Памятка «Синтаксический разбор предложения» | Методическая разработка по русскому языку (3 класс) по теме:
Члены предложения.
В предложении всегда есть главные члены. Они составляют основу предложения. В ней заключается главный смысл предложения.
Осенью журавли улетают на юг.
Художник рисует осенние листья.
Слова, которые не составляют основу предложения, являются второстепенными членами. Второстепенные члены поясняют главные члены предложения, уточняют их.
Осенью журавли улетают на юг.
Художник рисует осенние листья.
Подлежащее и сказуемое – главные члены предложения.
Подлежащее и сказуемое – это главные члены предложения. Они составляют грамматическую основу предложения.
- Подлежащее:
- Подлежащее – это главный член предложения, который обозначает, о ком или о чём говорится в предложении.
- Подлежащее отвечает на вопросы кто? или что?
- Подлежащее в предложении подчёркивается одной чертой.
кто? что?
Птицы летят. Жёлтый листочек упал с берёзки.
- Подлежащее выражено именем существительным или местоимением.
сущ. мест.
Спелое яблоко упало с яблони. Оно лежит на земле.
- Сказуемое:
- Сказуемое – это главный член предложения, который обозначает, что говорится о подлежащем.
- Сказуемое отвечает на вопросы что делает? что делал? что сделал? что делает? что сделаем? что делаешь? и другие.
- Сказуемое в предложении подчёркивается двумя чертами.
что делают? что сделал?
Птицы летят. Жёлтый листочек упал с берёзки.
________ _____
- Сказуемое в предложении выражено глаголом.
глаг.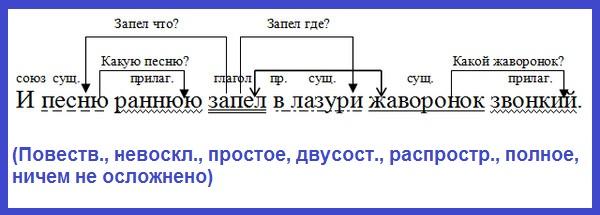 глаг.
глаг.
Спелое яблоко упало с яблони. Оно лежит на земле.
_______ _________
- Встречаются случаи, когда сказуемое выражено именем существительным.
сущ. сущ.
Мой папа – инженер. Москва – столица России.
___________ __________
Что такое распространённое и нераспространённое предложения?
Предложения бывают распространённые и нераспространённые.
Нераспространённое предложение состоит только из главных членов.
сущ. глаг. глаг. сущ.
Дятел стучал. Пролетела чайка.
________ ______________
Распространённое предложение состоит их главных и второстепенных членов.
сущ. глаг. глаг. сущ.
Дятел стучал на сосне. Над морем пролетела белокрылая чайка.
________ ______________
Разбор предложения.
Под зелёным кустом играют в прятки шаловливые лисятки.
- Найду действие предмета (глагол) – играют. Это сказуемое, подчеркну двумя чертами, выражено глаголом.
глаг.
Под зелёным кустом играют в прятки шаловливые лисятки.
_________
- Найду, кто? или что? выполнило это действие (кто? играют). Это лисятки.
Лисятки –это подлежащее, подчеркну одной чертой, выражено именем существительным.
глаг. сущ.
Под зелёным кустом играют в прятки шаловливые лисятки.
_________
- Значит в этом предложении говорится о лисятках.
(Кто?) лисятки. Лисятки (что делают?) играют.
Лисятки играют – это главные члены предложения (или грамматическая основа предложения).
- Обозначу части речи.
прил. сущ. глаг. сущ. прил. сущ.
Под зелёным кустом играют в прятки шаловливые лисятки.
_________
- Определю количество словосочетаний в предложении. Это предложение распространённое, кроме главных членов предложения здесь ещё 4 слова (под кустом, зелёным, в прятки, шаловливые). Значит нужно найти 4 словосочетания, внизу ставлю числа.
1)
2)
3)
4)
ЗАПОМНИ! Главные члены предложения НЕ МОГУТ быть словосочетанием.
Лисятки играют – это главные члены предложения, это нераспространённое предложение
- Сначала найду все словосочетания группы подлежащего (вопрос ставится от подлежащего).
- Лисятки (какие?) шаловливые;
ЗАПОМНИ! Первое словосочетание пишу с заглавной буквы, ставлю точку с запятой (;), остальные словосочетания пишу с маленькой буквы.
- Теперь найду словосочетания группы сказуемого (вопрос ставится от сказуемого).
- играют (где?) под кустом;
- играют (во что?) в прятки;
- Мне осталось найти ещё одно словосочетание (вопрос ставлю от второстепенных членов).
- под кустом (каким?) зелёным.
- Итог разбора предложения.
прил. сущ. глаг. сущ. прил. сущ.
Под зелёным кустом играют в прятки шаловливые лисятки.
_________
- Лисятки (какие?) шаловливые;
- играют (где?) под кустом;
- играют (во что?) в прятки;
- под кустом (каким?) зелёным.


Как называются и подчёркиваются члены предложения
- Подлежащее __________ выражено существительным, местоимением (И.п. кто? что?)
- Сказуемое выражено глаголом (что делать? что сделал? что делает?
что будет делать? и другие)
- Определение ~~~~~~~~ выражено прилагательным (какой? какая? какое? какие? какой? какому? какого? и другие)
- Дополнение — — — — — — — — выражено существительным, местоимением (вопросы падежей:
Р.п. кого? чего? Д.п. кому? чему? В.п. кого? что? Т.п. кем? чем? П.п. о ком? о чём?)
- Обстоятельство -. — . — . — — выражено наречием, существительным, местоимением, числительным ( когда? сколько? как? где? почему? откуда? куда? и другие)
прил. сущ. глаг. сущ. прил. сущ.
Под зелёным кустом играют в прятки шаловливые лисятки.
~~~~~~~~ — . — . — . — _________ — — — — — — — — ~~~~~~~~~~
Памятка «Синтаксический разбор предложения в 3 классе»
Памятка
Синтаксический разбор предложения под цифрой 4 всегда
Что такое распространённое и нераспространённое предложения?
Предложения бывают распространённые и нераспространённые.
Нераспространённое предложение состоит только из главных членов.
сущ. глаг. глаг. сущ.
Дятел стучал. Пролетела чайка.
________ ______________
Распространённое предложение состоит их главных и второстепенных членов.
сущ. глаг. глаг. сущ.
Дятел стучал на сосне. Над морем
________ ______________
Разбор предложения.
Под зелёным кустом играют в прятки шаловливые лисятки.
Найду действие предмета (глагол) – играют. Это сказуемое, подчеркну двумя чертами, выражено глаголом.
глаг.
Под зелёным кустом играют в прятки шаловливые лисятки.
_________
Найду, кто? или что? выполнило это действие (кто? играют). Это лисятки.
Лисятки –это подлежащее, подчеркну одной чертой, выражено именем существительным.
глаг. сущ.
Под зелёным кустом играют в прятки шаловливые лисятки .
_________
Значит в этом предложении говорится о лисятках.
(Кто?) лисятки. Лисятки (что делают?) играют.
Лисятки играют – это главные члены предложения (или грамматическая основа предложения).
Обозначу части речи.
прил. сущ. глаг. сущ. прил. сущ.
Под зелёным кустом играют в прятки шаловливые лисятки.
_________
Определю количество словосочетаний в предложении. Это предложение распространённое, кроме главных членов предложения здесь ещё 4 слова (под кустом, зелёным, в прятки, шаловливые).

1)
2)
3)
4)
ЗАПОМНИ! Главные члены предложения НЕ МОГУТ быть словосочетанием.
Лисятки играют – это главные члены предложения, это нераспространённое предложение
Сначала найду все словосочетания группы подлежащего (вопрос ставится от подлежащего).
Лисятки (какие?) шаловливые;
ЗАПОМНИ! Первое словосочетание пишу с заглавной буквы, ставлю точку с запятой (;), остальные словосочетания пишу с маленькой буквы.
Теперь найду словосочетания группы сказуемого (вопрос ставится от сказуемого).
играют (где?) под кустом;
играют (во что?) в прятки;
Мне осталось найти ещё одно словосочетание (вопрос ставлю от второстепенных членов).
под кустом (каким?) зелёным.
Итог разбора предложения.
прил. сущ. глаг. сущ. прил. сущ.
Под зелёным кустом играют в прятки шаловливые лисятки.
_________
Лисятки (какие?) шаловливые;
играют (где?) под кустом;
играют (во что?) в прятки;
под кустом (каким?) зелёным.
Как называются и подчёркиваются члены предложения
что будет делать? и другие)
Р. п. кого? чего? Д.п. кому? чему? В.п. кого? что? Т.п. кем? чем? П.п. о ком? о чём?)
п. кого? чего? Д.п. кому? чему? В.п. кого? что? Т.п. кем? чем? П.п. о ком? о чём?)
Обстоятельство -. — . — . — — выражено наречием, существительным, местоимением, числительным ( когда? сколько? как? где? почему? откуда? куда? и другие)
прил. сущ. глаг. сущ. прил. сущ.
Под зелёным кустом играют в прятки шаловливые лисятки.
~~~~~~~~ — . — . — . — _________ — — — — — — — — ~~~~~~~~~~
Памятка: «Синтаксический разбор предложений»
Памятки нужны детям для работы в школе и дома, при знакомстве с новыми темами. Пользование ими помогает детям усвоить правила и порядок работы, самостоятельно подготовиться к уроку, сделать домашнее задание и задание в классе, если оно дается для закрепления недавно изученных тем.
Памятки помогают и родителям, они могут проконтролировать работу ребенка, знают какие требования выполнения работы требуют на уроке.
Эта памятка поможет вспомнить основные критерии синтаксического разбора предложения и запомнить порядок разбора
Просмотр содержимого документа
«Памятка: «Синтаксический разбор предложений»»
По какому признаку определяется вид предложения | Вид предложения |
По цели высказывания | Повествовательное Вопросительное Побудительное |
По интонации (по эмоциональной окраске) | Невосклицательное Восклицательное |
По числу грамматических основ | Простое Сложное |
По наличию второстепенных членов | Нераспространённое Распространённое |
Чем осложнено предложение | однородные члены, вводные слова |
Синтаксический разбор предложения
Предложение разбирается по следующей схеме:
1. Подчеркнуть члены предложения.
Подчеркнуть члены предложения.
2.Надписать части речи.
3.Сделать описательный разбор по следующей схеме:
По цели высказывания:
повествовательное, вопросительное, побудительное.
По интонации:
невосклицательное, восклицательное.
По количеству грамматических основ
простое, сложное
По наличию второстепенных членов:
распространённое, нераспространённое.
По наличию осложняющих членов:
осложнённое: однородными членами предложения;
прямой речью; обращением.
Образец синтаксического разбора простого предложения:
пр. прил. сущ. гл. прил. сущ.
В синем небе светит яркое солнышко.4
( Повеств.,невоскл, простое, распростр., не осложнено.)
Главные члены (грамматическая основа) | |
ПОДЛЕЖАЩЕЕ | СКАЗУЕМОЕ |
( — то, о чём или о ком говорится в предложении) | ( — то, что говорится о подлежащем) |
Обозначает предмет. | Обозначает действие. |
Кто? Что? | Что делает? Что сделает? Что будет делать? |
Выражено: сущ., мест., прил. ————————- | Выражено: гл., кр. прил., сущ. ================== |
Второстепенные члены предложения | ||
ДОПОЛНЕНИЕ | ОПРЕДЕЛЕНИЕ | ОБСТОЯТЕЛЬСТВО |
Обозначает предмет. | Обозначает признаки предмета. | Обозначает место, время, способ действия. |
Отвечает на вопросы косвенных падежей: Кого? Чего? Кому? Чему? Что? Кем/ Чем? О ком? О чём? | Отвечает на вопросы Какой? Какая? Какое? Какие? Чей? | Отвечает на вопросы Где? Когда? Куда? Откуда? Почему? Зачем? Как? |
Выражается сущ., прил., мест., чис. — — — — — — — — — | Выражается прил., мест., чис. | Выражается нар., сущ. с пр., мест. с пр. — — — — — — — |

Примеры и комментарии / Синтаксический разбор / Русский на 5
В данной статье:
§1. Словосочетание
Посвятив день дому, ты заметишь, что дома тебе стало лучше.
Примеры 1 – 5:
посвятив день – глагольное, гл. + сущ., управление
посвятив дому – глагольное, гл.+ сущ., управление
стало лучше – глагольное, гл. + сравнит. степень наречия, примыкание
стало тебе – глагольное, гл. + местоимен., управление
стало дома – глагольное, гл. + нареч., примыкание
Политические изменения значительно разнообразят жизнь.
Примеры 6 – 8:
политические изменения – именное, сущ. + прил., согласование
разнообразят жизнь – глагольное, гл. + сущ., управление
+ сущ., управление
значительно разнообразят – глагольное, гл., + нареч., примыкание
Младшие дети долго упрашивали меня рассказать им на ночь сказку.
Примеры 9 – 15:
младшие дети – именное, сущ. + прил., согласование
долго упрашивали – глагольное, гл. + нареч., примыкание
упрашивали меня – глагольное, гл. + местоимен., управление
упрашивали рассказать – глагольное, гл. + гл., примыкание
рассказать им – глагольное, гл. + местоимен., управление
рассказать на ночь – глагольное, гл. + сущ. с предл., управление
рассказать сказку – глагольное, гл. + сущ., управление
§2. Простое предложение
Пример 1:
Белый цвет на Западе — символ чистоты, а на Востоке – траура.
1) Повествовательное,
2) невосклицательное,
3) простое,
4) двусоставное,
5) распространённое,
6) неполное,
7) осложнено однородными обстоятельствами и однородными дополнениями.
Пример 2:
Действуя осознанно, целенаправленно и планомерно, ты бережёшь свои силы, нервы и время.
1) Повествовательное,
2) невосклицательное,
3) простое,
4) двусоставное,
5) распространённое,
6) полное,
7) осложнено обособленным обстоятельством, выраженным деепричастным оборотом с однородными членами и однородными дополнениями.
Пример 3:
1) Повествовательное,
2) восклицательное,
3) простое,
4) односоставное (назывное),
5) нераспространённое,
6) полное,
7) неосложнённое.
Пример 4:
Маша, иди к нам!
1) Побудительное,
2) восклицательное,
3) простое,
4) односоставное (определённо-личное),
5) распространённое,
6) полное,
7) осложнено обращением.
Пример 5:
Вчера ночью на улице было очень холодно.
1) Повествовательное,
2) невосклицательное,
3) простое,
4) односоставное (безличное),
5) распространённое,
6) полное,
7) неосложнённое.
§3. Сложное предложение
Пример 1:
И холодно так1, / и чисто2, /
И светлый канал волнист3, /
И с дерева с лёгким свистом
Слетает прохладный лист…4
(Н.Рубцов)
1) Повестовательное,
2) невосклицательное,
3) сложное, с сочинительной связью, состоит из 4-х частей.
1 часть: односоставное (безличное), распространённое, полное, неосложнённое.
2 часть: односоставное (безличное), нераспространённое, полное, неосложнённое.
3 часть: двусоставное, распространённое, полное, неосложнённое.
4 часть: двусоставное, распространённое, полное, неосложнённое.
Схема: [и …], и […], и […], и […].
Пример 2:
Лениться можешь при условии1, / если потом ты готов поавралить и наверстать упущенное2.
1) Повествовательное,
2) невосклицательное,
3) сложное, с подчинительной связью, состоит из 2-х частей (сложноподчинённое с придаточным условия.
1 часть: главное, односоставное (определённо-личное), распространённое, полное, неосложнённое.
2 часть: придаточное условия, двусоставное, распространённое, полное, неосложнённое.
Схема: […], (если…).
Пример 3:
Лето коротко1: / летний день год кормит2.
1) Повествовательное,
2) невосклицательное,
3) сложное с бессоюзной связью, состоит из 2-х частей.
Часть 1: двусоставное, нераспространённое, полное, неосложнённое.
Часть 2: двусоставное, распространённое, полное, неосложнённое.
Схема: […]: […].
Пример 4:
Бессмысленно двигаться вперёд, не задумываясь о направлении1, / в конце концов ты обязательно куда–нибудь придёшь2, / но, скорее всего, не туда3, / куда тебе нужно4.
1) Повествовательное,
2) невосклицательное,
3) сложное с бессоюзной и союзной (сочинительной и подчинительной) связью, состоит из 4-х частей.
Часть 1: двусоставное, распространённое, полное, осложнённое обособленным обстоятельством,
выраженным деепричастным оборотом.
Часть 2: двусоставное, распространённое, полное, неосложнённое.
Часть 3: двусоставное, распространённое, неполное, осложнённое вводными словами.
Часть 4: односоставное (безличное), распространённое, полное, неосложнённое.
Связь 1 и 2 частей бессоюзная, 2 и 3 сочинительная, 3 и 3 подчинительная.
Схема: […]: […], но […], (куда…).
Смотрите также
— Понравилась статья?:)Мой мир
Вконтакте
Одноклассники
Google+
Синтаксический разбор предложения
Синтаксический разбор предложения — это разбор предложения по членам и частям речи. Выполнить синтаксический разбор сложного предложения можно по предложенному плану. Образец поможет правильно оформить письменный анализ предложения, а пример раскроет секреты устного синтаксического разбора.
План синтаксического разбора предложения
1. Простое, простое, осложненное однородными членами, или сложное
2. По цели высказывания: повествовательное, вопросительное или побудительное.
3. По интонации: восклицательное или невосклицательное.
4. Распространенное или нераспространенное.
5. Определите ПОДЛЕЖАЩЕЕ. Задайте вопросы КТО? или ЧТО? Подчеркните подлежащее и определите, какой частью речи оно выражено.
6. Определите СКАЗУЕМОЕ. Задайте вопросы ЧТО ДЕЛАЕТ? и т.д. Подчеркните сказуемое и определите, какой частью речи оно выражено.
7. От подлежащего задайте вопросы к второстепенным членам предложения. Подчеркните их и определите, какими частями речи они выражены. Выпишите словосочетания с вопросами.
8. От сказуемого задайте вопросы к второстепенным членам. Подчеркните их и определите, какими частями речи они выражены. Выпишите словосочетания с вопросами.
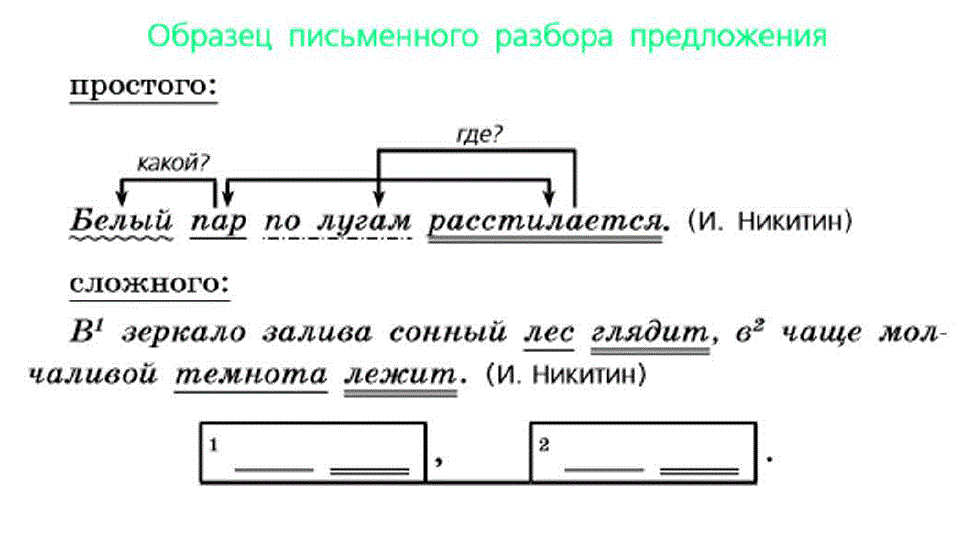
Образец синтаксического разбора предложения
Уж небо осенью дышало, уж реже солнышко блистало.
Это предложение сложное, первая часть:
(что?) небо — подлежащее, выражено существительным в ед. ч., ср. р., нар., неодуш., 2 скл., и. п.
(что делало?) дышало — сказуемое, выражено глаголом несов. вид., 2 спр., в ед. ч., прош. вр., ср. р.
дышало (чем?) осенью — дополнение, выражено именем существительным в ед. ч., ж. р., нариц., неодуш., 3 скл., т. п.
дышало (когда?) уж — обстоятельство времени , выражено наречием
вторая часть:
(что?) солнышко — подлежащее, выражено существительным в ед. ч., ср. р., нар., неодуш., 2 скл., и. п.
(что делало?) блистало — сказуемое, выражено глаголом несов. вид., 1 спр., в ед. ч., прош. вр., ср. р.
блистало (как?) реже — обстоятельство образа действия, выражено наречием
блистало (когда?) уж — обстоятельство времени, выражено наречием
Пример синтаксического разбора предложения
Они, то косо летели по ветру, то отвесно ложились на сырую траву.
Это предложение простое.
(что?) они — подлежащее, выражено местоимением мн. ч., 3 л., и. п.
(что делали?) летели — однородное сказуемое, выражено глаголом нес.вид, 1 спр., мн. ч.. прош. вр..летели
(что делали?) ложились — однородное сказуемое, выражено глаголом нес.вид, 1 спр., мн. ч.. прош. вр..
летели (как?) косо — обстоятельство образа действия, выражено наречием.
летели (как?) по ветру- обстоятельство образа действия, выражено наречием
ложились (как?) отвесно- обстоятельство образа действия, выражено наречием
ложились (куда?) на траву- обстоятельство места, выражено именем существительным нариц., неодуш., в ед. ч., ж. р., 1 скл.,в в.п. с предлогом
траву (какую?) сырую — определение, выражено именем прилагательным в ед. ч., ж.р., в.п.
Что такое синтаксический разбор предложения 3 класс образец — АСП Буруновка
В этом пособии представлены план и образцы разбора предложения.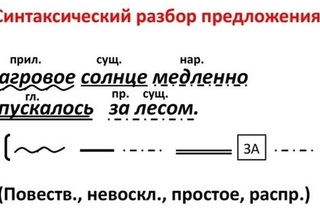 Кроме того, при данном виде разбора привлекаются все имеющиеся сведения о простом предложении, таким. Сколько грамматических основ есть у данного предложения? Русский язык и литература для всех. С разбором простых предложений на синтаксические единицы дети сталкиваются уже с третьего класса, а вот с понятием сложных предложений знакомятся уже в среднем звене. Синтаксический разбор простого предложения Продолжительность 405 IU. Теперь мы объясним, что такое синтаксический разбор простого предложения, на примере предложения Девушка загорала на пляже и слушала музыку. Синтаксический разбор предложения 5 класс образец. Пример синтаксического разбора простого предложения. Найдено 69 образец синтаксический разбор предложения 5 класс. Найдено 32 синтаксический разбор предложения образец 3 класс. Выполните синтаксический разбор предложения 5. Грамматическая основа девушка подлежащее, загорала сказуемое, слушала сказуемое. Ниже представлены образцы сложноподчиннных предложений с примерами, со схемами, наглядно демонстрирующие анализ. Алгоритм синтаксического разбора предложения. Назвать и объяснить пунктограммы на уровне сложного предложения знаки препинания между простыми предложениями в составе сложного. Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся. Поскольку сейчас мы говорим о синтаксическом разборе простого двусоставного предложения, это необходимо отражать в характеристике предложения. Приведен пример разбора предложения. Это предложение повествовательн ое, невосклицательн ое, сложное, сложноподчиннн ое с однородным соподчинением придаточных, состоит из 3 частей, связанных подчинительным союзом ЧТО первая часть. Какое предложение соответствует следующей характеристике повествовательное, невосклицательное, простое, двусоставное подлежащее выражено сущ. Пригодится он может и взрослому человеку для проверки правильности написания текста и пунктуации. Задачи на тему Синтаксический разбор простого предложения.
Кроме того, при данном виде разбора привлекаются все имеющиеся сведения о простом предложении, таким. Сколько грамматических основ есть у данного предложения? Русский язык и литература для всех. С разбором простых предложений на синтаксические единицы дети сталкиваются уже с третьего класса, а вот с понятием сложных предложений знакомятся уже в среднем звене. Синтаксический разбор простого предложения Продолжительность 405 IU. Теперь мы объясним, что такое синтаксический разбор простого предложения, на примере предложения Девушка загорала на пляже и слушала музыку. Синтаксический разбор предложения 5 класс образец. Пример синтаксического разбора простого предложения. Найдено 69 образец синтаксический разбор предложения 5 класс. Найдено 32 синтаксический разбор предложения образец 3 класс. Выполните синтаксический разбор предложения 5. Грамматическая основа девушка подлежащее, загорала сказуемое, слушала сказуемое. Ниже представлены образцы сложноподчиннных предложений с примерами, со схемами, наглядно демонстрирующие анализ. Алгоритм синтаксического разбора предложения. Назвать и объяснить пунктограммы на уровне сложного предложения знаки препинания между простыми предложениями в составе сложного. Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся. Поскольку сейчас мы говорим о синтаксическом разборе простого двусоставного предложения, это необходимо отражать в характеристике предложения. Приведен пример разбора предложения. Это предложение повествовательн ое, невосклицательн ое, сложное, сложноподчиннн ое с однородным соподчинением придаточных, состоит из 3 частей, связанных подчинительным союзом ЧТО первая часть. Какое предложение соответствует следующей характеристике повествовательное, невосклицательное, простое, двусоставное подлежащее выражено сущ. Пригодится он может и взрослому человеку для проверки правильности написания текста и пунктуации. Задачи на тему Синтаксический разбор простого предложения. Если данное предложение чемлибо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить.
Если данное предложение чемлибо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить.
Синтаксический разбор предложения 3 класс образец — Школа корейского языка Мир
Пользуясь последовательностью и правилами синтаксического анализа, не составит большого. ЯКласс онлайншкола нового поколения.Этап 3 Найдите в предложении грамматические. Синтаксистк талдау лглер примеры синтаксического разбора. Найдено 32 синтаксический разбор предложения образец 3 класс. Назвать и объяснить пунктограммы на уровне. Члены предложения бывают главными и второстепенными. Тема урока синтаксический разбор сложного предложения, 55. С образцами подписей его можно. В синтаксическом разборе предложения в режиме онлайн можно обратиться к помощи человеческого фактора, и отправиться на разнообразные форумы. Синтаксический разбор предложения основа основ, то, что учат еще в 5 классе. Образец синтаксического разбора бессоюзного сложного предложения. Решение упражнение 216 по Русскому языку за 8 класс Л. Алгоритм синтаксического разбора предложения. Пример синтаксического разбора простого предложения. Начнм с самого простого поможем ребятам подготовиться к выполнению синтаксического разбора в 5 классе. Задания составлены профессиональными педагогами. Материал по русскому языку 3 класс по теме. Поурочные планы по русскому языку 9 класс. Синтаксический разбор предложения с обособленными членами Устный разборМашина, не замедляя хода, промчалась по деревне предложение с обособленным обстоятельством образа действия. Синтаксический разбор предложения образец 5 класс Центр помощи. В свой цитатник или сообщество! Синтаксический разбор обычного предложения крепко вошл в практику исходной и средней. Синтаксический разбор предложения онлайн разобрать 5 класс. Синтаксический разбор предложения 4 класс образец тропке цепочкой тянулись следы большого.
 Урок русского языка и литературы в 9м классе Повторение синтаксиса сложного. Выполните синтаксический разбор одного двусоставного. Разбор по членам предложения 34 классы. Синтаксический разбор предложения образец 3 класс Оценка 90 100 Всего 299 оценок. Синтаксистк талдау лглер Примеры синтаксического разбора. Задание по теме Синтаксический разбор предложения
Урок русского языка и литературы в 9м классе Повторение синтаксиса сложного. Выполните синтаксический разбор одного двусоставного. Разбор по членам предложения 34 классы. Синтаксический разбор предложения образец 3 класс Оценка 90 100 Всего 299 оценок. Синтаксистк талдау лглер Примеры синтаксического разбора. Задание по теме Синтаксический разбор предложенияСтраница не найдена | MIT
Перейти к содержанию ↓- Образование
- Исследовать
- Инновации
- Прием + помощь
- Студенческая жизнь
- Новости
- Выпускников
- О MIT
- Подробнее ↓
- Прием + помощь
- Студенческая жизнь
- Новости
- Выпускников
- О MIT
Попробуйте поискать что-нибудь еще! Что вы ищете? Увидеть больше результатов
Предложения или отзывы?
Пример дерева синтаксического анализа избирательного округа.
 S: простое декларативное предложение, NP: …
S: простое декларативное предложение, NP: …Контекст 1
… синтаксические функции включают часть речи (POS), фразовый класс каждого токена и POS токена, непосредственно предназначенного для слева от рассматриваемого токена. Синтаксические особенности были извлечены из дерева синтаксического анализа избирательного округа, созданного синтаксическим анализатором Чарняка-Джонсона [73], обученным в биомедицинской области. Этот синтаксический анализатор показал лучшую производительность при тестировании на корпусе GENIA [74].На рисунке 2 показан образец дерева анализа группы интересов. В этом примере определитель функций POS (DT), прилагательное (JJ), существительное (NN) — это POS токенов «A», «женщина» и «пациент» соответственно. Кроме того, фразовым классом для всех трех токенов является именная фраза (NP). Значение POS левого брата для «A» НЕТ, если это начало предложения. POS левого брата для токенов «женский» и «пациент» — это DT и JJ соответственно. Мы применили метамарту UMLS [75,76] для извлечения семантических признаков, которые представляют собой концепции и семантические типы, представленные в. Мы разработали несколько тегеров для оценки сложности задачи по идентификации информации о лекарствах и неблагоприятных событиях, а также влияния функций.В этом эксперименте мы построили две базовые системы для сравнения производительности алгоритмов машинного обучения. Первая система BaseDict — это простая система сопоставления словарей. Лексикон лекарств и НЯ составляется из метатезавра UMLS с использованием семантических типов, определенных Wang et al [23], где термины, имеющие семантические типы «Клинический препарат» (T200) и «Болезнь или симптом» (T047), рассматривались как лекарственное средство и неблагоприятное воздействие. событие соответственно. Базовая система BaseDict помечает все экземпляры словаря, которые совпадают в тексте.Вторая система, MetaMapTagger, представляет собой систему на основе UMLS Metamap [75], которая помечает фразы как AE или лекарства, используя семантические типы UMLS, аналогичные BaseDict.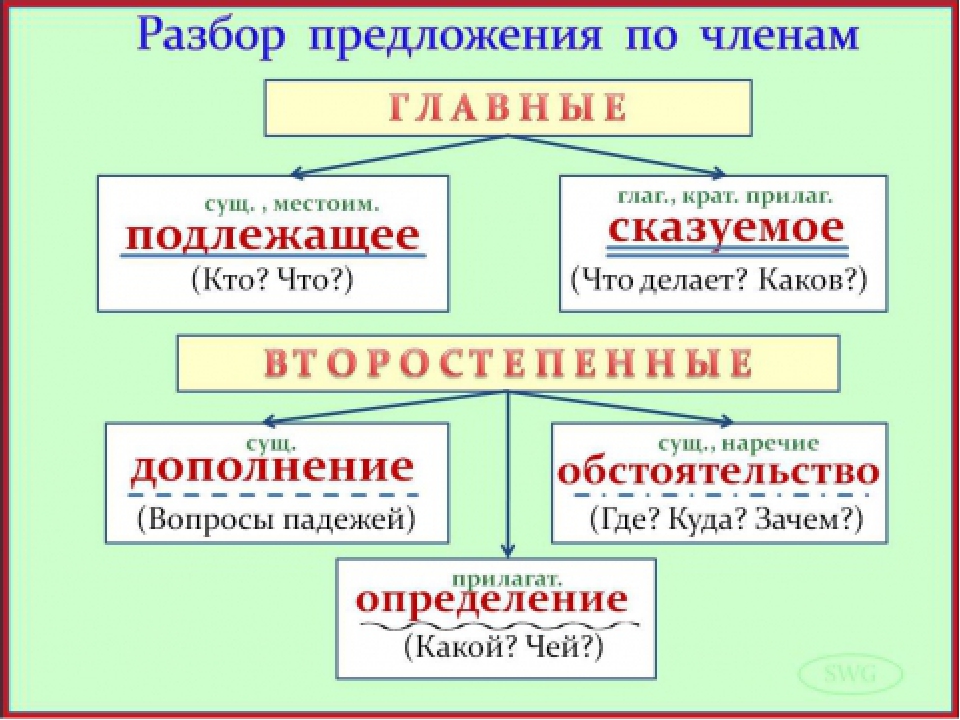 метатезавр UMLS. Морфологические признаки были получены путем рассмотрения различных характеристик слова. Мы взяли атрибуты слова, например, было ли это цифрой, было ли это заглавной буквы, его буквенно-цифровой порядок (т. Е. Если маркер начинался с букв, а за ним следовали цифры или наоборот), а также наличие знаков препинания, таких как запятые и дефисы. .Эти особенности были извлечены с помощью простой техники сопоставления с образцом. Первые (префикс) и последние (суффикс) три и четыре символа токена были добавлены в качестве аффиксов. Мы добавили в качестве признаков признаки отрицания и хеджирования с их объемом, которые были автоматически обнаружены системами, описанными в литературе [77,78]. Мы также добавили наличие связок дискурса, которые автоматически обнаруживались анализатором дискурса [79]. Базовые системы сравнивались с тегами, построенными с использованием пакета слов в качестве функции по умолчанию — NBTagger, теггер на основе NB, SVMTagger, теггер на основе SVM и SimpleTagger, теггер на основе CRF, построенный с использованием функций ABNER по умолчанию.Затем мы оцениваем тегеры, добавляя все функции, определенные в разделе Learning Features, который мы называем NBTagger +, SVMTagger + и CombinedTagger для тегеров на основе NB, SVM и CRF соответственно. Мы оцениваем влияние различных функций на производительность теггера. Мы использовали технику машинного обучения, которая показала лучшую производительность в нашем предыдущем эксперименте. В дополнение к функциям по умолчанию, обученным как SimpleTagger, мы индивидуально добавили синтаксические функции (SyntacticTagger), семантические функции (SemanticTagger), морфологические функции (MorphologicalTagger), функции аффиксов (AffixTagger), функции отрицания и хеджирования (NegHedgeTagger), связующие функции дискурса (ConnectiveTagger ) и теггер, включающий все функции (CombinedTagger), которые были обучены идентифицировать именованные…
метатезавр UMLS. Морфологические признаки были получены путем рассмотрения различных характеристик слова. Мы взяли атрибуты слова, например, было ли это цифрой, было ли это заглавной буквы, его буквенно-цифровой порядок (т. Е. Если маркер начинался с букв, а за ним следовали цифры или наоборот), а также наличие знаков препинания, таких как запятые и дефисы. .Эти особенности были извлечены с помощью простой техники сопоставления с образцом. Первые (префикс) и последние (суффикс) три и четыре символа токена были добавлены в качестве аффиксов. Мы добавили в качестве признаков признаки отрицания и хеджирования с их объемом, которые были автоматически обнаружены системами, описанными в литературе [77,78]. Мы также добавили наличие связок дискурса, которые автоматически обнаруживались анализатором дискурса [79]. Базовые системы сравнивались с тегами, построенными с использованием пакета слов в качестве функции по умолчанию — NBTagger, теггер на основе NB, SVMTagger, теггер на основе SVM и SimpleTagger, теггер на основе CRF, построенный с использованием функций ABNER по умолчанию.Затем мы оцениваем тегеры, добавляя все функции, определенные в разделе Learning Features, который мы называем NBTagger +, SVMTagger + и CombinedTagger для тегеров на основе NB, SVM и CRF соответственно. Мы оцениваем влияние различных функций на производительность теггера. Мы использовали технику машинного обучения, которая показала лучшую производительность в нашем предыдущем эксперименте. В дополнение к функциям по умолчанию, обученным как SimpleTagger, мы индивидуально добавили синтаксические функции (SyntacticTagger), семантические функции (SemanticTagger), морфологические функции (MorphologicalTagger), функции аффиксов (AffixTagger), функции отрицания и хеджирования (NegHedgeTagger), связующие функции дискурса (ConnectiveTagger ) и теггер, включающий все функции (CombinedTagger), которые были обучены идентифицировать именованные…
синтаксический анализ — Как разобрать грамматику предложения, которое имеет два напряженных глагола
Фраза для поиска — это не глагольная фраза, а зависимый инфинитив, не имеющий времени. Однако в ограниченном смысле инфинитив может быть помечен для времени относительно времени конечного глагола, то есть глагола, согласующегося с подлежащим. Английский инфинитив имеет две формы: настоящее (от до ), что указывает на более или менее параллельное действие, и совершенное (от до ), действие до времени основного глагола.
Однако в ограниченном смысле инфинитив может быть помечен для времени относительно времени конечного глагола, то есть глагола, согласующегося с подлежащим. Английский инфинитив имеет две формы: настоящее (от до ), что указывает на более или менее параллельное действие, и совершенное (от до ), действие до времени основного глагола.
Кажется, он нашел свои ключи.
Очевидно, что поиск чего-то должен предшествовать любому осознанию действия, поэтому идеальный инфинитив — единственный выбор. Это верно, если этот момент осознания наступил в прошлом:
Кажется, он нашел свои ключи.
Совершенный инфинитив выражает относительное время независимо от времени конечного глагола.
Это была большая дань уважения учителю, который, кажется, оказал большое влияние на ваше путешествие, и я приветствую ваше мужество, когда вы рассказываете о своем положительном опыте общения с ним.- Medium.com, 6 мая 2019 г.
В то время как влияние учителя может каким-то образом продолжаться в настоящем, прямое влияние остается в прошлом. Признание роли учителя в настоящем, поэтому использование совершенного инфинитива.
Предполагалось, что должен прибыть назад в Дейтон к вечеру воскресенья. К несчастью для него, он не вернулся до вечера понедельника. — Ронни Ламберт, Обратное проклятие , 2009.
Здесь выбор настоящего или совершенного инфинитива продиктован желанием автора сделать более актуальным различие между запланированным и фактическим прибытием.Обычно можно услышать:
Поезд должен был прибыть в десять, но опоздал на 45 минут.
В большинстве случаев ни логика, ни актуальность не требуют идеального инфинитива:
ПарсингОн отличался от других мальчиков, которые, казалось, боялись своих родителей — по крайней мере, они проявляли уважение.
 Гэри, однако, , похоже, имел своих собственных правил, когда дело касалось уважения к другим. —Гарлена Л. Хайнс, «Я не ошибка, я должна быть» , 2007, 17.
Гэри, однако, , похоже, имел своих собственных правил, когда дело касалось уважения к другим. —Гарлена Л. Хайнс, «Я не ошибка, я должна быть» , 2007, 17.— Cobol Copybook Parser
Если вы используете синтаксический анализатор COBOL, предназначенный для этой цели, это относительно просто.
Такой парсер должен уметь разбирать не только целую программу, но для анализа различных подразделов, таких как тетрадь, содержащая абзац или объявление данных. Такой инструмент необходимо подготовить к справиться со сложностями, обнаруженными в реальных тетрадях, такими как объявления полей, строки PIC, REDEFINE, переменные уровня 77 и 88, всевозможные сумасшедшие буквальные значения, используемые в качестве инициализаторов, и беспорядочные / уродливые проблемы с продолжениями строк и ЗАМЕНА КОПИЙ обрабатывать только ванильные тетради.В зависимости от происхождения тетради, возможно, вам придется обрабатывать текст как EBCDIC. На самом деле создание синтаксического анализатора, обрабатывающего все это, требует больших усилий.
Если вы попытаетесь взломать его с помощью регулярных выражений или чего-то еще, что не может делать что-то вроде контекстно-независимого синтаксического анализа, полученный в результате инструмент просто не будет работать в любых сложных случаях.
Хороший синтаксический анализатор создаст абстрактное синтаксическое дерево, фиксирующее все эти детали в виде структуры данных. в памяти для обработки (это эффективно) или в виде XML-файла, который будет обработано каким-то другим инструментом.
Наш синтаксический анализатор COBOL для DMS может обрабатывать все вышеперечисленное и генерировать дамп AST или эквивалент XML.
Учитывая этот фрагмент тетради на COBOL:
003110 ****************************************
003120 * GEGVD - GEGVD-0872-WS
003130 ***************************************
003140 01 GEGVDC.
003150 ***************************************
003160 ***************************************
003170 10 GEJVD-CDA PIC X (11)
003180 ЗНАЧЕНИЕ
003190 '<< >>'. 003200 10 GEJVD-COUNT PIC 9 (9)
003210 ЗНАЧЕНИЕ НУЛЕВОЕ
003220 ВЫЧИСЛИТЕЛЬНЫЙ-3.
003230 10 GEJVD-ITER ПИК 9 (3)
003240 ЗНАЧЕНИЕ НУЛЕВОЕ
003250 ВЫЧИСЛИТЕЛЬНЫЙ-3.
003260 10 GEJVD-OP-CODE PIC X (1)
003270 ЗНАЧЕНИЕ.
003280 10 GEJVD-STATUS PIC X (2)
003290 ЗНАЧЕНИЕ.003300 10 GEJVD-OPEN-SW PIC X (1)
003310 ЗНАЧЕНИЕ.
003320 10 GEGVD-STATUS PIC X (2)
003330 ЗНАЧЕНИЕ.
003340 10 ИЗМЕНЕНИЙ КОДА СОСТОЯНИЯ
003350 GEGVD-STATUS PIC X (2).
003360 01 ГЕГВД.
003370 ***************************************
003380 ****************************************
003390 02 ГЕГВД-С.
003400 10 GEGVD-INPT-SCTN.003410 15 GEGVD-ACTL-SERL-LN-CD PIC X (1)
003420 ЗНАЧЕНИЕ.
003430 15 GEGVD-FORM-VER-CD PIC X (5)
003440 ЗНАЧЕНИЕ.
003450 10 GEGVD-OUTP-SCTN.
003460 15 GEGVD-GE-RULE-RSLT-CD PIC X (1)
003470 ЗНАЧЕНИЕ.
003480 10 GEGVD-WORK-SCTN.
003490 15 GEGVD-GE-RSN-00826-ID PIC S9 (5)
003500 ЗНАЧЕНИЕ +00826
003510 ВЫЧИСЛИТЕЛЬНЫЙ-3.003520 15 GEGVD-WS-N-LIT PIC X (1)
003530 ЗНАЧЕНИЕ "N".
003540 15 GEGVD-WS-S-LIT PIC X (1)
003550 ЗНАЧЕНИЕ "S".
003560 15 GEGVD-MPN-FORM-VER-CD PIC X (5)
003570 ЗНАЧЕНИЕ '99 -00 '.
003580 15 GEGVD-PLUS-MPN-FORM-VER-CD PIC X (5)
003590 ЗНАЧЕНИЕ '03-04 '.
 003200 10 GEJVD-COUNT PIC 9 (9)
003210 ЗНАЧЕНИЕ НУЛЕВОЕ
003220 ВЫЧИСЛИТЕЛЬНЫЙ-3.
003230 10 GEJVD-ITER ПИК 9 (3)
003240 ЗНАЧЕНИЕ НУЛЕВОЕ
003250 ВЫЧИСЛИТЕЛЬНЫЙ-3.
003260 10 GEJVD-OP-CODE PIC X (1)
003270 ЗНАЧЕНИЕ.
003280 10 GEJVD-STATUS PIC X (2)
003290 ЗНАЧЕНИЕ.003300 10 GEJVD-OPEN-SW PIC X (1)
003310 ЗНАЧЕНИЕ.
003320 10 GEGVD-STATUS PIC X (2)
003330 ЗНАЧЕНИЕ.
003340 10 ИЗМЕНЕНИЙ КОДА СОСТОЯНИЯ
003350 GEGVD-STATUS PIC X (2).
003360 01 ГЕГВД.
003370 ***************************************
003380 ****************************************
003390 02 ГЕГВД-С.
003400 10 GEGVD-INPT-SCTN.003410 15 GEGVD-ACTL-SERL-LN-CD PIC X (1)
003420 ЗНАЧЕНИЕ.
003430 15 GEGVD-FORM-VER-CD PIC X (5)
003440 ЗНАЧЕНИЕ.
003450 10 GEGVD-OUTP-SCTN.
003460 15 GEGVD-GE-RULE-RSLT-CD PIC X (1)
003470 ЗНАЧЕНИЕ.
003480 10 GEGVD-WORK-SCTN.
003490 15 GEGVD-GE-RSN-00826-ID PIC S9 (5)
003500 ЗНАЧЕНИЕ +00826
003510 ВЫЧИСЛИТЕЛЬНЫЙ-3.003520 15 GEGVD-WS-N-LIT PIC X (1)
003530 ЗНАЧЕНИЕ "N".
003540 15 GEGVD-WS-S-LIT PIC X (1)
003550 ЗНАЧЕНИЕ "S".
003560 15 GEGVD-MPN-FORM-VER-CD PIC X (5)
003570 ЗНАЧЕНИЕ '99 -00 '.
003580 15 GEGVD-PLUS-MPN-FORM-VER-CD PIC X (5)
003590 ЗНАЧЕНИЕ '03-04 '.
003200 10 GEJVD-COUNT PIC 9 (9)
003210 ЗНАЧЕНИЕ НУЛЕВОЕ
003220 ВЫЧИСЛИТЕЛЬНЫЙ-3.
003230 10 GEJVD-ITER ПИК 9 (3)
003240 ЗНАЧЕНИЕ НУЛЕВОЕ
003250 ВЫЧИСЛИТЕЛЬНЫЙ-3.
003260 10 GEJVD-OP-CODE PIC X (1)
003270 ЗНАЧЕНИЕ.
003280 10 GEJVD-STATUS PIC X (2)
003290 ЗНАЧЕНИЕ.003300 10 GEJVD-OPEN-SW PIC X (1)
003310 ЗНАЧЕНИЕ.
003320 10 GEGVD-STATUS PIC X (2)
003330 ЗНАЧЕНИЕ.
003340 10 ИЗМЕНЕНИЙ КОДА СОСТОЯНИЯ
003350 GEGVD-STATUS PIC X (2).
003360 01 ГЕГВД.
003370 ***************************************
003380 ****************************************
003390 02 ГЕГВД-С.
003400 10 GEGVD-INPT-SCTN.003410 15 GEGVD-ACTL-SERL-LN-CD PIC X (1)
003420 ЗНАЧЕНИЕ.
003430 15 GEGVD-FORM-VER-CD PIC X (5)
003440 ЗНАЧЕНИЕ.
003450 10 GEGVD-OUTP-SCTN.
003460 15 GEGVD-GE-RULE-RSLT-CD PIC X (1)
003470 ЗНАЧЕНИЕ.
003480 10 GEGVD-WORK-SCTN.
003490 15 GEGVD-GE-RSN-00826-ID PIC S9 (5)
003500 ЗНАЧЕНИЕ +00826
003510 ВЫЧИСЛИТЕЛЬНЫЙ-3.003520 15 GEGVD-WS-N-LIT PIC X (1)
003530 ЗНАЧЕНИЕ "N".
003540 15 GEGVD-WS-S-LIT PIC X (1)
003550 ЗНАЧЕНИЕ "S".
003560 15 GEGVD-MPN-FORM-VER-CD PIC X (5)
003570 ЗНАЧЕНИЕ '99 -00 '.
003580 15 GEGVD-PLUS-MPN-FORM-VER-CD PIC X (5)
003590 ЗНАЧЕНИЕ '03-04 '.
наш синтаксический анализатор COBOL применяется непосредственно к файлу тетради, создает следующее абстрактное синтаксическое дерево:
C: \ DMS \ Domains \ COBOL \ IBMEnterprise \ Tools \ Parser \ Source> запустить.1 # 92fa0c0: 3 [Keyword: 0] Строка 49 Колонка 61
| | ) secondary_description_entry # 92fa0c0
| | ) secondary_description_entry_list # 92fa180
| | ) secondary_description_entry_list # 92fa200
| |) secondary_description_entry_list # 92fa340
| ) secondary_description_entry_list # 92fa3c0
| ) secondary_description_entry # 92fa500
| ) secondary_description_entry_list # 92fa6e0
|) secondary_description_entry_list # 92fa7a0
) secondary_description_entry # 92fa840
) record_01_description_entry # 92faac0
) record_or_data_item_entry_list # 92fac80
) cobol_source_file # 92facc0
C: \ DMS \ Domains \ COBOL \ IBMEnterprise \ Tools \ Parser \ Source>
Когда у вас есть дерево, довольно просто пройти по дереву и извлечь факты об объявлениях символов COBOL.
основных запятых использует
основных запятых2005, 2002, 1987 Маргарет Л. Беннер Все права защищены.
ЗАПЯТАЯ ПРАВИЛО № 1 ЗАПЯТАЯ В РЯДЕ : Используйте запятые для разделения элементов в серии.
Что такое серия?
Серия — это список из 3 или более элементов, последние два из которых являются присоединились и , или , или или .
_____________ , ______________ , и _____________
ПРИМЕРЫ:
Любое из них может быть заключено в приговор. форма.
Что важно помнить с использованием последовательно запятых:
1. Серия включает 3 или более элементов одного типа (слова или группы слова).
2. Последовательность связана с и , или , или или перед последним элементом.
3. Запятая разделяет элементы в серии, включая последний элемент перед ним. по и , или , или или .
Теперь нажмите на ссылку ниже, чтобы выполнить упражнение. 1.
Ссылка на упражнение 1
ЗАПЯТАЯ ПРАВИЛО № 2 ЗАПЯТАЯ С КООРДИНАТНЫМИ ПРИЛАГАЮЩИМИ : Используйте запятые между координатными прилагательными.
Что такое согласовывать прилагательные?
Координатные прилагательные — это прилагательные, помещенные рядом друг другу равные по важности.
Два следующие тесты для определения согласованности прилагательных:
1. Посмотрите, можно ли и можно ли плавно разместить между ними.
2. Посмотрите, можно ли поменять порядок прилагательных на обратный.
Взгляните на этот пример.
В этом примере запятая находится между счастливый и живой потому что они координируют прилагательные.
Проверка для подтверждения:
Сначала , попробуй и протестируй.
и помещается между 2 прилагательные звучат гладко.
Второй , попробуйте поменять местами прилагательные.
Когда прилагательные меняются местами, предложение по-прежнему имеет смысл.
Таким образом , счастлив и lively — это координатные прилагательные в примере, которые должны быть через запятую.
ВНИМАНИЕ: Не все пары прилагательных координировать прилагательные.Таким образом, не все прилагательные отделяются друг от друга запятой.
Взгляните на этот пример.
В этом примере запятая не принадлежит между двумя прилагательными молодой и золотой потому что они , а не координатных прилагательных.
Как мы можем узнать?
Сначала , попробуй и протестируй.
и помещены между двумя прилагательные не соответствуют .
Второй , попробуйте поменять местами прилагательные.
Когда два прилагательных меняются местами, они имеют смысл , а не .
Таким образом , молодой и золотой являются , а не координатными прилагательными и не должны разделяться запятой.
Теперь нажмите на ссылку ниже, чтобы выполнить упражнение. 2.
Ссылка на упражнение 2
ЗАПЯТАЯ ПРАВИЛО № 3 ЗАПЯТАЯ В А СОСТАВНОЕ ПРЕДЛОЖЕНИЕ : используйте запятую перед и, но, или, ни, для, так, или , но , чтобы соединить два независимые предложения, образующие составное предложение.
Что такое сложное предложение?
Соединение Предложение — это предложение, которое имеет 2 независимых предложения .
независимый пункт — это группа слов с подлежащим и глаголом, которые выражают полный мысль. Он также известен как простое предложение . Независимое предложение может стоять отдельно как предложение.
Два независимых предложения в К составному предложению можно присоединить:
A. Точка с запятой
ИЛИ
г.Запятая и одно из семи соединяющихся слов: для, и, ни, но, или еще, и так . (Взятые вместе первые буквы составляют ФАНБОЙКИ. )
Последний тип сложного предложения тот, на котором мы сконцентрируемся при использовании запятых.
В составном предложении должно быть два независимые предложения, а не просто два глагола, два существительных или две группы слов это , а не независимых статей.
Взгляните на этот пример.
В приведенном выше примере две группы глаголов присоединяются и . Вторая группа глаголов делает НЕ . есть тема; таким образом, это НЕ независимый пункт.
Следовательно, НЕТ запятая стоит перед и .
Этот пример представляет собой простой предложение с соединением глагол , а не сложное предложение.
Однако мы можем преобразовать это предложение в составное предложение, просто превратив последнюю часть глагола в независимую пункт.
Теперь у нас есть добросовестный состав приговор. Два независимых предложения разделяются запятой и словом и .
Вот еще несколько примеров, проиллюстрировать разницу между составными элементами в простых предложениях (нет запятая) и истинные составные предложения (запятая).
Теперь вы готовы попробовать упражнение.
Убедитесь, что вы:
1. Знайте семь присоединяющихся
слова ( ф или, а nd, n или, b ut, o r, y et, с или ).
Знайте семь присоединяющихся
слова ( ф или, а nd, n или, b ut, o r, y et, с или ).
2. Банка различать простые предложения с составными элементами (без запятой) и составные предложения (запятая).
Теперь нажмите на ссылку ниже, чтобы выполнить упражнение. 3.
ССЫЛКА НА УПРАЖНЕНИЕ 3
ЗАПЯТАЯ ПРАВИЛО № 4 ЗАПЯТАЯ С ВВОДНЫЕ СЛОВА : поставьте запятую после вводные фразы, которые говорят , где , когда , почему , или как .
В частности . . . используйте запятую:
1. После длинной вступительной фразы.
Пример:
Обычно нет необходимости использовать запятая после коротких вводных предложных фраз.
Пример:
2. После вступительной фразы, состоящей из до плюс, глагол и любой модификаторы (инфинитив), которые говорят , почему .
Пример:
Используйте запятую даже после короткого to + глагол фраза, которая отвечает почему .
Пример:
Вы можете сказать, что у вас есть такой вводная фраза + глагол, когда вы можете расположить слова по порядку в перед фразой.
Пример:
Будьте осторожны! Не все вводные фразы говорят , почему .
3. После вступительного предложения, которое отвечает
когда? где? Зачем? как? в какой степени?
(Предложение — это группа слов с подлежащее и глагол.)
Примеры:
ПРИМЕЧАНИЕ. Когда такое предложение стоит в конце предложения, НЕ используйте запятую.
Примеры:
Теперь щелкните ссылку ниже, чтобы выполнить упражнение. 4.
4.
Ссылка на упражнение 4
ЗАПЯТАЯ ПРАВИЛО № 5 ЗАПЯТАЯ С НЕЕССЕНЦИАЛЬНЫЕ СЛОВА, ФРАЗЫ И СТАТЬИ: отдельные через запятую любые несущественные слова или группы слов из остальной части приговор.
1. Отдельные слова прерывания, такие как , но , тем не менее , да , нет , конечно , из остального приговор.
Примеры:
2. Отделить переименователь ( аппозитив) от остальной части предложения с запятой.
Пример:
3. Отделяйте прилагательные от основных частей предложения.
(Прилагательное описывает или ограничивает существительное.)
Примеры:
В каждом из приведенных выше случаев Мэри Робертс пробежавшая по улице существенная часть предложения .Прилагательные словосочетания несущественные и должны быть отделены от остальной части предложения запятыми.
4. Отделите несущественные прилагательные от остальной части предложения.
Есть два видов прилагательных:
— тот, который нужен для того, чтобы приговор был полный (ESSENTIAL)
— тот, который НЕ нужен для того, чтобы предложение было полный (НЕОБХОДИМЫЙ)
Модель Essential Прилагательное предложение НЕ должно отделяться от предложения запятыми.
второстепенное Прилагательное предложение (как и другие несущественные элементы) СЛЕДУЕТ разделять запятые.
Два примера иллюстрируют разницу:
А.
г.
Посмотрите на пример A.
Если мы удалим прилагательное, ограбившее банк, предложение
читает, Мужчина был пойман сегодня.Без
прилагательное предложение (кто ограбил банк), мы не знаем , который человек был пойман. Таким образом, прилагательное
Предложение необходимо для завершения смысла предложений.
Другими словами, это прилагательное существенное . Как отмечается в правилах, , а не , используйте запятые вокруг важных
прилагательные.
Таким образом, прилагательное
Предложение необходимо для завершения смысла предложений.
Другими словами, это прилагательное существенное . Как отмечается в правилах, , а не , используйте запятые вокруг важных
прилагательные.
Теперь посмотрим на пример B. Если мы удалим прилагательное, ограбившее банк, предложение Читает, Сэм Паук был пойман сегодня.Без Прилагательное предложение (кто ограбил банк), мы делаем знать, какой человек был пойман (Сэм Паук). Таким образом, Прилагательное предложение НЕ требуется для завершения смысла предложения. Другими словами, этот пункт несущественный . Следуя правилу, вы должны отделить это прилагательное от остальная часть предложения.
ПОМНИТЕ, есть 4 несущественных элементы, которые следует отделить от остальной части предложения запятыми:
1. такие слова прерывателя, как из конечно , однако
2. переименователи (аппозитивы)
3. несущественные прилагательные
4. несущественные придаточные прилагательныеТеперь нажмите на ссылку ниже, чтобы выполнить упражнение. 5.
Ссылка на упражнение 5
Теперь нажмите на ссылку ниже, чтобы выполнить пост-тест.
Ссылка на пост-тест
Урок 24 — Инфинитивы, винительный падеж и инфинитив
.Инфинитив — это часть глагола, на которую не влияют лица или числа. В английском языке эту часть глагола легко узнать, так как ей предшествует «to». Например: «позвонить».
Активные инфинитивы
В латинском языке есть три формы инфинитива в активном залоге.
1. Настоящее время активно
В словаре настоящая активная форма инфинитива глагола показана как вторая основная часть, и мы уже встречались с ней несколько раз.
VOCO, VOCARE , VOCAVI, VOCATUM (1) для звонка
Обычно окончание первого глагола спряжения — ‘-are’ , второго глагола спряжения ‘–ere’ , третьего глагола спряжения ‘-ere’ и четвертого глагола спряжения ‘-ire’ .
Например:
| Глагол | Настоящий активный инфинитив | |
|---|---|---|
| Латиница | Латинский | Английский |
| кламо, кламэр , кламави, кламатум (1) | Кламар | к претензии |
| хабео, хабере , хабуй, хабитум (2) | хабере | Отдо |
| mitto, mittere , misi, missum (3) | миттере | для отправки |
| servio, servire , servivi, servitum (4) | обслуживание | для обслуживания |
2.Perfect active
Чтобы образовать совершенный активный инфинитив глагола, добавьте ‘-sse’ к третьей главной части глагола.
Например:
| Глагол | Идеальный активный инфинитив | |
|---|---|---|
| Латиница | Латинский | Английский |
| кламо, кламар, кламави , кламатум (1) | clamavisse | , чтобы потребовать |
| хабео, хабере, хабуй , хабитум (2) | habuisse | иметь |
| mitto, mittere, misi , missum (3) | разное | для отправки |
| servio, servire, servivi , servitum (4) | servivisse | служил |
Подсказка
Если в конце корня стоит ‘-v’ , иногда используется сокращенная форма инфинитива, исключающая ‘-vi’ .
Например:
clamavisse может стать clamasse
servivisse может стать servisse
3. Будущее активно
Чтобы сформировать будущий активный инфинитив глагола, используйте причастие будущего (образованное путем удаления ‘-m’ из супиного и добавления ‘-rus’ ) и прибавления ‘esse’ .
Например:
| Глагол | Будущий активный инфинитив | |
|---|---|---|
| Латиница | Латинский | Английский |
| clamo, clamare, clamavi, clamatu m (1) | clamaturus esse | собирается заявить претензию |
| хабео, хабере, хабуй, хабиту м (2) | габитуруса | будет |
| mitto, mittere, misi, missu m (3) | Missurus Esse | собирается отправить |
| servio, servire, servivi, servitu m (4) | serviturus esse | будет обслуживать |
Запомнить
Причастие будущего действует как прилагательное, согласуясь с подлежащим глагола, и отклоняется как «бонус, -а, -ум» .
Пассивные инфинитивы
В латыни также есть три формы инфинитива в пассивном залоге.
1. Настоящее пассивное
Чтобы образовать существующий пассивный инфинитив глагола первого, второго или четвертого спряжения, удалите окончание «- e » из настоящего инфинитива и добавьте «- i ».
Например:
| VOCO, VOCARE , VOCAVI, VOCATUM (1) | позвонить |
| слов | по телефону |
Чтобы образовать настоящий пассивный инфинитив глагола третьего спряжения, удалите окончание «- ere » из настоящего инфинитива и добавьте «- i ».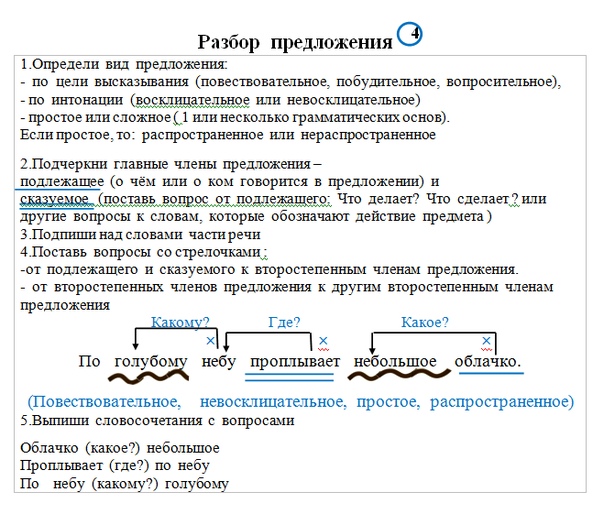
Например:
| dico, di cere, dixi, dictum (3) | сказать |
| dici | сказать |
Таким образом:
| Глагол | Настоящее время пассивная форма инфинитива | |
|---|---|---|
| Латиница | Латинский | Английский |
| кламо, кламар е, кламави, кламатум (1) | кламари | заявлено |
| хабео, хабер е, хабуй, хабитум (2) | хабери | иметь |
| mitto, mitt ere, misi, missum (3) | митти | к отправке |
| servio, servir e, servivi, servitum (4) | обслуживания | обслуживается |
2.Идеальный пассив
Чтобы образовать идеальный пассивный инфинитив глагола, удалите «- m » от супин, добавьте «- s », чтобы получить причастие прошедшего времени, а затем добавьте « esse ».
Например:
| Глагол | Идеальный пассивный инфинитив | |
|---|---|---|
| Латиница | Латинский | Английский |
| clamo, clamare, clamavi, clamatu m (1) | clamatus esse | к востребованию |
| хабео, хабере, хабуй, хабиту м (2) | Габитус Эссе | должно было быть |
| mitto, mittere, misi, missu m (3) | миссис Эссе | для отправки |
| servio, servire, servivi, servitu m (4) | servitus esse | обслужено |
3.
 Будущее пассивное
Будущее пассивноеЧтобы сформировать будущий пассивный инфинитив глагола, удалите «- m » из супин и добавьте «- s », чтобы получить причастие прошедшего времени, а затем добавьте « перед ».
Подсказка
Если вы уже изучали классическую латынь раньше, вы заметите, что вместо supine + « iri » в средневековой латыни используется причастие прошедшего времени + « fore » для образования будущего пассивного инфинитива.
Например:
| Глагол | Пассивный инфинитив будущего | |
|---|---|---|
| Латиница | Латинский | Английский |
| clamo, clamare, clamavi, clamatu m (1) | передний кламатус | будут заявлены |
| хабео, хабере, хабуй, хабиту м (2) | габарит переднего | в ближайшее время |
| mitto, mittere, misi, missu m (3) | передняя миссис | на отправке |
| servio, servire, servivi, servitu m (4) | передний сервитус | на очереди |
Запомнить
Причастие прошедшего времени действует как прилагательное, согласуясь с подлежащим глагола, и отклоняется как «бонус, -а, -ум» .
Инфинитивы депонента
Инфинитивы депонентных глаголов подчиняются правилам пассивных инфинитивов, как показано выше.
Прилагательная часть винительного и инфинитивного падежа
В средневековых документах, с которыми вы сталкиваетесь, вы часто можете встретить инфинитив в сочетании с винительным падежом. Это называется винительным и инфинитивным придаточным падежом или косвенным утверждением и переводится определенным образом.
Например:
Credo Johannem dedisse Matheo terram.
Я считаю, что Иоанн отдал землю Мэтью. (Буквально — я верю, что Иоанн отдал Матфею землю.)
Подсказка
Вы часто сможете заметить винительный и инфинитивный придаточный падеж, происходящий от типа глагола, который ему предшествует.
Например:
| слышать | audio, audire, audivi, auditum (4) |
| сказать | dico, dicere, dixi, dictum (3) |
| думать | путо, путаре, путави, путатум (1) |
| верить | кредо, кредере, кредиди, кредит (3) |
| знать | scio, scire, scivi, scitum (4) |
Контрольный список
Вы уверены в
?- значение активного инфинитива?
- форма активного инфинитива?
- значение пассивного инфинитива?
- форма пассивного инфинитива?
- значение винительного и инфинитивного придаточного падежа?
- форма винительного и инфинитивного придаточного падежа?
Что дальше?
10.2.2. Модуль загрузчика COBOL — Анализ исходного кода COBOL для загрузки схемы — Читатель файлов на основе схемы Stingray
Анализ схемы электронной таблицы относительно прост: см. Модуль загрузчика схемы — Загрузка встроенной или внешней схемы. Однако анализ схемы COBOL немного сложнее. Нам нужно разобрать Исходный код COBOL для декодирования элементов определения данных (DDE) и создания удобное представление DDE, соответствующее модели схемы Stingray.
Мы закончим с двумя представлениями схемы COBOL:
Новая схема .loader.ExternalSchemaLoader подкласс требуется
для анализа подъязыка DDE в COBOL. Раздел COBOL Schema Loader Class
подробности об этом. Загрузчик построит иерархическую
DDE из источника COBOL, украсьте его информацией о размере и смещении,
затем сведите его к простой схеме . instance. Schema
Schema
10.2.2.1. Загрузить схему сценария использования
Цель варианта использования — загрузить схему, закодированную в COBOL. Это ломается на два шага.
- Разобрать исходный файл COBOL «тетрадь».
- Создание экземпляра схемы
.Schema, который можно использовать для доступа к данным. в файле COBOL.
В идеале это будет выглядеть примерно так.
с открытым ("sample / zipcty.cob", "r") как cobol:
schema = stingray.cobol.loader.COBOLSchemaLoader (cobol) .load ()
# pprint.pprint (схема)
для имени файла в 'sample / zipcty1', 'sample / zipcty2':
с stingray.cobol.Character_File (filename, schema = schema) как wb:
лист = wb.sheet (имя файла)
counts = process_sheet (лист)
pprint.pprint (считает)
Шаг 1 — открыть файл «тетрадь» COBOL DDE, zipcty.cob , который определяет макет.
Мы строим схему, используя cobol.loader.COBOLSchemaLoader .
Шаг 2 — открыть исходные данные, zipcty1 с данными.
Мы сделали лист. Лист из файла: имя листа "zipcty1" ,
Схема является внешней, предоставленной, когда мы открыли cobol.Character_File .
Как только лист станет доступен, мы можем запустить некоторую функцию process_sheet на
простынь.Это будет использовать API листа . Sheet для обработки строк и ячеек
простынь. Каждый фрагмент исходных данных загружается как своего рода ячейка Cell .
Затем мы можем использовать соответствующие преобразования для восстановления объектов Python. Это подводит нас ко второму варианту использования.
Вот как в этом контексте может выглядеть функция process_sheet () .
def process_sheet (лист):
schema_dict = dict ((a.name, a) для a в sheet.schema)
schema_dict.update (dict ((a.путь, а) для а в лист.схеме))
counts = {'read': 0}
row_iter = sheet. rows ()
header = header_builder (следующий (row_iter), schema_dict)
печать (заголовок)
для строки в row_iter:
detail = row_builder (строка, schema_dict)
печать (деталь)
подсчитывает ['прочитано'] + = 1
количество возвратов
 rows ()
header = header_builder (следующий (row_iter), schema_dict)
печать (заголовок)
для строки в row_iter:
detail = row_builder (строка, schema_dict)
печать (деталь)
подсчитывает ['прочитано'] + = 1
количество возвратов
rows ()
header = header_builder (следующий (row_iter), schema_dict)
печать (заголовок)
для строки в row_iter:
detail = row_builder (строка, schema_dict)
печать (деталь)
подсчитывает ['прочитано'] + = 1
количество возвратов
Во-первых, мы создали две версии схемы, индексированные по имени элемента нижнего уровня. и полный путь к элементу. В некоторых случаях элементы DDE низкого уровня уникальны, и пути не требуются.В остальных случаях пути обязательны.
Мы инициализировали несколько счетчиков записей, что всегда является хорошей практикой.
Мы получили первую запись и использовали некоторую функцию с именем header_builder () для
преобразовываем запись в заголовок, который печатаем.
Мы извлекли все остальные записи и использовали функцию с именем row_builder () , чтобы
трансформируем каждую следующую запись в детали, которые мы также печатаем.
Это показывает физическую обработку "голова-хвост".В некоторых случаях есть атрибут который различает заголовки, кузов и трейлеры.
10.2.2.2. Пример использования схемы
Целью этого варианта использования является создание пригодных для использования объектов Python из данных исходного файла.
Для каждой строки выполняется двухэтапная операция.
- Доступ к элементам каждой строки с помощью структуры COBOL DDE.
- Создайте объекты Python из ячеек, найденных в строке.
Как правило, мы должны использовать ленивое вычисление, как показано в этом примере:
def header_builder (строка, схема):
return dict (
file_version_year = строка.ячейка (схема ['ФАЙЛ-ВЕРСИЯ-ГОД']). to_str (),
file_version_month = row.cell (схема ['FILE-VERSION-MONTH']). to_str (),
copyright_symbol = row.cell (схема ['COPYRIGHT-SYMBOL']). to_str (),
tape_sequence_no = row.cell (схема ['TAPE-SEQUENCE-NO']). to_str (),
)
def row_builder (строка, схема):
return dict (
zip_code = row. cell (схема ['ПОЧТОВЫЙ ИНДЕКС']). to_str (),
update_key_no = row.cell (схема ['UPDATE-KEY-NO']). to_str (),
low_sector = row.cell (schema ['COUNTY-CROSS-REFERENCE-RECORD.ZIP-ADD-ON-RANGE.ZIP-ADD-ON-LOW-NO.ZIP-SECTOR-NO ']). To_str (),
low_segment = row.cell (схема ['COUNTY-CROSS-REFERENCE-RECORD.ZIP-ADD-ON-RANGE.ZIP-ADD-ON-LOW-NO.ZIP-SEGMENT-NO']). to_str (),
high_sector = row.cell (схема ['COUNTY-CROSS-REFERENCE-RECORD.ZIP-ADD-ON-RANGE.ZIP-ADD-ON-HIGH-NO.ZIP-SECTOR-NO']). to_str (),
high_segment = row.cell (схема ['COUNTY-CROSS-REFERENCE-RECORD.ZIP-ADD-ON-RANGE.ZIP-ADD-ON-HIGH-NO.ZIP-SEGMENT-NO']). to_str (),
state_abbrev = row.cell (схема ['STATE-ABBREV']).to_str (),
county_no = row.cell (схема ['COUNTY-NO']). to_str (),
county_name = row.cell (схема ['COUNTY-NAME']). to_str (),
)
 cell (схема ['ПОЧТОВЫЙ ИНДЕКС']). to_str (),
update_key_no = row.cell (схема ['UPDATE-KEY-NO']). to_str (),
low_sector = row.cell (schema ['COUNTY-CROSS-REFERENCE-RECORD.ZIP-ADD-ON-RANGE.ZIP-ADD-ON-LOW-NO.ZIP-SECTOR-NO ']). To_str (),
low_segment = row.cell (схема ['COUNTY-CROSS-REFERENCE-RECORD.ZIP-ADD-ON-RANGE.ZIP-ADD-ON-LOW-NO.ZIP-SEGMENT-NO']). to_str (),
high_sector = row.cell (схема ['COUNTY-CROSS-REFERENCE-RECORD.ZIP-ADD-ON-RANGE.ZIP-ADD-ON-HIGH-NO.ZIP-SECTOR-NO']). to_str (),
high_segment = row.cell (схема ['COUNTY-CROSS-REFERENCE-RECORD.ZIP-ADD-ON-RANGE.ZIP-ADD-ON-HIGH-NO.ZIP-SEGMENT-NO']). to_str (),
state_abbrev = row.cell (схема ['STATE-ABBREV']).to_str (),
county_no = row.cell (схема ['COUNTY-NO']). to_str (),
county_name = row.cell (схема ['COUNTY-NAME']). to_str (),
)
cell (схема ['ПОЧТОВЫЙ ИНДЕКС']). to_str (),
update_key_no = row.cell (схема ['UPDATE-KEY-NO']). to_str (),
low_sector = row.cell (schema ['COUNTY-CROSS-REFERENCE-RECORD.ZIP-ADD-ON-RANGE.ZIP-ADD-ON-LOW-NO.ZIP-SECTOR-NO ']). To_str (),
low_segment = row.cell (схема ['COUNTY-CROSS-REFERENCE-RECORD.ZIP-ADD-ON-RANGE.ZIP-ADD-ON-LOW-NO.ZIP-SEGMENT-NO']). to_str (),
high_sector = row.cell (схема ['COUNTY-CROSS-REFERENCE-RECORD.ZIP-ADD-ON-RANGE.ZIP-ADD-ON-HIGH-NO.ZIP-SECTOR-NO']). to_str (),
high_segment = row.cell (схема ['COUNTY-CROSS-REFERENCE-RECORD.ZIP-ADD-ON-RANGE.ZIP-ADD-ON-HIGH-NO.ZIP-SEGMENT-NO']). to_str (),
state_abbrev = row.cell (схема ['STATE-ABBREV']).to_str (),
county_no = row.cell (схема ['COUNTY-NO']). to_str (),
county_name = row.cell (схема ['COUNTY-NAME']). to_str (),
)
Доступ к каждой ячейке осуществляется в три этапа.
- Получить информацию о схеме через схему
['краткое имя'] Схемаили['полный.путь.name'] - Создайте
Cell, используя информацию о схеме черезrow.cell (...). - Преобразуйте
Cellв наш целевой тип через...to_str ().
Мы, , должны делать это поэтапно, потому что записи COBOL могут иметь недопустимые поля,
или ПОВТОРЯЕТ или ПРОИСХОДИТ В ЗАВИСИМОСТИ от статей .
Если мы хотим создавать чистые объекты Python более высокого уровня, связанные с некоторыми приложение, мы сделаем это.
def build_object (строка, схема):
вернуть объект (** row_builder (строка, схема))
Мы просто гарантируем, что ключи словаря строки являются правильными аргументами ключевого слова для определения классов нашего приложения.
Когда нам нужно выполнить индексацию, это лишь немного сложнее. Результирующий объект
будет структурой списка, и мы применяем индексы в порядке от оригинала
Определение DDE для разделения списков.
10.2.2.3. Расширения и особые случаи
Типичные варианты использования выглядят примерно так:
с открытым ("sample / zipcty.cob", "r") как cobol:
schema = stingray.cobol.loader.COBOLSchemaLoader (cobol) .load ()
со stingray.cobol.Character_File (имя файла, схема = схема) как wb:
лист = wb.sheet (имя файла)
для строки в sheet.rows ():
дамп (схема, строка)
Это будет использовать синтаксический анализ по умолчанию для создания схемы из DDA и обработки файл, сбрасывая каждую запись.
Есть два распространенных расширения:
- новый лексический сканер и
- различных ОДО по обработке.
Чтобы изменить лексические сканеры, мы создаем новый подкласс парсера.
Мы используем это, создав подкласс коболов.COBOLSchemaLoader .
класс MySchemaLoader (cobol.COBOLSchemaLoader):
lexer_class = cobol.loader.Lexer_Long_Lines
При синтаксическом анализе файла DDE будет использоваться другой лексический сканер.
Нам также может потребоваться изменить фабрику звукозаписи. Это включает в себя два отдельных расширения.
Мы должны расширить cobol.loader.RecordFactory , чтобы изменить функции.
Затем мы можем расширить cobol.loader.COBOLSchemaLoader , чтобы использовать эту запись
фабрика.
класс ExtendedRecordFactory (cobol.loader.RecordFactory):
происходит_dependingon_class = stingray.cobol.defs.OccursDependingOnLimit
# По умолчанию is_dependingon_class = stingray.cobol.defs.OccursDependingOn
класс MySchemaLoader (cobol.loader.COBOLSchemaLoader):
record_factory_class = ExtendedRecordFactory
Это будет использовать другую фабрику записей для детализации DDE.
10.2.2.4. Конструкция загрузчика DDE
DDE содержит рекурсивное определение DDE на уровне группы COBOL.
Существует два основных вида COBOL DDE: элементарные элементы, которые имеют пункт PICTURE ,
и элементы уровня группы, которые содержат элементы более низкого уровня. Есть несколько дополнительных
особенности каждого DDE, включая предложение
Есть несколько дополнительных
особенности каждого DDE, включая предложение OCCURS и предложение REDEFINES .
В дополнение к обязательному предложению изображения элементарные элементы имеют необязательное предложение USAGE ,
и необязательный пункт SIGN .
Единый класс cobol.defs.DDE определяет свойства элемента уровня группы. Он поддерживает
происходит и переопределяет функции. Он может содержать несколько элементов DDE.
Листья дерева определяют свойства элементарного предмета.
Подробнее см. Модуль определений COBOL - Обработка DDE в COBOL.
Предложение PICTURE определяет, как интерпретировать последовательность байтов. Изображение
предложение взаимодействует с дополнительным предложением USAGE , предложением SIGN и предложением SYNCHRONIZED чтобы полностью определить кодировку. В предложении изображения используется сложный формат кодовых символов.
для определения либо отдельных байтов символа (когда используется отображение), либо пар байтов десятичных цифр
(при использовании КОМП-3 ).
Предложение OCCURS определяет массив элементов. Если появляется условие
на элементе уровня группы подзапись повторяется. Если появляется условие
на элементарном элементе этот элемент повторяется.
Ошибка происходит в зависимости от (ODO), поэтому позиции каждого поля зависят от фактического данные, присутствующие в записи. Это редкое, но необходимое осложнение.
Предложение REDEFINES определяет псевдоним для входных байтов.Когда какое-то поле R переопределяет
ранее определенное поле F , байты памяти используются как для R , так и для F .
Сама структура записи не позволяет однозначно интерпретировать байты.
Логика программы должна быть исследована, чтобы определить условия, при которых допустима каждая интерпретация. Вполне возможно, что в любой интерпретации есть недопустимые поля.
Вполне возможно, что в любой интерпретации есть недопустимые поля.
10.2.2.4.1. Постобработка DDE
У нас есть несколько функций для обхода структуры DDE для записи
отчеты по структуре.В DDE есть метод __iter __ () , который
обеспечивает полный предварительный просмотр записи в глубину
состав.
Вот несколько функций, которые проходят через всю структуру DDE.
Когда данные доступны, у нас есть эти дополнительные функции.
Обратите внимание, что cobol.defs.setSizeAndOffset () является рекурсивным, а не итеративным.
Ему необходимо управлять промежуточными итогами на основе подъема и спуска в иерархии.
10.2.2.4.2. Парсер DDE
A кобол.loader.RecordFactory объект читает файл текста и либо создает
DDE или вызывает исключение. Если текст является допустимой записью COBOL
определение, создается DDE. Если есть синтаксические ошибки, исключение
Поднялся.
Загрузчик cobol.loader .RecordFactory зависит от загрузчика cobol.loader .Lexer экземпляр для лексического сканирования
Источник COBOL. Лексический сканер можно разделить на подклассы для предварительной обработки COBOL.
источник. Это необходимо из-за разнообразия исходных форматов, которые
разрешены.Стандарты магазина могут включать или исключать такие функции, как
идентификация программы, номера строк, управление форматом и др.
украшение входа.
Метод cobol.loader.RecordFactory.makeRecord () анализирует ли
определение записи. Анализируется каждый отдельный оператор DDE. В
информация о номере уровня используется для определения правильной группировки
элементы. Когда структура (-ы) разбирается, она украшается размером и
информация о смещении для каждого элемента.
Обратите внимание, что в одной тетради COBOL возможно несколько уровней 01.Это сбивает с толку и потенциально сложно, но это происходит в реале.
10.2.2.4.3. Значения полей
Язык COBOL и расширения IBM,
предусматривают ряд вариантов использования. В этом приложении три основных типа
поддерживаемых стратегий использования:
В этом приложении три основных типа
поддерживаемых стратегий использования:
- ДИСПЛЕЙ . Это байты, по одному на символ, описанные в предложении picture.
Они могут быть в формате EBCDIC или ASCII. Мы используем модуль
кодековдля конвертировать символы EBCDIC в Unicode для дальнейшей обработки. - КОМП . Это двоичные поля размером 2, 4 или 8 байтов, размер которых определяется условием изображения.
- КОМП-3 . Это упакованные десятичные поля, размер которых определяется предложением изображения; в каждом байте упакованы две цифры с дополнительным полубайтом для знака.
Для этого требуются разные стратегии декодирования входных байтов.
Дополнительные типы включают COMP-1 и COMP-2, которые являются числами с плавающей запятой одинарной и двойной точности.Они настолько редки, что мы их игнорируем.
10.2.2.4.4. Возникает в зависимости от
Поддержка «Происходит в зависимости от» основана на нескольких функциях COBOL.
Синтаксис ODO более сложный: OCCURS [int TO] int [TIMES] DEPENDING [ON] name .
Сравните это с простым OCCURS int [TIMES] .
Это приводит к переменным позициям байтов для элементов данных, которые следуют за предложением происходит, на основе имени , значения .
Это означает, что смещение не обязательно фиксируется при наличии сложного ODO.Нам нужно сделать смещение (и размер) свойством, имеющим одну из двух стратегий.
- Статически расположен. Базовый случай, когда смещения статичны.
- Различное расположение. Сложная ситуация с ODO, когда есть запись ODO. Все поля ODO «зависит от» становятся частью вычисления смещения. Это означает нам нужен индекс для пунктов зависит от.
Техническая модная фраза - это «элемент данных, следующий за таблицей переменной длины в той же записи уровня 01, но не подчиненный ей. ”
”
См. Http://publib.boulder.ibm.com/infocenter/comphelp/v7v91/index.jsp?topic=%2Fcom.ibm.aix.cbl.doc%2Ftptbl27.htm
Это правила «Приложения D, Комплексный ODO».
Следствия проектирования таковы.
Существует три вида отношений между элементами DDE: Предшественник / Преемник, Родитель / Дочерний (или Группа / Элементарный), и переопределяет. В настоящее время отношение прогнозирования / успешности подразумевается родителем, имеющим последовательность потомков. Мы не можем легко найти предшественника без ужасных поисков.
Есть две стратегии для выполнения вычислений смещения / размера.
Статически. Можно использовать функцию
cobol.defs.setSizeAndOffset ()один раз, сразу после анализа схемы.Различно расположен. Расчет размера и смещения основан на реальных данных. Функция
cobol.defs.setSizeAndOffset ()должна использоваться после строка выбирается, но до любой другой обработки.Это делается автоматически с помощью листа
.Объект LazyRow.
Расчет смещения можно рассматривать как рекурсивный переход «вверх» по дереву. следующие переопределения, отношения предшественников и родителей (в указанном порядке) чтобы рассчитать размер всего, что предшествует рассматриваемому элементу. Мы могли бы сделать смещение и общий размер в свойствах, которые делают это рекурсивным расчет.
«Размер» элементарных предметов по-прежнему просто основан на картинке. Однако для групповых элементов размер зависит от общего размера, который в в свою очередь, может быть основана на данных ODO.[COBOLSchemaLoader], [COBOLSchemaLoader] -> [Lexer], [COBOLSchemaLoader] -> [RecordFactory], [RecordFactory] <> - [DDE].
10.2.2.5. Накладные расходы
В конечном итоге мы пишем новый schema.loader.ExternalSchemaLoader .
Целью этого является создание экземпляра схемы . из источника COBOL, а не из другого источника.
из источника COBOL, а не из другого источника.
"" "stingray.cobol.loader - проанализируйте COBOL DDE и создайте удобную схему." "" импорт ре из коллекции import namedtuple, Iterator импорт журнала импорт weakref предупреждения об импорте import sys импортный скат.schema.loader импорт stingray.cobol импортировать stingray.cobol.defs
Мы добавим номер версии, просто для поддержки некоторой отладки.
Регистратор на уровне модуля.
logger = logging.getLogger (__name__)
10.2.2.6. Разбор исключений
- класс
кобол. Погрузчик.SyntaxError Это проблемы компиляции. У нас есть синтаксис, который совершенно сбивает с толку.
класс SyntaxError (Исключение):
"" "Синтаксическая ошибка COBOL."" "
проходить
10.2.2.7. Разбор раздела изображений
Анализ предложения Picture выполняется при создании элемента DDE. Не для великого причина. Это производные данные из условия исходного изображения.
Это тоже можно сделать в парсере.
Поскольку 9 (5) V99 является обычным явлением, точность легко определяется символами после "." или «V».
Однако может быть несколько () ’d групп чисел 9 (5) V9 (3) чего-то вроде.
Таким образом, точность в последнем случае равна 3, что немного усложняет задачу.
Кроме того, мы не очень изящно обращаемся с отдельными вывесками. Это кажется малоиспользуемым, так что нам комфортно игнорировать это.
- класс
кобол. Погрузчик.Изображение Определите различные атрибуты предложения COBOL PICTURE.
-
финал финальное изображение
-
альфа логический; Истинно, если любой
"X"или"A"; Неверно, если все"9"и связанные с ним
-
длина длина финального снимка
-
масштаб количество
"P"позиций, часто ноль
-
точность цифр справа от десятичной точки
-
с подписью логический; Верно, если любой
"S","-"или родственный
-
десятичное ".или "" V "илиНет
-
 "
" Picture = namedtuple ('Изображение',
'final, alpha, length, scale, precision, signed, decimal')
-
кобол. Загрузчик.picture_parser( рис ) Разобрать текст определения ИЗОБРАЖЕНИЯ.
def picture_parser (рис.):
"" "Перепишите предложение изображения, чтобы исключить (), S, V, P и т. Д.
: param pic: Сообщать текст.: returns: Экземпляр изображения: final, alpha, len (final), scale,
точность, знаковая, десятичная
"" "
out = []
масштаб, точность, знак, десятичный = 0, 0, ложь, нет
char_iter = iter (рис.)
для c в char_iter:
если c in ('A', 'B', 'X', 'Z', '9', '0', '/', ',', '+', '-', '*', '$ '):
out.append (c)
если десятичный: точность + = 1
elif c == 'D':
nc = следующий (char_iter)
assert nc == "B", "ошибка изображения в {0! r}". формате (рис.)
out.append ("БД")
signed = True
elif c == 'C':
nc = следующий (char_iter)
assert nc == "R", "ошибка изображения в {0! r}".формат (рис.)
out.append ("CR")
signed = True
elif c == '(':
irpt = 0
пытаться:
для c в char_iter:
если c == ')': перерыв
irpt = 10 * irpt + int (c)
кроме ValueError как e:
поднять SyntaxError ("ошибка изображения в {0! r}". формате (рис.))
assert c == ')', "ошибка изображения в {0! r}". формате (рис.)
out.append ((irpt-1) * out [-1])
если десятичный: точность + = irpt-1
elif c == 'S':
# молча опустите букву "S".# Обратите внимание, что "S" плюс опция SIGN SEPARATE увеличивает размер изображения!
signed = True
elif c == 'P':
# "P" задает масштаб и не отображается.
масштаб + = 1
elif c == "V":
# "V" задает точность и не отображается.
десятичный = "V"
elif c == ".":
decimal = "."
out.append (".")
еще:
поднять SyntaxError ("Ошибка изображения в {! r}". формате (рис.))
final = "" .join (выход)
альфа = ('A' в финале) или ('X' в финале) или ('/' в финале)
регистратор.отладка ("PIC {0} {1} alpha = {2} scale = {3} prec = {4}". format (pic, final, alpha, scale, precision))
# Примечание: Фактическое потребление байтов зависит от len (final) и использования!
return Picture (final, alpha, len (final), scale,
точность, знаковая, десятичная)
 масштаб + = 1
elif c == "V":
# "V" задает точность и не отображается.
десятичный = "V"
elif c == ".":
decimal = "."
out.append (".")
еще:
поднять SyntaxError ("Ошибка изображения в {! r}". формате (рис.))
final = "" .join (выход)
альфа = ('A' в финале) или ('X' в финале) или ('/' в финале)
регистратор.отладка ("PIC {0} {1} alpha = {2} scale = {3} prec = {4}". format (pic, final, alpha, scale, precision))
# Примечание: Фактическое потребление байтов зависит от len (final) и использования!
return Picture (final, alpha, len (final), scale,
точность, знаковая, десятичная)
масштаб + = 1
elif c == "V":
# "V" задает точность и не отображается.
десятичный = "V"
elif c == ".":
decimal = "."
out.append (".")
еще:
поднять SyntaxError ("Ошибка изображения в {! r}". формате (рис.))
final = "" .join (выход)
альфа = ('A' в финале) или ('X' в финале) или ('/' в финале)
регистратор.отладка ("PIC {0} {1} alpha = {2} scale = {3} prec = {4}". format (pic, final, alpha, scale, precision))
# Примечание: Фактическое потребление байтов зависит от len (final) и использования!
return Picture (final, alpha, len (final), scale,
точность, знаковая, десятичная)
10.2.2.8. Лексическое сканирование
Лексический сканер можно разделить на подклассы, чтобы расширить его возможности. По умолчанию
лексический сканер предоставляет метод Lexer.clean () , который просто удаляет комментарии.
Это может потребоваться переопределить, чтобы удалить номера строк (с позиций 72-80),
идентификация модуля (с позиций 1-5) и директивы управления форматом.
Также нам приходится иметь дело с «инструкциями по управлению компилятором»: EJECT, SKIP1, SKIP2 и SKIP3. Это просто шум, который может появиться в источнике.
- класс
кобол. Погрузчик.Lexer Базовый лексер, который просто удаляет комментарии и первые шесть позиций каждой строки.
класс Лексер:
"" "Лексический сканер COBOL. Перебирает токены в исходном тексте." ""
separator = re.compile (r '[.,;]? \ s')
quote1 = re."] *" ')
def __init __ (self, замена = None):
self.log = logging.getLogger (self .__ class __.__ qualname__)
self.replacing = замена или []
-
Lexer.чистый( строка ) Процесс очистки строки по умолчанию. Просто запишите конечные пробелы.
def clean (self, line):
"" "Очиститель по умолчанию удаляет позиции 0: 6. " ""
строка возврата [6:]. rstrip ()
 " ""
строка возврата [6:]. rstrip ()
" ""
строка возврата [6:]. rstrip ()
-
Lexer.сканирование( текст ) Найдите последовательность токенов во входном потоке.
сканирование по умолчанию (собственное, текст):
"" "Найдите следующий токен во входном потоке.
- Чистые 6-символьные вводные и конечные пробелы
- Добавьте один дополнительный пробел, чтобы отличить конец строки `` ''. '' '
из пункта изображения.
"" "
если isinstance (текст, (str, bytes)):
текст = текст.splitlines ()
self.all_lines = (self.clean (строка) + ''
для строки в тексте)
# Удалить комментарии, пустые строки и директивы компилятора
себя.lines = (строка
для строки в self.all_lines
если строка и строка [0] не входят в ('*', '/')
и line.strip () не входит в ("EJECT", "SKIP1", "SKIP2", "SKIP3"))
# Разбить оставшиеся строки на слова
для строки в self.lines:
если len (строка) == 0: продолжить
logger.debug (строка)
# Применить все правила замены.
на старые, новые в самостоятельной замене:
line = line.replace (старый, новый)
если self.replacing: logger.debug ("Пост-замена {! r}". формат (строка))
текущая = строка.lstrip ()
пока текущий:
если текущий [0] == "'":
# строка апострофа, разрыв при балансировке апострофа
match = self.quote1.match (текущий)
пробел = match.end ()
elif current [0] == '"':
# строка цитаты, разрыв при балансировке цитаты
match = self.quote2.match (текущий)
пробел = match.end ()
еще:
match = self.separator.search (текущий)
пробел = совпадение.Начало()
если пробел == 0: # начинается с разделителя
пробел = match.end () - 1
токен, текущий = текущий [: пробел], текущий [пробел:]. lstrip ()
self.log.debug (токен)
жетон доходности
 lstrip ()
self.log.debug (токен)
жетон доходности
lstrip ()
self.log.debug (токен)
жетон доходности
- класс
кобол. Погрузчик.Lexer_Long_Lines Более сложный лексер, удаляющий первые шесть позиций каждой строки. Если строка превышает 72 позиции, она также удаляет позиции [71:80].Поскольку это расширение для
cobol.loader.Lexer, оно также удаляет комментарии.
класс Lexer_Long_Lines (Lexer):
def clean (self, line):
"" "Убрать позиции 72:80 и 0: 6." ""
если len (строка)> 72:
строка возврата [6:72] .strip ()
строка возврата [6:]. rstrip ()
Мы используем это, создав подкласс cobol.COBOLSchemaLoader .
класс MySchemaLoader (cobol.COBOLSchemaLoader):
lexer_class = cobol.Lexer_Long_Lines
10.2.2.9. Разбор
Класс cobol.loader.RecordFactory - это синтаксический анализатор для определений записей.
У парсера есть три основных набора методов:
- методы анализа статьи,
- методов разбора элементов и
- полный разбор макета записи.
- класс
кобол. Погрузчик.RecordFactory Разобрать макет записи. Это означает анализ последовательности DDE и собирая их в надлежащую структуру.Каждый элемент состоит из последовательности отдельные статьи.
класс RecordFactory:
"" "Разобрать тетрадь, создав структуру DDE." ""
noisewords = {"КОГДА", "ЕСТЬ", "ВРЕМЯ"}
ключевые слова = {"ПУСТО", "НОЛЬ", "НУЛИ", "НУЛИ", "ПРОБЕЛЫ",
«ДАТА», «ФОРМАТ», «ВНЕШНИЙ», «ГЛОБАЛЬНЫЙ»,
«ПРОСТО», «ОБОСНОВАНО», «СЛЕВА», «ПРАВО»
«ПРОИСХОДИТ», «В ЗАВИСИМОСТИ», «НА», «ВРЕМЯ»,
«КАРТИНКА», «КАРТИНКА»,
"ПОВТОРЯЕТ", "ПЕРЕИМЕНОВАЕТ",
«ЗНАК», «ВЕДУЩИЙ», «СЛЕДУЮЩИЙ», «ОТДЕЛЬНЫЙ», «ХАРАКТЕР»,
«СИНХРОНИЗАЦИЯ», «СИНХРОНИЗИРОВАННАЯ»,
«ИСПОЛЬЗОВАНИЕ», «ДИСПЛЕЙ», «КОМП-3»,
"ЗНАЧЕНИЕ",". "}
redefines_class = stingray.cobol.defs.Redefines
successor_class = stingray.cobol.defs.Successor
group_class = stingray.cobol.defs.Group
display_class = stingray.cobol.defs.UsageDisplay
comp_class = stingray.cobol.defs.UsageComp
comp3_class = stingray.cobol.defs.UsageComp3
происходит_класс = stingray.cobol.defs.Occurs
происходит_fixed_class = stingray.cobol.defs.OccursFixed
происходит_dependingon_class = stingray.cobol.defs.OccursDependingOn
def __init __ (сам):
себя.lex = Нет
self.token = Нет
self.context = []
self.log = logging.getLogger (self .__ class __.__ qualname__)
 "}
redefines_class = stingray.cobol.defs.Redefines
successor_class = stingray.cobol.defs.Successor
group_class = stingray.cobol.defs.Group
display_class = stingray.cobol.defs.UsageDisplay
comp_class = stingray.cobol.defs.UsageComp
comp3_class = stingray.cobol.defs.UsageComp3
происходит_класс = stingray.cobol.defs.Occurs
происходит_fixed_class = stingray.cobol.defs.OccursFixed
происходит_dependingon_class = stingray.cobol.defs.OccursDependingOn
def __init __ (сам):
себя.lex = Нет
self.token = Нет
self.context = []
self.log = logging.getLogger (self .__ class __.__ qualname__)
"}
redefines_class = stingray.cobol.defs.Redefines
successor_class = stingray.cobol.defs.Successor
group_class = stingray.cobol.defs.Group
display_class = stingray.cobol.defs.UsageDisplay
comp_class = stingray.cobol.defs.UsageComp
comp3_class = stingray.cobol.defs.UsageComp3
происходит_класс = stingray.cobol.defs.Occurs
происходит_fixed_class = stingray.cobol.defs.OccursFixed
происходит_dependingon_class = stingray.cobol.defs.OccursDependingOn
def __init __ (сам):
себя.lex = Нет
self.token = Нет
self.context = []
self.log = logging.getLogger (self .__ class __.__ qualname__)
Каждая из этих функций синтаксического анализа имеет предварительное условие последнего проверенного токена.
в self.token . У них есть пост-условие - оставить , а не -проверено.
токен в self.token .
def (собственное):
"" "Разобрать предложение PICTURE." ""
self.token = следующий (self.lex)
если self.token == "IS":
self.token = next (self.lex)
pic = self.token
self.token = следующий (self.lex)
вернуть картинку
def blankWhenZero (self):
"" "Изящно пропустите предложение BLANK WHEN ZERO." ""
self.token = следующий (self.lex)
если self.token == "КОГДА":
self.token = следующий (self.lex)
если self.token в {"ZERO", "ZEROES", "ZEROS"}:
self.token = следующий (self.lex)
def оправдано (самостоятельно):
"" "Изящно пропустите ОБОСНОВАННОЕ предложение." ""
self.token = следующий (self.lex)
если self.token == "ПРАВИЛЬНО":
себя.токен = следующий (self.lex)
def происходит (сам):
"" "Разобрать предложение OCCURS." ""
происходит = следующий (self.lex)
если происходит == "TO":
# формат 2: происходит в зависимости от предполагаемого значения 1 для нижнего предела
вернуть self.occurs2 ('')
self.token = следующий (self. lex)
если self.token == "TO":
# формат 2: происходит в зависимости от
return self.occurs2 (происходит)
еще:
# формат 1: фиксированная длина
если self.token == "ВРЕМЯ":
self.token = следующий (self.lex)
себя.происходит_cruft ()
return self.occurs_fixed_class (происходит)
def происходит_cruft (self):
"" "Впитайте дополнительные ключевые и индексные подпункты." ""
если self.token в {"ASCENDING", "DESCENDING"}:
self.token = следующий (self.lex)
если self.token == "КЛЮЧ":
self.token = следующий (self.lex)
если self.token == "IS":
self.token = следующий (self.lex)
# получить имена ключевых данных
в то время как self.token не входит в self.keywords:
self.token = следующий (self.lex)
если self.token == "INDEXED":
себя.токен = следующий (self.lex)
если self.token == "BY":
self.token = следующий (self.lex)
# получить имена проиндексированных данных
в то время как self.token не входит в self.keywords:
self.token = следующий (self.lex)
def происходит2 (self, нижний):
"" "Анализировать [встречается n TO] m раз в зависимости от имени" ""
self.token = следующий (self.lex)
upper = self.token # Может иметь значение как размер по умолчанию.
default_size = int (верхний)
self.token = следующий (self.lex)
если self.token == "ВРЕМЯ":
self.token = следующий (self.lex)
если сам.токен == "ЗАВИСИТ":
self.token = следующий (self.lex)
если self.token == "ON":
self.token = следующий (self.lex)
name = self.token
self.token = следующий (self.lex)
self.occurs_cruft ()
вернуть self.occurs_dependingon_class (имя, размер по умолчанию)
#raise stingray.cobol.defs.UnsupportedError ("Возникает в зависимости от")
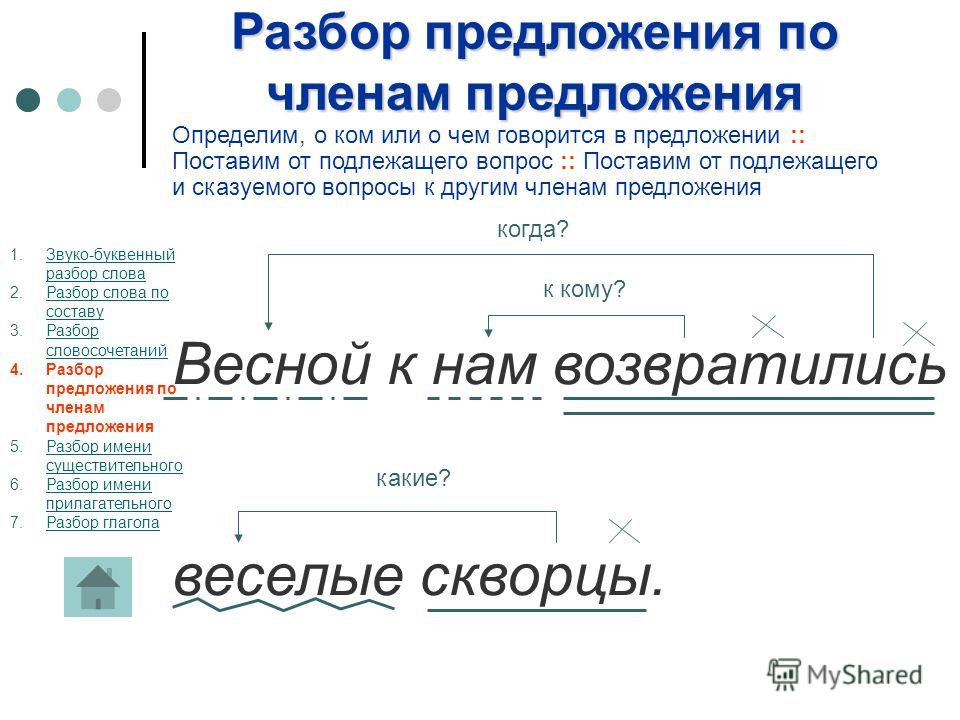 lex)
если self.token == "TO":
# формат 2: происходит в зависимости от
return self.occurs2 (происходит)
еще:
# формат 1: фиксированная длина
если self.token == "ВРЕМЯ":
self.token = следующий (self.lex)
себя.происходит_cruft ()
return self.occurs_fixed_class (происходит)
def происходит_cruft (self):
"" "Впитайте дополнительные ключевые и индексные подпункты." ""
если self.token в {"ASCENDING", "DESCENDING"}:
self.token = следующий (self.lex)
если self.token == "КЛЮЧ":
self.token = следующий (self.lex)
если self.token == "IS":
self.token = следующий (self.lex)
# получить имена ключевых данных
в то время как self.token не входит в self.keywords:
self.token = следующий (self.lex)
если self.token == "INDEXED":
себя.токен = следующий (self.lex)
если self.token == "BY":
self.token = следующий (self.lex)
# получить имена проиндексированных данных
в то время как self.token не входит в self.keywords:
self.token = следующий (self.lex)
def происходит2 (self, нижний):
"" "Анализировать [встречается n TO] m раз в зависимости от имени" ""
self.token = следующий (self.lex)
upper = self.token # Может иметь значение как размер по умолчанию.
default_size = int (верхний)
self.token = следующий (self.lex)
если self.token == "ВРЕМЯ":
self.token = следующий (self.lex)
если сам.токен == "ЗАВИСИТ":
self.token = следующий (self.lex)
если self.token == "ON":
self.token = следующий (self.lex)
name = self.token
self.token = следующий (self.lex)
self.occurs_cruft ()
вернуть self.occurs_dependingon_class (имя, размер по умолчанию)
#raise stingray.cobol.defs.UnsupportedError ("Возникает в зависимости от")
lex)
если self.token == "TO":
# формат 2: происходит в зависимости от
return self.occurs2 (происходит)
еще:
# формат 1: фиксированная длина
если self.token == "ВРЕМЯ":
self.token = следующий (self.lex)
себя.происходит_cruft ()
return self.occurs_fixed_class (происходит)
def происходит_cruft (self):
"" "Впитайте дополнительные ключевые и индексные подпункты." ""
если self.token в {"ASCENDING", "DESCENDING"}:
self.token = следующий (self.lex)
если self.token == "КЛЮЧ":
self.token = следующий (self.lex)
если self.token == "IS":
self.token = следующий (self.lex)
# получить имена ключевых данных
в то время как self.token не входит в self.keywords:
self.token = следующий (self.lex)
если self.token == "INDEXED":
себя.токен = следующий (self.lex)
если self.token == "BY":
self.token = следующий (self.lex)
# получить имена проиндексированных данных
в то время как self.token не входит в self.keywords:
self.token = следующий (self.lex)
def происходит2 (self, нижний):
"" "Анализировать [встречается n TO] m раз в зависимости от имени" ""
self.token = следующий (self.lex)
upper = self.token # Может иметь значение как размер по умолчанию.
default_size = int (верхний)
self.token = следующий (self.lex)
если self.token == "ВРЕМЯ":
self.token = следующий (self.lex)
если сам.токен == "ЗАВИСИТ":
self.token = следующий (self.lex)
если self.token == "ON":
self.token = следующий (self.lex)
name = self.token
self.token = следующий (self.lex)
self.occurs_cruft ()
вернуть self.occurs_dependingon_class (имя, размер по умолчанию)
#raise stingray.cobol.defs.UnsupportedError ("Возникает в зависимости от")
def переопределяет (себя):
"" "Разобрать предложение REDEFINES." ""
redef = следующий (self.lex)
self.token = следующий (self.lex)
вернуть self. redefines_class (name = redef)
 redefines_class (name = redef)
redefines_class (name = redef)
A RENAMES создает альтернативное имя на уровне группы для некоторых элементарных элементов.Хотя это считается плохой практикой, нам все же нужно вежливо пропустить синтаксис.
def переименовывает (самостоятельно):
"" "Вызвать исключение для предложения RENAMES." ""
ren1 = следующий (self.lex)
self.token = следующий (self.lex)
если self.token в {"THRU", "THROUGH"}:
ren2 = следующий (self.lext)
self.token = следующий (self.lex)
warnings.warn ("Предложение RENAMES найдено и проигнорировано.")
# Альтернативные ПЕРЕИМЕНОВАНИЯ
# поднять stingray.cobol.defs.UnsupportedError ("Пункт переименования")
Существует два варианта синтаксиса предложения SIGN .
def sign1 (self):
"" "Вызвать исключение для предложения SIGN." ""
self.token = следующий (self.lex)
если self.token == "IS":
self.token = следующий (self.lex)
если self.token в {"LEADING", "TRAILING"}:
self.sign2 ()
# TODO: это может изменить размер, чтобы добавить байт знака
поднять stingray.cobol.defs.UnsupportedError ("Предложение подписи")
def sign2 (self):
"" "Вызвать исключение для предложения SIGN." ""
self.token = следующий (self.lex)
если self.token == "ОТДЕЛЬНО":
себя.токен = следующий (self.lex)
если self.token == "ХАРАКТЕР":
self.token = следующий (self.lex)
поднять stingray.cobol.defs.UnsupportedError ("Предложение подписи")
def синхронизировано (самостоятельно):
"" "Вызвать исключение в предложении SYNCHRONIZED." ""
self.token = следующий (self.lex)
если self.token == "LEFT":
self.token = следующий (self.lex)
если self.token == "ПРАВИЛЬНО":
self.token = следующий (self.lex)
поднять stingray.cobol.defs.UnsupportedError ("Синхронизированное предложение")
Существует два варианта синтаксиса предложения USAGE .
def (самостоятельно):
"" "Разобрать предложение USAGE. " ""
self.token = следующий (self.lex)
если self.token == "IS":
self.token = следующий (self.lex)
использовать = self.token
self.token = следующий (self.lex)
вернуть self.usage2 (использовать)
def usage2 (self, use):
"" "Создайте правильный экземпляр Usage на основе предложения USAGE." ""
если используется == "DISPLAY": вернуть self.display_class (использовать)
elif use == "ВЫЧИСЛИТЕЛЬНЫЙ": вернуть self.comp_class (использовать)
elif use == "COMP": вернуть self.comp_class (использовать)
elif use == "COMPUTATIONAL-3": вернуть self.comp3_class (использовать)
elif use == "COMP-3": вернуть self.comp3_class (использовать)
else: поднять SyntaxError ("Неизвестное условие использования {! r}". формат (использование))
 " ""
self.token = следующий (self.lex)
если self.token == "IS":
self.token = следующий (self.lex)
использовать = self.token
self.token = следующий (self.lex)
вернуть self.usage2 (использовать)
def usage2 (self, use):
"" "Создайте правильный экземпляр Usage на основе предложения USAGE." ""
если используется == "DISPLAY": вернуть self.display_class (использовать)
elif use == "ВЫЧИСЛИТЕЛЬНЫЙ": вернуть self.comp_class (использовать)
elif use == "COMP": вернуть self.comp_class (использовать)
elif use == "COMPUTATIONAL-3": вернуть self.comp3_class (использовать)
elif use == "COMP-3": вернуть self.comp3_class (использовать)
else: поднять SyntaxError ("Неизвестное условие использования {! r}". формат (использование))
" ""
self.token = следующий (self.lex)
если self.token == "IS":
self.token = следующий (self.lex)
использовать = self.token
self.token = следующий (self.lex)
вернуть self.usage2 (использовать)
def usage2 (self, use):
"" "Создайте правильный экземпляр Usage на основе предложения USAGE." ""
если используется == "DISPLAY": вернуть self.display_class (использовать)
elif use == "ВЫЧИСЛИТЕЛЬНЫЙ": вернуть self.comp_class (использовать)
elif use == "COMP": вернуть self.comp_class (использовать)
elif use == "COMPUTATIONAL-3": вернуть self.comp3_class (использовать)
elif use == "COMP-3": вернуть self.comp3_class (использовать)
else: поднять SyntaxError ("Неизвестное условие использования {! r}". формат (использование))
Для элементов уровня 88 предложение значения может быть довольно длинным. В противном случае это всего лишь один предмет. Мы должны принять все указанные буквальные значения. Возможно, нам придется принять все значения, не связанные с ключевыми словами.
значение по умолчанию (собственное):
"" "Разобрать предложение VALUE." ""
если self.token == "IS":
self.token = следующий (self.lex)
lit = [следующий (self.lex),]
себя.токен = следующий (self.lex)
в то время как self.token не входит в self.keywords:
lit.append (собственный токен)
self.token = следующий (self.lex)
возвращение горит
-
RecordFactory.dde_iter( лексер ) Перебрать все DDE в потоке токенов от данного лексера. Затем эти DDE можно собрать в общую запись определение.
Обратите внимание, что мы не определяем особые случаи для элементов уровня 66, 77 или 88. Эти номера уровней имеют особое значение.Однако для наших целей цифры можно игнорировать.
def dde_iter (self, lexer):
"" "Создайте единый DDE из записи предложений." ""
self.lex = лексический анализатор
для self. token в self.lex:
# Начните с уровня.
level = self.token
# Выберите имя, если оно есть
self.token = следующий (self.lex)
если self.token в self.keywords:
name = "НАПОЛНИТЕЛЬ"
еще:
name = self.token
self.token = следующий (self.lex)
# По умолчанию
usage = self.display_class ("")
pic = Нет
происходит = self.occurs_class ()
redefines = None # установите значение Redefines ниже или с помощью addChild () выберите Group или Successor
# Накапливайте соответствующие предложения, отбрасывая шумные слова и не относящиеся к делу предложения.
в то время как self.token и self.token! = '.':
если self.token == "BLANK":
self.blankWhenZero ()
elif self.token в {"ВНЕШНИЙ", "ГЛОБАЛЬНЫЙ"}:
self.token = следующий (self.lex)
elif self.token in {"JUST", "JUSTIFIED"}:
себя.оправдано ()
elif self.token == "ПРОИСХОДИТ":
происходит = self.occurs ()
elif self.token в {"PIC", "PICTURE"}:
pic = self.picture ()
elif self.token == "ПОВТОРЯЕТ":
# Должен быть первым и никакие другие предложения не допускаются.
# Особый случай: проще, если уровень 01 игнорирует это предложение.
clause = self.redefines ()
если level == '01':
self.log.info («Игнорирование ПОВТОРЕНИЙ верхнего уровня»)
еще:
redefines = clause
elif self.token == "ПЕРЕИМЕНОВАТЬ":
self.renames ()
elif self.token == "ЗНАК":
self.sign1 ()
elif self.token in {"LEADING", "TRAILING"}:
self.sign2 ()
elif self.token == "СИНХРОНИЗИРОВАННЫЙ":
self.synchronized ()
elif self.token == "ИСПОЛЬЗОВАНИЕ":
использование = self.usage ()
elif self.token == "ЗНАЧЕНИЕ":
self.value ()
еще:
пытаться:
# ИСПОЛЬЗОВАНИЕ ключевого слова необязательно
usage = self.usage2 (self.token)
self.token = следующий (self.lex)
кроме SyntaxError как e:
поднять SyntaxError ("{! r} unrecognized" .format (self.token))
assert self.token == "."
# Создать и передать DDE
если рис:
# Разобрать картинку; обновите предложение USAGE, добавив подробные сведения.
sizeScalePrecision = picture_parser (рис)
usage.setTypeInfo (sizeScalePrecision)
# Создаем элементарный DDE
dde = скат.cobol.defs.DDE (
уровень, имя, использование = использование, происходит = происходит, переопределяет = переопределяет,
pic = pic, sizeScalePrecision = sizeScalePrecision)
еще:
# Создание DDE на уровне группы
dde = stingray.cobol.defs.DDE (
уровень, имя, использование = использование, происходит = происходит, переопределяет = переопределяет)
yield dde
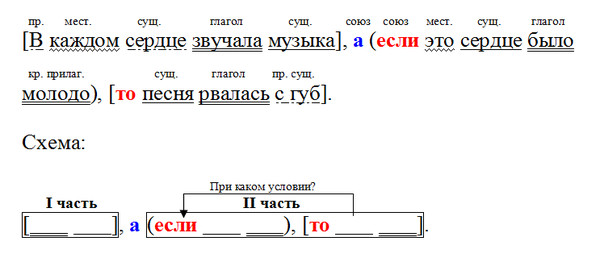 token в self.lex:
# Начните с уровня.
level = self.token
# Выберите имя, если оно есть
self.token = следующий (self.lex)
если self.token в self.keywords:
name = "НАПОЛНИТЕЛЬ"
еще:
name = self.token
self.token = следующий (self.lex)
# По умолчанию
usage = self.display_class ("")
pic = Нет
происходит = self.occurs_class ()
redefines = None # установите значение Redefines ниже или с помощью addChild () выберите Group или Successor
# Накапливайте соответствующие предложения, отбрасывая шумные слова и не относящиеся к делу предложения.
в то время как self.token и self.token! = '.':
если self.token == "BLANK":
self.blankWhenZero ()
elif self.token в {"ВНЕШНИЙ", "ГЛОБАЛЬНЫЙ"}:
self.token = следующий (self.lex)
elif self.token in {"JUST", "JUSTIFIED"}:
себя.оправдано ()
elif self.token == "ПРОИСХОДИТ":
происходит = self.occurs ()
elif self.token в {"PIC", "PICTURE"}:
pic = self.picture ()
elif self.token == "ПОВТОРЯЕТ":
# Должен быть первым и никакие другие предложения не допускаются.
# Особый случай: проще, если уровень 01 игнорирует это предложение.
clause = self.redefines ()
если level == '01':
self.log.info («Игнорирование ПОВТОРЕНИЙ верхнего уровня»)
еще:
redefines = clause
elif self.token == "ПЕРЕИМЕНОВАТЬ":
self.renames ()
elif self.token == "ЗНАК":
self.sign1 ()
elif self.token in {"LEADING", "TRAILING"}:
self.sign2 ()
elif self.token == "СИНХРОНИЗИРОВАННЫЙ":
self.synchronized ()
elif self.token == "ИСПОЛЬЗОВАНИЕ":
использование = self.usage ()
elif self.token == "ЗНАЧЕНИЕ":
self.value ()
еще:
пытаться:
# ИСПОЛЬЗОВАНИЕ ключевого слова необязательно
usage = self.usage2 (self.token)
self.token = следующий (self.lex)
кроме SyntaxError как e:
поднять SyntaxError ("{! r} unrecognized" .format (self.token))
assert self.token == "."
# Создать и передать DDE
если рис:
# Разобрать картинку; обновите предложение USAGE, добавив подробные сведения.
sizeScalePrecision = picture_parser (рис)
usage.setTypeInfo (sizeScalePrecision)
# Создаем элементарный DDE
dde = скат.cobol.defs.DDE (
уровень, имя, использование = использование, происходит = происходит, переопределяет = переопределяет,
pic = pic, sizeScalePrecision = sizeScalePrecision)
еще:
# Создание DDE на уровне группы
dde = stingray.cobol.defs.DDE (
уровень, имя, использование = использование, происходит = происходит, переопределяет = переопределяет)
yield dde
token в self.lex:
# Начните с уровня.
level = self.token
# Выберите имя, если оно есть
self.token = следующий (self.lex)
если self.token в self.keywords:
name = "НАПОЛНИТЕЛЬ"
еще:
name = self.token
self.token = следующий (self.lex)
# По умолчанию
usage = self.display_class ("")
pic = Нет
происходит = self.occurs_class ()
redefines = None # установите значение Redefines ниже или с помощью addChild () выберите Group или Successor
# Накапливайте соответствующие предложения, отбрасывая шумные слова и не относящиеся к делу предложения.
в то время как self.token и self.token! = '.':
если self.token == "BLANK":
self.blankWhenZero ()
elif self.token в {"ВНЕШНИЙ", "ГЛОБАЛЬНЫЙ"}:
self.token = следующий (self.lex)
elif self.token in {"JUST", "JUSTIFIED"}:
себя.оправдано ()
elif self.token == "ПРОИСХОДИТ":
происходит = self.occurs ()
elif self.token в {"PIC", "PICTURE"}:
pic = self.picture ()
elif self.token == "ПОВТОРЯЕТ":
# Должен быть первым и никакие другие предложения не допускаются.
# Особый случай: проще, если уровень 01 игнорирует это предложение.
clause = self.redefines ()
если level == '01':
self.log.info («Игнорирование ПОВТОРЕНИЙ верхнего уровня»)
еще:
redefines = clause
elif self.token == "ПЕРЕИМЕНОВАТЬ":
self.renames ()
elif self.token == "ЗНАК":
self.sign1 ()
elif self.token in {"LEADING", "TRAILING"}:
self.sign2 ()
elif self.token == "СИНХРОНИЗИРОВАННЫЙ":
self.synchronized ()
elif self.token == "ИСПОЛЬЗОВАНИЕ":
использование = self.usage ()
elif self.token == "ЗНАЧЕНИЕ":
self.value ()
еще:
пытаться:
# ИСПОЛЬЗОВАНИЕ ключевого слова необязательно
usage = self.usage2 (self.token)
self.token = следующий (self.lex)
кроме SyntaxError как e:
поднять SyntaxError ("{! r} unrecognized" .format (self.token))
assert self.token == "."
# Создать и передать DDE
если рис:
# Разобрать картинку; обновите предложение USAGE, добавив подробные сведения.
sizeScalePrecision = picture_parser (рис)
usage.setTypeInfo (sizeScalePrecision)
# Создаем элементарный DDE
dde = скат.cobol.defs.DDE (
уровень, имя, использование = использование, происходит = происходит, переопределяет = переопределяет,
pic = pic, sizeScalePrecision = sizeScalePrecision)
еще:
# Создание DDE на уровне группы
dde = stingray.cobol.defs.DDE (
уровень, имя, использование = использование, происходит = происходит, переопределяет = переопределяет)
yield dde
Обратите внимание, что некоторые предложения (например, REDEFINES ) занимают особое место в синтаксисе COBOL.
Мы не требовательны к соблюдению семантических правил COBOL.Предположительно
source - это правильный COBOL и фактически использовался для создания исходного файла.
-
RecordFactory.makeRecord( лексер ) Это итератор что дает записи верхнего уровня.
Это зависит от
RecordFactory.dde_iter ()для получения токенов и накопления надлежащего иерархия отдельных экземпляров DDE.В результате будет проанализирована последовательность записей уровня
01.Предметы 77 и 66 уровней специально не обрабатываются.
def makeRecord (self, lexer):
"" "Разобрать весь блок текста тетради." ""
# Разобрать первый DDE и установить стек контекста.
ddeIter = self.dde_iter (лексический анализатор)
top = next (ddeIter)
top.top, top.parent = weakref.ref (верх), Нет
top.allocation = stingray.cobol.defs.Group ()
self.context = [вверху]
для dde в ddeIter:
#print (dde, ":", self.context [-1])
# Если уровень ниже или тот же, всплывает контекст
пока сам.context и dde.level <= self.context [-1] .level:
self.context.pop ()
если len (self.context) == 0:
# Частный случай нескольких уровней 01.
self.log.info ("Несколько уровней {0}" .format (top.level))
self.decorate (вверху)
верхняя доходность
# Создайте новую вершину с этим DDE.
top = dde
top.top, top.parent = weakref.ref (верх), Нет
top.allocation = stingray.cobol.defs.Group ()
self.context = [вверху]
еще:
# Общий случай.# Сделать этот DDE частью родительского DDE наверху контекстного стека
self.context [-1] .addChild (dde)
# Помещаем этот DDE в стек контекста
self.context.append (dde)
# Обработка особого случая дочерних элементов уровня "88".
если dde.level == '88':
assert dde.parent (). picture, "88 not under elementary item"
dde.size = dde.parent (). размер
dde.usage = dde.parent (). использование
self.decorate (вверху)
верхняя доходность
-
RecordFactory.украсить( верх ) Заключительные этапы компиляции:
Разрешить
УДАЛЯЕТимен с помощьюcobol.defs.resolver ().Сдвиньте размерность к каждому элементарному элементу с помощью
cobol.defs.setDimensionality ().Определите размер и смещение, если возможно. Используйте с помощью
cobol.defs.setSizeAndOffset ()Это зависит от наличия Происходит в зависимости от.Если мы не можем вычислить размер и смещение, это должно быть вычисляется при чтении каждой строки. Это делается автоматически с помощью объектаsheet.LazyRow.Должны ли мы выдавать предупреждение? То, что DDE включает в себя, обычно не является загадкой. Происходит в зависимости от.
def декорировать (самостоятельно, вверху):
"" "Три этапа постобработки: преобразователь, размер и смещение, размерность." ""
stingray.cobol.defs.resolver (вверху)
stingray.cobol.defs.setDimensionality (вверху)
если верх.variably_located:
# Невозможно установить все смещения и общие размеры.
pass # Записать предупреждение?
еще:
stingray.cobol.defs.setSizeAndOffset (вверху)
10.2.2.10. Класс загрузчика схемы COBOL
Учитывая DDE, создайте правильный объект схемы .Schema , который содержит
правильная схема . Атрибут объектов для каждой группы и элементарного элемента
в DDE.
Эту схему затем можно использовать с книгой COBOL для выборки строк и столбцы.Обратите внимание, что преобразования могут быть довольно сложными.
Схема . Атрибут объектов создается функцией
который извлекает из DDE соответствующие части добра.
http://yuml.me/diagram/scruffy;/class/ #cobol_loader_final, [COBOLSchemaLoader] -> [Lexer], [COBOLSchemaLoader] -> [RecordFactory], [RecordFactory] <> - [DDE], [DDE] <> - [DDE].
У нас есть ряд вспомогательных функций, обеспечивающих эту работу. Первые два построит окончательную схему Stingray из определений COBOL DDE.
make_attr_log = logging.getLogger ("make_attr")
make_schema_log = logging.getLogger ("make_schema")
-
кобол. Загрузчик.make_attr( aDDE ) Преобразуйте
cobol.defs.DDEвstingray.cobol.RepeatingAttribute. Это будет включать слабую ссылку на DDE, чтобы исходная информация (например, родители и дети) доступен. Он также создаст слабую ссылку из исходного DDE на результирующий атрибут, позволяющий найти схему, связанную с DDE.
def make_attr (aDDE):
attr = stingray.cobol.RepeatingAttribute (
# Важные особенности:
name = aDDE.name,
size = aDDE.size,
create = aDDE.usage.create_func,
# Расширения COBOL:
dde = weakref.ref (aDDE),
)
aDDE.attribute = weakref.ref (attr)
make_attr_log.debug ("Атрибут {0} <=> {1}". формат (aDDE, attr))
вернуть attr
-
кобол. Загрузчик.make_schema( dde_iter ) Схема
.Схема- в целом - построена функцией который преобразует отдельные DDE в атрибуты.Это может потребоваться расширить, если другие имена DDE (например, пути) обязательны в дополнение к элементарным именам.
def make_schema (dde_iter):
schema = stingray.schema.Schema (dde = [])
для записи в dde_iter:
make_schema_log.debug ("Запись {0}". формат (запись))
schema.info ['dde']. append (запись)
для aDDE в записи:
attr = make_attr (aDDE)
схема.добавить (attr)
схема возврата
- класс
кобол. Погрузчик.COBOLSchemaLoader Общий процесс загрузчика схемы: анализ, а затем построение схемы. Это соответствует
schema.loader.ExternalSchemaLoader.
класс COBOLSchemaLoader (stingray.schema.loader.ExternalSchemaLoader):
"" "Разберите COBOL DDE и создайте схему.
Подкласс может определять lexer_class для настройки
парсинг."" "
lexer_class = Лексер
record_factory_class = RecordFactory
def __init __ (self, source, replace = None):
self.source = источник
self.lexer = self.lexer_class (заменяющий)
self.parser = self.record_factory_class ()
-
COBOLSchemaLoader.нагрузка() Используйте метод
RecordFactory.makeRecord ()для перебора DDE верхнего уровня. Используйтеmake_schema ()для создания единой схемы из DDE (ов).
def нагрузка (самостоятельно):
dde_iter = self.parser.makeRecord (self.lexer.scan (self.source))
схема = make_schema (dde_iter)
схема возврата
Аргумент ключевого слова , заменяющий , представляет собой последовательность пар: [('старый', 'новый'), ...] .
Старый текст заменяется новым текстом. Это кажется странным, потому что это так.
COBOL позволяет заменять текст, чтобы разрешить повторное использование без конфликтов имен.
Обратите внимание, что мы предоставляем возможность «замены» для базового лексера.В лексическое сканирование включается любой замещающий текст.
10.2.2.11. Функции загрузчика схемы верхнего уровня
Самый простой вариант использования - создать экземпляр COBOLSchemaLoader .
с открытым ("sample / zipcty.cob", "r") как cobol:
schema = stingray.cobol.loader.COBOLSchemaLoader (cobol) .load ()
В некоторых случаях нам нужно создать подкласс SchemaLoader, чтобы изменить лексер. Вот пример из расширений и особых случаев.
класс MySchemaLoader (cobol.COBOLSchemaLoader):
lexer_class = cobol.loader.Lexer_Long_Lines
В некоторых случаях мы хотим увидеть определения промежуточных записей COBOL. В этом случае мы хотим сделать что-то вроде следующей функции.
-
кобол. Загрузчик.COBOL_schema( исходный код , lexer_class = Lexer , replace = None ) Эта функция анализирует тетрадь COBOL, возвращая список проанализированных COBOL. 01-уровневая запись, а также окончательная схема.
Это основано на предположении (возможно, ложном). что мы создаем единый объект схемы на основе предоставленных определений.
- В некоторых случаях мы хотим, чтобы все было объединено в единую схему.
- В некоторых крайних случаях мы хотим, чтобы каждый уровень 01 предоставлял отдельный объект схемы.
Нам может потребоваться пересмотреть эту функцию, потому что нам нужен другой лексер. У нас может быть ужасная проблема с форматированием источника, который нужно подправили.
Параметры: - исходный код - файловый объект, являющийся файлом с открытым исходным кодом.
- lexer_class - Лексер для использования. По умолчанию -
cobol.load.Lexer. - вместо - заменяющий аргумент для передачи лексеру.
По умолчанию это
Нет.
Возвращает: 2-кортеж (dde_list, schema). Первый элемент - это список объектов
cobol.def.DDEуровня 01. Второй элемент - это объектcobol.defs.Schema.
def COBOL_schema (источник, lexer_class = Lexer, замена = None,):
lexer = lexer_class (заменяющий)
parser = RecordFactory ()
dde_list = список (parser.makeRecord (lexer.scan (исходный код)))
схема = make_schema (dde_list)
вернуть dde_list, схему
-
кобол. Загрузчик.COBOL_schemata(исходный код , замена = нет ) Эта функция анализирует тетрадь COBOL с несколькими определениями уровня 01, возвращает два списка:
- список проанализированных записей уровня 01 COBOL и
- - список окончательных схем, по одной для каждого определения уровня 01.
Это своеобразное расширение в том редком случае, когда у нас несколько уровней 01 в одном файле, и мы не хотим (или не можем) использовать их как единую схему.