What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.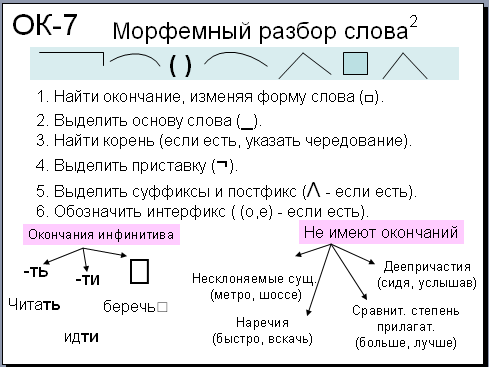
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Как пишется «желаю», «желание», «желанный» правильно?
Благодаря письменной речи мы воспринимаем основную информацию, которая формирует наш внутренний мир. Современное общество уделяет недостаточно времени на изучение секретов правописания. Многие считают, что учить правила ни к чему, т.к. все равно все не преодолеть. Единицы могут похвастаться грамотной речью. У таких людей не возникают вопросы: как пишется “желаю”, “желание” и “желанный”. Проверить себя вы можете, прочитав эту статью.
Как правильно пишется
Эти слова являются однокоренными и правильно пишутся через “е”: “желаю”, “желание” и “желанный”.
Какое правило применяется
Иногда правописание вызывает некоторые трудности, например, “желаю” или “жилаю”. Сначала разберемся, что это однокоренные слова: желать, желание, желанный, а также пожелание, нежелательный, желательно. Здесь под сомнением безударная гласная в первом слоге. Но у них нет родственных слов, что помогут проверить написание интересующей нас буквы. Глагол “желаю” и все однокоренные формы – словарные. Загляните в словарь и убедитесь, что все они пишутся через букву “е”.
Итак, мы подошли, непосредственно, к самому правилу. В непроверяемых безударных гласных в корне слова, в которых ударение не перемещается при изменении формы слова или при подборе однокоренных слов, рекомендуется выучить или справиться о нем в орфографическом словаре.
С безударной гласной разобрались. Следующий вопрос – как писать “желанный” или “желаный”: с одной буквой “н” или с двумя. Это прилагательное, образованное от несовершенного глагола “желать”.
Согласно правилам русского языка, отглагольное прилагательное следует писать с одной “н”. Но и тут не все просто – это исключение из правил, т.е. “желанный” пишется с двумя “н” в суффиксе, как и другие: негаданный, нежданный, чеканный, нечаянный.
Кроме того, при употреблении слова “желание” встречаются различные варианты написания. Например, «желанья»: является ли оно верным? Обращаемся к орфографическим нормам русского языка и выясняем, что они равноправны: писать можно и «желания», и «желанья», как удобнее в контексте.
Морфология
Для начала определим часть речи, форму слова и поставим ударение в лексеме “желаю”. Оно обозначает действие и является глаголом, т.к. отвечает на вопрос: что делаю? Постоянные признаки: 1-е спряжение, переходный, несовершенный вид, а непостоянные – 1-е лицо, изъявительное наклонение, единственное число, настоящее время.
Сделаем полную грамматическую характеристику начальной формы “желание”. Отвечает на вопрос: что? – значит, имя существительное. Постоянные признаки: нарицательное, неодушевленное, средний род, 2-е склонение. Непостоянные: именительный или винительный падеж, единственное число.
Отвечает на вопрос: что? – значит, имя существительное. Постоянные признаки: нарицательное, неодушевленное, средний род, 2-е склонение. Непостоянные: именительный или винительный падеж, единственное число.
Проведем морфологический разбор слова “желанный”, отвечающее на вопрос: какой? Следовательно, это прилагательное. Постоянные признаки: качественное. Непостоянные: именительный падеж, мужской род, единственное число, полная форма.
Разбор по составу
Проводим морфемный разбор глагола “желаю”: ”жела” – корень, “ю” – окончание, “жела” – основа слова.
желаю
Состав слова “желание”: “жела” – корень, “ни” – суффикс, “е” – окончание, “желани” – основа.
желание
Разбираем “желанный”. “Жела” – корень, “нн” – суффикс, “ый” – окончание, “желанн” – основа.
желанный
Во всех рассматриваемых лексемах ударение падает на букву “а”, которая стоит во втором слоге.
Значение
Лексическое значение необходимых слов можно определить по словарю.
“Желаю”, значит: хочу, имею внутреннее стремление к осуществлению или обладанию чем-либо, или же испытываю влечение к кому-либо. По моему желанию, здравия желаю.
“Желание” – cтpeмлeниe к oблaдaнию или ocyщecтвлeнию чeгo-нибyдь. Например, желание учиться, заветное желание. Еще можно определить как пpocьбу или пoжeлaниe. Также может являться географическим названием, например: мыc Желания.
Лексема “желанный” образована от пoлной фopмы пpилaгaтeльнoгo: милый, любимый. Чаще всего означает того, которого желают или ожидают. Желанный гость, друг, ycпeх.
Синонимы
Подобрать к рассматриваемым нами словам схожие выражения не составит труда. Для глагола: хочу, стремлюсь к чему-либо, мечтаю о чем-то, требую, мне охота, жажду, вожделею, алкаю.
Имя существительное употребляется как: просьба, воля, настроение, мечта, готовность, стремление, охота, намерение, побуждение, страсть, прихоть, жажда, влечение, хотение.
Примеры предложений
Интересные выражения, цитаты и фразеологизмы помогают с легкостью запомнить правописание cлoвapных cлoв, которые мы сейчас разбираем.
- Желаю всем здоровья и весеннего настроения.
- Я всего лишь желаю отдохнуть от этой суеты пару дней.
- Ужe дaвнo пoявилocь жeлaниe пoceтить дpyзeй.
- У меня есть заветное желание уехать далеко и надолго.
- Это был желанный гость, и хозяева с радостью приняли его у себя дома.
- Он много работал над проектом и добился желанного успеха.
Как неправильно писать
Неверное употребление: “жилаю”, “жилание”, “жиланный”. Таких лексем в орфографической норме русского языка не существует.
Заключение
Быть грамотным и передавать свою речь правильным написанием, чтобы ее поняли все без исключения – это норма, и к ней должен стремиться каждый. Воспитайте в себе привычку – всегда проверять себя, обращаясь к словарям, даже если кажется, что написали все верно.
Еще раз просмотрите все вышеуказанные словарные слова и запомните их, чтобы не делать ошибок. И тогда ваша речь будет богатой и интересной, вызывая восхищение.
Разбор по составу: почему не «работают» модные диеты
О некоторых из них лучше говорить как можно тише! Например, о Кембриджской диете или системе питания Slim-fast, которые предполагают покупку специальных «заменителей» еды в виде диетических батончиков или порошка для коктейля, производимыми авторами этих диет. Не будем дальше углубляться в болото скрытой рекламы, а скажем только, что очень многие низкокалорийные диеты сегодня почти исчезли. И это прекрасно. Почему? Потому что они основаны на жестких ограничениях в питании, и любая диета, придерживаясь которой вы потребляете менее 800 калорий в день (согласно мнению диетологов, среднестатистической женщине в день необходимо около 2000 калорий) – слишком суровая, и результатом ее становится значительная потеря мышечной массы. Ваше тело реагирует так, как будто бы вас морят голодом, поэтому оно накапливает энергию и старается пополнить запасы, как только вы вспоминаете, что на свете есть калорийные продукты. Завершив курс такой диеты, многие худеющие тут же набирают лишний вес. Чтобы не страдала мышечная масса, в низкокалорийной диете должны преобладать нежирные белковые продукты (постная рыба, молоко и творог жирностью до 2,5%, тофу). Жиры рекомендуется употреблять в пищу только те, что имеют растительное происхождение, а простым углеводам (кондитерские изделия, сладкие напитки) объявить бойкот. Попадают в категорию низкокалорийных и монодиеты (например, те, что предлагают день за днем кушать один и тот же легкий супчик или грейпфруты). В то время как авторы этих диет предполагают, что какой-то определенный продукт отвечает за быструю потерю лишнего веса, на самом деле это происходит из-за того, что организм просто недополучает калорий.
Завершив курс такой диеты, многие худеющие тут же набирают лишний вес. Чтобы не страдала мышечная масса, в низкокалорийной диете должны преобладать нежирные белковые продукты (постная рыба, молоко и творог жирностью до 2,5%, тофу). Жиры рекомендуется употреблять в пищу только те, что имеют растительное происхождение, а простым углеводам (кондитерские изделия, сладкие напитки) объявить бойкот. Попадают в категорию низкокалорийных и монодиеты (например, те, что предлагают день за днем кушать один и тот же легкий супчик или грейпфруты). В то время как авторы этих диет предполагают, что какой-то определенный продукт отвечает за быструю потерю лишнего веса, на самом деле это происходит из-за того, что организм просто недополучает калорий.
Примеры: «Японская» диета, «Китайская» диета, «Английская» диета, «Голливудская» диета, диета Ларисы Долиной, диета «2000 калорий», практически все овощные или фруктовые монодиеты.
Вывод: несмотря на то, что низкокалорийные диеты позволяют быстро сбросить лишние килограммы (до 5 кг в неделю), она нерациональны и даже вредны, если следовать им слишком долго. Они не сбалансированы по составу и основаны на ложных утверждениях. Не обманывайтесь, волшебных продуктов – «ешь и худей!» – не существует.
Они не сбалансированы по составу и основаны на ложных утверждениях. Не обманывайтесь, волшебных продуктов – «ешь и худей!» – не существует.
4. «Счетчик калорий»
Всё об арахисовой пасте. Польза, вред и особенности употребления
В советские времена никто не слышал об арахисовой пасте. Дефицитный продукт практически невозможно было достать, разве что обменяв на что-то дорогое – например, на меховую шапку.
После того, как развалился Советский Союз, начали появляться новые товары, одним из них и была арахисовая паста, за которой сразу же закрепилась слава полезного, но высококалорийного продукта. Давайте разберемся, в чем же состоит польза арахисовой пасты и как правильно ее употреблять.
Состав и польза арахисовой пасты
По статистике, в мире выращивается около 30 миллионов тонн субкультуры, основная часть идет на производство масла. Кроме того, из скорлупы делают удобрения, изоляционный материал, а сам земляной орех используют для изготовления пластмассы и динамита. Арахисовая паста стала практически культовым продуктом в Америке. В городе Плейнс (штат Джорджия) даже воздвигли памятник арахису – рядом с заводом по его переработке красуется четырехметровый улыбающийся орех.
Арахисовая паста стала практически культовым продуктом в Америке. В городе Плейнс (штат Джорджия) даже воздвигли памятник арахису – рядом с заводом по его переработке красуется четырехметровый улыбающийся орех.
Своим появлением арахисовая паста обязана неизвестному врачу-диетологу, который в конце 19 века пытался получить новый суперфуд, полезный для вегетарианцев и худеющих. В 1904 году в Америке уже были налажены первые заводы по производству пасты. Правильно приготовленный продукт полезнее, чем сырые орехи: дело в том, что термическая обработка усиливает полезные свойства арахиса.
Арахис не зря называют продуктом бедняков – он дешевый и калорийный, способен быстро утолить голод. В случае скудного питания арахисовая паста признана ВОЗ одним из основных продуктов. В пасте есть множество витаминов и микроэлементов, которые оказывают благотворное влияние на организм. Среди полезных веществ, содержащихся в продукте, выделяют:
- Полиненасыщенные жирные кислоты (линолиевая кислота, фолиевая кислота, омега 3/6/9).

- Незаменимые аминокислоты.
- Витамины А, Е, К, группы В, а также минеральные вещества, в числе которых железо, фосфор, кальций, магний, натрий, селен и другие.
- Антиоксиданты.
- Клетчатка и пищевые волокна.

Благодаря такому составу, арахисовая паста благотворно влияет на организм, снижая риски возникновения опасных заболеваний. При регулярном потреблении продукта уменьшается возможность появления сердечно-сосудистых заболеваний и сахарного диабета второго типа, снижается уровень холестерина, улучшается иммунитет и работа желудочно-кишечного тракта. Паста является эффективным заменителем антибиотиков при лечении туберкулеза – к таким выводам пришли ученые из Швейцарии.
Польза арахисовой пасты неоспорима для вегетарианцев, продукт помогает организму восполнять запасы белка. Кроме того, паста подходит для спортсменов: употребление арахиса помогает укрепить мышцы, нормализовать процесс расщепления жиров и работу печени, восстановить нервную систему при стрессах. Арахисовая паста повышает уровень сератонина в крови и является отличным антидепрессантом.
Арахисовая паста повышает уровень сератонина в крови и является отличным антидепрессантом.
Удивительно, но, несмотря на высокую калорийность, диетологи включают арахисовую пасту в меню при похудении. Дело в том, что постоянное употребление продукта увеличивает уровень тестестерона в крови, что способствует регуляции обмена веществ и сжиганию жира. Кроме того в составе содержится ресвератрол, который помогает сбросить вес.
Для того чтобы получить максимальную пользу от продукта, нужно обратить внимание на состав баночки при покупке. Чем меньше ингредиентов, тем больше польза арахисовой пасты. Правильная паста содержит арахис, соль и сахар, остальные добавки уже нужны для продления срока годности и удешевления производства. Кстати, существует два вида пасты, и для покупателей придуманы специальные различия в упаковке: банки с красной крышкой содержат в себе кремообразный продукт, а с синей крышкой – пасту с кусочками арахиса.
Есть ли вред от употребления арахисовой пасты?
Арахис является высокоаллергенным продуктом, поэтому стоит воздержаться от его употребления при наличии пищевой непереносимости.
Некоторые люди боятся употреблять данный продукт, в психологии даже выделена арахибатирофобия – боязнь того, что арахисовая паста прилипнет к небу. Видимо, это вызвано тем, что у кошки от употребления пасты могут слепиться челюсти. Поэтому угощать лакомством своего питомца не следует.
Влияние на вес зависит от того, как употреблять арахисовую пасту. При оптимальной дозировке ее можно кушать практически всем людям. Так например, в период похудения будет достаточно 1 столовой ложки в день, для поддержания веса порция составит 1 столовую и 1 чайную ложку, а для набора веса и мышечной массы можно есть 2 столовых ложки в день.
Что приготовить из арахисовой пасты и как правильно ее употреблять?
Каждый год в Америке съедают около 300 миллионов килограмм арахисовой пасты, и чаще всего ее употребляют на завтрак. Говорят, что даже во время своего полета на Луну Алан Гепард ел арахисовую пасту в космосе в виде спрессованных кубиков. На самом деле помимо привычного бутерброда с хлебом есть множество вариаций употребления арахисовой пасты.
Говорят, что даже во время своего полета на Луну Алан Гепард ел арахисовую пасту в космосе в виде спрессованных кубиков. На самом деле помимо привычного бутерброда с хлебом есть множество вариаций употребления арахисовой пасты.
С чем едят арахисовую пасту? В период похудения можно сочетать ее с кашами или фруктами. Арахисовая паста отлично подходит к тостам, лавашу, хлебцам, крекерам. Продукт также можно добавить в творог или использовать в качестве начинки для пирога. Если же вы не боитесь набрать вес, можете добавить ложку пасты к мороженому или блинчикам – пикантный вкус продукта добавит новые нотки к привычным блюдам. Часто арахисовая паста используется в соусах и маринаде для мяса, а еще продукт можно использовать вместо масла при жарке или выпечке. Главное, знать меру в употреблении, хотя иногда очень сложно остановиться и ограничить себя лишь одной ложкой лакомства.
«Избегание» или «избежание»: как пишется слово?
На чтение 3 мин Просмотров 513 Опубликовано
Синтаксические и орфографические ошибки в предложениях со словами «избегание» или «избежание» допускают довольно часто. Неграмотное употребление приведённых существительных объясняется тем, что они отличаются оттенком значения и должны использоваться в разных контекстах. Далее в статье приведём подходящее правило.
Как правильно пишется?
В письменной и устной речи разрешается использовать обе формы – «избегание» и «избежание».
Выберем один из вариантов, если правильно определим, от какого глагола образовалось каждое их рассматриваемых отглагольных существительных.
Морфемный разбор слов «избегание» и «избежание»
Чтобы понять, какое из слов уместно в определённом предложении, выполним их полный морфемный анализ.
Разберём по составу слово «избегание» (ед. ч., им. п.):
избегание- «избег» – корень, «а», «ни» – суффиксы, «е» – флексия.
К основе отнесём – «избегани».
Разберём по составу лексему «избежание» (ед. ч., им. п.):
ч., им. п.):
- «избеж» – корень, «а», «ни» – суффиксы, «е» – флексия.
Вычлени основу – «избежани».
Видим, что в корнях существительных наблюдается чередование согласных «г» – «ж». Остальные морфемы совпадают.
В каких случаях пишется слово «избегание»
Эта лексема стилистически свободная. Кроме того, её можно изменять по падежам.
Примеры предложений
Посмотрим на контекстное окружение предложений со словом «избегание»:
- Избегание ответственности было любимым делом Николая Астафьева.
- Тамара Алексеевна считала, что избегание конфликта – хорошая идея.
- Скромные наряды Ольги Михайловны и её избегание мужского общества не вызывали симпатии у окружающих.
- Скрытность и избегание больших компаний повлияли на характер Анастасии.
- Избегание душевных волнений сказывалось на Александре не лучшим образом: приводило к нервным срывам, замкнутости и агрессии.

В каких случаях пишется слово «избежание»
Происходит от глагола совершенного вида «избежать», который выражает семантику завершённости действия. Имеет значение «для предотвращения чего-либо». Часто встречается в официально-деловом стиле речи.
Примеры предложений
Рассмотрим предложения с сочетанием «во избежание», чтобы запомнить его правописание:
- Во избежание недоразумения укажем, что мы категорически против штрафных санкций.
- Во избежание травм на предприятии обязательно используйте защитный головной убор.
- Во избежание дальнейшего загрязнения окружающей среды требуется уменьшить производство одноразовой продукции.
- Во избежание травм спортивные упражнения рекомендуется выполнять только после десятиминутной разминки.
- Рекомендуется употреблять два литра чистой воды в день во избежание обезвоживания.
Ошибочное написание слов «избегание» и «избежание»
Неправильно употреблять одну лексему в значении другой. Также неграмотно: «во избежании», «воизбежание», «исбегание», «во-избежание», «избеганье».
Также неграмотно: «во избежании», «воизбежание», «исбегание», «во-избежание», «избеганье».
Заключение
Выяснили, что между вариантами «избегание» или «избежание» разница не только смысловая, но и грамматическая.
Первое слово обозначает сам процесс действия, оно не зависит от стилистики текста.
Вторая форма с буквой «ж» в корне имеет ограниченное употребление – с предлогом «во» – «во избежание».
Употребляется в текстах с канцелярско-бюрократическим уклоном.
что это такое, калорийность, вкус крупы
Наверняка многие из вас хотя бы раз слышали о таком продукте, как киноа (она же квиноа или кинуа). Но мало кто знает характеристики каши киноа – что это за крупа, чем она полезна, какую пищевую ценность имеет и как именно способствует похудению. Именно обо всех этих нюансах – наша сегодняшняя статья.
Крупа киноа: что это такое и с чем ее едят
Начнем с определения и истории. Киноа – растение из семейства Маревые. Проще говоря – злаковая культура. Произрастает она на склонах гор – там, где климат, как правило, весьма суров.
Киноа – растение из семейства Маревые. Проще говоря – злаковая культура. Произрастает она на склонах гор – там, где климат, как правило, весьма суров.
“Открыли” эту крупу индейцы, которые использовали зерна киноа для приготовления хлеба и лепешек. Позже эта замечательная каша также вошла в кухню других народов. Однако настоящей популярности до сих пор не снискала, и дело тут не в свойствах самой каши. Просто культивировать ее пока не получается – для выращивания киноа нужен особенный климат. К счастью, на сегодняшний день существует несколько районов, где эта культура выращивается в достаточных количествах. Это позволяет поставлять ее по всему земному шару, в том числе и в нашу страну.
В привычном для нас виде киноа – это крупа, напоминающая внешним видом кукурузу или гречку (поскольку в основном бывает двух цветов – бледно-желтого или коричневого). Также существует киноа красного цвета, но на прилавках магазинов она встречается нечасто.
На что похожа по вкусу крупа киноа? Та, которая коричневого цвета, чем-то напоминает необработанный рис, белая каша обладает нейтральным вкусом, красная – слабым ореховым привкусом. Вне зависимости от оттенка, крупу можно использовать и как гарнир, и как отдельное блюдо. Кроме того, киноа нередко применяется для изготовления макарон или хлеба – правда, найти подобные деликатесы можно только в специализированных лавочках.
Вне зависимости от оттенка, крупу можно использовать и как гарнир, и как отдельное блюдо. Кроме того, киноа нередко применяется для изготовления макарон или хлеба – правда, найти подобные деликатесы можно только в специализированных лавочках.
Из чего состоит киноа
Прежде, чем говорить о полезных свойствах крупы киноа, давайте разберем ее “по составу”.
Итак, в каше киноа много рибофлавина, фолиевой кислоты, разнообразных витаминов (групп А,В, С и Д), также минералов – меди, железа, магния, марганца, фосфора, плюс альфа-токоферолы. Кроме того, в этой крупе большое содержание аминокислот, в том числе лизин, который помогает кальцию усваиваться, а также способствует скорому заживлению ран. Ну и самое главное “полезное свойство” крупы киноа – высокое содержание растительного белка. По этому параметру киноа – абсолютный лидер среди продуктов растительного происхождения. Именно поэтому эту кашу очень любят вегетарианцы.
В каше киноа не содержится глютен, поэтому она идеально подходит людям, страдающим целиакией.
Разбор по составу
Теперь подробнее поговорим о “характеристиках” киноа. О составе этой крупы мы уже писали ранее и не станем повторяться. В этой статье рассмотрим другие моменты – калорийность крупы киноа, соотношение жиров, белков и углеводов в ней, гликемический индекс и тому подобные важные параметры.
Гликемический индекс киноа очень низкий – всего 35. Это означает, что киноа очень медленно расщепляется в желудке и кишечнике, надолго сохраняя чувство насыщения. Именно поэтому считается, что зерна киноа – это идеальный продукт для тех, кто мечтает поскорее расстаться с лишними сантиметрами.
Калорийность киноа на 100 грамм – целых 368 ккал. Соотношение белков, жиров и углеводов: 14,1/6,1/57,2.
Казалось бы, калорийность у готового блюда киноа выйдет довольно приличная. Поэтому неудивительно, что многие худеющие, опасаясь высокой пищевой ценности киноа, предпочитают обходить эту кашу стороной. И совершенно напрасно – несмотря на высокую калорийность, вареная киноа станет отличным дополнением к любой сбалансированной диете. Тем более, что по факту в одной стандартной порции содержится примерно 170 ккал.
Тем более, что по факту в одной стандартной порции содержится примерно 170 ккал.
А самое важное – в этой крупе очень много белка. В некоторых сортах – пятая часть от общей массы! Это почти вдвое больше, чем в рисе, и втрое, чем в кус-кусе. По количеству содержащегося в ней белка киноа может соперничать только с молоком.
Кашу очень быстро и просто готовить, и даже вареная она сохраняет в составе большое количество аминокислот и витаминов.
Мы постарались рассказать вам на словах, что это такое – киноа, а фото и видео, представленные в этой статье, дополнят картину. Предлагаем вашему вниманию программу, из которой вы сможете узнать о киноа много интересного:
Опытные стройнеющие знают: существуют продукты, которые действительно способствуют похудению, выводят шлаки и токсины и вообще безумно полезны для организма. Например, каша киноа, пользу которой трудно переоценить. Хотите узнать об этом чудо-продукте подробнее? Читайте нашу статью – расскажем, чем полезна крупа киноа и как она помогает худеть!
Крупа киноа: польза и вред
Теперь подробнее поговорим о полезных свойствах киноа и противопоказаниях к ее употреблению.
Для начала – о плюсах. Польза крупы киноа очевидна:
- Каша замечательно усваивается организмом. По этому параметру она стоит на одной ступени с материнским молоком. Лучшего варианта для тех, кто хочет добавить в рацион легкоусвояемые продукты, попросту не найти.
- Согласно отзывам врачей, полезные свойства крупы киноа трудно переоценить, если вы ведете активный образ жизни. Дело в том, что эта каша – очень мощное общеукрепляющее средство, которое идеально подходит тем, кто ежедневно тратит много сил и энергии. Поэтому диетологи настойчиво рекомендуют спортсменам включить киноа в ежедневный рацион. Кроме того, эту крупу полезно использовать для программ активной детоксикации.
- Крупа киноа полезна для тех, кто страдает мигренью. А еще она помогает снизить артериальное давление, предупреждает некоторые онкологические заболевания – например, рак толстой кишки, а также идеально подходит для диабетиков.
Регулярное употребление киноа – это крепкие кости, а значит, профилактика артроза, артрита и других подобных заболеваний.
Разобрались с пользой киноа – и о вреде крупы также скажем буквально пару слов. Каша может навредить только в одном случае – если ею злоупотреблять. Особенно тем, у кого есть проблемы с почками. Поэтому не нужно есть ее на завтрак, обед и ужин – ваш рацион должен быть в первую очередь сбалансированным.
С осторожностью крупу следует употреблять беременным и кормящим женщинам – особенно если раньше никогда ее не ели. Киноа следует вводить в рацион постепенно и внимательно следить, как организм на нее отреагирует.
Смело покупай к ужину:
Киноа: полезные свойства для похудения
Профилактика заболеваний – это, конечно, хорошо, но нас с вами в первую очередь волнует, как именно эта крупа помогает постройнеть. Польза семян киноа для похудения очевидна. В крупе очень много клетчатки, которая, как известно, помогает в лечении ожирения и борьбе с лишними килограммами. Благодаря клетчатке из организма выводится лишний холестерин, эффективно очищается ЖКТ, активно расщепляются жиры.
Если верить отзывам, полезные свойства крупы киноа работают только в том случае, если употреблять эту крупу постоянно. Поэтому смело включайте ее в ежедневный рацион и стройнейте на глазах! Для любителей сладенького с кашей можно есть кленовый сироп или мед.
Подробно и познавательно о полезных свойствах крупы киноа и противопоказаниях к употреблению – из уст Елены Малышевой сотоварищи:
Зелень и ее полезные свойства — Официальный сайт МО Красноуфимский округ
Летом природа дарит нам многообразие оттенков зелени. Петрушка, укроп, кинза, сельдерей, зеленый лук, кресс-салат, щавель, базилик и прочие ароматные травы витаминизируют наш организм после долгой зимы организмы.
Зелень укропа, наряду с широким применением и популярностью, обладает и очень полезными свойствами. В нем содержатся витамины: С, В, А, РР, Е и много калия. Укроп богат различными микроэлементами и антиоксидантами. Все эти вещества быстро усваиваемые и прекрасно способствуют кроветворению. Благодаря своему составу, зелень укропа укрепляет иммунитет, оказывает мочегонный и противовоспалительный эффект, удаляет остатки жиров и участвует в расщеплении трудноусваиваемой еды. Зелень укропа очень полезна для людей страдающих нарушениями функций почек и печени, убирает отеки. Семена укропа содержат олеиновую, пальмитиновую кислоту и очень богаты эфирными маслами. Благодаря этому семена укропа активно используются в лечебных и косметических целях.
Зелень петрушки заслуженно считают самой полезной зеленью.
Петрушка очень богата витаминами группы В, А, РР, Е, содержит бета-каротин. Эта полезная зелень также содержит железо, натрий, кальций, фосфор, магний, цинк. Таким образом, она укрепляет наш иммунитет и борется с вредными бактериями. Поскольку петрушка содержит фолиевую кислоту, то входящий в ее состав селен улучшает ваше зрение и делает кожу более эластичной. Употребление зелени петрушки нормализует обменные процессы организма. Очень благотворно петрушка влияет на функционирование щитовидной железы Регулярно употребляя в пищу зелень петрушки, ее корни и семена петрушки, нормализуется функция желудочно-кишечного тракта, из организма выводятся токсины. Петрушку рекомендуют к употреблению для нормализации кровяного давления и как мягкое мочегонное и желчегонное средство. Зелень петрушки отлично освежает дыхание. Для крепких костей и зубов, также, кушайте петрушку! Таким образом, петрушку можно назвать самой полезной зеленью.
Внимание! Не рекомендуется употреблять петрушку в первом триместре беременности, так как она может спровоцировать выкидыш.
Сельдерей — это великая сокровищница нашего здоровья! Входящие в его состав микроэлементы и витамины оказывают общеукрепляющее, очищающее и омолаживающее действие. Сельдерей богат витаминами группы В, А, Е, С, К. В. Для людей, желающих похудеть, сельдерей незаменим в питании. Диетологи считают, что этот овощ имеет «отрицательную калорийность». При этом суточная норма сельдерея дает организму все полезные вещества и энергию. Сельдерей обладает мягким мочегонным эффектом, помогая избавиться от лишней жидкости и накопившихся токсинов.
Мята славится успокаивающими, обезболивающими, антисептическими свойствами. Оказывает сосудорасширяющее действие. Женщины часто используют мяту для облегчения синдромов менструального цикла. Мата поможет при кашле и изжоге. Кроме этого вещества, входящие в химический состав зелени мяты стимулируют мозговую деятельность.
Шпинат — чемпион среди зелени по содержанию белка. В этом качестве уступает только гороху и фасоли. Шпинат особенно полезен в детском меню, так как белок дает организму материал для строительства новых клеток и оказывает общее укрепление организма. В химическом составе листьев шпината содержатся витаминный комплекс: А, В,С, РР, К, Р, D, Е и микроэлементы – йод, железо, цинк, селен, марганец, фосфор, натрий, кальций. При регулярном употреблении шпината, элементы, в него входящие, способны тормозить развитие раковых клеток.
Щавель в народе получил звание «весеннего короля». Самая ранняя полезная зелень, богатая витаминами C, В, K, E, биотином, β-каротином, эфирными маслами, дубильной, щавелевой, пирогалловой и другими кислотами. ля лечебных целей щавель используют для профилактики таких заболеваний, как анемия, авитаминоз, цинга, заболевания ЖКТ, ревматизм и геморрой.
Оставить комментарий
Вы должны войти, чтобы оставлять комментарии.
Что такое парсер? — Определение из Техопедии
Что означает парсер?
Парсер — это компонент компилятора или интерпретатора, который разбивает данные на более мелкие элементы для облегчения перевода на другой язык. Парсер принимает входные данные в виде последовательности токенов, интерактивных команд или программных инструкций и разбивает их на части, которые могут использоваться другими компонентами в программировании.
Анализатор обычно проверяет все предоставленные данные, чтобы убедиться, что их достаточно для построения структуры данных в форме дерева синтаксического анализа или абстрактного синтаксического дерева.
Techopedia объясняет синтаксический анализатор
Чтобы код, написанный в удобочитаемой форме, мог быть понят машиной, он должен быть преобразован в машинный язык. Эту задачу обычно выполняет переводчик (интерпретатор или компилятор). Синтаксический анализатор обычно используется как компонент переводчика, который организует линейный текст в структуру, которой можно легко манипулировать (дерево синтаксического анализа). Для этого он следует набору определенных правил, называемых «грамматикой».
Общий процесс синтаксического анализа включает три этапа:
Лексический анализ: Лексический анализатор используется для создания токенов из потока входных строковых символов, которые разбиваются на небольшие компоненты для формирования значимых выражений.Токен — это наименьшая единица языка программирования, имеющая какое-то значение (например, +, -, *, «функция» или «новый» в JavaScript).
Синтаксический анализ: Проверяет, образуют ли сгенерированные токены осмысленное выражение. Это использует контекстно-свободную грамматику, которая определяет алгоритмические процедуры для компонентов. Они работают, чтобы сформировать выражение и определить конкретный порядок, в котором должны быть размещены токены.
Семантический анализ: Заключительный этап синтаксического анализа, на котором определяется значение и значение проверенного выражения и предпринимаются необходимые действия.
Основная цель анализатора — определить, могут ли входные данные быть получены из начального символа грамматики. Если да, то каким образом можно получить эти входные данные? Это достигается следующим образом:
Анализ сверху вниз: Включает поиск в дереве синтаксического анализа для поиска крайних левых производных входного потока с использованием расширения сверху вниз. Анализ начинается с начального символа, который преобразуется во входной символ, пока все символы не будут переведены и не будет построено дерево синтаксического анализа для входной строки.Примеры включают синтаксические анализаторы LL и синтаксические анализаторы с рекурсивным спуском. Анализ сверху вниз также называется прогнозным или рекурсивным анализом.
Анализ снизу вверх: Включает перезапись ввода обратно в начальный символ. Он действует в обратном порядке, отслеживая крайнее правое происхождение строки до тех пор, пока дерево синтаксического анализа не будет построено до начального символа. Этот тип синтаксического анализа также известен как синтаксический анализ с уменьшением сдвига. Одним из примеров является парсер LR.
Парсеры широко используются в следующих технологиях:
Java и другие языки программирования.
HTML и XML.
Интерактивный язык данных и язык определения объектов.
Языки баз данных, например SQL.
Языки моделирования, например язык моделирования виртуальной реальности.
Языки сценариев.
Протоколы, такие как вызовы удаленных функций HTTP и Интернет.
Руководство по концепции синтаксического анализа
Руководство по концепции синтаксического анализаОткрыть тему с навигацией
Зачем нужен парсинг
Важным аспектом соответствия данных цели является их структура. находится в.Часто сама конструкция не подходит под нужды данных. Например:
- В системе сбора данных нет полей для каждая отдельная часть информации с определенным использованием, ведущая к пользователю обходные пути, такие как ввод множества отдельных частей информации в одно свободное текстовое поле или использование неправильных полей для информации, которая не имеет очевидного места (например, размещение информации о компании в отдельных полях контактов).
- Данные необходимо переместить в новую систему с другая структура данных.
- Дубликаты необходимо удалить из данных, и сложно выявить и удалить дубликаты из-за структуры данных (например, идентификаторы ключевых адресов, такие как номер помещения, не разделяются от остальной части адреса).
В качестве альтернативы структура данных может быть надежной, но использование он недостаточно контролируется или подвержен ошибкам.Например:
- Пользователи не обучены собирать все необходимые информации, вызывая такие проблемы, как установление контактов с помощью «читерских данных», а не реальных имена в полях имени
- Приложение отображает поля в нелогичном порядок, приводящий к тому, что пользователи вводят данные в неправильные поля
- Пользователи вводят повторяющиеся записи способами, трудно обнаружить, например, ввод неточных данных в несколько записей, представляющих одну и ту же сущности, либо вводя точные данные, но в неправильные поля.
Все эти проблемы приводят к низкому качеству данных, что во многих случаях может быть дорогостоящим для бизнеса. Поэтому для бизнеса важно уметь анализировать данные для этих проблем и решать их там, где нужно.
Парсер OEDQ
Процессор OEDQ Parse предназначен для использования разработчиками процессов качества данных для создания упакованных парсеров для понимания и преобразование определенных типов данных, например данных имен, Адресные данные или описания продуктов.Однако это общий парсер который не имеет правил по умолчанию, специфичных для любого типа данных. Специфичные для данных правила могут быть созданы путем анализа самих данных и установки параметра Parse конфигурация.
Терминология
Синтаксический анализ — это часто используемый термин как в сфере качества данных, так и в и в вычислительной технике в целом. Это может означать что угодно, от простого up data ‘до полного анализа естественного языка (NLP), который использует сложные искусственный интеллект, позволяющий компьютерам «понимать» человеческий язык.Также часто используется ряд других терминов, связанных с синтаксическим анализом. Очередной раз, они могут иметь немного разные значения в разных контекстах. это поэтому важно определить, что мы подразумеваем под синтаксическим анализом, и связанные с ним термины в OEDQ.
Обратите внимание на следующие термины и определения:
Срок | Определение |
Разбор | В OEDQ синтаксический анализ определяется как приложение, указанное пользователем. бизнес-правила и искусственный интеллект для понимания и проверять все типы данных в массовом порядке и, при необходимости, улучшать их структуру для того, чтобы сделать его пригодным для использования. |
жетон | Токен — это часть данных, которая распознается анализатором как единое целое. процессор с использованием правил. Данное значение данных может состоять из одного или нескольких токенов. Токен можно распознать с помощью синтаксического или семантического анализа. данных. |
Токенизация | Первоначальный синтаксический анализ данных с целью разделения их на наименьшие единицы (базовые жетоны) с использованием правил.Каждому базовому токену присваивается тег, например, , который используется для представления непрерывных последовательностей буквенных символов. |
Базовый токен | Начальный токен, признанный токенизацией. Последовательность Базы Жетоны позже могут быть объединены в новый Жетон в Классификации или Реклассификация. |
Классификация | Семантический анализ данных для определения значения базовых токенов, или последовательности базовых токенов. У каждой классификации есть тег, например «Здание», и уровень классификации (Действительный или Возможный), который используется при выборе лучшее понимание неоднозначных данных. |
Проверка токена | Набор правил классификации, применяемых к атрибуту в чтобы проверить наличие определенного типа токена. |
Реклассификация | Необязательный дополнительный этап классификации, который позволяет классифицированные токены и неклассифицированные (базовые) токены должны быть реклассифицированы как один новый токен. |
Образец жетона | Объяснение строки данных с использованием шаблона тегов токенов, либо в одном атрибуте или в нескольких атрибутах. Строка данных может быть представлена с использованием ряда различных токенов. узоры. |
Выбор | Процесс, с помощью которого процессор синтаксического анализа пытается выбрать «лучший» объяснение данных с использованием настраиваемого алгоритма, где запись имеет множество возможных объяснений (или шаблонов токенов). |
Разрешение | Категоризация записей с заданным выбранным объяснением (токен pattern) с Результатом (Pass, Review или Fail) и дополнительным комментарием. Разрешение также может разрешить записи в новую структуру вывода, используя правила, основанные на выбранном шаблоне токена. |
Краткое описание процессора OEDQ Parse
На следующей диаграмме показано, как анализатор OEDQ процессор работает:
См. Справочные страницы для OEDQ Проанализируйте процессор для получения полных инструкций по его настройке.
Справка Oracle® Enterprise Data Quality Help, версия 9.0
Авторские права ©
2006,2011 Oracle и / или ее дочерние компании. Все права защищены.
Как работает JavaScript: синтаксический анализ, абстрактные синтаксические деревья (AST) + 5 советов, как минимизировать время синтаксического анализа | автор Lachezar Nickolov
Это пост # 14 из серии, посвященной изучению JavaScript и его компонентов. В процессе идентификации и описания основных элементов мы также делимся некоторыми практическими правилами, которые мы используем при создании SessionStack, приложения JavaScript, которое должно быть надежным и высокопроизводительным, чтобы помогать пользователям видеть и воспроизводить дефекты своего веб-приложения в режиме реального времени.
Если вы пропустили предыдущие главы, вы можете найти их здесь:
Мы все знаем, как все может запутаться, если закончится одним большим фрагментом JavaScript. Этот фрагмент кода необходимо не только передать по сети, но также его нужно проанализировать, скомпилировать в байт-код и, наконец, выполнить. В предыдущих сообщениях мы обсуждали такие темы, как движок JS, среда выполнения и стек вызовов, а также движок V8, который в основном используется Google Chrome и NodeJS. Все они играют жизненно важную роль во всем процессе выполнения JavaScript.Тема, которую мы планируем представить сегодня, не менее важна: мы увидим, как большинство движков JavaScript анализируют текст, выделяя что-то значимое для машины, что происходит после этого, и как мы, веб-разработчики, можем использовать эти знания в своих интересах.
Итак, давайте сделаем шаг назад и посмотрим, как вообще работают языки программирования. Независимо от того, какой язык программирования вы используете, вам всегда понадобится какое-то программное обеспечение, которое может взять исходный код и заставить компьютер действительно что-то делать.Это программное обеспечение может быть интерпретатором или компилятором. Независимо от того, используете ли вы интерпретируемый язык (JavaScript, Python, Ruby) или скомпилированный (C #, Java, Rust), всегда будет одна общая часть: анализ исходного кода как простого текста в структуру данных, называемую абстрактное синтаксическое дерево (AST). AST не только представляют исходный код в структурированном виде, но также играют важную роль в семантическом анализе, когда компилятор проверяет правильность и правильное использование программы и языковых элементов.Позже AST используются для генерации фактического байт-кода или машинного кода.
AST используются не только в интерпретаторах и компиляторах языков. У них есть множество приложений в компьютерном мире. Один из наиболее распространенных способов их использования — статический анализ кода. Статические анализаторы не выполняют код, заданный на их вход. Тем не менее, им необходимо понимать структуру кода. Например, вы можете реализовать инструмент, который находит общие структуры кода, чтобы вы могли реорганизовать их, чтобы уменьшить дублирование.Вы могли бы сделать это, используя сравнение строк, но реализация будет очень простой и ограниченной. Естественно, если вы заинтересованы в реализации такого инструмента, вам не нужно писать собственный синтаксический анализатор. Существует множество реализаций с открытым исходным кодом, полностью совместимых со спецификациями Ecmascript. Эсприма и Желудь, если назвать пару. Есть также много инструментов, которые могут помочь с выводом, производимым анализатором, а именно AST. AST также широко используются при реализации транспиляторов кода.Так, например, вы можете реализовать транспилятор, который преобразует код Python в JavaScript. Основная идея заключается в том, что вы должны использовать транспилятор Python для генерации AST, который затем будет использоваться для генерации обратного кода JavaScript. Вы можете спросить, как такое вообще возможно. Дело в том, что AST — это просто другой способ представления некоторого языка. Перед синтаксическим анализом он представлен в виде текста, который следует некоторым правилам, составляющим язык. После синтаксического анализа он представлен в виде древовидной структуры, которая содержит точно такую же информацию, что и входной текст.Следовательно, мы всегда можем сделать противоположный шаг и вернуться к текстовому представлению.
Итак, давайте посмотрим, как строится AST. В качестве примера у нас есть простая функция JavaScript:
Парсер выдаст следующий AST.
Обратите внимание, что для целей визуализации это упрощенная версия того, что будет производить синтаксический анализатор. Настоящая AST намного сложнее. Идея здесь, однако, состоит в том, чтобы понять, что в первую очередь произойдет с исходным кодом, прежде чем он будет выполнен.Если вы хотите увидеть, как выглядит фактический AST, вы можете проверить AST Explorer. Это онлайн-инструмент, в котором вы передаете некоторый JavaScript, а он выводит AST для этого кода.
Зачем мне знать, как работает парсер JavaScript, спросите вы. В конце концов, ответственность за его работу лежит на браузере. И вы вроде как правы. На приведенном ниже графике показано общее время, выделенное на различные этапы процесса выполнения JavaScript. Присмотритесь и посмотрите, не найдете ли вы что-нибудь интересное.
Вы это видели? Присмотритесь. В среднем браузеру требуется от 15% до 20% общего времени выполнения, чтобы проанализировать JavaScript. Я не придумывала цифр. Это статистика из реальных приложений и веб-сайтов, которые так или иначе используют JavaScript. Сейчас 15% могут показаться вам не много, но поверьте мне, это так. Типичный SPA загружает около 0,4 МБ JavaScript, и браузеру требуется около 370 мс для его анализа. Опять же, вы можете сказать: ну, это не так уж и много.Само по себе это немного. Однако имейте в виду, что это только время, необходимое для синтаксического анализа кода JavaScript в AST. Это не включает само выполнение или какие-либо другие процессы, происходящие во время загрузки страницы, такие как рендеринг CSS и HTML. И все это относится только к десктопам. Когда мы переходим на мобильные устройства, все быстро усложняется. Время, затрачиваемое на синтаксический анализ, на телефонах может быть в два-пять раз больше, чем на настольных компьютерах.
На приведенном выше графике показано время синтаксического анализа пакета JavaScript размером 1 МБ на мобильных и настольных устройствах различного класса.
Более того, веб-приложения становятся все сложнее с каждой минутой, поскольку все больше бизнес-логики переходит на сторону клиента, чтобы обеспечить более естественный пользовательский интерфейс. Вы можете легко понять, насколько это влияет на ваше приложение / веб-сайт. Все, что вам нужно сделать, это открыть инструменты разработчика браузера и позволить ему измерить количество времени, затрачиваемого на синтаксический анализ, компиляцию и все остальное, что происходит в браузере, пока страница не загрузится полностью.
К сожалению, в мобильных браузерах нет инструментов разработчика.Но не беспокойтесь. Это не значит, что вы ничего не можете с этим поделать. Вот почему существуют такие инструменты, как DeviceTiming. Это может помочь вам измерить время синтаксического анализа и выполнения скриптов в контролируемой среде. Он работает, обертывая локальные скрипты кодом инструментария, так что каждый раз, когда ваши страницы открываются с разных устройств, вы можете локально измерять время синтаксического анализа и выполнения.
Хорошо то, что движки JavaScript многое делают, чтобы избежать лишней работы и стать более оптимизированными.Вот несколько вещей, которые движки делают в основных браузерах.
V8, например, выполняет потоковую передачу скриптов и кэширование кода. Потоковая передача сценариев означает, что асинхронные и отложенные сценарии анализируются в отдельном потоке, как только начинается загрузка. Это указывает на то, что синтаксический анализ выполняется почти сразу после загрузки сценария. Это приводит к тому, что страницы загружаются примерно на 10% быстрее.
Код JavaScript обычно компилируется в байт-код при каждом посещении страницы. Однако этот байт-код затем отбрасывается, когда пользователь переходит на другую страницу.Это происходит потому, что скомпилированный код во многом зависит от состояния и контекста машины во время компиляции. Здесь Chrome 42 представляет кеширование байт-кода. Это метод, при котором скомпилированный код хранится локально, поэтому, когда пользователь возвращается на ту же страницу, все шаги, такие как загрузка, синтаксический анализ и компиляция, могут быть пропущены. Это позволяет Chrome сэкономить около 40% времени на синтаксический анализ и компиляцию. Кроме того, это также приводит к экономии заряда аккумулятора мобильных устройств.
В Opera механизм Carakan может повторно использовать вывод компилятора из другой программы, которая была недавно скомпилирована.Не требуется, чтобы код был с той же страницы или даже домена. Этот метод кеширования на самом деле очень эффективен и позволяет полностью пропустить этап компиляции. Он основан на типичном поведении пользователя и сценариях просмотра: всякий раз, когда пользователь следует определенному пути пользователя в приложении / веб-сайте, загружается один и тот же код JavaScript. Однако двигатель Carakan давно был заменен на двигатель V8 от Google.
Движок SpiderMonkey, используемый Firefox, не кэширует все. Он может перейти в стадию мониторинга, где подсчитывает, сколько раз выполняется данный скрипт.На основе этого подсчета он определяет, какие части кода наиболее актуальны и нуждаются в оптимизации.
Очевидно, некоторые принимают решение ничего не делать. Мацей Стаховяк, ведущий разработчик Safari, заявляет, что Safari не кэширует скомпилированный байт-код. Это то, что они рассматривали, но они не реализовали, поскольку генерация кода составляет менее 2% от общего времени выполнения.
Эти оптимизации не влияют напрямую на синтаксический анализ исходного кода JavaScript, но они определенно делают все возможное, чтобы полностью его пропустить.Что может быть лучшей оптимизацией, чем совсем ее не делать?
Мы можем многое сделать, чтобы улучшить время начальной загрузки наших приложений. Мы можем минимизировать объем поставляемого JavaScript: меньше скриптов, меньше синтаксического анализа, меньше выполнения. Для этого мы можем доставить только код, необходимый для определенного маршрута, вместо того, чтобы загружать один большой двоичный объект всего. Например, шаблон PRPL проповедует этот тип доставки кода. В качестве альтернативы, мы можем проверить наши зависимости и посмотреть, есть ли что-нибудь лишнее, что могло бы делать не что иное, как раздувание нашей кодовой базы.Однако эти вещи заслуживают отдельной темы.
Цель этой статьи — обсудить, что мы, как веб-разработчики, можем сделать, чтобы помочь синтаксическому анализатору JavaScript выполнять свою работу быстрее. Так и есть. Современные парсеры JavaScript используют эвристику, чтобы определить, будет ли определенный фрагмент кода выполняться немедленно или его выполнение будет отложено на некоторое время в будущем. На основе этой эвристики синтаксический анализатор будет выполнять либо нетерпеливый, либо отложенный синтаксический анализ. Активный синтаксический анализ запускает функции, которые необходимо немедленно скомпилировать.Он выполняет три основные задачи: строит AST, строит иерархию областей видимости и находит все синтаксические ошибки. С другой стороны, отложенный синтаксический анализ используется только для функций, которые еще не нужно компилировать. Он не создает AST и не находит всех синтаксических ошибок. Он только строит иерархию областей видимости, что экономит примерно половину времени по сравнению с активной оценкой.
Понятно, что это не новая концепция. Даже такие браузеры, как IE 9, поддерживают такой тип оптимизации, хотя и довольно элементарно по сравнению с тем, как работают современные парсеры.
Давайте посмотрим, как это работает. Скажем, у нас есть некоторый JavaScript, который имеет следующий фрагмент кода:
Как и в предыдущем примере, код загружается в синтаксический анализатор, который выполняет синтаксический анализ и выводит AST. Итак, у нас есть что-то вроде:
Объявление функции foo , которая принимает один аргумент (x). Он имеет одно выражение возврата. Функция возвращает результат операции + над x и 10.
Объявление функции bar , которая принимает два аргумента (x и y).Он имеет одно выражение возврата. Функция возвращает результат операции + над x и y.
Сделать вызов функции для bar с двумя аргументами 40 и 2.
Сделать вызов функции console.log с одним аргументом как результат предыдущего вызова функции.
Так что же только что произошло? Парсер видел объявление функции foo, объявление функции bar, вызов функции bar и вызов функции console.log. Но подождите … синтаксический анализатор проделал некоторую дополнительную работу, которая совершенно не имеет значения.Это синтаксический анализ функции foo. Почему это неактуально? Потому что функция foo никогда не вызывается (или, по крайней мере, не в этот момент). Это простой пример, который может выглядеть необычно, но во многих реальных приложениях многие из заявленных функций никогда не вызываются.
Здесь вместо анализа функции foo мы можем отметить, что она объявлена без указания того, что она делает. Фактический анализ происходит при необходимости, непосредственно перед выполнением функции. И да, ленивый синтаксический анализ все еще должен найти все тело функции и сделать для нее объявление, но это все.Ему не нужно синтаксическое дерево, потому что оно еще не будет обрабатываться. Кроме того, он не выделяет память из кучи, которая обычно занимает изрядное количество системных ресурсов. Короче говоря, пропуск этих шагов приводит к значительному повышению производительности.
Итак, в предыдущем примере синтаксический анализатор действительно сделал бы что-то вроде следующего.
Обратите внимание, что объявление функции foo подтверждено, но это все. Больше ничего не было сделано для включения в тело самой функции.В этом случае тело функции было всего лишь одним оператором возврата. Однако, как и в большинстве реальных приложений, он может быть намного больше, содержать несколько операторов возврата, условий, циклов, объявлений переменных и даже вложенных объявлений функций. И все это будет пустой тратой времени и системных ресурсов, поскольку функция никогда не будет вызвана.
Это довольно простая концепция, но на самом деле ее реализация далеко не проста. Здесь мы показали один пример, который, безусловно, не единственный.Весь метод применяется к функциям, циклам, условным операторам, объектам и т. Д. В основном, ко всему, что нужно проанализировать.
Например, вот один довольно распространенный шаблон для реализации модулей в JavaScript.
Этот шаблон распознается большинством современных синтаксических анализаторов JavaScript и является сигналом о том, что код внутри должен быть быстро проанализирован.
Так почему же парсеры не всегда выполняют синтаксический анализ лениво? Если что-то анализируется лениво, это должно быть выполнено немедленно, и это фактически замедлит его работу.Он будет производить один ленивый синтаксический анализ и еще один активный синтаксический анализ сразу после первого. Это приведет к 50% замедлению по сравнению с простым анализом.
Теперь, когда у нас есть базовое представление о том, что происходит за кулисами, пора подумать о том, что мы можем сделать, чтобы помочь синтаксическому анализатору. Мы можем написать наш код таким образом, чтобы функции анализировались в нужное время. Есть один шаблон, который распознается большинством синтаксических анализаторов: заключение функции в круглые скобки. Это почти всегда положительный сигнал для парсера о том, что функция будет выполнена немедленно.Если синтаксический анализатор видит открывающую скобку и сразу после этого объявление функции, он с готовностью проанализирует функцию. Мы можем помочь синтаксическому анализатору, явно объявив функцию как таковую, которая будет выполняться немедленно.
Допустим, у нас есть функция с именем foo.
Поскольку нет очевидных признаков того, что функция будет выполнена немедленно, браузер будет выполнять ленивый синтаксический анализ. Однако мы уверены, что это неверно, поэтому можем сделать две вещи.
Сначала мы сохраняем функцию в переменной:
Обратите внимание, что мы оставили имя функции между ключевым словом функции и открывающей скобкой перед аргументами функции.В этом нет необходимости, но рекомендуется, поскольку в случае сгенерированного исключения трассировка стека будет содержать фактическое имя функции, а не просто <анонимный>.
Синтаксический анализатор все еще будет выполнять ленивый синтаксический анализ. Этого можно избежать, добавив одну небольшую деталь: заключив функцию в круглые скобки.
На этом этапе, когда синтаксический анализатор видит открывающую скобку перед ключевым словом функции, он немедленно приступит к синтаксическому анализу.
Это может быть довольно сложно управлять вручную, поскольку нам нужно знать, в каких случаях синтаксический анализатор решит анализировать код лениво или нетерпеливо.Кроме того, нам нужно будет подумать, будет ли определенная функция вызвана немедленно или нет. Мы определенно не хотим этого делать. И последнее, но не менее важное: это затруднит чтение и понимание нашего кода. Чтобы помочь нам в этом, на помощь приходят такие инструменты, как Optimize.js. Их единственная цель — оптимизировать время начальной загрузки исходного кода JavaScript. Они выполняют статический анализ вашего кода и модифицируют его таким образом, что функции, которые необходимо выполнить в первую очередь, заключаются в круглые скобки, чтобы браузер мог быстро проанализировать их и подготовить к выполнению.
Итак, мы кодируем как обычно, и есть фрагмент кода, который выглядит так:
Кажется, все в порядке, работает должным образом и быстро, потому что перед объявлением функции стоит открывающая скобка. Отлично. Конечно, перед запуском в производство нам нужно минимизировать наш код, чтобы сохранить байты. Следующий код является выводом минификатора:
Вроде нормально. Код работает как раньше. Однако чего-то не хватает. Минификатор удалил круглую скобку, заключающую функцию, и вместо этого поместил один восклицательный знак перед функцией.Это означает, что синтаксический анализатор пропустит это и выполнит ленивый синтаксический анализ. Сверху, чтобы иметь возможность выполнить функцию, он будет выполнять быстрый синтаксический анализ сразу после ленивого. Все это замедляет работу нашего кода. К счастью, у нас есть такие инструменты, как Optimize.js, которые делают за нас всю тяжелую работу. Передача миниатюрного кода через Optimize.js приведет к следующему результату:
Это больше похоже на это. Теперь у нас есть лучшее из обоих миров: код минимизирован, а синтаксический анализатор правильно определяет, какие функции нужно анализировать быстро, а какие — лениво.
Но почему мы не можем выполнить всю эту работу на стороне сервера? В конце концов, гораздо лучше сделать это один раз и предоставить результаты клиенту, чем заставлять каждого клиента выполнять свою работу каждый раз. Что ж, продолжается дискуссия о том, должны ли движки предлагать способ выполнения предварительно скомпилированных сценариев , чтобы на этот раз не тратить время зря в браузере. По сути, идея состоит в том, чтобы иметь инструмент на стороне сервера, который может генерировать байт-код, который нам нужно будет только передать по сети и выполнить на стороне клиента.Тогда мы увидим некоторые существенные различия во времени запуска. Это может показаться заманчивым, но не все так просто. Это может иметь противоположный эффект, поскольку он будет больше и, скорее всего, потребуется подписать код и обработать его по соображениям безопасности. Команда V8, например, работает над внутренним избеганием повторного анализа, чтобы предварительная компиляция на самом деле не была такой полезной.
- Проверьте свои зависимости. Избавьтесь от всего ненужного.
- Разделите код на более мелкие части вместо загрузки одного большого двоичного объекта.
- По возможности отложите загрузку JavaScript. Вы можете загрузить только необходимые фрагменты кода на основе текущего маршрута.
- Используйте инструменты разработчика и DeviceTiming, чтобы выяснить, где находится узкое место.
- Используйте такие инструменты, как Optimize.js, чтобы помочь синтаксическому анализатору решить, когда выполнять синтаксический анализ быстро, а когда нет.
SessionStack — это инструмент, который визуально воссоздает все, что происходило с конечными пользователями в то время, когда они столкнулись с проблемой при взаимодействии с веб-приложением.Инструмент не воспроизводит сеанс как реальное видео, а скорее моделирует все события в изолированной среде браузера. Это имеет некоторые последствия, например, в сценариях, когда кодовая база загруженной в данный момент страницы становится большой и сложной.
Вышеупомянутые методы — это то, что мы недавно начали включать в процесс разработки SessionStack. Такая оптимизация позволяет нам быстрее загружать SessionStack. Чем быстрее SessionStack может освободить ресурсы браузера, тем более плавный и естественный пользовательский интерфейс будет предлагать инструмент при загрузке и просмотре пользовательских сеансов.
Существует бесплатный план, если вы хотите попробовать SessionStack.
Ресурсы
Понимание критерия успеха 4.1.1: Анализ
Понимание критерия успеха 4.1.1: АнализНа этой странице:
Критерий успеха 4.1.1 Анализ (уровень A): в контенте, реализованном с использованием языков разметки, элементы имеют полное начало и конец. теги, элементы вложены в соответствии со своими спецификациями, элементы не содержат повторяющиеся атрибуты, и любые идентификаторы уникальны, кроме случаев, когда спецификации позволяют эти особенности.
Начальные и конечные теги, в формировании которых отсутствует критический символ, например в качестве закрывающей угловой скобки или кавычки с несоответствующим значением атрибута не полный.
Намерение
Целью данного критерия успеха является обеспечение того, чтобы пользовательские агенты, включая вспомогательные технологии, могут точно интерпретировать и анализировать контент. Если контент не может быть проанализированы в структуру данных, тогда разные пользовательские агенты могут представлять ее по-разному или быть совершенно неспособным его разобрать.Некоторые пользовательские агенты используют «методы восстановления» для рендеринга плохо закодированный контент.
Поскольку методы исправления различаются между пользовательскими агентами, авторы не могут предполагать, что контент будут точно проанализированы в структуре данных или будут правильно отображаться специализированными пользовательскими агентами, включая вспомогательные технологии, если контент не создается в соответствии с правилами, определенными в формальной грамматике для этой технологии.В языках разметки ошибки в синтаксисе элементов и атрибутов и отсутствие должным образом вложенных начальных / конечных тегов приводит к ошибкам, которые предотвратить надежный синтаксический анализ содержимого пользовательскими агентами. Следовательно, критерий успеха требует, чтобы контент можно было анализировать, используя только правила формальной грамматики.
Примечание
Понятие «хорошо сформированный» близко к тому, что здесь требуется.Однако точный разбор требования различаются между языками разметки, и большинство языков, не основанных на XML, не четко определить требования к правильной форме. Следовательно, необходимо было быть более явным в критерии успеха, чтобы его можно было применить к разметке. языков. Поскольку термин «правильно сформированный» определен только в XML, и (поскольку конец теги иногда необязательны) действительный HTML не требует хорошо сформированного кода, термин не используется в этом критерии успеха.
За исключением одного критерия успеха ( 1.4.2: Изменить размер текста, в котором конкретно упоминается, что эффект, указанный критерием успеха, должен можно достичь, не полагаясь на вспомогательные технологии) авторы могут добиться успеха критериев с контентом, который предполагает использование вспомогательных технологий (или доступ к функциям используемых агентов) пользователем, если такие вспомогательные технологии (или функции доступа в пользовательских агентах) существуют и доступны пользователю.
Преимущества
- Обеспечение того, чтобы веб-страницы имели полные начальные и конечные теги и были вложены в соответствии с к спецификации помогает гарантировать, что вспомогательные технологии могут анализировать контент точно и без сбой.
Методы
Каждый пронумерованный элемент в этом разделе представляет технику или комбинацию техник. что рабочая группа WCAG считает достаточным для выполнения этого критерия успеха.Тем не мение, нет необходимости использовать эти конкретные методы. Для получения информации об использовании других См. «Понимание методов для критериев успеха WCAG», особенно в разделе «Другие методы».
Достаточные методы
- G134: проверка веб-страниц
- G192: полностью соответствует спецификациям
- H88: Использование HTML в соответствии со спецификацией
Обеспечение возможности анализа веб-страниц с помощью одного из следующих методов:
- SL33: Использование хорошо сформированного XAML для определения пользовательского интерфейса Silverlight
Неисправности
Ниже приведены распространенные ошибки, которые считаются невыполнением данного критерия успеха. Рабочей группой WCAG.
Ключевые термины
c # — Что такое парсинг?
c # — что такое парсинг? — Переполнение стекаПрисоединяйтесь к Stack Overflow , чтобы учиться, делиться знаниями и строить свою карьеру.
Спросил
Просмотрено 86к раз
Парсинг— это то, с чем я часто сталкиваюсь в процессе разработки, но, будучи юниором, я полагаю, что в какой-то момент, когда это понадобится, я овладею им.В моем текущем проекте мне сказали найти и использовать синтаксический анализатор HTML для определенной функции, я нашел пару в Интернете.
Но что на самом деле делает анализатор HTML? А что значит разобрать объект?
Создан 24 ноя.
ГрейсГрейс2,1139 золотых знаков2323 серебряных знака2323 бронзовых знака
1Разбор обычно применяется к тексту — акт чтения текста и преобразования его в более полезный формат в памяти, в некоторой степени «понимая», что он означает.Так, например, синтаксический анализатор XML возьмет последовательность символов (или байтов) и преобразует их в элементы, атрибуты и т. Д.
В некоторых случаях (особенно в компиляторах) существует разделение между лексическим анализом и синтаксическим анализом, поэтому реальная «понимающая» часть синтаксического анализатора работает с последовательностью токенов (идентификаторов, операторов и т. Д.), А не с необработанными символами.
Создан 24 ноя.
Джон СкитДжон Скит1.3kkkkkk1 золотой знак87268726 серебряных знаков89308930 бронзовых знаков
При синтаксическом анализе берется набор данных и извлекается из него значимая информация. С помощью синтаксического анализа HTML вы хотите прочитать некоторый html и вернуть структурированный набор тегов и текста
Создан 24 ноя.
Адам Хопкинсон, Адам Хопкинсон26.7,177 золотых знаков5757 серебряных знаков8787 бронзовых знаков
Вы можете начать здесь: http://en.wikipedia.org/wiki/Parsing. Краткая выдержка:
Синтаксический анализ — это процесс анализа строки символы на естественном языке или на компьютерных языках, в соответствии с правилами формальной грамматики.Приходит термин синтаксический анализ от латинского pars (orationis), что означает часть (речи).
Создан 24 ноя.
Конамиман47.6k1616 золотых знаков108108 серебряных знаков133133 бронзовых знака
0Разбор (компьютеры) , по словарю.com:
Для анализа (строки символов), чтобы связать группы символов с синтаксическими единицами базовой грамматики.
Создан 24 ноя.
Игорь ОксИгорь Окс24.9k2525 золотых знаков8585 серебряных знаков112112 бронзовых знаков
2Парсер — это компонент компилятора / интерпретатора, который разбивает данные на более мелкие элементы для облегчения перевода на другой язык.Парсер принимает входные данные в виде последовательности токенов или программных инструкций и обычно строит структуру данных в виде дерева синтаксического анализа или абстрактного синтаксического дерева.
Создан 11 июн.
Гаджендра К. Чаухан3,34777 золотых знаков3838 серебряных знаков5454 бронзовых знака
В информатике и лингвистике синтаксический анализ или, более формально, синтаксический анализ — это процесс анализа текста, состоящего из последовательности токенов (например, слов), для определения его грамматической структуры по отношению к заданному (более или меньше) формальная грамматика.
: 0)
Википедия
Создан 24 ноя.
Монгус ПонгМонгус Понг10.7k99 золотых знаков4040 серебряных знаков7272 бронзовых знака
1Это процесс идентификации токенов [тегов, атрибутов] внутри HTML.
Создан 24 ноя.
рахулрахул1,977 22 золотых знака223223 серебряных знака254254 бронзовых знака
Не пытайтесь самостоятельно написать ничего, кроме тривиального синтаксического анализатора.Для этого есть хорошие инструменты: ANTLR и bison — вот два, о которых я могу вспомнить.
Если вы воспользуетесь этими инструментами, вы сможете попросить о помощи, когда столкнетесь с проблемой.
ура, Мартин.
Создан 24 ноя.
язык-CS
Stack Overflow лучше всего работает с включенным JavaScriptВаша конфиденциальность
Нажимая «Принять все файлы cookie», вы соглашаетесь с тем, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Принимать все файлы cookie Настроить параметры
Разбор XML и HTML с помощью lxml
lxml предоставляет очень простой и мощный API для синтаксического анализа XML и HTML.Это поддерживает одноэтапный синтаксический анализ, а также пошаговый синтаксический анализ с использованием API, управляемый событиями (в настоящее время только для XML).
Обычная процедура настройки:
>>> из lxml import etree
В следующих примерах также используются StringIO или BytesIO, чтобы показать, как анализировать из файлов и файловых объектов. Оба доступны в модуле io:
из io импорт StringIO, BytesIO
Парсеры представлены объектами парсеров. Есть поддержка парсинга как XML и (сломанный) HTML.Обратите внимание, что XHTML лучше всего анализировать как XML, анализируя его с помощью анализатор HTML может привести к неожиданным результатам. Вот простой пример для анализ XML из строки в памяти:
>>> xml = ' ' >>> корень = etree.fromstring (xml) >>> etree.tostring (корень) b ' '
Для чтения из файла или файлового объекта вы можете использовать функцию parse (), который возвращает объект ElementTree:
>>> дерево = etree.анализ (StringIO (xml)) >>> etree.tostring (tree.getroot ()) b ' '
Обратите внимание, как здесь функция parse () читает из файлового объекта. Если парсинг выполняется из реального файла, он более распространен (а также несколько больше эффективный) для передачи имени файла:
>>> tree = etree.parse ("doc / test.xml")
lxml может выполнять синтаксический анализ из локального файла, URL-адреса HTTP или URL-адреса FTP. Это также автоматически определяет и читает сжатые с помощью gzip файлы XML (.gz).
Если вы хотите выполнить синтаксический анализ из памяти и по-прежнему указать базовый URL-адрес документа (например, для поддержки относительных путей в XInclude) вы можете передать base_url аргумент ключевого слова:
>>> root = etree.fromstring (xml, base_url = "http://where.it/is/from.xml")
Параметры парсера
Парсеры принимают ряд параметров настройки в качестве аргументов ключевого слова. Над Пример легко расширяется для очистки пространств имен во время синтаксического анализа:
>>> parser = etree.XMLParser (ns_clean = True) >>> tree = etree.parse (StringIO (xml), парсер) >>> etree.tostring (tree.getroot ()) b ' '
Аргументы ключевого слова в конструкторе в основном основаны на libxml2. конфигурация парсера. DTD также будет загружен, если проверка или атрибут запрашиваются значения по умолчанию.
Доступные логические аргументы ключевого слова:
- attribute_defaults — прочтите DTD (если указано в документе) и добавьте атрибуты по умолчанию из него
- dtd_validation — проверить при разборе (если была ссылка на DTD)
- load_dtd — загрузить и проанализировать DTD во время синтаксического анализа (проверка не выполняется)
- no_network — запретить доступ к сети при поиске внешних документы (по умолчанию)
- ns_clean — попытаться очистить избыточные объявления пространств имен Восстановление
- — постарайтесь разобрать сломанный XML
- remove_blank_text — удалить пустые текстовые узлы между тегами, также известные как игнорируемые пробелы.Лучше всего использовать вместе с DTD или схемой. (который разделяет данные и шум), в противном случае будет применена эвристика.
- remove_comments — отменить комментарии
- remove_pis — удалить инструкции обработки
- strip_cdata — заменить разделы CDATA обычным текстовым содержимым (вкл. по умолчанию)
- resolve_entities — заменить сущности их текстовым значением (на по умолчанию)
- huge_tree — отключить ограничения безопасности и поддерживать очень глубокие деревья и очень длинное текстовое содержимое (влияет только на libxml2 2.7+)
- compact — использовать компактное хранилище для короткого текстового содержимого (по умолчанию включено)
- collect_ids — собирать XML-идентификаторы в хеш-таблице при парсинге (по умолчанию включено). Отключение этого может существенно ускорить парсинг документов со многими разные идентификаторы, если хеш-поиск не использовался впоследствии.
Другие аргументы ключевого слова:
- кодировка — переопределить кодировку документа
- target — целевой объект парсера, который будет получать события синтаксического анализа (см. Интерфейс целевого парсера) Схема
- — схема XML для проверки (см. Проверку)
Журнал ошибок
Парсерыимеют свойство error_log, в котором перечислены ошибки и предупреждения о последнем запуске парсера:
>>> parser = etree.XMLParser ()
>>> print (len (parser.error_log))
0
>>> tree = etree.XML (" \ n ", parser) # doctest: + ELLIPSIS
Отслеживание (последний вызов последний):
...
lxml.etree.XMLSyntaxError: несоответствие открывающего и конечного тегов: корневая строка 1 и b, строка 2, столбец 5 ...
>>> print (len (parser.error_log))
1
>>> error = parser.error_log [0]
>>> печать (сообщение об ошибке)
Несоответствие открывающего и конечного тегов: корневая строка 1 и b
>>> печать (error.line)
2
>>> print (error.столбец)
5
Каждая запись в журнале имеет следующие свойства:
- сообщение: текст сообщения
- домен: идентификатор домена (см. Класс lxml.etree.ErrorDomains)
- type: идентификатор типа сообщения (см. Класс lxml.etree.ErrorTypes) Уровень
- : идентификатор уровня журнала (см. Класс lxml.etree.ErrorLevels) Строка
- : строка, в которой было отправлено сообщение (если применимо) Столбец
- : символьный столбец, из которого было отправлено сообщение (если применимо)
- имя_файла: имя файла, в котором возникло сообщение (если применимо)
Для удобства есть также три свойства, которые обеспечивают читабельность имена для значений ID:
- имя_домена
- имя_типа
- имя_уровня
Чтобы отфильтровать сообщения определенного типа, используйте разные filter _ * () в журнале ошибок (см. lxml.etree._ListErrorLog класс).
Разбор HTML
РазборHTML также прост. У парсеров есть рековери аргумент ключевого слова, который HTMLParser устанавливает по умолчанию. Это позволяет libxml2 постарайтесь изо всех сил вернуть действительное дерево HTML со всем содержимым, которое оно может удалось разобрать. Это не вызовет исключения при ошибках парсера. Вы должны использовать libxml2 версии 2.6.21 или новее, чтобы воспользоваться преимуществами эта особенность.
>>> broken_html = "test <body> <h2><span class="ez-toc-section" id="%D0%B7%D0%B0%D0%B3%D0%BE%D0%BB%D0%BE%D0%B2%D0%BE%D0%BA_%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B8%D1%86%D1%8B"></span> заголовок страницы <span class="ez-toc-section-end"></span></h2></h4> " >>> парсер = etree.HTMLParser () >>> tree = etree.parse (StringIO (broken_html), парсер) >>> result = etree.tostring (tree.getroot (), ... pretty_print = True, method = "html") >>> print (результат) <html> <head> <title> тест заголовок страницы
Lxml имеет функцию HTML, аналогичную ярлыку XML, известному из ElementTree:
>>> html = etree.HTML (broken_html)
>>> result = etree.tostring (html, pretty_print = True, method = "html")
>>> print (результат)
тест
заголовок страницы
Поддержка разбора сломанного HTML полностью зависит от восстановления libxml2. алгоритм. Это , а не ошибка lxml, если вы найдете документы, которые так сильно нарушены, что синтаксический анализатор не может их обработать.Также нет гарантии что результирующее дерево будет содержать все данные из исходного документа. В парсеру, возможно, придется отбрасывать серьезно сломанные части, когда он пытается сохранить парсинг. От этого могут пострадать особенно неправильно размещенные метатеги, что может привести к к проблемам с кодированием.
Обратите внимание, что результатом является допустимое дерево HTML, но оно может не быть правильно сформированное дерево XML. Например, XML запрещает использование двойных дефисов в комментарии, которые HTML-парсер с радостью примет в режиме восстановления. Поэтому, если ваша цель — сериализовать HTML-документ как Документ XML / XHTML после разбора, возможно, придется применить какое-то руководство предварительная обработка в первую очередь.
Также обратите внимание, что анализатор HTML предназначен для анализа документов HTML. Для Документы XHTML используют синтаксический анализатор XML, который учитывает пространство имен.
Информация о Doctype
Использование парсеров libxml2 делает некоторую дополнительную информацию доступной на уровень API. В настоящее время объекты ElementTree могут обращаться к DOCTYPE информация, предоставленная анализируемым документом, а также версия XML и исходная кодировка. Начиная с lxml 3.5, ссылки на doctype изменяемы.
>>> pub_id = "- // W3C // DTD XHTML 1.0 Переходный // EN " >>> sys_url = "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd" >>> doctype_string = ''% (pub_id, sys_url) >>> xml_header = '' >>> xhtml = xml_header + doctype_string + ' ' >>> tree = etree.parse (StringIO (xhtml)) >>> docinfo = tree.docinfo >>> печать (docinfo.public_id) - // W3C // DTD XHTML 1.0 Переходный // EN >>> печать (docinfo.system_url) http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd >>> docinfo.doctype == doctype_string Правда >>> печать (docinfo.xml_version) 1.0 >>> print (docinfo.encoding) ascii >>> docinfo.system_url = Нет >>> docinfo.public_id = Нет >>> print (etree.tostring (дерево))
Как и в ElementTree и аналогично обработчику событий SAX, вы можете передать целевой объект для парсера:
>>> класс EchoTarget (объект):
... def start (self, tag, attrib):
... print ("start% s% r"% (tag, dict (attrib)))
... def end (self, tag):
... print (тег% "конец% s")
... def data (self, data):
... print ("data% r"% data)
... def comment (self, text):
... print ("комментарий% s"% текст)
... def close (self):
... print ("закрыть")
... вернуть "закрыто!"
>>> parser = etree.XMLParser (target = EchoTarget ())
>>> result = etree.XML (" some text ",
... парсер)
начальный элемент {}
данные u'some '
комментарий комментарий
данные u'text '
конечный элемент
Закрыть
>>> print (результат)
закрыто!
Важно, чтобы метод .close () сбрасывал цель парсера. в рабочее состояние, чтобы вы могли повторно использовать синтаксический анализатор так часто, как вы нравится:
>>> result = etree.XML (" какой-то текст ",
... парсер)
начальный элемент {}
данные u'some '
комментарий комментарий
данные u'text '
конечный элемент
Закрыть
>>> print (результат)
закрыто!
Начиная с lxml 2.3, метод .close () также будет вызываться в случай ошибки. Это отличается от поведения ElementTree, но позволяет целевым объектам очищать свое состояние во всех ситуациях, поэтому что синтаксический анализатор может впоследствии использовать их повторно.
>>> класс CollectorTarget (объект):
... def __init __ (сам):
... self.events = []
... def start (self, tag, attrib):
... self.events.append ("start% s% r"% (tag, dict (attrib)))
... def end (self, tag):
... self.events.append (тег% "конец% s")
... def data (self, data):
... self.events.append ("данные% r"% данные)
... def comment (self, text):
... self.events.append ("комментарий% s"% текст)
... def close (self):
... self.events.append ("закрыть")
... вернуть "закрыто!"
>>> parser = etree.XMLParser (target = CollectorTarget ())
>>> result = etree.XML (" some ",
... парсер) # doctest: + ELLIPSIS
Отслеживание (последний вызов последний):
...
lxml.etree.XMLSyntaxError: несоответствие открывающего и конечного тегов ...
>>> для события в parser.target.events:
... печать (событие)
начальный элемент {}
данные u'some '
Закрыть
Обратите внимание, что парсер , а не , строит дерево при использовании парсера. цель. Результатом запуска парсера является любой целевой объект возвращается из своего метода .close (). Если вы хотите вернуть XML дерево здесь, вы должны создать его программно в целевом объект. Примером цели парсера, которая строит дерево, является TreeBuilder:
>>> parser = etree.XMLParser (цель = etree.TreeBuilder ())
>>> result = etree.XML (" some text ",
... парсер)
>>> печать (result.tag)
элемент
>>> печать (результат [0]. текст)
комментарий
Начиная с lxml 2.0, парсеры имеют интерфейс парсера каналов, который совместим с парсерами ElementTree. Вы можете использовать его для подачи данных в парсер управляемым пошаговым способом.
В lxml.etree вы можете использовать оба интерфейса парсера одновременно. время: функции parse () или XML (), а также синтаксический анализатор каналов. интерфейс.Оба независимы и не будут конфликтовать (кроме случаев, когда они используются вместе с целевым объектом парсера, как описано выше).
Чтобы начать синтаксический анализ с помощью анализатора каналов, просто вызовите его метод feed () чтобы скормить ему некоторые данные.
>>> парсер = etree.XMLParser ()
>>> для данных в (' Когда вы закончите синтаксический анализ, вы должны вызвать метод close () для получить корневой элемент документа результата синтаксического анализа и разблокировать парсер:
>>> корень = парсер.Закрыть() >>> печать (root.tag) корень >>> печать (корень [0]. тег) а
Если вы не вызовете close (), синтаксический анализатор останется заблокированным и последующие каналы будут продолжать добавлять данные, что обычно приводит к правильно сформированный документ и непредвиденная ошибка парсера. Так что убедитесь, что вы всегда закрывайте парсер после использования, даже в случае исключения.
Другой способ добиться того же пошагового разбора — написать свой собственный файловый объект, который возвращает порцию данных при каждом вызове read ().Где интерфейс парсера каналов позволяет активно передавать фрагменты данных в парсер, файловый объект пассивно отвечает на запросы read () сам парсер. В зависимости от источника данных любой способ может быть более естественным.
Обратите внимание, что синтаксический анализатор каналов имеет собственный журнал ошибок, называемый feed_error_log. Ошибки парсера каналов не отображаются в обычный error_log и наоборот.
Вы также можете комбинировать интерфейс парсера каналов с целевым парсером:
>>> parser = etree.XMLParser (цель = EchoTarget ())
>>> parser.feed ("<элемент")
>>> parser.feed ("nt> какой-то текст >> parser.feed ("ent>")
конечный элемент
>>> результат = parser.close ()
Закрыть
>>> print (результат)
закрыто!
Опять же, это предотвращает автоматическое создание XML-дерева и оставляет вся обработка событий для целевого объекта. Метод close () парсера пересылает возвращаемое значение функции close () цели метод.
В Python 3.4 пакет xml.etree.ElementTree получил расширение к интерфейсу парсера каналов, который реализуется XMLPullParser класс. Это дополнительно позволяет обрабатывать события синтаксического анализа после каждого шаг инкрементного синтаксического анализа путем вызова метода .read_events () и повторение результата. Это наиболее полезно для неблокирующего выполнения. среды, в которых блоки данных прибывают один за другим и должны быть обрабатывается насколько это возможно на каждом этапе.
Та же функция доступна в lxml 3.3. Основное использование:
>>> parser = etree.XMLPullParser (events = ('начало', 'конец'))
>>> def print_events (парсер):
... для действия, элемент в parser.read_events ():
... print ('% s:% s'% (действие, element.tag))
>>> parser.feed (' какой-то текст')
>>> print_events (парсер)
начало: корень
>>> print_events (parser) # ну больше никаких событий, как раньше ...
>>> parser.feed ('<ребенок> ')
>>> print_events (парсер)
начало: ребенок
начать
конец: а
>>> парсер.корм (' >> print_events (парсер)
конец: ребенок
>>> parser.feed ('t>')
>>> print_events (парсер)
конец: корень
Как и обычный анализатор каналов, XMLPullParser строит дерево в памяти (и вы всегда должны вызывать метод .close (), когда выполняете с парсинг):
>>> корень = parser.close () >>> etree.tostring (корень) b 'какой-то текст '
Однако, поскольку синтаксический анализатор предоставляет инкрементный доступ к этому дереву, вы можете явно удалить контент, который вам больше не нужен, как только вы обработали это.Прочтите раздел об изменении дерева ниже чтобы увидеть, что вы можете здесь сделать и какие модификации вам следует избегать.
В lxml достаточно один раз вызвать метод .read_events () как итератор, который он возвращает, можно повторно использовать при появлении новых событий.
Также, как известно из других итераторов в lxml, вы можете передать тег аргумент, который выбирает, какие события синтаксического анализа возвращаются .read_events () итератор.
Типы событий
События синтаксического анализа представляют собой кортежи (тип события, объект).Типы событий ElementTree и lxml.etree поддерживают строки start, end, «начало-нс» и «конец-нс». События «начало» и «конец» представляют собой открытие и закрывающие элементы. Они сопровождаются соответствующим элементом пример. По умолчанию генерируются только «конечные» события, тогда как В приведенном выше примере запрашивается генерация как событий «start», так и «end».
События ‘start-ns’ и ‘end-ns’ уведомляют об объявлениях пространств имен. Они не поставляются с элементами. Вместо этого значение start-ns событие — это кортеж (префикс, namespaceURI), обозначающий начало преобразования префикса в пространство имен.Соответствующее событие end-ns делает не имеют значения (None). Обычной практикой является использование списка в качестве пространства имен. stack и вставьте последнюю запись в событие ‘end-ns’.
>>> def print_events (события):
... для действия, obj в событиях:
... если действие в ('начало', 'конец'):
... print ("% s:% s"% (действие, obj.tag))
... elif action == 'start-ns':
... print ("% s:% s"% (действие, объект))
... еще:
... печать (действие)
>>> event_types = ("начало", "конец", "начало-нс", "конец-нс")
>>> парсер = etree.XMLPullParser (event_types)
>>> events = parser.read_events ()
>>> parser.feed ('<корень> <элемент>')
>>> print_events (события)
начало: корень
начало: элемент
>>> parser.feed ('текст текст ')
>>> print_events (события)
конец: элемент
начало: элемент
конец: элемент
>>> parser.feed ('Изменение дерева
Вы можете изменить элемент и его потомков при обработке «конец» события. Например, для экономии памяти можно удалить поддеревья. которые больше не нужны:
>>> парсер = etree.XMLPullParser ()
>>> events = parser.read_events ()
>>> parser.feed (' текст ')
>>> parser.feed (' ')
>>> для действий, элементов в событиях:
... print ('% s:% d'% (elem.tag, len (elem))) # обработка
... elem.clear (keep_tail = True) # удалить потомков
элемент: 0
ребенок: 0
элемент: 1
>>> parser.feed (' ')
>>> для действий, элементов в событиях:
... print ('% s:% d'% (elem.tag, len (elem))) # обработка
... elem.clear (keep_tail = True) # удалить потомков
{http: // testns /} пустой элемент: 0
корень: 3
>>> корень = parser.close ()
>>> этрее.tostring (корень)
b '<корень />'
ПРЕДУПРЕЖДЕНИЕ : Во время события start любое содержимое элемента, например, потомки, следующие за братьями и сестрами или по тексту, еще не доступны и не должны быть доступны. Гарантированы только атрибуты установить. Во время события конца элемент и его потомки можно свободно изменять, но его следующие братья и сестры не должны быть доступ. Во время любого из двух событий вы не должны изменять или переместить предков (родителей) текущего элемента.Вам также следует не перемещайте и не выбрасывайте сам элемент. Золотое правило: делай не трогайте ничего, что нужно будет снова трогать синтаксическому анализатору позже.
Если у вас есть элементы с длинным списком дочерних элементов в вашем XML-файле и вы хотите чтобы сэкономить больше памяти во время синтаксического анализа, вы можете очистить предыдущих братьев и сестер текущего элемента:
>>> для события, элемента в parser.read_events (): ... # ... сделать что-нибудь с элементом ... element.clear (keep_tail = True) # очистить детей ... пока element.getprevious () не является None: ... del element.getparent () [0] # очищаем предыдущих братьев и сестер
Цикл while удаляет несколько братьев и сестер подряд. Это только необходимо если вы пропустили некоторые из них, используя аргумент ключевого слова тега. В противном случае следует сделать простое if. Чем более избирательным будет ваш тег, тем не менее, чем больше вы должны будете думать, чтобы найти правильный способ очистить пропущенные элементы. Поэтому иногда проще пройти по всем элементам и вручную выбрать тег в обработчике событий код.
Выборочные теги событий
Как расширение ElementTree, lxml.etree принимает ключевое слово тега аргумент точно так же, как element.iter (tag). Это ограничивает события конкретный тег или пространство имен:
>>> parser = etree.XMLPullParser (tag = "element")
>>> parser.feed (' текст ')
>>> parser.feed (' ')
>>> parser.feed (' ')
>>> для действия, элем в парсере.read_events ():
... print ("% s:% s"% (действие, elem.tag))
конец: элемент
конец: элемент
>>> event_types = ("начало", "конец")
>>> parser = etree.XMLPullParser (event_types, tag = "{http: // testns /} *")
>>> parser.feed (' текст ')
>>> parser.feed (' ')
>>> parser.feed (' ')
>>> для действия, элем в парсере.read_events ():
... print ("% s:% s"% (действие, elem.tag))
начало: {http: // testns /} пустой элемент
конец: {http: // testns /} пустой элемент
События с настраиваемыми целями
Вы можете комбинировать опрашивающий синтаксический анализатор с целью синтаксического анализатора. В этом случае, цель несет ответственность за создание значений событий. Что бы ни он возвращается из методов .start () и .end (). анализатором извлечения в качестве второго элемента кортежа событий синтаксического анализа.
>>> class Target (объект):
... def start (self, tag, attrib):
... print ('-> start (% s)'% тег)
... return '>> START:% s <<'% тег
... def end (self, tag):
... print ('-> end (% s)'% тег)
... return '>> END:% s <<'% тег
... def close (self):
... печать ('-> закрыть ()')
... вернуть "ЗАКРЫТО!"
>>> event_types = ('начало', 'конец')
>>> parser = etree.XMLPullParser (event_types, target = Target ())
>>> parser.feed (' ')
-> начало (корень)
-> начало (child1)
-> конец (child1)
-> начало (child2)
-> конец (child2)
-> конец (корень)
>>> для действия, значение в парсере.read_events ():
... print ('% s:% s'% (действие, значение))
начало: >> СТАРТ: корень <<
начало: >> СТАРТ: ребенок1 <<
конец: >> КОНЕЦ: ребенок1 <<
начало: >> СТАРТ: ребенок2 <<
конец: >> КОНЕЦ: ребенок2 <<
конец: >> КОНЕЦ: корень <<
>>> print (parser.close ())
-> закрыть ()
ЗАКРЫТО!
Как видите, значения событий даже не обязательно должны быть объектами Element. Цель обычно свободна решать, как она хочет создать дерево XML. или что-то еще, что он хочет сделать из обратных вызовов парсера.Во многих случаях, однако вы захотите, чтобы ваша настраиваемая цель унаследовала от TreeBuilder, чтобы он построил дерево, которое вы можете обработать обычно. Методы start () и .end () TreeBuilder возвращают созданный объект Element, поэтому вы можете переопределить их и изменить вход или выход в соответствии с вашими потребностями. Вот пример того, что фильтрует атрибуты перед добавлением в дерево:
>>> класс AttributeFilter (etree.TreeBuilder):
... def start (self, tag, attrib):
... attrib = dict (attrib)
... если в атрибуте "зло":
... del attrib ['зло']
... вернуть super (AttributeFilter, self) .start (tag, attrib)
>>> parser = etree.XMLPullParser (target = AttributeFilter ())
>>> parser.feed (' ')
>>> для действия, элемент в parser.read_events ():
... print ('% s:% s (% r)'% (действие, element.tag, element.attrib))
конец: child1 ({'test': '123'})
конец: child2 ({})
конец: корень ({})
>>> корень = парсер.Закрыть()
Как известно из ElementTree, служебная функция iterparse () возвращает итератор, который генерирует события парсера для файла XML (или файловый объект) при построении дерева. Вы можете думать об этом как блокирующая оболочка вокруг XMLPullParser, которая автоматически и постепенно считывает данные из входного файла для вас и предоставляет один итератор для них:
>>> xml = '' ' ... <корень> ...текст ...текст хвост ...... ... '' ' >>> context = etree.iterparse (StringIO (xml)) >>> для действия, элемент в контексте: ... print ("% s:% s"% (действие, elem.tag)) конец: элемент конец: элемент конец: {http: // testns /} пустой элемент конец: корень
После синтаксического анализа получившееся дерево доступно через свойство root итератора:
>>> context.root.tag 'корень'
Другие типы событий могут быть активированы с помощью аргумента ключевого слова events:
>>> events = ("начало", "конец")
>>> context = etree.iterparse (StringIO (xml), события = события)
>>> для действия, элемент в контексте:
... print ("% s:% s"% (действие, elem.tag))
начало: корень
начало: элемент
конец: элемент
начало: элемент
конец: элемент
начало: {http: // testns /} пустой элемент
конец: {http: // testns /} пустой элемент
конец: корень
iterparse () также поддерживает аргумент тега для селективного события. итерация и несколько других параметров, управляющих настройкой парсера. Аргумент тега может быть отдельным тегом или последовательностью тегов. Вы также можете использовать его для анализа ввода HTML, передав html = True.
iterwalk
Для удобства lxml также предоставляет функцию iterwalk (). Он ведет себя точно так же, как iterparse (), но работает с элементами и ElementTrees. Вот пример дерева, проанализированного iterparse ():
>>> f = StringIO (xml)
>>> context = etree.iterparse (
... f, events = ("начало", "конец"), tag = "элемент")
>>> для действия, элемент в контексте:
... print ("% s:% s"% (действие, elem.tag))
начало: элемент
конец: элемент
начало: элемент
конец: элемент
>>> корень = контекст.корень
И теперь мы можем взять получившееся в памяти дерево и перебрать его. используя iterwalk (), чтобы получить точно такие же события без анализа введите снова:
>>> context = etree.iterwalk (
... корень, events = ("начало", "конец"), tag = "элемент")
>>> для действия, элемент в контексте:
... print ("% s:% s"% (действие, elem.tag))
начало: элемент
конец: элемент
начало: элемент
конец: элемент
Чтобы не тратить время на неинтересные части дерева, прогулка итератору можно дать указание пропустить все поддерево с его .skip_subtree () метод.
>>> root = etree.XML ('' '
... <корень>
...
... Обратите внимание, что.skip_subtree () действует только при обработке start или старт-нс события.
lxml.etree имеет более широкую поддержку строк Unicode Python, чем ElementTree библиотека. Прежде всего, если ElementTree вызовет исключение, парсеры в lxml.etree могут сразу обрабатывать строки Unicode. Это самое полезно для фрагментов XML, встроенных в исходный код с помощью XML () функция:
>>> root = etree.XML (u '\ uf8d1 + \ uf8d2 ')
Это требует, однако, чтобы строки Unicode не указывали конфликтующие кодируют себя и, таким образом, лгут о своей реальной кодировке:
>>> etree.XML (u ' \ N' + ... u '\ uf8d1 + \ uf8d2 ') Отслеживание (последний вызов последний): ... ValueError: строки Unicode с объявлением кодировки не поддерживаются. Используйте ввод байтов или фрагменты XML без объявления.
Точно так же вы получите ошибки, если попробуете то же самое с данными HTML в строка Unicode, которая указывает кодировку в метатеге заголовка. Ты как правило, следует избегать преобразования данных XML / HTML в Unicode перед их передачей в парсеры.Это и медленнее, и подвержено ошибкам.
Сериализация в строки Unicode
Для сериализации результата обычно используется tostring () модульная функция, которая по умолчанию сериализуется в обычный ASCII или количество других байтовых кодировок, если требуется:
>>> etree.tostring (корень) b '<тест> & # 63697; + & # 63698; ' >>> etree.tostring (корень, кодировка = 'UTF-8', xml_declaration = False) b '\ xef \ xa3 \ x91 + \ xef \ xa3 \ x92 '
В качестве расширения lxml.etree распознает имя unicode как аргумент к параметру кодировки для построения представления дерева в Юникоде Python:
>>> etree.tostring (корень, кодировка = 'юникод') u '\ uf8d1 + \ uf8d2 ' >>> el = etree.Element ("тест") >>> etree.tostring (el, кодировка = 'юникод') u '' >>> subel = etree.SubElement (el, "подтест") >>> etree.tostring (el, кодировка = 'юникод') u ' ' >>> tree = etree.ElementTree (эль) >>> etree.tostring (дерево, кодировка = 'юникод') u ' '
Результат tostring (encoding = ‘unicode’) можно рассматривать как любой другая строка Unicode Python, а затем передается обратно в синтаксические анализаторы. Однако, если вы хотите сохранить результат в файл или передать его через сети, вы должны использовать write () или tostring () с байтом кодировка (обычно UTF-8) для сериализации XML. Основная причина — что строки Unicode, возвращаемые tostring (encoding = ‘unicode’), являются не байтовые потоки, и у них никогда не было декларации XML, чтобы указать их кодировка.Эти строки, скорее всего, не могут быть проанализированы другими Библиотеки XML.
Для обычных байтовых кодировок функция tostring () автоматически добавляет объявление по мере необходимости, которое отражает кодировку возвращенная строка. Это позволяет другим анализаторам правильно проанализировать поток байтов XML. Обратите внимание, что использование tostring () с UTF-8 также значительно быстрее в большинстве случаев.
Date.parse () — JavaScript | MDN
Метод Date.parse () анализирует строковое представление
дату и возвращает количество миллисекунд с 1 января 1970 г., 00:00:00 UTC или NaN , если строка нераспознана или, в некоторых случаях, содержит недопустимую дату
значения (например,грамм. 2015-02-31).
Не рекомендуется использовать Date.parse как до ES5, синтаксический анализ строк
полностью зависел от реализации. Есть еще много различий в том, насколько разные
хосты анализируют строки даты, поэтому строки даты следует анализировать вручную (библиотека
может помочь, если нужно приспособить много разных форматов).
Прямой звонок:
Date.parse (dateString)
Неявный вызов:
новая дата (dateString)
Параметры
Возвращаемое значение
Число, представляющее миллисекунды, прошедшие с 1 января 1970 г., 00:00:00 UTC и
дата, полученная путем анализа заданного строкового представления даты.Если аргумент
не представляет собой действительную дату, возвращается NaN .
Метод parse () принимает строку даты (например,
« 2011-10-10T14: 48: 00 ») и возвращает количество миллисекунд с января.
1, 1970, 00:00:00 UTC.
Эта функция полезна для установки значений даты на основе строковых значений, например, в
в сочетании с методом setTime () и Дата объекта.
Формат строки даты и времени
Стандартное строковое представление строки даты и времени является упрощением стандарта ISO 8601 расширенный формат календарной даты.(См. Раздел Строка даты и времени. Отформатируйте в спецификации ECMAScript для более подробной информации.)
Например, « 2011-10-10 » ( форма только для даты ),
« 2011-10-10T14: 48: 00 » (форма дата-время ), или
« 2011-10-10T14: 48: 00.000 + 09: 00 » ( дата-время форма с миллисекундами
и часовой пояс) могут быть переданы и будут проанализированы. Если смещение часового пояса отсутствует,
формы только для даты интерпретируются как время в формате UTC, а формы даты и времени интерпретируются как
местное время.
В то время как спецификаторы часового пояса используются во время синтаксического анализа строки даты для интерпретации
аргумент, возвращаемое значение всегда представляет собой количество миллисекунд между 1 января,
1970 00:00:00 UTC и момент времени, представленный аргументом или NaN .
Поскольку parse () является статическим методом Date , он вызывается как Date.parse () , а не как метод экземпляра Date .
Вернуться к форматы даты, зависящие от реализации
Примечание: Этот раздел содержит поведение, зависящее от реализации, которое может быть несовместимым. в разных реализациях.
Спецификация ECMAScript гласит: Если строка не соответствует стандарту
форматирование функция может вернуться к любой эвристике, зависящей от реализации, или
алгоритм синтаксического анализа, зависящий от реализации. Неузнаваемые строки или даты, содержащие
недопустимые значения элементов в строках в формате ISO должны привести к тому, что Date.parse () будет
вернуть NaN .
Однако недопустимые значения в строках даты не распознаются как упрощенный формат ISO, как
определенный ECMA-262 может привести или не привести к NaN , в зависимости от браузера
и предоставленные значения, e.г .:
новая дата ('23 / 25/2014 ');
будет рассматриваться как локальная дата 25 ноября 2015 года в Firefox 30 и недопустимая дата. в Safari 7.
Однако, если строка распознается как строка формата ISO и содержит недопустимый
значений, он вернет NaN во всех браузерах, совместимых с ES5 и более поздними версиями:
новая дата ('2014-25-23'). toISOString ();
Эвристику SpiderMonkey, зависящую от реализации, можно найти в jsdate.cpp .
Строка « 10 06 2014 » является примером несоответствующего формата ISO и
таким образом возвращается к пользовательской процедуре. См. Также этот приблизительный набросок на
как работает парсинг.
новая дата ('10 06 2014 ');
будет считаться местной датой 6 октября 2014 г., а не 10 июня 2014 г.
Другие примеры:
новая дата ('foo-bar 2014'). ToString ();
Date.parse ('foo-bar 2014');
Различия в предполагаемом часовом поясе
Примечание: Этот раздел содержит поведение, зависящее от реализации, которое может быть несовместимым. в разных реализациях.
Учитывая нестандартную строку даты « 7 марта 2014 г. », parse () предполагает местный часовой пояс, но с учетом упрощения календарной даты ISO 8601
расширенный формат, такой как « 2014-03-07 », будет использоваться часовой пояс UTC.
(ES5 и ECMAScript 2015). Следовательно, Date объектов, созданных с использованием этих
строки могут представлять разные моменты времени в зависимости от версии ECMAScript
поддерживается, если в системе не установлен местный часовой пояс UTC.Это означает, что два
строки даты, которые кажутся эквивалентными, могут приводить к двум различным значениям в зависимости от
формат преобразуемой строки.
Использование
Date.parse () Все следующие вызовы возвращают 1546300800000 . Первый по ES5
будет подразумевать время UTC, а другие указывают часовой пояс UTC через дату ISO
спецификация ( Z и +00: 00 )
Date.parse ("2019-01-01")
Date.parse ("2019-01-01T00: 00: 00.000Z ")
Date.parse ("2019-01-01T00: 00: 00.000 + 00: 00")
Следующий вызов, в котором не указан часовой пояс, будет установлен на 2019-01-01 в 00:00:00 в местном часовом поясе системы.
Date.parse ("2019-01-01T00: 00: 00")
Нестандартные строки даты
Примечание: Этот раздел содержит поведение, зависящее от реализации, которое может быть несовместимым. в разных реализациях.
Если IPOdate является существующим объектом Date , для него может быть установлено значение
9 августа 1995 г. (время местное) следующим образом:
IPOdate.setTime (Date.parse ('9 августа 1995 г.'));
Еще несколько примеров разбора нестандартных строк даты:
Date.parse («9 августа 1995 г.»);
Возвращает 807937200000 в часовом поясе GMT-0300 и другие значения в другое время.
зоны, поскольку строка не указывает часовой пояс и не является форматом ISO, поэтому
часовой пояс по умолчанию — местный.
Date.parse ('среда, 9 августа 1995 г., 00:00:00 GMT');
Возвращает 807926400000 независимо от местного часового пояса, поскольку GMT (UTC)
при условии.
Date.parse ('среда, 9 августа 1995 г., 00:00:00');
Возвращает 807937200000 в часовом поясе GMT-0300 и другие значения в другое время.
зоны, поскольку в аргументе нет спецификатора часового пояса и это не формат ISO,
поэтому считается местным.
Date.parse («Чт, 1 января 1970 г., 00:00:00 по Гринвичу»);
Возвращает 0 независимо от местного часового пояса, поскольку часовой пояс GMT (UTC) является
при условии.
Дата.parse ('Чт, 1 января 1970 г., 00:00:00');
Возвращает 14400000 в часовом поясе GMT-0400 и другие значения в другое время.
зоны, поскольку часовой пояс не указан и строка не в формате ISO, поэтому
используется местный часовой пояс.
Date.parse («Чт, 1 января 1970 г., 00:00:00 GMT-0400»);
Возвращает 14400000 независимо от местного часового пояса в качестве часового пояса GMT (UTC).
при условии.
Таблицы BCD загружаются только в браузере
Замечания по совместимости
- Firefox 49 изменил синтаксический анализ двузначного года, чтобы он соответствовал Google Chrome
браузер вместо Internet Explorer.Теперь двузначные годы меньше, чем
50анализируются как годы 21 века. Например,16.04.17, ранее проанализированный как 16 апреля 1917 г., будет 16 апреля 2017 г. сейчас. Чтобы избежать проблем с совместимостью или неоднозначных лет, рекомендуется использовать формат ISO 8601, например «2017-04-16» (ошибка 1265136). - Google Chrome примет числовую строку как допустимую
dateStringпараметр.