова минимизирует возникновение в тексте грамматических ошибок. Фонетика является частью языка, поэтому нацелена на совершенствование соответствующих умений. Произношение способно искажать правильное написание слов, поэтому важно владеть всеми азами языковых норм: правила письменной речи и устная речь могут кардинально разниться. Чтобы восстановить этот баланс важно разбираться в буквах и звуках, знать фонетические особенности отдельных букв (какие звуки способно давать и в каких случаях и пр. ) и т.д.
Фонетический анализ слова также способствует совершенствованию текста и упрощению его читабельности. В данном сегменте методика фонетики облегчает чтение и восприятие. Ее миссия – подобрать простую и понятную комбинацию слов, не вызывающую сложностей в процессе изучения и понимания, усвоения материала. Чаще всего данная методика применяется при подготовке учебных пособий и научной литературы с целью упрощения при подаче информации пользователю. Согласитесь, что трудновыговариваемые фразы плохо запоминаются, с трудом понимаются читателями. Фонетический анализ слова позволяет выделить проблемные участки текста и подобрать достойную альтернативу.
Таким образом, фонетический анализ слов и текста является основополагающим принципом для повышения степени понимания и усвоения материала, содействующим конкретизации смысла и сути поданной информации и повышению уровня грамотности автора или пользователя. Он позволяет развить орфографическую зоркость, бдительность и внимательность индивида.
По статистике, более 90% правил русского языка основывается на фонематическом анализе текста, а это значит, что при владении «искусством фонетики» можно в разы сократить корректировку и доработку любой курсовой, дипломной или научной работы!
Ключевые правила и общая схема проведения фонетического анализа слова
Важно отметить, что фонетический анализ слова и фонетический анализ текста – немного разные категории, но основанные на одном (схожем) алгоритме и принципе – звуковая оценка.
Для проведения фонетического анализа каждой словесной единицы или работы в целом потребуется:
- Знание правил русского языка и фонетических азов.
Важно различать категории «буква» и «звук», «правописание» и «произношение», а также уметь корректно записывать обозначение каждого звука с помощью специальной транскрипции.
Под транскрипцией слова понимают перевод буквенного состава в звуковой, то есть происходит переход от письменной речи к устной (как произносится слово, как оно слышится, какие звуки содержит и пр. ). В этом и есть ключевая особенность фонетического разбора – перевод письменной речи в устную с выявлением особенностей, сходств и отличий (в написании и произношении).
Для транскрипции также необходимо знать обозначение звуков и порядок их отражения в виде специальной техники: заключение звуков в скобки, дополнительные символы (смягчение, ударение и пр.) и т.д.
Особенности фонетического анализа слов и текста- Владение ключевыми категориями фонематического анализа.
В данном русле существуют свои правила и критерии оценки текста, его составных единиц. Поэтому эксперт или «аналитик» должен хорошо владеть буквенным составом (как минимум знать алфавит), правила написания слов и текста (правописание: проверочные схемы, словарные слова и пр.), знать варианты «звукоподачи» (какие буквы, при каких условиях на какие звуки разлагаются и пр.).
Проведение фонетического разбора и анализа слова можно представить в виде простейшей схемы:
- Для начала необходимо правильно и грамотно записать слово – без ошибок, описок и прочих неурядиц. Если есть сомнения, лучше переспросить у педагога/наставника, обратиться за помощью к орфографическим словарям и пр. Важно убедиться, что запись произведена корректно и верно, в противном случае дальнейшие действия будут также ошибочными.
- Далее следует правильно поставить ударение в слове, чтобы выделить ударный звук и приступить к анализу слова. Согласно правилам русского языка в одном слове должно быть одно ударение, но в некоторых случаях допускается двоякое произношение терминов, тогда придется делать «двойной» фонетический разбор (разобрать каждый вариант).
- Затем необходимо разделить слово на слоги.
- Записать транскрипцию слова. Данный этап разбивается на несколько дополнительных действий: сначала можно записать каждую букву и соответствующий ей звук (согласно произношению слова). Затем сформировать полную транскрипцию (звуковую комбинацию) всего слова в единой схеме.
Запомните ключевые правила транскрипции: каждый звук записывается строго по звучанию и может давать, как один так и два звука (в зависимости от сочетания), звуки заключаются в квадратные скобки, мягкий и твердый знак не имеют самостоятельного звука и призваны смягчить/утвердить звук и пр.
- По результатам формирования транскрипции важно констатировать количество бук и количество звуков, их характер (гласный/согласный, глухой/звонкий, твердый/мягкий и пр.). Данные категории нельзя путать: соотношение букв и звуков может разниться!
- В случае несоответствия звука и букв важно отметить данный нюанс, при необходимости разъяснить его.
Специфика проведения фонетического анализа слова проявляется в следующих моментах:
- Все звуки принято делить на гласные и согласные каждая из указанных групп обладает своей спецификой. В частности, согласные могут быть звонкими и глухими, твёрдыми и мягкими, а гласные – ударными и безударными. Роль каждого из них зависит от места расположения: в одном случае звуки смягчаются, в другом – твердеют и пр.
- Не все буквы могут давать аналогичный и привычный звук, присутствовать в транскрипции в прямом виде. В частности, вы никогда не найдете в звуковой записи е, ё, я, ю, так как они всегда мягкие и дают «двойной звук».
- Некоторые буквы подлежат звуковой замене при произношении. Например, буква И в слогах жи/ши дает звук [ы] и пр.
- В случае разбора слова с удвоенными согласными, не придется отдельно разбирать каждую букву. Достаточно в транскрипции поставить «символ удлинения» в виде двоеточия. Например, слово теннис – [тэн:ис]. В некоторых случаях двойные согласные могут давать одинарный звук, поэтому важно вслушиваться в произношение слова и его особенности.
- Некоторые буквы могут и вовсе не давать звука, поэтому будут отсутствовать в транскрипции (здесь заметно отличие количества бук в правописании и звуков при фонетическом разборе). Например, слово солнце – [сонц’э].
Таким образом, для проведения фонетического анализа слова важно тотально владеть орфографическими и звуковыми навыками, отличать буквы от звуков и знать правила их соотношения, оценивания. Притом немаловажную роль в фонетике играет именно корректность произношения и слух: как человек произносит слово (правильно ли ставит ударение, говорит звуки и пр.
Ключевые правила и общая схема проведения фонетического анализа текста
Фонетический анализ текста проходит несколько иначе и не требует столь жесткого разбора. В данном случае исследователю не придется записывать транскрипцию каждого слова. Миссия фонетического разбора текста в целом состоит в упрощении его чтения и понимания путем грамотного подбора слов, которые будут легко, корректно и красиво сочетаться.
Этапы проведения фонетического анализа слов и текстаВ данном случае схема проведения фонетического анализа материала сводится к следующим действиям:
- Ознакомиться с произведением и выделить трудночитаемые или трудно воспринимаемые на слух моменты. Чаще всего на данном этапе выделяют слова, в составе которых наблюдается последовательное употребление нескольких согласных ил гласных, длинные конструкции, профессионализмы, сложные сочетания, категории иноязычного плана (перешедшие в обиход из другого языка) и пр. Главное – показать трудность и ее проявление: чтение, понимание, произношение и пр.
- Проанализировать трудно выговариваемые и трудно воспринимаемые моменты и выделить, в чем именно заключается сложность. Данный анализ позволит определить необходимость преобразований, а также предопределит альтернативные пути разрешения ситуации.
На втором этапе фонетического анализа текста важно не просто изучить сложности, но и понять: как они сочетаются с жанром и видом произведения, допустимы ли изменения и пр.
- Поиск решений, корректура и редактура. Если нюансы заметны в отношении фразеологизмов или профессиональных терминов, то придется либо оставить все как есть, либо подобрать подходящий по смыслу и жанру синоним, пересмотреть формулировку предложения или фрагмента текста. В данном случае внесение изменения будет сопровождаться коррективами и повторной проверкой на уникальность, нормоконтроль и пр.
Фонетический анализ текста учитывает следующие основные принципы.
Принцип №1. Корректность и смысловая нагрузка. Любое изменение слова, предложения не должны подвергать искажению изначальный замысел текста. Суть высказывания остается прежней, но обретает лишь иной внешний вид.
Принцип №2. Легкость и простота изучения и восприятия. Если в ходе фонетического анализа были выявлены сложности в части изучения материала (трудно выговорить текст или непонятные термины), то важно подобрать простую и достойную замену, которая впишется в контекст и внесет ясности, не вызовет сомнений у читателей и экспертов.
Принцип №3. Созвучность. Данный параметр означает, что трудные моменты будут ликвидированы однозначными по смыслу фразами или конструкциями, которые будут простыми в произношении, а сочетание новоподобранной фразы не будет пререкаться с общим контекстом. То есть аргументация, суть останутся прежними, а новый «внешний облик» будет иным — более мягким. Обратите внимание, что одна и та же буква в разных сочетаниях (словах, слогах) может произноситься и восприниматься по-разному. Важно подобрать такую комбинацию, которая будет удобна пользователю во всех смыслах.
Принцип №4. Жанровая принадлежность. Фонетический анализ помогает устранить недостатки в работе, сохранив при этом авторскую позицию и стиль изложения информации.
Кто и когда пользуется фонетическим анализом слова или текста?
Фонетический анализ слов и текста крайне редко востребован среди студентов. Чаще всего с необходимостью его реализации сталкиваются лишь тогда, когда освоение этого навыка предусмотрено учебной программой или специализацией: педагогика, лингвистика, переводоведение и пр. То есть в 90% случаев изучают и оттачивают навыки по проведению фонетического разбора слов/материалов студенты педагогических, лингвистических, логопедических профессий, где язык – основной инструмент работы, а владение им важно на всех уровнях.
Студенческие работы и исследования не подвергаются тотальному фонетическому анализу. Данная мера реализуется сугубо по инициативе автора. Притом чаще всего данный вид анализа проводится им самостоятельно с учетом уровня его подготовки. Но некоторые научные работы, художественные произведения в обязательном порядке исследуют данным способом для упрощения подачи информации с ориентацией на целевую аудиторию, ее особенности, потребности и пр.
Как Вы уже поняли в самом начале нашей статьи, проводить данный вид «языковых исследований» может каждый желающий – от школьника до студента, квалифицированного специалиста. Разница результатов данного мероприятия будет заметна лишь в качестве итогов и зависеть от квалификации аналитика, его внимательности, словарного запаса и пр. Но лучше всего доверять столь важную миссию опытным и компетентным специалистам языковой и научной среды.
Кто чаще пользуется фонетическим анализом слов и текста?Студенческие работы не подлежат обязательной фонетической проверке. Данная мера выполняется каждым автором «автоматически» при подготовке текста, когда он перечитывает подготовленную рукопись или сдает ее на проверку научному руководителю, проходит нормоконтроль. Замечали ли вы, что в некоторых случаях кураторы просят перефразировать текст, изменить выражение отдельных фраз или словосочетаний. Чаще всего данная необходимость возникает на фоне смысловой некорректности или фонетического дисбаланса.
Научные работы также не подвергаются обязательной проверке в рамках фонетики, но каждый автор заинтересован в грамотной, связной подаче информации. Поэтому также проводит фонетический анализ самостоятельно в меру своих возможностей.
Перед публикацией научных статей и работ в серьёзных изданиях перед защитой (особенно перед Диссоветом или в рамках международных конференций и пр.) проект проходит все стадии проверки: начиная от смысловой, логической и заканчивая технической, фонетической и научной. В этом случае при выявлении нестыковок и нюансов материал возвращается автору на доработку или направляется на изменение к профессионалам, «мастерам пера» — корректорам, редакторам, лингвистам и филологам и пр.
Конечно же, результаты фонетического разбора слов и текста, а также предлагаемые коррективы со стороны дипломированных и опытных специалистов будут обоснованными, грамотными, облегчающими изучение и восприятие произведения.
Советы Disshelp по проведению фонетического анализа слов и текста
В большинстве случаев фонетический анализ текста проводится на интуитивном уровне и неформально (в рамках общей комплексной проверки материалов перед защитой или публикацией).
Перед тем как приступить к аналитической мысли в рамках фонетики, важно убедиться, что слово записано правильно. Поэтому не стесняйтесь, не бойтесь и не отклоняйтесь от использования орфографических словарей. Если есть малейшие сомнения относительно правописания. Важно их развеять и убедиться в правильности отражения.
Тщательно проверяйте фонетический разбор слова. Сегодня это можно сделать с помощью специальных сервисов онлайн-программ, массы учебников и пр. Учитывайте все правила фонетического разбора (для этого важно хорошо владеть правилами русского языка и пр.). Как гласит народная мудрость: доверяй, но проверяй.
Если самостоятельно определить или ликвидировать «фонетические неурядицы» не удается, то лучше всего обратиться за помощью к научному руководителю или квалифицированным специалистам в области языкознания: лингвистам, корректорам, редакторам, филологам, преподавателям русского языка и пр.
Поверьте, читать простой, понятный и аргументированный текст (научный, художественный или любой другой) намного легче и приятнее. Поэтому не стоит пренебрегать его анализом и проверкой, корректурой и редактурой. Ведь все эти действия помогают автору повысить качество исследования и заработать достойную репутацию в соответствующих кругах.
Научные протоколы — Анализ развития фонетического синтаксиса в лепете младенцев
Авторы: Дуглас К. Бемис, Гарри Ф. Маркус, Дина Липкинд и Офер Черниховски
Abstract
В рамках сравнительного исследования раннего обучения вокалу у певчих птиц и младенцев человека мы проанализировали развитие фонетического синтаксиса в лепетных высказываниях младенцев, используя данные из базы данных CHILDES. Здесь мы представляем подробное описание использованных данных и методов анализа.
Введение
Материалы
Данные для анализа человеческого лепета были получены от 9 детей в корпусе Дэвиса (Davis & MacNeilage, 1995) базы данных CHILDES (MacWhinney, 2000) [Специально – Ben, Cameron, Charlotte , Джорджия, Пакстон, Рэйчел, Ребекка, Роуэн, Сэм]. В среднем этим детям было 9 месяцев 28,3 дня (2 месяца, 1,3 дня, стандарт) на первом сеансе, а данные собирались в среднем в течение 1 года, 7 месяцев (7 месяцев, 12,8 дня, стандарт) после этого. время. Данные для каждого ребенка состояли из 38,8 сеансов в среднем (10,2 стандарта), каждый из которых регистрировался в среднем с интервалом в 16,07 дней (6,4 дня стандарт).
Анализ данных
Наш анализ был сосредоточен на характеристике структуры младенческого лепета, а именно на том, как дети комбинируют слоги во время доязыкового вокального исследования. Таким образом, мы ограничили наш анализ высказываниями, для которых в транскрипциях CHILDES не были назначены лексические единицы. Мы разобрали эти бессвязные высказывания на слоги из транскрибированных фонем, используя полуавтоматический метод, как описано ниже. Затем мы провели анализ тех высказываний, которые прошли полный слоговый разбор. В среднем это составило 2135 высказываний на ребенка (924 станд.) и 62,0 высказывания за сеанс (37,5 станд.)
Алгоритм синтаксического анализа
Данные CHILDES состоят из фонетически расшифрованных высказываний. Чтобы преобразовать эти данные в слоги, мы использовали итеративный процесс для анализа каждого бормотания на последовательность принятых слогов. Высказывание считалось проанализированным (и, таким образом, пригодным для анализа) только в том случае, если каждая фонема в высказывании была успешно сопоставлена слогу с помощью этого алгоритма. Другими словами, мы рассматривали высказывание для нашего анализа только в том случае, если мы могли подобрать последовательность слогов к фонемам так, чтобы каждая фонема использовалась ровно один раз в слоге. На каждой итерации алгоритма синтаксического анализа мы сначала вручную назначали полные синтаксические разборы нескольким не проанализированным высказываниям. Затем мы добавили эти новые слоги к набору возможных слогов, которые можно было бы использовать для разбора высказываний. Затем мы автоматически проверили все высказывания, чтобы увидеть, могут ли они быть полностью проанализированы с использованием текущего хранилища слогов. Например, высказыванию badaja будет вручную присвоен слоговый разбор ba, da, ja. На следующем проходе автоматического синтаксического анализа высказывание baja может быть автоматически разобрано на слоги ba и ja. Высказывания, которые не могли быть полностью проанализированы с использованием набора определенных слогов, затем анализировались вручную, добавляя к набору допустимых слогов. Таким образом, каждый слог, использованный для анализа данных, был вручную проверен как допустимый слог в данных. Если высказыванию можно было присвоить два разных синтаксических анализа, то мы использовали эвристику таким образом, что выбирали синтаксический анализ с большим количеством двух фонемных слогов (CV или VC). Если несколько синтаксических анализов для высказывания были равны в этом показателе, мы вручную назначали синтаксический анализ высказыванию или оставляли его неоднозначным. Все такие неоднозначные разборы были исключены из анализа. Затем этот процесс повторялся до тех пор, пока значительное количество данных не было преобразовано из фонем в слоги (58,2% лепетных высказываний [19].0,0% стандарт.]).
Исходная таблица
Из этого набора проанализированных бормотаний мы затем свели в таблицу частоту каждого слога в каждом сеансе и его место в его произнесении. Чтобы провести параллель с анализом пения птиц, мы затем ограничили наш анализ ниже теми слогами, которые достигли определенного порога частоты во время сеанса, установленного на уровне 1% от общего количества слогов в сеансе. Таким образом, мы сосредоточились только на тех слогах, которые ребенок произносил с незначительной скоростью в течение данного сеанса записи. Наконец, мы также вычислили частоту всех переходов между слогами. Переход определялся как любые два последовательных слога, которые произошли в пределах одного высказывания.
Нормализация с начальной загрузкой
В конечном счете, нас интересовала характеристика эволюции переходной изменчивости во времени. Ясно, что любое измерение этого развития в какой-то степени искажается ростом с течением времени как количества слогов, используемых ребенком, так и длины его высказываний. Таким образом, чтобы контролировать эти факторы, мы использовали процедуру начальной нормализации для статистических данных, представленных ниже. Чтобы установить базовое значение для каждой меры, которая отражала бы случайное размещение слогов, но сохраняла постоянный размер словарного запаса и длину высказывания, мы случайным образом перемешивали слоги в каждом сеансе записи, сохраняя при этом длину каждого высказывания. Таким образом, порядок слогов был случайным, в то время как частота каждого типа слога оставалась постоянной в каждом сеансе, как и длина каждого высказывания. Статистические данные, представленные ниже, были затем пересчитаны по этим рандомизациям с начальной загрузкой, чтобы установить базовое значение. Сравнивая наблюдаемые данные с этими измерениями, мы смогли выделить эффекты, связанные со структурой, наложенной ребенком на лепет, контролируя изменения во времени количества слогов, используемых ребенком, и длины его высказываний.
Показатели
Показатели, описанные ниже, были рассчитаны для каждого типа слога в каждом сеансе. Затем сеансы выравнивались по первому появлению типа слога, и для каждого сеанса рассчитывалось среднее значение по типам слогов. В анализ включались только те слоговые типы, которые впервые появились в течение экспериментального периода (а именно отсутствовали в первом сеансе).
Исполнение новых слогов на краях: мы рассчитали долю вхождений типа слога на краю высказывания по сравнению с теми, которые были в середине высказывания. Для целей этой меры мы не учитывали редупликации (т. е. повторения слога) в середине высказывания. Затем эти частоты сравнивали с рандомизированным (самозагруженным) базовым уровнем.
Добавление новых переходов: мы подсчитали количество новых переходов на слог, используемое в каждом сеансе, и сравнили его с базовыми уровнями. Эта мера указывает, насколько вероятно, что каждое вхождение слога должно было участвовать в ранее невидимом переходе.
Повторное дублирование: мы рассчитали долю вхождений каждого типа слогов в повторяющихся переходах (например, AA) по сравнению с повторениями в пестрых переходах (например, AB) и сравнили их с исходными уровнями.
Реагенты
Девять детей из корпуса Дэвиса (Davis & MacNeilage, 1995) базы данных CHILDES (MacWhinney, 2000)
http://childes.psy.cmu.edu/browser/index.php?url=Eng- Северная Америка/Дэвис/ :
Бен, Кэмерон, Шарлотта, Джорджия, Пакстон, Рэйчел, Ребекка, Роуэн, Сэм.
Оборудование
Анализ был выполнен с использованием кода Matlab, который доступен для загрузки по адресу http://ofer. sci.ccny.cuny.edu/publications (см. процедуры).
Процедура
- Загрузите коды Matlab для анализа с http://ofer.hunter.cuny.edu/publications/publications (нажмите на ссылку «+ общий протокол для анализа лепета». Коды находятся в заархивированной папке.
- Загрузите данные транскрипции голоса младенцев с http://childes.psy.cmu.edu/browser/index.php?url=Eng-NA/.
- Если вы хотите повторить анализ бормотания, использованный в статье, загрузите 9 младенцев, перечисленных в разделе «Реагенты», с http://childes.psy.cmu.edu/browser/index.php?url=Eng- NA/Дэвис/.
- Поместите все данные в папку внутри папки, содержащей коды Matlab (пункт 1). Назовите папку «English-Davis_CHAT» или соответствующим образом обновите код Matlab (см. ниже).
- Откройте Matlab и «Analysis.m». Этот скрипт содержит две ячейки. Первый анализирует файлы .cha из базы данных, а второй создает графики, представленные в статье.
Устранение неполадок
- Убедитесь, что коды Matlab размещены в каталоге, для которого задан путь в Matlab (см. справку по «установить путь» в Matlab).
- Если имя каталога данных о младенцах отличается от «English-Davis_CHAT», замените правильное имя папки в файле «Analysis.m».
Ожидаемые результаты
Графики Matlab, содержащие результаты анализа, показанные на рисунке 4 в статье (Пошаговое приобретение комбинаторных способностей у певчих птиц и младенцев человека).
Ссылки
- Davis, B.L., & MacNeilage, P.F. (1995). Артикуляционная основа лепета. Журнал исследований речи и слуха , 38, 1199-1211.
- MacNeilage, PF (2008). Происхождение речи : Издательство Оксфордского университета, США.
- Макнейладж, П.Ф., и Дэвис, Б.Л. (2000). О происхождении внутренней структуры словоформ. Наука , 288, 527-531.
- Макнейладж, П.Ф., и Дэвис, Б.Л. (2011). В защиту «кадров, затем содержания» (FC) Взгляд на овладение речью: ответ на две критические замечания. Изучение и развитие языков , 7, 234-242.
- MacNeilage, PF, Davis, B.L., & Matyear, C.L. (1997). Лепет и первые слова: фонетические сходства и различия. Речевое общение, 22, 269-277.
- МакВинни, Б. (2000). Проект CHILDES: инструменты для анализа разговоров (Том третье изд.): Psychology Press.
- Оллер, Д.К. (1980). Возникновение звуков речи в младенчестве. In G. Yeni-Komshian, JF Kavanagh & GA Ferguson (Eds.), Child phonology 1. Production (стр. 9).3-112). Нью-Йорк, штат Нью-Йорк: Academic Press.
- Смит, Б.Л., Браун-Суини, С., и Стул-Гаммон, К. (1989). Количественный анализ повторного и пестрого лепета. Первый язык , 9, 175-189.
- Старк, Р. Э. (1980). Этапы развития речи на первом году жизни. В G. Yeni-Komshian, JF Kavanagh & GA Ferguson (Eds.), Child phonology 1. Production (стр. 73-90). Нью-Йорк, штат Нью-Йорк: Academic Press.
Благодарности
Исследование было поддержано грантом Службы общественного здравоохранения США для Ofer Tchernichovski.
Associated Publications
Поэтапное приобретение голосовых комбинаторных способностей у певчих птиц и младенцев человека . Дина Липкинд, Гэри Ф. Маркус, Дуглас К. Бемис, Казутоши Сасахара, Нори Джейкоби, Мики Такахаси, Кента Судзуки, Ольга Фехер, Примоз Равбар, Казуо Оканоя и Офер Черниховски. Природа 498 (7452) 104 — 108 doi:10.1038/nature12173
Информация об авторе
Дуглас К. Бемис , Когнитивная нейровизуализация INSERM-CEA, центр CEA/SAC/DSV/DRM/Neurospin, Bât 145, Point Courier 156, F-
Gif-sur-Yvette Cedex FRANCEGarry F. Маркус , факультет психологии, Нью-Йоркский университет
Дина Липкинд и Офер Черниховски , лаборатория Офера Черниховски, Хантер-колледж, CUNY
Адрес для переписки: Дуглас К. Бемис ([электронная почта защищена])
: 9006 Протокол 2013) doi:10.1038/protex.2013.057. Первоначально опубликовано в сети 10 июня 2013 г. .
Фонетика в Оксфордском университете
Вы здесь: Домашняя страница / Ресурсы / IPOX / Примечания IPOX / Амби
Фонетическая интерпретация в YorkTalk/IPOX композиционная, то есть многосложные слова состоят из отдельных слогов. Как следствие, не существует отдельных правил для групп интервокальных согласных.
Амбисиллабичность используется для того, чтобы интервокальные согласные правильно сочленялись с соседними гласными. То есть в таком слове, как /bot@l/ , /t/ следует интерпретировать:
- как коду с сохранением предшествующей гласной 9.0068
- как начало следующей гласной
Таким образом, интервокальный /t/ следует анализировать как коду первого слога и как начало второго слога:
В фонетической интерпретации начало накладывается на коду предыдущего слога . В разных контекстах используется различное количество перекрытий (Coleman 1995):
- очень короткое закрытие («хлопание»)
--Гласная-|-Закрытие-|---Закрытие---|-Выпуск-|---
-Закрытие-|-Выпуск-|-Гласная-- - нормальное интервокальное смыкание
--Гласная-|-Закрытие-|---Закрытие---|-Освобождение-|---
-Закрытие-|-Освобождение-|-Гласная-- - длинная застежка («геминация»)
--Гласная-|-Закрытие-|---Закрытие---|-Освобождение-|---
-Закрытие-|-Освобождение-|-Гласная--
Пример
Следующее правило используется для создания правильной степени перекрытия для двусложного /t/ в /bot@l/ :
cons:[+coda, ГЛУШОЙ, -cnt, -nas, str=A, cns=B, squish=C]
+
cons:[-coda , VOICELESS, -cnt, -nas, str=A, cns=B]
=>
C * (250 - A*50) + 140.
В этом правиле функция squish кодирует степень назначенного сжатия до первого слога.
Многосложность не ограничивается одиночными интервокальными согласными (как в большинстве фонологических теорий). Внутри (латинских частей) слов интервокальные кластеры анализируются с помощью максимальная двусложность :
- /win[t]@r/
- /а[сп]рин/
- /си[ст]@м/
Анализируя группы в квадратных скобках как двусложные, мы получаем, что:
- в каждом из этих случаев первый слог тяжелый
- /t/ в /wint@r/ с аспирацией, но в /sist@m/ без аспирации, так как это происходит в кластере onset /st/
Реализация
- В YorkTalk согласные становятся двусложными за счет повторного анализа (анализа без использования ввода)
- В IPOX не разрешен повторный разбор, поэтому на данный момент двусложные согласные должны быть прописаны дважды во вводе
В качестве более принципиального решения мы в настоящее время экспериментируем с алгоритмом синтаксического анализа «сначала головой», адаптированным из Van Noord (1993):
ввода(Голова, Вход, L0, R0),
head_first(L0, L, R0, R, Голова, Цель).
head_first(L0, L, R0, R, Head, Target):-
Фраза —> (NonHead / Head),
parse(L0, L1, [], NonHead),
head_first(L1, L, R0, R, фраза, цель).
head_first(L0, L, R0, R, Head, Target):-
Phrase —> (Head \ NonHead),
parse(R0, [], R1, NonHead),
head_first(L0, L, R1, R, фраза, цель).
head_first(L0, L, R0, R, Голова, Цель) :-
Фраза —> Голова,
head_first(L0, L, R0, R, Фраза, Цель).
head_first(L, L, R, R, Цель, Цель).
input(Head, [Terminal|L], [], L) :-
lex(Terminal, Head).
вход(головка, [клемма|L1], [клемма|L2], L3) :-
вход(головка, L1, L2, L3).
Этот алгоритм анализа имеет следующие свойства:
- это «жадный» алгоритм, т. е. он пытается проанализировать столько входных данных, сколько позволяет грамматика
- дерево синтаксического анализа строится снизу вверх, начиная с головы компонента
Мы планируем использовать этот алгоритм следующим образом:
- слогов строятся по алгоритму в начале
- между слогами допускаем перекрытие
Примеры
- /wint@r/ анализируется как /wint/+/t@r/
- /asprin/ анализируется как /asp/+/sprin/
- /sist@m/ анализируется как /sist/+/st@m/
Также:
- /aspsprin/ анализируется так же, как /asprin/
- /asprsprin/ отклонено, так как /r/ остается неразобранным
Помогает создавать тексты с заданными фонетическими свойствами (например, поэтические).
Версия 0.15.0.0 исправила давно существующие проблемы с неработающими предварительными конкатенациями для текста в модуль Data.Phonetic.Languages.PrepareText. Добавлена также возможность не только добавлять нужные слова, но и добавлять их. Это вносит критические изменения, поэтому, пожалуйста, проверьте код, который использует библиотечные функции.
Версия 0.2.0.0 подготовлена ко Дню святых Кирилла и Мефодия, «Апостолов славян», и ко Дню славянской письменности и культуры.
Функции в модулях Phonetic.Languages.General.Simple.Parsing, Phonetic.Languages.General.Lines.Parsing, Phonetic.Languages.General.GetInfo.Parsing сильно зависит от типов данных в фонетических-языках-фонетических основах. упаковка.
Они используют парсинг со сбойными возможностями, поэтому для их корректной работы нужно указать каждую кусок данных в соответствии со спецификациями в импортированных модулях и в самих новых модулях.
В противном случае функции точно не будут работать корректно.
Предоставляются в основном для целей тестирования, могут быть недостаточно производительными для производственного использования.
Вы можете использовать дополнительно программу espeak-ng (см.: https://github.com/espeak-ng/espeak-ng) и в Терминал Unix/Linux (оболочка bash) можно ввести в виде команды что-то вроде:
cat — | тр -д [:пункт:] | espeak-ng -v{lang} -x -g 1 -s 130 —ipa
, где {lang} — необходимый код языка (см. вывод espeak-ng —voices и, кроме того, страницу руководства для эспик-нг).
Информацию о символах IPA можно взять с https://www.internationalphoneticassociation.org/content/full-ipa-chart.
или https://www.internationalphoneticassociation.org/sites/default/files/phonsymbol.pdf
Пожалуйста, обратите внимание на лицензионную информацию: график IPA и все его подразделы
защищены авторским правом 2018/2005 Международной фонетической ассоциации. По состоянию на июль 2012 года они производятся свободно.
доступно по лицензии Creative Commons Attribution-Sharealike 3. 0 Unported License (CC-BY-SA). Эта лицензия
разрешает любое повторное использование (включая коммерческое воспроизведение и производные работы) при условии указания авторства
дается, и воспроизведение или производная работа находятся под той же лицензией.
См. http://creativecommons.org/licenses/by-sa/3.0/ для дальнейшего описания.
Довольно легко создать соответствующую информацию GWritingSystemPRPLX с помощью IPA, но вы можете использовать какое-то другое представление. Идея заключается в том, что вы можете использовать линейку IPA, произведенную espeak-ng, в качестве строка ввода’.
Библиотека phonetic-languages-simplified-generalized-examples-array основана на идее определенного
длительности фонетических явлений во время речи. Определенно, у них есть какая-то продолжительность, вопрос
интерес в том, что нет стабильных, неизменных. Продолжительность варьируется не только от ситуации к ситуации,
от одного говорящего к другому, от обстоятельств и т. д., но и длительности некоторых фонем могут различаться
зависящие от соседних и, следовательно, являющиеся некоторой (вероятно, в каждом случае новой) функцией
соседних фонем. Этот факт не учтен в данной версии пакета и библиотеки, но
это имеет какое-то значение.
Когда ребенок только начинает читать слова на языке (или может быть просто кто-то новый для языка), он или она начинается с произношения фонем для каждого значимого написанного (и, следовательно, читаемого) символа. Потом, через некоторое практики, он/она начинает плавно читать. Тем не менее, если текст на самом деле является поэтическим произведением, т.е. грамм. немного стихотворение, ЧАСТО (может быть, обычно, или иногда, или изредка и т. д.) просто видно, что читаемый текст таким образом, обладает некоторыми свойствами ритмичности, несмотря на то, что фонемы читаются и произносятся в манера нерегулярной и в какой-то мере не относящейся к нормальному речевому моду длительности (длительности). Мы можем отличать (часто) поэтический текст от непоэтического только по некоторому расположению элементов.
Такая же ситуация возникает, когда человек с акцентом (вероятно, сильным, а точнее необычным) читает поэтический текст. Или в других ситуациях. Дизайн библиотеки работает точно так же, как и в этих ситуациях. Он предполагает предопределенную продолжительность, но
имея несколько разумных (осмысленных) можно оценить (приблизительно, конечно) свойства ритмичности
и некоторые другие, как и алгоритмы, представленные здесь.
Это, по мнению автора, является основанием для использования библиотеки и ее функционала в таких случаях.
Для этого можно использовать модуль EspeakNG_IPA, начиная с версии 0.4.0.0.
Начиная с версии 0.5.0.0 вы также можете использовать ряды свойств «w» и «x». Они используют более сложные подхода и рассчитаны на 4 элемента в ритмических группах. Для получения дополнительной информации, пожалуйста, обратитесь к раздел ‘Аргумент WX’ на украинском языке инструкция:
Краткая (возможно) инструкция как пользоваться программами пакета набор фонетических-языков-упрощенных-примеров на украинском языке находится здесь:
https://oleksandrzhabenko.github.io/uk/rhythmicity/PhLADiPreLiO. Ukr.21.pdf
или: https://oleksandrzhabenko.github.io/uk/rhythmicity/PhLADiPreLiO.Ukr.21.html
в формате html,
или здесь:
(попробуйте https://web.archive.org/web/20220
2723/https://oleksandrzhabenko.github.io/uk/rhythmicity/PhLADiPreLiO.Ukr.21.pdfили https://web.archive.org/web/20220
2509/https://oleksandrzhabenko.github.io/uk/rhythmicity/PhLADiPreLiO.Ukr.21.htmlв формате html ).
Инструкция на английском здесь:
https://oleksandrzhabenko.github.io/uk/rhythmicity/PhLADiPreLiO.Eng.21.pdf
или:
https://oleksandrzhabenko.github.io/uk/ ритмичность/PhLADiPreLiO.Eng.21.html
в формате html,
или здесь:
(попробуйте https://web.archive.org/web/20220
2921/https://oleksandrzhabenko.github.io/uk/ ритмичность/PhLADiPreLiO.Eng.21.pdfили https://web.archive.org/web/20220
3012/https://oleksandrzhabenko.github.io/uk/rhythmicity/PhLADiPreLiO.Eng.21.html в формате html
).
Там же есть дополнительная информация об изменениях в версии 0.6.0.0.
Начиная с версии 0.6.0.0 внесено несколько существенных изменений. Изменено обозначение модификаторов аргументов командной строки на маленькие буквы, удален двойной знак ++ (заменен на одинарный +), чтобы упростить использование аргументов командной строки. Также изменен способ подписи записи в файл для модуля Phonetic.Languages.General.Simple. Добавлены новые строки свойств для обработки (гипотетической) полиритмии. Среди них Строки «c», «s», «t», «u», «v». Изменены зависимости границы. Добавлена возможность «наращивать строки» в Phonetic.Languages.General.Lines и Модули Phonetic.Languages.General.GetTextualInfo.
Начиная с версии 0.7.0.0 ряды «c», «s», «t», «u» и «v» могут иметь отрицательный (по знаку) результат характеристики. Это не влияет на общее поведение функций.
Начиная с версии 0.8.0.0 также используются новые «взвешенные» строки свойств.
Начиная с версии 0.9.0. 0 также доступен рекурсивный интерактивный режим
Функции модуля Phonetic.Languages.General.Simple.
Начиная с версии 0.13.0.0 добавлены попарные перестановки режим (с аргументом командной строки +p), где только попарно используются перестановки, и длина строки может быть до 10 слов или их конкатенаций.
Начиная с версии 0.14.0.0 вы можете использовать два сокращенных набора режимов перестановки в дополнение к стандартному полному универсальному набору режимов перестановок. К используйте их, пожалуйста, добавьте «+p {1 или 2}» к аргументам командной строки. Для получения дополнительной информации, пожалуйста, обратитесь к инструкциям по ссылкам выше.
В версии 0.16.0.0 исправлены проблемы с изменением структуры вывода
(интервалы переставляются), так что теперь программы работают как
описано. Если вы ранее использовали изменяющуюся структуру с аргументами
то все результаты надо пересмотреть (переделать)
с исправленной версией 0.16.0.0.
Автор прошу прощения за такую затянувшуюся проблему. Улучшенная документация.
Исправлены проблемы со строковым интерпретатором (см. соответствующую информацию) и добавлена возможность настроить разбиение.
3 Фонетическая ошибка в изменении звука | Истоки изменения звука: подходы к фонологизации
Фильтр поиска панели навигации Oxford Academic Origins of Sound Change: подходы к фонологизацииИсторическая и диахроническая лингвистикаФонетика и фонологияПсихолингвистикаКнигиЖурналы Термин поиска мобильного микросайта
Закрыть
Фильтр поиска панели навигации Oxford Academic Origins of Sound Change: подходы к фонологизацииИсторическая и диахроническая лингвистикаФонетика и фонологияПсихолингвистикаКнигиЖурналы Термин поиска на микросайте
Расширенный поиск
Иконка Цитировать Цитировать
Разрешения
- Делиться
- Твиттер
- Подробнее
Cite
Garrett, Andrew, and Keith Johnson,
‘3 Фонетическая предвзятость в изменении звука’
,
in Alan C. L. Yu (ed.)
,
7
Origins of Soundization
(
Oxford,
2013;
онлайн-издание,
Oxford Academic
, 23 мая 2013 г.
), https://doi.org/10.1093/acprof:oso/9780199573745.003.0003,
, по состоянию на 13 сентября 2022 г.
Выберите формат Выберите format.ris (Mendeley, Papers, Zotero).enw (EndNote).bibtex (BibTex).txt (Medlars, RefWorks)
Закрыть
Фильтр поиска панели навигации Oxford Academic Origins of Sound Change: подходы к фонологизацииИсторическая и диахроническая лингвистикаФонетика и фонологияПсихолингвистикаКнигиЖурналы Термин поиска мобильного микросайта
Закрыть
Фильтр поиска панели навигации Oxford Academic Origins of Sound Change: подходы к фонологизацииИсторическая и диахроническая лингвистикаФонетика и фонологияПсихолингвистикаКнигиЖурналы Термин поиска на микросайте
Advanced Search
Abstract
Большинство типологий звуковых изменений проводят либо двустороннее различие между изменениями, основанными на артикуляции и восприятии, либо трехстороннее различие между путаницей восприятия, гипокоррекционными изменениями и гиперкоррекционными изменениями. Первый подход определяет господствующую неограмматистскую, структуралистскую и генеративную традицию; второй подход встречается в работах Охала, Блевинса и их коллег. В этой главе делается попытка разработать типологию асимметричных паттернов изменения звука, основанную на предубеждениях, возникающих из-за четырех элементов производства и восприятия речи: моторного планирования, аэродинамических ограничений, механики жестов и разбора восприятия. Первые три из них установлены наиболее надежно. Кроме того, некоторые асимметрии в звуковых изменениях и фонологических паттернах также могут быть следствием системно-зависимых предубеждений, действующих при фонологизации. Наконец, в главе обрисованы черты теории, связывающей предубеждения в производстве речи и восприятии с появлением новых речевых норм.
Ключевые слова: приведение в действие, фонологизация, изменение звука, типология
Предмет
Фонетика и фонологияИсторико-диахроническая лингвистикаПсихолингвистика
В настоящее время у вас нет доступа к этой главе.
Войти
Получить помощь с доступом
Получить помощь с доступом
Доступ для учреждений
Доступ к контенту в Oxford Academic часто предоставляется посредством институциональных подписок и покупок. Если вы являетесь членом учреждения с активной учетной записью, вы можете получить доступ к контенту одним из следующих способов:
Доступ на основе IP
Как правило, доступ предоставляется через институциональную сеть к диапазону IP-адресов. Эта аутентификация происходит автоматически, и невозможно выйти из учетной записи с IP-аутентификацией.
Войдите через свое учреждение
Выберите этот вариант, чтобы получить удаленный доступ за пределами вашего учреждения. Технология Shibboleth/Open Athens используется для обеспечения единого входа между веб-сайтом вашего учебного заведения и Oxford Academic.
- Щелкните Войти через свое учреждение.
- Выберите свое учреждение из предоставленного списка, после чего вы перейдете на веб-сайт вашего учреждения для входа.
- Находясь на сайте учреждения, используйте учетные данные, предоставленные вашим учреждением. Не используйте личную учетную запись Oxford Academic.
- После успешного входа вы вернетесь в Oxford Academic.
Если вашего учреждения нет в списке или вы не можете войти на веб-сайт своего учреждения, обратитесь к своему библиотекарю или администратору.
Войти с помощью читательского билета
Введите номер своего читательского билета, чтобы войти в систему. Если вы не можете войти в систему, обратитесь к своему библиотекарю.
Члены общества
Доступ члена общества к журналу достигается одним из следующих способов:
Войти через сайт сообщества
Многие общества предлагают единый вход между веб-сайтом общества и Oxford Academic. Если вы видите «Войти через сайт сообщества» на панели входа в журнале:
- Щелкните Войти через сайт сообщества.
- При посещении сайта общества используйте учетные данные, предоставленные этим обществом. Не используйте личную учетную запись Oxford Academic.
- После успешного входа вы вернетесь в Oxford Academic.
Если у вас нет учетной записи сообщества или вы забыли свое имя пользователя или пароль, обратитесь в свое общество.
Вход через личный кабинет
Некоторые общества используют личные аккаунты Oxford Academic для предоставления доступа своим членам. Смотри ниже.
Личный кабинет
Личную учетную запись можно использовать для получения оповещений по электронной почте, сохранения результатов поиска, покупки контента и активации подписок.
Некоторые общества используют личные аккаунты Oxford Academic для предоставления доступа своим членам.
Просмотр учетных записей, вошедших в систему
Щелкните значок учетной записи в правом верхнем углу, чтобы:
- Просмотр вашей личной учетной записи и доступ к функциям управления учетной записью.
- Просмотр институциональных учетных записей, предоставляющих доступ.
Выполнен вход, но нет доступа к содержимому
Oxford Academic предлагает широкий ассортимент продукции. Подписка учреждения может не распространяться на контент, к которому вы пытаетесь получить доступ. Если вы считаете, что у вас должен быть доступ к этому контенту, обратитесь к своему библиотекарю.
Ведение счетов организаций
Для библиотекарей и администраторов ваша личная учетная запись также предоставляет доступ к управлению институциональной учетной записью. Здесь вы найдете параметры для просмотра и активации подписок, управления институциональными настройками и параметрами доступа, доступа к статистике использования и т. д.
Покупка
Наши книги можно приобрести по подписке или приобрести в библиотеках и учреждениях.
Информация о покупке
Фонетическое соответствие | Справочное руководство по Apache Solr 7.1
Алгоритмы фонетического сопоставления могут использоваться для кодирования токенов таким образом, чтобы два разных написания, которые произносятся одинаково, совпадали.
Обзоры и сравнения алгоритмов см. на http://en.wikipedia.org/wiki/Phonetic_algorithm и http://ntz-develop.blogspot.com/2011/03/phonetic-algorithms.html
Фонетическое сопоставление Бейдера-Морзе (BMPM)
Примеры использования этой кодировки в вашем анализаторе см. в разделе Фильтр Бейдера-Морзе в разделе Описание фильтров.
Beider-Morse Phonetic Matching (BMPM) — это «звукоподобный» инструмент, который позволяет выполнять поиск с использованием новой системы фонетического сопоставления. BMPM помогает вам искать личные имена (или просто фамилии) в индексе Solr/Lucene и намного превосходит существующие фонетические кодеки, такие как обычный soundex, метафон, каверфон и т. д.
Как правило, фонетическое сопоставление позволяет искать в списке имен имена, фонетически эквивалентные желаемому имени. BMPM похож на поиск soundex в том смысле, что точное написание не требуется. В отличие от soundex, он не генерирует большого количества ложных срабатываний.
По написанию имени BMPM пытается определить язык. Затем он применяет фонетические правила для этого конкретного языка, чтобы транслитерировать имя в фонетический алфавит. Если невозможно определить язык с достаточной степенью уверенности, вместо этого используется общая фонетика. Наконец, он применяет независимые от языка правила в отношении таких вещей, как звонкие и глухие согласные и гласные, чтобы дополнительно гарантировать надежность совпадений.
Например, предположим, что при поиске Стивена в базе данных найдены совпадения «Стефан», «Стеф», «Стивен», «Стив», «Стивен», «Плита» и «Стаффин». «Стефан», «Стивен» и «Стивен», вероятно, имеют значение, и это имена, которые вы хотите видеть. «Штуффин», впрочем, наверное, не актуален. Также были отклонены «Стеф», «Стив» и «Печь». Из них «Печка», наверное, не та, которую хотелось бы. Но «Стеф» и «Стив», возможно, вас заинтересуют.0007
Для Solr поиск BMPM доступен для следующих языков:
Английский
французский
немецкий
Греческий
Иврит, написанный еврейскими буквами
Венгерский
итальянский
польский
Румынский
Русский кириллицей
русский транслитерируется английскими буквами
Испанский
Турецкий
Сопоставление имен также применимо к нееврейским фамилиям из стран, в которых говорят на этих языках.
Дополнительную информацию см. здесь: http://stevemorse.org/phoneticinfo.htm и http://stevemorse.org/phonetics/bmpm. htm.
Daitch-Mokotoff Soundex
Чтобы использовать эту кодировку в вашем анализаторе, см. Фильтр Daitch-Mokotoff Soundex в разделе «Описание фильтров».
Алгоритм Daitch-Mokotoff Soundex представляет собой усовершенствование алгоритмов Russel и American Soundex, обеспечивающее большую точность сопоставления особенно славянских и идишских фамилий с похожим произношением, но с разным написанием.
Основные отличия от других вариантов soundex:
закодированные имена состоят из 6 цифр
начальный символ имени закодирован
правил кодирования многосимвольных n-грамм
несколько возможных кодировок для одного и того же имени (ветвления)
Примечание: реализация, используемая Solr (commons-codec’s DaitchMokotoffSoundex ), имеет дополнительные правила ветвления по сравнению с исходным описанием алгоритма.
Для получения дополнительной информации см. http://en.wikipedia.org/wiki/Daitch%E2%80%93Mokotoff_Soundex и http://www.avotaynu.com/soundex.htm
Двойной метафон
Для использования этой кодировки в вашем анализаторе см. Фильтр двойного метафона в разделе Описание фильтра. В качестве альтернативы вы можете указать encoding="DoubleMetaphone" с Фонетическим фильтром, но обратите внимание, что версия Фонетического фильтра , а не будет предоставлять вторую («альтернативную») кодировку, которая генерируется Фильтром двойного метафона для некоторых токенов.
Кодирует токены с использованием алгоритма двойного метафона Лоуренса Филипса. См. оригинальную статью на http://www.drdobbs.com/the-double-metaphone-search-algorithm/184401251?pgno=2
Метафон
Чтобы использовать эту кодировку в вашем анализаторе, укажите encoding="Metaphone" с Фонетическим фильтром.
Кодирует токены с использованием алгоритма Metaphone Лоуренса Филипса, описанного в «Hanging on the Metaphone» на языке программирования, декабрь 1990 г.
Soundex
Чтобы использовать эту кодировку в вашем анализаторе, укажите encoding="Soundex" в фонетическом фильтре.
Кодирует токены с помощью алгоритма Soundex, который используется для сопоставления похожих имен, но также может использоваться как схема общего назначения для поиска слов с похожими фонемами.
См. также http://en.wikipedia.org/wiki/Soundex.
Refined Soundex
Чтобы использовать эту кодировку в вашем анализаторе, укажите encoding="RefinedSoundex" в фонетическом фильтре.
Кодирует токены с использованием улучшенной версии алгоритма Soundex.
См. http://en.wikipedia.org/wiki/Soundex.
Caverphone
Чтобы использовать эту кодировку в вашем анализаторе, укажите encoding="Caverphone" в фонетическом фильтре.
Caverphone — это алгоритм, созданный проектом Caversham Project в Университете Отаго. Алгоритм оптимизирован для акцентов, присутствующих в южной части города Данидин, Новая Зеландия.
См. http://en.wikipedia.org/wiki/Caverphone и спецификацию Caverphone 2.0 на http://caversham.otago.ac.nz/files/working/ctp150804.pdf
Kölner Phonetik, также известный как Cologne Phonetic
Чтобы использовать эту кодировку в вашем анализаторе, укажите encoding="ColognePhonetic" с Фонетическим фильтром.
Алгоритм Kölner Phonetik, опубликованный Гансом Иоахимом Постелом в 1969 году, оптимизирован для немецкого языка.
См. http://de.wikipedia.org/wiki/K%C3%B6lner_Phonetik
NYSIIS
Чтобы использовать эту кодировку в вашем анализаторе, укажите encoding="Nysiis" с Фонетическим фильтром.
NYSIIS — это кодировка, используемая для сопоставления похожих имен, но ее также можно использовать в качестве схемы общего назначения для поиска слов с похожими фонемами.
См. http://en.wikipedia.org/wiki/NYSIIS и http://www.dropby.com/NYSIIS.html
Простота и сложность фонологии L2: мини-обзор
Введение
Почему некоторые звуки труднее выучить, чем другие? Японец, изучающий английский язык, может испытывать трудности с усвоением нового контраста L2 английского языка [l]/[ɹ] (Brown, 2000), но с меньшими трудностями с приобретением нового контраста L2 русского языка [l]/[r] (Larson Hall, 2004). Тот же носитель японского языка может без труда усвоить новые контрасты L2 [b]/[v] или [s]/[θ] (Matthews, 2000). Бразильский португальский, изучающий английский язык, может испытывать трудности с усвоением групп согласных, таких как [sl], [sn] или [st], которые отсутствуют в L1 (Cardoso, 2007), в то время как персидский, изучающий английский язык, у которого также отсутствует L1 [sl] , [sn] и [st] их довольно легко приобрести (Archibald and Yousefi, 2018). Испанцу, изучающему английский язык, может быть легче усвоить контраст [i]/[ɪ] (отсутствующий в L1) при изучении шотландского английского, чем британского английского (Escudero, 2002). Есть также примеры так называемой направленности эффектов сложности (Eckman, 2004). Например, английскому языку, изучающему немецкий язык, может быть легче подавить окончательный голосовой контраст, чем немецкому, изучающему английский язык, научиться создавать новый окончательный голосовой контраст L2. Это типы фактов, которые исследователи должны объяснить ( объяснение ). В этой короткой статье я представлю обзор некоторых из предложенных фонологических описаний ( объяснений ) таких случаев легкости или сложности.
Начнем с вопроса, что значит, когда приобретает звук. Исследуя такой вопрос с фонологической точки зрения, мы должны заняться вопросом о контрасте . Фонемы используются для представления лексических контрастов. Такие контрасты также должны быть фонетически реализованы как в воспроизведении, так и в восприятии. Учитывая, что производство и восприятие L2 вполне могут быть неродными, это поднимает интересный вопрос для фонолога L2: определить, 1) воспроизводит ли индивидуум неточное представление точно или 2) воспроизводит ли точное представление неточно. Случай 1) будет иметь место, когда учащийся L2 может иметь одинаковое представление как для /l/, так и для /r/ (т. е. не создавая фонематического жидкого контраста), и он также объединил производство [l] и [r]. Случай 2) будет иметь место, когда учащийся может иметь репрезентативный контраст для /b/ и /p/ (т. е. создавать фонематический контраст VOT), но не реализовывать контраст родным способом. С методологической точки зрения это показывает, что исследователи (и преподаватели) не могут полагаться на неточное производство как на диагностику неродственного представления.
Это подводит нас к родственному вопросу, касающемуся производства и восприятия. Большая часть работы над речью L2 основывается на предположении, что точное восприятие должно (логически и с точки зрения развития) предшествовать точному воспроизведению (Flege, 1995). Таким образом, большая часть литературы посвящена оценке того, могут ли испытуемые надежно различать фонетические контрасты и точно представлять фонологические контрасты. Тем не менее, есть определенные случаи, когда учащиеся могут быть точными в любой постановке (Гото, 1971) или лексической дискриминации (Darcy et al., 2012) и все же остаются неточными в задачах на дискриминацию. В обоих случаях может оказаться, что металингвистические знания играют важную роль.
Начиная с Гипотезы контрастного анализа (Lado, 1957), лингвисты пытались предсказать, какие аспекты речи L2 будет легко или трудно выучить. С 50-х годов как репрезентативные модели фонологии, так и теории обучения стали более изощренными, и это привело к учету множества факторов при изучении конструкции 9.0096 сложность . Такие подходы резко контрастируют с моделями производства речи на разных языках (Flege, 1995) и восприятия речи на разных языках (Best and Tyler, 2007), которые в первую очередь обращаются к акустическим и артикуляционным факторам для объяснения трудности усвоения.
В области освоения второго языка (SLA) было изучено множество факторов, объясняющих аспекты вариативности учащихся, в том числе вариации родственной речи L2. Были исследованы следующие факторы:
• Передача L1 (Trofimovich and Baker, 2006)
• Количество опыта (Bohn and Flege, 1992)
• Количество использования L2 (Guion et al., 2000)
• Возраст обучения (Abrahamsson and Hyltenstam) , 2009)
• орфография (Escudero and Wanrooi, 2010; Bassetti et al. , 2015)
• частота (Davidson, 2006)
• внимание (Guion and Pederson, 2007)
• обучение (Wang et al., 2003)
Само собой разумеется, что все эти факторы 9От 0096 до вступают в игру при учете поведения учащегося. В этом мини-обзоре я сосредоточусь на ключевых проблемах репрезентации, которые легли в основу фонологических подходов к построению легкости и трудности.
Репрезентативные подходы
Этот мини-обзор посвящен репрезентативным моделям фонологии. Существует обширная литература по подходам, основанным на результатах (Tessier et al., 2013; Jesney, 2014), которые, как правило, делают акцент на вычислительной системе, которая генерирует форму вывода, а не на форме лежащей в ее основе (или 9).0096 ввод ) представление.
Маркировка
Некоторые рассматривали понятие маркированности (Parker, 2012) как объяснение, предполагая, что немаркированные структуры легче приобрести, чем маркированные (Carlisle, 1998). Например, можно утверждать, что начало 3-согласных (например, [str]) было труднее усвоить, чем начало 2-согласных (например, [tr]) , потому что они были более заметными. Даже в двухсогласных последовательностях работают, например, Брозелоу и Файнер (1991), Экман и Айверсон (19).93) демонстрируют, что такие принципы, как секвенирование звучности, реализуют маркировку с большим расстоянием звучности между соседними сегментами, которые являются менее маркированными (т. е. [pj] будет менее маркированным, чем [fl]). Такой механизм разработан с учетом наблюдения, что не все структуры, отсутствующие в L1, одинаково трудно приобрести в L2. Путь развития будет идти от немаркированных структур к маркированным.
Некоторые предположили, что континуума маркировки недостаточно, а скорее, что маркированность дифференциал был местом объяснения (Eckman, 1985). При таком подходе будет трудно получить структуру, отсутствующую в L1 и более выраженную, чем структура L1, в то время как структуру, отсутствующую в L1, но менее выраженную, чем структура L1, получить будет легче.
Часто, однако, неотмеченные формы являются наиболее частыми (например, группы из 3 согласных более заметны, чем группы из 2 согласных, а группы из 3 согласных также менее часты, чем группы из 2 согласных), поэтому их трудно дразнить. факторы отдельно. Если учащиеся более точны в кластерах из 2 согласных, это потому, что они более часты или менее отмечены?
Подходы, основанные на частоте
Подходы, основанные на использовании (Wulff and Ellis, 2018) и байесовском подходе (Wilson and Davidson, 2009), утверждают, что подобная цели точность производства коррелирует с входной частотой. Таким образом, если есть два элемента, отсутствующих в L1, и один из них часто встречается во входных данных L2, а другой встречается редко, то часто встречающаяся структура может быть усвоена легче.
Частота против маркировки
Cardoso (2007) документирует сценарий, в котором наиболее часто встречающаяся структура является наиболее маркированной, поэтому мы можем сказать, какая конструкция является наиболее объяснительной. Рассматривая приобретение групп согласных английского языка L2 носителями бразильского португальского языка L1, он сосредоточился на [st], [sn] и [sl]. Не вдаваясь здесь в подробности фактов маркировки, [st] является и наиболее частым, и наиболее маркированным из кластеров. Когда дело дошло до продукции учащихся, учащиеся были наименее точны в наиболее отмеченном кластере ([st]), даже несмотря на то, что они чаще всего вводили его. Для производства (но не для восприятия) маркировка оказалась более объяснительной, чем частота.
Сама конструкция маркировки имеет своих критиков (Haspelmath, 2006; Zerbian, 2015). Если понятие является плохо определенной мерой сложности — трудности или ненормальности? — тогда как оно может быть действительным explanans ? Отвечая Арчибальду (1998), который предположил, что постулирование маркировки как объяснения (а не описания) лишь отбрасывает проблему объяснения на поколение назад (потому что чем объясняется маркировка?), Экман (2008; 105) возражает, что «отвергнуть гипотеза, потому что она отодвигает проблему объяснения на один шаг назад, упуская из виду то, что все гипотез отодвигают проблему объяснения на один шаг назад — действительно, такое «отталкивание» необходимо, если мы хотим перейти к объяснениям более высокого уровня».
Обработка учетных записей
В то время как было проделано больше работы над ролью процессора в морфосинтаксисе в SLA (O’Grady, 1996; O’Grady, 2006; Truscott and Sharwood Smith, 2004), Кэрролл (2001) исследует роль фонологического синтаксического анализатора в отображении акустического сигнала на фонологические представления. Кэрролл (2013) эмпирически решает эти вопросы у учащихся L2 в начальном состоянии. Также была проделана некоторая работа по фонологическому анализу L2 на уровне слога (Archibald, 2003; Archibald, 2004; Archibald, 2017), которая предполагает, что структуры, которые можно проанализировать, легче получить, чем структуры, которые синтаксический анализатор еще не может обработать. .
Такие модели пересекаются с литературой по восприятию, поскольку акустический вход L2 фильтруется фонологической системой L1 (Pallier et al., 2001). В свою очередь, такая перцептивная манипуляция может привести к активации фантомных лексических конкурентов (Broersma and Cutler, 2007), что может замедлить лексическую активацию.
Представление о том, что только некоторые входные данные могут быть обработаны в любой момент времени, что приводит к тому, что поступление к процессору является подмножеством входных данных среды, хорошо изучено в прикладной лингвистике (Corder, 19).67; Шмидт, 1990). Что оказалось более неуловимым, так это объяснить, когда ввод становится потреблением (а когда нет). Конечно, одна из проблем состоит в том, чтобы избежать цикличности следующего вида:
Вопрос: почему x производится/воспринимается точно раньше y?
A: Потому что это стало потреблением
Q: Как вы узнали, что оно стало потреблением?
A: Потому что это было произведено/воспринято точно.
Учетные записи обработки не обязательно независимы от абстрактных фонологических исследований, поскольку они также важны для документирования жизнеспособности абстрактных фонологических признаков (Lahiri and Reetz, 2010; Schluter et al., 2017). Особенности могут быть объяснительными, когда мы отмечаем классы звуков, ведущих себя аналогичным образом, например, в кодах слогов в данном L1 разрешены только носовые звуки. Таким образом, могут возникнуть трудности, когда эти учащиеся пытаются разобрать остановки L2 в коду. Обратите внимание, что сложность повлияет, скажем, на [ptk] как на класс глухих остановок.
Репрезентативные счета
Теории фонологической репрезентации помогают нам моделировать как синхронические, так и диахронические аспекты фонологических грамматик L2. Озчелик (2016) обращается к общему вопросу о пути развития в грамматиках L2 (фундаментальная проблема в этой области, когда мы пытаемся разработать теорию перехода). Он предлагает модель на основе сигналов, которая разъясняет, какие структурные свойства (то есть параметры) являются логическими предшественниками приобретения последующих параметров. Озчелик и Спроус (2016) демонстрируют, что межъязыковые грамматики ограничены фонологическими универсалиями (такими как поведение распространения признаков).
Модели на основе признаков (Brown, 2000) можно противопоставить моделям на основе сегментов (Flege, 1995). Модель на основе сегментов может сказать, что новый сегмент будет трудно получить на основе сравнения фонетических категорий L1 и L2. Учет на уровне функций будет утверждать, что новые контрасты L2, основанные на отличительных чертах, отсутствующих в L1, будут трудными, в то время как новые контрасты, основанные на функциях L1, будут легкими. Браун (2000) показал, что корейские изучающие английский язык могут усваивать новые контрасты, если контрасты были основаны на существующей функции L1 (например, [continuant]), в то время как контрасты L2, которые не были основаны на функциях L1 (например, [distributed]), были более значительными. трудно приобрести.
LaCharité и Prévost (1999) предполагают, что это был слишком сильный подход и что некоторые отсутствующие признаки (т. е. терминальные узлы) можно было бы приобрести, а другие (т. е. узлы артикулятора) — нет, как показано на (1).
Элементы, выделенные жирным шрифтом, отсутствуют во французском инвентаре L1. Они предсказывают, что овладение английским языком L2 [h] будет более сложным, чем овладение [θ], потому что [h] требует от учащегося активировать новый узел артикулятора. В задании на различение учащиеся были значительно менее точны в определении [h], чем в определении [θ], однако в задании на определение слова (включая лексический доступ) не было существенной разницы между результатами [h] и [θ] . Озчелик и Спроус (2016), однако, показывают, что учащиеся L2 способны приобретать черты вторичной артикуляции (например, палатализованные согласные). Хансин-Бхатт (1994) предположил, что функциональная нагрузка конкретной функции при реализации контраста в языке будет определять ее вес (предполагается, что функции с высокой функциональной нагрузкой будут иметь большее межъязыковое влияние, чем функции с низкой функциональной нагрузкой).
Арчибальд (2005) предложил Гипотезу передислокации, согласно которой было бы проще приобрести новые структуры L2, которые можно было бы построить из существующих строительных блоков L1 (например, функций или мор), чем приобретать новые строительные блоки. В некотором смысле этот подход предвосхищает подход Лардьера (2009 г. ) Гипотеза повторной сборки признаков, которая призвана объяснить трудности, с которыми учащиеся L2 сталкиваются с освоением морфологии L2.
Одним из примеров перераспределения является приобретение близнецовых согласных японского языка на уровне L2 носителями английского языка на уровне L1. Японские близнецовые согласные имеют моральную структуру, показанную в (2).
В английском языке нет близнецовых согласных, но есть чувствительная к весу система ударения, показанная в (3), где согласные коды проецируют моры, которые привлекают ударение к тяжелым слогам.
Таким образом, английская система, чувствительная к количеству, может быть перераспределена для приобретения близнецов L2. Следствием этого будет то, что структуры L2, которые нельзя построить из компонентов L1, будет труднее приобрести.
Кабрелли и др. (2019), глядя на бразильских португальских учащихся, изучающих английские кодовые согласные, также демонстрируют, что изучающие L2 могут реструктурировать свои фонологические грамматики, поскольку изучающие L2 лицензируют согласные коды, которых нет в L1. Карлсон (2018) обнаружил аналогичные эффекты в испанском языке L1.
Garcia (2020) описывает интересный случай, когда свойство L2 (размещение напряжения), которое можно было бы получить на основе переноса свойства L1 чувствительности к весу, на самом деле трудно приобрести, потому что другое свойство L1 может учитывать данные L2, и это свойство (позиционное смещение) более надежно во входных данных L2.
Производство, восприятие и представление
Darcy et al. (2012) представляют данные, которые показывают, вопреки Flege (1995), что некоторые учащиеся, которые были в состоянии лексически представить контраст, не смогли точно различить его. Модель известна как DMAP, что означает 9.0096 прямое сопоставление акустики с фонологией. Основным эмпирическим открытием, о котором они сообщают, является профиль, в котором изучающие французский язык L2 (с английским языком L1, в котором отсутствует /y/) могут различать лексические единицы, которые основаны на различии /y/ — /u/, в то же время ненадежно различая [ y] из [u] в задаче ABX. Выявление акустических свойств может привести к фонологической перестройке (в соответствии с общими принципами экономии фонологического инвентаря), что приведет к лексическому контрасту, но фонетические категории могут еще не быть целевыми. Учащиеся полагаются на свою текущую иерархию межъязыковых признаков, чтобы установить контрастные лексические репрезентации даже в процессе формирования фонетических категорий.
Это напоминает исследование Гото (1971), в котором учащиеся японского языка смогли воспроизвести жидкий контраст /l/-/r/, даже не будучи в состоянии различить их в деконтекстуализированном задании. Возможно, тактильная обратная связь, полученная при воспроизведении этих двух звуков, и орфографическое различие между «л» и «р» смогли указать на системы воспроизведения учащихся. Такого рода металингвистические знания могут влиять на производство.
Дэвидсон и Уилсон (Davidson and Wilson, 2016) расширяют объем исследований, в которых задокументирована чувствительность учащихся L2 к неконтрастным фонетическим свойствам (которые могут объяснить появление протезов и эпентезов при ремонте кластеров), чтобы изучить поведение учащихся в классе. В то время как испытуемые, слушающие в классе (по сравнению со звуковой кабиной), показали некоторые различия (например, меньшее количество ремонтов протезов), в целом результаты были очень похожими. Это говорит о том, что лабораторные исследования вполне могут иметь прямое значение для учащихся в классе.
Обучаемость и фонология L2
Подходы к обучаемости (Wexler and Culicover, 1980; Pinker, 1989; White, 1991) утверждали, что обучение будет проходить быстрее, когда есть убедительные доказательства того, что грамматика L1 должна измениться, в то время как изменение, которое было вызвано только сигналом по отрицательным свидетельствам будет приобретаться медленнее. Позитивное свидетельство – это свидетельство в языковой среде правильно сформированных структур. Отрицательное свидетельство — это свидетельство, данное учащемуся, что конкретная строка не грамматична. Было бы легче перейти от L1, являющегося подмножеством L2 (поскольку существуют убедительные доказательства того, что текущая грамматика неверна), чем перейти от L1, являющегося надмножеством L2 (поскольку это потребуются отрицательные доказательства).
Рассмотрим пример английского языка L1 и венгерского языка L2, как показано на рисунке 1. Венгерское вторичное ударение (Kerek, 1971) зависит от количества ядра (это означает, что только разветвленные ядра (т. е. долгие гласные (CVV)) рассматриваются как Тяжелые, но не ветвящиеся рифмы (т. е. закрытые слоги (CVC)). Ударение в английском языке зависит от количества ветвящихся ядер и ветвящихся рифм.
РИСУНОК 1 . ) доказательства и легкость или трудность обучения, иллюстрируемые чувствительностью к количеству при назначении ударения в венгерском и английском языках 9.0007
Если ваш L1 воспринимал долгие (т.е. биморальные) гласные (CVV) и закрытые слоги (CVC) как тяжелые (как в английском языке), а L2 воспринимал как тяжелые только долгие гласные, то учащемуся может потребоваться некоторое время, чтобы выдвинуть гипотезу. «подождите, я никогда не слышал второстепенного ударения на закрытый слог!». Но перевод с L1 венгерского языка на L2 английский будет иметь четкие положительные доказательства, когда учащийся слышит ударение на закрытом слоге (как в повестке дня ) . Английский, изучающий венгерский язык, должен был бы заметить, что венгерский никогда ударные закрытые слоги. Дрешер и Кэй (1991) утверждали, что когда данные показывают, что закрытые слоги и ядра ветвления ведут себя одинаково в отношении назначения ударения, это является универсальным признаком того, что система чувствительна к количеству рифмы. См. Archibald (1991) для дальнейшего обсуждения и эмпирического исследования.
Гипотеза асимметрии Янга-Шолтена (1994, 2004) предсказывает, что если фонологическое правило L2 применяется в просодической области, которая является надмножеством фонологической области L1, то положительные доказательства облегчат получение. Однако, когда целевой домен меньше, чем домен L1, отсутствие положительных доказательств затруднит приобретение. В английском языке правило взмахивания применяется в пределах фонологического высказывания (например, Не садись на коврик [ɾ], он грязный .). В немецком есть правило окончательного обращения, которое применяется к фонологическому слову (например, Ich ha [b] e ∼ Ich hab [p]). Таким образом, предполагается, что изучающие немецкий язык на английском языке будут испытывать трудности с усвоением фонологических моделей, которые разрешены только в более мелких фонологических областях.
Однако в дополнение к положительным или прямым отрицательным (т. В этом случае было показано, что английский язык с акцентом L2 является для некоторых испытуемых источником доказательств фонотактики бразильского португальского языка.
Есть одна область, которая только начинает изучаться в фонологии L2, и это Dresher (2009) контрастивная иерархия как инструмент объяснения простоты и сложности. Модель Дрешера предполагает, что функции L2, которые являются активными (т. е. участвуют во многих фонологических процессах в языке), будут легче изучаться, чем функции L2, которые неактивны из-за типа свидетельств, которые они представляют учащемуся. Активные функции дают учащемуся надежные подсказки о том, что данная функция должна иметь высокий рейтинг в контрастной иерархии и, следовательно, является свидетельством реструктуризации иерархии L1. Арчибальд (2020) исследовал эту модель при анализе фонологических систем L3. Такой механизм напоминает Ханчин-Бхатт (1994) представление о том, как функциональная нагрузка определяет выраженность признаков.
Заключение
В этом мини-обзоре я попытался показать, что существует богатая история решения вопроса о легкости и сложности в фонологии L2. Я надеюсь, что этот обзор будет полезен читателям этого сборника. Неудивительно, что нет простого ответа на сложный вопрос легкости против сложности .
Вклад автора
Я единственный автор этой статьи.
Конфликт интересов
Авторы заявляют, что исследование проводилось в отсутствие каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов.
Благодарности
Я хотел бы поблагодарить рецензентов за эту статью. Их острый взгляд на ясность и точность значительно улучшил этот мини-обзор. Но я должен сказать, что дружеский, поддерживающий научный обмен был столь же приятным, сколь и редким.
Каталожные номера
Абрахамссон, Н., и Хилтенстам, К. (2009). Возраст начала и сходство с родным на втором языке: восприятие слушателя против лингвистического изучения. Ланг. Учиться. 59 (2), 249–306. doi:10.1111/j.1467-9922.2009.00507.x
CrossRef Full Text | Google Scholar
Арчибальд Дж. (1991). Изучаемость языка и фонология L2: приобретение метрических параметров. Дордрехт: Клувер.
Полнотекстовая перекрестная ссылка | Google Scholar
Арчибальд Дж. (2004). Интерфейсы в просодической иерархии: новые структуры и фонологический синтаксический анализатор. Междунар. Ж. Билингвизм 8 (1), 29–50. doi:10.1177/1367006
80010301
CrossRef Full Text | Google Scholar
Арчибальд Дж. (2003). Учимся анализировать кластеры согласных второго языка. Кан. Журнал лингвистики 48 (3/4), 149–177. doi:10.1353/cjl.2004.0023
Полный текст CrossRef | Google Scholar
Арчибальд Дж. (1998). Фонология второго языка . Амстердам, Нидерланды: Джон Бенджаминс.
CrossRef Полный текст
Archibald, J. (2005). Фонология второго языка как перераспределение фонологических знаний L1. Кан. J. Лингвистика 50 (1/2/3/4), 285–314. doi:10.1353/cjl.2007.0000
Полный текст CrossRef | Google Scholar
Арчибальд Дж. (2017). «Перенос, сопоставительный анализ и межъязыковая фонология», в Справочник Routledge по английскому произношению . Редакторы Р. Томпсон, О. Канг и Дж. Мерфи (Лондон, Великобритания: Routledge), 9–24.
Google Scholar
Арчибальд Дж. (2020). в Микроизменение в многоязычных ситуациях: важность приобретения объекта за свойством . Черепахи на всем пути вниз: микроподсказки и частичная передача в фонологии L3. Комментарий к Вестергорду. Исследование второго языка . doi:10.1177/0267658320941036
Полный текст CrossRef | Google Scholar
Арчибальд Дж. и Юсефи М. (2018). «Перераспределение отмеченных персидских кодов L1 при приобретении отмеченных английских начал L2: перераспределение как теория перехода», в статье, представленной на конференции по центральноазиатскому языку и лингвистике, Блумингтон, Индиана, 17–19 апреля. , 2020 (Блумингтон, Индиана: Университет Индианы).
Google Scholar
Бассетти Б., Эскудеро П. и Хейс-Харб Р. (2015). Фонология второго языка на стыке акустического и орфографического ввода. Заяв. Психолингвистика 36, 1–6. doi:10.1017/s0142716414000393
CrossRef Full Text | Google Scholar
Бест, К., и Тайлер, доктор медицины (2007). «Восприятие речи на неродном и втором языке: общие черты и взаимодополняемость», в Изучение речи на втором языке: роль языкового опыта в восприятии и воспроизведении речи . Редакторы М. Дж. Манро и О.-С. Бон (Амстердам, Нидерланды: John Benjamins Publishing), 13–34.
Полнотекстовая перекрестная ссылка | Google Scholar
Бон, О.С., и Флеге, Дж.Э. (1992). Произведение новых и похожих гласных взрослыми, изучающими немецкий язык на английском языке. Шпилька. Второй Ланг. Комплектация 14 (2), 131–158. doi:10.1017/s0272263100010792
CrossRef Full Text | Google Scholar
Броерсма, М. , и Катлер, А. (2007). Активация фантомного слова в L2. Система 36, 22–34. doi:10.1016/j.system.2007.11.003
CrossRef Полный текст | Google Scholar
Брозелоу Э. и Файнер Д. (1991). Настройка параметров фонологии и синтаксиса второго языка. Второй язык. Рез. 7 (1), 35–59. doi:10.1177/0267658300102
CrossRef Full Text | Google Scholar
Браун, К. (2000). «Взаимосвязь между восприятием речи и фонологическим усвоением от младенца до взрослого», в Овладение вторым языком и лингвистическая теория . Редактор Дж. Арчибальд (Хобокен, Нью-Джерси: Wiley-Blackwell), 4–63.
Google Scholar
Кабрелли Дж., Луке А. и Финестрат-Мартинес И. (2019). Влияние фонотактики английского языка L2 на восприятие иллюзорных гласных в бразильском португальском языке L1. J. Фонетика 73, 55–69. doi:10.1016/j.wocn.2018.10.006
Полный текст CrossRef | Google Scholar
Cardoso, W. (2007). «Развитие кластеров начала sC в межъязыковом: маркировка против частотных эффектов», в Proceedings of the 9Конференция по генеративным подходам к овладению вторым языком (GASLA 2007), 18–20 мая 2007 г. Редакторы Р. Слабакова, Дж. Ротман, П. Кемпчински и Э. Гаврусева (Cascadilla Press), 15–29.
Google Scholar
Карлайл, Р. С. (1998). Приобретение приступов в отношениях маркировки: лонгитюдное исследование. Исследования по овладению вторым языком 20, 254–260. doi:10.1017/S027226319800206X
CrossRef Full Text | Google Scholar
Карлсон, М. Т. (2018). Освобождение места для фонотактики второго языка: влияние обучения L2 и окружающей среды на восприятие речи на первом языке. Ланг. Речь 61, 598–614. doi:10.1177/0023830918767208
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Кэрролл С. (2001). Ввод и доказательства: исходный материал для овладения вторым языком . Амстердам, Нидерланды: John Benjamins Publishing
Полный текст CrossRef
Кэрролл, С. (2013). Введение в специальный выпуск: аспекты изучения слов при первом знакомстве со вторым языком. Второй язык. Рез. 29 (2), 131–144. дои: 10.1177/0267658312463375
Полнотекстовая перекрестная ссылка | Google Scholar
Corder, SP (1967). Значение ошибок учащихся. Междунар. Преподобный заявл. Лингвистика 5, 160–170. doi:10.1515/iral.1967.5.1-4.161
Полный текст CrossRef | Google Scholar
Дарси И., Декидтспоттер Л., Спроус Р., Гловер Дж., Каден К., Макгуайр М. и Скотт Дж. (2012). Прямое сопоставление акустики с фонологией: лексическое кодирование округлых гласных переднего ряда в приобретении L1 английского языка-L2 французского языка. Второй язык. Рез. 28 (1), 5–40. doi:10.1177/0267658311423455
CrossRef Полный текст | Google Scholar
Дэвидсон, Л. (2006). Фонология, фонетика или частота: влияние на создание неродных последовательностей. J. Фонетика 34, 104–137. doi:10.1016/j.wocn.2005.03.004
Полный текст CrossRef | Google Scholar
Дэвидсон Л. и Уилсон К. (2016). Обработка кластеров неродных согласных в классе: восприятие и воспроизведение фонетических деталей. Второй язык. Рез. 32 (4), 471–501. doi:10.1177/0267658316637899
Полный текст CrossRef | Google Scholar
Дрешер, Б. Э., и Кэй, Дж. (1991). Вычислительная модель обучения для метрической фонологии. Познание 34, 137–195.
Google Scholar
Дрешер, Э. Б. (2009). Сравнительная иерархия в фонологии . Кембридж, Великобритания: Издательство Кембриджского университета.
Экман, Ф. (2004). От фонематических различий к ранжированию ограничений. SSLA 26 (4), 513–549. doi:10.1017/s027226310404001x
CrossRef Full Text | Google Scholar
Экман Ф. и Айверсон Г. (1993). Звучность и маркировка среди кластеров начала межъязыкового общения изучающих ESL. Второй язык. Рез. 9, 234–252. doi:10.1177/0267658393002
CrossRef Full Text | Google Scholar
Экман, Ф. (1985). Некоторые теоретические и педагогические следствия дифференциальной гипотезы маркированности. Шпилька. Второй Ланг. Приобретение 7, 289–307. doi:10.1017/S0272263100005544
CrossRef Полный текст | Google Scholar
Экман, Ф. (2008). «Типологическая маркировка и фонология второго языка», в Фонология и овладение вторым языком . Редакторы Дж. Хансен и М. Зампини (Амстердам, Нидерланды: John Benjamins Publishing), 95–115.
Полнотекстовая перекрестная ссылка | Google Scholar
Эскудеро, П. (2002). «Восприятие контрастов английских гласных: опора на акустические сигналы в развитии новых контрастов», в материалах 4-го Международного симпозиума по овладению иноязычной речью, Новые звуки, сентябрь 2000 г.
Google Scholar
Эскудеро П. и Ванройдж К. (2010). Влияние орфографии L1 на восприятие неродных гласных. Ланг. Речь 53 (3), 343–365. doi:10.1177/00238301447
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Флеге, Дж. Э. (1995). «Обучение речи второму языку: теория, выводы и проблемы», в Восприятие речи и лингвистический опыт: вопросы кросс-лингвистического исследования . Редактор В. Стрэндж (Йорк, Великобритания: York Press), 233–277.
Google Scholar
Гарсия, Г. Д. (2020). Языковой перенос и позиционное смещение в английском ударении. Второй язык. Рез. 36 (4), 445–474. doi:10.1177/0267658319882457
Полный текст CrossRef | Google Scholar
Гото, Х. (1971). Слуховое восприятие нормальными взрослыми японцами звуков «Л» и «Р». Нейропсихология 9, 317–323. doi:10.1016/0028-3932(71)
-3PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Guion, S., Flege, JE, Liu, S., and Yeni-Komshian, G. (2000). Возраст обучения влияет на продолжительность предложений, произносимых на втором языке. Заявл. Психолингвистика 21, 205–228. doi:10.1017/s0142716400002034
CrossRef Full Text | Google Scholar
Guion, S., and Pederson, E. (2007). «Исследование роли внимания в фонетическом обучении», в Изучение речи на втором языке: роль языкового опыта в восприятии речи и производстве . Редакторы О.-С. Бон и М. Манро (Амстердам, Нидерланды: John Benjamins Publishing), 99–116.
Google Scholar
Хансин-Бхатт, Б. (1994). Передача сегмента: следствие динамической системы. Второй язык. Рез. 10 (3), 241–269. doi:10.1177/026765839401000304
CrossRef Full Text | Google Scholar
Хаспелмат, М. (2006). Против маркизированности (и чем ее заменить). J. Лингвистика 42, 25–70. doi:10.1017/s0022226705003683
CrossRef Full Text | Google Scholar
Джесни, К. (2014). «Отчет о различиях в восстановлении кластеров L1 и L2, основанный на обучении», в Избранных материалах 5-й конференции по генеративным подходам к овладению языком в Северной Америке (GALANA 2012), Канзасский университет, 11–13 октября 2012 г. Редакторы С. Ю. Чу , CE Coughlin, BL Prego, U. Minai и A. Tremblay (Somerville, MA: Cascadilla Proceedings Project), 10–21.
Google Scholar
Керек, А. (1971). Венгерские метрики . Блумингтон, Индиана: Университет Индианы.
Лашарите, Д., и Прево, П. (1999). «Роль L1 и обучения в усвоении английских звуков франкофонами», в Proceedings of BUCLD 23 . Редакторы А. Гринхилл, Х. Литтлфилд и К. Тано (Сомервилль, Массачусетс: Cascadilla Press), 373–385.
Google Scholar
Ладо, Р. (1957). Лингвистика в разных культурах . Анн-Арбор, Мичиган: Издательство Мичиганского университета.
Лахири, А., и Ритц, Х. (2010). Отличительные черты: фонологическая недоопределенность в представлении и обработке. J. Фонетика 38, 44–59. doi:10.1016/j.wocn.2010.01.002
CrossRef Full Text | Google Scholar
Лардьер, Д. (2009). Некоторые мысли о сравнительном анализе особенностей овладения вторым языком. Второй язык. Рез. 25 (2), 173–227. дои: 10.1177/0267658308100283
Полнотекстовая перекрестная ссылка | Google Scholar
Ларсон-Холл, Дж. (2004). Прогнозирование успеха восприятия с помощью сегментов: тест японцев, говорящих по-русски. Второй язык. Рез. 20 (1), 33–76. doi:10.1191/0267658304sr230oa
CrossRef Full Text | Google Scholar
Мэтьюз, Дж. (2000). «Влияние тренировки произношения на восприятие контрастов второго языка», в Новые звуки 1999 . Редакторы Дж. Лезер и А. Джеймс (Клагенфуртский университет Press), 223–229..
Google Scholar
Озчелик, О., и Спроус, Р. (2016). Новое знание универсального фонологического принципа при усвоении гармонии гласных на языке L2 в турецком языке: «четырехкратная» бедность стимула при усвоении языка L2. Второй язык. Рез. 33 (2), 179–206. doi:10.1177/0267658316679226
CrossRef Полный текст | Google Scholar
Озчелик, О. (2016). Гипотеза пути овладения просодией: к объяснению изменчивости в овладении фонологией L2. Глосса 1 (1), 1–48. doi:10.5334/gjgl.47
CrossRef Full Text | Google Scholar
О’Грэйди В. (1996). Овладение языком без универсальной грамматики: общее нативистское предложение для обучения L2. Второй язык. Рез. 12 (4), 364–397. doi:10.1177/026765839601200403
CrossRef Full Text | Google Scholar
О’Грэйди В. (2006). «Синтаксис количественной оценки в SLA: эмерджентный подход», в материалах 8-й конференции по генеративным подходам к овладению вторым языком (GASLA 2006): конференция в Банфе, Банф, Канада, 27–30 апреля 2006 г. Редакторы М. О’ Брайен, К. Ши и Дж. Арчибальд (Сомервилль, Массачусетс: Cascadilla Press), 98–113.
Google Scholar
Палье К., Коломе А. и Себастьян-Галлес Н. (2001). Влияние фонологии родного языка на лексический доступ: основанные на образцах и абстрактные лексические статьи. Психолог. науч. 12, 445–449. doi:10.1111/1467-9280.00383
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Паркер, С. (2012). «Расстояние звучности против дисперсии звучности — типологическое исследование», в г. Споры о звучности . Редакторы С. Паркер и А. Лахири (Берлин, Германия: De Gruyter Mouton), 101–166.
Google Scholar
Пинкер, С. (1989). Языковая обучаемость и познание: овладение структурой аргументации . Кембридж, Массачусетс: MIT Press.
Шлютер К., Политцер-Ахлес С., Аль Кааби М. и Алмейда Д. (2017). Признаки гортани фонетически абстрактны: несоответствие негативных свидетельств арабского, английского и русского языков. Перед. Психол. 8, 746. doi:10.3389/fpsyg.2017.00746
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Шмидт, Р. (1990). Роль сознания в изучении второго языка. Заяв. Лингвистика 11, 129–158. doi:10.1093/applin/11.2.129
Полный текст CrossRef | Google Scholar
Шварц М. и Гоуд Х. (2017). Косвенное положительное свидетельство в приобретении грамматики подмножества. Ланг. Комплектация 24 (3), 234–264. doi:10.1080/10489223.2016.1187616
CrossRef Полный текст | Google Scholar
Тессье, А. М., Соренсон Дункан, Т., и Паради, Дж. (2013). Тенденции развития и эффекты L1 у учащихся раннего L2 начинают производство кластеров. Двуязычие: яз. Познан. 16 (3). doi:10.1017/s1366728048x
CrossRef Full Text | Google Scholar
Трофимович П. и Бейкер В. (2006). Изучение надсегментов второго языка: влияние опыта L2 на просодию и характеристики беглости речи L2. Шпилька. Второй Ланг. Комплектация 28 (1), 1–30. doi:10.1017/s0272263106060013
CrossRef Full Text | Google Scholar
Траскотт, Дж., и Шарвуд Смит, М. (2004). Приобретение путем обработки: модульный взгляд на развитие языка. Двуязычие: яз. Познан. 7 (1), 1–20. doi:10.1017/s1366728
1178
CrossRef Full Text | Google Scholar
Ван Ю., Джонгман А. и Серено Дж. (2003). Акустическая и перцептивная оценка производства тонов китайского языка до и после перцептивной тренировки. J. Акустический. соц. Являюсь. 113, 1033. doi:10.1121/1.1531176
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Векслер К. и Куликовер П. (1980). Формальные принципы овладения языком . Кембридж, Массачусетс: MIT Press.
Уайт, Л. (1991). Размещение наречий при овладении вторым языком: некоторые эффекты положительных и отрицательных доказательств в классе. Второй язык. Рез. 7, 133–161. doi:10.1177/0267658300205
CrossRef Full Text | Google Scholar
Уилсон, К., и Дэвидсон, Л. (2009). Байесовский анализ продукции неродного кластера. Проц. NELS 40.
Google Scholar
Вульф С. и Эллис С. Н. (2018). «Подходы к изучению второго языка, основанные на использовании», в Двуязычное познание и язык: состояние науки в его подобластях . Редакторы Д. Т. Миллер, Ф. Байрам, Дж. Ротман и Л. Серратрис (Амстердам, Нидерланды: John Benjamins Publishing), 37–56.
Полнотекстовая перекрестная ссылка | Google Scholar
Янг-Шолтен, М. (1994). О положительном свидетельстве и окончательном достижении фонологии L2. Второй язык. Рез. 10, 193–214. doi:10.1177/026765839401000302
CrossRef Full Text | Google Scholar
Янг-Шолтен, М.