Морфемный разбор слова — пошаговая инструкция, примеры ученикам
Содержание:
- Морфемика
- Корень
- Приставка
- Суффикс
- Окончание
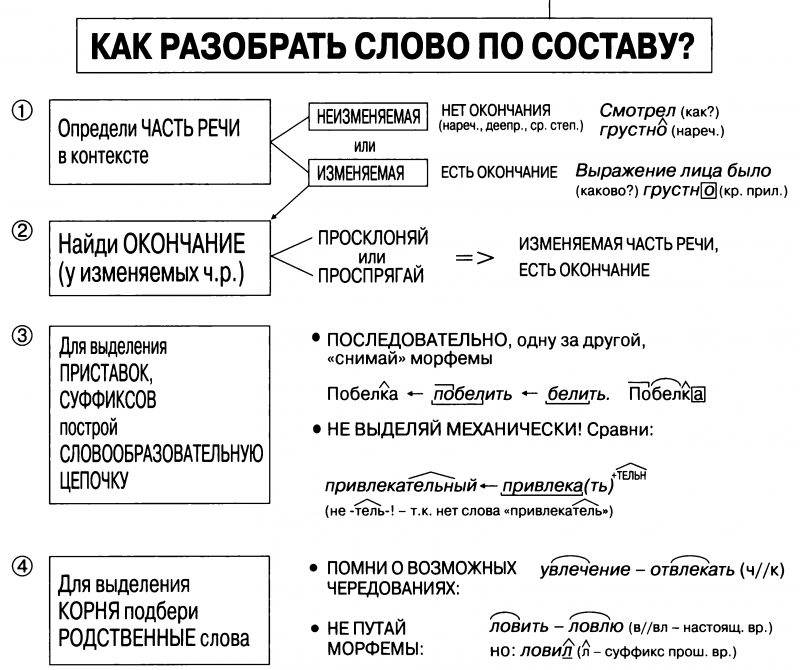
Морфемика
Для анализа каждой словоформы существует отдельная наука — морфемика, а также специально предназначенный морфемный разбор. Так, обычно слово состоит из трех и более так называемых морфем.
Морфема — это часть слова, составная часть, за счет изменения которой слова и меняют смысл.
Корень
Корень является основой слова. Даже заменяя другие морфемы, смысл сохранится. Обычно корень выделяется самым последним. Связанно это с тем, что порой сразу его достаточно сложно заметить.
Важно! Всего существует 2 слова-исключения, которые просто не имеют корня: снять и поднять.
Чтобы найти корень, необходимо подобрать примерное однокоренное слово.
Приставка
Далеко не каждое слово должно иметь в своем составе приставку. Обычно она указывает на незаконченность действия или, как в случае “при”, — на приближение или отдаление объекта. Всего существует не так много вариаций, которые можно просто запомнить.
Некоторые приставки, которые оканчиваются на “з” и “с”, очень часто путаются. Для того чтобы не допустить ошибки в их написании, важно использовать правило: если следующая буква является звонкой, или сонорной, то необходимо использовать приставку, оканчивающуюся на “з”.
Рис. 2. Порядок разбора слова по составуСуффикс
При анализе словоформ суффиксы выделяются треугольником сверху. Каждая часть речи имеет свои необычные суффиксы, которые надо запомнить при изучении существительных, глаголов, прилагательных и т.д.
Каждая часть речи имеет свои необычные суффиксы, которые надо запомнить при изучении существительных, глаголов, прилагательных и т.д.
Окончание
Данная морфема является единственной, которая не образует новое слово, а лишь видоизменяет уже существующее, то есть образует новую так называемую словоформу. Если окончания нет, его тоже отмечают, но как нулевое. Тема морфемного анализа не должна вызывать каких-то сложностей, если ученик хорошо усвоил материал по разными частям речи. Выучив несколько таблиц с различными словоформами, можно с легкостью научиться разбирать абсолютно любое слово. В предложенном видео вы найдете много выполненных наглядных примеров для лучшего понимания темы.
Разбор языка для поиска важных слов
Задавать вопрос
спросил
Изменено 7 лет, 11 месяцев назад
Просмотрено 6к раз
Я ищу информацию и теорию о том, как подходить к лексической теме.
Допустим, у меня есть набор строк, который может состоять из одного предложения или потенциально из нескольких предложений. Я хотел бы проанализировать эти строки и вырвать самые важные слова, возможно, с оценкой, которая указывает, насколько вероятно, что слово будет важным.
Давайте рассмотрим несколько примеров того, что я имею в виду.
Пример №1:
«Я очень хочу Кеуриг, но не могу себе его позволить!»
Это очень простой пример, всего одно предложение. Как человек, я легко понимаю, что слово «Кеуриг» здесь самое важное. Кроме того, слово «позволить себе» относительно важно, хотя явно не является основным смыслом предложения. Слово «я» появляется дважды, но это совершенно не важно, так как на самом деле не сообщает нам никакой информации. Я мог бы ожидать увидеть хеш слов/оценок примерно так:
"Кеуриг" => 0,9 "позволить себе" => 0,4 "хочу" => 0,2 "действительно" => 0,1 и т. д...
Пример #2:
«Только что у меня была одна из лучших тренировок по плаванию в моей жизни.
Надеюсь, я смогу сохранить свое время перед соревнованиями. Если бы я только не забыл взять свои не водонепроницаемые часы.»
 Надеюсь, я смогу сохранить свое время перед соревнованиями. Если бы я только не забыл взять свои не водонепроницаемые часы.»
Надеюсь, я смогу сохранить свое время перед соревнованиями. Если бы я только не забыл взять свои не водонепроницаемые часы.»В этом примере несколько предложений, поэтому в нем будут более важные слова. Не повторяя точечное упражнение из примера № 1, я, вероятно, ожидал бы увидеть два или три действительно важных слова из этого: «плавание» (или «практика плавания»), «соревнования» и «часы» (или «водонепроницаемость»). часы» или «не водонепроницаемые часы» в зависимости от того, как пишется дефис).
Имея пару таких примеров, как бы вы поступили, чтобы сделать что-то подобное? Существуют ли какие-либо существующие (с открытым исходным кодом) библиотеки или алгоритмы в программировании, которые уже делают это?
- разбор
- языков
2
Определенно есть люди, которые думают о проблеме, которую вы описываете. Книга Жоао Вентура и Жоакима Феррейра да Силва «Рейтинг и извлечение релевантных отдельных слов в тексте» (pdf) представляет собой хорошее введение в существующие методы ранжирования, а также предложения по их улучшению. Все методы, которые они описывают, основаны на корпусе (много текста), а не на одной или двух строках текста. Ваш корпус должен представлять собой набор всех образцов или, возможно, многих корпусов собранных образцов из определенных источников. Имейте в виду, что релевантность одного слова (униграммы) — во многом нерешенная проблема. Как описано в документе:
Все методы, которые они описывают, основаны на корпусе (много текста), а не на одной или двух строках текста. Ваш корпус должен представлять собой набор всех образцов или, возможно, многих корпусов собранных образцов из определенных источников. Имейте в виду, что релевантность одного слова (униграммы) — во многом нерешенная проблема. Как описано в документе:
«…используя чисто статистические методы, такая классификация не всегда прямолинейна и даже точна, потому что, хотя понятие релевантности — это понятие, которое легко понять, обычно нет единого мнения о границе, которая отделяет релевантность от неактуальность. Например, такие слова, как «Республика» или «Лондон», сигнификативной релевантности, а такие слова, как «или» и «так как» не имеют релевантности вообще, но как насчет таких слов, как «прочитать», «завершить» и «следующий»? Такие слова проблематичны, потому что обычно их нет. консенсус относительно их семантической ценности».0003
Существует множество наборов инструментов для обработки естественного языка с открытым исходным кодом. (Будьте осторожны. Некоторые инструменты бесплатны для исследований, но для коммерческого использования требуется коммерческая лицензия.) Они сделают вашу жизнь проще, независимо от выбранного вами подхода.
(Будьте осторожны. Некоторые инструменты бесплатны для исследований, но для коммерческого использования требуется коммерческая лицензия.) Они сделают вашу жизнь проще, независимо от выбранного вами подхода.
Я хорошо знаком с Natural Language Toolkit (NLTK). Он прост в использовании, хорошо документирован и описан в книге «Обработка естественного языка с помощью Python» (бесплатно доступна в Интернете). В качестве простого примера того, что NLTK может сделать для вас, представьте, что вы используете его тегировщик частей речи. После определения части речи каждого слова вы можете считать имена собственные очень важными, а прилагательные — менее важными. Глаголы могут быть важны, а наречия менее важны. Это ни в коем случае не современный рейтинг, но вы получаете полезную информацию без особых усилий. Когда вы будете готовы перейти к более сложному анализу, встроенная в NLTK возможность токенизации, тегирования, фрагментирования и классификации позволит вам сосредоточиться на других деталях вашего решения.
Обработка естественного языка — это отдельная дисциплина, по которой проведено довольно много формальных исследований. Я бы начал с поиска там.
Я бы тоже пересмотрел свои потребности. Даже после 50 с лишним лет исследований лучшим компьютерным ученым удалось придумать Siri. Я бы не ожидал, что компьютер будет успешно делать то, о чем вы говорите, с регулярностью.
Если есть определенные ограничения для речи (например, Siri предполагает, что у вас есть простая команда или вопрос), это может быть лучше. Пересмотр моих потребностей (при условии, что мне действительно нужно НЛП) включал бы определение моих ограничений. После этого я, вероятно, буду охотиться за кучей примеров. Отчасти для проверки всего, что я придумал, но многие современные решения включают машинное обучение. Мне нужны эти примеры в качестве входных данных для кривой обучения.
Подводя итог, я серьезно сомневаюсь, что что-либо сможет дать вам хорошие оценки в таком сценарии без контекста.
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания, политикой конфиденциальности и политикой использования файлов cookie
СоставRegExp — 💡 Идеи
pygy 1
Было бы полезно иметь возможность составлять регулярные выражения, не прибегая к склеиванию исходных строк. Это позволило бы создавать сложные синтаксические анализаторы из более простых, не думая о незахватываемых группах, и писать тесты для частей. Вместо полных выражений, используемых в строках шаблона, можно было бы что-то вроде /(?>id)/ , где id — это переменная JS.
Я не отслеживал все предложения, но по крайней мере два из текущих предложений (модификаторы шаблона и нотация множества), которые вводят довольно много синтаксиса, могут быть включены в это.
Предложение «модификаторы» становится спорным, если в композиции учитываются флаги вставляемого выражения.
Операции set могут быть реализованы как простой JS API, работающий с регулярными выражениями, использующими ровно одну кодовую точку.
Это позволит значительно сэкономить на синтаксисе.
Синтаксис RegExp уже громоздкий, он был изобретен для создания искателей только для записи в командной строке (сам построен на математической нотации, где подшаблоны абстрагируются как однобуквенные переменные), и это видно. Сложные регулярные выражения — это кошмар для редактирования и обновления.
Если кто-то наткнется на синтаксическую конструкцию, он не знает, что его поиск будет сопряжен с трудностями. Правила экранирования, введенные предложением об установленной нотации, еще больше ухудшают читабельность.
OTOH, регулярный формализм основан на композиции, регулярные операторы предназначены для работы с произвольными выражениями, но текущий синтаксис затрудняет использование преимуществ.
Вот пример сложного синтаксического анализатора на основе регулярных выражений, а вот порт, использующий мою библиотеку compose-regexp. Мы надеемся, что преимущества в удобочитаемости очевидны и будут еще лучше при надлежащей синтаксической поддержке.
Изменить: альтернативный синтаксис: /\e{js. также может работать. expression}/
expression}/
4 лайков
2
В этой ветке было достаточно много обсуждений, связанных с этой идеей: RegExp: Комментарии
Одно из основных препятствий: как составить флаги регулярных выражений? Некоторые флаги вообще не складываются. Есть и другие флаги, но было бы неплохо, если бы вы могли создавать такие же регулярные выражения без компоновки, как если бы вы строили с композицией.
В конце концов, основные различия между составлением регулярных выражений и составлением строк, которые вы передаете в конструктор регулярных выражений, заключается в этой раздражающей ситуации с флагами и многословии.
Например, вы можете сделать это для достижения композиции:
const part1 = String.raw`\d{3}`
константная часть2 = String. raw`\d{4}`
const pattern1 = новое регулярное выражение (часть 1)
const pattern2 = новое регулярное выражение (часть 2)
conts completePattern = новое регулярное выражение (`(${part1}) ${part1)-${part2}`)
 raw`\d{4}`
const pattern1 = новое регулярное выражение (часть 1)
const pattern2 = новое регулярное выражение (часть 2)
conts completePattern = новое регулярное выражение (`(${part1}) ${part1)-${part2}`)
raw`\d{4}`
const pattern1 = новое регулярное выражение (часть 1)
const pattern2 = новое регулярное выражение (часть 2)
conts completePattern = новое регулярное выражение (`(${part1}) ${part1)-${part2}`)
пиги 3
Вы можете выдать TypeError для флагов, которые не имеют смысла.
Подход на основе строк подходит для тривиальных шаблонов. Если вы хотите использовать квантификаторы или дизъюнкции, вам нужно либо систематически добавлять незахватывающие группы (NCG), либо анализировать входные данные для объединения, чтобы проверить, нужен ли NCG . ComposeRegExp делает последнее, чтобы результирующие регулярные выражения были как можно более короткими и удобочитаемыми, но это не тривиально. Если для этого не использовать специальную библиотеку, это может легко привести к ошибкам, особенно при рефакторинге.
константная часть1 = "а"
константная часть2 = "б"
const в сочетании1 = `${part1}-${part2}`
const в сочетании2 = `${part1}|${part2}`
const badStar1 = new RegExp(`${combined1}*`) // /a-b*/
const badStar2 = new RegExp(`${combined2}*`) // /a|b*/
const goodStar2 = new RegExp(`(?:${combined2})*`) // /(:a|b)*/
const badSequence = RegExp(`${combined1}${combined2}`) // /a-ba|b/
const goodSequence = RegExp(`${combined1}(?:${combined2})`) // /a-b(?:a|b)/
Теперь представьте, что вы установили part1 в "a|c" . Получайте удовольствие от отладки, если вы не были осторожны, добавляя NCG повсюду.
Вы можете посмотреть на чудовище, которое представляет собой синтаксический анализатор SemVer, используемый NPM, это то, что вы получаете на практике, используя подход, который вы предлагаете.
пиги 4
@theScottyJam Я просмотрел предложение «комментарии регулярных выражений». новый RegExp(RegExp.from источник , флаги) было бы разумным решением.
@trusktr написал библиотеку, которая реализует эту идею: GitHub — trusktr/regexr: легко составлять регулярные выражения без необходимости двойного экранирования внутри строк. .. new RegExp(RegExp.from — много визуального шума. Подсветка синтаксиса также должна быть осведомлена о RegExp.from , тогда как /(?>id)/ можно было бы использовать из коробки ( и будет работать с регулярными выражениями, отличными от Юникода).0003
пиг 5
Хотя идея составления регулярных выражений давно была у меня в голове, предложения модификаторов и операций над множествами для меня новы, и я только что понял, что композиция не может полностью включать в себя предложения, потому что я предполагаю, что мы захотим быть способен сериализовать результат композиции во что-то, что может быть проанализировано RegExp конструктор.
Однако, если мы предоставим операции композиции и установки в виде JS API, удобочитаемость формата сериализации станет менее важной, и мы могли бы использовать его в реальном времени, например. внутри блока \op{} , так что правила экранирования в кодировках не нужно обновлять.
баккот 6
Иногда это всплывает при обсуждении предложения RegExp.escape — некоторые делегаты настоятельно предпочитают иметь построитель тегов шаблона вместо метода RegExp.escape. (На самом деле это был один из основных вариантов использования тегов шаблонов, когда они добавлялись в язык в первую очередь.) Однако никто еще не выступил в защиту этого.
Пример такого билдера (уже совсем устаревшего с новыми фичами) —
GitHubGitHub — mikesamuel/regexp-make-js: тег шаблона строки ES6 для создания.
 ..
..Тег шаблона строки ES6 для создания динамических регулярных выражений — GitHub — mikesamuel/regexp-make-js: Тег шаблона строки ES6 для создания динамических регулярных выражений
1 Нравится
морикен 7
Как насчет добавления нового синтаксиса RegExp Builder, такого как Swift, вместо того, чтобы основывать его на существующем литерале шаблона?
пусть слово = OneOrMore(.word)
пусть emailPattern = регулярное выражение {
Захватывать {
ноль или больше {
слово
"."
}
слово
}
"@"
Захватывать {
слово
Один или больше {
"."
слово
}
}
}
https://developer.apple.com/documentation/RegexBuilder
github.comapple/swift-evolution/blob/8711a202af97640eaa0ee040502a365d8b9430c2/proposals/0351-regex-builder.
 md
md # DSL построителя регулярных выражений * Предложение: [SE-0351](0351-regex-builder.md) * Авторы: [Ричард Вей] (https://github.com/rxwei), [Майкл Ильсман] (https://github.com/milseman), [Нейт Кук] (https://github.com/natecook1000) , [Алехандро Алонсо] (https://github.com/azoy) * Менеджер по обзору: [Бен Коэн] (https://github.com/airspeedswift) * Реализация: [apple/swift-experimental-string-processing](https://github.com/apple/swift-experimental-string-processing/tree/main/Sources/RegexBuilder) * Доступно в ночных снимках цепочки инструментов с помощью `import _StringProcessing` * Статус: **Принято** * Обзор: ([шаг](https://forums.swift.org/t/pitch-regex-builder-dsl/56007)) ([первый обзор](https://forums.swift.org/t/se-0351-regex-builder-dsl/56531)) ([редакция](https://forums.swift.org/t/returned-for-revision-se-0351-regex-builder-dsl/57224)) ([второй обзор](https://forums.swift.org/t/se-0351-second-review-regex-builder-dsl/58721)) ([принятие](https://forums.