Как пользоваться словарём морфемных разборов
Какая информация о словах содержится в словаре
Это словарь морфемных разборов. Морфемный разбор — это разбор слов по составу. Каждое слово рассматривается с точки зрения его морфемной структуры. Информация включает ответы на вопросы:
- Из каких частей состоит слово?
- Есть ли в слове окончания?
- Есть ли в слове приставка или приставки (если их несколько)?
- Есть ли в слове суффикс или суффиксы (если их несколько)?
- Какой в слове корень или какие в слове корни (для сложных слов) ?
Ошибкоопасные слова содержат комментарии в примечаниях.
Словарь показывает результат разбора слов. О том, как, в каком порядке нужно производить разбор, узнай здесь: Особенности морфемного разбора слова.
Все слова выверены по «Морфемно-орфографическому словарю русского языка» А. Н. Тихонова (М.: АСТ: Астрель, 2010). Это самый большой и авторитетный словарь, показывающий морфемное членение слов. Это капитальный труд: он включает 100000 слов.
У нас слово представлено так:
Принятые обозначения
В словаре используются общепринятые символы для обозначения морфем (частей слова).
берег — корень слова
прибрежный — приставка
прибрежный — суффикс
прибрежный — окончание
прибрежный — основа слова
Отбор слов
Слова в словарь отбирались по поисковым запросам посетителей сайта. При этом учитывалась статистика запросов. Были проанализированы данные за несколько лет, а это тысячи поисковых запросов. В словарь в первую очередь были включены наиболее востребованные слова.
Кроме того, в словарь были добавлены примеры слов с высоким обучающим потенциалом, то есть таких слов, которые особенно характерны для русского языка с точки зрения своей морфемной структуры. Поскольку вид слова меняется при его изменении, то в словарь включались и отдельные формы слов, отражающие закономерности морфемного строения форм слов.
Попроси разобрать слово
Можно участвовать в расширении словаря. Если нужного слова пока в словаре нет, оставь заявку — слово будет добавлено.
Для того чтобы попросить добавить слово в словарь, найди форму «Поиск». Введи желаемое слово. Если оно не найдётся, то система предложит включить данное слово в словарь. Пожалуйста, старайтесь вносить слова без искажений: без пропуска букв, без добавления лишних букв, без замен нужной буквы другими. Если слово написано неправильно, система поиска не сможет его идентифицировать.
Популярные слова
Словарь отображает списки популярных, т.е. наиболее часто запрашиваемых слов. Это удобно, так как информирует о том, какие слова являются наиболее востребованными в школьной практике. Не ограничивайся информацией только об искомом слове. Просмотри списки популярных слов, подумай, знаешь ли ты, как они разбираются, проверь себя, открыв слово из этого списка.
Если слово открыто, то на экране слева видны другие слова из данного списка. Для их просмотра не нужно возвращаться к исходному списку. Кликай по словам слева, разборы будут открываться.
Все слова на …
Так называются полные списки слов на данную букву, например: «Все слова на Л». Полные списки существенно длиннее и полнее списков популярных слов. Ссылка: Все слова на Л даётся в конце списка популярных слов на данную букву. Если нужно увидеть, какие слова включены в словарь на какую-либо букву, можно найти соответствующую ссылку, например: Все слова на П. Если открыть список и щёлкнуть мышью по слову, то откроется разбор данного слова, а слева появятся слова из полного списка слов на данную букву.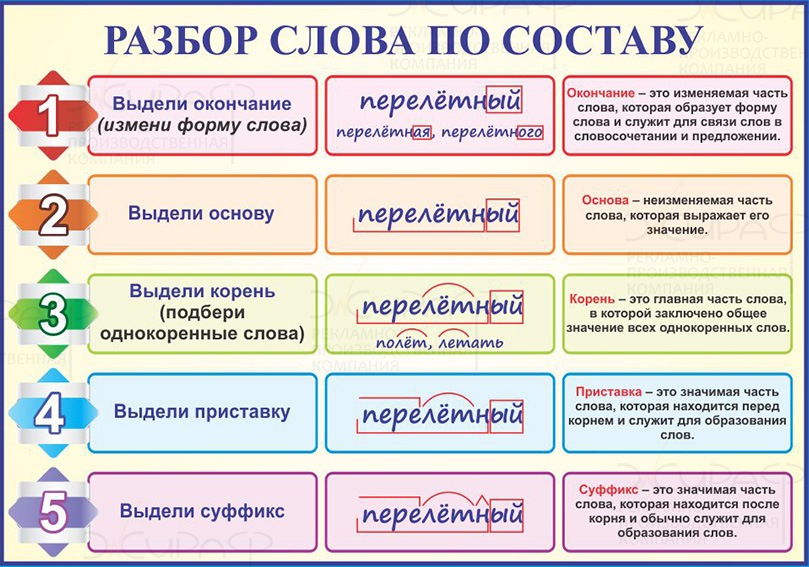
В полных списках слов на каждую букву слова расположены по алфавиту в трёх стобцах. Последовательность слов: слева направо и сверху вниз.
Если появятся вопросы
Если что-либо в разборе слова покажется непонятным, пиши об этом на Форуме. Автор с удовольствием даст разъяснения.
Чтобы оставить вопрос, нужно зарегистрироваться на Форуме.
Смотрите также
— Понравилась статья?:)Мой мир
Вконтакте
Одноклассники
Google+
разобрать по составу слово: «словари»
Помогите пожалуйста дам 10 баллов
напишите эссе на тему:Как стать сильным
Помогите пж по братски.❤
ПРОЧИТАЙ СПИШИ ТРЕТЬЕ И ЧЕТВЕРТОЕ ПРЕДЛОЖЕНИЕ ДОМОЛНИ ОДНОРОДНЫМИ ЧЛЕНАМИ МОЛОДОЙ МЕСЯЦ ПОКАЗАЛСЯ НА ЯСНОМ НЕБЕ. НА ДУШИСТЫХ ТОПОЛЯХ ЛОПНУЛИ БОЛЬШИЕ П … ОЧКИ
1. Как вы понимаете эпиграф — строки из стихотворения русского поэта начала XX века Николая Гумилёва «Слово»? . Солнце останавливали словом, Словом ра
… зрушали города. В чём божественное богатство Слова? Согласны ли вы с тем, что слово, заряженное определенной энергией, может влиять на окружающий мир? Великая сила воспитания словом Повествование в рассказе С.Н.Назаровой «Мой зеленоглазый аруах» идёт от лица молодого человека по имени Мади, который вспоминает о своих аульных стариках- аташке Кабидене и ажеске Мурселе, у которых он воспитывался до школы и которых он называл «вторые папа и мама».В произведении нашли отражение следующие традиции казахского народа: — следование обычаям предков, исповедующих мусульманскую религию; — «усыновление» старшего внука, который с рождения «передавался» на воспитание бабушке и дедушке .; -казахский язык гостеприимства қонақ асы, когда самая вкусная и лакомая еда предназначалась для гостей ..; -методы народного лечения.
помогите пожалуйста
1. Как вы понимаете эпиграф — строки из стихотворения русского поэта начала XX века Николая Гумилёва «Слово»? . Солнце останавливали словом, Словом ра
… зрушали города. В чём божественное богатство Слова? Согласны ли вы с тем, что слово, заряженное определенной энергией, может влиять на окружающий мир? Великая сила воспитания словом Повествование в рассказе С.
Выпиши выделинные наречия вместе со словами, к которым они относется. Поставь к наречиям вопросы. С помощью таблицы упр 1 опредили, что обозначает каж … дое наречие. пожалуста у кого будет правильно дам корону
5. Послушай чтение одноклассников. Какие факты о космосе показались тебе наиболее интересными? Что ты можешь добавить?1. В космосе в условиях невесомо … сти пониженное давле-ние действует на позвоночник. (Где?) Здесь космонавтыстановятся выше в среднем на 5 сантиметров.2. (Когда?) Недавно космонавтысделали первый телефонный звонокна планету Земля.3. Самый полезный продукт в кос-клубника. Эта ягода (как?) бы-стро нейтрализует вредное воздействиекосмических лучей на космонавтов.4. В космосе каждый человек может(как?) легко почувствовать себя мужественным, потому чтов невесомости слёзы не текут.5. Если бы до Луны можно было дойти (как?) пешком, тоидти пришлось бы (в какой степени?) слишком (как?) долго -целых 9 лет.MOce
5. Послушай чтение одноклассников. Какие факты о космосе по-казались тебе наиболее интересными? Что ты можешь добавить?1. В космосе в условиях невесом … ости пониженное давле-ние действует на позвоночник. (Где?) Здесь космонавтыстановятся выше в среднем на 5 сантиметров.2. (Когда?) Недавно космонавтысделали первый телефонный звонокна планету Земля.3. Самый полезный продукт в кос-мосе — Клубника. Эта ягода (как?) бы-стро нейтрализует вредное воздействиекосмических лучей на космонавтов.4. В космосе каждый человек может(как?) легко почувствовать себя мужественным, потому чтов невесомости слёзы не текут.5. Если бы до Луны можно было дойти (как?) пешком, тоидти пришлось бы (в какой степени?) слишком (как?) долго –целых 9 лет.
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences.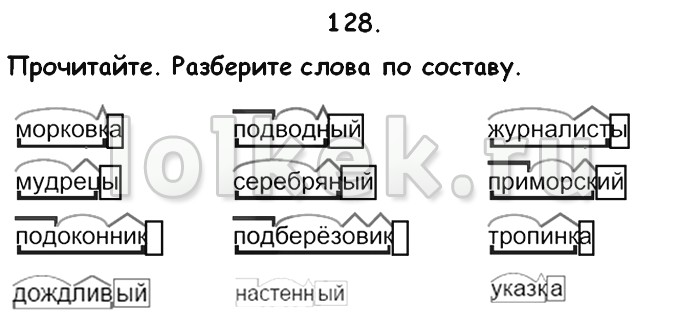 Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Словарь синонимов русского языка онлайн
Словарь русских синонимов
и сходных по смыслу выражений
synonymonline.ru — бесплатный онлайн-словарь русских синонимов. Словарь насчитывает более 220 тысяч синонимических рядов, которых вполне достаточно, как минимум, для покрытия обиходно-бытовой лексики.
Подбор синонимов
Слова в словаре представлены в начальных формах: существительные — в именительном падеже, прилагательные — в мужском роде именительного падежа, глаголы — в инфинитиве. Если вы ищете слова, отличные от начальной формы, то синонимы для них могут быть легко получены из нашего словаря путем приведения их к нужному склонению, числу, роду или времени.
synonymonline.ru не является сервисом онлайн синонимайзера, но является вашим помощником для подбора синонимов и поиска слов по словарю. Воскользуйтесь алфавитным указателем и формой поиска.
Состав и структура словаря
Сайт synonymonline.ru был создан в декабре 2012 года. С того момента сайт структурно не изменился, а идеология до сих пор сводится к двум моментам: большая база слов и удобный поиск по словарю. Словарь содержит синонимы для более чем 220 тысяч слов. Из них существительных — 35%, прилагательных — 20%, причастий — 15%, глаголов — 16% и слов других частей речи — 14%.
Цитата: «Мы видели сайты словарей синонимов и больше — в 500-700 тысяч синонимических рядов. Почему ваш словарь считаете большим?» Ответ на вопрос состоит из двух пунктов.
- Наш словарь содержит слова только в начальной форме: именительный падеж, единственное число, инфинитив. Добавление в словарь слов во всех формах считаем неоправданным дублированием — синонимические ряды от этого не изменятся.
- Словарь не содержит синонимы для словосочетаний и фраз. Для подбора синонимов к словосочетаниям можно подобрать синоним к одному из слов, что в большинстве случае достаточно. Число вариантов сочетания различных слов велико, их добавление приведёт к «замусориванию» словаря.
Сейчас словарём пользуются тысячи людей, есть постоянная аудитория, которая обращается к словарю еженедельно. В чём отличие synonymonline.ru от остальных словарей? Главных отличий три.
1. Новые слова
Словарь содержит не только слова, включенные в известные изданные словари синонимов, но и новые, появившиеся в русском языке последнее десятилетие. Среди них: сникерс, гугл, твитнуть, хэтчбек, фитоняшка, инфоцыган и другие. Словарь синонимов synonymonline.ru создавался на основе нескольких словарей синонимов из открытых источников. Время от времени выявляются опечатки и неточности, встречаются «проблемные» синонимические ряды с искажением смысла. Просим с пониманием относиться к данному факту: общий объём слов в словаре более 200 тысяч, доскональная проверка всех синонимических рядов требует титанических усилий. Проводилась и проводится работа по исключению ошибок и дополнению словаря, не без помощи посетителей, оставляющих замечания и новые варианты в комментариях.
Время от времени выявляются опечатки и неточности, встречаются «проблемные» синонимические ряды с искажением смысла. Просим с пониманием относиться к данному факту: общий объём слов в словаре более 200 тысяч, доскональная проверка всех синонимических рядов требует титанических усилий. Проводилась и проводится работа по исключению ошибок и дополнению словаря, не без помощи посетителей, оставляющих замечания и новые варианты в комментариях.
2. Разнообразие синонимов
Словарь включает синонимы из всех возможных областей и сфер деятельности человека, в которых слово имеет место быть, включая переносный смысл и образные выражения. Например, крыша — это не только дом и кровля, но также покровительство, связи, башка, репа и т.п. Таким образом, за счёт включения не только популярных синонимов, а всех возможных, у ряда слов наблюдается избыточность. Мы преследуем цель предоставить синонимы для лиц разных областей, социальных статусов, профессий. И считаем, что избыточность лучше недостаточности: из десятка синонимов вы можете выбрать 2-3 подходящих и отбросить остальные непонятные, которые могут, напротив, подойти кому-либо другому. Комментарии вида «это не синоним», «причём тут это?», «что за бред?» часто свидетельствуют об отсутствии всесторонних знаний комментирующих.
3. Слова и фразы
В педагогических изданиях в качестве синонимов выступают слова, а не словосочетания. Традиционный подход хорош, например, для школьников в подготовке домашних заданий, но не достаточен для журналистов, копирайтеров, писателей и представителей других профессий. В нашем словаре в качестве синонимов выступают не только слова, но и словосочетания, устойчивые выражения. Во-первых, для некоторых слов нет хороших синонимов в одно слово, например: Япония — страна восходящего солнца. Во-вторых, наличие фраз вместе со словами даёт авторам больше подходящих вариантов, помогает не повторяться, позволяет точнее выразить отношение, например: пусто — «шаром покати», далеко — «у чёрта на куличках».
Дополнительную информацию о словаре можно найти на страницах возможностей словаря и обратной связи.
synonymonline.ru — словарь синонимов онлайн, подбор синонимов и сходных по смыслу выражений
Пара тысяч чертова дюжина — текущий год 🙂
границ | Доказательства морфологического состава сложных слов с использованием MEG
1. Введение
Некоторые слова простые, а некоторые нет. Поначалу это звучит как очень банальная тавтология, но споры о том, хранятся ли мультиморфемные слова просто в виде целой словоформы (Butterworth, 1983; Giraudo and Grainger, 2001) или всегда строятся из их морфемных частей (Taft, 2004). ) был развлекательным, провокационным и спорным в области лексической обработки в течение последних 40 лет.Комплексная модель того, как слова сохраняются и извлекаются, требует понимания того, как связаны форма и значение и как эта связь разворачивается во времени в естественной речи.
Потенциальный контраст между хранением целого слова и хранением морфем впервые обсуждался в классической модели удаления аффиксов (Taft and Forster, 1975), которая предполагала, что лексический доступ включает доступ к основе морфологически сложных слов. Это исследование показало, что псевдосложные слова с реальной основой (например,g., de- juvenate ) потребовалось больше времени для отклонения в задаче лексического решения (и часто неправильно выбирались как слова), чем псевдосложные слова с реальными префиксами и несуществующими основами (например, de- pertoire ). Это было воспринято как доказательство того, что к морфемам обращались до лексического доступа, и они способствуют поиску лексического элемента в памяти. При использовании различных парадигм прайминга накопились доказательства в пользу доступности морфем во время лексического доступа (Marslen-Wilson et al., 1994; Растл и Дэвис, 2003; Тафт, 2004). Это привело к появлению моделей обработки, в которых морфологическая декомпозиция является автоматическим и необходимым этапом обработки сложных слов (Rastle et al., 2004). В недавних исследованиях (Fiorentino et al., 2014; Semenza and Luzzatti, 2014) изучались этапы разложения, чтобы увидеть, как значение морфемы интегрируется в значение сложного слова. Результаты электрофизиологии (Fiorentino et al., 2014) показали большую отрицательность для лексикализованных соединений (например,g., teacup) и новые соединения (например, tombnote) по сравнению с мономорфемными словами во временном окне 275–400 мс, что указывает на стадию, на которой значения морфем объединяются в английских соединениях. Эти психологические модели делают четкие прогнозы относительно стадий и динамики лексического доступа, но в настоящее время отсутствуют доказательства привязки этих стадий к определенным областям мозга. Это исследование направлено на выявление области, ответственной за состав значений морфем. Исследования из литературы по именованию картинок (Dohmes et al., 2004) предполагает, что на этом этапе должна быть большая активация для семантически прозрачных сложных слов, поскольку они демонстрируют большую концептуальную активацию и конкуренцию лемм в дополнение к эффекту морфологического перекрытия. Следовательно, эта область должна быть чувствительной только к составу сложных слов, значение морфемы которых имеет семантически прозрачное отношение к общему значению по сравнению со сложными словами, морфемы которых не разделяют семантические отношения, непрозрачный .
Это привело к появлению моделей обработки, в которых морфологическая декомпозиция является автоматическим и необходимым этапом обработки сложных слов (Rastle et al., 2004). В недавних исследованиях (Fiorentino et al., 2014; Semenza and Luzzatti, 2014) изучались этапы разложения, чтобы увидеть, как значение морфемы интегрируется в значение сложного слова. Результаты электрофизиологии (Fiorentino et al., 2014) показали большую отрицательность для лексикализованных соединений (например,g., teacup) и новые соединения (например, tombnote) по сравнению с мономорфемными словами во временном окне 275–400 мс, что указывает на стадию, на которой значения морфем объединяются в английских соединениях. Эти психологические модели делают четкие прогнозы относительно стадий и динамики лексического доступа, но в настоящее время отсутствуют доказательства привязки этих стадий к определенным областям мозга. Это исследование направлено на выявление области, ответственной за состав значений морфем. Исследования из литературы по именованию картинок (Dohmes et al., 2004) предполагает, что на этом этапе должна быть большая активация для семантически прозрачных сложных слов, поскольку они демонстрируют большую концептуальную активацию и конкуренцию лемм в дополнение к эффекту морфологического перекрытия. Следовательно, эта область должна быть чувствительной только к составу сложных слов, значение морфемы которых имеет семантически прозрачное отношение к общему значению по сравнению со сложными словами, морфемы которых не разделяют семантические отношения, непрозрачный .
Один из способов взглянуть на лексическую обработку сложных слов — посмотреть, может ли активация морфологической структуры модулировать доступность сложного слова. Некоторые исследования кросс-модального прайминга (Marslen-Wilson et al., 1994) показали, что праймирование в лексическом решении между словами, имеющими общую основу, происходило только тогда, когда простое число и цель имели связанные значения (например, , отклонение , штрих , отклонение , но , отдел — нет), в то время как другие исследования (Zwitserlood, 1994) с использованием прайминга с частичным повторением показали, что прайминг не зависит от семантических отношений между простым числом и целью. Однако исследования с использованием замаскированного прайминга, парадигмы сублиминального прайминга, где простому слову предшествует прямая маска, а за ним следует целевое слово (Forster and Davis, 1984), обнаружили, что при манипулировании семантической прозрачностью эффекты облегчения возникали для сложных слов независимо от имеют ли прайм и мишень один и тот же морфологический корень (Longtin et al., 2003; Rastle et al., 2004; Fiorentino and Poeppel, 2007; McCormick et al., 2008). Эти эффекты не проявлялись для морфологически простых слов (например,г., публичный дом ). Более быстрое время лексического решения было обнаружено для сложных слов, которые можно сегментировать на существующие морфемы, что означает, что замаскированные простые / немаскированные целевые пары без семантических отношений, такие как угол-кукуруза и бутлег-ботинок , показали ускоренное распознавание целевых слов с помощью величины, неотличимые от пар с семантическими отношениями, такими как очиститель-очиститель и чашка-чай .
Однако исследования с использованием замаскированного прайминга, парадигмы сублиминального прайминга, где простому слову предшествует прямая маска, а за ним следует целевое слово (Forster and Davis, 1984), обнаружили, что при манипулировании семантической прозрачностью эффекты облегчения возникали для сложных слов независимо от имеют ли прайм и мишень один и тот же морфологический корень (Longtin et al., 2003; Rastle et al., 2004; Fiorentino and Poeppel, 2007; McCormick et al., 2008). Эти эффекты не проявлялись для морфологически простых слов (например,г., публичный дом ). Более быстрое время лексического решения было обнаружено для сложных слов, которые можно сегментировать на существующие морфемы, что означает, что замаскированные простые / немаскированные целевые пары без семантических отношений, такие как угол-кукуруза и бутлег-ботинок , показали ускоренное распознавание целевых слов с помощью величины, неотличимые от пар с семантическими отношениями, такими как очиститель-очиститель и чашка-чай .
Поскольку общепринято, что морфологическая декомпозиция выполняется для каждого сложного слова, которое может быть исчерпывающим образом разобрано на существующие морфемы, исследования визуального распознавания слов должны сместить акцент с декомпозиции на последующие механизмы, задействованные для активации фактического значения сложного целевого слова. .Менье и Лонгтин (2007) предположили, что активация слова вступает в игру поэтапно, которые включают по крайней мере одну раннюю стадию морфологической декомпозиции и более позднюю стадию семантической интеграции морфологических частей. Fiorentino et al. (2014) представили доказательства основанного на морфемах пути активации слова, который включает разложение на морфологические составляющие и комбинаторные процессы, действующие на эти представления. Поскольку предыдущие исследования показали, что ранняя декомпозиция, вызванная морфологической структурой, происходит автоматически для прозрачных и непрозрачных слов, разница между этими двумя типами слов может проявиться на более позднем этапе комбинаторных операций.
Другой способ взглянуть на лексическую обработку сложных слов — это посмотреть, как форма отображается на значение. Это очень важно при обработке морфологически сложных слов, чтобы отделить то, как мозг воспринимает прозрачные слова от того, как он воспринимает непрозрачные. Это можно исследовать, посмотрев, как значения морфем складываются в мозгу. Существуют модели общего механизма связывания в построении предложений (Friederici et al., 2000) и в базовой композиции именных фраз (Bemis and Pylkkänen, 2011), которые вовлекают левую переднюю височную долю (LATL) в состав слов во фразы. .В парадигме минимальной композиции Bemis и Pylkkänen (2011) обнаружили, что два составных элемента во фразе прилагательное-существительное (например, красная лодка ) вызывают большую активацию в левой передней височной доле, LATL, примерно на 225 мс, чем два. несоставные элементы (например, xkq boat , случайная последовательность букв и слова). Это было воспринято как доказательство того, что базовая комбинаторная обработка данных поддерживается LATL. В сложных словах есть особый подкласс слов, которые имеют структуру, параллельную существительным фразам, известным как составные слова.Сложные слова обладают уникальным свойством состоять только из свободных морфем (отдельных слов). Составные слова также различаются по измерению семантической прозрачности , степени, в которой комбинация значений морфем соответствует общему значению слова. Это означает, что мы можем варьировать вклад морфем в композицию значения. Эти свойства делают составные слова отличным кандидатом для исследования морфологического состава сложных слов, поскольку они могут обеспечивать аналогичную структуру для работы, выполняемой на уровне фразы.Эти параллели приводят к тому, что LATL является кандидатом на композицию в пределах слова, и это обеспечивает интересную основу для изучения эффектов внутрилексической семантической композиции как аналога композиции на уровне фразы.
Таким образом, семантически прозрачные составные слова (например, почтовый ящик) должны вызывать большую активность в этой области, чем простые слова, поскольку их значения происходят из состава их морфемических частей, тогда как семантически непрозрачные составные слова (например,, бутлег) не должны вызывать большей активности, поскольку между их частями и значениями нет никакой связи.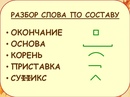 В общем, модель сложного распознавания слов потребует, по крайней мере, этих двух этапов обработки: разбора на базовые единицы (декомпозиция) и композиции этих словоформ в сложное значение. Чтобы распаковать эти этапы, мы предлагаем использовать два типа парадигм грунтования: грунтовку с частичным повторением (например, ДОРОГА-обочина), аналогичные парадигмам, используемым в исследованиях замаскированного грунтования, которые будут использоваться для исследования эффектов разложения в соединениях, и грунтовка с полным повторением (например,g., ROADSIDE-roadside), которые будут использованы для исследования композиционных эффектов их морфем. Штрихи условия повторения примирования использовали для оценки эффекта композиции в отсутствие поведенческой реакции. В этом отношении метод анализа аналогичен принятому Zweig и Pylkkänen (2009), в котором авторы напрямую сравнивают сложные (производные) слова, таким образом стремясь найти эффекты разложения, которые не зависят от прайминга. В этом исследовании используется задача создания именования слов для изучения этих этапов лексической обработки, поскольку она обеспечивает сопоставимые эффекты с задачами лексического принятия решений (Neely, 1991) и не требует пробных проб.Эта задача была выполнена, пока активность мозга регистрировалась с помощью МЭГ, чтобы исследовать, есть ли в левой височной доле область, отвечающая за морфологический состав. Это исследование вносит свой вклад в работу по характеристике нейронных основ лексической обработки сложных слов, предоставляя доказательства композиции в составных словах и связывая их с их нейронными коррелятами. Учитывая предшествующую литературу, мы ожидаем найти доказательства разложения для сложных слов, но не для симплексных слов.Это открытие согласуется с литературой по визуальному распознаванию слов, особенно с литературой по замаскированному праймингу, где есть облегчающие эффекты при прайминге морфологически сложных слов, но не морфологически простых слов. Однако мы не ожидаем увидеть это общее преимущество морфологической сложности в составе.
В общем, модель сложного распознавания слов потребует, по крайней мере, этих двух этапов обработки: разбора на базовые единицы (декомпозиция) и композиции этих словоформ в сложное значение. Чтобы распаковать эти этапы, мы предлагаем использовать два типа парадигм грунтования: грунтовку с частичным повторением (например, ДОРОГА-обочина), аналогичные парадигмам, используемым в исследованиях замаскированного грунтования, которые будут использоваться для исследования эффектов разложения в соединениях, и грунтовка с полным повторением (например,g., ROADSIDE-roadside), которые будут использованы для исследования композиционных эффектов их морфем. Штрихи условия повторения примирования использовали для оценки эффекта композиции в отсутствие поведенческой реакции. В этом отношении метод анализа аналогичен принятому Zweig и Pylkkänen (2009), в котором авторы напрямую сравнивают сложные (производные) слова, таким образом стремясь найти эффекты разложения, которые не зависят от прайминга. В этом исследовании используется задача создания именования слов для изучения этих этапов лексической обработки, поскольку она обеспечивает сопоставимые эффекты с задачами лексического принятия решений (Neely, 1991) и не требует пробных проб.Эта задача была выполнена, пока активность мозга регистрировалась с помощью МЭГ, чтобы исследовать, есть ли в левой височной доле область, отвечающая за морфологический состав. Это исследование вносит свой вклад в работу по характеристике нейронных основ лексической обработки сложных слов, предоставляя доказательства композиции в составных словах и связывая их с их нейронными коррелятами. Учитывая предшествующую литературу, мы ожидаем найти доказательства разложения для сложных слов, но не для симплексных слов.Это открытие согласуется с литературой по визуальному распознаванию слов, особенно с литературой по замаскированному праймингу, где есть облегчающие эффекты при прайминге морфологически сложных слов, но не морфологически простых слов. Однако мы не ожидаем увидеть это общее преимущество морфологической сложности в составе. Поскольку состав смысла регулируется семантически, мы ожидаем обнаружить влияние композиции на активность мозга только для прозрачных соединений.
Поскольку состав смысла регулируется семантически, мы ожидаем обнаружить влияние композиции на активность мозга только для прозрачных соединений.
2.Материалы и методы
2.1 Участники
Восемнадцать правшей, носителей английского языка в возрасте от 18 до 30 лет, с нормальным или исправленным зрением, все дали информированное согласие и приняли участие в этом эксперименте. Исследование было одобрено Университетским комитетом по деятельности с участием людей (UCAIHS) Нью-Йоркского университета. Данные MEG от трех участников были исключены из-за большого количества отказов от испытаний, вызванных шумовыми помехами (> 25%). Подробности отказа описаны в процедуре.
2.2. Материал
Все стимулы состояли из английских би-морфемных соединений (например, чашка) и морфологически простых существительных (например, шпинат), сопоставленных по длине и поверхностной частоте. Мы манипулировали семантической прозрачностью, включая полностью семантически прозрачные (например, чайная чашка) слова, в которых обе составляющие морфемы имеют семантическое отношение к значению всего соединения, и полностью семантически непрозрачные слова (например, фигня), в которых ни один из составляющих морфемы имеют семантическое отношение к составному значению.
311 английских словосочетаний были собраны из предыдущих исследований (Juhasz et al., 2003; Fiorentino and Poeppel, 2007; Fiorentino and Fund-Reznicek, 2009; Drieghe et al., 2010) и классифицированы с точки зрения семантической прозрачности с помощью семантики. задача на соответствие, выполняемая с помощью инструмента Amazon Mechanical Turk. В этом задании 20 участникам было предложено оценить по шкале от 1 до 7, насколько каждый компонент соединения относится к целому слову. По шкале 1 соответствует несвязанному, а 7 — очень близкому.Каждому участнику случайным образом представили один из компонентов каждого соединения. Соединения классифицировались как семантически непрозрачные (далее , непрозрачные, ), если сумма баллов их составляющих находилась в интервале 2–6, и как семантически прозрачные (далее , прозрачные ), если сумма была в интервале 10–14. Например, непрозрачный состав deadline получил суммарный рейтинг 3,76 с dead , что дает рейтинг прозрачности 1.44 и строка дает рейтинг 2.32. Точно так же составной кукольный домик получил суммарную оценку 11,79, где кукла внесла свой вклад в рейтинг прозрачности 6,47, а дом дал оценку 5,32. Для каждого типа слова было выбрано шестьдесят словосочетаний. Этот метод нормирования семантической прозрачности соответствовал методам, использованным в упомянутых предыдущих исследованиях. Морфологически простые слова (далее simplex : например, шпинат) были объединены из Rastle et al.(2004) и English Lexicon Project отбирали слова, закодированные на наличие только одной морфемы (Balota et al., 2007). Симплексные слова (например, бордел ) были выбраны так, чтобы они имели неморфологическую связь формы с их простыми числами (например, бульон ). Кроме того, эти слова были ограничены и выбраны таким образом, чтобы простое слово нельзя было разбить на более мелкие части без создания недопустимых морфем.
Например, непрозрачный состав deadline получил суммарный рейтинг 3,76 с dead , что дает рейтинг прозрачности 1.44 и строка дает рейтинг 2.32. Точно так же составной кукольный домик получил суммарную оценку 11,79, где кукла внесла свой вклад в рейтинг прозрачности 6,47, а дом дал оценку 5,32. Для каждого типа слова было выбрано шестьдесят словосочетаний. Этот метод нормирования семантической прозрачности соответствовал методам, использованным в упомянутых предыдущих исследованиях. Морфологически простые слова (далее simplex : например, шпинат) были объединены из Rastle et al.(2004) и English Lexicon Project отбирали слова, закодированные на наличие только одной морфемы (Balota et al., 2007). Симплексные слова (например, бордел ) были выбраны так, чтобы они имели неморфологическую связь формы с их простыми числами (например, бульон ). Кроме того, эти слова были ограничены и выбраны таким образом, чтобы простое слово нельзя было разбить на более мелкие части без создания недопустимых морфем.
2.3. Типовой проект дома
Три разных типа слов были сопоставлены в двух условиях прайминга: полное повторение и частичное (составляющее) повторение (см. Таблицу 1).Для условия повторного прайминга в качестве прайма и мишени использовали одно и то же соединение (например, чашка TEACUP). Для прайминга с частичным повторением мы использовали первый компонент соединения в качестве праймера (например, чайную чашку TEA). Для симплексного условия неморфологическая родственная форма использовалась в качестве составляющей в условии частичного повторения прайминга (например, SPIN-шпинат). Эти два условия прайминга были объединены для управления условиями, в которых прайм не имел семантического отношения к цели (например,г., DOORBELL-чашка; ДВЕРЬ-чашка).
Таблица 1. Матрица расчета .
2.4. Процедура
Все участники прочитали все элементы во всех условиях (всего 720), которые были разделены на три списка по 240 слов и рандомизированы в каждом списке. Порядок представления списков был сбалансирован между испытуемыми. Экспериментальной задачей было наименование слов: испытуемым предлагались пары слов, и их просили прочитать вслух второе слово каждой пары.Стимулы были представлены белым шрифтом Courier размером 30 пунктов на сером фоне с помощью PsychToolbox (Brainard, 1997). Каждое испытание начиналось с предъявления фиксирующего креста, затем штриховки, затем мишени. Каждая из этих визуальных презентаций была представлена в течение 300 мс с последующим пропуском 300 мс (см. Рисунок 1). Мы записали начальную латентность речи и высказывания каждого испытуемого для поведенческого анализа.
Порядок представления списков был сбалансирован между испытуемыми. Экспериментальной задачей было наименование слов: испытуемым предлагались пары слов, и их просили прочитать вслух второе слово каждой пары.Стимулы были представлены белым шрифтом Courier размером 30 пунктов на сером фоне с помощью PsychToolbox (Brainard, 1997). Каждое испытание начиналось с предъявления фиксирующего креста, затем штриховки, затем мишени. Каждая из этих визуальных презентаций была представлена в течение 300 мс с последующим пропуском 300 мс (см. Рисунок 1). Мы записали начальную латентность речи и высказывания каждого испытуемого для поведенческого анализа.
Рис. 1. Структура эксперимента .
Перед экспериментом форма головы каждого участника была оцифрована с использованием системы Polhemus Fastscan вместе с пятью точками индикатора положения головы, которые используются для совместной регистрации положения головы по отношению к датчикам MEG во время сбора данных.Электромагниты, прикрепленные к этим точкам, локализуются после того, как участники лежат внутри массива датчиков МЭГ, что обеспечивает совместную регистрацию систем координат головы и датчика. Форма головы используется во время анализа для совместной регистрации головы на МРТ участников. Половине участников МРТ не проводились; поэтому мы масштабировали общий эталонный мозг, который предоставляется в FreeSurfer, чтобы он соответствовал размеру голов этих участников.
Во время эксперимента участники оставались лежать в комнате с магнитным экраном, а реакцию их мозга контролировали градиентометры MEG.Экспериментальные элементы проецировались на экран, чтобы участник мог прочитать и выполнить задание. Данные МЭГ были собраны с использованием аксиальной системы градиентометра для всей головки с 157 каналами и тремя опорными каналами (Канадзавский технологический институт, Ноноичи, Япония). Запись проводилась в режиме постоянного тока, то есть без фильтра верхних частот, с фильтром нижних частот 300 Гц и режекторным фильтром 60 Гц.
2,5. Анализ
Мы исследовали латентность начала, время реакции на наименование слова, чтобы оценить эффекты морфологического разложения на основе Fiorentino and Poeppel (2007).Поскольку время реакции чувствительно к лексическим свойствам слов (Fiorentino and Poeppel, 2007), составные слова должны обрабатываться быстрее при праймировании, чем симплексные слова из-за остаточной активации ранее активированных морфем. Недекомпозиционный счет не предсказывает никаких различий из-за структуры слова, если слова правильно сопоставлены для соответствующих свойств всего слова. Таким образом, начальная задержка может использоваться, чтобы понять, есть ли эффект разложения. Поведенческие данные были проанализированы с использованием традиционного дисперсионного анализа для типа слова с помощью модели взаимодействия с частичным повторением.Прайминг с частичным повторением в задачах лексического решения использовался, чтобы продемонстрировать доступность морфем в сложных словах (Rastle et al., 2004). Подобные поведенческие эффекты были также обнаружены при использовании именования слов (см. Neely, 1991 для сравнительного обзора лексического решения и именования слов). Таким образом, свидетельство эффектов разложения можно наблюдать во времени реакции, чтобы говорить, , задержка начала . Предыдущие исследования привели к предсказанию, что должен быть стимулирующий эффект более короткой задержки начала из-за прайминга для соединений по сравнению с их эквивалентами из симплексных слов, поскольку сегментация на морфемы приводит к более быстрому доступу к сложному слову.
После сбора данных мозга мы применили метод непрерывно скорректированных наименьших квадратов (Adachi et al., 2001), процедуру снижения шума в программном обеспечении MEG160 (Yokogawa Electric Corporation и Eagle Technology Corporation, Токио, Япония), которая вычитает шум из Градиометры МЭГ основаны на измерениях шума в опорных каналах, удаленных от головы. Данные подвергались полосовой фильтрации в диапазоне 1–40 Гц с использованием БИХ-фильтра. Запись всего эксперимента была разделена на представляющие интерес эпохи, от -200 мс до до 600 мс после визуального отображения основного слова.Мы отклонили испытания, в которых максимальная амплитуда размаха превышала предел 4000fT, и уравняли испытания, чтобы иметь равное количество испытаний для каждого условия и для каждого типа слова для правильного сравнения. Средний процент отклоненных испытаний среди субъектов составлял 1,9%, а для каждого типа слова: 1,3% для непрозрачных, 2,2% для симплексных, 1,8% для прозрачных. Каналы датчиков были отмечены как плохие и отбрасывались для каждого испытуемого, если полное отклонение канала превышало 10%.
Запись всего эксперимента была разделена на представляющие интерес эпохи, от -200 мс до до 600 мс после визуального отображения основного слова.Мы отклонили испытания, в которых максимальная амплитуда размаха превышала предел 4000fT, и уравняли испытания, чтобы иметь равное количество испытаний для каждого условия и для каждого типа слова для правильного сравнения. Средний процент отклоненных испытаний среди субъектов составлял 1,9%, а для каждого типа слова: 1,3% для непрозрачных, 2,2% для симплексных, 1,8% для прозрачных. Каналы датчиков были отмечены как плохие и отбрасывались для каждого испытуемого, если полное отклонение канала превышало 10%.
Матрица ковариации шума была вычислена для каждого участника с использованием процедуры автоматического выбора модели (Engemann and Gramfort, 2015) на случайном выборе базовых эпох (120 эпох) от -200 мс до начала представления креста фиксации.Для участников с МРТ кортикальные реконструкции были сгенерированы с использованием FreeSurfer, в результате чего пространство источника составляло 5124 вершины (CorTechs Labs Inc., Ла-Хойя, Калифорния и MGH / HMS / MIT Центр биомедицинской визуализации Athinoula A. Martinos, Чарльстон, Массачусетс). Метод модели граничных элементов (БЭМ) использовался для моделирования активности в каждой вершине для расчета прямого решения. Обратное решение было сгенерировано с использованием этой прямой модели и матрицы ковариации шума и вычислено с ограничением фиксированной ориентации, требующим, чтобы дипольные источники были перпендикулярны кортикальной поверхности.Затем данные датчиков для каждого субъекта проецировались в их индивидуальное исходное пространство с использованием оценки минимальной нормы с корковыми ограничениями (все анализы проводились с использованием MNE-Python: Gramfort et al., 2013, 2014), в результате чего получались нормализованные по шуму карты динамических статистических параметров. (dSPM: Dale et al., 2000).
Для этого анализа наш дизайн (таблица 2) сводится к простому сравнению между составными (например, TEACUP) и симплексными словами (например, SPINACH) одного и того же размера, которые служили простыми числами в условии повторения (например,g. , TEACUP-teacup), описанный выше в разделе «Дизайн». Поскольку для этого анализа мы используем нейрофизиологические данные, относящиеся к молчаливому чтению слов, которые служили простыми числами, поведенческих данных для этих слов нет. Таким образом, мы также избегаем артефактов, связанных с произвольными движениями, которые могут поставить под угрозу анализ эффектов, представляющих интерес для исследования (Hansen et al., 2010).
, TEACUP-teacup), описанный выше в разделе «Дизайн». Поскольку для этого анализа мы используем нейрофизиологические данные, относящиеся к молчаливому чтению слов, которые служили простыми числами, поведенческих данных для этих слов нет. Таким образом, мы также избегаем артефактов, связанных с произвольными движениями, которые могут поставить под угрозу анализ эффектов, представляющих интерес для исследования (Hansen et al., 2010).
Таблица 2. Анализ простых чисел .
Мы исследовали нервную активность, локализованную во всей левой височной доле.Этот регион был выбран на основе композиционных эффектов, обнаруженных в предложениях (Friederici et al., 2000) или фразах прилагательное-существительное (Bemis and Pylkkänen, 2011). Чтобы проверить, была ли повышена активность соединений в этой области, был проведен тест t на остаточную активацию типа составного слова (непрозрачный, прозрачный) после удаления активации из симплексного контрольного слова от 100 до 600. мс после появления стимула. Карта мозга с p была создана для временных рядов, а пространственно-временные кластеры были идентифицированы для смежных пространственно-временных кластеров, у которых значение p было меньше 0.05 и длительностью не менее 10 мс. Значения t были суммированы для тех точек в кластере, которые соответствовали этим критериям. Затем сначала был выполнен тест непараметрической перестановки путем перетасовки меток типов слов, а затем вычисления кластеров, образованных новыми метками. Распределение, сгенерированное из 10 000 перестановок, было вычислено путем вычисления значимых уровней наблюдаемого кластера. Скорректированное значение p было определено из процента кластеров, которые были больше, чем исходный вычисленный кластер (Maris and Oostenveld, 2007).Эти тесты были рассчитаны с использованием пакета статистического анализа данных MEG, Eelbrain (https://pythonhosted.org/eelbrain/).
3. Результаты
3.
 1. Морфологическая декомпозиция
1. Морфологическая декомпозицияС точки зрения поведения мы обнаружили значительный эффект прайминга с частичным повторением [ F (1, 17) = 25,91, p <0,001], но, что наиболее важно, взаимодействие типа слова с помощью прайминга [ F ( 2, 17) = 9,24, p <0,001] (рисунок 2).Этот эффект показывает, что именование составных слов облегчается в большей степени, чем для морфологически простых слов, если они начислены. В запланированных сравнениях были обнаружены достоверные различия между непрозрачными соединениями и симплексными словами [ F (1, 17) = 5,93, p <0,03], а также прозрачными соединениями и симплексными словами [ F (1, 17) = 14,46, p <0,005], но не между прозрачными и непрозрачными соединениями [ F (1, 17) = 2.84, p. > 0,1]. Эти результаты показывают, что даже в словообразовании существует чувствительность к морфологической структуре помимо орфографического и фонологического перекрытия, но этот этап обработки нечувствителен к значению морфем по отношению к составному слову, что согласуется с предыдущим литература по морфологическому разложению (Rastle et al., 2004; McCormick et al., 2008).
Рис. 2. Средство разницы задержки начала частичного повторения прайминга .
3.2. Морфологический состав
Результаты показывают достоверные эффекты большей активации прозрачных соединений по сравнению с их симплексными контролями в височной доле. С этим различием связаны два значимых кластера: первый кластер был локализован в передней средней височной извилине от 250 до 470 мс ( t = 4552,3, p <0,05, рисунок 3), а второй кластер активности был локализуется в задней верхней височной извилине от 430 до 600 мс (∑ t = 5654, p <0.05, рисунок 4). Однако не было обнаружено надежных кластеров для различия непрозрачных соединений и симплексных слов в височной доле.
Рис. 3. Разница между прозрачностью и симплексом в левой передней височной доле (LATL) .
Рис. 4. Разница между прозрачностью и симплексом в задней верхней височной мышце (pSTG) .
4. Обсуждение
Анализ разных типов слов по отдельности выявил очень последовательные доказательства того, что существует разница в том, как простые и сложные слова обрабатываются в мозгу.Поведенческие результаты подтвердили, что существует стадия лексического доступа, которая чувствительна к морфологическим формам в сложных словах, и продемонстрировали, что эти эффекты также могут наблюдаться в других модальностях тестирования, а именно, в именовании слов. Эффект начального латентного взаимодействия, когда составные слова создавались быстрее, чем морфологически простые слова, когда они начинались с их составной морфемы, в значительной степени согласуется с результатами в литературе по замаскированному праймингу по распознаванию слов и дает дополнительные доказательства того, что в лексическом доступе есть стадия декомпозиции. где сложные слова разбираются на свои морфемы (Rastle et al., 2004; Тафт, 2004; Моррис и др., 2007; Маккормик и др., 2008; Fiorentino и Fund-Reznicek, 2009). Операция синтаксического анализа происходит независимо от семантических отношений между составляющими морфемами и их сложным словом. Поскольку ранняя активация составляющих посредством морфологического разложения происходит независимо от семантической прозрачности, то, что отличает прозрачное и непрозрачное соединение, должно происходить, таким образом, на более поздней стадии морфемного состава. Повышенная активность прозрачных соединений в передней височной доле с 250 до 470 мс свидетельствует о стадии лексического доступа, на которой значения морфемы играют роль в доступе к общему значению слова.Bemis и Pylkkänen (2011) показывают комбинаторные эффекты в LATL для прилагательных слов примерно через 225 мс после предъявления критического слова. Разницу во времени можно объяснить разными моментами времени, в которые мы фиксируем начало действия стимула. В Bemis и Pylkkänen (2011) начало совпадает с началом существительного boat во фразе red boat , тогда как в нашем исследовании критическим стимулом является весь состав sailboat .
Повышенная активация в задней височной доле прозрачных соединений с 430 до 600 мс, которая следует за активностью в LATL, согласуется с тем фактом, что эта область участвует в лексическом поиске (Hickok and Poeppel, 2007; Lau et al., 2008). Lau et al. (2008) предположили, что задняя область височной доли является лучшим кандидатом для лексического хранения слов. Поскольку LATL отвечает за составление значения составляющих морфем, задняя височная доля будет отвечать за извлечение информации из сохраненного лексико-семантического представления. Эта область также участвует в преобразовании звука в значение (Binder et al., 2000), которое включает поиск фонологической информации. Это исследование согласуется с моделями декомпозиции из литературы по визуальному распознаванию слов и обеспечивает нейронную основу для этапа лексического доступа, участвующего в композиции значения в составных словах, тем самым помогая распутать когнитивные процессы, которые нечеткие, когда время реакции является единственной мерой .Объединяя результаты психолингвистических исследований с записями МЭГ активности мозга, полученные результаты предполагают, что распознавание соединений включает в себя отдельные стадии: стадию декомпозиции, которая не зависит от семантики, и стадию композиции, которая регулируется семантикой. Мы показали, что ход активации различается по сложности слова и семантической прозрачности.
Авторские взносы
Авторы TB и DC являются первыми авторами, поскольку оба они в равной степени внесли свой вклад в работу.
Финансирование
Эта работа поддержана Национальным научным фондом в рамках гранта № BCS-0843969 и Исследовательским советом Нью-Йоркского университета в Абу-Даби в рамках гранта № G1001 Института NYUAD Нью-Йоркского университета Абу-Даби. Работа по туберкулезу была поддержана исследовательской стипендией Национального научного фонда под номером DGE-1342536. Работа DC была поддержана Координацией повышения квалификации кадров высшего образования и Комиссией Фулбрайта в соответствии с Законом о взаимном образовательном обмене, спонсируемой Государственным департаментом Соединенных Штатов Америки, Бюро по вопросам образования и культуры.
Заявление о конфликте интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Благодарности
Мы хотели бы поблагодарить Алека Маранца за его поддержку и руководство этим проектом. Мы также хотели бы поблагодарить Машу Вестерлунд и Фиби Гастон за критические отзывы для этой статьи. Мы также хотели бы поблагодарить Джеффа Уокера из NYU MEG Lab за его помощь во время тестирования участников.
Список литературы
Адачи Ю., Симогавара М., Хигучи М., Харута Ю. и Очиаи М. (2001). Снижение непериодического магнитного шума окружающей среды при измерении МЭГ методом наименьших квадратов с постоянной корректировкой. заявл. Сверхпроводимость. IEEE Trans . 11: 669–672. DOI: 10.1109 / 77.3
CrossRef Полный текст | Google Scholar
Балота Д. А., Яп М. Дж., Кортезе М. Дж., Хатчисон К. А., Кесслер Б., Лофтис Б. и др. (2007). Проект английской лексики. Behav. Res. Методы 39, 445–459. DOI: 10.3758 / BF031
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Бемис, Д. К., и Пюлкканен, Л. (2011). Простая композиция: магнитоэнцефалографическое исследование понимания минимальных языковых фраз. Дж. Neurosci . 31, 2801–2814. DOI: 10.1523 / JNEUROSCI.5003-10.2011
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Биндер, Дж.R., Frost, J. A., Hammeke, T. A., Bellgowan, P. S., Springer, J. A., Kaufman, J. N., et al. (2000). Активация височной доли человека речью и неречевыми звуками. Cereb. Cortex 10, 512–528. DOI: 10.1093 / cercor / 10.5.512
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Баттерворт, Б. (1983). «Лексическое представление», в Language Production , Vol. 2, изд Б. Баттерворт (Лондон: Academic Press), 257–294.
Дейл, А.М., Лю, А. К., Фишл, Б. Р., Бакнер, Р. Л., Белливо, Дж. У., Левин, Дж. Д. и др. (2000). Динамическое статистическое параметрическое картирование: комбинирование ФМРТ и МЭГ для получения изображений корковой активности с высоким разрешением. Neuron 26, 55–67. DOI: 10.1016 / S0896-6273 (00) 81138-1
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Фиорентино, Р., Фунд-Резничек, Э. (2009). Маскированная морфологическая грунтовка составных компонентов. Ment. Lexicon 4, 159–193.DOI: 10,1075 / мл. 4.2.01fio
CrossRef Полный текст | Google Scholar
Фиорентино, Р., Найто-Биллен, Ю., Бост, Дж., И Фунд-Резничек, Э. (2014). Электрофизиологические доказательства комбинаторной обработки английских соединений на основе морфем. Cogn. Neuropsychol . 31, 123–146. DOI: 10.1080 / 02643294.2013.855633
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Фиорентино, Р., Поппель, Д. (2007). Сложные слова и структура в лексике. Lang. Cogn. Процесс . 22, 953–1000. DOI: 10.1080 / 0167011
CrossRef Полный текст | Google Scholar
Форстер К. И. и Дэвис К. (1984). Прайминг повторения и ослабление частоты в лексическом доступе. J. Exp. Psychol. Учиться. Mem. Cogn . 10, 680–698. DOI: 10.1037 / 0278-7393.10.4.680
CrossRef Полный текст | Google Scholar
Friederici, A. D., Wang, Y., Herrmann, C. S., Maess, B., and Oertel, U. (2000). Локализация ранних синтаксических процессов в лобных и височных областях коры: магнитоэнцефалографическое исследование. Hum. Brain Mapp . 11, 1–11. DOI: 10.1002 / 1097-0193 (200009) 11: 1 <1 :: AID-HBM10> 3.0.CO; 2-B
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Gramfort, A., Luessi, M., Larson, E., Engemann, D.A., Strohmeier, D., Brodbeck, C., et al. (2013). Анализ данных МЭГ и ЭЭГ с помощью MNE-python. Фронт. Neurosci . 7: 267. DOI: 10.3389 / fnins.2013.00267
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Грамфорт, А., Луесси, М., Ларсон, Э., Энгеманн, Д. А., Стромайер, Д., Бродбек, К. и др. (2014). Программное обеспечение МНЭ для обработки данных МЭГ и ЭЭГ. Neuroimage 86, 446–460. DOI: 10.1016 / j.neuroimage.2013.10.027
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Хансен, П. К., Крингельбах, М. Л., и Салмелин, Р. (2010). MEG: Введение в методы . Нью-Йорк, Нью-Йорк: Издательство Оксфордского университета.
Google Scholar
Юхас, Б.Дж., Старр, М. С., Инхофф, А. В., и Плак, Л. (2003). Влияние морфологии на обработку составных слов: свидетельства от именования, лексических решений и фиксации взгляда. руб. Дж. Психол . 94, 223–244. DOI: 10.1348 / 000712603321661903
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Longtin, C.-M., Segui, J., and Hallé, P.A. (2003). Морфологическая грунтовка без морфологической связи. Lang. Cogn. Процесс . 18, 313–334.DOI: 10.1080 / 016244000036
CrossRef Полный текст | Google Scholar
Марслен-Уилсон, В., Тайлер, Л. К., Вакслер, Р., и Олдер, Л. (1994). Морфология и значение в английской ментальной лексике. Psychol. Ред. . 101, 3–33. DOI: 10.1037 / 0033-295X.101.1.3
CrossRef Полный текст | Google Scholar
Маккормик, С. Ф., Растл, К., и Дэвис, М. Х. (2008). Есть ли в слове «фетиш» праздник? влияние орфографической непрозрачности на морфо-орфографическую сегментацию при визуальном распознавании слов. J. Mem. Lang . 58, 307–326. DOI: 10.1016 / j.jml.2007.05.006
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Нили, Дж. Х. (1991). «Эффекты семантического прайминга в визуальном распознавании слов: выборочный обзор текущих результатов и теорий», в Basic Processes in Reading: Visual Word Recognition , ред. Д. Беснер и Г. В. Хамфрис (Хиллсдейл, штат Нью-Джерси: L. Erlbaum Associates), 264 –336.
Google Scholar
Растл, К.и Дэвис М. Х. (2003). Чтение морфологически сложных слов . Нью-Йорк, Нью-Йорк: Психология Пресс.
Google Scholar
Тафт, М., и Форстер, К. И. (1975). Лексическое хранение и поиск слов с префиксом. J. Verb. Учиться. Глагол. Поведение . 14, 638–647. DOI: 10.1016 / S0022-5371 (75) 80051-X
CrossRef Полный текст | Google Scholar
Цвейг, Э., Пюлкканен, Л. (2009). Визуальный эффект m170 морфологической сложности. Lang.Cogn. Процесс . 24, 412–439. DOI: 10.1080 / 016802180420
CrossRef Полный текст | Google Scholar
Zwitserlood, P. (1994). Роль семантической прозрачности в обработке и представлении нидерландских словосочетаний. Lang. Cogn. Процесс . 9, 341–368. DOI: 10.1080 / 016408402123
CrossRef Полный текст | Google Scholar
Инструменты автоматической сегментации и аннотации
Инструменты автоматической сегментации и аннотации
Инструменты, описанные в этом разделе, работают без прямого взаимодействия с пользователем, создание аннотированного или сегментированного ресурса на выходе.Многие из них требуют обучение и может быть доступно уже обученным для некоторых задач или быть доступным для пользователей тренироваться в соответствии с их потребностями.
Инструменты, которые в настоящее время доступны через WebLicht — веб-сайт CLARIN-D сервисный лингвистический рабочий процесс и среда выполнения инструмента — отмечены с маленьким значком:
Перечисленные здесь инструменты не являются исчерпывающим списком инструментов, доступных для WebLicht, и, как сервис растет, будет интегрировано больше инструментов. Для получения актуального и исчерпывающего списка инструментов, доступных через WebLicht, войдите на сайт WebLicht.
Разделение предложений и токенизация обычно понимаются как способ сегментирования. тексты, а не преобразовывать их или добавлять информацию о функциях. Каждый сегмент, будь то предложение или токен, соответствует определенной последовательности элементов более низкого уровня (токены или символы), который в целях дальнейшего исследования или обработки формирует единичный блок. Сегментация цифровых текстов может быть сложной в зависимости от языка текст и лингвистические соображения, необходимые для его обработки.
разделителей предложений, иногда называемых разделителями предложений , разбивать текст на отдельные предложения с однозначными разделителями.
Распознавание границ предложений в текстах звучит очень легко, но может оказаться сложной задачей. проблема на практике. Предложения не имеют четкого определения в общей лингвистике, и Программы разделения предложений основаны на пунктуации текстов и практических проблемы компьютерной лингвистики, а не лингвистической теории.
Знаки препинания появились очень давно, по крайней мере, в 9 веке до нашей эры. Стела Меша — камень с надписями, найденный в современной Иордании. описание военных походов моавитского царя Меши — это самая старая аттестация различных знаков препинания для обозначения слова разделение и грамматические фразы [ Compston1919 ], [ Martens 2011 ]. Однако до наших дней не во всех письменных языках использовалась пунктуация. Идея разделения письменных текстов на отдельные предложения с использованием некоторой формы пунктуация является изобретением итальянских печатников 16 века и не дошла до некоторых части света до середины 20 века.Это очень затрудняет разработать корпусы исторического языка, совместимые с инструментами, основанными на современных пунктуация. Добавление знаков препинания к старым текстам занимает много времени, и исследователи разные школы не всегда могут прийти к единому мнению о том, где должна стоять пунктуация.
На многих языках, включая большинство европейских языков, предложение разделительная пунктуация выполняет несколько функций, помимо пометки предложений. В точка часто обозначает аббревиатуры, а также используется для записи порядковых чисел или для разделения больших числовых выражений на группы по три цифры.Приговоры также могут заканчиваются множеством знаков препинания, кроме точки. Вопросительные знаки, восклицательные знаки, многоточие ( пропущенных слов, ), двоеточия, точки с запятой и множество других маркеров должны иметь свое назначение в конкретных контексты правильно определены, прежде чем их можно будет уверенно рассматривать в качестве приговора разделители. Дополнительные проблемы возникают с кавычками, URL-адресами и именами собственными, которые использовать нестандартную пунктуацию. Кроме того, большинство текстов содержат ошибки и несоответствия пунктуации, которые простые алгоритмы не могут легко определить или правильный.
Разделители предложений часто интегрируются в токенизаторы, но есть отдельные инструменты. в наличии в том числе:
- MX Терминатор
Разветвитель для английского языка, который можно обучить другим языкам.
- Стэнфорд ssplit
Разветвитель для английского, но достаточно эффективный для других языков, используйте аналогичные знаки препинания.
- Предложение OpenNLP Обнаружение
Разветвитель для английского языка, который можно обучить другим языкам.
Токен — это единица языка, похожая на слово, но не совсем то же самое. В компьютерной лингвистике часто более практично обсуждать токены, а не слова, так как токен включает в себя множество лингвистически нерелевантных и / или дефектных элементы, встречающиеся в реальных текстах (числа, сокращения, знаки препинания и т. д.) и избегает многих сложных теоретических соображений, связанных с обсуждением слова.
В наше время большинство языков имеют системы письма, заимствованные из древних языки, используемые на Ближнем Востоке и торговцами в Средиземном море, начиная с около 3000 лет назад.Латинский, греческий, кириллица, иврит и арабский алфавиты являются все произошли из общего древнего источника — широко распространенного финикийского используется в торговле и дипломатии — и большинство историков думают, что письменность системы Индии и Средней Азии имеют одинаковое происхождение. См. [ Fischer 2005 ] и [ Schmandt-Besserat 1992 ] для более полных историй письма.
Все написание системы, заимствованные из древних финикийцев, используют буквы, соответствующие определенным звукам.Когда слова написаны буквами, обозначающими звуки, слова могут быть только отличаются друг от друга, если они каким-то образом отделены друг от друга или если читатели буквы должны выяснить, где паузы и паузы. Первые языки систематически использовать буквы для обозначения звуков, обычно разделяя текст на словесные единицы с какой-либо отметкой — обычно полоса («|») Или двойная точка, похожая на двоеточие («:»). Однако эти знаки использовались непоследовательно, и многие языки имели алфавиты. со временем перестала использовать явные маркеры.Латынь, греческий, иврит и языки Индия не была написана с помощью какого-либо последовательного словесного маркера на протяжении многих веков. Пробелы между словами были введены в Западной Европе в 12 веке, вероятно, изобретен монахами в Великобритании или Ирландии и медленно распространился среди других страны и языки [ Saenger 1997 ]. С конца 19-го века, большинство языков — все, кроме нескольких в Тихоокеанской Азии — имеют было написано с регулярными пробелами между словами.
Для этих языков — большая, но далеко не вся работа по токенизации цифровых текстов. выполняется пробельными символами и знаками препинания.Самые простые токенизаторы просто разделите текст на пробелы, а затем отделите пунктуацию от концы и начала слов. Но то, как эти пробелы используются в все языки, и полагаясь исключительно на пробелы для идентификации токенов, в практика, работают очень хорошо. Токенизация может быть очень сложной, потому что жетонов не всегда совпадают с расположением пробелов.
Составные слова существуют во многих языках и часто требуют более сложной обработки.Немецкое слово Telekommunikationsvorratsdatenspeicherung («Сохранение телекоммуникационных данных») — это один случай, но В английском есть лингвистически похожие составы, например low-budget и первоклассных . Токенизаторы — или иногда похожие инструменты, которые можно назвать декомпаундерами или составными разветвители — часто предполагается, что такие соединения разделят на части, или предполагается, что они разделят только некоторые из них. Должны ли соединения быть разделение может зависеть от дальнейших этапов обработки.Для синтаксического анализа немецкого языка например, это часто нежелательно, потому что соединения обрабатываются синтаксически и морфологически как одно слово, т. е. множественное число и склонение изменяют только конец всего соединения, и синтаксические анализаторы могут распознавать части речи из последнего часть соединения. Во французском языке часто бывает наоборот, и такие соединения, как arc-en-ciel («радуга») и не может быть рассматриваются как отдельные слова, поскольку множественное число изменяет середину составного ( arcs-en-ciel ).Для поиска информации, напротив, Немецкие слова почти всегда разуплотняются, потому что поиск Vorratsdatenspeicherung («данные удержание ») должны совпадать с документами, содержащими Telekommunikationsvorratsdatenspeicherung . На французском, однако никому не нужно arc («арка», «Дуга» или «лук») или ciel («небо» или «Небо»), чтобы соответствовать arc-en-ciel . английский есть примеры обоих видов соединений, со словами вроде плавучих домов , которые ведут себя как немецкие соединения, но также частей речи , которые ведут себя как французские.
В других случаях что-то, что лучше всего рассматривать как один токен, может отображаться в тексте как несколько слов с пробелами, например New York . Это также неоднозначные соединения, где они могут иногда появляться как отдельные слова, а иногда нет. Взбиватель для яиц , Взбиватель для яиц и eggbeater все возможные на английском языке и означают то же самое предмет.
Короткие фразы, состоящие из нескольких слов, разделенных пробелами, также могут иногда лучше всего анализировать как одно слово, например фразу by and большая или боль в шее по англ.Это называется многословными терминами и может совпадать с тем, что люди обычно называют идиом .
Сокращения типа Я и тоже не создают проблемы, поскольку многие аналитические инструменты более высокого уровня, такие как тегеры части речи и синтаксические анализаторы могут потребовать их разбиения, и многие лингвистические теории рассматривают их как более одного слова для грамматических целей.
Фразовых глаголов в английском языке и отделяемых глаголов в немецком языке — еще одна категория проблема для токенизаторов, поскольку их часто лучше рассматривать как отдельные слова, но они разделены на части, которые могут не появляться в текстах рядом друг с другом.Для пример:
Когда мы любим других, мы, естественно, хотим говорить о них, мы хотим показать им от , как эмоциональные трофеи. (Александр МакКолл Смит, Друзья, любовники, Шоколадный )
Die Liebe im Menschen spricht das rechte Wort авс . («Народная любовь говорит правду слово », Фердинанд Эбнер, Schriften , vol.2.)
таких глаголов, как , чтобы показать в английском и aussprechen на немецком языке часто требуют лечения как холостого слова, но в приведенных выше примерах появляются не только как отдельные слова, но и с другими слова между их частями. Простые программы, которые просто ищут определенные виды персонажи не могут идентифицировать эти структуры как токены.
Какие соединения, если таковые имеются, должны быть разделены, а какие составные части должны быть обрабатывается как единый токен, зависит от языка текста и цели обработка.Последовательная токенизация обычно связана с определением лексической сущности, которые можно найти в каком-либо лексическом ресурсе, и для этого может потребоваться очень много комплексная обработка обычных текстов. Его цель — упростить и удалить отклонения от данных для дальнейшей обработки. Поскольку идентификация основных единиц в тексте должна предшествовать почти всем видам дальнейших обработка, токенизация — это первое или почти первое, что делается для любого задача лингвистической обработки.
Дополнительные проблемы могут возникнуть на некоторых языках. Из основных современных языков только Китайцы, японцы и корейцы в настоящее время используют системы письма, которые не считаются производными. от общего ближневосточного предка, и они не отмечают систематически слова в обычные тексты с пробелами или любым другим видимым маркером. Несколько юго-восточных азиатских языки — тайский, лаосский, кхмерский и некоторые другие, менее распространенные языки — до сих пор не используют пробелов или используют их редко и непоследовательно, несмотря на наличие систем письма, заимствованных из тех, что используются в Индии.Вьетнамский — который сегодня пишется с помощью латинского алфавита, но раньше писали как китайский — ставили пробелы между каждым слог, так что даже несмотря на то, что в нем используются пробелы, они не имеют большого значения в токенизация. Токенизация на этих языках — очень сложный процесс, который может использовать большие словари и сложные процедуры машинного обучения.
Как упоминалось в предыдущем разделе, токенизация часто сочетается с разделение предложений в одном инструменте.Вот несколько примеров реализации токенизаторов:
Тегеры части речи (PoS-тегеры) — это программы которые принимают токенизированный текст в качестве входных данных и связывают часть речи тег (тег PoS) с каждым токеном. Тегер PoS использует конкретный закрытый набор частей речи — обычно называется набором тегов в компьютерная лингвистика. Различные тегеры для разных языков обычно имеют разные, иногда радикально разные, наборы тегов или системы части речи.Однако для некоторых языков стандарты де-факто существуют в том смысле, что большинство тегеры части речи используют тот же набор тегов. Например, на немецком языке набор тегов STTS очень широко распространен, но в английском языке часто используются несколько различных наборов тегов, как набор тегов Penn Treebank и несколько версий набора тегов CLAWS.
Часть речи — это категория, которая абстрагирует некоторые свойства слов или жетоны. Например, в предложении Собака съела обед есть другими словами, мы можем заменить dog и по-прежнему иметь правильный предложение, такие слова, как кот или человек .Те слова имеют некоторые общие свойства и принадлежат к общей категории слов. PoS схемы предназначены для улавливания подобных сходств. Слова с одинаковыми PoS в некотором смысле похожи по своему использованию, значению или функции.
Части речи были изобретены независимо друг от друга по крайней мере три раза в далекое прошлое. Они задокументированы в 5 веке до нашей эры в Греции, примерно на тот же период в Индии, а со 2 века нашей эры в Китай.Нет никаких доказательств того, что какое-либо из этих трех изобретений было скопировано из других культур. Происхождение частей речи более подробно описано в [ Martens 2011 ]. Греческий грамматический текст 2-го века до н.э. The Art of Грамматика обрисовала в общих чертах систему из девяти категорий PoS, которые стали очень влиятельные в европейских языках: существительные, глаголы, причастия, артикли, местоимения, предлоги, наречия и союзы с именами собственными как подкатегория существительные.Эта схема повлияла на большинство используемых сегодня PoS-систем.
Современные лингвисты больше не думают о частях речи как о фиксированном коротком списке категории, единые для всех языков. Они не согласны с тем, стоит ли ни одна из этих категорий не является универсальной или какие категории относятся к каким конкретные слова, контексты и языки. Разные лингвистические теории, разные языки, и разные подходы к аннотации используют разные схемы PoS.
Наборы теговтакже различаются уровнем детализации. Современный корпус PoS схема, такая как набор тегов CLAWS, используемый для Британского национального корпуса, может далеко зайти выходя за рамки классических девяти частей речи и проводя десятки тонких различий. КОГТИ версия 7 содержит 22 различные части речи только для существительных. Сложные наборы тегов обычно организованы иерархически, чтобы отразить общие черты между разными классами слов.
Примеры широко используемых наборов тегов включают STTS для немецкого языка. [ Schiller et al.1999 ], набор тегов Penn Treebank для английского языка [ Санторини 1990 ], и набор тегов CLAWS для английского языка [ Garside et al. 1997 ]. Большинство наборов тегов PoS были разработаны для конкретных корпуса и часто вдохновляются старыми корпусами и схемами PoS. PoS-тегеры сегодня почти все инструменты, использующие машинное обучение и специально обученные для языка и набора тегов, которые они используют. Обычно их можно переобучить для новых наборов тегов. и языки.
ТегерыPoS почти всегда ожидают ввода токенизированных текстов, и это важно. что токены в текстах соответствуют тем, которые тегер PoS был обучен распознавать.Как В результате важно убедиться, что токенизатор, используемый для предварительной обработки текстов совпадает с тем, который использовался для создания обучающих данных для теггера PoS.
Еще одним важным фактором в разработке тегеров PoS является их обработка слов вне словарного запаса . Значительное количество токенов в любой большой текст не будет распознаваться теггером, независимо от того, насколько большой словарь, который у них есть, или сколько обучающих данных было использовано. PoS-тегеры могут просто выводит специальный «неизвестный» тег или может угадать, что должно быть правильным PoS дать остальной контекст.Для некоторых языков, особенно со сложными системы префиксов и суффиксов для слов, тегеры PoS могут использовать морфологические анализирует, чтобы попытаться найти нужный тег.
Реализации тегеров PoS включают:
- TreeTagger
Тегер PoS для немецкого, английского, французского, итальянского, голландского, испанского, Болгарский, русский, греческий, португальский, китайский, суахили, латынь, эстонский и старофранцузский, и его можно обучить многим другим.
- Тегер OpenNLP
Тегер PoS для английского и немецкого языков, распространяемый как часть Apache Инструментарий OpenNLP.
- Стэнфорд PoS-теггер
Тегер PoS для английского языка, распространяемый как часть Stanford Core NLP Инструментарий.
- Brill теггер
Тегер PoS для английского, датского, голландского и норвежского языков. (Нюнорск).
Морфологические анализаторы и лемматизаторы
Морфология — это исследование того, как слова и фразы меняют форму в зависимости от их значение, функция и контекст.Морфологические инструменты иногда пересекаются в своих функции с тегами PoS и токенизаторами.
Поскольку лингвисты не всегда соглашаются, что есть слово, а что нет, разные лингвисты могут расходиться во мнениях относительно того, какие явления являются частью морфологии, а какие — часть синтаксиса, фонетики или других частей лингвистики. Как правило, морфологические явления считаются флективными или деривационными в зависимости от их роли на языке.
Флективная морфология — это способ изменения слов по правилам языка в зависимости от их синтаксической роли или значения.В большинстве европейских языков, многие слова должны менять форму в зависимости от того, как они использовал.
Как традиционно называют глаголы, меняющие форму конъюгация . В английском языке глаголы в настоящем времени должны быть сопряжены в зависимости от их предметов. Итак, мы говорим I играть , вы играете , мы играем и они играть но он играет и она играет . Это называется соглашением, и мы говорим что в английском языке глаголы в настоящем времени должны согласовываться со своим подлежащим, потому что свойства любого подлежащего глагола определяют форму глагола берет.Но в прошедшем времени английские глаголы должны принимать особую форму, чтобы указывают, что они относятся к прошлому, но не должны соглашаться. Мы говорим Я играл в и он сыграл .
Языки могут иметь очень сложные схемы, определяющие формы глаголов, отражающие очень тонкие различия значений и требующие согласия со многими различные особенности их предметов, объектов, модификаторов или любой другой части контекст, в котором они появляются.Эти различия иногда выражаются используя дополнительные слова (обычно называемые вспомогательными или иногда вспомогательных слов ), а иногда префиксами, суффиксы или другие изменения слов. Многие языки также комбинируют схемы для производить потенциально неограниченные вариации в формах глаголов.
Существительные в английском языке изменяют форму, чтобы отразить их количество: единица собака но несколько собак . Несколько слов в Английский также меняет форму в зависимости от пола людей, к которым они относятся, например актеров и актрис .Это редко на английском языке, но распространен в большинстве других европейских языков. В большинстве европейских языков, всем существительным присущ грамматический род и любое другое слово обращение к ним может потребоваться для изменения формы, чтобы отразить этот пол.
Во многих языках существительные также претерпевают гораздо более сложные изменения, чтобы отразить их грамматическая функция. Это традиционно называется склонение или случай . В немецком предложении Das Auto des Lehrers ist grün («Учительская машина зеленая»), слово Lehrer («Учитель») заменяется на Lehrers , потому что оно используется, чтобы сказать чья машина имеется в виду.
Соглашение часто присутствует между существительными и связанными с ними словами грамматически. В немецком языке существительные мало меняют форму при отклонении, но статьи и прилагательные, используемые с ними, делают. Статьи и прилагательные в языках с грамматическими родовыми категориями обычно также должны изменить форму, чтобы отразить род существительных, к которым они относятся. Местоимения в большинстве европейских языков также должны соглашаться с лингвистическими свойствами вещей, к которым они относятся, а также отклоняются или трансформируются их контекстом другими способами.
Сравнительная и превосходная формы прилагательных — сейф , безопаснее , самый безопасный — один из примеров — также обычно мыслится как флективная морфология.
Некоторые языки имеют очень сложную флективную морфологию. Среди европейских языки, финский и венгерский, как известно, являются особенно сложными, со многими формы для каждого глагола и существительного, а французский известен своими сложными правилами соглашение. Остальные очень простые.Существительные в английском языке различаются только между единственное и множественное число, и даже местоимения и неправильные глаголы, такие как до быть и , чтобы иметь , обычно не более нескольких специфические формы. Некоторые языки (в основном не говорят на Europe) не считаются имеющими флективно-морфологическую вариация вообще.
То, что слово было изменено, не означает, что это другое слово. На английском языке собака и собак — это не разные слова. просто из-за того, что -s добавлено для обозначения множественного числа.Для каждой поверхностной форме существует базовое слово, к которому она относится, независимо от ее морфология. Эта базовая абстракция называется ее лемма , от слова, которое древние греки использовали для обозначения «Сущность» слова. Иногда его называют каноническая форма слова и указывает на написание вы найдете их в словаре (см. раздел «Лексические ресурсы»).
Один из источников неоднозначности, который можно ожидать от лемматизаторов и морфологических анализаторов. решение состоит в том, что конкретный токен может быть измененной формой более чем одного лемма.Например, в английском языке слово tear может обозначать к существительному, означающему «выделение воды из чьих-то глаз», или к глаголу, который означает «разобрать что-то», среди прочего возможные значения. При осмотре изолированно, разрывают и слез может относиться к любому, но tearing обычно может относиться только к глаголу. Практически все языки имеют похожие случаи, т. Е. Немецкий die Schale означает либо the чаша (единственное число) или г. шарфы (множественное число).Устранение неоднозначности может включать многие виды информации, кроме форм слов, и могут использовать сложная статистическая информация и машинное обучение. Многие аннотированные корпуса систематически устранять неоднозначность лемм как часть их разметки.
Флективная морфология в европейских языках чаще всего означает изменение окончания слов, либо добавляя к ним, либо изменяя их каким-либо образом, но это может включать изменение любой части слова. На английском, некоторые глаголы изменяются изменением одной или нескольких гласных, например перерыв , перерыв , и битые .В немецком языке много распространенных глаголов — называется сильных глаголов — изменяются путем изменения середина слова. На арабском и иврите все существительные, глаголы и многие другие слова изменяются путем вставки, удаления и изменения гласных в середина слова. В языках банту в Африке слова склоняются добавление префиксов и изменение начала слов. Другие языки указывают перегиб, вставляя целые слоги в середину слов, повторяя части слов или почти любые другие мыслимые вариации.Во многих языках используется более один из способов сделать перегиб.
Деривационная морфология — это процесс образования слова из другого слова, обычно меняя форму, одновременно меняя значение или грамматику функционируют каким-то образом. Это может означать добавление префиксов или суффиксов к словам, например как английский конструирует существительное счастье и наречие к несчастью от прилагательного счастлив . Такие процессы часто используются для изменить часть речи или синтаксические функции слов — сделав глагол от существительного, прилагательное от наречия и т. д.Но иногда они используются только для изменения значения слова, например, для добавления префикса un- на английском и немецком языках, что может отрицать или каким-то образом инвертировать значение слова, но не меняет его грамматическое свойства или часть речи.
Как и в случае флективной морфологии, в языках могут использоваться почти любые вариация для получения новых слов из старых, а не только префиксов и суффиксов. Не существует простой фиксированной линии для отделения деривационной морфологии от флективной морфологии, и отдельные лингвисты иногда не соглашаются как классифицировать отдельные процессы словообразования.Некоторые не согласятся есть ли какое-либо значимое различие между перегибом и производным на все.
Один из распространенных производных процессов, встречающихся во многих разных языках, — это создание составные слова. Как известно, в немецком языке таким образом создаются очень длинные слова, а в английском имеет много составных конструкций, которые иногда записываются одним словом или дефис, или как отдельные слова, которые люди понимают, чтобы иметь одно общее смысл. Обратный процесс — разбиение одного слова на несколько части — также существует на некоторых языках.Фразовые глаголы в английском и разделимые глаголы в немецком языке являются двумя примерами (см. раздел «Токенизаторы»), и морфологическому анализатору, возможно, придется идентифицировать эти конструкции и обрабатывать их соответствующим образом.
Один из старейших и простейших инструментов для вычислительного морфологического анализа. это стеммер . Термин основа относится к оставшейся части слова. окончание, когда флективные и деривационные префиксы и суффиксы были удалены от слова, и части слов, оставшиеся после разделения составного слова на его части.Многие слова имеют общую «основу», как и немецкие слова. sehen , absehen , absehbar и Sehhilfe , которые все имеют общий стержень seh . Этот стебель обычно отражает общий смысл.
Возможность приведения групп похожих слов к общей форме, соответствующей к общему смыслу сделало стеммеры привлекательными для поиска информации Приложения. Стеммеры алгоритмически очень просты и обычно используют каталог регулярных выражений — простые шаблоны буквы — для определения и удаления флективных и производных элементы.Они не очень сложны в лингвистическом отношении и пропускают многие виды морфологическая изменчивость. По возможности следует использовать более сложные инструменты. использовал.
Тем не менее, стеммеры относительно легко сделать для новых языков и часто используется, когда лучшие инструменты недоступны. Стеммер Портера это классический простой в реализации алгоритм для стемминга [ Porter 1980 ].
Лемматизаторы — это программы, которые принимают на вход токенизированные тексты и возвращают набор лемм или канонических форм.Обычно они используют комбинацию правил для разложение слов и словаря, иногда вместе со статистическими правилами и машинное обучение для устранения неоднозначности омонимов. Некоторые лемматизаторы также сохраняют некоторый класс слов информации, например, отметить, что слово заканчивается на -s , которое было снятый, или -ing — обычно достаточно, чтобы реконструировать исходный токен, но не столько, сколько полное морфологическое анализ.
Реализаций лемматизаторов:
Полные морфологические анализаторы принимают токенизированный текст как ввод и возвращают как завершенный информация о флективных категориях, к которым принадлежит каждый токен, а также их лемма.Они часто сочетаются с тегами PoS, а иногда и с синтаксические парсеры, потому что полный анализ морфологической категории слово обычно затрагивает синтаксис и почти всегда включает категоризацию слова по его части речи.
Некоторые анализаторы могут также предоставлять информацию о деривационной морфологии и разбивать соединения на составные части.
Качественные морфологические анализаторы почти всегда используют большие базы данных слова и правила композиции и разложения.Многие также используют машины методы обучения и прошли обучение на данных, проанализированных вручную. Разработка комплексных морфологических анализаторов является очень сложной задачей, особенно если нужно анализировать деривационные явления.
Реализации морфологических анализаторов:
- RFTagger
RFTagger назначает детализированные теги части речи на основе морфологический анализ. Он работает для немецкого, чешского, словенского и Данные на венгерском языке, и можно обучить другим языкам.
- СМОР
Содержит морфологический анализатор немецкого языка.
- Морфа
Морфологический анализатор английского языка.
Синтаксис — это изучение связей между частями предложений. Это предназначено учитывать значимые аспекты порядка слов и фраз в язык. Принципы, определяющие, какие слова и фразы связаны между собой, как они связаны, и какое влияние это оказывает на порядок частей предложения называются грамматикой .
Существует множество различных теорий синтаксиса и идей о том, как работает синтаксис. Отдельные лингвисты обычно привязаны к определенным школам мысли в зависимости от где они получили образование, с какими языками и с какими проблемами работают, а также в значительной степени их личные предпочтения.
Большинство теорий синтаксиса делятся на две большие категории, которые отражают разные истории, приоритеты и теории о том, как работает язык: зависимости грамматики и грамматики округа .Разделение между этими двумя подходами восходит к их истокам в конце 1950-е годы, и дебаты между ними все еще ведутся. Обе школы мысли представляют связи внутри предложений в виде деревьев или ориентированных графов, и оба школы соглашаются, что представление этих связей требует неявных структурных информация сделана явной. Отношения между словами не могут быть банальными представлен в виде последовательности токенов, и разработка программного обеспечения, которое распознает эти отношения в текстах — сложная проблема.
В грамматиках зависимостей связи обычно устанавливаются между словами или токенами, и соединяющие их края имеют метки из небольшого набора типов соединений определяется какой-то теорией грамматики. Рисунок 7.2, «Анализ зависимостей» — это анализ зависимостей от конкретной теории грамматики зависимостей.
Грамматики зависимостей, как правило, популярны среди людей, работающих с языками в порядок слов очень гибкий, а слова подвержены сложным морфологическим правила соглашения.Он имеет очень сильные традиции в Восточной Европе, но также в разной степени присутствуют в других странах.
Рисунок 7.2. Анализ зависимостей
Грамматики избирательных округов рассматривают связи между словами как иерархические отношения между фразами. Обычно они разбивают предложения на части, но не всегда непрерывные, а затем разбивать каждую часть на более мелкие части, пока они не достигнут уровня отдельных жетонов.Деревья нарисованы для демонстрации грамматики избирательных округов отражают эту структуру. Края в грамматиках избирательных округов обычно не маркируется.
Грамматика округа во многом опирается на теорию формальных языков в информатика, но обычно использует формальную грамматику в сочетании с другими понятия, чтобы лучше объяснить явления на человеческом языке. Например, там известные теории синтаксиса, которые включают формализованные процедуры для дерева переписывание, иерархия типов и логика более высокого порядка, среди прочего.Мало лингвисты в настоящее время считают, что только теория формальных языков может объяснить синтаксис.
Как школа мысли, грамматика округа исторически связана с работа Ноама Хомского и американская лингвистическая традиция. Это имеет тенденцию быть популярен среди лингвистов, работающих с такими языками, как английский, в котором морфологическое соответствие не очень важно, и порядок слов относительно строго фиксированный. Он очень силен в англоязычных странах, но также присутствует в большей части Западной Европы и в разной степени в других частях Мир.См. Рисунок 7.3, «Анализ избирательного округа», где показан пример избирательного округа. анализ английского предложения.
Рисунок 7.3. Анализ группы интересов
Метки на краях на Рисунке 7.2, «Анализ зависимостей» и на узлах дерева на Рисунке 7.3 «Анализ избирательного округа» является частью конкретного синтаксические теории, из которых взяты эти примеры. Более подробные объяснения их и их значения можно найти в упомянутых текстах. Специфический синтаксические анализаторы и лингвистические инструменты могут использовать совершенно разные метки на основе на разные представления о языке, даже если общая форма синтаксического представления, которые они генерируют, напоминают приведенные здесь примеры.
Среди компьютерных лингвистов и людей, работающих с естественным языком обработки, растет тенденция к использованию гибридных грамматик, сочетающих элементы традиций как избирательного округа, так и зависимости. Эти грамматики принимают преимущество свойства грамматики избирательного округа, называемое Голова . Во многих структурах избирательных округов фразы, идентифицированные грамматикой, имеют единственную составляющую, которая обозначается как его голова .Анализ избирательного округа, в котором все фразы головы, и где все края имеют метки, в целом эквивалентно зависимости анализ.
Рисунок 7.4, «Гибридный синтаксический анализ» — это дерево из TüBa-D / Z берега деревьев Немецкий язык и его обозначения объяснены в [ Hinrichs 2004 ]. Этот treebank использует гибридный анализ предложений, содержащих составляющие, которые часто имеют головки и края с метками зависимостей. Как и во многих гибридных анализах, не все составляющие имеют головки, а некоторые края имеют пустые метки, поэтому это не полностью совместим со строгой зависимостью.Однако добавленный информация на краях также делает его несовместимым со строгой аудиторией рамки. Такой синкретический подход обычно находит большее признание в корпусной и компьютерной лингвистики, чем в теоретической лингвистике.
Рисунок 7.4. Гибридный синтаксический анализ
Синтаксический синтаксический анализ — это процесс (автоматический или ручной) выполнения синтаксический анализ. Компьютерная программа, анализирующая естественный язык, называется парсер .Внешне процесс разбора естественного язык похож на синтаксический анализ в информатике — как компьютер имеет смысл команд, которые пользователи вводят в командной строке или вводят как исходный код для программ — и вычисления позаимствовали большую часть его словаря для синтаксический анализ из лингвистики. Но на практике синтаксический анализ естественного языка — это очень другое начинание.
Самые старые парсеры естественного языка были созданы с использованием тех же типов конечные грамматики и правила распознавания как синтаксический анализ компьютерных команд, но разнообразие, сложность и двусмысленность человеческого языка делают такие парсеры сложно построить и склонны к сбоям.Самый точный и надежные парсеры сегодня в некоторой степени включают статистические принципы и имеют часто обучались на основе вручную проанализированных текстов с использованием машинного обучения техники.
Парсеры обычно требуют некоторой предварительной обработки входного текста, хотя некоторые представляют собой интегрированные приложения, выполняющие внутреннюю предварительную обработку. В целом, входные данные синтаксического анализатора должны содержать предложения, четко разграниченные и обычно токенизированные. Многие распространенные парсеры работают с PoS-tagger в качестве препроцессора, а вывод PoS-tagger должен использовать теги, ожидаемые парсером.Когда парсеры обучены с использованием машинного обучения, предварительная обработка должна соответствовать предварительная обработка, используемая для обучающих данных.
Вывод парсера никогда не бывает простым текстом — данные должны быть структурированным способом, который кодирует связи между словами, которые не рядом друг с другом.
Реализации парсеров:
- Berkeley parser
Синтаксический анализатор для английского, немецкого и многих других языков. языков.Этот парсер опционально создает гибридную зависимость выход.
- Анализатор OpenNLP
Синтаксический анализатор для английского языка.
- BitPar
Синтаксический анализатор для немецкого и английского языков.
- Bohnet парсер
Анализатор зависимостей для английского, немецкого, испанского и китайского языков. это часть инструментов Mate.
Высококачественные парсеры — это очень сложные программы, которые очень сложно построить и может потребовать очень мощных компьютеров для работы или может обрабатывать тексты очень медленно. Для многих языков нет хороших автоматических парсеров на все.
Chunkers, также известные как мелкие парсеры , являются более легкое решение [ Abney1991 ]. Они обеспечивают частичное и упрощенный синтаксический анализ избирательного округа, часто просто разбиение предложений на предложения путем поиска определенных слов, которые обычно указывают на начало фраза.Их намного проще писать, они более надежны и гораздо менее эффективны. ресурсоемки для запуска, чем полные парсеры, и доступны во многих языков.
Реализации чункеров:
Устранение неоднозначности слов (WSD)
Слова могут иметь более одного значения. Например, слово стакан может относиться к «стакану для питья». и к «материальной субстанции стекло». Люди обычно могут понять вне, учитывая контекст слова, какое из многих значений слова подразумевается, но для компьютера это не так-то просто.Автоматическое определение правильного значение слова в контексте (иногда его называют смыслом ) называется смысловой неоднозначностью (WSD).
Automatic WSD обычно использует комбинацию оцифрованного словаря — a база данных слов и возможных значений — и информация о контексты, в которых слова могут принимать определенные значения. Программы, которые делают при этом часто используются методы машинного обучения и учебные корпуса. Входы в WSD программы обычно представляют собой токенизированные тексты, но иногда теги PoS и даже синтаксический анализ могут потребуются перед устранением неоднозначности.
Реализация инструмента WSD:
- UKB
Набор инструментов WSD и определения смыслового подобия на основе графиков для Английский.
Разрешение Coreference и анафора
Coreferences возникают, когда два или более выражения относятся к одному и тому же. Обычно лингвисты говорят о кореференциях только в тех случаях, когда синтаксический и морфологические правила языка не дают понять, что эти выражения обязательно относятся к одному и тому же.Вместо этого ораторы должны использовать их память о том, что уже было сказано, и их знание реального мировой контекст общения, чтобы определить, какие слова относятся к одному и тому же какие нет.
Анафорическое выражение является частным случаем кореферентности, которая может можно разрешить, указав предыдущее выражение, относящееся к тому же самому. Для Например, в предложении Автомобиль заглох и больше никогда не заводился слово это относится к автомобилю.Но в предложении Автомобиль врезался в грузовик, и он больше не заводился неясно, относится ли к к автомобилю или грузовик. В предложениях Джон был с Дэйвом, когда увидел Мэри. Он думал, что Мэри его видела, но она полностью проигнорировал его. не ясно, есть ли у экземпляра он и ему относится к Джону или Дэйву.
Такого рода неоднозначности решаются при разрешении кореференции.Они могут быть очень важен во многих приложениях НЛП, таких как поиск информации и машинное перевод. Существует несколько автоматических инструментов для решения таких проблем, и большинство использовать какую-либо форму машинного обучения.
Реализации для разрешения кореференции:
Признание зарегистрированного лица (NER)
Именованные сущности — это обобщение идеи существительного собственного. Они относятся к имена людей, места, торговые марки, необщие вещи, а иногда и очень предметные термины, среди многих других возможностей.Нет фиксированного лимита на что составляет именованную сущность, но такие узкоспециализированные виды использования образуют большая доля слов в текстах, которых нет в словарях и некорректно распознается лингвистическими средствами. Они могут быть очень важны для информации поиск, машинный перевод, определение темы и многие другие задачи в компьютерная лингвистика.
ИнструментыNER могут быть основаны на правилах, статистических методах и машинном обучении. алгоритмы или комбинации этих методов.Правила, которые они применяют, иногда очень ad hoc — как поиск последовательностей из двух или слова, написанные с большой буквы — и обычно не следуют из каких-либо организованных лингвистическая теория. Часто формируются большие базы данных имен людей, мест и вещей. часть инструмента NER.
ИнструментыNER иногда также пытаются классифицировать элементы, которые они находят. Определение относится ли конкретная фраза к человеку, месту, названию компании или другому вещи могут быть важны для исследования или дальнейшей обработки.
Специальным приложением NER является геовизуализация — определение географических названий и их местонахождения. Зная, что именованная сущность относится к определенному месту, может значительно облегчить компьютерам устранение неоднозначности другие ссылки. Ссылка на Bismarck рядом со ссылкой на место в Германии, вероятно, относится к немецкому политику 19 века Отто фон Бисмарк, но недалеко от ссылки на Север Дакота, скорее всего, относится к небольшому американскому городу Бисмарк.
Реализации инструментов NER:
- Немецкий NER
Инструмент NER для немецкого языка на основе Stanford Named Entity Распознаватель.
- Stanford NER
Инструмент NER для английского языка, распространяемый как часть Stanford Core Инструментарий НЛП.
- ПолуНЕР
Инструмент NER для обучения немецкому языку из крупных корпусов и Википедии данные.
Выравниватели предложений и слов
Элайнеры — это инструменты, которые в основном используются с двуязычными корпусами — два корпуса в разные языки, где один является переводом другого, или оба переводы из одних рук.Программы статистического машинного перевода используют выровненные корпуса, чтобы научиться переводить один язык на другой.
Выравнивания могут быть на разных уровнях. Выравниватели предложений соответствуют предложениям в два корпуса, в то время как средства выравнивания слов пытаются выровнять отдельные слова. Эти программы обычно носят статистический характер и обычно не зависят от языка.
Реализации элайнеров:
- GIZA ++
Выравниватель уровня слов, предназначенный для работы со всеми языками. пары.
- Гаргантюа
Выравниватель на уровне предложений, предназначенный для работы со всеми языковыми парами, это хорошо работает, когда два текста не являются приговором к предложению переводы.
Последние достижения в области машинного обучения
Рекомендации для читателей
Что это за страница? На этой странице слева показаны таблицы, извлеченные из документов arXiv. Он показывает извлеченные результаты с правой стороны, которые соответствуют таксономии в Papers With Code.
Какие цветные прямоугольники справа? Это результаты, извлеченные из статьи и связанные с таблицами слева. Результат состоит из значения метрики, имени модели, имени набора данных и имени задачи.
Что означают цвета? Зеленый означает, что результат одобрен и показан на сайте. Желтый — результат того, что вы добавили, но еще не сохранили. Синий — это результат ссылки, полученный из другой бумаги.
Откуда берутся предлагаемые результаты? У нас есть модель машинного обучения, работающая в фоновом режиме, которая дает рекомендации по статьям.
Откуда берутся ссылочные результаты? Если мы находим в таблице результаты со ссылками на другие статьи, мы показываем проанализированный справочный блок, который редакторы могут использовать для аннотирования, чтобы получить эти дополнительные результаты из других статей.
Руководство для редактора
Я впервые редактирую и боюсь ошибиться.Помощь! Не волнуйтесь! Если вы сделаете ошибки, мы можем исправить их: все версионировано! Так что просто сообщите нам на канале Slack, если вы что-то случайно удалили (и так далее) — это вообще не проблема, так что дерзайте!
Как добавить новый результат из таблицы? Щелкните ячейку в таблице слева, откуда берется результат. Затем выберите одно из 5 лучших предложений. Вы можете вручную отредактировать неправильные или отсутствующие поля. Затем выберите задачу, набор данных и название метрики из таксономии «Документы с кодом».Вы должны проверить, существует ли уже эталонный тест, чтобы предотвратить дублирование; если его не существует, вы можете создать новый набор данных. Например. ImageNet по классификации изображений уже существует с показателями Top 1 Accuracy и Top 5 Accuracy.
Каковы соглашения об именах моделей? Название модели должно быть простым, как указано в документе. Обратите внимание, что вы можете использовать круглые скобки для выделения деталей, например: BERT Large (12 слоев), FoveaBox (ResNeXt-101), EfficientNet-B7 (NoisyStudent).
Другие советы и рекомендации
- Если эталонный тест уже существует для пары набор данных / задача, которую вы вводите, вы увидите ссылку.
- Если эталонный тест не существует, появится значок «новый», обозначающий новый рейтинг.
- Если вам повезет, Cmd + щелкните ячейку в таблице, чтобы получить первый результат автоматически.
- При редактировании нескольких результатов из одной и той же таблицы вы можете нажать кнопку «Заменить все», чтобы скопировать текущее значение во все другие записи из этой таблицы.
Как добавить результаты, на которые имеются ссылки? Если в таблице есть ссылки, вы можете использовать функцию синтаксического анализа ссылок, чтобы получить больше результатов из других документов. Во-первых, вам понадобится хотя бы одна запись в ячейке с результатами (пример см. На изображении ниже). Затем нажмите кнопку «Анализировать ссылки», чтобы связать ссылки с статьями в PapersWithCode и аннотировать результаты. Ниже вы можете увидеть пример.
Таблица сравнения извлечена из документа Универсальная языковая модель «Тонкая настройка для классификации текста» (Howard and Ruder, 2018) с проанализированными ссылками.Как сохранить изменения? Когда вы будете довольны своим изменением, нажмите «Сохранить», и предложенные вами изменения станут зелеными!
(PDF) Распределенные представления слов и фраз и их композиционность
Ссылки
[1] Йошуа Бенжио, Риджан Дюшар, Паскаль Винсент и Кристиан Жанвин. Модель нейронно-вероятностного языка
. Журнал исследований машинного обучения, 3: 1137–1155, 2003.
[2] Ронан Коллоберт и Джейсон Уэстон.Единая архитектура для обработки естественного языка: глубокие нейронные сети с многозадачным обучением. В материалах 25-й международной конференции по машинному обучению
, страницы 160–167. ACM, 2008.
[3] Ксавье Глоро, Антуан Бордес и Йошуа Бенжио. Адаптация предметной области для крупномасштабной классификации тональности
: подход на основе глубокого обучения. In ICML, 513–520, 2011.
[4] Майкл У Гутманн и Аапо Хювдаринен. Шумоконтрастная оценка ненормализованной статистической модели —
els, с приложениями к статистике естественных изображений.The Journal of Machine Learning Research, 13: 307–361,
2012.
[5] Томас Миколов, Стефан Комбринк, Лукас Бургет, Ян Чернокки и Санджив Худанпур. Расширения модели рекуррентной нейронной сети
. В области акустики, речи и обработки сигналов (ICASSP), 2011 г.
Международная конференция IEEE, стр. 5528–5531. IEEE, 2011.
[6] Томас Миколов, Ануп Деорас, Даниэль Пови, Лукас Бургет и Ян Чернокки. Стратегии обучения
Крупномасштабные языковые модели нейронных сетей.В Proc. Автоматическое распознавание и понимание речи —
ing, 2011.
[7] Томас Миколов. Статистические языковые модели на основе нейронных сетей. Кандидатская диссертация, докторская диссертация, Брно
Технологический университет, 2012.
[8] Томас Миколов, Кай Чен, Грег Коррадо и Джеффри Дин. Эффективная оценка представлений слов
в векторном пространстве. ICLR Workshop, 2013.
[9] Томас Миколов, Вен-тау Йих и Джеффри Цвейг. Лингвистические закономерности в непрерывном пространственном слове
Представления.In Proceedings of NAACL HLT, 2013.
[10] Андрей Мних и Джеффри Э. Хинтон. Масштабируемая иерархическая распределенная языковая модель. Достижения
нейронных систем обработки информации, 21: 1081–1088, 2009.
[11] Андрей Мних и Йи Уай Тех. Быстрый и простой алгоритм обучения нейронно-вероятностного языка
моделей. Препринт arXiv arXiv: 1206.6426, 2012.
[12] Фредерик Морин и Йошуа Бенжио. Иерархическая вероятностная языковая модель нейронной сети.В Pro-
ceedings международного семинара по искусственному интеллекту и статистике, страницы 246–252, 2005 г.
[13] Дэвид Э. Рамелхарт, Джеффри Э. Хинтонт и Рональд Дж. Уильямс. Изучение представлений назад-
распространяющихся ошибок. Nature, 323 (6088): 533–536, 1986.
[14] Holger Schwenk. Модели языка непрерывного пространства. Компьютерная речь и язык, т. 21, 2007.
[15] Ричард Сочер, Клифф К. Лин, Эндрю Й. Нг и Кристофер Д. Мэннинг.Разбор естественных сцен и
естественного языка с помощью рекурсивных нейронных сетей. В материалах 26-й Международной конференции по машинному обучению
(ICML), том 2, 2011 г.
[16] Ричард Сошер, Броди Хьюваль, Кристофер Д. Мэннинг и Эндрю Й. Нг. Семантическая композиционность
через рекурсивные матрично-векторные пространства. В материалах конференции 2012 года по эмпирическим методам
в обработке естественного языка (EMNLP), 2012.
[17] Джозеф Туриан, Лев Ратинов и Йошуа Бенжио.Представления слов: простой и общий метод для
полу-контролируемого обучения. В материалах 48-го ежегодного собрания Ассоциации компьютерной лингвистики
, страницы 384–394. Ассоциация компьютерной лингвистики, 2010.
[18] Питер Д. Терни и Патрик Пантел. От частоты к значению: векторные пространственные модели семантики. В
Журнал исследований искусственного интеллекта, 37: 141-188, 2010.
[19] Питер Д. Терни. Распределительная семантика за пределами слов: контролируемое изучение аналогии и перефразирования.
В трудах Ассоциации компьютерной лингвистики (TACL), 353–366, 2013.
[20] Джейсон Уэстон, Сами Бенжио и Николя Усунье. Wsabie: Масштабирование изображения до большого словарного запаса аннотации —
. В материалах двадцать второй международной совместной конференции по искусственному интеллекту — том
, том третий, страницы 2764–2770. AAAI Press, 2011.
9
7 техник НЛП, которые изменят ваше общение в будущем (Часть II) | Джеймс Ли
Механизмы внимания в нейронных сетях слабо основаны на механизме визуального внимания, обнаруженном у людей.Зрительное внимание человека хорошо изучено, и, хотя существуют разные модели, все они по сути сводятся к способности сосредоточиться на определенной области изображения с «высоким разрешением», воспринимая окружающее изображение с «низким разрешением», а затем корректировка фокуса с течением времени.
Представьте, что вы читаете эссе целиком: вместо того, чтобы рассматривать каждое слово или символ последовательно, вы подсознательно сосредотачиваетесь на нескольких предложениях с максимальной информационной плотностью и отфильтровываете остальное.Ваше внимание эффективно захватывает контекстную информацию в иерархическом порядке, так что этого достаточно для принятия решений при одновременном сокращении накладных расходов. Механизмы внимания в нейронных сетях слабо основаны на механизме визуального внимания, обнаруженном у людей.
Так почему это важно? Такие модели, как LSTM и GRU, полагаются на чтение полного предложения и сжатие всей информации в вектор фиксированной длины. Это требует сложной разработки функций, основанной на статистических свойствах текста.Предложение, состоящее из сотен слов, представленных несколькими словами, обязательно приведет к потере информации, неадекватному переводу и т. Д.
С помощью механизма внимания мы больше не пытаемся кодировать предложение с полным всплеском в вектор фиксированной длины. Скорее, мы позволяем декодеру обращать внимание на разные части исходного предложения на каждом этапе генерации вывода. Мы позволяем модели узнать, на что следует обратить внимание, на основе входного предложения и того, что она уже произвела.
Согласно изображению выше из Эффективные подходы к нейронному машинному переводу на основе внимания, синий представляет кодировщик, а красный — декодер, поэтому мы можем видеть, что вектор контекста принимает выходные данные всех ячеек в качестве входных для вычисления распределения вероятностей слов исходного языка. для каждого слова, которое декодер хочет сгенерировать.Используя этот механизм, декодер может захватывать глобальную информацию, а не делать выводы только на основе одного скрытого состояния.
Помимо машинного перевода, модель внимания работает над множеством других задач НЛП. В статье «Показать, присутствовать и рассказать: создание нейронных подписей к изображениям с визуальным вниманием» авторы применяют механизмы внимания к проблеме создания описаний изображений. Они используют сверточную нейронную сеть для кодирования изображения и рекуррентную нейронную сеть с механизмами внимания для генерации описания.Визуализируя веса внимания, они интерпретируют то, на что смотрит модель, генерируя слово:
В грамматике как иностранном языке авторы используют рекуррентную нейронную сеть с механизмом внимания для создания деревьев, разбираемых предложениями. Визуализированная матрица внимания дает представление о том, как сеть генерирует эти деревья:
В книге «Обучающие машины для чтения и понимания» авторы используют рекуррентную нейронную сеть, чтобы прочитать текст, прочитать вопрос и затем дать ответ.Визуализируя матрицу внимания, они показывают, куда смотрит сеть, пытаясь найти ответ на вопрос:
Однако за внимание приходится платить. Нам нужно рассчитать значение внимания для каждой комбинации входного и выходного слова. Если у вас есть входная последовательность из 100 слов и генерируется выходная последовательность из 100 слов, это будет 10 000 значений внимания. Если вы выполняете вычисления на уровне персонажа и имеете дело с последовательностями, состоящими из сотен токенов, вышеупомянутые механизмы могут стать чрезмерно дорогими.
Следует отметить, что в каждой из 7 техник НЛП, которые я обсуждал в этих двух постах, исследователям приходилось сталкиваться с множеством препятствий: ограничениями алгоритмов, масштабируемостью моделей, нечетким пониманием человеческого языка. . Хорошая новость заключается в том, что развитие этой области похоже на гигантский проект с открытым исходным кодом: исследователи продолжают создавать более совершенные модели для решения существующих проблем и делиться своими результатами с сообществом. Вот основные препятствия в НЛП, которые были разрешены благодаря недавнему прогрессу академических исследований:
- Не существует единой модели архитектуры с согласованными современными результатами для задач .Например, при ответе на вопрос мы имеем строго контролируемые сквозные сети памяти; в Анализе настроений у нас есть Tree-LSTM; а в Sequence Tagging у нас есть Bidirectional LSTM-CRF. Сеть динамической памяти, о которой я упоминал ранее в разделе «Ответы на вопросы», каким-то образом решает эту проблему, поскольку она может стабильно работать в нескольких доменах.
- Мощным подходом в машинном обучении является многозадачное обучение , которое разделяет представления между связанными задачами, чтобы позволить модели лучше обобщить исходную задачу.Однако полностью совместное многозадачное обучение сложно, поскольку оно обычно ограничено нижними уровнями, полезно только в том случае, если задачи связаны (часто ухудшает производительность, если задачи не связаны), и имеет тот же декодер / классификатор в предлагаемой модели. В статье «Совместная многозадачная модель: развитие сети для нескольких задач НЛП» авторы заранее определяют иерархическую архитектуру, состоящую из нескольких задач НЛП, в качестве совместной модели для многозадачного обучения. Модель включает в себя символьные n-граммы и короткие замыкания, а также современный синтаксический анализатор с прямой связью, способный выполнять синтаксический анализ зависимостей, задачи с несколькими предложениями и совместное обучение.
- Обучение с нулевым выстрелом — это способность решать задачу, несмотря на отсутствие обучающих примеров этой задачи. Существует не так много моделей, способных выполнять нулевое обучение для НЛП, поскольку ответы можно предсказать, только если они были замечены во время обучения и как часть функции softmax. Чтобы преодолеть это препятствие, авторы Pointer Sentinel Mixture Models объединили стандартный LSTM softmax с Pointer Networks в смешанной модели. Сети указателей помогают с редкими словами и долгосрочными зависимостями, в то время как стандартный softmax может ссылаться на слова, которых нет во входных данных.
- Другой проблемой является проблема дублированных представлений слов , где разные кодировки для кодера и декодера в модели приводят к дублированию параметров / значений. Самое простое решение для этого — связать векторы слов вместе и обучить отдельные веса вместе, как показано в разделе «Связывание векторов слов и классификаторов слов: структура потерь для языкового моделирования».
- Еще одним большим препятствием является то, что рекуррентные нейронные сети, основной строительный блок для любых техник глубокого НЛП, довольно медленны по сравнению, скажем, со сверточными нейронными сетями или нейронными сетями с прямой связью.Квази-рекуррентные нейронные сети используют лучшие части RNN и CNN для повышения скорости обучения, используя свертки для параллелизма во времени и поэлементную стробированную рекуррентность для параллелизма по каналам. Этот подход лучше и быстрее любых других моделей языкового моделирования и анализа настроений.
- Наконец, в NLP, поиск архитектуры — процесс использования машинного обучения для автоматизации проектирования искусственных нейронных сетей — довольно медленный, поскольку традиционный ручной процесс требует большого опыта.Что, если бы мы могли использовать ИИ, чтобы найти правильную архитектуру для любой проблемы? Поиск нейронной архитектуры с обучением с подкреплением от Google Brain — наиболее жизнеспособное решение, разработанное на данный момент. Авторы используют рекуррентную сеть для создания описаний моделей нейронных сетей и обучения этой RNN с помощью обучения с подкреплением, чтобы максимизировать ожидаемую точность сгенерированных архитектур на проверочном наборе.
Итак, поехали! Я показал вам краткое изложение основных методов обработки естественного языка, которые могут помочь компьютеру извлекать, анализировать и понимать полезную информацию из одного текста или последовательности текстов.
От машинного перевода, объединяющего людей разных культур, до разговорных чат-ботов, которые помогают в обслуживании клиентов; от анализа настроений, который глубоко понимает настроение человека, до механизмов внимания, которые могут имитировать наше визуальное внимание, область НЛП слишком обширна, чтобы охватить ее полностью, поэтому я рекомендую вам изучить ее дальше, будь то через онлайн-курсы, учебные материалы для блогов, или исследовательские работы.
Я настоятельно рекомендую Stanford CS 224 для начинающих, так как вы научитесь реализовывать, обучать, отлаживать, визуализировать и изобретать собственные модели нейронных сетей для задач НЛП.В качестве бонуса вы можете получить все слайды лекций, инструкции по выполнению заданий и исходный код из моего репозитория на GitHub . Надеюсь, это поможет вам изменить то, как мы будем общаться в будущем!
Если вам понравилась эта вещь, я бы хотел, чтобы вы нажали кнопку хлопка 👏 , чтобы другие могли наткнуться на нее. Вы можете найти мой собственный код на GitHub и другие мои работы и проекты на https://jameskle.com/ . Вы также можете подписаться на меня в Twitter , написать мне напрямую или найти меня в LinkedIn . Подпишитесь на мой информационный бюллетень , чтобы получать мои последние мысли о данных, машинном обучении и искусственном интеллекте прямо на свой почтовый ящик!
Обсудить сообщение на Hacker News .
Учебник по факторам от andreaferretti
Factor — зрелый язык с динамической типизацией, основанный на конкатенативной парадигме. Начало работы с Factor может быть пугающим, поскольку парадигма конкатенации отличается от большинства основных языков.Это руководство познакомит вас с основами Factor, чтобы вы могли оценить его простоту и мощь. Я предполагаю, что вы опытный программист, знакомый с функциональным языком, и предполагаю, что вы понимаете такие концепции, как сворачивание, функции высшего порядка и каррирование.
Несмотря на то, что Factor является нишевым языком, он зрел и имеет обширную стандартную библиотеку, охватывающую задачи от сериализации JSON до программирования сокетов и создания шаблонов HTML. Он работает на собственной оптимизированной виртуальной машине с очень высокой производительностью для динамически типизированного языка.Он также имеет гибкую объектную систему, FFI to C и асинхронный ввод-вывод, который немного похож на Node.js, но с гораздо более простой моделью для совместной многопоточности.
Вы можете задаться вопросом, почему вы должны настолько заботиться о Factor, чтобы прочитать это руководство. Factor имеет несколько существенных преимуществ перед другими языками, большинство из которых связано с отсутствием синтаксиса:
- рефакторинг очень прост, что приводит к коротким и содержательным определениям функций;
- он чрезвычайно лаконичен, позволяя программисту сосредоточиться на том, что важно, а не на шаблонном;
- он обладает мощными возможностями метапрограммирования, превосходящими даже LISP;
- идеально подходит для создания DSL;
- легко интегрируется с мощными инструментами.
Перед тем, как начать это руководство, загрузите копию Factor, чтобы вы могли следовать примерам в слушателе (Factor REPL).
Я предполагаю, что вы используете Mac OS X или какой-либо дистрибутив Linux, но все должно работать так же в других системах, при условии, что вы измените пути к файлам в примерах.
Первый раздел дает некоторую мотивацию для довольно своеобразной модели вычисления конкатенативных языков, но не стесняйтесь пропустить его, если вы хотите замочить ноги и вернуться к нему после некоторой практики с Factor.
Конкатенативные языки
Factor — это конкатенативный язык программирования в духе Forth. Что это вообще значит?
Чтобы понять конкатенативное программирование, представьте себе мир, в котором каждое значение является функцией, а единственная разрешенная операция — это композиция функций. Поскольку композиция функций настолько широко распространена, она является неявной, и функции могут быть буквально сопоставлены друг с другом, чтобы составить их. Итак, если f и g — две функции, их состав будет всего f g (в отличие от математической записи функции читаются слева направо, это означает, что сначала выполняется f , а затем выполняется g ).
Это требует некоторого объяснения, поскольку мы знаем, что функции часто имеют несколько входов и выходов, и не всегда выход f совпадает с входом g . Например, g может потребоваться доступ к значениям, вычисленным более ранними функциями. Но единственное, что может видеть g , — это вывод f , поэтому вывод f — это все состояние мира в отношении g . Чтобы это работало, функции должны распределять глобальное состояние потоками, передавая его друг другу.
Существуют различные способы кодирования этого глобального состояния. Самые наивные будут использовать хэш-карту, которая сопоставляет имена переменных с их значениями. Это оказывается слишком гибким: если каждая функция может получить доступ к любой части глобального состояния, мало контроля над тем, что функции могут делать, мало инкапсуляции, и в конечном итоге программы превращаются в неструктурированный беспорядок подпрограмм, изменяющих глобальные переменные.
На практике хорошо работает представление состояния мира в виде стека. Функции могут ссылаться только на самый верхний элемент стека, поэтому элементы ниже него фактически находятся вне области видимости.Если несколько примитивов заданы для управления несколькими элементами в стеке (например, swap , который меняет местами два верхних элемента в стеке), тогда становится возможным обращаться к значениям вниз по стеку, но чем дальше значение вниз по стеку, тем труднее к нему обращаться.
Таким образом, рекомендуется, чтобы функции оставались небольшими и обращались только к двум или трем верхним элементам в стеке. В некотором смысле нет различия между локальными и глобальными переменными, но значения могут быть более или менее локальными в зависимости от их расстояния от вершины стека.
Обратите внимание, что если каждая функция принимает состояние всего мира и возвращает следующее состояние, ее ввод больше не используется. Таким образом, даже несмотря на то, что удобно думать о чистых функциях как о получении стека на входе и выводе стека, семантика языка может быть реализована более эффективно путем изменения одного стека.
Это оставляет конкатенативные языки, такие как Factor, в странном положении, они оба чрезвычайно функциональны — позволяют объединять только более простые функции в более сложные — и в значительной степени обязательны — описывают операции в изменяемом стеке.
Игра со стеком
Давайте начнем смотреть, что на самом деле чувствует Фактор. Наши первые слова будут буквальными, например 3 , 12,58 или «Чак Норрис» . Литералы можно рассматривать как функции, которые помещаются в стек. Попробуйте написать в слушателе 5 , а затем нажмите Enter для подтверждения. Вы увидите, что стек, изначально пустой, теперь выглядит как
5
Вы можете ввести несколько чисел, разделенных пробелами, например 7 3 1 , и получить
5
7
3
1
(интерфейс показывает верх стека снизу).А как насчет операций? Если вы напишете + , вы запустите функцию + , которая выталкивает два самых верхних элемента и подталкивает их сумму, оставляя нас с
5
7
4
Вы можете поместить дополнительные входные данные в одну строку, так, например, - * оставит единственное число 15 в стеке (вы понимаете, почему?).
Функция . (точка или точка) печатает элемент в верхней части стопки, выталкивая его из стопки, оставляя стопку пустой.
Если мы напишем все в одной строке, наша программа пока выглядит как
5 7 3 1 + - *.
, который показывает особый способ выполнения арифметических операций Factor, помещая аргументы первыми, а оператор — последним — соглашение, которое называется обратной польской нотацией (RPN). Обратите внимание, что RPN не требует скобок, в отличие от полированной нотации Lisps, где оператор стоит первым, а RPN не требует правил приоритета, в отличие от инфиксной нотации, используемой в большинстве языков программирования и в повседневной арифметике.Например, в любом Лиспе одно и то же вычисление будет записано как
(* 5 (- 7 (+ 3 1)))
и в знакомой инфиксной нотации
(7 - (3 + 1)) * 5
Также обратите внимание, что мы смогли разбить наши вычисления на множество строк или объединить их на меньшее количество строк довольно произвольно, и что каждая строка имеет смысл сама по себе.
Определение нашего первого слова
Теперь мы определим нашу первую функцию. У Factor несколько странное наименование функций: поскольку функции читаются слева направо, они называются просто слов , и теперь мы будем называть их именно так.Модули в Factor определяют слова в терминах предыдущих слов, и эти наборы слов затем называются словарями .
Предположим, мы хотим вычислить факториал. Чтобы начать с конкретного примера, мы вычислим факториал 10 , поэтому мы начнем с записи 10 в стек. Теперь факториал — это произведение чисел от 1 до 10 , поэтому мы должны сначала составить такой список чисел.
Слово для создания диапазона называется [a, b] (токенизация тривиальна в Factor, потому что слова всегда разделяются пробелами, поэтому это позволяет вам использовать любую комбинацию непробельных символов в качестве имени слова; нет семантики для [, , и ] в [a, b] , поскольку это просто токен, например foo или bar ).
Диапазон, который нам нужен, начинается с 1 , поэтому мы можем использовать более простое слово [1, b] , которое предполагает, что диапазон начинается с 1 и ожидает, что в стеке будет находиться только верхнее значение диапазона. . Если вы напишете в слушателе [1, b] , Factor предложит вам выбор, потому что слово [1, b] не импортируется по умолчанию. Фактор может предложить вам импортировать словарь math.ranges , поэтому выберите этот вариант и продолжайте.
Теперь у вас в стеке должна быть довольно непрозрачная структура, которая выглядит как
. T {диапазон f 1 10 1}
Это потому, что наши функции диапазона ленивы и создают диапазон только тогда, когда мы пытаемся его использовать.Чтобы подтвердить, что мы действительно создали список чисел от 1 до 10 , мы конвертируем ленивый ответ в стеке в массив, используя слово > массив . Введите это слово, и ваша стопка должна выглядеть как
{1 2 3 4 5 6 7 8 9 10}
, что многообещающе!
Затем мы хотим получить произведение этих чисел. Во многих функциональных языках это можно сделать с помощью функции под названием reduce или fold. Поищем одну.Нажатие F1 в слушателе откроет контекстную справочную систему, где вы можете найти уменьшить . Оказывается, уменьшить — это на самом деле слово, которое мы ищем, но на данный момент может быть неочевидно, как его использовать.
Попробуйте написать 1 [*] reduce и посмотрите на результат: это действительно факториал 10 . Итак, reduce обычно принимает три аргумента: последовательность (а один у нас был в стеке), начальное значение (это 1 , которое мы помещаем в стек следующим) и двоичная операция.Это, безусловно, должно быть * , но как насчет квадратных скобок вокруг * ?
Если бы мы написали только * , Factor попытался бы применить умножение к двум самым верхним элементам в стеке, а это не то, что мы хотели. Нам нужен способ поместить слово в стек, не применяя его. Если придерживаться нашей текстовой метафоры, этот механизм называется цитата . Чтобы процитировать одно или несколько слов, вы просто окружаете их [ и ] (оставляя пробелы!).То, что вы получаете, похоже на анонимную функцию на других языках.
Давайте введем слово drop в слушатель, чтобы очистить стек, и попробуем записать то, что мы сделали до сих пор, в одной строке: 10 [1, b] 1 [*] reduce . Как и ожидалось, в стеке останется 3628800 .
Теперь мы хотим определить слово для факториала, которое можно использовать всякий раз, когда нам нужен факториал. Мы будем называть наше слово фактом (хотя ! обычно используется как символ факториала, в Факторе ! — это слово, используемое для комментариев).Чтобы определить его, нам сначала нужно использовать слово : . Затем мы помещаем имя определяемого слова, затем стек , эффекты и, наконец, тело, заканчивающееся ; слово:
: fact (n - n!) [1, b] 1 [*] уменьшить;
Что такое стековые эффекты? В нашем случае это (n - n!) . Эффекты стека — это то, как вы документируете входные данные из стека и выходы в стек для вашего слова. Вы можете использовать любой идентификатор для именования элементов стека, здесь мы используем n .Фактор выполнит проверку согласованности, чтобы количество указанных вами входов и выходов соответствовало тому, что делает тело.
Если попробовать написать
: fact (m n - n!) [1, b] 1 [*] уменьшить;
Коэффициент сигнализирует об ошибке, что 2 входа ( m и n ) не соответствуют тексту слова. Чтобы восстановить предыдущее правильное определение, нажмите Ctrl + P два раза, чтобы вернуться к предыдущему вводу, а затем введите его.
Мы можем рассматривать эффекты стека в определениях как инструмент документации и как очень простую систему типов, которая, тем не менее, выявляет несколько ошибок.
В любом случае, вы успешно определили свое первое слово: если вы напишете 10 факт в слушателе, вы можете это доказать.
Обратите внимание, что часть определения 1 [*] reduce имеет смысл сама по себе, будучи продуктом последовательности. В конкатенативном языке хорошо то, что мы можем просто выделить эту часть и написать
: prod ({x1 ,..., xn} - x1 * ... * xn) 1 [*] уменьшить;
: fact (n - n!) [1, b] prod;
Наши определения стали проще, и не было необходимости передавать параметры, переименовывать локальные переменные или делать что-либо еще, что было бы необходимо для рефакторинга нашей функции на большинстве языков.
Конечно, в Factor уже есть слово для факториала (на самом деле существует целый словарь math.factorials , включая множество вариантов обычного факториала) и слово для продукта ( произведение в словарях последовательностей ) , но, как это часто бывает, вводные примеры частично совпадают со стандартной библиотекой.
Разбор слов
Если вы до сих пор уделяли пристальное внимание, вы понимаете, что я солгал вам. Я сказал, что каждое слово действует в стеке по порядку, но есть несколько слов вроде [, ] , : и ; , которые, похоже, не следуют этому правилу.
Это слов синтаксического анализа , и они ведут себя иначе, чем более простые слова, такие как 5 , [1, b] или drop . Мы рассмотрим их более подробно, когда будем говорить о метапрограммировании, но пока достаточно знать, что слова синтаксического анализа являются особенными.
Они определяются не словом : , а словом SYNTAX: . Когда встречается синтаксический анализ слов, он может взаимодействовать с синтаксическим анализатором, используя четко определенный API, чтобы влиять на то, как анализируются последовательные слова. Например, : запрашивает следующие токены от парсеров до ; обнаружен и пытается скомпилировать этот поток токенов в определение слова.
Обычно слова синтаксического анализа используются для определения литералов. Например, { — слово синтаксического анализа, которое начинает определение массива и заканчивается } .Все, что находится между ними, является частью массива. Примером массива, который мы видели ранее, является {1 2 3 4 5 6 7 8 9 10} .
Существуют также литералы для хэш-карт, H {{"Perl" "Ларри Уолл"} {"Фактор" "Слава Пестов"} {"Scala" "Мартин Одерски"}} и байтовые массивы, B {1 14 18 23} .
Другие варианты использования слова синтаксического анализа включают модульную систему, объектно-ориентированные функции Factor, перечисления, мемоизированные функции, модификаторы конфиденциальности и многое другое. Теоретически даже SYNTAX: можно определить в терминах самого себя, хотя, конечно, систему нужно каким-то образом настроить.
Перетасовка стека
Теперь, когда вы знаете основы Factor, вы можете начать собирать более сложные слова. Иногда может потребоваться использовать переменные, которые не находятся на вершине стека, или использовать переменные более одного раза. Есть несколько слов, которые могут помочь в этом. Я упоминаю о них сейчас, так как вы должны знать о них, но предупреждаю вас, что использование слишком большого количества этих слов для управления стеком приведет к тому, что ваш код быстро станет труднее читать и писать.Перестановка стека требует мысленного моделирования перемещения значений в стеке, что не является естественным способом программирования. В следующем разделе мы увидим гораздо более эффективный способ удовлетворить большинство потребностей.
Вот список наиболее часто используемых слов с указанием их влияния на стек. Попробуйте их в слушателе, чтобы почувствовать, как они манипулируют стеком, и изучите онлайн-справку, чтобы узнать больше.
dup (x - x x)
капля (х -)
своп (x y - y x)
над (x y - x y x)
dupd (х у - х х у)
swapd (x y z - y x z)
зажим (x y - y)
гниль (x y z - y z x)
-rot (x y z - z x y)
2dup (x y - x y x y)
Комбинаторы
Хотя слова, упомянутые в предыдущем абзаце, иногда бывают полезны (особенно более простые dup , drop и swap ), вы должны написать код, который делает как можно меньше перетасовки стека.Это требует практики, чтобы аргументы функции располагались в правильном порядке. Тем не менее, существуют определенные общие шаблоны необходимых манипуляций со стеком, которые лучше абстрагировать их собственными словами.
Предположим, мы хотим определить слово, чтобы определить, является ли данное число n простым. Простой алгоритм состоит в том, чтобы проверить каждое число от 2 до квадратного корня из n и посмотреть, является ли оно делителем n . В этом случае n используется в двух местах: как верхняя граница последовательности и как число для проверки делимости.
Слово bi применяет две разные кавычки к одному элементу в стеке над ними, и это именно то, что нам нужно. Например, 5 [2 *] [3 +] bi дает
10
8
bi применяет котировку [2 *] к значению 5 , а затем котировку [3 +] к значению 5 , оставляя в стеке 10 , а затем 8 . Без bi нам пришлось бы сначала dup 5 , затем умножить, а затем поменять местами результат умножения на второй 5 , чтобы мы могли выполнить сложение
5 дубли 2 * обмен 3 +
Вы можете видеть, что bi заменяет общий шаблон dup , затем вычисляет, затем меняет местами и снова вычисляет.
Чтобы продолжить наш основной пример, нам нужен способ сделать диапазон, начиная с 2 . Мы можем определить собственное слово для этого [2, b] , используя слово диапазона [a, b] , которое мы обсуждали ранее
: [2, b] (n - {2, ..., n}) 2 поменять местами [a, b]; в соответствии
Что случилось с этим встроенным словом? Это один из модификаторов, который мы можем использовать после определения слова, еще один — рекурсивный . Это позволит нам иметь определение короткого слова, встроенного везде, где оно используется, вместо того, чтобы вызывать вызов функции.
Попробуйте наше новое слово [2, b] и убедитесь, что оно работает
6 [2, b]> массив.
Использовать [2, b] для получения диапазона чисел от 2 до квадратного корня из n , который уже находится в стеке, просто: sqrt floor [2, b] (технически floor здесь не требуется, так как [a, b] работает для нецелочисленных границ). Давайте попробуем
16 sqrt [2, b]> массив. Теперь нам нужно слово для проверки делимости. Быстрый поиск в онлайн-справке показывает, что делитель ? — это то слово, которое мы хотим. Это поможет иметь аргументы в пользу проверки делимости в другом направлении, поэтому мы определяем multiple?
: несколько? (a b -?) поменять местами делитель? ; в соответствии
Оба они возвращают т
9 3 делитель? .
3 9 кратный? .
Если мы собираемся использовать bi в нашем определении prime , как мы подразумевали выше, нам нужна вторая цитата.Наша вторая цитата должна проверить, является ли значение в диапазоне делителем n — другими словами, нам нужно частично применить слово multiple? . Это можно сделать с помощью слова карри , например: [несколько? ] карри .
Наконец, когда у нас есть диапазон потенциальных делителей и тестовая функция в стеке, мы можем проверить, удовлетворяет ли какой-либо элемент делимости с любым? , а затем отрицайте этот ответ , а не .Наше полное определение простое выглядит как
: простое? (n -?) [sqrt [2, b]] [[несколько? ] карри] би любой? нет ;
Хотя определение простого числа сложно, перетасовка стека минимальна и используется только в небольших вспомогательных функциях, которые проще рассуждать, чем простое число ? .
Обратите внимание, что prime? использует два уровня вложенности цитат, поскольку bi оперирует двумя котировками, а наша вторая цитата содержит слово curry , которое также оперирует цитатой.В общем, факторные слова имеют тенденцию быть довольно мелкими, используя один уровень вложенности для каждой функции более высокого порядка, в отличие от Lisps или более общих языков, основанных на лямбда-исчислении, которые используют один уровень вложенности для каждой функции, высшего порядка или нет. .
Существует гораздо больше комбинаторов, кроме bi (и его родственника tri ), и вам следует познакомиться хотя бы с bi , tri , bi * и bi @ , прочитав о них в онлайн-справку и опробовать их в слушателе.
Словари
Теперь пора начать писать свои функции в файлах и научиться импортировать их в слушатель. Factor организует слова во вложенные пространства имен, называемые словарями . Вы можете импортировать все имена из словаря с помощью слова USE: . На самом деле, вы могли видеть что-то вроде
ИСПОЛЬЗОВАНИЕ: math.ranges
, когда вы попросили слушателя импортировать за вас слово [1, b] . Вы также можете использовать более одного словаря одновременно со словом USING: , за которым следует список словарей и завершается словом ; , как
ИСПОЛЬЗОВАНИЕ: математ.диапазоны последовательностей.deep;
Наконец, вы определяете словарь, в котором хранятся ваши определения, с помощью слова IN: . Если вы выполните поиск в онлайн-справке по слову, которое вы уже определили, например, prime? , вы увидите, что ваши определения сгруппированы в словарь по умолчанию блокнота . Кстати, это показывает, что онлайн-справка автоматически собирает информацию о ваших собственных словах, что является очень полезной функцией.
Есть еще несколько слов, например QUALIFIED: , FROM: , EXCLUDE: и RENAME: , которые позволяют более детально контролировать импорт, но USING: является наиболее распространенным.
На диске словари хранятся в нескольких корневых каталогах, как и путь к классам в языках JVM. По умолчанию система начинает поиск в каталогах , базовых , основных , дополнительных , рабочих под Factor home. Вы можете добавить больше, как во время выполнения со словом add-vocab-root , так и путем создания файла конфигурации .factor-rc , но пока мы будем хранить наши словари в каталоге work , который зарезервирован для пользователя.
Создание шаблона для написания словаря
ПРИМЕНЕНИЕ: tools.scaffold
"github.tutorial" строительные леса
Вы найдете файл work / github / tutorial / tutorial.factor , содержащий пустой словарь. Factor интегрируется со многими редакторами, поэтому вы можете попробовать "github.tutorial" отредактировать : вам будет предложено выбрать свой любимый редактор и использовать этот редактор для открытия вновь созданного словаря.
Вы можете добавить определения из предыдущего абзаца, чтобы он выглядел как
! Авторское право (C) 2014 Андреа Ферретти.! См. Http://factorcode.org/license.txt для получения лицензии BSD.
С ИСПОЛЬЗОВАНИЕМ: ;
IN: github.tutorial
: [2, b] (n - {2, ..., n}) 2 поменять местами [a, b]; в соответствии
: несколько? (a b -?) поменять местами делитель? ; в соответствии
: основной? (n -?) [sqrt [2, b]] [[несколько? ] карри] би любой? нет ;
Поскольку словарь уже был загружен, когда вы его создали, нам нужен способ обновить его с диска. Вы можете сделать это с помощью обновления "github.tutorial" . Также есть обновить все слово с ярлыком F2 .
Вам будет несколько раз предложено использовать словари, поскольку ваш оператор USING: пуст. После принятия всех из них Factor предлагает вам новый заголовок со всем необходимым импортом:
ИСПОЛЬЗОВАНИЕ: ядро math.functions math.ranges последовательности;
IN: github.tutorial
Теперь, когда в вашем словаре есть несколько слов, вы можете отредактировать, скажем, кратное число ? слово с \ кратным? отредактировать . Вы найдете свой редактор открытым в соответствующей строке нужного файла.Это также работает для слов в Факторном распределении, хотя изменять их может быть плохой идеей.
Это слово \ требует небольшого пояснения. Это работает как своего рода escape, позволяя нам поместить ссылку на следующее слово в стеке, не выполняя его. Это именно то, что нам нужно, потому что edit — это слово, которое принимает сами слова в качестве аргументов. Этот механизм похож на цитаты, но, хотя цитата создает новую анонимную функцию, здесь мы напрямую ссылаемся на слово multiple? .
Возвращаясь к нашей задаче, вы можете заметить, что слова [2, b] и кратны? — это просто вспомогательные функции, которые вы, возможно, не захотите раскрывать напрямую. Чтобы скрыть их от просмотра, вы можете заключить их в приватный блок, например,
<ЧАСТНЫЙ
: [2, b] (n - {2, ..., n}) 2 поменять местами [a, b]; в соответствии
: несколько? (a b -?) поменять местами делитель? ; в соответствии
ЧАСТНЫЙ>
После внесения этого изменения и обновления словаря вы увидите, что слушатель больше не может ссылаться на такие слова, как [2, b] .Слово github.tutorial.private .
По-прежнему можно ссылаться на слова в частных словарях, что вы можете подтвердить, выполнив поиск по [2, b] в онлайн-справке, но, конечно, это не рекомендуется, поскольку люди не гарантируют стабильность API для частных слов . Слова под github.tutorial могут относиться к словам в github.tutorial.private напрямую, например, prime? делает.
Тесты и документация
Это хорошее время, чтобы начать писать несколько модульных тестов. Вы можете создать скелет с
scaffold-тесты "github.tutorial"
Найдите сгенерированный файл в work / github / tutorial / tutorial-tests.factor , который вы можете открыть с помощью "github.tutorial" edit-tests . Обратите внимание на строку
ИСПОЛЬЗОВАНИЕ: tools.test github.руководство ;
, который импортирует модуль модульного тестирования, а также ваш собственный. Будем тестировать только публичный prime? функция.
Тесты написаны с использованием слова unit-test , которое предполагает две цитаты: первая содержит ожидаемые результаты, а вторая — слова, которые нужно выполнить, чтобы получить этот результат. Добавьте эти строки в github.tutorial-tests :
[t] [2 простых? ] модульный тест
[t] [13 простых? ] модульный тест
[t] [29 простое? ] модульный тест
[f] [15 простых? ] модульный тест
[f] [377 простое? ] модульный тест
[f] [1 простое число? ] модульный тест
[t] [20750750228539 простое? ] модульный тест
Теперь вы можете запускать тесты с помощью "github.учебник »test . Вы увидите, что мы действительно допустили ошибку, и нажатие F3 покажет более подробную информацию. Кажется, что наши утверждения не работают для 2 .
Фактически, если вы вручную попытаетесь запустить наши функции для 2 , вы увидите, что наше определение [2, b] возвращает {2} для 2 sqrt , поскольку квадрат корень из двух меньше двух, поэтому мы получаем интервал по убыванию. Попробуйте исправить, чтобы тесты прошли.
Есть еще несколько слов для проверки ошибок и вывода эффектов стека. unit-test пока достаточно, но позже вы можете захотеть проверить must-fail и must-infer .
Мы также можем добавить некоторую документацию к нашему словарю. Автоматически созданная документация всегда доступна для пользовательских слов (даже в слушателе), но мы можем написать несколько полезных комментариев вручную или даже добавить пользовательские статьи, которые появятся в онлайн-справке. Как и ожидалось, начнем с github .учебник "scaffold-docs , а затем " github.tutorial "edit-docs .
Сгенерированный файл work / github / tutorial-docs.factor импортирует help.markup и help.syntax . Эти два словаря определяют слова для создания документации. Фактическая страница справки создается синтаксическим словом HELP: .
Аргументы HELP: представляют собой вложенный массив формы {$ directive content ...} . В частности, вы видите здесь директивы $, значения и $, описание , но существует еще несколько, например $ ошибок , $ примеры и $ см. Также .
Обратите внимание, что тип вывода ? Предполагается, что является логическим. Измените первые строки, чтобы они выглядели как
ИСПОЛЬЗОВАНИЕ: help.markup help.syntax kernel math;
IN: github.tutorial
СПРАВКА: премьер?
{$ values
{"n" fixnum}
{"?" логическое}
}
{$ description "Проверяет, является ли n простым. Предполагается, что n - положительное целое число." };
и обновите словарь github.tutorial . Если теперь посмотреть справку по prime? , например с \ prime? help , вы увидите обновленную документацию.
Вы также можете отображать директивы в слушателе для более быстрой обратной связи. Например, попробуйте написать
{$ values
{"n" целое число}
{"?" логическое}
} print-content
Разметка справки содержит множество возможных директив, и вы можете использовать их для написания отдельных статей в справочной системе. Взгляните на еще несколько с справкой "типы элементов" .
Объектная система и протоколы
Хотя это не очевидно из того, что мы сказали до сих пор, Factor имеет объектно-ориентированные функции, и многие ключевые слова на самом деле являются вызовами методов.Чтобы лучше понять, как объекты ведут себя в Factor, приведем цитату:
Я придумал термин «объектно-ориентированный» и могу сказать, что не имел в виду C ++.
Алан Кей
Термин «объектно-ориентированный» имеет столько же значений, сколько и люди, которые его используют. Одна точка зрения — которая фактически была центральной в работе Алана Кея — заключается в том, что речь идет о позднем связывании имен функций. В Smalltalk, языке, на котором родилась эта концепция, люди не говорят о вызове метода, а скорее об отправке сообщения объекту.Объект должен решить, как ответить на это сообщение, и вызывающий не должен знать о реализации. Например, можно отправить сообщение карта как в массив, так и в связанный список, но внутренне итерация будет обрабатываться по-разному.
Связывание имени сообщения с реализацией метода является динамическим, и это рассматривается как основная сила объектов. В результате довольно сложные системы могут развиться из взаимодействия независимых объектов, которые не вмешиваются друг в друга.
Честно говоря, Factor сильно отличается от Smalltalk, но все же существует концепция классов, и общие слова могут быть определены с разными реализациями в разных классах.
Некоторые классы встроены в Factor, например string , boolean , fixnum или word . Далее, наиболее распространенный способ определения класса — это кортеж . Кортежи определяются с помощью слова синтаксического анализа TUPLE: , за которым следуют имя кортежа и поля класса, который мы хотим определить, которые называются слотами на языке Factor.
Определим класс для фильмов:
ПАРАМЕТР: название фильма, режиссер, актеры;
Это также генерирует сеттеры >> заголовок , >> режиссер и >> актеры и геттеры заголовок >> , режиссер >> и актеры >> . Например, мы можем создать новый фильм с
фильм новый "Престиж" >> название
"Кристофер Нолан" >> режиссер
{"Хью Джекман" "Кристиан Бэйл" "Скарлетт Йоханссон"} >> актеры
Мы также можем сократить это до
«Престиж» «Кристофер Нолан»
{"Хью Джекман" "Кристиан Бэйл" "Скарлетт Йоханссон"}
фильм удав
Слово boa означает «по порядку аргументов» и является конструктором, который заполняет слоты кортежа элементами в стеке по порядку. фильм удав называется конструктором удава , каламбур на удаве Констриктор. Принято определять наиболее распространенный конструктор с именем , который в нашем случае может быть просто
: <фильм> (название режиссера, актеры - фильм), фильм удав;
На самом деле, конструкторы удавов встречаются довольно часто, и указанную выше строку можно сократить до
. C: <фильм> фильм
В других случаях вы можете использовать некоторые значения по умолчанию или вычислить некоторые поля.
Функционально мыслящие люди будут беспокоиться об изменчивости кортежей. Фактически, слоты могут быть объявлены доступными только для чтения с {имя-слота только для чтения} . В этом случае установщик поля не будет сгенерирован, и значение должно быть установлено в начале с помощью конструктора boa. Другими допустимыми модификаторами слота являются начальный: — для объявления значения по умолчанию — и слово класса, такое как целое число , чтобы ограничить значения, которые могут быть вставлены.
В качестве примера мы определяем другой класс кортежей для рок-групп
TUPLE: группа
{строка клавиатуры только для чтения}
{гитарная струна только для чтения}
{басовая струна только для чтения}
{барабанная струна только для чтения};
: <группа> (клавишные гитара бас-барабаны - группа) группа boa;
вместе с одним экземпляром
«Ричард Райт» «Дэвид Гилмор» «Роджер Уотерс» «Ник Мейсон» <группа>
Теперь, конечно, все знают, что звезда в кино — первый актер, а в рок-группе — басист.Чтобы кодировать это, мы сначала определяем общее слово
GENERIC: звездочка (позиция - звезда)
Как вы можете видеть, он объявлен с помощью слова синтаксического анализа GENERIC: и объявляет свои эффекты стека, но в настоящее время у него нет реализации, поэтому нет необходимости в закрывающем ; . Общие слова используются для динамической отправки. Мы можем определить реализации для различных классов, используя слово M:
M: кинозвезды актеры >> первый;
M: звездный бас группы >>;
Если написать звездочка. два раза, вы можете увидеть различный эффект вызова универсального слова для экземпляров разных классов.
Встроенные классы и классы кортежей — это еще не все, что есть в объектной системе: можно определить больше классов с помощью операций над множествами, например UNION: и INTERSECTION: . Другой способ определить класс — это примесь .
миксинов определяется словом MIXIN: , и существующие классы могут быть добавлены к миксину, написав
INSTANCE: примесь класса
Методы, определенные в миксине, будут доступны для всех классов, которые принадлежат миксину.Если вы знакомы с классами типов Haskell, вы заметите сходство, хотя Haskell обеспечивает во время компиляции, что экземпляры классов типов реализуют определенные функции, в то время как в Factor это неофициально указано в документации.
Двумя важными примерами миксинов являются последовательность и assoc . Первый определяет протокол, доступный для всех конкретных последовательностей, таких как строки, связанные списки или массивы, а второй определяет протокол для ассоциативных массивов, таких как хэш-таблицы или списки ассоциаций.
Это позволяет воздействовать на все последовательности в Factor с помощью общего набора слов, при этом различаясь по реализации и минимизируя повторение кода (поскольку требуется только несколько примитивов, а другие операции определены для класса последовательности ). Наиболее распространенными операциями, которые вы будете использовать с последовательностями, являются карта , фильтр и сокращение , но их гораздо больше — как вы можете видеть с помощью «последовательности» справки .
Изучение инструментов
Большая часть продуктивности Factor достигается за счет глубокой интеграции языка и библиотек с окружающими их инструментами, которые воплощены в слушателе.Многие функции слушателя можно использовать программно и наоборот. Вы видели несколько примеров:
- справка доступна в Интернете, но вы также можете вызвать ее с помощью справки
print-content; - ярлык
F2или словаобновитьиобновить всеможно использовать для обновления словарей с диска при продолжении работы в слушателе; -
editword обеспечивает интеграцию с редактором, но вы также можете щелкнуть имена файлов на страницах справки для словарей, чтобы открыть их.
Обновление на самом деле довольно умное. Каждый раз, когда слово переопределяется, слова, которые от него зависят, перекомпилируются в соответствии с новым определением. Вы можете проверить самостоятельно, сделав
: инкр (х - у) 1 +;
: inc-print (x -) inc. ;
5 вкл-принт
, а затем
: инкр (х - у) 2 +;
5 вкл-принт
Это позволяет вам всегда держать слушателя открытым, улучшая ваши определения, периодически сохраняя ваши определения в файл и обновляя, без необходимости перезагружать Factor.
Вы также можете сохранить все состояние Factor с помощью слова save-image и позже восстановить его, запустив Factor с
./factor -i = путь к изображению
Фактически, Factor основан на изображениях и использует файлы только при загрузке и обновлении словарей.
Сила слушателя на этом не заканчивается. Элементы стека можно просмотреть, щелкнув по ним или вызвав слово инспектор . Например, попробуйте написать
TUPLE: трилогия первая вторая треть;
: <трилогия> (первая вторая треть - трилогия) трилогия удав;
«Новая надежда» «Империя наносит ответный удар» «Возвращение джедая» <трилогия>
"Джордж Лукас" 2массив
Вы получите предмет, который выглядит как
{~ трилогия ~ "Джордж Лукас"}
в стеке.Попробуйте щелкнуть по нему: вы сможете увидеть слоты массива и сосредоточиться на трилогии или на строке, дважды щелкнув по ним. Это чрезвычайно полезно для интерактивного прототипирования. Специальные объекты могут настраивать инспектор, реализуя метод content-gadget .
Есть еще один инспектор ошибок. Всякий раз, когда возникает ошибка, ее можно проверить с помощью F3 . Это позволяет вам исследовать исключения, объявления плохих эффектов стека и так далее. Отладчик позволяет вам переходить к коду как вперед, так и назад, и вам нужно немного познакомиться с ним.Вы также можете запустить отладчик вручную, введя некоторый код в прослушиватель и нажав Ctrl + w .
Еще одна функция слушателя позволяет тестировать код. В качестве примера мы пишем намеренно неэффективное значение Фибоначчи:
DEFER: fib-rec
: fib (n - f (n)) dup 2 <[] [fib-rec] если;
: fib-rec (n - f (n)) [1 - fib] [2 - fib] bi +;
(обратите внимание на использование DEFER: для определения двух взаимно рекурсивных слов).Вы можете измерить время работы, написав 40 fib , а затем нажав Ctrl + t вместо Enter. Вы получите информацию о времени, а также другую статистику. Программно вы можете использовать слово , время в цитате, чтобы сделать то же самое.
Вы также можете добавить часы по словам, чтобы распечатать входы и выходы при входе и выходе. Попробуйте написать
\ fib часы
, а затем запустите 10 fib , чтобы посмотреть, что произойдет. Затем вы можете снять часы с помощью \ fib reset .
Еще один очень полезный инструмент - словарь lint . Это сканирует определения слов, чтобы найти повторяющийся код, который можно исключить. В качестве примера давайте определим слово, чтобы проверить, начинается ли строка с другого. Создать тестовый словарь
строительные леса "линтме"
и добавьте следующее определение
ИСПОЛЬЗОВАНИЕ: последовательности ядра;
IN: lintme
: начинается с? (str sub -?) длина dup swapd head =;
Загрузите инструмент lint с USE: lint и напишите "lintme" lint-vocab .Вы получите отчет, в котором упоминается, что последовательность слов length swapd уже используется в слове (split) of splitting.private , поэтому ее можно исключить.
Теперь вы, конечно, не захотите изменять источник слова в стандартной библиотеке - не говоря уже о частной - но в более сложных случаях инструмент lint может найти фактические повторы. Рекомендуется время от времени обновлять словарный запас, чтобы избежать дублирования кода и как хороший способ обнаружить слова из библиотеки, которые вы могли случайно переопределить.
Наконец, есть несколько утилит для проверки слов. Вы можете увидеть определение слова в справке, но более быстрый способ - см. . Или, наоборот, вы можете использовать . , чтобы проверить вызывающих данное слово. Попробуйте \ обратное использование и \ обратное использование. .
Метапрограммирование
Теперь мы отправляемся в мир метапрограммирования и пишем наше первое слово для синтаксического анализа. К настоящему времени вы видели много слов синтаксического анализа, например [. {, H {, ИСПОЛЬЗОВАНИЕ: , IN: , <ЧАСТНОЕ , ОБЩЕЕ: и так далее. Каждый из них определяется словом синтаксического анализа SYNTAX: и взаимодействует с синтаксическим анализатором Factor.
Анализатор накапливает токены в векторе аккумулятора, если не находит слово синтаксического анализа, которое выполняется немедленно. Поскольку слова синтаксического анализа выполняются во время компиляции, они не могут взаимодействовать со стеком, но имеют доступ к вектору аккумулятора.Их стековый эффект должен быть (накопление - накопление) . Обычно они запрашивают у синтаксического анализатора еще несколько токенов, что-то делают с ними и, наконец, помещают результат в вектор-аккумулятор с суффиксом слова ! .
В качестве примера мы определим литерал для последовательностей ДНК. Последовательность ДНК - это последовательность одного из оснований цитозина, гуанина, аденина и тимина, которую мы будем обозначать буквами c, g, a, t. Поскольку существует четыре возможных базиса, мы можем кодировать каждую двумя битами.Позвольте использовать определение слова
: dna> bits (токен - биты) {
{"а" [{ж е}]}
{"с" [{т т}]}
{"г" [{ф т}]}
{"т" [{т ф}]}
} кейс ;
, где первый бит указывает, является ли основание пурином или пиримидином, а второй идентифицирует основания, которые образуют пару вместе.
Наша цель - прочитать последовательность букв a, c, g, t - возможно, с пробелами - и преобразовать их в битовый массив. Фактор поддерживает битовые массивы, а литеральные битовые массивы выглядят как ? {F f t} .
Наш синтаксис для ДНК начинается с ДНК { и получает все токены до тех пор, пока не будет найден закрывающий токен } . Промежуточные токены будут помещены в строку, и с помощью нашей функции dna> биты мы отобразим эту строку в битовый массив. Для чтения токенов мы будем использовать слово parse-tokens . Есть несколько слов более высокого уровня для взаимодействия с анализатором, например parse-until и parse-literal , но мы не можем применить их в нашем случае, поскольку найденные нами токены представляют собой просто последовательности acgt. допустимых слов фактора.Давайте начнем с простого приближения, которое просто считывает токены между нашими разделителями и выводит строку, полученную конкатенацией
СИНТАКСИС: суффикс конкатенации маркеров синтаксического анализа ДНК {"}"!
Вы можете проверить эффект, выполнив DNA {a ccg t a g} , который должен вывести «accgtag» . Во втором приближении мы преобразовываем каждую букву в логическую пару:
СИНТАКСИС: соединение синтаксических анализаторов ДНК {"}"
[1-е кольцо ДНК> биты] {} суффикс map-as! ;
Обратите внимание на использование map-as вместо map .Поскольку целевая коллекция не является строкой, мы не использовали карту , которая сохраняет тип, а карту как , которая принимает в качестве дополнительного аргумента пример целевой коллекции - здесь {} . Наша последняя версия сглаживает массив пар с помощью concat и, наконец, превращается в битовый массив:
СИНТАКСИС: соединение синтаксических анализаторов ДНК {"}"
[ДНК 1-го кольца> биты] {} map-as
concat> суффикс битового массива! ;
Если вы попробуете это с DNA {a ccg t a g} , вы должны получить
`? {F f t t t t f t t f f f f t}`
Давайте приведем еще один очень простой пример, украденный у Джона Бенедиктссона, который касается инфиксного синтаксиса для диапазонов.До сих пор мы использовали [a, b] для создания диапазона. Мы можем сделать синтаксис, более удобный для людей, переходящих с других языков, используя ... в качестве инфиксного слова.
Мы можем использовать scan-object , чтобы запросить у синтаксического анализатора следующий анализируемый объект, и unclip-last , чтобы получить верхний элемент из вектора аккумулятора. Таким образом, мы можем определить ... просто с помощью
СИНТАКСИС: ... суффикс [a, b] объекта сканирования unclip-last! ;
Вы можете попробовать это с 12... 18> массив .
Мы только прикоснулись к синтаксическому анализу слов; в общем, они позволяют выполнять произвольные вычисления во время компиляции, обеспечивая мощные формы метапрограммирования.
В некотором смысле синтаксис Factor является полностью плоским, а синтаксический анализ слов позволяет вам вводить синтаксис более сложный, чем поток токенов, который будет использоваться локально. Это позволяет расширить язык Factor, добавив много новых функций в виде библиотек. В принципе, можно было бы даже скомпилировать внешний язык для Factor - скажем, JavaScript - и встроить его как Factor DSL внутри границ парсинг слова. Нужен некоторый вкус, чтобы не злоупотреблять этим слишком много, чтобы вводить стили, слишком чуждые конкатенативному миру.
Когда стека не хватает
До сих пор я немного жульничал и старался избегать написания примеров, которые были бы слишком сложными для написания в конкатенативном стиле. По правде говоря, вы, , найдете случаев, когда это слишком ограничительно. К счастью, синтаксический анализ слов позволяет вам обойти эти ограничения, и Factor предлагает некоторые из них, чтобы справиться с наиболее распространенными неприятностями.
Возможно, вы захотите дать имя локальным переменным. Слово :: работает так же, как : , но позволяет вам фактически связывать имя параметров стека с переменными, чтобы вы могли использовать их несколько раз в нужном вам порядке. Например, давайте определим слово для решения квадратных уравнений. Я избавлю вас от версии, основанной исключительно на стеке, и представлю вам версию с локальными переменными (для этого потребуется словарь locals ):
:: решить q (a b c - x)
b neg
б б * 4 а в * * - sqrt
+
2 а * /;
В этом случае мы выбрали знак +, но мы можем сделать лучше и вывести оба решения:
:: решить q (a b c - x1 x2)
b neg
б б * 4 а в * * - sqrt
[+] [-] 2bi
[2 a * /] bi @;
Вы можете проверить, работает ли это определение с чем-то вроде 2-16 30 resolveq , которое должно выводить как 3.0 и 5,0 . Помимо написания в стиле RPN, наша первая версия resolveq выглядит точно так же, как и на языке с локальными переменными. Для второго определения мы применяем операции + и - к -b и delta, используя комбинатор 2bi , а затем делим оба результата на 2a, используя bi @ .
Также есть поддержка местных жителей в котировках - с помощью [| - и методы - с использованием M :: - и можно также создать область для привязки локальных переменных вне определений с помощью [let .Конечно, все они на самом деле компилируются в конкатенативный код с некоторой перетасовкой стека. Я рекомендую вам просмотреть примеры этих слов, но имейте в виду, что их использование на практике гораздо менее заметно, чем можно было бы ожидать - около 1% собственной кодовой базы Factor.
Другой, более распространенный случай, случается, когда вам нужно специализировать цитату для некоторых значений, но они не появляются в нужном месте. Помните, что вы можете частично применить цитату, используя карри .Но это предполагает, что значение, которое вы применяете, должно появиться в цитате слева; в других случаях вам понадобится перетасовка стека. Слово с - это что-то вроде частичного употребления с дыркой. Он также формирует цитату, но использует третий элемент в стеке вместо второго. Кроме того, получившаяся каррированная цитата будет применена к элементу, вставившему ее во вторую позицию.
Пример из документации, вероятно, говорит больше, чем приведенное выше предложение: попробуйте написать 1 {1 2 3} [/] с картой .
Разрешите еще раз взять прайм? , но на этот раз напишите его без вспомогательных слов:
: простое? (n -?) [sqrt 2 swap [a, b]] [[поменять местами делитель? ] карри] би любой? нет ;
Используя с вместо карри , это упрощается до
: простое? (n -?) 2 над sqrt [a, b] [divisor? ] с любой? нет ;
Если вы не представляете себе, что происходит, вы можете рассмотреть словарь fry .Он определяет жареных котировок ; это цитаты, в которых есть дыры, отмеченные цифрами _ , которые заполнены значениями из стека.
Первая цитата переписывается проще как
['[2 _ sqrt [a, b]] call]
Здесь мы используем жареную цитату - начиная с '[ - чтобы вставить элемент в верхнюю часть стека во вторую позицию, а затем используем вызов для оценки результирующей цитаты.Вторая цитата становится просто
['[_ поменять местами делитель? ]]
так что альтернативное определение prime? это
: простое? (n -?) ['[2 _ sqrt [a, b]] call] [' [_ делитель подкачки? ]] би любой? нет ;
В зависимости от вашего вкуса, эта версия может показаться вам более читаемой. В этом случае добавленная ясность, вероятно, теряется из-за того, что жареные цитаты сами находятся внутри цитат, но иногда их использование может значительно упростить поток.
Наконец, бывают случаи, когда нужно просто дать имена переменным, которые доступны внутри некоторой области, и использовать их там, где это необходимо. Эти переменные могут содержать глобальные значения или, по крайней мере, не локальные для отдельного слова. Типичным примером могут быть потоки ввода и вывода или соединения с базой данных.
Факторпозволяет создавать динамических переменных и связывать их в области видимости. Первым делом нужно создать символ для переменной, скажем
. СИМВОЛ: любимый язык
Затем можно использовать слово set для привязки переменной и get для получения ее значений, например
Набор любимых языков "Фактор"
любимый язык получить
Области действия вложены, и можно создавать новые области с помощью слова с областью действия .Попробуйте например
: on-the-jvm (-) [
Набор любимых языков "Scala"
любимый язык получить.
] с областью действия;
Если вы запустите на-jvm , вы получите напечатанное «Scala» , но все равно после выполнения любимый язык получить вернет «Фактор» .
Все инструменты, которые мы видели в этом разделе, следует использовать при необходимости, поскольку они нарушают конкатенативность и затрудняют разбиение слов на множители, но они могут значительно повысить ясность, когда это необходимо.Factor имеет очень практичный подход и не стесняется предлагать менее чистые, но, тем не менее, часто полезные функции.
Вход / выход
Теперь мы завершаем экскурсию по языку и начинаем исследовать, как взаимодействовать с внешним миром. Я начну в этом разделе с некоторых примеров ввода / вывода, но это неизбежно приведет к обсуждению асинхронности. Затем в оставшейся части учебника будет более подробно рассказано о параллельных и распределенных вычислениях.
Factor реализует эффективные средства асинхронного ввода / вывода, аналогичные NIO на JVM или Node.js системы ввода-вывода. Это означает, что операции ввода и вывода выполняются в фоновом режиме, оставляя задачу переднего плана свободной для выполнения работы, пока диск вращается или сеть буферизует пакеты. Фактор в настоящее время является однопоточным, но асинхронность позволяет ему быть достаточно производительным для приложений, привязанных к вводу-выводу.
Все слова ввода / вывода фактора сосредоточены на потоках . Потоки - это ленивые последовательности, которые можно читать или записывать, типичными примерами являются файлы, сетевые порты или стандартный ввод и вывод.Фактор содержит пару динамических переменных, называемых входным потоком и выходным потоком , которые используются большинством слов ввода-вывода. Эти переменные могут быть восстановлены локально с помощью with-input-stream , with-output-stream и with-streams . Когда вы находитесь в слушателе, потоки по умолчанию пишут и читают в слушателе, но как только вы развертываете свое приложение как исполняемый файл, они обычно привязываются к стандартному вводу и выводу вашей консоли.
Слова и (или ) могут использоваться для создания потока чтения или записи в файл, учитывая его путь и кодировку.Собирая все вместе, мы делаем простой пример слова, которое читает каждую строку файла, закодированного в UTF8, и записывает первую букву строки в слушатель.
Во-первых, нам нужно безопасное слово , которое работает как head , но возвращает ввод, если последовательность слишком короткая. Для этого мы будем использовать слово recovery , которое позволяет нам объявить блок try-catch. Для этого требуются две цитаты: первая выполняется, а в случае неудачи вторая выполняется с ошибкой в качестве входных данных.Следовательно, мы можем определить
: безопасная голова (seq n - seq ') [head] [2drop] recovery;
Это в основном повод показать пример исключений, поскольку Factor определяет короткое слово , которое принимает последовательность и число и возвращает минимум между длиной последовательности и числом. Это позволяет нам написать просто
: безопасная головка (seq n - seq ') короткая головка;
С этим определением мы можем сделать слово, читающее первый символ первой строки:
: первые буквы чтения (путь -)
utf8 <файл-читатель> [
readln 1 безопасная запись nl
] с потоком ввода;
Используя вспомогательное слово with-file-reader , мы также можем сократить его до
: первые буквы чтения (путь -)
utf8 [
readln 1 безопасная запись nl
] с файловым ридером;
К сожалению, мы ограничены одной строкой.Чтобы прочитать больше строк, мы должны связать вызовы с readln до тех пор, пока один из них не вернет f . Фактор помогает нам со словом файл-строки , которое лениво перебирает строки. Наше окончательное определение становится
: первые буквы чтения (путь -)
utf8 строки файла [1 безопасная запись nl] каждая;
Если файл небольшой, можно также использовать file-contents для чтения всего содержимого файла в одной строке. Фактор определяет гораздо больше слов для ввода / вывода, которые охватывают гораздо больше случаев, таких как двоичные файлы или сокеты.
Мы заканчиваем этот раздел, исследуя несколько слов для обхода файловой системы. Наша цель - минимальная реализация команды ls .
Слово каталог-записей перечисляет содержимое каталога, давая список элементов кортежа, каждый из которых имеет слоты с именем и типа . Вы можете убедиться в этом, попробовав "/ home" записи каталога [имя >>] карту . Если вы проверите записи в каталоге, вы увидите, что это либо + directory + , либо + regular-file + (ну, есть и символические ссылки, но мы проигнорируем их для простоты).Следовательно, мы можем определить слово, в котором перечислены файлы и каталоги с
: список-файлов-и-каталогов (путь - каталоги файлов)
каталог-записей [тип >> + обычный-файл + =] раздел;
С его помощью мы можем определить слово ls , которое будет печатать содержимое каталога следующим образом:
: ls (путь -)
список файлов и каталогов
"СПРАВОЧНИКИ:" напишите nl
"------------" напишите nl
[имя >> написать nl] каждый
"ФАЙЛЫ:" напишите nl
"------" написать nl
[имя >> напишите nl] каждый;
Попробуйте ввести слово в своем домашнем каталоге, чтобы увидеть эффект.В следующем разделе мы рассмотрим, как создать исполняемый файл для нашей простой программы.
Развертывание программ
Есть два способа запускать программы Factor вне слушателя: как сценарии, которые интерпретируются Factor, или как отдельный исполняемый файл, скомпилированный для вашей платформы. Оба требуют, чтобы вы определили словарь с точкой входа (хотя для скриптов есть еще более простой способ), так что давайте сделаем это в первую очередь.
Начните с создания нашего словаря ls с помощью scaffold-work "ls" и сделайте его таким:
! Авторское право (C) 2014 Андреа Ферретти.! См. Http://factorcode.org/license.txt для получения лицензии BSD.
ИСПОЛЬЗОВАНИЕ: командная строка аксессоров io io.directories io.files.types
последовательности пространств имен ядра;
IN: ls
<ЧАСТНЫЙ
: list-files-and-dirs (путь - каталоги файлов)
каталог-записей [тип >> + обычный-файл + =] раздел;
ЧАСТНЫЙ>
: ls (путь -)
список файлов и каталогов
"СПРАВОЧНИКИ:" напишите nl
"------------" напишите nl
[имя >> написать nl] каждый
"ФАЙЛЫ:" напишите nl
"------" написать nl
[имя >> напишите nl] каждый;
Когда мы запускаем наш словарь, нам нужно будет прочитать аргументы из командной строки.Аргументы командной строки хранятся в динамической переменной командной строки , которая содержит массив строк. Следовательно - забывая о проверке ошибок - мы можем определить слово, которое запускает ls в первом аргументе командной строки с
: командная строка ls-run (-) получить сначала ls;
Наконец, мы используем слово MAIN: , чтобы объявить главное слово нашего словаря:
ГЛАВНАЯ: ls-run
Добавив эти две строчки в свой словарь, теперь вы готовы к его запуску.Самый простой способ - запустить словарь как сценарий с флагом -run , переданным в Factor. Например, чтобы перечислить содержимое моего дома, я могу сделать
./factor -run = ls / home / andrea
Чтобы создать исполняемый файл, мы должны установить некоторые параметры и вызвать слово deploy . Самый простой способ сделать это графически - вызвать слово средства развертывания . Если вы напишете «ls» deploy-tool , вам будет представлено окно для выбора вариантов развертывания.В нашем простом случае мы оставим параметры по умолчанию и выберем «Развернуть».
Через некоторое время вам должен быть представлен исполняемый файл, который вы можете запустить как
cd ls
./ls / home / andrea
Попробуйте сделать программу ls более устойчивой, обрабатывая отсутствующие аргументы командной строки и несуществующие аргументы или аргументы, не относящиеся к каталогу.
Многопоточность
Как мы уже сказали, среда выполнения Factor является однопоточной, как и Node. Тем не менее, можно эмулировать параллелизм в однопоточном режиме, используя сопрограмм .По сути, это кооперативные потоки, которые периодически освобождают управление с помощью слова yield , так что планировщик может решить, какую сопрограмму запустить следующей.
Хотя совместные потоки не позволяют использовать несколько ядер, они все же имеют некоторые преимущества:
- операции ввода / вывода могут избежать блокировки всего времени выполнения, так что можно реализовать достаточно производительные приложения, если ввод / вывод является узким местом; Пользовательские интерфейсы
- , естественно, представляют собой многопоточную конструкцию, и они могут быть реализованы в этой модели, как показывает сам слушатель;
- , наконец, некоторые проблемы, естественно, может быть проще написать с использованием многопоточных конструкций.
Для случаев, когда нужно использовать несколько ядер, Factor предлагает возможность порождения других процессов и взаимодействия между ними с использованием каналов , как мы увидим в следующем разделе.
Threads in Factors создаются из цитаты и имени, с порождением слова. Давайте воспользуемся этим, чтобы напечатать первые несколько строк «Звездных войн», по одной в секунду, причем каждая строка печатается внутри своего собственного потока. Во-первых, давайте запишем эти строки внутри динамической переменной:
СИМВОЛ: звездные войны
"Давным-давно, в далекой-далекой галактике....
Это период гражданской войны. Мятежник
космические корабли, поражающие из скрытого
база, одержали свою первую победу
против злой Галактической Империи.
Во время боя шпионам повстанцев удалось
украсть секретные планы Империи
абсолютное оружие, ЗВЕЗДА СМЕРТИ,
бронированная космическая станция с достаточным
власть уничтожить целую планету.
Преследуемые зловещими агентами Империи,
Принцесса Лея мчится домой на ее борту
звездолет, хранитель украденных планов
что может спасти ее людей и восстановить
свобода галактики.... "
"\ n" набор разделенных звездных войн
Мы создадим 18 потоков, каждый из которых будет печатать строку. Операция, которую должен выполнить поток, составляет
. Звездные войны получают печать
Обратите внимание, что динамические переменные распределяются между потоками, поэтому каждый из них имеет доступ к звездным войнам. Это нормально, поскольку он доступен только для чтения, но применяются обычные предостережения относительно разделяемой памяти в многопоточных настройках.
Определим слово для нагрузки потока
: печать в строке (i -) "Звездные войны" получает четвертый отпечаток;
Если мы дадим i-му потоку имя «i», то в нашем примере будет
18 [0, б) [
[[print-a-line] карри]
[число> строка]
би спаун
] каждый
Обратите внимание на использование curry для отправки i в котировку, которая выводит i-ю строку.Это почти то, что нам нужно, но работает слишком быстро. Нам нужно на время усыпить поток. Итак, мы очищаем стек, который теперь содержит множество объектов потоков, и ищем в справке слово sleep .
Оказывается, что спящий режим делает именно то, что нам нужно, но в качестве входных данных требуется объект длительностью . Мы можем создать продолжительность i секунд с ... ну i секунд . Итак, мы определяем
: ожидание и печать (i -) dup секунд, спящий режим, печать строки;
Попробуем
18 [0, б) [
[[подождите и распечатайте] карри]
[число> строка]
би спаун
] каждый
Вместо порождения мы также можем использовать внутри потока , который использует фиктивное имя потока и отбрасывает возвращенный поток, упрощая приведенное выше до
18 [0, б) [
[wait-and-print] карри в потоке
] каждый
Этого достаточно для нашей простой цели.В серьезных приложениях аддоны будут долго работать. Чтобы заставить их взаимодействовать, можно использовать слово yield , чтобы сигнализировать, что поток выполнил единицу работы, и другие потоки могут получить управление. Вы также можете посмотреть другие слова, чтобы остановить , приостановить или возобновить потока.
Серверы и печи
Очень распространенный случай использования более чем одного потока - это создание серверных приложений. При написании сетевых приложений обычно запускают поток для каждого входящего соединения (помните, что это зеленые потоки, поэтому они намного легче, чем потоки ОС).
Для упрощения в Factor есть слово spawn-server , которое работает как spawn , но, кроме того, многократно порождает цитату, пока не вернет f . Это все еще очень низкоуровневое слово: на самом деле нужно делать гораздо больше: прослушивать TCP-соединения на данном порту, обрабатывать ограничения на количество подключений и так далее.
Словарь io.servers позволяет писать и настраивать TCP-серверы. Сервер создается со словом , которое требует кодировки в качестве параметра.Затем его слоты можно настроить для настройки ведения журнала, ограничений подключения, портов и т. Д. Самый важный слот для заполнения - это обработчик , который содержит расценки, которые выполняются для каждого входящего соединения. Вы можете увидеть очень простой пример сервера с
"resource: extra / time-server / time-server.factor" файл редактирования
Мы еще больше поднимем уровень абстракции и покажем, как запустить простой HTTP-сервер. Во-первых, ИСПОЛЬЗУЙТЕ: http.server .
Приложение HTTP построено из ответчика .Ответчик - это, по сути, функция от пути и HTTP-запроса к HTTP-ответу, но, более конкретно, это все, что реализует метод call-Responder * . Ответы являются экземплярами кортежа ответа , поэтому обычно генерируются вызовом и настройкой нескольких слотов. Напишем простой эхо-ответчик:
TUPLE: эхо-ответчик;
: <эхо-ответчик> (- ответчик) эхо-ответчик новый;
M: эхо-ответчик на вызов-ответчик *
уронить
<ответ>
200 >> код
«Документ следует» >> сообщение
"текст / обычный" >> тип-содержимого
поменять местами concat >> body;
Ответчикиобычно объединяются в более сложные ответчики для реализации маршрутизации и других функций.В нашем упрощенном примере мы будем использовать только этого одного респондента и установить его глобально с
основной ответчик set-global
Как только вы это сделаете, вы можете запустить сервер с 8080 httpd . Затем вы можете посетить http: // localhost: 8080 / hello /% 20 / from /% 20 / factor в своем браузере, чтобы увидеть своего первого респондента в действии. Затем вы можете остановить сервер с помощью стоп-сервера .
Итак, если бы это было все, что Factor предлагает для написания веб-приложений, это все равно было бы довольно низким уровнем.На самом деле веб-приложения обычно пишутся с использованием веб-фреймворка под названием Furnace .
Furnace позволяет нам, помимо прочего, писать более сложные действия с использованием языка шаблонов. Фактически, по умолчанию поставляются два языка шаблонов, и мы будем использовать Chloe . Furnace позволяет нам использовать действия для создания страниц из шаблонов Chloe, и для создания ответчика нам нужно будет добавить маршрутизацию.
Давайте сначала рассмотрим простой пример маршрутизации.Для этого мы создаем специальный тип ответчика, называемый диспетчером , который отправляет запросы на основе параметров пути. Давайте создадим простой диспетчер, который будет выбирать между нашим эхо-ответчиком и ответчиком по умолчанию, используемым для обслуживания статических файлов.
диспетчер new-диспетчер
"echo" - ответчик добавления
"/ home / andrea" "домашний" ответчик
главный респондент set-global
Конечно, замените путь / home / andrea на любую понравившуюся папку.Если вы снова запустите сервер с 8080 httpd , вы сможете увидеть как наш простой эхо-ответчик (под / echo ), так и содержимое ваших файлов (под / home ). Обратите внимание, что список каталогов отключен по умолчанию, вы можете получить доступ только к содержимому файлов.
Теперь, когда вы знаете, как выполнять маршрутизацию, мы можем писать действия со страницами в Chloe. Вещи начинают усложняться, поэтому мы добавляем в словарь «привет-печь» строительные леса .Сделайте это так:
! Авторское право (C) 2014 Андреа Ферретти.
! См. Http://factorcode.org/license.txt для получения лицензии BSD.
ИСПОЛЬЗОВАНИЕ: аксессоры печь. Действия http http.server
http.server.dispatchers http.server.static последовательности ядра;
В: привет-печь
ТУПЛ: эхо-ответчик;
: <эхо-ответчик> (- ответчик) эхо-ответчик новый;
M: эхо-ответчик на вызов-ответчик *
уронить
<ответ>
200 >> код
«Документ следует» >> сообщение
"текст / обычный" >> тип-содержимого
поменять местами concat >> body;
ТУПЛ: привет-диспетчер <диспетчер;
: (- респондент)
привет-диспетчер новый диспетчер
"echo" - ответчик добавления
"/ home / andrea" "домашний" ответчик
{привет-диспетчер "привет"} >> шаблон
ответчик "хлоя";
Большинство вещей такие же, как и в слушателе.Единственное отличие состоит в том, что мы добавили в диспетчер третьего респондента под номером chloe . Этот респондент создается с помощью действия страницы. Действие страницы имеет много слотов - скажем, для объявления поведения получения результата формы - но мы устанавливаем только его шаблон. Это пара с классом диспетчера и относительным путем к файлу шаблона.
Для того, чтобы все это работало, создайте файл work / hello-cabin / greetings.xml с содержанием вроде
Привет от Хлои
Перезагрузите словарь hello-cabin и . Вы должны увидеть результаты своих усилий по адресу http: // localhost: 8080 / chloe . Обратите внимание, что не было необходимости перезапускать сервер, мы можем динамически изменять основного респондента.
На этом наш очень короткий тур по Печи заканчивается.На самом деле он делает гораздо больше: проверку и обработку форм, аутентификацию, ведение журнала и многое другое. Но этот раздел уже становится слишком длинным, и вам придется узнать больше в документации.
Процессы и каналы
Как я уже сказал, Factor является однопоточным с точки зрения ОС. Если мы хотим использовать несколько ядер, нам нужен способ создания процессов Factor и взаимодействия между ними. Factor реализует две разные модели параллелизма при передаче сообщений: модель актора, которая основана на идее асинхронной отправки сообщений между потоками, и модель CSP, основанная на использовании каналов .
В качестве разминки мы сделаем простой пример взаимодействия между потоками в одном процессе.
ОТ: concurrency.messaging => отправить получить;
Мы можем запустить цепочку, которая будет получать сообщение и печатать его повторно:
: повторная печать (-) получение. печать-повторно;
[печать-повторно] порождение "принтера"
Поток, котировка которого начинается с , получает и вызывает себя рекурсивно, ведет себя как актер в Erlang или Akka.Затем мы можем использовать send для отправки ему сообщений. Попробуйте "hello" вместо отправки , а затем "threading" вместо отправки .
Каналы - это немного разные абстракции, используемые, например, в Go и Clojure core.async. Они разделяют отправителя и получателя и обычно используются синхронно. Например, одна сторона может получать по каналу до того, как какая-то другая сторона что-то ей отправит. Это просто означает, что принимающая сторона передает управление планировщику, который ожидает отправки сообщения, прежде чем снова передать управление получателю.Эта функция иногда упрощает синхронизацию многопоточных приложений.
Опять же, мы сначала используем канал для связи между потоками одного и того же процесса. Как и ожидалось, USE: каналы . Вы можете создать канал с , записать в него с по и читать из него с из . Обратите внимание, что обе операции являются блокирующими: с по будут блокироваться до тех пор, пока значение не будет считано в другом потоке, а с из будет блокироваться до тех пор, пока значение не станет доступным.
Создаем канал и даем ему имя с
СИМВОЛ: ch
<канал> набор каналов
Потом пишем в него отдельным потоком, чтобы не блокировать UI
["hello" ch get to] внутри потока
Затем мы можем прочитать значение в пользовательском интерфейсе с помощью
ch получить от
Мы также можем инвертировать заказ:
[ч получить от. ] в потоке
"привет"
Это прекрасно работает, так как мы сначала установили считыватель.
Теперь самое интересное: мы запустим второй экземпляр Factor и будем общаться посредством отправки сообщений. Factor прозрачно поддерживает отправку сообщений по сети, сериализуя значения с помощью словаря serialize .
Запустите еще один экземпляр Factor и запустите на нем сервер узла. Мы будем использовать слово , которое создает IPv4-адрес из хоста и порта, и конструктор
ИСПОЛЬЗОВАНИЕ: параллелизм.распределен
f 9000 <узел-сервер> start-server
Здесь мы использовали f как host, что означает localhost. Мы также запустим поток, который ведет текущий счет полученных чисел.
ОТ: concurrency.messaging => отправить получить;
: добавить (x - y) получить + dup. добавлять ;
[0 добавить] порождение "гадюки"
После того, как мы запустили сервер, мы можем сделать поток доступным с помощью register-remote-thread :
дублирующее имя >> регистр-удаленный-поток
Теперь мы переходим к другому экземпляру Factor.Здесь мы получим ссылку на удаленный поток и начнем посылать ему числа. Адрес потока - это просто адрес его сервера и имя, под которым мы зарегистрировали поток, поэтому мы получаем ссылку на наш поток сумматора с
f 9000 "сумматор"
Теперь мы повторно импортируем send на всякий случай (есть совпадение со словом с таким же именем в io.sockets , которое мы импортировали)
ОТ: параллелизм.обмен сообщениями => отправить получить;
, и мы можем начать отправлять на него номера. Попробуйте 3 вместо отправки , а затем 8 вместо отправки - вы должны увидеть промежуточную сумму, напечатанную в другом экземпляре Factor.
А как насчет каналов? Мы возвращаемся на наш сервер и запускаем там канал, как указано выше. Однако на этот раз мы, , публикуем , чтобы сделать его доступным удаленно:
ИСПОЛЬЗОВАНИЕ: каналы channels.remote;
дублирующая публикация
Взамен вы получаете идентификатор, который можно использовать удаленно для связи.Например, я только что получил 7258137261527471887797889512223128430848967856434408703359628058956 (да, они действительно хотят быть уверены в его уникальности!).
Будем ждать на этом канале, тем самым заблокировав UI:
своп с.
В другом экземпляре Factor мы используем идентификатор, чтобы получить ссылку на удаленный канал и записать в него
f 9000 7258137261527471887797889512223128430848967856434408703359628058956
"Привет, каналы" на
В экземпляре сервера сообщение должно быть напечатано.
Удаленные каналы и потоки полезны для реализации распределенных приложений и эффективного использования многоядерных серверов. Конечно, остается вопрос, как запустить рабочие узлы в первую очередь. Здесь мы сделали это вручную - если набор узлов фиксированный, это действительно вариант.
В противном случае можно было бы использовать словарь io.launcher для программного запуска других экземпляров Factor.
Куда пойти отсюда?
Мы прошли большой путь, и я надеюсь, что к настоящему времени вы уже знаете, подходит ли вам Factor.Теперь вы можете работать с документацией и, надеюсь, сами внести свой вклад в Factor.
Позвольте мне закончить несколькими советами:
- когда начинаешь писать Фактор, очень легко иметь дело с перетасовкой стека. Хорошо изучите комбинаторы и не бойтесь выбросить свои первые примеры;
- нет определения слишком короткое: стремиться к одной линии;
- справочная система и инспектор - ваши лучшие друзья.
Справедливости ради стоит отметить и некоторые недостатки Factor:
- во-первых, сообщество действительно невелико.То, что они сделали, впечатляет, но они не надеются найти много информации в Интернете;
- конкатенативная модель очень эффективна, но ее очень трудно понять;
- Factor не хватает потоков: хотя распределенные процессы компенсируют это, они несут некоторые затраты на сериализацию;
- наконец, Factor в настоящее время не имеет диспетчера пакетов, и это, вероятно, препятствует внесению изменений.
Мы должны сбалансировать последнее наблюдение с удобством наличия всего исходного дерева Factor, доступного в образе, что, безусловно, облегчает изучение библиотек.Позвольте мне предложить несколько словарей, которые вы, возможно, захотите посмотреть:
- во-первых, об ошибках и исключениях особо не говорил. Узнайте больше с помощью справки по
«ошибкам»; - макрос
Словарьреализует форму метапрограммирования времени компиляции, менее общую, чем синтаксический анализ слов, но все же довольно удобную; - модели
Словарьпозволяет реализовать форму программирования потока данных с использованием объектов с наблюдаемыми слотами; - соответствие
Словарьреализует форму сопоставления с образцом; - монады
Словарьреализует монады в стиле Haskell.
Я думаю, что эти словари являются свидетельством силы и выразительности Factor. Удачного взлома!
ИСПОЛЬЗОВАНИЕ: images.http
http-изображение "http://factorcode.org/logo.png".
Создание слов и фраз в левой височной доле
Abstract
Центральная часть знания языка - это способность комбинировать базовые языковые единицы для формирования сложных представлений. Хотя наше нейробиологическое понимание того, как слова объединяются в более крупные структуры, значительно продвинулось в последние годы, комбинаторные операции, которые создают сами слова, остаются неизвестными.Созданы ли сложные слова, такие как tombstone и starlet , с помощью тех же механизмов, которые строят фразы из слов, таких как серый камень или яркая звезда ? Здесь мы обратились к этому с помощью двух экспериментов по магнитоэнцефалографии (МЭГ), которые одновременно меняли требования, связанные с фразовым составом и обработкой морфологической сложности в составных и суффиксных существительных. Повторяя предыдущие результаты, мы показываем, что части левой передней височной доли (LATL) задействованы в сочетании модификаторов и мономорфных существительных во фразах (например,г., коричневый кролик ). Что касается компаундирования, мы показываем, что семантически прозрачные соединения (например, надгробная плита ) также задействуют левую переднюю височную кору, хотя пространственно-временные детали этого эффекта отличались от фразового состава. Кроме того, когда фраза была построена из модификатора и прозрачного соединения (например, гранитное надгробие ), типичный ответ фразовой композиции LATL появлялся с задержкой, которая возникает, если начальная операция внутри слова ( могила + камень ) должно происходить перед объединением соединения с предыдущим модификатором ( гранит + надгробие ).В отличие от компаундирования, суффиксирование (например, звездочка + let ) никак не взаимодействует с LATL, что предполагает отдельный путь обработки. Наконец, наши результаты предлагают интригующее обобщение, что морфо-орфографическая сложность, которая не задействует LATL, может блокировать участие LATL в последующем построении фраз.