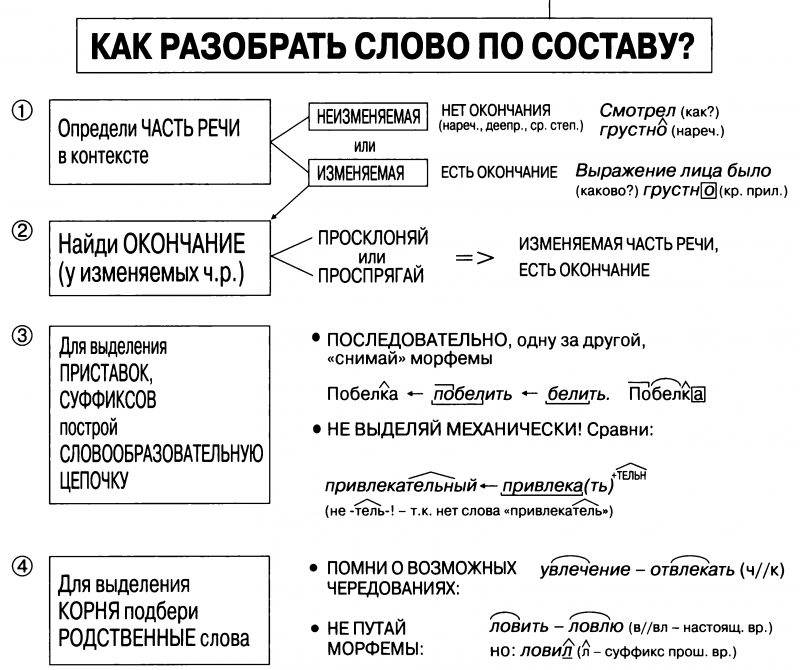
Страница не найдена
wordmap
Данная страница не найдена или была удалена.
Только что искали:
гаи 4 секунды назад
фкаел 7 секунд назад
адовая 18 секунд назад
ивутина 21 секунда назад
бесконечный 28 секунд назад
адсорбционный насос 28 секунд назад
блюдим 33 секунды назад
книга 34 секунды назад
крышки 35 секунд назад
плеоно 37 секунд назад
ратрикт 45 секунд назад
в состоянии нервного срыва 47 секунд назад
разглядеть противника 51 секунда назад
побрести к фонтану 53 секунды назад
буяоли 54 секунды назад
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Откуда | |
|---|---|---|---|---|
| Игрок 1 | неготовность | 5 слов | 176.59.8.171 | |
| Игрок 2 | семимесячная | 11 слов | 176. 59.145.123 59.145.123 |
|
| Игрок 3 | шевингование | 10 слов | 176.59.145.123 | |
| Игрок 4 | холодильник | 10 слов | 217.107.106.15 | |
| Игрок 5 | книга | 0 слов | 217.107.106.15 | |
| Игрок 6 | перешнуровка | 0 слов | 178.121.171.215 | |
| Игрок 7 | кулебяка | 27 слов | 95.29.167.54 | |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | эссеист | 28:33 | 176.59.211.187 | |
| Игрок 2 | годовик | 111:111 | 176. 59.211.187 59.211.187 |
|
| Игрок 3 | казан | 53:49 | 176.98.51.142 | |
| Игрок 4 | кащей | 44:45 | 176.98.51.142 | |
| Игрок 5 | бурре | 50:54 | 176.98.51.142 | |
| Игрок 6 | пятак | 40:43 | 176.59.111.151 | |
| В | канавка | 45:45 | 94.139.134.101 | |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| Про | На одного | 20 вопросов | 195.19.127.83 | |
| София | На одного | 20 вопросов | 95.165.30.129 | |
| Даня | На одного | 10 вопросов | 5. 3.244.115 3.244.115 |
|
| Даня | На одного | 20 вопросов | 5.3.244.115 | |
| Рири | На двоих | 10 вопросов | 88.78.159.61 | |
| Ляйсян | На одного | 10 вопросов | 145.255.9.219 | |
| Ляйсян | На одного | 10 вопросов | 145.255.9.219 | |
| Играть в Чепуху! | ||||
Контрольный диктант в 9 классе № 1 | Сборник диктантов по Русскому языку в 9 классе с русским языком обучения
Цель: проверить соответствие знаний, умений и навыков учащихся требованиям государственного стандарта и программы по русскому языку.
Содержание контрольного диктанта направлено на выявление качества усвоения учебного материала за 8-й класс и направлено на повторение предыдущего:
— правописание проверяемых безударных гласных;
— правописание непроверяемых безударных гласных;
— правописание окончаний прилагательных и причастий;
— написание не с наречиями и глаголами;
-правильное написание наречий;
— написание н-нн в прилагательных и наречиях;
— дефисное написание
местоимений и наречий.
Знаки препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении;
— запятые при причастном и деепричастном обороте.
— запятые при уточнении и вводных словах.
Грамматические задания направлены на выявления умений:
1. Фонетического разбора;
2. разбора по составу;
3. синтаксического разбора предложения;
4.работа по схеме.
Незнакомая усадьба
Однажды, возвращаясь
домой, я нечаянно
забрёл в какую-то
незнакомую усадьбу. Солнце
уже пряталось, и на цветущей
ржи растянулись вечерние
тени. Два ряда старых,
тесно посаженных елей
стояли, образуя красивую
аллею. Я перелез
через изгородь и
пошёл по ней,
скользя по еловым
иглам. Было тихо и
темно, и только
на вершинах кое-где
дрожал яркий золотой
свет и переливался
радугой в сетях
паука. Я повернул на
длинную липовую аллею.
Грамматические задания.
1. Сделать фонетический разбор слова:
Солнце (1-й вариант) Старая (1-й вариант)
2. Разобрать слова по составу:
Посаженных, растянулись (1-й вариант) заходившее, переливался (2-й вариант)
3. Из текста диктанта
выписать по одному
словосочетанию на все
виды подчинительной связи.
4. Выписать из текста по 3 слова:
1-й вариант: прилагательные, указать разряд
2-й вариант: причастия, указать время
5. Сделать синтаксический разбор предложения:
Однажды, возвращаясь домой, я нечаянно забрёл в какую-то незнакомую усадьбу.
(1-й вариант)
Два ряда старых, тесно посаженных елей стояли, образуя красивую аллею. (2-й вариант)
6. Выписать из диктанта предложения по схеме:
1-й вариант: [ ], и [ ]. 2-й вариант: [ __O и O, |-.-.-.-.| ].
CSE230 Wi15 — монадический анализ
CSE230 Wi15 — монадический анализHome оценка Лекции Задания Ссылки Пьяцца
> {-@ ЖИДКОСТЬ "--без завершения" @-}
> {-@ LIQUID "--short-names" @-}
>
> {-# ЯЗЫК LambdaCase #-}
> импортировать Data.Char
> импортировать Data.Functor
> импортировать Control.Monad Прежде чем мы продолжим, слово от наших спонсоров:
**Не бойтесь монад**
Это просто (чрезвычайно универсальная) абстракция, как карта или сложите .
Что такое парсер?
Анализатор — это часть программного обеспечения, которая принимает необработанную строку (или последовательность байтов) и возвращает некоторый структурированный объект, например, список опций, дерево XML или объект JSON, абстрактное синтаксическое дерево программы и т. д. . Синтаксический анализ является одной из самых основных вычислительных задач. Каждая серьезная программная система имеет парсер, спрятанный где-то внутри, например
Системный анализ
----------------------------- ----------------
Параметры командной строки сценариев оболочки
Браузеры HTML
Дескрипторы уровня игр
Пакеты маршрутизаторов (Действительно, я бросаю вам вызов, чтобы найти какую-либо серьезную систему, в которой не где-то занимается разбором!)
Самый простой и точный способ представить синтаксический анализатор как функцию
тип Parser = String -> StructuredObject
Составление парсеров
Обычный способ создания синтаксического анализатора заключается в указании грамматики и использовании генератора синтаксического анализа (например, yacc, bison, antlr) для создания фактической функции синтаксического анализа. Несмотря на элегантность, одним из основных ограничений подхода, основанного на грамматике, является отсутствие модульности. Например, предположим, что у меня есть два вида примитивных значений
Несмотря на элегантность, одним из основных ограничений подхода, основанного на грамматике, является отсутствие модульности. Например, предположим, что у меня есть два вида примитивных значений Thingy и Whatsit .
Вещь: правило { действие }
;
Что: правило { действие }
; Если вам нужен синтаксический анализатор для последовательностей Thingy и Whatsit , мы должны тщательно продублировать правила как
Штучки : Штучки { ... }
Пустая вещь { ... }
;
Whatsits : Whatsit Whatsits { ... }
ПустоЧто { ... }
; Это затрудняет повторное использование подпарсеров. Далее мы увидим, как составить мини-парсера для подзначений, чтобы получить большие парсеры для сложных значений.
Для этого мы немного обобщим приведенный выше тип синтаксического анализатора, отметив, что (суб-)парсеру не нужно (действительно, не будет) потреблять все его входных данных, и поэтому мы можем просто иметь синтаксический анализатор вернуть неиспользованный ввод
тип Parser = String -> (StructuredObject, String)
Конечно, было бы глупо иметь разные типы парсеров для разных типов объектов, поэтому мы можем сделать его параметризованным типом
тип Parser a = String -> (a, String)
Последнее обобщение: синтаксический анализатор может возвращать несколько результатов, например, мы можем захотеть проанализировать строку
.
"2 - 3 - 4"
либо как
Минус (Минус 2 3) 4
или как
Минус 2 (Минус 3 4)
Таким образом, мы можем заставить наши синтаксические анализаторы возвращать список возможных результатов (где пустой список соответствует сбою синтаксического анализа.)
> Парсер нового типа a = P (String -> [(a, String)])
Вышеупомянутое просто синтаксический анализатор ( кашель действие) фактический синтаксический анализ выполняется
> doParse (P p) s = p s
Давайте создадим несколько парсеров!
ВИКТОРИНА
Отзыв
Парсер нового типа a = P (String -> [(a, String)])
Что из следующего является допустимым односимвольным синтаксическим анализатором, который возвращает first Char из строки (если она существует.)
-- а
oneChar = P $ \cs -> голова cs
-- б
oneChar = P $ \case -> {[] -> [('', []) | с: кс -> (с, кс)}
-- с
oneChar = P $ \cs -> (голова cs, хвост cs)
-- д
oneChar = P $ \cs -> [(голова cs, хвост cs)]
-- е
oneChar = P $ \case -> { [] -> [] | cs -> [(голова cs, хвост cs)]} Да, можем!
> oneChar :: Parser Char > oneChar = P (\cs -> case cs of > c:cs' -> [(c, cs')] > _ -> [])
Запускаем анализатор
ghci> doParse oneChar "эй!"
[('Привет!")]
ghci> doParse oneChar ""
[] Теперь мы можем написать другой синтаксический анализатор, который захватывает пару из значений Char
twoChar :: Парсер (Char, Char) twoChar = P (\cs ->case cs of c1:c2:cs' -> [((c1, c2), cs')] _ -> [])
Запускаем анализатор
ghci> doParse twoChar "эй!"
[(('Привет!")]
ghci> doParse twoChar "h"
[] Парсер Состав
ВИКТОРИНА
Отзыв
twoChar :: Парсер (Char, Char)
twoChar = P (\cs -> case cs of
c1:c2:cs' -> [((c1, c2), cs')]
_ -> []) Предположим, у нас есть некоторые foo такие, что ведет себя идентично twoChar .
twoChar' = foo oneChar oneChar
Каким должен быть тип foo ?
-
Парсер (Char, Char) -
Parser Char -> Parser (Char, Char) -
Парсер а -> Парсер а -> Парсер (а, а) -
Парсер a -> Парсер b -> Парсер (a, b) -
Парсер а -> Парсер (а, а)
Действительно, foo — это комбинатор синтаксических анализаторов , который принимает два синтаксических анализатора и возвращает новый синтаксический анализатор, который возвращает пару значений:
парыP :: Парсер a -> Парсер b -> Парсер (a, b)
параP p1 p2 = P (\cs ->
[((х, у), cs'') | (x, cs' ) <- doParse p1 cs,
(y, cs'') <- doParse p2 cs']
) Теперь мы можем более аккуратно написать:
> twoChar = параP oneChar oneChar
который будет работать так
ghci> doParse twoChar "эй!"
[(('ч','е'), "у!")] УПРАЖНЕНИЕ: Можете ли вы объяснить, почему мы получаем следующее поведение?
ghci> doParse twoChar "h" []
Теперь мы могли бы продолжать это делать, но часто, чтобы двигаться вперед, полезно сделать шаг назад и взглянуть на более широкую картину.
Вот тип парсера
Парсер нового типа a = P (String -> [(a, String)])
это должно напоминать тебе о чем-то другом, помнишь это?
тип ST a = S (состояние -> (a, состояние))
(барабанная дробь…)
Парсер — это монада
Действительно, синтаксический анализатор, как и преобразователь состояний, является монадой! если правильно прищуриться.
Нам нужно определить функции return и >>= .
Связывание немного сложное, но мы только что видели это выше!
:тип bindP bindP :: Парсер a -> (a -> Парсер b) -> Парсер b
, поэтому нам нужно высосать значения и из первого синтаксического анализатора и вызвать второй синтаксический анализатор с ними для оставшейся части строки.
ВИКТОРИНА
Отзыв
doParse :: Parser a -> String -> [(a, String)] doParse (P p) ул = p ул
Рассмотрим функцию bindP :
bindP :: Парсер a -> (a -> Парсер b) -> Парсер b
bindP p1 fp2 = P $ \cs -> [(y, cs'') | (x, cs') <- не определено -- 1
, (y, cs'') <- не определено -- 2
] Что мы должны заполнить для двух неопределенных , чтобы получить код для проверки типов?
-
p1 csиfp2 x cs -
doParse p1 csиdoParse (fp2 x) cs' -
p1 csиfp2 x cs' -
doParse p1 csиdoParse (fp2 x) cs -
doParse p1 csиdoParse fp2 x cs
Действительно, мы можем определить функцию bindP для Parser как:
> bindP p1 fp2 = P $ \cs -> [(y, cs'') | (x, cs') <- doParse p1 cs > , (y, cs'') <- doParse (fp2 x) cs']
Посмотрите, как мы вытягиваем значения a из первого синтаксического анализатора (запустив doParse ) и вызываем второй синтаксический анализатор для каждого возможного a (и оставшейся строки), чтобы получить окончательные b и оставшиеся строковые кортежи. .
.
Возврат очень прост, мы можем позволить типам вести нас
: тип returnP returnP::a -> Парсер a
, что означает, что мы должны игнорировать входную строку и просто вернуть элемент ввода
> returnP x = P (\cs -> [(x, cs)])
Вооружившись ими, мы можем официально называть парсеры монадами
> экземпляр Monad Parser, где > (>>=) = привязкаP > возврат = возвратP
Это сделает вещи по-настоящему сладкими…
Комбинаторы парсеров
Поскольку синтаксические анализаторы являются монадами, мы можем написать кучу высокоуровневых комбинаторов для составления более мелких синтаксических анализаторов в более крупные.
Например, мы можем использовать нашу любимую сделать нотацию , чтобы переписать паруP как
> параP :: Парсер a -> Парсер b -> Парсер (a, b) > параP px py = do x <- px > у <- ру > вернуть (х, у)
поразительно, точно так же, как пар функция отсюда.
Теперь давайте разомнем наши монадические мускулы и напишем несколько новых парсеров. Будет полезно иметь синтаксический анализатор сбоя , который всегда сгорает, то есть возвращает [] – нет успешных синтаксических анализов.
> сбойP = P $ const []
Кажется немного глупым писать вышеизложенное, но полезно создать более богатые синтаксические анализаторы, такие как следующие, которые анализируют Char , если удовлетворяет предикату p
> satP :: (Char -> Bool) -> Parser Char > satP p = do c <- oneChar > если p c, то вернуть c, иначе failP
мы можем написать несколько простых парсеров для конкретных символов
> нижний регистрP = satP isAsciiLower
ghci> doParse (satP ('h' ==)) "mugatu"
[]
ghci> doParse (satP ('h' ==)) "привет"
[('ч',"привет")] Следующий алфавит и числовые символы синтаксического анализа соответственно
> alphaChar = satP isAlpha > digitChar = satP isDigit
и этот малыш возвращает первую цифру строки как Int
> digitInt = do c <- digitChar > return ((читать [c]) :: Int)
который работает так
ghci> doParse digitInt "92" [(9,"2")] ghci> doParse digitInt "кошка" []
Наконец, этот синтаксический анализатор будет анализировать только определенный Char , переданный в качестве входных данных
> char c = satP (== c)
УПРАЖНЕНИЕ: Напишите функцию strP :: String -> Parser String такую, что strP s анализирует ровно строку s и ничего больше, то есть
ghci> dogeP = strP "дож"
ghci> doParse dogeP "догерель"
[("дож", "отн")]
ghci> doParse dogeP "собачье"
[] Комбинатор недетерминированного выбора
Теперь давайте напишем комбинатор, который берет два подпарсера и недетерминированно выбирает между ними.
ChooseP :: Парсер a -> Парсер a -> Парсер a
То есть мы хотим, чтобы ChooseP p1 p2 возвращал успешный анализ, если либо p1 , либо p2 завершаются успешно.
Мы можем использовать ChooseP для создания синтаксического анализатора, который возвращает либо алфавит, либо числовой символ
> alphaNumChar = alphaChar `выберитеP` digitChar
После определения вышеуказанного мы должны получить что-то вроде:
ghci> doParse alphaNumChar "кошка"
[('кошка")]
ghci> doParse alphaNumChar "2cat"
[('2', "кошка")]
ghci> doParse alphaNumChar "230"
[('2', "30")] ВИКТОРИНА
Как бы мы закодировали выбор в наших парсерах?
-- а
p1 `выбрать P` p2 = сделать xs <- p1
да <- р2
возврат (х1++х2)
-- б
p1 `выбрать P` p2 = сделать xs <- p1
случай xs из
[] -> п2
_ -> вернуть хз
-- с
p1 `chooseP` p2 = P $ \cs -> doParse p1 cs ++ doParse p2 cs
-- д
p1 `chooseP` p2 = P $ \cs -> case doParse p1 cs из
[] -> doParse p2 cs
рс -> рс > > ChooseP :: Парсер a -> Парсер a -> Парсер a > p1 `chooseP` p2 = P (\cs -> doParse p1 cs ++ doParse p2 cs)
Таким образом, еще приятнее то, что если оба парсера завершатся успешно, вы получите все результаты.
Вот синтаксический анализатор, который берет n символов из ввода
> грабить :: Int -> Строка парсера > схватил н > | п <= 0 = вернуть "" > | иначе = do c <- oneChar > cs <- грабн (n-1) > вернуть (с:с)
ДЕЛАТЬ В КЛАССЕ Как бы вы уничтожили неприятную рекурсию из захваченного ?
ВИКТОРИНА
Давайте теперь используем наш комбинатор выбора, чтобы определить:
> foo = захватить 2 `выбратьP` захватить 4
Что оценивает следующее?
ghci> doParse foo "миккимаус"
-
[] -
[("ми","ckeymouse")] -
[("мик","эймаус")] -
[("ми","ckeymouse"),("мик","eymouse")] -
[("мик","эймаус"), ("ми","скеймаус")]
и только один результат, если это возможно
ghci> doParse grab2or4 "микрофон"
[("ми","с")]
ghci> doParse захватить2или4 "м"
[] Даже имея в своем распоряжении рудиментарные синтаксические анализаторы, мы можем начать делать некоторые довольно интересные вещи. Например, вот небольшой калькулятор. Сначала разбираем операцию
Например, вот небольшой калькулятор. Сначала разбираем операцию
> intOp = плюс `chooseP` минус `chooseP` умножить на `chooseP` разделить > где > плюс = символ '+' >> возврат (+) > минус = символ '-' >> возврат (-) > раз = символ '*' >> возврат (*) > разделить = символ '/' >> вернуть дел.
ДЕЛАТЬ В КЛАССЕ Можете ли вы угадать тип приведенного выше синтаксического анализатора?
Далее мы можем разобрать выражение
> вычислить = сделать х <- digitInt > op <- intOp > у <- digitInt > вернуть $ x `op` y
, который при запуске будет анализировать и вычислять
ghci> doParse вычислить "8/2" [(4,"")] ghci> doParse вычислить "8+2cat" [(10,"кошка")] ghci> doParse вычислить "8/2cat" [(4,"кошка")] ghci> doParse вычислить "8-2cat" [(6,"кошка")] ghci> doParse вычислить "8*2cat" [(16,"кошка")]
ВИКТОРИНА
Что возвращает следующее:
ghci> doParse вычислить "99 бутылок"
- Ошибка типа
-
[] -
[(9, "9 бутылок")] -
[(99, "бутылки")] - Исключение во время выполнения
Рекурсивный анализ
Чтобы начать парсить интересные вещи, нам нужно добавить рекурсию в наши комбинаторы. Например, очень хорошо разбирать отдельные символы (как в
Например, очень хорошо разбирать отдельные символы (как в char выше), но было бы намного больше, если бы мы могли получить определенные токены String .
Попробуем написать!
строка :: Строка -> Строка парсера
строка "" = возврат ""
строка (c:cs) = do char c
строка cs
возврат (к: кс) ДЕЛАТЬ В КЛАССЕ Фу-у-у! Это явная рекурсия?! Давайте попробуем еще раз (можете найти закономерность)
> строка :: строка -> строка синтаксического анализатора > string = undefined -- заполните это
Гораздо лучше!
ghci> doParse (строка "микрофон") "mickeyMouse"
[("Микки Маус")]
ghci> doParse (строка "микрофон") "дональд дак"
[] Хорошо, я думаю, тогда это было не совсем рекурсивно!
Давайте попробуем еще раз.
Давайте напишем комбинатор, который принимает синтаксический анализатор p , который возвращает и , и возвращает синтаксический анализатор, который возвращает много значений и . То есть он продолжает захватывать как можно больше значений
То есть он продолжает захватывать как можно больше значений и и возвращает их как 9.0011 [а] .
> manyP :: Парсер a -> Парсер [a] > многоP p = много1 `выбратьP` много0 > где > много0 = вернуть [] > many1 = сделать x <- p > xs <- многоP p > вернуть (x:xs)
Но будьте осторожны! Вышеприведенное может дать много результатов
ghci> doParse (manyP digitInt) "123a" [([], "123а"), ([1], "23а"), ([1, 2], "3а"), ([1, 2, 3], "а")]
, который просто представляет собой все возможные способы извлечения последовательностей целых чисел из входной строки.
Детерминированный максимальный анализ
Часто нам нужен один результат, а не набор результатов. Например, более интуитивным поведением многих будет возврат максимальной последовательности элементов, а не всех префиксов.
Для этого нам понадобится детерминированный комбинатор выбора
> (<|>) :: Парсер а -> Парсер а -> Парсер а > p1 <|> p2 = P $ \cs -> case doParse (p1 `выбрать P` p2) cs из > [] -> [] > х:_ -> [х]
Приведенный выше синтаксический анализатор запускает выбор, но возвращает только первый результат. Теперь мы можем вернуться к комбинатору
Теперь мы можем вернуться к комбинатору manyP и убедиться, что он возвращает одну максимальную последовательность
> mmanyP :: Парсер a -> Парсер [a] > mmanyP p = mmany1 <|> mmany0 > где > mmany0 = вернуть [] > mmany1 = сделать x <- p > xs <- mmanyP p > вернуть (x:xs)
ДЕЛАТЬ В КЛАССЕ Минуточку! В чем именно разница между вышеуказанным и оригинальным многоP ? Как это объяснить:
ghci> doParse (manyP digitInt) "123a" [([1,2,3],"а"),([1,2],"3а"),([1],"23а"),([],"123а")] ghci> doParse (mmanyP digitInt) "123a" [([1,2,3],"а")]
Давайте воспользуемся этим, чтобы написать синтаксический анализатор, который будет возвращать целое число (а не только одну цифру).
oneInt :: Целое число парсера
oneInt = do xs <- mmanyP digitChar
return $ ((читать xs) :: Целое число) Помимо , можете ли вы найти шаблон выше? Взяли парсер mmanyP digitChar и просто преобразовал его вывод, используя функцию чтения . Это повторяющаяся тема, и тип того, что мы сделали, дает нам подсказку
Это повторяющаяся тема, и тип того, что мы сделали, дает нам подсказку
(a -> b) -> парсер a -> парсер b
Ага! очень похоже на карту . Действительно, существует обобщенная версия map , которую мы видели ранее ( lift1 ), и мы ограничиваем шаблон, объявляя Parser экземпляром Functor класса типов 9.0003
> экземпляр Functor Parser, где > fmap f p = do x <- p > возврат (ф х)
после чего мы можем переписать
> oneInt :: Parser Int > oneInt = прочитать `fmap` mmanyP digitChar
Давай попробуем
ghci> doParse oneInt "123a" [(123, "а")]
Разбор арифметических выражений
Давайте воспользуемся вышеизложенным для создания небольшого калькулятора, который анализирует и вычисляет арифметические выражения. По сути, выражение представляет собой либо двоичный операнд, применяемый к двум подвыражениям, либо целое число. Мы можем сформулировать это как
> calc0 :: Parser Int > calc0 = binExp <|> oneInt > где > binExp = do x <- oneInt > о <- intOp > у <- расч0 > вернуть $ x `o` y
Это работает очень хорошо!
ghci> doParse calc0 "1+2+33" [(36,"")] ghci> doParse calc0 "11+22-33" [(0,"")]
, но с минусом
все становится немного странно.
ghci> doParse calc0 "11+22-33+45" [(-45,"")]
А? Что ж, если вы снова посмотрите на код, вы поймете, что приведенное выше было проанализировано как
.11 + ( 22 - (33 + 45))
, потому что в каждом binExp мы требуем, чтобы левый операнд был целым числом. Другими словами, мы предполагаем, что каждый оператор является правой ассоциативностью , отсюда и полученный выше результат.
Интересно, можем ли мы попытаться это исправить, просто перевернув заказ
> calc1 :: Parser Int > calc1 = binExp <|> oneInt > где > binExp = do x <- calc1 > о <- intOp > y <- oneInt > вернуть $ x `o` y
ВИКТОРИНА
Что оценивает следующее?
ghci> doParse calc1 "11+22-33+45"
-
[( 11 , "+22-33+45")] -
[( 33 , "-33+45")] -
[( 0, "+45")] -
[( 45 , "")] - Ничего из вышеперечисленного
Действительно, здесь есть ошибка… Вы можете это понять?
Подсказка: что вернет следующее?
ghci> doParse calc1 "2+2"
Хуже того, у нас нет приоритета, и поэтому
ghci> doParse calc0 "10*2+100" [(1020,"")]
, так как строка анализируется как
10*(2+100)
Приоритет
Мы можем добавить как ассоциативность, так и приоритет, разделив синтаксический анализатор на разные уровни. Здесь давайте разделим наши операции на сложение-
Здесь давайте разделим наши операции на сложение-
> addOp = плюс `выберите P` минус > где > плюс = символ '+' >> возврат (+) > минус = символ '-' >> возврат (-)
и приоритет умножения.
> mulOp = деление на `chooseP` > где > раз = символ '*' >> возврат (*) > разделить = символ '/' >> вернуть div
Теперь мы можем разделить наш язык на (взаимно рекурсивные) подъязыки, где каждое выражение верхнего уровня анализируется как сумма произведений
> sumE = addE <|> prodE > где > addE = сделать x <- prodE > о <-допОп > у <- суммаE > вернуть $ x `o` y > > prodE = mulE <|> factorE > где > mulE = do x <- factorE > о <- mulOp > у <- prodE > вернуть $ x `o` y > > factorE = parenP sumE <|> oneInt
Мы можем запустить это
ghci> doParse sumE "10*2+100" [(120,"")] ghci> doParse sumE "10*(2+100)" [(1020,"")]
Вы понимаете, почему первый синтаксический анализ вернул 120 ? Что произойдет, если мы поменяем местами порядок prodE и sumE в теле addE (или factorE и prodE в теле prodE )? Почему?
ВИКТОРИНА
Напомним, что в приведенном выше
factorE :: Parser Int factorE = parenP sumE <|> oneInt
Какой тип parenP ?
-
Parser Int -
Парсер а -> Парсер а -
а -> парсер -
Парсер а -> -
Parser Int -> Parser a
Давайте напишем parenP
> parenP p = do char '('
> х <- р
> символ ')'
> возврат х Шаблон синтаксического анализа: Цепочка
Нет особого смысла злорадствовать по поводу комбинаторов, если мы собираемся писать код, подобный приведенному выше — корпуса sumE и prodE практически идентичны!
Давайте посмотрим на них поближе. В сущности,
В сущности, sumE имеет вид
prodE + < prodE + < prodE + ... < prodE >>>
, то есть мы продолжаем связывать вместе значения prodE и добавлять их столько, сколько сможем. Аналогично prodE имеет вид
фактор E * < фактор E * < фактор E * ... < фактор E >>>
, где мы продолжаем связывать значения factorE и умножать их столько, сколько сможем. В вышесказанном есть что-то неприятное: операторы сложения правоассоциативны
ghci> doParse sumE "10-1-1" [(10,"")]
Ух! Надеюсь, вы понимаете, почему: это потому, что приведенное выше было проанализировано как 10 - (1 - 1) (правоассоциативный), а не (10 - 1) - 1 (левоассоциативный). У вас может возникнуть соблазн исправить это, просто поменяв местами prodE и sumE
sumE = addE <|> prodE
куда
addE = сделать x <- sumE
о <- addOp
у <- prodE
вернуть $ x `o` y , но это было бы катастрофой. Вы видите, почему?
Вы видите, почему?
Парсер для sumE напрямую (рекурсивно) вызывает сам себя без каких-либо входных данных! Таким образом, он уходит в глубокий конец и никогда не возвращается. Вместо этого мы хотим убедиться, что мы продолжаем потреблять значения prodE и суммировать их (скорее, как складывать), и поэтому мы можем сделать
> sumE1 = prodE1 >>= addE1 > где > addE1 x = захватить x <|> вернуть x > захватить x = сделать о <- addOp > у <- prodE1 > addE1 $ x `o` y > > prodE1 = factorE1 >>= mulE1 > где > mulE1 x = захватить x <|> вернуть x > схватить x = сделать о <- mulOp > у <- факторE1 > mulE1 $ x `o` y > > factorE1 = parenP sumE1 <|> oneInt
Легко проверить, что приведенное выше действительно ассоциативно слева.
ghci> doParse sumE1 "10-1-1" [(8,"")]
, а также очень легко определить и заключить шаблон вычисления цепочки: единственными отличиями являются парсер base ( prodE1 vs factorE1 ) и бинарная операция ( addOp vs mulOp ). Мы просто вносим эти параметры в наш комбинатор
Мы просто вносим эти параметры в наш комбинатор
> p `chainl` pop = p >>= rest > где > отдых x = захватить x <|> вернуть x > схватить x = сделать о <- поп > у <- р > отдых $ x `o` y
после чего мы можем переписать грамматику в три строки
> sumE2 = prodE2 `chainl` addOp > prodE2 = factorE2 `chainl` mulOp > factorE2 = parenP sumE2 <|> oneInt
ghci> doParse sumE2 "10-1-1" [(8,"")] ghci> doParse sumE2 "10*2+1" [(21,"")] ghci> doParse sumE2 "10+2*1" [(12,"")]
На этом мы завершаем наше изучение монадического разбора в классе. Это всего лишь верхушка айсберга. Хотя синтаксический анализ — очень старая проблема, и ее изучали на заре вычислительной техники, мы увидели, как монады привносят свежий взгляд, который недавно был перенесен из Haskell во многие другие языки. Недавно было опубликовано несколько захватывающих статей на эту тему, которые вы можете изучить самостоятельно. Наконец, Haskell поставляется с несколькими библиотеками комбинаторов синтаксических анализаторов, включая Parsec, с которым вы поэкспериментируете в HW2.
λ >
возвратов · PyPI
Сделайте так, чтобы ваши функции возвращали что-то осмысленное, типизированное и безопасное!
Возможности
- Привносит функциональное программирование в мир Python
- Предоставляет набор примитивов для написания декларативной бизнес-логики
- Обеспечивает лучшую архитектуру
- Полностью напечатано с аннотациями и проверено с помощью
mypy, совместимо с PEP561 - Добавляет поддержку эмулируемых типов высшего порядка
- Обеспечивает типобезопасные интерфейсы для создания собственных типов данных с применением законов
- Имеет кучу помощников для лучшей композиции
- Pythonic и приятно писать и читать 🐍
- Функции поддержки и сопрограммы, не зависящие от фреймворка
- Легко начать: содержит множество документов, тестов и учебных пособий
Быстрый старт прямо сейчас!
Установка
pip install возвращает
Также необходимо настроить mypy правильно и устанавливаем наш плагин
чтобы исправить эту существующую проблему:
# В setup. cfg или mypy.ini:
[mypy]
плагины =
возвращает.contrib.mypy.returns_plugin
cfg или mypy.ini:
[mypy]
плагины =
возвращает.contrib.mypy.returns_plugin
 cfg или mypy.ini:
[mypy]
плагины =
возвращает.contrib.mypy.returns_plugin
cfg или mypy.ini:
[mypy]
плагины =
возвращает.contrib.mypy.returns_plugin
Мы также рекомендуем использовать те же настройки mypy , которые мы используем.
Убедитесь, что вы знаете, как начать работу, ознакомьтесь с нашей документацией! Попробуйте нашу демоверсию.
Содержимое
- Возможно, контейнер, позволяющий писать
Нет-бесплатный код - Контейнер RequiresContext, который позволяет использовать внедрение типизированной функциональной зависимости
- Контейнер результатов, позволяющий избавиться от исключений
- Контейнер ввода-вывода и IOResult, который отмечает все нечистые операции и структурирует их
- Контейнер Future и FutureResult для работы с
asynccode - Напиши свой собственный контейнер! У вас по-прежнему будут все функции для ваших собственных типов (включая полное повторное использование существующего кода и безопасность типов)
Возможно контейнер
Нет называют самой большой ошибкой в истории информатики.
Итак, что мы можем сделать, чтобы проверить наличие None в наших программах?
Вы можете использовать встроенный необязательный тип
и напишите много если какое-то нет None: условий.
Но с нулевыми проверками здесь и там делает ваш код нечитаемым .
пользователь: Необязательно[Пользователь]
Discount_program: Необязательно['DiscountProgram'] = Нет
если пользователь не None:
баланс = user.get_balance()
если баланс не None:
кредит = баланс.credit_amount()
если кредит не None и кредит > 0:
Discount_program = выберите_скидку (кредит)
Или вы можете использовать
Может контейнер!
Он состоит из типов Some и Nothing ,
представляющие существующее состояние и пустое (вместо None ) состояние соответственно.
от ввода импорта Необязательно
из return.maybe импорт
@maybe # декоратор для преобразования существующего Optional[int] в Maybe[int]
def bad_function() -> Дополнительно[int]:
. ..
возможно_число: Возможно[плавающая] = плохая_функция().bind_Optional(
лямбда число: число / 2,
)
# => Maybe вернет Some[float], только если есть значение, отличное от None
# В противном случае ничего не вернется
 ..
возможно_число: Возможно[плавающая] = плохая_функция().bind_Optional(
лямбда число: число / 2,
)
# => Maybe вернет Some[float], только если есть значение, отличное от None
# В противном случае ничего не вернется
..
возможно_число: Возможно[плавающая] = плохая_функция().bind_Optional(
лямбда число: число / 2,
)
# => Maybe вернет Some[float], только если есть значение, отличное от None
# В противном случае ничего не вернется
Вы можете быть уверены, что метод .bind_Optional() не будет вызываться для Ничего .
Забудьте об ошибках, связанных с None , навсегда!
Мы также можем привязать Необязательную функцию возврата к контейнеру.
Для этого мы будем использовать метод .bind_Optional .
И вот как будет выглядеть ваш первоначальный рефакторинговый код:
пользователь: Необязательный[Пользователь]
# Подсказка здесь необязательна, она только помогает читателю:
Discount_program: Возможно['DiscountProgram'] = Возможно.from_необязательно(
пользователь,
).bind_Optional( # Это не будет вызываться, если `user is None`
лямбда реальный_пользователь: real_user.get_balance(),
).bind_Optional( # Это не будет вызываться, если `real_user. get_balance()` равно None
лямбда-баланс: balance.credit_amount(),
).bind_Optional( # И так далее!
лямбда-кредит: Choose_discount(кредит), если кредит> 0 иначе нет,
)
 get_balance()` равно None
лямбда-баланс: balance.credit_amount(),
).bind_Optional( # И так далее!
лямбда-кредит: Choose_discount(кредит), если кредит> 0 иначе нет,
)
get_balance()` равно None
лямбда-баланс: balance.credit_amount(),
).bind_Optional( # И так далее!
лямбда-кредит: Choose_discount(кредит), если кредит> 0 иначе нет,
)
Гораздо лучше, не правда ли?
Контейнер RequiresContext
Многие разработчики используют некоторые виды внедрения зависимостей в Python. И обычно это основано на идее что есть какой-то контейнер и процесс сборки.
Функциональный подход намного проще!
Представьте, что у вас есть игра на основе django , где вы начисляете пользователям очки за каждую угаданную букву в слове (неугаданные буквы помечаются как '.' ):
из django.http импорт HttpRequest, HttpResponse
из words_app.logic импорта calculate_points
представление защиты (запрос: HttpRequest) -> HttpResponse:
user_word: str = request.POST['word'] # просто пример
баллы = calculate_points (пользовательское_слово)
... # позже вы каким-то образом показываете результат пользователю
# Где-то в вашем `words_app/logic. py`:
def calculate_points (word: str) -> int:
угаданный_letters_count = len([буква вместо буквы в слове, если буква != '.'])
вернуть _award_points_for_letters (угаданное_число_букв)
def _award_points_for_letters (предположительно: int) -> int:
вернуть 0, если угадано < 5, иначе угадано # возможно минимум 6 баллов!
 py`:
def calculate_points (word: str) -> int:
угаданный_letters_count = len([буква вместо буквы в слове, если буква != '.'])
вернуть _award_points_for_letters (угаданное_число_букв)
def _award_points_for_letters (предположительно: int) -> int:
вернуть 0, если угадано < 5, иначе угадано # возможно минимум 6 баллов!
py`:
def calculate_points (word: str) -> int:
угаданный_letters_count = len([буква вместо буквы в слове, если буква != '.'])
вернуть _award_points_for_letters (угаданное_число_букв)
def _award_points_for_letters (предположительно: int) -> int:
вернуть 0, если угадано < 5, иначе угадано # возможно минимум 6 баллов!
Отлично! Это работает, пользователи довольны, ваша логика чиста и удивительна. Но позже вы решаете сделать игру более увлекательной: давайте сделаем минимальный порог ответственных писем настраивается для дополнительной задачи.
Вы можете просто сделать это напрямую:
def _award_points_for_letters(угадано: int, threshold: int) -> int:
вернуть 0, если угадано < порога, иначе угадано
Проблема в том, что _award_points_for_letters глубоко вложены.
И тогда вы должны пройти порог через весь стек вызовов,
включая calculate_points и все другие функции, которые могут быть в пути. Все они должны будут принимать в качестве параметра
Все они должны будут принимать в качестве параметра порог !
Это совсем не полезно!
Большие кодовые базы будут сильно страдать от этого изменения.
Хорошо, вы можете напрямую использовать django.settings (или аналогичный)
в вашей функции _award_points_for_letters .
И разрушает вашу чистую логику специфическими для фреймворка деталями . Это некрасиво!
Или вы можете использовать контейнер RequiresContext . Посмотрим, как изменится наш код:
из настроек импорта django.conf
из django.http импортировать HttpRequest, HttpResponse
из words_app.logic импорта calculate_points
представление защиты (запрос: HttpRequest) -> HttpResponse:
user_word: str = request.POST['word'] # просто пример
points = calculate_points(user_words)(settings) # передача зависимостей
... # позже вы каким-то образом показываете результат пользователю
# Где-то в вашем `words_app/logic.py`:
из протокола импорта typing_extensions
из импорта return. context RequiresContext
class _Deps(Protocol): # мы полагаемся на абстракции, а не на прямые значения или типы
WORD_THRESHOLD: целое
def calculate_points(word: str) -> RequiresContext[int, _Deps]:
угаданный_letters_count = len([буква вместо буквы в слове, если буква != '.'])
вернуть _award_points_for_letters (угаданное_число_букв)
def _award_points_for_letters (предположительно: int) -> RequiresContext[int, _Deps]:
вернуть RequiresContext(
lambda deps: 0, если угадано, < deps.WORD_THRESHOLD, иначе угадано,
)
 context RequiresContext
class _Deps(Protocol): # мы полагаемся на абстракции, а не на прямые значения или типы
WORD_THRESHOLD: целое
def calculate_points(word: str) -> RequiresContext[int, _Deps]:
угаданный_letters_count = len([буква вместо буквы в слове, если буква != '.'])
вернуть _award_points_for_letters (угаданное_число_букв)
def _award_points_for_letters (предположительно: int) -> RequiresContext[int, _Deps]:
вернуть RequiresContext(
lambda deps: 0, если угадано, < deps.WORD_THRESHOLD, иначе угадано,
)
context RequiresContext
class _Deps(Protocol): # мы полагаемся на абстракции, а не на прямые значения или типы
WORD_THRESHOLD: целое
def calculate_points(word: str) -> RequiresContext[int, _Deps]:
угаданный_letters_count = len([буква вместо буквы в слове, если буква != '.'])
вернуть _award_points_for_letters (угаданное_число_букв)
def _award_points_for_letters (предположительно: int) -> RequiresContext[int, _Deps]:
вернуть RequiresContext(
lambda deps: 0, если угадано, < deps.WORD_THRESHOLD, иначе угадано,
)
И теперь вы можете передавать свои зависимости действительно прямым и явным образом.
И имейте тип-безопасность, чтобы проверить, что вы передаете, чтобы прикрыть спину.
Ознакомьтесь с документацией RequiresContext для получения дополнительной информации. Там вы узнаете, как сделать '.' также настраивается.
У нас также есть RequiresContextResult
для операций, связанных с контекстом, которые могут завершиться ошибкой. А также RequiresContextIOResult и RequiresContextFutureResult.
Контейнер результатов
Убедитесь, что вы также знаете Железнодорожное программирование.
Простой подход
Рассмотрим этот код, который вы можете найти в любом проекте Python .
запросов на импорт
def fetch_user_profile(user_id: int) -> 'UserProfile':
"""Выбирает профиль пользователя из внешнего API."""
ответ = запросы.get('/api/users/{0}'.format(user_id))
ответ.raise_for_status()
вернуть ответ.json()
Кажется законным, не так ли?
Это также кажется довольно простым кодом для тестирования.
Все, что вам нужно, это издеваться над request.get , чтобы вернуть нужную структуру.
Но в этом крошечном примере кода есть скрытые проблемы которые почти невозможно заметить с первого взгляда.
Скрытые проблемы
Взглянем на точно такой же код, но со всеми скрытыми проблемами объяснил.
запросов на импорт
def fetch_user_profile(user_id: int) -> 'UserProfile':
"""Выбирает профиль пользователя из внешнего API. """
ответ = запросы.get('/api/users/{0}'.format(user_id))
# Что если мы попытаемся найти несуществующего пользователя?
# Или сеть выйдет из строя? Или сервер вернет 500?
# В этом случае следующая строка завершится ошибкой с исключением.
# Нам нужно обработать все возможные ошибки в этой функции
# и не возвращать поврежденные данные потребителям.
ответ.raise_for_status()
# Что делать, если мы получили неверный JSON?
# Следующая строка вызовет исключение!
вернуть ответ.json()
 """
ответ = запросы.get('/api/users/{0}'.format(user_id))
# Что если мы попытаемся найти несуществующего пользователя?
# Или сеть выйдет из строя? Или сервер вернет 500?
# В этом случае следующая строка завершится ошибкой с исключением.
# Нам нужно обработать все возможные ошибки в этой функции
# и не возвращать поврежденные данные потребителям.
ответ.raise_for_status()
# Что делать, если мы получили неверный JSON?
# Следующая строка вызовет исключение!
вернуть ответ.json()
"""
ответ = запросы.get('/api/users/{0}'.format(user_id))
# Что если мы попытаемся найти несуществующего пользователя?
# Или сеть выйдет из строя? Или сервер вернет 500?
# В этом случае следующая строка завершится ошибкой с исключением.
# Нам нужно обработать все возможные ошибки в этой функции
# и не возвращать поврежденные данные потребителям.
ответ.raise_for_status()
# Что делать, если мы получили неверный JSON?
# Следующая строка вызовет исключение!
вернуть ответ.json()
Теперь все (возможно, все?) проблемы решены. Как мы можем быть уверены, что эта функция будет безопасной использовать внутри нашей сложной бизнес-логики?
Мы действительно не можем быть уверены!
Нам нужно будет создать лот из попробовать и кроме случаев
просто чтобы поймать ожидаемые исключения. Со всем этим бардаком наш код станет сложным и нечитаемым!
Или мы можем использовать верхний уровень , кроме Исключения: случай поймать буквально все.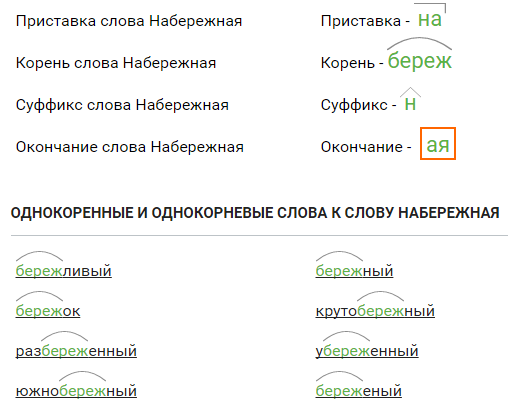 И таким образом мы закончим тем, что поймаем нежелательных.
Такой подход может надолго скрыть от нас серьезные проблемы.
И таким образом мы закончим тем, что поймаем нежелательных.
Такой подход может надолго скрыть от нас серьезные проблемы.
Пример трубы
запросы на импорт
from return.result import Результат, безопасный
из потока импорта return.pipeline
привязка импорта из return.pointfree
def fetch_user_profile(user_id: int) -> Результат['UserProfile', Exception]:
"""Выбирает `UserProfile` TypedDict из стороннего API."""
обратный поток(
Идентификатор пользователя,
_Сделать запрос,
привязать (_parse_json),
)
@Безопасно
def _make_request (user_id: int) -> запросы. Ответ:
# TODO: мы еще не закончили с этим примером, читайте больше о `IO`:
ответ = запросы.get('/api/users/{0}'.format(user_id))
ответ.raise_for_status()
вернуть ответ
@Безопасно
def _parse_json (ответ: запросы. Ответ) -> «Профиль пользователя»:
вернуть ответ.json()
Теперь у нас есть чистый, безопасный и декларативный способ чтобы выразить наши потребности бизнеса:
- Мы начинаем с запроса, который может не получиться в любой момент,
- Затем анализ ответа, если запрос был успешным,
- А затем вернуть результат.

Теперь вместо возврата обычных значений мы возвращаем значения, завернутые в специальный контейнер благодаря @Безопасно декоратор. Он вернет Success[YourType] или Failure[Exception]. И никогда не будет бросать нам исключение!
Мы также используем поток и связать функции для удобной и декларативной композиции.
Таким образом, мы можем быть уверены, что наш код не взломает случайные места из-за некоторого неявного исключения. Теперь мы контролируем все детали и готовы к явным ошибкам.
Мы еще не закончили с этим примером, давайте продолжим улучшать его в следующей главе.
IO-контейнер
Давайте посмотрим на наш пример под другим углом. Все его функции выглядят как обычные: невозможно сказать, чистые ли они или нечистым с первого взгляда.
Это приводит к очень важному следствию: мы начинаем смешивать чистый и нечистый код вместе . Мы не должны этого делать!
Когда эти два понятия смешаны
мы очень сильно страдаем при тестировании или повторном использовании. Почти все должно быть чистым по умолчанию.
И мы должны явно помечать нечистые части программы.
Почти все должно быть чистым по умолчанию.
И мы должны явно помечать нечистые части программы.
Вот почему мы создали контейнер IO чтобы пометить нечистые функции, которые никогда не выходят из строя.
Эти нечистые функции используют random , текущая дата и время, среда или консоль:
случайный импорт
импортировать дату и время как dt
из return.io импортировать IO
def get_random_number() -> IO[int]: # или используйте декоратор `@impure`
return IO(random.randint(1, 10)) # не является чистым, потому что случайный
сейчас: Callable[[], IO[dt.datetime]] = impure(dt.datetime.now)
@нечистый
def return_and_show_next_number (предыдущий: int) -> int:
следующий_номер = предыдущий + 1
print(next_number) # не является чистым, потому что IO
вернуть следующий_номер
Теперь мы ясно видим, какие функции чистые, а какие нечистые.
Это очень помогает нам в создании больших приложений, модульном тестировании вашего кода,
и совместное составление бизнес-логики.
Troublesome IO
Как уже было сказано, мы используем IO , когда обрабатываем функции, которые не дают сбоев.
Что, если наша функция может дать сбой и окажется нечистой?
Подобно request.get() у нас было ранее в нашем примере.
Тогда мы должны использовать специальный IOResult 9Тип 0012 вместо обычного Результат .
Давайте найдем разницу:
- Наша функция
_parse_jsonвсегда возвращает тот же результат (надеюсь) для того же ввода: вы можете либо проанализировать действительныйjson, либо потерпеть неудачу на недопустимом. Вот почему мы возвращаем чистыйResult, внутри нет - Наша функция
_make_requestнечиста и может дать сбой. Попробуйте отправить два одинаковых запроса с подключением к Интернету и без него. Результат будет другим для одного и того же ввода. Вот почему мы должны использоватьIOResultздесь: он может выйти из строя и имеетIO
IO Итак, чтобы выполнить наше требование и отделить чистый код от нечистого,
мы должны реорганизовать наш пример.
Явный ввод-вывод
Давайте сделаем наш ввод-вывод явный!
запросов на импорт
из return.io импортировать IOResult, impure_safe
из return.result безопасно импортировать
из потока импорта return.pipeline
из return.pointfree импортировать bind_result
def fetch_user_profile(user_id: int) -> IOResult['UserProfile', Exception]:
"""Выбирает `UserProfile` TypedDict из стороннего API."""
обратный поток(
Идентификатор пользователя,
_Сделать запрос,
# до: def (Ответ) -> UserProfile
# после сейфа: def (Response) -> ResultE[UserProfile]
# после bind_result: def (IOResultE[Response]) -> IOResultE[UserProfile]
результат связывания (_parse_json),
)
@impure_safe
def _make_request (user_id: int) -> запросы. Ответ:
ответ = запросы.get('/api/users/{0}'.format(user_id))
ответ.raise_for_status()
вернуть ответ
@Безопасно
def _parse_json (ответ: запросы. Ответ) -> «Профиль пользователя»:
вернуть ответ. json()
 json()
json()
И позже мы можем использовать unsafe_perform_io где-то на верхнем уровне нашей программы, чтобы получить чистое (или «настоящее») значение.
В результате этого сеанса рефакторинга мы знаем все о нашем коде:
- Какие части могут выйти из строя,
- Какие части нечисты,
- Как составить их умным, удобочитаемым и типобезопасным способом.
Будущий контейнер
Есть несколько проблем с асинхронным кодом в Python:
- Вы не можете вызвать
асинхроннуюфункцию из синхронной - Любое неожиданно созданное исключение может разрушить весь цикл обработки событий
- Уродливая композиция с лотами
awaitутверждений Контейнеры
Future и FutureResult решают эти проблемы!
Смешивание синхронного и асинхронного кода
Основная особенность Future
заключается в том, что он позволяет запускать асинхронный код
при сохранении контекста синхронизации. Давайте посмотрим пример.
Давайте посмотрим пример.
Допустим, у нас есть две функции, первый возвращает число, а второй увеличивает его:
async def first() -> int:
вернуть 1
def second(): # Как мы можем вызвать `first()` отсюда?
return first() + 1 # Бум! Не делай этого. Мы иллюстрируем проблему здесь.
Если мы попытаемся просто запустить first() , мы просто создадим нежданную сопрограмму.
Он не вернет нужное нам значение.
Но если мы попытаемся запустить await first() ,
тогда нам нужно будет изменить second на async .
А иногда это невозможно по разным причинам.
Однако с Future мы можем «притвориться», что вызываем асинхронный код из кода синхронизации:
из return.future import Future
def second() -> Future[int]:
вернуть будущее (первый ()). карта (лямбда число: число + 1)
Не касаясь нашей первой асинхронной функции
или сделав секунд асинхронными, мы достигли своей цели. Теперь наше асинхронное значение увеличивается внутри функции синхронизации.
Теперь наше асинхронное значение увеличивается внутри функции синхронизации.
Однако Future по-прежнему требует выполнения внутри надлежащего цикла обработки событий:
import anyio # или asyncio, или любая другая библиотека
# Затем мы можем передать наше `Future` любой библиотеке: asyncio, trio, curio.
# И использовать любой цикл событий: обычный, uvloop, даже собственный и т.д.
утверждать anyio.run(second().awaitable) == 2
Как видите, Future позволяет вам
для работы с асинхронными функциями из контекста синхронизации.
И смешать эти две сферы вместе.
Используйте необработанный Будущее для операций, которые не могут завершиться ошибкой или вызвать исключения.
Практически та же логика была у нас с контейнером IO .
Асинхронный код без исключений
Мы уже рассмотрели, как работает Результат как для чистого, так и для нечистого кода.
Основная идея такова: мы не вызываем исключения, мы их возвращаем.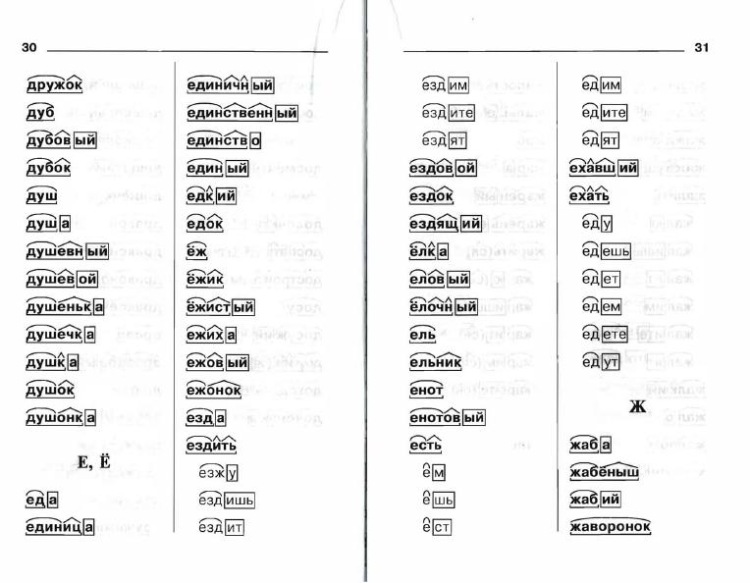 Это , особенно критично в асинхронном коде,
потому что одно исключение может разрушить
все наши сопрограммы работают в одном цикле событий.
Это , особенно критично в асинхронном коде,
потому что одно исключение может разрушить
все наши сопрограммы работают в одном цикле событий.
У нас есть удобная комбинация из Future и Result контейнеры: FutureResult .
Опять же, это точно так же, как IOResult , но для нечистого асинхронного кода.
Используйте его, когда у вашего Future могут возникнуть проблемы:
например HTTP-запросы или операции с файловой системой.
Вы можете легко превратить любую дикую сопрограмму в спокойную FutureResult :
import anyio
из return.future импортировать future_safe
из return.io импортировать IOFailure
@future_safe
асинхронное повышение защиты():
поднять ValueError('Не так быстро!')
ioresult = anyio.run(raising.awaitable) # все контейнеры `Future` return IO
assert ioresult == IOFailure(ValueError('Не так быстро!')) # True
Использование FutureResult защитит ваш код от исключений. Вы всегда можете
Вы всегда можете await или выполнить внутри цикла событий любой FutureResult чтобы получить экземпляр IOResult синхронизации для работы с ним в режиме синхронизации.
Лучшая асинхронная композиция
Раньше вам приходилось делать довольно много await ing при написании async code:
async def fetch_user(user_id: int) -> 'User':
...
async def get_user_permissions (пользователь: «Пользователь») -> «Разрешения»:
...
async def sure_allowed (разрешения: «Разрешения») -> логическое значение:
...
async def main(user_id: int) -> bool:
# Кроме того, не забудьте обработать все возможные ошибки с помощью `try/except`!
user = await fetch_user(user_id) # Мы будем ждать каждый раз, когда будем использовать coro!
разрешения = ожидание get_user_permissions (пользователь)
возврат ожидания гарантировать_разрешение (разрешения)
Некоторым это нравится, но некоторым этот императивный стиль не нравится. Проблема в том, что выбора не было.
Проблема в том, что выбора не было.
Но теперь вы можете сделать то же самое в функциональном стиле!
С помощью контейнеров Future и FutureResult :
import anyio
из return.future импортировать FutureResultE, future_safe
из return.io импортировать IOSuccess, IOFailure
@future_safe
async def fetch_user(user_id: int) -> 'Пользователь':
...
@future_safe
async def get_user_permissions (пользователь: «Пользователь») -> «Разрешения»:
...
@future_safe
async def sure_allowed (разрешения: «Разрешения») -> логическое значение:
...
def main(user_id: int) -> FutureResultE[bool]:
# Теперь мы можем превратить main в функцию синхронизации, она вообще не ожидает.
# Мы также больше не заботимся об исключениях, они уже обработаны.
вернуть fetch_user(user_id).bind(get_user_permissions).bind(ensure_allowed)
correct_user_id: int # имеет необходимые разрешения
Banned_user_id: int # не имеет необходимых разрешений
неправильно_user_id: int # не существует
# Мы можем получить правильные бизнес-результаты:
утверждать anyio. run(main(correct_user_id).awaitable) == IOSuccess(True)
утверждать anyio.run(main(banned_user_id).awaitable) == IOSuccess(False)
# Или у нас могут быть ошибки по пути:
утверждать anyio.run(main(wrong_user_id).awaitable) == IOFailure(
UserDoesNotExistError(...),
)
 run(main(correct_user_id).awaitable) == IOSuccess(True)
утверждать anyio.run(main(banned_user_id).awaitable) == IOSuccess(False)
# Или у нас могут быть ошибки по пути:
утверждать anyio.run(main(wrong_user_id).awaitable) == IOFailure(
UserDoesNotExistError(...),
)
run(main(correct_user_id).awaitable) == IOSuccess(True)
утверждать anyio.run(main(banned_user_id).awaitable) == IOSuccess(False)
# Или у нас могут быть ошибки по пути:
утверждать anyio.run(main(wrong_user_id).awaitable) == IOFailure(
UserDoesNotExistError(...),
)
Или даже что-то действительно причудливое:
из return.pointfree import bind
из потока импорта return.pipeline
def main(user_id: int) -> FutureResultE[bool]:
обратный поток(
fetch_user(user_id),
привязать (get_user_permissions),
привязать (обеспечить_разрешение),
)
Позже мы также можем реорганизовать наши логические функции для синхронизации
и вернуть FutureResult .
Красиво, не так ли?
Еще!
Хотите больше? Перейти к документам! Или прочитайте эти статьи:
- Исключения Python считаются анти-шаблоном
- Применение принципа единой ответственности в Python
- Внедрение типизированной функциональной зависимости в Python
- Какой должна быть асинхронность
- Высшие родственные типы в Python
- Сделайте тесты частью вашего приложения
У вас есть статья для отправки? Не стесняйтесь открывать запрос на вытягивание!
— ⭐️ —
Drylabs поддерживает dry-python и помогает тем, кто хочет использовать его в своих организациях.