Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «стена», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
СТЕНА, ы, вин. стену, мн. стены, стен, стенам и (устар.) стенам, ж.
1. Вертикальная часть здания, помещения. Наружная, внутренняя с. Бетонная, кирпичная, деревянная с.
2. Высокая ограда. Крепостная с. Под стенами Москвы (перен.: на подступах к городу, обычно о битве; высок.). Отгородиться китайской стеной от кого-чего-н. (перен.: полностью обособиться от кого-чего-н.). Как за каменной стеной (под надёжной защитой).
3. перен. В сражении, кулачном бою: тесный, сомкнутый ряд людей. Идти в бой стеною.
4. перен., ед., чего. Сплошная масса чего-н., образующая преграду, завесу. С. деревьев. С. тумана, дождя. С. огня. С. народа. Людская с.
5. перен. То, что невозможно преодолеть, осилить. С. равнодушия, безразличия, непонимания, эгоизма, себялюбия.
• В стенах чего, в знач. предлога с род. п. внутри (какого-н. здания, учреждения, места, где что-н. происходит). В стенах университета. Вырос в стенах родного дома.
В четырёх стенах (сидеть, жить) не выходя из дома, не общаясь ни с кем.
Как об стену горох кому что (разг. неодобр.) бесполезны, не доходят слова, уговоры, внушения. Говорить с ним как об стену горох.
На стену (на стенку) лезть (разг.) приходить в крайнее раздражение, исступление.
Стеной стоять за кого-что защищать, отстаивать упорно, ни в чём не уступая.
| уменьш. стенка, и, ж. (к 1 и 2 знач.).
| прил. стенной, ая, ое (к 1 и 2 знач.) и стеновой, ая, ое (к 1 и 2 знач.; спец.). Стенная живопись. Стенная газета (стенгазета). Стеновые блоки, панели.
Фонетический (звуко-буквенный) разбор
стена́
стена — слово из 2 слогов: сте-на. Ударение падает на 2-й слог.
Транскрипция слова: [ст’ина]
с — [с] — согласный, глухой парный, твёрдый (парный)
т — [т’] — согласный, глухой парный, мягкий (парный)
е — [и] — гласный, безударный
а — [а] — гласный, ударный
В слове 5 букв и 5 звуков.
Цветовая схема: стена
Разбор слова «стена» по составу
стена
Части слова «стена»: стен/а
Состав слова:
стен — корень,
а — окончание,
стен — основа слова.
Проверочная работа по русскому языку для 3 класса по теме «Состав слова» | Тест по русскому языку (3 класс) на тему:
Проверочная работа по русскому языку для 3 класса
по теме «Состав слова»
1 вариант
К каждому из заданий 1-8 даны 4 варианта ответов, из которых только один правильный. Выбери его и обведи цифру правильного ответа.
1. Отметь слово, в котором есть приставка.
1) | посуда |
2) | поездка |
3) | поймать |
4) | посещать |
2. Отметь слово, которое не является однокоренным
Отметь слово, которое не является однокоренным
1) | пруд | 2) | прудик | 3) | запруда | 4) | пруды |
3. Отметь, какая часть слова, кроме корня, есть в слове «поезда»
1) | Только приставка |
2) | Только окончание |
3) | Приставка и окончание |
4) | Суффикс и окончание |
4. Отметь слово, которое соответствует составу: приставка, корень, окончание.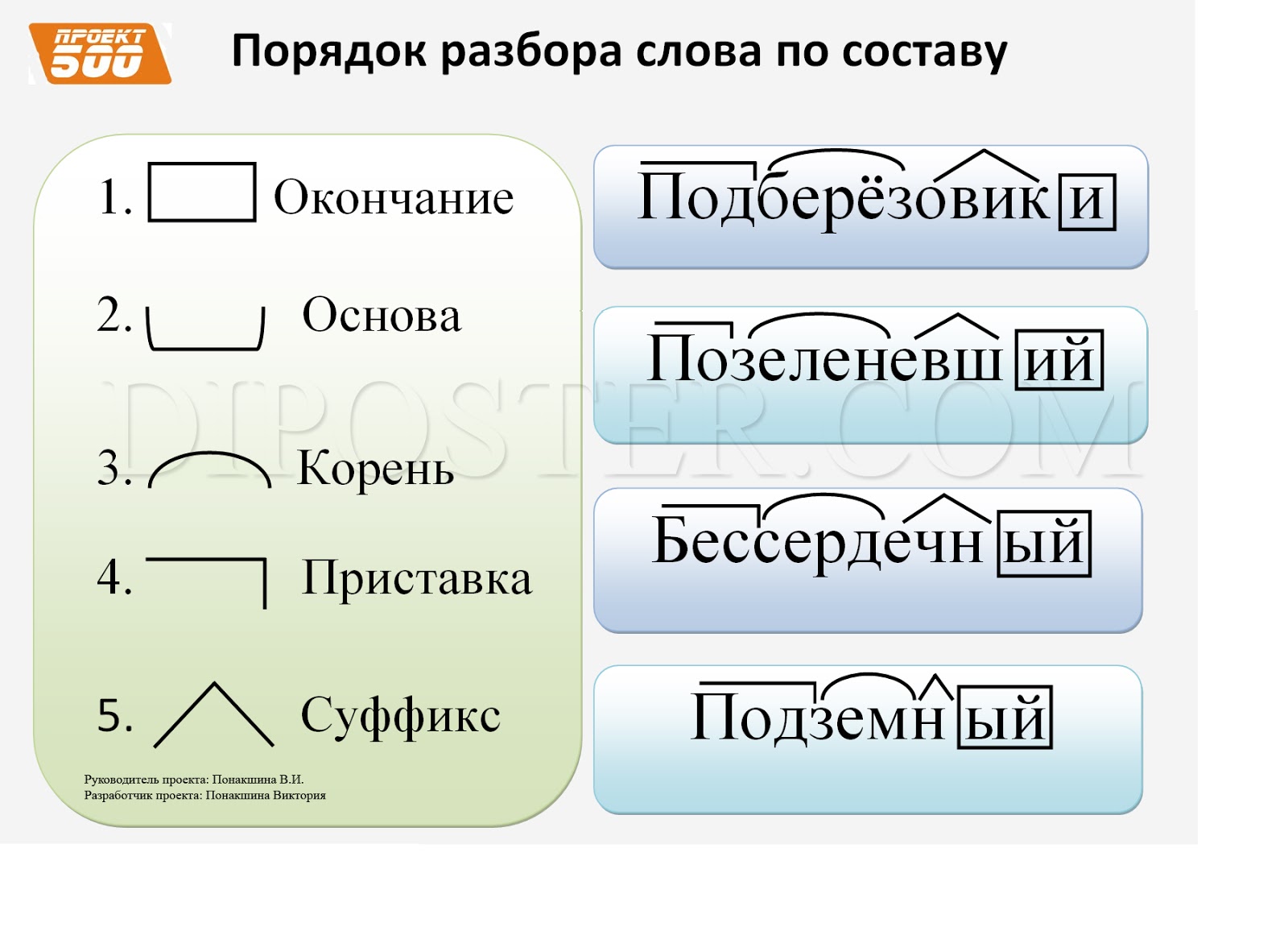
1) | рыбак |
2) | подруга |
3) | подарок |
4) | дорога |
5. Отметь ряд, в котором все слова являются однокоренными
1) | Летать, лето, лётчик. |
2) | Корм, накормить, кормушка. |
3) | Гористый, пригорок, горе. |
4) | Рисовый, рисовать, рисунок. |
При выполнении заданий 6 -11 запиши краткий ответ в указанном месте.
6. Продолжи высказывание.
Общая часть родственных слов, в которой передаётся их основное лексическое значение это_________________________________________
7. Продолжи высказывание.
Часть слова, которая стоит после корня и служит для образования новых слов это______________________________________________________
8. Продолжи высказывание
Чтобы найти в слове окончание надо__________________________________
9. Составь и запиши слово, используя для этого приставку слова «забег», корень слова «гадать», суффикс слова «дорожка», окончание слова «дрова»
__________________________________________________________________
10. Найди среди данных слов «лишнее». Запиши его.
Перевозка, пришкольный, лесник, пробежка.
__________________________________________________________________
11. Найди все правильные утверждения о составе слова.
В слове может не быть корня. ________________________________________
В слове может не быть приставки. ____________________________________
____________________________________
В слове может не быть суффикса. ____________________________________
В слове может не быть окончания.____________________________________
Рядом с каждым из выбранных тобой утверждений запиши одно слово из списка, которое его подтверждает.
Городок, стена, ключик, поход, выход, пальто, зонтик, лесник.
12. Прочитай слова.
Ведро, подружка, осинка, пальто, норка, накидка, снегопад, озеро, разъезды.
Запиши в каждый столбик таблицы по два примера, выбирая из слов, данных выше. Дополни каждый столбик своим примером.
Корень, окончание | Корень, суффикс, окончание. | Приставка, корень, суффикс, окончание. |
Контрольный диктант в 7 классе № 11 | Сборник диктантов по Русскому языку в 7 классе с русским языком обучения
Контрольный диктант в 7 классе № 11
24. 09.2014 68289 0
09.2014 68289 0 Цель: проверить знания, умения и навыки учащихся на конец 3-й четверти по теме « Наречие. Служебные части речи».
Содержание контрольного диктанта направлено на выявление качества усвоения программного материала.
а также уровня сформированности орфографической зоркости и пунктуационных умений и навыков:
— правописание проверяемых безударных гласных;
— правописание непроверяемых безударных гласных;
— написание корней с чередованием;
— написание е-и в суффиксах существительных;
— написание сложных прилагательных;
— правильное написание глагольных окончаний;
— написание не с глаголами.
Знаки препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— находить предлоги в тексте;
— разбор слова по составу;
— синтаксический разбор предложения;
— разбирать
слово фонетически.
Зимой и летом
Это был обычный лес. Мимо него по блестящему асфальту навстречу друг другу шли машины, спешили люди.
Деревья и подлесок были в виде зелёной стены. В глубине леса сумрак сгущался до черноты.
Сколько раз в течение последних месяцев приходилось мне проезжать мимо этого леса! Быстро мчится машина вдоль зелёной стены. Глазу не проникнуть дальше первого ряда деревьев. Они раскинули ветви, плотно сошлись кронами, из-за них не заглянуть в глубь леса.
Лес вроде зелёной преграды.
… И снова я в пути, но уже в январе.
По привычке поворачиваю голову влево, чтобы увидеть знакомый лес.
Весь белый, кружевной от инея, он виден со стороны дороги насквозь. Белые веточки тонко вырисовываются каждым своим изгибом, касаются одна другой, переплетаются.
Безотрывно
гляжу на белый
зимний лес.
(119 слов) (По М. Усову)
Грамматические задания
1. Найти предлоги, заключить их в прямоугольник, над производным предлогом поставить п, над непроизводным — н.
2. Сделать фонетический разбор слова:
Друг — 1-й вариант глубь — 2-й вариант
3. Разобрать слова по составу:
Навстречу, вырисовываются — 1-й вариант
Переплетаются, безотрывно — 2-й вариант
4. Произвести морфологический разбор слова:
Мимо (леса) — 1-й вариант вдоль (стены) — 2-й вариант
5. Сделать синтаксический разбор предложения:
Быстро мчится машина вдоль зелёной стены. — 1-й вариант
В глубине
леса сумрак сгущался
до черноты. —
2-й вариант
—
2-й вариант
Неприступный Тульский Кремль » Вcероссийский отраслевой интернет-журнал «Строительство.RU»
В этом году Тула отмечает юбилей: 500-летие возведения городского Кремля как начала Большой засечной черты. Значение этого уникального фортификационного сооружения для того времени было настолько велико, что в праздновании следовало бы участвовать и Москве, и очень многим городам центральной России.
Лес как защитник русских границ
Засеки применяли на Руси задолго до Батыева нашествия. Наши древние предки умело и расчетливо выбирали оборонительную тактику. Крестоносных рыцарей, шведов, поляков и литовцев сдерживали мощные каменные стены Пскова, Изборска, Новгорода, Смоленска. Против легкой конницы, особенно — быстрых на подъем степняков, создавали преграды, конструкции которых подсказала родная природа, русские леса с их непроходимыми чащами, завалами сухостоя и другими естественными препятствиями.
Засека — вовсе не беспорядочная свалка деревьев. Лес рубили, укладывая стволы крест-накрест, вершинами в сторону потенциального противника, скрепляя поясами из коры. Дерево перерубали на высоте человеческого роста и не до конца. Завалившись, оно еще некоторое время продолжало расти, сплетаясь ветвями и побегами от корней с другими. Быстро растащить такую преграду в стороны, освобождая дорогу войску, было невозможно. Поджечь — значит, обнаружить себя и направление удара. Степняки в быстрых набегах не утруждали себя осадами крепостей — им важно было неожиданно налететь на русские поселения, разграбить их, охотясь прежде всего за «живым товаром», столь ценившимся на невольничьих рынках.
Образец рубки деревьев Засечной черты
Столь специфичное налогообложение проблемы, конечно, не решало, тем более, что и крымцы, и казанцы угрожали крупным городам и, в первую очередь, самой Москве. Наиболее эффективным с точки зрения стратегии и тактики того времени решением стало сооружение вдоль южной и юго-восточной границ страны внушительной сторожевой линии, за несколько десятилетий превратившейся в сплошной, непрерывный оборонительный вал с городами-крепостями, вставшими над главными дорогами юга. И центральное место в Большой засечной черте заняла Тула.
Южных рубежей сердце и мозг
Стены Тульского кремля
Считается, что город основан в 1146 г. Подтверждением служит Никоновская летопись — XVI века, а потому современными историками сей факт подвергается сомнению. Но это не так уж и важно: для многих древнерусских городов нет точной даты закладки первого камня, и рукописи, способные предоставить доподлинные сведения, сгорали в пламени пожаров. По версии В. И. Даля, тулой называли скрытое место, укрытие (отсюда — притулиться). Корень слова «тула» присутствует в именах северных рек, вдоль которых селились финно-угорские племена. Сам город стоит на реке Упе при впадении в нее речки Тулицы. Интересно, что в литовском, латышском и даже тюркском языках имена Тула и Упа имеют схожее смысловое значение со словами, означающими «река», «ручей», «болото». Впрочем, простому люду приходилось укрываться от набегов захватчиков не только в лесах, но и на болотах. И не только простому — заболоченная Мещера порой служила надежной защитой прославленному рязанскому князю Олегу.
Но это не так уж и важно: для многих древнерусских городов нет точной даты закладки первого камня, и рукописи, способные предоставить доподлинные сведения, сгорали в пламени пожаров. По версии В. И. Даля, тулой называли скрытое место, укрытие (отсюда — притулиться). Корень слова «тула» присутствует в именах северных рек, вдоль которых селились финно-угорские племена. Сам город стоит на реке Упе при впадении в нее речки Тулицы. Интересно, что в литовском, латышском и даже тюркском языках имена Тула и Упа имеют схожее смысловое значение со словами, означающими «река», «ручей», «болото». Впрочем, простому люду приходилось укрываться от набегов захватчиков не только в лесах, но и на болотах. И не только простому — заболоченная Мещера порой служила надежной защитой прославленному рязанскому князю Олегу.
Еще «тулом» называли на Руси длинный колчан со стрелами в вооружении пешего воина. И замечательный писатель-фольклорист И. Ф. Панькин, осевший в Туле навсегда и ставший ее Почетным гражданином, оставил нам такие строки :
«По преданиям мужиков березового края одна женщина-богатырь с давних пор и по сей день носит в своем колчане вместо стрел целый город с мастеровыми людьми. Женщину зовут Россией, а город — Тулой, где придерживаются такого завета: «Если стрелы о себе говорят в полете, то мастера — только творением рук».
Женщину зовут Россией, а город — Тулой, где придерживаются такого завета: «Если стрелы о себе говорят в полете, то мастера — только творением рук».
Эти слова отлиты в бронзе перед оградой «Туламашзавода». Вот еще одна версия, и все они имеют право на существование.
Литва граничила с тульскими землями Рязанского княжества на западе, степная конница угрожала с юга и востока. Тула побыла во власти рязанских князей, недолго принадлежала жене хана Золотой Орды Узбека Тайдуле, вернулась к рязанцам, а с начала XVI в. вошла в состав объединенного Московского государства.
Памятник Дмитрию Донскому в Тульском Кремле
Первой линией обороны от кочевников стал «Берег» — череда крепостных сооружений от Серпухова до Коломны вдоль относительно мелководной до слияния с Москва-рекой Оки. От городов, стоящих на крупных торговых путях, хорошо известных захватчикам, в разные стороны протянулись засеки, на местах безлесных представлявших собой земляные валы с частоколами, а на мелях — преграды в виде забитых свай и уложенных на дно бревен с острыми железными спицами. Этот сторожевой вал встал на пути завоевателей по всей южной линии от земель Великого княжества Литовского до полей, за которыми начинались Ногайские степи — и в народе прозвали его Поясом Богородицы. Оборонительный рубеж не был сплошной линией, и крымцы, наступавшие по Муравскому, Изюмскому шляхам и другим ведущим на Русь путям, не доходя до крепостей и острогов, разделяли свое войско на отряды по несколько тысяч человек, скрытно огибая преграды. Так было сподручнее грабить, вихрем проносясь по беззащитным деревням. Порой потомки распавшейся Орды объединялись — одновременно в набег с востока и юга шла конница из Казани и Крыма, а то и ногайцы с юго-востока.
Этот сторожевой вал встал на пути завоевателей по всей южной линии от земель Великого княжества Литовского до полей, за которыми начинались Ногайские степи — и в народе прозвали его Поясом Богородицы. Оборонительный рубеж не был сплошной линией, и крымцы, наступавшие по Муравскому, Изюмскому шляхам и другим ведущим на Русь путям, не доходя до крепостей и острогов, разделяли свое войско на отряды по несколько тысяч человек, скрытно огибая преграды. Так было сподручнее грабить, вихрем проносясь по беззащитным деревням. Порой потомки распавшейся Орды объединялись — одновременно в набег с востока и юга шла конница из Казани и Крыма, а то и ногайцы с юго-востока.
Тула преграждала Муравский шлях, наиболее опасное направление. Уже в 1507-1509 гг. повелением Василия III здесь возводится мощный деревянный кремль и, сразу, под его прикрытием, начинается строительство каменных стен и башен, завершившееся в 1520 г. От Тульского Кремля, ставшего центром обороны Юга Руси, в течение нескольких десятилетий, ведется сооружение непрерывной Заокской засечной черты.
Башня Ивановских ворот
Линия с опорными пунктами в Рязани (тогда — Переяславле-Рязанском), Кашире, Венёве, Козельске, Белеве, Болхове, Перемышле, Одоеве и других городах протянулясь от Брянских лесов до Мещерских чащ и болот. В наиболее тревожных местах строили дополнительные участки, увеличивали вдвое-втрое глубину заграждения. За первым рядом засеки шла проездная дорога, по которой непрерывно сновали конные сторожевые разъезды, в городах засечной черты сосредотачивались войска для оперативного отражения нападения. Глубина такого укрепрайона составляла несколько километров, в отдельных местах — до двадцати и более. Проникать через засеки иначе, чем через охраняемые ворота и даже просто находиться в засечном лесу посторонним было строжайше запрещено.
Делами Засечной черты ведал Пушкарский приказ, где следили за состоянием оборонительной линии, снабжением засечной стражи и полевого войска — а штаб находился в Туле. Отсюда руководили дальнейшим строительством, в ходе которого рубежи обороны перемещались на юг и восток.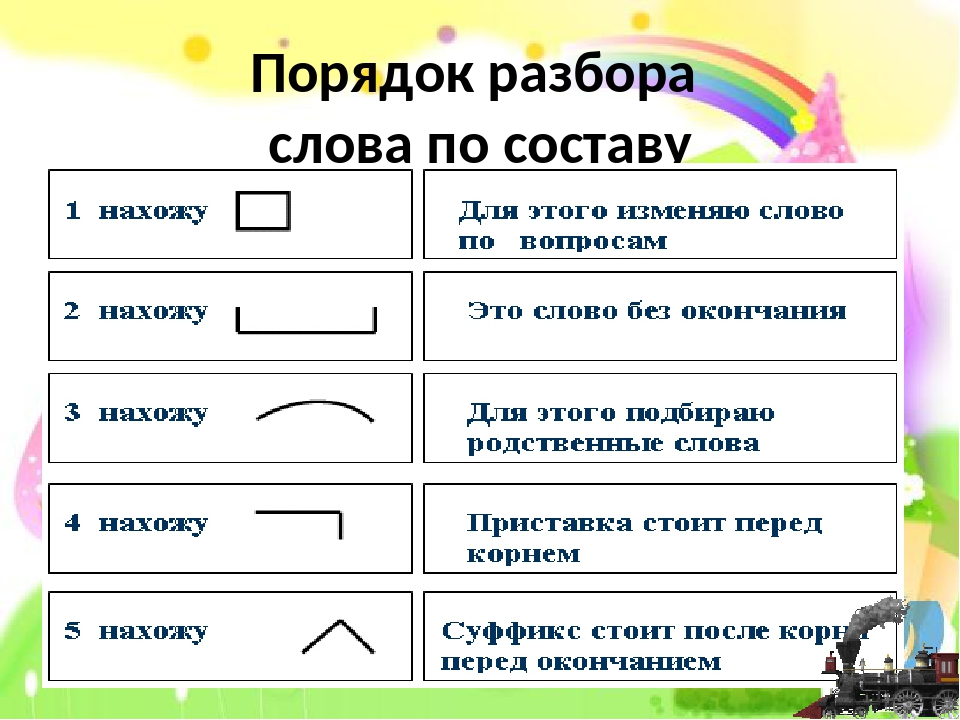
Тульский Кремль. Спасская башня
Тульский Кремль, в отличие от многих русских твердынь, расположился не на холме, а в низинке. Зато с трех сторон его окружали естественные преграды: реки Упа, уже забытая ныне Хомутовка и болото, что оборонительный потенциал Тулы усилило и, можно сказать, углубило, тем более, что в дополнении к водным преградам природным вырыли и наполнили водой глубокий ров.
В плане Тульский Кремль — прямоугольник с девятью башнями: круглыми в сечении угловыми (Спасская, Наугольная, Ивановская и Никитская) и почти квадратными проездными (Пятницкая, Одоевская, башни Водяных и Ивановских ворот). Девятая устроена рядом с башней Водяных ворот и называется «На погребу».
Башня «На погребу»
Толщина стен достигает трех метров, высота — десяти при общей протяженности около километра. Стены завершаются характерными зубцами в форме «ласточкин хвост» и, так же, как и башни, имеют несколько рядов боя — подошвенного, пищального и варницкого. Интересно, что сложены они отчасти из кирпича, а отчасти — из белого камня, на известковом растворе, и специалисты предполагают, что на строительстве ввиду его срочного характера трудились несколько бригад, различавшихся навыками и предпочтениями в выборе материала. А может быть, все проще — строили из того, что было, тем более, что крымцы скучать не давали, совершая порой несколько набегов в год.
Интересно, что сложены они отчасти из кирпича, а отчасти — из белого камня, на известковом растворе, и специалисты предполагают, что на строительстве ввиду его срочного характера трудились несколько бригад, различавшихся навыками и предпочтениями в выборе материала. А может быть, все проще — строили из того, что было, тем более, что крымцы скучать не давали, совершая порой несколько набегов в год.
Два цвета стен
Белый камень добывали неподалеку, и кирпичи тоже делали здесь. Весили кирпичи 8 кг, и их называли «двуручными», потому что поднимать их для установки приходилось вдвоем. Каждый камень или кирпич перед укладкой внимательно проверяли. Фундамент под стенами выполнен из дубовых свай. При раскопках несколько свай были извлечены из земли и переданы музейному комплексу Тульского Кремля.
У каждой башни своя история. На Спасской была установлена смотровая вышка с колоколом, и потому ее называли еще Вестовой. В Пятницкой башне хранили запасы «зелья» — пороха, и в пожар 1568 г. здесь прогремел взрыв, после чего башню отстроили заново, на этот раз только из кирпича. Наугольную башню прозывали Мясницкой — под ней торговали мясники. Сейчас же Торговыми рядами стали ниши в стенах внутри Кремля, в этом же углу. Башню Водяных ворот именовали также Воскресенской, в честь старой Воскресенской церкви, она стояла на нынешней территории оружейного завода и сейчас восстановлена.
здесь прогремел взрыв, после чего башню отстроили заново, на этот раз только из кирпича. Наугольную башню прозывали Мясницкой — под ней торговали мясники. Сейчас же Торговыми рядами стали ниши в стенах внутри Кремля, в этом же углу. Башню Водяных ворот именовали также Воскресенской, в честь старой Воскресенской церкви, она стояла на нынешней территории оружейного завода и сейчас восстановлена.
Торговые ряды
Следующей возвышается, расширяясь немного внутрь, почти прямоугольная, непроездная башня «На погребу», где держали запасы провианта на случай осады. Затем — угловая Ивановская башня, у которой было несколько имен: «Предтеченская», в честь расположенного рядом монастыря, и «Тайницкая» — отсюда к реке вел подземный ход. Башня Ивановских ворот, смотревшая на Муравский шлях, прежде называлась Никитской. После завершения строительства ее переименовали, а прежнее название перешло к круглой угловой башне. В той в той сначала укрывали порох, а потом устроили пыточную, и для особо любознательных ныне в башне организована соответствующая экспозиция.
Башня Одоевских ворот
Проездная башня Одоевских ворот часто украшает собой тульские буклеты, открытки и путеводители. Высокая круглая башенка со шпилем выросла над ней много позже, когда Екатерина Великая признала историческую ценность городского Кремля и распорядилась провести его ремонт. Отводными стрельницами эта и Пятницкая башня были усилены двумя столетиями раньше.
Город, не покорившийся никомуМакет Тульского Кремля
Под надежным прикрытием разрастался торгово-ремесленный посад. Вскоре его обнесли деревянными стенами, общей длиной три с половиной километра, примкнув их к Наугольной и Ивановской каменным башням. Соединенная с засечной чертой крепость вскоре прошла проверку на прочность, выдержав четырехдневную осаду войсками Девлет-Гирея в июне 1552 г. Это был не просто отвлекающий маневр турецкого вассала: армия Ивана Грозного двигалась уже на Казань, также входившую в круг интересов Османской империи. Москва оставалась беззащитной перед 30-тысячной ордой. К ночи третьего дня обороны одни из ворот были проломлены, но до рассвета туляки, в том числе женщины и дети, сумели завалить их подручным материалом, а при подходе царских конных дружин вместе с ними ударили на врага, обратив гордых степняков в бегство.
К ночи третьего дня обороны одни из ворот были проломлены, но до рассвета туляки, в том числе женщины и дети, сумели завалить их подручным материалом, а при подходе царских конных дружин вместе с ними ударили на врага, обратив гордых степняков в бегство.
Фрагмент диорамы
В 1566 г. Иван Грозный лично принимал работы, завершившие создание Заокской черты, проинспектировав ее на нескольких участках. Этим годом сооружение сплошной Большой засечной черты, как правило, и датируется. Реально оценивая ситуацию, царь распорядился принимать в засечную стражу и беглых — с засеки тоже «выдачи» не было. Шло формирование порубежных казачьих войск; к защитникам черты присоединились служилые татары, присягнувшие Москве на верность. В крепостях устанавливали пушки и создавали запасы пороха, «жребия» и «чеснока» — миниатюрного, но страшного для конницы прообраза противотанковых «ежей», своими острыми шипами навсегда выводившего скакуна из строя. Вперед за линию засек высылались дозоры, иногда — на 3-5 дней конного перехода, чтобы своевременно отслеживать любое движение в Дикой степи. Сквозь Большую засечную черту враг смог прорваться только дважды, и то — ценой предательства. В том числе — в 1571 г., когда Девлет-Гирей сжег Москву. Через год он попытался повторить успех, был наголову разбит при Молодях — и крымцы не ходили на Русь почти двадцать лет, пока в их степях не выросли новые воины. Стены Тульского Кремля не пропустили иноземных захватчиков ни разу.
Сквозь Большую засечную черту враг смог прорваться только дважды, и то — ценой предательства. В том числе — в 1571 г., когда Девлет-Гирей сжег Москву. Через год он попытался повторить успех, был наголову разбит при Молодях — и крымцы не ходили на Русь почти двадцать лет, пока в их степях не выросли новые воины. Стены Тульского Кремля не пропустили иноземных захватчиков ни разу.
Кремль изнутри. Башни «На погребу» и Ивановская
В Смуту Тула поддержала первого самозванца, потом в город вошел Иван Болотников, выдержавший со своим войском четырехмесячную осаду. Царь Василий Шуйский смог вынудить восставших сдаться, лишь запрудив Упу и затопив крепость. Обещанной милости самодержец к бунтовщикам не проявил, Болотникова ослепили и утопили — но и Шуйскому недолго оставалось занимать московский трон. Последним побывавшим в городе смутьяном был «Тушинский вор». Позже тульская твердыня успешно противостояла интервентам, но засечная черта приходила в упадок, и восстановить ее смогли через много лет после Смуты. А с присоединением левобережной Украины рубеж обороны переместился на юг. Заокскую линию дополнила Белгородская черта, прошедшая уже по степям и своими валами, частоколами и двумя десятками укрепленных городов надежно прикрывшая южные русские земли. Продолженная впоследствии засеками на Каме и Средней Волге и, уже в XVIII в., в оренбургских степях, Большая засечная черта России стала непреодолимым, глубоко эшелонированным рубежом обороны на юге и юго-востоке страны.
А с присоединением левобережной Украины рубеж обороны переместился на юг. Заокскую линию дополнила Белгородская черта, прошедшая уже по степям и своими валами, частоколами и двумя десятками укрепленных городов надежно прикрывшая южные русские земли. Продолженная впоследствии засеками на Каме и Средней Волге и, уже в XVIII в., в оренбургских степях, Большая засечная черта России стала непреодолимым, глубоко эшелонированным рубежом обороны на юге и юго-востоке страны.
Пятницкая башня
Усиливая оборонительную мощь тульской крепости, взамен части обветшавших деревянных стен были устроены земляные валы с пятью вынесенными вперед бастионами. К концу XVIII столетия, когда Крым уже вошел в состав Российской империи, военное значение Тулы ослабло, и деревянные укрепления разобрали. Посягали эффективные менеджеры начала XX века и на сам Кремль, но тогда нашлись люди, сумевшие этот архитектурный памятник отстоять.
В военно-историческом музее. 1812 год
Наполеон до Тулы не дошел, хотя разжиться продовольствием в богатых южных российских губерниях подумывал. Но — не дали, и французскому гению суждено было бесславное путешествие восвояси по Старой Смоленской дороге в сопровождении русских воинов и партизан. А в страшную осень 1941-го этот город заслонил собой Москву, и вместе с ней — всю Россию.
Но — не дали, и французскому гению суждено было бесславное путешествие восвояси по Старой Смоленской дороге в сопровождении русских воинов и партизан. А в страшную осень 1941-го этот город заслонил собой Москву, и вместе с ней — всю Россию.
Бронепоезд на Московском вокзале
Бои за Тулу шли с конца октября, когда немецкие войска вышли на подступы к городу, и завершились отражением их последней попытки штурма 7 декабря 1941 г. А дальше врага погнали уже в ходе общего московского контрнаступления. Танкисты Гудериана, стремясь прорваться к столице с юга, не отвлекались на уничтожение попадавших в окружение советских дивизий, и те, выходя с боями к городу, занимали позиции — хотя в иных дивизиях от личного состава оставалось по 200-300 человек. День и ночь работали тульские оружейники. Кроме трех армий, гарнизона и охранявших оборонные предприятия частей НКВД врагу противостояли сформированный в городе Тульский рабочий полк, два собранных здесь бронепоезда, зенитчики и перебрасываемые с других фронтов и из тыла дивизии, бригады, дивизион «Катюш» и активно действующие партизаны. Враг атаковал — его отражали, враг захватывал населенные пункты — их отбивали, враг обходил город с севера и востока — ему наносили удары с тыла. Внимательно прослеживая ход Тульской оборонительной операции, понимаешь, что в битве за Москву счет шел не только на дни, порой — на часы и минуты. Подходили эшелоны со свежими частями — и бойцы тут же вступали в бой. В ходе боев были разрушены города Епифань, Венёв, Чернь, Богородицк, сожжено свыше 300 деревень и почти три сотни школ — но скованным тульской обороной немцам не удалось ни ударить на Москву с юга, ни обойти ее с востока. В 1966 г. Тула была награждена орденом Ленина, а десять лет спустя заслуженно вошла в число советских городов-героев. Памятью о тех днях служат не только стелы и постаменты, но и тульские топонимы: улицы Болдина (командующий 50-й армией), Тульского рабочего полка, Оборонная, Красноармейский проспект, площадь Победы…
Враг атаковал — его отражали, враг захватывал населенные пункты — их отбивали, враг обходил город с севера и востока — ему наносили удары с тыла. Внимательно прослеживая ход Тульской оборонительной операции, понимаешь, что в битве за Москву счет шел не только на дни, порой — на часы и минуты. Подходили эшелоны со свежими частями — и бойцы тут же вступали в бой. В ходе боев были разрушены города Епифань, Венёв, Чернь, Богородицк, сожжено свыше 300 деревень и почти три сотни школ — но скованным тульской обороной немцам не удалось ни ударить на Москву с юга, ни обойти ее с востока. В 1966 г. Тула была награждена орденом Ленина, а десять лет спустя заслуженно вошла в число советских городов-героев. Памятью о тех днях служат не только стелы и постаменты, но и тульские топонимы: улицы Болдина (командующий 50-й армией), Тульского рабочего полка, Оборонная, Красноармейский проспект, площадь Победы…
Башня Одоевских ворот в просвете арки Успенского собора
После установления Советской власти кремлевскую территорию использовали прагматично: здесь построили стадион, в храмах разместились склады и спортивные секции. К возвращению исторического облика приступили в 1960-х, но завершилось возрождение этой национальной реликвии уже в нашем тысячелетии, когда удалось добиться выделения необходимых средств. Расчищена и благоустроена площадь, восстановлена колокольня Успенского собора, создан объединенный музейный комплекс. Один его зал посвящен строительству Кремля. В другом — военно-историческая экспозиция от времен дружинников и стрельцов до Великой Отечественной. Третий зал отведен под археологические находки. Скоро откроется четвертый — в память воинов-афганцев» и других участников вооруженных конфликтов.
К возвращению исторического облика приступили в 1960-х, но завершилось возрождение этой национальной реликвии уже в нашем тысячелетии, когда удалось добиться выделения необходимых средств. Расчищена и благоустроена площадь, восстановлена колокольня Успенского собора, создан объединенный музейный комплекс. Один его зал посвящен строительству Кремля. В другом — военно-историческая экспозиция от времен дружинников и стрельцов до Великой Отечественной. Третий зал отведен под археологические находки. Скоро откроется четвертый — в память воинов-афганцев» и других участников вооруженных конфликтов.
Завершается реставрация Успенского собора Кремля — разобранную в 1936 г. колокольню в 2014-м восстановили, и внутри ее первого яруса проводятся службы. История самого же собора ведется от второй половины XVII в., когда было воздвигнуто первое каменное храмовое здание с двумя приделами, а многочисленные жилые и хозяйственные строения вывели за кремлевскую стену. Столетием позже обветшавший собор разобрали — хотя для каменной постройки это не срок, а значит, или были просчеты, или нашлись иные серьезные причины. Деньги на новое строительство собрали тульские купцы. В мае 1764 г. строительные работы закончились, и в центре Кремля поднялся двухсветный четверик храма, богато украшенный каменной резьбой и лепными украшениями, характерными для архитектуры XVI-XVII веков: наборные полуколонки, розетки, раковины, растительный орнамент и — двуглавый орел над западным входом. Над четырехскатной крышей возвышались традиционные пять луковичных глав на восьмигранных барабанах с решетчатыми окошками; к востоку примыкал односветный алтарь с полукруглым апсидным выступом. Над росписью интерьера работали ярославские иконописцы; считается, что это — один из последних примеров их самобытной манеры.
Деньги на новое строительство собрали тульские купцы. В мае 1764 г. строительные работы закончились, и в центре Кремля поднялся двухсветный четверик храма, богато украшенный каменной резьбой и лепными украшениями, характерными для архитектуры XVI-XVII веков: наборные полуколонки, розетки, раковины, растительный орнамент и — двуглавый орел над западным входом. Над четырехскатной крышей возвышались традиционные пять луковичных глав на восьмигранных барабанах с решетчатыми окошками; к востоку примыкал односветный алтарь с полукруглым апсидным выступом. Над росписью интерьера работали ярославские иконописцы; считается, что это — один из последних примеров их самобытной манеры.
Успенский собор
Колокольню в четыре яруса, типично классическую, соединенную с храмом арочным переходом, достроили в 1776 г., в конце века на ней установили часы. Действующий в нижнем ее ярусе теплый храм посвятили св. Тихону Амафунтскому, в память о приделе, бывшем в разобранном соборе. Недавно перед аркой установили памятник Дмитрию Донскому: Куликово поле лежит на тульской земле, и именно по Муравскому шляху вел на Русь свои полчища Мамай. А сам Успенский собор — летний, и службы в нем велись только от Пасхи и до Покрова. Это, кстати, стало одной из главных причин появления рядом теплого Богоявленского собора, в котором сейчас размещается часть экспозиции Тульского Музея оружия.
А сам Успенский собор — летний, и службы в нем велись только от Пасхи и до Покрова. Это, кстати, стало одной из главных причин появления рядом теплого Богоявленского собора, в котором сейчас размещается часть экспозиции Тульского Музея оружия.
Богоявленский собор
В истории Богоявленского собора, стоящего в нескольких сотнях шагов, прослеживается множество совпадений с хроникой возведения в Москве храма Христа Спасителя. Они и внешне похожи, только вот тульской святыне повезло больше — в годы Советской власти ее не взорвали, а только обезглавили. Храм намеревались возвести после визита в 1817 г. в Тулу Александра I – в честь победы над Наполеоном, и посвятить его первоначально предполагали небесному покровителю царя — Александру Невскому. Проект составили в Туле, император им остался недоволен и поручил доработку В. П. Стасову, одному из родоначальников русского ампира, а затем — историзма в отечественной архитектуре. Что тот и исполнил, однако на том процесс и остановился.
Вернулись к этой теме в Туле не скоро: когда встали перед выбором — перестраивать Успенский собор, чтобы сделать его теплым, или возвести второе здание. На последнем и порешили, избрав комитет из трехсот влиятельных туляков. На обсуждение, обследования старого собора и принятие окончательного решения ушло время с 1840 по 1849 гг. Новый проект — архитектора Тульского оружейного завода М. А. Михайлова — в столице не утвердили, но и обратно не вернули. Зодчий выполнил новый, который «притормозили» вновь. В результате на составление проекта было потрачено пять лет, и только в конце 1854 г. Николай I начертал на бумагах свою положительную резолюцию. Собор построили за три года, столько же лет его расписывали московские мастера. Средства на строительство вносили представители всех сословий города. Освящение храма состоялось в 1862 г., тогда же праздновалось тысячелетие России. Позже духовое отопление от печей по дымовым трубам переделали на водяное, а заодно устроили вентиляцию.
Дореволюционные кремлевские виды. ..
..
Ныне о пятиглавии собора напоминают лишь старые фотографии и уцелевший центральный барабан. Когда здание передавали для размещения в нем Музея оружия, то вход сделали со стороны алтаря, соорудив здесь выступающую вперед пристройку.
Перед кремлевской стенойУспенский кафедральный собор
Интересно, что в Туле, в непосредственной близости один от другого стоят два Успенских собора. Порой их путают, не зная, что высокий кирпичный храм, выстроенный в русском стиле, служил главным собором Успенского женского монастыря. Обитель укрывалась за стенами «деревянного города» — так называли окружившую посад крепостную стену — и тоже была обнесена оградой, причем каменной. Основание монастыря относят к первым годам царствования Алексея Михайловича, т. е., второй половине 1640-х. Собор строился и перестраивался не единожды, и существующий двухэтажный храм по проекту Э. В. Скавронского, возвели в 1898-1902 гг., явив городу строгий четверик с трифолийным завершением стен и пятиглавием на световых восьмигранных барабанах.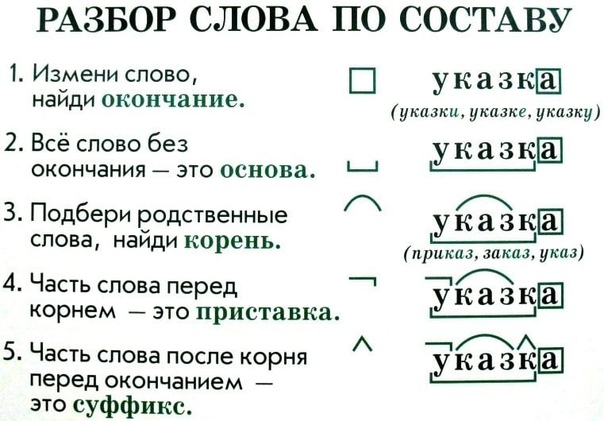 «Кирпичный стиль», как порой называли это течение в русской архитектуре конца XIX века, в сочетании с современными на тот момент конструктивными решениями позволял щедро использовать декор, заимствованный из разных строительных эпох — здесь поребрик, ширинки, килевидные кокошники и порталы звучат отголоском узорочья, а граненые боковые главы — дань периоду барокко. Роспись интерьера копирует работы Виктора Васнецова во Владимирском соборе Киева. А прочностные характеристики и устойчивость всей постройки — намек добрым молодцам из нынешних проектных институтов: в 1930-х собор пытались взорвать, но так и не смогли. Только главы снесли — их вернули в конце 1980-х.
«Кирпичный стиль», как порой называли это течение в русской архитектуре конца XIX века, в сочетании с современными на тот момент конструктивными решениями позволял щедро использовать декор, заимствованный из разных строительных эпох — здесь поребрик, ширинки, килевидные кокошники и порталы звучат отголоском узорочья, а граненые боковые главы — дань периоду барокко. Роспись интерьера копирует работы Виктора Васнецова во Владимирском соборе Киева. А прочностные характеристики и устойчивость всей постройки — намек добрым молодцам из нынешних проектных институтов: в 1930-х собор пытались взорвать, но так и не смогли. Только главы снесли — их вернули в конце 1980-х.
Преображенский собор
Чуть поодаль возвышается классический Преображенский собор (архитектор В. Ф. Федосеев), и, если бы не пять зеленых куполов на ротондах, эту постройку можно было бы принять за образцовое гражданское здание середины XIX в., когда оно и было сооружено. Два этих архитектурных памятника — все, что осталось от монастыря — стены, башни, Знаменский храм и жилые корпуса по упразднению обители после революции снесли. Сейчас оба собора отреставрированы и возвращены церкви.
Сейчас оба собора отреставрированы и возвращены церкви.
Кремлевский сад появился в 1834-1837 гг. стараниями тульского губернатора Е. А. Зурова на месте Сенной площади после пожара, когда сгорело множество деревянных построек. Он простирался от башни Одоевских ворот до угловой Никитской. Через четверть века пришедший в запустение, но в результате активных действий губернатора Ю. К. Арсеньева и тульских купцов был приведен в порядок и продлился уже до башни Водяных ворот. Старую часть стали называть Верхним Кремлевским садом, новую — Нижним. Здесь устроили беседку, фонтан, ресторан, летний театр, а потом и кинотеатр. В 1904 г. на берегу Упы городом был бесплатно выделен участок земли для устройства ботанического сада для учащихся и павильона садоводства. Сейчас, в преддверии кремлевского юбилея, в Туле ведутся масштабные работы по благоустройству набережной, прилегающих к Кремлю улиц, расчистке русла Упы — и уже сделано очень многое.
«Конь из букв»
На Казанской набережной, помимо занятного арт-объекта «Конь из букв» и информационных стендов со старинными фотографиями городских видов, установлен экран, благодаря которому туляки, прогуливаясь, могут в режиме реального времени наблюдать, как москвичи входят в вестибюль станции метро «Тульская» и приветствовать их.
Окно в Москву на Казанской набережной
Те, правда, как правило, проносятся мимо своего экрана: вход в метро — не лучшее место для неторопливого общения…
Евгений ШАПОЧКИН
Текст песни «На Тихорецкую состав отправится» Михаила Львовского
Уже много лет перед новогодним боем курантов мы смотрим «Иронию судьбы…» и вместе с героями фильма поём текст песни «На Тихорецкую состав отправится». Правда, лишь немногие знают, что композиция Микаэла Таривердиева на стихи Михаила Львовского была создана ещё задолго до появления всеми любимого кинофильма.
Да-да, песня со строками «Вагончик тронется, перрон останется…» родилась в далёком 1960 году и создавалась она авторами для пьесы Ролана Быкова «Друг детства». И более десяти лет эти строки, под гитарное сопровождение, звучали из уст самого Владимира Высоцкого. И только в 1975 году в «Иронии судьбы…» заново возродились из недолгого забытья
Слова песни «На Тихорецкую состав отправится»
На Тихорецкую состав отправится,
Вагончик тронется, перрон останется.
Стена кирпичная, часы вокзальные,
Платочки белые, платочки белые, платочки белые,
Платочки белые, глаза печальные.
Одна в окошечко гляжу не грустная,
И только корочка в руке арбузная.
Ну что с девчонкою такою станется?
Вагончик тронется, вагончик тронется, вагончик тронется,
Вагончик тронется, перрон останется.
Начнёт выпытывать купе курящее
Про моё прошлое и настоящее.
Навру с три короба, пусть удивляются.
С кем распрощалась я, с кем распрощалась я, с кем распрощалась я,
С кем распрощалась я, вас не касается.
Откроет душу мне матрос в тельняшечке,
Как тяжело на свете жить, бедняжечке.
Сойдёт на станции и распрощается.
Вагончик тронется, вагончик тронется, вагончик тронется,
Вагончик тронется, а он останется.
На Тихорецкую состав отправится,
Вагончик тронется, перрон останется.
Стена кирпичная, часы вокзальные,
Платочки белые, платочки белые, платочки белые,
Платочки белые, глаза печальные.
Песня «На Тихорецкую состав отправится» видео
ДВЕ РЖЕВСКИЕ. Часть 2 — D.K.C. — LiveJournal
Часть 1 находится тут https://kasymus.livejournal.com/23057.htmlА пока я продолжаю повествование.
Высадился я из автобуса уже минуты через три на площади перед вокзалом. Столько топали пешком в горку по жаре, а всё оказывается так рядом, если передвигаешься на средствах малой механизации, к коим «кубик» ЛиАЗ-4292 можно бесспорно отнести.
И начал осмотр железнодорожных достопримечательностей Ржесвского Мемориала с новой для себя традиции, заведённой в Пищалкино для превью отчётов – панорамы от переезда.
https://cloud.mail.ru/public/y3gb/XvtrB9JRe
После чего приступил к фотографированию.
Сама платформа была цельнометаллическая, быстрововозводимая, что объяснимо, ведь открытие готовили в большой спешке. На Рижском вокзале платформу тоже построили, но там деревянная. Хотя, есть подозрение, что Ласточка ходит от электричечной платформы, классической бетонной, так как нагрузка на неё там невелика пока.
На Рижском вокзале платформу тоже построили, но там деревянная. Хотя, есть подозрение, что Ласточка ходит от электричечной платформы, классической бетонной, так как нагрузка на неё там невелика пока.
Подойдя к тыльной стороне вокзала неожиданно обнаружил весьма душевную диораму. Правда, я так и не понял, почему её разместили с обратной, малозаметной стороны здания, где хозблок, в общем-то можно пролететь мимо и не увидеть вовсе. Однозначно ошибка.
Внутри вокзала всё было в целом как и в Яхроме https://kasymus.livejournal.com/21926.html . Я так понимаю, это вообще типовой проект быстровозводимого вокзального комплекса. Считаю, что это отличная фишка для местностей без исторических зданий, для, так сказать, «в-чистом-поле». Другой вопрос, насколько это всё долговечно. Подозреваю, что не очень. А при нашей народной спешке, любви начать в последний момент и открыть к «дате», не удивлюсь, если всё это уже осенью потечёт, а к весне развалится. Но ничего, к 9 мая 2022 подлатают.
Среди сидений обнаружилось и своё ноу-хау. Лежак. Возможно, это вызвано предполагаемым контингентом посещающих мемориал, пожилому человеку иногда надо по здоровью и прилечь. Только все эти лежачие места находились на солнечной стороне, и больше подходили для загара, ибо штор не было предусмотрено от слова совсем.
От парадной двери вид вокзала был вообще один в один Яхрома.
В Яхроме на стенах располагались стенды со схемой проезда к горнолыжным курортам, здесь же согласно специфике была ещё одна очень задушевная инсталляция из стилизованных фронтовых писем.
В целом всё было очень аккуратно, лаконично, без излишеств. Смотреть внутри больше было не на что, и я вышел на площадь.
Центральной фигурой антуража сделали почему-то паровоз. Да, их сейчас пихают куда только можно, на любой, даже самой захудалой станции, уже располагается подобный экспонат, а сколько их на реальной пассажирской работе таскает туристические поезда, уже и сосчитать сложно. В общем, задумку я не понял и не оценил. Возможно, просто уже объелся этими паровозами.
В общем, задумку я не понял и не оценил. Возможно, просто уже объелся этими паровозами.
Но величественности махины это всё равно не отменяет. У детишек до 18 лет паровоз пользовался огромной популярностью. Ровно как и рында. Звон стоял не прекращаясь всё время до самого убытия на Москву, потому что ни один киндер спокойно мимо неё пройти не мог. И это было явно санкционированно.
Особенно порадовал альпинистский карабин, на котором рында висела. Очевидно, что на ночь её убирают во избежание утраты. И ведь самое обидное, что тот, кто её однажды всё-таки стащит, не повесит её на даче, а сдаст на цветмет. Я в металлах не очень шуруплю, но подозреваю, что это бронза или даже ещё что покруче, какой-нибудь особый малиновый валдайский сплав.
Закончив с паровозами и рындами, я прогулялся по маленькой привокзальной площади. Ничего лишнего. Паровоз, вокзал, разворотное кольцо для автобусов и павильон для их ожидания.
Дальше моё внимание привлекли две буквенных инсталляции. Их художественная ценность мне так и не открылась, даже наоборот, смотрелось весьма убого. Хотя и использовались они по полной программе – внутрь буквы помещались детишки для фотографирования.
Их художественная ценность мне так и не открылась, даже наоборот, смотрелось весьма убого. Хотя и использовались они по полной программе – внутрь буквы помещались детишки для фотографирования.
И если «ПОБЕДА» ещё хоть как-то вменяемо выглядела, то вот слово «РАЕВ» (я его именно так прочитал в первый раз), закрывающее вид на перепаханную стройплощадку, просто убивало своей чудовищностью.
После этого настал черёд самой платформы. Сразу же на входе прибило табло, которое утверждало, что наш поезд пойдёт со всеми остановками. Учитывая, что до вокзала их должно было быть заметно менее десяти. Хотя, если предположить, что поезд пойдёт со всеми остановками, которые он должен сделать, то всё становится нормальным.
Очень порадовало обилие лавочек, причём, все без исключения были под навесами, что защищали и от солнца, и от возможного дождя.
Внутри павильончика обнаружилась схема данного направления, выполненная вполне в духе современных московских тенденций. Идея запихивать информацию в круг, мягко говоря, сомнительна, но сначала такие штуки появились в метро, потом на железнодорожных станциях и вот, наконец, вирус добрался и до глубинки в Тверской области. По моему глубокому убеждению, схема, размещённая в кругу, абсолютно нечитаема и лишь сбивает с толку, полностью дезинформируя и дезориентируя её читателя.
Идея запихивать информацию в круг, мягко говоря, сомнительна, но сначала такие штуки появились в метро, потом на железнодорожных станциях и вот, наконец, вирус добрался и до глубинки в Тверской области. По моему глубокому убеждению, схема, размещённая в кругу, абсолютно нечитаема и лишь сбивает с толку, полностью дезинформируя и дезориентируя её читателя.
Вид в сторону Москвы. Классическая фотка с табличкой про первый вагон.
И взгляд в обратную сторону, на запад.
Я спустился с платформы на аллею. Думаю, будет очень круто всё это выглядеть лет через пятьдесят, когда деревья поднимуться в свой полный, положенный им природой рост.
Ну и там, где кончалась парадная часть, сразу начиналась обычная. Вообще, в подобных случаях ставят заборчик с какими-нибудь патриотическими картинками или лозунгами, но в данном случае явно сэкономили. Хотя, в глаза стройка особо не бросалась и позитивного впечатления от всего комплекса не испортила от слова совсем.
Настало время обеда. Я расположился на платформе под навесом и стал ждать Костяна, который уже ехал из глубин Ржева на таксо, затарившись нехитрыми закусками. Пока я его ждал, в рощице пососедству проснулась кукушка. Она не затыкалась минут двадцать, из чего я сделал вывод, что все мы – свидетели этого события – стали бессмертные Дунканы МакЛауды.
Народу было мало, так что когда Костя появился, мы заняли половину мест, накрыв стол прямо на широком подлокотнике. Времени до поезда оставалось ещё прилично, можно было особо не торопиться, трапеза была восхитительна. Тут и припасённый заранее коньячок пригодился. Беседа становилась громче и жарче.
На соседней лавке расположились парень с девушкой. И в какой-то момент я стал замечать, что парень проявляет к нам с Костей повышенный интерес, бесстыдно пялясь и грея уши. Потом стало ясно, что интерес был чисто профессиональный, поскольку мы с Костей дискутировали о поездках прошлых, будущих, вообще о специфике железнодорожных покатушек, а чувак оказался трансфаном. Это выяснилось, когда на горизонте появился прожектор поезда в сторону Москвы. На табло его не было, мы предположили, что это товарняк какой-нибудь, но парень сказал, что это Рашка из Западной Двины до Ржева, заодно спросив, из каких мы частей транспортного интернета. Мы сказали, что с ФОТа и Наштранспорта, он ответил, что с ТрейнПикса, сел в Рашку и больше мы не имели возможности пообщаться, хотя беседа могла бы быть взаимно обогатительной.
Это выяснилось, когда на горизонте появился прожектор поезда в сторону Москвы. На табло его не было, мы предположили, что это товарняк какой-нибудь, но парень сказал, что это Рашка из Западной Двины до Ржева, заодно спросив, из каких мы частей транспортного интернета. Мы сказали, что с ФОТа и Наштранспорта, он ответил, что с ТрейнПикса, сел в Рашку и больше мы не имели возможности пообщаться, хотя беседа могла бы быть взаимно обогатительной.
Минут через несколько в обратную сторону с весьма малой скоростью прополз рабочий поезд с вагоном путеизмерителем, в задние панорманые окна которого приветливо помахивал мужичок, которого все с удовольствием фоткали и одаривали ответными взмахами рук.
Настало время сходить в сортир, облегчиться, помыть руки, чтоб в Ласточке до Москвы уже особо всем этим не заморачиваться, ведь в иных поездах подобного плана из-за того, что только два сортира по торцам состава, очереди могут достигать двадцати и более минут.
В сортире прозошло событие, однозначно меня поразившее. Ладно, если к автосливу мы все давно привыкли, но вот как только я приготовился к выходу после мытья рук, у выхода проснулась нано-урна, то есть она пикнула и сама открылась, призывая что-нибудь в неё положить. Общаться с искусственным ителлектом в виде помойки мне ранее не доводилось. В знак уважения я даже в неё плюнул, потому что положить туда было нечего. И она закрылась. Это впечатлило.
И почти сразу же прибыла наша Ласточка. Народу было не очень много, так что наш первый вагон сособым спросом не пользовался. Первый класс за отдельными дверками полностью выкупила какая-то организованная экскурсия с детьми, и слава богу, ведь они сидели в своём отдельном аквариуме, орали там же, а в нашем отсеке было тихо, публика подобралась взрослая и вменяемая. Отправились с половиной свободных мест. Я ехал с надеждой через несколько минут повстречать нашего дикого прапора и поездки https://kasymus.livejournal.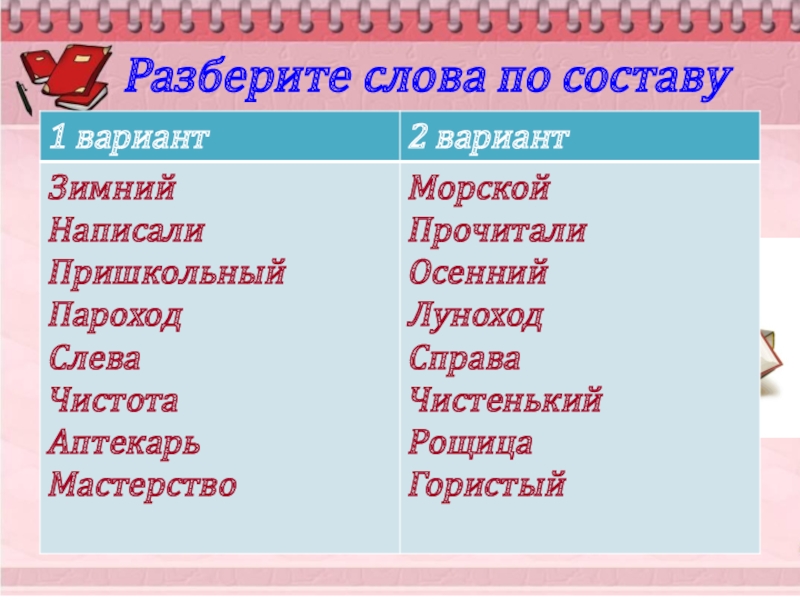 com/13332.html , но в этот раз судьба с ним не свела. И на то были причины.
com/13332.html , но в этот раз судьба с ним не свела. И на то были причины.
А вот то, что произошло дальше, во Ржеве-Балтийском, описанию не поддаётся. Я пошёл к единственной открывающейся двери в нашем вагоне, к самой первой, чтоб выйти на платформу и сделать пару фотографий, но меня просто вдавила обратно в вагон огромная толпа. Посадка была дикая, и не только по поведению людей, но и по их количеству. Особенно было жалко первый класс, ведь табуны обвешанных вещами дачников повалили нескончаемой стеной через их салон повышенной комфортности.
Вот все говорят, что, мол, народ у нас тупой, все танкисты, пока не разжуёшь новую инфу и не повторишь сто раз, не начинают думать. Посадка во Ржеве это опровергла, люди раскурили что к чему и вычислили новый поезд очень быстро. Правда, не до конца, но это не их вина, и вот почему.
Это всё было только стартом веселья, которое продолжалось потом всю дорогу. Тут мы возвращаемся в самое начало моего повествования, к полной импотенции ЦППК в части информирования пассажиров. Люди твиттер не читали, даже мне пришлось ответы клещами тянуть из перевозчиков, люди не знали, что первый вагон едет по своим отдельным билетам, а четыре других – общие, так что плюхались на первое свободное место. И сразу же, как только мы отъехали от Ржева, начались скандалы, так как нашей проводнице раз десять пришлось читать лекцию «это вагон с местами, пройдите в другие вагоны», а там уже всё занято. Народ орал, ругался, но уходил. Их можно понять, ехать пять часов стоя (заплатив серьёзные деньги) только потому что до них не довели точную информацию малоприятно. Ведь если б знали, то переплатив жалкую сотку ехали бы на этих местах законно…
Люди твиттер не читали, даже мне пришлось ответы клещами тянуть из перевозчиков, люди не знали, что первый вагон едет по своим отдельным билетам, а четыре других – общие, так что плюхались на первое свободное место. И сразу же, как только мы отъехали от Ржева, начались скандалы, так как нашей проводнице раз десять пришлось читать лекцию «это вагон с местами, пройдите в другие вагоны», а там уже всё занято. Народ орал, ругался, но уходил. Их можно понять, ехать пять часов стоя (заплатив серьёзные деньги) только потому что до них не довели точную информацию малоприятно. Ведь если б знали, то переплатив жалкую сотку ехали бы на этих местах законно…
Тех, кто совсем не хотел уходить, мол, «мы не знали ни про какой комиссионный сбор» ((с) «Двенадцать стульев»), настойчиво просили покинуть салон особо активные легитимные пассажиры с билетами, в числе которых один раз оказался и я, когда пришлось удалить максимально агрессивного дяденьку. Комплекция у меня такая, что спорить и драться со мной малоперспективно, а, по-хорошему, вообще бесполезно, так что товарищ тоже проследовал в хвостовые вагоны.
Изгнание «зайцев», то есть их тотальная зачистка, продолжалась всю дорогу. И есть подозрение, что кто-то и впрямь мог поехать всю дорогу стоя, но этого я не знаю, за остальными вагонами я не следил и туда не ходил.
К слову, посадка везде была приличная и активная. Поезд народу зашёл в тему. Зубцов.
Погорелое Городище.
Приятно, кстати, что повсеместно ещё остались артефакты паровозной эпохи, как, например, эта водонапорная башня.
Княжьи Горы.
Эта фотка мне особенно нравится. Удалось таким удивительным образом сочетать природные мотивы и современный подвижной состав, который и сам стал симпатичнее, почти слившись с окружающим миром. Кайф, а не фотка. Просто удачный день и зоркий глаз.
В Волоколамске, естественно, была зафиксирована отцепка тепловоза, видео с характерным звуком сцепки СА-3 можно посмотреть по ссылке внизу поста. Дальше фоткать было уже неинтересно, поскольку всё езжено переезжено сто тысяч раз. В общем в Истре я даже не пошёл на улицу, всю дорогу мы с Костей просто проговорили.
В общем в Истре я даже не пошёл на улицу, всю дорогу мы с Костей просто проговорили.
А вот то, что в Тушино я не смог сделать фотографию, это не моя вина. Хоть билеты у нас были до вокзала, выйти мы решили раньше, в Тушино, и как выяснилось уже на месте, подобное решение приняло 99% всего народонаселения Ласточки. Подобное я видал только в самые жопные пики. И если бы турникеты на выход не открыли, поскольку «а чего к ним прикладывать», то их смели бы нахрен вместе с охраной и зданием. Посадку во Ржеве умножаем на пять и вот мы получаем дикие стада, напирающие без разбора. Нас с Костей просто подхватила толпа и буквально внесла в турникетный домик, поэтому и нет фотографии, я телефон просто физически не мог достать из кармана.
Учитывая, что метро «Рижская» закрыта на капремонт, люди приняли правильное решение выйти на «Тушинской». И вот тут я горько пожалел о сказанном на форуме. Я тогда спорил, что не надо данному поезду вообще никаких остановок по городу… Это заблуждение. Как минимум вечером воскресенья надо останавливаться не только на Тушинской, но и на Стрешнево и Дмитровской. В остальные дни это вряд ли так уж необходимо.
Как минимум вечером воскресенья надо останавливаться не только на Тушинской, но и на Стрешнево и Дмитровской. В остальные дни это вряд ли так уж необходимо.
Вечер подходил к концу стремительно, но расходиться не хотелось. Оперативное совещание постановило, что можно продолжить у меня, поэтому мы быстро доехали до «Планерной», заскочили в один из магазинчиков передать привет моей бывшей супруге, что трудится там на благо Родины, после чего вызвали такси и уже минут через двадцать были возле моего дома в Северном.
На этом по сути и заканчивается рассказ о данной покатушке. Как всегда по традиции надо зафиналить какой-то пафосной фигнёй, типа саузпарковского «мы сегодня многое поняли»… Да ни хрена мы не поняли и не собирались понимать. Просто прокатились на поезде, что назначен был на три дня в году и, возможно, больше никогда не будет назначен. Просто посмотрели Рижский Мемориал и новый вокзал, специально для него построенный. Просто вернулись домой на поезде, который ходил всего лишь четвёртый день. Ну, и какие тут можно построить выводы?
Ну, и какие тут можно построить выводы?
Кроме чисто профессиональных не вижу никаких других. А именно: Ласточка будет круглый год возить воздух, кроме 9 мая и официальной даты памяти Ржевского котла, которую я, каюсь, не знаю. В остальное время вангую сильное наполнение только утренней субботней от Москвы до Ржева-Балтийского и вечерней воскресной в обратную сторону. Всё остальное время поезд этот будет возить поездную бригаду как та же «Яхрома». Нужен ли он? Однозначно да, ведь появилась прямая связь Ржева и Москвы, которой раньше не было (ночной ПДС не в счёт), но не велика ли цена? Не проще ли назначить дизель-поезд РА-3? Он выглядит не хуже Ласточки, по комфорту не уступает, опять же тепловоз ему не нужен, он сам себе тепловоз. Это было бы соломоновым решением. А на выходных можно и Ласточку погонять, как любят выражаться в РЖД «в связи с повышенным спросом».
Но это нам дуракам тут на земле всё ясно и очевидно, а им там наверху, с их тонкими политическими интригами и «Потёмкинскими деревнями» нужна Ласточка до Ржевского Мемориала. И пусть каждый сам сделает свои выводы…
За сим вечно ваши Константин «Ремр» Головащенко и Илья «Касым» Ковалёв
(с) Касым, 2021
все фото и видео поездки https://cloud.mail.ru/public/gCmh/Zp6KinzaZ
все фото Костяна https://yadi.sk/a/ghuQtgNyWfsoFg
P.S. Только что заметил… Посмотрите на автоматически сформированную облаком ссылку на фото тремя строками выше… Все в конце видят КиндзаДза или только я?… )))))))
какие бывают штукатурки, виды работ
Общие сведения о штукатурных работах
Штукатурные работы — это работы по нанесению выравнивающих и защитных покрытий. Эти покрытия могут быть на основе вяжущего гидравлического и воздушного затвердения. Они наносятся на наружные и внутренние поверхности элементов строительных конструкций. Штукатурка нужна в первую очередь, чтобы скрыть погрешности кладки, чтобы закрыть швы. То есть это просто декорирование. Вторая задача штукатурки более практическая. Она служит как изоляция от проникновения влаги, улучшает звуко- и теплоизоляционные свойства стены. Если же поверхность деревянная, то штукатурка служит также и противопожарной защитой.
Декоративная штукатурка в нашем каталоге:
Выделяют два вида штукатурных работ — наружные и внутренние.Штукатуркой отделываются стены из кирпича, из мелкоразмерных иных материалов, из крупнопористого беспесчаного камня, если без штукатурки воздухопроницание этих стен не соответствует нормам, которые на данный момент определены СНиПАми. Так же штукатурку применяют при ремонте зданий, стены которых ранее были оштукатурены; штукатурку применяют, если разные участки сделаны из различных материалов ; для отделки оконных и дверных откосов, цоколей; штукатурку можно использовать как защиту от огня, заменяя ей облицовку из несгораемых материалов, если таковые применить невозможно или же просто нецелесообразно. Штукатуркой также отделываются стены рядом с вентиляционными или же дымовыми отверстиями.
История состава штукатурки и сухих строительных смесей
В начале XX века сухими строительными смесями (сокращенно — ССС) назывались смеси из вяжущего вещества (это могла быть известь, цемент либо гипс) и песка. Их называли «гарцовка» Эти смеси могли наноситься только толстым слоем – 10-20 мм — потому что если слой был более тонким, то материал отсасывал воду и смеси становились непластичными, с ними было невозможно дальше работать, штукатурка просто сыпалась. Так же их минусом было то, то цементно-песчаные смеси хороши были при сжатии, но они плохо работали на изгиб, растяжение. Они так же плохо сцепливались с маловпитывающими основаниями.
Ситуация кардинально изменилась в 1912 году в связи с тем, что в Германии химическим концерном «Хехст» был найден способ получения целлюлозы, которая очень хороша впитывала и удерживала воду.
И уже в 20-годах прошлого века началось массовое производство эфиров целлюлозы, которые на данный момент являются основным составляющими СС.
Инструменты для нанесения штукатурки
Давайте рассмотрим инструменты, которые пригодятся вам при оштукатуривании в домашних условиях. В первую очередь вам понадобится полутерок (рис.1), чтобы ровнять и уплотнять штукатурный намет. Он состоит из полотна и ручки. Для его производства чаще всего используют пенополиуретан. Теркой вы затираете поверхность штукатурного слоя. Иногда для этой цели используется опять же полутерок, но уже металлический или резиновый. Или же затирочная кельма (рис.2) Чтобы перенести штукатурку из емкости, в которой мы её замешали, мы используем сокол (рис.3). Им же мы разравниваем слой штукатурки.
Для накладывания раствора на оштукатуриваемую поверхность мастер может использовать штукатурную кельму, штукатурную лопатку либо мастерок. Они могут быть различными по форме:
- Трапециевидная (рис.4) . Это кельма отделочника
- Треугольная (рис.5). Это кельма бетонщика.
- Каплевидная (рис.6).Это кельма штукатура.
- Угловая кельма. (рис.7) Эта кельма используется для отделки внутренних и наружных углов.
- Для того, чтобы заделать тонкие швы, мастер использует шовную кельму.(рис.8)
- Если поверхность слишком большая и раствора нужно сразу нанести много, то можно использовать штукатурный ковш.(рис.9)
- У инструмента, который по форме напоминает лавровый лист, есть несколько названий — отрезовка, штукатурный нож, малая штукатурная лопатка.(рис.10) Это полотно, которое используется для того, чтобы расшить швы, подправить их. Так же им очищают раковины и трещины.
- Такие инструменты как скребок и шпатель (рис.11) мастер использует, чтобы освободить поверхность от покрытия, которое было нанесено на него ранее. К тому же шпатель используется для нанесения шпатлевки.
Если нужно нанести грунтовку или другой раствор, мастер может использовать валики, кисти и еще много разных инструментов. Так же в работе не обойтись без ящика для раствора, шнура, отвеса, укрепляющего фасадного уголка, строительного гидравлического уровня, сетки из стекловолокна и многого другого.
Штукатурки на различных вяжущих
Чтобы считаться хорошей, минеральная штукатурка должна обязательно отвечать ряду требований:
- Она должна хорошо прилегать к основе.
- Плохо впитывать воду и хорошо её отталкивать.
- У неё должна быть высокая степень паронепроницаемости.
- Она должна быть устойчивой к механическим и атмосферным воздействиям .
В зависимости от того, какие вяжущие используются, можно выделить разные виды штукаторок: известковые, цементные, гипсоизвестковые и гопсовые. В ДИН 1850 существует следующее определение штукатурки «штукатуркой считается покрытие, наносимое в виде строительного раствора на стены и потолки в один или несколько слоев определенной толщины, которое достигает своих окончательных свойств только после отверждения на основе».
Штукатурные слои
Монолитная штукатурка состоит из нескольких слоев. Их технологическая последовательность зависит от вида штукатурки. Первый слой называется слоем обрызга. Он наносится обязательно штукатурным ковшом и составляет примерно 8-9 мм. Не стоит наносить этой слой штукатурной кельмой, потому что в этом случае не достигается нужное сцепление с основой. Этот слой по густоте должен быть, примерно, как густая сметана. Наносится он резким выбрасыванием раствора из штукатурного ковша с одинакового расстояния. Второй слой наносится после того, как схватился обрызг . Этот слой называется грунтом. Он наносится так же, как и обрызг выбросом из штукатурного ковша. Но этот слой должен быть боле густым, тестообразным. Его толщина не должна превышать 20 мм, так как если слой будет толще, он не будет хорошо держаться. После нанесения раствора излишки нужно убрать. Убирается лишний раствор правилом. Движения производятся снизу вверх зигзагообразно. Обычно одного выравнивания недостаточно. Лишний раствор, который собирается на правиле, сбрасывается обратно в ящик и выравнивание продолжается. Начисто выравнивание производится полутерком , пока поверхность не станет почти гладкой. Не идеально гладкой, потому что на ней еще должен будет держаться накрывочный слой. Если грунтовочный слой должен быть не толстым, 5-6 мм, то его не набрасывают ковшом, а наносят полутерком. Имейте виду, что если поверхность основы гладкая и твердая, то наносить полутерком не стоит, потому что нанесенный слой сцепливается с основой хуже, чем наброшенный. Последний слой — накрывочный. Его толщина не более 2 мм и он наносится на шероховатый грунтовочный слой после схватывания последнего. Потом его аккуратно затирают и заглаживают. Раствор мастер накладывает кельмой на деревянный полутерок и уже им наносит на поверхность грунтовочного слоя. Раствор наносят зигзагообразными движениями, стараясь нанести равномерно по всей поверхности, насколько это возможно затирают полутерком, а потом разглаживают стальными или пластмассовыми терками. Затирать накрывочный слой следует, пока он еще влажный. Для этого терка плотно прижимается к поверхности и затирка производится круговыми движениями. Лишнее срезается и попадает в углубления, в которых раствора не хватало. Накрывочный слой является завершением, поэтому затирка должна быть выполнена тщательно. Можно провести в конце мокрой щеткой. Существует так же так называемый декоративный накрывочный слой. Его толщина не более 7 мм. Его нанесение производится широким шпателем либо как вариант швейцарской теркой (рис.12).
Подготовка поверхностей под штукатурку
Чтобы штукатурка была прочной и держалась долго, в первую очередь надо идеально подготовить поверхность основы. Все работы нацелены на то, чтобы увеличить адгезию . Сделать это можно разными способами:
- Можно применить механический способ (нарубить поверхность).
- Можно физико-химический (прогрунтовать)
- Можно создать несущий каркас (набивка драни)
Но сначала следует оценить качество уже существующего основания.
Новые каменные, кирпичные и бетонные поверхности
Если кладка шероховата и видно, что на ней есть пыль, её нужно почистить. Для этого вы можете обмести жесткой метлой, промыть водой. Швы, если они заполнены раствором, надо очистить от него минимум на 1 см. Когда поверхность высохнет от воды, можно нанести на неё проникающую грунтовку. Если вам придется иметь дело с бетонными элементами, то их достаточно очистить от пыли и промыть водой. После этого стоит либо нанести грунтовку либо же насечь поверхность. В том случае, если бетон был выполнен в строганной деревянной опалубке или металлической, то насекать его необходимо. Особо грязные места придется зачистить стальными щетками, если возможно, их можно просто срубить и нанести специальную грунтовку для бетона «Бетон-контакт» Эта грунтовка обладает очень высокой адгезионной способностью, поэтому штукатурку можно наносить прямо на неё. Обязательно подвергаются механическому способу обработки и поверхности, которые были неоштукатуренны больше года и сильно загрязнены. После нарубки их тоже стоит прогрунтовать. Особое внимание надо уделить местам, загрязненным глиной или окрашенным масляной краской. Если же поверхность ранее уже была оштукатурена, то следует её тщательно осмотреть. Если при простукивании вы слышите «бубнящий» звук, значит, штукатурка в этом месте отслоилась. Обязательно удалите её. Простые царапины на поверхности наоборот стоит оставить. Они увеличат адгезионную способность поверхности. Если вы заметили, что на каком-то участке развились микроорганизмы, обработайте этот участок с особой тщательностью. Если повреждения незначительные — просто почистите место металлической щеткой и промойте водой. Если они слишком сильные — удалите этот участок штукатурки полностью. В любом случае вы должны обработать пораженный участок специальным фунгипидным препаратом.
Подготовка деревянных поверхностей
Если вам придется штукатурить деревянную поверхность, то сначала подготовьте дрань для неё. Дрань это основа, сделанная из деревянных реек толщиной 3 -5 мм. Дрань разделяют на простильную (нижнюю) и выходную (верхнюю).Более толстая и ровная дрань пойдет для выходной, для нижней годится и тонкая, кривая или узкая. Ширина драни должна быть 15-20 мм. Не больше и не меньше. Потому что если дрань будет тоньше 15, она будет расщепляться при забивке гвоздей, если же шире 20мм, то она может размокнуть, деформироваться и испортить штукатурку. Толщина простильной драни не должна быть меньше 3 мм, чтобы при наложении на неё выходной драни между ними образовались пустоты. Эти пустоты впоследствии заполнятся раствором, который хорошо сцепится с выходной дранью. Не стоит применять и особо толстую дрань, ведь чем толще дрань, тем толще должен быть слой штукатурки. Под углом 45 гр. к полу сначала прибиваются простильные ряды, на них прибивают выходную дрань. Угол наклона сохраняется таким же. Дрань дополнительно скрепляет отдельные доски деревянных поверхностей , тем самым увеличивая жесткость стены. Расстояние между простильными рядами драни рекомендуется делать на стенах 45 х 45 мм, на потолках 40 х 40 мм. Поверх драни на выступающих углах деревянной конструкции укрепите полоски стальной сетки , ширина которой должна быть 15-20см, чтобы укрепить углы. Если оштукатуриваемые поверхности были выполнены из разных материалов, то следует обить места их сопряжения металлической сеткой. Сетка должна заходить на обе стороны на 4-5 см.
Разметка поверхностей
Естественно, оштукатуренная поверхность должна быть ровной. Чтобы этого добиться, применяются так называемые маяки. Это направляющие, выполненные из гипсового раствора, которые накладываются на поверхность. Делаются маяки следующим образом. По углам стены снизу и сверху забивают гвозди, которые отступают от поверхности стены на 3 см. Затем между этими гвоздями натягивают шнуры по горизонтали, по вертикали и по диагонали. Шнур должен отступать от поверхности на 18 мм но ни в одном месте он не должен приближаться к стене ближе чем на 8 мм. Под шнуром делают штукатурные марки высотой от 15 мм и выше. При провешивании стены первый гвоздь забивают на расстоянии 30-40 см от угла и потолка. Над поверхностью стены гвоздь должен выступать на высоту, равную толщине будущей штукатурки. К шляпке гвоздя прикладывается и подвешивается отвес. В нижней части стены на высоте 250 мм от пола забивают второй гвоздь так, чтобы шляпка его касалась шнура. В зависимости от того, насколько высокое помещение, вдоль шнура забивают промежуточные гвозди. Таким же образом поступают на противоположной стороне стены.
Далее следует натянуть шнур по диагонали. Если видите, что шнур в каком-либо месте касается стены или же толщина штукатурки будет слишком маленькой, то верхний гвоздь следует забить с учетом минимальной толщины штукатурки. Если где-то есть небольшие неровности, их можно просто срубить. Затем провешивание повторяется и забиваются новые гвозди. Следуя так же, мы определяем уровень и забиваем промежуточные гвозди по горизонтали. Таким образом гвозди, выступая, показывают нам толщину штукатурки в том или ином месте. Вокруг гвоздей устраивают гипсовые марки. Гвозди обмазываем гипсовым раствором и ровняем верхнюю марку по уровню шляпки гвоздя, после чего придаем ей форму четырехгранных пирамидок-марок. Так же провешивают и потолки, только вместо отвеса можно использовать строительный уровень. Если в потолок невозможно забить гвозди, можно выполнить вместо них марки из гипса. Последовательность сохраняется такая же, как и при забивке гвоздей.
По маркам устанавливают маяки из гипсового раствора. Для этого к маркам вертикаль¬но прикладывают правило или другую ровную рейку и закрепляют ее гипсовым раствором. Пространство между стеной и правилом заполняют раствором. После схватывания раствора на поверхности стены остается полоса, равная ширине правила. В некоторых случаях при не¬больших площадях стены в качестве маяков применяют две вертикально установленные деревянные или металлические рейки. При этом длина реек подбирается такой, чтобы они не доходили до потолка и пола на расстояние 50 мм, а их толщина соответствовала толщине штукатурного слоя. В местах, где рейка не прилегает к стене, пространство между рейкой и стеной заполняют раствором , чтобы избежать прогиба рейки. Как вы , наверное, заметили, установка маяков по маркам невообразимо трудное и хлопотное занятие, поэтому в наше время от него практически отказались. Вместо это широкое распространение получила другая идея — установка маячковых профилей.(рис.15) Эта работа наоборот очень быстрая, простая и удобная. На поверхность, которую вы собираетесь штукатурить, через каждые 30 см точечно наносится раствор, в который вдавливаются маячковые профили. После этого они по правилу-уровню (рис.16) выравниваются в одной плоскости: вертикальной и горизонтальной. Обратите внимание, что на ширине правила должно находиться минимум три маячковые рейки.
Оштукатуривание граней и углов также очень сложный вопрос, так как именно на них особенно заметны все погрешности в работе. Это можно сделать двумя способами.
- Вы можете просто приложить к краю стены ровную доску, чтобы она выступала над стеной на слой штукатурки. Потом мы оштукатуриваем стену так, чтобы отделочный слой штукатурки был в одной плоскости с выступающей гранью доски. После того, как штукатурка застыла, доску нужно аккуратно снять. Углы лучше укрепить сеткой или стальной планкой.
- Можно поступить еще проще, нанеся раствор на внутреннюю сторону угловых профилей с шагом в 20 см. Профиль же устанавливается на углы. Начинаем от центра и двигаемся к краям, следя за тем, чтобы профиль находился в одной плоскости с маячковыми профилями.
- Защитный угловой профиль под штукатурку. В нем грани угла сделаны с особой перфорацией, которая образует сетку. Это позволяет наносить более толстые слои штукатурки. (рис. 17)
- Существует и особый угловой профиль под шпаклевку. Его еще называют малярный уголок (рис.18) Там обычная перфорация. К этому же типу относится и арочный уголок (рис. 19) Его отличие в том, что он может изгибаться, повторяя сферические кромки (как выпуклые так и вогнутые).
- Еще один вид углового профиля — это профиль для фасада. Его отличает наличие стеклотканевой сетки и он используется обычно для наружных работ.
Приготовление раствора штукатурки
Естественно, чтобы что-то штукатурить, нам необходим раствор. Рассмотрим его приготовление. Сначала зальем в бак воду. Следует иметь виду, что на 30 кг сухой смеси нам нужно примерно 18 л чистой воды. В бак с водой мы засыпаем 5-7 мастерков штукатурки и тщательно размешиваем. Следом высыпаем всю штукатурку и перемешиваем с помощью строительного миксера. В итоге должна получиться совершенно однородная масса, не содержащая никаких комков. Вы можете попытаться размешать и вручную, но вряд ли у вас получится действительно хороший раствор.
О миксере нужно знать следующее.
- Существуют штукатурные и малярные миксеры. Для штукатурных растворов лопасти миксера сделаны из прута (рис.20), а для малярных — лопасти представляют из себя плоскости (рис.21) Эти миксеры нельзя путать и пытаться заменить один другим.
- Мощность дрели для замешивания должна быть минимум 650-700 В.
- Не следует вынимать миксер из раствора, пока он полностью не остановился. Вы можете добавлять воду или смесь в процессе перемешивания, делать это в несколько заходов, выдерживая интервалы в пять минут. Но нельзя добавлять воду или сухую смесь в раствор, который вы уже наносите на поверхность. Так же не добавляйте в раствор посторонние компоненты.
Нанесение штукатурки
Как только вы замешали раствор, начинайте его использование. Вы должны использовать его за 20-25 минут. Если вы оштукатуриваете потолок, то раствор стоит наносить штукатурным соколом «на себя». На стену вы можете набрасывать раствор с помощью кельмы или же намазывать полутерком снизу вверх. Потом не забудьте разровнять раствор трапециевидным правилом или просто ровной рейкой. Движения должны быть зигзагообразными. Если слой должен быть толстый, то наносите первый слой, пока он еще мягкий, зубчатым металлическим шпателем либо кельмой (рис.12). Второй слой можете наносить не ранее чем через сутки. Если размер оштукатуриваемого участка небольшой, то вы можете наносить раствор мастерком, разравнивая его потом полутерком. Основания из ЦСП, пенополистирола нужно оштукатуривать с армированием по всей поверхности стеклотканевой сеткой с ячейкой 5 х 5 мм, которую заделать внутрь штукатурного слоя на треть толщины (рис. 28). Перекрывание слоев сетки должно составлять не менее 10 см.(рис.29).
Выравнивание поверхности
Через 45-60 минут после затворения раствора он начнет схватываться. В это время вы должны выровнять поверхность. Это можно сделать широким металлическим шпателем или просто металлической рейкой, срезая излишки и заполняя углубления. На углах и откосах вы должны выполнять работу, используя угловые кельмы (рис.30)
Затирка поверхности
Если вы готовите поверхность под поклейку обоями или же под покраску, то выдержите штукатурку минут 15, а потом обильно смочите водой и затрите кругообразными движениями. Вы можете использовать для затирки жесткую войлочную или жесткую губчатую терку. Это делается, чтобы убрать следы после выравнивания поверхности рейкой или правилом.
Заглаживание поверхности
Заглаживание поверхности — это последний штрих перед поклейкой обоев. Заглаживать поверхность стоит через некоторое времени после затирки, когда поверхность уже стала матовой. Делать это можно, проводя широкие движения с помощью широкого шпателя или нержавеющей металлической терки. После того, как поверхность высохнет, можно смело клеить на неё обои. Они будут держаться хорошо. Если вам нужна глянцевая поверхность под покраску, то через 2,5- 3 часа после замешивания раствора штукатурку снова нужно смочит водой и тщательно загладить металлической теркой.
Структурирование поверхности
В зависимости от ваших желаний вы можете структурировать поверхность. Она может быть выполнена с нанесением рисунка или фактуры. Для этого вы должны прокатать еще не затвердевшую поверхность рельефным валиком либо придать ей желаемую структуру с помощью формовочного инструмента (рис. 31) либо мастерка, жесткой щетки.
Если вы работаете на фасадной поверхности, то можете придать ей желаемую структуру с помощью пневмопистолета для штукатурки.(рис.32)
Виды декоративной штукатурки
Декоративная (структурная) штукатурка
Если вы хотите, чтобы оштукатуренная поверхность была оформлена оригинальным образом, вы можете воспользоваться не только специальными терками, валиками и другими приспособлениями, но и собственно структурной штукатуркой. В состав структурной штукатурки для стен входят различные структурные добавки – «зерна». Они бывают разные по величине, поэтому их называют крупно- или мелкозернистыми. Поверхность, обработанная такими штукатурками, выглядит тоже по- разному. Если штукатурка была мелкозернистой, то поверхность почти ровная. Крупнозернистая создает более объемный рисунок. Он может выглядеть как поперечные или же продольные круглые бороздки. Такой рисунок бывает разным, потому что наносить штукатурку тоже можно по-разному: валиком, шпателем и даже распылителем. В продаже структурная штукатурка всегда белая, но вы легко можете это исправить. Во- первых вы можете просто купить пигмент нужного вам цвета и добавить его в домашних условиях. Только нужно быть очень осторожным и не добавить его слишком много. А во-вторых- вы можете сделать профессиональную колеровку в магазинах, которые занимаются продажей штукатурки и пигмента.
У структурных штукатурок есть очень много плюсов :
- Ими можно оштукатурить любые поверхности, будь то кирпич, дерево, гипсокартон и т.д.
- Ими хорошо скрывать недостатки поверхности, если на последней, например, есть какие-либо трещины или вздутия.
- Структурные штукатурки водонепроницаемы. Это значит, что их можно мыть.
- Они выдерживаю очень большой диапазон температур- от -50 до + 50С.
- Так как они пористые, то стены могут «дышать».
- Они устойчивы к механическим воздействиям.
- Немалый плюс их цена. Из всех декоративных они наиболее доступны.
- Они долговечны.
- Они высокопластичны и позволяют создавать различные рельефы.
Нанесение декоративных штукатурок
Подготовка стены. Как и для любой штукатурки ,поверхность должна быть сухой и чистой, но зато она не обязательно должна быть идеально ровной, ведь штукатурка сама выровняет поверхность за счет своей рельефности. Конечно, больших углублений, как и выступов, быть не должно. Грунтование можно производить абсолютно любыми грунтовочными растворами. Нанесение штукатурки. Наносить штукатурку нужно лишь после того, как подсохла грунтовка. Наносить её можно разными способами и инструментами, все зависит от того, какая поверхность вам нужна. Чтобы увидеть на стене расцарапанные бороздки вы должны взять мелкозернистую штукатурку с добавлением гранул натурального камня либо просто крупного зерна. Наносить лучше фактурным валиком. Если вы хотите, чтобы стена выглядела как натуральный камень, то наносите крупнозернистую штукатурку круговыми движениями шпателя.
«Венецианская» штукатурка
Одним из видов декоративной штукатурки является Венецианская штукатурка она принципиально отличается от всех, которые мы здесь описывали раньше. Чтобы получить желаемый эффект, мало просто нанести раствор на поверхность, обязательно надо сделать это правильно. В состав этой штукатурки входит мраморная мука, гашеная известь и водная эмульсия. Когда смотришь на покрытие, обработанное «венецианской» штукатуркой, то кажется, что оно сделано из прозрачного мрамора. «Венецианской» штукатуркой украшают колонны, карнизы. Но, чтобы сотворить такое чудо, надо действительно быть мастером своего дела. Найти «венецианскую» штукатурку в продаже можно уже в готовом жидком виде. Она продается в банках либо ведерках. Наносить её нужно на идеально ровную, чистую поверхность. Не забудьте, что этот материал прозрачный, поэтому все погрешности поверхности будут видны как на ладони. Эту штукатурку тоже можно колеровать любым цветом, но профессионалы советуют смешивать несколько оттенков одного цвета. Так поверхность будет еще лучше и будет больше похожа на мрамор.
Чтобы добиться нужной прозрачности и глубины покрытия, надо нанести от 4 до 10 слоев штукатурки. Наносится она по специальной технике, маленькими штришками треугольным шпателем либо же специальными кельмами. (рис.33) После того, как стена высохнет, её надо покрыть натуральным пчелиным воском. Это делается для того, чтобы защитить покрытие. Воск абсолютно прозрачный и на цвет не влияет. Правда, в продаже есть и такая «венецианская» штукатурка, которую ничем покрывать не надо. В её состав уже все включено.
У «венецианской «штукатурки есть свои преимущества:
- Существует большая палитра цветов;
- Она обладает эффектом мраморной поверхности
- С её помощью можно создавать «мраморные» Эффект мозаики
- Она водонепроницаема. Её можно мыть и чистить не боясь, что она растворится.
Этапы нанесения
Подготовка поверхности. Поверхность должна быть идеальной во всех отношениях. На ней не должно быть никаких неровностей, никакой грязи и пыли. Она обязательно должна быть сухой. После того, как это условие выполнено, вы наносите несколько слоев специальной грунтовки. Можете нанести вместо грунтовки один слой виниловой (акриловой) краски.
Нанесение «венецианской» штукатурки. Вы можете начинать к работе сразу же, как увидите, что грунтовочный слой высох. Эта работа очень щепетильная. Покрытие наносят очень аккуратно при помощи шпателя. Большие штрихи можно наносить кельмами. Чтобы не было неровностей, каждому слою дают высохнуть и после этого его зачищают. Первые слои вы можете наносить широким, а последние лучше всего наносить узким шпателем. Примерно через 20 минут после того, как вы нанесли последний слой, вы можете начинать зачищать поверхность. Делать это лучше всего мелкой наждачной бумагой круговыми движениями. Не стоит применять лаки при работе с «венецианской» штукатуркой, так как от них поверхность может помутнеть и штукатурка потеряет свое основное преимущество — красивую прозрачность.
Цветная штукатурка «каменная крошка»
Каменная крошка это настоящие мелкие камушки, которые перемешиваются с клеящими и связующими материалами. Каменная крошка может быть разноцветной, но в любом случае каждый цвет состоит из нескольких оттенков. Каменная крошка наносится шпателем на поверхность и разравнивается по ней равномерно. Если вы собираетесь отделывать фасад, то вам лучше взять крупную каменную крошку, в особенности для отделки цоколя. Если же вам предстоят внутренние работы, лучше возьмите мелкую крошку. Существует кварцевая, мраморная и гранитная крошка. Каменная крошка отлично переносит любые погодные явления.
Хотя это покрытие и считается тяжелым, так как включает в себя вкрапления натуральных камней, но имеет все же ряд преимуществ:
- Она особенно хорошо выносит любые механические воздействия.
- Гидро-, жаро- и морозоустойчива.
- Очень долговечна.
- Её можно наносить на бетон и пенобетон.
- Отлично скрывает любые неровности поверхности.
- За счет пористости позволяет «дышать» поверхности, на которую наносится.
Этапы нанесения
Подготовка поверхности . Как всегда стена должна быть чистой и сухой.
Грунтование . При грунтовке можно использовать любую краску.
Нанесение цветной каменной крошки . Чтобы масса была не такой густой и проще наносилась, вы можете добавить в неё немножко воды. Потом очень хорошо перемешайте массу. Наносить крошку лучше набрасывая на стену и размазывая движениями сверху вниз. Шпателем снимайте излишки массы. Имейте ввиду, что крошка может стираться, поэтому не стоит водить по ней шпателем больше 2 раз. Сохнет оштукатуренная поверхность не менее 6 часов.
Нанесение лака . По истечении двух недель вы можете покрыть поверхность лаком. Это сохранит крошку более яркой в течение долгого времени.
Штукатурка для печи. Составы растворов
Несмотря на то, что сейчас в большинстве домов есть централизованное отопление, существует до сих пор спрос на кладку печей. Во-первых они все же часто встречаются в деревнях, во-вторых — часто дома украшаются каминами. Так как поверхность печей особая, то оштукатуривание печей связано со специальной технологией. Эта штукатурка должна выдерживать достаточно высокие температуры. Ниже мы приводим составы, которые можно применять при оштукатуривания печи .
- Одна часть гипса, две части известкового теста, одна часть песка, 0,2 части асбеста № 6-7.
- Одна часть глины, одна часть известкового теста, две части песка, 0,1 части асбеста № 6-7.
- Одна часть глины, две части песка, 0,1 ча¬сти асбеста № 6—7.
- Одна часть глины, одна часть цемента, две части песка, 0,1 части асбеста № 6-7.
Все сухие компоненты нужно смешать между собой и после этого добавить воды. Смесь должна получиться достаточно густой. Асбест добавляется для придания штукатурке прочности.
Смотрите также по данной теме:
Статья » Декоративная штукатурка: создаем шедевры «.
«Мир Красок» — это торговая сеть, объединяющая более 60 торговых точек по продаже лакокрасочных материалов и сопутствующих товаров, а так же интернет магазин с возможностью доставки по Москве и Московской области. У нас Вы всегда можете купить декоративную штукатурку .
Что это за слово? Используйте Word Type, чтобы узнать!
К сожалению, с текущей базой данных, в которой работает этот сайт, у меня нет данных о том, какие значения ~ term ~ используются чаще всего. У меня есть идеи, как это исправить, но мне нужно найти источник «чувственных» частот. Надеюсь, выше приведено достаточно информации, чтобы помочь вам понять часть речи ~ term ~ и угадать его наиболее распространенное использование.
Тип слова
Для тех, кто интересуется небольшой информацией об этом сайте: это побочный проект, который я разработал во время работы над описанием слов и связанных слов.Оба этих проекта основаны на словах, но преследуют гораздо более грандиозные цели. У меня была идея для веб-сайта, который просто объясняет типы слов в словах, которые вы ищете — точно так же, как словарь, но сосредоточенный на части речи слов. И так как у меня уже была большая часть инфраструктуры с двух других сайтов, я подумал, что для ее запуска и работы не потребуется много работы.
Словарь основан на замечательном проекте Wiktionary от Викимедиа.Сначала я начал с WordNet, но затем понял, что в нем не хватает многих типов слов / лемм (определителей, местоимений, сокращений и многого другого). Это побудило меня исследовать словарь Вебстера издания 1913 года, который сейчас находится в открытом доступе. Однако после целого дня работы над его преобразованием в базу данных я понял, что было слишком много ошибок (особенно с тегами части речи), чтобы это было жизнеспособным для Word Type.
Наконец, я вернулся к Викисловарь, о котором я уже знал, но избегал, потому что он неправильно структурирован для синтаксического анализа.Именно тогда я наткнулся на проект UBY — удивительный проект, который требует большего признания. Исследователи проанализировали весь Викисловарь и другие источники и собрали все в единый унифицированный ресурс. Я просто извлек записи из Викисловаря и закинул их в этот интерфейс! Так что работы потребовалось немного больше, чем ожидалось, но я счастлив, что продолжил работать после пары первых промахов.
Особая благодарность разработчикам открытого исходного кода, который использовался в этом проекте: проекту UBY (упомянутому выше), @mongodb и express.js.
В настоящее время это основано на версии викисловаря, которой несколько лет. Я планирую в ближайшее время обновить его до более новой версии, и это обновление должно внести множество новых смысловых значений для многих слов (или, точнее, леммы).
Яйцо устаревшее! — Схема КУРИЦЫ вики
Яйцо устаревшее!
Это яйцо для CHICKEN 4, неподдерживаемой старой версии. Вы почти наверняка ищете версию этого яйца для КУРИЦЫ 5, если она существует.
Если он не существует, может быть эквивалентная функциональность, предоставляемая другим яйцом; взгляните на индекс яиц. В противном случае рассмотрите возможность переноса этого яйца на текущую версию CHICKEN.
ссылка-грамматика
Привязки для системы синтаксического анализа грамматики ссылок CMU.
Ссылка на грамматику
Синтаксический анализатор грамматики ссылок — это синтаксический анализатор английского языка, основанный на грамматике ссылок, оригинальной теории синтаксиса английского языка. Данному предложению система присваивает ему синтаксическую структуру, которая состоит из набора помеченных ссылок, соединяющих пары слов.Синтаксический анализатор также производит «составное» представление предложения (показывая словосочетания с существительными, словосочетания глаголов и т. Д.).
Автор
Дэвид Айрленд (djireland79, gmail dot com)
Восходящий поток
https://www.abisource.com/projects/link-grammar/
Исходный код яйца
https://gitlab.com/maxwell79/chicken-link-grammar
ссылка-грамматика
[модуль] грамматика ссылок
Документация
Пример использования
(импортная схема)
(cond-expand
(курица-4
(используйте (prefix link-grammar lg :)))
(курица-5
(импорт (префикс ссылка-грамматика lg :))))
( определить (предложение отображения-связи выбирает индекс)
( let * ((ссылки найдены (lg: предложение найдено ссылок))
(linkage (lg: предложение индекса create-linkage opts)))
(при увязке
( лет ((составляющие
(lg: get-constituents linkage lg: display-multi-line))
(диаграмма (lg: get-diagram linkage #t 80)))
(печатные составляющие)
(распечатать схему)
(lg: delete-linkage! ссылка)))
(когда (<= index links-found) (предложение display-linkage opts (+ index 1)))))
( определить (варианты синтаксического анализа текстового словаря)
( let * ((предложение (lg: текстовый словарь для создания предложений))
(num-linkages (lg: выбор предложения синтаксического анализа)))
(когда (= число-ссылок 0)
(lg: set-min-null-count! вариант 1)
(lg: set-max-null-count! opts (lg: предложение длиной в предложение))
(set! num-linkages (lg: выбор предложения синтаксического анализа)))
(предложение display-linkage выбирает 0)
(lg: удалить-предложение! предложение)))
( определить словарь (lg: create-default-dictionary))
( определяют опций (lg: init-opts))
(lg: set-linkage-limit! opts 1000)
(lg: set-short-length! opts 10)
(lg: set-verbosity! opts 1)
(lg: set-max-parse-time! варианты 30)
(lg: set-linkage-limit! opts 1000)
(lg: set-min-null-count! вариант 0)
(lg: set-max-null-count! вариант 0)
(lg: set-short-length! opts 16)
(lg: set-Islands-ok! opts #f)
(синтаксический анализ словаря "Черная лисица убежала от охотников")
(lg: параметры удаления-синтаксического анализа! оптс)
(LG: удалить-словарь! словарь) (S (НП черный.лиса.n)
(В.П. ран.в-д
(ПП от
(Н.П. Охотники.н)))) + ------------------------ Xp ----------------------- - + + -----------> WV -----------> + | + --------- Wd -------- + | | | + ---- Ds ** x --- + | + ---- Jp ---- + | | | + --- A - + - Ss - + - MVp- + + - Dmc- + + - RW - + | | | | | | | | | | ЛЕВАЯ СТЕНКА черная.лиса.н. бежал.в-д от охотников.н. ПРАВАЯ СТЕНКА
(S (НП черн.а лисица)
(В.П. ран.в-д
(ПП от
(Н.П. Охотники.н)))) + ------------------------ Xp ----------------------- - + + --------- Wd -------- + | | + ---- Ds ** x --- + + ---- Jp ---- + | | | + --- A - + - Ss - + - MVp- + + - Dmc- + + - RW - + | | | | | | | | | | ЛЕВАЯ СТЕНКА черная. Лиса.п ран.в-д от охотников.п. ПРАВАЯ СТЕНКА
Простое использование
Анализировать текст с использованием значений по умолчанию для словаря и парсера
parse-with-default
[procedure] (parse-with-default text) → (значения слов ссылки схем постскриптум)Анализировать текст с использованием значений по умолчанию
- текст
- строка для синтаксического анализа
предложений
Предложение — это представление входной строки в API, размеченное и интерпретируемое согласно определенному Словарю.После создания и анализа предложения можно получить различные атрибуты результирующего набора связей.
создать предложение
[процедура] (словарь ввода создания предложения) → предложениесоздает объект предложения из входной строки, используя словарь, который был создан ранее для токенизации и определения слов
- ввод
- Входная строка (строка)
- словарь
- словарь для использования
удалить предложение!
[процедура] (удалить предложение! Предложение) → не указаноУдаляет конкретное предложение
- предложение
- Исключить (приговор)
разделенное предложение
[процедура] (варианты синтаксического анализа разделенного предложения) → числоРазбивает (токенизирует) предложение на составляющие слова и знаки препинания.Это включает в себя разделение некоторых дополнительных выражений, таких как «12 футов». который разделен на «12» и «футы». Если в opts включено угадывание орфографии, токенизатор также разделит большинство повторных слов, то есть пары слов без промежуточного пробела. Эта процедура возвращает ноль в случае успеха; иначе ненулевое значение, если произошла ошибка.
- предложение
- Приговор к разделению (приговор)
- параметры синтаксического анализа
синтаксический анализ предложения
[процедура] (синтаксический анализ предложения варианты синтаксического анализа) → числоЭта процедура представляет собой сердце программы.При синтаксическом анализе предложения выполняется несколько действий: 1. Словарные выражения извлекаются из словаря и сокращаются. 2. Строятся дизъюнкты. 3. Выполняется ряд операций по обрезке. 4. Подсчитываются ссылки, имеющие минимальное количество нулевых ссылок. 5. Создается «набор для анализа» связей. 6. Связи проходят постобработку.
«Набор синтаксического анализа» прикреплен к предложению, и это одна из ключевых причин гибкости и модульности API. Вся необходимая информация для построения связей хранится в наборе синтаксического анализа.Это означает, что другие предложения могут быть проанализированы, возможно, с использованием других словарей и других параметров, не нарушая при этом информацию, полученную в результате обращения к запросу предложения_parse. Если другой вызов синтаксического анализа предложения сделан для того же предложения, информация синтаксического анализа для предыдущего вызова удаляется. Как и почти все другие подпрограммы, этот вызов является потокобезопасным: то есть предложения могут анализироваться одновременно в нескольких потоках.
- предложение
- параметры синтаксического анализа
длина предложения
[процедура] (предложение длины предложения) → числоВозвращает длину предложения
- предложение
предложение-нулевой счет
[процедура] (нулевое предложение-счет) → числоВозвращает количество слов, которые не удалось связать с остальной частью предложения во время синтаксического анализа.Это число больше нуля, когда кажется, что слово не помещается ни в одном месте синтаксического анализа, либо из-за плохой грамматики, либо из-за недостатка словаря.
найденных связей
[процедура] (найденных связей) → номерВозвращает количество ссылок, найденных поиском
действительные ссылки
[процедура] (действительные ссылки) → номерВозвращает количество ссылок, в которых не было нарушений при постобработке.
ссылок — после обработки
[процедура] (ссылки — после обработки) → номерВозвращает количество ссылок, которые были фактически обработаны после обработки.
связи нарушены
[процедура] (связи нарушены) → номерВозвращает количество нарушений постобработки в i-й связи
во время последнего обращения к предложению_parse.
предложение-дизъюнкция-стоимость
[процедура] (индекс предложения-дизъюнкция-стоимость предложения) → числоВозвращает сумму всех затрат на все дизъюнкты, использованные в i-й связи предложения. Чем выше стоимость, тем меньше вероятность правильного анализа. Очень грубо это можно интерпретировать так, как если бы это было (минус) логарифмической вероятностью правильности синтаксического анализа.
- предложение Индекс
предложение-ссылка-стоимость
[процедура] (индекс предложения-ссылка-стоимость предложения) → числоВозвращает сумму длин ссылок в i-м синтаксическом анализе.Отношение этой длины к общей длине предложения дает приблизительную оценку сложности предложения. То есть наличие дальних связей между далекими словами указывает на то, что предложение может быть трудным для понимания; альтернативно, это может указывать на то, что анализ не очень точен.
- предложение Индекс
Словарь
Словарь — это указатель программиста на набор определений слов, определяющих грамматику. Пользователь создает словарь из файла грамматики и файла знаний пост-обработки, а затем передает его различным процедурам синтаксического анализа.
создать словарь с языком
[процедура] (создать словарь с языком) → словарьСоздает словарь с указанным языком
- язык
- Используемый язык (строка)
создать словарь по умолчанию
[процедура] (создать словарь по умолчанию) → словарьИщет словарь на том же языке, что и текущая среда, и, если он найден, создает объект словаря.
получить-словарь-язык
[процедура] (получить-словарь-язык-словарь) → строкаВозвращает язык указанного словаря
- словарь
- указанный словарь (словарь)
удалить словарь!
[процедура] (удалить словарь! Словарь) → не указаноУдаляет указанный словарь
- словарь
- указанный словарь (словарь)
набор-словарь-данные-каталог!
[процедура] (путь-каталог-данных-словаря!) → не указанУкажите путь к используемым словарям; чтобы быть эффективной, эта процедура должна вызываться до открытия словарей.
- путь
- Имя файла с путем
get-dictionary-data-dir
[процедура] (get-dictionary-data-dir) → строкаВозвращает путь к файлу словарей
Связи
создание связи
[процедура] (создание связи) → связьЭта функция создает индексную ссылку из отправленного (проанализированного) предложения. С полученной связкой можно выполнить несколько операций; например, его можно распечатать, обработать с помощью другого постпроцессора или извлечь информацию об отдельных ссылках.Если синтаксический анализ имеет соединение, то связь будет состоять из двух или более подсвязок.
удаление ссылки!
[процедура] (удаление-связь! Linakge) → не указаноУдалить указанную связь
- linakge
числовые слова
[процедура] (соединение числовых слов) → числоКоличество слов в предложении, для которых это связь.
- рычажный
num-links
[процедура] (num-linkage) → номерКоличество ссылок, используемых в связи.
- рычажный
длина ссылки
[процедура] (индекс связи длины ссылки) → числоЗначение, возвращаемое процедурой num-links, — это количество слов, охваченных индексной ссылкой ссылки.
- рычажный
- индекс
- (номер)
get-lword
[процедура] (get-lword) → числоВозвращаемое значение — это номер слова на левом конце индексной ссылки текущей подссылки.
get-rword
[процедура] (get-rword) → числоВозвращаемое значение — это номер слова на правом конце индексной ссылки текущей подссылки.
ссылка-метка
[процедура] (индекс ссылки-метки) → строкаМетка ссылки на схеме создается путем «пересечения» левого и правого соединителей, составляющих ссылку. Например, «I.p eat, следовательно I.p think.v» имеет метку Sp * i на связи между словами I.p и eat формируются из соединителя Sp * i в его левом слове и соединителя Sp в правом слове. Итак, в этом примере и link-label, и link-llabel возвращают «Sp * i», а link-rlabel возвращает «Sp» для этой ссылки.
- рычажный Индекс
link-llabel
[процедура] (индекс ссылки link-llabel) → строкаСм. Ссылку на этикетке
- рычажный Индекс
link-rlabel
[процедура] (индекс связи link-rlabel) → строкаСм. Ссылку на этикетке
- рычажный Индекс
num-domains
[процедура] (индекс связи num-доменов) → числоnum-domain, link-domain-names позволяют получить доступ к большей части доменной структуры, извлеченной во время постобработки.Параметр index в первых двух вызовах указывает, для какой ссылки в ссылке требуется извлечь информацию. В приведенном выше примере «Я ем, поэтому я думаю» связь между словами «следовательно» и «I.p» принадлежит двум доменам «m». Если связь нарушает какие-либо правила постобработки, имя нарушенного правила в файле знаний постпроцессора может быть определено с помощью вызова get-abuse-name.
- рычажный Индекс
link-domain-names
[процедура] (link-domain-names link-index) → списокПолучает структуру домена, извлеченную во время постобработки
- рычажный
- индекс слов
- Указывает, для какой ссылки в ссылке требуется извлечь информацию.
get-words
[процедура] (связывание get-слов) → списокВозвращает массив написания слов или написания отдельного слова для связи. Это написания с нижним индексом, например «dog.n». Исходные варианты написания могут быть получены с помощью обращения к предложению-поиску слова.
- рычажный
get-word
[процедура] (число-слово для связи get-word) → строкаВозвращает написание отдельного слова
- рычажный
- слово-номер
- Специфическое слово
disjunct-str
[процедура] (номер-слово связи ссылки disjunct-str) → строкаВозвращает строку, показывающую дизъюнкты, которые фактически использовались в связи с указанным словом в текущей связи.Строка показывает дизъюнкты в правильном порядке; то есть слева направо в том порядке, в котором они ссылаются на другие слова. Возвращенную строку можно рассматривать как очень точную метку, подобную части речи, для слова, указывающую, как оно было использовано в данном предложении; это может быть полезно для статистики корпуса.
- рычажный
- Удельная связь
- рычажный
- слово-номер
- Специфическое слово
стоимость дизъюнкции
[процедура] (стоимость дизъюнкции) → числоВозвращает стоимость слова, используемого в конкретной связи, на основе
в словаре.
disjunct-corpus-score
[procedure] (disjunct-corpus-score) → числоВозвращает стоимость на основе базы данных статистики корпуса.
get-constituents
[процедура] (стиль отображения связи get-constituents) → строкаВозвращает составляющие для конкретной связи
- рычажный
- в стиле дисплея
- (номер
get-diagram
[procedure] (get-diagram linkage display-wall? Screen-width) → строкаВозвращает схему соединений
- рычажный
- витрин?
- Логическое значение, указывающее, следует ли печатать слова на стене и соединительные элементы с ними.
- ширина экрана
- Ширина экрана — целое число, указывающее количество столбцов, которые следует использовать во время печати; длинные предложения, ширина которых превышает количество столбцов, автоматически переносятся так, чтобы они всегда умещались.
get-postscript
[процедура] (get-postscript связывает экранные стены? Print-ps-header?) → строкаВозвращает макросы, необходимые для распечатки связи в файле postscript.
- рычажный
- витрин?
- Логическое значение, указывающее, следует ли печатать слова на стене и соединительные элементы с ними.
- print-ps-header?
- Логическое значение, указывающее, следует ли включать шаблон заголовка postscript.
get-disjuncts
[процедура] (связывание get-disjuncts) → строкаВозвращает строку, которая показывает все дизъюнкты и их стоимость, которые использовались для создания связи.
- рычажный
get-links-domains
[процедура] (связывание get-links-domains) → строкаВозвращает строку, в которой перечислены все ссылки и доменные имена для связи.
- рычажный
стоимость неиспользуемого слова
[процедура] (связь стоимости неиспользованного слова) → номерДолжен возвращать то же значение, что и счет-нулевого предложения.
- рычажный
дизъюнкт-стоимость
[процедура] (связь дизъюнкт-стоимость) → числоДолжен возвращать то же значение, что и предложение-дизъюнкт-стоимость.
- рычажный
стоимость ссылки
[процедура] (привязка стоимости ссылки) → номерДолжен возвращать то же значение, что и цена-ссылка-предложение.
- рычажный
corpus-cost
[процедура] (связь corpus-cost) → номерВозвращает общую стоимость этой конкретной связи, основанную на стоимости дизъюнктов, хранящихся в базе данных corpus-statistics.
- рычажный
ссылка-> eps-файл
[процедура] (ссылка-> eps-файл имя файла postscript) → не указаноСохраняет ссылку на файл postscript
- путь
- имя файла
- постскриптум
- Строка PostScript
get-version
[процедура] (get-version) → строкаПолучает версию грамматики ссылок
get-dictionary-version
[процедура] (get-dictionary-version словарь) → строкаПолучает версию словаря
- словарь
- Словарь
get-Dictionary-locale
[процедура] (get-dictionary-locale) → строкаПолучает языковой стандарт словаря
отключение дисплея
[постоянно] отключение дисплея → 0Отключить дисплей
многострочный дисплей
[постоянный] многострочный дисплей → 1Распечатать диаграмму в несколько строк
дерево скобок дисплея
[константа] дерево скобок дисплея → 2Используйте скобки при печати диаграммы
однострочный дисплей
[постоянный] однострочный дисплей → 3Распечатать диаграмму в одну строку
display-max-styles
[константа] display-max-styles → 3Распечатать диаграмму в одну строку
набор-дисплей-морфология!
[процедура] (set-display-morphology! Значение parse-options) → не указаноУстанавливает морфологию отображения в параметрах синтаксического анализа
- параметры синтаксического анализа
- значение
- (номер)
get-display-morphology
[процедура] (параметры синтаксического анализа get-display-morphology) → числоПолучает значение морфологии отображения
- параметры синтаксического анализа
Параметры синтаксического анализа
Опции синтаксического анализа определяют различные параметры, которые используются для синтаксического анализа предложений.Примеры того, что контролируется параметрами синтаксического анализа, включают максимальное время синтаксического анализа и память, использование нулевых ссылок и использование режима «паники». Эта структура данных передается в различные процедуры синтаксического анализа и печати вместе с предложением.
Значение по умолчанию для элементов parse-option:
многословие → 0
лимит связи → 10000
мин-нулевой счет → 0
максимальное количество нулей → 0
нулевой блок → 1
острова-ок → #f
короткие → 6
полностью короткие → #f
дисплей-короткий → #t
индексов отображаемых слов → #t
отображать-ссылки-индексы → #t
витрины → #f
allow-null → #t
эхо-сигнал → #f
пакетный режим → #f
режим паники → #f
ширина экрана → 79
отображение → #t
дисплей-постскриптум → #f
плохой дисплей → #f
отображаемых ссылок → #f
init-opts
[процедура] (init-opts) → параметры синтаксического анализаИнициализировать параметры синтаксического анализа до значений по умолчанию
set-max-parse-time!
[процедура] (set-max-parse-time! Значение parse-options) → не указаноУстановить максимальное время синтаксического анализа
- параметры синтаксического анализа
- значение
- (номер)
set-linkage-limit!
[процедура] (set-linkage-limit! Parse-options linkage-limit) → не указаноУстановить предел сцепления
- параметры синтаксического анализа
- предел сцепления
- (номер)
комплект короткой длины!
[процедура] (set-short-length! Parse-options short-length) → не указаноПараметр short_length определяет допустимую длину ссылок.Предполагаемое использование этого — ускорить синтаксический анализ, не учитывая очень длинные ссылки для большинства соединителей, поскольку они очень редко используются при правильном синтаксическом анализе. Запись для UNLIMITED-CONNECTORS в словаре будет указывать, какие соединители освобождены от ограничения длины.
- параметры синтаксического анализа
- короткое
- (номер)
set-disjunct-cost!
[процедура] (set-disjunct-cost! Parse-options disjunt-cost) → не указаноОпределяет максимальную стоимость дизъюнкции, используемую во время синтаксического анализа, где стоимость дизъюнкции равна максимальной стоимости всех его соединителей.По умолчанию учитываются только дизъюнкты стоимостью до 2,9.
- параметры синтаксического анализа
- дизъюнт-стоимость
set-min-null-count!
[процедура] (set-min-null-count! Parse-options null-count) → не указаноПри синтаксическом анализе предложения синтаксический анализатор найдет все решения, имеющие минимальное количество нулевых ссылок. Он выполняет поиск в диапазоне счетчиков нулевых ссылок между min_null_count и max_null_count. По умолчанию минимальное и максимальное количество пустых ссылок равно 0, поэтому пустые ссылки не используются.
- параметры синтаксического анализа
- нулевой счет
set-max-null-count!
[процедура] (set-max-null-count! Parse-options null-count) → не указаноПри синтаксическом анализе предложения синтаксический анализатор найдет все решения, имеющие минимальное количество нулевых ссылок. Он выполняет поиск в диапазоне счетчиков нулевых ссылок между min-null-count и max-null-count. По умолчанию минимальное и максимальное количество пустых ссылок равно 0, поэтому пустые ссылки не используются.
- параметры синтаксического анализа
- нулевой счет
ресет-ресурсов!
[процедура] (reset-resources! Parse-options) → не указаноСбросить полученные ресурсы
- параметры синтаксического анализа
-исчерпаны?
[процедура] (ресурсы исчерпаны? Параметры синтаксического анализа) → логическоеResources_exhausted означает исчерпание памяти? ИЛИ истек срок действия таймера?
- параметры синтаксического анализа
память исчерпана?
[процедура] (исчерпана память? Параметры синтаксического анализа) → числоПроверяет, не была ли исчерпана память при разборе
- параметры синтаксического анализа
истек срок действия таймера?
[процедура] (истек срок действия таймера? Parse-options) → номерПроверяет, не превышен ли таймер во время синтаксического анализа.
- параметры синтаксического анализа
набор-острова-ок!
[процедура] (set-Islands-ok! Parse-options Islands-ok?) → не указаноЭта опция определяет, разрешены ли «островки» ссылок.
- параметры синтаксического анализа
- островов — ок?
- Логическое значение, указывающее, разрешены ли острова
набор-многословие!
[процедура] (set-verbosity! Parse-options verbosity-level) → не указаноУстанавливает / получает уровень описания, выводимого на stderr / stdout о процессе синтаксического анализа.
- параметры синтаксического анализа
- уровень детализации
get-verbosity
[procedure] (get-verbosity-options) → числоПолучить уровень детализации
- параметры синтаксического анализа
параметры удаления-синтаксического анализа!
[процедура] (delete-parse-options! Parse-options) → числоУдалить объект опции синтаксического анализа
- параметры синтаксического анализа
Лицензия
Это бесплатное программное обеспечение; вы можете распространять и / или изменять его в соответствии с условиями Стандартной общественной лицензии ограниченного применения GNU, опубликованной Free Software Foundation; либо версии 2 Лицензии, либо (по вашему выбору) любой более поздней версии.
Эта программа распространяется в надежде, что она будет полезной, но БЕЗ КАКИХ-ЛИБО ГАРАНТИЙ; даже без подразумеваемой гарантии ТОВАРНОЙ ПРИГОДНОСТИ или ПРИГОДНОСТИ ДЛЯ КОНКРЕТНОЙ ЦЕЛИ. Подробнее см. Стандартную общественную лицензию GNU.
Вы должны были получить копию Стандартной общественной лицензии GNU вместе с этой программой; в противном случае напишите в Free Software Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
Об этом яйце
Автор
Дэвид Ирландия
Репозиторий
https: // gitlab.com / maxwell79 / курица-ссылка-грамматика
Лицензия
LGPL-2.1
Зависимости
Версии
- 1,6
Колофон
Документировано hahn.
Гибкое тестирование: простой синтаксический анализ с помощью pyparsing
Если вы еще не использовали модуль pyparsing Пола Макгуайра, вы упустили отличный инструмент. Всякий раз, когда вы ударяетесь о стену, пытаясь разобрать текст с помощью регулярных выражений или строковых операций, подумайте о пипарсинге. Мне нужно было проанализировать файл конфигурации балансировщика нагрузки и сохранить определенные значения в базе данных.Большинство необходимых мне вещей было довольно легко получить с помощью регулярных выражений или строковых операций Python. Однако я был озадачен, когда наткнулся на такую строку, как:
bind http "Сервер клиента 1" http "Сервер клиента 2" http
Эта строка «связывает» порт «виртуального сервера» с одним или несколькими » реальных серверов ‘и их порты (здесь я использую жаргон этого конкретного балансировщика нагрузки, но концепции одинаковы для всех балансировщиков нагрузки).
Синтаксис: «привязка», за которым следует слово, обозначающее порт виртуального сервера, за которым следует один или несколько пар реальных имен серверов и портов.Кикер состоит в том, что настоящие имена серверов могут быть либо одним словом без пробелов, либо несколькими словами, заключенными в двойные кавычки.
Разделение строки пробелами или двойными кавычками в этом случае не является решением. Я начал с прокрутки моего собственного небольшого алгоритма и отслеживания того, где я нахожусь внутри строки, затем я понял, что на самом деле сейчас пишу свой собственный анализатор. Пора заняться пипарсингом.
Я не буду вдаваться в подробности того, как использовать pyparsing, поскольку существует отличная документация (см. Презентацию Paul PyCon06, примеры на сайте pyparsing, а также книгу Paul O’Reilly Shortcut).По сути, вам нужно определить грамматику для выражения, которое нужно проанализировать, а затем перевести его в конструкции, специфичные для pyparsing. Поскольку API-интерфейс pyparsing настолько интуитивно понятен и эффективен, процесс перевода прост.
Вот как я реализовал свою грамматику pyparsing:
from pyparsing import *def parse_bind_line (line):
quoted_real_server = dblQuotedString.setParseAction (removeQuotes)
alphasserver = Word quoted_real_server
port = Word (alphanums)
real_server_port = Group (real_server + port)
bind_expr = Suppress (Literal ("bind")) + \
port + \
OneOrMore (real_server_port)
return bind_expr.parseString (line)
Вот и все. Вам нужно прочитать его снизу вверх, чтобы увидеть, как выражение раскладывается на элементы, а элементы раскладываются на подэлементы.
Я объясню каждую строку, начиная с последней перед возвратом:
bind_expr = Suppress (Literal ("bind")) + \
port + \
OneOrMore (real_server_port)
Запуск выражения привязки с буквальным «bind», за которым следует порт, за которым следует одна или несколько реальных пар сервер / порт.Это в значительной степени то, что на самом деле говорит строка выше, не так ли. Конструкция Suppress сообщает pyparsing, что мы не заинтересованы в возвращении буквального «bind» в окончательном списке токенов.
real_server_port = Группа (real_server + port)
Настоящая пара сервер / порт — это просто имя реального сервера, за которым следует порт. Конструкция Group сообщает pyparsing, что мы хотим сгруппировать эти 2 токена в список внутри окончательного списка токенов.
порт = Word (буквенные символы)
Порт — это слово, состоящее из буквенно-цифровых символов.В общем, слово означает «последовательность символов, не содержащую пробелов». Переменная alphanums — это специальная переменная синтаксического анализа, уже содержащая список буквенно-цифровых символов.
real_server = Word (альфа, печатные формы) | quoted_real_server
Настоящий сервер — это либо отдельное слово, либо выражение в кавычках. Обратите внимание, что мы можем объявить парсирующий Word с двумя аргументами; 1-й аргумент определяет разрешенные символы для начального символа слова, тогда как 2-й аргумент определяет разрешенные символы для тела слова.В этом случае мы говорим, что хотим, чтобы настоящее имя сервера начиналось с алфавитного символа, но кроме этого оно может содержать любой печатный символ.
quoted_real_server = dblQuotedString.setParseAction (removeQuotes)
Вот где вы можете увидеть мощь pyparsing. С помощью этого единственного оператора мы анализируем последовательность слов, заключенных в двойные кавычки, и говорим, что нас не интересуют кавычки. Также существует класс sglQuotedString для слов, заключенных в одинарные кавычки.Спасибо Полу за то, что обратил на это мое внимание. Моя неуклюжая попытка вручную объявить последовательность слов, заключенных в двойные кавычки, выглядела примерно так:
no_quote_word = Word (alphanums + "-.")
quoted_real_server = Suppress (Literal ("\" ")) + \
OneOrMore (no_quote_word ) + \
Подавить (Literal ("\" "))
quoted_real_server.setParseAction (лямбда-токены:" ".join (tokens))
Единственная полезная вещь, которую вы можете убрать из этой болтовни, — это то, что вы можете связать действие с каждым токеном.Когда pyparsing обнаружит этот токен, он применит действие (функцию или класс), которое вы указали для этого токена. Это полезно для проверки ваших токенов, например, для свидания. Очень мощная штука.
Теперь пора протестировать мою функцию на нескольких строках:
if __name__ == "__main__":
tests = "" "\
bind http" Сервер клиента 1 "http" Сервер клиента 2 "http
bind http «Сервер клиента - 11» 81 «Сервер клиента 12» 82
привязать http www.mywebsite.com-server1 http www.mywebsite.com-server2 http
bind ssl www.mywebsite.com-server1 ssl www.mywebsite.com-server2 ssl
bind http TEST-server http
bind http MY-cluster-web11 83 MY-cluster -web-12 83
bind http cust1-server1.site.com http cust1-server2.site.com http
"" ".splitlines ()для t в тестах:
печать parse_bind_line (t)
Запуск приведенный выше код дает следующий результат:
$ ./parse_bind.py
['http', ['Клиентский сервер 1', 'http'], ['Клиентский сервер 2', 'http']]
['http' , ['Сервер клиента - 11', '81'], ['Сервер клиента 12', '82']]
['http', ['www.mywebsite.com-server1 ',' http '], [' www.mywebsite.com-server2 ',' http ']]
[' ssl ', [' www.mywebsite.com-server1 ',' ssl '], ['www.mywebsite.com-server2', 'ssl']]
['http', ['ТЕСТ-сервер', 'http']]
['http', ['MY-cluster-web11', ' 83 '], [' MY-cluster-web-12 ',' 83 ']]
[' http ', [' cust1-server1.site.com ',' http '], [' cust1-server2.site. com ',' http ']]
Отсюда я смог быстро идентифицировать для данного виртуального сервера все, что мне было нужно: порт виртуального сервера и все пары реальных сервер / порт, связанные с ним.Вставка всего этого в базу данных была еще одним шагом. Тяжелая работа уже была проделана посредством pyparsing.
Еще раз благодарим Пола Макгуайра за создание такого полезного и увлекательного инструмента.
DM4 §36: Анализ неанглийских языков
§36 Разбор неанглийских языков
Это , черт возьми. У нее было Те .
— Дороти Паркер (1893–1967), рецензирование романтического романа ‘ It ’
Прежде чем приступить к работе над файлом определения нового языка, переводчик может захотеть обдумать, на какие компромиссы стоит пойти, опуская сложные но не совсем необходимые особенности языка.Например, в немецком языке прилагательные принимают форму в соответствии с тем, принимает ли их существительное определенный или неопределенный артикль:
ein großer Mann высокий мужчина (немецкий)
der große Mann высокий мужчина
Это очень важно. Но у немецкого есть и «нейтральный» форма прилагательных, используемых в предложениях типа
Der Mann ist groß Мужчина высокий
Теперь можно утверждать, что если парсер запрашивает Немецкий эквивалент
Кого вы имеете в виду, высокого или низкого?
, то игрок должен иметь возможность ответить «groß».Но это, наверное, не стоит усилий.
Другой пример из немецкого языка: важно ли это для синтаксический анализатор для распознавания команд, помещенных в вежливую форму при обращении кому-нибудь кроме игрока? Например,
фредди, öffne den ofen Фредди, открой духовку
herr krüger, öffnen sie den ofen Мистер Крюгер, откройте духовку
указывают на то, что Фредди — друг, а мистер Крюгер — просто знакомство. У переводчика могут возникнуть проблемы с реализацией это, но в равной степени может не беспокоить, а просто сказать игрокам всегда используйте знакомую форму.Труднее избежать вопроса о том, комп игроку знаком. Обращается ли плеер к компьютеру или главный герой игры? По-английски без разницы, но есть языки, где глагол повелительного наклонения согласуется с полом человека, к которому обращается. Компьютер мужчина? Это все еще мужчина, если главная героиня игры — женщина?
Другой выбор — требовать ли от игрока используйте буквы, отличные от «a» до «z» в клавиатура. Французские читатели привыкли видеть слова, написанные заглавными буквами буквы без диакритических знаков, так что нет необходимости делать плеер типовые акценты.В финском же ‘ä’ и «Ö» значительно отличаются от «а» и ‘o’: «vaara» означает «опасность», но «ваара» означает «неправильный».
Наконец, есть еще диалектные формы. Число 80 «quatre-vingt» на столичном французском языке, «octante» на бельгийском и «huitante» на швейцарском французском. В таких случаях, переводчик может захотеть записать файл определения языка в справляюсь со всеми возможными диалектами. Например, что-то вроде
#ifdef DIALECT_FRANCOPHONE; печать «септанте»; #если не; печать "soixante-dix"; #endif;
позволит использовать тот же файл определения
Бельгийские авторы и члены Французской академии
одинаково.Стандартное определение «English.h»
уже есть такая константа: DIALECT_US , который использует американский
написания, так что если игра Inform определяет
Константа DIALECT_US;
перед включением Parser , затем (для
пример) число 106 будет напечатано словами как «один
сто шесть »вместо« сто шесть ».
▲
Альтернатива — позволить игроку менять диалект во время игры.
и кодировать все варианты написания внутри переменных строк.Ральф
Herrmann’s «German.h» делает это, чтобы позволить
игрок, чтобы выбрать традиционные, реформированные или швейцарско-немецкие соглашения на
использование «ß». Младшие строковые переменные @ 30 и @ 31 каждая из них удерживает либо «ss», либо «ß» для использования
такими словами, как "schlie @ 30t" и "mu @ 31t" .
Организация файлов определения языков
Сам файл определения языка написан на Информируйте, и достаточно читабельно. При этом информируйте: вы можете захотеть копия «англ.h «, чтобы ссылаться на него при чтении остальная часть этого раздела. Он разделен на четыре части:
- Предварительные мероприятия
- Словарь
- Перевод на Informese
- Печать
Для всех языковых определений полезно следуйте порядку и стилю размещения «English.h». Пример, используемый в остальной части раздела, касается разработки определение «French.h».
(I.1) Номер версии и алфавит
Файл должен начинаться следующим образом:
! ================================================== =========
! Файл определения библиотеки Inform: французский
!
! (c) Анджела М.Рога 1996
! -------------------------------------------------- ---------
System_file;
! -------------------------------------------------- ---------
! Часть I. Предварительные сведения.
! -------------------------------------------------- ---------
Постоянный язык
= "Перевод fran @ ccais 961205 от Анджелы М. Хорнс";
(«English.h» определяет константу с именем EnglishNaturalLanguage здесь, но это только для того, чтобы помочь
библиотека сохраняет старый код, работающий с новым парсером: не определяйте
аналогично константе себя.) Обратите внимание на c-cedilla, написанную с использованием escape
символов, @cc , а не ç , что является мерой предосторожности
чтобы быть абсолютно уверенным, что файл будет читаемым на любом
система, даже та, чей набор символов не имеет диакритических знаков
обычным способом.
Следующий ингредиент Части I объявляет акцентированный буквы, которые должны быть «дешевыми» в следующем смысле. Внутри файлов историй словарные слова хранятся с определенным «разрешением». из девяти Z-символов: то есть только первые девять Z-символов являются посмотрел, так что
«хризантема» хранится как «хризантемы»
«хризантемы» хранятся как 'chrysanth'
(Это одна из причин, почему Informese не делает лингвистическое использование окончаний слов.) Нормально без проблем, но к сожалению Z-символы — это не то же самое, что буквы. Буквы «А» до «Z» являются «дешевыми» и принимают только один символ Z каждое, но буквы с ударением, такие как «é», обычно выньте четыре Z-символа. Если ваш перевод будет спрашивать игрок набирает на клавиатуре буквы с диакритическими знаками (что даже на французском перевод делать не нужно: см. выше) разрешение может быть неприемлемо низкий:
«телекарта»
сохраняется как 't @' el '
«телефон» сохраняется как ' t @ 'el'
, так как не хватает даже девяти Z-символов осталось закодировать вторую ‘é’, не говоря уже о ‘c’ или «р», которая будет различать эти два слова.е ‘; ! E-циркумфлекс
(Обратите внимание, что поскольку Z-машина автоматически уменьшает все, что игрок вводит в нижний регистр, нам нужно включить только нижний регистр акцентированные буквы здесь. Также обратите внимание, что есть много других французских буквы с ударением (ï, û и т. д.), но это необычно здесь достаточно неважно.) После внесения этого изменения,
«телекарта»
хранится как 't @' el @ 'ecar'
«телефон» хранится как 't @' el @ 'epho'
, позволяющий правильно соединить телефонную карту и телефон различается парсером.
▲▲
В любом файле истории 78 персонажей из набора ZSCII обозначены
как «дешевый», помещенный в так называемый «алфавит»
Таблица». Один из них обязательно должен быть новой строкой, другой обязательно
двойные кавычки и третьи не могут использоваться, остается 75. Zcharacter перемещает символ ZSCII в таблицу алфавита, выбрасывая символ
который еще не использовался, чтобы уступить дорогу. В качестве альтернативы и при условии
пока никакие символы не использовались, вы можете написать Zcharacter директива, которая устанавливает всю таблицу алфавита.Требуемая форма — это три строки, содержащие 26, 26 и 23
ZSCII символов соответственно. Например:
Zcharacter "abcdefghijklmnopqrstuvwxyz"
"АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЫЭЮЯ"
"0123456789! $ & * ():;., <> @ {386}";
символов в алфавите 1, верхний ряд, занимает только один
Z-символ для печати; символы в алфавитах 2 и 3 занимают два Z-символа
печатать; персонажей, которых нет в таблице, занимают четыре. Обратите внимание, что это предполагает
тот Unicode $ 0386 (греческая заглавная буква Alpha с ударением тонос,
как это бывает) присутствует в ZSCII.Обычно этого не было бы, но
блок кодов символов ZSCII от 155 до 251 настраивается
и, в принципе, может содержать любые символы Юникода по вашему выбору.
По умолчанию, если Inform читает ISO 8859-n (значение переключателя -Cn)
тогда этот блок настроен так, чтобы содержать все буквенные символы, отличные от ASCII
в ISO 8859-n. В наиболее частом случае -C1 для
ISO Latin-1, лигатуры ‘œ’ и ‘’
затем добавляются, но при этом остаются незанятыми 28 символьных кодов.
Z Таблица символов + '@ {9a}'; добавляет символ Unicode $ 009a , авторское право
символ ZSCII.а ‘;
— это то, что ZSCII 155 будет символом авторского права, 156 будет
быть греческой заглавной альфой с тоносом, 157 будет а-циркумфлексом
и 158–251 будут неопределенными; и все другие буквы с диакритическими знаками
будет недоступен. Такие директивы Zcharacter должны
быть сделано до того, как рассматриваемые персонажи впервые будут использованы в игре
текст. В любом случае вам не нужно знать значения ZSCII: вы всегда можете
напишите @ {9a} , если вам нужен символ авторского права.
(I.2) Компасные объекты
Все, что осталось в части I, это объявить стандарт компас направления.Соответствующая часть «English.h», приведенный ниже, следует как можно точнее имитировать:
Класс CompassDirection
со статьей "the", номер
есть декорации;
Объект Компас «компас» скрыл;
Ifndef WITHOUT_DIRECTIONS;
CompassDirection -> n_obj "северная стена"
с именем 'n //' 'северная' 'стена', door_dir n_to;
CompassDirection -> s_obj "южная стена"
с именем 's //' 'южная' 'стена', door_dir s_to;
CompassDirection -> e_obj "восточная стена"
с именем 'e //' 'east' 'wall', door_dir e_to;
CompassDirection -> w_obj "западная стена"
с именем 'w //' 'west' 'wall', door_dir w_to;
CompassDirection -> ne_obj "северо-восточная стена"
с названием 'ne' 'northeast' 'wall', door_dir ne_to;
CompassDirection -> nw_obj "северо-западная стена"
с именем 'nw' 'northwest' 'wall', door_dir nw_to;
CompassDirection -> se_obj "юго-восточная стена"
с именем 'se' southeast '' wall ', door_dir se_to;
CompassDirection -> sw_obj "юго-западная стена"
с именем 'sw' 'southwest' 'wall', door_dir sw_to;
CompassDirection -> u_obj "потолок"
с именем 'u //' 'вверх' 'потолок', door_dir u_to;
CompassDirection -> d_obj "пол"
с именем 'd //' 'down' 'floor', door_dir d_to;
Endif;
CompassDirection -> out_obj "снаружи"
с door_dir out_to;
CompassDirection -> in_obj "внутри"
с door_dir in_to;
Например, «Французский.h «будет содержать:
Класс CompassDirection
с артиклем "ле", номер
есть декорации;
Объект Компас «компас» спрятал;
...
CompassDirection -> n_obj "мур норд"
с именем 'n //' 'nord' 'mur', door_dir n_to;
(II.1) Неформальный словарь: малые категории
Здесь небольшие грамматические категории, такие как ‹Again-word› определены. Должны быть определены следующие константы:
СНОВА * __ WD | слов типа ‹Again-word› |
UNDO * __ WD | слов типа ‹Undo-word› |
OOPS * __ WD | слов типа ‹Oops-word› |
ТОГДА * __ WD | слов типа ‹Then-word› |
И * __ WD | слов типа ‹And-word› |
НО * __ WD | слов типа ‹But-word› |
ВСЕ * __ WD | слов типа ‹All-word› |
ДРУГОЕ * __ WD | слов типа ‹Другое слово› |
ME * __ WD | слов типа ‹Me-word› |
OF * __ WD | слов типа ‹Of-word› |
ДА * __ WD | слов типа ‹Yes-word› |
NO * __ WD | слов типа ‹No-word› |
В каждом случае * работает от 1 до 3,
за исключением ALL * __ WD , где он работает с 1 по 5, и OF * __ WD где от 1 до 4.‹Of-words› имеют
не упоминалось ранее: они используются в смысле «трех
ящиков », при разборе ссылки на заданное количество
вещи. Они повторяются на английском языке, потому что игрок мог напечатать
просто «три коробки», но Информ все равно их предоставляет.
По-французски мы можем начать с:
Константа AGAIN1__WD = 'бис'; Константа AGAIN2__WD = 'c //'; Константа AGAIN3__WD = 'бис';
Здесь мы не можем придумать третье слово-синоним для «снова», но мы все равно должны определить AGAIN3__WD, и не должен допускать, чтобы он был равен нулю.И так далее до:
Константа YES1__WD = 'o //'; Константа YES2__WD = 'oui'; Константа YES3__WD = 'oui';
‹yes-words› и ‹no-words› используются для синтаксического анализа ответы на вопросы типа «да» или «нет» на французском, конечно). Нетрудно понять, что слово «о» также является аббревиатурой от «ouest», потому что они используются в разных контекстах. С другой стороны, ‹oops-words›, ‹Again-words› и ‹Undo-words› должно быть другим от любого глагола или названия направления компаса.
После вышеизложенного необходимо добавить еще несколько слов. определены как возможные ответы на вопрос, заданный по окончании игры. Вот французский пример:
Константа AMUSING__WD = 'amusant'; Константа FULLSCORE1__WD = 'grandscore'; Константа FULLSCORE2__WD = 'grand'; Константа QUIT1__WD = 'a //'; Константа QUIT2__WD = 'arret'; Константа RESTART__WD = 'reprand'; Константа RESTORE__WD = 'restitue';
(II.2) Неформальный словарь: местоимения
Часть II продолжается таблицей местоимений, лучшая объяснил на примере.Следующая таблица определяет стандарт Английские местоимения винительного падежа:
Таблица Array LanguagePronouns
! слово возможные GNA: подключено к:
! а я
! s p s p
! mfnmfnmfnmfn
'it' $$ 001000111000 NULL
'он' $$ 100000100000 NULL
'ее' $$ 010000010000 NULL
'их' $$ 000111000111 NULL;
Столбец «подключен к» всегда должен
быть создано с NULL записями.Узор 1 и 0
в среднем столбце указывает, какие типы
‹Именная фраза› может быть передана
с данным ‹pronoun›.
Это действительно краткий способ выразить набор возможных GNA.
значения, например, говоря, что «они» могут соответствовать
именные словосочетания с любым GNA в наборе {3, 4, 5, 9, 10, 11}.
Винительный и дательный местоимения в английском языке идентичны: например, «она» в «дать ей цветы »имеет дательный падеж, а в« поцелуй ее »- винительный падеж. Французский язык богаче формами местоимений:
donne-le-lui дать ему / ей
mange avec lui поесть с ним
Здесь «-луи» и «луи» означают грамматически совершенно иная, одна подразумевает мужественность, где другой нет.Необходимая таблица:
Таблица Array LanguagePronouns
! слово возможные GNA: подключено к:
! а я
! s p s p
! mfnmfnmfnmfn
'-le' $$ 100000100000 NULL
'-la' $$ 010000010000 NULL
'-les' $$ 000110000110 NULL
'-lui' $$ 110000110000 NULL
'-leur' $$ 000110000110 NULL
'lui' $$ 100000100000 NULL
elle $$ 010000010000 NULL
'eux' $$ 000100000100 NULL
'elles' $$ 000010000010 NULL;
В этой таблице предполагается, что «-le» может быть рассматривается как самостоятельное слово, а не как часть слово «donne-le-lui» и раздел (III.1) ниже будет опишите, как этого добиться. Обратите внимание, что «-les» и «-leur» рассматриваются как синонимы: Informese не (обычно) заботятся о том, что дательный и винительный падежи различны.
Использование глагола «местоимения» в любом игра распечатает текущие значения, которые могут быть полезны при отладке приведенная выше таблица. Вот такая же игровая позиция, внутри здания в конце дороги, параллельно английский, немецкий и испанский текст:
Английский язык: «Адвент»
В настоящее время «оно» означает бутылочку, «он».
не настроен, «она» не настроен, а «они» не настроен.
Немецкий: «Abenteuer»
Im Augenblick, «er» heisst der Schlüsselbund,
«Sie» heisst die Flasche, «es» heisst das
Эссен, «ihn» heisst der Schlüsselbund, «ihm»
heisst das Essen und «ihnen» ist nicht gesetzt.
Испанский: «Авентура»
En este momento, «-lo» значение el grupo de llaves,
«-Los» no está definido, «-la»
значение la pequeña botella, «-las» значение
las par de tuberí as de unos 15 cm de diámetro,
«-Le» значение la pequeña botella, «-les»
значение las par de tuberí as de unos 15 cm de diámetro,
«Él» означает эль групо-де-ллавес, «элла»
значение la pequeña botella, ellos no está
Definido y «ellas», значение las par de tuberí
as de unos 15 cm de diámetro.
(II.3) Неформальный словарь: дескрипторы
Часть II продолжается таблицей дескрипторов в аналогичный формат.
Таблица Array LanguageDescriptors
! слово возможный дескриптор GNAs подключен
! следовать: type: to:
! а я
! s p s p
! mfnmfnmfnmfn
'мой' $$ 111111111111 POSSESS_PK 0
'this' $$ 111000111000 POSSESS_PK 0
'эти' $$ 000111000111 POSSESS_PK 0
'that' $$ 111111111111 POSSESS_PK 1
'те' $$ 000111000111 POSSESS_PK 1
'его' $$ 111111111111 POSSESS_PK 'его'
'ее' $$ 111111111111 POSSESS_PK 'ее'
'их' $$ 111111111111 POSSESS_PK 'они'
"это" $$ 111111111111 POSSESS_PK "это"
'the' $$ 111111111111 DEFART_PK NULL
'a //' $$ 111000111000 INDEFART_PK NULL
'an' $$ 111000111000 INDEFART_PK NULL
'some' $$ 000111000111 INDEFART_PK NULL;
Это дает три из четырех типов
‹Descriptor›.Постоянная POSSESS_PK означает ‹притяжательное прилагательное›,
связан либо с 0, что означает объект-игрок, либо с 1, что означает
что-либо кроме объекта-игрока (используется для «этого»
и подобные слова) или к объекту, на который ссылается данный
‹Pronoun›, что должно быть
из тех, что в таблице местоимений. DEFART_PK означает
определенные ‹article› и INDEFART_PK неопределенный ‹article›:
они оба должны дать значение подключенного к NULL во всех случаях.
Четвертый вид позволяет добавлять дополнительные дескрипторы которые заставляют следующие объекты иметь или не иметь заданный атрибут. Например, в следующих трех строках будет реализовано «горит», «Горит» и «не горит» как прилагательные автоматически понимает английский синтаксический анализатор:
'lit' $$ 111111111111 light NULL
'lighted' $$ 111111111111 light NULL
'unlit' $$ 111111111111 (-светлый) NULL
Имя атрибута означает «должен иметь этот атрибут», в то время как его отрицание означает «не должно иметь этого атрибута».’$$ 110000110000 DEFART_PK NULL ‘les’ $$ 000110000110 DEFART_PK NULL ‘un’ $$ 100000100000 INDEFART_PK NULL ‘une’ $$ 010000010000 INDEFART_PK NULL ‘des’ $$ 000110000110 INDEFART_PK NULL ‘пн’ $$ 100000100000 POSSESS_PK 0 ‘ma’ $$ 010000010000 POSSESS_PK 0 ‘mes’ $$ 000110000110 POSSESS_PK 0 ‘сын’ $$ 100000100000 POSSESS_PK ‘-lui’ ‘sa’ $$ 010000010000 POSSESS_PK ‘-lui’ ‘ses’ $$ 000110000110 POSSESS_PK ‘-lui’ ‘leur’ $$ 110000110000 POSSESS_PK ‘-les’ ‘leurs’ $$ 000110000110 POSSESS_PK ‘-les’;
(напомним, что в словарных словах апостроф
написано ^ ).Таким образом, «сын уазо» означает «его
птица »или« ее птица », согласно нынешнему значению
«-lui», т. е. по полу наиболее
упомянутое недавнее существительное в единственном числе.
Анализатор автоматически пробует оба значения, если одно и то же слово встречается как в таблицах местоимений, так и в таблицах дескрипторов. Это случилось на английском языке, где «она» может означать женский род единственное притяжательное прилагательное («возьми сумочку») или местоимение женского рода единственного числа («разбуди ее»).
(II.4) Неформальный словарь: числа
Должен быть дан массив слов типа <номер>.Они должны включать достаточно, чтобы выразить числа от 1 до 20, как в примере:
Таблица массивов LanguageNumbers
'un' 1 'une' 1 'deux' 2 'trois' 3 'quatre' 4 'cinq' 5
'six' 6 'sept' 7 'huit' 8 'neuf' 9 'dix' 10
'onze' 11 'douze' 12 'treize' 13 'quatorze' 14 'quinze' 15
'seize' 16 'dix-sept' 17 'dix-huit' 18 'dix-neuf' 19 'vingt' 20;
В некоторых языках, например в русском, есть числа больше 1, которые изменяются с полом: учтите все возможности здесь.Если одно и то же слово присутствует и в таблицах чисел, и в таблицах дескрипторов, его значение как дескриптора имеет приоритет, что полезно на французском языке поскольку это означает, что гендерные группы «un» и «une» признаются в конце концов.
(III.1) Перевод естественного языка на Informese
Часть III содержит процедуру преобразования того, что игрок набрал на Informese. В «English.h» это делает вообще ничего:
[LanguageToInformese; ];
Это могло бы сработать для Dogg, воображаемого языка в
который написан по пьесе Тома Стоппарда Гамлет Догга , где
слова — это более или менее переставленные английские слова.(Это начинается с кого-то
нажимая на микрофон и говоря: «Завтрак, завтрак…
солнце, док, трог… »и« Велосипеды! » является
ругательство.) Другие языки структурно не похожи Английский язык и задача LanguageToInformese — переставить или переписать
команды, чтобы они больше походили на английские. Вот несколько типичных
Порядок действий для LanguageToInformese :
- Удалите лишние акценты. Например, «German.h»
просматривает команду, заменяя ü на
ueи так далее и заменив ß наss.Это избавляет от чтобы распознать обе формы написания. - Разбивайте слова дефисами и апострофами, чтобы:
donne-lui l’oiseau отдай ему птицу → donne -lui l ‘oiseau
- Удалите интонации, не несущие полезной информации. Для Например, большинство немецких императивов могут принимать две формы: одна с «Е» на конце: «леге» означает «нога» (Немецкий: «положить») и «schaue» означает «schau» (Нем. «Смотреть»). Было бы полезно удалить это «Е», лишь бы не забивать игровые словари полными по существу повторяющихся записей.(«German.h» Тони Арнольда идет дальше и удаляет все склонения существительных, в то время как Ральф Херрманн сохраняет флексию для последующего анализа.)
- Уберите аффиксы со слов, к которым они приклеены. Например:
della из (итальянский) → di la
так что аффиксная часть «ля» становится отдельным словом и можно рассматривать как местоимение.
cogela take (испанский) → coge la - Заменить части речи, отсутствующие в Informese, например местоимения
наречия с подходящей альтернативой.Например:
dessus сверху (французский) → sur lui
dedans внутри → dans lui - Изменить порядок слов. Например, разорвите энклитику и переместите ее.
между двумя существительными; или если определенный артикль написан как суффикс,
вырежьте его и переместите перед существительным:
arma virumque оружия и человека (латиница) → arma et virum
kakane the cakes (норвежский) → ne kake
При звонке на LanguageToInformese , текст, набранный игроком, хранится в -> массив, называемый , буфер , и некоторая полезная информация о нем.
хранится в другом массиве под названием parse .Содержание
эти массивы подробно описаны в §2.5.
Процесс перевода должен выполняться смещением
и изменяя их в буфере . Конечно
в момент изменения чего-либо в буфере информация в парс устарел. Можно обновить , синтаксический анализ с оператором ассемблера
анализ буфера @tokenise;
(И парсер делает именно это, когда LanguageToInformese рутина закончилась.) Наиболее часто вносимые изменения сводятся к
вставка символов, часто пробелов, между словами и удаление других
символов, перезаписав их пробелами. Вставка символов означает
перемещение оставшейся части буфера на один символ, изменение длины buffer-> 1 , и убедившись, что не происходит переполнения.
Таким образом, библиотека предоставляет служебную программу
LTI_Insert (позиция, символ)
для вставки данного символа в данную позицию
в буфере .
• УПРАЖНЕНИЕ 110
Напишите подпрограмму LanguageToInformese для вставки пробелов перед
каждый дефис и после каждого апострофа, чтобы:
donne-lui l’oiseau give Птица ему → donne -lui l ‘oiseau
• EXERCISE 111
Сделайте дополнительные переводы для французских местоименных наречий:
dessus наверху → sur lui
dedans внутри → dans lui
• ▲ УПРАЖНЕНИЕ 112
Напишите процедуру под названием LTI_Shift (from, chars) , которая сдвигает
хвост массива буфера на символов позиций для
правый (так что он перемещается влево, если символов отрицательное),
где «хвост» — это часть буфера, начинающаяся в от и до конца.
• ▲ УПРАЖНЕНИЕ 113
Напишите программу LanguageToInformese , которая сортирует
Немецкие местоименные наречия, образованные добавлением «да».
или «дар» к любому предлогу. Остерегайтесь сломать имя
как «Даррен», которое может иметь значение в
игра, правда, так что:
дэвон → фон эс
даррен → auf es
даррен — / → рен эс
парсер ссылок: разбирает предложения на естественном языке
парсер ссылок: анализирует предложения на естественном языке
Команда для отображения руководства по синтаксическому анализатору ссылок в Linux: $ man 1 link-parser
НАЗВАНИЕ
link-parser — разбирает предложения на естественном языке
ОБЗОР
парсер ссылок [язык] [-pp файл_знаний-пп] [-c файл_знаний-пп] [-a affix_file] [-ppoff] [-coff] [-aoff] [-batch] [-]ОПИСАНИЕ
В Селаторе Д.и Темперли Д. «Анализ английского языка с помощью грамматики ссылок» (1991) авторы определили новую формальную грамматическую систему, названную «грамматика ссылок». Последовательность слов на языке ссылки грамматика, если есть способ провести «связи» между словами таким образом что местные требования к каждому слову удовлетворены, ссылки делают не пересекаются, и слова образуют непротиворечивый связный граф. Авторы закодировали Грамматики английского языка в такую систему, и написал линк-синтаксический анализатор на разбирать английский язык, используя эту грамматику.
Этот пакет можно использовать для лингвистического анализа информации. поиск или извлечение из документов на естественном языке. Абиворд также использует его как средство проверки грамматики.
ОПЦИИ
- -pp pp_knowledge_file
- -c constituent_knowledge_file
- -a affix_file
- -ppoff
- -крышка
- -aoff
- — партия
- — <специальные! команда>
ПРИМЕНЯТЬ
link-parser при вызове вручную возьмет на себя управление Терминал; линк-парсер попытается проанализировать грамматику весь ввод, если он не экранирован восклицательным знаком, в соответствии с файл словаря, предоставленный в качестве аргумента.Если экранирован, вход будет рассматриваться как «специальная команда»; «! help» перечисляет все специальные доступные команды.
парсер ссылок зависит от словаря грамматики ссылок, который содержит списки слов и связанные с ними метаданные об их грамматических свойства для анализа предложений. Связно-грамматический словарь предоставленная авторами линк-грамматика обычно включается в link-grammar, и его часто можно найти где-нибудь в / usr / share / грамматика ссылок / иерархия. В этом случае только двухбуквенный код языка необходимо указать в командной строке.В качестве альтернативы пользователь может предоставить их собственный словарь в качестве аргумента, и в этом случае словарь каталог должен быть указан. Следовательно, любая из команд
- синтаксический анализатор ссылок в
- парсер ссылок / usr / share / link-grammar / en
- запустит анализатор ссылок, используя английский словарь, включенный в парсер.
В сеансе парсера ссылок некоторые примеры выходных данных могут быть такими:
- linkparser> Чтение справочной страницы является информативным.
++++ Время 0,00 секунды (0,01 общее)
Обнаружена 1 связь (1 без нарушений P.P.)
Уникальная связь, вектор стоимости = (НЕИСПОЛЬЗУЕМЫЙ = 0 DIS = 0 И = 0 LEN = 12)
+ ———————— Xp ———————- — +
| + ——— SS * g ——— + |
| + ——- Os ——- + | |
| | + —- Ds —- + | |
+ —- Wd — + | + — AN — + + — Pa — + |
| | | | | | | | ЛЕВАЯ СТЕНА чтение.g a man.n page.n is.v информативный. a.
А П.P. нарушение — нарушение постобработки; это пост-связь шаг, используемый для отклонения недопустимого синтаксического анализа. Показанные типы ссылок являются конкретными на английский; на других языках будут разные типы ссылок.
link-parser также можно использовать не интерактивно, либо через его API или с помощью опции -batch. При использовании с параметром -batch link-parser пассивно получает ввод со стандартного ввода, а когда поток заканчивается, затем он выводит свой анализ. Так что можно было создать специальную программу проверки грамматики, пропустив текст через синтаксический анализатор ссылок с пакетной опцией и определение того, какие предложения не соответствуют проанализировать как действительный:
- кошачья диссертация.txt | парсер ссылок /usr/share/link-grammar/en/4.0.dict -batch
АВТОР
парсер ссылок был написан Daniel Sleator Эта страница руководства была написана Кеном Блумом
Страницы, относящиеся к парсеру ссылок
Начальные парсеры с PEG.js (пример)
Грамматики PEG или синтаксического анализа похожи на CFG (контекстно-свободные грамматики) с некоторыми изменениями. Есть отличная библиотека под названием PEG.js, которую я собираюсь представить здесь; Я обнаружил, что это замечательный генератор парсеров для большинства моих потребностей в синтаксическом анализе простых языков. Самым удивительным в PEG.js является то, что он позволяет использовать встроенный javascript, поэтому вместо того, чтобы просто создавать скучные деревья синтаксического анализа и т. Д., Вы даже можете решать проблемы изнутри парсера.
Я написал длинный пост до того, как написал этот абзац.Это было слишком техническим, и я удалил его. Надеюсь, эта версия прижится. Кроме того, это моя первая публикация здесь, поэтому я буду благодарен за любые отзывы.
Готовимся
Вместо объяснения, определения правильного маршрута и следования ему. Я бы порекомендовал вам перейти к онлайн-раннеру peg.js и начать выпаливать грамматику.
Слева вы найдете текстовую область, и просто потому, что вам хочется последовать моему примеру, удалите весь текст. Теперь вы обнаружите, что Peg.js это не совсем понравилось, и он дает нам предупреждение под текстовой областью.Давайте исправим это. Введите:
myspecialrule = "" Это заставит предупреждение исчезнуть, но вы все равно получите еще одно предупреждение с тестовым вводом. Пока мы ничего не делаем, так что давайте просто удалим и это. Позже мы добавим наши тестовые данные.
Хорошо, теперь, когда у нас был чистый лист, пришло время подумать о том, что делать. Для нашего самого первого опыта давайте попробуем запустить простой счетчик слов.
Моя первая грамматика PEG.js
Вот что мы хотим: для ввода «это мой первый пост на coderwall» в результате мы должны получить 7.Теперь я знаю, я знаю, это глупо легко сделать в javascript, но потерпите меня.
Начнем с начального правила. Первое правило, с которым сталкивается PEG.js в вашем тексте, — это «основное» правило. Отсюда и начинается весь парсинг. Итак, первое правило
wordCounter = word * Теперь, если вы знакомы с регулярными выражениями, это очень похоже на них, но здесь слово представляет другое правило. Для тех, кто не знаком с регулярными выражениями, прочтите, пожалуйста, и узнайте, как их использовать, они потрясающие.В регулярных выражениях * означает, что предыдущий токен (скажем, в некоторых случаях a * , a является токеном) может присутствовать 0 или много раз во входной строке (0-n). Изменение здесь состоит в том, что слово ссылается на другое правило, и PEG.js ожидает, что оно будет определено, поэтому, если вы введете это, вы обнаружите, что PEG.js жалуется, что он не может найти правило слова .
Тогда давайте сделаем это правило. Сейчас мы не особо заботимся об интернационализации, поэтому сделаем это очень просто.(Последний раз я проверял, что в PEG.js нет поддержки интернационализации, но это можно сделать. Если вам нужна помощь, вы можете спросить меня или посмотреть примеры в исходном коде peg.js)
слово = буква + Опять же, как и регулярные выражения, мы используем оператор + . Оператор + означает, что токен должен присутствовать как минимум один раз, но может повторяться много раз (1 - n). Теперь мы решили проблему правила слова , но создали другое правило буква , которого нет.Двигаемся дальше…
буква = [a-zA-Z0-9] Оператор [] в основном означает, что можно сопоставить любой символ внутри скобок. Это как набор. Что-нибудь внутри совпадает. Если вы присмотритесь, там есть еще более забавный синтаксис. Внутри оператора набора [] , a-z PEG.js будет знать (и большинство механизмов регулярных выражений тоже, поскольку это также допустимый синтаксис регулярных выражений) интерполировать символы. Короче говоря, a-z буквально означает символа от a до z .
Теперь мы получаем зеленый сигнал, что все в порядке. Давайте добавим тестовый ввод. Скажи привет'. Мы волшебным образом надеялись получить 1. Увы, это не работает так, вместо этого Hello был разобран, и это результат. Не хорошо.
Давайте добавим сюда встроенный JavaScript для подсчета слов. Поскольку мы говорим о подсчете слов, единственное правило, которое знает, сколько слов найдено, - это правило wordCount . Давайте добавим к нему javascript.
Чтобы добавить javascript, добавьте выражение с {} , содержащее любой javascript, который вы хотите.Итак, мы модифицируем wordCount на:
wordCount = word * {return 1; } Итак, мы получаем желаемый результат, но обманываем. Чтобы подсчитать слова, нам нужно иметь возможность ссылаться на них в javascript. Чтобы ссылаться на что-либо, мы ставим перед ним метку вроде этого:
wordCount = w: word * {return 1; } Метка : синтаксис позволяет получить доступ к фактическому сопоставленному тексту в вашем коде javascript.Довольно круто, а? Теперь, чтобы найти ему хорошее применение.
wordCount = w: word * {return w.length; } токенов, совпадающих с * или + , автоматически становятся массивами javascript в коде javascript, что прекрасно.
Как видите, в результате мы получаем 1. Хороший! Однако, если мы добавим больше слов, вы увидите, что мы получим ошибку. При ближайшем рассмотрении вы увидите, что PEG.js ожидал правила , буква , но вместо этого был ошеломлен, когда вместо него получил пробел.Поскольку слова разбиты на пробелы, нам нужно добавить это в наш набор правил. Опять же, единственное правило, касающееся целых слов - wordCount , нам нужно его изменить. Но прежде нам нужно добавить правило, которое соответствует пробелам. (Мы могли бы просто добавить "" к правилу wordCount , но на практике извлечение общих фрагментов в правила делает грамматику более читаемой)
пробел = "" , а затем нам нужно добавить его в правило wordCount .Однако есть еще одна хитрость. Если мы напишем,
wordCount = w: слово * пробел {return w.length; } он не будет делать ничего, кроме как ожидать пробела после слова. Несколько слов все еще не подобраны. Чтобы исправить это, нам нужно лучше объяснить наши потребности PEG.js. Нам не нужно много слов, и ввод должен заканчиваться пробелом, нам нужны слова, разделенные пробелами.
wordCount = w: (пробел) * {return w.length; } Это дает нам большую часть пути, но мы все еще видим ошибку.PEG.js по-прежнему ожидает, что за последним словом будет стоять пробел. Нам это не нужно, поэтому исправляем:
wordCount = w: (пробел?) * {Return w.length; } ? Оператор здесь означает, что мы ожидаем, что правило пространство будет иногда присутствовать и не будет присутствовать в другое время (0-1). Теперь попробуйте ввести ввод, и вы обнаружите, что синтаксический анализатор работает должным образом. Ура!
Немного более сложный пример
Теперь, когда мы закончили, давайте попробуем сделать что-нибудь, что было бы немного сложнее сделать с простым javascript.Давайте добавим здесь систему команд. Скажем, если кто-то наберет wc: Hello world , мы должны вернуть 2. Но если кто-то скажет lc: Hello world , мы должны вернуть количество букв в тексте, в данном случае 10 (не 11, мы не подсчет пробелов). До сих пор мы имели дело только с простыми правилами сопоставления одного и того же объекта, но теперь нам приходится иметь дело с гораздо более сложной системой. Вот парсер до сих пор:
wordCount = w: (пробел?) * {Return w.length;}
слово = буква +
письмо = [a-zA-Z0-9]
space = "" Давайте добавим новое правило верхнего уровня, которое будет анализировать входную строку, определять, какой тип операции выполнять с оставшимся текстом, и запускать это правило.
textWorks
= "wc:" пробел * wc: wordCount {return wc; }
/ "lc:" пробел * lc: letterCount {return lc; } Каждый раз, когда я работаю с синтаксическими анализаторами, мне нравится сначала генерировать самые верхние правила, чтобы я мог понять, как все взаимосвязано. Единственное новшество в приведенном выше синтаксисе - это использование оператора /. Думайте об операторе / как об операторе ИЛИ . Если синтаксический анализатор не может сопоставить первый вариант, он просматривает следующий вариант и так далее, пока либо не найдет первый подходящий вариант, либо не найдет ни одного, и в этом случае он вернется к родительскому правилу и повторится.Если все маршруты исчерпаны, а входная строка не соответствует полностью, она возвращается и сообщает вам, где произошла ошибка. Так что в этом случае, если мы начнем ввод текста с «pc:», синтаксический анализатор завершится ошибкой. Теперь давайте сделаем letterCount .
letterCount = w: (iw: слово пробел? {Return iw;}) * {
var total = 0;
for (var i = 0; i Теперь это немного сложнее, но, по сути, это
- В пределах
(), если имеется более одного токена, PEG.js преобразует его в массив результатов, однако каждый()может иметь свой собственный встроенный javascript, поэтому я использовал его, чтобы просто вернуть результат правилаword, игнорируя совпадающий текст правила пробела. - перебирая совпавшие слова, мы продолжаем считать буквы в каждом слове и возвращаем общее
Это работает, потому что мы определили слово как буква + , которое по умолчанию возвращает массив совпадающих букв.
А теперь попробуйте.Вы увидите, что когда вы набираете «wc: Hello World», он возвращает 2 и меняет «wc» на «lc», и вы получаете 10.
Есть еще много вещей, которые я здесь не рассмотрел, но я надеюсь, что получил представление о мощи PEG.js и о том, как начать с ним работать. Вы можете скачать получившийся синтаксический анализатор из онлайн-версии после того, как закончите его создание. Вы также можете загрузить его с помощью npm install -g pegjs , если у вас есть node. Вы также можете запустить синтаксический анализатор в браузере во время выполнения, но я думаю, что он имеет ограниченное применение.Просто предварительно скомпилируйте синтаксический анализатор для повышения производительности, если вы не планируете динамически генерировать саму грамматику.
Ссылки
PEG.js
Онлайн-версия PEG.js
Документация PEG.js
Проект Github
PEG.js разработан Дэвидом Майда (@dmajda).
Не настоящий языковой курс
Не настоящий языковой курсДетерминированный анализ - использование эвристики
Как упоминалось ранее, механизмы синтаксического анализа, которые мы искали пока это моделирование недетерминированных процессов.Где-нибудь еще в этой программе вы узнаете больше о недетерминизме, но для теперь достаточно сказать, что недетерминированный процесс всегда возвращает правильный ответ, и теоретическая основа для этого правильного ответ - нечто, называемое "оракулом", который всегда знает, какой выбор - правильный выбор. Однако у вас, вероятно, нет оракула удобно. Таким образом, нам приходится моделировать недетерминизм, который обычно означает, что мы должны провести исчерпывающий поиск. Сетевой подход перехода к синтаксическому анализу, который мы видели до сих пор, реализует не что иное, как поиск в глубину всех возможных путей, которые можно было бы получить от начальное состояние (обозначенное узлом S) для терминальной строки, которая соответствует входное предложение.Этот поиск в глубину - это исчерпывающий поиск того, что может быть большим пространством состояний, и, как вы знаете из своих предыдущих ИИ классы, исчерпывающий поиск очень дорого обходятся. Так что из чисто с практической точки зрения, мы хотели бы отойти от опоры на моделирование недетерминизма, чтобы найти правильное дерево разбора для какое-то предложение. И я уверен, что вы также вспомните, что вы узнали о как сократить поиск --- вы пользуетесь эвристикой. Будет ли проблемой отсутствие недетерминированного синтаксического анализа? для нас? Скорее всего, нет, потому что люди, кажется, делают надежную работу по синтаксический анализ, и похоже, что люди детерминированы, а не недетерминированы, парсеры.Люди, понимающие, похоже, используют эвристику, чтобы направлять их решения о синтаксической структуре, и их решения не всегда правильно. Они, конечно, не делают этого сознательно, но их поведение можно до некоторой степени объяснить моделью обработки который использует эвристику для принятия решений о синтаксической неоднозначности.
Минимальное навесное оборудование
Одна эвристика была предложена, чтобы объяснить, как люди делают программа синтаксического анализа решений называется "минимальным вложением"." Для Например, учитывая предложение «Я видел человека с телескопом», как парсер мог определить где ПП "с телескопом" прикрепляется, если используется следующая грамматика?
S
Вот один из возможных вариантов синтаксического анализа, в котором предложная фраза "с
телескоп "присоединяется к глагольной фразе и изменяет глагол" пила ":
S
/ \
/ \
/ \
/ \
НП ВП
| / | \
| / | \
| / | \
ПРОН ГЛАГОЛ НП ПП
| | / \ | \
| | / \ | \
| | / \ | \
ART NOUN PREP НП
Я видел | | | / \
| | | / \
| | | / \
ИСКУССТВО СУЩЕСТВИТЕЛЬНОЕ
мужчина с | |
| |
| |
телескоп
Вот еще одно приемлемое дерево синтаксического анализа для того же предложения, но это
время, когда предложная фраза присоединяется к существительному внизу дерева
фраза и модифицирует "мужчина":
S
/ \
/ \
/ \
/ \
НП ВП
| / \
| / \
| / \
ПРОН ГЛАГОЛ Н.П.
| | / \
| | / \
| | / \
НП ПП
Я видел /\ / \
/ \ / \
/ \ / \
ART NOUN PREP НП
| | | / \
| | | / \
| | | / \
ИСКУССТВО СУЩЕСТВИТЕЛЬНОЕ
мужчина с | |
| |
| |
телескоп
Принцип минимального присоединения гласит, что предпочтительным синтаксическим анализом является
простейший синтаксический анализ, и простота здесь измеряется количеством
нетерминалов в дереве синтаксического анализа, где меньше нетерминалов
считается более простым.Таким образом, первое дерево синтаксического анализа выше, которое
содержит 13 нетерминалов, предпочтение отдается минимальному креплению
принцип над вторым деревом синтаксического анализа, которое содержит 14 нетерминалов.
Однако этот принцип не всегда работает. Если вы использовали минимальный
вложение в разборе "Покрасили все стены в трещины",
эвристика выберет неправильный синтаксический анализ. (Добавьте следующее
Правило грамматики выше:
НП
и обратите внимание, что "все"
является КОЛИЧЕСТВОМ.) О, причина, по которой мы знаем, что это неправильный синтаксический анализ, -
что мы знаем, что должно означать предложение.Итак, как вы можете
Видишь ли, будет очень трудно поддерживать эту притворство насчет
четкое разделение синтаксиса и смысла.
S
/ \
/ \
/ \
/ \
/ \
НП ВП
| / | \
| / | \
| / | \
ПРОН ГЛАГОЛ НП ПП
| | / | \ | \
| | / | \ | \
| | / | \ | \
QUANT ART NOUN PREP NP
Мы нарисовали | | | | |
| | | | |
| | | | |
СУЩЕСТВИТЕЛЬНОЕ
все стены с |
|
|
трещины
Дерево синтаксического анализа выше имеет только 13 нетерминалов, в то время как альтернативное ниже
имеет 14 нетерминалов:
S
/ \
/ \
/ \
/ \
/ \
НП ВП
| / \
| / \
| / \
ПРОН ГЛАГОЛ Н.П.
| | / \
| | / \
| | / \
НП ПП
Мы нарисовали / | \ | \
/ | \ | \
/ | \ | \
QUANT ART NOUN PREP NP
| | | | |
| | | | |
| | | | |
СУЩЕСТВИТЕЛЬНОЕ
все стены с |
|
|
трещины
Несмотря на то, что последнее дерево синтаксического анализа имеет больше смысла
(Я имею в виду, вы на самом деле не использовали трещины, чтобы красить стены,
вы?), минимальная эвристика привязанности предпочитает первую
дерево разбора.Следовательно, можно с уверенностью заключить, что минимальная
эвристика привязанности не идеальна.
Правое товарищество
Еще одна предлагаемая эвристика, которая используется при минимальном вложении
не может принять решение, это называется «правильная ассоциация». Право
принцип ассоциации гласит, что если все остальное равно
(например, такое же количество нетерминалов в каждом дереве синтаксического анализа), любые новые
составной или фразовый компонент должен быть присоединен к составному
в настоящее время в стадии строительства (т.е., ниже в дереве синтаксического анализа) вместо
компонента выше в дереве синтаксического анализа. Следовательно,
принцип правильной ассоциации лучше всего выберет дерево синтаксического анализа
отражая эту интерпретацию. Например, следующие два
анализировать деревья на предмет "Я слышал, вчера ваш компьютер умер"
содержат по 13 нетерминалов в каждом, поэтому минимальное вложение
нет помощи, но правильная ассоциация предпочитает первое дерево, потому что
предложная фраза, о которой идет речь, прикрепляется ниже в дереве:
S
/ \
/ \
/ \
НП ВП
| / \
| / \
| / \
ДОПОЛНИТЕЛЬНЫЙ ГЛАГОЛ
| | / \
| | / \
| | / \
S
Я слышал, что / \
/ \
/ \
НП ВП
/ \ / \
/ \ / \
/ \ / \
ПОСС СУЩЕСТВИТЕЛЬНОЕ ГЛАГОЛ PP
| | | |
| | | |
| | | |
твой компьютер умер вчера
S
/ \
/ \
/ \
НП ВП
| / | \
| / | \
| / | \
ДОПОЛНИТЕЛЬНЫЙ ГЛАГОЛ PP
| | / \ \
| | / \ \
| | / \ \
S
Я слышал это / \ вчера
/ \
/ \
НП ВП
/ \ |
/ \ |
/ \ |
ПОСС СУЩЕСТВИТЕЛЬНОЕ ГЛАГОЛ
| | |
| | |
| | |
твой компьютер умер
Лексические предпочтения
Правильная ассоциация тоже не всегда работает.Иногда это выглядит
как главный глагол влияет на решение о привязке. Например,
К чему относится слово «в доме» в следующих предложениях? Может
решения о привязанности меняются? (Какие решения были бы минимальными
вложение сделать? Как насчет правильной ассоциации? Есть конфликт?)
Я хотел собаку в доме.
Я держал собаку в доме.
Я поставил собаку в дом.
В своем основополагающем учебнике Джеймс Аллен указывает, что в первом
предложение выше, "в доме" следует присоединить к словосочетанию "существительное"
собака".Автор считает, что это интуитивно лучше, чем
присоединение PP к глаголу «разыскивается» - то есть «разыскивается» не
действительно нужно место, чтобы желание могло произойти - но наши неформальные
эксперименты в прошлых предложениях урока естественного языка предполагают
что интуиция автора не совпадает с чьей-либо еще, хотя
результаты никогда не были полностью решающими.
Что касается второго предложения, то вы единодушно поддержали добавление
ПП - «держать» вместо «собаку», а в третьем - «положить»
предложение абсолютно положительно требует, чтобы «в доме»
к глаголу, а не к НП "собака".
Так что здесь происходит? Ну может быть
еще одна эвристика, учитывающая влияние глагола. В
Принцип «лексического предпочтения» гласит, что для каждого глагола синтаксический анализатор
должен знать, какие предлоги указывают на то, что ПЗ должен присоединяться к
VP (например, "положить"), и какие предпочитают, чтобы PP прикреплял
к ВП (например, «сохранил»). Если сочетание глагола и предлога в
вопрос не попадает ни в одну из этих двух категорий,
принцип по умолчанию заключается в использовании
правильная ассоциация.
Как реализовать эти принципы
Во-первых, вы не хотите создавать все возможные деревья синтаксического анализа для
любое данное предложение, чтобы вы могли сосчитать все нетерминалы или что-то еще.
Этого мы пытаемся избежать. Помнить? Это уродливый поиск
снова проблема. Итак, вам нужно реализовать эти принципы в парсере
таким образом, чтобы вы могли принимать необходимые решения в качестве парсера
продолжается. Но, как объясняется в вашем учебнике, любое стремление к
конкретная реализация любого или всех этих принципов всегда
были проблемы.Итак, хотя эти принципы могут объяснить некоторые из
происходит в человеческом разборе, они явно не все объясняют.
Если вы когда-нибудь попытаетесь воплотить эти принципы в каком-нибудь парсере,
вам просто нужно быть готовым принять тот факт, что они собираются
время от времени принимать неправильные решения (если не
происходит между сейчас и потом).
Еще один эвристический подход
Вкратце проблема заключается в следующем: когда вы (при условии, что вы парсер)
разбираете какое-то предложение, и вы столкнулись с синтаксической двусмысленностью,
вам нужно сделать выбор, и вы хотите сделать правильный выбор
каждый раз.Если бы вы были недетерминированными, то есть если бы у вас был доступ
к «оракулу» всегда можно было сделать правильный выбор. Но ты не
оракул; вы не знаете всего, что произойдет в
будущее. Что вы делаете? Ты жульничаешь. Ты не можешь смотреть бесконечно
будущее, но вы можете заглянуть вперед на несколько слов или составляющих, не можете
Вы? Конечно, и это принцип "упреждающего синтаксического анализа".
Принцип упреждающего синтаксического анализа просто гласит, что при каждом решении
точки в вашем парсере, вы добавляете набор тестов, которые смотрят вперед на
Вход.Основываясь на том, что будет дальше, вы можете сделать обоснованное предположение, как
какой выбор лучше сделать сейчас. В парсере ATN вы
добавьте эти тесты в узлы или состояния вашего ATN - это
точки принятия решения (если узел имеет более одной дуги, ведущей от
Это). Эти опережающие тесты похожи на функциональные тесты, но они
отличается, потому что (1) они выполняются на узле перед пересечением
дугу, потому что они являются эвристикой для выбора дуги, и (2)
не требуется, чтобы предварительные тесты были верными для правильного синтаксического анализа,
но функциональные тесты должны быть верными.
Простые парсеры с упреждением просматривают фиксированное количество слов вперед. Более
сложные синтаксические анализаторы просматривают фиксированное количество составляющих впереди.
Но, как и в случае с описанной выше эвристикой, просмотр вперед
парсеры тоже не всегда правильно разбираются. Если вы этого не сделаете
Загляните в будущее, вы получите недочеловеческую производительность. Если ты смотришь вперед
слишком много, вы получите сверхчеловеческую производительность, но все равно не идеальную.
Кроме того, ваш парсер начинает выглядеть так, как будто у каждого узла есть другой парсер.
прикреплен к нему. Если вы слишком много смотрите в будущее, вы можете
просто попробуйте недетерминированные симуляции.Фу. Что такое магическое число
составляющих или слов, чтобы получить точную человеческую производительность? Ничей
нашел его, что предполагает, что предварительный анализ не может быть
ответ тоже.
Итак, что вы делаете?
Пунт. На самом деле никто не знает, что находится внутри «синтаксической коробки». Мы можем
предлагать грамматики для английского языка, но они всегда неполные.
Мы можем предложить механизмы синтаксического анализа, которые работают во многих или в большинстве случаев,
но они не будут работать во всех случаях. Мы можем предложить эвристику
выручают, но и полностью не решают проблему.