Морфологический разбор глагола «умеет» онлайн. План разбора.
Для слова «умеет» найден 1 вариант морфологического разбора
- Часть речи. Общее значение
Часть речи слова «умеет» — глагол - Морфологические признаки.
- уметь (инфинитив)
- Постоянные признаки:
- 1-е спряжение
- непереходный
- несовершенный вид
- изъявительное наклонение
- единственное число
- настоящее время
- 3-е лицо.
- Может относится к разным членам предложения.
Поделитесь страницей с друзьями — это лучшая благодарность
Морфологический разбор другого слова
План разбора глагола
- Часть речи. Общее значение
- Морфологические признаки.
- Начальная форма (инфинитив)
- Постоянные признаки:
- Вид (совершенный (что сделать?) или несовершенный (что делать?)
- переходный (употребляется с сущeствительным в винительном падеже без предлога)/ непереходный (не употребляется с существительным в винительном падеже без предлога).

- Спряжение
- Наклонение в зависимости от вопроса:
- Изъявительное — что делал? что делает? что сделает?
- Повелительное — что делай?
- условное — что делал бы? что сделал бы?
- Число
- Время (если есть)
- Лицо (если есть)
- Род (если есть)
- Синтаксическая роль (подчеркнуть как член предложения, является главным или второстепенным членом предложения)

Поделитесь страницей с друзьями — это лучшая благодарность
Оцени материал
14 голосов, оценка 4.500 из 5
План разбора составлен на основе общих правил, в зависимости от класса и предпочтений учителя ответ может отличаться. Если ваш план разбора отличается от представленного, просто сопоставьте его с данными нашего ответа.
Если морфологический разбор глагола «умеет» имеет несколько вариантов, то выберите наиболее подходящий вариант разбора исходя из контекста предложения.
Разборы производились исходя из заложенного программного алгоритма, результаты в редких случаях могут быть недостоверны, если вы нашли несоответствие пожалуйста сообщите нам. Представленный результат используется вами на свой страх и риск.
Морфологический разбор глагола Умеет. Начальная форма, часть речи, постоянные и непостоянные признаки
Выполним онлайн морфологический разбор слова «умеет» (часть речи: глагол) в соответствии с правилами русского языка. Слово состоит из трех слогов. Ударение в слове «умЕет» падает на букву «е».
Часть речи
глагол
Синтаксическая роль
В зависимости от контекста
Морфологические признаки
| Постоянные признаки | непереходный, несовершенный вид, 1 спряжение |
| Непостоянные признаки | настоящее время, 3-e лицо, изъявительное наклонение, единственное число |
| Начальная форма | уметь |
Фонетический (звуко-буквенный) разбор слова
ум’`эй’ит
Слово по слогам (3)
у-ме-ет
Перенос слова
уме-ет
Данный разбор был сделан с помощью искусственного интеллекта и может быть не правильным.
 Результаты разбора могут быть использованы исключительно для самопроверки.
Если вы нашли ошибку, оставьте комментарий в форме ниже.
Результаты разбора могут быть использованы исключительно для самопроверки.
Если вы нашли ошибку, оставьте комментарий в форме ниже.Ещё никто не оставил комментария, вы будете первым.
Написать комментарий
Спасибо за комментарий, он будет опубликован после проверки
Морфологический разбор слова: песчаный удавчик умеет ползать
Введите слово или предложение и получите морфологический разбор с указанием части речи, падежа, рода, времени и т.д.
Начальная форма: ПЕСЧАНЫЙ
Часть речи: прилагательное
Грамматика: единственное число, именительный падеж, качественное прилагательное, мужской род, неодушевленное, одушевленное
Формы: песчаный, песчаного, песчаному, песчаным, песчаном, песчаная, песчаной, песчаную, песчаною, песчаное, песчаные, песчаных, песчаными, песчан, песчана, песчано, песчаны, песчанее, песчаней, попесчанее, попесчаней
Начальная форма: УДАВЧИК
Грамматика: единственное число, именительный падеж, мужской род, одушевленное, фамилия
Формы: удавчик, удавчика, удавчику, удавчиком, удавчике, удавчики, удавчиков, удавчикам, удавчиками, удавчиках
Начальная форма: УМЕТЬ
Часть речи: глагол в личной форме
Грамматика: третье лицо, действительный залог, единственное число, переходный, несовершенный вид, настоящее время
Формы: уметь, умею, умеем, умеешь, умеете, умеет, умеют, умел, умела, умело, умели, умея, умев, умевши, умей, умейте, умеющий, умеющего, умеющему, умеющим, умеющем, умеющая, умеющей, умеющую, умеющею, умеющее, умеющие, умеющих, умеющими, умевший, умевшего, умевшему, умевшим, умевшем, умевшая, умевшей, умевшую, умевшею, умевшее, умевшие, умевших, умевшими
Начальная форма: ПОЛЗАТЬ
Часть речи : инфинитив
Грамматика: действительный залог, переходный, несовершенный вид
Формы: ползать, ползаю, ползаем, ползаешь, ползаете, ползает, ползают, ползал, ползала, ползало, ползали, ползая, ползав, ползавши, ползай, ползайте, ползающий, ползающего, ползающему, ползающим, ползающем, ползающая, ползающей, ползающую, ползающею, ползающее, ползающие, ползающих, ползающими, ползавший, ползавшего, ползавшему, ползавшим, ползавшем, ползавшая, ползавшей, ползавшую, ползавшею, ползавшее, ползавшие, ползавших, ползавшими
Телеканал «Россия-РТР» / Программа телепередач на сегодня и на неделю
Выбрать страну:
АвстралияАвстрияАзербайджанАлбанияАлжирАмериканское СамоаАнгильяАнголаАндорраАнтарктидаАнтигуа и БарбудаАргентинаАрменияАрубаАфганистанБагамыБангладешБарбадосБахрейнБеларусьБелизБельгияБенинБермудыБолгарияБоливияБосния и ГерцеговинаБотсванаБразилияБританская территория в Индийском океанеБруней-ДаруссаламБуркина-ФасоБурундиБутанВануатуВеликобританияВенгрияВенесуэлаВиргинские острова, БританскиеВиргинские острова, СШАВьетнамГабонГаитиГайанаГамбияГанаГваделупаГватемалаГвинеяГвинея-БисауГерманияГернсиГибралтарГондурасГонконгГренадаГренландияГрецияГрузияГуамДанияДжерсиДжибутиДоминикаДоминиканская РеспубликаЕгипетЗамбияЗападная СахараЗимбабвеИзраильИндияИндонезияИорданияИракИранИрландияИсландияИспанияИталияЙеменКабо-ВердеКазахстанКамбоджаКамерунКанадаКатарКенияКипрКиргизияКирибатиКитайКокосовые (Килинг) островаКолумбияКоморыКонгоКонго, Демократическая РеспубликаКоста-РикаКот д’ИвуарКубаКувейтЛаосЛатвияЛесотоЛиберияЛиванЛивийская Арабская ДжамахирияЛитваЛихтенштейнЛюксембургМаврикийМавританияМадагаскарМайоттаМакаоМалавиМалайзияМалиМалые Тихоокеанские отдаленные острова Соединенных ШтатовМальдивыМальтаМароккоМартиникаМаршалловы островаМексикаМикронезия, Федеративные ШтатыМозамбикМолдова, РеспубликаМонакоМонголияМонтсерратМьянмаНамибияНауруНепалНигерНигерияНидерландыНикарагуаНиуэНовая ЗеландияНовая КаледонияНорвегияОАЭОманОстров МэнОстров НорфолкОстров РождестваОстров Святого МартинаОстрова КайманОстрова КукаОстрова Теркс и КайкосПакистанПалауПалестинская территория, оккупированнаяПанамаПапский Престол (Государство -; город Ватикан)Папуа-Новая ГвинеяПарагвайПеруПиткернПольшаПортугалияПуэрто-РикоРеспублика МакедонияРеюньонРоссияРуандаРумынияСамоаСан-МариноСан-Томе и ПринсипиСаудовская АравияСвазилендСвятая ЕленаСеверная КореяСеверные Марианские островаСейшелыСен-БартельмиСенегалСен-Пьер и МикелонСент-Винсент и ГренадиныСент-Китс и НевисСент-ЛюсияСербияСингапурСирияСловакияСловенияСоломоновы островаСомалиСуданСуринамСШАСьерра-ЛеонеТаджикистанТаиландТайваньТанзанияТимор-ЛестеТогоТокелауТонгаТринидад и ТобагоТувалуТунисТуркменияТурцияУгандаУзбекистанУкраинаУоллис и ФутунаУругвайФарерские островаФиджиФилиппиныФинляндияФолклендские острова (Мальвинские)ФранцияФранцузская ГвианаФранцузская ПолинезияФранцузские Южные территорииХорватияЦентрально-Африканская РеспубликаЧадЧерногорияЧехияЧилиШвейцарияШвецияШпицберген и Ян МайенШри-ЛанкаЭквадорЭкваториальная ГвинеяЭландские островаЭль-СальвадорЭритреяЭстонияЭфиопияЮжная АфрикаЮжная Джорджия и Южные Сандвичевы островаЮжная КореяЯмайкаЯпонияВыбрать зону:
Europe/Moscow GMT +02:00Europe/Kaliningrad GMT +02:00Europe/Volgograd GMT +03:00Europe/Samara GMT +04:00Asia/Yekaterinburg GMT +04:00Asia/Omsk GMT +05:00Asia/Novokuznetsk GMT +07:00Asia/Novosibirsk GMT +06:00Asia/Krasnoyarsk GMT +06:00Asia/Irkutsk GMT +07:00Asia/Yakutsk GMT +08:00Asia/Khandyga GMT +09:00Asia/Vladivostok GMT +09:00Asia/Sakhalin GMT +10:00Asia/Magadan GMT +10:00Asia/Ust-Nera GMT +10:00Asia/Kamchatka GMT +12:00Asia/Anadyr GMT +12:00 Алгоритм— синтаксический анализатор для анализа условий поиска и извлечения ценной информации алгоритм
— синтаксический анализатор для анализа условий поиска и извлечения ценной информации — qaru Присоединяйтесь к Stack Overflow , чтобы учиться, делиться знаниями и строить свою карьеру.
Спросил
Просмотрено 467 раз
Хотите улучшить этот вопрос? Обновите вопрос, чтобы он соответствовал теме Stack Overflow.
Закрыт 7 лет назад.
Я хотел бы понять термин «пользователь». Подумайте о том, что кто-то ищет «основные продукты в Нью-Йорке» — я хотел бы понять, что это поиск по местоположению, где ключевое слово — это основные продукты, а местоположение — Нью-Йорк.
331k7070 золотых знаков694694 серебряных знака805805 бронзовых знаков
Создан 20 июн.
ШамикШамик 6,48299 золотых знаков5252 серебряных знака7272 бронзовых знака Проблема, которую вы описываете, называется извлечением информации.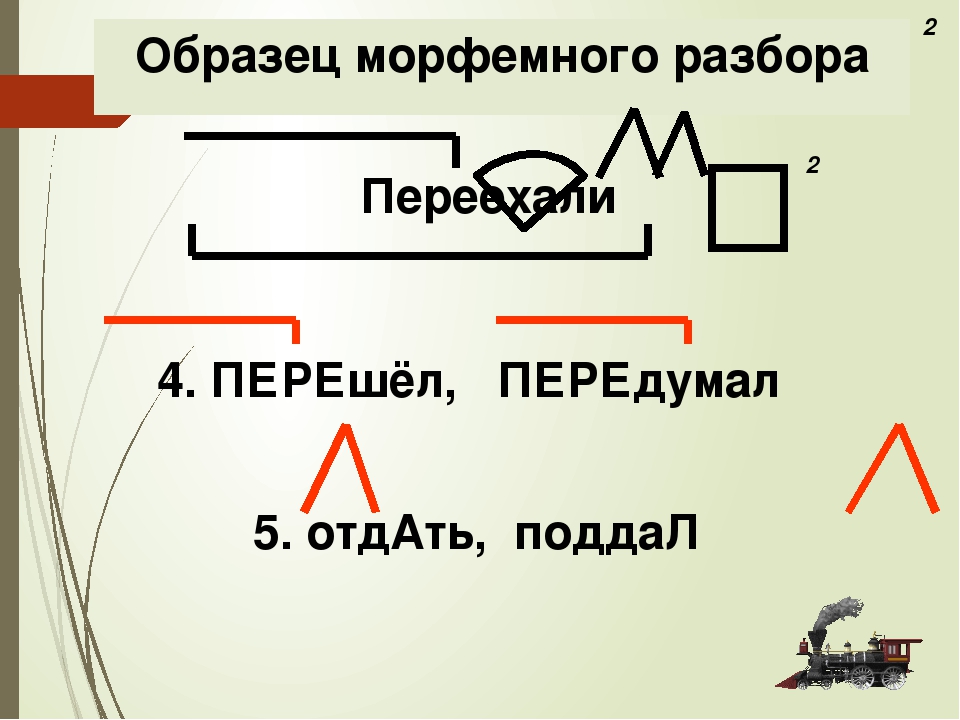 Существует множество алгоритмов, самым простым из которых является сопоставление регулярных выражений, лучше всего структурированное машинное обучение. Сначала попробуйте регулярные выражения и посмотрите на что-нибудь вроде NLTK, если вы знаете Python.
Существует множество алгоритмов, самым простым из которых является сопоставление регулярных выражений, лучше всего структурированное машинное обучение. Сначала попробуйте регулярные выражения и посмотрите на что-нибудь вроде NLTK, если вы знаете Python.
Отличить «основные продукты в Нью-Йорке» от «кот в шляпе» можно, если ваша программа знает, что «Нью-Йорк» — это место. Вы можете сказать либо по заглавным буквам, либо потому, что «NY» встречается в списке, который называется географическим справочником.
Создан 20 июн.
Фред ФуФред Фу331k7070 золотых знаков694694 серебряных знака805805 бронзовых знаков
3 Вы должны написать такие лингвистические правила в грамматиках, таких как GATE и http: // code.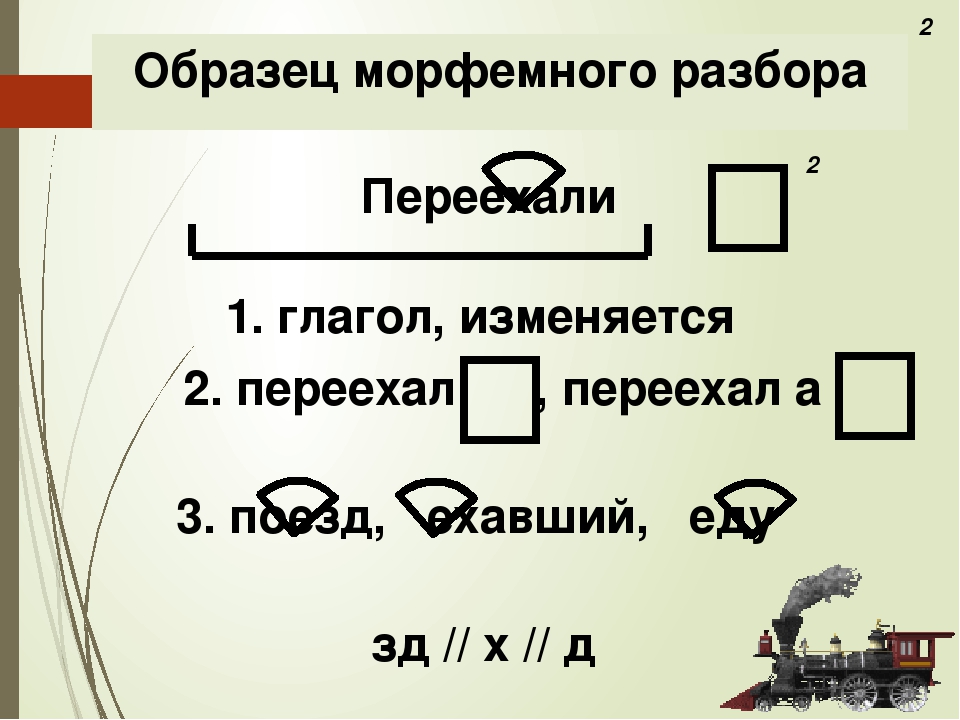 google.com/p/graph-expression/.
Примеры:
Токен + в (LocationLookup).
google.com/p/graph-expression/.
Примеры:
Токен + в (LocationLookup).
Создан 21 июн.
Юраюра14.2k1919 золотых знаков7171 серебряный знак123123 бронзовых знака
Не совсем уверен, но два подхода согласно моему опыту синтаксического анализа —
Определите грамматику, которая может анализировать выражение и собирать значения / параметры.Возможно, вы захотите составить словарь ключевых слов, с помощью которого вы сможете определить тип поиска.
Будьте строги при определении вашей грамматики, чтобы само выражение говорило вам о типе поиска. например, LOC: A в B, VALUE $ в евро.
пр.
 пр.
пр.Для синтаксического анализатора см. ANTLR / jcup & jflex.
Создан 20 июн.
NrjNrj6,27666 золотых знаков4444 серебряных знака5757 бронзовых знаков
Stack Overflow лучше всего работает с включенным JavaScriptВаша конфиденциальность
Нажимая «Принять все файлы cookie», вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Принимать все файлы cookie Настроить параметры
ios — Разбор JSON в предопределенный класс в Objective C
Мы можем автоматически сопоставить ответ json в наших классах модели с помощью сторонней библиотеки
JSONMode https: // github.ru / mattiaslevin / ObjectMapper
Просто создайте свой класс, как показано ниже, и определите свойства вашей модели данных. Будьте осторожны, ключи вашего ответа json должны быть такими же, как и свойство, которое вы определяете. Вы получите более четкое изображение ниже, потому что я делюсь своим ответом json со структурой классов модели —
Ответ json
{
«код»: 200,
"данные": [
{
"stockName": "sh000001",
"категория": "китай",
"stockStatus": "открыто",
"дорожная карта": [
{
"stockTimeStamp": "10:25",
«stockValue»: «2789. 915 ",
«число1»: 1,
«число2»: 5
},
{
"stockTimeStamp": "10:30",
"stockValue": "2790.153",
«число1»: 5,
«число2»: 3
}
],
"gameData": [
{
"gameUUID": "e4fcd001-2499-45c3-a21c-d573b9e378cc",
"gameStatus": "Открыть"
}
]
},
{
"stockName": "usindex",
"category": "usa",
"stockStatus": "открыто",
"дорожная карта": [
{
"stockTimeStamp": "10:20",
"stockValue": "100.1020 ",
«число1»: 2,
"число2": 0
},
{
"stockTimeStamp": "10:25",
"stockValue": "100.0958",
«число1»: 5,
«число2»: 8
}
],
"gameData": [
{
"gameUUID": "1a6c9889-41e9-410a-a409-e10126ffeeb5",
"gameStatus": "Открыть"
}
]
},
{
"stockName": "btc1",
«категория»: «криптовалюта»,
"stockStatus": "открыто",
"дорожная карта": [
{
"stockTimeStamp": "02:26",
"stockValue": "7670. 00 ",
«число1»: 0,
"число2": 0
},
{
"stockTimeStamp": "02:25",
"stockValue": "7670.00",
«число1»: 0,
"число2": 0
}
],
"gameData": [
{
"gameUUID": "40526121-f199-4649-b169-9913bd883186",
"gameStatus": "Открыть"
}
]
}
],
"статус": правда,
"сообщение": [
"успех"
]
}
 915 ",
«число1»: 1,
«число2»: 5
},
{
"stockTimeStamp": "10:30",
"stockValue": "2790.153",
«число1»: 5,
«число2»: 3
}
],
"gameData": [
{
"gameUUID": "e4fcd001-2499-45c3-a21c-d573b9e378cc",
"gameStatus": "Открыть"
}
]
},
{
"stockName": "usindex",
"category": "usa",
"stockStatus": "открыто",
"дорожная карта": [
{
"stockTimeStamp": "10:20",
"stockValue": "100.1020 ",
«число1»: 2,
"число2": 0
},
{
"stockTimeStamp": "10:25",
"stockValue": "100.0958",
«число1»: 5,
«число2»: 8
}
],
"gameData": [
{
"gameUUID": "1a6c9889-41e9-410a-a409-e10126ffeeb5",
"gameStatus": "Открыть"
}
]
},
{
"stockName": "btc1",
«категория»: «криптовалюта»,
"stockStatus": "открыто",
"дорожная карта": [
{
"stockTimeStamp": "02:26",
"stockValue": "7670.
915 ",
«число1»: 1,
«число2»: 5
},
{
"stockTimeStamp": "10:30",
"stockValue": "2790.153",
«число1»: 5,
«число2»: 3
}
],
"gameData": [
{
"gameUUID": "e4fcd001-2499-45c3-a21c-d573b9e378cc",
"gameStatus": "Открыть"
}
]
},
{
"stockName": "usindex",
"category": "usa",
"stockStatus": "открыто",
"дорожная карта": [
{
"stockTimeStamp": "10:20",
"stockValue": "100.1020 ",
«число1»: 2,
"число2": 0
},
{
"stockTimeStamp": "10:25",
"stockValue": "100.0958",
«число1»: 5,
«число2»: 8
}
],
"gameData": [
{
"gameUUID": "1a6c9889-41e9-410a-a409-e10126ffeeb5",
"gameStatus": "Открыть"
}
]
},
{
"stockName": "btc1",
«категория»: «криптовалюта»,
"stockStatus": "открыто",
"дорожная карта": [
{
"stockTimeStamp": "02:26",
"stockValue": "7670. 00 ",
«число1»: 0,
"число2": 0
},
{
"stockTimeStamp": "02:25",
"stockValue": "7670.00",
«число1»: 0,
"число2": 0
}
],
"gameData": [
{
"gameUUID": "40526121-f199-4649-b169-9913bd883186",
"gameStatus": "Открыть"
}
]
}
],
"статус": правда,
"сообщение": [
"успех"
]
}
00 ",
«число1»: 0,
"число2": 0
},
{
"stockTimeStamp": "02:25",
"stockValue": "7670.00",
«число1»: 0,
"число2": 0
}
],
"gameData": [
{
"gameUUID": "40526121-f199-4649-b169-9913bd883186",
"gameStatus": "Открыть"
}
]
}
],
"статус": правда,
"сообщение": [
"успех"
]
}
Ваша модель.h файл
#import "JSONModel.h"
@interface RoadmapElementModel: JSONModel
@property (неатомарный) NSInteger number1;
@property (неатомарный) NSInteger number2;
@property (неатомный) NSString * stockTimeStamp;
@property (неатомный) NSString * stockValue;
@конец
@interface RoadmapDataModel: JSONModel
@property (неатомный) NSString * stockName;
@property (неатомарный) NSString * category;
@property (неатомный) NSString * stockStatus;
@property (неатомарный) NSArray * roadMap;
@конец
@interface RoadMapModel: JSONModel
@property (неатомарный) код NSInteger;
@property (неатомный) статус BOOL;
@property (неатомный) NSArray * данные;
@property (неатомарный) NSArray * message;
@конец
Примечание: — Вам не нужно ничего писать в вашу модель YourModel. файл. h
h
Теперь просто напишите ниже код после получения ответа JsonString в вашем классе ViewController
NSError * error;
RoadMapModel * дорожная карта = [[распределение RoadMapModel] initWithString: ошибка myString: & ошибка];
Как автоматически копировать данные из ваших электронных писем
eBay отправлено по электронной почте — кто-то заказал что-то в вашем магазине. Ваш банк отправил вам ежемесячный отчет по электронной почте, ваша кредитная карта напоминает вам об оплате счета, а Apple напоминает вам о приложении, которое вы купили вчера вечером.И контактная форма на вашем веб-сайте хороша, но каждое сообщение — это еще одна вещь, которая накапливается в вашем почтовом ящике.
В вашем почтовом ящике уведомления — это только больше беспорядка, больше вещей, которые нужно архивировать и забыть. Было бы проще сортировать эту информацию и управлять ею в электронной таблице или базе данных, но для этого вам потребуется время, чтобы скопировать текст из электронных писем и вставить его в другое место.
Или вы можете позволить приложению сделать эту работу за вас. Вот как автоматически анализировать текст электронных писем и эффективно использовать их данные.
Что такое анализатор электронной почты?
Когда ваш босс или лучший друг пишет по электронной почте, вы, вероятно, читаете каждое слово.
В остальное время, скорее всего, вы просматриваете сообщение. Ваш взгляд быстро бегает по экрану, выбирая ключевые слова и фразы, такие как Новая распродажа и 4,99 долл. США и Срок платежа: пятница, 3 ноября .
Сделайте свой бизнес более эффективным с Zapier
Парсеры электронной почты работают таким же образом. Вы учите эти программы распознавать закономерности в ваших электронных письмах, сообщаете им, какие данные на самом деле важны, а все остальное можно игнорировать, а затем заставляете их сохранять только важные данные.Затем подключите анализатор электронной почты к инструменту автоматизации, например Zapier, чтобы сохранить этот важный текст в других приложениях, чтобы вы могли регистрировать заказы, например, в электронной таблице или получать напоминание об оплате счета по кредитной карте завтра. Поскольку все электронные письма в целом составлены одинаково, анализатор электронной почты должен уметь определять, что важно, и копировать данные за вас.
Поскольку все электронные письма в целом составлены одинаково, анализатор электронной почты должен уметь определять, что важно, и копировать данные за вас.
Понял? ОК. Давайте сделаем резервную копию и шаг за шагом создадим парсер электронной почты, который может копировать текст из ваших писем и заставлять его работать.Мы будем использовать парсер электронной почты Zapier — бесплатный инструмент для копирования текста из ваших писем. Если вы используете другой инструмент синтаксического анализа электронной почты, эти указания по-прежнему будут применяться — основы работают одинаково в каждом приложении, и как только вы знаете, как анализировать одно электронное письмо, вы знаете, как анализировать их все.
и далее.
Как анализировать электронную почту
Создать новый почтовый ящик парсера электронной почты
Отправить электронное письмо парсеру
Научить синтаксический анализатор читать вашу электронную почту
Автоматически пересылать электронные письма парсеру
Используйте проанализированные данные электронной почты
1.
 Создайте новый почтовый ящик парсера электронной почты
Создайте новый почтовый ящик парсера электронной почтыПервый шаг — самый простой. Просто перейдите на parser.zapier.com, войдите в свою учетную запись Zapier или создайте новую учетную запись, затем нажмите любую из кнопок Create Mailbox (обозначены стрелками на снимке экрана ниже), чтобы добавить новый почтовый ящик.
Email Parser покажет вам адрес электронной почты, например [email protected].
Скопируйте этот адрес и держите его под рукой, потому что именно по нему вам нужно будет отправлять электронные письма для последующего анализа.
2. Отправьте электронное письмо синтаксическому анализатору
Теперь, когда у вас скопирован новый адрес электронной почты, откройте приложение электронной почты, найдите (или напишите) электронное письмо, подобное тем, которые вы хотите использовать с анализатором электронной почты. Я хочу, чтобы Email Parser сообщал мне о новых сообщениях в блоге Zapier (мета, я знаю), поэтому я пересылаю недавнее электронное письмо от Деб из Zapier.
Нажмите кнопку, чтобы переслать электронное письмо, введите свой адрес электронной почты @ robot.zapier.com в поле Кому: и нажмите Отправить .
3. Научите синтаксический анализатор читать вашу электронную почту.
Выберите текст, который синтаксический анализатор должен скопировать, затем дайте ему уникальное имя.Пора надеть шляпу учителя. Как только Zapier Email Parser получит ваше письмо, он покажет текстовую версию вашего письма в поле Initial Template . Все, что вам нужно сделать, это найти важные данные и сказать парсеру, что именно это нужно скопировать.
Прокрутите вниз до текста, который вы хотите, чтобы анализатор электронной почты скопировал, и выберите его.Используя электронную почту, которую я использовал, я хочу знать заголовки в разделе «Рекомендуемая литература от команды блога Zapier», поэтому я выбираю текст из каждого из них. Для каждого выделенного фрагмента текста введите имя этого элемента в поле и нажмите Сохранить . Анализатор электронной почты заменит текст на имя в фигурных скобках, например
Анализатор электронной почты заменит текст на имя в фигурных скобках, например {{headline1}} .
Повторите это для каждого фрагмента текста, который синтаксический анализатор электронной почты должен скопировать. Я тоже выбрал каждую тему и дал каждому элементу уникальное имя.
Как только это будет сделано, нажмите синюю кнопку Сохранить адрес и шаблон внизу — и ваш анализатор электронной почты готов к работе.
Анализатор электронной почты будет работать лучше всего, если выбранный вами текст будет написан одинаково в каждом электронном письме — возможно, цифра после слова Всего или ссылка, написанная после слова Щелкните здесь . Значение может измениться, но анализатор электронной почты будет работать лучше всего, если предыдущий текст будет всегда одинаковым и в одном и том же месте.
Хотите сделать парсер электронной почты более надежным? Перешлите другое аналогичное электронное письмо на тот же адрес, затем щелкните Просмотр электронных писем рядом с именем вашего анализатора в списке Почтовых ящиков Zapier Email Parser, чтобы просмотреть все электронные письма, полученные этим почтовым ящиком.
Щелкните Показать на одном из элементов, чтобы увидеть текст сообщения электронной почты, при этом текст Email Parser выделен желтым цветом.
Если что-то выглядит неправильно (как в моем примере выше), щелкните ссылку Изменить дополнительный шаблон внизу.Выберите тот же текст, который вы изначально хотели скопировать из своих писем, дайте ему те же имена, а затем сохраните новый шаблон. Вы можете повторить это несколько раз, чтобы сделать ваш синтаксический анализатор более надежным.
Вы можете использовать тот же метод для анализа любого обычного электронного письма, которое вы получаете. Например, вы можете научить его распознавать названия продуктов и цены в электронных письмах с подтверждением покупки от Amazon или Apple.
4. Автоматическая пересылка новых писем в анализатор
Созданный вами анализатор электронной почты теперь готов копировать текст из других похожих писем — в данном случае из новостной рассылки Zapier Blog. Нам нужно отправлять каждую новую рассылку на анализатор электронной почты.
Нам нужно отправлять каждую новую рассылку на анализатор электронной почты.
Лучшим вариантом является автоматизация работы с помощью фильтра в приложении электронной почты для автоматической пересылки сообщений, соответствующих тому, которое вы отправили в Email Parser. Как правило, все ваши электронные письма с уведомлениями имеют что-то общее — они исходят от одного и того же отправителя и часто имеют одну и ту же тему. В моем примере эти электронные письма приходят с адреса [email protected] и содержат слова «Рекомендуемая литература от команды разработчиков блога Zapier».
Чтобы отслеживать эти электронные письма в Gmail, вам сначала нужно добавить свой адрес парсера электронной почты в Gmail для автоматической пересылки писем.Вот как:
Откройте настройки пересылки Gmail — щелкните значок шестеренки, выберите Настройки , затем щелкните вкладку Пересылка .
Нажмите кнопку Добавить адрес пересылки там.
Введите адрес электронной почты вашего парсера электронной почты @ robot.zapier.com в текстовое поле и щелкните рядом с .
Проверьте свою электронную почту — Zapier должен отправить вам письмо с подтверждением от Gmail. Если вы его не видите, проверьте почтовый ящик приложения Email Parser — в нем должен быть адрес электронной почты.В любом случае скопируйте код подтверждения , затем вставьте его в поле в настройках Gmail Forwarding .

Теперь вы можете настроить автоматическую пересылку писем в Gmail парсеру электронной почты. Сначала найдите адрес электронной почты и / или тему сообщений, которые вы будете обрабатывать парсером электронной почты; Я вхожу с: [email protected] И «Рекомендуемая литература от команды блогов Zapier». Щелкните крошечную стрелку вниз справа от строки поиска, чтобы просмотреть все параметры расширенного поиска — затем щелкните кнопку или ссылку Создать фильтр в правом нижнем углу. Попросите этот фильтр пересылать электронное письмо на адрес парсера электронной почты, который вы только что добавили, и все должно быть настроено.
Попросите этот фильтр пересылать электронное письмо на адрес парсера электронной почты, который вы только что добавили, и все должно быть настроено.
После небольшого упражнения с мышью и клавиатурой все готово. Каждый раз, когда Деб из Zapier присылает вам последний информационный бюллетень Zapier — или всякий раз, когда вы получаете любые другие сообщения электронной почты, которые хотите проанализировать, — Gmail отправляет их парсеру электронной почты.
Если вы используете другую службу электронной почты, проверьте свою документацию, чтобы узнать, может ли ваше приложение или служба автоматически пересылать сообщения электронной почты.
5. Заставьте ваши проанализированные данные электронной почты работать
Одного копирования текста из электронных писем недостаточно — вам нужно что-то делать с этими данными. Самый простой вариант — подключить парсер электронной почты к приложениям автоматизации Zapier, что позволяет отправлять данные из ваших электронных писем в тысячи других популярных рабочих приложений — от Airtable до Zoho.
Посетите Zapier и войдите в систему или зарегистрируйтесь, если вы еще этого не сделали. Затем нажмите Make a Zap , чтобы начать. Выберите Email Parser в качестве триггерного приложения, затем выберите триггерное событие New Email .Подключите свою учетную запись парсера электронной почты, если вы еще этого не сделали, и выберите адрес парсера, который вы только что настроили.
Zapier может использовать текст, который анализатор электронной почты находит, но вы хотитеПосле этого вы можете использовать данные электронной почты. На шаге Action выберите приложение, в которое вы хотите отправить данные электронной почты. Я хотел получать SMS-уведомление о последних заголовках, поэтому выбрал действие SMS приложения Zapier «Отправить SMS ».
Чтобы использовать данные электронной почты, щелкните любое поле в действии Zap и выберите любое из значений из триггера Zap. Здесь я добавил темы и заголовки из имени и цены из Email Parser в SMS-уведомления — вы, возможно, можете добавить имена и адреса электронной почты в свой информационный бюллетень по электронной почте, записывать информацию о продажах в строки электронной таблицы или, тем не менее, использовать свои данные электронной почты. ты хочешь.
Здесь я добавил темы и заголовки из имени и цены из Email Parser в SMS-уведомления — вы, возможно, можете добавить имена и адреса электронной почты в свой информационный бюллетень по электронной почте, записывать информацию о продажах в строки электронной таблицы или, тем не менее, использовать свои данные электронной почты. ты хочешь.
Проверьте Zap, чтобы убедиться, что все работает так, как вы хотите, включите его, и все готово!
Еще не знаете, куда отправлять эти электронные письма? Начните сохранять их с помощью этих ZapЕсли вы похожи на меня, у вас есть много писем, которые, как вы знаете, вы уже хотите автоматизировать, но вы не совсем уверены, куда нужно отправлять всю информацию. еще.В таких случаях может быть удобно запустить Zap, который анализирует электронные письма и сохраняет их в электронную таблицу, чтобы вы могли позже вернуться к хорошо организованным данным.
Нажмите Попробовать в одном из этих рекомендуемых Zap-файлов, чтобы сразу же начать сохранять проанализированные электронные письма в Google Таблицах или Airtable, или чтобы настроить собственное SMS-уведомление для электронной почты:
Теперь, когда вы анализируете свою электронную почту, узнайте больше способы автоматизации этой информации и использования ее в других приложениях. Автоматически отправляйте проанализированную информацию в приложение для управления задачами или проектами, настраивайте пользовательские уведомления, создавайте события календаря, обновляйте контакты и т. Д.
Автоматически отправляйте проанализированную информацию в приложение для управления задачами или проектами, настраивайте пользовательские уведомления, создавайте события календаря, обновляйте контакты и т. Д.
Электронная почта является способом по умолчанию для большинства приложений для отправки уведомлений и другой информации, и может быть лучшим способом автоматизации приложений, которые не имеют своей интеграции. Благодаря синтаксическому анализатору электронной почты и рабочим процессам Zapier ваш почтовый ящик может заставить ваши самые важные электронные письма работать на вас, как только они приходят — больше не нужно копировать и вставлять из вашего почтового ящика.Если инструмент анализа электронной почты Zapier не помогает вам, попробуйте один из этих лучших инструментов анализа электронной почты.
Хотите, чтобы ваш почтовый ящик стал еще более продуктивным? Вот несколько отличных руководств Zapier, которые помогут:
Эта статья была первоначально опубликована в октябре 2018 года. Она была обновлена в декабре 2020 года Тайлером Робертсоном, членом персонала Zapier.
Она была обновлена в декабре 2020 года Тайлером Робертсоном, членом персонала Zapier.
Кредиты изображений: фоновая фотография океана от Димитрис Ветсикас через Pixabay
Разбор с разделителями в Pega
Последнее обновление 1 января 2019 г.
Введение
В этом посте мы увидим более подробно правила синтаксического анализа и различные методы синтаксического анализа
Правило с разделителями для синтаксического анализа работает в основном вместе с правилами служебных файлов, которые используются при обработке файлов.
Что такое обработка файлов?
Мы знаем, что почти все приложения работают с данными. Данные можно собирать разными способами. Самый распространенный способ сбора данных в pega — с портала конечного пользователя.
Мы храним данные как свойства в Pega
Сбор данных с портала конечного пользователя — не единственный способ получения данных. Данные могут быть получены через веб-службы (REST, SOAP и т. Д.), Службы обмена сообщениями, электронную почту и файлы.
Данные могут быть получены через веб-службы (REST, SOAP и т. Д.), Службы обмена сообщениями, электронную почту и файлы.
Давайте сконцентрируемся на данных, которые мы получаем от файловых сервисов.
Мы знаем, что Pega может связываться с другими системами (Java, DotNet ..) через службы. Если нам нужна загрузка данных из других систем, мы можем предпочесть получать данные в виде файла. Таким образом, можно заключить соглашение с внешней системой таким образом, чтобы внешняя система снабжала нас файлом (ежедневно, еженедельно или через любой временной интервал).
Мы должны использовать данные из файла и сопоставить их со свойствами Pega. Чтобы мы могли использовать данные и процессы в Pega.
Pega предоставляет определенные правила синтаксического анализа для отображения данных, которые мы получаем из внешней системы, в систему Pega.
Доступные правила синтаксического анализа:
- Анализировать с разделителями
- Разбор Нормализовать
- Структурированный анализ
- Разобрать XML
Здесь я остановился на обработке файлов.
Но… сообщения о слушателе файлов, служебном файле скоро появятся. Кто знает, может быть следующим постом
В этом посте я сосредоточусь на правилах с разделителями, которые широко используются при обработке файлов.
Что такое правило parse с разделителями?
- Правило синтаксического анализа с разделителями используется для синтаксического анализа данных из файлов и сопоставления свойствам Pega.
- Любой символ может использоваться в качестве разделителя и может использоваться для различения данных.
Примечание: Обычно, когда внешняя система предоставляет данные, они всегда используют некоторый разделитель (запятая, | или кавычки для различения данных)
Если в качестве разделителя используется запятая, тогда необработанные данные Premkumar, G, Male могут быть сопоставлены со свойствами FirstName, LastName, Gender.
Где можно сослаться на правило с разделителями синтаксического анализа?
- Используется в основном вместе с правилами служебных файлов.
- Может использоваться в действии с использованием метода Apply-Parse-Delimited.

Каковы точки конфигурации в правиле с разделителями синтаксического анализа?
Давайте начнем с создания нового правила синтаксического анализа с разделителями
Шаг 1: записей -> Интеграция-сопоставление -> Анализировать с разделителями -> Создать
Тип записи может использоваться для группировки похожих правил с разделителями, используемых для определенных целей. Я просто назвал его как образец, и у меня есть более одного правила с разделителями синтаксического анализа с образцом типа записи.
Шаг 2: Создать и открыть
Правила разбора — это единственная основная вкладка, которая содержит всю конфигурацию
Каковы точки конфигурации в правиле с разделителями синтаксического анализа ?
Во вкладке Parse rules нам может понадобиться настроить 3 блока
- Описание поля
- Способ обработки
- Детали анализа
Описание поля
Формат поля — указывает формат входных данных
Это могут быть значения, разделенные запятыми, или пользовательское определение.
a) Значения, разделенные запятыми — название поясняет :).Запятая действует как разделитель.
Всегда используется, если входной файл имеет формат .CSV. Вы всегда можете экспортировать файл Excel в файл csv.
Демо, мы увидим позже.
b) Пользовательское определение — вы можете определить некоторые пользовательские параметры разделителя.
Здесь я снова использовал запятую в качестве разделителя.
Escape character — Зачем нам это ?!
Скажем, пример, в котором данные о клиенте предоставляются в качестве входных данных
Три клиентских поля: имя, пол и адрес
Aarti, Female, Тамилнад, Индия
Здесь мне нужно сопоставить, как показано ниже
Имя = Аарти
Пол = Женский
Адрес = Тамилнад, Индия
Но будет ли он так разбираться, если мы используем запятую в качестве разделителя ?! Да и нет
- Да, если вы используете правильный escape-символ.Я указал / как escape-символ, и тогда мои входные данные должны быть Aarti, Female, TamilNadu /, India
Теперь вы знаете, какова роль персонажа побега.
- Escape-символ всегда должен стоять перед разделителем, который необходимо игнорировать.
Способ обработки
Этот блок позволяет нам выбрать любой из методов парсинга
Метод— у вас есть 4 разных варианта синтаксического анализа
a) Составьте список тегов
б) Использовать список тегов
c) Используйте детали синтаксического анализа
d) Построить список значений
c) Используйте детали синтаксического анализа
(Не думайте, что я пропустил списки тегов :), подождите!)
При выборе этой опции вы можете использовать блок деталей синтаксического анализа , чтобы указать детали синтаксического анализа
Слить оставшиеся данные
Скажем, например, внешняя система предоставляет чертовски много данных во входном файле.Если нас интересуют только первые 3 поля, то мы можем проанализировать только первые 3 поля и слить оставшиеся данные.
В большинстве случаев мы используем выбранную опцию «Слить оставшиеся данные»!
Подробности анализа
- Этот блок используется только двумя методами синтаксического анализа — использовать сведения о синтаксическом анализе и метод построения списка значений
Обязательно — вы знаете, зачем он используется. Анализ будет остановлен, если обязательное поле недоступно во входном файле data
Описание — объяснять не буду
Карта — у вас есть разные варианты.
Выберите карту для значения — здесь вы можете либо использовать свойство буфера обмена для прямого сопоставления, либо мы также можем ссылаться на другие правила синтаксического анализа, такие как правило синтаксического анализа XML, правило синтаксического анализа с разделителями и правило структурированного синтаксического анализа.
Выберите правило-служебная функция-функция — Здесь вы можете использовать функции, принадлежащие библиотеке MapTo.
А пока давайте воспользуемся буфером обмена в качестве карты для
.Map to Key — на основе Map to type мы можем указать ключ
Поскольку мы использовали буфер обмена, нам нужно использовать свойство.
Ха, пора тестировать 🙂
Как проверить правило синтаксического анализа с разделителями?
Шаг 1: Создайте новый синтаксический анализ с разделителями, как показано в этом сообщении
Шаг 2: Выполните следующую конфигурацию
Формат поля — значения, разделенные запятыми
Метод — Используйте детали синтаксического анализа
Детали синтаксического анализа — Сопоставить с двумя свойствами буфера обмена pyLabel и pyNote
Шаг 4: Запустите правило синтаксического анализа с разделителями и введите ввод, как показано ниже.Выберите текст для анализа.
Шаг 5: Откройте трассировщик и нажмите «Выполнить».
Примечание: Правило синтаксического анализа можно выбрать в настройках трассировщика.
Нажмите «Выполнить» и проверьте правило трассировки.
Как видите, правило синтаксического анализа выполнено успешно путем синтаксического анализа ввода с использованием разделителя.
pyNote = Разбор; pyLabel = FirstTest
Хорошо
Повторите шаги 2–5, используя другой формат поля, и проверьте его.
Давайте проверим конфигурацию escape-символа.
Шаг 1: Выполните следующую конфигурацию
Разделитель как% и escape-символ как &
Шаг 2: введите данные, как показано ниже.
Например, некоторые люди используют псевдоним в своем имени. В таком случае, когда символ @ используется в качестве разделителя, он распознает псевдоним @ как символ разделителя. Нам нужно указать escape-символ, чтобы преодолеть его
Myknowpega @ Рави и @ Радж
Итак, символы и должны выходить за пределы разделителя @ , предшествующего Raj
Шаг 3: отследите и найдите его на странице.
Теперь давайте проверим другие методы синтаксического анализа
d) Создать список значений
Вы знаете, когда нам нужно использовать эту опцию?
Просто выберите эту опцию, очистите блок деталей синтаксического анализа и попробуйте сохранить его.
Вы видите два ограничения в сообщении об ошибке
- В блоке сведений о парсинге должна быть настроена только одна строка.
- Он должен отображаться в свойство буфера обмена типа список значений!
Сценарий: скажем, внешняя система отправляет список телефонных номеров в виде значений, разделенных запятыми, и вам необходимо сохранить телефонные номера в свойстве списка значений PhoneNumber
Шаг 1: укажите следующую конфигурацию в правиле синтаксического анализа.
Примечание. TelephoneNumber — это свойство списка значений OOTB.
Шаг 2: Запустите правило синтаксического анализа и введите ввод, как показано ниже
Шаг 3: Проверьте выходные данные трассировщика. Он должен видеть, что номера телефонов встроены в свойство списка значений «TelephoneNumber»
.Последние два метода — близнецы
Обычно мы используем его вместе.
a и b) Создание списка тегов и использование списка тегов
Чем они занимаются?
Сборка списка тегов — создает список значений (такой же, как список значений сборки), но использует стандартное свойство — pyTagList, определенный встроенным, и сопоставляется со страницей «Работа».Вы не можете изменить эти настройки по умолчанию!
Почему он так устроен, где он будет использоваться?
Может использоваться другим правилом синтаксического анализа с методом синтаксического анализа использовать список тегов 🙂
- Таким образом, использование метода синтаксического анализа списка тегов всегда ожидает свойства значения pyTagList на странице «Работа».
Итак, создать список тегов и использовать список тегов являются партнерами группы тегов 😀
Все еще запутались ?!
Приведу вам пример.
Представьте себе, внешняя система отправляет имя и возраст клиента в файле csv.Часть заголовка (первая строка файла csv) содержит имена свойств pega, которые содержат значения в следующих строках.
Примерно так
Здесь первая строка соответствует свойствам pega Имя, Возраст. Остальные строки соответствуют значениям.
Примечание: Когда вы используете список тегов сборки и опцию списка тегов, оставьте блок сведений о синтаксическом анализе пустым, потому что он не используется , , потому что вы используете свойство OOTB .pyTagList.
Давайте посмотрим на это в действии.
Шаг 1: Используйте приведенную ниже конфигурацию в правиле с разделителями для синтаксического анализа, как показано ниже
Сначала мы создаем список тегов.
Шаг 2: На данный момент я не хочу использовать какие-либо файлы. Мы будем использовать это в моем следующем посте
Использовать входные данные первой строки. Имя и возраст
Примечание: Имя и возраст должны быть созданы уже как свойство pega . Если свойство pega недоступно, проверка страницы может завершиться ошибкой
Шаг 3: Выполнить.Нет необходимости отслеживать. Щелкните буфер обмена, чтобы проверить страницу Работа в стандарте потока.
Теперь мы успешно проанализировали заголовок и сопоставили его со свойством pyTagList.
Шаг 4: для тестирования, просто обновите то же правило синтаксического анализа, используя метод списка тегов.
Шаг 5: предоставьте входное значение, соответствующее заголовку, который мы проанализировали при последнем запуске.
Шаг 6: Откройте трассировщик и выполните его
Примечание: Только список тегов сборки создает новую страницу Работа и сохраняет заголовок в pyTagList.Использовать тег Метод списка использует значения .pyTagList (анализируемые свойства) обновляет значение на первичной странице.
Теперь вы знаете, как использовать список тегов сборки и список тегов.
Список тегов сборки анализирует строку заголовка, а список тегов использования сохраняет данные, соответствующие строке заголовка синтаксического анализа.
У Pega уже есть две функции MapTo, выполняющие аналогичную работу
1. parseCsvHeader — Разобрать строку заголовка и сохранить ее в формате.pyTagList свойство. Вы можете проверить базовый код Java.
2. ParseCsvDetail — находит рабочую страницу и использует значения .pyTagList для анализа данных
Хорошо !!
Мы знаем, что правило с разделителями синтаксического анализа может использоваться в правилах служебных файлов и правилах действий.
Как использовать синтаксический анализ в правиле активности?
- Используйте метод «Apply-Parse-Delimited» для ссылки на правило синтаксического анализа с разделителями.
Примечание: В правиле активности вы всегда можете проанализировать строку с помощью разделителя
В этом примере мы собираемся воссоздать пример номера телефона, используя список значений сборки
.Шаг 1: Создайте новую тестовую операцию «ParseSample»
Шаг 2: Добавьте шаг установки свойств и добавьте строку номера телефона в pyLabel
Шаг 3: Используйте конфигурацию синтаксического анализа с разделителями, как показано ниже
Шаг 4: Теперь добавьте новый шаг в правило активности с помощью метода Apply-Parse-Delimited и добавьте правило Parse с разделителями.
Параметры метода : Namespace и RecordType используются для идентификации правила синтаксического анализа с разделителями, а SourceProperty должно ссылаться на свойство или параметр, содержащий строку входных данных
Шаг 5: Сохраните правило. Откройте трассировку и запустите правило
Готово
Я чувствую, что перетащил этот пост !! Если это так, пожалуйста, дайте мне знать. При необходимости могу отредактировать.
Этот пост открывает дверь для постов по служебному файлу, слушателю файла.До скорой встречи с новыми сообщениями 🙂
Нравится:
Нравится Загрузка …
СвязанныеКак использовать действие Parse JSON в Power Automate
Мы можем видеть много JSON в нашей истории выполнения потока Power Automate, и если вам интересно, как вы можете проанализировать JSON, чтобы сделать из него динамический контент (который выбирается), чтобы вам было легче использовать объект , то этот пост создан для вас.
Если вы хотите узнать, что такое JSON и что вам нужно знать о нем, прочтите эту замечательную статью Боба Германа в сообществе Microsoft 365 PnP в TechCommunity или сначала посмотрите это классное видео от Эйприл Даннэм, я просто подожду здесь для тебя.
небольшой пример использования
Снова вернулся? Прохладный. Теперь, когда вы знаете, что такое JSON, рассмотрим небольшой пример использования. Допустим, мы хотели каждый день публиковать случайный элемент из списка SharePoint в Twitter с помощью Power Automate.Это скриншот моего списка:
, и это обзор потока, который мы собираемся построить:
Спусковой крючок
Перво-наперво, нашим триггером должен быть триггер Recurrence , в котором мы указываем, в каком ритме должен выполняться этот поток.
SharePoint Получить элементы
Теперь наш поток должен получить все элементы из списка, из которого мы хотим случайным образом выбрать один элемент.
Составить
Нам нужно сделать некоторую магию, чтобы получить случайный предмет, я использовал для этого следующее выражение:
body ('Get_items')? ['Value'] [rand (1, length (body ('Get_items')? ['Value']))]
Мы используем выражение rand (), чтобы получить случайный элемент списка из этого списка. Аргументы внутри выражения 1, length (body ('Get_items')? ['Value']) означают, что наш поток должен выбрать случайное число от 1 до (поскольку это значение может измениться со временем) количество элементы списка (который выражается нашим выражением length (body ('Get_items')? ['value'])) .Результат этого действия Compose будет отражать случайный элемент списка.
Разбор JSON
Теперь к интересной части этого потока: мы хотим точно опубликовать этот случайный элемент списка, но если мы заглянем в наш динамический контент, он даст нам только контент из действия Получить элементы, но это происходит до того, как мы получим случайный элемент списка. , и поскольку мы не хотим твитнуть ВСЕ элементы списка, это плохая идея. Как решить эту проблему сейчас? Итак, мы анализируем JSON, что означает, что мы снова превращаем код в объекты, и эти объекты затем отражаются в динамическом содержимом в Power Automate.
Прежде чем мы добавим действие Parse JSON, нам нужно выяснить, КАКОЙ JSON нам нужно проанализировать. Как уже упоминалось, мы можем видеть код JSON в нашей истории выполнения, поэтому мы сохраняем незаконченный поток и позволяем ему работать. Затем мы открываем историю выполнения и смотрим на выходные данные действия Compose и копируем все, что находится внутри этого поля.
Теперь мы снова редактируем наш поток, добавляем действие Parse JSON, добавляем выходные данные из нашего действия Compose в качестве входов к этому действию и нажимаем кнопку Generate from sample .Теперь мы вставим скопированный JSON в поле Insert a sample JSON Payload и нажмите Done . Что мы сделали с этим, так это сказали потоку, какие объекты он должен анализировать. Если мы теперь посмотрим на это действие, мы можем увидеть JSON внутри нашего действия Parse JSON, но все значения из истории запусков заменены заполнителями: «строка» (если это был текст), «логическое» (если это был да / нет) и т. д.
Теперь, когда это действие знает, что анализировать, мы можем перейти к следующему действию
Отправить твит
Теперь мы можем видеть много нового динамического контента, который поступает из нашего действия Parse JSON .
Теперь мы можем выбрать все значения, которые нам нужны в этом твите, плюс несколько более или менее общих хэштегов (Pro добавит хэштеги в специальный столбец в SharePoint). Если мы сейчас сохраним и запустим наш поток, он сначала ПОЛУЧИТ все элементы из list, затем определите случайный элемент списка и отправьте твит с заголовком и URL-адресом именно для этого элемента списка.
Заключение и что дальше?
Действие Parse JSON может помочь вам превратить выходные данные из предыдущих действий в динамический контент, который затем можно использовать в своем потоке.Я хотел бы знать, что вы делаете с Parse JSON, дайте мне знать!
Если вы сейчас голодны из-за рецептов в списке: ThatKitchenPrincess.com
Впервые опубликовано на m365princess.com
Тупой способ разобрать. Это плохой совет, используйте его на своем… | Максим Закс
В любом случае, давайте начнем с тупого способа синтаксического анализа. Прежде всего нам нужно понять, что текст — это одномерный массив чисел.В зависимости от кодировки это могут быть разные числа, представляющие один и тот же текст. Итак, чтобы иметь возможность анализировать текст, нам нужно согласовать одну кодировку. Я определяю, что текст, который я хочу проанализировать, представлен в UTF-8.
Теперь правильный способ синтаксического анализа текста основан на двух этапах: лексировании и синтаксическом анализе (подробнее см. Статью «Руководство по синтаксическому анализу», о которой я упоминал ранее). Я говорю, к черту, мы используем тупой способ для синтаксического анализа , поэтому у нас будет только одна фаза, которую мы называем eat .
Пожалуйста, посмотрите следующий файл:
Там у нас есть функция eat , которая принимает:
- статическую строку — строку, которую мы хотим съесть
- указатель на память, где мы хотим начать есть от
- и длины, которая сообщает нам, как далеко мы можем захотеть съесть
Он возвращает необязательный указатель, означающий, что если мы смогли съесть строку, мы вернем указатель, на котором мы перестали есть, если мы не были возможность есть, мы возвращаем ноль .
Однако, прежде чем мы начнем есть саму строку, мы съедим пустое пространство. Пробелы — это символы, не имеющие никакого семантического значения для человека. Если мы посмотрим на таблицу кодировки символов для первых 128 символов в ASCII, которая равна UTF8:
ascii-code-tabelle-new-Excellent-ascii-home-design-symbols-generator-code-table-of- ascii-code-tabelle.png
Мы видим, что первые 0 .. <33 являются невидимыми символами и могут рассматриваться как пробелы.Отсюда тупая реализация функции eatWhiteSpace :
public func eatWhiteSpace (
_ p: UnsafePointer, длина
: Int
) -> UnsafePointer? {
var p1 = p
, а p1.pointee <33 {
p1 = p1.advanced (by: 1)
if p.distance (to: p1)> length {
return nil
}
}
return p1
}
Он перемещается по числам, меньшим 33 , и возвращает указатель на первое число, которое больше или равно 33 .Он также проверяет, что мы не едим слишком много. Еда должна быть безопасной!
Говоря о безопасности в первую очередь, если вы уже решили использовать тупой способ синтаксического анализа, вам следует хотя бы выполнить модульное тестирование вашего парсера, что, кстати,. действительно приятное впечатление. Вот несколько модульных тестов для нашей логики питания:
| |||||||||