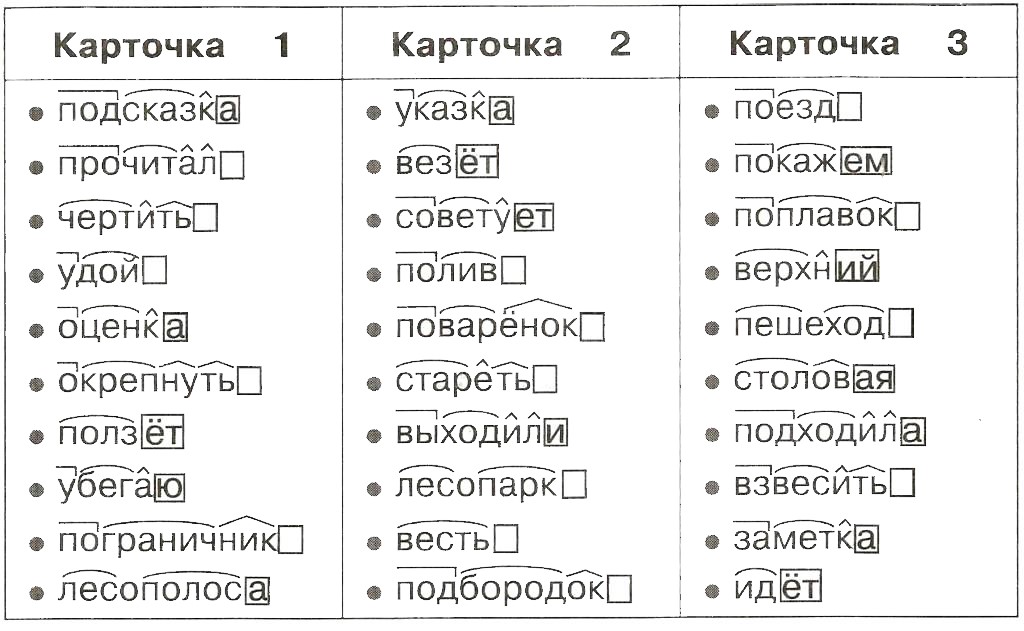
Идентификация пассивного залога
Прежде чем читать о том, как наш веб-сайт идентифицирует пассивный залог, читатель должен знать, что такое пассивный залог. Если вы не знакомы с разницей между активным и пассивным залогом, вы можете показать (или скрыть) наше объяснение пассивного залога. В противном случае, пожалуйста, продолжайте чтение.
Мы дадим вам две версии того, как самостоятельно определить пассивный залог. Первая версия очень многословна и полна лингвистического жаргона. который большинству людей кажется довольно скучным, а вторая версия, к которой вы, скорее всего, захотите сразу перейти, связана с зомби.
Версия 1
Активные предложения обычно имеют форму Субъект + Глагол + Объект . В качестве модельного предложения мы рассматриваем следующее:
собака преследовала кошку.
Записав наше примерное предложение в пассивной форме, мы получим следующее:
Кот был

Типичное пассивное предложение выглядит как Объект + [быть] + Причастие прошедшего времени глагола + by + подлежащее. Мы используем [to be] для обозначения глагола «to be», написанного в том же времени, что и as. активное предложение. Например, в нашем примере активное предложение выше написано в простом прошедшем времени. Таким образом, пассивная форма предложения использует «простое прошедшее время» глагола «быть», то есть «было».
Кроме того, причастие прошедшего времени от глагола — это действие, которое, или было сделано . Например, причастие прошедшего времени от «есть» — «съеден». Причастие прошедшего времени от «делать» — «сделано». Причастие прошедшего времени слова «открыть» — «открыто». Причастие прошедшего времени от «написать» — «написано». Он съел бутерброд. Она открыла дверь. Они вместе написали книгу.
Итак, можете ли вы построить пассивную форму следующего предложения?
Автор написал шедевр .
Шедевр был написан автором .
Читатель также заметит, что часть предложения может быть опущена. Например, «за кошкой погнались» или «был написан шедевр» — вполне прекрасные предложения сами по себе. а если совершенно неважно, кто или что погналось за кошкой, или кто написал шедевр, то, если угодно, можно и не упоминать.
Дети, для которых английский язык является родным, быстро усваивают это. Например, ни один ребенок не признался бы своей матери в следующем без некоторого страха: «Мама, я разбила твою вазу .» Чтобы смягчить удар и, возможно, снять с себя часть ответственности, ребенок, скорее всего, использовал бы пассивную конструкцию: «Мама, твоя ваза
Итак, вкратце, как распознать, когда используется пассивный залог? Я только что использовал его! « пассивный голос — это будучи использованным мной ПРЯМО СЕЙЧАС!»
Другими словами, если вы видите:
1. | глагол «быть» в той или иной форме (т. е. есть, есть, есть, был, были, был, был, был, был и т. д.) |
| 2. | за которым следует причастие прошедшего времени глагола (например, съел, написал, сделал, остановился и т. д.) |
Версия 2:
Если вы можете добавить слова «зомби» к вашему предложению, и это все еще имеет смысл, тогда это, скорее всего, пассивное предложение. Например… «Город был захвачен…» можно прикончить с помощью «…зомби!»
«Мою машину угнали сегодня утром …зомби!»
«»Титаник» был номинирован на премию Академии …зомби!»
«Мэр снят с должности …зомби!»
Все приведенные выше зомби-предложения являются пассивными конструкциями.
Они были написаны с комическим эффектом. .. зомби.
.. зомби.
Наше программное обеспечение идентифицирует слова, которые встречаются в типичных пассивных конструкциях, а именно: любая форма глагола «быть» в сочетании с причастием прошедшего времени, и если любые два из них достаточно близко друг к другу, наш пассивный детектор голоса на нашей домашней странице указывает на это как на вероятную пассивную конструкцию. Он также определяет слово «по», чтобы помочь вам сделать оценку.
[PDF] К композициям на уровне подслов для анализа тональности хинди-английского кода, смешанного текста
- Идентификатор корпуса: 5068554
title={К композициям на уровне подслов для анализа тональности хинди-английского кода смешанного текста},
автор = {Амея Прабху и Адитья Джоши и Маниш Шривастава и Васудева Варма},
booktitle={Международная конференция по компьютерной лингвистике},
год = {2016}
} Анализ настроений (SA) с использованием смешанного кода данных из социальных сетей имеет несколько применений для сбора мнений, начиная от удовлетворенности клиентов и заканчивая анализом социальных кампаний в многоязычных обществах. Продвижению в этой области препятствует отсутствие подходящего аннотированного набора данных. Мы представляем набор данных со смешанным кодом на хинди и английском (Hi-En) для анализа настроений и проводим эмпирический анализ, сравнивая пригодность и эффективность различных современных методов SA в социальных сетях. В этой статье…
Продвижению в этой области препятствует отсутствие подходящего аннотированного набора данных. Мы представляем набор данных со смешанным кодом на хинди и английском (Hi-En) для анализа настроений и проводим эмпирический анализ, сравнивая пригодность и эффективность различных современных методов SA в социальных сетях. В этой статье…
Просмотр в ACL
aclweb.orgБилингвальный анализ тональности на основе Bi-LSTM и ансамбля для хинди-английского текста социальных сетей со смешанным кодом
В этой работе была проведена классификация тональности для одной из наиболее распространенных языковых пар со смешанным кодом. в Индии, т.е. хинди-английский, и предложил подход, основанный на объединении, который основан на гибридизации классификаторов наивного Байеса, SVM, линейной регрессии и SGD, а также на новом двунаправленном подходе на основе LSTM.
JUNLP@SemEval-2020 Задача 9: Анализ тональности смешанных данных хинди-английского кода
- Авишек Гарайн, С.
 Махата, Дипанкар Дас
Махата, Дипанкар Дас Информатика
ArXiv
- 2020
 Махата, Дипанкар Дас
Махата, Дипанкар ДасCode-Mixed Sentiment Analysis и использовали алгоритмы извлечения признаков в сочетании с традиционными алгоритмами машинного обучения, такими как SVR и Grid Search, для решения задачи.
JUNLP на SemEval-2020 Задача 9: Анализ тональности смешанных данных хинди-английского кода с использованием перекрестной проверки в поиске по сетке
- Авишек Гарайн, С. Махата, Дипанкар Дас
Информатика
SEMEVAL
- 2020
- Bharathi Raja Chakravarthi, V. Muralidaran, R. Priyadharshini, John P. McCrae
Computer Science
SLTU
- 2020
- Soumil Mandal, S. Mahata, Dipankar Das
Computer Science
ArXiv
- 2018
- Madan Gopal Jhanwar, Arpita Das
Computer Science
ArXiv
- 2018
- Siddharth Yadav, Tanmoy Chakraborty
Информатика
ArXiv
- 2020
- Бхарати Раджа Чакраварти, Навья Хосе, Шардул Сурьяванши, Э. Шерли, Джон П. МакКрей
Информатика
SLTU
- 2020
- Н. Гарг
Информатика
- 2020
- Юинг Чжу, Сяобинг Чжоу, Хунлин Ли, Кунджи Донг
Информатика
SE MEVAL 900
3
- 2020
- Адитья Джоши, П. Бхаттачарья
Информатика
- 2010
- A. Das, Sivaji Bandyopadhyay
Информатика
- 2010
- S. Sharma, Srinivas Pykl, R. Balabantaray
Computer Science
2015 International Conference on Advances in Computing, Communications and Informatics (ICACCI)
- 2015
- R. Socher, Alex Perelygin, Christopher Potts
Компьютерная наука
EMNLP
- 2013
- Йогарши Вьяс, Спандана Гелла, Джатин Шарма, Калика Бали, М. Чоудхури
Информатика
EMNLP
- 2014
- М. Табоада, Джулиан Брук, Милан Тофилоски, Кимберли Д. Фолл, Манфред Стеде
Информатика
CL
- 2011
- Андреа Эсули, Ф. Себастьяни
Информатика
LREC
- 2006
- C. D. Santos, B. Zadrozny
Компьютерная наука
ICML
- 2014
- Utsab Barman, Amitava Das, Joachim Wagner, Jennifer Foster
Computer Science
CodeSwitch@EMNLP
- 2014
- C.
- решение для области Code-Mixed Sentiment Analysis, где для решения задачи использовались алгоритмы извлечения признаков в сочетании с традиционными алгоритмами машинного обучения, такими как SVR и Grid Search.
Corpus Creation for Sentiment Analysis in Code-Mixed Tamil-English Text
A Создан золотой стандартный корпус с переключением кода на тамильско-английском языке и аннотациями настроений, содержащий 15 744 комментариев с YouTube, и представлено соглашение между аннотаторами, а также показаны результаты анализа настроений, обученного на этом корпусе.
Preparing Bengali-English Code-Mixed Corpus for Sentiment Analysis of Indian Languages
In order to reduce manual work while аннотаций, гибридные системы, сочетающие модели, основанные на правилах, и контролируемые модели, были разработаны как для языковых, так и для тональных тегов, а полученный корпус золотого стандарта имеет впечатляющее согласие между аннотаторами, полученное с точки зрения значений Каппа.
An Ensemble Model for Sentiment Analysis of Hindi-English Code-Mixed Data
An ensemble of character-trigrams based LSTM model and Предлагается модель полиномиальной наивной байесовской модели (MNB), основанная на словесных граммах, для определения тональности данных смешанного кода на хинди-английском (Hi-En).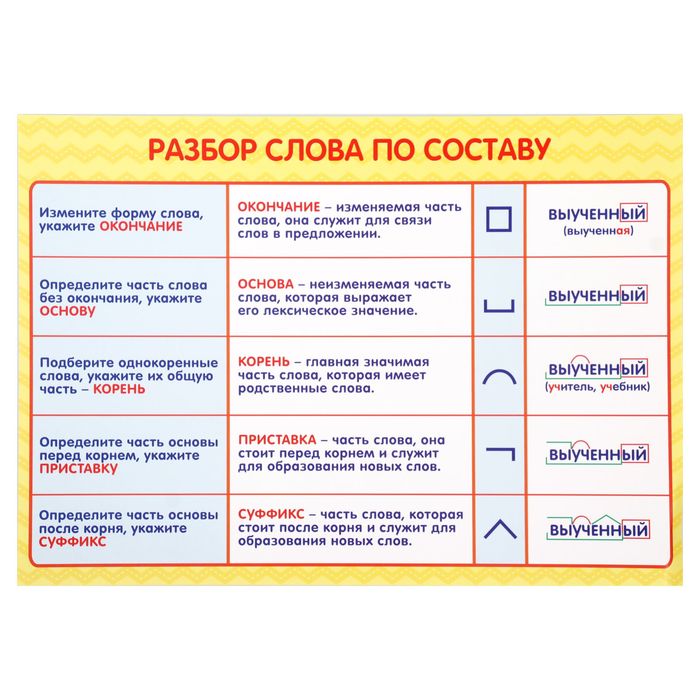
Неконтролируемый анализ тональности для смешанных кодовых данных
В этой работе представлены методы, использующие различные виды многоязычного и межъязыкового кодирования для эффективного переноса знаний в текстовые вложения. анализ тональности текста, смешанного с кодом.
Набор данных анализа настроений для малаяламского и английского языков со смешанным кодом
Представлен новый корпус золотого стандарта для анализа тональности смешанного кода на малаялам-английском языке, аннотированного добровольными аннотаторами, который получил альфа Криппендорфа выше 0,8 для набора данных.
Создание аннотированного корпуса для анализа настроений в данных социальных сетей со смешанным кодом на хинди и английском (хинглиш)
 Гарг
ГаргПредлагаемая работа представляет собой стандартный аннотированный корпус для текста социальных сетей с переключением кода на хинди, английском и хинглише, и обнаружено, что если рассматривать текст со смешанным кодом, точность может быть повышена.
Команда Zyy1510 на SemEval-2020 Задача 9: Анализ настроений для текста социальных сетей со смешанным кодом и представлениями на уровне подслов
В этом документе сообщается о работе команды zyy1510 на Международном семинаре по семантической оценке (SemEval-2020) по совместному заданию по анализу тональности для кода-смешанного (хинди-английский, англо-испанский) социального…
ПОКАЗЫВАЕТ 1 -10 ИЗ 39 ЛИТЕРАТУРЫ
СОРТИРОВАТЬ ПОРелевантность Наиболее влиятельные статьиНедавность
Стратегия отката для анализа настроений на хинди: пример
 Бхаттачарья
БхаттачарьяВ этой статье предлагается запасная стратегия для проведения анализа настроений для документов на хинди, проблема, над которой, насколько нам известно, до сих пор не было сделано никакой работы.
SentiWordNet для индийских языков
Несколько вычислительных методов, таких как, s) для индийских языков.
Text normalization of code mix and sentiment analysis
В этой статье представлены различные методы нормализации текста и оценивается полярность утверждения как положительная или отрицательная с использованием различных ресурсов настроений.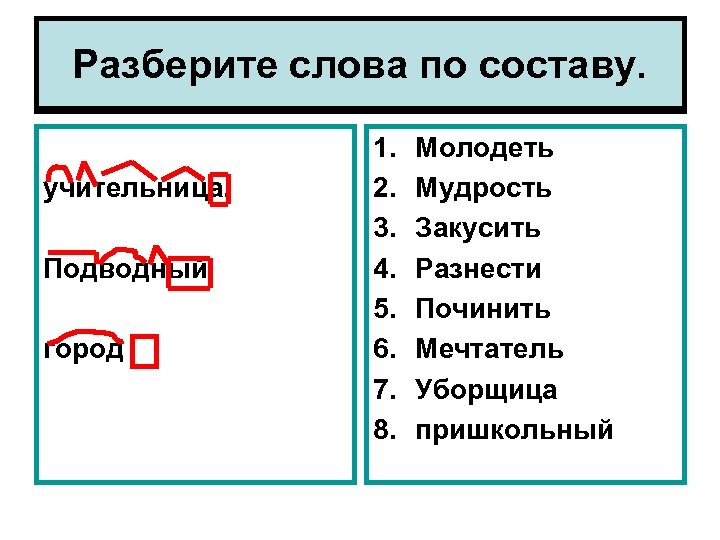
Рекурсивные глубокие модели для семантической композиционности банка деревьев настроений
Сентиментальные деревья, которые включают изысканные сентиментальные сентиментальные лаборатории. для композиционности настроений и представляет рекурсивную нейронную тензорную сеть.
Маркировка POS-тегов англо-хинди-кодового смешанного контента социальных сетей
Описаны первоначальные усилия по созданию многоуровневого аннотированного корпуса смешанных текстов на хинди и английском, собранных с форумов Facebook, а также языковая идентификация, обратная транслитерация, нормализация и POS. тегирование этих данных исследуется.
Методы анализа настроений на основе лексикона
Калькулятор семантической ориентации (SO-CAL) использует словари слов с аннотациями их семантической ориентации (полярность и сила), включает усиление и отрицание и применяется к задача классификации полярности.
SENTIWORDNET: общедоступный лексический ресурс для сбора мнений
SENTIWORDNET — это лексический ресурс, в котором каждый синсет WORDNET связан с тремя числовыми оценками Obj, Pos и Neg, описывающими, насколько объективны, позитивны и негативны термины, содержащиеся в синсете.
Учебные представления на уровне персонажа для чарсов речи
 Zadrozny
ZadroznyA Deep Neplosed Specative Specative Specative Specative Specativesessentavation Is Specatoedsivesestentavation. слов и связывать их с обычными представлениями слов для выполнения тегов POS и создавать современные теги POS для двух языков.
Code Mixing: A Challenge for Language Identification in the Language of Social Media
A new dataset описывается, который содержит посты и комментарии в Facebook, демонстрирующие смешение кода между бенгальским, английским и хинди, и обнаружено, что подход на основе словаря превосходит контролируемая классификация и маркировка последовательностей, и что важно принимать во внимание контекстуальные подсказки. .
