Члены предложения — главные и второстепенные, а также пример разбора предложения по членам
Обновлено 23 июля 2021 Просмотров: 137 278 Автор: Дмитрий ПетровЗдравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы погорим о том, что такое члены предложения и какие они бывают. Эту тему каждый школьник проходит еще в начальных классах.
Но многое из того, что мы когда-то учили, позабылось. А что-то, возможно, будет для кого-то и открытием.
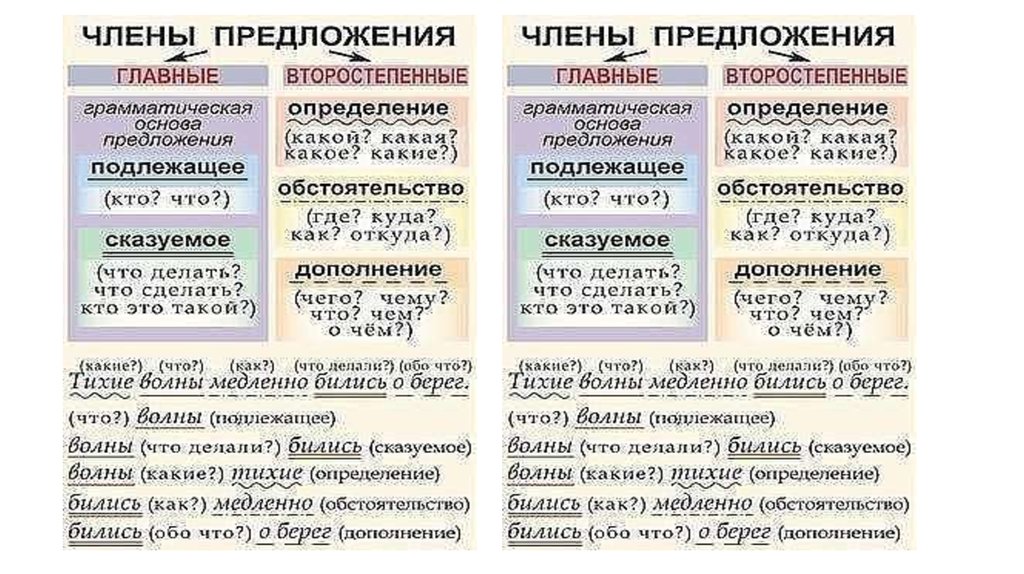
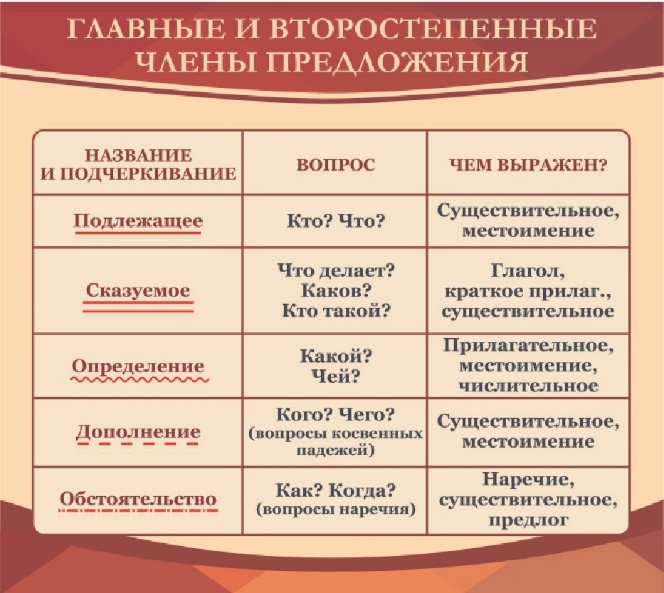
Главные и второстепенные члены предложения
Члены предложения – это слова и словосочетания, которые связаны друг с другом различными способами. Каждый из них призван дать более точную информацию о предмете повествования.
Все члены предложения делятся на две категории – главные и второстепенные.
- К главным относятся подлежащее и сказуемое
- К второстепенным – определение, обстоятельство и дополнение
Подлежащее — самый главный член предложения
Подлежащее – это то, на чем строится все предложение. Это главный член, так же как и сказуемое. Но если можно так сказать, то подлежащее в данном случае главнее.
Это главный член, так же как и сказуемое. Но если можно так сказать, то подлежащее в данном случае главнее.
Распознать его просто. Во-первых, именно вокруг этого слова или словосочетания (что это?) строятся все остальные. А во-вторых, оно всегда употребляется в именительном падеже и отвечает на вопросы «Кто?» или «Что?».
Например:
На столе лежит КНИГА
МАША прыгает по лужам
Выделенные слова и есть подлежащее – человек или предмет, о котором и рассказывает конкретное предложение.
Подлежащее может состоять из одного или нескольких слов.
Когда слово одно, то оно может быть следующим:
- ИМЯ СУЩЕСТВИТЕЛЬНОЕ. Мама (кто?) мыла раму.
- МЕСТОИМЕНИЕ. Он (кто?) не выучил уроки.
- ИМЯ ПРИЛАГАТЕЛЬНОЕ. Слепой (кто?) не мог самостоятельно перейти дорогу.
- ПРИЧАСТИЕ. Упавший (кто?) сломал себе ногу.
- ИМЯ ЧИСЛИТЕЛЬНОЕ. Трое (кто?) шли по лесу.
- ГЛАГОЛ (только в форме инфинитива). Жить (что?), как говорится, хорошо!
Но есть предложения, в которых в качестве подлежащего выступают сразу несколько слов:
- КОЛИЧЕСТВЕННОЕ ЗНАЧЕНИЕ.
 Четверо друзей (кто?) поехали в отпуск.
Четверо друзей (кто?) поехали в отпуск. - ИЗБИРАТЕЛЬНОЕ ЗНАЧЕНИЕ. Каждый из нас (кто?) должен внести свой вклад.
- ЗНАЧЕНИЕ СОВМЕСТИМОСТИ. Отец с сыном (кто?) поехали на рыбалку.
- ЗНАЧЕНИЕ ФАЗЫ (периода). На дворе был конец августа (что?).
- ПРИНЦИП НЕДЕЛИМОСТИ (слова только вместе обозначают конкретное понятие). Млечный путь (что?) выглядит недосягаемым.
- ЗНАЧЕНИЕ НЕОПРЕДЕЛЕННОСТИ. Что-то непонятное (что?) творилось с ним.
 Четверо друзей (кто?) поехали в отпуск.
Четверо друзей (кто?) поехали в отпуск.Кстати, в редких случаях подлежащее может употребляться и не в именительном падеже. Но только тогда, когда речь идет о чем-то приблизительном. Например, около десяти самолетов (что?) вылетели на задание.
Сказуемое — второй главный член предложения
Сказуемое – это второй главный член предложения. Оно обозначает действие, которое совершает сказуемое, или его состояние.
Сказуемое отвечает на вопросы – «Что делает?», «Что сделает?», «Что сделал?» и «Каков?». Чаще всего в этой роли выступает глагол, но бывают и другие части речи.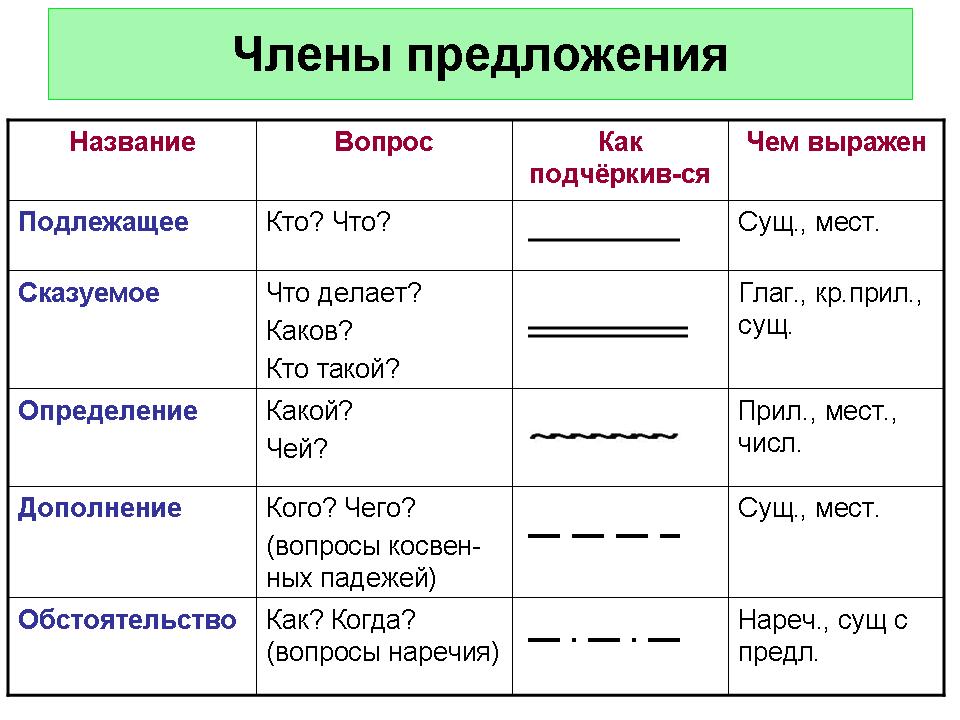
Все сказуемые можно поделить на три части:
- ПРОСТОЕ ГЛАГОЛЬНОЕ. Мама мыла (что делала?) раму.
- СОСТАВНОЕ ГЛАГОЛЬНОЕ – оно состоит из глагола и инфинитива. Вася мечтал поступить (что делал?) в институт.
- СОСТАВНОЕ ИМЕННОЕ – может быть глаголом или другой частью речи, например, существительным, наречием, причастием, местоимением. Погода была мерзкая (какова?). Пес – верный друг (каков?). У него нервы тверже (каковы?) стали.
Определение — второстепенный член
Определение – это второстепенный член предложения, который всегда относится к существительному, местоимению или части речи, которое в конкретном случае выступает в роли существительного.
Определение отвечает на вопросы – «Какой?», «Который?» и «Чей?».
Все определения делятся на категории:
- СОГЛАСОВАННЫЕ – относятся непосредственно к члену предложения в различном падеже, числе и роде. В этой роли часто выступают прилагательные, причастия, числительные и местоимения. Мама мыла грязные (какие?) окна. Он спал уже восьмой (какой?) час.
- НЕСОГЛАСОВАННЫЕ – выражаются в виде существительных, сравнительных прилагательных, наречий и глагола в форме инфинитива. Он отдыхал в доме родителей (чьем?).
 Мама мыла грязные (какие?) окна. Он спал уже восьмой (какой?) час.
Мама мыла грязные (какие?) окна. Он спал уже восьмой (какой?) час.К определениям также относятся слова существительные, которые пишут с основными через дефис, или являются названиями, которые употребляются часто в кавычках. Например, город-герой, Архип-кузнец, газета «Московский комсомолец».
Обстоятельство
Обстоятельство – это еще один второстепенный член предложения, который обозначает характеристику какого-либо действия или состояния.
Отвечает на вопросы – «Как?», «Где?», «Почему?», «Откуда?», «Каким образом?», «Куда?» и «Зачем?».
Чаще всего обстоятельство выражается в форме наречий, существительных в косвенных падежах глаголом-инфинитивом или деепричастием. Вдали (где?) слышались раскаты грома. Он шел очень тихо (как?). Он приехал из соседней страны (откуда?).
Дополнение
Дополнение – еще один второстепенный член предложения, который отвечает на вопросы косвенных падежей.
Например, «Кого/Чего?», «Кому/Чему?», «Кем/Чем?», «О ком/О чем?».
Выражается в форме существительного, местоимения или именных словосочетаний. Он любил сына (кого?). Этот подарок он приготовил для нее (кому?).
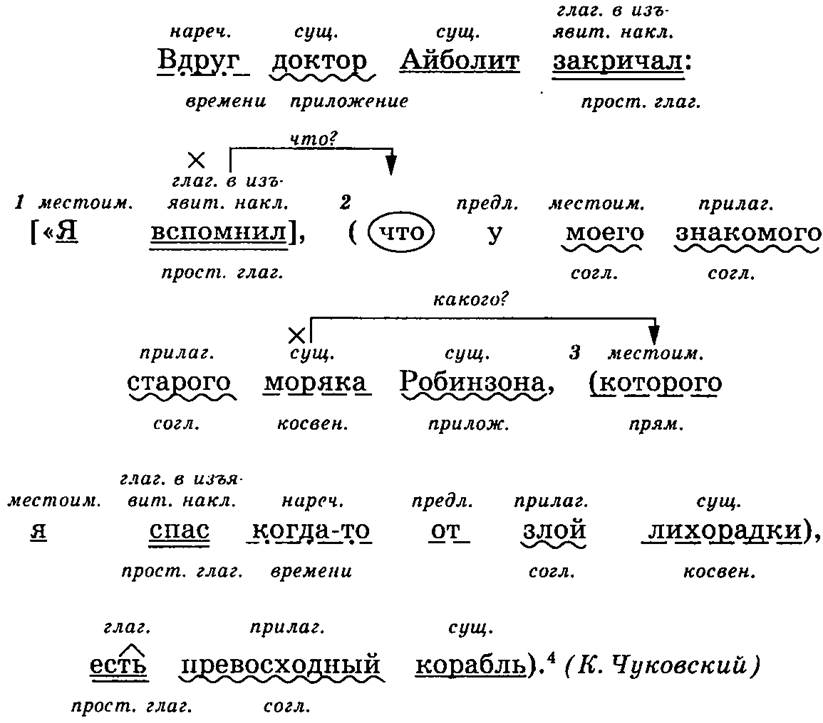
Разбор предложения по членам
В школе ученикам часто дают задание – разобрать предложение по членам. Это означает, что надо найти в нем подлежащее, сказуемое и второстепенные члены, если они есть. А для выделения в тексте каждого члена предложения используют подчеркивания, которые указаны в следующей таблице:
Приведем пример. Нужно разобрать предложение:
Опытный охотник крался тихо по лесу и искал добычу.
В данном случае подлежащим будет слово «охотник». Сказуемых здесь сразу два – «крался» и «искал». Определением будет слово «опытный», так как отвечает на вопрос «какой охотник?». Дополнение – это «добыча» (кого искал?). И обстоятельства здесь тоже два – «тихо» (как крался?) и «по лесу» (где крался?).
И в итоге правильный разбор предложения будет выглядеть как показано чуть выше.
Заключение
В русском языке члены предложения могут находиться в каком угодно месте.
Например, подлежащее, как главное слово, не обязано располагаться в самом начале. Им может и заканчиваться фраза. И этим наш «великий и могучий» отличается от большинства иностранных языков.
Например, в английском любое предложение строится по формуле – сначала подлежащее и сказуемое, а уже потом все остальное. С одной стороны, так, конечно, проще. Но с другой – теряется эмоциональность и разнообразие, которым славится русский язык.
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Таблица как разобрать предложение по составу. Синтаксический разбор предложения
С первого класса школьников знакомят с различными видами лингвистического разбора. Начинается все с деления лексем на слоги и звуки. Во втором классе добавляется разбор слова по составу. Предложение — следующая единица, с которой дети должны познакомиться. Поговорим о том, как правильно выполнять синтаксический разбор и с какими трудностями тут можно столкнуться.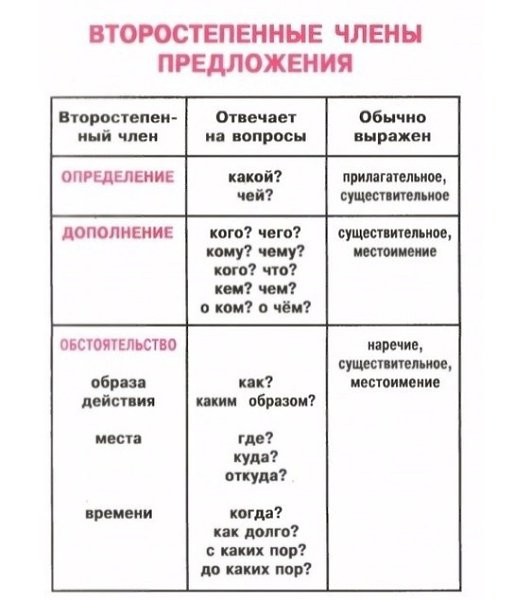
Грамматическая основа
Предложение — это синтаксическая единица, состоящая из связанных между собой слов. Оно передает относительно законченную мысль. Разбор предложения по составу предполагает определение ролей, которые выполняют отдельные слова.
- Подлежащее, которое называет предмет или объект речи. Оно отвечает на вопросы именительного падежа: «Кто? Что?». Чаще всего подлежащим оказывается имя существительное (кот спит) или местоимение (я пошел). При разборе этот член предложения подчеркивается одной линией.
- Сказуемое, рассказывающее о том, что произошло с подлежащим. Чаще всего к нему задают вопрос: «Что делает?», хотя возможны и другие варианты (Что он? Какой он?). Обычно в роли сказуемого выступает глагол, но бывают исключения (Этот человек — мой отец). Подчеркивают его двумя чертами.
В предложении могут присутствовать оба главных члена либо один из них. Например: «Зима. Светает».
Второстепенные члены
Грамматическая основа — необходимый атрибут любого предложения.
- Определение описывает предмет, называя его признаки. К нему задают вопросы: «Какой/ая/ое/ие?» или «Чей?». Чаще всего эту роль выполняют прилагательные или причастия. При разборе определение принято обозначать волнистой чертой.
- Дополнение конкретизирует информацию о предмете и отвечает на вопросы любых падежей, кроме именительного (чем? о ком? чему?). Часто им оказываются существительные. Подчеркивают дополнение пунктиром.
- Обстоятельство рассказывает об особенностях действия: его цели, месте, причине, времени и пр. Этот член предложения отвечает на вопросы: «Как? Откуда? Где? Зачем? Когда? Куда? Почему?». Часто выражается существительными, наречием, деепричастием. Выделяется пунктирной чертой с точками.
Трудные случаи
Какие проблемы возникают у учащихся при разборе предложения по составу? Далеко не все могут четко определить роль конкретного слова.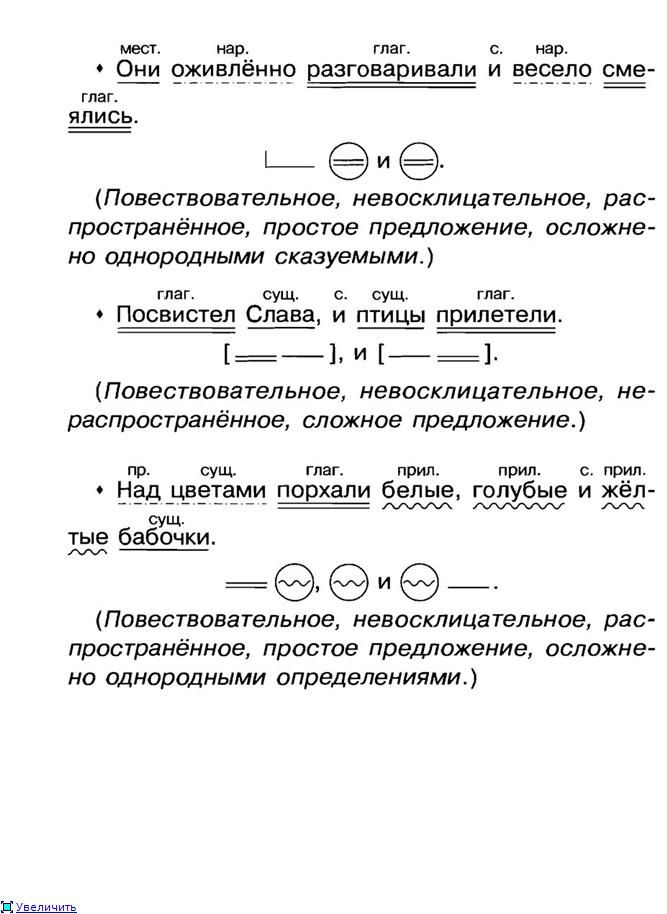 Тем более, что к некоторым членам предложения можно задать сразу два вопроса. Например: «жил (где? в чем?) в доме». В таком случае предлагается остановиться на одном варианте.
Тем более, что к некоторым членам предложения можно задать сразу два вопроса. Например: «жил (где? в чем?) в доме». В таком случае предлагается остановиться на одном варианте.
Проблемы возникают и с определением роли различных оборотов (причастного, деепричастного). В школе принято выделять их как один член предложения. Если в разбираемом высказывании присутствует прямая речь, то она считается отдельным предложением.
Много вопросов связано со служебными частями речи. С одной стороны, они не являются членами предложения. Но могут входить в состав обособленных оборотов (купающийся в речке) или сказуемых (пусть приходят, не видел). Во многих учебниках русского языка детей учат подчеркивать предлоги вместе с существительными, к которым они относятся. А вот вводные слова, обращения никак не выделяются.
Разбор предложения по составу: пример
Посмотрим, как на практике выполняется этот вид разбора. Возьмем простое предложение, которое вы можете прочесть на картинке.
- Находим подлежащее. Для этого используем вопрос: «Что?». В предложении говорится о солнце, подчеркиваем это слово. Сверху помечаем часть речи.
- Что сделало солнце? Осветило. Мы нашли сказуемое, оно выражено глаголом. Сверху рисуем стрелку, подписываем вопрос.
- Теперь выделяем второстепенные члены предложения. Осветило когда? Утром. Значит, перед нами обстоятельство. Подчеркиваем, подписываем часть речи — существительное, проводим стрелку от сказуемого.
- Осветило что? Деревню. Мы нашли дополнение, и оно тоже выражено существительным. Помечаем все это в тетради, обозначаем графически.
- Деревню какую? Родную. Это имя прилагательное является определением. Подчеркнем его волнистой чертой, подпишем сверху вопрос, а также часть речи.
 Для этого используем вопрос: «Что?». В предложении говорится о солнце, подчеркиваем это слово. Сверху помечаем часть речи.
Для этого используем вопрос: «Что?». В предложении говорится о солнце, подчеркиваем это слово. Сверху помечаем часть речи.Разбор по составу сложных предложений
В приведенном выше примере присутствовала одна грамматическая основа. Однако их может быть и несколько. Такие предложения называются сложными. Одно из них перед вами на картинке. Разберем его по членам предложения.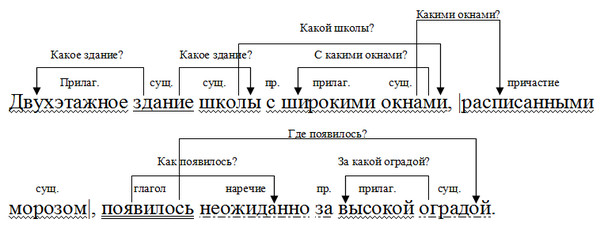
- Находим грамматические основы. Что? Листок. Это подлежащее. Что листок делает? Летит. Перед нами сказуемое. Подчеркиваем их, подписываем части речи. Читаем предложение дальше. Что? Холодок. Как видите, в предложении два подлежащих. Что холодок делает? Набегает. Вторая грамматическая основа найдена.
- Находим границы простых предложений, нумеруем каждую часть сверху. Можно разграничить их вертикальной чертой.
- Выделяем второстепенные члены сначала в одной части предложения, а затем в другой. Обозначаем их графически. Подписываем части речи.
Разбор предложения по составу — задача нелегкая. Порой профессиональные лингвисты не могут прийти к однозначному решению, определяя роль того или иного слова. Однако с практикой он будет даваться вам все легче и легче. Главное — не бояться ошибок и проявлять терпение.
Синтаксический разбор предложения — это разбор предложения по членам и частям речи. Выполнить синтаксический разбор сложного предложения можно по предложенному плану. Образец поможет правильно оформить письменный анализ предложения, а пример раскроет секреты устного синтаксического разбора.
Образец поможет правильно оформить письменный анализ предложения, а пример раскроет секреты устного синтаксического разбора.
План синтаксического разбора предложения
1. Простое, простое, осложненное однородными членами, или сложное
2. По цели высказывания: повествовательное, вопросительное или побудительное.
3. По интонации: восклицательное или невосклицательное.
4. Распространенное или нераспространенное.
5. Определите ПОДЛЕЖАЩЕЕ. Задайте вопросы КТО? или ЧТО? Подчеркните подлежащее и определите, какой частью речи оно выражено.
6. Определите СКАЗУЕМОЕ. Задайте вопросы ЧТО ДЕЛАЕТ? и т.д. Подчеркните сказуемое и определите, какой частью речи оно выражено.
7. От подлежащего задайте вопросы к второстепенным членам предложения. Подчеркните их и определите, какими частями речи они выражены. Выпишите словосочетания с вопросами.
8. От сказуемого задайте вопросы к второстепенным членам. Подчеркните их и определите, какими частями речи они выражены.
Образец синтаксического разбора предложения
Уж небо осенью дышало, уж реже солнышко блистало.
Это предложение сложное, первая часть:
(что?) небо — подлежащее, выражено существительным в ед. ч., ср. р., нар., неодуш., 2 скл., и. п.
(что делало?) дышало — сказуемое, выражено глаголом несов. вид., 2 спр., в ед. ч., прош. вр., ср. р.
дышало (чем?) осенью — дополнение, выражено именем существительным в ед. ч., ж. р., нариц., неодуш., 3 скл., т. п.
дышало (когда?) уж — обстоятельство времени, выражено наречием
вторая часть:
(что?) солнышко — подлежащее, выражено существительным в ед. ч., ср. р., нар., неодуш., 2 скл., и. п.
(что делало?) блистало — сказуемое, выражено глаголом несов. вид., 1 спр., в ед. ч., прош. вр., ср. р.
блистало (как?) реже — обстоятельство образа действия, выражено наречием
Пример синтаксического разбора предложения
Они, то косо летели по ветру, то отвесно ложились на сырую траву.
Это предложение простое.
(что?) они — подлежащее, выражено местоимением мн. ч., 3 л., и. п.
(что делали?) летели — однородное сказуемое, выражено глаголом нес.вид, 1 спр., мн. ч.. прош. вр..летели
(что делали?) ложились — однородное сказуемое, выражено глаголом нес.вид, 1 спр., мн. ч.. прош. вр..
летели (как?) косо — обстоятельство образа действия, выражено наречием.
летели (как?) по ветру- обстоятельство образа действия, выражено наречием
ложились (как?) отвесно- обстоятельство образа действия, выражено наречием
ложились (куда?) на траву- обстоятельство места, выражено именем существительным нариц., неодуш., в ед. ч., ж. р., 1 скл.,в в.п. с предлогом
траву (какую?) сырую — определение, выражено именем прилагательным в ед. ч., ж.р., в.п.
Запомни:
Член предложения | Обозначает/ показывает | Отвечает на вопросы | Подчеркивается | |
Подлежащее | главные члены предложения | о ком или о чем говорится в предложении | кто? что? | |
Сказуемое | называет то, что совершает предмет, его состояние, каков он | что делает? что делал? что будет делать? каков? | ||
Определение | второстепенные члены предложения | признак предмета | ||
Дополнение | на какой предмет или явление направлено действие | кого? чего? кому? чему? кого? что? кем? чем? о ком? о чём? | ||
Обстоятельство | как совершается действие, когда совершается действие, где совершается действие, по какой причине совершается действие, с какой целью совершается действие | где? куда? когда? откуда? почему? зачем? и как? |
Выпиши
предложение.
Делай так : С высоких гор побежали звонкие ручейки .
1.Основа предложения:
в предложении говорится о ручейках
, следовательно, ручейки — это подлежащее,побежали , следовательно, побежали – это сказуемое.
2.В предложении есть второстепенные члены.
Задаю вопрос от подлежащего:
ручейки какие?- звонкие – это определение.
Задаю вопрос от сказуемого:
побежали откуда? –с гор – это обстоятельство места.
с гор каких? – высоких – это определение.
39. Схема разбора предложения (синтаксический разбор).
I. Вид предложения по цели высказывания.
II. Вид предложения по интонации.
III. Основа предложения (подлежащее и сказуемое).
IV. Вид предложения по наличию второстепенных членов.
V. Второстепенные члены предложения.
Выпиши
предложение.
Делай так : С высоких гор побежали звонкие
Это предложение
I. Повествовательное.
II. Невосклицательное.
III.Основа предложения:
в предложении говорится о ручейках , следовательно, ручейки — это подлежащее,
о ручейках говорится, что они побежали , следовательно, побежали – это сказуемое.
IV. В предложении есть второстепенные члены, поэтому оно распространённое.
V. Задаю вопрос от подлежащего:
ручейки какие?- звонкие – это определение.
Задаю вопрос от сказуемого:
побежали откуда? – с гор – это обстоятельство места.
Задаю вопрос от второстепенных членов предложения:
С гор каких? – высоких – это определение.
Запомни:
III. Пунктуация
40.Знаки
препинания в конце предложений(. ?!).
?!).
Выпиши предложение правильно. Придумай свое или найди в учебнике предложение с таким же знаком. Подчеркни знак препинания.
Делай так : Слава нашей Родине ! Слава труду !
41. Однородные члены предложения.
Выпиши предложение. Правильно расставь знаки. Подчеркни однородные члены предложения. Начерти схему предложения.
Делай так : Грачи , скворцы и жаворонки улетели в теплые края. (О,О и О)
Знаки препинания при однородных членах:
О да (=и) О
О, да (= но) О
и О, и О,и О,и О
или О, или О,или О,или О
О, и О,и О,и О
42.Сложное предложение.
Выпиши правильно предложение. Подчеркни грамматические основы. Начерти схемы.
Делай так:
Дремлют рыбы под водой, почивает сом седой.
[ ], [ ].
43. Предложения
с прямой речью.
Предложения
с прямой речью.
Запиши правильно предложение. Составь схему.
Делай так :
1) Олег успокаивал мать: «Все будет хорошо».
2) Он крикнул: «Вперёд, ребята!»
3) Он спросил: «Ты откуда, парень?»
4) «Я тебя не выдам», — обещал Иван.
5)»Пожар!» – крикнула Таня.
6) «Кто это был?» – спросила Оля.
7) «Я врач, — сказал он,- сегодня дежурю».
«П, — а, — п».
8) «Наше присутствие необходимо, — закончил Петров.- Выезжаем утром».
«П, — а. — П».
9) «Почему в пять? – спросил брат.- Это очень рано».
«П? — а. — П».
10) «Ну и отлично! – воскликнула Аня.- Поедем вместе».
«П! — а. — П».
11) «Он из нашей группы, – сказал Иван.- Садись, Пётр!»
«П, — а. – П!»
УЧИТЕЛЮ И РОДИТЕЛЯМ
«Памятка по выполнению работы над ошибками по русскому языку» состоит из трёх разделов: «Правила правописания», «Виды разборов», «Пунктуация».
В
первом и третьем разделе даны указания
о том, какие операции и в какой
последовательности необходимо произвести
учащимся при выполнении работы над
ошибками. Для того чтобы ученик мог
быстро и легко найти в памятке нужную
орфограмму, каждое правило имеет свой
порядковый номер.
Для того чтобы ученик мог
быстро и легко найти в памятке нужную
орфограмму, каждое правило имеет свой
порядковый номер.
Работу по памятке мы предлагаем проводить следующим образом. К традиционным обозначениям ошибок на полях приписывать номер орфограммы, помещенной в памятке. После проверенной работы пропускать две строчки и на последующих строчках указывать эти номера.
Ученик, получив тетрадь, должен выполнить работу над ошибками строго по памятке. Каждую работу учитель проверяет и оценивает, при этом учитывается правильность и точность исправления.
Например: на улице сильный морос – на полях ученик видит| №20. Он открывает книжку-памятку и читает алгоритм работы:
№20 Мороз – мороз ы .
Таким образом, основными видами самостоятельной работы учащихся над ошибками являются:
Самостоятельное исправление (потом можно предложить самостоятельное отыскивание) ошибок;
Самостоятельное выписывание слов, в которых допущена ошибка;
Подбор проверочных слов;
Повторение правил.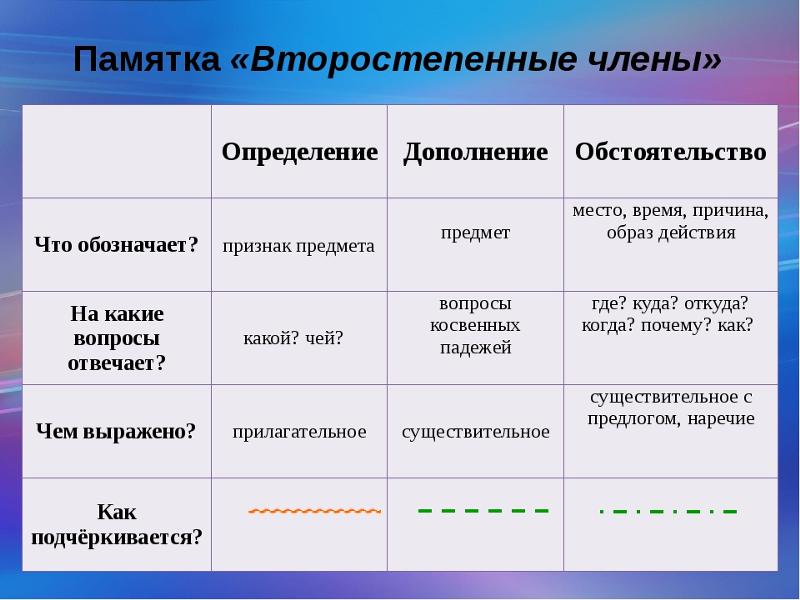
Учитывая необходимость преемственности начальной и средней ступени обучения при составлении третьего раздела «Виды разборов» (морфемный, фонетический, морфологический, синтаксический) мы опирались на учебник для 5 класса общеобразовательных учреждений, авторы Т.А. Ладыженская, М.Т. Баранов, Л.А. Тростенцова и др.
«Памятка по выполнению работы над ошибками по русскому языку» может быть использована в учебной работе по любой программе начальной школы, как при групповой форме работы, так и при индивидуальной, самостоятельной работе ученика в классе или дома.
Литература
1.Русский язык: 3 класс: комментарии к урокам/ С.В. Иванов, М.И. Кузнецова.- М.: Вентана-Граф, 2011.-464 с.- (Начальная школа XXI века).
2.Русский язык: Теория: Учебник для 5-9 кл. общеобразоват. учеб. заведений /В.В. Бабайцева, Л.Д. Чеснокова- М.: Просвещение,1994.-256 с.
3.
Русский язык: учеб.для 5 кл. общеобразоват.
учреждений / Т.А.Ладыженская, М.Т.Баранов,
Л.А. Тростенцова и др.- М.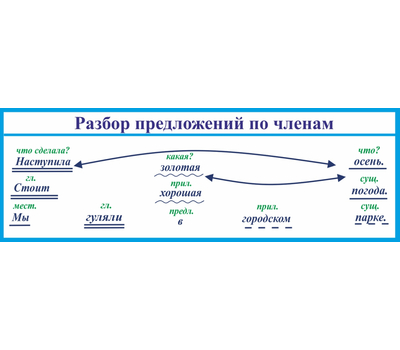 : Просвещение,
2007.-317 с.
: Просвещение,
2007.-317 с.
4. Справочник для начальных классов. Пособие для учащихся 3-5 классов, их родителей и учителей. /Т.В. Шклярова — М.: «Грамотей», 2012, 128 с.
Разбор предложения по составу называют синтаксическим. Он один из первых, который изучают в школе. Сначала процесс может вызывать трудности, однако, уже после двух разборов многие люди быстро находят все составляющие. Поможет в разборе знание частей речи, правила об основе и второстепенных членах предложения, понимание связи слов в словосочетании. Это проходят к концу начальной школы, поэтому ученики 5 класса выполняют разбор без труда.
Придерживаясь определённой последовательности, можно быстро сделать разбор. Для этого понадобится обратить внимание на такие этапы:
- Определить, к какому типу относится фраза: повествовательному, вопросительному или побудительному.
- По эмоциональному окрасу отличают восклицательное и невосклицательное предложение.
- Затем переходят к грамматической основе. Её нужно найти, обозначить способ выражения, указать, является предложение простым или сложным.
- Определить односоставность и двусоставность написанного.
- Найти дополнительные члены предложения. Они покажут, является оно распространённым или нет.
- С помощью определённых видов линий выделить каждый второстепенный член предложения. При этом над словом указывают, каким оно является членом предложения.
- Обозначить, имеются ли пропущенные члены предложения в предлагаемой фразе, что позволит определить, полным или неполным является высказывание.
- Имеются ли осложнения.
- Дать характеристику написанному.
- Составить схему.
 Её нужно найти, обозначить способ выражения, указать, является предложение простым или сложным.
Её нужно найти, обозначить способ выражения, указать, является предложение простым или сложным.Чтобы правильно и быстро провести синтаксический разбор, нужно знать, что представляет собой основа и второстепенные члены.
Основа
В любой основе имеется подлежащее и сказуемое. При разборе первое слово подчёркивается одной линией, второе – двумя. Например, «Наступила ночь ». Здесь грамматической основой выступает полная фраза. В ней подлежащее слово «ночь». Подлежащее не может находиться ни в каком другом падеже, кроме именительного.
В ней подлежащее слово «ночь». Подлежащее не может находиться ни в каком другом падеже, кроме именительного.
По соседству находится сказуемое «наступила», которое описывает действие, совершённое с подлежащим. (Пришёл рассвет. Наступила осень.) В зависимости от того, простым или сложным является предложение, выделяют одну или две основы. В высказывании «Жёлтые листья опадают с деревьев» одна грамматическая основа. А здесь две основы: «Луна спряталась – наступило утро».
Перед синтаксическим разбором фразы необходимо найти дополнительные члены предложения:
- Чаще всего дополнение — это существительное или местоимение. Ко второму члену предложения могут добавляться предлоги. Оно отвечает на все вопросы падежей. Сюда не входит именительный падеж, так как он может быть только у подлежащего. Посмотри (куда?) на небо. Обсудим (что?) вопрос. В семантическом значении они стоят в одном ряду с существительным.
- Определение выполняет описательную функцию, отвечая на вопрос «Какой? Чей?». Часто сложно выявить член предложения из-за того, что оно бывает двух видов. Согласованное, когда два слова находятся в одном лице, роде, числе и падеже. Несогласованное выступает словосочетанием с управлением и примыканием. Например: «На стене висит книжная полка. На стене висит полка для книг» . В обоих случаях можно задать вопрос: какая? Однако отличием является согласованность и несогласованность определения.
- Обстоятельство описывает образ действия, время. Считается самым обширным членом предложения. Мы встретились (где?) в магазине. (Когда?) Вчера мы ходили в кино. Я (как?) легко сделаю упражнение. Это приводит к тому, что обстоятельство часто путают с дополнением. Здесь важно правильно поставить вопрос от главного слова к зависимому.
 Часто сложно выявить член предложения из-за того, что оно бывает двух видов. Согласованное, когда два слова находятся в одном лице, роде, числе и падеже. Несогласованное выступает словосочетанием с управлением и примыканием. Например: «На стене висит книжная полка. На стене висит полка для книг» . В обоих случаях можно задать вопрос: какая? Однако отличием является согласованность и несогласованность определения.
Часто сложно выявить член предложения из-за того, что оно бывает двух видов. Согласованное, когда два слова находятся в одном лице, роде, числе и падеже. Несогласованное выступает словосочетанием с управлением и примыканием. Например: «На стене висит книжная полка. На стене висит полка для книг» . В обоих случаях можно задать вопрос: какая? Однако отличием является согласованность и несогласованность определения.Взаимосвязь при написании
Важно сказать, что все второстепенные члены обязательно связаны с одним из главных слов. Определение находится в составе подлежащего, поэтому вопросы задают именно от этого члена предложения. А вот дополнение и обстоятельство связано со сказуемым.
А вот дополнение и обстоятельство связано со сказуемым.
На письме при разборе следует обозначить второстепенные члены. Если подлежащее и сказуемое подчёркивают одной и двумя линиями соответственно, то дополнение выделяют пунктирной линией, определение – волнистой, обстоятельство – точкой и тире. При синтаксическом разборе следует обязательно указывать в графическом варианте, чем является каждое слово.
Практическое занятие
Рассмотрим простое предложение:
Зимой туристы отправляются на горнолыжный курорт.
Начинают с основы. Здесь она представлена словосочетанием «туристы отправляются». То есть подлежащее — туристы, сказуемое – отправляются. Это единственная основа, значит, написанное является простым высказыванием. Так как имеются дополнительные члены, то оно является распространённым.
Теперь можно заняться поиском дополнений. Здесь при написании его не использовали. За ним следует определение: на (какой?) горнолыжный курорт. И можно выделить обстоятельства. Отправляются (куда?) на курорт, отправляются (когда?) зимой.
Отправляются (куда?) на курорт, отправляются (когда?) зимой.
Вот так выглядит предложение при разборе по составу: Зимой (обст.) туристы (подл.) отправляются (сказ.) на горнолыжный (опр.) курорт (доп.).
Пример сложного предложения:
Солнце зашло за тучу, с неба пошёл мелкий дождь.
Сначала ищем основу. В предложении речь идёт о солнце и дожде. Значит, основы в предложении две: солнце зашло, и дождь пошёл. Теперь нужно найти дополнительные члены предложения в каждой основе. Зашло (куда?) за тучу; пошёл (какой?) мелкий, пошёл (откуда?) с неба.
Вот так нужно разбирать распространённые предложения по составу:
Мальчик сидел на крыше дома и смотрел на звёздное небо, притягивающее взгляд.
(Повествовательное, невосклицательное, простое, двусоставное, распространённое, полное, осложнено однородными сказуемыми и обособленным определением, выраженным причастным оборотом).
Здесь основа – мальчик сидел и смотрел, поэтому сказуемых два. Находим второстепенные члены предложения. Сидел (где?) на крыше (чего?) дома. Смотрел (куда?) на небо, (какое?) звёздное. Небо (какое?), притягивающее взгляд.
Находим второстепенные члены предложения. Сидел (где?) на крыше (чего?) дома. Смотрел (куда?) на небо, (какое?) звёздное. Небо (какое?), притягивающее взгляд.
То есть после нахождения всех составляющих высказывания, оно будет выглядеть так:
Мальчик (подл.) сидел (сказ.) на крыше (обст.) дома (доп.) и смотрел (сказ.) на звёздное (опред.) небо (обст.), притягивающее взгляд (опред.).
Синтаксический разбор предложения делать несложно. Главное, придерживаться шагов, начиная с поиска главных членов предложения. Они являются основой. Затем переходят к второстепенным. В конце разбора каждый из них подчёркивают определённой линией.
Видео
Из видео вы узнаете, как правильно сделать синтаксический разбор предложения.
Не получили ответ на свой вопрос? Предложите авторам тему.
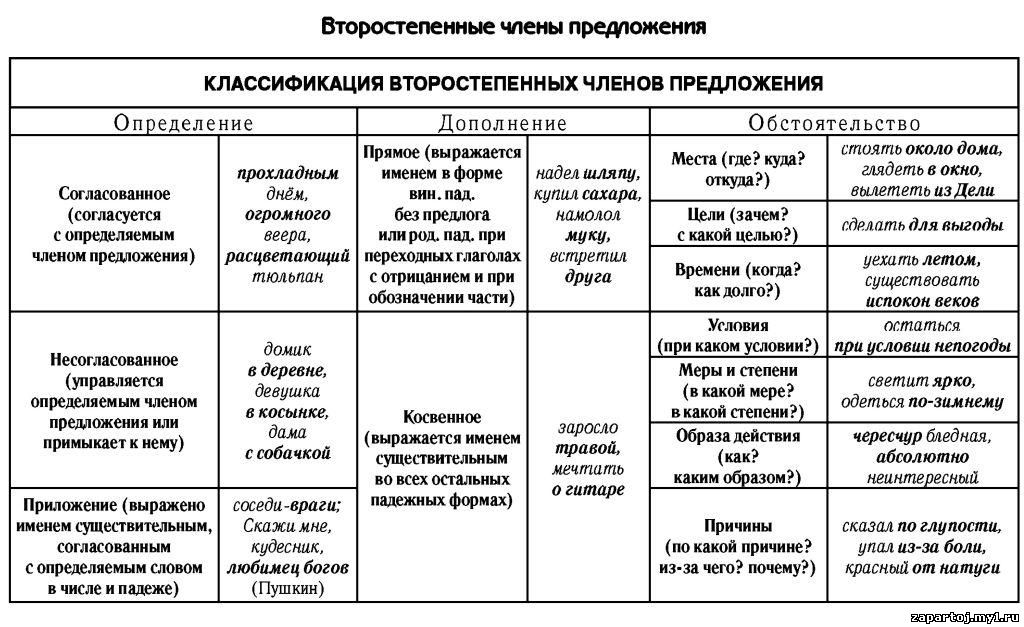
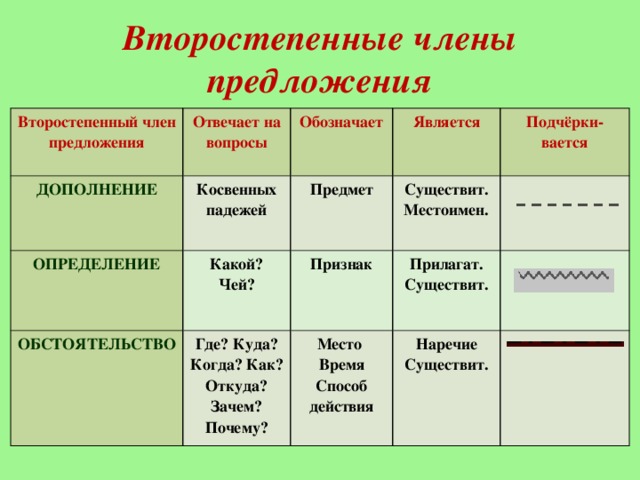
Кроме грамматической основы (подлежащего и сказуемого, либо только сказуемого, либо только подлежащего) в предложении могут присутствовать и второстепенные члены предложения.
К второстепенным членам предложения относятся
дополнения,
обстоятельства,
определения.
Предложение, в котором присутствует хотя бы один второстепенный член, называется распространенным. Если таких членов предложения нет, тогда это будет нераспространенное предложение.
Также предложения могут быть осложненные. В них могут быть однородные члены, также слова и различные конструкции, которые грамматически не связаны с остальными членами предложения. К ним относятся, например, обращения, вводные слова и предложения, междометия.
Осложнены предложения могут быть причастными и деепричастными оборотами, вставными конструкциями.
При разборе предложения по членам предложения нужно подчеркнуть графически все слова в зависимости от их синтаксической роли в предложении. Например, подлежащее подчеркивается одной чертой,
сказуемое — двумя чертами,
дополнение — пунктирной,
обстоятельство — черточка с точкой,
определение — волнистой линией.
Разбор предложения по составу выполняется в следующем порядке.
- Сначала отмечаются главные члены предложения. А именно сказуемое и подлежащее.
- Затем переходим к второстепенным. Они могут быть определениями, дополнениями и обстоятельствами.
- Указываем тип предложения (дву- или односоставное).
- Определяем полноту (полное или нет).
- Уточняем распространено ли оно?
- Осложнено ли?
 А именно сказуемое и подлежащее.
А именно сказуемое и подлежащее.Рома взял красивую книгу. Предложение двусоставное, распространенное, не осложненное, полное
По составу можно разобрать только слово, а предложение разбирают по членам (т.е. производят синтаксический разбор)
Чтобы разобрать предложение, необходимо придерживаться определенного плана.
Теперь рассмотрим несколько примеров разбора предложений, дабы стало понятнее.
Если на каком-то этапе разбора предложения возникают трудности, необходимо выучить основной теоретический материал по этой теме. Ниже предоставлю основные положения и информацию, которая требуется при разборе предложений.
По составу предложение не разбирается.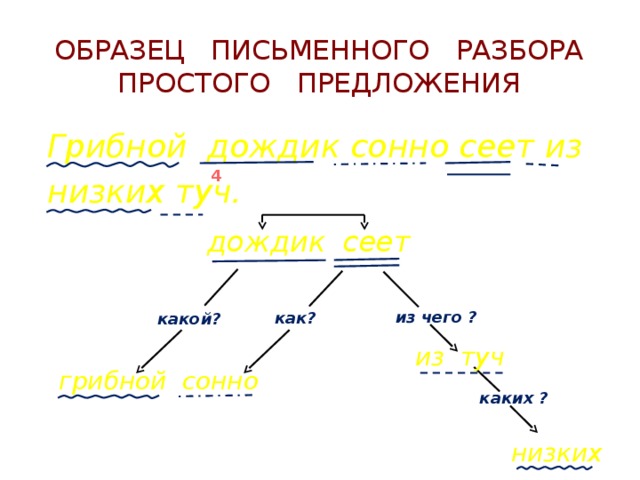 Разобрать предложение можно только синтаксическим разбором. То есть находим главное предложение, сказуемое и остальные члены предложения (дополнения, обстоятельства, наречия и т.д). А также можно определить вид подчинения, если имеется.
Разобрать предложение можно только синтаксическим разбором. То есть находим главное предложение, сказуемое и остальные члены предложения (дополнения, обстоятельства, наречия и т.д). А также можно определить вид подчинения, если имеется.
Я полагаю, что вы имели в виду не разбор предложения по составу, а синтаксический разбор предложения или иначе разбор по членам предложения. Для начала нужно дать характеристику предложения по цели высказывания: повествовательное, вопросительное или побудительное. Затем обозначить эмоциональную окраску предложения (восклицательное или невосклицательное). Выделить грамматические основы и дать характеристику предложению (простое или сложное). Далее:
1) Если предложение простое:
Дать характеристику предложения по наличию основ(двусоставное или односоставное)
Написать распространено или не распространено предложение второстепенными членами
Написать осложнено или не осложнено предложение оборотами, обращением, вводными словами
Подчеркнуть члены предложения и составить схему.
2)если предложение сложное:
написать какая связь в предложении союзная или бессоюзная
Обозначить средство связи(подчинительный союз, сочинительный союз или интонация)
Сделать вывод какое предложение (сложноподчиненное, сложносочиненное или бессоюзное)
Выполнить для каждой части предложения пункты для простого предложения.
Составить схему.
Как правило, в русском языке, любое предложение состоит из двух главных членов, это подлежащего и сказуемого, составляющих его основу. В предложение так же может быть либо одно подлежащее, либо сказуемое, и уже в зависимости от этого признака они делятся на односоставные (один главный член в предложении) и двусоставные (в предложении есть и подлежащее и сказуемое). При разборе предложения, нужно обязательно найти его основу, то есть выявить подлежащее и сказуемое, после чего, определяем второстепенные члены предложения, если они есть, разумеется. Так же необходимо выявить полноту предложения, указать его вид и тип (односоставное или двусоставное)
Предложение можно разобрать по синтаксическому разбору. В таком случае в предложении нужно найти и определить члены предложения (подлежащее, сказуемое,определение, дополнение и обстоятельство). В предложении могут быть как все члены предложения, так и только подлежащее со сказуемым.
В таком случае в предложении нужно найти и определить члены предложения (подлежащее, сказуемое,определение, дополнение и обстоятельство). В предложении могут быть как все члены предложения, так и только подлежащее со сказуемым.
Предложение можно разобрать на подлежащее и сказуемые. От главных слов предложения задаем вопросы к другим словам. Выявляем следующие части предложения. Смотрите разбор на таблице.
Служебные части речи, например, предлоги, считаются членом предложения вместе с существительным, к которому относятся. А частицы, которые относятся ко всем словам в предложении членом предложения не являются. Союзы не являются членом предложения, если являются связующим звеном в сложном предложении. А если относятся к отдельным словам, тогда определяются как член предложения с тем словом.
Чтобы разобрать предложение по составу для начала необходимо выделить его главные члены, а именно его грамматическую основу, к которой относятся как подлежащее, так и сказуемое.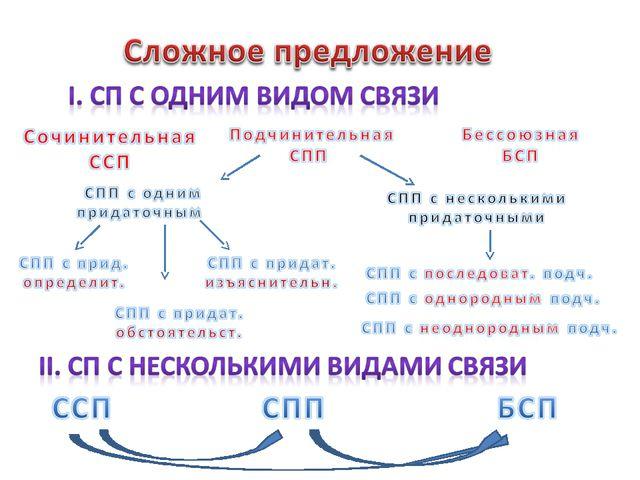
Следует сразу отметить, что предложение может включать как все главные члены, так и состоять из одного.
Можно определить вид предложения по составу грамматической основы. Предложения бывают двусоставные и односоставные. В двусоставном предложении мы видим налицо состав подлежащего(подлежащее+ определения) и состав сказуемого (сказуемое, дополнение и обстоятельство).
Желтые одуванчики тянутся к солнцу. Что? одуванчики-подлежащее. Одуванчики. что делают? тянутся —сказуемое. Одуванчики тянутся -грамматическая основа двусоставного предложения.Тянутся куда? к солнцу —обстоятельство. Одуванчики какие? желтые определение.
В односоставном предложении присутствует только один главный член.Если это сказуемое, то различают определенно-личные, неопределенно-личные и безличные предложения. Если в предложении главный член выражен существительным,то это назывное предложение. Пример: Ночь. Холодная землянка. Перестрелка.Тишина.
В определенно-личных предложениях сказуемое выражается глаголом настоящего или будущего времени в форме 1 или 2 лица или глаголом повелительного наклонения,который всегда имеет форму 2 лица единственного или множественного числа.
Не рвите серебряные струны. Пойдем погуляем в парк. Ищите и найдете спутника жизни.
В неопределенно-личных предложениях сказуемое выражается глаголом 3 лица настоящего и будущего времени или глаголом прошедшего времени множественного числа,а также глаголом условного наклонения.
Меня премировали. Пассажиров пригласили пройти в самолет. Звонят.
В безличных предложениях сказуемое,в первую очередь, выражается безличным глаголом (Смеркалось.Вечерело. Мне нездоровится.), инфинитивом (Не нагнать тебе бешеной тройки.), предикативным наречием (Душно в вагонном плену.), кратким страдательным причастием среднего рода (Послано за доктором.), безличным глаголом+ инфинитивом (Пришлось мне подождать поезд), предикативным наречием+ инфинитивом (Плохо жить без работы).
В заданиях по русскому языку производится разбор слов по составу, а то, что делают с предложением — это синтаксический разбор.
На первом этапе синтаксического разбора находят главные члены предложения — подлежащее и сказуемое. Затем определяют роль остальных слов, являющихся второстепенными членами предложения — дополнения, определения, обстоятельства.
Затем определяют роль остальных слов, являющихся второстепенными членами предложения — дополнения, определения, обстоятельства.
Таблица члены простого предложения — Dudom
Таблица — памятка Члены предложения поможет ученикам быстрее запомнить синтаксический разбор предложения
Скачать:
| Вложение | Размер |
|---|---|
| chleny_predlozheniya.docx | 11.99 КБ |
Предварительный просмотр:
Вопросы падежей (кроме Именительного)
Вопросы падежей (кроме Именительного)
Вопросы падежей (кроме Именительного)
Вопросы падежей (кроме Именительного)
По теме: методические разработки, презентации и конспекты
на опорной таблице представлено правило «Знаки препинания в предложениях с однородными членами». таблица предназначена для урока русского языка в 4 классе.
Яркая таблица по русскому языку «Члены предложения» для начальной школы и 5-6 классов.
Алгоритм разбора предложения.
Таблица-памятка «Члены предложения» 4 кл.
Памятка «Главные и второстепенные члены предложения. Синтаксический разбор предложения» для учащихся 3 — 4 классов.
Памятка поможет ученикам 4 классов в разборе предложений на уроках русского языка и при выполнении домашних заданий.
Что ты хочешь узнать?
Ответ
Проверено экспертом
1. Главные члены предложения:
А) подлежащее (кто?что?) Ярко светит солнце.
Б) сказуемое (что делает, что сделают. ). Сейчас я напишу ответ.
2. Второстепенные члены предложения:
А) определение (какой?чей?). Наступила долгожданная весна.
Б) дополнение (кого?чего?кому?чему?кем?чем?о ком? о чем?). Я люблю свой город.
В) обстоятельство(где?когда?куда?откуда?почему?зачем?как?). Вчера было теплее.
Этот видеоурок доступен по абонементу
У вас уже есть абонемент? Войти
Рис.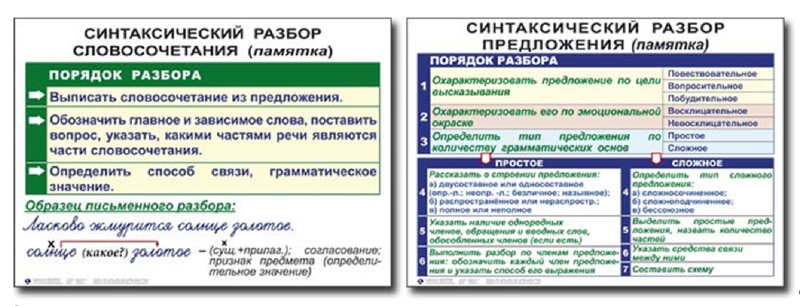 1. Типы предложений относительно состава грамматической основы (Источник)
1. Типы предложений относительно состава грамматической основы (Источник)
Примеры двусоставных предложений:
Очень страшная история произошла со мной вчера вечером.
Если грамматическая основа состоит из одного главного члена, такое предложение называется односоставным.
Примеры односоставных предложений:
Главный член односоставного предложения по своим свойствам и структуре похож либо на сказуемое двусоставного, либо на подлежащее.
Распространённые и нераспространённые предложения
В зависимости от того, есть ли в предложении второстепенные члены, предложения бывают распространённые и нераспространённые (рис. 2).
Рис. 2. Типы предложений относительно наличия/отсутствия второстепенных членов (Источник)
В нераспространённых предложениях, кроме главных членов, нет никаких других членов предложения.
Примеры нераспространённых предложений:
Если в предложении есть хотя бы один второстепенный член, такое предложение называется распространённым.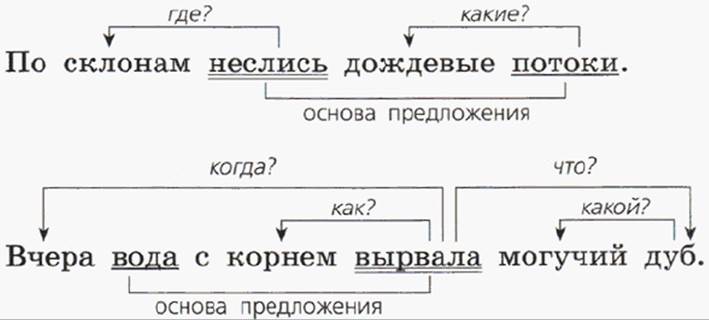
Примеры распространённых предложений:
Подул жуткий пронизывающий ветер.
Из-за портьеры показалось привидение.
Таким образом, определить, распространённое предложение или нераспространённое, можно по наличию в нём второстепенных членов.
Обратите внимание на то, что слова, которые не являются членами предложения (обращения, вводные слова и конструкции), не делают предложение распространённым.
Кажется, стемнело – простое нераспространённое предложение.
Лишь только стемнело, естественно, показалось привидение – сложное предложение, состоящее из двух простых и нераспространённых.
Полные и неполные предложения
Простые предложения подразделяются на полные и неполные (рис. 3).
Рис. 3. Типы предложений относительно наличия/отсутствия необходимых членов (Источник)
Если в предложении присутствуют все необходимые для его понимания компоненты, если для того, чтобы понять смысл предложения, нам не нужно обращаться к другим предложениям, такие предложения называются полными:
Я не боюсь привидений.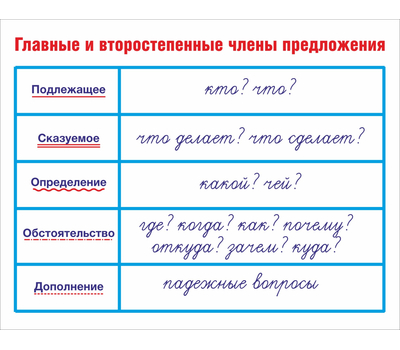
Если для понимания предложения нам не хватает компонентов, если, чтобы понять его смысл, нам нужно обратиться к соседним предложениям, такое предложение будет неполным:
Я не боюсь привидений.
Я тоже (смысл этого предложения будет скрыт, пока не узнаем контекст его употребления).
Рис. 4. Как отличить неполное предложение от односоставного (Источник)
Как видим, смысл неполного предложения легко восстановить, если добавить в него необходимые компоненты из контекста (рис. 4). Отметим, что в неполном предложении могут отсутствовать все главные члены предложения:
– Вы видели привидение?
– Жуткое! (это распространённое неполное предложение)
Кроме того, в неполном предложении могут отсутствовать необходимые для понимания второстепенные члены предложения:
Выводы
Признаки распространённости и нераспространённости и полноты и неполноты простого предложения никак не связаны друг с другом.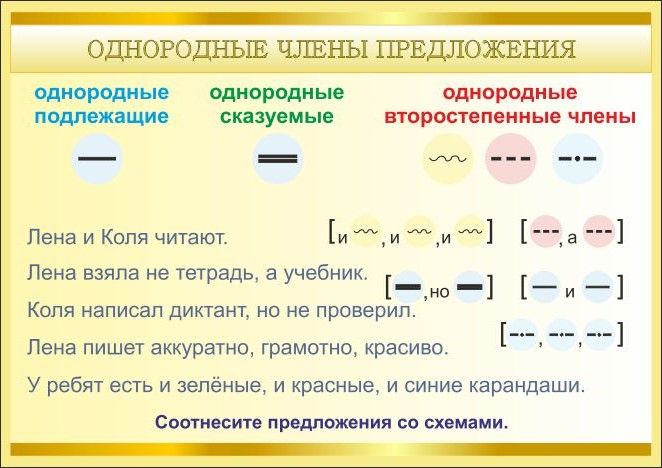 Предложение может быть полным, но нераспространённым, например предложение «Оно приближается». Или наоборот, предложение может быть распространённым, но неполным, как предложение «Жуткое».
Предложение может быть полным, но нераспространённым, например предложение «Оно приближается». Или наоборот, предложение может быть распространённым, но неполным, как предложение «Жуткое».
Рис. 5. Типы простого предложения (Источник)
Таким образом, распространённость или нераспространённость предложения определяется по формальному признаку: есть или нет в предложении второстепенный член. А деление предложения на полное или неполное производится по семантическому, или смысловому, признаку. Т. е. если второстепенный член в предложении отсутствует, но при этом необходим для его понимания, как в вопросе «Ты справился?», такое предложение будет неполным и нераспространённым.
Список литературы
1. Учебник: Русский язык: учебник для 8 кл. общеобразоват. учреждений / Т.А. Ладыженская, М.Т. Баранов, Л.А. Тростенцова и др. – М.: Просвещение, ОАО «Московские учебники», 2008.
2. Угроватова Т.Ю. Тесты по русскому языку. – 2011.
3. Упражнения, практические задания / авт. -сост. Н.Ю. Кадашникова. – Волгоград: Учитель, 2009.
-сост. Н.Ю. Кадашникова. – Волгоград: Учитель, 2009.
Дополнительные рекомендованные ссылки на ресурсы сети Интернет
1. Интернет-сайт urokirusskogo.ru (Источник)
2. Интернет-сайт doc4web.ru (Источник)
3. Интернет-сайт repetitor.biniko.com (Источник)
Домашнее задание
1. Прочитайте и перепишите тексты. Найдите в них односоставные, нераспространённые и неполные предложения.
А. Кабинет в ялтинском доме у Антона Павловича был небольшой, шагов двенадцать в длину и шесть в ширину. Прямо против входной двери – большое квадратное окно в раме. С правой стороны, посредине стены, – коричневый кафельный камин. На камине несколько безделушек и между ними прекрасно сделанная модель парусной шхуны.
Б. В первый раз она появилась вечером. Подбежала чуть ли не к самому костру, схватила рыбий хвостик, который валялся на земле, и утащила под гнилое бревно. Я сразу понял, что это не простая мышь. Куда меньше полевки. Темней. И главное – нос! Лопаточкой, как у крота. Скоро она вернулась, стала шмыгать у меня под ногами, собирать рыбьи косточки и, только когда я сердито топнул, спряталась. «Хоть и не простая, а все-таки мышь, – думал я. – Пусть знает свое место». А место ее было под гнилым кедровым бревном. Туда тащила она добычу. Оттуда вылезла и на другой день.
Скоро она вернулась, стала шмыгать у меня под ногами, собирать рыбьи косточки и, только когда я сердито топнул, спряталась. «Хоть и не простая, а все-таки мышь, – думал я. – Пусть знает свое место». А место ее было под гнилым кедровым бревном. Туда тащила она добычу. Оттуда вылезла и на другой день.
В. Этой осенью я ночевал у деда Лариона. Созвездия, холодные, как крупинки льда, плавали в воде. Шумел сухой тростник. Утки зябли в зарослях и жалобно крякали всю ночь. Деду не спалось. Он сидел у печки и чинил рваную рыболовную сеть. Потом поставил самовар – от него окна в избе сразу запотели.
Если вы нашли ошибку или неработающую ссылку, пожалуйста, сообщите нам – сделайте свой вклад в развитие проекта.
«>
Стратегии синтаксического анализа — синтаксический анализатор TTP
Серия сообщений в блоге о стратегиях синтаксического анализа продолжается введением синтаксического анализатора TTP. TTP — это относительно новая библиотека Python, которая получила некоторое признание в сообществе Network Automation. Он предоставляет простой способ анализа текста в структурированные данные с подходом, аналогичным TextFSM, но, на мой взгляд, может предложить гораздо больше, например, модификаторы вывода, макросы, встроенные функции, форматирование результатов и многие другие функции, которые будут обсуждаться на протяжении всего блога. Присоединяйтесь к каналу Slack TTP (#ttp-template-text-parser) в нашем Networktocode Slack, если вы хотите присоединиться к беседе.
Он предоставляет простой способ анализа текста в структурированные данные с подходом, аналогичным TextFSM, но, на мой взгляд, может предложить гораздо больше, например, модификаторы вывода, макросы, встроенные функции, форматирование результатов и многие другие функции, которые будут обсуждаться на протяжении всего блога. Присоединяйтесь к каналу Slack TTP (#ttp-template-text-parser) в нашем Networktocode Slack, если вы хотите присоединиться к беседе.
В этом сообщении блога представлен обзор TTP. Если вам нужны базовые инструкции о том, как начать использовать синтаксические анализаторы с Ansible (NTC-Templates, TTP и т. д.), начните здесь: Ansible Parsers
Что такое TTP?
TTP — это библиотека Python, которая использует подразумеваемые шаблоны RegEx для анализа данных, но при этом она невероятно гибкая. Эта стратегия синтаксического анализа обеспечивает способ обработки данных во время выполнения, в отличие от постобработки с использованием встроенных функций, пользовательских макросов и средств форматирования вывода во время синтаксического анализа. Мы углубимся в это в следующем разделе. Использование макросов (функций Python) для манипулирования данными и создания желаемого вывода — одна из моих любимых функций библиотеки, поэтому я предпочитаю стратегию синтаксического анализа, когда речь идет о любом иерархическом выводе конфигурации. TTP предоставляет ряд средств форматирования вывода для преобразования данных в форматы YAML, JSON, Table, CSV и другие форматы. TTP может использоваться как утилита CLI, библиотека Python или доступна с Netmiko и Ansible.
Мы углубимся в это в следующем разделе. Использование макросов (функций Python) для манипулирования данными и создания желаемого вывода — одна из моих любимых функций библиотеки, поэтому я предпочитаю стратегию синтаксического анализа, когда речь идет о любом иерархическом выводе конфигурации. TTP предоставляет ряд средств форматирования вывода для преобразования данных в форматы YAML, JSON, Table, CSV и другие форматы. TTP может использоваться как утилита CLI, библиотека Python или доступна с Netmiko и Ansible.
Группы
Группы захвата объявляются с помощью групповых тегов XML, что позволяет вкладывать другие группы для создания иерархии. Любое совпадение внутри группы добавляется к списку результатов. У групп есть несколько атрибутов, которые можно установить, но требуется только атрибут «имя». Важным атрибутом, который следует выделить, является значение «метод», для которого можно установить значение «группа» или «таблица». При анализе вывода CLI рекомендуется установить метод table.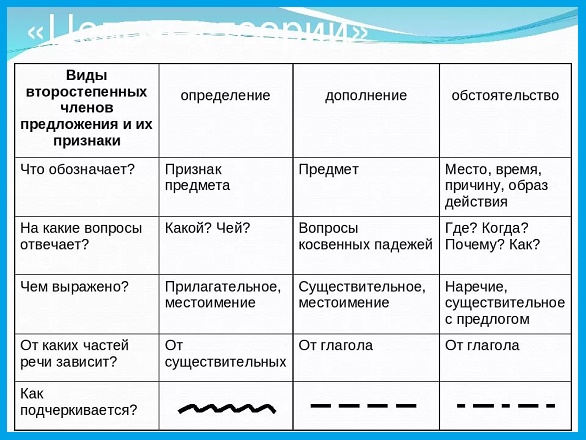 Это говорит синтаксическому анализатору рассматривать каждую строку как начало захвата для группы. В противном случае установка “ start ” Индикатор на совпадение потребуется, если у вас есть вариант регулярных выражений для захвата в группе. Хотя группы используют групповые теги XML, шаблоны TTP имеют более глубокое сходство с шаблонами Jinja и имеют схожие характеристики.
Это говорит синтаксическому анализатору рассматривать каждую строку как начало захвата для группы. В противном случае установка “ start ” Индикатор на совпадение потребуется, если у вас есть вариант регулярных выражений для захвата в группе. Хотя группы используют групповые теги XML, шаблоны TTP имеют более глубокое сходство с шаблонами Jinja и имеют схожие характеристики.
Пример группы:
данные для разбора <имя группы="вложенный"> больше данных для разбора
Шаблоны индикаторов регулярных выражений
TTP позволяет указать шаблоны регулярных выражений для захвата в переменной соответствия. Если мы посмотрим на исходный код, мы сможем просмотреть точные шаблоны RegEx, которые применяются для сбора данных. Важно понимать, что такое шаблон регулярного выражения, прежде чем применять его, чтобы убедиться, что вы правильно захватываете переменные.
Шаблоны
ФРАЗА = r"(\S+ {1})+?\S+"
СТРОКА = г"(\S+ +)+?\S+"
ОРФРАЗА = r"\S+|(\S+ {1})+?\S+"
ЦИФРА = r"\d+"
IP = r"(?:[0-9]{1,3}\. ){3}[0-9]{1,3}"
ПРЕФИКС = r"(?:[0-9]{1,3}\.){3}[0-9]{1,3}/[0-9]{1,2}"
ИПВ6 = r"(?:[a-fA-F0-9]{1,4}:|:){1,7}(?:[a-fA-F0-9]{1,4}|:? )"
ПРЕФИКСV6 = r"(?:[a-fA-F0-9]{1,4}:|:){1,7}(?:[a-fA-F0-9]{1,4}|:? )/[0-9]{1,3}"
_строка_ = г".+"
СЛОВО = г"\S+"
MAC = r"(?:[0-9a-fA-F]{2}(:|\.|\-)){5}([0-9a-fA-F]{2})|(?: [0-9a-fA-F]{4}(:|\.|\-)){2}([0-9a-fA-F]{4})"
 ){3}[0-9]{1,3}"
ПРЕФИКС = r"(?:[0-9]{1,3}\.){3}[0-9]{1,3}/[0-9]{1,2}"
ИПВ6 = r"(?:[a-fA-F0-9]{1,4}:|:){1,7}(?:[a-fA-F0-9]{1,4}|:? )"
ПРЕФИКСV6 = r"(?:[a-fA-F0-9]{1,4}:|:){1,7}(?:[a-fA-F0-9]{1,4}|:? )/[0-9]{1,3}"
_строка_ = г".+"
СЛОВО = г"\S+"
MAC = r"(?:[0-9a-fA-F]{2}(:|\.|\-)){5}([0-9a-fA-F]{2})|(?: [0-9a-fA-F]{4}(:|\.|\-)){2}([0-9a-fA-F]{4})"
){3}[0-9]{1,3}"
ПРЕФИКС = r"(?:[0-9]{1,3}\.){3}[0-9]{1,3}/[0-9]{1,2}"
ИПВ6 = r"(?:[a-fA-F0-9]{1,4}:|:){1,7}(?:[a-fA-F0-9]{1,4}|:? )"
ПРЕФИКСV6 = r"(?:[a-fA-F0-9]{1,4}:|:){1,7}(?:[a-fA-F0-9]{1,4}|:? )/[0-9]{1,3}"
_строка_ = г".+"
СЛОВО = г"\S+"
MAC = r"(?:[0-9a-fA-F]{2}(:|\.|\-)){5}([0-9a-fA-F]{2})|(?: [0-9a-fA-F]{4}(:|\.|\-)){2}([0-9a-fA-F]{4})"
Макросы
Как указано в документации, «Макросы — это код Python внутри тега макроса. Этот код может содержать ряд определений функций, на эти функции можно ссылаться в шаблонах TTP». Это позволяет нам обрабатывать данные во время синтаксического анализа, отправляя захваченный вывод из нашего шаблона в функцию и возвращая обработанный результат. Это помогает устранить необходимость в постобработке значений после анализа данных. TTP предлагает возможность использовать эти макрофункции в сопоставлении переменных, групп, выходных и входных данных. Ниже мы рассмотрим пару примеров использования макросов для сопоставленных переменных.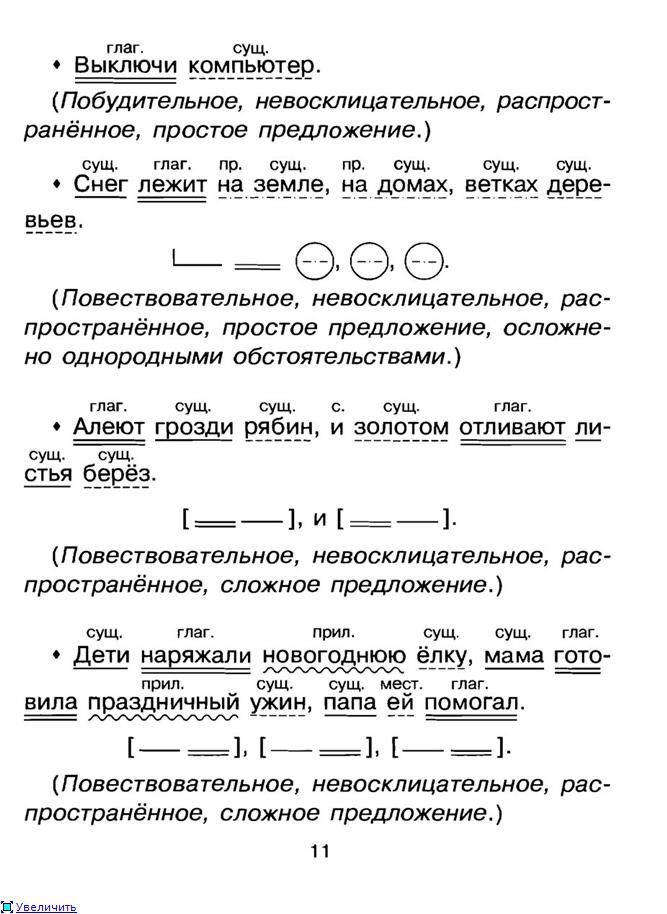
Пример макроса:
<макрос>
определение уровня_подписки (данные):
данные = данные.заменить('"','').split()
если len(данные) >= 3:
return {"тип карты": данные [0], "уровень подписки": данные [2]}
возвращаемые данные[0]
Структурирование вывода (моделирование данных)
Еще одна замечательная особенность TTP — возможность манипулировать структурированием и представлением данных для нас. Я не буду вдаваться во все подробности и возможности, но вы можете видеть из нашего примера ниже, что у нас есть список соседей под нашими результатами BGP для семейства адресов IPV4. Однако под нашими пиринговыми соседями мы сгенерировали словарь с ключом соседа, который был найден в последующем результате. Можете ли вы найти различия в том, как парсер был структурирован для работы с различными структурами данных? Под примером Dynamic Path есть подсказка «Awesome»!
Простой список:
<имя группы="сосед">
сосед {{ сосед }} {{ активировать | макрос("to_bool") }}
сосед 10. 1.0.1 сообщество отправки {{сообщество отправки}}
сосед 10.1.0.1 route-map {{ route-map }} {{ route-map-direction }}
 1.0.1 сообщество отправки {{сообщество отправки}}
сосед 10.1.0.1 route-map {{ route-map }} {{ route-map-direction }}
1.0.1 сообщество отправки {{сообщество отправки}}
сосед 10.1.0.1 route-map {{ route-map }} {{ route-map-direction }}
Фрагмент результата:
"сосед": [
{
«активировать»: правда,
"сосед": "10.1.0.1",
"карта маршрутов": "PL-EBGP-PE1-OUT",
"маршрут-карта-направление": "выход",
"отправить-сообщество": "оба"
},
{
«активировать»: правда,
"сосед": "10.1.0.5",
"карта маршрутов": "PL-EBGP-PE2-OUT",
"маршрут-карта-направление": "выход",
"отправить-сообщество": "оба"
}
Динамический путь:
<------ Отлично! сосед {{сосед}} удаленный-как {{ удаленный-как}} сосед 10.1.0.1 источник обновления {{ источник обновления }}
Фрагмент результата:
"сосед": {
"10.1.0.1": {
"удаленный-как": "65000",
"источник обновления": "GigabitEthernet2.1001"
},
"10.1.0.5": {
"удаленный-как": "65000",
"источник обновления": "GigabitEthernet3. 1001"
}
 1001"
}
1001"
}
Существует несколько других методов форматирования структуры, и я настоятельно рекомендую вам ознакомиться с документацией, чтобы получить максимальную отдачу от функции формирования структуры результатов.
Анализ иерархической конфигурации
Давайте приступим! Я знаю, ты не можешь дождаться хороших вещей. Вот пример использования групп, макросов, указанных индикаторов RegEx ( ORPHRASE & DIGIT ), средств форматирования пути и индикаторов соответствия переменных (« начало », « конец », « игнорировать ») для анализа Nokia 7750. конфигурация карты.
#--------------------------------------------------------------- ---
эхо "Конфигурация карты"
#------------------------------------------------- -
карта 1
карта типа "иом-1" уровень кр
отказ-при-ошибке
мда 1
mda-тип "me6-100gb-qsfp28"
вход-xpl
окно 10
выход
выход-xpl
окно 10
выход
отказ-при-ошибке
нет выключения
выход
нет выключения
выход
Шаблон TTP:
<макрос>
определение уровня_подписки (данные):
данные = данные. заменить('"','').split()
return {"тип карты": данные [0], "уровень подписки": данные [2]}
#------------------------------------------------- - {{игнорировать}}
echo "Конфигурация карты" {{ _start_ }}
#------------------------------------------------- - {{игнорировать}}
<имя группы="configure.card">
карта {{номер слота | ЦИФРА }}
тип карты {{ тип карты | ОРФРАЗА | макрос('уровень_подписки') }}
сбой при ошибке {{сбой при ошибке | установить (истина) }}
<имя группы="mda">
mda {{mda-слот}}
выключение {{ состояние администратора | установить(ложь) }}
mda-тип {{ mda-тип | заменять('"', '') }}
<имя группы="вход-xpl">
вход-xpl {{ _start_ }}
окно {{окно}}
выход {{ _end_ }}
<имя группы="выход-xpl">
выход-xpl {{ _start_ }}
окно {{окно}}
выход {{ _end_ }}
сбой при ошибке {{ сбой при ошибке | установить (истина) }}
без выключения {{ состояние администратора | установить (истина) }}
выйти {{игнорировать}}
#------------------------------------------------- - {{ _конец_ }}
 заменить('"','').split()
return {"тип карты": данные [0], "уровень подписки": данные [2]}
#------------------------------------------------- - {{игнорировать}}
echo "Конфигурация карты" {{ _start_ }}
#------------------------------------------------- - {{игнорировать}}
<имя группы="configure.card">
карта {{номер слота | ЦИФРА }}
тип карты {{ тип карты | ОРФРАЗА | макрос('уровень_подписки') }}
сбой при ошибке {{сбой при ошибке | установить (истина) }}
<имя группы="mda">
mda {{mda-слот}}
выключение {{ состояние администратора | установить(ложь) }}
mda-тип {{ mda-тип | заменять('"', '') }}
<имя группы="вход-xpl">
вход-xpl {{ _start_ }}
окно {{окно}}
выход {{ _end_ }}
<имя группы="выход-xpl">
выход-xpl {{ _start_ }}
окно {{окно}}
выход {{ _end_ }}
сбой при ошибке {{ сбой при ошибке | установить (истина) }}
без выключения {{ состояние администратора | установить (истина) }}
выйти {{игнорировать}}
#------------------------------------------------- - {{ _конец_ }}
заменить('"','').split()
return {"тип карты": данные [0], "уровень подписки": данные [2]}
#------------------------------------------------- - {{игнорировать}}
echo "Конфигурация карты" {{ _start_ }}
#------------------------------------------------- - {{игнорировать}}
<имя группы="configure.card">
карта {{номер слота | ЦИФРА }}
тип карты {{ тип карты | ОРФРАЗА | макрос('уровень_подписки') }}
сбой при ошибке {{сбой при ошибке | установить (истина) }}
<имя группы="mda">
mda {{mda-слот}}
выключение {{ состояние администратора | установить(ложь) }}
mda-тип {{ mda-тип | заменять('"', '') }}
<имя группы="вход-xpl">
вход-xpl {{ _start_ }}
окно {{окно}}
выход {{ _end_ }}
<имя группы="выход-xpl">
выход-xpl {{ _start_ }}
окно {{окно}}
выход {{ _end_ }}
сбой при ошибке {{ сбой при ошибке | установить (истина) }}
без выключения {{ состояние администратора | установить (истина) }}
выйти {{игнорировать}}
#------------------------------------------------- - {{ _конец_ }}
Результат:
[
{
"настроить": {
"открытка":{
"тип карты":{
"тип карты": "iom-1",
«уровень подписки»: «cr»
},
«сбой при ошибке»: правда,
"мда": {
«админ-состояние»: правда,
"выход-XPL": {
"окно": "10"
},
«сбой при ошибке»: правда,
"вход-XPL": {
"окно": "10"
},
"mda-слот":"1",
"mda-тип": "me6-100gb-qsfp28"
},
"номер слота": "1"
}
}
}
]
Потрясающе! Но что именно происходит с нашим макросом «subscription_level»? Наш шаблон включает следующую переменную соответствия:
"тип карты {{ тип карты | ORPHRASE | макрос('уровень_подписки') }}".

Это использует «ORPHRASE» для захвата одного слова или фразы, а соответствующий текст («iom-1» level cr») затем отправляется в функцию «subscription_level» для обработки. Функция берет эту захваченную строку и манипулирует текстом, разбивая его, чтобы создать следующий список: «[‘iom-1’, ‘level’, ‘cr’]». Наконец, он возвращает словарь с ключами для «типа карты» и «уровня подписки».
{
"тип карты":{
"тип карты": "iom-1",
«уровень подписки»: «cr»
}
}
Давайте рассмотрим еще один пример шаблона для анализа конфигурации Cisco IOS BGP, в которой также используются встроенные функции TTP. Цель состоит в том, чтобы преобразовать значения, которые были бы лучше представлены как логические значения в нашей модели данных, в частности, следующие строки: «log-neighbor-changes» и «activate». Хотя мы можем использовать функцию «set», как и в предыдущем примере, для достижения чего-то подобного, я действительно хочу подчеркнуть тот факт, что мы можем использовать функции python для достижения желаемого состояния совпадающей переменной. Также макросы имеют уникальное поведение при возврате данных, которое мы рассмотрим подробнее. Мы также будем использовать is_ip для проверки того, что адрес нашего соседа на самом деле является IP-адресом, и DIGIT в качестве индикатора RegEx для соответствия числу.
Также макросы имеют уникальное поведение при возврате данных, которое мы рассмотрим подробнее. Мы также будем использовать is_ip для проверки того, что адрес нашего соседа на самом деле является IP-адресом, и DIGIT в качестве индикатора RegEx для соответствия числу.
Вот необработанный вывод текущей конфигурации для BGP:
router bgp 65001 идентификатор маршрутизатора bgp 192.168.10.1 bgp log-neighbour-changes сосед 10.1.0.1 удаленный-как 65000 сосед 10.1.0.1 источник обновления GigabitEthernet2.1001 сосед 10.1.0.5 удаленный-как 65000 сосед 10.1.0.5 источник обновления GigabitEthernet3.1001 ! адрес-семейство ipv4 перераспределить подключенный сосед 10.1.0.1 активировать сосед 10.1.0.1 send-community оба карта маршрутов соседа 10.1.0.1 PL-EBGP-PE1-OUT сосед 10.1.0.5 активировать сосед 10.1.0.5 send-community оба сосед 10.1.0.5 карта маршрутов PL-EBGP-PE2-OUT выход-адрес-семья
Шаблон:
<макрос>
def to_bool (захваченные_данные):
represent_as_bools = ["активировать", "лог-соседние-изменения"]
если захваченные_данные в представляют_как_боулы:
вернуть захваченные_данные, {захваченные_данные: Истина}
<имя группы="bgp">
маршрутизатор bgp {{ asn | ЦИФРА }}
идентификатор маршрутизатора bgp {{ идентификатор маршрутизатора }}
bgp {{ log-neighbour-changes | макрос("to_bool") }}
 {{ сосед }}">
сосед {{ сосед | is_ip }} удаленный-как {{ удаленный-как }}
сосед 10.1.0.1 источник обновления {{ источник обновления }}
! {{игнорировать}}
{{ сосед }}">
сосед {{ сосед | is_ip }} удаленный-как {{ удаленный-как }}
сосед 10.1.0.1 источник обновления {{ источник обновления }}
! {{игнорировать}}
семейство адресов {{ afi }}
перераспределить {{ перераспределить }}
<имя группы="сосед">
сосед {{ сосед | is_ip }} {{ активировать | макрос("to_bool") }}
сосед 10.1.0.1 сообщество отправки {{сообщество отправки}}
сосед 10.1.0.1 route-map {{ route-map }} {{ route-map-direction }}
выход-адрес-семья {{ игнорировать }}
Результат нашей задачи Ansible:
TASK [DEBUG] **************************************** **********************************
хорошо: [AS65001_CE1] => {
"сообщение": [
[
{
"бгп": {
"афи": {
"ipv4": {
"сосед": [
{
«активировать»: правда,
"сосед": "10. 1.0.1",
"карта маршрутов": "PL-EBGP-PE1-OUT",
"маршрут-карта-направление": "выход",
"отправить-сообщество": "оба"
},
{
«активировать»: правда,
"сосед": "10.1.0.5",
"карта маршрутов": "PL-EBGP-PE2-OUT",
"маршрут-карта-направление": "выход",
"отправить-сообщество": "оба"
}
],
«распространить»: «подключено»
}
},
"asn": "65001",
"log-neighbor-changes": правда,
"сосед": {
"10.1.0.1": {
"удаленный-как": "65000",
"источник обновления": "GigabitEthernet2. 1001"
},
"10.1.0.5": {
"удаленный-как": "65000",
"источник обновления": "GigabitEthernet3.1001"
}
},
"идентификатор маршрутизатора": "192.168.10.1"
}
}
]
]
}
 1.0.1",
"карта маршрутов": "PL-EBGP-PE1-OUT",
"маршрут-карта-направление": "выход",
"отправить-сообщество": "оба"
},
{
«активировать»: правда,
"сосед": "10.1.0.5",
"карта маршрутов": "PL-EBGP-PE2-OUT",
"маршрут-карта-направление": "выход",
"отправить-сообщество": "оба"
}
],
«распространить»: «подключено»
}
},
"asn": "65001",
"log-neighbor-changes": правда,
"сосед": {
"10.1.0.1": {
"удаленный-как": "65000",
"источник обновления": "GigabitEthernet2.
1.0.1",
"карта маршрутов": "PL-EBGP-PE1-OUT",
"маршрут-карта-направление": "выход",
"отправить-сообщество": "оба"
},
{
«активировать»: правда,
"сосед": "10.1.0.5",
"карта маршрутов": "PL-EBGP-PE2-OUT",
"маршрут-карта-направление": "выход",
"отправить-сообщество": "оба"
}
],
«распространить»: «подключено»
}
},
"asn": "65001",
"log-neighbor-changes": правда,
"сосед": {
"10.1.0.1": {
"удаленный-как": "65000",
"источник обновления": "GigabitEthernet2. 1001"
},
"10.1.0.5": {
"удаленный-как": "65000",
"источник обновления": "GigabitEthernet3.1001"
}
},
"идентификатор маршрутизатора": "192.168.10.1"
}
}
]
]
}
1001"
},
"10.1.0.5": {
"удаленный-как": "65000",
"источник обновления": "GigabitEthernet3.1001"
}
},
"идентификатор маршрутизатора": "192.168.10.1"
}
}
]
]
}
Ну, это было легко. Все, что нам нужно было сделать, это заменить интересующие значения синтаксисом, подобным jinja, и определить несколько групп с тегами групп XML, чтобы правильно структурировать наши результаты. Функция макроса «to_bool» использовалась для обработки захваченных данных и возврата логического значения. Вы, возможно, заметили, что в нашем макросе мы вернули захваченные_данные и словарь, в отличие от нашего предыдущего примера, возвращающего только простой словарь. Это связано с тем, что макросы будут вести себя по-разному в зависимости от возвращаемых данных. Вот объяснение из документации:
«Если макрос возвращает True или False — исходные данные не изменяются, макрос обрабатывается как функция условия, делает недействительным результат при False и продолжает обработку результата при True
Если макрос возвращает None — обработка данных продолжается, дополнительная логика не связана
Если макрос возвращает один элемент — этот элемент заменяет исходные данные, переданные в макрос и обработанные в дальнейшем. Если макрос возвращает кортеж из двух элементов — первый элемент должен быть строкой — результат совпадения, второй — словарь дополнительных полей для добавления к результатам»
Если макрос возвращает кортеж из двух элементов — первый элемент должен быть строкой — результат совпадения, второй — словарь дополнительных полей для добавления к результатам»
Анализ команд Show
Давайте продолжим шаблон серии и проанализируем вывод простой команды «show lldp Neighbours» для IOS.
Необработанный вывод:
Коды возможностей:
(R) Маршрутизатор, (B) Мост, (T) Телефон, (C) Кабельное устройство DOCSIS
(W) точка доступа WLAN, (P) повторитель, (S) станция, (O) другое
ID устройства Local Intf Hold-time Capability Port ID
R3.admin-save.com Gi0/1 120 R Gi0/0
R2.admin-save.com Gi0/0 120 R Gi0/0
Всего отображаемых записей: 2
Теперь давайте посмотрим, насколько прост шаблон TTP для анализа рабочих команд вывода шоу:
ID устройства Local Intf Hold-time Capability Port ID {{ignore}} {{DEVICE_ID}} {{LOCAL_INT}} {{HOLD_TIME | ЦИФРА}} {{ВОЗМОЖНОСТИ}} {{ PORT_ID }} <имя группы="TOTAL_ENTRIES"> Всего отображаемых записей: {{ COUNT | ЦИФРА}}
Вот оно! Давайте рассмотрим некоторые важные моменты, чтобы сделать этот шаблон успешным.
- Метод
- «метод = ‘таблица’» применяется к группе «LLDP_NEIGHBORS», поскольку мы анализируем рабочие команды show в формате таблицы.
- Игнорировать
- ”” используется, чтобы указать синтаксическому анализатору отбрасывать строки, которые нам не нужны внутри нашей группы захвата. Любые строки вне группы просто игнорируются и отбрасываются по умолчанию.
Пример Playbook:
---
- название: "ПРИМЕР TTP PLAYBOOK"
хосты: R1
подключение: network_cli
задачи:
- название: "10. РАЗБИРАТЬ СОСЕДЕЙ LLDP С TTP"
ansible.netcommon.cli_parse:
команда: "показать соседей lldp"
парсер:
имя: ansible.netcommon.ttp
set_fact: lldp
- имя: ОТЛАДКА
отлаживать:
сообщение: "{{lldp}}"
Приведенный выше плейбук ссылается на шаблон в следующем относительном месте: «templates/ios_show_lldp_neighbors.ttp». Каталог templates содержит шаблон, начинающийся с ansible_network_os, за которым следует команда.
Проанализированный вывод:
ok: [R1] => {
"сообщение": [
[
{
"LLDP_NEIGHBORS": [
{
"ВОЗМОЖНОСТЬ": "R",
"DEVICE_ID": "R3.admin-save.com",
"HOLD_TIME": "120",
"LOCAL_INT": "Gi0/1",
"PORT_ID": "Gi0/0"
},
{
"ВОЗМОЖНОСТЬ": "R",
"DEVICE_ID": "R2.admin-save.com",
"HOLD_TIME": "120",
"LOCAL_INT": "Gi0/0",
"PORT_ID": "Gi0/0"
}
],
"TOTAL_ENTRIES": {
"СЧЕТ": "2"
}
}
]
Наконец, следует помнить о нескольких созданных вложенных списках. Это так же просто, как убедиться, что вы обращаетесь к правильному списку при оценке результатов.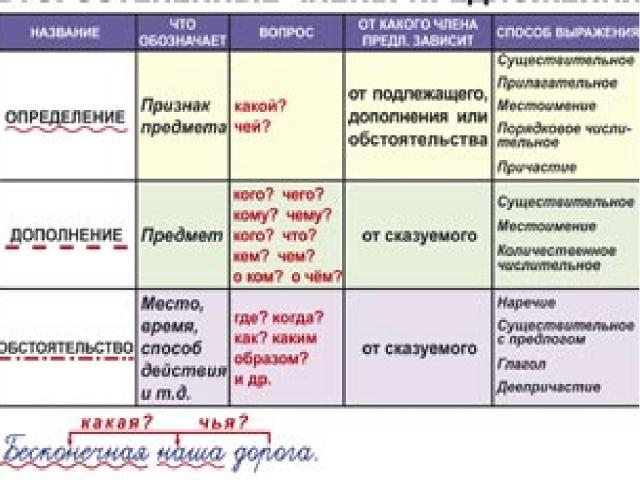
Пример задачи отладки Ansible:
— имя: DEBUG
отлаживать:
сообщение: "{{ lldp[0][0]['TOTAL_ENTRIES'] }}"
Выход:
ЗАДАЧА [ОТЛАДКА] ******************************************* ******************************
хорошо: [R1] => {
"сообщение": {
"СЧЕТ": "2"
}
}
Резюме
Хотя мы только слегка коснулись поверхности, вы можете видеть, что TTP предлагает множество замечательных функций. Я нахожу его очень удобным при анализе полных иерархических выходных данных текущей конфигурации, в большей степени, чем другие доступные парсеры. Библиотека постоянно развивается и внедряет новые функции. Найдите секунду, чтобы присоединиться к каналу Slack, чтобы не отставать от разработки и задавать любые вопросы, которые могут у вас возникнуть!
-Hugo
Что такое анализ данных? Описание процесса
Содержание
- Что такое анализ данных?
- Как работает синтаксический анализ?
- Типы парсеров
- Технологии парсинга
- Почему парсинг и искусственный интеллект (ИИ) неразлучны?
- Что такое обработка естественного языка (NLP)?
- Синтаксический анализ в гуманитарных науках
25 августа 2021 г.
12
минут прочитано
Точно так же, как мы переводим естественные языки для эффективного международного общения, нам необходимо выполнять аналогичные процессы с языками программирования, чтобы обеспечить успех в компьютерных науках. Поэтому и появился парсинг.
Синтаксический анализ данных превращает необработанные неструктурированные данные в хорошо структурированную и понятную информацию. Таким образом, если вы получаете данные в необработанном HTML-коде после очистки страницы с помощью прокси-серверов, вам все равно придется пропускать эти данные через синтаксический анализатор. Он возьмет HTML и преобразует его в удобочитаемый формат, который вы сможете легко понять.
Что такое разбор данных?
В основном синтаксический анализ данных представляет собой процесс, когда компьютерное программное обеспечение преобразует строку часто неразборчивых данных в удобочитаемый формат, который легко понять. У этого процесса есть несколько синонимов, включая синтаксический анализ и синтаксический анализ.
У этого процесса есть несколько синонимов, включая синтаксический анализ и синтаксический анализ.
На более техническом уровне синтаксический анализатор данных — это программный компонент, который использует входные данные (например, HTML) для создания структурного, удобочитаемого представления этих входных данных.
Парсеры работают с разными форматами данных. Все зависит от кода и набора правил, на которых он построен. Например, синтаксический анализатор может извлечь необходимую информацию из строки HTML и преобразовать ее в JSON, CSV, диаграмму или таблицу.
Как работает синтаксический анализ?
Разбор — это не простой процесс анализа строк символов на языке программирования. Это двухэтапная процедура, в которой парсер программно разрабатывается, чтобы знать, какие данные читать и как их анализировать и преобразовывать.
Анализатор данных состоит из двух компонентов: лексического анализа и синтаксического анализа. За ними следует семантический анализ, который на самом деле не вписывается в синтаксический анализ, но всегда следует за ним. Ниже мы собираемся переварить их все.
Ниже мы собираемся переварить их все.
Лексический анализ
Это первый шаг разбора данных. Все начинается, когда в синтаксический анализатор поступает строка необработанных неструктурированных данных. Затем лексер, также известный как сканер или токенизатор, преобразует этот поток данных в последовательность токенов. 9, 3 . По сути, лексический анализ — это процесс генерации токенов.
Синтаксический анализ
Следующим этапом является проверка того, составляют ли сгенерированные токены допустимое осмысленное выражение в соответствии с заранее определенными правилами. Звучит супер сложно? Продолжайте читать, мы постараемся сделать это яснее.
Здесь нужно ввести еще одно понятие из компьютерных наук – контекстно-свободная грамматика. Это набор правил, определяющих синтаксис языка. Проще говоря, контекстно-свободная грамматика — это компьютерные коды, которые определяют допустимую последовательность токенов. Он четко определяет, какие компоненты могут составлять допустимое выражение в токенах, и порядок, в котором эти компоненты должны идти.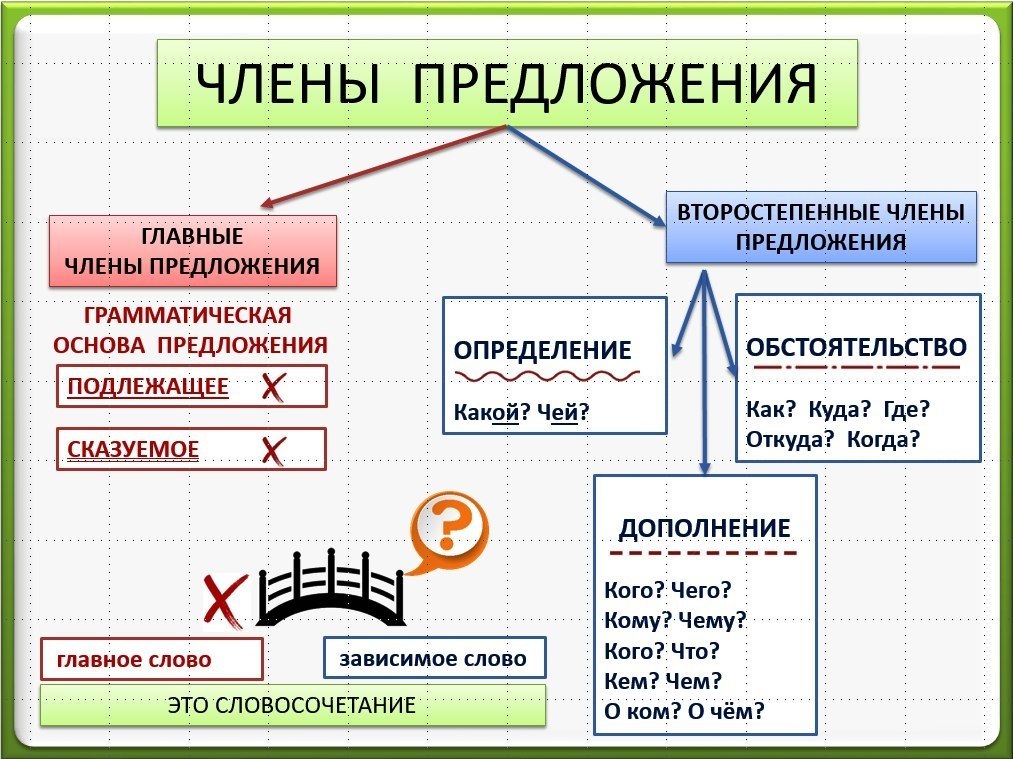
Результатом синтаксического анализа является дерево разбора, состоящее из ветвей с листовыми узлами. Рисование дерева синтаксического анализа означает рисование иерархической структуры, показывающей, какие элементы исходных данных имеют смысл и какова их роль.
В своей простейшей форме лексический анализ создает токены, а синтаксический анализ рисует деревья из этих токенов.
Семантический анализ
Понятие синтаксического анализа не включает семантический анализ, но это то, что всегда следует за синтаксическим анализом. Это выполняется семантическими анализаторами, а не самими парсерами.
Семантический анализ — это процесс перевода исходного кода (написанного на языке программирования высокого уровня) в объектный код (написанный на языке программирования низкого уровня). Это процесс, который преобразует исходный код в исполняемую программу.
На этом этапе семантические анализаторы идентифицируют все оставшиеся ошибки из синтаксического анализа и генерируют аннотированное дерево синтаксического анализа, также известное как безошибочное дерево синтаксического анализа.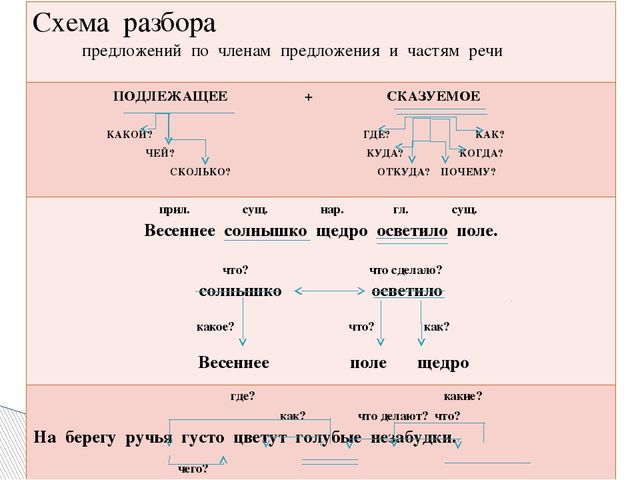 Этот этап жизненно важен, потому что синтаксический анализ не может обнаружить все ошибки в исходном коде.
Этот этап жизненно важен, потому что синтаксический анализ не может обнаружить все ошибки в исходном коде.
Если исходная строка символов не содержит ошибок, семантический анализ дает зеленый свет для преобразования необработанных и неструктурированных данных в четко читаемую часть информации.
Типы синтаксических анализаторов
Основная цель использования синтаксических анализаторов — определить, можно ли получить ввод из исходной строки символов на основе предварительно определенного набора правил. Есть два способа сделать это: сверху вниз и снизу вверх.
Технологии синтаксического анализа
Парсеры данных сочетаются с различными технологиями, поскольку они чрезвычайно гибкие. Взгляните на некоторые примеры технологий, которые идут рука об руку с синтаксическим анализом:
1. Языки разметки.
HTML означает язык гипертекстовой разметки. Разработчики используют его для создания веб-сайтов и веб-приложений, которые отображают данные. XML — это сокращение от расширяемого языка разметки. Он устанавливает правила кодирования документов в формате, удобочитаемом человеком и машиной.
XML — это сокращение от расширяемого языка разметки. Он устанавливает правила кодирования документов в формате, удобочитаемом человеком и машиной.
2. Интернет-протоколы.
Языки интернет-протокола, такие как безопасный протокол передачи гипертекста (HTTPS), лежат в основе передачи данных в Интернете. Эти протоколы обеспечивают безопасную связь по компьютерной сети.
3. Языки баз данных.
Эти языки помогают нам читать, обновлять и хранить информацию в базах данных. Например, SQL или язык структурированных запросов — один из самых популярных языков программирования, позволяющий управлять данными в системах баз данных.
4. Скриптовые языки.
Это языки программирования, которые автоматизируют выполнение задач без участия человека. Такие языки определяют ряд команд, которые не требуют компиляции. Веб-приложения, мультимедиа, игры, расширения и плагины — все они используют языки сценариев.
5. Языки моделирования.
Это искусственный графический или текстовый язык, выражающий информацию в определенной структуре, определяемой набором определенных правил. Разработчики, аналитики и инвесторы используют языки моделирования, чтобы понять, как работают интересующие их системы.
6. Интерактивные языки данных.
IDL, т. е. интерактивный язык данных, представляет собой язык программирования, чрезвычайно полезный для анализа и визуализации данных. Специалисты по космическим наукам и физике Солнца используют IDL ежедневно.
7. Языки программирования общего назначения.
Вполне вероятно, что Java является самым популярным языком программирования такого рода. Это объектно-ориентированный язык, основанный на классах, который может похвастаться своей переносимостью. После того как вы написали код для Java-программы на компьютере, очень легко перенести этот код на мобильное устройство.
Как мы делаем парсинг в Smartproxy
Здесь, в Smartproxy, мы одержимы данными. Вот почему у нас есть множество инструментов, которые могут сделать ваш веб-скраппинг быстрым, плавным и полезным. Прежде всего, если вы используете полностью разработанные продукты, такие как Octoparse или Scrapy, не забудьте использовать резидентные прокси для ускорения парсинга с помощью этих инструментов.
Вот почему у нас есть множество инструментов, которые могут сделать ваш веб-скраппинг быстрым, плавным и полезным. Прежде всего, если вы используете полностью разработанные продукты, такие как Octoparse или Scrapy, не забудьте использовать резидентные прокси для ускорения парсинга с помощью этих инструментов.
Но лучше всего то, что у нас есть собственные решения, которые могут анализировать данные. Наш No-Code Scraper предлагает селектор, который может идентифицировать и выбирать несколько полей с одинаковым значением одним щелчком мыши. Он предоставит вам предварительный просмотр собранных данных в виде таблицы и возможность мгновенного экспорта данных в форматах JSON или CSV.
Если ваша цель — отправить миллионы запросов в Google, простое расширение прокси не сработает. Для таких задач вам понадобится специальный инструмент SERP Scraping API. Его легко использовать. Просто укажите свой запрос или URL-адрес, и Smartproxy вернет данные в правильном формате в формате JSON.
Загрузка видео…
Почему синтаксический анализ и искусственный интеллект (ИИ) неразлучные друзья?
Итак, теперь мы знаем, что данные, которые мы получаем из веб-скрапинга, плохо структурированы и поэтому теряют смысл, если они не анализируются правильно. Мы также установили, что синтаксический анализ данных чрезвычайно сложен. И дело не только в том, что синтаксический анализ состоит из двух анализов, за которыми следует семантический анализ.
Характер структуры веб-сайта также очень динамичен. Только представьте все эти миллиарды веб-сайтов по всему миру. Все они разные: в их программировании используются разные коды, их форматы все время меняются… Вот почему парсеры нуждаются в обслуживании и должны адаптироваться к разным форматам страниц.
Если бы вам пришлось следить за динамикой веб-структур самостоятельно, это потребовало бы много ручной работы, времени и ресурсов. И все равно вряд ли вы выполните все задания.
Решение здесь заключается в использовании искусственного интеллекта (ИИ).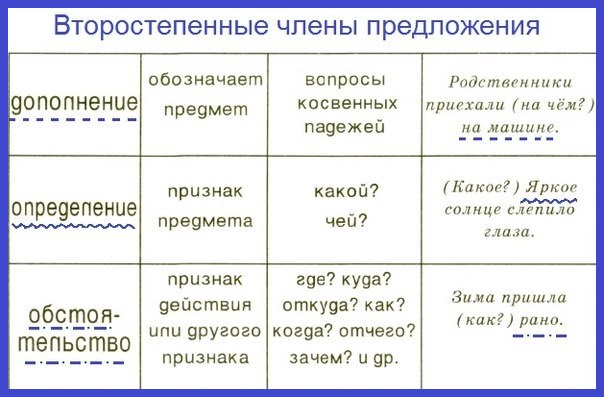 ИИ автоматизирует задачи обслуживания и проведет ваши бизнес-операции со скоростью света. Поэтому парсинг данных в современном мире просто невозможен без помощи некоего «разума».
ИИ автоматизирует задачи обслуживания и проведет ваши бизнес-операции со скоростью света. Поэтому парсинг данных в современном мире просто невозможен без помощи некоего «разума».
Что такое обработка естественного языка (NLP)?
Обработка естественного языка, или сокращенно НЛП, — это область искусственного интеллекта, целью которой является определение того, как программировать компьютеры для обработки, анализа и представления больших объемов данных человеческого языка. Тем не менее, мы не можем представить синтаксический анализ без обработки естественного языка.
Поскольку обработка естественного языка связана с тем, как компьютеры анализируют и обрабатывают обширные данные естественного языка, синтаксический анализ — не единственная область, в которой НЛП играет значительную роль. НЛП является неотъемлемой частью следующей области (просто упомянем несколько):
- Машинный перевод
- Оптическое распознавание символов (OCR)
- Чат-боты
- Включение голоса
- Статистика
Итак, НЛП — это технология, которая делает возможным взаимодействие между компьютерами и человеческим языком. Он позволяет компьютерам правильно понимать входные данные на естественном языке и правильно обеспечивать вывод на естественном языке.
Он позволяет компьютерам правильно понимать входные данные на естественном языке и правильно обеспечивать вывод на естественном языке.
Разбор в гуманитарных науках
Когда кто-то слышит слово «разбор», он обычно ассоциирует его с информатикой. И они совершенно правы! Компьютерщики часто говорят о синтаксическом анализе в программировании, Python, PHP, XML, JSON, HTML, Javascript, Java или C++. Даже в этом сообщении в блоге синтаксический анализ рассматривался с более технической точки зрения.
Но знаете ли вы, что синтаксический анализ существует и вне программирования? Вы спрашиваете, как это возможно? Ниже вы узнаете, как анализировать данные в области гуманитарных наук.
Разбор в языкознании, или что такое разбор предложений?
Разобрать в лингвистике означает разделить предложение на составные части, чтобы понять смысл предложения. Самый популярный инструмент для этого — диаграммы предложений. Они наглядно представляют синтаксическую конструкцию предложения.
Традиционный метод разбора предложений заключается в различении элементов предложения и их частей речи, например. существительные, глаголы, прилагательные и т. д. Читатель также обращает внимание на другие элементы, такие как грамматическое время предложения, то есть настоящее, прошлое или будущее. Сделав все это, читатель использует этот анализ, чтобы понять и интерпретировать значение предложения.
Чтобы было понятнее, рассмотрим следующее предложение:
- Максу нужны прокси.
Чтобы разобрать это предложение, нам сначала нужно определить самые большие компоненты предложения, а именно существительные и глагольные фразы. В данном случае Макс. — именная группа, а требуется несколько прокси. — глагольная группа.
Также интересно отметить, что это не простая глагольная фраза. Он включает в себя не только глагол ( нуждается в ), но и именное словосочетание ( некоторые прокси ).
Затем нам нужно углубиться и установить часть речи каждого слова. В нашем примере мы можем видеть имя собственное ( Макс. ), глагол ( нуждается в ), определитель ( какой-то ) и существительное ( прокси ). Наконец, поскольку глагол нуждается в , мы можем понять, что действие не произошло и предложение стоит в настоящем времени.
В нашем примере мы можем видеть имя собственное ( Макс. ), глагол ( нуждается в ), определитель ( какой-то ) и существительное ( прокси ). Наконец, поскольку глагол нуждается в , мы можем понять, что действие не произошло и предложение стоит в настоящем времени.
Это простой пример. Тем не менее, он показывает, как синтаксический анализ может помочь понять смысл текста. Такие визуализации особенно полезны при анализе очень длинных и сложных предложений.
Парсинг в психологии
Когда мы говорим о синтаксическом анализе в психологии, мы в основном имеем в виду синтаксический анализ в когнитивной психологии (или психолингвистике). Это область исследования, которая анализирует отношения между языками и психологией.
Ученые в этой области изучают и объясняют, как мозг обрабатывает язык для преобразования знаков и символов в осмысленные утверждения. Они стремятся понять, как различные структуры мозга облегчают овладение языком и его понимание.
Очень простой пример разбора в психолингвистике — словесные ассоциации. Например, когда мы слышим слово «кроссовки», мы можем думать о следующих атрибутах, связанных с этим словом: спорт, бег, тренировка, Nike, Adidas, резина и т. д.
Подводя итоги
Синтаксический анализ — широкая тема, которая вышла за пределы компьютерных наук и проложила путь для дальнейших приложений в области гуманитарных наук. Мы надеемся, что нам удалось довести ваше понимание парсинга данных до нужного уровня.
Если вам нужны способы развития вашего бизнеса, зарегистрируйтесь здесь, чтобы начать использовать наши инструменты. И да, если у вас есть какие-либо вопросы об анализе данных, пообщайтесь с нашей службой поддержки!
Темы:Разбор
Джеймс Кинан
Старший автор контента
Проповедник автоматизации и анонимности в Smartproxy. Он верит в свободу данных и право каждого стать самостоятельным. Джеймс здесь, чтобы поделиться знаниями и помочь вам добиться успеха с резидентными прокси.
Часто задаваемые вопросы
Что такое разбор синонимов?
Синтаксический анализ и синтаксический анализ являются синонимами синтаксического анализа.
Зачем мне ПО для синтаксического анализа?
Если у вас есть прокси, вы уже собираете общедоступные данные без ограничений. Тем не менее, если вы хотите принимать бизнес-решения на основе данных, которые автоматизируют ваши задачи и оптимизируют рабочий процесс, вам необходимо преобразовать неструктурированные, необработанные данные из извлечения в четко читаемую и понятную информацию. Здесь на помощь приходит синтаксический анализ. Для получения дополнительной информации есть отличная запись в блоге о синтаксическом анализе вариантов использования.
Что такое разбор резюме?
Анализ резюме — это процесс импорта резюме в программное обеспечение для анализа с целью извлечения информации для дальнейшего анализа. Если вы анализируете резюме, вы можете легко сортировать, хранить и анализировать данные из них.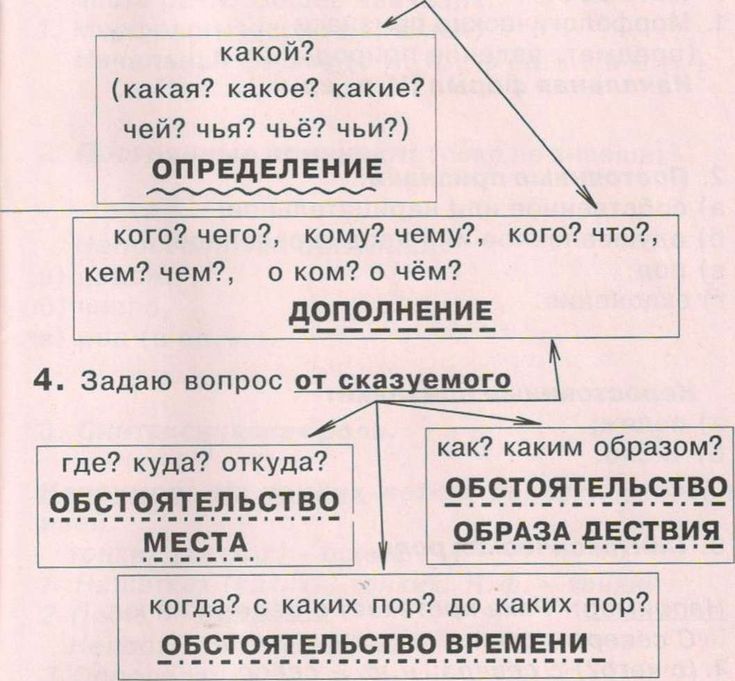 Анализ резюме является синонимом анализа резюме, извлечения резюме или извлечения резюме.
Анализ резюме является синонимом анализа резюме, извлечения резюме или извлечения резюме.
Что такое анализ электронной почты?
Анализ электронной почты — это процесс использования программного обеспечения для анализа для поиска и извлечения определенных данных в электронной почте. Это может помочь вам избежать ручного ввода данных, сэкономив вам много времени, денег и ресурсов.
В чем разница между сканированием, очисткой и синтаксическим анализом?
Хотя эти термины определяют разные вещи, иногда люди используют некоторые из них взаимозаменяемо. Тем не менее, между ними есть четкое различие:
— сканирование — это процесс автоматического просмотра веб-страниц, т. е. переход к страницам, поиск URL-адресов в гиперссылках этих страниц, копирование их в браузер и повторное повторение последовательности. Обычно это сопровождается инструментами очистки, которые загружают данные с посещенных страниц.
— Скрапинг — это процесс сбора общедоступных данных для маркетинговых и исследовательских целей.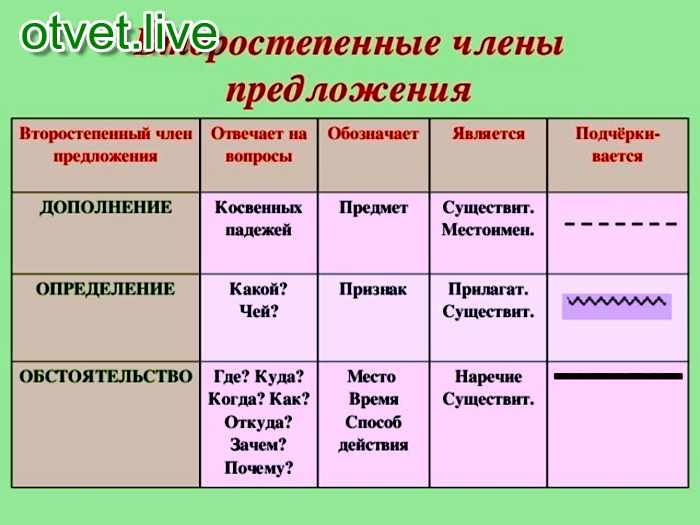
— Парсинг — это процесс преобразования неструктурированных и трудночитаемых данных в структурированную и понятную информацию.
По большому счету, сначала происходит сканирование, а затем следует парсинг. Наконец, данные, собранные во время очистки, далее разбиваются на читаемые части во время синтаксического анализа.
Что такое индексация в поисковых системах и чем она отличается от парсинга?
Индексирование — это процесс организации информации перед поиском, позволяющий быстро отвечать на запросы. Индексирование берет информацию из синтаксического анализа, т. е. синтаксический анализ разбивает необработанные данные, которые могут быть организованы индексами.
Парсеры и компиляторы — это одно и то же?
Нет, это не так. Парсер просто обрабатывает входные данные и возвращает их четкое представление. Компилятор, с другой стороны, генерирует что-то из этого представления, например, фактические машинные коды или другой язык. На самом деле внутри компилятора всегда есть парсер.
На самом деле внутри компилятора всегда есть парсер.
json — кодировщик и декодер JSON — документация по Python 3.10.7
Исходный код: Lib/json/__init__.py
JSON (обозначение объекта JavaScript), указанный RFC 7159 (который заменяет RFC 4627 ) и ЭКМА-404, это облегченный формат обмена данными, вдохновленный Синтаксис литерала объекта JavaScript (хотя это не строгое подмножество JavaScript 1 ).
Предупреждение
Будьте осторожны при анализе данных JSON из ненадежных источников. злонамеренный Строка JSON может привести к тому, что декодер потребляет значительное количество ресурсов ЦП и памяти. Ресурсы. Рекомендуется ограничить размер анализируемых данных.
json предоставляет API, знакомый пользователям стандартной библиотеки
Модули marshal и pickle .
Кодирование базовых иерархий объектов Python:
>>> импорт json >>> json.
 dumps(['foo', {'bar': ('baz', None, 1.0, 2)}])
'["foo", {"bar": ["baz", null, 1.0, 2]}]'
>>> print(json.dumps("\"foo\bar"))
"\"фу\бар"
>>> печать (json.dumps ('\ u1234'))
"\u1234"
>>> печать (json.dumps ('\\'))
"\\"
>>> print(json.dumps({"c": 0, "b": 0, "a": 0}, sort_keys=True))
{"а": 0, "б": 0, "в": 0}
>>> из io импортировать StringIO
>>> ио = StringIO()
>>> json.dump(['API потоковой передачи'], io)
>>> io.getvalue()
'["API потоковой передачи"]'
dumps(['foo', {'bar': ('baz', None, 1.0, 2)}])
'["foo", {"bar": ["baz", null, 1.0, 2]}]'
>>> print(json.dumps("\"foo\bar"))
"\"фу\бар"
>>> печать (json.dumps ('\ u1234'))
"\u1234"
>>> печать (json.dumps ('\\'))
"\\"
>>> print(json.dumps({"c": 0, "b": 0, "a": 0}, sort_keys=True))
{"а": 0, "б": 0, "в": 0}
>>> из io импортировать StringIO
>>> ио = StringIO()
>>> json.dump(['API потоковой передачи'], io)
>>> io.getvalue()
'["API потоковой передачи"]'
Компактная кодировка:
>>> импорт json
>>> json.dumps([1, 2, 3, {'4': 5, '6': 7}], separators=(',', ':'))
'[1,2,3,{"4":5,"6":7}]'
Красивая печать:
>>> импорт json
>>> print(json.dumps({'4': 5, '6': 7}, sort_keys=True, отступ=4))
{
«4»: 5,
«6»: 7
}
Декодирование JSON:
>>> импорт json
>>> json.loads('["foo", {"bar":["baz", null, 1.0, 2]}]')
['foo', {'bar': ['baz', None, 1.0, 2]}]
>>> json.loads('"\\"foo\\bar"')
'"foo\x08ar'
>>> из io импортировать StringIO
>>> io = StringIO('["API потоковой передачи"]')
>>> json. load(io)
['API потоковой передачи']
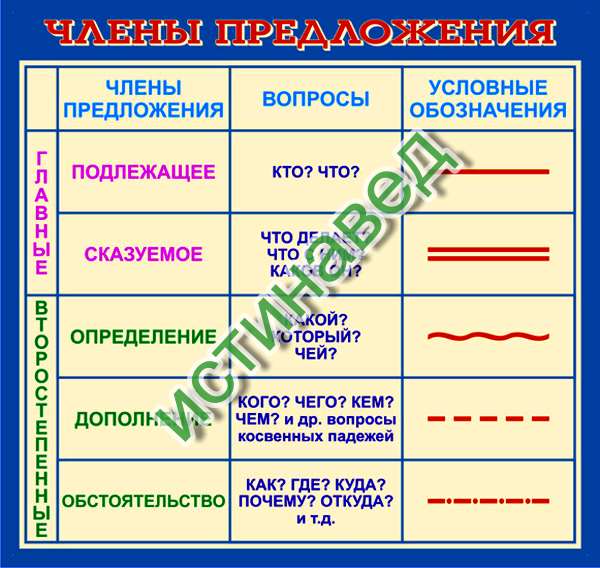 load(io)
['API потоковой передачи']
load(io)
['API потоковой передачи']
Специализация декодирования объектов JSON:
>>> импорт json
>>> определение as_complex(dct):
... если '__complex__' в dct:
... возвращаемый комплекс (dct['real'], dct['imag'])
... возврат ДКП
...
>>> json.loads('{"__complex__": true, "real": 1, "imag": 2}',
... object_hook=as_complex)
(1+2к)
>>> импорт десятичного
>>> json.loads('1.1', parse_float=decimal.Decimal)
Десятичный ('1.1')
Расширение JSONEncoder :
>>> импортировать json >>> класс ComplexEncoder(json.JSONEncoder): ... по умолчанию (я, объект): ... если isinstance (obj, комплекс): ... вернуть [obj.real, obj.imag] ... # Пусть метод по умолчанию базового класса вызовет TypeError ... вернуть json.JSONEncoder.default(self, obj) ... >>> json.dumps(2 + 1j, cls=ComplexEncoder) '[2.0, 1.0]' >>> ComplexEncoder().encode(2 + 1j) '[2.0, 1.0]' >>> list(ComplexEncoder().iterencode(2 + 1j)) ['[2.0', ', 1.0', ']']
Использование json. из оболочки для проверки и красивой печати: tool
tool
$ эхо '{"json":"obj"}' | питон-м json.tool
{
"json": "объект"
}
$ эхо '{1.2:3.4}' | питон-м json.tool
Ожидается имя свойства, заключенное в двойные кавычки: строка 1 столбец 2 (char 1)
Подробную документацию см. в разделе Интерфейс командной строки.
Примечание
JSON является подмножеством YAML 1.2. JSON, созданный настройки этого модуля по умолчанию (в частности, по умолчанию сепараторы value) также является подмножеством YAML 1.0 и 1.1. Таким образом, этот модуль также может быть используется как сериализатор YAML.
Примечание
Кодировщики и декодеры этого модуля сохраняют порядок ввода и вывода, дефолт. Порядок теряется только в том случае, если базовые контейнеры неупорядочены.
Основное использование
-
json.дамп( obj , fp , * , skipkeys=False , sure_ascii=True , check_circular = true , Allive_nan = true , CLS = нет , odent = none , Разделители = Нет , По умолчанию = None , SORT_KEYS = FALSE , ** KW ) ). Сериализация obj в виде потока в формате JSON в fp (поддержка
.write()файлоподобный объект), используя эту таблицу преобразования.Если skipkeys имеет значение true (по умолчанию:
False), то ключи dict, которые не базового типа (str,int,float,bool,None) будет пропущен вместо того, чтобы вызватьTypeError.Модуль
jsonвсегда создает объектыstr, а небайтаобъектов. Следовательно,fp.write()должен поддерживатьstrвход.Если обеспечить_ascii истинно (по умолчанию), выход гарантированно экранировать все входящие символы, отличные от ASCII. Если обеспечить_ascii есть false, эти символы будут выводиться как есть.
Если check_circular имеет значение false (по умолчанию:
True), то круговой проверка ссылок для типов контейнеров будет пропущена, а циклическая ссылка приведет к ошибкеRecursionError(или хуже).Если allow_nan имеет значение false (по умолчанию:
True), то это будетValueErrorдля сериализации вне диапазонаfloatзначений (nan,inf,-inf) в строгом соответствии спецификации JSON. Если allow_nan истинно, их эквиваленты в JavaScript (NaN,Infinity,-Infinity).Если отступ является неотрицательным целым числом или строкой, то элементы массива JSON и члены объекта будут красиво напечатаны с этим уровнем отступа. Уровень отступа 0, отрицательный или
""будет вставлять только новые строки.Нет(по умолчанию) выбирает наиболее компактное представление. Использование положительного целочисленного отступа отступов столько пробелов на уровень. Если отступ является строкой (например,"\t"), эта строка используется для отступа каждого уровня.Изменено в версии 3.2: Разрешены строки для с отступом в дополнение к целым числам.
Если указано, разделители должны быть
(item_separator, key_separator)кортеж. По умолчанию(', ', ': '), если отступ равенНети(',', ':')иначе. Чтобы получить наиболее компактное представление JSON, вы должны указать(',', ':')для устранения пробелов.Изменено в версии 3.4: Используйте
(',', ': ')по умолчанию, если отступ не равенНет.Если указано, по умолчанию должна быть функцией, которая вызывается для объектов, которые иначе не может быть сериализован. Он должен возвращать закодированную версию JSON объект или поднимите
Ошибка типа. Если не указано,TypeErrorПоднялся.Если sort_keys равно true (по умолчанию:
False), то вывод словари будут отсортированы по ключу.Чтобы использовать пользовательский подкласс
JSONEncoder(например, тот, который переопределяетdefault()для сериализации дополнительных типов), укажите его с помощью параметра класс кварг; в противном случае используетсяJSONEncoder.Изменено в версии 3.6: Все необязательные параметры теперь содержат только ключевые слова.
Примечание
В отличие от
pickleиmarshal, JSON не является фреймовым протоколом, поэтому попытка сериализовать несколько объектов с повторными вызовамиdump()с использованием того же fp приведет к созданию недопустимого файла JSON.


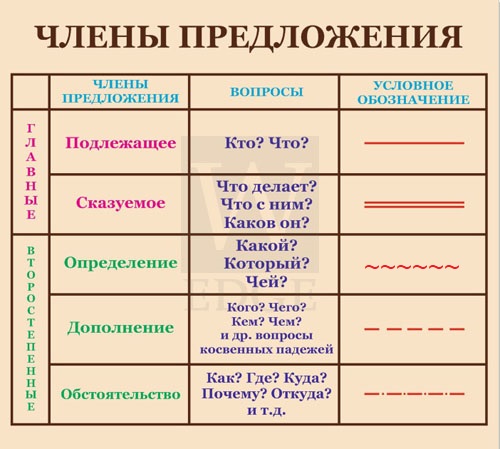
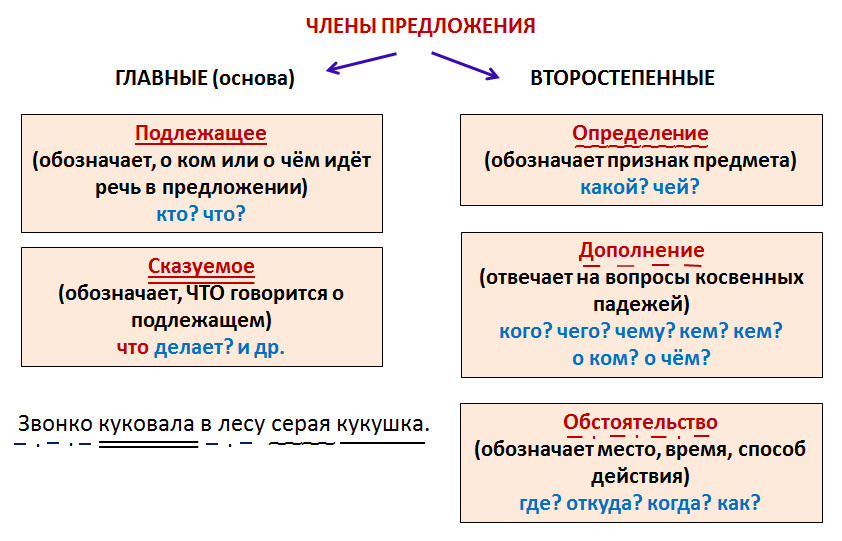
-
json.дампы( obj , * , skipkeys=False , sure_ascii=True , check_circular=True , allow_nan0014, cls=нет , отступ=нет , разделители=нет , по умолчанию=нет , sort_keys=ложь , **kw ) Сериализация obj в формате JSON
strс помощью этого преобразования стол. Аргументы имеют тот же смысл, что и в дамп().Примечание
Ключи в парах ключ/значение JSON всегда имеют тип
str. Когда словарь конвертируется в JSON, все ключи словаря принуждают к струнам. В результате этого, если словарь преобразуется в JSON, а затем обратно в словарь, словарь может не совпадать оригинальный. то естьload(dumps(x)) != x, если x имеет нестроковый ключи.
 Аргументы имеют тот же смысл, что и в
Аргументы имеют тот же смысл, что и в -
json.Load( FP , * , Cls = None , Object_hook = None , Parse_flaoat = None , PARSE_INT = , Parse_ConSk = , , , , , , , , , , , , , , , , , , , , , , , . **кВт ) Десериализовать fp (поддерживающий текстовый файл
.read()или двоичный файл, содержащий документ JSON) в объект Python, используя эта таблица преобразования.object_hook — необязательная функция, которая будет вызываться с результатом декодируется литерал любого объекта (
dict). Возвращаемое значение object_hook будет использоваться вместоdict. Эту функцию можно использовать для реализации пользовательских декодеров (например, JSON-RPC подсказка класса).object_pairs_hook — необязательная функция, которая будет вызываться с результат любого литерала объекта, декодированного с помощью упорядоченного списка пар. возвращаемое значение object_pairs_hook будет использоваться вместо
дикт. Эту функцию можно использовать для реализации пользовательских декодеров. Если object_hook также определен, object_pairs_hook имеет приоритет.Изменено в версии 3.1: Добавлена поддержка object_pairs_hook .
parse_float , если указано, будет вызываться со строкой каждого JSON float для декодирования.
По умолчанию это эквивалентно float(num_str). Это можно использовать для использования другого типа данных или парсера для JSON с плавающей запятой. (например, 9Десятичное число 0464. Десятичное число ).parse_int , если указано, будет вызываться со строкой каждого JSON int быть расшифрованным. По умолчанию это эквивалентно
int(num_str). Это может использоваться для использования другого типа данных или парсера для целых чисел JSON (например,с плавающей запятой).Изменено в версии 3.10.7: значение по умолчанию parse_int из
int()теперь ограничивает максимальную длину целочисленная строка через целочисленную строку интерпретатора ограничение длины конверсии, чтобы избежать отказа сервисных атак.parse_constant , если указано, будет вызываться с одним из следующих строки:
'-Infinity','Infinity','NaN'. Это можно использовать для создания исключения, если недопустимые числа JSON встречаются.Изменено в версии 3.1: parse_constant больше не вызывается для значений «null», «true», «false».
Чтобы использовать пользовательский подкласс
JSONDecoder, укажите его с помощьюclsкварг; иначеИспользуется JSONDecoder. Дополнительные аргументы ключевого слова будет передан конструктору класса.Если десериализуемые данные не являются действительным документом JSON,
Будет вызвана ошибка JSONDecodeError.Изменено в версии 3.6: Все необязательные параметры теперь содержат только ключевые слова.
Изменено в версии 3.6: fp теперь может быть бинарным файлом. Входная кодировка должна быть UTF-8, UTF-16 или UTF-32.
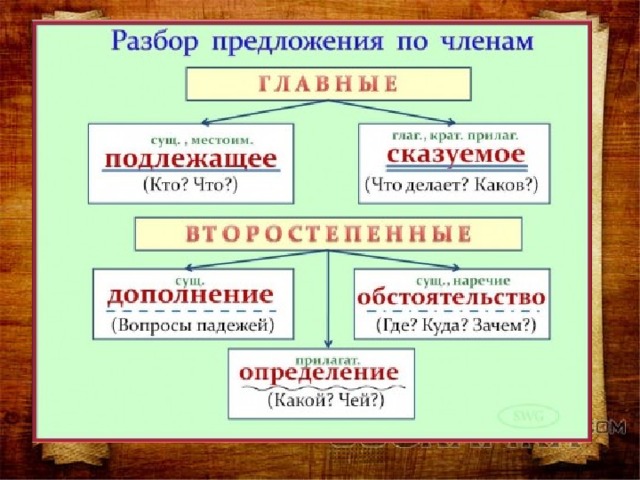
 По умолчанию это эквивалентно
По умолчанию это эквивалентно 
-
json.loads( s , * , cls=None , object_hook=None , parse_float=None , parse_int=None , parse_constant=None , object_pairs_hook=None , **кВт ) Десериализовать s (a
str,байтаилиbytearrayэкземпляр, содержащий документ JSON) в объект Python, используя этот таблица преобразования.Остальные аргументы имеют то же значение, что и в
загрузка().Если десериализуемые данные не являются действительным документом JSON,
Будет вызвана ошибка JSONDecodeError.Изменено в версии 3.6: s теперь может иметь тип
bytesилиbytearray. входная кодировка должна быть UTF-8, UTF-16 или UTF-32.Изменено в версии 3.9: Аргумент ключевого слова , кодирующий , был удален.
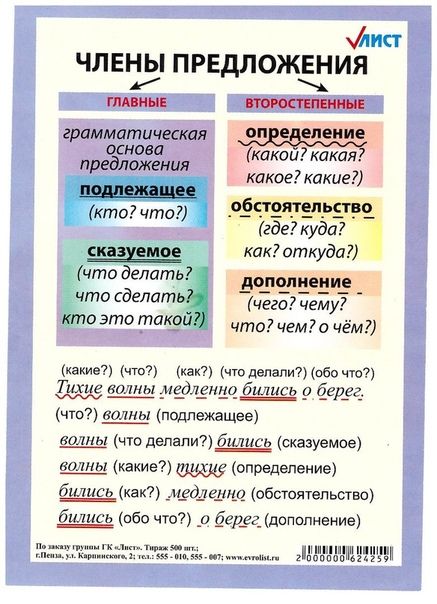
Кодировщики и декодеры
- класс
json.Jsondecoder( * , Object_hook = None , Parse_float = None , Parse_int = none , Parse_Constant = None , strict = истин.Простой декодер JSON.
По умолчанию выполняет следующие преобразования при декодировании:
JSON
Питон
Объект
дикт
массив
список
строка
ул
номер (внутренний)
инт
номер (реальный)
поплавок
правда
Правда
ложный
Ложь
ноль
Нет
Он также понимает
NaN,Infinityи-Infinityкак их соответствующие значенияс плавающей запятой, что выходит за рамки спецификации JSON.object_hook , если указано, будет вызываться с результатом каждого JSON объект декодируется, и его возвращаемое значение будет использоваться вместо заданного
дикт. Это можно использовать для предоставления пользовательских десериализаций (например, для поддержка подсказок класса JSON-RPC).object_pairs_hook , если указано, будет вызываться с результатом каждого Объект JSON декодируется с помощью упорядоченного списка пар. Возвращаемое значение object_pairs_hook будет использоваться вместо
dict. Этот функция может использоваться для реализации пользовательских декодеров. Если object_hook также Определено, object_pairs_hook имеет приоритет.Изменено в версии 3.1: Добавлена поддержка object_pairs_hook .
parse_float , если указано, будет вызываться со строкой каждого JSON float для декодирования. По умолчанию это эквивалентно
float(num_str). Это можно использовать для использования другого типа данных или парсера для JSON с плавающей запятой.
(например, десятичное число. Десятичное число).parse_int , если указано, будет вызываться со строкой каждого JSON int быть расшифрованным. По умолчанию это эквивалентно
int(num_str). Это может использоваться для использования другого типа данных или парсера для целых чисел JSON (например,с плавающей запятой).parse_constant , если указано, будет вызываться с одним из следующих строки:
'-Infinity','Infinity','NaN'. Это можно использовать для создания исключения, если недопустимые числа JSON встречаются.Если strict является ложным (
Trueпо умолчанию), то управляющие символы будут разрешены внутри строк. Управляющие символы в этом контексте те, у которых коды символов находятся в диапазоне 0–31, включая'\t'(вкладка),'\n','\r'и'\0'.Если десериализуемые данные не являются действительным документом JSON,
Будет вызвана ошибка JSONDecodeError.Изменено в версии 3.6: Все параметры теперь содержат только ключевые слова.
-
декодировать( с ) Вернуть представление Python s (экземпляр
strсодержащий документ JSON).JSONDecodeErrorбудет поднято, если данный документ JSON не действительный.
-
raw_decode( с ) Декодировать документ JSON из s (
str, начинающийся с документ JSON) и вернуть 2-кортеж представления Python и индекс в s , где документ закончился.Это можно использовать для декодирования документа JSON из строки, которая может иметь лишние данные в конце.

 Это можно использовать для использования другого типа данных или парсера для JSON с плавающей запятой.
(например,
Это можно использовать для использования другого типа данных или парсера для JSON с плавающей запятой.
(например, 
- класс
json.JSONEncoder( * , skipkeys=False , ensure_ascii=True , check_circular=True , allow_nan=True , sort_keys=False , indent=None , separators=None , по умолчанию = нет ) Расширяемый кодировщик JSON для структур данных Python.
По умолчанию поддерживает следующие объекты и типы:
Питон
JSON
дикт
объект
список, кортеж
массив
ул
строка
int, float, int и производные от float перечисления
номер
Правда
правда
Ложь
ложный
Нет
ноль
Изменено в версии 3.4: Добавлена поддержка классов Enum, производных от int и float.
Чтобы расширить это, чтобы распознавать другие объекты, создать подкласс и реализовать
метод default()с другим методом, возвращающим сериализуемый объект наили, если возможно, в противном случае следует вызвать реализацию суперкласса (поднятьTypeError).Если skipkeys имеет значение false (по умолчанию),
TypeErrorбудет вызвано, когда попытка закодировать ключи, которые не являютсяstr,int,floatилиНет. Если skipkeys истинно, такие элементы просто пропускаются.Если обеспечить_ascii истинно (по умолчанию), выход гарантированно экранировать все входящие символы, отличные от ASCII. Если обеспечить_ascii есть false, эти символы будут выводиться как есть.
Если check_circular имеет значение true (по умолчанию), то списки, словари и пользовательские закодированные объекты будут проверяться на циклические ссылки во время кодирования, чтобы предотвратить бесконечную рекурсию (что вызовет
RecursionError). В противном случае такой проверки не происходит.Если allow_nan равно true (по умолчанию), то
NaN,Infinityи-Бесконечностьбудет закодирован как таковой. Это поведение не является JSON
соответствует спецификации, но совместим с большинством основанных на JavaScript
кодеры и декодеры. В противном случае это будет ValueErrorдля кодирования такие поплавки.Если sort_keys равно true (по умолчанию:
False), то вывод словарей будет отсортирован по ключу; это полезно для регрессионных тестов, чтобы убедиться, что Сериализации JSON можно сравнивать изо дня в день.Если отступ — неотрицательное целое число или строка, затем элементы массива JSON и члены объекта будут красиво напечатаны с этим уровнем отступа. Уровень отступа 0, отрицательный или
""будет вставлять только новые строки.Нет(по умолчанию) выбирает наиболее компактное представление. Использование положительного целочисленного отступа отступов столько пробелов на уровень. Если отступ является строкой (например,"\t"), эта строка используется для отступа каждого уровня.Изменено в версии 3.2: Разрешить строки для отступ в дополнение к целым числам.
Если указано, разделители должны быть
(item_separator, key_separator)кортеж. По умолчанию используется(', ', ': '), если отступ равенНети(',', ':')иначе. Чтобы получить наиболее компактное представление JSON, вы должны указать(',', ':')для устранения пробелов.Изменено в версии 3.4: Используйте
(',', ': ')по умолчанию, если отступ неНет.Если указано, по умолчанию должна быть функцией, которая вызывается для объектов, которые иначе не может быть сериализован. Он должен возвращать закодированную версию JSON объект или вызвать
TypeError. Если не указано,TypeErrorПоднялся.Изменено в версии 3.6: Все параметры теперь содержат только ключевые слова.
-
по умолчанию( или ) Реализуйте этот метод в подклассе таким образом, чтобы он возвращал сериализуемый объект на или , или вызывает базовую реализацию (для
TypeError).Например, для поддержки произвольных итераторов можно реализовать
по умолчанию()вот так:по умолчанию (я, о): пытаться: итерируемый = итер (о) кроме TypeError: проходить еще: список возврата (повторяемый) # Пусть метод по умолчанию базового класса вызовет TypeError вернуть json.JSONEncoder.default (я, о)
-
кодировать( или ) Возвращает строковое представление структуры данных Python в формате JSON, или . За пример:
>>> json.JSONEncoder().encode({"foo": ["бар", "баз"]}) '{"foo": ["бар", "баз"]}'
-
iterencode( или ) Закодируйте данный объект, или , и выведите каждое строковое представление как доступный. Например:
для чанка в json.JSONEncoder().iterencode(bigobject): mysocket.write(чанк)
-


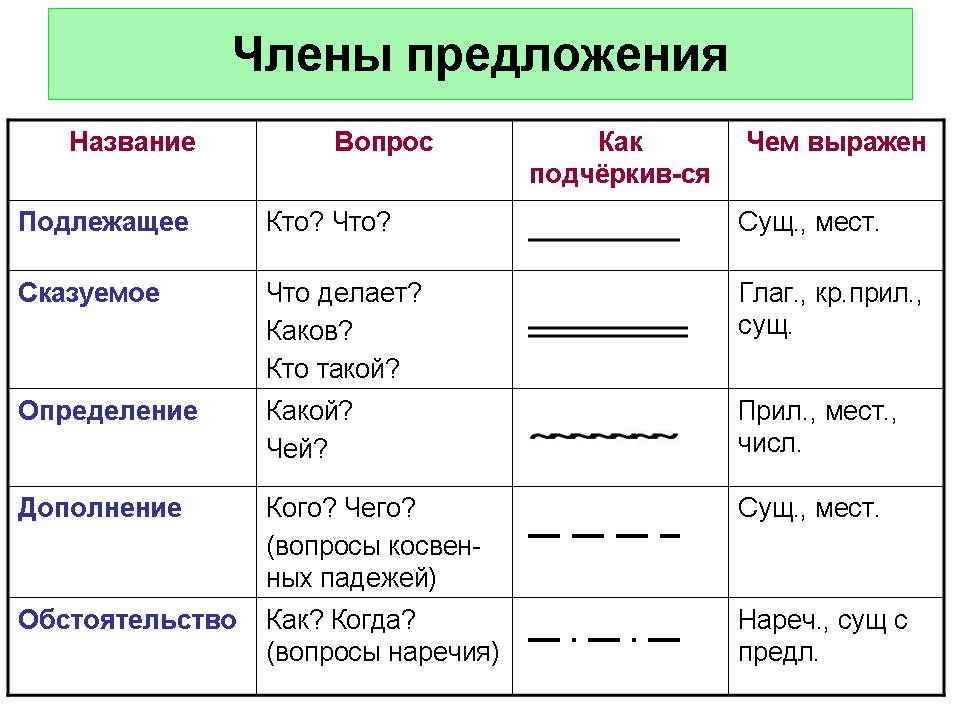 Это поведение не является JSON
соответствует спецификации, но совместим с большинством основанных на JavaScript
кодеры и декодеры. В противном случае это будет
Это поведение не является JSON
соответствует спецификации, но совместим с большинством основанных на JavaScript
кодеры и декодеры. В противном случае это будет 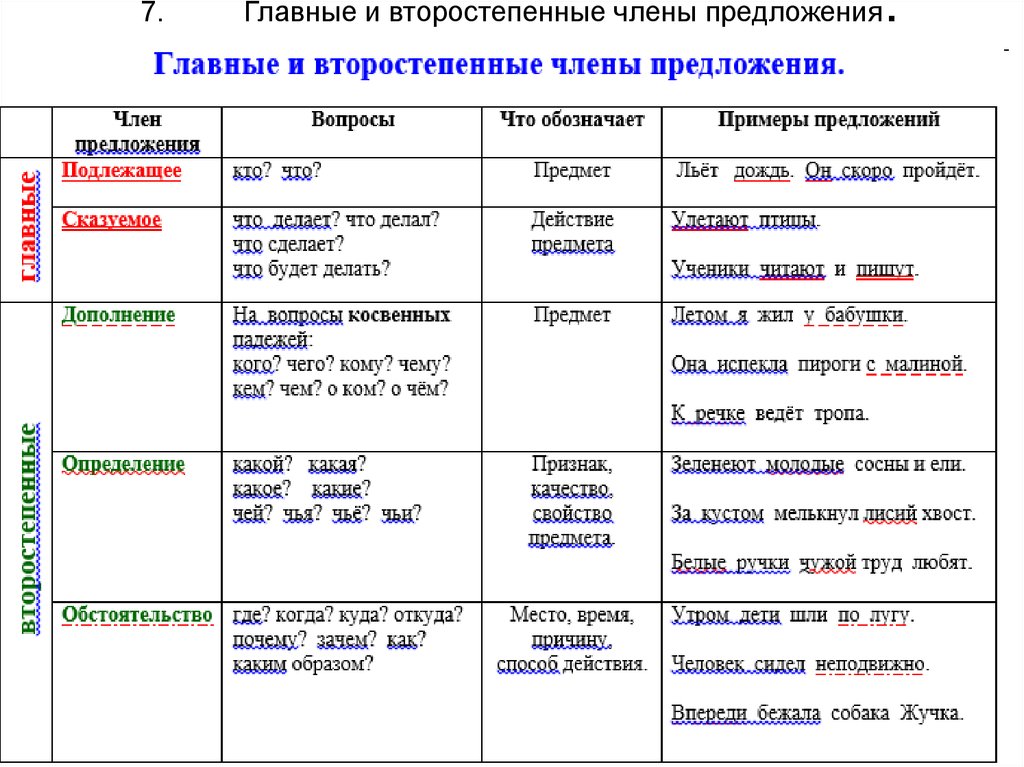
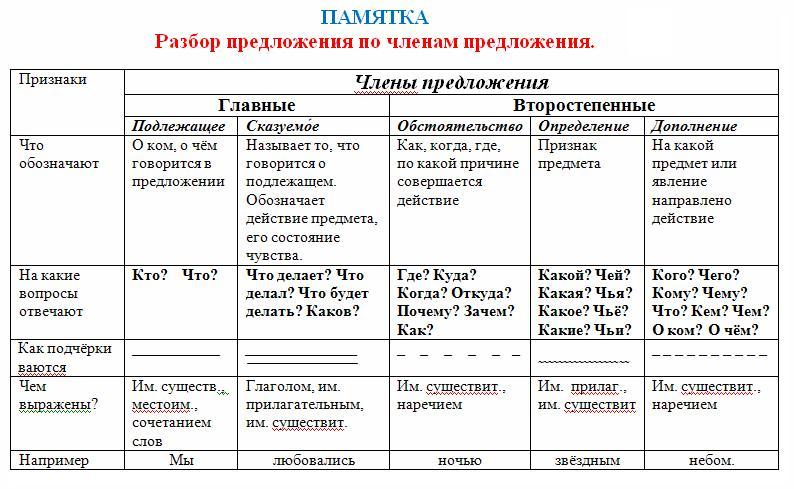
Исключения
- исключение
json. JSONDecodeError( msg , doc , pos ) Подкласс
ValueErrorсо следующими дополнительными атрибутами:-
сообщение Неформатированное сообщение об ошибке.
-
док Документ JSON анализируется.
-
поз. Начальный индекс документа , синтаксический анализ которого завершился неудачно.
-
линено Строка, соответствующая поз. .
-
Колно Столбец, соответствующий поз. .
Новое в версии 3.5.
-
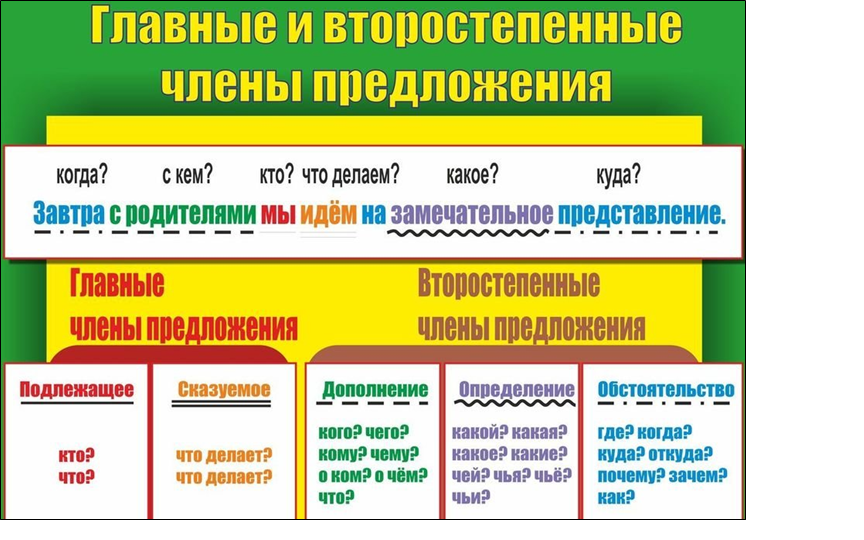
Соответствие стандартам и совместимость
Формат JSON указан в RFC 7159 и
ЭКМА-404.
В этом разделе подробно описывается уровень соответствия этого модуля RFC.
Для простоты подклассы JSONEncoder и JSONDecoder и
параметры, кроме явно упомянутых, не учитываются.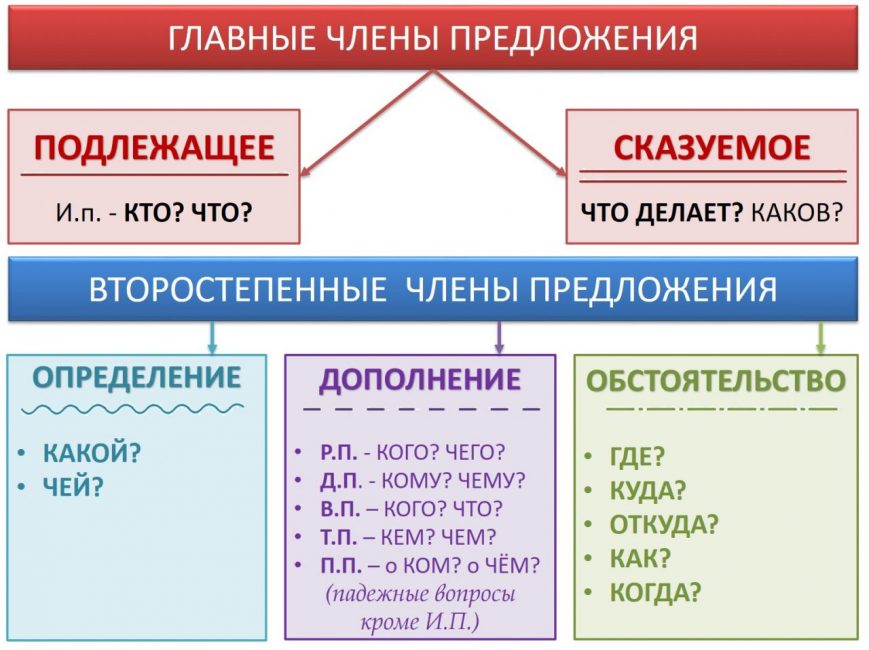
Этот модуль строго не соответствует RFC, реализуя некоторые расширения, которые являются действительным JavaScript, но не действительным JSON. В частности:
Принимаются и выводятся бесконечные и числовые значения NaN;
Повторяющиеся имена внутри объекта допускаются, и только значение последнего используется пара имя-значение.
Поскольку RFC разрешает синтаксическим анализаторам, совместимым с RFC, принимать входные тексты, которые не RFC-совместимый десериализатор этого модуля технически соответствует RFC в настройки по умолчанию.
Кодировки символов
RFC требует, чтобы JSON был представлен с использованием UTF-8, UTF-16 или UTF-32, при этом UTF-8 рекомендуется по умолчанию для максимальной совместимости.
Как разрешено, хотя и не требуется RFC, сериализатор этого модуля устанавливает sure_ascii=True по умолчанию, что позволяет избежать вывода, чтобы результирующий
строки содержат только символы ASCII.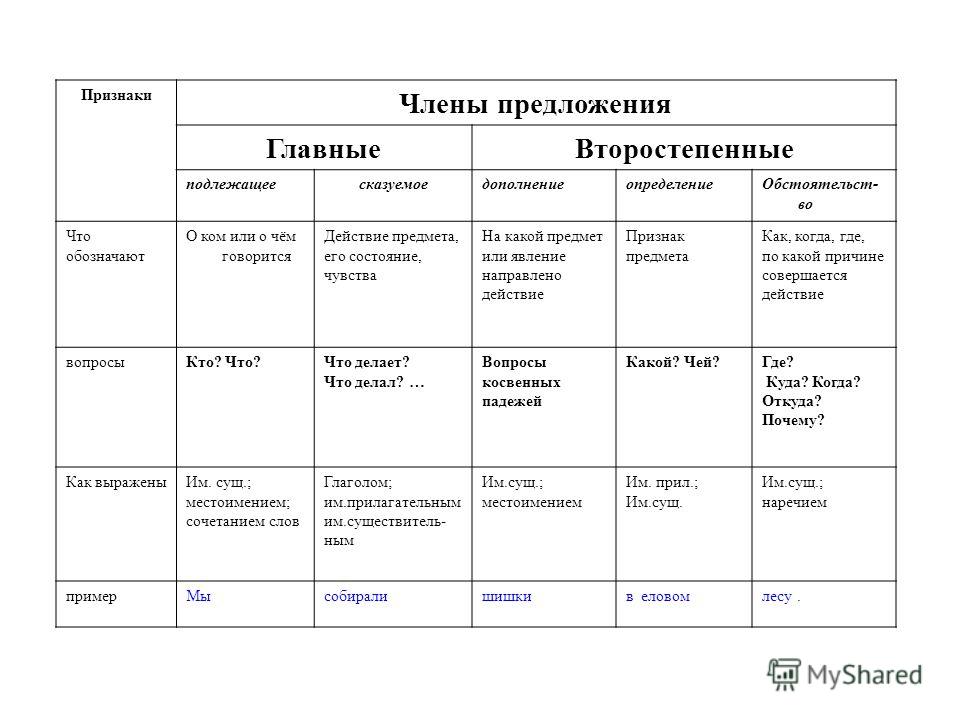
Кроме параметра sure_ascii , этот модуль определен строго в
условия преобразования между объектами Python и строки Unicode , и, таким образом, напрямую не адресует
вопрос кодировки символов.
RFC запрещает добавлять метку порядка байтов (BOM) в начало текста JSON,
и сериализатор этого модуля не добавляет спецификацию к своему выводу.
RFC разрешает, но не требует, чтобы десериализаторы JSON игнорировали начальный
BOM на их входе. Десериализатор этого модуля поднимает ЗначениеОшибка при наличии начальной спецификации.
RFC явно не запрещает строки JSON, содержащие последовательности байтов.
которые не соответствуют допустимым символам Unicode (например, непарные символы UTF-16
суррогаты), но отмечает, что они могут вызвать проблемы совместимости.
По умолчанию этот модуль принимает и выводит (при наличии в исходном str ) кодовые точки для таких последовательностей.
Бесконечные и числовые значения NaN
RFC не разрешает представление бесконечных или числовых значений NaN.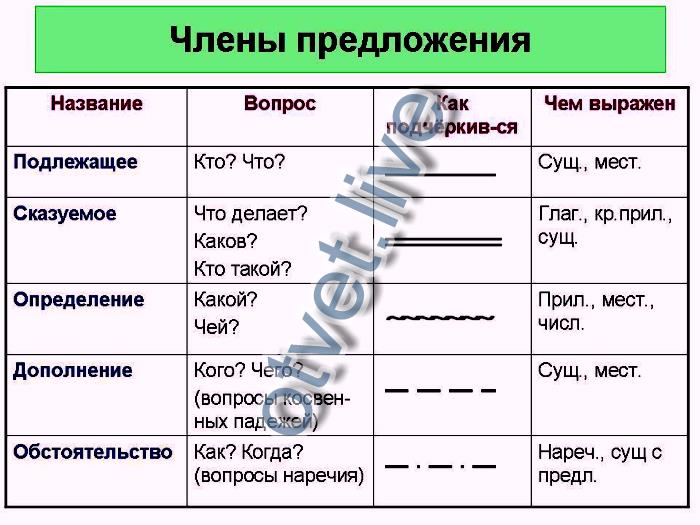 Несмотря на это, по умолчанию этот модуль принимает и выводит
Несмотря на это, по умолчанию этот модуль принимает и выводит Бесконечность , -Infinity и NaN , как если бы они были действительными числовыми литеральными значениями JSON:
>>> # Ни один из этих вызовов не вызывает исключение, но результаты недействительны JSON
>>> json.dumps(с плавающей запятой('-inf'))
'-Бесконечность'
>>> json.dumps(float('nan'))
'НаН'
>>> # То же самое при десериализации
>>> json.loads('-Бесконечность')
-инф
>>> json.loads('NaN')
нан
В сериализаторе параметр allow_nan можно использовать для изменения этого поведение. В десериализаторе параметр parse_constant можно использовать для изменить это поведение.
Повторяющиеся имена внутри объекта
RFC указывает, что имена в объекте JSON должны быть уникальными, но не указывает, как следует обрабатывать повторяющиеся имена в объектах JSON. По по умолчанию этот модуль не вызывает исключения; вместо этого он игнорирует все, кроме последняя пара имя-значение для данного имени:
>>> странный_json = '{"х": 1, "х": 2, "х": 3}'
>>> json. loads(weird_json)
{'х': 3}
 loads(weird_json)
{'х': 3}
loads(weird_json)
{'х': 3}
Параметр object_pairs_hook можно использовать для изменения этого поведения.
Значения верхнего уровня, не являющиеся объектами, не являющиеся массивами
Старая версия JSON, указанная в устаревшем RFC 4627 , требовала, чтобы
значение верхнего уровня текста JSON должно быть либо объектом JSON, либо массивом
(Python dict или list ) и не может быть нулевым значением JSON,
логическое, числовое или строковое значение. RFC 7159 снял это ограничение, и
этот модуль не реализует и никогда не реализовывал это ограничение ни в
сериализатор или его десериализатор.
Несмотря на это, для максимальной совместимости вы можете добровольно присоединиться к к ограничению самостоятельно.
Ограничения реализации
Некоторые реализации десериализатора JSON могут устанавливать ограничения на:
размер принимаемых текстов JSON
максимальный уровень вложенности объектов и массивов JSON
диапазон и точность чисел JSON
содержание и максимальная длина строк JSON
Этот модуль не налагает никаких таких ограничений, кроме тех, которые установлены соответствующими
Сами типы данных Python или сам интерпретатор Python.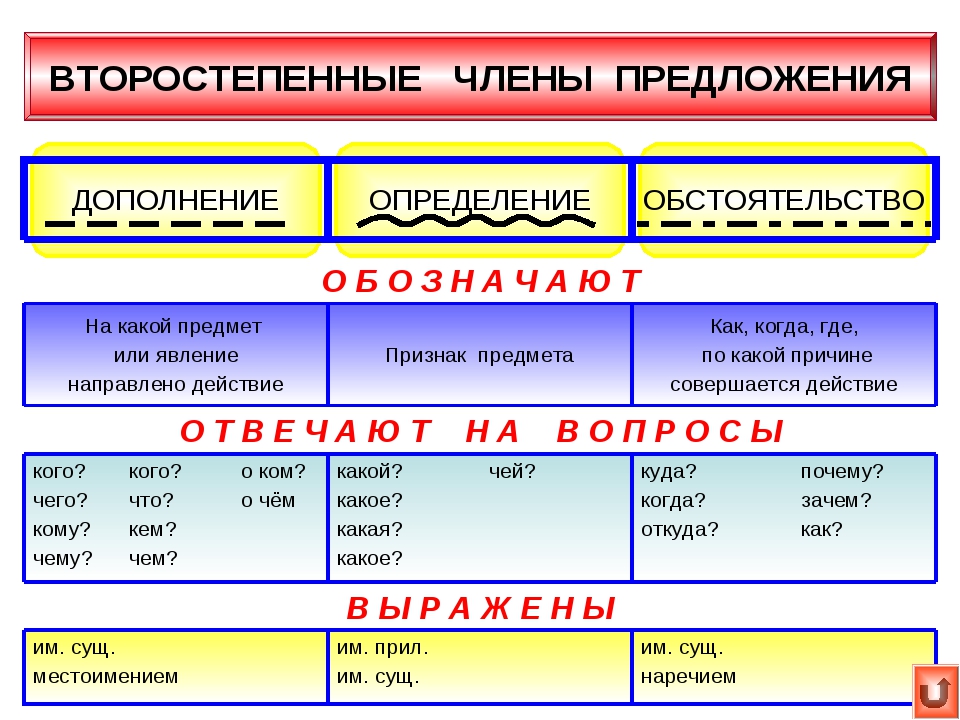
При сериализации в JSON помните о любых таких ограничениях в приложениях, которые могут
потребляйте свой JSON. В частности, номера JSON часто бывают
десериализованы в числа двойной точности IEEE 754 и, таким образом, подлежат этому
диапазон представления и ограничения точности. Это особенно актуально
при сериализации Python int значений чрезвычайно большой величины или
при сериализации экземпляров «экзотических» числовых типов, таких как десятичный. Десятичный .
Интерфейс командной строки
Исходный код: Lib/json/tool.py
Модуль json.tool предоставляет простой интерфейс командной строки для проверки
и красиво печатать объекты JSON.
Если необязательные аргументы infile и outfile не
указано, sys.stdin и sys.stdout будет использоваться соответственно:
$ эхо '{"json": "obj"}' | питон-м json.tool
{
"json": "объект"
}
$ эхо '{1. 2:3.4}' | питон-м json.tool
Ожидается имя свойства, заключенное в двойные кавычки: строка 1 столбец 2 (char 1)
 2:3.4}' | питон-м json.tool
Ожидается имя свойства, заключенное в двойные кавычки: строка 1 столбец 2 (char 1)
2:3.4}' | питон-м json.tool
Ожидается имя свойства, заключенное в двойные кавычки: строка 1 столбец 2 (char 1)
Изменено в версии 3.5: вывод теперь в том же порядке, что и ввод. Использовать --sort-keys опция для сортировки вывода словарей
в алфавитном порядке по ключу.
Параметры командной строки
-
профиль Файл JSON для проверки или корректной печати:
$ python -m json.tool mp_films.json [ { "title": "А теперь кое-что совершенно другое", "год": 1971 }, { "title": "Монти Пайтон и Святой Грааль", "год": 1975 } ]Если infile не указан, читать из
sys.stdin.
-
внешний файл Записать вывод infile в заданный outfile . В противном случае напишите это до
sys.stdout.
-
--sort-keys Сортировка вывода словарей в алфавитном порядке по ключу.