32.7. Содержание обучения в 11 классе \ КонсультантПлюс
32.7. Содержание обучения в 11 классе.
32.7.1. Язык, общие сведения о языке, разделы науки о языке.
Морфемика и словообразование. Основные понятия морфемики и словообразования. Состав слова. Морфемы корневые и аффиксальные. Основа слова. Основы производные и непроизводные. Морфемный разбор слова.
Словообразование. Морфологические и неморфологические способы современного кабардино-черкесского словообразования. Понятие о словообразовательной цепочке. Морфемный и словообразовательный разбор.
32.7.2. Морфология.
Общая характеристика морфологической системы. Части речи. Именные части речи, их общие и отличительные признаки. Морфологические признаки именных частей речи (имя существительное, имя прилагательное, имя числительное, местоимение). Особенности функционирования именных частей речи в тексте. Спрягаемые части речи. Глагол. Переходные и непереходные глаголы. Категория лица, числа и времени глагола. Одноличные и многоличные глаголы. Категория наклонения глагола. Отглагольные образования (причастие и деепричастие). Наречие как часть речи. Разряды наречий.
Одноличные и многоличные глаголы. Категория наклонения глагола. Отглагольные образования (причастие и деепричастие). Наречие как часть речи. Разряды наречий.
Служебные слова (послелоги, союзы, частицы) и междометия.
32.7.3. Синтаксис и пунктуация.
Обобщающее повторение синтаксиса. Словосочетание. Связь слов в словосочетании (смысловая и грамматическая). Главное и зависимые слова в словосочетании.
Простое предложение. Односоставные и двусоставные предложения. Главные члены предложения. Тире между подлежащим и сказуемым. Второстепенные члены предложения. Полные и неполные предложения. Тире в неполном предложении. Порядок слов в простом предложении. Синтаксический разбор простого предложения.
Однородные члены предложения. Знаки препинания в предложениях с однородными членами. Обобщающие слова при однородных членах. Знаки препинания при обобщающих словах.
Осложненное предложение. Знаки препинания в осложненном предложении (обращение).
Обособленные члены предложения.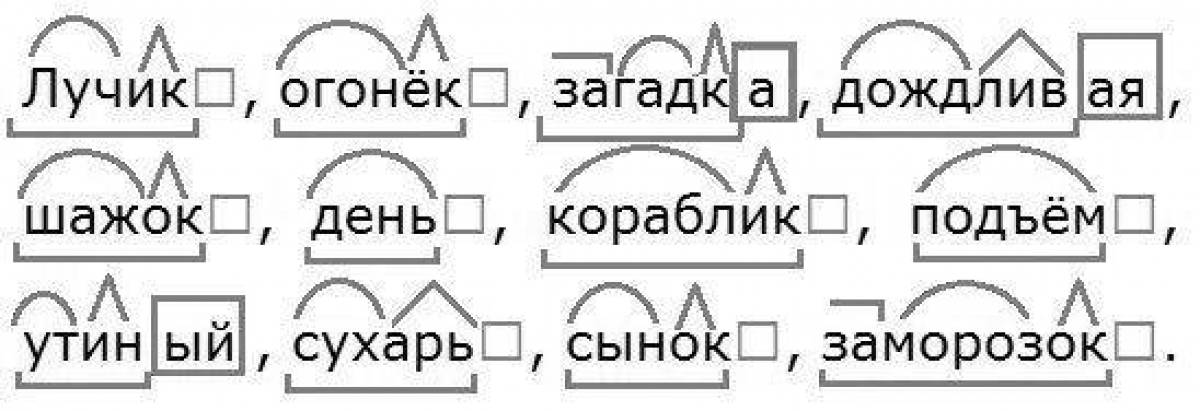 Знаки препинания при обособленных членах предложения.
Знаки препинания при обособленных членах предложения.
Сложное предложение. Сложносочиненное предложение. Знаки препинания в сложносочиненном предложении. Синтаксический разбор сложносочиненного предложения. Сложноподчиненное предложение. Знаки препинания в сложноподчиненных предложениях с одним и несколькими придаточными. Синтаксический разбор сложноподчиненного предложения.
Бессоюзное сложное предложение. Знаки препинания в бессоюзном сложном предложении. Синтаксический разбор бессоюзного сложного предложения.
Основные принципы пунктуации кабардино-черкесского языка — логический, синтаксический и интонационный. Знаки препинания по значению и интонационные. Пунктуационный анализ.
32.7.4. Речь, речевое общение и культура речи.
Стилистика и культура речи. Стилистика как раздел науки о языке, изучающий стили языка и стили речи, а также изобразительно-выразительные средства.
Стиль. Классификация функциональных стилей. Научный стиль. Официальноделовой стиль. Публицистический стиль. Разговорный стиль. Художественный стиль. Основные жанры научного (доклад, аннотация, статья, тезисы, конспект, реферат), публицистического (выступление, статья, интервью, очерк), официальноделового (расписка, резюме, характеристика, заявление, доверенность) стилей, разговорной речи (рассказ, беседа, спор).
Публицистический стиль. Разговорный стиль. Художественный стиль. Основные жанры научного (доклад, аннотация, статья, тезисы, конспект, реферат), публицистического (выступление, статья, интервью, очерк), официальноделового (расписка, резюме, характеристика, заявление, доверенность) стилей, разговорной речи (рассказ, беседа, спор).
Функционально-смысловые виды сочинений: повествование, описание, рассуждение.
Язык художественной литературы. Основные виды тропов, их использование мастерами художественного слова. Практическая работа с текстами адыгских писателей.
Стилистическое употребление однозначных и многозначных слов, омонимов, синонимов, антонимов, профессиональных терминов, архаизмов, неологизмов, диалектных и заимствованных слов, жаргонизмов, фразеологизмов, крылатых выражений, местоимений, глаголов в различных временных формах, предложений с прямым и обратным порядком слов.
Стилистические ошибки и их типы. Лингвистический эксперимент.
Основные аспекты культуры речи: нормативный, коммуникативный, этический. Культура разговорной речи. Ораторское искусство.
Культура разговорной речи. Ораторское искусство.
Особенности адыгского речевого этикета. Культура межъязыкового общения в условиях билингвизма. Перевод устных и письменных текстов с кабардино-черкесского на русский язык и с русского языка на кабардино-черкесский язык.
32.7.5. Язык и культура речи.
Язык и общество. Язык и речь — две стороны одной и той же речевой деятельности, их связь и особенности. Взаимосвязь языка и традиций, истории народа.
Диалог разных культур, характерный для Кабардино-Балкарской Республики. Взаимообогащение и взаимовлияние языков как результат взаимодействия национальных культур. Отражение в современном кабардино-черкесском языке культур других народов.
Известные ученые лингвисты и их работы о кабардино-черкесском языке. Актуальные проблемы сохранения и развития кабардино-черкесского языка. Республиканские целевые программы сохранения и развития кабардино-черкесского языка.
Разбор слова по составу и словообразование (Галина Сычева)
Купить офлайн
Цена на сайте может отличаться от цены в магазинах сети. Внешний вид книги может отличаться от изображения на
сайте.
Внешний вид книги может отличаться от изображения на
сайте.
Цена на сайте может отличаться от цены в магазинах сети. Внешний вид книги может отличаться от изображения на сайте.
В программе начальной школы по русскому языку большое внимание уделяется различным видам грамматических разборов, которые являются показателями усвоения учащимися программного материала.
.Разбор слова по составу — один из важных видов грамматического разбора слова. В начальной школе этому виду разбора уделяется большое внимание, так как знание особенностей частей слова, их орфографической структуры и правильное их написание, безусловно, способствуют улучшению грамотности учащихся.
.Видение состава слова необходимо довести у учащегося до автоматизма восприятия, так как для каждой части слова существуют свои орфографические правила и исключения, которые можно запомнить только в результате многократного повторения и тренировочных упражнений.
.Каждый из видов грамматических разборов заключает в себе материал для закрепления огромного пласта знаний по русскому языку.
Описание
Характеристики
В программе начальной школы по русскому языку большое внимание уделяется различным видам грамматических разборов, которые являются показателями усвоения учащимися программного материала.
.Разбор слова по составу — один из важных видов грамматического разбора слова. В начальной школе этому виду разбора уделяется большое внимание, так как знание особенностей частей слова, их орфографической структуры и правильное их написание, безусловно, способствуют улучшению грамотности учащихся.
.Видение состава слова необходимо довести у учащегося до автоматизма восприятия, так как для каждой части слова существуют свои орфографические правила и исключения, которые можно запомнить только в результате многократного повторения и тренировочных упражнений.
.Каждый из видов грамматических разборов заключает в себе материал для закрепления огромного пласта знаний по русскому языку.
Феникс
На товар пока нет отзывов
Поделитесь своим мнением раньше всех
Как получить бонусы за отзыв о товаре
1
Сделайте заказ в интернет-магазине2
Напишите развёрнутый отзыв от 300 символов только на то, что вы купили3
Дождитесь, пока отзыв опубликуют.Если он окажется среди первых десяти, вы получите 30 бонусов на Карту Любимого Покупателя. Можно писать неограниченное количество отзывов к разным покупкам – мы начислим бонусы за каждый, опубликованный в первой десятке.
Правила начисления бонусов Если он окажется среди первых десяти, вы получите 30 бонусов на Карту Любимого Покупателя. Можно писать
неограниченное количество отзывов к разным покупкам – мы начислим бонусы за каждый, опубликованный в
первой десятке.
Книга «Разбор слова по составу и словообразование» есть в наличии в интернет-магазине «Читай-город» по привлекательной цене. Если вы находитесь в Москве, Санкт-Петербурге, Нижнем Новгороде, Казани, Екатеринбурге, Ростове-на-Дону или любом другом регионе России, вы можете оформить заказ на книгу Галина Сычева «Разбор слова по составу и словообразование» и выбрать удобный способ его получения: самовывоз, доставка курьером или отправка почтой. Чтобы покупать книги вам было ещё приятнее, мы регулярно проводим акции и конкурсы.
Эпизод #126: Обобщенный анализ: Часть 3
Эпизод #126: Обобщенный анализ: Часть 3- Цены
- Коллекции
- Блог
- Подарки
- Войти 9001 3
- Без каких-либо изменений в нашем базовом типе парсера мы можем создать новый оператор парсера, который позволит нам поэтапно анализировать поток данных, поступающих из внешнего источника, например стандартный ввод, и даже инкрементно направлять поток вывода во внешний источник, такой как файл, стандартный вывод или что-то еще.
 Это может значительно повысить производительность синтаксических анализаторов, которым необходимо работать с большими наборами данных, для которых нецелесообразно помещать большой блок данных в память и анализировать его в большой массив данных для обработки.
Это может значительно повысить производительность синтаксических анализаторов, которым необходимо работать с большими наборами данных, для которых нецелесообразно помещать большой блок данных в память и анализировать его в большой массив данных для обработки. - Это невероятно, но становится лучше. Обобщая, мы теперь можем увидеть совершенно новую форму композиции, которая находится рядом с нашими любимыми операторами
map,zipиflatMap. Этот оператор имеет ту же форму, которую мы снова и снова обнаруживали в Point-Free, и он поможет нам взять синтаксический анализатор, работающий с небольшим фрагментом данных, и преобразовать его в синтаксический анализатор, работающий с более крупным и сложным фрагментом данных. - И если этого было недостаточно, стало еще лучше. Эта новая форма композиции оказывается ключом к открытию нового уровня производительности наших парсеров. Мы можем увеличить производительность некоторых наших парсеров в 5-10 раз с минимальными изменениями в самих парсерах, что делает их производительность конкурентоспособной с парсерами, свернутыми вручную, и даже превосходит производительность вспомогательных парсеров Apple, таких как сканер
Реализуйте следующий метод на анализаторе
extension Parser { func f(_ parser: Parser Для чего может быть полезен этот метод?
РешениеАнализатор расширений { func f(_ parser: Parser run(&input) else { return nil }
охранять let newOutput = parser.run(&output) else {
ввод = оригинал
вернуть ноль
}
вернуть новый вывод
}
}
}
Строки Swift имеют низкоуровневое представление, называемое
UnicodeScalarView, с которым можно работать более эффективно. ОбобщитьParser.intдля анализаSubstring.UnicodeScalarView:extension Parser, где Input == Substring.UnicodeScalarView, Output == Int { static let int = Self { ввод в фатальная ошибка ("нереализовано") } } пусть строка = "123 Привет" var input = строка[...].unicodeScalars предварительное условие (Parser.int.run (& input) == 123) предварительное условие (Подстрока (ввод) == "Привет")Каковы характеристики производительности по сравнению с
РешениеSubstring?Следите за решением в следующих эпизодах!
Еще более низким уровнем, чем
UnicodeScalarView, являетсяUTF8View. Обобщить Parser.intдля анализаSubstring.UTF8View:extension Parser, где Input == Substring.UTF8View, Output == Int { static let int = Self { ввод в фатальная ошибка ("нереализовано") } } пусть строка = "123 Привет" входная переменная = строка[...].utf8 предварительное условие (Parser.int.run (& input) == 123) предварительное условие (Подстрока (ввод) == "Привет")Как соотносятся характеристики производительности с
РешениеSubstringиSubstring.UnicodeScalarView?Следите за решением в следующих эпизодах!
Эпизод № 126 • 23 ноября 2020 г. • Только для подписчиков
Обобщение типа синтаксического анализатора позволило нам анализировать больше типов входных данных, но это только царапины на поверхности. Он также открывает множество новых вещей, которые раньше было невозможно увидеть, в том числе возможность анализировать поток входных данных и передавать его выходные данные, что делает наши синтаксические анализаторы намного более производительными. 9
Он также открывает множество новых вещей, которые раньше было невозможно увидеть, в том числе возможность анализировать поток входных данных и передавать его выходные данные, что делает наши синтаксические анализаторы намного более производительными. 9
Часть 3
16:38
Потоковая передача вывода парсера
26:26
Заключение
34:35
Упражнения
Загрузки
Un lock This Episode
Наш бесплатный план включает в себя 1 выпуск на ваш выбор только для подписчиков, а также еженедельные обновления из нашего информационного бюллетеня.
Введение
00:05
Это впечатляет. Мы добавили всего 70 дополнительных строк парсеров в нашу базовую библиотеку и открыли возможность очень кратко и выразительно анализировать входящие запросы, чтобы мы могли направлять их в разные части нашего приложения или веб-сайта. Существуют целые библиотеки, посвященные этой функциональности, и все же здесь мы обнаружили, что это всего лишь небольшое следствие наличия мощной, универсальной библиотеки синтаксического анализа, доступной нам.
00:31
Единственное, чего не хватает в этой микробиблиотеке маршрутизации, — это еще нескольких комбинаторов для анализа заголовков и тела запроса, а также способа превратить туманное значение URLRequest в одно из этих значений RequestData , но мы оставим обе эти вещи в качестве упражнений для представления. э.
00:47
Так что я думаю, что это невероятно. Мы сильно обобщили нашу библиотеку синтаксического анализа, все ранее написанные синтаксические анализаторы по-прежнему компилируются и работают так же, как и раньше, но теперь мы можем выполнять задачи синтаксического анализа для всех новых типов ввода, которые ранее были невозможны.
01:07
Но как бы круто все это ни было, мы все же хотим задать крайне важный вопрос, который мы задаем в конце каждой серии эпизодов Point-Free: в чем смысл? Потому что, хотя мы и обобщили синтаксический анализ, мы также сделали его немного более сложным. Мы не только должны думать немного усерднее, когда дело доходит до написания общего синтаксического анализатора, и должны иметь некоторые знания об обобщениях и протоколе
Collection, но мы также иногда должны давать компилятору некоторые дополнительные подсказки, чтобы он вычислил типы. 01:42
Так стоит ли такая дополнительная сложность? Вместо того, чтобы обобщать синтаксические анализаторы, должны ли мы потратить немного больше времени на создание более надежных синтаксических анализаторов, которые, возможно, могли бы справиться со сложностями синтаксического анализа необработанного URLRequest , а не изобретать тип RequestData и пытаться его проанализировать?
01:58
И мы, конечно же, считаем, что эта дополнительная сложность стоит того. Обобщение сигнатуры синтаксического анализатора позволило нам анализировать все новые типы ввода, но это только начало. Сам акт обобщения открыл все новые возможности, которые раньше невозможно было увидеть. Например:
02:19
02:52
03:16
03:43
Мы делаем очень большие заявления. Мы говорим, что, просто обобщая тип ввода наших парсеров, мы можем разблокировать возможность потоковой передачи ввода в наши парсеры, открывать новые формы композиции и немедленно улучшать производительность наших парсеров, в основном бесплатно.
Подпишитесь на Point-Free
Получите доступ к этому эпизоду, а также ко всем прошлым и будущим эпизодам, когда вы станете подписчиком.
Посмотреть планы и цены Уже подписчик? Войти
Упражнения
Загрузки
Образец кода
0126-generalized-parsing-pt3 Учебное пособие по YAML: все, что вам нужно, чтобы начать работу за считанные минуты
YAML не является языком разметки ( 9 0189 YAML ) — это язык сериализации данных, который неизменно входит в число самых популярных языков программирования. Он часто используется в качестве формата для файлов конфигурации, но его возможности сериализации объектов делают его жизнеспособной заменой для таких языков, как JSON. Это руководство по YAML продемонстрирует синтаксис языка с помощью руководства и нескольких простых примеров кодирования на Питон . YAML имеет широкую языковую поддержку и легко сопоставляется с собственными структурами данных. Его также легко читать людям, поэтому это хороший выбор для настройки. Аббревиатура YAML была сокращением от «Еще один язык разметки». Но сопровождающие переименовали его в YAML — это не язык разметки, чтобы уделить больше внимания его функциям, ориентированным на данные.
Краткое руководство по YAML: простой файл
Давайте кратко рассмотрим файл YAML.
---
лань: «олень, олень»
луч: "капля золотого солнца"
Пи: 3,14159Рождество: правда
французские куры: 3
кричащие птицы:
- хьюи
- Дьюи
- Луи
- Фред
рождество пятого дня:
призывные птицы: четыре
французские куры: 3
золотые кольца: 5
куропатки:
количество: 1
локация: "грушевое дерево"
горлицы: две
Файл начинается с трех дефисов. Эти тире обозначают начало нового документа YAML. YAML поддерживает несколько документов, и совместимые синтаксические анализаторы распознают каждый набор дефисов как начало нового. Далее мы видим конструкцию, которая составляет большую часть типичного документа YAML: пару ключ-значение. «Лань» — это ключ, указывающий на строковое значение: «олень, олень». YAML поддерживает не только строковые значения. Файл начинается с шести пар ключ-значение. Они имеют четыре разных типа данных. «лань» и «луч» — это строки. «Пи» — это число с плавающей запятой. "xmas" является логическим значением. «Французские куры» — целое число. Вы можете заключать строки в одинарные (‘) или двойные кавычки (“) или вообще без кавычек. YAML распознает числа без кавычек как целые числа или числа с плавающей запятой. Седьмой элемент — это массив. «Зовящие птицы» состоят из четырех элементов, каждый из которых обозначается открывающим тире. Я сделал отступ между элементами в «Calling-birds» двумя пробелами. Отступ — это то, как YAML обозначает вложенность. Количество пробелов может варьироваться от файла к файлу, но вкладки не допускаются. Ниже мы рассмотрим, как работает отступ. Наконец, мы видим «xmas-fifth-day», внутри которого есть еще пять элементов, каждый из которых имеет отступ. Мы можем рассматривать «xmas-fifth-day» как словарь, содержащий две строки, два целых числа и еще один словарь. YAML поддерживает вложение ключей и значений и смешивание типов. Прежде чем углубляться, давайте посмотрим, как этот документ выглядит в формате JSON. Я брошу это в этот удобный Конвертер JSON в YAML .
{
"лань": "олень, олень",
"луч": "капля золотого солнца",
"пи": 3.14159,
"рождество": правда,
«французские куры»: 3,
"звонящие птицы": [
"Хьюи",
"Дьюи",
"Луи",
"Фред"
],
"рождество-пятый день": {
«звонящие птицы»: «четыре»,
«французские куры»: 3,
«золотые кольца»: 5,
"куропатки": {
"количество": 1,
"местоположение": "грушевое дерево"
},
"горлицы": "два"
}
} JSON и YAML имеют схожие возможности, и вы можете конвертировать большинство документов между этими форматами.
Отступ контура и пробелы
Пробелы являются частью форматирования YAML. Если не указано иное, символы новой строки указывают на конец поля. Вы структурируете документ YAML с отступом. Уровень отступа может быть одним или несколькими пробелами. Спецификация запрещает вкладки, потому что инструменты обрабатывают их по-разному. Рассмотрим этот документ. Элементы внутри имеют отступ с двумя пробелами.
foo: бар
Пле: помогите
вещи:
фу: бар
бар: фу
Давайте посмотрим, как простой скрипт на питоне просматривает этот документ. Мы сохраним его как файл с именем foo.yaml . Пакет PyYAML сопоставит файловый поток YAML со словарем. Мы пройдемся по самому внешнему набору ключей и значений и напечатаем ключ и строковое представление каждого значения. Вы можете найти процессор для вашей любимой платформы здесь.
Ямл импортный
из загрузки импорта yaml
пытаться:
из yaml импортировать CLoader как загрузчик
кроме ошибки импорта:
из загрузчика импорта yaml
если __name__ == '__main__':
поток = открыть ("foo.yaml", 'r')
словарь = yaml. load (поток)
для ключа, значение в словаре.items():
печать (клавиша + ": " + ул (значение))
Вывод:
foo : бар
Пле: помогите
stuff : {'foo': 'bar', 'bar': 'foo'} Когда мы говорим python напечатать словарь в виде строки, он использует встроенный синтаксис, который мы увидим ниже. Из вывода видно, что наш документ представляет собой словарь Python с двумя строками и еще одним словарем, вложенным в него. Простая вложенность YAML дает нам возможность создавать сложные объекты. Но это только начало.
Комментарии
Комментарии начинаются со знака решетки. Они могут стоять после значения документа или занимать целую строку.
___
# Это комментарий на всю строку
foo: bar # это тоже комментарий
Комментарии предназначены для людей. Процессоры YAML отбросят их.
Типы данных YAML
Значения в парах ключ-значение YAML являются скалярными. Они действуют как скалярные типы в таких языках, как Perl, Javascript и Python. Обычно достаточно заключать строки в кавычки, оставлять числа без кавычек и позволить синтаксическому анализатору разобраться с этим. Но это только верхушка айсберга. YAML способен на гораздо большее.
Пары "ключ-значение" и словари
Ключ-значение — это основной строительный блок YAML. Каждый элемент в документе YAML является членом хотя бы одного словаря. Ключ всегда является строкой. Значение является скаляром, поэтому может быть любым типом данных. Итак, как мы уже видели, значение может быть строкой, числом или другим словарем.
Числовые типы
YAML распознает числовые типы. Выше мы видели числа с плавающей запятой и целые числа. YAML поддерживает несколько других числовых типов. Целое число может быть десятичным, шестнадцатеричным или восьмеричным.
---
фу: 12345
бар: 0x12d4
plop: 023332
Давайте запустим наш скрипт Python для этого документа.
фу : 12345
бар : 4820
plop : 9946
Как и следовало ожидать, Ox указывает, что значение является шестнадцатеричным, а начальный ноль обозначает восьмеричное значение. YAML поддерживает как фиксированные, так и экспоненциальные числа с плавающей запятой.
---
фу: 1230.15
bar: 12.3015e+05
Когда мы оцениваем эти записи, мы видим:
foo : 1230.15
bar : 1230150.0
Наконец, мы можем представить не-число (NAN) или бесконечность.
---
фу: .inf
бар: -.Inf
plop: .NAN
Значение foo равно бесконечности. Bar — это отрицательная бесконечность, а plop — это NAN.
Строки
Строки YAML имеют кодировку Unicode. В большинстве случаев вам не нужно указывать их в кавычках.
---
foo: это обычная строка
Наша тестовая программа обрабатывает это как:
foo: это обычная строка
Но если мы хотим обрабатывать escape-последовательности, нам нужно использовать двойные кавычки.
---
foo: "это не обычная строка\n"
bar: это не обычная строка\n
YAML обрабатывает первое значение как заканчивающееся возвратом каретки и переводом строки. Поскольку второе значение не заключено в кавычки, YAML рассматривает \n как два символа.
foo: это не обычная строка
bar: это не обычная строка\n
YAML не экранирует строки с одинарными кавычками, но одинарные кавычки позволяют избежать интерпретации содержимого строки как форматирования документа. Строковые значения могут занимать более одной строки. С помощью символа сгиба (больше чем) вы можете указать строку в блоке.
бар: >
это не обычная строка это
охватывает более
одна линия
видеть?
Но интерпретируется без перевода строки.
бар: это не обычная строка, она занимает более одной строки, понимаете?
Символ блока (вертикальной черты) имеет аналогичную функцию, но YAML интерпретирует поле точно так, как оно есть.
бар: |
это не обычная строка это
охватывает более
одна линия
видеть?
Итак, мы видим новые строки там, где они есть в документе.
бар: это не обычная строка
охватывает более
одна линия
видеть?
Пустые значения
Вы вводите пустые значения с помощью тильды (~) или строкового литерала нулевого значения без кавычек.
---
фу: ~
bar: null
Наша программа выводит:
foo : None
bar : None
Представление Python для null равно None.
Логические значения
YAML указывает логические значения с ключевыми словами True, On и Yes для true. False обозначается False, Off или №
---
фу: правда
бар: Ложь
включить свет
ТВ: Выкл.
Массивы
Вы можете указать массивы или списки в одной строке.
---
предметы: [ 1, 2, 3, 4, 5 ]
имена: [ "один", "два", "три", "четыре" ]
Или вы можете поместить их в несколько строк.
---
предметы:
- 1
- 2
- 3
- 4
- 5
имена:
- "один"
- "два"
- "три"
- "четыре"
Многострочный формат удобен для списков, содержащих сложные объекты вместо скаляров.
___
предметы:
- вещи:
вещь 1: хьюи
вещи2: Дьюи
вещь 3: Луи
- другие вещи:
ключ: значение
Массив может содержать любое допустимое значение YAML. Значения в списке не обязательно должны быть одного типа.
Словари
Мы рассмотрели словари выше, но это еще не все. Как и массивы, вы можете поместить словари в строку. Мы видели этот формат выше. Так Python печатает словари.
---
foo: { вещь1: Хьюи, вещь2: Луи, вещь3: Дьюи } Мы уже видели, как они соединяют строки раньше.
---
фу: бар
bar: foo
И, конечно же, они могут быть вложенными и содержать любое значение.
---
фу:
бар:
- бар
- раб
- plop
Дополнительные параметры
Модификаторы Chomp
Многострочные значения могут заканчиваться пробелами, и в зависимости от того, как вы хотите обработать документ, вы можете не захотеть его сохранять. В YAML есть операторы strip chomp и save chomp. Чтобы сохранить последний символ, добавьте плюс к операторам fold или block.
бар: >+
это не обычная строка это
охватывает более
одна линия
видеть?
Таким образом, если значение заканчивается пробелом, например новой строкой, YAML сохранит его. Чтобы убрать символ, используйте оператор полосы.
бар: |-
это не обычная строка это
охватывает более
одна линия
видеть?
Несколько документов
Документ начинается с трех дефисов и заканчивается тремя точками. Некоторым процессорам YAML требуется оператор запуска документа. Конечный оператор обычно необязателен. Например, Jackson в Java не будет обрабатывать документ YAML без начала, а PyYAML в Python — сможет. Обычно вы будете использовать оператор конца документа, когда файл содержит несколько документов. Давайте изменим наш код Python.
импортный ямл
из загрузки импорта yaml
пытаться:
из yaml импортировать CLoader как загрузчик
кроме ошибки импорта:
из загрузчика импорта yaml
если __name__ == '__main__':
поток = открыть ("foo.yaml", 'r')
словарь = yaml.load_all (поток, загрузчик)
для документа в словаре:
print("Новый документ:")
для ключа, значение в doc.items():
печать (ключ + ": " + ул (значение))
если тип (значение) список:
print(str(len(value))) PyYAML load_all будет обрабатывать все документы в потоке. Теперь давайте обработаем с его помощью составной документ.
---
бар: фу
фу: бар
...
---
один два
три: четыре
Сценарий находит два документа YAML.
Новый документ:
бар: фу
фу : бар
Новый документ:
один два
three : Four
Заключение
YAML — мощный язык, который можно использовать для файлов конфигурации, сообщений между приложениями и сохранения состояния приложения. Мы рассмотрели его наиболее часто используемые функции, в том числе то, как использовать встроенные типы данных и структурировать сложные документы. Некоторые 9Платформы 0189 поддерживают расширенные функции YAML, включая пользовательские типы данных.
CloudBees предоставляет множество сообщений в блоге , в которых обсуждаются преимущества использования YAML для управления данными приложений и конфигурации. Если вам интересно узнать больше о YAML и его приложениях, мы приглашаем вас изучить множество сообщений в блогах, созданных CloudBees, о технологиях, связанных с YAML.

 Это может значительно повысить производительность синтаксических анализаторов, которым необходимо работать с большими наборами данных, для которых нецелесообразно помещать большой блок данных в память и анализировать его в большой массив данных для обработки.
Это может значительно повысить производительность синтаксических анализаторов, которым необходимо работать с большими наборами данных, для которых нецелесообразно помещать большой блок данных в память и анализировать его в большой массив данных для обработки.
 run(&input) else { return nil }
охранять let newOutput = parser.run(&output) else {
ввод = оригинал
вернуть ноль
}
вернуть новый вывод
}
}
}
run(&input) else { return nil }
охранять let newOutput = parser.run(&output) else {
ввод = оригинал
вернуть ноль
}
вернуть новый вывод
}
}
}
 Обобщить
Обобщить  Это руководство по YAML продемонстрирует синтаксис языка с помощью руководства и нескольких простых примеров кодирования на Питон . YAML имеет широкую языковую поддержку и легко сопоставляется с собственными структурами данных. Его также легко читать людям, поэтому это хороший выбор для настройки. Аббревиатура YAML была сокращением от «Еще один язык разметки». Но сопровождающие переименовали его в YAML — это не язык разметки, чтобы уделить больше внимания его функциям, ориентированным на данные.
Это руководство по YAML продемонстрирует синтаксис языка с помощью руководства и нескольких простых примеров кодирования на Питон . YAML имеет широкую языковую поддержку и легко сопоставляется с собственными структурами данных. Его также легко читать людям, поэтому это хороший выбор для настройки. Аббревиатура YAML была сокращением от «Еще один язык разметки». Но сопровождающие переименовали его в YAML — это не язык разметки, чтобы уделить больше внимания его функциям, ориентированным на данные. YAML поддерживает несколько документов, и совместимые синтаксические анализаторы распознают каждый набор дефисов как начало нового. Далее мы видим конструкцию, которая составляет большую часть типичного документа YAML: пару ключ-значение. «Лань» — это ключ, указывающий на строковое значение: «олень, олень». YAML поддерживает не только строковые значения. Файл начинается с шести пар ключ-значение. Они имеют четыре разных типа данных. «лань» и «луч» — это строки. «Пи» — это число с плавающей запятой. "xmas" является логическим значением. «Французские куры» — целое число. Вы можете заключать строки в одинарные (‘) или двойные кавычки (“) или вообще без кавычек. YAML распознает числа без кавычек как целые числа или числа с плавающей запятой. Седьмой элемент — это массив. «Зовящие птицы» состоят из четырех элементов, каждый из которых обозначается открывающим тире. Я сделал отступ между элементами в «Calling-birds» двумя пробелами. Отступ — это то, как YAML обозначает вложенность. Количество пробелов может варьироваться от файла к файлу, но вкладки не допускаются.
YAML поддерживает несколько документов, и совместимые синтаксические анализаторы распознают каждый набор дефисов как начало нового. Далее мы видим конструкцию, которая составляет большую часть типичного документа YAML: пару ключ-значение. «Лань» — это ключ, указывающий на строковое значение: «олень, олень». YAML поддерживает не только строковые значения. Файл начинается с шести пар ключ-значение. Они имеют четыре разных типа данных. «лань» и «луч» — это строки. «Пи» — это число с плавающей запятой. "xmas" является логическим значением. «Французские куры» — целое число. Вы можете заключать строки в одинарные (‘) или двойные кавычки (“) или вообще без кавычек. YAML распознает числа без кавычек как целые числа или числа с плавающей запятой. Седьмой элемент — это массив. «Зовящие птицы» состоят из четырех элементов, каждый из которых обозначается открывающим тире. Я сделал отступ между элементами в «Calling-birds» двумя пробелами. Отступ — это то, как YAML обозначает вложенность. Количество пробелов может варьироваться от файла к файлу, но вкладки не допускаются. Ниже мы рассмотрим, как работает отступ. Наконец, мы видим «xmas-fifth-day», внутри которого есть еще пять элементов, каждый из которых имеет отступ. Мы можем рассматривать «xmas-fifth-day» как словарь, содержащий две строки, два целых числа и еще один словарь. YAML поддерживает вложение ключей и значений и смешивание типов. Прежде чем углубляться, давайте посмотрим, как этот документ выглядит в формате JSON. Я брошу это в этот удобный Конвертер JSON в YAML .
Ниже мы рассмотрим, как работает отступ. Наконец, мы видим «xmas-fifth-day», внутри которого есть еще пять элементов, каждый из которых имеет отступ. Мы можем рассматривать «xmas-fifth-day» как словарь, содержащий две строки, два целых числа и еще один словарь. YAML поддерживает вложение ключей и значений и смешивание типов. Прежде чем углубляться, давайте посмотрим, как этот документ выглядит в формате JSON. Я брошу это в этот удобный Конвертер JSON в YAML . Если не указано иное, символы новой строки указывают на конец поля. Вы структурируете документ YAML с отступом. Уровень отступа может быть одним или несколькими пробелами. Спецификация запрещает вкладки, потому что инструменты обрабатывают их по-разному. Рассмотрим этот документ. Элементы внутри имеют отступ с двумя пробелами.
Если не указано иное, символы новой строки указывают на конец поля. Вы структурируете документ YAML с отступом. Уровень отступа может быть одним или несколькими пробелами. Спецификация запрещает вкладки, потому что инструменты обрабатывают их по-разному. Рассмотрим этот документ. Элементы внутри имеют отступ с двумя пробелами. load (поток)
для ключа, значение в словаре.items():
печать (клавиша + ": " + ул (значение))
load (поток)
для ключа, значение в словаре.items():
печать (клавиша + ": " + ул (значение))
 Обычно достаточно заключать строки в кавычки, оставлять числа без кавычек и позволить синтаксическому анализатору разобраться с этим. Но это только верхушка айсберга. YAML способен на гораздо большее.
Обычно достаточно заключать строки в кавычки, оставлять числа без кавычек и позволить синтаксическому анализатору разобраться с этим. Но это только верхушка айсберга. YAML способен на гораздо большее. YAML поддерживает как фиксированные, так и экспоненциальные числа с плавающей запятой.
YAML поддерживает как фиксированные, так и экспоненциальные числа с плавающей запятой. Поскольку второе значение не заключено в кавычки, YAML рассматривает \n как два символа.
Поскольку второе значение не заключено в кавычки, YAML рассматривает \n как два символа.

 Чтобы убрать символ, используйте оператор полосы.
Чтобы убрать символ, используйте оператор полосы. Теперь давайте обработаем с его помощью составной документ.
Теперь давайте обработаем с его помощью составной документ.